47 KiB
实验 6:网络驱动程序
实验 6:网络驱动程序(缺省的最终设计)
简介
这个实验是缺省的最终项目中你自己能够做的最后的实验。
现在你有了一个文件系统,一个典型的操作系统都应该有一个网络栈。在本实验中,你将继续为一个网卡去写一个驱动程序。这个网卡基于 Intel 82540EM 芯片,也就是众所周知的 E1000 芯片。
预备知识
使用 Git 去提交你的实验 5 的源代码(如果还没有提交的话),获取课程仓库的最新版本,然后创建一个名为 lab6 的本地分支,它跟踪我们的远程分支 origin/lab6:
athena% cd ~/6.828/lab
athena% add git
athena% git commit -am 'my solution to lab5'
nothing to commit (working directory clean)
athena% git pull
Already up-to-date.
athena% git checkout -b lab6 origin/lab6
Branch lab6 set up to track remote branch refs/remotes/origin/lab6.
Switched to a new branch "lab6"
athena% git merge lab5
Merge made by recursive.
fs/fs.c | 42 +++++++++++++++++++
1 files changed, 42 insertions(+), 0 deletions(-)
athena%
然后,仅有网卡驱动程序并不能够让你的操作系统接入因特网。在新的实验 6 的代码中,我们为你提供了网络栈和一个网络服务器。与以前的实验一样,使用 git 去拉取这个实验的代码,合并到你自己的代码中,并去浏览新的 net/ 目录中的内容,以及在 kern/ 中的新文件。
除了写这个驱动程序以外,你还需要去创建一个访问你的驱动程序的系统调用。你将要去实现那些在网络服务器中缺失的代码,以便于在网络栈和你的驱动程序之间传输包。你还需要通过完成一个 web 服务器来将所有的东西连接到一起。你的新 web 服务器还需要你的文件系统来提供所需要的文件。
大部分的内核设备驱动程序代码都需要你自己去从头开始编写。本实验提供的指导比起前面的实验要少一些:没有框架文件、没有现成的系统调用接口、并且很多设计都由你自己决定。因此,我们建议你在开始任何单独练习之前,阅读全部的编写任务。许多学生都反应这个实验比前面的实验都难,因此请根据你的实际情况计划你的时间。
实验要求
与以前一样,你需要做实验中全部的常规练习和至少一个挑战问题。在实验中写出你的详细答案,并将挑战问题的方案描述写入到 answers-lab6.txt 文件中。
QEMU 的虚拟网络
我们将使用 QEMU 的用户模式网络栈,因为它不需要以管理员权限运行。QEMU 的文档的这里有更多关于用户网络的内容。我们更新后的 makefile 启用了 QEMU 的用户模式网络栈和虚拟的 E1000 网卡。
缺省情况下,QEMU 提供一个运行在 IP 地址 10.2.2.2 上的虚拟路由器,它给 JOS 分配的 IP 地址是 10.0.2.15。为了简单起见,我们在 net/ns.h 中将这些缺省值硬编码到网络服务器上。
虽然 QEMU 的虚拟网络允许 JOS 随意连接因特网,但 JOS 的 10.0.2.15 的地址并不能在 QEMU 中的虚拟网络之外使用(也就是说,QEMU 还得做一个 NAT),因此我们并不能直接连接到 JOS 上运行的服务器,即便是从运行 QEMU 的主机上连接也不行。为解决这个问题,我们配置 QEMU 在主机的某些端口上运行一个服务器,这个服务器简单地连接到 JOS 中的一些端口上,并在你的真实主机和虚拟网络之间传递数据。
你将在端口 7(echo)和端口 80(http)上运行 JOS,为避免在共享的 Athena 机器上发生冲突,makefile 将为这些端口基于你的用户 ID 来生成转发端口。你可以运行 make which-ports 去找出是哪个 QEMU 端口转发到你的开发主机上。为方便起见,makefile 也提供 make nc-7 和 make nc-80,它允许你在终端上直接与运行这些端口的服务器去交互。(这些目标仅能连接到一个运行中的 QEMU 实例上;你必须分别去启动它自己的 QEMU)
包检查
makefile 也可以配置 QEMU 的网络栈去记录所有的入站和出站数据包,并将它保存到你的实验目录中的 qemu.pcap 文件中。
使用 tcpdump 命令去获取一个捕获的 hex/ASCII 包转储:
tcpdump -XXnr qemu.pcap
或者,你可以使用 Wireshark 以图形化界面去检查 pcap 文件。Wireshark 也知道如何去解码和检查成百上千的网络协议。如果你在 Athena 上,你可以使用 Wireshark 的前辈:ethereal,它运行在加锁的保密互联网协议网络中。
调试 E1000
我们非常幸运能够去使用仿真硬件。由于 E1000 是在软件中运行的,仿真的 E1000 能够给我们提供一个人类可读格式的报告、它的内部状态以及它遇到的任何问题。通常情况下,对祼机上做驱动程序开发的人来说,这是非常难能可贵的。
