mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-15 01:50:08 +08:00
20140821-2 选题
This commit is contained in:
parent
40f8d28a69
commit
fe662bc605
66
sources/talk/20140821 What is a good EPUB reader on Linux.md
Normal file
66
sources/talk/20140821 What is a good EPUB reader on Linux.md
Normal file
@ -0,0 +1,66 @@
|
||||
What is a good EPUB reader on Linux
|
||||
================================================================================
|
||||
If the habit on reading books on electronic tablets is still on its way, reading books on a computer is even rarer. It is hard enough to focus on the classics of the 16th century literature, so who needs the Facebook chat pop up sound in the background in addition? But if for some reasons you wish to open an electronic book in your computer, chances are that you will need specific software. Indeed, most editors agreed with using the EPUB format for electronic books (for "Electronic PUBlication"). Hopefully, Linux is not deprived of good programs capable of dealing with such format. In short, here is a non-exhaustive list of good EPUB readers on Linux.
|
||||
|
||||
### 1. Calibre ###
|
||||
|
||||
|
||||
|
||||
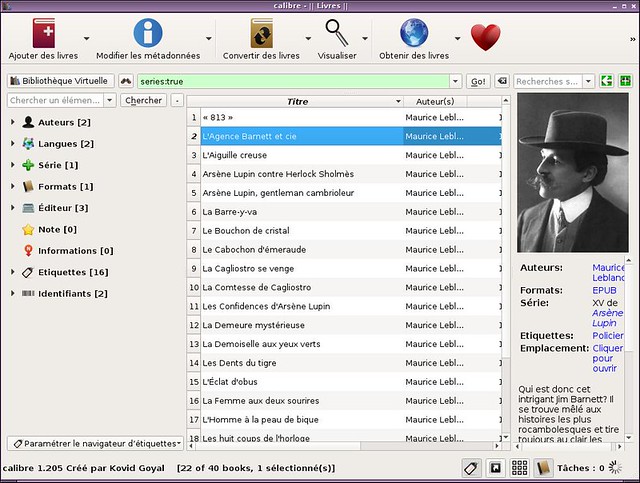
Let's dive in with maybe the biggest name of that list: [Calibre][1]. More than just an ebook reader, Calibre is a fully packaged e-library. It supports a plethora of formats (almost every I can think of), integrates a reader, a manager, a meta-data editor which can download covers from the Internet, an EPUB editor, a news reader, and a search engine to download additional books. To top it all, the interface is slick and has nothing to envy to other professional software. The only potential downside is that if you are looking for an EPUB reader, and are not interested in the whole library manager aspect, the program is too heavy for your needs.
|
||||
|
||||
### 2. FBReader ###
|
||||
|
||||
|
||||
|
||||
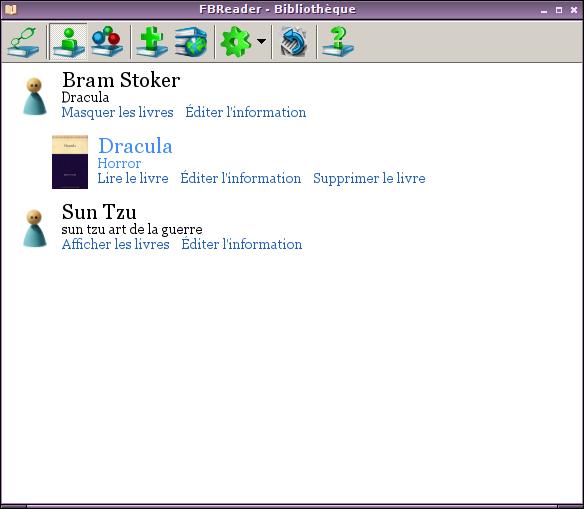
[FBReader][2] is also a library manager, but in a lighter way than Calibre. The interface is more sober, and is clearly cut in two: (1) the library aspect where you can add files, edit the meta-data, or download new books, and (2) the reader aspect. If you like simplicity, you might enjoy this program. I personally appreciate its straightforward tag and series system for classifying books.
|
||||
|
||||
### 3. Cool Reader ###
|
||||
|
||||

