Restructure user-technical
Reviewers: buda Reviewed By: buda Subscribers: pullbot, mferencevic Differential Revision: https://phabricator.memgraph.io/D1547
This commit is contained in:
parent
dab95af366
commit
6615a9de53
docs/user_technical
README.mdconcepts.md
concepts
data
drivers.mdexamples.mdhow-to_guides
open-cypher.mdquick-start.mdquick_start.mdreference__create_index.mdreference_guide
differences.mddynamic_graph_partitioner.mdgraph_algorithms.mdgraph_streams.mdindexing.mdother_features.mdreading_and_writing.mdreading_existing_data.mdreference_overview.mdwriting_new_data.md
tutorials
analyzing_TED_talks.mdexploring_the_european_road_network.mdgraphing_the_premier_league.mdtutorials_overview.md
upcoming_features.md@ -12,13 +12,10 @@ data structures, multi-version concurrency control and asynchronous IO.
|
||||
|
||||
* [About Memgraph](#about-memgraph)
|
||||
* [Quick Start](quick-start.md)
|
||||
* [Examples](examples.md)
|
||||
* [Drivers](drivers.md)
|
||||
* [Data Storage](storage.md)
|
||||
* [Integrations](integrations.md)
|
||||
* [openCypher Query Language](open-cypher.md)
|
||||
* [Import Tools](import-tools.md)
|
||||
* [Concepts](concepts.md)
|
||||
* [Tutorials](tutorials/tutorials_overview.md)
|
||||
* [How-to Guides](how-to_guides/how-to_guides_overview.md)
|
||||
* [Concepts](concepts/concepts_overview.md)
|
||||
* [Reference Guide](reference_guide/reference_overview.md)
|
||||
* [Upcoming Features](upcoming-features.md)
|
||||
|
||||
[//]: # (Nothing should go below the contents section)
|
||||
|
||||
@ -1,72 +0,0 @@
|
||||
## Concepts
|
||||
|
||||
### Weighted Shortest Path
|
||||
|
||||
Weighted shortest path problem is the problem of finding a path between two
|
||||
nodes in a graph such that the sum of the weights of edges connecting nodes on
|
||||
the path is minimized.
|
||||
More about the *weighted shortest path* problem can be found
|
||||
[here](https://en.wikipedia.org/wiki/Shortest_path_problem).
|
||||
|
||||
## Implementation
|
||||
|
||||
Our implementation of the *weighted shortest path* algorithm uses a modified
|
||||
version of Dijkstra's algorithm that can handle length restriction. The length
|
||||
restriction parameter is optional, and when it's not set it could increase the
|
||||
complexity of the algorithm.
|
||||
|
||||
A sample query that finds a shortest path between two nodes can look like this:
|
||||
|
||||
```opencypher
|
||||
MATCH (a {id: 723})-[edge_list *wShortest 10 (e, n | e.weight) total_weight]-(b {id: 882}) RETURN *
|
||||
```
|
||||
|
||||
This query has an upper bound length restriction set to `10`. This means that no
|
||||
path that traverses more than `10` edges will be considered as a valid result.
|
||||
|
||||
|
||||
#### Upper Bound Implications
|
||||
|
||||
Since the upper bound parameter is optional, we can have different results based
|
||||
on this parameter.
|
||||
|
||||
Lets take a look at the following graph and queries.
|
||||
|
||||
```
|
||||
5 5
|
||||
/-----[1]-----\
|
||||
/ \
|
||||
/ \ 2
|
||||
[0] [4]---------[5]
|
||||
\ /
|
||||
\ /
|
||||
\--[2]---[3]--/
|
||||
3 3 3
|
||||
```
|
||||
|
||||
```opencypher
|
||||
MATCH (a {id: 0})-[edge_list *wShortest 3 (e, n | e.weight) total_weight]-(b {id: 5}) RETURN *
|
||||
```
|
||||
|
||||
```opencypher
|
||||
MATCH (a {id: 0})-[edge_list *wShortest (e, n | e.weight) total_weight]-(b {id: 5}) RETURN *
|
||||
```
|
||||
|
||||
The first query will try to find the weighted shortest path between nodes `0`
|
||||
and `5` with the restriction on the path length set to `3`, and the second query
|
||||
will try to find the weighted shortest path with no restriction on the path
|
||||
length.
|
||||
|
||||
The expected result for the first query is `0 -> 1 -> 4 -> 5` with total cost of
|
||||
`12`, while the expected result for the second query is `0 -> 2 -> 3 -> 4 -> 5`
|
||||
with total cost of `11`. Obviously, the second query can find the true shortest
|
||||
path because it has no restrictions on the length.
|
||||
|
||||
To handle cases when the length restriction is set, *weighted shortest path*
|
||||
algorithm uses both node and distance as the state. This causes the search
|
||||
space to increase by the factor of the given upper bound. On the other hand, not
|
||||
setting the upper bound parameter, the search space might contain the whole
|
||||
graph.
|
||||
|
||||
Because of this, one should always try to narrow down the upper bound limit to
|
||||
be as precise as possible in order to have a more performant query.
|
||||
11
docs/user_technical/concepts/concepts_overview.md
Normal file
11
docs/user_technical/concepts/concepts_overview.md
Normal file
@ -0,0 +1,11 @@
|
||||
## Concepts Overview
|
||||
|
||||
Articles within the concepts section serve as an in-depth introduction into
|
||||
inner workings of Memgraph. These tend to be quite technical in nature and
|
||||
are recommended for advanced users and other graph database enthusiasts.
|
||||
|
||||
So far we have covered the following topics:
|
||||
|
||||
* [Data Storage](storage.md)
|
||||
* [Graph Algorithms](graph_algorithms.md)
|
||||
* [Indexing](indexing.md)
|
||||
@ -1,6 +1,6 @@
|
||||
# Graph Algorithms
|
||||
## Graph Algorithms
|
||||
|
||||
## Introduction
|
||||
### Introduction
|
||||
|
||||
The graph is a mathematical structure used to describe a set of objects in which
|
||||
some pairs of objects are "related" in some sense. Generally, we consider
|
||||
@ -27,7 +27,7 @@ Contents of this article include:
|
||||
* [Weighted Shortest Path (WSP)](#weighted-shortest-path)
|
||||
|
||||
|
||||
## Breadth First Search
|
||||
### Breadth First Search
|
||||
|
||||
[Breadth First Search](https://en.wikipedia.org/wiki/Breadth-first_search)
|
||||
is a way of traversing a graph data structure. The
|
||||
@ -62,16 +62,16 @@ a FIFO (first in, first out) queue data structure. Nevertheless, the
|
||||
functionality is equivalent and its runtime is bounded by `O(|V| + |E|)` where
|
||||
`V` denotes the set of nodes and `E` denotes the set of edges. Therefore,
|
||||
it provides a more efficient way of finding unweighted shortest paths than
|
||||
running [Dijkstra's algorithm](concept__weighted_shortest_path.md) on a graph
|
||||
running [Dijkstra's algorithm](#weighted-shortest-path) on a graph
|
||||
with edge weights equal to `1`.
|
||||
|
||||
## Weighted Shortest Path
|
||||
### Weighted Shortest Path
|
||||
|
||||
In [graph theory](https://en.wikipedia.org/wiki/Graph_theory), weighted shortest
|
||||
path problem is the problem of finding a path between two nodes in a graph such
|
||||
that the sum of the weights of edges connecting nodes on the path is minimized.
|
||||
|
||||
### Dijkstra's algorithm
|
||||
#### Dijkstra's algorithm
|
||||
|
||||
One of the most important algorithms for finding weighted shortest paths is
|
||||
[Dijkstra's algorithm](https://en.wikipedia.org/wiki/Dijkstra%27s_algorithm).
|
||||
@ -112,14 +112,14 @@ MATCH (a {id: 723})-[edge_list *wShortest 10 (e, n | e.weight) total_weight]-(b
|
||||
This query has an upper bound length restriction set to `10`. This means that no
|
||||
path that traverses more than `10` edges will be considered as a valid result.
|
||||
|
||||
#### Upper Bound Implications
|
||||
##### Upper Bound Implications
|
||||
|
||||
Since the upper bound parameter is optional, we can have different results based
|
||||
on this parameter.
|
||||
|
||||
Consider the following graph and sample queries.
|
||||
|
||||

|
||||

|
||||
|
||||
```opencypher
|
||||
MATCH (a {id: 0})-[edge_list *wShortest 3 (e, n | e.weight) total_weight]-(b {id: 5}) RETURN *
|
||||
@ -149,8 +149,8 @@ graph.
|
||||
Because of this, one should always try to narrow down the upper bound limit to
|
||||
be as precise as possible in order to have a more performant query.
|
||||
|
||||
## Where to next?
|
||||
### Where to next?
|
||||
|
||||
For some real-world application of WSP we encourage you to visit our article
|
||||
on [exploring the European road network](tutorial__exploring_the_european_road_network.md)
|
||||
on [exploring the European road network](../tutorials/exploring_the_european_road_network.md)
|
||||
which was specially crafted to showcase our graph algorithms.
|
||||
@ -1,4 +1,4 @@
|
||||
## Indexing {#indexing-concept}
|
||||
## Indexing
|
||||
|
||||
### Introduction
|
||||
|
||||
@ -90,7 +90,3 @@ in a skip list):
|
||||
* Average deletion time is `O(log(n))`
|
||||
* Average search time is `O(log(n))`
|
||||
* Average memory consumption is `O(n)`
|
||||
|
||||
### Index Commands
|
||||
|
||||
* [CREATE INDEX ON](reference__create_index.md)
|
||||
@ -26,7 +26,8 @@ usually found in `/etc/memgraph/memgraph.conf`.
|
||||
|
||||
In addition to the above mentioned data durability and recovery, a
|
||||
snapshot file may be generated using *Memgraph's* import tools. For more
|
||||
information, take a look at [Import Tools](import-tools.md) chapter.
|
||||
information, take a look at the [Import Tools](../how-to_guides/import_tools.md)
|
||||
article.
|
||||
|
||||
## Storable Data Types
|
||||
|
||||
BIN
docs/user_technical/data/graph.png
Normal file
BIN
docs/user_technical/data/graph.png
Normal file
{kind=link}
Binary file not shown.
|
After 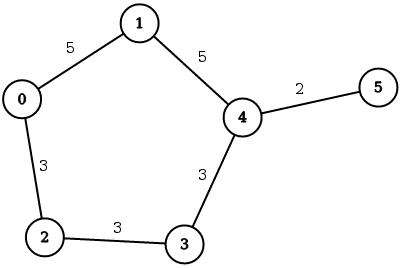
(image error) Size: 12 KiB |
@ -1,191 +0,0 @@
|
||||
## Bolt Drivers
|
||||
|
||||
### Python Driver Example
|
||||
|
||||
Neo4j officially supports Python for interacting with an openCypher and Bolt
|
||||
compliant database. For details consult the
|
||||
[official documentation](http://neo4j.com/docs/api/python-driver) and the
|
||||
[GitHub project](https://github.com/neo4j/neo4j-python-driver). Following is
|
||||
a basic usage example:
|
||||
|
||||
```python
|
||||
from neo4j.v1 import GraphDatabase, basic_auth
|
||||
|
||||
# Initialize and configure the driver.
|
||||
# * provide the correct URL where Memgraph is reachable;
|
||||
# * use an empty user name and password.
|
||||
driver = GraphDatabase.driver("bolt://localhost:7687",
|
||||
auth=basic_auth("", ""))
|
||||
|
||||
# Start a session in which queries are executed.
|
||||
session = driver.session()
|
||||
|
||||
# Execute openCypher queries.
|
||||
# After each query, call either `consume()` or `data()`
|
||||
session.run('CREATE (alice:Person {name: "Alice", age: 22})').consume()
|
||||
|
||||
# Get all the nodes from the database (potentially multiple rows).
|
||||
nodes = session.run('MATCH (n) RETURN n').data()
|
||||
# Assuming we started with an empty database, we should have Alice
|
||||
# as the only row in the results.
|
||||
only_row = nodes.pop()
|
||||
alice = only_row["n"]
|
||||
|
||||
# Print out what we retrieved.
|
||||
print("Found a node with labels '{}', name '{}' and age {}".format(
|
||||
alice['name'], alice.labels, alice['age'])
|
||||
|
||||
# Remove all the data from the database.
|
||||
session.run('MATCH (n) DETACH DELETE n').consume()
|
||||
|
||||
# Close the session and the driver.
|
||||
session.close()
|
||||
driver.close()
|
||||
```
|
||||
|
||||
### Java Driver Example
|
||||
|
||||
The details about Java driver can be found
|
||||
[on GitHub](https://github.com/neo4j/neo4j-java-driver).
|
||||
|
||||
The example below is equivalent to Python example. Major difference is that
|
||||
`Config` object has to be created before the driver construction.
|
||||
|
||||
```java
|
||||
import org.neo4j.driver.v1.*;
|
||||
import org.neo4j.driver.v1.types.*;
|
||||
import static org.neo4j.driver.v1.Values.parameters;
|
||||
import java.util.*;
|
||||
|
||||
public class JavaQuickStart {
|
||||
public static void main(String[] args) {
|
||||
// Initialize driver.
|
||||
Config config = Config.build().toConfig();
|
||||
Driver driver = GraphDatabase.driver("bolt://localhost:7687",
|
||||
AuthTokens.basic("",""),
|
||||
config);
|
||||
// Execute basic queries.
|
||||
try (Session session = driver.session()) {
|
||||
StatementResult rs1 = session.run("MATCH (n) DETACH DELETE n");
|
||||
StatementResult rs2 = session.run(
|
||||
"CREATE (alice: Person {name: 'Alice', age: 22})");
|
||||
StatementResult rs3 = session.run( "MATCH (n) RETURN n");
|
||||
List<Record> records = rs3.list();
|
||||
Record record = records.get(0);
|
||||
Node node = record.get("n").asNode();
|
||||
System.out.println(node.get("name").asString());
|
||||
} catch (Exception e) {
|
||||
System.out.println(e);
|
||||
System.exit(1);
|
||||
}
|
||||
// Cleanup.
|
||||
driver.close();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Javascript Driver Example
|
||||
|
||||
The details about Javascript driver can be found
|
||||
[on GitHub](https://github.com/neo4j/neo4j-javascript-driver).
|
||||
|
||||
The Javascript example below is equivalent to Python and Java examples.
|
||||
|
||||
Here is an example related to `Node.js`. Memgraph doesn't have integrated
|
||||
support for `WebSocket` which is required during the execution in any web
|
||||
browser. If you want to run `openCypher` queries from a web browser,
|
||||
[websockify](https://github.com/novnc/websockify) has to be up and running.
|
||||
Requests from web browsers are wrapped into `WebSocket` messages, and a proxy
|
||||
is needed to handle the overhead. The proxy has to be configured to point out
|
||||
to Memgraph's Bolt port and web browser driver has to send requests to the
|
||||
proxy port.
|
||||
|
||||
```javascript
|
||||
var neo4j = require('neo4j-driver').v1;
|
||||
var driver = neo4j.driver("bolt://localhost:7687",
|
||||
neo4j.auth.basic("neo4j", "1234"));
|
||||
var session = driver.session();
|
||||
|
||||
function die() {
|
||||
session.close();
|
||||
driver.close();
|
||||
}
|
||||
|
||||
function run_query(query, callback) {
|
||||
var run = session.run(query, {});
|
||||
run.then(callback).catch(function (error) {
|
||||
console.log(error);
|
||||
die();
|
||||
});
|
||||
}
|
||||
|
||||
run_query("MATCH (n) DETACH DELETE n", function (result) {
|
||||
console.log("Database cleared.");
|
||||
run_query("CREATE (alice: Person {name: 'Alice', age: 22})", function (result) {
|
||||
console.log("Record created.");
|
||||
run_query("MATCH (n) RETURN n", function (result) {
|
||||
console.log("Record matched.");
|
||||
var alice = result.records[0].get("n");
|
||||
console.log(alice.labels[0]);
|
||||
console.log(alice.properties["name"]);
|
||||
session.close();
|
||||
driver.close();
|
||||
});
|
||||
});
|
||||
});
|
||||
```
|
||||
|
||||
### C# Driver Example
|
||||
|
||||
The C# driver is hosted
|
||||
[on GitHub](https://github.com/neo4j/neo4j-dotnet-driver). The example below
|
||||
performs the same work as all of the previous examples.
|
||||
|
||||
```csh
|
||||
using System;
|
||||
using System.Linq;
|
||||
using Neo4j.Driver.V1;
|
||||
|
||||
public class Basic {
|
||||
public static void Main(string[] args) {
|
||||
// Initialize the driver.
|
||||
var config = Config.DefaultConfig;
|
||||
using(var driver = GraphDatabase.Driver("bolt://localhost:7687", AuthTokens.None, config))
|
||||
using(var session = driver.Session())
|
||||
{
|
||||
// Run basic queries.
|
||||
session.Run("MATCH (n) DETACH DELETE n").Consume();
|
||||
session.Run("CREATE (alice:Person {name: \"Alice\", age: 22})").Consume();
|
||||
var result = session.Run("MATCH (n) RETURN n").First();
|
||||
var alice = (INode) result["n"];
|
||||
Console.WriteLine(alice["name"]);
|
||||
Console.WriteLine(string.Join(", ", alice.Labels));
|
||||
Console.WriteLine(alice["age"]);
|
||||
}
|
||||
Console.WriteLine("All ok!");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Secure Sockets Layer (SSL)
|
||||
|
||||
Secure connections are supported and enabled by default. The server initially
|
||||
ships with a self-signed testing certificate. The certificate can be replaced
|
||||
by editing the following parameters in `/etc/memgraph/memgraph.conf`:
|
||||
```
|
||||
--cert-file=/path/to/ssl/certificate.pem
|
||||
--key-file=/path/to/ssl/privatekey.pem
|
||||
```
|
||||
To disable SSL support and use insecure connections to the database you should
|
||||
set both parameters (`--cert-file` and `--key-file`) to empty values.
|
||||
|
||||
### Limitations
|
||||
|
||||
Memgraph is currently in early stage, and has a number of limitations we plan
|
||||
to remove in future versions.
|
||||
|
||||
#### Multiple Users & Authorization
|
||||
|
||||
Memgraph is currently single-user only. There is no way to control user
|
||||
privileges. The default user has read and write privileges over the whole
|
||||
database.
|
||||
@ -1,520 +0,0 @@
|
||||
## Examples
|
||||
|
||||
This chapter shows you how to use Memgraph on real-world data and how to get
|
||||
interesting and useful information out of it.
|
||||
|
||||
### TED Talks Example
|
||||
|
||||
[TED](https://www.ted.com/) is a nonprofit organization devoted to spreading
|
||||
ideas, usually in the form of short, powerful talks.
