41 KiB
2016 Git 新视界
2016 年 Git 发生了 惊天动地 地变化,发布了五大新特性¹ (从 v2.7 到 v2.11 )和十六个补丁²。189 位作者³贡献了 3676 个提交⁴到 master 分支,比 2015 年多了 15%⁵!总计有 1545 个文件被修改,其中增加了 276799 行并移除了 100973 行。
但是,通过统计提交的数量和代码行数来衡量生产力是一种十分愚蠢的方法。除了深度研究过的开发者可以做到凭直觉来判断代码质量的地步,我们普通人来作仲裁难免会因我们常人的判断有失偏颇。
谨记这一条于心,我决定整理这一年里六个我最喜爱的 Git 特性涵盖的改进,来做一次分类回顾。这篇文章作为一篇中篇推文有点太过长了,所以我不介意你们直接跳到你们特别感兴趣的特性去。
- 完成
git worktree命令 - 更多方便的
git rebase选项 git lfs梦幻的性能加速git diff实验性的算法和更好的默认结果git submodules差强人意git stash的90 个增强
在我们开始之前,请注意在大多数操作系统上都自带有 Git 的旧版本,所以你需要检查你是否在使用最新并且最棒的版本。如果在终端运行 git --version 返回的结果小于 Git v2.11.0,请立刻跳转到 Atlassian 的快速指南 更新或安装 Git 并根据你的平台做出选择。
###[所需的“引用”]
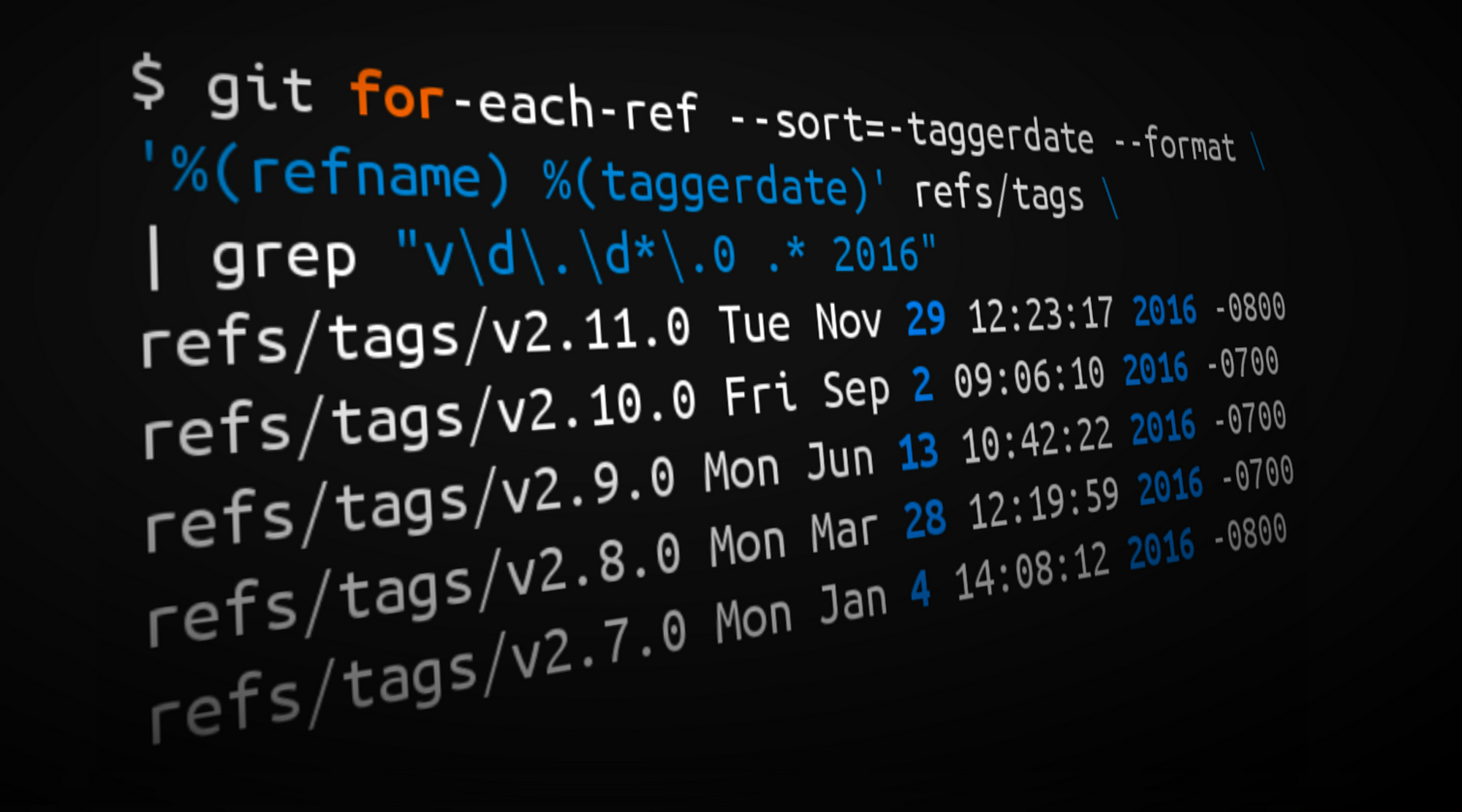
在我们进入高质量内容之前还需要做一个短暂的停顿:我觉得我需要为你展示我是如何从公开文档生成统计信息(以及开篇的封面图片)的。你也可以使用下面的命令来对你自己的仓库做一个快速的 年度回顾!
¹ Tags from 2016 matching the form vX.Y.0
$ git for-each-ref --sort=-taggerdate --format \
'%(refname) %(taggerdate)' refs/tags | grep "v\d\.\d*\.0 .* 2016"
² Tags from 2016 matching the form vX.Y.Z
$ git for-each-ref --sort=-taggerdate --format '%(refname) %(taggerdate)' refs/tags | grep "v\d\.\d*\.[^0] .* 2016"
³ Commits by author in 2016
$ git shortlog -s -n --since=2016-01-01 --until=2017-01-01
⁴ Count commits in 2016
$ git log --oneline --since=2016-01-01 --until=2017-01-01 | wc -l
⁵ ... and in 2015
$ git log --oneline --since=2015-01-01 --until=2016-01-01 | wc -l
⁶ Net LOC added/removed in 2016
$ git diff --shortstat `git rev-list -1 --until=2016-01-01 master` \
`git rev-list -1 --until=2017-01-01 master`
以上的命令是在 Git 的 master 分支运行的,所以不会显示其他出色的分支上没有合并的工作。如果你使用这些命令,请记住提交的数量和代码行数不是应该值得信赖的度量方式。请不要使用它们来衡量你的团队成员的贡献。
现在,让我们开始说好的回顾……
完成 Git 工作树(worktree)
git worktree 命令首次出现于 Git v2.5 ,但是在 2016 年有了一些显著的增强。两个有价值的新特性在 v2.7 被引入:list 子命令,和为二分搜索增加了命令空间的 refs。而 lock/unlock 子命令则是在 v2.10 被引入。
什么是工作树呢?
