mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-26 21:30:55 +08:00
85 lines
12 KiB
Markdown
85 lines
12 KiB
Markdown
剖析内存中的程序之秘
|
||
============================================================
|
||
|
||
内存管理是操作系统的核心任务;它对程序员和系统管理员来说也是至关重要的。在接下来的几篇文章中,我将从实践出发着眼于内存管理,并深入到它的内部结构。虽然这些概念很通用,但示例大都来自于 32 位 x86 架构的 Linux 和 Windows 上。这第一篇文章描述了在内存中程序如何分布。
|
||
|
||
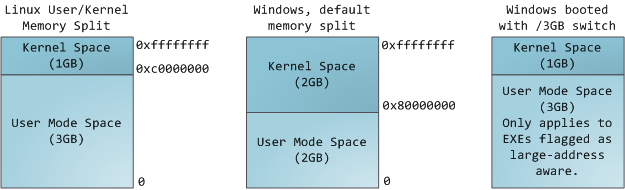
在一个多任务操作系统中的每个进程都运行在它自己的内存“沙箱”中。这个沙箱是一个<ruby>虚拟地址空间<rt>virtual address space</rt></ruby>,在 32 位的模式中它总共有 4GB 的内存地址块。这些虚拟地址是通过内核<ruby>页表<rt>page table</rt></ruby>映射到物理地址的,并且这些虚拟地址是由操作系统内核来维护,进而被进程所消费的。每个进程都有它自己的一组页表,但是这里有点玄机。一旦虚拟地址被启用,这些虚拟地址将被应用到这台电脑上的 _所有软件_,_包括内核本身_。因此,一部分虚拟地址空间必须保留给内核使用:
|
||
|
||
|
||
|
||
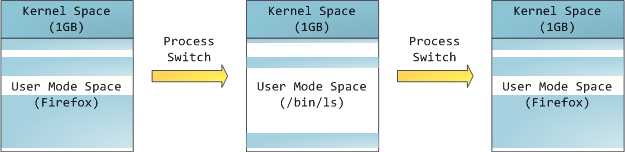
但是,这并**不是**说内核就使用了很多的物理内存,恰恰相反,它只使用了很少一部分可用的地址空间映射到其所需要的物理内存。内核空间在内核页表中被标记为独占使用于 [特权代码][1] (ring 2 或更低),因此,如果一个用户模式的程序尝试去访问它,将触发一个页面故障错误。在 Linux 中,内核空间是始终存在的,并且在所有进程中都映射相同的物理内存。内核代码和数据总是可寻址的,准备随时去处理中断或者系统调用。相比之下,用户模式中的地址空间,在每次进程切换时都会发生变化:
|
||
|
||
|
||
|
||
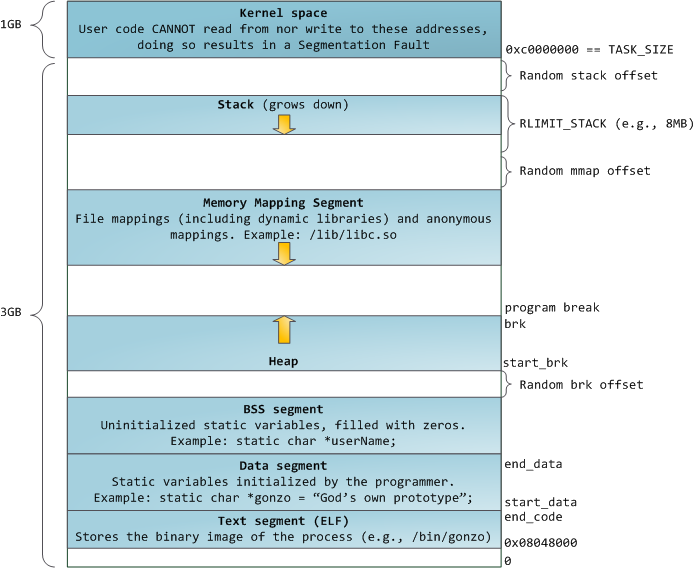
蓝色的区域代表映射到物理地址的虚拟地址空间,白色的区域是尚未映射的部分。在上面的示例中,众所周知的内存“饕餮” Firefox 使用了大量的虚拟内存空间。在地址空间中不同的条带对应了不同的内存段,像<ruby>堆<rt>heap</rt></ruby>、<ruby>栈<rt>stack</rt></ruby>等等。请注意,这些段只是一系列内存地址的简化表示,它与 [Intel 类型的段][2] _并没有任何关系_ 。不过,这是一个在 Linux 进程的标准段布局:
