mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
commit
fedcac7620
@ -0,0 +1,245 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10625-1.html)
|
||||
[#]: subject: (Advanced Techniques for Reducing Emacs Startup Time)
|
||||
[#]: via: (https://blog.d46.us/advanced-emacs-startup/)
|
||||
[#]: author: (Joe Schafer https://blog.d46.us/)
|
||||
|
||||
降低 Emacs 启动时间的高级技术
|
||||
======
|
||||
|
||||
> 《[Emacs Start Up Profiler][1]》 的作者教你六项减少 Emacs 启动时间的技术。
|
||||
|
||||
简而言之:做下面几个步骤:
|
||||
|
||||
1. 使用 Esup 进行性能检测。
|
||||
2. 调整垃圾回收的阀值。
|
||||
3. 使用 use-package 来自动(延迟)加载所有东西。
|
||||
4. 不要使用会引起立即加载的辅助函数。
|
||||
5. 参考我的 [配置][2]。
|
||||
|
||||
### 从 .emacs.d 的失败到现在
|
||||
|
||||
我最近宣布了 .emacs.d 的第三次失败,并完成了第四次 Emacs 配置的迭代。演化过程为:
|
||||
|
||||
1. 拷贝并粘贴 elisp 片段到 `~/.emacs` 中,希望它能工作。
|
||||
2. 借助 `el-get` 来以更结构化的方式来管理依赖关系。
|
||||
3. 放弃自己从零配置,以 Spacemacs 为基础。
|
||||
4. 厌倦了 Spacemacs 的复杂性,基于 `use-package` 重写配置。
|
||||
|
||||
本文汇聚了三次重写和创建 《[Emacs Start Up Profiler][1]》过程中的技巧。非常感谢 Spacemacs、use-package 等背后的团队。没有这些无私的志愿者,这项任务将会困难得多。
|
||||
|
||||
### 不过守护进程模式又如何呢
|
||||
|
||||
在我们开始之前,让我反驳一下优化 Emacs 时的常见观念:“Emacs 旨在作为守护进程来运行的,因此你只需要运行一次而已。”
|
||||
|
||||
这个观点很好,只不过:
|
||||
|
||||
- 速度总是越快越好。
|
||||
- 配置 Emacs 时,可能会有不得不通过重启 Emacs 的情况。例如,你可能为 `post-command-hook` 添加了一个运行缓慢的 `lambda` 函数,很难删掉它。
|
||||
- 重启 Emacs 能帮你验证不同会话之间是否还能保留配置。
|
||||
|
||||
### 1、估算当前以及最佳的启动时间
|
||||
|
||||
第一步是测量当前的启动时间。最简单的方法就是在启动时显示后续步骤进度的信息。
|
||||
|
||||
```
|
||||
;; Use a hook so the message doesn't get clobbered by other messages.
|
||||
(add-hook 'emacs-startup-hook
|
||||
(lambda ()
|
||||
(message "Emacs ready in %s with %d garbage collections."
|
||||
(format "%.2f seconds"
|
||||
(float-time
|
||||
(time-subtract after-init-time before-init-time)))
|
||||
gcs-done)))
|
||||
```
|
||||
|
||||
第二步、测量最佳的启动速度,以便了解可能的情况。我的是 0.3 秒。
|
||||
|
||||
```
|
||||
# -q ignores personal Emacs files but loads the site files.
|
||||
emacs -q --eval='(message "%s" (emacs-init-time))'
|
||||
|
||||
;; For macOS users:
|
||||
open -n /Applications/Emacs.app --args -q --eval='(message "%s" (emacs-init-time))'
|
||||
```
|
||||
|
||||
### 2、检测 Emacs 启动指标对你大有帮助
|
||||
|
||||
《[Emacs StartUp Profiler][1]》(ESUP)将会给你顶层语句执行的详细指标。
|
||||
|
||||
![esup.png][3]
|
||||
|
||||
*图 1: Emacs Start Up Profiler 截图*
|
||||
|
||||
> 警告:Spacemacs 用户需要注意,ESUP 目前与 Spacemacs 的 init.el 文件有冲突。遵照 <https://github.com/jschaf/esup/issues/48> 上说的进行升级。
|
||||
|
||||
### 3、调高启动时垃圾回收的阀值
|
||||
|
||||
这为我节省了 **0.3 秒**。
|
||||
|
||||
Emacs 默认值是 760kB,这在现代机器看来极其保守。真正的诀窍在于初始化完成后再把它降到合理的水平。这为我节省了 0.3 秒。
|
||||
|
||||
```
|
||||
;; Make startup faster by reducing the frequency of garbage
|
||||
;; collection. The default is 800 kilobytes. Measured in bytes.
|
||||
(setq gc-cons-threshold (* 50 1000 1000))
|
||||
|
||||
;; The rest of the init file.
|
||||
|
||||
;; Make gc pauses faster by decreasing the threshold.
|
||||
(setq gc-cons-threshold (* 2 1000 1000))
|
||||
```
|
||||
|
||||
*~/.emacs.d/init.el*
|
||||
|
||||
### 4、不要 require 任何东西,而是使用 use-package 来自动加载
|
||||
|
||||
让 Emacs 变坏的最好方法就是减少要做的事情。`require` 会立即加载源文件,但是很少会出现需要在启动阶段就立即需要这些功能的。
|
||||
|
||||
在 [use-package][4] 中你只需要声明好需要哪个包中的哪个功能,`use-package` 就会帮你完成正确的事情。它看起来是这样的:
|
||||
|
||||
```
|
||||
(use-package evil-lisp-state ; the Melpa package name
|
||||
|
||||
:defer t ; autoload this package
|
||||
|
||||
:init ; Code to run immediately.
|
||||
(setq evil-lisp-state-global nil)
|
||||
|
||||
:config ; Code to run after the package is loaded.
|
||||
(abn/define-leader-keys "k" evil-lisp-state-map))
|
||||
```
|
||||
|
||||
可以通过查看 `features` 变量来查看 Emacs 现在加载了那些包。想要更好看的输出可以使用 [lpkg explorer][5] 或者我在 [abn-funcs-benchmark.el][6] 中的变体。输出看起来类似这样的:
|
||||
|
||||
```
|
||||
479 features currently loaded
|
||||
- abn-funcs-benchmark: /Users/jschaf/.dotfiles/emacs/funcs/abn-funcs-benchmark.el
|
||||
- evil-surround: /Users/jschaf/.emacs.d/elpa/evil-surround-20170910.1952/evil-surround.elc
|
||||
- misearch: /Applications/Emacs.app/Contents/Resources/lisp/misearch.elc
|
||||
- multi-isearch: nil
|
||||
- <many more>
|
||||
```
|
||||
|
||||
### 5、不要使用辅助函数来设置模式
|
||||
|
||||
通常,Emacs 包会建议通过运行一个辅助函数来设置键绑定。下面是一些例子:
|
||||
|
||||
* `(evil-escape-mode)`
|
||||
* `(windmove-default-keybindings) ; 设置快捷键。`
|
||||
* `(yas-global-mode 1) ; 复杂的片段配置。`
|
||||
|
||||
可以通过 `use-package` 来对此进行重构以提高启动速度。这些辅助函数只会让你立即加载那些尚用不到的包。
|
||||
|
||||
下面这个例子告诉你如何自动加载 `evil-escape-mode`。
|
||||
|
||||
```
|
||||
;; The definition of evil-escape-mode.
|
||||
(define-minor-mode evil-escape-mode
|
||||
(if evil-escape-mode
|
||||
(add-hook 'pre-command-hook 'evil-escape-pre-command-hook)
|
||||
(remove-hook 'pre-command-hook 'evil-escape-pre-command-hook)))
|
||||
|
||||
;; Before:
|
||||
(evil-escape-mode)
|
||||
|
||||
;; After:
|
||||
(use-package evil-escape
|
||||
:defer t
|
||||
;; Only needed for functions without an autoload comment (;;;###autoload).
|
||||
:commands (evil-escape-pre-command-hook)
|
||||
|
||||
;; Adding to a hook won't load the function until we invoke it.
|
||||
;; With pre-command-hook, that means the first command we run will
|
||||
;; load evil-escape.
|
||||
:init (add-hook 'pre-command-hook 'evil-escape-pre-command-hook))
|
||||
```
|
||||
|
||||
下面来看一个关于 `org-babel` 的例子,这个例子更为复杂。我们通常的配置时这样的:
|
||||
|
||||
```
|
||||
(org-babel-do-load-languages
|
||||
'org-babel-load-languages
|
||||
'((shell . t)
|
||||
(emacs-lisp . nil)))
|
||||
```
|
||||
|
||||
这不是个好的配置,因为 `org-babel-do-load-languages` 定义在 `org.el` 中,而该文件有超过 2 万 4 千行的代码,需要花 0.2 秒来加载。通过查看源代码可以看到 `org-babel-do-load-languages` 仅仅只是加载 `ob-<lang>` 包而已,像这样:
|
||||
|
||||
```
|
||||
;; From org.el in the org-babel-do-load-languages function.
