mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-29 21:41:00 +08:00
1033 lines
49 KiB
Markdown
1033 lines
49 KiB
Markdown
搭个 Web 服务器(三)
|
||
=====================================
|
||
|
||
>“当我们必须创造时,才能够学到更多。” ——皮亚杰
|
||
|
||
在本系列的[第二部分](https://linux.cn/article-7685-1.html)中,你创造了一个可以处理基本 HTTP GET 请求的、朴素的 WSGI 服务器。当时我问了一个问题:“你该如何让你的服务器在同一时间处理多个请求呢?”在这篇文章中,你会找到答案。系好安全带,我们要认真起来,全速前进了!你将会体验到一段非常快速的旅程。准备好你的 Linux、Mac OS X(或者其他 *nix 系统),还有你的 Python。本文中所有源代码均可在 [GitHub][1] 上找到。
|
||
|
||
### 服务器的基本结构及如何处理请求
|
||
|
||
首先,我们来回顾一下 Web 服务器的基本结构,以及服务器处理来自客户端的请求时,所需的必要步骤。你在[第一部分](https://linux.cn/article-7662-1.html)及[第二部分](https://linux.cn/article-7685-1.html)中创建的轮询服务器只能够一次处理一个请求。在处理完当前请求之前,它不能够接受新的客户端连接。所有请求为了等待服务都需要排队,在服务繁忙时,这个队伍可能会排的很长,一些客户端可能会感到不开心。
|
||
|
||
|
||
|
||
这是轮询服务器 [webserver3a.py][2] 的代码:
|
||
|
||
```
|
||
#####################################################################
|
||
# 轮询服务器 - webserver3a.py #
|
||
# #
|
||
# 使用 Python 2.7.9 或 3.4 #
|
||
# 在 Ubuntu 14.04 及 Mac OS X 环境下测试通过 #
|
||
#####################################################################
|
||
import socket
|
||
|
||
SERVER_ADDRESS = (HOST, PORT) = '', 8888
|
||
REQUEST_QUEUE_SIZE = 5
|
||
|
||
|
||
def handle_request(client_connection):
|
||
request = client_connection.recv(1024)
|
||
print(request.decode())
|
||
http_response = b"""\
|
||
HTTP/1.1 200 OK
|
||
|
||
Hello, World!
|
||
"""
|
||
client_connection.sendall(http_response)
|
||
|
||
|
||
def serve_forever():
|
||
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
||
listen_socket.bind(SERVER_ADDRESS)
|
||
listen_socket.listen(REQUEST_QUEUE_SIZE)
|
||
print('Serving HTTP on port {port} ...'.format(port=PORT))
|
||
|
||
while True:
|
||
client_connection, client_address = listen_socket.accept()
|
||
handle_request(client_connection)
|
||
client_connection.close()
|
||
|
||
if __name__ == '__main__':
|
||
serve_forever()
|
||
```
|
||
|
||
为了观察到你的服务器在同一时间只能处理一个请求的行为,我们对服务器的代码做一点点修改:在将响应发送至客户端之后,将程序阻塞 60 秒。这个修改只需要一行代码,来告诉服务器进程暂停 60 秒钟。
|
||
|
||
|
||
|
||
这是我们更改后的代码,包含暂停语句的服务器 [webserver3b.py][3]:
|
||
|
||
```
|
||
#########################################################################
|
||
# 轮询服务器 - webserver3b.py #
|
||
# #
|
||
# 使用 Python 2.7.9 或 3.4 #
|
||
# 在 Ubuntu 14.04 及 Mac OS X 环境下测试通过 #
|
||
# #
|
||
# - 服务器向客户端发送响应之后,会阻塞 60 秒 #
|
||
#########################################################################
|
||
import socket
|
||
import time
|
||
|
||
SERVER_ADDRESS = (HOST, PORT) = '', 8888
|
||
REQUEST_QUEUE_SIZE = 5
|
||
|
||
|
||
def handle_request(client_connection):
|
||
request = client_connection.recv(1024)
|
||
print(request.decode())
|
||
http_response = b"""\
|
||
HTTP/1.1 200 OK
|
||
|
||
Hello, World!
|
||
"""
|
||
client_connection.sendall(http_response)
|
||
time.sleep(60) ### 睡眠语句,阻塞该进程 60 秒
|
||
|
||
|
||
def serve_forever():
|
||
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
||
listen_socket.bind(SERVER_ADDRESS)
|
||
listen_socket.listen(REQUEST_QUEUE_SIZE)
|
||
print('Serving HTTP on port {port} ...'.format(port=PORT))
|
||
|
||
while True:
|
||
client_connection, client_address = listen_socket.accept()
|
||
handle_request(client_connection)
|
||
client_connection.close()
|
||
|
||
if __name__ == '__main__':
|
||
serve_forever()
|
||
```
|
||
|
||
用以下命令启动服务器:
|
||
|
||
```
|
||
$ python webserver3b.py
|
||
```
|
||
|
||
现在,打开一个新的命令行窗口,然后运行 `curl` 语句。你应该可以立刻看到屏幕上显示的字符串“Hello, World!”:
|
||
|
||
```
|
||
$ curl http://localhost:8888/hello
|
||
Hello, World!
|
||
```
|
||
|
||
然后,立刻打开第二个命令行窗口,运行相同的 `curl` 命令:
|
||
|
||
```
|
||
$ curl http://localhost:8888/hello
|
||
```
|
||
|
||
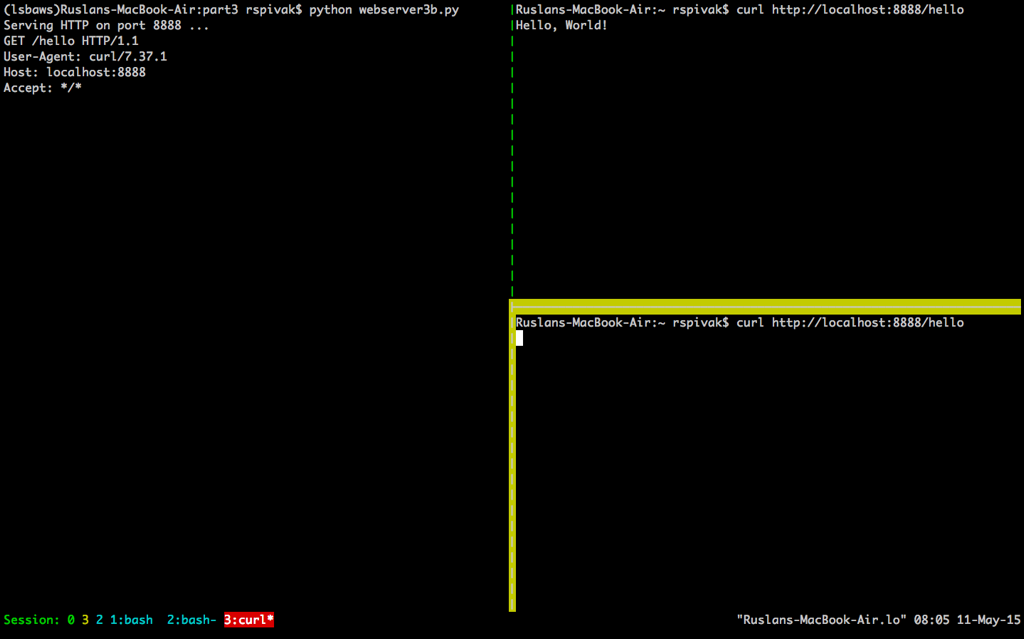
如果你在 60 秒之内完成了以上步骤,你会看到第二条 `curl` 指令不会立刻产生任何输出,而只是挂在了哪里。同样,服务器也不会在标准输出流中输出新的请求内容。这是这个过程在我的 Mac 电脑上的运行结果(在右下角用黄色框标注出来的窗口中,我们能看到第二个 `curl` 指令被挂起,正在等待连接被服务器接受):
|
||
|
||
|
||
|
||
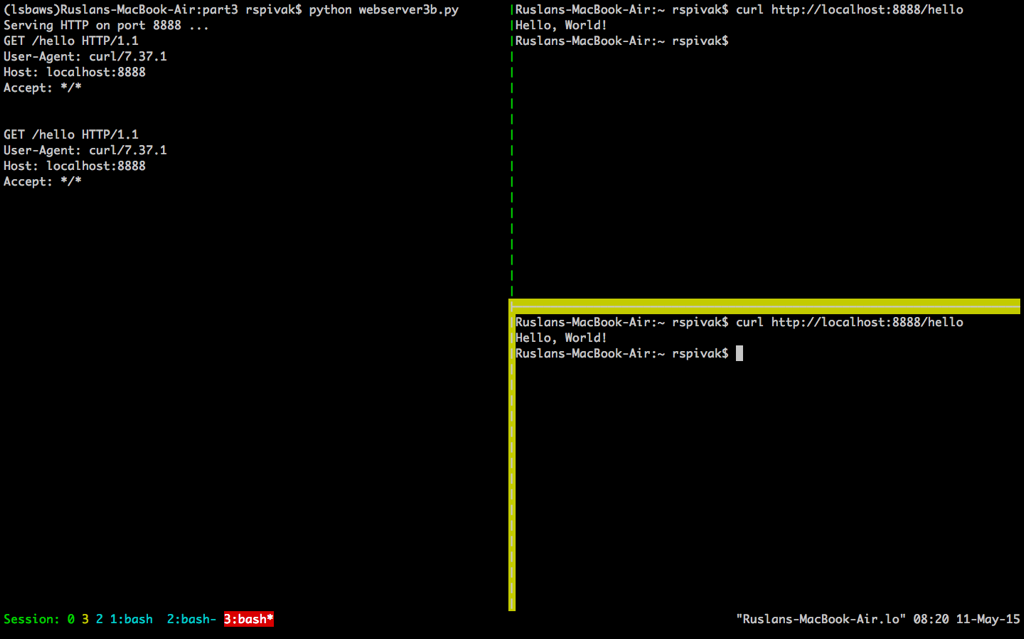
当你等待足够长的时间(60 秒以上)后,你会看到第一个 `curl` 程序完成,而第二个 `curl` 在屏幕上输出了“Hello, World!”,然后休眠 60 秒,进而终止。
|
||
|
||
|
||
|
||
这样运行的原因是因为在服务器在处理完第一个来自 `curl` 的请求之后,只有等待 60 秒才能开始处理第二个请求。这个处理请求的过程按顺序进行(也可以说,迭代进行),一步一步进行,在我们刚刚给出的例子中,在同一时间内只能处理一个请求。
|
||
|
||
现在,我们来简单讨论一下客户端与服务器的交流过程。为了让两个程序在网络中互相交流,它们必须使用套接字。你应当在本系列的前两部分中见过它几次了。但是,套接字是什么?