|
||
|
||
|
||
|
||
当计算机还是快乐、安全的时代时,在机器中的几乎每个进程上,那些段的起始虚拟地址都是**完全相同**的。这将使远程挖掘安全漏洞变得容易。漏洞利用经常需要去引用绝对内存位置:比如在栈中的一个地址,一个库函数的地址,等等。远程攻击可以闭着眼睛选择这个地址,因为地址空间都是相同的。当攻击者们这样做的时候,人们就会受到伤害。因此,地址空间随机化开始流行起来。Linux 会通过在其起始地址上增加偏移量来随机化[栈][3]、[内存映射段][4]、以及[堆][5]。不幸的是,32 位的地址空间是非常拥挤的,为地址空间随机化留下的空间不多,因此 [妨碍了地址空间随机化的效果][6]。
|
||
|
||
在进程地址空间中最高的段是栈,在大多数编程语言中它存储本地变量和函数参数。调用一个方法或者函数将推送一个新的<ruby>栈帧<rt>stack frame</rt></ruby>到这个栈。当函数返回时这个栈帧被删除。这个简单的设计,可能是因为数据严格遵循 [后进先出(LIFO)][7] 的次序,这意味着跟踪栈内容时不需要复杂的数据结构 —— 一个指向栈顶的简单指针就可以做到。推入和弹出也因此而非常快且准确。也可能是,持续的栈区重用往往会在 [CPU 缓存][8] 中保持活跃的栈内存,这样可以加快访问速度。进程中的每个线程都有它自己的栈。
|
||
|
||
向栈中推送更多的而不是刚合适的数据可能会耗尽栈的映射区域。这将触发一个页面故障,在 Linux 中它是通过 [`expand_stack()`][9] 来处理的,它会去调用 [`acct_stack_growth()`][10] 来检查栈的增长是否正常。如果栈的大小低于 `RLIMIT_STACK` 的值(一般是 8MB 大小),那么这是一个正常的栈增长和程序的合理使用,否则可能是发生了未知问题。这是一个栈大小按需调节的常见机制。但是,栈的大小达到了上述限制,将会发生一个栈溢出,并且,程序将会收到一个<ruby>段故障<rt>Segmentation Fault</rt></ruby>错误。当映射的栈区为满足需要而扩展后,在栈缩小时,映射区域并不会收缩。就像美国联邦政府的预算一样,它只会扩张。
|
||
|
||
动态栈增长是 [唯一例外的情况][11] ,当它去访问一个未映射的内存区域,如上图中白色部分,是允许的。除此之外的任何其它访问未映射的内存区域将触发一个页面故障,导致段故障。一些映射区域是只读的,因此,尝试去写入到这些区域也将触发一个段故障。
|
||
|
||
