68 KiB
第四章:編碼與演化

唯變所適
——以弗所的赫拉克利特,為柏拉圖所引(公元前360年)
[TOC]
應用程式不可避免地隨時間而變化。新產品的推出,對需求的深入理解,或者商業環境的變化,總會伴隨著**功能(feature)**的增增改改。第一章介紹了可演化性(evolvability)的概念:應該盡力構建能靈活適應變化的系統(參閱“可演化性:擁抱變化”)。
在大多數情況下,修改應用程式的功能也意味著需要更改其儲存的資料:可能需要使用新的欄位或記錄型別,或者以新方式展示現有資料。
我們在第二章討論的資料模型有不同的方法來應對這種變化。關係資料庫通常假定資料庫中的所有資料都遵循一個模式:儘管可以更改該模式(透過模式遷移,即ALTER語句),但是在任何時間點都有且僅有一個正確的模式。相比之下,讀時模式(schema-on-read)(或 無模式(schemaless))資料庫不會強制一個模式,因此資料庫可以包含在不同時間寫入的新老資料格式的混合(參閱 “文件模型中的模式靈活性” )。
當資料**格式(format)或模式(schema)**發生變化時,通常需要對應用程式程式碼進行相應的更改(例如,為記錄新增新欄位,然後修改程式開始讀寫該欄位)。但在大型應用程式中,程式碼變更通常不會立即完成:
- 對於 服務端(server-side) 應用程式,可能需要執行 滾動升級 (rolling upgrade) (也稱為 階段釋出(staged rollout) ),一次將新版本部署到少數幾個節點,檢查新版本是否執行正常,然後逐漸部完所有的節點。這樣無需中斷服務即可部署新版本,為頻繁釋出提供了可行性,從而帶來更好的可演化性。
- 對於 客戶端(client-side) 應用程式,升不升級就要看使用者的心情了。使用者可能相當長一段時間裡都不會去升級軟體。
這意味著,新舊版本的程式碼,以及新舊資料格式可能會在系統中同時共處。系統想要繼續順利執行,就需要保持雙向相容性:
向後相容 (backward compatibility)
新程式碼可以讀舊資料。
向前相容 (forward compatibility)
舊程式碼可以讀新資料。
向後相容性通常並不難實現:新程式碼的作者當然知道由舊程式碼使用的資料格式,因此可以顯示地處理它(最簡單的辦法是,保留舊程式碼即可讀取舊資料)。
向前相容性可能會更棘手,因為舊版的程式需要忽略新版資料格式中新增的部分。
本章中將介紹幾種編碼資料的格式,包括 JSON,XML,Protocol Buffers,Thrift和Avro。尤其將關注這些格式如何應對模式變化,以及它們如何對新舊程式碼資料需要共存的系統提供支援。然後將討論如何使用這些格式進行資料儲存和通訊:在Web服務中,具象狀態傳輸(REST)和遠端過程呼叫(RPC),以及訊息傳遞系統(如Actor和訊息佇列)。
編碼資料的格式
程式通常(至少)使用兩種形式的資料:
- 在記憶體中,資料儲存在物件,結構體,列表,陣列,雜湊表,樹等中。 這些資料結構針對CPU的高效訪問和操作進行了最佳化(通常使用指標)。
- 如果要將資料寫入檔案,或透過網路傳送,則必須將其 編碼(encode) 為某種自包含的位元組序列(例如,JSON文件)。 由於每個程序都有自己獨立的地址空間,一個程序中的指標對任何其他程序都沒有意義,所以這個位元組序列表示會與通常在記憶體中使用的資料結構完全不同1。
所以,需要在兩種表示之間進行某種型別的翻譯。 從記憶體中表示到位元組序列的轉換稱為 編碼(Encoding) (也稱為序列化(serialization)或編組(marshalling)),反過來稱為解碼(Decoding)2(解析(Parsing),反序列化(deserialization),反編組( unmarshalling))3。
術語衝突
不幸的是,在第七章: 事務(Transaction) 的上下文裡,序列化(Serialization) 這個術語也出現了,而且具有完全不同的含義。儘管序列化可能是更常見的術語,為了避免術語過載,本書中堅持使用 編碼(Encoding) 表達此含義。
這是一個常見的問題,因而有許多庫和編碼格式可供選擇。 首先讓我們概覽一下。
語言特定的格式
許多程式語言都內建了將記憶體物件編碼為位元組序列的支援。例如,Java有java.io.Serializable 【1】,Ruby有Marshal【2】,Python有pickle【3】等等。許多第三方庫也存在,例如Kryo for Java 【4】。
這些編碼庫非常方便,可以用很少的額外程式碼實現記憶體物件的儲存與恢復。但是它們也有一些深層次的問題:
- 這類編碼通常與特定的程式語言深度繫結,其他語言很難讀取這種資料。如果以這類編碼儲存或傳輸資料,那你就和這門語言綁死在一起了。並且很難將系統與其他組織的系統(可能用的是不同的語言)進行整合。
- 為了恢復相同物件型別的資料,解碼過程需要例項化任意類的能力,這通常是安全問題的一個來源【5】:如果攻擊者可以讓應用程式解碼任意的位元組序列,他們就能例項化任意的類,這會允許他們做可怕的事情,如遠端執行任意程式碼【6,7】。
- 在這些庫中,資料版本控制通常是事後才考慮的。因為它們旨在快速簡便地對資料進行編碼,所以往往忽略了前向後向相容性帶來的麻煩問題。
- 效率(編碼或解碼所花費的CPU時間,以及編碼結構的大小)往往也是事後才考慮的。 例如,Java的內建序列化由於其糟糕的效能和臃腫的編碼而臭名昭著【8】。
因此,除非臨時使用,採用語言內建編碼通常是一個壞主意。
JSON,XML和二進位制變體
談到可以被許多程式語言編寫和讀取的標準化編碼,JSON和XML是顯眼的競爭者。它們廣為人知,廣受支援,也“廣受憎惡”。 XML經常被批評為過於冗長和不必要的複雜【9】。 JSON倍受歡迎,主要由於它在Web瀏覽器中的內建支援(透過成為JavaScript的一個子集)以及相對於XML的簡單性。 CSV是另一種流行的與語言無關的格式,儘管功能較弱。
JSON,XML和CSV是文字格式,因此具有人類可讀性(儘管語法是一個熱門辯題)。除了表面的語法問題之外,它們也有一些微妙的問題:
- 數字的編碼多有歧義之處。XML和CSV不能區分數字和字串(除非引用外部模式)。 JSON雖然區分字串和數字,但不區分整數和浮點數,而且不能指定精度。
- 當處理大量資料時,這個問題更嚴重了。例如,大於$2^{53}$的整數不能在IEEE 754雙精度浮點數中精確表示,因此在使用浮點數(例如JavaScript)的語言進行分析時,這些數字會變得不準確。 Twitter上有一個大於$2^{53}$的數字的例子,它使用一個64位的數字來標識每條推文。 Twitter API返回的JSON包含了兩種推特ID,一個JSON數字,另一個是十進位制字串,以此避免JavaScript程式無法正確解析數字的問題【10】。
