13 KiB
理解 Python 的 Dataclasses(一)
如果你正在阅读本文,那么你已经意识到了 Python 3.7 以及它所包含的新特性。就我个人而言,我对 Dataclasses 感到非常兴奋,因为我等了它一段时间了。
本系列包含两部分:
- Dataclass 特点概述
- 在下一篇文章概述 Dataclass 的
fields
介绍
Dataclasses 是 Python 的类(LCTT 译注:更准确的说,它是一个模块),适用于存储数据对象。你可能会问什么是数据对象?下面是定义数据对象的一个不太详细的特性列表:
- 它们存储数据并代表某种数据类型。例如:一个数字。对于熟悉 ORM 的人来说,模型实例就是一个数据对象。它代表一种特定的实体。它包含那些定义或表示实体的属性。
- 它们可以与同一类型的其他对象进行比较。例如:一个数字可以是
greater than(大于)、less than(小于) 或equal(等于) 另一个数字。
当然还有更多的特性,但是这个列表足以帮助你理解问题的关键。
为了理解 Dataclasses,我们将实现一个包含数字的简单类,并允许我们执行上面提到的操作。
首先,我们将使用普通类,然后我们再使用 Dataclasses 来实现相同的结果。
但在我们开始之前,先来谈谈 Dataclasses 的用法。
Python 3.7 提供了一个装饰器 dataclass,用于将类转换为 dataclass。
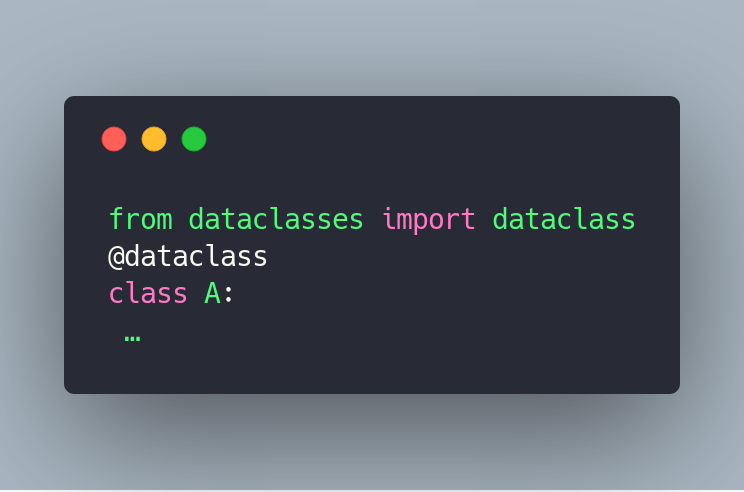
你所要做的就是将类包在装饰器中:
from dataclasses import dataclass
@dataclass
class A:
...
现在,让我们深入了解一下 dataclass 带给我们的变化和用途。
初始化
通常是这样:
class Number:
def __init__(self, val):
self.val = val
>>> one = Number(1)
>>> one.val
>>> 1
用 dataclass 是这样:
@dataclass
class Number:
val:int
>>> one = Number(1)
>>> one.val
>>> 1
以下是 dataclass 装饰器带来的变化:
- 无需定义
__init__,然后将值赋给self,dataclass负责处理它(LCTT 译注:此处原文可能有误,提及一个不存在的d) - 我们以更加易读的方式预先定义了成员属性,以及类型提示。我们现在立即能知道
val是int类型。这无疑比一般定义类成员的方式更具可读性。
Python 之禅: 可读性很重要
它也可以定义默认值:
@dataclass
class Number:
val:int = 0
表示
对象表示指的是对象的一个有意义的字符串表示,它在调试时非常有用。
默认的 Python 对象表示不是很直观:
class Number:
def __init__(self, val = 0):
self.val = val
>>> a = Number(1)
>>> a
>>> <__main__.Number object at 0x7ff395b2ccc0>
这让我们无法知悉对象的作用,并且会导致糟糕的调试体验。
一个有意义的表示可以通过在类中定义一个 __repr__ 方法来实现。
def __repr__(self):
return self.val
现在我们得到这个对象有意义的表示:
>>> a = Number(1)
>>> a
>>> 1
dataclass 会自动添加一个 __repr__ 函数,这样我们就不必手动实现它了。
@dataclass
class Number:
val: int = 0
>>> a = Number(1)
>>> a
>>> Number(val = 1)
数据比较
通常,数据对象之间需要相互比较。
两个对象 a 和 b 之间的比较通常包括以下操作:
a < ba > ba == ba >= ba <= b
在 Python 中,能够在可以执行上述操作的类中定义方法。为了简单起见,不让这篇文章过于冗长,我将只展示 == 和 < 的实现。
通常这样写:
class Number:
def __init__( self, val = 0):
self.val = val
def __eq__(self, other):
return self.val == other.val
def __lt__(self, other):
return self.val < other.val
使用 dataclass:
@dataclass(order = True)
class Number:
val: int = 0
是的,就是这样简单。
我们不需要定义 __eq__ 和 __lt__ 方法,因为当 order = True 被调用时,dataclass 装饰器会自动将它们添加到我们的类定义中。
那么,它是如何做到的呢?
