21 KiB
【Translating by JanzenLiu】 Beyond public key encryption
One of the saddest and most fascinating things about applied cryptography is _how
 little cryptography we actually use. _ This is not to say that cryptography isn’t widely used in industry — it is. Rather, what I mean is that cryptographic researchers have developed so many useful technologies, and yet industry on a day to day basis barely uses any of them. In fact, with a few minor exceptions, the vast majority of the cryptography we use was settled by the early-2000s.*
little cryptography we actually use. _ This is not to say that cryptography isn’t widely used in industry — it is. Rather, what I mean is that cryptographic researchers have developed so many useful technologies, and yet industry on a day to day basis barely uses any of them. In fact, with a few minor exceptions, the vast majority of the cryptography we use was settled by the early-2000s.*
Most people don’t sweat this, but as a cryptographer who works on the boundary of research and deployed cryptography it makes me unhappy. So while I can’t solve the problem entirely, what I can do is talk about some of these newer technologies. And over the course of this summer that’s what I intend to do: talk. Specifically, in the next few weeks I’m going to write a series of posts that describe some of the advanced cryptography that we don’t generally see used.
Today I’m going to start with a very simple question: what lies beyond public key cryptography? Specifically, I’m going to talk about a handful of technologies that were developed in the past 20 years, each of which allows us to go beyond the traditional notion of public keys.
This is a wonky post, but it won’t be mathematically-intense. For actual definitions of the schemes, I’ll provide links to the original papers, and references to cover some of the background. The point here is to explain what these new schemes do — and how they can be useful in practice.
Identity Based Cryptography
In the mid-1980s, a cryptographer named Adi Shamir proposed a radical new idea.The idea, put simply, was to get rid of public keys .
To understand where Shamir was coming from, it helps to understand a bit about public key encryption. You see, prior to the invention of public key crypto, all cryptography involved secret keys. Dealing with such keys was a huge drag. Before you could communicate securely, you needed to exchange a secret with your partner. This process was fraught with difficulty and didn’t scale well.
Public key encryption (beginning with Diffie-Hellman and Shamir’s RSAcryptosystem) hugely revolutionized cryptography by dramatically simplifying this key distribution process. Rather than sharing secret keys, users could now transmit their public key to other parties. This public key allowed the recipient to encrypt to you (or verify your signature) but it could not be used to perform the corresponding decryption (or signature generation) operations. That part would be done with a secret key you kept to yourself.
While the use of public keys improved many aspects of using cryptography, it also gave rise to a set of new challenges. In practice, it turns out that having public keys is only half the battle — people still need to use distribute them securely.
For example, imagine that I want to send you a PGP-encrypted email. Before I can do this, I need to obtain a copy of your public key. How do I get this? Obviously we could meet in person and exchange that key on physical media — but nobody wants to do this. It would much more desirable to obtain your public key electronically. In practice this means either (1) we have to exchange public keys by email, or (2) I have to obtain your key from a third piece of infrastructure, such as a website or key server. And now we come to the problem: if that email or key server is _untrustworthy _ (or simply allows anyone to upload a key in your name),I might end up downloading a malicious party’s key by accident. When I send a message to “you”, I’d actually be encrypting it to Mallory.
 Mallory.
Mallory.
Solving this problem — of exchanging public keys and verifying their provenance — has motivated a huge amount of practical cryptographic engineering, including the entire web PKI. In most cases, these systems work well. But Shamir wasn’t satisfied. What if, he asked, we could do it better? More specifically, he asked: could we replace those pesky public keys with something better?
Shamir’s idea was exciting. What he proposed was a new form of public key cryptography in which the user’s “public key” could simply be their identity . This identity could be a name (e.g., “Matt Green”) or something more precise like an email address. Actually, it didn’t realy matter. What did matter was that the public key would be some arbitrary string — and not a big meaningless jumble of characters like “7cN5K4pspQy3ExZV43F6pQ6nEKiQVg6sBkYPg1FG56Not”.
Of course, using an arbitrary string as a public key raises a big problem. Meaningful identities sound great — but I don’t own them. If my public key is “Matt Green”, how do I get the corresponding private key? And if I can get out that private key, what stops some other Matt Green from doing the same, and thus reading my messages? And ok, now that I think about this, what stops some random person who isn’t named Matt Green from obtaining it? Yikes. We’re headed straight into Zooko’s triangle.
