44 KiB
第六章:分割槽
我們必須跳出電腦指令序列的窠臼。 敘述定義、描述元資料、梳理關係,而不是編寫過程。
—— Grace Murray Hopper,未來的計算機及其管理(1962)
[TOC]
在 第五章 中,我們討論了複製 —— 即資料在不同節點上的副本,對於非常大的資料集,或非常高的吞吐量,僅僅進行復制是不夠的:我們需要將資料進行 分割槽(partitions),也稱為 分片(sharding)1。
術語澄清
上文中的 分割槽 (partition),在 MongoDB,Elasticsearch 和 Solr Cloud 中被稱為 分片 (shard),在 HBase 中稱之為 區域 (Region),Bigtable 中則是 表塊(tablet),Cassandra 和 Riak 中是 虛節點(vnode),Couchbase 中叫做 虛桶 (vBucket)。但是 分割槽 (partitioning) 是最約定俗成的叫法。
通常情況下,每條資料(每條記錄,每行或每個文件)屬於且僅屬於一個分割槽。有很多方法可以實現這一點,本章將進行深入討論。實際上,每個分割槽都是自己的小型資料庫,儘管資料庫可能支援同時進行多個分割槽的操作。
分割槽主要是為了 可伸縮性。不同的分割槽可以放在不共享叢集中的不同節點上(請參閱 第二部分 關於 無共享架構 的定義)。因此,大資料集可以分佈在多個磁碟上,並且查詢負載可以分佈在多個處理器上。
對於在單個分割槽上執行的查詢,每個節點可以獨立執行對自己的查詢,因此可以透過新增更多的節點來擴大查詢吞吐量。大型,複雜的查詢可能會跨越多個節點並行處理,儘管這也帶來了新的困難。
分割槽資料庫在 20 世紀 80 年代由 Teradata 和 NonStop SQL【1】等產品率先推出,最近因為 NoSQL 資料庫和基於 Hadoop 的資料倉庫重新被關注。有些系統是為事務性工作設計的,有些系統則用於分析(請參閱 “事務處理還是分析”):這種差異會影響系統的運作方式,但是分割槽的基本原理均適用於這兩種工作方式。
在本章中,我們將首先介紹分割大型資料集的不同方法,並觀察索引如何與分割槽配合。然後我們將討論 分割槽再平衡(rebalancing),如果想要新增或刪除叢集中的節點,則必須進行再平衡。最後,我們將概述資料庫如何將請求路由到正確的分割槽並執行查詢。
分割槽與複製
分割槽通常與複製結合使用,使得每個分割槽的副本儲存在多個節點上。這意味著,即使每條記錄屬於一個分割槽,它仍然可以儲存在多個不同的節點上以獲得容錯能力。
一個節點可能儲存多個分割槽。如果使用主從複製模型,則分割槽和複製的組合如 圖 6-1 所示。每個分割槽領導者(主庫)被分配給一個節點,追隨者(從庫)被分配給其他節點。 每個節點可能是某些分割槽的主庫,同時是其他分割槽的從庫。
{kind=link}
我們在 第五章 討論的關於資料庫複製的所有內容同樣適用於分割槽的複製。大多數情況下,分割槽方案的選擇與複製方案的選擇是獨立的,為簡單起見,本章中將忽略複製。
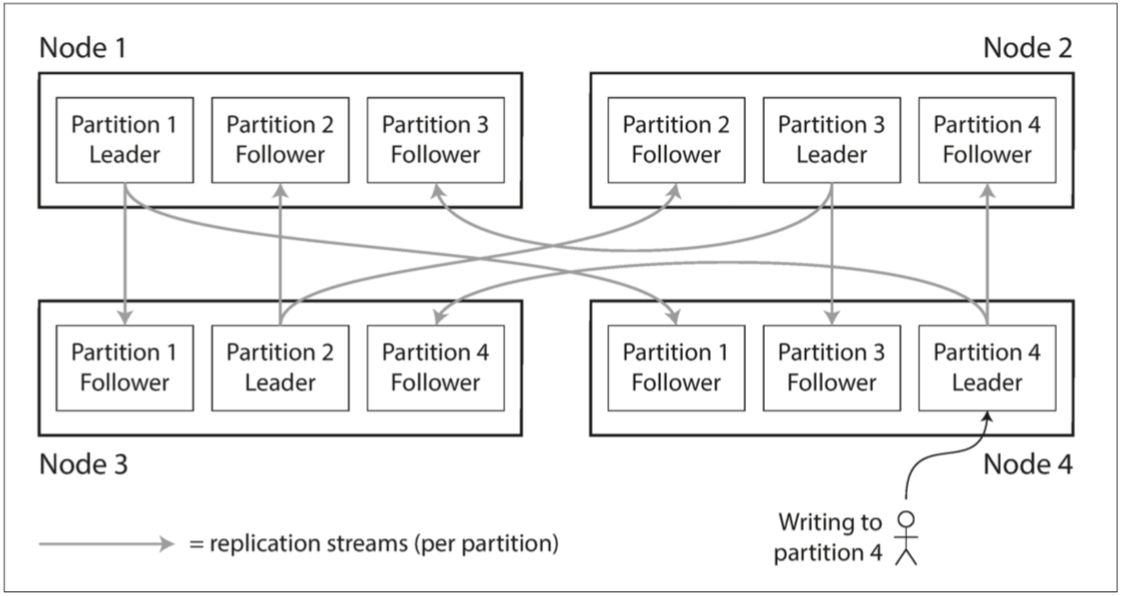
圖 6-1 組合使用複製和分割槽:每個節點充當某些分割槽的主庫,其他分割槽充當從庫。
鍵值資料的分割槽
假設你有大量資料並且想要分割槽,如何決定在哪些節點上儲存哪些記錄呢?
