16 KiB
Interactive Workflows for C++ with Jupyter
Scientists, educators and engineers not only use programming languages to build software systems, but also in interactive workflows, using the tools available to _explore _ a problem and _reason _ about it.
Running some code, looking at a visualization, loading data, and running more code. Quick iteration is especially important during the exploratory phase of a project.
For this kind of workflow, users of the C++ programming language currently have no choice but to use a heterogeneous set of tools that don’t play well with each other, making the whole process cumbersome, and difficult to reproduce.
We currently lack a good story for interactive computing in C++ .
In our opinion, this hurts the productivity of C++ developers:
-
Most of the progress made in software projects comes from incrementalism. Obstacles to fast iteration hinder progress.
-
This also makes C++ more difficult to teach. The first hours of a C++ class are rarely rewarding as the students must learn how to set up a small project before writing any code. And then, a lot more time is required before their work can result in any visual outcome.
Project Jupyter and Interactive Computing

The goal of Project Jupyter is to provide a consistent set of tools for scientific computing and data science workflows, from the exploratory phase of the analysis to the presentation and the sharing of the results. The Jupyter stack was designed to be agnostic of the programming language, and also to allow alternative implementations of any component of the layered architecture (back-ends for programming languages, custom renderers for file types associated with Jupyter). The stack consists of
-
a low-level specification for messaging protocols, standardized file formats,
-
a reference implementation of these standards,
-
applications built on the top of these libraries: the Notebook, JupyterLab, Binder, JupyterHub
-
and visualization libraries integrated into the Notebook and JupyterLab.
Adoption of the Jupyter ecosystem has skyrocketed in the past years, with millions of users worldwide, over a million Jupyter notebooks shared on GitHub and large-scale deployments of Jupyter in universities, companies and high-performance computing centers.
Jupyter and C++
One of the main extension points of the Jupyter stack is the kernel , the part of the infrastructure responsible for executing the user’s code. Jupyter kernels exist for numerous programming languages.
Most Jupyter kernels are implemented in the target programming language: the reference implementation ipykernel in Python, IJulia in Julia, leading to a duplication of effort for the implementation of the protocol. A common denominator to a lot of these interpreted languages is that the interpreter generally exposes a C API, allowing the embedding into a native application. In an effort to consolidate these commonalities and save work for future kernel builders, we developed xeus .

Xeus is a C++ implementation of the Jupyter kernel protocol. It is not a kernel itself but a library that facilitates the authoring of kernels, and other applications making use of the Jupyter kernel protocol.
A typical kernel implementation using xeus would in fact make use of the target interpreter _ as a library._
There are a number of benefits of using xeus over implementing your kernel in the target language:
-
Xeus provides a complete implementation of the protocol, enabling a lot of features from the start for kernel authors, who only need to deal with the language bindings.
-
Xeus-based kernels can very easily provide a back-end for Jupyter interactive widgets.
-
Finally, xeus can be used to implement kernels for domain-specific languages such as SQL flavors. Existing approaches use a Python wrapper. With xeus, the resulting kernel won't require Python at run-time, leading to large performance benefits.

Interpreted C++ is already a reality at CERN with the ClingC++ interpreter in the context of the ROOT data analysis environment.
As a first example for a kernel based on xeus, we have implemented xeus-cling, a pure C++ kernel.
