8.5 KiB
translation by strugglingyouth
How to Recover Data and Rebuild Failed Software RAID’s – Part 8
In the previous articles of this RAID series you went from zero to RAID hero. We reviewed several software RAID configurations and explained the essentials of each one, along with the reasons why you would lean towards one or the other depending on your specific scenario.

Recover Rebuild Failed Software RAID’s – Part 8
In this guide we will discuss how to rebuild a software RAID array without data loss when in the event of a disk failure. For brevity, we will only consider a RAID 1 setup – but the concepts and commands apply to all cases alike.
RAID Testing Scenario
Before proceeding further, please make sure you have set up a RAID 1 array following the instructions provided in Part 3 of this series: How to set up RAID 1 (Mirror) in Linux.
The only variations in our present case will be:
-
a different version of CentOS (v7) than the one used in that article (v6.5), and
-
different disk sizes for /dev/sdb and /dev/sdc (8 GB each).
In addition, if SELinux is enabled in enforcing mode, you will need to add the corresponding labels to the directory where you’ll mount the RAID device. Otherwise, you’ll run into this warning message while attempting to mount it:
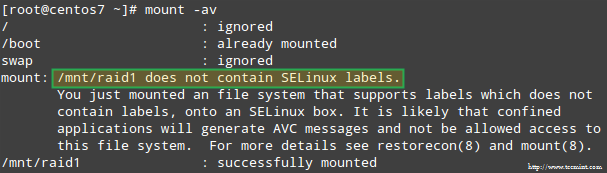
SELinux RAID Mount Error
You can fix this by running:
# restorecon -R /mnt/raid1
Setting up RAID Monitoring
There is a variety of reasons why a storage device can fail (SSDs have greatly reduced the chances of this happening, though), but regardless of the cause you can be sure that issues can occur anytime and you need to be prepared to replace the failed part and to ensure the availability and integrity of your data.
A word of advice first. Even when you can inspect /proc/mdstat in order to check the status of your RAIDs, there’s a better and time-saving method that consists of running mdadm in monitor + scan mode, which will send alerts via email to a predefined recipient.
To set this up, add the following line in /etc/mdadm.conf:
MAILADDR user@<domain or localhost>
In my case:
MAILADDR gacanepa@localhost

RAID Monitoring Email Alerts
To run mdadm in monitor + scan mode, add the following crontab entry as root:
@reboot /sbin/mdadm --monitor --scan --oneshot
By default, mdadm will check the RAID arrays every 60 seconds and send an alert if it finds an issue. You can modify this behavior by adding the --delay option to the crontab entry above along with the amount of seconds (for example, --delay 1800 means 30 minutes).
Finally, make sure you have a Mail User Agent (MUA) installed, such as mutt or mailx. Otherwise, you will not receive any alerts.
In a minute we will see what an alert sent by mdadm looks like.
Simulating and Replacing a failed RAID Storage Device
To simulate an issue with one of the storage devices in the RAID array, we will use the --manage and --set-faulty options as follows:
# mdadm --manage --set-faulty /dev/md0 /dev/sdc1
This will result in /dev/sdc1 being marked as faulty, as we can see in /proc/mdstat:
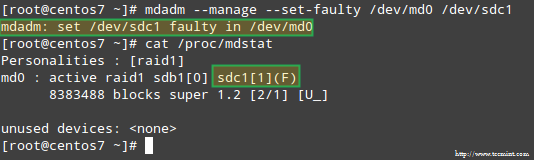
Stimulate Issue with RAID Storage
More importantly, let’s see if we received an email alert with the same warning:

Email Alert on Failed RAID Device
In this case, you will need to remove the device from the software RAID array:
# mdadm /dev/md0 --remove /dev/sdc1
Then you can physically remove it from the machine and replace it with a spare part (/dev/sdd, where a partition of type fd has been previously created):
# mdadm --manage /dev/md0 --add /dev/sdd1
Luckily for us, the system will automatically start rebuilding the array with the part that we just added. We can test this by marking /dev/sdb1 as faulty, removing it from the array, and making sure that the file tecmint.txt is still accessible at /mnt/raid1:
# mdadm --detail /dev/md0
# mount | grep raid1
# ls -l /mnt/raid1 | grep tecmint
# cat /mnt/raid1/tecmint.txt

Confirm Rebuilding RAID Array
The image above clearly shows that after adding /dev/sdd1 to the array as a replacement for /dev/sdc1, the rebuilding of data was automatically performed by the system without intervention on our part.
Though not strictly required, it’s a great idea to have a spare device in handy so that the process of replacing the faulty device with a good drive can be done in a snap. To do that, let’s re-add /dev/sdb1 and /dev/sdc1:
# mdadm --manage /dev/md0 --add /dev/sdb1
# mdadm --manage /dev/md0 --add /dev/sdc1

Replace Failed Raid Device
Recovering from a Redundancy Loss
As explained earlier, mdadm will automatically rebuild the data when one disk fails. But what happens if 2 disks in the array fail? Let’s simulate such scenario by marking /dev/sdb1 and /dev/sdd1 as faulty:
# umount /mnt/raid1
# mdadm --manage --set-faulty /dev/md0 /dev/sdb1
# mdadm --stop /dev/md0
# mdadm --manage --set-faulty /dev/md0 /dev/sdd1
Attempts to re-create the array the same way it was created at this time (or using the --assume-clean option) may result in data loss, so it should be left as a last resort.
Let’s try to recover the data from /dev/sdb1, for example, into a similar disk partition (/dev/sde1 – note that this requires that you create a partition of type fd in /dev/sde before proceeding) using ddrescue:
# ddrescue -r 2 /dev/sdb1 /dev/sde1
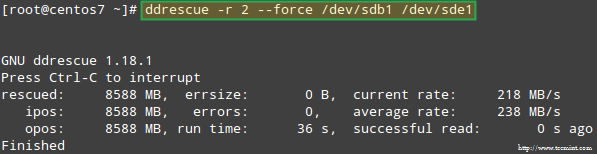
Recovering Raid Array
Please note that up to this point, we haven’t touched /dev/sdb or /dev/sdd, the partitions that were part of the RAID array.
Now let’s rebuild the array using /dev/sde1 and /dev/sdf1:
# mdadm --create /dev/md0 --level=mirror --raid-devices=2 /dev/sd[e-f]1
Please note that in a real situation, you will typically use the same device names as with the original array, that is, /dev/sdb1 and /dev/sdc1 after the failed disks have been replaced with new ones.
In this article I have chosen to use extra devices to re-create the array with brand new disks and to avoid confusion with the original failed drives.
When asked whether to continue writing array, type Y and press Enter. The array should be started and you should be able to watch its progress with:
# watch -n 1 cat /proc/mdstat
When the process completes, you should be able to access the content of your RAID:
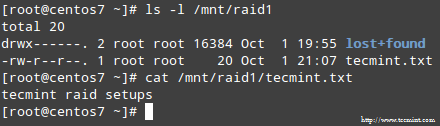
Confirm Raid Content
Summary
In this article we have reviewed how to recover from RAID failures and redundancy losses. However, you need to remember that this technology is a storage solution and DOES NOT replace backups.
The principles explained in this guide apply to all RAID setups alike, as well as the concepts that we will cover in the next and final guide of this series (RAID management).
If you have any questions about this article, feel free to drop us a note using the comment form below. We look forward to hearing from you!
via: http://www.tecmint.com/recover-data-and-rebuild-failed-software-raid/
作者:Gabriel Cánepa 译者:译者ID 校对:校对者ID