mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-03 01:10:13 +08:00
commit
ff6be6db82
@ -0,0 +1,236 @@
|
||||
使用 Python 和 Asyncio 编写在线多用人游戏(二)
|
||||
==================================================================
|
||||
|
||||

|
||||
|
||||
> 你在 Python 中用过异步编程吗?本文中我会告诉你怎样做,而且用一个[能工作的例子][1]来展示它:这是一个流行的贪吃蛇游戏,而且是为多人游戏而设计的。
|
||||
|
||||
介绍和理论部分参见“[第一部分 异步化][2]”。
|
||||
|
||||
- [游戏入口在此,点此体验][1]。
|
||||
|
||||
### 3、编写游戏循环主体
|
||||
|
||||
游戏循环是每一个游戏的核心。它持续地运行以读取玩家的输入、更新游戏的状态,并且在屏幕上渲染游戏结果。在在线游戏中,游戏循环分为客户端和服务端两部分,所以一般有两个循环通过网络通信。通常客户端的角色是获取玩家输入,比如按键或者鼠标移动,将数据传输给服务端,然后接收需要渲染的数据。服务端处理来自玩家的所有数据,更新游戏的状态,执行渲染下一帧的必要计算,然后将结果传回客户端,例如游戏中对象的新位置。如果没有可靠的理由,不混淆客户端和服务端的角色是一件很重要的事。如果你在客户端执行游戏逻辑的计算,很容易就会和其它客户端失去同步,其实你的游戏也可以通过简单地传递客户端的数据来创建。
|
||||
|
||||
> 游戏循环的一次迭代称为一个嘀嗒(tick)。嘀嗒是一个事件,表示当前游戏循环的迭代已经结束,下一帧(或者多帧)的数据已经就绪。
|
||||
|
||||
在后面的例子中,我们使用相同的客户端,它使用 WebSocket 从一个网页上连接到服务端。它执行一个简单的循环,将按键码发送给服务端,并显示来自服务端的所有信息。[客户端代码戳这里][4]。
|
||||
|
||||
### 例子 3.1:基本游戏循环
|
||||
|
||||
> [例子 3.1 源码][5]。
|
||||
|
||||
我们使用 [aiohttp][6] 库来创建游戏服务器。它可以通过 asyncio 创建网页服务器和客户端。这个库的一个优势是它同时支持普通 http 请求和 websocket。所以我们不用其他网页服务器来渲染游戏的 html 页面。
|
||||
|
||||
下面是启动服务器的方法:
|
||||
|
||||
```
|
||||
app = web.Application()
|
||||
app["sockets"] = []
|
||||
|
||||
asyncio.ensure_future(game_loop(app))
|
||||
|
||||
app.router.add_route('GET', '/connect', wshandler)
|
||||
app.router.add_route('GET', '/', handle)
|
||||
|
||||
web.run_app(app)
|
||||
```
|
||||
|
||||
`web.run_app` 是创建服务主任务的快捷方法,通过它的 `run_forever()` 方法来执行 `asyncio` 事件循环。建议你查看这个方法的源码,弄清楚服务器到底是如何创建和结束的。
|
||||
|
||||
`app` 变量就是一个类似于字典的对象,它用于在所连接的客户端之间共享数据。我们使用它来存储连接的套接字的列表。随后会用这个列表来给所有连接的客户端发送消息。`asyncio.ensure_future()` 调用会启动主游戏循环的任务,每隔2 秒向客户端发送嘀嗒消息。这个任务会在同样的 asyncio 事件循环中和网页服务器并行执行。
|
||||
|
||||
有两个网页请求处理器:`handle` 是提供 html 页面的处理器;`wshandler` 是主要的 websocket 服务器任务,处理和客户端之间的交互。在事件循环中,每一个连接的客户端都会创建一个新的 `wshandler` 任务。这个任务会添加客户端的套接字到列表中,以便 `game_loop` 任务可以给所有的客户端发送消息。然后它将随同消息回显客户端的每个击键。
|
||||
|
||||
在启动的任务中,我们在 `asyncio` 的主事件循环中启动 worker 循环。任务之间的切换发生在它们之间任何一个使用 `await`语句来等待某个协程结束时。例如 `asyncio.sleep` 仅仅是将程序执行权交给调度器一段指定的时间;`ws.receive` 等待 websocket 的消息,此时调度器可能切换到其它任务。
|
||||
|
||||
在浏览器中打开主页,连接上服务器后,试试随便按下键。它们的键值会从服务端返回,每隔 2 秒这个数字会被游戏循环中发给所有客户端的嘀嗒消息所覆盖。
|
||||
|
||||
我们刚刚创建了一个处理客户端按键的服务器,主游戏循环在后台做一些处理,周期性地同时更新所有的客户端。
|
||||
|
||||
### 例子 3.2: 根据请求启动游戏
|
||||
|
||||
> [例子 3.2 的源码][7]
|
||||
|
||||
在前一个例子中,在服务器的生命周期内,游戏循环一直运行着。但是现实中,如果没有一个人连接服务器,空运行游戏循环通常是不合理的。而且,同一个服务器上可能有不同的“游戏房间”。在这种假设下,每一个玩家“创建”一个游戏会话(比如说,多人游戏中的一个比赛或者大型多人游戏中的副本),这样其他用户可以加入其中。当游戏会话开始时,游戏循环才开始执行。
|
||||
|
||||
在这个例子中,我们使用一个全局标记来检测游戏循环是否在执行。当第一个用户发起连接时,启动它。最开始,游戏循环没有执行,标记设置为 `False`。游戏循环是通过客户端的处理方法启动的。
|
||||
|
||||
```
|
||||
if app["game_is_running"] == False:
|
||||
asyncio.ensure_future(game_loop(app))
|
||||
```
|
||||
|
||||
当 `game_loop()` 运行时,这个标记设置为 `True`;当所有客户端都断开连接时,其又被设置为 `False`。
|
||||
|
||||
### 例子 3.3:管理任务
|
||||
|
||||
> [例子3.3源码][8]
|
||||
|
||||
这个例子用来解释如何和任务对象协同工作。我们把游戏循环的任务直接存储在游戏循环的全局字典中,代替标记的使用。在像这样的一个简单例子中并不一定是最优的,但是有时候你可能需要控制所有已经启动的任务。
|
||||
|
||||
```
|
||||
if app["game_loop"] is None or \
|
||||
app["game_loop"].cancelled():
|
||||
app["game_loop"] = asyncio.ensure_future(game_loop(app))
|
||||
```
|
||||
|
||||
这里 `ensure_future()` 返回我们存放在全局字典中的任务对象,当所有用户都断开连接时,我们使用下面方式取消任务:
|
||||
|
||||
```
|
||||
app["game_loop"].cancel()
|
||||
```
|
||||
|
||||
这个 `cancel()` 调用将通知调度器不要向这个协程传递执行权,而且将它的状态设置为已取消:`cancelled`,之后可以通过 `cancelled()` 方法来检查是否已取消。这里有一个值得一提的小注意点:当你持有一个任务对象的外部引用时,而这个任务执行中发生了异常,这个异常不会抛出。取而代之的是为这个任务设置一个异常状态,可以通过 `exception()` 方法来检查是否出现了异常。这种悄无声息地失败在调试时不是很有用。所以,你可能想用抛出所有异常来取代这种做法。你可以对所有未完成的任务显式地调用 `result()` 来实现。可以通过如下的回调来实现:
|
||||
|
||||
```
|
||||
app["game_loop"].add_done_callback(lambda t: t.result())
|
||||
```
|
||||
|
||||
如果我们打算在我们代码中取消这个任务,但是又不想产生 `CancelError` 异常,有一个检查 `cancelled` 状态的点:
|
||||
|
||||
```
|
||||
app["game_loop"].add_done_callback(lambda t: t.result()
|
||||
if not t.cancelled() else None)
|
||||
```
|
||||
|
||||
注意仅当你持有任务对象的引用时才需要这么做。在前一个例子,所有的异常都是没有额外的回调,直接抛出所有异常。
|
||||
|
||||
### 例子 3.4:等待多个事件
|
||||
|
||||
> [例子 3.4 源码][9]
|
||||
|
||||
在许多场景下,在客户端的处理方法中你需要等待多个事件的发生。除了来自客户端的消息,你可能需要等待不同类型事件的发生。比如,如果你的游戏时间有限制,那么你可能需要等一个来自定时器的信号。或者你需要使用管道来等待来自其它进程的消息。亦或者是使用分布式消息系统的网络中其它服务器的信息。
|
||||
|
||||
为了简单起见,这个例子是基于例子 3.1。但是这个例子中我们使用 `Condition` 对象来与已连接的客户端保持游戏循环的同步。我们不保存套接字的全局列表,因为只在该处理方法中使用套接字。当游戏循环停止迭代时,我们使用 `Condition.notify_all()` 方法来通知所有的客户端。这个方法允许在 `asyncio` 的事件循环中使用发布/订阅的模式。
|
||||
|
||||
为了等待这两个事件,首先我们使用 `ensure_future()` 来封装任务中这个可等待对象。
|
||||
|
||||
```
|
||||
if not recv_task:
|
||||
recv_task = asyncio.ensure_future(ws.receive())
|
||||
if not tick_task:
|
||||
await tick.acquire()
|
||||
tick_task = asyncio.ensure_future(tick.wait())
|
||||
```
|
||||
|
||||
在我们调用 `Condition.wait()` 之前,我们需要在它后面获取一把锁。这就是我们为什么先调用 `tick.acquire()` 的原因。在调用 `tick.wait()` 之后,锁会被释放,这样其他的协程也可以使用它。但是当我们收到通知时,会重新获取锁,所以在收到通知后需要调用 `tick.release()` 来释放它。
|
||||
|
||||
我们使用 `asyncio.wait()` 协程来等待两个任务。
|
||||
|
||||
```
|
||||
done, pending = await asyncio.wait(
|
||||
[recv_task,
|
||||
tick_task],
|
||||
return_when=asyncio.FIRST_COMPLETED)
|
||||
```
|
||||
|
||||
程序会阻塞,直到列表中的任意一个任务完成。然后它返回两个列表:执行完成的任务列表和仍然在执行的任务列表。如果任务执行完成了,其对应变量赋值为 `None`,所以在下一个迭代时,它可能会被再次创建。
|
||||
|
||||
### 例子 3.5: 结合多个线程
|
||||
|
||||
> [例子 3.5 源码][10]
|
||||
|
||||
在这个例子中,我们结合 `asyncio` 循环和线程,在一个单独的线程中执行主游戏循环。我之前提到过,由于 `GIL` 的存在,Python 代码的真正并行执行是不可能的。所以使用其它线程来执行复杂计算并不是一个好主意。然而,在使用 `asyncio` 时结合线程有原因的:当我们使用的其它库不支持 `asyncio` 时就需要。在主线程中调用这些库会阻塞循环的执行,所以异步使用他们的唯一方法是在不同的线程中使用他们。
|
||||
|
||||