|
||||
|
||||
For all of you who are just looking for a way to visualize the content of an EPUB file, I recommend [Cool Reader][5]. In the spirit of Linux applications which do only one thing and do it well, Cool Reader is optimized to just open an EPUB file, and navigate through it via handy shortcuts. And since it is based on Qt, it also follows Qt's mentality by giving a ton of settings to mess around with.
|
||||
|
||||
### 4. Okular ###
|
||||
|
||||

|
||||
|
||||
Since we were talking about Qt applications, one of KDE's main document viewer, [Okular][3], also has the capacity to view EPUB files, once an EPUB library has been installed on the system. However, this is probably not a very good option if you are not a KDE user.
|
||||
|
||||
### 5. pPub ###
|
||||
|
||||

|
||||
|
||||
[pPub][4] is an old project that you can still find on Github. Its latest change seems to have been made two years ago. However, pPub is one of those programs that really deserve a second life. Written in Python and based on GTK3 and WebKit, pPub is lightweight and intuitive. The interface probably needs a little updating and is beyond sober, but the core is very good. It even supports JavaScript. So please, someone kick that up again.
|
||||
|
||||
### 6. epub ###
|
||||
|
||||
|
||||
|
||||
If all you need is a quick and easy way to check the content of an EPUB file, without caring about any fancy GUI, maybe an EPUB reader with command line interface might just do. [epub][6] is a minimalistic EPUB reader written in Python, which allows you to read an EPUB file in a terminal environment. You can switch between chapter/TOC views, up/down a page, and nothing more. This is as simple as any EPUB reader can possibly get.
|
||||
|
||||
### 7. Sigil ###
|
||||
|
||||
|
||||
|
||||
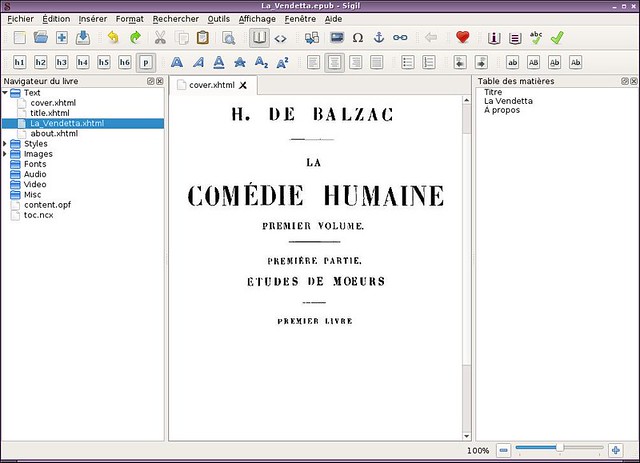
Finally, last of the list is not actually an EPUB reader, but more of a standalone editor. [Sigil][7] is able to extract the content of an EPUB file, and break it down for what it really is: xhtml text, images, styles, and sometimes audio. The interface is a lot more complex than the one for a basic reader, but remains clear and well thought, on par with the features it provides. I particularly appreciate the tab system. If you are familiar with editing web pages, you will be in know territory here.
|
||||
|
||||
To conclude, there are a lot of open source EPUB readers out there. Some do nothing more, while others go way beyond that. As usual, I recommend using the one that makes the most sense for you to use. If you know more good EPUB readers on Linux that you like, please let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/good-epub-reader-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://calibre-ebook.com/
|
||||
[2]:http://fbreader.org/
|
||||
[3]:http://okular.kde.org/
|
||||
[4]:https://github.com/sakisds/pPub
|
||||
[5]:http://crengine.sourceforge.net/
|
||||
[6]:https://github.com/rupa/epub
|
||||
[7]:https://github.com/user-none/Sigil
|
||||
@ -0,0 +1,200 @@
|
||||
How to configure a network printer and scanner on Ubuntu desktop
|
||||
================================================================================
|
||||
In a [previous article][1](注:这篇文章在2014年8月12号的原文里做过,不知道翻译了没有,如果翻译发布了,发布此文章的时候可改成翻译后的链接), we discussed how to install several kinds of printers (and also a network scanner) in a Linux server. Today we will deal with the other end of the line: how to access the network printer/scanner devices from a desktop client.
|
||||
|
||||
### Network Environment ###
|
||||
|
||||
For this setup, our server's (Debian Wheezy 7.2) IP address is 192.168.0.10, and our client's (Ubuntu 12.04) IP address is 192.168.0.105. Note that both boxes are on the same network (192.168.0.0/24). If we want to allow printing from other networks, we need to modify the following section in the cupsd.conf file on the sever:
|
||||
|
||||
<Location />
|
||||
Order allow,deny
|
||||
Allow localhost
|
||||
Allow from XXX.YYY.ZZZ.*
|
||||
</Location>
|
||||
|
||||
(in the above example, we grant access to the printer from localhost and from any system whose IPv4 address starts with XXX.YYY.ZZZ)
|
||||
|
||||
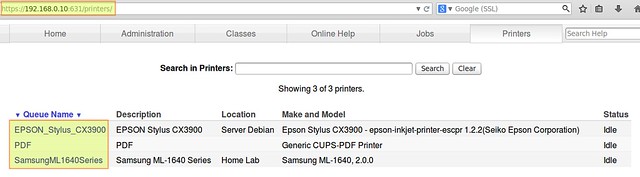
To verify which printers are available on our server, we can either use lpstat command on the server, or browse to the https://192.168.0.10:631/printers page.
|
||||
|
||||
root@debian:~# lpstat -a
|
||||
|
||||
----------
|
||||
|
||||
EPSON_Stylus_CX3900 accepting requests since Mon 18 Aug 2014 10:49:33 AM WARST
|
||||
PDF accepting requests since Mon 06 May 2013 04:46:11 PM WARST
|
||||
SamsungML1640Series accepting requests since Wed 13 Aug 2014 10:13:47 PM WARST
|
||||
|
||||
|
||||
|
||||
### Installing Network Printers in Ubuntu Desktop ###
|
||||
|
||||
In our Ubuntu 12.04 client, we will open the "Printing" menu (Dash -> Printing). Note that in other distributions the name may differ a little (such as "Printers" or "Print & Fax", for example):
|
||||
|
||||