- JSON和XML對Unicode字串(即人類可讀的文字)有很好的支援,但是它們不支援二進位制資料(不帶字元編碼(character encoding)的位元組序列)。二進位制串是很實用的功能,所以人們透過使用Base64將二進位制資料編碼為文字來繞開這個限制。模式然後用於表示該值應該被解釋為Base64編碼。這個工作,但它有點hacky,並增加了33%的資料大小。 XML 【11】和JSON 【12】都有可選的模式支援。這些模式語言相當強大,所以學習和實現起來相當複雜。 XML模式的使用相當普遍,但許多基於JSON的工具嫌麻煩才不會使用模式。由於資料的正確解釋(例如數字和二進位制字串)取決於模式中的資訊,因此不使用XML/JSON模式的應用程式可能需要對相應的編碼/解碼邏輯進行硬編碼。
- CSV沒有任何模式,因此應用程式需要定義每行和每列的含義。如果應用程式更改新增新的行或列,則必須手動處理該變更。 CSV也是一個相當模糊的格式(如果一個值包含逗號或換行符,會發生什麼?)。儘管其轉義規則已經被正式指定【13】,但並不是所有的解析器都正確的實現了標準。
儘管存在這些缺陷,但JSON,XML和CSV已經足夠用於很多目的。特別是作為資料交換格式(即將資料從一個組織傳送到另一個組織),它們很可能仍然很受歡迎。這種情況下,只要人們對格式是什麼意見一致,格式多麼美觀或者高效就沒有關係。讓不同的組織達成一致的難度超過了其他大多數問題。
二進位制編碼
對於僅在組織內部使用的資料,使用最小公分母編碼格式的壓力較小。例如,可以選擇更緊湊或更快的解析格式。雖然對小資料集來說,收益可以忽略不計,但一旦達到TB級別,資料格式的選擇就會產生巨大的影響。
JSON比XML簡潔,但與二進位制格式一比,還是太佔地方。這一事實導致大量二進位制編碼版本JSON & XML的出現,JSON(MessagePack,BSON,BJSON,UBJSON,BISON和Smile等)(例如WBXML和Fast Infoset)。這些格式已經被各種各樣的領域所採用,但是沒有一個像JSON和XML的文字版本那樣被廣泛採用。
這些格式中的一些擴充套件了一組資料型別(例如,區分整數和浮點數,或者增加對二進位制字串的支援),另一方面,它們沒有蓋面JSON / XML的資料模型。特別是由於它們沒有規定模式,所以它們需要在編碼資料中包含所有的物件欄位名稱。也就是說,在例4-1中的JSON文件的二進位制編碼中,需要在某處包含字串userName,favoriteNumber和interest。
例4-1 本章中用於展示二進位制編碼的示例記錄
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}
我們來看一個MessagePack的例子,它是一個JSON的二進位制編碼。圖4-1顯示瞭如果使用MessagePack 【14】對例4-1中的JSON文件進行編碼,則得到的位元組序列。前幾個位元組如下:
- 第一個位元組
0x83表示接下來是3個欄位(低四位=0x03)的物件 object(高四位=0x80)。 (如果想知道如果一個物件有15個以上的欄位會發生什麼情況,欄位的數量塞不進4個bit裡,那麼它會用另一個不同的型別識別符號,欄位的數量被編碼兩個或四個位元組)。 - 第二個位元組
0xa8表示接下來是8位元組長的字串(最高四位= 0x08)。 - 接下來八個位元組是ASCII字串形式的欄位名稱
userName。由於之前已經指明長度,不需要任何標記來標識字串的結束位置(或者任何轉義)。 - 接下來的七個位元組對字首為
0xa6的六個字母的字串值Martin進行編碼,依此類推。
二進位制編碼長度為66個位元組,僅略小於文字JSON編碼所取的81個位元組(刪除了空白)。所有的JSON的二進位制編碼在這方面是相似的。空間節省了一丁點(以及解析加速)是否能彌補可讀性的損失,誰也說不準。
在下面的章節中,能達到比這好得多的結果,只用32個位元組對相同的記錄進行編碼。

圖4-1 使用MessagePack編碼的記錄(例4-1)
Thrift與Protocol Buffers
Apache Thrift 【15】和Protocol Buffers(protobuf)【16】是基於相同原理的二進位制編碼庫。 Protocol Buffers最初是在Google開發的,Thrift最初是在Facebook開發的,並且在2007~2008年都是開源的【17】。 Thrift和Protocol Buffers都需要一個模式來編碼任何資料。要在Thrift的例4-1中對資料進行編碼,可以使用Thrift 介面定義語言(IDL) 來描述模式,如下所示:
struct Person {
1: required string userName,
2: optional i64 favoriteNumber,
3: optional list<string> interests
}
Protocol Buffers的等效模式定義看起來非常相似:
message Person {
required string user_name = 1;
optional int64 favorite_number = 2;
repeated string interests = 3;
}
Thrift和Protocol Buffers每一個都帶有一個程式碼生成工具,它採用了類似於這裡所示的模式定義,並且生成了以各種程式語言實現模式的類【18】。您的應用程式程式碼可以呼叫此生成的程式碼來對模式的記錄進行編碼或解碼。 用這個模式編碼的資料是什麼樣的?令人困惑的是,Thrift有兩種不同的二進位制編碼格式4,分別稱為BinaryProtocol和CompactProtocol。先來看看BinaryProtocol。使用這種格式的編碼來編碼例4-1中的訊息只需要59個位元組,如圖4-2所示【19】。
{kind=link}
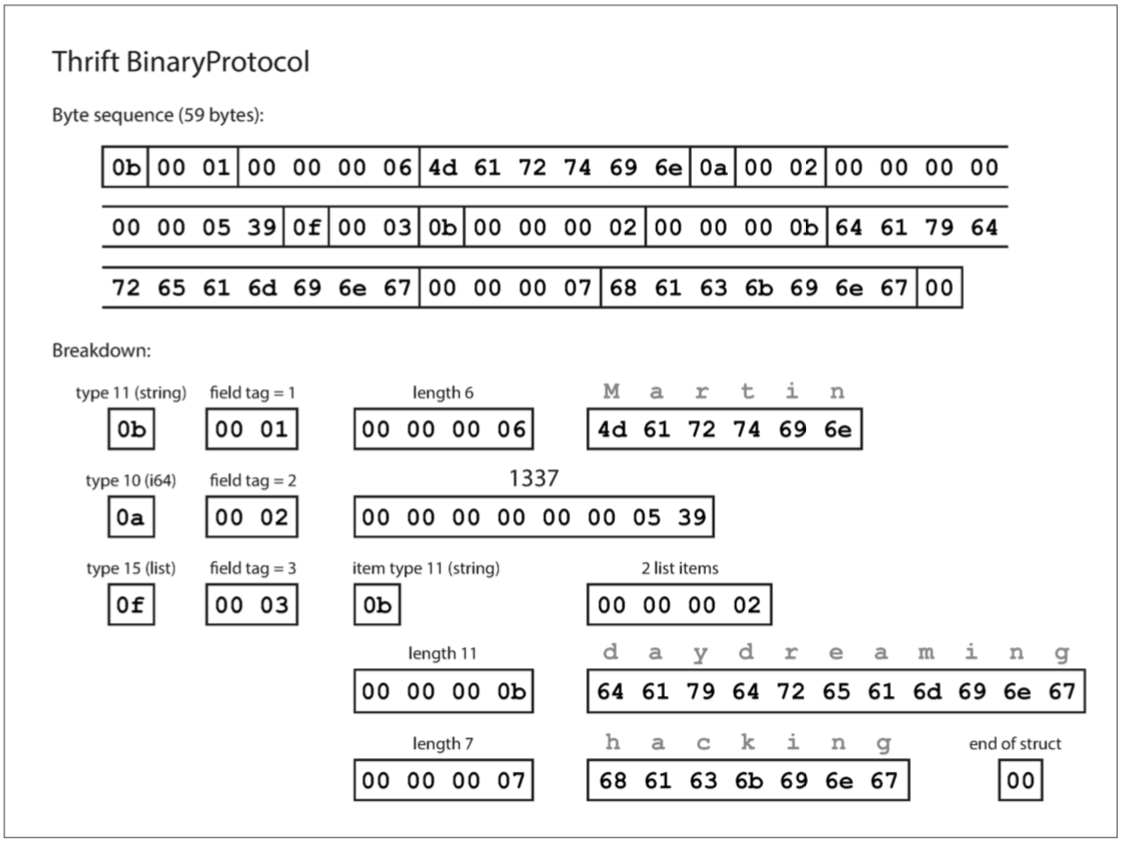
圖4-2 使用Thrift二進位制協議編碼的記錄
與圖4-1類似,每個欄位都有一個型別註釋(用於指示它是一個字串,整數,列表等),還可以根據需要指定長度(字串的長度,列表中的專案數) 。出現在資料中的字串(“Martin”, “daydreaming”, “hacking”)也被編碼為ASCII(或者說,UTF-8),與之前類似。
{kind=link}
與圖4-1相比,最大的區別是沒有欄位名(userName, favoriteNumber, interest)。相反,編碼資料包含欄位標籤,它們是數字(1, 2和3)。這些是模式定義中出現的數字。欄位標記就像欄位的別名 - 它們是說我們正在談論的欄位的一種緊湊的方式,而不必拼出欄位名稱。
