36 KiB
Chapter 3. Data Models and Query Languages
The limits of my language mean the limits of my world.
— Ludwig Wittgenstein, Tractatus Logico-Philosophicus (1922)
Data models are perhaps the most important part of developing software, because they have such a profound effect: not only on how the software is written, but also on how we think about the problem that we are solving.
Most applications are built by layering one data model on top of another. For each layer, the key question is: how is it represented in terms of the next-lower layer? For example:
- As an application developer, you look at the real world (in which there are people, organizations, goods, actions, money flows, sensors, etc.) and model it in terms of objects or data structures, and APIs that manipulate those data structures. Those structures are often specific to your application.
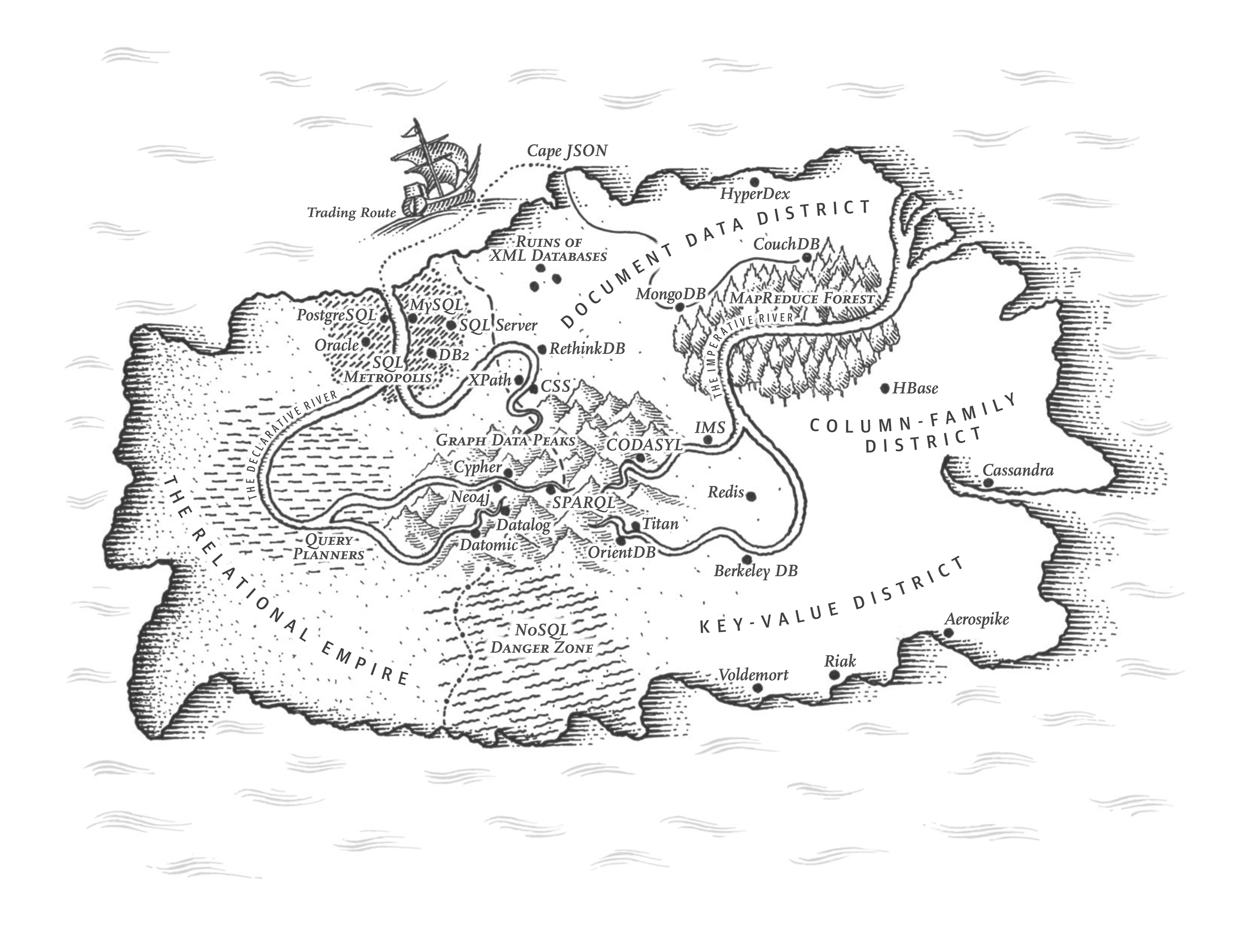
- When you want to store those data structures, you express them in terms of a general-purpose data model, such as JSON or XML documents, tables in a relational database, or vertices and edges in a graph. Those data models are the topic of this chapter.