E1000 能够产生一些调试输出,因此你可以去打开一个专门的日志通道。其中一些对你有用的通道如下:
| 标志 | 含义 |
|---|---|
| tx | 包发送日志 |
| txerr | 包发送错误日志 |
| rx | 到 RCTL 的日志通道 |
| rxfilter | 入站包过滤日志 |
| rxerr | 接收错误日志 |
| unknown | 未知寄存器的读写日志 |
| eeprom | 读取 EEPROM 的日志 |
| interrupt | 中断和中断寄存器变更日志 |
例如,你可以使用 make E1000_DEBUG=tx,txerr 去打开 "tx" 和 "txerr" 日志功能。
注意:E1000_DEBUG 标志仅能在打了 6.828 补丁的 QEMU 版本上工作。
你可以使用软件去仿真硬件,来做进一步的调试工作。如果你使用它时卡壳了,不明白为什么 E1000 没有如你预期那样响应你,你可以查看在 hw/e1000.c 中的 QEMU 的 E1000 实现。
网络服务器
从头开始写一个网络栈是很困难的。因此我们将使用 lwIP,它是一个开源的、轻量级 TCP/IP 协议套件,它能做包括一个网络栈在内的很多事情。你能在 这里 找到很多关于 IwIP 的信息。在这个任务中,对我们而言,lwIP 就是一个实现了一个 BSD 套接字接口和拥有一个包输入端口和包输出端口的黑盒子。
一个网络服务器其实就是一个有以下四个环境的混合体:
- 核心网络服务器环境(包括套接字调用派发器和 lwIP)
- 输入环境
- 输出环境
- 定时器环境
下图展示了各个环境和它们之间的关系。下图展示了包括设备驱动的整个系统,我们将在后面详细讲到它。在本实验中,你将去实现图中绿色高亮的部分。
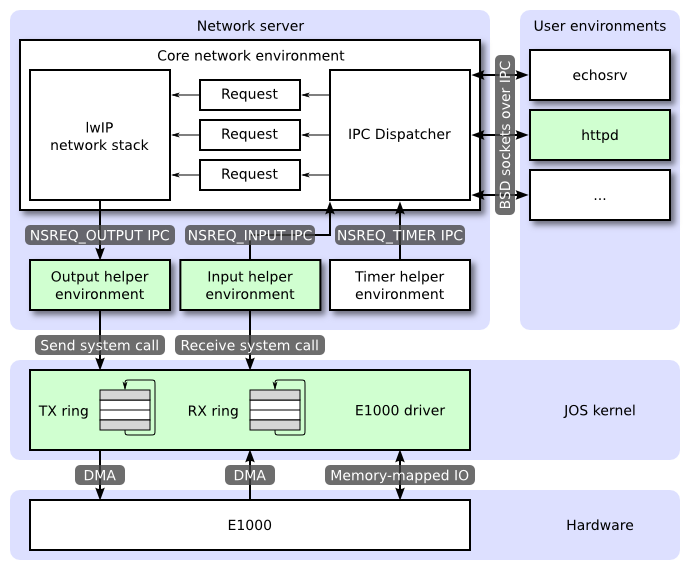
核心网络服务器环境
核心网络服务器环境由套接字调用派发器和 IwIP 自身组成的。套接字调用派发器就像一个文件服务器一样。用户环境使用 stubs(可以在 lib/nsipc.c 中找到它)去发送 IPC 消息到核心网络服务器环境。如果你看了 lib/nsipc.c,你就会发现核心网络服务器与我们创建的文件服务器 i386_init 的工作方式是一样的,i386_init 是使用 NS_TYPE_NS 创建的 NS 环境,因此我们检查 envs,去查找这个特殊的环境类型。对于每个用户环境的 IPC,网络服务器中的派发器将调用相应的、由 IwIP 提供的、代表用户的 BSD 套接字接口函数。
普通用户环境不能直接使用 nsipc_* 调用。而是通过在 lib/sockets.c 中的函数来使用它们,这些函数提供了基于文件描述符的套接字 API。以这种方式,用户环境通过文件描述符来引用套接字,就像它们引用磁盘上的文件一样。一些操作(connect、accept、等等)是特定于套接字的,但 read、write、和 close 是通过 lib/fd.c 中一般的文件描述符设备派发代码的。就像文件服务器对所有的打开的文件维护唯一的内部 ID 一样,lwIP 也为所有的打开的套接字生成唯一的 ID。不论是文件服务器还是网络服务器,我们都使用存储在 struct Fd 中的信息去映射每个环境的文件描述符到这些唯一的 ID 空间上。
尽管看起来文件服务器的网络服务器的 IPC 派发器行为是一样的,但它们之间还有很重要的差别。BSD 套接字调用(像 accept 和 recv)能够无限期阻塞。如果派发器让 lwIP 去执行其中一个调用阻塞,派发器也将被阻塞,并且在整个系统中,同一时间只能有一个未完成的网络调用。由于这种情况是无法接受的,所以网络服务器使用用户级线程以避免阻塞整个服务器环境。对于每个入站 IPC 消息,派发器将创建一个线程,然后在新创建的线程上来处理请求。如果线程被阻塞,那么只有那个线程被置入休眠状态,而其它线程仍然处于运行中。
除了核心网络环境外,还有三个辅助环境。核心网络服务器环境除了接收来自用户应用程序的消息之外,它的派发器也接收来自输入环境和定时器环境的消息。
输出环境
在为用户环境套接字调用提供服务时,lwIP 将为网卡生成用于发送的包。IwIP 将使用 NSREQ_OUTPUT 去发送在 IPC 消息页参数中附加了包的 IPC 消息。输出环境负责接收这些消息,并通过你稍后创建的系统调用接口来转发这些包到设备驱动程序上。
输入环境
网卡接收到的包需要传递到 lwIP 中。输入环境将每个由设备驱动程序接收到的包拉进内核空间(使用你将要实现的内核系统调用),并使用 NSREQ_INPUT IPC 消息将这些包发送到核心网络服务器环境。
包输入功能是独立于核心网络环境的,因为在 JOS 上同时实现接收 IPC 消息并从设备驱动程序中查询或等待包有点困难。我们在 JOS 中没有实现 select 系统调用,这是一个允许环境去监视多个输入源以识别准备处理哪个输入的系统调用。
如果你查看了 net/input.c 和 net/output.c,你将会看到在它们中都需要去实现那个系统调用。这主要是因为实现它要依赖你的系统调用接口。在你实现了驱动程序和系统调用接口之后,你将要为这两个辅助环境写这个代码。