我们使用 `asyncio` 循环的`run_in_executor()` 方法和 `ThreadPoolExecutor` 来执行游戏循环。注意 `game_loop()` 已经不再是一个协程了。它是一个由其它线程执行的函数。然而我们需要和主线程交互,在游戏事件到来时通知客户端。`asyncio` 本身不是线程安全的,它提供了可以在其它线程中执行你的代码的方法。普通函数有 `call_soon_threadsafe()`,协程有 `run_coroutine_threadsafe()`。我们在 `notify()` 协程中增加了通知客户端游戏的嘀嗒的代码,然后通过另外一个线程执行主事件循环。
|
||||
|
||||
```
|
||||
def game_loop(asyncio_loop):
|
||||
print("Game loop thread id {}".format(threading.get_ident()))
|
||||
async def notify():
|
||||
print("Notify thread id {}".format(threading.get_ident()))
|
||||
await tick.acquire()
|
||||
tick.notify_all()
|
||||
tick.release()
|
||||
|
||||
while 1:
|
||||
task = asyncio.run_coroutine_threadsafe(notify(), asyncio_loop)
|
||||
# blocking the thread
|
||||
sleep(1)
|
||||
# make sure the task has finished
|
||||
task.result()
|
||||
```
|
||||
|
||||
当你执行这个例子时,你会看到 “Notify thread id” 和 “Main thread id” 相等,因为 `notify()` 协程在主线程中执行。与此同时 `sleep(1)` 在另外一个线程中执行,因此它不会阻塞主事件循环。
|
||||
|
||||
### 例子 3.6:多进程和扩展
|
||||
|
||||
> [例子 3.6 源码][11]
|
||||
|
||||
单线程的服务器可能运行得很好,但是它只能使用一个 CPU 核。为了将服务扩展到多核,我们需要执行多个进程,每个进程执行各自的事件循环。这样我们需要在进程间交互信息或者共享游戏的数据。而且在一个游戏中经常需要进行复杂的计算,例如路径查找之类。这些任务有时候在一个游戏嘀嗒中没法快速完成。在协程中不推荐进行费时的计算,因为它会阻塞事件的处理。在这种情况下,将这个复杂任务交给其它并行执行的进程可能更合理。
|
||||
|
||||
最简单的使用多个核的方法是启动多个使用单核的服务器,就像之前的例子中一样,每个服务器占用不同的端口。你可以使用 `supervisord` 或者其它进程控制的系统。这个时候你需要一个像 `HAProxy` 这样的负载均衡器,使得连接的客户端分布在多个进程间。已经有一些可以连接 asyncio 和一些流行的消息及存储系统的适配系统。例如:
|
||||
|
||||
- [aiomcache][12] 用于 memcached 客户端
|
||||
- [aiozmq][13] 用于 zeroMQ
|
||||
- [aioredis][14] 用于 Redis 存储,支持发布/订阅
|
||||
|
||||
你可以在 github 或者 pypi 上找到其它的软件包,大部分以 `aio` 开头。
|
||||
|
||||
使用网络服务在存储持久状态和交换某些信息时可能比较有效。但是如果你需要进行进程间通信的实时处理,它的性能可能不足。此时,使用标准的 unix 管道可能更合适。`asyncio` 支持管道,在`aiohttp`仓库有个 [使用管道的服务器的非常底层的例子][15]。
|
||||
|
||||
在当前的例子中,我们使用 Python 的高层类库 [multiprocessing][16] 来在不同的核上启动复杂的计算,使用 `multiprocessing.Queue` 来进行进程间的消息交互。不幸的是,当前的 `multiprocessing` 实现与 `asyncio` 不兼容。所以每一个阻塞方法的调用都会阻塞事件循环。但是此时线程正好可以起到帮助作用,因为如果在不同线程里面执行 `multiprocessing` 的代码,它就不会阻塞主线程。所有我们需要做的就是把所有进程间的通信放到另外一个线程中去。这个例子会解释如何使用这个方法。和上面的多线程例子非常类似,但是我们从线程中创建的是一个新的进程。
|
||||
|
||||
```
|
||||
def game_loop(asyncio_loop):
|
||||
# coroutine to run in main thread
|
||||
async def notify():
|
||||
await tick.acquire()
|
||||
tick.notify_all()
|
||||
tick.release()
|
||||
|
||||
queue = Queue()
|
||||
|
||||
# function to run in a different process
|
||||
def worker():
|
||||
while 1:
|
||||
print("doing heavy calculation in process {}".format(os.getpid()))
|
||||
sleep(1)
|
||||
queue.put("calculation result")
|
||||
|
||||
Process(target=worker).start()
|
||||
|
||||
while 1:
|
||||
# blocks this thread but not main thread with event loop
|
||||
result = queue.get()
|
||||
print("getting {} in process {}".format(result, os.getpid()))
|
||||
task = asyncio.run_coroutine_threadsafe(notify(), asyncio_loop)
|
||||
task.result()
|
||||
```
|
||||
|
||||
这里我们在另外一个进程中运行 `worker()` 函数。它包括一个执行复杂计算并把计算结果放到 `queue` 中的循环,这个 `queue` 是 `multiprocessing.Queue` 的实例。然后我们就可以在另外一个线程的主事件循环中获取结果并通知客户端,就和例子 3.5 一样。这个例子已经非常简化了,它没有合理的结束进程。而且在真实的游戏中,我们可能需要另外一个队列来将数据传递给 `worker`。
|
||||
|
||||
有一个项目叫 [aioprocessing][17],它封装了 `multiprocessing`,使得它可以和 `asyncio` 兼容。但是实际上它只是和上面例子使用了完全一样的方法:从线程中创建进程。它并没有给你带来任何方便,除了它使用了简单的接口隐藏了后面的这些技巧。希望在 Python 的下一个版本中,我们能有一个基于协程且支持 `asyncio` 的 `multiprocessing` 库。
|
||||
|
||||
> 注意!如果你从主线程或者主进程中创建了一个不同的线程或者子进程来运行另外一个 `asyncio` 事件循环,你需要显式地使用 `asyncio.new_event_loop()` 来创建循环,不然的话可能程序不会正常工作。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-and-asyncio-writing-game-loop/
|
||||
|
||||
作者:[Kyrylo Subbotin][a]
|
||||
译者:[chunyang-wen](https://github.com/chunyang-wen)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-and-asyncio-writing-game-loop/
|
||||
[1]: http://snakepit-game.com/
|
||||
[2]: https://linux.cn/article-7767-1.html
|
||||
[3]: http://snakepit-game.com/
|
||||
[4]: https://github.com/7WebPages/snakepit-game/blob/master/simple/index.html
|
||||
[5]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_basic.py
|
||||
[6]: http://aiohttp.readthedocs.org/
|
||||
[7]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_handler.py
|
||||
[8]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_global.py
|
||||
[9]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_wait.py
|
||||
[10]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_thread.py
|
||||
[11]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_process.py
|
||||
[12]: https://github.com/aio-libs/aiomcache
|
||||
[13]: https://github.com/aio-libs/aiozmq
|
||||
[14]: https://github.com/aio-libs/aioredis
|
||||
[15]: https://github.com/KeepSafe/aiohttp/blob/master/examples/mpsrv.py
|
||||
[16]: https://docs.python.org/3.5/library/multiprocessing.html
|
||||
[17]: https://github.com/dano/aioprocessing
|
||||
@ -0,0 +1,180 @@
|
||||
Using webpack with the Amazon Cognito Identity SDK for JavaScript
|
||||
=====
|
||||
|
||||
This blog post is aimed at developers of all experience levels who develop and deploy JavaScript based applications (whether server-side with Node.js or client side) that incorporate the AWS SDK, the Amazon Cognito Identity SDK for JavaScript and who also use the popular [webpack][1] module bundler.
|
||||
|
||||
In July 2016, Amazon Web Services [launched Amazon Cognito User Pools][2], a feature that makes it easy for developers to add sign-up and sign-in functionality to mobile and web applications. To help developers easily realize the power of user pools within their own applications, we also released the [Amazon Cognito Identity SDK for JavaScript][3].