- The engineers who built your database software decided on a way of representing that JSON/relational/graph data in terms of bytes in memory, on disk, or on a network. The representation may allow the data to be queried, searched, manipulated, and processed in various ways. We will discuss these storage engine designs in [Link to Come].
- On yet lower levels, hardware engineers have figured out how to represent bytes in terms of electrical currents, pulses of light, magnetic fields, and more.
In a complex application there may be more intermediary levels, such as APIs built upon APIs, but the basic idea is still the same: each layer hides the complexity of the layers below it by providing a clean data model. These abstractions allow different groups of people—for example, the engineers at the database vendor and the application developers using their database—to work together effectively.
Several different data models are widely used in practice, often for different purposes. Some types of data and some queries are easy to express in one model, and awkward in another. In this chapter we will explore those trade-offs by comparing the relational model, the document model, graph-based data models, event sourcing, and dataframes. We will also briefly look at query languages that allow you to work with these models. This comparison will help you decide when to use which model.
……
Summary
Data models are a huge subject, and in this chapter we have taken a quick look at a broad variety of different models. We didn’t have space to go into all the details of each model, but hopefully the overview has been enough to whet your appetite to find out more about the model that best fits your application’s requirements.
Historically, data started out being represented as one big tree (the hierarchical model), but that wasn’t good for representing many-to-many relationships, so the relational model was invented to solve that problem. More recently, developers found that some applications don’t fit well in the relational model either. New nonrelational “NoSQL” datastores have diverged in two main directions:
-
Document databases target use cases where data comes in self-contained docu‐ ments and relationships between one document and another are rare.
-
Graph databases go in the opposite direction, targeting use cases where anything is potentially related to everything.
All three models (document, relational, and graph) are widely used today, and each is good in its respective domain. One model can be emulated in terms of another model —for example, graph data can be represented in a relational database—but the result is often awkward. That’s why we have different systems for different purposes, not a single one-size-fits-all solution.
One thing that document and graph databases have in common is that they typically don’t enforce a schema for the data they store, which can make it easier to adapt applications to changing requirements. However, your application most likely still assumes that data has a certain structure; it’s just a question of whether the schema is explicit (enforced on write) or implicit (handled on read).
Each data model comes with its own query language or framework, and we discussed several examples: SQL, MapReduce, MongoDB’s aggregation pipeline, Cypher, SPARQL, and Datalog. We also touched on CSS and XSL/XPath, which aren’t data‐ base query languages but have interesting parallels.
Although we have covered a lot of ground, there are still many data models left unmentioned. To give just a few brief examples:
- Researchers working with genome data often need to perform sequence- similarity searches, which means taking one very long string (representing a DNA molecule) and matching it against a large database of strings that are simi‐ lar, but not identical. None of the databases described here can handle this kind of usage, which is why researchers have written specialized genome database software like GenBank [48].
- Particle physicists have been doing Big Data–style large-scale data analysis for decades, and projects like the Large Hadron Collider (LHC) now work with hun‐ dreds of petabytes! At such a scale custom solutions are required to stop the hardware cost from spiraling out of control [49].
- Full-text search is arguably a kind of data model that is frequently used alongside databases. Information retrieval is a large specialist subject that we won’t cover in great detail in this book, but we’ll touch on search indexes in Chapter 3 and Part III.
We have to leave it there for now. In the next chapter we will discuss some of the trade-offs that come into play when implementing the data models described in this chapter.
Summary
Data models are a huge subject, and in this chapter we have taken a quick look at a broad variety of different models. We didn’t have space to go into all the details of each model, but hopefully the overview has been enough to whet your appetite to find out more about the model that best fits your application’s requirements.