|
||
|
||
|
||
|
||
套接字(socket)是一个通讯通道端点(endpoint)的抽象描述,它可以让你的程序通过文件描述符来与其它程序进行交流。在这篇文章中,我只会单独讨论 Linux 或 Mac OS X 中的 TCP/IP 套接字。这里有一个重点概念需要你去理解:TCP 套接字对(socket pair)。
|
||
|
||
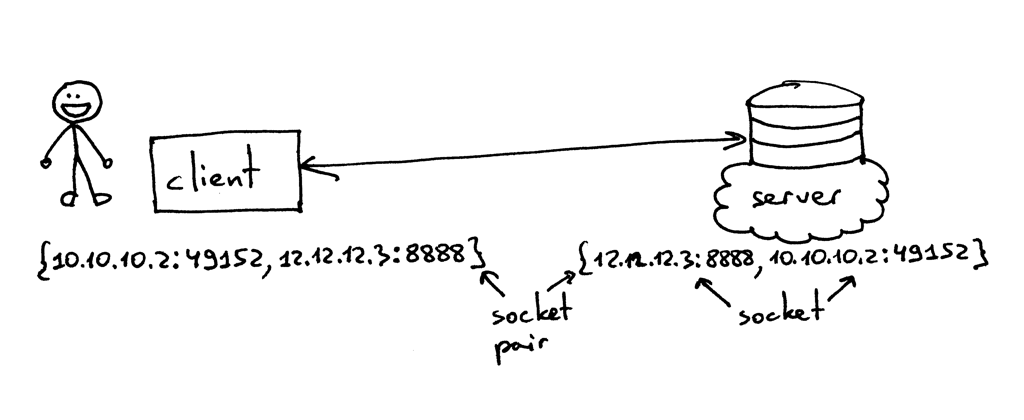
> TCP 连接使用的套接字对是一个由 4 个元素组成的元组,它确定了 TCP 连接的两端:本地 IP 地址、本地端口、远端 IP 地址及远端端口。一个套接字对唯一地确定了网络中的每一个 TCP 连接。在连接一端的两个值:一个 IP 地址和一个端口,通常被称作一个套接字。(引自[《UNIX 网络编程 卷1:套接字联网 API (第3版)》][4])
|
||
|
||
|
||
|
||
所以,元组 `{10.10.10.2:49152, 12.12.12.3:8888}` 就是一个能够在客户端确定 TCP 连接两端的套接字对,而元组 `{12.12.12.3:8888, 10.10.10.2:49152}` 则是在服务端确定 TCP 连接两端的套接字对。在这个例子中,确定 TCP 服务端的两个值(IP 地址 `12.12.12.3` 及端口 `8888`),代表一个套接字;另外两个值则代表客户端的套接字。
|
||
|
||
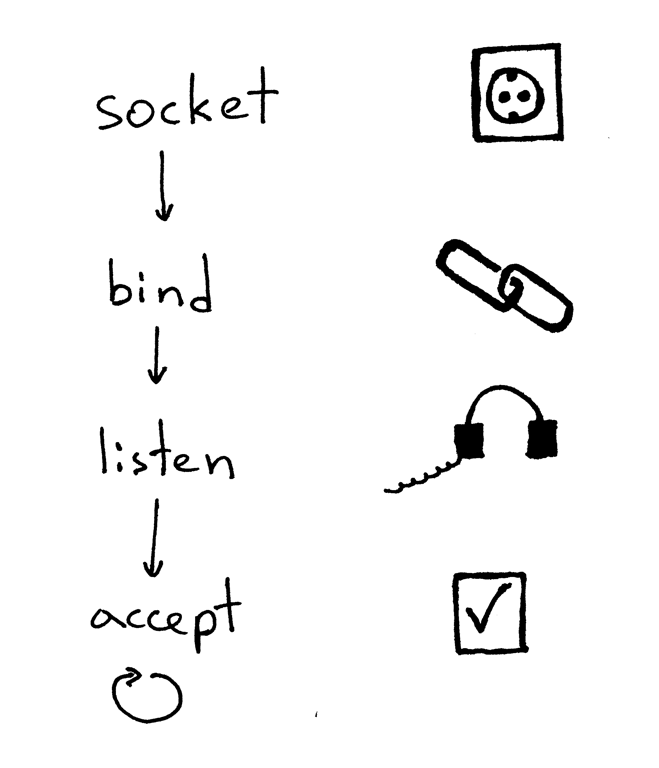
一个服务器创建一个套接字并开始建立连接的基本工作流程如下:
|
||
|
||
|
||
|
||
1. 服务器创建一个 TCP/IP 套接字。我们可以用这条 Python 语句来创建:
|
||
|
||
```
|
||
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||
```
|
||
2. 服务器可能会设定一些套接字选项(这个步骤是可选的,但是你可以看到上面的服务器代码做了设定,这样才能够在重启服务器时多次复用同一地址):
|
||
|
||
```
|
||
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
||
```
|
||
3. 然后,服务器绑定一个地址。绑定函数 `bind` 可以将一个本地协议地址赋给套接字。若使用 TCP 协议,调用绑定函数 `bind` 时,需要指定一个端口号,一个 IP 地址,或两者兼有,或两者全无。(引自[《UNIX网络编程 卷1:套接字联网 API (第3版)》][4])
|
||
|
||
```
|
||
listen_socket.bind(SERVER_ADDRESS)
|
||
```
|
||
4. 然后,服务器开启套接字的监听模式。
|
||
|
||
```
|
||
listen_socket.listen(REQUEST_QUEUE_SIZE)
|
||
```
|
||
|
||
监听函数 `listen` 只应在服务端调用。它会通知操作系统内核,表明它会接受所有向该套接字发送的入站连接请求。
|
||
|
||
以上四步完成后,服务器将循环接收来自客户端的连接,一次循环处理一条。当有连接可用时,接受请求函数 `accept` 将会返回一个已连接的客户端套接字。然后,服务器从这个已连接的客户端套接字中读取请求数据,将数据在其标准输出流中输出出来,并向客户端回送一条消息。然后,服务器会关闭这个客户端连接,并准备接收一个新的客户端连接。
|
||
|
||
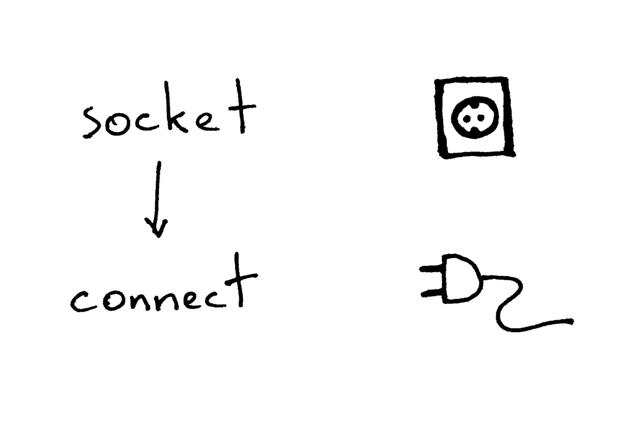
这是客户端使用 TCP/IP 协议与服务器通信的必要步骤:
|
||
|
||
|
||
|
||
下面是一段示例代码,使用这段代码,客户端可以连接你的服务器,发送一个请求,并输出响应内容:
|
||
|
||
```
|
||
import socket
|
||
|
||
### 创建一个套接字,并连接值服务器
|
||
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||
sock.connect(('localhost', 8888))
|
||
|
||
### 发送一段数据,并接收响应数据
|
||
sock.sendall(b'test')
|
||
data = sock.recv(1024)
|
||
print(data.decode())
|
||
```
|
||
|
||
在创建套接字后,客户端需要连接至服务器。我们可以调用连接函数 `connect` 来完成这个操作:
|
||
|
||
```
|
||
sock.connect(('localhost', 8888))
|
||
```
|
||
|
||
客户端只需提供待连接的远程服务器的 IP 地址(或主机名),及端口号,即可连接至远端服务器。
|
||
|
||
你可能已经注意到了,客户端不需要调用 `bind` 及 `accept` 函数,就可以与服务器建立连接。客户端不需要调用 `bind` 函数是因为客户端不需要关注本地 IP 地址及端口号。操作系统内核中的 TCP/IP 协议栈会在客户端调用 `connect` 函数时,自动为套接字分配本地 IP 地址及本地端口号。这个本地端口被称为临时端口(ephemeral port),即一个短暂开放的端口。
|
||
|
||

|
||
|
||
服务器中有一些端口被用于承载一些众所周知的服务,它们被称作通用(well-known)端口:如 80 端口用于 HTTP 服务,22 端口用于 SSH 服务。打开你的 Python shell,与你在本地运行的服务器建立一个连接,来看看内核给你的客户端套接字分配了哪个临时端口(在尝试这个例子之前,你需要运行服务器程序 `webserver3a.py` 或 `webserver3b.py`):
|
||
|
||
```
|
||
>>> import socket
|
||
>>> sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||
>>> sock.connect(('localhost', 8888))
|
||
>>> host, port = sock.getsockname()[:2]
|
||
>>> host, port
|
||
('127.0.0.1', 60589)
|
||
```
|
||
|
||
在上面的例子中,内核将临时端口 60589 分配给了你的套接字。
|
||
|
||
在我开始回答我在第二部分中提出的问题之前,我还需要快速讲解一些概念。你很快就会明白这些概念为什么非常重要。这两个概念,一个是进程,另外一个是文件描述符。
|
||
|
||
什么是进程?进程就是一个程序执行的实体。举个例子:当你的服务器代码被执行时,它会被载入内存,而内存中表现此次程序运行的实体就叫做进程。内核记录了进程的一系列有关信息——比如进程 ID——来追踪它的运行情况。当你在执行轮询服务器 `webserver3a.py` 或 `webserver3b.py` 时,你其实只是启动了一个进程。
|
||
|
||
|
||
|
||
我们在终端窗口中运行 `webserver3b.py`:
|
||
|
||
```
|
||
$ python webserver3b.py
