mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-09 01:30:10 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject into new
This commit is contained in:
commit
fdced2dca8
@ -1,11 +1,10 @@
|
||||
五种加速 Go 的特性
|
||||
============================================================
|
||||
========
|
||||
|
||||
_Anthony Starks 使用他出色的 Deck 演示工具重构了我原来的基于 Google Slides 的幻灯片。你可以在他的博客上查看他重构后的幻灯片, [mindchunk.blogspot.com.au/2014/06/remixing-with-deck][5]._
|
||||
_Anthony Starks 使用他出色的 Deck 演示工具重构了我原来的基于 Google Slides 的幻灯片。你可以在他的博客上查看他重构后的幻灯片,
|
||||
[mindchunk.blogspot.com.au/2014/06/remixing-with-deck][5]。_
|
||||
|
||||
* * *
|
||||
|
||||
我最近被邀请在 Gocon 发表演讲,这是一个每半年在日本东京举行的精彩 Go 的大会。[Gocon 2014][6] 是一个完全由社区驱动的为期一天的活动,由培训和一整个下午的围绕着 <q style="border: 0px; vertical-align: baseline; quotes: none;">生产环境中的 Go</q> 这个主题的演讲组成.
|
||||
我最近被邀请在 Gocon 发表演讲,这是一个每半年在日本东京举行的 Go 的精彩大会。[Gocon 2014][6] 是一个完全由社区驱动的为期一天的活动,由培训和一整个下午的围绕着生产环境中的 Go</q> 这个主题的演讲组成.(LCTT 译注:本文发表于 2014 年)
|
||||
|
||||
以下是我的讲义。原文的结构能让我缓慢而清晰的演讲,因此我已经编辑了它使其更可读。
|
||||
|
||||
@ -19,14 +18,16 @@
|
||||
|
||||
我很高兴今天能来到 Gocon。我想参加这个会议已经两年了,我很感谢主办方能提供给我向你们演讲的机会。
|
||||
|
||||
[][9]
|
||||
[][9]
|
||||
|
||||
我想以一个问题开始我的演讲。
|
||||
|
||||
为什么选择 Go?
|
||||
|
||||
当大家讨论学习或在生产环境中使用 Go 的原因时,答案不一而足,但因为以下三个原因的最多。
|
||||
|
||||
[][10]
|
||||
[][10]
|
||||
|
||||
这就是 TOP3 的原因。
|
||||
|
||||
第一,并发。
|
||||
@ -37,29 +38,29 @@ Go 的 <ruby>并发原语<rt>Concurrency Primitives</rt></ruby> 对于来自 Nod
|
||||
|
||||
我们今天从经验丰富的 Gophers 那里听说过,他们非常欣赏部署 Go 应用的简单性。
|
||||
|
||||
[][11]
|
||||
[][11]
|
||||
|
||||
然后是性能。
|
||||
|
||||
我相信人们选择 Go 的一个重要原因是它 _快_。
|
||||
|
||||
[][12]
|
||||
[][12]
|
||||
|
||||
在今天的演讲中,我想讨论五个有助于提高 Go 性能的特性。
|
||||
|
||||
我还将与大家分享 Go 如何实现这些特性的细节。
|
||||
|
||||
[][13]
|
||||
[][13]
|
||||
|
||||
我要谈的第一个特性是 Go 对于值的高效处理和存储。
|
||||
|
||||
[][14]
|
||||
[][14]
|
||||
|
||||
这是 Go 中一个值的例子。编译时,`gocon` 正好消耗四个字节的内存。
|
||||
|
||||
让我们将 Go 与其他一些语言进行比较
|
||||
|
||||
[][15]
|
||||
[][15]
|
||||
|
||||
由于 Python 表示变量的方式的开销,使用 Python 存储相同的值会消耗六倍的内存。
|
||||
|
||||
@ -67,19 +68,19 @@ Python 使用额外的内存来跟踪类型信息,进行 <ruby>引用计数<rt
|
||||
|
||||
让我们看另一个例子:
|
||||
|
||||
[][16]
|
||||
[][16]
|
||||
|
||||
与 Go 类似,Java 消耗 4 个字节的内存来存储 `int` 型。
|
||||
|
||||
但是,要在像 `List` 或 `Map` 这样的集合中使用此值,编译器必须将其转换为 `Integer` 对象。
|
||||
|
||||
[][17]
|
||||
[][17]
|
||||
|
||||
因此,Java 中的整数通常消耗 16 到 24 个字节的内存。
|
||||
|
||||
为什么这很重要? 内存便宜且充足,为什么这个开销很重要?
|
||||
|
||||
[][18]
|
||||
[][18]
|
||||
|
||||
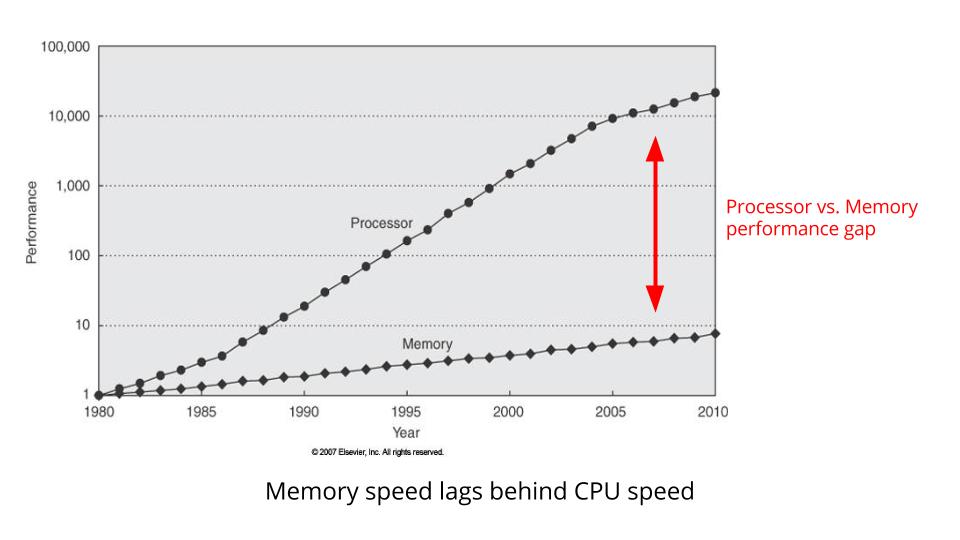
这是一张显示 CPU 时钟速度与内存总线速度的图表。
|
||||
|
||||
@ -87,13 +88,13 @@ Python 使用额外的内存来跟踪类型信息,进行 <ruby>引用计数<rt
|
||||
|
||||
两者之间的差异实际上是 CPU 花费多少时间等待内存。
|
||||
|
||||
[][19]
|
||||
[][19]
|
||||
|
||||
自 1960 年代后期以来,CPU 设计师已经意识到了这个问题。
|
||||
|
||||
他们的解决方案是一个缓存,一个更小,更快的内存区域,介入 CPU 和主存之间。
|
||||
他们的解决方案是一个缓存,一个更小、更快的内存区域,介入 CPU 和主存之间。
|
||||
|
||||
[][20]
|
||||
[][20]
|
||||
|
||||
这是一个 `Location` 类型,它保存物体在三维空间中的位置。它是用 Go 编写的,因此每个 `Location` 只消耗 24 个字节的存储空间。
|
||||
|
||||
@ -103,7 +104,7 @@ Python 使用额外的内存来跟踪类型信息,进行 <ruby>引用计数<rt
|
||||
|
||||
这很重要,因为现在所有 1000 个 `Location` 结构体都按顺序放在缓存中,紧密排列在一起。
|
||||
|
||||
[][21]
|
||||
[][21]
|
||||
|
||||
Go 允许您创建紧凑的数据结构,避免不必要的填充字节。
|
||||
|
||||
@ -111,11 +112,11 @@ Go 允许您创建紧凑的数据结构,避免不必要的填充字节。
|
||||
|
||||
更好的缓存利用率可带来更好的性能。
|
||||
|
||||
[][22]
|
||||
[][22]
|
||||
|
||||
函数调用不是无开销的。
|
||||
|
||||
[][23]
|
||||
[][23]
|
||||
|
||||
调用函数时会发生三件事。
|
||||
|
||||
@ -125,7 +126,7 @@ Go 允许您创建紧凑的数据结构,避免不必要的填充字节。
|
||||
|
||||
处理器计算函数的地址并执行到该新地址的分支。
|
||||
|
||||
[][24]
|
||||
[][24]
|
||||
|
||||
由于函数调用是非常常见的操作,因此 CPU 设计师一直在努力优化此过程,但他们无法消除开销。
|
||||
|
||||
@ -133,7 +134,7 @@ Go 允许您创建紧凑的数据结构,避免不必要的填充字节。
|
||||
|
||||
减少函数调用开销的解决方案是 <ruby>内联<rt>Inlining</rt></ruby>。
|
||||
|
||||
[][25]
|
||||
[][25]
|
||||
|
||||
Go 编译器通过将函数体视为调用者的一部分来内联函数。
|
||||
|
||||
@ -143,13 +144,13 @@ Go 编译器通过将函数体视为调用者的一部分来内联函数。
|
||||
|
||||
复杂的函数通常不受调用它们的开销所支配,因此不会内联。
|
||||
|
||||
[][26]
|
||||
[][26]
|
||||
|
||||
这个例子显示函数 `Double` 调用 `util.Max`。
|
||||
|
||||
为了减少调用 `util.Max` 的开销,编译器可以将 `util.Max` 内联到 `Double` 中,就象这样
|
||||
|
||||
[][27]
|
||||
[][27]
|
||||
|
||||
内联后不再调用 `util.Max`,但是 `Double` 的行为没有改变。
|
||||
|
||||
@ -159,7 +160,7 @@ Go 实现非常简单。编译包时,会标记任何适合内联的小函数
|
||||
|
||||
然后函数的源代码和编译后版本都会被存储。
|
||||
|
||||
[][28]
|
||||
[][28]
|
||||
|
||||
此幻灯片显示了 `util.a` 的内容。源代码已经过一些转换,以便编译器更容易快速处理。
|
||||
|
||||
@ -169,13 +170,13 @@ Go 实现非常简单。编译包时,会标记任何适合内联的小函数
|
||||
|
||||
拥有该函数的源代码可以实现其他优化。
|
||||
|
||||
[][29]
|
||||
[][29]
|
||||
|
||||
在这个例子中,尽管函数 `Test` 总是返回 `false`,但 `Expensive` 在不执行它的情况下无法知道结果。
|
||||
|
||||
当 `Test` 被内联时,我们得到这样的东西
|
||||
当 `Test` 被内联时,我们得到这样的东西。
|
||||
|
||||
[][30]
|
||||
[][30]
|
||||
|
||||
编译器现在知道 `Expensive` 的代码无法访问。
|
||||
|
||||
@ -183,7 +184,7 @@ Go 实现非常简单。编译包时,会标记任何适合内联的小函数
|
||||
|
||||
Go 编译器可以跨文件甚至跨包自动内联函数。还包括从标准库调用的可内联函数的代码。
|
||||
|
||||
[][31]
|
||||
[][31]
|
||||
|
||||
<ruby>强制垃圾回收<rt>Mandatory Garbage Collection</rt></ruby> 使 Go 成为一种更简单,更安全的语言。
|
||||
|
||||
@ -191,13 +192,13 @@ Go 编译器可以跨文件甚至跨包自动内联函数。还包括从标准
|
||||
|
||||
这意味着在堆上分配的内存是有代价的。每次 GC 运行时都会花费 CPU 时间,直到释放内存为止。
|
||||
|
||||
[][32]
|
||||
[][32]
|
||||
|
||||
然而,有另一个地方分配内存,那就是栈。
|
||||
|
||||
与 C 不同,它强制您选择是否将值通过 `malloc` 将其存储在堆上,还是通过在函数范围内声明将其储存在栈上;Go 实现了一个名为 <ruby>逃逸分析<rt>Escape Analysis</rt></ruby> 的优化。
|
||||
|
||||
[][33]
|
||||
[][33]
|
||||
|
||||
逃逸分析决定了对一个值的任何引用是否会从被声明的函数中逃逸。
|
||||
|
||||
@ -207,7 +208,7 @@ Go 编译器可以跨文件甚至跨包自动内联函数。还包括从标准
|
||||
|
||||
让我们看一些例子
|
||||
|
||||
[][34]
|
||||
[][34]
|
||||
|
||||
`Sum` 返回 1 到 100 的整数的和。这是一种相当不寻常的做法,但它说明了逃逸分析的工作原理。
|
||||
|
||||
@ -215,7 +216,7 @@ Go 编译器可以跨文件甚至跨包自动内联函数。还包括从标准
|
||||
|
||||
没有必要回收 `numbers`,它会在 `Sum` 返回时自动释放。
|
||||
|
||||
[][35]
|
||||
[][35]
|
||||
|
||||
第二个例子也有点尬。在 `CenterCursor` 中,我们创建一个新的 `Cursor` 对象并在 `c` 中存储指向它的指针。
|
||||
|
||||
@ -225,7 +226,7 @@ Go 编译器可以跨文件甚至跨包自动内联函数。还包括从标准
|
||||
|
||||
即使 `c` 被 `new` 函数分配了空间,它也不会存储在堆上,因为没有引用 `c` 的变量逃逸 `CenterCursor` 函数。
|
||||
|
||||
[][36]
|
||||
[][36]
|
||||
|
||||
默认情况下,Go 的优化始终处于启用状态。可以使用 `-gcflags = -m` 开关查看编译器的逃逸分析和内联决策。
|
||||
|
||||
@ -233,11 +234,11 @@ Go 编译器可以跨文件甚至跨包自动内联函数。还包括从标准
|
||||
|
||||
我将在本演讲的其余部分详细讨论栈。
|
||||
|
||||
[][37]
|
||||
[][37]
|
||||
|
||||
Go 有 goroutines。 这是 Go 并发的基石。
|
||||
Go 有 goroutine。 这是 Go 并发的基石。
|
||||
|
||||
我想退一步,探索 goroutines 的历史。
|
||||
我想退一步,探索 goroutine 的历史。
|
||||
|
||||
最初,计算机一次运行一个进程。在 60 年代,多进程或 <ruby>分时<rt>Time Sharing</rt></ruby> 的想法变得流行起来。
|
||||
|
||||
@ -245,7 +246,7 @@ Go 有 goroutines。 这是 Go 并发的基石。
|
||||
|
||||
这称为 _进程切换_。
|
||||
|
||||
[][38]
|
||||
[][38]
|
||||
|
||||
进程切换有三个主要开销。
|
||||
|
||||