{kind=link}
Thrift CompactProtocol編碼在語義上等同於BinaryProtocol,但是如圖4-3所示,它只將相同的資訊打包成只有34個位元組。它透過將欄位型別和標籤號打包到單個位元組中,並使用可變長度整數來實現。數字1337不是使用全部八個位元組,而是用兩個位元組編碼,每個位元組的最高位用來指示是否還有更多的位元組來。這意味著-64到63之間的數字被編碼為一個位元組,-8192和8191之間的數字以兩個位元組編碼,等等。較大的數字使用更多的位元組。
{kind=link}

圖4-3 使用Thrift壓縮協議編碼的記錄
最後,Protocol Buffers(只有一種二進位制編碼格式)對相同的資料進行編碼,如圖4-4所示。 它的打包方式稍有不同,但與Thrift的CompactProtocol非常相似。 Protobuf將同樣的記錄塞進了33個位元組中。
{kind=link}
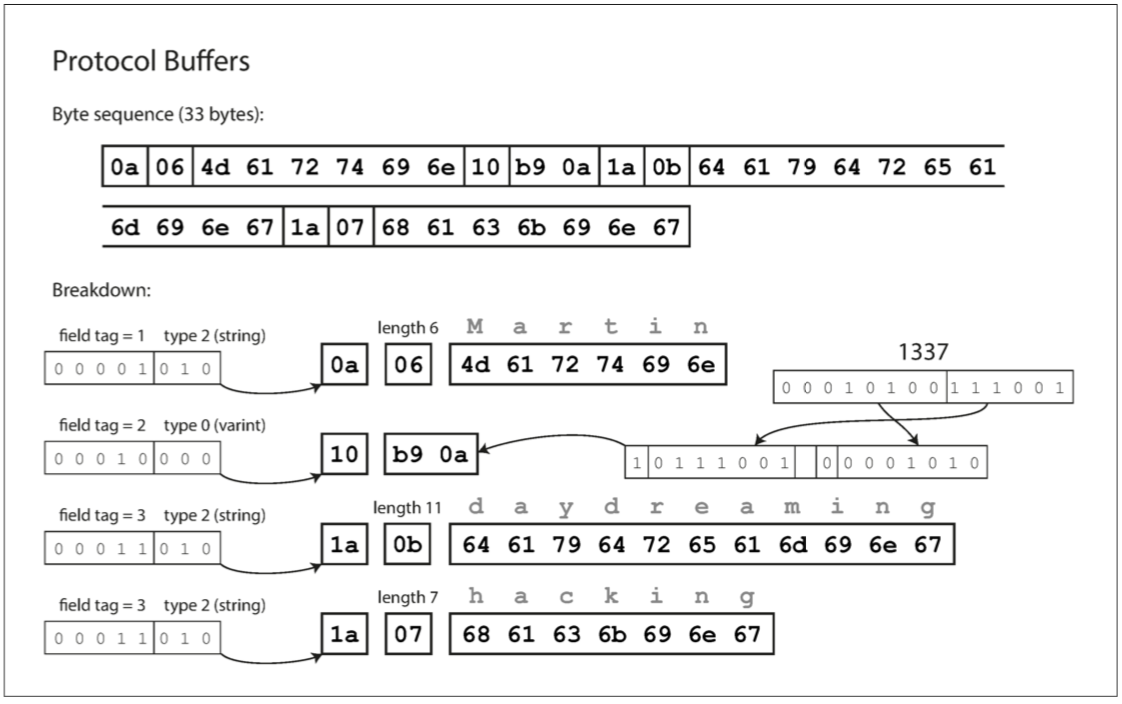
圖4-4 使用Protobuf編碼的記錄
需要注意的一個細節:在前面所示的模式中,每個欄位被標記為必需或可選,但是這對欄位如何編碼沒有任何影響(二進位制資料中沒有任何欄位指示是否需要欄位)。所不同的是,如果未設定該欄位,則所需的執行時檢查將失敗,這對於捕獲錯誤非常有用。
欄位標籤和模式演變
我們之前說過,模式不可避免地需要隨著時間而改變。我們稱之為模式演變。 Thrift和Protocol Buffers如何處理模式更改,同時保持向後相容性?
從示例中可以看出,編碼的記錄就是其編碼欄位的拼接。每個欄位由其標籤號碼(樣本模式中的數字1,2,3)標識,並用資料型別(例如字串或整數)註釋。如果沒有設定欄位值,則簡單地從編碼記錄中省略。從中可以看到,欄位標記對編碼資料的含義至關重要。您可以更改架構中欄位的名稱,因為編碼的資料永遠不會引用欄位名稱,但不能更改欄位的標記,因為這會使所有現有的編碼資料無效。
您可以新增新的欄位到架構,只要您給每個欄位一個新的標籤號碼。如果舊的程式碼(不知道你新增的新的標籤號碼)試圖讀取新程式碼寫入的資料,包括一個新的欄位,其標籤號碼不能識別,它可以簡單地忽略該欄位。資料型別註釋允許解析器確定需要跳過的位元組數。這保持了前向相容性:舊程式碼可以讀取由新程式碼編寫的記錄。
向後相容性呢?只要每個欄位都有一個唯一的標籤號碼,新的程式碼總是可以讀取舊的資料,因為標籤號碼仍然具有相同的含義。唯一的細節是,如果你新增一個新的領域,你不能要求。如果您要新增一個欄位並將其設定為必需,那麼如果新程式碼讀取舊程式碼寫入的資料,則該檢查將失敗,因為舊程式碼不會寫入您新增的新欄位。因此,為了保持向後相容性,在模式的初始部署之後 新增的每個欄位必須是可選的或具有預設值。
刪除一個欄位就像新增一個欄位,倒退和向前相容性問題相反。這意味著您只能刪除一個可選的欄位(必填欄位永遠不能刪除),而且您不能再次使用相同的標籤號碼(因為您可能仍然有資料寫在包含舊標籤號碼的地方,而該欄位必須被新程式碼忽略)。
資料型別和模式演變
如何改變欄位的資料型別?這可能是可能的——檢查檔案的細節——但是有一個風險,值將失去精度或被扼殺。例如,假設你將一個32位的整數變成一個64位的整數。新程式碼可以輕鬆讀取舊程式碼寫入的資料,因為解析器可以用零填充任何缺失的位。但是,如果舊程式碼讀取由新程式碼寫入的資料,則舊程式碼仍使用32位變數來儲存該值。如果解碼的64位值不適合32位,則它將被截斷。
Protobuf的一個奇怪的細節是,它沒有列表或陣列資料型別,而是有一個欄位的重複標記(這是第三個選項旁邊必要和可選)。如圖4-4所示,重複欄位的編碼正如它所說的那樣:同一個欄位標記只是簡單地出現在記錄中。這具有很好的效果,可以將可選(單值)欄位更改為重複(多值)欄位。讀取舊資料的新程式碼會看到一個包含零個或一個元素的列表(取決於該欄位是否存在)。讀取新資料的舊程式碼只能看到列表的最後一個元素。
Thrift有一個專用的列表資料型別,它使用列表元素的資料型別進行引數化。這不允許Protocol Buffers所做的從單值到多值的相同演變,但是它具有支援巢狀列表的優點。
Avro
Apache Avro 【20】是另一種二進位制編碼格式,與Protocol Buffers和Thrift有趣的不同。 它是作為Hadoop的一個子專案在2009年開始的,因為Thrift不適合Hadoop的用例【21】。
Avro也使用模式來指定正在編碼的資料的結構。 它有兩種模式語言:一種(Avro IDL)用於人工編輯,一種(基於JSON),更易於機器讀取。
我們用Avro IDL編寫的示例模式可能如下所示:
record Person {
string userName;
union { null, long } favoriteNumber = null;
array<string> interests;
}
等價的JSON表示:
{
"type": "record",
"name": "Person",
"fields": [
{"name": "userName", "type": "string"},
{"name": "favoriteNumber", "type": ["null", "long"], "default": null},
{"name": "interests", "type": {"type": "array", "items": "string"}
]
}
首先,請注意架構中沒有標籤號碼。 如果我們使用這個模式編碼我們的例子記錄(例4-1),Avro二進位制編碼只有32個位元組長,這是我們所見過的所有編碼中最緊湊的。 編碼位元組序列的分解如圖4-5所示。
{kind=link}
如果您檢查位元組序列,您可以看到沒有什麼可以識別字段或其資料型別。 編碼只是由連在一起的值組成。 一個字串只是一個長度字首,後跟UTF-8位元組,但是在被包含的資料中沒有任何內容告訴你它是一個字串。 它可以是一個整數,也可以是其他的整數。 整數使用可變長度編碼(與Thrift的CompactProtocol相同)進行編碼。
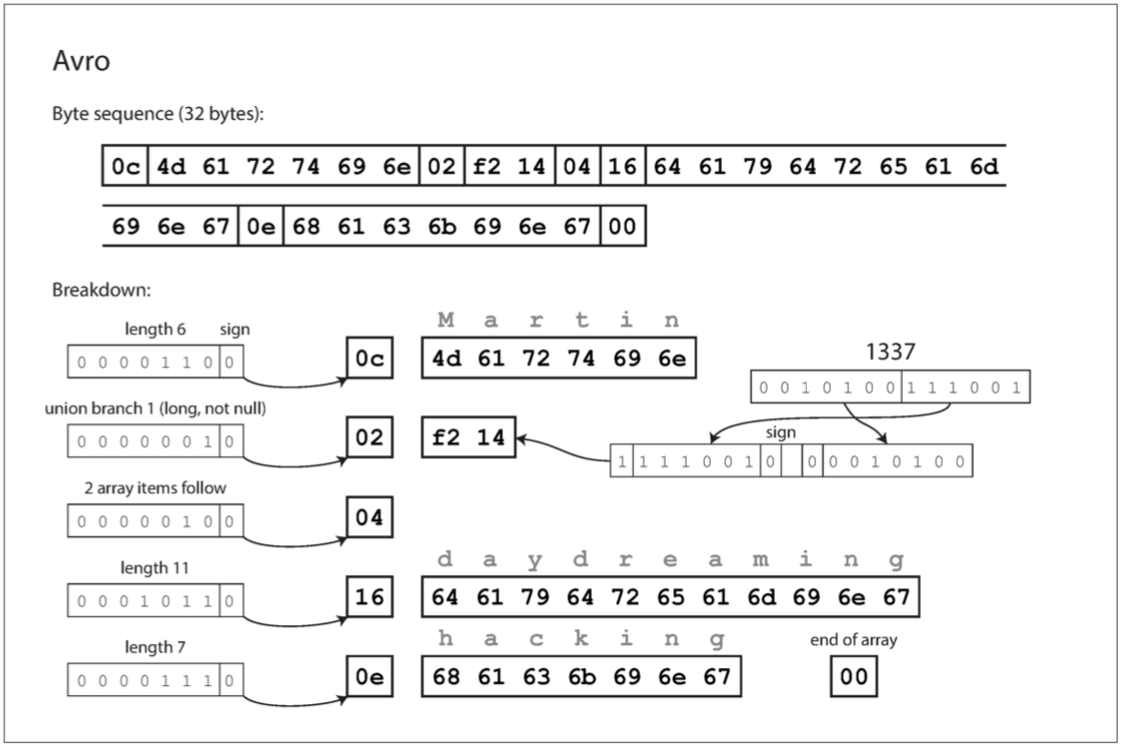
圖4-5 使用Avro編碼的記錄
為了解析二進位制資料,您按照它們出現在架構中的順序遍歷這些欄位,並使用架構來告訴您每個欄位的資料型別。這意味著如果讀取資料的程式碼使用與寫入資料的程式碼完全相同的模式,則只能正確解碼二進位制資料。閱讀器和作者之間的模式不匹配意味著錯誤地解碼資料。
那麼,Avro如何支援模式演變呢?
