113 KiB
第八章:分散式系統的麻煩

邂逅相遇
網路延遲
存之為吾
無食我數
—— Kyle Kingsbury, Carly Rae Jepsen 《網路分割槽的危害》(2013 年)1
[TOC]
最近幾章中反覆出現的主題是,系統如何處理錯誤的事情。例如,我們討論了 副本故障切換(“處理節點中斷”),複製延遲(“複製延遲問題”)和事務控制(“弱隔離級別”)。當我們瞭解可能在實際系統中出現的各種邊緣情況時,我們會更好地處理它們。
但是,儘管我們已經談了很多錯誤,但之前幾章仍然過於樂觀。現實更加黑暗。我們現在將悲觀主義最大化,假設任何可能出錯的東西 都會 出錯 2。(經驗豐富的系統運維會告訴你,這是一個合理的假設。如果你問得好,他們可能會一邊治療心理創傷一邊告訴你一些可怕的故事)
使用分散式系統與在一臺計算機上編寫軟體有著根本的區別,主要的區別在於,有許多新穎和刺激的方法可以使事情出錯【1,2】。在這一章中,我們將瞭解實踐中出現的問題,理解我們能夠依賴,和不可以依賴的東西。
最後,作為工程師,我們的任務是構建能夠完成工作的系統(即滿足使用者期望的保證),儘管一切都出錯了。 在 第九章 中,我們將看看一些可以在分散式系統中提供這種保證的演算法的例子。 但首先,在本章中,我們必須瞭解我們面臨的挑戰。
本章對分散式系統中可能出現的問題進行徹底的悲觀和沮喪的總結。 我們將研究網路的問題(“不可靠的網路”); 時鐘和時序問題(“不可靠的時鐘”); 我們將討論他們可以避免的程度。 所有這些問題的後果都是困惑的,所以我們將探索如何思考一個分散式系統的狀態,以及如何推理發生的事情(“知識、真相與謊言”)。
故障與部分失效
當你在一臺計算機上編寫一個程式時,它通常會以一種相當可預測的方式執行:無論是工作還是不工作。充滿錯誤的軟體可能會讓人覺得電腦有時候也會有 “糟糕的一天”(這種問題通常是重新啟動就恢復了),但這主要是軟體寫得不好的結果。
單個計算機上的軟體沒有根本性的不可靠原因:當硬體正常工作時,相同的操作總是產生相同的結果(這是確定性的)。如果存在硬體問題(例如,記憶體損壞或聯結器鬆動),其後果通常是整個系統故障(例如,核心恐慌,“藍色畫面宕機”,啟動失敗)。裝有良好軟體的個人計算機通常要麼功能完好,要麼完全失效,而不是介於兩者之間。
這是計算機設計中的一個有意的選擇:如果發生內部錯誤,我們寧願電腦完全崩潰,而不是返回錯誤的結果,因為錯誤的結果很難處理。因為計算機隱藏了模糊不清的物理實現,並呈現出一個理想化的系統模型,並以數學一樣的完美的方式運作。 CPU 指令總是做同樣的事情;如果你將一些資料寫入記憶體或磁碟,那麼這些資料將保持不變,並且不會被隨機破壞。從第一臺數字計算機開始,始終正確地計算 這個設計目標貫穿始終【3】。
當你編寫執行在多臺計算機上的軟體時,情況有本質上的區別。在分散式系統中,我們不再處於理想化的系統模型中,我們別無選擇,只能面對現實世界的混亂現實。而在現實世界中,各種各樣的事情都可能會出現問題【4】,如下面的軼事所述:
在我有限的經驗中,我已經和很多東西打過交道:單個 資料中心(DC) 中長期存在的網路分割槽,配電單元 PDU 故障,交換機故障,整個機架的意外重啟,整個資料中心主幹網路故障,整個資料中心的電源故障,以及一個低血糖的司機把他的福特皮卡撞在資料中心的 HVAC(加熱,通風和空調)系統上。而且我甚至不是一個運維。
—— 柯達黑爾
在分散式系統中,儘管系統的其他部分工作正常,但系統的某些部分可能會以某種不可預知的方式被破壞。這被稱為 部分失效(partial failure)。難點在於部分失效是 不確定性的(nondeterministic):如果你試圖做任何涉及多個節點和網路的事情,它有時可能會工作,有時會出現不可預知的失敗。正如我們將要看到的,你甚至不知道是否成功了,因為訊息透過網路傳播的時間也是不確定的!
這種不確定性和部分失效的可能性,使得分散式系統難以工作【5】。
雲計算與超級計算機
關於如何構建大型計算系統有一系列的哲學:
- 一個極端是高效能計算(HPC)領域。具有數千個 CPU 的超級計算機通常用於計算密集型科學計算任務,如天氣預報或分子動力學(模擬原子和分子的運動)。
- 另一個極端是 雲計算(cloud computing),雲計算並不是一個良好定義的概念【6】,但通常與多租戶資料中心,連線 IP 網路(通常是乙太網)的商用計算機,彈性 / 按需資源分配以及計量計費等相關聯。
- 傳統企業資料中心位於這兩個極端之間。
不同的哲學會導致不同的故障處理方式。在超級計算機中,作業通常會不時地將計算的狀態存檔到持久儲存中。如果一個節點出現故障,通常的解決方案是簡單地停止整個叢集的工作負載。故障節點修復後,計算從上一個檢查點重新開始【7,8】。因此,超級計算機更像是一個單節點計算機而不是分散式系統:透過讓部分失敗升級為完全失敗來處理部分失敗 —— 如果系統的任何部分發生故障,只是讓所有的東西都崩潰(就像單臺機器上的核心恐慌一樣)。
在本書中,我們將重點放在實現網際網路服務的系統上,這些系統通常與超級計算機看起來有很大不同:
-
許多與網際網路有關的應用程式都是 線上(online) 的,因為它們需要能夠隨時以低延遲服務使用者。使服務不可用(例如,停止叢集以進行修復)是不可接受的。相比之下,像天氣模擬這樣的離線(批處理)工作可以停止並重新啟動,影響相當小。
-
超級計算機通常由專用硬體構建而成,每個節點相當可靠,節點透過共享記憶體和 遠端直接記憶體訪問(RDMA) 進行通訊。另一方面,雲服務中的節點是由商用機器構建而成的,由於規模經濟,可以以較低的成本提供相同的效能,而且具有較高的故障率。
-
大型資料中心網路通常基於 IP 和乙太網,以 CLOS 拓撲排列,以提供更高的對分(bisection)頻寬【9】。超級計算機通常使用專門的網路拓撲結構,例如多維網格和 Torus 網路 【10】,這為具有已知通訊模式的 HPC 工作負載提供了更好的效能。
-
系統越大,其元件之一就越有可能壞掉。隨著時間的推移,壞掉的東西得到修復,新的東西又壞掉,但是在一個有成千上萬個節點的系統中,有理由認為總是有一些東西是壞掉的【7】。當錯誤處理的策略只由簡單放棄組成時,一個大的系統最終會花費大量時間從錯誤中恢復,而不是做有用的工作【8】。
-
如果系統可以容忍發生故障的節點,並繼續保持整體工作狀態,那麼這對於運營和維護非常有用:例如,可以執行滾動升級(請參閱 第四章),一次重新啟動一個節點,同時繼續給使用者提供不中斷的服務。在雲環境中,如果一臺虛擬機器執行不佳,可以殺死它並請求一臺新的虛擬機器(希望新的虛擬機器速度更快)。
-
在地理位置分散的部署中(保持資料在地理位置上接近使用者以減少訪問延遲),通訊很可能透過網際網路進行,與本地網路相比,通訊速度緩慢且不可靠。超級計算機通常假設它們的所有節點都靠近在一起。
如果要使分散式系統工作,就必須接受部分故障的可能性,並在軟體中建立容錯機制。換句話說,我們需要從不可靠的元件構建一個可靠的系統(正如 “可靠性” 中所討論的那樣,沒有完美的可靠性,所以我們需要理解我們可以實際承諾的極限)。
即使在只有少數節點的小型系統中,考慮部分故障也是很重要的。在一個小系統中,很可能大部分元件在大部分時間都正常工作。然而,遲早會有一部分系統出現故障,軟體必須以某種方式處理。故障處理必須是軟體設計的一部分,並且作為軟體的運維,你需要知道在發生故障的情況下,軟體可能會表現出怎樣的行為。
簡單地假設缺陷很罕見並希望始終保持最好的狀況是不明智的。考慮一系列可能的錯誤(甚至是不太可能的錯誤),並在測試環境中人為地建立這些情況來檢視會發生什麼是非常重要的。在分散式系統中,懷疑,悲觀和偏執狂是值得的。
從不可靠的元件構建可靠的系統
你可能想知道這是否有意義 —— 直觀地看來,系統只能像其最不可靠的元件(最薄弱的環節)一樣可靠。事實並非如此:事實上,從不太可靠的潛在基礎構建更可靠的系統是計算機領域的一個古老思想【11】。例如:
- 糾錯碼允許數字資料在通訊通道上準確傳輸,偶爾會出現一些錯誤,例如由於無線網路上的無線電干擾【12】。
- 網際網路協議(Internet Protocol, IP) 不可靠:可能丟棄、延遲、重複或重排資料包。 傳輸控制協議(Transmission Control Protocol, TCP)在網際網路協議(IP)之上提供了更可靠的傳輸層:它確保丟失的資料包被重新傳輸,消除重複,並且資料包被重新組裝成它們被傳送的順序。
雖然這個系統可以比它的底層部分更可靠,但它的可靠性總是有限的。例如,糾錯碼可以處理少量的單位元錯誤,但是如果你的訊號被幹擾所淹沒,那麼透過通道可以得到多少資料,是有根本性的限制的【13】。 TCP 可以隱藏資料包的丟失,重複和重新排序,但是它不能神奇地消除網路中的延遲。
雖然更可靠的高階系統並不完美,但它仍然有用,因為它處理了一些棘手的低階錯誤,所以其餘的錯誤通常更容易推理和處理。我們將在 “資料庫的端到端原則” 中進一步探討這個問題。
不可靠的網路
正如在 第二部分 的介紹中所討論的那樣,我們在本書中關注的分散式系統是無共享的系統,即透過網路連線的一堆機器。網路是這些機器可以通訊的唯一途徑 —— 我們假設每臺機器都有自己的記憶體和磁碟,一臺機器不能訪問另一臺機器的記憶體或磁碟(除了透過網路向伺服器發出請求)。
無共享 並不是構建系統的唯一方式,但它已經成為構建網際網路服務的主要方式,其原因如下:相對便宜,因為它不需要特殊的硬體,可以利用商品化的雲計算服務,透過跨多個地理分佈的資料中心進行冗餘可以實現高可靠性。
網際網路和資料中心(通常是乙太網)中的大多數內部網路都是 非同步分組網路(asynchronous packet networks)。在這種網路中,一個節點可以向另一個節點發送一個訊息(一個數據包),但是網路不能保證它什麼時候到達,或者是否到達。如果你傳送請求並期待響應,則很多事情可能會出錯(其中一些如 圖 8-1 所示):
{kind=link}
- 請求可能已經丟失(可能有人拔掉了網線)。
- 請求可能正在排隊,稍後將交付(也許網路或接收方過載)。
- 遠端節點可能已經失效(可能是崩潰或關機)。
- 遠端節點可能暫時停止了響應(可能會遇到長時間的垃圾回收暫停;請參閱 “程序暫停”),但稍後會再次響應。
- 遠端節點可能已經處理了請求,但是網路上的響應已經丟失(可能是網路交換機配置錯誤)。
- 遠端節點可能已經處理了請求,但是響應已經被延遲,並且稍後將被傳遞(可能是網路或者你自己的機器過載)。

圖 8-1 如果傳送請求並沒有得到響應,則無法區分(a)請求是否丟失,(b)遠端節點是否關閉,或(c)響應是否丟失。
傳送者甚至不能分辨資料包是否被傳送:唯一的選擇是讓接收者傳送響應訊息,這可能會丟失或延遲。這些問題在非同步網路中難以區分:你所擁有的唯一資訊是,你尚未收到響應。如果你向另一個節點發送請求並且沒有收到響應,則不可能判斷是什麼原因。
處理這個問題的通常方法是 超時(Timeout):在一段時間之後放棄等待,並且認為響應不會到達。但是,當發生超時時,你仍然不知道遠端節點是否收到了請求(如果請求仍然在某個地方排隊,那麼即使傳送者已經放棄了該請求,仍然可能會將其傳送給接收者)。
真實世界的網路故障
我們幾十年來一直在建設計算機網路 —— 有人可能希望現在我們已經找出了使網路變得可靠的方法。但是現在似乎還沒有成功。