git worktree 命令允许你同步地检出和操作处于不同路径下的同一仓库的多个分支。例如,假如你需要做一次快速的修复工作但又不想扰乱你当前的工作区,你可以使用以下命令在一个新路径下检出一个新分支:
$ git worktree add -b hotfix/BB-1234 ../hotfix/BB-1234
Preparing ../hotfix/BB-1234 (identifier BB-1234)
HEAD is now at 886e0ba Merged in bedwards/BB-13430-api-merge-pr (pull request #7822)
工作树不仅仅是为分支工作。你可以检出多个里程碑(tags)作为不同的工作树来并行构建或测试它们。例如,我从 Git v2.6 和 v2.7 的里程碑中创建工作树来检验不同版本 Git 的行为特征。
$ git worktree add ../git-v2.6.0 v2.6.0
Preparing ../git-v2.6.0 (identifier git-v2.6.0)
HEAD is now at be08dee Git 2.6
$ git worktree add ../git-v2.7.0 v2.7.0
Preparing ../git-v2.7.0 (identifier git-v2.7.0)
HEAD is now at 7548842 Git 2.7
$ git worktree list
/Users/kannonboy/src/git 7548842 [master]
/Users/kannonboy/src/git-v2.6.0 be08dee (detached HEAD)
/Users/kannonboy/src/git-v2.7.0 7548842 (detached HEAD)
$ cd ../git-v2.7.0 && make
你也使用同样的技术来并行构造和运行你自己应用程序的不同版本。
列出工作树
git worktree list 子命令(于 Git v2.7 引入)显示所有与当前仓库有关的工作树。
$ git worktree list
/Users/kannonboy/src/bitbucket/bitbucket 37732bd [master]
/Users/kannonboy/src/bitbucket/staging d5924bc [staging]
/Users/kannonboy/src/bitbucket/hotfix-1234 37732bd [hotfix/1234]
二分查找工作树
gitbisect 是一个简洁的 Git 命令,可以让我们对提交记录执行一次二分搜索。通常用来找到哪一次提交引入了一个指定的退化。例如,如果在我的 master 分支最后的提交上有一个测试没有通过,我可以使用 git bisect 来贯穿仓库的历史来找寻第一次造成这个错误的提交。
$ git bisect start
# 找到已知通过测试的最后提交
# (例如最新的发布里程碑)
$ git bisect good v2.0.0
# 找到已知的出问题的提交
# (例如在 `master` 上的提示)
$ git bisect bad master
# 告诉 git bisect 要运行的脚本/命令;
# git bisect 会在 “good” 和 “bad”范围内
# 找到导致脚本以非 0 状态退出的最旧的提交
$ git bisect run npm test
在后台,bisect 使用 refs 来跟踪 “good” 与 “bad” 的提交来作为二分搜索范围的上下界限。不幸的是,对工作树的粉丝来说,这些 refs 都存储在寻常的 .git/refs/bisect 命名空间,意味着 git bisect 操作如果运行在不同的工作树下可能会互相干扰。
到了 v2.7 版本,bisect 的 refs 移到了 .git/worktrees/$worktree_name/refs/bisect, 所以你可以并行运行 bisect 操作于多个工作树中。
锁定工作树
当你完成了一颗工作树的工作,你可以直接删除它,然后通过运行 git worktree prune 等它被当做垃圾自动回收。但是,如果你在网络共享或者可移除媒介上存储了一颗工作树,如果工作树目录在删除期间不可访问,工作树会被完全清除——不管你喜不喜欢!Git v2.10 引入了 git worktree lock 和 unlock 子命令来防止这种情况发生。
# 在我的 USB 盘上锁定 git-v2.7 工作树
$ git worktree lock /Volumes/Flash_Gordon/git-v2.7 --reason \
"In case I remove my removable media"
# 当我完成时,解锁(并删除)该工作树
$ git worktree unlock /Volumes/Flash_Gordon/git-v2.7
$ rm -rf /Volumes/Flash_Gordon/git-v2.7
$ git worktree prune
--reason 标签允许为未来的你留一个记号,描述为什么当初工作树被锁定。git worktree unlock 和 lock 都要求你指定工作树的路径。或者,你可以 cd 到工作树目录然后运行 git worktree lock . 来达到同样的效果。
更多 Git 变基(rebase)选项
2016 年三月,Git v2.8 增加了在拉取过程中交互进行变基的命令 git pull --rebase=interactive 。对应地,六月份 Git v2.9 发布了通过 git rebase -x 命令对执行变基操作而不需要进入交互模式的支持。
Re-啥?
