43 KiB
第六章:分区
我们必须跳出电脑指令序列的窠臼。 叙述定义、描述元数据、梳理关系,而不是编写过程。
—— Grace Murray Hopper,未来的计算机及其管理(1962)
[TOC]
在第5章中,我们讨论了复制——即数据在不同节点上的副本,对于非常大的数据集,或非常高的吞吐量,仅仅进行复制是不够的:我们需要将数据进行分区(partitions),也称为分片(sharding)1。
术语澄清
上文中的分区(partition),在MongoDB,Elasticsearch和Solr Cloud中被称为分片(shard),在HBase中称之为区域(Region),Bigtable中则是 表块(tablet),Cassandra和Riak中是虚节点(vnode),Couchbase中叫做虚桶(vBucket)。但是分区(partitioning) 是最约定俗成的叫法。
通常情况下,每条数据(每条记录,每行或每个文档)属于且仅属于一个分区。有很多方法可以实现这一点,本章将进行深入讨论。实际上,每个分区都是自己的小型数据库,尽管数据库可能支持同时进行多个分区的操作。
分区主要是为了可伸缩性。不同的分区可以放在不共享集群中的不同节点上(参阅第二部分关于无共享架构的定义)。因此,大数据集可以分布在多个磁盘上,并且查询负载可以分布在多个处理器上。
对于在单个分区上运行的查询,每个节点可以独立执行对自己的查询,因此可以通过添加更多的节点来扩大查询吞吐量。大型,复杂的查询可能会跨越多个节点并行处理,尽管这也带来了新的困难。
分区数据库在20世纪80年代由Teradata和NonStop SQL【1】等产品率先推出,最近因为NoSQL数据库和基于Hadoop的数据仓库重新被关注。有些系统是为事务性工作设计的,有些系统则用于分析(参阅“事务处理还是分析”):这种差异会影响系统的运作方式,但是分区的基本原理均适用于这两种工作方式。
在本章中,我们将首先介绍分割大型数据集的不同方法,并观察索引如何与分区配合。然后我们将讨论分区再平衡(rebalancing),如果想要添加或删除集群中的节点,则必须进行再平衡。最后,我们将概述数据库如何将请求路由到正确的分区并执行查询。
分区与复制
分区通常与复制结合使用,使得每个分区的副本存储在多个节点上。 这意味着,即使每条记录属于一个分区,它仍然可以存储在多个不同的节点上以获得容错能力。
一个节点可能存储多个分区。 如果使用主从复制模型,则分区和复制的组合如图6-1所示。 每个分区领导者(主)被分配给一个节点,追随者(从)被分配给其他节点。 每个节点可能是某些分区的领导者,同时是其他分区的追随者。 我们在第5章讨论的关于数据库复制的所有内容同样适用于分区的复制。 大多数情况下,分区方案的选择与复制方案的选择是独立的,为简单起见,本章中将忽略复制。
{kind=link}
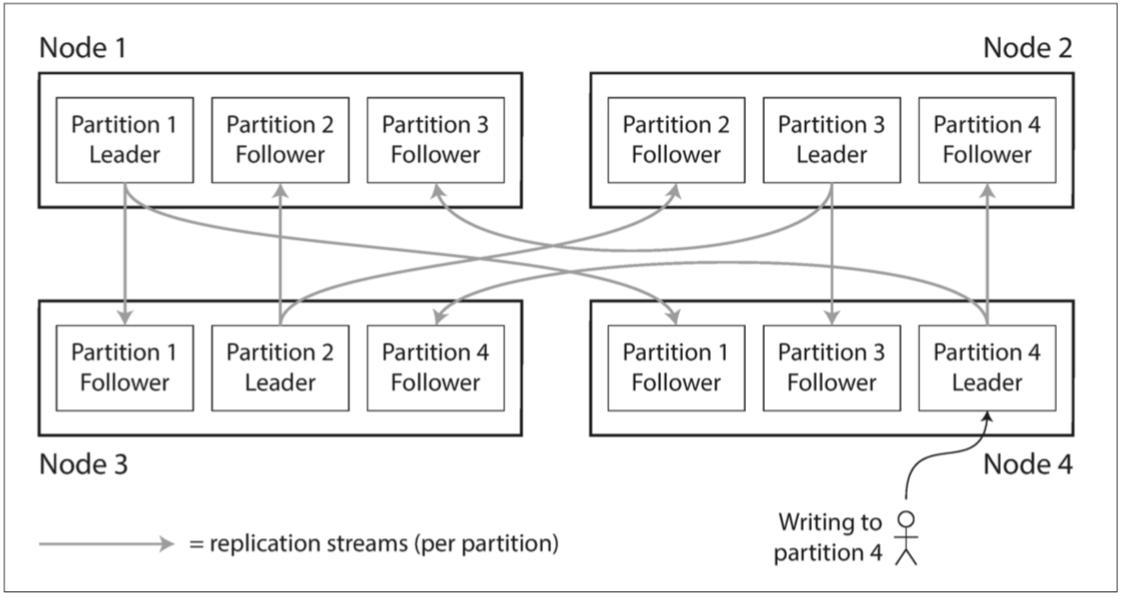
图6-1 组合使用复制和分区:每个节点充当某些分区的领导者,其他分区充当追随者。
键值数据的分区
假设你有大量数据并且想要分区,如何决定在哪些节点上存储哪些记录呢?