有一些系統的研究和大量的軼事證據表明,即使在像一家公司運營的資料中心那樣的受控環境中,網路問題也可能出乎意料地普遍。在一家中型資料中心進行的一項研究發現,每個月大約有 12 個網路故障,其中一半斷開一臺機器,一半斷開整個機架【15】。另一項研究測量了架頂式交換機,匯聚交換機和負載平衡器等元件的故障率【16】。它發現新增冗餘網路裝置不會像你所希望的那樣減少故障,因為它不能防範人為錯誤(例如,錯誤配置的交換機),這是造成中斷的主要原因。
諸如 EC2 之類的公有云服務因頻繁的暫態網路故障而臭名昭著【14】,管理良好的私有資料中心網路可能是更穩定的環境。儘管如此,沒有人不受網路問題的困擾:例如,交換機軟體升級過程中的一個問題可能會引發網路拓撲重構,在此期間網路資料包可能會延遲超過一分鐘【17】。鯊魚可能咬住海底電纜並損壞它們 【18】。其他令人驚訝的故障包括網路介面有時會丟棄所有入站資料包,但是成功傳送出站資料包 【19】:僅僅因為網路連結在一個方向上工作,並不能保證它也在相反的方向工作。
網路分割槽
當網路的一部分由於網路故障而被切斷時,有時稱為 網路分割槽(network partition) 或 網路斷裂(netsplit)。在本書中,我們通常會堅持使用更一般的術語 網路故障(network fault),以避免與 第六章 討論的儲存系統的分割槽(分片)相混淆。
即使網路故障在你的環境中非常罕見,故障可能發生的事實,意味著你的軟體需要能夠處理它們。無論何時透過網路進行通訊,都可能會失敗,這是無法避免的。
如果網路故障的錯誤處理沒有定義與測試,武斷地講,各種錯誤可能都會發生:例如,即使網路恢復【20】,叢集可能會發生 死鎖,永久無法為請求提供服務,甚至可能會刪除所有的資料【21】。如果軟體被置於意料之外的情況下,它可能會做出出乎意料的事情。
處理網路故障並不意味著容忍它們:如果你的網路通常是相當可靠的,一個有效的方法可能是當你的網路遇到問題時,簡單地向用戶顯示一條錯誤資訊。但是,你確實需要知道你的軟體如何應對網路問題,並確保系統能夠從中恢復。有意識地觸發網路問題並測試系統響應(這是 Chaos Monkey 背後的想法;請參閱 “可靠性”)。
檢測故障
許多系統需要自動檢測故障節點。例如:
- 負載平衡器需要停止向已死亡的節點轉發請求(從輪詢列表移出,即 out of rotation)。
- 在單主複製功能的分散式資料庫中,如果主庫失效,則需要將從庫之一升級為新主庫(請參閱 “處理節點宕機”)。
不幸的是,網路的不確定性使得很難判斷一個節點是否工作。在某些特定的情況下,你可能會收到一些反饋資訊,明確告訴你某些事情沒有成功:
- 如果你可以連線到執行節點的機器,但沒有程序正在偵聽目標埠(例如,因為程序崩潰),作業系統將透過傳送 FIN 或 RST 來關閉並重用 TCP 連線。但是,如果節點在處理請求時發生崩潰,則無法知道遠端節點實際處理了多少資料【22】。
- 如果節點程序崩潰(或被管理員殺死),但節點的作業系統仍在執行,則指令碼可以通知其他節點有關該崩潰的資訊,以便另一個節點可以快速接管,而無需等待超時到期。例如,HBase 就是這麼做的【23】。
- 如果你有權訪問資料中心網路交換機的管理介面,則可以透過它們檢測硬體級別的鏈路故障(例如,遠端機器是否關閉電源)。如果你透過網際網路連線,或者如果你處於共享資料中心而無法訪問交換機,或者由於網路問題而無法訪問管理介面,則排除此選項。
- 如果路由器確認你嘗試連線的 IP 地址不可用,則可能會使用 ICMP 目標不可達資料包回覆你。但是,路由器不具備神奇的故障檢測能力 —— 它受到與網路其他參與者相同的限制。
關於遠端節點關閉的快速反饋很有用,但是你不能指望它。即使 TCP 確認已經傳送了一個數據包,應用程式在處理之前可能已經崩潰。如果你想確保一個請求是成功的,你需要應用程式本身的正確響應【24】。
相反,如果出了什麼問題,你可能會在堆疊的某個層次上得到一個錯誤響應,但總的來說,你必須假設你可能根本就得不到任何回應。你可以重試幾次(TCP 重試是透明的,但是你也可以在應用程式級別重試),等待超時過期,並且如果在超時時間內沒有收到響應,則最終宣告節點已經死亡。
超時與無窮的延遲
如果超時是檢測故障的唯一可靠方法,那麼超時應該等待多久?不幸的是沒有簡單的答案。
長時間的超時意味著長時間等待,直到一個節點被宣告死亡(在這段時間內,使用者可能不得不等待,或者看到錯誤資訊)。短的超時可以更快地檢測到故障,但有更高地風險誤將一個節點宣佈為失效,而該節點實際上只是暫時地變慢了(例如由於節點或網路上的負載峰值)。
過早地宣告一個節點已經死了是有問題的:如果這個節點實際上是活著的,並且正在執行一些動作(例如,傳送一封電子郵件),而另一個節點接管,那麼這個動作可能會最終執行兩次。我們將在 “知識、真相與謊言” 以及 第九章 和 第十一章 中更詳細地討論這個問題。
當一個節點被宣告死亡時,它的職責需要轉移到其他節點,這會給其他節點和網路帶來額外的負擔。如果系統已經處於高負荷狀態,則過早宣告節點死亡會使問題更嚴重。特別是如果節點實際上沒有死亡,只是由於過載導致其響應緩慢;這時將其負載轉移到其他節點可能會導致 級聯失效(即 cascading failure,表示在極端情況下,所有節點都宣告對方死亡,所有節點都將停止工作)。
設想一個虛構的系統,其網路可以保證資料包的最大延遲 —— 每個資料包要麼在一段時間內傳送,要麼丟失,但是傳遞永遠不會比 d 更長。此外,假設你可以保證一個非故障節點總是在一段時間內處理一個請求 $r$。在這種情況下,你可以保證每個成功的請求在 2d + r 時間內都能收到響應,如果你在此時間內沒有收到響應,則知道網路或遠端節點不工作。如果這是成立的,2d + r 會是一個合理的超時設定。
不幸的是,我們所使用的大多數系統都沒有這些保證:非同步網路具有無限的延遲(即儘可能快地傳送資料包,但資料包到達可能需要的時間沒有上限),並且大多數伺服器實現並不能保證它們可以在一定的最大時間內處理請求(請參閱 “響應時間保證”)。對於故障檢測,即使系統大部分時間快速執行也是不夠的:如果你的超時時間很短,往返時間只需要一個瞬時尖峰就可以使系統失衡。
網路擁塞和排隊
在駕駛汽車時,由於交通擁堵,道路交通網路的通行時間往往不盡相同。同樣,計算機網路上資料包延遲的可變性通常是由於排隊【25】:
- 如果多個不同的節點同時嘗試將資料包傳送到同一目的地,則網路交換機必須將它們排隊並將它們逐個送入目標網路鏈路(如 圖 8-2 所示)。在繁忙的網路鏈路上,資料包可能需要等待一段時間才能獲得一個插槽(這稱為網路擁塞)。如果傳入的資料太多,交換機佇列填滿,資料包將被丟棄,因此需要重新發送資料包 - 即使網路執行良好。
- 當資料包到達目標機器時,如果所有 CPU 核心當前都處於繁忙狀態,則來自網路的傳入請求將被作業系統排隊,直到應用程式準備好處理它為止。根據機器上的負載,這可能需要一段任意的時間。
- 在虛擬化環境中,正在執行的作業系統經常暫停幾十毫秒,因為另一個虛擬機器正在使用 CPU 核心。在這段時間內,虛擬機器不能從網路中消耗任何資料,所以傳入的資料被虛擬機器監視器 【26】排隊(緩衝),進一步增加了網路延遲的可變性。
- TCP 執行 流量控制(flow control,也稱為 擁塞避免,即 congestion avoidance,或 背壓,即 backpressure),其中節點會限制自己的傳送速率以避免網路鏈路或接收節點過載【27】。這意味著甚至在資料進入網路之前,在傳送者處就需要進行額外的排隊。
{kind=link}
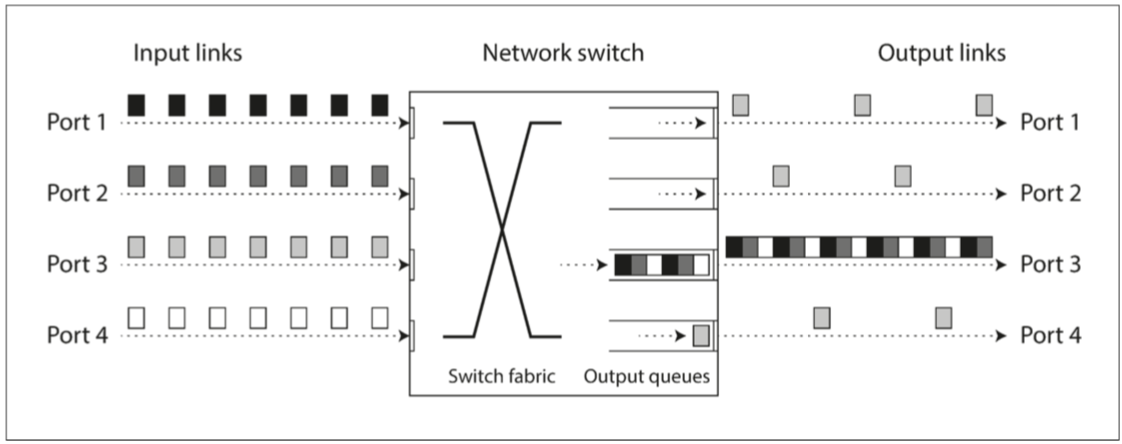
圖 8-2 如果有多臺機器將網路流量傳送到同一目的地,則其交換機佇列可能會被填滿。在這裡,埠 1,2 和 4 都試圖傳送資料包到埠 3
而且,如果 TCP 在某個超時時間內沒有被確認(這是根據觀察的往返時間計算的),則認為資料包丟失,丟失的資料包將自動重新發送。儘管應用程式沒有看到資料包丟失和重新傳輸,但它看到了延遲(等待超時到期,然後等待重新傳輸的資料包得到確認)。
TCP與UDP
一些對延遲敏感的應用程式,比如視訊會議和 IP 語音(VoIP),使用了 UDP 而不是 TCP。這是在可靠性和和延遲變化之間的折衷:由於 UDP 不執行流量控制並且不重傳丟失的分組,所以避免了網路延遲變化的一些原因(儘管它仍然易受切換佇列和排程延遲的影響)。
在延遲資料毫無價值的情況下,UDP 是一個不錯的選擇。例如,在 VoIP 電話呼叫中,可能沒有足夠的時間重新發送丟失的資料包,並在揚聲器上播放資料。在這種情況下,重發資料包沒有意義 —— 應用程式必須使用靜音填充丟失資料包的時隙(導致聲音短暫中斷),然後在資料流中繼續。重試發生在人類層。 (“你能再說一遍嗎?聲音剛剛斷了一會兒。“)
所有這些因素都會造成網路延遲的變化。當系統接近其最大容量時,排隊延遲的變化範圍特別大:擁有足夠備用容量的系統可以輕鬆排空佇列,而在高利用率的系統中,很快就能積累很長的佇列。
在公共雲和多租戶資料中心中,資源被許多客戶共享:網路連結和交換機,甚至每個機器的網絡卡和 CPU(在虛擬機器上執行時)。批處理工作負載(如 MapReduce,請參閱 第十章)能夠很容易使網路連結飽和。由於無法控制或瞭解其他客戶對共享資源的使用情況,如果附近的某個人(嘈雜的鄰居)正在使用大量資源,則網路延遲可能會發生劇烈變化【28,29】。
在這種環境下,你只能透過實驗方式選擇超時:在一段較長的時期內、在多臺機器上測量網路往返時間的分佈,以確定延遲的預期變化。然後,考慮到應用程式的特性,可以確定 故障檢測延遲 與 過早超時風險 之間的適當折衷。
更好的一種做法是,系統不是使用配置的常量超時時間,而是連續測量響應時間及其變化(抖動),並根據觀察到的響應時間分佈自動調整超時時間。這可以透過 Phi Accrual 故障檢測器【30】來完成,該檢測器在例如 Akka 和 Cassandra 【31】中使用。 TCP 的超時重傳機制也是以類似的方式工作【27】。
同步網路與非同步網路
如果我們可以依靠網路來傳遞一些 最大延遲固定 的資料包,而不是丟棄資料包,那麼分散式系統就會簡單得多。為什麼我們不能在硬體層面上解決這個問題,使網路可靠,使軟體不必擔心呢?
為了回答這個問題,將資料中心網路與非常可靠的傳統固定電話網路(非蜂窩,非 VoIP)進行比較是很有趣的:延遲音訊幀和掉話是非常罕見的。一個電話需要一個很低的端到端延遲,以及足夠的頻寬來傳輸你聲音的音訊取樣資料。在計算機網路中有類似的可靠性和可預測性不是很好嗎?
當你透過電話網路撥打電話時,它會建立一個電路:在兩個呼叫者之間的整個路線上為呼叫分配一個固定的,有保證的頻寬量。這個電路會保持至通話結束【32】。例如,ISDN 網路以每秒 4000 幀的固定速率執行。呼叫建立時,每個幀內(每個方向)分配 16 位空間。因此,在通話期間,每一方都保證能夠每 250 微秒傳送一個精確的 16 位音訊資料【33,34】。
這種網路是同步的:即使資料經過多個路由器,也不會受到排隊的影響,因為呼叫的 16 位空間已經在網路的下一跳中保留了下來。而且由於沒有排隊,網路的最大端到端延遲是固定的。我們稱之為 有限延遲(bounded delay)。
我們不能簡單地使網路延遲可預測嗎?
