理解监测指标,并使用 Python 去监测它们
======
> 通过学习这些关键的术语和概念来理解 Python 应用监测。

当我第一次看到术语“计数器”和“计量器”和使用颜色及标记着“平均数”和“大于 90%”的数字图表时,我的反应之一是逃避。就像我看到它们一样,我并不感兴趣,因为我不理解它们是干什么的或如何去使用。因为我的工作不需要我去注意它们,它们被我完全无视。
这都是在两年以前的事了。随着我的职业发展,我希望去了解更多关于我们的网络应用程序的知识,而那个时候就是我开始去学习监测指标的时候。
我的理解监测的学习之旅共有三个阶段(到目前为止),它们是:
* 阶段 1:什么?(王顾左右)
* 阶段 2:没有指标,我们真的是瞎撞。
* 阶段 3:出现不合理的指标我们该如何做?
我现在处于阶段 2,我将分享到目前为止我学到了些什么。我正在向阶段 3 进发,在本文结束的位置我提供了一些我正在使用的学习资源。
我们开始吧!
### 需要的软件
在文章中讨论时用到的 demo 都可以在 [我的 GitHub 仓库][6] 中找到。你需要安装 docker 和 docker-compose 才能使用它们。
### 为什么要监测?
关于监测的主要原因是:
* 理解 _正常的_ 和 _不正常的_ 系统和服务的特征
* 做容量规划、弹性伸缩
* 有助于排错
* 了解软件/硬件改变的效果
* 测量响应中的系统行为变化
* 当系统出现意外行为时发出警报
### 指标和指标类型
从我们的用途来看,一个**指标**就是在一个给定*时间*点上的某些数量的 _测量_ 值。博客文章的总点击次数、参与讨论的总人数、在缓存系统中数据没有被找到的次数、你的网站上的已登录用户数 —— 这些都是指标的例子。
它们总体上可以分为三类:
#### 计数器
以你的个人博客为例。你发布一篇文章后,过一段时间后,你希望去了解有多少点击量,这是一个只会增加的数字。这就是一个计数器指标。在你的博客文章的生命周期中,它的值从 0 开始增加。用图表来表示,一个计数器看起来应该像下面的这样:
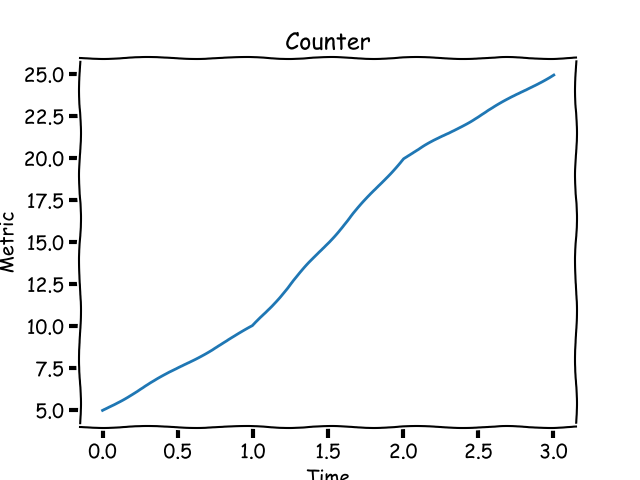
*一个计数器指标总是在增加的。*
#### 计量器
如果你想去跟踪你的博客每天或每周的点击量,而不是基于时间的总点击量。这种指标被称为一个计量器,它的值可上可下。用图表来表示,一个计量器看起来应该像下面的样子:
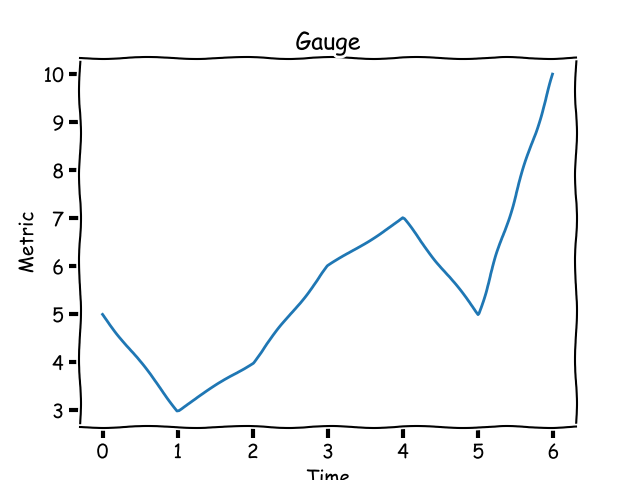
*一个计量器指标可以增加或减少。*
一个计量器的值在某些时间窗口内通常有一个最大值和floor。