定时器环境
定时器环境周期性发送 NSREQ_TIMER 类型的消息到核心服务器,以提醒它那个定时器已过期。IwIP 使用来自线程的定时器消息来实现各种网络超时。
Part A:初始化和发送包
你的内核还没有一个时间概念,因此我们需要去添加它。这里有一个由硬件产生的每 10 ms 一次的时钟中断。每收到一个时钟中断,我们将增加一个变量值,以表示时间已过去 10 ms。它在 kern/time.c 中已实现,但还没有完全集成到你的内核中。
练习 1、为 `kern/trap.c` 中的每个时钟中断增加一个到 `time_tick` 的调用。实现 `sys_time_msec` 并增加到 `kern/syscall.c` 中的 `syscall`,以便于用户空间能够访问时间。
使用 make INIT_CFLAGS=-DTEST_NO_NS run-testtime 去测试你的代码。你应该会看到环境计数从 5 开始以 1 秒为间隔减少。"-DTEST_NO_NS” 参数禁止在网络服务器环境上启动,因为在当前它将导致 JOS 崩溃。
网卡
写驱动程序要求你必须深入了解硬件和软件中的接口。本实验将给你提供一个如何使用 E1000 接口的高度概括的文档,但是你在写驱动程序时还需要大量去查询 Intel 的手册。
练习 2、为开发 E1000 驱动,去浏览 Intel 的 [软件开发者手册][5]。这个手册涵盖了几个与以太网控制器紧密相关的东西。QEMU 仿真了 82540EM。
现在,你应该去浏览第 2 章,以对设备获得一个整体概念。写驱动程序时,你需要熟悉第 3 到 14 章,以及 4.1(不包括 4.1 的子节)。你也应该去参考第 13 章。其它章涵盖了 E1000 的组件,你的驱动程序并不与这些组件去交互。现在你不用担心过多细节的东西;只需要了解文档的整体结构,以便于你后面需要时容易查找。
在阅读手册时,记住,E1000 是一个拥有很多高级特性的很复杂的设备,一个能让 E1000 工作的驱动程序仅需要它一小部分的特性和 NIC 提供的接口即可。仔细考虑一下,如何使用最简单的方式去使用网卡的接口。我们强烈推荐你在使用高级特性之前,只去写一个基本的、能够让网卡工作的驱动程序即可。
PCI 接口
E1000 是一个 PCI 设备,也就是说它是插到主板的 PCI 总线插槽上的。PCI 总线有地址、数据、和中断线,并且 PCI 总线允许 CPU 与 PCI 设备通讯,以及 PCI 设备去读取和写入内存。一个 PCI 设备在它能够被使用之前,需要先发现它并进行初始化。发现 PCI 设备是 PCI 总线查找已安装设备的过程。初始化是分配 I/O 和内存空间、以及协商设备所使用的 IRQ 线的过程。
我们在 kern/pci.c 中已经为你提供了使用 PCI 的代码。PCI 初始化是在引导期间执行的,PCI 代码遍历PCI 总线来查找设备。当它找到一个设备时,它读取它的供应商 ID 和设备 ID,然后使用这两个值作为关键字去搜索 pci_attach_vendor 数组。这个数组是由像下面这样的 struct pci_driver 条目组成:
struct pci_driver {
uint32_t key1, key2;
int (*attachfn) (struct pci_func *pcif);
};
如果发现的设备的供应商 ID 和设备 ID 与数组中条目匹配,那么 PCI 代码将调用那个条目的 attachfn 去执行设备初始化。(设备也可以按类别识别,那是通过 kern/pci.c 中其它的驱动程序表来实现的。)
绑定函数是传递一个 PCI 函数 去初始化。一个 PCI 卡能够发布多个函数,虽然这个 E1000 仅发布了一个。下面是在 JOS 中如何去表示一个 PCI 函数:
struct pci_func {
struct pci_bus *bus;
uint32_t dev;
uint32_t func;
uint32_t dev_id;
uint32_t dev_class;
uint32_t reg_base[6];
uint32_t reg_size[6];
uint8_t irq_line;
};
上面的结构反映了在 Intel 开发者手册里第 4.1 节的表 4-1 中找到的一些条目。struct pci_func 的最后三个条目我们特别感兴趣的,因为它们将记录这个设备协商的内存、I/O、以及中断资源。reg_base 和 reg_size 数组包含最多六个基址寄存器或 BAR。reg_base 为映射到内存中的 I/O 区域(对于 I/O 端口而言是基 I/O 端口)保存了内存的基地址,reg_size 包含了以字节表示的大小或来自 reg_base 的相关基值的 I/O 端口号,而 irq_line 包含了为中断分配给设备的 IRQ 线。在表 4-2 的后半部分给出了 E1000 BAR 的具体涵义。
当设备调用了绑定函数后,设备已经被发现,但没有被启用。这意味着 PCI 代码还没有确定分配给设备的资源,比如地址空间和 IRQ 线,也就是说,struct pci_func 结构的最后三个元素还没有被填入。绑定函数将调用 pci_func_enable,它将去启用设备、协商这些资源、并在结构 struct pci_func 中填入它。