|
||||
(require (intern (concat "ob-" lang)))
|
||||
```
|
||||
|
||||
而在 `ob-<lang>.el` 文件中,我们只关心其中的两个方法 `org-babel-execute:<lang>` 和 `org-babel-expand-body:<lang>`。我们可以延时加载 org-babel 相关功能而无需调用 `org-babel-do-load-languages`,像这样:
|
||||
|
||||
```
|
||||
;; Avoid `org-babel-do-load-languages' since it does an eager require.
|
||||
(use-package ob-python
|
||||
:defer t
|
||||
:ensure org-plus-contrib
|
||||
:commands (org-babel-execute:python))
|
||||
|
||||
(use-package ob-shell
|
||||
:defer t
|
||||
:ensure org-plus-contrib
|
||||
:commands
|
||||
(org-babel-execute:sh
|
||||
org-babel-expand-body:sh
|
||||
|
||||
org-babel-execute:bash
|
||||
org-babel-expand-body:bash))
|
||||
```
|
||||
|
||||
### 6、使用惰性定时器来推迟加载非立即需要的包
|
||||
|
||||
我推迟加载了 9 个包,这帮我节省了 **0.4 秒**。
|
||||
|
||||
有些包特别有用,你希望可以很快就能使用它们,但是它们本身在 Emacs 启动过程中又不是必须的。这些软件包包括:
|
||||
|
||||
- `recentf`:保存最近的编辑过的那些文件。
|
||||
- `saveplace`:保存访问过文件的光标位置。
|
||||
- `server`:开启 Emacs 守护进程。
|
||||
- `autorevert`:自动重载被修改过的文件。
|
||||
- `paren`:高亮匹配的括号。
|
||||
- `projectile`:项目管理工具。
|
||||
- `whitespace`:高亮行尾的空格。
|
||||
|
||||
不要 `require` 这些软件包,**而是等到空闲 N 秒后再加载它们**。我在 1 秒后加载那些比较重要的包,在 2 秒后加载其他所有的包。
|
||||
|
||||
```
|
||||
(use-package recentf
|
||||
;; Loads after 1 second of idle time.
|
||||
:defer 1)
|
||||
|
||||
(use-package uniquify
|
||||
;; Less important than recentf.
|
||||
:defer 2)
|
||||
```
|
||||
|
||||
### 不值得的优化
|
||||
|
||||
不要费力把你的 Emacs 配置文件编译成字节码了。这只节省了大约 0.05 秒。把配置文件编译成字节码还可能导致源文件与编译后的文件不一致从而难以重现错误进行调试。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.d46.us/advanced-emacs-startup/
|
||||
|
||||
作者:[Joe Schafer][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://blog.d46.us/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/jschaf/esup
|
||||
[2]: https://github.com/jschaf/dotfiles/blob/master/emacs/start.el
|
||||
[3]: https://blog.d46.us/images/esup.png
|
||||
[4]: https://github.com/jwiegley/use-package
|
||||
[5]: https://gist.github.com/RockyRoad29/bd4ca6fdb41196a71662986f809e2b1c
|
||||
[6]: https://github.com/jschaf/dotfiles/blob/master/emacs/funcs/abn-funcs-benchmark.el
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( pityonline )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: translator: (pityonline)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10626-1.html)
|
||||
[#]: subject: (How To Remove/Delete The Empty Lines In A File In Linux)
|
||||
[#]: via: (https://www.2daygeek.com/remove-delete-empty-lines-in-a-file-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
@ -10,26 +10,22 @@
|
||||
在 Linux 中如何删除文件中的空行
|
||||
======
|
||||
|
||||
有时你可能需要在 Linux 中删除某个文件中的空行。
|
||||
有时你可能需要在 Linux 中删除某个文件中的空行。如果是的,你可以使用下面方法中的其中一个。有很多方法可以做到,但我在这里只是列举一些简单的方法。
|
||||
|
||||
如果是的,你可以使用下面方法中的其中一个。
|
||||
你可能已经知道 `grep`、`awk` 和 `sed` 命令是专门用来处理文本数据的工具。
|
||||
|
||||
有很多方法可以做到,但我在这里只是列举一些简单的方法。
|
||||
|
||||
你可能已经知道 `grep`,`awk` 和 `sed` 命令是专门用来处理文本数据的工具。
|
||||
|
||||
如果你想了解更多关于这些命令的文章,请访问这几个 URL。**[在 Linux 中创建指定大小的文件的几种方法][1]**,**[在 Linux 中创建一个文件的几种方法][2]** 以及 **[在 Linux 中删除一个文件中的匹配的字符串][3]**。
|
||||
如果你想了解更多关于这些命令的文章,请访问这几个 URL:[在 Linux 中创建指定大小的文件的几种方法][1],[在 Linux 中创建一个文件的几种方法][2] 以及 [在 Linux 中删除一个文件中的匹配的字符串][3]。
|
||||
|
||||
这些属于高级命令,它们可用在大多数 shell 脚本中执行所需的操作。
|
||||
|
||||
下列 5 种方法可以做到。
|
||||
|
||||
* **`sed:`** 过滤和替换文本的流编辑器。
|
||||
* **`grep:`** 输出匹配到的行。
|
||||
* **`cat:`** 合并文件并打印内容到标准输出。
|
||||
* **`tr:`** 替换或删除字符。
|
||||
* **`awk:`** awk 工具用于执行 awk 语言编写的程序,专门用于文本处理。
|
||||
* **`perl:`** Perl 是一种用于处理文本的编程语言。
|
||||
* `sed`:过滤和替换文本的流编辑器。
|
||||
* `grep`:输出匹配到的行。
|
||||
* `cat`:合并文件并打印内容到标准输出。
|
||||
* `tr`:替换或删除字符。
|
||||
* `awk`:awk 工具用于执行 awk 语言编写的程序,专门用于文本处理。
|
||||
* `perl`:Perl 是一种用于处理文本的编程语言。
|
||||
|
||||
我创建了一个 `2daygeek.txt` 文件来测试这些命令。下面是文件的内容。
|
||||
|
||||
@ -50,7 +46,7 @@ Her names are Tanisha & Renusha.
|
||||
|
||||
### 使用 sed 命令
|
||||
|
||||
sed 是一个<ruby>流编辑器<rt>stream editor</rt></ruby>。流编辑器是用来编辑输入流(文件或管道)中的文本的。
|
||||
`sed` 是一个<ruby>流编辑器<rt>stream editor</rt></ruby>。流编辑器是用来编辑输入流(文件或管道)中的文本的。
|
||||
|
||||
```
|
||||
$ sed '/^$/d' 2daygeek.txt
|
||||
@ -63,12 +59,12 @@ Her names are Tanisha & Renusha.
|
||||
|
||||
以下是命令展开的细节:
|
||||
|
||||
* **`sed:`** 该命令本身。
|
||||
* **`//:`** 标记匹配范围。
|
||||
* **`^:`** 匹配字符串开头。
|
||||
* **`$:`** 匹配字符串结尾。
|
||||
* **`d:`** 删除匹配的字符串。
|
||||
* **`2daygeek.txt:`** 源文件名。
|
||||
* `sed`: 该命令本身。
|
||||
* `//`: 标记匹配范围。
|
||||
* `^`: 匹配字符串开头。
|
||||
* `$`: 匹配字符串结尾。
|
||||
* `d`: 删除匹配的字符串。
|
||||
* `2daygeek.txt`: 源文件名。
|
||||
|
||||
### 使用 grep 命令
|
||||
|
||||
@ -87,21 +83,20 @@ He got two GIRL babes.
|
||||
Her names are Tanisha & Renusha.
|
||||
```
|
||||
|
||||
Details are follow:
|
||||
以下是命令展开的细节:
|
||||
|
||||
* **`grep:`** 该命令本身。
|
||||
* **`.:`** 替换任意字符。
|
||||
* **`^:`** 匹配字符串开头。
|
||||
* **`$:`** 匹配字符串结尾。
|
||||
* **`E:`** 使用扩展正则匹配模式。
|
||||
* **`e:`** 使用常规正则匹配模式。
|
||||
* **`v:`** 反向匹配。
|
||||
* **`2daygeek.txt:`** 源文件名。
|
||||
* `grep`: 该命令本身。
|
||||
* `.`: 替换任意字符。
|
||||
* `^`: 匹配字符串开头。
|
||||
* `$`: 匹配字符串结尾。
|
||||
* `E`: 使用扩展正则匹配模式。
|
||||
* `e`: 使用常规正则匹配模式。
|
||||
* `v`: 反向匹配。
|
||||
* `2daygeek.txt`: 源文件名。
|
||||
|
||||
### 使用 awk 命令
|
||||
|
||||
`awk` 可以执行使用 awk 语言写的脚本,大多是专用于处理文本的。awk 脚本是一系列 awk 命令和正则的组合。
|
||||
`awk` 可以执行使用 awk 语言写的脚本,大多是专用于处理文本的。awk 脚本是一系列 `awk` 命令和正则的组合。
|
||||
|
||||
```
|
||||
$ awk NF 2daygeek.txt
|
||||
@ -118,21 +113,21 @@ Her names are Tanisha & Renusha.
