11 KiB
My favorite open source library for analyzing music files
Here's how I use the JAudiotagger library with a Groovy script I created to analyze my music files.
In my previous article, I created a framework for analyzing the directories and subdirectories of music files, using the groovy.File class, which extends and streamlines java.File and simplifies its use. In this article, I use the open source JAudiotagger library to analyze the tags of the music files in the music directory and subdirectories. Be sure to read the first article in this series if you intend to follow along.
Install Java and Groovy
Groovy is based on Java, and requires a Java installation. Both a recent and decent version of Java and Groovy might be in your Linux distribution's repositories. Groovy can also be installed directly from the Apache Foundation website. A nice alternative for Linux users is SDKMan, which can be used to get multiple versions of Java, Groovy, and many other related tools. For this article, I use SDK's releases of:
- Java: version 11.0.12-open of OpenJDK 11
- Groovy: version 3.0.8
Back to the problem
In the 15 or so years that I've been carefully ripping my CD collection and increasingly buying digital downloads, I have found that ripping programs and digital music download vendors are all over the map when it comes to tagging music files. Sometimes, my files are missing tags that can be useful to music players, such as ALBUMSORT. Sometimes this means my files are full of tags I don't care about, such as MUSICBRAINZ_DISCID, that cause some music players to change the order of presentation in obscure ways, so that one album appears to be many, or sorts in a strange order.
Given that I have nearly 10,000 tracks in nearly 700 albums, it's quite nice when my music player manages to display my collection in a reasonably understandable order. Therefore, the ultimate goal of this series is to create a few useful scripts to help identify missing or unusual tags and facilitate the creation of a work plan to fix tagging problems. This particular script analyzes the tags of music files and creates a CSV file that I can load into LibreOffice or OnlyOffice to look for problems. It won't look at missing cover.jpg files nor show album sub-subdirectories that contain other files, because this isn't relevant at the music file level.
My Groovy framework plus JAudiotagger
Once again, start with the code. As before, I've incorporated comments in the script that reflect the (relatively abbreviated) "comment notes" that I typically leave for myself:
1 @Grab('net.jthink:jaudiotagger:3.0.1')
2 import org.jaudiotagger.audio.*
3 def logger = java.util.logging.Logger.getLogger('org.jaudiotagger');
4 logger.setLevel(java.util.logging.Level.OFF);
5 // Define the music library directory
6 def musicLibraryDirName = '/var/lib/mpd/music'
7 // These are the music file tags we are happy to see
8 // Some tags can occur more than once in a given file
9 def wantedFieldIdSet = ['ALBUM', 'ALBUMARTIST',
10 'ALBUMARTISTSORT', 'ARTIST', 'ARTISTSORT',
11 'COMPOSER', 'COMPOSERSORT', 'COVERART', 'DATE',
12 'GENRE', 'TITLE', 'TITLESORT', 'TRACKNUMBER',
13 'TRACKTOTAL', 'VENDOR', 'YEAR'] as LinkedHashSet
14 // Print the CSV file header
15 print "artistDir|albumDir|contentFile"
16 print "|${wantedFieldIdSet*.toLowerCase().join('|')}"
17 println "|other tags"
18 // Iterate over each directory in the music libary directory
19 // These are assumed to be artist directories
20 new File(musicLibraryDirName).eachDir { artistDir ->
21 // Iterate over each directory in the artist directory
22 // These are assumed to be album directories
23 artistDir.eachDir { albumDir ->
24 // Iterate over each file in the album directory
25 // These are assumed to be content or related
26 // (cover.jpg, PDFs with liner notes etc)
27 albumDir.eachFile { contentFile ->
28 // Initialize the counter map for tags we like
29 // and the list for unwanted tags
30 def fieldKeyCounters = wantedFieldIdSet.collectEntries { e ->
31 [(e): 0]
32 }
33 def unwantedFieldIds = []
34 // Analyze the file and print the analysis
35 if (contentFile.name ==~ /.*\.(flac|mp3|ogg)/) {
36 def af = AudioFileIO.read(contentFile)
37 af.tag.fields.each { tagField ->
38 if (tagField.id in wantedFieldIdSet)
39 fieldKeyCounters[tagField.id]++
40 else
41 unwantedFieldIds << tagField.id
42 }
43 print "${artistDir.name}|${albumDir.name}|${contentFile.name}"
44 wantedFieldIdSet.each { fieldId ->
45 print "|${fieldKeyCounters[fieldId]}"
46 }
47 println "|${unwantedFieldIds.join(',')}"
48 }
49 }
50 }
51 }
Line 1 is one of those awesomely lovely Groovy facilities that simplify life enormously. It turns out that the kind developer of JAudiotagger makes a compiled version available on the Maven central repository. In Java, this requires some XML ceremony and configuration. Using Groovy, I just use the @Grab annotation, and Groovy handles the rest behind the scenes.