练习 3、实现一个绑定函数去初始化 E1000。添加一个条目到 `kern/pci.c` 中的数组 `pci_attach_vendor` 上,如果找到一个匹配的 PCI 设备就去触发你的函数(确保一定要把它放在表末尾的 `{0, 0, 0}` 条目之前)。你在 5.2 节中能找到 QEMU 仿真的 82540EM 的供应商 ID 和设备 ID。在引导期间,当 JOS 扫描 PCI 总线时,你也可以看到列出来的这些信息。
到目前为止,我们通过 `pci_func_enable` 启用了 E1000 设备。通过本实验我们将添加更多的初始化。
我们已经为你提供了 `kern/e1000.c` 和 `kern/e1000.h` 文件,这样你就不会把构建系统搞糊涂了。不过它们现在都是空的;你需要在本练习中去填充它们。你还可能在内核的其它地方包含这个 `e1000.h` 文件。
当你引导你的内核时,你应该会看到它输出的信息显示 E1000 的 PCI 函数已经启用。这时你的代码已经能够通过 `make grade` 的 `pci attach` 测试了。
内存映射的 I/O
软件与 E1000 通过内存映射的 I/O(MMIO) 来沟通。你在 JOS 的前面部分可能看到过 MMIO 两次:CGA 控制台和 LAPIC 都是通过写入和读取“内存”来控制和查询设备的。但这些读取和写入不是去往内存芯片的,而是直接到这些设备的。
pci_func_enable 为 E1000 协调一个 MMIO 区域,来存储它在 BAR 0 的基址和大小(也就是 reg_base[0] 和 reg_size[0]),这是一个分配给设备的一段物理内存地址,也就是说你可以通过虚拟地址访问它来做一些事情。由于 MMIO 区域一般分配高位物理地址(一般是 3GB 以上的位置),因此你不能使用 KADDR 去访问它们,因为 JOS 被限制为最大使用 256MB。因此,你可以去创建一个新的内存映射。我们将使用 MMIOBASE(从实验 4 开始,你的 mmio_map_region 区域应该确保不能被 LAPIC 使用的映射所覆盖)以上的部分。由于在 JOS 创建用户环境之前,PCI 设备就已经初始化了,因此你可以在 kern_pgdir 处创建映射,并且让它始终可用。
练习 4、在你的绑定函数中,通过调用 `mmio_map_region`(它就是你在实验 4 中写的,是为了支持 LAPIC 内存映射)为 E1000 的 BAR 0 创建一个虚拟地址映射。
你将希望在一个变量中记录这个映射的位置,以便于后面访问你映射的寄存器。去看一下 `kern/lapic.c` 中的 `lapic` 变量,它就是一个这样的例子。如果你使用一个指针指向设备寄存器映射,一定要声明它为 `volatile`;否则,编译器将允许缓存它的值,并可以在内存中再次访问它。
为测试你的映射,尝试去输出设备状态寄存器(第 12.4.2 节)。这是一个在寄存器空间中以字节 8 开头的 4 字节寄存器。你应该会得到 `0x80080783`,它表示以 1000 MB/s 的速度启用一个全双工的链路,以及其它信息。
提示:你将需要一些常数,像寄存器位置和掩码位数。如果从开发者手册中复制这些东西很容易出错,并且导致调试过程很痛苦。我们建议你使用 QEMU 的 e1000_hw.h 头文件做为基准。我们不建议完全照抄它,因为它定义的值远超过你所需要,并且定义的东西也不见得就是你所需要的,但它仍是一个很好的参考。
DMA
你可能会认为是从 E1000 的寄存器中通过写入和读取来传送和接收数据包的,其实这样做会非常慢,并且还要求 E1000 在其中去缓存数据包。相反,E1000 使用直接内存访问(DMA)从内存中直接读取和写入数据包,而且不需要 CPU 参与其中。驱动程序负责为发送和接收队列分配内存、设置 DMA 描述符、以及配置 E1000 使用的队列位置,而在这些设置完成之后的其它工作都是异步方式进行的。发送包的时候,驱动程序复制它到发送队列的下一个 DMA 描述符中,并且通知 E1000 下一个发送包已就绪;当轮到这个包发送时,E1000 将从描述符中复制出数据。同样,当 E1000 接收一个包时,它从接收队列中将它复制到下一个 DMA 描述符中,驱动程序将能在下一次读取到它。
总体来看,接收队列和发送队列非常相似。它们都是由一系列的描述符组成。虽然这些描述符的结构细节有所不同,但每个描述符都包含一些标志和包含了包数据的一个缓存的物理地址(发送到网卡的数据包,或网卡将接收到的数据包写入到由操作系统分配的缓存中)。
队列被实现为一个环形数组,意味着当网卡或驱动到达数组末端时,它将重新回到开始位置。它有一个头指针和尾指针,队列的内容就是这两个指针之间的描述符。硬件就是从头开始移动头指针去消费描述符,在这期间驱动程序不停地添加描述符到尾部,并移动尾指针到最后一个描述符上。发送队列中的描述符表示等待发送的包(因此,在平静状态下,发送队列是空的)。对于接收队列,队列中的描述符是表示网卡能够接收包的空描述符(因此,在平静状态下,接收队列是由所有的可用接收描述符组成的)。正确的更新尾指针寄存器而不让 E1000 产生混乱是很有难度的;要小心!