在栈的下面,有内存映射段。在这里,内核将文件内容直接映射到内存。任何应用程序都可以通过 Linux 的 [`mmap()`][12] 系统调用( [代码实现][13])或者 Windows 的 [`CreateFileMapping()`][14] / [`MapViewOfFile()`][15] 来请求一个映射。内存映射是实现文件 I/O 的方便高效的方式。因此,它经常被用于加载动态库。有时候,也被用于去创建一个并不匹配任何文件的匿名内存映射,这种映射经常被用做程序数据的替代。在 Linux 中,如果你通过 [`malloc()`][16] 去请求一个大的内存块,C 库将会创建这样一个匿名映射而不是使用堆内存。这里所谓的“大”表示是超过了`MMAP_THRESHOLD` 设置的字节数,它的缺省值是 128 kB,可以通过 [`mallopt()`][17] 去调整这个设置值。
|
||
|
||
接下来讲的是“堆”,就在我们接下来的地址空间中,堆提供运行时内存分配,像栈一样,但又不同于栈的是,它分配的数据生存期要长于分配它的函数。大多数编程语言都为程序提供了堆管理支持。因此,满足内存需要是编程语言运行时和内核共同来做的事情。在 C 中,堆分配的接口是 [`malloc()`][18] 一族,然而在支持垃圾回收的编程语言中,像 C#,这个接口使用 `new` 关键字。
|
||
|
||
如果在堆中有足够的空间可以满足内存请求,它可以由编程语言运行时来处理内存分配请求,而无需内核参与。否则将通过 [`brk()`][19] 系统调用([代码实现][20])来扩大堆以满足内存请求所需的大小。堆管理是比较 [复杂的][21],在面对我们程序的混乱分配模式时,它通过复杂的算法,努力在速度和内存使用效率之间取得一种平衡。服务一个堆请求所需要的时间可能是非常可观的。实时系统有一个 [特定用途的分配器][22] 去处理这个问题。堆也会出现 _碎片化_ ,如下图所示:
|
||
|
||

|
||
|
||
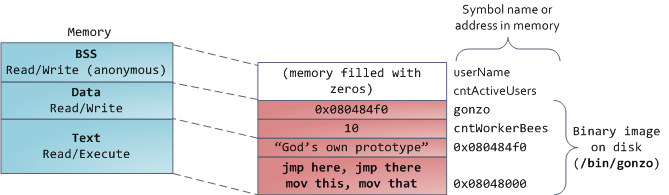
最后,我们抵达了内存的低位段:BSS、数据、以及程序文本。在 C 中,静态(全局)变量的内容都保存在 BSS 和数据中。它们之间的不同之处在于,BSS 保存 _未初始化的_ 静态变量的内容,它的值在源代码中并没有被程序员设置。BSS 内存区域是 _匿名_ 的:它没有映射到任何文件上。如果你在程序中写这样的语句 `static int cntActiveUsers`,`cntActiveUsers` 的内容就保存在 BSS 中。
|
||
|
||
反过来,数据段,用于保存在源代码中静态变量 _初始化后_ 的内容。这个内存区域是 _非匿名_ 的。它映射了程序的二进值镜像上的一部分,包含了在源代码中给定初始化值的静态变量内容。因此,如果你在程序中写这样的语句 `static int cntWorkerBees = 10`,那么,`cntWorkerBees` 的内容就保存在数据段中,并且初始值为 `10`。尽管可以通过数据段映射到一个文件,但是这是一个私有内存映射,意味着,如果改变内存,它并不会将这种变化反映到底层的文件上。必须是这样的,否则,分配的全局变量将会改变你磁盘上的二进制文件镜像,这种做法就太不可思议了!
