mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-18 02:00:18 +08:00
commit
ff0f523d3e
@ -1,5 +1,4 @@
|
||||
|
||||
Linux 有问必答 - 如何在 Linux 中统计一个进程的线程数
|
||||
Linux 有问必答:如何在 Linux 中统计一个进程的线程数
|
||||
================================================================================
|
||||
> **问题**: 我正在运行一个程序,它在运行时会派生出多个线程。我想知道程序在运行时会有多少线程。在 Linux 中检查进程的线程数最简单的方法是什么?
|
||||
|
||||
@ -7,11 +6,11 @@ Linux 有问必答 - 如何在 Linux 中统计一个进程的线程数
|
||||
|
||||
### 方法一: /proc ###
|
||||
|
||||
proc 伪文件系统,它驻留在 /proc 目录,这是最简单的方法来查看任何活动进程的线程数。 /proc 目录以可读文本文件形式输出,提供现有进程和系统硬件相关的信息如 CPU, interrupts, memory, disk, 等等.
|
||||
proc 伪文件系统,它驻留在 /proc 目录,这是最简单的方法来查看任何活动进程的线程数。 /proc 目录以可读文本文件形式输出,提供现有进程和系统硬件相关的信息如 CPU、中断、内存、磁盘等等.
|
||||
|
||||
$ cat /proc/<pid>/status
|
||||
|
||||
上面的命令将显示进程 <pid> 的详细信息,包括过程状态(例如, sleeping, running),父进程 PID,UID,GID,使用的文件描述符的数量,以及上下文切换的数量。输出也包括**进程创建的总线程数**如下所示。
|
||||
上面的命令将显示进程 \<pid> 的详细信息,包括过程状态(例如, sleeping, running),父进程 PID,UID,GID,使用的文件描述符的数量,以及上下文切换的数量。输出也包括**进程创建的总线程数**如下所示。
|
||||
|
||||
Threads: <N>
|
||||
|
||||
@ -23,11 +22,11 @@ Linux 有问必答 - 如何在 Linux 中统计一个进程的线程数
|
||||
|
||||
输出表明该进程有28个线程。
|
||||
|
||||
或者,你可以在 /proc/<pid>/task 中简单的统计目录的数量,如下所示。
|
||||
或者,你可以在 /proc/<pid>/task 中简单的统计子目录的数量,如下所示。
|
||||
|
||||
$ ls /proc/<pid>/task | wc
|
||||
|
||||
这是因为,对于一个进程中创建的每个线程,在 /proc/<pid>/task 中会创建一个相应的目录,命名为其线程 ID。由此在 /proc/<pid>/task 中目录的总数表示在进程中线程的数目。
|
||||
这是因为,对于一个进程中创建的每个线程,在 `/proc/<pid>/task` 中会创建一个相应的目录,命名为其线程 ID。由此在 `/proc/<pid>/task` 中目录的总数表示在进程中线程的数目。
|
||||
|
||||
### 方法二: ps ###
|
||||
|
||||
@ -35,7 +34,7 @@ Linux 有问必答 - 如何在 Linux 中统计一个进程的线程数
|
||||
|
||||
$ ps hH p <pid> | wc -l
|
||||
|
||||
如果你想监视一个进程的不同线程消耗的硬件资源(CPU & memory),请参阅[此教程][1]。(注:此文我们翻译过)
|
||||
如果你想监视一个进程的不同线程消耗的硬件资源(CPU & memory),请参阅[此教程][1]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -43,9 +42,9 @@ via: http://ask.xmodulo.com/number-of-threads-process-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://ask.xmodulo.com/view-threads-process-linux.html
|
||||
[1]:https://linux.cn/article-5633-1.html
|
||||
@ -1,14 +1,15 @@
|
||||
网络管理命令行工具基础,Nmcli
|
||||
Nmcli 网络管理命令行工具基础
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
### 介绍 ###
|
||||
|
||||
在本教程中,我们会在CentOS / RHEL 7中讨论网络管理工具,也叫**nmcli**。那些使用**ifconfig**的用户应该在CentOS 7中避免使用这个命令。
|
||||
在本教程中,我们会在CentOS / RHEL 7中讨论网络管理工具(NetworkManager command line tool),也叫**nmcli**。那些使用**ifconfig**的用户应该在CentOS 7中避免使用**ifconfig** 了。
|
||||
|
||||
让我们用nmcli工具配置一些网络设置。
|
||||
|
||||
### 要得到系统中所有接口的地址信息 ###
|
||||
#### 要得到系统中所有接口的地址信息 ####
|
||||
|
||||
[root@localhost ~]# ip addr show
|
||||
|
||||
@ -27,13 +28,13 @@
|
||||
inet6 fe80::20c:29ff:fe67:2f4c/64 scope link
|
||||
valid_lft forever preferred_lft forever
|
||||
|
||||
#### 检索与连接的接口相关的数据包统计 ####
|
||||
#### 检索与已连接的接口相关的数据包统计 ####
|
||||
|
||||
[root@localhost ~]# ip -s link show eno16777736
|
||||
|
||||
**示例输出:**
|
||||
|
||||

|
||||

|
||||
|
||||
#### 得到路由配置 ####
|
||||
|
||||
@ -50,11 +51,11 @@
|
||||
|
||||
输出像traceroute,但是更加完整。
|
||||
|
||||

|
||||

|
||||
|
||||
### nmcli 工具 ###
|
||||
|
||||
**Nmcli** 是一个非常丰富和灵活的命令行工具。nmcli使用的情况有:
|
||||
**nmcli** 是一个非常丰富和灵活的命令行工具。nmcli使用的情况有:
|
||||
|
||||
- **设备** – 正在使用的网络接口
|
||||
- **连接** – 一组配置设置,对于一个单一的设备可以有多个连接,可以在连接之间切换。
|
||||
@ -63,7 +64,7 @@
|
||||
|
||||
[root@localhost ~]# nmcli connection show
|
||||
|
||||

|
||||

|
||||
|
||||
#### 得到特定连接的详情 ####
|
||||
|
||||
@ -71,7 +72,7 @@
|
||||
|
||||
**示例输出:**
|
||||
|
||||

|
||||

|
||||
|
||||
#### 得到网络设备状态 ####
|
||||
|
||||
@ -89,7 +90,7 @@
|
||||
|
||||
这里,
|
||||
|
||||
- **Connection add** – 添加新的连接
|
||||
- **connection add** – 添加新的连接
|
||||
- **con-name** – 连接名
|
||||
- **type** – 设备类型
|
||||
- **ifname** – 接口名
|
||||
@ -100,7 +101,7 @@
|
||||
|
||||
Connection 'dhcp' (163a6822-cd50-4d23-bb42-8b774aeab9cb) successfully added.
|
||||
|
||||
#### 不同过dhcp分配IP,使用“static”添加地址 ####
|
||||
#### 不通过dhcp分配IP,使用“static”添加地址 ####
|
||||
|
||||
[root@localhost ~]# nmcli connection add con-name "static" ifname eno16777736 autoconnect no type ethernet ip4 192.168.1.240 gw4 192.168.1.1
|
||||
|
||||
@ -112,25 +113,23 @@
|
||||
|
||||
[root@localhost ~]# nmcli connection up eno1
|
||||
|
||||
Again Check, whether ip address is changed or not.
|
||||
再检查一遍,ip地址是否已经改变
|
||||
|
||||
[root@localhost ~]# ip addr show
|
||||
|
||||

|
||||

|
||||
|
||||
#### 添加DNS设置到静态连接中 ####
|
||||
|
||||
[root@localhost ~]# nmcli connection modify "static" ipv4.dns 202.131.124.4
|
||||
|
||||
#### 添加额外的DNS值 ####
|
||||
#### 添加更多的DNS ####
|
||||
|
||||
[root@localhost ~]# nmcli connection modify "static" +ipv4.dns 8.8.8.8
|
||||
[root@localhost ~]# nmcli connection modify "static" +ipv4.dns 8.8.8.8
|
||||
|
||||
**注意**:要使用额外的**+**符号,并且要是**+ipv4.dns**,而不是**ip4.dns**。
|
||||
|
||||
|
||||
添加一个额外的ip地址:
|
||||
####添加一个额外的ip地址####
|
||||
|
||||
[root@localhost ~]# nmcli connection modify "static" +ipv4.addresses 192.168.200.1/24
|
||||
|
||||
@ -138,11 +137,11 @@ Again Check, whether ip address is changed or not.
|
||||
|
||||
[root@localhost ~]# nmcli connection up eno1
|
||||
|
||||