The relational model, despite being more than half a century old, remains an important data model for many applications—especially in data warehousing and business analytics, where relational star or snowflake schemas and SQL queries are ubiquitous. However, several alternatives to relational data have also become popular in other domains:
- The document model targets use cases where data comes in self-contained JSON documents, and where relationships between one document and another are rare.
- Graph data models go in the opposite direction, targeting use cases where anything is potentially related to everything, and where queries potentially need to traverse multiple hops to find the data of interest (which can be expressed using recursive queries in Cypher, SPARQL, or Datalog).
- Dataframes generalize relational data to large numbers of columns, and thereby provide a bridge between databases and the multidimensional arrays that form the basis of much machine learning, statistical data analysis, and scientific computing.
To some degree, one model can be emulated in terms of another model—for example, graph data can be represented in a relational database—but the result can be awkward, as we saw with the support for recursive queries in SQL.
Various specialist databases have therefore been developed for each data model, providing query languages and storage engines that are optimized for a particular model. However, there is also a trend for databases to expand into neighboring niches by adding support for other data models: for example, relational databases have added support for document data in the form of JSON columns, document databases have added relational-like joins, and support for graph data within SQL is gradually improving.
Another model we discussed is event sourcing, which represents data as an append-only log of immutable events, and which can be advantageous for modeling activities in complex business domains. An append-only log is good for writing data (as we shall see in [Link to Come]); in order to support efficient queries, the event log is translated into read-optimized materialized views through CQRS.
One thing that non-relational data models have in common is that they typically don’t enforce a schema for the data they store, which can make it easier to adapt applications to changing requirements. However, your application most likely still assumes that data has a certain structure; it’s just a question of whether the schema is explicit (enforced on write) or implicit (assumed on read).
Although we have covered a lot of ground, there are still data models left unmentioned. To give just a few brief examples:
- Researchers working with genome data often need to perform sequence-similarity searches, which means taking one very long string (representing a DNA molecule) and matching it against a large database of strings that are similar, but not identical. None of the databases described here can handle this kind of usage, which is why researchers have written specialized genome database software like GenBank [68].
- Many financial systems use ledgers with double-entry accounting as their data model. This type of data can be represented in relational databases, but there are also databases such as TigerBeetle that specialize in this data model. Cryptocurrencies and blockchains are typically based on distributed ledgers, which also have value transfer built into their data model.
- Full-text search is arguably a kind of data model that is frequently used alongside databases. Information retrieval is a large specialist subject that we won’t cover in great detail in this book, but we’ll touch on search indexes and vector search in [Link to Come].
We have to leave it there for now. In the next chapter we will discuss some of the trade-offs that come into play when implementing the data models described in this chapter.
References
[1] Jamie Brandon. Unexplanations: query optimization works because sql is declarative. scattered-thoughts.net, February 2024. Archived at perma.cc/P6W2-WMFZ
[2] Joseph M. Hellerstein. The Declarative Imperative: Experiences and Conjectures in Distributed Logic. Tech report UCB/EECS-2010-90, Electrical Engineering and Computer Sciences, University of California at Berkeley, June 2010. Archived at perma.cc/K56R-VVQM
[3] Edgar F. Codd. A Relational Model of Data for Large Shared Data Banks. Communications of the ACM, volume 13, issue 6, pages 377–387, June 1970. doi:10.1145/362384.362685
[4] Michael Stonebraker and Joseph M. Hellerstein. What Goes Around Comes Around. In Readings in Database Systems, 4th edition, MIT Press, pages 2–41, 2005. ISBN: 9780262693141
[5] Markus Winand. Modern SQL: Beyond Relational. modern-sql.com, 2015. Archived at perma.cc/D63V-WAPN
[6] Martin Fowler. OrmHate. martinfowler.com, May 2012. Archived at perma.cc/VCM8-PKNG
[7] Vlad Mihalcea. N+1 query problem with JPA and Hibernate. vladmihalcea.com, January 2023. Archived at perma.cc/79EV-TZKB
[8] Jens Schauder. This is the Beginning of the End of the N+1 Problem: Introducing Single Query Loading. spring.io, August 2023. Archived at perma.cc/6V96-R333
[9] William Zola. 6 Rules of Thumb for MongoDB Schema Design. mongodb.com, June 2014. Archived at perma.cc/T2BZ-PPJB
[10] Sidney Andrews and Christopher McClister. Data modeling in Azure Cosmos DB. learn.microsoft.com, February 2023. Archived at archive.org
[11] Raffi Krikorian. Timelines at Scale. At QCon San Francisco, November 2012. Archived at perma.cc/V9G5-KLYK
[12] Ralph Kimball and Margy Ross. The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling, 3rd edition. John Wiley & Sons, July 2013. ISBN: 9781118530801
[13] Michael Kaminsky. Data warehouse modeling: Star schema vs. OBT. fivetran.com, August 2022. Archived at perma.cc/2PZK-BFFP
[14] Joe Nelson. User-defined Order in SQL. begriffs.com, March 2018. Archived at perma.cc/GS3W-F7AD
[15] Evan Wallace. Realtime Editing of Ordered Sequences. figma.com, March 2017. Archived at perma.cc/K6ER-CQZW
[16] David Greenspan. Implementing Fractional Indexing. observablehq.com, October 2020. Archived at perma.cc/5N4R-MREN
[17] Martin Fowler. Schemaless Data Structures. martinfowler.com, January 2013.
