add 6 chapters
1
.gitignore
vendored
Normal file
@ -0,0 +1 @@
|
||||
.DS_Store
|
||||
47
README.md
@ -1,11 +1,44 @@
|
||||
# ddia-meetup
|
||||
# DDIA 读书会
|
||||
|
||||
DDIA reading together.
|
||||
DDIA 读书分享会,会逐章进行分享,结合我在工业界分布式存储和数据库的一些经验,补充一些细节。每两周左右分享一次,欢迎加入,Schedule 在[这里](https://docs.qq.com/sheet/DWHFzdk5lUWx4UWJq)。我们有个对应的分布式&数据库讨论群,每次分享前会在群里通知。如想加入,可以加我的微信号:qtmuniao,简单自我介绍下,并注明:分布式系统群。
|
||||
|
||||
读书会安排和往期录屏: https://docs.qq.com/sheet/DWHFzdk5lUWx4UWJq.
|
||||
# 《DDIA 逐章精读》小册
|
||||
|
||||
在理解英文原文的基础上,结合我的一些工作经验,进行一些相应扩展,并参考 [github 上 Vonng 的中文翻译版](https://github.com/Vonng/ddia),对每一章用中文重新组织,作为每次分享的文字稿,在此集结为 gitbook 小册,希望可以对有需要的同学有所帮助,水平所限,难免疏漏,如发现有任何有误之处,欢迎提 issue 和 PR。
|
||||
|
||||
|
||||
Meetup schedule: https://docs.qq.com/sheet/DWHFzdk5lUWx4UWJq.
|
||||
Any issues and volunteers are welcome.
|
||||
## 目录
|
||||
### 第一部分:数据系统基础
|
||||
|
||||
|content |date |host |contact | readings | transcript | recording
|
||||
| ------ | ---- | ---- | ---- | ---- | ---- | ----
|
||||
| chapter1 | 2022/02/12 16:00-17:30 | muniao | https://www.zhihu.com/people/qtmuniao | https://vonng.gitbooks.io/ddia-cn/content/ch1.html | https://zhuanlan.zhihu.com/p/466593109 | https://www.bilibili.com/video/BV1bY411L7HA
|
||||
* [第一章:可靠、可扩展、可维护](ch01.md) [[视频](https://www.bilibili.com/video/BV1bY411L7HA)]
|
||||
* [本书为什么以数据系统为主题](ch01.md#本书为什么以数据系统为主题)
|
||||
* [可靠性(Reliability)](ch01.md#可靠性(Reliability))
|
||||
* [可伸缩性(Scalability)](ch01.md#可伸缩性(Scalability))
|
||||
* [可维护性(Maintainability)](ch01.md#可维护性(Maintainability))
|
||||
* [第二章:数据模型和查询语言](ch02.md) [[视频上:数据模型和查询语言](https://www.bilibili.com/video/BV19a411C7UN) | [视频下:图数据模型](https://www.bilibili.com/video/BV1BZ4y1r79M)]
|
||||
* [概要](ch02.md#概要)
|
||||
* [关系模型 vs 文档模型](ch02.md#关系模型与文档模型)
|
||||
* [数据查询语言](ch02.md#数据查询语言)
|
||||
* [Graph-Like 数据模型](ch02.md#图模型)
|
||||
* [第三章:存储与查询](ch03.md) [[视频上:LSM-Tree 和 B-Tree](https://www.bilibili.com/video/BV1mL411P72H/) | [视频下:TPAP和列存](https://www.bilibili.com/video/BV1bL411A7ga)]
|
||||
* [驱动数据库的底层数据结构](ch03.md#驱动数据库的底层数据结构)
|
||||
* [事务型还是分析型](ch03.md#事务型还是分析型)
|
||||
* [列存](ch03.md#列存)
|
||||
* [第四章:编码和演进](ch04.md) [[视频](https://www.bilibili.com/video/BV1Aa411q7u9)]
|
||||
* [数据编码的格式](ch04.md#数据编码的格式)
|
||||
* [几种数据流模型](ch04.md#几种数据流模型)
|
||||
|
||||
### 第二部分:分布式数据
|
||||
|
||||
* [第五章:冗余(Replication)](ch05.md) [[视频上:单主模型](https://www.bilibili.com/video/BV1VR4y1K7eK) | [视频下:多主和无主](https://www.bilibili.com/video/BV1ou4116779)]
|
||||
* [领导者与跟随者](ch05.md#领导者与跟随者)
|
||||
* [复制滞后问题](ch05.md#复制滞后问题)
|
||||
* [多主模型](ch05.md#多主模型)
|
||||
* [无主模型](ch05.md#无主模型)
|
||||
* [第六章:分区(Partition)](ch06.md) [[视频上:分片方式和次级索引](https://www.bilibili.com/video/BV1tY4y157Np) | [视频下:均衡策略和请求路由](https://www.bilibili.com/video/BV1AA4y1f7Hi)]
|
||||
* [分片与复制](ch06.md#分片与复制)
|
||||
* [键值对集的分片](ch06.md#键值对集的分片)
|
||||
* [分片和次级索引](ch06.md#分片和次级索引)
|
||||
* [分片均衡(Rebalancing)](ch06.md#分片均衡(rebalancing))
|
||||
* [请求路由(Routing)](ch06.md#请求路由)
|
||||
|
||||
315
ch01.md
Normal file
@ -0,0 +1,315 @@
|
||||
# DDIA 逐章精读(一):可靠、可扩展、可维护
|
||||
|
||||
# 本书为什么以数据系统为主题
|
||||
|
||||
**数据系统**(data system)是一种模糊的统称。在信息社会中,一切皆可信息化,或者,某种程度上来说——数字化。这些数据的采集、存储和使用,是构成信息社会的基础。我们常见的绝大部分应用背后都有一套数据系统支撑,比如微信、京东、微博等等。
|
||||
|
||||

|
||||
|
||||
因此,作为 IT 从业人员,有必要系统性的了解一下现代的、分布式的数据系统。学习本书,能够学习到数据系统的背后的原理、了解其常见的实践、进而将其应用到我们工作的系统设计中。
|
||||
|
||||
|
||||
## 常见的数据系统有哪些
|
||||
|
||||
- 存储数据,以便之后再次使用——**数据库**
|
||||
- 记住一些非常“重”的操作结果,方便之后加快读取速度——**缓存**
|
||||
- 允许用户以各种关键字搜索、以各种条件过滤数据——**搜索引擎**
|
||||
- 源源不断的产生数据、并发送给其他进程进行处理——**流式处理**
|
||||
- 定期处理累积的大量数据——**批处理**
|
||||
- 进行消息的传送与分发——**消息队列**
|
||||
|
||||
这些概念如此耳熟能详以至于我们在设计系统时拿来就用,而不用去想其实现细节,更不用从头进行实现。当然,这也侧面说明这些概念抽象的多么成功。
|
||||
|
||||
## 数据系统的日益复杂化
|
||||
|
||||
但这些年来,随着应用需求的进一步复杂化,出现了很多新型的数据采集、存储和处理系统,它们不拘泥于单一的功能,也难以生硬的归到某个类别。随便举几个例子:
|
||||
|
||||
1. **Kafka**:可以作为存储持久化一段时间日志数据、可以作为消息队列对数据进行分发、可以作为流式处理组件对数据反复蒸馏等等。
|
||||
2. **Spark**:可以对数据进行批处理、也可以化小批为流,对数据进行流式处理。
|
||||
3. **Redis**:可以作为缓存加速对数据库的访问、也可以作为事件中心对消息的发布订阅。
|
||||
|
||||
我们面临一个新的场景,以某种组合使用这些组件时,在某种程度上,便是创立了一个新的数据系统。书中给了一个常见的对用户数据进行采集、存储、查询、旁路等操作的数据系统示例。从其示意图中可以看到各种 Web Services 的影子。
|
||||
|
||||

|
||||
|
||||
但就这么一个小系统,在设计时,就可以有很多取舍:
|
||||
|
||||
1. 使用何种缓存策略?是旁路还是写穿透?
|
||||
2. 部分组件机器出现问题时,是保证可用性还是保证一致性?
|
||||
3. 当机器一时难以恢复,如何保证数据的正确性和完整性?
|
||||
4. 当负载增加时,是增加机器还是提升单机性能?
|
||||
5. 设计对外的 API 时,是力求简洁还是追求强大?
|
||||
|
||||
因此,有必要从根本上思考下如何评价一个好数据系统,如何构建一个好的数据系统,有哪些可以遵循的设计模式?有哪些通常需要考虑的方面?
|
||||
|
||||
书中用了三个词来回答:***可靠性(Reliability)、可伸缩性(Scalability)、可维护性(Maintainability)***
|
||||
|
||||
# 可靠性(Reliability)
|
||||
|
||||
如何衡量可靠性?
|
||||
|
||||
- **功能上**
|
||||
1. 正常情况下,应用行为满足 API 给出的行为
|
||||
2. 在用户误输入/误操作时,能够正常处理
|
||||
- **性能上**
|
||||
|
||||
在给定硬件和数据量下,能够满足承诺的性能指标。
|
||||
|
||||
- **安全上**
|
||||
|
||||
能够阻止未授权、恶意破坏。
|
||||
|
||||
|
||||
可用性也是可靠性的一个侧面,云服务通常以多少个 9 来衡量可用性。
|
||||
|
||||
---
|
||||
|
||||
两个易混淆的概念:**Fault(系统出现问题)** and **Failure(系统不能提供服务)**
|
||||
|
||||
不能进行 Fault-tolerance 的系统,积累的 fault 多了,就很容易 Failure。
|
||||
|
||||
如何预防?混沌测试:如 Netflix 的 [chaosmonkey](https://netflix.github.io/chaosmonkey/)。
|
||||
|
||||
## 硬件故障
|
||||
|
||||
在一个大型数据中心中,这是常态:
|
||||
|
||||
1. 网络抖动、不通
|
||||
2. 硬盘老化坏道
|
||||
3. 内存故障
|
||||
4. 机器过热导致 CPU 出问题
|
||||
5. 机房断电
|
||||
|
||||
数据系统中常见的需要考虑的硬件指标:
|
||||
|
||||
- **MTTF mean time to failure**
|
||||
|
||||
单块盘 平均故障时间 5 ~10 年,如果你有 1w+ 硬盘,则均匀期望下,每天都有坏盘出现。当然事实是硬盘会一波一波坏。
|
||||
|
||||
|
||||
解决办法,增加冗余度:
|
||||
|
||||
机房多路供电,双网络等等。
|
||||
|
||||
对于数据:
|
||||
|
||||
**单机**:可以做RAID 冗余。如:EC 编码。
|
||||
|
||||
**多机**:多副本 or EC 编码。
|
||||
|
||||
## 软件错误
|
||||
|
||||
相比硬件故障的随机性,软件错误的相关性更高:
|
||||
|
||||
1. 不能处理特定输入,导致系统崩溃。
|
||||
2. 失控进程(如循环未释放资源)耗尽 CPU、内存、网络资源。
|
||||
3. 系统依赖组件变慢甚至无响应。
|
||||
4. 级联故障。
|
||||
|
||||
在设计软件时,我们通常有一些**环境假设**,和一些**隐性约束**。随着时间的推移、系统的持续运行,如果这些假设不能够继续被满足;如果这些约束被后面维护者增加功能时所破坏;都有可能让一开始正常运行的系统,突然崩溃。
|
||||
|
||||
### 人为问题
|
||||
|
||||
系统中最不稳定的是人,因此要在设计层面尽可能消除人对系统影响。依据软件的生命周期,分几个阶段来考虑:
|
||||
|
||||
- **设计编码**
|
||||
1. 尽可能消除所有不必要的假设,提供合理的抽象,仔细设计 API
|
||||
2. 进程间进行隔离,对尤其容易出错的模块使用沙箱机制
|
||||
3. 对服务依赖进行熔断设计
|
||||
- **测试阶段**
|
||||
1. 尽可能引入第三方成员测试,尽量将测试平台自动化
|
||||
2. 单元测试、集成测试、e2e 测试、混沌测试
|
||||
- **运行阶段**
|
||||
1. 详细的仪表盘
|
||||
2. 持续自检
|
||||
3. 报警机制
|
||||
4. 问题预案
|
||||
- **针对组织**
|
||||
|
||||
科学的培训和管理
|
||||
|
||||
|
||||
## 可靠性有多重要?
|
||||
|
||||
事关用户数据安全,事关企业声誉,企业存活和做大的基石。
|
||||
|
||||
# 可伸缩性(Scalability)
|
||||
|
||||
可伸缩性,即系统应对负载增长的能力。它很重要,但在实践中又很难做好,因为存在一个基本矛盾:**只有能存活下来的产品才有资格谈伸缩,而过早为伸缩设计往往活不下去**。
|
||||
|
||||
但仍是可以了解一些基本的概念,来应对**可能会**暴增的负载。
|
||||
|
||||
## 衡量负载
|
||||
|
||||
应对负载之前,要先找到合适的方法来衡量负载,如**负载参数(load parameters)**:
|
||||
|
||||
- 应用日活月活
|
||||
- 每秒向Web服务器发出的请求
|
||||
- 数据库中的读写比率
|
||||
- 聊天室中同时活跃的用户数量
|
||||
|
||||
书中以 Twitter 2012年11 披露的信息为例进行了说明:
|
||||
|
||||
1. 识别主营业务:发布推文、首页 Feed 流。
|
||||
2. 确定其请求量级:发布推文(平均 4.6k请求/秒,峰值超过 12k请求/秒),查看其他人推文(300k请求/秒)
|
||||
|
||||

|
||||
|
||||
单就这个数据量级来说,无论怎么设计都问题不大。但 Twitter 需要根据用户之间的关注与被关注关系来对数据进行多次处理。常见的有推拉两种方式:
|
||||
|
||||
1. **拉**。每个人查看其首页 Feed 流时,从数据库现**拉取**所有关注用户推文,合并后呈现。
|
||||
2. **推**。为每个用户保存一个 Feed 流视图,当用户发推文时,将其插入所有关注者 Feed 流视图中。
|
||||
|
||||

|
||||
|
||||
前者是 Lazy 的,用户只有查看时才会去拉取,不会有无效计算和请求,但每次需要现算,呈现速度较慢。而且流量一大也扛不住。
|
||||
|
||||
后者实现算出视图,而不管用户看不看,呈现速度较快,但会引入很多无效请求。
|
||||
|
||||
最终,使用的是一种推拉结合的方式,这也是外国一道经典的系统设计考题。
|
||||
|
||||
## 描述性能
|
||||
|
||||
注意和系统负载区分,系统负载是从用户视角来审视系统,是一种**客观指标**。而系统性能则是描述的系统的一种**实际能力**。比如:
|
||||
|
||||
1. **吞吐量(throughput)**: 每秒可以处理的单位数据量,通常记为 QPS。
|
||||
2. **响应时间(response time)**: 从用户侧观察到的发出请求到收到回复的时间。
|
||||
3. **延迟(latency)**:日常中,延迟经常和响应时间混用指代响应时间;但严格来说,延迟只是只请求过程中排队等休眠时间,虽然其在响应时间中一般占大头;但只有我们把请求真正处理耗时认为是瞬时,延迟才能等同于响应时间。
|
||||
|
||||
响应时间通常以百分位点来衡量,比如 p95,p99和 p999,它们意味着95%,99%或 99.9% 的请求都能在该阈值内完成。在实际中,通常使用滑动窗口滚动计算最近一段时间的响应时间分布,并通常以折线图或者柱状图进行呈现。
|
||||
|
||||
## 应对负载
|
||||
|
||||
在有了描述和定义负载、性能的手段之后,终于来到正题,如何应对负载的不断增长,即使系统具有可伸缩性。
|
||||
|
||||
1. **纵向伸缩(scaling up)or 垂直伸缩(vertical scaling)**:换具有更强大性能的机器。e.g. 大型机机器学习训练。
|
||||
2. **横向伸缩(scaling out)or 水平伸缩(horizontal scaling)**:“并联”很多廉价机,分摊负载。 e.g. 马斯克造火箭。
|
||||
|
||||
负载伸缩的两种方式:
|
||||
|
||||
- **自动**
|
||||
|
||||
如果负载不好预测且多变,则自动较好。坏处在于不易跟踪负载,容易抖动,造成资源浪费。
|
||||
|
||||
- **手动**
|
||||
|
||||
如果负载容易预测且不长变化,最好手动。设计简单,且不容易出错。
|
||||
|
||||
|
||||
针对不同应用场景:
|
||||
|
||||
首先,如果规模很小,尽量还是用性能好一点的机器,可以省去很多麻烦。
|
||||
|
||||
其次,可以上云,利用云的可伸缩性。甚至如 Snowflake 等基础服务提供商也是 All In 云原生。
|
||||
|
||||
最后,实在不行再考虑自行设计可伸缩的分布式架构。
|
||||
|
||||
两种服务类型:
|
||||
|
||||
- **无状态服务**
|
||||
|
||||
比较简单,多台机器,外层罩一个 gateway 就行。
|
||||
|
||||
- **有状态服务**
|
||||
|
||||
根据需求场景,如读写负载、存储量级、数据复杂度、响应时间、访问模式,来进行取舍,设计合乎需求的架构。
|
||||
|
||||
|
||||
**不可能啥都要,没有万金油架构**! 但同时:万变不离其宗,组成不同架构的原子设计模式是有限的,这也是本书稍后要论述的重点。
|
||||
|
||||
# 可维护性(Maintainability)
|
||||
|
||||
从软件的整个生命周期来看,维护阶段绝对占大头。
|
||||
|
||||
但大部分人都喜欢挖坑,不喜欢填坑。因此有必要,在刚开就把坑开的足够好。有三个原则:
|
||||
|
||||
- ***可维护性(Operability)***
|
||||
|
||||
便于运维团队无痛接手。
|
||||
|
||||
- ***简洁性(Simplicity)***
|
||||
|
||||
便于新手开发平滑上手:这需要一个合理的抽象,并尽量消除各种复杂度。如,层次化抽象。
|
||||
|
||||
- ***可演化性(*Evolvability)***
|
||||
|
||||
便于后面需求快速适配:避免耦合过紧,将代码绑定到某种实现上。也称为**可扩展性(extensibility)**,**可修改性(modifiability)** 或**可塑性(plasticity)**。
|
||||
|
||||
|
||||
## **可运维性(Operability):人生苦短,关爱运维**
|
||||
|
||||
有效的运维绝对是个高技术活:
|
||||
|
||||
1. 紧盯系统状态,出问题时快速恢复。
|
||||
2. 恢复后,复盘问题,定位原因。
|
||||
3. 定期对平台、库、组件进行更新升级。
|
||||
4. 了解组件间相互关系,避免级联故障。
|
||||
5. 建立自动化配置管理、服务管理、更新升级机制。
|
||||
6. 执行复杂维护任务,如将存储系统从一个数据中心搬到另外一个数据中心。
|
||||
7. 配置变更时,保证系统安全性。
|
||||
|
||||
系统具有良好的可维护性,意味着将**可定义**的维护过程编写**文档和工具**以自动化,从而解放出人力关注更高价值事情:
|
||||
|
||||
1. 友好的文档和一致的运维规范。
|
||||
2. 细致的监控仪表盘、自检和报警。
|
||||
3. 通用的缺省配置。
|
||||
4. 出问题时的自愈机制,无法自愈时允许管理员手动介入。
|
||||
5. 将维护过程尽可能的自动化。
|
||||
6. 避免单点依赖,无论是机器还是人。
|
||||
|
||||
## **简洁性(Simplicity):复杂度管理**
|
||||
|
||||

|
||||
|
||||
推荐一本书:[A Philosophy of Software Design](https://book.douban.com/subject/30218046/) ,讲述在软件设计中如何定义、识别和降低复杂度。
|
||||
|
||||
复杂度表现:
|
||||
|
||||
1. 状态空间的膨胀。
|
||||
2. 组件间的强耦合。
|
||||
3. 不一致的术语和[命名](https://www.qtmuniao.com/2021/12/12/how-to-write-code-scrutinize-names/)。
|
||||
4. 为了提升性能的 hack。
|
||||
5. 随处可见的补丁( workaround)。
|
||||
|
||||
需求很简单,但不妨碍你实现的很复杂 😉:过多的引入了**额外复杂度**(*accidental* complexity
|
||||
)——非问题本身决定的,而由实现所引入的复杂度。
|
||||
|
||||
通常是问题理解的不够本质,写出了“**流水账**”(没有任何**抽象,abstraction**)式的代码。
|
||||
|
||||
如果你为一个问题找到了合适的抽象,那么问题就解决了一半,如:
|
||||
|
||||
1. 高级语言隐藏了机器码、CPU 和系统调用细节。
|
||||
2. SQL 隐藏了存储体系、索引结构、查询优化实现细节。
|
||||
|
||||
如何找到合适的抽象?
|
||||
|
||||
1. 从计算机领域常见的抽象中找。
|
||||
2. 从日常生活中常接触的概念找。
|
||||
|
||||
总之,一个合适的抽象,要么是**符合直觉**的;要么是和你的读者**共享上下文**的。
|
||||
|
||||
本书之后也会给出很多分布式系统中常用的抽象。
|
||||
|
||||
## 可演化性:降低改变门槛
|
||||
|
||||
系统需求没有变化,说明这个行业死了。
|
||||
|
||||
否则,需求一定是不断在变,引起变化的原因多种多样:
|
||||
|
||||
1. 对问题阈了解更全面
|
||||
2. 出现了之前未考虑到的用例
|
||||
3. 商业策略的改变
|
||||
4. 客户爸爸要求新功能
|
||||
5. 依赖平台的更迭
|
||||
6. 合规性要求
|
||||
7. 体量的改变
|
||||
|
||||
应对之道:
|
||||
|
||||
- 项目管理上
|
||||
|
||||
敏捷开发
|
||||
|
||||
- 系统设计上
|
||||
|
||||
依赖前两点。合理抽象,合理封装,对修改关闭,对扩展开放。
|
||||
765
ch02.md
Normal file
@ -0,0 +1,765 @@
|
||||
# DDIA 逐章精读(二):数据模型和查询语言
|
||||
|
||||
# 概要
|
||||
|
||||
本节围绕两个主要概念来展开。
|
||||
|
||||
如何分析一个**数据模型**:
|
||||
|
||||
1. 基本考察点:数据基本元素,和元素之间的对应关系(一对多,多对多)
|
||||
2. 利用几种常用模型来比较:(最为流行的)关系模型,(树状的)文档模型,(极大自由度的)图模型。
|
||||
3. schema 模式:强 Schema(写时约束);弱 Schema(读时解析)
|
||||
|
||||
如何考量**查询语言**:
|
||||
|
||||
1. 如何与数据模型关联、匹配
|
||||
2. 声明式(declarative)和命令式(imperative)
|
||||
|
||||
## 数据模型
|
||||
|
||||
> A **data model** is an [abstract model](https://en.wikipedia.org/wiki/Abstract_model) that organizes elements of [data](https://en.wikipedia.org/wiki/Data) and standardizes how they relate to one another and to the properties of real-world entities.。
|
||||
—[https://en.wikipedia.org/wiki/Data_model](https://en.wikipedia.org/wiki/Data_model)
|
||||
>
|
||||
|
||||
**数据模型**:如何组织数据,如何标准化关系,如何关联现实。
|
||||
|
||||
它既决定了我们构建软件的方式(**实现**),也左右了我们看待问题的角度(**认知**)。
|
||||
|
||||
作者开篇以计算机的不同抽象层次来让大家对**泛化的**数据模型有个整体观感。
|
||||
|
||||
大多数应用都是通过不同的数据模型层级累进构建的。
|
||||
|
||||