|
||||

|
||||
|
||||
你会看见,设置生效了。
|
||||
|
||||
完结
|
||||
完结。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -150,6 +149,6 @@ via: http://www.unixmen.com/basics-networkmanager-command-line-tool-nmcli/
|
||||
|
||||
作者:Rajneesh Upadhyay
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -18,9 +18,9 @@ Elementary OS 它自己本身借鉴了 OS X,也就不奇怪它的很多第三
|
||||
|
||||
### 在 Ubuntu、Elementary OS 和 Mint 上安装 NaSC ###
|
||||
|
||||
安装 NaSC 有一个可用的 PPA。PPA 中说 ‘每日’,意味着所有构建(包括不稳定),但作为我的快速测试,并没什么影响。
|
||||
安装 NaSC 有一个可用的 PPA。PPA 是 ‘每日’,意味着每日构建(意即,不稳定),但作为我的快速测试,并没什么影响。
|
||||
|
||||
打卡一个终端并运行下面的命令:
|
||||
打开一个终端并运行下面的命令:
|
||||
|
||||
sudo apt-add-repository ppa:nasc-team/daily
|
||||
sudo apt-get update
|
||||
@ -35,7 +35,7 @@ Elementary OS 它自己本身借鉴了 OS X,也就不奇怪它的很多第三
|
||||
sudo apt-get remove nasc
|
||||
sudo apt-add-repository --remove ppa:nasc-team/daily
|
||||
|
||||
如果你试用了这个软件,要分享你的经验哦。除此之外,你也可以在第三方 Elementary OS 应用中体验[Vocal podcast app for Linux][3]。
|
||||
如果你试用了这个软件,要分享你的经验哦。除此之外,你也可以在第三方 Elementary OS 应用中体验 [Vocal podcast app for Linux][3]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -43,7 +43,7 @@ via: http://itsfoss.com/math-ubuntu-nasc/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,14 +1,14 @@
|
||||
Linux有问必答--如何删除Ubuntu上不再使用的老内核
|
||||
Linux有问必答:如何删除Ubuntu上不再使用的旧内核
|
||||
================================================================================
|
||||
> **提问**:过去我已经在我的Ubuntu上升级了几次内核。现在我想要删除这些旧的内核镜像来节省我的磁盘空间。如何用最简单的方法删除Ubuntu上先前版本的内核?
|
||||
|
||||
在Ubuntu上,有几个方法来升级内核。在Ubuntu桌面中,软件更新允许你每天检查并更新到最新的内核上。在Ubuntu服务器上,一个无人值守的包会自动更新内核最为一项最要的安全更新。然而,你可以手动用apt-get或者aptitude命令来更新。
|
||||
在Ubuntu上,有几个方法来升级内核。在Ubuntu桌面中,软件更新允许你每天检查并更新到最新的内核上。在Ubuntu服务器上,最为重要的安全更新项目之一就是 unattended-upgrades 软件包会自动更新内核。然而,你也可以手动用apt-get或者aptitude命令来更新。
|
||||
|
||||
随着时间的流逝,持续的内核更新会在系统中积聚大量的不再使用的内核,浪费你的磁盘空间。每个内核镜像和其相关联的模块/头文件会占用200-400MB的磁盘空间,因此由不再使用的内核而浪费的磁盘空间会快速地增加。
|
||||
|
||||
|
||||
|
||||
GRUB管理器为每个旧内核都维护了一个GRUB入口,防止你想要进入它们。
|
||||
GRUB管理器为每个旧内核都维护了一个GRUB入口,以备你想要使用它们。
|
||||
|
||||
|
||||
|
||||
@ -18,7 +18,7 @@ GRUB管理器为每个旧内核都维护了一个GRUB入口,防止你想要进
|
||||
|
||||
在删除旧内核之前,记住最好留有2个最近的内核(最新的和上一个版本),以防主要的版本出错。现在就让我们看看如何在Ubuntu上清理旧内核。
|
||||
|
||||
在Ubuntu内核镜像包哈了以下的包。
|
||||
在Ubuntu内核镜像包含了以下的包。
|
||||
|
||||
- **linux-image-<VERSION-NUMBER>**: 内核镜像
|
||||
- **linux-image-extra-<VERSION-NUMBER>**: 额外的内核模块
|
||||
@ -36,7 +36,6 @@ GRUB管理器为每个旧内核都维护了一个GRUB入口,防止你想要进
|
||||
|
||||
上面的命令会删除内核镜像和它相关联的内核模块和头文件。
|
||||
|
||||
updated to remove the corresponding GRUB entry from GRUB menu.
|
||||
注意如果你还没有升级内核那么删除旧内核会自动触发安装新内核。这样在删除旧内核之后,GRUB配置会自动升级来移除GRUB菜单中相关GRUB入口。
|
||||
|
||||
如果你有很多没用的内核,你可以用shell表达式来一次性地删除多个内核。注意这个括号表达式只在bash或者兼容的shell中才有效。
|
||||
@ -52,7 +51,7 @@ updated to remove the corresponding GRUB entry from GRUB menu.
|
||||
|
||||
$ sudo update-grub2
|
||||
|
||||
现在就重启来验证GRUB菜单已经正确清理了。
|
||||
现在就重启来验证GRUB菜单是否已经正确清理了。
|
||||
|
||||
|
||||
|
||||
@ -62,7 +61,7 @@ via: http://ask.xmodulo.com/remove-kernel-images-ubuntu.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,41 +0,0 @@
|
||||
Ubuntu Linux-Based Open Source OS Runs 42 Percent of Dell PCs in China
|
||||
================================================================================
|
||||
> Dell says that 42 percent of the PCs it sells in the Chinese market run Kylin, an open source operating system based on Ubuntu Linux that Canonical helped to create.
|
||||
|
||||
Open source fans, rejoice: The Year of the Linux Desktop has arrived. Or something close to it is on the horizon in China, at least, where [Dell][1] has reported that more than 40 percent of the PCs it sells run a variant of [Ubuntu Linux][2] that [Canonical][3] helped develop.
|
||||
|
||||
Specifically, Dell said that 42 percent of computers in China run NeoKylin, an operating system that originated as an effort in China to build a home-grown alternative to [Microsoft][4] (MSFT) Windows. Also known simply Kylin, the OS has been based on Ubuntu since 2013, when Canonical began collaborating with the Chinese government to create an Ubuntu variant tailored for the Chinese market.
|
||||
|
||||
Earlier versions of Kylin, which has been around since 2001, were based on other operating systems, including FreeBSD, an open source Unix-like operating system that is distinct from Linux.
|
||||
|
||||
Ubuntu Kylin looks and feels a lot like modern versions of Ubuntu proper. It sports the [Unity][5] interface and runs the standard suite of open source apps, as well as specialized ones such as Youker Assistant, a graphical front end that helps users manage basic computing tasks. Kylin's default theme makes it look just a little more like Windows than stock Ubuntu, however.
|
||||
|
||||
Given the relative stagnation of the market for desktop Linux PCs in most of the world, Dell's announcement is striking. And in light of China's [hostility][6] toward modern editions of Windows, the news does not bode well for Microsoft's prospects in the Chinese market.
|
||||
|
||||
Dell's comment on Linux PC sales in China—which appeared in the form of a statement by an executive to the Wall Street Journal—comes on the heels of the company's [announcement][7] of $125 million of new investment in China.
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thevarguy.com/open-source-application-software-companies/091515/ubuntu-linux-based-open-source-os-runs-42-percent-dell-pc
|
||||
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://thevarguy.com/author/christopher-tozzi
|
||||
[1]:http://dell.com/
|
||||
[2]:http://ubuntu.com/
|
||||
[3]:http://canonical.com/
|
||||
[4]:http://microsoft.com/
|
||||
[5]:http://unity.ubuntu.com/
|
||||
[6]:http://www.wsj.com/articles/windows-8-faces-new-criticism-in-china-1401882772
|
||||
[7]:http://thevarguy.com/business-technology-solution-sales/091415/dell-125-million-directed-china-jobs-new-business-and-innovation
|
||||
@ -1,3 +1,4 @@
|
||||
(translating by runningwater)
|
||||
Best command line tools for linux performance monitoring
|
||||
================================================================================
|
||||
Sometimes a system can be slow and many reasons can be the root cause. To identify the process that is consuming memory, disk I/O or processor capacity you need to use tools to see what is happening in an operation system.
|
||||
@ -67,7 +68,7 @@ The sar utility, which is part of the systat package, can be used to review hist
|
||||
via: http://lintut.com/best-command-line-tools-for-linux-performance-monitring/
|
||||
|
||||
作者:[rasho][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,105 +0,0 @@
|
||||
|
||||
translating by ezio
|
||||
|
||||
How to Setup Node JS v4.0.0 on Ubuntu 14.04 / 15.04
|
||||
================================================================================
|
||||
Hi everyone, Node.JS Version 4.0.0 has been out, the popular server-side JavaScript platform has combines the Node.js and io.js code bases. This release represents the combined efforts encapsulated in both the Node.js project and the io.js project that are now combined in a single codebase. The most important change is this Node.js is ships with version 4.5 of Google's V8 JavaScript engine, which is the same version that ships with the current Chrome browser. So, being able to more closely track V8’s releases means Node.js runs JavaScript faster, more securely, and with the ability to use many desirable ES6 language features.
|
||||
|
||||

