mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-16 22:42:21 +08:00
commit
feb2cda84f
@ -0,0 +1,77 @@
|
||||
如何在 Ubuntu 上安装 Cinnamon 桌面环境
|
||||
======
|
||||
|
||||
> 这篇教程将会为你展示如何在 Ubuntu 上安装 Cinnamon 桌面环境。
|
||||
|
||||
[Cinnamon][1] 是 [Linux Mint][2] 的默认桌面环境。不同于 Ubuntu 的 Unity 桌面环境,Cinnamon 是一个更加传统而优雅的桌面环境,其带有底部面板和应用菜单。由于 Cinnamon 桌面以及它类 Windows 的用户界面,许多桌面用户[相较于 Ubuntu 更喜欢 Linux Mint][3]。
|
||||
|
||||
现在你无需[安装 Linux Mint][4] 就能够体验到 Cinnamon了。在这篇教程,我将会展示给你如何在 Ubuntu 18.04,16.04 和 14.04 上安装 Cinnamon。
|
||||
|
||||
在 Ubuntu 上安装 Cinnamon 之前,有一些事情需要你注意。有时候,安装的额外桌面环境可能会与你当前的桌面环境有冲突。可能导致会话、应用程序或功能等的崩溃。这就是为什么你需要在做这个决定时谨慎一点的原因。
|
||||
|
||||
### 如何在 Ubuntu 上安装 Cinnamon 桌面环境
|
||||
|
||||
![如何在 Ubuntu 上安装 Cinnamon 桌面环境][5]
|
||||
|
||||
过去有 Cinnamon 团队为 Ubuntu 提供的一系列的官方 PPA,但现在都已经失效了。不过不用担心,还有一个非官方的 PPA,而且它运行的很完美。这个 PPA 里包含了最新的 Cinnamon 版本。
|
||||
|
||||
```
|
||||
sudo add-apt-repository
|
||||
ppa:embrosyn/cinnamon
|
||||
sudo apt update && sudo apt install cinnamon
|
||||
```
|
||||
|
||||
下载的大小大概是 150 MB(如果我没记错的话)。这其中提供的 Nemo(Cinnamon 的文件管理器,基于 Nautilus)和 Cinnamon 控制中心。这些东西提供了一个更加接近于 Linux Mint 的感觉。
|
||||
|
||||
### 在 Ubuntu 上使用 Cinnamon 桌面环境
|
||||
|
||||
Cinnamon 安装完成后,退出当前会话,在登录界面,点击用户名旁边的 Ubuntu 符号:
|
||||
|
||||

|
||||
|
||||
之后,它将会显示所有系统可用的桌面环境。选择 Cinnamon。
|
||||
|
||||

|
||||
|
||||
现在你应该已经登录到有着 Cinnamon 桌面环境的 Ubuntu 中了。你还可以通过同样的方式再回到 Unity 桌面。这里有一张以 Cinnamon 做为桌面环境的 Ubuntu 桌面截图。
|
||||
|
||||

|
||||
|
||||
看起来是不是像极了 Linux Mint。此外,我并没有发现任何有关 Cinnamon 和 Unity 的兼容性问题。在 Unity 和 Cinnamon 来回切换,它们也依旧工作的很完美。
|
||||
|
||||
#### 从 Ubuntu 卸载 Cinnamon
|
||||
|
||||
如果你想卸载 Cinnamon,可以使用 PPA Purge 来完成。首先安装 PPA Purge:
|
||||
|
||||
```
|
||||
sudo apt-get install ppa-purge
|
||||
```
|
||||
|
||||
安装完成之后,使用下面的命令去移除该 PPA:
|
||||
|
||||
```
|
||||
sudo ppa-purge ppa:embrosyn/cinnamon
|
||||
```
|
||||
|
||||
更多的信息,我建议你去阅读 [如何从 Linux 移除 PPA][6] 这篇文章。
|
||||
|
||||
我希望这篇文章能够帮助你在 Ubuntu 上安装 Cinnamon。也可以分享一下你使用 Cinnamon 的经验。
|
||||
|
||||
------
|
||||
|
||||
via: https://itsfoss.com/install-cinnamon-on-ubuntu/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: http://cinnamon.linuxmint.com/
|
||||
[2]: http://www.linuxmint.com/
|
||||
[3]: https://itsfoss.com/linux-mint-vs-ubuntu/
|
||||
[4]: https://itsfoss.com/guide-install-linux-mint-16-dual-boot-windows/
|
||||
[5]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/install-cinnamon-ubuntu.png
|
||||
[6]: https://itsfoss.com/how-to-remove-or-delete-ppas-quick-tip/
|
||||
132
published/20171124 How do groups work on Linux.md
Normal file
132
published/20171124 How do groups work on Linux.md
Normal file
@ -0,0 +1,132 @@
|
||||
“用户组”在 Linux 上到底是怎么工作的?
|
||||
========
|
||||
|
||||
嗨!就在上周,我还自认为对 Linux 上的用户和组的工作机制了如指掌。我认为它们的关系是这样的:
|
||||
|
||||
1. 每个进程都属于一个用户(比如用户 `julia`)
|
||||
2. 当这个进程试图读取一个被某个组所拥有的文件时, Linux 会
|
||||
a. 先检查用户`julia` 是否有权限访问文件。(LCTT 译注:此处应该是指检查文件的所有者是否就是 `julia`)
|
||||
b. 检查 `julia` 属于哪些组,并进一步检查在这些组里是否有某个组拥有这个文件或者有权限访问这个文件。
|
||||
3. 如果上述 a、b 任一为真(或者“其它”位设为有权限访问),那么这个进程就有权限访问这个文件。
|
||||
|
||||
比如说,如果一个进程被用户 `julia` 拥有并且 `julia` 在`awesome` 组,那么这个进程就能访问下面这个文件。
|
||||
|
||||
```
|
||||
r--r--r-- 1 root awesome 6872 Sep 24 11:09 file.txt
|
||||
```
|
||||
|
||||
然而上述的机制我并没有考虑得非常清楚,如果你硬要我阐述清楚,我会说进程可能会在**运行时**去检查 `/etc/group` 文件里是否有某些组拥有当前的用户。
|
||||
|
||||
### 然而这并不是 Linux 里“组”的工作机制
|
||||
|
||||
我在上个星期的工作中发现了一件有趣的事,事实证明我前面的理解错了,我对组的工作机制的描述并不准确。特别是 Linux **并不会**在进程每次试图访问一个文件时就去检查这个进程的用户属于哪些组。
|
||||
|
||||
我在读了《[Linux 编程接口][1]》这本书的第九章(“进程资格”)后才恍然大悟(这本书真是太棒了),这才是组真正的工作方式!我意识到之前我并没有真正理解用户和组是怎么工作的,我信心满满的尝试了下面的内容并且验证到底发生了什么,事实证明现在我的理解才是对的。
|
||||
|
||||
### 用户和组权限检查是怎么完成的
|
||||
|
||||
现在这些关键的知识在我看来非常简单! 这本书的第九章上来就告诉我如下事实:用户和组 ID 是**进程的属性**,它们是:
|
||||
|
||||
* 真实用户 ID 和组 ID;
|
||||
* 有效用户 ID 和组 ID;
|
||||
* 保存的 set-user-ID 和保存的 set-group-ID;
|
||||
* 文件系统用户 ID 和组 ID(特定于 Linux);
|
||||
* 补充的组 ID;
|
||||
|
||||
这说明 Linux **实际上**检查一个进程能否访问一个文件所做的组检查是这样的:
|
||||
|
||||
* 检查一个进程的组 ID 和补充组 ID(这些 ID 就在进程的属性里,**并不是**实时在 `/etc/group` 里查找这些 ID)
|
||||
* 检查要访问的文件的访问属性里的组设置
|
||||
* 确定进程对文件是否有权限访问(LCTT 译注:即文件的组是否是以上的组之一)
|
||||
|
||||
通常当访问控制的时候使用的是**有效**用户/组 ID,而不是**真实**用户/组 ID。技术上来说当访问一个文件时使用的是**文件系统**的 ID,它们通常和有效用户/组 ID 一样。(LCTT 译注:这句话针对 Linux 而言。)
|
||||
|
||||
### 将一个用户加入一个组并不会将一个已存在的进程(的用户)加入那个组
|
||||
|
||||
下面是一个有趣的例子:如果我创建了一个新的组:`panda` 组并且将我自己(`bork`)加入到这个组,然后运行 `groups` 来检查我是否在这个组里:结果是我(`bork`)竟然不在这个组?!
|
||||
|
||||
```
|
||||
bork@kiwi~> sudo addgroup panda
|
||||
Adding group `panda' (GID 1001) ...
|
||||
Done.
|
||||
bork@kiwi~> sudo adduser bork panda
|
||||
Adding user `bork' to group `panda' ...
|
||||
Adding user bork to group panda
|
||||
Done.
|
||||
bork@kiwi~> groups
|
||||
bork adm cdrom sudo dip plugdev lpadmin sambashare docker lxd
|
||||
|
||||
```
|
||||
|
||||
`panda` 并不在上面的组里!为了再次确定我们的发现,让我们建一个文件,这个文件被 `panda` 组拥有,看看我能否访问它。
|
||||
|
||||
```
|
||||
$ touch panda-file.txt
|
||||
$ sudo chown root:panda panda-file.txt
|
||||
$ sudo chmod 660 panda-file.txt
|
||||
$ cat panda-file.txt
|
||||
cat: panda-file.txt: Permission denied
|
||||
```
|
||||
|
||||
好吧,确定了,我(`bork`)无法访问 `panda-file.txt`。这一点都不让人吃惊,我的命令解释器并没有将 `panda` 组作为补充组 ID,运行 `adduser bork panda` 并不会改变这一点。
|
||||
|
||||
### 那进程一开始是怎么得到用户的组的呢?
|
||||
|
||||
这真是个非常令人困惑的问题,对吗?如果进程会将组的信息预置到进程的属性里面,进程在初始化的时候怎么取到组的呢?很明显你无法给你自己指定更多的组(否则就会和 Linux 访问控制的初衷相违背了……)
|
||||
|
||||
有一点还是很清楚的:一个新的进程是怎么从我的命令行解释器(`/bash/fish`)里被**执行**而得到它的组的。(新的)进程将拥有我的用户 ID(`bork`),并且进程属性里还有很多组 ID。从我的命令解释器里执行的所有进程是从这个命令解释器里 `fork()` 而来的,所以这个新进程得到了和命令解释器同样的组。
|
||||
|
||||
因此一定存在一个“第一个”进程来把你的组设置到进程属性里,而所有由此进程而衍生的进程将都设置这些组。而那个“第一个”进程就是你的<ruby>登录程序<rt>login shell</rt></ruby>,在我的笔记本电脑上,它是由 `login` 程序(`/bin/login`)实例化而来。登录程序以 root 身份运行,然后调用了一个 C 的库函数 —— `initgroups` 来设置你的进程的组(具体来说是通过读取 `/etc/group` 文件),因为登录程序是以 root 运行的,所以它能设置你的进程的组。
|
||||
|
||||
### 让我们再登录一次
|
||||
|
||||
好了!假如说我们正处于一个登录程序中,而我又想刷新我的进程的组设置,从我们前面所学到的进程是怎么初始化组 ID 的,我应该可以通过再次运行登录程序来刷新我的进程组并启动一个新的登录命令!
|
||||
|
||||
让我们试试下边的方法:
|
||||
|
||||
```
|
||||
$ sudo login bork
|
||||
$ groups
|
||||
bork adm cdrom sudo dip plugdev lpadmin sambashare docker lxd panda
|
||||
$ cat panda-file.txt # it works! I can access the file owned by `panda` now!
|
||||
```
|
||||
|
||||
当然,成功了!现在由登录程序衍生的程序的用户是组 `panda` 的一部分了!太棒了!这并不会影响我其他的已经在运行的登录程序(及其子进程),如果我真的希望“所有的”进程都能对 `panda` 组有访问权限。我必须完全的重启我的登录会话,这意味着我必须退出我的窗口管理器然后再重新登录。(LCTT 译注:即更新进程树的树根进程,这里是窗口管理器进程。)
|
||||
|
||||
### newgrp 命令
|
||||
|
||||
在 Twitter 上有人告诉我如果只是想启动一个刷新了组信息的命令解释器的话,你可以使用 `newgrp`(LCTT 译注:不启动新的命令解释器),如下:
|
||||
|
||||
```
|
||||
sudo addgroup panda
|
||||
sudo adduser bork panda
|
||||
newgrp panda # starts a new shell, and you don't have to be root to run it!
|
||||
```
|
||||
|
||||
你也可以用 `sg panda bash` 来完成同样的效果,这个命令能启动一个`bash` 登录程序,而这个程序就有 `panda` 组。
|
||||
|
||||
### seduid 将设置有效用户 ID
|
||||
|
||||
其实我一直对一个进程如何以 `setuid root` 的权限来运行意味着什么有点似是而非。现在我知道了,事实上所发生的是:`setuid` 设置了
|
||||
“有效用户 ID”! 如果我(`julia`)运行了一个 `setuid root` 的进程( 比如 `passwd`),那么进程的**真实**用户 ID 将为 `julia`,而**有效**用户 ID 将被设置为 `root`。
|
||||
|
||||
`passwd` 需要以 root 权限来运行,但是它能看到进程的真实用户 ID 是 `julia` ,是 `julia` 启动了这个进程,`passwd` 会阻止这个进程修改除了 `julia` 之外的用户密码。
|
||||
|
||||
### 就是这些了!
|
||||
|
||||
在《[Linux 编程接口][1]》这本书里有很多 Linux 上一些功能的罕见使用方法以及 Linux 上所有的事物到底是怎么运行的详细解释,这里我就不一一展开了。那本书棒极了,我上面所说的都在该书的第九章,这章在 1300 页的书里只占了 17 页。
|
||||
|
||||
我最爱这本书的一点是我只用读 17 页关于用户和组是怎么工作的内容,而这区区 17 页就能做到内容完备、详实有用。我不用读完所有的 1300 页书就能得到有用的东西,太棒了!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/11/20/groups/
|
||||
|
||||
作者:[Julia Evans][a]
|
||||
译者:[DavidChen](https://github.com/DavidChenLiang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/
|
||||
[1]:http://man7.org/tlpi/
|
||||
@ -1,65 +1,58 @@
|
||||
你没听说过的 Go 语言惊人优点
|
||||
============================================================
|
||||
=========
|
||||
|
||||

|
||||
|
||||
来自 [https://github.com/ashleymcnamara/gophers][1] 的图稿
|
||||
*来自 [https://github.com/ashleymcnamara/gophers][1] 的图稿*
|
||||
|
||||
在这篇文章中,我将讨论为什么你需要尝试一下 Go,以及应该从哪里学起。
|
||||
在这篇文章中,我将讨论为什么你需要尝试一下 Go 语言,以及应该从哪里学起。
|
||||
|
||||
Golang 是可能是最近几年里你经常听人说起的编程语言。尽管它在 2009 年已经发布,但它最近才开始流行起来。
|
||||
Go 语言是可能是最近几年里你经常听人说起的编程语言。尽管它在 2009 年已经发布了,但它最近才开始流行起来。
|
||||
|
||||
|
||||
|
||||
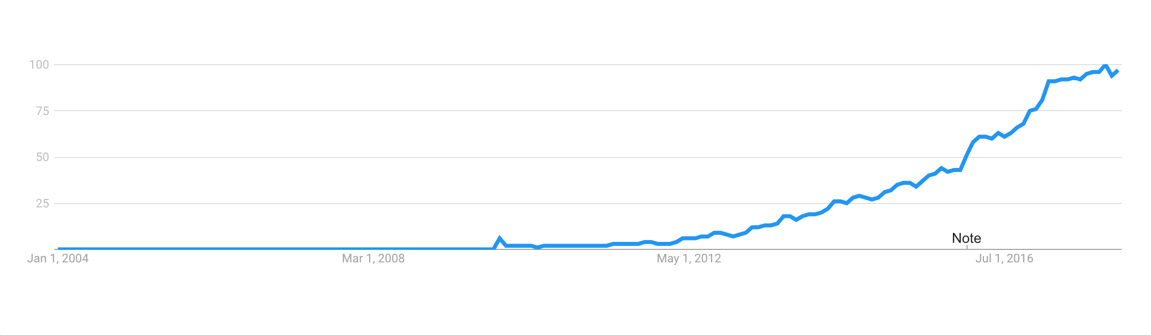
根据 Google 趋势,Golang 语言非常流行。
|
||||
*根据 Google 趋势,Go 语言非常流行。*
|
||||
|
||||
这篇文章不会讨论一些你经常看到的 Golang 的主要特性。
|
||||
这篇文章不会讨论一些你经常看到的 Go 语言的主要特性。
|
||||
|
||||
相反,我想向您介绍一些相当小众但仍然很重要的功能。在您决定尝试Go后,您才会知道这些功能。
|
||||
相反,我想向您介绍一些相当小众但仍然很重要的功能。只有在您决定尝试 Go 语言后,您才会知道这些功能。
|
||||
|
||||
这些都是表面上没有体现出来的惊人特性,但它们可以为您节省数周或数月的工作量。而且这些特性还可以使软件开发更加愉快。
|
||||
|
||||
阅读本文不需要任何语言经验,所以不比担心 Golang 对你来说是新的事物。如果你想了解更多,可以看看我在底部列出的一些额外的链接,。
|
||||
阅读本文不需要任何语言经验,所以不必担心你还不了解 Go 语言。如果你想了解更多,可以看看我在底部列出的一些额外的链接。
|
||||
|
||||
我们将讨论以下主题:
|
||||
|
||||
* GoDoc
|
||||
|
||||
* 静态代码分析
|
||||
|
||||
* 内置的测试和分析框架
|
||||
|
||||
* 竞争条件检测
|
||||
|
||||
* 学习曲线
|
||||
|
||||
* 反射(Reflection)
|
||||
|
||||
* Opinionatedness(专制独裁的 Go)
|
||||
|
||||
* 反射
|
||||
* Opinionatedness
|
||||
* 文化
|
||||
|
||||
请注意,这个列表不遵循任何特定顺序来讨论。
|
||||
|
||||
### GoDoc
|
||||
|
||||
Golang 非常重视代码中的文档,简洁也是如此。
|
||||
Go 语言非常重视代码中的文档,所以也很简洁。
|
||||
|
||||
[GoDoc][4] 是一个静态代码分析工具,可以直接从代码中创建漂亮的文档页面。GoDoc 的一个显着特点是它不使用任何其他的语言,如 JavaDoc,PHPDoc 或 JSDoc 来注释代码中的结构,只需要用英语。
|
||||
[GoDoc][4] 是一个静态代码分析工具,可以直接从代码中创建漂亮的文档页面。GoDoc 的一个显著特点是它不使用任何其他的语言,如 JavaDoc、PHPDoc 或 JSDoc 来注释代码中的结构,只需要用英语。
|
||||
|
||||
它使用从代码中获取的尽可能多的信息来概述、构造和格式化文档。它有多而全的功能,比如:交叉引用,代码示例以及一个指向版本控制系统仓库的链接。
|
||||
它使用从代码中获取的尽可能多的信息来概述、构造和格式化文档。它有多而全的功能,比如:交叉引用、代码示例,并直接链接到你的版本控制系统仓库。
|
||||
|
||||
而你需要做的只有添加一些好的,像 `// MyFunc transforms Foo into Bar` 这样子的注释,而这些注释也会反映在的文档中。你甚至可以添加一些通过网络接口或者在本地可以实际运行的 [代码示例][5]。
|
||||
而你需要做的只有添加一些像 `// MyFunc transforms Foo into Bar` 这样子的老牌注释,而这些注释也会反映在的文档中。你甚至可以添加一些通过网络界面或者在本地可以实际运行的 [代码示例][5]。
|
||||
|
||||
GoDoc 是 Go 的唯一文档引擎,供整个社区使用。这意味着用 Go 编写的每个库或应用程序都具有相同的文档格式。从长远来看,它可以帮你在浏览这些文档时节省大量时间。
|
||||
GoDoc 是 Go 的唯一文档引擎,整个社区都在使用。这意味着用 Go 编写的每个库或应用程序都具有相同的文档格式。从长远来看,它可以帮你在浏览这些文档时节省大量时间。
|
||||
|
||||
例如,这是我最近一个小项目的 GoDoc 页面:[pullkee — GoDoc][6]。
|
||||
|
||||
### 静态代码分析
|
||||
|
||||
Go 严重依赖于静态代码分析。例子包括 godoc 文档,gofmt 代码格式化,golint 代码风格统一,等等。
|
||||
Go 严重依赖于静态代码分析。例如用于文档的 [godoc][7],用于代码格式化的 [gofmt][8],用于代码风格的 [golint][9],等等。
|
||||
|
||||
其中有很多甚至全部包含在类似 [gometalinter][10] 的项目中,这些将它们全部组合成一个实用程序。
|
||||
它们是如此之多,甚至有一个总揽了它们的项目 [gometalinter][10] ,将它们组合成了单一的实用程序。
|
||||
|
||||
这些工具通常作为独立的命令行应用程序实现,并可轻松与任何编码环境集成。
|
||||
|
||||
@ -67,21 +60,21 @@ Go 严重依赖于静态代码分析。例子包括 godoc 文档,gofmt 代码
|
||||
|
||||
创建自己的分析器非常简单,因为 Go 有专门的内置包来解析和加工 Go 源码。
|
||||
|
||||
你可以从这个链接中了解到更多相关内容: [GothamGo Kickoff Meetup: Go Static Analysis Tools by Alan Donovan][11].
|
||||
你可以从这个链接中了解到更多相关内容: [GothamGo Kickoff Meetup: Alan Donovan 的 Go 静态分析工具][11]。
|
||||
|
||||
### 内置的测试和分析框架
|
||||
|
||||
您是否曾尝试为一个从头开始的 Javascript 项目选择测试框架?如果是这样,你可能会明白经历这种分析瘫痪的斗争。您可能也意识到您没有使用其中 80% 的框架。
|
||||
您是否曾尝试为一个从头开始的 JavaScript 项目选择测试框架?如果是这样,你或许会理解经历这种<ruby>过度分析<rt>analysis paralysis</rt></ruby>的痛苦。您可能也意识到您没有使用其中 80% 的框架。
|
||||
|
||||
一旦您需要进行一些可靠的分析,问题就会重复出现。
|
||||
|
||||
Go 附带内置测试工具,旨在简化和提高效率。它为您提供了最简单的 API,并做出最小的假设。您可以将它用于不同类型的测试,分析,甚至可以提供可执行代码示例。
|
||||
Go 附带内置测试工具,旨在简化和提高效率。它为您提供了最简单的 API,并做出最小的假设。您可以将它用于不同类型的测试、分析,甚至可以提供可执行代码示例。
|
||||
|
||||
它可以开箱即用地生成持续集成友好的输出,而且它的用法很简单,只需运行 `go test`。当然,它还支持高级功能,如并行运行测试,跳过标记代码,以及其他更多功能。
|
||||
它可以开箱即用地生成便于持续集成的输出,而且它的用法很简单,只需运行 `go test`。当然,它还支持高级功能,如并行运行测试,跳过标记代码,以及其他更多功能。
|
||||
|
||||
### 竞争条件检测
|
||||
|
||||
您可能已经了解了 Goroutines,它们在 Go 中用于实现并发代码执行。如果你未曾了解过,[这里][12]有一个非常简短的解释。
|
||||
您可能已经听说了 Goroutine,它们在 Go 中用于实现并发代码执行。如果你未曾了解过,[这里][12]有一个非常简短的解释。
|
||||
|
||||
无论具体技术如何,复杂应用中的并发编程都不容易,部分原因在于竞争条件的可能性。
|
||||
|
||||
@ -93,13 +86,13 @@ Go 附带内置测试工具,旨在简化和提高效率。它为您提供了
|
||||
|
||||
### 学习曲线
|
||||
|
||||
您可以在一个晚上学习所有 Go 的语言功能。我是认真的。当然,还有标准库,以及不同,更具体领域的最佳实践。但是两个小时就足以让你自信地编写一个简单的 HTTP 服务器或命令行应用程序。
|
||||
您可以在一个晚上学习**所有**的 Go 语言功能。我是认真的。当然,还有标准库,以及不同的,更具体领域的最佳实践。但是两个小时就足以让你自信地编写一个简单的 HTTP 服务器或命令行应用程序。
|
||||
|
||||
Golang 拥有[出色的文档][14],大部分高级主题已经在博客上进行了介绍:[The Go Programming Language Blog][15]。
|
||||
Go 语言拥有[出色的文档][14],大部分高级主题已经在他们的博客上进行了介绍:[Go 编程语言博客][15]。
|
||||
|
||||
比起 Java(以及 Java 家族的语言),Javascript,Ruby,Python 甚至 PHP,你可以更轻松地把 Go 语言带到你的团队中。由于环境易于设置,您的团队在完成第一个生产代码之前需要进行的投资要小得多。
|
||||
比起 Java(以及 Java 家族的语言)、Javascript、Ruby、Python 甚至 PHP,你可以更轻松地把 Go 语言带到你的团队中。由于环境易于设置,您的团队在完成第一个生产代码之前需要进行的投资要小得多。
|
||||
|
||||
### 反射(Reflection)
|
||||
### 反射
|
||||
|
||||
代码反射本质上是一种隐藏在编译器下并访问有关语言结构的各种元信息的能力,例如变量或函数。
|
||||
|
||||
@ -107,19 +100,19 @@ Golang 拥有[出色的文档][14],大部分高级主题已经在博客上进
|
||||
|
||||
此外,Go [没有实现一个名为泛型的概念][16],这使得以抽象方式处理多种类型更具挑战性。然而,由于泛型带来的复杂程度,许多人认为不实现泛型对语言实际上是有益的。我完全同意。
|
||||
|
||||
根据 Go 的理念(这是一个单独的主题),您应该努力不要过度设计您的解决方案。这也适用于动态类型编程。尽可能坚持使用静态类型,并在确切知道要处理的类型时使用接口(interfaces)。接口在 Go 中非常强大且无处不在。
|
||||
根据 Go 的理念(这是一个单独的主题),您应该努力不要过度设计您的解决方案。这也适用于动态类型编程。尽可能坚持使用静态类型,并在确切知道要处理的类型时使用<ruby>接口<rt>interface</rt></ruby>。接口在 Go 中非常强大且无处不在。
|
||||
|
||||
但是,仍然存在一些情况,你无法知道你处理的数据类型。一个很好的例子是 JSON。您可以在应用程序中来回转换所有类型的数据。字符串,缓冲区,各种数字,嵌套结构等。
|
||||
但是,仍然存在一些情况,你无法知道你处理的数据类型。一个很好的例子是 JSON。您可以在应用程序中来回转换所有类型的数据。字符串、缓冲区、各种数字、嵌套结构等。
|
||||
|
||||
为了解决这个问题,您需要一个工具来检查运行时的数据并根据其类型和结构采取不同行为。反射(Reflect)可以帮到你。Go 拥有一流的反射包,使您的代码能够像 Javascript 这样的语言一样动态。
|
||||
为了解决这个问题,您需要一个工具来检查运行时的数据并根据其类型和结构采取不同行为。<ruby>反射<rt>Reflect</rt></ruby>可以帮到你。Go 拥有一流的反射包,使您的代码能够像 Javascript 这样的语言一样动态。
|
||||
|
||||
一个重要的警告是知道你使用它所带来的代价 - 并且只有知道在没有更简单的方法时才使用它。
|
||||
一个重要的警告是知道你使用它所带来的代价 —— 并且只有知道在没有更简单的方法时才使用它。
|
||||
|
||||
你可以在这里阅读更多相关信息: [反射的法则 — Go 博客][18].
|
||||
|
||||
您还可以在此处阅读 JSON 包源码中的一些实际代码: [src/encoding/json/encode.go — Source Code][19]
|
||||
|
||||
### Opinionatedness
|
||||
### Opinionatedness(专制独裁的 Go)
|
||||
|
||||
顺便问一下,有这样一个单词吗?
|
||||
|
||||
@ -127,9 +120,9 @@ Golang 拥有[出色的文档][14],大部分高级主题已经在博客上进
|
||||
|
||||
这有时候基本上让我卡住了。我需要花时间思考这些事情而不是编写代码并满足用户。
|
||||
|
||||
首先,我应该注意到我完全可以得到这些惯例的来源,它总是来源于你或者你的团队。无论如何,即使是一群经验丰富的 Javascript 开发人员也可以轻松地发现自己拥有完全不同的工具和范例的大部分经验,以实现相同的结果。
|
||||
首先,我应该注意到我完全知道这些惯例的来源,它总是来源于你或者你的团队。无论如何,即使是一群经验丰富的 Javascript 开发人员也很容易发现他们在实现相同的结果时,而大部分的经验却是在完全不同的工具和范例上。
|
||||
|
||||
这导致整个团队中分析的瘫痪,并且使得个体之间更难以相互协作。
|
||||
这导致整个团队中出现过度分析,并且使得个体之间更难以相互协作。
|
||||
|
||||
嗯,Go 是不同的。即使您对如何构建和维护代码有很多强烈的意见,例如:如何命名,要遵循哪些结构模式,如何更好地实现并发。但你只有一个每个人都遵循的风格指南。你只有一个内置在基本工具链中的测试框架。
|
||||
|
||||
@ -141,11 +134,11 @@ Golang 拥有[出色的文档][14],大部分高级主题已经在博客上进
|
||||
|
||||
人们说,每当你学习一门新的口语时,你也会沉浸在说这种语言的人的某些文化中。因此,您学习的语言越多,您可能会有更多的变化。
|
||||
|
||||
编程语言也是如此。无论您将来如何应用新的编程语言,它总能给的带来新的编程视角或某些特别的技术。
|
||||
编程语言也是如此。无论您将来如何应用新的编程语言,它总能给你带来新的编程视角或某些特别的技术。
|
||||
|
||||
无论是函数式编程,模式匹配(pattern matching)还是原型继承(prototypal inheritance)。一旦你学会了它们,你就可以随身携带这些编程思想,这扩展了你作为软件开发人员所拥有的问题解决工具集。它们也改变了你阅读高质量代码的方式。
|
||||
无论是函数式编程,<ruby>模式匹配<rt>pattern matching</rt></ruby>还是<ruby>原型继承<rt>prototypal inheritance</rt></ruby>。一旦你学会了它们,你就可以随身携带这些编程思想,这扩展了你作为软件开发人员所拥有的问题解决工具集。它们也改变了你阅读高质量代码的方式。
|
||||
|
||||
而 Go 在方面有一项了不起的财富。Go 文化的主要支柱是保持简单,脚踏实地的代码,而不会产生许多冗余的抽象概念,并将可维护性放在首位。大部分时间花费在代码的编写工作上,而不是在修补工具和环境或者选择不同的实现方式上,这也是 Go文化的一部分。
|
||||
而 Go 在这方面有一项了不起的财富。Go 文化的主要支柱是保持简单,脚踏实地的代码,而不会产生许多冗余的抽象概念,并将可维护性放在首位。大部分时间花费在代码的编写工作上,而不是在修补工具和环境或者选择不同的实现方式上,这也是 Go 文化的一部分。
|
||||
|
||||
Go 文化也可以总结为:“应当只用一种方法去做一件事”。
|
||||
|
||||
@ -161,12 +154,11 @@ Go 文化也可以总结为:“应当只用一种方法去做一件事”。
|
||||
|
||||
这不是 Go 的所有惊人的优点的完整列表,只是一些被人低估的特性。
|
||||
|
||||
请尝试一下从 [Go 之旅(A Tour of Go)][20]来开始学习 Go,这将是一个令人惊叹的开始。
|
||||
请尝试一下从 [Go 之旅][20] 来开始学习 Go,这将是一个令人惊叹的开始。
|
||||
|
||||
如果您想了解有关 Go 的优点的更多信息,可以查看以下链接:
|
||||
|
||||
* [你为什么要学习 Go? - Keval Patel][2]
|
||||
|
||||
* [告别Node.js - TJ Holowaychuk][3]
|
||||
|
||||
并在评论中分享您的阅读感悟!
|
||||
@ -175,30 +167,16 @@ Go 文化也可以总结为:“应当只用一种方法去做一件事”。
|
||||
|
||||
不断为您的工作寻找最好的工具!
|
||||
|
||||
* * *
|
||||
|
||||
If you like this article, please consider following me for more, and clicking on those funny green little hands right below this text for sharing. 👏👏👏
|
||||
|
||||
Check out my [Github][21] and follow me on [Twitter][22]!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Software Engineer and Traveler. Coding for fun. Javascript enthusiast. Tinkering with Golang. A lot into SOA and Docker. Architect at Velvica.
|
||||
|
||||
------------
|
||||
|
||||
|
||||
-------------------------------------------------------
|
||||
via: https://medium.freecodecamp.org/here-are-some-amazing-advantages-of-go-that-you-dont-hear-much-about-1af99de3b23a
|
||||
|
||||
作者:[Kirill Rogovoy][a]
|
||||
译者:[译者ID](https://github.com/imquanquan)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[imquanquan](https://github.com/imquanquan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[a]:https://twitter.com/krogovoy
|
||||
[1]:https://github.com/ashleymcnamara/gophers
|
||||
[2]:https://medium.com/@kevalpatel2106/why-should-you-learn-go-f607681fad65
|
||||
[3]:https://medium.com/@tjholowaychuk/farewell-node-js-4ba9e7f3e52b
|
||||
181
published/20180516 Manipulating Directories in Linux.md
Normal file
181
published/20180516 Manipulating Directories in Linux.md
Normal file
@ -0,0 +1,181 @@
|
||||
在 Linux 上操作目录
|
||||
======
|
||||
|
||||

|
||||
|
||||
> 让我们继续学习一下 Linux 文件系统的树形结构,并展示一下如何在其中创建你的目录。
|
||||
|
||||
如果你不熟悉本系列(以及 Linux),[请查看我们的第一部分][1]。在那篇文章中,我们贯穿了 Linux 文件系统的树状结构(或者更确切地说是<ruby>文件层次结构标准<rt>File Hierarchy Standard</rt></ruby>,FHS)。我建议你仔细阅读,确保你理解自己能安全的做哪些操作。因为这一次,我将向你展示目录操作的魅力。
|
||||
|
||||
### 新建目录
|
||||
|
||||
在破坏之前,先让我们来创建。首先,打开一个终端窗口并使用命令 `mkdir` 创建一个新目录,如下所示:
|
||||
|
||||
```
|
||||
mkdir <directoryname>
|
||||
```
|
||||
如果你只输入了目录名称,该目录将显示在您当前所在目录中。如果你刚刚打开一个终端,你当前位置为你的家目录。在这个例子中,我们展示了将要创建的目录与你当前所处位置的关系:
|
||||
|
||||
```
|
||||
$ pwd # 告知你当前所在位置(参见第一部分)
|
||||
/home/<username>
|
||||
$ mkdir newdirectory # 创建 /home/<username>/newdirectory
|
||||
```
|
||||
|
||||
(注:你不用输入 `#` 后面的文本。`#` 后面的文本为注释内容,用于解释发生了什么。它会被 shell 忽略,不会被执行)。
|
||||
|
||||
你可以在当前位置中已经存在的某个目录下创建新的目录,方法是在命令行中指定它:
|
||||
|
||||
```
|
||||
mkdir Documents/Letters
|
||||
```
|
||||
|
||||
这将在 `Documents` 目录中创建 `Letters` 目录。
|
||||
|
||||
你还可以在路径中使用 `..` 在当前目录的上一级目录中创建目录。假设你进入刚刚创建的 `Documents/Letters/` 目录,并且想要创建`Documents/Memos/` 目录。你可以这样做:
|
||||
|
||||
```
|
||||
cd Documents/Letters # 进入到你刚刚创建的 Letters/ 目录
|
||||
mkdir ../Memos
|
||||
```
|
||||
|
||||
同样,以上所有内容都是相对于你当前的位置做的。这就是使用了相对路径。
|
||||
|
||||
你还可以使用目录的绝对路径:这意味着告诉 `mkdir` 命令将目录放在和根目录(`/`)有关的位置:
|
||||
|
||||
```
|
||||
mkdir /home/<username>/Documents/Letters
|
||||
```
|
||||
|
||||
在上面的命令中将 `<username>` 更改为你的用户名,这相当于从你的主目录执行 `mkdir Documents/Letters`,通过使用绝对路径你可以在目录树中的任何位置完成这项工作。
|
||||
|
||||
无论你使用相对路径还是绝对路径,只要命令成功执行,`mkdir` 将静默的创建新目录,而没有任何明显的反馈。只有当遇到某种问题时,`mkdir`才会在你敲下回车键后打印一些反馈。
|
||||
|
||||
与大多数其他命令行工具一样,`mkdir` 提供了几个有趣的选项。 `-p` 选项特别有用,因为它允许你嵌套创建目录,即使目录不存在也可以。例如,要在 `Documents/` 中创建一个目录存放写给妈妈的信,你可以这样做:
|
||||
|
||||
```
|
||||
mkdir -p Documents/Letters/Family/Mom
|
||||
```
|
||||
|
||||
`mkdir` 会创建 `Mom/` 之上的整个目录分支,并且也会创建 `Mom/` 目录,无论其上的目录在你敲入该命令时是否已经存在。
|
||||
|
||||
你也可以用空格来分隔目录名,来同时创建几个目录:
|
||||
|
||||
```
|
||||
mkdir Letters Memos Reports
|
||||
```
|
||||
|
||||
这将在当前目录下创建目录 `Letters`、`Memos` 和 `Reports`。
|
||||
|
||||
### 目录名中可怕的空格
|
||||
|
||||
……这带来了目录名称中关于空格的棘手问题。你能在目录名中使用空格吗?是的你可以。那么建议你使用空格吗?不,绝对不建议。空格使一切变得更加复杂,并且可能是危险的操作。
|
||||
|
||||
假设您要创建一个名为 `letters mom/` 的目录。如果你不知道如何更好处理,你可能会输入:
|
||||
|
||||
```
|
||||
mkdir letters mom
|
||||
```
|
||||
|
||||
但这是错误的!错误的!错误的!正如我们在上面介绍的,这将创建两个目录 `letters/` 和 `mom/`,而不是一个目录 `letters mom/`。
|
||||
|
||||
得承认这是一个小麻烦:你所要做的就是删除这两个目录并重新开始,这没什么大不了。
|
||||
|
||||
可是等等!删除目录可是个危险的操作。想象一下,你使用图形工具[Dolphin][2] 或 [Nautilus][3] 创建了目录 `letters mom/`。如果你突然决定从终端删除目录 `letters mom`,并且您在同一目录下有另一个名为 `letters` 的目录,并且该目录中包含重要的文档,结果你为了删除错误的目录尝试了以下操作:
|
||||
|
||||
```
|
||||
rmdir letters mom
|
||||
```
|
||||
|
||||
你将会有删除目录 letters 的风险。这里说“风险”,是因为幸运的是`rmdir` 这条用于删除目录的指令,有一个内置的安全措施,如果你试图删除一个非空目录时,它会发出警告。
|
||||
|
||||
但是,下面这个:
|
||||
|
||||
```
|
||||
rm -Rf letters mom
|
||||
```
|
||||
|
||||
(注:这是删除目录及其内容的一种非常标准的方式)将完全删除 `letters/` 目录,甚至永远不会告诉你刚刚发生了什么。)
|
||||
|
||||
`rm` 命令用于删除文件和目录。当你将它与选项 `-R`(递归删除)和 `-f`(强制删除)一起使用时,它会深入到目录及其子目录中,删除它们包含的所有文件,然后删除子目录本身,然后它将删除所有顶层目录中的文件,再然后是删除目录本身。
|
||||
|
||||
`rm -Rf` 是你必须非常小心处理的命令。
|
||||
|
||||
我的建议是,你可以使用下划线来代替空格,但如果你仍然坚持使用空格,有两种方法可以使它们起作用。您可以使用单引号或双引号,如下所示:
|
||||
|
||||
```
|
||||
mkdir 'letters mom'
|
||||
mkdir "letters dad"
|
||||
```
|
||||
|
||||
或者,你可以转义空格。有些字符对 shell 有特殊意义。正如你所见,空格用于在命令行上分隔选项和参数。 “分离选项和参数”属于“特殊含义”范畴。当你想让 shell 忽略一个字符的特殊含义时,你需要转义,你可以在它前面放一个反斜杠(`\`)如:
|
||||
|
||||
```
|
||||
mkdir letters\ mom
|
||||
mkdir letter\ dad
|
||||
```
|
||||
|
||||
还有其他特殊字符需要转义,如撇号或单引号(`'`),双引号(`“`)和&符号(`&`):
|
||||
|
||||
```
|
||||
mkdir mom\ \&\ dad\'s\ letters
|
||||
```
|
||||
|
||||
我知道你在想什么:如果反斜杠有一个特殊的含义(即告诉 shell 它必须转义下一个字符),这也使它成为一个特殊的字符。然后,你将如何转义转义字符(`\`)?
|
||||
|
||||
事实证明,你转义任何其他特殊字符都是同样的方式:
|
||||
|
||||
```
|
||||
mkdir special\\characters
|
||||
```
|
||||
|
||||
这将生成一个名为 `special\characters/` 的目录。
|
||||
|
||||
感觉困惑?当然。这就是为什么你应该避免在目录名中使用特殊字符,包括空格。
|
||||
|
||||
以防误操作你可以参考下面这个记录特殊字符的列表。(LCTT 译注:此处原文链接丢失。)
|
||||
|
||||
### 总结
|
||||
|
||||
* 使用 `mkdir <directory name>` 创建新目录。
|
||||
* 使用 `rmdir <directory name>` 删除目录(仅在目录为空时才有效)。
|
||||
* 使用 `rm -Rf <directory name>` 来完全删除目录及其内容 —— 请务必谨慎使用。
|
||||
* 使用相对路径创建相对于当前目录的目录: `mkdir newdir`。
|
||||
* 使用绝对路径创建相对于根目录(`/`)的目录: `mkdir /home/<username>/newdir`。
|
||||
* 使用 `..` 在当前目录的上级目录中创建目录: `mkdir ../newdir`。
|
||||
* 你可以通过在命令行上使用空格分隔目录名来创建多个目录: `mkdir onedir twodir threedir`。
|
||||
* 同时创建多个目录时,你可以混合使用相对路径和绝对路径: `mkdir onedir twodir /home/<username>/threedir`。
|
||||
* 在目录名称中使用空格和特殊字符真的会让你很头疼,你最好不要那样做。
|
||||
|
||||
有关更多信息,您可以查看 `mkdir`、`rmdir` 和 `rm` 的手册:
|
||||
|
||||
```
|
||||
man mkdir
|
||||
man rmdir
|
||||
man rm
|
||||
```
|
||||
|
||||
要退出手册页,请按键盘 `q` 键。
|
||||
|
||||
### 下次预告
|
||||
|
||||
在下一部分中,你将学习如何创建、修改和删除文件,以及你需要了解的有关权限和特权的所有信息!
|
||||
|
||||
通过 Linux 基金会和 edX 免费提供的[“Introduction to Linux”][4]课程了解有关Linux的更多信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2018/5/manipulating-directories-linux
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[way-ww](https://github.com/way-ww)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/bro66
|
||||
[1]:https://linux.cn/article-9798-1.html
|
||||
[2]:https://userbase.kde.org/Dolphin
|
||||
[3]:https://projects-old.gnome.org/nautilus/screenshots.html
|
||||
[4]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,80 +1,84 @@
|
||||
这 7 个 Python 库让你写出更易维护的代码
|
||||
让 Python 代码更易维护的七种武器
|
||||
======
|
||||
|
||||
> 检查你的代码的质量,通过这些外部库使其更易维护。
|
||||
|
||||