|
||||
Today, TED talks are influential videos from expert speakers on almost all
|
||||
topics — from science to business to global issues.
|
||||
Here we present a small dataset which consists of 97 talks. We'll show you how
|
||||
to model this data as a graph and demonstrate a few example queries.
|
||||
|
||||
#### Data Model
|
||||
Each TED talk has a main speaker, so we
|
||||
identify two node labels — `Talk` and `Speaker`. Also, we will add
|
||||
an edge labelled `Gave` pointing to a node labelled `Talk` from its
|
||||
main `Speaker`. Each speaker has a name so we can add property `name` to
|
||||
`Speaker` node. Likewise, we'll add properties `name`, `title` and `description`
|
||||
to node `Talk`. Furthermore, each talk is given in a specific TED event, so we
|
||||
can create a node `Event` with property `name` and an edge `InEvent` between
|
||||
talk and event.
|
||||
|
||||
Talks are tagged with keywords to facilitate searching, hence we
|
||||
add a node `Tag` with property `name` and an edge `HasTag` between talk and
|
||||
tag. Moreover, users give ratings to each talk by selecting up to three
|
||||
predefined string values. Therefore we add a node `Rating` with these values as
|
||||
property `name` and an edge `HasRating` with property `user_count` between
|
||||
talk and rating nodes.
|
||||
|
||||
#### Example Queries
|
||||
|
||||
We have prepared a database snapshot for this example, so you can easily import
|
||||
it when starting Memgraph using the `--durability-directory` option.
|
||||
|
||||
```bash
|
||||
/usr/lib/memgraph/memgraph --durability-directory /usr/share/memgraph/examples/TEDTalk \
|
||||
--durability-enabled=false --snapshot-on-exit=false
|
||||
```
|
||||
|
||||
When using Memgraph installed from DEB or RPM package, you may need to stop
|
||||
the currently running Memgraph server before you can import the example. Use
|
||||
the following command:
|
||||
|
||||
```bash
|
||||
systemctl stop memgraph
|
||||
```
|
||||
|
||||
When using Docker, you can import the example with the following command:
|
||||
|
||||
```bash
|
||||
docker run -p 7687:7687 \
|
||||
-v mg_lib:/var/lib/memgraph -v mg_log:/var/log/memgraph -v mg_etc:/etc/memgraph \
|
||||
memgraph --durability-directory /usr/share/memgraph/examples/TEDTalk \
|
||||
--durability-enabled=false --snapshot-on-exit=false
|
||||
```
|
||||
|
||||
Now you're ready to try out some of the following queries.
|
||||
|
||||
NOTE: If you modify the dataset, the changes will stay only during this run of
|
||||
Memgraph.
|
||||
|
||||
1) Find all talks given by specific speaker:
|
||||
|
||||
```opencypher
|
||||
MATCH (n:Speaker {name: "Hans Rosling"})-[:Gave]->(m:Talk)
|
||||
RETURN m.title;
|
||||
```
|
||||
|
||||
2) Find the top 20 speakers with most talks given:
|
||||
|
||||
```opencypher
|
||||
MATCH (n:Speaker)-[:Gave]->(m)
|
||||
RETURN n.name, COUNT(m) AS TalksGiven
|
||||
ORDER BY TalksGiven DESC LIMIT 20;
|
||||
```
|
||||
|
||||
3) Find talks related by tag to specific talk and count them:
|
||||
|
||||
```opencypher
|
||||
MATCH (n:Talk {name: "Michael Green: Why we should build wooden skyscrapers"})
|
||||
-[:HasTag]->(t:Tag)<-[:HasTag]-(m:Talk)
|
||||
WITH * ORDER BY m.name
|
||||
RETURN t.name, COLLECT(m.name), COUNT(m) AS TalksCount
|
||||
ORDER BY TalksCount DESC;
|
||||
```
|
||||
|
||||
4) Find 20 most frequently used tags:
|
||||
|
||||
```opencypher
|
||||
MATCH (t:Tag)<-[:HasTag]-(n:Talk)
|
||||
RETURN t.name AS Tag, COUNT(n) AS TalksCount
|
||||
ORDER BY TalksCount DESC, Tag LIMIT 20;
|
||||
```
|
||||
|
||||
5) Find 20 talks most rated as "Funny". If you want to query by other ratings,
|
||||
possible values are: Obnoxious, Jaw-dropping, OK, Persuasive, Beautiful,
|
||||
Confusing, Longwinded, Unconvincing, Fascinating, Ingenious, Courageous, Funny,
|
||||
Informative and Inspiring.
|
||||
|
||||
```opencypher
|
||||
MATCH (r:Rating{name:"Funny"})<-[e:HasRating]-(m:Talk)
|
||||
RETURN m.name, e.user_count ORDER BY e.user_count DESC LIMIT 20;
|
||||
```
|
||||
|
||||
6) Find inspiring talks and their speakers from the field of technology:
|
||||
|
||||
```opencypher
|
||||
MATCH (n:Talk)-[:HasTag]->(m:Tag {name: "technology"})
|
||||
MATCH (n)-[r:HasRating]->(p:Rating {name: "Inspiring"})
|
||||
MATCH (n)<-[:Gave]-(s:Speaker)
|
||||
WHERE r.user_count > 1000
|
||||
RETURN n.title, s.name, r.user_count ORDER BY r.user_count DESC;
|
||||
```
|
||||
|
||||
7) Now let's see one real-world example — how to make a real-time
|
||||
recommendation. If you've just watched a talk from a certain
|
||||
speaker (e.g. Hans Rosling) you might be interested in finding more talks from
|
||||
the same speaker on a similar topic:
|
||||
|
||||
```opencypher
|
||||
MATCH (n:Speaker {name: "Hans Rosling"})-[:Gave]->(m:Talk)
|
||||
MATCH (t:Talk {title: "New insights on poverty"})-[:HasTag]->(tag:Tag)<-[:HasTag]-(m)
|
||||
WITH * ORDER BY tag.name
|
||||
RETURN m.title as Title, COLLECT(tag.name), COUNT(tag) as TagCount
|
||||
ORDER BY TagCount DESC, Title;
|
||||
```
|
||||
|
||||
The following few queries are focused on extracting information about
|
||||
TED events.
|
||||
|
||||
8) Find how many talks were given per event:
|
||||
|
||||
```opencypher
|
||||
MATCH (n:Event)<-[:InEvent]-(t:Talk)
|
||||
RETURN n.name as Event, COUNT(t) AS TalksCount
|
||||
ORDER BY TalksCount DESC, Event
|
||||
LIMIT 20;
|
||||
```
|
||||
|
||||
9) Find the most popular tags in the specific event:
|
||||
|
||||
```opencypher
|
||||
MATCH (n:Event {name:"TED2006"})<-[:InEvent]-(t:Talk)-[:HasTag]->(tag:Tag)
|
||||
RETURN tag.name as Tag, COUNT(t) AS TalksCount
|
||||
ORDER BY TalksCount DESC, Tag
|
||||
LIMIT 20;
|
||||
```
|
||||
|
||||
10) Discover which speakers participated in more than 2 events:
|
||||
|
||||
```opencypher
|
||||
MATCH (n:Speaker)-[:Gave]->(t:Talk)-[:InEvent]->(e:Event)
|
||||
WITH n, COUNT(e) AS EventsCount WHERE EventsCount > 2
|
||||
RETURN n.name as Speaker, EventsCount
|
||||
ORDER BY EventsCount DESC, Speaker;
|
||||
```
|
||||
|
||||
11) For each speaker search for other speakers that participated in same
|
||||
events:
|
||||
|
||||
```opencypher
|
||||
MATCH (n:Speaker)-[:Gave]->()-[:InEvent]->(e:Event)<-[:InEvent]-()<-[:Gave]-(m:Speaker)
|
||||
WHERE n.name != m.name
|
||||
WITH DISTINCT n, m ORDER BY m.name
|
||||
RETURN n.name AS Speaker, COLLECT(m.name) AS Others
|
||||
ORDER BY Speaker;
|
||||
```
|
||||
|
||||
### Football Example
|
||||
|
||||
[Football](https://en.wikipedia.org/wiki/Association_football)
|
||||
is a team sport played between two teams of eleven
|
||||
players with a spherical ball. The game is played on a rectangular pitch with
|
||||
a goal at each and. The object of the game is to score by moving the ball
|
||||
beyond the goal line into the opposing goal. The game is played by more than
|
||||
250 million players in over 200 countries, making it the world's most
|
||||
popular sport.
|
||||
|
||||
In this example, we will present a graph model of a reasonably sized dataset
|
||||
of football matches across world's most popular leagues.
|
||||
|
||||
#### Data Model
|
||||
|
||||
In essence, we are trying to model a set of football matches. All information
|
||||
about a single match is going to be contained in three nodes and two edges.
|
||||
Two of the nodes will represent the teams that have played the match, while the
|
||||
third node will represent the game itself. Both edges are directed from the
|
||||
team nodes to the game node and are labeled as `:Played`.
|
||||
|
||||
Let us consider a real life example of this model—Arsene Wenger's 1000th
|
||||
game in charge of Arsenal. This was a regular fixture of a 2013/2014
|
||||
English Premier League, yet it was written in the stars that this historic
|
||||
moment would be a big London derby against Chelsea on Stanford Bridge. The
|
||||
sketch below shows how this game is being modeled in our database.
|
||||
|
||||
```
|
||||
+---------------+ +-----------------------------+
|
||||
|n: Team | |w: Game |
|
||||
| |-[:Played {side: "home", outcome: "won"}]-->| |
|
||||
|name: "Chelsea"| |HT_home_score: 4 |
|
||||
+---------------+ |HT_away_score: 0 |
|
||||
|HT_result: "H" |
|
||||
|FT_home_score: 6 |
|
||||
|FT_away_score: 0 |
|
||||
|FT_result: "H" |
|
||||
+---------------+ |date: "2014-03-22" |
|
||||
|m: Team | |league: "ENG-Premier League" |
|
||||
| |-[:Played {side: "away", outcome: "lost"}]->|season: 2013 |
|
||||
|name: "Arsenal"| |referee: "Andre Marriner" |
|
||||
+---------------+ +-----------------------------+
|
||||
```
|
||||
|
||||
#### Example Queries
|
||||
|
||||
We have prepared a database snapshot for this example, so you can easily import
|
||||
it when starting Memgraph using the `--durability-directory` option.
|
||||
|
||||
```bash
|
||||
/usr/lib/memgraph/memgraph --durability-directory /usr/share/memgraph/examples/football \
|
||||
--durability-enabled=false --snapshot-on-exit=false
|
||||
```
|
||||
|
||||
When using Docker, you can import the example with the following command:
|
||||
|
||||
```bash
|
||||
docker run -p 7687:7687 \
|
||||
-v mg_lib:/var/lib/memgraph -v mg_log:/var/log/memgraph -v mg_etc:/etc/memgraph \
|
||||
memgraph --durability-directory /usr/share/memgraph/examples/football \
|
||||
--durability-enabled=false --snapshot-on-exit=false
|
||||
```
|
||||
|
||||
Now you're ready to try out some of the following queries.
|
||||
|
||||
NOTE: If you modify the dataset, the changes will stay only during this run of
|
||||
Memgraph.
|
||||
|
||||
1) You might wonder, what leagues are supported?
|
||||
|
||||
```opencypher
|
||||
MATCH (n:Game)
|
||||
RETURN DISTINCT n.league AS League
|
||||
ORDER BY League;
|
||||
```
|
||||
|
||||
2) We have stored a certain number of seasons for each league. What is the
|
||||
oldest/newest season we have included?
|
||||
|
||||
```opencypher
|
||||
MATCH (n:Game)
|
||||
RETURN DISTINCT n.league AS League, MIN(n.season) AS Oldest, MAX(n.season) AS Newest
|
||||
ORDER BY League;
|
||||
```
|
||||
|
||||
3) You have already seen one game between Chelsea and Arsenal, let's list all of
|
||||
them in chronological order.
|
||||
|
||||
```opencypher
|
||||
MATCH (n:Team {name: "Chelsea"})-[e:Played]->(w:Game)<-[f:Played]-(m:Team {name: "Arsenal"})
|
||||
RETURN w.date AS Date, e.side AS Chelsea, f.side AS Arsenal,
|
||||
w.FT_home_score AS home_score, w.FT_away_score AS away_score
|
||||
ORDER BY Date;
|
||||
```
|
||||
|
||||
4) How about filtering games in which Chelsea won?
|
||||
|
||||
```opencypher
|
||||
MATCH (n:Team {name: "Chelsea"})-[e:Played {outcome: "won"}]->
|
||||
(w:Game)<-[f:Played]-(m:Team {name: "Arsenal"})
|
||||
RETURN w.date AS Date, e.side AS Chelsea, f.side AS Arsenal,
|
||||
w.FT_home_score AS home_score, w.FT_away_score AS away_score
|
||||
ORDER BY Date;
|
||||
```
|
||||
|
||||
5) Home field advantage is a thing in football. Let's list the number of home
|
||||
defeats for each Premier League team in the 2016/2017 season.
|
||||
|
||||
```opencypher
|
||||
MATCH (n:Team)-[:Played {side: "home", outcome: "lost"}]->
|
||||
(w:Game {league: "ENG-Premier League", season: 2016})
|
||||
RETURN n.name AS Team, count(w) AS home_defeats
|
||||
ORDER BY home_defeats, Team;
|
||||
```
|
||||
|
||||
6) At the end of the season the team with the most points wins the league. For
|
||||
each victory, a team is awarded 3 points and for each draw it is awarded
|
||||
1 point. Let's find out how many points did reigning champions (Chelsea) have
|
||||
at the end of 2016/2017 season.
|
||||
|
||||
```opencypher
|
||||
MATCH (n:Team {name: "Chelsea"})-[:Played {outcome: "drew"}]->(w:Game {season: 2016})
|
||||
WITH n, COUNT(w) AS draw_points
|
||||
MATCH (n)-[:Played {outcome: "won"}]->(w:Game {season: 2016})
|
||||
RETURN draw_points + 3 * COUNT(w) AS total_points;
|
||||
```
|
||||
|
||||
7) In fact, why not retrieve the whole table?
|
||||
|
||||
```opencypher
|
||||
MATCH (n)-[:Played {outcome: "drew"}]->(w:Game {league: "ENG-Premier League", season: 2016})
|
||||
WITH n, COUNT(w) AS draw_points
|
||||
MATCH (n)-[:Played {outcome: "won"}]->(w:Game {league: "ENG-Premier League", season: 2016})
|
||||
RETURN n.name AS Team, draw_points + 3 * COUNT(w) AS total_points
|
||||
ORDER BY total_points DESC;
|
||||
```
|
||||
|
||||
8) People have always debated which of the major leagues is the most exciting.
|
||||
One basic metric is the average number of goals per game. Let's see the results
|
||||
at the end of the 2016/2017 season. WARNING: This might shock you.
|
||||
|
||||
```opencypher
|
||||
MATCH (w:Game {season: 2016})
|
||||
RETURN w.league, AVG(w.FT_home_score) + AVG(w.FT_away_score) AS avg_goals_per_game
|
||||
ORDER BY avg_goals_per_game DESC;
|
||||
```
|
||||
|
||||
9) Another metric might be the number of comebacks—games where one side
|
||||
was winning at half time but were overthrown by the other side by the end
|
||||
of the match. Let's count such occurrences during all supported seasons across
|
||||
all supported leagues.
|
||||
|
||||
```opencypher
|
||||
MATCH (g:Game) WHERE
|
||||
(g.HT_result = "H" AND g.FT_result = "A") OR
|
||||
(g.HT_result = "A" AND g.FT_result = "H")
|
||||
RETURN g.league AS League, count(g) AS Comebacks
|
||||
ORDER BY Comebacks DESC;
|
||||
```
|
||||
|
||||
10) Exciting leagues also tend to be very unpredictable. On that note, let's list
|
||||
all triplets of teams where, during the course of one season, team A won against
|
||||
team B, team B won against team C and team C won against team A.
|
||||
|
||||
```opencypher
|
||||
MATCH (a)-[:Played {outcome: "won"}]->(p:Game {league: "ENG-Premier League", season: 2016})<--
|
||||
(b)-[:Played {outcome: "won"}]->(q:Game {league: "ENG-Premier League", season: 2016})<--
|
||||
(c)-[:Played {outcome: "won"}]->(r:Game {league: "ENG-Premier League", season: 2016})<--(a)
|
||||
WHERE p.date < q.date AND q.date < r.date
|
||||
RETURN a.name AS Team1, b.name AS Team2, c.name AS Team3;
|
||||
```
|
||||
|
||||
### European road network example
|
||||
|
||||
In this section we will show how to use some of Memgraph's built-in graph
|
||||
algorithms. More specifically, we will show how to use breadth-first search
|
||||
graph traversal algorithm, and Dijkstra's algorithm for finding weighted
|
||||
shortest paths between nodes in the graph.
|
||||
|
||||
#### Data model
|
||||
|
||||
One of the most common applications of graph traversal algorithms is driving
|
||||
route computation, so we will use European road network graph as an example.
|
||||
The graph consists of 999 major European cities from 39 countries in total.
|
||||
Each city is connected to the country it belongs to via an edge of type `:In_`.
|
||||
There are edges of type `:Road` connecting cities less than 500 kilometers
|
||||
apart. Distance between cities is specified in the `length` property of the
|
||||
edge.
|
||||
|
||||
|
||||
#### Example queries
|
||||
|
||||
We have prepared a database snapshot for this example, so you can easily import
|
||||
it when starting Memgraph using the `--durability-directory` option.
|
||||
|
||||
```bash
|
||||
/usr/lib/memgraph/memgraph --durability-directory /usr/share/memgraph/examples/Europe \
|
||||
--durability-enabled=false --snapshot-on-exit=false
|
||||
```
|
||||
|
||||
When using Docker, you can import the example with the following command:
|
||||
|
||||
```bash
|
||||
docker run -p 7687:7687 \
|
||||
-v mg_lib:/var/lib/memgraph -v mg_log:/var/log/memgraph -v mg_etc:/etc/memgraph \
|
||||
memgraph --durability-directory /usr/share/memgraph/examples/Europe \
|
||||
--durability-enabled=false --snapshot-on-exit=false
|
||||
```
|
||||
|
||||
Now you're ready to try out some of the following queries.
|
||||
|
||||
NOTE: If you modify the dataset, the changes will stay only during this run of
|
||||
Memgraph.
|
||||
|
||||
Let's start off with a few simple queries.
|
||||
|
||||
1) Let's list all of the countries in our road network.
|
||||
|
||||
```opencypher
|
||||
MATCH (c:Country) RETURN c.name ORDER BY c.name;
|
||||
```
|
||||
|
||||
2) Which Croatian cities are in our road network?