作者模式與讀者模式
有了Avro,當應用程式想要編碼一些資料(將其寫入檔案或資料庫,透過網路傳送等)時,它使用它知道的任何版本的模式編碼資料,例如,架構可能被編譯到應用程式中。這被稱為作者的模式。
當一個應用程式想要解碼一些資料(從一個檔案或資料庫讀取資料,從網路接收資料等)時,它希望資料在某個模式中,這就是讀者的模式。這是應用程式程式碼所依賴的模式,在應用程式的構建過程中,程式碼可能是從該模式生成的。
Avro的關鍵思想是作者的模式和讀者的模式不必是相同的 - 他們只需要相容。當資料解碼(讀取)時,Avro庫透過並排檢視作者的模式和讀者的模式並將資料從作者的模式轉換到讀者的模式來解決差異。 Avro規範【20】確切地定義了這種解析的工作原理,如圖4-6所示。
{kind=link}
例如,如果作者的模式和讀者的模式的欄位順序不同,這是沒有問題的,因為模式解析透過欄位名匹配欄位。如果讀取資料的程式碼遇到出現在作者模式中但不在讀者模式中的欄位,則忽略它。如果讀取資料的程式碼需要某個欄位,但是作者的模式不包含該名稱的欄位,則使用在讀者模式中宣告的預設值填充。

圖4-6 一個Avro Reader解決讀寫模式的差異
模式演變規則
使用Avro,向前相容性意味著您可以將新版本的架構作為編寫器,並將舊版本的架構作為讀者。相反,向後相容意味著你可以有一個作為讀者的新版本的模式和作為作者的舊版本。
為了保持相容性,您只能新增或刪除具有預設值的欄位。 (我們的Avro模式中的欄位favourNumber的預設值為null)。例如,假設您新增一個預設值的欄位,所以這個新的欄位存在於新的模式中,而不是舊的。當使用新模式的閱讀器讀取使用舊模式寫入的記錄時,將為缺少的欄位填充預設值。
如果你要新增一個沒有預設值的欄位,新的閱讀器將無法讀取舊作者寫的資料,所以你會破壞向後相容性。如果您要刪除沒有預設值的欄位,舊的閱讀器將無法讀取新作者寫入的資料,因此您會打破相容性。在一些程式語言中,null是任何變數可以接受的預設值,但在Avro中並不是這樣:如果要允許一個欄位為null,則必須使用聯合型別。例如,union {null,long,string}欄位;表示該欄位可以是數字或字串,也可以是null。如果它是union的分支之一,那麼只能使用null作為預設值5。這比預設情況下可以為null是更加冗長的,但是透過明確什麼可以和不可以是什麼,有助於防止錯誤的null 【22】。
因此,Avro沒有像Protocol Buffers和Thrift那樣的optional和required標記(它有聯合型別和預設值)。
只要Avro可以轉換型別,就可以改變欄位的資料型別。更改欄位的名稱是可能的,但有點棘手:讀者的模式可以包含欄位名稱的別名,所以它可以匹配舊作家的模式欄位名稱與別名。這意味著更改欄位名稱是向後相容的,但不能向前相容。同樣,向聯合型別新增分支也是向後相容的,但不能向前相容。
但作者模式到底是什麼?
到目前為止,我們已經討論了一個重要的問題:讀者如何知道作者的模式是哪一部分資料被編碼的?我們不能只將整個模式包括在每個記錄中,因為模式可能比編碼的資料大得多,從而使二進位制編碼節省的所有空間都是徒勞的。 答案取決於Avro使用的上下文。舉幾個例子:
-
有很多記錄的大檔案
Avro的一個常見用途 - 尤其是在Hadoop環境中 - 用於儲存包含數百萬條記錄的大檔案,所有記錄都使用相同的模式進行編碼。 (我們將在第10章討論這種情況。)在這種情況下,該檔案的作者可以在檔案的開頭只包含一次作者的模式。 Avro指定一個檔案格式(物件容器檔案)來做到這一點。
-
支援獨立寫入的記錄的資料庫
在一個數據庫中,不同的記錄可能會在不同的時間點使用不同的作者的模式編寫 - 你不能假定所有的記錄都有相同的模式。最簡單的解決方案是在每個編碼記錄的開始處包含一個版本號,並在資料庫中保留一個模式版本列表。讀者可以獲取記錄,提取版本號,然後從資料庫中獲取該版本號的作者模式。使用該作者的模式,它可以解碼記錄的其餘部分。 (例如Espresso 【23】就是這樣工作的。)
-
透過網路連線傳送記錄
當兩個程序透過雙向網路連線進行通訊時,他們可以在連線設定上協商模式版本,然後在連線的生命週期中使用該模式。 Avro RPC協議(參閱“透過服務的資料流:REST和RPC”)如此工作。
具有模式版本的資料庫在任何情況下都是非常有用的,因為它充當文件併為您提供了檢查模式相容性的機會【24】。作為版本號,你可以使用一個簡單的遞增整數,或者你可以使用模式的雜湊。
動態生成的模式
與Protocol Buffers和Thrift相比,Avro方法的一個優點是架構不包含任何標籤號碼。但為什麼這很重要?在模式中保留一些數字有什麼問題?
