sources/tech/20190308 Virtual filesystems in Linux- Why we need them and how they work.md
22 KiB
Virtual filesystems in Linux: Why we need them and how they work
Virtual filesystems are the magic abstraction that makes the "everything is a file" philosophy of Linux possible.

What is a filesystem? According to early Linux contributor and author [Robert Love][1], "A filesystem is a hierarchical storage of data adhering to a specific structure." However, this description applies equally well to VFAT (Virtual File Allocation Table), Git, and [Cassandra][2] (a [NoSQL database][3]). So what distinguishes a filesystem?
Filesystem basics
The Linux kernel requires that for an entity to be a filesystem, it must also implement the open() , read() , and write() methods on persistent objects that have names associated with them. From the point of view of [object-oriented programming][4], the kernel treats the generic filesystem as an abstract interface, and these big-three functions are "virtual," with no default definition. Accordingly, the kernel's default filesystem implementation is called a virtual filesystem (VFS).
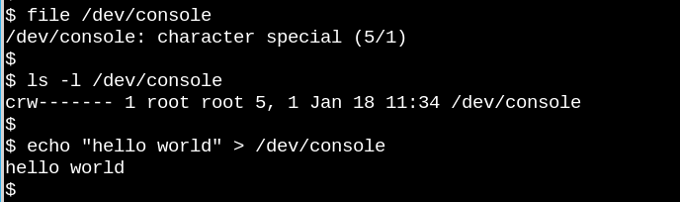
![][5] If we can open(), read(), and write(), it is a file as this console session shows.
VFS underlies the famous observation that in Unix-like systems "everything is a file." Consider how weird it is that the tiny demo above featuring the character device /dev/console actually works. The image shows an interactive Bash session on a virtual teletype (tty). Sending a string into the virtual console device makes it appear on the virtual screen. VFS has other, even odder properties. For example, it's [possible to seek in them][6].
The familiar filesystems like ext4, NFS, and /proc all provide definitions of the big-three functions in a C-language data structure called [file_operations][7] . In addition, particular filesystems extend and override the VFS functions in the familiar object-oriented way. As Robert Love points out, the abstraction of VFS enables Linux users to blithely copy files to and from foreign operating systems or abstract entities like pipes without worrying about their internal data format. On behalf of userspace, via a system call, a process can copy from a file into the kernel's data structures with the read() method of one filesystem, then use the write() method of another kind of filesystem to output the data.
The function definitions that belong to the VFS base type itself are found in the [fs/*.c files][8] in kernel source, while the subdirectories of fs/ contain the specific filesystems. The kernel also contains filesystem-like entities such as cgroups, /dev, and tmpfs, which are needed early in the boot process and are therefore defined in the kernel's init/ subdirectory. Note that cgroups, /dev, and tmpfs do not call the file_operations big-three functions, but directly read from and write to memory instead.
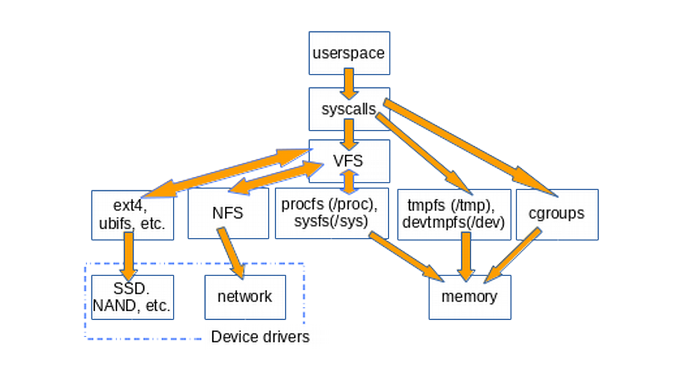
The diagram below roughly illustrates how userspace accesses various types of filesystems commonly mounted on Linux systems. Not shown are constructs like pipes, dmesg, and POSIX clocks that also implement struct file_operations and whose accesses therefore pass through the VFS layer.