分割槽目標是將資料和查詢負載均勻分佈在各個節點上。如果每個節點公平分享資料和負載,那麼理論上 10 個節點應該能夠處理 10 倍的資料量和 10 倍的單個節點的讀寫吞吐量(暫時忽略複製)。
如果分割槽是不公平的,一些分割槽比其他分割槽有更多的資料或查詢,我們稱之為 偏斜(skew)。資料偏斜的存在使分割槽效率下降很多。在極端的情況下,所有的負載可能壓在一個分割槽上,其餘 9 個節點空閒的,瓶頸落在這一個繁忙的節點上。不均衡導致的高負載的分割槽被稱為 熱點(hot spot)。
避免熱點最簡單的方法是將記錄隨機分配給節點。這將在所有節點上平均分配資料,但是它有一個很大的缺點:當你試圖讀取一個特定的值時,你無法知道它在哪個節點上,所以你必須並行地查詢所有的節點。
我們可以做得更好。現在假設你有一個簡單的鍵值資料模型,其中你總是透過其主鍵訪問記錄。例如,在一本老式的紙質百科全書中,你可以透過標題來查詢一個條目;由於所有條目按字母順序排序,因此你可以快速找到你要查詢的條目。
根據鍵的範圍分割槽
一種分割槽的方法是為每個分割槽指定一塊連續的鍵範圍(從最小值到最大值),如紙質百科全書的卷(圖 6-2)。如果知道範圍之間的邊界,則可以輕鬆確定哪個分割槽包含某個值。如果你還知道分割槽所在的節點,那麼可以直接向相應的節點發出請求(對於百科全書而言,就像從書架上選取正確的書籍)。
{kind=link}

圖 6-2 印刷版百科全書按照關鍵字範圍進行分割槽
鍵的範圍不一定均勻分佈,因為資料也很可能不均勻分佈。例如在 圖 6-2 中,第 1 捲包含以 A 和 B 開頭的單詞,但第 12 卷則包含以 T、U、V、X、Y 和 Z 開頭的單詞。只是簡單的規定每個捲包含兩個字母會導致一些卷比其他卷大。為了均勻分配資料,分割槽邊界需要依據資料調整。
分割槽邊界可以由管理員手動選擇,也可以由資料庫自動選擇(我們會在 “分割槽再平衡” 中更詳細地討論分割槽邊界的選擇)。 Bigtable 使用了這種分割槽策略,以及其開源等價物 HBase 【2, 3】,RethinkDB 和 2.4 版本之前的 MongoDB 【4】。
在每個分割槽中,我們可以按照一定的順序儲存鍵(請參閱 “SSTables 和 LSM 樹”)。好處是進行範圍掃描非常簡單,你可以將鍵作為聯合索引來處理,以便在一次查詢中獲取多個相關記錄(請參閱 “多列索引”)。例如,假設我們有一個程式來儲存感測器網路的資料,其中主鍵是測量的時間戳(年月日時分秒)。範圍掃描在這種情況下非常有用,因為我們可以輕鬆獲取某個月份的所有資料。
然而,Key Range 分割槽的缺點是某些特定的訪問模式會導致熱點。 如果主鍵是時間戳,則分割槽對應於時間範圍,例如,給每天分配一個分割槽。 不幸的是,由於我們在測量發生時將資料從感測器寫入資料庫,因此所有寫入操作都會轉到同一個分割槽(即今天的分割槽),這樣分割槽可能會因寫入而過載,而其他分割槽則處於空閒狀態【5】。
為了避免感測器資料庫中的這個問題,需要使用除了時間戳以外的其他東西作為主鍵的第一個部分。 例如,可以在每個時間戳前新增感測器名稱,這樣會首先按感測器名稱,然後按時間進行分割槽。 假設有多個感測器同時執行,寫入負載將最終均勻分佈在不同分割槽上。 現在,當想要在一個時間範圍內獲取多個感測器的值時,你需要為每個感測器名稱執行一個單獨的範圍查詢。
根據鍵的雜湊分割槽
由於偏斜和熱點的風險,許多分散式資料儲存使用雜湊函式來確定給定鍵的分割槽。
一個好的雜湊函式可以將偏斜的資料均勻分佈。假設你有一個 32 位雜湊函式,無論何時給定一個新的字串輸入,它將返回一個 0 到 2^{32} -1 之間的 “隨機” 數。即使輸入的字串非常相似,它們的雜湊也會均勻分佈在這個數字範圍內。
出於分割槽的目的,雜湊函式不需要多麼強壯的加密演算法:例如,Cassandra 和 MongoDB 使用 MD5,Voldemort 使用 Fowler-Noll-Vo 函式。許多程式語言都有內建的簡單雜湊函式(它們用於散列表),但是它們可能不適合分割槽:例如,在 Java 的 Object.hashCode() 和 Ruby 的 Object#hash,同一個鍵可能在不同的程序中有不同的雜湊值【6】。
一旦你有一個合適的鍵雜湊函式,你可以為每個分割槽分配一個雜湊範圍(而不是鍵的範圍),每個透過雜湊雜湊落在分割槽範圍內的鍵將被儲存在該分割槽中。如 圖 6-3 所示。
{kind=link}

圖 6-3 按雜湊鍵分割槽
這種技術擅長在分割槽之間公平地分配鍵。分割槽邊界可以是均勻間隔的,也可以是偽隨機選擇的(在這種情況下,該技術有時也被稱為 一致性雜湊,即 consistent hashing)。
一致性雜湊