|
||
```
|
||
|
||
在另一个终端窗口中,我们可以使用 `ps` 命令获取该进程的相关信息:
|
||
|
||
```
|
||
$ ps | grep webserver3b | grep -v grep
|
||
7182 ttys003 0:00.04 python webserver3b.py
|
||
```
|
||
|
||
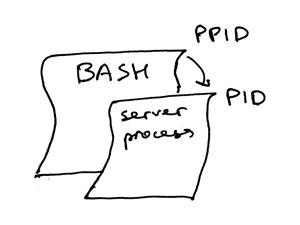
`ps` 命令显示,我们刚刚只运行了一个 Python 进程 `webserver3b.py`。当一个进程被创建时,内核会为其分配一个进程 ID,也就是 PID。在 UNIX 中,所有用户进程都有一个父进程;当然,这个父进程也有进程 ID,叫做父进程 ID,缩写为 PPID。假设你默认使用 BASH shell,那当你启动服务器时,就会启动一个新的进程,同时被赋予一个 PID,而它的父进程 PID 会被设为 BASH shell 的 PID。
|
||
|
||
|
||
|
||
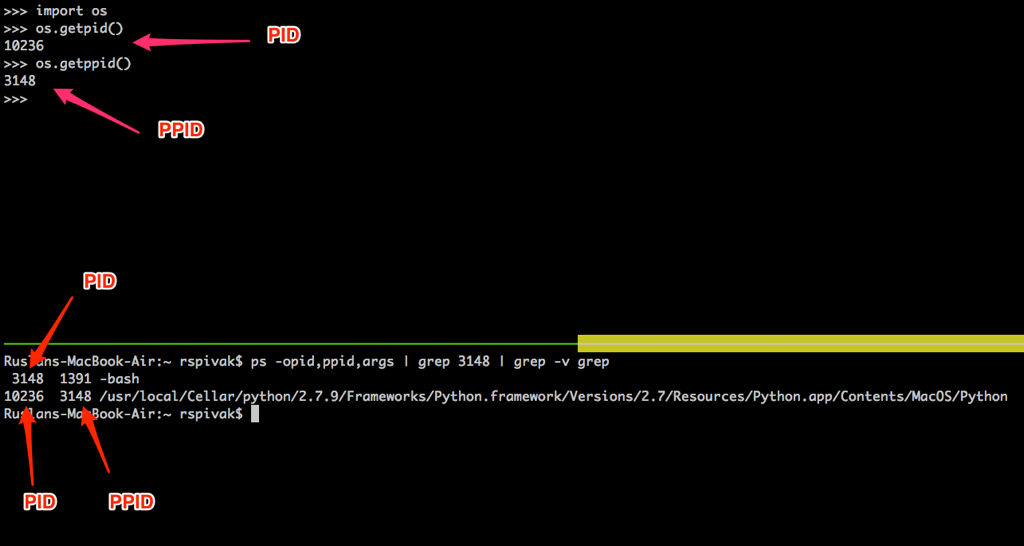
自己尝试一下,看看这一切都是如何工作的。重新开启你的 Python shell,它会创建一个新进程,然后在其中使用系统调用 `os.getpid()` 及 `os.getppid()` 来获取 Python shell 进程的 PID 及其父进程 PID(也就是你的 BASH shell 的 PID)。然后,在另一个终端窗口中运行 `ps` 命令,然后用 `grep` 来查找 PPID(父进程 ID,在我的例子中是 3148)。在下面的屏幕截图中,你可以看到一个我的 Mac OS X 系统中关于进程父子关系的例子,在这个例子中,子进程是我的 Python shell 进程,而父进程是 BASH shell 进程:
|
||
|
||
|
||
|
||
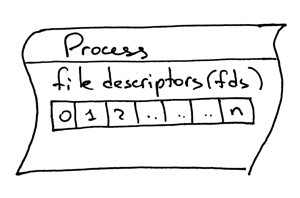
另外一个需要了解的概念,就是文件描述符。什么是文件描述符?文件描述符是一个非负整数,当进程打开一个现有文件、创建新文件或创建一个新的套接字时,内核会将这个数返回给进程。你以前可能听说过,在 UNIX 中,一切皆是文件。内核会按文件描述符来找到一个进程所打开的文件。当你需要读取文件或向文件写入时,我们同样通过文件描述符来定位这个文件。Python 提供了高层次的操作文件(或套接字)的对象,所以你不需要直接通过文件描述符来定位文件。但是,在高层对象之下,我们就是用它来在 UNIX 中定位文件及套接字,通过这个整数的文件描述符。
|
||
|
||
|
||
|
||
一般情况下,UNIX shell 会将一个进程的标准输入流(STDIN)的文件描述符设为 0,标准输出流(STDOUT)设为 1,而标准错误打印(STDERR)的文件描述符会被设为 2。
|
||
|
||
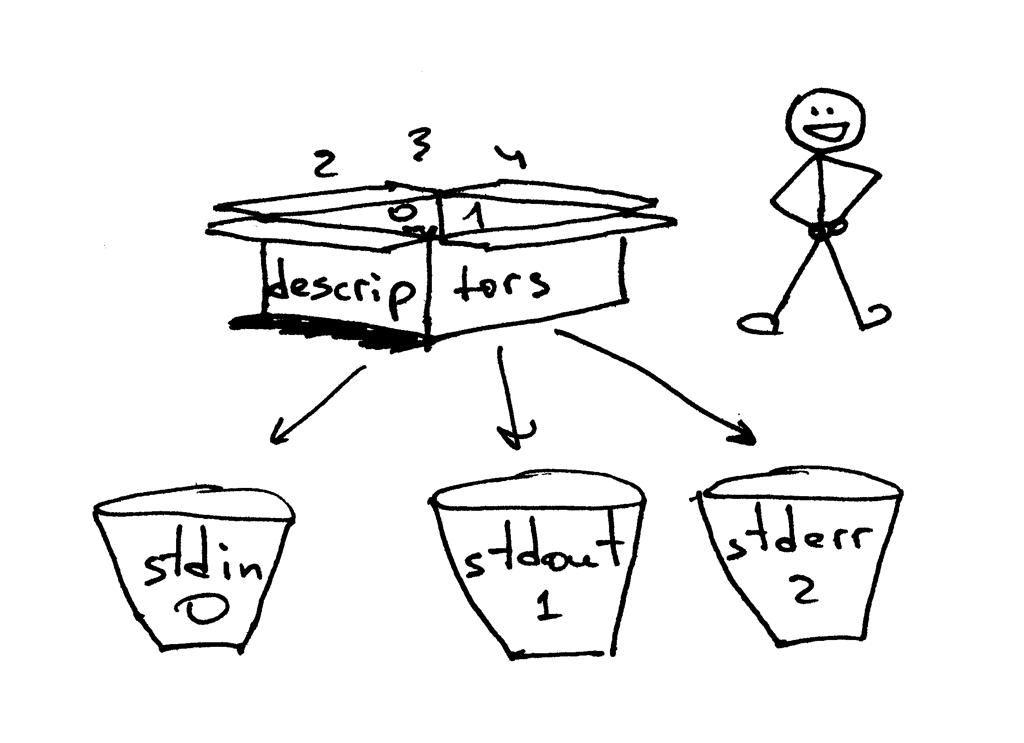
|
||
|
||
我之前提到过,即使 Python 提供了高层次的文件对象或类文件对象来供你操作,你仍然可以在对象上使用 `fileno()` 方法,来获取与该文件相关联的文件描述符。回到 Python shell 中,我们来看看你该怎么做到这一点:
|
||
|
||
|
||
```
|
||
>>> import sys
|
||
>>> sys.stdin
|
||
<open file '<stdin>', mode 'r' at 0x102beb0c0>
|
||
>>> sys.stdin.fileno()
|
||
0
|
||
>>> sys.stdout.fileno()
|
||
1
|
||
>>> sys.stderr.fileno()
|
||
2
|
||
```
|
||
|
||
当你在 Python 中操作文件及套接字时,你可能会使用高层次的文件/套接字对象,但是你仍然有可能会直接使用文件描述符。下面有一个例子,来演示如何用文件描述符做参数来进行一次写入的系统调用:
|
||
|
||
```
|
||
>>> import sys
|
||
>>> import os
|
||
>>> res = os.write(sys.stdout.fileno(), 'hello\n')
|
||
hello
|
||
```
|
||
|
||
下面是比较有趣的部分——不过你可能不会为此感到惊讶,因为你已经知道在 Unix 中,一切皆为文件——你的套接字对象同样有一个相关联的文件描述符。和刚才操纵文件时一样,当你在 Python 中创建一个套接字时,你会得到一个对象而不是一个非负整数,但你永远可以用我之前提到过的 `fileno()` 方法获取套接字对象的文件描述符,并可以通过这个文件描述符来直接操纵套接字。
|
||
|
||
```
|
||
>>> import socket
|
||
>>> sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||
>>> sock.fileno()
|
||
3
|
||
```
|
||
|
||
我还想再提一件事:不知道你有没有注意到,在我们的第二个轮询服务器 `webserver3b.py` 中,当你的服务器休眠 60 秒的过程中,你仍然可以通过第二个 `curl` 命令连接至服务器。当然 `curl` 命令并没有立刻输出任何内容而是挂在哪里,但是既然服务器没有接受连接,那它为什么不立即拒绝掉连接,而让它还能够继续与服务器建立连接呢?这个问题的答案是:当我在调用套接字对象的 `listen` 方法时,我为该方法提供了一个 `BACKLOG` 参数,在代码中用 `REQUEST_QUEUE_SIZE` 常量来表示。`BACKLOG` 参数决定了在内核中为存放即将到来的连接请求所创建的队列的大小。当服务器 `webserver3b.py` 在睡眠的时候,你运行的第二个 `curl` 命令依然能够连接至服务器,因为内核中用来存放即将接收的连接请求的队列依然拥有足够大的可用空间。
|
||
|
||
尽管增大 `BACKLOG` 参数并不能神奇地使你的服务器同时处理多个请求,但当你的服务器很繁忙时,将它设置为一个较大的值还是相当重要的。这样,在你的服务器调用 `accept` 方法时,不需要再等待一个新的连接建立,而可以立刻直接抓取队列中的第一个客户端连接,并不加停顿地立刻处理它。
|
||
|
||
欧耶!现在你已经了解了一大块内容。我们来快速回顾一下我们刚刚讲解的知识(当然,如果这些对你来说都是基础知识的话,那我们就当复习好啦)。
|
||
|
||

|
||
|
||
- 轮询服务器
|
||
- 服务端套接字创建流程(创建套接字,绑定,监听及接受)
|
||
- 客户端连接创建流程(创建套接字,连接)
|
||
- 套接字对
|
||
- 套接字
|
||
- 临时端口及通用端口
|
||
- 进程
|
||
- 进程 ID(PID),父进程 ID(PPID),以及进程父子关系
|
||
- 文件描述符
|
||
- 套接字的 `listen` 方法中,`BACKLOG` 参数的含义
|
||
|
||
### 如何并发处理多个请求
|
||
|
||
现在,我可以开始回答第二部分中的那个问题了:“你该如何让你的服务器在同一时间处理多个请求呢?”或者换一种说法:“如何编写一个并发服务器?”