|
||||
|
||||
以下是命令展开的细节:
|
||||
|
||||
* **`awk:`** 该命令本身。
|
||||
* **`//:`** 标记匹配范围。
|
||||
* **`^:`** 匹配字符串开头。
|
||||
* **`$:`** 匹配字符串结尾。
|
||||
* **`.:`** 匹配任意字符。
|
||||
* **`!:`** 删除匹配的字符串。
|
||||
* **`2daygeek.txt:`** 源文件名。
|
||||
* `awk`: 该命令本身。
|
||||
* `//`: 标记匹配范围。
|
||||
* `^`: 匹配字符串开头。
|
||||
* `$`: 匹配字符串结尾。
|
||||
* `.`: 匹配任意字符。
|
||||
* `!`: 删除匹配的字符串。
|
||||
* `2daygeek.txt`: 源文件名。
|
||||
|
||||
### 使用 cat 和 tr 命令 组合
|
||||
|
||||
`cat` 是<ruby>串联(拼接)<rt>concatenate</rt></ruby>的简写。经常用于在 Linux 中读取一个文件的内容。
|
||||
|
||||
cat 是在类 Unix 系统中使用频率最高的命令之一。它提供了常用的三个处理文本文件的功能:显示文件内容,将多个文件拼接成一个,以及创建一个新文件。
|
||||
`cat` 是在类 Unix 系统中使用频率最高的命令之一。它提供了常用的三个处理文本文件的功能:显示文件内容、将多个文件拼接成一个,以及创建一个新文件。
|
||||
|
||||
tr 可以将标准输入中的字符转换,压缩或删除,然后重定向到标准输出。
|
||||
`tr` 可以将标准输入中的字符转换,压缩或删除,然后重定向到标准输出。
|
||||
|
||||
```
|
||||
$ cat 2daygeek.txt | tr -s '\n'
|
||||
@ -145,12 +140,12 @@ Her names are Tanisha & Renusha.
|
||||
|
||||
以下是命令展开的细节:
|
||||
|
||||
* **`cat:`** cat 命令本身。
|
||||
* **`tr:`** tr 命令本身。
|
||||
* **`|:`** 管道符号。它可以将前面的命令的标准输出作为下一个命令的标准输入。
|
||||
* **`s:`** 替换标数据集中任意多个重复字符为一个。
|
||||
* **`\n:`** 添加一个新的换行。
|
||||
* **`2daygeek.txt:`** 源文件名。
|
||||
* `cat`: cat 命令本身。
|
||||
* `tr`: tr 命令本身。
|
||||
* `|`: 管道符号。它可以将前面的命令的标准输出作为下一个命令的标准输入。
|
||||
* `s`: 替换标数据集中任意多个重复字符为一个。
|
||||
* `\n`: 添加一个新的换行。
|
||||
* `2daygeek.txt`: 源文件名。
|
||||
|
||||
### 使用 perl 命令
|
||||
|
||||
@ -167,14 +162,14 @@ Her names are Tanisha & Renusha.
|
||||
|
||||
以下是命令展开的细节:
|
||||
|
||||
* **`perl:`** perl 命令。
|
||||
* **`n:`** 逐行读入数据。
|
||||
* **`e:`** 执行某个命令。
|
||||
* **`print:`** 打印信息。
|
||||
* **`if:`** if 条件分支。
|
||||
* **`//:`** 标记匹配范围。
|
||||
* **`\S:`** 匹配任意非空白字符。
|
||||
* **`2daygeek.txt:`** 源文件名。
|
||||
* `perl`: perl 命令。
|
||||
* `n`: 逐行读入数据。
|
||||
* `e`: 执行某个命令。
|
||||
* `print`: 打印信息。
|
||||
* `if`: if 条件分支。
|
||||
* `//`: 标记匹配范围。
|
||||
* `\S`: 匹配任意非空白字符。
|
||||
* `2daygeek.txt`: 源文件名。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -183,7 +178,7 @@ via: https://www.2daygeek.com/remove-delete-empty-lines-in-a-file-in-linux/
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[pityonline](https://github.com/pityonline)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,212 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (GraveAccent)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (JSON vs XML vs TOML vs CSON vs YAML)
|
||||
[#]: via: (https://www.zionandzion.com/json-vs-xml-vs-toml-vs-cson-vs-yaml/)
|
||||
[#]: author: (Tim Anderson https://www.zionandzion.com)
|
||||
|
||||
JSON vs XML vs TOML vs CSON vs YAML
|
||||
======
|
||||
|
||||
|
||||
### A Super Serious Segment About Sets, Subsets, and Supersets of Sample Serialization
|
||||
|
||||
I’m a developer. I read code. I write code. I write code that writes code. I write code that writes code for other code to read. It’s all very mumbo-jumbo, but beautiful in its own way. However, that last bit, writing code that writes code for other code to read, can get more convoluted than this paragraph—quickly. There are a lot of ways to do it. One not-so-convoluted way and a favorite among the developer community is through data serialization. For those who aren’t savvy on the super buzzword I just threw at you, data serialization is the process of taking some information from one system, churning it into a format that other systems can read, and then passing it along to those other systems.
|
||||
|
||||
While there are enough [data serialization formats][1] out there to bury the Burj Khalifa, they all mostly fall into two categories:
|
||||
|
||||
* simplicity for humans to read and write,
|
||||
* and simplicity for machines to read and write.
|
||||
|
||||
|
||||
|
||||
It’s difficult to have both as we humans enjoy loosely typed, flexible formatting standards that allow us to be more expressive, whereas machines tend to enjoy being told exactly what everything is without doubt or lack of detail, and consider “strict specifications” to be their favorite flavor of Ben & Jerry’s.
|
||||
|
||||
Since I’m a web developer and we’re an agency who creates websites, we’ll stick to those special formats that web systems can understand, or be made to understand without much effort, and that are particularly useful for human readability: XML, JSON, TOML, CSON, and YAML. Each has benefits, cons, and appropriate use cases.
|
||||
|
||||
### Facts First
|
||||
|
||||
Back in the early days of the interwebs, [some really smart fellows][2] decided to put together a standard language which every system could read and creatively named it Standard Generalized Markup Language, or SGML for short. SGML was incredibly flexible and well defined by its publishers. It became the father of languages such as XML, SVG, and HTML. All three fall under the SGML specification, but are subsets with stricter rules and shorter flexibility.
|
||||
|
||||
Eventually, people started seeing a great deal of benefit in having very small, concise, easy to read, and easy to generate data that could be shared programmatically between systems with very little overhead. Around that time, JSON was born and was able to fulfil all requirements. In turn, other languages began popping up to deal with more specialized cases such as CSON, TOML, and YAML.
|
||||
|
||||
### XML: Ixnayed
|
||||
|
||||
Originally, the XML language was amazingly flexible and easy to write, but its drawback was that it was verbose, difficult for humans to read, really difficult for computers to read, and had a lot of syntax that wasn’t entirely necessary to communicate information.
|
||||
|
||||
Today, it’s all but dead for data serialization purposes on the web. Unless you’re writing HTML or SVG, both siblings to XML, you probably aren’t going to see XML in too many other places. Some outdated systems still use it today, but using it to pass data around tends to be overkill for the web.
|
||||
|
||||
I can already hear the XML greybeards beginning to scribble upon their stone tablets as to why XML is ah-may-zing, so I’ll provide a small addendum: XML can be easy to read and write by systems and people. However, it is really, and I mean ridiculously, hard to create a system that can read it to specification. Here’s a simple, beautiful example of XML:
|
||||
|
||||
```
|
||||
<book id="bk101">
|
||||
<author>Gambardella, Matthew</author>
|
||||
<title>XML Developer's Guide</title>
|
||||
<genre>Computer</genre>
|
||||
<price>44.95</price>
|
||||
<publish_date>2000-10-01</publish_date>
|
||||
<description>An in-depth look at creating applications
|
||||
with XML.</description>
|
||||
</book>
|
||||
```
|
||||
|
||||
Wonderful. Easy to read, reason about, write, and code a system that can read and write. But consider this example:
|
||||
|
||||
```
|
||||
<!DOCTYPE r [ <!ENTITY y "a]>b"> ]>
|
||||
<r>
|
||||
<a b="&y;>" />
|
||||
<![CDATA[[a>b <a>b <a]]>
|
||||
<?x <a> <!-- <b> ?> c --> d
|
||||
</r>
|
||||
```
|
||||
|
||||
The above is 100% valid XML. Impossible to read, understand, or reason about. Writing code that can consume and understand this would cost at least 36 heads of hair and 248 pounds of coffee grounds. We don’t have that kind of time nor coffee, and most of us greybeards are balding nowadays. So let’s let it live only in our memory alongside [css hacks][3], [internet explorer 6][4], and [vacuum tubes][5].
|
||||
|
||||
### JSON: Juxtaposition Jamboree
|
||||
|
||||
Okay, we’re all in agreement. XML = bad. So, what’s a good alternative? JavaScript Object Notation, or JSON for short. JSON (read like the name Jason) was invented by Brendan Eich, and made popular by the great and powerful Douglas Crockford, the [Dutch Uncle of JavaScript][6]. It’s used just about everywhere nowadays. The format is easy to write by both human and machine, fairly easy to [parse][7] with strict rules in the specification, and flexible—allowing deep nesting of data, all of the primitive data types, and interpretation of collections as either arrays or objects. JSON became the de facto standard for transferring data from one system to another. Nearly every language out there has built-in functionality for reading and writing it.