分区目标是将数据和查询负载均匀分布在各个节点上。如果每个节点公平分享数据和负载,那么理论上10个节点应该能够处理10倍的数据量和10倍的单个节点的读写吞吐量(暂时忽略复制)。
如果分区是不公平的,一些分区比其他分区有更多的数据或查询,我们称之为偏斜(skew)。数据偏斜的存在使分区效率下降很多。在极端的情况下,所有的负载可能压在一个分区上,其余9个节点空闲的,瓶颈落在这一个繁忙的节点上。不均衡导致的高负载的分区被称为热点(hot spot)。
避免热点最简单的方法是将记录随机分配给节点。这将在所有节点上平均分配数据,但是它有一个很大的缺点:当你试图读取一个特定的值时,你无法知道它在哪个节点上,所以你必须并行地查询所有的节点。
我们可以做得更好。现在假设您有一个简单的键值数据模型,其中您总是通过其主键访问记录。例如,在一本老式的纸质百科全书中,你可以通过标题来查找一个条目;由于所有条目按字母顺序排序,因此您可以快速找到您要查找的条目。
根据键的范围分区
一种分区的方法是为每个分区指定一块连续的键范围(从最小值到最大值),如纸质百科全书的卷(图6-2)。如果知道范围之间的边界,则可以轻松确定哪个分区包含某个值。如果您还知道分区所在的节点,那么可以直接向相应的节点发出请求(对于百科全书而言,就像从书架上选取正确的书籍)。

图6-2 印刷版百科全书按照关键字范围进行分区
键的范围不一定均匀分布,因为数据也很可能不均匀分布。例如在图6-2中,第1卷包含以A和B开头的单词,但第12卷则包含以T,U,V,X,Y和Z开头的单词。只是简单的规定每个卷包含两个字母会导致一些卷比其他卷大。为了均匀分配数据,分区边界需要依据数据调整。
{kind=link}
分区边界可以由管理员手动选择,也可以由数据库自动选择(我们会在“分区再平衡”中更详细地讨论分区边界的选择)。 Bigtable使用了这种分区策略,以及其开源等价物HBase 【2, 3】,RethinkDB和2.4版本之前的MongoDB 【4】。
在每个分区中,我们可以按照一定的顺序保存键(参见“SSTables和LSM树”)。好处是进行范围扫描非常简单,您可以将键作为联合索引来处理,以便在一次查询中获取多个相关记录(参阅“多列索引”)。例如,假设我们有一个程序来存储传感器网络的数据,其中主键是测量的时间戳(年月日时分秒)。范围扫描在这种情况下非常有用,因为我们可以轻松获取某个月份的所有数据。
然而,Key Range分区的缺点是某些特定的访问模式会导致热点。 如果主键是时间戳,则分区对应于时间范围,例如,给每天分配一个分区。 不幸的是,由于我们在测量发生时将数据从传感器写入数据库,因此所有写入操作都会转到同一个分区(即今天的分区),这样分区可能会因写入而过载,而其他分区则处于空闲状态【5】。
为了避免传感器数据库中的这个问题,需要使用除了时间戳以外的其他东西作为主键的第一个部分。 例如,可以在每个时间戳前添加传感器名称,这样会首先按传感器名称,然后按时间进行分区。 假设有多个传感器同时运行,写入负载将最终均匀分布在不同分区上。 现在,当想要在一个时间范围内获取多个传感器的值时,您需要为每个传感器名称执行一个单独的范围查询。
根据键的散列分区
由于偏斜和热点的风险,许多分布式数据存储使用散列函数来确定给定键的分区。
一个好的散列函数可以将偏斜的数据均匀分布。假设你有一个32位散列函数,无论何时给定一个新的字符串输入,它将返回一个0到2^{32} -1之间的“随机”数。即使输入的字符串非常相似,它们的散列也会均匀分布在这个数字范围内。
出于分区的目的,散列函数不需要多么强壮的加密算法:例如,Cassandra和MongoDB使用MD5,Voldemort使用Fowler-Noll-Vo函数。许多编程语言都有内置的简单哈希函数(它们用于哈希表),但是它们可能不适合分区:例如,在Java的Object.hashCode()和Ruby的Object#hash,同一个键可能在不同的进程中有不同的哈希值【6】。
一旦你有一个合适的键散列函数,你可以为每个分区分配一个散列范围(而不是键的范围),每个通过哈希散列落在分区范围内的键将被存储在该分区中。如图6-3所示。
{kind=link}

图6-3 按哈希键分区
这种技术擅长在分区之间公平地分配键。分区边界可以是均匀间隔的,也可以是伪随机选择的(在这种情况下,该技术有时也被称为一致性哈希(consistent hashing))。
一致性哈希