@ -255,44 +256,41 @@ Go 有 goroutines。 这是 Go 并发的基石。
|
||||
|
||||
最后是操作系统 <ruby>上下文切换<rt>Context Switch</rt></ruby> 的成本,以及 <ruby>调度函数<rt>Scheduler Function</rt></ruby> 选择占用 CPU 的下一个进程的开销。
|
||||
|
||||
[][39]
|
||||
[][39]
|
||||
|
||||
现代处理器中有数量惊人的寄存器。我很难在一张幻灯片上排开它们,这可以让你知道保护和恢复它们需要多少时间。
|
||||
|
||||
由于进程切换可以在进程执行的任何时刻发生,因此操作系统需要存储所有寄存器的内容,因为它不知道当前正在使用哪些寄存器。
|
||||
|
||||
[][40]
|
||||
[][40]
|
||||
|
||||
这导致了线程的出生,这些线程在概念上与进程相同,但共享相同的内存空间。
|
||||
|
||||
由于线程共享地址空间,因此它们比进程更轻,因此创建速度更快,切换速度更快。
|
||||
|
||||
[][41]
|
||||
[][41]
|
||||
|
||||
Goroutines 升华了线程的思想。
|
||||
Goroutine 升华了线程的思想。
|
||||
|
||||
Goroutines 是 <ruby>协作式调度<rt>Cooperative Scheduled
|
||||
Goroutine 是 <ruby>协作式调度<rt>Cooperative Scheduled
|
||||
</rt></ruby>的,而不是依靠内核来调度。
|
||||
|
||||
当对 Go <ruby>运行时调度器<rt>Runtime Scheduler</rt></ruby> 进行显式调用时,goroutine 之间的切换仅发生在明确定义的点上。
|
||||
|
||||
编译器知道正在使用的寄存器并自动保存它们。
|
||||
|
||||
[][42]
|
||||
[][42]
|
||||
|
||||
虽然 goroutine 是协作式调度的,但运行时会为你处理。
|
||||
|
||||
Goroutines 可能会给禅让给其他协程时刻是:
|
||||
Goroutine 可能会给禅让给其他协程时刻是:
|
||||
|
||||
* 阻塞式通道发送和接收。
|
||||
|
||||
* Go 声明,虽然不能保证会立即调度新的 goroutine。
|
||||
|
||||
* 文件和网络操作式的阻塞式系统调用。
|
||||
|
||||
* 在被垃圾回收循环停止后。
|
||||
|
||||
[][43]
|
||||
[][43]
|
||||
|
||||
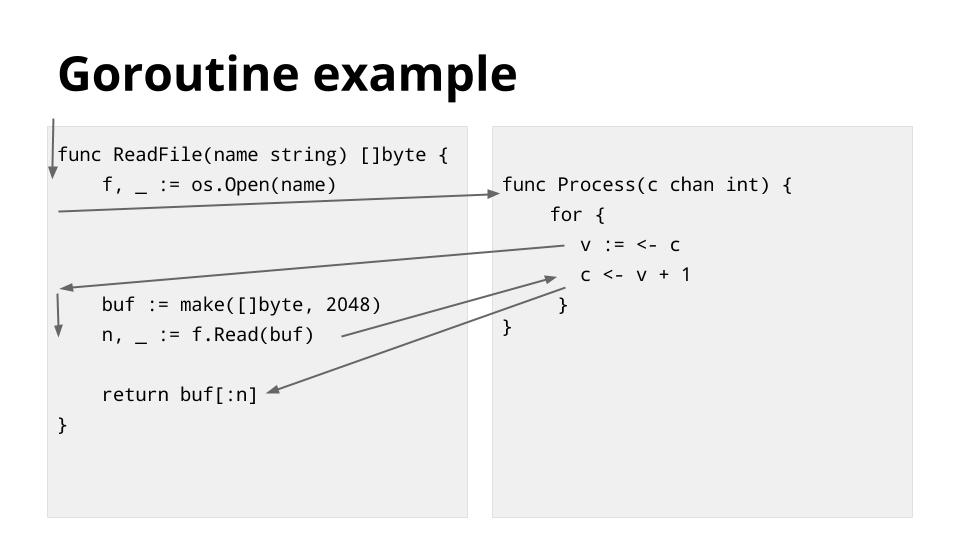
这个例子说明了上一张幻灯片中描述的一些调度点。
|
||||
|
||||
@ -304,7 +302,7 @@ Goroutines 可能会给禅让给其他协程时刻是:
|
||||
|
||||
最后,当 `Read` 操作完成并且数据可用时,线程切换回左侧。
|
||||
|
||||
[][44]
|
||||
[][44]
|
||||
|
||||
这张幻灯片显示了低级语言描述的 `runtime.Syscall` 函数,它是 `os` 包中所有函数的基础。
|
||||
|
||||
@ -316,13 +314,13 @@ Goroutines 可能会给禅让给其他协程时刻是:
|
||||
|
||||
这导致每 Go 进程的操作系统线程相对较少,Go 运行时负责将可运行的 Goroutine 分配给空闲的操作系统线程。
|
||||
|
||||
[][45]
|
||||
[][45]
|
||||
|
||||
在上一节中,我讨论了 goroutine 如何减少管理许多(有时是数十万个并发执行线程)的开销。
|
||||
|
||||
Goroutine故事还有另一面,那就是栈管理,它引导我进入我的最后一个话题。
|
||||
|
||||
[][46]
|
||||
[][46]
|
||||
|
||||
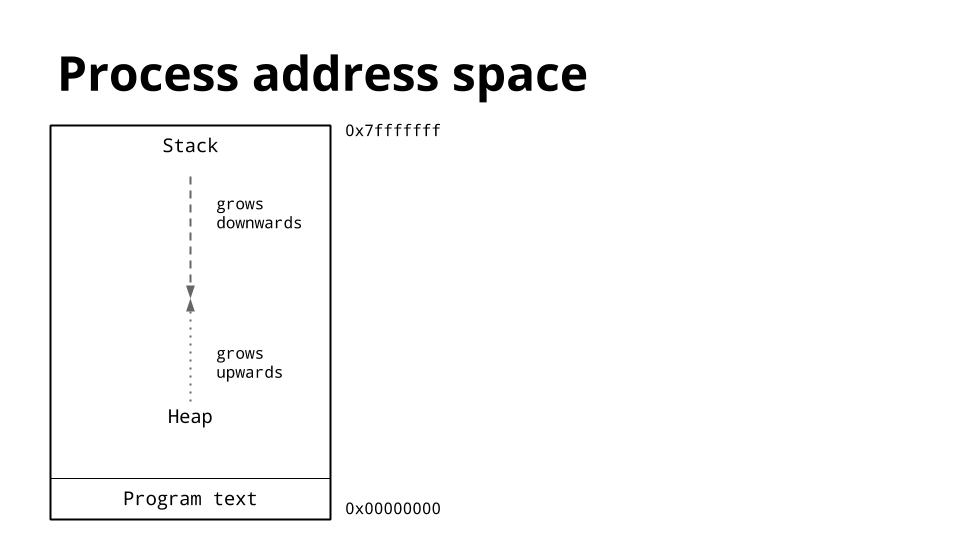
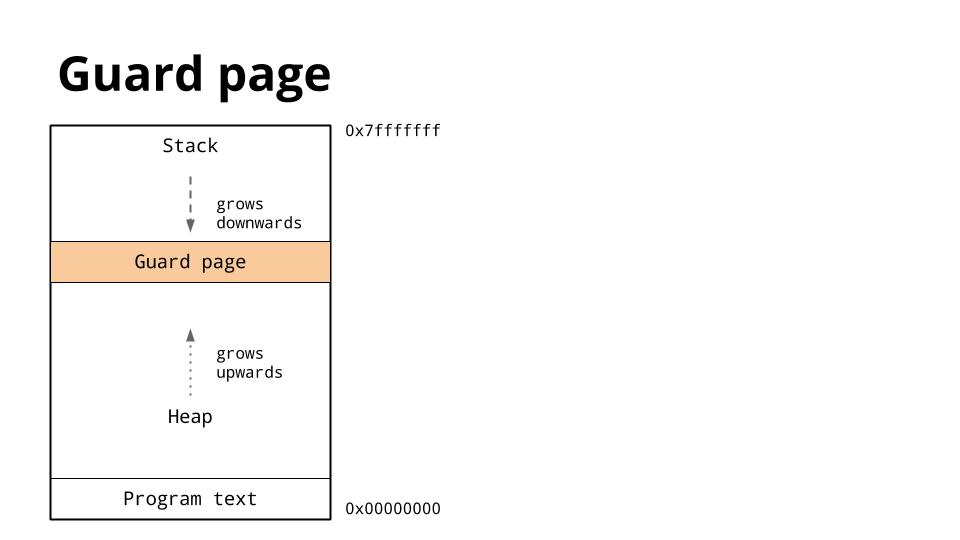
这是一个进程的内存布局图。我们感兴趣的关键是堆和栈的位置。
|
||||
|
||||
@ -330,13 +328,13 @@ Goroutine故事还有另一面,那就是栈管理,它引导我进入我的
|
||||
|
||||
栈位于虚拟地址空间的顶部,并向下增长。
|
||||
|
||||
[][47]
|
||||
[][47]
|
||||
|
||||
因为堆和栈相互覆盖的结果会是灾难性的,操作系统通常会安排在栈和堆之间放置一个不可写内存区域,以确保如果它们发生碰撞,程序将中止。
|
||||
|
||||
这称为保护页,有效地限制了进程的栈大小,通常大约为几兆字节。
|
||||
|
||||
[][48]
|
||||
[][48]
|
||||
|
||||
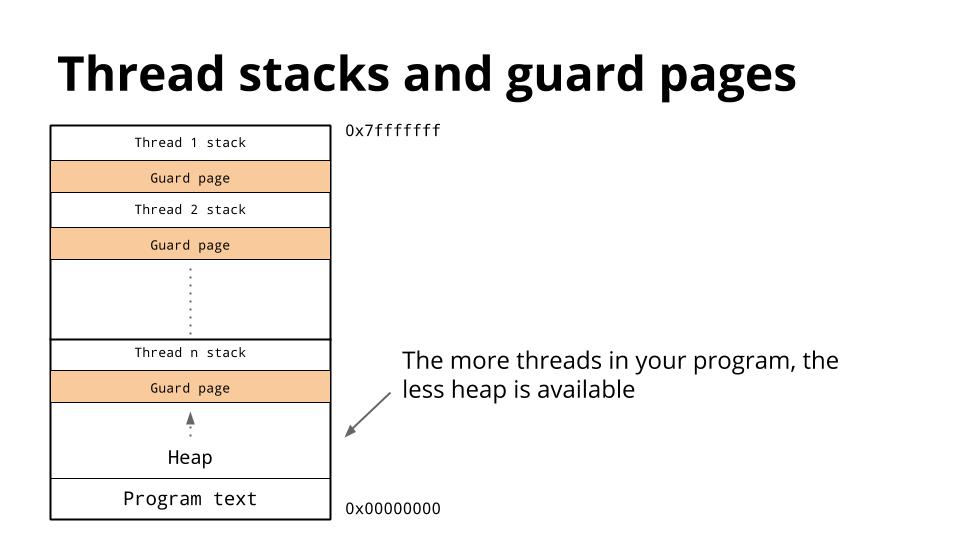
我们已经讨论过线程共享相同的地址空间,因此对于每个线程,它必须有自己的栈。
|
||||
|
||||
@ -346,7 +344,7 @@ Goroutine故事还有另一面,那就是栈管理,它引导我进入我的
|
||||
|
||||
缺点是随着程序中线程数的增加,可用地址空间的数量会减少。
|
||||
|
||||
[][49]
|
||||
[][49]
|
||||
|
||||
我们已经看到 Go 运行时将大量的 goroutine 调度到少量线程上,但那些 goroutines 的栈需求呢?
|
||||
|
||||
@ -354,13 +352,13 @@ Go 编译器不使用保护页,而是在每个函数调用时插入一个检
|
||||
|
||||
由于这种检查,goroutines 初始栈可以做得更小,这反过来允许 Go 程序员将 goroutines 视为廉价资源。
|
||||
|
||||
[][50]
|
||||
[][50]
|
||||
|
||||
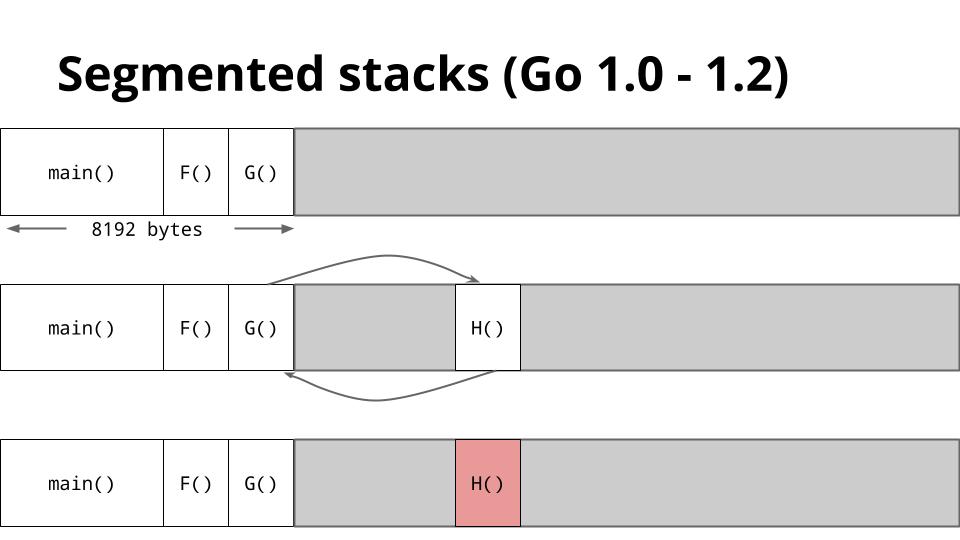
这是一张显示了 Go 1.2 如何管理栈的幻灯片。
|
||||
|
||||
当 `G` 调用 `H` 时,没有足够的空间让 `H` 运行,所以运行时从堆中分配一个新的栈帧,然后在新的栈段上运行 `H`。当 `H` 返回时,栈区域返回到堆,然后返回到 `G`。
|
||||
|
||||
[][51]
|
||||
[][51]
|
||||
|
||||
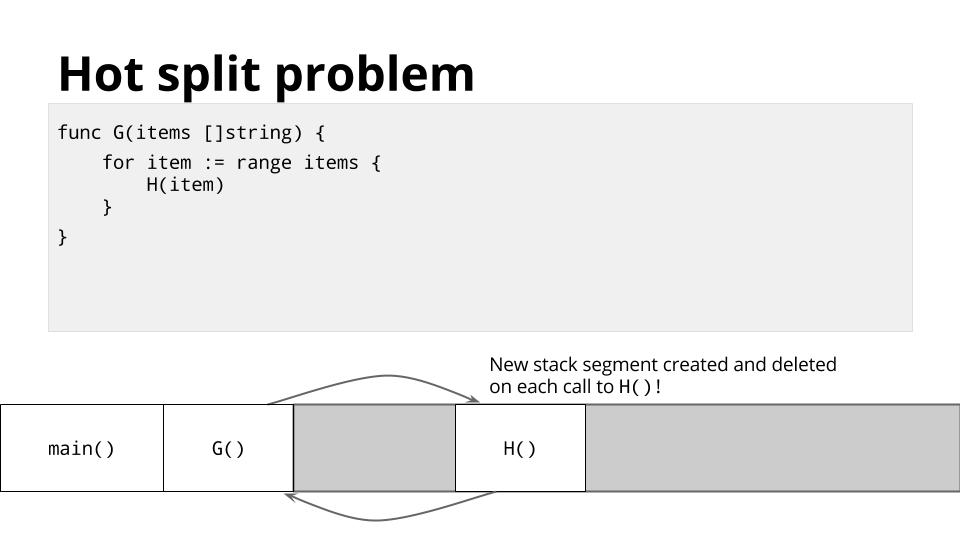
这种管理栈的方法通常很好用,但对于某些类型的代码,通常是递归代码,它可能导致程序的内部循环跨越这些栈边界之一。
|
||||
|
||||
@ -368,7 +366,7 @@ Go 编译器不使用保护页,而是在每个函数调用时插入一个检
|
||||
|
||||
每次都会导致栈拆分。 这被称为 <ruby>热分裂<rt>Hot Split</rt></ruby> 问题。
|
||||
|
||||
[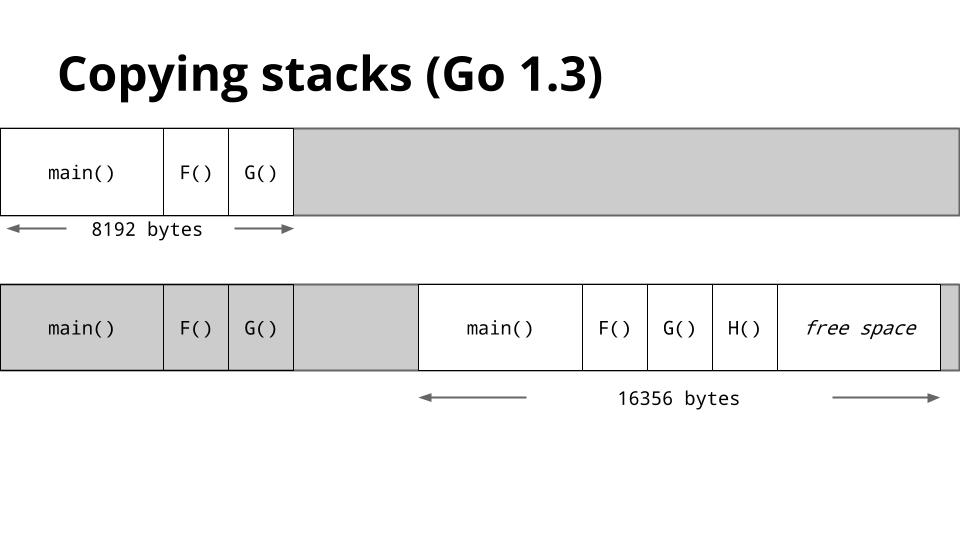][52]
|
||||
[][52]
|
||||
|
||||
为了解决热分裂问题,Go 1.3 采用了一种新的栈管理方法。
|
||||
|
||||
@ -380,7 +378,7 @@ Go 编译器不使用保护页,而是在每个函数调用时插入一个检
|
||||
|
||||
这解决了热分裂问题。
|
||||
|
||||
[][53]
|
||||
[][53]
|
||||
|
||||
值,内联,逃逸分析,Goroutines 和分段/复制栈。
|
||||
|
||||
@ -398,7 +396,7 @@ Go 编译器不使用保护页,而是在每个函数调用时插入一个检
|
||||
|
||||
如果没有可增长的栈,逃逸分析可能会对栈施加太大的压力。
|
||||
|
||||
[][54]
|
||||
[][54]
|
||||
|
||||
* 感谢 Gocon 主办方允许我今天发言
|
||||
* twitter / web / email details
|
||||
@ -407,11 +405,8 @@ Go 编译器不使用保护页,而是在每个函数调用时插入一个检
|
||||
### 相关文章:
|
||||
|
||||
1. [听我在 OSCON 上关于 Go 性能的演讲][1]
|
||||
|
||||
2. [为什么 Goroutine 的栈是无限大的?][2]
|
||||
|
||||
3. [Go 的运行时环境变量的旋风之旅][3]
|
||||
|
||||
4. [没有事件循环的性能][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -431,9 +426,9 @@ David 是来自澳大利亚悉尼的程序员和作者。
|
||||
|
||||
via: https://dave.cheney.net/2014/06/07/five-things-that-make-go-fast
|
||||
|
||||
作者:[Dave Cheney ][a]
|
||||
作者:[Dave Cheney][a]
|
||||
译者:[houbaron](https://github.com/houbaron)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,11 +1,12 @@
|
||||
树莓派自建 NAS 云盘之-树莓派搭建网络存储盘
|
||||
树莓派自建 NAS 云盘之——树莓派搭建网络存储盘
|
||||
======
|
||||
> 跟随这些逐步指导构建你自己的基于树莓派的 NAS 系统。
|
||||
|
||||

|
||||
|
||||
我将在接下来的三篇文章中讲述如何搭建一个简便、实用的 NAS 云盘系统。我在这个中心化的存储系统中存储数据,并且让它每晚都会自动的备份增量数据。本系列文章将利用 NFS 文件系统将磁盘挂载到同一网络下的不同设备上,使用 [Nextcloud][1] 来离线访问数据、分享数据。
|
||||
我将在接下来的这三篇文章中讲述如何搭建一个简便、实用的 NAS 云盘系统。我在这个中心化的存储系统中存储数据,并且让它每晚都会自动的备份增量数据。本系列文章将利用 NFS 文件系统将磁盘挂载到同一网络下的不同设备上,使用 [Nextcloud][1] 来离线访问数据、分享数据。
|
||||
|
||||
本文主要讲述将数据盘挂载到远程设备上的软硬件步骤。本系列第二篇文章将讨论数据备份策略、如何添加定时备份数据任务。最后一篇文章中我们将会安装 Nextcloud 软件,用户通过Nextcloud 提供的 web 接口可以方便的离线或在线访问数据。本系列教程最终搭建的 NAS 云盘支持多用户操作、文件共享等功能,所以你可以通过它方便的分享数据,比如说你可以发送一个加密链接,跟朋友分享你的照片等等。
|
||||
本文主要讲述将数据盘挂载到远程设备上的软硬件步骤。本系列第二篇文章将讨论数据备份策略、如何添加定时备份数据任务。最后一篇文章中我们将会安装 Nextcloud 软件,用户通过 Nextcloud 提供的 web 界面可以方便的离线或在线访问数据。本系列教程最终搭建的 NAS 云盘支持多用户操作、文件共享等功能,所以你可以通过它方便的分享数据,比如说你可以发送一个加密链接,跟朋友分享你的照片等等。
|
||||
|
||||
最终的系统架构如下图所示:
|
||||
|
||||
@ -16,11 +17,11 @@
|
||||
|
||||
首先需要准备硬件。本文所列方案只是其中一种示例,你也可以按不同的硬件方案进行采购。
|
||||
|
||||
最主要的就是[树莓派3][2],它带有四核 CPU,1G RAM,以及(有些)快速的网络接口。数据将存储在两个 USB 磁盘驱动器上(这里使用 1TB 磁盘);其中一个磁盘用于每天数据存储,另一个用于数据备份。请务必使用有源 USB 磁盘驱动器或者带附加电源的 USB 集线器,因为树莓派无法为两个 USB 磁盘驱动器供电。
|
||||
最主要的就是[树莓派 3][2],它带有四核 CPU、1G RAM,以及(比较)快速的网络接口。数据将存储在两个 USB 磁盘驱动器上(这里使用 1TB 磁盘);其中一个磁盘用于每天数据存储,另一个用于数据备份。请务必使用有源 USB 磁盘驱动器或者带附加电源的 USB 集线器,因为树莓派无法为两个 USB 磁盘驱动器供电。
|
||||
|
||||
### 软件
|
||||
|
||||
社区中最活跃的操作系统当属 [Raspbian][3],便于定制个性化项目。已经有很多 [操作指南][4] 讲述如何在树莓派中安装 Raspbian 系统,所以这里不再赘述。在撰写本文时,最新的官方支持版本是 [Raspbian Stretch][5],它对我来说很好使用。
|
||||
在该社区中最活跃的操作系统当属 [Raspbian][3],便于定制个性化项目。已经有很多 [操作指南][4] 讲述如何在树莓派中安装 Raspbian 系统,所以这里不再赘述。在撰写本文时,最新的官方支持版本是 [Raspbian Stretch][5],它对我来说很好使用。
|
||||
|
||||
到此,我将假设你已经配置好了基本的 Raspbian 系统并且可以通过 `ssh` 访问到你的树莓派。
|
||||
|
||||
@ -31,51 +32,28 @@
|
||||
```
|
||||
pi@raspberrypi:~ $ sudo fdisk -l
|
||||
|
||||
|
||||
|
||||
<...>
|
||||
|
||||
|
||||
|
||||
Disk /dev/sda: 931.5 GiB, 1000204886016 bytes, 1953525168 sectors
|
||||
|
||||
Units: sectors of 1 * 512 = 512 bytes
|
||||
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
Disklabel type: dos
|
||||
|
||||
Disk identifier: 0xe8900690
|
||||
|
||||
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
|
||||
/dev/sda1 2048 1953525167 1953523120 931.5G 83 Linux
|
||||
|
||||
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