不同之處在於Avro對動態生成的模式更友善。例如,假如你有一個關係資料庫,你想要把它的內容轉儲到一個檔案中,並且你想使用二進位制格式來避免前面提到的文字格式(JSON,CSV,SQL)的問題。如果你使用Avro,你可以很容易地從關係模式生成一個Avro模式(在我們之前看到的JSON表示中),並使用該模式對資料庫內容進行編碼,並將其全部轉儲到Avro物件容器檔案【25】中。您為每個資料庫表生成一個記錄模式,每個列成為該記錄中的一個欄位。資料庫中的列名稱對映到Avro中的欄位名稱。
現在,如果資料庫模式發生變化(例如,一個表中添加了一列,刪除了一列),則可以從更新的資料庫模式生成新的Avro模式,並在新的Avro模式中匯出資料。資料匯出過程不需要注意模式的改變 - 每次執行時都可以簡單地進行模式轉換。任何讀取新資料檔案的人都會看到記錄的欄位已經改變,但是由於欄位是透過名字來標識的,所以更新的作者的模式仍然可以與舊的讀者模式匹配。
相比之下,如果您為此使用Thrift或Protocol Buffers,則欄位標記可能必須手動分配:每次資料庫模式更改時,管理員都必須手動更新從資料庫列名到欄位標籤。 (這可能會自動化,但模式生成器必須非常小心,不要分配以前使用的欄位標記。)這種動態生成的模式根本不是Thrift或Protocol Buffers的設計目標,而是為Avro。
程式碼生成和動態型別的語言
Thrift和Protobuf依賴於程式碼生成:在定義了模式之後,可以使用您選擇的程式語言生成實現此模式的程式碼。這在Java,C ++或C#等靜態型別語言中很有用,因為它允許將高效的記憶體中結構用於解碼的資料,並且在編寫訪問資料結構的程式時允許在IDE中進行型別檢查和自動完成。
在動態型別程式語言(如JavaScript,Ruby或Python)中,生成程式碼沒有太多意義,因為沒有編譯時型別檢查器來滿足。程式碼生成在這些語言中經常被忽視,因為它們避免了明確的編譯步驟。而且,對於動態生成的模式(例如從資料庫表生成的Avro模式),程式碼生成對獲取資料是一個不必要的障礙。
Avro為靜態型別程式語言提供了可選的程式碼生成功能,但是它也可以在不生成任何程式碼的情況下使用。如果你有一個物件容器檔案(它嵌入了作者的模式),你可以簡單地使用Avro庫開啟它,並以與檢視JSON檔案相同的方式檢視資料。該檔案是自描述的,因為它包含所有必要的元資料。
這個屬性特別適用於動態型別的資料處理語言如Apache Pig 【26】。在Pig中,您可以開啟一些Avro檔案,開始分析它們,並編寫派生資料集以Avro格式輸出檔案,而無需考慮模式。
模式的優點
正如我們所看到的,Protocol Buffers,Thrift和Avro都使用模式來描述二進位制編碼格式。他們的模式語言比XML模式或者JSON模式簡單得多,它支援更詳細的驗證規則(例如,“該欄位的字串值必須與該正則表示式匹配”或“該欄位的整數值必須在0和100之間“)。由於Protocol Buffers,Thrift和Avro實現起來更簡單,使用起來也更簡單,所以它們已經發展到支援相當廣泛的程式語言。
這些編碼所基於的想法絕不是新的。例如,它們與ASN.1有很多相似之處,它是1984年首次被標準化的模式定義語言【27】。它被用來定義各種網路協議,其二進位制編碼(DER)仍然被用於編碼SSL證書(X.509),例如【28】。 ASN.1支援使用標籤號碼的模式演進,類似於Protocol Buf-fers和Thrift 【29】。然而,這也是非常複雜和嚴重的檔案記錄,所以ASN.1可能不是新應用程式的好選擇。
許多資料系統也為其資料實現某種專有的二進位制編碼。例如,大多數關係資料庫都有一個網路協議,您可以透過該協議向資料庫傳送查詢並獲取響應。這些協議通常特定於特定的資料庫,並且資料庫供應商提供將來自資料庫的網路協議的響應解碼為記憶體資料結構的驅動程式(例如使用ODBC或JDBC API)。
所以,我們可以看到,儘管JSON,XML和CSV等文字資料格式非常普遍,但基於模式的二進位制編碼也是一個可行的選擇。他們有一些很好的屬性:
- 它們可以比各種“二進位制JSON”變體更緊湊,因為它們可以省略編碼資料中的欄位名稱。
- 模式是一種有價值的文件形式,因為模式是解碼所必需的,所以可以確定它是最新的(而手動維護的文件可能很容易偏離現實)。
- 保留模式資料庫允許您在部署任何內容之前檢查模式更改的向前和向後相容性。
- 對於靜態型別程式語言的使用者來說,從模式生成程式碼的能力是有用的,因為它可以在編譯時進行型別檢查。
總而言之,模式進化允許與JSON資料庫提供的無模式/模式讀取相同的靈活性(請參閱第39頁的“文件模型中的模式靈活性”),同時還可以更好地保證資料和更好的工具。
資料流的型別
在本章的開始部分,我們曾經說過,無論何時您想要將某些資料傳送到不共享記憶體的另一個程序,例如,只要您想透過網路傳送資料或將其寫入檔案,就需要將它編碼為一個位元組序列。然後我們討論了做這個的各種不同的編碼。 我們討論了向前和向後的相容性,這對於可演化性來說非常重要(透過允許您獨立升級系統的不同部分,而不必一次改變所有內容,可以輕鬆地進行更改)。相容性是編碼資料的一個程序和解碼它的另一個程序之間的一種關係。
這是一個相當抽象的概念 - 資料可以透過多種方式從一個流程流向另一個流程。誰編碼資料,誰解碼?在本章的其餘部分中,我們將探討資料如何在流程之間流動的一些最常見的方式:
- 透過資料庫(參閱“透過資料庫的資料流”)
- 透過服務呼叫(參閱“透過服務傳輸資料流:REST和RPC”)
- 透過非同步訊息傳遞(參閱“訊息傳遞資料流”)
資料庫中的資料流
在資料庫中,寫入資料庫的過程對資料進行編碼,從資料庫讀取的過程對資料進行解碼。可能只有一個程序訪問資料庫,在這種情況下,讀者只是相同程序的後續版本 - 在這種情況下,您可以考慮將資料庫中的內容儲存為向未來的自我傳送訊息。
向後相容性顯然是必要的。否則你未來的自己將無法解碼你以前寫的東西。
一般來說,幾個不同的程序同時訪問資料庫是很常見的。這些程序可能是幾個不同的應用程式或服務,或者它們可能只是幾個相同服務的例項(為了可擴充套件性或容錯性而並行執行)。無論哪種方式,在應用程式發生變化的環境中,訪問資料庫的某些程序可能會執行較新的程式碼,有些程序可能會執行較舊的程式碼,例如,因為新版本當前正在部署在滾動升級,所以有些例項已經更新,而其他例項尚未更新。
這意味著資料庫中的一個值可能會被更新版本的程式碼寫入,然後被仍舊執行的舊版本的程式碼讀取。因此,資料庫也經常需要向前相容。
但是,還有一個額外的障礙。假設您將一個欄位新增到記錄模式,並且較新的程式碼將該新欄位的值寫入資料庫。隨後,舊版本的程式碼(尚不知道新欄位)將讀取記錄,更新記錄並將其寫回。在這種情況下,理想的行為通常是舊程式碼保持新的領域完整,即使它不能被解釋。
前面討論的編碼格式支援未知域的儲存,但是有時候需要在應用程式層面保持謹慎,如圖4-7所示。例如,如果將資料庫值解碼為應用程式中的模型物件,稍後重新編碼這些模型物件,那麼未知欄位可能會在該翻譯過程中丟失。
解決這個問題不是一個難題,你只需要意識到它。

圖4-7 當較舊版本的應用程式更新以前由較新版本的應用程式編寫的資料時,如果不小心,資料可能會丟失。
在不同的時間寫入不同的值
資料庫通常允許任何時候更新任何值。這意味著在一個單一的資料庫中,可能有一些值是五毫秒前寫的,而一些值是五年前寫的。
在部署應用程式的新版本(至少是伺服器端應用程式)時,您可能會在幾分鐘內完全用新版本替換舊版本。資料庫內容也是如此:五年前的資料仍然存在於原始編碼中,除非您已經明確地重寫了它。這種觀察有時被總結為資料超出程式碼。
將資料重寫(遷移)到一個新的模式當然是可能的,但是在一個大資料集上執行是一個昂貴的事情,所以大多數資料庫如果可能的話就避免它。大多數關係資料庫都允許簡單的模式更改,例如新增一個預設值為空的新列,而不重寫現有資料6讀取舊行時,資料庫將填充編碼資料中缺少的任何列的空值在磁碟上。 LinkedIn的文件資料庫Espresso使用Avro儲存,允許它使用Avro的模式演變規則【23】。
因此,架構演變允許整個資料庫看起來好像是用單個模式編碼的,即使底層儲存可能包含用模式的各種歷史版本編碼的記錄。
歸檔儲存
也許您不時為資料庫建立一個快照,例如備份或載入到資料倉庫(參閱“資料倉庫”)。在這種情況下,即使源資料庫中的原始編碼包含來自不同時代的模式版本的混合,資料轉儲通常也將使用最新模式進行編碼。既然你正在複製資料,那麼你可能會一直對資料的副本進行編碼。
由於資料轉儲是一次寫入的,而且以後是不可變的,所以Avro物件容器檔案等格式非常適合。這也是一個很好的機會,可以將資料編碼為面向分析的列式格式,例如Parquet(請參閱第97頁的“列壓縮”)。
在第10章中,我們將詳細討論在檔案儲存中使用資料。
服務中的資料流:REST與RPC
當您需要透過網路進行通訊的程序時,安排該通訊的方式有幾種。最常見的安排是有兩個角色:客戶端和伺服器。伺服器透過網路公開API,並且客戶端可以連線到伺服器以向該API發出請求。伺服器公開的API被稱為服務。