|
||||
|
||||
```opencypher
|
||||
MATCH (c:City)-[:In_]->(:Country {name: "Croatia"})
|
||||
RETURN c.name ORDER BY c.name;
|
||||
```
|
||||
|
||||
3) Which cities in our road network are less than 200 km away from Zagreb?
|
||||
|
||||
```opencypher
|
||||
MATCH (:City {name: "Zagreb"})-[r:Road]->(c:City)
|
||||
WHERE r.length < 200
|
||||
RETURN c.name ORDER BY c.name;
|
||||
```
|
||||
|
||||
Now let's try some queries using Memgraph's graph traversal capabilities.
|
||||
|
||||
4) Say you want to drive from Zagreb to Paris. You might wonder, what is the
|
||||
least number of cities you have to visit if you don't want to drive more than
|
||||
500 kilometers between stops. Since the edges in our road network don't connect
|
||||
cities that are more than 500 km apart, this is a great use case for the
|
||||
breadth-first search (BFS) algorithm.
|
||||
|
||||
```opencypher
|
||||
MATCH p = (:City {name: "Zagreb"})
|
||||
-[:Road * bfs]->
|
||||
(:City {name: "Paris"})
|
||||
RETURN nodes(p);
|
||||
```
|
||||
|
||||
5) What if we want to bike to Paris instead of driving? It is unreasonable (and
|
||||
dangerous!) to bike 500 km per day. Let's limit ourselves to biking no more
|
||||
than 200 km in one go.
|
||||
|
||||
```opencypher
|
||||
MATCH p = (:City {name: "Zagreb"})
|
||||
-[:Road * bfs (e, n | e.length <= 200)]->
|
||||
(:City {name: "Paris"})
|
||||
RETURN nodes(p);
|
||||
```
|
||||
|
||||
"What is this special syntax?", you might wonder.
|
||||
|
||||
`(e, n | e.length <= 200)` is called a *filter lambda*. It's a function that
|
||||
takes an edge symbol `e` and a node symbol `n` and decides whether this edge
|
||||
and node pair should be considered valid in breadth-first expansion by
|
||||
returning true or false (or Null). In the above example, lambda is returning
|
||||
true if edge length is not greater than 200, because we don't want to bike more
|
||||
than 200 km in one go.
|
||||
|
||||
6) Let's say we also don't want to visit Vienna on our way to Paris, because we
|
||||
have a lot of friends there and visiting all of them would take up a lot of our
|
||||
time. We just have to update our filter lambda.
|
||||
|
||||
```opencypher
|
||||
MATCH p = (:City {name: "Zagreb"})
|
||||
-[:Road * bfs (e, n | e.length <= 200 AND n.name != "Vienna")]->
|
||||
(:City {name: "Paris"})
|
||||
RETURN nodes(p);
|
||||
```
|
||||
|
||||
As you can see, without the additional restriction we could visit 11 cities. If
|
||||
we want to avoid Vienna, we must visit at least 12 cities.
|
||||
|
||||
7) Instead of counting the cities visited, we might want to find the shortest
|
||||
paths in terms of distance travelled. This is a textbook application of
|
||||
Dijkstra's algorithm. The following query will return the list of cities on the
|
||||
shortest path from Zagreb to Paris along with the total length of the path.
|
||||
|
||||
```opencypher
|
||||
MATCH p = (:City {name: "Zagreb"})
|
||||
-[:Road * wShortest (e, n | e.length) total_weight]->
|
||||
(:City {name: "Paris"})
|
||||
RETURN nodes(p) as cities, total_weight;
|
||||
```
|
||||
|
||||
As you can see, the syntax is quite similar to breadth-first search syntax.
|
||||
Instead of a filter lambda, we need to provide a *weight lambda* and the *total
|
||||
weight symbol*. Given an edge and node pair, weight lambda must return the
|
||||
cost of expanding to the given node using the given edge. The path returned
|
||||
will have the smallest possible sum of costs and it will be stored in the total
|
||||
weight symbol. A limitation of Dijkstra's algorithm is that the cost must be
|
||||
non-negative.
|
||||
|
||||
8) We can also combine weight and filter lambdas in the shortest-path query.
|
||||
Let's say we're interested in the shortest path that doesn't require travelling
|
||||
more that 200 km in one go for our bike route.
|
||||
|
||||
```opencypher
|
||||
MATCH p = (:City {name: "Zagreb"})
|
||||
-[:Road * wShortest (e, n | e.length) total_weight (e, n | e.length <= 200)]->
|
||||
(:City {name: "Paris"})
|
||||
RETURN nodes(p) as cities, total_weight;
|
||||
```
|
||||
|
||||
9) Let's try and find 10 cities that are furthest away from Zagreb.
|
||||
|
||||
```opencypher
|
||||
MATCH (:City {name: "Zagreb"})
|
||||
-[:Road * wShortest (e, n | e.length) total_weight]->
|
||||
(c:City)
|
||||
RETURN c, total_weight
|
||||
ORDER BY total_weight DESC LIMIT 10;
|
||||
```
|
||||
|
||||
It is not surprising to see that they are all in Siberia.
|
||||
|
||||
|
||||
To learn more about these algorithms, we suggest you check out their Wikipedia
|
||||
pages:
|
||||
|
||||
* [Breadth-first search](https://en.wikipedia.org/wiki/Breadth-first_search)
|
||||
* [Dijkstra's algorithm](https://en.wikipedia.org/wiki/Dijkstra%27s_algorithm)
|
||||
|
||||
|
||||
Now you're ready to explore the world of graph databases with Memgraph
|
||||
by yourself and try it on many more examples and datasets.
|
||||
|
||||
### Graph Gists Examples
|
||||
|
||||
A nice looking set of small graph examples can be found
|
||||
[here](https://neo4j.com/graphgists/). You can take any use-case and try to
|
||||
execute the queries against Memgraph. To clear the database between trying out
|
||||
examples, execute the query:
|
||||
|
||||
```opencypher
|
||||
MATCH (n) DETACH DELETE n;
|
||||
```
|
||||
11
docs/user_technical/how-to_guides/how-to_guides_overview.md
Normal file
11
docs/user_technical/how-to_guides/how-to_guides_overview.md
Normal file
@ -0,0 +1,11 @@
|
||||
## How-to Guides Overview
|
||||
|
||||
Articles within the how-to guides section serve as a cookbook for getting
|
||||
things done as fast as possible. These articles tend to provide a step-by-step
|
||||
guide on how to use certain Memgraph feature or solve a particular problem.
|
||||
|
||||
So far we have covered the following topics:
|
||||
|
||||
* [Import Tools](import_tools.md)
|
||||
* [Programmatic Querying](programmatic_querying.md)
|
||||
* [Integrations](integrations.md)
|
||||
@ -9,122 +9,10 @@ real-time data feeds.
|
||||
Memgraph offers easy data import at the source using Kafka as the
|
||||
high-throughput messaging system.
|
||||
|
||||
#### openCypher
|
||||
At this point, we strongly advise you to read the streaming section of our
|
||||
[reference guide](../reference_guide/streaming.md)
|
||||
|
||||
Memgraphs custom openCypher clause for creating a stream is:
|
||||
```opencypher
|
||||
CREATE STREAM stream_name AS
|
||||
LOAD DATA KAFKA 'URI'
|
||||
WITH TOPIC 'topic'
|
||||
WITH TRANSFORM 'URI'
|
||||
[BATCH_INTERVAL milliseconds]
|
||||
[BATCH_SIZE count]
|
||||
```
|
||||
The `CREATE STREAM` clause happens in a transaction.
|
||||
|
||||
`WITH TOPIC` parameter specifies the Kafka topic from which we'll stream
|
||||
data.
|
||||
|
||||
`WITH TRANSFORM` parameter should contain a URI of the transform script.
|
||||
We cover more about the transform script later, in the [transform](#transform)
|
||||
section.
|
||||
|
||||
`BATCH_INTERVAL` parameter defines the time interval in milliseconds
|
||||
which is the time between two successive stream importing operations.
|
||||
|
||||
`BATCH_SIZE` parameter defines the count of Kafka messages that will be
|
||||
batched together before import.
|
||||
|
||||
If both `BATCH_INTERVAL` and `BATCH_SIZE` parameters are given, the condition
|
||||
that is satisfied first will trigger the batched import.
|
||||
|
||||
Default value for `BATCH_INTERVAL` is 100 milliseconds, and the default value
|
||||
for `BATCH_SIZE` is 10.
|
||||
|
||||
The `DROP` clause deletes a stream:
|
||||
```opencypher
|
||||
DROP STREAM stream_name;
|
||||
```
|
||||
|
||||
The `SHOW` clause enables you to see all configured streams:
|
||||
```opencypher
|
||||
SHOW STREAMS;
|
||||
```
|
||||
|
||||
You can also start/stop streams with the `START` and `STOP` clauses:
|
||||
```opencypher
|
||||
START STREAM stream_name [LIMIT count BATCHES];
|
||||
STOP STREAM stream_name;
|
||||
```
|
||||
A stream needs to be stopped in order to start it and it needs to be started in
|
||||
order to stop it. Starting a started or stopping a stopped stream will not
|
||||
affect that stream.
|
||||
|
||||
There are also convenience clauses to start and stop all streams:
|
||||
```opencypher
|
||||
START ALL STREAMS;
|
||||
STOP ALL STREAMS;
|
||||
```
|
||||
|
||||
|
||||
Before the actual import, you can also test the stream with the `TEST
|
||||
STREAM` clause:
|
||||
```opencypher
|
||||
TEST STREAM stream_name [LIMIT count BATCHES];
|
||||
```
|
||||
When a stream is tested, data extraction and transformation occurs, but nothing
|
||||
is inserted into the graph.
|
||||
|
||||
A stream needs to be stopped in order to test it. When the batch limit is
|
||||
omitted, `TEST STREAM` will run for only one batch by default.
|
||||
|
||||
#### Transform
|
||||
|
||||
The transform script allows Memgraph users to have custom Kafka messages and
|
||||
still be able to import data in Memgraph by adding the logic to decode the
|
||||
messages in the transform script.
|
||||
|
||||
The entry point of the transform script from Memgraph is the `stream` function.
|
||||
Input for the `stream` function is a list of bytes that represent byte encoded
|
||||
Kafka messages, and the output of the `stream` function must be a list of
|
||||
tuples containing openCypher string queries and corresponding parameters stored
|
||||
in a dictionary.
|
||||
|
||||
To be more precise, the signature of the `stream` function looks like the
|
||||
following:
|
||||
```plaintext
|
||||
stream : [bytes] -> [(str, {str : type})]
|
||||
type : none | bool | int | float | str | list | dict
|
||||
```
|
||||
|
||||
An example of a simple transform script that creates vertices if the message
|
||||
contains one number (the vertex id) or it creates edges if the message contains
|
||||
two numbers (origin vertex id and destination vertex id) would look like the
|
||||
following:
|
||||
```python
|
||||
def create_vertex(vertex_id):
|
||||
return ("CREATE (:Node {id: $id})", {"id": vertex_id})
|
||||
|
||||
|
||||
def create_edge(from_id, to_id):
|
||||
return ("MATCH (n:Node {id: $from_id}), (m:Node {id: $to_id}) "\
|
||||
"CREATE (n)-[:Edge]->(m)", {"from_id": from_id, "to_id": to_id})
|
||||
|
||||
|
||||
def stream(batch):
|
||||
result = []
|
||||
for item in batch:
|
||||
message = item.decode('utf-8').split()
|
||||
if len(message) == 1:
|
||||
result.append(create_vertex(message[0]))
|
||||
elif len(message) == 2:
|
||||
result.append(create_edge(message[0], message[1]))
|
||||
return result
|
||||
```
|
||||
|
||||
#### Example
|
||||
|
||||
For this example, we assume you have a local instance of Kafka. You can find
|
||||
In this article, we assume you have a local instance of Kafka. You can find
|
||||
more about running Kafka [here](https://kafka.apache.org/quickstart).
|
||||
|
||||
From this point forth, we assume you have a instance of Kafka running on
|
||||
@ -143,6 +31,7 @@ Lets also assume the Kafka topic contains two types of messages:
|
||||
destination node id.
|
||||
|
||||
In order to create a stream input the following query in the client:
|
||||
|
||||
```opencypher
|
||||
CREATE STREAM mystream AS LOAD DATA KAFKA 'localhost:9092' WITH TOPIC 'test' WITH
|
||||
TRANSFORM 'http://localhost/transform.py'
|
||||
@ -154,21 +43,25 @@ exist, the query will fail with an appropriate message.
|
||||
|
||||
E.g. if the transform script can't be found at the given URI, the following
|
||||
error will be shown:
|
||||
|
||||
```plaintext
|
||||
Client received exception: Couldn't get the transform script from http://localhost/transform.py
|
||||
```
|
||||
Similar, if the given Kafka topic doesn't exist, we'll get the following:
|
||||
Similarly, if the given Kafka topic doesn't exist, we'll get the following:
|
||||
|
||||
```plaintext
|
||||
Client received exception: Kafka stream mystream, topic not found
|
||||
```
|
||||
|
||||
After a successful stream creation, you can check the status of all streams by
|
||||
executing:
|
||||
|
||||
```opencypher
|
||||
SHOW STREAMS
|
||||
```
|
||||
|
||||
This should produce the following output:
|
||||
|
||||
```plaintext
|
||||
+----------+----------------+-------+------------------------------+---------+
|
||||
| name | uri | topic | transform | status |
|
||||
@ -179,6 +72,7 @@ This should produce the following output:
|
||||
As you can notice, the status of this stream is stopped.
|
||||
|
||||
In order to see if everything is correct, you can test the stream by executing:
|
||||
|
||||
```opencypher
|
||||
TEST STREAM mystream;
|
||||
```
|
||||
@ -188,6 +82,7 @@ just output the result.
|
||||
|
||||
If the `test` Kafka topic would contain two messages, `1` and `1 2` the result
|
||||
of the `TEST STREAM` query would look like:
|
||||
|
||||
```plaintext
|
||||
+-------------------------------------------------------------------------------+-------------------------+
|
||||
| query | params |
|
||||
@ -198,11 +93,13 @@ of the `TEST STREAM` query would look like:
|
||||
```
|
||||
|
||||
To start ingesting data from a stream, you need to execute the following query:
|
||||
|
||||
```opencypher
|
||||
START STREAM mystream;
|
||||
```
|
||||
|
||||
If we check the stream status now, the output would look like this:
|
||||
|
||||
```plaintext
|
||||
+----------+----------------+-------+------------------------------+---------+
|
||||
| name | uri | topic | transform | status |
|
||||
@ -212,6 +109,7 @@ If we check the stream status now, the output would look like this:
|
||||
```
|
||||
|
||||
To stop ingesting data, the stop stream query needs to be executed:
|
||||
|
||||
```opencypher
|
||||
STOP STREAM mystream;
|
||||
```
|
||||
@ -1,858 +0,0 @@
|
||||
## openCypher Query Language
|
||||
|
||||
[*openCypher*](http://www.opencypher.org/) is a query language for querying
|
||||
graph databases. It aims to be intuitive and easy to learn, while
|
||||
providing a powerful interface for working with graph based data.
|
||||
|
||||
*Memgraph* supports most of the commonly used constructs of the language. This
|
||||
chapter contains the details of implemented features. Additionally,
|
||||
not yet supported features of the language are listed.
|
||||
|
||||
* [Reading Existing Data](#reading-existing-data)
|
||||
* [Writing New Data](#writing-new-data)
|
||||
* [Reading & Writing](#reading-amp-writing)
|
||||
* [Indexing](#indexing)
|
||||
* [Other Features](#other-features)
|
||||
|
||||
### Reading Existing Data
|
||||
|
||||
The simplest usage of the language is to find data stored in the
|
||||
database. For that purpose, the following clauses are offered:
|
||||
|
||||
* `MATCH`, which searches for patterns;
|
||||
* `WHERE`, for filtering the matched data and
|
||||
* `RETURN`, for defining what will be presented to the user in the result
|
||||
set.
|
||||
* `UNION` and `UNION ALL` for combining results from multiple queries.
|
||||
|
||||
#### MATCH
|
||||
|
||||
This clause is used to obtain data from Memgraph by matching it to a given
|
||||
pattern. For example, to find each node in the database, you can use the
|
||||
following query.
|
||||
|
||||
```opencypher
|
||||
MATCH (node) RETURN node
|
||||
```
|
||||
|
||||
Finding connected nodes can be achieved by using the query:
|
||||
|
||||
```opencypher
|
||||
MATCH (node1)-[connection]-(node2) RETURN node1, connection, node2
|
||||
```
|
||||
|
||||
In addition to general pattern matching, you can narrow the search down by
|
||||
specifying node labels and properties. Similarly, edge types and properties
|
||||
can also be specified. For example, finding each node labeled as `Person` and
|
||||
with property `age` being 42, is done with the following query.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person {age: 42}) RETURN n
|
||||
```
|
||||
|
||||
While their friends can be found with the following.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person {age: 42})-[:FriendOf]-(friend) RETURN friend
|
||||
```
|
||||
|
||||
There are cases when a user needs to find data which is connected by
|
||||
traversing a path of connections, but the user doesn't know how many
|
||||
connections need to be traversed. openCypher allows for designating patterns
|
||||
with *variable path lengths*. Matching such a path is achieved by using the
|
||||
`*` (*asterisk*) symbol inside the edge element of a pattern. For example,
|
||||
traversing from `node1` to `node2` by following any number of connections in a
|
||||
single direction can be achieved with:
|
||||
|
||||
```opencypher
|
||||
MATCH (node1)-[r*]->(node2) RETURN node1, r, node2
|
||||
```
|
||||
|
||||
If paths are very long, finding them could take a long time. To prevent that,
|
||||
a user can provide the minimum and maximum length of the path. For example,
|
||||
paths of length between 2 and 4 can be obtained with a query like:
|
||||
|
||||
```opencypher
|
||||
MATCH (node1)-[r*2..4]->(node2) RETURN node1, r, node2
|
||||
```
|
||||
|
||||
It is possible to name patterns in the query and return the resulting paths.
|
||||
This is especially useful when matching variable length paths:
|
||||
|
||||
```opencypher
|
||||
MATCH path = ()-[r*2..4]->() RETURN path
|
||||
```
|
||||
|
||||
More details on how `MATCH` works can be found
|
||||
[here](https://neo4j.com/docs/developer-manual/current/cypher/clauses/match/).
|
||||
|
||||
The `MATCH` clause can be modified by prepending the `OPTIONAL` keyword.
|
||||
`OPTIONAL MATCH` clause behaves the same as a regular `MATCH`, but when it
|
||||
fails to find the pattern, missing parts of the pattern will be filled with
|
||||
`null` values. Examples can be found
|
||||
[here](https://neo4j.com/docs/developer-manual/current/cypher/clauses/optional-match/).