![How userspace accesses various types of filesystems][9] VFS are a "shim layer" between system calls and implementors of specific file_operations like ext4 and procfs. The file_operations functions can then communicate either with device-specific drivers or with memory accessors. tmpfs, devtmpfs and cgroups don't make use of file_operations but access memory directly.
VFS's existence promotes code reuse, as the basic methods associated with filesystems need not be re-implemented by every filesystem type. Code reuse is a widely accepted software engineering best practice! Alas, if the reused code [introduces serious bugs][10], then all the implementations that inherit the common methods suffer from them.
/tmp: A simple tip
An easy way to find out what VFSes are present on a system is to type mount | grep -v sd | grep -v :/ , which will list all mounted filesystems that are not resident on a disk and not NFS on most computers. One of the listed VFS mounts will assuredly be /tmp, right?
![Man with shocked expression][11] Everyone knows that keeping /tmp on a physical storage device is crazy! credit: https://tinyurl.com/ybomxyfo
Why is keeping /tmp on storage inadvisable? Because the files in /tmp are temporary(!), and storage devices are slower than memory, where tmpfs are created. Further, physical devices are more subject to wear from frequent writing than memory is. Last, files in /tmp may contain sensitive information, so having them disappear at every reboot is a feature.
Unfortunately, installation scripts for some Linux distros still create /tmp on a storage device by default. Do not despair should this be the case with your system. Follow simple instructions on the always excellent [Arch Wiki][12] to fix the problem, keeping in mind that memory allocated to tmpfs is not available for other purposes. In other words, a system with a gigantic tmpfs with large files in it can run out of memory and crash. Another tip: when editing the /etc/fstab file, be sure to end it with a newline, as your system will not boot otherwise. (Guess how I know.)
/proc and /sys
Besides /tmp, the VFSes with which most Linux users are most familiar are /proc and /sys. (/dev relies on shared memory and has no file_operations). Why two flavors? Let's have a look in more detail.
The procfs offers a snapshot into the instantaneous state of the kernel and the processes that it controls for userspace. In /proc, the kernel publishes information about the facilities it provides, like interrupts, virtual memory, and the scheduler. In addition, /proc/sys is where the settings that are configurable via the [sysctl command][13] are accessible to userspace. Status and statistics on individual processes are reported in /proc/ directories.
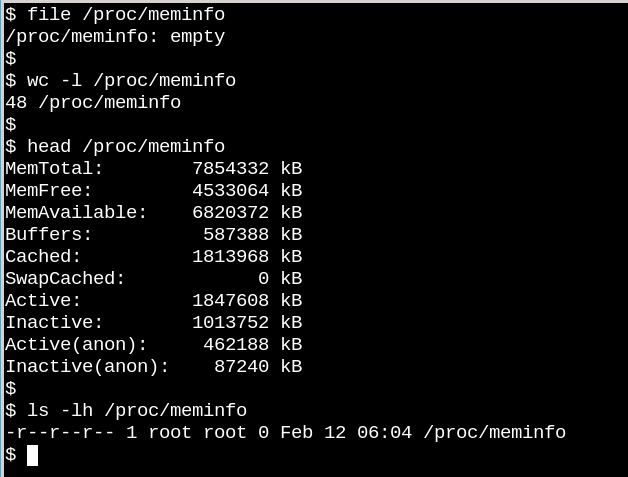
![Console][14] /proc/meminfo is an empty file that nonetheless contains valuable information.
The behavior of /proc files illustrates how unlike on-disk filesystems VFS can be. On the one hand, /proc/meminfo contains the information presented by the command free. On the other hand, it's also empty! How can this be? The situation is reminiscent of a famous article written by Cornell University physicist N. David Mermin in 1985 called "[Is the moon there when nobody looks?][15] Reality and the quantum theory." The truth is that the kernel gathers statistics about memory when a process requests them from /proc, and there actually is nothing in the files in /proc when no one is looking. As [Mermin said][16], "It is a fundamental quantum doctrine that a measurement does not, in general, reveal a preexisting value of the measured property." (The answer to the question about the moon is left as an exercise.)