在我们继续深入前,我假设读者中有些并不是很熟悉或者没有完全习惯变基命令或者交互式变基。从概念上说,它很简单,但是与很多 Git 的强大特性一样,变基散发着听起来很复杂的专业术语的气息。所以,在我们深入前,先来快速的复习一下什么是变基(rebase)。
变基操作意味着将一个或多个提交在一个指定分支上重写。git rebase 命令是被深度重载了,但是 rebase 这个名字的来源事实上还是它经常被用来改变一个分支的基准提交(你基于此提交创建了这个分支)。
从概念上说,rebase 通过将你的分支上的提交临时存储为一系列补丁包,接着将这些补丁包按顺序依次打在目标提交之上。
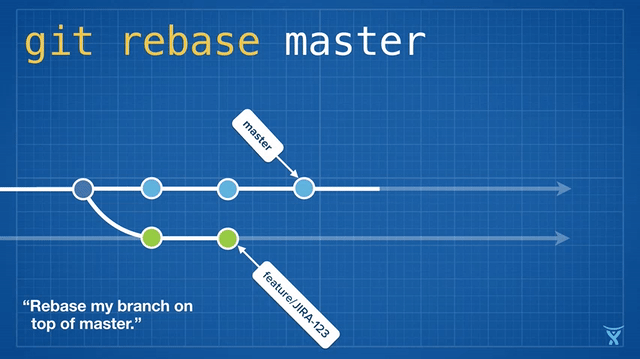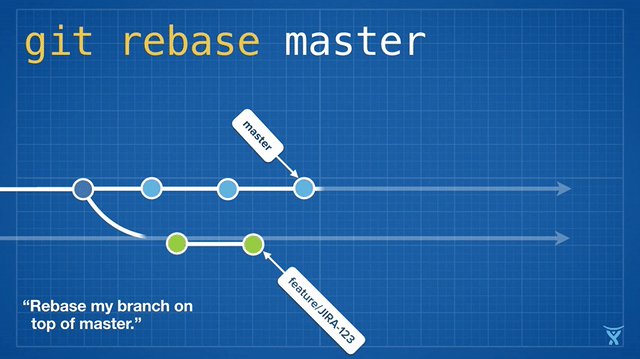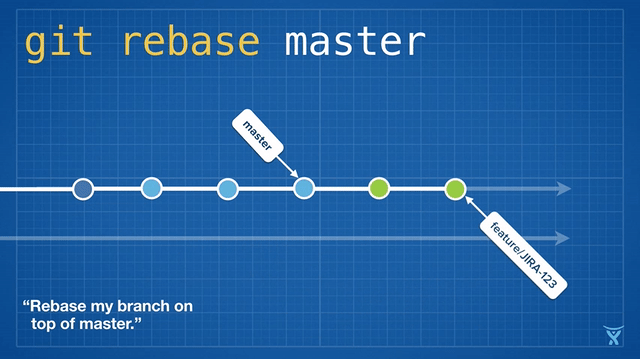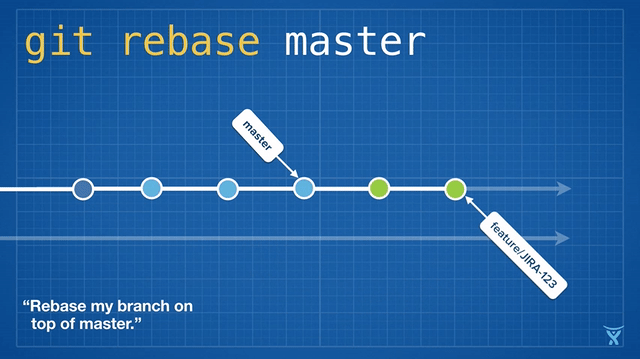
对 master 分支的一个功能分支执行变基操作 (git reabse master)是一种通过将 master 分支上最新的改变合并到功能分支的“保鲜法”。对于长期存在的功能分支,规律的变基操作能够最大程度的减少开发过程中出现冲突的可能性和严重性。
有些团队会选择在合并他们的改动到 master 前立即执行变基操作以实现一次快速合并 (git merge --ff <feature>)。对 master 分支快速合并你的提交是通过简单的将 master ref 指向你的重写分支的顶点而不需要创建一个合并提交。

变基是如此方便和功能强大以致于它已经被嵌入其他常见的 Git 命令中,例如拉取操作 git pull 。如果你在本地 master 分支有未推送的提交,运行 git pull 命令从 origin 拉取你队友的改动会造成不必要的合并提交。
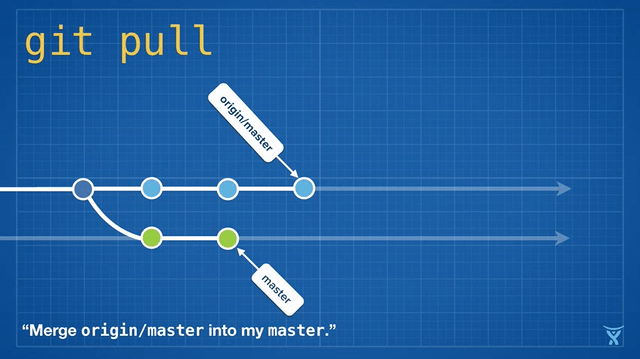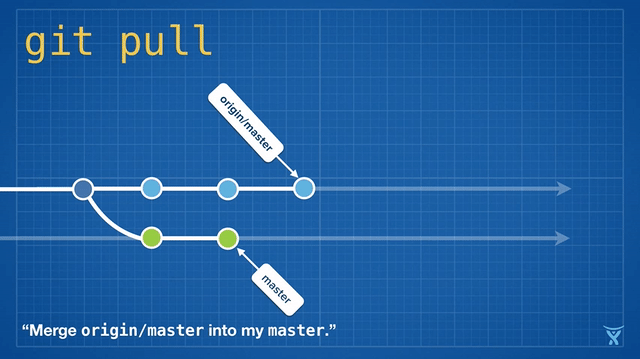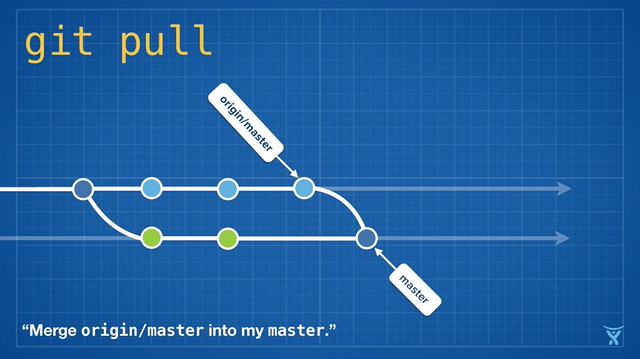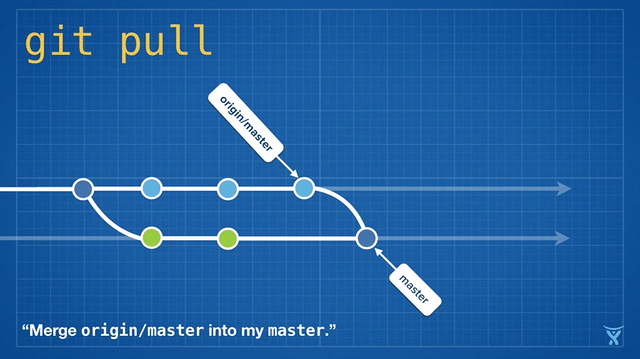
这有点混乱,而且在繁忙的团队,你会获得成堆的不必要的合并提交。git pull --rebase 将你本地的提交在你队友的提交上执行变基而不产生一个合并提交。
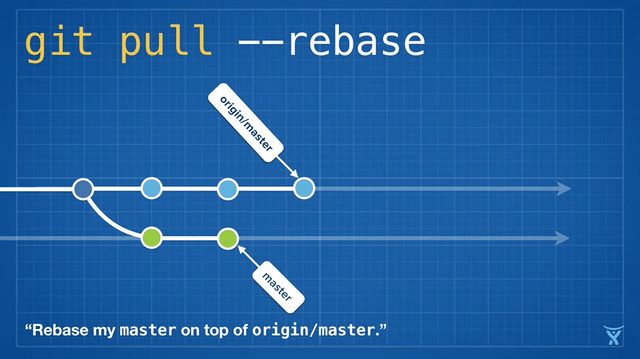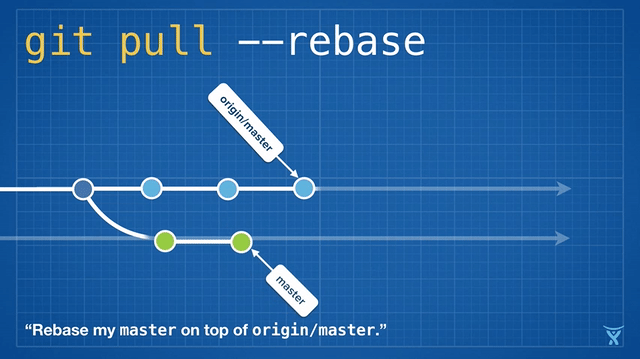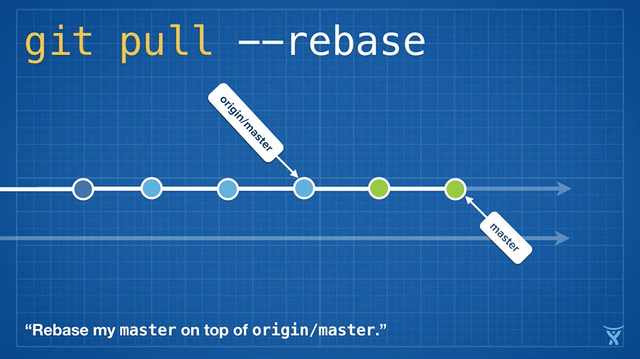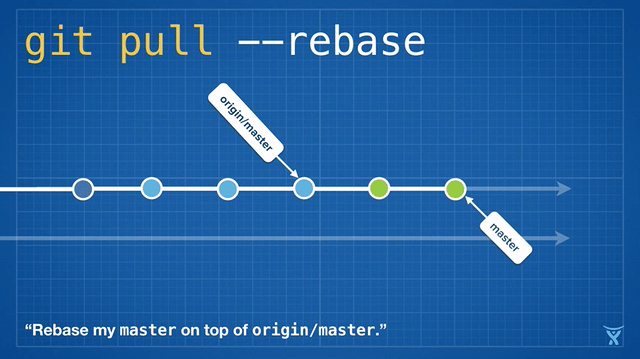
这很整洁吧!甚至更酷,Git v2.8 引入了一个新特性,允许你在拉取时 交互地 变基。
交互式变基
交互式变基是变基操作的一种更强大的形态。和标准变基操作相似,它可以重写提交,但它也可以向你提供一个机会让你能够交互式地修改这些将被重新运用在新基准上的提交。
当你运行 git rebase --interactive (或 git pull --rebase=interactive)时,你会在你的文本编辑器中得到一个可供选择的提交列表视图。
$ git rebase master --interactive
pick 2fde787 ACE-1294: replaced miniamalCommit with string in test
pick ed93626 ACE-1294: removed pull request service from test
pick b02eb9a ACE-1294: moved fromHash, toHash and diffType to batch
pick e68f710 ACE-1294: added testing data to batch email file
# Rebase f32fa9d..0ddde5f onto f32fa9d (4 commands)
#
# Commands:
# p, pick = use commit
# r, reword = use commit, but edit the commit message
# e, edit = use commit, but stop for amending
# s, squash = use commit, but meld into previous commit
# f, fixup = like "squash", but discard this commit's log message
# x, exec = run command (the rest of the line) using shell
# d, drop = remove commit
#
# These lines can be re-ordered; they are executed from top to
# bottom.