/dev/sda1 2048 1953525167 1953523120 931.5G 83 Linux
|
||||
|
||||
|
||||
Disk /dev/sdb: 931.5 GiB, 1000204886016 bytes, 1953525168 sectors
|
||||
|
||||
Units: sectors of 1 * 512 = 512 bytes
|
||||
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
Disklabel type: dos
|
||||
|
||||
Disk identifier: 0x6aa4f598
|
||||
|
||||
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
|
||||
/dev/sdb1 * 2048 1953521663 1953519616 931.5G 83 Linux
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
/dev/sdb1 * 2048 1953521663 1953519616 931.5G 83 Linux
|
||||
|
||||
```
|
||||
|
||||
@ -86,163 +64,101 @@ Device Boot Start End Sectors Size Id Type
|
||||
```
|
||||
pi@raspberrypi:~ $ sudo fdisk /dev/sda
|
||||
|
||||
|
||||
|
||||
Welcome to fdisk (util-linux 2.29.2).
|
||||
|
||||
Changes will remain in memory only, until you decide to write them.
|
||||
|
||||
Be careful before using the write command.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Command (m for help): o
|
||||
|
||||
Created a new DOS disklabel with disk identifier 0x9c310964.
|
||||
|
||||
|
||||
|
||||
Command (m for help): n
|
||||
|
||||
Partition type
|
||||
|
||||
p primary (0 primary, 0 extended, 4 free)
|
||||
|
||||
e extended (container for logical partitions)
|
||||
|
||||
p primary (0 primary, 0 extended, 4 free)
|
||||
e extended (container for logical partitions)
|
||||
Select (default p): p
|
||||
|
||||
Partition number (1-4, default 1):
|
||||
|
||||
First sector (2048-1953525167, default 2048):
|
||||
|
||||
Last sector, +sectors or +size{K,M,G,T,P} (2048-1953525167, default 1953525167):
|
||||
|
||||
|
||||
|
||||
Created a new partition 1 of type 'Linux' and of size 931.5 GiB.
|
||||
|
||||
|
||||
|
||||
Command (m for help): p
|
||||
|
||||
|
||||
|
||||
Disk /dev/sda: 931.5 GiB, 1000204886016 bytes, 1953525168 sectors
|
||||
|
||||
Units: sectors of 1 * 512 = 512 bytes
|
||||
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
Disklabel type: dos
|
||||
|
||||
Disk identifier: 0x9c310964
|
||||
|
||||
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
|
||||
/dev/sda1 2048 1953525167 1953523120 931.5G 83 Linux
|
||||
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
/dev/sda1 2048 1953525167 1953523120 931.5G 83 Linux
|
||||
|
||||
Command (m for help): w
|
||||
|
||||
The partition table has been altered.
|
||||
|
||||
Syncing disks.
|
||||
|
||||
```
|
||||
|
||||
现在,我们将用 ext4 文件系统格式化新创建的分区 `/dev/sda1`:
|
||||
|
||||
```
|
||||
pi@raspberrypi:~ $ sudo mkfs.ext4 /dev/sda1
|
||||
|
||||
mke2fs 1.43.4 (31-Jan-2017)
|
||||
|
||||
Discarding device blocks: done
|
||||
|
||||
|
||||
|
||||
<...>
|
||||
|
||||
|
||||
|
||||
Allocating group tables: done
|
||||
|
||||
Writing inode tables: done
|
||||
|
||||
Creating journal (1024 blocks): done
|
||||
|
||||
Writing superblocks and filesystem accounting information: done
|
||||
|
||||
```
|
||||
|
||||
重复以上步骤后,让我们根据用途来对它们建立标签:
|
||||
|
||||
```
|
||||
pi@raspberrypi:~ $ sudo e2label /dev/sda1 data
|
||||
|
||||
pi@raspberrypi:~ $ sudo e2label /dev/sdb1 backup
|
||||
|
||||
```
|
||||
|
||||
现在,让我们安装这些磁盘并存储一些数据。以我运营该系统超过一年的经验来看,当树莓派启动时(例如在断电后),USB 磁盘驱动器并不是总被安装,因此我建议使用 autofs 在需要的时候进行安装。
|
||||
现在,让我们安装这些磁盘并存储一些数据。以我运营该系统超过一年的经验来看,当树莓派启动时(例如在断电后),USB 磁盘驱动器并不是总被挂载,因此我建议使用 autofs 在需要的时候进行挂载。
|
||||
|
||||
首先,安装 autofs 并创建挂载点:
|
||||
|
||||
```
|
||||
pi@raspberrypi:~ $ sudo apt install autofs
|
||||
|
||||
pi@raspberrypi:~ $ sudo mkdir /nas
|
||||
|
||||
```
|
||||
|
||||
然后添加下面这行来挂载设备
|
||||
`/etc/auto.master`:
|
||||
然后添加下面这行来挂载设备 `/etc/auto.master`:
|
||||
|
||||
```
|
||||
/nas /etc/auto.usb
|
||||
|
||||
```
|
||||
|
||||
如果不存在以下内容,则创建 `/etc/auto.usb`,然后重新启动 autofs 服务:
|
||||
|
||||
```
|
||||
data -fstype=ext4,rw :/dev/disk/by-label/data
|
||||
|
||||
backup -fstype=ext4,rw :/dev/disk/by-label/backup
|
||||
|
||||
pi@raspberrypi3:~ $ sudo service autofs restart
|
||||
|
||||
```
|
||||
|
||||
现在你应该可以分别访问 `/nas/data` 以及 `/nas/backup` 磁盘了。显然,到此还不会令人太兴奋,因为你只是擦除了磁盘中的数据。不过,你可以执行以下命令来确认设备是否已经挂载成功:
|
||||
|
||||
```
|
||||
pi@raspberrypi3:~ $ cd /nas/data
|
||||
|
||||
pi@raspberrypi3:/nas/data $ cd /nas/backup
|
||||
|
||||
pi@raspberrypi3:/nas/backup $ mount
|
||||
|
||||
<...>
|
||||
|
||||
/etc/auto.usb on /nas type autofs (rw,relatime,fd=6,pgrp=463,timeout=300,minproto=5,maxproto=5,indirect)
|
||||
|
||||
<...>
|
||||
|
||||
/dev/sda1 on /nas/data type ext4 (rw,relatime,data=ordered)
|
||||
|
||||
/dev/sdb1 on /nas/backup type ext4 (rw,relatime,data=ordered)
|
||||
|
||||
```
|
||||
|
||||
首先进入对应目录以确保 autofs 能够挂载设备。Autofs 会跟踪文件系统的访问记录,并随时挂载所需要的设备。然后 `mount` 命令会显示这两个 USB 磁盘驱动器已经挂载到我们想要的位置了。
|
||||
首先进入对应目录以确保 autofs 能够挂载设备。autofs 会跟踪文件系统的访问记录,并随时挂载所需要的设备。然后 `mount` 命令会显示这两个 USB 磁盘驱动器已经挂载到我们想要的位置了。
|
||||
|
||||
设置 autofs 的过程容易出错,如果第一次尝试失败,请不要沮丧。你可以上网搜索有关教程。
|
||||
|
||||
@ -252,25 +168,21 @@ pi@raspberrypi3:/nas/backup $ mount
|
||||
|
||||
```
|
||||
pi@raspberrypi:~ $ sudo apt install nfs-kernel-server
|
||||
|
||||
```
|
||||
|
||||
然后,需要告诉 NFS 服务器公开 `/nas/data` 目录,这是从树莓派外部可以访问的唯一设备(另一个用于备份)。编辑 `/etc/exports` 添加如下内容以允许所有可以访问 NAS 云盘的设备挂载存储:
|
||||
|
||||
```
|
||||
/nas/data *(rw,sync,no_subtree_check)
|
||||
|
||||
```
|
||||
|
||||
更多有关限制挂载到单个设备的详细信息,请参阅 `man exports`。经过上面的配置,任何人都可以访问数据,只要他们可以访问 NFS 所需的端口:`111`和`2049`。我通过上面的配置,只允许通过路由器防火墙访问到我的家庭网络的 22 和 443 端口。这样,只有在家庭网络中的设备才能访问 NFS 服务器。
|
||||
更多有关限制挂载到单个设备的详细信息,请参阅 `man exports`。经过上面的配置,任何人都可以访问数据,只要他们可以访问 NFS 所需的端口:`111` 和 `2049`。我通过上面的配置,只允许通过路由器防火墙访问到我的家庭网络的 22 和 443 端口。这样,只有在家庭网络中的设备才能访问 NFS 服务器。
|
||||
|
||||
如果要在 Linux 计算机挂载存储,运行以下命令:
|
||||
|
||||
```
|
||||
you@desktop:~ $ sudo mkdir /nas/data
|
||||
|
||||
you@desktop:~ $ sudo mount -t nfs <raspberry-pi-hostname-or-ip>:/nas/data /nas/data
|
||||
|
||||
```
|
||||
|
||||
同样,我建议使用 autofs 来挂载该网络设备。如果需要其他帮助,请参看 [如何使用 Autofs 来挂载 NFS 共享][6]。
|
||||
@ -284,7 +196,7 @@ via: https://opensource.com/article/18/7/network-attached-storage-Raspberry-Pi
|
||||
作者:[Manuel Dewald][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[jrg](https://github.com/jrglinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -296,3 +208,4 @@ via: https://opensource.com/article/18/7/network-attached-storage-Raspberry-Pi
|
||||
[5]: https://www.raspberrypi.org/blog/raspbian-stretch/
|
||||
[6]: https://opensource.com/article/18/6/using-autofs-mount-nfs-shares
|
||||
|
||||
|
||||
133
published/20180824 What Stable Kernel Should I Use.md
Normal file
133
published/20180824 What Stable Kernel Should I Use.md
Normal file
@ -0,0 +1,133 @@
|
||||
我应该使用哪些稳定版内核?