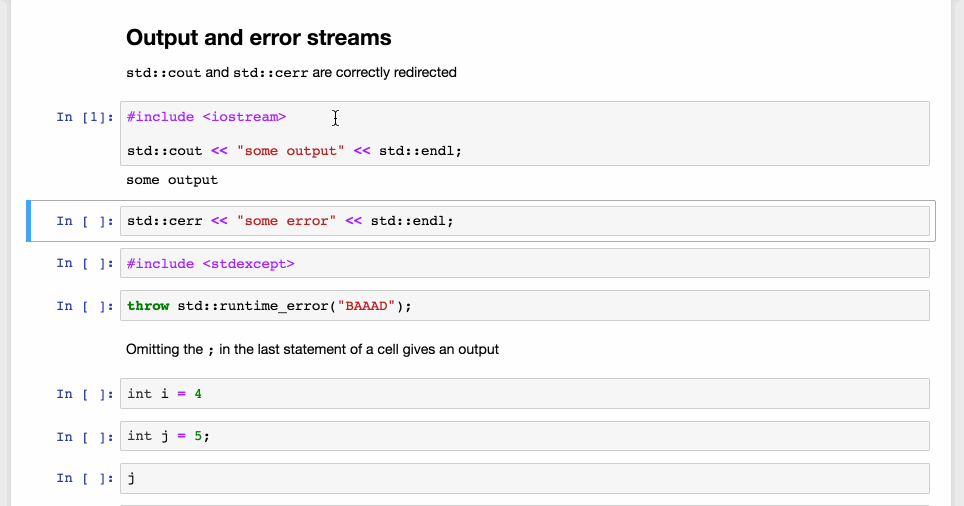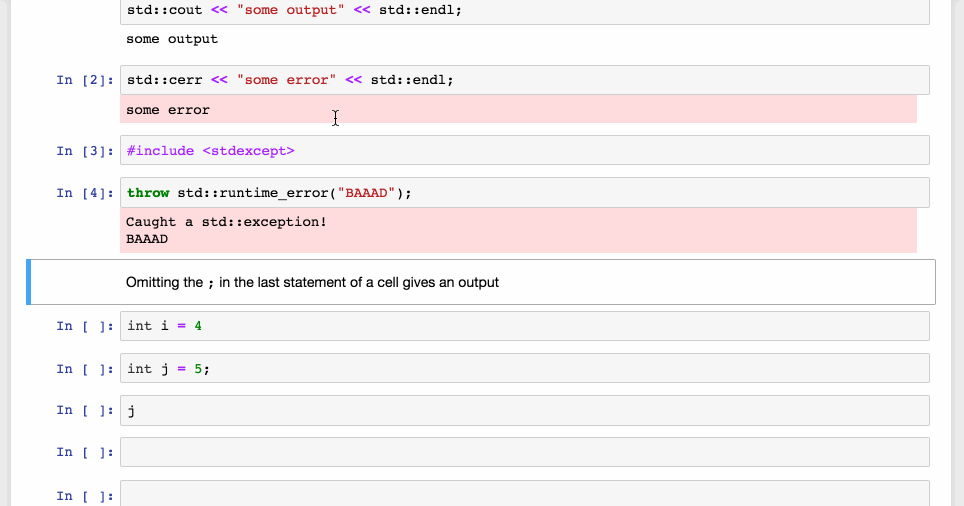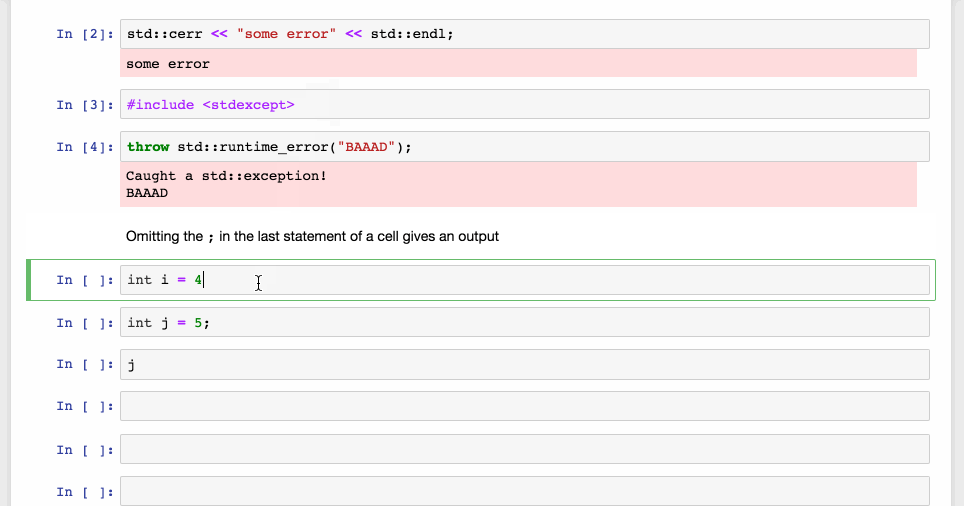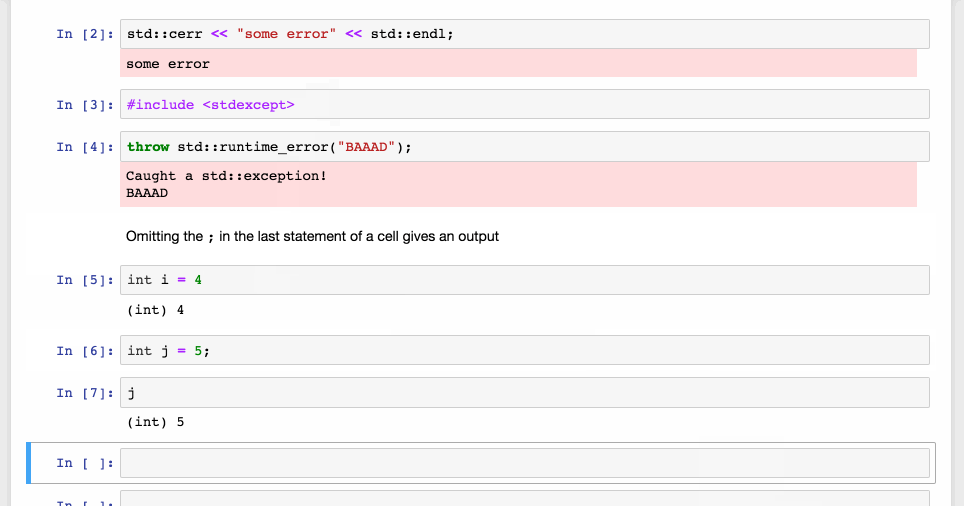 Redirection of outputs to the Jupyter front-end, with different styling in the front-end.