|
||||
|
||||
#### WHERE
|
||||
|
||||
You have already seen that simple filtering can be achieved by using labels
|
||||
and properties in `MATCH` patterns. When more complex filtering is desired,
|
||||
you can use `WHERE` paired with `MATCH` or `OPTIONAL MATCH`. For example,
|
||||
finding each person older than 20 is done with the this query.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) WHERE n.age > 20 RETURN n
|
||||
```
|
||||
|
||||
Additional examples can be found
|
||||
[here](https://neo4j.com/docs/developer-manual/current/cypher/clauses/where/).
|
||||
|
||||
#### RETURN
|
||||
|
||||
The `RETURN` clause defines which data should be included in the resulting
|
||||
set. Basic usage was already shown in the examples for `MATCH` and `WHERE`
|
||||
clauses. Another feature of `RETURN` is renaming the results using the `AS`
|
||||
keyword.
|
||||
|
||||
Example.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) RETURN n AS people
|
||||
```
|
||||
|
||||
That query would display all nodes under the header named `people` instead of
|
||||
`n`.
|
||||
|
||||
When you want to get everything that was matched, you can use the `*`
|
||||
(*asterisk*) symbol.
|
||||
|
||||
This query:
|
||||
|
||||
```opencypher
|
||||
MATCH (node1)-[connection]-(node2) RETURN *
|
||||
```
|
||||
|
||||
is equivalent to:
|
||||
|
||||
```opencypher
|
||||
MATCH (node1)-[connection]-(node2) RETURN node1, connection, node2
|
||||
```
|
||||
|
||||
`RETURN` can be followed by the `DISTINCT` operator, which will remove
|
||||
duplicate results. For example, getting unique names of people can be achieved
|
||||
with:
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) RETURN DISTINCT n.name
|
||||
```
|
||||
|
||||
Besides choosing what will be the result and how it will be named, the
|
||||
`RETURN` clause can also be used to:
|
||||
|
||||
* limit results with `LIMIT` sub-clause;
|
||||
* skip results with `SKIP` sub-clause;
|
||||
* order results with `ORDER BY` sub-clause and
|
||||
* perform aggregations (such as `count`).
|
||||
|
||||
More details on `RETURN` can be found
|
||||
[here](https://neo4j.com/docs/developer-manual/current/cypher/clauses/return/).
|
||||
|
||||
##### SKIP & LIMIT
|
||||
|
||||
These sub-clauses take a number of how many results to skip or limit.
|
||||
For example, to get the first 3 results you can use this query.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) RETURN n LIMIT 3
|
||||
```
|
||||
|
||||
If you want to get all the results after the first 3, you can use the
|
||||
following.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) RETURN n SKIP 3
|
||||
```
|
||||
|
||||
The `SKIP` and `LIMIT` can be combined. So for example, to get the 2nd result,
|
||||
you can do:
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) RETURN n SKIP 1 LIMIT 1
|
||||
```
|
||||
|
||||
##### ORDER BY
|
||||
|
||||
Since the patterns which are matched can come in any order, it is very useful
|
||||
to be able to enforce some ordering among the results. In such cases, you can
|
||||
use the `ORDER BY` sub-clause.
|
||||
|
||||
For example, the following query will get all `:Person` nodes and order them
|
||||
by their names.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) RETURN n ORDER BY n.name
|
||||
```
|
||||
|
||||
By default, ordering will be in the ascending order. To change the order to be
|
||||
descending, you should append `DESC`.
|
||||
|
||||
For example, to order people by their name descending, you can use this query.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) RETURN n ORDER BY n.name DESC
|
||||
```
|
||||
|
||||
You can also order by multiple variables. The results will be sorted by the
|
||||
first variable listed. If the values are equal, the results are sorted by the
|
||||
second variable, and so on.
|
||||
|
||||
Example. Ordering by first name descending and last name ascending.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) RETURN n ORDER BY n.name DESC, n.lastName
|
||||
```
|
||||
|
||||
Note that `ORDER BY` sees only the variable names as carried over by `RETURN`.
|
||||
This means that the following will result in an error.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) RETURN old AS new ORDER BY old.name
|
||||
```
|
||||
|
||||
Instead, the `new` variable must be used:
|
||||
|
||||
```opencypher
|
||||
MATCH (n: Person) RETURN old AS new ORDER BY new.name
|
||||
```
|
||||
|
||||
The `ORDER BY` sub-clause may come in handy with `SKIP` and/or `LIMIT`
|
||||
sub-clauses. For example, to get the oldest person you can use the following.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) RETURN n ORDER BY n.age DESC LIMIT 1
|
||||
```
|
||||
|
||||
##### Aggregating
|
||||
|
||||
openCypher has functions for aggregating data. Memgraph currently supports
|
||||
the following aggregating functions.
|
||||
|
||||
* `avg`, for calculating the average.
|
||||
* `collect`, for collecting multiple values into a single list or map. If given a single expression values are collected into a list. If given two expressions, values are collected into a map where the first expression denotes map keys (must be string values) and the second expression denotes map values.
|
||||
* `count`, for counting the resulting values.
|
||||
* `max`, for calculating the maximum result.
|
||||
* `min`, for calculating the minimum result.
|
||||
* `sum`, for getting the sum of numeric results.
|
||||
|
||||
Example, calculating the average age:
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) RETURN avg(n.age) AS averageAge
|
||||
```
|
||||
|
||||
Collecting items into a list:
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) RETURN collect(n.name) AS list_of_names
|
||||
```
|
||||
|
||||
Collecting items into a map:
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) RETURN collect(n.name, n.age) AS map_name_to_age
|
||||
```
|
||||
|
||||
Click
|
||||
[here](https://neo4j.com/docs/developer-manual/current/cypher/functions/aggregating/)
|
||||
for additional details on how aggregations work.
|
||||
|
||||
#### UNION and UNION ALL
|
||||
|
||||
openCypher supports combining results from multiple queries into a single result
|
||||
set. That result will contain rows that belong to queries in the union
|
||||
respecting the union type.
|
||||
|
||||
Using `UNION` will contain only distinct rows while `UNION ALL` will keep all
|
||||
rows from all given queries.
|
||||
|
||||
Restrictions when using `UNION` or `UNION ALL`:
|
||||
* The number and the names of columns returned by queries must be the same
|
||||
for all of them.
|
||||
* There can be only one union type between single queries, i.e. a query can't
|
||||
contain both `UNION` and `UNION ALL`.
|
||||
|
||||
Example, get distinct names that are shared between persons and movies:
|
||||
|
||||
```opencypher
|
||||
MATCH(n: Person) RETURN n.name AS name UNION MATCH(n: Movie) RETURN n.name AS name
|
||||
```
|
||||
|
||||
Example, get all names that are shared between persons and movies (including duplicates):
|
||||
|
||||
```opencypher
|
||||
MATCH(n: Person) RETURN n.name AS name UNION ALL MATCH(n: Movie) RETURN n.name AS name
|
||||
```
|
||||
|
||||
### Writing New Data
|
||||
|
||||
For adding new data, you can use the following clauses.
|
||||
|
||||
* `CREATE`, for creating new nodes and edges.
|
||||
* `SET`, for adding new or updating existing labels and properties.
|
||||
* `DELETE`, for deleting nodes and edges.
|
||||
* `REMOVE`, for removing labels and properties.
|
||||
|
||||
You can still use the `RETURN` clause to produce results after writing, but it
|
||||
is not mandatory.
|
||||
|
||||
Details on which kind of data can be stored in *Memgraph* can be found in
|
||||
[Data Storage](storage.md) chapter.
|
||||
|
||||
#### CREATE
|
||||
|
||||
This clause is used to add new nodes and edges to the database. The creation
|
||||
is done by providing a pattern, similarly to `MATCH` clause.
|
||||
|
||||
For example, to create 2 new nodes connected with a new edge, use this query.
|
||||
|
||||
```opencypher
|
||||
CREATE (node1)-[:edge_type]->(node2)
|
||||
```
|
||||
|
||||
Labels and properties can be set during creation using the same syntax as in
|
||||
[MATCH](#match) patterns. For example, creating a node with a label and a
|
||||
property:
|
||||
|
||||
```opencypher
|
||||
CREATE (node :Label {property: "my property value"})
|
||||
```
|
||||
|
||||
Additional information on `CREATE` is
|
||||
[here](https://neo4j.com/docs/developer-manual/current/cypher/clauses/create/).
|
||||
|
||||
#### SET
|
||||
|
||||
The `SET` clause is used to update labels and properties of already existing
|
||||
data.
|
||||
|
||||
Example. Incrementing everyone's age by 1.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) SET n.age = n.age + 1
|
||||
```
|
||||
|
||||
Click
|
||||
[here](https://neo4j.com/docs/developer-manual/current/cypher/clauses/create/)
|
||||
for a more detailed explanation on what can be done with `SET`.
|
||||
|
||||
#### DELETE
|
||||
|
||||
This clause is used to delete nodes and edges from the database.
|
||||
|
||||
Example. Removing all edges of a single type.
|
||||
|
||||
```opencypher
|
||||
MATCH ()-[edge :type]-() DELETE edge
|
||||
```
|
||||
|
||||
When testing the database, you want to often have a clean start by deleting
|
||||
every node and edge in the database. It is reasonable that deleting each node
|
||||
should delete all edges coming into or out of that node.
|
||||
|
||||
```opencypher
|
||||
MATCH (node) DELETE node
|
||||
```
|
||||
|
||||
But, openCypher prevents accidental deletion of edges. Therefore, the above
|
||||
query will report an error. Instead, you need to use the `DETACH` keyword,
|
||||
which will remove edges from a node you are deleting. The following should
|
||||
work and *delete everything* in the database.
|
||||
|
||||
```opencypher
|
||||
MATCH (node) DETACH DELETE node
|
||||
```
|
||||
|
||||
More examples are
|
||||
[here](https://neo4j.com/docs/developer-manual/current/cypher/clauses/delete/).
|
||||
|
||||
#### REMOVE
|
||||
|
||||
The `REMOVE` clause is used to remove labels and properties from nodes and
|
||||
edges.
|
||||
|
||||
Example.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :WrongLabel) REMOVE n :WrongLabel, n.property
|
||||
```
|
||||
|
||||
### Reading & Writing
|
||||
|
||||
OpenCypher supports combining multiple reads and writes using the
|
||||
`WITH` clause. In addition to combining, the `MERGE` clause is provided which
|
||||
may create patterns if they do not exist.
|
||||
|
||||
#### WITH
|
||||
|
||||
The write part of the query cannot be simply followed by another read part. In
|
||||
order to combine them, `WITH` clause must be used. The names this clause
|
||||
establishes are transferred from one part to another.
|
||||
|
||||
For example, creating a node and finding all nodes with the same property.
|
||||
|
||||
```opencypher
|
||||
CREATE (node {property: 42}) WITH node.property AS propValue
|
||||
MATCH (n {property: propValue}) RETURN n
|
||||
```
|
||||
|
||||
Note that the `node` is not visible after `WITH`, since only `node.property`
|
||||
was carried over.
|
||||
|
||||
This clause behaves very much like `RETURN`, so you should refer to features
|
||||
of `RETURN`.
|
||||
|
||||
#### MERGE
|
||||
|
||||
The `MERGE` clause is used to ensure that a pattern you are looking for exists
|
||||
in the database. This means that if the pattern is not found, it will be
|
||||
created. In a way, this clause is like a combination of `MATCH` and `CREATE`.
|
||||
|
||||
|
||||
Example. Ensure that a person has at least one friend.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) MERGE (n)-[:FriendOf]->(m)
|
||||
```
|
||||
|
||||
The clause also provides additional features for updating the values depending
|
||||
on whether the pattern was created or matched. This is achieved with `ON
|
||||
CREATE` and `ON MATCH` sub clauses.
|
||||
|
||||
Example. Set a different properties depending on what `MERGE` did.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) MERGE (n)-[:FriendOf]->(m)
|
||||
ON CREATE SET m.prop = "created" ON MATCH SET m.prop = "existed"
|
||||
```
|
||||
|
||||
For more details, click [this
|
||||
link](https://neo4j.com/docs/developer-manual/current/cypher/clauses/merge/).
|
||||
|
||||
### Indexing
|
||||
|
||||
An index stores additional information on certain types of data, so that
|
||||
retrieving said data becomes more efficient. Downsides of indexing are:
|
||||
|
||||
* requiring extra storage for each index and
|
||||
* slowing down writes to the database.
|
||||
|
||||
Carefully choosing which data to index can tremendously improve data retrieval
|
||||
efficiency, and thus make index downsides negligible.
|
||||
|
||||
Memgraph automatically indexes labeled data. This improves queries
|
||||
which fetch nodes by label:
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Label) ... RETURN n
|
||||
```
|
||||
|
||||
Indexing can also be applied to data with a specific combination of label and
|
||||
property. These are not automatically created, instead a user needs to create
|
||||
them explicitly. Creation is done using a special
|
||||
`CREATE INDEX ON :Label(property)` language construct.
|
||||
|
||||
For example, to index nodes which is labeled as `:Person` and has a property
|
||||
named `age`:
|
||||
|
||||
```opencypher
|
||||
CREATE INDEX ON :Person(age)
|
||||
```
|
||||
|
||||
After the index is created, retrieving those nodes will become more efficient.
|
||||
For example, the following query will retrieve all nodes which have an `age`
|
||||
property, instead of fetching each `:Person` node and checking whether the
|
||||
property exists.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person {age: 42}) RETURN n
|
||||
```
|
||||
|
||||
Using index based retrieval also works when filtering labels and properties
|
||||
with `WHERE`. For example, the same effect as in the previous example can be
|
||||
done with:
|
||||
|
||||
```opencypher
|
||||
MATCH (n) WHERE n:Person AND n.age = 42 RETURN n
|
||||
```
|
||||
|
||||
Since the filter inside `WHERE` can contain any kind of an expression, the
|
||||
expression can be complicated enough so that the index does not get used. We
|
||||
are continuously improving the recognition of index usage opportunities from a
|
||||
`WHERE` expression. If there is any suspicion that an index may not be used,
|
||||
we recommend putting properties and labels inside the `MATCH` pattern.
|
||||
|
||||
Currently, once an index is created it cannot be deleted. This feature will be
|
||||
implemented very soon. The expected syntax for removing an index will be `DROP
|
||||
INDEX ON :Label(property)`.
|
||||
|
||||
### Other Features
|
||||
|
||||
The following sections describe some of the other supported features.
|
||||
|
||||
#### Filtering Variable Length Paths
|
||||
|
||||
OpenCypher supports only simple filtering when matching variable length paths.
|
||||
For example:
|
||||
|
||||
```opencypher
|
||||
MATCH (n)-[edge_list:Type * {x: 42}]-(m)
|
||||
```
|
||||
|
||||
This will produce only those paths whose edges have the required `Type` and `x`
|
||||
property value. Edges that compose the produced paths are stored in a symbol
|
||||
named `edge_list`. Naturally, the user could have specified any other symbol
|
||||
name.
|
||||
|
||||
Memgraph extends openCypher with a syntax for arbitrary filter expressions
|
||||
during path matching. The next example filters edges which have property `x`
|
||||
between `0` and `10`.
|
||||
|
||||
```opencypher
|
||||
MATCH (n)-[edge_list * (edge, node | 0 < edge.x < 10)]-(m)
|
||||
```
|
||||
|
||||
Here we introduce a lambda function with parentheses, where the first two
|
||||
arguments, `edge` and `node`, correspond to each edge and node during path
|
||||
matching. `node` is the destination node we are moving to across the current
|
||||
`edge`. The last `node` value will be the same value as `m`. Following the
|
||||
pipe (`|`) character is an arbitrary expression which must produce a boolean
|
||||
value. If `True`, matching continues, otherwise the path is discarded.
|
||||
|
||||
The previous example can be written using the `all` function:
|
||||
|
||||
```opencypher
|
||||
MATCH (n)-[edge_list *]-(m) WHERE all(edge IN edge_list WHERE 0 < edge.x < 10)
|
||||
```
|
||||
|
||||
However, filtering using a lambda function is more efficient because paths
|
||||
may be discarded earlier in the traversal. Furthermore, it provides more
|
||||
flexibility for deciding what kind of paths are matched due to more expressive
|
||||
filtering capabilities. Therefore, filtering through lambda functions should
|
||||
be preferred whenever possible.
|
||||
|
||||
#### Breadth First Search
|
||||
|
||||
A typical graph use-case is searching for the shortest path between nodes.
|
||||
The openCypher standard does not define this feature, so Memgraph provides
|
||||
a custom implementation, based on the edge expansion syntax.
|
||||
|
||||
Finding the shortest path between nodes can be done using breadth-first
|
||||
expansion:
|
||||
|
||||
```opencypher
|
||||
MATCH (a {id: 723})-[edge_list:Type *bfs..10]-(b {id: 882}) RETURN *
|
||||
```
|
||||
|
||||
The above query will find all paths of length up to 10 between nodes `a` and `b`.
|
||||
The edge type and maximum path length are used in the same way like in variable
|
||||
length expansion.
|
||||
|
||||
To find only the shortest path, simply append `LIMIT 1` to the `RETURN` clause.
|
||||
|
||||
```opencypher
|
||||
MATCH (a {id: 723})-[edge_list:Type *bfs..10]-(b {id: 882}) RETURN * LIMIT 1
|
||||
```
|
||||
|
||||
Breadth-first expansion allows an arbitrary expression filter that determines
|
||||
if an expansion is allowed. Following is an example in which expansion is
|
||||
allowed only over edges whose `x` property is greater than `12` and nodes `y`
|
||||
whose property is less than `3`:
|
||||
|
||||
```opencypher
|
||||
MATCH (a {id: 723})-[*bfs..10 (e, n | e.x > 12 AND n.y < 3)]-() RETURN *
|
||||
```
|
||||
|
||||
The filter is defined as a lambda function over `e` and `n`, which denote the edge
|
||||
and node being expanded over in the breadth first search. Note that if the user
|
||||
omits the edge list symbol (`edge_list` in previous examples) it will not be included
|
||||
in the result.
|
||||
|
||||
There are a few benefits of the breadth-first expansion approach, as opposed to
|
||||
a specialized `shortestPath` function. For one, it is possible to inject
|
||||
expressions that filter on nodes and edges along the path itself, not just the final
|
||||
destination node. Furthermore, it's possible to find multiple paths to multiple destination
|
||||
nodes regardless of their length. Also, it is possible to simply go through a node's
|
||||
neighbourhood in breadth-first manner.
|
||||
|
||||
Currently, it isn't possible to get all shortest paths to a single node using
|
||||
Memgraph's breadth-first expansion.
|
||||
|
||||
#### Weighted Shortest Path
|
||||
|
||||
Another standard use-case in a graph is searching for the weighted shortest
|
||||
path between nodes. The openCypher standard does not define this feature, so
|
||||
Memgraph provides a custom implementation, based on the edge expansion syntax.