|
||||
|
||||
> 可读性很重要。
|
||||
> — [Python 之禅(The Zen of Python)][1], Tim Peters
|
||||
> — <ruby>[Python 之禅][1]<rt>The Zen of Python</rt></ruby>,Tim Peters
|
||||
|
||||
尽管很多项目一开始的时候就有可读性和编码标准的要求,但随着项目进入“维护模式”,这些要求都会变得虎头蛇尾。然而,在代码库中保持一致的代码风格和测试标准能够显著减轻维护的压力,也能确保新的开发者能够快速了解项目的情况,同时能更好地保持应用程序的运行良好。
|
||||
随着软件项目进入“维护模式”,对可读性和编码标准的要求很容易落空(甚至从一开始就没有建立过那些标准)。然而,在代码库中保持一致的代码风格和测试标准能够显著减轻维护的压力,也能确保新的开发者能够快速了解项目的情况,同时能更好地全程保持应用程序的质量。
|
||||
|
||||
使用外部库来检查代码的质量不失为保护项目未来可维护性的一个好方法。以下会推荐一些我们最喜爱的[检查代码][2](包括检查 PEP 8 和其它代码风格错误)的库,用它们来强制保持代码风格一致,并确保在项目成熟时有一个可接受的测试覆盖率。
|
||||
|
||||
### 检查你的代码风格
|
||||
|
||||
使用外部库来检查代码运行情况不失为保护项目未来可维护性的一个好方法。以下会推荐一些我们最喜爱的[检查代码][2](包括检查 PEP 8 和其它代码风格错误)的库,用它们来强制保持代码风格一致,并确保在项目成熟时有一个可接受的测试覆盖率。
|
||||
[PEP 8][3] 是 Python 代码风格规范,它规定了类似行长度、缩进、多行表达式、变量命名约定等内容。尽管你的团队自身可能也会有稍微不同于 PEP 8 的代码风格规范,但任何代码风格规范的目标都是在代码库中强制实施一致的标准,使代码的可读性更强、更易于维护。下面三个库就可以用来帮助你美化代码。
|
||||
|
||||
[PEP 8][3]是Python代码风格规范,规定了行长度,缩进,多行表达式、变量命名约定等内容。尽管你的团队自身可能也会有不同于 PEP 8 的代码风格规范,但任何代码风格规范的目标都是在代码库中强制实施一致的标准,使代码的可读性更强、更易于维护。下面三个库就可以用来帮助你美化代码。
|
||||
#### 1、 Pylint
|
||||
|
||||
#### 1\. Pylint
|
||||
[Pylint][4] 是一个检查违反 PEP 8 规范和常见错误的库。它在一些流行的[编辑器和 IDE][5] 中都有集成,也可以单独从命令行运行。
|
||||
|
||||
[Pylint][4] 是一个检查违反 PEP 8 规范和常见错误的库。它在一些流行的编辑器和 IDE 中都有集成,也可以单独从命令行运行。
|
||||
|
||||
执行 `pip install pylint`安装 Pylint 。然后运行 `pylint [options] path/to/dir` 或者 `pylint [options] path/to/module.py` 就可以在命令行中使用 Pylint,它会向控制台输出代码中违反规范和出现错误的地方。
|
||||
执行 `pip install pylint` 安装 Pylint 。然后运行 `pylint [options] path/to/dir` 或者 `pylint [options] path/to/module.py` 就可以在命令行中使用 Pylint,它会向控制台输出代码中违反规范和出现错误的地方。
|
||||
|
||||
你还可以使用 `pylintrc` [配置文件][6]来自定义 Pylint 对哪些代码错误进行检查。
|
||||
|
||||
#### 2\. Flake8
|
||||
#### 2、 Flake8
|
||||
|
||||
对 [Flake8][7] 的描述是“将 PEP 8、Pyflakes(类似 Pylint)、McCabe(代码复杂性检查器)、第三方插件整合到一起,以检查 Python 代码风格和质量的一个 Python 工具”。
|
||||
[Flake8][7] 是“将 PEP 8、Pyflakes(类似 Pylint)、McCabe(代码复杂性检查器)和第三方插件整合到一起,以检查 Python 代码风格和质量的一个 Python 工具”。
|
||||
|
||||
执行 `pip install flake8` 安装 flake8 ,然后执行 `flake8 [options] path/to/dir` 或者 `flake8 [options] path/to/module.py` 可以查看报出的错误和警告。
|
||||
|
||||
和 Pylint 类似,Flake8 允许通过[配置文件][8]来自定义检查的内容。它有非常清晰的文档,包括一些有用的[提交钩子][9],可以将自动检查代码纳入到开发工作流程之中。
|
||||
|
||||
Flake8 也允许集成到一些流行的编辑器和 IDE 当中,但在文档中并没有详细说明。要将 Flake8 集成到喜欢的编辑器或 IDE 中,可以搜索插件(例如 [Sublime Text 的 Flake8 插件][10])。
|
||||
Flake8 也可以集成到一些流行的编辑器和 IDE 当中,但在文档中并没有详细说明。要将 Flake8 集成到喜欢的编辑器或 IDE 中,可以搜索插件(例如 [Sublime Text 的 Flake8 插件][10])。
|
||||
|
||||
#### 3\. Isort
|
||||
#### 3、 Isort
|
||||
|
||||
[Isort][11] 这个库能将你在项目中导入的库按字母顺序,并将其[正确划分为不同部分][12](例如标准库、第三方库,自建的库等)。这样提高了代码的可读性,并且可以在导入的库较多的时候轻松找到各个库。
|
||||
[Isort][11] 这个库能将你在项目中导入的库按字母顺序排序,并将其[正确划分为不同部分][12](例如标准库、第三方库、自建的库等)。这样提高了代码的可读性,并且可以在导入的库较多的时候轻松找到各个库。
|
||||
|
||||
执行 `pip install isort` 安装 isort,然后执行 `isort path/to/module.py` 就可以运行了。文档中还提供了更多的配置项,例如通过配置 `.isort.cfg` 文件来决定 isort 如何处理一个库的多行导入。
|
||||
执行 `pip install isort` 安装 isort,然后执行 `isort path/to/module.py` 就可以运行了。[文档][13]中还提供了更多的配置项,例如通过[配置][14] `.isort.cfg` 文件来决定 isort 如何处理一个库的多行导入。
|
||||
|
||||
和 Flake8、Pylint 一样,isort 也提供了将其与流行的[编辑器和 IDE][15] 集成的插件。
|
||||
|
||||
### 共享代码风格
|
||||
### 分享你的代码风格
|
||||
|
||||
每次文件发生变动之后都用命令行手动检查代码是一件痛苦的事,你可能也不太喜欢通过运行 IDE 中某个插件来实现这个功能。同样地,你的同事可能会用不同的代码检查方式,也许他们的编辑器中也没有安装插件,甚至自己可能也不会严格检查代码和按照警告来更正代码。总之,你共享的代码库将会逐渐地变得混乱且难以阅读。
|
||||
每次文件发生变动之后都用命令行手动检查代码是一件痛苦的事,你可能也不太喜欢通过运行 IDE 中某个插件来实现这个功能。同样地,你的同事可能会用不同的代码检查方式,也许他们的编辑器中也没有那种插件,甚至你自己可能也不会严格检查代码和按照警告来更正代码。总之,你分享出来的代码库将会逐渐地变得混乱且难以阅读。
|
||||
|
||||
一个很好的解决方案是使用一个库,自动将代码按照 PEP 8 规范进行格式化。我们推荐的三个库都有不同的自定义级别来控制如何格式化代码。其中有一些设置较为特殊,例如 Pylint 和 Flake8 ,你需要先行测试,看看是否有你无法忍受蛋有不能修改的默认配置。
|
||||
一个很好的解决方案是使用一个库,自动将代码按照 PEP 8 规范进行格式化。我们推荐的三个库都有不同的自定义级别来控制如何格式化代码。其中有一些设置较为特殊,例如 Pylint 和 Flake8 ,你需要先行测试,看看是否有你无法忍受但又不能修改的默认配置。
|
||||
|
||||
#### 4\. Autopep8
|
||||
#### 4、 Autopep8
|
||||
|
||||
[Autopep8][16] 可以自动格式化指定的模块中的代码,包括重新缩进行,修复缩进,删除多余的空格,并重构常见的比较错误(例如布尔值和 `None` 值)。你可以查看文档中完整的[更正列表][17]。
|
||||
[Autopep8][16] 可以自动格式化指定的模块中的代码,包括重新缩进行、修复缩进、删除多余的空格,并重构常见的比较错误(例如布尔值和 `None` 值)。你可以查看文档中完整的[更正列表][17]。
|
||||
|
||||
运行 `pip install --upgrade autopep8` 安装 autopep8。然后执行 `autopep8 --in-place --aggressive --aggressive <filename>` 就可以重新格式化你的代码。`aggressive` 标记的数量表示 auotopep8 在代码风格控制上有多少控制权。在这里可以详细了解 [aggressive][18] 选项。
|
||||
运行 `pip install --upgrade autopep8` 安装 Autopep8。然后执行 `autopep8 --in-place --aggressive --aggressive <filename>` 就可以重新格式化你的代码。`aggressive` 选项的数量表示 Auotopep8 在代码风格控制上有多少控制权。在这里可以详细了解 [aggressive][18] 选项。
|
||||
|
||||
#### 5\. Yapf
|
||||
#### 5、 Yapf
|
||||
|
||||
[Yapf][19] 是另一种有自己的[配置项][20]列表的重新格式化代码的工具。它与 autopep8 的不同之处在于它不仅会指出代码中违反 PEP 8 规范的地方,还会对没有违反 PEP 8 但代码风格不一致的地方重新格式化,旨在令代码的可读性更强。
|
||||
[Yapf][19] 是另一种有自己的[配置项][20]列表的重新格式化代码的工具。它与 Autopep8 的不同之处在于它不仅会指出代码中违反 PEP 8 规范的地方,还会对没有违反 PEP 8 但代码风格不一致的地方重新格式化,旨在令代码的可读性更强。
|
||||
|
||||
执行`pip install yapf` 安装 Yapf,然后执行 `yapf [options] path/to/dir` 或 `yapf [options] path/to/module.py` 可以对代码重新格式化。
|
||||
执行 `pip install yapf` 安装 Yapf,然后执行 `yapf [options] path/to/dir` 或 `yapf [options] path/to/module.py` 可以对代码重新格式化。[定制选项][20]的完整列表在这里。
|
||||
|
||||
#### 6\. Black
|
||||
#### 6、 Black
|
||||
|
||||
[Black][21] 在代码检查工具当中算是比较新的一个。它与 autopep8 和 Yapf 类似,但限制较多,没有太多的自定义选项。这样的好处是你不需要去决定使用怎么样的代码风格,让 black 来给你做决定就好。你可以在这里查阅 black 的[自定义选项][22]以及[如何在配置文件中对其进行设置][23]。
|
||||
[Black][21] 在代码检查工具当中算是比较新的一个。它与 Autopep8 和 Yapf 类似,但限制较多,没有太多的自定义选项。这样的好处是你不需要去决定使用怎么样的代码风格,让 Black 来给你做决定就好。你可以在这里查阅 Black [有限的自定义选项][22]以及[如何在配置文件中对其进行设置][23]。
|
||||
|
||||
Black 依赖于 Python 3.6+,但它可以格式化用 Python 2 编写的代码。执行 `pip install black` 安装 black,然后执行 `black path/to/dir` 或 `black path/to/module.py` 就可以使用 black 优化你的代码。
|
||||
Black 依赖于 Python 3.6+,但它可以格式化用 Python 2 编写的代码。执行 `pip install black` 安装 Black,然后执行 `black path/to/dir` 或 `black path/to/module.py` 就可以使用 Black 优化你的代码。
|
||||
|
||||
### 检查你的测试覆盖率
|
||||
|
||||
如果你正在进行测试工作,你需要确保提交到代码库的新代码都已经测试通过,并且不会降低测试覆盖率。虽然测试覆盖率不是衡量测试有效性和充分性的唯一指标,但它是确保项目遵循基本测试标准的一种方法。对于计算测试覆盖率,我们推荐使用 Coverage 这个库。
|
||||
如果你正在进行编写测试,你需要确保提交到代码库的新代码都已经测试通过,并且不会降低测试覆盖率。虽然测试覆盖率不是衡量测试有效性和充分性的唯一指标,但它是确保项目遵循基本测试标准的一种方法。对于计算测试覆盖率,我们推荐使用 Coverage 这个库。
|
||||
|
||||
#### 7\. Coverage
|
||||
#### 7、 Coverage
|
||||
|
||||
[Coverage][24] 有数种显示测试覆盖率的方式,包括将结果输出到控制台或 HTML 页面,并指出哪些具体哪些地方没有被覆盖到。你可以通过配置文件自定义 Coverage 检查的内容,让你更方便使用。
|
||||
[Coverage][24] 有数种显示测试覆盖率的方式,包括将结果输出到控制台或 HTML 页面,并指出哪些具体哪些地方没有被覆盖到。你可以通过[配置文件][25]自定义 Coverage 检查的内容,让你更方便使用。
|
||||
|
||||
执行 `pip install coverage` 安装 Converage 。然后执行 `coverage [path/to/module.py] [args]` 可以运行程序并查看输出结果。如果要查看哪些代码行没有被覆盖,执行 `coverage report -m` 即可。
|
||||
|
||||
持续集成(Continuous integration, CI)是在合并和部署代码之前自动检查代码风格错误和测试覆盖率最小值的过程。很多免费或付费的工具都可以用于执行这项工作,具体的过程不在本文中赘述,但 CI 过程是令代码更易读和更易维护的重要步骤,关于这一部分可以参考 [Travis CI][26] 和 [Jenkins][27]。
|
||||
### 持续集成工具
|
||||
|
||||
<ruby>持续集成<rt>Continuous integration</rt></ruby>(CI)是在合并和部署代码之前自动检查代码风格错误和测试覆盖率最小值的过程。很多免费或付费的工具都可以用于执行这项工作,具体的过程不在本文中赘述,但 CI 过程是令代码更易读和更易维护的重要步骤,关于这一部分可以参考 [Travis CI][26] 和 [Jenkins][27]。
|
||||
|
||||
以上这些只是用于检查 Python 代码的各种工具中的其中几个。如果你有其它喜爱的工具,欢迎在评论中分享。
|
||||
|
||||
@ -85,7 +89,7 @@ via: https://opensource.com/article/18/7/7-python-libraries-more-maintainable-co
|
||||
作者:[Jeff Triplett][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -16,12 +16,8 @@ Linux DNS 查询剖析(第四部分)
|
||||
|
||||
在第四部分中,我将介绍容器如何完成 DNS 查询。你想的没错,也不是那么简单。
|
||||
|
||||
* * *
|
||||
|
||||
### 1) Docker 和 DNS
|
||||
|
||||
============================================================
|
||||
|
||||
在 [Linux DNS 查询剖析(第三部分)][3] 中,我们介绍了 `dnsmasq`,其工作方式如下:将 DNS 查询指向到 localhost 地址 `127.0.0.1`,同时启动一个进程监听 `53` 端口并处理查询请求。
|
||||
|
||||
在按上述方式配置 DNS 的主机上,如果运行了一个 Docker 容器,容器内的 `/etc/resolv.conf` 文件会是怎样的呢?
|
||||
@ -72,29 +68,29 @@ google.com. 112 IN A 172.217.23.14
|
||||
|
||||
在这个问题上,Docker 的解决方案是忽略所有可能的复杂情况,即无论主机中使用什么 DNS 服务器,容器内都使用 Google 的 DNS 服务器 `8.8.8.8` 和 `8.8.4.4` 完成 DNS 查询。
|
||||
|
||||
_我的经历:在 2013 年,我遇到了使用 Docker 以来的第一个问题,与 Docker 的这种 DNS 解决方案密切相关。我们公司的网络屏蔽了 `8.8.8.8` 和 `8.8.4.4`,导致容器无法解析域名。_
|
||||
_我的经历:在 2013 年,我遇到了使用 Docker 以来的第一个问题,与 Docker 的这种 DNS 解决方案密切相关。我们公司的网络屏蔽了 `8.8.8.8` 和 `8.8.4.4`,导致容器无法解析域名。_
|
||||
|
||||
这就是 Docker 容器的情况,但对于包括 Kubernetes 在内的容器 _<ruby>编排引擎<rt>orchestrators</rt></ruby>_,情况又有些不同。
|
||||
这就是 Docker 容器的情况,但对于包括 Kubernetes 在内的容器 <ruby>编排引擎<rt>orchestrators</rt></ruby>,情况又有些不同。
|
||||
|
||||
### 2) Kubernetes 和 DNS
|
||||
|
||||
在 Kubernetes 中,最小部署单元是 `pod`;`pod` 是一组相互协作的容器,共享 IP 地址(和其它资源)。
|
||||
在 Kubernetes 中,最小部署单元是 pod;它是一组相互协作的容器,共享 IP 地址(和其它资源)。
|
||||
|
||||
Kubernetes 面临的一个额外的挑战是,将 Kubernetes 服务请求(例如,`myservice.kubernetes.io`)通过对应的<ruby>解析器<rt>resolver</rt></ruby>,转发到具体服务地址对应的<ruby>内网地址<rt>private network</rt></ruby>。这里提到的服务地址被称为归属于“<ruby>集群域<rt>cluster domain</rt></ruby>”。集群域可由管理员配置,根据配置可以是 `cluster.local` 或 `myorg.badger` 等。
|
||||
|
||||
在 Kubernetes 中,你可以为 `pod` 指定如下四种 `pod` 内 DNS 查询的方式。
|
||||
在 Kubernetes 中,你可以为 pod 指定如下四种 pod 内 DNS 查询的方式。
|
||||
|
||||
* Default
|
||||
**Default**
|
||||
|
||||
在这种(名称容易让人误解)的方式中,`pod` 与其所在的主机采用相同的 DNS 查询路径,与前面介绍的主机 DNS 查询一致。我们说这种方式的名称容易让人误解,因为该方式并不是默认选项!`ClusterFirst` 才是默认选项。
|
||||
在这种(名称容易让人误解)的方式中,pod 与其所在的主机采用相同的 DNS 查询路径,与前面介绍的主机 DNS 查询一致。我们说这种方式的名称容易让人误解,因为该方式并不是默认选项!`ClusterFirst` 才是默认选项。
|
||||
|
||||
如果你希望覆盖 `/etc/resolv.conf` 中的条目,你可以添加到 `kubelet` 的配置中。
|
||||
|
||||
* ClusterFirst
|
||||
**ClusterFirst**
|
||||
|
||||
在 `ClusterFirst` 方式中,遇到 DNS 查询请求会做有选择的转发。根据配置的不同,有以下两种方式:
|
||||
|
||||
第一种方式配置相对古老但更简明,即采用一个规则:如果请求的域名不是集群域的子域,那么将其转发到 `pod` 所在的主机。
|
||||
第一种方式配置相对古老但更简明,即采用一个规则:如果请求的域名不是集群域的子域,那么将其转发到 pod 所在的主机。
|
||||
|
||||
第二种方式相对新一些,你可以在内部 DNS 中配置选择性转发。
|
||||
|
||||
@ -115,27 +111,27 @@ data:
|
||||
|
||||
在 `stubDomains` 条目中,可以为特定域名指定特定的 DNS 服务器;而 `upstreamNameservers` 条目则给出,待查询域名不是集群域子域情况下用到的 DNS 服务器。
|
||||
|
||||
这是通过在一个 `pod` 中运行我们熟知的 `dnsmasq` 实现的。
|
||||
这是通过在一个 pod 中运行我们熟知的 `dnsmasq` 实现的。
|
||||
|
||||

|
||||
|
||||
剩下两种选项都比较小众:
|
||||
|
||||
* ClusterFirstWithHostNet
|
||||
**ClusterFirstWithHostNet**
|
||||
|
||||
适用于 `pod` 使用主机网络的情况,例如绕开 Docker 网络配置,直接使用与 `pod` 对应主机相同的网络。
|
||||
适用于 pod 使用主机网络的情况,例如绕开 Docker 网络配置,直接使用与 pod 对应主机相同的网络。
|
||||
|
||||
* None
|
||||
**None**
|
||||
|
||||
`None` 意味着不改变 DNS,但强制要求你在 `pod` <ruby>规范文件<rt>specification</rt></ruby>的 `dnsConfig` 条目中指定 DNS 配置。
|
||||
|
||||
### CoreDNS 即将到来
|
||||
|
||||
除了上面提到的那些,一旦 `CoreDNS` 取代Kubernetes 中的 `kube-dns`,情况还会发生变化。`CoreDNS` 相比 `kube-dns` 具有可配置性更高、效率更高等优势。
|
||||
除了上面提到的那些,一旦 `CoreDNS` 取代 Kubernetes 中的 `kube-dns`,情况还会发生变化。`CoreDNS` 相比 `kube-dns` 具有可配置性更高、效率更高等优势。
|
||||
|
||||
如果想了解更多,参考[这里][5]。
|
||||
|
||||
如果你对 OpenShift 的网络感兴趣,我曾写过一篇[文章][6]可供你参考。但文章中 OpenShift 的版本是 `3.6`,可能有些过时。
|
||||
如果你对 OpenShift 的网络感兴趣,我曾写过一篇[文章][6]可供你参考。但文章中 OpenShift 的版本是 3.6,可能有些过时。
|
||||
|
||||
### 第四部分总结
|
||||
|
||||
@ -152,14 +148,14 @@ via: https://zwischenzugs.com/2018/08/06/anatomy-of-a-linux-dns-lookup-part-iv/
|
||||
|
||||
作者:[zwischenzugs][a]
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://zwischenzugs.com/
|
||||
[1]:https://zwischenzugs.com/2018/06/08/anatomy-of-a-linux-dns-lookup-part-i/
|
||||
[2]:https://zwischenzugs.com/2018/06/18/anatomy-of-a-linux-dns-lookup-part-ii/
|
||||
[3]:https://zwischenzugs.com/2018/07/06/anatomy-of-a-linux-dns-lookup-part-iii/
|
||||
[1]:https://linux.cn/article-9943-1.html
|
||||
[2]:https://linux.cn/article-9949-1.html
|
||||
[3]:https://linux.cn/article-9972-1.html
|
||||
[4]:https://kubernetes.io/docs/tasks/administer-cluster/dns-custom-nameservers/#impacts-on-pods
|
||||
[5]:https://coredns.io/
|
||||
[6]:https://zwischenzugs.com/2017/10/21/openshift-3-6-dns-in-pictures/
|
||||
@ -0,0 +1,118 @@
|
||||
怎样解决 Ubuntu 中的 “sub process usr bin dpkg returned an error code 1” 错误
|
||||
======
|
||||
|
||||
> 如果你在 Ubuntu Linux 上安装软件时遇到 “sub process usr bin dpkg returned an error code 1”,请按照以下步骤进行修复。
|
||||
|
||||
Ubuntu 和其他基于 Debian 的发行版中的一个常见问题是已经损坏的包。你尝试更新系统或安装新软件包时会遇到类似 “Sub-process /usr/bin/dpkg returned an error code” 的错误。
|
||||
|
||||
这就是前几天发生在我身上的事。我试图在 Ubuntu 中安装一个电台程序时,它给我了这个错误:
|
||||
|
||||
```
|
||||
Unpacking python-gst-1.0 (1.6.2-1build1) ...
|
||||
Selecting previously unselected package radiotray.
|
||||
Preparing to unpack .../radiotray_0.7.3-5ubuntu1_all.deb ...
|
||||
Unpacking radiotray (0.7.3-5ubuntu1) ...
|
||||
Processing triggers for man-db (2.7.5-1) ...
|
||||
Processing triggers for desktop-file-utils (0.22-1ubuntu5.2) ...
|
||||
Processing triggers for bamfdaemon (0.5.3~bzr0+16.04.20180209-0ubuntu1) ...
|
||||
Rebuilding /usr/share/applications/bamf-2.index...
|
||||
Processing triggers for gnome-menus (3.13.3-6ubuntu3.1) ...
|
||||
Processing triggers for mime-support (3.59ubuntu1) ...
|
||||
Setting up polar-bookshelf (1.0.0-beta56) ...
|
||||
ln: failed to create symbolic link '/usr/local/bin/polar-bookshelf': No such file or directory
|
||||
dpkg: error processing package polar-bookshelf (--configure):
|
||||
subprocess installed post-installation script returned error exit status 1
|
||||
Setting up python-appindicator (12.10.1+16.04.20170215-0ubuntu1) ...
|
||||
Setting up python-gst-1.0 (1.6.2-1build1) ...
|
||||
Setting up radiotray (0.7.3-5ubuntu1) ...
|
||||
Errors were encountered while processing:
|
||||
polar-bookshelf
|
||||
E: Sub-process /usr/bin/dpkg returned an error code (1)
|
||||
|
||||
```
|
||||
|
||||
这里最后三行非常重要。
|
||||
|
||||
```
|
||||
Errors were encountered while processing:
|
||||
polar-bookshelf
|
||||
E: Sub-process /usr/bin/dpkg returned an error code (1)
|
||||
```
|
||||
|
||||
它告诉我 polar-bookshelf 包引发了问题。这可能对你如何修复这个错误至关重要。
|
||||
|
||||
### 修复 Sub-process /usr/bin/dpkg returned an error code (1)
|
||||
|
||||
![Fix update errors in Ubuntu Linux][1]
|
||||
|
||||
让我们尝试修复这个损坏的错误包。我将展示几种你可以逐一尝试的方法。最初的那些易于使用,几乎不用动脑子。
|
||||
|
||||
在试了这里讨论的每一种方法之后,你应该尝试运行 `sudo apt update`,接着尝试安装新的包或升级。
|
||||
|
||||
#### 方法 1:重新配包数据库
|
||||
|
||||
你可以尝试的第一种方法是重新配置包数据库。数据库可能在安装包时损坏了。重新配置通常可以解决问题。
|
||||
|
||||
```
|
||||
sudo dpkg --configure -a
|
||||
```
|
||||
|
||||
#### 方法 2:强制安装
|
||||
|
||||
如果是之前包安装过程被中断,你可以尝试强制安装。
|
||||
|
||||
```
|
||||
sudo apt-get install -f
|
||||
```
|
||||
|
||||
#### 方法3:尝试删除有问题的包
|
||||
|
||||
如果这不是你的问题,你可以尝试手动删除包。但不要对 Linux 内核包(以 linux- 开头)执行此操作。
|
||||
|
||||
```
|
||||
sudo apt remove
|
||||
```
|
||||
|
||||
#### 方法 4:删除有问题的包中的信息文件
|
||||
|
||||
这应该是你最后的选择。你可以尝试从 `/var/lib/dpkg/info` 中删除与相关软件包关联的文件。
|
||||
|
||||
**你需要了解一些基本的 Linux 命令来了解发生了什么以及如何对应你的问题**
|
||||
|
||||
就我而言,我在 polar-bookshelf 中遇到问题。所以我查找了与之关联的文件:
|
||||
|
||||
```
|
||||
ls -l /var/lib/dpkg/info | grep -i polar-bookshelf
|
||||
-rw-r--r-- 1 root root 2324811 Aug 14 19:29 polar-bookshelf.list
|
||||
-rw-r--r-- 1 root root 2822824 Aug 10 04:28 polar-bookshelf.md5sums
|
||||
-rwxr-xr-x 1 root root 113 Aug 10 04:28 polar-bookshelf.postinst
|
||||
-rwxr-xr-x 1 root root 84 Aug 10 04:28 polar-bookshelf.postrm
|
||||
```
|
||||
|
||||
现在我需要做的就是删除这些文件:
|
||||
|
||||
```
|
||||
sudo mv /var/lib/dpkg/info/polar-bookshelf.* /tmp
|
||||
```
|
||||
|
||||
使用 `sudo apt update`,接着你应该就能像往常一样安装软件了。
|
||||
|
||||
#### 哪种方法适合你(如果有效)?
|
||||
|
||||
我希望这篇快速文章可以帮助你修复 “E: Sub-process /usr/bin/dpkg returned an error code (1)” 的错误。
|
||||
|
||||
如果它对你有用,是那种方法?你是否设法使用其他方法修复此错误?如果是,请分享一下以帮助其他人解决此问题。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/dpkg-returned-an-error-code-1/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/fix-common-update-errors-ubuntu.jpeg
|
||||
@ -0,0 +1,161 @@
|
||||
Bat:一种具有语法高亮和 Git 集成的 Cat 类命令
|
||||
======
|
||||
|
||||

|
||||
|
||||
在类 UNIX 系统中,我们使用 `cat` 命令去打印和连接文件。使用 `cat` 命令,我们能将文件目录打印到到标准输出,合成几个文件为一个目标文件,还有追加几个文件到目标文件中。今天,我偶然发现一个具有相似作用的命令叫做 “Bat” ,它是 `cat` 命令的一个克隆版,具有一些例如语法高亮、 Git 集成和自动分页等非常酷的特性。在这个简略指南中,我们将讲述如何在 Linux 中安装和使用 `bat` 命令。
|
||||
|
||||
### 安装
|
||||
|
||||
Bat 可以在 Arch Linux 的默认软件源中获取。 所以你可以使用 `pacman` 命令在任何基于 arch 的系统上来安装它。
|
||||
|
||||
```
|
||||
$ sudo pacman -S bat
|
||||
```
|
||||
|
||||
在 Debian、Ubuntu、Linux Mint 等系统中,从其[发布页面][1]下载 **.deb** 文件,然后用下面的命令来安装。
|
||||
|
||||
```
|
||||
$ sudo apt install gdebi
|
||||
$ sudo gdebi bat_0.5.0_amd64.deb
|
||||
```
|
||||
|
||||
对于其他系统,你也许需要从软件源编译并安装。确保你已经安装了 Rust 1.26 或者更高版本。
|
||||
|
||||
然后运行以下命令来安装 Bat:
|
||||
|
||||
```
|
||||
$ cargo install bat
|
||||
```
|
||||
|
||||
或者,你可以从 [Linuxbrew][2] 软件包管理中来安装它。
|
||||
|
||||
```
|
||||
$ brew install bat
|
||||
```
|
||||
|
||||
### bat 命令的使用
|
||||
|
||||
`bat` 命令的使用与 `cat` 命令的使用非常相似。
|
||||
|
||||
使用 `bat` 命令创建一个新的文件:
|
||||
|
||||
```
|
||||
$ bat > file.txt
|
||||
```
|
||||
|
||||
使用 `bat` 命令来查看文件内容,只需要:
|
||||
|
||||
```
|
||||
$ bat file.txt
|
||||
```
|
||||
|
||||
你能同时查看多个文件:
|
||||
|
||||
```
|
||||
$ bat file1.txt file2.txt
|
||||
```
|
||||
|
||||
将多个文件的内容合并至一个单独文件中:
|
||||
|
||||
```
|
||||
$ bat file1.txt file2.txt file3.txt > document.txt
|
||||
```
|
||||
|
||||
就像我之前提到的那样,除了浏览和编辑文件以外,`bat` 命令有一些非常酷的特性。
|
||||
|
||||
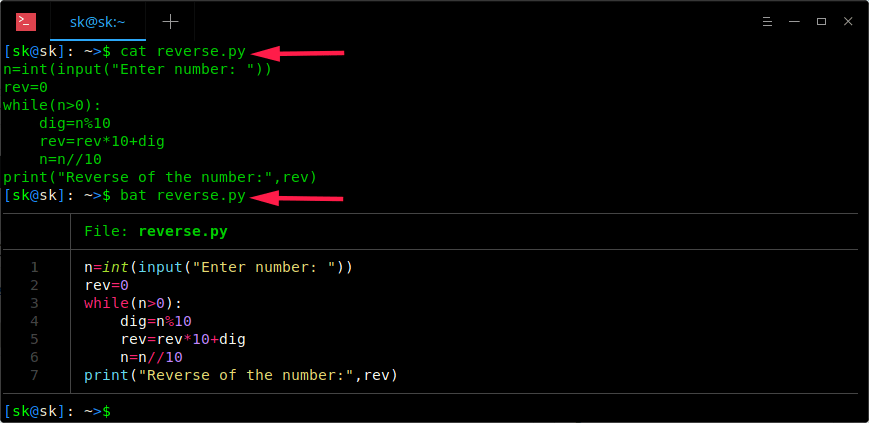
`bat` 命令支持大多数编程和标记语言的<ruby>语法高亮<rt>syntax highlighting</rt></ruby>。比如,下面这个例子。我将使用 `cat` 和 `bat` 命令来展示 `reverse.py` 的内容。
|
||||
|
||||
|
||||
|
||||
你注意到区别了吗? `cat` 命令以纯文本格式显示文件的内容,而 `bat` 命令显示了语法高亮和整齐的文本对齐格式。更好了不是吗?
|
||||
|
||||
如果你只想显示行号(而没有表格)使用 `-n` 标记。
|
||||
|
||||
```
|
||||
$ bat -n reverse.py
|
||||
```
|
||||
|
||||

|
||||
|
||||
另一个 `bat` 命令中值得注意的特性是它支持<ruby>自动分页<rt>automatic paging</rt></ruby>。 它的意思是当文件的输出对于屏幕来说太大的时候,`bat` 命令自动将自己的输出内容传输到 `less` 命令中,所以你可以一页一页的查看输出内容。
|
||||
|
||||
让我给你看一个例子,使用 `cat` 命令查看跨多个页面的文件的内容时,提示符会快速跳至文件的最后一页,你看不到内容的开头和中间部分。
|
||||
|
||||
看一下下面的输出:
|
||||
|
||||

|
||||
|
||||
正如你所看到的,`cat` 命令显示了文章的最后一页。
|
||||
|
||||
所以你也许需要去将使用 `cat` 命令的输出传输到 `less` 命令中去从开头一页一页的查看内容。
|
||||
|
||||
```
|
||||
$ cat reverse.py | less
|
||||
```
|
||||
|
||||
现在你可以使用回车键去一页一页的查看输出。然而当你使用 `bat` 命令时这些都是不必要的。`bat` 命令将自动传输跨越多个页面的文件的输出。
|
||||
|
||||
```
|
||||
$ bat reverse.py
|
||||
```
|
||||
|
||||

|
||||
|
||||
现在按下回车键去往下一页。
|
||||
|
||||
`bat` 命令也支持 <ruby>Git 集成<rt>**GIT integration**</rt></ruby>,这样您就可以轻松查看/编辑 Git 存储库中的文件。 它与 Git 连接可以显示关于索引的修改。(看左栏)
|
||||
|
||||

|
||||
|
||||
### 定制 Bat
|
||||
|
||||
如果你不喜欢默认主题,你也可以修改它。Bat 同样有修改它的选项。
|
||||
|
||||
若要显示可用主题,只需运行:
|
||||
|
||||
```
|
||||
$ bat --list-themes
|
||||
1337
|
||||
DarkNeon
|
||||
Default
|
||||
GitHub
|
||||
Monokai Extended
|
||||
Monokai Extended Bright
|
||||
Monokai Extended Light
|
||||
Monokai Extended Origin
|
||||
TwoDark
|
||||
```
|
||||
|
||||
|
||||
要使用其他主题,例如 TwoDark,请运行:
|
||||
|
||||
```
|
||||
$ bat --theme=TwoDark file.txt
|
||||
```
|
||||
|
||||
如果你想永久改变主题,在你的 shells 启动文件中加入 `export BAT_THEME="TwoDark"`。
|
||||
|
||||
`bat` 还可以选择修改输出的外观。使用 `--style` 选项来修改输出外观。仅显示 Git 的更改和行号但不显示网格和文件头,请使用 `--style=numbers,changes`。
|
||||
|
||||
更多详细信息,请参阅 Bat 项目的 GitHub 库(链接在文末)。
|
||||
|
||||
最好,这就是目前的全部内容了。希望这篇文章会帮到你。更多精彩文章即将到来,敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/bat-a-cat-clone-with-syntax-highlighting-and-git-integration/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[z52527](https://github.com/z52527)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://github.com/sharkdp/bat/releases
|
||||
[2]:https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
|
||||
@ -1,8 +1,9 @@
|
||||
如何使用 Steam Play 在 Linux 上玩仅限 Windows 的游戏
|
||||
======
|
||||
Steam 的新实验功能允许你在 Linux 上玩仅限 Windows 的游戏。以下是如何在 Steam 中使用此功能。
|
||||
|
||||
你已经听说过这个消息。游戏发行平台[ Steam 正在实现一个 WINE 分支来允许你玩仅在 Windows 上的游戏][1]。对于 Linux 用户来说,这绝对是一个好消息,因为我们抱怨 Linux 的游戏数量不足。
|
||||
> Steam 的新实验功能允许你在 Linux 上玩仅限 Windows 的游戏。以下是如何在 Steam 中使用此功能。
|
||||
|
||||
你已经听说过这个消息。游戏发行平台 [Steam 正在复刻一个 WINE 分支来允许你玩仅限于 Windows 上的游戏][1]。对于 Linux 用户来说,这绝对是一个好消息,因为我们总抱怨 Linux 的游戏数量不足。
|
||||
|
||||
这个新功能仍处于测试阶段,但你现在可以在 Linux 上试用它并在 Linux 上玩仅限 Windows 的游戏。让我们看看如何做到这一点。
|
||||
|
||||
@ -14,20 +15,19 @@ Steam 的新实验功能允许你在 Linux 上玩仅限 Windows 的游戏。以
|
||||
|
||||
安装了 Steam 并且你已登录到 Steam 帐户,就可以了解如何在 Steam Linux 客户端中启用 Windows 游戏。
|
||||
|
||||
|
||||
#### 步骤 1:进入帐户设置
|
||||
|
||||
运行 Steam 客户端。在左上角,单击 Steam,然后单击 Settings。
|
||||
运行 Steam 客户端。在左上角,单击 “Steam”,然后单击 “Settings”。
|
||||
|
||||
![Enable steam play beta on Linux][4]
|
||||
|
||||
#### 步骤 2:选择加入测试计划
|
||||
|
||||
在“设置”中,从左侧窗口中选择“帐户”,然后单击 “Beta participation” 下的 “CHANGE” 按钮。
|
||||
在“Settings”中,从左侧窗口中选择“Account”,然后单击 “Beta participation” 下的 “CHANGE” 按钮。
|
||||
|
||||
![Enable beta feature in Steam Linux][5]
|
||||
|
||||
你应该在此处选择 Steam Beta Update。
|
||||
你应该在此处选择 “Steam Beta Update”。
|
||||
|
||||
![Enable beta feature in Steam Linux][6]
|
||||
|
||||
@ -37,32 +37,29 @@ Steam 的新实验功能允许你在 Linux 上玩仅限 Windows 的游戏。以
|
||||
|
||||
下载好 Steam 新的测试版更新后,它将重新启动。到这里就差不多了。
|
||||
|
||||
再次进入“设置”。你现在可以在左侧窗口看到新的 Steam Play 选项。单击它并选中复选框:
|
||||
再次进入“Settings”。你现在可以在左侧窗口看到新的 “Steam Play” 选项。单击它并选中复选框:
|
||||
|
||||
* Enable Steam Play for supported titles (你可以玩列入白名单的 Windows 游戏)
|
||||
* Enable Steam Play for all titles (你可以尝试玩所有仅限 Windows 的游戏)
|
||||
|
||||
|
||||
|
||||
![Play Windows games on Linux using Steam Play][7]
|
||||
|
||||
我不记得 Steam 是否会再次重启,但我想这是微不足道的。你现在应该可以在 Linux 上看到安装仅限 Windows 的游戏的选项了。
|
||||
我不记得 Steam 是否会再次重启,但我想这无所谓。你现在应该可以在 Linux 上看到安装仅限 Windows 的游戏的选项了。
|
||||
|
||||
比如,我的 Steam 库中有 Age of Empires,正常情况下这个在 Linux 中没有。但我在 Steam Play 测试版启用所有 Windows 游戏后,现在我可以选择在 Linux 上安装 Age of Empires 了。
|
||||
比如,我的 Steam 库中有《Age of Empires》,正常情况下这个在 Linux 中没有。但我在 Steam Play 测试版启用所有 Windows 游戏后,现在我可以选择在 Linux 上安装《Age of Empires》了。
|
||||
|
||||
![Install Windows-only games on Linux using Steam][8]
|
||||
现在可以在 Linux 上安装仅限 Windows 的游戏
|
||||
|
||||
*现在可以在 Linux 上安装仅限 Windows 的游戏*
|
||||
|
||||
### 有关 Steam Play 测试版功能的信息
|
||||
|
||||
在 Linux 上使用 Steam Play 测试版玩仅限 Windows 的游戏有一些事情你需要知道并且牢记。
|
||||
|
||||
* If you have games downloaded on Windows via Steam, you can save some download data by [sharing Steam game files between Linux and Windows][12].
|
||||
* 目前,[只有 27 个 Steam Play 中的 Windows 游戏被列入白名单][9]。这些白名单游戏在 Linux 上无缝运行。
|
||||
* 你可以使用 Steam Play 测试版尝试任何 Windows 游戏,但它可能无法一直运行。有些游戏有时会崩溃,而某些游戏可能根本无法运行。
|
||||
* 目前,[只有 27 个 Steam Play 中的 Windows 游戏被列入白名单][9]。这些白名单游戏可以在 Linux 上无缝运行。
|
||||
* 你可以使用 Steam Play 测试版尝试任何 Windows 游戏,但它可能不是总能运行。有些游戏有时会崩溃,而某些游戏可能根本无法运行。
|
||||
* 在测试版中,你无法 Steam 商店中看到适用于 Linux 的 Windows 限定游戏。你必须自己尝试游戏或参考[这个社区维护的列表][10]以查看该 Windows 游戏的兼容性状态。你也可以通过填写[此表][11]来为列表做出贡献。
|
||||
* 如果你通过 Steam 在 Windows 上下载游戏,那么可以通过[在 Linux 和 Windows 之间共享 Steam 游戏文件][12]来保存一些下载数据。
|
||||
|
||||
* 如果你在 Windows 中通过 Steam 下载了游戏,你可以[在 Linux 和 Windows 之间共享 Steam 游戏文件][12]来节省下载的数据。
|
||||
|
||||
我希望本教程能帮助你在 Linux 上运行仅限 Windows 的游戏。你期待在 Linux 上玩哪些游戏?
|
||||
|
||||
@ -73,12 +70,12 @@ via: https://itsfoss.com/steam-play/
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://itsfoss.com/steam-play-proton/
|
||||
[1]:https://linux.cn/article-10054-1.html
|
||||
[2]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/play-windows-games-on-linux-featured.jpeg
|
||||
[3]:https://itsfoss.com/install-steam-ubuntu-linux/
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta.jpeg
|
||||
@ -89,4 +86,4 @@ via: https://itsfoss.com/steam-play/
|
||||
[9]:https://steamcommunity.com/games/221410
|
||||
[10]:https://docs.google.com/spreadsheets/d/1DcZZQ4HL_Ol969UbXJmFG8TzOHNnHoj8Q1f8DIFe8-8/htmlview?sle=true#
|
||||
[11]:https://docs.google.com/forms/d/e/1FAIpQLSeefaYQduMST_lg0IsYxZko8tHLKe2vtVZLFaPNycyhY4bidQ/viewform
|
||||
[12]:https://itsfoss.com/share-steam-files-linux-windows/
|
||||
[12]:https://linux.cn/article-8027-1.html
|
||||
@ -1,14 +1,15 @@
|
||||
让你提高效率的 Linux 技巧
|
||||
======
|
||||
想要在 Linux 命令行工作中提高效率,你需要使用一些技巧。
|
||||
|
||||
> 想要在 Linux 命令行工作中提高效率,你需要使用一些技巧。
|
||||
|
||||

|
||||
|
||||
巧妙的 Linux 命令行技巧能让你节省时间、避免出错,还能让你记住和复用各种复杂的命令,专注在需要做的事情本身,而不是做事的方式。以下介绍一些好用的命令行技巧。
|
||||
巧妙的 Linux 命令行技巧能让你节省时间、避免出错,还能让你记住和复用各种复杂的命令,专注在需要做的事情本身,而不是你要怎么做。以下介绍一些好用的命令行技巧。
|
||||
|
||||
### 命令编辑
|
||||
|
||||
如果要对一个已输入的命令进行修改,可以使用 ^a(ctrl + a)或 ^e(ctrl + e)将光标快速移动到命令的开头或命令的末尾。
|
||||
如果要对一个已输入的命令进行修改,可以使用 `^a`(`ctrl + a`)或 `^e`(`ctrl + e`)将光标快速移动到命令的开头或命令的末尾。
|
||||
|
||||
还可以使用 `^` 字符实现对上一个命令的文本替换并重新执行命令,例如 `^before^after^` 相当于把上一个命令中的 `before` 替换为 `after` 然后重新执行一次。
|
||||
|
||||
@ -59,11 +60,11 @@ alias show_dimensions='xdpyinfo | grep '\''dimensions:'\'''
|
||||
|
||||
### 冻结、解冻终端界面
|
||||
|
||||
^s(ctrl + s)将通过执行流量控制命令 XOFF 来停止终端输出内容,这会对 PuTTY 会话和桌面终端窗口产生影响。如果误输入了这个命令,可以使用 ^q(ctrl + q)让终端重新响应。所以只需要记住^q 这个组合键就可以了,毕竟这种情况并不多见。
|
||||
`^s`(`ctrl + s`)将通过执行流量控制命令 XOFF 来停止终端输出内容,这会对 PuTTY 会话和桌面终端窗口产生影响。如果误输入了这个命令,可以使用 `^q`(`ctrl + q`)让终端重新响应。所以只需要记住 `^q` 这个组合键就可以了,毕竟这种情况并不多见。
|
||||
|
||||
### 复用命令
|
||||
|
||||
Linux 提供了很多让用户复用命令的方法,其核心是通过历史缓冲区收集执行过的命令。复用命令的最简单方法是输入 `!` 然后接最近使用过的命令的开头字母;当然也可以按键盘上的向上箭头,直到看到要复用的命令,然后按 Enter 键。还可以先使用 `history` 显示命令历史,然后输入 `!` 后面再接命令历史记录中需要复用的命令旁边的数字。
|
||||
Linux 提供了很多让用户复用命令的方法,其核心是通过历史缓冲区收集执行过的命令。复用命令的最简单方法是输入 `!` 然后接最近使用过的命令的开头字母;当然也可以按键盘上的向上箭头,直到看到要复用的命令,然后按回车键。还可以先使用 `history` 显示命令历史,然后输入 `!` 后面再接命令历史记录中需要复用的命令旁边的数字。
|
||||
|
||||
```
|
||||
!! <== 复用上一条命令
|
||||
@ -129,7 +130,7 @@ $ rm -i <== 请求确认
|
||||
$ unalias rm
|
||||
```
|
||||
|
||||
如果已经将 `rm -i` 默认设置为 `rm` 的别名,但你希望在删除文件之前不必进行确认,则可以将 `unalias` 命令放在一个启动文件(例如 ~/.bashrc)中。
|
||||
如果已经将 `rm -i` 默认设置为 `rm` 的别名,但你希望在删除文件之前不必进行确认,则可以将 `unalias` 命令放在一个启动文件(例如 `~/.bashrc`)中。
|
||||
|
||||
### 使用 sudo
|
||||
|
||||
@ -151,8 +152,6 @@ md () { mkdir -p "$@" && cd "$1"; }
|
||||
|
||||
使用 Linux 命令行是在 Linux 系统上工作最有效也最有趣的方法,但配合命令行技巧和巧妙的别名可以让你获得更好的体验。
|
||||
|
||||
加入 [Facebook][1] 和 [LinkedIn][2] 上的 Network World 社区可以和我们一起讨论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3305811/linux/linux-tricks-that-even-you-can-love.html
|
||||
@ -160,7 +159,7 @@ via: https://www.networkworld.com/article/3305811/linux/linux-tricks-that-even-y
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -3,7 +3,7 @@
|
||||
|
||||

|
||||
|
||||
**APT**, 是 **A** dvanced **P** ackage **T** ool 的缩写,是基于 Debian 的系统的默认包管理器。我们可以使用 APT 安装、更新、升级和删除应用程序。最近,我一直遇到一个奇怪的错误。每当我尝试更新我的 Ubuntu 16.04 时,我都会收到此错误 - **“0% [Connecting to in.archive.ubuntu.com (2001:67c:1560:8001::14)]”** ,同时更新流程会卡住很长时间。我的网络连接没问题,我可以 ping 通所有网站,包括 Ubuntu 官方网站。在搜索了一番谷歌后,我意识到 Ubuntu 镜像有时无法通过 IPv6 访问。在我强制将 APT 包管理器在更新系统时使用 IPv4 代替 IPv6 访问 Ubuntu 镜像后,此问题得以解决。如果你遇到过此错误,可以按照以下说明解决。
|
||||
**APT**, 是 **A** dvanced **P** ackage **T** ool 的缩写,是基于 Debian 的系统的默认包管理器。我们可以使用 APT 安装、更新、升级和删除应用程序。最近,我一直遇到一个奇怪的错误。每当我尝试更新我的 Ubuntu 16.04 时,我都会收到此错误 - **“0% [Connecting to in.archive.ubuntu.com (2001:67c:1560:8001::14)]”** ,同时更新流程会卡住很长时间。我的网络连接没问题,我可以 ping 通所有网站,包括 Ubuntu 官方网站。在搜索了一番谷歌后,我意识到 Ubuntu 镜像站点有时无法通过 IPv6 访问。在我强制将 APT 包管理器在更新系统时使用 IPv4 代替 IPv6 访问 Ubuntu 镜像站点后,此问题得以解决。如果你遇到过此错误,可以按照以下说明解决。
|
||||
|
||||
### 强制 APT 包管理器在 Ubuntu 16.04 中使用 IPv4
|
||||
|
||||
@ -11,13 +11,12 @@
|
||||
|
||||
```
|
||||
$ sudo apt-get -o Acquire::ForceIPv4=true update
|
||||
|
||||
$ sudo apt-get -o Acquire::ForceIPv4=true upgrade
|
||||
```
|
||||
|
||||
瞧!这次更新很快就完成了。
|
||||
|
||||
你还可以使用以下命令在 **/etc/apt/apt.conf.d/99force-ipv4** 中添加以下行,以便将来对所有 **apt-get** 事务保持持久性:
|
||||
你还可以使用以下命令在 `/etc/apt/apt.conf.d/99force-ipv4` 中添加以下行,以便将来对所有 `apt-get` 事务保持持久性:
|
||||
|
||||
```
|
||||
$ echo 'Acquire::ForceIPv4 "true";' | sudo tee /etc/apt/apt.conf.d/99force-ipv4
|
||||
@ -25,7 +24,7 @@ $ echo 'Acquire::ForceIPv4 "true";' | sudo tee /etc/apt/apt.conf.d/99force-ipv4
|
||||
|
||||
**免责声明:**
|
||||
|
||||
我不知道最近是否有人遇到这个问题,但我今天在我的 Ubuntu 16.04 LTS 虚拟机中遇到了至少四五次这样的错误,我按照上面的说法解决了这个问题。我不确定这是推荐的解决方案。请浏览 Ubuntu 论坛来确保此方法合法。由于我只是一个 VM,我只将它用于测试和学习目的,我不介意这种方法的真实性。请自行承担使用风险。
|
||||
我不知道最近是否有人遇到这个问题,但我今天在我的 Ubuntu 16.04 LTS 虚拟机中遇到了至少四、五次这样的错误,我按照上面的说法解决了这个问题。我不确定这是推荐的解决方案。请浏览 Ubuntu 论坛来确保此方法合法。由于我只是一个 VM,我只将它用于测试和学习目的,我不介意这种方法的真实性。请自行承担使用风险。
|
||||
|
||||
希望这有帮助。还有更多的好东西。敬请关注!
|
||||
|
||||
@ -40,7 +39,7 @@ via: https://www.ostechnix.com/how-to-force-apt-package-manager-to-use-ipv4-in-u
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
translating by leowang
|
||||
Moving to Linux from dated Windows machines
|
||||
======
|
||||
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
translating by ynmlml
|
||||
|
||||
Write Dumb Code
|
||||
======
|
||||
The best way you can contribute to an open source project is to remove lines of code from it. We should endeavor to write code that a novice programmer can easily understand without explanation or that a maintainer can understand without significant time investment.
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
Translating by FelixYFZ 20 questions DevOps job candidates should be prepared to answer
|
||||
20 questions DevOps job candidates should be prepared to answer Translating by FelixYFZ
|
||||
======
|
||||
|
||||

|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
(translating by runningwater)
|
||||
Microservices Explained
|
||||
======
|
||||
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
translating by aiwhj
|
||||
3 tips for organizing your open source project's workflow on GitHub
|
||||
======
|
||||
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
Translating by jessie-pang
|
||||
|
||||
Why moving all your workloads to the cloud is a bad idea
|
||||
======
|
||||
|
||||
|
||||
@ -1,80 +0,0 @@
|
||||
How to Install Cinnamon Desktop on Ubuntu
|
||||
======
|
||||
**This tutorial shows you how to install Cinnamon desktop environment on Ubuntu.**
|
||||
|
||||
[Cinnamon][1] is the default desktop environment of [Linux Mint][2]. Unlike Unity desktop environment in Ubuntu, Cinnamon is more traditional but elegant looking desktop environment with the bottom panel and app menu etc. Many Windows migrants [prefer Linux Mint over Ubuntu][3] because of Cinnamon desktop and its Windows-resembling user interface.
|
||||
|
||||
Now, you don’t need to [install Linux Mint][4] just for trying Cinnamon. In this tutorial, I’ll show you **how to install Cinnamon in Ubuntu 18.04, 16.04 and 14.04**.
|
||||
|
||||
You should note something before you install Cinnamon desktop on Ubuntu. Sometimes, installing additional desktop environments leads to conflict between the desktop environments. This may result in a broken session, broken applications and features etc. This is why you should be careful in making this choice.
|
||||
|
||||
### How to Install Cinnamon on Ubuntu
|
||||
|
||||
![How to install cinnamon desktop on Ubuntu Linux][5]
|
||||
|
||||
There used to be a-sort-of official PPA from Cinnamon team for Ubuntu but it doesn’t exist anymore. Don’t lose heart. There is an unofficial PPA available and it works perfectly. This PPA consists of the latest Cinnamon version.
|
||||
|
||||
Open a terminal and use the following commands:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:embrosyn/cinnamon
|
||||
sudo apt update && sudo apt install cinnamon
|
||||
|
||||
```
|
||||
|
||||
It will download files of around 150 MB in size (if I remember correctly). This also provides you with Nemo (Nautilus fork) and Cinnamon Control Center. This bonus stuff gives a closer feel of Linux Mint.
|
||||
|
||||
### Using Cinnamon desktop environment in Ubuntu
|
||||
|
||||
Once you have installed Cinnamon, log out of the current session. At the login screen, click on the Ubuntu symbol beside the username:
|
||||
|
||||