#
# If you remove a line here THAT COMMIT WILL BE LOST.
注意到每一条提交旁都有一个 pick。这是对 rebase 而言,“照原样留下这个提交”。如果你现在就退出文本编辑器,它会执行一次如上文所述的普通变基操作。但是,如果你将 pick 改为 edit 或者其他 rebase 命令中的一个,变基操作会允许你在它被重新运用前改变它。有效的变基命令有如下几种:
reword:编辑提交信息。edit:编辑提交了的文件。squash:将提交与之前的提交(同在文件中)合并,并将提交信息拼接。fixup:将本提交与上一条提交合并,并且逐字使用上一条提交的提交信息(这很方便,如果你为一个很小的改动创建了第二个提交,而它本身就应该属于上一条提交,例如,你忘记暂存了一个文件)。exec: 运行一条任意的 shell 命令(我们将会在下一节看到本例一次简洁的使用场景)。drop: 这将丢弃这条提交。
你也可以在文件内重新整理提交,这样会改变它们被重新应用的顺序。当你对不同的主题创建了交错的提交时这会很顺手,你可以使用 squash 或者 fixup 来将其合并成符合逻辑的原子提交。
当你设置完命令并且保存这个文件后,Git 将递归每一条提交,在每个 reword 和 edit 命令处为你暂停来执行你设计好的改变,并且自动运行 squash, fixup,exec 和 drop 命令。
####非交互性式执行
当你执行变基操作时,本质上你是在通过将你每一条新提交应用于指定基址的头部来重写历史。git pull --rebase 可能会有一点危险,因为根据上游分支改动的事实,你的新建历史可能会由于特定的提交遭遇测试失败甚至编译问题。如果这些改动引起了合并冲突,变基过程将会暂停并且允许你来解决它们。但是,整洁的合并改动仍然有可能打断编译或测试过程,留下破败的提交弄乱你的提交历史。
但是,你可以指导 Git 为每一个重写的提交来运行你的项目测试套件。在 Git v2.9 之前,你可以通过绑定 git rebase --interactive 和 exec 命令来实现。例如这样:
$ git rebase master −−interactive −−exec=”npm test”
……这会生成一个交互式变基计划,在重写每条提交后执行 npm test ,保证你的测试仍然会通过:
pick 2fde787 ACE-1294: replaced miniamalCommit with string in test
exec npm test
pick ed93626 ACE-1294: removed pull request service from test
exec npm test
pick b02eb9a ACE-1294: moved fromHash, toHash and diffType to batch
exec npm test
pick e68f710 ACE-1294: added testing data to batch email file
exec npm test
# Rebase f32fa9d..0ddde5f onto f32fa9d (4 command(s))
如果出现了测试失败的情况,变基会暂停并让你修复这些测试(并且将你的修改应用于相应提交):
291 passing
1 failing
1) Host request "after all" hook:
Uncaught Error: connect ECONNRESET 127.0.0.1:3001
…
npm ERR! Test failed.
Execution failed: npm test
You can fix the problem, and then run
git rebase −−continue
这很方便,但是使用交互式变基有一点臃肿。到了 Git v2.9,你可以这样来实现非交互式变基:
$ git rebase master -x "npm test"
可以简单替换 npm test 为 make,rake,mvn clean install,或者任何你用来构建或测试你的项目的命令。
小小警告
就像电影里一样,重写历史可是一个危险的行当。任何提交被重写为变基操作的一部分都将改变它的 SHA-1 ID,这意味着 Git 会把它当作一个全新的提交对待。如果重写的历史和原来的历史混杂,你将获得重复的提交,而这可能在你的团队中引起不少的疑惑。
为了避免这个问题,你仅仅需要遵照一条简单的规则:
永远不要变基一条你已经推送的提交!