|
||||
|
||||
Amazon Cognito User Pools allows you to easily add user sign-up and sign-in to your mobile and web applications. The fully managed user pool can scale to hundreds of millions of users and you can have multiple directories per AWS account. Creating a user pool takes just a few minutes and allows you to decide exactly which attributes (including address, email, phone number as well as custom attributes) are mandatory and even optional when a new user signs up for your application or service. Your application can also specify the desired password strength, whether the use of Multi-Factor Authentication (MFA) is required, and verify new users via phone number or email address to further enhance the security of your application.
|
||||
|
||||
If you are new to the Amazon Cognito Identity SDK for JavaScript [this AWS blog post][4] is a great place to start.
|
||||
|
||||
### Why Use Asset & Module Bundling with the Amazon Cognito Identity SDK for JavaScript
|
||||
|
||||
Today, modern web applications for both mobile and desktop have to provide the user with a secure, fast, responsive, and native-app-like experience. There is no doubt that modern browsers are extremely powerful and cater to a vast array of possible implementation approaches. Many of the more popular implementations rely heavily on the deployment of a JavaScript application through some form of asset packaging and/or module bundling. This allows a developer to take their JavaScript application and create one or more files that can be loaded by the client browser by using script tags.
|
||||
|
||||
There are many schools of thought on how you can achieve this packaging , including task runners such as [Grunt][5] and [Gulp][6], and bundlers such as [Browserify][7]. However, there is a general consensus that asset packaging is not only about improving load times—it enables the modularization of your application while ensuring testability and robustness.
|
||||
|
||||
### Using webpack with the Amazon Cognito Identity SDK for JavaScript
|
||||
|
||||
In the many requests we get to provide more detail on how to integrate the Amazon Cognito Identity SDK for JavaScript within a webpack environment, we’re specifically asked how to ensure that webpack correctly manages the following third-party dependencies:
|
||||
|
||||
- [JavaScript BN library for BigInteger computation][8] (jsbn)
|
||||
- [an extension to jsbn][9] the with the rest of the jsbn methods including most public BigInteger methods (jsbn2)
|
||||
- the [Stanford JavaScript Crypto Library][10] (sjcl)
|
||||
|
||||
Throughout these examples, the following bower libraries are used by bower.json
|
||||
|
||||
```
|
||||
"aws-cognito-sdk": "https://raw.githubusercontent.com/aws/amazon-cognito-identity-js/master/dist/aws-cognito-sdk.js",
|
||||
"amazon-cognito-identity": "https://raw.githubusercontent.com/aws/amazon-cognito-identity-js/master/dist/amazon-cognito-identity.min.js",
|
||||
"sjcl": "https://raw.githubusercontent.com/bitwiseshiftleft/sjcl/master/sjcl.js",
|
||||
"jsbn": "https://raw.githubusercontent.com/andyperlitch/jsbn/master/index.js",
|
||||
```
|
||||
|
||||
For all the reasons we gave earlier for the importance of asset packaging to development processes, and unless your application is extremely small, the use of an asset packaging tool such as webpack is almost always recommended. Of course, one could simply pull in all of these dependencies using tags. However, this would pollute global namespace, and not provide the most optimal resource management and loading approach. Many developers start with a standard webpack.config.js file that has a standard babel loader, as shown here.
|
||||
|
||||
```
|
||||
{
|
||||
/** test for file ending in js or jsx
|
||||
* exclude node_module and bower_components - we dont want to babel these
|
||||
* use the babel loader
|
||||
* apply the react and es2015 (es6) transformations **/
|
||||
|
||||
test: /\.jsx?$/,
|
||||
exclude: /(node_modules|bower_components)/,
|
||||
loader: 'babel',
|
||||
query: {
|
||||
presets: ['react', 'es2015']
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
It’s important to remember that this configuration doesn’t take into account that some of third-party dependencies used by the Amazon Cognito Identity SDK for JavaScript currently do not use the [Universal Module Definition (UMD) pattern for JavaScript][11].
|
||||
|
||||
The UMD pattern attempts to offer Asynchronous Module Definition (AMD) based compatibility with the most popular script loaders of the day such as [RequireJS][12] and [CommonJS][13].
|
||||
|
||||
This is a pattern that webpack relies on, and so we must make some changes to how webpack loads these modules. Without these changes, you may encounter errors such as the following.
|
||||
|
||||
```
|
||||
amazon-cognito-identity.min.js:19 Uncaught ReferenceError: BigInteger is not defined
|
||||
```
|
||||
|
||||
Such an error may be encountered when making a call to AWSCognito.CognitoIdentityServiceProvider.CognitoUser property authenticateUser This is an example of where we can make use of the webpack imports and exports loader capability to overcome this error.
|
||||
|
||||
### Using webpack Loaders
|
||||
|
||||
According to the [webpack documentation][14] "loaders allow you to preprocess files as you require() or “load” them. Loaders are kind of like “tasks” are in other build tools, and provide a powerful way to handle front-end build steps. Loaders can transform files from a different language like, CoffeeScript to JavaScript, or inline images as data URLs"
|
||||
|
||||
In order to resolve the lack of UMD compatibility, you will rely to two specific loaders, import and export.
|
||||
|
||||
#### Using the Export Loader
|
||||
|
||||
In the case of the Amazon Cognito Identity SDK for JavaScript, we need to ensure we export theAWSCognito variables into the scope of the module that requires/imports (for ES6) them.
|
||||
|
||||
```
|
||||
{
|
||||
test: /aws-cognito-sdk\/index\.js/,
|
||||
loader: 'exports?AWSCognito'
|
||||
}
|
||||
```
|
||||
|
||||
Using the exports loader has the effect of exporting a module method within bundle created by webpack. As a result, both AWSCognito and AWS are now accessible when required or import(ed) (for ES6).
|
||||
|
||||
```
|
||||
var AWSCognito = require('aws-cognito-sdk')
|
||||
|
||||
/*** EXPORTS from export-loader ***/
|
||||
module.exports = AWSCongito
|
||||
```
|
||||
|
||||
More information about the exports loader can be found here
|
||||
|
||||
#### Using the Import Loader
|
||||
|
||||
The import loader is mostly used to inject (import) variables into the scope of another module. This is especially useful if third-party modules are relying on global variables like BitInteger or sjcl as is the case with Amazon Cognito Identity SDK for JavaScript.
|
||||
|
||||
If you don’t use the webpack loader, the following is generated within the bundle.
|
||||
|
||||
```
|
||||
__webpack_require__(431); // refers to jsbin
|
||||
__webpack_require__(432); // refers to sjcl
|
||||
```
|
||||
|
||||
Beacuse neither jsbin or sjcl export anything, any calls that rely on these modules will result in an error.
|
||||
|
||||
To resolve this, we can use the following webpack loader configuration:
|
||||
|
||||
```
|
||||
{
|
||||
test: /amazon-cognito-identity\/index\.js/,
|
||||
loader: 'imports?jsbn,BigInteger=>jsbn.BigInteger,sjcl'
|
||||
},
|
||||
{
|
||||
test: /sjcl\/index\.js/,
|
||||
loader: 'imports?sjcl'
|
||||
}
|
||||
```
|
||||
|
||||
This injects the following into the bundle (in this case bundle.js) created by webpack.
|
||||
|
||||
````
|
||||
/*** IMPORTS FROM imports-loader ***/
|
||||
var jsbn = __webpack_require__(431);
|
||||
var BigInteger = jsbn.BigInteger;
|
||||
var sjcl = __webpack_require__(432);
|
||||
```
|
||||
|
||||
As a result, jsbn, BigInteger and sjcl are all imported from their respective modules into Amazon Cognito Identity SDK for JavaScript.
|
||||
|
||||
More information about the import loader can be found [here][15]
|
||||
|
||||
### Next Steps
|
||||
|
||||
We encourage you to download the [Amazon Cognito Identity SDK for JavaScript][16] and start building your application. Coupled with webpack, and by following the guidance in this blog, you we hope you have a smooth development experience.
|
||||
|
||||
If you have any comments or questions, please free to comment below, reach out via email (teichtah@amazon.com) or raise an issue [here][17].
