23 KiB
服务端 I/O 性能:Node、PHP、Java、Go 的对比
了解应用程序的输入/输出(I/O)模型意味着理解了应用程序对其所要处理的数据的载入差异,以及在真实环境的例子。或许你的应用程序很小,在不承受很大的负载时,这并不是个严重的问题;但随着应用程序的流量负载增加,可能因为使用了低效的 I/O 模型导致承受不了而崩溃。
和大多数情况一样,处理这种问题的方法是多种的,这不仅仅是一个择优的问题,而是理解权衡的问题。 接下来我们来看看 I/O 到底是什么。

在本文中,我们将对 Node、Java、Go 和 PHP + Apache 进行对比,讨论不同语言如何构造其 I/O ,每个模型的优缺点,并总结一些基本的规律。如果你担心你的下一个 Web 应用程序的 I/O 性能,本文将给你最优的解答。
I/O 基础知识: 快速复习
要了解 I/O 涉及的因素,我们首先在操作系统层面复习这些概念。虽然不用与这些概念直接打交道,但你会一直通过应用程序的运行时环境与它们间接接触。了解细节很重要。
系统调用
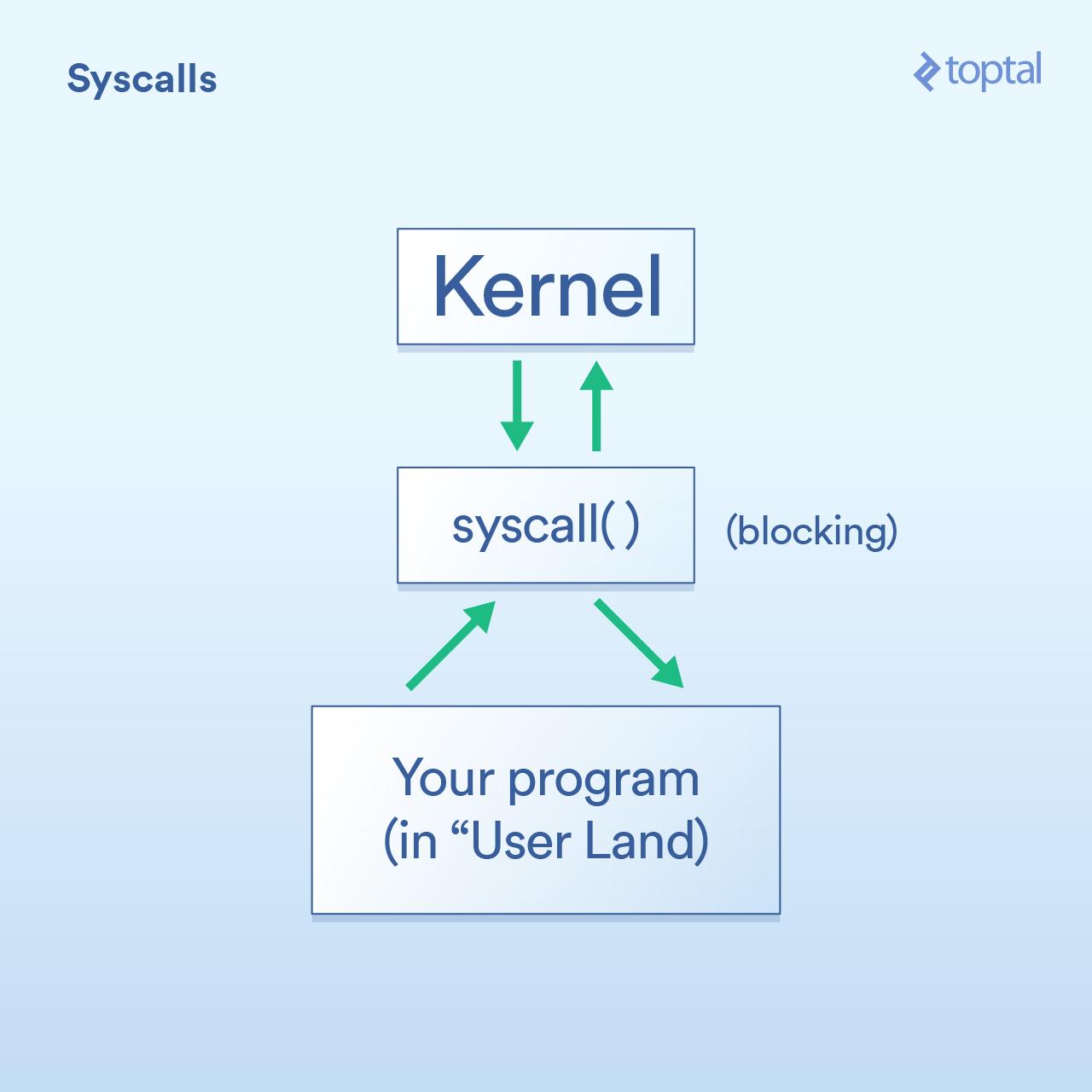
首先是系统调用,其被描述如下:
- (用户端)程序必须请求操作系统内核代表它执行 I/O 操作。
- “系统调用”是你的程序要求内核执行某些操作的方法。这些实现的细节在操作系统之间有所不同,但基本概念是相同的。有一些具体的指令会将控制权从你的程序转移到内核(类似函数调用,但是是使用专门用于处理这种情况的专用方式)。一般来说,系统调用会被阻塞,这意味着你的程序会等待内核返回(控制权到)你的代码。
- 内核在所需的物理设备( 磁盘、网卡等 )上执行底层的 I/O 操作,并回应系统调用。在实际情况中,内核可能需要做许多事情来满足你的要求,包括等待设备准备就绪、更新其内部状态等,但作为应用程序开发人员,你不需要关心这些。这是内核的工作。
阻塞与非阻塞
现在,我刚刚在上面说过,系统调用是阻塞的,一般来说是这样。然而,一些调用被归类为“非阻塞”,这意味着内核会接收你的请求,将其放在队列或缓冲区之类的地方,然后立即返回而不等待实际的 I/O 发生。所以它只是在很短的时间内“阻塞”,只需要排队你的请求即可。
举一些 Linux 系统调用例子可能有助于理解:
read()是一个阻塞调用 - 你传递一个句柄,指出哪个文件和缓冲区在哪里传送它读取的数据,当数据在那里时,该调用返回。这具有简单友好的优点。- 分别调用
epoll_create()、epoll_ctl()和epoll_wait(),你可以创建一组句柄来侦听,添加/删除该组中的处理程序,然后阻塞直到有任何活动发生。这允许你通过单个线程有效地控制大量的 I/O 操作,但是现在谈这个还太早。如果你需要这个功能当然好,但是你要知道它使用起来是比较复杂的。