|
||||
|
||||
每层模型核心问题:如何用下一层的接口来对本层进行建模?
|
||||
|
||||
1. 作为**应用开发者,** 你将现实中的具体问题抽象为一组对象、**数据结构(data structure)** 以及作用于其上的 API。
|
||||
2. 作为**数据库管理员(DBA)**,为了持久化上述数据结构,你需要将他们表达为通用的**数据模型(data model)**,如文档数据库中的XML/JSON、关系数据库中的表、图数据库中的图。
|
||||
3. 作为**数据库系统开发者**,你需要将上述数据模型组织为内存中、硬盘中或者网络中的**字节(Bytes)** 流,并提供多种操作数据集合的方法。
|
||||
4. 作为**硬件工程师**,你需要将字节流表示为二极管的电位(内存)、磁场中的磁极(磁盘)、光纤中的光信号(网络)。
|
||||
|
||||
> 在每一层,通过对外暴露简洁的**数据模型**,我们**隔离**和**分解**了现实世界的**复杂度**。
|
||||
>
|
||||
|
||||
这也反过来说明了,好的数据模型需有两个特点:
|
||||
|
||||
1. 简洁直观
|
||||
2. 具有组合性
|
||||
|
||||
第二章首先探讨了关系模型、文档模型及其对比,其次是相关查询语言,最后探讨了图模型。
|
||||
|
||||
|
||||
# 关系模型与文档模型
|
||||
|
||||
## 关系模型
|
||||
|
||||
关系模型无疑是当今最流行的数据库模型。
|
||||
|
||||
关系模型是 [埃德加·科德(](https://zh.wikipedia.org/wiki/%E5%9F%83%E5%BE%B7%E5%8A%A0%C2%B7%E7%A7%91%E5%BE%B7)[E. F. Codd](https://en.wikipedia.org/wiki/E._F._Codd))于 1969 年首先提出,并用“[科德十二定律](https://zh.wikipedia.org/wiki/%E7%A7%91%E5%BE%B7%E5%8D%81%E4%BA%8C%E5%AE%9A%E5%BE%8B)”来解释。但是商业落地的数据库基本没有能完全遵循的,因此关系模型后来通指这一类数据库。特点如下:
|
||||
|
||||
1. 将数据以**关系**呈现给用户(比如:一组包含行列的二维表)。
|
||||
2. 提供操作数据集合的**关系算子**。
|
||||
|
||||
**常见分类**
|
||||
|
||||
1. 事务型(TP):银行交易、火车票
|
||||
2. 分析型(AP):数据报表、监控表盘
|
||||
3. 混合型(HTAP):
|
||||
|
||||
关系模型诞生很多年后,虽有不时有各种挑战者(比如上世纪七八十年代的**网状模型** network model 和**层次模型** hierarchical model ),但始终仍未有根本的能撼动其地位的新模型。
|
||||
|
||||
直到近十年来,随着移动互联网的普及,数据爆炸性增长,各种处理需求越来越精细化,催生了数据模型的百花齐放。
|
||||
|
||||
## NoSQL 的诞生
|
||||
|
||||
NoSQL(最初表示Non-SQL,后来有人转解为Not only SQL),是对不同于传统的关系数据库的数据库管理系统的统称。根据 [DB-Engines 排名](https://db-engines.com/en/ranking),现在最受欢迎的 NoSQL 前几名为:MongoDB,Redis,ElasticSearch,Cassandra。
|
||||
|
||||
其催动因素有:
|
||||
|
||||
1. 处理更大数据集:更强伸缩性、更高吞吐量
|
||||
2. 开源免费的兴起:冲击了原来把握在厂商的标准
|
||||
3. 特化的查询操作:关系数据库难以支持的,比如图中的多跳分析
|
||||
4. 表达能力更强:关系模型约束太严,限制太多
|
||||
|
||||
## 面向对象和关系模型的不匹配
|
||||
|
||||
核心冲突在于面向对象的**嵌套性**和关系模型的**平铺性**(?我随便造的)。
|
||||
|
||||
当然有 ORM 框架可以帮我们搞定这些事情,但仍是不太方便。
|
||||
|
||||

|
||||
|
||||
换另一个角度来说,关系模型很难直观的表示**一对多**的关系。比如简历上,一个人可能有多段教育经历和多段工作经历。
|
||||
|
||||
**文档模型**:使用 Json 和 XML 的天然嵌套。
|
||||
|
||||
**关系模型**:使用 SQL 模型就得将职位、教育单拎一张表,然后在用户表中使用外键关联。
|
||||
|
||||
在简历的例子中,文档模型还有几个优势:
|
||||
|
||||
1. **模式灵活**:可以动态增删字段,如工作经历。
|
||||
2. **更好的局部性**:一个人的所有属性被集中访问的同时,也被集中存储。
|
||||
3. **结构表达语义**:简历与联系信息、教育经历、职业信息等隐含一对多的树状关系可以被 JSON 的树状结构明确表达出来。
|
||||
|
||||
|
||||
|
||||
## 多对一和多对多
|
||||
|
||||
是一个对比各种数据模型的切入角度。
|
||||
|
||||
region 在存储时,为什么不直接存储纯字符串:“Greater Seattle Area”,而是先存为 region_id → region name,其他地方都引用 region_id?
|
||||
|
||||
1. **统一样式**:所有用到相同概念的地方都有相同的拼写和样式
|
||||
2. **避免歧义**:可能有同名地区
|
||||
3. **易于修改**:如果一个地区改名了,我们不用去逐一修改所有引用他的地方
|
||||
4. **本地化支持**:如果翻译成其他语言,可以只翻译名字表。
|
||||
5. **更好搜索**:列表可以关联地区,进行树形组织
|
||||
|
||||
类似的概念还有:面向抽象编程,而非面向细节。
|
||||
|
||||
关于用 ID 还是文本,作者提到了一点:ID 对人类是**无意义**的,无意义的意味着不会随着现实世界的将来的改变而改动。
|
||||
|
||||
这在关系数据库表设计时需要考虑,即如何控制**冗余(duplication)**。会有几种**范式(normalization)** 来消除冗余。
|
||||
|
||||
文档型数据库很擅长处理一对多的树形关系,却不擅长处理多对多的图形关系。如果其不支持 Join,则处理多对多关系的复杂度就从数据库侧移动到了应用侧。
|
||||
|
||||
如,多个用户可能在同一个组织工作过。如果我们想找出在同一个学校和组织工作过的人,如果数据库不支持 Join,则需要在应用侧进行循环遍历来 Join。
|
||||
|
||||