Redirection of outputs to the Jupyter front-end, with different styling in the front-end.
Complex features of the C++ programming language such as, polymorphism, templates, lambdas, are supported by the cling interpreter, making the C++ Jupyter notebook a great prototyping and learning platform for the C++ users. See the image below for a demonstration:
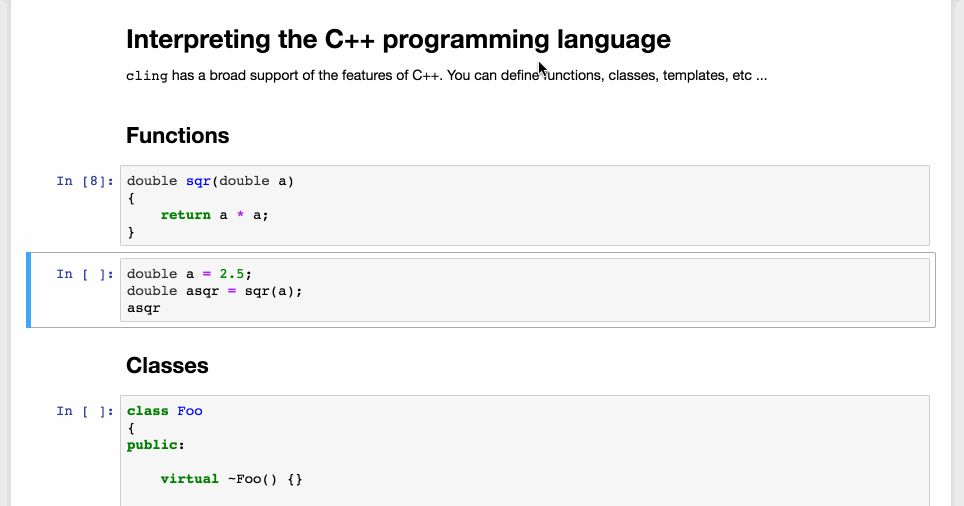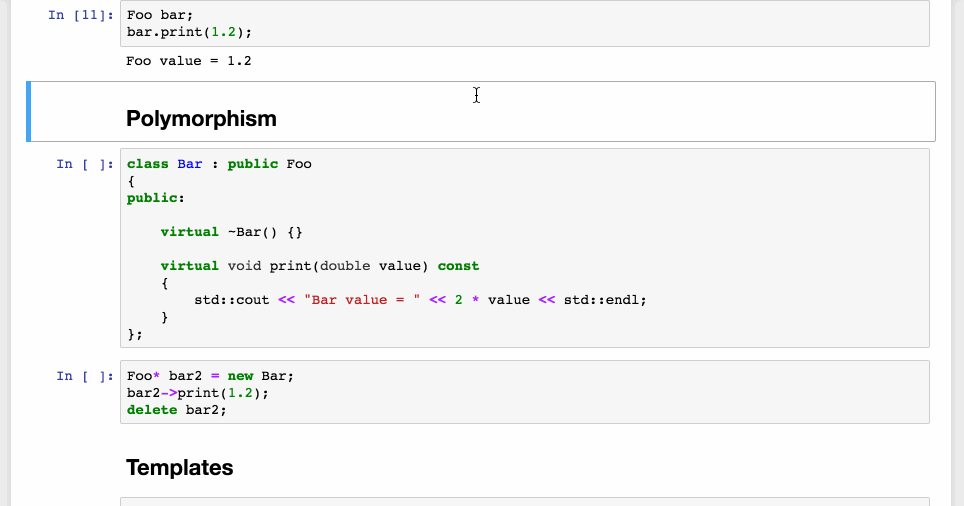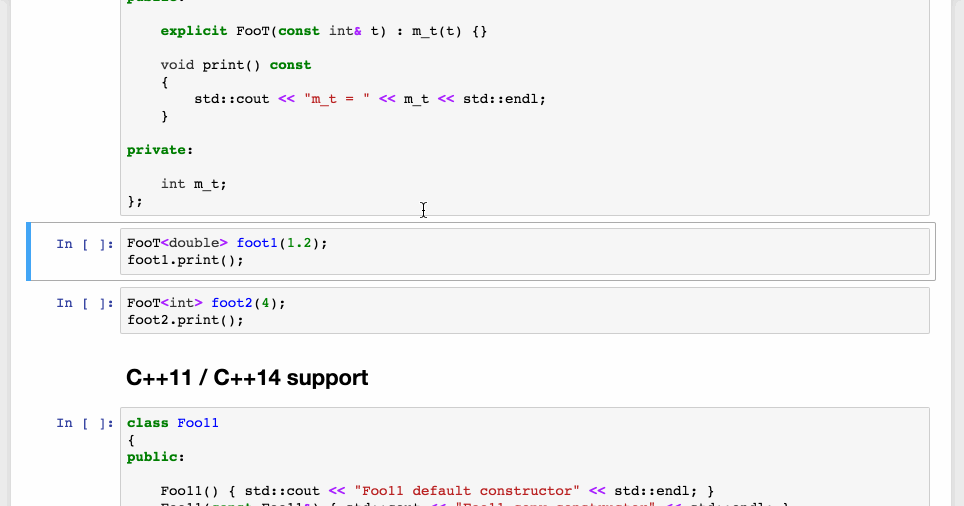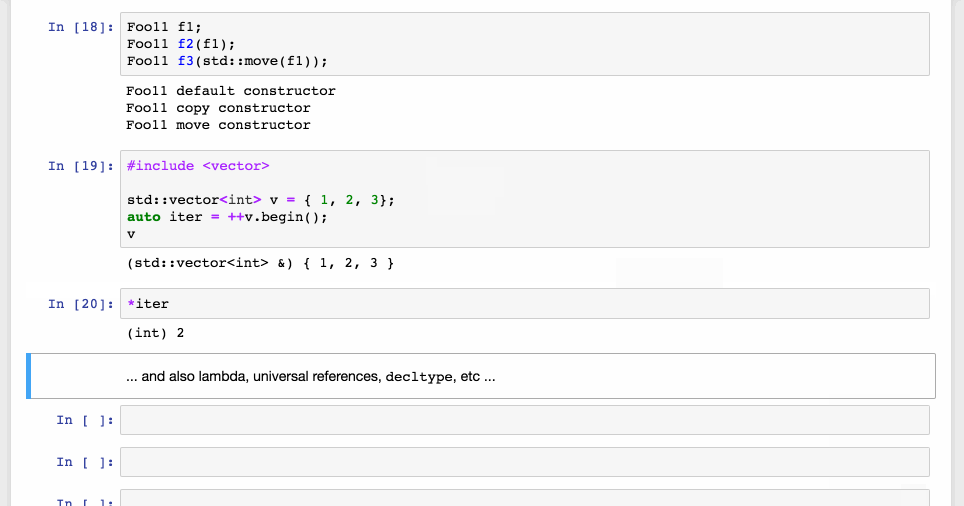 Features of the C++ programming language supported by the cling interpreter
Features of the C++ programming language supported by the cling interpreter
Finally, xeus-cling supports live quick-help, fetching the content on cppreference in the case of the standard library.
 Live help for the C++standard library in the Jupyter notebook
Live help for the C++standard library in the Jupyter notebook
We realized that we started using the C++ kernel ourselves very early in the development of the project. For quick experimentation, or reproducing bugs. No need to set up a project with a cpp file and complicated project settings for finding the dependencies… Just write some code and hit Shift+Enter.
Visual output can also be displayed using the rich display mechanism of the Jupyter protocol.
