24 KiB
为什么(大部分)高级语言运行效率较慢Why (most) High Level Languages are Slow
内容
In the last month or two I’ve had basically the same conversation half a dozen times, both online and in real life, so I figured I’d just write up a blog post that I can refer to in the future.
在近两个个月中,我多次的和线上线下的朋友讨论了这个话题,所以我干脆直接把它写在博客中,以便以后查阅。
The reason most high level languages are slow is usually because of two reasons:
大部分高级语言运行效率较慢的原因通常有两点:
-
They don’t play well with the cache.
-
They have to do expensive garbage collections
-
没有很好的利用缓存;
-
垃圾回收机制性能消耗高。
But really, both of these boil down to a single reason: the language heavily encourages too many allocations.
但事实上,这两个原因可以归因于:高级语言强烈地鼓励编程人员分配很多的内存。
First, I’ll just state up front that for all of this I’m talking mostly about client-side applications. If you’re spending 99.9% of your time waiting on the network then it probably doesn’t matter how slow your language is – optimizing network is your main concern. I’m talking about applications where local execution speed is important.
首先,下文内容主要讨论客户端应用。如果你的程序有 99.9% 的时间都在等待网络,那么这很可能不是拖慢语言运行效率的原因——优先考虑的问题当然是优化网络。在本文中,我们主要讨论程序在本地执行的速度。
I’m going to pick on C# as the specific example here for two reasons: the first is that it’s the high level language I use most often these days, and because if I used Java I’d get a bunch of C# fans telling me how it has value types and therefore doesn’t have these issues (this is wrong).
我将选用 C# 语言作为本文的参考语言,其原因有二:首先它是我常用的高级语言;其次如果我使用 Java 语言,许多使用 C# 的朋友会告诉我 C# 不会有这些问题,因为它有值类型(但这是错误的)。
In the following I will be talking about what happens when you write idiomatic code. When you work “with the grain” of the language. When you write code in the style of the standard libraries and tutorials. I’m not very interested in ugly workarounds as “proof” that there’s no problem. Yes, you can sometimes fight the language to avoid a particular issue, but that doesn’t make the language unproblematic.
接下来我将会讨论,出于编程习惯编写的代码、使用普遍编程方法(with the grain)的代码或使用库或教程中提到的常用代码来编写程序时会发生什么。我对那些使用难搞的办法来解决语言自身毛病以“证明”语言没毛病这事没兴趣,当然你可以和语言抗争来避免它的毛病,但这并不能说明语言本身是没有问题的。
Cache costs review
回顾缓存消耗问题
First, let’s review the importance of playing well with the cache. Here’s a graph based on this data on memory latencies for Haswell:
首先我们先来回顾一下合理使用缓存的重要性。下图是基于在 Haswell 架构下内存潜在因素对其影响的 数据:
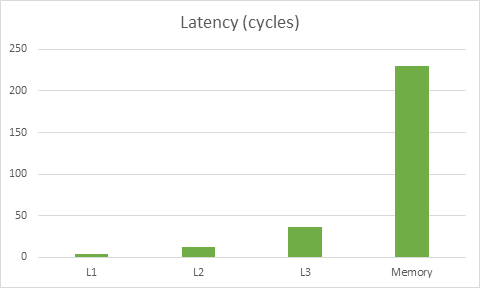
The latency for this particular CPU to get to memory is about 230 cycles, meanwhile the cost of reading data from L1 is 4 cycles. The key takeaway here is that doing the wrong thing for the cache can make code ~50x slower. In fact, it may be even worse than that – modern CPUs can often do multiple things at once so you could be loading stuff from L1 while operating on stuff that’s already in registers, thus hiding the L1 load cost partially or completely.
针对这款 CPU 的内存因素,读取内存的数据需要近 230 个运算周期,同时需要消耗 L1 缓冲区的 4 个运算周期。因此错误的去使用缓存可导致运行速度拖慢近 50 倍。还好这并不是最糟糕的——在现代 CPU 中它们能同时地做多种操作,所以当你加载 L1 缓冲区内容的同时这个内容已经进入到了寄存器,因此数据从 L1 缓冲区加载这个过程的性能消耗就被完整的隐藏了起来。
Without exaggerating we can say that aside from making reasonable algorithm choices, cache misses are the main thing you need to worry about for performance. Once you’re accessing data efficiently you can worry about fine tuning the actual operations you do. In comparison to cache misses, minor inefficiencies just don’t matter much.