|
||||
|
||||
文档 vs 关系
|
||||
|
||||
1. 对于一对多关系,文档型数据库将嵌套数据放在父节点中,而非单拎出来放另外一张表。
|
||||
2. 对于多对一和多对多关系,本质上,两者都是使用外键(文档引用)进行索引。查询时需要进行 join 或者动态跟随。
|
||||
|
||||
## 文档模型是否在重复历史?
|
||||
|
||||
### 层次模型 **(hierarchical model)**
|
||||
|
||||
20 世纪 70 年代,IBM 的信息管理系统 IMS。
|
||||
|
||||
> A **hierarchical database model** is a [data model](https://en.wikipedia.org/wiki/Data_model) in which the data are organized into a [tree](https://en.wikipedia.org/wiki/Tree_data_structure)-like structure. The data are stored as **records** which are connected to one another through **links.** A record is a collection of fields, with each field containing only one value. The **type** of a record defines which fields the record contains. — wikipedia
|
||||
>
|
||||
|
||||
几个要点:
|
||||
|
||||
1. 树形组织,每个子节点只允许有一个父节点
|
||||
2. 节点存储数据,节点有类型
|
||||
3. 节点间使用类似指针方式连接
|
||||
|
||||
可以看出,它跟文档模型很像,也因此很难解决多对多的关系,并且不支持 Join。
|
||||
|
||||
为了解决层次模型的局限,人们提出了各种解决方案,最突出的是:
|
||||
|
||||
1. 关系模型
|
||||
2. 网状模型
|
||||
|
||||
### 网状模型(network model)
|
||||
|
||||
network model 是 hierarchical model 的一种扩展:允许一个节点有多个父节点。它被数据系统语言会议(CODASYL)的委员会进行了标准化,因此也被称为 CODASYL 模型。
|
||||
|
||||
多对一和多对多都可以由路径来表示。访问记录的唯一方式是顺着元素和链接组成的链路进行访问,这个链路叫**访问路径** (access path)。难度犹如在 n-维空间中进行导航。
|
||||
|
||||
内存有限,因此需要严格控制遍历路径。并且需要事先知道数据库的拓扑结构,这就意味着得针对不同应用写大量的专用代码。
|
||||
|
||||
### 关系模型
|
||||
|
||||
在关系模型中,数据被组织成**元组(tuples)**,进而集合成**关系(relations)**;在 SQL 中分别对应行(rows)和表(tables)。
|
||||
|
||||
- 不知道大家好奇过没,明明看起来更像表模型,为什叫**关系模型**?
|
||||
|
||||
表只是一种实现。
|
||||
|
||||
关系(relation)的说法来自集合论,指的是几个集合的笛卡尔积的子集。
|
||||
|
||||
R ⊆ (D1×D2×D3 ··· ×Dn)
|
||||
|
||||
(关系用符号 R 表示,属性用符号 Ai 表示,属性的定义域用符号 Di 表示)
|
||||
|
||||
|
||||
其主要目的和贡献在于提供了一种**声明式**的描述数据和构建查询的方法。
|
||||
|
||||
即,相比网络模型,关系模型的查询语句和执行路径相解耦,**查询优化器**(Query Optimizer 自动决定执行顺序、要使用的索引),即将逻辑和实现解耦。
|
||||
|
||||
举个例子:如果想使用新的方式对你的数据集进行查询,你只需要在新的字段上建立一个索引。那么在查询时,你并不需要改变的你用户代码,查询优化器便会动态的选择可用索引。
|
||||
|
||||
## 文档型 vs 关系型
|
||||
|
||||
根据数据类型来选择数据模型
|
||||
|
||||
| | 文档型 | 关系型 |
|
||||
| --- | --- | --- |
|
||||
| 对应关系 | 数据有天然的一对多、树形嵌套关系,如简历。 | 通过外键+ Join 可以处理 多对一,多对多关系 |
|
||||
| 代码简化 | 数据具有文档结构,则文档模型天然合适,用关系模型会使得建模繁琐、访问复杂。
|
||||
但不宜嵌套太深,因为只能手动指定访问路径,或者范围遍历 | 主键,索引,条件过滤 |
|
||||
| Join 支持 | 对 Join 支持的不太好 | 支持的还可以,但 Join 的实现会有很多难点 |
|
||||
| 模式灵活性 | 弱 schema,支持动态增加字段 | 强 schema,修改 schema 代价很大 |
|
||||
| 访问局部性 | 1. 一次性访问整个文档,较优 <br/>2. 只访问文档一部分,较差 | 分散在多个表中 |
|
||||
|
||||
|
||||
对于高度关联的数据集,使用文档型表达比较奇怪,使用关系型可以接受,使用图模型最自然。
|
||||
|
||||
### 文档模型中 Schema 的灵活性
|
||||
|
||||
说文档型数据库是 schemaless 不太准确,更贴切的应该是 **schema-on-read。**
|
||||
|
||||
| 数据模型 | | 编程语言 | | 性能 & 空间 |
|
||||
| --- | --- | --- | --- | --- |
|
||||
| schema-on-read | 写入时不校验,而在读取时进行动态解析。 | 弱类型 | 动态,在运行时解析 | 读取时动态解析,性能较差。写入时无法确定类型,无法对齐空间利用率较差。 |
|
||||
| schema-on-write | 写入时校验,数据对齐到 schema | 强类型 | 静态,编译时确定 | 性能和空间使用都较优。 |
|
||||
|
||||
文档型数据库使用场景特点:
|
||||
|
||||
1. 有多种类型的数据,但每个放一张表又不合适。
|
||||
2. 数据类型和结构又外部决定,你没办法控制数据的变化。
|
||||
|
||||
### 查询时的数据局部性
|
||||
|
||||
如果你同时需要文档中所有内容,把文档顺序存会效率比较高。
|
||||
|
||||
但如果你只需要访问文档中的某些字段,则文档仍需要将文档全部加载出。
|
||||
|
||||
但运用这种局部性不局限于文档型数据库。不同的数据库,会针对不同场景,调整数据物理分布以适应常用访问模式的局部性。
|
||||
|
||||
- 如 Spanner 中允许表被声明为嵌入到父表中——常见关联内嵌
|
||||
- HBase 和 Cassandra 使用列族来聚集数据——分析型
|
||||
- 图数据库中,将点和出边存在一个机器上——图遍历
|
||||
|
||||
### 关系型和文档型的融合
|
||||
|
||||
- MySQL 和 PostgreSQL 开始支持 JSON
|
||||
|
||||
原生支持 JSON 可以理解为,MySQL 可以理解 JSON 格式。如 Date 格式一样,可以把某个字段作为 JSON 格式,可以修改其中的某个字段,可以在其中某个字段建立索引。
|
||||
|
||||
- RethinkDB 在查询中支持 relational-link Joins
|
||||
|
||||
|
||||
|
||||
科德(Codd):**nonsimple domains**,记录中的值除了简单类型(数字、字符串),还可以一个嵌套关系(表)。这很像 SQL 对 XML、JSON 的支持。
|
||||
|
||||
# 数据查询语言
|
||||
|
||||
获取动物表中所有鲨鱼类动物。
|
||||
|
||||
```jsx
|
||||
function getSharks() { var sharks = [];
|
||||
for (var i = 0; i < animals.length; i++) {
|
||||
if (animals[i].family === "Sharks") {
|
||||
sharks.push(animals[i]);
|
||||
}
|
||||
}
|
||||
return sharks;
|
||||
}
|
||||
```
|
||||
|
||||
```sql
|
||||
SELECT * FROM animals WHERE family = 'Sharks';
|
||||
```
|
||||
|
||||
| | 声明式(declarative)语言 | 命令式(imperative)语言 |
|
||||
| --- | --- | --- |
|
||||
| 概念 | 描述控制逻辑而非执行流程 | 描述命令的执行过程,用一系列语句来不断改变状态 |
|
||||
| 举例 | SQL,CSS,XSL | IMS,CODASYL,通用语言如 C,C++,JS |
|
||||
| 抽象程度 | 高 | 低 |
|
||||
| 解耦程度 | 与实现解耦。 <br/>可以持续优化查询引擎性能; | 与实现耦合较深。
|
||||
| 解析执行 | 词法分析→ 语法分析 → 语义分析 <br/>生成执行计划→ 执行计划优化 | 词法分析→ 语法分析 → 语义分析 <br/>中间代码生成→ 代码优化 → 目标代码生成 |
|
||||
| 多核并行 | 声明式更具多核潜力,给了更多运行时优化空间 | 命令式由于指定了代码执行顺序,编译时优化空间较小。 |
|
||||
- Q:相对声明式语言,命令式语言有什么优点?
|
||||
1. 当描述的目标变得复杂时,声明式表达能力不够。
|
||||
2. 实现命令式的语言往往不会和声明式那么泾渭分明,通过合理抽象,通过一些编程范式(函数式),可以让代码兼顾表达力和清晰性。
|
||||
|
||||
## 数据库以外:Web 中的声明式
|
||||
|
||||
**需求**:选中页背景变蓝。
|
||||
|
||||
```html
|
||||
<ul>
|
||||
<li class="selected">
|
||||
<p>Sharks</p>
|
||||
<ul>
|
||||
<li>Great White Shark</li>
|
||||
<li>Tiger Shark</li>
|
||||
<li>Hammerhead Shark</li>
|
||||
</ul>
|
||||
</li>
|
||||
<li>
|
||||
<p>Whales</p>
|
||||
<ul>
|
||||
<li>Blue Whale</li>
|
||||
<li>Humpback Whale</li>
|
||||
<li>Fin Whale</li>
|
||||
</ul>
|
||||
</li>
|
||||
</ul>
|
||||
```
|
||||
|
||||
如果使用 CSS,则只需(CSS selector):
|
||||
|
||||
```css
|
||||
li.selected > p {
|
||||
background-color: blue;
|
||||
}
|
||||
```
|
||||
|
||||
如果使用 XSL,则只需(XPath selector):
|
||||
|
||||
```css
|
||||
<xsl:template match="li[@class='selected']/p">
|
||||
<fo:block background-color="blue">
|
||||
<xsl:apply-templates/>
|
||||
</fo:block>
|
||||
</xsl:template>
|
||||
```
|
||||
|
||||
但如果使用 JavaScript(而不借助上述 selector 库):
|
||||
|
||||
```jsx
|
||||
var liElements = document.getElementsByTagName("li");
|
||||
for (var i = 0; i < liElements.length; i++) {
|
||||
if (liElements[i].className === "selected") {
|
||||
var children = liElements[i].childNodes;
|
||||
for (var j = 0; j < children.length; j++) {
|
||||
var child = children[j];
|
||||
if (child.nodeType === Node.ELEMENT_NODE && child.tagName === "P") {
|
||||
child.setAttribute("style", "background-color: blue");
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## MapReduce 查询
|
||||
|
||||
**Google 的 MapReduce 模型**
|
||||
|
||||
1. 借鉴自函数式编程。
|
||||
2. 一种相当简单的编程模型,或者说原子的抽象,现在不太够用。
|
||||
3. 但在大数据处理工具匮乏的蛮荒时代(03年以前),谷歌提出的这套框架相当有开创性。
|
||||
|
||||

|
||||
|
||||
**MongoDB 的 MapReduce 模型**
|
||||
|
||||
MongoDB 使用的 MapReduce 是一种介于
|
||||
|
||||
1. **声明式**:用户不必显式定义数据集的遍历方式、shuffle 过程等执行过程。
|
||||
2. **命令式**:用户又需要定义针对单条数据的执行过程。
|
||||
|
||||
两者间的混合数据模型。
|
||||
|
||||
**需求**:统计每月观察到鲨类鱼的次数。
|
||||
|
||||
**查询语句**:
|
||||
|
||||
**PostgresSQL**
|
||||
|
||||
```sql
|
||||
SELECT date_trunc('month', observation_timestamp) AS observation_month,
|
||||
sum(num_animals) AS total_animals
|
||||
FROM observations
|
||||
WHERE family = 'Sharks' GROUP BY observation_month;
|
||||
```
|
||||
|
||||
**MongoDB**
|
||||
|
||||
```jsx
|
||||
db.observations.mapReduce(
|
||||
function map() { // 2. 对所有符合条件 doc 执行 map
|
||||
var year = this.observationTimestamp.getFullYear();
|
||||
var month = this.observationTimestamp.getMonth() + 1;
|
||||
emit(year + "-" + month, this.numAnimals); // 3. 输出一个 kv pair
|
||||
},
|
||||
function reduce(key, values) { // 4. 按 key 聚集
|
||||
return Array.sum(values); // 5. 相同 key 加和
|
||||
},
|
||||
{
|
||||
query: { family: "Sharks" }, // 1. 筛选
|
||||
out: "monthlySharkReport" // 6. reduce 结果集
|
||||
}
|
||||
);
|
||||
```
|
||||
|
||||
上述语句在执行时,经历了:筛选→ 遍历并执行 map → 对输出按 key 聚集(shuffle)→ 对聚集的数据注意 reduce → 输出结果集。
|
||||
|
||||
MapReduce 一些特点:
|
||||
|
||||
1. **要求 Map 和 Reduce 是纯函数**。即无任何副作用,在任意地点、以任意次序执行任何多次,对相同的输入都能得到相同的输出。因此容易并发调度。
|
||||
2. **非常底层、但表达力强大的编程模型**。可基于其实现 SQL 等高级查询语言,如 Hive。
|
||||
|
||||
但要注意:
|
||||
|
||||
1. 不是所有的分布式 SQL 都基于 MapReduce 实现。
|
||||
2. 不是只有 MapReduce 才允许嵌入通用语言(如 js)模块。
|
||||
3. MapReduce 是有一定**理解成本**的,需要熟悉其执行逻辑才能让两个函数紧密配合。
|
||||
|
||||
MongoDB 2.2+ 进化版,*aggregation pipeline:*
|
||||
|
||||
```jsx
|
||||
db.observations.aggregate([
|
||||
{ $match: { family: "Sharks" } },
|
||||
{ $group: {
|
||||
_id: {
|
||||
year: { $year: "$observationTimestamp" },
|
||||
month: { $month: "$observationTimestamp" }
|
||||
},
|
||||
totalAnimals: { $sum: "$numAnimals" } }}
|
||||
]);
|
||||
```
|
||||
|
||||
# 图模型
|
||||
|
||||
- 文档模型的适用场景?
|
||||
|
||||
你的数据集中存在着大量**一对多**(one-to-many)的关系。
|
||||
|
||||
- 图模型的适用场景?
|
||||
|
||||
你的数据集中存在大量的**多对多**(many-to-many)的关系。
|
||||
|
||||
|
||||
## 基本概念
|
||||
|
||||
图数据模型的基本概念一般有三个:**点**,**边**和附着于两者之上的**属性**。
|
||||
|
||||
常见的可以用图建模的场景:
|
||||
|
||||
| 例子 | 建模 | 应用 |
|
||||
| --- | --- | --- |
|
||||
| 社交图谱 | 人是点, follow 关系是边 | 六度分隔,信息流推荐 |
|
||||
| 互联网 | 网页是点,链接关系是边 | PageRank |
|
||||
| 路网 | 交通枢纽是点,铁路/公路是边 | 路径规划,导航最短路径 |
|
||||
| 洗钱 | 账户是点,转账关系是边 | 判断是否有环 |
|
||||
| 知识图谱 | 概念时点,关联关系是边 | 启发式问答 |
|
||||
|
||||
- 同构(*homogeneous*)数据和异构数据
|
||||
|
||||
图中的点可以都具有相同类型,但是,也可以具有不同类型,并且更为强大。
|
||||
|
||||
|
||||
本节都会以下图为例,它表示了一对夫妇,来自美国爱达荷州的 Lucy 和来自法国 的 Alain。他们已婚,住在伦敦。
|
||||
|
||||

|
||||
|
||||
有多种对图的建模方式:
|
||||
|
||||
1. 属性图(property graph):比较主流,如 Neo4j、Titan、InfiniteGraph
|
||||
2. 三元组(triple-store):如 Datomic、AllegroGraph
|
||||
|
||||
## 属性图(PG,Property Graphs)
|
||||
|
||||
| 点(vertices, nodes, entities) | 边(edges, relations, arcs) |
|
||||
| --- | --- |
|
||||
| 全局唯一 ID | 全局唯一 ID |
|
||||
| 出边集合 | 起始点 |
|
||||
| 入边集合 | 终止点 |
|
||||
| 属性集(kv 对表示) | 属性集(kv 对表示) |
|
||||
| 表示点类型的 type? | 表示边类型的 label |
|
||||
- Q:有一个疑惑点,为什么书中对于 PG 点的定义中没有 Type ?
|
||||
|
||||
如果数据是异构的,应该有才对;莫非是通过不同的属性来标记不同的类型?
|
||||
|
||||
|
||||
如果感觉不直观,可以使用我们熟悉的 SQL 语义来构建一个图模型,如下图。(Facebook TAO 论文中的单机存储引擎便是 MySQL)
|
||||
|
||||
```sql
|
||||
// 点表
|
||||
CREATE TABLE vertices (
|
||||
vertex_id integer PRIMARYKEY, properties json
|
||||
);
|
||||
|
||||
// 边表
|
||||
CREATE TABLE edges (
|
||||
edge_id integer PRIMARY KEY,
|
||||
tail_vertex integer REFERENCES vertices (vertex_id),
|
||||
head_vertex integer REFERENCES vertices (vertex_id),
|
||||
label text,
|
||||
properties json
|
||||
);
|
||||
|
||||
// 对点的反向索引,图遍历时用。给定点,找出点的所有入边和出边。
|
||||
CREATE INDEX edges_tails ON edges (tail_vertex);
|
||||
CREATE INDEX edges_heads ON edges (head_vertex);
|
||||
```
|
||||
|
||||
图是一种很灵活的建模方式:
|
||||
|
||||
1. 任何两点间都可以插入边,没有任何模式限制。
|
||||
2. 对于任何顶点都可以高效(思考:如何高效?)找到其入边和出边,从而进行图遍历。
|
||||
3. 使用多种**标签**来标记不同类型边(关系)。
|
||||
|
||||
相对于关系型数据来说,**可以在同一个图中保存异构类型的数据和关系,给了图极大的表达能力!**
|
||||
|
||||
这种表达能力,根据图中的例子,包括:
|
||||
|
||||
1. 对同样的概念,可以用不同结构表示。如不同国家的行政划分。
|
||||
2. 对同样的概念,可以用不同粒度表示。比如 Lucy 的现居住地和诞生地。
|
||||
3. 可以很自然的进行演化。
|
||||
|
||||
将异构的数据容纳在一张图中,可以通过**图遍历**,轻松完成关系型数据库中需要**多次 Join** 的操作。
|
||||
|
||||
## Cypher 查询语言
|
||||
|
||||
Cypher 是 Neo4j 创造的一种查询语言。
|
||||
|
||||
Cypher 和 Neo 名字应该都是来自 《黑客帝国》(The Matrix)。想想 Oracle。
|
||||
|
||||
Cypher 的一大特点是可读性强,尤其在表达路径模式(Path Pattern)时。
|
||||
|
||||
结合前图,看一个 Cypher 插入语句的例子:
|
||||
|
||||
```sql
|
||||
CREATE
|
||||
(NAmerica:Location {name:'North America', type:'continent'}),
|
||||
(USA:Location {name:'United States', type:'country' }),
|
||||
(Idaho:Location {name:'Idaho', type:'state' }),
|
||||
(Lucy:Person {name:'Lucy' }),
|
||||
(Idaho) -[:WITHIN]-> (USA) -[:WITHIN]-> (NAmerica),
|
||||
(Lucy) -[:BORN_IN]-> (Idaho)
|
||||
```
|
||||
|
||||
如果我们要进行一个这样的查询:找出所有从美国移居到欧洲的人名。
|
||||
|
||||
转化为图语言,即为:给定条件, BORN_IN 指向美国的地点,并且 LIVING_IN 指向欧洲的地点,找到所有符合上述条件的点,并且返回其名字属性。
|
||||
|
||||
用 Cypher 语句可表示为:
|
||||
|
||||
```sql
|
||||
MATCH
|
||||
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (us:Location {name:'United States'}),
|
||||
(person) -[:LIVES_IN]-> () -[:WITHIN*0..]-> (eu:Location {name:'Europe'})
|
||||
RETURN person.name
|
||||
```
|
||||
|
||||
注意到:
|
||||
|
||||
1. 点 `()`,边 `-[]→`,标签\类型 `:`,属性 `{}`。
|
||||
2. 名字绑定或者说变量:`person`
|
||||
3. 0 到多次通配符: `*0...`
|
||||
|
||||
正如声明式查询语言的一贯特点,你只需描述问题,不必担心执行过程。但与 SQL 的区别在于,SQL 基于关系代数,Cypher 类似正则表达式。
|
||||
|
||||
无论是 BFS、DFS 还是剪枝等实现细节,都不需要关心。
|
||||
|
||||
## 使用 SQL 进行图查询
|
||||
|
||||
前面看到可以用 SQL 存储点和边,以表示图。
|
||||
|
||||
那可以用 SQL 进行图查询吗?
|
||||
|
||||
Oracle 的 [PGQL](https://docs.oracle.com/en/database/oracle/property-graph/20.4/spgdg/property-graph-query-language-pgql.html):
|
||||
|
||||
```sql
|
||||
CREATE PROPERTY GRAPH bank_transfers
|
||||
VERTEX TABLES (persons KEY(account_number))
|
||||
EDGE TABLES(
|
||||
transactions KEY (from_acct, to_acct, date, amount)
|
||||
SOURCE KEY (from_account) REFERENCES persons
|
||||
DESTINATION KEY (to_account) REFERENCES persons
|
||||
PROPERTIES (date, amount)
|
||||
)
|
||||
```
|
||||
|
||||
其中有一个难点,就是如何表达图中的路径模式(graph pattern),如**多跳查询**,对应到 SQL 中,就是不确定次数的 Join:
|
||||
|
||||
```sql
|
||||
() -[:WITHIN*0..]-> ()
|
||||
```
|
||||
|
||||
使用 SQL:1999 中 recursive common table expressions (PostgreSQL, IBM DB2, Oracle, and SQL Server 支持)的可以满足。但是,相当冗长和笨拙。
|
||||
|
||||
## **Triple-Stores and SPARQL**
|
||||
|
||||
**Triple-Stores**,可以理解为三元组存储,即用三元组存储图。
|
||||
|
||||

|
||||
|
||||
其含义如下:
|
||||
|
||||
| Subject | 对应图中的一个点 |
|
||||
| --- | --- |
|
||||
| Object | 1. 一个原子数据,如 string 或者 number。<br/>2. 另一个 Subject。 |
|
||||
| Predicate | 1. 如果 Object 是原子数据,则 <Predicate, Object> 对应点附带的 KV 对。<br/>2. 如果 Object 是另一个 Object,则 Predicate 对应图中的边。 |
|
||||
|
||||
仍是上边例子,用 Turtle triples (一种 **Triple-Stores** 语法**)**表达为**:**
|
||||
|
||||
```scheme
|
||||
@prefix : <urn:example:>.
|
||||
_:lucy a :Person.
|
||||
_:lucy :name "Lucy".
|
||||
_:lucy :bornIn _:idaho.
|
||||
_:idaho a :Location.
|
||||
_:idaho :name "Idaho".
|
||||
_:idaho :type "state".
|
||||
_:idaho :within _:usa.
|
||||
_:usa a :Location
|
||||
_:usa :name "United States"
|
||||
_:usa :type "country".
|
||||
_:usa :within _:namerica.
|
||||
_:namerica a :Location.
|
||||
_:namerica :name "North America".
|
||||
_:namerica :type "continent".
|
||||
```
|
||||
|
||||
一种更紧凑的写法:
|
||||
|
||||
```scheme
|
||||
@prefix : <urn:example:>.
|
||||
_:lucy a: Person; :name "Lucy"; :bornIn _:idaho
|
||||
_:idaho a: Location; :name "Idaho"; :type "state"; :within _:usa.
|
||||
_:usa a: Location; :name "United States"; :type "country"; :within _:namerica.
|
||||
_:namerica a :Location; :name "North America"; :type "continent".
|
||||
```
|
||||
|
||||
### 语义网(The **Semantic Web**)
|
||||
|
||||
万维网之父Tim Berners Lee于1998年提出,知识图谱前身。其目的在于对网络中的资源进行结构化,从而让计算机能够**理解**网络中的数据。即不是以文本、二进制流等等,而是通过某种标准结构化互相关联的数据。
|
||||
|
||||
**语义**:提供一种统一的方式对所有资源进行描述和**结构化**(机器可读)。
|
||||
|
||||
**网**:将所有资源勾连起来。
|
||||
|
||||
下面是**语义网技术栈**(Semantic Web Stack):
|
||||
|
||||

|
||||
|
||||
其中 **RDF** (*ResourceDescription Framework,资源描述框架*)提供了一种结构化网络中数据的标准。使发布到网络中的任何资源(文字、图片、视频、网页),都能以统一的形式被计算机理解。即,不需要让资源使用方深度学习抽取资源的语义,而是靠资源提供方通过 RDF 主动提供其资源语义。
|
||||
|
||||
感觉有点理想主义,但互联网、开源社区都是靠这种理想主义、分享精神发展起来的!
|
||||
|
||||
虽然语义网没有发展起来,但是其**中间数据交换**格式 RDF 所定义的 SPO三元组(Subject-Predicate-Object) 却是一种很好用的数据模型,也就是上面提到的 **Triple-Stores。**
|
||||
|
||||
### RDF 数据模型
|
||||
|
||||
上面提到的 Turtle 语言(SPO三元组)是一种简单易读的描述 RDF 数据的方式, RDF 也可以基于 XML 表示,但是要冗余难读的多(嵌套太深):
|
||||
|
||||
```xml
|
||||
<rdf:RDF xmlns="urn:example:"
|
||||
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
|
||||
<Location rdf:nodeID="idaho">
|
||||
<name>Idaho</name>
|
||||
<type>state</type>
|
||||
<within>
|
||||
<Location rdf:nodeID="usa">
|
||||
<name>United States</name>
|
||||
<type>country</type>
|
||||
<within>
|
||||
<Location rdf:nodeID="namerica">
|
||||
<name>North America</name>
|
||||
<type>continent</type>
|
||||
</Location>
|
||||
</within>
|
||||
</Location>
|
||||
</within>
|
||||
</Location>
|
||||
<Person rdf:nodeID="lucy">
|
||||
<name>Lucy</name>
|
||||
<bornIn rdf:nodeID="idaho"/>
|
||||
</Person>
|
||||
</rdf:RDF>
|
||||
```
|
||||
|
||||
为了标准化和去除二义性,一些看起来比较奇怪的点是:无论 subject,predicate 还是 object 都是由 URI 定义,如
|
||||
|
||||
```json
|
||||
lives_in 会表示为 <http://my-company.com/namespace#lives_in>
|
||||
```
|
||||
|
||||
其前缀只是一个 namespace,让定义唯一化,并且在网络上可访问。当然,一个简化的方法是可以在文件头声明一个公共前缀。
|
||||
|
||||
### **SPARQL 查询语言**
|
||||
|
||||
有了语义网,自然需要在语义网中进行遍历查询,于是有了 RDF 的查询语言:SPARQL Protocol and RDF Query Language, pronounced “sparkle.”
|
||||
|
||||
```json
|
||||
PREFIX : <urn:example:>
|
||||
SELECT ?personName WHERE {
|
||||
?person :name ?personName.
|
||||
?person :bornIn / :within* / :name "United States".
|
||||
?person :livesIn / :within* / :name "Europe".
|
||||
}
|
||||
```
|
||||
|
||||
他是 Cypher 的前驱,因此结构看起来很像:
|
||||
|
||||
```json
|
||||
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (location) # Cypher
|
||||
?person :bornIn / :within* ?location. # SPARQL
|
||||
```
|
||||
|
||||
但 **SPARQL** 没有区分边和属性的关系,都用了 Predicates。
|
||||
|
||||
```json
|
||||
(usa {name:'United States'}) # Cypher
|
||||
?usa :name "United States". # SPARQL
|
||||
```
|
||||
|
||||
虽然语义网没有成功落地,但其技术栈影响了后来的知识图谱和图查询语言。
|
||||
|
||||
### 图模型和网络模型
|
||||
|
||||
图模型是网络模型旧瓶装新酒吗?
|
||||
|
||||
否,他们在很多重要的方面都不一样。
|
||||
|
||||
| 模型 | 图模型(Graph Model) | 网络模型(Network Model) |
|
||||
| --- | --- | --- |
|
||||
| 连接方式 | 任意两个点之间都有可以有边 | 指定了嵌套约束 |
|
||||
| 记录查找 | 1. 使用全局 ID <br/>2. 使用属性索引。<br/>3. 使用图遍历。 | 只能使用路径查询 |
|
||||
| 有序性 | 点和边都是无序的 | 记录的孩子们是有序集合,在插入时需要考虑维持有序的开销 |
|
||||
| 查询语言 | 即可命令式,也可以声明式 | 命令式的 |
|
||||
|
||||
## 查询语言前驱:Datalog
|
||||
|
||||
有点像 triple-store,但是变了下次序:(*subject*, *predicate*, *object*) → *predicate*(*subject*, *object*).
|
||||
之前数据用 Datalog 表示为:
|
||||
|
||||
```json
|
||||
name(namerica, 'North America').
|
||||
type(namerica, continent).
|
||||
|
||||
name(usa, 'United States').
|
||||
type(usa, country).
|
||||
within(usa, namerica).
|
||||
|
||||
name(idaho, 'Idaho').
|
||||
type(idaho, state).
|
||||
within(idaho, usa).
|
||||
|
||||
name(lucy, 'Lucy').
|
||||
born_in(lucy, idaho).
|
||||
```
|
||||
|
||||
查询从*美国迁移到欧洲的人*可以表示为:
|
||||
|
||||
```json
|
||||
within_recursive(Location, Name) :- name(Location, Name). /* Rule 1 */
|
||||
within_recursive(Location, Name) :- within(Location, Via), /* Rule 2 */
|
||||
within_recursive(Via, Name).
|
||||
|
||||
migrated(Name, BornIn, LivingIn) :- name(Person, Name), /* Rule 3 */
|
||||
born_in(Person, BornLoc),
|
||||
within_recursive(BornLoc, BornIn),
|
||||
lives_in(Person, LivingLoc),
|
||||
within_recursive(LivingLoc, LivingIn).
|
||||
?- migrated(Who, 'United States', 'Europe'). /* Who = 'Lucy'. */
|
||||
```
|
||||
|
||||
1. 代码中以大写字母开头的元素是**变量**,字符串、数字或以小写字母开头的元素是**常量**。下划线(_)被称为匿名变量
|
||||
2. 可以使用基本 Predicate 自定义 Predicate,类似于使用基本函数自定义函数。
|
||||
3. 逗号连接的多个谓词表达式为且的关系。
|
||||
|
||||

|
||||
|
||||
基于集合的逻辑运算:
|
||||
|
||||
1. 根据基本数据子集选出符合条件集合。
|
||||
2. 应用规则,扩充原集合。
|
||||
3. 如果可以递归,则递归穷尽所有可能性。
|
||||
|
||||
Prolog(Programming in Logic的缩写)是一种逻辑编程语言。它创建在逻辑学的理论基础之上。
|
||||
|
||||
## 参考
|
||||
|
||||
1. 声明式(declarative) vs 命令式(imperative)**:**[https://lotabout.me/2020/Declarative-vs-Imperative-language/](https://lotabout.me/2020/Declarative-vs-Imperative-language/)
|
||||
2. **[SimmerChan](https://www.zhihu.com/people/simmerchan)** 知乎专栏,知识图谱,语义网,RDF:[https://www.zhihu.com/column/knowledgegraph](https://www.zhihu.com/column/knowledgegraph)
|
||||
3. MySQL 为什么叫“关系”模型:[https://zhuanlan.zhihu.com/p/64731206](https://zhuanlan.zhihu.com/p/64731206)
|
||||
500
ch03.md
Normal file
@ -0,0 +1,500 @@
|
||||
# DDIA 逐章精读(三):存储和查询
|
||||
|
||||
第二章讲了上层抽象:数据模型和查询语言。
|
||||
本章下沉一些,聚焦数据库底层如何处理查询和存储。这其中,有个**逻辑链条**:
|
||||
> 使用场景→ 查询类型 → 存储格式。
|
||||
|
||||
查询类型主要分为两大类:
|
||||
|
||||
| 引擎类型 | 请求数量 | 数据量 | 瓶颈 | 存储格式 | 用户 | 场景举例 | 产品举例 |
|
||||
| --- | --- | --- | --- | --- | --- | --- | --- |
|
||||
| OLTP | 相对频繁,侧重在线交易 | 总体和单次查询都相对较小 | Disk Seek | 多用行存 | 比较普遍,一般应用用的比较多 | 银行交易 | MySQL |
|
||||
| OLAP | 相对较少,侧重离线分析 | 总体和单次查询都相对巨大 | Disk Bandwidth | 列存逐渐流行 | 多为商业用户 | 商业分析 | ClickHouse |
|
||||
|
||||
其中,OLTP 侧,常用的存储引擎又有两种流派:
|
||||
|
||||
| 流派 | 主要特点 | 基本思想 | 代表 |
|
||||
| --- | --- | --- | --- |
|
||||
| log-structured 流 | 只允许追加,所有修改都表现为文件的追加和文件整体增删 | 变随机写为顺序写 | Bitcask、LevelDB、RocksDB、Cassandra、Lucene |
|
||||
| update-in-place 流 | 以页(page)为粒度对磁盘数据进行修改 | 面向页、查找树 | B族树,所有主流关系型数据库和一些非关系型数据库 |
|
||||
|
||||
此外,针对 OLTP, 还探索了常见的建索引的方法,以及一种特殊的数据库——全内存数据库。
|
||||
|
||||
对于数据仓库,本章分析了它与 OLTP 的主要不同之处。数据仓库主要侧重于聚合查询,需要扫描很大量的数据,此时,索引就相对不太有用。需要考虑的是存储成本、带宽优化等,由此引出列式存储。
|
||||
|
||||
# 驱动数据库的底层数据结构
|
||||
|
||||
本节由一个 shell 脚本出发,到一个相当简单但可用的存储引擎 Bitcask,然后引出 LSM-tree,他们都属于日志流范畴。之后转向存储引擎另一流派——B 族树,之后对其做了简单对比。最后探讨了存储中离不开的结构——索引。
|
||||
|
||||
首先来看,世界上“最简单”的数据库,由两个 Bash 函数构成:
|
||||
|
||||
```bash
|
||||
#!/bin/bash
|
||||
db_set () {
|
||||
echo "$1,$2" >> database
|
||||
}
|
||||
|
||||
db_get () {
|
||||
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
|
||||
}
|
||||
```
|
||||
|
||||
这两个函数实现了一个基于字符串的 KV 存储(只支持 get/set,不支持 delete):
|
||||
|
||||
```bash
|
||||
$ db_set 123456 '{"name":"London","attractions":["Big Ben","London Eye"]}'
|
||||
$ db_set 42 '{"name":"San Francisco","attractions":["Golden Gate Bridge"]}'
|
||||
$ db_get 42
|
||||
{"name":"San Francisco","attractions":["Golden Gate Bridge"]}
|
||||
```
|
||||
|
||||
来分析下它为什么 work,也反映了日志结构存储的最基本原理:
|
||||
|
||||
1. set:在文件末尾追加一个 KV 对。
|
||||
2. get:匹配所有 Key,返回最后(也即最新)一条 KV 对中的 Value。
|
||||
|
||||
可以看出:写很快,但是读需要全文逐行扫描,会慢很多。典型的以读换写。为了加快读,我们需要构建**索引:**一种允许基于某些字段查找的额外数据结构。
|
||||
|
||||
索引从原数据中构建,只为加快查找。因此索引会耗费一定额外空间,和插入时间(每次插入要更新索引),即,重新以空间和写换读取。
|
||||
|
||||
这便是数据库存储引擎设计和选择时最常见的**权衡(trade off)**:
|
||||
|
||||
1. 恰当的**存储格式**能加快写(日志结构),但是会让读取很慢;也可以加快读(查找树、B族树),但会让写入较慢。
|
||||
2. 为了弥补读性能,可以构建索引。但是会牺牲写入性能和耗费额外空间。
|
||||
|
||||
存储格式一般不好动,但是索引构建与否,一般交予用户选择。
|
||||
|
||||
## 哈希索引
|
||||
|
||||
本节主要基于最基础的 KV 索引。
|
||||
|
||||
依上小节的例子,所有数据顺序追加到磁盘上。为了加快查询,我们在内存中构建一个哈希索引:
|
||||
|
||||
1. Key 是查询 Key
|
||||
2. Value 是 KV 条目的起始位置和长度。
|
||||
|
||||

|
||||
|
||||
看来很简单,但这正是 [Bitcask](https://docs.riak.com/riak/kv/2.2.3/setup/planning/backend/bitcask/index.html "Bitcask") 的基本设计,但关键是,他 Work(在小数据量时,即所有 key 都能存到内存中时):能提供很高的读写性能:
|
||||
|
||||
1. 写:文件追加写。
|
||||
2. 读:一次内存查询,一次磁盘 seek;如果数据已经被缓存,则 seek 也可以省掉。
|
||||
|
||||
如果你的 key 集合很小(意味着能全放内存),但是每个 key 更新很频繁,那么 Bitcask 便是你的菜。举个栗子:频繁更新的视频播放量,key 是视频 url,value 是视频播放量。
|
||||
|
||||
> 但有个很重要问题,单个文件越来越大,磁盘空间不够怎么办?
|
||||
>
|
||||
> 在文件到达一定尺寸后,就新建一个文件,将原文件变为只读。同时为了回收多个 key 多次写入的造成的空间浪费,可以将只读文件进行紧缩( compact ),将旧文件进行重写,挤出“水分”(被覆写的数据)以进行垃圾回收。
|
||||
|
||||

|
||||
|
||||
当然,如果我们想让其**工业可用**,还有很多问题需要解决:
|
||||
|
||||
1. **文件格式**。对于**日志**来说,CSV 不是一种紧凑的数据格式,有很多空间浪费。比如,可以用 length + record bytes 。
|
||||
2. **记录删除**。之前只支持 put\get,但实际还需要支持 delete。但日志结构又不支持更新,怎么办呢?一般是写一个特殊标记(比如墓碑记录,tombstone)以表示该记录已删除。之后 compact 时真正删除即可。
|
||||
3. **宕机恢复**。在机器重启时,内存中的哈希索引将会丢失。当然,可以全盘扫描以重建,但通常一个小优化是,对于每个 segment file, 将其索引条目和数据文件一块持久化,重启时只需加载索引条目即可。
|
||||
4. **记录写坏、少写**。系统任何时候都有可能宕机,由此会造成记录写坏、少写。为了识别错误记录,我们需要增加一些校验字段,以识别并跳过这种数据。为了跳过写了部分的数据,还要用一些特殊字符来标识记录间的边界。
|
||||
5. **并发控制**。由于只有一个活动(追加)文件,因此写只有一个天然并发度。但其他的文件都是不可变的(compact 时会读取然后生成新的),因此读取和紧缩可以并发执行。
|
||||
|
||||
乍一看,基于日志的存储结构存在折不少浪费:需要以追加进行更新和删除。但日志结构有几个原地更新结构无法做的优点:
|
||||
|
||||
1. **以顺序写代替随机写**。对于磁盘和 SSD,顺序写都要比随机写快几个数量级。
|
||||
2. **简易的并发控制**。由于大部分的文件都是**不可变(immutable)**的,因此更容易做并发读取和紧缩。也不用担心原地更新会造成新老数据交替。
|
||||
3. **更少的内部碎片**。每次紧缩会将垃圾完全挤出。但是原地更新就会在 page 中留下一些不可用空间。
|
||||
|
||||
当然,基于内存的哈希索引也有其局限:
|
||||
|
||||
1. **所有 Key 必须放内存**。一旦 Key 的数据量超过内存大小,这种方案便不再 work。当然你可以设计基于磁盘的哈希表,但那又会带来大量的随机写。
|
||||
2. **不支持范围查询**。由于 key 是无序的,要进行范围查询必须全表扫描。
|
||||
|
||||
后面讲的 LSM-Tree 和 B+ 树,都能部分规避上述问题。
|
||||
|
||||
- 想想,会如何进行规避?
|
||||
|
||||
|
||||
|
||||
## SSTables 和 LSM-Trees
|
||||
|
||||
这一节层层递进,步步做引,从 SSTables 格式出发,牵出 LSM-Trees 全貌。
|
||||
|
||||
对于 KV 数据,前面的 BitCask 存储结构是:
|
||||
|
||||
1. 外存上日志片段
|
||||
2. 内存中的哈希表
|
||||
|
||||
其中外存上的数据是简单追加写而形成的,并没有按照某个字段有序。
|
||||
|
||||
假设加一个限制,让这些文件按 key 有序。我们称这种格式为:SSTable(Sorted String Table)。
|
||||
|
||||
这种文件格式有什么优点呢?
|
||||
|
||||
**高效的数据文件合并**。即有序文件的归并外排,顺序读,顺序写。不同文件出现相同 Key 怎么办?
|
||||
|
||||

|
||||
|
||||
|
||||
**不需要在内存中保存所有数据的索引**。仅需要记录下每个文件界限(以区间表示:[startKey, endKey],当然实际会记录的更细)即可。查找某个 Key 时,去所有包含该 Key 的区间对应的文件二分查找即可。
|
||||
|
||||

|
||||
|
||||
**分块压缩,节省空间,减少 IO**。相邻 Key 共享前缀,既然每次都要批量取,那正好一组 key batch 到一块,称为 block,且只记录 block 的索引。
|
||||
|
||||
### 构建和维护 SSTables
|
||||
|
||||
SSTables 格式听起来很美好,但须知数据是乱序的来的,我们如何得到有序的数据文件呢?
|
||||
|
||||
这可以拆解为两个小问题:
|
||||
|
||||
1. 如何构建。
|
||||
2. 如何维护。
|
||||
|
||||
**构建 SSTable 文件**。将乱序数据在外存(磁盘 or SSD)中上整理为有序文件,是比较难的。但是在内存就方便的多。于是一个大胆的想法就形成了:
|
||||
|
||||
1. 在内存中维护一个有序结构(称为 **MemTable**)。红黑树、AVL 树、条表。
|
||||
2. 到达一定阈值之后全量 dump 到外存。
|
||||
|
||||
**维护 SSTable 文件**。为什么需要维护呢?首先要问,对于上述复合结构,我们怎么进行查询:
|
||||
|
||||
1. 先去 MemTable 中查找,如果命中则返回。
|
||||
2. 再去 SSTable 按时间顺序由新到旧逐一查找。
|
||||
|
||||
如果 SSTable 文件越来越多,则查找代价会越来越大。因此需要将多个 SSTable 文件合并,以减少文件数量,同时进行 GC,我们称之为**紧缩**( Compaction)。
|
||||
|
||||
**该方案的问题**:如果出现宕机,内存中的数据结构将会消失。 解决方法也很经典:WAL。
|
||||
|
||||
### 从 SSTables 到 LSM-Tree
|
||||
|
||||
将前面几节的一些碎片有机的组织起来,便是时下流行的存储引擎 LevelDB 和 RocksDB 后面的存储结构:LSM-Tree:
|
||||
|
||||

|
||||
|
||||
这种数据结构是 Patrick O’Neil 等人,在 1996 年提出的:[The Log-Structured Merge-Tree](https://www.cs.umb.edu/~poneil/lsmtree.pdf "The Log-Structured Merge-Tree")。
|
||||
|
||||
Elasticsearch 和 Solr 的索引引擎 Lucene,也使用类似 LSM-Tree 存储结构。但其数据模型不是 KV,但类似:word → document list。
|
||||
|
||||
### 性能优化
|
||||
|
||||
如果想让一个引擎工程上可用,还会做大量的性能优化。对于 LSM-Tree 来说,包括:
|
||||
|
||||
**优化 SSTable 的查找。**常用 [**Bloom Filter**](https://www.qtmuniao.com/2020/11/18/leveldb-data-structures-bloom-filter/)。该数据结构可以使用较少的内存为每个 SSTable 做一些指纹,起到一些初筛的作用。
|
||||
|
||||
**层级化组织 SSTable**。以控制 Compaction 的顺序和时间。常见的有 size-tiered 和 leveled compaction。LevelDB 便是支持后者而得名。前者比较简单粗暴,后者性能更好,也因此更为常见。
|
||||
|
||||

|
||||
|
||||
对于 RocksDB 来说,工程上的优化和使用上的优化就更多了。在其 [Wiki](https://github.com/facebook/rocksdb/wiki "rocksdb wiki") 上随便摘录几点:
|
||||
|
||||
1. Column Family
|
||||
2. 前缀压缩和过滤
|
||||
3. 键值分离,BlobDB
|
||||
|
||||
但无论有多少变种和优化,LSM-Tree 的核心思想——**保存一组合理组织、后台合并的 SSTables** ——简约而强大。可以方便的进行范围遍历,可以变大量随机为少量顺序。
|
||||
|
||||
## B 族树
|
||||
|
||||
虽然先讲的 LSM-Tree,但是它要比 B+ 树新的多。
|
||||
|
||||
B 树于 1970 年被 R. Bayer and E. McCreight [提出](https://dl.acm.org/doi/10.1145/1734663.1734671 "b tree paper")后,便迅速流行了起来。现在几乎所有的关系型数据中,它都是数据索引标准一般的实现。
|
||||
|
||||
与 LSM-Tree 一样,它也支持高效的**点查**和**范围查**。但却使用了完全不同的组织方式。
|
||||
|
||||
其特点有:
|
||||
|
||||
1. 以页(在磁盘上叫 page,在内存中叫 block,通常为 4k)为单位进行组织。
|
||||
2. 页之间以页 ID 来进行逻辑引用,从而组织成一颗磁盘上的树。
|
||||
|
||||

|
||||
|
||||
**查找**。从根节点出发,进行二分查找,然后加载新的页到内存中,继续二分,直到命中或者到叶子节点。 查找复杂度,树的高度—— O(lgn),影响树高度的因素:分支因子(分叉数,通常是几百个)。
|
||||
|
||||

|
||||
|
||||
**插入 or 更新**。和查找过程一样,定位到原 Key 所在页,插入或者更新后,将页完整写回。如果页剩余空间不够,则分裂后写入。
|
||||
|
||||
**分裂 or 合并**。级联分裂和合并。
|
||||
|
||||
- 一个记录大于一个 page 怎么办?
|
||||
|
||||
树的节点是逻辑概念,page or block 是物理概念。一个逻辑节点可以对应多个物理 page。
|
||||
|
||||
|
||||
### 让 B 树更可靠
|
||||
|
||||
B 树不像 LSM-Tree ,会在原地修改数据文件。
|
||||
|
||||
在树结构调整时,可能会级联修改很多 Page。比如叶子节点分裂后,就需要写入两个新的叶子节点,和一个父节点(更新叶子指针)。
|
||||
|
||||
1. 增加预写日志(WAL),将所有修改操作记录下来,预防宕机时中断树结构调整而产生的混乱现场。
|
||||
2. 使用 latch 对树结构进行并发控制。
|
||||
|
||||
### B 树的优化
|
||||
|
||||
B 树出来了这么久,因此有很多优化:
|
||||
|
||||
1. 不使用 WAL,而在写入时利用 Copy On Write 技术。同时,也方便了并发控制。如 LMDB、BoltDB。
|
||||
2. 对中间节点的 Key 做压缩,保留足够的路由信息即可。以此,可以节省空间,增大分支因子。
|
||||
3. 为了优化范围查询,有的 B 族树将叶子节点存储时物理连续。但当数据不断插入时,维护此有序性的代价非常大。
|
||||
4. 为叶子节点增加兄弟指针,以避免顺序遍历时的回溯。即 B+ 树的做法,但远不局限于 B+ 树。
|
||||
5. B 树的变种,分形树,从 LSM-tree 借鉴了一些思想以优化 seek。
|
||||
|
||||
## B-Trees 和 LSM-Trees 对比
|
||||
|
||||
| 存储引擎 | B-Tree | LSM-Tree | 备注 |
|
||||
| --- | --- | --- | --- |
|
||||
| 优势 | 读取更快 | 写入更快 | |
|
||||
| 写放大 | 1. 数据和 WAL<br/>2. 更改数据时多次覆盖整个 Page | 1. 数据和 WAL<br/>2. Compaction | SSD 不能过多擦除。因此 SSD 内部的固件中也多用日志结构来减少随机小写。 |
|
||||
| 写吞吐 | 相对较低:<br/>1. 大量随机写。 | 相对较高:<br/>1. 较低的写放大(取决于数据和配置)<br/>2. 顺序写入。<br/>3. 更为紧凑。 | |
|
||||
| 压缩率 | 1. 存在较多内部碎片。 | 1. 更加紧凑,没有内部碎片。<br/>2. 压缩潜力更大(共享前缀)。 | 但紧缩不及时会造成 LSM-Tree 存在很多垃圾 |
|
||||
| 后台流量 | 1. 更稳定可预测,不会受后台 compaction 突发流量影响。 | 1. 写吞吐过高,compaction 跟不上,会进一步加重读放大。<br/>2. 由于外存总带宽有限,compaction 会影响读写吞吐。<br/>3. 随着数据越来越多,compaction 对正常写影响越来越大。 | RocksDB 写入太过快会引起 write stall,即限制写入,以期尽快 compaction 将数据下沉。 |
|
||||
| 存储放大 | 1. 有些 Page 没有用满 | 1. 同一个 Key 存多遍 | |
|
||||
| 并发控制 | 1. 同一个 Key 只存在一个地方<br/>2. 树结构容易加范围锁。 | 同一个 Key 会存多遍,一般使用 MVCC 进行控制。 | |
|
||||
|
||||
## 其他索引结构
|
||||
|
||||
**次级索引(secondary indexes)**。即,非主键的其他属性到该元素(SQL 中的行,MongoDB 中的文档和图数据库中的点和边)的映射。
|
||||
|
||||
### **聚集索引和非聚集索引(cluster indexes and non-cluster indexes)**
|
||||
|
||||
对于存储数据和组织索引,我们可以有多种选择:
|
||||
|
||||
1. 数据本身**无序**的存在文件中,称为 **堆文件(heap file)**,索引的值指向对应数据在 heap file 中的位置。这样可以避免多个索引时的数据拷贝。
|
||||
2. 数据本身按某个字段有序存储,该字段通常是主键。则称基于此字段的索引为**聚集索引**(clustered index),从另外一个角度理解,即将索引和数据存在一块。则基于其他字段的索引为**非聚集索引**,在索引中仅存数据的引用。
|
||||
3. 一部分列内嵌到索引中存储,一部分列数据额外存储。称为**覆盖索引(covering index)**
|
||||
或 **包含列的索引(index with included columns)**。
|
||||
|
||||
索引可以加快查询速度,但需要占用额外空间,并且牺牲了部分更新开销,且需要维持某种一致性。
|
||||
|
||||
### **多列索引**(**Multi-column indexes**)。
|
||||
|
||||
现实生活中,多个字段联合查询更为常见。比如查询某个用户周边一定范围内的商户,需要经度和纬度二维查询。
|
||||
|
||||
```sql
|
||||
SELECT * FROM restaurants WHERE latitude > 51.4946 AND latitude < 51.5079
|
||||
AND longitude > -0.1162 AND longitude < -0.1004;
|
||||
```
|
||||
|
||||
可以:
|
||||
|
||||
1. 将二维编码为一维,然后按普通索引存储。
|
||||
2. 使用特殊数据结构,如 R 树。
|
||||
|
||||
### **全文索引和模糊索引(Full-text search and fuzzy indexes)**。
|
||||
|
||||
前述索引只提供全字段的精确匹配,而不提供类似搜索引擎的功能。比如,按字符串中包含的单词查询,针对笔误的单词查询。
|
||||
|
||||
在工程中常用 [Apace Lucene](https://lucene.apache.org/ "Apace Lucene") 库,和其包装出来的服务:[Elasticsearch](https://www.elastic.co/cn/ "Elasticsearch")。他也使用类似 LSM-tree 的日志存储结构,但其索引是一个有限状态自动机,在行为上类似 Trie 树。
|
||||
|
||||
### 全内存数据结构
|
||||
|
||||
随着单位内存成本下降,甚至支持持久化(*non-volatile memory,*NVM,如 Intel 的 [傲腾](https://www.intel.cn/content/www/cn/zh/products/details/memory-storage/optane-dc-persistent-memory.html "傲腾")),全内存数据库也逐渐开始流行。
|
||||
|
||||
根据是否需要持久化,内存数据大概可以分为两类:
|
||||
|
||||
1. **不需要持久化**。如只用于缓存的 Memcached。
|
||||
2. **需要持久化**。通过 WAL、定期 snapshot、远程备份等等来对数据进行持久化。但使用内存处理全部读写,因此仍是内存数据库。
|
||||
|
||||
> VoltDB, MemSQL, and Oracle TimesTen 是提供关系模型的内存数据库。RAMCloud 是提供持久化保证的 KV 数据库。Redis and Couchbase 仅提供弱持久化保证。
|
||||
>
|
||||
|
||||
内存数据库存在优势的原因不仅在于不需要读取磁盘,而在更于不需要对数据结构进行**序列化、编码**后以适应磁盘所带来的**额外开销**。
|
||||
|
||||
当然,内存数据库还有以下优点:
|
||||
|
||||
1. **提供更丰富的数据抽象**。如 set 和 queue 这种只存在于内存中的数据抽象。
|
||||
2. **实现相对简单**。因为所有数据都在内存中。
|
||||
|
||||
此外,内存数据库还可以通过类似操作系统 swap 的方式,提供比物理机内存更大的存储空间,但由于其有更多数据库相关信息,可以将换入换出的粒度做的更细、性能做的更好。
|
||||
|
||||
基于**非易失性存储器**(non-volatile memory,NVM) 的存储引擎也是这些年研究的一个热点。
|
||||
|
||||
# 事务型还是分析型
|
||||
|
||||
术语 **OL**(Online)主要是指交互式的查询。
|
||||
|
||||
术语**事务**( transaction )由来有一些历史原因。早期的数据库使用方多为商业交易(commercial ),比如买卖、发工资等等。但是随着数据库应用不断扩大,交易\事务作为名词保留了下来。
|
||||
|
||||
> 事务不一定具有 ACID 特性,事务型处理多是随机的以较低的延迟进行读写,与之相反,分析型处理多为定期的批处理,延迟较高。
|
||||
|
||||
下表是一个对比:
|
||||
|
||||
| 属性 | OLTP | OLAP |
|
||||
| --- | --- | --- |
|
||||
| 主要读取模式 | 小数据量的随机读,通过 key 查询 | 大数据量的聚合(max,min,sum, avg)查询 |
|
||||
| 主要写入模式 | 随机访问,低延迟写入 | 批量导入(ETL)或者流式写入 |
|
||||
| 主要应用场景 | 通过 web 方式使用的最终用户 | 互联网分析,为了辅助决策 |
|
||||
| 如何看待数据 | 当前时间点的最新状态 | 随着时间推移的 |
|
||||
| 数据尺寸 | 通常 GB 到 TB | 通常 TB 到 PB |
|
||||
|
||||
一开始对于 AP 场景,仍然使用的传统数据库。在模型层面来说,SQL 足够灵活,能够基本满足 AP 查询需求。但在实现层面,传统数据库在 AP 负载中的表现(大数据量吞吐较低)不尽如人意,因此大家开始转向在专门设计的数据库中进行 AP 查询,我们称之为**数据仓库**(Data Warehouse)。
|
||||
|
||||
## 数据仓库
|
||||
|
||||
对于一个企业来说,一般都会有很多偏交易型的系统,如用户网站、收银系统、仓库管理、供应链管理、员工管理等等。通常要求**高可用**与**低延迟**,因此直接在原库进行业务分析,会极大影响正常负载。因此需要一种手段将数据从原库导入到专门的**数仓**。
|
||||
|
||||
我们称之为 **ETL:extract-transform-load**。
|
||||
|
||||
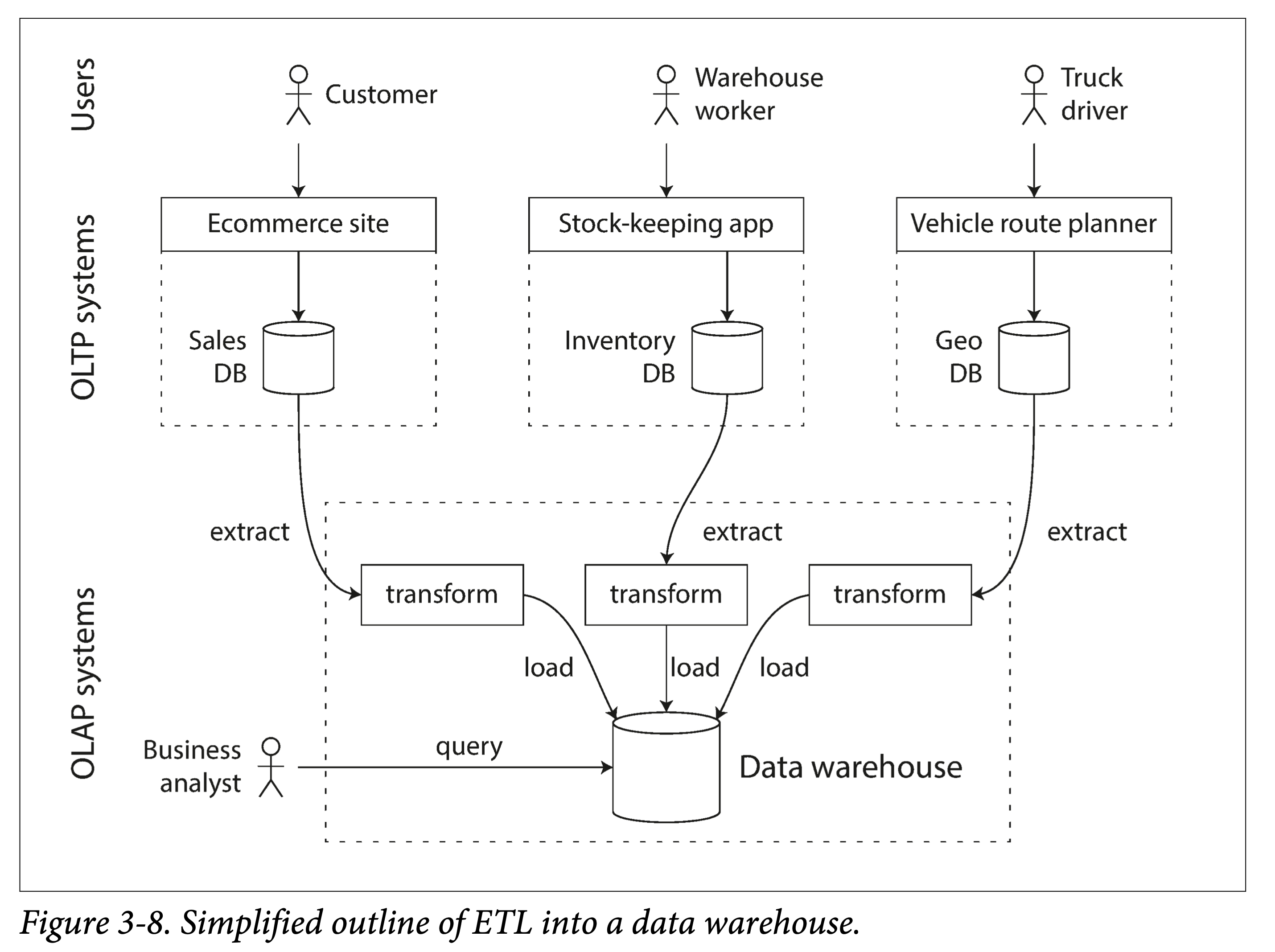
|
||||
|
||||
一般企业的数据量达到一定的量级才会需要进行 AP 分析,毕竟在小数据量尺度下,用 Excel 进行聚合查询都够了。当然,现在一个趋势是,随着移动互联网、物联网的普及,接入终端的类型和数量越来越多,产生的数据增量也越来越大,哪怕初创不久的公司可能也会积存大量数据,进而也需要 AP 支持。
|
||||
|
||||
AP 场景下的**聚合查询**分析和传统 TP 型有所不同。因此,需要构建索引的方式也多有不同。
|
||||
|
||||
### 同样接口后的不同
|
||||
|
||||
TP 和 AP 都可以使用 SQL 模型进行查询分析。但是由于其负载类型完全不同,在查询引擎实现和存储格式优化时,做出的设计决策也就大相径庭。因此,在同一套 SQL 接口的表面下,两者对应的数据库实现结构差别很大。
|
||||
|
||||
虽然有的数据库系统号称两者都支持,比如之前的 Microsoft SQL Server 和 SAP HANA,但是也正日益发展成两种独立的查询引擎。近年来提的较多的 HTAP 系统也是类似,其为了 serve 不同类型负载底层其实有两套不同的存储,只不过系统内部会自动的做数据的冗余和重新组织,对用户透明。
|
||||
|
||||
## AP 建模:星状型和雪花型
|
||||
|
||||
AP 中的处理模型相对较少,比较常用的有**星状模型**,也称为**维度模型**。
|
||||
|
||||

|
||||
|
||||
如上图所示,星状模型通常包含一张**事件表(*fact table*)**和多张**维度表(*dimension tables*****)**。事件表以事件流的方式将数据组织起来,然后通过外键指向不同的维度。
|
||||
|
||||
星状模型的一个变种是雪花模型,可以类比雪花(❄️)图案,其特点是在维度表中会进一步进行二次细分,讲一个维度分解为几个子维度。比如品牌和产品类别可能有单独的表格。星状模型更简单,雪花模型更精细,具体应用中会做不同取舍。
|
||||
|
||||
在典型的数仓中,事件表可能会非常宽,即有很多的列:一百到数百列。
|
||||
|
||||
# 列存
|
||||
|
||||
前一小节提到的**分维度表**和**事实表**,对于后者来说,有可能达到数十亿行和数 PB 大。虽然事实表可能通常有几十上百列,但是单次查询通常只关注其中几个维度(列)。
|
||||
|
||||
如查询**人们是否更倾向于在一周的某一天购买新鲜水果或糖果**:
|
||||
|
||||
```sql
|
||||
SELECT
|
||||
dim_date.weekday,
|
||||
dim_product.category,
|
||||
SUM(fact_sales.quantity) AS quantity_sold
|
||||
FROM fact_sales
|
||||
JOIN dim_date ON fact_sales.date_key = dim_date.date_key
|
||||
JOIN dim_product ON fact_sales.product_sk = dim_product.product_sk
|
||||
WHERE
|
||||
dim_date.year = 2013 AND
|
||||
dim_product.category IN ('Fresh fruit', 'Candy')
|
||||
GROUP BY
|
||||
dim_date.weekday, dim_product.category;
|
||||
```
|
||||
|
||||
由于传统数据库通常是按行存储的,这意味着对于属性(列)很多的表,哪怕只查询一个属性,也必须从磁盘上取出很多属性,无疑浪费了 IO 带宽、增大了读放大。
|
||||
|
||||
于是一个很自然的想法呼之欲出:每一个列分开存储好不好?
|
||||
|
||||

|
||||
|
||||
不同列之间同一个行的字段可以通过下标来对应。当然也可以内嵌主键来对应,但那样存储成本就太高了。
|
||||
|
||||
## 列压缩
|
||||
|
||||
将所有数据分列存储在一块,带来了一个意外的好处,由于同一属性的数据相似度高,因此更易压缩。
|
||||
|
||||
如果每一列中值阈相比行数要小的多,可以用**位图编码( *[bitmap encoding](https://en.wikipedia.org/wiki/Bitmap_index "bitmap encoding")* )**。举个例子,零售商可能有数十亿的销售交易,但只有 100,000 个不同的产品。
|
||||
|
||||

|
||||
|
||||
上图中,是一个列分片中的数据,可以看出只有 {29, 30, 31, 68, 69, 74} 六个离散值。针对每个值出现的位置,我们使用一个 bit array 来表示:
|
||||
|
||||
1. bit map 下标对应列的下标
|
||||
2. 值为 0 则表示该下标没有出现该值
|
||||
3. 值为 1 则表示该下标出现了该值
|
||||
|
||||
如果 bit array 是稀疏的,即大量的都是 0,只要少量的 1。其实还可以使用 **[游程编码](https://zh.wikipedia.org/zh/%E6%B8%B8%E7%A8%8B%E7%BC%96%E7%A0%81 "游程编码")(RLE, Run-length encoding)** 进一步压缩:
|
||||
|
||||
1. 将连续的 0 和 1,改写成 `数量+值`,比如 `product_sk = 29` 是 `9 个 0,1 个 1,8 个 0`。
|
||||
2. 使用一个小技巧,将信息进一步压缩。比如将同值项合并后,肯定是 0 1 交错出现,固定第一个值为 0,则交错出现的 0 和 1 的值也不用写了。则 `product_sk = 29` 编码变成 `9,1,8`
|
||||
3. 由于我们知道 bit array 长度,则最后一个数字也可以省掉,因为它可以通过 `array len - sum(other lens)` 得到,则 `product_sk = 29` 的编码最后变成:`9,1`
|
||||
|
||||
位图索引很适合应对查询中的逻辑运算条件,比如:
|
||||
|
||||
```sql
|
||||
WHERE product_sk IN(30,68,69)
|
||||
```
|
||||
|
||||
可以转换为 `product_sk = 30`、`product_sk = 68`和 `product_sk = 69`这三个 bit array 按位或(OR)。
|
||||
|
||||
```sql
|
||||
WHERE product_sk = 31 AND store_sk = 3
|
||||
```
|
||||
|
||||
可以转换为 `product_sk = 31`和 `store_sk = 3`的 bit array 的按位与,就可以得到所有需要的位置。
|
||||
|
||||
### 列族
|
||||
|
||||
书中特别提到**列族(column families)**。它是 Cassandra 和 HBase 中的的概念,他们都起源于自谷歌的 [BigTable](https://en.wikipedia.org/wiki/Bigtable "BigTable") 。注意到他们和**列式(column-oriented)存储**有相似之处,但绝不完全相同:
|
||||
|
||||
1. 同一个列族中多个列是一块存储的,并且内嵌行键(row key)。
|
||||
2. 并且列不压缩(存疑?)
|
||||
|
||||
因此 BigTable 在用的时候主要还是面向行的,可以理解为每一个列族都是一个子表。
|
||||
|
||||
### 内存带宽和向量化处理
|
||||
|
||||
数仓的超大规模数据量带来了以下瓶颈:
|
||||
|
||||
1. 内存处理带宽
|
||||
2. CPU 分支预测错误和[流水线停顿](https://zh.wikipedia.org/wiki/%E6%B5%81%E6%B0%B4%E7%BA%BF%E5%81%9C%E9%A1%BF "流水线停顿")
|
||||
|
||||
关于内存的瓶颈可已通过前述的数据压缩来缓解。对于 CPU 的瓶颈可以使用:
|
||||
|
||||
1. 列式存储和压缩可以让数据尽可能多地缓存在 L1 中,结合位图存储进行快速处理。
|
||||
2. 使用 SIMD 用更少的时钟周期处理更多的数据。
|
||||
|
||||
## 列式存储的排序
|
||||
|
||||
由于数仓查询多集中于聚合算子(比如 sum,avg,min,max),列式存储中的存储顺序相对不重要。但也免不了需要对某些列利用条件进行筛选,为此我们可以如 LSM-Tree 一样,对所有行按某一列进行排序后存储。
|
||||
|
||||
> 注意,不可能同时对多列进行排序。因为我们需要维护多列间的下标间的对应关系,才可能按行取数据。
|
||||
>
|
||||
|
||||
同时,排序后的那一列,压缩效果会更好。
|
||||
|
||||
### 不同副本,不同排序
|
||||
|
||||
在分布式数据库(数仓这么大,通常是分布式的)中,同一份数据我们会存储多份。对于每一份数据,我们可以按不同列有序存储。这样,针对不同的查询需求,便可以路由到不同的副本上做处理。当然,这样也最多只能建立副本数(通常是 3 个左右)列索引。
|
||||
|
||||
这一想法由 C-Store 引入,并且为商业数据仓库 Vertica 采用。
|
||||
|
||||
## 列式存储的写入
|
||||
|
||||
上述针对数仓的优化(列式存储、数据压缩和按列排序)都是为了解决数仓中常见的读写负载,读多写少,且读取都是超大规模的数据。
|
||||
|
||||
> 我们针对读做了优化,就让写入变得相对困难。
|
||||
>
|
||||
|
||||
比如 B 树的**原地更新流**是不太行的。举个例子,要在中间某行插入一个数据,**纵向**来说,会影响所有的列文件(如果不做 segment 的话);为了保证多列间按下标对应,**横向**来说,又得更新该行不同列的所有列文件。
|
||||
|
||||
所幸我们有 LSM-Tree 的追加流。
|
||||
|
||||
1. 将新写入的数据在**内存**中 Batch 好,按行按列,选什么数据结构可以看需求。
|
||||
2. 然后达到一定阈值后,批量刷到**外存**,并与老数据合并。
|
||||
|
||||
数仓 Vertica 就是这么做的。
|
||||
|
||||
## 聚合:数据立方和物化视图
|
||||
|
||||
不一定所有的数仓都是列式存储,但列式存储的种种好处让其变得流行了起来。
|
||||
|
||||
其中一个值得一提的是**物化聚合(materialized aggregates,或者物化汇总)**。
|
||||
|
||||
> 物化,可以简单理解为持久化。本质上是一种空间换时间的 tradeoff。
|
||||
>
|
||||
|
||||
数据仓库查询通常涉及聚合函数,如 SQL 中的 COUNT、SUM、AVG、MIN 或 MAX。如果这些函数被多次用到,每次都即时计算显然存在巨大浪费。因此一个想法就是,能不能将其缓存起来。
|
||||
|
||||
其与关系数据库中的**视图**(View)区别在于,视图是**虚拟的、逻辑存在**的,只是对用户提供的一种抽象,是一个查询的中间结果,并没有进行持久化(有没有缓存就不知道了)。
|
||||
|
||||
物化视图本质上是对数据的一个摘要存储,如果原数据发生了变动,该视图要被重新生成。因此,如果**写多读少**,则维持物化视图的代价很大。但在数仓中往往反过来,因此物化视图才能较好的起作用。
|
||||
|
||||
物化视图一个特化的例子,是**数据立方**(data cube,或者 OLAP cube):按不同维度对量化数据进行聚合。
|
||||
|
||||

|
||||
|
||||
上图是一个按**日期和产品分类**两个维度进行加和的数据立方,当针对日期和产品进行汇总查询时,由于该表的存在,就会变得非常快。
|
||||
|
||||
当然,现实中,一个表中常常有多个维度,比如 3-9 中有日期、产品、商店、促销和客户五个维度。但构建数据立方的意义和方法都是相似的。
|
||||
|
||||
但这种构建出来的视图只能针对固定的查询进行优化,如果有的查询不在此列,则这些优化就不再起作用。
|
||||
|
||||
> 在实际中,需要针对性的识别(或者预估)每个场景查询分布,针对性的构建物化视图。
|
||||
457
ch04.md
Normal file
@ -0,0 +1,457 @@
|
||||
# DDIA 逐章精读(四):编码和演进
|
||||
|
||||
第三章讲了存储引擎,本章继续下探,探讨编码相关问题。
|
||||
|
||||
所有涉及跨进程通信的地方,都需要对数据进行**编码**(**Encoding**),或者说**序列化**(**Serialization**)。因为持久化存储和网络传输都是面向字节流的。序列化本质上是一种“**降维**”操作,将内存中高维的数据结构降维成单维的字节流,于是底层硬件和相关协议,只需要处理一维信息即可。
|
||||
|
||||
|
||||
编码主要涉及两方面问题:
|
||||
|
||||
1. 如何编码能够节省空间、提高性能。
|
||||
2. 如何编码以适应数据的演化和兼容。
|
||||
|
||||
第一小节,以几种常见的编码工具(JSON,XML,Protocol Buffers 和 Avro)为例,逐一探讨了其如何进行编码、如何进行多版本兼容。这里引出了两个非常重要的概念:
|
||||
|
||||
1. 向后兼容 (backward compatibility):当前代码可以读取旧版本代码写入的数据。
|
||||
2. 向前兼容(forward compatibility):当前代码可以读取新版本代码写入的数据。
|
||||
|
||||
> 翻译成中文后,很容易混淆,主要原因在于“后”的歧义性,到底指**身后**(过去),还是指**之后**(将来),私以为还不如翻译为,*兼容过去*和*兼容将来*。但为了习惯,后面行文仍然用向后/前兼容。
|
||||
>
|
||||
|
||||
其中,向后兼容比较常见,因为时间总是向前流逝,版本总是升级,那么升级之后的代码总要处理历史积压的数据,自然会产生向后兼容的问题。向前兼容比较少见,书中给出的例子是多实例滚动升级,但其持续时间也很短。
|
||||
|
||||
第二小节,结合几个具体的应用场景:数据库、服务和消息系统,来分别谈了相关数据流中涉及到的编码与演化。
|
||||
|
||||
# 数据编码的格式
|
||||
|
||||

|
||||
|
||||
编码(Encoding)有多种称谓,如**序列化(serialization)**或 **编组(marshalling)**。对应的,解码(Decoding)也有多种别称,**解析(Parsing)**,**反序列化(deserialization)**,**反编组 (unmarshalling)。**
|
||||
|
||||
- 为什么内存中数据和外存、网络中的会有如此不同呢?
|
||||
|
||||
在内存中,借助编译器,我们可以将内存解释为各种数据结构;但在文件系统和网络中,我们只能通过 seek\read 等几个有限的操作来流式的读取字节流。那 mmap 呢?
|
||||
|
||||
- 编码和序列化撞车了?
|
||||
|
||||
在事务中,也有序列化相关的术语,所以这里专用编码,以避免歧义。
|
||||
|
||||
- 编码(encoding)和加密(**encryption**)?
|
||||
|
||||
研究的范畴不太一样,编码是为了持久化或者传输,着重点在格式和演化;而加密是为了安全,着重点在于安全、防破解。
|
||||
|
||||
|
||||
## 编程语言内置
|
||||
|
||||
很多编程语言内置了一些缺省的编码方法:
|
||||
|
||||
1. Java 有 `java.io.Serializable`
|
||||
2. Ruby 有 `Marshal`
|
||||
3. Python 有 `pickle`
|
||||
|
||||
如果你确定你的数据只会被某种特定的语言所读取,那么这种内置的编码方法很好用。比如深度学习研究员因为基本都用 Python,所以常会把数据以 [pickle](https://docs.python.org/zh-cn/3/library/pickle.html "pickle 官方文档") 的格式传来传去。
|
||||
|
||||
但这些编程语言内置的编码格式有以下缺点:
|
||||
|
||||
1. 和特定语言绑定
|
||||
2. 安全问题
|
||||
3. 兼容性支持不够
|
||||
4. 效率不高
|
||||
|
||||
## JSON、XML 及其二进制变体
|
||||
|
||||
JSON,XML 和 CSV 属于常用的**文本编码**格式,其好处在于肉眼可读,坏处在于不够紧凑,占空间较多。
|
||||
|
||||
JSON 最初由 JavaScript 引入,因此在 Web Service 中用的较多,当然随着 web 的火热,现在成为了比较通用的编码格式,比如很多日志格式就是 JSON 的。
|
||||
|
||||
XML 比较古老了,比 JSON 冗余度还高,有时候配置文件中会用,但总体而言用的越来越少了。
|
||||
|
||||
CSV (以逗号\TAB、换行符分割)还算紧凑,但是表达能力有限。数据库表导出有时会用。
|
||||
|
||||
除了不够紧凑外,**文本编码(text encoding)** 还有以下缺点:
|
||||
|
||||
1. 对**数值类型支持不够**。CSV 和 XML 直接不支持,万物皆字符串。JSON 虽区分字符串和数值,但是不进一步区分细分数值类型。可以理解,毕竟文本编码嘛,主要还是面向字符串。
|
||||
2. **对二进制数据支持不够**。支持 Unicode,但是对二进制串支持不够,可能会显示为乱码。虽然可以通过 Base64 编码来绕过,但有点做无用功的感觉。
|
||||
3. **XML和 JSON 支持额外的模式**。模式会描述数据的类型,告诉你如何理解数据。配合这些模式语言,虽然可以让 XML 和 JSON 变得强大,但是大大增加了复杂度。
|
||||
4. **CSV 没有任何模式**。
|
||||
|
||||
凡事讲究够用,很多场景下需要数据可读,并且不关心编码效率,那么这几种编码格式就够用了。
|
||||
|
||||
### 二进制编码
|
||||
|
||||
如果数据只被单一程序读取,不需要进行交换,不需要考虑易读性等问题。则可以用二进制编码,在数据量到达一定程度后,二进制编码所带来的空间节省、速度提高都很可观。
|
||||
|
||||
因此,JSON 有很多二进制变种:MessagePack、BSON、BJSON、UBJSON、BISON 和 Smile 等。
|
||||
|
||||
对于下面例子,
|
||||
|
||||
```json
|
||||
{
|
||||
"userName": "Martin",
|
||||
"favoriteNumber": 1337,
|
||||
"interests": ["daydreaming", "hacking"]
|
||||
}
|
||||
```
|
||||
|
||||
如果用 MessagePack 来编码,则为:
|
||||
|
||||

|
||||
|
||||
可以看出其基本编码策略为:使用类型,长度,bit 串,顺序编码,去掉无用的冒号、引号、花括号。
|
||||
|
||||
从而将 JSON 编码的 81 字节缩小到了 66 字节,微有提高。
|
||||
|
||||
## Thrift 和 Protocol Buffers
|
||||
|
||||
Thrift 最初由 Facebook,ProtoBuf 由 Google 在 07~08 年左右开源。他们都有对应的 RPC 框架和编解码工具。表达能力类似,语法也类似,在编码前都需要由接口定义语言(IDL)来描述模式:
|
||||
|
||||
```protobuf
|
||||
struct Person {
|
||||
1: required string userName,
|
||||
2: optional i64 favoriteNumber,
|
||||
3: optional list<string> interests
|
||||
}
|
||||
```
|
||||
|
||||
```protobuf
|
||||
message Person {
|
||||
required string user_name = 1;
|
||||
optional int64 favorite_number = 2;
|
||||
repeated string interests = 3;
|
||||
}
|
||||
```
|
||||
|
||||
IDL 是编程语言无关的,可以利用相关代码生成工具,可以将上述 IDL 翻译为指定语言的代码。即,集成这些生成的代码,无论什么样的语言,都可以使用同样的格式编解码。
|
||||
|
||||
这也是不同 service 可以使用不同编码语言,且能够互相通信的基础。
|
||||
|
||||
此外,Thrift 还支持多种不同的编码格式,常用的有:Binary、Compact、JSON。可以让用户自行在:编码速度、占用空间、可读性方便进行取舍。
|
||||
|
||||

|
||||
|
||||
可以看出其特点:
|
||||
|
||||
1. **使用 field tag 编码**。field tag 其实蕴含了字段**类型**和**名字**。
|
||||
2. 使用类型、tag、长度、bit 数组的顺序编码。
|
||||
|
||||

|
||||
|
||||
相比 Binary Protocol,Compact Protocol 由以下优化:
|
||||
|
||||
1. filed tag 只记录 delta。
|
||||
2. 从而将 field tag 和 type 压缩到一个字节中。
|
||||
3. 对数字使用变长编码和[Zigzag编码](img/ch04-fig04.png)。
|
||||
|
||||
ProtoBuf 与 Thrift Compact Protocol 编码方式很类似,也用了变长编码和 Zigzag 编码。但 ProtoBuf 对于数组的处理与 Thrift 显著不同,使用了 repeated 前缀而非真数组,好处后面说。
|
||||
|
||||
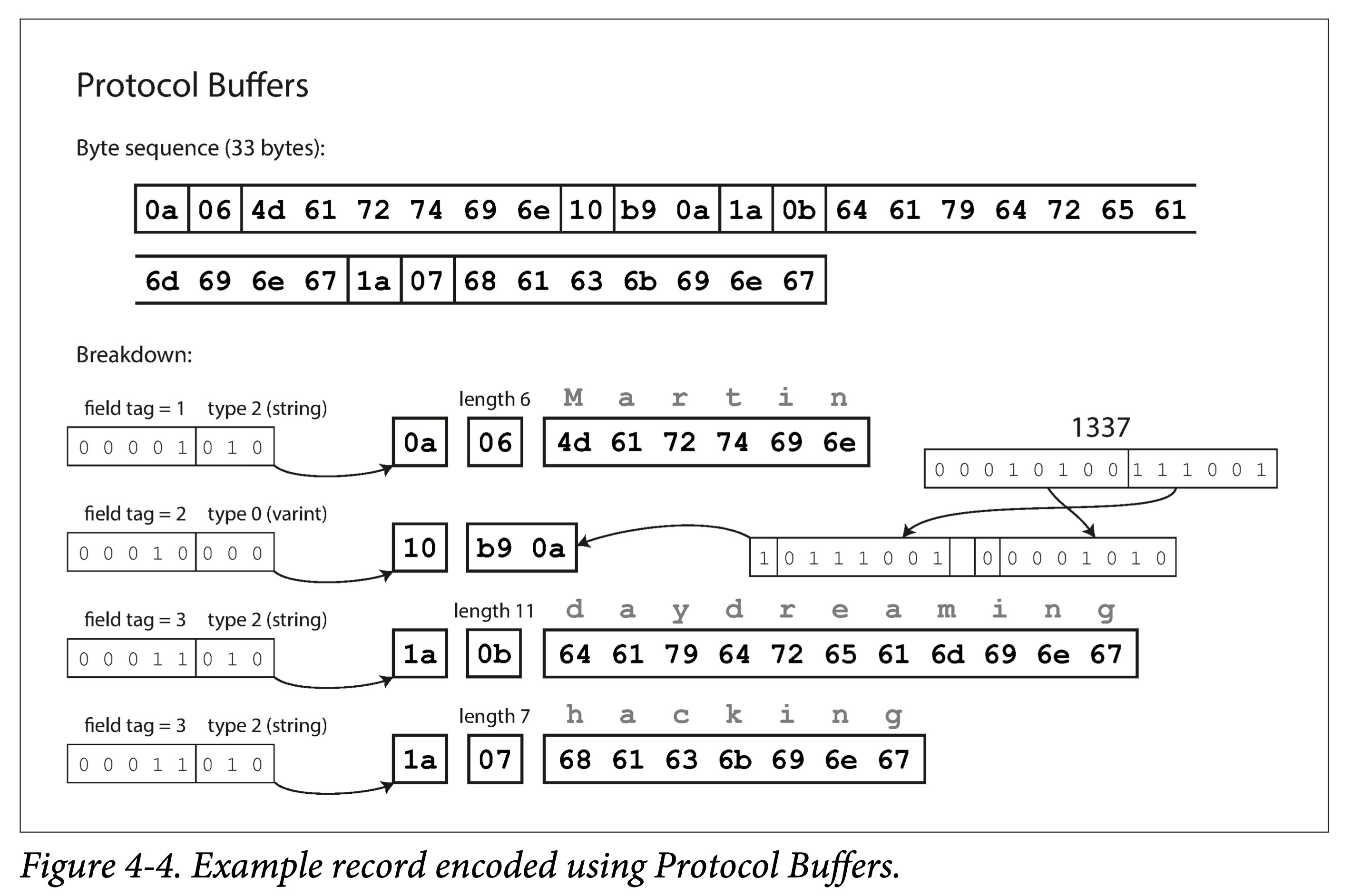
|
||||
|
||||
### 字段标号和模式演变
|
||||
|
||||
**模式**,即有哪些字段,字段分别为什么类型。
|
||||
|
||||
随着时间的推移,业务总会发生变化,我们也不可避免的**增删字段**,**修改字段类型**,即**模式演变**。
|
||||
|
||||
在模式发生改变后,需要:
|
||||
|
||||
1. **向后兼容**:新的代码,在处理新的增量数据格式的同时,也得处理旧的存量数据。
|
||||
2. **向前兼容**:旧的代码,如果遇到新的数据格式,不能 crash。
|
||||
- ProtoBuf 和 Thrift 是怎么解决这两个问题的呢?
|
||||
|
||||
**字段标号** + **限定符**(optional、required)
|
||||
|
||||
向后兼容:新加的字段需为 optional。这样在解析旧数据时,才不会出现字段缺失的情况。
|
||||
|
||||
向前兼容:字段标号不能修改,只能追加。这样旧代码在看到不认识的标号时,省略即可。
|
||||
|
||||
|
||||
### 数据类型和模式演变
|
||||
|
||||
修改数据类型比较麻烦:只能够在相容类型中进行修改。
|
||||
|
||||
如不能将字符串修改为整形,但是可以在整形内修改: 32 bit 到 64 bit 整形。
|
||||
|
||||
ProtoBuf 没有列表类型,而有一个 repeated 类型。其好处在于**兼容数组类型**的同时,支持将可选(optional)**单值字段**,修改为**多值字段**。修改后,旧代码在看到新的多值字段时,只会使用最后一个元素。
|
||||
|
||||
Thrift 列表类型虽然没这个灵活性,但是可以**嵌套**呀。
|
||||
|
||||
## Avro
|
||||
|
||||
Apache Avro 是 Apache Hadoop 的一个子项目,专门为数据密集型场景设计,对模式演变支持的很好。支持 **Avro IDL** 和 **JSON** 两种模式语言,前者适合人工编辑,后者适合机器读取。
|
||||
|
||||
```protobuf
|
||||
record Person {
|
||||
string userName;
|
||||
union { null, long } favoriteNumber = null;
|
||||
array<string> interests;
|
||||
}
|
||||
```
|
||||
|
||||
```json
|
||||
{
|
||||
"type": "record",
|
||||
"name": "Person",
|
||||
"fields": [
|
||||
{"name": "userName", "type": "string"},
|
||||
{"name": "favoriteNumber", "type": ["null", "long"], "default": null},
|
||||
{"name": "interests", "type": {"type": "array", "items": "string"}}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
可以看到 Avro 没有使用字段标号。
|
||||
|
||||
- 仍是编码之前例子,Avro 只用了 32 个字节,为什么呢?
|
||||
|
||||
他没有编入类型。
|
||||
|
||||
|
||||