了解这里的时间差异的数量级是很重要的。如果 CPU 内核运行在 3GHz,在没有进行 CPU 优化的情况下,那么它每秒执行 30 亿次周期(或每纳秒 3 个周期)。非阻塞系统调用可能需要几十个周期来完成,或者说 “相对较少的纳秒” 的时间完成。一个被跨网络接收信息所阻塞的调用可能需要更长的时间 - 例如 200 毫秒(1/5 秒)。这就是说,如果非阻塞调用需要 20 纳秒,阻塞调用就需要 2 亿纳秒。你的进程因阻塞调用而等待了 1000 万倍的时长。

内核既提供了阻塞 I/O (“从网络连接读取并给出数据”),也提供了非阻塞 I/O (“告知我何时这些网络连接具有新数据”)的方法。使用的哪种机制对调用进程的阻塞时长有截然不同的影响。
调度
关键的第三件事是当你有很多线程或进程开始阻止时会发生什么。
根据我们的理解,线程和进程之间没有很大的区别。在现实生活中,最显著的性能相关差异在于,由于线程共享相同的内存,而进程每个都有自己的内存空间,使得单独的进程往往占用更多的内存。但是当我们谈论调度时,它真正归结为一类事情(线程和进程),每个都需要在可用的 CPU 内核上获得一段执行时间。如果你有 300 个线程运行在 8 个内核上,则必须将时间分成几份,以便每个线程和进程都能分享它,每个运行一段时间,然后交给下一个。这是通过 “上下文切换” 完成的,使 CPU 从运行到一个线程/进程到切换下一个。
这些上下文切换也有相关的成本 - 它们需要一些时间。在某些快速的情况下,它可能小于 100 纳秒,但根据实际情况、处理器速度/体系结构、CPU 缓存等,偶见花费 1000 纳秒或更长时间。
而线程(或进程)越多,上下文切换就越多。当我们涉及数以千计的线程时,每个线程花费数百纳秒,就会变得很慢。
然而,非阻塞调用告诉内核“只有在这些连接中有一些新的数据或事件时才会给我”。这些非阻塞调用旨在有效地处理大量 I/O 负载并减少上下文交换。
现在你明白了么?让我们现在看看有趣的部分:我们来看看一些流行的语言对那些工具的使用,并得出关于易用性和性能之间的权衡的结论,以及一些其他有趣小东西。
声明,本文中显示的示例是零碎的(片面的,只能显示相关的信息); 数据库访问、外部缓存系统( memcache 等等)以及任何需要 I/O 的东西都将执行某种类型的 I/O 调用,其实质与上面所示的简单示例效果相同。此外,对于将 I/O 描述为“阻塞”( PHP、Java )的情况,HTTP 请求和响应读取和写入本身就是阻塞调用:系统中隐藏着更多 I/O 及其伴生的性能问题需要考虑。