|
||||
======
|
||||
> 本文作者 Greg Kroah-Hartman 是 Linux 稳定版内核的维护负责人。
|
||||
|
||||
很多人都问我这样的问题,在他们的产品/设备/笔记本/服务器等上面应该使用什么样的稳定版内核。一直以来,尤其是那些现在已经延长支持时间的内核,都是由我和其他人提供支持,因此,给出这个问题的答案并不是件容易的事情。在这篇文章我将尝试去给出我在这个问题上的看法。当然,你可以任意选用任何一个你想去使用的内核版本,这里只是我的建议。
|
||||
|
||||
和以前一样,在这里给出的这些看法只代表我个人的意见。
|
||||
|
||||
### 可选择的内核有哪些
|
||||
|
||||
下面列出了我建议你应该去使用的内核的列表,从最好的到最差的都有。我在下面将详细介绍,但是如果你只想得到一个结论,它就是你想要的:
|
||||
|
||||
建议你使用的内核的分级,从最佳的方案到最差的方案如下:
|
||||
|
||||
* 你最喜欢的 Linux 发行版支持的内核
|
||||
* 最新的稳定版
|
||||
* 最新的 LTS (长期支持)版本
|
||||
* 仍然处于维护状态的老的 LTS 版本
|
||||
|
||||
绝对不要去使用的内核:
|
||||
|
||||
* 不再维护的内核版本
|
||||
|
||||
给上面的列表给出具体的数字,今天是 2018 年 8 月 24 日,kernel.org 页面上可以看到是这样:
|
||||
|
||||
![][1]
|
||||
|
||||
因此,基于上面的列表,那它应该是:
|
||||
|
||||
* 4.18.5 是最新的稳定版
|
||||
* 4.14.67 是最新的 LTS 版本
|
||||
* 4.9.124、4.4.152、以及 3.16.57 是仍然处于维护状态的老的 LTS 版本
|
||||
* 4.17.19 和 3.18.119 是过去 60 天内有过发布的 “生命周期终止” 的内核版本,它们仍然保留在 kernel.org 站点上,是为了仍然想去使用它们的那些人。
|
||||
|
||||
非常容易,对吗?
|
||||
|
||||
Ok,现在我给出这样选择的一些理由:
|
||||
|
||||
### Linux 发行版内核
|
||||
|
||||
对于大多数 Linux 用户来说,最好的方案就是使用你喜欢的 Linux 发行版的内核。就我本人而言,我比较喜欢基于社区的、内核不断滚动升级的用最新内核的 Linux 发行版,并且它也是由开发者社区来支持的。这种类型的发行版有 Fedora、openSUSE、Arch、Gentoo、CoreOS,以及其它的。
|
||||
|
||||
所有这些发行版都使用了上游的最新的稳定版内核,并且确保定期打了需要的 bug 修复补丁。当它拥有了最新的修复之后([记住所有的修复都是安全修复][2]),这就是你可以使用的最安全、最好的内核之一。
|
||||
|
||||
有些社区的 Linux 发行版需要很长的时间才发行一个新内核版本,但是最终发行的版本和所支持的内核都是非常好的。这些也都非常好用,Debian 和 Ubuntu 就是这样的例子。
|
||||
|
||||
如果我没有在这里列出你所喜欢的发行版,并不是意味着它们的内核不够好。查看这些发行版的网站,确保它们的内核包是不断应用最新的安全补丁进行升级过的,那么它就应该是很好的。
|
||||
|
||||
许多人好像喜欢旧式、“传统” 模式的发行版,使用 RHEL、SLES、CentOS 或者 “LTS” Ubuntu 发行版。这些发行版挑选一个特定的内核版本,然后使用好几年,甚至几十年。他们反向移植了最新的 bug 修复,有时也有一些内核的新特性,所有的只是追求堂吉诃德式的保持版本号不变而已,尽管他们已经在那个旧的内核版本上做了成千上万的变更。这项工作是一项真正吃力不讨好的工作,分配到这些任务的开发人员做了一些精彩的工作才能实现这些目标。所以如果你希望永远不看到你的内核版本号发生过变化,那么就使用这些发行版。他们通常会为使用而付出一些钱,当发生错误时能够从这些公司得到一些支持,那就是值得的。
|
||||
|
||||
所以,你能使用的最好的内核是你可以求助于别人,而别人可以为你提供支持的内核。使用那些支持,你通常都已经为它支付过费用了(对于企业发行版),而这些公司也知道他们职责是什么。
|
||||
|
||||
但是,如果你不希望去依赖别人,而是希望你自己管理你的内核,或者你有发行版不支持的硬件,那么你应该去使用最新的稳定版:
|
||||
|
||||
### 最新的稳定版
|
||||
|
||||
最新的稳定版内核是 Linux 内核开发者社区宣布为“稳定版”的最新的一个内核。大约每三个月,社区发行一个包含了对所有新硬件支持的、新的稳定版内核,最新版的内核不但改善内核性能,同时还包含内核各部分的 bug 修复。接下来的三个月之后,进入到下一个内核版本的 bug 修复将被反向移植进入这个稳定版内核中,因此,使用这个内核版本的用户将确保立即得到这些修复。
|
||||
|
||||
最新的稳定版内核通常也是主流社区发行版所使用的内核,因此你可以确保它是经过测试和拥有大量用户使用的内核。另外,内核社区(全部开发者超过 4000 人)也将帮助这个发行版提供对用户的支持,因为这是他们做的最新的一个内核。
|
||||
|
||||
三个月之后,将发行一个新的稳定版内核,你应该去更新到它以确保你的内核始终是最新的稳定版,因为当最新的稳定版内核发布之后,对你的当前稳定版内核的支持通常会落后几周时间。
|
||||
|
||||
如果你在上一个 LTS (长期支持)版本发布之后购买了最新的硬件,为了能够支持最新的硬件,你几乎是绝对需要去运行这个最新的稳定版内核。对于台式机或新的服务器,最新的稳定版内核通常是推荐运行的内核。
|
||||
|
||||
### 最新的 LTS 版本
|
||||
|
||||
如果你的硬件为了保证正常运行(像大多数的嵌入式设备),需要依赖供应商的源码<ruby>树外<rt>out-of-tree</rt></ruby>的补丁,那么对你来说,最好的内核版本是最新的 LTS 版本。这个版本拥有所有进入稳定版内核的最新 bug 修复,以及大量的用户测试和使用。
|
||||
|
||||
请注意,这个最新的 LTS 版本没有新特性,并且也几乎不会增加对新硬件的支持,因此,如果你需要使用一个新设备,那你的最佳选择就是最新的稳定版内核,而不是最新的 LTS 版内核。
|
||||
|
||||
另外,对于这个 LTS 版本的用户来说,他也不用担心每三个月一次的“重大”升级。因此,他们将一直坚持使用这个 LTS 版本,并每年升级一次,这是一个很好的实践。
|
||||
|
||||
使用这个 LTS 版本的不利方面是,你没法得到在最新版本内核上实现的内核性能提升,除非在未来的一年中,你升级到下一个 LTS 版内核。
|
||||
|
||||
另外,如果你使用的这个内核版本有问题,你所做的第一件事情就是向任意一位内核开发者报告发生的问题,并向他们询问,“最新的稳定版内核中是否也存在这个问题?”并且,你需要意识到,对它的支持不会像使用最新的稳定版内核那样容易得到。
|
||||
|
||||
现在,如果你坚持使用一个有大量的补丁集的内核,并且不希望升级到每年一次的新 LTS 版内核上,那么,或许你应该去使用老的 LTS 版内核:
|
||||
|
||||
### 老的 LTS 版本
|
||||
|
||||
传统上,这些版本都由社区提供 2 年时间的支持,有时候当一个重要的 Linux 发行版(像 Debian 或 SLES)依赖它时,这个支持时间会更长。然而在过去一年里,感谢 Google、Linaro、Linaro 成员公司、[kernelci.org][3]、以及其它公司在测试和基础设施上的大量投入,使得这些老的 LTS 版内核得到更长时间的支持。
|
||||
|
||||
最新的 LTS 版本以及它们将被支持多长时间,这是 2018 年 8 月 24 日显示在 [kernel.org/category/releases.html][4] 上的信息:
|
||||
|
||||
![][5]
|
||||
|
||||
Google 和其它公司希望这些内核使用的时间更长的原因是,由于现在几乎所有的 SoC 芯片的疯狂的(也有人说是打破常规)开发模型。这些设备在芯片发行前几年就启动了他们的开发周期,而那些代码从来不会合并到上游,最终结果是新打造的芯片是基于一个 2 年以前的老内核发布的。这些 SoC 的代码树通常增加了超过 200 万行的代码,这使得它们成为我们前面称之为“类 Linux 内核“的东西。
|
||||
|
||||
如果在 2 年后,这个 LTS 版本停止支持,那么来自社区的支持将立即停止,并且没有人对它再进行 bug 修复。这导致了在全球各地数以百万计的非常不安全的设备仍然在使用中,这对任何生态系统来说都不是什么好事情。
|
||||
|
||||
由于这种依赖,这些公司现在要求新设备不断更新到最新的 LTS 版本——这些为它们特定发布的版本(例如现在的每个 4.9.y 版本)。其中一个这样的例子就是新 Android 设备对内核版本的要求,这些新设备所带的 “Andrid O” 版本(和现在的 “Android P” 版本)指定了最低允许使用的内核版本,并且 Andoird 安全更新版本也开始越来越频繁在设备上要求使用这些 “.y” 版本。
|
||||
|
||||
我注意到一些生产商现在已经在做这些事情。Sony 是其中一个非常好的例子,在他们的大多数新手机上,通过他们每季度的安全更新版本,将设备更新到最新的 4.4.y 发行版上。另一个很好的例子是一家小型公司 Essential,据我所知,他们持续跟踪 4.4.y 版本的速度比其它公司都快。
|
||||
|
||||
当使用这种老的内核时有个重大警告。反向移植到这种内核中的安全修复不如最新版本的 LTS 内核多,因为这些使用老的 LTS 内核的设备的传统模式是一个更加简化的用户模式。这些内核不能用于任何“通用计算”模式中,在这里用的是<ruby>不可信用户<rt>untrusted user</rt></ruby>或虚拟机,极大地削弱了对老的内核做像最近的 Spectre 这样的修复的能力,如果在一些分支中存在这样的 bug 的话。
|
||||
|
||||
因此,仅在你能够完全控制的设备,或者限定在一个非常强大的安全模型(像 Android 一样强制使用 SELinux 和应用程序隔离)时使用老的 LTS 版本。绝对不要在有不可信用户/程序,或虚拟机的服务器上使用这些老的 LTS 版内核。
|
||||
|
||||
此外,如果社区对它有支持的话,社区对这些老的 LTS 版内核相比正常的 LTS 版内核的支持要少的多。如果你使用这些内核,那么你只能是一个人在战斗,你需要有能力去独自支持这些内核,或者依赖你的 SoC 供应商为你提供支持(需要注意的是,几乎没有供应商会为你提供支持,因此,你要特别注意 ……)。
|
||||
|
||||
### 不再维护的内核发行版
|
||||
|
||||
更让人感到惊讶的事情是,许多公司只是随便选一个内核发行版,然后将它封装到它们的产品里,并将它毫不犹豫地承载到数十万的部件中。其中一个这样的糟糕例子是 Lego Mindstorm 系统,不知道是什么原因在它们的设备上随意选取了一个 -rc 的内核发行版。-rc 的发行版是开发中的版本,根本没有 Linux 内核开发者认为它适合任何人使用,更不用说是数百万的用户了。
|
||||
|
||||
当然,如果你愿意,你可以随意地使用它,但是需要注意的是,可能真的就只有你一个人在使用它。社区不会为你提供支持,因为他们不可能关注所有内核版本的特定问题,因此如果出现错误,你只能独自去解决它。对于一些公司和系统来说,这么做可能还行,但是如果没有为此有所规划,那么要当心因此而产生的“隐性”成本。
|
||||
|
||||
### 总结
|
||||
|
||||
基于以上原因,下面是一个针对不同类型设备的简短列表,这些设备我推荐适用的内核如下:
|
||||
|
||||
* 笔记本 / 台式机:最新的稳定版内核
|
||||
* 服务器:最新的稳定版内核或最新的 LTS 版内核
|
||||
* 嵌入式设备:最新的 LTS 版内核或老的 LTS 版内核(如果使用的安全模型非常强大和严格)
|
||||
|
||||
至于我,在我的机器上运行什么样的内核?我的笔记本运行的是最新的开发版内核(即 Linus 的开发树)再加上我正在做修改的内核,我的服务器上运行的是最新的稳定版内核。因此,尽管我负责 LTS 发行版的支持工作,但我自己并不使用 LTS 版内核,除了在测试系统上。我依赖于开发版和最新的稳定版内核,以确保我的机器运行的是目前我们所知道的最快的也是最安全的内核版本。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://kroah.com/log/blog/2018/08/24/what-stable-kernel-should-i-use/
|
||||
|
||||
作者:[Greg Kroah-Hartman][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://kroah.com
|
||||
[1]:https://s3.amazonaws.com/kroah.com/images/kernel.org_2018_08_24.png
|
||||
[2]:http://kroah.com/log/blog/2018/02/05/linux-kernel-release-model/
|
||||
[3]:https://kernelci.org/
|
||||
[4]:https://www.kernel.org/category/releases.html
|
||||
[5]:https://s3.amazonaws.com/kroah.com/images/kernel.org_releases_2018_08_24.png
|
||||
@ -1,10 +1,9 @@
|
||||
Clinews - 从命令行阅读新闻和最新头条
|
||||
Clinews:从命令行阅读新闻和最新头条
|
||||
======
|
||||
|
||||

|
||||
|
||||
不久前,我们写了一个名为 [**InstantNews**][1] 的命令行新闻客户端,它可以帮助你立即在命令行阅读新闻和最新头条新闻。今天,我偶然发现了一个名为 **Clinews** 的类似,它的其功能与此相同 - 在终端阅读来自热门网站的新闻和最新头条,还有博客。你无需安装 GUI 应用或移动应用。你可以直接从终端阅读世界上正在发生的事情。它是使用 **NodeJS** 编写的免费开源程序。
|
||||
|
||||
不久前,我们写了一个名为 [InstantNews][1] 的命令行新闻客户端,它可以帮助你立即在命令行阅读新闻和最新头条新闻。今天,我偶然发现了一个名为 **Clinews** 的类似,它的其功能与此相同 —— 在终端阅读来自热门网站的新闻和最新头条,还有博客。你无需安装 GUI 应用或移动应用。你可以直接从终端阅读世界上正在发生的事情。它是使用 **NodeJS** 编写的自由开源程序。
|
||||
|
||||
### 安装 Clinews
|
||||
|
||||
@ -30,22 +29,20 @@ $ npm -i yarn
|
||||
|
||||
### 配置 News API
|
||||
|
||||
Clinews 从 [**News API**][2] 中检索所有新闻标题。News API 是一个简单易用的API,它返回当前在一系列新闻源和博客上发布的头条的 JSON 元数据。它目前提供来自 70 个热门源的实时头条,包括 Ars Technica、BBC、Blooberg、CNN、每日邮报、Engadget、ESPN、金融时报、谷歌新闻、hacker News,IGN、Mashable、国家地理、Reddit r/all、路透社、 Speigel Online、Techcrunch、The Guardian、The Hindu、赫芬顿邮报、纽约时报、The Next Web、华尔街日报,今日美国和[**等等**][3]。
|
||||
Clinews 从 [News API][2] 中检索所有新闻标题。News API 是一个简单易用的 API,它返回当前在一系列新闻源和博客上发布的头条的 JSON 元数据。它目前提供来自 70 个热门源的实时头条,包括 Ars Technica、BBC、Blooberg、CNN、每日邮报、Engadget、ESPN、金融时报、谷歌新闻、hacker News,IGN、Mashable、国家地理、Reddit r/all、路透社、 Speigel Online、Techcrunch、The Guardian、The Hindu、赫芬顿邮报、纽约时报、The Next Web、华尔街日报,今日美国和[等等][3]。
|
||||
|
||||
首先,你需要 News API 的 API 密钥。进入 [**https://newsapi.org/register**][4] 并注册一个免费帐户来获取 API 密钥。
|
||||
首先,你需要 News API 的 API 密钥。进入 [https://newsapi.org/register][4] 并注册一个免费帐户来获取 API 密钥。
|
||||
|
||||
从 News API 获得 API 密钥后,编辑 **.bashrc**:
|
||||
从 News API 获得 API 密钥后,编辑 `.bashrc`:
|
||||
|
||||
```
|
||||
$ vi ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
在最后添加 newsapi API 密钥,如下所示:
|
||||
|
||||
```
|
||||
export IN_API_KEY="Paste-API-key-here"
|
||||
|
||||
```
|
||||
|
||||
请注意,你需要将密钥粘贴在双引号内。保存并关闭文件。
|
||||
@ -54,7 +51,6 @@ export IN_API_KEY="Paste-API-key-here"
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
完成。现在继续并从新闻源获取最新的头条新闻。
|
||||
@ -65,10 +61,9 @@ $ source ~/.bashrc
|
||||
|
||||
```
|
||||
$ news fetch the-hindu
|
||||
|
||||
```
|
||||
|
||||
这里,**“the-hindu”** 是新闻源的源id(获取 id)。
|
||||
这里,`the-hindu` 是新闻源的源id(获取 id)。
|
||||
|
||||
上述命令将从 The Hindu 新闻站获取最新的 10 个头条,并将其显示在终端中。此外,它还显示新闻的简要描述、发布的日期和时间以及到源的实际链接。
|
||||
|
||||
@ -82,7 +77,6 @@ $ news fetch the-hindu
|
||||
|
||||
```
|
||||
$ news sources
|
||||
|
||||
```
|
||||
|
||||
**示例输出:**
|
||||
@ -91,22 +85,20 @@ $ news sources
|
||||
|
||||
正如你在上面的截图中看到的,Clinews 列出了所有新闻源,包括新闻源的名称、获取 ID、网站描述、网站 URL 以及它所在的国家/地区。在撰写本指南时,Clinews 目前支持 70 多个新闻源。
|
||||
|
||||
Clinews 还可以搜索符合搜索条件/术语的所有源的新闻报道。例如,要列出包含单词 **“Tamilnadu”** 的所有新闻报道,请使用以下命令:
|
||||
Clinews 还可以搜索符合搜索条件/术语的所有源的新闻报道。例如,要列出包含单词 “Tamilnadu” 的所有新闻报道,请使用以下命令:
|
||||
|
||||
```
|
||||
$ news search "Tamilnadu"
|
||||
```
|
||||
|
||||
此命令将会筛选所有新闻源中含有 **Tamilnadu** 的报道。
|
||||
此命令将会筛选所有新闻源中含有 “Tamilnadu” 的报道。
|
||||
|
||||
Clinews有一些额外的标志可以帮助你
|
||||
Clinews 有一些其它选项可以帮助你
|
||||
|
||||
* 限制你想看的新闻报道的数量,
|
||||
* 排序新闻报道(热门、最新),
|
||||
* 智能显示新闻报道分类(例如商业、娱乐、游戏、大众、音乐、政治、科学和自然、体育、技术)
|
||||
|
||||
|
||||
|
||||
更多详细信息,请参阅帮助部分:
|
||||
|
||||
```
|
||||
@ -126,7 +118,7 @@ via: https://www.ostechnix.com/clinews-read-news-and-latest-headlines-from-comma
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,86 @@
|
||||
一款免费且安全的在线 PDF 转换软件
|
||||
======
|
||||
|
||||

|
||||
|
||||
我们总在寻找一个更好用且更高效的解决方案,来我们的生活理加方便。 比方说,在处理 PDF 文档时,你肯定会想拥有一款工具,它能够在任何情形下都显得快速可靠。在这,我们想向你推荐 **EasyPDF** —— 一款可以胜任所有场合的在线 PDF 软件。通过大量的测试,我们可以保证:这款工具能够让你的 PDF 文档管理更加容易。
|
||||
|
||||
不过,关于 EasyPDF 有一些十分重要的事情,你必须知道。
|
||||
|
||||
* EasyPDF 是免费的、匿名的在线 PDF 转换软件。
|
||||
* 能够将 PDF 文档转换成 Word、Excel、PowerPoint、AutoCAD、JPG、GIF 和文本等格式格式的文档。
|
||||
* 能够从 Word、Excel、PowerPoint 等其他格式的文件创建 PDF 文件。
|
||||
* 能够进行 PDF 文档的合并、分割和压缩。
|
||||
* 能够识别扫描的 PDF 和图片中的内容。
|
||||
* 可以从你的设备或者云存储(Google Drive 和 DropBox)中上传文档。
|
||||
* 可以在 Windows、Linux、Mac 和智能手机上通过浏览器来操作。
|
||||
* 支持多种语言。
|
||||
|
||||
### EasyPDF的用户界面
|
||||
|
||||

|
||||
|
||||
EasyPDF 最吸引你眼球的就是平滑的用户界面,营造一种整洁的环境,这会让使用者感觉更加舒服。由于网站完全没有一点广告,EasyPDF 的整体使用体验相比以前会好很多。
|
||||
|
||||
每种不同类型的转换都有它们专门的菜单,只需要简单地向其中添加文件,你并不需要知道太多知识来进行操作。
|