|
||||
|
||||
JSON syntax is straightforward. Square brackets denote arrays, curly braces denote records, and two values separated by semicolons denote properties (or ‘keys’) on the left, and values on the right. All keys must be wrapped in double quotes:
|
||||
|
||||
```
|
||||
{
|
||||
"books": [
|
||||
{
|
||||
"id": "bk102",
|
||||
"author": "Crockford, Douglas",
|
||||
"title": "JavaScript: The Good Parts",
|
||||
"genre": "Computer",
|
||||
"price": 29.99,
|
||||
"publish_date": "2008-05-01",
|
||||
"description": "Unearthing the Excellence in JavaScript"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
This should make complete sense to you. It’s nice and concise, and has stripped much of the extra nonsense from XML to convey the same amount of information. JSON is king right now, and the rest of this article will go into other language formats that are nothing more than JSON boiled down in an attempt to be either more concise or more readable by humans, but follow very similar structure.
|
||||
|
||||
### TOML: Truncated to Total Altruism
|
||||
|
||||
TOML (Tom’s Obvious, Minimal Language) allows for defining deeply-nested data structures rather quickly and succinctly. The name-in-the-name refers to the inventor, [Tom Preston-Werner][8], an inventor and software developer who’s active in our industry. The syntax is a bit awkward when compared to JSON, and is more akin to an [ini file][9]. It’s not a bad syntax, but could take some getting used to:
|
||||
|
||||
```
|
||||
[[books]]
|
||||
id = 'bk101'
|
||||
author = 'Crockford, Douglas'
|
||||
title = 'JavaScript: The Good Parts'
|
||||
genre = 'Computer'
|
||||
price = 29.99
|
||||
publish_date = 2008-05-01T00:00:00+00:00
|
||||
description = 'Unearthing the Excellence in JavaScript'
|
||||
```
|
||||
|
||||
A couple great features have been integrated into TOML, such as multiline strings, auto-escaping of reserved characters, datatypes such as dates, time, integers, floats, scientific notation, and “table expansion”. That last bit is special, and is what makes TOML so concise:
|
||||
|
||||
```
|
||||
[a.b.c]
|
||||
d = 'Hello'
|
||||
e = 'World'
|
||||
```
|
||||
|
||||
The above expands to the following:
|
||||
|
||||
```
|
||||
{
|
||||
"a": {
|
||||
"b": {
|
||||
"c": {
|
||||
"d": "Hello"
|
||||
"e": "World"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
You can definitely see how much you can save in both time and file length using TOML. There are few systems which use it or something very similar for configuration, and that is its biggest con. There simply aren’t very many languages or libraries out there written to interpret TOML.
|
||||
|
||||
### CSON: Simple Samples Enslaved by Specific Systems
|
||||
|
||||
First off, there are two CSON specifications. One stands for CoffeeScript Object Notation, the other stands for Cursive Script Object Notation. The latter isn’t used too often, so we won’t be getting into it. Let’s just focus on the CoffeeScript one.
|
||||
|
||||
[CSON][10] will take a bit of intro. First, let’s talk about CoffeeScript. [CoffeeScript][11] is a language that runs through a compiler to generate JavaScript. It allows you to write JavaScript in a more syntactically concise way, and have it [transcompiled][12] into actual JavaScript, which you would then use in your web application. CoffeeScript makes writing JavaScript easier by removing a lot of the extra syntax necessary in JavaScript. A big one that CoffeeScript gets rid of is curly braces—no need for them. In that same token, CSON is JSON without the curly braces. It instead relies on indentation to determine hierarchy of your data. CSON is very easy to read and write and usually requires fewer lines of code than JSON because there are no brackets.
|
||||
|
||||
CSON also offers up some extra niceties that JSON doesn’t have to offer. Multiline strings are incredibly easy to write, you can enter [comments][13] by starting a line with a hash, and there’s no need for separating key-value pairs with commas.
|
||||
|
||||
```
|
||||
books: [
|
||||
id: 'bk102'
|
||||
author: 'Crockford, Douglas'
|
||||
title: 'JavaScript: The Good Parts'
|
||||
genre: 'Computer'
|
||||
price: 29.99
|
||||
publish_date: '2008-05-01'
|
||||
description: 'Unearthing the Excellence in JavaScript'
|
||||
]
|
||||
```
|
||||
|
||||
Here’s the big issue with CSON. It’s **CoffeeScript** Object Notation. Meaning CoffeeScript is what you use to parse/tokenize/lex/transcompile or otherwise use CSON. CoffeeScript is the system that reads the data. If the intent of data serialization is to allow data to be passed from one system to another, and here we have a data serialization format that’s only read by a single system, well that makes it about as useful as a fireproof match, or a waterproof sponge, or that annoyingly flimsy fork part of a spork.
|
||||
|
||||
If this format is adopted by other systems, it could be pretty useful in the developer world. Thus far that hasn’t happened in a comprehensive manner, so using it in alternative languages such as PHP or JAVA are a no-go.
|
||||
|
||||
### YAML: Yielding Yips from Youngsters
|
||||
|
||||
Developers rejoice, as YAML comes into the scene from [one of the contributors to Python][14]. YAML has the same feature set and similar syntax as CSON, a boatload of new features, and parsers available in just about every web programming language there is. It also has some extra features, like circular referencing, soft-wraps, multi-line keys, typecasting tags, binary data, object merging, and [set maps][15]. It has incredibly good human readability and writability, and is a superset of JSON, so you can use fully qualified JSON syntax inside YAML and all will work well. You almost never need quotes, and it can interpret most of your base data types (strings, integers, floats, booleans, etc.).
|
||||
|
||||
```
|
||||
books:
|
||||
- id: bk102
|
||||
author: Crockford, Douglas
|
||||
title: 'JavaScript: The Good Parts'
|
||||
genre: Computer
|
||||
price: 29.99
|
||||
publish_date: !!str 2008-05-01
|
||||
description: Unearthing the Excellence in JavaScript
|
||||
```
|
||||
|
||||
The younglings of the industry are rapidly adopting YAML as their preferred data serialization and system configuration format. They are smart to do so. YAML has all the benefits of being as terse as CSON, and all the features of datatype interpretation as JSON. YAML is as easy to read as Canadians are to hang out with.
|
||||
|
||||
There are two issues with YAML that stick out to me, and the first is a big one. At the time of this writing, YAML parsers haven’t yet been built into very many languages, so you’ll need to use a third-party library or extension for your chosen language to parse .yaml files. This wouldn’t be a big deal, however it seems most developers who’ve created parsers for YAML have chosen to throw “additional features” into their parsers at random. Some allow [tokenization][16], some allow [chain referencing][17], some even allow inline calculations. This is all well and good (sort of), except that none of these features are part of the specification, and so are difficult to find amongst other parsers in other languages. This results in system-locking; you end up with the same issue that CSON is subject to. If you use a feature found in only one parser, other parsers won’t be able to interpret the input. Most of these features are nonsense that don’t belong in a dataset, but rather in your application logic, so it’s best to simply ignore them and write your YAML to specification.
|
||||
|
||||
The second issue is there are few parsers that yet completely implement the specification. All the basics are there, but it can be difficult to find some of the more complex and newer things like soft-wraps, document markers, and circular references in your preferred language. I have yet to see an absolute need for these things, so hopefully they shouldn’t slow you down too much. With the above considered, I tend to keep to the more matured feature set presented in the [1.1 specification][18], and avoid the newer stuff found in the [1.2 specification][19]. However, programming is an ever-evolving monster, so by the time you finish reading this article, you’re likely to be able to use the 1.2 spec.
|
||||
|
||||
### Final Philosophy
|
||||
|
||||
The final word here is that each serialization language should be treated with a case-by-case reverence. Some are the bee’s knees when it comes to machine readability, some are the cat’s meow for human readability, and some are simply gilded turds. Here’s the ultimate breakdown: If you are writing code for other code to read, use YAML. If you are writing code that writes code for other code to read, use JSON. Finally, if you are writing code that transcompiles code into code that other code will read, rethink your life choices.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.zionandzion.com/json-vs-xml-vs-toml-vs-cson-vs-yaml/
|
||||
|
||||
作者:[Tim Anderson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.zionandzion.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Comparison_of_data_serialization_formats
|
||||
[2]: https://en.wikipedia.org/wiki/Standard_Generalized_Markup_Language#History
|
||||
[3]: https://www.quirksmode.org/css/csshacks.html
|
||||
[4]: http://www.ie6death.com/
|
||||
[5]: https://en.wikipedia.org/wiki/Vacuum_tube
|
||||
[6]: https://twitter.com/BrendanEich/status/773403975865470976
|
||||
[7]: https://en.wikipedia.org/wiki/Parsing#Parser
|
||||
[8]: https://en.wikipedia.org/wiki/Tom_Preston-Werner
|
||||
[9]: https://en.wikipedia.org/wiki/INI_file
|
||||
[10]: https://github.com/bevry/cson#what-is-cson
|
||||
[11]: http://coffeescript.org/
|
||||
[12]: https://en.wikipedia.org/wiki/Source-to-source_compiler
|
||||
[13]: https://en.wikipedia.org/wiki/Comment_(computer_programming)
|
||||
[14]: http://clarkevans.com/
|
||||
[15]: http://exploringjs.com/es6/ch_maps-sets.html
|
||||
[16]: https://www.tutorialspoint.com/compiler_design/compiler_design_lexical_analysis.htm
|
||||
[17]: https://en.wikipedia.org/wiki/Fluent_interface
|
||||
[18]: http://yaml.org/spec/1.1/current.html
|
||||
[19]: http://www.yaml.org/spec/1.2/spec.html
|
||||
@ -1,67 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Fix “Network Protocol Error” On Mozilla Firefox)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-fix-network-protocol-error-on-mozilla-firefox/)
|
||||
[#]: author: (SK https://www.ostechnix.com/author/sk/)
|
||||
|
||||
How To Fix “Network Protocol Error” On Mozilla Firefox
|
||||
======
|
||||

|
||||
|
||||
Mozilla Firefox is my default web browser for years. I have been using it for my day to day web activities, such as accessing my mails, browsing favorite websites etc. Today, I experienced a strange error while using Firefox. I tried to share one of our guide on Reddit platform and got the following error message.