|
||||
|
||||
When you do this, it will give you all the desktop environments available for your system. No need to tell you that you have to choose Cinnamon:
|
||||
|
||||

|
||||
|
||||
Now you should be logged in to Ubuntu with Cinnamon desktop environment. Remember, you can do the same to switch back to Unity. Here is a quick screenshot of what it looked like to run **Cinnamon in Ubuntu** :
|
||||
|
||||

|
||||
|
||||
Looks completely like Linux Mint, isn’t it? I didn’t find any compatibility issue between Cinnamon and Unity. I switched back and forth between Unity and Cinnamon and both worked perfectly.
|
||||
|
||||
#### Remove Cinnamon from Ubuntu
|
||||
|
||||
It is understandable that you might want to uninstall Cinnamon. We will use PPA Purge for this purpose. Let’s install PPA Purge first:
|
||||
|
||||
```
|
||||
sudo apt-get install ppa-purge
|
||||
|
||||
```
|
||||
|
||||
Afterward, use the following command to purge the PPA:
|
||||
|
||||
```
|
||||
sudo ppa-purge ppa:embrosyn/cinnamon
|
||||
|
||||
```
|
||||
|
||||
In related articles, I suggest you to read more about [how to remove PPA in Linux][6].
|
||||
|
||||
I hope this post helps you to **install Cinnamon in Ubuntu**. Do share your experience with Cinnamon.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-cinnamon-on-ubuntu/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: http://cinnamon.linuxmint.com/
|
||||
[2]: http://www.linuxmint.com/
|
||||
[3]: https://itsfoss.com/linux-mint-vs-ubuntu/
|
||||
[4]: https://itsfoss.com/guide-install-linux-mint-16-dual-boot-windows/
|
||||
[5]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/install-cinnamon-ubuntu.png
|
||||
[6]: https://itsfoss.com/how-to-remove-or-delete-ppas-quick-tip/
|
||||
@ -1,4 +1,4 @@
|
||||
# mandeler translating A CEO's Guide to Emacs
|
||||
A CEO's Guide to Emacs
|
||||
============================================================
|
||||
|
||||
Years—no, decades—ago, I lived in Emacs. I wrote code and documents, managed email and calendar, and shelled all in the editor/OS. I was quite happy. Years went by and I moved to newer, shinier things. As a result, I forgot how to do tasks as basic as efficiently navigating files without a mouse. About three months ago, noticing just how much of my time was spent switching between applications and computers, I decided to give Emacs another try. It was a good decision for several reasons that will be covered in this post. Covered too are `.emacs` and Dropbox tips so that you can set up a good, movable environment.
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
hankchow translating
|
||||
|
||||
Build a bikesharing app with Redis and Python
|
||||
======
|
||||
|
||||
|
||||
@ -1,183 +0,0 @@
|
||||
Translating by way-ww
|
||||
Manipulating Directories in Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
If you are new to this series (and to Linux), [take a look at our first installment][1]. In that article, we worked our way through the tree-like structure of the Linux filesystem, or more precisely, the File Hierarchy Standard. I recommend reading through it to make sure you understand what you can and cannot safely touch. Because this time around, I’ll show how to get all touchy-feely with your directories.
|
||||
|
||||
### Making Directories
|
||||
|
||||
Let's get creative before getting destructive, though. To begin, open a terminal window and use `mkdir` to create a new directory like this:
|
||||
```
|
||||
mkdir <directoryname>
|
||||
|
||||
```
|
||||
|
||||
If you just put the directory name, the directory will appear hanging off the directory you are currently in. If you just opened a terminal, that will be your home directory. In a case like this, we say the directory will be created _relative_ to your current position:
|
||||
```
|
||||
$ pwd #This tells you where you are now -- see our first tutorial
|
||||
/home/<username>
|
||||
$ mkdir newdirectory #Creates /home/<username>/newdirectory
|
||||
|
||||
```
|
||||
|
||||
(Note that you do not have to type the text following the `#`. Text following the pound symbol `#` is considered a comment and is used to explain what is going on. It is ignored by the shell).
|
||||
|
||||
You can create a directory within an existing directory hanging off your current location by specifying it in the command line:
|
||||
```
|
||||
mkdir Documents/Letters
|
||||
|
||||
```
|
||||
|
||||
Will create the _Letters_ directory within the _Documents_ directory.
|
||||
|
||||
You can also create a directory above where you are by using `..` in the path. Say you move into the _Documents/Letters/_ directory you just created and you want to create a _Documents/Memos/_ directory. You can do:
|
||||
```
|
||||
cd Documents/Letters # Move into your recently created Letters/ directory
|
||||
mkdir ../Memos
|
||||
|
||||
```
|
||||
|
||||
Again, all of the above is done relative to you current position. This is called using a _relative path_.
|
||||
|
||||
You can also use an _absolute path_ to directories: This means telling `mkdir` where to put your directory in relation to the root (`/`) directory:
|
||||
```
|
||||
mkdir /home/<username>/Documents/Letters
|
||||
|
||||
```
|
||||
|
||||
Change `<username>` to your user name in the command above and it will be equivalent to executing `mkdir Documents/Letters` from your home directory, except that it will work from wherever you are located in the directory tree.
|
||||
|
||||
As a side note, regardless of whether you use a relative or an absolute path, if the command is successful, `mkdir` will create the directory silently, without any apparent feedback whatsoever. Only if there is some sort of trouble will `mkdir` print some feedback after you hit _[Enter]_.
|
||||
|
||||
As with most other command-line tools, `mkdir` comes with several interesting options. The `-p` option is particularly useful, as it lets you create directories within directories within directories, even if none exist. To create, for example, a directory for letters to your Mom within _Documents/_ , you could do:
|
||||
```
|
||||
mkdir -p Documents/Letters/Family/Mom
|
||||
|
||||
```
|
||||
|
||||
And `mkdir` will create the whole branch of directories above _Mom/_ and also the directory _Mom/_ for you, regardless of whether any of the parent directories existed before you issued the command.
|
||||
|
||||
You can also create several folders all at once by putting them one after another, separated by spaces:
|
||||
```
|
||||
mkdir Letters Memos Reports
|
||||
|
||||
```
|
||||
|
||||
will create the directories _Letters/_ , _Memos/_ and _Reports_ under the current directory.
|
||||
|
||||
### In space nobody can hear you scream
|
||||
|
||||
... Which brings us to the tricky question of spaces in directory names. Can you use spaces in directory names? Yes, you can. Is it advised you use spaces? No, absolutely not. Spaces make everything more complicated and, potentially, dangerous.
|
||||
|
||||
Say you want to create a directory called _letters mom/_. If you didn't know any better, you could type:
|
||||
```
|
||||
mkdir letters mom
|
||||
|
||||
```
|
||||
|
||||
But this is WRONG! WRONG! WRONG! As we saw above, this will create two directories, _letters/_ and _mom/_ , but not _letters mom/_.
|
||||
|
||||
Agreed that this is a minor annoyance: all you have to do is delete the two directories and start over. No big deal.
|
||||
|
||||
But, wait! Deleting directories is where things get dangerous. Imagine you did create _letters mom/_ using a graphical tool, like, say [Dolphin][2] or [Nautilus][3]. If you suddenly decide to delete _letters mom/_ from a terminal, and you have another directory just called _letters/_ under the same directory, and said directory is full of important documents, and you tried this:
|
||||
```
|
||||
rmdir letters mom
|
||||
|
||||
```
|
||||
|
||||
You would risk removing _letters/_. I say "risk" because fortunately `rmdir`, the instruction used to remove directories, has a built in safeguard and will warn you if you try to delete a non-empty directory.
|
||||
|
||||
However, this:
|
||||
```
|
||||
rm -Rf letters mom
|
||||
|
||||
```
|
||||
|
||||
(and this is a pretty standard way of getting rid of directories and their contents) will completely obliterate _letters/_ and will never even tell you what just happened.
|
||||
|
||||
The `rm` command is used to delete files and directories. When you use it with the options `-R` (delete _recursively_ ) and `-f` ( _force_ deletion), it will burrow down into a directory and its subdirectories, deleting all the files they contain, then deleting the subdirectories themselves, then it will delete all the files in the top directory and then the directory itself.
|
||||
|
||||
`rm -Rf` is an instruction you must handle with extreme care.
|
||||
|
||||
My advice is, instead of spaces, use underscores (`_`), but if you still insist on spaces, there are two ways of getting them to work. You can use single or double quotes (`'` or `"`) like so:
|
||||
```
|
||||
mkdir 'letters mom'
|
||||
mkdir "letters dad"
|
||||
|
||||
```
|
||||
|
||||
Or, you can _escape_ the spaces. Some characters have a special meaning for the shell. Spaces, as you have seen, are used to separate options and arguments on the command line. "Separating options and arguments" falls under the category of "special meaning". When you want the shell to ignore the special meaning of a character, you need to _escape_ it and to escape a character, you put a backslash (`\`) in front of it:
|
||||
```
|
||||
mkdir letters\ mom
|
||||
mkdir letter\ dad
|
||||
|
||||
```
|
||||
|
||||
There are other special characters that would need escaping, like the apostrophe or single quote (`'`), double quotes (`"`), and the ampersand (`&`):
|
||||
```
|
||||
mkdir mom\ \&\ dad\'s\ letters
|
||||
|
||||
```
|
||||
|
||||
I know what you're thinking: If the backslash has a special meaning (to wit, telling the shell it has to escape the next character), that makes it a special character, too. Then, how would you escape the escape character which is `\`?
|
||||
|
||||
Turns out, the exact way you escape any other special character:
|
||||
```
|
||||
mkdir special\\characters
|
||||
|
||||
```
|
||||
|
||||
will produce a directory called _special\characters_.
|
||||
|
||||
Confusing? Of course. That's why you should avoid using special characters, including spaces, in directory names.
|
||||
|
||||
For the record, here is a list of special characters you can refer to just in case.
|
||||
|
||||
### Things to Remember
|
||||
|
||||
* Use `mkdir <directory name>` to create a new directory.
|
||||
* Use `rmdir <directory name>` to delete a directory (only works if it is empty).
|
||||
* Use `rm -Rf <directory name>` to annihilate a directory -- use with extreme caution.
|
||||
* Use a relative path to create directories relative to your current directory: `mkdir newdir.`.
|
||||
* Use an absolute path to create directories relative to the root directory (`/`): `mkdir /home/<username>/newdir`
|
||||
* Use `..` to create a directory in the directory above the current directory: `mkdir ../newdir`
|
||||
* You can create several directories all in one go by separating them with spaces on the command line: `mkdir onedir twodir threedir`
|
||||
* You can mix and mash relative and absolute paths when creating several directories simultaneously: `mkdir onedir twodir /home/<username>/threedir`
|
||||
* Using spaces and special characters in directory names guarantees plenty of headaches and heartburn. Don't do it.
|
||||
|
||||
|
||||
|
||||
For more information, you can look up the manuals of `mkdir`, `rmdir` and `rm`:
|
||||
```
|
||||
man mkdir
|
||||
man rmdir
|
||||
man rm
|
||||
|
||||
```
|
||||
|
||||
To exit the man pages, press _[q]_.
|
||||
|
||||
### Next Time
|
||||
|
||||
In the next installment, you'll learn about creating, modifying, and erasing files, as well as everything you need to know about permissions and privileges. See you then!
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][4]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2018/5/manipulating-directories-linux
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/bro66
|
||||
[1]:https://www.linux.com/blog/learn/intro-to-linux/2018/4/linux-filesystem-explained
|
||||
[2]:https://userbase.kde.org/Dolphin
|
||||
[3]:https://projects-old.gnome.org/nautilus/screenshots.html
|
||||
[4]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,5 +1,3 @@
|
||||
translating by Auk7F7
|
||||
|
||||
How to Manage Fonts in Linux
|
||||
======
|
||||
|
||||
|
||||
@ -1,308 +0,0 @@
|
||||
translating by Flowsnow
|
||||
What is behavior-driven Python?
|
||||
======
|
||||

|
||||
Have you heard about [behavior-driven development][1] (BDD) and wondered what all the buzz is about? Maybe you've caught team members talking in "gherkin" and felt left out of the conversation. Or perhaps you're a Pythonista looking for a better way to test your code. Whatever the circumstance, learning about BDD can help you and your team achieve better collaboration and test automation, and Python's `behave` framework is a great place to start.
|
||||
|
||||
### What is BDD?
|
||||
|
||||
* Submitting forms on a website
|
||||
* Searching for desired results
|
||||
* Saving a document
|
||||
* Making REST API calls
|
||||
* Running command-line interface commands
|
||||
|
||||
|
||||
|
||||
In software, a behavior is how a feature operates within a well-defined scenario of inputs, actions, and outcomes. Products can exhibit countless behaviors, such as:
|
||||
|
||||
Defining a product's features based on its behaviors makes it easier to describe them, develop them, and test them. This is the heart of BDD: making behaviors the focal point of software development. Behaviors are defined early in development using a [specification by example][2] language. One of the most common behavior spec languages is [Gherkin][3], the Given-When-Then scenario format from the [Cucumber][4] project. Behavior specs are basically plain-language descriptions of how a behavior works, with a little bit of formal structure for consistency and focus. Test frameworks can easily automate these behavior specs by "gluing" step texts to code implementations.
|
||||
|
||||
Below is an example of a behavior spec written in Gherkin:
|
||||
```
|
||||
Scenario: Basic DuckDuckGo Search
|
||||
|
||||
Given the DuckDuckGo home page is displayed
|
||||
|
||||
When the user searches for "panda"
|
||||
|
||||
Then results are shown for "panda"
|
||||
|
||||
```
|
||||
|
||||
At a quick glance, the behavior is intuitive to understand. Except for a few keywords, the language is freeform. The scenario is concise yet meaningful. A real-world example illustrates the behavior. Steps declaratively indicate what should happen—without getting bogged down in the details of how.
|
||||
|
||||
The [main benefits of BDD][5] are good collaboration and automation. Everyone can contribute to behavior development, not just programmers. Expected behaviors are defined and understood from the beginning of the process. Tests can be automated together with the features they cover. Each test covers a singular, unique behavior in order to avoid duplication. And, finally, existing steps can be reused by new behavior specs, creating a snowball effect.
|
||||
|
||||
### Python's behave framework
|
||||
|
||||
`behave` is one of the most popular BDD frameworks in Python. It is very similar to other Gherkin-based Cucumber frameworks despite not holding the official Cucumber designation. `behave` has two primary layers:
|
||||
|
||||
1. Behavior specs written in Gherkin `.feature` files
|
||||
2. Step definitions and hooks written in Python modules that implement Gherkin steps
|
||||
|
||||
|
||||
|
||||
As shown in the example above, Gherkin scenarios use a three-part format:
|
||||
|
||||
1. Given some initial state
|
||||
2. When an action is taken
|
||||
3. Then verify the outcome
|
||||
|
||||
|
||||
|
||||
Each step is "glued" by decorator to a Python function when `behave` runs tests.
|
||||
|
||||
### Installation
|
||||
|
||||
As a prerequisite, make sure you have Python and `pip` installed on your machine. I strongly recommend using Python 3. (I also recommend using [`pipenv`][6], but the following example commands use the more basic `pip`.)
|
||||
|
||||
Only one package is required for `behave`:
|
||||
```
|
||||
pip install behave
|
||||
|
||||
```
|
||||
|
||||
Other packages may also be useful, such as:
|
||||
```
|
||||
pip install requests # for REST API calls
|
||||
|
||||
pip install selenium # for Web browser interactions
|
||||
|
||||
```
|
||||
|
||||
The [behavior-driven-Python][7] project on GitHub contains the examples used in this article.
|
||||
|
||||
### Gherkin features
|
||||
|
||||
The Gherkin syntax that `behave` uses is practically compliant with the official Cucumber Gherkin standard. A `.feature` file has Feature sections, which in turn have Scenario sections with Given-When-Then steps. Below is an example:
|
||||
```
|
||||
Feature: Cucumber Basket
|
||||
|
||||
As a gardener,
|
||||
|
||||
I want to carry many cucumbers in a basket,
|
||||
|
||||
So that I don’t drop them all.
|
||||
|
||||
|
||||
|
||||
@cucumber-basket
|
||||
|
||||
Scenario: Add and remove cucumbers
|
||||
|
||||
Given the basket is empty
|
||||
|
||||
When "4" cucumbers are added to the basket
|
||||
|
||||
And "6" more cucumbers are added to the basket
|
||||
|
||||
But "3" cucumbers are removed from the basket
|
||||
|
||||
Then the basket contains "7" cucumbers
|
||||
|
||||
```
|
||||
|
||||
There are a few important things to note here:
|
||||
|
||||
* Both the Feature and Scenario sections have [short, descriptive titles][8].
|
||||
* The lines immediately following the Feature title are comments ignored by `behave`. It is a good practice to put the user story there.
|
||||
* Scenarios and Features can have tags (notice the `@cucumber-basket` mark) for hooks and filtering (explained below).
|
||||
* Steps follow a [strict Given-When-Then order][9].
|
||||
* Additional steps can be added for any type using `And` and `But`.
|
||||
* Steps can be parametrized with inputs—notice the values in double quotes.
|
||||
|
||||
|
||||
|
||||
Scenarios can also be written as templates with multiple input combinations by using a Scenario Outline:
|
||||
```
|
||||
Feature: Cucumber Basket
|
||||
|
||||
|
||||
|
||||
@cucumber-basket
|
||||
|
||||
Scenario Outline: Add cucumbers
|
||||
|
||||
Given the basket has “<initial>” cucumbers
|
||||
|
||||
When "<more>" cucumbers are added to the basket
|
||||
|
||||
Then the basket contains "<total>" cucumbers
|
||||
|
||||
|
||||
|
||||
Examples: Cucumber Counts
|
||||
|
||||
| initial | more | total |
|
||||
|
||||
| 0 | 1 | 1 |
|
||||
|
||||
| 1 | 2 | 3 |
|
||||
|
||||
| 5 | 4 | 9 |
|
||||
|
||||
```
|
||||
|
||||
Scenario Outlines always have an Examples table, in which the first row gives column titles and each subsequent row gives an input combo. The row values are substituted wherever a column title appears in a step surrounded by angle brackets. In the example above, the scenario will be run three times because there are three rows of input combos. Scenario Outlines are a great way to avoid duplicate scenarios.
|
||||
|
||||
There are other elements of the Gherkin language, but these are the main mechanics. To learn more, read the Automation Panda articles [Gherkin by Example][10] and [Writing Good Gherkin][11].
|
||||
|
||||
### Python mechanics
|
||||
|
||||
Every Gherkin step must be "glued" to a step definition, a Python function that provides the implementation. Each function has a step type decorator with the matching string. It also receives a shared context and any step parameters. Feature files must be placed in a directory named `features/`, while step definition modules must be placed in a directory named `features/steps/`. Any feature file can use step definitions from any module—they do not need to have the same names. Below is an example Python module with step definitions for the cucumber basket features.
|
||||
```
|
||||
from behave import *
|
||||
|
||||
from cucumbers.basket import CucumberBasket
|
||||
|
||||
|
||||
|
||||
@given('the basket has "{initial:d}" cucumbers')
|
||||
|
||||
def step_impl(context, initial):
|
||||
|
||||
context.basket = CucumberBasket(initial_count=initial)
|
||||
|
||||
|
||||
|
||||
@when('"{some:d}" cucumbers are added to the basket')
|
||||
|
||||
def step_impl(context, some):
|
||||
|
||||
context.basket.add(some)
|
||||
|
||||
|
||||
|
||||
@then('the basket contains "{total:d}" cucumbers')
|
||||
|
||||
def step_impl(context, total):
|
||||
|
||||
assert context.basket.count == total
|
||||
|
||||
```
|
||||
|
||||
Three [step matchers][12] are available: `parse`, `cfparse`, and `re`. The default and simplest marcher is `parse`, which is shown in the example above. Notice how parametrized values are parsed and passed into the functions as input arguments. A common best practice is to put double quotes around parameters in steps.
|
||||
|
||||
Each step definition function also receives a [context][13] variable that holds data specific to the current scenario being run, such as `feature`, `scenario`, and `tags` fields. Custom fields may be added, too, to share data between steps. Always use context to share data—never use global variables!
|
||||
|
||||
`behave` also supports [hooks][14] to handle automation concerns outside of Gherkin steps. A hook is a function that will be run before or after a step, scenario, feature, or whole test suite. Hooks are reminiscent of [aspect-oriented programming][15]. They should be placed in a special `environment.py` file under the `features/` directory. Hook functions can check the current scenario's tags, as well, so logic can be selectively applied. The example below shows how to use hooks to set up and tear down a Selenium WebDriver instance for any scenario tagged as `@web`.
|
||||
```
|
||||
from selenium import webdriver
|
||||
|
||||
|
||||
|
||||
def before_scenario(context, scenario):
|
||||
|
||||
if 'web' in context.tags:
|
||||
|
||||
context.browser = webdriver.Firefox()
|
||||
|
||||
context.browser.implicitly_wait(10)
|
||||
|
||||
|
||||
|
||||
def after_scenario(context, scenario):
|
||||
|
||||
if 'web' in context.tags:
|
||||
|
||||
context.browser.quit()
|
||||
|
||||
```
|
||||
|
||||
Note: Setup and cleanup can also be done with [fixtures][16] in `behave`.
|
||||
|
||||
To offer an idea of what a `behave` project should look like, here's the example project's directory structure:
|
||||
|
||||
|
||||
|
||||
Any Python packages and custom modules can be used with `behave`. Use good design patterns to build a scalable test automation solution. Step definition code should be concise.
|
||||
|
||||
### Running tests
|
||||
|
||||
To run tests from the command line, change to the project's root directory and run the `behave` command. Use the `–help` option to see all available options.
|
||||
|
||||
Below are a few common use cases:
|
||||
```
|
||||
# run all tests
|
||||
|
||||
behave
|
||||
|
||||
|
||||
|
||||
# run the scenarios in a feature file
|
||||
|
||||
behave features/web.feature
|
||||
|
||||
|
||||
|
||||
# run all tests that have the @duckduckgo tag
|
||||
|
||||
behave --tags @duckduckgo
|
||||
|
||||
|
||||
|
||||
# run all tests that do not have the @unit tag
|
||||
|
||||
behave --tags ~@unit
|
||||
|
||||
|
||||
|
||||
# run all tests that have @basket and either @add or @remove
|
||||
|
||||
behave --tags @basket --tags @add,@remove
|
||||
|
||||
```
|
||||
|
||||
For convenience, options may be saved in [config][17] files.
|
||||
|
||||
### Other options
|
||||
|
||||
`behave` is not the only BDD test framework in Python. Other good frameworks include:
|
||||
|
||||
* `pytest-bdd` , a plugin for `pytest``behave`, it uses Gherkin feature files and step definition modules, but it also leverages all the features and plugins of `pytest`. For example, it can run Gherkin scenarios in parallel using `pytest-xdist`. BDD and non-BDD tests can also be executed together with the same filters. `pytest-bdd` also offers a more flexible directory layout.
|
||||
|
||||
* `radish` is a "Gherkin-plus" framework—it adds Scenario Loops and Preconditions to the standard Gherkin language, which makes it more friendly to programmers. It also offers rich command line options like `behave`.
|
||||
|
||||
* `lettuce` is an older BDD framework very similar to `behave`, with minor differences in framework mechanics. However, GitHub shows little recent activity in the project (as of May 2018).
|
||||
|
||||
|
||||
|
||||
Any of these frameworks would be good choices.
|
||||
|
||||
Also, remember that Python test frameworks can be used for any black box testing, even for non-Python products! BDD frameworks are great for web and service testing because their tests are declarative, and Python is a [great language for test automation][18].
|
||||
|
||||
This article is based on the author's [PyCon Cleveland 2018][19] talk, [Behavior-Driven Python][20].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/behavior-driven-python
|
||||
|
||||
作者:[Andrew Knight][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/andylpk247
|
||||
[1]:https://automationpanda.com/bdd/
|
||||
[2]:https://en.wikipedia.org/wiki/Specification_by_example
|
||||
[3]:https://automationpanda.com/2017/01/26/bdd-101-the-gherkin-language/
|
||||
[4]:https://cucumber.io/
|
||||
[5]:https://automationpanda.com/2017/02/13/12-awesome-benefits-of-bdd/
|
||||
[6]:https://docs.pipenv.org/
|
||||
[7]:https://github.com/AndyLPK247/behavior-driven-python
|
||||
[8]:https://automationpanda.com/2018/01/31/good-gherkin-scenario-titles/
|
||||
[9]:https://automationpanda.com/2018/02/03/are-gherkin-scenarios-with-multiple-when-then-pairs-okay/
|
||||
[10]:https://automationpanda.com/2017/01/27/bdd-101-gherkin-by-example/
|
||||
[11]:https://automationpanda.com/2017/01/30/bdd-101-writing-good-gherkin/
|
||||
[12]:http://behave.readthedocs.io/en/latest/api.html#step-parameters
|
||||
[13]:http://behave.readthedocs.io/en/latest/api.html#detecting-that-user-code-overwrites-behave-context-attributes
|
||||
[14]:http://behave.readthedocs.io/en/latest/api.html#environment-file-functions
|
||||
[15]:https://en.wikipedia.org/wiki/Aspect-oriented_programming
|
||||
[16]:http://behave.readthedocs.io/en/latest/api.html#fixtures
|
||||
[17]:http://behave.readthedocs.io/en/latest/behave.html#configuration-files
|
||||
[18]:https://automationpanda.com/2017/01/21/the-best-programming-language-for-test-automation/
|
||||
[19]:https://us.pycon.org/2018/
|
||||
[20]:https://us.pycon.org/2018/schedule/presentation/87/
|
||||
@ -1,5 +1,3 @@
|
||||
heart4lor translating
|
||||
|
||||
How to Build an Amazon Echo with Raspberry Pi
|
||||
======
|
||||
|
||||
|
||||
@ -1,131 +0,0 @@
|
||||
【sd886393认领翻译中】How to create shortcuts in vi
|
||||
======
|
||||
|
||||

|
||||
|
||||
Learning the [vi text editor][1] takes some effort, but experienced vi users know that after a while, using basic commands becomes second nature. It's a form of what is known as muscle memory, which in this case might well be called finger memory.
|
||||
|
||||
After you get a grasp of the main approach and basic commands, you can make editing with vi even more powerful and streamlined by using its customization options to create shortcuts. I hope that the techniques described below will facilitate your writing, programming, and data manipulation.
|
||||
|
||||
Before proceeding, I'd like to thank Chris Hermansen (who recruited me to write this article) for checking my draft with [Vim][2], as I use another version of vi. I'm also grateful for Chris's helpful suggestions, which I incorporated here.
|
||||
|
||||
First, let's review some conventions. I'll use <RET> to designate pressing the RETURN or ENTER key, and <SP> for the space bar. CTRL-x indicates simultaneously pressing the Control key and the x key (whatever x happens to be).
|
||||
|
||||
Set up your own command abbreviations with the `map` command. My first example involves the `write` command, used to save the current state of the file you're working on:
|
||||
```
|
||||
:w<RET>
|
||||
|
||||
```
|
||||
|
||||
This is only three keystrokes, but since I do it so frequently, I'd rather use only one. The key I've chosen for this purpose is the comma, which is not part of the standard vi command set. The command to set this up is:
|
||||
```
|
||||
:map , :wCTRL-v<RET>
|
||||
|
||||
```
|
||||
|
||||
The CTRL-v is essential since without it the <RET> would signal the end of the map, and we want to include the <RET> as part of the mapped comma. In general, CTRL-v is used to enter the keystroke (or control character) that follows rather than being interpreted literally.
|
||||
|
||||
In the above map, the part on the right will display on the screen as `:w^M`. The caret (`^`) indicates a control character, in this case CTRL-m, which is the system's form of <RET>.
|
||||
|
||||
So far so good—sort of. If I write my current file about a dozen times while creating and/or editing it, this map could result in a savings of 2 x 12 keystrokes. But that doesn't account for the keystrokes needed to set up the map, which in the above example is 11 (counting CTRL-v and the shifted character `:` as one stroke each). Even with a net savings, it would be a bother to set up the map each time you start a vi session.
|
||||
|
||||
Fortunately, there's a way to put maps and other abbreviations in a startup file that vi reads each time it is invoked: the `.exrc` file, or in Vim, the `.vimrc` file. Simply create this file in your home directory with a list of maps, one per line—without the colon—and the abbreviation is defined for all subsequent vi sessions until you delete or change it.
|
||||
|
||||
Before going on to a variation of the `map` command and another type of abbreviation method, here are a few more examples of maps that I've found useful for streamlining my text editing:
|
||||
```
|
||||
Displays as
|
||||
|
||||
|
||||
|
||||
:map X :xCTRL-v<RET> :x^M
|
||||
|
||||
|
||||
|
||||
or
|
||||
|
||||
|
||||
|
||||
:map X ,:qCTRL-v<RET> ,:q^M
|
||||
|
||||
```
|
||||
|
||||
The above equivalent maps write and quit (exit) the file. The `:x` is the standard vi command for this, and the second version illustrates that a previously defined map may be used in a subsequent map.
|
||||
```
|
||||
:map v :e<SP> :e
|
||||
|
||||
```
|
||||
|
||||
The above starts the command to move to another file while remaining within vi; when using this, just follow the "v" with a filename, followed by <RET>.
|
||||
```
|
||||
:map CTRL-vCTRL-e :e<SP>#CTRL-v<RET> :e #^M
|
||||
|
||||
```
|
||||
|
||||
The `#` here is the standard vi symbol for "the alternate file," which means the filename last used, so this shortcut is handy for switching back and forth between two files. Here's an example of how I use this:
|
||||
```
|
||||
map CTRL-vCTRL-r :!spell %>err &CTRL-v<RET> :!spell %>err&^M
|
||||
|
||||
```
|
||||
|
||||
(Note: The first CTRL-v in both examples above is not needed in some versions of vi.) The `:!` is a way to run an external (non-vi) command. In this case (`spell`), `%` is the vi symbol denoting the current file, the `>` redirects the output of the spell-check to a file called `err`, and the `&` says to run this in the background so I can continue editing while `spell` completes its task. I can then type `verr<RET>` (using my previous shortcut, `v`, followed by `err`) to go the file of potential errors flagged by the `spell` command, then back to the file I'm working on with CTRL-e. After running the spell-check the first time, I can use CTRL-r repeatedly and return to the `err` file with just CTRL-e.
|
||||
|
||||
A variation of the `map` command may be used to abbreviate text strings while inputting. For example,
|
||||
```
|
||||
:map! CTRL-o \fI
|
||||
|
||||
:map! CTRL-k \fP
|
||||
|
||||
```
|
||||
|
||||
This will allow you to use CTRL-o as a shortcut for entering the `groff` command to italicize the word that follows, and this will allow you to use CTRL-k for the `groff` command reverts to the previous font.
|
||||
|
||||
Here are two other examples of this technique:
|
||||
```
|
||||
:map! rh rhinoceros
|
||||
|
||||
:map! hi hippopotamus
|
||||
|
||||
```
|
||||
|
||||
The above may instead be accomplished using the `ab` command, as follows (if you're trying these out in order, first use `unmap! rh` and `umap! hi`):
|
||||
```
|
||||
:ab rh rhinoceros
|
||||
|
||||
:ab hi hippopotamus
|
||||
|
||||
```
|
||||
|
||||
In the `map!` method above, the abbreviation immediately expands to the defined word when typed (in Vim), whereas with the `ab` method, the expansion occurs when the abbreviation is followed by a space or punctuation mark (in both Vim and my version of vi, where the expansion also works like this for the `map!` method).
|
||||
|
||||
To reverse any `map`, `map!`, or `ab` within a vi session, use `:unmap`, `:unmap!`, or `:unab`.
|
||||
|
||||
In my version of vi, undefined letters that are good candidates for mapping include g, K, q, v, V, and Z; undefined control characters are CTRL-a, CTRL-c, CTRL-k, CTRL-n, CTRL-o, CTRL-p, and CTRL-x; some other undefined characters are `#` and `*`. You can also redefine characters that have meaning in vi but that you consider obscure and of little use; for example, the X that I chose for two examples in this article is a built-in vi command to delete the character to the immediate left of the current character (easily accomplished by the two-key command `hx`).
|
||||
|
||||
Finally, the commands
|
||||
```
|
||||
:map<RET>
|
||||
|
||||
:map!<RET>
|
||||
|
||||
:ab
|
||||
|
||||
```
|
||||
|
||||
will show all the currently defined mappings and abbreviations.
|
||||
|
||||
I hope that all of these tips will help you customize vi and make it easier and more efficient to use.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/shortcuts-vi-text-editor
|
||||
|
||||
作者:[Dan Sonnenschein][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dannyman
|
||||
[1]:http://ex-vi.sourceforge.net/
|
||||
[2]:https://www.vim.org/
|
||||
@ -1,4 +1,3 @@
|
||||
translating by amwps290
|
||||
Complete Sed Command Guide [Explained with Practical Examples]
|
||||
======
|
||||
In a previous article, I showed the [basic usage of Sed][1], the stream editor, on a practical use case. Today, be prepared to gain more insight about Sed as we will take an in-depth tour of the sed execution model. This will be also an opportunity to make an exhaustive review of all Sed commands and to dive into their details and subtleties. So, if you are ready, launch a terminal, [download the test files][2] and sit comfortably before your keyboard: we will start our exploration right now!
|
||||
|
||||
@ -1,155 +0,0 @@
|
||||
Translating by qhwdw
|
||||
What's all the C Plus Fuss? Bjarne Stroustrup warns of dangerous future plans for his C++
|
||||
======
|
||||
|
||||

|
||||
|
||||
**Interview** Earlier this year, Bjarne Stroustrup, creator of C++, managing director in the technology division of Morgan Stanley, and a visiting professor of computer science at Columbia University in the US, wrote [a letter][1] inviting those overseeing the evolution of the programming language to “Remember the Vasa!”
|
||||
|
||||
Easy for a Dane to understand no doubt, but perhaps more of a stretch for those with a few gaps in their knowledge of 17th century Scandinavian history. The Vasa was a Swedish warship, commissioned by King Gustavus Adolphus. It was the most powerful warship in the Baltic Sea from its maiden voyage on the August 10, 1628, until a few minutes later when it sank.
|
||||
|
||||
The formidable Vasa suffered from a design flaw: it was top-heavy, so much so that it was [undone by a gust of wind][2]. By invoking the memory of the capsized ship, Stroustrup served up a cautionary tale about the risks facing C++ as more and more features get added to the language.
|
||||
|
||||
Quite a few such features have been suggested. Stroustrup cited 43 proposals in his letter. He contends those participating in the evolution of the ISO standard language, a group known as [WG21][3], are working to advance the language but not together.
|
||||
|
||||
In his letter, he wrote:
|
||||
|
||||
>Individually, many proposals make sense. Together they are insanity to the point of endangering the future of C++.
|
||||
|
||||
He makes clear that he doesn’t interpret the fate of the Vasa to mean that incremental improvements spell doom. Rather, he takes it as a lesson to build a solid foundation, to learn from experience and to test thoroughly.
|
||||
|
||||
With the recent conclusion of the C++ Standardization Committee Meeting in Rapperswil, Switzerland, earlier this month, Stroustrup addressed a few questions put to him by _The Register_ about what's next for the language. (The most recent version is C++17, which arrived last year; the next version C++20 is under development and expected in 2020.)
|
||||
|
||||
**_Register:_ In your note, Remember the Vasa!, you wrote:**
|
||||
|
||||
>The foundation begun in C++11 is not yet complete, and C++17 did little to make our foundation more solid, regular, and complete. Instead, it added significant surface complexity and increased the number of features people need to learn. C++ could crumble under the weight of these – mostly not quite fully-baked – proposals. We should not spend most our time creating increasingly complicated facilities for experts, such as ourselves.
|
||||
|
||||
**Is C++ too challenging for newcomers, and if so, what features do you believe would make the language more accessible?**
|
||||
|
||||
_**Stroustrup:**_ Some parts of C++ are too challenging for newcomers.
|
||||
|
||||
On the other hand, there are parts of C++ that makes it far more accessible to newcomers than C or 1990s C++. The difficulty is to get the larger community to focus on those parts and help beginners and casual C++ users to avoid the parts that are there to support implementers of advanced libraries.
|
||||
|
||||
I recommend the [C++ Core Guidelines][4] as an aide for that.
|
||||
|
||||
Also, my “A Tour of C++” can help people get on the right track with modern C++ without getting lost in 1990s complexities or ensnarled by modern facilities meant for expert use. The second edition of “A Tour of C++” covering C++17 and parts of C++20 is on its way to the stores.
|
||||
|
||||
I and others have taught C++ to 1st year university students with no previous programming experience in 3 months. It can be done as long as you don’t try to dig into every obscure corner of the language and focus on modern C++.
|
||||
|
||||
“Making simple things simple” is a long-term goal of mine. Consider the C++11 range-for loop:
|
||||
```
|
||||
for (int& x : v) ++x; // increment each element of the container v
|
||||
|
||||
```
|
||||
|
||||
where v can be just about any container. In C and C-style C++, that might look like this:
|
||||
```
|
||||
for (int i=0; i<MAX; i++) ++v[i]; // increment each element of the array v
|
||||
|
||||
```
|
||||
|
||||
Some people complained that adding the range-for loop made C++ more complicated, and they were obviously correct because it added a feature, but it made the _use_ of C++ simpler. It also eliminated some common errors with the use of the traditional for loop.
|
||||
|
||||
Another example is the C++11 standard thread library. It is far simpler to use and less error-prone than using the POSIX or Windows thread C APIs directly.
|
||||
|
||||
**_Register:_ How would you characterize the current state of the language?**
|
||||
|
||||
_**Stroustrup:**_ C++11 was a major improvement of C++ and C++14 completed that work. C++17 added quite a few features without offering much support for novel techniques. C++20 looks like it might become a major improvement. The state of compilers and standard-library implementations are excellent and very close to the latest standards. C++17 is already usable. The tool support is improving steadily. There are lots of third-party libraries and many new tools. Unfortunately, those can be hard to find.
|
||||
|
||||
The worries I expressed in the Vasa paper relate to the standards process that combines over-enthusiasm for novel facilities with perfectionism that delays significant improvements. “The best is the enemy of the good.” There were 160 participants at the June Rapperswil meeting. It is hard to keep a consistent focus in a group that large and diverse. There is also a tendency for experts to design more for themselves than for the community at large.
|
||||
|
||||
**Register: Is there a desired state for the language or rather do you strive simply for a desired adaptability to what programmers require at any given time?
|
||||
|
||||
**Stroustrup:** Both. I’d like to see C++ supporting a guaranteed completely type-safe and resource-safe style of programming. This should not be done by restricting applicability or adding cost, but by improved expressiveness and performance. I think it can be done and that the approach of giving programmers better (and easier to use) language facilities can get us there.
|
||||
|
||||
That end-goal will not be met soon or just through language design alone. We need a combination of improved language features, better libraries, static analysis, and rules for effective programming. The C++ Core Guidelines is part of my broad, long-term approach to improve the quality of C++ code.
|
||||
|
||||
**Register: Is there an identifiable threat to C++? If so, what form does that take? (e.g. slow evolution, the attraction of emerging low-level languages, etc...your note seems to suggest it may be too many proposals.)**
|
||||
|
||||
**Stroustrup:** Certainly; we have had 400 papers this year already. They are not all new proposals, of course. Many relate the necessary and unglamorous work on precisely specifying the language and its standard library, but the volume is getting unmanageable. You can find all the committee papers on the WG21 website.
|
||||
|
||||
I wrote the “Remember the Vasa!” as a call to action. I am scared of the pressure to add language features to address immediate needs and fashions, rather than to strengthen the language foundations (e.g. improving the static type system). Adding anything new, however minor carries a cost, such as implementation, teaching, tools upgrades. Major features are those that change the way we think about programming. Those are the ones we must concentrate on.
|
||||
|
||||
The committee has established a “Direction Group” of experienced people with strong track records in many areas of the language, the standard library, implementation, and real-word use. I’m a member and we wrote up something on direction, design philosophy, and suggested areas of emphasis.
|
||||
|
||||
For C++20, we recommend to focus on:
|
||||
|
||||
Concepts
|
||||
Modules (offering proper modularity and dramatic compile-time improvements)
|
||||
Ranges (incl. some of the infinite sequence extensions)
|
||||
Networking Concepts in the standard library
|
||||
|
||||
After the Rappwerwil meeting, the odds are reasonable, though getting modules and networking is obviously a stretch. I’m an optimist and the committee members are working very hard.
|
||||
|
||||
I don’t worry about other languages or new languages. I like programming languages. If a new language offers something useful that other languages don’t, it has a role and we can all learn from it. And then, of course, each language has its own problems. Many of C++’s problems relate to its very wide range of application areas, its very large and diverse user population, and overenthusiasm. Most language communities would love to have such problems.
|
||||
|
||||
**Register: Are there any architectural decisions about the language you've reconsidered?**
|
||||
|
||||
**Stroustrup:** I always consider older decisions and designs when I work on something new. For example, see my History of Programming papers 1, 2.
|
||||
|
||||
There are no major decisions I regret, though there is hardly any feature I wouldn’t do somewhat differently if I had to do it again.
|
||||
|
||||
As ever, the ability to deal directly with hardware plus zero-overhead abstraction is the guiding idea. The use of constructors and destructors to handle resources is key (RAII) and the STL is a good example of what can be done in a C++ library.
|
||||
|
||||
**Register: Does the three-year release cadence, adopted in 2011 it seems, still work? I ask because Java has been dealing with a desire for faster iteration.**
|
||||
|
||||
**Stroustrup:** I think C++20 will be delivered on time (like C++14 and C++17 were) and that the major compilers will conform to it almost instantly. I also hope that C++20 will be a major improvement over C++17.
|
||||
|
||||
I don’t worry too much about how other languages manage their releases. C++ is controlled by a committee working under ISO rules, rather by a corporation or a “beneficent dictator for life.” This will not change. For ISO standards, C++’s three-year cycle is a dramatic innovation. The standard is 5- or 10-year cycles.
|
||||
|
||||
**Register: In your note you wrote:**
|
||||
|
||||
We need a reasonably coherent language that can be used by 'ordinary programmers' whose main concern is to ship great applications on time.
|
||||
|
||||
Are changes to the language sufficient to address this or might this also involve more accessible tooling and educational support?
|
||||
|
||||
**Stroustrup:** I try hard to communicate my ideas of what C++ is and how it might be used and I encourage others to do the same.
|
||||
|
||||
In particular, I encourage presenters and authors to make useful ideas accessible to the great mass of C++ programmers, rather than demonstrating how clever they are by presenting complicated examples and techniques. My 2017 CppCon keynote was “Learning and Teaching C++” and it also pointed to the need for better tools.
|
||||
|
||||
I mentioned build support and package managers. Those have traditionally been areas of weakness for C++. The standards committee now has a tools Study Group and will probably soon have an Education Study group.
|
||||
|
||||
The C++ community has traditionally been completely disorganized, but over the last five years many more meetings and blogs have sprung up to satisfy the community’s appetite for news and support. CppCon, isocpp.org, and Meeting++ are examples.
|
||||
|
||||
Design in a committee is very hard. However committees are a fact of life in all large projects. I am concerned, but being concerned and facing up to the problems is necessary for success.
|
||||
|
||||
**Register: How would you characterize the C++ community process? Are there aspects of the communication and decision making procedure that you'd like to see change?**
|
||||
|
||||
**Stroustrup:** C++ doesn’t have a corporately controlled “community process”; it has an ISO standards process. We can’t significantly change the ISO rules. Ideally, we’d have a small full-time “secretariat” making the final decisions and setting directions, but that’s not going to happen. Instead, we have hundreds of people discussion on-line, about 160 people voting on technical issues, about 70 organizations and 11 nations formally voting on the resulting proposals. That’s messy, but sometimes we make it work.
|
||||
|
||||
**Register: Finally, what upcoming C++ features do you feel will be most beneficial for C++ users?**
|
||||
|
||||
**Stroustrup:**
|
||||
|
||||
+ Concepts to significantly simplify generic programming
|
||||
+ _Parallel algorithms – there is no easier way to use the power of the concurrency features of modern hardware
|
||||
+ Coroutines, if the committee can decide on those for C++20.
|
||||
+ Modules to improve the way organize our source code and dramatically improve compile times. I hope we can get such modules, but it is not yet certain that we can do that for C++20.
|
||||
+ A standard networking library, but it is not yet certain that we can do that for C++20.
|
||||
|
||||
In addition:
|
||||
|
||||
+ Contracts (run-time checked pre-conditions, post-conditions, and assertions) could become significant for many.
|
||||
+ The date and time-zone support library will be significant for many (in industry).
|
||||
|
||||
**Register: Is there anything else you'd like to add?**
|
||||
|
||||
**Stroustrup:** If the C++ standards committee can focus on major issues to solve major problems, C++20 will be great. Until then, we have C++17 that is still far better than many people’s outdated impressions of C++. ®
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.theregister.co.uk/2018/06/18/bjarne_stroustrup_c_plus_plus/
|
||||
|
||||
作者:[Thomas Claburn][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.theregister.co.uk/Author/3190
|
||||
[1]:http://open-std.org/JTC1/SC22/WG21/docs/papers/2018/p0977r0.pdf
|
||||
[2]:https://www.vasamuseet.se/en/vasa-history/disaster
|
||||
[3]:http://open-std.org/JTC1/SC22/WG21/
|
||||
[4]:https://github.com/isocpp/CppCoreGuidelines/blob/master/CppCoreGuidelines.md
|
||||
[5]:https://go.theregister.co.uk/tl/1755/shttps://continuouslifecycle.london/
|
||||
@ -1,5 +1,3 @@
|
||||
bestony is translating
|
||||
|
||||
Becoming a senior developer: 9 experiences you'll encounter
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
Translating by leemeans
|
||||
Setting Up a Timer with systemd in Linux
|
||||
======
|
||||
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
translating by wyxplus
|
||||
Building a network attached storage device with a Raspberry Pi
|
||||
======
|
||||
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
translated by stephenxs
|
||||
|
||||
Top Linux developers' recommended programming books
|
||||
======
|
||||
Without question, Linux was created by brilliant programmers who employed good computer science knowledge. Let the Linux programmers whose names you know share the books that got them started and the technology references they recommend for today's developers. How many of them have you read?
|
||||
|
||||
@ -1,76 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Add YouTube Player Controls To Your Linux Desktop With browser-mpris2 (Chrome Extension)
|
||||
======
|
||||
A Unity feature that I miss (it only actually worked for a short while though) is automatically getting player controls in the Ubuntu Sound Indicator when visiting a website like YouTube in a web browser, so you could pause or stop the video directly from the top bar, as well as see the video / song information and a preview.
|
||||
|
||||
This Unity feature is long dead, but I was searching for something similar for Gnome Shell and I came across **[browser-mpris2][1], an extension that implements a MPRIS v2 interface for Google Chrome / Chromium, which currently only supports YouTube** , and I thought there might be some Linux Uprising readers who'll like this.
|
||||
|
||||
**The extension also works with Chromium-based web browsers like Opera and Vivaldi.**
|
||||
**
|
||||
** **browser-mpris2 also supports Firefox but since loading extensions via about:debugging is temporary, and this is needed for browser-mpris2, this article doesn't include Firefox instructions. The developer[intends][2] to submit the extension to the Firefox addons website in the future.**
|
||||
|
||||
**Using this Chrome extension you get YouTube media player controls (play, pause, stop and seeking) in MPRIS2-capable applets**. For example, if you use Gnome Shell, you get YouTube media player controls as a permanent notification or, you can use an extension like Media Player Indicator for this. In Cinnamon / Linux Mint with Cinnamon, it shows up in the Sound Applet.
|
||||
|
||||
**It didn't work for me on Unity** , I'm not sure why. I didn't try this extension with other MPRIS2-capable applets available in various desktop environments (KDE, Xfce, MATE, etc.). If you give it a try, let us know if it works with your desktop environment / MPRIS2 enabled applet.
|
||||
|
||||
Here is a screenshot with [Media Player Indicator][3] displaying information about the currently playing YouTube video, along with its controls (play/pause, stop and seeking), on Ubuntu 18.04 with Gnome Shell and Chromium browser:
|
||||
|
||||
|
||||
|
||||
And in Linux Mint 19 Cinnamon with its default sound applet and Chromium browser:
|
||||
|
||||
|
||||
|
||||
### How to install browser-mpris2 for Google Chrome / Chromium
|
||||
|
||||
**1\. Install Git if you haven't already.**
|
||||
|
||||
In Debian / Ubuntu / Linux Mint, use this command to install git:
|
||||
```
|
||||
sudo apt install git
|
||||
|
||||
```
|
||||
|
||||
**2\. Download and install the[browser-mpris2][1] required files.**
|
||||
|
||||
The commands below clone the browser-mpris2 Git repository and install the chrome-mpris2 file to `/usr/local/bin/` (run the "git clone..." command in a folder where you can continue to keep the browser-mpris2 folder because you can't remove it, as it will be used by Chrome / Chromium):
|
||||
```
|
||||
git clone https://github.com/otommod/browser-mpris2
|
||||
sudo install browser-mpris2/native/chrome-mpris2 /usr/local/bin/
|
||||
|
||||
```
|
||||
|
||||
**3\. Load the extension in Chrome / Chromium-based web browsers.**
|
||||
|
||||
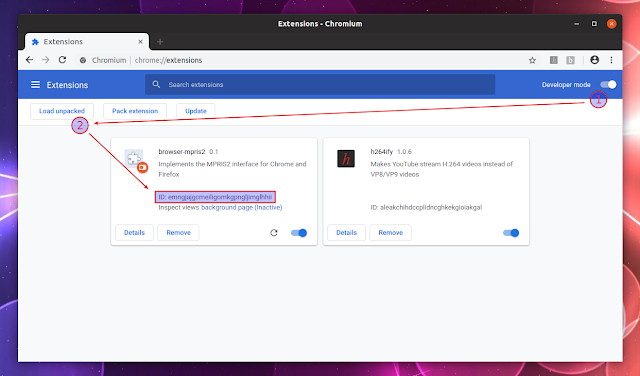
|
||||
|
||||
Open Google Chrome, Chromium, Opera or Vivaldi web browsers, go to the Extensions page (enter `chrome://extensions` in the URL bar), enable `Developer mode` using the toggle available in the top right-hand side of the screen, then select `Load Unpacked` and select the chrome-mpris2 directory (make sure to not select a subfolder).
|
||||
|
||||
Copy the extension ID and save it because you'll need it later (it's something like: `emngjajgcmeiligomkgpngljimglhhii` but it's different for you so make sure to use the ID from your computer!) .
|
||||
|
||||
**4\. Run** `install-chrome.py` (from the `browser-mpris2/native` folder), specifying the extension id and chrome-mpris2 path.
|
||||
|
||||
Use this command in a terminal (replace `REPLACE-THIS-WITH-EXTENSION-ID` with the browser-mpris2 extension ID displayed under `chrome://extensions` from the previous step) to install this extension:
|
||||
```
|
||||
browser-mpris2/native/install-chrome.py REPLACE-THIS-WITH-EXTENSION-ID /usr/local/bin/chrome-mpris2
|
||||
|
||||
```
|
||||
|
||||
You only need to run this command once, there's no need to add it to startup or anything like that. Any YouTube video you play in Google Chrome or Chromium browsers should show up in whatever MPRISv2 applet you're using. There's no need to restart the web browser.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/08/add-youtube-player-controls-to-your.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://github.com/otommod/browser-mpris2
|
||||
[2]:https://github.com/otommod/browser-mpris2/issues/11
|
||||
[3]:https://extensions.gnome.org/extension/55/media-player-indicator/
|
||||
@ -1,110 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
5 cool music player apps
|
||||
======
|
||||
|
||||

