12 KiB
页面缓存、内存和文件之间的那些事
上一篇文章中我们学习了内核怎么为一个用户进程 管理虚拟内存,而没有提及文件和 I/O。这一篇文章我们将专门去讲这个重要的主题 —— 页面缓存。文件和内存之间的关系常常很不好去理解,而它们对系统性能的影响却是非常大的。
在面对文件时,有两个很重要的问题需要操作系统去解决。第一个是相对内存而言,慢的让人发狂的硬盘驱动器,尤其是磁盘寻道。第二个是需要将文件内容一次性地加载到物理内存中,以便程序间共享文件内容。如果你在 Windows 中使用 进程浏览器 去查看它的进程,你将会看到每个进程中加载了大约 ~15MB 的公共 DLL。我的 Windows 机器上现在大约运行着 100 个进程,因此,如果不共享的话,仅这些公共的 DLL 就要使用高达 ~1.5 GB 的物理内存。如果是那样的话,那就太糟糕了。同样的,几乎所有的 Linux 进程都需要 ld.so 和 libc,加上其它的公共库,它们占用的内存数量也不是一个小数目。
幸运的是,这两个问题都用一个办法解决了:页面缓存 —— 保存在内存中的页面大小的文件块。为了用图去说明页面缓存,我捏造出一个名为 render 的 Linux 程序,它打开了文件 scene.dat,并且一次读取 512 字节,并将文件内容存储到一个分配到堆中的块上。第一次读取的过程如下:
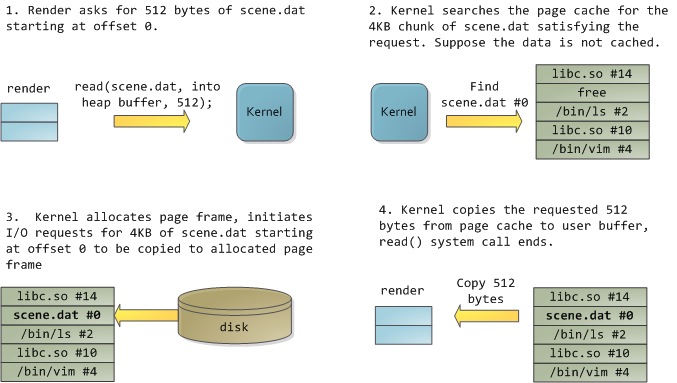
render请求scene.dat从位移 0 开始的 512 字节。- 内核搜寻页面缓存中
scene.dat的 4kb 块,以满足该请求。假设该数据没有缓存。 - 内核分配页面帧,初始化 I/O 请求,将
scend.dat从位移 0 开始的 4kb 复制到分配的页面帧。 - 内核从页面缓存复制请求的 512 字节到用户缓冲区,系统调用
read()结束。
读取完 12KB 的文件内容以后,render 程序的堆和相关的页面帧如下图所示:
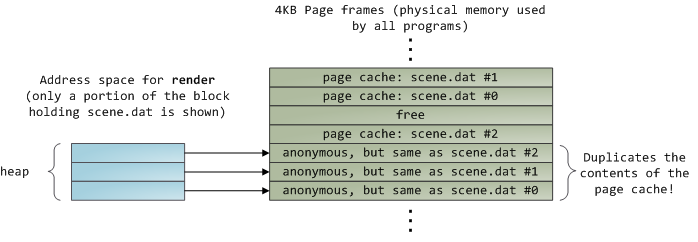
它看起来很简单,其实这一过程做了很多的事情。首先,虽然这个程序使用了普通的读取(read)调用,但是,已经有三个 4KB 的页面帧将文件 scene.dat 的一部分内容保存在了页面缓存中。虽然有时让人觉得很惊奇,但是,普通的文件 I/O 就是这样通过页面缓存来进行的。在 x86 架构的 Linux 中,内核将文件认为是一系列的 4KB 大小的块。如果你从文件中读取单个字节,包含这个字节的整个 4KB 块将被从磁盘中读入到页面缓存中。这是可以理解的,因为磁盘通常是持续吞吐的,并且程序一般也不会从磁盘区域仅仅读取几个字节。页面缓存知道文件中的每个 4KB 块的位置,在上图中用 #0、#1 等等来描述。Windows 使用 256KB 大小的视图,类似于 Linux 的页面缓存中的页面。