|
||||
|
||||
```
|
||||
Network Protocol Error
|
||||
|
||||
Firefox has experienced a network protocol violation that cannot be repaired.
|
||||
|
||||
The page you are trying to view cannot be shown because an error in the network protocol was detected.
|
||||
|
||||
Please contact the website owners to inform them of this problem.
|
||||
```
|
||||
|
||||

|
||||
|
||||
To be honest, I panicked a bit and thought my system might be affected with some kind of malware. LOL! I was wrong! I am using latest Firefox version on my Arch Linux desktop. I opened the same link in Chromium browser. It’s working fine! I guessed it is Firefox related error. After Googling a bit, I fixed this issue as described below.
|
||||
|
||||
This kind of problems occurs mostly because of the **browser’s cache**. If you’ve encountered these kind of errors, such as “Network Protocol Error” or “Corrupted Content Error”, follow any one of these methods.
|
||||
|
||||
**Method 1:**
|
||||
|
||||
To fix “Network Protocol Error” or “Corrupted Content Error”, you need to reload the webpage while bypassing the cache. To do so, Press **Ctrl + F5** or **Ctrl + Shift + R** keys. It will reload the webpage fresh from the server, not from the Firefox cache. Now the web page should work just fine.
|
||||
|
||||
**Method 2:**
|
||||
|
||||
If the method1 doesn’t work, please try this method.
|
||||
|
||||
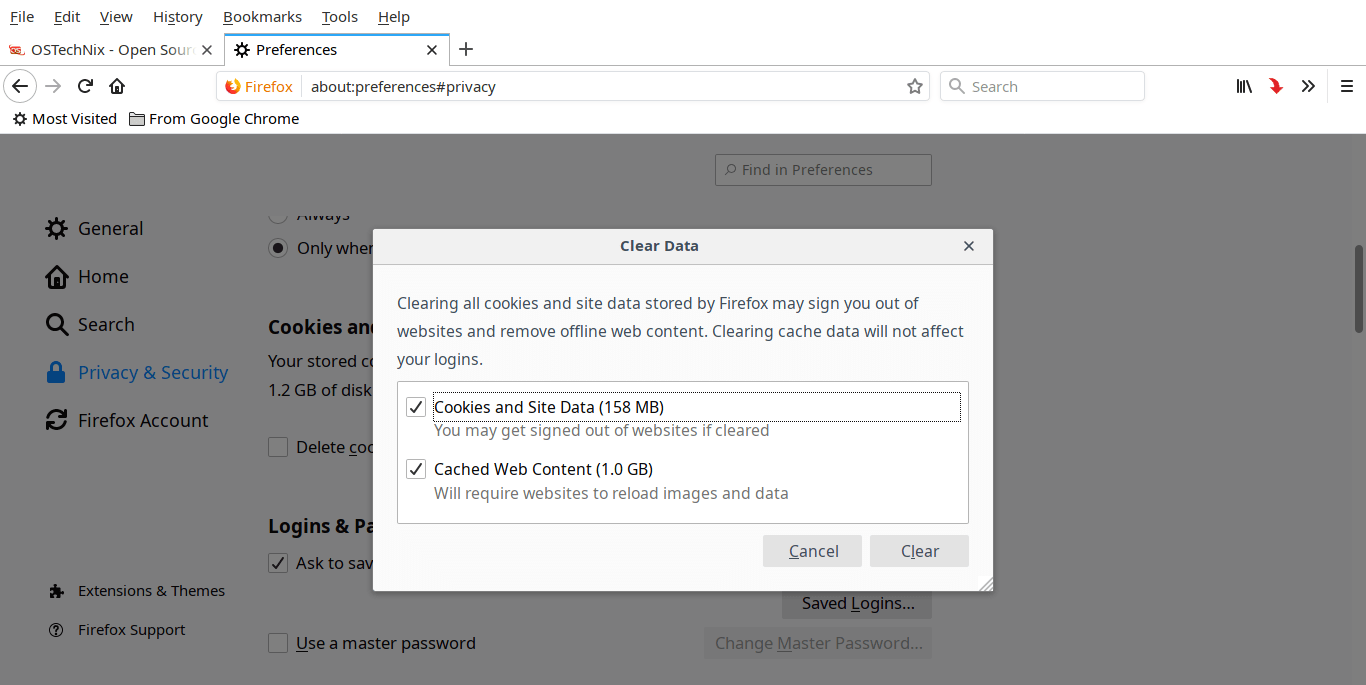
Go to **Edit - > Preferences**. From the Preferences window, navigate to **Privacy & Security** tab on the left pane. Now clear the Firefox cache by clicking on **“Clear Data”** option.
|
||||

|
||||
|
||||
Make sure you have checked both “Cookies and Site Data” and “Cached Web Content” options and click **“Clear”**.
|
||||
|
||||
|
||||
|
||||
Done! Now the cookies and offline content will be removed. Please note that Firefox may sign you out of the logged-in websites. You can re-login to those websites later. Finally, close the Firefox browser and restart your system. Now the webpage will load without any issues.
|
||||
|
||||
Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-fix-network-protocol-error-on-mozilla-firefox/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -1,256 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Advanced Techniques for Reducing Emacs Startup Time)
|
||||
[#]: via: (https://blog.d46.us/advanced-emacs-startup/)
|
||||
[#]: author: (Joe Schafer https://blog.d46.us/)
|
||||
|
||||
降低 Emacs 启动时间的高级技术
|
||||
======
|
||||
|
||||
[Emacs Start Up Profiler][1] 的作者教你六项技术减少 Emacs 启动时间。
|
||||
|
||||
简而言之:做下面几个步骤:
|
||||
|
||||
1。使用 Esup 进行性能检测。
|
||||
2。调整垃圾回收的阀值。
|
||||
3。使用 usge-page 来自动(延迟)加载所有东西。
|
||||
4。不要使用会引起立即加载的辅助函数。
|
||||
5。参考我的 [配置 ][2]。
|
||||
|
||||
|
||||
|
||||
### 从 .emacs.d 破产到现在
|
||||
|
||||
我最近宣布了第三次 .emacs.d 破产并完成了第四次 Emacs 配置的迭代。演化过程为:
|
||||
|
||||
1。拷贝并粘贴 elisp 片段到 `~/.emacs` 中,希望它能工作。
|
||||
2。借助 `el-get` 来以更结构化的方式来管理依赖关系。
|
||||
3。放弃自己从零配置,以 Spacemacs 为基础。
|
||||
4。厌倦了 Spacemacs 的复杂性,基于 `use-package` 重写配置。
|
||||
|
||||
本文汇聚了三次重写和创建 `Emacs Start Up Profiler` 过程中的技巧。
|
||||
非常感谢 Spacemacs,use-package 等背后的团队。
|
||||
没有这些无私的志愿者,这项任务将会困难得多。
|
||||
|
||||
|
||||
### 不过守护进程模式又如何呢
|
||||
|
||||
在我们开始之前,让我声明一下常见的反对优化 Emacs 的观念:“Emacs 旨在作为守护进程来运行的,因此你只需要运行一次而已。”
|
||||
这个观点很好,只不过:
|
||||
|
||||
- 速度总是越快越好
|
||||
- 配置 Emacs 时,可能会有不得不通过重启 Emacs 的情况。例如,你可能为 `post-command-hook` 添加了一个运行缓慢的 `lambda` 函数,很难删掉它。
|
||||
- 重启 Emacs 能帮你验证不同会话之间是否还能保留配置
|
||||
|
||||
### 估算当前以及最佳的启动时间
|
||||
|
||||
第一步是衡量当前的启动时间。最简单的方法就是在启动时显示后续步骤进度的信息。
|
||||
|
||||
```
|
||||
(add-hook 'emacs-startup-hook
|
||||
(lambda ()
|
||||
(message "Emacs ready in %s with %d garbage collections."
