16 KiB
Excel “过滤和编辑” - Pandas 中的示范操作

介绍
我听许多人说我之前的关于 pandas 处理一般的 Excel 任务的文章对于帮助新的 pandas 用户将 Excel 处理过程转化成对应的 pandas 代码是有用的。这篇文章将会保持传统,通过介绍不同的 pandas 使用 Excel 的过滤功能作为一个模型进行索引的例子来理解该处理过程。
大多数 pandas 的新手首先学到的东西就是基本的数据过滤。即使在过去的时间中使用 pandas 工作持续数月,我最近意识到我没有在我每天的工作中使用过的 pandas 过滤的方法还有另外一个好处。也就是说,你可以过滤一组给定的列,而使用一个简化的 pandas 的语法更新另一组列。这和我所说的 Excel 中的“过滤并编辑”很像。
这篇文章将会介绍一些基于各种条件过滤一个 pandas 数据帧并同时更新数据的例子。同时,我将更多的介绍一下 panda 的索引,和如何使用索引功能例如 .loc , .ix 和 .iloc 来简单、快速基于简单或者是复杂的条件来更新一个数据子集。
Excel: “过滤并编辑”
在数据透视表以外,在 EXCEL 顶部工具栏的工具之一是过滤器。这个简单的工具允许用户通过不同的数据、文本与格式条件去快速过滤与排序数据。这里是由几个不同的条件过滤数据产生的样本数据的基本截图:
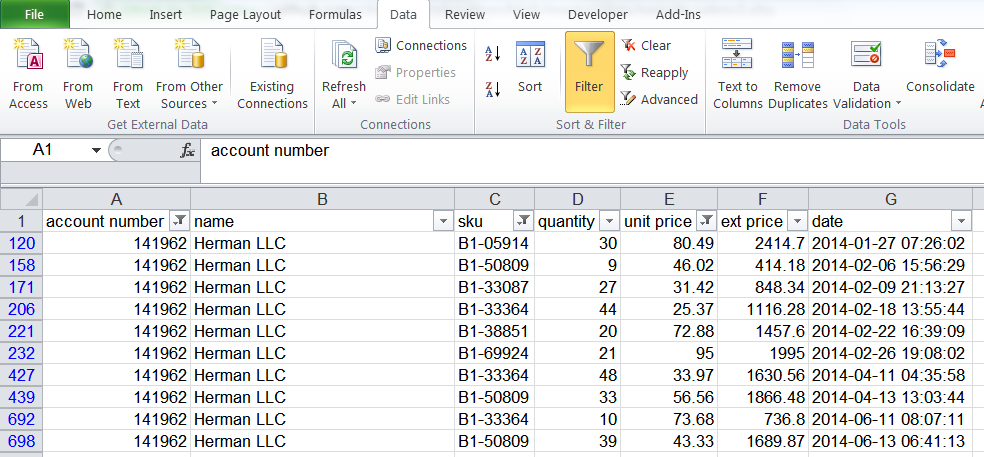
该过滤过程是直观的,即使是最新手的用户,也很容易掌握。我也注意到,人们会使用此功能来选择数据行,然后根据行的条件来更新其它的列。下面的例子显示了我所描述的情形:
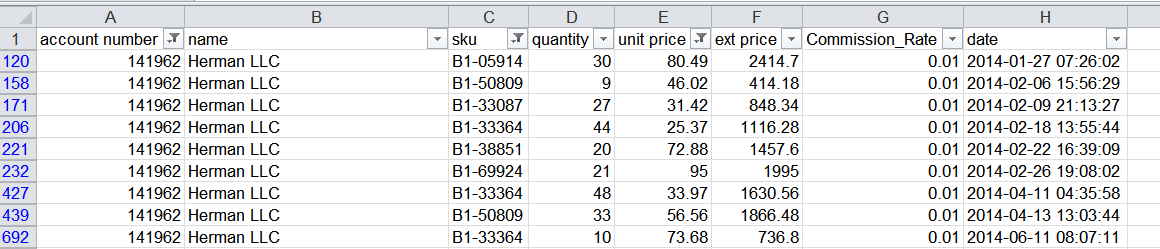
在这个例子中,我过滤了 Account Number、SKU 和 Unit Price 的数据。接着我手工增加了 Commission_Rate列,并且在每个单元格中输入 0.01。这种方法的好处是可以很容易理解,并有助于管理有联系的复杂数据而不用写长长的 Excel 公式或者使用 VBA。这种方法的缺点是,它是不可重复的,同时,对于刚入门的外行人了解哪些条件被用于过滤器可能是比较困难的。
例如,假设你看上述截图,如果不看每一列数据,没有明显的方法去知道什么被过滤了。幸运的是,我们可以在 pandas 中完成相似操作。不用奇怪,在 pandas 中使用简单干净的代码来执行“过滤并编辑”模式是很容易的。
布尔检索
现在,我想通过 pandas 中一些布尔索引的细节来使你对这个问题有点感觉。如果你想要去理解 pandas 的在多数情况下的索引和数据选择,那么这是一个要理解的重要概念。这种想法可能看起来有点复杂,对新的 pandas 用户(可能对经验丰富的用户来说太基础),但我认为重要的是要花一些时间了解它。如果你掌握了这一概念,用 pandas 进行数据工作的基本过程将更简单。
pandas 通过标签、基于数字的位置或者一个布尔值(True/False)列表来支持索引(或者选择数据)。使用一个布尔值的列表来选择一个行被称为布尔索引,将是本文其余部分的重点。
我发现,我的 pandas 的工作流程往往侧重于使用布尔值的列表选择我的数据。换句话说,当我创建了 pandas 数据帧,我倾向于保持数据框架的默认索引。因此,该布尔索引本身并不具有真正意义,同时也不是简单的选择数据。
关键点 pandas 中布尔索引是选择行的数据的强大的和有用的方法之一。
让我们看一些示例的数据帧来帮助澄清在 pandas 中布尔索引做的是什么。
首先,我们将创建一个来自 Python 的列表的非常小的数据帧,并使用它来展示布尔索引是如何工作的。
import pandas as pd
sales = [('account', ['Jones LLC', 'Alpha Co', 'Blue Inc', 'Mega Corp']),
('Total Sales', [150, 200, 75, 300]),
('Country', ['US', 'UK', 'US', 'US'])]
df = pd.DataFrame.from_items(sales)