#### 柱状图和计时器
柱状图(在 Prometheus 中这么叫它)或计时器(在 StatsD 中这么叫它)是一个跟踪 _已采样的观测结果_ 的指标。不像一个计数器类或计量器类指标,柱状图指标的值并不是显示为上或下的样式。我知道这可能并没有太多的意义,并且可能和一个计量器图看上去没有什么不同。它们的不同之处在于,你期望使用柱状图数据来做什么,而不是与一个计量器图做比较。因此,监测系统需要知道那个指标是一个柱状图类型,它允许你去做哪些事情。
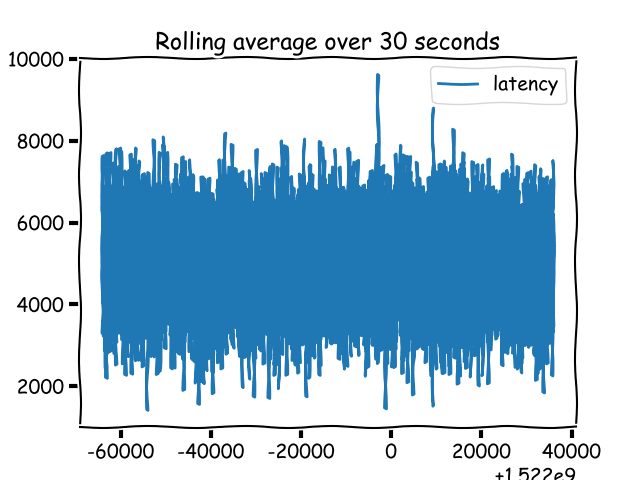
*一个柱状图指标可以增加或减少。*
### Demo 1:计算和报告指标
[Demo 1][7] 是使用 [Flask][8] 框架写的一个基本的 web 应用程序。它演示了我们如何去 _计算_ 和 _报告_ 指标。
在 `src` 目录中有 `app.py` 和 `src/helpers/middleware.py` 应用程序,包含以下内容:
```
from flask import request
import csv
import time
def start_timer():
request.start_time = time.time()
def stop_timer(response):
# convert this into milliseconds for statsd
resp_time = (time.time() - request.start_time)*1000
with open('metrics.csv', 'a', newline='') as f:
csvwriter = csv.writer(f)
csvwriter.writerow([str(int(time.time())), str(resp_time)])
return response
def setup_metrics(app):
app.before_request(start_timer)
app.after_request(stop_timer)
```
当在应用程序中调用 `setup_metrics()` 时,它配置在一个请求被处理之前调用 `start_timer()` 函数,然后在该请求处理之后、响应发送之前调用 `stop_timer()` 函数。在上面的函数中,我们写了时间戳并用它来计算处理请求所花费的时间。
当我们在 `demo1` 目录中运行 `docker-compose up`,它会启动这个 web 应用程序,然后在一个客户端容器中可以生成一些对 web 应用程序的请求。你将会看到创建了一个 `src/metrics.csv` 文件,它有两个字段:`timestamp` 和 `request_latency`。