請注意,電話網路中的電路與 TCP 連線有很大不同:電路是固定數量的預留頻寬,在電路建立時沒有其他人可以使用,而 TCP 連線的資料包 機會性地 使用任何可用的網路頻寬。你可以給 TCP 一個可變大小的資料塊(例如,一個電子郵件或一個網頁),它會盡可能在最短的時間內傳輸它。 TCP 連線空閒時,不使用任何頻寬 3。
如果資料中心網路和網際網路是電路交換網路,那麼在建立電路時就可以建立一個受保證的最大往返時間。但是,它們並不是:乙太網和 IP 是 分組交換協議,不得不忍受排隊的折磨,及其導致的網路無限延遲。這些協議沒有電路的概念。
為什麼資料中心網路和網際網路使用分組交換?答案是,它們針對 突發流量(bursty traffic) 進行了最佳化。一個電路適用於音訊或視訊通話,在通話期間需要每秒傳送相當數量的位元。另一方面,請求網頁,傳送電子郵件或傳輸檔案沒有任何特定的頻寬要求 —— 我們只是希望它儘快完成。
如果想透過電路傳輸檔案,你得預測一個頻寬分配。如果你猜的太低,傳輸速度會不必要的太慢,導致網路容量閒置。如果你猜的太高,電路就無法建立(因為如果無法保證其頻寬分配,網路不能建立電路)。因此,將電路用於突發資料傳輸會浪費網路容量,並且使傳輸不必要地緩慢。相比之下,TCP 動態調整資料傳輸速率以適應可用的網路容量。
已經有一些嘗試去建立同時支援電路交換和分組交換的混合網路,比如 ATM 4。InfiniBand 有一些相似之處【35】:它在鏈路層實現了端到端的流量控制,從而減少了在網路中排隊的需要,儘管它仍然可能因鏈路擁塞而受到延遲【36】。透過仔細使用 服務質量(quality of service,即 QoS,資料包的優先順序和排程)和 准入控制(admission control,限速傳送器),可以在分組網路上類比電路交換,或提供統計上的 有限延遲【25,32】。
但是,目前在多租戶資料中心和公共雲或透過網際網路 5 進行通訊時,此類服務質量尚未啟用。當前部署的技術不允許我們對網路的延遲或可靠性作出任何保證:我們必須假設網路擁塞,排隊和無限的延遲總是會發生。因此,超時時間沒有 “正確” 的值 —— 它需要透過實驗來確定。
延遲和資源利用
更一般地說,可以將 延遲變化 視為 動態資源分割槽 的結果。
假設兩臺電話交換機之間有一條線路,可以同時進行 10,000 個呼叫。透過此線路切換的每個電路都佔用其中一個呼叫插槽。因此,你可以將線路視為可由多達 10,000 個併發使用者共享的資源。資源以靜態方式分配:即使你現在是線路上唯一的呼叫,並且所有其他 9,999 個插槽都未使用,你的電路仍將分配與線路充分利用時相同的固定數量的頻寬。
相比之下,網際網路動態分享網路頻寬。傳送者互相推擠和爭奪,以讓他們的資料包儘可能快地透過網路,並且網路交換機決定從一個時刻到另一個時刻傳送哪個分組(即,頻寬分配)。這種方法有排隊的缺點,但其優點是它最大限度地利用了線路。線路固定成本,所以如果你更好地利用它,你透過線路傳送的每個位元組都會更便宜。
CPU 也會出現類似的情況:如果你在多個執行緒間動態共享每個 CPU 核心,則一個執行緒有時必須在作業系統的執行佇列裡等待,而另一個執行緒正在執行,這樣每個執行緒都有可能被暫停一個不定的時間長度。但是,與為每個執行緒分配靜態數量的 CPU 週期相比,這會更好地利用硬體(請參閱 “響應時間保證”)。更好的硬體利用率也是使用虛擬機器的重要動機。
如果資源是靜態分割槽的(例如,專用硬體和專用頻寬分配),則在某些環境中可以實現 延遲保證。但是,這是以降低利用率為代價的 —— 換句話說,它是更昂貴的。另一方面,動態資源分配的多租戶提供了更好的利用率,所以它更便宜,但它具有可變延遲的缺點。
網路中的可變延遲不是一種自然規律,而只是成本 / 收益權衡的結果。
不可靠的時鐘
時鐘和時間很重要。應用程式以各種方式依賴於時鐘來回答以下問題:
- 這個請求是否超時了?
- 這項服務的第 99 百分位響應時間是多少?
- 在過去五分鐘內,該服務平均每秒處理多少個查詢?
- 使用者在我們的網站上花了多長時間?
- 這篇文章在何時釋出?
- 在什麼時間傳送提醒郵件?
- 這個快取條目何時到期?
- 日誌檔案中此錯誤訊息的時間戳是什麼?
例 1-4 測量了 持續時間(durations,例如,請求傳送與響應接收之間的時間間隔),而 例 5-8 描述了 時間點(point in time,在特定日期和和特定時間發生的事件)。
在分散式系統中,時間是一件棘手的事情,因為通訊不是即時的:訊息透過網路從一臺機器傳送到另一臺機器需要時間。收到訊息的時間總是晚於傳送的時間,但是由於網路中的可變延遲,我們不知道晚了多少時間。這個事實導致有時很難確定在涉及多臺機器時發生事情的順序。
而且,網路上的每臺機器都有自己的時鐘,這是一個實際的硬體裝置:通常是石英晶體振盪器。這些裝置不是完全準確的,所以每臺機器都有自己的時間概念,可能比其他機器稍快或更慢。可以在一定程度上同步時鐘:最常用的機制是 網路時間協議(NTP),它允許根據一組伺服器報告的時間來調整計算機時鐘【37】。伺服器則從更精確的時間源(如 GPS 接收機)獲取時間。
單調鍾與日曆時鐘
現代計算機至少有兩種不同的時鐘:日曆時鐘(time-of-day clock)和單調鍾(monotonic clock)。儘管它們都衡量時間,但區分這兩者很重要,因為它們有不同的目的。
日曆時鐘
日曆時鐘是你直觀地瞭解時鐘的依據:它根據某個日曆(也稱為 掛鐘時間,即 wall-clock time)返回當前日期和時間。例如,Linux 上的 clock_gettime(CLOCK_REALTIME)6 和 Java 中的 System.currentTimeMillis() 返回自 epoch(UTC 時間 1970 年 1 月 1 日午夜)以來的秒數(或毫秒),根據公曆(Gregorian)日曆,不包括閏秒。有些系統使用其他日期作為參考點。
日曆時鐘通常與 NTP 同步,這意味著來自一臺機器的時間戳(理想情況下)與另一臺機器上的時間戳相同。但是如下節所述,日曆時鐘也具有各種各樣的奇特之處。特別是,如果本地時鐘在 NTP 伺服器之前太遠,則它可能會被強制重置,看上去好像跳回了先前的時間點。這些跳躍以及他們經常忽略閏秒的事實,使日曆時鐘不能用於測量經過時間(elapsed time)【38】。
歷史上的日曆時鐘還具有相當粗略的解析度,例如,在較早的 Windows 系統上以 10 毫秒為單位前進【39】。在最近的系統中這已經不是一個問題了。
單調鍾
單調鍾適用於測量持續時間(時間間隔),例如超時或服務的響應時間:Linux 上的 clock_gettime(CLOCK_MONOTONIC),和 Java 中的 System.nanoTime() 都是單調時鐘。這個名字來源於他們保證總是往前走的事實(而日曆時鐘可以往回跳)。
你可以在某個時間點檢查單調鐘的值,做一些事情,且稍後再次檢查它。這兩個值之間的差異告訴你兩次檢查之間經過了多長時間。但單調鐘的絕對值是毫無意義的:它可能是計算機啟動以來的納秒數,或類似的任意值。特別是比較來自兩臺不同計算機的單調鐘的值是沒有意義的,因為它們並不是一回事。
在具有多個 CPU 插槽的伺服器上,每個 CPU 可能有一個單獨的計時器,但不一定與其他 CPU 同步。作業系統會補償所有的差異,並嘗試嚮應用執行緒表現出單調鐘的樣子,即使這些執行緒被排程到不同的 CPU 上。當然,明智的做法是不要太把這種單調性保證當回事【40】。
如果 NTP 協議檢測到計算機的本地石英鐘比 NTP 伺服器要更快或更慢,則可以調整單調鍾向前走的頻率(這稱為 偏移(skewing) 時鐘)。預設情況下,NTP 允許時鐘速率增加或減慢最高至 0.05%,但 NTP 不能使單調時鐘向前或向後跳轉。單調時鐘的解析度通常相當好:在大多數系統中,它們能在幾微秒或更短的時間內測量時間間隔。
在分散式系統中,使用單調鍾測量 經過時間(elapsed time,比如超時)通常很好,因為它不假定不同節點的時鐘之間存在任何同步,並且對測量的輕微不準確性不敏感。
時鐘同步與準確性
單調鐘不需要同步,但是日曆時鐘需要根據 NTP 伺服器或其他外部時間源來設定才能有用。不幸的是,我們獲取時鐘的方法並不像你所希望的那樣可靠或準確 —— 硬體時鐘和 NTP 可能會變幻莫測。舉幾個例子:
- 計算機中的石英鐘不夠精確:它會 漂移(drifts,即執行速度快於或慢於預期)。時鐘漂移取決於機器的溫度。 Google 假設其伺服器時鐘漂移為 200 ppm(百萬分之一)【41】,相當於每 30 秒與伺服器重新同步一次的時鐘漂移為 6 毫秒,或者每天重新同步的時鐘漂移為 17 秒。即使一切工作正常,此漂移也會限制可以達到的最佳準確度。
- 如果計算機的時鐘與 NTP 伺服器的時鐘差別太大,可能會拒絕同步,或者本地時鐘將被強制重置【37】。任何觀察重置前後時間的應用程式都可能會看到時間倒退或突然跳躍。
- 如果某個節點被 NTP 伺服器的防火牆意外阻塞,有可能會持續一段時間都沒有人會注意到。有證據表明,這在實踐中確實發生過。
- NTP 同步只能和網路延遲一樣好,所以當你在擁有可變資料包延遲的擁塞網路上時,NTP 同步的準確性會受到限制。一個實驗表明,當透過網際網路同步時,35 毫秒的最小誤差是可以實現的,儘管偶爾的網路延遲峰值會導致大約一秒的誤差。根據配置,較大的網路延遲會導致 NTP 客戶端完全放棄。
- 一些 NTP 伺服器是錯誤的或者配置錯誤的,報告的時間可能相差幾個小時【43,44】。還好 NTP 客戶端非常健壯,因為他們會查詢多個伺服器並忽略異常值。無論如何,依賴於網際網路上的陌生人所告訴你的時間來保證你的系統的正確性,這還挺讓人擔憂的。
- 閏秒導致一分鐘可能有 59 秒或 61 秒,這會打破一些在設計之時未考慮閏秒的系統的時序假設【45】。閏秒已經使許多大型系統崩潰的事實【38,46】說明了,關於時鐘的錯誤假設是多麼容易偷偷溜入系統中。處理閏秒的最佳方法可能是讓 NTP 伺服器 “撒謊”,並在一天中逐漸執行閏秒調整(這被稱為 拖尾,即 smearing)【47,48】,雖然實際的 NTP 伺服器表現各異【49】。
- 在虛擬機器中,硬體時鐘被虛擬化,這對於需要精確計時的應用程式提出了額外的挑戰【50】。當一個 CPU 核心在虛擬機器之間共享時,每個虛擬機器都會暫停幾十毫秒,與此同時另一個虛擬機器正在執行。從應用程式的角度來看,這種停頓表現為時鐘突然向前跳躍【26】。
- 如果你在沒有完整控制權的裝置(例如,移動裝置或嵌入式裝置)上執行軟體,則可能完全不能信任該裝置的硬體時鐘。一些使用者故意將其硬體時鐘設定為不正確的日期和時間,例如,為了規避遊戲中的時間限制,時鐘可能會被設定到很遠的過去或將來。
如果你足夠在乎這件事並投入大量資源,就可以達到非常好的時鐘精度。例如,針對金融機構的歐洲法規草案 MiFID II 要求所有高頻率交易基金在 UTC 時間 100 微秒內同步時鐘,以便除錯 “閃崩” 等市場異常現象,並幫助檢測市場操縱【51】。
透過 GPS 接收機,精確時間協議(PTP)【52】以及仔細的部署和監測可以實現這種精確度。然而,這需要很多努力和專業知識,而且有很多東西都會導致時鐘同步錯誤。如果你的 NTP 守護程序配置錯誤,或者防火牆阻止了 NTP 通訊,由漂移引起的時鐘誤差可能很快就會變大。
依賴同步時鐘
時鐘的問題在於,雖然它們看起來簡單易用,但卻具有令人驚訝的缺陷:一天可能不會有精確的 86,400 秒,日曆時鐘 可能會前後跳躍,而一個節點上的時間可能與另一個節點上的時間完全不同。
本章早些時候,我們討論了網路丟包和任意延遲包的問題。儘管網路在大多數情況下表現良好,但軟體的設計必須假定網路偶爾會出現故障,而軟體必須正常處理這些故障。時鐘也是如此:儘管大多數時間都工作得很好,但需要準備健壯的軟體來處理不正確的時鐘。
有一部分問題是,不正確的時鐘很容易被視而不見。如果一臺機器的 CPU 出現故障或者網路配置錯誤,很可能根本無法工作,所以很快就會被注意和修復。另一方面,如果它的石英時鐘有缺陷,或者它的 NTP 客戶端配置錯誤,大部分事情似乎仍然可以正常工作,即使它的時鐘逐漸偏離現實。如果某個軟體依賴於精確同步的時鐘,那麼結果更可能是悄無聲息的,僅有微量的資料丟失,而不是一次驚天動地的崩潰【53,54】。
因此,如果你使用需要同步時鐘的軟體,必須仔細監控所有機器之間的時鐘偏移。時鐘偏離其他時鐘太遠的節點應當被宣告死亡,並從叢集中移除。這樣的監控可以確保你在損失發生之前注意到破損的時鐘。
有序事件的時間戳
讓我們考慮一個特別的情況,一件很有誘惑但也很危險的事情:依賴時鐘,在多個節點上對事件進行排序。 例如,如果兩個客戶端寫入分散式資料庫,誰先到達? 哪一個更近?
