7.7 KiB
如何在命令行中整理数据
命令行审计不会影响数据库,因为它使用从数据库中释放的数据。

我兼职做数据审计。把我想象成一个校对者,校对的是数据表格而不是一页一页的文章。这些表是从关系数据库导出的,并且规模相当小:100,000 到 1,000,000条记录,50 到 200 个字段。
我从来没有见过没有错误的数据表。如你所能想到的,这种混乱并不局限于重复记录、拼写和格式错误以及放置在错误字段中的数据项。我还发现:
- 损坏的记录分布在几行上,因为数据项具有内嵌的换行符
- 在同一记录中一个字段中的数据项与另一个字段中的数据项不一致
- 使用截断数据项的记录,通常是因为非常长的字符串被硬塞到具有 50 或 100 字符限制的字段中
- 字符编码失败产生称为乱码的垃圾
- 不可见的控制字符,其中一些会导致数据处理错误
- 由上一个程序插入的替换字符和神秘的问号,这是由于不知道数据的编码是什么
解决这些问题并不困难,但找到它们存在非技术障碍。首先,每个人都不愿处理数据错误。在我看到表格之前,数据所有者或管理人员可能已经经历了数据悲伤的所有五个阶段:
- 我们的数据没有错误。
- 好吧,也许有一些错误,但它们并不重要。
- 好的,有很多错误;我们会让我们的内部人员处理它们。
- 我们已经开始修复一些错误,但这很耗时间;我们将在迁移到新的数据库软件时执行此操作。
- 移至新数据库时,我们没有时间整理数据; 我们需要一些帮助。
第二个阻碍进展的是相信数据整理需要专用的应用程序——要么是昂贵的专有程序,要么是优秀的开源程序 OpenRefine 。为了解决专用应用程序无法解决的问题,数据管理人员可能会向程序员寻求帮助,比如擅长 Python 或 R 的人。
但是数据审计和整理通常不需要专用的应用程序。纯文本数据表已经存在了几十年,文本处理工具也是如此。打开 Bash shell,您将拥有一个工具箱,其中装载了强大的文本处理器,如 grep、cut、paste、sort、uniq、tr 和 awk。它们快速、可靠、易于使用。
我在命令行上执行所有的数据审计工作,并且在 “cookbook” 网站上发布了许多数据审计技巧。我经常将操作存储为函数和 shell 脚本(参见下面的示例)。
是的,命令行方法要求将要审计的数据从数据库中导出。而且,审计结果需要稍后在数据库中进行编辑,或者(数据库允许)将整理的数据项导入其中,以替换杂乱的数据项。
但其优势是显著的。awk 将在普通的台式机或笔记本电脑上以几秒钟的时间处理数百万条记录。不复杂的正则表达式将找到您可以想象的所有数据错误。所有这些都将安全地发生在数据库结构之外:命令行审计不会影响数据库,因为它使用从数据库中释放的数据。
受过 Unix 培训的读者此时会沾沾自喜。他们还记得许多年前用这些方法操纵命令行上的数据。从那时起,计算机的处理能力和 RAM 得到了显著提高,标准命令行工具的效率大大提高。数据审计从来没有这么快、这么容易过。现在微软的 Windows 10 可以运行 Bash 和 GNU/Linux 程序了,Windows 用户也可以用 Unix 和 Linux 的座右铭来处理混乱的数据:保持冷静,打开一个终端。