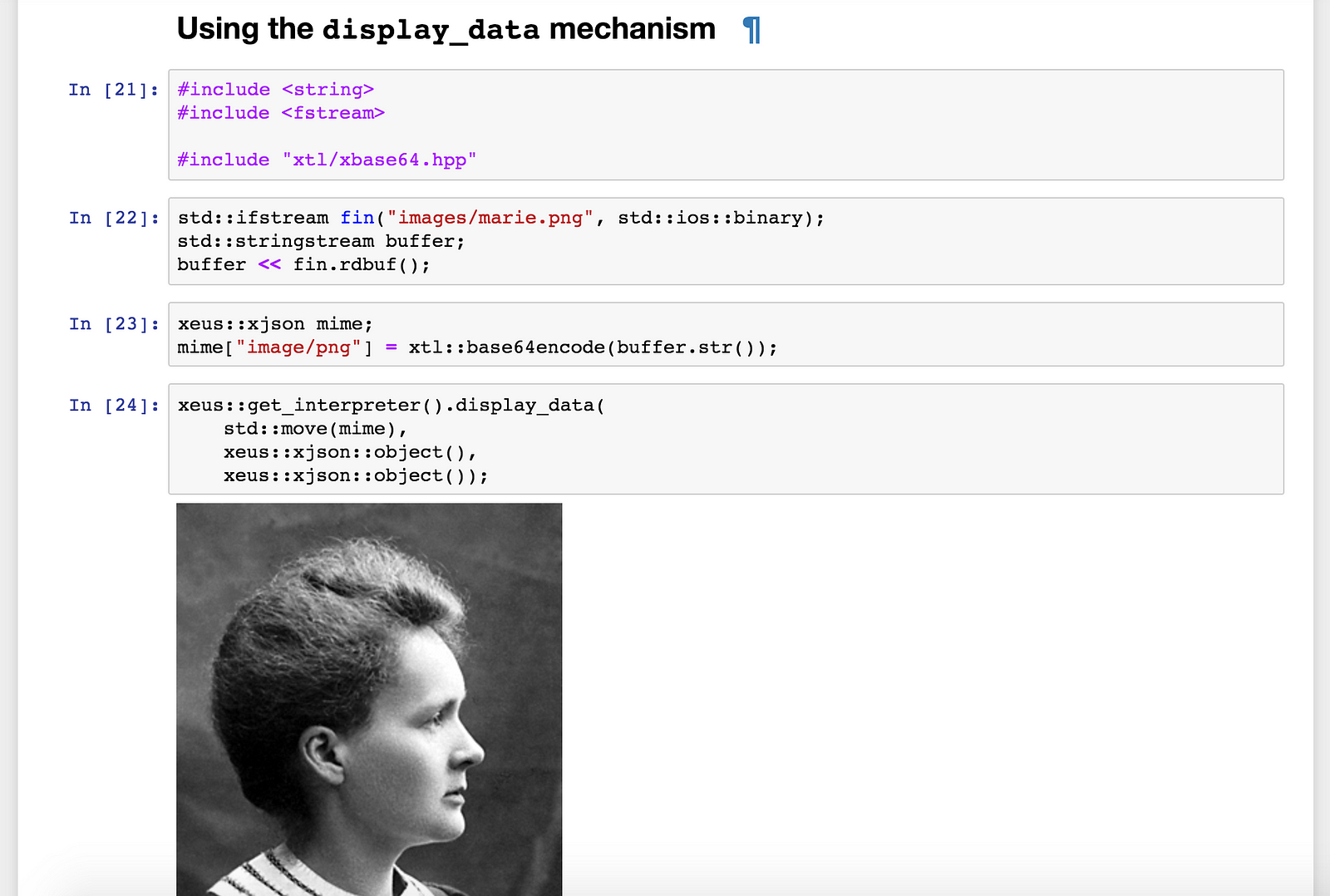 Using Jupyter's rich display mechanism to display an image inline in the notebook
Using Jupyter's rich display mechanism to display an image inline in the notebook

Another important feature of the Jupyter ecosystem are the Jupyter Interactive Widgets. They allow the user to build graphical interfaces and interactive data visualization inline in the Jupyter notebook. Moreover it is not just a collection of widgets, but a framework that can be built upon, to create arbitrary visual components. Popular interactive widget libraries include
-
bqplot (2-D plotting with d3.js)
-
pythreejs (3-D scene visualization with three.js)
-
ipyleaflet (maps visualization with leaflet.js)
-
ipyvolume (3-D plotting and volume rendering with three.js)
-
nglview (molecular visualization)
Just like the rest of the Jupyter ecosystem, Jupyter interactive widgets were designed as a language-agnostic framework. Other language back-ends can be created reusing the front-end component, which can be installed separately.
xwidgets, which is still at an early stage of development, is a native C++ implementation of the Jupyter widgets protocol. It already provides an implementation for most of the widget types available in the core Jupyter widgets package.