圖 8-3 顯示了在具有多主複製的資料庫中對時鐘的危險使用(該例子類似於 圖 5-9)。 客戶端 A 在節點 1 上寫入 x = 1;寫入被複制到節點 3;客戶端 B 在節點 3 上增加 x(我們現在有 x = 2);最後這兩個寫入都被複制到節點 2。
{kind=link}
{kind=link}
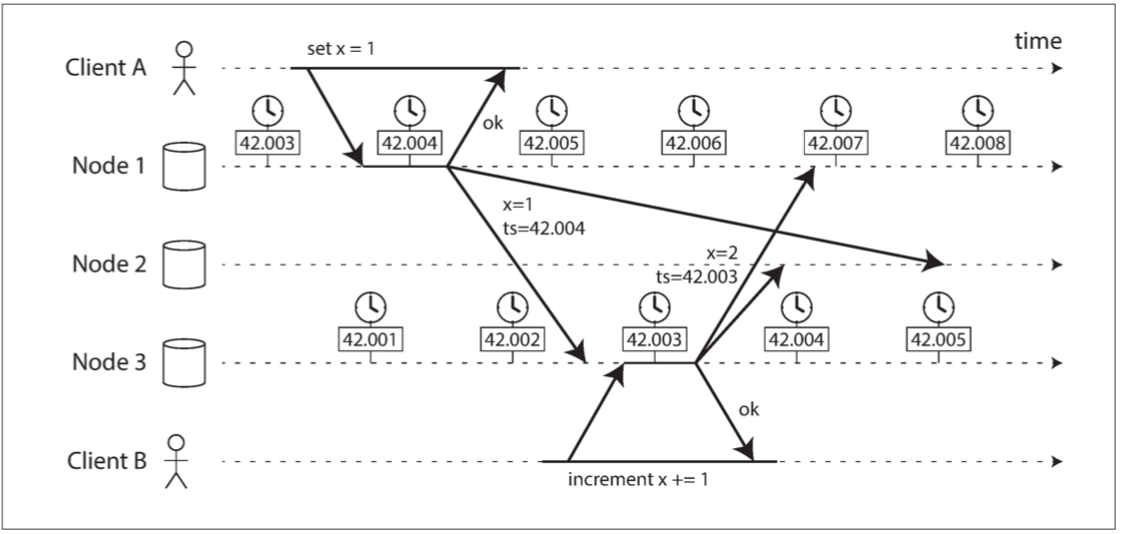
圖 8-3 客戶端 B 的寫入比客戶端 A 的寫入要晚,但是 B 的寫入具有較早的時間戳。
在 圖 8-3 中,當一個寫入被複制到其他節點時,它會根據發生寫入的節點上的日曆時鐘標記一個時間戳。在這個例子中,時鐘同步是非常好的:節點 1 和節點 3 之間的偏差小於 3ms,這可能比你在實踐中能預期的更好。
儘管如此,圖 8-3 中的時間戳卻無法正確排列事件:寫入 x = 1 的時間戳為 42.004 秒,但寫入 x = 2 的時間戳為 42.003 秒,即使 x = 2 在稍後出現。當節點 2 接收到這兩個事件時,會錯誤地推斷出 x = 1 是最近的值,而丟棄寫入 x = 2。效果上表現為,客戶端 B 的增量操作會丟失。
這種衝突解決策略被稱為 最後寫入勝利(LWW),它在多主複製和無主資料庫(如 Cassandra 【53】和 Riak 【54】)中被廣泛使用(請參閱 “最後寫入勝利(丟棄併發寫入)” 一節)。有些實現會在客戶端而不是伺服器上生成時間戳,但這並不能改變 LWW 的基本問題:
- 資料庫寫入可能會神秘地消失:具有滯後時鐘的節點無法覆蓋之前具有快速時鐘的節點寫入的值,直到節點之間的時鐘偏差消逝【54,55】。此方案可能導致一定數量的資料被悄悄丟棄,而未嚮應用報告任何錯誤。
- LWW 無法區分 高頻順序寫入(在 圖 8-3 中,客戶端 B 的增量操作 一定 發生在客戶端 A 的寫入之後)和 真正併發寫入(寫入者意識不到其他寫入者)。需要額外的因果關係跟蹤機制(例如版本向量),以防止違背因果關係(請參閱 “檢測併發寫入”)。
- 兩個節點很可能獨立地生成具有相同時間戳的寫入,特別是在時鐘僅具有毫秒解析度的情況下。為了解決這樣的衝突,還需要一個額外的 決勝值(tiebreaker,可以簡單地是一個大隨機數),但這種方法也可能會導致違背因果關係【53】。
因此,儘管透過保留最 “最近” 的值並放棄其他值來解決衝突是很誘惑人的,但是要注意,“最近” 的定義取決於本地的 日曆時鐘,這很可能是不正確的。即使用嚴格同步的 NTP 時鐘,一個數據包也可能在時間戳 100 毫秒(根據傳送者的時鐘)時傳送,並在時間戳 99 毫秒(根據接收者的時鐘)處到達 —— 看起來好像資料包在傳送之前已經到達,這是不可能的。
NTP 同步是否能足夠準確,以至於這種不正確的排序不會發生?也許不能,因為 NTP 的同步精度本身,除了石英鐘漂移這類誤差源之外,還受到網路往返時間的限制。為了進行正確的排序,你需要一個比測量物件(即網路延遲)要精確得多的時鐘。
所謂的 邏輯時鐘(logic clock)【56,57】是基於遞增計數器而不是振盪石英晶體,對於排序事件來說是更安全的選擇(請參閱 “檢測併發寫入”)。邏輯時鐘不測量一天中的時間或經過的秒數,而僅測量事件的相對順序(無論一個事件發生在另一個事件之前還是之後)。相反,用來測量實際經過時間的 日曆時鐘 和 單調鍾 也被稱為 物理時鐘(physical clock)。我們將在 “順序保證” 中來看順序問題。
時鐘讀數存在置信區間
你可能能夠以微秒或甚至納秒的精度讀取機器的時鐘。但即使可以得到如此細緻的測量結果,這並不意味著這個值對於這樣的精度實際上是準確的。實際上,大機率是不準確的 —— 如前所述,即使你每分鐘與本地網路上的 NTP 伺服器進行同步,幾毫秒的時間漂移也很容易在不精確的石英時鐘上發生。使用公共網際網路上的 NTP 伺服器,最好的準確度可能達到幾十毫秒,而且當網路擁塞時,誤差可能會超過 100 毫秒【57】。
因此,將時鐘讀數視為一個時間點是沒有意義的 —— 它更像是一段時間範圍:例如,一個系統可能以 95% 的置信度認為當前時間處於本分鐘內的第 10.3 秒和 10.5 秒之間,它可能沒法比這更精確了【58】。如果我們只知道 ±100 毫秒的時間,那麼時間戳中的微秒數字部分基本上是沒有意義的。
不確定性界限可以根據你的時間源來計算。如果你的 GPS 接收器或原子(銫)時鐘直接連線到你的計算機上,預期的錯誤範圍由製造商告知。如果從伺服器獲得時間,則不確定性取決於自上次與伺服器同步以來的石英鐘漂移的期望值,加上 NTP 伺服器的不確定性,再加上到伺服器的網路往返時間(只是獲取粗略近似值,並假設伺服器是可信的)。
不幸的是,大多數系統不公開這種不確定性:例如,當呼叫 clock_gettime() 時,返回值不會告訴你時間戳的預期錯誤,所以你不知道其置信區間是 5 毫秒還是 5 年。
一個有趣的例外是 Spanner 中的 Google TrueTime API 【41】,它明確地報告了本地時鐘的置信區間。當你詢問當前時間時,你會得到兩個值:[最早,最晚],這是最早可能的時間戳和最晚可能的時間戳。在不確定性估計的基礎上,時鐘知道當前的實際時間落在該區間內。區間的寬度取決於自從本地石英鐘最後與更精確的時鐘源同步以來已經過了多長時間。
全域性快照的同步時鐘
在 “快照隔離和可重複讀” 中,我們討論了快照隔離,這是資料庫中非常有用的功能,需要支援小型快速讀寫事務和大型長時間執行的只讀事務(用於備份或分析)。它允許只讀事務看到特定時間點的處於一致狀態的資料庫,且不會鎖定和干擾讀寫事務。
快照隔離最常見的實現需要單調遞增的事務 ID。如果寫入比快照晚(即,寫入具有比快照更大的事務 ID),則該寫入對於快照事務是不可見的。在單節點資料庫上,一個簡單的計數器就足以生成事務 ID。
但是當資料庫分佈在許多機器上,也許可能在多個數據中心中時,由於需要協調,(跨所有分割槽)全域性單調遞增的事務 ID 會很難生成。事務 ID 必須反映因果關係:如果事務 B 讀取由事務 A 寫入的值,則 B 必須具有比 A 更大的事務 ID,否則快照就無法保持一致。在有大量的小規模、高頻率的事務情景下,在分散式系統中建立事務 ID 成為一個難以處理的瓶頸 7。
我們可以使用同步時鐘的時間戳作為事務 ID 嗎?如果我們能夠獲得足夠好的同步性,那麼這種方法將具有很合適的屬性:更晚的事務會有更大的時間戳。當然,問題在於時鐘精度的不確定性。
Spanner 以這種方式實現跨資料中心的快照隔離【59,60】。它使用 TrueTime API 報告的時鐘置信區間,並基於以下觀察結果:如果你有兩個置信區間,每個置信區間包含最早和最晚可能的時間戳($A = [A_{earliest}, A_{latest}]$, $B=[B_{earliest}, B_{latest}]$),這兩個區間不重疊(即:$A_{earliest} <A_{latest} <B_{earliest} <B_{latest}$)的話,那麼 B 肯定發生在 A 之後 —— 這是毫無疑問的。只有當區間重疊時,我們才不確定 A 和 B 發生的順序。
為了確保事務時間戳反映因果關係,在提交讀寫事務之前,Spanner 在提交讀寫事務時,會故意等待置信區間長度的時間。透過這樣,它可以確保任何可能讀取資料的事務處於足夠晚的時間,因此它們的置信區間不會重疊。為了保持儘可能短的等待時間,Spanner 需要保持儘可能小的時鐘不確定性,為此,Google 在每個資料中心都部署了一個 GPS 接收器或原子鐘,這允許時鐘同步到大約 7 毫秒以內【41】。
對分散式事務語義使用時鐘同步是一個活躍的研究領域【57,61,62】。這些想法很有趣,但是它們還沒有在谷歌之外的主流資料庫中實現。
程序暫停
讓我們考慮在分散式系統中使用危險時鐘的另一個例子。假設你有一個數據庫,每個分割槽只有一個領導者。只有領導被允許接受寫入。一個節點如何知道它仍然是領導者(它並沒有被別人宣告為死亡),並且它可以安全地接受寫入?