|
||
|
||
用图去展示一个数据段是很困难的,因为它使用一个指针。在那种情况下,指针 `gonzo` 的_内容_(一个 4 字节的内存地址)保存在数据段上。然而,它并没有指向一个真实的字符串。而这个字符串存在于文本段中,文本段是只读的,它用于保存你的代码中的类似于字符串常量这样的内容。文本段也会在内存中映射你的二进制文件,但是,如果你的程序写入到这个区域,将会触发一个段故障错误。尽管在 C 中,它比不上从一开始就避免这种指针错误那么有效,但是,这种机制也有助于避免指针错误。这里有一个展示这些段和示例变量的图:
|
||
|
||
|
||
|
||
你可以通过读取 `/proc/pid_of_process/maps` 文件来检查 Linux 进程中的内存区域。请记住,一个段可以包含很多的区域。例如,每个内存映射的文件一般都在 mmap 段中的它自己的区域中,而动态库有类似于 BSS 和数据一样的额外的区域。下一篇文章中我们将详细说明“<ruby>区域<rt>area</rt></ruby>”的真正含义是什么。此外,有时候人们所说的“<ruby>数据段<rt>data segment</rt></ruby>”是指“<ruby>数据<rt>data</rt></ruby> + BSS + 堆”。
|
||
|
||
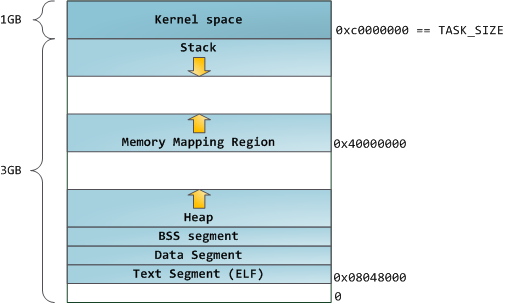
你可以使用 [nm][23] 和 [objdump][24] 命令去检查二进制镜像,去显示它们的符号、地址、段等等。最终,在 Linux 中上面描述的虚拟地址布局是一个“弹性的”布局,这就是这几年来的缺省情况。它假设 `RLIMIT_STACK` 有一个值。如果没有值的话,Linux 将恢复到如下所示的“经典” 布局:
|
||
|
||
|
||
|
||
这就是虚拟地址空间布局。接下来的文章将讨论内核如何对这些内存区域保持跟踪、内存映射、文件如何读取和写入、以及内存使用数据的意义。
|
||
|
||
--------------------------------------------------------------------------------
|
||
|
||
via: http://duartes.org/gustavo/blog/post/anatomy-of-a-program-in-memory/
|
||
|
||
作者:[Gustavo Duarte][a]
|
||
译者:[qhwdw](https://github.com/qhwdw)
|
||
校对:[wxy](https://github.com/wxy)
|
||
|
||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||
|
||
[a]:http://duartes.org/gustavo/blog/about/
|
||
[1]:http://duartes.org/gustavo/blog/post/cpu-rings-privilege-and-protection
|
||
[2]:http://duartes.org/gustavo/blog/post/memory-translation-and-segmentation
|
||
[3]:http://lxr.linux.no/linux+v2.6.28.1/fs/binfmt_elf.c#L542
|
||
[4]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/mm/mmap.c#L84
|
||
[5]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/kernel/process_32.c#L729
|
||
[6]:http://www.stanford.edu/~blp/papers/asrandom.pdf
|
||
[7]:http://en.wikipedia.org/wiki/Lifo
|
||
[8]:http://duartes.org/gustavo/blog/post/intel-cpu-caches
|
||
[9]:http://lxr.linux.no/linux+v2.6.28/mm/mmap.c#L1716
|
||
[10]:http://lxr.linux.no/linux+v2.6.28/mm/mmap.c#L1544
|
||
[11]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/mm/fault.c#L692
|
||
[12]:http://www.kernel.org/doc/man-pages/online/pages/man2/mmap.2.html
|
||
[13]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/kernel/sys_i386_32.c#L27
|
||
[14]:http://msdn.microsoft.com/en-us/library/aa366537(VS.85).aspx
|
||
[15]:http://msdn.microsoft.com/en-us/library/aa366761(VS.85).aspx
|
||
[16]:http://www.kernel.org/doc/man-pages/online/pages/man3/malloc.3.html
|
||
[17]:http://www.kernel.org/doc/man-pages/online/pages/man3/undocumented.3.html
|
||
[18]:http://www.kernel.org/doc/man-pages/online/pages/man3/malloc.3.html
|
||
[19]:http://www.kernel.org/doc/man-pages/online/pages/man2/brk.2.html
|
||
[20]:http://lxr.linux.no/linux+v2.6.28.1/mm/mmap.c#L248
|
||
[21]:http://g.oswego.edu/dl/html/malloc.html
|
||
[22]:http://rtportal.upv.es/rtmalloc/
|
||
[23]:http://manpages.ubuntu.com/manpages/intrepid/en/man1/nm.1.html
|
||
[24]:http://manpages.ubuntu.com/manpages/intrepid/en/man1/objdump.1.html
|