mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-23 21:20:42 +08:00
135 lines
7.5 KiB
Markdown
135 lines
7.5 KiB
Markdown
关于 BPF 和 eBPF 的笔记
|
||
============================================================
|
||
|
||
今天,我喜欢的 meetup 网站上有一篇我超爱的文章![Suchakra Sharma][6]([@tuxology][7] 在 twitter/github)的一篇非常棒的关于传统 BPF 和在 Linux 中最新加入的 eBPF 的讨论文章,正是它促使我想去写一个 eBPF 的程序!
|
||
|
||
这篇文章就是 —— [BSD 包过滤器:一个新的用户级包捕获架构][8]
|
||
|
||
我想在讨论的基础上去写一些笔记,因为,我觉得它超级棒!
|
||
|
||
开始前,这里有个 [幻灯片][9] 和一个 [pdf][10]。这个 pdf 非常好,结束的位置有一些链接,在 PDF 中你可以直接点击这个链接。
|
||
|
||
### 什么是 BPF?
|
||
|
||
在 BPF 出现之前,如果你想去做包过滤,你必须拷贝所有的包到用户空间,然后才能去过滤它们(使用 “tap”)。
|
||
|
||
这样做存在两个问题:
|
||
|
||
1. 如果你在用户空间中过滤,意味着你将拷贝所有的包到用户空间,拷贝数据的代价是很昂贵的。
|
||
2. 使用的过滤算法很低效。
|
||
|
||
问题 #1 的解决方法似乎很明显,就是将过滤逻辑移到内核中。(虽然具体实现的细节并没有明确,我们将在稍后讨论)
|
||
|
||
但是,为什么过滤算法会很低效?
|
||
|
||
如果你运行 `tcpdump host foo`,它实际上运行了一个相当复杂的查询,用下图的这个树来描述它:
|
||
|
||
