5.8 KiB
A day in the life of a log message
Navigating a modern distributed system from the perspective of a log message.

Chaotic systems tend to be unpredictable. This is especially evident when architecting something as complex as a distributed system. Left unchecked, this unpredictability can waste boundless amounts of time. This is why every single component of a distributed system, no matter how small, must be designed to fit together in a streamlined way.
Kubernetes provides a promising model for abstracting compute resources—but even it must be reconciled with other distributed platforms such as Apache Kafka to ensure reliable data delivery. If someone were to integrate these two platforms, how would it work? Furthermore, if you were to trace something as simple as a log message through such a system, what would it look like? This article will focus on how a log message from an application running inside OKD, the Origin Community Distribution of Kubernetes that powers Red Hat OpenShift, gets to a data warehouse through Kafka.
OKD-defined environment
Such a journey begins in OKD, since the container platform completely overlays the hardware it abstracts. This means that the log message waits to be written to stdout or stderr streams by an application residing in a container. From there, the log message is redirected onto the node's filesystem by a container engine such as CRI-O.
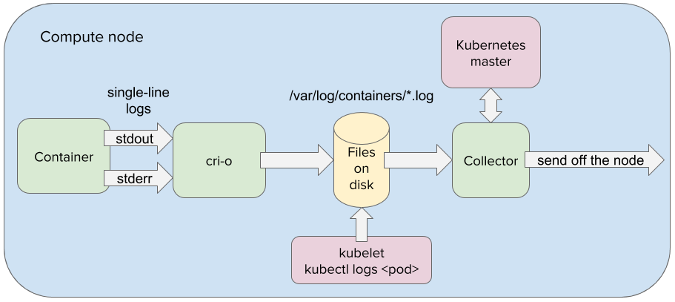
ithin OpenShift, one or more containers are encapsulated within virtual compute nodes known as pods. In fact, all applications running within OKD are abstracted as pods. This allows the applications to be manipulated in a uniform way. This also greatly simplifies communication between distributed components, since pods are systematically addressable through IP addresses and load-balanced services . So when the log message is taken from the node's filesystem by a log-collector application, it can easily be delivered to another pod running within OpenShift.
Two peas in a pod
To ensure ubiquitous dispersal of the log message throughout the distributed system, the log collector needs to deliver the log message into a Kafka cluster data hub running within OpenShift. Through Kafka, the log message can be delivered to the consuming applications in a reliable and fault-tolerant way with low latency. However, in order to reap the benefits of Kafka within an OKD-defined environment, Kafka needs to be fully integrated into OKD.
Running a Strimzi operator will instantiate all Kafka components as pods and integrate them to run within an OKD environment. This includes Kafka brokers for queuing log messages, Kafka connectors for reading and writing from Kafka brokers, and Zookeeper nodes for managing the Kafka cluster state. Strimzi can also instantiate the log collector to double as a Kafka connector, allowing the log collector to feed the log messages directly into a Kafka broker pod running within OKD.
Kafka inside OKD
When the log-collector pod delivers the log message to a Kafka broker, the collector writes to a single broker partition, appending the message to the end of the partition. One of the advantages of using Kafka is that it decouples the log collector from the log's final destination. Thanks to the decoupling, the log collector doesn't care whether the logs end up in Elasticsearch, Hadoop, Amazon S3, or all of them at the same time. Kafka is well-connected to all infrastructure, so the Kafka connectors can take the log message wherever it needs to go.
Once written to a Kafka broker's partition, the log message is replicated across the broker partitions within the Kafka cluster. This is a very powerful concept on its own; combined with the self-healing features of the platform, it creates a very resilient distributed system. For example, when a node becomes unavailable, the applications running on the node are almost instantaneously spawned on healthy node(s). So even if a node with the Kafka broker is lost or damaged, the log message is guaranteed to survive as many deaths as it was replicated and a new Kafka broker will quickly take the original's place.
Off to storage
After it is committed to a Kafka topic, the log message waits to be consumed by a Kafka connector sink, which relays the log message to either an analytics engine or logging warehouse. Upon delivery to its final destination, the log message could be studied for anomaly detection, queried for immediate root-cause analysis, or used for other purposes. Either way, the log message is delivered by Kafka to its destination in a safe and reliable manner.
OKD and Kafka are powerful distributed platforms that are evolving rapidly. It is vital to create systems that can abstract the complicated nature of distributed computing without compromising performance. After all, how can we boast of systemwide efficiency if we cannot simplify the journey of a single log message?
via: https://opensource.com/article/18/9/life-log-message
作者:Josef Karásek 选题:lujun9972 译者:译者ID 校对:校对者ID