|account |Total Sales |Country :--|:-- |:-- |: 0 |Jones LLC |150 |US 1 |Alpha Co |200 |UK 2 |Blue Inc |75 |US 3 |Mega Corp |300 |US
注意值 0-3,是怎么样会自动分配给行的?这些都是索引,在这个数据集它们不是特别有意义的,但对 pandas 是有用的,对于了解如下其他没有描述的用例是重要的。
当我们引用布尔索引时,我们只是说,我们可以通过一个 True 或 Flse 的值的列表表示我们要查看的每一行。
在这种情况下,如果我们想查看Jones LLC、Blue Inc 和 Mega Corp 的数据,我们可以看到,True、False 列表看起来会像这样:
indices = [True, False, True, True]
这没什么奇怪的,你可以通过把这个列表传入到你的数据帧,你就看到它只会显示该值是 True 的行:
df[indices]
| account | Total Sales | Country | |
|---|---|---|---|
| 0 | Jones LLC | 150 | US |
| 2 | Blue Inc | 75 | US |
| 3 | Mega Corp | 300 | US |
这里是一个刚刚发生了什么的示意图:
手工创建索引列表是可以工作的,但是显然对任何一个稍微大点的数据集来说却不是可扩展的或非常有用的。幸运的是,pandas 可以用一个简单的查询语言创建这些布尔索引,对熟悉使用 Python (或任何语言)的人应该很容易。
例如,让我们看看来自美国的所有销售的行。如果我们执行一个基于 Country 列的 Python 表达式:
df.Country == 'US'
0 True
1 False
2 True
3 True
Name: Country, dtype: bool
这个例子显示了 pandas 如何将你的 Python 的常规逻辑,把它应用到一个数据帧并返回一个布尔值列表。那么这个布尔值的列表可以传递到数据帧来获取相应的行。
在真正的代码中,你不需要做这两个步骤。简洁的做这事的方法典型的看上去如下:
df[df["Country"] == 'US']
| account | Total Sales | Country | |
|---|---|---|---|
| 0 | Jones LLC | 150 | US |
| 2 | Blue Inc | 75 | US |
| 3 | Mega Corp | 300 | US |
虽然这个概念很简单,但你可以编写非常复杂的逻辑,使用 Python 的威力来过滤数据。
关键点 在这个例子中,
df[df.Country == 'US']等价于df[df["Country"] == 'US']‘.’ 标记法是简洁的但是在你列名中有空格时不会工作。
选择需要的列
现在,我们已经指出了如何选择行的数据,我们如何控制显示哪些列?在上面的例子中,没有明确的方法完成这个。Pandas 能使用三种基于位置的索引支持这个用法:.loc 、iloc 和 .ix 。这些功能也允许我们在所看到的行之外挑选列。
关于什么时候选择使用 .loc 、iloc 或者是 .ix,在这里很容易困惑。 快速总结的区别是:
- .loc 用于标签索引
- .iloc 用于基于整数的位置
- .ix 是一个快捷方式,它将尝试使用标签(比如 .loc)但失败后将退而求其次使用基于整数的位置(比如 .iloc)
因此问题是我该使用哪个?我必须坦诚地说,我有的时候也会被这些搞混。我发现我最常使用 .loc 。主要是因为我的数据不适合于有意义的基于位置的索引(换句话说,我很少发现自己需要使用 .iloc),所以我坚持使用 .loc。
公平地讲,每一个方法都有自己的用途,在许多情况下都是有用的。特别是处理多索引数据帧时。我不会在这篇文章中讨论那个话题-也许在未来的博文会说。
现在我们已经涵盖了这样一个话题,让我们来展示如何筛选一行的值的数据帧,具体选择要显示的列。
继续我们的例子,如果我们只是想显示对应于我们的索引的帐户名称,该怎么做?使用 .loc 很简单:
df.loc[[True, True, False, True], "account"]
1 Alpha Co
2 Blue Inc
3 Mega Corp
Name: account, dtype: object
如果你想看到多个列,只需传递一个列表:
df.loc[[True, True, False, True], ["account", "Country"]]
| account | Country | |
|---|---|---|
| 0 | Jones LLC | US |
| 1 | Alpha Co | UK |
| 3 | Mega Corp | US |
真正的威力是当你在你的数据上创建更复杂的查询。在这种情况下,让我们展示所有的帐户名称和 sales > 200 的国家:
df.loc[df["Total Sales"] > 200, ["account", "Country"]]
|account| Country :--|:--|:-- 3 |Mega Corp| US
这个过程可以看做有点相当于我们上面讨论过的 Excel 过滤器。但是有更多的好处,你还可以限制你检索的列数,而不仅仅是行。
编辑列
所有这些都是好的背景知识,但当你使用一个类似的方法基于选择的行来更新一个或多个列时,这个处理过程就真的是非常漂亮。
作为一个简单的例子,让我们增加一个 rate 列到我们的数据:
df["rate"] = 0.02
| account | Total Sales | Country | rate | |
|---|---|---|---|---|
| 0 | Jones LLC | 150 | US | 0.02 |
| 1 | Alpha Co | 200 | UK | 0.02 |
| 2 | Blue Inc | 75 | US | 0.02 |
| 3 | Mega Corp | 300 | US | 0.02 |
假如说如果你卖了超过 100,你的利率是 5%。基本的过程是设置一个布尔索引来选择列,然后将该值赋给利率列:
df.loc[df["Total Sales"] > 100, ["rate"]] = .05
| account | Total Sales | Country | rate | |
|---|---|---|---|---|
| 0 | Jones LLC | 150 | US | 0.05 |
| 1 | Alpha Co | 200 | UK | 0.05 |
| 2 | Blue Inc | 75 | US | 0.02 |
| 3 | Mega Corp | 300 | US | 0.05 |
希望你逐步看过这篇文章,这将对于帮助你理解这个语法是如何工作的是有意义的。现在你明白了“过滤并编辑”方法的基本原理。最后一节将介绍 Excel 和 pandas 这个过程的更多细节。
将这些组合在一起
对于最后的例子,我们将创建一个简单的佣金计算器,使用以下规则:
- 所有的佣金计算在交易水平
- 所有销售的基础佣金为 2%
- 所有 shirt 都将获得 2.5% 的佣金
- 有个特殊的环节,在一个交易中销售的数额 >10 的 belt 将得到 4% 的佣金
- 所有在一个单一的 shoe 类交易中 > 1000 美元,有一个特别的 250 美元奖金加上一个 4.5% 的佣金
要在 Excel 中做到这一点,使用的过滤器和编辑方法:
- 添加一个 2% 的佣金列
- 添加一个 0 美元的奖金列
- 过滤 shirts,并将 vale 改为 2.5%
- 清除过滤器
- 过滤数量 > 10 的 belt ,并将值更改为 4%
- 清除过滤器
- 过滤 > 1000 美元 shoe,并相应的增加佣金和奖金为 4.5% 和 250 美元
我不会显示每一步的屏幕快照,但这里是最后一个过滤器的屏幕快照:
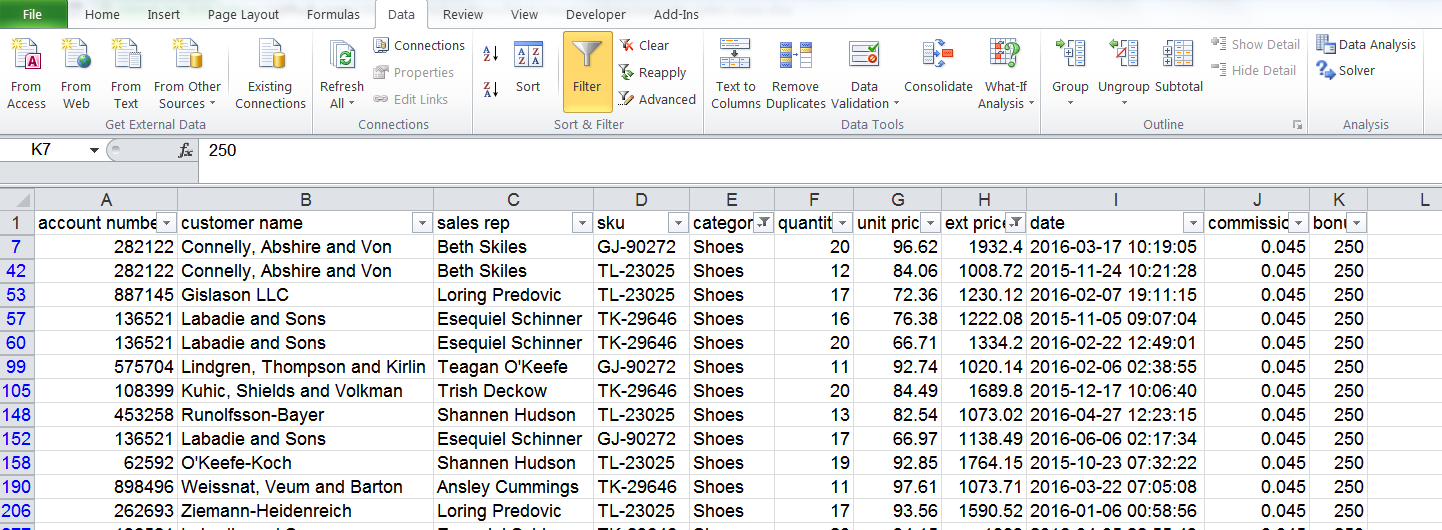
这种方法很简单,便于操作,但它不具备很好的可重复性,也不能审核。当然还有其他的方法,如在 Excel 公式或 VBA 中实现这些。然而,这种过滤器和编辑的方法是常用的,可以说明 pandas 的逻辑。