Shamir’s idea thus requires a bit more finesse. Rather than expecting identities to be global, he proposed a special server called a “key generation authority” that would be responsible for generating the private keys. At setup time, this authority would generate a single _master public key (MPK), _ which it would publish to the world. If you wanted to encrypt a message to “Matt Green” (or verify my signature), then you could do so using my identity and the single MPK of an authority we’d both agree to use. To _decrypt _ that message (or sign one), I would have to visit the same key authority and ask for a copy of my secret key. The key authority would compute my key based on a master secret key (MSK) , which it would keep very secret.
With all algorithms and players specified, whole system looks like this:
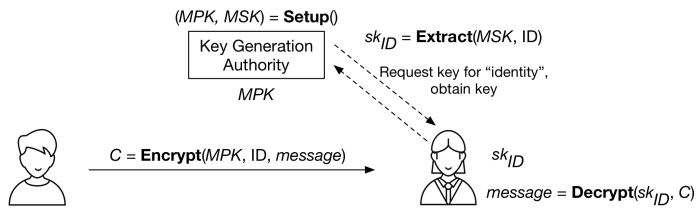 Overview of an Identity-Based Encryption (IBE) system. The Setup algorithm of the Key Generation Authority generates the master public key (MPK) and master secret key (MSK). The authority can use the Extract algorithm to derive the secret key corresponding to a specific ID. The encryptor (left) encrypts using only the identity and MPK. The recipient requests the secret key for her identity, and then uses it to decrypt. (Icons by Eugen Belyakoff)
Overview of an Identity-Based Encryption (IBE) system. The Setup algorithm of the Key Generation Authority generates the master public key (MPK) and master secret key (MSK). The authority can use the Extract algorithm to derive the secret key corresponding to a specific ID. The encryptor (left) encrypts using only the identity and MPK. The recipient requests the secret key for her identity, and then uses it to decrypt. (Icons by Eugen Belyakoff)
This design has some important advantages — and more than a few obvious drawbacks. On the plus side, it removes the need for any key exchange at all with the person you’re sending the message to. Once you’ve chosen a master key authority (and downloaded its MPK), you can encrypt to anyone in the entire world. Even cooler: at the time you encrypt, your recipient doesn’t even need to have contacted the key authority yet . She can obtain her secret key after I send her a message.
Of course, this “feature” is also a bug. Because the key authority generates all the secret keys, it has an awful lot of power. A dishonest authority could easily generate your secret key and decrypt your messages. The polite way to say this is that standard IBE systems effectively “bake in” key escrow.**
Putting the “E” in IBE
All of these ideas and more were laid out by Shamir in his 1984 paper. There was just one small problem: Shamir could only figure out half the problem.
Specifically, Shamir’s proposed a scheme for identity-based signature (IBS) — a signature scheme where the public verification key is an identity, but the signing key is generated by the key authority. Try as he might, he could not find a solution to the problem of building identity-based _ encryption _ (IBE). This was left as an open problem.***
It would take more than 16 years before someone answered Shamir’s challenge. Surprisingly, when the answer came it came not once but three times .
The first, and probably most famous realization of IBE was developed by Dan Boneh and Matthew Franklin much later — in 2001. The timing of Boneh and Franklin’s discovery makes a great deal of sense. The Boneh-Franklin scheme relies fundamentally on elliptic curves that support an efficient “bilinear map” (or “pairing”).**** The algorithms needed to compute such pairings were not known when Shamir wrote his paper, and weren’t employed constructively — that is, as a useful thing rather than an attack — until about 2000. The same can be said about a second scheme called Sakai-Kasahara, which would be independently discovered around the same time.
(For a brief tutorial on the Boneh-Franklin IBE scheme, see this page.)
The third realization of IBE was not as efficient as the others, but was much more surprising. This scheme was developed by Clifford Cocks, a senior cryptologist at Britain’s GCHQ. It’s noteworthy for two reasons. First, Cocks’ IBE scheme does not require bilinear pairings at all — it is based in the much older RSA setting, which means _in principle _ it spent all those years just waiting to be found. Second, Cocks himself had recently become known for something even more surprising: discovering the RSA cryptosystem, nearly five years before RSA did. To bookend that accomplishment with a second major advance in public key cryptography was a pretty impressive accomplishment.