当你使用 dataclass 时,它会在类定义中添加函数 __eq__ 和 __lt__ 。我们已经知道这点了。那么,这些函数是怎样知道如何检查相等并进行比较呢?
生成 __eq__ 函数的 dataclass 类会比较两个属性构成的元组,一个由自己属性构成的,另一个由同类的其他实例的属性构成。在我们的例子中,自动生成的 __eq__ 函数相当于:
def __eq__(self, other):
return (self.val,) == (other.val,)
让我们来看一个更详细的例子:
我们会编写一个 dataclass 类 Person 来保存 name 和 age。
@dataclass(order = True)
class Person:
name: str
age:int = 0
自动生成的 __eq__ 方法等同于:
def __eq__(self, other):
return (self.name, self.age) == ( other.name, other.age)
请注意属性的顺序。它们总是按照你在 dataclass 类中定义的顺序生成。
同样,等效的 __le__ 函数类似于:
def __le__(self, other):
return (self.name, self.age) <= (other.name, other.age)
当你需要对数据对象列表进行排序时,通常会出现像 __le__ 这样的函数的定义。Python 内置的 sorted 函数依赖于比较两个对象。
>>> import random
>>> a = [Number(random.randint(1,10)) for _ in range(10)] #generate list of random numbers
>>> a
>>> [Number(val=2), Number(val=7), Number(val=6), Number(val=5), Number(val=10), Number(val=9), Number(val=1), Number(val=10), Number(val=1), Number(val=7)]
>>> sorted_a = sorted(a) #Sort Numbers in ascending order
>>> [Number(val=1), Number(val=1), Number(val=2), Number(val=5), Number(val=6), Number(val=7), Number(val=7), Number(val=9), Number(val=10), Number(val=10)]
>>> reverse_sorted_a = sorted(a, reverse = True) #Sort Numbers in descending order
>>> reverse_sorted_a
>>> [Number(val=10), Number(val=10), Number(val=9), Number(val=7), Number(val=7), Number(val=6), Number(val=5), Number(val=2), Number(val=1), Number(val=1)]
dataclass 作为一个可调用的装饰器
定义所有的 dunder(LCTT 译注:这是指双下划线方法,即魔法方法)方法并不总是值得的。你的用例可能只包括存储值和检查相等性。因此,你只需定义 __init__ 和 __eq__ 方法。如果我们可以告诉装饰器不生成其他方法,那么它会减少一些开销,并且我们将在数据对象上有正确的操作。
幸运的是,这可以通过将 dataclass 装饰器作为可调用对象来实现。
从官方文档来看,装饰器可以用作具有如下参数的可调用对象:
@dataclass(init=True, repr=True, eq=True, order=False, unsafe_hash=False, frozen=False)
class C:
…
init:默认将生成__init__方法。如果传入False,那么该类将不会有__init__方法。repr:__repr__方法默认生成。如果传入False,那么该类将不会有__repr__方法。eq:默认将生成__eq__方法。如果传入False,那么__eq__方法将不会被dataclass添加,但默认为object.__eq__。order:默认将生成__gt__、__ge__、__lt__、__le__方法。如果传入False,则省略它们。
我们在接下来会讨论 frozen。由于 unsafe_hash 参数复杂的用例,它值得单独发布一篇文章。
现在回到我们的用例,以下是我们需要的:
1. __init__
2. __eq__
默认会生成这些函数,因此我们需要的是不生成其他函数。那么我们该怎么做呢?很简单,只需将相关参数作为 false 传入给生成器即可。
@dataclass(repr = False) # order, unsafe_hash and frozen are False
class Number:
val: int = 0
>>> a = Number(1)
>>> a
>>> <__main__.Number object at 0x7ff395afe898>
>>> b = Number(2)
>>> c = Number(1)
>>> a == b
>>> False
>>> a < b
>>> Traceback (most recent call last):
File “<stdin>”, line 1, in <module>