现在,让我们在 pandas 中运行这个例子。
首先,读入 Excel 文件同时加入默认值为 2% 的 rate 一列:
import pandas as pd
df = pd.read_excel("https://github.com/chris1610/pbpython/blob/master/data/sample-sales-reps.xlsx?raw=true")
df["commission"] = .02
df.head()
| account number | customer name | sales rep | sku | category | quantity | unit price | ext price | date | commission | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 680916 | Mueller and Sons | Loring Predovic | GP-14407 | Belt | 19 | 88.49 | 1681.31 | 2015-11-17 05:58:34 | 0.02 | |
| 1 | 680916 | Mueller and Sons | Loring Predovic | FI-01804 | Shirt | 3 | 78.07 | 234.21 | 2016-02-13 04:04:11 | 0.02 | |
| 2 | 530925 | Purdy and Sons | Teagan O’Keefe | EO-54210 | Shirt | 19 | 30.21 | 573.99 | 2015-08-11 12:44:38 | 0.02 | |
| 3 | 14406 | Harber, Lubowitz and Fahey | Esequiel Schinner | NZ-99565 | Shirt | 12 | 90.29 | 1083.48 | 2016-01-23 02:15:50 | 0.02 | |
| 4 | 398620 | Brekke Ltd | Esequiel Schinner | NZ-99565 | Shirt | 5 | 72.64 | 363.20 | 2015-08-10 07:16:03 | 0.02 |
下一个规则是所有 shirt 获得 2.5% 和 Belt 销售 > 10 得到一个 4% 的 rate:
df.loc[df["category"] == "Shirt", ["commission"]] = .025
df.loc[(df["category"] == "Belt") & (df["quantity"] >= 10), ["commission"]] = .04
df.head()
| account number |customer name |sales rep| sku |category |quantity| unit price| ext price |date |commission :--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:-- 0 |680916| Mueller and Sons| Loring Predovic| GP-14407| Belt| 19 |88.49| 1681.31 |2015-11-17 05:58:34| 0.040 1 |680916| Mueller and Sons| Loring Predovic| FI-01804| Shirt |3 |78.07 |234.21| 2016-02-13 04:04:11 |0.025 2 |530925 |Purdy and Sons |Teagan O’Keefe| EO-54210 |Shirt| 19 |30.21 |573.99 |2015-08-11 12:44:38| 0.025 3 |14406| Harber, Lubowitz and Fahey| Esequiel Schinner| NZ-99565| Shirt| 12| 90.29| 1083.48| 2016-01-23 02:15:50 |0.025 4 |398620| Brekke Ltd| Esequiel Schinner| NZ-99565| Shirt| 5 |72.64 |363.20| 2015-08-10 07:16:03 |0.025