一致性哈希由Karger等人定义。【7】 用于跨互联网级别的缓存系统,例如CDN中,是一种能均匀分配负载的方法。它使用随机选择的 分区边界(partition boundaries) 来避免中央控制或分布式共识的需要。 请注意,这里的一致性与复制一致性(请参阅第5章)或ACID一致性(参阅第7章)无关,而只是描述了一种重新平衡(reblancing)的特定方法。
正如我们将在“分区再平衡”中所看到的,这种特殊的方法对于数据库实际上并不是很好,所以在实际中很少使用(某些数据库的文档仍然会使用一致性哈希的说法,但是它往往是不准确的)。 因为有可能产生混淆,所以最好避免使用一致性哈希这个术语,而只是把它称为散列分区(hash partitioning)。
不幸的是,通过使用键散列进行分区,我们失去了键范围分区的一个很好的属性:高效执行范围查询的能力。曾经相邻的键现在分散在所有分区中,所以它们之间的顺序就丢失了。在MongoDB中,如果您使用了基于散列的分区模式,则任何范围查询都必须发送到所有分区【4】。Riak 【9】,Couchbase 【10】或Voldemort不支持主键上的范围查询。
Cassandra采取了折衷的策略【11, 12, 13】。 Cassandra中的表可以使用由多个列组成的复合主键来声明。键中只有第一列会作为散列的依据,而其他列则被用作Casssandra的SSTables中排序数据的连接索引。尽管查询无法在复合主键的第一列中按范围扫表,但如果第一列已经指定了固定值,则可以对该键的其他列执行有效的范围扫描。
组合索引方法为一对多关系提供了一个优雅的数据模型。例如,在社交媒体网站上,一个用户可能会发布很多更新。如果更新的主键被选择为(user_id, update_timestamp),那么您可以有效地检索特定用户在某个时间间隔内按时间戳排序的所有更新。不同的用户可以存储在不同的分区上,对于每个用户,更新按时间戳顺序存储在单个分区上。
负载偏斜与热点消除
如前所述,哈希分区可以帮助减少热点。但是,它不能完全避免它们:在极端情况下,所有的读写操作都是针对同一个键的,所有的请求都会被路由到同一个分区。
这种场景也许并不常见,但并非闻所未闻:例如,在社交媒体网站上,一个拥有数百万追随者的名人用户在做某事时可能会引发一场风暴【14】。这个事件可能导致同一个键的大量写入(键可能是名人的用户ID,或者人们正在评论的动作的ID)。哈希策略不起作用,因为两个相同ID的哈希值仍然是相同的。
如今,大多数数据系统无法自动补偿这种高度偏斜的负载,因此应用程序有责任减少偏斜。例如,如果一个主键被认为是非常火爆的,一个简单的方法是在主键的开始或结尾添加一个随机数。只要一个两位数的十进制随机数就可以将主键分散为100种不同的主键,从而存储在不同的分区中。
然而,将主键进行分割之后,任何读取都必须要做额外的工作,因为他们必须从所有100个主键分布中读取数据并将其合并。此技术还需要额外的记录:只需要对少量热点附加随机数;对于写入吞吐量低的绝大多数主键来说是不必要的开销。因此,您还需要一些方法来跟踪哪些键需要被分割。
也许在将来,数据系统将能够自动检测和补偿偏斜的工作负载;但现在,您需要自己来权衡。
分区与次级索引
到目前为止,我们讨论的分区方案依赖于键值数据模型。如果只通过主键访问记录,我们可以从该键确定分区,并使用它来将读写请求路由到负责该键的分区。
如果涉及次级索引,情况会变得更加复杂(参考“其他索引结构”)。辅助索引通常并不能唯一地标识记录,而是一种搜索记录中出现特定值的方式:查找用户123的所有操作,查找包含词语hogwash的所有文章,查找所有颜色为红色的车辆等等。
次级索引是关系型数据库的基础,并且在文档数据库中也很普遍。许多键值存储(如HBase和Volde-mort)为了减少实现的复杂度而放弃了次级索引,但是一些(如Riak)已经开始添加它们,因为它们对于数据模型实在是太有用了。并且次级索引也是Solr和Elasticsearch等搜索服务器的基石。
次级索引的问题是它们不能整齐地映射到分区。有两种用二级索引对数据库进行分区的方法:基于文档的分区(document-based)和基于关键词(term-based)的分区。
基于文档的二级索引进行分区
假设你正在经营一个销售二手车的网站(如图6-4所示)。 每个列表都有一个唯一的ID——称之为文档ID——并且用文档ID对数据库进行分区(例如,分区0中的ID 0到499,分区1中的ID 500到999等)。
{kind=link}