坚持这一点你会没事的。
Git LFS 的性能提升
Git 是一个分布式版本控制系统,意味着整个仓库的历史会在克隆阶段被传送到客户端。对包含大文件的项目——尤其是大文件经常被修改——初始克隆会非常耗时,因为每一个版本的每一个文件都必须下载到客户端。Git LFS(Large File Storage 大文件存储) 是一个 Git 拓展包,由 Atlassian、GitHub 和其他一些开源贡献者开发,通过需要时才下载大文件的相对版本来减少仓库中大文件的影响。更明确地说,大文件是在检出过程中按需下载的而不是在克隆或抓取过程中。
在 Git 2016 年的五大发布中,Git LFS 自身就有四个功能版本的发布:v1.2 到 v1.5。你可以仅对 Git LFS 这一项来写一系列回顾文章,但是就这篇文章而言,我将专注于 2016 年解决的一项最重要的主题:速度。一系列针对 Git 和 Git LFS 的改进极大程度地优化了将文件传入/传出服务器的性能。
长期过滤进程
当你 git add 一个文件时,Git 的净化过滤系统会被用来在文件被写入 Git 目标存储之前转化文件的内容。Git LFS 通过使用净化过滤器(clean filter)将大文件内容存储到 LFS 缓存中以缩减仓库的大小,并且增加一个小“指针”文件到 Git 目标存储中作为替代。
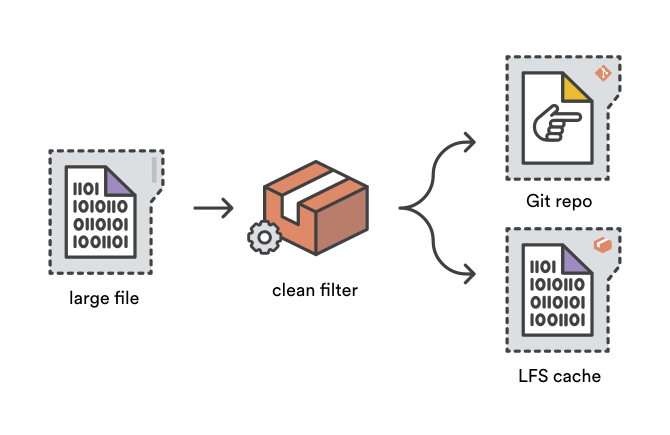
污化过滤器(smudge filter)是净化过滤器的对立面——正如其名。在 git checkout 过程中从一个 Git 目标仓库读取文件内容时,污化过滤系统有机会在文件被写入用户的工作区前将其改写。Git LFS 污化过滤器通过将指针文件替代为对应的大文件将其转化,可以是从 LFS 缓存中获得或者通过读取存储在 Bitbucket 的 Git LFS。
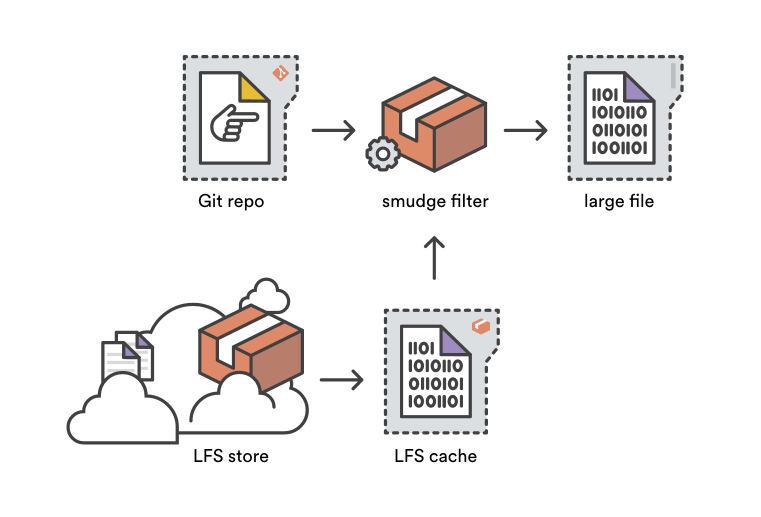
传统上,污化和净化过滤进程在每个文件被增加和检出时只能被唤起一次。所以,一个项目如果有 1000 个文件在被 Git LFS 追踪 ,做一次全新的检出需要唤起 git-lfs-smudge 命令 1000 次。尽管单次操作相对很迅速,但是经常执行 1000 次独立的污化进程总耗费惊人。、
针对 Git v2.11(和 Git LFS v1.5),污化和净化过滤器可以被定义为长期进程,为第一个需要过滤的文件调用一次,然后为之后的文件持续提供污化或净化过滤直到父 Git 操作结束。Lars Schneider,Git 的长期过滤系统的贡献者,简洁地总结了对 Git LFS 性能改变带来的影响。
使用 12k 个文件的测试仓库的过滤进程在 macOS 上快了 80 倍,在 Windows 上 快了 58 倍。在 Windows 上,这意味着测试运行了 57 秒而不是 55 分钟。
这真是一个让人印象深刻的性能增强!