|
||
|
||
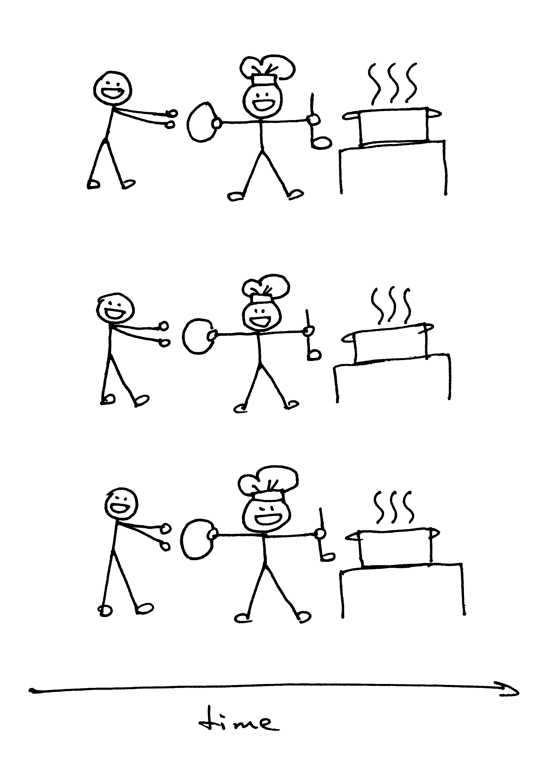
|
||
|
||
在 UNIX 系统中编写一个并发服务器最简单的方法,就是使用系统调用 `fork()`。
|
||
|
||
|
||
|
||
下面是全新出炉的并发服务器 `webserver3c.py` 的代码,它可以同时处理多个请求(和我们之前的例子 `webserver3b.py` 一样,每个子进程都会休眠 60 秒):
|
||
|
||

|
||
|
||
```
|
||
#######################################################
|
||
# 并发服务器 - webserver3c.py #
|
||
# #
|
||
# 使用 Python 2.7.9 或 3.4 #
|
||
# 在 Ubuntu 14.04 及 Mac OS X 环境下测试通过 #
|
||
# #
|
||
# - 完成客户端请求处理之后,子进程会休眠 60 秒 #
|
||
# - 父子进程会关闭重复的描述符 #
|
||
# #
|
||
#######################################################
|
||
import os
|
||
import socket
|
||
import time
|
||
|
||
SERVER_ADDRESS = (HOST, PORT) = '', 8888
|
||
REQUEST_QUEUE_SIZE = 5
|
||
|
||
|
||
def handle_request(client_connection):
|
||
request = client_connection.recv(1024)
|
||
print(
|
||
'Child PID: {pid}. Parent PID {ppid}'.format(
|
||
pid=os.getpid(),
|
||
ppid=os.getppid(),
|
||
)
|
||
)
|
||
print(request.decode())
|
||
http_response = b"""\
|
||
HTTP/1.1 200 OK
|
||
|
||
Hello, World!
|
||
"""
|
||
client_connection.sendall(http_response)
|
||
time.sleep(60)
|
||
|
||
|
||
def serve_forever():
|
||
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
||
listen_socket.bind(SERVER_ADDRESS)
|
||
listen_socket.listen(REQUEST_QUEUE_SIZE)
|
||
print('Serving HTTP on port {port} ...'.format(port=PORT))
|
||
print('Parent PID (PPID): {pid}\n'.format(pid=os.getpid()))
|
||
|
||
while True:
|
||
client_connection, client_address = listen_socket.accept()
|
||
pid = os.fork()
|
||
if pid == 0: ### 子进程
|
||
listen_socket.close() ### 关闭子进程中复制的套接字对象
|
||
handle_request(client_connection)
|
||
client_connection.close()
|
||
os._exit(0) ### 子进程在这里退出
|
||
else: ### 父进程
|
||
client_connection.close() ### 关闭父进程中的客户端连接对象,并循环执行
|
||
|
||
if __name__ == '__main__':
|
||
serve_forever()
|
||
```
|
||
|
||
在深入研究代码、讨论 `fork` 如何工作之前,先尝试运行它,自己看一看这个服务器是否真的可以同时处理多个客户端请求,而不是像轮询服务器 `webserver3a.py` 和 `webserver3b.py` 一样。在命令行中使用如下命令启动服务器:
|
||
|
||
```
|
||
$ python webserver3c.py
|
||
```
|
||
|
||
然后,像我们之前测试轮询服务器那样,运行两个 `curl` 命令,来看看这次的效果。现在你可以看到,即使子进程在处理客户端请求后会休眠 60 秒,但它并不会影响其它客户端连接,因为他们都是由完全独立的进程来处理的。你应该看到你的 `curl` 命令立即输出了“Hello, World!”然后挂起 60 秒。你可以按照你的想法运行尽可能多的 `curl` 命令(好吧,并不能运行特别特别多 `^_^`),所有的命令都会立刻输出来自服务器的响应 “Hello, World!”,并不会出现任何可被察觉到的延迟行为。试试看吧。
|
||
|
||
如果你要理解 `fork()`,那最重要的一点是:**你调用了它一次,但是它会返回两次** —— 一次在父进程中,另一次是在子进程中。当你创建了一个新进程,那么 `fork()` 在子进程中的返回值是 0。如果是在父进程中,那 `fork()` 函数会返回子进程的 PID。
|
||
|
||
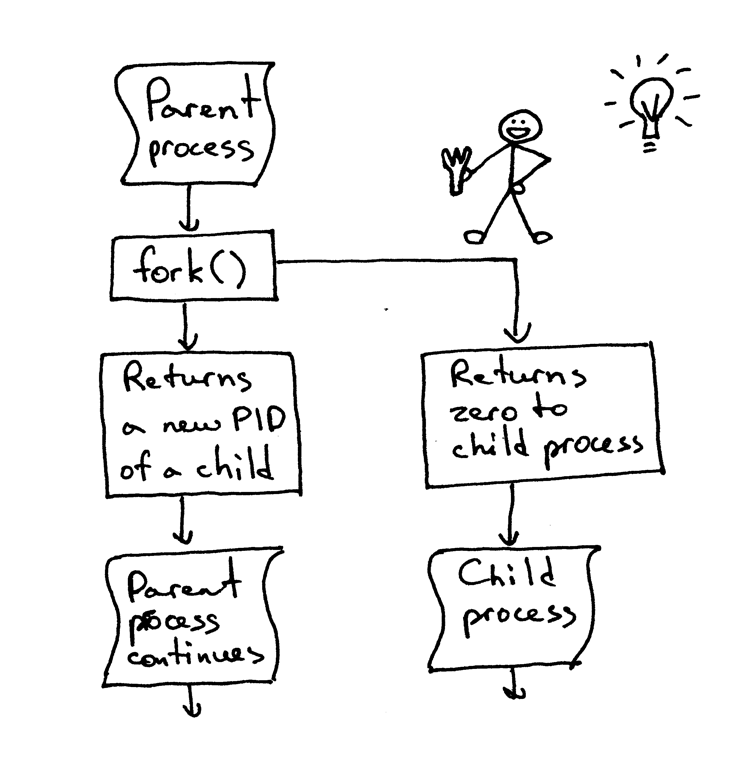
|
||
|
||
我依然记得在第一次看到它并尝试使用 `fork()` 的时候,我是多么的入迷。它在我眼里就像是魔法一样。这就好像我在读一段顺序执行的代码,然后“砰!”地一声,代码变成了两份,然后出现了两个实体,同时并行地运行相同的代码。讲真,那个时候我觉得它真的跟魔法一样神奇。
|
||
|
||
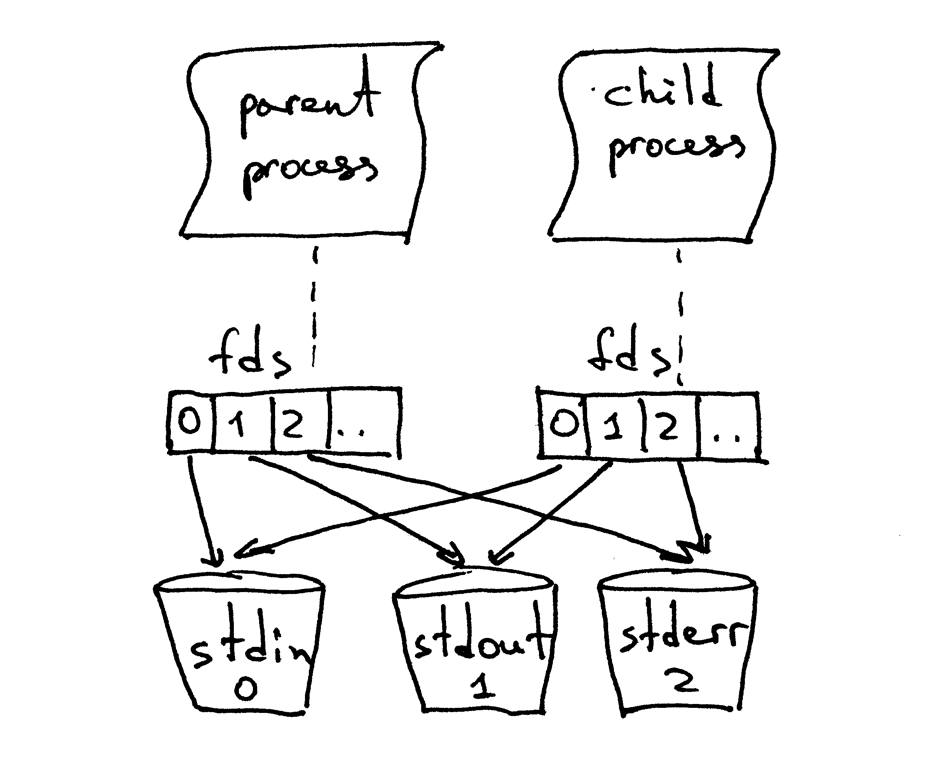
当父进程创建出一个新的子进程时,子进程会复制从父进程中复制一份文件描述符:
|
||
|
||
|
||
|
||
你可能注意到,在上面的代码中,父进程关闭了客户端连接:
|
||
|
||
```
|
||
else: ### parent
|
||