|
||||
|
||||
Finding the weighted shortest path between nodes is done using the weighted
|
||||
shortest path expansion:
|
||||
|
||||
```opencypher
|
||||
MATCH (a {id: 723})-[
|
||||
edge_list *wShortest 10 (e, n | e.weight) total_weight
|
||||
]-(b {id: 882})
|
||||
RETURN *
|
||||
```
|
||||
|
||||
The above query will find the shortest path of length up to 10 nodes between
|
||||
nodes `a` and `b`. The length restriction parameter is optional.
|
||||
|
||||
Weighted Shortest Path expansion allows an arbitrary expression that determines
|
||||
the weight for the current expansion. Total weight of a path is calculated as
|
||||
the sum of all weights on the path between two nodes. Following is an example in
|
||||
which the weight between nodes is defined as the product of edge weights
|
||||
(instead of sum), assuming all weights are greater than '1':
|
||||
|
||||
```opencypher
|
||||
MATCH (a {id: 723})-[
|
||||
edge_list *wShortest 10 (e, n | log(e.weight)) total_weight
|
||||
]-(b {id: 882})
|
||||
RETURN exp(total_weight)
|
||||
```
|
||||
|
||||
Weighted Shortest Path expansions also allows an arbitrary expression filter
|
||||
that determines if an expansion is allowed. Following is an example in which
|
||||
expansion is allowed only over edges whose `x` property is greater than `12`
|
||||
and nodes `y` whose property is less than `3`:
|
||||
|
||||
```opencypher
|
||||
MATCH (a {id: 723})-[
|
||||
edge_list *wShortest 10 (e, n | e.weight) total_weight (e, n | e.x > 12 AND n.y < 3)
|
||||
]-(b {id: 882})
|
||||
RETURN exp(total_weight)
|
||||
```
|
||||
|
||||
Both weight and filter expression are defined as lambda functions over `e` and
|
||||
`n`, which denote the edge and the node being expanded over in the weighted
|
||||
shortest path search.
|
||||
|
||||
#### UNWIND
|
||||
|
||||
The `UNWIND` clause is used to unwind a list of values as individual rows.
|
||||
|
||||
Example. Produce rows out of a single list.
|
||||
|
||||
```opencypher
|
||||
UNWIND [1,2,3] AS listElement RETURN listElement
|
||||
```
|
||||
|
||||
More examples are
|
||||
[here](https://neo4j.com/docs/developer-manual/current/cypher/clauses/unwind/).
|
||||
|
||||
#### Functions
|
||||
|
||||
You have already been introduced to one type of functions, [aggregating
|
||||
functions](#aggregating). This section contains the list of other supported
|
||||
functions.
|
||||
|
||||
Name | Description
|
||||
-----------------|------------
|
||||
`coalesce` | Returns the first non null argument.
|
||||
`startNode` | Returns the starting node of an edge.
|
||||
`endNode` | Returns the destination node of an edge.
|
||||
`degree` | Returns the number of edges (both incoming and outgoing) of a node.
|
||||
`head` | Returns the first element of a list.
|
||||
`last` | Returns the last element of a list.
|
||||
`properties` | Returns the properties of a node or an edge.
|
||||
`size` | Returns the number of elements in a list or a map. When given a string it returns the number of characters. When given a path it returns the number of expansions (edges) in that path.
|
||||
`toBoolean` | Converts the argument to a boolean.
|
||||
`toFloat` | Converts the argument to a floating point number.
|
||||
`toInteger` | Converts the argument to an integer.
|
||||
`type` | Returns the type of an edge as a character string.
|
||||
`keys` | Returns a list keys of properties from an edge or a node. Each key is represented as a string of characters.
|
||||
`labels` | Returns a list of labels from a node. Each label is represented as a character string.
|
||||
`nodes` | Returns a list of nodes from a path.
|
||||
`relationships` | Returns a list of relationships (edges) from a path.
|
||||
`range` | Constructs a list of value in given range.
|
||||
`tail` | Returns all elements after the first of a given list.
|
||||
`abs` | Returns the absolute value of a number.
|
||||
`ceil` | Returns the smallest integer greater than or equal to given number.
|
||||
`floor` | Returns the largest integer smaller than or equal to given number.
|
||||
`round` | Returns the number, rounded to the nearest integer. Tie-breaking is done using the *commercial rounding*, where -1.5 produces -2 and 1.5 produces 2.
|
||||
`exp` | Calculates `e^n` where `e` is the base of the natural logarithm, and `n` is the given number.
|
||||
`log` | Calculates the natural logarithm of a given number.
|
||||
`log10` | Calculates the logarithm (base 10) of a given number.
|
||||
`sqrt` | Calculates the square root of a given number.
|
||||
`acos` | Calculates the arccosine of a given number.
|
||||
`asin` | Calculates the arcsine of a given number.
|
||||
`atan` | Calculates the arctangent of a given number.
|
||||
`atan2` | Calculates the arctangent2 of a given number.
|
||||
`cos` | Calculates the cosine of a given number.
|
||||
`sin` | Calculates the sine of a given number.
|
||||
`tan` | Calculates the tangent of a given number.
|
||||
`sign` | Applies the signum function to a given number and returns the result. The signum of positive numbers is 1, of negative -1 and for 0 returns 0.
|
||||
`e` | Returns the base of the natural logarithm.
|
||||
`pi` | Returns the constant *pi*.
|
||||
`rand` | Returns a random floating point number between 0 (inclusive) and 1 (exclusive).
|
||||
`startsWith` | Check if the first argument starts with the second.
|
||||
`endsWith` | Check if the first argument ends with the second.
|
||||
`contains` | Check if the first argument has an element which is equal to the second argument.
|
||||
`left` | Returns a string containing the specified number of leftmost characters of the original string.
|
||||
`lTrim` | Returns the original string with leading whitespace removed.
|
||||
`replace` | Returns a string in which all occurrences of a specified string in the original string have been replaced by another (specified) string.
|
||||
`reverse` | Returns a string in which the order of all characters in the original string have been reversed.
|
||||
`right` | Returns a string containing the specified number of rightmost characters of the original string.
|
||||
`rTrim` | Returns the original string with trailing whitespace removed.
|
||||
`split` | Returns a list of strings resulting from the splitting of the original string around matches of the given delimiter.
|
||||
`substring` | Returns a substring of the original string, beginning with a 0-based index start and length.
|
||||
`toLower` | Returns the original string in lowercase.
|
||||
`toString` | Converts an integer, float or boolean value to a string.
|
||||
`toUpper` | Returns the original string in uppercase.
|
||||
`trim` | Returns the original string with leading and trailing whitespace removed.
|
||||
`all` | Check if all elements of a list satisfy a predicate.<br/>The syntax is: `all(variable IN list WHERE predicate)`.<br/> NOTE: Whenever possible, use Memgraph's lambda functions when [matching](#filtering-variable-length-paths) instead.
|
||||
`single` | Check if only one element of a list satisfies a predicate.<br/>The syntax is: `single(variable IN list WHERE predicate)`.
|
||||
`reduce` | Accumulate list elements into a single result by applying an expression. The syntax is:<br/>`reduce(accumulator = initial_value, variable IN list | expression)`.
|
||||
`extract` | A list of values obtained by evaluating an expression for each element in list. The syntax is:<br>`extract(variable IN list | expression)`.
|
||||
`assert` | Raises an exception reported to the client if the given argument is not `true`.
|
||||
`counter` | Generates integers that are guaranteed to be unique on the database level, for the given counter name.
|
||||
`counterSet` | Sets the counter with the given name to the given value.
|
||||
`indexInfo` | Returns a list of all the indexes available in the database. The list includes indexes that are not yet ready for use (they are concurrently being built by another transaction).
|
||||
`timestamp` | Returns the difference, measured in milliseconds, between the current time and midnight, January 1, 1970 UTC.
|
||||
`id` | Returns identifier for a given node or edge. The identifier is generated during the initialization of node or edge and will be persisted through the durability mechanism.
|
||||
|
||||
#### String Operators
|
||||
|
||||
Apart from comparison and concatenation operators openCypher provides special
|
||||
string operators for easier matching of substrings:
|
||||
|
||||
Operator | Description
|
||||
-------------------|------------
|
||||
`a STARTS WITH b` | Returns true if prefix of string a is equal to string b.
|
||||
`a ENDS WITH b` | Returns true if suffix of string a is equal to string b.
|
||||
`a CONTAINS b` | Returns true if some substring of string a is equal to string b.
|
||||
|
||||
#### Parameters
|
||||
|
||||
When automating the queries for Memgraph, it comes in handy to change only
|
||||
some parts of the query. Usually, these parts are values which are used for
|
||||
filtering results or similar, while the rest of the query remains the same.
|
||||
|
||||
Parameters allow reusing the same query, but with different parameter values.
|
||||
The syntax uses the `$` symbol to designate a parameter name. We don't allow
|
||||
old Cypher parameter syntax using curly braces. For example, you can parameterize
|
||||
filtering a node property:
|
||||
|
||||
```opencypher
|
||||
MATCH (node1 {property: $propertyValue}) RETURN node1
|
||||
```
|
||||
|
||||
You can use parameters instead of any literal in the query, but not instead of
|
||||
property maps even though that is allowed in standard openCypher. Following
|
||||
example is illegal in Memgraph:
|
||||
|
||||
```opencypher
|
||||
MATCH (node1 $propertyValue) RETURN node1
|
||||
```
|
||||
|
||||
To use parameters with Python driver use following syntax:
|
||||
|
||||
```python
|
||||
session.run('CREATE (alice:Person {name: $name, age: $ageValue}',
|
||||
name='Alice', ageValue=22)).consume()
|
||||
```
|
||||
|
||||
To use parameters which names are integers you will need to wrap parameters in
|
||||
a dictionary and convert them to strings before running a query:
|
||||
|
||||
```python
|
||||
session.run('CREATE (alice:Person {name: $0, age: $1}',
|
||||
{'0': "Alice", '1': 22})).consume()
|
||||
```
|
||||
|
||||
To use parameters with some other driver please consult appropriate
|
||||
documentation.
|
||||
|
||||
#### CASE
|
||||
|
||||
Conditional expressions can be expressed in openCypher language by simple and
|
||||
generic form of `CASE` expression. A simple form is used to compare an expression
|
||||
against multiple predicates. For the first matched predicate result of the
|
||||
expression provided after the `THEN` keyword is returned. If no expression is
|
||||
matched value following `ELSE` is returned is provided, or `null` if `ELSE` is not
|
||||
used:
|
||||
|
||||
```opencypher
|
||||
MATCH (n)
|
||||
RETURN CASE n.currency WHEN "DOLLAR" THEN "$" WHEN "EURO" THEN "€" ELSE "UNKNOWN" END
|
||||
```
|
||||
|
||||
In generic form, you don't need to provide an expression whose value is compared to
|
||||
predicates, but you can list multiple predicates and the first one that evaluates
|
||||
to true is matched:
|
||||
|
||||
```opencypher
|
||||
MATCH (n)
|
||||
RETURN CASE WHEN n.height < 30 THEN "short" WHEN n.height > 300 THEN "tall" END
|
||||
```
|
||||
|
||||
### Differences
|
||||
|
||||
Although we try to implement openCypher query language as closely to the
|
||||
language reference as possible, we had to make some changes to enhance the
|
||||
user experience.
|
||||
|
||||
#### Symbolic Names
|
||||
|
||||
We don't allow symbolic names (variables, label names...) to be openCypher
|
||||
keywords (WHERE, MATCH, COUNT, SUM...).
|
||||
|
||||
#### Unicode Codepoints in String Literal
|
||||
|
||||
Use `\u` followed by 4 hex digits in string literal for UTF-16 codepoint and
|
||||
`\U` with 8 hex digits for UTF-32 codepoint in Memgraph.
|
||||
|
||||
|
||||
### Difference from Neo4j's Cypher Implementation
|
||||
|
||||
The openCypher initiative stems from Neo4j's Cypher query language. Following is a list
|
||||
of most important differences between Neo's Cypher and Memgraph's openCypher implementation,
|
||||
for users that are already familiar with Neo4j. There might be other differences not documented
|
||||
here (especially subtle semantic ones).
|
||||
|
||||
#### Unsupported Constructs
|
||||
|
||||
* Data importing. Memgraph doesn't support Cypher's CSV importing capabilities.
|
||||
* The `FOREACH` language construct for performing an operation on every list element.
|
||||
* The `CALL` construct for a standalone function call. This can be expressed using
|
||||
`RETURN functioncall()`. For example, with Memgraph you can get information about
|
||||
the indexes present in the database using the `RETURN indexinfo()` openCypher query.
|
||||
* Stored procedures.
|
||||
* Regular expressions for string matching.
|
||||
* `shortestPath` and `allShortestPaths` functions. `shortestPath` can be expressed using
|
||||
Memgraph's breadth-first expansion syntax already described in this document.
|
||||
* Patterns in expressions. For example, Memgraph doesn't support `size((n)-->())`. Most of the time
|
||||
the same functionalities can be expressed differently in Memgraph using `OPTIONAL` expansions,
|
||||
function calls etc.
|
||||
* Map projections such as `MATCH (n) RETURN n {.property1, .property2}`.
|
||||
|
||||
#### Unsupported Functions
|
||||
|
||||
General purpose functions:
|
||||
|
||||
* `exists(n.property)` - This can be expressed using `n.property IS NOT NULL`.
|
||||
* `length()` is named `size()` in Memgraph.
|
||||
|
||||
Aggregation functions:
|
||||
|
||||
* `count(DISTINCT variable)` - This can be expressed using `WITH DISTINCT variable RETURN count(variable)`.
|
||||
|
||||
Mathematical functions:
|
||||
|
||||
* `percentileDisc()`
|
||||
* `stDev()`
|
||||
* `point()`
|
||||
* `distance()`
|
||||
* `degrees()`
|
||||
|
||||
List functions:
|
||||
|
||||
* `any()`
|
||||
* `none()`
|
||||
@ -1,282 +0,0 @@
|
||||
## Quick Start
|
||||
|
||||
This chapter outlines installing and running Memgraph, as well as executing
|
||||
basic queries against the database.
|
||||
|
||||
### Installation
|
||||
|
||||
The Memgraph binary is offered as:
|
||||
|
||||
* Debian package for Debian 9 (Stretch);
|
||||
* RPM package for CentOS 7 and
|
||||
* Docker image.
|
||||
|
||||
After downloading the binary, proceed to the corresponding section below.
|
||||
|
||||
NOTE: Currently, newer versions of Memgraph are not backward compatible with
|
||||
older versions. This is mainly noticeable by unsupported loading of storage
|
||||
snapshots between different versions.
|
||||
|
||||
#### Docker Installation
|
||||
|
||||
Before proceeding with the installation, please install the Docker engine on
|
||||
the system. Instructions on how to install Docker can be found on the
|
||||
[official Docker website](https://docs.docker.com/engine/installation).
|
||||
Memgraph Docker image was built with Docker version `1.12` and should be
|
||||
compatible with all later versions.
|
||||
|
||||
After installing and running Docker, download the Memgraph Docker image and
|
||||
import it with the following command.
|
||||
|
||||
```bash
|
||||
docker load -i /path/to/memgraph-<version>-docker.tar.gz
|
||||
```
|
||||
|
||||
Memgraph is then started with another docker command.
|
||||
|
||||
```bash
|
||||
docker run -p 7687:7687 \
|
||||
-v mg_lib:/var/lib/memgraph -v mg_log:/var/log/memgraph -v mg_etc:/etc/memgraph \
|
||||
memgraph
|
||||
```
|
||||
|
||||
On success, expect to see output similar to the following.
|
||||
|
||||
```bash
|
||||
Starting 8 workers
|
||||
Server is fully armed and operational
|
||||
Listening on 0.0.0.0 at 7687
|
||||
```
|
||||
|
||||
Memgraph is now ready to process queries, you may now proceed to
|
||||
[querying](#querying). To stop Memgraph, press `Ctrl-c`.
|
||||
|
||||
Memgraph configuration is available in Docker's named volume `mg_etc`. On
|
||||
Linux systems it should be in
|
||||
`/var/lib/docker/volumes/mg_etc/_data/memgraph.conf`. After changing the
|
||||
configuration, Memgraph needs to be restarted.
|
||||
|
||||
##### Note about named volumes
|
||||
|
||||
In case named volumes are reused between different versions of Memgraph, a user
|
||||
has to be careful because Docker will overwrite a folder within the container
|
||||
with existing data from the host machine. In the case where a new file is
|
||||
introduced, or two versions of Memgraph are not compatible, the new feature
|
||||
won't work or Memgraph won't be able to work correctly. The easiest way to
|
||||
solve the issue is to use another named volume or to remove existing named
|
||||
volume from the host with the following command.
|
||||
|
||||
```bash
|
||||
docker volume rm <volume_name>
|
||||
```
|
||||
|
||||
Named Docker volumes used in this documentation are: `mg_etc`, `mg_log` and
|
||||
`mg_lib`. E.g. to avoid any configuration issues between different Memgraph
|
||||
versions, `docker volume rm mg_etc` can be executed before running a new
|
||||
container.
|
||||
|
||||
Another valid option is to try to migrate your existing volume to a
|
||||
newer version of Memgraph. In case of any issues, send an email to
|
||||
`tech@memgraph.com`.
|
||||
|
||||
##### Note for OS X/macOS Users
|
||||
|
||||
Although unlikely, some OS X/macOS users might experience minor difficulties
|
||||
after following the Docker installation instructions. Instead of running on
|
||||
`localhost`, a Docker container for Memgraph might be running on a custom IP
|
||||
address. Fortunately, that IP address can be found using the following
|
||||
algorithm:
|
||||
|
||||
1) Find out the container ID of the Memgraph container
|
||||
|
||||
By issuing the command `docker ps` the user should get an output similar to the
|
||||
following:
|
||||
|
||||
```bash
|
||||
CONTAINER ID IMAGE COMMAND CREATED ...
|
||||
9397623cd87e memgraph "/usr/lib/memgraph/m…" 2 seconds ago ...
|
||||
```
|
||||
|
||||
At this point, it is important to remember the container ID of the Memgraph
|
||||
image. In our case, that is `9397623cd87e`.
|
||||
|
||||
2) Use the container ID to retrieve an IP of the container
|
||||
|
||||
```bash
|
||||
docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' 9397623cd87e
|
||||
```
|
||||
|
||||
The command above should yield the sought IP. If that IP does not correspond to
|
||||
`localhost`, it should be used instead of `localhost` when firing up the
|
||||
`neo4j-client` in the [querying](#querying) section.
|
||||
|
||||
#### Debian Package Installation
|
||||
|
||||
After downloading Memgraph as a Debian package, install it by running the
|
||||
following.
