mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-29 21:41:00 +08:00
111 lines
7.9 KiB
Markdown
111 lines
7.9 KiB
Markdown
Quiet log noise with Python and machine learning
|
||
======
|
||
|
||
Logreduce saves debugging time by picking out anomalies from mountains of log data.
|
||
|
||
|
||
|
||
Continuous integration (CI) jobs can generate massive volumes of data. When a job fails, figuring out what went wrong can be a tedious process that involves investigating logs to discover the root cause—which is often found in a fraction of the total job output. To make it easier to separate the most relevant data from the rest, the [Logreduce][1] machine learning model is trained using previous successful job runs to extract anomalies from failed runs' logs.
|
||
|
||
This principle can also be applied to other use cases, for example, extracting anomalies from [Journald][2] or other systemwide regular log files.
|
||
|
||
### Using machine learning to reduce noise
|
||
|
||
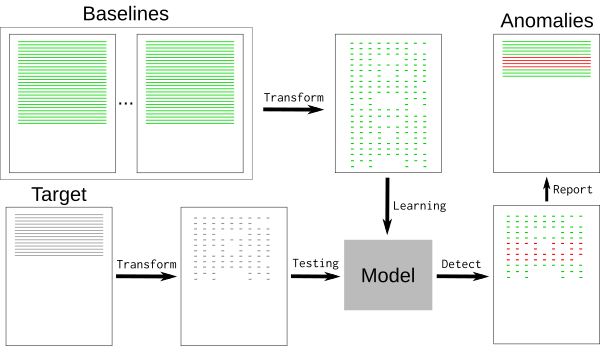
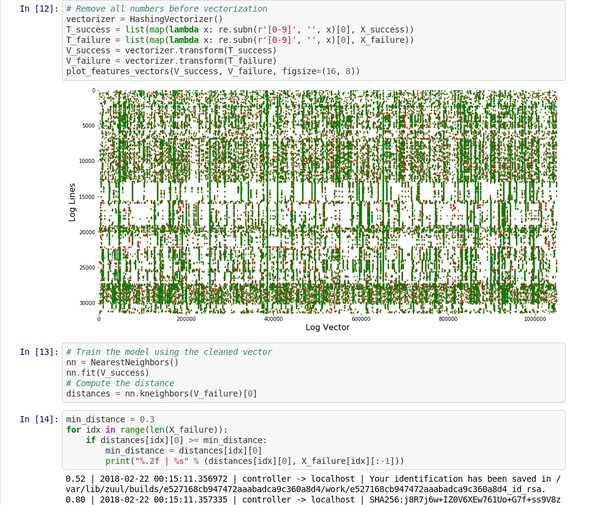
A typical log file contains many nominal events ("baselines") along with a few exceptions that are relevant to the developer. Baselines may contain random elements such as timestamps or unique identifiers that are difficult to detect and remove. To remove the baseline events, we can use a [k-nearest neighbors pattern recognition algorithm][3] (k-NN).
|
||
|
||
|
||
|
||
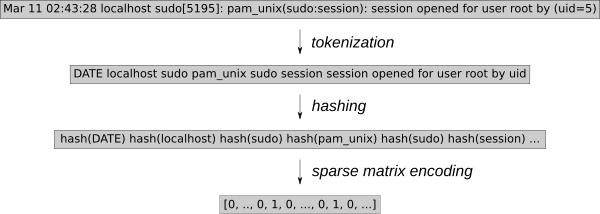
Log events must be converted to numeric values for k-NN regression. Using the generic feature extraction tool [HashingVectorizer][4] enables the process to be applied to any type of log. It hashes each word and encodes each event in a sparse matrix. To further reduce the search space, tokenization removes known random words, such as dates or IP addresses.
|
||
|
||
|
||
|
||
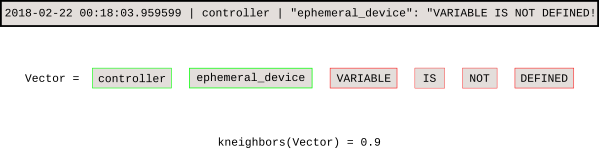
Once the model is trained, the k-NN search tells us the distance of each new event from the baseline.
|
||
|
||
|
||
|
||
This [Jupyter notebook][5] demonstrates the process and graphs the sparse matrix vectors.