一種選擇是領導者從其他節點獲得一個 租約(lease),類似一個帶超時的鎖【63】。任一時刻只有一個節點可以持有租約 —— 因此,當一個節點獲得一個租約時,它知道它在某段時間內自己是領導者,直到租約到期。為了保持領導地位,節點必須週期性地在租約過期前續期。
如果節點發生故障,就會停止續期,所以當租約過期時,另一個節點可以接管。
可以想象,請求處理迴圈看起來像這樣:
while (true) {
request = getIncomingRequest();
// 確保租約還剩下至少 10 秒
if (lease.expiryTimeMillis - System.currentTimeMillis() < 10000){
lease = lease.renew();
}
if (lease.isValid()) {
process(request);
}
}
這個程式碼有什麼問題?首先,它依賴於同步時鐘:租約到期時間由另一臺機器設定(例如,當前時間加上 30 秒,計算到期時間),並將其與本地系統時鐘進行比較。如果時鐘不同步超過幾秒,這段程式碼將開始做奇怪的事情。
其次,即使我們將協議更改為僅使用本地單調時鐘,也存在另一個問題:程式碼假定在執行剩餘時間檢查 System.currentTimeMillis() 和實際執行請求 process(request) 中間的時間間隔非常短。通常情況下,這段程式碼執行得非常快,所以 10 秒的緩衝區已經足夠確保 租約 在請求處理到一半時不會過期。
但是,如果程式執行中出現了意外的停頓呢?例如,想象一下,執行緒在 lease.isValid() 行周圍停止 15 秒,然後才繼續。在這種情況下,在請求被處理的時候,租約可能已經過期,而另一個節點已經接管了領導。然而,沒有什麼可以告訴這個執行緒已經暫停了這麼長時間了,所以這段程式碼不會注意到租約已經到期了,直到迴圈的下一個迭代 —— 到那個時候它可能已經做了一些不安全的處理請求。
假設一個執行緒可能會暫停很長時間,這是瘋了嗎?不幸的是,這種情況發生的原因有很多種:
- 許多程式語言執行時(如 Java 虛擬機器)都有一個垃圾收集器(GC),偶爾需要停止所有正在執行的執行緒。這些 “停止所有處理(stop-the-world)”GC 暫停有時會持續幾分鐘【64】!甚至像 HotSpot JVM 的 CMS 這樣的所謂的 “並行” 垃圾收集器也不能完全與應用程式程式碼並行執行,它需要不時地停止所有處理【65】。儘管通常可以透過改變分配模式或調整 GC 設定來減少暫停【66】,但是如果我們想要提供健壯的保證,就必須假設最壞的情況發生。
- 在虛擬化環境中,可以 掛起(suspend) 虛擬機器(暫停執行所有程序並將記憶體內容儲存到磁碟)並恢復(恢復記憶體內容並繼續執行)。這個暫停可以在程序執行的任何時候發生,並且可以持續任意長的時間。這個功能有時用於虛擬機器從一個主機到另一個主機的實時遷移,而不需要重新啟動,在這種情況下,暫停的長度取決於程序寫入記憶體的速率【67】。
- 在終端使用者的裝置(如膝上型電腦)上,執行也可能被暫停並隨意恢復,例如當用戶關閉膝上型電腦的蓋子時。
- 當作業系統上下文切換到另一個執行緒時,或者當管理程式切換到另一個虛擬機器時(在虛擬機器中執行時),當前正在執行的執行緒可能在程式碼中的任意點處暫停。在虛擬機器的情況下,在其他虛擬機器中花費的 CPU 時間被稱為 竊取時間(steal time)。如果機器處於沉重的負載下(即,如果等待執行的執行緒佇列很長),暫停的執行緒再次執行可能需要一些時間。
- 如果應用程式執行同步磁碟訪問,則執行緒可能暫停,等待緩慢的磁碟 I/O 操作完成【68】。在許多語言中,即使程式碼沒有包含檔案訪問,磁碟訪問也可能出乎意料地發生 —— 例如,Java 類載入器在第一次使用時惰性載入類檔案,這可能在程式執行過程中隨時發生。 I/O 暫停和 GC 暫停甚至可能合謀組合它們的延遲【69】。如果磁碟實際上是一個網路檔案系統或網路塊裝置(如亞馬遜的 EBS),I/O 延遲進一步受到網路延遲變化的影響【29】。
- 如果作業系統配置為允許交換到磁碟(頁面交換),則簡單的記憶體訪問可能導致 頁面錯誤(page fault),要求將磁碟中的頁面裝入記憶體。當這個緩慢的 I/O 操作發生時,執行緒暫停。如果記憶體壓力很高,則可能需要將另一個頁面換出到磁碟。在極端情況下,作業系統可能花費大部分時間將頁面交換到記憶體中,而實際上完成的工作很少(這被稱為 抖動,即 thrashing)。為了避免這個問題,通常在伺服器機器上禁用頁面排程(如果你寧願幹掉一個程序來釋放記憶體,也不願意冒抖動風險)。
- 可以透過傳送 SIGSTOP 訊號來暫停 Unix 程序,例如透過在 shell 中按下 Ctrl-Z。 這個訊號立即阻止程序繼續執行更多的 CPU 週期,直到 SIGCONT 恢復為止,此時它將繼續執行。 即使你的環境通常不使用 SIGSTOP,也可能由運維工程師意外發送。
所有這些事件都可以隨時 搶佔(preempt) 正在執行的執行緒,並在稍後的時間恢復執行,而執行緒甚至不會注意到這一點。這個問題類似於在單個機器上使多執行緒程式碼執行緒安全:你不能對時序做任何假設,因為隨時可能發生上下文切換,或者出現並行執行。
當在一臺機器上編寫多執行緒程式碼時,我們有相當好的工具來實現執行緒安全:互斥量,訊號量,原子計數器,無鎖資料結構,阻塞佇列等等。不幸的是,這些工具並不能直接轉化為分散式系統操作,因為分散式系統沒有共享記憶體,只有透過不可靠網路傳送的訊息。
分散式系統中的節點,必須假定其執行可能在任意時刻暫停相當長的時間,即使是在一個函式的中間。在暫停期間,世界的其它部分在繼續運轉,甚至可能因為該節點沒有響應,而宣告暫停節點的死亡。最終暫停的節點可能會繼續執行,在再次檢查自己的時鐘之前,甚至可能不會意識到自己進入了睡眠。
響應時間保證
在許多程式語言和作業系統中,執行緒和程序可能暫停一段無限制的時間,正如討論的那樣。如果你足夠努力,導致暫停的原因是 可以 消除的。
某些軟體的執行環境要求很高,不能在特定時間內響應可能會導致嚴重的損失:控制飛機、火箭、機器人、汽車和其他物體的計算機必須對其感測器輸入做出快速而可預測的響應。在這些系統中,軟體必須有一個特定的 截止時間(deadline),如果截止時間不滿足,可能會導致整個系統的故障。這就是所謂的 硬實時(hard real-time) 系統。
實時是真的嗎?
在嵌入式系統中,實時是指系統經過精心設計和測試,以滿足所有情況下的特定時間保證。這個含義與 Web 上對實時術語的模糊使用相反,後者描述了伺服器將資料推送到客戶端以及沒有嚴格的響應時間限制的流處理(見 第十一章)。
例如,如果車載感測器檢測到當前正在經歷碰撞,你肯定不希望安全氣囊釋放系統因為 GC 暫停而延遲彈出。
在系統中提供 實時保證 需要各級軟體棧的支援:一個實時作業系統(RTOS),允許在指定的時間間隔內保證 CPU 時間的分配。庫函式必須申明最壞情況下的執行時間;動態記憶體分配可能受到限制或完全不允許(實時垃圾收集器存在,但是應用程式仍然必須確保它不會給 GC 太多的負擔);必須進行大量的測試和測量,以確保達到保證。
所有這些都需要大量額外的工作,嚴重限制了可以使用的程式語言、庫和工具的範圍(因為大多數語言和工具不提供實時保證)。由於這些原因,開發實時系統非常昂貴,並且它們通常用於安全關鍵的嵌入式裝置。而且,“實時” 與 “高效能” 不一樣 —— 事實上,實時系統可能具有較低的吞吐量,因為他們必須讓及時響應的優先順序高於一切(另請參閱 “延遲和資源利用“)。
對於大多數伺服器端資料處理系統來說,實時保證是不經濟或不合適的。因此,這些系統必須承受在非實時環境中執行的暫停和時鐘不穩定性。
限制垃圾收集的影響
程序暫停的負面影響可以在不訴諸昂貴的實時排程保證的情況下得到緩解。語言執行時在計劃垃圾回收時具有一定的靈活性,因為它們可以跟蹤物件分配的速度和隨著時間的推移剩餘的空閒記憶體。
一個新興的想法是將 GC 暫停視為一個節點的短暫計劃中斷,並在這個節點收集其垃圾的同時,讓其他節點處理來自客戶端的請求。如果執行時可以警告應用程式一個節點很快需要 GC 暫停,那麼應用程式可以停止向該節點發送新的請求,等待它完成處理未完成的請求,然後在沒有請求正在進行時執行 GC。這個技巧向客戶端隱藏了 GC 暫停,並降低了響應時間的高百分比【70,71】。一些對延遲敏感的金融交易系統【72】使用這種方法。
這個想法的一個變種是隻用垃圾收集器來處理短命物件(這些物件可以快速收集),並定期在積累大量長壽物件(因此需要完整 GC)之前重新啟動程序【65,73】。一次可以重新啟動一個節點,在計劃重新啟動之前,流量可以從該節點移開,就像 第四章 裡描述的滾動升級一樣。
這些措施不能完全阻止垃圾回收暫停,但可以有效地減少它們對應用的影響。
知識、真相與謊言
本章到目前為止,我們已經探索了分散式系統與執行在單臺計算機上的程式的不同之處:沒有共享記憶體,只有透過可變延遲的不可靠網路傳遞的訊息,系統可能遭受部分失效,不可靠的時鐘和處理暫停。
如果你不習慣於分散式系統,那麼這些問題的後果就會讓人迷惑不解。網路中的一個節點無法確切地知道任何事情 —— 它只能根據它透過網路接收到(或沒有接收到)的訊息進行猜測。節點只能透過交換訊息來找出另一個節點所處的狀態(儲存了哪些資料,是否正確執行等等)。如果遠端節點沒有響應,則無法知道它處於什麼狀態,因為網路中的問題不能可靠地與節點上的問題區分開來。
這些系統的討論與哲學有關:在系統中什麼是真什麼是假?如果感知和測量的機制都是不可靠的,那麼關於這些知識我們又能多麼確定呢?軟體系統應該遵循我們對物理世界所期望的法則,如因果關係嗎?
幸運的是,我們不需要去搞清楚生命的意義。在分散式系統中,我們可以陳述關於行為(系統模型)的假設,並以滿足這些假設的方式設計實際系統。演算法可以被證明在某個系統模型中正確執行。這意味著即使底層系統模型提供了很少的保證,也可以實現可靠的行為。
但是,儘管可以使軟體在不可靠的系統模型中表現良好,但這並不是可以直截了當實現的。在本章的其餘部分中,我們將進一步探討分散式系統中的知識和真相的概念,這將有助於我們思考我們可以做出的各種假設以及我們可能希望提供的保證。在 第九章 中,我們將著眼於分散式系統的一些例子,這些演算法在特定的假設條件下提供了特定的保證。
真相由多數所定義
設想一個具有不對稱故障的網路:一個節點能夠接收發送給它的所有訊息,但是來自該節點的任何傳出訊息被丟棄或延遲【19】。即使該節點執行良好,並且正在接收來自其他節點的請求,其他節點也無法聽到其響應。經過一段時間後,其他節點宣佈它已經死亡,因為他們沒有聽到節點的訊息。這種情況就像夢魘一樣:半斷開(semi-disconnected) 的節點被拖向墓地,敲打尖叫道 “我沒死!” —— 但是由於沒有人能聽到它的尖叫,葬禮隊伍繼續以堅忍的決心繼續行進。
在一個稍微不那麼夢魘的場景中,半斷開的節點可能會注意到它傳送的訊息沒有被其他節點確認,因此意識到網路中必定存在故障。儘管如此,節點被其他節點錯誤地宣告為死亡,而半連線的節點對此無能為力。
第三種情況,想象一個經歷了一個長時間 停止所有處理垃圾收集暫停(stop-the-world GC Pause) 的節點。節點的所有執行緒被 GC 搶佔並暫停一分鐘,因此沒有請求被處理,也沒有響應被傳送。其他節點等待,重試,不耐煩,並最終宣佈節點死亡,並將其丟到靈車上。最後,GC 完成,節點的執行緒繼續,好像什麼也沒有發生。其他節點感到驚訝,因為所謂的死亡節點突然從棺材中抬起頭來,身體健康,開始和旁觀者高興地聊天。GC 後的節點最初甚至沒有意識到已經經過了整整一分鐘,而且自己已被宣告死亡。從它自己的角度來看,從最後一次與其他節點交談以來,幾乎沒有經過任何時間。
這些故事的寓意是,節點不一定能相信自己對於情況的判斷。分散式系統不能完全依賴單個節點,因為節點可能隨時失效,可能會使系統卡死,無法恢復。相反,許多分散式演算法都依賴於法定人數,即在節點之間進行投票(請參閱 “讀寫的法定人數“):決策需要來自多個節點的最小投票數,以減少對於某個特定節點的依賴。
這也包括關於宣告節點死亡的決定。如果法定數量的節點宣告另一個節點已經死亡,那麼即使該節點仍感覺自己活著,它也必須被認為是死的。個體節點必須遵守法定決定並下臺。