|
||||
|
||||
No printers have been added to our Ubuntu client yet:
|
||||
|
||||

|
||||
|
||||
Here are the steps to install a network printer on Ubuntu desktop client.
|
||||
|
||||
**1)** The "Add" button will fire up the "New Printer" menu. We will choose "Network printer" -> "Find Network Printer" and enter the IP address of our server, then click "Find":
|
||||
|
||||

|
||||
|
||||
**2)** At the bottom we will see the names of the available printers. Let's choose the Samsung printer and press "Forward":
|
||||
|
||||

|
||||
|
||||
**3)** We will be asked to fill in some information about our printer. When we're done, we'll click on "Apply":
|
||||
|
||||

|
||||
|
||||
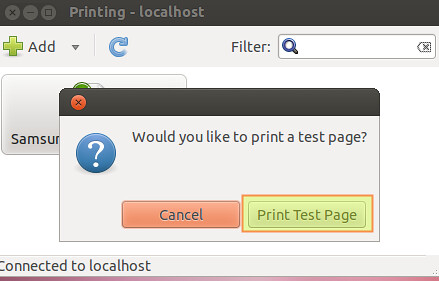
**4)** We will then be asked whether we want to print a test page. Let’s click on "Print test page":
|
||||
|
||||
|
||||
|
||||
The print job was created with local id 2:
|
||||
|
||||

|
||||
|
||||
5) Using our server's CUPS web interface, we can observe that the print job has been submitted successfully (Printers -> SamsungML1640Series -> Show completed jobs):
|
||||
|
||||

|
||||
|
||||
We can also display this same information by running the following command on the printer server:
|
||||
|
||||
root@debian:~# cat /var/log/cups/page_log | grep -i samsung
|
||||
|
||||
----------
|
||||
|
||||
SamsungML1640Series root 27 [13/Aug/2014:22:15:34 -0300] 1 1 - localhost Test Page - -
|
||||
SamsungML1640Series gacanepa 28 [18/Aug/2014:11:28:50 -0300] 1 1 - 192.168.0.105 Test Page - -
|
||||
SamsungML1640Series gacanepa 29 [18/Aug/2014:11:45:57 -0300] 1 1 - 192.168.0.105 Test Page - -
|
||||
|
||||
The page_log log file shows every page that has been printed, along with the user who sent the print job, the date & time, and the client's IPv4 address.
|
||||
|
||||
To install the Epson inkjet and PDF printers, we need to repeat steps 1 through 5, and choose the right print queue each time. For example, in the image below we are selecting the PDF printer:
|
||||
|
||||