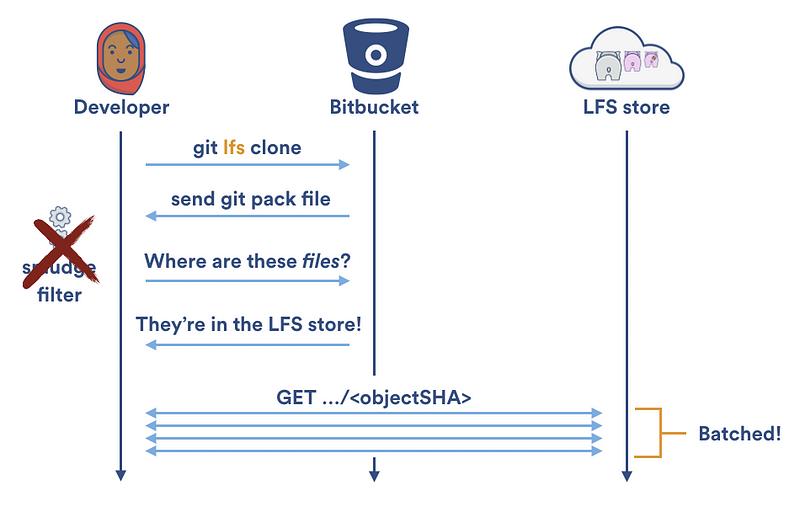
LFS 专有克隆
长期运行的污化和净化过滤器在对向本地缓存读写的加速做了很多贡献,但是对大目标传入/传出 Git LFS 服务器的速度提升贡献很少。 每次 Git LFS 污化过滤器在本地 LFS 缓存中无法找到一个文件时,它不得不使用两次 HTTP 请求来获得该文件:一个用来定位文件,另外一个用来下载它。在一次 git clone 过程中,你的本地 LFS 缓存是空的,所以 Git LFS 会天真地为你的仓库中每个 LFS 所追踪的文件创建两个 HTTP 请求:
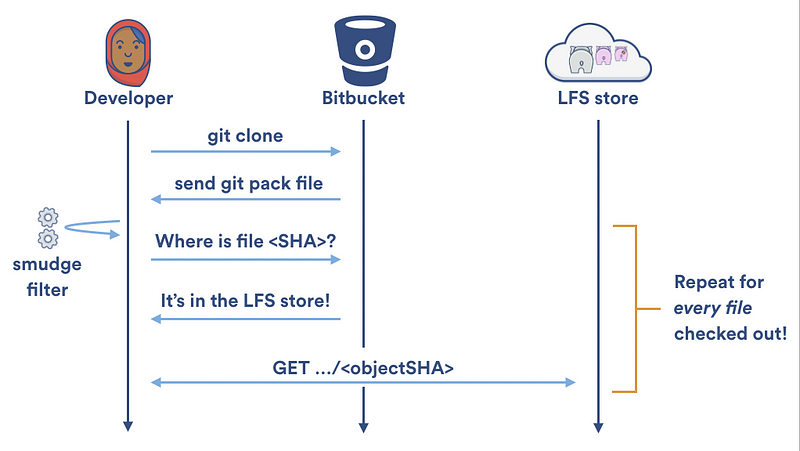
幸运的是,Git LFS v1.2 提供了专门的 git lfs clone 命令。不再是一次下载一个文件; git lfs clone 禁止 Git LFS 污化过滤器,等待检出结束,然后从 Git LFS 存储中按批下载任何需要的文件。这允许了并行下载并且将需要的 HTTP 请求数量减半。
自定义传输路由器(Transfer Adapter)
正如之前讨论过的,Git LFS 在 v1.5 中提供对长期过滤进程的支持。不过,对另外一种类型的可插入进程的支持早在今年年初就发布了。 Git LFS 1.3 包含了对可插拔传输路由器(pluggable transfer adapter)的支持,因此不同的 Git LFS 托管服务可以定义属于它们自己的协议来向或从 LFS 存储中传输文件。
直到 2016 年底,Bitbucket 是唯一一个执行专属 Git LFS 传输协议 Bitbucket LFS Media Adapter 的托管服务商。这是为了从 Bitbucket 的一个被称为 chunking 的 LFS 存储 API 独特特性中获益。Chunking 意味着在上传或下载过程中,大文件被分解成 4MB 的文件块(chunk)。

分块给予了 Bitbucket 支持的 Git LFS 三大优势:
- 并行下载与上传。默认地,Git LFS 最多并行传输三个文件。但是,如果只有一个文件被单独传输(这也是 Git LFS 污化过滤器的默认行为),它会在一个单独的流中被传输。Bitbucket 的分块允许同一文件的多个文件块同时被上传或下载,经常能够神奇地提升传输速度。
- 可续传的文件块传输。文件块都在本地缓存,所以如果你的下载或上传被打断,Bitbucket 的自定义 LFS 流媒体路由器会在下一次你推送或拉取时仅为丢失的文件块恢复传输。
- 免重复。Git LFS,正如 Git 本身,是一种可定位的内容;每一个 LFS 文件都由它的内容生成的 SHA-256 哈希值认证。所以,哪怕你稍微修改了一位数据,整个文件的 SHA-256 就会修改而你不得不重新上传整个文件。分块允许你仅仅重新上传文件真正被修改的部分。举个例子,想想一下 Git LFS 在追踪一个 41M 的精灵表格(spritesheet)。如果我们增加在此精灵表格上增加 2MB 的新的部分并且提交它,传统上我们需要推送整个新的 43M 文件到服务器端。但是,使用 Bitbucket 的自定义传输路由,我们仅仅需要推送大约 7MB:先是 4MB 文件块(因为文件的信息头会改变)和我们刚刚添加的包含新的部分的 3MB 文件块!其余未改变的文件块在上传过程中被自动跳过,节省了巨大的带宽和时间消耗。
可自定义的传输路由器是 Git LFS 的一个伟大的特性,它们使得不同服务商在不重载核心项目的前提下体验适合其服务器的优化后的传输协议。
更佳的 git diff 算法与默认值
不像其他的版本控制系统,Git 不会明确地存储文件被重命名了的事实。例如,如果我编辑了一个简单的 Node.js 应用并且将 index.js 重命名为 app.js,然后运行 git diff,我会得到一个看起来像一个文件被删除另一个文件被新建的结果。

我猜测移动或重命名一个文件从技术上来讲是一次删除后跟着一次新建,但这不是对人类最友好的描述方式。其实,你可以使用 -M 标志来指示 Git 在计算差异时同时尝试检测是否是文件重命名。对之前的例子,git diff -M 给我们如下结果:

第二行显示的 similarity index 告诉我们文件内容经过比较后的相似程度。默认地,-M 会处理任意两个超过 50% 相似度的文件。这意味着,你需要编辑少于 50% 的行数来确保它们可以被识别成一个重命名后的文件。你可以通过加上一个百分比来选择你自己的 similarity index,如,-M80%。
到 Git v2.9 版本,无论你是否使用了 -M 标志, git diff 和 git log 命令都会默认检测重命名。如果不喜欢这种行为(或者,更现实的情况,你在通过一个脚本来解析 diff 输出),那么你可以通过显式的传递 --no-renames 标志来禁用这种行为。
详细的提交
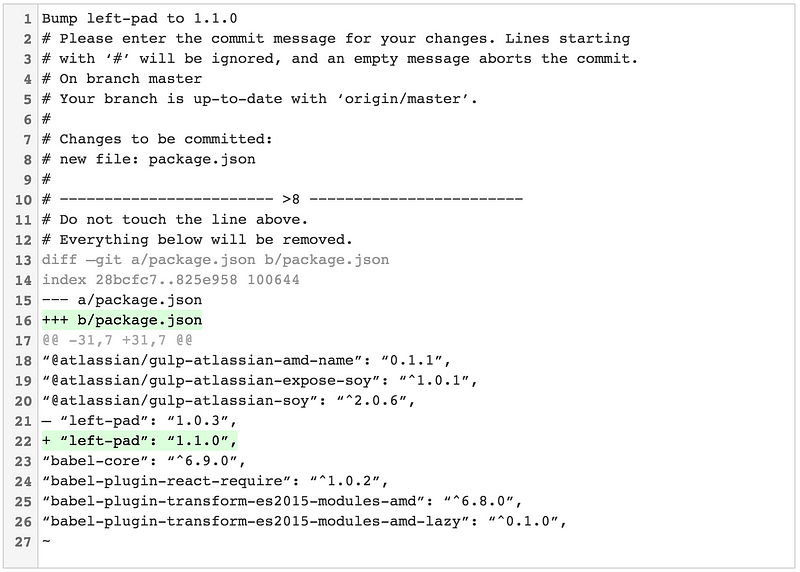
你经历过调用 git commit 然后盯着空白的 shell 试图想起你刚刚做过的所有改动吗?verbose 标志就为此而来!