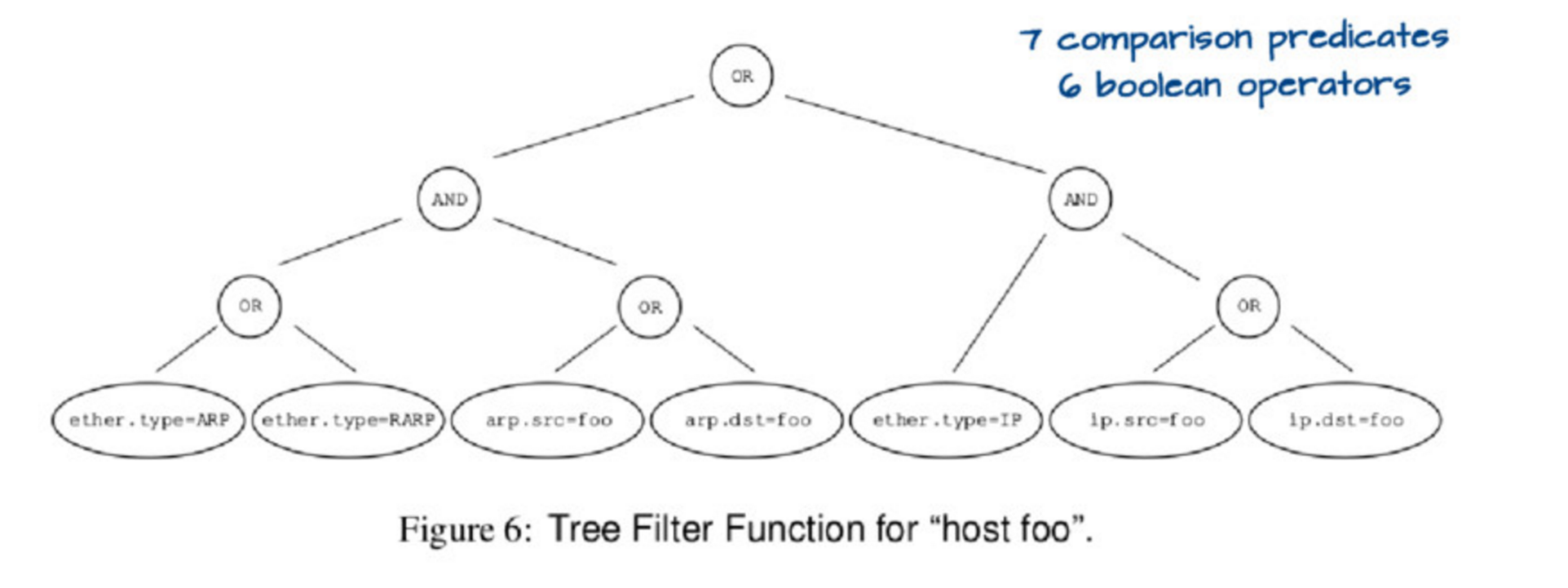
|
||
|
||
评估这个树有点复杂。因此,可以用一种更简单的方式来表示这个树,像这样:
|
||
|
||
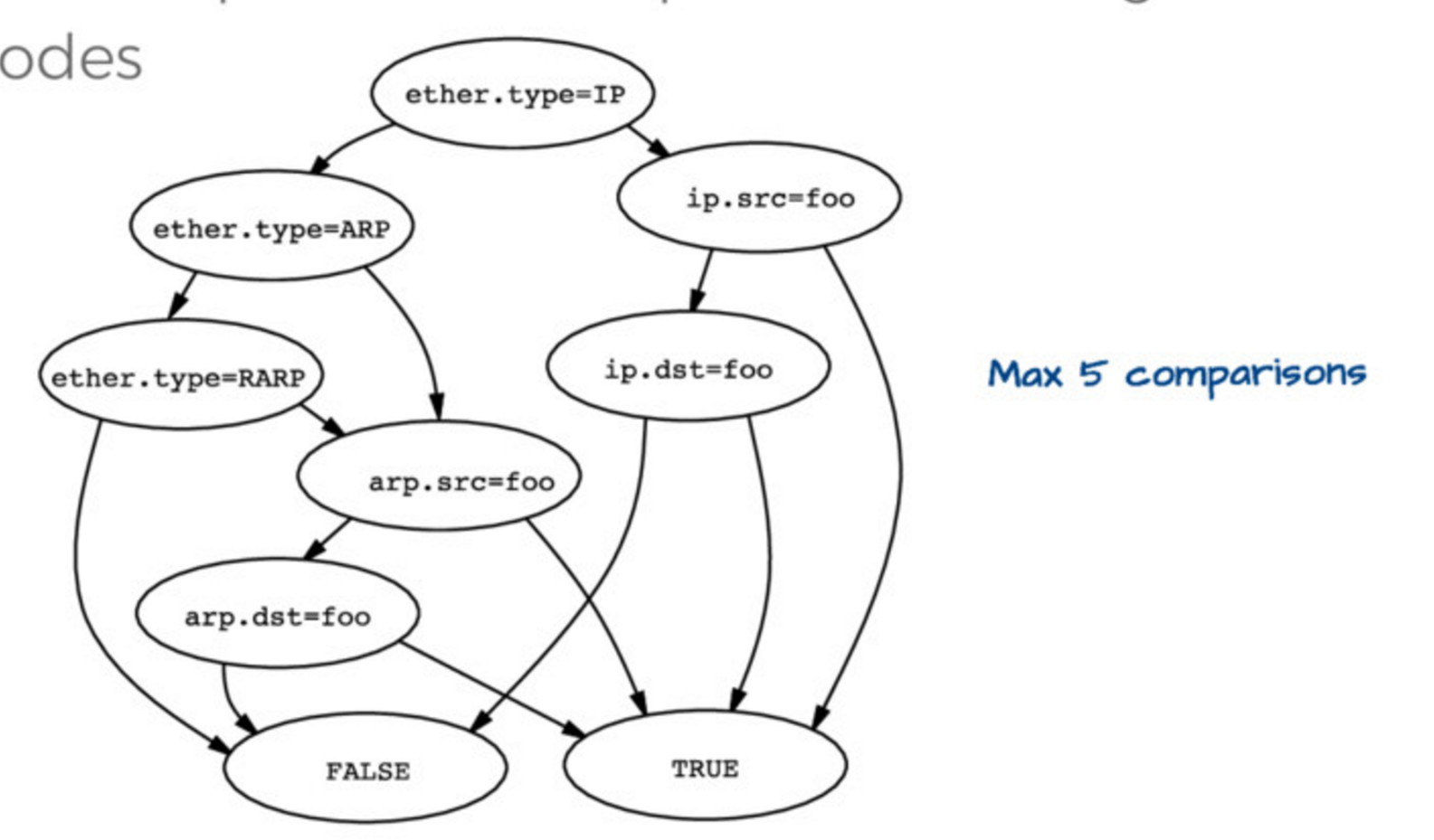
|
||
|
||
然后,如果你设置 `ether.type = IP` 和 `ip.src = foo`,你必然明白匹配的包是 `host foo`,你也不用去检查任何其它的东西了。因此,这个数据结构(它们称为“控制流图” ,或者 “CFG”)是表示你真实希望去执行匹配检查的程序的最佳方法,而不是用前面的树。
|
||
|
||
### 为什么 BPF 要工作在内核中
|
||
|
||
这里的关键点是,包仅仅是个字节的数组。BPF 程序是运行在这些字节的数组之上。它们不允许有循环(loop),但是,它们 _可以_ 有聪明的办法知道 IP 包头(IPv6 和 IPv4 长度是不同的)以及基于它们的长度来找到 TCP 端口:
|
||
|
||
```
|
||
x = ip_header_length
|
||
port = *(packet_start + x + port_offset)
|
||
```
|
||
|
||
(看起来不一样,其实它们基本上都相同)。在这个论文/幻灯片上有一个非常详细的虚拟机的描述,因此,我不打算解释它。
|
||
|
||
当你运行 `tcpdump host foo` 后,这时发生了什么?就我的理解,应该是如下的过程。
|
||
|
||
1. 转换 `host foo` 为一个高效的 DAG 规则
|
||
2. 转换那个 DAG 规则为 BPF 虚拟机的一个 BPF 程序(BPF 字节码)
|
||
3. 发送 BPF 字节码到 Linux 内核,由 Linux 内核验证它
|
||
4. 编译这个 BPF 字节码程序为一个<ruby>原生<rt>native</rt></ruby>代码。例如,这是个[ARM 上的 JIT 代码][1] 以及 [x86][2] 的机器码
|
||