client_connection.close() # close parent copy and loop over
|
||
```
|
||
|
||
不过,既然父进程关闭了这个套接字,那为什么子进程仍然能够从来自客户端的套接字中读取数据呢?答案就在上面的图片中。内核会使用描述符引用计数器来决定是否要关闭一个套接字。当你的服务器创建一个子进程时,子进程会复制父进程的所有文件描述符,内核中该描述符的引用计数也会增加。如果只有一个父进程及一个子进程,那客户端套接字的文件描述符引用数应为 2;当父进程关闭客户端连接的套接字时,内核只会减少它的引用计数,将其变为 1,但这仍然不会使内核关闭该套接字。子进程也关闭了父进程中 `listen_socket` 的复制实体,因为子进程不需要关注新的客户端连接,而只需要处理已建立的客户端连接中的请求。
|
||
|
||
```
|
||
listen_socket.close() ### 关闭子进程中的复制实体
|
||
```
|
||
|
||
我们将会在后文中讨论,如果你不关闭那些重复的描述符,会发生什么。
|
||
|
||
你可以从你的并发服务器源码中看到,父进程的主要职责为:接受一个新的客户端连接,复制出一个子进程来处理这个连接,然后继续循环来接受另外的客户端连接,仅此而已。服务器父进程并不会处理客户端连接——子进程才会做这件事。
|
||
|
||
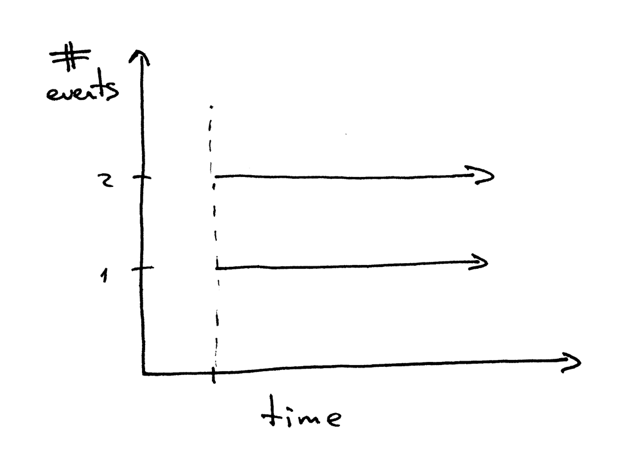
打个岔:当我们说两个事件并发执行时,我们所要表达的意思是什么?
|
||
|
||
|
||
|
||
当我们说“两个事件并发执行”时,它通常意味着这两个事件同时发生。简单来讲,这个定义没问题,但你应该记住它的严格定义:
|
||
|
||
> 如果你不能在代码中判断两个事件的发生顺序,那这两个事件就是并发执行的。(引自[《信号系统简明手册 (第二版): 并发控制深入浅出及常见错误》][5])
|
||
|
||
好的,现在你又该回顾一下你刚刚学过的知识点了。
|
||
|
||

|
||
|
||
- 在 Unix 中,编写一个并发服务器的最简单的方式——使用 `fork()` 系统调用;
|
||
- 当一个进程分叉(`fork`)出另一个进程时,它会变成刚刚分叉出的进程的父进程;
|
||
- 在进行 `fork` 调用后,父进程和子进程共享相同的文件描述符;
|
||
- 系统内核通过描述符的引用计数来决定是否要关闭该描述符对应的文件或套接字;
|
||
- 服务器父进程的主要职责:现在它做的只是从客户端接受一个新的连接,分叉出子进程来处理这个客户端连接,然后开始下一轮循环,去接收新的客户端连接。
|
||
|
||
### 进程分叉后不关闭重复的套接字会发生什么?
|
||
|
||
我们来看看,如果我们不在父进程与子进程中关闭重复的套接字描述符会发生什么。下面是刚才的并发服务器代码的修改版本,这段代码(`webserver3d.py` 中,服务器不会关闭重复的描述符):
|
||
|
||
```
|
||
#######################################################
|
||
# 并发服务器 - webserver3d.py #
|
||
# #
|
||
# 使用 Python 2.7.9 或 3.4 #
|
||
# 在 Ubuntu 14.04 及 Mac OS X 环境下测试通过 #
|
||
#######################################################
|
||
import os
|
||
import socket
|
||
|
||
SERVER_ADDRESS = (HOST, PORT) = '', 8888
|
||
REQUEST_QUEUE_SIZE = 5
|
||
|
||
|
||
def handle_request(client_connection):
|
||
request = client_connection.recv(1024)
|
||
http_response = b"""\
|
||
HTTP/1.1 200 OK
|
||
|
||
Hello, World!
|
||
"""
|
||
client_connection.sendall(http_response)
|
||
|
||
|
||
def serve_forever():
|
||
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
||
listen_socket.bind(SERVER_ADDRESS)
|
||
listen_socket.listen(REQUEST_QUEUE_SIZE)
|
||
print('Serving HTTP on port {port} ...'.format(port=PORT))
|
||
|
||
clients = []
|
||
while True:
|
||
client_connection, client_address = listen_socket.accept()
|
||
### 将引用存储起来,否则在下一轮循环时,他们会被垃圾回收机制销毁
|
||
clients.append(client_connection)
|
||
pid = os.fork()
|
||
if pid == 0: ### 子进程
|
||
listen_socket.close() ### 关闭子进程中多余的套接字
|
||
handle_request(client_connection)
|
||
client_connection.close()
|
||
os._exit(0) ### 子进程在这里结束
|
||
else: ### 父进程
|
||
# client_connection.close()
|
||
print(len(clients))
|
||
|
||
if __name__ == '__main__':
|
||
serve_forever()
|
||
```
|
||
|
||
用以下命令来启动服务器:
|
||
|
||
```
|
||
$ python webserver3d.py
|
||
```
|
||
|
||
用 `curl` 命令连接服务器:
|
||
|
||
```
|
||
$ curl http://localhost:8888/hello
|
||
Hello, World!