不像这样:
Ah crap, which dependency did I just rev?
# Please enter the commit message for your changes. Lines starting
# with ‘#’ will be ignored, and an empty message aborts the commit.
# On branch master
# Your branch is up-to-date with ‘origin/master’.
#
# Changes to be committed:
# new file: package.json
#
……你可以调用 git commit --verbose 来查看你改动造成的行内差异。不用担心,这不会包含在你的提交信息中:
--verbose 标志并不是新出现的,但是直到 Git v2.9 你才可以通过 git config --global commit.verbose true 永久的启用它。
实验性的 Diff 改进
当一个被修改部分前后几行相同时,git diff 可能产生一些稍微令人迷惑的输出。如果在一个文件中有两个或者更多相似结构的函数时这可能发生。来看一个有些刻意人为的例子,想象我们有一个 JS 文件包含一个单独的函数:
/* @return {string} "Bitbucket" */
function productName() {
return "Bitbucket";
}
现在想象一下我们刚提交的改动包含一个我们专门做的 _另一个_可以做相似事情的函数:
/* @return {string} "Bitbucket" */
function productId() {
return "Bitbucket";
}
/* @return {string} "Bitbucket" */
function productName() {
return "Bitbucket";
}
我们希望 git diff 显示开头五行被新增,但是实际上它不恰当地将最初提交的第一行也包含进来。

错误的注释被包含在了 diff 中!这虽不是世界末日,但每次发生这种事情总免不了花费几秒钟的意识去想 啊?
在十二月,Git v2.11 介绍了一个新的实验性的 diff 选项,--indent-heuristic,尝试生成从美学角度来看更赏心悦目的 diff。

在后台,--indent-heuristic 在每一次改动造成的所有可能的 diff 中循环,并为它们分别打上一个 “不良” 分数。这是基于启发式的,如差异文件块是否以不同等级的缩进开始和结束(从美学角度讲“不良”),以及差异文件块前后是否有空白行(从美学角度讲令人愉悦)。最后,有着最低不良分数的块就是最终输出。
这个特性还是实验性的,但是你可以通过应用 --indent-heuristic 选项到任何 git diff 命令来专门测试它。如果,如果你喜欢尝鲜,你可以这样将其在你的整个系统内启用:
$ git config --global diff.indentHeuristic true
子模块(Submodule)差强人意
子模块允许你从 Git 仓库内部引用和包含其他 Git 仓库。这通常被用在当一些项目管理的源依赖也在被 Git 跟踪时,或者被某些公司用来作为包含一系列相关项目的 monorepo 的替代品。
由于某些用法的复杂性以及使用错误的命令相当容易破坏它们的事实,Submodule 得到了一些坏名声。
但是,它们还是有着它们的用处,而且,我想这仍然是用于需要厂商依赖项的最好选择。 幸运的是,2016 对子模块的用户来说是伟大的一年,在几次发布中落地了许多意义重大的性能和特性提升。
并行抓取
当克隆或则抓取一个仓库时,加上 --recurse-submodules 选项意味着任何引用的子模块也将被克隆或更新。传统上,这会被串行执行,每次只抓取一个子模块。直到 Git v2.8,你可以附加 --jobs=n 选项来使用 n 个并行线程来抓取子模块。
我推荐永久的配置这个选项:
$ git config --global submodule.fetchJobs 4
……或者你可以选择使用任意程度的平行化。
浅层化子模块
Git v2.9 介绍了 git clone —shallow-submodules 标志。它允许你抓取你仓库的完整克隆,然后递归地以一个提交的深度浅层化克隆所有引用的子模块。如果你不需要项目的依赖的完整记录时会很有用。
例如,一个仓库有着一些混合了的子模块,其中包含有其他厂商提供的依赖和你自己其它的项目。你可能希望初始化时执行浅层化子模块克隆,然后深度选择几个你想工作与其上的项目。
另一种情况可能是配置持续集成或部署工作。Git 需要一个包含了子模块的超级仓库以及每个子模块最新的提交以便能够真正执行构建。但是,你可能并不需要每个子模块全部的历史记录,所以仅仅检索最新的提交可以为你省下时间和带宽。
子模块的替代品
--reference 选项可以和 git clone 配合使用来指定另一个本地仓库作为一个替代的对象存储,来避免跨网络重新复制你本地已经存在的对象。语法为:
$ git clone --reference <local repo> <url>
到 Git v2.11,你可以使用 —reference 选项与 —recurse-submodules 结合来设置子模块指向一个来自另一个本地仓库的子模块。其语法为:
$ git clone --recurse-submodules --reference <local repo> <url>
这潜在的可以省下大量的带宽和本地磁盘空间,但是如果引用的本地仓库不包含你克隆的远程仓库所必需的所有子模块时,它可能会失败。
幸运的是,方便的 —-reference-if-able 选项将会让它优雅地失败,然后为丢失了的被引用的本地仓库的所有子模块回退为一次普通的克隆。
$ git clone --recurse-submodules --reference-if-able \
<local repo> <url>
子模块的 diff
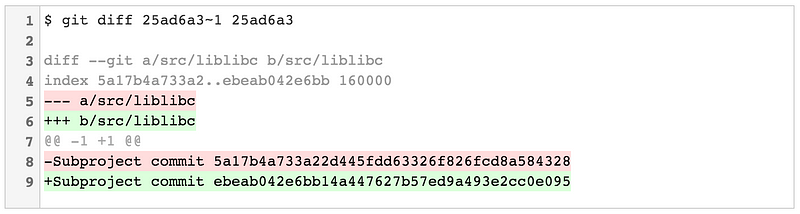
在 Git v2.11 之前,Git 有两种模式来显示对更新你的仓库子模块的提交之间的差异。
git diff —-submodule=short 显示你的项目引用的子模块中的旧提交和新提交(这也是如果你整体忽略 --submodule 选项的默认结果):
git diff —submodule=log 有一点啰嗦,显示更新了的子模块中任意新建或移除的提交的信息中统计行。

Git v2.11 引入了第三个更有用的选项:—-submodule=diff。这会显示更新后的子模块所有改动的完整的 diff。
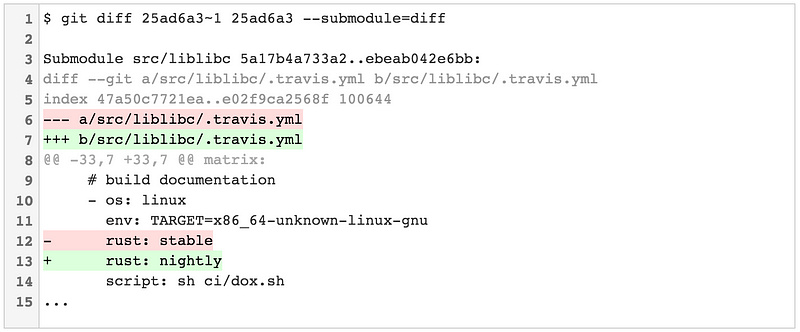
git stash 的 90 个增强
不像子模块,几乎没有 Git 用户不钟爱 git stash。 git stash 临时搁置(或者 藏匿)你对工作区所做的改动使你能够先处理其他事情,结束后重新将搁置的改动恢复到先前状态。
自动搁置
如果你是 git rebase 的粉丝,你可能很熟悉 --autostash 选项。它会在变基之前自动搁置工作区所有本地修改然后等变基结束再将其复用。
$ git rebase master --autostash
Created autostash: 54f212a
HEAD is now at 8303dca It's a kludge, but put the tuple from the database in the cache.