为一个项目选择编程语言要考虑很多因素。甚至当你只考虑效率时,还有很多因素。但是,如果你担心你的程序将主要受到 I/O 的限制,如果 I/O 性能影响到项目的成败,那么这些是你需要了解的。
“保持简单”方法:PHP
早在 90 年代,很多人都穿着 Converse 鞋,并用 Perl 编写 CGI 脚本。然后 PHP 来了,就像一些人喜欢咒骂的一样,它使得动态网页更容易。
PHP 使用的模型相当简单。有一些出入,但你的 PHP 服务器基本上是这样:
HTTP 请求来自用户的浏览器,并且访问你的 Apache Web 服务器。Apache 为每个请求创建一个单独的进程,有一些优化可以重新使用它们,以最大限度地减少创建次数( 相对而言,创建进程较慢 )。Apache 调用 PHP 并告诉它运行磁盘上合适的 .php 文件。PHP 代码执行并阻塞 I/O 调用。你在 PHP 中调用 file_get_contents() ,其底层会调用 read() 系统调用并等待结果。
当然,实际的代码是直接嵌入到你的页面,并且操作被阻止:
<?php
// blocking file I/O
$file_data = file_get_contents(‘/path/to/file.dat’);
// blocking network I/O
$curl = curl_init('http://example.com/example-microservice');
$result = curl_exec($curl);
// some more blocking network I/O
$result = $db->query('SELECT id, data FROM examples ORDER BY id DESC limit 100');
?>
关于如何与系统集成,就像这样:
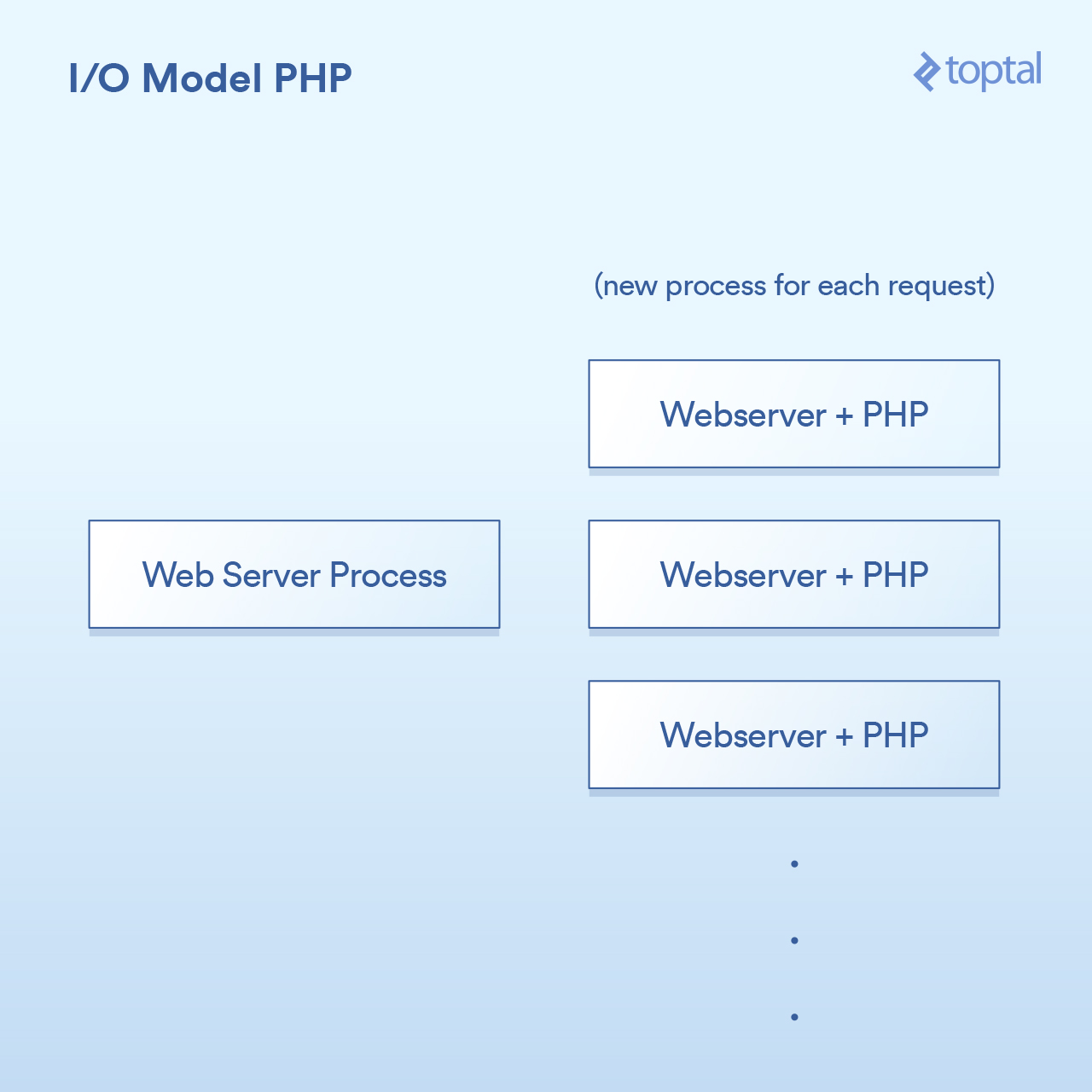
很简单:每个请求一个进程。 I/O 调用就阻塞。优点是简单可工作,缺点是,同时与 20,000 个客户端连接,你的服务器将会崩溃。这种方法不能很好地扩展,因为内核提供的用于处理大容量 I/O (epoll 等) 的工具没有被使用。 雪上加霜的是,为每个请求运行一个单独的进程往往会使用大量的系统资源,特别是内存,这通常是你在这样一个场景中遇到的第一件问题。
注意:Ruby 使用的方法与 PHP 非常相似,在大致的方面上,它们可以被认为是相同的。
多线程方法: Java
所以 Java 来了,就是你购买你的第一个域名的时候,在一个句子后随机说出 “dot com” 很酷。而 Java 具有内置于该语言中的多线程(特别是在创建时)非常棒。