Web以這種方式工作:客戶(Web瀏覽器)向Web伺服器發出請求,使GET請求下載HTML,CSS,JavaScript,影象等,並向POST請求提交資料到伺服器。 API包含一組標準的協議和資料格式(HTTP,URL,SSL/TLS,HTML等)。由於網路瀏覽器,網路伺服器和網站作者大多同意這些標準,您可以使用任何網路瀏覽器訪問任何網站(至少在理論上!)。
Web瀏覽器不是唯一的客戶端型別。例如,在移動裝置或桌面計算機上執行的本地應用程式也可以向伺服器發出網路請求,並且在Web瀏覽器內執行的客戶端JavaScript應用程式可以使用XMLHttpRequest成為HTTP客戶端(該技術被稱為Ajax 【30】)。在這種情況下,伺服器的響應通常不是用於顯示給人的HTML,而是用於便於客戶端應用程式程式碼(如JSON)進一步處理的編碼資料。儘管HTTP可能被用作傳輸協議,但頂層實現的API是特定於應用程式的,客戶端和伺服器需要就該API的細節達成一致。
此外,伺服器本身可以是另一個服務的客戶端(例如,典型的Web應用伺服器充當資料庫的客戶端)。這種方法通常用於將大型應用程式按照功能區域分解為較小的服務,這樣當一個服務需要來自另一個服務的某些功能或資料時,就會向另一個服務發出請求。這種構建應用程式的方式傳統上被稱為面向服務的體系結構(service-oriented architecture,SOA),最近被改進和更名為微服務架構【31,32】。
在某些方面,服務類似於資料庫:它們通常允許客戶端提交和查詢資料。但是,雖然資料庫允許使用我們在第2章 中討論的查詢語言進行任意查詢,但是服務公開了一個特定於應用程式的API,它只允許由服務的業務邏輯(應用程式程式碼)預定的輸入和輸出【33】。這種限制提供了一定程度的封裝:服務可以對客戶可以做什麼和不可以做什麼施加細粒度的限制。
面向服務/微服務架構的一個關鍵設計目標是透過使服務獨立部署和演化來使應用程式更易於更改和維護。例如,每個服務應該由一個團隊擁有,並且該團隊應該能夠經常釋出新版本的服務,而不必與其他團隊協調。換句話說,我們應該期望伺服器和客戶端的舊版本和新版本同時執行,因此伺服器和客戶端使用的資料編碼必須在不同版本的服務API之間相容——正是我們所做的本章一直在談論。
Web服務
當服務使用HTTP作為底層通訊協議時,可稱之為Web服務。這可能是一個小錯誤,因為Web服務不僅在Web上使用,而且在幾個不同的環境中使用。例如:
- 執行在使用者裝置上的客戶端應用程式(例如,移動裝置上的本地應用程式,或使用Ajax的JavaScript web應用程式)透過HTTP向服務發出請求。這些請求通常透過公共網際網路進行。
- 一種服務向同一組織擁有的另一項服務提出請求,這些服務通常位於同一資料中心內,作為面向服務/微型架構的一部分。 (支援這種用例的軟體有時被稱為 中介軟體(middleware) )
- 一種服務透過網際網路向不同組織所擁有的服務提出請求。這用於不同組織後端系統之間的資料交換。此類別包括由線上服務(如信用卡處理系統)提供的公共API,或用於共享訪問使用者資料的OAuth。
有兩種流行的Web服務方法:REST和SOAP。他們在哲學方面幾乎是截然相反的,往往是各自支持者之間的激烈辯論(即使在每個陣營內也有很多爭論。 例如,**HATEOAS(超媒體作為應用程式狀態的引擎)**經常引發討論【35】。)
REST不是一個協議,而是一個基於HTTP原則的設計哲學【34,35】。它強調簡單的資料格式,使用URL來標識資源,並使用HTTP功能進行快取控制,身份驗證和內容型別協商。與SOAP相比,REST已經越來越受歡迎,至少在跨組織服務整合的背景下【36】,並經常與微服務相關[31]。根據REST原則設計的API稱為RESTful。
相比之下,SOAP是用於製作網路API請求的基於XML的協議( 儘管首字母縮寫詞相似,SOAP並不是SOA的要求。 SOAP是一種特殊的技術,而SOA是構建系統的一般方法。)。雖然它最常用於HTTP,但其目的是獨立於HTTP,並避免使用大多數HTTP功能。相反,它帶有龐大而複雜的多種相關標準(Web服務框架,稱為WS-*),它們增加了各種功能【37】。
SOAP Web服務的API使用稱為Web服務描述語言(WSDL)的基於XML的語言來描述。 WSDL支援程式碼生成,客戶端可以使用本地類和方法呼叫(編碼為XML訊息並由框架再次解碼)訪問遠端服務。這在靜態型別程式語言中非常有用,但在動態型別程式語言中很少(參閱“程式碼生成和動態型別化語言”)。
由於WSDL的設計不是人類可讀的,而且由於SOAP訊息通常是手動構建的過於複雜,所以SOAP的使用者在很大程度上依賴於工具支援,程式碼生成和IDE【38】。對於SOAP供應商不支援的程式語言的使用者來說,與SOAP服務的整合是困難的。
儘管SOAP及其各種擴充套件表面上是標準化的,但是不同廠商的實現之間的互操作性往往會造成問題【39】。由於所有這些原因,儘管許多大型企業仍然使用SOAP,但在大多數小公司中已經不再受到青睞。
REST風格的API傾向於更簡單的方法,通常涉及較少的程式碼生成和自動化工具。定義格式(如OpenAPI,也稱為Swagger 【40】)可用於描述RESTful API並生成文件。
遠端過程呼叫(RPC)的問題
Web服務僅僅是透過網路進行API請求的一系列技術的最新版本,其中許多技術受到了大量的炒作,但是存在嚴重的問題。 Enterprise JavaBeans(EJB)和Java的**遠端方法呼叫(RMI)**僅限於Java。**分散式元件物件模型(DCOM)**僅限於Microsoft平臺。**公共物件請求代理體系結構(CORBA)**過於複雜,不提供前向或後向相容性【41】。
所有這些都是基於 遠端過程呼叫(RPC) 的思想,該過程呼叫自20世紀70年代以來一直存在【42】。 RPC模型試圖向遠端網路服務發出請求,看起來與在同一程序中呼叫程式語言中的函式或方法相同(這種抽象稱為位置透明)。儘管RPC起初看起來很方便,但這種方法根本上是有缺陷的【43,44】。網路請求與本地函式呼叫非常不同:
- 本地函式呼叫是可預測的,並且成功或失敗,這僅取決於受您控制的引數。網路請求是不可預知的:由於網路問題,請求或響應可能會丟失,或者遠端計算機可能很慢或不可用,這些問題完全不在您的控制範圍之內。網路問題是常見的,所以你必須預測他們,例如透過重試失敗的請求。
- 本地函式呼叫要麼返回結果,要麼丟擲異常,或者永遠不返回(因為進入無限迴圈或程序崩潰)。網路請求有另一個可能的結果:由於超時,它可能會返回沒有結果。在這種情況下,你根本不知道發生了什麼:如果你沒有得到來自遠端服務的響應,你無法知道請求是否透過。 (我們將在第8章更詳細地討論這個問題。)
- 如果您重試失敗的網路請求,可能會發生請求實際上正在透過,只有響應丟失。在這種情況下,重試將導致該操作被執行多次,除非您在協議中引入除重( 冪等(idempotence))機制。本地函式呼叫沒有這個問題。 (在第十一章更詳細地討論冪等性)
- 每次呼叫本地功能時,通常需要大致相同的時間來執行。網路請求比函式呼叫要慢得多,而且其延遲也是非常可變的:在不到一毫秒的時間內它可能會完成,但是當網路擁塞或者遠端服務超載時,可能需要幾秒鐘的時間完全一樣的東西。
- 呼叫本地函式時,可以高效地將引用(指標)傳遞給本地記憶體中的物件。當你發出一個網路請求時,所有這些引數都需要被編碼成可以透過網路傳送的一系列位元組。沒關係,如果引數是像數字或字串這樣的基本型別,但是對於較大的物件很快就會變成問題。
客戶端和服務可以用不同的程式語言實現,所以RPC框架必須將資料型別從一種語言翻譯成另一種語言。這可能會捅出大簍子,因為不是所有的語言都具有相同的型別 —— 例如回想一下JavaScript的數字大於$2^{53}$的問題(參閱“JSON,XML和二進位制變體”)。用單一語言編寫的單個程序中不存在此問題。
所有這些因素意味著嘗試使遠端服務看起來像程式語言中的本地物件一樣毫無意義,因為這是一個根本不同的事情。 REST的部分吸引力在於,它並不試圖隱藏它是一個網路協議的事實(儘管這似乎並沒有阻止人們在REST之上構建RPC庫)。
RPC的當前方向
儘管有這樣那樣的問題,RPC不會消失。在本章提到的所有編碼的基礎上構建了各種RPC框架:例如,Thrift和Avro帶有RPC支援,gRPC是使用Protocol Buffers的RPC實現,Finagle也使用Thrift,Rest.li使用JSON over HTTP。
這種新一代的RPC框架更加明確的是,遠端請求與本地函式呼叫不同。例如,Finagle和Rest.li 使用futures(promises)來封裝可能失敗的非同步操作。Futures還可以簡化需要並行發出多項服務的情況,並將其結果合併【45】。 gRPC支援流,其中一個呼叫不僅包括一個請求和一個響應,還包括一系列的請求和響應【46】。
其中一些框架還提供服務發現,即允許客戶端找出在哪個IP地址和埠號上可以找到特定的服務。我們將在“請求路由”中回到這個主題。