通过查看这个文件,我们可以推断出两件事情:
* 生成了很多数据
* 没有观测到任何与指标相关的特征
没有观测到与指标相关的特征,我们就不能说这个指标与哪个 HTTP 端点有关联,或这个指标是由哪个应用程序的节点所生成的。因此,我们需要使用合适的元数据去限定每个观测指标。
### 《Statistics 101》
(LCTT 译注:这是一本统计学入门教材的名字)
假如我们回到高中数学,我们应该回忆起一些统计术语,虽然不太确定,但应该包括平均数、中位数、百分位和柱状图。我们来简要地回顾一下它们,不用去管它们的用法,就像是在上高中一样。
#### 平均数
平均数,即一系列数字的平均值,是将数字汇总然后除以列表的个数。3、2 和 10 的平均数是 (3+2+10)/3 = 5。
#### 中位数
中位数是另一种类型的平均,但它的计算方式不同;它是列表从小到大排序(反之亦然)后取列表的中间数字。以我们上面的列表中(2、3、10),中位数是 3。计算并不是非常直观,它取决于列表中数字的个数。
#### 百分位
百分位是指那个百(千)分比数字低于我们给定的百分数的程度。在一些场景中,它是指这个测量值低于我们数据的百(千)分比数字的程度。比如,上面列表中 95% 是 9.29999。百分位的测量范围是 0 到 100(不包括)。0% 是一组数字的最小分数。你可能会想到它的中位数是 50%,它的结果是 3。
一些监测系统将百分位称为 `upper_X`,其中 _X_ 就是百分位;`upper 90` 指的是在 90% 的位置的值。
#### 分位数
“q-分位数”是将有 _N_ 个数的集合等分为 `qN` 级。`q` 的取值范围为 0 到 1(全部都包括)。当 `q` 取值为 0.5 时,值就是中位数。(分位数)和百分位数的关系是,分位数值 `q` 等于 `100` 百分位值。
#### 柱状图
histogram这个指标,我们前面学习过,它是监测系统中一个_实现细节_。在统计学中,一个柱状图是一个将数据分组为 _桶_ 的图表。我们来考虑一个人为的不同示例:阅读你的博客的人的年龄。如果你有一些这样的数据,并想将它进行大致的分组,绘制成的柱状图将看起来像下面的这样:
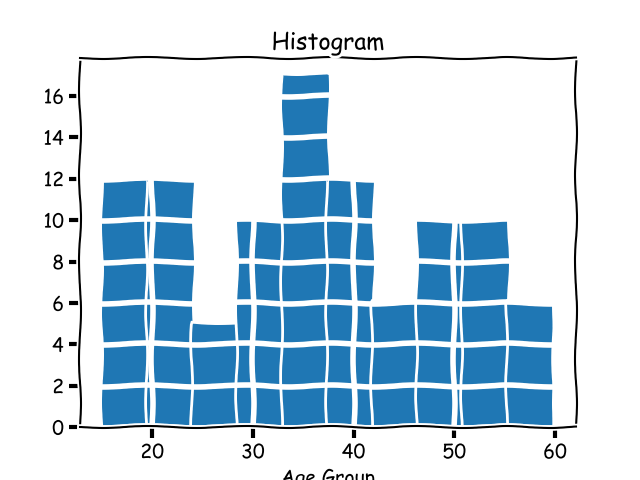
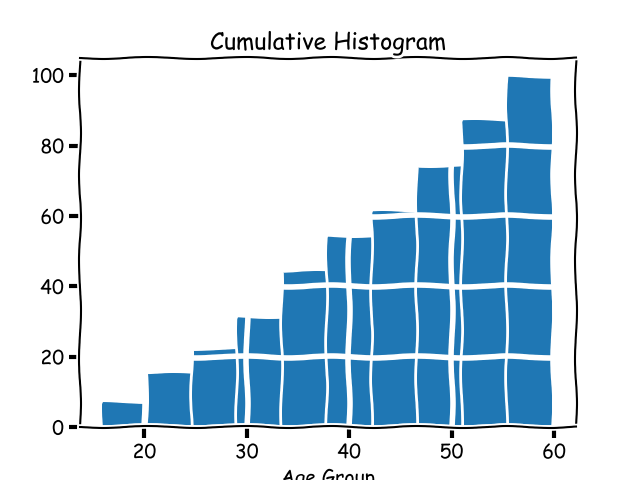
#### 累积柱状图
一个累积柱状图也是一个柱状图,它的每个桶的数包含前一个桶的数,因此命名为_累积_。将上面的数据集做成累积柱状图后,看起来应该是这样的:
#### 我们为什么需要做统计?
在上面的 Demo 1 中,我们注意到在我们报告指标时,这里生成了许多数据。当我们将它们用于指标时我们需要做统计,因为它们实在是太多了。我们需要的是整体行为,我们没法去处理单个值。我们预期展现出来的值的行为应该是代表我们观察的系统的行为。
### Demo 2:在指标上增加特征
在我们上面的的 Demo 1 应用程序中,当我们计算和报告一个请求的延迟时,它指向了一个由一些_特征_ 唯一标识的特定请求。下面是其中一些:
* HTTP 端点
* HTTP 方法
* 运行它的主机/节点的标识符
如果我们将这些特征附加到要观察的指标上,每个指标将有更多的内容。我们来解释一下 [Demo 2][9] 中添加到我们的指标上的特征。
在写入指标时,`src/helpers/middleware.py` 文件将在 CSV 文件中写入多个列:
```
node_ids = ['10.0.1.1', '10.1.3.4']
def start_timer():
request.start_time = time.time()
def stop_timer(response):
# convert this into milliseconds for statsd
resp_time = (time.time() - request.start_time)*1000
node_id = node_ids[random.choice(range(len(node_ids)))]
with open('metrics.csv', 'a', newline='') as f:
csvwriter = csv.writer(f)
csvwriter.writerow([
str(int(time.time())), 'webapp1', node_id,
request.endpoint, request.method, str(response.status_code),
str(resp_time)
])
return response
```
因为这只是一个演示,在报告指标时,我们将随意的报告一些随机 IP 作为节点的 ID。当我们在 `demo2` 目录下运行 `docker-compose up` 时,我们的结果将是一个有多个列的 CSV 文件。
#### 用 pandas 分析指标
我们将使用 [pandas][10] 去分析这个 CSV 文件。运行 `docker-compose up` 将打印出一个 URL,我们将使用它来打开一个 [Jupyter][11] 会话。一旦我们上传 `Analysis.ipynb notebook` 到会话中,我们就可以将 CSV 文件读入到一个 pandas 数据帧中:
```
import pandas as pd
metrics = pd.read_csv('/data/metrics.csv', index_col=0)
```
`index_col` 表明我们要指定时间戳作为索引。
因为每个特征我们都要在数据帧中添加一个列,因此我们可以基于这些列进行分组和聚合:
```
import numpy as np
metrics.groupby(['node_id', 'http_status']).latency.aggregate(np.percentile, 99.999)
```
更多内容请参考 Jupyter notebook 在数据上的分析示例。
### 我应该监测什么?
一个软件系统有许多的变量,这些变量的值在它的生命周期中不停地发生变化。软件是运行在某种操作系统上的,而操作系统同时也在不停地变化。在我看来,当某些东西出错时,你所拥有的数据越多越好。
我建议去监测的关键操作系统指标有:
* CPU 使用
* 系统内存使用
* 文件描述符使用
* 磁盘使用
还需要监测的其它关键指标根据你的软件应用程序不同而不同。
#### 网络应用程序
如果你的软件是一个监听客户端请求和为它提供服务的网络应用程序,需要测量的关键指标还有:
* 入站请求数(计数器)
* 未处理的错误(计数器)
* 请求延迟(柱状图/计时器)
* 排队时间,如果在你的应用程序中有队列(柱状图/计时器)
* 队列大小,如果在你的应用程序中有队列(计量器)
* 工作进程/线程用量(计量器)
如果你的网络应用程序在一个客户端请求的环境中向其它服务发送请求,那么它应该有一个指标去记录它与那个服务之间的通讯行为。需要监测的关键指标包括请求数、请求延迟、和响应状态。
#### HTTP web 应用程序后端
HTTP 应用程序应该监测上面所列出的全部指标。除此之外,还应该按 HTTP 状态代码分组监测所有非 200 的 HTTP 状态代码的大致数据。如果你的 web 应用程序有用户注册和登录功能,同时也应该为这个功能设置指标。
#### 长时间运行的进程
长时间运行的进程如 Rabbit MQ 消费者或任务队列的工作进程,虽然它们不是网络服务,它们以选取一个任务并处理它的工作模型来运行。因此,我们应该监测请求的进程数和这些进程的请求延迟。
不管是什么类型的应用程序,都有指标与合适的**元数据**相关联。
### 将监测集成到一个 Python 应用程序中
将监测集成到 Python 应用程序中需要涉及到两个组件:
* 更新你的应用程序去计算和报告指标
* 配置一个监测基础设施来容纳应用程序的指标,并允许去查询它们
下面是记录和报告指标的基本思路:
```
def work():
requests += 1
# report counter
start_time = time.time()
# < do the work >
# calculate and report latency
work_latency = time.time() - start_time
...