大多数 Java Web 服务器通过为每个请求启动一个新的执行线程,然后在该线程中最终调用你作为应用程序开发人员编写的函数。
在 Java Servlet 中执行 I/O 往往看起来像:
public void doGet(HttpServletRequest request,
HttpServletResponse response) throws ServletException, IOException
{
// blocking file I/O
InputStream fileIs = new FileInputStream("/path/to/file");
// blocking network I/O
URLConnection urlConnection = (new URL("http://example.com/example-microservice")).openConnection();
InputStream netIs = urlConnection.getInputStream();
// some more blocking network I/O
out.println("...");
}
由于我们 doGet 上面的方法对应于一个请求并且在其自己的线程中运行,而不是需要自己内存每个请求单独进程,我们有一个单独的线程。这样有一些好的优点,就像能够在线程之间共享状态,缓存的数据等,因为它们可以访问对方的内存,但是它与调度的交互影响与 PHP 中的内容几乎相同以前的例子。每个请求获得一个新线程和该线程内的各种 I/O 操作块,直到请求被完全处理为止。线程被汇集以最小化创建和销毁它们的成本,但是仍然有数千个连接意味着数千个线程,这对调度程序是不利的。
重要的里程碑中,在1.4版本的Java(和 1.7 中的重要升级)中,获得了执行非阻塞 I/O 调用的能力。大多数应用程序,网络和其他,不使用它,但至少它是可用的。一些 Java Web 服务器尝试以各种方式利用这一点; 然而,绝大多数部署的 Java 应用程序仍然如上所述工作。
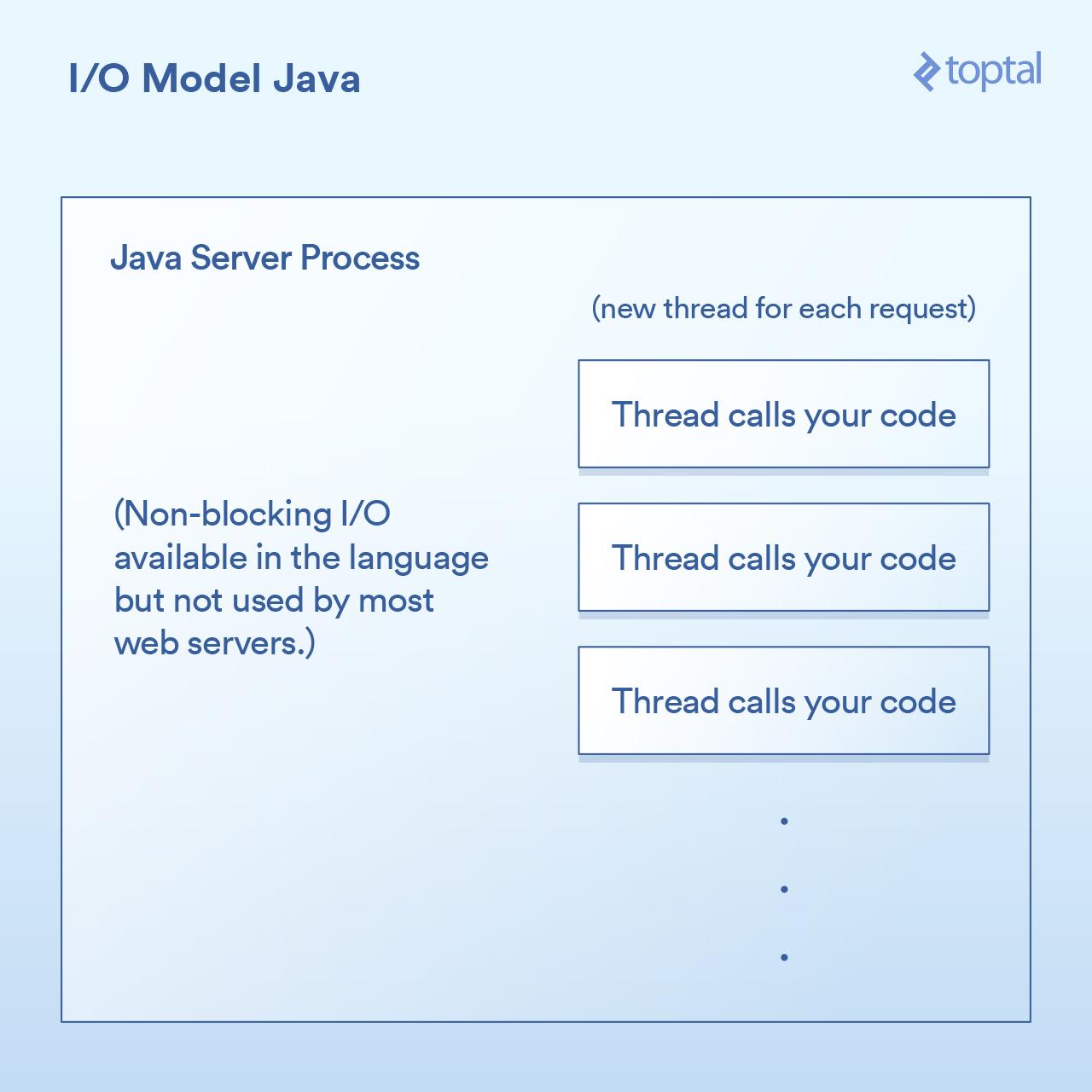
Java 让我们更接近,肯定有一些很好的开箱即用的 I/O 功能,但它仍然没有真正解决当你有一个大量的 I/O 绑定的应用程序被捣毁时会发生什么的问题,有数千个阻塞线程?。
无阻塞 I/O 作为一流公民: Node
操作块更好的 I/O 是 Node.js. 曾经对 Node 的最简单的介绍的人都被告知这是“非阻塞”,它有效地处理 I/O。这在一般意义上是正确的。但魔鬼的细节和这个巫术的实现手段在涉及演出时是重要的。