使用二進位制編碼格式的自定義RPC協議可以實現比通用的JSON over REST更好的效能。但是,RESTful API還有其他一些顯著的優點:對於實驗和除錯(只需使用Web瀏覽器或命令列工具curl,無需任何程式碼生成或軟體安裝即可向其請求),它是受支援的所有的主流程式語言和平臺,還有大量可用的工具(伺服器,快取,負載平衡器,代理,防火牆,監控,除錯工具,測試工具等)的生態系統。由於這些原因,REST似乎是公共API的主要風格。 RPC框架的主要重點在於同一組織擁有的服務之間的請求,通常在同一資料中心內。
資料編碼與RPC的演化
對於可演化性,重要的是可以獨立更改和部署RPC客戶端和伺服器。與透過資料庫流動的資料相比(如上一節所述),我們可以在透過服務進行資料流的情況下做一個簡化的假設:假定所有的伺服器都會先更新,其次是所有的客戶端。因此,您只需要在請求上具有向後相容性,並且對響應具有前向相容性。
RPC方案的前後向相容性屬性從它使用的編碼方式中繼承
- Thrift,gRPC(Protobuf)和Avro RPC可以根據相應編碼格式的相容性規則進行演變。
- 在SOAP中,請求和響應是使用XML模式指定的。這些可以演變,但有一些微妙的陷阱【47】。
- RESTful API通常使用JSON(沒有正式指定的模式)用於響應,以及用於請求的JSON或URI編碼/表單編碼的請求引數。新增可選的請求引數並向響應物件新增新的欄位通常被認為是保持相容性的改變。
由於RPC經常被用於跨越組織邊界的通訊,所以服務的相容性變得更加困難,因此服務的提供者經常無法控制其客戶,也不能強迫他們升級。因此,需要長期保持相容性,也許是無限期的。如果需要進行相容性更改,則服務提供商通常會並排維護多個版本的服務API。
關於API版本化應該如何工作(即,客戶端如何指示它想要使用哪個版本的API)沒有一致意見【48】)。對於RESTful API,常用的方法是在URL或HTTP Accept頭中使用版本號。對於使用API金鑰來標識特定客戶端的服務,另一種選擇是將客戶端請求的API版本儲存在伺服器上,並允許透過單獨的管理介面更新該版本選項【49】。
訊息傳遞中的資料流
我們一直在研究從一個過程到另一個過程的編碼資料流的不同方式。到目前為止,我們已經討論了REST和RPC(其中一個程序透過網路向另一個程序傳送請求並期望儘可能快的響應)以及資料庫(一個程序寫入編碼資料,另一個程序在將來再次讀取)。
在最後一節中,我們將簡要介紹一下RPC和資料庫之間的非同步訊息傳遞系統。它們與RPC類似,因為客戶端的請求(通常稱為訊息)以低延遲傳送到另一個程序。它們與資料庫類似,不是透過直接的網路連線傳送訊息,而是透過稱為訊息代理(也稱為訊息佇列或面向訊息的中介軟體)的中介來臨時儲存訊息。
與直接RPC相比,使用訊息代理有幾個優點:
- 如果收件人不可用或過載,可以充當緩衝區,從而提高系統的可靠性。
- 它可以自動將訊息重新發送到已經崩潰的程序,從而防止訊息丟失。
- 避免發件人需要知道收件人的IP地址和埠號(這在虛擬機器經常出入的雲部署中特別有用)。
- 它允許將一條訊息傳送給多個收件人。
- 將發件人與收件人邏輯分離(發件人只是釋出郵件,不關心使用者)。
然而,與RPC相比,差異在於訊息傳遞通訊通常是單向的:傳送者通常不期望收到其訊息的回覆。一個程序可能傳送一個響應,但這通常是在一個單獨的通道上完成的。這種通訊模式是非同步的:傳送者不會等待訊息被傳遞,而只是傳送它,然後忘記它。
訊息掮客
過去,資訊掮客主要是TIBCO,IBM WebSphere和webMethods等公司的商業軟體的秀場。最近像RabbitMQ,ActiveMQ,HornetQ,NATS和Apache Kafka這樣的開源實現已經流行起來。我們將在第11章中對它們進行更詳細的比較。
詳細的交付語義因實現和配置而異,但通常情況下,訊息代理的使用方式如下:一個程序將訊息傳送到指定的佇列或主題,代理確保將訊息傳遞給一個或多個消費者或訂閱者到那個佇列或主題。在同一主題上可以有許多生產者和許多消費者。
一個主題只提供單向資料流。但是,消費者本身可能會將訊息釋出到另一個主題上(因此,可以將它們連結在一起,就像我們將在第11章中看到的那樣),或者傳送給原始訊息的傳送者使用的回覆佇列(允許請求/響應資料流,類似於RPC)。
訊息代理通常不會執行任何特定的資料模型 - 訊息只是包含一些元資料的位元組序列,因此您可以使用任何編碼格式。如果編碼是向後相容的,則您可以靈活地更改發行商和消費者的獨立編碼,並以任意順序進行部署。
如果消費者重新發布訊息到另一個主題,則可能需要小心保留未知欄位,以防止前面在資料庫環境中描述的問題(圖4-7)。
{kind=link}
分散式的Actor框架
Actor模型是單個程序中併發的程式設計模型。邏輯被封裝在角色中,而不是直接處理執行緒(以及競爭條件,鎖定和死鎖的相關問題)。每個角色通常代表一個客戶或實體,它可能有一些本地狀態(不與其他任何角色共享),它透過傳送和接收非同步訊息與其他角色通訊。訊息傳送不保證:在某些錯誤情況下,訊息將丟失。由於每個角色一次只能處理一條訊息,因此不需要擔心執行緒,每個角色可以由框架獨立排程。
在分散式的行為者框架中,這個程式設計模型被用來跨越多個節點來擴充套件應用程式。不管傳送方和接收方是在同一個節點上還是在不同的節點上,都使用相同的訊息傳遞機制。如果它們在不同的節點上,則該訊息被透明地編碼成位元組序列,透過網路傳送,並在另一側解碼。
位置透明在actor模型中比在RPC中效果更好,因為actor模型已經假定訊息可能會丟失,即使在單個程序中也是如此。儘管網路上的延遲可能比同一個程序中的延遲更高,但是在使用參與者模型時,本地和遠端通訊之間的基本不匹配是較少的。
分散式的Actor框架實質上是將訊息代理和角色程式設計模型整合到一個框架中。但是,如果要執行基於角色的應用程式的滾動升級,則仍然需要擔心向前和向後相容性問題,因為訊息可能會從執行新版本的節點發送到執行舊版本的節點,反之亦然。
三個流行的分散式actor框架處理訊息編碼如下:
- 預設情況下,Akka使用Java的內建序列化,不提供前向或後向相容性。 但是,你可以用類似緩衝區的東西替代它,從而獲得滾動升級的能力【50】。
- Orleans 預設使用不支援滾動升級部署的自定義資料編碼格式; 要部署新版本的應用程式,您需要設定一個新的群集,將流量從舊群集遷移到新群集,然後關閉舊群集【51,52】。 像Akka一樣,可以使用自定義序列化外掛。
- 在Erlang OTP中,對記錄模式進行更改是非常困難的(儘管系統具有許多為高可用性設計的功能)。 滾動升級是可能的,但需要仔細計劃【53】。 一個新的實驗性的
maps資料型別(2014年在Erlang R17中引入的類似於JSON的結構)可能使得這個資料型別在未來更容易【54】。
本章小結
在本章中,我們研究了將資料結構轉換為網路中的位元組或磁碟上的位元組的幾種方法。我們看到了這些編碼的細節不僅影響其效率,更重要的是應用程式的體系結構和部署它們的選項。
特別是,許多服務需要支援滾動升級,其中新版本的服務逐步部署到少數節點,而不是同時部署到所有節點。滾動升級允許在不停機的情況下發布新版本的服務(從而鼓勵在罕見的大型版本上頻繁釋出小型版本),並使部署風險降低(允許在影響大量使用者之前檢測並回滾有故障的版本)。這些屬性對於可演化性,以及對應用程式進行更改的容易性都是非常有利的。
在滾動升級期間,或出於各種其他原因,我們必須假設不同的節點正在執行我們的應用程式程式碼的不同版本。因此,在系統周圍流動的所有資料都是以提供向後相容性(新程式碼可以讀取舊資料)和向前相容性(舊程式碼可以讀取新資料)的方式進行編碼是重要的。
我們討論了幾種資料編碼格式及其相容性屬性:
- 程式語言特定的編碼僅限於單一程式語言,並且往往無法提供前向和後向相容性。
- JSON,XML和CSV等文字格式非常普遍,其相容性取決於您如何使用它們。他們有可選的模式語言,這有時是有用的,有時是一個障礙。這些格式對於資料型別有些模糊,所以你必須小心數字和二進位制字串。
- 像Thrift,Protocol Buffers和Avro這樣的二進位制模式驅動格式允許使用清晰定義的前向和後向相容性語義進行緊湊,高效的編碼。這些模式可以用於靜態型別語言的文件和程式碼生成。但是,他們有一個缺點,就是在資料可讀之前需要對資料進行解碼。
我們還討論了資料流的幾種模式,說明了資料編碼是重要的不同場景:
- 資料庫,寫入資料庫的程序對資料進行編碼,並從資料庫讀取程序對其進行解碼
- RPC和REST API,客戶端對請求進行編碼,伺服器對請求進行解碼並對響應進行編碼,客戶端最終對響應進行解碼
- 非同步訊息傳遞(使用訊息代理或參與者),其中節點之間透過傳送訊息進行通訊,訊息由傳送者編碼並由接收者解碼
我們可以小心地得出這樣的結論:前向相容性和滾動升級在某種程度上是可以實現的。願您的應用程式的演變迅速、敏捷部署。
參考文獻
-
“Java Object Serialization Specification,” docs.oracle.com, 2010.