|
||||
(format "%.2f seconds"
|
||||
(float-time
|
||||
(time-subtract after-init-time before-init-time)))
|
||||
gcs-done)))
|
||||
```
|
||||
|
||||
第二部,衡量最佳的启动速度,以便了解可能的情况。我的是 0.3 秒。
|
||||
|
||||
```
|
||||
emacs -q --eval='(message "%s" (emacs-init-time))'
|
||||
|
||||
;; For macOS users:
|
||||
open -n /Applications/Emacs.app --args -q --eval='(message "%s" (emacs-init-time))'
|
||||
```
|
||||
|
||||
### 2。检测 Emacs 启动指标对你大有帮助
|
||||
|
||||
[Emacs StartUp Profiler][1] (ESUP) 将会给你顶层语句执行的详细指标。
|
||||
|
||||
![esup.png][3]
|
||||
|
||||
|
||||
图 1: Emacs Start Up Profiler 截图
|
||||
|
||||
警告:Spacemacs 用户需要注意,ESUP 目前与 Spacemacs 的 init.el 文件有冲突。遵照 <https://github.com/jschaf/esup/issues/48> 上说的进行升级。
|
||||
|
||||
### 启动时调高垃圾回收的阀值
|
||||
|
||||
这为我节省了 **0.3 秒**。
|
||||
|
||||
Emacs 默认值是 760kB,这在现代机器看来及其的保守。
|
||||
真正的诀窍在于初始化完成后再把它降到合理的水平。
|
||||
这为了节省了 0.3 秒
|
||||
|
||||
```
|
||||
;; Make startup faster by reducing the frequency of garbage
|
||||
;; collection. The default is 800 kilobytes. Measured in bytes.
|
||||
(setq gc-cons-threshold (* 50 1000 1000))
|
||||
|
||||
;; The rest of the init file.
|
||||
|
||||
;; Make gc pauses faster by decreasing the threshold.
|
||||
(setq gc-cons-threshold (* 2 1000 1000))
|
||||
```
|
||||
|
||||
### 4。不要 require 任何东西,转而使用 use-package 来自动加载
|
||||
|
||||
让 Emacs 变坏的最好方法就是减少要做的事情。`require` 会立即加载源文件。
|
||||
但是很少会出现需要在启动阶段就立即需要这些功能的。
|
||||
|
||||
在 [`use-package`][4] 中你只需要声明好需要哪个包中的哪个功能,`use-package` 就会帮你完成正确的事情。
|
||||
它看起来是这样的:
|
||||
|
||||
```
|
||||
(use-package evil-lisp-state ; the Melpa package name
|
||||
|
||||
:defer t ; autoload this package
|
||||
|
||||
:init ; Code to run immediately.
|
||||
(setq evil-lisp-state-global nil)
|
||||
|
||||
:config ; Code to run after the package is loaded.
|
||||
(abn/define-leader-keys "k" evil-lisp-state-map))
|
||||
```
|
||||
|
||||
可以通过查看 `features` 变量来查看 Emacs 现在加载了那些包。
|
||||
想要更好看的输出可以使用 [lpkg explorer][5] 或者我在 [abn-funcs-benchmark.el][6] 中的变体。
|
||||
输出看起来类似这样的:
|
||||
|
||||
```
|
||||
479 features currently loaded
|
||||
- abn-funcs-benchmark: /Users/jschaf/.dotfiles/emacs/funcs/abn-funcs-benchmark.el
|
||||
- evil-surround: /Users/jschaf/.emacs.d/elpa/evil-surround-20170910.1952/evil-surround.elc
|
||||
- misearch: /Applications/Emacs.app/Contents/Resources/lisp/misearch.elc
|
||||
- multi-isearch: nil
|
||||
- <many more>
|
||||
```
|
||||
|
||||
### 5。不要使用辅助函数来设置模式
|
||||
|
||||
通常,Emacs packages 会建议通过运行一个辅助函数来设置键绑定。下面是一些例子:
|
||||
|
||||
* `(evil-escape-mode)`
|
||||
* `(windmove-default-keybindings) ; 设置快捷键。`
|
||||
* `(yas-global-mode 1) ;复杂的片段配置。`
|
||||
|
||||
可以通过 use-package 来对此进行重构以提高启动速度。这些辅助函数只会让你立即加载那些尚用不到的 package。
|
||||
|
||||
下面这个例子告诉你如何自动加载 `evil-escape-mode`。
|
||||
|
||||
```
|
||||
;; The definition of evil-escape-mode.
|
||||
(define-minor-mode evil-escape-mode
|
||||
(if evil-escape-mode
|
||||
(add-hook 'pre-command-hook 'evil-escape-pre-command-hook)
|
||||
(remove-hook 'pre-command-hook 'evil-escape-pre-command-hook)))
|
||||
|
||||
;; Before:
|
||||
(evil-escape-mode)
|
||||
|
||||
;; After:
|
||||
(use-package evil-escape
|
||||
:defer t
|
||||
;; Only needed for functions without an autoload comment (;;;###autoload).
|
||||
:commands (evil-escape-pre-command-hook)
|
||||
|
||||
;; Adding to a hook won't load the function until we invoke it.
|
||||
;; With pre-command-hook, that means the first command we run will
|
||||
;; load evil-escape.
|
||||
:init (add-hook 'pre-command-hook 'evil-escape-pre-command-hook))
|
||||
```
|
||||
|
||||
下面来看一个关于 `org-babel` 的例子,这个例子更为复杂。我们通常的配置时这样的:
|
||||
|
||||
```
|
||||
(org-babel-do-load-languages
|
||||
'org-babel-load-languages
|
||||
'((shell . t)
|
||||
(emacs-lisp . nil)))
|
||||
```
|
||||
|
||||
这种不是个好的配置,因为 `org-babel-do-load-languages` 定义在 `org.el` 中,而该文件有超过 2 万 4 千行的代码,需要花 0.2 秒来加载。
|
||||
通过查看源代码可以看到 `org-babel-do-load-languages` 仅仅只是加载 `ob-<lang>` 包而已,像这样:
|
||||
|
||||
```
|
||||
;; From org.el in the org-babel-do-load-languages function.
|
||||
(require (intern (concat "ob-" lang)))
|
||||
```
|
||||
|
||||
而在 `ob-<lang>.el` 文件中,我们只关心其中的两个方法 `org-babel-execute:<lang>` 和 `org-babel-expand-body:<lang>`。
|
||||
我们可以延时加载 org-babel 相关功能而无需调用 `org-babel-do-load-languages`,像这样:
|
||||
|
||||
```
|
||||
;; Avoid `org-babel-do-load-languages' since it does an eager require.
|
||||
(use-package ob-python
|
||||
:defer t
|
||||
:ensure org-plus-contrib
|
||||
:commands (org-babel-execute:python))
|
||||
|
||||
(use-package ob-shell
|
||||
:defer t
|
||||
:ensure org-plus-contrib
|
||||
:commands
|
||||
(org-babel-execute:sh
|
||||
org-babel-expand-body:sh
|
||||
|
||||
org-babel-execute:bash
|
||||
org-babel-expand-body:bash))
|
||||
```
|
||||
|
||||
### 6。使用惰性定时器 (idle timer) 来推迟加载非立即需要的包
|
||||
|
||||
我推迟加载了 9 个包,这帮我节省了 **0.4 秒**。
|
||||
|
||||
有些包特别有用,你希望可以很快就能使用它们,但是它们本身在 Emacs 启动过程中又不是必须的。这些 mode 包括:
|
||||
|
||||
- `recentf`: 保存最近的编辑过的那些文件。
|
||||
- `saveplace`: 保存访问过文件的光标位置。
|
||||
- `server`: 开启 Emacs 守护进程。
|
||||
- `autorevert`: 自动重载被修改过的文件。
|
||||
- `paren`: 高亮匹配的括号。
|
||||
- `projectile`: 项目管理工具。
|
||||
- `whitespace`: 高亮行尾的空格。
|
||||
|
||||
不要 require 这些 mode,** 而是等到空闲 N 秒后再加载它们**。
|
||||
我在 1 秒后加载那些比较重要的包,在 2 秒后加载其他所有的包。
|
||||
|
||||
```
|
||||
(use-package recentf
|
||||
;; Loads after 1 second of idle time.
|
||||
:defer 1)
|
||||
|
||||
(use-package uniquify
|
||||
;; Less important than recentf.