最常見的法定人數是超過一半的絕對多數(儘管其他型別的法定人數也是可能的)。多數法定人數允許系統繼續工作,如果單個節點發生故障(三個節點可以容忍單節點故障;五個節點可以容忍雙節點故障)。系統仍然是安全的,因為在這個制度中只能有一個多數 —— 不能同時存在兩個相互衝突的多數決定。當我們在 第九章 中討論 共識演算法(consensus algorithms) 時,我們將更詳細地討論法定人數的應用。
領導者和鎖
通常情況下,一些東西在一個系統中只能有一個。例如:
- 資料庫分割槽的領導者只能有一個節點,以避免 腦裂(即 split brain,請參閱 “處理節點宕機”)。
- 特定資源的鎖或物件只允許一個事務 / 客戶端持有,以防同時寫入和損壞。
- 一個特定的使用者名稱只能被一個使用者所註冊,因為使用者名稱必須唯一標識一個使用者。
在分散式系統中實現這一點需要注意:即使一個節點認為它是 “天選者(the choosen one)”(分割槽的負責人,鎖的持有者,成功獲取使用者名稱的使用者的請求處理程式),但這並不一定意味著有法定人數的節點同意!一個節點可能以前是領導者,但是如果其他節點在此期間宣佈它死亡(例如,由於網路中斷或 GC 暫停),則它可能已被降級,且另一個領導者可能已經當選。
如果一個節點繼續表現為 天選者,即使大多數節點已經宣告它已經死了,則在考慮不周的系統中可能會導致問題。這樣的節點能以自己賦予的權能向其他節點發送訊息,如果其他節點相信,整個系統可能會做一些不正確的事情。
例如,圖 8-4 顯示了由於不正確的鎖實現導致的資料損壞錯誤。 (這個錯誤不僅僅是理論上的:HBase 曾經有這個問題【74,75】)假設你要確保一個儲存服務中的檔案一次只能被一個客戶訪問,因為如果多個客戶試圖對此寫入,該檔案將被損壞。你嘗試透過在訪問檔案之前要求客戶端從鎖定服務獲取租約來實現此目的。
{kind=link}
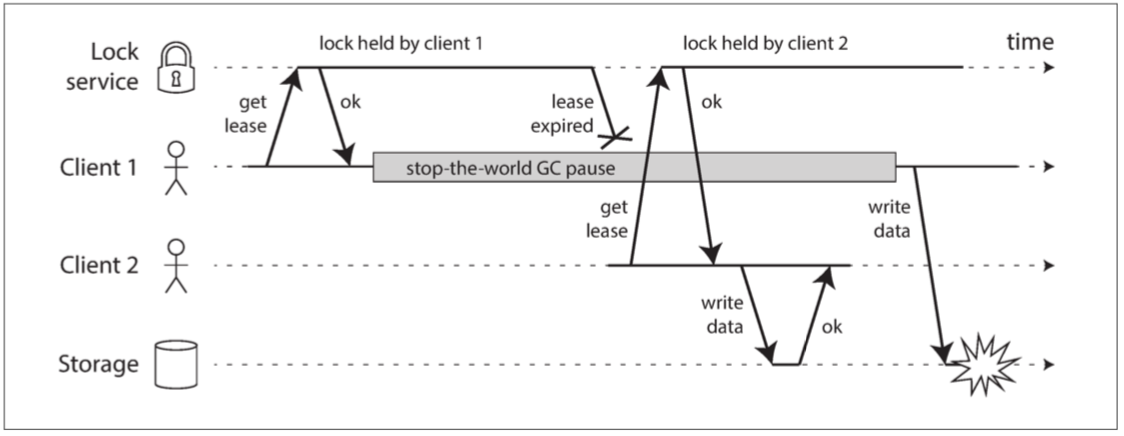
圖 8-4 分散式鎖的實現不正確:客戶端 1 認為它仍然具有有效的租約,即使它已經過期,從而破壞了儲存中的檔案
這個問題就是我們先前在 “程序暫停” 中討論過的一個例子:如果持有租約的客戶端暫停太久,它的租約將到期。另一個客戶端可以獲得同一檔案的租約,並開始寫入檔案。當暫停的客戶端回來時,它認為(不正確)它仍然有一個有效的租約,並繼續寫入檔案。結果,客戶的寫入將產生衝突並損壞檔案。
防護令牌
當使用鎖或租約來保護對某些資源(如 圖 8-4 中的檔案儲存)的訪問時,需要確保一個被誤認為自己是 “天選者” 的節點不能擾亂系統的其它部分。實現這一目標的一個相當簡單的技術就是 防護(fencing),如 圖 8-5 所示
{kind=link}
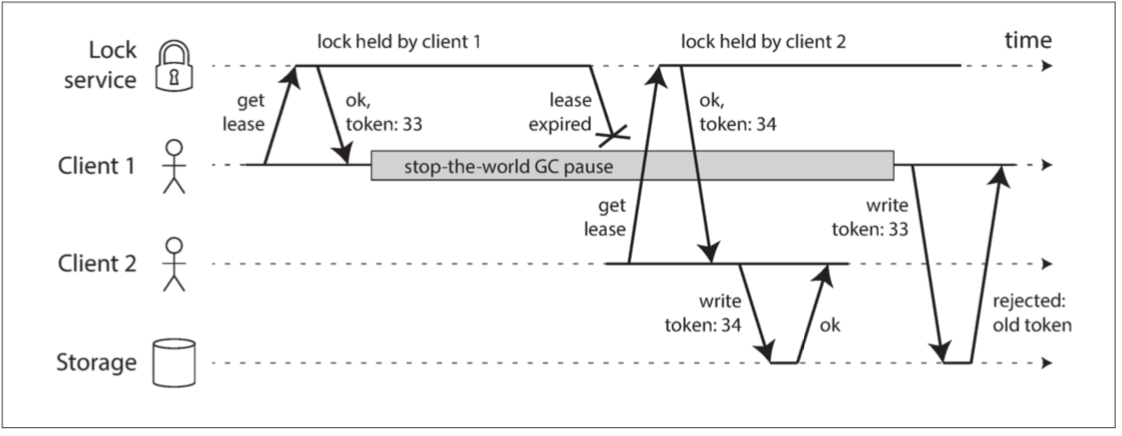
圖 8-5 只允許以增加防護令牌的順序進行寫操作,從而保證儲存安全
我們假設每次鎖定伺服器授予鎖或租約時,它還會返回一個 防護令牌(fencing token),這個數字在每次授予鎖定時都會增加(例如,由鎖定服務增加)。然後,我們可以要求客戶端每次向儲存服務傳送寫入請求時,都必須包含當前的防護令牌。
在 圖 8-5 中,客戶端 1 以 33 的令牌獲得租約,但隨後進入一個長時間的停頓並且租約到期。客戶端 2 以 34 的令牌(該數字總是增加)獲取租約,然後將其寫入請求傳送到儲存服務,包括 34 的令牌。稍後,客戶端 1 恢復生機並將其寫入儲存服務,包括其令牌值 33。但是,儲存伺服器會記住它已經處理了一個具有更高令牌編號(34)的寫入,因此它會拒絕帶有令牌 33 的請求。
如果將 ZooKeeper 用作鎖定服務,則可將事務標識 zxid 或節點版本 cversion 用作防護令牌。由於它們保證單調遞增,因此它們具有所需的屬性【74】。
請注意,這種機制要求資源本身在檢查令牌方面發揮積極作用,透過拒絕使用舊的令牌,而不是已經被處理的令牌來進行寫操作 —— 僅僅依靠客戶端檢查自己的鎖狀態是不夠的。對於不明確支援防護令牌的資源,可能仍然可以解決此限制(例如,在檔案儲存服務的情況下,可以將防護令牌包含在檔名中)。但是,為了避免在鎖的保護之外處理請求,需要進行某種檢查。
在伺服器端檢查一個令牌可能看起來像是一個缺點,但這可以說是一件好事:一個服務假定它的客戶總是守規矩並不明智,因為使用客戶端的人與執行服務的人優先順序非常不一樣【76】。因此,任何服務保護自己免受意外客戶的濫用是一個好主意。
拜占庭故障
防護令牌可以檢測和阻止無意中發生錯誤的節點(例如,因為它尚未發現其租約已過期)。但是,如果節點有意破壞系統的保證,則可以透過使用假防護令牌傳送訊息來輕鬆完成此操作。
在本書中,我們假設節點是不可靠但誠實的:它們可能很慢或者從不響應(由於故障),並且它們的狀態可能已經過時(由於 GC 暫停或網路延遲),但是我們假設如果節點它做出了回應,它正在說出 “真相”:盡其所知,它正在按照協議的規則扮演其角色。
如果存在節點可能 “撒謊”(傳送任意錯誤或損壞的響應)的風險,則分散式系統的問題變得更困難了 —— 例如,如果節點可能聲稱其實際上沒有收到特定的訊息。這種行為被稱為 拜占庭故障(Byzantine fault),在不信任的環境中達成共識的問題被稱為拜占庭將軍問題【77】。
拜占庭將軍問題
拜占庭將軍問題是對所謂 “兩將軍問題” 的泛化【78】,它想象兩個將軍需要就戰鬥計劃達成一致的情況。由於他們在兩個不同的地點建立了營地,他們只能透過信使進行溝通,信使有時會被延遲或丟失(就像網路中的資訊包一樣)。我們將在 第九章 討論這個共識問題。
在這個問題的拜占庭版本里,有 n 位將軍需要同意,他們的努力因為有一些叛徒在他們中間而受到阻礙。大多數的將軍都是忠誠的,因而發出了真實的資訊,但是叛徒可能會試圖透過傳送虛假或不真實的資訊來欺騙和混淆他人(在試圖保持未被發現的同時)。事先並不知道叛徒是誰。
拜占庭是後來成為君士坦丁堡的古希臘城市,現在在土耳其的伊斯坦布林。沒有任何歷史證據表明拜占庭將軍比其他地方更容易出現詭計和陰謀。相反,這個名字來源於拜占庭式的過度複雜,官僚,迂迴等意義,早在計算機之前就已經在政治中被使用了【79】。Lamport 想要選一個不會冒犯任何讀者的國家,他被告知將其稱為阿爾巴尼亞將軍問題並不是一個好主意【80】。
當一個系統在部分節點發生故障、不遵守協議、甚至惡意攻擊、擾亂網路時仍然能繼續正確工作,稱之為 拜占庭容錯(Byzantine fault-tolerant) 的,這種擔憂在某些特定情況下是有意義的:
- 在航空航天環境中,計算機記憶體或 CPU 暫存器中的資料可能被輻射破壞,導致其以任意不可預知的方式響應其他節點。由於系統故障非常昂貴(例如,飛機撞毀和炸死船上所有人員,或火箭與國際空間站相撞),飛行控制系統必須容忍拜占庭故障【81,82】。
- 在多個參與組織的系統中,一些參與者可能會試圖欺騙或詐騙他人。在這種情況下,節點僅僅信任另一個節點的訊息是不安全的,因為它們可能是出於惡意的目的而被傳送的。例如,像比特幣和其他區塊鏈一樣的對等網路可以被認為是讓互不信任的各方同意交易是否發生的一種方式,而不依賴於中心機構(central authority)【83】。
然而,在本書討論的那些系統中,我們通常可以安全地假設沒有拜占庭式的錯誤。在你的資料中心裡,所有的節點都是由你的組織控制的(所以他們可以信任),輻射水平足夠低,記憶體損壞不是一個大問題。製作拜占庭容錯系統的協議相當複雜【84】,而容錯嵌入式系統依賴於硬體層面的支援【81】。在大多數伺服器端資料系統中,部署拜占庭容錯解決方案的成本使其變得不切實際。
Web 應用程式確實需要預期受終端使用者控制的客戶端(如 Web 瀏覽器)的任意和惡意行為。這就是為什麼輸入驗證,資料清洗和輸出轉義如此重要:例如,防止 SQL 注入和跨站點指令碼。然而,我們通常不在這裡使用拜占庭容錯協議,而只是讓伺服器有權決定是否允許客戶端行為。但在沒有這種中心機構的對等網路中,拜占庭容錯更為重要。
軟體中的一個錯誤(bug)可能被認為是拜占庭式的錯誤,但是如果你將相同的軟體部署到所有節點上,那麼拜占庭式的容錯演算法幫不到你。大多數拜占庭式容錯演算法要求超過三分之二的節點能夠正常工作(即,如果有四個節點,最多隻能有一個故障)。要使用這種方法對付 bug,你必須有四個獨立的相同軟體的實現,並希望一個 bug 只出現在四個實現之一中。
同樣,如果一個協議可以保護我們免受漏洞,安全滲透和惡意攻擊,那麼這將是有吸引力的。不幸的是,這也是不現實的:在大多數系統中,如果攻擊者可以滲透一個節點,那他們可能會滲透所有這些節點,因為它們可能都執行著相同的軟體。因此,傳統機制(認證,訪問控制,加密,防火牆等)仍然是抵禦攻擊者的主要保護措施。
弱謊言形式
儘管我們假設節點通常是誠實的,但值得向軟體中新增防止 “撒謊” 弱形式的機制 —— 例如,由硬體問題導致的無效訊息,軟體錯誤和錯誤配置。這種保護機制並不是完全的拜占庭容錯,因為它們不能抵擋決心堅定的對手,但它們仍然是簡單而實用的步驟,以提高可靠性。例如:
- 由於硬體問題或作業系統、驅動程式、路由器等中的錯誤,網路資料包有時會受到損壞。通常,損壞的資料包會被內建於 TCP 和 UDP 中的校驗和所俘獲,但有時它們也會逃脫檢測【85,86,87】 。要對付這種破壞通常使用簡單的方法就可以做到,例如應用程式級協議中的校驗和。
- 可公開訪問的應用程式必須仔細清理來自使用者的任何輸入,例如檢查值是否在合理的範圍內,並限制字串的大小以防止透過大記憶體分配的拒絕服務。防火牆後面的內部服務對於輸入也許可以只採取一些不那麼嚴格的檢查,但是採取一些基本的合理性檢查(例如,在協議解析中)仍然是一個好主意。
- NTP 客戶端可以配置多個伺服器地址。同步時,客戶端聯絡所有的伺服器,估計它們的誤差,並檢查大多數伺服器是否對某個時間範圍達成一致。只要大多數的伺服器沒問題,一個配置錯誤的 NTP 伺服器報告的時間會被當成特異值從同步中排除【37】。使用多個伺服器使 NTP 更健壯(比起只用單個伺服器來)。
系統模型與現實
已經有很多演算法被設計以解決分散式系統問題 —— 例如,我們將在 第九章 討論共識問題的解決方案。為了有用,這些演算法需要容忍我們在本章中討論的分散式系統的各種故障。
演算法的編寫方式不應該過分依賴於執行的硬體和軟體配置的細節。這就要求我們以某種方式將我們期望在系統中發生的錯誤形式化。我們透過定義一個系統模型來做到這一點,這個模型是一個抽象,描述一個演算法可以假設的事情。
關於時序假設,三種系統模型是常用的:
-
同步模型
同步模型(synchronous model) 假設網路延遲、程序暫停和和時鐘誤差都是受限的。這並不意味著完全同步的時鐘或零網路延遲;這隻意味著你知道網路延遲、暫停和時鐘漂移將永遠不會超過某個固定的上限【88】。同步模型並不是大多數實際系統的現實模型,因為(如本章所討論的)無限延遲和暫停確實會發生。
-
部分同步模型
部分同步(partial synchronous) 意味著一個系統在大多數情況下像一個同步系統一樣執行,但有時候會超出網路延遲,程序暫停和時鐘漂移的界限【88】。這是很多系統的現實模型:大多數情況下,網路和程序表現良好,否則我們永遠無法完成任何事情,但是我們必須承認,在任何時刻都存在時序假設偶然被破壞的事實。發生這種情況時,網路延遲、暫停和時鐘錯誤可能會變得相當大。
-
非同步模型
在這個模型中,一個演算法不允許對時序做任何假設 —— 事實上它甚至沒有時鐘(所以它不能使用超時)。一些演算法被設計為可用於非同步模型,但非常受限。
進一步來說,除了時序問題,我們還要考慮 節點失效。三種最常見的節點系統模型是:
-
崩潰 - 停止故障
在 崩潰停止(crash-stop) 模型中,演算法可能會假設一個節點只能以一種方式失效,即透過崩潰。這意味著節點可能在任意時刻突然停止響應,此後該節點永遠消失 —— 它永遠不會回來。
-
崩潰 - 恢復故障
我們假設節點可能會在任何時候崩潰,但也許會在未知的時間之後再次開始響應。在 崩潰 - 恢復(crash-recovery) 模型中,假設節點具有穩定的儲存(即,非易失性磁碟儲存)且會在崩潰中保留,而記憶體中的狀態會丟失。
-
拜占庭(任意)故障
節點可以做(絕對意義上的)任何事情,包括試圖戲弄和欺騙其他節點,如上一節所述。
對於真實系統的建模,具有 崩潰 - 恢復故障(crash-recovery) 的 部分同步模型(partial synchronous) 通常是最有用的模型。分散式演算法如何應對這種模型?