|
||||
|
||||
```bash
|
||||
dpkg -i /path/to/memgraph_<version>.deb
|
||||
```
|
||||
|
||||
If the installation was successful, Memgraph should already be running. To
|
||||
make sure that is true, start it explicitly with the command:
|
||||
|
||||
```bash
|
||||
systemctl start memgraph
|
||||
```
|
||||
|
||||
To verify that Memgraph is running, run the following command.
|
||||
|
||||
```bash
|
||||
journalctl --unit memgraph
|
||||
```
|
||||
|
||||
It is expected to see something like the following output.
|
||||
|
||||
```bash
|
||||
Nov 23 13:40:13 hostname memgraph[14654]: Starting 8 BoltS workers
|
||||
Nov 23 13:40:13 hostname memgraph[14654]: BoltS server is fully armed and operational
|
||||
Nov 23 13:40:13 hostname memgraph[14654]: BoltS listening on 0.0.0.0 at 7687
|
||||
```
|
||||
|
||||
Memgraph is now ready to process queries, you may now proceed to
|
||||
[querying](#querying). To shutdown Memgraph server, issue the following
|
||||
command.
|
||||
|
||||
```bash
|
||||
systemctl stop memgraph
|
||||
```
|
||||
|
||||
Memgraph configuration is available in `/etc/memgraph/memgraph.conf`. After
|
||||
changing the configuration, Memgraph needs to be restarted.
|
||||
|
||||
#### RPM Package Installation
|
||||
|
||||
If you downloaded the RPM package of Memgraph, you can install it by running
|
||||
the following command.
|
||||
|
||||
```bash
|
||||
rpm -U /path/to/memgraph-<version>.rpm
|
||||
```
|
||||
|
||||
After the successful installation, Memgraph can be started as a service. To do
|
||||
so, type the following command.
|
||||
|
||||
```bash
|
||||
systemctl start memgraph
|
||||
```
|
||||
|
||||
To verify that Memgraph is running, run the following command.
|
||||
|
||||
```bash
|
||||
journalctl --unit memgraph
|
||||
```
|
||||
|
||||
It is expected to see something like the following output.
|
||||
|
||||
```bash
|
||||
Nov 23 13:40:13 hostname memgraph[14654]: Starting 8 BoltS workers
|
||||
Nov 23 13:40:13 hostname memgraph[14654]: BoltS server is fully armed and operational
|
||||
Nov 23 13:40:13 hostname memgraph[14654]: BoltS listening on 0.0.0.0 at 7687
|
||||
```
|
||||
|
||||
Memgraph is now ready to process queries, you may now proceed to
|
||||
[querying](#querying). To shutdown Memgraph server, issue the following
|
||||
command.
|
||||
|
||||
```bash
|
||||
systemctl stop memgraph
|
||||
```
|
||||
|
||||
Memgraph configuration is available in `/etc/memgraph/memgraph.conf`. After
|
||||
changing the configuration, Memgraph needs to be restarted.
|
||||
|
||||
### Querying
|
||||
|
||||
Memgraph supports the openCypher query language which has been developed by
|
||||
[Neo4j](http://neo4j.com). The language is currently going through a
|
||||
vendor-independent standardization process. It's a declarative language
|
||||
developed specifically for interaction with graph databases.
|
||||
|
||||
The easiest way to execute openCypher queries against Memgraph, is using
|
||||
Neo4j's command-line tool. The command-line `neo4j-client` can be installed as
|
||||
described [on the official website](https://neo4j-client.net).
|
||||
|
||||
After installing `neo4j-client`, connect to the running Memgraph instance by
|
||||
issuing the following shell command.
|
||||
|
||||
```bash
|
||||
neo4j-client -u "" -p "" localhost 7687
|
||||
```
|
||||
|
||||
After the client has started it should present a command prompt similar to:
|
||||
|
||||
```bash
|
||||
neo4j-client 2.1.3
|
||||
Enter `:help` for usage hints.
|
||||
Connected to 'neo4j://@localhost:7687'
|
||||
neo4j>
|
||||
```
|
||||
|
||||
At this point it is possible to execute openCypher queries on Memgraph. Each
|
||||
query needs to end with the `;` (*semicolon*) character. For example:
|
||||
|
||||
```opencypher
|
||||
CREATE (u:User {name: "Alice"})-[:Likes]->(m:Software {name: "Memgraph"});
|
||||
```
|
||||
|
||||
The above will create 2 nodes in the database, one labeled "User" with name
|
||||
"Alice" and the other labeled "Software" with name "Memgraph". It will also
|
||||
create an edge labeled "Likes". Those three graph elements jointly represent
|
||||
the fact that "Alice" *likes* "Memgraph".
|
||||
|
||||
To find created nodes and edges, execute the following query:
|
||||
|
||||
```opencypher
|
||||
MATCH (u:User)-[r]->(x) RETURN u, r, x;
|
||||
```
|
||||
|
||||
#### Supported Languages
|
||||
|
||||
If users wish to query Memgraph programmatically, they can do so using the
|
||||
[Bolt protocol](https://boltprotocol.org). Bolt was designed for efficient
|
||||
communication with graph databases and Memgraph supports
|
||||
[Version 1](https://boltprotocol.org/v1) of the protocol. Bolt protocol drivers
|
||||
for some popular programming languages are listed below:
|
||||
|
||||
* [Java](https://github.com/neo4j/neo4j-java-driver)
|
||||
* [Python](https://github.com/neo4j/neo4j-python-driver)
|
||||
* [JavaScript](https://github.com/neo4j/neo4j-javascript-driver)
|
||||
* [C#](https://github.com/neo4j/neo4j-dotnet-driver)
|
||||
* [Ruby](https://github.com/neo4jrb/neo4j)
|
||||
* [Haskell](https://github.com/zmactep/hasbolt)
|
||||
* [PHP](https://github.com/graphaware/neo4j-bolt-php)
|
||||
|
||||
We have included some basic usage examples for some of the supported languages
|
||||
in the [Drivers](drivers.md) section.
|
||||
|
||||
### Telemetry
|
||||
|
||||
Telemetry is an automated process by which some useful data is collected at
|
||||
a remote point. At Memgraph, we use telemetry for the sole purpose of improving
|
||||
our product, thereby collecting some data about the machine that executes the
|
||||
database (CPU, memory, OS and kernel information) as well as some data about the
|
||||
database runtime (CPU usage, memory usage, node and edge count).
|
||||
|
||||
Here at Memgraph, we deeply care about the privacy of our users and do not
|
||||
collect any sensitive information. If users wish to disable Memgraph's telemetry
|
||||
features, they can easily do so by either altering the line in
|
||||
`/etc/memgraph/memgraph.conf` that enables telemetry (`--telemetry-enabled=true`)
|
||||
into `--telemetry-enabled=false`, or by including the `--telemetry-enabled=false`
|
||||
as a command-line argument when running the executable.
|
||||
|
||||
### Where to Next
|
||||
|
||||
To learn more about the openCypher language, visit [openCypher Query
|
||||
Language](open-cypher.md) chapter in this document. For real-world examples
|
||||
of how to use Memgraph visit [Examples](examples.md) chapter. Details on
|
||||
what can be stored in Memgraph are in [Data Storage](storage.md) chapter.
|
||||
|
||||
We *welcome and encourage* your feedback!
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
## Quick Start {#tutorial-quick-start}
|
||||
## Quick Start
|
||||
|
||||
This article briefly outlines the basic steps necessary to install and run
|
||||
Memgraph. It also gives a brief glimpse into the world of OpenCypher and
|
||||
@ -256,7 +256,7 @@ for some popular programming languages are listed below:
|
||||
* [PHP](https://github.com/graphaware/neo4j-bolt-php)
|
||||
|
||||
We have included some basic usage examples for some of the supported languages
|
||||
in the article about [programmatic querying](tutorial__programmatic_querying.md).
|
||||
in the article about [programmatic querying](how-to_guides/programmatic_querying.md).
|
||||
|
||||
### Telemetry {#telemetry}
|
||||
|
||||
@ -276,16 +276,15 @@ as a command-line argument when running the executable.
|
||||
### Where to Next
|
||||
|
||||
To learn more about the openCypher language, the user should visit our
|
||||
[openCypher Query Language](open-cypher.md) article. For real-world examples
|
||||
of how to use Memgraph, we strongly suggest reading through the following
|
||||
articles:
|
||||
[reference guide](reference_guide/reference_overview.md) article.
|
||||
For real-world examples of how to use Memgraph, we strongly suggest reading
|
||||
through the following articles:
|
||||
|
||||
* [Analyzing TED Talks](tutorial__analyzing_TED_talks.md)
|
||||
* [Graphing the Premier League](tutorial__graphing_the_premier_league.md)
|
||||
* [Exploring the European Road Network](tutorial__exploring_the_european_road_network.md)
|
||||
* [Analyzing TED Talks](tutorials/analyzing_TED_talks.md)
|
||||
* [Graphing the Premier League](tutorials/graphing_the_premier_league.md)
|
||||
* [Exploring the European Road Network](tutorials/exploring_the_european_road_network.md)
|
||||
|
||||
<!--- TODO(ipaljak) Possible broken link on docs update -->
|
||||
Details on what can be stored in Memgraph can be found in the article about
|
||||
[Data Storage](storage.md).
|
||||
[Data Storage](concepts/storage.md).
|
||||
|
||||
We *welcome and encourage* your feedback!
|
||||
@ -1,17 +0,0 @@
|
||||
## CREATE INDEX
|
||||
|
||||
### Summary
|
||||
|
||||
Create an index on the specified label, property pair.
|
||||
|
||||
### Syntax
|
||||
|
||||
```opencypher
|
||||
CREATE INDEX ON :<label_name>(<property_name>)
|
||||
```
|
||||
|
||||
### Remarks
|
||||
|
||||
* `label_name` is the name of the record label.
|
||||
* `property_name` is the name of the property within a record.
|
||||
* At the moment, created indexes cannot be deleted.
|
||||
63
docs/user_technical/reference_guide/differences.md
Normal file
63
docs/user_technical/reference_guide/differences.md
Normal file
@ -0,0 +1,63 @@
|
||||
## Differences
|
||||
|
||||
Although we try to implement openCypher query language as closely to the
|
||||
language reference as possible, we had to make some changes to enhance the
|
||||
user experience.
|
||||
|
||||
### Symbolic Names
|
||||
|
||||
We don't allow symbolic names (variables, label names...) to be openCypher
|
||||
keywords (WHERE, MATCH, COUNT, SUM...).
|
||||
|
||||
### Unicode Codepoints in String Literal
|
||||
|
||||
Use `\u` followed by 4 hex digits in string literal for UTF-16 codepoint and
|
||||
`\U` with 8 hex digits for UTF-32 codepoint in Memgraph.
|
||||
|
||||
|
||||
### Difference from Neo4j's Cypher Implementation
|
||||
|
||||
The openCypher initiative stems from Neo4j's Cypher query language. Following is a list
|
||||
of most important differences between Neo's Cypher and Memgraph's openCypher implementation,
|
||||
for users that are already familiar with Neo4j. There might be other differences not documented
|
||||
here (especially subtle semantic ones).
|
||||
|
||||
#### Unsupported Constructs
|
||||
|
||||
* Data importing. Memgraph doesn't support Cypher's CSV importing capabilities.
|
||||
* The `FOREACH` language construct for performing an operation on every list element.
|
||||
* The `CALL` construct for a standalone function call. This can be expressed using
|
||||
`RETURN functioncall()`. For example, with Memgraph you can get information about
|
||||
the indexes present in the database using the `RETURN indexinfo()` openCypher query.
|
||||
* Stored procedures.
|
||||
* Regular expressions for string matching.
|
||||
* `shortestPath` and `allShortestPaths` functions. `shortestPath` can be expressed using
|
||||
Memgraph's breadth-first expansion syntax already described in this document.
|
||||
* Patterns in expressions. For example, Memgraph doesn't support `size((n)-->())`. Most of the time
|
||||
the same functionalities can be expressed differently in Memgraph using `OPTIONAL` expansions,
|
||||
function calls etc.
|
||||
* Map projections such as `MATCH (n) RETURN n {.property1, .property2}`.
|
||||
|
||||
#### Unsupported Functions
|
||||
|
||||
General purpose functions:
|
||||
|
||||
* `exists(n.property)` - This can be expressed using `n.property IS NOT NULL`.
|
||||
* `length()` is named `size()` in Memgraph.
|
||||
|
||||
Aggregation functions:
|
||||
|
||||
* `count(DISTINCT variable)` - This can be expressed using `WITH DISTINCT variable RETURN count(variable)`.
|
||||
|
||||
Mathematical functions:
|
||||
|
||||
* `percentileDisc()`
|
||||
* `stDev()`
|
||||
* `point()`
|
||||
* `distance()`
|
||||
* `degrees()`
|
||||
|
||||
List functions:
|
||||
|
||||
* `any()`
|
||||
* `none()`
|
||||
@ -1,4 +1,6 @@
|
||||
## Dynamic Graph Partitioner
|
||||
|
||||
Memgraph supports dynamic graph partitioning which improves performance on badly partitioned dataset over workers dynamically. To enable it, use the
|
||||
Memgraph supports dynamic graph partitioning which improves performance on badly
|
||||
partitioned dataset over workers dynamically. To enable it, use the
|
||||
|
||||
```--dynamic_graph_partitioner_enabled``` flag.
|
||||
137
docs/user_technical/reference_guide/graph_algorithms.md
Normal file
137
docs/user_technical/reference_guide/graph_algorithms.md
Normal file
@ -0,0 +1,137 @@
|
||||
## Graph Algorithms
|
||||
|
||||
### Filtering Variable Length Paths
|
||||
|
||||
OpenCypher supports only simple filtering when matching variable length paths.
|
||||
For example:
|
||||
|
||||
```opencypher
|
||||
MATCH (n)-[edge_list:Type * {x: 42}]-(m)
|
||||
```
|
||||
|
||||
This will produce only those paths whose edges have the required `Type` and `x`
|
||||
property value. Edges that compose the produced paths are stored in a symbol
|
||||
named `edge_list`. Naturally, the user could have specified any other symbol
|
||||
name.
|
||||
|
||||
Memgraph extends openCypher with a syntax for arbitrary filter expressions
|
||||
during path matching. The next example filters edges which have property `x`
|
||||
between `0` and `10`.
|
||||
|
||||
```opencypher
|
||||
MATCH (n)-[edge_list * (edge, node | 0 < edge.x < 10)]-(m)
|
||||
```
|
||||
|
||||
Here we introduce a lambda function with parentheses, where the first two
|
||||
arguments, `edge` and `node`, correspond to each edge and node during path
|
||||
matching. `node` is the destination node we are moving to across the current
|
||||
`edge`. The last `node` value will be the same value as `m`. Following the
|
||||
pipe (`|`) character is an arbitrary expression which must produce a boolean
|
||||
value. If `True`, matching continues, otherwise the path is discarded.
|
||||
|
||||
The previous example can be written using the `all` function:
|
||||
|
||||
```opencypher
|
||||
MATCH (n)-[edge_list *]-(m) WHERE all(edge IN edge_list WHERE 0 < edge.x < 10)
|
||||
```
|
||||
|
||||
However, filtering using a lambda function is more efficient because paths
|
||||
may be discarded earlier in the traversal. Furthermore, it provides more
|
||||
flexibility for deciding what kind of paths are matched due to more expressive
|
||||
filtering capabilities. Therefore, filtering through lambda functions should
|
||||
be preferred whenever possible.
|
||||
|
||||
### Breadth First Search
|
||||
|
||||
A typical graph use-case is searching for the shortest path between nodes.
|
||||
The openCypher standard does not define this feature, so Memgraph provides
|
||||
a custom implementation, based on the edge expansion syntax.
|
||||
|
||||
Finding the shortest path between nodes can be done using breadth-first
|
||||
expansion:
|
||||
|
||||
```opencypher
|
||||
MATCH (a {id: 723})-[edge_list:Type *bfs..10]-(b {id: 882}) RETURN *
|
||||
```
|
||||
|
||||
The above query will find all paths of length up to 10 between nodes `a` and `b`.
|
||||
The edge type and maximum path length are used in the same way like in variable
|
||||
length expansion.
|
||||
|
||||
To find only the shortest path, simply append `LIMIT 1` to the `RETURN` clause.
|
||||
|
||||
```opencypher
|
||||
MATCH (a {id: 723})-[edge_list:Type *bfs..10]-(b {id: 882}) RETURN * LIMIT 1
|
||||
```
|
||||
|
||||
Breadth-first expansion allows an arbitrary expression filter that determines
|
||||
if an expansion is allowed. Following is an example in which expansion is
|
||||
allowed only over edges whose `x` property is greater than `12` and nodes `y`
|
||||
whose property is less than `3`:
|
||||
|
||||
```opencypher
|
||||
MATCH (a {id: 723})-[*bfs..10 (e, n | e.x > 12 AND n.y < 3)]-() RETURN *
|
||||
```
|
||||
|
||||
The filter is defined as a lambda function over `e` and `n`, which denote the edge
|
||||
and node being expanded over in the breadth first search. Note that if the user
|
||||
omits the edge list symbol (`edge_list` in previous examples) it will not be included
|
||||
in the result.
|
||||
|
||||
There are a few benefits of the breadth-first expansion approach, as opposed to
|
||||
a specialized `shortestPath` function. For one, it is possible to inject
|
||||
expressions that filter on nodes and edges along the path itself, not just the final
|
||||
destination node. Furthermore, it's possible to find multiple paths to multiple destination
|
||||
nodes regardless of their length. Also, it is possible to simply go through a node's
|
||||
neighbourhood in breadth-first manner.
|
||||
|
||||
Currently, it isn't possible to get all shortest paths to a single node using
|
||||
Memgraph's breadth-first expansion.
|
||||
|
||||
### Weighted Shortest Path
|
||||
|
||||
Another standard use-case in a graph is searching for the weighted shortest
|
||||
path between nodes. The openCypher standard does not define this feature, so
|
||||
Memgraph provides a custom implementation, based on the edge expansion syntax.
|
||||
|
||||
Finding the weighted shortest path between nodes is done using the weighted
|
||||
shortest path expansion:
|
||||
|
||||
```opencypher
|
||||
MATCH (a {id: 723})-[
|
||||
edge_list *wShortest 10 (e, n | e.weight) total_weight
|
||||
]-(b {id: 882})
|
||||
RETURN *
|
||||
```
|
||||
|
||||
The above query will find the shortest path of length up to 10 nodes between
|
||||
nodes `a` and `b`. The length restriction parameter is optional.