指向到这些数组及描述符中的包缓存地址的指针都必须是物理地址,因为硬件是直接在物理内存中且不通过 MMU 来执行 DMA 的读写操作的。
发送包
E1000 中的发送和接收功能本质上是独立的,因此我们可以同时进行发送接收。我们首先去攻克简单的数据包发送,因为我们在没有先去发送一个 “I'm here!" 包之前是无法测试接收包功能的。
首先,你需要初始化网卡以准备发送,详细步骤查看 14.5 节(不必着急看子节)。发送初始化的第一步是设置发送队列。队列的详细结构在 3.4 节中,描述符的结构在 3.3.3 节中。我们先不要使用 E1000 的 TCP offload 特性,因此你只需专注于 “传统的发送描述符格式” 即可。你应该现在就去阅读这些章节,并要熟悉这些结构。
C 结构
你可以用 C struct 很方便地描述 E1000 的结构。正如你在 struct Trapframe 中所看到的结构那样,C struct 可以让你很方便地在内存中描述准确的数据布局。C 可以在字段中插入数据,但是 E1000 的结构就是这样布局的,这样就不会是个问题。如果你遇到字段对齐问题,进入 GCC 查看它的 "packed” 属性。
查看手册中表 3-8 所给出的一个传统的发送描述符,将它复制到这里作为一个示例:
63 48 47 40 39 32 31 24 23 16 15 0
+---------------------------------------------------------------+
| Buffer address |
+---------------|-------|-------|-------|-------|---------------+
| Special | CSS | Status| Cmd | CSO | Length |
+---------------|-------|-------|-------|-------|---------------+
从结构右上角第一个字节开始,我们将它转变成一个 C 结构,从上到下,从右到左读取。如果你从右往左看,你将看到所有的字段,都非常适合一个标准大小的类型:
struct tx_desc
{
uint64_t addr;
uint16_t length;
uint8_t cso;
uint8_t cmd;
uint8_t status;
uint8_t css;
uint16_t special;
};
你的驱动程序将为发送描述符数组去保留内存,并由发送描述符指向到包缓冲区。有几种方式可以做到,从动态分配页到在全局变量中简单地声明它们。无论你如何选择,记住,E1000 是直接访问物理内存的,意味着它能访问的任何缓存区在物理内存中必须是连续的。
处理包缓存也有几种方式。我们推荐从最简单的开始,那就是在驱动程序初始化期间,为每个描述符保留包缓存空间,并简单地将包数据复制进预留的缓冲区中或从其中复制出来。一个以太网包最大的尺寸是 1518 字节,这就限制了这些缓存区的大小。主流的成熟驱动程序都能够动态分配包缓存区(即:当网络使用率很低时,减少内存使用量),或甚至跳过缓存区,直接由用户空间提供(就是“零复制”技术),但我们还是从简单开始为好。
练习 5、执行一个 14.5 节中的初始化步骤(它的子节除外)。对于寄存器的初始化过程使用 13 节作为参考,对发送描述符和发送描述符数组参考 3.3.3 节和 3.4 节。
要记住,在发送描述符数组中要求对齐,并且数组长度上有限制。因为 TDLEN 必须是 128 字节对齐的,而每个发送描述符是 16 字节,你的发送描述符数组必须是 8 个发送描述符的倍数。并且不能使用超过 64 个描述符,以及不能在我们的发送环形缓存测试中溢出。
对于 TCTL.COLD,你可以假设为全双工操作。对于 TIPG、IEEE 802.3 标准的 IPG(不要使用 14.5 节中表上的值),参考在 13.4.34 节中表 13-77 中描述的缺省值。
尝试运行 make E1000_DEBUG=TXERR,TX qemu。如果你使用的是打了 6.828 补丁的 QEMU,当你设置 TDT(发送描述符尾部)寄存器时你应该会看到一个 “e1000: tx disabled" 的信息,并且不会有更多 "e1000” 信息了。
现在,发送初始化已经完成,你可以写一些代码去发送一个数据包,并且通过一个系统调用使它可以访问用户空间。你可以将要发送的数据包添加到发送队列的尾部,也就是说复制数据包到下一个包缓冲区中,然后更新 TDT 寄存器去通知网卡在发送队列中有另外的数据包。(注意,TDT 是一个进入发送描述符数组的索引,不是一个字节偏移量;关于这一点文档中说明的不是很清楚。)
但是,发送队列只有这么大。如果网卡在发送数据包时卡住或发送队列填满时会发生什么状况?为了检测这种情况,你需要一些来自 E1000 的反馈。不幸的是,你不能只使用 TDH(发送描述符头)寄存器;文档上明确说明,从软件上读取这个寄存器是不可靠的。但是,如果你在发送描述符的命令字段中设置 RS 位,那么,当网卡去发送在那个描述符中的数据包时,网卡将设置描述符中状态字段的 DD 位,如果一个描述符中的 DD 位被设置,你就应该知道那个描述符可以安全地回收,并且可以用它去发送其它数据包。
如果用户调用你的发送系统调用,但是下一个描述符的 DD 位没有设置,表示那个发送队列已满,该怎么办?在这种情况下,你该去决定怎么办了。你可以简单地丢弃数据包。网络协议对这种情况的处理很灵活,但如果你丢弃大量的突发数据包,协议可能不会去重新获得它们。可能需要你替代网络协议告诉用户环境让它重传,就像你在 sys_ipc_try_send 中做的那样。在环境上回推产生的数据是有好处的。
练习 6、写一个函数去发送一个数据包,它需要检查下一个描述符是否空闲、复制包数据到下一个描述符并更新 TDT。确保你处理的发送队列是满的。
现在,应该去测试你的包发送代码了。通过从内核中直接调用你的发送函数来尝试发送几个包。在测试时,你不需要去创建符合任何特定网络协议的数据包。运行 make E1000_DEBUG=TXERR,TX qemu 去测试你的代码。你应该看到类似下面的信息:
e1000: index 0: 0x271f00 : 9000002a 0
...