|
||||
|
||||
### References
|
||||
|
||||
This blog post makes reference to the following third party resources
|
||||
|
||||
- webpack - https://webpack.github.io/
|
||||
- webpack documentation - http://webpack.github.io/docs/what-is-webpack.html
|
||||
- webpack exports loader - https://github.com/webpack/exports-loader
|
||||
- webpack imports loader - https://github.com/webpack/imports-loader
|
||||
- JavaScript BN library for BigInteger computation - http://www-cs-students.stanford.edu/~tjw/jsbn/jsbn.js
|
||||
- jsbns - http://www-cs-students.stanford.edu/~tjw/jsbn/jsbn2.js
|
||||
- Stanford JavaScript Crypto Library - https://github.com/bitwiseshiftleft/sjcl
|
||||
- RequireJS - http://requirejs.org/
|
||||
- CommonJS - http://www.commonjs.org/
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://mobile.awsblog.com/post/Tx1A84CLMDJ744T/Using-webpack-with-the-Amazon-Cognito-Identity-SDK-for-JavaScript?utm_source=webopsweekly&utm_medium=email
|
||||
|
||||
作者:[Marc Teichtahl ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://mobile.awsblog.com/blog/author/Marc+Teichtahl
|
||||
[1]: https://webpack.github.io/
|
||||
[2]: https://blogs.aws.amazon.com/security/post/Tx13NVD4AWG9QK9/Amazon-Cognito-Your-User-Pools-is-Now-Generally-Available
|
||||
[3]: https://github.com/aws/amazon-cognito-identity-js
|
||||
[4]: http://mobile.awsblog.com/post/Tx2O14ZY8A5LFHT/Accessing-Your-User-Pools-using-the-Amazon-Cognito-Identity-SDK-for-JavaScript
|
||||
[5]: http://gruntjs.com/
|
||||
[6]: http://gulpjs.com/
|
||||
[7]: http://browserify.org/
|
||||
[8]: http://www-cs-students.stanford.edu/~tjw/jsbn/jsbn.js
|
||||
[9]: http://www-cs-students.stanford.edu/~tjw/jsbn/jsbn2.js
|
||||
[10]: https://github.com/bitwiseshiftleft/sjcl
|
||||
[11]: https://github.com/umdjs/umd
|
||||
[12]: http://requirejs.org/
|
||||
[13]: http://www.commonjs.org/
|
||||
[14]: http://webpack.github.io/docs/what-is-webpack.html
|
||||
[15]: https://github.com/webpack/imports-loader
|
||||
[16]: https://github.com/aws/amazon-cognito-identity-js
|
||||
[17]: https://github.com/aws/amazon-cognito-identity-js/issues
|
||||
|
||||
@ -0,0 +1,436 @@
|
||||
HOSTING .NET CORE ON LINUX WITH DOCKER - A NOOB'S GUIDE
|
||||
=====
|
||||
|
||||
This post builds on my previous [introduction to .NET Core][1]. First I upgrade that RESTful API from .NET Core RC1 to .NET Core 1.0, then I add support for Docker and describe how to host it on Linux in a production environment.
|
||||
|
||||
|
||||

|
||||
|
||||
I’m completely new to Docker and I’m far from a Linux expert, so these are very much the thoughts of a noob.
|
||||
|
||||
### INSTALLATION
|
||||
|
||||
Follow the instructions on https://www.microsoft.com/net/core to install .NET Core on your development machine. This will include the dotnet command line tool and the latest Visual Studio tooling for Windows.
|
||||
|
||||
### SOURCE CODE
|
||||
|
||||
You can jump straight to the finished source code on GitHub.
|
||||
|
||||
### CONVERTING TO .NET CORE 1.0
|
||||
|
||||
Naturally, my first port of call when thinking about how to upgrade the API from RC1 to 1.0 was to Google it with Bing. There are two pretty comprehensive guides that I followed:
|
||||
|
||||
- [Migrating from DNX to .NET Core CLI][2]
|
||||
- [Migrating from ASP.NET 5 RC1 to ASP.NET Core 1.0][3]
|
||||
|
||||
I advise reading through both of these very carefully when migrating your code because I tried to skim read the second one without reading the first one and got very confused and frustrated!
|
||||
|
||||
I won’t describe the changes in detail because you can look at the commit on GitHub. Here is a summary of what I changed:
|
||||
|
||||
- Updated version numbers on global.json and project.json
|
||||
- Removed obsolete sections from project.json
|
||||
- Using the more lightweight ControllerBase rather than Controller because I don’t need methods related to MVC views (this was an optional change)
|
||||
- Removed the Http prefix from helper methods e.g. HttpNotFound -> NotFound
|
||||
- LogVerbose -> LogTrace
|
||||
- Namespace changes: Microsoft.AspNetCore.*
|
||||
- Using SetBasePath in Startup (appsettings.json won’t be found without this)
|
||||
- Running via WebHostBuilder rather than WebApplication.Run
|
||||
- Removed Serilog (at the time of writing it does not support .NET Core 1.0)
|
||||
|
||||
The only real headache here is the need to remove Serilog. I could have implemented my own file logger, but I just deleted file logging because I didn’t want to focus on it for this exercise.
|
||||
|
||||
Unfortunately, there will be plenty of third party developers that will be playing catch up with support for .NET Core 1.0 but I have sympathy for them because they are often working in their spare time without anything close to the resources available to Microsoft. I recommend reading Travis Illig’s [.NET Core 1.0 is Released, but Where is Autofac][4]? for a third party developer’s point of view on this!
|
||||
|
||||
Having made these changes I was able to dotnet restore, dotnet build and dotnet run from the project.json directory and see the API working as before.
|
||||
|
||||
### RUNNING WITH DOCKER
|
||||
|
||||
At the time of writing, Docker only really works on Linux. There is beta support for Docker on Windows and OS X but they both rely on virtualisation so I’ve chosen to run Ubuntu 14.04 as a VirtualBox. Follow these instructions if you haven’t already got Docker installed.
|
||||
|
||||
I’ve been doing a bit of reading about Docker recently but I’ve never tried to actually do anything with it until now. I’ll assume the reader has no Docker knowledge so I’ll explain all parts of the commands that I’m using.
|
||||
|
||||
#### HELLO DOCKER
|
||||
|
||||
Having installed Docker on my Ubuntu machine, my next move was to follow the instructions at https://www.microsoft.com/net/core#docker to see how to get started with .NET Core and Docker.
|
||||
|
||||
First start a container with .NET Core installed:
|
||||
|
||||
```
|
||||
docker run -it microsoft/dotnet:latest
|
||||
```
|
||||
|
||||
The -it option means interactive so having executed this command you will be inside the container and free to run any bash commands you like.
|
||||
|
||||
Then we can run five commands to get Microsoft’s Hello World .NET Core console application running inside Docker!
|
||||
|
||||
1. mkdir hwapp
|
||||
2. cd hwapp
|
||||
3. dotnet new
|
||||
4. dotnet restore
|
||||
5. dotnet run
|
||||
|
||||
You can exit to leave the container, then docker ps -a to show that you have created a container which has exited. You should really now tidy up that container using docker rm <container_name>.
|
||||
|
||||
#### MOUNTING THE SOURCE
|
||||
|
||||
My next move was to use the same microsoft/dotnet image as above but to mount the source for my application as a data volume.
|
||||
|
||||
First check out the repository at the relevant commit:
|
||||
|
||||
1. git clone https://github.com/niksoper/aspnet5-books.git
|
||||
2. cd aspnet5-books/src/MvcLibrary
|
||||
3. git checkout dotnet-core-1.0
|
||||
|
||||
Now start a container running .NET Core 1.0 with the source located at /books. Note that you’ll need to change the /path/to/repo part to match your machine:
|
||||
|
||||
```
|
||||
docker run -it \
|
||||
-v /path/to/repo/aspnet5-books/src/MvcLibrary:/books \
|
||||
microsoft/dotnet:latest
|
||||
```
|
||||
|
||||
Now you can run the application inside the container!
|
||||
|
||||
```
|
||||
cd /books
|
||||
dotnet restore
|
||||
dotnet run
|
||||
```
|
||||
|
||||
That’s great as a proof of concept but we don’t really want to have to worry about mounting the source code into a container like this whenever we want to start the application.
|
||||
|
||||
#### ADDING A DOCKERFILE
|
||||
|
||||
The next step I took was to introduce a Dockerfile, which will allow the application to be started easily inside its own container.
|
||||
|
||||
My Dockerfile lives in the src/MvcLibrary directory alongside project.json and looks like this:
|
||||
|
||||
```
|
||||
FROM microsoft/dotnet:latest
|
||||
|
||||
# Create directory for the app source code
|
||||
RUN mkdir -p /usr/src/books
|
||||
WORKDIR /usr/src/books
|
||||
|
||||
# Copy the source and restore dependencies
|
||||
COPY . /usr/src/books
|
||||
RUN dotnet restore
|
||||
|
||||
# Expose the port and start the app
|
||||
EXPOSE 5000
|
||||
CMD [ "dotnet", "run" ]
|
||||
```
|
||||
|
||||
Strictly, the `RUN mkdir -p /usr/src/books` command is not needed because COPY will create any missing directories automatically.
|
||||
|
||||
Docker images are built in layers. We start from the image containing .NET Core and add another layer which builds the application from source then runs the application.
|
||||
|
||||
Having added the Dockerfile, I then ran the following commands to build the image and start a container using that image (make sure you are in the same directory as the Dockerfile and you should really use your own username):
|
||||
|
||||
1. docker build -t niksoper/netcore-books .
|
||||
2. docker run -it niksoper/netcore-books
|
||||
|
||||
You should see that the application started listening just as before, except this time we don’t need to bother mounting the source code because it’s already contained in the docker image.
|
||||
|
||||
#### EXPOSING AND PUBLISHING A PORT
|
||||
|
||||
This API isn’t going to be very useful unless we can communicate with it from outside the container. Docker has the concept of exposing and publishing ports, which are two very different things.
|
||||
|
||||
From the official Docker documentation:
|
||||
|
||||
>The EXPOSE instruction informs Docker that the container listens on the specified network ports at runtime. EXPOSE does not make the ports of the container accessible to the host. To do that, you must use either the -p flag to publish a range of ports or the -P flag to publish all of the exposed ports.
|
||||
|
||||
EXPOSE only adds metadata to the image so you can think of it as documentation for the consumers of the image. Technically, I could have left out the EXPOSE 5000 line completely because I know the port that the API is listening on but leaving it in is helpful and certainly recommended.
|
||||
|
||||
At this stage I want to access the API directly from the host so I need to use -p to publish the port - this allows a request to port 5000 on the host be forwarded to port 5000 in the container regardless of whether the port has previously been exposed via the Dockerfile:
|
||||
|
||||
```
|
||||
docker run -d -p 5000:5000 niksoper/netcore-books
|
||||
```
|
||||
|
||||
Using -d tells docker to run the container in detached mode so we won’t see its output but it will still be running and listening on port 5000 - prove this to yourself with docker ps.