|
||||
|
||||
Node.js 4.0.0 aims to provide an easy update path for current users of io.js and node as there are no major API changes. Let’s see how you can easily get it installed and setup on Ubuntu server by following this simple article.
|
||||
|
||||
### Basic System Setup ###
|
||||
|
||||
Node works perfectly on Linux, Macintosh, and Solaris operating systems and among the Linux operating systems it has the best results using Ubuntu OS. That's why we are to setup it Ubuntu 15.04 while the same steps can be followed using Ubuntu 14.04.
|
||||
|
||||
#### 1) System Resources ####
|
||||
|
||||
The basic system resources for Node depend upon the size of your infrastructure requirements. So, here in this tutorial we will setup Node with 1 GB RAM, 1 GHz Processor and 10 GB of available disk space with minimal installation packages installed on the server that is no web or database server packages are installed.
|
||||
|
||||
#### 2) System Update ####
|
||||
|
||||
It always been recommended to keep your system upto date with latest patches and updates, so before we move to the installation on Node, let's login to your server with super user privileges and run update command.
|
||||
|
||||
# apt-get update
|
||||
|
||||
#### 3) Installing Dependencies ####
|
||||
|
||||
Node JS only requires some basic system and software utilities to be present on your server, for its successful installation like 'make' 'gcc' and 'wget'. Let's run the below command to get them installed if they are not already present.
|
||||
|
||||
# apt-get install python gcc make g++ wget
|
||||
|
||||
### Download Latest Node JS v4.0.0 ###
|
||||
|
||||
Let's download the latest Node JS version 4.0.0 by following this link of [Node JS Download Page][1].
|
||||
|
||||

|
||||
|
||||
We will copy the link location of its latest package and download it using 'wget' command as shown.
|
||||
|
||||
# wget https://nodejs.org/download/rc/v4.0.0-rc.1/node-v4.0.0-rc.1.tar.gz
|
||||
|
||||
Once download completes, unpack using 'tar' command as shown.
|
||||
|
||||
# tar -zxvf node-v4.0.0-rc.1.tar.gz
|
||||
|
||||

|
||||
|
||||
### Installing Node JS v4.0.0 ###
|
||||
|
||||
Now we have to start the installation of Node JS from its downloaded source code. So, change your directory and configure the source code by running its configuration script before compiling it on your ubuntu server.
|
||||
|
||||
root@ubuntu-15:~/node-v4.0.0-rc.1# ./configure
|
||||
|
||||

|
||||
|
||||
Now run the 'make install' command to compile the Node JS installation package as shown.
|
||||
|
||||
root@ubuntu-15:~/node-v4.0.0-rc.1# make install
|
||||
|
||||
The make command will take a couple of minutes while compiling its binaries so after executinf above command, wait for a while and keep calm.
|
||||
|
||||
### Testing Node JS Installation ###
|
||||
|
||||
Once the compilation process is complete, we will test it if every thing went fine. Let's run the following command to confirm the installed version of Node JS.
|
||||
|
||||
root@ubuntu-15:~# node -v
|
||||
v4.0.0-pre
|
||||
|
||||
By executing 'node' without any arguments from the command-line you will be dropped into the REPL (Read-Eval-Print-Loop) that has simplistic emacs line-editing where you can interactively run JavaScript and see the results.
|
||||
|
||||

|
||||
|
||||
### Writing Test Program ###
|
||||
|
||||
We can also try out a very simple console program to test the successful installation and proper working of Node JS. To do so we will create a file named "test.js" and write the following code into it and save the changes made in the file as shown.
|
||||
|
||||
root@ubuntu-15:~# vim test.js
|
||||
var util = require("util");
|
||||
console.log("Hello! This is a Node Test Program");
|
||||
:wq!
|
||||
|
||||
Now in order to run the above program, from the command prompt run the below command.
|
||||
|
||||
root@ubuntu-15:~# node test.js
|
||||
|
||||

|
||||
|
||||
So, upon successful installation we will get the output as shown in the screen, where as in the above program it loads the "util" class into a variable "util" and then uses the "util" object to perform the console tasks. While the console.log is a command similar to the cout in C++.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
That’s it. Hope this gives you a good idea of Node.js going with Node.js on Ubuntu. If you are new to developing applications with Node.js. After all we can say that we can expect significant performance gains with Node JS Version 4.0.0.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/setup-node-js-4-0-ubuntu-14-04-15-04/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
[1]:https://nodejs.org/download/rc/v4.0.0-rc.1/
|
||||
@ -1,78 +0,0 @@
|
||||
translating by ezio
|
||||
|
||||
Linux FAQs with Answers--How to check weather forecasts from the command line on Linux
|
||||
================================================================================
|
||||
> **Question**: I often check local weather forecasts on the Linux desktop. However, is there an easy way to access weather forecast information in the terminal environment, where I don't have access to desktop widgets or web browser?
|
||||
|
||||
For Linux desktop users, there are many ways to access weather forecasts, e.g., using standalone weather apps, desktop widgets, or panel applets. If your work environment is terminal-based, there are also several ways to access weather forecasts from the command line.
|
||||
|
||||
Among them is [wego][1], **a cute little weather app for the terminal**. Using an ncurses-based fancy interface, this command-line app allows you to see current weather conditions and forecasts at a glance. It retrieves the weather forecasts for the next 5 days via a weather forecast API.
|
||||
|
||||
### Install Wego on Linux ###
|
||||
|
||||
Installation of wego is pretty simple. wego is written in Go language, thus the first step is to [install Go language][2]. After installing Go, proceed to install wego as follows.
|
||||
|
||||
$ go get github.com/schachmat/wego
|
||||
|
||||
The wego tool will be installed under $GOPATH/bin. So add $GOPATH/bin to your $PATH variable.
|
||||
|
||||
$ echo 'export PATH="$PATH:$GOPATH/bin"' >> ~/.bashrc
|
||||
$ source ~/.bashrc
|
||||
|
||||
Now go ahead and invoke wego from the command line.
|
||||
|
||||
$ wego
|
||||
|
||||
The first time you run wego, it will generate a config file (~/.wegorc), where you need to specify a weather API key.
|
||||
|
||||
You can obtain a free API key from [worldweatheronline.com][3]. Free sign-up is quick and easy. You only need a valid email address.
|
||||
|
||||

|
||||
|
||||
Your .wegorc will look like the following.
|
||||
|
||||

|
||||
|
||||
Other than API key, you can specify in ~/.wegorc your preferred location, use of metric/imperial units, and language.
|
||||
|
||||
Note that the weather API is rate-limited; 5 queries per second, and 250 queries per day.
|
||||
|
||||
When you invoke wego command again, you will see the latest weather forecast (of your preferred location), shown as follows.
|
||||
|
||||

|
||||
|
||||
The displayed weather information includes: (1) temperature, (2) wind direction and speed, (3) viewing distance, and (4) precipitation amount and probability.
|
||||
|
||||
By default, it will show 3-day weather forecast. To change this behavior, you can supply the number of days (upto five) as an argument. For example, to see 5-day forecast:
|
||||
|
||||
$ wego 5
|
||||
|
||||
If you want to check the weather of any other location, you can specify the city name.
|
||||
|
||||
$ wego Seattle
|
||||
|
||||
### Troubleshooting ###
|
||||
|
||||
1. You encounter the following error while running wego.
|
||||
|
||||
user: Current not implemented on linux/amd64
|
||||
|
||||
This error can happen when you run wego on a platform which is not supported by the native Go compiler gc (e.g., Fedora). In that case, you can compile the program using gccgo, a compiler-frontend for Go language. This can be done as follows.
|
||||
|
||||
$ sudo yum install gcc-go
|
||||
$ go get -compiler=gccgo github.com/schachmat/wego
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/weather-forecasts-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:https://github.com/schachmat/wego
|
||||
[2]:http://ask.xmodulo.com/install-go-language-linux.html
|
||||
[3]:https://developer.worldweatheronline.com/auth/register
|
||||
@ -1,48 +0,0 @@
|
||||
Enable Automatic System Updates In Ubuntu
|
||||
================================================================================
|
||||
Before seeing **how to enable automatic system updates in Ubuntu**, first let’s see why should we do it in the first place.
|
||||
|
||||
By default Ubuntu checks for updates daily. When there are security updates, it shows immediately but for other updates (i.e. regular software updates) it pop ups once a week. So, if you have been using Ubuntu for a while, this may be a familiar sight for you:
|
||||
|
||||

|
||||
|
||||
Now if you are a normal desktop user, you don’t really care about what kind of updates are these. And this is not entirely a bad thing. You trust Ubuntu to provide you good updates, right? So, you just select ‘Install Now’ most of the time, don’t you?
|
||||
|
||||
And all you do is to click on Install Now, why not enable the automatic system updates? Enabling automatic system updates means all the latest updates will be automatically downloaded and installed without requiring any actions from you. Isn’t it convenient?
|
||||
|
||||
### Enable automatic updates in Ubuntu ###
|
||||
|
||||
I am using Ubuntu 15.04 in this tutorial but the steps are the same for Ubuntu 14.04 as well.
|
||||
|
||||
Go to Unity Dash and look for Software & Updates:
|
||||
|
||||