First, rewinding head to replay your work on top of it...
Applied autostash.
这很方便,因为它使得你可以在一个不洁的工作区执行变基。有一个方便的配置标志叫做 rebase.autostash 可以将这个特性设为默认,你可以这样来全局启用它:
$ git config --global rebase.autostash true
rebase.autostash 实际上自从 Git v1.8.4 就可用了,但是 v2.7 引入了通过 --no-autostash 选项来取消这个标志的功能。如果你对未暂存的改动使用这个选项,变基会被一条工作树被污染的警告禁止:
$ git rebase master --no-autostash
Cannot rebase: You have unstaged changes.
Please commit or stash them.
补丁式搁置
说到配置标签,Git v2.7 也引入了 stash.showPatch。git stash show 的默认行为是显示你搁置文件的汇总。
$ git stash show
package.json | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
将 -p 标志传入会将 git stash show 变为 “补丁模式”,这将会显示完整的 diff:
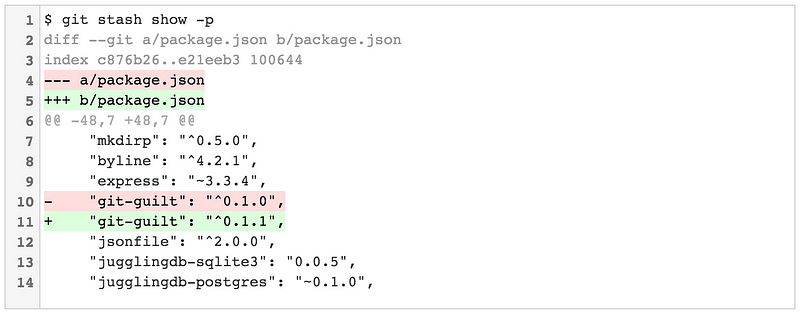
stash.showPatch 将这个行为定为默认。你可以将其全局启用:
$ git config --global stash.showPatch true
如果你使能 stash.showPatch 但却之后决定你仅仅想要查看文件总结,你可以通过传入 --stat 选项来重新获得之前的行为。
$ git stash show --stat
package.json | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
顺便一提:--no-patch 是一个有效选项但它不会如你所希望的取消 stash.showPatch。不仅如此,它会传递给用来生成补丁时潜在调用的 git diff 命令,然后你会发现完全没有任何输出。
简单的搁置标识
如果你惯用 git stash ,你可能知道你可以搁置多次改动然后通过 git stash list 来查看它们:
$ git stash list
stash@{0}: On master: crazy idea that might work one day
stash@{1}: On master: desperate samurai refactor; don't apply
stash@{2}: On master: perf improvement that I forgot I stashed
stash@{3}: On master: pop this when we use Docker in production
但是,你可能不知道为什么 Git 的搁置有着这么难以理解的标识(stash@{1}、stash@{2} 等),或许你可能将它们勾勒成 “仅仅是 Git 的癖好吧”。实际上就像很多 Git 特性一样,这些奇怪的标志实际上是 Git 数据模型的一个非常巧妙使用(或者说是滥用了的)的结果。
在后台,git stash 命令实际创建了一系列特定的提交目标,这些目标对你搁置的改动做了编码并且维护一个 reglog 来保存对这些特殊提交的引用。 这也是为什么 git stash list 的输出看起来很像 git reflog 的输出。当你运行 git stash apply stash@{1} 时,你实际上在说,“从 stash reflog 的位置 1 上应用这条提交。”
到了 Git v2.11,你不再需要使用完整的 stash@{n} 语句。相反,你可以通过一个简单的整数指出该搁置在 stash reflog 中的位置来引用它们。
$ git stash show 1
$ git stash apply 1
$ git stash pop 1
讲了很多了。如果你还想要多学一些搁置是怎么保存的,我在 这篇教程 中写了一点这方面的内容。
</2016> <2017>
好了,结束了。感谢您的阅读!我希望您喜欢阅读这份长篇大论,正如我乐于在 Git 的源码、发布文档和 man 手册中探险一番来撰写它。如果你认为我忘记了一些重要的事,请留下一条评论或者在 Twitter 上让我知道,我会努力写一份后续篇章。
至于 Git 接下来会发生什么,这要靠广大维护者和贡献者了(其中有可能就是你!)。随着 Git 的采用日益增长,我猜测简化、改进的用户体验,和更好的默认结果将会是 2017 年 Git 主要的主题。随着 Git 仓库变得越来越大、越来越旧,我猜我们也可以看到继续持续关注性能和对大文件、深度树和长历史的改进处理。
如果你关注 Git 并且很期待能够和一些项目背后的开发者会面,请考虑来 Brussels 花几周时间来参加 Git Merge 。我会在那里发言!但是更重要的是,很多维护 Git 的开发者将会出席这次会议而且一年一度的 Git 贡献者峰会很可能会指定来年发展的方向。
或者如果你实在等不及,想要获得更多的技巧和指南来改进你的工作流,请参看这份 Atlassian 的优秀作品: Git 教程 。
封面图片是由 instaco.de 生成的。
via: https://medium.com/hacker-daily/git-in-2016-fad96ae22a15
作者:Tim Pettersen 译者:xiaow6 校对:wxy