|
||||
|
||||
因此,Avro 必须配合模式定义来解析,如 Client-Server 在通信的握手阶段会先交换数据模式。
|
||||
|
||||
### 写入模式和读取模式
|
||||
|
||||
- 没有字段标号,Avro 如何支持模式演进呢?
|
||||
|
||||
答案是**显式的**使用两种模式。
|
||||
|
||||
|
||||
即,在对数据进行编码(写入文件或者进行传输)时,使用模式 A,称为**写入模式**(writer schema);在对数据进行解码(从文件或者网络读取)时,使用模式 B,称为**读取模式**(reader schema),而两者不必相同,只需兼容。
|
||||
|
||||
也就是说,只要模式在演进时,是**兼容**的,那么 Avro 就能够处理向后兼容和向前兼容。
|
||||
|
||||
**向后兼容**:新代码读取旧数据。即读取时首先得到旧数据的写入模式(即旧模式),然后将其与读取模式(即新模式)对比,得到转换映射,即可拿着此映射去解析旧数据。
|
||||
|
||||
**向前兼容**:旧代码读取新数据。原理类似,只不过是需要得到一个逆向映射。
|
||||
|
||||
在由写入模式到读取模式建立映射时有一些规则:
|
||||
|
||||
1. **使用字段名来进行匹配**。因此写入模式和读取模式字段名顺序不一样无所谓。
|
||||
2. **忽略多出的字段**。
|
||||
3. **对缺少字段填默认值**。
|
||||
|
||||