你想让用户搜索汽车,允许他们通过颜色和厂商过滤,所以需要一个在颜色和厂商上的次级索引(文档数据库中这些是字段(field),关系数据库中这些是列(column) )。 如果您声明了索引,则数据库可以自动执行索引2。例如,无论何时将红色汽车添加到数据库,数据库分区都会自动将其添加到索引条目color:red的文档ID列表中。
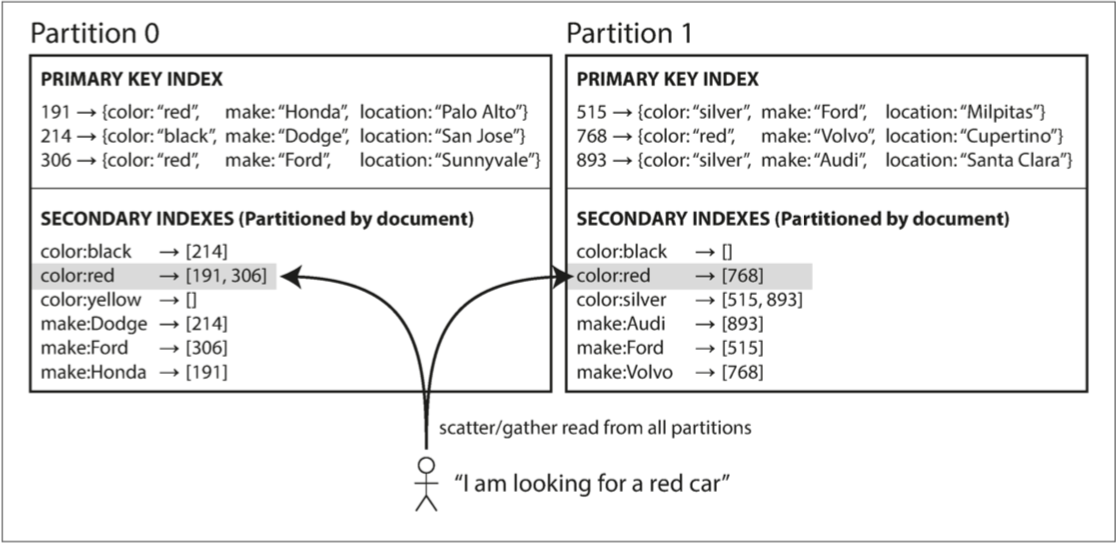
图6-4 基于文档的二级索引进行分区
在这种索引方法中,每个分区是完全独立的:每个分区维护自己的二级索引,仅覆盖该分区中的文档。它不关心存储在其他分区的数据。无论何时您需要写入数据库(添加,删除或更新文档),只需处理包含您正在编写的文档ID的分区即可。出于这个原因,文档分区索引也被称为本地索引(local index)(而不是将在下一节中描述的全局索引(global index))。
但是,从文档分区索引中读取需要注意:除非您对文档ID做了特别的处理,否则没有理由将所有具有特定颜色或特定品牌的汽车放在同一个分区中。在图6-4中,红色汽车出现在分区0和分区1中。因此,如果要搜索红色汽车,则需要将查询发送到所有分区,并合并所有返回的结果。
这种查询分区数据库的方法有时被称为分散/聚集(scatter/gather),并且可能会使二级索引上的读取查询相当昂贵。即使并行查询分区,分散/聚集也容易导致尾部延迟放大(参阅“实践中的百分位点”)。然而,它被广泛使用:MongoDB,Riak 【15】,Cassandra 【16】,Elasticsearch 【17】,SolrCloud 【18】和VoltDB 【19】都使用文档分区二级索引。大多数数据库供应商建议您构建一个能从单个分区提供二级索引查询的分区方案,但这并不总是可行,尤其是当在单个查询中使用多个二级索引时(例如同时需要按颜色和制造商查询)。
基于关键词(Term)的二级索引进行分区
我们可以构建一个覆盖所有分区数据的全局索引,而不是给每个分区创建自己的次级索引(本地索引)。但是,我们不能只把这个索引存储在一个节点上,因为它可能会成为瓶颈,违背了分区的目的。全局索引也必须进行分区,但可以采用与主键不同的分区方式。
图6-5描述了这可能是什么样子:来自所有分区的红色汽车在红色索引中,并且索引是分区的,首字母从a到r的颜色在分区0中,s到z的在分区1。汽车制造商的索引也与之类似(分区边界在f和h之间)。
{kind=link}
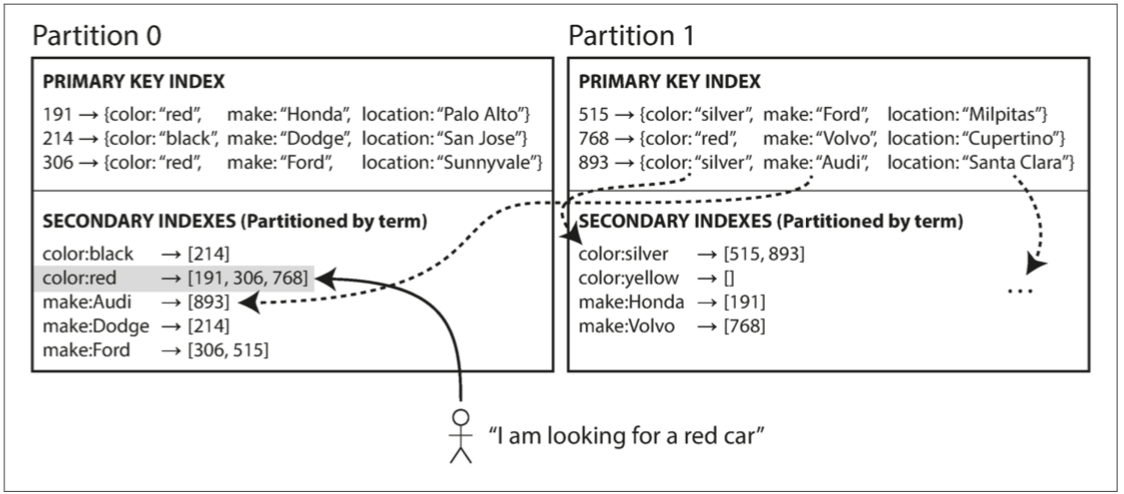
图6-5 基于关键词对二级索引进行分区
我们将这种索引称为关键词分区(term-partitioned),因为我们寻找的关键词决定了索引的分区方式。例如,一个关键词可能是:color:red。关键词(Term) 这个名称来源于全文搜索索引(一种特殊的次级索引),指文档中出现的所有单词。
和之前一样,我们可以通过关键词本身或者它的散列进行索引分区。根据关键词本身来分区对于范围扫描非常有用(例如对于数值类的属性,像汽车的报价),而对关键词的哈希分区提供了负载均衡的能力。
关键词分区的全局索引优于文档分区索引的地方点是它可以使读取更有效率:不需要分散/收集所有分区,客户端只需要向包含关键词的分区发出请求。全局索引的缺点在于写入速度较慢且较为复杂,因为写入单个文档现在可能会影响索引的多个分区(文档中的每个关键词可能位于不同的分区或者不同的节点上) 。
理想情况下,索引总是最新的,写入数据库的每个文档都会立即反映在索引中。但是,在关键词分区索引中,这需要跨分区的分布式事务,并不是所有数据库都支持(请参阅第7章和第9章)。
在实践中,对全局二级索引的更新通常是异步的(也就是说,如果在写入之后不久读取索引,刚才所做的更改可能尚未反映在索引中)。例如,Amazon DynamoDB声称在正常情况下,其全局次级索引会在不到一秒的时间内更新,但在基础架构出现故障的情况下可能会有延迟【20】。
全局关键词分区索引的其他用途包括Riak的搜索功能【21】和Oracle数据仓库,它允许您在本地和全局索引之间进行选择【22】。我们将在第12章中继续关键词分区二级索引实现的话题。
分区再平衡
随着时间的推移,数据库会有各种变化:
- 查询吞吐量增加,所以您想要添加更多的CPU来处理负载。
- 数据集大小增加,所以您想添加更多的磁盘和RAM来存储它。
- 机器出现故障,其他机器需要接管故障机器的责任。
所有这些更改都需要数据和请求从一个节点移动到另一个节点。 将负载从集群中的一个节点向另一个节点移动的过程称为再平衡(rebalancing)。
无论使用哪种分区方案,再平衡通常都要满足一些最低要求:
- 再平衡之后,负载(数据存储,读取和写入请求)应该在集群中的节点之间公平地共享。
- 再平衡发生时,数据库应该继续接受读取和写入。
- 节点之间只移动必须的数据,以便快速再平衡,并减少网络和磁盘I/O负载。
再平衡策略
有几种不同的分区分配方法【23】,让我们依次简要讨论一下。
反面教材:hash mod N
我们在前面说过(图6-3),最好将可能的散列分成不同的范围,并将每个范围分配给一个分区(例如,如果$0≤hash(key)<b_0$,则将键分配给分区0,如果$b_0 ≤ hash(key) <b_1$,则分配给分区1)
也许你想知道为什么我们不使用 取模(mod)(许多编程语言中的%运算符)。例如,hash(key) mod 10会返回一个介于0和9之间的数字(如果我们将散列写为十进制数,散列模10将是最后一个数字)。如果我们有10个节点,编号为0到9,这似乎是将每个键分配给一个节点的简单方法。
模N($mod N$)方法的问题是,如果节点数量N发生变化,大多数密钥将需要从一个节点移动到另一个节点。例如,假设$hash(key)=123456$。如果最初有10个节点,那么这个键一开始放在节点6上(因为$123456\ mod\ 10 = 6$)。当您增长到11个节点时,密钥需要移动到节点3($123456\ mod\ 11 = 3$),当您增长到12个节点时,需要移动到节点0($123456\ mod\ 12 = 0$)。这种频繁的举动使得重新平衡过于昂贵。
我们需要一种只移动必需数据的方法。
固定数量的分区
幸运的是,有一个相当简单的解决方案:创建比节点更多的分区,并为每个节点分配多个分区。例如,运行在10个节点的集群上的数据库可能会从一开始就被拆分为1,000个分区,因此大约有100个分区被分配给每个节点。
现在,如果一个节点被添加到集群中,新节点可以从当前每个节点中窃取一些分区,直到分区再次公平分配。这个过程如图6-6所示。如果从集群中删除一个节点,则会发生相反的情况。
{kind=link}
只有分区在节点之间的移动。分区的数量不会改变,键所指定的分区也不会改变。唯一改变的是分区所在的节点。这种变更并不是即时的 — 在网络上传输大量的数据需要一些时间 — 所以在传输过程中,原有分区仍然会接受读写操作。

图6-6 将新节点添加到每个节点具有多个分区的数据库群集。
原则上,您甚至可以解决集群中的硬件不匹配问题:通过为更强大的节点分配更多的分区,可以强制这些节点承载更多的负载。在Riak 【15】,Elasticsearch 【24】,Couchbase 【10】和Voldemort 【25】中使用了这种再平衡的方法。
在这种配置中,分区的数量通常在数据库第一次建立时确定,之后不会改变。虽然原则上可以分割和合并分区(请参阅下一节),但固定数量的分区在操作上更简单,因此许多固定分区数据库选择不实施分区分割。因此,一开始配置的分区数就是您可以拥有的最大节点数量,所以您需要选择足够多的分区以适应未来的增长。但是,每个分区也有管理开销,所以选择太大的数字会适得其反。
如果数据集的总大小难以预估(例如,可能它开始很小,但随着时间的推移会变得更大),选择正确的分区数是困难的。由于每个分区包含了总数据量固定比率的数据,因此每个分区的大小与集群中的数据总量成比例增长。如果分区非常大,再平衡和从节点故障恢复变得昂贵。但是,如果分区太小,则会产生太多的开销。当分区大小“恰到好处”的时候才能获得很好的性能,如果分区数量固定,但数据量变动很大,则难以达到最佳性能。
动态分区
对于使用键范围分区的数据库(参阅“根据键的范围分区”),具有固定边界的固定数量的分区将非常不便:如果出现边界错误,则可能会导致一个分区中的所有数据或者其他分区中的所有数据为空。手动重新配置分区边界将非常繁琐。
出于这个原因,按键的范围进行分区的数据库(如HBase和RethinkDB)会动态创建分区。当分区增长到超过配置的大小时(在HBase上,默认值是10GB),会被分成两个分区,每个分区约占一半的数据【26】。与之相反,如果大量数据被删除并且分区缩小到某个阈值以下,则可以将其与相邻分区合并。此过程与B树顶层发生的过程类似(参阅“B树”)。
每个分区分配给一个节点,每个节点可以处理多个分区,就像固定数量的分区一样。大型分区拆分后,可以将其中的一半转移到另一个节点,以平衡负载。在HBase中,分区文件的传输通过HDFS(底层使用的分布式文件系统)来实现【3】。
动态分区的一个优点是分区数量适应总数据量。如果只有少量的数据,少量的分区就足够了,所以开销很小;如果有大量的数据,每个分区的大小被限制在一个可配置的最大值【23】。