```
考虑到上面的模式,我们经常使用修饰符、内容管理器、中间件(对于网络应用程序)所带来的好处去计算和报告指标。在 Demo 1 和 Demo 2 中,我们在一个 Flask 应用程序中使用修饰符。
#### 指标报告时的拉取和推送模型
大体来说,在一个 Python 应用程序中报告指标有两种模式。在 _拉取_ 模型中,监测系统在一个预定义的 HTTP 端点上“刮取”应用程序。在_推送_ 模型中,应用程序发送数据到监测系统。

工作在 _拉取_ 模型中的监测系统的一个例子是 [Prometheus][12]。而 [StatsD][13] 是 _推送_ 模型的一个例子。
#### 集成 StatsD
将 StatsD 集成到一个 Python 应用程序中,我们将使用 [StatsD Python 客户端][14],然后更新我们的指标报告部分的代码,调用合适的库去推送数据到 StatsD 中。
首先,我们需要去创建一个客户端实例:
```
statsd = statsd.StatsClient(host='statsd', port=8125, prefix='webapp1')
```
`prefix` 关键字参数将为通过这个客户端报告的所有指标添加一个指定的前缀。
一旦我们有了客户端,我们可以使用如下的代码为一个计时器报告值:
```
statsd.timing(key, resp_time)
```
增加计数器:
```
statsd.incr(key)
```
将指标关联到元数据上,一个键的定义为:`metadata1.metadata2.metric`,其中每个 metadataX 是一个可以进行聚合和分组的字段。
这个演示应用程序 [StatsD][15] 是将 statsd 与 Python Flask 应用程序集成的一个完整示例。
#### 集成 Prometheus
要使用 Prometheus 监测系统,我们使用 [Promethius Python 客户端][16]。我们将首先去创建有关的指标类对象:
```
REQUEST_LATENCY = Histogram('request_latency_seconds', 'Request latency',
['app_name', 'endpoint']
)
```
在上面的语句中的第三个参数是与这个指标相关的标识符。这些标识符是由与单个指标值相关联的元数据定义的。
去记录一个特定的观测指标:
```
REQUEST_LATENCY.labels('webapp', request.path).observe(resp_time)
```
下一步是在我们的应用程序中定义一个 Prometheus 能够刮取的 HTTP 端点。这通常是一个被称为 `/metrics` 的端点:
```
@app.route('/metrics')
def metrics():
return Response(prometheus_client.generate_latest(), mimetype=CONTENT_TYPE_LATEST)