|
||||
|
||||
So then I prepared to celebrate by making a request from the host to the container:
|
||||
|
||||
```
|
||||
curl http://localhost:5000/api/books
|
||||
```
|
||||
|
||||
It didn’t work.
|
||||
|
||||
Making the same curl request repeatedly, I see one of two errors - either curl: (56) Recv failure: Connection reset by peer or curl: (52) Empty reply from server.
|
||||
|
||||
I went back to the docker run documentation and double checked I was using the -p option correctly as well as EXPOSE in the Dockerfile. I couldn’t see the problem and became a bit sad…
|
||||
|
||||
After pulling myself together, I decided to consult one of my local DevOps heroes - Dave Wybourn (also mentioned in this post on Docker Swarm). His team had run into this exact problem and the issue was the way that I had (not) configured Kestrel - the new lightweight, cross platform web server used for .NET Core.
|
||||
|
||||
By default, Kestrel will listen on http://localhost:5000. The problem here is that localhost is a loopback interface.
|
||||
|
||||
From Wikipedia:
|
||||
|
||||
>In computer networking, localhost is a hostname that means this computer. It is used to access the network services that are running on the host via its loopback network interface. Using the loopback interface bypasses any local network interface hardware.
|
||||
|
||||
This is a problem when running inside a container because localhost can only be reached from within that container. The solution was to update the Main method in Startup.cs to configure the URLs that Kestrel will listen on:
|
||||
|
||||
```
|
||||
public static void Main(string[] args)
|
||||
{
|
||||
var host = new WebHostBuilder()
|
||||
.UseKestrel()
|
||||
.UseContentRoot(Directory.GetCurrentDirectory())
|
||||
.UseUrls("http://*:5000") // listen on port 5000 on all network interfaces
|
||||
.UseIISIntegration()
|
||||
.UseStartup<Startup>()
|
||||
.Build();
|
||||
|
||||
host.Run();
|
||||
}
|
||||
```
|
||||
|
||||
With this extra configuration in place, I could then rebuild image and run the application in a container which will accept requests from the host:
|
||||
|
||||
1. docker build -t niksoper/netcore-books .
|
||||
2. docker run -d -p 5000:5000 niksoper/netcore-books
|
||||
3. curl -i http://localhost:5000/api/books
|
||||
|
||||
I now get the following response:
|
||||
|
||||
```
|
||||
HTTP/1.1 200 OK
|
||||
Date: Tue, 30 Aug 2016 15:25:43 GMT
|
||||
Transfer-Encoding: chunked
|
||||
Content-Type: application/json; charset=utf-8
|
||||
Server: Kestrel
|
||||
|
||||
[{"id":"1","title":"RESTful API with ASP.NET Core MVC 1.0","author":"Nick Soper"}]
|
||||
```
|
||||
|
||||
### KESTREL IN PRODUCTION
|
||||
|
||||
Microsoft’s words:
|
||||
|
||||
>Kestrel is great for serving dynamic content from ASP.NET, however the web serving parts aren’t as feature rich as full-featured servers like IIS, Apache or Nginx. A reverse proxy-server can allow you to offload work like serving static content, caching requests, compressing requests, and SSL termination from the HTTP server.
|
||||
|
||||
So I need to set up Nginx on my Linux machine to act as my reverse proxy. Microsoft spell out how to do this in Publish to a Linux Production Environment. I’ll summarise the instructions here:
|
||||
|
||||
1. Use dotnet publish to produce a self contained package for the application
|
||||
2. Copy the published application to the server
|
||||
3. Install and configure Nginx (as a reverse proxy server)
|
||||
4. Install and configure supervisor (for keeping the Kestrel server running)
|
||||
5. Enable and configure AppArmor (for limiting the resources available to an application)
|
||||
6. Configure the server firewall
|
||||
7. Secure Nginx (involves building from source and configuring SSL)
|
||||
|
||||
It’s beyond the scope of this post to cover all of that, so I’m only going to concentrate on configuring Nginx as a reverse proxy - and naturally, I’m going to use Docker to do it.
|
||||
|
||||
### RUN NGINX IN ANOTHER CONTAINER
|
||||
|
||||
My aim is to run Nginx in a second Docker container and configure it as a reverse proxy to my application container.
|
||||
|
||||
I’ve used the official Nginx image from Docker Hub. First I tried it out like this:
|
||||
|
||||
```
|
||||
docker run -d -p 8080:80 --name web nginx
|
||||
```
|
||||
|
||||
This starts a container running Nginx and maps port 8080 on the host to port 80 in the container. Hitting http://localhost:8080 in the browser now shows the default Nginx landing page.
|
||||
|
||||
Now we’ve proved how easy it is to get Nginx running, we can kill the container.
|
||||
|
||||
```
|
||||
docker rm -f web
|
||||
```
|
||||
|
||||
### CONFIGURING NGINX AS A REVERSE PROXY
|
||||
|
||||
Nginx can be configured as a reverse proxy by editing the config file at /etc/nginx/conf.d/default.conf like this:
|
||||
|
||||
```
|
||||
server {
|
||||
listen 80;
|
||||
|
||||
location / {
|
||||
proxy_pass http://localhost:6666;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
The config above will cause Nginx to proxy all requests from the root to http://localhost:6666. Remember localhost here refers to the container running Nginx. We can use our own config file inside the Nginx container using a volume:
|
||||
|
||||
```
|
||||
docker run -d -p 8080:80 \
|
||||
-v /path/to/my.conf:/etc/nginx/conf.d/default.conf \
|
||||
nginx
|
||||
```
|
||||
|
||||
Note: this maps a single file from the host to the container, rather than an entire directory.
|
||||
|
||||
### COMMUNICATING BETWEEN CONTAINERS
|
||||
|
||||
Docker allows inter-container communication using shared virtual networks. By default, all containers started by the Docker daemon will have access to a virtual network called bridge. This allows containers to be referenced from other containers on the same network via IP address and port.
|
||||
|
||||
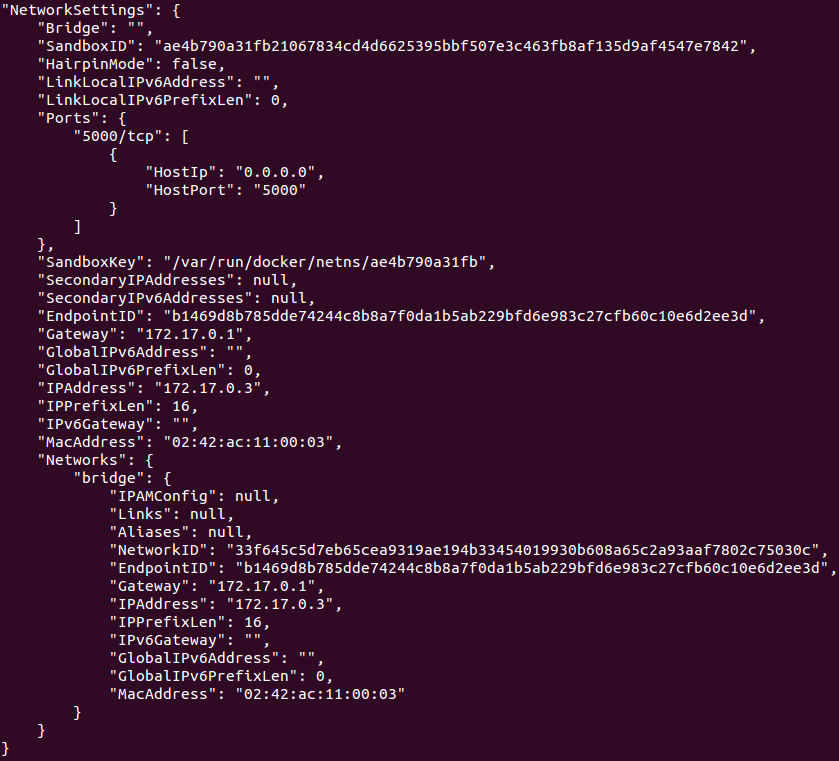
You can discover the IP address of a running container by inspecting it. I’ll start a container from the niksoper/netcore-books image that I created earlier, and inspect it:
|
||||
|
||||
1. docker run -d -p 5000:5000 --name books niksoper/netcore-books
|
||||
2. docker inspect books
|
||||
|
||||
|
||||
|
||||
We can see this container has "IPAddress": "172.17.0.3".
|
||||
|
||||
So now if I create the following Nginx config file, then start an Nginx container using that file, then it will proxy requests to my API:
|
||||
|
||||
```
|
||||
server {
|
||||
listen 80;
|
||||
|
||||
location / {
|
||||
proxy_pass http://172.17.0.3:5000;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Now I can start an Nginx container using that config (note I’m mapping port 8080 on the host to port 80 on the Nginx container):
|
||||
|
||||
```
|
||||
docker run -d -p 8080:80 \
|
||||
-v ~/dev/nginx/my.nginx.conf:/etc/nginx/conf.d/default.conf \
|
||||
nginx
|
||||
```
|
||||
|
||||
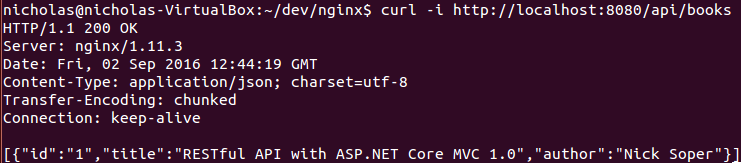
A request to http://localhost:8080 will now be proxied to my application. Note the Server header in the following curl response:
|
||||
|
||||
|
||||
|
||||
### DOCKER COMPOSE
|
||||
|
||||
At this point I was fairly pleased with my progress but I thought there must be a better way of configuring Nginx without needing to know the exact IP address of the application container. Another of the local Scott Logic DevOps heroes - Jason Ebbin - stepped up at this point and suggested Docker Compose.