撇开选择合理的算法不谈,不夸张地讲,在性能优化中你要考虑的最主要因素其实是缓存未命中。当你能够有效的访问一个数据时候,你才可以调整你的每个具体的操作。与缓存未命中的问题相比,那些次要的低效问题对运行速度并没有什么过多的影响。
This is actually good news for language designers! You don’t have to build the most efficient compiler on the planet, and you totally can get away with some extra overhead here and there for your abstractions (e.g. array bounds checking), all you need to do is make sure that your design makes it easy to write code that accesses data efficiently and programs in your language won’t have any problems running at speeds that are competitive with C.
这对于编程语言的设计者来说是一个好消息!你都_不必_去编写一个更高效的编译器,你可以完全摆脱一些额外的开销(比如:数组边界检查),你只需要专注怎么设计能使你的语言访问数据更高效,也不用担心与 C 语言代码比较运行速度。
Why C# introduces cache misses
为什么 C# 存在缓存未命中问题
To put it bluntly, C# is a language that simply isn’t designed to run efficiently with modern cache realities in mind. Again, I’m now talking about the limitations of the design and the “pressure” it puts on the programmer to do things in inefficient ways. Many of these things have theoretical workarounds that you could do at great inconvenience. I’m talking about idiomatic code, what the language “wants” you to do.
坦率地讲 C# 在设计时就没打算在现代缓存中实现高效运行。我又一次提到程序语言设计的局限性以及其带给程序员无法编写高效的代码的“压力”。大部分的理论解决方法都非常的不便。我是在说那些编程语言“希望”你这样编写的习惯性代码。
The basic problem with C# is that it has very poor support for value-based programming. Yes, it has structs which are values that are stored “embedded” where they are declared (e.g. on the stack, or inside another object). But there are a several big issues with structs that make them more of a band-aid than a solution.
C# 最基本的问题是对基础值类型(value-base)低下的支持性。其大部分的数据结构都是“内置”在语言内定义的(例如:栈,或其他内置对象)。但这些具有帮助性的内置结构体恰恰好会造成一些大问题。
-
You have to declare your data types as struct up front – which means that if you ever need this type to exist as a heap allocation then all of them need to be heap allocations. You could make some kind of class-wrapper for your struct and forward all the members but it’s pretty painful. It would be better if classes and structs were declared the same way and could be used in both ways on a case-by-case basis. So when something can live on the stack you declare it as a value, and when it needs to be on the heap you declare it as an object. This is how C++ works, for example. You’re not encouraged to make everything into an object-type just because there’s a few things here and there that need them on the heap.
-
你得把自己定义的结构体类型在最先声明——这意味着你如果需要用到这个类型作为堆分配,那么所有的结构体都会被堆分配。你也可以使用一些类包装器来打包你的结构体和其中的成员变量,但这十分的痛苦。如果类和结构体可以相同的方式声明,并且可根据具体情况来使用,这将是更好的。当数据可以作为值地存储在自定义的栈中,当这个数据需要被对分配时你就可以将其定义为一个对象,比如 C++ 就是这样工作的。因为只有少数的内容需要被堆分配,所以我们不鼓励所有的内容都被定义为对象类型。
-
Referencing values is extremely limited. You can pass values by reference to functions, but that’s about it. You can’t just grab a reference to an element in a List, you have to store both a reference to the list and an index. You can’t grab a pointer to a stack-allocated value, or a value stored inside an object (or value). You can only copy them, unless you’re passing them to a function (by ref). This is all understandable, by the way. If type safety is a priority, it’s pretty difficult (though not imposible) to support flexible referencing of values while also guaranteeing type safety. The rationale behind these restrictions don’t change the fact that the restrictions are there, though.
-
引用 值被苛刻的限制。你可以将一个引用值传给函数,但只能这样。你不能直接引用
List<int>中的元素,你必须先把所有的引用和索引全部存储下来。你不能直接取得指向栈、对象中的变量(或其他变量)的指针。你只能把他们复制一份,除了将他们传给一个函数(使用引用的方式)。当然这也是可以理解的。如果类型安全是一个先驱条件,灵活的引用变量和保证类型安全这两项要同时支持太难了(虽然这不可能)。 -
Fixed sized buffers don’t support custom types and also requires you to use an unsafe keyword.
-
固定大小的缓冲区 不支持自定义类型,而且还必须使用
unsafe关键字。 -
Limited “array slice” functionality. There’s an ArraySegment class, but it’s not really used by anyone, which means that in order to pass a range of elements from an array you have to create an IEnumerable, which means allocation (boxing). Even if the APIs accepted ArraySegment parameters it’s still not good enough – you can only use it for normal arrays, not for List, not for stack-allocated arrays, etc.