演算法的正確性
為了定義演算法是正確的,我們可以描述它的屬性。例如,排序演算法的輸出具有如下特性:對於輸出列表中的任何兩個不同的元素,左邊的元素比右邊的元素小。這只是定義對列表進行排序含義的一種形式方式。
同樣,我們可以寫下我們想要的分散式演算法的屬性來定義它的正確含義。例如,如果我們正在為一個鎖生成防護令牌(請參閱 “防護令牌”),我們可能要求演算法具有以下屬性:
-
唯一性(uniqueness)
沒有兩個防護令牌請求返回相同的值。
-
單調序列(monotonic sequence)
如果請求
x返回了令牌 $t_x$,並且請求y返回了令牌 $t_y$,並且x在y開始之前已經完成,那麼 $t_x < t_y$。 -
可用性(availability)
請求防護令牌並且不會崩潰的節點,最終會收到響應。
如果一個系統模型中的演算法總是滿足它在所有我們假設可能發生的情況下的性質,那麼這個演算法是正確的。但這如何有意義?如果所有的節點崩潰,或者所有的網路延遲突然變得無限長,那麼沒有任何演算法能夠完成任何事情。
安全性和活性
為了澄清這種情況,有必要區分兩種不同的屬性:安全(safety)屬性 和 活性(liveness)屬性。在剛剛給出的例子中,唯一性 和 單調序列 是安全屬性,而 可用性 是活性屬性。
這兩種性質有什麼區別?一個試金石就是,活性屬性通常在定義中通常包括 “最終” 一詞(是的,你猜對了 —— 最終一致性是一個活性屬性【89】)。
安全通常被非正式地定義為:沒有壞事發生,而活性通常就類似:最終好事發生。但是,最好不要過多地閱讀那些非正式的定義,因為好與壞的含義是主觀的。安全和活性的實際定義是精確的和數學的【90】:
- 如果安全屬性被違反,我們可以指向一個特定的安全屬性被破壞的時間點(例如,如果違反了唯一性屬性,我們可以確定重複的防護令牌被返回的特定操作)。違反安全屬性後,違規行為不能被撤銷 —— 損失已經發生。
- 活性屬性反過來:在某個時間點(例如,一個節點可能傳送了一個請求,但還沒有收到響應),它可能不成立,但總是希望在未來能成立(即透過接受答覆)。
區分安全屬性和活性屬性的一個優點是可以幫助我們處理困難的系統模型。對於分散式演算法,在系統模型的所有可能情況下,要求 始終 保持安全屬性是常見的【88】。也就是說,即使所有節點崩潰,或者整個網路出現故障,演算法仍然必須確保它不會返回錯誤的結果(即保證安全屬性得到滿足)。
但是,對於活性屬性,我們可以提出一些注意事項:例如,只有在大多數節點沒有崩潰的情況下,只有當網路最終從中斷中恢復時,我們才可以說請求需要接收響應。部分同步模型的定義要求系統最終返回到同步狀態 —— 即任何網路中斷的時間段只會持續一段有限的時間,然後進行修復。
將系統模型對映到現實世界
安全屬性和活性屬性以及系統模型對於推理分散式演算法的正確性非常有用。然而,在實踐中實施演算法時,現實的混亂事實再一次地讓你咬牙切齒,很明顯系統模型是對現實的簡化抽象。
例如,在崩潰 - 恢復(crash-recovery)模型中的演算法通常假設穩定儲存器中的資料在崩潰後可以倖存。但是,如果磁碟上的資料被破壞,或者由於硬體錯誤或錯誤配置導致資料被清除,會發生什麼情況【91】?如果伺服器存在韌體錯誤並且在重新啟動時無法識別其硬碟驅動器,即使驅動器已正確連線到伺服器,那又會發生什麼情況【92】?
法定人數演算法(請參閱 “讀寫的法定人數”)依賴節點來記住它聲稱儲存的資料。如果一個節點可能患有健忘症,忘記了以前儲存的資料,這會打破法定條件,從而破壞演算法的正確性。也許需要一個新的系統模型,在這個模型中,我們假設穩定的儲存大多能在崩潰後倖存,但有時也可能會丟失。但是那個模型就變得更難以推理了。
演算法的理論描述可以簡單宣稱一些事是不會發生的 —— 在非拜占庭式系統中,我們確實需要對可能發生和不可能發生的故障做出假設。然而,真實世界的實現,仍然會包括處理 “假設上不可能” 情況的程式碼,即使程式碼可能就是 printf("Sucks to be you") 和 exit(666),實際上也就是留給運維來擦屁股【93】。(這可以說是計算機科學和軟體工程間的一個差異)。
這並不是說理論上抽象的系統模型是毫無價值的,恰恰相反。它們對於將實際系統的複雜性提取成一個個我們可以推理的可處理的錯誤型別是非常有幫助的,以便我們能夠理解這個問題,並試圖系統地解決這個問題。我們可以證明演算法是正確的,透過表明它們的屬性在某個系統模型中總是成立的。
證明演算法正確並不意味著它在真實系統上的實現必然總是正確的。但這邁出了很好的第一步,因為理論分析可以發現演算法中的問題,這種問題可能會在現實系統中長期潛伏,直到你的假設(例如,時序)因為不尋常的情況被打破。理論分析與經驗測試同樣重要。
本章小結
在本章中,我們討論了分散式系統中可能發生的各種問題,包括:
- 當你嘗試透過網路傳送資料包時,資料包可能會丟失或任意延遲。同樣,答覆可能會丟失或延遲,所以如果你沒有得到答覆,你不知道訊息是否傳送成功了。
- 節點的時鐘可能會與其他節點顯著不同步(儘管你盡最大努力設定 NTP),它可能會突然跳轉或跳回,依靠它是很危險的,因為你很可能沒有好的方法來測量你的時鐘的錯誤間隔。
- 一個程序可能會在其執行的任何時候暫停一段相當長的時間(可能是因為停止所有處理的垃圾收集器),被其他節點宣告死亡,然後再次復活,卻沒有意識到它被暫停了。
這類 部分失效(partial failure) 可能發生的事實是分散式系統的決定性特徵。每當軟體試圖做任何涉及其他節點的事情時,偶爾就有可能會失敗,或者隨機變慢,或者根本沒有響應(最終超時)。在分散式系統中,我們試圖在軟體中建立 部分失效 的容錯機制,這樣整個系統在即使某些組成部分被破壞的情況下,也可以繼續執行。
為了容忍錯誤,第一步是 檢測 它們,但即使這樣也很難。大多數系統沒有檢測節點是否發生故障的準確機制,所以大多數分散式演算法依靠 超時 來確定遠端節點是否仍然可用。但是,超時無法區分網路失效和節點失效,並且可變的網路延遲有時會導致節點被錯誤地懷疑發生故障。此外,有時一個節點可能處於降級狀態:例如,由於驅動程式錯誤,千兆網絡卡可能突然下降到 1 Kb/s 的吞吐量【94】。這樣一個 “跛行” 而不是死掉的節點可能比一個乾淨的失效節點更難處理。
一旦檢測到故障,使系統容忍它也並不容易:沒有全域性變數,沒有共享記憶體,沒有共同的知識,或機器之間任何其他種類的共享狀態。節點甚至不能就現在是什麼時間達成一致,就不用說更深奧的了。資訊從一個節點流向另一個節點的唯一方法是透過不可靠的網路傳送資訊。重大決策不能由一個節點安全地完成,因此我們需要一個能從其他節點獲得幫助的協議,並爭取達到法定人數以達成一致。
如果你習慣於在理想化的數學完美的單機環境(同一個操作總能確定地返回相同的結果)中編寫軟體,那麼轉向分散式系統的凌亂的物理現實可能會有些令人震驚。相反,如果能夠在單臺計算機上解決一個問題,那麼分散式系統工程師通常會認為這個問題是平凡的【5】,現在單個計算機確實可以做很多事情【95】。如果你可以避免開啟潘多拉的盒子,把東西放在一臺機器上,那麼通常是值得的。
但是,正如在 第二部分 的介紹中所討論的那樣,可伸縮性並不是使用分散式系統的唯一原因。容錯和低延遲(透過將資料放置在距離使用者較近的地方)是同等重要的目標,而這些不能用單個節點實現。
在本章中,我們也轉換了幾次話題,探討了網路、時鐘和程序的不可靠性是否是不可避免的自然規律。我們看到這並不是:有可能給網路提供硬實時的響應保證和有限的延遲,但是這樣做非常昂貴,且導致硬體資源的利用率降低。大多數非安全關鍵系統會選擇 便宜而不可靠,而不是 昂貴和可靠。
我們還談到了超級計算機,它們採用可靠的元件,因此當元件發生故障時必須完全停止並重新啟動。相比之下,分散式系統可以永久執行而不會在服務層面中斷,因為所有的錯誤和維護都可以在節點級別進行處理 —— 至少在理論上是如此。 (實際上,如果一個錯誤的配置變更被應用到所有的節點,仍然會使分散式系統癱瘓)。
本章一直在講存在的問題,給我們展現了一幅黯淡的前景。在 下一章 中,我們將繼續討論解決方案,並討論一些旨在解決分散式系統中所有問題的演算法。
參考文獻
- Mark Cavage: Just No Getting Around It: You’re Building a Distributed System](http://queue.acm.org/detail.cfm?id=2482856),” ACM Queue, volume 11, number 4, pages 80-89, April 2013. doi:10.1145/2466486.2482856
- Jay Kreps: “Getting Real About Distributed System Reliability,” blog.empathybox.com, March 19, 2012.
- Sydney Padua: The Thrilling Adventures of Lovelace and Babbage: The (Mostly) True Story of the First Computer. Particular Books, April ISBN: 978-0-141-98151-2
- Coda Hale: “You Can’t Sacrifice Partition Tolerance,” codahale.com, October 7, 2010.
- Jeff Hodges: “Notes on Distributed Systems for Young Bloods,” somethingsimilar.com, January 14, 2013.
- Antonio Regalado: “Who Coined 'Cloud Computing’?,” technologyreview.com, October 31, 2011.
- Luiz André Barroso, Jimmy Clidaras, and Urs Hölzle: “The Datacenter as a Computer: An Introduction to the Design of Warehouse-Scale Machines, Second Edition,” Synthesis Lectures on Computer Architecture, volume 8, number 3, Morgan & Claypool Publishers, July 2013.doi:10.2200/S00516ED2V01Y201306CAC024, ISBN: 978-1-627-05010-4
- David Fiala, Frank Mueller, Christian Engelmann, et al.: “Detection and Correction of Silent Data Corruption for Large-Scale High-Performance Computing,” at International Conference for High Performance Computing, Networking, Storage and Analysis (SC12), November 2012.
- Arjun Singh, Joon Ong, Amit Agarwal, et al.: “Jupiter Rising: A Decade of Clos Topologies and Centralized Control in Google’s Datacenter Network,” at Annual Conference of the ACM Special Interest Group on Data Communication (SIGCOMM), August 2015. doi:10.1145/2785956.2787508
- Glenn K. Lockwood: “Hadoop's Uncomfortable Fit in HPC,” glennklockwood.blogspot.co.uk, May 16, 2014.
- John von Neumann: “Probabilistic Logics and the Synthesis of Reliable Organisms from Unreliable Components,” in Automata Studies (AM-34), edited by Claude E. Shannon and John McCarthy, Princeton University Press, 1956. ISBN: 978-0-691-07916-5
- Richard W. Hamming: The Art of Doing Science and Engineering. Taylor & Francis, 1997. ISBN: 978-9-056-99500-3
- Claude E. Shannon: “A Mathematical Theory of Communication,” The Bell System Technical Journal, volume 27, number 3, pages 379–423 and 623–656, July 1948.
- Peter Bailis and Kyle Kingsbury: “The Network Is Reliable,” ACM Queue, volume 12, number 7, pages 48-55, July 2014. doi:10.1145/2639988.2639988
- Joshua B. Leners, Trinabh Gupta, Marcos K. Aguilera, and Michael Walfish: “Taming Uncertainty in Distributed Systems with Help from the Network,” at 10th European Conference on Computer Systems (EuroSys), April 2015. doi:10.1145/2741948.2741976
- Phillipa Gill, Navendu Jain, and Nachiappan Nagappan: “Understanding Network Failures in Data Centers: Measurement, Analysis, and Implications,” at ACM SIGCOMM Conference, August 2011. doi:10.1145/2018436.2018477
- Mark Imbriaco: “Downtime Last Saturday,” github.com, December 26, 2012.
- Will Oremus: “The Global Internet Is Being Attacked by Sharks, Google Confirms,” slate.com, August 15, 2014.
- Marc A. Donges: “Re: bnx2 cards Intermittantly Going Offline,” Message to Linux netdev mailing list, spinics.net, September 13, 2012.
- Kyle Kingsbury: “Call Me Maybe: Elasticsearch,” aphyr.com, June 15, 2014.
- Salvatore Sanfilippo: “A Few Arguments About Redis Sentinel Properties and Fail Scenarios,” antirez.com, October 21, 2014.
- Bert Hubert: “The Ultimate SO_LINGER Page, or: Why Is My TCP Not Reliable,” blog.netherlabs.nl, January 18, 2009.
- Nicolas Liochon: “CAP: If All You Have Is a Timeout, Everything Looks Like a Partition,” blog.thislongrun.com, May 25, 2015.