|
||
|
||
|
||
|
||
### Introducing Logreduce
|
||
|
||
The Logreduce Python software transparently implements this process. Logreduce's initial goal was to assist with [Zuul CI][6] job failure analyses using the build database, and it is now integrated into the [Software Factory][7] development forge's job logs process.
|
||
|
||
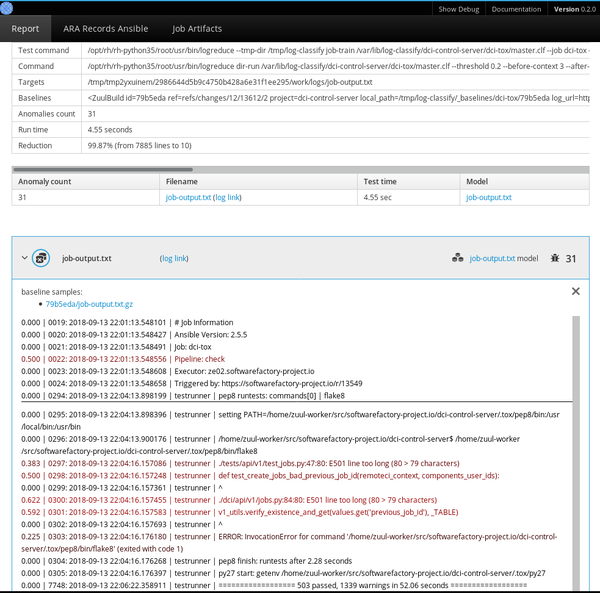
At its simplest, Logreduce compares files or directories and removes lines that are similar. Logreduce builds a model for each source file and outputs any of the target's lines whose distances are above a defined threshold by using the following syntax: **distance | filename:line-number: line-content**.
|
||
|
||
```
|
||
$ logreduce diff /var/log/audit/audit.log.1 /var/log/audit/audit.log
|
||
INFO logreduce.Classifier - Training took 21.982s at 0.364MB/s (1.314kl/s) (8.000 MB - 28.884 kilo-lines)
|
||
0.244 | audit.log:19963: type=USER_AUTH acct="root" exe="/usr/bin/su" hostname=managesf.sftests.com
|
||
INFO logreduce.Classifier - Testing took 18.297s at 0.306MB/s (1.094kl/s) (5.607 MB - 20.015 kilo-lines)
|
||
99.99% reduction (from 20015 lines to 1
|
||
|
||
```
|
||
|
||
A more advanced Logreduce use can train a model offline to be reused. Many variants of the baselines can be used to fit the k-NN search tree.
|
||
|
||
```
|
||
$ logreduce dir-train audit.clf /var/log/audit/audit.log.*
|
||
INFO logreduce.Classifier - Training took 80.883s at 0.396MB/s (1.397kl/s) (32.001 MB - 112.977 kilo-lines)
|
||
DEBUG logreduce.Classifier - audit.clf: written
|
||
$ logreduce dir-run audit.clf /var/log/audit/audit.log
|
||
```
|
||
|
||
Logreduce also implements interfaces to discover baselines for Journald time ranges (days/weeks/months) and Zuul CI job build histories. It can also generate HTML reports that group anomalies found in multiple files in a simple interface.
|
||
|
||
|
||
|
||
### Managing baselines
|
||
|
||
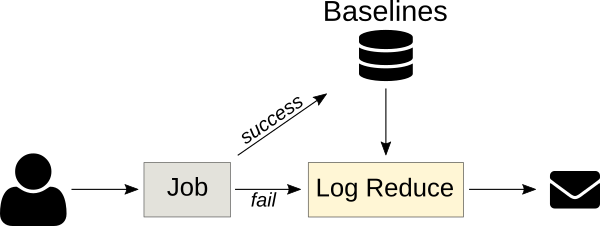
The key to using k-NN regression for anomaly detection is to have a database of known good baselines, which the model uses to detect lines that deviate too far. This method relies on the baselines containing all nominal events, as anything that isn't found in the baseline will be reported as anomalous.
|
||
|
||
CI jobs are great targets for k-NN regression because the job outputs are often deterministic and previous runs can be automatically used as baselines. Logreduce features Zuul job roles that can be used as part of a failed job post task in order to issue a concise report (instead of the full job's logs). This principle can be applied to other cases, as long as baselines can be constructed in advance. For example, a nominal system's [SoS report][8] can be used to find issues in a defective deployment.