```
这个演示应用程序 [Prometheus][17] 是将 prometheus 与 Python Flask 应用程序集成的一个完整示例。
#### 哪个更好:StatsD 还是 Prometheus?
本能地想到的下一个问题便是:我应该使用 StatsD 还是 Prometheus?关于这个主题我写了几篇文章,你可能发现它们对你很有帮助:
* [使用 Prometheus 监测多进程 Python 应用的方式][18]
* [使用 Prometheus 监测你的同步 Python 应用][19]
* [使用 Prometheus 监测你的异步 Python 应用][20]
### 指标的使用方式
我们已经学习了一些关于为什么要在我们的应用程序上配置监测的原因,而现在我们来更深入地研究其中的两个用法:报警和自动扩展。
#### 使用指标进行报警
指标的一个关键用途是创建警报。例如,假如过去的五分钟,你的 HTTP 500 的数量持续增加,你可能希望给相关的人发送一封电子邮件或页面提示。对于配置警报做什么取决于我们的监测设置。对于 Prometheus 我们可以使用 [Alertmanager][21],而对于 StatsD,我们使用 [Nagios][22]。
#### 使用指标进行自动扩展
在一个云基础设施中,如果我们当前的基础设施供应过量或供应不足,通过指标不仅可以让我们知道,还可以帮我们实现一个自动伸缩的策略。例如,如果在过去的五分钟里,在我们服务器上的工作进程使用率达到 90%,我们可以水平扩展。我们如何去扩展取决于云基础设施。AWS 的自动扩展,缺省情况下,扩展策略是基于系统的 CPU 使用率、网络流量、以及其它因素。然而,让基础设施伸缩的应用程序指标,我们必须发布 [自定义的 CloudWatch 指标][23]。
### 在多服务架构中的应用程序监测
当我们超越一个单应用程序架构时,比如当客户端的请求在响应被发回之前,能够触发调用多个服务,就需要从我们的指标中获取更多的信息。我们需要一个统一的延迟视图指标,这样我们就能够知道响应这个请求时每个服务花费了多少时间。这可以用 [分布式跟踪][24] 来实现。
你可以在我的博客文章 《[在你的 Python 应用程序中通过 Zipkin 引入分布式跟踪][25]》 中看到在 Python 中进行分布式跟踪的示例。
### 划重点
总之,你需要记住以下几点:
* 理解你的监测系统中指标类型的含义
* 知道监测系统需要的你的数据的测量单位
* 监测你的应用程序中的大多数关键组件
* 监测你的应用程序在它的大多数关键阶段的行为
以上要点是假设你不去管理你的监测系统。如果管理你的监测系统是你的工作的一部分,那么你还要考虑更多的问题!
### 其它资源
以下是我在我的监测学习过程中找到的一些非常有用的资源:
#### 综合的
* [监测分布式系统][26]
* [观测和监测最佳实践][27]
* [谁想使用秒?][28]
#### StatsD/Graphite
* [StatsD 指标类型][29]
#### Prometheus
* [Prometheus 指标类型][30]
* [Prometheus 计量器如何工作?][31]
* [为什么用 Prometheus 累积柱形图?][32]
* [在 Python 中监测批量作业][33]
* [Prometheus:监测 SoundCloud][34]
### 避免犯错(即第 3 阶段的学习)
在我们学习监测的基本知识时,时刻注意不要犯错误是很重要的。以下是我偶然发现的一些很有见解的资源:
* [如何不测量延迟][35]
* [Prometheus 柱形图:悲伤的故事][36]
* [为什么平均值很讨厌,而百分位很棒][37]
* [对延迟的认知错误][38]
* [谁动了我的 99% 延迟?][39]
* [日志、指标和图形][40]
* [HdrHistogram:一个更好的延迟捕获方式][41]
---
想学习更多内容,参与到 [PyCon Cleveland 2018][43] 上的 Amit Saha 的讨论,[Counter, gauge, upper 90—Oh my!][42]
## 关于作者
[][44]
Amit Saha — 我是一名对基础设施、监测、和工具感兴趣的软件工程师。我是“用 Python 做数学”的作者和创始人,以及 Fedora Scientific Spin 维护者。
[关于我的更多信息][45]
* [Learn how you can contribute][46]
---
via: [https://opensource.com/article/18/4/metrics-monitoring-and-python][47]
作者: [Amit Saha][48] 选题者: [lujun9972][49] 译者: [qhwdw][50] 校对: [wxy][51]
本文由 [LCTT][52] 原创编译,[Linux中国][53] 荣誉推出
[1]: https://opensource.com/resources/python?intcmp=7016000000127cYAAQ
[2]: https://opensource.com/resources/python/ides?intcmp=7016000000127cYAAQ
[3]: https://opensource.com/resources/python/gui-frameworks?intcmp=7016000000127cYAAQ
[4]: https://opensource.com/tags/python?intcmp=7016000000127cYAAQ
[5]: https://developers.redhat.com/?intcmp=7016000000127cYAAQ
[6]: https://github.com/amitsaha/python-monitoring-talk
[7]: https://github.com/amitsaha/python-monitoring-talk/tree/master/demo1
[8]: http://flask.pocoo.org/
[9]: https://github.com/amitsaha/python-monitoring-talk/tree/master/demo2