|
||||
|
||||
### 模式演化规则
|
||||
|
||||
- 那么如何保证写入模式的兼容呢?
|
||||
1. 在增删字段时,只能添加或删除具有默认值的字段。
|
||||
2. 在更改字段类型时,需要 Avro 支持相应的类型转换。
|
||||
|
||||
Avro 没有像 ProtoBuf、Thrift 那样的 optional 和 required 限定符,是通过 union 的方式,里指定默认值,甚至多种类型:
|
||||
|
||||
```c
|
||||
union {null, long, string} field;
|
||||
```
|
||||
|
||||
**注**:默认值必须是联合的第一个分支的类型。
|
||||
|
||||
更改字段名和在 union 中添加类型,都是向后兼容,但是不能向前兼容的,想想为什么?
|
||||
|
||||
### 如何从编码中获取写入模式
|
||||
|
||||
对于一段给定的 Avro 编码数据,Reader 如何从其中获得其对应的写入模式?
|
||||
|
||||
这取决于不同的应用场景。
|
||||
|
||||
- **所有数据条目同构的大文件**
|
||||
|
||||
典型的就是 Hadoop 生态中。如果一个大文件所有记录都使用相同模式编码,则在文件头包含一次写入模式即可。
|
||||
|
||||
- **支持模式变更的数据库表**
|
||||
|
||||
由于数据库表允许模式修改,其中的行可能写入于不同模式阶段。对于这种情况,可以在编码时额外记录一个模式版本号(比如自增),然后在某个地方存储所有的模式版本。
|
||||
|
||||
解码时,通过版本去查询对应的写入模式即可。
|
||||
|
||||
- **网络中发送数据**
|
||||
|
||||
在两个进程通信的握手阶段,交换写入模式。比如在一个 session 开始时交换模式,然后在整个 session 生命周期内都用此模式。
|
||||
|
||||
|
||||
### 动态生成数据中的模式
|
||||
|
||||
Avro 没有使用字段标号的一个好处是,不需要手动维护字段标号到字段名的映射,这对于动态生成的数据模式很友好。
|
||||
|
||||
书中给的例子是对数据库做导出备份,注意和数据库本身使用 Avro 编码不是一个范畴,此处是指导出的数据使用 Avro 编码。
|
||||
|
||||
在数据库表模式发生改变前后,Avro 只需要在导出时依据当时的模式,做相应的转换,生成相应的模式数据即可。但如果使用 PB,则需要自己处理多个备份文件中,字段标号到字段名称的映射关系。其本质在于,Avro 的数据模式可以和数据存在一块,但是 ProtoBuf 的数据模式只能体现在生成的代码中,需要手动维护新旧版本备份数据与PB 生成的代码间的映射。
|
||||
|
||||
### 代码生成和动态语言
|
||||
|
||||
Thrift 和 Protobuf 会依据语言无关的 IDL 定义的模式,生成给定语言的编解码的代码。这对静态语言很有用,因为它允许利用 IDE 和编译器进行类型检查,并且能够提高编解码效率。
|
||||
|
||||
**上述思路本质上在于,将模式内化到了生成的代码中。**
|
||||
|
||||
但对于动态语言,或者说解释型语言,如 JavaScript、Ruby 或 Python,由于没有了编译期检查,生成代码的意义没那么大,反而会有一定的冗余。这时 Avro 这种支持不生成代码的框架就节省一些,它可以将模式写入数据文件,读取时利用 Avro 进行动态解析即可。
|
||||
|
||||
## 模式的优点
|
||||
|
||||
**模式的本质是显式类型约束,即,先有模式,才能有数据。**
|
||||
|
||||
相比于没有任何类型约束的文本编码 JSON,XML 和 CSV,Protocol Buffers,Thrift 和 Avro 这些基于显式定义二进制编码优点有:
|
||||
|
||||
1. 省去字段名,从而更加紧凑。
|
||||
2. 模式是数据的注释或者文档,并且总是最新的。
|
||||
3. 数据模式允许不读取数据,仅比对模式来做低成本的兼容性检查。
|
||||
4. 对于静态类型来说,可以利用代码生成做编译时的类型检查。
|
||||
|
||||
模式演化 vs 读时模式
|
||||
|
||||
# 几种数据流模型
|
||||
|
||||
数据可以以很多种形式从一个系统流向另一个系统,但不变的是,流动时都需要编码与解码。
|
||||
|
||||
在数据流动时,会涉及编解码双方模式匹配问题,上一小节已经讨论,本小节主要探讨几种进程间典型的数据流方式:
|
||||
|
||||
1. 通过数据库
|
||||
2. 通过服务调用
|
||||
3. 通过异步消息传递
|
||||
|
||||
## 经由数据库的数据流
|
||||
|
||||
访问数据库的程序,可能:
|
||||
|
||||
1. **只由同一个进程访问**。则数据库可以理解为该进程向将来发送数据的中介。
|
||||
2. **由多个进程访问**。则多个进程可能有的是旧版本,有的是新版本,此时数据库需要考虑向前和向后兼容的问题。
|
||||
|
||||
还有一种比较棘手的情况:在某个时刻,你给一个表增加了一个字段,较新的代码写入带有该字段的行,之后又被较旧的代码覆盖成缺少该字段的行。这时候就会出现一个问题:我们更新了一个字段 A,更新完后,却发现字段 B 没了。
|
||||
|
||||