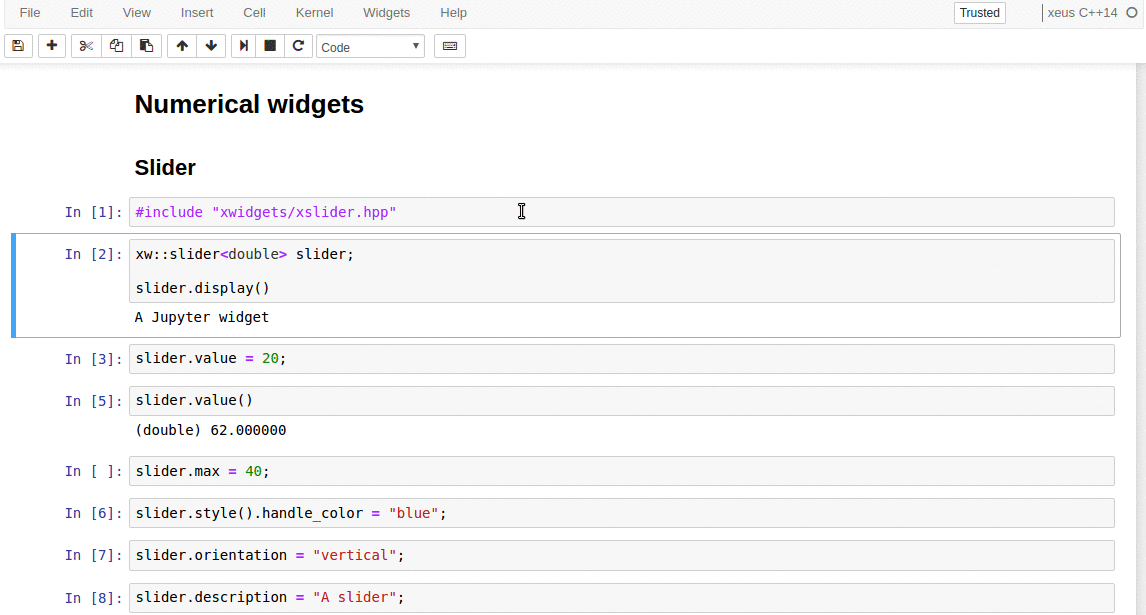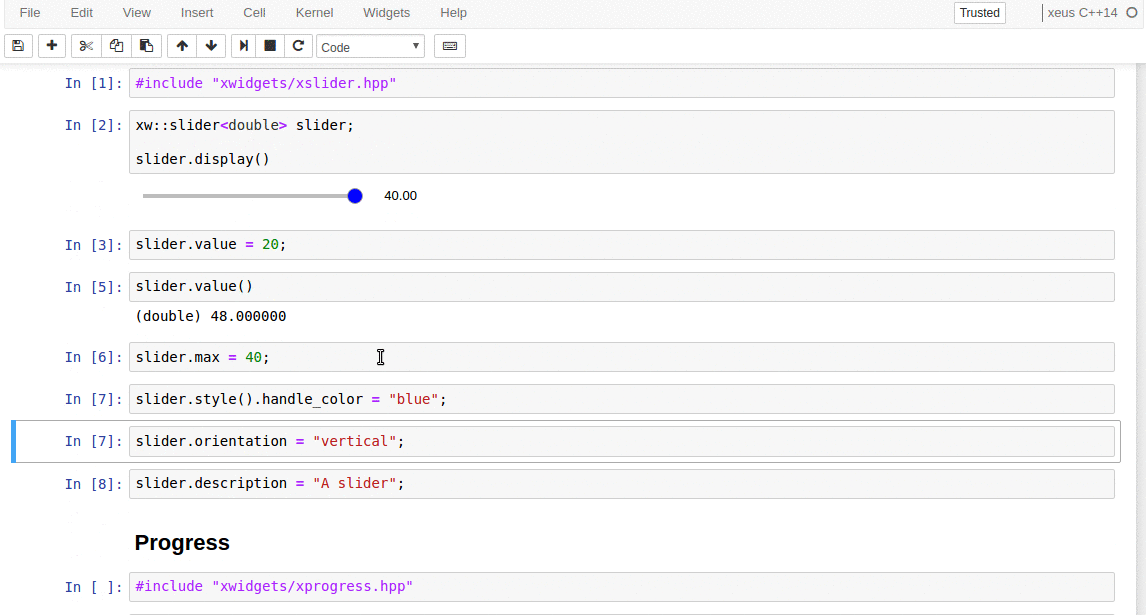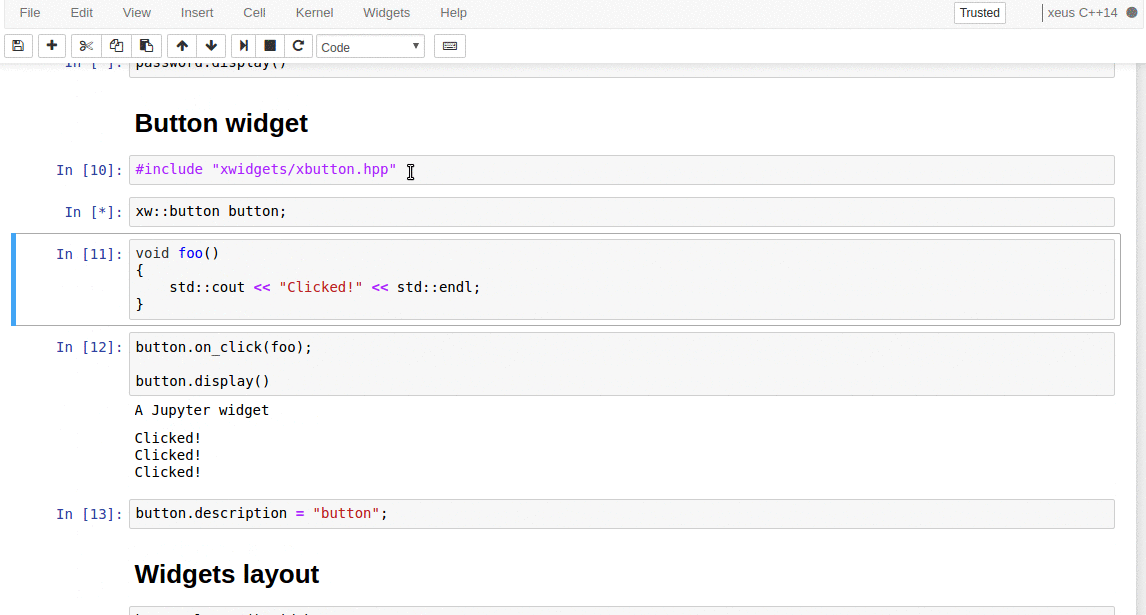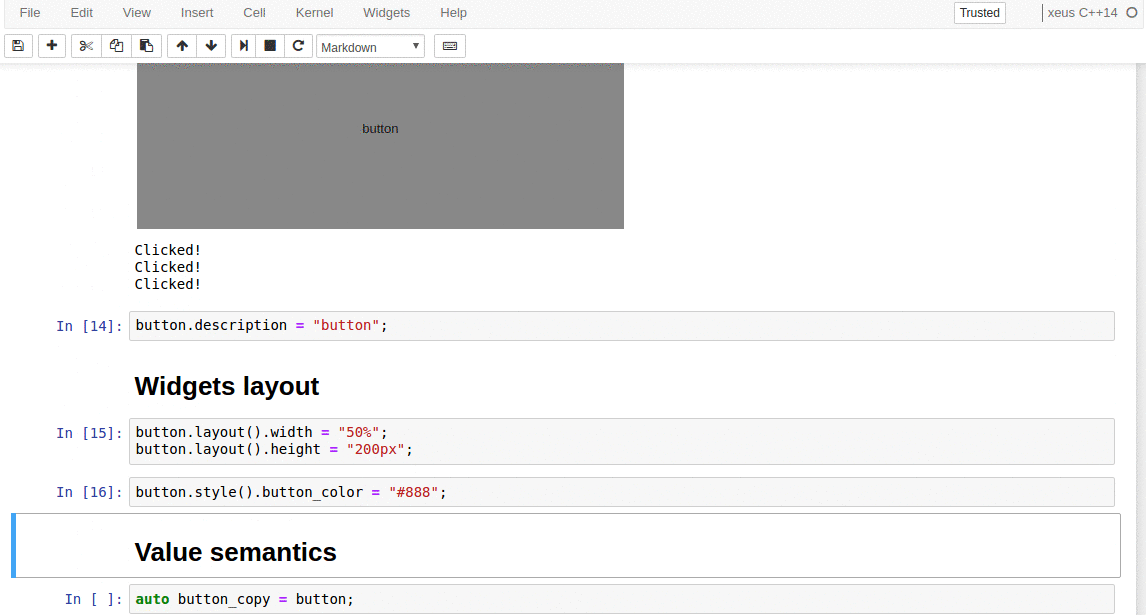 C++ back-end to the Jupyter interactive widgets
C++ back-end to the Jupyter interactive widgets
Just like with ipywidgets, one can build upon xwidgets and implement C++ back-ends for the Jupyter widget libraries listed earlier, effectively enabling them for the C++ programming language and other xeus-based kernels: xplot, xvolume, xthreejs…

xplot is an experimental C++ back-end for the bqplot 2-D plotting library. It enables an API following the constructs of the Grammar of Graphics in C++.
In xplot, every item in a chart is a separate object that can be modified from the back-end, dynamically .
Changing a property of a plot item, a scale, an axis or the figure canvas itself results in the communication of an update message to the front-end, which reflects the new state of the widget visually.
 Changing the data of a scatter plot dynamically to update the chart
Changing the data of a scatter plot dynamically to update the chart
Warning: the xplot and xwidgets projects are still at an early stage of development and are changing drastically at each release.