|
||||
|
||||
This will open the Software sources settings for you. Click on Updates tab here:
|
||||
|
||||

|
||||
|
||||
In here, you’ll see the default settings which is daily check for updates and immediate notification for security updates.
|
||||
|
||||

|
||||
|
||||
All you need to do is to change the action which reads “When there are” to “Download and install automatically”. This will download all the available updates and install them automatically.
|
||||
|
||||

|
||||
|
||||
That’s it. Close it and you have automatic updates enabled in Ubuntu. In fact this tutorial is pretty similar to [changing update notification frequency in Ubuntu][1].
|
||||
|
||||
Do you use automatic updates installation or you prefer to install them manually?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/automatic-system-updates-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/ubuntu-notify-updates-frequently/
|
||||
@ -1,3 +1,4 @@
|
||||
translation by strugglingyouth
|
||||
Linux FAQs with Answers--How to find out which CPU core a process is running on
|
||||
================================================================================
|
||||
> Question: I have a Linux process running on my multi-core processor system. How can I find out which CPU core the process is running on?
|
||||
@ -78,4 +79,4 @@ via: http://ask.xmodulo.com/cpu-core-process-is-running.html
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/identify-cpu-processor-architecture-linux.html
|
||||
[2]:http://xmodulo.com/run-program-process-specific-cpu-cores-linux.html
|
||||
[3]:http://ask.xmodulo.com/install-htop-centos-rhel.html
|
||||
[3]:http://ask.xmodulo.com/install-htop-centos-rhel.html
|
||||
|
||||
@ -0,0 +1,202 @@
|
||||
A Repository with 44 Years of Unix Evolution
|
||||
================================================================================
|
||||
### Abstract ###
|
||||
|
||||
The evolution of the Unix operating system is made available as a version-control repository, covering the period from its inception in 1972 as a five thousand line kernel, to 2015 as a widely-used 26 million line system. The repository contains 659 thousand commits and 2306 merges. The repository employs the commonly used Git system for its storage, and is hosted on the popular GitHub archive. It has been created by synthesizing with custom software 24 snapshots of systems developed at Bell Labs, Berkeley University, and the 386BSD team, two legacy repositories, and the modern repository of the open source FreeBSD system. In total, 850 individual contributors are identified, the early ones through primary research. The data set can be used for empirical research in software engineering, information systems, and software archaeology.
|
||||
|
||||
### 1 Introduction ###
|
||||
|
||||
The Unix operating system stands out as a major engineering breakthrough due to its exemplary design, its numerous technical contributions, its development model, and its widespread use. The design of the Unix programming environment has been characterized as one offering unusual simplicity, power, and elegance [[1][1]]. On the technical side, features that can be directly attributed to Unix or were popularized by it include [[2][2]]: the portable implementation of the kernel in a high level language; a hierarchical file system; compatible file, device, networking, and inter-process I/O; the pipes and filters architecture; virtual file systems; and the shell as a user-selectable regular process. A large community contributed software to Unix from its early days [[3][3]], [[4][4],pp. 65-72]. This community grew immensely over time and worked using what are now termed open source software development methods [[5][5],pp. 440-442]. Unix and its intellectual descendants have also helped the spread of the C and C++ programming languages, parser and lexical analyzer generators (*yacc, lex*), document preparation tools (*troff, eqn, tbl*), scripting languages (*awk, sed, Perl*), TCP/IP networking, and configuration management systems (*SCCS, RCS, Subversion, Git*), while also forming a large part of the modern internet infrastructure and the web.
|
||||
|
||||
Luckily, important Unix material of historical importance has survived and is nowadays openly available. Although Unix was initially distributed with relatively restrictive licenses, the most significant parts of its early development have been released by one of its right-holders (Caldera International) under a liberal license. Combining these parts with software that was developed or released as open source software by the University of California, Berkeley and the FreeBSD Project provides coverage of the system's development over a period ranging from June 20th 1972 until today.
|
||||
|
||||
Curating and processing available snapshots as well as old and modern configuration management repositories allows the reconstruction of a new synthetic Git repository that combines under a single roof most of the available data. This repository documents in a digital form the detailed evolution of an important digital artefact over a period of 44 years. The following sections describe the repository's structure and contents (Section [II][6]), the way it was created (Section [III][7]), and how it can be used (Section [IV][8]).
|
||||
|
||||
### 2 Data Overview ###
|
||||
|
||||
The 1GB Unix history Git repository is made available for cloning on [GitHub][9].[1][10] Currently[2][11] the repository contains 659 thousand commits and 2306 merges from about 850 contributors. The contributors include 23 from the Bell Labs staff, 158 from Berkeley's Computer Systems Research Group (CSRG), and 660 from the FreeBSD Project.
|
||||
|
||||
The repository starts its life at a tag identified as *Epoch*, which contains only licensing information and its modern README file. Various tag and branch names identify points of significance.
|
||||
|
||||
- *Research-VX* tags correspond to six research editions that came out of Bell Labs. These start with *Research-V1* (4768 lines of PDP-11 assembly) and end with *Research-V7* (1820 mostly C files, 324kLOC).
|
||||
- *Bell-32V* is the port of the 7th Edition Unix to the DEC/VAX architecture.
|
||||
- *BSD-X* tags correspond to 15 snapshots released from Berkeley.
|
||||
- *386BSD-X* tags correspond to two open source versions of the system, with the Intel 386 architecture kernel code mainly written by Lynne and William Jolitz.
|
||||
- *FreeBSD-release/X* tags and branches mark 116 releases coming from the FreeBSD project.
|
||||
|
||||
In addition, branches with a *-Snapshot-Development* suffix denote commits that have been synthesized from a time-ordered sequence of a snapshot's files, while tags with a *-VCS-Development* suffix mark the point along an imported version control history branch where a particular release occurred.
|
||||
|
||||
The repository's history includes commits from the earliest days of the system's development, such as the following.
|
||||
|
||||
commit c9f643f59434f14f774d61ee3856972b8c3905b1
|
||||
Author: Dennis Ritchie <research!dmr>
|
||||
Date: Mon Dec 2 18:18:02 1974 -0500
|
||||
Research V5 development
|
||||
Work on file usr/sys/dmr/kl.c
|
||||
|
||||
Merges between releases that happened along the system's evolution, such as the development of BSD 3 from BSD 2 and Unix 32/V, are also correctly represented in the Git repository as graph nodes with two parents.
|
||||
|
||||
More importantly, the repository is constructed in a way that allows *git blame*, which annotates source code lines with the version, date, and author associated with their first appearance, to produce the expected code provenance results. For example, checking out the *BSD-4* tag, and running git blame on the kernel's *pipe.c* file will show lines written by Ken Thompson in 1974, 1975, and 1979, and by Bill Joy in 1980. This allows the automatic (though computationally expensive) detection of the code's provenance at any point of time.
|
||||
|
||||
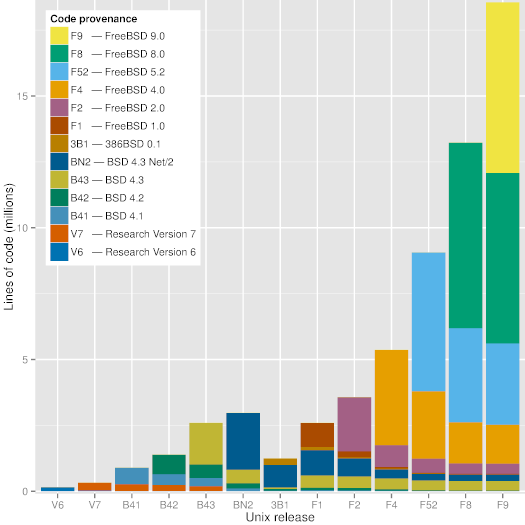
|
||||
|
||||
Figure 1: Code provenance across significant Unix releases.
|
||||
|
||||
As can be seen in Figure [1][12], a modern version of Unix (FreeBSD 9) still contains visible chunks of code from BSD 4.3, BSD 4.3 Net/2, and FreeBSD 2.0. Interestingly, the Figure shows that code developed during the frantic dash to create an open source operating system out of the code released by Berkeley (386BSD and FreeBSD 1.0) does not seem to have survived. The oldest code in FreeBSD 9 appears to be an 18-line sequence in the C library file timezone.c, which can also be found in the 7th Edition Unix file with the same name and a time stamp of January 10th, 1979 - 36 years ago.
|
||||
|
||||
### 3 Data Collection and Processing ###
|
||||
|
||||
The goal of the project is to consolidate data concerning the evolution of Unix in a form that helps the study of the system's evolution, by entering them into a modern revision repository. This involves collecting the data, curating them, and synthesizing them into a single Git repository.
|
||||
|
||||
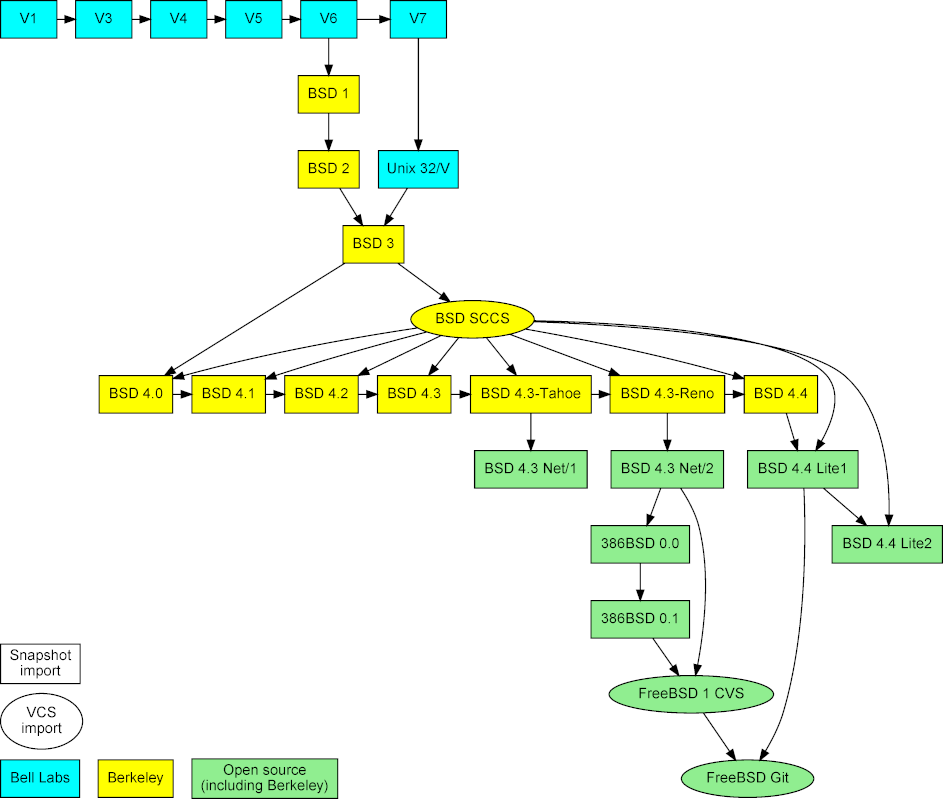
|
||||
|
||||
Figure 2: Imported Unix snapshots, repositories, and their mergers.
|
||||
|
||||
The project is based on three types of data (see Figure [2][13]). First, snapshots of early released versions, which were obtained from the [Unix Heritage Society archive][14],[3][15] the [CD-ROM images][16] containing the full source archives of CSRG,[4][17] the [OldLinux site][18],[5][19] and the [FreeBSD archive][20].[6][21] Second, past and current repositories, namely the CSRG SCCS [[6][22]] repository, the FreeBSD 1 CVS repository, and the [Git mirror of modern FreeBSD development][23].[7][24] The first two were obtained from the same sources as the corresponding snapshots.
|
||||
|
||||
The last, and most labour intensive, source of data was **primary research**. The release snapshots do not provide information regarding their ancestors and the contributors of each file. Therefore, these pieces of information had to be determined through primary research. The authorship information was mainly obtained by reading author biographies, research papers, internal memos, and old documentation scans; by reading and automatically processing source code and manual page markup; by communicating via email with people who were there at the time; by posting a query on the Unix *StackExchange* site; by looking at the location of files (in early editions the kernel source code was split into `usr/sys/dmr` and `/usr/sys/ken`); and by propagating authorship from research papers and manual pages to source code and from one release to others. (Interestingly, the 1st and 2nd Research Edition manual pages have an "owner" section, listing the person (e.g. *ken*) associated with the corresponding system command, file, system call, or library function. This section was not there in the 4th Edition, and resurfaced as the "Author" section in BSD releases.) Precise details regarding the source of the authorship information are documented in the project's files that are used for mapping Unix source code files to their authors and the corresponding commit messages. Finally, information regarding merges between source code bases was obtained from a [BSD family tree maintained by the NetBSD project][25].[8][26]
|
||||
|
||||
The software and data files that were developed as part of this project, are [available online][27],[9][28] and, with appropriate network, CPU and disk resources, they can be used to recreate the repository from scratch. The authorship information for major releases is stored in files under the project's `author-path` directory. These contain lines with a regular expressions for a file path followed by the identifier of the corresponding author. Multiple authors can also be specified. The regular expressions are processed sequentially, so that a catch-all expression at the end of the file can specify a release's default authors. To avoid repetition, a separate file with a `.au` suffix is used to map author identifiers into their names and emails. One such file has been created for every community associated with the system's evolution: Bell Labs, Berkeley, 386BSD, and FreeBSD. For the sake of authenticity, emails for the early Bell Labs releases are listed in UUCP notation (e.g. `research!ken`). The FreeBSD author identifier map, required for importing the early CVS repository, was constructed by extracting the corresponding data from the project's modern Git repository. In total the commented authorship files (828 rules) comprise 1107 lines, and there are another 640 lines mapping author identifiers to names.
|
||||
|
||||
The curation of the project's data sources has been codified into a 168-line `Makefile`. It involves the following steps.
|
||||
|
||||
**Fetching** Copying and cloning about 11GB of images, archives, and repositories from remote sites.
|
||||
|
||||
**Tooling** Obtaining an archiver for old PDP-11 archives from 2.9 BSD, and adjusting it to compile under modern versions of Unix; compiling the 4.3 BSD *compress* program, which is no longer part of modern Unix systems, in order to decompress the 386BSD distributions.
|
||||
|
||||
**Organizing** Unpacking archives using tar and *cpio*; combining three 6th Research Edition directories; unpacking all 1 BSD archives using the old PDP-11 archiver; mounting CD-ROM images so that they can be processed as file systems; combining the 8 and 62 386BSD floppy disk images into two separate files.
|
||||
|
||||
**Cleaning** Restoring the 1st Research Edition kernel source code files, which were obtained from printouts through optical character recognition, into a format close to their original state; patching some 7th Research Edition source code files; removing metadata files and other files that were added after a release, to avoid obtaining erroneous time stamp information; patching corrupted SCCS files; processing the early FreeBSD CVS repository by removing CVS symbols assigned to multiple revisions with a custom Perl script, deleting CVS *Attic* files clashing with live ones, and converting the CVS repository into a Git one using *cvs2svn*.
|
||||
|
||||
An interesting part of the repository representation is how snapshots are imported and linked together in a way that allows *git blame* to perform its magic. Snapshots are imported into the repository as sequential commits based on the time stamp of each file. When all files have been imported the repository is tagged with the name of the corresponding release. At that point one could delete those files, and begin the import of the next snapshot. Note that the *git blame* command works by traversing backwards a repository's history, and using heuristics to detect code moving and being copied within or across files. Consequently, deleted snapshots would create a discontinuity between them, and prevent the tracing of code between them.