![Full moon][17] The files in /proc are empty when no process accesses them. ([Source][18])
The apparent emptiness of procfs makes sense, as the information available there is dynamic. The situation with sysfs is different. Let's compare how many files of at least one byte in size there are in /proc versus /sys.

Procfs has precisely one, namely the exported kernel configuration, which is an exception since it needs to be generated only once per boot. On the other hand, /sys has lots of larger files, most of which comprise one page of memory. Typically, sysfs files contain exactly one number or string, in contrast to the tables of information produced by reading files like /proc/meminfo.
The purpose of sysfs is to expose the readable and writable properties of what the kernel calls "kobjects" to userspace. The only purpose of kobjects is reference-counting: when the last reference to a kobject is deleted, the system will reclaim the resources associated with it. Yet, /sys constitutes most of the kernel's famous "[stable ABI to userspace][19]" which [no one may ever, under any circumstances, "break."][20] That doesn't mean the files in sysfs are static, which would be contrary to reference-counting of volatile objects.
The kernel's stable ABI instead constrains what can appear in /sys, not what is actually present at any given instant. Listing the permissions on files in sysfs gives an idea of how the configurable, tunable parameters of devices, modules, filesystems, etc. can be set or read. Logic compels the conclusion that procfs is also part of the kernel's stable ABI, although the kernel's [documentation][19] doesn't state so explicitly.
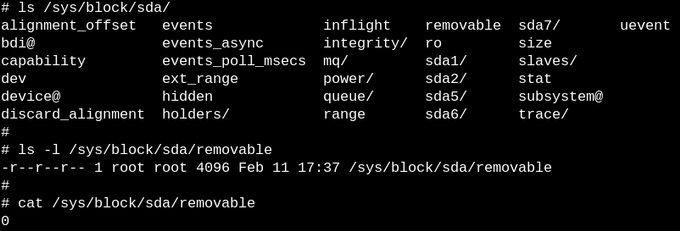
![Console][21] Files in sysfs describe exactly one property each for an entity and may be readable, writable or both. The "0" in the file reveals that the SSD is not removable.
Snooping on VFS with eBPF and bcc tools
The easiest way to learn how the kernel manages sysfs files is to watch it in action, and the simplest way to watch on ARM64 or x86_64 is to use eBPF. eBPF (extended Berkeley Packet Filter) consists of a [virtual machine running inside the kernel][22] that privileged users can query from the command line. Kernel source tells the reader what the kernel can do; running eBPF tools on a booted system shows instead what the kernel actually does.
Happily, getting started with eBPF is pretty easy via the [bcc][23] tools, which are available as [packages from major Linux distros][24] and have been [amply documented][25] by Brendan Gregg. The bcc tools are Python scripts with small embedded snippets of C, meaning anyone who is comfortable with either language can readily modify them. At this count, [there are 80 Python scripts in bcc/tools][26], making it highly likely that a system administrator or developer will find an existing one relevant to her/his needs.
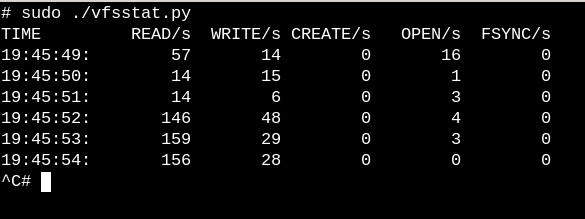
To get a very crude idea about what work VFSes are performing on a running system, try the simple [vfscount][27] or [vfsstat][28], which show that dozens of calls to vfs_open() and its friends occur every second.
![Console - vfsstat.py][29] vfsstat.py is a Python script with an embedded C snippet that simply counts VFS function calls.