|
||||
|
||||
Weighted Shortest Path expansion allows an arbitrary expression that determines
|
||||
the weight for the current expansion. Total weight of a path is calculated as
|
||||
the sum of all weights on the path between two nodes. Following is an example in
|
||||
which the weight between nodes is defined as the product of edge weights
|
||||
(instead of sum), assuming all weights are greater than '1':
|
||||
|
||||
```opencypher
|
||||
MATCH (a {id: 723})-[
|
||||
edge_list *wShortest 10 (e, n | log(e.weight)) total_weight
|
||||
]-(b {id: 882})
|
||||
RETURN exp(total_weight)
|
||||
```
|
||||
|
||||
Weighted Shortest Path expansions also allows an arbitrary expression filter
|
||||
that determines if an expansion is allowed. Following is an example in which
|
||||
expansion is allowed only over edges whose `x` property is greater than `12`
|
||||
and nodes `y` whose property is less than `3`:
|
||||
|
||||
```opencypher
|
||||
MATCH (a {id: 723})-[
|
||||
edge_list *wShortest 10 (e, n | e.weight) total_weight (e, n | e.x > 12 AND n.y < 3)
|
||||
]-(b {id: 882})
|
||||
RETURN exp(total_weight)
|
||||
```
|
||||
|
||||
Both weight and filter expression are defined as lambda functions over `e` and
|
||||
`n`, which denote the edge and the node being expanded over in the weighted
|
||||
shortest path search.
|
||||
113
docs/user_technical/reference_guide/graph_streams.md
Normal file
113
docs/user_technical/reference_guide/graph_streams.md
Normal file
@ -0,0 +1,113 @@
|
||||
## Graph Streams
|
||||
|
||||
Memgraphs custom openCypher clause for creating a stream is:
|
||||
```opencypher
|
||||
CREATE STREAM stream_name AS
|
||||
LOAD DATA KAFKA 'URI'
|
||||
WITH TOPIC 'topic'
|
||||
WITH TRANSFORM 'URI'
|
||||
[BATCH_INTERVAL milliseconds]
|
||||
[BATCH_SIZE count]
|
||||
```
|
||||
The `CREATE STREAM` clause happens in a transaction.
|
||||
|
||||
`WITH TOPIC` parameter specifies the Kafka topic from which we'll stream
|
||||
data.
|
||||
|
||||
`WITH TRANSFORM` parameter should contain a URI of the transform script.
|
||||
We cover more about the transform script later, in the [transform](#transform)
|
||||
section.
|
||||
|
||||
`BATCH_INTERVAL` parameter defines the time interval in milliseconds
|
||||
which is the time between two successive stream importing operations.
|
||||
|
||||
`BATCH_SIZE` parameter defines the count of Kafka messages that will be
|
||||
batched together before import.
|
||||
|
||||
If both `BATCH_INTERVAL` and `BATCH_SIZE` parameters are given, the condition
|
||||
that is satisfied first will trigger the batched import.
|
||||
|
||||
Default value for `BATCH_INTERVAL` is 100 milliseconds, and the default value
|
||||
for `BATCH_SIZE` is 10.
|
||||
|
||||
The `DROP` clause deletes a stream:
|
||||
```opencypher
|
||||
DROP STREAM stream_name;
|
||||
```
|
||||
|
||||
The `SHOW` clause enables you to see all configured streams:
|
||||
```opencypher
|
||||
SHOW STREAMS;
|
||||
```
|
||||
|
||||
You can also start/stop streams with the `START` and `STOP` clauses:
|
||||
```opencypher
|
||||
START STREAM stream_name [LIMIT count BATCHES];
|
||||
STOP STREAM stream_name;
|
||||
```
|
||||
A stream needs to be stopped in order to start it and it needs to be started in
|
||||
order to stop it. Starting a started or stopping a stopped stream will not
|
||||
affect that stream.
|
||||
|
||||
There are also convenience clauses to start and stop all streams:
|
||||
```opencypher
|
||||
START ALL STREAMS;
|
||||
STOP ALL STREAMS;
|
||||
```
|
||||
|
||||
Before the actual import, you can also test the stream with the `TEST
|
||||
STREAM` clause:
|
||||
```opencypher
|
||||
TEST STREAM stream_name [LIMIT count BATCHES];
|
||||
```
|
||||
When a stream is tested, data extraction and transformation occurs, but nothing
|
||||
is inserted into the graph.
|
||||
|
||||
A stream needs to be stopped in order to test it. When the batch limit is
|
||||
omitted, `TEST STREAM` will run for only one batch by default.
|
||||
|
||||
### Transform
|
||||
|
||||
The transform script allows Memgraph users to have custom Kafka messages and
|
||||
still be able to import data in Memgraph by adding the logic to decode the
|
||||
messages in the transform script.
|
||||
|
||||
The entry point of the transform script from Memgraph is the `stream` function.
|
||||
Input for the `stream` function is a list of bytes that represent byte encoded
|
||||
Kafka messages, and the output of the `stream` function must be a list of
|
||||
tuples containing openCypher string queries and corresponding parameters stored
|
||||
in a dictionary.
|
||||
|
||||
To be more precise, the signature of the `stream` function looks like the
|
||||
following:
|
||||
|
||||
```plaintext
|
||||
stream : [bytes] -> [(str, {str : type})]
|
||||
type : none | bool | int | float | str | list | dict
|
||||
```
|
||||
|
||||
An example of a simple transform script that creates vertices if the message
|
||||
contains one number (the vertex id) or it creates edges if the message contains
|
||||
two numbers (origin vertex id and destination vertex id) would look like the
|
||||
following:
|
||||
|
||||
```python
|
||||
def create_vertex(vertex_id):
|
||||
return ("CREATE (:Node {id: $id})", {"id": vertex_id})
|
||||
|
||||
|
||||
def create_edge(from_id, to_id):
|
||||
return ("MATCH (n:Node {id: $from_id}), (m:Node {id: $to_id}) "\
|
||||
"CREATE (n)-[:Edge]->(m)", {"from_id": from_id, "to_id": to_id})
|
||||
|
||||
|
||||
def stream(batch):
|
||||
result = []
|
||||
for item in batch:
|
||||
message = item.decode('utf-8').split()
|
||||
if len(message) == 1:
|
||||
result.append(create_vertex(message[0]))
|
||||
elif len(message) == 2:
|
||||
result.append(create_edge(message[0], message[1]))
|
||||
return result
|
||||
```
|
||||
56
docs/user_technical/reference_guide/indexing.md
Normal file
56
docs/user_technical/reference_guide/indexing.md
Normal file
@ -0,0 +1,56 @@
|
||||
## Indexing
|
||||
|
||||
An index stores additional information on certain types of data, so that
|
||||
retrieving said data becomes more efficient. Downsides of indexing are:
|
||||
|
||||
* requiring extra storage for each index and
|
||||
* slowing down writes to the database.
|
||||
|
||||
Carefully choosing which data to index can tremendously improve data retrieval
|
||||
efficiency, and thus make index downsides negligible.
|
||||
|
||||
Memgraph automatically indexes labeled data. This improves queries
|
||||
which fetch nodes by label:
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Label) ... RETURN n
|
||||
```
|
||||
|
||||
Indexing can also be applied to data with a specific combination of label and
|
||||
property. These are not automatically created, instead a user needs to create
|
||||
them explicitly. Creation is done using a special
|
||||
`CREATE INDEX ON :Label(property)` language construct.
|
||||
|
||||
For example, to index nodes which is labeled as `:Person` and has a property
|
||||
named `age`:
|
||||
|
||||
```opencypher
|
||||
CREATE INDEX ON :Person(age)
|
||||
```
|
||||
|
||||
After the index is created, retrieving those nodes will become more efficient.
|
||||
For example, the following query will retrieve all nodes which have an `age`
|
||||
property, instead of fetching each `:Person` node and checking whether the
|
||||
property exists.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person {age: 42}) RETURN n
|
||||
```
|
||||
|
||||
Using index based retrieval also works when filtering labels and properties
|
||||
with `WHERE`. For example, the same effect as in the previous example can be
|
||||
done with:
|
||||
|
||||
```opencypher
|
||||
MATCH (n) WHERE n:Person AND n.age = 42 RETURN n
|
||||
```
|
||||
|
||||
Since the filter inside `WHERE` can contain any kind of an expression, the
|
||||
expression can be complicated enough so that the index does not get used. We
|
||||
are continuously improving the recognition of index usage opportunities from a
|
||||
`WHERE` expression. If there is any suspicion that an index may not be used,
|
||||
we recommend putting properties and labels inside the `MATCH` pattern.
|
||||
|
||||
Currently, once an index is created it cannot be deleted. This feature will be
|
||||
implemented very soon. The expected syntax for removing an index will be `DROP
|
||||
INDEX ON :Label(property)`.
|
||||
160
docs/user_technical/reference_guide/other_features.md
Normal file
160
docs/user_technical/reference_guide/other_features.md
Normal file
@ -0,0 +1,160 @@
|
||||
## Other Features
|
||||
|
||||
The following sections describe some of the other supported features.
|
||||
|
||||
### UNWIND
|
||||
|
||||
The `UNWIND` clause is used to unwind a list of values as individual rows.
|
||||
|
||||
Example. Produce rows out of a single list.
|
||||
|
||||
```opencypher
|
||||
UNWIND [1,2,3] AS listElement RETURN listElement
|
||||
```
|
||||
|
||||
More examples are
|
||||
[here](https://neo4j.com/docs/developer-manual/current/cypher/clauses/unwind/).
|
||||
|
||||
### Functions
|
||||
|
||||
This section contains the list of other supported functions.
|
||||
|
||||
Name | Description
|
||||
-----------------|------------
|
||||
`coalesce` | Returns the first non null argument.
|
||||
`startNode` | Returns the starting node of an edge.
|
||||
`endNode` | Returns the destination node of an edge.
|
||||
`degree` | Returns the number of edges (both incoming and outgoing) of a node.
|
||||
`head` | Returns the first element of a list.
|
||||
`last` | Returns the last element of a list.
|
||||
`properties` | Returns the properties of a node or an edge.
|
||||
`size` | Returns the number of elements in a list or a map. When given a string it returns the number of characters. When given a path it returns the number of expansions (edges) in that path.
|
||||
`toBoolean` | Converts the argument to a boolean.
|
||||
`toFloat` | Converts the argument to a floating point number.
|
||||
`toInteger` | Converts the argument to an integer.
|
||||
`type` | Returns the type of an edge as a character string.
|
||||
`keys` | Returns a list keys of properties from an edge or a node. Each key is represented as a string of characters.
|
||||
`labels` | Returns a list of labels from a node. Each label is represented as a character string.
|
||||
`nodes` | Returns a list of nodes from a path.
|
||||
`relationships` | Returns a list of relationships (edges) from a path.
|
||||
`range` | Constructs a list of value in given range.
|
||||
`tail` | Returns all elements after the first of a given list.
|
||||
`abs` | Returns the absolute value of a number.
|
||||
`ceil` | Returns the smallest integer greater than or equal to given number.
|
||||
`floor` | Returns the largest integer smaller than or equal to given number.
|
||||
`round` | Returns the number, rounded to the nearest integer. Tie-breaking is done using the *commercial rounding*, where -1.5 produces -2 and 1.5 produces 2.
|
||||
`exp` | Calculates `e^n` where `e` is the base of the natural logarithm, and `n` is the given number.
|
||||
`log` | Calculates the natural logarithm of a given number.
|
||||
`log10` | Calculates the logarithm (base 10) of a given number.
|
||||
`sqrt` | Calculates the square root of a given number.
|
||||
`acos` | Calculates the arccosine of a given number.
|
||||
`asin` | Calculates the arcsine of a given number.
|
||||
`atan` | Calculates the arctangent of a given number.
|
||||
`atan2` | Calculates the arctangent2 of a given number.
|
||||
`cos` | Calculates the cosine of a given number.
|
||||
`sin` | Calculates the sine of a given number.
|
||||
`tan` | Calculates the tangent of a given number.
|
||||
`sign` | Applies the signum function to a given number and returns the result. The signum of positive numbers is 1, of negative -1 and for 0 returns 0.
|
||||
`e` | Returns the base of the natural logarithm.
|
||||
`pi` | Returns the constant *pi*.
|
||||
`rand` | Returns a random floating point number between 0 (inclusive) and 1 (exclusive).
|
||||
`startsWith` | Check if the first argument starts with the second.
|
||||
`endsWith` | Check if the first argument ends with the second.
|
||||
`contains` | Check if the first argument has an element which is equal to the second argument.
|
||||
`left` | Returns a string containing the specified number of leftmost characters of the original string.
|
||||
`lTrim` | Returns the original string with leading whitespace removed.
|
||||
`replace` | Returns a string in which all occurrences of a specified string in the original string have been replaced by another (specified) string.
|
||||
`reverse` | Returns a string in which the order of all characters in the original string have been reversed.
|
||||
`right` | Returns a string containing the specified number of rightmost characters of the original string.
|
||||
`rTrim` | Returns the original string with trailing whitespace removed.
|
||||
`split` | Returns a list of strings resulting from the splitting of the original string around matches of the given delimiter.
|
||||
`substring` | Returns a substring of the original string, beginning with a 0-based index start and length.
|
||||
`toLower` | Returns the original string in lowercase.
|
||||
`toString` | Converts an integer, float or boolean value to a string.
|
||||
`toUpper` | Returns the original string in uppercase.
|
||||
`trim` | Returns the original string with leading and trailing whitespace removed.
|
||||
`all` | Check if all elements of a list satisfy a predicate.<br/>The syntax is: `all(variable IN list WHERE predicate)`.<br/> NOTE: Whenever possible, use Memgraph's lambda functions when matching instead.
|
||||
`single` | Check if only one element of a list satisfies a predicate.<br/>The syntax is: `single(variable IN list WHERE predicate)`.
|
||||
`reduce` | Accumulate list elements into a single result by applying an expression. The syntax is:<br/>`reduce(accumulator = initial_value, variable IN list | expression)`.
|
||||
`extract` | A list of values obtained by evaluating an expression for each element in list. The syntax is:<br>`extract(variable IN list | expression)`.
|
||||
`assert` | Raises an exception reported to the client if the given argument is not `true`.
|
||||
`counter` | Generates integers that are guaranteed to be unique on the database level, for the given counter name.
|
||||
`counterSet` | Sets the counter with the given name to the given value.
|
||||
`indexInfo` | Returns a list of all the indexes available in the database. The list includes indexes that are not yet ready for use (they are concurrently being built by another transaction).
|
||||
`timestamp` | Returns the difference, measured in milliseconds, between the current time and midnight, January 1, 1970 UTC.
|
||||
`id` | Returns identifier for a given node or edge. The identifier is generated during the initialization of node or edge and will be persisted through the durability mechanism.
|
||||
|
||||
### String Operators
|
||||
|
||||
Apart from comparison and concatenation operators openCypher provides special
|
||||
string operators for easier matching of substrings:
|
||||
|
||||
Operator | Description
|
||||
-------------------|------------
|
||||
`a STARTS WITH b` | Returns true if prefix of string a is equal to string b.
|
||||
`a ENDS WITH b` | Returns true if suffix of string a is equal to string b.
|
||||
`a CONTAINS b` | Returns true if some substring of string a is equal to string b.
|
||||
|
||||
### Parameters
|
||||
|
||||
When automating the queries for Memgraph, it comes in handy to change only
|
||||
some parts of the query. Usually, these parts are values which are used for
|
||||
filtering results or similar, while the rest of the query remains the same.
|
||||
|
||||
Parameters allow reusing the same query, but with different parameter values.
|
||||
The syntax uses the `$` symbol to designate a parameter name. We don't allow
|
||||
old Cypher parameter syntax using curly braces. For example, you can parameterize
|
||||
filtering a node property:
|
||||
|
||||
```opencypher
|
||||
MATCH (node1 {property: $propertyValue}) RETURN node1
|
||||
```
|
||||
|
||||
You can use parameters instead of any literal in the query, but not instead of
|
||||
property maps even though that is allowed in standard openCypher. Following
|
||||
example is illegal in Memgraph:
|
||||
|
||||
```opencypher
|
||||
MATCH (node1 $propertyValue) RETURN node1
|
||||
```
|
||||
|
||||
To use parameters with Python driver use following syntax:
|
||||
|
||||
```python
|
||||
session.run('CREATE (alice:Person {name: $name, age: $ageValue}',
|
||||
name='Alice', ageValue=22)).consume()
|
||||
```
|
||||
|
||||
To use parameters which names are integers you will need to wrap parameters in
|
||||
a dictionary and convert them to strings before running a query:
|
||||
|
||||
```python
|
||||
session.run('CREATE (alice:Person {name: $0, age: $1}',
|
||||
{'0': "Alice", '1': 22})).consume()
|
||||
```
|
||||
|
||||
To use parameters with some other driver please consult appropriate
|
||||
documentation.
|
||||
|
||||
### CASE
|
||||
|
||||
Conditional expressions can be expressed in openCypher language by simple and
|
||||
generic form of `CASE` expression. A simple form is used to compare an expression
|
||||
against multiple predicates. For the first matched predicate result of the
|
||||
expression provided after the `THEN` keyword is returned. If no expression is
|
||||
matched value following `ELSE` is returned is provided, or `null` if `ELSE` is not
|
||||
used:
|
||||
|
||||
```opencypher
|
||||
MATCH (n)
|
||||
RETURN CASE n.currency WHEN "DOLLAR" THEN "$" WHEN "EURO" THEN "€" ELSE "UNKNOWN" END
|
||||
```
|
||||
|
||||
In generic form, you don't need to provide an expression whose value is compared to
|
||||
predicates, but you can list multiple predicates and the first one that evaluates
|
||||
to true is matched:
|
||||
|
||||
```opencypher
|
||||
MATCH (n)
|
||||
RETURN CASE WHEN n.height < 30 THEN "short" WHEN n.height > 300 THEN "tall" END
|
||||
```
|
||||
51
docs/user_technical/reference_guide/reading_and_writing.md
Normal file
51
docs/user_technical/reference_guide/reading_and_writing.md
Normal file
@ -0,0 +1,51 @@
|
||||
## Reading and Writing
|
||||
|
||||
OpenCypher supports combining multiple reads and writes using the
|
||||
`WITH` clause. In addition to combining, the `MERGE` clause is provided which
|
||||
may create patterns if they do not exist.
|
||||
|
||||
### WITH
|
||||
|
||||
The write part of the query cannot be simply followed by another read part. In
|
||||
order to combine them, `WITH` clause must be used. The names this clause
|
||||
establishes are transferred from one part to another.
|
||||
|
||||
For example, creating a node and finding all nodes with the same property.
|
||||
|
||||
```opencypher
|
||||
CREATE (node {property: 42}) WITH node.property AS propValue
|
||||
MATCH (n {property: propValue}) RETURN n
|
||||
```
|
||||
|
||||
Note that the `node` is not visible after `WITH`, since only `node.property`
|
||||
was carried over.