|
||||
:defer 2)
|
||||
```
|
||||
|
||||
### 不值得的优化
|
||||
|
||||
不要费力把你的 Emacs 配置文件编译成字节码了。这只节省了大约 0.05 秒。
|
||||
把配置文件编译成字节码可能导致源文件与编译后的文件不匹配从而导致难以出现错误调试。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.d46.us/advanced-emacs-startup/
|
||||
|
||||
作者:[Joe Schafer][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://blog.d46.us/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/jschaf/esup
|
||||
[2]: https://github.com/jschaf/dotfiles/blob/master/emacs/start.el
|
||||
[3]: https://blog.d46.us/images/esup.png
|
||||
[4]: https://github.com/jwiegley/use-package
|
||||
[5]: https://gist.github.com/RockyRoad29/bd4ca6fdb41196a71662986f809e2b1c
|
||||
[6]: https://github.com/jschaf/dotfiles/blob/master/emacs/funcs/abn-funcs-benchmark.el
|
||||
212
translated/tech/20180220 JSON vs XML vs TOML vs CSON vs YAML.md
Normal file
212
translated/tech/20180220 JSON vs XML vs TOML vs CSON vs YAML.md
Normal file
@ -0,0 +1,212 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (GraveAccent)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (JSON vs XML vs TOML vs CSON vs YAML)
|
||||
[#]: via: (https://www.zionandzion.com/json-vs-xml-vs-toml-vs-cson-vs-yaml/)
|
||||
[#]: author: (Tim Anderson https://www.zionandzion.com)
|
||||
|
||||
JSON vs XML vs TOML vs CSON vs YAML
|
||||
======
|
||||
|
||||
|
||||
### 一段超级严肃的关于样本序列化的集合、子集和超集的文字
|
||||
|
||||
我是开发者。我读代码。我写代码。我写会写代码的代码。我写会写供其它代码读的代码的代码。这些都非常火星语,但是有其美妙之处。然而,最后一点,写会写供其它代码读的代码的代码,可以很快变得比这段文字更费解。有很多方法可以做到这一点。一种不那么复杂而且开发者社区最爱的方式是数据序列化。对于那些不了解我刚刚向你抛的时髦词的人,数据序列化是从一个系统获取一些信息,将其转换为其它系统可以读取的格式,然后将其传递给其它系统的过程。
|
||||
|
||||
虽然[数据序列化格式][1]多到可以埋葬哈利法塔,但它们大多分为两类:
|
||||
|
||||
* 易于人类读写,
|
||||
* 易于机器读写。
|
||||
|
||||
|
||||
|
||||
很难两全其美,因为人类喜欢让我们更具表现力的松散类型和灵活格式标准,而机器倾向于被确切告知一切事情不带疑惑和细节缺失,并且认为“严格规范”是他们最爱的 Ben & Jerry's 口味。
|
||||
|
||||
由于我是一名 web 开发者而且我们是一个创建网站的代理商,我们将坚持使用 web 系统可以理解或不需要太多努力就能理解以及对人类可读性特别有用的特殊格式:XML,JSON,TOML,CSON以及 YAML。每个都有各自的优缺点和适当的用例。
|
||||
|
||||
### 事实最先
|
||||
|
||||
回到互联网的早期,[一些非常聪明的家伙][2]决定整合一种标准语言,即每个系统都能理解,创造性地将其命名为标准通用标记语言(简称SGML)。SGML 非常灵活,发布者也很好地定义了它。他成为了 XML,SVG 和 HTML 等语言之父。所有这三个都符合 SGML 规范,可是它们都是规则更严格、灵活性更少的子集。
|
||||
|
||||
最终,人们开始看到大量非常小、简洁、易读且易于生成的数据,这些数据可以在系统之间以程序的方式共享,而开销很小。大约在那个时候,JSON 诞生了并且能够满足所有的需求。反过来,其它语言开始出现以处理更多的专业用例,如 CSON,TOML 和 YAML。
|
||||
|
||||
### XML: 不行了
|
||||
|
||||
最初,XML语言非常灵活且易于编写,但它的缺点是冗长,人类难以阅读,计算机非常难以读取,并且有很多语法对于传达信息并不是完全必要的。
|
||||
|
||||
今天,它在 web 上的数据序列化目的已经消失了。除非你在编写 HTML 或者 SVG,否则你不太能在许多其它地方看到XML。一些过时的系统今天仍在使用它,但是用它传递数据往往太重了。
|
||||
|
||||
我已经可以听到 XML 老人开始在他们的石碑上乱写为什么 XML 是了不起的,所以我将提供一个小的附录:XML可以很容易地由系统和人读写。然而,真的,我的意思是荒谬,很难创建一个可以将其读入规范的系统。这是一个简单美观的 XML 示例:
|
||||
|
||||
```
|
||||
<book id="bk101">
|
||||
<author>Gambardella, Matthew</author>
|
||||
<title>XML Developer's Guide</title>
|
||||
<genre>Computer</genre>
|
||||
<price>44.95</price>
|
||||
<publish_date>2000-10-01</publish_date>
|
||||
<description>An in-depth look at creating applications
|
||||
with XML.</description>
|
||||
</book>
|
||||
```
|
||||
|
||||
太棒了。易于阅读,推理,编写和编码的可以读写的系统。但请考虑这个例子:
|
||||
|
||||
```
|
||||
<!DOCTYPE r [ <!ENTITY y "a]>b"> ]>
|
||||
<r>
|
||||
<a b="&y;>" />
|
||||
<![CDATA[[a>b <a>b <a]]>
|
||||
<?x <a> <!-- <b> ?> c --> d
|
||||
</r>
|
||||
```
|
||||
|
||||
这上面是 100% 有效的 XML。不可能阅读、理解或推理。编写可以使用和理解这个的代码将花费至少36头的头发和248磅咖啡。我们没有那么多时间或咖啡,而且我们大多数老人现在都是秃头。所以,让它活在我们的记忆里,就像 [css hacks][3],[internet explorer][4] 和[真空管][5]那样。
|
||||
|
||||
### JSON: 并列聚会
|
||||
|
||||
好吧,我们都同意了。XML = 差劲。那么,什么是好的替代品?JavaScript 对象表示法,简称 JSON。JSON(读起来像 Jason 这个名字) 是 Brendan Eich 发明的,并且被 [JavaScript 的荷兰叔叔][6] Douglas Crockford 推广。它现在几乎用在任何地方。这种格式很容易由人和机器编写,相当容易用规范中的严格规则[解析][7],并且灵活-允许深层嵌套数据,所有原始数据类型和集合如数组和对象的解释。JSON 成为了将数据从一个系统传输到另一个系统的事实标准。几乎所有语言都有内置读写它的功能。
|
||||
|
||||
JSON语法很简单。 方括号表示数组,花括号表示记录,由冒号分隔两个值表示属性(或“键”)在左边,值在右边。所有键必须用双引号括起来:
|
||||
|
||||
```
|
||||
{
|
||||
"books": [
|
||||
{
|
||||
"id": "bk102",
|
||||
"author": "Crockford, Douglas",
|
||||
"title": "JavaScript: The Good Parts",
|
||||
"genre": "Computer",
|
||||
"price": 29.99,
|
||||
"publish_date": "2008-05-01",
|
||||
"description": "Unearthing the Excellence in JavaScript"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
这对你来说应该是完全合理的。它简洁明了,并且从 XML 中删除了大量额外废话以传达相同数量的信息。JSON 现在是王道,本文剩下的部分会介绍其它语言格式,这些格式只不过是煮沸了的 JSON,尝试让其更简洁或更易读,可结构还是非常相似的。
|
||||
|
||||
### TOML: 缩短到彻底的利他主义
|
||||
|
||||
TOML(Tom 的显而易见最低限度语言)允许快速简洁地定义深层嵌套的数据结构。名字中的名字是指发明者 [Tom Preston Werner][8],他是一位活跃于我们行业的创造者和软件开发人员。与 JSON 相比,语法有点尴尬,更类似 [ini 文件][9]。这不是一个糟糕的语法,但是需要一些时间适应。
|
||||
|
||||
```
|
||||
[[books]]
|
||||
id = 'bk101'
|
||||
author = 'Crockford, Douglas'
|
||||
title = 'JavaScript: The Good Parts'
|
||||
genre = 'Computer'
|
||||
price = 29.99
|
||||
publish_date = 2008-05-01T00:00:00+00:00
|
||||
description = 'Unearthing the Excellence in JavaScript'
|
||||
```
|
||||
|
||||
TOML 中集成了一些很棒的功能,例如多行字符串,保留字符的自动转义,日期,时间,整数,浮点数,科学记数法和“表扩展”等数据类型。最后一点是特别的,是TOML如此简洁的原因:
|
||||
|
||||
```
|
||||
[a.b.c]
|
||||
d = 'Hello'
|
||||
e = 'World'
|
||||
```
|
||||
|
||||
以上扩展到以下内容:
|
||||
|
||||
```
|
||||
{
|
||||
"a": {
|
||||
"b": {
|
||||
"c": {
|
||||
"d": "Hello"
|
||||
"e": "World"
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
使用TOML,你可以肯定在时间和文件长度上会节省不少。很少有系统使用它或非常类似的东西作为配置,这是它最大的缺点。根本没有很多语言或库可以用来解释 TOML。
|
||||
|
||||
### CSON: 特定系统所包含的简单样本
|
||||
|
||||
首先,有两个 CSON 规范。 一个代表 CoffeeScript Object Notation,另一个代表 Cursive Script Object Notation。后者不经常使用,所以我们不会关注它。我们只关注 CoffeeScript。
|
||||
|
||||
[CSON][10] 会介绍一点。首先,我们来谈谈 CoffeeScript。[CoffeeScript][11] 是一种通过运行编译器生成 JavaScript 的语言。它允许你以更加简洁的语法编写 JavaScript 并[转译][12]成实际的 JavaScript,然后你可以在你的 web 应用程序中使用它。CoffeeScript 通过删除 JavaScript 中必需的许多额外语法,使编写 JavaScript 变得更容易。CoffeeScript 摆脱的一个大问题是花括号 - 不需要他们。同样,CSON 是没有大括号的 JSON。它依赖于缩进来确定数据的层次结构。CSON 非常易于读写,并且通常比 JSON 需要更少的代码行,因为没有括号。