For a less trivial example, let's watch what happens in sysfs when a USB stick is inserted on a running system.
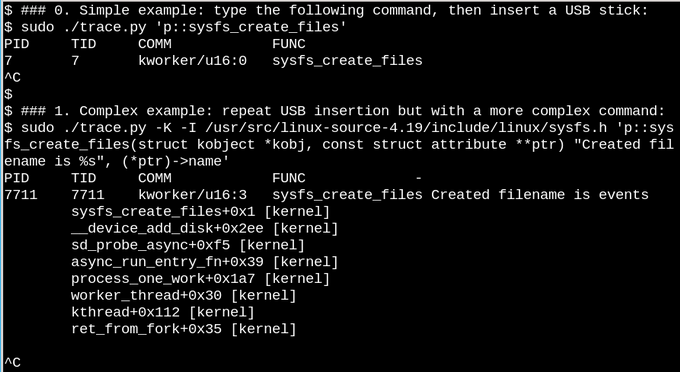
![Console when USB is inserted][30] Watch with eBPF what happens in /sys when a USB stick is inserted, with simple and complex examples.
In the first simple example above, the [trace.py][31] bcc tools script prints out a message whenever the sysfs_create_files() command runs. We see that sysfs_create_files() was started by a kworker thread in response to the USB stick insertion, but what file was created? The second example illustrates the full power of eBPF. Here, trace.py is printing the kernel backtrace (-K option) plus the name of the file created by sysfs_create_files(). The snippet inside the single quotes is some C source code, including an easily recognizable format string, that the provided Python script [induces a LLVM just-in-time compiler][32] to compile and execute inside an in-kernel virtual machine. The full sysfs_create_files() function signature must be reproduced in the second command so that the format string can refer to one of the parameters. Making mistakes in this C snippet results in recognizable C-compiler errors. For example, if the -I parameter is omitted, the result is "Failed to compile BPF text." Developers who are conversant with either C or Python will find the bcc tools easy to extend and modify.
When the USB stick is inserted, the kernel backtrace appears showing that PID 7711 is a kworker thread that created a file called "events" in sysfs. A corresponding invocation with sysfs_remove_files() shows that removal of the USB stick results in removal of the events file, in keeping with the idea of reference counting. Watching sysfs_create_link() with eBPF during USB stick insertion (not shown) reveals that no fewer than 48 symbolic links are created.
What is the purpose of the events file anyway? Using [cscope][33] to find the function [__device_add_disk()][34] reveals that it calls disk_add_events(), and either "media_change" or "eject_request" may be written to the events file. Here, the kernel's block layer is informing userspace about the appearance and disappearance of the "disk." Consider how quickly informative this method of investigating how USB stick insertion works is compared to trying to figure out the process solely from the source.
Read-only root filesystems make embedded devices possible
Assuredly, no one shuts down a server or desktop system by pulling out the power plug. Why? Because mounted filesystems on the physical storage devices may have pending writes, and the data structures that record their state may become out of sync with what is written on the storage. When that happens, system owners will have to wait at next boot for the [fsck filesystem-recovery tool][35] to run and, in the worst case, will actually lose data.
Yet, aficionados will have heard that many IoT and embedded devices like routers, thermostats, and automobiles now run Linux. Many of these devices almost entirely lack a user interface, and there's no way to "unboot" them cleanly. Consider jump-starting a car with a dead battery where the power to the [Linux-running head unit][36] goes up and down repeatedly. How is it that the system boots without a long fsck when the engine finally starts running? The answer is that embedded devices rely on [a read-only root fileystem][37] (ro-rootfs for short).
![Photograph of a console][38] ro-rootfs are why embedded systems don't frequently need to fsck. Credit (with permission): https://tinyurl.com/yxoauoub
A ro-rootfs offers many advantages that are less obvious than incorruptibility. One is that malware cannot write to /usr or /lib if no Linux process can write there. Another is that a largely immutable filesystem is critical for field support of remote devices, as support personnel possess local systems that are nominally identical to those in the field. Perhaps the most important (but also most subtle) advantage is that ro-rootfs forces developers to decide during a project's design phase which system objects will be immutable. Dealing with ro-rootfs may often be inconvenient or even painful, as [const variables in programming languages][39] often are, but the benefits easily repay the extra overhead.
