5.0 KiB
面试题
了解什么是 Redis 的雪崩、穿透和击穿?Redis 崩溃之后会怎么样?系统该如何应对这种情况?如何处理 Redis 的穿透?
面试官心理分析
其实这是问到缓存必问的,因为缓存雪崩和穿透,是缓存最大的两个问题,要么不出现,一旦出现就是致命性的问题,所以面试官一定会问你。
面试题剖析
缓存雪崩(Cache Avalanche)
对于系统 A,假设每天高峰期每秒 5000 个请求,本来缓存在高峰期可以扛住每秒 4000 个请求,但是缓存机器意外发生了全盘宕机。缓存挂了,此时 1 秒 5000 个请求全部落数据库,数据库必然扛不住,它会报一下警,然后就挂了。此时,如果没有采用什么特别的方案来处理这个故障,DBA 很着急,重启数据库,但是数据库立马又被新的流量给打死了。
这就是缓存雪崩。

大约在 3 年前,国内比较知名的一个互联网公司,曾因为缓存事故,导致雪崩,后台系统全部崩溃,事故从当天下午持续到晚上凌晨 3~4 点,公司损失了几千万。
缓存雪崩的事前事中事后的解决方案如下:
- 事前:Redis 高可用,主从+哨兵,Redis cluster,避免全盘崩溃。
- 事中:本地 ehcache 缓存 + hystrix 限流&降级,避免 MySQL 被打死。
- 事后:Redis 持久化,一旦重启,自动从磁盘上加载数据,快速恢复缓存数据。
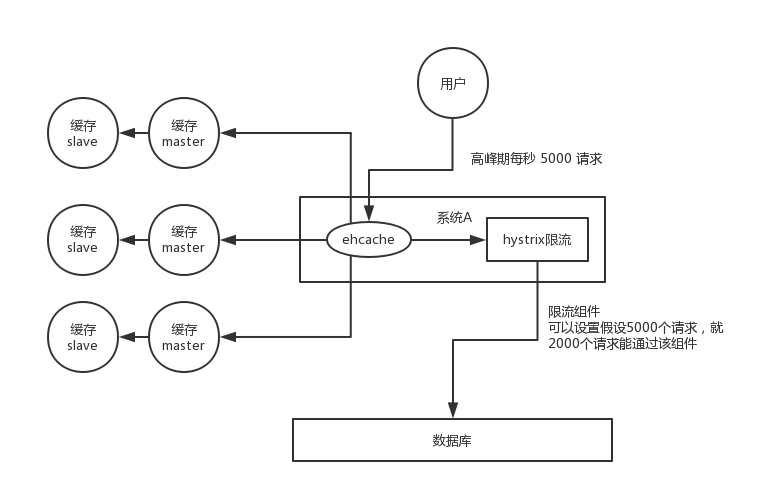
用户发送一个请求,系统 A 收到请求后,先查本地 ehcache 缓存,如果没查到再查 Redis。如果 ehcache 和 Redis 都没有,再查数据库,将数据库中的结果,写入 ehcache 和 Redis 中。
限流组件,可以设置每秒的请求,有多少能通过组件,剩余的未通过的请求,怎么办?走降级!可以返回一些默认的值,或者友情提示,或者空值。
好处:
- 数据库绝对不会死,限流组件确保了每秒只有多少个请求能通过。
- 只要数据库不死,就是说,对用户来说,2/5 的请求都是可以被处理的。
- 只要有 2/5 的请求可以被处理,就意味着你的系统没死,对用户来说,可能就是点击几次刷不出来页面,但是多点几次,就可以刷出来了。
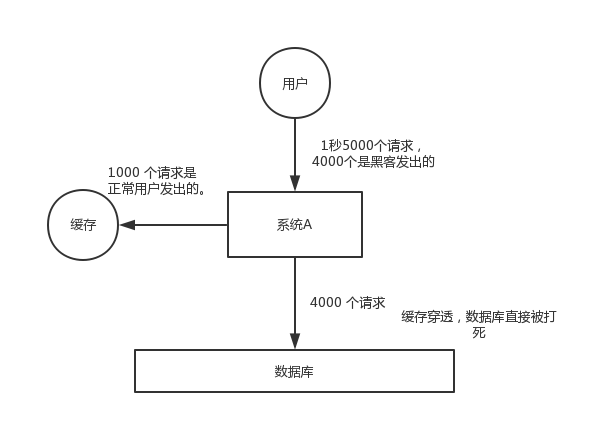