需要注意的是,一个空的数据库从一个分区开始,因为没有关于在哪里绘制分区边界的先验信息。数据集开始时很小,直到达到第一个分区的分割点,所有写入操作都必须由单个节点处理,而其他节点则处于空闲状态。为了解决这个问题,HBase和MongoDB允许在一个空的数据库上配置一组初始分区(这被称为预分割(pre-splitting))。在键范围分区的情况中,预分割需要提前知道键是如何进行分配的【4,26】。
动态分区不仅适用于数据的范围分区,而且也适用于散列分区。从版本2.4开始,MongoDB同时支持范围和散列分区,并且都支持动态分割分区。
按节点比例分区
通过动态分区,分区的数量与数据集的大小成正比,因为拆分和合并过程将每个分区的大小保持在固定的最小值和最大值之间。另一方面,对于固定数量的分区,每个分区的大小与数据集的大小成正比。在这两种情况下,分区的数量都与节点的数量无关。
Cassandra和Ketama使用的第三种方法是使分区数与节点数成正比——换句话说,每个节点具有固定数量的分区【23,27,28】。在这种情况下,每个分区的大小与数据集大小成比例地增长,而节点数量保持不变,但是当增加节点数时,分区将再次变小。由于较大的数据量通常需要较大数量的节点进行存储,因此这种方法也使每个分区的大小较为稳定。
当一个新节点加入集群时,它随机选择固定数量的现有分区进行拆分,然后占有这些拆分分区中每个分区的一半,同时将每个分区的另一半留在原地。随机化可能会产生不公平的分割,但是平均在更大数量的分区上时(在Cassandra中,默认情况下,每个节点有256个分区),新节点最终从现有节点获得公平的负载份额。 Cassandra 3.0引入了另一种再平衡的算法来避免不公平的分割【29】。
随机选择分区边界要求使用基于散列的分区(可以从散列函数产生的数字范围中挑选边界)。实际上,这种方法最符合一致性哈希的原始定义【7】(参阅“一致性哈希”)。最新的哈希函数可以在较低元数据开销的情况下达到类似的效果【8】。
运维:手动还是自动再平衡
关于再平衡有一个重要问题:自动还是手动进行?
在全自动重新平衡(系统自动决定何时将分区从一个节点移动到另一个节点,无须人工干预)和完全手动(分区指派给节点由管理员明确配置,仅在管理员明确重新配置时才会更改)之间有一个权衡。例如,Couchbase,Riak和Voldemort会自动生成建议的分区分配,但需要管理员提交才能生效。
全自动重新平衡可以很方便,因为正常维护的操作工作较少。但是,这可能是不可预测的。再平衡是一个昂贵的操作,因为它需要重新路由请求并将大量数据从一个节点移动到另一个节点。如果没有做好,这个过程可能会使网络或节点负载过重,降低其他请求的性能。
这种自动化与自动故障检测相结合可能十分危险。例如,假设一个节点过载,并且对请求的响应暂时很慢。其他节点得出结论:过载的节点已经死亡,并自动重新平衡集群,使负载离开它。这会对已经超负荷的节点,其他节点和网络造成额外的负载,从而使情况变得更糟,并可能导致级联失败。
出于这个原因,再平衡的过程中有人参与是一件好事。这比完全自动的过程慢,但可以帮助防止运维意外。
请求路由
现在我们已经将数据集分割到多个机器上运行的多个节点上。但是仍然存在一个悬而未决的问题:当客户想要发出请求时,如何知道要连接哪个节点?随着分区重新平衡,分区对节点的分配也发生变化。为了回答这个问题,需要有人知晓这些变化:如果我想读或写键“foo”,需要连接哪个IP地址和端口号?
这个问题可以概括为 服务发现(service discovery) ,它不仅限于数据库。任何可通过网络访问的软件都有这个问题,特别是如果它的目标是高可用性(在多台机器上运行冗余配置)。许多公司已经编写了自己的内部服务发现工具,其中许多已经作为开源发布【30】。
概括来说,这个问题有几种不同的方案(如图6-7所示):
- 允许客户联系任何节点(例如,通过循环策略的负载均衡(Round-Robin Load Balancer))。如果该节点恰巧拥有请求的分区,则它可以直接处理该请求;否则,它将请求转发到适当的节点,接收回复并传递给客户端。
- 首先将所有来自客户端的请求发送到路由层,它决定了应该处理请求的节点,并相应地转发。此路由层本身不处理任何请求;它仅负责分区的负载均衡。
- 要求客户端知道分区和节点的分配。在这种情况下,客户端可以直接连接到适当的节点,而不需要任何中介。
以上所有情况中的关键问题是:作出路由决策的组件(可能是节点之一,还是路由层或客户端)如何了解分区-节点之间的分配关系变化?