|
||||
Do you like music? Then Fedora may have just what you’re looking for. This article introduces different music player apps that run on Fedora. You’re covered whether you have an extensive music library, a small one, or none at all. Here are four graphical application and one terminal-based music player that will have you jamming.
|
||||
|
||||
### Quod Libet
|
||||
|
||||
Quod Libet is a complete manager for your large audio library. If you have an extensive audio library that you would like not just listen to, but also manage, Quod Libet might a be a good choice for you.
|
||||
|
||||
![][1]
|
||||
|
||||
Quod Libet can import music from multiple locations on your disk, and allows you to edit tags of the audio files — so everything is under your control. As a bonus, there are various plugins available for anything from a simple equalizer to a [last.fm][2] sync. You can also search and play music directly from [Soundcloud][3].
|
||||
|
||||
Quod Libet works great on HiDPI screens, and is available as an RPM in Fedora or on [Flathub][4] in case you run [Silverblue][5]. Install it using Gnome Software or the command line:
|
||||
```
|
||||
$ sudo dnf install quodlibet
|
||||
|
||||
```
|
||||
|
||||
### Audacious
|
||||
|
||||
If you like a simple music player that could even look like the legendary Winamp, Audacious might be a good choice for you.
|
||||
|
||||
![][6]
|
||||
|
||||
Audacious probably won’t manage all your music at once, but it works great if you like to organize your music as files. You can also export and import playlists without reorganizing the music files themselves.
|
||||
|
||||
As a bonus, you can make it look likeWinamp. To make it look the same as on the screenshot above, go to Settings / Appearance, select Winamp Classic Interface at the top, and choose the Refugee skin right below. And Bob’s your uncle!
|
||||
|
||||
Audacious is available as an RPM in Fedora, and can be installed using the Gnome Software app or the following command on the terminal:
|
||||
```
|
||||
$ sudo dnf install audacious
|
||||
|
||||
```
|
||||
|
||||
### Lollypop
|
||||
|
||||
Lollypop is a music player that provides great integration with GNOME. If you enjoy how GNOME looks, and would like a music player that’s nicely integrated, Lollypop could be for you.
|
||||
|
||||
![][7]
|
||||
|
||||
Apart from nice visual integration with the GNOME Shell, it woks nicely on HiDPI screens, and supports a dark theme.
|
||||
|
||||
As a bonus, Lollypop has an integrated cover art downloader, and a so-called Party Mode (the note button at the top-right corner) that selects and plays music automatically for you. It also integrates with online services such as [last.fm][2] or [libre.fm][8].
|
||||
|
||||
Available as both an RPM in Fedora or a [Flathub][4] for your [Silverblue][5] workstation, install it using the Gnome Software app or using the terminal:
|
||||
```
|
||||
$ sudo dnf install lollypop
|
||||
|
||||
```
|
||||
|
||||
### Gradio
|
||||
|
||||
What if you don’t own any music, but still like to listen to it? Or you just simply love radio? Then Gradio is here for you.
|
||||
|
||||
![][9]
|
||||
|
||||
Gradio is a simple radio player that allows you to search and play internet radio stations. You can find them by country, language, or simply using search. As a bonus, it’s visually integrated into GNOME Shell, works great with HiDPI screens, and has an option for a dark theme.
|
||||
|
||||
Gradio is available on [Flathub][4] which works with both Fedora Workstation and [Silverblue][5]. Install it using the Gnome Software app.
|
||||
|
||||
### sox
|
||||
|
||||
Do you like using the terminal instead, and listening to some music while you work? You don’t have to leave the terminal thanks to sox.
|
||||
|
||||
![][10]
|
||||
|
||||
sox is a very simple, terminal-based music player. All you need to do is to run a command such as:
|
||||
```
|
||||
$ play file.mp3
|
||||
|
||||
```
|
||||
|
||||
…and sox will play it for you. Apart from individual audio files, sox also supports playlists in the m3u format.
|
||||
|
||||
As a bonus, because sox is a terminal-based application, you can run it over ssh. Do you have a home server with speakers attached to it? Or do you want to play music from a different computer? Try using it together with [tmux][11], so you can keep listening even when the session closes.
|
||||
|
||||
sox is available in Fedora as an RPM. Install it by running:
|
||||
```
|
||||
$ sudo dnf install sox
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/5-cool-music-player-apps/
|
||||
|
||||
作者:[Adam Šamalík][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/asamalik/
|
||||
[1]:https://fedoramagazine.org/wp-content/uploads/2018/08/qodlibet-300x217.png
|
||||
[2]:https://last.fm
|
||||
[3]:https://soundcloud.com/
|
||||
[4]:https://flathub.org/home
|
||||
[5]:https://teamsilverblue.org/
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/08/audacious-300x136.png
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2018/08/lollypop-300x172.png
|
||||
[8]:https://libre.fm
|
||||
[9]:https://fedoramagazine.org/wp-content/uploads/2018/08/gradio.png
|
||||
[10]:https://fedoramagazine.org/wp-content/uploads/2018/08/sox-300x179.png
|
||||
[11]:https://fedoramagazine.org/use-tmux-more-powerful-terminal/
|
||||
@ -1,118 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
[Solved] “sub process usr bin dpkg returned an error code 1″ Error in Ubuntu
|
||||
======
|
||||
If you are encountering “sub process usr bin dpkg returned an error code 1” while installing software on Ubuntu Linux, here is how you can fix it.
|
||||
|
||||
One of the common issue in Ubuntu and other Debian based distribution is the broken packages. You try to update the system or install a new package and you encounter an error like ‘Sub-process /usr/bin/dpkg returned an error code’.
|
||||
|
||||
That’s what happened to me the other day. I was trying to install a radio application in Ubuntu when it threw me this error:
|
||||
```
|
||||
Unpacking python-gst-1.0 (1.6.2-1build1) ...
|
||||
Selecting previously unselected package radiotray.
|
||||
Preparing to unpack .../radiotray_0.7.3-5ubuntu1_all.deb ...
|
||||
Unpacking radiotray (0.7.3-5ubuntu1) ...
|
||||
Processing triggers for man-db (2.7.5-1) ...
|
||||
Processing triggers for desktop-file-utils (0.22-1ubuntu5.2) ...
|
||||
Processing triggers for bamfdaemon (0.5.3~bzr0+16.04.20180209-0ubuntu1) ...
|
||||
Rebuilding /usr/share/applications/bamf-2.index...
|
||||
Processing triggers for gnome-menus (3.13.3-6ubuntu3.1) ...
|
||||
Processing triggers for mime-support (3.59ubuntu1) ...
|
||||
Setting up polar-bookshelf (1.0.0-beta56) ...
|
||||
ln: failed to create symbolic link '/usr/local/bin/polar-bookshelf': No such file or directory
|
||||
dpkg: error processing package polar-bookshelf (--configure):
|
||||
subprocess installed post-installation script returned error exit status 1
|
||||
Setting up python-appindicator (12.10.1+16.04.20170215-0ubuntu1) ...
|
||||
Setting up python-gst-1.0 (1.6.2-1build1) ...
|
||||
Setting up radiotray (0.7.3-5ubuntu1) ...
|
||||
Errors were encountered while processing:
|
||||
polar-bookshelf
|
||||
E: Sub-process /usr/bin/dpkg returned an error code (1)
|
||||
|
||||
```
|
||||
|
||||
The last three lines are of the utmost importance here.
|
||||
```
|
||||
Errors were encountered while processing:
|
||||
polar-bookshelf
|
||||
E: Sub-process /usr/bin/dpkg returned an error code (1)
|
||||
|
||||
```
|
||||
|
||||
It tells me that the package polar-bookshelf is causing and issue. This might be crucial to how you fix this error here.
|
||||
|
||||
### Fixing Sub-process /usr/bin/dpkg returned an error code (1)
|
||||
|
||||
![Fix update errors in Ubuntu Linux][1]
|
||||
|
||||
Let’s try to fix this broken error package. I’ll show several methods that you can try one by one. The initial ones are easy to use and simply no-brainers.
|
||||
|
||||
You should try to run sudo apt update and then try to install a new package or upgrade after trying each of the methods discussed here.
|
||||
|
||||
#### Method 1: Reconfigure Package Database
|
||||
|
||||
The first method you can try is to reconfigure the package database. Probably the database got corrupted while installing a package. Reconfiguring often fixes the problem.
|
||||
```
|
||||
sudo dpkg --configure -a
|
||||
|
||||
```
|
||||
|
||||
#### Method 2: Use force install
|
||||
|
||||
If a package installation was interrupted previously, you may try to do a force install.
|
||||
```
|
||||
sudo apt-get install -f
|
||||
|
||||
```
|
||||
|
||||
#### Method 3: Try removing the troublesome package
|
||||
|
||||
If it’s not an issue for you, you may try to remove the package manually. Please don’t do it for Linux Kernels (packages starting with linux-).
|
||||
```
|
||||
sudo apt remove
|
||||
|
||||
```
|
||||
|
||||
#### Method 4: Remove post info files of the troublesome package
|
||||
|
||||
This should be your last resort. You can try removing the files associated to the package in question from /var/lib/dpkg/info.
|
||||
|
||||
**You need to know a little about basic Linux commands to figure out what’s happening and how can you use the same with your problem.**
|
||||
|
||||
In my case, I had an issue with polar-bookshelf. So I looked for the files associated with it:
|
||||
```
|
||||
ls -l /var/lib/dpkg/info | grep -i polar-bookshelf
|
||||
-rw-r--r-- 1 root root 2324811 Aug 14 19:29 polar-bookshelf.list
|
||||
-rw-r--r-- 1 root root 2822824 Aug 10 04:28 polar-bookshelf.md5sums
|
||||
-rwxr-xr-x 1 root root 113 Aug 10 04:28 polar-bookshelf.postinst
|
||||
-rwxr-xr-x 1 root root 84 Aug 10 04:28 polar-bookshelf.postrm
|
||||
|
||||
```
|
||||
|
||||
Now all I needed to do was to remove these files:
|
||||
```
|
||||
sudo mv /var/lib/dpkg/info/polar-bookshelf.* /tmp
|
||||
|
||||
```
|
||||
|
||||
Use the sudo apt update and then you should be able to install software as usual.
|
||||
|
||||
#### Which method worked for you (if it worked)?
|
||||
|
||||
I hope this quick article helps you in fixing the ‘E: Sub-process /usr/bin/dpkg returned an error code (1)’ error.
|
||||
|
||||
If it did work for you, which method was it? Did you manage to fix this error with some other method? If yes, please share that to help others with this issue.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/dpkg-returned-an-error-code-1/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/fix-common-update-errors-ubuntu.jpeg
|
||||
@ -1,170 +0,0 @@
|
||||
Translating by z52527
|
||||
|
||||
|
||||
A Cat Clone With Syntax Highlighting And Git Integration
|
||||
======
|
||||
|
||||

|
||||
|
||||
In Unix-like systems, we use **‘cat’** command to print and concatenate files. Using cat command, we can print the contents of a file to the standard output, concatenate several files into the target file, and append several files into the target file. Today, I stumbled upon a similar utility named **“Bat”** , a clone to the cat command, with some additional cool features such as syntax highlighting, git integration and automatic paging etc. In this brief guide, we will how to install and use Bat command in Linux.
|
||||
|
||||
### Installation
|
||||
|
||||
Bat is available in the default repositories of Arch Linux. So, you can install it using pacman on any arch-based systems.
|
||||
```
|
||||
$ sudo pacman -S bat
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint systems, download the **.deb** file from the [**Releases page**][1] and install it as shown below.
|
||||
```
|
||||
$ sudo apt install gdebi
|
||||
|
||||
$ sudo gdebi bat_0.5.0_amd64.deb
|
||||
|
||||
```
|
||||
|
||||
For other systems, you may need to compile and install from source. Make sure you have installed Rust 1.26 or higher.
|
||||
|
||||
|
||||
|
||||
Then, run the following command to install Bat:
|
||||
```
|
||||
$ cargo install bat
|
||||
|
||||
```
|
||||
|
||||
Alternatively, you can install it using [**Linuxbrew**][2] package manager.
|
||||
```
|
||||
$ brew install bat
|
||||
|
||||
```
|
||||
|
||||
### Bat command Usage
|
||||
|
||||
The Bat command’s usage is very similar to cat command.
|
||||
|
||||
To create a new file using bat command, do:
|
||||
```
|
||||
$ bat > file.txt
|
||||
|
||||
```
|
||||
|
||||
To view the contents of a file using bat command, just do:
|
||||
```
|
||||
$ bat file.txt
|
||||
|
||||
```
|
||||
|
||||
You can also view multiple files at once:
|
||||
```
|
||||
$ bat file1.txt file2.txt
|
||||
|
||||
```
|
||||
|
||||
To append the contents of the multiple files in a single file:
|
||||
```
|
||||
$ bat file1.txt file2.txt file3.txt > document.txt
|
||||
|
||||
```
|
||||
|
||||
Like I already mentioned, apart from viewing and editing files, the Bat command has some additional cool features though.
|
||||
|
||||
The bat command supports **syntax highlighting** for large number of programming and markup languages. For instance, look at the following example. I am going to display the contents of the **reverse.py** file using both cat and bat commands.
|
||||
|
||||

|
||||
|
||||
Did you notice the difference? Cat command shows the contents of the file in plain text format, whereas bat command shows output with syntax highlighting, order number in a neat tabular column format. Much better, isn’t it?
|
||||
|
||||
If you want to display only the line numbers (not the tabular column), use **-n** flag.
|
||||
```
|
||||
$ bat -n reverse.py
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||

|
||||
|
||||
Another notable feature of Bat command is it supports **automatic paging**. That means if output of a file is too large for one screen, the bat command automatically pipes its own output to **less** command, so you can view the output page by page.
|
||||
|
||||
Let me show you an example. When you view the contents of a file which spans multiple pages using cat command, the prompt quickly jumps to the last page of the file, and you do not see the content in the beginning or in the middle.
|
||||
|
||||
Have a look at the following output:
|
||||
|
||||

|
||||
|
||||
As you can see, the cat command displays last page of the file.
|
||||
|
||||
So, you may need to pipe the output of the cat command to **less** command to view it’s contents page by page from the beginning.
|
||||
```
|
||||
$ cat reverse.py | less
|
||||
|
||||
```
|
||||
|
||||
Now, you can view output page by page by hitting the ENTER key. However, it is not necessary if you use bat command. The bat command will automatically pipe the output of a file which spans multiple pages.
|
||||
```
|
||||
$ bat reverse.py
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
|
||||

|
||||
|
||||
Now hit the ENTER key to go to the next page.
|
||||
|
||||
The bat command also supports **GIT integration** , so you can view/edit the files in your Git repository without much hassle. It communicates with git to show modifications with respect to the index (see left side bar).
|
||||
|
||||

|
||||
|
||||
**Customizing Bat**
|
||||
|
||||
If you don’t like the default themes, you can change it too. Bat has option for that too.
|
||||
|
||||
To list the available themes, just run:
|
||||
```
|
||||
$ bat --list-themes
|
||||
1337
|
||||
DarkNeon
|
||||
Default
|
||||
GitHub
|
||||
Monokai Extended
|
||||
Monokai Extended Bright
|
||||
Monokai Extended Light
|
||||
Monokai Extended Origin
|
||||
TwoDark
|
||||
|
||||
```
|
||||
|
||||
To use a different theme, for example TwoDark, run:
|
||||
```
|
||||
$ bat --theme=TwoDark file.txt
|
||||
|
||||
```
|
||||
|
||||
If you want to make the theme permanent, use `export BAT_THEME="TwoDark"` in your shells startup file.
|
||||
|
||||
Bat also have the option to control the appearance of the output. To do so, use the `--style` option. To show only Git changes and line numbers but no grid and no file header, use `--style=numbers,changes`.
|
||||
|
||||
For more details, refer the Bat project GitHub Repository (Link at the end).
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/bat-a-cat-clone-with-syntax-highlighting-and-git-integration/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://github.com/sharkdp/bat/releases
|
||||
[2]:https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
|
||||
@ -1,3 +1,5 @@
|
||||
translating by Flowsnow
|
||||
|
||||
How to build rpm packages
|
||||
======
|
||||
|
||||
|
||||
@ -1,109 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Backup Installed Packages And Restore Them On Freshly Installed Ubuntu
|
||||
======
|
||||
|
||||

|
||||
|
||||
Installing the same set of packages on multiple Ubuntu systems is time consuming and boring task. You don’t want to spend your time to install the same packages over and over on multiple systems. When it comes to install packages on similar architecture Ubuntu systems, there are many methods available to make this task easier. You could simply migrate your old Ubuntu system’s applications, settings and data to a newly installed system with a couple mouse clicks using [**Aptik**][1]. Or, you can take the [**backup entire list of installed packages**][2] using your package manager (Eg. APT), and install them later on a freshly installed system. Today, I learned that there is also yet another dedicated utility available to do this job. Say hello to **apt-clone** , a simple tool that lets you to create a list of installed packages for Debian/Ubuntu systems that can be restored on freshly installed systems or containers or into a directory.
|
||||
|
||||
Apt-clone will help you on situations where you want to,
|
||||
|
||||
* Install consistent applications across multiple systems running with similar Ubuntu (and derivatives) OS.
|
||||
* Install same set of packages on multiple systems often.
|
||||
* Backup the entire list of installed applications and restore them on demand wherever and whenever necessary.
|
||||
|
||||
|
||||
|
||||
In this brief guide, we will be discussing how to install and use Apt-clone on Debian-based systems. I tested this utility on Ubuntu 18.04 LTS system, however it should work on all Debian and Ubuntu-based systems.
|
||||
|
||||
### Backup Installed Packages And Restore Them Later On Freshly Installed Ubuntu System
|
||||
|
||||
Apt-clone is available in the default repositories. To install it, just enter the following command from the Terminal:
|
||||
|
||||
```
|
||||
$ sudo apt install apt-clone
|
||||
```
|
||||
|
||||
Once installed, simply create the list of installed packages and save them in any location of your choice.
|
||||
|
||||
```
|
||||
$ mkdir ~/mypackages
|
||||
|
||||
$ sudo apt-clone clone ~/mypackages
|
||||
```
|
||||
|
||||
The above command saved all installed packages in my Ubuntu system in a file named **apt-clone-state-ubuntuserver.tar.gz** under **~/mypackages** directory.
|
||||
|
||||
To view the details of the backup file, run:
|
||||
|
||||
```
|
||||
$ apt-clone info mypackages/apt-clone-state-ubuntuserver.tar.gz
|
||||
Hostname: ubuntuserver
|
||||
Arch: amd64
|
||||
Distro: bionic
|
||||
Meta:
|
||||
Installed: 516 pkgs (33 automatic)
|
||||
Date: Sat Sep 15 10:23:05 2018
|
||||
```
|
||||
|
||||
As you can see, I have 516 packages in total in my Ubuntu server.
|
||||
|
||||
Now, copy this file on your USB or external drive and go to any other system that want to install the same set of packages. Or you can also transfer the backup file to the system on the network and install the packages by using the following command:
|
||||
|
||||
```
|
||||
$ sudo apt-clone restore apt-clone-state-ubuntuserver.tar.gz
|
||||
```
|
||||
|
||||
Please be mindful that this command will overwrite your existing **/etc/apt/sources.list** and will install/remove packages. You have been warned! Also, just make sure the destination system is on same arch and same OS. For example, if the source system is running with 18.04 LTS 64bit, the destination system must also has the same.
|
||||
|
||||
If you don’t want to restore packages on the system, you can simply use `--destination /some/location` option to debootstrap the clone into this directory.
|
||||
|
||||
```
|
||||
$ sudo apt-clone restore apt-clone-state-ubuntuserver.tar.gz --destination ~/oldubuntu
|
||||
```
|
||||
|
||||
In this case, the above command will restore the packages in a folder named **~/oldubuntu**.
|
||||
|
||||
For more details, refer help section:
|
||||
|
||||
```
|
||||
$ apt-clone -h
|
||||
```
|
||||
|
||||
Or, man pages:
|
||||
|
||||
```
|
||||
$ man apt-clone
|
||||
```
|
||||
|
||||
**Suggested read:**
|
||||
|
||||
+ [Systemback – Restore Ubuntu Desktop and Server to previous state][3]
|
||||
+ [Cronopete – An Apple’s Time Machine Clone For Linux][4]
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/backup-installed-packages-and-restore-them-on-freshly-installed-ubuntu-system/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.ostechnix.com/how-to-migrate-system-settings-and-data-from-an-old-system-to-a-newly-installed-ubuntu-system/
|
||||
[2]: https://www.ostechnix.com/create-list-installed-packages-install-later-list-centos-ubuntu/#comment-12598
|
||||
|
||||
[3]: https://www.ostechnix.com/systemback-restore-ubuntu-desktop-and-server-to-previous-state/
|
||||
|
||||
[4]: https://www.ostechnix.com/cronopete-apples-time-machine-clone-linux/
|
||||
@ -1,72 +0,0 @@
|
||||
4 scanning tools for the Linux desktop
|
||||
======
|
||||
Go paperless by driving your scanner with one of these open source applications.
|
||||
|
||||

|
||||
|
||||
While the paperless world isn't here quite yet, more and more people are getting rid of paper by scanning documents and photos. Having a scanner isn't enough to do the deed, though. You need software to drive that scanner.
|
||||
|
||||
But the catch is many scanner makers don't have Linux versions of the software they bundle with their devices. For the most part, that doesn't matter. Why? Because there are good scanning applications available for the Linux desktop. They work with a variety of scanners and do a good job.
|
||||
|
||||
Let's take a look at four simple but flexible open source Linux scanning tools. I've used each of these tools (and even wrote about three of them [back in 2014][1]) and found them very useful. You might, too.
|
||||
|
||||
### Simple Scan
|
||||
|
||||
One of my longtime favorites, [Simple Scan][2] is small, quick, efficient, and easy to use. If you've seen it before, that's because Simple Scan is the default scanner application on the GNOME desktop, as well as for a number of Linux distributions.
|
||||
|
||||
Scanning a document or photo takes one click. After scanning something, you can rotate or crop it and save it as an image (JPEG or PNG only) or as a PDF. That said, Simple Scan can be slow, even if you scan documents at lower resolutions. On top of that, Simple Scan uses a set of global defaults for scanning, like 150dpi for text and 300dpi for photos. You need to go into Simple Scan's preferences to change those settings.
|
||||
|
||||
If you've scanned something with more than a couple of pages, you can reorder the pages before you save. And if necessary—say you're submitting a signed form—you can email from within Simple Scan.
|
||||
|
||||
### Skanlite
|
||||
|
||||
In many ways, [Skanlite][3] is Simple Scan's cousin in the KDE world. Skanlite has few features, but it gets the job done nicely.
|
||||
|
||||
The software has options that you can configure, including automatically saving scanned files, setting the quality of the scan, and identifying where to save your scans. Skanlite can save to these image formats: JPEG, PNG, BMP, PPM, XBM, and XPM.
|
||||
|
||||
One nifty feature is the software's ability to save portions of what you've scanned to separate files. That comes in handy when, say, you want to excise someone or something from a photo.
|
||||
|
||||
### Gscan2pdf
|
||||
|
||||
Another old favorite, [gscan2pdf][4] might be showing its age, but it still packs a few more features than some of the other applications mentioned here. Even so, gscan2pdf is still comparatively light.
|
||||
|
||||
In addition to saving scans in various image formats (JPEG, PNG, and TIFF), gscan2pdf also saves them as PDF or [DjVu][5] files. You can set the scan's resolution, whether it's black and white or color, and paper size before you click the Scan button. That beats going into gscan2pdf's preferences every time you want to change any of those settings. You can also rotate, crop, and delete pages.
|
||||
|
||||
While none of those features are truly killer, they give you a bit more flexibility.
|
||||
|
||||
### GIMP
|
||||
|
||||
You probably know [GIMP][6] as an image-editing tool. But did you know you can use it to drive your scanner?
|
||||
|
||||
You'll need to install the [XSane][7] scanner software and the GIMP XSane plugin. Both of those should be available from your Linux distro's package manager. From there, select File > Create > Scanner/Camera. From there, click on your scanner and then the Scan button.
|
||||
|
||||
If that's not your cup of tea, or if it doesn't work, you can combine GIMP with a plugin called [QuiteInsane][8]. With either plugin, GIMP becomes a powerful scanning application that lets you set a number of options like whether to scan in color or black and white, the resolution of the scan, and whether or not to compress results. You can also use GIMP's tools to touch up or apply effects to your scans. This makes it great for scanning photos and art.
|
||||
|
||||
### Do they really just work?
|
||||
|
||||
All of this software works well for the most part and with a variety of hardware. I've used them with several multifunction printers that I've owned over the years—whether connecting using a USB cable or over wireless.
|
||||
|
||||
You might have noticed that I wrote "works well for the most part" in the previous paragraph. I did run into one exception: an inexpensive Canon multifunction printer. None of the software I used could detect it. I had to download and install Canon's Linux scanner software, which did work.
|
||||
|
||||
What's your favorite open source scanning tool for Linux? Share your pick by leaving a comment.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/linux-scanner-tools
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[1]: https://opensource.com/life/14/8/3-tools-scanners-linux-desktop
|
||||
[2]: https://gitlab.gnome.org/GNOME/simple-scan
|
||||
[3]: https://www.kde.org/applications/graphics/skanlite/
|
||||
[4]: http://gscan2pdf.sourceforge.net/
|
||||
[5]: http://en.wikipedia.org/wiki/DjVu
|
||||
[6]: http://www.gimp.org/
|
||||
[7]: https://en.wikipedia.org/wiki/Scanner_Access_Now_Easy#XSane
|
||||
[8]: http://sourceforge.net/projects/quiteinsane/
|
||||
@ -1,170 +0,0 @@
|
||||
heguangzhi translating
|
||||
|
||||
Linux firewalls: What you need to know about iptables and firewalld
|
||||
======
|
||||
Here's how to use the iptables and firewalld tools to manage Linux firewall connectivity rules.
|
||||
|
||||