[10]: https://pandas.pydata.org/
[11]: http://jupyter.org/
[12]: https://prometheus.io/
[13]: https://github.com/etsy/statsd
[14]: https://pypi.python.org/pypi/statsd
[15]: https://github.com/amitsaha/python-monitoring-talk/tree/master/statsd
[16]: https://pypi.python.org/pypi/prometheus_client
[17]: https://github.com/amitsaha/python-monitoring-talk/tree/master/prometheus
[18]: http://echorand.me/your-options-for-monitoring-multi-process-python-applications-with-prometheus.html
[19]: https://blog.codeship.com/monitoring-your-synchronous-python-web-applications-using-prometheus/
[20]: https://blog.codeship.com/monitoring-your-asynchronous-python-web-applications-using-prometheus/
[21]: https://github.com/prometheus/alertmanager
[22]: https://www.nagios.org/about/overview/
[23]: https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/publishingMetrics.html
[24]: http://opentracing.io/documentation/
[25]: http://echorand.me/introducing-distributed-tracing-in-your-python-application-via-zipkin.html
[26]: https://landing.google.com/sre/book/chapters/monitoring-distributed-systems.html
[27]: http://www.integralist.co.uk/posts/monitoring-best-practices/?imm_mid=0fbebf&cmp=em-webops-na-na-newsltr_20180309
[28]: https://www.robustperception.io/who-wants-seconds/
[29]: https://github.com/etsy/statsd/blob/master/docs/metric_types.md
[30]: https://prometheus.io/docs/concepts/metric_types/
[31]: https://www.robustperception.io/how-does-a-prometheus-gauge-work/
[32]: https://www.robustperception.io/why-are-prometheus-histograms-cumulative/
[33]: https://www.robustperception.io/monitoring-batch-jobs-in-python/
[34]: https://developers.soundcloud.com/blog/prometheus-monitoring-at-soundcloud
[35]: https://www.youtube.com/watch?v=lJ8ydIuPFeU&feature=youtu.be
[36]: http://linuxczar.net/blog/2017/06/15/prometheus-histogram-2/
[37]: https://www.dynatrace.com/news/blog/why-averages-suck-and-percentiles-are-great/
[38]: https://bravenewgeek.com/everything-you-know-about-latency-is-wrong/
[39]: https://engineering.linkedin.com/performance/who-moved-my-99th-percentile-latency
[40]: https://grafana.com/blog/2016/01/05/logs-and-metrics-and-graphs-oh-my/
[41]: http://psy-lob-saw.blogspot.com.au/2015/02/hdrhistogram-better-latency-capture.html
[42]: https://us.pycon.org/2018/schedule/presentation/133/
[43]: https://us.pycon.org/2018/
[44]: https://opensource.com/users/amitsaha
[45]: https://opensource.com/users/amitsaha
[46]: https://opensource.com/participate
[47]: https://opensource.com/article/18/4/metrics-monitoring-and-python
[48]: https://opensource.com/users/amitsaha
[49]: https://github.com/lujun9972
[50]: https://github.com/qhwdw
[51]: https://github.com/wxy
[52]: https://github.com/LCTT/TranslateProject
[53]: https://linux.cn/