|
||
```
|
||
|
||
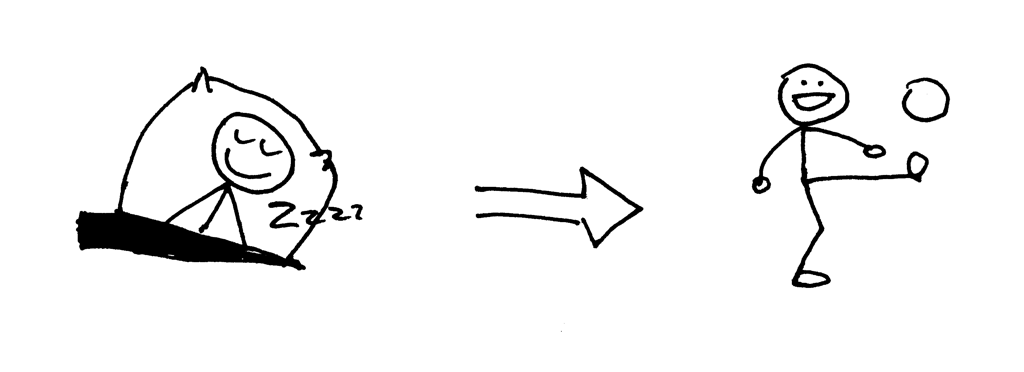
好,`curl` 命令输出了来自并发服务器的响应内容,但程序并没有退出,而是仍然挂起。到底发生了什么?这个服务器并不会挂起 60 秒:子进程只处理客户端连接,关闭连接然后退出,但客户端的 `curl` 命令并没有终止。
|
||
|
||
|
||
|
||
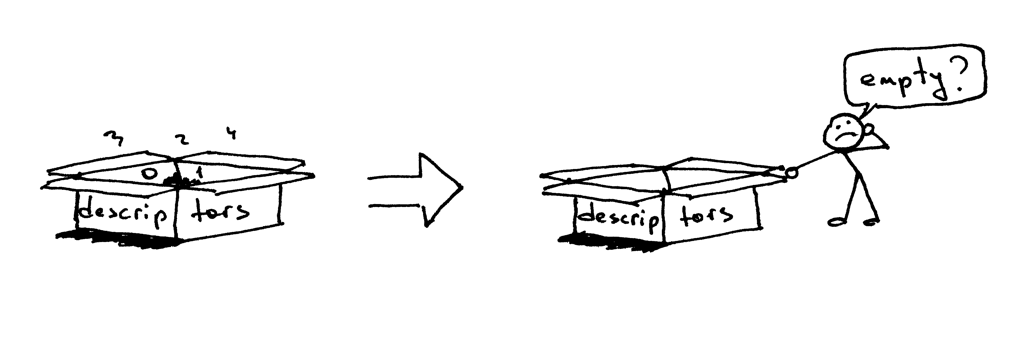
所以,为什么 `curl` 不终止呢?原因就在于文件描述符的副本。当子进程关闭客户端连接时,系统内核会减少客户端套接字的引用计数,将其变为 1。服务器子进程退出了,但客户端套接字并没有被内核关闭,因为该套接字的描述符引用计数并没有变为 0,所以,这就导致了连接终止包(在 TCP/IP 协议中称作 `FIN`)不会被发送到客户端,所以客户端会一直保持连接。这里也会出现另一个问题:如果你的服务器长时间运行,并且不关闭文件描述符的副本,那么可用的文件描述符会被消耗殆尽:
|
||
|
||
|
||
|
||
使用 `Control-C` 关闭服务器 `webserver3d.py`,然后在 shell 中使用内置命令 `ulimit` 来查看系统默认为你的服务器进程分配的可用资源数:
|
||
|
||
```
|
||
$ ulimit -a
|
||
core file size (blocks, -c) 0
|
||
data seg size (kbytes, -d) unlimited
|
||
scheduling priority (-e) 0
|
||
file size (blocks, -f) unlimited
|
||
pending signals (-i) 3842
|
||
max locked memory (kbytes, -l) 64
|
||
max memory size (kbytes, -m) unlimited
|
||
open files (-n) 1024
|
||
pipe size (512 bytes, -p) 8
|
||
POSIX message queues (bytes, -q) 819200
|
||
real-time priority (-r) 0
|
||
stack size (kbytes, -s) 8192
|
||
cpu time (seconds, -t) unlimited
|
||
max user processes (-u) 3842
|
||
virtual memory (kbytes, -v) unlimited
|
||
file locks (-x) unlimited
|
||
```
|
||
|
||
你可以从上面的结果看到,在我的 Ubuntu 机器中,系统为我的服务器进程分配的最大可用文件描述符(文件打开)数为 1024。
|
||
|
||
现在我们来看一看,如果你的服务器不关闭重复的描述符,它会如何消耗可用的文件描述符。在一个已有的或新建的终端窗口中,将你的服务器进程的最大可用文件描述符设为 256:
|
||
|
||
```
|
||
$ ulimit -n 256
|
||
```
|
||
|
||
在你刚刚运行 `ulimit -n 256` 的终端窗口中运行服务器 `webserver3d.py`:
|
||
|
||
```
|
||
$ python webserver3d.py
|
||
```
|
||
|
||
然后使用下面的客户端 `client3.py` 来测试你的服务器。
|
||
|
||
```
|
||
#######################################################
|
||
# 测试客户端 - client3.py #
|
||
# #
|
||
# 使用 Python 2.7.9 或 3.4 #
|
||
# 在 Ubuntu 14.04 及 Mac OS X 环境下测试通过 #
|
||
#######################################################
|
||
import argparse
|
||
import errno
|
||
import os
|
||
import socket
|
||
|
||
|
||
SERVER_ADDRESS = 'localhost', 8888
|
||
REQUEST = b"""\
|
||
GET /hello HTTP/1.1
|
||
Host: localhost:8888
|
||
|
||
"""
|
||
|
||
|
||
def main(max_clients, max_conns):
|
||
socks = []
|
||
for client_num in range(max_clients):
|
||
pid = os.fork()
|
||
if pid == 0:
|
||
for connection_num in range(max_conns):
|
||
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||
sock.connect(SERVER_ADDRESS)
|
||
sock.sendall(REQUEST)
|
||
socks.append(sock)
|
||
print(connection_num)
|
||
os._exit(0)
|
||
|
||
|
||
if __name__ == '__main__':
|
||
parser = argparse.ArgumentParser(
|
||
description='Test client for LSBAWS.',
|
||
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
|
||
)
|
||
parser.add_argument(
|
||
'--max-conns',
|
||
type=int,
|
||
default=1024,
|
||
help='Maximum number of connections per client.'
|
||
)
|
||
parser.add_argument(
|
||
'--max-clients',
|
||
type=int,
|
||
default=1,
|
||
help='Maximum number of clients.'
|
||
)
|
||
args = parser.parse_args()
|
||
main(args.max_clients, args.max_conns)
|
||
```
|
||
|
||
在一个新建的终端窗口中,运行 `client3.py` 然后让它与服务器同步创建 300 个连接:
|
||
|
||
```
|
||
$ python client3.py --max-clients=300
|
||
```
|
||
|
||
过一会,你的服务器进程就该爆了。这是我的环境中出现的异常截图:
|
||
|
||
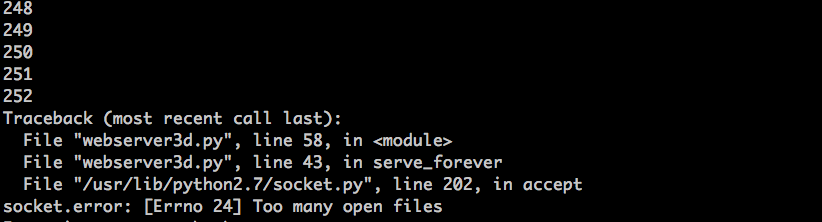
|
||
|
||
这个例子很明显——你的服务器应该关闭描述符副本。
|
||
|
||
#### 僵尸进程
|
||
|
||
但是,即使你关闭了描述符副本,你依然没有摆脱险境,因为你的服务器还有一个问题,这个问题在于“僵尸(zombies)”!
|
||
|
||
|
||
|
||
没错,这个服务器代码确实在制造僵尸进程。我们来看看怎么回事。重新运行你的服务器:
|
||
|
||
```
|
||
$ python webserver3d.py
|
||
```
|
||
|
||
在另一个终端窗口中运行以下 `curl` 命令:
|
||
|
||
```
|
||
$ curl http://localhost:8888/hello
|
||
```
|
||
|
||
现在,运行 `ps` 环境,来查看正在运行的 Python 进程。下面是我的环境中 `ps` 的运行结果:
|
||
|
||
```
|
||
$ ps auxw | grep -i python | grep -v grep
|
||
vagrant 9099 0.0 1.2 31804 6256 pts/0 S+ 16:33 0:00 python webserver3d.py
|
||
vagrant 9102 0.0 0.0 0 0 pts/0 Z+ 16:33 0:00 [python] <defunct>
|
||
```
|
||
|
||
你看到第二行中,pid 为 9102,状态为 `Z+`,名字里面有个 `<defunct>` 的进程了吗?那就是我们的僵尸进程。这个僵尸进程的问题在于:你无法将它杀掉!
|
||
|
||
|
||
|
||
就算你尝试使用 `kill -9` 来杀死僵尸进程,它们仍旧会存活。自己试试看,看看结果。
|
||
|
||
这个僵尸到底是什么,为什么我们的服务器会造出它们呢?一个僵尸进程(zombie)是一个已经结束的进程,但它的父进程并没有等待(`waited`)它结束,并且也没有收到它的终结状态。如果一个进程在父进程退出之前退出,系统内核会把它变为一个僵尸进程,存储它的部分信息,以便父进程读取。内核保存的进程信息通常包括进程 ID、进程终止状态,以及进程的资源占用情况。OK,所以僵尸进程确实有存在的意义,但如果服务器不管这些僵尸进程,你的系统将会被壅塞。我们来看看这个会如何发生。首先,关闭你运行的服务器;然后,在一个新的终端窗口中,使用 `ulimit` 命令将最大用户进程数设为 400(同时,要确保你的最大可用描述符数大于这个数字,我们在这里设为 500):
|
||
|
||
```
|
||
$ ulimit -u 400
|
||
$ ulimit -n 500
|
||
```
|
||
|
||
在你刚刚运行 `ulimit -u 400` 命令的终端中,运行服务器 `webserver3d.py`:
|
||
|
||
```
|
||
$ python webserver3d.py
|
||
```
|
||
|
||
在一个新的终端窗口中,运行 `client3.py`,并且让它与服务器同时创建 500 个连接:
|
||
|
||
```
|
||
$ python client3.py --max-clients=500
|
||
```
|
||
|
||
然后,过一会,你的服务器进程应该会再次爆了,它会在创建新进程时抛出一个 `OSError: 资源暂时不可用` 的异常。但它并没有达到系统允许的最大进程数。这是我的环境中输出的异常信息截图:
|
||
|
||
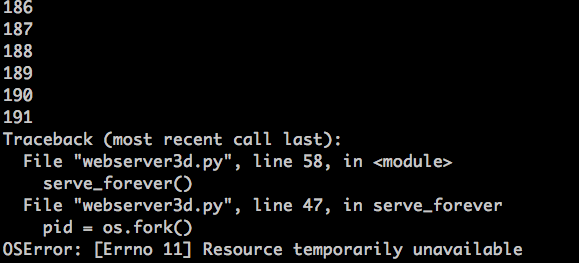
|
||
|
||
你可以看到,如果服务器不管僵尸进程,它们会引发问题。接下来我会简单探讨一下僵尸进程问题的解决方案。
|
||
|
||
我们来回顾一下你刚刚掌握的知识点:
|
||
|
||

|
||
|
||
- 如果你不关闭文件描述符副本,客户端就不会在请求处理完成后终止,因为客户端连接没有被关闭;
|
||
- 如果你不关闭文件描述符副本,长久运行的服务器最终会把可用的文件描述符(最大文件打开数)消耗殆尽;
|
||
- 当你创建一个新进程,而父进程不等待(`wait`)子进程,也不在子进程结束后收集它的终止状态,它会变为一个僵尸进程;
|
||
- 僵尸通常都会吃东西,在我们的例子中,僵尸进程会吃掉资源。如果你的服务器不管僵尸进程,它最终会消耗掉所有的可用进程(最大用户进程数);