-
有限的“数组切片”功能。虽然有提供
ArraySegment类,但并没有人会使用它,这意味着如果只需要传递数组的一部分,你必须去创建一个IEnumerable对象,也就意味着要分配大小(包装)。就算接口接受ArraySegment对象作为参数,也是不够的——你只能用普通数组,而不能用List<T>,也不能用 栈数组 等等。
The bottom line is that for all but very simple cases, the language pushes you very strongly towards heap allocations. If all your data is on the heap, it means that accessing it is likely to cause a cache misses (since you can’t decide how objects are organized in the heap). So while a C++ program poses few challenges to ensuring that data is organized in cache-efficient ways, C# typically encourages you to allocate each part of that data in a separate heap allocation. This means the programmers loses control over data layout, which means unnecessary cache misses are introduced and performance drops precipitously. It doesn’t matter that you can now compile C# programs natively ahead of time – improvement to code quality is a drop in the bucket compared to poor memory locality. 最重要的是,除了非常简单的情况之外,C# 非常惯用堆分配。如果所有的数据都被堆分配,这意味着被访问时会造成缓存未命中(从你无法决定对象是如何在堆中存储开始)。所以当 C++ 程序面临着如何有效的组织数据在缓存中的存储这个挑战时,C# 则鼓励程序员去将数据分开的存放在一个个堆分配空间中。这就意味着程序员无法控制数据层了,也就意味着开始产生不必要的缓存未命中问题,也就导致性能急速的下降了。C# 已经支持原生编译 也不会提升太多性能——毕竟在内存不足的情况下,提高代码质量本就杯水车薪。
Plus, there’s storage overhead. Each reference is 8 bytes on a 64-bit machine, and each allocation has its own overhead in the form of various metadata. A heap full of tiny objects with lots of references everywhere has a lot of space overhead compared to a heap with very few large allocations where most data is just stored embedded within their owners at fixed offsets. Even if you don’t care about memory requirements, the fact that the heap is bloated with header words and references means that cache lines have more waste in them, this in turn means even more cache misses and reduced performance. 存储是有开销的。在64位的机器上每个地址值占8位内存,而每次分配都会有存储元数据而产生的开销。与存储着少量大数据(以固定偏移的方式存储在其中)的堆相比,存储着大量小数据的堆(并且其中的数据到处都被引用)会产生更多的内存开销。尽管你可能不怎么关心内存怎么用,但事实上就是那些头部内容和地址信息导致堆变得臃肿,也就是在浪费缓存了,所以也造成了更多的缓存未命中,降低了代码性能。
There are sometimes workarounds you can do, for example you can use structs and allocate them in a pool using a big List. This allows you to e.g. traverse the pool and update all of the objects in-bulk, getting good locality. This does get pretty messy though, because now anything else wanting to refer to one of these objects have to have a reference to the pool as well as an index, and then keep doing array-indexing all over the place. For this reason, and the reasons above, it is significantly more painful to do this sort of stuff in C# than it is to do it in C++, because it’s just not something the language was designed to do. Furthermore, accessing a single element in the pool is now more expensive than just having an allocation per object - you now get two cache misses because you have to first dereference the pool itself (since it’s a class). Ok, so you can duplicate the functionality of List in struct-form and avoid this extra cache miss and make things even uglier. I’ve written plenty of code just like this and it’s just extremely low level and error prone.
当然有些时候也是有办法的,比如你可以使用一个很大的 List<T> 来构造数据池以存储分配你需要的数据和自己的结构体。这样你就可以方便的遍历或者批量更新你的数据池中的数据了。但这也会很混乱,因为无论你在哪要引用什么对象都要先能引用这个池,然后每次引用都需要做数组索引。从上文可以得出,在 C# 中做类似这样的处理的痛感比在 C++ 中做来的更痛,因为 C# 在设计时就是这样。此外,通过这种方式来访问池中的单个对象比直接将这个对象分配到内存来访问更加的昂贵——前者你得先访问池(这是个类)的地址,这意味着可能产生 2 次缓存未命中。你还可以通过复制 List<T> 的结构形式来避免更多的缓存未命中问题,但这就更难搞了。我就写过很多类似的代码,自然这样的代码只会很低水平而且容易出错。
Finally, I want to point out that this isn’t just an issue for “hot spot” code. Idiomatically written C# code tends to have classes and references basically everywhere . This means that all over your code at relatively uniform frequency there are random multi-hundred cycle stalls, dwarfing the cost of surrounding operations. Yes there could be hotspots too, but after you’ve optimized them you’re left with a program that’s just uniformly slow. So unless you want to write all your code with memory pools and indices, effectively operating at a lower level of abstraction than even C++ does (and at that point, why bother with C#?), there’s not a ton you can do to avoid this issue. 最后,我想说我指出的问题不仅是那些“热门”的代码。惯用手段编写的 C# 代码倾向于几乎所有地方都用类和引用。意思就是在你的代码中会均匀频率地随机出现数百次的运算周期损耗,使得操作的损耗似乎降低了。这虽然也可以被找出来,但你优化了这问题后,这还是一个 均匀变慢 的程序。
Garbage Collection
垃圾回收
I’m just going to assume in the following that you already understand why garbage collection is a performance problem in a lot of cases. That pausing randomly for many milliseconds just is usually unacceptable for anything with animation. I won’t linger on it and move on to explaining why the language design itself exacerbates this issue. 在读下文之前我会假设你已经知道为什么在许多用例中垃圾回收是影响性能问题的重要原因。播放动画时总是随机的暂停通常都是大家都不能接受的吧。我会继续解释为什么设计语言时还加剧了这个问题。
Because of the limitations when it comes to dealing with values, the language very strongly discourages you from using big chunky allocations consisting mostly of values embedded within other values (perhaps stored on the stack), pressuring you instead to use lots of small classes which have to be allocated on the heap. Roughly speaking, more allocations means more time spent collecting garbage.