[18] Amr Awadallah. Schema-on-Read vs. Schema-on-Write. At Berkeley EECS RAD Lab Retreat, Santa Cruz, CA, May 2009. Archived at perma.cc/DTB2-JCFR
[19] Martin Odersky. The Trouble with Types. At Strange Loop, September 2013. Archived at perma.cc/85QE-PVEP
[20] Conrad Irwin. MongoDB—Confessions of a PostgreSQL Lover. At HTML5DevConf, October 2013. Archived at perma.cc/C2J6-3AL5
[21] Percona Toolkit Documentation: pt-online-schema-change. docs.percona.com, 2023. Archived at perma.cc/9K8R-E5UH
[22] Shlomi Noach. gh-ost: GitHub’s Online Schema Migration Tool for MySQL. github.blog, August 2016. Archived at perma.cc/7XAG-XB72
[23] Shayon Mukherjee. pg-osc: Zero downtime schema changes in PostgreSQL. shayon.dev, February 2022. Archived at perma.cc/35WN-7WMY
[24] Carlos Pérez-Aradros Herce. Introducing pgroll: zero-downtime, reversible, schema migrations for Postgres. xata.io, October 2023. Archived at archive.org
[25] James C. Corbett, Jeffrey Dean, Michael Epstein, Andrew Fikes, Christopher Frost, JJ Furman, Sanjay Ghemawat, Andrey Gubarev, Christopher Heiser, Peter Hochschild, Wilson Hsieh, Sebastian Kanthak, Eugene Kogan, Hongyi Li, Alexander Lloyd, Sergey Melnik, David Mwaura, David Nagle, Sean Quinlan, Rajesh Rao, Lindsay Rolig, Dale Woodford, Yasushi Saito, Christopher Taylor, Michal Szymaniak, and Ruth Wang. Spanner: Google’s Globally-Distributed Database. At 10th USENIX Symposium on Operating System Design and Implementation (OSDI), October 2012.
[26] Donald K. Burleson. Reduce I/O with Oracle Cluster Tables. dba-oracle.com. Archived at perma.cc/7LBJ-9X2C
[27] Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, and Robert E. Gruber. Bigtable: A Distributed Storage System for Structured Data. At 7th USENIX Symposium on Operating System Design and Implementation (OSDI), November 2006.
[28] Priscilla Walmsley. XQuery, 2nd Edition. O’Reilly Media, December 2015. ISBN: 9781491915080
[29] Paul C. Bryan, Kris Zyp, and Mark Nottingham. JavaScript Object Notation (JSON) Pointer. RFC 6901, IETF, April 2013.
[30] Stefan Gössner, Glyn Normington, and Carsten Bormann. JSONPath: Query Expressions for JSON. RFC 9535, IETF, February 2024.