|
||||
|
||||
### 不同时间写入的数据
|
||||
|
||||
对于应用程序,可能很短时间就可以由旧版本替换为新版本。但是对于数据,旧版本的代码写入的数据量,经年累月,可能很大。在变更了模式之后,由于这些旧模式的数据量很大,全部更新对齐到新版本的代价很高。
|
||||
|
||||
这种情况我们称之为:**数据的生命周期超过了其对应代码的生命周期**。
|
||||
|
||||
在读取时,数据库一般会对缺少对应列的旧数据:
|
||||
|
||||
1. 填充新版本字段的**默认值**(default value)
|
||||
2. 如果没有默认值则填充**空值**(nullable)
|
||||
|
||||
后返回给用户。一般来说,在更改模式时(比如 alter table),数据库不允许增加既没有默认值、也不允许为空的列。
|
||||
|
||||
### 存储归档
|
||||
|
||||
有时候需要对数据库做备份到外存。在做备份(或者说快照)时,虽然会有不同时间点生成的数据,但通常会将各种版本数据转化、对齐到最新版本。毕竟,总是要全盘拷贝数据,那就顺便做下转换好了。
|
||||
|
||||
之前也提到了,对于这种场景,生成的是一次性的不可变的备份或者快照数据,使用 Avro 比较合适。此时也是一个很好地契机,可以将数据按需要的格式输出,比如面向分析的按列存储格式:[Parquet](https://parquet.apache.org/docs/file-format/ "Parquet")。
|
||||
|
||||
## 经由服务的数据流:REST 和 RPC
|
||||
|
||||
通过网络通信时,通常涉及两种角色:服务器(server)和客户端(client)。
|
||||
|
||||
通常来说,暴露于公网的多为 HTTP 服务,而 RPC 服务常在内部使用。
|
||||
|
||||
服务器也可以同时是客户端:
|
||||
|
||||
1. 作为客户端访问数据库。
|
||||
2. 作为客户端访问其他服务。
|
||||
|
||||
对于后者,是因为我们常把一个大的服务拆成一组功能独立、相对解耦的服务,这就是 **面向服务的架构(service-oriented architecture,SOA)**,或者最近比较火的**微服务架构(micro-services architecture)**。这两者有一些不同,但这里不再展开。
|
||||
|
||||
服务在某种程度上和数据库类似:允许客户端以某种方式存储和查询数据。但不同的是,数据库通常提供某种灵活的查询语言,而服务只能提供相对死板的 API。
|
||||
|
||||
### web 服务
|
||||
|
||||
当服务使用 HTTP 作为通信协议时,我们通常将其称为 **web 服务**。但其并不局限于 web,还包括:
|
||||
|
||||
1. 用户终端(如移动终端)通过 HTTP 向服务器请求。
|
||||
2. 同组织内的一个服务向另一个服务发送 HTTP 请求(微服务架构,其中的一些组件有时被称为中间件)。
|
||||
3. 不同组织的服务进行数据交换。一般要通过某种手段进行验证,比如 OAuth。
|
||||
|
||||
有两种设计 HTTP API 的方法:REST 和 SOAP。
|
||||
|
||||
1. **REST 并不是一种协议,而是一种设计哲学**。它强调简单的 API 格式,使用 URL 来标识资源,使用 HTTP 的动作(GET、POST、PUT、DELETE )来对资源进行增删改查。由于其简洁风格,越来越受欢迎。
|
||||
2. SOAP 是基于 XML 的协议。虽然使用 HTTP,但目的在于独立于 HTTP。现在提的比较少了。
|
||||
|
||||
### RPC 面临的问题
|
||||
|
||||
RPC 想让调用远端服务像调用本地(同进程中)函数一样自然,虽然设想比较好、现在用的也比较多,但也存在一些问题:
|
||||
|
||||
1. 本地函数调用要么成功、要么不成功。但是 RPC 由于经过网络,可能会有各种复杂情况,比如请求丢失、响应丢失、hang 住以至于超时等等。因此,可能需要重试。
|
||||
2. 如果重试,需要考虑**幂等性**问题。因为上一次的请求可能已经到达了服务端,只是请求没有成功返回。那么多次调用远端函数,就要保证不会造成额外副作用。
|
||||
3. 远端调用延迟不可用,受网络影响较大。
|
||||
4. 客户端与服务端使用的编程语言可能不同,但如果有些类型不是两种语言都有,就会出一些问题。
|
||||
|
||||
REST 相比 RPC 的好处在于,它不试图隐去网络,更为显式,让使用者不易忽视网络的影响。
|
||||
|
||||
### RPC 当前方向
|
||||
|
||||
尽管有上述问题,但其实在工程中,大部分情况下,上述情况都在容忍范围内:
|
||||
|
||||
1. 比如局域网的网络通常比较快速、可控。
|
||||
2. 多次调用,使用幂等性来解决。
|
||||
3. 跨语言,可以使用 RPC 框架的 IDL 来解决。
|
||||
|
||||
但 RPC 程序需要考虑上面提到的极端情况,否则可能会偶然出一个很难预料的 BUG。
|
||||
|
||||
另外,基于二进制编码的 RPC 通常比基于 HTTP 服务效率更高。但 HTTP 服务,或者更具体一点,RESTful API 的好处在于,生态好、有大量的工具支持。而 RPC 的 API 通常和 RPC 框架生成的代码高度相关,因此很难在不同组织中无痛交换和升级。
|
||||
|
||||
因此,如本节开头所说:暴露于公网的多为 HTTP 服务,而 RPC 服务常在内部使用。
|
||||
|
||||
### 数据编码和 RPC 的演化
|
||||
|
||||
通过服务的数据流通常可以假设:所有的服务器先更新,然后服务端再更新。因此,只需要在请求里考虑后向兼容性,在响应中考虑前向兼容性:
|
||||
|
||||
1. Thrift、gRPC(Protobuf)和 Avro RPC 可以根据编码格式的兼容性规则进行演变。
|
||||
2. RESTful API 通常使用 JSON 作为请求响应的格式,JSON 比较容易添加新的字段来进行演进和兼容。
|
||||
3. SOAP 按下不表。
|
||||
|
||||
对于 RPC,服务的兼容性比较困难,因为一旦 RPC 服务的 SDK 提供出去之后,你就无法对其生命周期进行控制:总有用户因为各种原因,不会进行主动升级。因此可能需要长期保持兼容性,或者提前通知和不断预告,或者维护多个版本 SDK 并逐渐对早期版本进行淘汰。
|
||||
|
||||
对于 RESTful API,常用的兼容方法是,将版本号做到 URL 或者 HTTP 请求头中。
|
||||
|
||||
## 经由消息传递的数据流
|
||||
|
||||
前面研究了编码解码的不同方式:
|
||||
|
||||
1. 数据库:一个进程写入(编码),将来一个进程读取(解码)
|
||||
2. RPC 和 REST:一个进程通过网络(发送前会编码)向另一个进程发送请求(收到后会解码)并同步等待响应。
|
||||
|
||||
本节研究介于数据库和 RPC 间的**异步消息系统**:一个存储(消息 broker、消息队列来临时存储消息)+ 两次 RPC(生产者一次,消费者一次)。
|
||||
|
||||
与 RPC 相比,使用消息队列的优点:
|
||||
|
||||
1. 如果消费者暂时不可用,可以充当暂存系统。
|
||||
2. 当消费者宕机重启后,自动地重新发送消息。
|
||||
3. 生产者不必知道消费者 IP 和端口。
|
||||
4. 能将一条消息发送给多个消费者。
|
||||
5. 将生产者和消费者解耦。
|
||||
|
||||
### 消息队列
|
||||
|
||||
书中用的是**消息代理**(Message Broker),但另一个名字,消息队列,可能更为大家熟知,因此,本小节之后行文都用消息队列。
|
||||
|
||||
过去,消息队列为大厂所垄断。但近年来,开源的消息队列越来越多,可以适应不同场景,如 RabbitMQ、ActiveMQ、HornetQ、NATS 和 Apache Kafka 等等。
|
||||
|
||||
消息队列的**送达保证**因实现和配置而异,包括:
|
||||
|
||||
1. **最少一次 (at-least-once)**:同一条数据可能会送达多次给消费者。
|
||||
2. **最多一次(at-most-once)**:同一条数据最多会送达一次给消费者,有可能丢失。
|
||||
3. **严格一次(exactly-once)**:同一条数据保证会送达一次,且最多一次给消费者。
|
||||
|
||||
消息队列的逻辑抽象叫做 **Queue** 或者 **Topic**,常用的消费方式两种:
|
||||
|
||||
1. 多个消费者互斥消费一个 Topic
|
||||
2. 每个消费者独占一个 Topic
|
||||
|
||||
**注**:我们有时会区分这两个概念:将点对点的互斥消费称为 Queue,多点对多点的发布订阅称为 Topic,但这并不通用,或者说没有形成共识。
|
||||
|
||||
一个 Topic 提供一个单向数据流,但可以组合多个 Topic,形成复杂的数据流拓扑。
|
||||
|
||||
消息队列通常是面向**字节数组**的,因此你可以将消息按任意格式进行编码。如果编码是前后向兼容的,同一个主题的消息格式,便可以进行灵活演进。
|
||||
|
||||
### 分布式的 Actor 框架
|
||||
|
||||
**Actor 模型**是一种基于消息传递的并发编程模型。 Actor 通常是由状态(State)、行为(Behavior)和信箱(MailBox,可以认为是一个消息队列)三部分组成:
|
||||
|
||||
1. 状态:Actor 中包含的状态信息。
|
||||
2. 行为:Actor 中对状态的计算逻辑。
|
||||
3. 信箱:Actor 接受到的消息缓存地。
|
||||
|
||||
由于 Actor 和外界交互都是通过消息,因此本身可以并行的,且不需要加锁。
|
||||
|
||||
分布式的 Actor 框架,本质上是将消息队列和 actor 编程模型集成到一块。自然,在 Actor 滚动升级是,也需要考虑前后向兼容问题。
|
||||
672
ch05.md
Normal file
@ -0,0 +1,672 @@
|
||||
# DDIA 逐章精读(五): 冗余(Replication)
|
||||
|
||||
本书第一部分讲单机数据系统,第二部分讲多机数据系统。
|
||||
|
||||
**冗余(Replication)** 是指将同一份数据复制多份,放到通过网络互联的多个机器上去。其好处有:
|
||||
|
||||
1. **降低延迟**:可以在地理上同时接近不同地区的用户。
|
||||
2. **提高可用性**:当系统部分故障时仍然能够正常提供服务。
|
||||
3. **提高读吞吐**:平滑扩展可用于查询的机器。
|
||||
|
||||
> 本章假设我们的数据系统中所有数据能够存放到一台机器中,则本章只需考虑多机冗余的问题。如果数据超过单机尺度该怎么办?那是下一章要解决的事情。
|
||||
>
|
||||
|
||||
如果数据是**只读**的,则冗余很好做,直接复制到多机即可。我们有时可以利用这个特性,使用分治策略,将数据分为只读部分和读写部分,则只读部分的冗余就会容易处理的多,甚至可以用 EC 方式做冗余,减小存储放大的同时,还提高了可用性。
|
||||
|
||||
- 想想 EC 牺牲了什么?
|
||||
|
||||
以计算换存储。
|
||||
|
||||
|
||||
但难点就在于,数据允许数据变更时,如何维护多机冗余且一致。常用的冗余控制算法有:
|
||||
|
||||
1. 单领导者(single leader)
|
||||
2. 多领导者(multi-leader)
|
||||
3. 无领导者(leaderless)
|
||||
|
||||
这需要在多方面做取舍:
|
||||
|
||||
1. 使用同步复制还是异步复制
|
||||
2. 如何处理失败的副本
|
||||
|
||||
数据库冗余问题在学术界不是一个新问题了,但在工业界,大部分人都是新手——分布式数据库是近些年才大规模的在工业界落地的。
|
||||
|
||||
# 领导者与跟随者
|
||||
|
||||
冗余存储的每份数据称为**副本**(replica)。多副本所带来的最主要的一个问题是:如何保证所有数据被同步到了所有副本上?
|
||||
|
||||
基于**领导者(leader-based)** 的同步算法,是最常用解决办法。
|
||||
|
||||
1. 其中一个副本称为**领导者**(leader),别称**主副本**(primary、master)。主副本作为写入的协调者,所有写入都要发给主副本。
|
||||
2. 其他副本称为**跟随者**(follower),也称为**只读副本**(read replicas)、**从副本**(slaves)、**次副本**(secondaries)、**热备**(hot-standby)。主副本将改动写到本地后,将其发送给各个从副本,从副本收变动到后应用到自己状态机,这个过程称为**日志同步**(replication log)、**变更流**(change steam)。
|
||||
3. 对于读取,客户端可以从主副本和从副本中读取;但写入,客户端只能将请求发到主副本。
|
||||
|
||||

|
||||
|
||||
根据我的习惯,下面通称主副本和从副本。
|
||||
|
||||
有很多**数据系统**都用了此模式:
|
||||
|
||||
1. **关系型数据库**:PostgreSQL(9.0+)、MySQL 和 Oracle Data Guard 和 SQL Server 的 AlwaysOn
|
||||
2. **非关系型数据库**:MonogoDB、RethinkDB 和 Espresso
|
||||
3. **消息队列**:Kafka 和 RabbitMQ。
|
||||
|
||||
## 同步复制和异步复制
|
||||
|
||||
**同步(synchronously)复制**和**异步(asynchronously)复制**和关键区别在于:请求何时返回给客户端。
|
||||
|
||||
1. 如果等待某副本写完成后,则该副本为同步复制。
|
||||
2. 如果不等待某副本写完成,则该副本为异步复制。
|
||||
|
||||

|
||||
|
||||
两者的对比如下:
|
||||
|
||||
1. 同步复制牺牲了**响应延迟**和**部分可用性**(在某些副本有问题时不能完成写入操作),换取了所有副本的一致性(但并不能严格保证)。
|
||||
2. 异步复制放松了**一致性**,而换来了较低的写入延迟和较高的可用性。
|
||||
|
||||
在实践中,会根据对一致性和可用性的要求,进行取舍。针对所有从副本来说,可以有以下选择:
|
||||
|
||||
1. **全同步**:所有的从副本都同步写入。如果副本数过多,可能性能较差,当然也可以做并行化、流水线化处理。
|
||||
2. **半同步**:(**semi-synchronous**),有一些副本为同步,另一些副本为异步。
|
||||
3. **全异步**:所有的从副本都异步写入。网络环境比较好的话,可以这么配置。
|
||||
|
||||
> 异步复制可能会造成副本丢失等严重问题,为了能兼顾一致性和性能,学术界也在不断研究新的复制方法。如,**链式复制(chain-replication)**。
|
||||
>
|
||||
|
||||
> 多副本的一致性和共识性有诸多联系,本书后面章节会讨论。
|
||||
>
|
||||
|
||||
## 新增副本
|
||||
|
||||
在很多情况下,需要给现有系统新增副本。
|
||||
|
||||
如果原副本是只读(read-only)的,只需要简单拷贝即可。但是如果是可写副本,则问题要复杂很多。因此,比较简单的一种解决方法是:禁止写入,然后拷贝。这在某些情况下很有用,比如夜间没有写入流量,同时一晚上肯定能复制完。
|
||||
|
||||
如果要不停机,可以:
|
||||
|
||||
1. 主副本在本地做**一致性**快照。何谓一致性?
|
||||
2. 将快照复制到从副本节点。
|
||||
3. 从主副本拉取快照之后的操作日志,应用到从副本。如何知道快照与其后日志的对应关系?序列号。
|
||||
4. 当从副本赶上主副本进度后,就可以正常跟随主副本了。
|
||||
|
||||
这个过程一般是自动化的,比如 Raft 中;当然也可以手动化,比如写一些脚本。
|
||||
|
||||
## 宕机处理
|
||||
|
||||
系统中任何节点都可能在计划内或者计划外宕机。那么如何应对这些宕机情况,保持整个系统的可用性呢?
|
||||
|
||||
### **从副本宕机:追赶恢复**。
|
||||
|
||||
类似于新增从副本。如果落后的多,可以直接向主副本拉取快照+日志;如果落后的少,可以仅拉取缺失日志。
|
||||
|
||||
### **主副本宕机:故障转移。**
|
||||
|
||||
处理相对麻烦,首先要选出新的主副本,然后要通知所有客户端主副本变更。具体来说,包含下面步骤:
|
||||
|
||||
1. **确认主副本故障**。要防止由于网络抖动造成的误判。一般会用心跳探活,并设置合理超时(timeout)阈值,超过阈值后没有收到该节点心跳,则认为该节点故障。
|
||||
2. **选择新的主副本**。新的主副本可以通过**选举**(共识问题)或者**指定**(外部控制程序)来产生。选主时,要保证备选节点数据尽可能的新,以最小化数据损失。
|
||||
3. **让系统感知新主副本**。系统其他参与方,包括从副本、客户端和旧主副本。前两者不多说,旧主副本在恢复时,需要通过某种手段,让其知道已经失去领导权,避免**脑裂**。
|
||||
|
||||
主副本切换时,会遇到很多问题:
|
||||
|
||||
1. **新老主副本数据冲突**。新主副本在上位前没有同步完所有日志,旧主副本恢复后,可能会发现和新主副本数据冲突。
|
||||
2. **相关外部系统冲突**。即新主副本,和使用该副本数据的外部系统冲突。书中举了 github 数据库 MySQL 和缓存系统 redis 冲突的例子。
|
||||
3. **新老主副本角色冲突**。即新老主副本都以为自己才是主副本,称为**脑裂(split brain)**。如果他们两个都能接受写入,且没有冲突解决机制,数据会丢失或者损坏。有的系统会在检测到脑裂后,关闭其中一个副本,但设计的不好可能将两个主副本都关闭调。
|
||||
4. **超时阈值选取**。如果超时阈值选取的过小,在不稳定的网络环境中(或者主副本负载过高)可能会造成主副本频繁的切换;如果选取过大,则不能及时进行故障切换,且恢复时间也增长,从而造成服务长时间不可用。
|
||||
|
||||
所有上述问题,在不同需求、不同环境、不同时间点,都可能会有不同的解决方案。因此在系统上线初期,不少运维团队更愿意手动进行切换;等积累一定经验后,再进行逐步自动化。
|
||||
|
||||
节点故障;不可靠网络;在一致性、持久化、可用性和延迟间的取舍;等等问题,都是设计分布式系统时,所面临的的基本问题。根据实际情况,对这些问题进行艺术化的取舍,便是分布式系统之美。
|
||||
|
||||
## 日志复制
|
||||
|
||||
在数据库中,基于领导者的多副本是如何实现的?在不同层次有多种方法,包括:
|
||||
|
||||
1. **语句层面的复制。**
|
||||
2. **预写日志的复制**。
|
||||
3. **逻辑日志的复制**。
|
||||
4. **触发器的复制**。
|
||||
|
||||
对于一个**系统**来说,多副本同步的是什么?**增量修改**。
|
||||
|
||||
具体到一个由数据库构成的**数据系统**,通常由数据库外部的**应用层**、数据库内部**查询层**和**存储层**组成。**修改**在查询层表现为:语句;在存储层表现为:存储引擎相关的预写日志、存储引擎无关的逻辑日志;修改完成后,在应用层表现为:触发器逻辑。
|
||||
|
||||
### 基于语句的复制
|
||||
|
||||
主副本记录下所有更新语句:`INSERT`、`UPDATE` 或 `DELETE` 然后发给从库。主副本在这里类似于充当其他从副本的**伪客户端**。
|
||||
|
||||
但这种方法有一些问题:
|
||||
|
||||
1. **非确定性函数(nondeterministic)**的语句可能会在不同副本造成不同改动。如 NOW()、RAND()
|
||||
2. **使用自增列,或依赖于现有数据**。则不同用户的语句需要完全按相同顺序执行,当有并发事务时,可能会造成不同的执行顺序,进而导致副本不一致。
|
||||
3. **有副作用**(触发器、存储过程、UDF)的语句,可能不同副本由于上下文不同,产生的副作用不一样。除非副作用是确定的输出。
|
||||
|
||||
当然也有解决办法:
|
||||
|
||||
1. 识别所有产生非确定性结果的语句。
|
||||
2. 对于这些语句同步值而非语句。
|
||||
|
||||
但是 Corner Case 实在太多,步骤 1 需要考虑的情况太多。
|
||||
|
||||
### 传输预写日志( WAL)
|
||||
|
||||
我们发现主流的存储引擎都有**预写日志**(WAL,为了宕机恢复):
|
||||
|
||||
1. 对于日志流派(LSM-Tree,如 LevelDB),每次修改先写入 log 文件,防止写入 MemTable 中的数据丢失。
|
||||
2. 对于原地更新流派(B+ Tree),每次修改先写入 WAL,以进行崩溃恢复。
|
||||
|
||||
所有用户层面的改动,最终都要作为状态落到存储引擎里,而存储引擎通常会维护一个:
|
||||
|
||||
1. 追加写入
|
||||
2. 可重放
|
||||
|
||||
这种结构,天然适合备份同步。本质是因为磁盘的读写特点和网络类似:**磁盘是顺序写比较高效,网络是只支持流式写**。具体来说,主副本在写入 WAL 时,会同时通过网络发送对应的日志给所有从副本。
|
||||
|
||||
书中提到一个数据库版本升级的问题:
|
||||
|
||||
1. 如果允许旧版本代码给新版本代码(应该会自然做到后向兼容)发送日志(前向兼容)。则在升级时可以先升级从库,再切换升级主库。
|
||||
2. 否则,只能进行停机升级软件版本。
|
||||
|
||||
### 逻辑日志复制(基于行)
|
||||
|
||||
为了和具体的存储引擎物理格式解耦,在做数据同步时,可以使用不同的日志格式:**逻辑日志**。
|
||||
|
||||
对于关系型数据库来说,行是一个合适的粒度:
|
||||
|
||||
1. **对于插入行**:日志需包含所有列值。
|
||||
2. **对于删除行**:日志需要包含待删除行标识,可以是主键,也可以是其他任何可以唯一标识行的信息。
|
||||
3. **对于更新行**:日志需要包含待更新行的标志,以及所有列值(至少是要更新的列值)
|
||||
|
||||
对于多行修改来说,比如事务,可以在修改之后增加一条事务提交的记录。 MySQL 的 binlog 就是这么干的。
|
||||
|
||||
使用逻辑日志的**好处**有:
|
||||
|
||||
1. 方便新旧版本的代码兼容,更好的进行滚动升级。
|
||||
2. 允许不同副本使用不同的存储引擎。
|
||||
3. 允许导出变动做各种**变换**。如导出到数据仓库进行离线分析、建立索引、增加缓存等等。
|
||||
|
||||
之前分析过一种基于日志,统一各种数据系统的[文章](https://zhuanlan.zhihu.com/p/458683164),很有意思。
|
||||
|
||||
### 基于触发器的复制
|
||||
|
||||
前面所说方法,都是在**数据库内部**对数据进行多副本同步。
|
||||
|
||||
但有些情况下,可能需要用户决策,如何对数据进行复制:
|
||||
|
||||
1. 对需要复制的数据进行过滤,只复制一个子集。
|
||||
2. 将数据从一种数据库复制到另外一种数据库。
|
||||
|
||||
有些数据库如 Oracle 会提供一些工具。但对于另外一些数据库,可以使用**触发器和存储过程**。即,将用户代码 hook 到数据库中去执行。
|
||||
|
||||
基于触发器的复制,性能较差且更易出错;但是给了用户更多的灵活性。
|
||||
|
||||
# 复制滞后问题
|
||||
|
||||
如前所述,使用多副本的好处有:
|
||||
|
||||
1. **可用性**:容忍部分节点故障
|
||||
2. **可伸缩性**:增加读副本处理更多读请求
|
||||
3. **低延迟**:让用户选择一个就近的副本访问
|
||||
|
||||
### **引出**
|
||||
|
||||
对于读多写少的场景,想象中,可以通过使劲增加读副本来均摊流量。但有个**隐含**的条件是,多副本建的同步得做成**异步**的,否则,读副本一多,某些副本就很容易出故障,进而阻塞写入。
|
||||
|
||||
但若是异步复制,就会引入不一致问题:某些副本进度落后于主副本。
|
||||
|
||||
如果此时不再有写入,经过一段时间后,多副本最终会达到一致:**最终一致性**。
|
||||
|
||||
在实际中,网络通常比较快,**副本滞后(replication lag)**不太久,也即这个*最终***通常**不会太久,比如 ms 级别,最多 s 级别。但是,对于分布式系统,谁都不敢打包票,由于网络分区、机器高负载等等软硬件问题,在极端情况下,这个*最终*可能会非常久。
|
||||
|
||||
> 总之,**最终**是一个非常不精确的限定词。
|
||||
>
|
||||
|
||||
对于这种最终一致的系统,在工程中,要考虑到由于副本滞后所带来的一致性问题。
|
||||
|
||||
## 读你所写
|
||||
|
||||

|
||||
|
||||
上图问题在于,在一个**异步复制**的分布式数据库里,同一个客户端,写入**主副本**后返回;稍后再去读一个落后的**从副本**,就会发现:读不到自己刚写的内容!
|
||||
|
||||
为了避免这种反直觉的事情发生,我们引入一种新的一致性:**读写一致性(read-after-write consistency)**,或者 **读你所写一致性(read-your-writes consistency)**。
|
||||
|
||||
若数据库提供这种一致性保证,对于**单个客户端**来说,就一定能够读到其所写变动。也即,这种一致性是从**单个客户端**角度来看的一种因果一致性。
|
||||
|
||||
那么如何提供这种保证,或者说,实现这种一致性呢?列举几种方案:
|
||||
|
||||
1. **按内容分类**。对于客户端可能修改的内容集,**只从主副本读取**。如社交网络上的个人资料,读自己的资料时,从主副本读取;但读其他人资料时,可以向从副本读。
|
||||
2. **按时间分类**。 如果每个客户端都能访问基本所有数据,则方案一就会退化成所有数据都要从主副本读取,这显然不可接受。此时,可以按时间分情况讨论,近期内有过改动的数据,从主副本读,其他的,向从副本读。那这个区分是否最近的**时间阈值**(比如一分钟)如何选取呢?可以监控从副本一段时间内的最大延迟这个经验值,来设置。
|
||||
3. **利用时间戳**。客户端记下本客户端上次改动时的时间戳,在读从副本时,利用此时间戳来看某个从副本是否已经同步了改时间戳之前内容。可以在所有副本中找到一个已同步了的;或者阻塞等待某个副本同步到改时间戳后再读取。时间戳可以是逻辑时间戳,也可以是物理时间戳(此时多机时钟同步非常重要)。
|
||||
|
||||
会有一些实际的复杂 case:
|
||||
|
||||
1. **数据分布在多个物理中心**。所有需要发送给主副本的请求都要首先路由到主副本所在的数据中心。
|
||||
2. **一个逻辑用户有多个物理客户端**。比如一个用户通过电脑、手机多终端同时访问,此时就不能用设备 id,而需要使用用户 id,来保证用户角度的读写一致性。但不同设备有不同物理时间戳,不同设备访问时可能会路由到不同数据中心。
|
||||
|
||||
## 单调读
|
||||
|
||||
异步复制可能带来的另外一个问题:对于一个客户端来说,系统可能会发生**时光倒流(moving backward in time)**。
|
||||
|
||||

|
||||
|
||||
于是,我们再引入一种一致性保证:**单调读(Monotonic reads)**。
|
||||
|
||||
- 读写一致性和单调读有什么区别?
|
||||
|
||||
写后读保证的是写后读顺序,单调读保证的是**多次读**之间的顺序。
|
||||
|
||||
|
||||
如何实现单调读?
|
||||
|
||||
1. 只从一个副本读数据。
|
||||
2. 前面提到的时间戳机制。
|
||||
|
||||
## 一致前缀读
|
||||
|
||||

|
||||
|
||||
异步复制所带来的第三个问题:有时候会违反因果关系。
|
||||
|
||||
本质在于:如果数据库由多个分区(Partition)组成,而分区间的事件顺序无法保证。此时,如果有因果关系的两个事件落在了不同分区,则有可能会出现**果在前,因在后**。
|
||||
|
||||
为了防止这种问题,我们又引入了一种一致性:**一致前缀读(consistent prefix reads)**。奇怪的名字。
|
||||
|
||||
实现这种一致性保证的方法:
|
||||
|
||||
1. 不分区。
|
||||
2. 让所有有因果关系的事件路由到一个分区。
|
||||
|
||||
但如何追踪因果关系是个难题。
|
||||
|
||||
## 副本滞后的终极解决方案
|
||||
|
||||
事务!
|
||||
|
||||
多副本异步复制所带来的一致性问题,都可以通过**事务(transaction)**来解决。单机事务已经存在了很长时间,但在数据库走向分布式时代,一开始很多 NoSQL 系统抛弃了事务。
|
||||
|
||||
- 这是为什么?
|
||||
1. 更容易的实现。2. 更好的性能。3. 更好的可用性。
|
||||
|
||||
于是复杂度被转移到了应用层。
|
||||
|
||||
这是数据库系统刚大规模步入分布式(**多副本、多分区**)时代的一种妥,在经验积累的够多之后,事务必然会被引回。
|
||||
|
||||
于是近年来越来越多的分布式数据库开始支持事务,是为**分布式事务**。
|
||||
|
||||
# 多主模型
|
||||
|
||||
**单主模型一个最大问题**:所有写入都要经过它,如果由于任何原因,客户端无法连接到主副本,就无法向数据库写入。
|
||||
|
||||
于是自然产生一种想法:多主行不行?
|
||||
|
||||
**多主复制(multi-leader replication)**:有多个可以接受写入的主副本,每个主副本在接收到写入之后,都要转给所有其他副本。即一个系统,有多个**写入点**。
|
||||
|
||||
## 多主模型应用场景
|
||||
|
||||
单个数据中心,多主模型意义不大:复杂度超过了收益。总体而言,由于一致性等问题,多主模型应用场景较少,但有一些场景,很适合多主:
|
||||
|
||||
1. 数据库横跨多个数据中心
|
||||
2. 需要离线工作的客户端
|
||||
3. 协同编辑
|
||||
|
||||
### 多个数据中心
|
||||
|
||||
假设一个数据库的副本,横跨多个数据中心,如果使用单主模型,在写入时的延迟会很大。那么每个数据中心能不能各配一个主副本?
|
||||
|
||||