||||
|
||||
许多类似网站没有做好相关的优化,使得在手机上的使用体验并不太友好。然而,EasyPDF 突破了这一个瓶颈。在智能手机上,EasyPDF 几乎可以秒开,并且可以顺畅的操作。你也通过 Chrome 的“三点菜单”把 EasyPDF 添加到手机的主屏幕上。
|
||||
|
||||

|
||||
|
||||
### 特性
|
||||
|
||||
除了好看的界面,EasyPDF 还非常易于使用。为了使用它,你 **不需要注册一个账号** 或者**留下一个邮箱**,它是完全匿名的。另外, EasyPDF 也不会对要转换的文件进行数量或者大小的限制,完全不需要安装!酷极了,不是吗?
|
||||
|
||||
首先,你需要选择一种想要进行的格式转换,比如,将 PDF 转换成 Word。然后,选择你想要转换的 PDF 文件。你可以通过两种方式来上传文件:直接拖拉或者从设备上的文件夹进行选择。还可以选择从[Google Drive][1] 或 [Dropbox][2]来上传文件。
|
||||
|
||||
选择要进行格式转换的文件后,点击 Convert 按钮开始转换过程。转换过程会在一分钟内完成,你并不需要等待太长时间。如果你还有对其他文件进行格式转换,在接着转换前,不要忘了将前面已经转换完成的文件下载保存。不然的话,你将会丢失前面的文件。
|
||||
|
||||
|
||||
|
||||
要进行其他类型的格式转换,直接返回到主页。
|
||||
|
||||
目前支持的几种格式转换类型如下:
|
||||
|
||||
* **PDF to Word** – 将 PDF 文档 转换成 Word 文档
|
||||
* **PDF 转换成 PowerPoint** – 将 PDF 文档 转换成 PowerPoint 演示讲稿
|
||||
* **PDF 转换成 Excel** – 将 PDF 文档 转换成 Excel 文档
|
||||
* **PDF 创建** – 从一些其他类型的文件(如,文本、doc、odt)来创建PDF文档
|
||||
* **Word 转换成 PDF** – 将 Word 文档 转换成 PDF 文档
|
||||
* **JPG 转换成 PDF** – 将 JPG images 转换成 PDF 文档
|
||||
* **PDF 转换成 AutoCAD** – 将 PDF 文档 转换成 .dwg 格式(DWG 是 CAD 文件的原生的格式)
|
||||
* **PDF 转换成 Text** – 将 PDF 文档 转换成 Text 文档
|
||||
* **PDF 分割** – 把 PDF 文件分割成多个部分
|
||||
* **PDF 合并** – 把多个 PDF 文件合并成一个文件
|
||||
* **PDF 压缩** – 将 PDF 文档进行压缩
|
||||
* **PDF 转换成 JPG** – 将 PDF 文档 转换成 JPG 图片
|
||||
* **PDF 转换成 PNG** – 将 PDF 文档 转换成 PNG 图片
|
||||
* **PDF 转换成 GIF** – 将 PDF 文档 转换成 GIF 文件
|
||||
* **在线文字内容识别** – 将扫描的纸质文档转换成能够进行编辑的文件(如,Word、Excel、文本)
|
||||
|
||||
想试一试吗?好极了!点击下面的链接,然后开始格式转换吧!
|
||||
|
||||
[][https://easypdf.com/]
|
||||
|
||||
### 总结
|
||||
|
||||
EasyPDF 名符其实,能够让 PDF 管理更加容易。就我测试过的 EasyPDF 服务而言,它提供了**完全免费**的简单易用的转换功能。它十分快速、安全和可靠。你会对它的服务质量感到非常满意,因为它不用支付任何费用,也不用留下像邮箱这样的个人信息。值得一试,也许你会找到你自己更喜欢的 PDF 工具。
|
||||
|
||||
好吧,我就说这些。更多的好东西还在后后面,请继续关注!
|
||||
|
||||
加油!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/easypdf-a-free-and-secure-online-pdf-conversion-suite/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[zhousiyu325](https://github.com/zhousiyu325)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.ostechnix.com/how-to-mount-google-drive-locally-as-virtual-file-system-in-linux/
|
||||
[2]: https://www.ostechnix.com/install-dropbox-in-ubuntu-18-04-lts-desktop/
|
||||
@ -1,133 +0,0 @@
|
||||
Translating by Ryze-Borgia
|
||||
|
||||
Linux vs Mac: 7 Reasons Why Linux is a Better Choice than Mac
|
||||
======
|
||||
Recently, we highlighted a few points about [why Linux is better than Windows][1]. Unquestionably, Linux is a superior platform. But, like other operating systems it has its drawbacks as well. For a very particular set of tasks (such as Gaming), Windows OS might prove to be better. And, likewise, for another set of tasks (such as video editing), a Mac-powered system might come in handy. It all trickles down to your preference and what you would like to do with your system. So, in this article, we will highlight a number of reasons why Linux is better than Mac.
|
||||
|
||||
If you’re already using a Mac or planning to get one, we recommend you to thoroughly analyze the reasons and decide whether you want to switch/keep using Linux or continue using Mac.
|
||||
|
||||
### 7 Reasons Why Linux is Better Than Mac
|
||||
|
||||
![Linux vs Mac: Why Linux is a Better Choice][2]
|
||||
|
||||
Both Linux and macOS are Unix-like OS and give access to Unix commands, BASH and other shells. Both of them have fewer applications and games than Windows. But the similarity ends here.
|
||||
|
||||
Graphic designers and video editors swear by macOS whereas Linux is a favorite of developers, sysadmins and devops.
|
||||
|
||||
So the question is should you use Linux over Mac? If yes, why? Let me give you some practical and some ideological reasons why Linux is better than Mac.
|
||||
|
||||
#### 1\. Price
|
||||
|
||||
![Linux vs Mac: Why Linux is a Better Choice][3]
|
||||
|
||||
Let’s suppose, you use the system only to browse stuff, watch movies, download photos, write a document, create a spreadsheet, and other similar stuff. And, in addition to those activities, you want to have a secure operating system.
|
||||
|
||||
In that case, you could choose to spend a couple of hundred bucks for a system to get things done. Or do you think spending more for a MacBook is a good idea? Well, you are the judge.
|
||||
|
||||
So, it really depends on what you prefer. Whether you want to spend on a Mac-powered system or get a budget laptop/PC and install any Linux distro for free. Personally, I’ll be happy with a Linux system except for editing videos and music production. In that case, Final Cut Pro (for video editing) and Logic Pro X (for music production) will be my preference.
|
||||
|
||||
#### 2\. Hardware Choices
|
||||
|
||||
![Linux vs Mac: Why Linux is a Better Choice][4]
|
||||
|
||||
Linux is free. You can install it on computers with any configuration. No matter how powerful/old your system is, Linux will work. [Even if you have an 8-year old PC laying around, you can have Linux installed and expect it to run smoothly by selecting the right distro][5].
|
||||
|
||||
But, Mac is as an Apple-exclusive. If you want to assemble a PC or get a budget laptop (with DOS) and expect to install Mac OS, it’s almost impossible. Mac comes baked in with the system Apple manufactures.
|
||||
|
||||
There are [ways to install macOS on non Apple devices][6]. However, the kind of expertise and troubles it requires, it makes you question whether it’s worth the effort.
|
||||
|
||||
You will have a wide range of hardware choices when you go with Linux but a minimal set of configurations when it comes to Mac OS.
|
||||
|
||||
#### 3\. Security
|
||||
|
||||
![Linux vs Mac: Why Linux is a Better Choice][7]
|
||||
|
||||
A lot of people are all praises for iOS and Mac for being a secure platform. Well, yes, it is secure in a way (maybe more secure than Windows OS), but probably not as secure as Linux.
|
||||
|
||||
I am not bluffing. There are malware and adware targeting macOS and the [number is growing every day][8]. I have seen not-so-techie users struggling with their slow mac. A quick investigation revealed that a [browser hijacking malware][9] was the culprit.
|
||||
|
||||
There are no 100% secure operating systems and Linux is not an exception. There are vulnerabilities in the Linux world as well but they are duly patched by the timely updates provided by Linux distributions.
|
||||
|
||||
Thankfully, we don’t have auto-running viruses or browser hijacking malwares in Linux world so far. And that’s one more reason why you should use Linux instead of a Mac.
|
||||
|
||||
#### 4\. Customization & Flexibility
|
||||
|
||||
![Linux vs Mac: Why Linux is a Better Choice][10]
|
||||
|
||||
You don’t like something? Customize it or remove it. End of the story.
|
||||
|
||||
For example, if you do not like the [Gnome desktop environment][11] on Ubuntu 18.04.1, you might as well change it to [KDE Plasma][11]. You can also try some of the [Gnome extensions][12] to enhance your desktop experience. You won’t find this level of freedom and customization on Mac OS.
|
||||
|
||||
Besides, you can even modify the source code of your OS to add/remove something (which requires necessary technical knowledge) and create your own custom OS. Can you do that on Mac OS?
|
||||
|
||||
Moreover, you get an array of Linux distributions to choose from as per your needs. For instance, if you need to mimic the workflow on Mac OS, [Elementary OS][13] would help. Do you want to have a lightweight Linux distribution installed on your old PC? We’ve got you covered in our list of [lightweight Linux distros][5]. Mac OS lacks this kind of flexibility.
|
||||
|
||||
#### 5\. Using Linux helps your professional career [For IT/Tech students]
|
||||
|
||||
![Linux vs Mac: Why Linux is a Better Choice][14]
|
||||
|
||||
This is kind of controversial and applicable to students and job seekers in the IT field. Using Linux doesn’t make you a super-intelligent being and could possibly get you any IT related job.
|
||||
|
||||
However, as you start using Linux and exploring it, you gain experience. As a techie, sooner or later you dive into the terminal, learning your way to move around the file system, installing applications via command line. You won’t even realize that you have learned the skills that newcomers in IT companies get trained on.
|
||||
|
||||
In addition to that, Linux has enormous scope in the job market. There are so many Linux related technologies (Cloud, Kubernetes, Sysadmin etc.) you can learn, earn certifications and get a nice paying job. And to learn these, you have to use Linux.
|
||||
|
||||
#### 6\. Reliability
|
||||
|
||||
![Linux vs Mac: Why Linux is a Better Choice][15]
|
||||
|
||||
Ever wondered why Linux is the best OS to run on any server? Because it is more reliable!
|
||||
|
||||
But, why is that? Why is Linux more reliable than Mac OS?
|
||||
|
||||
The answer is simple – more control to the user while providing better security. Mac OS does not provide you with the full control of its platform. It does that to make things easier for you simultaneously enhancing your user experience. With Linux, you can do whatever you want – which may result in poor user experience (for some) – but it does make it more reliable.
|
||||
|
||||
#### 7\. Open Source
|
||||
|
||||
![Linux vs Mac: Why Linux is a Better Choice][16]
|
||||
|
||||
Open Source is something not everyone cares about. But to me, the most important aspect of Linux being a superior choice is its Open Source nature. And, most of the points discussed below are the direct advantages of an Open Source software.
|
||||
|
||||
To briefly explain, you get to see/modify the source code yourself if it is an open source software. But, for Mac, Apple gets an exclusive control. Even if you have the required technical knowledge, you will not be able to independently take a look at the source code of Mac OS.
|
||||
|
||||
In other words, a Mac-powered system enables you to get a car for yourself but the downside is you cannot open up the hood to see what’s inside. That’s bad!
|
||||
|
||||
If you want to dive in deeper to know about the benefits of an open source software, you should go through [Ben Balter’s article][17] on OpenSource.com.