5. 当包进入时,Linux 运行原生代码去决定是否过滤这个包。对于每个需要去处理的包,它通常仅需运行 100 - 200 个 CPU 指令就可以完成,这个速度是非常快的!
|
||
|
||
### 现状:eBPF
|
||
|
||
毕竟 BPF 出现已经有很长的时间了!现在,我们可以拥有一个更加令人激动的东西,它就是 eBPF。我以前听说过 eBPF,但是,我觉得像这样把这些片断拼在一起更好(我在 4 月份的 netdev 上我写了这篇 [XDP & eBPF 的文章][11]回复)
|
||
|
||
关于 eBPF 的一些事实是:
|
||
|
||
* eBPF 程序有它们自己的字节码语言,并且从那个字节码语言编译成内核原生代码,就像 BPF 程序一样
|
||
* eBPF 运行在内核中
|
||
* eBPF 程序不能随心所欲的访问内核内存。而是通过内核提供的函数去取得一些受严格限制的所需要的内容的子集
|
||
* 它们 _可以_ 与用户空间的程序通过 BPF 映射进行通讯
|
||
* 这是 Linux 3.18 的 `bpf` 系统调用
|
||
|
||
### kprobes 和 eBPF
|
||
|
||
你可以在 Linux 内核中挑选一个函数(任意函数),然后运行一个你写的每次该函数被调用时都运行的程序。这样看起来是不是很神奇。
|
||
|
||
例如:这里有一个 [名为 disksnoop 的 BPF 程序][12],它的功能是当你开始/完成写入一个块到磁盘时,触发它执行跟踪。下图是它的代码片断:
|
||
|
||
```
|
||
BPF_HASH(start, struct request *);
|
||
void trace_start(struct pt_regs *ctx, struct request *req) {
|
||
// stash start timestamp by request ptr
|
||
u64 ts = bpf_ktime_get_ns();
|
||
start.update(&req, &ts);
|
||
}
|
||
...