|
||||
This article is excerpted from my book, [Linux in Action][1], and a second Manning project that’s yet to be released.
|
||||
|
||||
### The firewall
|
||||
|
||||
A firewall is a set of rules. When a data packet moves into or out of a protected network space, its contents (in particular, information about its origin, target, and the protocol it plans to use) are tested against the firewall rules to see if it should be allowed through. Here’s a simple example:
|
||||
|
||||
![firewall filtering request][3]
|
||||
|
||||
A firewall can filter requests based on protocol or target-based rules.
|
||||
|
||||
On the one hand, [iptables][4] is a tool for managing firewall rules on a Linux machine.
|
||||
|
||||
On the other hand, [firewalld][5] is also a tool for managing firewall rules on a Linux machine.
|
||||
|
||||
You got a problem with that? And would it spoil your day if I told you that there was another tool out there, called [nftables][6]?
|
||||
|
||||
OK, I’ll admit that the whole thing does smell a bit funny, so let me explain. It all starts with Netfilter, which controls access to and from the network stack at the Linux kernel module level. For decades, the primary command-line tool for managing Netfilter hooks was the iptables ruleset.
|
||||
|
||||
Because the syntax needed to invoke those rules could come across as a bit arcane, various user-friendly implementations like [ufw][7] and firewalld were introduced as higher-level Netfilter interpreters. Ufw and firewalld are, however, primarily designed to solve the kinds of problems faced by stand-alone computers. Building full-sized network solutions will often require the extra muscle of iptables or, since 2014, its replacement, nftables (through the nft command line tool).
|
||||
|
||||
iptables hasn’t gone anywhere and is still widely used. In fact, you should expect to run into iptables-protected networks in your work as an admin for many years to come. But nftables, by adding on to the classic Netfilter toolset, has brought some important new functionality.
|
||||
|
||||
From here on, I’ll show by example how firewalld and iptables solve simple connectivity problems.
|
||||
|
||||
### Configure HTTP access using firewalld
|
||||
|
||||
As you might have guessed from its name, firewalld is part of the [systemd][8] family. Firewalld can be installed on Debian/Ubuntu machines, but it’s there by default on Red Hat and CentOS. If you’ve got a web server like Apache running on your machine, you can confirm that the firewall is working by browsing to your server’s web root. If the site is unreachable, then firewalld is doing its job.
|
||||
|
||||
You’ll use the `firewall-cmd` tool to manage firewalld settings from the command line. Adding the `–state` argument returns the current firewall status:
|
||||
|
||||
```
|
||||
# firewall-cmd --state
|
||||
running
|
||||
```
|
||||
|
||||
By default, firewalld will be active and will reject all incoming traffic with a couple of exceptions, like SSH. That means your website won’t be getting too many visitors, which will certainly save you a lot of data transfer costs. As that’s probably not what you had in mind for your web server, though, you’ll want to open the HTTP and HTTPS ports that by convention are designated as 80 and 443, respectively. firewalld offers two ways to do that. One is through the `–add-port` argument that references the port number directly along with the network protocol it’ll use (TCP in this case). The `–permanent` argument tells firewalld to load this rule each time the server boots:
|
||||
|
||||
```
|
||||
# firewall-cmd --permanent --add-port=80/tcp
|
||||
# firewall-cmd --permanent --add-port=443/tcp
|
||||
```
|
||||
|
||||
The `–reload` argument will apply those rules to the current session:
|
||||
|
||||
```
|
||||
# firewall-cmd --reload
|
||||
```
|
||||
|
||||
Curious as to the current settings on your firewall? Run `–list-services`:
|
||||
|
||||
```
|
||||
# firewall-cmd --list-services
|
||||
dhcpv6-client http https ssh
|
||||
```
|
||||
|
||||
Assuming you’ve added browser access as described earlier, the HTTP, HTTPS, and SSH ports should now all be open—along with `dhcpv6-client`, which allows Linux to request an IPv6 IP address from a local DHCP server.
|
||||
|
||||
### Configure a locked-down customer kiosk using iptables
|
||||
|
||||
I’m sure you’ve seen kiosks—they’re the tablets, touchscreens, and ATM-like PCs in a box that airports, libraries, and business leave lying around, inviting customers and passersby to browse content. The thing about most kiosks is that you don’t usually want users to make themselves at home and treat them like their own devices. They’re not generally meant for browsing, viewing YouTube videos, or launching denial-of-service attacks against the Pentagon. So to make sure they’re not misused, you need to lock them down.
|
||||
|
||||
One way is to apply some kind of kiosk mode, whether it’s through clever use of a Linux display manager or at the browser level. But to make sure you’ve got all the holes plugged, you’ll probably also want to add some hard network controls through a firewall. In the following section, I'll describe how I would do it using iptables.
|
||||
|
||||
There are two important things to remember about using iptables: The order you give your rules is critical, and by themselves, iptables rules won’t survive a reboot. I’ll address those here one at a time.
|
||||
|
||||
### The kiosk project
|
||||
|
||||
To illustrate all this, let’s imagine we work for a store that’s part of a larger chain called BigMart. They’ve been around for decades; in fact, our imaginary grandparents probably grew up shopping there. But these days, the guys at BigMart corporate headquarters are probably just counting the hours before Amazon drives them under for good.
|
||||
|
||||
Nevertheless, BigMart’s IT department is doing its best, and they’ve just sent you some WiFi-ready kiosk devices that you’re expected to install at strategic locations throughout your store. The idea is that they’ll display a web browser logged into the BigMart.com products pages, allowing them to look up merchandise features, aisle location, and stock levels. The kiosks will also need access to bigmart-data.com, where many of the images and video media are stored.
|
||||
|
||||
Besides those, you’ll want to permit updates and, whenever necessary, package downloads. Finally, you’ll want to permit inbound SSH access only from your local workstation, and block everyone else. The figure below illustrates how it will all work:
|
||||
|
||||
![kiosk traffic flow ip tables][10]
|
||||
|
||||
The kiosk traffic flow being controlled by iptables.
|
||||
|
||||
### The script
|
||||
|
||||
Here’s how that will all fit into a Bash script:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
iptables -A OUTPUT -p tcp -d bigmart.com -j ACCEPT
|
||||
iptables -A OUTPUT -p tcp -d bigmart-data.com -j ACCEPT
|
||||
iptables -A OUTPUT -p tcp -d ubuntu.com -j ACCEPT
|
||||
iptables -A OUTPUT -p tcp -d ca.archive.ubuntu.com -j ACCEPT
|
||||
iptables -A OUTPUT -p tcp --dport 80 -j DROP
|
||||
iptables -A OUTPUT -p tcp --dport 443 -j DROP
|
||||
iptables -A INPUT -p tcp -s 10.0.3.1 --dport 22 -j ACCEPT
|
||||
iptables -A INPUT -p tcp -s 0.0.0.0/0 --dport 22 -j DROP
|
||||
```
|
||||
|
||||
The basic anatomy of our rules starts with `-A`, telling iptables that we want to add the following rule. `OUTPUT` means that this rule should become part of the OUTPUT chain. `-p` indicates that this rule will apply only to packets using the TCP protocol, where, as `-d` tells us, the destination is [bigmart.com][11]. The `-j` flag points to `ACCEPT` as the action to take when a packet matches the rule. In this first rule, that action is to permit, or accept, the request. But further down, you can see requests that will be dropped, or denied.
|
||||
|
||||
Remember that order matters. And that’s because iptables will run a request past each of its rules, but only until it gets a match. So an outgoing browser request for, say, [youtube.com][12] will pass the first four rules, but when it gets to either the `–dport 80` or `–dport 443` rule—depending on whether it’s an HTTP or HTTPS request—it’ll be dropped. iptables won’t bother checking any further because that was a match.
|
||||
|
||||
On the other hand, a system request to ubuntu.com for a software upgrade will get through when it hits its appropriate rule. What we’re doing here, obviously, is permitting outgoing HTTP or HTTPS requests to only our BigMart or Ubuntu destinations and no others.
|
||||
|
||||
The final two rules will deal with incoming SSH requests. They won’t already have been denied by the two previous drop rules since they don’t use ports 80 or 443, but 22. In this case, login requests from my workstation will be accepted but requests for anywhere else will be dropped. This is important: Make sure the IP address you use for your port 22 rule matches the address of the machine you’re using to log in—if you don’t do that, you’ll be instantly locked out. It's no big deal, of course, because the way it’s currently configured, you could simply reboot the server and the iptables rules will all be dropped. If you’re using an LXC container as your server and logging on from your LXC host, then use the IP address your host uses to connect to the container, not its public address.
|
||||
|
||||
You’ll need to remember to update this rule if my machine’s IP ever changes; otherwise, you’ll be locked out.
|
||||
|
||||
Playing along at home (hopefully on a throwaway VM of some sort)? Great. Create your own script. Now I can save the script, use `chmod` to make it executable, and run it as `sudo`. Don’t worry about that `bigmart-data.com not found` error—of course it’s not found; it doesn’t exist.
|
||||
|
||||
```
|
||||
chmod +X scriptname.sh
|
||||
sudo ./scriptname.sh
|
||||
```
|
||||
|
||||
You can test your firewall from the command line using `cURL`. Requesting ubuntu.com works, but [manning.com][13] fails.
|
||||
|
||||
```
|
||||
curl ubuntu.com
|
||||
curl manning.com
|
||||
```
|
||||
|
||||
### Configuring iptables to load on system boot
|
||||
|
||||
Now, how do I get these rules to automatically load each time the kiosk boots? The first step is to save the current rules to a .rules file using the `iptables-save` tool. That’ll create a file in the root directory containing a list of the rules. The pipe, followed by the tee command, is necessary to apply my `sudo` authority to the second part of the string: the actual saving of a file to the otherwise restricted root directory.
|
||||
|
||||
I can then tell the system to run a related tool called `iptables-restore` every time it boots. A regular cron job of the kind we saw in the previous module won’t help because they’re run at set times, but we have no idea when our computer might decide to crash and reboot.
|
||||
|
||||
There are lots of ways to handle this problem. Here’s one:
|
||||
|
||||
On my Linux machine, I’ll install a program called [anacron][14] that will give us a file in the /etc/ directory called anacrontab. I’ll edit the file and add this `iptables-restore` command, telling it to load the current values of that .rules file into iptables each day (when necessary) one minute after a boot. I’ll give the job an identifier (`iptables-restore`) and then add the command itself. Since you’re playing along with me at home, you should test all this out by rebooting your system.
|
||||
|
||||
```
|
||||
sudo iptables-save | sudo tee /root/my.active.firewall.rules
|
||||
sudo apt install anacron
|
||||
sudo nano /etc/anacrontab
|
||||
1 1 iptables-restore iptables-restore < /root/my.active.firewall.rules
|
||||
|
||||
```
|
||||
|
||||
I hope these practical examples have illustrated how to use iptables and firewalld for managing connectivity issues on Linux-based firewalls.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/linux-iptables-firewalld
|
||||
|
||||
作者:[David Clinton][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/remyd
|
||||
[1]: https://www.manning.com/books/linux-in-action?a_aid=bootstrap-it&a_bid=4ca15fc9&chan=opensource
|
||||
[2]: /file/409116
|
||||
[3]: https://opensource.com/sites/default/files/uploads/iptables1.jpg (firewall filtering request)
|
||||
[4]: https://en.wikipedia.org/wiki/Iptables
|
||||
[5]: https://firewalld.org/
|
||||
[6]: https://wiki.nftables.org/wiki-nftables/index.php/Main_Page
|
||||
[7]: https://en.wikipedia.org/wiki/Uncomplicated_Firewall
|
||||
[8]: https://en.wikipedia.org/wiki/Systemd
|
||||
[9]: /file/409121
|
||||
[10]: https://opensource.com/sites/default/files/uploads/iptables2.jpg (kiosk traffic flow ip tables)
|
||||
[11]: http://bigmart.com/
|
||||
[12]: http://youtube.com/
|
||||
[13]: http://manning.com/
|
||||
[14]: https://sourceforge.net/projects/anacron/
|
||||
@ -1,3 +1,5 @@
|
||||
translating----geekpi
|
||||
|
||||
Clinews – Read News And Latest Headlines From Commandline
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating by Flowsnow
|
||||
|
||||
A Simple, Beautiful And Cross-platform Podcast App
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
【moria(knuth.fan at gmail.com)翻译中】
|
||||
9 Easiest Ways To Find Out Process ID (PID) In Linux
|
||||
======
|
||||
Everybody knows about PID, Exactly what is PID? Why you want PID? What are you going to do using PID? Are you having the same questions on your mind? If so, you are in the right place to get all the details.
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Hegemon – A Modular System Monitor Application Written In Rust
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,90 @@
|
||||
translating by belitex
|
||||
|
||||
3 open source distributed tracing tools
|
||||
======
|
||||
|
||||
Find performance issues quickly with these tools, which provide a graphical view of what's happening across complex software systems.
|
||||
|
||||

|
||||
|
||||
Distributed tracing systems enable users to track a request through a software system that is distributed across multiple applications, services, and databases as well as intermediaries like proxies. This allows for a deeper understanding of what is happening within the software system. These systems produce graphical representations that show how much time the request took on each step and list each known step.
|
||||
|
||||
A user reviewing this content can determine where the system is experiencing latencies or blockages. Instead of testing the system like a binary search tree when requests start failing, operators and developers can see exactly where the issues begin. This can also reveal where performance changes might be occurring from deployment to deployment. It’s always better to catch regressions automatically by alerting to the anomalous behavior than to have your customers tell you.
|
||||
|
||||
How does this tracing thing work? Well, each request gets a special ID that’s usually injected into the headers. This ID uniquely identifies that transaction. This transaction is normally called a trace. The trace is the overall abstract idea of the entire transaction. Each trace is made up of spans. These spans are the actual work being performed, like a service call or a database request. Each span also has a unique ID. Spans can create subsequent spans called child spans, and child spans can have multiple parents.
|
||||
|
||||
Once a transaction (or trace) has run its course, it can be searched in a presentation layer. There are several tools in this space that we’ll discuss later, but the picture below shows [Jaeger][1] from my [Istio walkthrough][2]. It shows multiple spans of a single trace. The power of this is immediately clear as you can better understand the transaction’s story at a glance.
|
||||
|
||||
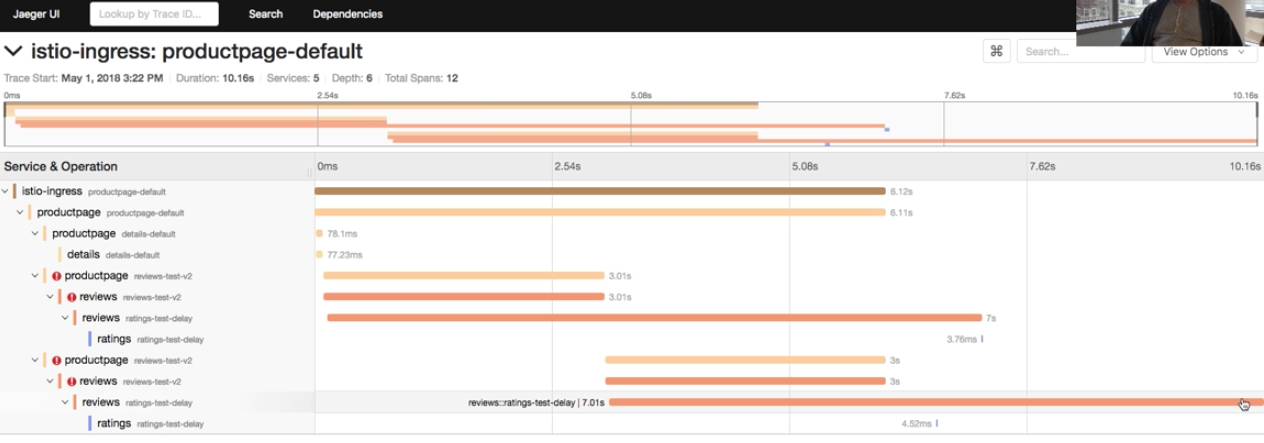
|
||||
|
||||
This demo uses Istio’s built-in OpenTracing implementation, so I can get tracing without even modifying my application. It also uses Jaeger, which is OpenTracing-compatible.
|
||||
|
||||
So what is OpenTracing? Let’s find out.
|
||||
|
||||
### OpenTracing API
|
||||
|
||||
[OpenTracing][3] is a spec that grew out of [Zipkin][4] to provide cross-platform compatibility. It offers a vendor-neutral API for adding tracing to applications and delivering that data into distributed tracing systems. A library written for the OpenTracing spec can be used with any system that is OpenTracing-compliant. Zipkin, Jaeger, and Appdash are examples of open source tools that have adopted the open standard, but even proprietary tools like [Datadog][5] and [Instana][6] are adopting it. This is expected to continue as OpenTracing reaches ubiquitous status.
|
||||
|
||||
### OpenCensus
|
||||
|
||||
Okay, we have OpenTracing, but what is this [OpenCensus][7] thing that keeps popping up in my searches? Is it a competing standard, something completely different, or something complementary?
|
||||
|
||||
The answer depends on who you ask. I will do my best to explain the difference (as I understand it): OpenCensus takes a more holistic or all-inclusive approach. OpenTracing is focused on establishing an open API and spec and not on open implementations for each language and tracing system. OpenCensus provides not only the specification but also the language implementations and wire protocol. It also goes beyond tracing by including additional metrics that are normally outside the scope of distributed tracing systems.
|
||||
|
||||
OpenCensus allows viewing data on the host where the application is running, but it also has a pluggable exporter system for exporting data to central aggregators. The current exporters produced by the OpenCensus team include Zipkin, Prometheus, Jaeger, Stackdriver, Datadog, and SignalFx, but anyone can create an exporter.
|
||||
|
||||
From my perspective, there’s a lot of overlap. One isn’t necessarily better than the other, but it’s important to know what each does and doesn’t do. OpenTracing is primarily a spec, with others doing the implementation and opinionation. OpenCensus provides a holistic approach for the local component with more opinionation but still requires other systems for remote aggregation.
|
||||
|
||||
### Tool options
|
||||
|
||||
#### Zipkin
|
||||
|
||||
Zipkin was one of the first systems of this kind. It was developed by Twitter based on the [Google Dapper paper][8] about the internal system Google uses. Zipkin was written using Java, and it can use Cassandra or ElasticSearch as a scalable backend. Most companies should be satisfied with one of those options. The lowest supported Java version is Java 6. It also uses the [Thrift][9] binary communication protocol, which is popular in the Twitter stack and is hosted as an Apache project.
|
||||
|
||||
The system consists of reporters (clients), collectors, a query service, and a web UI. Zipkin is meant to be safe in production by transmitting only a trace ID within the context of a transaction to inform receivers that a trace is in process. The data collected in each reporter is then transmitted asynchronously to the collectors. The collectors store these spans in the database, and the web UI presents this data to the end user in a consumable format. The delivery of data to the collectors can occur in three different methods: HTTP, Kafka, and Scribe.
|
||||
|
||||
The [Zipkin community][10] has also created [Brave][11], a Java client implementation compatible with Zipkin. It has no dependencies, so it won’t drag your projects down or clutter them with libraries that are incompatible with your corporate standards. There are many other implementations, and Zipkin is compatible with the OpenTracing standard, so these implementations should also work with other distributed tracing systems. The popular Spring framework has a component called [Spring Cloud Sleuth][12] that is compatible with Zipkin.
|
||||
|
||||
#### Jaeger
|
||||
|
||||
[Jaeger][1] is a newer project from Uber Technologies that the [CNCF][13] has since adopted as an Incubating project. It is written in Golang, so you don’t have to worry about having dependencies installed on the host or any overhead of interpreters or language virtual machines. Similar to Zipkin, Jaeger also supports Cassandra and ElasticSearch as scalable storage backends. Jaeger is also fully compatible with the OpenTracing standard.
|
||||
|
||||
Jaeger’s architecture is similar to Zipkin, with clients (reporters), collectors, a query service, and a web UI, but it also has an agent on each host that locally aggregates the data. The agent receives data over a UDP connection, which it batches and sends to a collector. The collector receives that data in the form of the [Thrift][14] protocol and stores that data in Cassandra or ElasticSearch. The query service can access the data store directly and provide that information to the web UI.
|
||||
|
||||
By default, a user won’t get all the traces from the Jaeger clients. The system samples 0.1% (1 in 1,000) of traces that pass through each client. Keeping and transmitting all traces would be a bit overwhelming to most systems. However, this can be increased or decreased by configuring the agents, which the client consults with for its configuration. This sampling isn’t completely random, though, and it’s getting better. Jaeger uses probabilistic sampling, which tries to make an educated guess at whether a new trace should be sampled or not. [Adaptive sampling is on its roadmap][15], which will improve the sampling algorithm by adding additional context for making decisions.
|
||||
|
||||
#### Appdash
|
||||
|
||||
[Appdash][16] is a distributed tracing system written in Golang, like Jaeger. It was created by [Sourcegraph][17] based on Google’s Dapper and Twitter’s Zipkin. Similar to Jaeger and Zipkin, Appdash supports the OpenTracing standard; this was a later addition and requires a component that is different from the default component. This adds risk and complexity.
|
||||
|
||||
At a high level, Appdash’s architecture consists mostly of three components: a client, a local collector, and a remote collector. There’s not a lot of documentation, so this description comes from testing the system and reviewing the code. The client in Appdash gets added to your code. Appdash provides Python, Golang, and Ruby implementations, but OpenTracing libraries can be used with Appdash’s OpenTracing implementation. The client collects the spans and sends them to the local collector. The local collector then sends the data to a centralized Appdash server running its own local collector, which is the remote collector for all other nodes in the system.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/distributed-tracing-tools
|
||||
|
||||
作者:[Dan Barker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/barkerd427
|
||||
[1]: https://www.jaegertracing.io/
|
||||
[2]: https://www.youtube.com/watch?v=T8BbeqZ0Rls
|
||||
[3]: http://opentracing.io/
|
||||
[4]: https://zipkin.io/
|
||||
[5]: https://www.datadoghq.com/
|
||||
[6]: https://www.instana.com/
|
||||
[7]: https://opencensus.io/
|
||||
[8]: https://research.google.com/archive/papers/dapper-2010-1.pdf
|
||||
[9]: https://thrift.apache.org/
|
||||
[10]: https://zipkin.io/pages/community.html
|
||||
[11]: https://github.com/openzipkin/brave
|
||||
[12]: https://cloud.spring.io/spring-cloud-sleuth/
|
||||
[13]: https://www.cncf.io/
|
||||
[14]: https://en.wikipedia.org/wiki/Apache_Thrift
|
||||
[15]: https://www.jaegertracing.io/docs/roadmap/#adaptive-sampling
|
||||
[16]: https://github.com/sourcegraph/appdash
|
||||
[17]: https://about.sourcegraph.com/
|
||||
@ -1,3 +1,5 @@
|
||||
heguangzhi Translating
|
||||
|
||||
An introduction to swap space on Linux systems
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating by Flowsnow
|
||||
|
||||
How to use the Scikit-learn Python library for data science projects
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,441 @@
|
||||
How To Find And Delete Duplicate Files In Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
I always backup the configuration files or any old files to somewhere in my hard disk before edit or modify them, so I can restore them from the backup if I accidentally did something wrong. But the problem is I forgot to clean up those files and my hard disk is filled with a lot of duplicate files after a certain period of time. I feel either too lazy to clean the old files or afraid that I may delete an important files. If you’re anything like me and overwhelming with multiple copies of same files in different backup directories, you can find and delete duplicate files using the tools given below in Unix-like operating systems.
|
||||
|
||||
**A word of caution:**
|
||||
|
||||
Please be careful while deleting duplicate files. If you’re not careful, it will lead you to [**accidental data loss**][1]. I advice you to pay extra attention while using these tools.
|
||||
|
||||
### Find And Delete Duplicate Files In Linux
|
||||
|
||||
For the purpose of this guide, I am going to discuss about three utilities namely,
|
||||
|
||||
1. Rdfind,
|
||||
2. Fdupes,
|
||||
3. FSlint.
|
||||
|
||||
|
||||
|
||||
These three utilities are free, open source and works on most Unix-like operating systems.
|
||||
|
||||
##### 1. Rdfind
|
||||
|
||||
**Rdfind** , stands for **r** edundant **d** ata **find** , is a free and open source utility to find duplicate files across and/or within directories and sub-directories. It compares files based on their content, not on their file names. Rdfind uses **ranking** algorithm to classify original and duplicate files. If you have two or more equal files, Rdfind is smart enough to find which is original file, and consider the rest of the files as duplicates. Once it found the duplicates, it will report them to you. You can decide to either delete them or replace them with [**hard links** or **symbolic (soft) links**][2].
|
||||
|
||||
**Installing Rdfind**
|
||||
|
||||
Rdfind is available in [**AUR**][3]. So, you can install it in Arch-based systems using any AUR helper program like [**Yay**][4] as shown below.
|
||||
|
||||
```
|
||||
$ yay -S rdfind
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint:
|
||||
|
||||
```
|
||||
$ sudo apt-get install rdfind
|
||||
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
|
||||
```
|
||||
$ sudo dnf install rdfind
|
||||
|
||||
```
|
||||
|
||||
On RHEL, CentOS:
|
||||
|
||||
```
|
||||
$ sudo yum install epel-release
|
||||
|
||||
$ sudo yum install rdfind
|
||||
|
||||
```
|
||||
|
||||
**Usage**
|
||||
|
||||
Once installed, simply run Rdfind command along with the directory path to scan for the duplicate files.
|
||||
|
||||
```
|
||||
$ rdfind ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
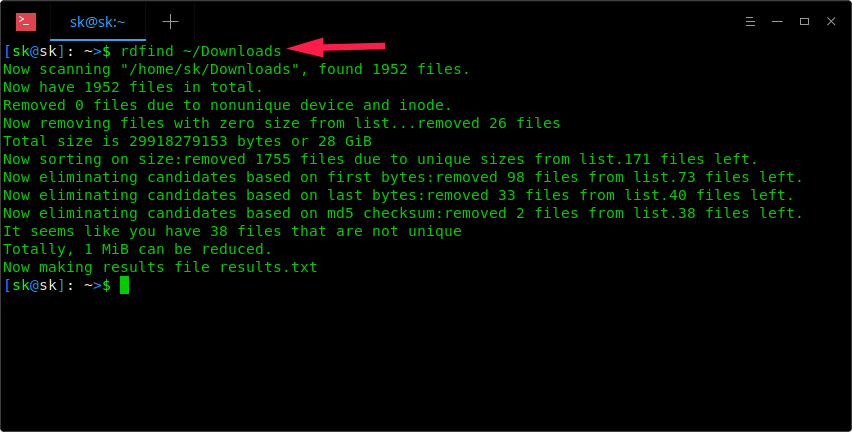
|
||||
|
||||
As you see in the above screenshot, Rdfind command will scan ~/Downloads directory and save the results in a file named **results.txt** in the current working directory. You can view the name of the possible duplicate files in results.txt file.
|
||||
|
||||
```
|
||||
$ cat results.txt
|
||||
# Automatically generated
|
||||
# duptype id depth size device inode priority name
|
||||
DUPTYPE_FIRST_OCCURRENCE 1469 8 9 2050 15864884 1 /home/sk/Downloads/tor-browser_en-US/Browser/TorBrowser/Tor/PluggableTransports/fte/tests/dfas/test5.regex
|
||||
DUPTYPE_WITHIN_SAME_TREE -1469 8 9 2050 15864886 1 /home/sk/Downloads/tor-browser_en-US/Browser/TorBrowser/Tor/PluggableTransports/fte/tests/dfas/test6.regex
|
||||
[...]
|
||||
DUPTYPE_FIRST_OCCURRENCE 13 0 403635 2050 15740257 1 /home/sk/Downloads/Hyperledger(1).pdf
|
||||
DUPTYPE_WITHIN_SAME_TREE -13 0 403635 2050 15741071 1 /home/sk/Downloads/Hyperledger.pdf
|
||||
# end of file
|
||||
|
||||
```
|
||||
|
||||
By reviewing the results.txt file, you can easily find the duplicates. You can remove the duplicates manually if you want to.
|
||||
|
||||
Also, you can **-dryrun** option to find all duplicates in a given directory without changing anything and output the summary in your Terminal:
|
||||
|
||||
```
|
||||
$ rdfind -dryrun true ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
Once you found the duplicates, you can replace them with either hardlinks or symlinks.
|
||||
|
||||
To replace all duplicates with hardlinks, run:
|
||||
|
||||
```
|
||||
$ rdfind -makehardlinks true ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
To replace all duplicates with symlinks/soft links, run:
|
||||
|
||||
```
|
||||
$ rdfind -makesymlinks true ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
You may have some empty files in a directory and want to ignore them. If so, use **-ignoreempty** option like below.
|
||||
|
||||
```
|
||||
$ rdfind -ignoreempty true ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
If you don’t want the old files anymore, just delete duplicate files instead of replacing them with hard or soft links.
|
||||
|
||||
To delete all duplicates, simply run:
|
||||
|
||||
```
|
||||
$ rdfind -deleteduplicates true ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
If you do not want to ignore empty files and delete them along with all duplicates, run:
|
||||
|
||||
```
|
||||
$ rdfind -deleteduplicates true -ignoreempty false ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
For more details, refer the help section:
|
||||
|
||||
```
|
||||
$ rdfind --help
|
||||
|
||||
```
|
||||
|
||||
And, the manual pages:
|
||||
|
||||
```
|
||||
$ man rdfind
|
||||
|
||||
```
|
||||
|
||||
##### 2. Fdupes
|
||||
|
||||
**Fdupes** is yet another command line utility to identify and remove the duplicate files within specified directories and the sub-directories. It is free, open source utility written in **C** programming language. Fdupes identifies the duplicates by comparing file sizes, partial MD5 signatures, full MD5 signatures, and finally performing a byte-by-byte comparison for verification.
|
||||
|
||||
Similar to Rdfind utility, Fdupes comes with quite handful of options to perform operations, such as:
|
||||
|
||||
* Recursively search duplicate files in directories and sub-directories
|
||||
* Exclude empty files and hidden files from consideration
|
||||
* Show the size of the duplicates
|
||||
* Delete duplicates immediately as they encountered
|
||||
* Exclude files with different owner/group or permission bits as duplicates
|
||||
* And a lot more.
|
||||
|
||||
|
||||
|
||||
**Installing Fdupes**
|
||||
|
||||
Fdupes is available in the default repositories of most Linux distributions.
|
||||
|
||||
On Arch Linux and its variants like Antergos, Manjaro Linux, install it using Pacman like below.
|
||||
|
||||
```
|
||||
$ sudo pacman -S fdupes
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint:
|
||||
|
||||
```
|
||||
$ sudo apt-get install fdupes
|
||||
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
|
||||
```
|
||||
$ sudo dnf install fdupes
|
||||
|
||||
```
|
||||
|
||||
On RHEL, CentOS:
|
||||
|
||||
```
|
||||
$ sudo yum install epel-release
|
||||
|
||||
$ sudo yum install fdupes
|
||||
|
||||
```
|
||||
|
||||
**Usage**
|
||||
|
||||
Fdupes usage is pretty simple. Just run the following command to find out the duplicate files in a directory, for example **~/Downloads**.
|
||||
|
||||
```
|
||||
$ fdupes ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
Sample output from my system:
|
||||
|
||||
```
|
||||
/home/sk/Downloads/Hyperledger.pdf
|
||||
/home/sk/Downloads/Hyperledger(1).pdf
|
||||
|
||||
```
|
||||
|
||||
As you can see, I have a duplicate file in **/home/sk/Downloads/** directory. It shows the duplicates from the parent directory only. How to view the duplicates from sub-directories? Just use **-r** option like below.
|
||||
|
||||
```
|
||||
$ fdupes -r ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
Now you will see the duplicates from **/home/sk/Downloads/** directory and its sub-directories as well.
|
||||
|
||||
Fdupes can also be able to find duplicates from multiple directories at once.
|
||||
|
||||
```
|
||||
$ fdupes ~/Downloads ~/Documents/ostechnix
|
||||
|
||||
```
|
||||
|
||||
You can even search multiple directories, one recursively like below:
|
||||
|
||||
```
|
||||
$ fdupes ~/Downloads -r ~/Documents/ostechnix
|
||||
|
||||
```
|
||||
|
||||
The above commands searches for duplicates in “~/Downloads” directory and “~/Documents/ostechnix” directory and its sub-directories.
|
||||
|
||||
Sometimes, you might want to know the size of the duplicates in a directory. If so, use **-S** option like below.
|
||||
|
||||
```
|
||||
$ fdupes -S ~/Downloads
|
||||
403635 bytes each:
|
||||
/home/sk/Downloads/Hyperledger.pdf
|
||||
/home/sk/Downloads/Hyperledger(1).pdf
|
||||
|
||||
```
|
||||
|
||||
Similarly, to view the size of the duplicates in parent and child directories, use **-Sr** option.
|
||||
|
||||
We can exclude empty and hidden files from consideration using **-n** and **-A** respectively.
|
||||
|
||||
```
|
||||
$ fdupes -n ~/Downloads
|
||||
|
||||
$ fdupes -A ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
The first command will exclude zero-length files from consideration and the latter will exclude hidden files from consideration while searching for duplicates in the specified directory.
|
||||
|
||||
To summarize duplicate files information, use **-m** option.
|
||||
|
||||
```
|
||||
$ fdupes -m ~/Downloads
|
||||
1 duplicate files (in 1 sets), occupying 403.6 kilobytes
|
||||
|
||||
```
|
||||
|
||||
To delete all duplicates, use **-d** option.
|
||||
|
||||
```
|
||||
$ fdupes -d ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
```
|
||||
[1] /home/sk/Downloads/Hyperledger Fabric Installation.pdf
|
||||
[2] /home/sk/Downloads/Hyperledger Fabric Installation(1).pdf
|
||||
|
||||
Set 1 of 1, preserve files [1 - 2, all]:
|
||||
|
||||
```
|
||||
|
||||
This command will prompt you for files to preserve and delete all other duplicates. Just enter any number to preserve the corresponding file and delete the remaining files. Pay more attention while using this option. You might delete original files if you’re not be careful.
|
||||
|
||||
If you want to preserve the first file in each set of duplicates and delete the others without prompting each time, use **-dN** option (not recommended).
|
||||
|
||||
```
|
||||
$ fdupes -dN ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
To delete duplicates as they are encountered, use **-I** flag.
|
||||
|
||||
```
|
||||
$ fdupes -I ~/Downloads
|
||||
|
||||
```
|
||||
|
||||
For more details about Fdupes, view the help section and man pages.
|
||||
|
||||
```
|
||||
$ fdupes --help
|
||||
|
||||
$ man fdupes
|
||||
|
||||
```
|
||||
|
||||
##### 3. FSlint
|
||||
|
||||
**FSlint** is yet another duplicate file finder utility that I use from time to time to get rid of the unnecessary duplicate files and free up the disk space in my Linux system. Unlike the other two utilities, FSlint has both GUI and CLI modes. So, it is more user-friendly tool for newbies. FSlint not just finds the duplicates, but also bad symlinks, bad names, temp files, bad IDS, empty directories, and non stripped binaries etc.
|
||||
|
||||
**Installing FSlint**
|
||||
|
||||
FSlint is available in [**AUR**][5], so you can install it using any AUR helpers.
|
||||
|
||||
```
|
||||
$ yay -S fslint
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint:
|
||||
|
||||
```
|
||||
$ sudo apt-get install fslint
|
||||
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
|
||||
```
|
||||
$ sudo dnf install fslint
|
||||
|
||||
```
|
||||
|
||||
On RHEL, CentOS:
|
||||
|
||||
```
|
||||
$ sudo yum install epel-release
|
||||
|
||||
```
|
||||
|
||||
$ sudo yum install fslint
|
||||
|
||||
Once it is installed, launch it from menu or application launcher.
|
||||
|
||||
This is how FSlint GUI looks like.
|
||||
|
||||
|
||||
|
||||
As you can see, the interface of FSlint is user-friendly and self-explanatory. In the **Search path** tab, add the path of the directory you want to scan and click **Find** button on the lower left corner to find the duplicates. Check the recurse option to recursively search for duplicates in directories and sub-directories. The FSlint will quickly scan the given directory and list out them.
|
||||
|
||||
|
||||
|
||||
From the list, choose the duplicates you want to clean and select any one of them given actions like Save, Delete, Merge and Symlink.
|
||||
|
||||
In the **Advanced search parameters** tab, you can specify the paths to exclude while searching for duplicates.
|
||||
|
||||

|
||||
|
||||
**FSlint command line options**
|
||||
|
||||
FSlint provides a collection of the following CLI utilities to find duplicates in your filesystem:
|
||||
|
||||
* **findup** — find DUPlicate files
|
||||
* **findnl** — find Name Lint (problems with filenames)
|
||||
* **findu8** — find filenames with invalid utf8 encoding
|
||||
* **findbl** — find Bad Links (various problems with symlinks)
|
||||
* **findsn** — find Same Name (problems with clashing names)
|
||||
* **finded** — find Empty Directories
|
||||
* **findid** — find files with dead user IDs
|
||||
* **findns** — find Non Stripped executables
|
||||
* **findrs** — find Redundant Whitespace in files
|
||||
* **findtf** — find Temporary Files
|
||||
* **findul** — find possibly Unused Libraries
|
||||
* **zipdir** — Reclaim wasted space in ext2 directory entries
|
||||
|
||||
|
||||
|
||||
All of these utilities are available under **/usr/share/fslint/fslint/fslint** location.
|
||||
|
||||
For example, to find duplicates in a given directory, do:
|
||||
|
||||
```
|
||||
$ /usr/share/fslint/fslint/findup ~/Downloads/
|
||||
|
||||
```
|
||||
|
||||
Similarly, to find empty directories, the command would be:
|
||||
|
||||
```
|
||||
$ /usr/share/fslint/fslint/finded ~/Downloads/
|
||||
|
||||
```
|
||||
|
||||
To get more details on each utility, for example **findup** , run:
|
||||
|
||||
```
|
||||
$ /usr/share/fslint/fslint/findup --help
|
||||
|
||||
```
|
||||
|
||||
For more details about FSlint, refer the help section and man pages.
|
||||
|
||||
```
|
||||
$ /usr/share/fslint/fslint/fslint --help
|
||||
|
||||
$ man fslint
|
||||
|
||||
```
|
||||
|
||||
##### Conclusion
|
||||
|
||||
You know now about three tools to find and delete unwanted duplicate files in Linux. Among these three tools, I often use Rdfind. It doesn’t mean that the other two utilities are not efficient, but I am just happy with Rdfind so far. Well, it’s your turn. Which is your favorite tool and why? Let us know them in the comment section below.
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-find-and-delete-duplicate-files-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.ostechnix.com/prevent-files-folders-accidental-deletion-modification-linux/
|
||||
[2]: https://www.ostechnix.com/explaining-soft-link-and-hard-link-in-linux-with-examples/
|
||||
[3]: https://aur.archlinux.org/packages/rdfind/
|
||||
[4]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[5]: https://aur.archlinux.org/packages/fslint/
|
||||
118
sources/tech/20180928 10 handy Bash aliases for Linux.md
Normal file
118
sources/tech/20180928 10 handy Bash aliases for Linux.md
Normal file
@ -0,0 +1,118 @@
|
||||
translating---geekpi
|
||||
|
||||
10 handy Bash aliases for Linux
|
||||
======
|
||||
Get more efficient by using condensed versions of long Bash commands.
|
||||
|
||||

|
||||
|
||||
How many times have you repeatedly typed out a long command on the command line and wished there was a way to save it for later? This is where Bash aliases come in handy. They allow you to condense long, cryptic commands down to something easy to remember and use. Need some examples to get you started? No problem!
|
||||
|
||||
To use a Bash alias you've created, you need to add it to your .bash_profile file, which is located in your home folder. Note that this file is hidden and accessible only from the command line. The easiest way to work with this file is to use something like Vi or Nano.
|
||||
|
||||
### 10 handy Bash aliases
|
||||
|
||||
1. How many times have you needed to unpack a .tar file and couldn't remember the exact arguments needed? Aliases to the rescue! Just add the following to your .bash_profile file and then use **untar FileName** to unpack any .tar file.
|
||||
|
||||
|
||||
|
||||
```
|
||||
alias untar='tar -zxvf '
|
||||
|
||||
```
|
||||
|
||||
2. Want to download something but be able to resume if something goes wrong?
|
||||
|
||||
|
||||
|
||||
```
|
||||
alias wget='wget -c '
|
||||
|
||||
```
|
||||
|
||||
3. Need to generate a random, 20-character password for a new online account? No problem.
|
||||
|
||||
|
||||
|
||||
```
|
||||
alias getpass="openssl rand -base64 20"
|
||||
|
||||
```
|
||||
|
||||
4. Downloaded a file and need to test the checksum? We've got that covered too.
|
||||
|
||||
|
||||
|
||||
```
|
||||
alias sha='shasum -a 256 '
|
||||
|
||||
```
|
||||
|
||||
5. A normal ping will go on forever. We don't want that. Instead, let's limit that to just five pings.
|
||||
|
||||
|
||||
|
||||
```
|
||||
alias ping='ping -c 5'
|
||||
|
||||
```
|
||||
|
||||
6. Start a web server in any folder you'd like.
|
||||
|
||||
|
||||
|
||||
```
|
||||
alias www='python -m SimpleHTTPServer 8000'
|
||||
|
||||
```
|
||||
|
||||
7. Want to know how fast your network is? Just download Speedtest-cli and use this alias. You can choose a server closer to your location by using the **speedtest-cli --list** command.
|
||||
|
||||
|
||||
|
||||
```
|
||||
alias speed='speedtest-cli --server 2406 --simple'
|
||||
|
||||
```
|
||||
|
||||
8. How many times have you needed to know your external IP address and had no idea how to get that info? Yeah, me too.
|
||||
|
||||
|
||||
|
||||
```
|
||||
alias ipe='curl ipinfo.io/ip'
|
||||
|
||||
```
|
||||
|
||||
9. Need to know your local IP address?
|
||||
|
||||
|
||||
|
||||
```
|
||||
alias ipi='ipconfig getifaddr en0'
|
||||
|
||||
```
|
||||
|
||||
10. Finally, let's clear the screen.
|
||||
|
||||
|
||||
|
||||
```
|
||||
alias c='clear'
|
||||
|
||||
```
|
||||
|
||||
As you can see, Bash aliases are a super-easy way to simplify your life on the command line. Want more info? I recommend a quick Google search for "Bash aliases" or a trip to GitHub.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/handy-bash-aliases
|
||||
|
||||
作者:[Patrick H.Mullins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/pmullins
|
||||
@ -0,0 +1,111 @@
|
||||
A Free And Secure Online PDF Conversion Suite
|
||||
======
|
||||
|
||||

|
||||
|
||||
We are always in search for a better and more efficient solution that can make our lives more convenient. That is why when you are working with PDF documents you need a fast and reliable tool that you can use in every situation. Therefore, we wanted to introduce you to **EasyPDF** Online PDF Suite for every occasion. The promise behind this tool is that it can make your PDF management easier and we tested it to check that claim.
|
||||
|
||||
But first, here are the most important things you need to know about EasyPDF:
|
||||
|
||||
* EasyPDF is free and anonymous online PDF Conversion Suite.
|
||||
* Convert PDF to Word, Excel, PowerPoint, AutoCAD, JPG, GIF and Text.
|
||||
* Create PDF from Word, PowerPoint, JPG, Excel files and many other formats.
|
||||
* Manipulate PDFs with PDF Merge, Split and Compress.
|
||||
* OCR conversion of scanned PDFs and images.
|
||||
* Upload files from your device or the Cloud (Google Drive and DropBox).
|
||||
* Available on Windows, Linux, Mac, and smartphones via any browser.
|
||||
* Multiple languages supported.
|
||||
|
||||
|
||||
|
||||
### EasyPDF User Interface
|
||||
|
||||

|
||||
|
||||
One of the first things that catches your eye is the sleek user interface which gives the tool clean and functional environment in where you can work comfortably. The whole experience is even better because there are no ads on a website at all.
|
||||
|
||||
All different types of conversions have their dedicated menu with a simple box to add files, so you don’t have to wonder about what you need to do.
|
||||
|
||||
Most websites aren’t optimized to work well and run smoothly on mobile phones, but EasyPDF is an exception from that rule. It opens almost instantly on smartphone and is easy to navigate. You can also add it as the shortcut on your home screen from the **three dots menu** on the Chrome app.
|
||||
|
||||

|
||||
|
||||
### Functionality
|
||||
|
||||
Apart from looking nice, EasyPDF is pretty straightforward to use. You **don’t need to register** or leave an **email** to use the tool. It is completely anonymous. Additionally, it doesn’t put any limitations to the number or size of files for conversion. No installation required either! Cool, yeah?
|
||||
|
||||
You choose a desired conversion format, for example, PDF to Word. Select the PDF file you want to convert. You can upload a file from the device by either drag & drop or selecting the file from the folder. There is also an option to upload a document from [**Google Drive**][1] or [**Dropbox**][2].
|
||||
|
||||
After you choose the file, press the Convert button to start the conversion process. You won’t wait for a long time to get your file because conversion will finish in a minute. If you have some more files to convert, remember to download the file before you proceed further. If you don’t download the document first, you will lose it.
|
||||
|
||||
|
||||
|
||||
For a different type of conversion, return to the homepage.
|
||||
|
||||
The currently available types of conversions are:
|
||||
|
||||
* **PDF to Word** – Convert PDF documents to Word documents
|
||||
|
||||
* **PDF to PowerPoint** – Convert PDF documents to PowerPoint Presentations
|
||||
|
||||
* **PDF to Excel** – Convert PDF documents to Excel documents
|
||||
|
||||
* **PDF Creation** – Create PDF documents from any type of file (E.g text, doc, odt)
|
||||
|
||||
* **Word to PDF** – Convert Word documents to PDF documents
|
||||
|
||||
* **JPG to PDF** – Convert JPG images to PDF documents
|
||||
|
||||
* **PDF to AutoCAD** – Convert PDF documents to .dwg format (DWG is native format for CAD packages)
|
||||
|
||||
* **PDF to Text** – Convert PDF documents to Text documents
|
||||
|
||||
* **PDF Split** – Split PDF files into multiple parts
|
||||
|
||||
* **PDF Merge** – Merge multiple PDF files into one
|
||||
|
||||
* **PDF Compress** – Compress PDF documents
|
||||
|
||||
* **PDF to JPG** – Convert PDF documents to JPG images
|
||||
|
||||
* **PDF to PNG** – Convert PDF documents to PNG images
|
||||
|
||||
* **PDF to GIF** – Convert PDF documents to GIF files
|
||||
|
||||
* **OCR Online** –
|
||||
|
||||
Convert scanned paper documents
|
||||
|
||||
to editable files (E.g Word, Excel, Text)
|
||||
|
||||
|
||||
|
||||
|
||||
Want to give it a try? Great! Click the following link and start converting!
|
||||
|
||||
[][https://easypdf.com/]
|
||||
|
||||
### Conclusion
|
||||
|
||||
EasyPDF lives up to its name and enables easier PDF management. As far as I tested EasyPDF service, It offers out of the box conversion feature completely **FREE!** It is fast, secure and reliable. You will find the quality of services most satisfying without having to pay anything or leaving your personal data like email address. Give it a try and who knows maybe you will find your new favorite PDF tool.
|
||||
|
||||
And, that’s all for now. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/easypdf-a-free-and-secure-online-pdf-conversion-suite/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.ostechnix.com/how-to-mount-google-drive-locally-as-virtual-file-system-in-linux/
|
||||
[2]: https://www.ostechnix.com/install-dropbox-in-ubuntu-18-04-lts-desktop/
|
||||
@ -0,0 +1,233 @@
|
||||
Translating by dianbanjiu How to Install Popcorn Time on Ubuntu 18.04 and Other Linux Distributions
|
||||
======
|
||||
**Brief: This tutorial shows you how to install Popcorn Time on Ubuntu and other Linux distributions. Some handy Popcorn Time tips have also been discussed.**
|
||||
|
||||
[Popcorn Time][1] is an open source [Netflix][2] inspired [torrent][3] streaming application for Linux, Mac and Windows.
|
||||
|
||||
With the regular torrents, you have to wait for the download to finish before you could watch the videos.
|
||||
|
||||
[Popcorn Time][4] is different. It uses torrent underneath but allows you to start watching the videos (almost) immediately. It’s like you are watching videos on streaming websites like YouTube or Netflix. You don’t have to wait for the download to finish here.
|
||||
|
||||
![Popcorn Time in Ubuntu Linux][5]
|
||||
Popcorn Time
|
||||
|
||||
If you want to watch movies online without those creepy ads, Popcorn Time is a good alternative. Keep in mind that the streaming quality depends on the number of available seeds.
|
||||
|
||||
Popcorn Time also provides a nice user interface where you can browse through available movies, tv-series and other contents. If you ever used [Netflix on Linux][6], you will find it’s somewhat a similar experience.
|
||||
|
||||
Using torrent to download movies is illegal in several countries where there are strict laws against piracy. In countries like the USA, UK and West European you may even get legal notices. That said, it’s up to you to decide if you want to use it or not. You have been warned.
|
||||
(If you still want to take the risk and use Popcorn Time, you should use a VPN service like [Ivacy][7] that has been specifically designed for using Torrents and protecting your identity. Even then it’s not always easy to avoid the snooping authorities.)
|
||||
|
||||
Some of the main features of Popcorn Time are:
|
||||
|
||||
* Watch movies and TV Series online using Torrent
|
||||
* A sleek user interface lets you browse the available movies and TV series
|
||||
* Change streaming quality
|
||||
* Bookmark content for watching later
|
||||
* Download content for offline viewing
|
||||
* Ability to enable subtitles by default, change the subtitles size etc
|
||||
* Keyboard shortcuts to navigate through Popcorn Time
|
||||
|
||||
|
||||
|
||||
### How to install Popcorn Time on Ubuntu and other Linux Distributions
|
||||
|
||||
I am using Ubuntu 18.04 in this tutorial but you can use the same instructions for other Linux distributions such as Linux Mint, Debian, Manjaro, Deepin etc.
|
||||
|
||||
Let’s see how to install Popcorn time on Linux. It’s really easy actually. Simply follow the instructions and copy paste the commands I have mentioned.
|
||||
|
||||
#### Step 1: Download Popcorn Time
|
||||
|
||||
You can download Popcorn Time from its official website. The download link is present on the homepage itself.
|
||||
|
||||
[Get Popcorn Time](https://popcorntime.sh/)
|
||||
|
||||
#### Step 2: Install Popcorn Time
|
||||
|
||||
Once you have downloaded Popcorn Time, it’s time to use it. The downloaded file is a tar file that consists of an executable among other files. While you can extract this tar file anywhere, the [Linux convention is to install additional software in][8] /[opt directory.][8]
|
||||
|
||||
Create a new directory in /opt:
|
||||
|
||||
```
|
||||
sudo mkdir /opt/popcorntime
|
||||
```
|
||||
|
||||
Now go to the Downloads directory.
|
||||
|
||||
```
|
||||
cd ~/Downloads
|
||||
```
|
||||
|
||||
Extract the downloaded Popcorn Time files into the newly created /opt/popcorntime directory.
|
||||
|
||||
```
|
||||
sudo tar Jxf Popcorn-Time-* -C /opt/popcorntime
|
||||
```
|
||||
|
||||
#### Step 3: Make Popcorn Time accessible for everyone
|
||||
|
||||
You would want every user on your system to be able to run Popcorn Time without sudo access, right? To do that, you need to create a [symbolic link][9] to the executable in /usr/bin directory.
|
||||
|
||||
```
|
||||
ln -sf /opt/popcorntime/Popcorn-Time /usr/bin/Popcorn-Time
|
||||
```
|
||||
|
||||
#### Step 4: Create desktop launcher for Popcorn Time
|
||||
|
||||
So far so good. But you would also like to see Popcorn Time in the application menu, add it to your favorite application list etc.
|
||||
|
||||
For that, you need to create a desktop entry.
|
||||
|
||||
Open a terminal and create a new file named popcorntime.desktop in /usr/share/applications.
|
||||
|
||||
You can use any [command line based text editor][10]. Ubuntu has [Nano][11] installed by default so you can use that.
|
||||
|
||||
```
|
||||
sudo nano /usr/share/applications/popcorntime.desktop
|
||||
```
|
||||
|
||||
Insert the following lines here:
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Version = 1.0
|
||||
Type = Application
|
||||
Terminal = false
|
||||
Name = Popcorn Time
|
||||
Exec = /usr/bin/Popcorn-Time
|
||||
Icon = /opt/popcorntime/popcorn.png
|
||||
Categories = Application;
|
||||
```
|
||||
|
||||
If you used Nano editor, save it using shortcut Ctrl+X. When asked for saving, enter Y and then press enter again to save and exit.
|
||||
|
||||
We are almost there. One last thing to do here is to have the correct icon for Popcorn Time. For that, you can download a Popcorn Time icon and save it as popcorn.png in /opt/popcorntime directory.
|
||||
|
||||
You can do that using the command below:
|
||||
|
||||
```
|
||||
sudo wget -O /opt/popcorntime/popcorn.png https://upload.wikimedia.org/wikipedia/commons/d/df/Pctlogo.png
|
||||
|
||||
```
|
||||
|
||||
That’s it. Now you can search for Popcorn Time and click on it to launch it.
|
||||
|
||||
![Popcorn Time installed on Ubuntu][12]
|
||||
Search for Popcorn Time in Menu
|
||||
|
||||
On the first launch, you’ll have to accept the terms and conditions.
|
||||
|
||||
![Popcorn Time in Ubuntu Linux][13]
|
||||
Accept the Terms of Service
|
||||
|
||||
Once you do that, you can enjoy the movies and TV shows.
|
||||
|
||||
![Watch movies on Popcorn Time][14]
|
||||
|
||||
Well, that’s all you needed to install Popcorn Time on Ubuntu or any other Linux distribution. You can start watching your favorite movies straightaway.
|
||||
|
||||
However, if you are interested, I would suggest reading these Popcorn Time tips to get more out of it.
|
||||
|
||||
[![][15]][16]
|
||||
![][17]
|
||||
|
||||
### 7 Tips for using Popcorn Time effectively
|
||||
|
||||
Now that you have installed Popcorn Time, I am going to tell you some nifty Popcorn Time tricks. I assure you that it will enhance your experience with Popcorn Time multiple folds.
|
||||
|
||||
#### 1\. Use advanced settings
|
||||
|
||||
Always have the advanced settings enabled. It gives you more options to tweak Popcorn Time. Go to the top right corner and click on the gear symbol. Click on it and check advanced settings on the next screen.
|
||||
|
||||

|
||||
|
||||
#### 2\. Watch the movies in VLC or other players
|
||||
|
||||
Did you know that you can choose to watch a file in your preferred media player instead of the default Popcorn Time player? Of course, that media player should have been installed in the system.
|
||||
|
||||
Now you may ask why would one want to use another player. And my answer is because other players like VLC has hidden features which you might not find in the Popcorn Time player.
|
||||
|
||||
For example, if a file has very low volume, you can use VLC to enhance the audio by 400 percent. You can also [synchronize incoherent subtitles with VLC][18]. You can switch between media players before you start to play a file:
|
||||
|
||||

|
||||
|
||||
#### 3\. Bookmark movies and watch it later
|
||||
|
||||
Just browsing through movies and TV series but don’t have time or mood to watch those? No issues. You can add the movies to the bookmark and can access these bookmarked videos from the Favorites tab. This enables you to create a list of movies you would watch later.
|
||||
|
||||

|
||||
|
||||
#### 4\. Check torrent health and seed information
|
||||
|
||||
As I had mentioned earlier, your viewing experience in Popcorn Times depends on torrent speed. Good thing is that Popcorn time shows the health of the torrent file so that you can be aware of the streaming speed.
|
||||
|
||||
You will see a green/yellow/red dot on the file. Green means there are plenty of seeds and the file will stream easily. Yellow means a medium number of seeds, streaming should be okay. Red means there are very few seeds available and the streaming will be poor or won’t work at all.
|
||||
|
||||

|
||||
|
||||
#### 5\. Add custom subtitles
|
||||
|
||||
If you need subtitles and it is not available in your preferred language, you can add custom subtitles downloaded from external websites. Get the .srt files and use it inside Popcorn Time:
|
||||
|
||||

|
||||
|
||||
This is where VLC comes handy as you can [download subtitles automatically with VLC][19].
|
||||
|
||||
|
||||
#### 6\. Save the files for offline viewing
|
||||
|
||||
When Popcorn Times stream a content, it downloads it and store temporarily. When you close the app, it’s cleaned out. You can change this behavior so that the downloaded file remains there for your future use.
|
||||
|
||||
In the advanced settings, scroll down a bit. Look for Cache directory. You can change this to some other directory like Downloads. This way, even if you close Popcorn Time, the file will be available for viewing.
|
||||
|
||||

|
||||
|
||||
#### 7\. Drag and drop external torrent files to play immediately
|
||||
|
||||
I bet you did not know about this one. If you don’t find a certain movie on Popcorn Time, download the torrent file from your favorite torrent website. Open Popcorn Time and just drag and drop the torrent file in Popcorn Time. It will start playing the file, depending upon seeds. This way, you don’t need to download the entire file before watching it.
|
||||
|
||||
When you drag and drop the torrent file in Popcorn Time, it will give you the option to choose which video file should it play. If there are subtitles in it, it will play automatically or else, you can add external subtitles.
|
||||
|
||||

|
||||
|
||||
There are plenty of other features in Popcorn Time. But I’ll stop with my list here and let you explore Popcorn Time on Ubuntu Linux. I hope you find these Popcorn Time tips and tricks useful.
|
||||
|
||||
I am repeating again. Using Torrents is illegal in many countries. If you do that, take precaution and use a VPN service. If you are looking for my recommendation, you can go for [Swiss-based privacy company ProtonVPN][20] (of [ProtonMail][21] fame). Singapore based [Ivacy][7] is another good option. If you think these are expensive, you can look for [cheap VPN deals on It’s FOSS Shop][22].
|
||||
|
||||
Note: This article contains affiliate links. Please read our [affiliate policy][23].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/popcorn-time-ubuntu-linux/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: https://popcorntime.sh/
|
||||
[2]: https://netflix.com/
|
||||
[3]: https://en.wikipedia.org/wiki/Torrent_file
|
||||
[4]: https://en.wikipedia.org/wiki/Popcorn_Time
|
||||
[5]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/popcorn-time-linux.jpeg
|
||||
[6]: https://itsfoss.com/netflix-firefox-linux/
|
||||
[7]: https://billing.ivacy.com/page/23628
|
||||
[8]: http://tldp.org/LDP/Linux-Filesystem-Hierarchy/html/opt.html
|
||||
[9]: https://en.wikipedia.org/wiki/Symbolic_link
|
||||
[10]: https://itsfoss.com/command-line-text-editors-linux/
|
||||
[11]: https://itsfoss.com/nano-3-release/
|
||||
[12]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/popcorn-time-ubuntu-menu.jpg
|
||||
[13]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/popcorn-time-ubuntu-license.jpeg
|
||||
[14]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/popcorn-time-watch-movies.jpeg
|
||||
[15]: https://ivacy.postaffiliatepro.com/accounts/default1/vdegzkxbw/7f82d531.png
|
||||
[16]: https://billing.ivacy.com/page/23628/7f82d531
|
||||
[17]: http://ivacy.postaffiliatepro.com/scripts/vdegzkxiw?aff=23628&a_bid=7f82d531
|
||||
[18]: https://itsfoss.com/how-to-synchronize-subtitles-with-movie-quick-tip/
|
||||
[19]: https://itsfoss.com/download-subtitles-automatically-vlc-media-player-ubuntu/
|
||||
[20]: https://protonvpn.net/?aid=chmod777
|
||||
[21]: https://itsfoss.com/protonmail/
|
||||
[22]: https://shop.itsfoss.com/search?utf8=%E2%9C%93&query=vpn
|
||||
[23]: https://itsfoss.com/affiliate-policy/
|
||||
@ -0,0 +1,110 @@
|
||||
Quiet log noise with Python and machine learning
|
||||
======
|
||||
|
||||
Logreduce saves debugging time by picking out anomalies from mountains of log data.
|
||||
|
||||
|
||||
|
||||
Continuous integration (CI) jobs can generate massive volumes of data. When a job fails, figuring out what went wrong can be a tedious process that involves investigating logs to discover the root cause—which is often found in a fraction of the total job output. To make it easier to separate the most relevant data from the rest, the [Logreduce][1] machine learning model is trained using previous successful job runs to extract anomalies from failed runs' logs.
|
||||
|
||||
This principle can also be applied to other use cases, for example, extracting anomalies from [Journald][2] or other systemwide regular log files.
|
||||
|
||||
### Using machine learning to reduce noise
|
||||
|
||||
A typical log file contains many nominal events ("baselines") along with a few exceptions that are relevant to the developer. Baselines may contain random elements such as timestamps or unique identifiers that are difficult to detect and remove. To remove the baseline events, we can use a [k-nearest neighbors pattern recognition algorithm][3] (k-NN).
|
||||
|
||||
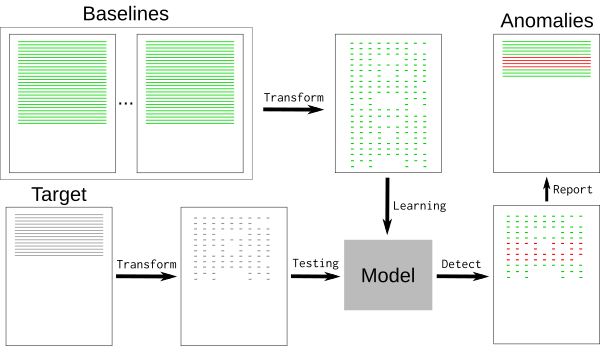
|
||||
|
||||
Log events must be converted to numeric values for k-NN regression. Using the generic feature extraction tool [HashingVectorizer][4] enables the process to be applied to any type of log. It hashes each word and encodes each event in a sparse matrix. To further reduce the search space, tokenization removes known random words, such as dates or IP addresses.
|
||||
|
||||
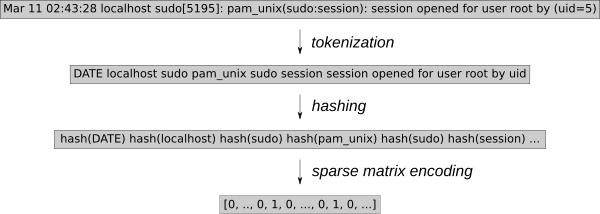
|
||||
|
||||
Once the model is trained, the k-NN search tells us the distance of each new event from the baseline.
|
||||
|
||||
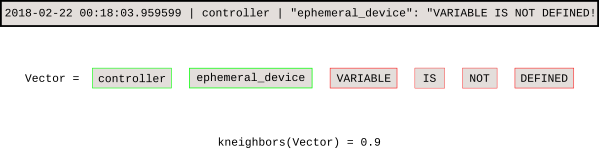
|
||||
|
||||
This [Jupyter notebook][5] demonstrates the process and graphs the sparse matrix vectors.
|
||||
|
||||
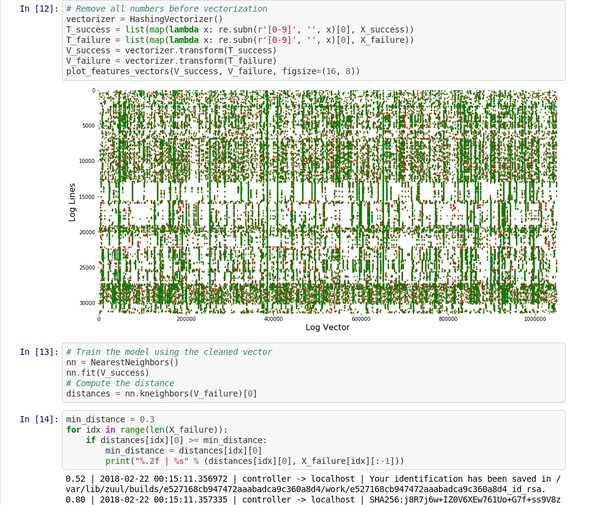
|
||||
|
||||
### Introducing Logreduce
|
||||
|
||||
The Logreduce Python software transparently implements this process. Logreduce's initial goal was to assist with [Zuul CI][6] job failure analyses using the build database, and it is now integrated into the [Software Factory][7] development forge's job logs process.
|
||||
|
||||
At its simplest, Logreduce compares files or directories and removes lines that are similar. Logreduce builds a model for each source file and outputs any of the target's lines whose distances are above a defined threshold by using the following syntax: **distance | filename:line-number: line-content**.
|
||||
|
||||
```
|
||||
$ logreduce diff /var/log/audit/audit.log.1 /var/log/audit/audit.log
|
||||
INFO logreduce.Classifier - Training took 21.982s at 0.364MB/s (1.314kl/s) (8.000 MB - 28.884 kilo-lines)
|
||||
0.244 | audit.log:19963: type=USER_AUTH acct="root" exe="/usr/bin/su" hostname=managesf.sftests.com
|
||||
INFO logreduce.Classifier - Testing took 18.297s at 0.306MB/s (1.094kl/s) (5.607 MB - 20.015 kilo-lines)
|
||||
99.99% reduction (from 20015 lines to 1
|
||||
|
||||
```
|
||||
|
||||
A more advanced Logreduce use can train a model offline to be reused. Many variants of the baselines can be used to fit the k-NN search tree.
|
||||
|
||||
```
|
||||
$ logreduce dir-train audit.clf /var/log/audit/audit.log.*
|
||||
INFO logreduce.Classifier - Training took 80.883s at 0.396MB/s (1.397kl/s) (32.001 MB - 112.977 kilo-lines)
|
||||
DEBUG logreduce.Classifier - audit.clf: written
|
||||
$ logreduce dir-run audit.clf /var/log/audit/audit.log
|
||||
```
|
||||
|
||||
Logreduce also implements interfaces to discover baselines for Journald time ranges (days/weeks/months) and Zuul CI job build histories. It can also generate HTML reports that group anomalies found in multiple files in a simple interface.
|
||||
|
||||
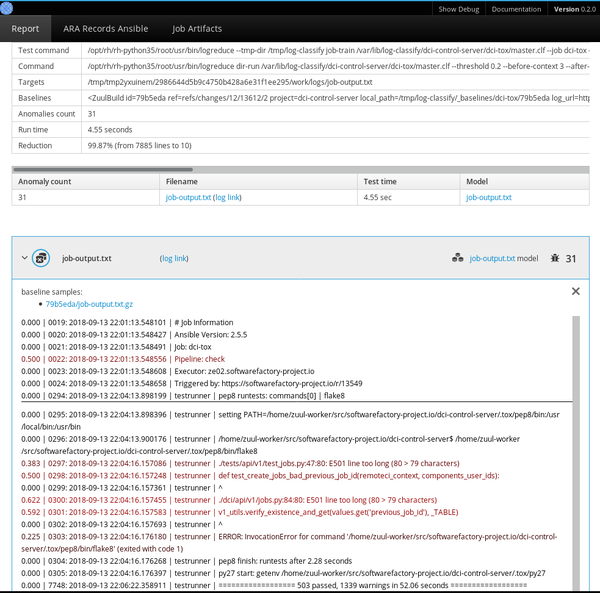
|
||||
|
||||
### Managing baselines
|
||||
|
||||
The key to using k-NN regression for anomaly detection is to have a database of known good baselines, which the model uses to detect lines that deviate too far. This method relies on the baselines containing all nominal events, as anything that isn't found in the baseline will be reported as anomalous.
|
||||
|
||||
CI jobs are great targets for k-NN regression because the job outputs are often deterministic and previous runs can be automatically used as baselines. Logreduce features Zuul job roles that can be used as part of a failed job post task in order to issue a concise report (instead of the full job's logs). This principle can be applied to other cases, as long as baselines can be constructed in advance. For example, a nominal system's [SoS report][8] can be used to find issues in a defective deployment.
|
||||
|
||||
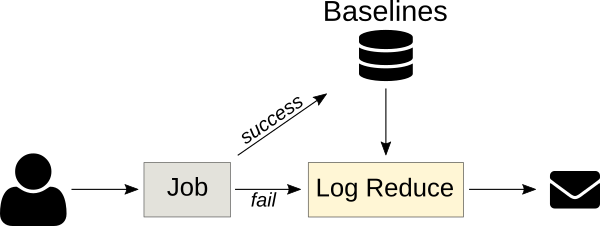
|
||||
|
||||
### Anomaly classification service
|
||||
|
||||
The next version of Logreduce introduces a server mode to offload log processing to an external service where reports can be further analyzed. It also supports importing existing reports and requests to analyze a Zuul build. The services run analyses asynchronously and feature a web interface to adjust scores and remove false positives.
|
||||
|
||||
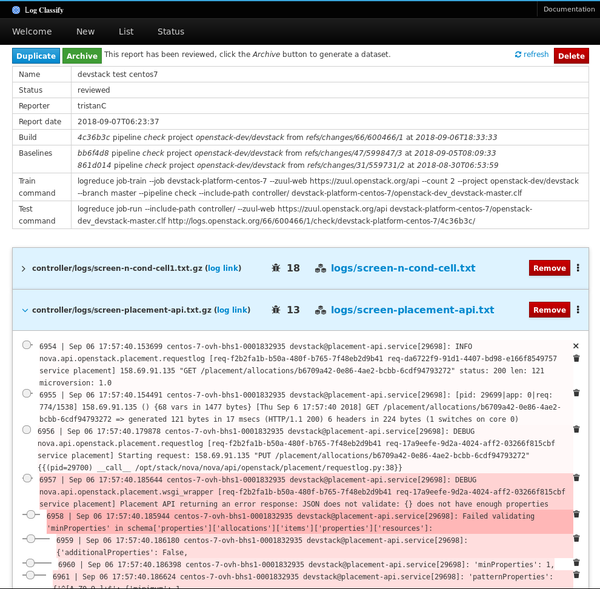
|
||||
|
||||
Reviewed reports can be archived as a standalone dataset with the target log files and the scores for anomalous lines recorded in a flat JSON file.
|
||||
|
||||
### Project roadmap
|
||||
|
||||
Logreduce is already being used effectively, but there are many opportunities for improving the tool. Plans for the future include:
|
||||
|
||||
* Curating many annotated anomalies found in log files and producing a public domain dataset to enable further research. Anomaly detection in log files is a challenging topic, and having a common dataset to test new models would help identify new solutions.
|
||||
* Reusing the annotated anomalies with the model to refine the distances reported. For example, when users mark lines as false positives by setting their distance to zero, the model could reduce the score of those lines in future reports.
|
||||
* Fingerprinting archived anomalies to detect when a new report contains an already known anomaly. Thus, instead of reporting the anomaly's content, the service could notify the user that the job hit a known issue. When the issue is fixed, the service could automatically restart the job.
|
||||
* Supporting more baseline discovery interfaces for targets such as SOS reports, Jenkins builds, Travis CI, and more.
|
||||
|
||||
|
||||
|
||||
If you are interested in getting involved in this project, please contact us on the **#log-classify** Freenode IRC channel. Feedback is always appreciated!
|
||||
|
||||
Tristan Cacqueray will present [Reduce your log noise using machine learning][9] at the [OpenStack Summit][10], November 13-15 in Berlin.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/quiet-log-noise-python-and-machine-learning
|
||||
|
||||
作者:[Tristan de Cacqueray][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/tristanc
|
||||
[1]: https://pypi.org/project/logreduce/
|
||||
[2]: http://man7.org/linux/man-pages/man8/systemd-journald.service.8.html
|
||||
[3]: https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
|
||||
[4]: http://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.HashingVectorizer.html
|
||||
[5]: https://github.com/TristanCacqueray/anomaly-detection-workshop-opendev/blob/master/datasets/notebook/anomaly-detection-with-scikit-learn.ipynb
|
||||
[6]: https://zuul-ci.org
|
||||
[7]: https://www.softwarefactory-project.io
|
||||
[8]: https://sos.readthedocs.io/en/latest/
|
||||
[9]: https://www.openstack.org/summit/berlin-2018/summit-schedule/speakers/4307
|
||||
[10]: https://www.openstack.org/summit/berlin-2018/
|
||||
544
sources/tech/20180928 Using Grails with jQuery and DataTables.md
Normal file
544
sources/tech/20180928 Using Grails with jQuery and DataTables.md
Normal file
@ -0,0 +1,544 @@
|
||||
Using Grails with jQuery and DataTables
|
||||
======
|
||||
|
||||
Learn to build a Grails-based data browser that lets users visualize complex tabular data.
|
||||
|
||||