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
Now that you’ve known why Linux is better than Mac OS. What do you think about it? Are these reasons enough for you to choose Linux over Mac OS? If not, then what do you prefer and why?
|
||||
|
||||
Let us know your thoughts in the comments below.
|
||||
|
||||
Note: The artwork here is based on Club Penguins.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/linux-vs-mac/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[1]: https://itsfoss.com/linux-better-than-windows/
|
||||
[2]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/Linux-vs-mac-featured.png
|
||||
[3]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-1.jpeg
|
||||
[4]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-4.jpeg
|
||||
[5]: https://itsfoss.com/lightweight-linux-beginners/
|
||||
[6]: https://hackintosh.com/
|
||||
[7]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-2.jpeg
|
||||
[8]: https://www.computerworld.com/article/3262225/apple-mac/warning-as-mac-malware-exploits-climb-270.html
|
||||
[9]: https://www.imore.com/how-to-remove-browser-hijack
|
||||
[10]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-3.jpeg
|
||||
[11]: https://www.gnome.org/
|
||||
[12]: https://itsfoss.com/best-gnome-extensions/
|
||||
[13]: https://elementary.io/
|
||||
[14]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-5.jpeg
|
||||
[15]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-6.jpeg
|
||||
[16]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-7.jpeg
|
||||
[17]: https://opensource.com/life/15/12/why-open-source
|
||||
@ -1,3 +1,4 @@
|
||||
translating by belitex
|
||||
How Writing Can Expand Your Skills and Grow Your Career
|
||||
======
|
||||
|
||||
|
||||
108
sources/talk/20181008 3 areas to drive DevOps change.md
Normal file
108
sources/talk/20181008 3 areas to drive DevOps change.md
Normal file
@ -0,0 +1,108 @@
|
||||
3 areas to drive DevOps change
|
||||
======
|
||||
Driving large-scale organizational change is painful, but when it comes to DevOps, the payoff is worth the pain.
|
||||

|
||||
|
||||
Pain avoidance is a powerful motivator. Some studies hint that even [plants experience a type of pain][1] and take steps to defend themselves. Yet we have plenty of examples of humans enduring pain on purpose—exercise often hurts, but we still do it. When we believe the payoff is worth the pain, we'll endure almost anything.
|
||||
|
||||
The truth is that driving large-scale organizational change is painful. It hurts for those having to change their values and behaviors, it hurts for leadership, and it hurts for the people just trying to do their jobs. In the case of DevOps, though, I can tell you the pain is worth it.
|
||||
|
||||
I've seen firsthand how teams learn they must spend time improving their technical processes, take ownership of their automation pipelines, and become masters of their fate. They gain the tools they need to be successful.
|
||||
|
||||
![Improvements after DevOps transformation][3]
|
||||
|
||||
Image by Lee Eason. CC BY-SA 4.0
|
||||
|
||||
This chart shows the value of that change. In a company where I directed a DevOps transformation, its 60+ teams submitted more than 900 requests per month to release management. If you add up the time those tickets stayed open, it came to more than 350 days per month. What could your company do with an extra 350 person-days per month? In addition to the improvements seen above, they went from 100 to 9,000 deployments per month, a 24% decrease in high-severity bugs, happier engineers, and improved net promoter scores (NPS). The biggest NPS improvements link to the teams furthest along on their DevOps journey, as the [Puppet State of DevOps][4] report predicted. The bottom line is that investments into technical process improvement translate into better business outcomes.
|
||||
|
||||
DevOps leaders must focus on three main areas to drive this change: executives, culture, and team health.
|
||||
|
||||
### Executives
|
||||
|
||||
The bottom line is that investments into technical process improvement translate into better business outcomes.
|
||||
|
||||
The larger your organization, the greater the distance (and opportunities for misunderstanding) between business leadership and the individuals delivering services to your customers. To make things worse, the landscape of tools and practices in technology is changing at an accelerating rate. This makes it practically impossible for business leaders to understand on their own how transformations like DevOps or agile work.
|
||||
|
||||
The larger your organization, the greater the distance (and opportunities for misunderstanding) between business leadership and the individuals delivering services to your customers. To make things worse, the landscape of tools and practices in technology is changing at an accelerating rate. This makes it practically impossible for business leaders to understand on their own how transformations like DevOps or agile work.
|
||||
|
||||
DevOps leaders must help executives come along for the ride. Educating leaders gives them options when they're making decisions and makes it more likely they'll choose paths that help your company.
|
||||
|
||||
For example, let's say your executives believe DevOps is going to improve how you deploy your products into production, but they don't understand how. You've been working with a software team to help automate their deployment. When an executive hears about a deploy failure (and there will be failures), they will want to understand how it occurred. When they learn the software team did the deployment rather than the release management team, they may try to protect the business by decreeing all production releases must go through traditional change controls. You will lose credibility, and teams will be far less likely to trust you and accept further changes.
|
||||
|
||||
It takes longer to rebuild trust with executives and get their support after an incident than it would have taken to educate them in the first place. Put the time in upfront to build alignment, and it will pay off as you implement tactical changes.
|
||||
|
||||
Two pieces of advice when building that alignment:
|
||||
|
||||
* First, **don't ignore any constraints** they raise. If they have worries about contracts or security, make the heads of legal and security your new best friends. By partnering with them, you'll build their trust and avoid making costly mistakes.
|
||||
* Second, **use metrics to build a bridge** between what your delivery teams are doing and your executives' concerns. If the business has a goal to reduce customer churn, and you know from research that many customers leave because of unplanned downtime, reinforce that your teams are committed to tracking and improving Mean Time To Detection and Resolution (MTTD and MTTR). You can use those key metrics to show meaningful progress that teams and executives understand and get behind.
|
||||
|
||||
|
||||
|
||||
### Culture
|
||||
|
||||
DevOps is a culture of continuous improvement focused on code, build, deploy, and operational processes. Culture describes the organization's values and behaviors. Essentially, we're talking about changing how people behave, which is never easy.
|
||||
|
||||
I recommend reading [The Wolf in CIO's Clothing][5]. Spend time thinking about psychology and motivation. Read [Drive][6] or at least watch Daniel Pink's excellent [TED Talk][7]. Read [The Hero with a Thousand Faces][8] and learn to identify the different journeys everyone is on. If none of these things sound interesting, you are not the right person to drive change in your company. Otherwise, read on!
|
||||
|
||||
Essentially, we're talking about changing how people behave, which is never easy.
|
||||
|
||||
Most rational people behave according to their values. Most organizations don't have explicit values everyone understands and lives by. Therefore, you'll need to identify the organization's values that have led to the behaviors that have led to the current state. You also need to make sure you can tell the story about how those values came to be and how they led to where you are. When you tell that story, be careful not to demonize those values—they aren't immoral or evil. People did the best they could at the time, given what they knew and what resources they had.
|
||||
|
||||
Most rational people behave according to their values. Most organizations don't have explicit values everyone understands and lives by. Therefore, you'll need to identify the organization's values that have led to the behaviors that have led to the current state. You also need to make sure you can tell the story about how those values came to be and how they led to where you are. When you tell that story, be careful not to demonize those values—they aren't immoral or evil. People did the best they could at the time, given what they knew and what resources they had.
|
||||
|
||||
Explain that the company and its organizational goals are changing, and the team must alter its values. It's helpful to express this in terms of contrast. For example, your company may have historically valued cost savings above all else. That value is there for a reason—the company was cash-strapped. To get new products out, the infrastructure group had to tightly couple services by sharing database clusters or servers. Over time, those practices created a real mess that became hard to maintain. Simple changes started breaking things in unexpected ways. This led to tight change-control processes that were painful for delivery teams, so they stopped changing things.
|
||||
|
||||
Play that movie for five years, and you end up with little to no innovation, legacy technology, attraction and retention problems, and poor-quality products. You've grown the company, but you've hit a ceiling, and you can't continue to grow with those same values and behaviors. Now you must put engineering efficiency above cost saving. If one option will help teams maintain their service easier, but the other option is cheaper in the short term, you go with the first option.
|
||||
|
||||
You must tell this story again and again. Then you must celebrate any time a team expresses the new value through their behavior—even if they make a mistake. When a team has a deploy failure, congratulate them for taking the risk and encourage them to keep learning. Explain how their behavior is leading to the right outcome and support them. Over time, teams will see the message is real, and they'll feel safe altering their behavior.
|
||||
|
||||
### Team health
|
||||
|
||||
Have you ever been in a planning meeting and heard something like this: "We can't really estimate that story until John gets back from vacation. He's the only one who knows that area of the code well enough." Or: "We can't get this task done because it's got a cross-team dependency on network engineering, and the guy that set up the firewall is out sick." Or: "John knows that system best; if he estimated the story at a 3, then let's just go with that." When the team works on that story, who will most likely do the work? That's right, John will, and the cycle will continue.
|
||||
|
||||
For a long time, we've accepted that this is just the nature of software development. If we don't solve for it, we perpetuate the cycle.
|
||||
|
||||
Entropy will always drive teams naturally towards disorder and bad health. Our job as team members and leaders is to intentionally manage against that entropy and keep our teams healthy. Transformations like DevOps, agile, moving to the cloud, or refactoring a legacy application all amplify and accelerate that entropy. That's because transformations add new skills and expertise needed for the team to take on that new type of work.
|
||||
|
||||
Let's look at an example of a product team refactoring its legacy monolith. As usual, they build those new services in AWS. The legacy monolith was deployed to the data center, monitored, and backed up by IT. IT made sure the application's infosec requirements were met at the infrastructure layer. They conducted disaster recovery tests, patched the servers, and installed and configured required intrusion detection and antivirus agents. And they kept change control records, required for the annual audit process, of everything was done to the application's infrastructure.
|
||||
|
||||
I often see product teams make the fatal mistake of thinking IT is all cost and bottleneck. They're hungry to shed the skin of IT and use the public cloud, but they never stop to appreciate the critical services IT provides. Moving to the cloud means you implement these things differently; they don't go away. AWS is still a data center, and any team utilizing it accepts the related responsibilities.
|
||||
|
||||
In practice, this means product teams must learn how to do those IT services when they move to the cloud. So, when our fictional product team starts refactoring its legacy application and putting new services in in the cloud, it will need a vastly expanded skillset to be successful. Those skills don't magically appear—they're learned or hired—and team leaders and managers must actively manage the process.
|
||||
|
||||
I built [Tekata.io][9] because I couldn't find any tools to support me as I helped my teams evolve. Tekata is free and easy to use, but the tool is not as important as the people and process. Make sure you build continuous learning into your cadence and keep track of your team's weak spots. Those weak spots affect your ability to deliver, and filling them usually involves learning new things, so there's a wonderful synergy here. In fact, 76% of millennials think professional development opportunities are [one of the most important elements][10] of company culture.
|
||||
|
||||
### Proof is in the payoff
|
||||
|
||||
DevOps transformations involve altering the behavior, and therefore the culture, of your teams. That must be done with executive support and understanding. At the same time, those behavior changes mean learning new skills, and that process must also be managed carefully. But the payoff for pulling this off is more productive teams, happier and more engaged team members, higher quality products, and happier customers.
|
||||
|
||||
Lee Eason will present [Tales From A DevOps Transformation][11] at [All Things Open][12], October 21-23 in Raleigh, N.C.
|
||||
|
||||
Disclaimer: All opinions are statements in this article are exclusively those of Lee Eason and are not representative of Ipreo or IHS Markit.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/tales-devops-transformation
|
||||
|
||||
作者:[Lee Eason][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/leeeason
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://link.springer.com/article/10.1007%2Fs00442-014-2995-6
|
||||
[2]: /file/411061
|
||||
[3]: https://opensource.com/sites/default/files/uploads/devops-delays.png (Improvements after DevOps transformation)
|
||||
[4]: https://puppet.com/resources/whitepaper/state-of-devops-report
|
||||
[5]: https://www.gartner.com/en/publications/wolf-cio
|
||||
[6]: https://en.wikipedia.org/wiki/Drive:_The_Surprising_Truth_About_What_Motivates_Us
|
||||
[7]: https://www.ted.com/talks/dan_pink_on_motivation?language=en#t-2094
|
||||
[8]: https://en.wikipedia.org/wiki/The_Hero_with_a_Thousand_Faces
|
||||
[9]: https://tekata.io/
|
||||
[10]: https://www.execu-search.com/~/media/Resources/pdf/2017_Hiring_Outlook_eBook
|
||||
[11]: https://allthingsopen.org/talk/tales-from-a-devops-transformation/
|
||||
[12]: https://allthingsopen.org/
|
||||
@ -0,0 +1,47 @@
|
||||
4 best practices for giving open source code feedback
|
||||
======
|
||||
A few simple guidelines can help you provide better feedback.
|
||||
|
||||

|
||||
|
||||
In the previous article I gave you tips for [how to receive feedback][1], especially in the context of your first free and open source project contribution. Now it's time to talk about the other side of that same coin: providing feedback.
|
||||
|
||||
If I tell you that something you did in your contribution is "stupid" or "naive," how would you feel? You'd probably be angry, hurt, or both, and rightfully so. These are mean-spirited words that when directed at people, can cut like knives. Words matter, and they matter a great deal. Therefore, put as much thought into the words you use when leaving feedback for a contribution as you do into any other form of contribution you give to the project. As you compose your feedback, think to yourself, "How would I feel if someone said this to me? Is there some way someone might take this another way, a less helpful way?" If the answer to that last question has even the chance of being a yes, backtrack and rewrite your feedback. It's better to spend a little time rewriting now than to spend a lot of time apologizing later.
|
||||
|
||||
When someone does make a mistake that seems like it should have been obvious, remember that we all have different experiences and knowledge. What's obvious to you may not be to someone else. And, if you recall, there once was a time when that thing was not obvious to you. We all make mistakes. We all typo. We all forget commas, semicolons, and closing brackets. Save yourself a lot of time and effort: Point out the mistake, but leave out the judgement. Stick to the facts. After all, if the mistake is that obvious, then no critique will be necessary, right?
|
||||
|
||||
1. **Avoid ad hominem comments.** Remember to review only the contribution and not the person who contributed it. That is to say, point out, "the contribution could be more efficient here in this way…" rather than, "you did this inefficiently." The latter is ad hominem feedback. Ad hominem is a Latin phrase meaning "to the person," which is where your feedback is being directed: to the person who contributed it rather than to the contribution itself. By providing feedback on the person you make that feedback personal, and the contributor is justified in taking it personally. Be careful when crafting your feedback to make sure you're addressing only the contents of the contribution and not accidentally criticizing the person who submitted it for review.
|
||||
|
||||
2. **Include positive comments.** Not all of your feedback has to (or should) be critical. As you review the contribution and you see something that you like, provide feedback on that as well. Several academic studies—including an important one by [Baumeister, Braslavsky, Finkenauer, and Vohs][2]—show that humans focus more on negative feedback than positive. When your feedback is solely negative, it can be very disheartening for contributors. Including positive reinforcement and feedback is motivating to people and helps them feel good about their contribution and the time they spent on it, which all adds up to them feeling more inclined to provide another contribution in the future. It doesn't have to be some gushing paragraph of flowery praise, but a quick, "Huh, that's a really smart way to handle that. It makes everything flow really well," can go a long way toward encouraging someone to keep contributing.
|
||||
|
||||
3. **Questions are feedback, too.** Praise is one less common but valuable type of review feedback. Questions are another. If you're looking at a contribution and can't tell why the submitter
|
||||
|
||||
When your feedback is solely negative, it can be very disheartening for contributors.
|
||||
|
||||
did things the way they did, or if the contribution just doesn't make a lot of sense to you, asking for more information acts as feedback. It tells the submitter that something they contributed isn't as clear as they thought and that it may need some work to make the approach more obvious, or if it's a code contribution, a comment to explain what's going on and why. A simple, "I don't understand this part here. Could you please tell me what it's doing and why you chose that way?" can start a dialogue that leads to a contribution that's much easier for future contributors to understand and maintain.
|
||||
|
||||
4. **Expect a negotiation.** Using questions as a form of feedback implies that there will be answers to those questions, or perhaps other questions in response. Whether your feedback is in question or statement format, you should expect to generate some sort of dialogue throughout the process. An alternative is to see your feedback as incontrovertible, your word as law. Although this is definitely one approach you can take, it's rarely a good one. When providing feedback on a contribution, it's best to collaborate rather than dictate. As these dialogues arise, embracing them as opportunities for conversation and learning on both sides is important. Be willing to discuss their approach and your feedback, and to take the time to understand their perspective.
|
||||
|
||||
|
||||
|
||||
|
||||
The bottom line is: Don't be a jerk. If you're not sure whether the feedback you're planning to leave makes you sound like a jerk, pause to have someone else review it before you click Send. Have empathy for the person at the receiving end of that feedback. While the maxim is thousands of years old, it still rings true today that you should try to do unto others as you would have them do unto you. Put yourself in their shoes and aim to be helpful and supportive rather than simply being right.