在你发送包时,每行都给出了在发送数组中的序号、那个发送的描述符的缓存地址、cmd/CSO/length 字段、以及 special/CSS/status 字段。如果 QEMU 没有从你的发送描述符中输出你预期的值,检查你的描述符中是否有合适的值和你配置的正确的 TDBAL 和 TDBAH。如果你收到的是 "e1000: TDH wraparound @0, TDT x, TDLEN y" 的信息,意味着 E1000 的发送队列持续不断地运行(如果 QEMU 不去检查它,它将是一个无限循环),这意味着你没有正确地维护 TDT。如果你收到了许多 "e1000: tx disabled" 的信息,那么意味着你没有正确设置发送控制寄存器。
一旦 QEMU 运行,你就可以运行 tcpdump -XXnr qemu.pcap 去查看你发送的包数据。如果从 QEMU 中看到预期的 "e1000: index” 信息,但你捕获的包是空的,再次检查你发送的描述符,是否填充了每个必需的字段和位。(E1000 或许已经遍历了你的发送描述符,但它认为不需要去发送)
练习 7、添加一个系统调用,让你从用户空间中发送数据包。详细的接口由你来决定。但是不要忘了检查从用户空间传递给内核的所有指针。
发送包:网络服务器
现在,你已经有一个系统调用接口可以发送包到你的设备驱动程序端了。输出辅助环境的目标是在一个循环中做下面的事情:从核心网络服务器中接收 NSREQ_OUTPUT IPC 消息,并使用你在上面增加的系统调用去发送伴随这些 IPC 消息的数据包。这个 NSREQ_OUTPUT IPC 是通过 net/lwip/jos/jif/jif.c 中的 low_level_output 函数来发送的。它集成 lwIP 栈到 JOS 的网络系统。每个 IPC 将包含一个页,这个页由一个 union Nsipc 和在 struct jif_pkt pkt 字段中的一个包组成(查看 inc/ns.h)。struct jif_pkt 看起来像下面这样:
struct jif_pkt {
int jp_len;
char jp_data[0];
};
jp_len 表示包的长度。在 IPC 页上的所有后续字节都是为了包内容。在结构的结尾处使用一个长度为 0 的数组来表示缓存没有一个预先确定的长度(像 jp_data 一样),这是一个常见的 C 技巧(也有人说这是一个令人讨厌的做法)。因为 C 并不做数组边界的检查,只要你确保结构后面有足够的未使用内存即可,你可以把 jp_data 作为一个任意大小的数组来使用。
当设备驱动程序的发送队列中没有足够的空间时,一定要注意在设备驱动程序、输出环境和核心网络服务器之间的交互。核心网络服务器使用 IPC 发送包到输出环境。如果输出环境在由于一个发送包的系统调用而挂起,导致驱动程序没有足够的缓存去容纳新数据包,这时核心网络服务器将阻塞以等待输出服务器去接收 IPC 调用。
练习 8、实现 `net/output.c`。
你可以使用 net/testoutput.c 去测试你的输出代码而无需整个网络服务器参与。尝试运行 make E1000_DEBUG=TXERR,TX run-net_testoutput。你将看到如下的输出:
Transmitting packet 0
e1000: index 0: 0x271f00 : 9000009 0
Transmitting packet 1
e1000: index 1: 0x2724ee : 9000009 0
...
运行 tcpdump -XXnr qemu.pcap 将输出:
reading from file qemu.pcap, link-type EN10MB (Ethernet)
-5:00:00.600186 [|ether]
0x0000: 5061 636b 6574 2030 30 Packet.00
-5:00:00.610080 [|ether]
0x0000: 5061 636b 6574 2030 31 Packet.01
...
使用更多的数据包去测试,可以运行 make E1000_DEBUG=TXERR,TX NET_CFLAGS=-DTESTOUTPUT_COUNT=100 run-net_testoutput。如果它导致你的发送队列溢出,再次检查你的 DD 状态位是否正确,以及是否告诉硬件去设置 DD 状态位(使用 RS 命令位)。
你的代码应该会通过 make grade 的 testoutput 测试。
问题
1、你是如何构造你的发送实现的?在实践中,如果发送缓存区满了,你该如何处理?
Part B:接收包和 web 服务器
接收包
就像你在发送包中做的那样,你将去配置 E1000 去接收数据包,并提供一个接收描述符队列和接收描述符。在 3.2 节中描述了接收包的操作,包括接收队列结构和接收描述符、以及在 14.4 节中描述的详细的初始化过程。
练习 9、阅读 3.2 节。你可以忽略关于中断和 offload 校验和方面的内容(如果在后面你想去使用这些特性,可以再返回去阅读),你现在不需要去考虑阈值的细节和网卡内部缓存是如何工作的。
除了接收队列是由一系列的等待入站数据包去填充的空缓存包以外,接收队列的其它部分与发送队列非常相似。所以,当网络空闲时,发送队列是空的(因为所有的包已经被发送出去了),而接收队列是满的(全部都是空缓存包)。
当 E1000 接收一个包时,它首先与网卡的过滤器进行匹配检查(例如,去检查这个包的目标地址是否为这个 E1000 的 MAC 地址),如果这个包不匹配任何过滤器,它将忽略这个包。否则,E1000 尝试从接收队列头部去检索下一个接收描述符。如果头(RDH)追上了尾(RDT),那么说明接收队列已经没有空闲的描述符了,所以网卡将丢弃这个包。如果有空闲的接收描述符,它将复制这个包的数据到描述符指向的缓存中,设置这个描述符的 DD 和 EOP 状态位,并递增 RDH。
如果 E1000 在一个接收描述符中接收到了一个比包缓存还要大的数据包,它将按需从接收队列中检索尽可能多的描述符以保存数据包的全部内容。为表示发生了这种情况,它将在所有的这些描述符上设置 DD 状态位,但仅在这些描述符的最后一个上设置 EOP 状态位。在你的驱动程序上,你可以去处理这种情况,也可以简单地配置网卡拒绝接收这种”长包“(这种包也被称为”巨帧“),你要确保接收缓存有足够的空间尽可能地去存储最大的标准以太网数据包(1518 字节)。
练习 10、设置接收队列并按 14.4 节中的流程去配置 E1000。你可以不用支持 ”长包“ 或多播。到目前为止,我们不用去配置网卡使用中断;如果你在后面决定去使用接收中断时可以再去改。另外,配置 E1000 去除以太网的 CRC 校验,因为我们的评级脚本要求必须去掉校验。