Node实现的范例基本上不是说 “在这里写代码来处理请求”,而是说 “在这里编写代码来开始处理请求”。每次你需要做一些涉及到 I/O ,你提出请求并给出一个回调函数,Node 将在完成之后调用该函数。
在请求中执行 I/O 操作的典型节点代码如下所示:
http.createServer(function(request, response) {
fs.readFile('/path/to/file', 'utf8', function(err, data) {
response.end(data);
});
});
你可以看到,这里有两个回调函数。当请求开始时,第一个被调用,当文件数据可用时,第二个被调用。
这样做的基本原理是让 Node 有机会有效地处理这些回调之间的 I/O 。在 Node 中进行数据库调用的方式更为相关,但是我不会在这个例子中啰嗦,因为它是完全相同的原则:启动数据库调用,并给 Node 一个回调函数使用非阻塞调用单独执行 I/O 操作,然后在你要求的数据可用时调用回调函数。排队 I/O 调用和让 Node 处理它然后获取回调的机制称为“事件循环”。它的工作原理很好。
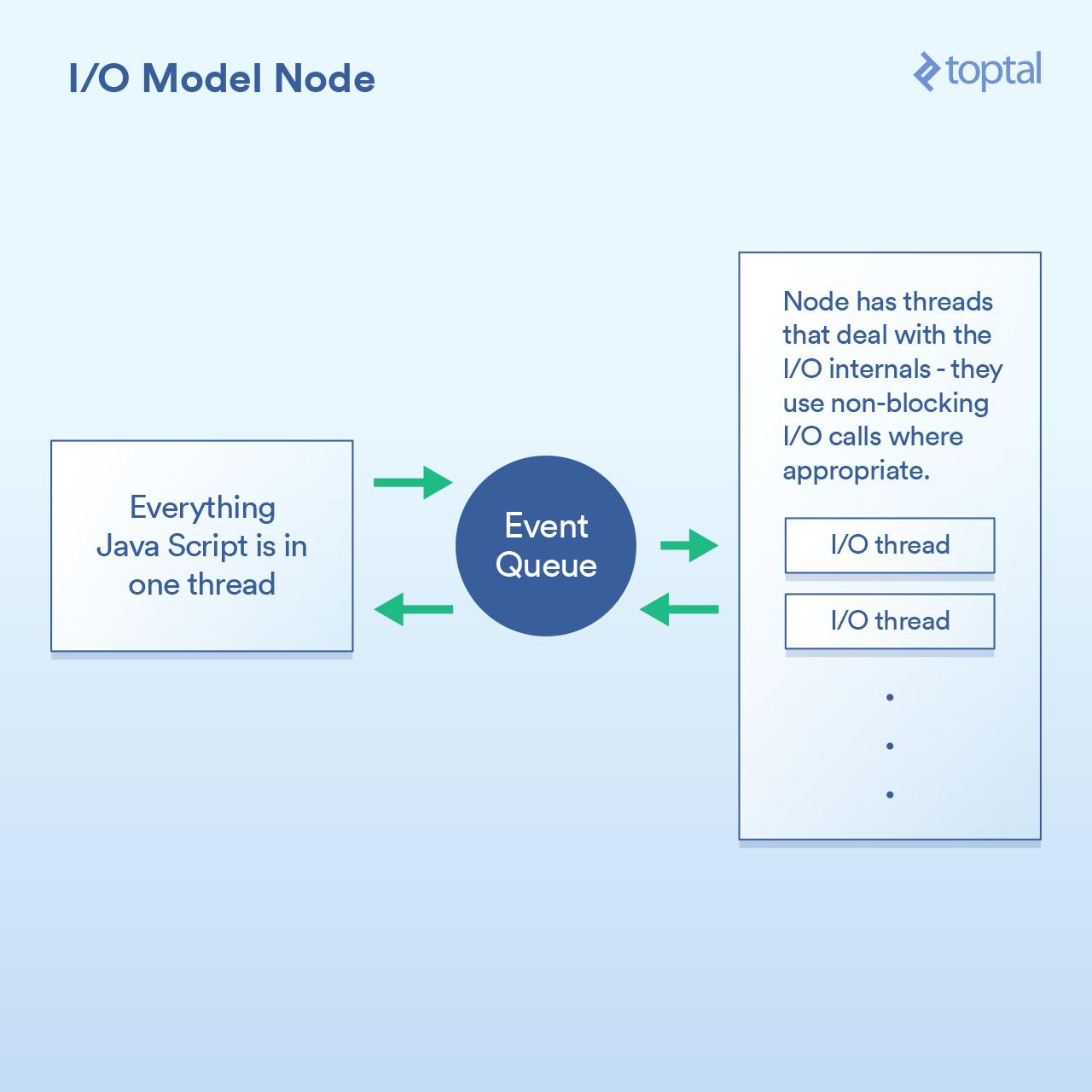
然而,这个模型的要点是在引擎盖下,其原因有很多更多的是如何在 V8 JavaScript 引擎(即使用节点 Chrome 浏览器的 JS 引擎)实现 1 比什么都重要。你编写的所有 JS 代码都运行在单个线程中。想一会儿 这意味着当使用高效的非阻塞技术执行 I/O 时,你的 JS 可以在单个线程中运行 CPU 绑定操作,每个代码块阻止下一个。可能出现这种情况的一个常见例子是在数据库记录之前循环,以某种方式处理它们,然后再将其输出到客户端。这是一个示例,显示如何工作:
var handler = function(request, response) {
connection.query('SELECT ...', function (err, rows) {
if (err) { throw err };
for (var i = 0; i < rows.length; i++) {
// do processing on each row
}
response.end(...); // write out the results
})
};
虽然 Node 确实有效地处理了 I/O ,但是 for 上面的例子中的循环是在你的一个主线程中使用 CPU 周期。这意味着如果你有 10,000 个连接,则该循环可能会使你的整个应用程序进行爬网,具体取决于需要多长时间。每个请求必须在主线程中共享一段时间,一次一个。
这个整体概念的前提是 I/O 操作是最慢的部分,因此最重要的是要有效地处理这些操作,即使这意味着连续进行其他处理。这在某些情况下是正确的,但不是全部。