|
||||
|
||||
I’m a huge fan of [Grails][1]. Granted, I’m mostly a data person who likes to explore and analyze data using command-line tools. But even data people sometimes need to _look at_ the data, and sometimes using data means having a great data browser. With Grails, [jQuery][2], and the [DataTables jQuery plugin][3], we can make really nice tabular data browsers.
|
||||
|
||||
The [DataTables website][3] offers a lot of decent “recipe-style” documentation that shows how to put together some fine sample applications, and it includes the necessary JavaScript, HTML, and occasional [PHP][4] to accomplish some pretty spiffy stuff. But for those who would rather use Grails as their backend, a bit of interpretation is necessary. Also, the sample application data used is a single flat table of employees of a fictional company, so the complexity of dealing with table relations serves as an exercise for the reader.
|
||||
|
||||
In this article, we’ll fill those two gaps by creating a Grails application with a slightly more complex data structure and a DataTables browser. In doing so, we’ll cover Grails criteria, which are [Groovy][5] -fied Java Hibernate criteria. I’ve put the code for the application on [GitHub][6] , so this article is oriented toward explaining the nuances of the code.
|
||||
|
||||
For prerequisites, you will need Java, Groovy, and Grails environments set up. With Grails, I tend to use a terminal window and [Vim][7], so that’s what’s used here. To get a modern Java, I suggest downloading and installing the [Open Java Development Kit][8] (OpenJDK) provided by your Linux distro (which should be Java 8, 9, 10 or 11; at the time of writing, I’m working with Java 8). From my point of view, the best way to get up-to-date Groovy and Grails is to use [SDKMAN!][9].
|
||||
|
||||
Readers who have never tried Grails will probably need to do some background reading. As a starting point, I recommend [Creating Your First Grails Application][10].
|
||||
|
||||
### Getting the employee browser application
|
||||
|
||||
As mentioned above, I’ve put the source code for this sample employee browser application on [GitHub][6]. For further explanation, the application **embrow** was built using the following commands in a Linux terminal window:
|
||||
|
||||
```
|
||||
cd Projects
|
||||
grails create-app com.nuevaconsulting.embrow
|
||||
```
|
||||
|
||||
The domain classes and unit tests are created as follows:
|
||||
|
||||
```
|
||||
grails create-domain-class com.nuevaconsulting.embrow.Position
|
||||
grails create-domain-class com.nuevaconsulting.embrow.Office
|
||||
grails create-domain-class com.nuevaconsulting.embrow.Employeecd embrowgrails createdomaincom.grails createdomaincom.grails createdomaincom.
|
||||
```
|
||||
|
||||
The domain classes built this way have no attributes, so they must be edited as follows:
|
||||
|
||||
The Position domain class:
|
||||
|
||||
```
|
||||
package com.nuevaconsulting.embrow
|
||||
|
||||
class Position {
|
||||
|
||||
String name
|
||||
int starting
|
||||
|
||||
static constraints = {
|
||||
name nullable: false, blank: false
|
||||
starting nullable: false
|
||||
}
|
||||
}com.Stringint startingstatic constraintsnullableblankstarting nullable
|
||||
```
|
||||
|
||||
The Office domain class:
|
||||
|
||||
```
|
||||
package com.nuevaconsulting.embrow
|
||||
|
||||
class Office {
|
||||
|
||||
String name
|
||||
String address
|
||||
String city
|
||||
String country
|
||||
|
||||
static constraints = {
|
||||
name nullable: false, blank: false
|
||||
address nullable: false, blank: false
|
||||
city nullable: false, blank: false
|
||||
country nullable: false, blank: false
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
And the Employee domain class:
|
||||
|
||||
```
|
||||
package com.nuevaconsulting.embrow
|
||||
|
||||
class Employee {
|
||||
|
||||
String surname
|
||||
String givenNames
|
||||
Position position
|
||||
Office office
|
||||
int extension
|
||||
Date hired
|
||||
int salary
|
||||
static constraints = {
|
||||
surname nullable: false, blank: false
|
||||
givenNames nullable: false, blank: false
|
||||
: false
|
||||
office nullable: false
|
||||
extension nullable: false
|
||||
hired nullable: false
|
||||
salary nullable: false
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Note that whereas the Position and Office domain classes use predefined Groovy types String and int, the Employee domain class defines fields that are of type Position and Office (as well as the predefined Date). This causes the creation of the database table in which instances of Employee are stored to contain references, or foreign keys, to the tables in which instances of Position and Office are stored.
|
||||
|
||||
Now you can generate the controllers, views, and various other test components:
|
||||
|
||||
```
|
||||
-all com.nuevaconsulting.embrow.Position
|
||||
grails generate-all com.nuevaconsulting.embrow.Office
|
||||
grails generate-all com.nuevaconsulting.embrow.Employeegrails generateall com.grails generateall com.grails generateall com.
|
||||
```
|
||||
|
||||
At this point, you have a basic create-read-update-delete (CRUD) application ready to go. I’ve included some base data in the **grails-app/init/com/nuevaconsulting/BootStrap.groovy** to populate the tables.
|
||||
|
||||
If you run the application with the command:
|
||||
|
||||
```
|
||||
grails run-app
|
||||
```
|
||||
|
||||
you will see the following screen in the browser at **<http://localhost:8080/:>**
|
||||
|
||||
![Embrow home screen][12]
|
||||
|
||||
The Embrow application home screen
|
||||
|
||||
Clicking on the link for the OfficeController gives you a screen that looks like this:
|
||||
|
||||
![Office list][14]
|
||||
|
||||
The office list
|
||||
|
||||
Note that this list is generated by the **OfficeController index** method and displayed by the view `office/index.gsp`.
|
||||
|
||||
Similarly, clicking on the **EmployeeController** gives a screen that looks like this:
|
||||
|
||||
![Employee controller][16]
|
||||
|
||||
The employee controller
|
||||
|
||||
Ok, that’s pretty ugly—what’s with the Position and Office links?
|
||||
|
||||
Well, the views generated by the `generate-all` commands above create an **index.gsp** file that uses the Grails <f:table/> tag that by default shows the class name ( **com.nuevaconsulting.embrow.Position** ) and the persistent instance identifier ( **30** ). This behavior can be customized to yield something better looking, and there is some pretty neat stuff with the autogenerated links, the autogenerated pagination, and the autogenerated sortable columns.
|
||||
|
||||
But even when it's fully cleaned up, this employee browser offers limited functionality. For example, what if you want to find all employees whose position includes the text “dev”? What if you want to combine columns for sorting so that the primary sort key is a surname and the secondary sort key is an office name? Or what if you want to export a sorted subset to a spreadsheet or PDF to email to someone who doesn’t have access to the browser?
|
||||
|
||||
The jQuery DataTables plugin provides this kind of extra functionality and allows you to create a full-fledged tabular data browser.
|
||||
|
||||
### Creating the employee browser view and controller methods
|
||||
|
||||
In order to create an employee browser based on jQuery DataTables, you must complete two tasks:
|
||||
|
||||
1. Create a Grails view that incorporates the HTML and JavaScript required to enable the DataTables
|
||||
|
||||
2. Add a method to the Grails controller to handle the new view
|
||||
|
||||
|
||||
|
||||
|
||||
#### The employee browser view
|
||||
|
||||
In the directory **embrow/grails-app/views/employee** , start by making a copy of the **index.gsp** file, calling it **browser.gsp** :
|
||||
|
||||
```
|
||||
cd Projects
|
||||
cd embrow/grails-app/views/employee
|
||||
cp gsp browser.gsp
|
||||
```
|
||||
|
||||
At this point, you want to customize the new **browser.gsp** file to add the relevant jQuery DataTables code.
|
||||
|
||||
As a rule, I like to grab my JavaScript and CSS from a content provider when feasible; to do so in this case, after the line:
|
||||
|
||||
```
|
||||
<title><g:message code="default.list.label" args="[entityName]" /></title>
|
||||
```
|
||||
|
||||
insert the following lines:
|
||||
|
||||
```
|
||||
<script src="https://code.jquery.com/jquery-2.2.4.min.js" integrity="sha256-BbhdlvQf/xTY9gja0Dq3HiwQF8LaCRTXxZKRutelT44=" crossorigin="anonymous"></script>
|
||||
<link rel="stylesheet" type="text/css" href="https://cdn.datatables.net/1.10.16/css/jquery.dataTables.css">
|
||||
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/1.10.16/js/jquery.dataTables.js"></script>
|
||||
<link rel="stylesheet" type="text/css" href="https://cdn.datatables.net/scroller/1.4.4/css/scroller.dataTables.min.css">
|
||||
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/scroller/1.4.4/js/dataTables.scroller.min.js"></script>
|
||||
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/buttons/1.5.1/js/dataTables.buttons.min.js"></script>
|
||||
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/buttons/1.5.1/js/buttons.flash.min.js"></script>
|
||||
<script type="text/javascript" charset="utf8" src="https://cdnjs.cloudflare.com/ajax/libs/jszip/3.1.3/jszip.min.js"></script>
|
||||
<script type="text/javascript" charset="utf8" src="https://cdnjs.cloudflare.com/ajax/libs/pdfmake/0.1.32/pdfmake.min.js"></script>
|
||||
<script type="text/javascript" charset="utf8" src="https://cdnjs.cloudflare.com/ajax/libs/pdfmake/0.1.32/vfs_fonts.js"></script>
|
||||
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/buttons/1.5.1/js/buttons.html5.min.js"></script>
|
||||
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/buttons/1.5.1/js/buttons.print.min.js "></script>
|
||||
```
|
||||
|
||||
Next, remove the code that provided the data pagination in **index.gsp** :
|
||||
|
||||
```
|
||||
<div id="list-employee" class="content scaffold-list" role="main">
|
||||
<h1><g:message code="default.list.label" args="[entityName]" /></h1>
|
||||
<g:if test="${flash.message}">
|
||||
<div class="message" role="status">${flash.message}</div>
|
||||
</g:if>
|
||||
<f:table collection="${employeeList}" />
|
||||
|
||||
<div class="pagination">
|
||||
<g:paginate total="${employeeCount ?: 0}" />
|
||||
</div>
|
||||
</div>
|
||||
```
|
||||
|
||||
and insert the code that materializes the jQuery DataTables.
|
||||
|
||||
The first part to insert is the HTML that creates the basic tabular structure of the browser. For the application where DataTables talks to a database backend, provide only the table headers and footers; the DataTables JavaScript takes care of the table contents.
|
||||
|
||||
```
|
||||
<div id="employee-browser" class="content" role="main">
|
||||
<h1>Employee Browser</h1>
|
||||
<table id="employee_dt" class="display compact" style="width:99%;">
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Surname</th>
|
||||
<th>Given name(s)</th>
|
||||
<th>Position</th>
|
||||
<th>Office</th>
|
||||
<th>Extension</th>
|
||||
<th>Hired</th>
|
||||
<th>Salary</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tfoot>
|
||||
<tr>
|
||||
<th>Surname</th>
|
||||
<th>Given name(s)</th>
|
||||
<th>Position</th>
|
||||
<th>Office</th>
|
||||
<th>Extension</th>
|
||||
<th>Hired</th>
|
||||
<th>Salary</th>
|
||||
</tr>
|
||||
</tfoot>
|
||||
</table>
|
||||
</div>
|
||||
```
|
||||
|
||||
Next, insert a JavaScript block, which serves three primary functions: It sets the size of the text boxes shown in the footer for column filtering, it establishes the DataTables table model, and it creates a handler to do the column filtering.
|
||||
|
||||
```
|
||||
<g:javascript>
|
||||
$('#employee_dt tfoot th').each( function() {javascript
|
||||
```
|
||||
|
||||
The code below handles sizing the filter boxes at the bottoms of the table columns:
|
||||
|
||||
```
|
||||
var title = $(this).text();
|
||||
if (title == 'Extension' || title == 'Hired')
|
||||
$(this).html('<input type="text" size="5" placeholder="' + title + '?" />');
|
||||
else
|
||||
$(this).html('<input type="text" size="15" placeholder="' + title + '?" />');
|
||||
});titletitletitletitletitle
|
||||
```
|
||||
|
||||
Next, define the table model. This is where all the table options are provided, including the scrolling, rather than paginated, nature of the interface, the cryptic decorations to be provided according to the dom string, the ability to export data to CSV and other formats, as well as where the Ajax connection to the server is established. Note that the URL is created with a Groovy GString call to the Grails **createLink()** method, referring to the **browserLister** action in the **EmployeeController**. Also of interest is the definition of the columns of the table. This information is sent across to the back end, which queries the database and returns the appropriate records.
|
||||
|
||||
```
|
||||
var table = $('#employee_dt').DataTable( {
|
||||
"scrollY": 500,
|
||||
"deferRender": true,
|
||||
"scroller": true,
|
||||
"dom": "Brtip",
|
||||
"buttons": [ 'copy', 'csv', 'excel', 'pdf', 'print' ],
|
||||
"processing": true,
|
||||
"serverSide": true,
|
||||
"ajax": {
|
||||
"url": "${createLink(controller: 'employee', action: 'browserLister')}",
|
||||
"type": "POST",
|
||||
},
|
||||
"columns": [
|
||||
{ "data": "surname" },
|
||||
{ "data": "givenNames" },
|
||||
{ "data": "position" },
|
||||
{ "data": "office" },
|
||||
{ "data": "extension" },
|
||||
{ "data": "hired" },
|
||||
{ "data": "salary" }
|
||||
]
|
||||
});
|
||||
```
|
||||
|
||||
Finally, monitor the filter columns for changes and use them to apply the filter(s).
|
||||
|
||||
```
|
||||
table.columns().every(function() {
|
||||
var that = this;
|
||||
$('input', this.footer()).on('keyup change', function(e) {
|
||||
if (that.search() != this.value && 8 < e.keyCode && e.keyCode < 32)
|
||||
that.search(this.value).draw();
|
||||
});
|
||||
```
|
||||
|
||||
And that’s it for the JavaScript. This completes the changes to the view code.
|
||||
|
||||
```
|
||||
});
|
||||
</g:javascript>
|
||||
```
|
||||
|
||||
Here’s a screenshot of the UI this view creates:
|
||||
|
||||
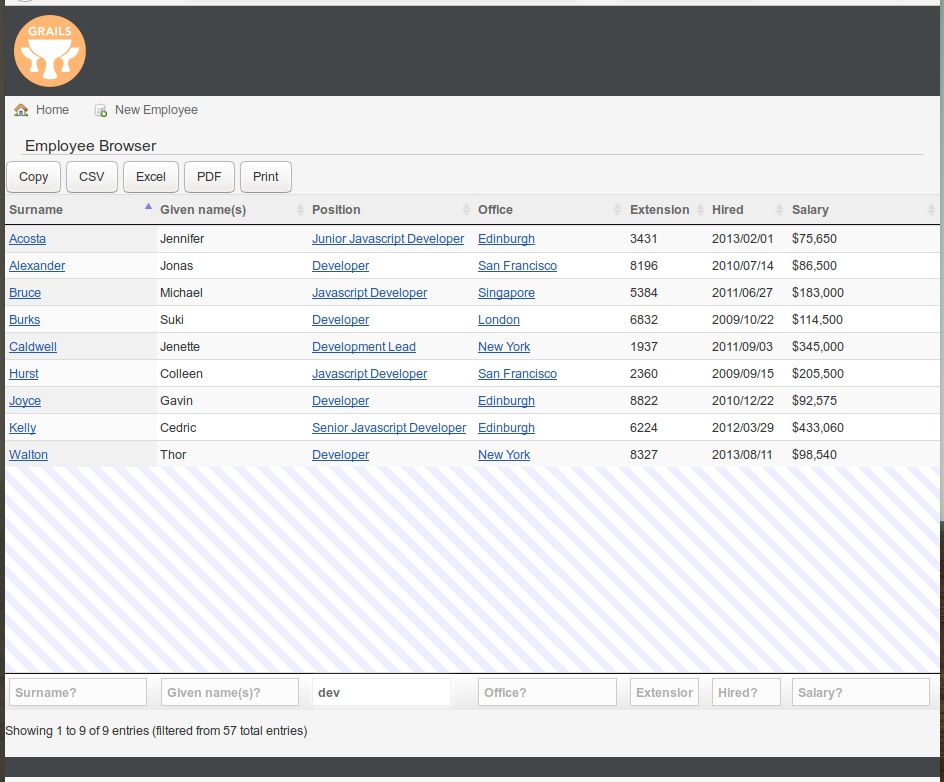
|
||||
|
||||
Here’s another screenshot showing the filtering and multi-column sorting at work (looking for employees whose positions include the characters “dev”, ordering first by office, then by surname):
|
||||
|
||||
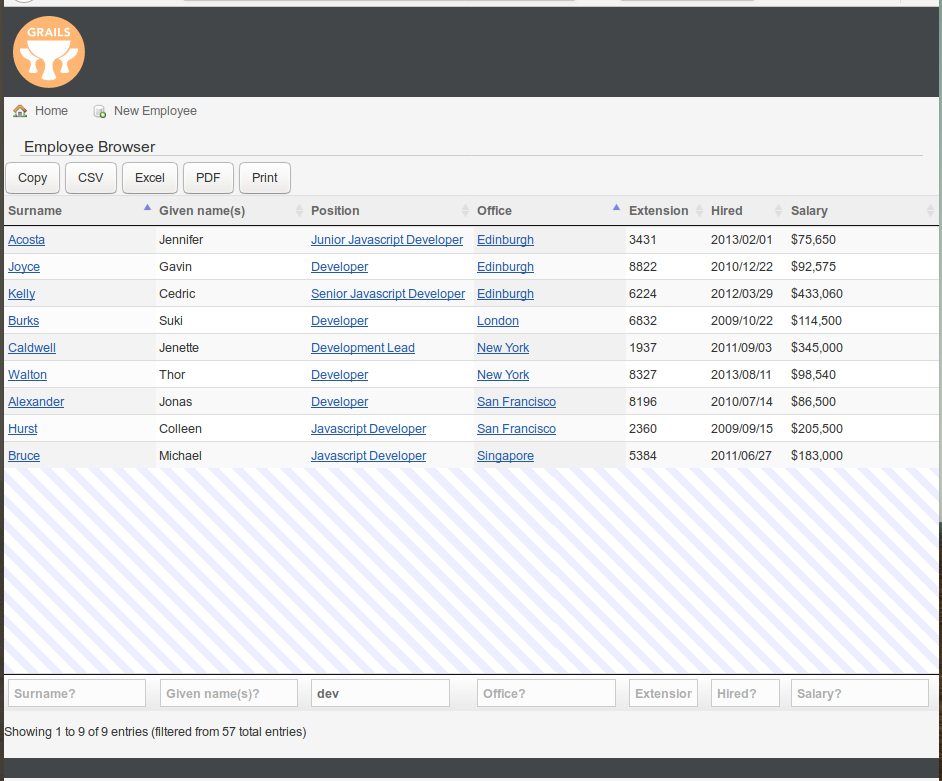
|
||||
|
||||
Here’s another screenshot, showing what happens when you click on the CSV button:
|
||||
|
||||
|
||||
|
||||
And finally, here’s a screenshot showing the CSV data opened in LibreOffice:
|
||||
|
||||
|
||||
|
||||
Ok, so the view part looked pretty straightforward; therefore, the controller action must do all the heavy lifting, right? Let’s see…
|
||||
|
||||
#### The employee controller browserLister action
|
||||
|
||||
Recall that we saw this string
|
||||
|
||||
```
|
||||
"${createLink(controller: 'employee', action: 'browserLister')}"
|
||||
```
|
||||
|
||||
as the URL used for the Ajax calls from the DataTables table model. [createLink() is the method][17] behind a Grails tag that is used to dynamically generate a link as the HTML is preprocessed on the Grails server. This ends up generating a link to the **EmployeeController** , located in
|
||||
|
||||
```
|
||||
embrow/grails-app/controllers/com/nuevaconsulting/embrow/EmployeeController.groovy
|
||||
```
|
||||
|
||||
and specifically to the controller method **browserLister()**. I’ve left some print statements in the code so that the intermediate results can be seen in the terminal window where the application is running.
|
||||
|
||||
```
|
||||
def browserLister() {
|
||||
// Applies filters and sorting to return a list of desired employees
|
||||
```
|
||||
|
||||
First, print out the parameters passed to **browserLister()**. I usually start building controller methods with this code so that I’m completely clear on what my controller is receiving.
|
||||
|
||||
```
|
||||
println "employee browserLister params $params"
|
||||
println()
|
||||
```
|
||||
|
||||
Next, process those parameters to put them in a more usable shape. First, the jQuery DataTables parameters, a Groovy map called **jqdtParams** :
|
||||
|
||||
```
|
||||
def jqdtParams = [:]
|
||||
params.each { key, value ->
|
||||
def keyFields = key.replace(']','').split(/\[/)
|
||||
def table = jqdtParams
|
||||
for (int f = 0; f < keyFields.size() - 1; f++) {
|
||||
def keyField = keyFields[f]
|
||||
if (!table.containsKey(keyField))
|
||||
table[keyField] = [:]
|
||||
table = table[keyField]
|
||||
}
|
||||
table[keyFields[-1]] = value
|
||||
}
|
||||
println "employee dataTableParams $jqdtParams"
|
||||
println()
|
||||
```
|
||||
|
||||
Next, the column data, a Groovy map called **columnMap** :
|
||||
|
||||
```
|
||||
def columnMap = jqdtParams.columns.collectEntries { k, v ->
|
||||
def whereTerm = null
|
||||
switch (v.data) {
|
||||
case 'extension':
|
||||
case 'hired':
|
||||
case 'salary':
|
||||
if (v.search.value ==~ /\d+(,\d+)*/)
|
||||
whereTerm = v.search.value.split(',').collect { it as Integer }
|
||||
break
|
||||
default:
|
||||
if (v.search.value ==~ /[A-Za-z0-9 ]+/)
|
||||
whereTerm = "%${v.search.value}%" as String
|
||||
break
|
||||
}
|
||||
[(v.data): [where: whereTerm]]
|
||||
}
|
||||
println "employee columnMap $columnMap"
|
||||
println()
|
||||
```
|
||||
|
||||
Next, a list of all column names, retrieved from **columnMap** , and a corresponding list of how those columns should be ordered in the view, Groovy lists called **allColumnList** and **orderList** , respectively:
|
||||
|
||||
```
|
||||
def allColumnList = columnMap.keySet() as List
|
||||
println "employee allColumnList $allColumnList"
|
||||
def orderList = jqdtParams.order.collect { k, v -> [allColumnList[v.column as Integer], v.dir] }
|
||||
println "employee orderList $orderList"
|
||||
```
|
||||
|
||||
We’re going to use Grails’ implementation of Hibernate criteria to actually carry out the selection of elements to be displayed as well as their ordering and pagination. Criteria requires a filter closure; in most examples, this is given as part of the creation of the criteria instance itself, but here we define the filter closure beforehand. Note in this case the relatively complex interpretation of the “date hired” filter, which is treated as a year and applied to establish date ranges, and the use of **createAlias** to allow us to reach into related classes Position and Office:
|
||||
|
||||
```
|
||||
def filterer = {
|
||||
createAlias 'position', 'p'
|
||||
createAlias 'office', 'o'
|
||||
|
||||
if (columnMap.surname.where) ilike 'surname', columnMap.surname.where
|
||||
if (columnMap.givenNames.where) ilike 'givenNames', columnMap.givenNames.where
|
||||
if (columnMap.position.where) ilike 'p.name', columnMap.position.where
|
||||
if (columnMap.office.where) ilike 'o.name', columnMap.office.where
|
||||
if (columnMap.extension.where) inList 'extension', columnMap.extension.where
|
||||
if (columnMap.salary.where) inList 'salary', columnMap.salary.where
|
||||
if (columnMap.hired.where) {
|
||||
if (columnMap.hired.where.size() > 1) {
|
||||
or {
|
||||
columnMap.hired.where.each {
|
||||
between 'hired', Date.parse('yyyy/MM/dd',"${it}/01/01" as String),
|
||||
Date.parse('yyyy/MM/dd',"${it}/12/31" as String)
|
||||
}
|
||||
}
|
||||
} else {
|
||||
between 'hired', Date.parse('yyyy/MM/dd',"${columnMap.hired.where[0]}/01/01" as String),
|
||||
Date.parse('yyyy/MM/dd',"${columnMap.hired.where[0]}/12/31" as String)
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
At this point, it’s time to apply the foregoing. The first step is to get a total count of all the Employee instances, required by the pagination code:
|
||||
|
||||
```
|
||||
def recordsTotal = Employee.count()
|
||||
println "employee recordsTotal $recordsTotal"
|
||||
```
|
||||
|
||||
Next, apply the filter to the Employee instances to get the count of filtered results, which will always be less than or equal to the total number (again, this is for the pagination code):
|
||||
|
||||
```
|
||||
def c = Employee.createCriteria()
|
||||
def recordsFiltered = c.count {
|
||||
filterer.delegate = delegate
|
||||
filterer()
|
||||
}
|
||||
println "employee recordsFiltered $recordsFiltered"
|
||||
|
||||
```
|
||||
|
||||
Once you have those two counts, you can get the actual filtered instances using the pagination and ordering information as well.
|
||||
|
||||
```
|
||||
def orderer = Employee.withCriteria {
|
||||
filterer.delegate = delegate
|
||||
filterer()
|
||||
orderList.each { oi ->
|
||||
switch (oi[0]) {
|
||||
case 'surname': order 'surname', oi[1]; break
|
||||
case 'givenNames': order 'givenNames', oi[1]; break
|
||||
case 'position': order 'p.name', oi[1]; break
|
||||
case 'office': order 'o.name', oi[1]; break
|
||||
case 'extension': order 'extension', oi[1]; break
|
||||
case 'hired': order 'hired', oi[1]; break
|
||||
case 'salary': order 'salary', oi[1]; break
|
||||
}
|
||||
}
|
||||
maxResults (jqdtParams.length as Integer)
|
||||
firstResult (jqdtParams.start as Integer)
|
||||
}
|
||||
```
|
||||
|
||||
To be completely clear, the pagination code in JTables manages three counts: the total number of records in the data set, the number resulting after the filters are applied, and the number to be displayed on the page (whether the display is scrolling or paginated). The ordering is applied to all the filtered records and the pagination is applied to chunks of those filtered records for display purposes.
|
||||
|
||||
Next, process the results returned by the orderer, creating links to the Employee, Position, and Office instance in each row so the user can click on these links to get all the detail on the relevant instance:
|
||||
|
||||
```
|
||||
def dollarFormatter = new DecimalFormat('$##,###.##')
|
||||
def employees = orderer.collect { employee ->
|
||||
['surname': "<a href='${createLink(controller: 'employee', action: 'show', id: employee.id)}'>${employee.surname}</a>",
|
||||
'givenNames': employee.givenNames,
|
||||
'position': "<a href='${createLink(controller: 'position', action: 'show', id: employee.position?.id)}'>${employee.position?.name}</a>",
|
||||
'office': "<a href='${createLink(controller: 'office', action: 'show', id: employee.office?.id)}'>${employee.office?.name}</a>",
|
||||
'extension': employee.extension,
|
||||
'hired': employee.hired.format('yyyy/MM/dd'),
|
||||
'salary': dollarFormatter.format(employee.salary)]
|
||||
}
|
||||
```
|
||||
|
||||
And finally, create the result you want to return and give it back as JSON, which is what jQuery DataTables requires.
|
||||
|
||||
```
|
||||
def result = [draw: jqdtParams.draw, recordsTotal: recordsTotal, recordsFiltered: recordsFiltered, data: employees]
|
||||
render(result as JSON)
|
||||
}
|
||||
```
|
||||
|
||||
That’s it.
|
||||
|
||||
If you’re familiar with Grails, this probably seems like more work than you might have originally thought, but there’s no rocket science here, just a lot of moving parts. However, if you haven’t had much exposure to Grails (or to Groovy), there’s a lot of new stuff to understand—closures, delegates, and builders, among other things.
|
||||
|
||||
In that case, where to start? The best place is to learn about Groovy itself, especially [Groovy closures][18] and [Groovy delegates and builders][19]. Then go back to the reading suggested above on Grails and Hibernate criteria queries.
|
||||
|
||||
### Conclusions
|
||||
|
||||
jQuery DataTables make awesome tabular data browsers for Grails. Coding the view isn’t too tricky, but the PHP examples provided in the DataTables documentation take you only so far. In particular, they aren’t written with Grails programmers in mind, nor do they explore the finer details of using elements that are references to other classes (essentially lookup tables).
|
||||
|
||||
I’ve used this approach to make a couple of data browsers that allow the user to select which columns to view and accumulate record counts, or just to browse the data. The performance is good even in million-row tables on a relatively modest VPS.
|
||||
|
||||
One caveat: I have stumbled upon some problems with the various Hibernate criteria mechanisms exposed in Grails (see my other GitHub repositories), so care and experimentation is required. If all else fails, the alternative approach is to build SQL strings on the fly and execute them instead. As of this writing, I prefer to work with Grails criteria, unless I get into messy subqueries, but that may just reflect my relative lack of experience with subqueries in Hibernate.
|
||||
|
||||
I hope you Grails programmers out there find this interesting. Please feel free to leave comments or suggestions below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/using-grails-jquery-and-datatables
|
||||
|
||||
作者:[Chris Hermansen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/clhermansen
|
||||
[1]: https://grails.org/
|
||||
[2]: https://jquery.com/
|
||||
[3]: https://datatables.net/
|
||||
[4]: http://php.net/
|
||||
[5]: http://groovy-lang.org/
|
||||
[6]: https://github.com/monetschemist/grails-datatables
|
||||
[7]: https://www.vim.org/
|
||||
[8]: http://openjdk.java.net/
|
||||
[9]: http://sdkman.io/
|
||||
[10]: http://guides.grails.org/creating-your-first-grails-app/guide/index.html
|
||||
[11]: https://opensource.com/file/410061
|
||||
[12]: https://opensource.com/sites/default/files/uploads/screen_1.png (Embrow home screen)
|
||||
[13]: https://opensource.com/file/410066
|
||||
[14]: https://opensource.com/sites/default/files/uploads/screen_2.png (Office list screenshot)
|
||||
[15]: https://opensource.com/file/410071
|
||||
[16]: https://opensource.com/sites/default/files/uploads/screen3.png (Employee controller screenshot)
|
||||
[17]: https://gsp.grails.org/latest/ref/Tags/createLink.html
|
||||
[18]: http://groovy-lang.org/closures.html
|
||||
[19]: http://groovy-lang.org/dsls.html
|
||||
@ -0,0 +1,100 @@
|
||||
认领:by sd886393
|
||||
What containers can teach us about DevOps
|
||||
======
|
||||
|
||||
The use of containers supports the three pillars of DevOps practices: flow, feedback, and continual experimentation and learning.
|
||||
|
||||
|
||||
|
||||
One can argue that containers and DevOps were made for one another. Certainly, the container ecosystem benefits from the skyrocketing popularity of DevOps practices, both in design choices and in DevOps’ use by teams developing container technologies. Because of this parallel evolution, the use of containers in production can teach teams the fundamentals of DevOps and its three pillars: [The Three Ways][1].
|
||||
|
||||
### Principles of flow
|
||||
|
||||
**Container flow**
|
||||
|
||||
A container can be seen as a silo, and from inside, it is easy to forget the rest of the system: the host node, the cluster, the underlying infrastructure. Inside the container, it might appear that everything is functioning in an acceptable manner. From the outside perspective, though, the application inside the container is a part of a larger ecosystem of applications that make up a service: the web API, the web app user interface, the database, the workers, and caching services and garbage collectors. Teams put constraints on the container to limit performance impact on infrastructure, and much has been done to provide metrics for measuring container performance because overloaded or slow container workloads have downstream impact on other services or customers.
|
||||
|
||||
**Real-world flow**
|
||||
|
||||
This lesson can be applied to teams functioning in a silo as well. Every process (be it code release, infrastructure creation or even, say, manufacturing of [Spacely’s Sprockets][2]), follows a linear path from conception to realization. In technology, this progress flows from development to testing to operations and release. If a team working alone becomes a bottleneck or introduces a problem, the impact is felt all along the entire pipeline. A defect passed down the line destroys productivity downstream. While the broken process within the scope of the team itself may seem perfectly correct, it has a negative impact on the environment as a whole.
|
||||
|
||||
**DevOps and flow**
|
||||
|
||||
The first way of DevOps, principles of flow, is about approaching the process as a whole, striving to comprehend how the system works together and understanding the impact of issues on the entire process. To increase the efficiency of the process, pain points and waste are identified and removed. This is an ongoing process; teams must continually strive to increase visibility into the process and find and fix trouble spots and waste.
|
||||
|
||||
> “The outcomes of putting the First Way into practice include never passing a known defect to downstream work centers, never allowing local optimization to create global degradation, always seeking to increase flow, and always seeking to achieve a profound understanding of the system (as per Deming).”
|
||||
|
||||
–Gene Kim, [The Three Ways: The Principles Underpinning DevOps][3], IT Revolution, 25 Apr. 2017
|
||||
|
||||
### Principles of feedback
|
||||
|
||||
**Container feedback**
|
||||
|
||||
In addition to limiting containers to prevent impact elsewhere, many products have been created to monitor and trend container metrics in an effort to understand what they are doing and notify when they are misbehaving. [Prometheus][4], for example, is [all the rage][5] for collecting metrics from containers and clusters. Containers are excellent at separating applications and providing a way to ship an environment together with the code, sometimes at the cost of opacity, so much is done to try to provide rapid feedback so issues can be addressed promptly within the silo.
|
||||
|
||||
**Real-world feedback**
|
||||
|
||||
The same is necessary for the flow of the system. From inception to realization, an efficient process quickly provides relevant feedback to identify when there is an issue. The key words here are “quick” and “relevant.” Burying teams in thousands of irrelevant notifications make it difficult or even impossible to notice important events that need immediate action, and receiving even relevant information too late may allow small, easily solved issues to move downstream and become bigger problems. Imagine [if Lucy and Ethel][6] had provided immediate feedback that the conveyor belt was too fast—there would have been no problem with the chocolate production (though that would not have been nearly as funny).
|
||||
|
||||
**DevOps and feedback**
|
||||
|
||||
The Second Way of DevOps, principles of feedback, is all about getting relevant information quickly. With immediate, useful feedback, problems can be identified as they happen and addressed before impact is felt elsewhere in the development process. DevOps teams strive to “optimize for downstream” and immediately move to fix problems that might impact other teams that come after them. As with flow, feedback is a continual process to identify ways to quickly get important data and act on problems as they occur.
|
||||
|
||||
> “Creating fast feedback is critical to achieving quality, reliability, and safety in the technology value stream.”
|
||||
|
||||
–Gene Kim, et al., The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations, IT Revolution Press, 2016
|
||||
|
||||
### Principles of continual experimentation and learning
|
||||
|
||||
**Container continual experimentation and learning**
|
||||
|
||||
It is a bit more challenging applying operational learning to the Third Way of DevOps:continual experimentation and learning. Trying to salvage what we can grasp of the very edges of the metaphor, containers make development easy, allowing developers and operations teams to test new code or configurations locally and safely outside of production and incorporate discovered benefits into production in a way that was difficult in the past. Changes can be radical and still version-controlled, documented, and shared quickly and easily.
|
||||
|
||||
**Real-world continual experimentation and learning**
|
||||
|
||||
For example, consider this anecdote from my own experience: Years ago, as a young, inexperienced sysadmin (just three weeks into the job), I was asked to make changes to an Apache virtual host running the website of the central IT department for a university. Without an easy-to-use test environment, I made a configuration change to the production site that I thought would accomplish the task and pushed it out. Within a few minutes, I overheard coworkers in the next cube:
|
||||
|
||||
“Wait, is the website down?”
|
||||
|
||||
“Hrm, yeah, it looks like it. What the heck?”
|
||||
|
||||
There was much eye-rolling involved.
|
||||
|
||||
Mortified (the shame is real, folks), I sunk down as far as I could into my seat and furiously tried to back out the changes I’d introduced. Later that same afternoon, the director of the department—the boss of my boss’s boss—appeared in my cube to talk about what had happened. “Don’t worry,” she told me. “We’re not mad at you. It was a mistake and now you have learned.”
|
||||
|
||||
In the world of containers, this could have been easily changed and tested on my own laptop and the broken configuration identified by more skilled team members long before it ever made it into production.
|
||||
|
||||
**DevOps continual experimentation and learning**
|
||||
|
||||
A real culture of experimentation promotes the individual’s ability to find where a change in the process may be beneficial, and to test that assumption without the fear of retaliation if they fail. For DevOps teams, failure becomes an educational tool that adds to the knowledge of the individual and organization, rather than something to be feared or punished. Individuals in the DevOps team dedicate themselves to continuous learning, which in turn benefits the team and wider organization as that knowledge is shared.
|
||||
|
||||
As the metaphor completely falls apart, focus needs to be given to a specific point: The other two principles may appear at first glance to focus entirely on process, but continual learning is a human task—important for the future of the project, the person, the team, and the organization. It has an impact on the process, but it also has an impact on the individual and other people.
|
||||
|
||||
> “Experimentation and risk-taking are what enable us to relentlessly improve our system of work, which often requires us to do things very differently than how we’ve done it for decades.”
|
||||
|
||||
–Gene Kim, et al., [The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win][7], IT Revolution Press, 2013
|
||||
|
||||
### Containers can teach us DevOps
|
||||
|
||||
Learning to work effectively with containers can help teach DevOps and the Three Ways: principles of flow, principles of feedback, and principles of continuous experimentation and learning. Looking holistically at the application and infrastructure rather than putting on blinders to everything outside the container teaches us to take all parts of the system and understand their upstream and downstream impacts, break out of silos, and work as a team to increase global performance and deep understanding of the entire system. Working to provide timely and accurate feedback teaches us to create effective feedback patterns within our organizations to identify problems before their impact grows. Finally, providing a safe environment to try new ideas and learn from them teaches us to create a culture where failure represents a positive addition to our knowledge and the ability to take big chances with educated guesses can result in new, elegant solutions to complex problems.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/containers-can-teach-us-devops
|
||||
|
||||
作者:[Chris Hermansen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/clhermansen
|
||||
[1]: https://itrevolution.com/the-three-ways-principles-underpinning-devops/
|
||||
[2]: https://en.wikipedia.org/wiki/The_Jetsons
|
||||
[3]: http://itrevolution.com/the-three-ways-principles-underpinning-devops
|
||||
[4]: https://prometheus.io/
|
||||
[5]: https://opensource.com/article/18/9/prometheus-operational-advantage
|
||||
[6]: https://www.youtube.com/watch?v=8NPzLBSBzPI
|
||||
[7]: https://itrevolution.com/book/the-phoenix-project/
|
||||
138
sources/tech/20180929 Use Cozy to Play Audiobooks in Linux.md
Normal file
138
sources/tech/20180929 Use Cozy to Play Audiobooks in Linux.md
Normal file
@ -0,0 +1,138 @@
|
||||
Use Cozy to Play Audiobooks in Linux
|
||||
======
|
||||
**We review Cozy, an audiobook player for Linux. Read to find out if it’s worth to install Cozy on your Linux system or not.**
|
||||
|
||||
![Audiobook player for Linux][1]
|
||||
|
||||
Audiobooks are a great way to consume literature. Many people who don’t have time to read, choose to listen. Most people, myself included, just use a regular media player like VLC or [MPV][2] for listening to audiobooks on Linux.
|
||||
|
||||
Today, we will look at a Linux application built solely for listening to audiobooks.
|
||||
|
||||
![][3]Cozy Audiobook Player
|
||||
|
||||
### Cozy Audiobook Player for Linux
|
||||
|
||||
The [Cozy Audiobook Player][4] is created by [Julian Geywitz][5] from Germany. It is built using both Python and GTK+ 3. According to the site, Julian wrote Cozy on Fedora and optimized it for [elementary OS][6].
|
||||
|
||||
The player borrows its layout from iTunes. The player controls are placed along the top of the application The library takes up the rest. You can sort all of your audiobooks based on the title, author and reader, and search very quickly.
|
||||
|
||||
![][7]Initial setup
|
||||
|
||||
When you first launch [Cozy][8], you are given the option to choose where you will store your audiobook files. Cozy will keep an eye on that folder and update your library as you add new audiobooks. You can also set it up to use an external or network drive.
|
||||
|
||||
#### Features of Cozy
|
||||
|
||||
Here is a full list of the features that [Cozy][9] has to offer.
|
||||
|
||||
* Import all your audiobooks into Cozy to browse them comfortably
|
||||
* Sort your audiobooks by author, reader & title
|
||||
* Remembers your playback position
|
||||
* Sleep timer
|
||||
* Playback speed control
|
||||
* Search your audiobook library
|
||||
* Add multiple storage locations
|
||||
* Drag & Drop to import new audio books
|
||||
* Support for DRM free mp3, m4a (aac, ALAC, …), flac, ogg, wav files
|
||||
* Mpris integration (Media keys & playback info for the desktop environment)
|
||||
* Developed on Fedora and tested under elementaryOS
|
||||
|
||||
|
||||
|
||||
#### Experiencing Cozy
|
||||
|
||||
![][10]Audiobook library
|
||||
|
||||
At first, I was excited to try our Cozy because I like to listen to audiobooks. However, I ran into a couple of issues. There is no way to edit the information of an audiobook. For example, I downloaded a couple audiobooks from [LibriVox][11] to test it. All three audiobooks were listed under “Unknown” for the reader. There was nothing to edit or change the audiobook info. I guess you could edit all of the files, but that would take quite a bit of time.
|
||||
|
||||
When I listen to an audiobook, I like to know what track is currently playing. Cozy only has a single progress bar for the whole audiobook. I know that Cozy is designed to remember where you left off in an audiobook, but if I was going to continue to listen to the audiobook on my phone, I would like to know what track I am on.
|
||||
|
||||
![][12]Settings
|
||||
|
||||
There was also an option in the setting menu to turn on a dark theme. As you can see in the screenshots, the application has a black theme, to begin with. I turned the option on, but nothing happened. There isn’t even an option to add a theme or change any of the colors. Overall, the application had a feeling of not being finished.
|
||||
|
||||
#### Installing Cozy on Linux
|
||||
|
||||
If you would like to install Cozy, you have several options for different distros.
|
||||
|
||||
##### Ubuntu, Debian, openSUSE, Fedora
|
||||
|
||||
Julian used the [openSUSE Build Service][13] to create custom repos for Ubuntu, Debian, openSUSE and Fedora. Each one only takes a couple terminal commands to install.
|
||||
|
||||
##### Install Cozy using Flatpak on any Linux distribution (including Ubuntu)
|
||||
|
||||
If your [distro supports Flatpak][14], you can install Cozy using the following commands:
|
||||
|
||||
```
|
||||
flatpak remote-add --user --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
|
||||
flatpak install --user flathub com.github.geigi.cozy
|
||||
```
|
||||
|
||||
##### Install Cozy on elementary OS
|
||||
|
||||
If you have elementary OS installed, you can install Cozy from the [built-in App Store][15].
|
||||
|
||||
##### Install Cozy on Arch Linux
|
||||
|
||||
Cozy is available in the [Arch User Repository][16]. All you have to do is search for `cozy-audiobooks`.
|
||||
|
||||
### Where to find free Audiobooks?
|
||||
|
||||
In order to try out this application, you will need to find some audiobooks to listen to. My favorite site for audiobooks is [LibriVox][11]. Since [LibriVox][17] depends on volunteers to record audiobooks, the quality can vary. However, there are a number of very talented readers.
|
||||
|
||||
Here is a list of free audiobook sources:
|
||||
|
||||
+ [Open Culture][20]
|
||||
+ [Project Gutenberg][21]
|
||||
+ [Digitalbook.io][22]
|
||||
+ [FreeClassicAudioBooks.com][23]
|
||||
+ [MindWebs][24]
|
||||
+ [Scribl][25]
|
||||
|
||||
|
||||
### Final Thoughts on Cozy
|
||||
|
||||
For now, I think I’ll stick with my preferred audiobook software (VLC) for now. Cozy just doesn’t add anything. I won’t call it a [must-have application for Linux][18] just yet. There is no compelling reason for me to switch. Maybe, I’ll revisit it again in the future, maybe when it hits 1.0.
|
||||
|
||||
Take Cozy for a spin. You might come to a different conclusion.
|
||||
|
||||
Have you ever used Cozy? If not, what is your favorite audiobook player? What is your favorite source for free audiobooks? Let us know in the comments below.
|
||||
|
||||
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][19].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/cozy-audiobook-player/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/audiobook-player-linux.png
|
||||
[2]: https://itsfoss.com/mpv-video-player/
|
||||
[3]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/cozy3.jpg
|
||||
[4]: https://cozy.geigi.de/
|
||||
[5]: https://github.com/geigi
|
||||
[6]: https://elementary.io/
|
||||
[7]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/cozy1.jpg
|
||||
[8]: https://github.com/geigi/cozy
|
||||
[9]: https://www.patreon.com/geigi
|
||||
[10]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/cozy2.jpg
|
||||
[11]: https://librivox.org/
|
||||
[12]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/cozy4.jpg
|
||||
[13]: https://software.opensuse.org//download.html?project=home%3Ageigi&package=com.github.geigi.cozy
|
||||
[14]: https://itsfoss.com/flatpak-guide/
|
||||
[15]: https://elementary.io/store/
|
||||
[16]: https://aur.archlinux.org/
|
||||
[17]: https://archive.org/details/librivoxaudio
|
||||
[18]: https://itsfoss.com/essential-linux-applications/
|
||||
[19]: http://reddit.com/r/linuxusersgroup
|
||||
[20]: http://www.openculture.com/freeaudiobooks
|
||||
[21]: http://www.gutenberg.org/browse/categories/1
|
||||
[22]: https://www.digitalbook.io/
|
||||
[23]: http://freeclassicaudiobooks.com/
|
||||
[24]: https://archive.org/details/MindWebs_201410
|
||||
[25]: https://scribl.com/
|
||||
@ -1,152 +0,0 @@
|
||||
"组"在 Linux 上到底是怎么工作的?
|
||||
============================================================
|
||||
|
||||
|
||||
你好!就在上周,我还自认为对 Linux 上的用户和组的工作机制了如指掌。我认为它们的关系是这样的:
|
||||
|
||||
1. 每个进程都属于一个用户( 比如用户`julia`)
|
||||
|
||||
2. 当这个进程试图读取一个被某个组所拥有的文件时, Linux 会 a)先检查用户`julia` 是否有权限访问文件。(LCTT译注:检查文件的所有者是否就是`julia`) b)检查`julia` 属于哪些组,并进一步检查在这些组里是否有某个组拥有这个文件或者有权限访问这个文件。
|
||||
|
||||
3. 如果上述a,b任一为真( 或者`其他`位设为有权限访问),那么这个进程就有权限访问这个文件。
|
||||
|
||||
比如说,如果一个进程被用户`julia`拥有并且`julia` 在`awesome`组,那么这个进程就能访问下面这个文件。
|
||||
|
||||
```
|
||||
r--r--r-- 1 root awesome 6872 Sep 24 11:09 file.txt
|
||||
|
||||
```
|
||||
|
||||
然而上述的机制我并没有考虑得非常清楚,如果你硬要我阐述清楚,我会说进程可能会在**运行时**去检查`/etc/group` 文件里是否有某些组拥有当前的用户。
|
||||
|
||||
### 然而这并不是Linux 里“组”的工作机制
|
||||
|
||||
我在上个星期的工作中发现了一件有趣的事,事实证明我前面的理解错了,我对组的工作机制的描述并不准确。特别是Linux**并不会**在进程每次试图访问一个文件时就去检查这个进程的用户属于哪些组。
|
||||
|
||||
我在读了[The Linux Programming
|
||||
Interface][1]这本书的第九章后才恍然大悟(这本书真是太棒了。)这才是组真正的工作方式!我意识到之前我并没有真正理解用户和组是怎么工作的,我信心满满的尝试了下面的内容并且验证到底发生了什么,事实证明现在我的理解才是对的。
|
||||
|
||||
### 用户和组权限检查是怎么完成的
|
||||
|
||||
现在这些关键的知识在我看来非常简单! 这本书的第九章上来就告诉我如下事实:用户和组ID是**进程的属性**,它们是:
|
||||
|
||||
* 真实用户ID和组ID;
|
||||
|
||||
* 有效用户ID和组ID;
|
||||
|
||||
* 被保存的set-user-ID和被保存的set-group-ID;
|
||||
|
||||
* 文件系统用户ID和组ID(特定于 Linux);
|
||||
|
||||
* 增补的组ID;
|
||||
|
||||
这说明Linux**实际上**检查一个进程能否访问一个文件所做的组检查是这样的:
|
||||
|
||||
* 检查一个进程的组ID和补充组ID(这些ID就在进程的属性里,**并不是**实时在`/etc/group`里查找这些ID)
|
||||
|
||||
* 检查要访问的文件的访问属性里的组设置
|
||||
|
||||
|
||||
* 确定进程对文件是否有权限访问(LCTT 译注:即文件的组是否是以上的组之一)
|
||||
|
||||
通常当访问控制的时候使用的是**有效**用户/组ID,而不是**真实**用户/组ID。技术上来说当访问一个文件时使用的是**文件系统**ID,他们实际上和有效用户/组ID一样。(LCTT译注:这句话针对 Linux 而言。)
|
||||
|
||||
### 将一个用户加入一个组并不会将一个已存在的进程(的用户)加入那个组
|
||||
|
||||
下面是一个有趣的例子:如果我创建了一个新的组:`panda` 组并且将我自己(bork)加入到这个组,然后运行`groups` 来检查我是否在这个组里:结果是我(bork)竟然不在这个组?!
|
||||
|
||||
|
||||
```
|
||||
bork@kiwi~> sudo addgroup panda
|
||||
Adding group `panda' (GID 1001) ...
|
||||
Done.
|
||||
bork@kiwi~> sudo adduser bork panda
|
||||
Adding user `bork' to group `panda' ...
|
||||
Adding user bork to group panda
|
||||
Done.
|
||||
bork@kiwi~> groups
|
||||
bork adm cdrom sudo dip plugdev lpadmin sambashare docker lxd
|
||||
|
||||
```
|
||||
|
||||
`panda`并不在上面的组里!为了再次确定我们的发现,让我们建一个文件,这个文件被`panda`组拥有,看看我能否访问它。
|
||||
|
||||
|
||||
```
|
||||
$ touch panda-file.txt
|
||||
$ sudo chown root:panda panda-file.txt
|
||||
$ sudo chmod 660 panda-file.txt
|
||||
$ cat panda-file.txt
|
||||
cat: panda-file.txt: Permission denied
|
||||
|
||||
```
|
||||
|
||||
好吧,确定了,我(bork)无法访问`panda-file.txt`。这一点都不让人吃惊,我的命令解释器并没有`panda` 组作为补充组ID,运行`adduser bork panda`并不会改变这一点。
|
||||
|
||||
|
||||
### 那进程一开始是怎么得到用户的组的呢?
|
||||
|
||||
|
||||
这真是个非常令人困惑的问题,对吗?如果进程会将组的信息预置到进程的属性里面,进程在初始化的时候怎么取到组的呢?很明显你无法给你自己指定更多的组(否则就会和Linux访问控制的初衷相违背了。。。)
|
||||
|
||||
有一点还是很清楚的:一个新的进程是怎么从我的命令行解释器(/bash/fish)里被**执行**而得到它的组的。(新的)进程将拥有我的用户 ID(bork),并且进程属性里还有很多组ID。从我的命令解释器里执行的所有进程是从这个命令解释器里`复刻`而来的,所以这个新进程得到了和命令解释器同样的组。
|
||||
|
||||
因此一定存在一个“第一个”进程来把你的组设置到进程属性里,而所有由此进程而衍生的进程将都设置这些组。而那个“第一个”进程就是你的**登录命令**,在我的笔记本电脑上,它是由‘登录’程序(`/bin/login`)实例化而来。` 登录程序` 以root身份运行,然后调用了一个 C 的库函数-`initgroups`来设置你的进程的组(具体来说是通过读取`/etc/group` 文件),因为登录程序是以root运行的,所以它能设置你的进程的组。
|
||||
|
||||
|
||||
### 让我们再登录一次
|
||||
|
||||
好了!既然我们的`login shell`正在运行,而我又想刷新我的进程的组设置,从我们前面所学到的进程是怎么初始化组ID的,我应该可以通过再次运行`login` 程序来刷新我的进程组并启动一个新的`login shell`!
|
||||
|
||||
让我们试试下边的方法:
|
||||
|
||||
```
|
||||
$ sudo login bork
|
||||
$ groups
|
||||
bork adm cdrom sudo dip plugdev lpadmin sambashare docker lxd panda
|
||||
$ cat panda-file.txt # it works! I can access the file owned by `panda` now!
|
||||
|
||||
```
|
||||
|
||||
当然,成功了!现在由登录程序衍生的程序的用户是组`panda`的一部分了!太棒了!这并不会影响我其他的已经在运行的登录程序(及其子进程),如果我真的希望“所有的”进程都能对`panda`
|
||||
组有访问权限。我必须完全的重启我的登陆会话,这意味着我必须退出我的窗口管理器然后再重新`login`。(LCTT译注:即更新进程树的树根进程,这里是窗口管理器进程。)
|
||||
|
||||
### newgrp命令
|
||||
|
||||
|
||||
在 Twitter 上有人告诉我如果只是想启动一个刷新了组信息的命令解释器的话,你可以使用`newgrp`(LCTT译注:不启动新的命令解释器),如下:
|
||||
|
||||
```
|
||||
sudo addgroup panda
|
||||
sudo adduser bork panda
|
||||
newgrp panda # starts a new shell, and you don't have to be root to run it!
|
||||
|
||||
```
|
||||
|
||||
|
||||
你也可以用`sg panda bash` 来完成同样的效果,这个命令能启动一个`bash` 登录程序,而这个程序就有`panda` 组。
|
||||
|
||||
### seduid 将设置有效用户 ID
|
||||
|
||||
其实我一直对一个进程如何以`setuid root`的权限来运行意味着什么有点似是而非。现在我知道了,事实上所发生的是:setuid 设置了`有效用户ID`! 如果我('julia')运行了一个`setuid root` 的进程( 比如`passwd`),那么进程的**真实**用户 ID 将为`julia`,而**有效**用户 ID 将被设置为`root`。
|
||||
|
||||
`passwd` 需要以root权限来运行,但是它能看到进程的真实用户ID是`julia` ,是`julia`启动了这个进程,`passwd`会阻止这个进程修改除了`julia`之外的用户密码。
|
||||
|
||||
### 就是这些了!
|
||||
|
||||
在 Linux Programming Interface 这本书里有很多Linux上一些功能的罕见使用方法以及Linux上所有的事物到底是怎么运行的详细解释,这里我就不一一展开了。那本书棒极了,我上面所说的都在该书的第九章,这章在1300页的书里只占了17页。
|
||||
|
||||
我最爱这本书的一点是我只用读17页关于用户和组是怎么工作的内容,而这区区17页就能做到内容完备,详实有用。我不用读完所有的1300页书就能得到有用的东西,太棒了!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/11/20/groups/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
译者:[DavidChen](https://github.com/DavidChenLiang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/
|
||||
[1]:http://man7.org/tlpi/
|
||||
237
translated/tech/20180528 What is behavior-driven Python.md
Normal file
237
translated/tech/20180528 What is behavior-driven Python.md
Normal file
@ -0,0 +1,237 @@
|
||||
什么是行为驱动的Python?
|
||||
======
|
||||

|
||||
|
||||
您是否听说过[行为驱动开发][1](BDD),并想知道所有的新奇事物是什么? 也许你已经发现了团队成员在使用“gherkin”了,并感到被排除在外无法参与其中。 或许你是一个Python爱好者,正在寻找更好的方法来测试你的代码。 无论在什么情况下,了解BDD都可以帮助您和您的团队实现更好的协作和测试自动化,而Python的`行为`框架是一个很好的起点。
|
||||
|
||||
### 什么是BDD?
|
||||
|
||||
* 在网站上提交表单
|
||||
* 搜索想要的结果
|
||||
* 保存文档
|
||||
* 进行REST API调用
|
||||
* 运行命令行界面命令
|
||||
|
||||
在软件中,行为是指在明确定义的输入,行为和结果场景中功能是如何运转的。 产品可以表现出无数的行为,例如:
|
||||
|
||||
根据产品的行为定义产品的功能可以更容易地描述产品,并对其进行开发和测试。 BDD的核心是:使行为成为软件开发的焦点。 在开发早期使用示例语言的规范来定义行为。 最常见的行为规范语言之一是Gherkin,Cucumber项目中的Given-When-Then场景格式。 行为规范基本上是对行为如何工作的简单语言描述,具有一致性和焦点的一些正式结构。 通过将步骤文本“粘合”到代码实现,测试框架可以轻松地自动化这些行为规范。
|
||||
|
||||
下面是用Gherkin编写的行为规范的示例:
|
||||
|
||||
根据产品的行为定义产品的功能可以更容易地描述产品,开发产品并对其进行测试。 这是BDD的核心:使行为成为软件开发的焦点。 在开发早期使用[示例规范][2]的语言来定义行为。 最常见的行为规范语言之一是[Gherkin][3],[Cucumber][4]项目中的Given-When-Then场景格式。 行为规范基本上是对行为如何工作的简单语言描述,具有一致性和焦点的一些正式结构。 通过将步骤文本“粘合”到代码实现,测试框架可以轻松地自动化这些行为规范。
|
||||
|
||||
下面是用Gherkin编写的行为规范的示例:
|
||||
|
||||
```
|
||||
Scenario: Basic DuckDuckGo Search
|
||||
Given the DuckDuckGo home page is displayed
|
||||
When the user searches for "panda"
|
||||
Then results are shown for "panda"
|
||||
```
|
||||
|
||||
快速浏览一下,行为是直观易懂的。 除少数关键字外,该语言为自由格式。 场景简洁而有意义。 一个真实的例子说明了这种行为。 步骤以声明的方式表明应该发生什么——而不会陷入如何如何的细节中。
|
||||
|
||||
[BDD的主要优点][5]是良好的协作和自动化。 每个人都可以为行为开发做出贡献,而不仅仅是程序员。 从流程开始就定义并理解预期的行为。 测试可以与它们涵盖的功能一起自动化。 每个测试都包含一个单一的,独特的行为,以避免重复。 最后,现有的步骤可以通过新的行为规范重用,从而产生雪球效果。
|
||||
|
||||
### Python的behave框架
|
||||
|
||||
`behave`是Python中最流行的BDD框架之一。 它与其他基于Gherkin的Cucumber框架非常相似,尽管没有得到官方的Cucumber定名。 `behave`有两个主要层:
|
||||
|
||||
1. 用Gherkin的`.feature`文件编写的行为规范
|
||||
2. 用Python模块编写的步骤定义和钩子,用于实现Gherkin步骤
|
||||
|
||||
如上例所示,Gherkin场景有三部分格式:
|
||||
|
||||
1. 鉴于一些初始状态
|
||||
2. 当行为发生时
|
||||
3. 然后验证结果
|
||||
|
||||
当`behave`运行测试时,每个步骤由装饰器“粘合”到Python函数。
|
||||
|
||||
### 安装
|
||||
|
||||
作为先决条件,请确保在你的计算机上安装了Python和`pip`。 我强烈建议使用Python 3.(我还建议使用[`pipenv`][6],但以下示例命令使用更基本的`pip`。)
|
||||
|
||||
`behave`框架只需要一个包:
|
||||
|
||||
```
|
||||
pip install behave
|
||||
```
|
||||
|
||||
其他包也可能有用,例如:
|
||||
```
|
||||
pip install requests # 用于调用REST API
|
||||
pip install selenium # 用于web浏览器交互
|
||||
```
|
||||
|
||||
GitHub上的[behavior-driven-Python][7]项目包含本文中使用的示例。
|
||||
|
||||
### Gherkin特点
|
||||
|
||||
`behave`框架使用的Gherkin语法实际上是符合官方的Cucumber Gherkin标准的。 `.feature`文件包含功能Feature部分,而Feature部分又包含具有Given-When-Then步骤的场景Scenario部分。 以下是一个例子:
|
||||
|
||||
```
|
||||
Feature: Cucumber Basket
|
||||
As a gardener,
|
||||
I want to carry many cucumbers in a basket,
|
||||
So that I don’t drop them all.
|
||||
|
||||
@cucumber-basket
|
||||
Scenario: Add and remove cucumbers
|
||||
Given the basket is empty
|
||||
When "4" cucumbers are added to the basket
|
||||
And "6" more cucumbers are added to the basket
|
||||
But "3" cucumbers are removed from the basket
|
||||
Then the basket contains "7" cucumbers
|
||||
```
|
||||
|
||||
这里有一些重要的事情需要注意:
|
||||
|
||||
- Feature和Scenario部分都有[简短的描述性标题][8]。
|
||||
- 紧跟在Feature标题后面的行是会被`behave`框架忽略掉的注释。将功能描述放在那里是一种很好的做法。
|
||||
- Scenarios和Features可以有标签(注意`@cucumber-basket`标记)用于钩子和过滤(如下所述)。
|
||||
- 步骤都遵循[严格的Given-When-Then顺序][9]。
|
||||
- 使用`And`和`Bu`t可以为任何类型添加附加步骤。
|
||||
- 可以使用输入对步骤进行参数化——注意双引号里的值。
|
||||
|
||||
通过使用场景大纲,场景也可以写为具有多个输入组合的模板:
|
||||
|
||||
```
|
||||
Feature: Cucumber Basket
|
||||
|
||||
@cucumber-basket
|
||||
Scenario Outline: Add cucumbers
|
||||
Given the basket has “<initial>” cucumbers
|
||||
When "<more>" cucumbers are added to the basket
|
||||
Then the basket contains "<total>" cucumbers
|
||||
|
||||
Examples: Cucumber Counts
|
||||
| initial | more | total |
|
||||
| 0 | 1 | 1 |
|
||||
| 1 | 2 | 3 |
|
||||
| 5 | 4 | 9 |
|
||||
```
|
||||
|
||||
场景大纲总是有一个Examples表,其中第一行给出列标题,后续每一行给出一个输入组合。 只要列标题出现在由尖括号括起的步骤中,行值就会被替换。 在上面的示例中,场景将运行三次,因为有三行输入组合。 场景大纲是避免重复场景的好方法。
|
||||
|
||||
Gherkin语言还有其他元素,但这些是主要的机制。 想了解更多信息,请阅读Automation Panda这个网站的文章[Gherkin by Example][10]和[Writing Good Gherkin][11]。
|
||||
|
||||
### Python机制
|
||||
|
||||
每个Gherkin步骤必须“粘合”到步骤定义,即提供了实现的Python函数。 每个函数都有一个带有匹配字符串的步骤类型装饰器。 它还接收共享的上下文和任何步骤参数。 功能文件必须放在名为`features/`的目录中,而步骤定义模块必须放在名为`features/steps/`的目录中。 任何功能文件都可以使用任何模块中的步骤定义——它们不需要具有相同的名称。 下面是一个示例Python模块,其中包含cucumber basket功能的步骤定义。
|
||||
|
||||
```
|
||||
from behave import *
|
||||
from cucumbers.basket import CucumberBasket
|
||||
|
||||
@given('the basket has "{initial:d}" cucumbers')
|
||||
def step_impl(context, initial):
|
||||
context.basket = CucumberBasket(initial_count=initial)
|
||||
|
||||
@when('"{some:d}" cucumbers are added to the basket')
|
||||
def step_impl(context, some):
|
||||
context.basket.add(some)
|
||||
|
||||
@then('the basket contains "{total:d}" cucumbers')
|
||||
def step_impl(context, total):
|
||||
assert context.basket.count == total
|
||||
```
|
||||
|
||||
可以使用三个[步骤匹配器][12]:`parse`,`cfparse`和`re`。默认和最简单的匹配器是`parse`,如上例所示。注意如何解析参数化值并将其作为输入参数传递给函数。一个常见的最佳实践是在步骤中给参数加双引号。
|
||||
|
||||
每个步骤定义函数还接收一个[上下文][13]变量,该变量保存当前正在运行的场景的数据,例如`feature`, `scenario`和`tags`字段。也可以添加自定义字段,用于在步骤之间共享数据。始终使用上下文来共享数据——永远不要使用全局变量!
|
||||
|
||||
`behave`框架还支持[钩子][14]来处理Gherkin步骤之外的自动化问题。钩子是一个将在步骤,场景,功能或整个测试套件之前或之后运行的功能。钩子让人联想到[面向方面的编程][15]。它们应放在`features/`目录下的特殊`environment.py`文件中。钩子函数也可以检查当前场景的标签,因此可以有选择地应用逻辑。下面的示例显示了如何使用钩子为标记为`@web`的任何场景生成和销毁一个Selenium WebDriver实例。
|
||||
|
||||
```
|
||||
from selenium import webdriver
|
||||
|
||||
def before_scenario(context, scenario):
|
||||
if 'web' in context.tags:
|
||||
context.browser = webdriver.Firefox()
|
||||
context.browser.implicitly_wait(10)
|
||||
|
||||
def after_scenario(context, scenario):
|
||||
if 'web' in context.tags:
|
||||
context.browser.quit()
|
||||
```
|
||||
|
||||
注意:也可以使用[fixtures][16]进行构建和清理。
|
||||
|
||||
要了解一个`behave`项目应该是什么样子,这里是示例项目的目录结构:
|
||||
|
||||

|
||||
|
||||
任何Python包和自定义模块都可以与`behave`框架一起使用。 使用良好的设计模式构建可扩展的测试自动化解决方案。步骤定义代码应简明扼要。
|
||||
|
||||
### 运行测试
|
||||
|
||||
要从命令行运行测试,请切换到项目的根目录并运行`behave`命令。 使用`-help`选项查看所有可用选项。
|
||||
|
||||
以下是一些常见用例:
|
||||
|
||||
```
|
||||
# run all tests
|
||||
behave
|
||||
|
||||
# run the scenarios in a feature file
|
||||
behave features/web.feature
|
||||
|
||||
# run all tests that have the @duckduckgo tag
|
||||
behave --tags @duckduckgo
|
||||
|
||||
# run all tests that do not have the @unit tag
|
||||
behave --tags ~@unit
|
||||
|
||||
# run all tests that have @basket and either @add or @remove
|
||||
behave --tags @basket --tags @add,@remove
|
||||
```
|
||||
|
||||
为方便起见,选项可以保存在[config][17]文件中。
|
||||
|
||||
### 其他选择
|
||||
|
||||
`behave`不是Python中唯一的BDD测试框架。其他好的框架包括:
|
||||
|
||||
- `pytest-bdd`,`pytest`的插件,和`behave`一样,它使用Gherkin功能文件和步骤定义模块,但它也利用了`pytest`的所有功能和插件。例如,它可以使用`pytest-xdist`并行运行Gherkin场景。 BDD和非BDD测试也可以与相同的过滤器一起执行。 `pytest-bdd`还提供更灵活的目录布局。
|
||||
- `radish`是一个“Gherkin增强版”框架——它将Scenario循环和前提条件添加到标准的Gherkin语言中,这使得它对程序员更友好。它还提供丰富的命令行选项,如`behave`。
|
||||
- `lettuce`是一种较旧的BDD框架,与`behave`非常相似,在框架机制方面存在细微差别。然而,GitHub最近显示该项目的活动很少(截至2018年5月)。
|
||||
|
||||
任何这些框架都是不错的选择。
|
||||
|
||||
另外,请记住,Python测试框架可用于任何黑盒测试,即使对于非Python产品也是如此! BDD框架非常适合Web和服务测试,因为它们的测试是声明性的,而Python是一种[很好的测试自动化语言][18]。
|
||||
|
||||
本文基于作者的[PyCon Cleveland 2018][19]演讲,[行为驱动的Python][20]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/behavior-driven-python
|
||||
|
||||
作者:[Andrew Knight][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/andylpk247
|
||||
[1]:https://automationpanda.com/bdd/
|
||||
[2]:https://en.wikipedia.org/wiki/Specification_by_example
|
||||
[3]:https://automationpanda.com/2017/01/26/bdd-101-the-gherkin-language/
|
||||
[4]:https://cucumber.io/
|
||||
[5]:https://automationpanda.com/2017/02/13/12-awesome-benefits-of-bdd/
|
||||
[6]:https://docs.pipenv.org/
|
||||
[7]:https://github.com/AndyLPK247/behavior-driven-python
|
||||
[8]:https://automationpanda.com/2018/01/31/good-gherkin-scenario-titles/
|
||||
[9]:https://automationpanda.com/2018/02/03/are-gherkin-scenarios-with-multiple-when-then-pairs-okay/
|
||||
[10]:https://automationpanda.com/2017/01/27/bdd-101-gherkin-by-example/
|
||||
[11]:https://automationpanda.com/2017/01/30/bdd-101-writing-good-gherkin/
|
||||
[12]:http://behave.readthedocs.io/en/latest/api.html#step-parameters
|
||||
[13]:http://behave.readthedocs.io/en/latest/api.html#detecting-that-user-code-overwrites-behave-context-attributes
|
||||
[14]:http://behave.readthedocs.io/en/latest/api.html#environment-file-functions
|
||||
[15]:https://en.wikipedia.org/wiki/Aspect-oriented_programming
|
||||
[16]:http://behave.readthedocs.io/en/latest/api.html#fixtures
|
||||
[17]:http://behave.readthedocs.io/en/latest/behave.html#configuration-files
|
||||
[18]:https://automationpanda.com/2017/01/21/the-best-programming-language-for-test-automation/
|
||||
[19]:https://us.pycon.org/2018/
|
||||
[20]:https://us.pycon.org/2018/schedule/presentation/87/
|
||||
134
translated/tech/20180531 How to create shortcuts in vi.md
Normal file
134
translated/tech/20180531 How to create shortcuts in vi.md
Normal file
@ -0,0 +1,134 @@
|
||||
如何在 vi 中创建快捷键
|
||||
======
|
||||
|
||||

|
||||
|
||||
学习使用 [vi 文本编辑器][1] 确实得花点功夫,不过 vi 的老手们都知道,经过一小会的锻炼,就可以将基本的 vi 操作融汇贯通。我们都知道“肌肉记忆”,那么学习 vi 的过程可以称之为“手指记忆”。
|
||||
|
||||
当你抓住了基础的操作窍门之后,你就可以定制化地配置 vi 的快捷键,从而让其处理的功能更为强大、流畅。
|
||||
|
||||
在开始之前,我想先感谢下 Chris Hermansen(他雇佣我写了这篇文章)仔细地检查了我的另一篇关于使用 vi 增强版本[Vim][2]的文章。当然还有他那些我未采纳的建议。
|
||||
|
||||
首先,我们来说明下面几个惯例设定。我会使用符号<RET>来代表按下 RETURN 或者 ENTER 键,<SP> 代表按下空格键,CTRL-x 表示一起按下 Control 键和 x 键
|
||||
|
||||
使用 `map` 命令来进行按键的映射。第一个例子是 `write` 命令,通常你之前保存使用这样的命令:
|
||||
|
||||
```
|
||||
:w<RET>
|
||||
|
||||
```
|
||||
|
||||
虽然这里只有三个键,不过考虑到我用这个命令实在是太频繁了,我更想“一键”搞定它。在这里我选择逗号键,比如这样:
|
||||
```
|
||||
:map , :wCTRL-v<RET>
|
||||
|
||||
```
|
||||
|
||||
这里的 CTRL-v 事实上是对 <RET> 做了转义的操作,如果不加这个的话,默认 <RET> 会作为这条映射指令的结束信号,而非映射中的一个操作。 CTRL-v 后面所跟的操作会翻译为用户的实际操作,而非该按键平常的操作。
|
||||
|
||||
在上面的映射中,右边的部分会在屏幕中显示为 `:w^M`,其中 `^` 字符就是指代 `control`,完整的意思就是 CTRL-m,表示就是系统中一行的结尾
|
||||
|
||||
|
||||
目前来说,就很不错了。如果我编辑、创建了十二次文件,这个键位映射就可以省掉了 2*12 次按键。不过这里没有计算你建立这个键位映射所花费的 11次按键(计算CTRL-v 和 冒号均为一次按键)。虽然这样已经省了很多次,但是每次打开 vi 都要重新建立这个映射也会觉得非常麻烦。
|
||||
|
||||
幸运的是,这里可以将这些键位映射放到 vi 的启动配置文件中,让其在每次启动的时候自动读取:文件为 `.exrc`,对于 vim 是 `.vimrc`。只需要将这些文件放在你的用户根目录中即可,并在文件中每行写入一个键位映射,之后就会在每次启动 vi 生效直到你删除对应的配置。
|
||||
|
||||
在继续说明 `map` 其他用法以及其他的缩写机制之前,这里在列举几个我常用提高文本处理效率的 map 设置:
|
||||
```
|
||||
Displays as
|
||||
|
||||
|
||||
|
||||
:map X :xCTRL-v<RET> :x^M
|
||||
|
||||
|
||||
|
||||
or
|
||||
|
||||
|
||||
|
||||
:map X ,:qCTRL-v<RET> ,:q^M
|
||||
|
||||
```
|
||||
|
||||
上面的 map 指令的意思是写入并关闭当前的编辑文件。其中 `:x` 是 vi 原本的命令,而下面的版本说明之前的 map 配置可以继续用作第二个 map 键位映射。
|
||||
```
|
||||
:map v :e<SP> :e
|
||||
|
||||
```
|
||||
|
||||
上面的指令意思是在 vi 编辑器内部 切换文件,使用这个时候,只需要按 `v` 并跟着输入文件名,之后按 `<RET>` 键。
|
||||
```
|
||||
:map CTRL-vCTRL-e :e<SP>#CTRL-v<RET> :e #^M
|
||||
|
||||
```
|
||||
|
||||
`#` 在这里是 vi 中标准的符号,意思是最后使用的文件名。所以切换当前与上一个文件的方法就使用上面的映射。
|
||||
```
|
||||
map CTRL-vCTRL-r :!spell %>err &CTRL-v<RET> :!spell %>err&^M
|
||||
|
||||
```
|
||||
|
||||
(注意:在两个例子中出现的第一个 CRTL-v 在某些 vi 的版本中是不需要的)其中,`:!` 用来运行一个外部的(非 vi 内部的)命令。在这个拼写检查的例子中,`%` 是 vi 中的符号用来只带目前的文件, `>` 用来重定向拼写检查中的输出到 `err` 文件中,之后跟上 `&` 说明该命令是一个后台运行的任务,这样可以保证在拼写检查的同时还可以进行编辑文件的工作。这里我可以键入 `verr<RET>`(使用我之前定义的快捷键 `v` 跟上 `err`),进入 `spell` 输出结果的文件,之后再输入 `CTRL-e` 来回到刚才编辑的文件中。这样我就可以在拼写检查之后,使用 CTRL-r 来查看检查的错误,再通过 CTRL-e 返回刚才编辑的文件。
|
||||
|
||||
还用很多字符串输入的缩写,也使用了各种 map 命令,比如:
|
||||
```
|
||||
:map! CTRL-o \fI
|
||||
|
||||
:map! CTRL-k \fP
|
||||
|
||||
```
|
||||
|
||||
这个映射允许你使用 CTRL-o 作为 `groff` 命令的缩写,从而让让接下来书写的单词有斜体的效果,并使用 CTRL-k 进行恢复
|
||||
|
||||
还有两个类似的映射:
|
||||
```
|
||||
:map! rh rhinoceros
|
||||
|
||||
:map! hi hippopotamus
|
||||
|
||||
```
|
||||
|
||||
上面的也可以使用 `ab` 命令来替换,就像下面这样(如果想这么用的话,需要首先按顺序运行 1. `unmap! rh` 2. `umap! hi`):
|
||||
```
|
||||
:ab rh rhinoceros
|
||||
|
||||
:ab hi hippopotamus
|
||||
|
||||
```
|
||||
|
||||
在上面 `map!` 的命令中,缩写会马上的展开成原有的单词,而在 `ab` 命令中,单词展开的操作会在输入了空格和标点之后才展开(不过在Vim 和 本机使用的 vi中,展开的形式与 `map!` 类似)
|
||||
|
||||
想要取消刚才设定的按键映射,可以对应的输入 `:unmap`, `unmap!`, `:unab`
|
||||
|
||||
在我使用的 vi 版本中,比较好用的候选映射按键包括 `g, K, q, v, V, Z`,控制字符包括:`CTRL-a, CTRL-c, CTRL-k, CTRL-n, CTRL-p, CTRL-x`;还有一些其他的字符如`#, *`,当然你也可以使用那些已经在 vi 中有过定义但不经常使用的字符,比如本文选择`X`和`I`,其中`X`表示删除左边的字符,并立刻左移当前字符。
|
||||
|
||||
最后,下面的命令
|
||||
```
|
||||
:map<RET>
|
||||
|
||||
:map!<RET>
|
||||
|
||||
:ab
|
||||
|
||||
```
|
||||
|
||||
将会显示,目前所有的缩写和键位映射。
|
||||
will show all the currently defined mappings and abbreviations.
|
||||
|
||||
希望上面的技巧能够更好地更高效地帮助你使用 vi。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/shortcuts-vi-text-editor
|
||||
|
||||
作者:[Dan Sonnenschein][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/sd886393)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dannyman
|
||||
[1]:http://ex-vi.sourceforge.net/
|
||||
[2]:https://www.vim.org/
|
||||
@ -0,0 +1,163 @@
|
||||
# 关于 C ++ 的所有争论?Bjarne Stroustrup 警告他的 C++ 未来的计划很危险
|
||||
|
||||

|
||||
|
||||
今年早些时候,我们**访谈**了 Bjarne Stroustrup,他是 C++ 语言的创始人,摩根士丹利技术部门的董事总经理,美国哥伦比亚大学计算机科学的客座教授,他写了[一封信][1]邀请那些关注编程语言演进的人去“想想瓦萨号!”
|
||||
|
||||
毫无疑问,对于丹麦人来说,这句话很容易理解,而那些对于 17 世纪的斯堪的纳维亚历史了解不多的人,还需要展开说一下。瓦萨号是一艘瑞典军舰,由国王 Gustavus Adolphus 委托建造。它是在 1628 年 8 月 10 日首航时,当时波罗的海国家中最强大的军舰,但是它在首航几分钟之后就沉没了。
|
||||
|
||||
巨大的瓦萨号有一个难以解决的设计缺陷:头重脚轻,以至于它被[一阵狂风刮翻了][2]。通过这段翻船历史的回忆,Stroustrup 警示了 C++ 所面临的风险,因为现在越来越多的特性被添加到了 C++ 中。
|
||||
|
||||
现在已经提议了不少这样的特性。Stroustrup 在他的信中引用了 43 条提议。他认为那些参与 C++ 语言 ISO 标准演进的人(指众所周知的 [WG21][3]),正在努力地让语言更高级,但他们的努力方向却并不一致。
|
||||
|
||||
在他的信中,他写道:
|
||||
|
||||
> 分开来看,许多提议都很有道理。但将它们综合到一起,这些提议是很愚蠢的,将危害 C++ 的未来。
|
||||
|
||||
他明确表示,不希望 C++ 重蹈瓦萨号的覆辙,这种渐近式的改进将敲响 C++ 的丧钟。相反,应该吸取瓦萨号的教训,构建一个坚实的基础,吸取经验教训,并做彻底的测试。
|
||||
|
||||
在瑞士拉普斯威尔(Rapperswill)召开的 C++ 标准化委员会会议之后,本月早些时候,Stroustrup 接受了_《The Register》_ 的采访,回答了有关 C++ 语言下一步发展方向方面的几个问题。(最新版是 C++17,它去年刚发布;下一个版本是 C++20,它正在开发中,预计于 2020 年发布。)
|
||||
|
||||
**Register:在你的信件《想想瓦萨号!》中,你写道:**
|
||||
|
||||
> 在 C++11 开始基础不再完整,而 C++17 中在使基础更加稳固、规范和完整方面几乎没有改善。相反地,却增加了重要接口的复杂度,让人们需要学习的特性数量越来越多。C++ 可能在这种提议的重压之下崩溃 —— 这些提议大多数都不成熟。我们不应该花费大量的时间为专家级用户们(比如我们自己)去创建越来越复杂的东西。~~(还要考虑普通用户的学习曲线,越复杂的东西越不易普及。)~~
|
||||
|
||||
**对新人来说,C++ 很难吗?如果是这样,你认为怎样的特性让新人更易理解?**
|
||||
|
||||
**Stroustrup:**C++ 的有些东西对于新人来说确实很难。
|
||||
|
||||
换句话说,C++ 中有些东西对于新人来说,比起 C 或上世纪九十年代的 C++ 更容易理解了。而难点是让大型社区专注于这些部分,并且帮助新手和普通 C++ 用户去规避那些对高级库实现提供支持的部分。
|
||||
|
||||
我建议使用 [C++ 核心准则][4] 作为实现上述目标的一个辅助。
|
||||
|
||||
此外,我的 “C++ 教程” 也可以帮助人们在使用现代 C++ 时走上正确的方向,而不会迷失在自上世纪九十年代以来的复杂性中,或困惑于只有专家级的用户才能理解的东西中。第二版的 “C++ 教程” 涵盖了 C++17 和部分 C++20 的内容,这本书即将要出版了。
|
||||
|
||||
我和其他人给没有编程经验的大一新生教过 C++,只要你不去深挖编程语言的每个晦涩难懂的角落,把注意力集中到 C++ 中最主流的部分,在三个月内新可以学会 C++。
|
||||
|
||||
“让简单的东西保持简单” 是我长期追求的目标。比如 C++11 的 `range-for` 循环:
|
||||
|
||||
```
|
||||
for (int& x : v) ++x; // increment each element of the container v
|
||||
|
||||
```
|
||||
|
||||
`v` 的位置可以是任何容器。在 C 和 C 风格的 C++ 中,它可能看到的是这样:
|
||||
|
||||
```
|
||||
for (int i=0; i<MAX; i++) ++v[i]; // increment each element of the array v
|
||||
|
||||
```
|
||||
|
||||
一些人报怨说添加了 `range-for` 循环让 C++ 变得更复杂了,很显然,他们是正确的,因为它添加了一个新特性,但它却让 C++ 用起来更简单。同时它还解决掉了传统 for 循环中出现的一些常见错误。
|
||||
|
||||
另外的一个例子是 C++11 的标准线程库。它比起使用 POSIX 或直接使用 Windows 的 C API 来说更简单,并且更不易出错。
|
||||
|
||||
**Register:你如何看待 C++ 现在的状况?**
|
||||
|
||||
**Stroustrup:** C++11 是 C++ 的最重大的改进版,并且在 C++14 上全面完成了改进工作。C++17 添加了相当多的新特性,但是没有提供对新技术的很多支持。C++20 目前看上去可能会成为一个重大改进版。编译器的状况和标准库实现的非常好,非常接近最新的标准。C++17 已经可用。持续改进了对工具的支持。已经有了许多第三方的库和许多新工具。而不幸的是,这些东西不太好找到。
|
||||
|
||||
我在《想想瓦萨号!》一文中所表达的担忧与标准化过程有关,对新东西的过度热情与完美主义的组合拖延了重大的改进。“追述完美是优秀的敌人”,在六月份拉普斯威尔的会议上有 160 人参与。在这样一个数量庞大和多样化的人群中很难取得一致意见。这就导致了专家们更多地为他们自己去设计,而不是为了整个社区。
|
||||
|
||||
**Register: C++ 是否有一个期望的状况,或为了期望的适应性而努力简化以满足程序员们在任意时间的需要?**
|
||||
|
||||
**Stroustrup:** 二者都有。我很乐意看到 C++ 支持彻底保证类型安全和资源安全的编程方式。这不应该通过限制适用性或增加成本来实现,而是应该通过改进的表达能力和性能来实现。我认为可以做到这些,通过让程序员使用更好的(更易用的)语言可以实现这一点。
|
||||
|
||||
终极目标不会马上实现,也不会单靠语言的设计来实现。为了让编程更高效,我们需要通过改进语言特性、最好的库、静态分析、以及规则的组合来实现。C++ 核心准则是我提升 C++ 代码质量的广泛而长远的方法。
|
||||
|
||||
**Register:对于 C++ 是否有明显的风险?如果有,它是如何产生的?(如,改进过于缓慢,新出现的低级语言,等等,从你的信中看,似乎是提议过多。)**
|
||||
|
||||
**Stroustrup:**毫无疑问,今年我们已经收到了 400 个提议。当然,它们并不都是新提议。许多提议都与规范语言和标准库这一必需而乏味的工作相关,但是量大到难以管理。你可以在 WG21 的网站上找到所有这些文章。
|
||||
|
||||
我写了《想想瓦萨号!》这封信作为一个呼吁。我感受到了这种压力,为解决紧急需要和赶时髦而增加语言特性,而不是去加强语言基础(比如,改善静态类型系统)。增加的任何新东西,无论它是多小都会产生成本,比如实现、学习、工具升级。重大的特性是那些改变我们编程思想的特性。那才是我们必须关注的东西。
|
||||
|
||||
委员会已经设立了一个”指导小组“,这个小组由在语言、标准库、实现、以及实际使用领域中拥有极强履历的人组成。我是其中的成员之一。我们负责为重点领域写一些关于方向、设计理念和建议方面的东西。
|
||||
|
||||
对于 C++20,我们建议去关注:
|
||||
|
||||
```
|
||||
概念
|
||||
模块(提供适当的模块化和令人称奇的编译时改进)
|
||||
Ranges(包括一些无限序列的扩展)
|
||||
标准库中的网络概念
|
||||
```
|
||||
|
||||
在拉普斯威尔会议之后,虽然带来的模块和网络化很显然只是一种延伸,但机会还是有的。我是一个乐观主义者,并且委员会的成员们都非常努力。
|
||||
|
||||
我并不担心其它语言或新语言会取代它。我喜欢编程语言。如果一个新的语言提供了其它编程语言没有提供的非常有用的东西,那它就是我们从中学习的榜样,当然,每个语言都有它自己的问题。许多 C++ 的问题都与它广泛的应用领域、大量的使用人群和过度的热情有关。大多数语言的社区都喜欢有这样的问题。
|
||||
|
||||
**Register:关于 C++ 你是否重新考虑过任何架构方面的决策?**
|
||||
|
||||
**Stroustrup:** 当我使用一些新的编程语言时,我经常思考 C++ 原来的决策和设计。例如,可以看我的《编程的历史》论文第 1、2 部分。
|
||||
|
||||
并没有让我觉得很懊悔的重大决策,如果让我重新再做一次决策,几乎不会对现有的特性做任何不同的改变。
|
||||
|
||||
与以前一样,能够直接处理硬件加上零开销的抽象是设计的指导思想。使用构造函数和析构函数去处理资源是关键(RAII),STL 就是在 C++ 库中能够做什么的一个很好的例子。
|
||||
|
||||
**Register:在 2011 年采纳的每三年发布一个标准的节奏是否仍然有效?我之所以这样问是因为 Java 为了更快地迭代,一直在解决需求。**
|
||||
|
||||
**Stroustrup:**我认为 C++20 将会按时发布(就像 C++14 和 C++17 那样),并且主要的编译器也会立即遵从它。我也希望 C++20 比起 C++17 能有重大的改进。
|
||||
|
||||
对于其它语言如何管理它们的发行版我并不焦虑。C++ 是由一个遵循 ISO 规则的委员会来管理的,并不是由一个大公司或一个”创造它的权威“来管理。这一点不会改变。关于 ISO 标准,C++ 每三年发布一次的周期是一个激动人心的创举。标准的周期是 5 或 10 年。
|
||||
|
||||
**Register:在你的信中你写道:**
|
||||
|
||||
```
|
||||
我们需要一个能够被”普通程序员“使用的条理还算清楚的编程语言,他们主要关心的是能否按时高质量地交付他们的应用程序。
|
||||
```
|
||||
|
||||
对语言的改变是否能够去解决这个问题,或者还可能涉及到更多容易获得的工具和教育支持?
|
||||
|
||||
**Stroustrup:**我努力去宣传我的理念 —— C++ 是什么以及如何使用它,并且我鼓励其他人也和我一样去做。
|
||||
|
||||
特别是,我鼓励讲师和作者们向 C++ 程序员们宣扬有用易用的理念,而不是去示范复杂的示例和技术来展示他们自己有多高明。我在 2017 年的 CppCon 大会上的演讲主题就是”学习和教学 C++“,并且也指出 C++ 需要更好的工具。
|
||||
|
||||
我在演讲中提到构建支持和包管理器。这些历来都是 C++ 的弱点项。标准化委员会现在有一个工具研究小组,或许不久的将来也会有一个教育研究小组。
|
||||
|
||||
C++ 的社区以前基本上是很乱的,但是在过去的五年里,为了满足社区对新闻和支持的需要,出现了很多会议和博客。CppCon、isocpp.org、以及 Meeting++ 就是这样的例子。
|
||||
|
||||
在委员会中做设计是非常困难的。但是,对于所有的大型项目来说,委员会又是必不可少的。我很关注它们,但是为了成功,关注和面对问题是必需的。
|
||||
|
||||
**Register:你如何看待 C++ 社区的流程?在沟通和决策方面你希望看到哪些变化?**
|
||||
|
||||
**Stroustrup:**C++ 并没有企业管理的”社区流程“;它有一个 ISO 标准流程。我们不能对 ISO 的角色做重大的改变。理想的情况是,我们设立一个小的全职的”秘书处“来做最终决策和方向管理,但这种理想情况是不会出现的。相反,我们有成百上千的人在线来讨论,大约有 160 人在技术问题上进行投票,大约有 70 组织和 11 个国家在结果提议上正式投票。这样是很混乱的,但是在将来某个时候我们会让它好起来。
|
||||
|
||||
**Register:最终你认为那些即将推出的 C++ 特性中,对 C++ 用户最有帮助的是哪些?**
|
||||
|
||||
**Stroustrup:**
|
||||
|
||||
```
|
||||
大大地简化了一般编程的概念
|
||||
并行算法 – 没有比使用现代化硬件的并发特性更好的方法了
|
||||
协程,如果委员会能够确定在 C++20 上推出。
|
||||
模块改进了组织源代码的方式,并且大幅改善了编译时间。我希望能有这样的模块,但是它还不能确定能否在 C++20 上推出。
|
||||
一个标准的网络库,但是它还不能确定能否在 C++20 上推出。
|
||||
```
|
||||
|
||||
此外:
|
||||
|
||||
```
|
||||
Contracts(运行时检查的先决条件、后置条件、和断言)可能对许多人都非常重要。
|
||||
date 和 time-zone 支持库可能对许多人(行业)非常重要。
|
||||
```
|
||||
|
||||
**Register:最后你还有需要向读者说的话吗?**
|
||||
|
||||
**Stroustrup:**如果 C++ 标准化委员会能够专注于重大问题,去解决重大问题,那么 C++20 将会是非常优秀的。但是在 C++20 推出之前,我们的 C++17 仍然是非常好的,它将改变很多人关于 C++ 已经落伍的旧印象。®
|
||||
|
||||
------
|
||||
|
||||
via: https://www.theregister.co.uk/2018/06/18/bjarne_stroustrup_c_plus_plus/
|
||||
|
||||
作者:[Thomas Claburn][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.theregister.co.uk/Author/3190
|
||||
[1]: http://open-std.org/JTC1/SC22/WG21/docs/papers/2018/p0977r0.pdf
|
||||
[2]: https://www.vasamuseet.se/en/vasa-history/disaster
|
||||
[3]: http://open-std.org/JTC1/SC22/WG21/
|
||||
[4]: https://github.com/isocpp/CppCoreGuidelines/blob/master/CppCoreGuidelines.md
|
||||
[5]: https://go.theregister.co.uk/tl/1755/shttps://continuouslifecycle.london/
|
||||
@ -0,0 +1,76 @@
|
||||
使用 browser-mpris2(Chrome 扩展)将 YouTube 播放器控件添加到 Linux 桌面
|
||||
======
|
||||
一个我怀念的 Unity 功能(虽然只使用了一小段时间)是在 Web 浏览器中访问 YouTube 等网站时自动获取 Ubuntu 声音指示器中的播放器控件,因此你可以直接从顶部栏暂停或停止视频,以及浏览视频/歌曲信息和预览。
|
||||
|
||||
这个 Unity 功能已经消失很久了,但我正在为 Gnome Shell 寻找类似的东西,然后我遇到了 **[browser-mpris2][1],这是一个为 Google Chrome/Chromium 实现 MPRIS v2 接口的扩展,目前只支持 YouTube**,我想可能会有一些 Linux Uprising 的读者会喜欢这个。
|
||||
|
||||
**该扩展还适用于 Opera 和 Vivaldi 等基于 Chromium 的 Web 浏览器。**
|
||||
**
|
||||
** **browser-mpris2 也支持 Firefox,但因为通过 about:debugging 加载扩展是临时的,而这是 browser-mpris2 所需要的,因此本文不包括 Firefox 的指导。开发人员[打算][2]将来将扩展提交到 Firefox 插件网站上。**
|
||||
|
||||
**使用此 Chrome 扩展,你可以在支持 MPRIS2 的 applets 中获得 YouTube 媒体播放器控件(播放、暂停、停止和查找
|
||||
)**。例如,如果你使用 Gnome Shell,你可将 YouTube 媒体播放器控件作为永久通知,或者你可以使用 Media Player Indicator 之类的扩展来实现此目的。在 Cinnamon /Linux Mint with Cinnamon 中,它出现在声音 Applet 中。
|
||||
|
||||
**我无法在 Unity 上用它**,我不知道为什么。我没有在不同桌面环境(KDE、Xfce、MATE 等)中使用其他支持 MPRIS2 的 applet 尝试此扩展。如果你尝试过,请告诉我们它是否适用于你的桌面环境/支持 MPRIS2 的 applet。
|
||||
|
||||
以下是在使用 Gnome Shell 的 Ubuntu 18.04 并装有 Chromium 浏览器的[媒体播放器指示器][3]的截图,其中显示了有关当前正在播放的 YouTube 视频的信息及其控件(播放/暂停,停止和查找):
|
||||
|
||||

|
||||
|
||||
在 Linux Mint 19 Cinnamon 中使用其默认声音 applet 和 Chromium 浏览器的截图:
|
||||
|
||||
|
||||

|
||||
|
||||
### 如何为 Google Chrom/Chromium安装 browser-mpris2
|
||||
|
||||
**1\. 如果你还没有安装 Git 就安装它**
|
||||
|
||||
在 Debian/Ubuntu/Linux Mint 中,使用此命令安装 git:
|
||||
```
|
||||
sudo apt install git
|
||||
|
||||
```
|
||||
|
||||
**2\. 下载并安装 [browser-mpris2][1] 所需文件。**
|
||||
|
||||
下面的命令克隆了 browser-mpris2 的 Git 仓库并将 chrome-mpris2 安装到 `/usr/local/bin/`(在一个你可以保存 browser-mpris2 文件夹的地方运行 “git clone ...” 命令,由于它会被 Chrome/Chromium 使用,你不能删除它):
|
||||
```
|
||||
git clone https://github.com/otommod/browser-mpris2
|
||||
sudo install browser-mpris2/native/chrome-mpris2 /usr/local/bin/
|
||||
|
||||
```
|
||||
|
||||
**3\. 在基于 Chrome/Chromium 的 Web 浏览器中加载此扩展。**
|
||||
|
||||

|
||||
|
||||
打开 Google Chrome、Chromium、Opera 或 Vivaldi 浏览器,进入 Extensions 页面(在 URL 栏中输入 `chrome://extensions`),在屏幕右上角切换到`开发者模式`。然后选择 `Load Unpacked` 并选择 chrome-mpris2 目录(确保没有选择子文件夹)。
|
||||
|
||||
复制扩展 ID 并保存它,因为你以后需要它(它类似于这样:`emngjajgcmeiligomkgpngljimglhhii`,但它会与你的不一样,因此确保使用你计算机中的 ID!)。
|
||||
|
||||
**4\. 运行 **`install-chrome.py`**(在 `browser-mpris2/native` 文件夹中),指定扩展 id 和 chrome-mpris2 路径。
|
||||
|
||||
在终端中使用此命令(将 `REPLACE-THIS-WITH-EXTENSION-ID` 替换为上一步中 `chrome://extensions` 下显示的 browser-mpris2 扩展 ID)安装此扩展:
|
||||
```
|
||||
browser-mpris2/native/install-chrome.py REPLACE-THIS-WITH-EXTENSION-ID /usr/local/bin/chrome-mpris2
|
||||
|
||||
```
|
||||
|
||||
你只需要运行此命令一次,无需将其添加到启动或其他类似的地方。你在 Google Chrome 或 Chromium 浏览器中播放的任何 YouTube 视频都应显示在你正在使用的任何 MPRISv2 applet 中。你无需重启 Web 浏览器。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/08/add-youtube-player-controls-to-your.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://github.com/otommod/browser-mpris2
|
||||
[2]:https://github.com/otommod/browser-mpris2/issues/11
|
||||
[3]:https://extensions.gnome.org/extension/55/media-player-indicator/
|
||||
108
translated/tech/20180824 5 cool music player apps.md
Normal file
108
translated/tech/20180824 5 cool music player apps.md
Normal file
@ -0,0 +1,108 @@
|
||||
5 个很酷的音乐播放器
|
||||
======
|
||||
|
||||

|
||||
你喜欢音乐吗?那么 Fedora 中可能有你正在寻找的东西。本文介绍在 Fedora 上运行的不同音乐播放器。无论你有大量的音乐库,还是小型音乐库,或者根本没有音乐库,你都会被覆盖到。这里有四个图形程序和一个基于终端的音乐播放器,可以让你挑选。
|
||||
|
||||
### Quod Libet
|
||||
|
||||
Quod Libet 是你的大型音频库的管理员。如果你有一个大量的音频库,你不想只听,但也要管理,Quod Libet 可能是一个很好的选择。
|
||||
|
||||
![][1]
|
||||
|
||||
Quod Libet 可以从磁盘上的多个位置导入音乐,并允许你编辑音频文件的标签 - 因此一切都在你的控制之下。额外地,它还有各种插件可用,从简单的均衡器到 [last.fm][2] 同步。你也可以直接从 [Soundcloud][3] 搜索和播放音乐。
|
||||
|
||||
Quod Libet 在 HiDPI 屏幕上工作得很好,它有 Fedora 的 RPM 包,如果你运行[Silverblue][5],它在 [Flathub][4] 中也有。使用 Gnome Software 或命令行安装它:
|
||||
```
|
||||
$ sudo dnf install quodlibet
|
||||
|
||||
```
|
||||
|
||||
### Audacious
|
||||
|
||||
如果你喜欢简单的音乐播放器,甚至可能看起来像传说中的 Winamp,Audacious 可能是你的不错选择。
|
||||
|
||||
![][6]
|
||||
|
||||
Audacious 可能不会立即管理你的所有音乐,但你如果想将音乐组织为文件,它能做得很好。你还可以导出和导入播放列表,而无需重新组织音乐文件本身。
|
||||
|
||||
额外地,你可以让它看起来像 Winamp。要让它与上面的截图相同,请进入 “Settings/Appearance,”,选择顶部的 “Winamp Classic Interface”,然后选择右下方的 “Refugee” 皮肤。而鲍勃是你的叔叔!这就完成了。
|
||||
|
||||
Audacious 在 Fedora 中作为 RPM 提供,可以使用 Gnome Software 或在终端运行以下命令安装:
|
||||
```
|
||||
$ sudo dnf install audacious
|
||||
|
||||
```
|
||||
|
||||
### Lollypop
|
||||
|
||||
Lollypop 是一个音乐播放器,它与 GNOME 集成良好。如果你喜欢 GNOME 的外观,并且想要一个集成良好的音乐播放器,Lollypop 可能适合你。
|
||||
|
||||
![][7]
|
||||
|
||||
除了与 GNOME Shell 的良好视觉集成之外,它还可以很好地用于 HiDPI 屏幕,并支持黑暗主题。
|
||||
|
||||
额外地,Lollypop 有一个集成的封面下载器和一个所谓的派对模式(右上角的音符按钮),它可以自动选择和播放音乐。它还集成了 [last.fm][2] 或 [libre.fm][8] 等在线服务。
|
||||
|
||||
它有 Fedora 的 RPM 也有用于 [Silverblue][5] 工作站的 [Flathub][4],使用 Gnome Software 或终端进行安装:
|
||||
```
|
||||
$ sudo dnf install lollypop
|
||||
|
||||
```
|
||||
|
||||
### Gradio
|
||||
|
||||
如果你没有任何音乐但仍喜欢听怎么办?或者你只是喜欢收音机?Gradio 就是为你准备的。
|
||||
|
||||
![][9]
|
||||
|
||||
Gradio 是一个简单的收音机,它允许你搜索和播放网络电台。你可以按国家、语言或直接搜索找到它们。额外地,它可视化地集成到了 GNOME Shell 中,可以与 HiDPI 屏幕配合使用,并且可以选择黑暗主题。
|
||||
|
||||
可以在 [Flathub][4] 中找到 Gradio,它同时可以运行在 Fedora Workstation 和 [Silverblue][5] 中。使用 Gnome Software 安装它
|
||||
|
||||
### sox
|
||||
|
||||
你喜欢使用终端在工作时听一些音乐吗?多亏有了 sox,你不必离开终端。
|
||||
|
||||
![][10]
|
||||
|
||||
sox 是一个非常简单的基于终端的音乐播放器。你需要做的就是运行如下命令:
|
||||
```
|
||||
$ play file.mp3
|
||||
|
||||
```
|
||||
|
||||
接着 sox 就会为你播放。除了单独的音频文件外,sox 还支持 m3u 格式的播放列表。
|
||||
|
||||
额外地,因为 sox 是基于终端的程序,你可以在 ssh 中运行它。你有一个带扬声器的家用服务器吗?或者你想从另一台电脑上播放音乐吗?尝试将它与 [tmux][11] 一起使用,这样即使会话关闭也可以继续听。
|
||||
|
||||
sox 在 Fedora 中以 RPM 提供。运行下面的命令安装:
|
||||
```
|
||||
$ sudo dnf install sox
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/5-cool-music-player-apps/
|
||||
|
||||
作者:[Adam Šamalík][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/asamalik/
|
||||
[1]:https://fedoramagazine.org/wp-content/uploads/2018/08/qodlibet-300x217.png
|
||||
[2]:https://last.fm
|
||||
[3]:https://soundcloud.com/
|
||||
[4]:https://flathub.org/home
|
||||
[5]:https://teamsilverblue.org/
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/08/audacious-300x136.png
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2018/08/lollypop-300x172.png
|
||||
[8]:https://libre.fm
|
||||
[9]:https://fedoramagazine.org/wp-content/uploads/2018/08/gradio.png
|
||||
[10]:https://fedoramagazine.org/wp-content/uploads/2018/08/sox-300x179.png
|
||||
[11]:https://fedoramagazine.org/use-tmux-more-powerful-terminal/
|
||||
@ -0,0 +1,107 @@
|
||||
备份安装包并在全新安装的 Ubuntu 上恢复它们
|
||||
======
|
||||
|
||||