最后的佣金规则是加上特别的奖金:
df["bonus"] = 0
df.loc[(df["category"] == "Shoes") & (df["ext price"] >= 1000 ), ["bonus", "commission"]] = 250, 0.045
# Display a sample of rows that show this bonus
df.ix[3:7]
| account number| customer name |sales rep| sku |category| quantity| unit price| ext price| date| commission| bonus :--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:-- 3| 14406| Harber, Lubowitz and Fahey| Esequiel Schinner| NZ-99565| Shirt |12 |90.29| 1083.48 |2016-01-23 02:15:50 |0.025 |0 4| 398620| Brekke Ltd| Esequiel Schinner |NZ-99565| Shirt| 5| 72.64| 363.20| 2015-08-10 07:16:03| 0.025| 0 5| 282122| Connelly, Abshire and Von Beth| Skiles| GJ-90272| Shoes| 20| 96.62| 1932.40 |2016-03-17 10:19:05 |0.045 |250 6 |398620 |Brekke Ltd| Esequiel Schinner |DU-87462 |Shirt| 10| 67.64 |676.40| 2015-11-25 22:05:36| 0.025| 0 7| 218667| Jaskolski-O’Hara| Trish Deckow| DU-87462| Shirt |11| 91.86| 1010.46 |2016-04-24 15:05:58| 0.025| 0
为了做好佣金的计算:
# Calculate the compensation for each row
df["comp"] = df["commission"] * df["ext price"] + df["bonus"]
# Summarize and round the results by sales rep
df.groupby(["sales rep"])["comp"].sum().round(2)
sales rep
Ansley Cummings 2169.76
Beth Skiles 3028.60
Esequiel Schinner 10451.21
Loring Predovic 10108.60
Shannen Hudson 5275.66
Teagan O'Keefe 7989.52
Trish Deckow 5807.74
Name: comp, dtype: float64
如果你有兴趣,一个例子手册放在github。
总结
感谢阅读文章。 我发现,在学习如何使用 pandas 的新用户所面临最大的挑战之一,是根据他们基于 Excel 的知识,如何找出建立一个等效的基于 pandas 的解决方案。在许多情况下,pandas 的解决方案将是更健壮、更快、更容易审计和更强大的。然而,学习曲线需要花费一些时间。我希望这个展示了如何使用电子表格的过滤工具来解决一个问题的例子,将有助于那些刚刚在开始 pandas 之旅的同学们。祝你好运!
via: http://pbpython.com/excel-filter-edit.html
作者:Chris Moffitt 译者:zky001 校对:wxy