一致性雜湊由 Karger 等人定義。【7】 用於跨網際網路級別的快取系統,例如 CDN 中,是一種能均勻分配負載的方法。它使用隨機選擇的 分割槽邊界(partition boundaries) 來避免中央控制或分散式共識的需要。 請注意,這裡的一致性與複製一致性(請參閱 第五章)或 ACID 一致性(請參閱 第七章)無關,而只是描述了一種重新平衡(reblancing)的特定方法。
正如我們將在 “分割槽再平衡” 中所看到的,這種特殊的方法對於資料庫實際上並不是很好,所以在實際中很少使用(某些資料庫的文件仍然會使用一致性雜湊的說法,但是它往往是不準確的)。 因為有可能產生混淆,所以最好避免使用一致性雜湊這個術語,而只是把它稱為 雜湊分割槽(hash partitioning)。
不幸的是,透過使用鍵雜湊進行分割槽,我們失去了鍵範圍分割槽的一個很好的屬性:高效執行範圍查詢的能力。曾經相鄰的鍵現在分散在所有分割槽中,所以它們之間的順序就丟失了。在 MongoDB 中,如果你使用了基於雜湊的分割槽模式,則任何範圍查詢都必須傳送到所有分割槽【4】。Riak【9】、Couchbase 【10】或 Voldemort 不支援主鍵上的範圍查詢。
Cassandra 採取了折衷的策略【11, 12, 13】。 Cassandra 中的表可以使用由多個列組成的複合主鍵來宣告。鍵中只有第一列會作為雜湊的依據,而其他列則被用作 Casssandra 的 SSTables 中排序資料的連線索引。儘管查詢無法在複合主鍵的第一列中按範圍掃表,但如果第一列已經指定了固定值,則可以對該鍵的其他列執行有效的範圍掃描。
組合索引方法為一對多關係提供了一個優雅的資料模型。例如,在社交媒體網站上,一個使用者可能會發布很多更新。如果更新的主鍵被選擇為 (user_id, update_timestamp),那麼你可以有效地檢索特定使用者在某個時間間隔內按時間戳排序的所有更新。不同的使用者可以儲存在不同的分割槽上,對於每個使用者,更新按時間戳順序儲存在單個分割槽上。
負載偏斜與熱點消除
如前所述,雜湊分割槽可以幫助減少熱點。但是,它不能完全避免它們:在極端情況下,所有的讀寫操作都是針對同一個鍵的,所有的請求都會被路由到同一個分割槽。
這種場景也許並不常見,但並非聞所未聞:例如,在社交媒體網站上,一個擁有數百萬追隨者的名人使用者在做某事時可能會引發一場風暴【14】。這個事件可能導致同一個鍵的大量寫入(鍵可能是名人的使用者 ID,或者人們正在評論的動作的 ID)。雜湊策略不起作用,因為兩個相同 ID 的雜湊值仍然是相同的。
如今,大多數資料系統無法自動補償這種高度偏斜的負載,因此應用程式有責任減少偏斜。例如,如果一個主鍵被認為是非常火爆的,一個簡單的方法是在主鍵的開始或結尾新增一個隨機數。只要一個兩位數的十進位制隨機數就可以將主鍵分散為 100 種不同的主鍵,從而儲存在不同的分割槽中。
然而,將主鍵進行分割之後,任何讀取都必須要做額外的工作,因為他們必須從所有 100 個主鍵分佈中讀取資料並將其合併。此技術還需要額外的記錄:只需要對少量熱點附加隨機數;對於寫入吞吐量低的絕大多數主鍵來說是不必要的開銷。因此,你還需要一些方法來跟蹤哪些鍵需要被分割。
也許在將來,資料系統將能夠自動檢測和補償偏斜的工作負載;但現在,你需要自己來權衡。
分割槽與次級索引
到目前為止,我們討論的分割槽方案依賴於鍵值資料模型。如果只通過主鍵訪問記錄,我們可以從該鍵確定分割槽,並使用它來將讀寫請求路由到負責該鍵的分割槽。
如果涉及次級索引,情況會變得更加複雜(參考 “其他索引結構”)。次級索引通常並不能唯一地標識記錄,而是一種搜尋記錄中出現特定值的方式:查詢使用者 123 的所有操作,查詢包含詞語 hogwash 的所有文章,查詢所有顏色為紅色的車輛等等。
次級索引是關係型資料庫的基礎,並且在文件資料庫中也很普遍。許多鍵值儲存(如 HBase 和 Volde-mort)為了減少實現的複雜度而放棄了次級索引,但是一些(如 Riak)已經開始新增它們,因為它們對於資料模型實在是太有用了。並且次級索引也是 Solr 和 Elasticsearch 等搜尋伺服器的基石。
次級索引的問題是它們不能整齊地對映到分割槽。有兩種用次級索引對資料庫進行分割槽的方法:基於文件的分割槽(document-based) 和 基於關鍵詞(term-based)的分割槽。
基於文件的次級索引進行分割槽
假設你正在經營一個銷售二手車的網站(如 圖 6-4 所示)。 每個列表都有一個唯一的 ID—— 稱之為文件 ID—— 並且用文件 ID 對資料庫進行分割槽(例如,分割槽 0 中的 ID 0 到 499,分割槽 1 中的 ID 500 到 999 等)。
{kind=link}