[31] Lawrence Page, Sergey Brin, Rajeev Motwani, and Terry Winograd. The PageRank Citation Ranking: Bringing Order to the Web. Technical Report 1999-66, Stanford University InfoLab, November 1999. Archived at perma.cc/UML9-UZHW
[32] Nathan Bronson, Zach Amsden, George Cabrera, Prasad Chakka, Peter Dimov, Hui Ding, Jack Ferris, Anthony Giardullo, Sachin Kulkarni, Harry Li, Mark Marchukov, Dmitri Petrov, Lovro Puzar, Yee Jiun Song, and Venkat Venkataramani. TAO: Facebook’s Distributed Data Store for the Social Graph. At USENIX Annual Technical Conference (ATC), June 2013.
[33] Natasha Noy, Yuqing Gao, Anshu Jain, Anant Narayanan, Alan Patterson, and Jamie Taylor. Industry-Scale Knowledge Graphs: Lessons and Challenges. Communications of the ACM, volume 62, issue 8, pages 36–43, August 2019. doi:10.1145/3331166
[34] Xiyang Feng, Guodong Jin, Ziyi Chen, Chang Liu, and Semih Salihoğlu. KÙZU Graph Database Management System. At 3th Annual Conference on Innovative Data Systems Research (CIDR 2023), January 2023.
[35] Maciej Besta, Emanuel Peter, Robert Gerstenberger, Marc Fischer, Michał Podstawski, Claude Barthels, Gustavo Alonso, Torsten Hoefler. Demystifying Graph Databases: Analysis and Taxonomy of Data Organization, System Designs, and Graph Queries. arxiv.org, October 2019.
[36] Apache TinkerPop 3.6.3 Documentation. tinkerpop.apache.org, May 2023. Archived at perma.cc/KM7W-7PAT
[37] Nadime Francis, Alastair Green, Paolo Guagliardo, Leonid Libkin, Tobias Lindaaker, Victor Marsault, Stefan Plantikow, Mats Rydberg, Petra Selmer, and Andrés Taylor. Cypher: An Evolving Query Language for Property Graphs. At International Conference on Management of Data (SIGMOD), pages 1433–1445, May 2018. doi:10.1145/3183713.3190657
[38] Emil Eifrem. Twitter correspondence, January 2014. Archived at perma.cc/WM4S-BW64
[39] Francesco Tisiot. Explore the new SEARCH and CYCLE features in PostgreSQL® 14. aiven.io, December 2021. Archived at perma.cc/J6BT-83UZ
[40] Gaurav Goel. Understanding Hierarchies in Oracle. towardsdatascience.com, May 2020. Archived at perma.cc/5ZLR-Q7EW
[41] Alin Deutsch, Nadime Francis, Alastair Green, Keith Hare, Bei Li, Leonid Libkin, Tobias Lindaaker, Victor Marsault, Wim Martens, Jan Michels, Filip Murlak, Stefan Plantikow, Petra Selmer, Oskar van Rest, Hannes Voigt, Domagoj Vrgoč, Mingxi Wu, and Fred Zemke. Graph Pattern Matching in GQL and SQL/PGQ. At International Conference on Management of Data (SIGMOD), pages 2246–2258, June 2022. doi:10.1145/3514221.3526057
[42] Alastair Green. SQL... and now GQL. opencypher.org, September 2019. Archived at perma.cc/AFB2-3SY7
[43] Alin Deutsch, Yu Xu, and Mingxi Wu. [Seamless Syntactic and Semantic Integration of Query Primitives over Relational and Graph Data in GSQL](https://cdn2.hubspot.net/hubfs/4114546/IntegrationQuery PrimitivesGSQL.pdf). tigergraph.com, November 2018. Archived at perma.cc/JG7J-Y35X
[44] Oskar van Rest, Sungpack Hong, Jinha Kim, Xuming Meng, and Hassan Chafi. PGQL: a property graph query language. At 4th International Workshop on Graph Data Management Experiences and Systems (GRADES), June 2016. doi:10.1145/2960414.2960421
[45] Amazon Web Services. Neptune Graph Data Model. Amazon Neptune User Guide, docs.aws.amazon.com. Archived at perma.cc/CX3T-EZU9
[46] Cognitect. Datomic Data Model. Datomic Cloud Documentation, docs.datomic.com. Archived at perma.cc/LGM9-LEUT
[47] David Beckett and Tim Berners-Lee. Turtle – Terse RDF Triple Language. W3C Team Submission, March 2011.