|
||
b.attach_kprobe(event="blk_start_request", fn_name="trace_start")
|
||
b.attach_kprobe(event="blk_mq_start_request", fn_name="trace_start")
|
||
|
||
```
|
||
|
||
本质上它声明一个 BPF 哈希(它的作用是当请求开始/完成时,这个程序去触发跟踪),一个名为 `trace_start` 的函数将被编译进 BPF 字节码,然后附加 `trace_start` 到内核函数 `blk_start_request` 上。
|
||
|
||
这里使用的是 `bcc` 框架,它可以让你写 Python 式的程序去生成 BPF 代码。你可以在 [https://github.com/iovisor/bcc][13] 找到它(那里有非常多的示例程序)。
|
||
|
||
### uprobes 和 eBPF
|
||
|
||
因为我知道可以附加 eBPF 程序到内核函数上,但是,我不知道能否将 eBPF 程序附加到用户空间函数上!那会有更多令人激动的事情。这是 [在 Python 中使用一个 eBPF 程序去计数 malloc 调用的示例][14]。
|
||
|
||
### 附加 eBPF 程序时应该考虑的事情
|
||
|
||
* 带 XDP 的网卡(我之前写过关于这方面的文章)
|
||
* tc egress/ingress (在网络栈上)
|
||
* kprobes(任意内核函数)
|
||
* uprobes(很明显,任意用户空间函数??像带调试符号的任意 C 程序)
|
||
* probes 是为 dtrace 构建的名为 “USDT probes” 的探针(像 [这些 mysql 探针][3])。这是一个 [使用 dtrace 探针的示例程序][4]
|
||
* [JVM][5]
|
||
* 跟踪点
|
||
* seccomp / landlock 安全相关的事情
|
||
* 等等
|
||
|
||
### 这个讨论超级棒
|
||
|
||
在幻灯片里有很多非常好的链接,并且在 iovisor 仓库里有个 [LINKS.md][15]。虽然现在已经很晚了,但是我马上要去写我的第一个 eBPF 程序了!
|
||
|
||
--------------------------------------------------------------------------------
|
||
|
||
via: https://jvns.ca/blog/2017/06/28/notes-on-bpf---ebpf/
|
||
|
||
作者:[Julia Evans][a]
|
||
译者:[qhwdw](https://github.com/qhwdw)
|
||
校对:[wxy](https://github.com/wxy)
|
||
|
||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||
|
||
[a]:https://jvns.ca/
|
||
[1]:https://github.com/torvalds/linux/blob/v4.10/arch/arm/net/bpf_jit_32.c#L512
|
||
[2]:https://github.com/torvalds/linux/blob/v3.18/arch/x86/net/bpf_jit_comp.c#L189
|
||
[3]:https://dev.mysql.com/doc/refman/5.7/en/dba-dtrace-ref-query.html
|
||
[4]:https://github.com/iovisor/bcc/blob/master/examples/tracing/mysqld_query.py
|
||
[5]:http://blogs.microsoft.co.il/sasha/2016/03/31/probing-the-jvm-with-bpfbcc/
|
||
[6]:http://suchakra.in/
|
||
[7]:https://twitter.com/tuxology
|
||
[8]:http://www.vodun.org/papers/net-papers/van_jacobson_the_bpf_packet_filter.pdf
|
||
[9]:https://speakerdeck.com/tuxology/the-bsd-packet-filter
|
||
[10]:http://step.polymtl.ca/~suchakra/PWL-Jun28-MTL.pdf
|
||
[11]:https://jvns.ca/blog/2017/04/07/xdp-bpf-tutorial/
|
||
[12]:https://github.com/iovisor/bcc/blob/0c8c179fc1283600887efa46fe428022efc4151b/examples/tracing/disksnoop.py
|
||
[13]:https://github.com/iovisor/bcc
|
||
[14]:https://github.com/iovisor/bcc/blob/00f662dbea87a071714913e5c7382687fef6a508/tests/lua/test_uprobes.lua
|
||
[15]:https://github.com/iovisor/bcc/blob/master/LINKS.md
|