Creating a read-only rootfs does require some additional amount of effort for embedded developers, and that's where VFS comes in. Linux needs files in /var to be writable, and in addition, many popular applications that embedded systems run will try to create configuration dot-files in $HOME. One solution for configuration files in the home directory is typically to pregenerate them and build them into the rootfs. For /var, one approach is to mount it on a separate writable partition while / itself is mounted as read-only. Using bind or overlay mounts is another popular alternative.
Bind and overlay mounts and their use by containers
Running [man mount][40] is the best place to learn about bind and overlay mounts, which give embedded developers and system administrators the power to create a filesystem in one path location and then provide it to applications at a second one. For embedded systems, the implication is that it's possible to store the files in /var on an unwritable flash device but overlay- or bind-mount a path in a tmpfs onto the /var path at boot so that applications can scrawl there to their heart's delight. At next power-on, the changes in /var will be gone. Overlay mounts provide a union between the tmpfs and the underlying filesystem and allow apparent modification to an existing file in a ro-rootfs, while bind mounts can make new empty tmpfs directories show up as writable at ro-rootfs paths. While overlayfs is a proper filesystem type, bind mounts are implemented by the [VFS namespace facility][41].
Based on the description of overlay and bind mounts, no one will be surprised that [Linux containers][42] make heavy use of them. Let's spy on what happens when we employ [systemd-nspawn][43] to start up a container by running bcc's mountsnoop tool:
![Console - system-nspawn invocation][44] The system-nspawn invocation fires up the container while mountsnoop.py runs.
And let's see what happened:
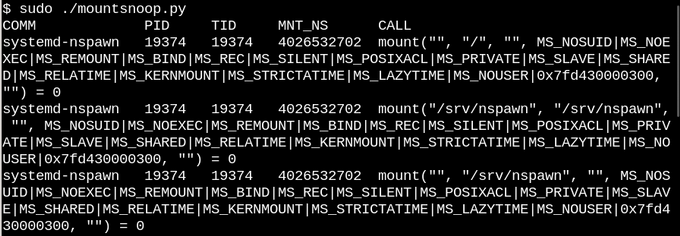
![Console - Running mountsnoop][45] Running mountsnoop during the container "boot" reveals that the container runtime relies heavily on bind mounts. (Only the beginning of the lengthy output is displayed)
Here, systemd-nspawn is providing selected files in the host's procfs and sysfs to the container at paths in its rootfs. Besides the MS_BIND flag that sets bind-mounting, some of the other flags that the "mount" system call invokes determine the relationship between changes in the host namespace and in the container. For example, the bind-mount can either propagate changes in /proc and /sys to the container, or hide them, depending on the invocation.
Summary
Understanding Linux internals can seem an impossible task, as the kernel itself contains a gigantic amount of code, leaving aside Linux userspace applications and the system-call interface in C libraries like glibc. One way to make progress is to read the source code of one kernel subsystem with an emphasis on understanding the userspace-facing system calls and headers plus major kernel internal interfaces, exemplified here by the file_operations table. The file operations are what makes "everything is a file" actually work, so getting a handle on them is particularly satisfying. The kernel C source files in the top-level fs/ directory constitute its implementation of virtual filesystems, which are the shim layer that enables broad and relatively straightforward interoperability of popular filesystems and storage devices. Bind and overlay mounts via Linux namespaces are the VFS magic that makes containers and read-only root filesystems possible. In combination with a study of source code, the eBPF kernel facility and its bcc interface makes probing the kernel simpler than ever before.
Much thanks to [Akkana Peck][46] and [Michael Eager][47] for comments and corrections.