|
||||
|
||||
Instead, before the next snapshot is imported, all the files of the preceding snapshot are moved into a hidden look-aside directory named `.ref` (reference). They remain there, until all files of the next snapshot have been imported, at which point they are deleted. Because every file in the `.ref` directory matches exactly an original file, *git blame* can determine how source code moves from one version to the next via the `.ref` file, without ever displaying the `.ref` file. To further help the detection of code provenance, and to increase the representation's realism, each release is represented as a merge between the branch with the incremental file additions (*-Development*) and the preceding release.
|
||||
|
||||
For a period in the 1980s, only a subset of the files developed at Berkeley were under SCCS version control. During that period our unified repository contains imports of both the SCCS commits, and the snapshots' incremental additions. At the point of each release, the SCCS commit with the nearest time stamp is found and is marked as a merge with the release's incremental import branch. These merges can be seen in the middle of Figure [2][29].
|
||||
|
||||
The synthesis of the various data sources into a single repository is mainly performed by two scripts. A 780-line Perl script (`import-dir.pl`) can export the (real or synthesized) commit history from a single data source (snapshot directory, SCCS repository, or Git repository) in the *Git fast export* format. The output is a simple text format that Git tools use to import and export commits. Among other things, the script takes as arguments the mapping of files to contributors, the mapping between contributor login names and their full names, the commit(s) from which the import will be merged, which files to process and which to ignore, and the handling of "reference" files. A 450-line shell script creates the Git repository and calls the Perl script with appropriate arguments to import each one of the 27 available historical data sources. The shell script also runs 30 tests that compare the repository at specific tags against the corresponding data sources, verify the appearance and disappearance of look-aside directories, and look for regressions in the count of tree branches and merges and the output of *git blame* and *git log*. Finally, *git* is called to garbage-collect and compress the repository from its initial 6GB size down to the distributed 1GB.
|
||||
|
||||
### 4 Data Uses ###
|
||||
|
||||
The data set can be used for empirical research in software engineering, information systems, and software archeology. Through its unique uninterrupted coverage of a period of more than 40 years, it can inform work on software evolution and handovers across generations. With thousandfold increases in processing speed and million-fold increases in storage capacity during that time, the data set can also be used to study the co-evolution of software and hardware technology. The move of the software's development from research labs, to academia, and to the open source community can be used to study the effects of organizational culture on software development. The repository can also be used to study how notable individuals, such as Turing Award winners (Dennis Ritchie and Ken Thompson) and captains of the IT industry (Bill Joy and Eric Schmidt), actually programmed. Another phenomenon worthy of study concerns the longevity of code, either at the level of individual lines, or as complete systems that were at times distributed with Unix (Ingres, Lisp, Pascal, Ratfor, Snobol, TMG), as well as the factors that lead to code's survival or demise. Finally, because the data set stresses Git, the underlying software repository storage technology, to its limits, it can be used to drive engineering progress in the field of revision management systems.
|
||||
|
||||
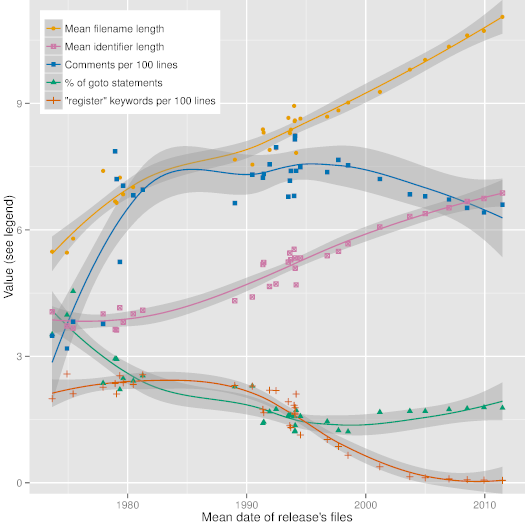
|
||||
|
||||
Figure 3: Code style evolution along Unix releases.
|
||||
|
||||
Figure [3][30], which depicts trend lines (obtained with R's local polynomial regression fitting function) of some interesting code metrics along 36 major releases of Unix, demonstrates the evolution of code style and programming language use over very long timescales. This evolution can be driven by software and hardware technology affordances and requirements, software construction theory, and even social forces. The dates in the Figure have been calculated as the average date of all files appearing in a given release. As can be seen in it, over the past 40 years the mean length of identifiers and file names has steadily increased from 4 and 6 characters to 7 and 11 characters, respectively. We can also see less steady increases in the number of comments and decreases in the use of the *goto* statement, as well as the virtual disappearance of the *register* type modifier.
|
||||
|
||||
### 5 Further Work ###
|
||||
|
||||
Many things can be done to increase the repository's faithfulness and usefulness. Given that the build process is shared as open source code, it is easy to contribute additions and fixes through GitHub pull requests. The most useful community contribution would be to increase the coverage of imported snapshot files that are attributed to a specific author. Currently, about 90 thousand files (out of a total of 160 thousand) are getting assigned an author through a default rule. Similarly, there are about 250 authors (primarily early FreeBSD ones) for which only the identifier is known. Both are listed in the build repository's unmatched directory, and contributions are welcomed. Furthermore, the BSD SCCS and the FreeBSD CVS commits that share the same author and time-stamp can be coalesced into a single Git commit. Support can be added for importing the SCCS file comment fields, in order to bring into the repository the corresponding metadata. Finally, and most importantly, more branches of open source systems can be added, such as NetBSD OpenBSD, DragonFlyBSD, and *illumos*. Ideally, current right holders of other important historical Unix releases, such as System III, System V, NeXTSTEP, and SunOS, will release their systems under a license that would allow their incorporation into this repository for study.
|
||||
|
||||
#### Acknowledgements ####
|
||||
|
||||
The author thanks the many individuals who contributed to the effort. Brian W. Kernighan, Doug McIlroy, and Arnold D. Robbins helped with Bell Labs login identifiers. Clem Cole, Era Eriksson, Mary Ann Horton, Kirk McKusick, Jeremy C. Reed, Ingo Schwarze, and Anatole Shaw helped with BSD login identifiers. The BSD SCCS import code is based on work by H. Merijn Brand and Jonathan Gray.
|
||||
|
||||
This research has been co-financed by the European Union (European Social Fund - ESF) and Greek national funds through the Operational Program "Education and Lifelong Learning" of the National Strategic Reference Framework (NSRF) - Research Funding Program: Thalis - Athens University of Economics and Business - Software Engineering Research Platform.
|
||||
|
||||
### References ###
|
||||
|
||||
[[1]][31]
|
||||
M. D. McIlroy, E. N. Pinson, and B. A. Tague, "UNIX time-sharing system: Foreword," *The Bell System Technical Journal*, vol. 57, no. 6, pp. 1899-1904, July-August 1978.
|
||||
|
||||
[[2]][32]
|
||||
D. M. Ritchie and K. Thompson, "The UNIX time-sharing system," *Bell System Technical Journal*, vol. 57, no. 6, pp. 1905-1929, July-August 1978.
|
||||
|
||||
[[3]][33]
|
||||
D. M. Ritchie, "The evolution of the UNIX time-sharing system," *AT&T Bell Laboratories Technical Journal*, vol. 63, no. 8, pp. 1577-1593, Oct. 1984.
|
||||
|
||||
[[4]][34]
|
||||
P. H. Salus, *A Quarter Century of UNIX*. Boston, MA: Addison-Wesley, 1994.
|
||||
|
||||
[[5]][35]
|
||||
E. S. Raymond, *The Art of Unix Programming*. Addison-Wesley, 2003.
|
||||
|
||||
[[6]][36]
|
||||
M. J. Rochkind, "The source code control system," *IEEE Transactions on Software Engineering*, vol. SE-1, no. 4, pp. 255-265, 1975.
|
||||
|
||||
----------
|
||||
|
||||
#### Footnotes: ####
|
||||
|
||||
[1][37] - [https://github.com/dspinellis/unix-history-repo][38]
|
||||
|
||||
[2][39] - Updates may add or modify material. To ensure replicability the repository's users are encouraged to fork it or archive it.
|
||||
|
||||
[3][40] - [http://www.tuhs.org/archive_sites.html][41]
|
||||
|
||||
[4][42] - [https://www.mckusick.com/csrg/][43]
|
||||
|
||||
[5][44] - [http://www.oldlinux.org/Linux.old/distributions/386BSD][45]
|
||||
|
||||
[6][46] - [http://ftp-archive.freebsd.org/pub/FreeBSD-Archive/old-releases/][47]
|
||||
|
||||
[7][48] - [https://github.com/freebsd/freebsd][49]
|
||||
|
||||
[8][50] - [http://ftp.netbsd.org/pub/NetBSD/NetBSD-current/src/share/misc/bsd-family-tree][51]
|
||||
|
||||
[9][52] - [https://github.com/dspinellis/unix-history-make][53]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#MPT78
|
||||
[2]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#RT78
|
||||
[3]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#Rit84
|
||||
[4]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#Sal94
|
||||
[5]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#Ray03
|
||||
[6]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#sec:data
|
||||
[7]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#sec:dev
|
||||
[8]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#sec:use
|
||||
[9]:https://github.com/dspinellis/unix-history-repo
|
||||
[10]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAB
|
||||
[11]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAC
|
||||
[12]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#fig:provenance
|
||||
[13]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#fig:branches
|
||||
[14]:http://www.tuhs.org/archive_sites.html
|
||||
[15]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAD
|
||||
[16]:https://www.mckusick.com/csrg/
|
||||
[17]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAE
|
||||
[18]:http://www.oldlinux.org/Linux.old/distributions/386BSD
|
||||
[19]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAF
|
||||
[20]:http://ftp-archive.freebsd.org/pub/FreeBSD-Archive/old-releases/
|
||||
[21]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAG
|
||||
[22]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#SCCS
|
||||
[23]:https://github.com/freebsd/freebsd
|
||||
[24]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAH
|
||||
[25]:http://ftp.netbsd.org/pub/NetBSD/NetBSD-current/src/share/misc/bsd-family-tree
|
||||
[26]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAI
|
||||
[27]:https://github.com/dspinellis/unix-history-make
|
||||
[28]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAJ
|
||||
[29]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#fig:branches
|
||||
[30]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#fig:metrics
|
||||
[31]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITEMPT78
|
||||
[32]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITERT78
|
||||
[33]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITERit84
|
||||
[34]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITESal94
|
||||
[35]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITERay03
|
||||
[36]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITESCCS
|
||||
[37]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAB
|
||||
[38]:https://github.com/dspinellis/unix-history-repo
|
||||
[39]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAC
|
||||
[40]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAD
|
||||
[41]:http://www.tuhs.org/archive_sites.html
|
||||
[42]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAE
|
||||
[43]:https://www.mckusick.com/csrg/
|
||||
[44]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAF
|
||||
[45]:http://www.oldlinux.org/Linux.old/distributions/386BSD
|
||||
[46]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAG
|
||||
[47]:http://ftp-archive.freebsd.org/pub/FreeBSD-Archive/old-releases/
|
||||
[48]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAH
|
||||
[49]:https://github.com/freebsd/freebsd
|
||||
[50]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAI
|
||||
[51]:http://ftp.netbsd.org/pub/NetBSD/NetBSD-current/src/share/misc/bsd-family-tree
|
||||
[52]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAJ
|
||||
[53]:https://github.com/dspinellis/unix-history-make
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by KnightJoker
|
||||
|
||||
Learn with Linux: Master Your Math with These Linux Apps
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -0,0 +1,41 @@
|
||||
基于Linux的Ubuntu开源操作系统在中国42%的Dell PC上运行
|
||||
================================================================================
|
||||
> Dell称它在中国市场出售的42%的PC运行的是Kylin,一款Canonical帮助创建的基于Ubuntu的操作系统。
|
||||
|
||||
让开源粉丝欢喜的是:Linux桌面年来了。或者说中国正在接近这个目标,[Dell][1]报告称超过40%售卖的PC机运行的是 [Canonical][3]帮助开发的[Ubuntu Linux][2]。
|
||||
|
||||
特别地,Dell称42%的中国电脑运行NeoKylin,一款中国本土倾力打造的用于替代[Microsoft][4] (MSFT) Windows的操作系统。它也简称麒麟,一款从2013年出来的基于Ubuntu的操作系统,也是这年开始Canonical公司与中国政府合作来建立一个专为中国市场Ubuntu变种。
|
||||
|
||||
2001年左右早期版本的麒麟,都是基于其他操作系统,包括FreeBSD,一个开放源码的区别于Linux的类Unix操作系统。
|
||||
|
||||
Ubuntu的麒麟的外观和感觉很像Ubuntu的现代版本。它拥有的[Unity][5]界面,并运行标准开源套件,以及专门的如Youker助理程序,它是一个图形化的前端,帮助用户管理的基本计算任务。但是麒麟的默认主题使得它看起来有点像Windows而不是Ubuntu。
|
||||
|
||||
鉴于桌面Linux PC市场在世界上大多数国家的相对停滞,戴尔的宣布是惊人的。并结合中国对现代windows的轻微[敌意][6],这个消息并不预示着微软在中国市场的前景。
|
||||
|
||||
在Dell公司[宣布][7]在华投资1.25亿美元很快之后一位行政官给华尔街杂志的评论中提到了Dell在中国市场上PC的销售。
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thevarguy.com/open-source-application-software-companies/091515/ubuntu-linux-based-open-source-os-runs-42-percent-dell-pc
|
||||
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[geekpi](https://github.com/geeekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://thevarguy.com/author/christopher-tozzi
|
||||
[1]:http://dell.com/
|
||||
[2]:http://ubuntu.com/
|
||||
[3]:http://canonical.com/
|
||||
[4]:http://microsoft.com/
|
||||
[5]:http://unity.ubuntu.com/
|
||||
[6]:http://www.wsj.com/articles/windows-8-faces-new-criticism-in-china-1401882772
|
||||
[7]:http://thevarguy.com/business-technology-solution-sales/091415/dell-125-million-directed-china-jobs-new-business-and-innovation
|
||||
@ -1,62 +0,0 @@
|
||||
在 Ubuntu 和 Elementary 上使用 NaSC 做简单数学运算
|
||||
================================================================================
|
||||