|
||||
|
||||
As a high level description - Docker Compose makes it very easy to start up a collection of interconnected containers using a declarative syntax. I won’t go into the details of how Docker Compose works because you can read about it in this previous post.
|
||||
|
||||
I’ll start with the docker-compose.yml file that I’m using:
|
||||
|
||||
```
|
||||
version: '2'
|
||||
services:
|
||||
books-service:
|
||||
container_name: books-api
|
||||
build: .
|
||||
|
||||
reverse-proxy:
|
||||
container_name: reverse-proxy
|
||||
image: nginx
|
||||
ports:
|
||||
- "9090:8080"
|
||||
volumes:
|
||||
- ./proxy.conf:/etc/nginx/conf.d/default.conf
|
||||
```
|
||||
|
||||
This is version 2 syntax, so you’ll need to have at least version 1.6 of Docker Compose in order for this to work.
|
||||
|
||||
This file tells Docker to create two services - one for the application and another for the Nginx reverse proxy.
|
||||
|
||||
### BOOKS-SERVICE
|
||||
|
||||
This builds a container called books-api from the Dockerfile in the same directory as this docker-compose.yml. Note that this container does not need to publish any ports because it only needs to be accessed from the reverse-proxy container rather than the host operating system.
|
||||
|
||||
### REVERSE-PROXY
|
||||
|
||||
This starts a container called reverse-proxy based on the nginx image with a proxy.conf file mounted as the config from the current directory. It maps port 9090 on the host to port 8080 in the container which allows us to access the container from the host at http://localhost:9090.
|
||||
|
||||
The proxy.conf file looks like this:
|
||||
|
||||
```
|
||||
server {
|
||||
listen 8080;
|
||||
|
||||
location / {
|
||||
proxy_pass http://books-service:5000;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
The key point here is that we can now refer to books-service by name so we don’t need to know the IP address of the books-api container!
|
||||
|
||||
Now we can start the two containers with a working reverse proxy (-d means detached so we don’t see the output from the containers):
|
||||
|
||||
```
|
||||
docker compose up -d
|
||||
```
|
||||
|
||||
Prove the containers were created:
|
||||
|
||||
```
|
||||
docker ps
|
||||
```
|
||||
|
||||
And finally confirm that we can hit the API via the reverse proxy:
|
||||
|
||||
```
|
||||
curl -i http://localhost:9090/api/books
|
||||
```
|
||||
|
||||
### WHAT’S GOING ON?
|
||||
|
||||
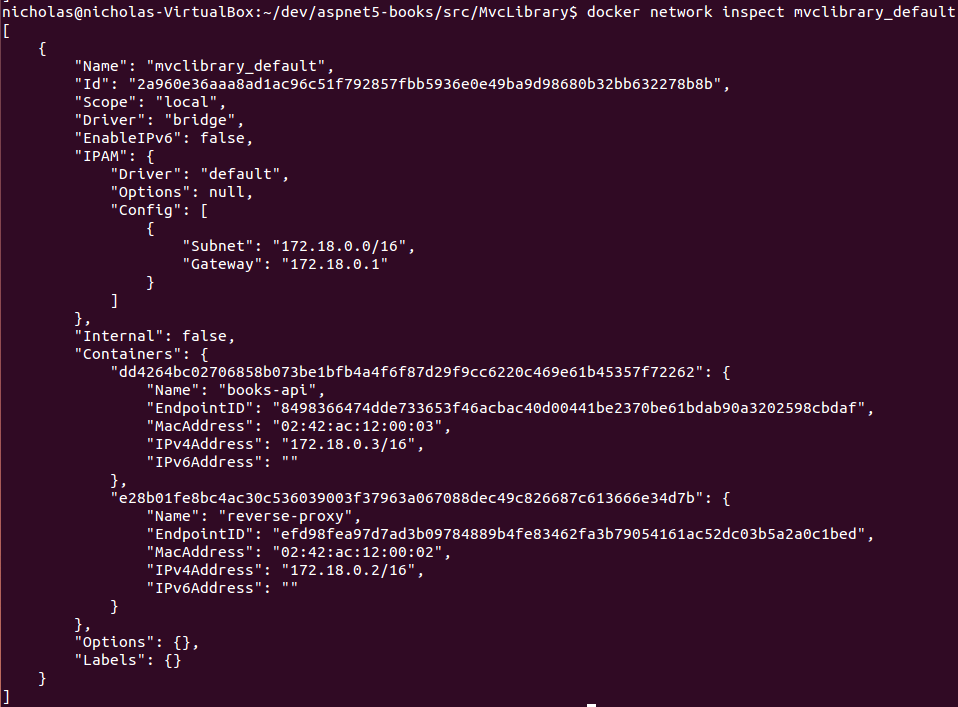
Docker Compose makes this happen by creating a new virtual network called mvclibrary_default which is used by both books-api and reverse-proxy containers (the name is based on the parent directory of the docker-compose.yml file).
|
||||
|
||||
Prove the network exists with docker network ls:
|
||||
|
||||

|
||||
|
||||
You can see the details of the new network using docker network inspect mvclibrary_default:
|
||||
|
||||
|
||||
|
||||
Note that Docker has assigned "Subnet": "172.18.0.0/16" to the network. The /16 part is CIDR notation and a full explanation is way beyond the scope of this post but CIDR just refers to a range of IP addresses. Running docker network inspect bridge shows "Subnet": "172.17.0.0/16" so the two networks do not overlap.
|
||||
|
||||
Now docker inspect books-api to confirm the application container is using this network:
|
||||
|
||||
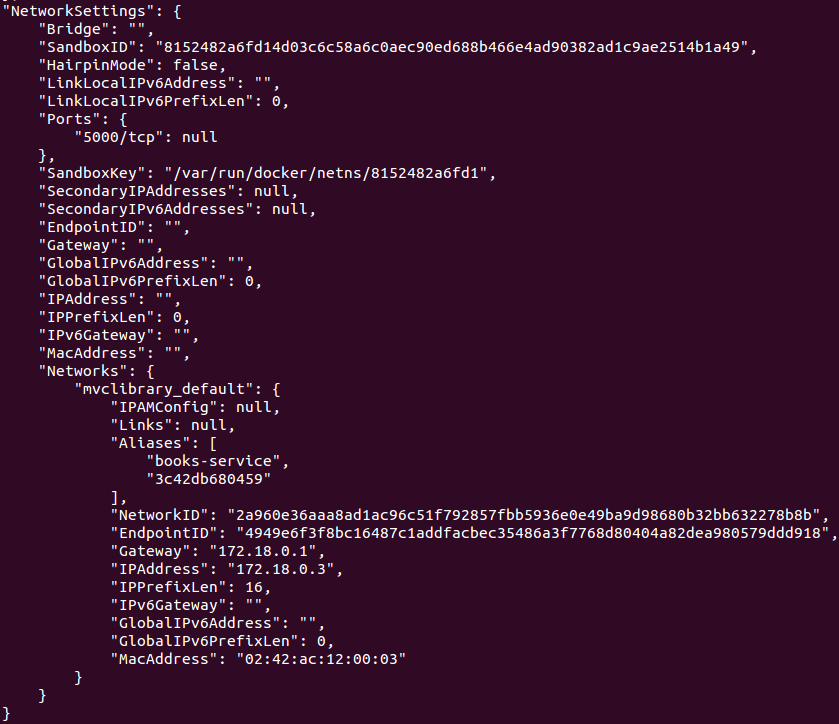
|
||||
|
||||
Notice the two "Aliases" for the container are the container identifier (3c42db680459) and the service name given in docker-compose.yml (books-service). We’re using the books-service alias to reference the application container in the custom Nginx configuration file. This could have been done manually with docker network create but I like Docker Compose because it wraps up container creation and interdependencies cleanly and succinctly.
|
||||
|
||||
### CONCLUSION
|
||||
|
||||
So now I can get the application running on Linux with Nginx in a few easy steps, without making any lasting changes to the host operating system:
|
||||
|
||||
```
|
||||
git clone https://github.com/niksoper/aspnet5-books.git
|
||||
cd aspnet5-books/src/MvcLibrary
|
||||
git checkout blog-docker
|
||||
docker-compose up -d
|
||||
curl -i http://localhost:9090/api/books
|
||||
```
|
||||
|
||||
I know what I have described in this post is not a truly production ready setup because I’ve not spoken about any of the following, but most of these topics could take an entire post on their own:
|
||||
|
||||
- Security concerns like firewalls or SSL configuration
|
||||
- How to ensure the application keeps running
|
||||
- How to be selective about what to include in a Docker image (I dumped everything in via the Dockerfile)
|
||||
- Databases - how to manage them in containers
|
||||
|
||||
This has been a very interesting learning experience for me because for a while now I have been curious to explore the new cross platform support that comes with ASP.NET Core, and the opportunity to explore a little bit of the DevOps world using Docker Compose for a “Configuration as Code” approach has been both enjoyable and educational.