|
||||
|
||||
However, please note that according to the [CUPS-PDF documentation][2], by default:
|
||||
|
||||
> PDF files will be placed in subdirectories named after the owner of the print job. In case the owner cannot be identified (i.e. does not exist on the server) the output is placed in the directory for anonymous operation (if not disabled in cups-pdf.conf - defaults to /var/spool/cups-pdf/ANONYMOUS/).
|
||||
|
||||
These default directories can be modified by changing the value of the **Out** and **AnonDirName** variables in the /etc/cups/cups-pdf.conf file. Here, ${HOME} is expanded to the user's home directory:
|
||||
|
||||
Out ${HOME}/PDF
|
||||
AnonDirName /var/spool/cups-pdf/ANONYMOUS
|
||||
|
||||
### Network Printing Examples ###
|
||||
|
||||
#### Example #1 ####
|
||||
|
||||
Printing from Ubuntu 12.04, logged on locally as gacanepa (an account with the same name exists on the printer server).
|
||||
|
||||

|
||||
|
||||
After printing to the PDF printer, let's check the contents of the /home/gacanepa/PDF directory on the printer server:
|
||||
|
||||
root@debian:~# ls -l /home/gacanepa/PDF
|
||||
|
||||
----------
|
||||
|
||||
total 368
|
||||
-rw------- 1 gacanepa gacanepa 279176 Aug 18 13:49 Test_Page.pdf
|
||||
-rw------- 1 gacanepa gacanepa 7994 Aug 18 13:50 Untitled1.pdf
|
||||
-rw------- 1 gacanepa gacanepa 74911 Aug 18 14:36 Welcome_to_Conference_-_Thomas_S__Monson.pdf
|
||||
|
||||
The PDF files are created with permissions set to 600 (-rw-------), which means that only the owner (gacanepa in this case) can have access to them. We can change this behavior by editing the value of the **UserUMask** variable in the /etc/cups/cups-pdf.conf file. For example, a umask of 0033 will cause the PDF printer to create files with all permissions for the owner, but read-only privileges to all others.
|
||||
|
||||
root@debian:~# grep -i UserUMask /etc/cups/cups-pdf.conf
|
||||
|
||||
----------
|
||||
|
||||
### Key: UserUMask
|
||||
UserUMask 0033
|
||||
|
||||
For those unfamiliar with umask (aka user file-creation mode mask), it acts as a set of permissions that can be used to control the default file permissions that are set for new files when they are created. Given a certain umask, the final file permissions are calculated by performing a bitwise boolean AND operation between the file base permissions (0666) and the unary bitwise complement of the umask. Thus, for a umask set to 0033, the default permissions for new files will be NOT (0033) AND 0666 = 644 (read / write / execute privileges for the owner, read-only for all others.
|
||||
|
||||
### Example #2 ###
|
||||
|
||||
Printing from Ubuntu 12.04, logged on locally as jdoe (an account with the same name doesn't exist on the server).
|
||||
|
||||
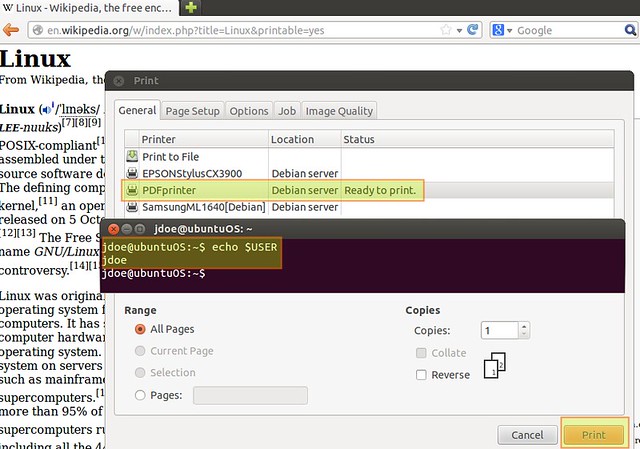
|
||||
|
||||
root@debian:~# ls -l /var/spool/cups-pdf/ANONYMOUS
|
||||
|
||||
----------
|
||||
|
||||
total 5428
|
||||
-rw-rw-rw- 1 nobody nogroup 5543070 Aug 18 15:57 Linux_-_Wikipedia__the_free_encyclopedia.pdf
|
||||
|
||||
The PDF files are created with permissions set to 666 (-rw-rw-rw-), which means that everyone has access to them. We can change this behavior by editing the value of the **AnonUMask** variable in the /etc/cups/cups-pdf.conf file.
|
||||
|
||||
At this point, you may be wondering about this: Why bother to install a network PDF printer when most (if not all) current Linux desktop distributions come with a built-in "Print to file" utility that allows users to create PDF files on-the-fly?
|
||||
|
||||
There are a couple of benefits of using a network PDF printer:
|
||||
|
||||
- A network printer (of whatever kind) lets you print directly from the command line without having to open the file first.
|
||||
- In a network with other operating system installed on the clients, a PDF network printer spares the system administrator from having to install a PDF creator utility on each individual machine (and also the danger of allowing end-users to install such tools).
|
||||
- The network PDF printer allows to print directly to a network share with configurable permissions, as we have seen.
|
||||
|
||||
### Installing a Network Scanner in Ubuntu Desktop ###
|
||||
|
||||
Here are the steps to installing and accessing a network scanner from Ubuntu desktop client. It is assumed that the network scanner server is already up and running as described [here][3].
|
||||
|
||||
**1)** Let us first check whether there is a scanner available on our Ubuntu client host. Without any prior setup, you will see the message saying that "No scanners were identified."
|
||||
|
||||
$ scanimage -L
|
||||
|
||||