|
||
- 你不能杀死(`kill`)僵尸进程,你需要等待(`wait`)它。
|
||
|
||
### 如何处理僵尸进程?
|
||
|
||
所以,你需要做什么来处理僵尸进程呢?你需要修改你的服务器代码,来等待(`wait`)僵尸进程,并收集它们的终止信息。你可以在代码中使用系统调用 `wait` 来完成这个任务。不幸的是,这个方法离理想目标还很远,因为在没有终止的子进程存在的情况下调用 `wait` 会导致服务器进程阻塞,这会阻碍你的服务器处理新的客户端连接请求。那么,我们有其他选择吗?嗯,有的,其中一个解决方案需要结合信号处理以及 `wait` 系统调用。
|
||
|
||

|
||
|
||
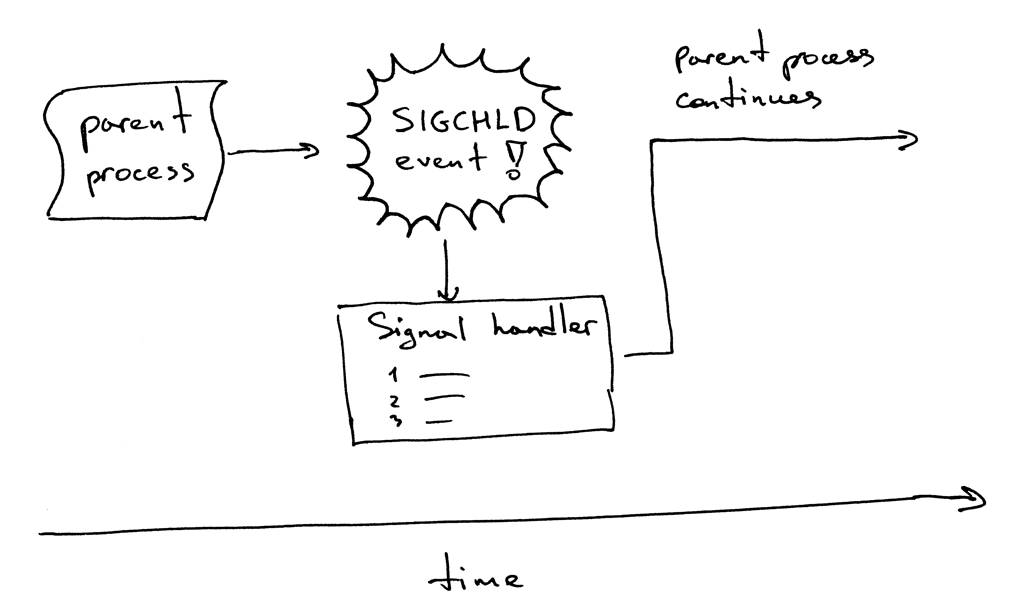
这是它的工作流程。当一个子进程退出时,内核会发送 `SIGCHLD` 信号。父进程可以设置一个信号处理器,它可以异步响应 `SIGCHLD` 信号,并在信号响应函数中等待(`wait`)子进程收集终止信息,从而阻止了僵尸进程的存在。
|
||
|
||
|
||
|
||
顺便说一下,异步事件意味着父进程无法提前知道事件的发生时间。
|
||
|
||
修改你的服务器代码,设置一个 `SIGCHLD` 信号处理器,在信号处理器中等待(`wait`)终止的子进程。修改后的代码如下(webserver3e.py):
|
||
|
||
```
|
||
#######################################################
|
||
# 并发服务器 - webserver3e.py #
|
||
# #
|
||
# 使用 Python 2.7.9 或 3.4 #
|
||
# 在 Ubuntu 14.04 及 Mac OS X 环境下测试通过 #
|
||
#######################################################
|
||
import os
|
||
import signal
|
||
import socket
|
||
import time
|
||
|
||
SERVER_ADDRESS = (HOST, PORT) = '', 8888
|
||
REQUEST_QUEUE_SIZE = 5
|
||
|
||
|
||
def grim_reaper(signum, frame):
|
||
pid, status = os.wait()
|
||
print(
|
||
'Child {pid} terminated with status {status}'
|
||
'\n'.format(pid=pid, status=status)
|
||
)
|
||
|
||
|
||
def handle_request(client_connection):
|
||
request = client_connection.recv(1024)
|
||
print(request.decode())
|
||
http_response = b"""\
|
||
HTTP/1.1 200 OK
|
||
|
||
Hello, World!
|
||
"""
|
||
client_connection.sendall(http_response)
|
||
### 挂起进程,来允许父进程完成循环,并在 "accept" 处阻塞
|
||
time.sleep(3)
|
||
|
||
|
||
def serve_forever():
|
||
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
||
listen_socket.bind(SERVER_ADDRESS)
|
||
listen_socket.listen(REQUEST_QUEUE_SIZE)
|
||
print('Serving HTTP on port {port} ...'.format(port=PORT))
|
||
|
||
signal.signal(signal.SIGCHLD, grim_reaper)
|
||
|
||
while True:
|
||
client_connection, client_address = listen_socket.accept()
|
||
pid = os.fork()
|
||
if pid == 0: ### 子进程
|
||
listen_socket.close() ### 关闭子进程中多余的套接字
|
||
handle_request(client_connection)
|
||
client_connection.close()
|
||
os._exit(0)
|
||
else: ### 父进程
|
||
client_connection.close()
|
||
|
||
if __name__ == '__main__':
|
||
serve_forever()
|
||
```
|
||
|
||
运行服务器:
|
||
|
||
```
|
||
$ python webserver3e.py
|
||
```
|
||
|
||
使用你的老朋友——`curl` 命令来向修改后的并发服务器发送一个请求:
|
||
|
||
```
|
||
$ curl http://localhost:8888/hello
|
||
```
|
||
|
||
再来看看服务器:
|
||
|
||
|
||
|
||
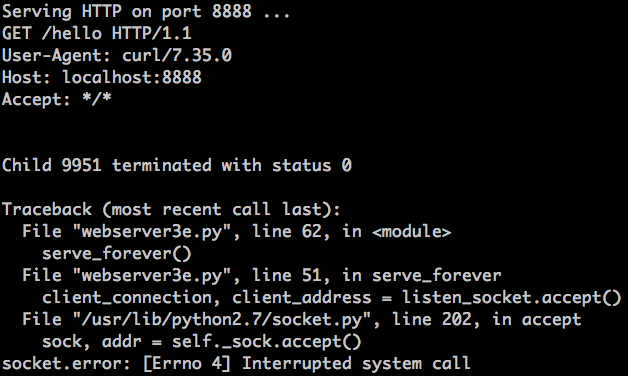
刚刚发生了什么?`accept` 调用失败了,错误信息为 `EINTR`。
|
||
|
||

|
||
|
||
当子进程退出并触发 `SIGCHLD` 事件时,父进程的 `accept` 调用被阻塞了,系统转去运行信号处理器,当信号处理函数完成时,`accept` 系统调用被打断:
|
||
|
||
|
||
|
||
别担心,这个问题很好解决。你只需要重新运行 `accept` 系统调用即可。这是修改后的服务器代码 `webserver3f.py`,它可以解决这个问题:
|
||
|
||
|
||
```
|
||
#######################################################
|
||
# 并发服务器 - webserver3f.py #
|
||
# #
|
||
# 使用 Python 2.7.9 或 3.4 #
|
||
# 在 Ubuntu 14.04 及 Mac OS X 环境下测试通过 #
|
||
#######################################################
|
||
import errno
|
||
import os
|
||
import signal
|
||
import socket
|
||
|
||
SERVER_ADDRESS = (HOST, PORT) = '', 8888
|
||
REQUEST_QUEUE_SIZE = 1024
|
||
|
||
|
||
def grim_reaper(signum, frame):
|
||
pid, status = os.wait()
|
||
|
||
|
||
def handle_request(client_connection):
|
||
request = client_connection.recv(1024)
|
||
print(request.decode())
|
||
http_response = b"""\
|
||
HTTP/1.1 200 OK
|
||
|
||
Hello, World!
|
||
"""
|
||
client_connection.sendall(http_response)
|
||
|
||
|
||
def serve_forever():
|
||
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
||
listen_socket.bind(SERVER_ADDRESS)
|
||
listen_socket.listen(REQUEST_QUEUE_SIZE)
|
||
print('Serving HTTP on port {port} ...'.format(port=PORT))
|
||
|
||
signal.signal(signal.SIGCHLD, grim_reaper)
|
||
|
||
while True:
|
||
try:
|
||
client_connection, client_address = listen_socket.accept()
|
||
except IOError as e:
|
||
code, msg = e.args
|
||
### 若 'accept' 被打断,那么重启它
|
||
if code == errno.EINTR:
|
||
continue
|
||
else:
|
||
raise
|
||
|
||
pid = os.fork()
|
||
if pid == 0: ### 子进程
|
||
listen_socket.close() ### 关闭子进程中多余的描述符
|
||
handle_request(client_connection)
|
||
client_connection.close()
|
||
os._exit(0)
|
||
else: ### 父进程
|
||
client_connection.close() ### 关闭父进程中多余的描述符,继续下一轮循环
|
||
|
||
|
||
if __name__ == '__main__':
|
||
serve_forever()
|
||
```
|
||
|
||
运行更新后的服务器 `webserver3f.py`:
|
||
|
||
```
|
||
$ python webserver3f.py
|
||
```
|
||
|
||
用 `curl` 来向更新后的并发服务器发送一个请求:
|
||
|
||
```
|
||
$ curl http://localhost:8888/hello
|
||
```
|
||
|
||
看到了吗?没有 EINTR 异常出现了。现在检查一下,确保没有僵尸进程存活,调用 `wait` 函数的 `SIGCHLD` 信号处理器能够正常处理被终止的子进程。我们只需使用 `ps` 命令,然后看看现在没有处于 `Z+` 状态(或名字包含 `<defunct>` )的 Python 进程就好了。很棒!僵尸进程没有了,我们很安心。
|
||
|
||

|
||
|
||
- 如果你创建了一个子进程,但是不等待它,它就会变成一个僵尸进程;
|
||
- 使用 `SIGCHLD` 信号处理器可以异步地等待子进程终止,并收集其终止状态;
|
||
- 当使用事件处理器时,你需要牢记,系统调用可能会被打断,所以你需要处理这种情况发生时带来的异常。
|
||
|
||
#### 正确处理 SIGCHLD 信号
|
||
|
||
好的,一切顺利。是不是没问题了?额,几乎是。重新尝试运行 `webserver3f.py` 但我们这次不会只发送一个请求,而是同步创建 128 个连接:
|
||
|
||
```
|
||
$ python client3.py --max-clients 128
|
||
```
|
||
|
||
现在再次运行 `ps` 命令:
|
||
|
||
```
|
||
$ ps auxw | grep -i python | grep -v grep
|
||
```
|
||
|
||
看到了吗?天啊,僵尸进程又出来了!