你想讓使用者搜尋汽車,允許他們透過顏色和廠商過濾,所以需要一個在顏色和廠商上的次級索引(文件資料庫中這些是 欄位(field),關係資料庫中這些是 列(column) )。 如果你聲明瞭索引,則資料庫可以自動執行索引 2。例如,無論何時將紅色汽車新增到資料庫,資料庫分割槽都會自動將其新增到索引條目 color:red 的文件 ID 列表中。

圖 6-4 基於文件的次級索引進行分割槽
在這種索引方法中,每個分割槽是完全獨立的:每個分割槽維護自己的次級索引,僅覆蓋該分割槽中的文件。它不關心儲存在其他分割槽的資料。無論何時你需要寫入資料庫(新增,刪除或更新文件),只需處理包含你正在編寫的文件 ID 的分割槽即可。出於這個原因,文件分割槽索引 也被稱為 本地索引(而不是將在下一節中描述的 全域性索引)。
但是,從文件分割槽索引中讀取需要注意:除非你對文件 ID 做了特別的處理,否則沒有理由將所有具有特定顏色或特定品牌的汽車放在同一個分割槽中。在 圖 6-4 中,紅色汽車出現在分割槽 0 和分割槽 1 中。因此,如果要搜尋紅色汽車,則需要將查詢傳送到所有分割槽,併合並所有返回的結果。
這種查詢分割槽資料庫的方法有時被稱為 分散 / 聚集(scatter/gather),並且可能會使次級索引上的讀取查詢相當昂貴。即使並行查詢分割槽,分散 / 聚集也容易導致尾部延遲放大(請參閱 “實踐中的百分位點”)。然而,它被廣泛使用:MongoDB,Riak 【15】,Cassandra 【16】,Elasticsearch 【17】,SolrCloud 【18】和 VoltDB 【19】都使用文件分割槽次級索引。大多數資料庫供應商建議你構建一個能從單個分割槽提供次級索引查詢的分割槽方案,但這並不總是可行,尤其是當在單個查詢中使用多個次級索引時(例如同時需要按顏色和製造商查詢)。
基於關鍵詞(Term)的次級索引進行分割槽
我們可以構建一個覆蓋所有分割槽資料的 全域性索引,而不是給每個分割槽建立自己的次級索引(本地索引)。但是,我們不能只把這個索引儲存在一個節點上,因為它可能會成為瓶頸,違背了分割槽的目的。全域性索引也必須進行分割槽,但可以採用與主鍵不同的分割槽方式。
圖 6-5 描述了這可能是什麼樣子:來自所有分割槽的紅色汽車在紅色索引中,並且索引是分割槽的,首字母從 a 到 r 的顏色在分割槽 0 中,s 到 z 的在分割槽 1。汽車製造商的索引也與之類似(分割槽邊界在 f 和 h 之間)。
{kind=link}
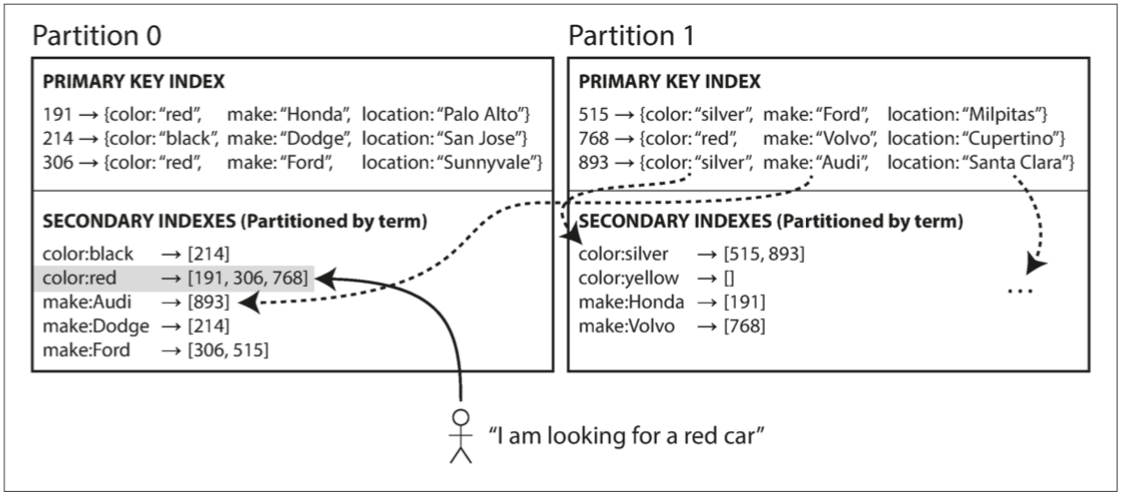
圖 6-5 基於關鍵詞對次級索引進行分割槽
我們將這種索引稱為 關鍵詞分割槽(term-partitioned),因為我們尋找的關鍵詞決定了索引的分割槽方式。例如,一個關鍵詞可能是:color:red。關鍵詞(Term) 這個名稱來源於全文搜尋索引(一種特殊的次級索引),指文件中出現的所有單詞。
和之前一樣,我們可以透過 關鍵詞 本身或者它的雜湊進行索引分割槽。根據關鍵詞本身來分割槽對於範圍掃描非常有用(例如對於數值類的屬性,像汽車的報價),而對關鍵詞的雜湊分割槽提供了負載均衡的能力。
關鍵詞分割槽的全域性索引優於文件分割槽索引的地方點是它可以使讀取更有效率:不需要 分散 / 收集 所有分割槽,客戶端只需要向包含關鍵詞的分割槽發出請求。全域性索引的缺點在於寫入速度較慢且較為複雜,因為寫入單個文件現在可能會影響索引的多個分割槽(文件中的每個關鍵詞可能位於不同的分割槽或者不同的節點上) 。
理想情況下,索引總是最新的,寫入資料庫的每個文件都會立即反映在索引中。但是,在關鍵詞分割槽索引中,這需要跨分割槽的分散式事務,並不是所有資料庫都支援(請參閱 第七章 和 第九章)。
在實踐中,對全域性次級索引的更新通常是 非同步 的(也就是說,如果在寫入之後不久讀取索引,剛才所做的更改可能尚未反映在索引中)。例如,Amazon DynamoDB 聲稱在正常情況下,其全域性次級索引會在不到一秒的時間內更新,但在基礎架構出現故障的情況下可能會有延遲【20】。
全域性關鍵詞分割槽索引的其他用途包括 Riak 的搜尋功能【21】和 Oracle 資料倉庫,它允許你在本地和全域性索引之間進行選擇【22】。我們將在 第十二章 中繼續關鍵詞分割槽次級索引實現的話題。
分割槽再平衡
隨著時間的推移,資料庫會有各種變化:
- 查詢吞吐量增加,所以你想要新增更多的 CPU 來處理負載。
- 資料集大小增加,所以你想新增更多的磁碟和 RAM 來儲存它。
- 機器出現故障,其他機器需要接管故障機器的責任。
所有這些更改都需要資料和請求從一個節點移動到另一個節點。 將負載從叢集中的一個節點向另一個節點移動的過程稱為 再平衡(rebalancing)。
無論使用哪種分割槽方案,再平衡通常都要滿足一些最低要求:
- 再平衡之後,負載(資料儲存,讀取和寫入請求)應該在叢集中的節點之間公平地共享。