另一点是,虽然这只是一个意见,但是写一堆嵌套回调可能是相当令人讨厌的,有些则认为它使代码更难以遵循。看到回调在 Node 代码中嵌套甚至更多级别并不罕见。
我们再回到权衡。如果你的主要性能问题是 I/O,则 Node 模型工作正常。然而,它的跟腱是,你可以进入处理 HTTP 请求的功能,并放置 CPU 密集型代码,并将每个连接都抓取。
最自然的非阻塞: Go
在我进入Go部分之前,我应该披露我是一个Go的粉丝。我已经使用它为许多项目,我公开表示其生产力优势的支持者,我看到他们在我的工作中。
也就是说,我们来看看它如何处理 I/O 。Go 语言的一个关键特征是它包含自己的调度程序。而不是每个线程的执行对应于一个单一的 OS 线程,它的作用与 “goroutines” 的概念。而 Go 运行时可以将一个 goroutine 分配给一个 OS 线程,并使其执行或暂停它,并且它不与一个 OS 线程,基于 goroutine 正在做什么。来自 Go 的 HTTP 服务器的每个请求都在单独的 Goroutine 中处理。
调度程序的工作原理如图所示:
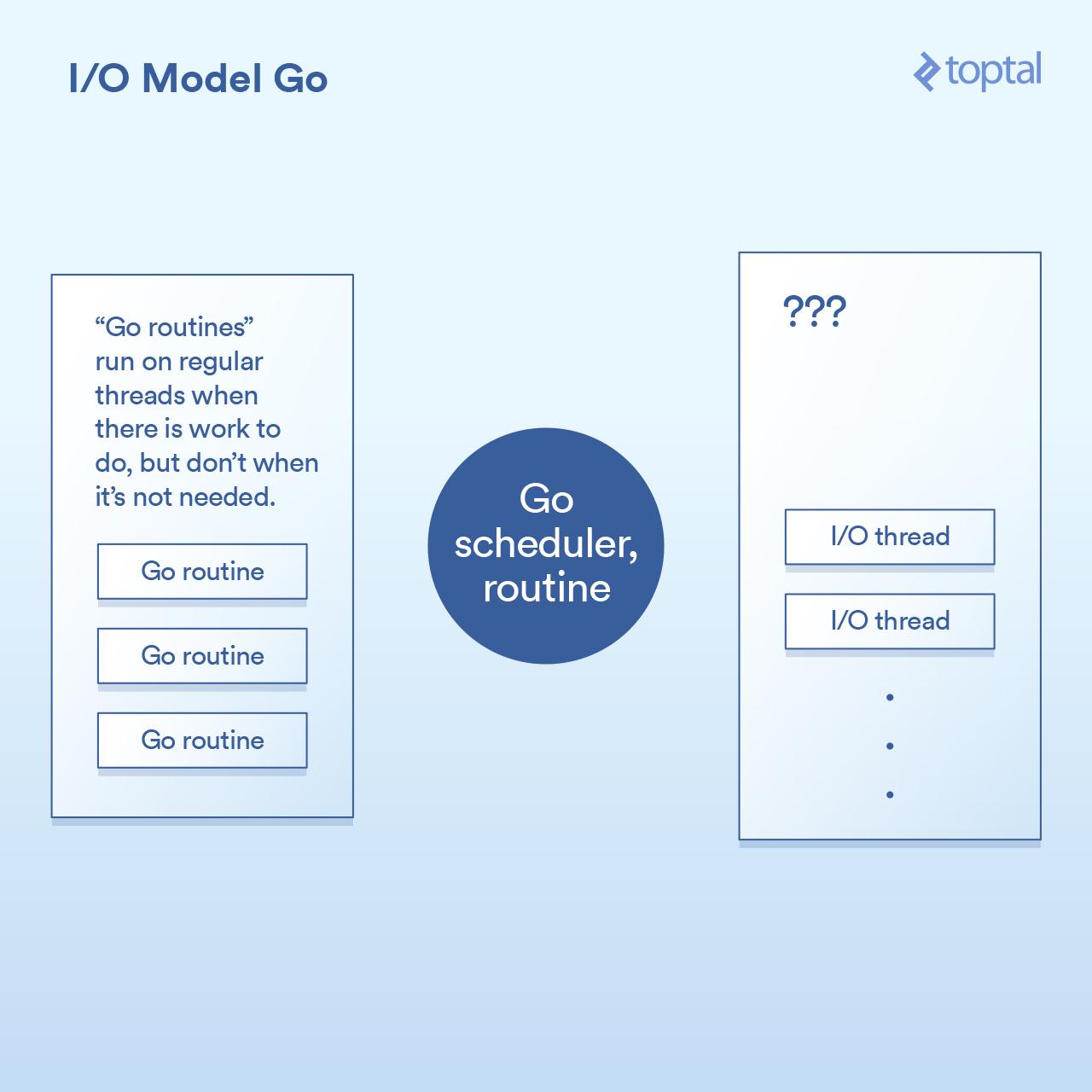
在引擎下,通过 Go 执行程序中的各个点实现的,通过使当前的 goroutine 进入睡眠状态,通过将请求写入/读取/连接等来实现 I/O 调用,通过将信息唤醒回来可采取进一步行动。
实际上,Go 运行时正在做一些与 Node 正在做的不太相似的事情,除了回调机制内置到 I/O 调用的实现中,并自动与调度程序交互。它也不会受到必须让所有处理程序代码在同一个线程中运行的限制,Go 将根据其调度程序中的逻辑自动将 Goroutines 映射到其认为适当的 OS 线程。结果是这样的代码:
func ServeHTTP(w http.ResponseWriter, r *http.Request) {
// the underlying network call here is non-blocking
rows, err := db.Query("SELECT ...")
for _, row := range rows {
// do something with the rows,
// each request in its own goroutine
}
w.Write(...) // write the response, also non-blocking
}
如上所述,我们正在做的类似于更简单的方法的基本代码结构,并且在引擎下实现了非阻塞 I/O。