|
||||
|
||||
NaSC(Not a Soulver Clone,并非 Soulver 的克隆品)是为 Elementary 操作系统进行数学计算而设计的一款开源软件。类似于 Mac 上的 [Soulver][1]。
|
||||
|
||||
> 它能使你像平常那样进行计算。它允许你输入任何你想输入的,智能识别其中的数学部分并在右边面板打印出结果。然后你可以在后面的等式中使用这些结果,如果结果发生了改变,等式中使用的也会同样变化。
|
||||
|
||||
用 NaSC,你可以:
|
||||
|
||||
- 自己定义复杂的计算
|
||||
- 改变单位和值(英尺、米、厘米,美元、欧元等)
|
||||
- 了解行星的表面积
|
||||
- 解二次多项式
|
||||
- 以及其它
|
||||
|
||||
|
||||
|
||||
第一次启动时,NaSC 提供了一个关于现有功能的教程。以后你还可以通过点击标题栏上的帮助图标再次查看。
|
||||
|
||||
|
||||
|
||||
另外,这个软件还允许你保存文件以便以后继续工作。还可以在一定时间内通过粘贴板共用。
|
||||
|
||||
### 在 Ubuntu 或 Elementary OS Freya 上安装 NaSC: ###
|
||||
|
||||
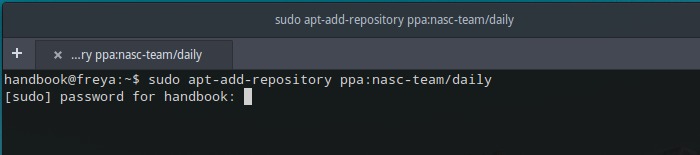
对于 Ubuntu 15.04,Ubuntu 15.10,Elementary OS Freya,从 Dash 或应用启动器中打开终端,逐条运行下面的命令:
|
||||
|
||||
1. 通过命令添加 [NaSC PPA][2]:
|
||||
|
||||
sudo apt-add-repository ppa:nasc-team/daily
|
||||
|
||||
|
||||
|
||||
2. 如果安装了 Synaptic 软件包管理器,点击 ‘Reload’ 后搜索并安装 ‘nasc’。
|
||||
|
||||
或者运行下面的命令更新系统缓存并安装软件:
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install nasc
|
||||
|
||||
3. **(可选)** 要卸载软件以及 NaSC,运行:
|
||||
|
||||
sudo apt-get remove nasc && sudo add-apt-repository -r ppa:nasc-team/daily
|
||||
|
||||
对于不想添加 PPA 的人,可以直接从[该网页][3]获取 .deb 安装包。、
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ubuntuhandbook.org/index.php/2015/09/make-math-simple-in-ubuntu-elementary-os-via-nasc/
|
||||
|
||||
作者:[Ji m][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ubuntuhandbook.org/index.php/about/
|
||||
[1]:http://www.acqualia.com/soulver/
|
||||
[2]:https://launchpad.net/~nasc-team/+archive/ubuntu/daily/
|
||||
[3]:http://ppa.launchpad.net/nasc-team/daily/ubuntu/pool/main/n/nasc/
|
||||
@ -0,0 +1,102 @@
|
||||
|
||||
在ubunt 14.04/15.04 上配置Node JS v4.0.0
|
||||
================================================================================
|
||||
大家好,Node.JS 4.0 发布了,主流的服务器端JS 平台已经将Node.js 和io.js 结合到一起。4.0 版就是两者结合的产物——共用一个代码库。这次最主要的变化是Node.js 封装了Google V8 4.5 JS 引擎,而这一版与当前的Chrome 一致。所以,紧跟V8 的版本号可以让Node.js 运行的更快、更安全,同时更好的利用ES6 的很多语言特性。
|
||||
|
||||