|
||
|
||

|
||
|
||
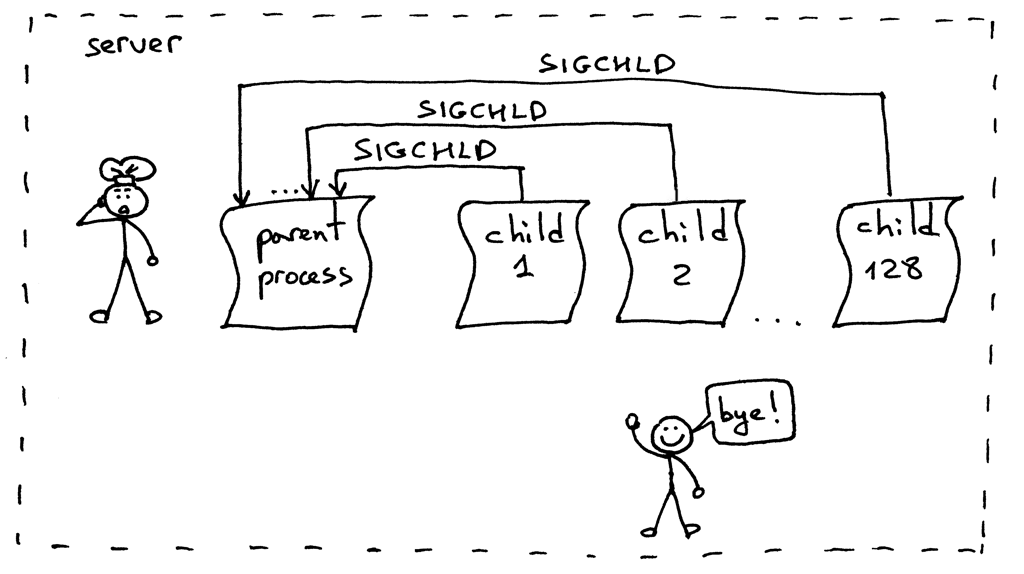
这回怎么回事?当你同时运行 128 个客户端,建立 128 个连接时,服务器的子进程几乎会在同一时间处理好你的请求,然后退出。这会导致非常多的 `SIGCHLD` 信号被发送到父进程。问题在于,这些信号不会存储在队列中,所以你的服务器进程会错过很多信号,这也就导致了几个僵尸进程处于无主状态:
|
||
|
||
|
||
|
||
这个问题的解决方案依然是设置 `SIGCHLD` 事件处理器。但我们这次将会用 `WNOHANG` 参数循环调用 `waitpid` 来替代 `wait`,以保证所有处于终止状态的子进程都会被处理。下面是修改后的代码,`webserver3g.py`:
|
||
|
||
```
|
||
#######################################################
|
||
# 并发服务器 - webserver3g.py #
|
||
# #
|
||
# 使用 Python 2.7.9 或 3.4 #
|
||
# 在 Ubuntu 14.04 及 Mac OS X 环境下测试通过 #
|
||
#######################################################
|
||
import errno
|
||
import os
|
||
import signal
|
||
import socket
|
||
|
||
SERVER_ADDRESS = (HOST, PORT) = '', 8888
|
||
REQUEST_QUEUE_SIZE = 1024
|
||
|
||
|
||
def grim_reaper(signum, frame):
|
||
while True:
|
||
try:
|
||
pid, status = os.waitpid(
|
||
-1, ### 等待所有子进程
|
||
os.WNOHANG ### 无终止进程时,不阻塞进程,并抛出 EWOULDBLOCK 错误
|
||
)
|
||
except OSError:
|
||
return
|
||
|
||
if pid == 0: ### 没有僵尸进程存在了
|
||
return
|
||
|
||
|
||
def handle_request(client_connection):
|
||
request = client_connection.recv(1024)
|
||
print(request.decode())
|
||
http_response = b"""\
|
||
HTTP/1.1 200 OK
|
||
|
||
Hello, World!
|
||
"""
|
||
client_connection.sendall(http_response)
|
||
|
||
|
||
def serve_forever():
|
||
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
||
listen_socket.bind(SERVER_ADDRESS)
|
||
listen_socket.listen(REQUEST_QUEUE_SIZE)
|
||
print('Serving HTTP on port {port} ...'.format(port=PORT))
|
||
|
||
signal.signal(signal.SIGCHLD, grim_reaper)
|
||
|
||
while True:
|
||
try:
|
||
client_connection, client_address = listen_socket.accept()
|
||
except IOError as e:
|
||
code, msg = e.args
|
||
### 若 'accept' 被打断,那么重启它
|
||
if code == errno.EINTR:
|
||
continue
|
||
else:
|
||
raise
|
||
|
||
pid = os.fork()
|
||
if pid == 0: ### 子进程
|
||
listen_socket.close() ### 关闭子进程中多余的描述符
|
||
handle_request(client_connection)
|
||
client_connection.close()
|
||
os._exit(0)
|
||
else: ### 父进程
|
||
client_connection.close() ### 关闭父进程中多余的描述符,继续下一轮循环
|
||
|
||
if __name__ == '__main__':
|
||
serve_forever()
|
||
```
|
||
|
||
运行服务器:
|
||
|
||
```
|
||
$ python webserver3g.py
|
||
```
|
||
|
||
使用测试客户端 `client3.py`:
|
||
|
||
```
|
||
$ python client3.py --max-clients 128
|
||
```
|
||
|
||
现在来查看一下,确保没有僵尸进程存在。耶!没有僵尸的生活真美好 `^_^`。
|
||
|
||

|
||
|
||
### 大功告成
|
||
|
||
恭喜!你刚刚经历了一段很长的旅程,我希望你能够喜欢它。现在你拥有了自己的简易并发服务器,并且这段代码能够为你在继续研究生产级 Web 服务器的路上奠定基础。
|
||
|
||
我将会留一个作业:你需要将第二部分中的 WSGI 服务器升级,将它改造为一个并发服务器。你可以在[这里][12]找到更改后的代码。但是,当你实现了自己的版本之后,你才应该来看我的代码。你已经拥有了实现这个服务器所需的所有信息。所以,快去实现它吧 `^_^`。
|
||
|
||
然后要做什么呢?乔希·比林斯说过:
|
||
|
||
> “就像一枚邮票一样——专注于一件事,不达目的不罢休。”
|
||
|
||
开始学习基本知识。回顾你已经学过的知识。然后一步一步深入。
|
||
|
||
|
||
|
||
> “如果你只学会了方法,你将会被这些方法所困。但如果你学会了原理,那你就能发明出新的方法。”——拉尔夫·沃尔多·爱默生
|
||
|
||
下面是一份书单,我从这些书中提炼出了这篇文章所需的素材。他们能助你在我刚刚所述的几个方面中发掘出兼具深度和广度的知识。我极力推荐你们去搞到这几本书看看:从你的朋友那里借,在当地的图书馆中阅读,或者直接在亚马逊上把它买回来。下面是我的典藏秘籍:
|
||
|
||
1. [《UNIX 网络编程 卷1:套接字联网 API (第3版)》][6]
|
||
2. [《UNIX 环境高级编程(第3版)》][7]
|
||
3. [《Linux/UNIX 系统编程手册》][8]
|
||
4. [《TCP/IP 详解 卷1:协议(第2版)][9]
|
||
5. [《信号系统简明手册 (第二版): 并发控制深入浅出及常见错误》][10],这本书也可以从[作者的个人网站][11]中免费下载到。
|
||
|
||
顺便,我在撰写一本名为《搭个 Web 服务器:从头开始》的书。这本书讲解了如何从头开始编写一个基本的 Web 服务器,里面包含本文中没有的更多细节。订阅[原文下方的邮件列表][13],你就可以获取到这本书的最新进展,以及发布日期。
|
||
|
||
--------------------------------------------------------------------------------
|
||
|
||
via: https://ruslanspivak.com/lsbaws-part3/
|
||
|
||
作者:[Ruslan][a]
|
||
译者:[StdioA](https://github.com/StdioA)
|
||
校对:[wxy](https://github.com/wxy)
|
||
|
||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||
|
||
[a]: https://github.com/rspivak/
|
||
|
||
[1]: https://github.com/rspivak/lsbaws/blob/master/part3/
|
||
[2]: https://github.com/rspivak/lsbaws/blob/master/part3/webserver3a.py
|
||
[3]: https://github.com/rspivak/lsbaws/blob/master/part3/webserver3b.py
|
||
[4]: http://www.epubit.com.cn/book/details/1692
|
||
[5]: http://www.amazon.com/gp/product/1441418687/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=1441418687&linkCode=as2&tag=russblo0b-20&linkId=QFOAWARN62OWTWUG
|
||
[6]: http://www.epubit.com.cn/book/details/1692
|
||
[7]: http://www.epubit.com.cn/book/details/1625
|
||
[8]: http://www.epubit.com.cn/book/details/1432
|
||
[9]: http://www.epubit.com.cn/book/details/4232
|
||
[10]: http://www.amazon.com/gp/product/1441418687/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=1441418687&linkCode=as2&tag=russblo0b-20&linkId=QFOAWARN62OWTWUG
|
||
[11]: http://greenteapress.com/semaphores/
|
||
[12]: https://github.com/rspivak/lsbaws/blob/master/part3/webserver3h.py
|
||
[13]: https://ruslanspivak.com/lsbaws-part1/ |