|
||||
|
||||
**2)** Now we need to enable saned daemon which comes pre-installed on Ubuntu desktop. To enable it, we need to edit the /etc/default/saned file, and set the RUN variable to yes:
|
||||
|
||||
$ sudo vim /etc/default/saned
|
||||
|
||||
----------
|
||||
|
||||
# Set to yes to start saned
|
||||
RUN=yes
|
||||
|
||||
**3)** Let's edit the /etc/sane.d/net.conf file, and add the IP address of the server where the scanner is installed:
|
||||
|
||||
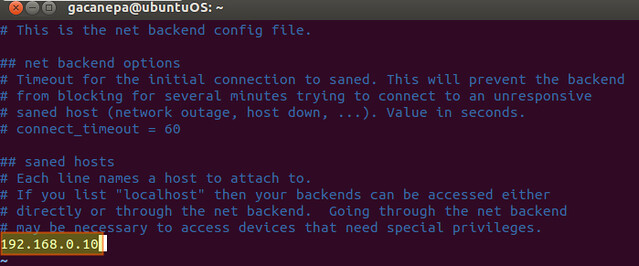
|
||||
|
||||
**4)** Restart saned:
|
||||
|
||||
$ sudo service saned restart
|
||||
|
||||
**5)** Let's see if the scanner is available now:
|
||||
|
||||

|
||||
|
||||
Now we can open "Simple Scan" (or other scanning utility) and start scanning documents. We can rotate, crop, and save the resulting image:
|
||||
|
||||