|
||||
|
||||
单主和多主,在多数据中心场景下的对比:
|
||||
|
||||
| 对比项 | 单主模型 | 多主模型 |
|
||||
| --- | --- | --- |
|
||||
| 性能 | 所有写入都要路由到一个数据中心 | 写入可以就近 |
|
||||
| 可用性 | 主副本所在数据中心故障,需要有个切主的过程 | 每个数据中心可以独立工作 |
|
||||
| 网络 | 跨数据中心,写入对网络抖动更敏感 | 数据中心间异步复制,对公网容错性更高 |
|
||||
|
||||
但是多主模型在一致性方面有很大缺陷:如果两个数据中心同时修改同样的数据,必须合理解决写冲突。另外,对于数据库来说,多主很难保证一些自增主键、触发器和完整性约束的一致性。因此在工程实践中,多主用的相对较少。
|
||||
|
||||
### 离线工作的客户端
|
||||
|
||||
离线工作的一个应用的多个设备上的客户端,如果也允许继续写入数据。如:日历应用。在电脑上和手机上离线时如果也支持添加日程。则在各个设备联网时,需要互相同步数据。
|
||||
|
||||
则离线后还继续工作的多个副本,本质上就是一个多主模型:每个主都可以独立的写入数据,然后在网络连通后解决冲突。
|
||||
|
||||
但,如何支持离线后正常地工作,联网后优雅的解决冲突,是一个难题。
|
||||
|
||||
Apache CouchDB 的一个特点便是支持多主模型。
|
||||
|
||||
### 协同编辑
|
||||
|
||||
Google Docs 等类似 SaaS 模式的在线协同应用越来越流行。
|
||||
|
||||
这种应用允许多人在线同时编辑文档或者电子表格,其背后的原理,与上一节离线工作的客户端很像。
|
||||
|
||||
为了实现协同,并解决冲突,可以:
|
||||
|
||||
1. **悲观方式**。加锁以避免冲突,但粒度需要尽可能小,否则无法允许多人同时编辑一个文档。
|
||||
2. **乐观方式**。允许每个用户无脑写入,然后如果有冲突,交由用户解决。
|
||||
|
||||
git 也是一个类似的协议。
|
||||
|
||||
## 处理写入冲突
|
||||
|
||||
多主模型最大的问题是:如何解决冲突。
|
||||
|
||||

|
||||
|
||||
考虑 wiki 一个页面标题的修改:
|
||||
|
||||
1. 用户 1 将该页面标题从 A 修改到 B
|
||||
2. 用户 2 将该页面标题从 A 修改到 C
|
||||
|
||||
两个操作在本地都修改成功,然后**异步同步**时,会出现冲突。
|
||||
|
||||
### 冲突检测
|
||||
|
||||
**有同步**或者**异步**的方式进行冲突检测。
|
||||
|
||||
对于**单主模型**,当检测到冲突时,由于只有一个主副本,可以同步的检测冲突,从而解决冲突:
|
||||
|
||||
1. 让第二个写入阻塞,直到第一个写完成。
|
||||
2. 让第二个写入失败,进行重试。
|
||||
|
||||
但对于**多主模型**,两个写入可能会在不同主副本立即成功。然后异步同步时,发现冲突,但为时已晚(没有办法简单决定如何解决冲突)。
|
||||
|
||||
虽然,可以在多主间使用同步方式写入所有副本后,再返回请求给客户端。但这会失掉多主模型的主要优点:**允许多个主副本独立接受写入**。此时,蜕化成单主模型。
|
||||
|
||||
### 冲突避免
|
||||
|
||||
**解决冲突最好的方式是在设计上避免冲突**。
|
||||
|
||||
由于多主模型在冲突发生后再去解决会有很大的复杂度,因此常使用冲突避免的设计。
|
||||
|
||||
假设你的数据集可以分成多个分区,让不同分区的主副本放在不同数据中心中,那么从任何一个分区的角度来看,变成了单主模型。
|
||||
|
||||
举个栗子:对于服务全球用户的应用,每个用户就近固定路由到附近的数据中心。则,每个用户信息都有唯一的主副本。
|
||||
|
||||
但如果:
|
||||
|
||||
1. 用户从一个地点迁移到了另一个地点
|
||||
2. 某个数据中心损坏,导致路由变化
|
||||
|
||||
就会对该设计提出一些挑战。
|
||||
|
||||
### 冲突收敛
|
||||
|
||||
在单主模型中,所有事件比较容易进行**定序**,因此我们总可以用后一个写入覆盖前一个写入。
|
||||
|
||||
但在多主模型中,很多冲突无法定序:**从每个主副本来看,事件顺序是不一致的**,并且没有哪个更权威一些,那么就无法让所有副本最终**收敛(convergent)**。
|
||||
|
||||
此时,我们就需要一些规则,来让其收敛:
|
||||
|
||||
1. **给每个写入一个序号,并且后者胜**。本质上是使用外部系统对所有事件进行定序。但可能会产生数据丢失。举个例子,对于一个账户,原有 10 元,客户端 A - 8,客户端 B - 3,任何一个单独成功都有问题。
|
||||
2. **给每个副本一个序号,序号更高的副本有更高的优先级**。这也会造成低序号副本的数据丢失。
|
||||
3. **提供一种自动的合并冲突的方式**。如,假设结果是字符串,则可以将其排序后,使用连接符进行链接,如在之前 Wiki 的冲突中,合并后的标题为 “B/C”
|
||||
4. **使用程序定制一种保留所有冲突值信息的冲突解决策略**。也可以将这个定制权,交给用户。
|
||||
|
||||
### 自定义解决
|
||||
|
||||
由于只有用户知道数据本身的信息,因此较好的方式是,将如何解决冲突交给用户。即,允许用户编写回调代码,提供冲突解决逻。该回调可以在:
|
||||
|
||||
1. **写时执行**。在写入时发现冲突,调用回调代码,解决冲突后写入。这些代码通常在后台执行,并且不能阻塞,因此不能在调用时同步的通知用户。但打个日志之类的还是可以的。
|
||||
2. **读时执行**。在写入冲突时,所有冲突都会被保留(如使用多版本)。下次读取时,系统会将所有数据本版本返回给用户,进行交互式的或者自动的解决冲突,并将结果写回系统。
|
||||
|
||||
上述冲突解决只限于单个记录、行、文档层面。
|
||||
|
||||
TODO(自动冲突解决)
|
||||
|
||||
### 界定冲突
|
||||
|
||||
有些冲突显而易见:并发写同一个 Key。
|
||||
|
||||
有些冲突则更隐晦,考虑一个会议室预定系统。预定同一个会议室不一定会发生冲突,只有预定时间段有交叠,才会有冲突。
|
||||
|
||||
## 多主复制拓扑
|
||||
|
||||
**复制拓扑**(replication topology)描述了数据写入从一个节点到另一个节点的传播路径。
|
||||
|
||||
在只有两个主副本时,拓扑是确定的,如图 5-7。Leader1 和 Leader 都得把数据发给对方。但随着副本数的增多,数据复制拓扑就会有多种选择,如下图:
|
||||
|
||||

|
||||
|
||||
上图表示了 ≥ 4 个主副本时,常见的复制拓扑:
|
||||
|
||||
1. **环形拓扑**。通信跳数少,但是在转发时需要带上拓扑中前驱节点信息。如果一个节点故障,则可能中断复制链路。
|
||||
2. **星型拓扑**。中心节点负责接受并转发数据。如果中心节点故障,则会使得整个拓扑瘫痪。
|
||||
3. **全连接拓扑**。每个主库都要把数据发给剩余主库。通信链路冗余度较高,能较好的容错。
|
||||
|
||||
对于环形拓扑和星型拓扑,为了防止广播风暴,需要对每个节点打上一个唯一标志(ID),在收到他人发来的自己的数据时,及时丢弃并终止传播。
|
||||
|
||||
全连接拓扑也有自己问题:**尤其是所有复制链路速度不一致时**。考虑下面一个例子:
|
||||
|
||||

|
||||
|
||||
两个有因果依赖的(先插入,后更新)的语句,在复制到 Leader 2 时,由于速度不同,导致其接收到的数据违反了因果一致性。
|
||||
|
||||
要想对这些写入事件进行全局排序,仅用每个 Leader 的物理时钟是不够的,因为物理时钟:
|
||||
|
||||
1. 可能不能够充分同步
|
||||
2. 同步时可能会发生回退
|
||||
|
||||
可以用一种叫做**版本向量(version vectors)**的策略,对多个副本的事件进行排序,解决因果一致性问题。下一节会详细讨论。
|
||||
|
||||
最后忠告:如果你要使用基于多主模型的系统,一定要知晓上面提到的问题,多做测试,确保其提供的保证符合你的使用场景。
|
||||
|
||||
# 无主模型
|
||||
|
||||
有主模型中,由主副本决定写入顺序,从副本在写入上不直接和客户端打交道,只是重放其对应的主副本的写入顺序(也可以理解为主副本为从副本的客户端)。
|
||||
|
||||
而无主模型,则允许任何副本接受写入。
|
||||
|
||||
在关系数据库时代,无主模型已经快被忘却。从 Amazon 的 Dynamo 论文开始,无主模型又重新大放异彩,Riak,Cassandra 和 Voldemort 都受其启发,可以统称为 **Dynamo 流(Dynamo-style)**。
|
||||
|
||||
> 奇特的是,Amazon 的一款数据库产品 DynamoDB,和 Dynamo 并不是一个东西。
|
||||
>
|
||||
|
||||
通常来说,在无主模型中,写入时可以:
|
||||
|
||||
1. 由客户端直接写入副本。
|
||||
2. 由**协调者(coordinator)**接收写入,转发给多副本。但与主副本不同,协调者并不负责定序。
|
||||
|
||||
## 有节点故障时的写入
|
||||
|
||||
基于主副本(leader-based)的模型,在有副本故障时,需要进行故障切换。
|
||||
|
||||
但在无主模型中,简单忽略它就行。
|
||||
|
||||

|
||||
|
||||
多数派写入,多数派读取,以及读时修复。
|
||||
|
||||
由于写入时,简单的忽略了宕机副本;在读取时,就要多做些事情了:**同时读取多个副本,选取最新*版本*的值**。
|
||||
|
||||
### 读时修复和反熵
|
||||
|
||||
无主模型也需要维持多个副本数据的一致性。在某些节点宕机重启后,如何让其弥补错过的数据?
|
||||
|
||||
Dynamo 流派的存储中通常有两种机制:
|
||||
|
||||
1. **读时修复(read repair)**,本质上是一种捎带修复,在读取时发现旧的就顺手修了。
|
||||
2. **反熵过程(Anti-entropy process)**,本质上是一种兜底修复,读时修复不可能覆盖所有过期数据,因此需要一些后台进程,持续进行扫描,寻找陈旧数据,然后更新。[这个博文](https://www.influxdata.com/blog/eventual-consistency-anti-entropy/)对该词有展开描述。
|
||||
|
||||
### Quorum 读写
|
||||
|
||||
如果副本总数为 n,写入 w 个副本才认定写入成功,并且在查询时最少需要读取 r 个节点。只要满足 w + r > n,我们就能读到最新的数据(**鸽巢原理**)。此时 r 和 w 的值称为 **quorum 读写**。即这个约束是保证数据有效所需的最低(法定)票数。
|
||||
|
||||

|
||||
|
||||
在 Dynamo 流派的存储中,n、r 和 w 通常是可以配置的:
|
||||
|
||||
1. n 越大冗余度就越高,也就越可靠。
|
||||
2. r 和 w 都常都选择超过半数,如 `(n+1)/2`
|
||||
3. w = n 时,可以让 r = 1。此时是牺牲写入性能换来读取性能。
|
||||
|
||||
考量满足 w+r > n 系统对节点故障的容忍性:
|
||||
|
||||
1. 如果 w < n,则有节点不可用时,仍然能正常写入。
|
||||
2. 如果 r < n,则有节点不可用时,仍然能正常读取。
|
||||
|
||||
特化一下:
|
||||
|
||||
1. 如果 n = 3,r = w = 2,则系统可以容忍最多一个节点宕机。
|
||||
2. 如果 n = 5,r = w = 3,则系统可以容忍最多两个节点宕机。
|
||||
|
||||
通常来说,我们会将读或者写并行的发到全部 n 个副本,但是只要等到法定个副本的结果,就可以返回。
|
||||
|
||||
如果由于某种原因,可用节点数少于 r 或者 w,则读取或者写入就会出错。
|
||||
|
||||
## quorum 一致性的局限
|
||||
|
||||
由于 w + r > n 时,总会至少有一个节点(读写子集至少有一个节点的交集)保存了最新的数据,因此总是期望能读到最新的。
|
||||
|
||||
当 w + r ≤ n 时,则很可能会读到过期的数据。
|
||||
|
||||
但在 w + r > n 时,有一些边角情况(corner case),也会导致客户端读不到最新数据:
|
||||
|
||||
1. 使用宽松的 Quorum 时(n 台机器范围可以发生变化),w 和 r 可能并没有交集。
|
||||
2. 对于写入并发,如果处理冲突不当时。比如使用 last-win 策略,根据本地时间戳挑选时,可能由于时钟偏差造成数据丢失。
|
||||
3. 对于读写并发,写操作仅在部分节点成功就被读取,此时不能确定应当返回新值还是旧值。
|
||||
4. 如果写入节点数 < w 导致写入失败,但并没有对数据进行回滚时,客户端读取时,仍然会读到旧的数据。
|
||||
5. 虽然写入时,成功节点数 > w,但中间有故障造成了一些副本宕机,导致成功副本数 < w,则在读取时可能会出现问题。
|
||||
6. 即使都正常工作,也有可能出现一些关于时序(timing)的边角情况。
|
||||
|
||||
因此,虽然 Quorum 读写看起来能够保证返回最新值,但在工程实践中,有很多细节需要处理。
|
||||
|
||||
如果数据库不遵守之前副本滞后小节引入的几个一致性保障,前面提到的异常仍然可能会发生。
|
||||
|
||||
### 一致性监控
|
||||
|
||||
对副本数据陈旧性监控,能够让你了解副本的健康情况,当其落后太多时,可以及时调查原因。
|
||||
|
||||
基于领导者的多副本模型,由于每个副本复制顺序一致,则可以方便的给出每个副本的落后(lag)进度。
|
||||
|
||||
但对于无主模型,由于没有固定写入顺序,副本的落后进度变得难以界定。如果系统只使用读时修复策略,则对于一个副本的落后程度是没有限制的。读取频率很低数据可能版本很老。
|
||||
|
||||
最终一致性是一种很模糊的保证,但通过监控能够量化“最终”(比如到一个阈值),也是很棒的。
|
||||
|
||||
## 放松的 Quorum 和提示转交
|
||||
|
||||
正常的 Quorum 能够容忍一些副本节点的宕机。但在大型集群(总节点数目 > n)中,可能最初选中的 n 台机器,由于种种原因(宕机、网络问题),导致无法达到法定读写数目,则此时有两种选择:
|
||||
|
||||
1. 对于所有无法达到 r 或 w 个法定数目的读写,直接报错。
|
||||
2. 仍然接受写入,并且将新的写入暂时交给一些正常节点。
|
||||
|
||||
后者被认为是一种**宽松的法定数目** (**sloppy quorum**):写和读仍然需要 w 和 r 个成功返回,但是其所在节点集合可以发生变化。
|
||||
|
||||

|
||||
|
||||
一旦问题得到解决,数据将会根据线索移回其应该在的节点(D—> B),我们称之为**提示移交**(hinted handoff)。这个移交过程是由反熵 anti-entropy 后台进程完成的。
|
||||
|
||||
这是一种典型的牺牲部分一致性,换取更高可用性的做法。在常见的 Dynamo 实现中,放松的法定人数是可选的。在 Riak 中,它们默认是启用的,而在 Cassandra 和 Voldemort 中它们默认是禁用的
|
||||
|
||||
### 多数据中心
|
||||
|
||||
无主模型也适用于系统多数据中心部署。
|
||||
|
||||
为了同时兼顾**多数据中心**和**写入的低延迟**,有一些不同的基于无主模型的多数据中心的策略:
|
||||
|
||||
1. 其中 Cassandra 和 Voldemort 将 n 配置到所有数据中心,但写入时只等待本数据中心副本完成就可以返回。
|
||||
2. Riak 将 n 限制在一个数据中心内,因此所有客户端到存储节点的通信可以限制到单个数据中心内,而数据复制在后台异步进行。
|
||||
|
||||
## 并发写入检测
|
||||
|
||||
由于 Dynamo 允许多个客户端并发写入相同 Key,则即使使用严格的 Quorum 读写,也会产生冲突:**对于时间间隔很短(并发)的相同 key 两个写入,不同副本上收到的顺序可能不一致**。
|
||||
|
||||
此外,读时修复和提示移交时,也可能产生冲突。
|
||||
|
||||

|
||||
|
||||
如上图,如果每个节点不去检查顺序,而是简单的接受写入请求,就落到本地,不同副本间可能就会出现永久不一致:上图 Node1 和 Node3 上副本X 的值是 A,Node2 上副本 X 的值是 B。
|
||||
|
||||
为了使所有副本最终一致,需要有一种手段来解决并发冲突。
|
||||
|
||||
### 后者胜(Last-Write-Win)
|
||||
|
||||
后者胜(LWW,last write wins)的策略是,通过某种手段确定一种全局唯一的顺序,然后让后面的修改覆盖之前的修改。
|
||||
|
||||
如,为所有写入附加一个全局时间戳,如果对于某个 key 的写入有冲突,可以挑选具有最大时间戳的数据保留,并丢弃较早时间戳的写入。
|
||||
|
||||
LWW 有一个问题,就是多个并发写入的客户端,可能都认为自己成功了,但是最终只有一个值被保留了,其他都在后台被丢弃了。即,其迅速再读,会发现不是自己写入的数据。
|
||||
|
||||
使用 LWW 唯一安全的方法是:key 是一次可写,后变为只读。如 Cassandra 建议使用一个 UUID 作为主键,则每个写操作都只会有一个唯一的键。
|
||||
|
||||
### 发生于**之前(Happens-before)和并发关系
|
||||
|
||||
考虑之前的两个图:
|
||||
|
||||
1. 在 5-9 中,由于 client B 的更新依赖于 client A 的插入,因此他们是因果关系。
|
||||
2. 在 5-12 中,set X = A 和 set X = B 是并发的,因为他们都互相不知道对方存在,也不存在因果关系。
|
||||
|
||||
系统中任意的两个写入 A 和 B,只可能存在三种关系:
|
||||
|
||||
1. A happens before B
|
||||
2. B happens before A
|
||||
3. A B 并发
|
||||
|
||||
从另外一个角度来说(集合运算),
|
||||
|
||||
```c
|
||||
A 和 B 并发 < === > A 不 happens-before B && B 不 happens-before A
|
||||
```
|
||||
|
||||
如果两个操作可以定序,则 last write win;如果两个操作并发,则需要进行冲突解决。
|
||||
|
||||
> 并发、时间和相对性
|
||||
>
|
||||
|
||||
> Lamport 时钟相关论文中有详细推导相关概念关系。为了定义并发,事件发生的绝对时间先后并不重要,只要两个事件都意识不到对方的存在,则称两个操作 “并发”。 从狭义相对论上来说,只要两个事件发生的时间差,小于光在两者距离传播所用时间,则两个事件不可能互相影响。推广到计算机网络中,只要由于网络问题导致,在事件发生时间差内,两者不能互相意识到,则称其是并发的。
|
||||
>
|
||||
|
||||
### 确定 Happens-Before 关系
|
||||
|
||||
我们可以用某种算法来确定系统中任意两个事件,是否存在 happens-before 关系,还是并发关系。以一个两个 client 并发添加购物车例子来看:
|
||||
|
||||

|
||||
|
||||
需要注意:
|
||||
|
||||
1. 不会主动读取,只有主动写入,通过写入的返回值读取数据库当前状态。
|
||||
2. 客户端下一次写入,**依赖于**(因果关系)**本客户端**上一次写入后获取的返回值。
|
||||
3. 对于并发,数据库不会覆盖,而是保留多个**并发值**(每个 client 一个)。
|
||||
|
||||
上图中的数据流,如下图所示。箭头表示 happens-before 关系。本例中,客户端永远没办法完全获知服务器数据,因为总有另外的客户端进行并发操作。但是旧版本的值会被覆盖,并且不会丢失写入。
|
||||
|
||||

|
||||
|
||||
总结下,该算法如下:
|
||||
|
||||
1. 服务器为每个键分配一个版本号 V ,每次该键有写入时,将 V + 1,并将版本号与写入的值一块保存。
|
||||
2. 当客户端读取该键时,服务器将返回所有未被覆盖的值以及最新的版本号。
|
||||
3. 客户端在进行下次写入时,必须**包含**之前读到的版本号 Vx(说明基于哪个版本进行新的写入),并将读取的值合并到一块。
|
||||
4. 当服务器收到特定版本号 Vx 的写入时,可以用其值覆盖所有 V ≤ Vx 的值。、
|
||||
|
||||
如果又来一个新的写入,不基于任何版本号,则该写入不会覆盖任何内容。
|
||||
|
||||
### 合并并发值
|
||||
|
||||
该算法可以保证所有数据都不会被无声的丢弃。但,需要客户端在随后写入时合并之前的值来清理多个值。如果简单基于时间戳进行 LWW,则有些数据又会被丢掉。
|
||||
|
||||
因此需要根据实际情况,选择一些策略来解决冲突,合并数据。
|
||||
|
||||
1. 对于上述购物车中只增加物品的例子,可以使用“并集”来合并冲突数据。
|
||||
2. 如果购物车汇总还有删除操作,就不能简单并了,但是可以将删除变为增加(写一个 tombstone 标记)。
|
||||
|
||||
### 版本向量
|
||||
|
||||
上面例子只有单个副本。将该算法扩展到无主多副本模型时,只使用一个版本值显然不够,这时需要给每个副本的键都引入版本号,对于同一个键来说,不同副本的版本会构成**版本向量(version vector)**。
|
||||
|
||||
```c
|
||||
key1
|
||||
A Va
|
||||
B Vb
|
||||
C Vc
|
||||
|
||||
key1: [Va, Vb, Vc]
|
||||
|
||||
[Va-x, Vb-y, Vc-z] <= [Va-x1, Vb-y1, Vc-z1] <==>
|
||||
x <= x1 && y <= y1 && z <= z1
|
||||
```
|
||||
|
||||
每个副本在遇到写入时,会增加对应键的版本号,同时跟踪从其他副本中看到的版本号,通过比较版本号大小,来决定哪些值要覆盖哪些值要保留。
|
||||
278
ch06.md
Normal file
@ -0,0 +1,278 @@
|
||||
# DDIA 逐章精读(六): 分区(Partition)
|
||||
|
||||
上一章主要讲复制,本章转向分片。这是两个相对正交但勾连的两个概念:
|
||||
|
||||
1. **分片(Partition)**:解决数据集尺度与单机容量、负载不匹配的问题,分片之后可以利用多机容量和负载。
|
||||
2. **复制(Replication**):系统机器一多,单机故障概率便增大,为了防止数据丢失以及服务高可用,需要做多副本。
|
||||
|
||||
> 分片,Partition,有很多别称。通用的有 Shard;具体到实际系统,HBase 中叫 Region,Bigtable 中叫 tablet,等等。本质上是对数据集的一种逻辑划分,后面行文,分片和分区可能混用,且有时为名词,有时为动词。
|
||||
>
|
||||
|
||||
通常来说,数据系统在分布式系统中会有三级划分:数据集(如 Database、Bucket)——分片(Partition)——数据条目(Row、KV)。通常,每个分片只属于一个数据集,每个数据条目只属于一个分片。单个分片,就像一个小点的数据库。但是,跨分区的操作的,就要复杂的多。
|
||||
|
||||
本章首先会介绍数据集**切分的方法**,并讨论索引和分片的配合;然后将会讨论分片**再平衡**(rebalancing),集群节点增删会引起数据再平衡;最后,会探讨数据库如何将请求**路由**到相应的分片并执行。
|
||||
|
||||
# 分片和复制
|
||||
|
||||
分片通常和复制结合使用。每个分片有多个副本,可以分散到多机上去(更泛化一点:多个容错阈);同时,每个机器含有多个分片,但通常不会有一个分片的两个副本放到一个机器上。
|
||||
|
||||
如果使用多副本使用主从模型,则分片、副本、机器关系如下:
|
||||
|
||||
1. 从一个分片的角度看,主副本在一个机器上,从副本们在另外机器上。
|
||||
2. 从一个机器的角度看,既有一些主副本分片,也有一些从副本分片。实践中,也会尽量保证主副本在集群中均匀分布,避免过多的集中到一台机器上。想想为什么?
|
||||
|
||||