不幸的是,在一个普通的文件读取中,内核必须拷贝页面缓存中的内容到用户缓冲区中,它不仅花费 CPU 时间和影响 CPU 缓存,在复制数据时也浪费物理内存。如前面的图示,scene.dat 的内存被存储了两次,并且,程序中的每个实例都用另外的时间去存储内容。我们虽然解决了从磁盘中读取文件缓慢的问题,但是在其它的方面带来了更痛苦的问题。内存映射文件是解决这种痛苦的一个方法:
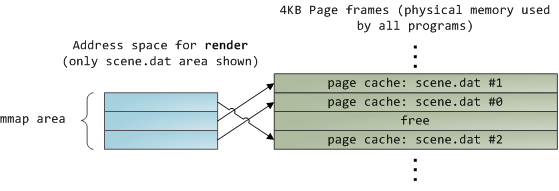
当你使用文件映射时,内核直接在页面缓存上映射你的程序的虚拟页面。这样可以显著提升性能:Windows 系统编程 报告指出,在相关的普通文件读取上运行时性能提升多达 30% ,在 Unix 环境中的高级编程 的报告中,文件映射在 Linux 和 Solaris 也有类似的效果。这取决于你的应用程序类型的不同,通过使用文件映射,可以节约大量的物理内存。
对高性能的追求是永恒不变的目标,测量是很重要的事情,内存映射应该是程序员始终要使用的工具。这个 API 提供了非常好用的实现方式,它允许你在内存中按字节去访问一个文件,而不需要为了这种好处而牺牲代码可读性。在一个类 Unix 的系统中,可以使用 mmap 查看你的 地址空间,在 Windows 中,可以使用 CreateFileMapping,或者在高级编程语言中还有更多的可用封装。当你映射一个文件内容时,它并不是一次性将全部内容都映射到内存中,而是通过 页面故障 来按需映射的。在 获取 需要的文件内容的页面帧后,页面故障句柄 映射你的虚拟页面 到页面缓存上。如果一开始文件内容没有缓存,这还将涉及到磁盘 I/O。
现在出现一个突发的状况,假设我们的 render 程序的最后一个实例退出了。在页面缓存中保存着 scene.dat 内容的页面要立刻释放掉吗?人们通常会如此考虑,但是,那样做并不是个好主意。你应该想到,我们经常在一个程序中创建一个文件,退出程序,然后,在第二个程序去使用这个文件。页面缓存正好可以处理这种情况。如果考虑更多的情况,内核为什么要清除页面缓存的内容?请记住,磁盘读取的速度要慢于内存 5 个数量级,因此,命中一个页面缓存是一件有非常大收益的事情。因此,只要有足够大的物理内存,缓存就应该保持全满。并且,这一原则适用于所有的进程。如果你现在运行 render 一周后, scene.dat 的内容还在缓存中,那么应该恭喜你!这就是什么内核缓存越来越大,直至达到最大限制的原因。它并不是因为操作系统设计的太“垃圾”而浪费你的内存,其实这是一个非常好的行为,因为,释放物理内存才是一种“浪费”。(LCTT 译注:释放物理内存会导致页面缓存被清除,下次运行程序需要的相关数据,需要再次从磁盘上进行读取,会“浪费” CPU 和 I/O 资源)最好的做法是尽可能多的使用缓存。
由于页面缓存架构的原因,当程序调用 write() 时,字节只是被简单地拷贝到页面缓存中,并将这个页面标记为“脏”页面。磁盘 I/O 通常并不会立即发生,因此,你的程序并不会被阻塞在等待磁盘写入上。副作用是,如果这时候发生了电脑死机,你的写入将不会完成,因此,对于至关重要的文件,像数据库事务日志,要求必须进行 fsync()(仍然还需要去担心磁盘控制器的缓存失败问题),另一方面,读取将被你的程序阻塞,直到数据可用为止。