-
“Ruby 2.2.0 API Documentation,” ruby-doc.org, Dec 2014.
-
“The Python 3.4.3 Standard Library Reference Manual,” docs.python.org, February 2015.
-
“EsotericSoftware/kryo,” github.com, October 2014.
-
“CWE-502: Deserialization of Untrusted Data,” Common Weakness Enumeration, cwe.mitre.org, July 30, 2014.
-
Steve Breen: “What Do WebLogic, WebSphere, JBoss, Jenkins, OpenNMS, and Your Application Have in Common? This Vulnerability,” foxglovesecurity.com, November 6, 2015.
-
Patrick McKenzie: “What the Rails Security Issue Means for Your Startup,” kalzumeus.com, January 31, 2013.
-
Eishay Smith: “jvm-serializers wiki,” github.com, November 2014.
-
“XML Is a Poor Copy of S-Expressions,” c2.com wiki.
-
Matt Harris: “Snowflake: An Update and Some Very Important Information,” email to Twitter Development Talk mailing list, October 19, 2010.
-
Shudi (Sandy) Gao, C. M. Sperberg-McQueen, and Henry S. Thompson: “XML Schema 1.1,” W3C Recommendation, May 2001.
-
Francis Galiegue, Kris Zyp, and Gary Court: “JSON Schema,” IETF Internet-Draft, February 2013.
-
Yakov Shafranovich: “RFC 4180: Common Format and MIME Type for Comma-Separated Values (CSV) Files,” October 2005.
-
“MessagePack Specification,” msgpack.org. Mark Slee, Aditya Agarwal, and Marc Kwiatkowski: “Thrift: Scalable Cross-Language Services Implementation,” Facebook technical report, April 2007.
-
“Protocol Buffers Developer Guide,” Google, Inc., developers.google.com.
-
Igor Anishchenko: “Thrift vs Protocol Buffers vs Avro - Biased Comparison,” slideshare.net, September 17, 2012.
-
“A Matrix of the Features Each Individual Language Library Supports,” wiki.apache.org.
-
Martin Kleppmann: “Schema Evolution in Avro, Protocol Buffers and Thrift,” martin.kleppmann.com, December 5, 2012.
-
“Apache Avro 1.7.7 Documentation,” avro.apache.org, July 2014.
-
Doug Cutting, Chad Walters, Jim Kellerman, et al.: “[PROPOSAL] New Subproject: Avro,” email thread on hadoop-general mailing list, mail-archives.apache.org, April 2009.
-
Tony Hoare: “Null References: The Billion Dollar Mistake,” at QCon London, March 2009.
-
Aditya Auradkar and Tom Quiggle: “Introducing Espresso—LinkedIn's Hot New Distributed Document Store,” engineering.linkedin.com, January 21, 2015.
-
Jay Kreps: “Putting Apache Kafka to Use: A Practical Guide to Building a Stream Data Platform (Part 2),” blog.confluent.io, February 25, 2015.
-
Gwen Shapira: “The Problem of Managing Schemas,” radar.oreilly.com, November 4, 2014.
-
“Apache Pig 0.14.0 Documentation,” pig.apache.org, November 2014.
-
John Larmouth: ASN.1Complete. Morgan Kaufmann, 1999. ISBN: 978-0-122-33435-1
-
Russell Housley, Warwick Ford, Tim Polk, and David Solo: “RFC 2459: Internet X.509 Public Key Infrastructure: Certificate and CRL Profile,” IETF Network Working Group, Standards Track, January 1999.
-
Lev Walkin: “Question: Extensibility and Dropping Fields,” lionet.info, September 21, 2010.
-
Jesse James Garrett: “Ajax: A New Approach to Web Applications,” adaptivepath.com, February 18, 2005.
-
Sam Newman: Building Microservices. O'Reilly Media, 2015. ISBN: 978-1-491-95035-7
-
Chris Richardson: “Microservices: Decomposing Applications for Deployability and Scalability,” infoq.com, May 25, 2014.
-
Pat Helland: “Data on the Outside Versus Data on the Inside,” at 2nd Biennial Conference on Innovative Data Systems Research (CIDR), January 2005.
-
Roy Thomas Fielding: “Architectural Styles and the Design of Network-Based Software Architectures,” PhD Thesis, University of California, Irvine, 2000.
-
Roy Thomas Fielding: “REST APIs Must Be Hypertext-Driven,” roy.gbiv.com, October 20 2008.
-
“REST in Peace, SOAP,” royal.pingdom.com, October 15, 2010.
-
“Web Services Standards as of Q1 2007,” innoq.com, February 2007.
-
Pete Lacey: “The S Stands for Simple,” harmful.cat-v.org, November 15, 2006.
-
Stefan Tilkov: “Interview: Pete Lacey Criticizes Web Services,” infoq.com, December 12, 2006.
-
“OpenAPI Specification (fka Swagger RESTful API Documentation Specification) Version 2.0,” swagger.io, September 8, 2014.
-
Michi Henning: “The Rise and Fall of CORBA,” ACM Queue, volume 4, number 5, pages 28–34, June 2006. doi:10.1145/1142031.1142044
-
Andrew D. Birrell and Bruce Jay Nelson: “Implementing Remote Procedure Calls,” ACM Transactions on Computer Systems (TOCS), volume 2, number 1, pages 39–59, February 1984. doi:10.1145/2080.357392
-
Jim Waldo, Geoff Wyant, Ann Wollrath, and Sam Kendall: “A Note on Distributed Computing,” Sun Microsystems Laboratories, Inc., Technical Report TR-94-29, November 1994.
-
Steve Vinoski: “Convenience over Correctness,” IEEE Internet Computing, volume 12, number 4, pages 89–92, July 2008. doi:10.1109/MIC.2008.75
-
Marius Eriksen: “Your Server as a Function,” at 7th Workshop on Programming Languages and Operating Systems (PLOS), November 2013. doi:10.1145/2525528.2525538
-
“grpc-common Documentation,” Google, Inc., github.com, February 2015.
-
Aditya Narayan and Irina Singh: “Designing and Versioning Compatible Web Services,” ibm.com, March 28, 2007.
-
Troy Hunt: “Your API Versioning Is Wrong, Which Is Why I Decided to Do It 3 Different Wrong Ways,” troyhunt.com, February 10, 2014.
-
“API Upgrades,” Stripe, Inc., April 2015.
-
Jonas Bonér: “Upgrade in an Akka Cluster,” email to akka-user mailing list, grokbase.com, August 28, 2013.
-
Philip A. Bernstein, Sergey Bykov, Alan Geller, et al.: “Orleans: Distributed Virtual Actors for Programmability and Scalability,” Microsoft Research Technical Report MSR-TR-2014-41, March 2014.
-
“Microsoft Project Orleans Documentation,” Microsoft Research, dotnet.github.io, 2015.
-
David Mercer, Sean Hinde, Yinso Chen, and Richard A O'Keefe: “beginner: Updating Data Structures,” email thread on erlang-questions mailing list, erlang.com, October 29, 2007.
-
Fred Hebert: “Postscript: Maps,” learnyousomeerlang.com, April 9, 2014.
| 上一章 | 目錄 | 下一章 |
|---|---|---|
| 第三章:儲存與檢索 | 設計資料密集型應用 | 第二部分:分散式資料 |
-
請注意,編碼(encode) 與 加密(encryption) 無關。 本書不討論加密。 ↩︎
-
Marshal與Serialization的區別:Marshal不僅傳輸物件的狀態,而且會一起傳輸物件的方法(相關程式碼)。 ↩︎
-
實際上,Thrift有三種二進位制協議:CompactProtocol和DenseProtocol,儘管DenseProtocol只支援C ++實現,所以不算作跨語言[18]。 除此之外,它還有兩種不同的基於JSON的編碼格式【19】。 真逗! ↩︎
-
確切地說,預設值必須是聯合的第一個分支的型別,儘管這是Avro的特定限制,而不是聯合型別的一般特徵。 ↩︎
-
除了MySQL,即使並非真的必要,它也經常會重寫整個表,正如“文件模型中的架構靈活性”中所提到的。 ↩︎