|
||||
|
||||
Node.js 4.0 的目标是为io.js 当前用户提供一个简单的升级途径,所以这次并没有太多重要的API 变更。剩下的内容会让我们看到如何轻松的在ubuntu server 上安装、配置Node.js。
|
||||
|
||||
### 基础系统安装 ###
|
||||
|
||||
Node 在Linux,Macintosh,Solaris 这几个系统上都可以完美的运行,同时linux 的发行版本当中Ubuntu 是最合适的。这也是我们为什么要尝试在ubuntu 15.04 上安装Node,当然了在14.04 上也可以使用相同的步骤安装。
|
||||
#### 1) 系统资源 ####
|
||||
|
||||
The basic system resources for Node depend upon the size of your infrastructure requirements. So, here in this tutorial we will setup Node with 1 GB RAM, 1 GHz Processor and 10 GB of available disk space with minimal installation packages installed on the server that is no web or database server packages are installed.
|
||||
|
||||
#### 2) 系统更新 ####
|
||||
|
||||
It always been recommended to keep your system upto date with latest patches and updates, so before we move to the installation on Node, let's login to your server with super user privileges and run update command.
|
||||
|
||||
# apt-get update
|
||||
|
||||
#### 3) 安装依赖 ####
|
||||
|
||||
Node JS only requires some basic system and software utilities to be present on your server, for its successful installation like 'make' 'gcc' and 'wget'. Let's run the below command to get them installed if they are not already present.
|
||||
|
||||
# apt-get install python gcc make g++ wget
|
||||
|
||||
### 下载最新版的Node JS v4.0.0 ###
|
||||
|
||||
使用链接 [Node JS Download Page][1] 下载源代码.
|
||||
|
||||