- 再平衡發生時,資料庫應該繼續接受讀取和寫入。
- 節點之間只移動必須的資料,以便快速再平衡,並減少網路和磁碟 I/O 負載。
再平衡策略
有幾種不同的分割槽分配方法【23】,讓我們依次簡要討論一下。
反面教材:hash mod N
我們在前面說過(圖 6-3),最好將可能的雜湊分成不同的範圍,並將每個範圍分配給一個分割槽(例如,如果 $0 ≤ hash(key)< b_0$,則將鍵分配給分割槽 0,如果 $b_0 ≤ hash(key) < b_1$,則分配給分割槽 1)
也許你想知道為什麼我們不使用 取模(mod)(許多程式語言中的 % 運算子)。例如,hash(key) mod 10 會返回一個介於 0 和 9 之間的數字(如果我們將雜湊寫為十進位制數,雜湊模 10 將是最後一個數字)。如果我們有 10 個節點,編號為 0 到 9,這似乎是將每個鍵分配給一個節點的簡單方法。
模 N($mod N$)方法的問題是,如果節點數量 N 發生變化,大多數鍵將需要從一個節點移動到另一個節點。例如,假設 $hash(key)=123456$。如果最初有 10 個節點,那麼這個鍵一開始放在節點 6 上(因為 $123456\ mod\ 10 = 6$)。當你增長到 11 個節點時,鍵需要移動到節點 3($123456\ mod\ 11 = 3$),當你增長到 12 個節點時,需要移動到節點 0($123456\ mod\ 12 = 0$)。這種頻繁的舉動使得重新平衡過於昂貴。
我們需要一種只移動必需資料的方法。
固定數量的分割槽
幸運的是,有一個相當簡單的解決方案:建立比節點更多的分割槽,併為每個節點分配多個分割槽。例如,執行在 10 個節點的叢集上的資料庫可能會從一開始就被拆分為 1,000 個分割槽,因此大約有 100 個分割槽被分配給每個節點。
現在,如果一個節點被新增到叢集中,新節點可以從當前每個節點中 竊取 一些分割槽,直到分割槽再次公平分配。這個過程如 圖 6-6 所示。如果從叢集中刪除一個節點,則會發生相反的情況。
{kind=link}
只有分割槽在節點之間的移動。分割槽的數量不會改變,鍵所指定的分割槽也不會改變。唯一改變的是分割槽所在的節點。這種變更並不是即時的 — 在網路上傳輸大量的資料需要一些時間 — 所以在傳輸過程中,原有分割槽仍然會接受讀寫操作。

圖 6-6 將新節點新增到每個節點具有多個分割槽的資料庫叢集。
原則上,你甚至可以解決叢集中的硬體不匹配問題:透過為更強大的節點分配更多的分割槽,可以強制這些節點承載更多的負載。在 Riak 【15】、Elasticsearch 【24】、Couchbase 【10】和 Voldemort 【25】中使用了這種再平衡的方法。
在這種配置中,分割槽的數量通常在資料庫第一次建立時確定,之後不會改變。雖然原則上可以分割和合並分割槽(請參閱下一節),但固定數量的分割槽在操作上更簡單,因此許多固定分割槽資料庫選擇不實施分割槽分割。因此,一開始配置的分割槽數就是你可以擁有的最大節點數量,所以你需要選擇足夠多的分割槽以適應未來的增長。但是,每個分割槽也有管理開銷,所以選擇太大的數字會適得其反。
如果資料集的總大小難以預估(例如,可能它開始很小,但隨著時間的推移會變得更大),選擇正確的分割槽數是困難的。由於每個分割槽包含了總資料量固定比率的資料,因此每個分割槽的大小與叢集中的資料總量成比例增長。如果分割槽非常大,再平衡和從節點故障恢復變得昂貴。但是,如果分割槽太小,則會產生太多的開銷。當分割槽大小 “恰到好處” 的時候才能獲得很好的效能,如果分割槽數量固定,但資料量變動很大,則難以達到最佳效能。
動態分割槽
對於使用鍵範圍分割槽的資料庫(請參閱 “根據鍵的範圍分割槽”),具有固定邊界的固定數量的分割槽將非常不便:如果出現邊界錯誤,則可能會導致一個分割槽中的所有資料或者其他分割槽中的所有資料為空。手動重新配置分割槽邊界將非常繁瑣。
出於這個原因,按鍵的範圍進行分割槽的資料庫(如 HBase 和 RethinkDB)會動態建立分割槽。當分割槽增長到超過配置的大小時(在 HBase 上,預設值是 10GB),會被分成兩個分割槽,每個分割槽約佔一半的資料【26】。與之相反,如果大量資料被刪除並且分割槽縮小到某個閾值以下,則可以將其與相鄰分割槽合併。此過程與 B 樹頂層發生的過程類似(請參閱 “B 樹”)。
每個分割槽分配給一個節點,每個節點可以處理多個分割槽,就像固定數量的分割槽一樣。大型分割槽拆分後,可以將其中的一半轉移到另一個節點,以平衡負載。在 HBase 中,分割槽檔案的傳輸透過 HDFS(底層使用的分散式檔案系統)來實現【3】。
動態分割槽的一個優點是分割槽數量適應總資料量。如果只有少量的資料,少量的分割槽就足夠了,所以開銷很小;如果有大量的資料,每個分割槽的大小被限制在一個可配置的最大值【23】。