|
||||
|
||||
_Adapted from[Forge Your Future with Open Source][3] by VM (Vicky) Brasseur, Copyright © 2018 The Pragmatic Programmers LLC. Reproduced with the permission of the publisher._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/best-practices-giving-open-source-code-feedback
|
||||
|
||||
作者:[VM(Vicky) Brasseur][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/vmbrasseur
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/18/10/6-tips-receiving-feedback
|
||||
[2]: https://www.msudenver.edu/media/content/sri-taskforce/documents/Baumeister-2001.pdf
|
||||
[3]: http://www.pragprog.com/titles/vbopens
|
||||
@ -0,0 +1,82 @@
|
||||
GCC: Optimizing Linux, the Internet, and Everything
|
||||
======
|
||||
|
||||

|
||||
|
||||
Software is useless if computers can't run it. Even the most talented developer is at the mercy of the compiler when it comes to run-time performance - if you don’t have a reliable compiler toolchain you can’t build anything serious. The GNU Compiler Collection (GCC) provides a robust, mature and high performance partner to help you get the most out of your software. With decades of development by thousands of people GCC is one of the most respected compilers in the world. If you are building applications and not using GCC, you are missing out on the best possible solution.
|
||||
|
||||
GCC is the “de facto-standard open source compiler today” [1] according to LLVM.org and the foundation used to build complete systems - from the kernel upwards. GCC supports over 60 hardware platforms, including ARM, Intel, AMD, IBM POWER, SPARC, HP PA-RISC, and IBM Z, as well as a variety of operating environments, including GNU, Linux, Windows, macOS, FreeBSD, NetBSD, OpenBSD, DragonFly BSD, Solaris, AIX, HP-UX, and RTEMS. It offers highly compliant C/C++ compilers and support for popular C libraries, such as GNU C Library (glibc), Newlib, musl, and the C libraries included with various BSD operating systems, as well as front-ends for Fortran, Ada, and GO languages. GCC also functions as a cross compiler, creating executable code for a platform other than the one on which the compiler is running. GCC is the core component of the tightly integrated GNU toolchain, produced by the GNU Project, that includes glibc, Binutils, and the GNU Debugger (GDB).
|
||||
|
||||
"My all-time favorite GNU tool is GCC, the GNU Compiler Collection. At a time when developer tools were expensive, GCC was the second GNU tool and the one that enabled a community to write and build all the others. This tool single-handedly changed the industry and led to the creation of the free software movement, since a good, free compiler is a prerequisite to a community creating software." —Dave Neary, Open Source and Standards team at Red Hat. [2]
|
||||
|
||||
### Optimizing Linux
|
||||
|
||||
As the default compiler for the Linux kernel source, GCC delivers trusted, stable performance along with the additional extensions needed to correctly build the kernel. GCC is a standard component of popular Linux distributions, such as Arch Linux, CentOS, Debian, Fedora, openSUSE, and Ubuntu, where it routinely compiles supporting system components. This includes the default libraries used by Linux (such as libc, libm, libintl, libssh, libssl, libcrypto, libexpat, libpthread, and ncurses) which depend on GCC to provide correctness and performance and are used by applications and system utilities to access Linux kernel features. Many of the application packages included with a distribution are also built with GCC, such as Python, Perl, Ruby, nginx, Apache HTTP Server, OpenStack, Docker, and OpenShift. This combination of kernel, libraries, and application software translates into a large volume of code built with GCC for each Linux distribution. For the openSUSE distribution nearly 100% of native code is built by GCC, including 6,135 source packages producing 5,705 shared libraries and 38,927 executables. This amounts to about 24,540 source packages compiled weekly. [3]
|
||||
|
||||
The base version of GCC included in Linux distributions is used to create the kernel and libraries that define the system Application Binary Interface (ABI). User space developers have the option of downloading the latest stable version of GCC to gain access to advanced features, performance optimizations, and improvements in usability. Linux distributions offer installation instructions or prebuilt toolchains for deploying the latest version of GCC along with other GNU tools that help to enhance developer productivity and improve deployment time.
|
||||
|
||||
### Optimizing the Internet
|
||||
|
||||
GCC is one of the most widely adopted core compilers for embedded systems, enabling the development of software for the growing world of IoT devices. GCC offers a number of extensions that make it well suited for embedded systems software development, including fine-grained control using compiler built-ins, #pragmas, inline assembly, and application-focussed command-line options. GCC supports a broad base of embedded architectures, including ARM, AMCC, AVR, Blackfin, MIPS, RISC-V, Renesas Electronics V850, and NXP and Freescale Power-based processors, producing efficient, high quality code. The cross-compilation capability offered by GCC is critical to this community, and prebuilt cross-compilation toolchains [4] are a major requirement. For example, the GNU ARM Embedded toolchains are integrated and validated packages featuring the Arm Embedded GCC compiler, libraries, and other tools necessary for bare-metal software development. These toolchains are available for cross-compilation on Windows, Linux and macOS host operating systems and target the popular ARM Cortex-R and Cortex-M processors, which have shipped in tens of billions of internet capable devices. [5]
|
||||
|
||||
GCC empowers Cloud Computing, providing a reliable development platform for software that needs to directly manages computing resources, like database and web serving engines and backup and security software. GCC is fully compliant with C++11 and C++14 and offers experimental support for C++17 and C++2a [6], creating performant object code with a solid debugging information. Some examples of applications that utilize GCC include: MySQL Database Management System, which requires GCC for Linux [7]; the Apache HTTP Server, which recommends using GCC [8]; and Bacula, an enterprise ready network backup tool which require GCC. [9]
|
||||
|
||||
### Optimizing Everything
|
||||
|
||||
For the research and development of the scientific codes used in High Performance Computing (HPC), GCC offers mature C, C++, and Fortran front ends as well as support for OpenMP and OpenACC APIs for directive-based parallel programming. Because GCC offers portability across computing environments, it enables code to be more easily targeted and tested across a variety of new and legacy client and server platforms. GCC offers full support for OpenMP 4.0 for C, C++ and Fortran compilers and full support for OpenMP 4.5 for C and C++ compilers. For OpenACC, GCC supports most of the 2.5 specification and performance optimizations and is the only non-commercial, nonacademic compiler to provide [OpenACC][1] support.
|
||||
|
||||
Code performance is an important parameter to this community and GCC offers a solid performance base. A Nov. 2017 paper published by Colfax Research evaluates C++ compilers for the speed of compiled code parallelized with OpenMP 4.x directives and for the speed of compilation time. Figure 1 plots the relative performance of the computational kernels when compiled by the different compilers and run with a single thread. The performance values are normalized so that the performance of G++ is equal to 1.0.
|
||||
|
||||
![performance][3]
|
||||
|
||||
Figure 1. Relative performance of each kernel as compiled by the different compilers. (single-threaded, higher is better).
|
||||
|
||||
[Used with permission][4]
|
||||
|
||||
The paper summarizes “the GNU compiler also does very well in our tests. G++ produces the second fastest code in three out of six cases and is amongst the fastest compiler in terms of compile time.” [10]
|
||||
|
||||
### Who Is Using GCC?
|
||||
|
||||
In The State of Developer Ecosystem Survey in 2018 by JetBrains, out of 6,000 developers who took the survey GCC is regularly used by 66% of C++ programmers and 73% of C programmers. [11] Here is a quick summary of the benefits of GCC that make it so popular with the developer community.
|
||||
|
||||
* For developers required to write code for a variety of new and legacy computing platforms and operating environments, GCC delivers support for the broadest range of hardware and operating environments. Compilers offered by hardware vendors focus mainly on support for their products and other open source compilers are much more limited in the hardware and operating systems supported. [12]
|
||||
|
||||
* There is a wide variety of GCC-based prebuilt toolchains, which has particular appeal to embedded systems developers. This includes the GNU ARM Embedded toolchains and 138 pre-compiled cross compiler toolchains available on the Bootlin web site. [13] While other open source compilers, such as Clang/LLVM, can replace GCC in existing cross compiling toolchains, these would need to be completely rebuilt by the developer. [14]
|
||||
|
||||
* GCC delivers to application developers trusted, stable performance from a mature compiler platform. The GCC 8/9 vs. LLVM Clang 6/7 Compiler Benchmarks On AMD EPYC article provides results of 49 benchmarks ran across the four tested compilers at three optimization levels. Coming in first 34% of the time was GCC 8.2 RC1 using "-O3 -march=native" level, while at the same optimization level LLVM Clang 6.0 came in second with wins 20% of the time. [15]
|
||||
|
||||
* GCC delivers improved diagnostics for compile time debugging [16] and accurate and useful information for runtime debugging. GCC is tightly integrated with GDB, a mature and feature complete tool which offers ‘non-stop’ debugging that can stop a single thread at a breakpoint.
|
||||
|
||||
* GCC is a well supported platform with an active, committed community that supports the current and two previous releases. With releases schedule yearly this provides two years of support for a version.
|
||||
|
||||
|
||||
|
||||
|
||||
### GCC: Continuing to Optimize Linux, the Internet, and Everything
|
||||
|
||||
GCC continues to move forward as a world-class compiler. The most current version of GCC is 8.2, which was released in July 2018 and added hardware support for upcoming Intel CPUs, more ARM CPUs and improved performance for AMD’s ZEN CPU. Initial C17 support has been added along with initial work towards C++2A. Diagnostics have continued to be enhanced including better emitted diagnostics, with improved locations, location ranges, and fix-it hints, particularly in the C++ front end. A blog written by David Malcolm of Red Hat in March 2018 provides an overview of usability improvements in GCC 8. [17]
|
||||
|
||||
New hardware platforms continue to rely on the GCC toolchain for software development, such as RISC-V, a free and open ISA that is of interest to machine learning, Artificial Intelligence (AI), and IoT market segments. GCC continues to be a critical component in the continuing development of Linux systems. The Clear Linux Project for Intel Architecture, an emerging distribution built for cloud, client, and IoT use cases, provides a good example of how GCC compiler technology is being used and improved to boost the performance and security of a Linux-based system. GCC is also being used for application development for Microsoft's Azure Sphere, a Linux-based operating system for IoT applications that initially supports the ARM based MediaTek MT3620 processor. In terms of developing the next generation of programmers, GCC is also a core component of the Windows toolchain for Raspberry PI, the low-cost embedded board running Debian-based GNU/Linux that is used to promote the teaching of basic computer science in schools and developing countries.
|
||||
|
||||
GCC was first released on March 22, 1987 by Richard Stallman, the founder of the GNU Project and was considered a significant breakthrough since it was the first portable ANSI C optimizing compiler released as free software. GCC is maintained by a community of programmers from all over the world under the direction of a steering committee that ensures broad, representative oversight of the project. GCC’s community approach is one of its strengths, resulting in a large and diverse community of developers and users that contribute to and provide support for the project. According to Open Hub, GCC “is one of the largest open-source teams in the world, and is in the top 2% of all project teams on Open Hub.” [18]
|
||||
|
||||
There has been a lot of discussion about the licensing of GCC, most of which confuses rather than enlightens. GCC is distributed under the GNU General Public License version 3 or later with the Runtime Library Exception. This is a copyleft license, which means that derivative work can only be distributed under the same license terms. GPLv3 is intended to protect GCC from being made proprietary and requires that changes to GCC code are made available freely and openly. To the ‘end user’ the compiler is just the same as any other; using GCC makes no difference to any licensing choices you might make for your own code. [19]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/10/gcc-optimizing-linux-internet-and-everything
|
||||
|
||||
作者:[Margaret Lewis][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/margaret-lewis
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.openacc.org/tools
|
||||
[2]: /files/images/gccjpg-0
|
||||
[3]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/gcc_0.jpg?itok=HbGnRqWX (performance)
|
||||
[4]: https://www.linux.com/licenses/category/used-permission
|
||||
@ -1,100 +0,0 @@
|
||||
认领:by sd886393
|
||||
What containers can teach us about DevOps
|
||||
======
|
||||
|
||||
The use of containers supports the three pillars of DevOps practices: flow, feedback, and continual experimentation and learning.
|
||||
|
||||
|
||||
|
||||
One can argue that containers and DevOps were made for one another. Certainly, the container ecosystem benefits from the skyrocketing popularity of DevOps practices, both in design choices and in DevOps’ use by teams developing container technologies. Because of this parallel evolution, the use of containers in production can teach teams the fundamentals of DevOps and its three pillars: [The Three Ways][1].
|
||||
|
||||
### Principles of flow
|
||||
|
||||
**Container flow**
|
||||
|
||||
A container can be seen as a silo, and from inside, it is easy to forget the rest of the system: the host node, the cluster, the underlying infrastructure. Inside the container, it might appear that everything is functioning in an acceptable manner. From the outside perspective, though, the application inside the container is a part of a larger ecosystem of applications that make up a service: the web API, the web app user interface, the database, the workers, and caching services and garbage collectors. Teams put constraints on the container to limit performance impact on infrastructure, and much has been done to provide metrics for measuring container performance because overloaded or slow container workloads have downstream impact on other services or customers.
|
||||
|
||||
**Real-world flow**
|
||||
|
||||
This lesson can be applied to teams functioning in a silo as well. Every process (be it code release, infrastructure creation or even, say, manufacturing of [Spacely’s Sprockets][2]), follows a linear path from conception to realization. In technology, this progress flows from development to testing to operations and release. If a team working alone becomes a bottleneck or introduces a problem, the impact is felt all along the entire pipeline. A defect passed down the line destroys productivity downstream. While the broken process within the scope of the team itself may seem perfectly correct, it has a negative impact on the environment as a whole.
|
||||
|
||||
**DevOps and flow**
|
||||
|
||||
The first way of DevOps, principles of flow, is about approaching the process as a whole, striving to comprehend how the system works together and understanding the impact of issues on the entire process. To increase the efficiency of the process, pain points and waste are identified and removed. This is an ongoing process; teams must continually strive to increase visibility into the process and find and fix trouble spots and waste.
|
||||
|
||||
> “The outcomes of putting the First Way into practice include never passing a known defect to downstream work centers, never allowing local optimization to create global degradation, always seeking to increase flow, and always seeking to achieve a profound understanding of the system (as per Deming).”
|
||||
|
||||
–Gene Kim, [The Three Ways: The Principles Underpinning DevOps][3], IT Revolution, 25 Apr. 2017
|
||||
|
||||
### Principles of feedback
|
||||
|
||||
**Container feedback**
|
||||
|
||||
In addition to limiting containers to prevent impact elsewhere, many products have been created to monitor and trend container metrics in an effort to understand what they are doing and notify when they are misbehaving. [Prometheus][4], for example, is [all the rage][5] for collecting metrics from containers and clusters. Containers are excellent at separating applications and providing a way to ship an environment together with the code, sometimes at the cost of opacity, so much is done to try to provide rapid feedback so issues can be addressed promptly within the silo.
|
||||
|
||||
**Real-world feedback**
|
||||
|
||||
The same is necessary for the flow of the system. From inception to realization, an efficient process quickly provides relevant feedback to identify when there is an issue. The key words here are “quick” and “relevant.” Burying teams in thousands of irrelevant notifications make it difficult or even impossible to notice important events that need immediate action, and receiving even relevant information too late may allow small, easily solved issues to move downstream and become bigger problems. Imagine [if Lucy and Ethel][6] had provided immediate feedback that the conveyor belt was too fast—there would have been no problem with the chocolate production (though that would not have been nearly as funny).
|
||||
|
||||
**DevOps and feedback**
|
||||
|
||||
The Second Way of DevOps, principles of feedback, is all about getting relevant information quickly. With immediate, useful feedback, problems can be identified as they happen and addressed before impact is felt elsewhere in the development process. DevOps teams strive to “optimize for downstream” and immediately move to fix problems that might impact other teams that come after them. As with flow, feedback is a continual process to identify ways to quickly get important data and act on problems as they occur.
|
||||
|
||||
> “Creating fast feedback is critical to achieving quality, reliability, and safety in the technology value stream.”
|
||||
|
||||
–Gene Kim, et al., The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations, IT Revolution Press, 2016
|
||||
|
||||
### Principles of continual experimentation and learning
|
||||
|
||||
**Container continual experimentation and learning**
|
||||
|
||||
It is a bit more challenging applying operational learning to the Third Way of DevOps:continual experimentation and learning. Trying to salvage what we can grasp of the very edges of the metaphor, containers make development easy, allowing developers and operations teams to test new code or configurations locally and safely outside of production and incorporate discovered benefits into production in a way that was difficult in the past. Changes can be radical and still version-controlled, documented, and shared quickly and easily.