|
||||
|
||||
This clause behaves very much like `RETURN`, so you should refer to features
|
||||
of `RETURN`.
|
||||
|
||||
### MERGE
|
||||
|
||||
The `MERGE` clause is used to ensure that a pattern you are looking for exists
|
||||
in the database. This means that if the pattern is not found, it will be
|
||||
created. In a way, this clause is like a combination of `MATCH` and `CREATE`.
|
||||
|
||||
|
||||
Example. Ensure that a person has at least one friend.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) MERGE (n)-[:FriendOf]->(m)
|
||||
```
|
||||
|
||||
The clause also provides additional features for updating the values depending
|
||||
on whether the pattern was created or matched. This is achieved with `ON
|
||||
CREATE` and `ON MATCH` sub clauses.
|
||||
|
||||
Example. Set a different properties depending on what `MERGE` did.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) MERGE (n)-[:FriendOf]->(m)
|
||||
ON CREATE SET m.prop = "created" ON MATCH SET m.prop = "existed"
|
||||
```
|
||||
|
||||
For more details, click [this
|
||||
link](https://neo4j.com/docs/developer-manual/current/cypher/clauses/merge/).
|
||||
280
docs/user_technical/reference_guide/reading_existing_data.md
Normal file
280
docs/user_technical/reference_guide/reading_existing_data.md
Normal file
@ -0,0 +1,280 @@
|
||||
## Reading Existing Data
|
||||
|
||||
The simplest usage of the language is to find data stored in the
|
||||
database. For that purpose, the following clauses are offered:
|
||||
|
||||
* `MATCH`, which searches for patterns;
|
||||
* `WHERE`, for filtering the matched data and
|
||||
* `RETURN`, for defining what will be presented to the user in the result
|
||||
set.
|
||||
* `UNION` and `UNION ALL` for combining results from multiple queries.
|
||||
|
||||
### MATCH
|
||||
|
||||
This clause is used to obtain data from Memgraph by matching it to a given
|
||||
pattern. For example, to find each node in the database, you can use the
|
||||
following query.
|
||||
|
||||
```opencypher
|
||||
MATCH (node) RETURN node
|
||||
```
|
||||
|
||||
Finding connected nodes can be achieved by using the query:
|
||||
|
||||
```opencypher
|
||||
MATCH (node1)-[connection]-(node2) RETURN node1, connection, node2
|
||||
```
|
||||
|
||||
In addition to general pattern matching, you can narrow the search down by
|
||||
specifying node labels and properties. Similarly, edge types and properties
|
||||
can also be specified. For example, finding each node labeled as `Person` and
|
||||
with property `age` being 42, is done with the following query.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person {age: 42}) RETURN n
|
||||
```
|
||||
|
||||
While their friends can be found with the following.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person {age: 42})-[:FriendOf]-(friend) RETURN friend
|
||||
```
|
||||
|
||||
There are cases when a user needs to find data which is connected by
|
||||
traversing a path of connections, but the user doesn't know how many
|
||||
connections need to be traversed. openCypher allows for designating patterns
|
||||
with *variable path lengths*. Matching such a path is achieved by using the
|
||||
`*` (*asterisk*) symbol inside the edge element of a pattern. For example,
|
||||
traversing from `node1` to `node2` by following any number of connections in a
|
||||
single direction can be achieved with:
|
||||
|
||||
```opencypher
|
||||
MATCH (node1)-[r*]->(node2) RETURN node1, r, node2
|
||||
```
|
||||
|
||||
If paths are very long, finding them could take a long time. To prevent that,
|
||||
a user can provide the minimum and maximum length of the path. For example,
|
||||
paths of length between 2 and 4 can be obtained with a query like:
|
||||
|
||||
```opencypher
|
||||
MATCH (node1)-[r*2..4]->(node2) RETURN node1, r, node2
|
||||
```
|
||||
|
||||
It is possible to name patterns in the query and return the resulting paths.
|
||||
This is especially useful when matching variable length paths:
|
||||
|
||||
```opencypher
|
||||
MATCH path = ()-[r*2..4]->() RETURN path
|
||||
```
|
||||
|
||||
More details on how `MATCH` works can be found
|
||||
[here](https://neo4j.com/docs/developer-manual/current/cypher/clauses/match/).
|
||||
|
||||
The `MATCH` clause can be modified by prepending the `OPTIONAL` keyword.
|
||||
`OPTIONAL MATCH` clause behaves the same as a regular `MATCH`, but when it
|
||||
fails to find the pattern, missing parts of the pattern will be filled with
|
||||
`null` values. Examples can be found
|
||||
[here](https://neo4j.com/docs/developer-manual/current/cypher/clauses/optional-match/).
|
||||
|
||||
### WHERE
|
||||
|
||||
You have already seen that simple filtering can be achieved by using labels
|
||||
and properties in `MATCH` patterns. When more complex filtering is desired,
|
||||
you can use `WHERE` paired with `MATCH` or `OPTIONAL MATCH`. For example,
|
||||
finding each person older than 20 is done with the this query.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) WHERE n.age > 20 RETURN n
|
||||
```
|
||||
|
||||
Additional examples can be found
|
||||
[here](https://neo4j.com/docs/developer-manual/current/cypher/clauses/where/).
|
||||
|
||||
### RETURN
|
||||
|
||||
The `RETURN` clause defines which data should be included in the resulting
|
||||
set. Basic usage was already shown in the examples for `MATCH` and `WHERE`
|
||||
clauses. Another feature of `RETURN` is renaming the results using the `AS`
|
||||
keyword.
|
||||
|
||||
Example.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) RETURN n AS people
|
||||
```
|
||||
|
||||
That query would display all nodes under the header named `people` instead of
|
||||
`n`.
|
||||
|
||||
When you want to get everything that was matched, you can use the `*`
|
||||
(*asterisk*) symbol.
|
||||
|
||||
This query:
|
||||
|
||||
```opencypher
|
||||
MATCH (node1)-[connection]-(node2) RETURN *
|
||||
```
|
||||
|
||||
is equivalent to:
|
||||
|
||||
```opencypher
|
||||
MATCH (node1)-[connection]-(node2) RETURN node1, connection, node2
|
||||
```
|
||||
|
||||
`RETURN` can be followed by the `DISTINCT` operator, which will remove
|
||||
duplicate results. For example, getting unique names of people can be achieved
|
||||
with:
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) RETURN DISTINCT n.name
|
||||
```
|
||||
|
||||
Besides choosing what will be the result and how it will be named, the
|
||||
`RETURN` clause can also be used to:
|
||||
|
||||
* limit results with `LIMIT` sub-clause;
|
||||
* skip results with `SKIP` sub-clause;
|
||||
* order results with `ORDER BY` sub-clause and
|
||||
* perform aggregations (such as `count`).
|
||||
|
||||
More details on `RETURN` can be found
|
||||
[here](https://neo4j.com/docs/developer-manual/current/cypher/clauses/return/).
|
||||
|
||||
#### SKIP & LIMIT
|
||||
|
||||
These sub-clauses take a number of how many results to skip or limit.
|
||||
For example, to get the first 3 results you can use this query.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) RETURN n LIMIT 3
|
||||
```
|
||||
|
||||
If you want to get all the results after the first 3, you can use the
|
||||
following.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) RETURN n SKIP 3
|
||||
```
|
||||
|
||||
The `SKIP` and `LIMIT` can be combined. So for example, to get the 2nd result,
|
||||
you can do:
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) RETURN n SKIP 1 LIMIT 1
|
||||
```
|
||||
|
||||
#### ORDER BY
|
||||
|
||||
Since the patterns which are matched can come in any order, it is very useful
|
||||
to be able to enforce some ordering among the results. In such cases, you can
|
||||
use the `ORDER BY` sub-clause.
|
||||
|
||||
For example, the following query will get all `:Person` nodes and order them
|
||||
by their names.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) RETURN n ORDER BY n.name
|
||||
```
|
||||
|
||||
By default, ordering will be in the ascending order. To change the order to be
|
||||
descending, you should append `DESC`.
|
||||
|
||||
For example, to order people by their name descending, you can use this query.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) RETURN n ORDER BY n.name DESC
|
||||
```
|
||||
|
||||
You can also order by multiple variables. The results will be sorted by the
|
||||
first variable listed. If the values are equal, the results are sorted by the
|
||||
second variable, and so on.
|
||||
|
||||
Example. Ordering by first name descending and last name ascending.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) RETURN n ORDER BY n.name DESC, n.lastName
|
||||
```
|
||||
|
||||
Note that `ORDER BY` sees only the variable names as carried over by `RETURN`.
|
||||
This means that the following will result in an error.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) RETURN old AS new ORDER BY old.name
|
||||
```
|
||||
|
||||
Instead, the `new` variable must be used:
|
||||
|
||||
```opencypher
|
||||
MATCH (n: Person) RETURN old AS new ORDER BY new.name
|
||||
```
|
||||
|
||||
The `ORDER BY` sub-clause may come in handy with `SKIP` and/or `LIMIT`
|
||||
sub-clauses. For example, to get the oldest person you can use the following.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) RETURN n ORDER BY n.age DESC LIMIT 1
|
||||
```
|
||||
|
||||
##### Aggregating
|
||||
|
||||
openCypher has functions for aggregating data. Memgraph currently supports
|
||||
the following aggregating functions.
|
||||
|
||||
* `avg`, for calculating the average.
|
||||
* `collect`, for collecting multiple values into a single list or map. If
|
||||
given a single expression values are collected into a list. If given two
|
||||
expressions, values are collected into a map where the first expression
|
||||
denotes map keys (must be string values) and the second expression denotes
|
||||
map values.
|
||||
* `count`, for counting the resulting values.
|
||||
* `max`, for calculating the maximum result.
|
||||
* `min`, for calculating the minimum result.
|
||||
* `sum`, for getting the sum of numeric results.
|
||||
|
||||
Example, calculating the average age:
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) RETURN avg(n.age) AS averageAge
|
||||
```
|
||||
|
||||
Collecting items into a list:
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) RETURN collect(n.name) AS list_of_names
|
||||
```
|
||||
|
||||
Collecting items into a map:
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) RETURN collect(n.name, n.age) AS map_name_to_age
|
||||
```
|
||||
|
||||
Click
|
||||
[here](https://neo4j.com/docs/developer-manual/current/cypher/functions/aggregating/)
|
||||
for additional details on how aggregations work.
|
||||
|
||||
### UNION and UNION ALL
|
||||
|
||||
openCypher supports combining results from multiple queries into a single result
|
||||
set. That result will contain rows that belong to queries in the union
|
||||
respecting the union type.
|
||||
|
||||
Using `UNION` will contain only distinct rows while `UNION ALL` will keep all
|
||||
rows from all given queries.
|
||||
|
||||
Restrictions when using `UNION` or `UNION ALL`:
|
||||
* The number and the names of columns returned by queries must be the same
|
||||
for all of them.
|
||||
* There can be only one union type between single queries, i.e. a query can't
|
||||
contain both `UNION` and `UNION ALL`.
|
||||
|
||||
Example, get distinct names that are shared between persons and movies:
|
||||
|
||||
```opencypher
|
||||
MATCH(n: Person) RETURN n.name AS name UNION MATCH(n: Movie) RETURN n.name AS name
|
||||
```
|
||||
|
||||
Example, get all names that are shared between persons and movies (including duplicates):
|
||||
|
||||
```opencypher
|
||||
MATCH(n: Person) RETURN n.name AS name UNION ALL MATCH(n: Movie) RETURN n.name AS name
|
||||
21
docs/user_technical/reference_guide/reference_overview.md
Normal file
21
docs/user_technical/reference_guide/reference_overview.md
Normal file
@ -0,0 +1,21 @@
|
||||
## Reference Overview
|
||||
|
||||
[*openCypher*](http://www.opencypher.org/) is a query language for querying
|
||||
graph databases. It aims to be intuitive and easy to learn, while
|
||||
providing a powerful interface for working with graph based data.
|
||||
|
||||
*Memgraph* supports most of the commonly used constructs of the language. The
|
||||
reference guide contains the details of implemented features. Additionally,
|
||||
not yet supported features of the language are listed.
|
||||
|
||||
Our reference guide currently consists of the following articles:
|
||||
|
||||
* [Reading Existing Data](reading_existing_data.md)
|
||||
* [Writing New Data](writing_new_data.md)
|
||||
* [Reading and Writing](reading_and_writing.md)
|
||||
* [Indexing](indexing.md)
|
||||
* [Graph Algorithms](graph_algorithms.md)
|
||||
* [Streaming](streaming.md)
|
||||
* [Dynamic Graph Partitioner](dynamic_graph_partitioner.md)
|
||||
* [Other Features](other_features.md)
|
||||
* [Differences](differences.md)
|
||||
92
docs/user_technical/reference_guide/writing_new_data.md
Normal file
92
docs/user_technical/reference_guide/writing_new_data.md
Normal file
@ -0,0 +1,92 @@
|
||||
## Writing New Data
|
||||
|
||||
For adding new data, you can use the following clauses.
|
||||
|
||||
* `CREATE`, for creating new nodes and edges.
|
||||
* `SET`, for adding new or updating existing labels and properties.
|
||||
* `DELETE`, for deleting nodes and edges.
|
||||
* `REMOVE`, for removing labels and properties.
|
||||
|
||||
You can still use the `RETURN` clause to produce results after writing, but it
|
||||
is not mandatory.
|
||||
|
||||
Details on which kind of data can be stored in *Memgraph* can be found in
|
||||
[Data Storage](../concepts/storage.md) chapter.
|
||||
|
||||
### CREATE
|
||||
|
||||
This clause is used to add new nodes and edges to the database. The creation
|
||||
is done by providing a pattern, similarly to `MATCH` clause.
|
||||
|
||||
For example, to create 2 new nodes connected with a new edge, use this query.
|
||||
|
||||
```opencypher
|
||||
CREATE (node1)-[:edge_type]->(node2)
|
||||
```
|
||||
|
||||
Labels and properties can be set during creation using the same syntax as in
|
||||
`MATCH` patterns. For example, creating a node with a label and a
|
||||
property:
|
||||
|
||||
```opencypher
|
||||
CREATE (node :Label {property: "my property value"})
|
||||
```
|
||||
|
||||
Additional information on `CREATE` is
|
||||
[here](https://neo4j.com/docs/developer-manual/current/cypher/clauses/create/).
|
||||
|
||||
### SET
|
||||
|
||||
The `SET` clause is used to update labels and properties of already existing
|
||||
data.
|
||||
|
||||
Example. Incrementing everyone's age by 1.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :Person) SET n.age = n.age + 1
|
||||
```
|
||||
|
||||
Click
|
||||
[here](https://neo4j.com/docs/developer-manual/current/cypher/clauses/create/)
|
||||
for a more detailed explanation on what can be done with `SET`.
|
||||
|
||||
### DELETE
|
||||
|
||||
This clause is used to delete nodes and edges from the database.
|
||||
|
||||
Example. Removing all edges of a single type.
|
||||
|
||||
```opencypher
|
||||
MATCH ()-[edge :type]-() DELETE edge
|
||||
```
|
||||
|
||||
When testing the database, you want to often have a clean start by deleting
|
||||
every node and edge in the database. It is reasonable that deleting each node
|
||||
should delete all edges coming into or out of that node.
|
||||
|
||||
```opencypher
|
||||
MATCH (node) DELETE node
|
||||
```
|
||||
|
||||
But, openCypher prevents accidental deletion of edges. Therefore, the above
|
||||
query will report an error. Instead, you need to use the `DETACH` keyword,
|
||||
which will remove edges from a node you are deleting. The following should
|
||||
work and *delete everything* in the database.
|
||||
|
||||
```opencypher
|
||||
MATCH (node) DETACH DELETE node
|
||||
```
|
||||
|
||||
More examples are
|
||||
[here](https://neo4j.com/docs/developer-manual/current/cypher/clauses/delete/).
|
||||
|
||||
### REMOVE
|
||||
|
||||
The `REMOVE` clause is used to remove labels and properties from nodes and
|
||||
edges.
|
||||
|
||||
Example.
|
||||
|
||||
```opencypher
|
||||
MATCH (n :WrongLabel) REMOVE n :WrongLabel, n.property
|
||||
```
|
||||
@ -6,8 +6,8 @@ information.
|
||||
|
||||
We highly recommend checking out the other articles from this series:
|
||||
|
||||
* [Exploring the European Road Network](tutorial__exploring_the_european_road_network.md)
|
||||
* [Graphing the Premier League](tutorial__graphing_the_premier_league.md)
|
||||
* [Exploring the European Road Network](exploring_the_european_road_network.md)
|
||||
* [Graphing the Premier League](graphing_the_premier_league.md)
|
||||
|
||||
### Introduction
|
||||
|
||||
@ -6,8 +6,8 @@ information.
|
||||
|
||||
We highly recommend checking out the other articles from this series:
|
||||
|
||||
* [Analyzing TED Talks](tutorial__analyzing_ted_talks.md)
|
||||
* [Graphing the Premier League](tutorial__graphing_the_premier_league.md)
|
||||
* [Analyzing TED Talks](analyzing_TED_talks.md)
|
||||
* [Graphing the Premier League](graphing_the_premier_league.md)
|
||||
|
||||
### Introduction
|
||||
|
||||
@ -6,8 +6,8 @@ information.
|
||||
|
||||
We highly recommend checking out the other articles from this series:
|
||||
|
||||
* [Analyzing TED Talks](tutorial__analyzing_ted_talks.md)
|
||||
* [Exploring the European Road Network](tutorial__exploring_the_european_road_network.md)
|
||||
* [Analyzing TED Talks](analyzing_TED_talks.md)
|
||||
* [Exploring the European Road Network](exploring_the_european_road_network.md)
|
||||
|
||||
### Introduction
|
||||
|
||||
14
docs/user_technical/tutorials/tutorials_overview.md
Normal file
14
docs/user_technical/tutorials/tutorials_overview.md
Normal file
@ -0,0 +1,14 @@
|
||||
## Tutorials Overview
|
||||
|
||||
Articles within the tutorials section serve as real-world examples of using
|
||||
Memgraph. These articles tend to provide the user with a reasonably-sized
|
||||
dataset and some example queries that showcase how to use Memgraph on that
|
||||
particular dataset. We encourage all Memgraph users to go through at least
|
||||
one of the tutorials as they can also serve as a verification that Memgraph
|
||||
is successfully installed on your system.
|
||||
|
||||
So far we have covered the following topics:
|
||||
|
||||
* [Analyzing TED Talks](analyzing_TED_talks.md)
|
||||
* [Graphing the Premier League](graphing_the_premier_league.md)
|
||||
* [Exploring the European Road Network](exploring_the_european_road_network.md)
|
||||
Loading…
Reference in New Issue
Block a user