There are benchmarks that show how C# or Java beat C++ in some particular case, because an allocator based on a GC can have decent throughput (cheap allocations, and you batch all the deallocations up). However, this isn’t a common real world scenario. It takes a huge amount of effort to write a C# program with the same low allocation rate that even a very naïve C++ program has, so those kinds of comparisons are really comparing a highly tuned managed program with a naïve native one. Once you spend the same amount of effort on the C++ program, you’d be miles ahead of C# again.
I’m relatively convinced that you could write a GC more suitable for high performance and low latency applications (e.g. an incremental GC where you spend a fixed amount of time per frame doing collection), but this is not enough on its own. At the end of the day the biggest issue with most high level languages is simply that the design encourages far too much garbage being created in the first place. If idiomatic C# allocated at the same low rate a C program does, the GC would pose far fewer problems for high performance applications. And if you did have an incremental GC to support soft real-time applications, you’ll probably need a write barrier for it – which, as cheap as it is, means that a language that encourages pointers will add a performance tax to the mutators.
Look at the base class library for .Net, allocations are everywhere! By my count the .Net Core Framework contains 19x more public classes than structs, so in order to use it you’re very much expected to do quite a lot of allocation. Even the creators of .Net couldn’t resist the siren call of the language design! I don’t know how to gather statistics on this, but using the base class library you quickly notice that it’s not just in their choice of value vs. object types where the allocation-happiness shines through. Even within this code there’s just a ton of allocations. Everything seems to be written with the assumption that allocations are cheap. Hell, you can’t even print an int without allocating! Let that sink in for a second. Even with a pre-sized StringBuilder you can’t stick an int in there without allocating using the standard library. That’s pretty silly if you ask me.
This isn’t just in the standard library. Other C# libraries follow suit. Even Unity (a game engine , presumably caring more than average about performance issues) has APIs all over the place that return allocated objects (or arrays) or force the caller to allocate to call them. For example, by returning an array from GetComponents, they’re forcing an array allocation just to see what components are on a GameObject. There are a number of alternative APIs they could’ve chosen, but going with the grain of the language means allocations. The Unity folks wrote “Good C#”, it’s just bad for performance.
Closing remarks
If you’re designing a new language, please consider efficiency up front. It’s not something a “Sufficiently Smart Compiler” can fix after you’ve already made it impossible. Yes, it’s hard to do type safety without a garbage collector. Yes, it’s harder to do garbage collection when you don’t have uniform representation for data. Yes, it’s hard to reason about scoping rules when you can have pointers to random values. Yes, there are tons of problems to figure out here, but isn’t figuring those problems out what language design is supposed to be? Why make another minor iteration of languages that were already designed in the 1960s?
Even if you can’t fix all these issues, maybe you can get most of the way there? Maybe use region types (a la Rust) to ensure safety. Or maybe even consider abandoning “type safety at all costs” in favor of more runtime checks (if they don’t cause extra cache misses, they don’t really matter… and in fact C# already does similar things, see covariant arrays which are strictly speaking a type system violation, and leads to a runtime exception).
The bottom line is that if you want to be an alternative to C++ for high performance scenarios, you need to worry about data layout and locality.
作者简介:
My name is Sebastian Sylvan. I’m from Sweden but live in Seattle. I work at Microsoft on Hololens. Obviously my views are my own and don’t necessarily represent those of Microsoft.
I typically blog graphics, languages, performance, and such. Feel free to hit me up on twitter or email (see links in sidebar).
via: https://www.sebastiansylvan.com/post/why-most-high-level-languages-are-slow
作者:Sebastian Sylvan 译者:kenxx 校对:校对者ID