Line 2 imports the relevant class files from the JAudiotagger library.
Lines 3-4 configure the JAudiotagger library to turn off logging. In my own experiments, the default level is quite verbose and the output of any script using JAudiotagger is filled with logging information. This works well because Groovy builds the script into a static main class. I'm sure I'm not the only one who has configured the logger in some instance method only to see the configuration garbage collected after the instance method returns.
Lines 5-6 are from the framework introduced in Part 1.
Lines 7-13 create a LinkedHashSet containing the list of tags that I hope will be in each file (or, at least, I'm OK with having in each file). I use a LinkedHashSet here so that the tags are ordered.
This is a good time to point out a discrepancy in the terminology I've been using up until now and the class definitions in the JAudiotagger library. What I have been calling "tags" are what JAudiotagger calls org.jaudiotagger.tag.TagField instances. These instances live within an instance of org.jaudiotagger.tag.Tag. So the "tag" from JAudiotagger's point of view is the collection of "tag fields". I'm going to follow their naming convention for the rest of this article.
This collection of strings reflects a bit of prior digging with metaflac. Finally, it's worth mentioning that JAudiotagger's org.jaudiotagger.tag.FieldKey uses "_" to separate words in the field keys, which seems incompatible with the strings returned by org.jaudiotagger.tag.Tag.getFields(), so I don’t use FieldKey.
Lines 14-17 print the CSV file header. Note the use of Groovy's *. spread operator to apply toLowerCase() to each (upper case) string element of wantedFieldIdSet.
Lines 18-27 are from the framework introduced in Part 1, descending into the sub-sub-directories where the music files are found.
Lines 28-32 initialize a map of counters for the desired fields. I use counters here because some tag fields can occur more than once in a given file. Note the use of wantedFieldIdSet.collectEntries to build a map using the set elements as keys (the key value e is in parentheses, as it must be evaluated). I explain this in more detail in this article about maps in Groovy.
Line 33 initializes a list for accumulating unwanted tag field IDs.
Lines 34-48 analyzes any FLAC, MP3 or OGG music files found:
- Line 35 uses the Groovy match operator
==~and a "slashy" regular expression to check file name patterns; - Line 36 reads the music file metadata using
org.jaudiotagger.AudioFileIO.read()into the variable af - Line 37-48 loops over the tag fields found in the metadata:
- Line 37 uses Groovy's
each()method to iterate over the list of tag fields returned byaf.tag.getFields(), which in Groovy can be abbreviated toaf.tag.fields - Line 38-39 counts any occurrence of a wanted tag field ID
- Line 40-41 appends an occurrence of an unwanted tag field ID to the unwanted list
- Line 43-47 prints out the counts and unwanted fields (if any)
- Line 37 uses Groovy's
That's it!