默认情况下,网卡将过滤掉所有的数据包。你必须使用网卡的 MAC 地址去配置接收地址寄存器(RAL 和 RAH)以接收发送到这个网卡的数据包。你可以简单地硬编码 QEMU 的默认 MAC 地址 52:54:00:12:34:56(我们已经在 lwIP 中硬编码了这个地址,因此这样做不会有问题)。使用字节顺序时要注意;MAC 地址是从低位字节到高位字节的方式来写的,因此 52:54:00:12 是 MAC 地址的低 32 位,而 34:56 是它的高 16 位。
E1000 的接收缓存区大小仅支持几个指定的设置值(在 13.4.22 节中描述的 RCTL.BSIZE 值)。如果你的接收包缓存够大,并且拒绝长包,那你就不用担心跨越多个缓存区的包。另外,要记住的是,和发送一样,接收队列和包缓存必须是连接的物理内存。
你应该使用至少 128 个接收描述符。
现在,你可以做接收功能的基本测试了,甚至都无需写代码去接收包了。运行 make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-net_testinput。testinput 将发送一个 ARP(地址解析协议)通告包(使用你的包发送的系统调用),而 QEMU 将自动回复它,即便是你的驱动尚不能接收这个回复,你也应该会看到一个 "e1000: unicast match[0]: 52:54:00:12:34:56" 的消息,表示 E1000 接收到一个包,并且匹配了配置的接收过滤器。如果你看到的是一个 "e1000: unicast mismatch: 52:54:00:12:34:56” 消息,表示 E1000 过滤掉了这个包,意味着你的 RAL 和 RAH 的配置不正确。确保你按正确的顺序收到了字节,并不要忘记设置 RAH 中的 "Address Valid” 位。如果你没有收到任何 "e1000” 消息,或许是你没有正确地启用接收功能。
现在,你准备去实现接收数据包。为了接收数据包,你的驱动程序必须持续跟踪希望去保存下一下接收到的包的描述符(提示:按你的设计,这个功能或许已经在 E1000 中的一个寄存器来实现了)。与发送类似,官方文档上表示,RDH 寄存器状态并不能从软件中可靠地读取,因为确定一个包是否被发送到描述符的包缓存中,你需要去读取描述符中的 DD 状态位。如果 DD 位被设置,你就可以从那个描述符的缓存中复制出这个数据包,然后通过更新队列的尾索引 RDT 来告诉网卡那个描述符是空闲的。
如果 DD 位没有被设置,表明没有接收到包。这就与发送队列满的情况一样,这时你可以有几种做法。你可以简单地返回一个 ”重传“ 错误来要求对端重发一次。对于满的发送队列,由于那是个临时状况,这种做法还是很好的,但对于空的接收队列来说就不太合理了,因为接收队列可能会保持好长一段时间的空的状态。第二个方法是挂起调用环境,直到在接收队列中处理了这个包为止。这个策略非常类似于 sys_ipc_recv。就像在 IPC 的案例中,因为我们每个 CPU 仅有一个内核栈,一旦我们离开内核,栈上的状态就会被丢弃。我们需要设置一个标志去表示那个环境由于接收队列下溢被挂起并记录系统调用参数。这种方法的缺点是过于复杂:E1000 必须被指示去产生接收中断,并且驱动程序为了恢复被阻塞等待一个包的环境,必须处理这个中断。
练习 11、写一个函数从 E1000 中接收一个包,然后通过一个系统调用将它发布到用户空间。确保你将接收队列处理成空的。
小挑战!如果发送队列是满的或接收队列是空的,环境和你的驱动程序可能会花费大量的 CPU 周期是轮询、等待一个描述符。一旦完成发送或接收描述符,E1000 能够产生一个中断,以避免轮询。修改你的驱动程序,处理发送和接收队列是以中断而不是轮询的方式进行。
注意,一旦确定为中断,它将一直处于中断状态,直到你的驱动程序明确处理完中断为止。在你的中断服务程序中,一旦处理完成要确保清除掉中断状态。如果你不那样做,从你的中断服务程序中返回后,CPU 将再次跳转到你的中断服务程序中。除了在 E1000 网卡上清除中断外,也需要使用 `lapic_eoi` 在 LAPIC 上清除中断。
接收包:网络服务器
在网络服务器输入环境中,你需要去使用你的新的接收系统调用以接收数据包,并使用 NSREQ_INPUT IPC 消息将它传递到核心网络服务器环境。这些 IPC 输入消息应该会有一个页,这个页上绑定了一个 union Nsipc,它的 struct jif_pkt pkt 字段中有从网络上接收到的包。
练习 12、实现 `net/input.c`。
使用 make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-net_testinput 再次运行 testinput,你应该会看到:
Sending ARP announcement...
Waiting for packets...
e1000: index 0: 0x26dea0 : 900002a 0
e1000: unicast match[0]: 52:54:00:12:34:56
input: 0000 5254 0012 3456 5255 0a00 0202 0806 0001
input: 0010 0800 0604 0002 5255 0a00 0202 0a00 0202
input: 0020 5254 0012 3456 0a00 020f 0000 0000 0000
input: 0030 0000 0000 0000 0000 0000 0000 0000 0000
"input:” 打头的行是一个 QEMU 的 ARP 回复的十六进制转储。
你的代码应该会通过 make grade 的 testinput 测试。注意,在没有发送至少一个包去通知 QEMU 中的 JOS 的 IP 地址上时,是没法去测试包接收的,因此在你的发送代码中的 bug 可能会导致测试失败。
为彻底地测试你的网络代码,我们提供了一个称为 echosrv 的守护程序,它在端口 7 上设置运行 echo 的服务器,它将回显通过 TCP 连接发送给它的任何内容。使用 make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-echosrv 在一个终端中启动 echo 服务器,然后在另一个终端中通过 make nc-7 去连接它。你输入的每一行都被这个服务器回显出来。每次在仿真的 E1000 上接收到一个包,QEMU 将在控制台上输出像下面这样的内容:
e1000: unicast match[0]: 52:54:00:12:34:56
e1000: index 2: 0x26ea7c : 9000036 0
e1000: index 3: 0x26f06a : 9000039 0
e1000: unicast match[0]: 52:54:00:12:34:56
做到这一点后,你应该也就能通过 echosrv 的测试了。
问题
2、你如何构造你的接收实现?在实践中,如果接收队列是空的并且一个用户环境要求下一个入站包,你怎么办?