|
||||
|
||||
### Summary ###
|
||||
|
||||
Having one or more network printers and scanner is a nice convenience in any office or home network, and offers several advantages at the same time. To name a few:
|
||||
|
||||
- Multiple users (connecting from different platforms / places) are able to send print jobs to the printer's queue.
|
||||
- Cost and maintenance savings can be achieved due to hardware sharing.
|
||||
|
||||
I hope this article helps you make use of those advantages.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/configure-network-printer-scanner-ubuntu-desktop.html
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/gabriel
|
||||
[1]:http://xmodulo.com/2014/08/usb-network-printer-and-scanner-server-debian.html
|
||||
[2]:http://www.cups-pdf.de/documentation.shtml
|
||||
[3]:http://xmodulo.com/2014/08/usb-network-printer-and-scanner-server-debian.html#scanner
|
||||
@ -0,0 +1,103 @@
|
||||
How to sniff HTTP traffic from the command line on Linux
|
||||
================================================================================
|
||||
Suppose you want to sniff live HTTP web traffic (i.e., HTTP requests and responses) on the wire for some reason. For example, you may be testing experimental features of a web server. Or you may be debugging a web application or a RESTful service. Or you may be trying to troubleshoot [PAC (proxy auto config)][1] or check for any malware files surreptitiously downloaded from a website. Whatever the reason is, there are cases where HTTP traffic sniffing is helpful, for system admins, developers, or even end users.
|
||||
|
||||
While [packet sniffing tools][2] such as tcpdump are popularly used for live packet dump, you need to set up proper filtering to capture HTTP traffic, and even then, their raw output typically cannot be interpreted on the HTTP protocol level so easily. Real-time web server log parsers such as [ngxtop][3] provide human-readable real-time web traffic traces, but only applicable with a full access to live web server logs.
|
||||
|
||||
What will be nice is to have tcpdump-like traffic sniffing tool, but targeting HTTP traffic only. In fact, [httpry][4] is extactly that: **HTTP packet sniffing tool**. httpry captures live HTTP packets on the wire, and displays their content at the HTTP protocol level in a human-readable format. In this tutorial, let's see how we can sniff HTTP traffic with httpry.
|
||||
|
||||
### Install httpry on Linux ###
|
||||
|
||||
On Debian-based systems (Ubuntu or Linux Mint), httpry is not available in base repositories. So build it from the source:
|
||||
|
||||
$ sudo apt-get install gcc make git libpcap0.8-dev
|
||||
$ git clone https://github.com/jbittel/httpry.git
|
||||
$ cd httpry
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
On Fedora, CentOS or RHEL, you can install httpry with yum as follows. On CentOS/RHEL, enable [EPEL repo][5] before running yum.
|
||||
|
||||
$ sudo yum install httpry
|
||||
|
||||
If you still want to build httpry from the source, you can easily do that by:
|
||||
|
||||
$ sudo yum install gcc make git libpcap-devel
|
||||
$ git clone https://github.com/jbittel/httpry.git
|
||||
$ cd httpry
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
### Basic Usage of httpry ###
|
||||
|
||||
The basic use case of httpry is as follows.
|
||||
|
||||
$ sudo httpry -i <network-interface>
|
||||
|
||||
httpry then listens on a specified network interface, and displays captured HTTP requests/responses in real time.
|
||||
|
||||