Typically, I would run this as follows:
$ groovy TagAnalyzer2.groovy > tagAnalysis2.csv
And then I load the resulting CSV into a spreadsheet. For example, with LibreOffice Calc, I go to the Sheet menu and select Insert sheet from file. I set the delimiter character to |. In my case, the results look like this:
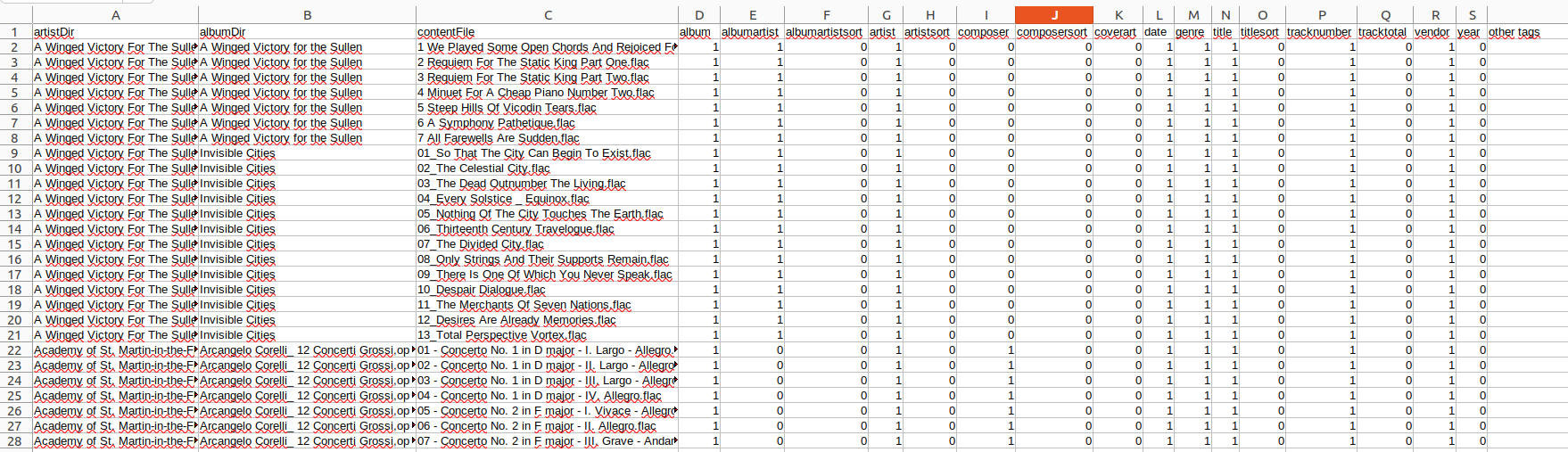
Image by: (Chris Hermansen, CC BY-SA 4.0)
I like to have the ALBUMARTIST defined as well as the ARTIST for some music players so that the files in an album are grouped together when artists on individual tracks vary. This happens in compilation albums, but also in some albums with guest artists where the ARTIST field might say for example "Tony Bennett and Snoop Dogg" (I made that up. I think.) Lines 22 and onward in the spreadsheet shown above don't specify the album artist, so I might want to fix that going forward.
Here is what the last column showing unwanted field ids looks like:
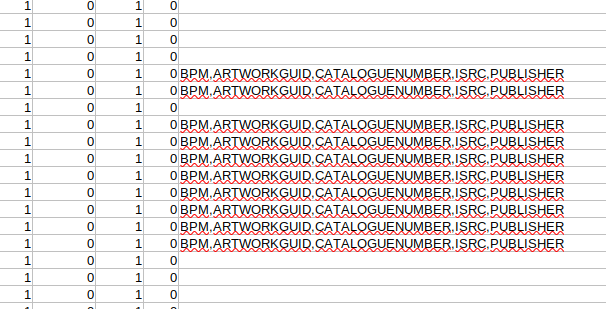
Image by: (Chris Hermansen, CC BY-SA 4.0)
Note that these tags may be of some interest and so the "wanted" list is modified to include them. I would set up some kind of script to delete field IDs BPM, ARTWORKGUID, CATALOGUENUMBER, ISRC and PUBLISHER.
Next steps
In the next article, I'll step back from tracks and check for cover.jpg and other non-music files lying around in artist subdirectories and album sub-subdirectories.
via: https://opensource.com/article/22/8/analyze-music-files-jaudiotagger
作者:Chris Hermansen 选题:lkxed 译者:译者ID 校对:校对者ID