需要注意的是,一個空的資料庫從一個分割槽開始,因為沒有關於在哪裡繪製分割槽邊界的先驗資訊。資料集開始時很小,直到達到第一個分割槽的分割點,所有寫入操作都必須由單個節點處理,而其他節點則處於空閒狀態。為了解決這個問題,HBase 和 MongoDB 允許在一個空的資料庫上配置一組初始分割槽(這被稱為 預分割,即 pre-splitting)。在鍵範圍分割槽的情況中,預分割需要提前知道鍵是如何進行分配的【4,26】。
動態分割槽不僅適用於資料的範圍分割槽,而且也適用於雜湊分割槽。從版本 2.4 開始,MongoDB 同時支援範圍和雜湊分割槽,並且都支援動態分割分割槽。
按節點比例分割槽
透過動態分割槽,分割槽的數量與資料集的大小成正比,因為拆分和合並過程將每個分割槽的大小保持在固定的最小值和最大值之間。另一方面,對於固定數量的分割槽,每個分割槽的大小與資料集的大小成正比。在這兩種情況下,分割槽的數量都與節點的數量無關。
Cassandra 和 Ketama 使用的第三種方法是使分割槽數與節點數成正比 —— 換句話說,每個節點具有固定數量的分割槽【23,27,28】。在這種情況下,每個分割槽的大小與資料集大小成比例地增長,而節點數量保持不變,但是當增加節點數時,分割槽將再次變小。由於較大的資料量通常需要較大數量的節點進行儲存,因此這種方法也使每個分割槽的大小較為穩定。
當一個新節點加入叢集時,它隨機選擇固定數量的現有分割槽進行拆分,然後佔有這些拆分分割槽中每個分割槽的一半,同時將每個分割槽的另一半留在原地。隨機化可能會產生不公平的分割,但是平均在更大數量的分割槽上時(在 Cassandra 中,預設情況下,每個節點有 256 個分割槽),新節點最終從現有節點獲得公平的負載份額。 Cassandra 3.0 引入了另一種再平衡的演算法來避免不公平的分割【29】。
隨機選擇分割槽邊界要求使用基於雜湊的分割槽(可以從雜湊函式產生的數字範圍中挑選邊界)。實際上,這種方法最符合一致性雜湊的原始定義【7】(請參閱 “一致性雜湊”)。最新的雜湊函式可以在較低元資料開銷的情況下達到類似的效果【8】。
運維:手動還是自動再平衡
關於再平衡有一個重要問題:自動還是手動進行?
在全自動重新平衡(系統自動決定何時將分割槽從一個節點移動到另一個節點,無須人工干預)和完全手動(分割槽指派給節點由管理員明確配置,僅在管理員明確重新配置時才會更改)之間有一個權衡。例如,Couchbase、Riak 和 Voldemort 會自動生成建議的分割槽分配,但需要管理員提交才能生效。
全自動重新平衡可以很方便,因為正常維護的操作工作較少。但是,這可能是不可預測的。再平衡是一個昂貴的操作,因為它需要重新路由請求並將大量資料從一個節點移動到另一個節點。如果沒有做好,這個過程可能會使網路或節點負載過重,降低其他請求的效能。
這種自動化與自動故障檢測相結合可能十分危險。例如,假設一個節點過載,並且對請求的響應暫時很慢。其他節點得出結論:過載的節點已經死亡,並自動重新平衡叢集,使負載離開它。這會對已經超負荷的節點,其他節點和網路造成額外的負載,從而使情況變得更糟,並可能導致級聯失敗。
出於這個原因,再平衡的過程中有人参與是一件好事。這比完全自動的過程慢,但可以幫助防止運維意外。
請求路由
現在我們已經將資料集分割到多個機器上執行的多個節點上。但是仍然存在一個懸而未決的問題:當客戶想要發出請求時,如何知道要連線哪個節點?隨著分割槽重新平衡,分割槽對節點的分配也發生變化。為了回答這個問題,需要有人知曉這些變化:如果我想讀或寫鍵 “foo”,需要連線哪個 IP 地址和埠號?
這個問題可以概括為 服務發現(service discovery) ,它不僅限於資料庫。任何可透過網路訪問的軟體都有這個問題,特別是如果它的目標是高可用性(在多臺機器上執行冗餘配置)。許多公司已經編寫了自己的內部服務發現工具,其中許多已經作為開源釋出【30】。
概括來說,這個問題有幾種不同的方案(如圖 6-7 所示):
- 允許客戶聯絡任何節點(例如,透過 迴圈策略的負載均衡,即 Round-Robin Load Balancer)。如果該節點恰巧擁有請求的分割槽,則它可以直接處理該請求;否則,它將請求轉發到適當的節點,接收回復並傳遞給客戶端。
- 首先將所有來自客戶端的請求傳送到路由層,它決定了應該處理請求的節點,並相應地轉發。此路由層本身不處理任何請求;它僅負責分割槽的負載均衡。
- 要求客戶端知道分割槽和節點的分配。在這種情況下,客戶端可以直接連線到適當的節點,而不需要任何中介。
以上所有情況中的關鍵問題是:作出路由決策的元件(可能是節點之一,還是路由層或客戶端)如何瞭解分割槽 - 節點之間的分配關係變化?