图6-7 将请求路由到正确节点的三种不同方式。
这是一个具有挑战性的问题,因为重要的是所有参与者都同意 - 否则请求将被发送到错误的节点,得不到正确的处理。 在分布式系统中有达成共识的协议,但很难正确地实现(见第9章)。
许多分布式数据系统都依赖于一个独立的协调服务,比如ZooKeeper来跟踪集群元数据,如图6-8所示。 每个节点在ZooKeeper中注册自己,ZooKeeper维护分区到节点的可靠映射。 其他参与者(如路由层或分区感知客户端)可以在ZooKeeper中订阅此信息。 只要分区分配发生了改变,或者集群中添加或删除了一个节点,ZooKeeper就会通知路由层使路由信息保持最新状态。
{kind=link}
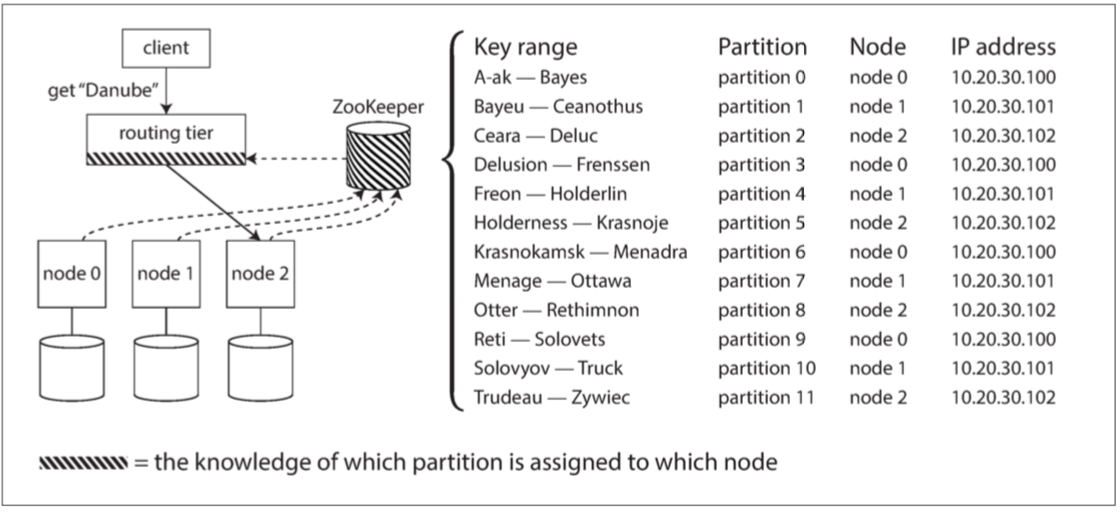
图6-8 使用ZooKeeper跟踪分区分配给节点。
例如,LinkedIn的Espresso使用Helix 【31】进行集群管理(依靠ZooKeeper),实现了如图6-8所示的路由层。 HBase,SolrCloud和Kafka也使用ZooKeeper来跟踪分区分配。 MongoDB具有类似的体系结构,但它依赖于自己的配置服务器(config server) 实现和mongos守护进程作为路由层。
Cassandra和Riak采取不同的方法:他们在节点之间使用流言协议(gossip protocol) 来传播群集状态的变化。请求可以发送到任意节点,该节点会转发到包含所请求的分区的适当节点(图6-7中的方法1)。这个模型在数据库节点中增加了更多的复杂性,但是避免了对像ZooKeeper这样的外部协调服务的依赖。
{kind=link}
Couchbase不会自动重新平衡,这简化了设计。通常情况下,它配置了一个名为moxi的路由层,它会从集群节点了解路由变化【32】。
当使用路由层或向随机节点发送请求时,客户端仍然需要找到要连接的IP地址。这些地址并不像分区的节点分布变化的那么快,所以使用DNS通常就足够了。
执行并行查询
到目前为止,我们只关注读取或写入单个键的非常简单的查询(加上基于文档分区的二级索引场景下的分散/聚集查询)。这也是大多数NoSQL分布式数据存储所支持的访问层级。
然而,通常用于分析的大规模并行处理(MPP, Massively parallel processing) 关系型数据库产品在其支持的查询类型方面要复杂得多。一个典型的数据仓库查询包含多个连接,过滤,分组和聚合操作。 MPP查询优化器将这个复杂的查询分解成许多执行阶段和分区,其中许多可以在数据库集群的不同节点上并行执行。涉及扫描大规模数据集的查询特别受益于这种并行执行。
数据仓库查询的快速并行执行是一个专门的话题,由于分析有很重要的商业意义,可以带来很多利益。我们将在第10章讨论并行查询执行的一些技巧。有关并行数据库中使用的技术的更详细的概述,请参阅参考文献【1,33】。
本章小结
在本章中,我们探讨了将大数据集划分成更小的子集的不同方法。数据量非常大的时候,在单台机器上存储和处理不再可行,而分区则十分必要。分区的目标是在多台机器上均匀分布数据和查询负载,避免出现热点(负载不成比例的节点)。这需要选择适合于您的数据的分区方案,并在将节点添加到集群或从集群删除时进行分区再平衡。
我们讨论了两种主要的分区方法:
键范围分区
其中键是有序的,并且分区拥有从某个最小值到某个最大值的所有键。排序的优势在于可以进行有效的范围查询,但是如果应用程序经常访问相邻的键,则存在热点的风险。
在这种方法中,当分区变得太大时,通常将分区分成两个子分区,动态地再平衡分区。
散列分区
散列函数应用于每个键,分区拥有一定范围的散列。这种方法破坏了键的排序,使得范围查询效率低下,但可以更均匀地分配负载。
通过散列进行分区时,通常先提前创建固定数量的分区,为每个节点分配多个分区,并在添加或删除节点时将整个分区从一个节点移动到另一个节点。也可以使用动态分区。
两种方法搭配使用也是可行的,例如使用复合主键:使用键的一部分来标识分区,而使用另一部分作为排序顺序。
我们还讨论了分区和二级索引之间的相互作用。次级索引也需要分区,有两种方法:
- 基于文档分区(本地索引),其中二级索引存储在与主键和值相同的分区中。这意味着只有一个分区需要在写入时更新,但是读取二级索引需要在所有分区之间进行分散/收集。
- 基于关键词分区(全局索引),其中二级索引存在不同的分区中。辅助索引中的条目可以包括来自主键的所有分区的记录。当文档写入时,需要更新多个分区中的二级索引;但是可以从单个分区中进行读取。
最后,我们讨论了将查询路由到适当的分区的技术,从简单的分区负载平衡到复杂的并行查询执行引擎。
按照设计,多数情况下每个分区是独立运行的 — 这就是分区数据库可以伸缩到多台机器的原因。但是,需要写入多个分区的操作结果可能难以预料:例如,如果写入一个分区成功,但另一个分区失败,会发生什么情况?我们将在下面的章节中讨论这个问题。
参考文献
-
David J. DeWitt and Jim N. Gray: “Parallel Database Systems: The Future of High Performance Database Systems,” Communications of the ACM, volume 35, number 6, pages 85–98, June 1992. doi:10.1145/129888.129894
-
Lars George: “HBase vs. BigTable Comparison,” larsgeorge.com, November 2009.