小挑战!在开发者手册中阅读关于 EEPROM 的内容,并写出从 EEPROM 中加载 E1000 的 MAC 地址的代码。目前,QEMU 的默认 MAC 地址是硬编码到你的接收初始化代码和 lwIP 中的。修复你的初始化代码,让它能够从 EEPROM 中读取 MAC 地址,和增加一个系统调用去传递 MAC 地址到 lwIP 中,并修改 lwIP 去从网卡上读取 MAC 地址。通过配置 QEMU 使用一个不同的 MAC 地址去测试你的变更。
小挑战!修改你的 E1000 驱动程序去使用 "零复制" 技术。目前,数据包是从用户空间缓存中复制到发送包缓存中,和从接收包缓存中复制回到用户空间缓存中。一个使用 ”零复制“ 技术的驱动程序可以通过直接让用户空间和 E1000 共享包缓存内存来实现。还有许多不同的方法去实现 ”零复制“,包括映射内容分配的结构到用户空间或直接传递用户提供的缓存到 E1000。不论你选择哪种方法,都要注意你如何利用缓存的问题,因为你不能在用户空间代码和 E1000 之间产生争用。
小挑战!把 ”零复制“ 的概念用到 lwIP 中。
一个典型的包是由许多头构成的。用户发送的数据被发送到 lwIP 中的一个缓存中。TCP 层要添加一个 TCP 包头,IP 层要添加一个 IP 包头,而 MAC 层有一个以太网头。甚至还有更多的部分增加到包上,这些部分要正确地连接到一起,以便于设备驱动程序能够发送最终的包。
E1000 的发送描述符设计是非常适合收集分散在内存中的包片段的,像在 IwIP 中创建的包的帧。如果你排队多个发送描述符,但仅设置最后一个描述符的 EOP 命令位,那么 E1000 将在内部把这些描述符串成包缓存,并在它们标记完 EOP 后仅发送串起来的缓存。因此,独立的包片段不需要在内存中把它们连接到一起。
修改你的驱动程序,以使它能够发送由多个缓存且无需复制的片段组成的包,并且修改 lwIP 去避免它合并包片段,因为它现在能够正确处理了。
小挑战!增加你的系统调用接口,以便于它能够为多于一个的用户环境提供服务。如果有多个网络栈(和多个网络服务器)并且它们各自都有自己的 IP 地址运行在用户模式中,这将是非常有用的。接收系统调用将决定它需要哪个环境来转发每个入站的包。
注意,当前的接口并不知道两个包之间有何不同,并且如果多个环境去调用包接收的系统调用,各个环境将得到一个入站包的子集,而那个子集可能并不包含调用环境指定的那个包。
在 [这篇][7] 外内核论文的 2.2 节和 3 节中对这个问题做了深度解释,并解释了在内核中(如 JOS)处理它的一个方法。用这个论文中的方法去解决这个问题,你不需要一个像论文中那么复杂的方案。
Web 服务器
一个最简单的 web 服务器类型是发送一个文件的内容到请求的客户端。我们在 user/httpd.c 中提供了一个非常简单的 web 服务器的框架代码。这个框架内码处理入站连接并解析请求头。
练习 13、这个 web 服务器中缺失了发送一个文件的内容到客户端的处理代码。通过实现 `send_file` 和 `send_data` 完成这个 web 服务器。
在你完成了这个 web 服务器后,启动这个 web 服务器(make run-httpd-nox),使用你喜欢的浏览器去浏览 http:// host : port /index.html 地址。其中 host 是运行 QEMU 的计算机的名字(如果你在 athena 上运行 QEMU,使用 hostname.mit.edu(其中 hostname 是在 athena 上运行 hostname 命令的输出,或者如果你在运行 QEMU 的机器上运行 web 浏览器的话,直接使用 localhost),而 port 是 web 服务器运行 make which-ports 命令报告的端口号。你应该会看到一个由运行在 JOS 中的 HTTP 服务器提供的一个 web 页面。
到目前为止,你的评级测试得分应该是 105 分(满分为105)。
小挑战!在 JOS 中添加一个简单的聊天服务器,多个人可以连接到这个服务器上,并且任何用户输入的内容都被发送到其它用户。为实现它,你需要找到一个一次与多个套接字通讯的方法,并且在同一时间能够在同一个套接字上同时实现发送和接收。有多个方法可以达到这个目的。lwIP 为 `recv`(查看 `net/lwip/api/sockets.c` 中的 `lwip_recvfrom`)提供了一个 MSG_DONTWAIT 标志,以便于你不断地轮询所有打开的套接字。注意,虽然网络服务器的 IPC 支持 `recv` 标志,但是通过普通的 `read` 函数并不能访问它们,因此你需要一个方法来传递这个标志。一个更高效的方法是为每个连接去启动一个或多个环境,并且使用 IPC 去协调它们。而且碰巧的是,对于一个套接字,在结构 Fd 中找到的 lwIP 套接字 ID 是全局的(不是每个环境私有的),因此,比如一个 `fork` 的子环境继承了它的父环境的套接字。或者,一个环境通过构建一个包含了正确套接字 ID 的 Fd 就能够发送到另一个环境的套接字上。
问题
3、由 JOS 的 web 服务器提供的 web 页面显示了什么?
4. 你做这个实验大约花了多长的时间?
**本实验到此结束了。**一如既往,不要忘了运行 make grade 并去写下你的答案和挑战问题的解决方案的描述。在你动手之前,使用 git status 和 git diff 去检查你的变更,并不要忘了去 git add answers-lab6.txt。当你完成之后,使用 git commit -am 'my solutions to lab 6’ 去提交你的变更,然后 make handin 并关注它的动向。
via: https://pdos.csail.mit.edu/6.828/2018/labs/lab6/