内核采取预加载的方式来缓解这个矛盾,它一般提前预读取几个页面并将它加载到页面缓存中,以备你后来的读取。在你计划进行一个顺序或者随机读取时(请查看 madvise()、readahead()、Windows 缓存提示 ),你可以通过提示帮助内核去调整这个预加载行为。Linux 会对内存映射的文件进行 预读取,但是我不确定 Windows 的行为。当然,在 Linux 中它可能会使用 O_DIRECT 跳过预读取,或者,在 Windows 中使用 NO_BUFFERING 去跳过预读,一些数据库软件就经常这么做。
一个文件映射可以是私有的,也可以是共享的。当然,这只是针对内存中内容的更新而言:在一个私有的内存映射上,更新并不会提交到磁盘或者被其它进程可见,然而,共享的内存映射,则正好相反,它的任何更新都会提交到磁盘上,并且对其它的进程可见。内核使用写时复制(CoW)机制,这是通过页面表条目(PTE)来实现这种私有的映射。在下面的例子中,render 和另一个被称为 render3d 的程序都私有映射到 scene.dat 上。然后 render 去写入映射的文件的虚拟内存区域:
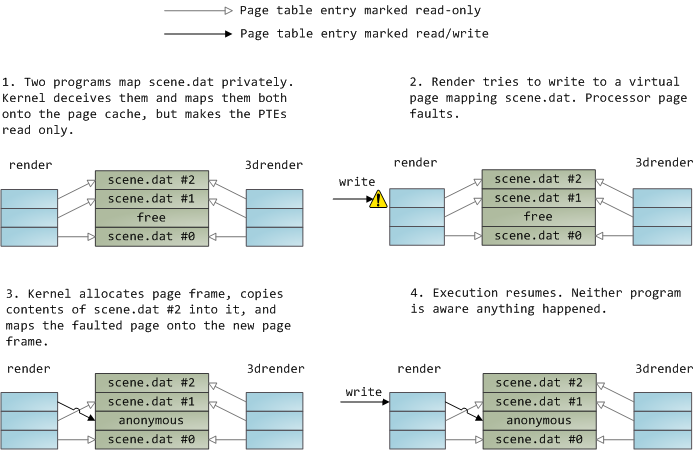
- 两个程序私有地映射
scene.dat,内核误导它们并将它们映射到页面缓存,但是使该页面表条目只读。 render试图写入到映射scene.dat的虚拟页面,处理器发生页面故障。- 内核分配页面帧,复制
scene.dat的第二块内容到其中,并映射故障的页面到新的页面帧。 - 继续执行。程序就当做什么都没发生。
上面展示的只读页面表条目并不意味着映射是只读的,它只是内核的一个用于共享物理内存的技巧,直到尽可能的最后一刻之前。你可以认为“私有”一词用的有点不太恰当,你只需要记住,这个“私有”仅用于更新的情况。这种设计的重要性在于,要想看到被映射的文件的变化,其它程序只能读取它的虚拟页面。一旦“写时复制”发生,从其它地方是看不到这种变化的。但是,内核并不能保证这种行为,因为它是在 x86 中实现的,从 API 的角度来看,这是有意义的。相比之下,一个共享的映射只是将它简单地映射到页面缓存上。更新会被所有的进程看到并被写入到磁盘上。最终,如果上面的映射是只读的,页面故障将触发一个内存段失败而不是写到一个副本。
动态加载库是通过文件映射融入到你的程序的地址空间中的。这没有什么可奇怪的,它通过普通的 API 为你提供与私有文件映射相同的效果。下面的示例展示了映射文件的 render 程序的两个实例运行的地址空间的一部分,以及物理内存,尝试将我们看到的许多概念综合到一起。
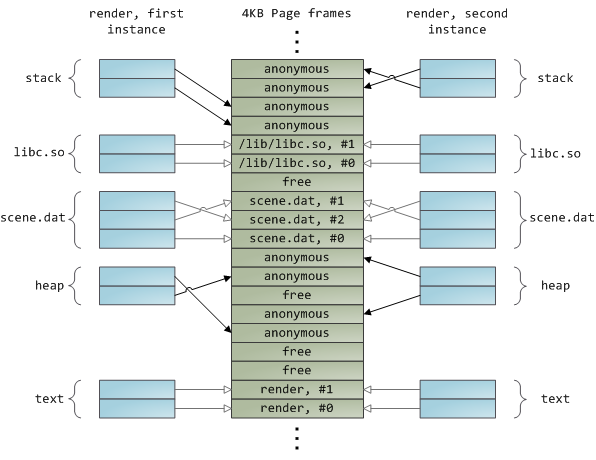
这是内存架构系列的第三部分的结论。我希望这个系列文章对你有帮助,对理解操作系统的这些主题提供一个很好的思维模型。
via:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
作者:Gustavo Duarte 译者:qhwdw 校对:wxy