缓存穿透(Cache Penetration)
对于系统 A,假设一秒 5000 个请求,结果其中 4000 个请求是黑客发出的恶意攻击。
黑客发出的那 4000 个攻击,缓存中查不到,每次你去数据库里查,也查不到。
举个栗子。数据库 id 是从 1 开始的,结果黑客发过来的请求 id 全部都是负数。这样的话,缓存中不会有,请求每次都“视缓存于无物”,直接查询数据库。这种恶意攻击场景的缓存穿透就会直接把数据库给打死。
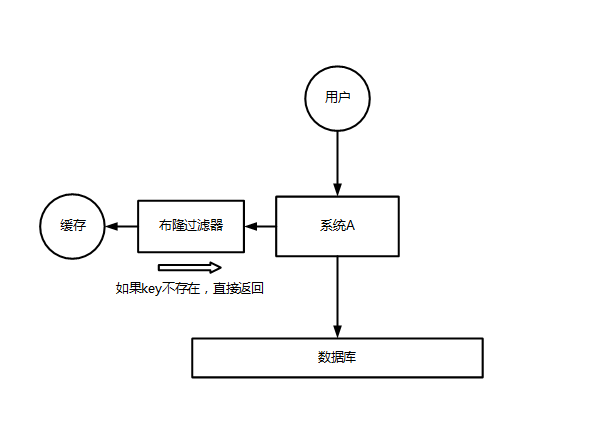
解决方式很简单,每次系统 A 从数据库中只要没查到,就写一个空值到缓存里去,比如 set -999 UNKNOWN 。然后设置一个过期时间,这样的话,下次有相同的 key 来访问的时候,在缓存失效之前,都可以直接从缓存中取数据。
当然,如果黑客如果每次使用不同的负数 id 来攻击,写空值的方法可能就不奏效了。更为经常的做法是在缓存之前增加布隆过滤器,将数据库中所有可能的数据哈希映射到布隆过滤器中。然后对每个请求进行如下判断:
- 请求数据的 key 不存在于布隆过滤器中,可以确定数据就一定不会存在于数据库中,系统可以立即返回不存在。
- 请求数据的 key 存在于布隆过滤器中,则继续再向缓存中查询。
使用布隆过滤器能够对访问的请求起到了一定的初筛作用,避免了因数据不存在引起的查询压力。
缓存击穿(Hotspot Invalid)
缓存击穿,就是说某个 key 非常热点,访问非常频繁,处于集中式高并发访问的情况,当这个 key 在失效的瞬间,大量的请求就击穿了缓存,直接请求数据库,就像是在一道屏障上凿开了一个洞。
不同场景下的解决方式可如下:
- 若缓存的数据是基本不会发生更新的,则可尝试将该热点数据设置为永不过期。
- 若缓存的数据更新不频繁,且缓存刷新的整个流程耗时较少的情况下,则可以采用基于 Redis、zookeeper 等分布式中间件的分布式互斥锁,或者本地互斥锁以保证仅少量的请求能请求数据库并重新构建缓存,其余线程则在锁释放后能访问到新缓存。
- 若缓存的数据更新频繁或者在缓存刷新的流程耗时较长的情况下,可以利用定时线程在缓存过期前主动地重新构建缓存或者延后缓存的过期时间,以保证所有的请求能一直访问到对应的缓存。