Interactive computing environments like Jupyter are not the only missing tool in the C++ world. Two key ingredients to the success of Python as the lingua franca of data science is the existence of libraries like NumPy and Pandas at the foundation of the ecosystem.

xtensor is a C++ library meant for numerical analysis with multi-dimensional array expressions.
xtensor provides
-
an extensible expression system enabling lazy NumPy-style broadcasting.
-
an API following the idioms of the C++ standard library.
-
tools to manipulate array expressions and build upon xtensor.
xtensor exposes an API similar to that of NumPy covering a growing portion of the functionalities. A cheat sheet can be found in the documentation:
 Scrolling the NumPy to xtensor cheat sheet
Scrolling the NumPy to xtensor cheat sheet
However, xtensor internals are very different from NumPy. Using modern C++ techniques (template expressions, closure semantics) xtensor is a lazily evaluated library, avoiding the creation of temporary variables and unnecessary memory allocations, even in the case complex expressions involving broadcasting and language bindings.
Still, from a user perspective, the combination of xtensor with the C++ notebook provides an experience very similar to that of NumPy in a Python notebook.
 Using the xtensor array expression library in a C++ notebook
Using the xtensor array expression library in a C++ notebook
In addition to the core library, the xtensor ecosystem has a number of other components
-
xtensor-blas: the counterpart to the numpy.linalg module.
-
xtensor-fftw: bindings to the fftw library.
-
xtensor-io: APIs to read and write various file formats (images, audio, NumPy's NPZ format).
-
xtensor-ros: bindings for ROS, the robot operating system.
-
xtensor-python: bindings for the Python programming language, allowing the use of NumPy arrays in-place, using the NumPy C API and the pybind11 library.
-
xtensor-julia: bindings for the Julia programming language, allowing the use of Julia arrays in-place, using the C API of the Julia interpreter, and the CxxWrap library.
-
xtensor-r: bindings for the R programming language, allowing the use of R arrays in-place.
Detailing further the features of the xtensor framework would be beyond the scope of this post.
If you are interested in trying the various notebooks presented in this post, there is no need to install anything. You can just use binder :

The Binder project, which is part of Project Jupyter, enables the deployment of containerized Jupyter notebooks, from a GitHub repository together with a manifest listing the dependencies (as conda packages).
All the notebooks in the screenshots above can be run online, by just clicking on one of the following links:
xtensor: the C++ N-D array expression library in a C++ notebook
xwidgets: the C++ back-end for Jupyter interactive widgets
xplot: the C++ back-end to the bqplot 2-D plotting library for Jupyter.

JupyterHub is the multi-user infrastructure underlying open wide deployments of Jupyter like Binder but also smaller deployments for authenticated users.
The modular architecture of JupyterHub enables a great variety of scenarios on how users are authenticated, and what service is made available to them. JupyterHub deployment for several hundreds of users have been done in various universities and institutions, including the Paris-Sud University, where the C++ kernel was also installed for the students to use.
In September 2017, the 350 first-year students at Paris-Sud University who took the “Info 111: Introduction to Computer Science” class wrote their first lines of C++ in a Jupyter notebook.
The use of Jupyter notebooks in the context of teaching C++ proved especially useful for the first classes, where students can focus on the syntax of the language without distractions such as compiling and linking.
Acknowledgements
The software presented in this post was built upon the work of a large number of people including the Jupyter team and the Cling developers.
We are especially grateful to Patrick Bos (who authored xtensor-fftw), Nicolas Thiéry, Min Ragan Kelley, Thomas Kluyver, Yuvi Panda, Kyle Cranmer, Axel Naumann and Vassil Vassilev.
We thank the DIANA/HEP organization for supporting travel to CERN and encouraging the collaboration between Project Jupyter and the ROOT team.
We are also grateful to the team at Paris-Sud University who worked on the JupyterHub deployment and the class materials, notably Viviane Pons.
The development of xeus, xtensor, xwidgets and related packages at QuantStack is sponsored by Bloomberg.
About the authors (alphabetical order)
Sylvain Corlay _, _ Scientific Software Developer at QuantStack
Loic Gouarin _, _ Research Engineer at Laboratoire de Mathématiques at Orsay
Johan Mabille _, _ Scientific Software Developer at QuantStack
Wolf Vollprecht , Scientific Software Developer at QuantStack
Thanks to Maarten Breddels, Wolf Vollprecht, Brian E. Granger, and Patrick Bos.
via: https://blog.jupyter.org/interactive-workflows-for-c-with-jupyter-fe9b54227d92
作者:QuantStack 译者:译者ID 校对:校对者ID