TypeError: ‘<’ not supported between instances of ‘Number’ and ‘Number’
Frozen(不可变) 实例
Frozen 实例是在初始化对象后无法修改其属性的对象。
无法创建真正不可变的 Python 对象
在 Python 中创建对象的不可变属性是一项艰巨的任务,我将不会在本篇文章中深入探讨。
以下是我们期望不可变对象能够做到的:
>>> a = Number(10) #Assuming Number class is immutable
>>> a.val = 10 # Raises Error
有了 dataclass,就可以通过使用 dataclass 装饰器作为可调用对象配合参数 frozen=True 来定义一个 frozen 对象。
当实例化一个 frozen 对象时,任何企图修改对象属性的行为都会引发 FrozenInstanceError。
@dataclass(frozen = True)
class Number:
val: int = 0
>>> a = Number(1)
>>> a.val
>>> 1
>>> a.val = 2
>>> Traceback (most recent call last):
File “<stdin>”, line 1, in <module>
File “<string>”, line 3, in __setattr__
dataclasses.FrozenInstanceError: cannot assign to field ‘val’
因此,一个 frozen 实例是一种很好方式来存储:
- 常数
- 设置
这些通常不会在应用程序的生命周期内发生变化,任何企图修改它们的行为都应该被禁止。
后期初始化处理
有了 dataclass,需要定义一个 __init__ 方法来将变量赋给 self 这种初始化操作已经得到了处理。但是我们失去了在变量被赋值之后立即需要的函数调用或处理的灵活性。
让我们来讨论一个用例,在这个用例中,我们定义一个 Float 类来包含浮点数,然后在初始化之后立即计算整数和小数部分。
通常是这样:
import math
class Float:
def __init__(self, val = 0):
self.val = val
self.process()
def process(self):
self.decimal, self.integer = math.modf(self.val)
>>> a = Float( 2.2)
>>> a.decimal
>>> 0.2000
>>> a.integer
>>> 2.0
幸运的是,使用 post_init 方法已经能够处理后期初始化操作。
生成的 __init__ 方法在返回之前调用 __post_init__ 返回。因此,可以在函数中进行任何处理。
import math
@dataclass
class FloatNumber:
val: float = 0.0
def __post_init__(self):
self.decimal, self.integer = math.modf(self.val)
>>> a = Number(2.2)
>>> a.val
>>> 2.2
>>> a.integer
>>> 2.0
>>> a.decimal
>>> 0.2
多么方便!
继承
Dataclasses 支持继承,就像普通的 Python 类一样。
因此,父类中定义的属性将在子类中可用。
@dataclass
class Person:
age: int = 0
name: str
@dataclass
class Student(Person):
grade: int
>>> s = Student(20, "John Doe", 12)
>>> s.age
>>> 20
>>> s.name
>>> "John Doe"
>>> s.grade
>>> 12
请注意,Student 的参数是在类中定义的字段的顺序。
继承过程中 __post_init__ 的行为是怎样的?
由于 __post_init__ 只是另一个函数,因此必须以传统方式调用它:
@dataclass
class A:
a: int
def __post_init__(self):
print("A")
@dataclass
class B(A):
b: int
def __post_init__(self):
print("B")
>>> a = B(1,2)
>>> B
在上面的例子中,只有 B 的 __post_init__ 被调用,那么我们如何调用 A 的 __post_init__ 呢?
因为它是父类的函数,所以可以用 super 来调用它。
@dataclass
class B(A):
b: int
def __post_init__(self):
super().__post_init__() # 调用 A 的 post init
print("B")
>>> a = B(1,2)
>>> A
B
结论
因此,以上是 dataclass 使 Python 开发人员变得更轻松的几种方法。
我试着彻底覆盖大部分的用例,但是,没有人是完美的。如果你发现了错误,或者想让我注意相关的用例,请联系我。
我将在另一篇文章中介绍 dataclasses.field 和 unsafe_hash。
更新:dataclasses.field 的文章可以在这里找到。
via: https://medium.com/mindorks/understanding-python-dataclasses-part-1-c3ccd4355c34
作者:Shikhar Chauhan 译者:MjSeven 校对:wxy