在大多数情况下,最终都是“两个世界最好的”。非阻塞 I/O 用于所有重要的事情,但是你的代码看起来像是阻塞,因此更容易理解和维护。Go 调度程序和OS调度程序之间的交互处理其余部分。这不是完整的魔法,如果你建立一个大型系统,那么值得我们来看看有关它的工作原理的更多细节; 但与此同时,你获得的“开箱即用”的环境可以很好地工作和扩展。
Go 可能有其缺点,但一般来说,它处理 I/O 的方式不在其中。
谎言,可恶的谎言和基准
对这些各种模式的上下文切换进行准确的定时是很困难的。我也可以认为这对你来说不太有用。相反,我会给出一些比较这些服务器环境的 HTTP 服务器性能的基本基准。请记住,整个端到端 HTTP 请求/响应路径的性能有很多因素,这里提供的数字只是我将一些样本放在一起进行基本比较。
对于这些环境中的每一个,我写了适当的代码以随机字节读取 64k 文件,在其上运行了一个 SHA-256 哈希 N 次( N 在 URL 的查询字符串中指定,例如 .../test.php?n=100),并打印出结果十六进制散列 我选择了这一点,因为使用一些一致的 I/O 和受控的方式来运行相同的基准测试是一个非常简单的方法来增加 CPU 使用率。
有关使用的环境的更多细节,请参阅 基准笔记 。
首先,我们来看一些低并发的例子。运行 2000 次迭代,具有 300 个并发请求,每个请求只有一个散列(N = 1)给我们这样:
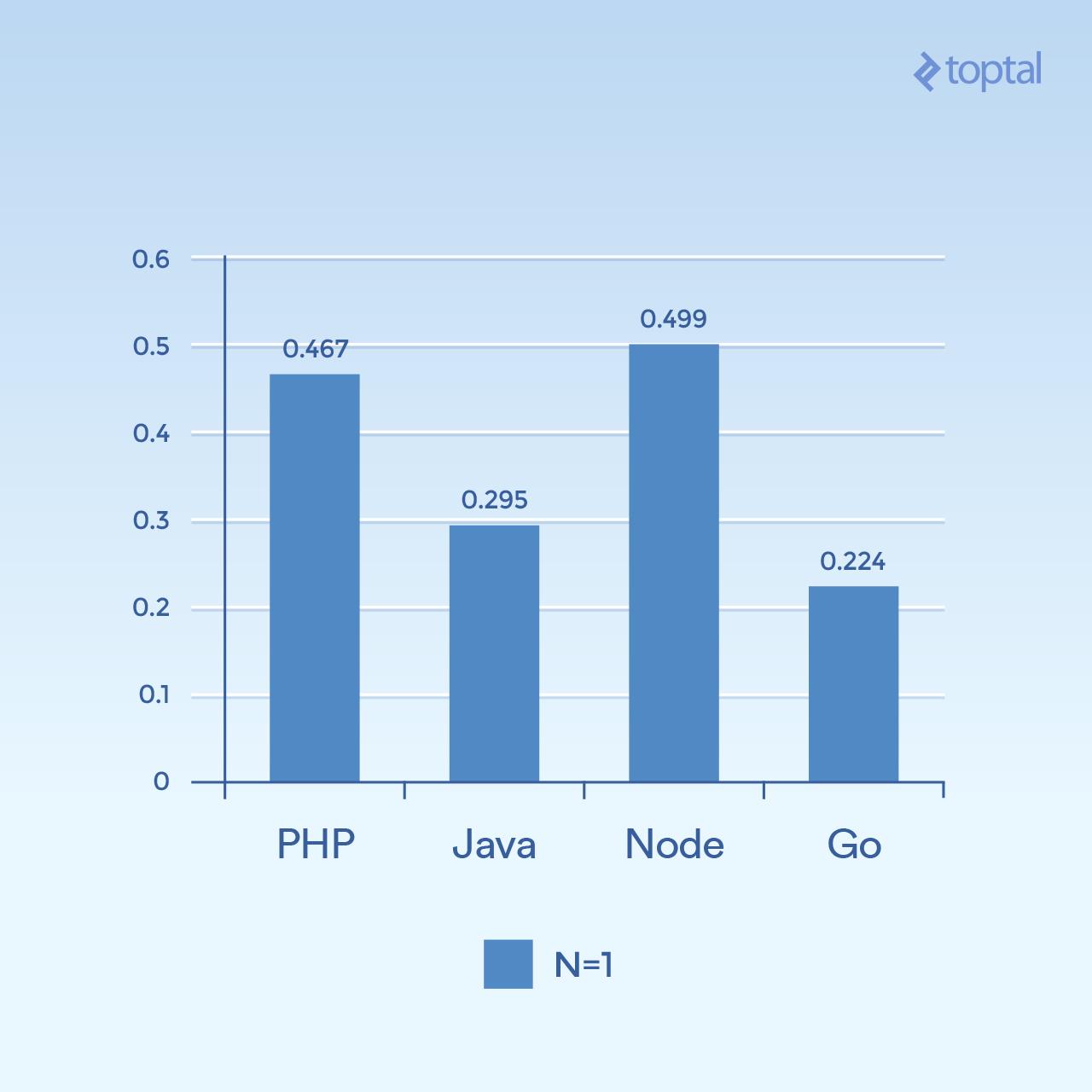
时间是在所有并发请求中完成请求的平均毫秒数。低于更好。
很难从这个图中得出结论,但是对我来说,似乎在这个连接和计算量上,我们看到时间更多地与语言本身的一般执行有关,这样更多的是 I/O。请注意,被认为是“脚本语言”(松散类型,动态解释)的语言执行速度最慢。
但是,如果我们将 N 增加到 1000,仍然有 300 个并发请求,则会发生相同的负载,但是更多的哈希迭代是 100 倍(显着增加了 CPU 负载):
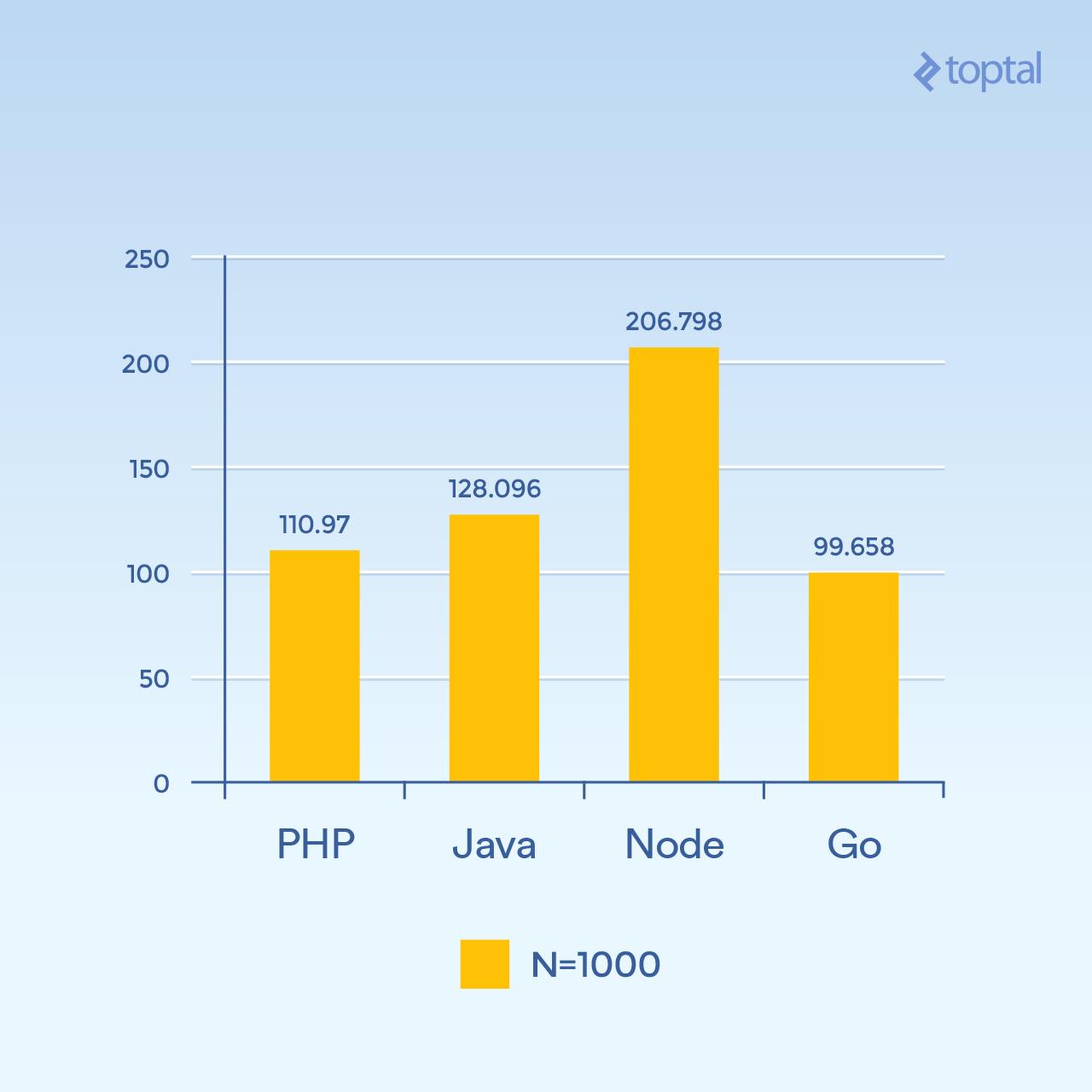
时间是在所有并发请求中完成请求的平均毫秒数。低于更好。
突然间,节点性能显着下降,因为每个请求中的 CPU 密集型操作都相互阻塞。有趣的是,在这个测试中,PHP 的性能要好得多(相对于其他的),并且打败了 Java。(值得注意的是,在 PHP 中,SHA-256 实现是用 C 编写的,执行路径在这个循环中花费更多的时间,因为现在我们正在进行 1000 个哈希迭代)。
现在让我们尝试 5000 个并发连接(N = 1) - 或者接近我可以来的连接。不幸的是,对于大多数这些环境,故障率并不显着。对于这个图表,我们来看每秒的请求总数。 越高越好 :