例子
假设我想在一个大的表中的特定字段中找到最长的数据项。 这不是一个真正的数据审计任务,但它会显示 shell 工具的工作方式。 为了演示目的,我将使用制表符分隔的表 full0 ,它有 1,122,023 条记录(加上一个标题行)和 49 个字段,我会查看 36 号字段。(我得到字段编号的函数在我的网站上有解释)
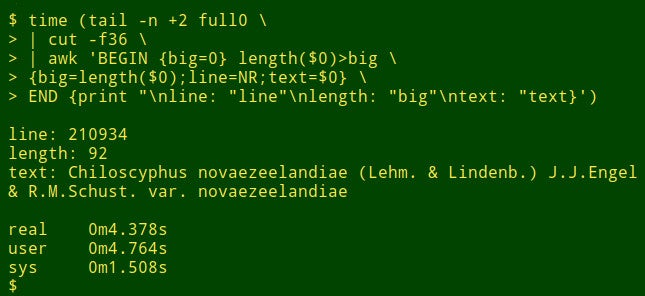
首先,使用 tail 命令从表 full0 移除标题行,结果管道至 cut 命令,截取第 36 个字段,接下来,管道至 awk ,这里有一个初始化为 0 的变量 big ,然后 awk 开始检测第一行数据项的长度,如果长度大于 0 ,awk 将会设置 big 变量为新的长度,同时存储行数到变量 line 中。整个数据项存储在变量 text 中。然后 awk 开始轮流处理剩余的 1,122,022 记录项。同时,如果发现更长的数据项时,更新 3 个变量。最后,它打印出行号、数据项的长度,以及最长数据项的内容。(在下面的代码中,为了清晰起见,将代码分为几行)
tail -n +2 full0 \
> | cut -f36 \
> | awk 'BEGIN {big=0} length($0)>big \
> {big=length($0);line=NR;text=$0} \
> END {print "\nline: "line"\nlength: "big"\ntext: "text}'
大约花了多长时间?我的电脑大约用了 4 秒钟(core i5,8GB RAM);
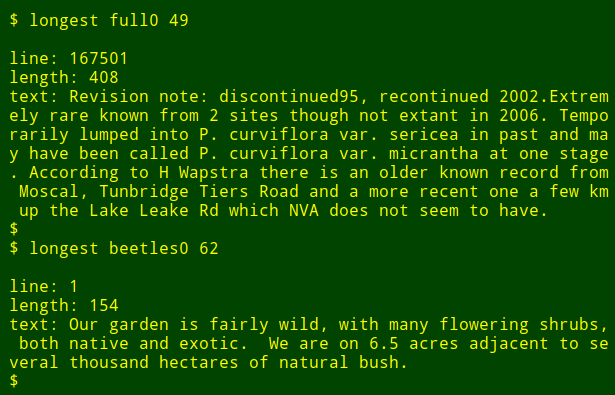
现在我可以将这个长长的命令封装成一个 shell 函数,longest,它把第一个参数认为是文件名,第二个参数认为是字段号:

现在,我可以以函数的方式重新运行这个命令,在另一个文件中的另一个字段中找最长的数据项,而不需要去记忆这个命令是如何写的:
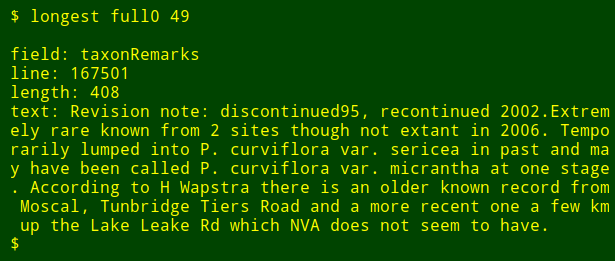
最后调整一下,我还可以输出我要查询字段的名称,我只需要使用 head 命令抽取表格第一行的标题行,然后将结果管道至 tr 命令,将制表位转换为换行,然后将结果管道至 tail 和 head 命令,打印出第二个参数在列表中名称,第二个参数就是字段号。字段的名字就存储到变量 field 中,然后将它传向 awk ,通过变量 fld 打印出来。(LCTT 译注:按照下面的代码,编号的方式应该是从右向左)
longest() { field=$(head -n 1 "$1" | tr '\t' '\n' | tail -n +"$2" | head -n 1); \
tail -n +2 "$1" \
| cut -f"$2" | \
awk -v fld="$field" 'BEGIN {big=0} length($0)>big \
{big=length($0);line=NR;text=$0}
END {print "\nfield: "fld"\nline: "line"\nlength: "big"\ntext: "text}'; }
注意,如果我在多个不同的字段中查找最长的数据项,我所要做的就是按向上箭头来获得最后一个最长的命令,然后删除字段号并输入一个新的。
via: https://opensource.com/article/18/5/command-line-data-auditing
作者:Bob Mesibov 选题:lujun9972 译者:amwps290 校对:wxy