In the years since 2001, a number of additional IBE constructions have been developed, using all sorts of cryptographic settings. Nonetheless, Boneh and Franklin’s early construction remains among the simplest and most efficient.
Even if you’re not interested in IBE for its own sake, it turns out that this primitive is really useful to cryptographers for many things beyond simple encryption. In fact, it’s more helpful to think of IBE as a way of “pluralizing” a single public/secret master keypair into billions of related keypairs. This makes it useful for applications as diverse as blocking chosen ciphertext attacks, forward-secure public key encryption, and short signature schemes.
Attribute Based Encryption
Of course, if you leave cryptographers alone with a tool like IBE, the first thing they’re going to do is find a way to make things more complicated improve on it.
One of the biggest such improvements is due to Sahai and Waters. It’s called Attribute-Based Encryption, or ABE.
The origin of this idea was not actually to encrypt with attributes. Instead Sahai and Waters were attempting to develop an Identity-Based encryption scheme that could encrypt using biometrics. To understand the problem, imagine I decide to use a biometric like your iris scan as the “identity” to encrypt you a ciphertext. Later on you’ll ask the authority for a decryption key that corresponds to your own iris scan — and if everything matches up and you’ll be able to decrypt.
The problem is that this will almost never work.
The issue here is that biometric readings (like iris scans or fingerprint templates) are inherently error-prone. This means every scan will typically be very close , but often there will be a few bits that disagree. With standard IBE
 Tell me this isn’t giving you nightmares.
Tell me this isn’t giving you nightmares.
this is fatal : if the encryption identity differs from your key identity by even a single bit, decryption will not work. You’re out of luck.
Sahai and Waters decided that the solution to this problem was to develop a form of IBE with a “threshold gate”. In this setting, each bit of the identity is represented as a different “attribute”. Think of each of these as components you’d encrypt under — something like “bit 5 of your iris scan is a 1” and “bit 23 of your iris scan is a 0”. The encrypting party lists all of these bits and encrypts under each one. The decryption key generated by the authority embeds a similar list of bit values. The scheme is defined so that decryption will work if and only if the number of matching attributes (between your key and the ciphertext) exceeds some pre-defined threshold: e.g., any 2024 out of 2048 bits must be identical in order to decrypt.
The beautiful thing about this idea is not fuzzy IBE. It’s that once you have a threshold gate and a concept of “attributes”, you can more interesting things. The main observation is that a threshold gate can be used to implement the boolean AND and OR gates, like so:
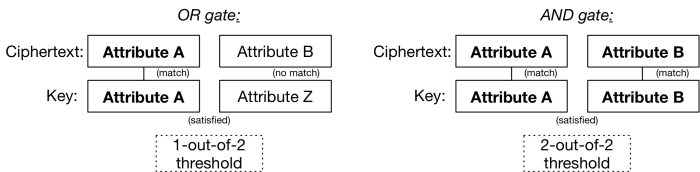
Even better, you can stack these gates on top of one another to assign a fairly complex boolean formula — which will itself determine what conditions your ciphertext can be decrypted under. For example, switching to a more realistic set of attributes, you could encrypt a medical record so that either a pediatrician in a hospital could read it, or an insurance adjuster could. All you’d need is to make sure people received keys that correctly described their attributes (which are just arbitrary strings, like identities).
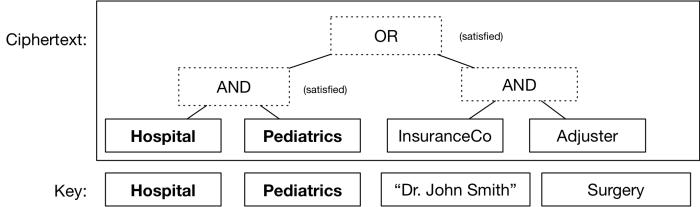 A simple “ciphertext policy”, in which the ciphertext can be decrypted if and only if a key matches an appropriate set of attributes. In this case, the key satisfies the formula and thus the ciphertext decrypts. The remaining key attributes are ignored.