-
“The Apache HBase Reference Guide,” Apache Software Foundation, hbase.apache.org, 2014.
-
MongoDB, Inc.: “New Hash-Based Sharding Feature in MongoDB 2.4,” blog.mongodb.org, April 10, 2013.
-
Ikai Lan: “App Engine Datastore Tip: Monotonically Increasing Values Are Bad,” ikaisays.com, January 25, 2011.
-
Martin Kleppmann: “Java's hashCode Is Not Safe for Distributed Systems,” martin.kleppmann.com, June 18, 2012.
-
David Karger, Eric Lehman, Tom Leighton, et al.: “Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web,” at 29th Annual ACM Symposium on Theory of Computing (STOC), pages 654–663, 1997. doi:10.1145/258533.258660
-
John Lamping and Eric Veach: “A Fast, Minimal Memory, Consistent Hash Algorithm,” arxiv.org, June 2014.
-
Eric Redmond: “A Little Riak Book,” Version 1.4.0, Basho Technologies, September 2013.
-
“Couchbase 2.5 Administrator Guide,” Couchbase, Inc., 2014.
-
Avinash Lakshman and Prashant Malik: “Cassandra – A Decentralized Structured Storage System,” at 3rd ACM SIGOPS International Workshop on Large Scale Distributed Systems and Middleware (LADIS), October 2009.
-
Jonathan Ellis: “Facebook’s Cassandra Paper, Annotated and Compared to Apache Cassandra 2.0,” datastax.com, September 12, 2013.
-
“Introduction to Cassandra Query Language,” DataStax, Inc., 2014.
-
Samuel Axon: “3% of Twitter's Servers Dedicated to Justin Bieber,” mashable.com, September 7, 2010.
-
“Riak 1.4.8 Docs,” Basho Technologies, Inc., 2014.
-
Richard Low: “The Sweet Spot for Cassandra Secondary Indexing,” wentnet.com, October 21, 2013.
-
Zachary Tong: “Customizing Your Document Routing,” elasticsearch.org, June 3, 2013.
-
“Apache Solr Reference Guide,” Apache Software Foundation, 2014.
-
Andrew Pavlo: “H-Store Frequently Asked Questions,” hstore.cs.brown.edu, October 2013.
-
“Amazon DynamoDB Developer Guide,” Amazon Web Services, Inc., 2014.
-
Rusty Klophaus: “Difference Between 2I and Search,” email to riak-users mailing list, lists.basho.com, October 25, 2011.
-
Donald K. Burleson: “Object Partitioning in Oracle,”dba-oracle.com, November 8, 2000.
-
Eric Evans: “Rethinking Topology in Cassandra,” at ApacheCon Europe, November 2012.
-
Rafał Kuć: “Reroute API Explained,” elasticsearchserverbook.com, September 30, 2013.
-
“Project Voldemort Documentation,” project-voldemort.com.
-
Enis Soztutar: “Apache HBase Region Splitting and Merging,” hortonworks.com, February 1, 2013.
-
Brandon Williams: “Virtual Nodes in Cassandra 1.2,” datastax.com, December 4, 2012.
-
Richard Jones: “libketama: Consistent Hashing Library for Memcached Clients,” metabrew.com, April 10, 2007.
-
Branimir Lambov: “New Token Allocation Algorithm in Cassandra 3.0,” datastax.com, January 28, 2016.
-
Jason Wilder: “Open-Source Service Discovery,” jasonwilder.com, February 2014.
-
Kishore Gopalakrishna, Shi Lu, Zhen Zhang, et al.: “Untangling Cluster Management with Helix,” at ACM Symposium on Cloud Computing (SoCC), October 2012. doi:10.1145/2391229.2391248
-
“Moxi 1.8 Manual,” Couchbase, Inc., 2014.
-
Shivnath Babu and Herodotos Herodotou: “Massively Parallel Databases and MapReduce Systems,” Foundations and Trends in Databases, volume 5, number 1, pages 1–104, November 2013.doi:10.1561/1900000036
| 上一章 | 目录 | 下一章 |
|---|---|---|
| 第五章:复制 | 设计数据密集型应用 | 第七章:事务 |