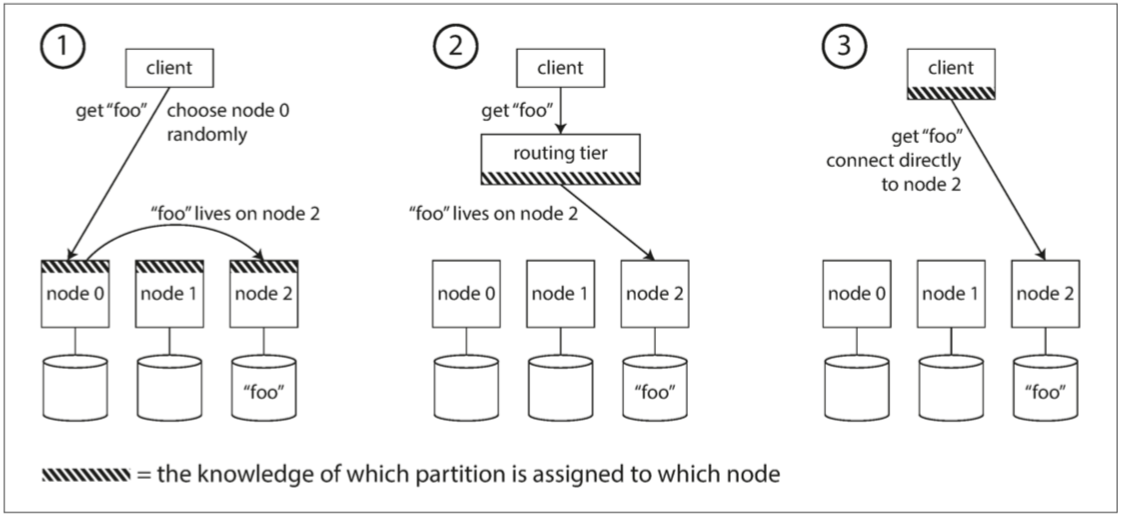
圖 6-7 將請求路由到正確節點的三種不同方式。
這是一個具有挑戰性的問題,因為重要的是所有參與者都達成共識 - 否則請求將被傳送到錯誤的節點,得不到正確的處理。 在分散式系統中有達成共識的協議,但很難正確地實現(見 第九章)。
許多分散式資料系統都依賴於一個獨立的協調服務,比如 ZooKeeper 來跟蹤叢集元資料,如 圖 6-8 所示。 每個節點在 ZooKeeper 中註冊自己,ZooKeeper 維護分割槽到節點的可靠對映。 其他參與者(如路由層或分割槽感知客戶端)可以在 ZooKeeper 中訂閱此資訊。 只要分割槽分配發生了改變,或者叢集中新增或刪除了一個節點,ZooKeeper 就會通知路由層使路由資訊保持最新狀態。
{kind=link}

圖 6-8 使用 ZooKeeper 跟蹤分割槽分配給節點。
例如,LinkedIn的Espresso使用Helix 【31】進行叢集管理(依靠ZooKeeper),實現瞭如圖6-8所示的路由層。 HBase、SolrCloud和Kafka也使用ZooKeeper來跟蹤分割槽分配。MongoDB具有類似的體系結構,但它依賴於自己的配置伺服器(config server) 實現和mongos守護程序作為路由層。
Cassandra 和 Riak 採取不同的方法:他們在節點之間使用 流言協議(gossip protocol) 來傳播叢集狀態的變化。請求可以傳送到任意節點,該節點會轉發到包含所請求的分割槽的適當節點(圖 6-7 中的方法 1)。這個模型在資料庫節點中增加了更多的複雜性,但是避免了對像 ZooKeeper 這樣的外部協調服務的依賴。
{kind=link}
Couchbase 不會自動重新平衡,這簡化了設計。通常情況下,它配置了一個名為 moxi 的路由層,它會從叢集節點了解路由變化【32】。
當使用路由層或向隨機節點發送請求時,客戶端仍然需要找到要連線的 IP 地址。這些地址並不像分割槽的節點分佈變化的那麼快,所以使用 DNS 通常就足夠了。
執行並行查詢
到目前為止,我們只關注讀取或寫入單個鍵的非常簡單的查詢(加上基於文件分割槽的次級索引場景下的分散 / 聚集查詢)。這也是大多數 NoSQL 分散式資料儲存所支援的訪問層級。
然而,通常用於分析的 大規模並行處理(MPP, Massively parallel processing) 關係型資料庫產品在其支援的查詢型別方面要複雜得多。一個典型的資料倉庫查詢包含多個連線,過濾,分組和聚合操作。 MPP 查詢最佳化器將這個複雜的查詢分解成許多執行階段和分割槽,其中許多可以在資料庫叢集的不同節點上並行執行。涉及掃描大規模資料集的查詢特別受益於這種並行執行。
資料倉庫查詢的快速並行執行是一個專門的話題,由於分析有很重要的商業意義,可以帶來很多利益。我們將在 第十章 討論並行查詢執行的一些技巧。有關並行資料庫中使用的技術的更詳細的概述,請參閱參考文獻【1,33】。
本章小結
在本章中,我們探討了將大資料集劃分成更小的子集的不同方法。資料量非常大的時候,在單臺機器上儲存和處理不再可行,而分割槽則十分必要。分割槽的目標是在多臺機器上均勻分佈資料和查詢負載,避免出現熱點(負載不成比例的節點)。這需要選擇適合於你的資料的分割槽方案,並在將節點新增到叢集或從叢集刪除時進行分割槽再平衡。
我們討論了兩種主要的分割槽方法:
-
鍵範圍分割槽
其中鍵是有序的,並且分割槽擁有從某個最小值到某個最大值的所有鍵。排序的優勢在於可以進行有效的範圍查詢,但是如果應用程式經常訪問相鄰的鍵,則存在熱點的風險。
在這種方法中,當分割槽變得太大時,通常將分割槽分成兩個子分割槽,動態地再平衡分割槽。
-
雜湊分割槽
雜湊函式應用於每個鍵,分割槽擁有一定範圍的雜湊。這種方法破壞了鍵的排序,使得範圍查詢效率低下,但可以更均勻地分配負載。
透過雜湊進行分割槽時,通常先提前建立固定數量的分割槽,為每個節點分配多個分割槽,並在新增或刪除節點時將整個分割槽從一個節點移動到另一個節點。也可以使用動態分割槽。
兩種方法搭配使用也是可行的,例如使用複合主鍵:使用鍵的一部分來標識分割槽,而使用另一部分作為排序順序。
我們還討論了分割槽和次級索引之間的相互作用。次級索引也需要分割槽,有兩種方法:
- 基於文件分割槽(本地索引),其中次級索引儲存在與主鍵和值相同的分割槽中。這意味著只有一個分割槽需要在寫入時更新,但是讀取次級索引需要在所有分割槽之間進行分散 / 收集。
- 基於關鍵詞分割槽(全域性索引),其中次級索引存在不同的分割槽中。次級索引中的條目可以包括來自主鍵的所有分割槽的記錄。當文件寫入時,需要更新多個分割槽中的次級索引;但是可以從單個分割槽中進行讀取。
最後,我們討論了將查詢路由到適當的分割槽的技術,從簡單的分割槽負載平衡到複雜的並行查詢執行引擎。
按照設計,多數情況下每個分割槽是獨立執行的 — 這就是分割槽資料庫可以伸縮到多臺機器的原因。但是,需要寫入多個分割槽的操作結果可能難以預料:例如,如果寫入一個分割槽成功,但另一個分割槽失敗,會發生什麼情況?我們將在下面的章節中討論這個問題。
參考文獻
- David J. DeWitt and Jim N. Gray: “Parallel Database Systems: The Future of High Performance Database Systems,” Communications of the ACM, volume 35, number 6, pages 85–98, June 1992. doi:10.1145/129888.129894
- Lars George: “HBase vs. BigTable Comparison,” larsgeorge.com, November 2009.
- “The Apache HBase Reference Guide,” Apache Software Foundation, hbase.apache.org, 2014.
- MongoDB, Inc.: “New Hash-Based Sharding Feature in MongoDB 2.4,” blog.mongodb.org, April 10, 2013.
- Ikai Lan: “App Engine Datastore Tip: Monotonically Increasing Values Are Bad,” ikaisays.com, January 25, 2011.
- Martin Kleppmann: “Java's hashCode Is Not Safe for Distributed Systems,” martin.kleppmann.com, June 18, 2012.