Alison Chaiken will present [Virtual filesystems: why we need them and how they work][48] at the 17th annual Southern California Linux Expo ([SCaLE 17x][49]) March 7-10 in Pasadena, Calif.
via: https://opensource.com/article/19/3/virtual-filesystems-linux
作者:[Alison Chariken][a] 选题:[lujun9972][b] 译者:译者ID 校对:校对者ID
[a]: [b]: https://github.com/lujun9972 [1]: https://www.pearson.com/us/higher-education/program/Love-Linux-Kernel-Development-3rd-Edition/PGM202532.html [2]: http://cassandra.apache.org/ [3]: https://en.wikipedia.org/wiki/NoSQL [4]: http://lwn.net/Articles/444910/ [5]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_1-console.png (Console) [6]: https://lwn.net/Articles/22355/ [7]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/include/linux/fs.h [8]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/fs [9]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_2-shim-layer.png (How userspace accesses various types of filesystems) [10]: https://lwn.net/Articles/774114/ [11]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_3-crazy.jpg (Man with shocked expression) [12]: https://wiki.archlinux.org/index.php/Tmpfs [13]: http://man7.org/linux/man-pages/man8/sysctl.8.html [14]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_4-proc-meminfo.png (Console) [15]: http://www-f1.ijs.si/~ramsak/km1/mermin.moon.pdf [16]: https://en.wikiquote.org/wiki/David_Mermin [17]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_5-moon.jpg (Full moon) [18]: https://commons.wikimedia.org/wiki/Moon#/media/File:Full_Moon_Luc_Viatour.jpg [19]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/ABI/stable [20]: https://lkml.org/lkml/2012/12/23/75 [21]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_7-sysfs.png (Console) [22]: https://events.linuxfoundation.org/sites/events/files/slides/bpf_collabsummit_2015feb20.pdf [23]: https://github.com/iovisor/bcc [24]: https://github.com/iovisor/bcc/blob/master/INSTALL.md [25]: http://brendangregg.com/ebpf.html [26]: https://github.com/iovisor/bcc/tree/master/tools [27]: https://github.com/iovisor/bcc/blob/master/tools/vfscount_example.txt [28]: https://github.com/iovisor/bcc/blob/master/tools/vfsstat.py [29]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_8-vfsstat.png (Console - vfsstat.py) [30]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_9-ebpf.png (Console when USB is inserted) [31]: https://github.com/iovisor/bcc/blob/master/tools/trace_example.txt [32]: https://events.static.linuxfound.org/sites/events/files/slides/bpf_collabsummit_2015feb20.pdf [33]: http://northstar-www.dartmouth.edu/doc/solaris-forte/manuals/c/user_guide/cscope.html [34]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/block/genhd.c#n665 [35]: http://www.man7.org/linux/man-pages/man8/fsck.8.html [36]: https://wiki.automotivelinux.org/_media/eg-rhsa/agl_referencehardwarespec_v0.1.0_20171018.pdf [37]: https://elinux.org/images/1/1f/Read-only_rootfs.pdf [38]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_10-code.jpg (Photograph of a console) [39]: https://www.meetup.com/ACCU-Bay-Area/events/drpmvfytlbqb/ [40]: http://man7.org/linux/man-pages/man8/mount.8.html [41]: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/filesystems/sharedsubtree.txt [42]: https://coreos.com/os/docs/latest/kernel-modules.html [43]: https://www.freedesktop.org/software/systemd/man/systemd-nspawn.html [44]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_11-system-nspawn.png (Console - system-nspawn invocation) [45]: https://opensource.com/sites/default/files/uploads/virtualfilesystems_12-mountsnoop.png (Console - Running mountsnoop) [46]: http://shallowsky.com/ [47]: http://eagercon.com/ [48]: https://www.socallinuxexpo.org/scale/17x/presentations/virtual-filesystems-why-we-need-them-and-how-they-work [49]: https://www.socallinuxexpo.org/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}