|
||||
|
||||
我们会复制最新源代码的链接,然后用`wget` 下载,命令如下:
|
||||
|
||||
# wget https://nodejs.org/download/rc/v4.0.0-rc.1/node-v4.0.0-rc.1.tar.gz
|
||||
|
||||
下载完成后使用命令`tar` 解压缩:
|
||||
|
||||
# tar -zxvf node-v4.0.0-rc.1.tar.gz
|
||||
|
||||

|
||||
|
||||
### 安装 Node JS v4.0.0 ###
|
||||
|
||||
现在可以开始使用下载好的源代码编译Nod JS。你需要在ubuntu serve 上开始编译前运行配置脚本来修改你要使用目录和配置参数。
|
||||
|
||||
root@ubuntu-15:~/node-v4.0.0-rc.1# ./configure
|
||||
|
||||

|
||||
|
||||
现在运行命令'make install' 编译安装Node JS:
|
||||
|
||||
root@ubuntu-15:~/node-v4.0.0-rc.1# make install
|
||||
|
||||
make 命令会花费几分钟完成编译,冷静的等待一会。
|
||||
|
||||
### 验证Node 安装 ###
|
||||
|
||||
一旦编译任务完成,我们就可以开始验证安装工作是否OK。我们运行下列命令来确认Node JS 的版本。
|
||||
|
||||
root@ubuntu-15:~# node -v
|
||||
v4.0.0-pre
|
||||
|
||||
在命令行下不带参数的运行`node` 就会进入REPL(Read-Eval-Print-Loop,读-执行-输出-循环)模式,它有一个简化版的emacs 行编辑器,通过它你可以交互式的运行JS和查看运行结果。
|
||||

|
||||
|
||||
### 写测试程序 ###
|
||||
|
||||
我们也可以写一个很简单的终端程序来测试安装是否成功,并且工作正常。要完成这一点,我们将会创建一个“tes.js” 文件,包含一下代码,操作如下:
|
||||
|
||||
root@ubuntu-15:~# vim test.js
|
||||
var util = require("util");
|
||||
console.log("Hello! This is a Node Test Program");
|
||||
:wq!
|
||||
|
||||
现在为了运行上面的程序,在命令行运行下面的命令。
|
||||
|
||||
root@ubuntu-15:~# node test.js
|
||||
|
||||

|
||||
|
||||
在一个成功安装了Node JS 的环境下运行上面的程序就会在屏幕上得到上图所示的输出,这个程序加载类 “util” 到变量“util” 中,接着用对象“util” 运行终端任务,console.log 这个命令作用类似C++ 里的cout
|
||||
|
||||
### 结论 ###
|
||||
|
||||
That’s it. Hope this gives you a good idea of Node.js going with Node.js on Ubuntu. If you are new to developing applications with Node.js. After all we can say that we can expect significant performance gains with Node JS Version 4.0.0.
|
||||
希望本文能够通过在ubuntu 上安装、运行Node.JS让你了解一下Node JS 的大概,如果你是刚刚开始使用Node.JS 开发应用程序。最后我们可以说我们能够通过Node JS v4.0.0 获取显著的性能。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/setup-node-js-4-0-ubuntu-14-04-15-04/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[译者ID](https://github.com/osk874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
[1]:https://nodejs.org/download/rc/v4.0.0-rc.1/
|
||||
@ -0,0 +1,70 @@
|
||||
Linux 问与答:如何在Linux 命令行下浏览天气预报
|
||||
================================================================================
|
||||
> **Q**: 我经常在Linux 桌面查看天气预报。然而,是否有一种在终端环境下,不通过桌面小插件或者网络查询天气预报的方法?
|
||||
|
||||
对于Linux 桌面用户来说,有很多办法获取天气预报,比如使用专门的天气应用,桌面小插件,或者面板小程序。但是如果你的工作环境实际与终端的,这里也有一些在命令行下获取天气的手段。
|
||||
|
||||
其中有一个就是 [wego][1],**一个终端下的小巧程序**。使用基于ncurses 的接口,这个命令行程序允许你查看当前的天气情况和之后的预报。它也会通过一个天气预报的API 收集接下来5 天的天气预报。
|
||||
|
||||
### 在Linux 下安装Wego ###
|
||||
安装wego 相当简单。wego 是用Go 编写的,引起第一个步骤就是安装[Go 语言][2]。然后再安装wego。
|
||||
|
||||
$ go get github.com/schachmat/wego
|
||||
|
||||
wego 会被安装到$GOPATH/bin,所以要将$GOPATH/bin 添加到$PATH 环境变量。
|
||||
|
||||
$ echo 'export PATH="$PATH:$GOPATH/bin"' >> ~/.bashrc
|
||||
$ source ~/.bashrc
|
||||
|
||||
现在就可与直接从命令行启动wego 了。
|
||||
|
||||
$ wego
|
||||
|
||||
第一次运行weg 会生成一个配置文件(~/.wegorc),你需要指定一个天气API key。
|
||||
你可以从[worldweatheronline.com][3] 获取一个免费的API key。免费注册和使用。你只需要提供一个有效的邮箱地址。
|
||||
|
||||

|
||||
|
||||
你的 .wegorc 配置文件看起来会这样:
|
||||
|
||||

|
||||
|
||||
除了API key,你还可以把你想要查询天气的地方、使用的城市/国家名称、语言配置在~/.wegorc 中。
|
||||
注意,这个天气API 的使用有限制:每秒最多5 次查询,每天最多250 次查询。
|
||||
当你重新执行wego 命令,你将会看到最新的天气预报(当然是你的指定地方),如下显示。
|
||||
|
||||

|
||||
|
||||
显示出来的天气信息包括:(1)温度,(2)风速和风向,(3)可视距离,(4)降水量和降水概率
|
||||
默认情况下会显示3 天的天气预报。如果要进行修改,可以通过参数改变天气范围(最多5天),比如要查看5 天的天气预报:
|
||||
|
||||
$ wego 5
|
||||
|
||||
如果你想检查另一个地方的天气,只需要提供城市名即可:
|
||||
|
||||
$ wego Seattle
|
||||
|
||||
### 问题解决 ###
|
||||
1. 可能会遇到下面的错误:
|
||||
|
||||
user: Current not implemented on linux/amd64
|
||||
|
||||
当你在一个不支持原生Go 编译器的环境下运行wego 时就会出现这个错误。在这种情况下你只需要使用gccgo ——一个Go 的编译器前端来编译程序即可。这一步可以通过下面的命令完成。
|
||||
|
||||
$ sudo yum install gcc-go
|
||||
$ go get -compiler=gccgo github.com/schachmat/wego
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/weather-forecasts-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:https://github.com/schachmat/wego
|
||||
[2]:http://ask.xmodulo.com/install-go-language-linux.html
|
||||
[3]:https://developer.worldweatheronline.com/auth/register
|
||||
@ -0,0 +1,48 @@
|
||||
开启Ubuntu系统自动升级
|
||||
================================================================================
|
||||
在学习如何开启Ubuntu系统自动升级之前,先解释下为什么需要自动升级。
|
||||
|
||||
默认情况下,ubuntu每天一次检查更新。但是一周只会弹出一次软件升级提醒,除非当有安全性升级时,才会立即弹出。所以,如果你已经使用Ubuntu一段时间,你肯定很熟悉这个画面:
|
||||
|
||||

|
||||
|
||||
但是做为一个正常桌面用户,根本不会去关心有什么更新细节。而且这个提醒完全就是浪费时间,你肯定信任Ubuntu提供的升级补丁,对不对?所以,大部分情况你肯定会选择“现在安装”,对不对?
|
||||
|
||||
所以,你需要做的就只是点一下升级按钮。现在,明白为什么需要自动系统升级了吧?开启自动系统升级意味着所有最新的更新都会自动下载并安装,并且没有请求确认。是不是很方便?
|
||||
|
||||
### 开启Ubuntu自动升级 ###
|
||||
|
||||
演示使用Ubuntu15.04,Ubuntu 14.04步骤类似。
|
||||
|
||||
打开Unity Dash ,找到软件&更新:
|
||||
|
||||

|
||||
|
||||
打开软件资源设置,切换到升级标签:
|
||||
|
||||

|
||||
|
||||
可以发现,默认设置就是每日检查并立即提醒安全升级。
|
||||
|
||||

|
||||
|
||||
改变 ‘当有安全升级’和‘当有其他升级’的选项为:下载并自动安装。
|
||||
|
||||

|
||||
|
||||
关闭对话框完成设定。这样每次Ubuntu检查更新后就会自动升级。事实上,这篇文章十分类似[改变Ubuntu升级提醒频率][1]。
|
||||
|
||||
你喜欢自动升级还是手动安装升级呢?欢迎评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/automatic-system-updates-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[Vic020/VicYu](http://vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/ubuntu-notify-updates-frequently/
|
||||
Loading…
Reference in New Issue
Block a user