|
||||
|
||||
在多个 Ubuntu 系统上安装同一组软件包是一项耗时且无聊的任务。你不会想花时间在多个系统上反复安装相同的软件包。在类似架构的 Ubuntu 系统上安装软件包时,有许多方法可以使这项任务更容易。你可以方便地通过 [**Aptik**][1] 并点击几次鼠标将以前的 Ubuntu 系统的应用程序、设置和数据迁移到新安装的系统中。或者,你可以使用软件包管理器(例如 APT)获取[**备份的已安装软件包的完整列表**][2],然后在新安装的系统上安装它们。今天,我了解到还有另一个专用工具可以完成这项工作。来看一下 **apt-clone**,这是一个简单的工具,可以让你为 Debian/Ubuntu 系统创建一个已安装的软件包列表,这些软件包可以在新安装的系统或容器上或目录中恢复。
|
||||
|
||||
Apt-clone 会帮助你处理你想要的情况,
|
||||
|
||||
* 在运行类似 Ubuntu(及衍生版)的多个系统上安装一致的应用程序。
|
||||
* 经常在多个系统上安装相同的软件包。
|
||||
* 备份已安装的应用程序的完整列表,并在需要时随时随地恢复它们。
|
||||
|
||||
|
||||
|
||||
在本简要指南中,我们将讨论如何在基于 Debian 的系统上安装和使用 Apt-clone。我在 Ubuntu 18.04 LTS 上测试了这个程序,但它应该适用于所有基于 Debian 和 Ubuntu 的系统。
|
||||
|
||||
### 备份已安装的软件包并在新安装的 Ubuntu 上恢复它们
|
||||
|
||||
Apt-clone 在默认仓库中有。要安装它,只需在终端输入以下命令:
|
||||
|
||||
```
|
||||
$ sudo apt install apt-clone
|
||||
```
|
||||
|
||||
安装后,只需创建已安装软件包的列表,并将其保存在你选择的任何位置。
|
||||
|
||||
```
|
||||
$ mkdir ~/mypackages
|
||||
|
||||
$ sudo apt-clone clone ~/mypackages
|
||||
```
|
||||
|
||||
上面的命令将我的 Ubuntu 中所有已安装的软件包保存在 **~/mypackages** 目录下名为 **apt-clone-state-ubuntuserver.tar.gz** 的文件中。
|
||||
|
||||
要查看备份文件的详细信息,请运行:
|
||||
|
||||
```
|
||||
$ apt-clone info mypackages/apt-clone-state-ubuntuserver.tar.gz
|
||||
Hostname: ubuntuserver
|
||||
Arch: amd64
|
||||
Distro: bionic
|
||||
Meta:
|
||||
Installed: 516 pkgs (33 automatic)
|
||||
Date: Sat Sep 15 10:23:05 2018
|
||||
```
|
||||
|
||||
如你所见,我的 Ubuntu 服务器总共有 516 个包。
|
||||
|
||||
现在,将此文件复制到 USB 或外部驱动器上,并转至要安装同一套软件包的任何其他系统。或者,你也可以将备份文件传输到网络上的系统,并使用以下命令安装软件包:
|
||||
|
||||
```
|
||||
$ sudo apt-clone restore apt-clone-state-ubuntuserver.tar.gz
|
||||
```
|
||||
|
||||
请注意,此命令将覆盖你现有的 **/etc/apt/sources.list** 并将安装/删除软件包。警告过你了!此外,只需确保目标系统是相同的架构和操作系统。例如,如果源系统是 18.04 LTS 64位,那么目标系统必须也是相同的。
|
||||
|
||||
如果你不想在系统上恢复软件包,可以使用 `--destination /some/location` 选项将克隆复制到这个文件夹中。
|
||||
|
||||
```
|
||||
$ sudo apt-clone restore apt-clone-state-ubuntuserver.tar.gz --destination ~/oldubuntu
|
||||
```
|
||||
|
||||
在此例中,上面的命令将软件包恢复到 **~/oldubuntu** 中。
|
||||
|
||||
有关详细信息,请参阅帮助部分:
|
||||
|
||||
```
|
||||
$ apt-clone -h
|
||||
```
|
||||
|
||||
或者手册页:
|
||||
|
||||
```
|
||||
$ man apt-clone
|
||||
```
|
||||
|
||||
**建议阅读:**
|
||||
|
||||
+ [Systemback - 将 Ubuntu 桌面版和服务器版恢复到以前的状态][3]
|
||||
+ [Cronopete - Linux 下的苹果时间机器][4]
|
||||
|
||||
就是这些了。希望这个有用。还有更多好东西。敬请期待!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/backup-installed-packages-and-restore-them-on-freshly-installed-ubuntu-system/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.ostechnix.com/how-to-migrate-system-settings-and-data-from-an-old-system-to-a-newly-installed-ubuntu-system/
|
||||
[2]: https://www.ostechnix.com/create-list-installed-packages-install-later-list-centos-ubuntu/#comment-12598
|
||||
|
||||
[3]: https://www.ostechnix.com/systemback-restore-ubuntu-desktop-and-server-to-previous-state/
|
||||
|
||||
[4]: https://www.ostechnix.com/cronopete-apples-time-machine-clone-linux/
|
||||
@ -0,0 +1,72 @@
|
||||
用于Linux桌面的4个扫描工具
|
||||
======
|
||||
使用其中一个开源软件驱动扫描仪来实现无纸化办公。
|
||||
|
||||