- David Karger, Eric Lehman, Tom Leighton, et al.: “Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web,” at 29th Annual ACM Symposium on Theory of Computing (STOC), pages 654–663, 1997. doi:10.1145/258533.258660
- John Lamping and Eric Veach: “A Fast, Minimal Memory, Consistent Hash Algorithm,” arxiv.org, June 2014.
- Eric Redmond: “A Little Riak Book,” Version 1.4.0, Basho Technologies, September 2013.
- “Couchbase 2.5 Administrator Guide,” Couchbase, Inc., 2014.
- Avinash Lakshman and Prashant Malik: “Cassandra – A Decentralized Structured Storage System,” at 3rd ACM SIGOPS International Workshop on Large Scale Distributed Systems and Middleware (LADIS), October 2009.
- Jonathan Ellis: “Facebook’s Cassandra Paper, Annotated and Compared to Apache Cassandra 2.0,” datastax.com, September 12, 2013.
- “Introduction to Cassandra Query Language,” DataStax, Inc., 2014.
- Samuel Axon: “3% of Twitter's Servers Dedicated to Justin Bieber,” mashable.com, September 7, 2010.
- “Riak 1.4.8 Docs,” Basho Technologies, Inc., 2014.
- Richard Low: “The Sweet Spot for Cassandra Secondary Indexing,” wentnet.com, October 21, 2013.
- Zachary Tong: “Customizing Your Document Routing,” elasticsearch.org, June 3, 2013.
- “Apache Solr Reference Guide,” Apache Software Foundation, 2014.
- Andrew Pavlo: “H-Store Frequently Asked Questions,” hstore.cs.brown.edu, October 2013.
- “Amazon DynamoDB Developer Guide,” Amazon Web Services, Inc., 2014.
- Rusty Klophaus: “Difference Between 2I and Search,” email to riak-users mailing list, lists.basho.com, October 25, 2011.
- Donald K. Burleson: “Object Partitioning in Oracle,”dba-oracle.com, November 8, 2000.
- Eric Evans: “Rethinking Topology in Cassandra,” at ApacheCon Europe, November 2012.
- Rafał Kuć: “Reroute API Explained,” elasticsearchserverbook.com, September 30, 2013.
- “Project Voldemort Documentation,” project-voldemort.com.
- Enis Soztutar: “Apache HBase Region Splitting and Merging,” hortonworks.com, February 1, 2013.
- Brandon Williams: “Virtual Nodes in Cassandra 1.2,” datastax.com, December 4, 2012.
- Richard Jones: “libketama: Consistent Hashing Library for Memcached Clients,” metabrew.com, April 10, 2007.
- Branimir Lambov: “New Token Allocation Algorithm in Cassandra 3.0,” datastax.com, January 28, 2016.
- Jason Wilder: “Open-Source Service Discovery,” jasonwilder.com, February 2014.
- Kishore Gopalakrishna, Shi Lu, Zhen Zhang, et al.: “Untangling Cluster Management with Helix,” at ACM Symposium on Cloud Computing (SoCC), October 2012. doi:10.1145/2391229.2391248
- “Moxi 1.8 Manual,” Couchbase, Inc., 2014.
- Shivnath Babu and Herodotos Herodotou: “Massively Parallel Databases and MapReduce Systems,” Foundations and Trends in Databases, volume 5, number 1, pages 1–104, November 2013.doi:10.1561/1900000036
| 上一章 | 目錄 | 下一章 |
|---|---|---|
| 第五章:複製 | 設計資料密集型應用 | 第七章:事務 |