|
||||
|
||||
If you’re at all curious about Docker then I encourage you to get stuck in by trying it out - especially if this puts you out of your comfort zone. Who knows, you might enjoy it?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://blog.scottlogic.com/2016/09/05/hosting-netcore-on-linux-with-docker.html?utm_source=webopsweekly&utm_medium=email
|
||||
|
||||
作者:[Nick Soper][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://blog.scottlogic.com/nsoper
|
||||
[1]: http://blog.scottlogic.com/2016/01/20/restful-api-with-aspnet50.html
|
||||
[2]: https://docs.microsoft.com/en-us/dotnet/articles/core/migrating-from-dnx
|
||||
[3]: https://docs.asp.net/en/latest/migration/rc1-to-rtm.html
|
||||
[4]: http://www.paraesthesia.com/archive/2016/06/29/netcore-rtm-where-is-autofac/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
GHLandy translating
|
||||
|
||||
17 tar command practical examples in Linux
|
||||
=====
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating by Chao-zhi
|
||||
|
||||
15 Top Open Source Artificial Intelligence Tools
|
||||
====
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating by Bestony
|
||||
|
||||
Insomnia 3.0 Is a Slick Desktop REST Client for Linux
|
||||
=====
|
||||
|
||||
|
||||
@ -1,234 +0,0 @@
|
||||
使用 Python 和 asyncio 编写在线多用人游戏 - 第2部分
|
||||
==================================================================
|
||||
|
||||

|
||||
|
||||
你曾经写过异步的 Python 程序吗?这里我将告诉你如果如何做,而且在接下来的部分用一个[实例][1] - 专为多玩家设计的、受欢迎的贪吃蛇游戏来演示。
|
||||
|
||||
介绍和理论部分参见第一部分[异步化[第1部分]][2]。
|
||||
|
||||
试玩游戏[3]。
|
||||
|
||||
### 3. 编写游戏循环主体
|
||||
|
||||
游戏循环是每一个游戏的核心。它持续地读取玩家的输入,更新游戏的状态,并且在屏幕上渲染游戏结果。在在线游戏中,游戏循环分为客户端和服务端两部分,所以一般有两个循环通过网络通信。通常客户端的角色是获取玩家输入,比如按键或者鼠标移动,将数据传输给服务端,然后接收需要渲染的数据。服务端处理来自玩家的所有数据,更新游戏的状态,执行渲染下一帧的必要计算,然后将结果传回客户端,例如游戏中对象的位置。如果没有可靠的理由,不混淆客户端和服务端的角色很重要。如果你在客户端执行游戏逻辑的计算,很容易就会和其它客户端失去同步,其实你的游戏也可以通过简单地传递客户端的数据来创建。
|
||||
|
||||
游戏循环的一次迭代称为一个嘀嗒。嘀嗒表示当前游戏循环的迭代已经结束,下一帧(或者多帧)的数据已经就绪。在后面的例子中,我们使用相同的客户端,使用 WebSocket 连接服务端。它执行一个简单的循环,将按键码发送给服务端,显示来自服务端的所有信息。[客户端代码戳这里][4]。
|
||||
|
||||
#### 例子3.1:基本游戏循环
|
||||
|
||||
[例子3.1源码][5]。
|
||||
|
||||
我们使用 [aiohttp][6] 库来创建游戏服务器。它可以通过 asyncio 创建网页服务器和客户端。这个库的一个优势是它同时支持普通 http 请求和 websocket。所以我们不用其他网页服务器来渲染游戏的 html 页面。
|
||||
|
||||
下面是启动服务器的方法:
|
||||
|
||||
```
|
||||
app = web.Application()
|
||||
app["sockets"] = []
|
||||
|
||||
asyncio.ensure_future(game_loop(app))
|
||||
|
||||
app.router.add_route('GET', '/connect', wshandler)
|
||||
app.router.add_route('GET', '/', handle)
|
||||
|
||||
web.run_app(app)
|
||||
```
|
||||
|
||||
`web.run_app` 是创建服务主任务的快捷方法,通过他的 `run_forever()` 方法来执行 asyncio 事件循环。建议你查看这个方法的源码,弄清楚服务器到底是如何创建和结束的。
|
||||
|
||||
`app` 变量就是一个类似于字典的对象,它可以在所连接的客户端之间共享数据。我们使用它来存储连接套接字的列表。随后会用这个列表来给所有连接的客户端发送消息。`asyncio.ensure_future()` 调用会启动主游戏循环的任务,每隔2s向客户端发送嘀嗒消息。这个任务会在同样的 asyncio 事件循环中和网页服务器并行执行。
|
||||
|
||||
有两个网页请求处理器:提供 html 页面的处理器 (`handle`);`wshandler` 是主要的 websocket 服务器任务,处理和客户端之间的交互。在事件循环中,每一个连接的客户端都会创建一个新的 `wshandler`。
|
||||
|
||||
在启动的任务中,我们在 asyncio 的主事件循环中启动 worker 循环。任务之间的切换发生在他们任何一个使用 `await`语句来等待某个协程结束。例如 `asyncio.sleep` 仅仅是将程序执行权交给调度器指定的时间;`ws.receive` 等待 websocket 的消息,此时调度器可能切换到其它任务。
|
||||
|
||||
在浏览器中打开主页,连接上服务器后,试试随便按下键。他们的键值会从服务端返回,每隔2秒这个数字会被游戏循环发给所有客户端的嘀嗒消息覆盖。
|
||||
|
||||
我们刚刚创建了一个处理客户端按键的服务器,主游戏循环在后台做一些处理,周期性地同时更新所有的客户端。
|
||||
|
||||
#### 例子 3.2: 根据请求启动游戏
|
||||
|
||||
[例子 3.2的源码][7]
|
||||
|
||||
在前一个例子中,在服务器的生命周期内,游戏循环一直运行着。但是现实中,如果没有一个人连接服务器,空运行游戏循环通常是不合理的。而且,同一个服务器上可能有不同的’游戏房间‘。在这种假设下,每一个玩家创建一个游戏会话(多人游戏中的一个比赛或者大型多人游戏中的副本),这样其他用户可以加入其中。当游戏会话开始时,游戏循环才开始执行。
|
||||
|
||||
在这个例子中,我们使用一个全局标记来检测游戏循环是否在执行。当第一个用户发起连接时,启动它。最开始,游戏循环不在执行,标记设置为 `False`。游戏循环是通过客户端的处理方法启动的。
|
||||
|
||||
```
|
||||
if app["game_is_running"] == False:
|
||||
asyncio.ensure_future(game_loop(app))
|
||||
```
|
||||
|
||||
当游戏的循环(`loop()`)运行时,这个标记设置为 `True`;当所有客户端都断开连接时,其又被设置为 `False`。
|
||||
|
||||
#### 例子 3.3:管理任务
|
||||
|
||||
[例子3.3源码][8]
|
||||
|
||||
这个例子用来解释如何和任务对象协同工作。我们把游戏循环的任务直接存储在游戏循环的全局字典中,代替标记的使用。在这个简单例子中并不一定是最优的,但是有时候你可能需要控制所有已经启动的任务。
|
||||
|
||||
```
|
||||
if app["game_loop"] is None or \
|
||||
app["game_loop"].cancelled():
|
||||
app["game_loop"] = asyncio.ensure_future(game_loop(app))
|
||||
```
|
||||
|
||||
这里 `ensure_future()` 返回我们存放在全局字典中的任务对象,当所有用户都断开连接时,我们使用下面方式取消任务:
|
||||
|
||||
```
|
||||
app["game_loop"].cancel()
|
||||
```
|
||||
|
||||
这个 `cancel()` 调用将通知所有的调度器不要向这个协程提交任何执行任务,而且将它的状态设置为已取消,之后可以通过 `cancelled()` 方法来检查是否已取消。这里有一个值得一提的小注意点:当你持有一个任务对象的外部引用时,而这个任务执行中抛出了异常,这个异常不会抛出。取而代之的是为这个任务设置一个异常状态,可以通过 `exception()` 方法来检查是否出现了异常。这种悄无声息地失败在调试时不是很有用。所以,你可能想用抛出所有异常来取代这种做法。你可以对所有未完成的任务显示地调用 `result()` 来实现。可以通过如下的回调来实现:
|
||||
|
||||
```
|
||||
app["game_loop"].add_done_callback(lambda t: t.result())
|
||||
```
|
||||
|
||||
如果我们打算在我们代码中取消任务,但是又不想产生 `CancelError` 异常,有一个检查 `cancelled` 状态的点:
|
||||
|
||||
```
|
||||
app["game_loop"].add_done_callback(lambda t: t.result()
|
||||
if not t.cancelled() else None)
|
||||
```
|
||||
|
||||
注意仅当你持有任务对象的引用时必须要这么做。在前一个例子,所有的异常都是没有额外的回调,直接抛出所有异常。
|
||||
|
||||
#### 例子 3.4:等待多个事件
|
||||
|
||||
[例子 3.4 源码][9]
|
||||
|
||||
在许多场景下,在客户端的处理方法中你需要等待多个事件的发生。除了客户端的消息,你可能需要等待不同类型事件的发生。比如,如果你的游戏时间有限制,那么你可能需要等一个来自定时器的信号。或者你需要使用管道来等待来自其它进程的消息。亦或者是使用分布式消息系统网络中其它服务器的信息。
|
||||
|
||||
为了简单起见,这个例子是基于例子 3.1。但是这个例子中我们使用 `Condition` 对象来保证已连接客户端游戏循环的同步。我们不保存套接字的全局列表,因为只在方法中使用套接字。当游戏循环停止迭代时,我们使用 `Condition.notify_all()` 方法来通知所有的客户端。这个方法允许在 `asyncio` 的事件循环中使用发布/订阅的模式。
|
||||
|
||||
为了等待两个事件,首先我们使用 `ensure_future()` 来封装任务中可以等待的对象。
|
||||
|
||||
```
|
||||
if not recv_task:
|
||||
recv_task = asyncio.ensure_future(ws.receive())
|
||||
if not tick_task:
|
||||
await tick.acquire()
|
||||
tick_task = asyncio.ensure_future(tick.wait())