|
||||
|
||||
由于分区方式和复制策略相对正交,本章会暂时忽略复制策略(在上章讲过),专注分析分区方式。
|
||||
|
||||
# 键值对集的分片
|
||||
|
||||
键值对是数据的一种最通用、泛化的表示,其他种类数据库都可以转化为键值对表示:
|
||||
|
||||
1. 关系型数据库,primary key → row
|
||||
2. 文档型数据库,document id → document
|
||||
3. 图数据库,vertex id → vertex props, edge id → edge props
|
||||
|
||||
因此,接下来主要针对键值对集合的分区方式,则其他数据库在构建存储层时,可以首先转化为 KV 对,然后进行分区。
|
||||
|
||||
**分片(Partition)**的本质是对数据集合的划分。但在实践中,可以细分为两个步骤:
|
||||
|
||||
1. 对数据集进行**逻辑**划分
|
||||
2. 将逻辑分片调度到**物理**节点
|
||||
|
||||
因此,在分片时,有一些基本要求:
|
||||
|
||||
1. 分片过程中,要保证每个分片的数据量多少尽量均匀,否则会有**数据偏斜**(**skew**),甚而形成**数据热点**。
|
||||
2. 分片后,需要保存路由信息,给一个 KV 条目,能知道去**哪个**机器上去查;稍差一些,可以知道去**哪几个**机器上去找;最差的,如果需要去所有机器逐一查询,但性能一般不可接受。
|
||||
|
||||
这两条是互相依赖和制约的。比如说,假设分片数目确定,为了分片均匀,每来一条数据,我们可以等概率随机选择一个分片;但在查询每个数据条目时,就得去所有机器上都查一遍。
|
||||
|
||||
保存所有数据条目路由信息,有三种常用的策略:
|
||||
|
||||
1. 通过某种固定规则,比如哈希,算出一个位置。
|
||||
2. 使用内存,保存所有数据条目到机器的映射。
|
||||
3. 结合两种,首先通过规则算出到逻辑分片的映射,然后通过内存保存逻辑分片到物理节点的映射。
|
||||
|
||||
本节主要讨论根据数据条目(Data Item)算出逻辑分区(Partition),常见的有两种方式:按键范围分区,按键哈希分区。
|
||||
|
||||
## 按键范围(Key Range)分区
|
||||
|
||||
对于 KV 数据来说,Key 通常会有个定义域,且在定义域内可(按某种维度)排序。则,将该连续的定义域进行切分,保存每个切分的上下界,在给出某个 Key 时,就能通过比较,定位其所在分区。
|
||||
|
||||
如,百科全书系列,通常是按照名词的字母序来分册的,每个分册可理解为该系列的一个分区,查阅时,可根据字母排序来首先找到所在分册,再使用分册目录查阅。图书馆图书的索引编号也是类似道理。
|
||||
|
||||

|
||||
|
||||
由于键并不一定在定义域内均匀分布,因此简单按照定义域等分,并不能将数据等分。因此,需要按照数据的分布,动态调整分区的界限,保证分区间数据大致均匀。这个调整的过程,既可以手动完成 ,也可以自动进行。
|
||||
|
||||
按键范围分区好处在于可以进行**快速的范围查询(Rang Query)**。如,某个应用是保存传感器数据,并将时间戳作为键进行分区,则可轻松获取一段时间内(如某年,某月)的数据。
|
||||
|
||||
但坏处在于,数据分散不均匀,且容易造成热点。可能需要动态的调整的分区边界,以维护分片的相对均匀。
|
||||
|
||||
仍以传感器数据存储为例,以时间戳为 Key,按天的粒度进行分区,所有最新写入都被路由到最后一个分区节点,造成严重的写入倾斜,不能充分利用所有机器的写入带宽。一个解决办法是**分级**或者**混合**,使用拼接主键,如使用传感器名称+时间戳作为主键,则可以将同时写入的多个传感器的数据分散到多机上去。
|
||||
|
||||
## 按键散列(Hash)分区
|
||||
|
||||
为了避免数据倾斜和读写热点,许多数据系统使用散列函数对键进行分区。
|
||||
|
||||
因此,选择散列函数的**依据**是,使得数据散列尽量均匀:即给定一个 Key,经过散列函数后,以等概率在哈希区间(如 `[0, 2^32-1)`)内产生一个值。即使原 Key 相似,他的散列值也能均匀分布。
|
||||
|
||||
而加密并不在考虑之列,因此并不需要多么复杂的加密算法,如,Cassandra 和 MongoDB 使用 MD5,Voldemort 使用 Fowler-Noll-Vo 函数。
|
||||
|
||||
选定哈希函数后,将原 Key 定义域映射到新的散列值阈,而散列值是均匀的,因此可以对散列值阈按给定分区数进行等分。
|
||||
|
||||

|
||||
|
||||
还有一种常提的哈希方法叫做**[一致性哈希](https://zh.m.wikipedia.org/zh-hans/%E4%B8%80%E8%87%B4%E5%93%88%E5%B8%8C)**。其特点是,会考虑逻辑分片和物理拓扑,将数据和物理节点按同样的哈希函数进行哈希,来决定如何将哈希分片路由到不同机器上。它可以避免在内存中维护**逻辑分片到物理节点的映射**,而是每次计算出来。即用一套算法同时解决了我们在最初提出的逻辑分片和物理路由的两个问题。 比较经典的数据系统,[Amazon Dynamo](https://www.qtmuniao.com/2020/06/13/dynamo/) 就用了这种方式。
|
||||
|
||||

|
||||
|
||||
如果不使用一致性哈希,我们需要在元数据节点中,维护逻辑分片到物理节点的映射。则在某些物理节点宕机后,需要调整该映射并手动进行数据迁移,而不能像一致性哈希一样,半自动的增量式迁移。
|
||||
|
||||
哈希分片在获取均匀散列能力的同时,也丧失了基于键高效的范围查询能力。如书中说,MongoDB 中选择基于哈希的分区方式,范围查询就要发送到所有分区节点;Riak 、Couchbase 或 Voldmort 干脆不支持主键的上的范围查询。
|
||||
|
||||
一种折中方式,和上小节一样,使用组合的方式,先散列,再顺序。如使用主键进行散列得到分区,在每个分区内使用其他列顺序存储。如在社交网络上,首先按 user_id 进行散列分区,再使用 update_time 对用户事件进行顺序排序,则可以通过 (user_id, update_timestamp) 高效查询某个用户一段事件的事件。
|
||||
|
||||
小结一下,两种分区方式区别在于,一个使用应用相关值( `Key` )分区,一个使用应用无关值(`Hash(key)`)分区,前者支持高效范围查询,后者可以均摊负载。但可使用多个字段,组合使用两种方式,使用一个字段进行分区,使用另一个字段在分区内进行排序,兼取两者优点。
|
||||
|
||||
## 负载偏斜和热点消除
|
||||
|
||||
在数据层,可以通过哈希将数据均匀散列,以期将对数据的请求均摊;但如果在应用层,不同数据条目的负载本就有倾斜,存在对某些键的热点。那么仅在数据层哈希,就不能起到消除热点的作用。
|
||||
|
||||
如在社交网络中的大 V,其发布的信息,天然会引起同一个键(假设键是用户 id)大量数据的写入,因为可能会有针对该用户信息的大量评论和互动。
|
||||
|
||||
此时,就只能在应用层进行热点消除,如可以用拼接主键,对这些大 V 用户主键进行“分身”,即在用户主键开始或者结尾添加一个随机数,两个十进制后缀就可以增加 100 中拆分可能。但这无疑需要应用层做额外的工作,请求时需要进行拆分,返回时需要进行合并。
|
||||
|
||||
可能之后能开发出检测热点,自动拆分合并分区,以消除倾斜和热点。
|
||||
|
||||
# 分片和次级索引
|
||||
|
||||
**次级索引(secondary index)**,即主键以外的列的索引;由于分区都是基于主键的,在针对有分区的数据建立次级索引时,就会遇到一些困难。
|
||||
|
||||
关于次级索引,举个例子,对于某个用户表(id, name, age, company),我们按用户 id(如身份证)对所有用户数据进行分区。但我们常常会根据名字对用户进行查询,为了加快查询,于是需要基于 name 字段,建立次级索引。
|
||||
|
||||
在关系型和文档型数据库中,次级索引很常见。在 KV 存储中,为了降低实现复杂度,一般不支持。但大部分场景,因为我们不可能只按单一维度对数据进行检索,因此次级索引很有用。尤其对于搜索场景,比如 Solr 和 Elasticsearch,次级索引(在搜索领域称为**倒排索引**)更是其实现基石。
|
||||
|
||||
在有分区的数据中,常见的建立次级索引的方法有:
|
||||
|
||||
1. 本地索引(local index),书中又称 document-based index
|
||||
2. 全局索引(global index),书中又称 term-based index
|
||||
|
||||
> 注:书中给的 document-based、term-based 两个名词(包括 document 和 term)是从搜索中来的。由于搜索中都是 term→ document id list 的映射,document-based 是指按 document id 进行分区,每个分区存的索引都是本地的 document ids,而不管其他分区,因此是本地索引,查询时需要发到所有分区逐个查询。term-based 是指按 term 进行分区,则每个倒排索引都是存的全局的 document id list,因此查询的时候只需要去 term 所在分区查询即可。
|
||||
>
|
||||
|
||||
## 本地索引
|
||||
|
||||
书中举了一个维护汽车信息数据例子:每种汽车信息由 (id, color, make, location) 四元组构成。首先会根据其主键 id 进行分区,其次为了方便查询,需要对汽车颜色( color )和制造商(make)字段(文档数据库中称为**field,字段**;关系型数据库中称为 **column,列**,图数据库中称为 **property,属性**)建立次级索引。
|
||||
|
||||
次级索引会对每个数据条目建立一个索引条目,这给数据库的实现带来了一些问题:
|
||||
|
||||
1. 当数据库已有数据时,建立索引,何时针对存量数据构建索引。
|
||||
2. 当数据库中数据条目发生更改时,如何维护数据和索引的一致性,尤其是多客户端并发修改时。
|
||||
|
||||

|
||||
|
||||
本地**索引(local index)**,就是对每个数据分区独立地建立次级索引,即,次级索引只针对本分区数据,而不关心其他分区数据。本地索引的**优点**是维护方便,在更新数据时,只需要在该分区所在机器同时更新索引即可。但**缺点**是,查询效率相对较低,所有基于索引的查询请求,都要发送到所有分区,并将结果合并,该过程也称为 **scatter/gather** 。但即使用多分区并发(而非顺序)进行索引查询优化,也仍然容易在某些机器上发生**长尾请求**(由于机器负载过高或者网络问题,导致改请求返回特别慢,称为长尾请求),导致整个请求过程变慢。
|
||||
|
||||
但由于实现简单,本地索引被广泛使用,如 MongoDB,Riak ,Cassandra,Elasticsearch ,SolrCloud 和 VoltDB 都使用本地索引。
|
||||
|
||||
## 全局索引
|
||||
|
||||
为了避免查询索引时将请求发到所有分区,可以建立**全局索引**,即每个次级索引条目都是针对全局数据。但为了避免索引查询热点,我们会将索引数据本身也分片,分散到多个机器上。
|
||||
|
||||

|
||||
|
||||
当然,与数据本身一样,对于索引进行分区,也可基于 Range 或基于 Hash,同样也是各有优劣(面向扫描还是均匀散列)。
|
||||
|
||||
全局索引能避免索引查询时的 scatter/gather 操作,但维护起来较为复杂,因为每个数据的插入,可能会影响多个索引分区(基于该数据不同字段可能会有多个二级索引)。因此,为了避免增加写入延迟,在实践中,全局索引多为异步更新。但由此会带来短暂(有时可能会比较长)的数据和索引不一致。如果想要保证强一致性,需要引入跨分区的分布式事务(实现复杂度高,且会带来较大的性能损耗),但并不是所有数据库都支持。
|
||||
|
||||
# 分片均衡(rebalancing)
|
||||
|
||||
数据库在运行过程中,数据和机器都会发生一些变化:
|
||||
|
||||
1. 查询吞吐增加,需要增加机器以应对增加的负载。
|
||||
2. 数据集变大,需要增加磁盘和 RAM 来存储增加数据。
|
||||
3. 有机器故障,需要其他机器来接管故障机器数据。
|
||||
|
||||
所有这些问题都会引起数据分片在节点间的迁移,我们将之称为:**均衡(rebalancing)**。对于 rebalancing 我们期望:
|
||||
|
||||
1. 均衡后负载(存储、读写)在节点间均匀分布
|
||||
2. 均衡时不能禁止读写,并且尽量减小影响
|
||||
3. 尽量减少不必要的数据移动,尽量降低网络和磁盘 IO
|
||||
|
||||
## 均衡策略
|
||||
|
||||
分区策略会影响均衡策略。比如动态分区、静态分区,对应的均衡策略就不太一样;此外,分区的粒度和数量也会影响均衡策略。
|
||||
|
||||
### 不要使用:hash mod N
|
||||
|
||||
在说如何进行均衡之前,先说下不应该怎样做。
|
||||
|
||||
之前提到过,分区包括**逻辑分区**和**物理调度**两个阶段,此处说的是将两者合二为一:假设集群有 N 个节点,编号 `0 ~ N-1`,一条键为 key 的数据到来后,通过 `hash(key) mod N` 得到一个编号 n,然后将该数据发送到编号为 n 的机器上去。
|
||||
|
||||
为什么说这种策略不好呢?因为他不能应对机器数量的变化,如果要增删节点,就会有大量的数据需要发生迁移,否则,就不能保证数据在 `hash(key) mod N` 标号的机器上。在大规模集群中,机器节点增删比较频繁,这种策略更是不可接受。
|
||||
|
||||
### 静态分区
|
||||
|
||||
静态分区,即,逻辑分区阶段的**分区数量是固定的**,并且最好让分区数量大于(比如高一个数量级)机器节点。相比**动态分区**策略(比如,允许分区分裂和合并),固定数量分区更容易实现和维护。
|
||||
|
||||
书中没有提,但是估计需要在类似元信息节点,维护逻辑分区到物理节点的映射,并根据此映射信息来发现不均衡,进而进行调度。
|
||||
|
||||
在静态分区中,让分区数量远大于机器节点的好处在于:
|
||||
|
||||
1. **应对将来可能的扩容**。加入分区数量等于机器数量,则将来增加机器,仅就单个数据集来说,并不能增加其存储容量和吞吐。
|
||||
2. **调度粒度更细,数据更容易均衡**。举个例子,假设只有 20 个分区,然后有 9 个机器,假设每个分区数据量大致相同,则最均衡的情况,也会有两个机器数的数据量比其他机器多 50%;
|
||||
3. **应对集群中的异构性**。比如集群中某些节点磁盘容量比其他机器大,则可以多分配几个分区到该机器上。
|
||||
|
||||

|
||||
|
||||
但当然,也不能太大,因为每个分区信息也是有管理成本的:比如元信息开销、均衡调度开销等。一般来说,可以取一个你将来集群可能扩展到的最多节点数量作为初始分区数量。
|
||||
|
||||
对于数据量会超预期增长的数据集,静态分区策略就会让用户进退两难,已经有很多数据,重新分区代价很大,不重新分区又难以应对数据量的进一步增长。
|
||||
|
||||
### 动态分区
|
||||
|
||||
对于按键范围(key range)进行分区的策略来说,由于数据在定义域内并**不均匀分布**,如果固定分区数量,则天然地难以均衡。因此,按范围分区策略下,都会支持动态分区。按生命周期来说:
|
||||
|
||||
1. 开始,数据量很少,只有一个分区。
|
||||
2. 随着数据量不断增长,单个分区超过一定**上界**,则按尺寸一分为二,变成两个新的分区。
|
||||
3. 如果某个分区,数据删除过多,少于某个**下界**,则会和相邻分区合并(合并后超过上界怎么办?)。
|
||||
|
||||
动态分区好处在于,小数据量使用少量分区,减少开销;大数据量增加分区,以均摊负载。
|
||||
|
||||
但同时,小数据量时,如果只有一个分区,会限制写入并发。因此,工程中有些数据库支持**预分区**(pre-splitting),如 HBase 和 MongoDB,即允许在空数据库中,配置最少量的初始分区,并确定每个分区的起止键。
|
||||
|
||||
另外,散列分区策略也可以支持动态分区,即,在**哈希空间中**对相邻数据集进行合并和分裂。
|
||||
|
||||
### 与节点成比例分区
|
||||
|
||||
前文所述,
|
||||
|
||||
1. 静态均衡的分区数量一开始就固定的,但是单分区尺寸会随着总数量增大而增大。
|
||||
2. 动态均衡会按着数据量多少进行动态切合,单分区尺寸相对保持不变,一直于某个设定的上下界。
|
||||
|
||||
但他们的分区数量都和集群节点数量没有直接关系。而另一种均衡策略,则是保持**总分区数量**和节点数量成正比,也即,保持每个节点分区数量不变。
|
||||
|
||||
假设集群有 m 个节点,每个节点有 n 个分区,在此种均衡策略下,当有新节点加入时,会从 m*n 个分区中随机选择 n 个分区,将其一分为二,一半由新节点分走,另一半留在原机器上。
|
||||
|
||||
随机选择,很容易产生有倾斜的分割。但如果 n 比较大,如 Cassandra 默认是 256,则新节点会比较容易均摊负载。
|
||||
|
||||
- 为什么?
|
||||
|
||||
是因为可以从每个节点选同样数量的分区吗?比如说 n = 256, m = 16,则可以从每个节点选 16 分区吗?
|
||||
|
||||
|
||||
随机选择分区,要求使用基于哈希的分区策略,这也是最接近原始一致性哈希的定义的方法。(同样存疑。
|
||||
|
||||
## 运维:自动均衡还是手动均衡
|
||||
|
||||
在实践中,均衡是自动进行还是手动进行需要慎重考虑。
|
||||
|
||||
1. **自动进行**。系统自动检测是否均衡,然后自动决策搬迁策略以及搬迁时间。
|
||||
2. **手动进行**。管理员指定迁移策略和迁移时间。
|
||||
|
||||
数据均衡是一项非常昂贵且易出错的操作,会给网络带来很大压力,甚至影正常负载。自动均衡诚然可以减少运维,但在实践中,如何有效甄别是否真的需要均衡(比如网络抖动了一段时间、节点宕机又重启、故障但能修复)是一个很复杂的事情,如果做出错误决策,就会带来大量无用的数据搬迁。
|
||||
|
||||
因此,数据均衡通常会半自动的进行,如系统通过负载情况给出搬迁策略,由管理员审核没问题后,决定某个时间段运行(避开正常流量高峰),Couchbase、Riak 和 Voldemort 便采用了类似做法。
|
||||
|
||||
# 请求路由(routing)
|
||||
|
||||
在我们将分区放到节点上去后,当客户端请求到来时,我们如何决定将请求路由到哪台机器?这势必要求我们**以某种方式**记下:
|
||||
|
||||
1. 数据条目到逻辑分区的映射。
|
||||
2. 逻辑分区到物理机器的映射。
|
||||
|
||||
这在我们之前已经讨论过。
|
||||
|
||||
其次,是在哪里记下这些路由(映射)信息,泛化一下,是一个**服务发现**(service discovery)问题。概括来说,由内而外,有几种方案:
|
||||
|
||||
1. **每个节点都有全局路由表**。客户端可以连接集群中任意一个节点,如该节点恰有该分区,则处理后返回;否则,根据路由信息,将其路由合适节点。
|
||||
2. **由一个专门的路由层来记录**。客户端所有请求都打到路由层,路由层依据分区路由信息,将请求转发给相关节点。路由层只负责请求路由,并不处理具体逻辑。
|
||||
3. **让客户端感知分区到节点映射**。客户端可以直接根据该映射,向某个节点发送请求。
|
||||
|
||||

|
||||
|
||||
无论记在何处,都有一个重要问题:如何让相关组件(节点本身、路由层、客户端)及时感知(分区到节点)的映射变化,将请求正确的路由到相关节点?也即,如何让所有节点就路由信息快速达成一致,业界有很多做法。
|
||||
|
||||
**依赖外部协调组件**。如 Zookeeper、Etcd,他们各自使用某种共识协议保持高可用,可以维护轻量的路由表,并提供发布订阅接口,在有路由信息更新时,让外部所有节点快速达成一致。
|
||||
|
||||

|
||||
|
||||
**使用内部元数据服务器**。如三节点的 Meta 服务器,每个节点都存储一份路由数据,使用某种共识协议达成一致。如 TiDB 的 Placement Driver。
|
||||
|
||||
**使用某种协议点对点同步**。如 Dynamo 、Cassandra 和 Riak 使用流言协议(Gossip Protocol),在集群内所有机器节点间就路由信息进行传播,并最终达成一致。
|
||||
|
||||
更简单一些,如 Couchbase 不支持自动的负载均衡,因此只需要使用一个路由层通过心跳从集群节点收集到所有路由信息即可。
|
||||
|
||||
当使用路由层(或者 Proxy 层,通常由多个实例构成),或者客户端将请求随机发动到某个集群节点时,客户端需要确定一个具体 IP 地址,但这些信息变化相对较少,因此直接使用 DNS 或者反向代理进行轮询即可。
|
||||
|
||||
## 并行查询执行
|
||||
|
||||
大部分 NoSQL 存储,所支持的查询都不太负载,如基于主键的查询、基于次级索引的 scatter/gather 查询。如前所述,都是针对单个键值非常简单的查询路由。
|
||||
|
||||
但对于关系型数据库产品,尤其是支持 **大规模并行处理(MPP, Massively parallel processing)**数仓,一个查询语句在执行层要复杂的多,可能会:
|
||||
|
||||
1. Stage:由多个阶段组成。
|
||||
2. Partition:每个阶段包含多个针对每个分区的并行的子查询计划。
|
||||
|
||||
数仓的大规模的快速并行执行是另一个需要专门讨论的话题,由于多用于支持 BI,因此其优化具有重要意义,本书后面第十章会专门讨论。
|
||||
BIN
img/ch01-book-software-design.jpeg
Normal file
{kind=link}
|
After Width: | Height: | Size: 160 KiB |
BIN
img/ch01-data-society.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 196 KiB |
BIN
img/ch01-fig01.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 555 KiB |
BIN
img/ch01-fig02.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 341 KiB |
BIN
img/ch01-fig03.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 434 KiB |
BIN
img/ch02-06.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 453 KiB |
BIN
img/ch02-fig01.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 1.0 MiB |
BIN
img/ch02-fig02.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 287 KiB |
BIN
img/ch02-fig05.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 557 KiB |
BIN
img/ch02-how-mr-works.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 94 KiB |
BIN
img/ch02-layered-data-models.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 105 KiB |
BIN
img/ch02-semantic-web-stack.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 69 KiB |
BIN
img/ch02-spo.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 97 KiB |
BIN
img/ch03-fig01.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 427 KiB |
BIN
img/ch03-fig03.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 498 KiB |
BIN
img/ch03-fig04.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 550 KiB |
BIN
img/ch03-fig05.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 386 KiB |
BIN
img/ch03-fig06.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 358 KiB |
BIN
img/ch03-fig07.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 350 KiB |
BIN
img/ch03-fig08.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 410 KiB |
BIN
img/ch03-fig10.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 656 KiB |
BIN
img/ch03-fig11.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 637 KiB |
BIN
img/ch03-fig12.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 494 KiB |
BIN
img/ch03-sized-tiered.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 70 KiB |
BIN
img/ch04-encodec.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 122 KiB |
BIN
img/ch04-fig01.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 652 KiB |
BIN
img/ch04-fig02.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 584 KiB |
BIN
img/ch04-fig03.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 503 KiB |
BIN
img/ch04-fig04.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 495 KiB |
BIN
img/ch04-fig05.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 448 KiB |
BIN
img/ch04-fig06.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 358 KiB |
BIN
img/ch04-fig07.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 531 KiB |
BIN
img/ch05-fig01.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 440 KiB |
BIN
img/ch05-fig02.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 369 KiB |
BIN
img/ch05-fig03.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 446 KiB |
BIN
img/ch05-fig04.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 544 KiB |
BIN
img/ch05-fig05.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 583 KiB |
BIN
img/ch05-fig06.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 427 KiB |
BIN
img/ch05-fig07.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 422 KiB |
BIN
img/ch05-fig08.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 306 KiB |
BIN
img/ch05-fig09.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 485 KiB |
BIN
img/ch05-fig10.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 533 KiB |
BIN
img/ch05-fig11.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 480 KiB |
BIN
img/ch05-fig12.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 444 KiB |
BIN
img/ch05-fig13.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 609 KiB |
BIN
img/ch05-fig14.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 237 KiB |
BIN
img/ch05-sloppy-quorum.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 219 KiB |
BIN
img/ch06-dynamo.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 74 KiB |
BIN
img/ch06-fig01.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 461 KiB |
BIN
img/ch06-fig02.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 437 KiB |
BIN
img/ch06-fig03.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 339 KiB |
BIN
img/ch06-fig04.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 647 KiB |
BIN
img/ch06-fig05.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 606 KiB |
BIN
img/ch06-fig06.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 552 KiB |
BIN
img/ch06-fig07.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 502 KiB |
BIN
img/ch06-fig08.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 757 KiB |