A simple “ciphertext policy”, in which the ciphertext can be decrypted if and only if a key matches an appropriate set of attributes. In this case, the key satisfies the formula and thus the ciphertext decrypts. The remaining key attributes are ignored.
The other direction can be implemented as well. It’s possible to encrypt a ciphertext under a long list of attributes, such as creation time, file name, and even GPS coordinates indicating where the file was created. You can then have the authority hand out keys that correspond to a very precise slice of your dataset — for example, “this key decrypts any radiology file encrypted in Chicago between November 3rd and December 12th that is tagged with ‘pediatrics’ or ‘oncology'”.
Functional Encryption
Once you have a related of primitives like IBE and ABE, the researchers’ instinct is to both extend and generalize. Why stop at simple boolean formulae? Can we make keys (or ciphertexts) that embed _arbitrary computer programs? _ The answer, it turns out, is yes — though not terribly efficiently. A set of recent works show that it is possible to build ABE that works over arbitrary polynomial-size circuits, using various lattice-based assumptions. So there is certainly a lot of potential here.
This potential has inspired researchers to generalize all of the above ideas into a single class of encryption called “functional encryption“. Functional encryption is more conceptual than concrete — it’s just a way to look at all of these systems as instances of a specific class. The basic idea is to represent the decryption procedure as an algorithm that computes an arbitary function F over (1) the plaintext inside of a ciphertext, and (2) the data embedded in the key. This function has the following profile:
output = F(key data, plaintext data)
In this model IBE can be expressed by having the encryption algorithm encrypt _ (identity, plaintext) _ and defining the function _F _ such that, if “ _key input == identity”, it _ outputs the plaintext, and outputs an empty string otherwise. Similarly, ABE can be expressed by a slightly more complex function. Following this paradigm, once can envision all sorts of interesting functions that might be computed by different functions and realized by future schemes.
But those will have to wait for another time. We’ve gone far enough for today.
So what’s the point of all this?
For me, the point is just to show that cryptography can do some pretty amazing things. We rarely see this on a day-to-day basis when it comes to industry and “applied” cryptography, but it’s all there waiting to be used.
Perhaps the perfect application is out there. Maybe you’ll find it.
Notes:
- An earlier version of this post said “mid-1990s”. In comments below, Tom Ristenpart takes issue with that and makes the excellent point that many important developments post-date that. So I’ve moved the date forward about five years, and I’m thinking about how to say this in a nicer way.
** There is also an intermediate form of encryption known as “certificateless encryption“. Proposed by Al-Riyami and Paterson, this idea uses a combination of standard public key encryption and IBE. The basic idea is to encrypt each message using both a traditional public key (generated by the recipient) and an IBE identity. The recipient must then obtain a copy of the secret key from the IBE authority to decrypt. The advantages here are twofold: (1) the IBE key authority can’t decrypt the message by itself, since it does not have the corresponding secret key, which solves the “escrow” problem. And (2) the sender does not need to verify that the public key really belongs to the sender (e.g., by checking a certificate), since the IBE portion prevents imposters from decrypting the resulting message. Unfortunately this system is more like traditional public key cryptography than IBE, and does not have the neat usability features of IBE.
*** A part of the challenge of developing IBE is the need to make a system that is secure against “collusion” between different key holders. For example, imagine a very simple system that has only 2-bit identities. This gives four possible identities: “00”, “01”, “10”, “11”. If I give you a key for the identity “01” and I give Bob a key for “10”, we need to ensure that you two cannot collude to produce a key for identities “00” and “11”. Many earlier proposed solutions have tried to solve this problem by gluing together standard public encryption keys in various ways (e.g., by having a separate public key for each bit of the identity and giving out the secret keys as a single “key”). However these systems tend to fail catastrophically when just a few users collude (or their keys are stolen). Solving the collusion problem is fundamentally what separates real IBE from its faux cousins.
**** A full description of Boneh and Franklin’s scheme can be found here, or in the original paper. Some code is here and here and here. I won’t spend more time on it, except to note that the scheme is very efficient. It was patented and implemented by Voltage Security, now part of HPE.
via: https://github.com/LCTT/TranslateProject/tree/master/sources/tech
作者:Matthew Green 译者:译者ID 校对:校对者ID