|
||
|
||
|
||
|
||
### Anomaly classification service
|
||
|
||
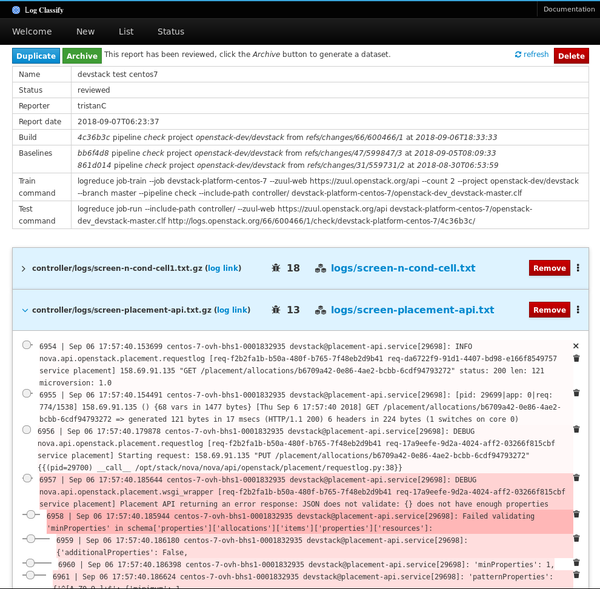
The next version of Logreduce introduces a server mode to offload log processing to an external service where reports can be further analyzed. It also supports importing existing reports and requests to analyze a Zuul build. The services run analyses asynchronously and feature a web interface to adjust scores and remove false positives.
|
||
|
||
|
||
|
||
Reviewed reports can be archived as a standalone dataset with the target log files and the scores for anomalous lines recorded in a flat JSON file.
|
||
|
||
### Project roadmap
|
||
|
||
Logreduce is already being used effectively, but there are many opportunities for improving the tool. Plans for the future include:
|
||
|
||
* Curating many annotated anomalies found in log files and producing a public domain dataset to enable further research. Anomaly detection in log files is a challenging topic, and having a common dataset to test new models would help identify new solutions.
|
||
* Reusing the annotated anomalies with the model to refine the distances reported. For example, when users mark lines as false positives by setting their distance to zero, the model could reduce the score of those lines in future reports.
|
||
* Fingerprinting archived anomalies to detect when a new report contains an already known anomaly. Thus, instead of reporting the anomaly's content, the service could notify the user that the job hit a known issue. When the issue is fixed, the service could automatically restart the job.
|
||
* Supporting more baseline discovery interfaces for targets such as SOS reports, Jenkins builds, Travis CI, and more.
|
||
|
||
|
||
|
||
If you are interested in getting involved in this project, please contact us on the **#log-classify** Freenode IRC channel. Feedback is always appreciated!
|
||
|
||
Tristan Cacqueray will present [Reduce your log noise using machine learning][9] at the [OpenStack Summit][10], November 13-15 in Berlin.
|
||
|
||
--------------------------------------------------------------------------------
|
||
|
||
via: https://opensource.com/article/18/9/quiet-log-noise-python-and-machine-learning
|
||
|
||
作者:[Tristan de Cacqueray][a]
|
||
选题:[lujun9972](https://github.com/lujun9972)
|
||
译者:[译者ID](https://github.com/译者ID)
|
||
校对:[校对者ID](https://github.com/校对者ID)
|
||
|
||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||
|
||
[a]: https://opensource.com/users/tristanc
|
||
[1]: https://pypi.org/project/logreduce/
|
||
[2]: http://man7.org/linux/man-pages/man8/systemd-journald.service.8.html
|
||
[3]: https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
|
||
[4]: http://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.HashingVectorizer.html
|
||
[5]: https://github.com/TristanCacqueray/anomaly-detection-workshop-opendev/blob/master/datasets/notebook/anomaly-detection-with-scikit-learn.ipynb
|
||
[6]: https://zuul-ci.org
|
||
[7]: https://www.softwarefactory-project.io
|
||
[8]: https://sos.readthedocs.io/en/latest/
|
||
[9]: https://www.openstack.org/summit/berlin-2018/summit-schedule/speakers/4307
|
||
[10]: https://www.openstack.org/summit/berlin-2018/
|