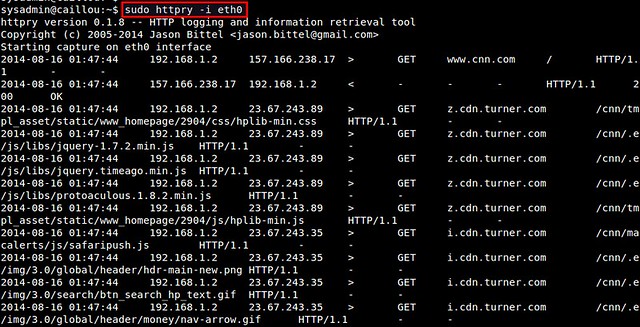
|
||||
|
||||
In most cases, however, you will be swamped with the fast scrolling output as packets are coming in and out. So you want to save captured HTTP packets for offline analysis. For that, use either '-b' or '-o' options. The '-b' option allows you to save raw HTTP packets into a binary file as is, which then can be replayed with httpry later. On the other hand, '-o' option saves human-readable output of httpry into a text file.
|
||||
|
||||
To save raw HTTP packets into a binary file:
|
||||
|
||||
$ sudo httpry -i eth0 -b output.dump
|
||||
|
||||
To replay saved HTTP packets:
|
||||
|
||||
$ httpry -r output.dump
|
||||
|
||||
Note that when you read a dump file with '-r' option, you don't need root privilege.
|
||||
|
||||
To save httpr's output to a text file:
|
||||
|
||||
$ sudo httpry -i eth0 -o output.txt
|
||||
|
||||
### Advanced Usage of httpry ###
|
||||
|
||||
If you want to monitor only specific HTTP methods (e.g., GET, POST, PUT, HEAD, CONNECT, etc), use '-m' option:
|
||||
|
||||
$ sudo httpry -i eth0 -m get,head
|
||||
|
||||
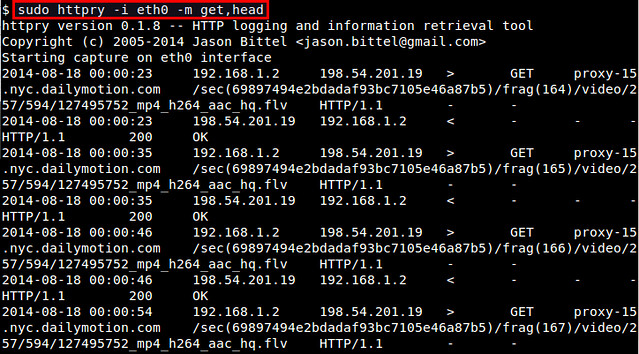
|
||||
|
||||
If you downloaded httpry's source code, you will notice that the source code comes with a collection of Perl scripts which aid in analyzing httpry's output. These scripts are found in httpry/scripts/plugins directory. If you want to write a custom parser for httpry's output, these scripts can be good examples to start from. Some of their capabilities are:
|
||||
|
||||
- **hostnames**: Displays a list of unique host names with counts.
|
||||
- **find_proxies**: Detect web proxies.
|
||||
- **search_terms**: Find and count search terms entered in search services.
|
||||
- **content_analysis**: Find URIs which contain specific keywords.
|
||||
- **xml_output**: Convert output into XML format.
|
||||
- **log_summary**: Generate a summary of log.
|
||||
- **db_dump**: Dump log file data into a database.
|
||||
|
||||
Before using these scripts, first run httpry with '-o' option for some time. Once you obtained the output file, run the scripts on it at once by using this command:
|
||||
|
||||
$ cd httpry/scripts
|
||||
$ perl parse_log.pl -d ./plugins <httpry-output-file>
|
||||
|
||||
You may encounter warnings with several plugins. For example, db_dump plugin may fail if you haven't set up a MySQL database with DBI interface. If a plugin fails to initialize, it will automatically be disabled. So you can ignore those warnings.
|
||||
|
||||
After parse_log.pl is completed, you will see a number of analysis results (*.txt/xml) in httpry/scripts directory. For example, log_summary.txt looks like the following.
|
||||
|
||||
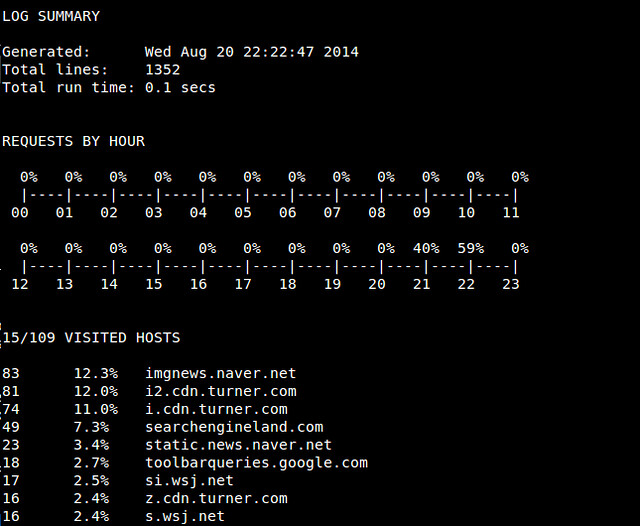
|
||||
|
||||
To conclude, httpry can be a life saver if you are in a situation where you need to interpret live HTTP packets. That might not be so common for average Linux users, but it never hurts to be prepared. What do you think of this tool?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/08/sniff-http-traffic-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/2012/12/how-to-set-up-proxy-auto-config-on-ubuntu-desktop.html
|
||||
[2]:http://xmodulo.com/2012/11/what-are-popular-packet-sniffers-on-linux.html
|
||||
[3]:http://xmodulo.com/2014/06/monitor-nginx-web-server-command-line-real-time.html
|
||||
[4]:http://dumpsterventures.com/jason/httpry/
|
||||
[5]:http://xmodulo.com/2013/03/how-to-set-up-epel-repository-on-centos.html
|
||||
Loading…
Reference in New Issue
Block a user