|
||||
|
||||
CSON 还提供一些 JSON 不提供的额外细节。多行字符串非常容易编写,你可以通过使用 hash 符号开始一行来输入[注释][13],并且不需要用逗号分隔键值对。
|
||||
|
||||
```
|
||||
books: [
|
||||
id: 'bk102'
|
||||
author: 'Crockford, Douglas'
|
||||
title: 'JavaScript: The Good Parts'
|
||||
genre: 'Computer'
|
||||
price: 29.99
|
||||
publish_date: '2008-05-01'
|
||||
description: 'Unearthing the Excellence in JavaScript'
|
||||
]
|
||||
```
|
||||
|
||||
这是 CSON 的重大问题。它是 **CoffeScript** 对象表示法。也就是说你用 CoffeeScript 解析/标记化/lex/转译或其它方式使用 CSON。CoffeeScript 是读取数据的系统。如果数据序列化的目的是允许数据从一个系统传递到另一个系统,这里我们有一个只能由单个系统读取的数据序列化格式,这使得它与防火的火柴、防水的海绵或者叉勺恼人的脆弱分叉处一样有用。
|
||||
|
||||
如果其它系统采用这种格式,它在开发者世界中可能非常有用。到目前为止这整体上没有发生,所以在 PHP 或 JAVA 等替代语言中使用它是不行的。
|
||||
|
||||
### YAML:年轻人的呼喊
|
||||
|
||||
开发人员感到高兴,因为 YAML 来自[一个 Python 的贡献者][14]。YAML 具有与 CSON 相同的功能集和类似的语法,一系列新功能,以及几乎所有 web 编程语言都可用的解析器。它还有一些额外的功能,如循环引用,软包装,多行键,类型转换标签,二进制数据,对象合并和[集合映射][15]。它具有令人难以置信的良好的可读性和可写性,并且是 JSON 的超集,因此你可以在 YAML 中使用完全合格的 JSON 语法并且一切正常工作。你几乎从不需要引号,它可以解释大多数基本数据类型(字符串,整数,浮点数,布尔值等)。
|
||||
|
||||
```
|
||||
books:
|
||||
- id: bk102
|
||||
author: Crockford, Douglas
|
||||
title: 'JavaScript: The Good Parts'
|
||||
genre: Computer
|
||||
price: 29.99
|
||||
publish_date: !!str 2008-05-01
|
||||
description: Unearthing the Excellence in JavaScript
|
||||
```
|
||||
|
||||
业界的年轻人正在迅速采用 YAML 作为他们首选的数据序列化和系统配置格式。他们这样做很机智。YAML 有像 CSON 一样简洁带来的所有好处,有 JSON 在数据类型解释方面的所有功能。YAML 像加拿大人容易相处一样容易阅读。
|
||||
|
||||
YAML 有两个问题,对我而言,第一个是大问题。在撰写本文时,YAML 解析器尚未内置于多种语言,因此你需要使用第三方库或扩展来为你选择的语言解析 .yaml 文件。这不是什么大问题,可似乎大多数为 YAML 创建解析器的开发人员都选择随机将“附加功能”放入解析器中。有些允许[标记化][16],有些允许[链引用][17],有些甚至允许内联计算。这一切都很好(某种意义上),除了这些功能都不是规范的一部分,因此很难在其他语言的其他解析器中找到。这导致系统锁定,你最终遇到了与 CSON 相同的问题。如果你使用仅在一个解析器中找到的功能,则其他解析器将无法解释输入。大多数这些功能都是无意义的,不属于数据集,而是属于你的应用程序逻辑,因此最好简单地忽略它们和编写符合规范的 YAML。
|
||||
|
||||
第二个问题是很少有解析器完全实现规范。所有的基本要素都在那里,但是很难找到一些更复杂和更新的东西,比如软包装,文档标记和首选语言的循环引用。我还没有看到对这些东西的刚需,所以希望它们不让你很失望。考虑到上述情况,我倾向于保持 [1.1 规范][18] 中呈现的更成熟的功能集,避免在 [1.2 规范][19] 中找到的新东西。然而,编程是一个不断发展的怪兽,所以当你读完这篇文章时,你或许可以使用 1.2 规范。
|
||||
|
||||
### 最终哲学
|
||||
|
||||
这是最后一段话。每个序列化语言都应该以其用例的标准评价。当涉及机器的可读性时,有些是蜜蜂的膝盖。对于人类可读性,有些是猫的喵喵声,有些只是镀金的粪便。以下是最终细分:如果你要编写供其他代码阅读的代码,请使用 YAML。如果你正在编写能写供其他代码读取的代码的代码,请使用 JSON。最后,如果你正在编写将代码转译为供其他代码读取的代码的代码,请重新考虑你的人生选择。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.zionandzion.com/json-vs-xml-vs-toml-vs-cson-vs-yaml/
|
||||
|
||||
作者:[Tim Anderson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/GraveAccent)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.zionandzion.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Comparison_of_data_serialization_formats
|
||||
[2]: https://en.wikipedia.org/wiki/Standard_Generalized_Markup_Language#History
|
||||
[3]: https://www.quirksmode.org/css/csshacks.html
|
||||
[4]: http://www.ie6death.com/
|
||||
[5]: https://en.wikipedia.org/wiki/Vacuum_tube
|
||||
[6]: https://twitter.com/BrendanEich/status/773403975865470976
|
||||
[7]: https://en.wikipedia.org/wiki/Parsing#Parser
|
||||
[8]: https://en.wikipedia.org/wiki/Tom_Preston-Werner
|
||||
[9]: https://en.wikipedia.org/wiki/INI_file
|
||||
[10]: https://github.com/bevry/cson#what-is-cson
|
||||
[11]: http://coffeescript.org/
|
||||
[12]: https://en.wikipedia.org/wiki/Source-to-source_compiler
|
||||
[13]: https://en.wikipedia.org/wiki/Comment_(computer_programming)
|
||||
[14]: http://clarkevans.com/
|
||||
[15]: http://exploringjs.com/es6/ch_maps-sets.html
|
||||
[16]: https://www.tutorialspoint.com/compiler_design/compiler_design_lexical_analysis.htm
|
||||
[17]: https://en.wikipedia.org/wiki/Fluent_interface
|
||||
[18]: http://yaml.org/spec/1.1/current.html
|
||||
[19]: http://www.yaml.org/spec/1.2/spec.html
|
||||
@ -0,0 +1,66 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Fix “Network Protocol Error” On Mozilla Firefox)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-fix-network-protocol-error-on-mozilla-firefox/)
|
||||
[#]: author: (SK https://www.ostechnix.com/author/sk/)
|
||||
|
||||
如何修复 Mozilla Firefox 中出现的 “Network Protocol Error”
|
||||
======
|
||||

|
||||
|
||||
Mozilla Firefox 多年来一直是我的默认 Web 浏览器,我每天用它来进行日常网络活动,例如访问邮件,浏览喜欢的网站等。今天,我在使用 Firefox 时遇到了一个奇怪的错误。我试图在 Reddit 平台上分享我们的一个指南时,在 Firefox 上出现了以下错误消息:
|
||||
|
||||
```
|
||||
Network Protocol Error
|
||||
|
||||
Firefox has experienced a network protocol violation that cannot be repaired.
|
||||
|
||||
The page you are trying to view cannot be shown because an error in the network protocol was detected.
|
||||
|
||||
Please contact the website owners to inform them of this problem.
|
||||
```
|
||||
|
||||

|
||||
|
||||
老实说,我有点慌,我以为可能是我的系统受到了某种恶意软件的影响。哈哈!但是我发现我错了。我在 Arch Linux 桌面上使用的是最新的 Firefox 版本,我在 Chromium 浏览器中打开了相同的链接,它正确显示了,我猜这是 Firefox 相关的错误。在谷歌上搜索后,我解决了这个问题,如下所述。
|
||||
|
||||
出现这种问题主要是因为“**浏览器缓存**”,如果你遇到此类错误,例如 "Network Protocol Error" 或 "Corrupted Content Error",遵循以下任何一种方法。
|
||||
|
||||
**方法 1:**
|
||||
|
||||
要修复 "Network Protocol Error" 或 "Corrupted Content Error",你需要在绕过缓存时重新加载网页。为此,按下 **Ctrl + F5** 或 **Ctrl + Shift + R** 快捷键,它将从服务器重新加载页面,而不是从 Firefox 缓存加载。这样网页就应该可以正常工作了。
|
||||
|
||||
**方法 2:**
|
||||
|
||||
如果方法 1 不起作用,尝试以下方法。
|
||||
|
||||
打开 **Edit - > Preferences**,在 "Preferences" 窗口中,打开左窗格中的 **Privacy & Security** 选项卡,单击 **“Clear Data”** 选项清除 Firefox 缓存。
|
||||
|
||||

|
||||
|
||||
确保你选中了 Cookies and Site Data” 和 "Cached Web Content" 选项,然后单击 **"Clear"**。
|
||||
|
||||

|
||||
|
||||
完成!现在 Cookie 和离线内容将被删除。注意,Firefox 可能会将你从登录的网站中注销,稍后你可以重新登录这些网站。最后,关闭 Firefox 浏览器并重新启动系统。现在网页加载没有任何问题。
|
||||
|
||||
希望这对你有帮助。更多好东西要来了,敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-fix-network-protocol-error-on-mozilla-firefox/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
Loading…
Reference in New Issue
Block a user