|
||||
|
||||
尽管无纸化世界还没有到来,但越来越多的人通过扫描文件和照片来摆脱纸张的束缚。不过,仅仅拥有一台扫描仪还不足够。你还需要软件来驱动扫描仪。
|
||||
|
||||
然而问题是许多扫描仪制造商没有将Linux版本的软件与他们的设备适配在一起。不过在大多数情况下,即使没有也没多大关系。因为在linux桌面上已经有很好的扫描软件了。它们能够与许多扫描仪配合很好的完成工作。
|
||||
|
||||
现在就让我们看看四个简单又灵活的开源Linux扫描工具。我已经使用过了下面这些工具(甚至[早在2014年][1]写过关于其中三个工具的文章)并且觉得它们非常有用。希望你也会这样认为。
|
||||
|
||||
### Simple Scan
|
||||
|
||||
这是我最喜欢的一个软件之一,[Simple Scan][2]小巧,迅速,高效,且易于使用。如果你以前见过它,那是因为Simple Scan是GNOME桌面上的默认扫描程序应用程序,也是许多Linux发行版的默认扫描程序。
|
||||
|
||||
你只需单击一下就能扫描文档或照片。扫描过某些内容后,你可以旋转或裁剪它并将其另存为图像(仅限JPEG或PNG格式)或PDF格式。也就是说Simple Scan可能会很慢,即使你用较低分辨率来扫描文档。最重要的是,Simple Scan在扫描时会使用一组全局的默认值,例如150dpi用于文本,300dpi用于照片。你需要进入Simple Scan的首选项才能更改这些设置。
|
||||
|
||||
如果你扫描的内容超过了几页,还可以在保存之前重新排序页面。如果有必要的话 - 假如你正在提交已签名的表格 - 你可以使用Simple Scan来发送电子邮件。
|
||||
|
||||
### Skanlite
|
||||
|
||||
从很多方面来看,[Skanlite][3]是Simple Scan在KDE世界中的表兄弟。虽然Skanlite功能很少,但它可以出色的完成工作。
|
||||
|
||||
你可以自己配置这个软件的选项,包括自动保存扫描文件,设置扫描质量以及确定扫描保存位置。 Skanlite可以保存为以下图像格式:JPEG,PNG,BMP,PPM,XBM和XPM。
|
||||
|
||||
其中一个很棒的功能是Skanlite能够将你扫描的部分内容保存到单独的文件中。当你想要从照片中删除某人或某物时,这就派上用场了。
|
||||
|
||||
### Gscan2pdf
|
||||
|
||||
这是我另一个最爱的老软件,[gscan2pdf][4]可能会显得很老旧了,但它仍然包含一些比这里提到的其他软件更好的功能。即便如此,gscan2pdf仍然显得很轻便。
|
||||
|
||||
除了以各种图像格式(JPEG,PNG和TIFF)保存扫描外,gscan2pdf还将它们保存为PDF或[DjVu][5]文件。你可以在单击“扫描”按钮之前设置扫描的分辨率,无论是黑白,彩色还是纸张大小,每当你想要更改任何这些设置时,这都会进入gscan2pdf的首选项。你还可以旋转,裁剪和删除页面。
|
||||
|
||||
虽然这些都不是真正的杀手级功能,但它们会给你带来更多的灵活性。
|
||||
|
||||
### GIMP
|
||||
|
||||
你大概会知道[GIMP][6]是一个图像编辑工具。但是你恐怕不知道可以用它来驱动你的扫描仪吧。
|
||||
|
||||
你需要安装[XSane][7]扫描软件和GIMP XSane插件。这两个应该都可以从你的Linux发行版的包管理器中获得。在软件里,选择文件>创建>扫描仪/相机。单击扫描仪,然后单击扫描按钮即可进行扫描。
|
||||
|
||||
如果这不是你想要的,或者它不起作用,你可以将GIMP和一个叫作[QuiteInsane][8]的插件结合起来。使用任一插件,都能使GIMP成为一个功能强大的扫描软件,它可以让你设置许多选项,如是否扫描彩色或黑白,扫描的分辨率,以及是否压缩结果等。你还可以使用GIMP的工具来修改或应用扫描后的效果。这使得它非常适合扫描照片和艺术品。
|
||||
|
||||
### 它们真的能够工作吗?
|
||||
|
||||
所有的这些软件在大多数时候都能够在各种硬件上运行良好。我将它们与我过去几年来拥有的多台多功能打印机一起使用 - 无论是使用USB线连接还是通过无线连接。
|
||||
|
||||
你可能已经注意到我在前一段中写过“大多数时候运行良好”。这是因为我确实遇到过一个例外:一个便宜的canon多功能打印机。我使用的软件都没有检测到它。最后我不得不下载并安装canon的Linux扫描仪软件才使它工作。
|
||||
|
||||
你最喜欢的Linux开源扫描工具是什么?发表评论,分享你的选择。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/linux-scanner-tools
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[way-ww](https://github.com/way-ww)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[1]: https://opensource.com/life/14/8/3-tools-scanners-linux-desktop
|
||||
[2]: https://gitlab.gnome.org/GNOME/simple-scan
|
||||
[3]: https://www.kde.org/applications/graphics/skanlite/
|
||||
[4]: http://gscan2pdf.sourceforge.net/
|
||||
[5]: http://en.wikipedia.org/wiki/DjVu
|
||||
[6]: http://www.gimp.org/
|
||||
[7]: https://en.wikipedia.org/wiki/Scanner_Access_Now_Easy#XSane
|
||||
[8]: http://sourceforge.net/projects/quiteinsane/
|
||||
@ -0,0 +1,178 @@
|
||||
Linux 防火墙: 关于 iptables 和 firewalld,你需要知道些什么
|
||||
======
|
||||
|
||||
以下是如何使用 iptables 和 firewalld 工具来管理 Linux 防火墙规则。
|
||||
|
||||

|
||||
这篇文章摘自我的书[Linux in Action][1],第二 Manning project 尚未发布。
|
||||
|
||||
### 防火墙
|
||||
|
||||
|
||||
防火墙是一组规则。当数据包进出受保护的网络时,进出内容(特别是关于其来源、目标和使用的协议等信息)会根据防火墙规则进行检测,以确定是否允许其通过。下面是一个简单的例子:
|
||||
|
||||
|
||||
![防火墙过滤请求] [3]
|
||||
|
||||
防火墙可以根据协议或基于目标的规则过滤请求。
|
||||
|
||||
一方面, [iptables][4] 是 Linux 机器上管理防火墙规则的工具。
|
||||
|
||||
另一方面,[firewalld][5]也是 Linux 机器上管理防火墙规则的工具。
|
||||
|
||||
你有什么问题吗?如果我告诉你还有另外一种工具,叫做 [nftables][6],这会不会糟蹋你的一天呢?
|
||||
|
||||
好吧,我承认整件事确实有点好笑,所以让我解释一下了。这一切都从 Netfilter 开始,在 Linux 内核模块级别, Netfilter 控制访问网络栈。几十年来,管理 Netfilter 钩子的主要命令行工具是 iptables 规则集。
|
||||
|
||||
因为调用这些规则所需的语法看起来有点晦涩难懂,所以各种用户友好的实现方式,如[ufw][7] 和 firewalld 被引入作,并为更高级别的 Netfilter 解释器。然而,Ufw 和 firewalld 主要是为解决独立计算机面临的各种问题而设计的。构建全方面的网络解决方案通常需要 iptables,或者从2014年起,它的替代品 nftables (nft 命令行工具)。
|
||||
|
||||
|
||||
iptables 没有消失,仍然被广泛使用着。事实上,在未来的许多年里,作为一名管理员,你应该会使用 iptables 来保护的网络。但是nftables 通过操作经典的 Netfilter 工具集带来了一些重要的崭新的功能。
|
||||
|
||||
|
||||
从现在开始,我将通过示例展示 firewalld 和 iptables 如何解决简单的连接问题。
|
||||
|
||||
### 使用 firewalld 配置 HTTP 访问
|
||||
|
||||
正如你能从它的名字中猜到的,firewalld 是 [systemd][8] 家族的一部分。Firewalld 可以安装在 Debian/Ubuntu 机器上,不过, 它默认安装在 RedHat 和 CentOS 上。如果您的计算机上运行着像 Apache 这样的 web 服务器,您可以通过浏览服务器的 web 根目录来确认防火墙是否正在工作。如果网站不可访问,那么 firewalld 正在工作。
|
||||
|
||||
你可以使用 `firewall-cmd` 工具从命令行管理 firewalld 设置。添加 `–state` 参数将返回当前防火墙的状态:
|
||||
|
||||
```
|
||||
# firewall-cmd --state
|
||||
running
|
||||
```
|
||||
|
||||
默认情况下,firewalld 将处于运行状态,并将拒绝所有传入流量,但有几个例外,如 SSH。这意味着你的网站不会有太多的访问者,这无疑会为你节省大量的数据传输成本。然而,这不是你对 web 服务器的要求,你希望打开 HTTP 和 HTTPS 端口,按照惯例,这两个端口分别被指定为80和443。firewalld 提供了两种方法来实现这个功能。一个是通过 `–add-port` 参数,该参数直接引用端口号及其将使用的网络协议(在本例中为TCP )。 另外一个是通过`–permanent` 参数,它告诉 firewalld 在每次服务器启动时加载此规则:
|
||||
|
||||
|
||||
```
|
||||
# firewall-cmd --permanent --add-port=80/tcp
|
||||
# firewall-cmd --permanent --add-port=443/tcp
|
||||
```
|
||||
|
||||
`–reload` 参数将这些规则应用于当前会话:
|
||||
|
||||
```
|
||||
# firewall-cmd --reload
|
||||
```
|
||||
|
||||
查看当前防火墙上的设置, 运行 `–list-services` :
|
||||
|
||||
```
|
||||
# firewall-cmd --list-services
|
||||
dhcpv6-client http https ssh
|
||||
```
|
||||
|
||||
假设您已经如前所述添加了浏览器访问,那么 HTTP、HTTPS 和 SSH 端口现在都应该是开放的—— `dhcpv6-client` ,它允许 Linux 从本地 DHCP 服务器请求 IPv6 IP地址。
|
||||
|
||||
### 使用 iptables 配置锁定的客户信息亭
|
||||
|
||||
我相信你已经看到了信息亭——它们是放在机场、图书馆和商务场所的盒子里的平板电脑、触摸屏和ATM类电脑,邀请顾客和路人浏览内容。大多数信息亭的问题是,你通常不希望用户像在自己家一样,把他们当成自己的设备。它们通常不是用来浏览、观看 YouTube 视频或对五角大楼发起拒绝服务攻击的。因此,为了确保它们没有被滥用,你需要锁定它们。
|
||||
|
||||
|
||||
一种方法是应用某种信息亭模式,无论是通过巧妙使用Linux显示管理器还是在浏览器级别。但是为了确保你已经堵塞了所有的漏洞,你可能还想通过防火墙添加一些硬网络控制。在下一节中,我将讲解如何使用iptables 来完成。
|
||||
|
||||
|
||||
关于使用iptables,有两件重要的事情需要记住:你给规则的顺序非常关键,iptables 规则本身在重新启动后将无法存活。我会一次一个地在解释这些。
|
||||
|
||||
### 信息亭项目
|
||||
|
||||
为了说明这一切,让我们想象一下,我们为一家名为 BigMart 的大型连锁商店工作。它们已经存在了几十年;事实上,我们想象中的祖父母可能是在那里购物并长大的。但是这些天,BigMart 公司总部的人可能只是在数着亚马逊将他们永远赶下去的时间。
|
||||
|
||||
尽管如此,BigMart 的IT部门正在尽他们最大努力提供解决方案,他们向你发放了一些具有 WiFi 功能信息亭设备,你在整个商店的战略位置使用这些设备。其想法是,登录到 BigMart.com 产品页面,允许查找商品特征、过道位置和库存水平。信息亭还允许进入 bigmart-data.com,那里储存着许多图像和视频媒体信息。
|
||||
|
||||
除此之外,您还需要允许下载软件包更新。最后,您还希望只允许从本地工作站访问SSH,并阻止其他人登录。下图说明了它将如何工作:
|
||||
|
||||
![信息亭流量IP表] [10]
|
||||
|
||||
信息亭业务流由 iptables 控制。
|
||||
|
||||
### 脚本
|
||||
|
||||
以下是 Bash 脚本内容:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
iptables -A OUTPUT -p tcp -d bigmart.com -j ACCEPT
|
||||
iptables -A OUTPUT -p tcp -d bigmart-data.com -j ACCEPT
|
||||
iptables -A OUTPUT -p tcp -d ubuntu.com -j ACCEPT
|
||||
iptables -A OUTPUT -p tcp -d ca.archive.ubuntu.com -j ACCEPT
|
||||
iptables -A OUTPUT -p tcp --dport 80 -j DROP
|
||||
iptables -A OUTPUT -p tcp --dport 443 -j DROP
|
||||
iptables -A INPUT -p tcp -s 10.0.3.1 --dport 22 -j ACCEPT
|
||||
iptables -A INPUT -p tcp -s 0.0.0.0/0 --dport 22 -j DROP
|
||||
```
|
||||
|
||||
我们从基本规则 `-A` 开始分析,它告诉iptables 我们要添加规则。`OUTPUT` 意味着这条规则应该成为输出的一部分。`-p` 表示该规则仅使用TCP协议的数据包,正如`-d` 告诉我们的,目的地址是 [bigmart.com][11]。`-j` 参数作用为数据包符合规则时要采取的操作是 `ACCEPT`。第一条规则表示允许或接受请求。但,最后一条规则表示删除或拒绝的请求。
|
||||
|
||||
规则顺序是很重要的。iptables 仅仅允许匹配规则的内容请求通过。一个向外发出的浏览器请求,比如访问[youtube.com][12] 是会通过的,因为这个请求匹配第四条规则,但是当它到达“dport 80”或“dport 443”规则时——取决于是HTTP还是HTTPS请求——它将被删除。iptables不再麻烦检查了,因为那是一场比赛。
|
||||
|
||||
另一方面,向ubuntu.com 发出软件升级的系统请求,只要符合其适当的规则,就会通过。显然,我们在这里做的是,只允许向我们的 BigMart 或 Ubuntu 发送 HTTP 或 HTTPS 请求,而不允许向其他目的地发送。
|
||||
|
||||
最后两条规则将处理 SSH 请求。因为它不使用端口80或443端口,而是使用22端口,所以之前的两个丢弃规则不会拒绝它。在这种情况下,来自我的工作站的登录请求将被接受,但是对其他任何地方的请求将被拒绝。这一点很重要:确保用于端口22规则的IP地址与您用来登录的机器的地址相匹配——如果不这样做,将立即被锁定。当然,这没什么大不了的,因为按照目前的配置方式,只需重启服务器,iptables 规则就会全部丢失。如果使用 LXC 容器作为服务器并从 LXC 主机登录,则使用主机 IP 地址连接容器,而不是其公共地址。
|
||||
|
||||
如果机器的IP发生变化,请记住更新这个规则;否则,你会被拒绝访问。
|
||||
|
||||
在家玩(是在某种性虚拟机上)?太好了。创建自己的脚本。现在我可以保存脚本,使用`chmod` 使其可执行,并以`sudo` 的形式运行它。不要担心 `igmart-data.com没找到`错误——当然没找到;它不存在。
|
||||
|
||||
```
|
||||
chmod +X scriptname.sh
|
||||
sudo ./scriptname.sh
|
||||
```
|
||||
|
||||
你可以使用`cURL` 命令行测试防火墙。请求 ubuntu.com 奏效,但请求 [manning.com][13]是失败的 。
|
||||
|
||||
|
||||
```
|
||||
curl ubuntu.com
|
||||
curl manning.com
|
||||
```
|
||||
|
||||
### 配置 iptables 以在系统启动时加载
|
||||
|
||||
现在,我如何让这些规则在每次 kiosk 启动时自动加载?第一步是将当前规则保存。使用`iptables-save` 工具保存规则文件。将在根目录中创建一个包含规则列表的文件。管道后面跟着 tee 命令,是将我的`sudo` 权限应用于字符串的第二部分:将文件实际保存到否则受限的根目录。
|
||||
|
||||
然后我可以告诉系统每次启动时运行一个相关的工具,叫做`iptables-restore` 。我们在上一模块中看到的常规cron 作业,因为它们在设定的时间运行,但是我们不知道什么时候我们的计算机可能会决定崩溃和重启。
|
||||
|
||||
有许多方法来处理这个问题。这里有一个:
|
||||
|
||||
|
||||
在我的 Linux 机器上,我将安装一个名为 [anacron][14] 的程序,该程序将在 /etc/ 目录中为我们提供一个名为anacrondab 的文件。我将编辑该文件并添加这个 `iptables-restore` 命令,告诉它加载该文件的当前值。引导后一分钟,规则每天(必要时)加载到 iptables 中。我会给作业一个标识符( `iptables-restore` ),然后添加命令本身。如果你在家和我一起这样,你应该通过重启系统来测试一下。
|
||||
|
||||
```
|
||||
sudo iptables-save | sudo tee /root/my.active.firewall.rules
|
||||
sudo apt install anacron
|
||||
sudo nano /etc/anacrontab
|
||||
1 1 iptables-restore iptables-restore < /root/my.active.firewall.rules
|
||||
|
||||
```
|
||||
|
||||
我希望这些实际例子已经说明了如何使用 iptables 和 firewalld 来管理基于Linux的防火墙上的连接问题。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/linux-iptables-firewalld
|
||||
|
||||
作者:[David Clinton][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[heguangzhi](https://github.com/heguangzhi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/remyd
|
||||
[1]: https://www.manning.com/books/linux-in-action?a_aid=bootstrap-it&a_bid=4ca15fc9&chan=opensource
|
||||
[2]: /file/409116
|
||||
[3]: https://opensource.com/sites/default/files/uploads/iptables1.jpg (firewall filtering request)
|
||||
[4]: https://en.wikipedia.org/wiki/Iptables
|
||||
[5]: https://firewalld.org/
|
||||
[6]: https://wiki.nftables.org/wiki-nftables/index.php/Main_Page
|
||||
[7]: https://en.wikipedia.org/wiki/Uncomplicated_Firewall
|
||||
[8]: https://en.wikipedia.org/wiki/Systemd
|
||||
[9]: /file/409121
|
||||
[10]: https://opensource.com/sites/default/files/uploads/iptables2.jpg (kiosk traffic flow ip tables)
|
||||
[11]: http://bigmart.com/
|
||||
[12]: http://youtube.com/
|
||||
[13]: http://manning.com/
|
||||
[14]: https://sourceforge.net/projects/anacron/
|
||||
@ -1,36 +1,24 @@
|
||||
HankChow translating
|
||||
|
||||
How To Find Out Which Port Number A Process Is Using In Linux
|
||||
如何在 Linux 中查看进程占用的端口号
|
||||
======
|
||||
As a Linux administrator, you should know whether the corresponding service is binding/listening with correct port or not.
|
||||
对于 Linux 系统管理员来说,清楚某个服务是否正确地绑定或监听某个端口,是至关重要的。如果你需要处理端口相关的问题,这篇文章可能会对你有用。
|
||||
|
||||
This will help you to easily troubleshoot further when you are facing port related issues.
|
||||
端口是 Linux 系统上特定进程之间逻辑连接的标识,包括物理端口和软件端口。由于 Linux 操作系统是一个软件,因此本文只讨论软件端口。软件端口始终与主机的 IP 地址和相关的通信协议相关联,因此端口常用于区分应用程序。大部分涉及到网络的服务都必须打开一个套接字来监听传入的网络请求,而每个服务都使用一个独立的套接字。
|
||||
|
||||
A port is a logical connection that identifies a specific process on Linux. There are two kind of port are available like, physical and software.
|
||||
**推荐阅读:**
|
||||
**(#)** [在 Linux 上查看进程 ID 的 4 种方法][1]
|
||||
**(#)** [在 Linux 上终止进程的 3 种方法][2]
|
||||
|
||||
Since Linux operating system is a software hence, we are going to discuss about software port.
|
||||
套接字是和 IP 地址,软件端口和协议结合起来使用的,而端口号对传输控制协议(Transmission Control Protocol, TCP)和 用户数据报协议(User Datagram Protocol, UDP)协议都适用,TCP 和 UDP 都可以使用0到65535之间的端口号进行通信。
|
||||
|
||||
Software port is always associated with an IP address of a host and the relevant protocol type for communication. The port is used to distinguish the application.
|
||||
以下是端口分配类别:
|
||||
|
||||
Most of the network related services have to open up a socket to listen incoming network requests. Socket is unique for every service.
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [4 Easiest Ways To Find Out Process ID (PID) In Linux][1]
|
||||
**(#)** [3 Easy Ways To Kill Or Terminate A Process In Linux][2]
|
||||
|
||||
Socket is combination of IP address, software Port and protocol. The port numbers area available for both TCP and UDP protocol.
|
||||
|
||||
The Transmission Control Protocol (TCP) and the User Datagram Protocol (UDP) use port numbers for communication. It is a value from 0 to 65535.
|
||||
|
||||
Below are port assignments categories.
|
||||
|
||||
* `0-1023:` Well Known Ports or System Ports
|
||||
* `1024-49151:` Registered Ports for applications
|
||||
* `49152-65535:` Dynamic Ports or Private Ports
|
||||
* `0-1023:` 常用端口和系统端口
|
||||
* `1024-49151:` 软件的注册端口
|
||||
* `49152-65535:` 动态端口或私有端口
|
||||
|
||||
|
||||
|
||||
You can check the details of the reserved ports in the /etc/services file on Linux.
|
||||
在 Linux 上的 `/etc/services` 文件可以查看到更多关于保留端口的信息。
|
||||
|
||||
```
|
||||
# less /etc/services
|
||||
@ -89,24 +77,25 @@ lmtp 24/udp # LMTP Mail Delivery
|
||||
|
||||
```
|
||||
|
||||
This can be achieved using the below six methods.
|
||||
可以使用以下六种方法查看端口信息。
|
||||
|
||||
* `ss:` ss is used to dump socket statistics.
|
||||
* `netstat:` netstat is displays a list of open sockets.
|
||||
* `lsof:` lsof – list open files.
|
||||
* `fuser:` fuser – list process IDs of all processes that have one or more files open
|
||||
* `nmap:` nmap – Network exploration tool and security / port scanner
|
||||
* `systemctl:` systemctl – Control the systemd system and service manager
|
||||
* `ss:` ss 可以用于转储套接字统计信息。
|
||||
* `netstat:` netstat 可以显示打开的套接字列表。
|
||||
* `lsof:` lsof 可以列出打开的文件。
|
||||
* `fuser:` fuser 可以列出那些打开了文件的进程的进程 ID。
|
||||
* `nmap:` nmap 是网络检测工具和端口扫描程序。
|
||||
* `systemctl:` systemctl 是 systemd 系统的控制管理器和服务管理器。
|
||||
|
||||
|
||||
|
||||
In this tutorial we are going to find out which port number the SSHD daemon is using.
|
||||
以下我们将找出 `sshd` 守护进程所使用的端口号。
|
||||
|
||||
### Method-1: Using ss Command
|
||||
### 方法1:使用 ss 命令
|
||||
|
||||
ss is used to dump socket statistics. It allows showing information similar to netstat. It can display more TCP and state informations than other tools.
|
||||
`ss` 一般用于转储套接字统计信息。它能够输出类似于 `netstat` 输出的信息,但它可以比其它工具显示更多的 TCP 信息和状态信息。
|
||||
|
||||
它还可以显示所有类型的套接字统计信息,包括 PACKET、TCP、UDP、DCCP、RAW、Unix 域等。
|
||||
|
||||
It can display stats for all kind of sockets such as PACKET, TCP, UDP, DCCP, RAW, Unix domain, etc.
|
||||
|
||||
```
|
||||
# ss -tnlp | grep ssh
|
||||
@ -114,7 +103,7 @@ LISTEN 0 128 *:22 *:* users:(("sshd",pid=997,fd=3))
|
||||
LISTEN 0 128 :::22 :::* users:(("sshd",pid=997,fd=4))
|
||||
```
|
||||
|
||||
Alternatively you can check this with port number as well.
|
||||
也可以使用端口号来检查。
|
||||
|
||||
```
|
||||
# ss -tnlp | grep ":22"
|
||||
@ -122,11 +111,11 @@ LISTEN 0 128 *:22 *:* users:(("sshd",pid=997,fd=3))
|
||||
LISTEN 0 128 :::22 :::* users:(("sshd",pid=997,fd=4))
|
||||
```
|
||||
|
||||
### Method-2: Using netstat Command
|
||||
### 方法2:使用 netstat 命令
|
||||
|
||||
netstat – Print network connections, routing tables, interface statistics, masquerade connections, and multicast memberships.
|
||||
`netstat` 能够显示网络连接、路由表、接口统计信息、伪装连接以及多播成员。
|
||||
|
||||
By default, netstat displays a list of open sockets. If you don’t specify any address families, then the active sockets of all configured address families will be printed. This program is obsolete. Replacement for netstat is ss.
|
||||
默认情况下,`netstat` 会列出打开的套接字。如果不指定任何地址族,则会显示所有已配置地址族的活动套接字。但 `netstat` 已经过时了,一般会使用 `ss` 来替代。
|
||||
|
||||
```
|
||||
# netstat -tnlp | grep ssh
|
||||
@ -134,7 +123,7 @@ tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 997/sshd
|
||||
tcp6 0 0 :::22 :::* LISTEN 997/sshd
|
||||
```
|
||||
|
||||
Alternatively you can check this with port number as well.
|
||||
也可以使用端口号来检查。
|
||||
|
||||
```
|
||||
# netstat -tnlp | grep ":22"
|
||||
@ -142,9 +131,9 @@ tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1208/sshd
|
||||
tcp6 0 0 :::22 :::* LISTEN 1208/sshd
|
||||
```
|
||||
|
||||
### Method-3: Using lsof Command
|
||||
### 方法3:使用 lsof 命令
|
||||
|
||||
lsof – list open files. The Linux lsof command lists information about files that are open by processes running on the system.
|
||||
`lsof` 能够列出打开的文件,并列出系统上被进程打开的文件的相关信息。
|
||||
|
||||
```
|
||||
# lsof -i -P | grep ssh
|
||||
@ -154,7 +143,7 @@ sshd 11584 root 4u IPv6 27627 0t0 TCP *:22 (LISTEN)
|
||||
sshd 11592 root 3u IPv4 27744 0t0 TCP vps.2daygeek.com:ssh->103.5.134.167:49902 (ESTABLISHED)
|
||||
```
|
||||
|
||||
Alternatively you can check this with port number as well.
|
||||
也可以使用端口号来检查。
|
||||
|
||||
```
|
||||
# lsof -i tcp:22
|
||||
@ -164,9 +153,9 @@ sshd 1208 root 4u IPv6 20921 0t0 TCP *:ssh (LISTEN)
|
||||
sshd 11592 root 3u IPv4 27744 0t0 TCP vps.2daygeek.com:ssh->103.5.134.167:49902 (ESTABLISHED)
|
||||
```
|
||||
|
||||
### Method-4: Using fuser Command
|
||||
### 方法4:使用 fuser 命令
|
||||
|
||||
The fuser utility shall write to standard output the process IDs of processes running on the local system that have one or more named files open.
|
||||
`fuser` 工具会将本地系统上打开了文件的进程的进程 ID 显示在标准输出中。
|
||||
|
||||
```
|
||||
# fuser -v 22/tcp
|
||||
@ -176,11 +165,11 @@ The fuser utility shall write to standard output the process IDs of processes ru
|
||||
root 49339 F.... sshd
|
||||
```
|
||||
|
||||
### Method-5: Using nmap Command
|
||||
### 方法5:使用 nmap 命令
|
||||
|
||||
Nmap (“Network Mapper”) is an open source tool for network exploration and security auditing. It was designed to rapidly scan large networks, although it works fine against single hosts.
|
||||
`nmap`(“Network Mapper”)是一款用于网络检测和安全审计的开源工具。它最初用于对大型网络进行快速扫描,但它对于单个主机的扫描也有很好的表现。
|
||||
|
||||
Nmap uses raw IP packets in novel ways to determine what hosts are available on the network, what services (application name and version) those hosts are offering, what operating systems (and OS versions) they are running, what type of packet filters/firewalls are in use, and dozens of other characteristics.
|
||||
`nmap` 使用原始 IP 数据包来确定网络上可用的主机,这些主机的服务(包括应用程序名称和版本)、主机运行的操作系统(包括操作系统版本等信息)、正在使用的数据包过滤器或防火墙的类型,以及很多其它信息。
|
||||
|
||||
```
|
||||
# nmap -sV -p 22 localhost
|
||||
@ -196,13 +185,13 @@ Service detection performed. Please report any incorrect results at http://nmap.
|
||||
Nmap done: 1 IP address (1 host up) scanned in 0.44 seconds
|
||||
```
|
||||
|
||||
### Method-6: Using systemctl Command
|
||||
### 方法6:使用 systemctl 命令
|
||||
|
||||
systemctl – Control the systemd system and service manager. This is the replacement of old SysV init system management and most of the modern Linux operating systems were adapted systemd.
|
||||
`systemctl` 是 systemd 系统的控制管理器和服务管理器。它取代了旧的 SysV init 系统管理,目前大多数现代 Linux 操作系统都采用了 systemd。
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [chkservice – A Tool For Managing Systemd Units From Linux Terminal][3]
|
||||
**(#)** [How To Check All Running Services In Linux][4]
|
||||
**推荐阅读:**
|
||||
**(#)** [chkservice – Linux 终端上的 systemd 单元管理工具][3]
|
||||
**(#)** [如何查看 Linux 系统上正在运行的服务][4]
|
||||
|
||||
```
|
||||
# systemctl status sshd
|
||||
@ -223,7 +212,7 @@ Sep 23 02:09:15 vps.2daygeek.com sshd[11589]: Connection closed by 103.5.134.167
|
||||
Sep 23 02:09:41 vps.2daygeek.com sshd[11592]: Accepted password for root from 103.5.134.167 port 49902 ssh2
|
||||
```
|
||||
|
||||
The above out will be showing the actual listening port of SSH service when you start the SSHD service recently. Otherwise it won’t because it updates recent logs in the output frequently.
|
||||
以上输出的内容显示了最近一次启动 `sshd` 服务时 `ssh` 服务的监听端口。但它不会将最新日志更新到输出中。
|
||||
|
||||
```
|
||||
# systemctl status sshd
|
||||
@ -250,7 +239,7 @@ Sep 23 12:50:40 vps.2daygeek.com sshd[23911]: Connection closed by 95.210.113.14
|
||||
Sep 23 12:50:40 vps.2daygeek.com sshd[23909]: Connection closed by 95.210.113.142 port 51666 [preauth]
|
||||
```
|
||||
|
||||
Most of the time the above output won’t shows the process actual port number. in this case i would suggest you to check the details using the below command from the journalctl log file.
|
||||
大部分情况下,以上的输出不会显示进程的实际端口号。这时更建议使用以下这个 `journalctl` 命令检查日志文件中的详细信息。
|
||||
|
||||
```
|
||||
# journalctl | grep -i "openssh\|sshd"
|
||||
@ -268,7 +257,7 @@ via: https://www.2daygeek.com/how-to-find-out-which-port-number-a-process-is-usi
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -278,3 +267,4 @@ via: https://www.2daygeek.com/how-to-find-out-which-port-number-a-process-is-usi
|
||||
[2]: https://www.2daygeek.com/kill-terminate-a-process-in-linux-using-kill-pkill-killall-command/
|
||||
[3]: https://www.2daygeek.com/chkservice-a-tool-for-managing-systemd-units-from-linux-terminal/
|
||||
[4]: https://www.2daygeek.com/how-to-check-all-running-services-in-linux/
|
||||
|
||||
@ -0,0 +1,98 @@
|
||||
如何在 Ubuntu Linux 中使用 RAR 文件
|
||||
======
|
||||
[RAR][1] 是一种非常好的归档文件格式。但相比之下 7-zip 能提供了更好的压缩率,并且默认情况下还可以在多个平台上轻松支持 Zip 文件。不过 RAR 仍然是最流行的归档格式之一。然而 [Ubuntu][2] 自带的归档管理器却不支持提取 RAR 文件,也不允许创建 RAR 文件。
|
||||
|
||||
方法总比问题多。只要安装 `unrar` 这款由 [RARLAB][3] 提供的免费软件,就能在 Ubuntu 上支持提取RAR文件了。你也可以试安装 `rar` 来创建和管理 RAR 文件。
|
||||
|
||||
![RAR files in Ubuntu Linux][4]
|
||||
|
||||
### 提取 RAR 文件
|
||||
|
||||
在未安装 unrar 的情况下,提取 RAR 文件会报出“未能提取”错误,就像下面这样(以 [Ubuntu 18.04][5] 为例):
|
||||
|
||||
![Error in RAR extraction in Ubuntu][6]
|
||||
|
||||
如果要解决这个错误并提取 RAR 文件,请按照以下步骤安装 unrar:
|
||||
|
||||
打开终端并输入:
|
||||
|
||||
```
|
||||
sudo apt-get install unrar
|
||||
|
||||
```
|
||||
|
||||
安装 unrar 后,直接输入 `unrar` 就可以看到它的用法以及如何使用这个工具处理 RAR 文件。
|
||||
|
||||
最常用到的功能是提取 RAR 文件。因此,可以**通过右键单击 RAR 文件并执行提取**,也可以借助此以下命令通过终端执行操作:
|
||||
|
||||
```
|
||||
unrar x FileName.rar
|
||||
|
||||
```
|
||||
|
||||
结果类似以下这样:
|
||||
|
||||
![Using unrar in Ubuntu][7]
|
||||
|
||||
如果家目录中不存在对应的文件,就必须使用 `cd` 命令移动到目标目录下。例如 RAR 文件如果在 `Music` 目录下,只需要使用 `cd Music` 就可以移动到相应的目录,然后提取 RAR 文件。
|
||||
|
||||
### 创建和管理 RAR 文件
|
||||
|
||||
![Using rar archive in Ubuntu Linux][8]
|
||||
|
||||
`unrar` 不允许创建 RAR 文件。因此还需要安装 `rar` 命令行工具才能创建 RAR 文件。
|
||||
|
||||
要创建 RAR 文件,首先需要通过以下命令安装 rar:
|
||||
|
||||
```
|
||||
sudo apt-get install rar
|
||||
|
||||
```
|
||||
|
||||
按照下面的命令语法创建 RAR 文件:
|
||||
|
||||
```
|
||||
rar a ArchiveName File_1 File_2 Dir_1 Dir_2
|
||||
|
||||
```
|
||||
|
||||
按照这个格式输入命令时,它会将目录中的每个文件添加到 RAR 文件中。如果需要某一个特定的文件,就要指定文件确切的名称或路径。
|
||||
|
||||
默认情况下,RAR 文件会放置在**家目录**中。
|
||||
|
||||
以类似的方式,可以更新或管理 RAR 文件。同样是使用以下的命令语法:
|
||||
|
||||
```
|
||||
rar u ArchiveName Filename
|
||||
|
||||
```
|
||||
|
||||
在终端输入 `rar` 就可以列出 RAR 工具的相关命令。
|
||||
|
||||
### 总结
|
||||
|
||||
现在你已经知道如何在 Ubuntu 上管理 RAR 文件了,你会更喜欢使用 7-zip、Zip 或 Tar.xz 吗?
|
||||
|
||||
欢迎在评论区中评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/use-rar-ubuntu-linux/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[1]: https://www.rarlab.com/rar_file.htm
|
||||
[2]: https://www.ubuntu.com/
|
||||
[3]: https://www.rarlab.com/
|
||||
[4]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/rar-ubuntu-linux.png
|
||||
[5]: https://itsfoss.com/things-to-do-after-installing-ubuntu-18-04/
|
||||
[6]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/extract-rar-error.jpg
|
||||
[7]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/unrar-rar-extraction.jpg
|
||||
[8]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/rar-update-create.jpg
|
||||
|
||||
Loading…
Reference in New Issue
Block a user