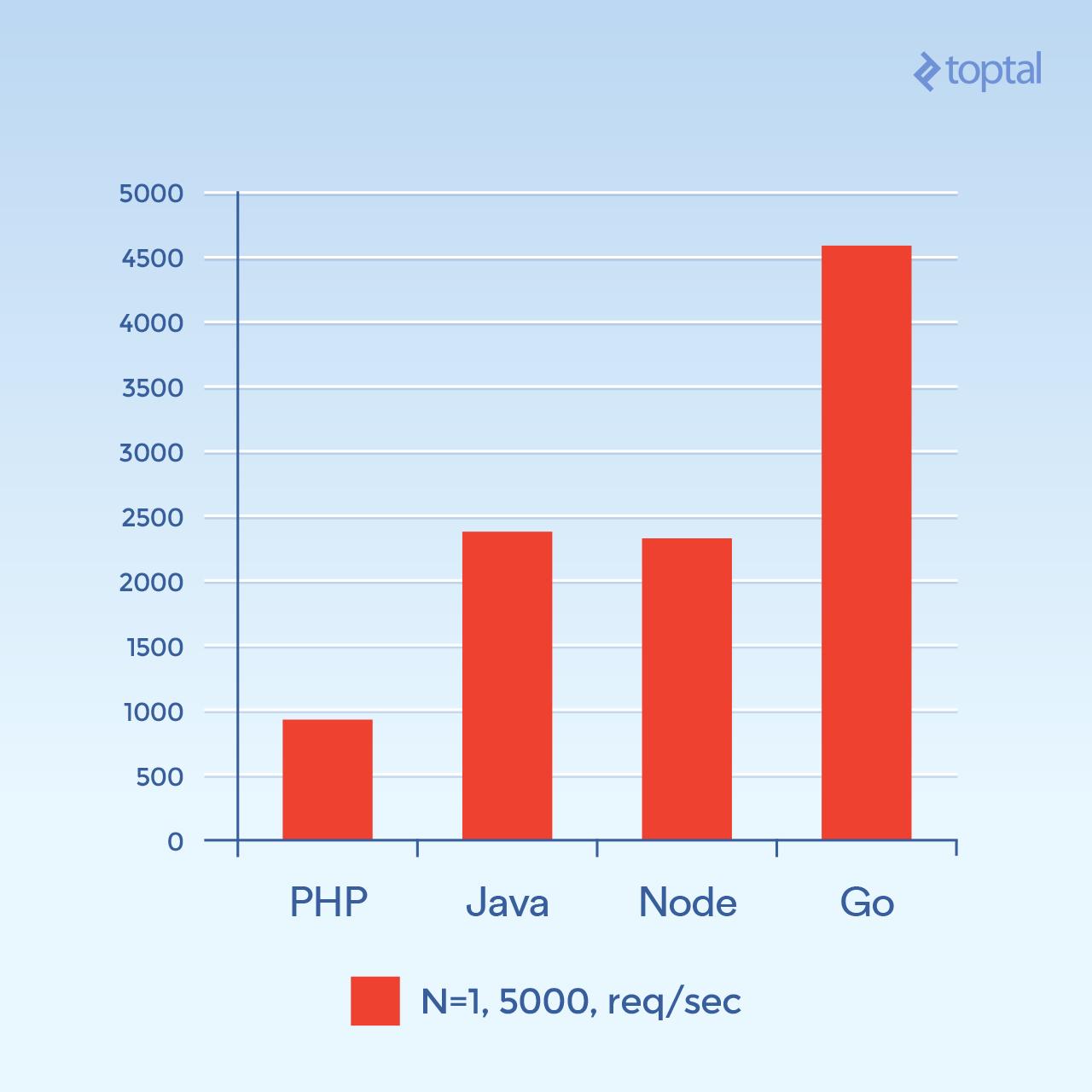
每秒请求总数。越高越好。
而且这张照片看起来有很大的不同 这是一个猜测,但是看起来像在高连接量时,产生新进程所涉及的每连接开销以及与 PHP + Apache 相关联的附加内存似乎成为主要因素,并阻止了 PHP 的性能。显然,Go 是这里的赢家,其次是 Java,Node 和 PHP。
虽然与你的整体吞吐量相关的因素很多,并且在应用程序之间也有很大的差异,但是你了解更多关于发生什么的事情以及所涉及的权衡,你将会越有效。
总结
以上所有这一切,很显然,随着语言的发展,处理大量 I/O 的大型应用程序的解决方案也随之发展。
为了公平起见,PHP 和 Java,尽管这篇文章中的描述,确实有 实现 非阻塞I/O 和 可使用 web 应用程序 。但是这些方法并不像上述方法那么常见,并且需要考虑使用这种方法来维护服务器的随之而来的操作开销。更不用说你的代码必须以与这些环境相适应的方式进行结构化; 你的 “正常” PHP 或 Java Web 应用程序通常不会在这样的环境中进行重大修改。
作为比较,如果我们考虑影响性能和易用性的几个重要因素,我们得出以下结论:
| 语言 | 线程与进程 | 非阻塞 I/O | 使用便捷性 |
|---|---|---|---|
| PHP | 进程 | No | |
| Java | 线程 | Available | 需要回调 |
| Node.js | 线程 | Yes | 需要回调 |
| Go | 线程 (Goroutines) | Yes | 不需要回调 |
线程通常要比进程更高的内存效率,因为它们共享相同的内存空间,而进程没有进程。结合与非阻塞 I/O 相关的因素,我们可以看到,至少考虑到上述因素,当我们向下移动列表时,与 I/O 相关的一般设置得到改善。所以如果我不得不在上面的比赛中选择一个赢家,那肯定会是 Go。
即使如此,在实践中,选择构建应用程序的环境与你的团队对所述环境的熟悉程度以及你可以实现的总体生产力密切相关。因此,每个团队只需潜入并开始在 Node 或 Go 中开发 Web 应用程序和服务可能就没有意义。事实上,寻找开发人员或你内部团队的熟悉度通常被认为是不使用不同语言和/或环境的主要原因。也就是说,过去十五年来,时代已经发生了变化。
希望以上内容可以帮助你更清楚地了解引擎下发生的情况,并为你提供如何处理应用程序的现实可扩展性的一些想法。
via: https://www.toptal.com/back-end/server-side-io-performance-node-php-java-go
作者: BRAD PEABODY 译者:MonkeyDEcho 校对:校对者ID