|
||||
```
|
||||
|
||||
在我们调用 `Condition.wait()` 之前,我们需要在背后获取一把锁。这就是我们为什么先调用 `tick.acquire()` 的原因。在调用 `tick.wait()` 之后,锁会被释放,这样其他的协程也可以使用它。但是当我们收到通知时,会重新获取锁,所以在收到通知后需要调用 `tick.release()` 来释放它。
|
||||
|
||||
我们使用 `asyncio.wait()` 协程来等待两个任务。
|
||||
|
||||
```
|
||||
done, pending = await asyncio.wait(
|
||||
[recv_task,
|
||||
tick_task],
|
||||
return_when=asyncio.FIRST_COMPLETED)
|
||||
```
|
||||
|
||||
程序会阻塞,直到列表中的任意一个任务完成。然后它返回两个列表:执行完成的任务列表和仍然在执行的任务列表。如果任务执行完成了,其对应变量赋值为 `None`,所以在下一个迭代时,它可能会被再次创建。
|
||||
|
||||
#### 例子 3.5: 结合多个线程
|
||||
|
||||
[例子 3.5 源码][10]
|
||||
|
||||
在这个例子中,我们结合 asyncio 循环和线程,在一个单独的线程中执行主游戏循环。我之前提到过,由于 `GIL` 的存在,Python 代码的真正并行执行是不可能的。所以使用其它线程来执行复杂计算并不是一个好主意。然而,在使用 `asyncio` 时结合线程有原因的:当我们使用的其它库不支持 `asyncio` 时。在主线程中调用这些库会阻塞循环的执行,所以异步使用他们的唯一方法是在不同的线程中使用他们。
|
||||
|
||||
在 asyncio 的循环和 `ThreadPoolExecutor` 中,我们通过 `run_in_executor()` 方法来执行游戏循环。注意 `game_loop()` 已经不再是一个协程了。它是一个由其它线程执行的函数。然而我们需要和主线程交互,在游戏事件到来时通知客户端。asyncio 本身不是线程安全的,它提供了可以在其它线程中执行你的代码的方法。普通函数有 `call_soon_threadsafe()`, 协程有 `run_coroutine_threadsafe()`。我们在 `notify()` 协程中增加代码通知客户端游戏的嘀嗒,然后通过另外一个线程执行主事件循环。
|
||||
|
||||
```
|
||||
def game_loop(asyncio_loop):
|
||||
print("Game loop thread id {}".format(threading.get_ident()))
|
||||
async def notify():
|
||||
print("Notify thread id {}".format(threading.get_ident()))
|
||||
await tick.acquire()
|
||||
tick.notify_all()
|
||||
tick.release()
|
||||
|
||||
while 1:
|
||||
task = asyncio.run_coroutine_threadsafe(notify(), asyncio_loop)
|
||||
# blocking the thread
|
||||
sleep(1)
|
||||
# make sure the task has finished
|
||||
task.result()
|
||||
```
|
||||
|
||||
当你执行这个例子时,你会看到 "Notify thread id" 和 "Main thread id" 相等,因为 `notify()` 协程在主线程中执行。与此同时 `sleep(1)` 在另外一个线程中执行,因此它不会阻塞主事件循环。
|
||||
|
||||
#### 例子 3.6:多进程和扩展
|
||||
|
||||
[例子 3.6 源码][11]
|
||||
|
||||
单线程的服务器可能运行得很好,但是它只能使用一个CPU核。为了将服务扩展到多核,我们需要执行多个进程,每个进程执行各自的事件循环。这样我们需要在进程间交互信息或者共享游戏的数据。而且在一个游戏中经常需要进行复杂的计算,例如路径查找。这些任务有时候在一个游戏嘀嗒中没法快速完成。在协程中不推荐进行费时的计算,因为它会阻塞事件的处理。在这种情况下,将这个复杂任务交给并行执行地其它进程可能更合理。
|
||||
|
||||
最简单的使用多个核的方法是启动多个使用单核的服务器,就像之前的例子中一样,每个服务器占用不同的端口。你可以使用 `supervisord` 或者其它进程控制的系统。这个时候你需要一个负载均衡器,像 `HAProxy`,使得连接的客户端在多个进程间均匀分布。有一些适配 asyncio 消息系统和存储系统。例如:
|
||||
|
||||
- [aiomcache][12] for memcached client
|
||||
- [aiozmq][13] for zeroMQ
|
||||
- [aioredis][14] for Redis storage and pub/sub
|
||||
|
||||
你可以在 github 或者 pypi 上找到其它的安装包,大部分以 `aio` 开头。
|
||||
|
||||
使用网络服务在存储持久状态和交互信息时可能比较有效。但是如果你需要进行进程通信的实时处理,它的性能可能不足。此时,使用标准的 unix 管道可能更合适。asyncio 支持管道,这个仓库有个 [使用pipe且比较底层的例子][15]
|
||||
|
||||
在当前的例子中,我们使用 Python 的高层库 [multiprocessing][16] 来在不同的核上启动复杂的计算,使用 `multiprocessing.Queue` 来进行进程间的消息交互。不幸的是,当前的 multiprocessing 实现与 asyncio 不兼容。所以每一个阻塞方法的调用都会阻塞事件循环。但是此时线程正好可以起到帮助作用,因为如果在不同线程里面执行 multiprocessing 的代码,它就不会阻塞主线程。所有我们需要做的就是把所有进程间的通信放到另外一个线程中去。这个例子会解释如何使用这个方法。和上面的多线程例子非常类似,但是我们从线程中创建的是一个新的进程。
|
||||
|
||||
```
|
||||
def game_loop(asyncio_loop):
|
||||
# coroutine to run in main thread
|
||||
async def notify():
|
||||
await tick.acquire()
|
||||
tick.notify_all()
|
||||
tick.release()
|
||||
|
||||
queue = Queue()
|
||||
|
||||
# function to run in a different process
|
||||
def worker():
|
||||
while 1:
|
||||
print("doing heavy calculation in process {}".format(os.getpid()))
|
||||
sleep(1)
|
||||
queue.put("calculation result")
|
||||
|
||||
Process(target=worker).start()
|
||||
|
||||
while 1:
|
||||
# blocks this thread but not main thread with event loop
|
||||
result = queue.get()
|
||||
print("getting {} in process {}".format(result, os.getpid()))
|
||||
task = asyncio.run_coroutine_threadsafe(notify(), asyncio_loop)
|
||||
task.result()
|
||||
```
|
||||
|
||||
这里我们在另外一个进程中运行 `worker()` 函数。它包括一个执行复杂计算的循环,然后把计算结果放到 `queue` 中,这个 `queue` 是 `multiprocessing.Queue` 的实例。然后我们就可以在另外一个线程的主事件循环中获取结果并通知客户端,就是例子 3.5 一样。这个例子已经非常简化了,它没有合理的结束进程。而且在真实的游戏中,我们可能需要另外一个队列来将数据传递给 `worker`。
|
||||
|
||||
有一个项目叫 [aioprocessing][17],它封装了 multiprocessing,使得它可以和 asyncio 兼容。但是实际上它只是和上面例子使用了完全一样的方法:从线程中创建进程。它并没有给你带来任何方便,除了它使用了简单的接口隐藏了后面的这些技巧。希望在 Python 的下一个版本中,我们能有一个基于协程且支持 asyncio 的 multiprocessing 库。
|
||||
|
||||
> 注意!如果你从主线程或者主进程中创建了一个不同的线程或者子进程来运行另外一个 asyncio 事件循环,你需要显示地使用 `asyncio.new_event_loop()` 来创建循环,不然的话可能程序不会正常工作。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-and-asyncio-writing-game-loop/
|
||||
|
||||
作者:[Kyrylo Subbotin][a]
|
||||
译者:[chunyang-wen](https://github.com/chunyang-wen)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-and-asyncio-writing-game-loop/
|
||||
[1]: http://snakepit-game.com/
|
||||
[2]: https://7webpages.com/blog/writing-online-multiplayer-game-with-python-asyncio-getting-asynchronous/
|
||||
[3]: http://snakepit-game.com/
|
||||
[4]: https://github.com/7WebPages/snakepit-game/blob/master/simple/index.html
|
||||
[5]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_basic.py
|
||||
[6]: http://aiohttp.readthedocs.org/
|
||||
[7]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_handler.py
|
||||
[8]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_global.py
|
||||
[9]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_wait.py
|
||||
[10]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_thread.py
|
||||
[11]: https://github.com/7WebPages/snakepit-game/blob/master/simple/game_loop_process.py
|
||||
[12]: https://github.com/aio-libs/aiomcache
|
||||
[13]: https://github.com/aio-libs/aiozmq
|
||||
[14]: https://github.com/aio-libs/aioredis
|
||||
[15]: https://github.com/KeepSafe/aiohttp/blob/master/examples/mpsrv.py
|
||||
[16]: https://docs.python.org/3.5/library/multiprocessing.html
|
||||
[17]: https://github.com/dano/aioprocessing
|
||||
Loading…
Reference in New Issue
Block a user