- Jerome H. Saltzer, David P. Reed, and David D. Clark: “End-To-End Arguments in System Design,” ACM Transactions on Computer Systems, volume 2, number 4, pages 277–288, November 1984. doi:10.1145/357401.357402
- Matthew P. Grosvenor, Malte Schwarzkopf, Ionel Gog, et al.: “Queues Don’t Matter When You Can JUMP Them!,” at 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI), May 2015.
- Guohui Wang and T. S. Eugene Ng: “The Impact of Virtualization on Network Performance of Amazon EC2 Data Center,” at 29th IEEE International Conference on Computer Communications (INFOCOM), March 2010. doi:10.1109/INFCOM.2010.5461931
- Van Jacobson: “Congestion Avoidance and Control,” at ACM Symposium on Communications Architectures and Protocols (SIGCOMM), August 1988. doi:10.1145/52324.52356
- Brandon Philips: “etcd: Distributed Locking and Service Discovery,” at Strange Loop, September 2014.
- Steve Newman: “A Systematic Look at EC2 I/O,” blog.scalyr.com, October 16, 2012.
- Naohiro Hayashibara, Xavier Défago, Rami Yared, and Takuya Katayama: “The ϕ Accrual Failure Detector,” Japan Advanced Institute of Science and Technology, School of Information Science, Technical Report IS-RR-2004-010, May 2004.
- Jeffrey Wang: “Phi Accrual Failure Detector,” ternarysearch.blogspot.co.uk, August 11, 2013.
- Srinivasan Keshav: An Engineering Approach to Computer Networking: ATM Networks, the Internet, and the Telephone Network. Addison-Wesley Professional, May 1997. ISBN: 978-0-201-63442-6
- Cisco, “Integrated Services Digital Network,” docwiki.cisco.com.
- Othmar Kyas: ATM Networks. International Thomson Publishing, 1995. ISBN: 978-1-850-32128-6
- “InfiniBand FAQ,” Mellanox Technologies, December 22, 2014.
- Jose Renato Santos, Yoshio Turner, and G. (John) Janakiraman: “End-to-End Congestion Control for InfiniBand,” at 22nd Annual Joint Conference of the IEEE Computer and Communications Societies (INFOCOM), April 2003. Also published by HP Laboratories Palo Alto, Tech Report HPL-2002-359. doi:10.1109/INFCOM.2003.1208949
- Ulrich Windl, David Dalton, Marc Martinec, and Dale R. Worley: “The NTP FAQ and HOWTO,” ntp.org, November 2006.
- John Graham-Cumming: “How and why the leap second affected Cloudflare DNS,” blog.cloudflare.com, January 1, 2017.
- David Holmes: “Inside the Hotspot VM: Clocks, Timers and Scheduling Events – Part I – Windows,” blogs.oracle.com, October 2, 2006.
- Steve Loughran: “Time on Multi-Core, Multi-Socket Servers,” steveloughran.blogspot.co.uk, September 17, 2015.
- James C. Corbett, Jeffrey Dean, Michael Epstein, et al.: “Spanner: Google’s Globally-Distributed Database,” at 10th USENIX Symposium on Operating System Design and Implementation (OSDI), October 2012.
- M. Caporaloni and R. Ambrosini: “How Closely Can a Personal Computer Clock Track the UTC Timescale Via the Internet?,” European Journal of Physics, volume 23, number 4, pages L17–L21, June 2012. doi:10.1088/0143-0807/23/4/103
- Nelson Minar: “A Survey of the NTP Network,” alumni.media.mit.edu, December 1999.
- Viliam Holub: “Synchronizing Clocks in a Cassandra Cluster Pt. 1 – The Problem,” blog.logentries.com, March 14, 2014.
- Poul-Henning Kamp: “The One-Second War (What Time Will You Die?),” ACM Queue, volume 9, number 4, pages 44–48, April 2011. doi:10.1145/1966989.1967009
- Nelson Minar: “Leap Second Crashes Half the Internet,” somebits.com, July 3, 2012.
- Christopher Pascoe: “Time, Technology and Leaping Seconds,” googleblog.blogspot.co.uk, September 15, 2011.
- Mingxue Zhao and Jeff Barr: “Look Before You Leap – The Coming Leap Second and AWS,” aws.amazon.com, May 18, 2015.
- Darryl Veitch and Kanthaiah Vijayalayan: “Network Timing and the 2015 Leap Second,” at 17th International Conference on Passive and Active Measurement (PAM), April 2016. doi:10.1007/978-3-319-30505-9_29
- “Timekeeping in VMware Virtual Machines,” Information Guide, VMware, Inc., December 2011.
- “MiFID II / MiFIR: Regulatory Technical and Implementing Standards – Annex I (Draft),” European Securities and Markets Authority, Report ESMA/2015/1464, September 2015.
- Luke Bigum: “Solving MiFID II Clock Synchronisation With Minimum Spend (Part 1),” lmax.com, November 27, 2015.
- Kyle Kingsbury: “Call Me Maybe: Cassandra,” aphyr.com, September 24, 2013.
- John Daily: “Clocks Are Bad, or, Welcome to the Wonderful World of Distributed Systems,” basho.com, November 12, 2013.
- Kyle Kingsbury: “The Trouble with Timestamps,” aphyr.com, October 12, 2013.
- Leslie Lamport: “Time, Clocks, and the Ordering of Events in a Distributed System,” Communications of the ACM, volume 21, number 7, pages 558–565, July 1978. doi:10.1145/359545.359563
- Sandeep Kulkarni, Murat Demirbas, Deepak Madeppa, et al.: “Logical Physical Clocks and Consistent Snapshots in Globally Distributed Databases,” State University of New York at Buffalo, Computer Science and Engineering Technical Report 2014-04, May 2014.
- Justin Sheehy: “There Is No Now: Problems With Simultaneity in Distributed Systems,” ACM Queue, volume 13, number 3, pages 36–41, March 2015. doi:10.1145/2733108
- Murat Demirbas: “Spanner: Google's Globally-Distributed Database,” muratbuffalo.blogspot.co.uk, July 4, 2013.
- Dahlia Malkhi and Jean-Philippe Martin: “Spanner's Concurrency Control,” ACM SIGACT News, volume 44, number 3, pages 73–77, September 2013. doi:10.1145/2527748.2527767
- Manuel Bravo, Nuno Diegues, Jingna Zeng, et al.: “On the Use of Clocks to Enforce Consistency in the Cloud,” IEEE Data Engineering Bulletin, volume 38, number 1, pages 18–31, March 2015.
- Spencer Kimball: “Living Without Atomic Clocks,” cockroachlabs.com, February 17, 2016.
- Cary G. Gray and David R. Cheriton:“Leases: An Efficient Fault-Tolerant Mechanism for Distributed File Cache Consistency,” at 12th ACM Symposium on Operating Systems Principles (SOSP), December 1989. doi:10.1145/74850.74870
- Todd Lipcon: “Avoiding Full GCs in Apache HBase with MemStore-Local Allocation Buffers: Part 1,” blog.cloudera.com, February 24, 2011.
- Martin Thompson: “Java Garbage Collection Distilled,” mechanical-sympathy.blogspot.co.uk, July 16, 2013.
- Alexey Ragozin: “How to Tame Java GC Pauses? Surviving 16GiB Heap and Greater,” java.dzone.com, June 28, 2011.
- Christopher Clark, Keir Fraser, Steven Hand, et al.: “Live Migration of Virtual Machines,” at 2nd USENIX Symposium on Symposium on Networked Systems Design & Implementation (NSDI), May 2005.
- Mike Shaver: “fsyncers and Curveballs,” shaver.off.net, May 25, 2008.
- Zhenyun Zhuang and Cuong Tran: “Eliminating Large JVM GC Pauses Caused by Background IO Traffic,” engineering.linkedin.com, February 10, 2016.
- David Terei and Amit Levy: “Blade: A Data Center Garbage Collector,” arXiv:1504.02578, April 13, 2015.
- Martin Maas, Tim Harris, Krste Asanović, and John Kubiatowicz: “Trash Day: Coordinating Garbage Collection in Distributed Systems,” at 15th USENIX Workshop on Hot Topics in Operating Systems (HotOS), May 2015.
- “Predictable Low Latency,” Cinnober Financial Technology AB, cinnober.com, November 24, 2013.
- Martin Fowler: “The LMAX Architecture,” martinfowler.com, July 12, 2011.
- Flavio P. Junqueira and Benjamin Reed: ZooKeeper: Distributed Process Coordination. O'Reilly Media, 2013. ISBN: 978-1-449-36130-3
- Enis Söztutar: “HBase and HDFS: Understanding Filesystem Usage in HBase,” at HBaseCon, June 2013.
- Caitie McCaffrey: “Clients Are Jerks: AKA How Halo 4 DoSed the Services at Launch & How We Survived,” caitiem.com, June 23, 2015.
- Leslie Lamport, Robert Shostak, and Marshall Pease: “The Byzantine Generals Problem,” ACM Transactions on Programming Languages and Systems (TOPLAS), volume 4, number 3, pages 382–401, July 1982. doi:10.1145/357172.357176
- Jim N. Gray: “Notes on Data Base Operating Systems,” in Operating Systems: An Advanced Course, Lecture Notes in Computer Science, volume 60, edited by R. Bayer, R. M. Graham, and G. Seegmüller, pages 393–481, Springer-Verlag, 1978. ISBN: 978-3-540-08755-7
- Brian Palmer: “How Complicated Was the Byzantine Empire?,” slate.com, October 20, 2011.
- Leslie Lamport: “My Writings,” research.microsoft.com, December 16, 2014. This page can be found by searching the web for the 23-character string obtained by removing the hyphens from the string
allla-mport-spubso-ntheweb. - John Rushby: “Bus Architectures for Safety-Critical Embedded Systems,” at 1st International Workshop on Embedded Software (EMSOFT), October 2001.
- Jake Edge: “ELC: SpaceX Lessons Learned,” lwn.net, March 6, 2013.
- Andrew Miller and Joseph J. LaViola, Jr.: “Anonymous Byzantine Consensus from Moderately-Hard Puzzles: A Model for Bitcoin,” University of Central Florida, Technical Report CS-TR-14-01, April 2014.
- James Mickens: “The Saddest Moment,” USENIX ;login: logout, May 2013.
- Evan Gilman: “The Discovery of Apache ZooKeeper’s Poison Packet,” pagerduty.com, May 7, 2015.
- Jonathan Stone and Craig Partridge: “When the CRC and TCP Checksum Disagree,” at ACM Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication (SIGCOMM), August 2000. doi:10.1145/347059.347561
- Evan Jones: “How Both TCP and Ethernet Checksums Fail,” evanjones.ca, October 5, 2015.
- Cynthia Dwork, Nancy Lynch, and Larry Stockmeyer: “Consensus in the Presence of Partial Synchrony,” Journal of the ACM, volume 35, number 2, pages 288–323, April 1988. doi:10.1145/42282.42283
- Peter Bailis and Ali Ghodsi: “Eventual Consistency Today: Limitations, Extensions, and Beyond,” ACM Queue, volume 11, number 3, pages 55-63, March 2013. doi:10.1145/2460276.2462076
- Bowen Alpern and Fred B. Schneider: “Defining Liveness,” Information Processing Letters, volume 21, number 4, pages 181–185, October 1985. doi:10.1016/0020-0190(85)90056-0
- Flavio P. Junqueira: “Dude, Where’s My Metadata?,” fpj.me, May 28, 2015.
- Scott Sanders: “January 28th Incident Report,” github.com, February 3, 2016.
- Jay Kreps: “A Few Notes on Kafka and Jepsen,” blog.empathybox.com, September 25, 2013.
- Thanh Do, Mingzhe Hao, Tanakorn Leesatapornwongsa, et al.: “Limplock: Understanding the Impact of Limpware on Scale-out Cloud Systems,” at 4th ACM Symposium on Cloud Computing (SoCC), October 2013. doi:10.1145/2523616.2523627
- Frank McSherry, Michael Isard, and Derek G. Murray: “Scalability! But at What COST?,” at 15th USENIX Workshop on Hot Topics in Operating Systems (HotOS), May 2015.
| 上一章 | 目錄 | 下一章 |
|---|---|---|
| 第七章:事務 | 設計資料密集型應用 | 第九章:一致性與共識 |
-
原詩為:Hey I just met you. The network’s laggy. But here’s my data. So store it maybe.Hey, 應改編自《Call Me Maybe》歌詞:I just met you, And this is crazy, But here's my number, So call me, maybe? ↩︎
-
除了偶爾的 keepalive 資料包,如果 TCP keepalive 被啟用。 ↩︎
-
非同步傳輸模式(Asynchronous Transfer Mode, ATM) 在 20 世紀 80 年代是乙太網的競爭對手【32】,但在電話網核心交換機之外並沒有得到太多的採用。它與自動櫃員機(也稱為自動取款機)無關,儘管共用一個縮寫詞。或許,在一些平行的世界裡,網際網路是基於像 ATM 這樣的東西,因此它們的網際網路視訊通話可能比我們的更可靠,因為它們不會遭受包的丟失和延遲。 ↩︎
-
網際網路服務提供商之間的對等協議和透過 BGP 閘道器協議(BGP) 建立的路由,與 IP 協議相比,更接近於電路交換。在這個級別上,可以購買專用頻寬。但是,網際網路路由在網路級別執行,而不是主機之間的單獨連線,而且執行時間要長得多。 ↩︎
-
存在分散式序列號生成器,例如 Twitter 的雪花(Snowflake),其以可伸縮的方式(例如,透過將 ID 空間的塊分配給不同節點)近似單調地增加唯一 ID。但是,它們通常無法保證與因果關係一致的排序,因為分配的 ID 塊的時間範圍比資料庫讀取和寫入的時間範圍要長。另請參閱 “順序保證”。 ↩︎