[48] Sinclair Target. Whatever Happened to the Semantic Web? twobithistory.org, May 2018. Archived at perma.cc/M8GL-9KHS
[49] Gavin Mendel-Gleason. The Semantic Web is Dead – Long Live the Semantic Web! terminusdb.com, August 2022. Archived at perma.cc/G2MZ-DSS3
[50] Manu Sporny. JSON-LD and Why I Hate the Semantic Web. manu.sporny.org, January 2014. Archived at perma.cc/7PT4-PJKF
[51] University of Michigan Library. Biomedical Ontologies and Controlled Vocabularies, guides.lib.umich.edu/ontology. Archived at perma.cc/Q5GA-F2N8
[52] Facebook. The Open Graph protocol, ogp.me. Archived at perma.cc/C49A-GUSY
[53] Matt Haughey. Everything you ever wanted to know about unfurling but were afraid to ask /or/ How to make your site previews look amazing in Slack. medium.com, November 2015. Archived at perma.cc/C7S8-4PZN
[54] W3C RDF Working Group. Resource Description Framework (RDF). w3.org, February 2004.
[55] Steve Harris, Andy Seaborne, and Eric Prud’hommeaux. SPARQL 1.1 Query Language. W3C Recommendation, March 2013.
[56] Todd J. Green, Shan Shan Huang, Boon Thau Loo, and Wenchao Zhou. Datalog and Recursive Query Processing. Foundations and Trends in Databases, volume 5, issue 2, pages 105–195, November 2013. doi:10.1561/1900000017
[57] Stefano Ceri, Georg Gottlob, and Letizia Tanca. What You Always Wanted to Know About Datalog (And Never Dared to Ask). IEEE Transactions on Knowledge and Data Engineering, volume 1, issue 1, pages 146–166, March 1989. doi:10.1109/69.43410
[58] Serge Abiteboul, Richard Hull, and Victor Vianu. Foundations of Databases. Addison-Wesley, 1995. ISBN: 9780201537710, available online at webdam.inria.fr/Alice
[59] Scott Meyer, Andrew Carter, and Andrew Rodriguez. LIquid: The soul of a new graph database, Part 2. engineering.linkedin.com, September 2020. Archived at perma.cc/K9M4-PD6Q
[60] Matt Bessey. Why, after 6 years, I’m over GraphQL. bessey.dev, May 2024. Archived at perma.cc/2PAU-JYRA
[61] Dominic Betts, Julián Domínguez, Grigori Melnik, Fernando Simonazzi, and Mani Subramanian. Exploring CQRS and Event Sourcing. Microsoft Patterns & Practices, July 2012. ISBN: 1621140164, archived at perma.cc/7A39-3NM8
[62] Greg Young. CQRS and Event Sourcing. At Code on the Beach, August 2014.
[63] Greg Young. CQRS Documents. cqrs.wordpress.com, November 2010. Archived at perma.cc/X5R6-R47F
[64] Devin Petersohn, Stephen Macke, Doris Xin, William Ma, Doris Lee, Xiangxi Mo, Joseph E. Gonzalez, Joseph M. Hellerstein, Anthony D. Joseph, and Aditya Parameswaran. Towards Scalable Dataframe Systems. Proceedings of the VLDB Endowment, volume 13, issue 11, pages 2033–2046. doi:10.14778/3407790.3407807
[65] Stavros Papadopoulos, Kushal Datta, Samuel Madden, and Timothy Mattson. The TileDB Array Data Storage Manager. Proceedings of the VLDB Endowment, volume 10, issue 4, pages 349–360, November 2016. doi:10.14778/3025111.3025117
[66] Florin Rusu. Multidimensional Array Data Management. Foundations and Trends in Databases, volume 12, numbers 2–3, pages 69–220, February 2023. doi:10.1561/1900000069
[67] Ed Targett. Bloomberg, Man Group team up to develop open source “ArcticDB” database. thestack.technology, March 2023. Archived at perma.cc/M5YD-QQYV
[68] Dennis A. Benson, Ilene Karsch-Mizrachi, David J. Lipman, James Ostell, and David L. Wheeler. GenBank. Nucleic Acids Research, volume 36, database issue, pages D25–D30, December 2007. doi:10.1093/nar/gkm929