|
||||
|
||||
**Real-world continual experimentation and learning**
|
||||
|
||||
For example, consider this anecdote from my own experience: Years ago, as a young, inexperienced sysadmin (just three weeks into the job), I was asked to make changes to an Apache virtual host running the website of the central IT department for a university. Without an easy-to-use test environment, I made a configuration change to the production site that I thought would accomplish the task and pushed it out. Within a few minutes, I overheard coworkers in the next cube:
|
||||
|
||||
“Wait, is the website down?”
|
||||
|
||||
“Hrm, yeah, it looks like it. What the heck?”
|
||||
|
||||
There was much eye-rolling involved.
|
||||
|
||||
Mortified (the shame is real, folks), I sunk down as far as I could into my seat and furiously tried to back out the changes I’d introduced. Later that same afternoon, the director of the department—the boss of my boss’s boss—appeared in my cube to talk about what had happened. “Don’t worry,” she told me. “We’re not mad at you. It was a mistake and now you have learned.”
|
||||
|
||||
In the world of containers, this could have been easily changed and tested on my own laptop and the broken configuration identified by more skilled team members long before it ever made it into production.
|
||||
|
||||
**DevOps continual experimentation and learning**
|
||||
|
||||
A real culture of experimentation promotes the individual’s ability to find where a change in the process may be beneficial, and to test that assumption without the fear of retaliation if they fail. For DevOps teams, failure becomes an educational tool that adds to the knowledge of the individual and organization, rather than something to be feared or punished. Individuals in the DevOps team dedicate themselves to continuous learning, which in turn benefits the team and wider organization as that knowledge is shared.
|
||||
|
||||
As the metaphor completely falls apart, focus needs to be given to a specific point: The other two principles may appear at first glance to focus entirely on process, but continual learning is a human task—important for the future of the project, the person, the team, and the organization. It has an impact on the process, but it also has an impact on the individual and other people.
|
||||
|
||||
> “Experimentation and risk-taking are what enable us to relentlessly improve our system of work, which often requires us to do things very differently than how we’ve done it for decades.”
|
||||
|
||||
–Gene Kim, et al., [The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win][7], IT Revolution Press, 2013
|
||||
|
||||
### Containers can teach us DevOps
|
||||
|
||||
Learning to work effectively with containers can help teach DevOps and the Three Ways: principles of flow, principles of feedback, and principles of continuous experimentation and learning. Looking holistically at the application and infrastructure rather than putting on blinders to everything outside the container teaches us to take all parts of the system and understand their upstream and downstream impacts, break out of silos, and work as a team to increase global performance and deep understanding of the entire system. Working to provide timely and accurate feedback teaches us to create effective feedback patterns within our organizations to identify problems before their impact grows. Finally, providing a safe environment to try new ideas and learn from them teaches us to create a culture where failure represents a positive addition to our knowledge and the ability to take big chances with educated guesses can result in new, elegant solutions to complex problems.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/containers-can-teach-us-devops
|
||||
|
||||
作者:[Chris Hermansen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/clhermansen
|
||||
[1]: https://itrevolution.com/the-three-ways-principles-underpinning-devops/
|
||||
[2]: https://en.wikipedia.org/wiki/The_Jetsons
|
||||
[3]: http://itrevolution.com/the-three-ways-principles-underpinning-devops
|
||||
[4]: https://prometheus.io/
|
||||
[5]: https://opensource.com/article/18/9/prometheus-operational-advantage
|
||||
[6]: https://www.youtube.com/watch?v=8NPzLBSBzPI
|
||||
[7]: https://itrevolution.com/book/the-phoenix-project/
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Tips for listing files with ls at the Linux command line
|
||||
======
|
||||
Learn some of the Linux 'ls' command's most useful variations.
|
||||
|
||||
@ -0,0 +1,328 @@
|
||||
6 Commands To Shutdown And Reboot The Linux System From Terminal
|
||||
======
|
||||
Linux administrator performing many tasks in their routine work. The system Shutdown and Reboot task also included in it.
|
||||
|
||||
It’s one of the risky task for them because some times it wont come back due to some reasons and they need to spend more time on it to troubleshoot.
|
||||
|
||||
These task can be performed through CLI in Linux. Most of the time Linux administrator prefer to perform these kind of tasks via CLI because they are familiar on this.
|
||||
|
||||
There are few commands are available in Linux to perform these tasks and user needs to choose appropriate command to perform the task based on the requirement.
|
||||
|
||||
All these commands has their own feature and allow Linux admin to use it.
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [11 Methods To Find System/Server Uptime In Linux][1]
|
||||
**(#)** [Tuptime – A Tool To Report The Historical And Statistical Running Time Of Linux System][2]
|
||||
|
||||
When the system is initiated for Shutdown or Reboot. It will be notified to all logged-in users and processes. Also, it wont allow any new logins if the time argument is used.
|
||||
|
||||
I would suggest you to double check before you perform this action because you need to follow few prerequisites to make sure everything is fine.
|
||||
|
||||
Those steps are listed below.
|
||||
|
||||
* Make sure you should have a console access to troubleshoot further in case any issues arise. VMWare access for VMs and IPMI/iLO/iDRAC access for physical servers.
|
||||
* You have to create a ticket as per your company procedure either Incident or Change ticket and get approval
|
||||
* Take the important configuration files backup and move to other servers for safety
|
||||
* Verify the log files (Perform the pre-check)
|
||||
* Communicate about your activity with other dependencies teams like DBA, Application, etc
|
||||
* Ask them to bring down their Database service or Application service and get a confirmation from them.
|
||||
* Validate the same from your end using the appropriate command to double confirm this.
|
||||
* Finally reboot the system
|
||||
* Verify the log files (Perform the post-check), If everything is good then move to next step. If you found something is wrong then troubleshoot accordingly.
|
||||
* If it’s back to up and running, ask the dependencies team to bring up their applications.
|
||||
* Monitor for some time, and communicate back to them saying everything is working fine as expected.
|
||||
|
||||
|
||||
|
||||
This task can be performed using following commands.
|
||||
|
||||
* **`shutdown Command:`** shutdown command used to halt, power-off or reboot the machine.
|
||||
* **`halt Command:`** halt command used to halt, power-off or reboot the machine.
|
||||
* **`poweroff Command:`** poweroff command used to halt, power-off or reboot the machine.
|
||||
* **`reboot Command:`** reboot command used to halt, power-off or reboot the machine.
|
||||
* **`init Command:`** init (short for initialization) is the first process started during booting of the computer system.
|
||||
* **`systemctl Command:`** systemd is a system and service manager for Linux operating systems.
|
||||
|
||||
|
||||
|
||||
### Method-1: How To Shutdown And Reboot The Linux System Using Shutdown Command
|
||||
|
||||
shutdown command used to power-off or reboot a Linux remote machine or local host. It’s offering
|
||||
multiple options to perform this task effectively. If the time argument is used, 5 minutes before the system goes down the /run/nologin file is created to ensure that further logins shall not be allowed.
|
||||
|
||||
The general syntax is
|
||||
|
||||
```
|
||||
# shutdown [OPTION] [TIME] [MESSAGE]
|
||||
|
||||
```
|
||||
|
||||
Run the below command to shutdown a Linux machine immediately. It will kill all the processes immediately and will shutdown the system.
|
||||
|
||||
```
|
||||
# shutdown -h now
|
||||
|
||||
```
|
||||
|
||||
* **`-h:`** Equivalent to –poweroff, unless –halt is specified.
|
||||
|
||||
|
||||
|
||||
Alternatively we can use the shutdown command with `halt` option to bring down the machine immediately.
|
||||
|
||||
```
|
||||
# shutdown --halt now
|
||||
or
|
||||
# shutdown -H now
|
||||
|
||||
```
|
||||
|
||||
* **`-H, --halt:`** Halt the machine.
|
||||
|
||||
|
||||
|
||||
Alternatively we can use the shutdown command with `poweroff` option to bring down the machine immediately.
|
||||
|
||||
```
|
||||
# shutdown --poweroff now
|
||||
or
|
||||
# shutdown -P now
|
||||
|
||||
```
|
||||
|
||||
* **`-P, --poweroff:`** Power-off the machine (the default).
|
||||
|
||||
|
||||
|
||||
Run the below command to shutdown a Linux machine immediately. It will kill all the processes immediately and will shutdown the system.
|
||||
|
||||
```
|
||||
# shutdown -h now
|
||||
|
||||
```
|
||||
|
||||
* **`-h:`** Equivalent to –poweroff, unless –halt is specified.
|
||||
|
||||
|
||||
|
||||
If you run the below commands without time parameter, it will wait for a minute then execute the given command.
|
||||
|
||||
```
|
||||
# shutdown -h
|
||||
Shutdown scheduled for Mon 2018-10-08 06:42:31 EDT, use 'shutdown -c' to cancel.
|
||||
|
||||
[email protected]#
|
||||
Broadcast message from [email protected] (Mon 2018-10-08 06:41:31 EDT):
|
||||
|
||||
The system is going down for power-off at Mon 2018-10-08 06:42:31 EDT!
|
||||
|
||||
```
|
||||
|
||||
All other logged in users can see a broadcast message in their terminal like below.
|
||||
|
||||
```
|
||||
[[email protected] ~]$
|
||||
Broadcast message from [email protected] (Mon 2018-10-08 06:41:31 EDT):
|
||||
|
||||
The system is going down for power-off at Mon 2018-10-08 06:42:31 EDT!
|
||||
|
||||
```
|
||||
|
||||
for Halt option.
|
||||
|
||||
```
|
||||
# shutdown -H
|
||||
Shutdown scheduled for Mon 2018-10-08 06:37:53 EDT, use 'shutdown -c' to cancel.
|
||||
|
||||
[email protected]#
|
||||
Broadcast message from [email protected] (Mon 2018-10-08 06:36:53 EDT):
|
||||
|
||||
The system is going down for system halt at Mon 2018-10-08 06:37:53 EDT!
|
||||
|
||||
```
|
||||
|
||||
for Poweroff option.
|
||||
|
||||
```
|
||||
# shutdown -P
|
||||
Shutdown scheduled for Mon 2018-10-08 06:40:07 EDT, use 'shutdown -c' to cancel.
|
||||
|
||||
[email protected]#
|
||||
Broadcast message from [email protected] (Mon 2018-10-08 06:39:07 EDT):
|
||||
|
||||
The system is going down for power-off at Mon 2018-10-08 06:40:07 EDT!
|
||||
|
||||
```
|
||||
|
||||
This can be cancelled by hitting `shutdown -c` option on your terminal.
|
||||
|
||||
```
|
||||
# shutdown -c
|
||||
|
||||
Broadcast message from [email protected] (Mon 2018-10-08 06:39:09 EDT):
|
||||
|
||||
The system shutdown has been cancelled at Mon 2018-10-08 06:40:09 EDT!
|
||||
|
||||
```
|
||||
|
||||
All other logged in users can see a broadcast message in their terminal like below.
|
||||
|
||||
```
|
||||
[[email protected] ~]$
|
||||
Broadcast message from [email protected] (Mon 2018-10-08 06:41:35 EDT):
|
||||
|
||||
The system shutdown has been cancelled at Mon 2018-10-08 06:42:35 EDT!
|
||||
|
||||
```
|
||||
|
||||
Add a time parameter, if you want to perform shutdown or reboot in `N` seconds. Here you can add broadcast a custom message to logged-in users. In this example, we are rebooting the machine in another 5 minutes.
|
||||
|
||||
```
|
||||
# shutdown -r +5 "To activate the latest Kernel"
|
||||
Shutdown scheduled for Mon 2018-10-08 07:13:16 EDT, use 'shutdown -c' to cancel.
|
||||
|
||||
[[email protected] ~]#
|
||||
Broadcast message from [email protected] (Mon 2018-10-08 07:08:16 EDT):
|
||||
|
||||
To activate the latest Kernel
|
||||
The system is going down for reboot at Mon 2018-10-08 07:13:16 EDT!
|
||||
|
||||
```
|
||||
|
||||
Run the below command to reboot a Linux machine immediately. It will kill all the processes immediately and will reboot the system.
|
||||
|
||||
```
|
||||
# shutdown -r now
|
||||
|
||||
```
|
||||
|
||||
* **`-r, --reboot:`** Reboot the machine.
|
||||
|
||||
|
||||
|
||||
### Method-2: How To Shutdown And Reboot The Linux System Using reboot Command
|
||||
|
||||
reboot command used to power-off or reboot a Linux remote machine or local host. Reboot command comes with two useful options.
|
||||
|
||||
It will perform a graceful shutdown and restart of the machine (This is similar to your restart option which is available in your system menu).
|
||||
|
||||
Run “reboot’ command without any option to reboot Linux machine.
|
||||
|
||||
```
|
||||
# reboot
|
||||
|
||||
```
|
||||
|
||||
Run the “reboot” command with `-p` option to power-off or shutdown the Linux machine.
|
||||
|
||||
```
|
||||
# reboot -p
|
||||
|
||||
```
|
||||
|
||||
* **`-p, --poweroff:`** Power-off the machine, either halt or poweroff commands is invoked.
|
||||
|
||||
|
||||
|
||||
Run the “reboot” command with `-f` option to forcefully reboot the Linux machine (This is similar to pressing the power button on the CPU).
|
||||
|
||||
```
|
||||
# reboot -f
|
||||
|
||||
```
|
||||
|
||||
* **`-f, --force:`** Force immediate halt, power-off, or reboot.
|
||||
|
||||
|
||||
|
||||
### Method-3: How To Shutdown And Reboot The Linux System Using init Command
|
||||
|
||||
init (short for initialization) is the first process started during booting of the computer system.
|
||||
|
||||
It will check the /etc/inittab file to decide the Linux run level. Also, allow users to perform shutdown and reboot the Linux machine. There are seven runlevels exist, from zero to six.
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [How To Check All Running Services In Linux][3]
|
||||
|
||||
Run the below init command to shutdown the system .
|
||||
|
||||
```
|
||||
# init 0
|
||||
|
||||
```
|
||||
|
||||
* **`0:`** Halt – to shutdown the system.
|
||||
|
||||
|
||||
|
||||
Run the below init command to reboot the system .
|
||||
|
||||
```
|
||||
# init 6
|
||||
|
||||
```
|
||||
|
||||
* **`6:`** Reboot – to reboot the system.
|
||||
|
||||
|
||||
|
||||
### Method-4: How To Shutdown The Linux System Using halt Command
|
||||
|
||||
halt command used to power-off or shutdown a Linux remote machine or local host.
|
||||
halt terminates all processes and shuts down the cpu.
|
||||
|
||||
```
|
||||
# halt
|
||||
|
||||
```
|
||||
|
||||
### Method-5: How To Shutdown The Linux System Using poweroff Command
|
||||
|
||||
poweroff command used to power-off or shutdown a Linux remote machine or local host. Poweroff is exactly like halt, but it also turns off the unit itself (lights and everything on a PC). It sends an ACPI command to the board, then to the PSU, to cut the power.
|
||||
|
||||
```
|
||||
# poweroff
|
||||
|
||||
```
|
||||
|
||||
### Method-6: How To Shutdown And Reboot The Linux System Using systemctl Command
|
||||
|
||||
Systemd is a new init system and system manager which was implemented/adapted into all the major Linux distributions over the traditional SysV init systems.
|
||||
|
||||
systemd is compatible with SysV and LSB init scripts. It can work as a drop-in replacement for sysvinit system. systemd is the first process get started by kernel and holding PID 1.
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [chkservice – A Tool For Managing Systemd Units From Linux Terminal][4]
|
||||
|
||||
It’s a parent process for everything and Fedora 15 is the first distribution which was adapted systemd instead of upstart.
|
||||
|
||||
systemctl is command line utility and primary tool to manage the systemd daemons/services such as (start, restart, stop, enable, disable, reload & status).
|
||||
|
||||
systemd uses .service files Instead of bash scripts (SysVinit uses). systemd sorts all daemons into their own Linux cgroups and you can see the system hierarchy by exploring /cgroup/systemd file.
|
||||
|
||||
```
|
||||
# systemctl halt
|
||||
# systemctl poweroff
|
||||
# systemctl reboot
|
||||
# systemctl suspend
|
||||
# systemctl hibernate
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/6-commands-to-shutdown-halt-poweroff-reboot-the-linux-system/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/11-methods-to-find-check-system-server-uptime-in-linux/
|
||||
[2]: https://www.2daygeek.com/tuptime-a-tool-to-report-the-historical-and-statistical-running-time-of-linux-system/
|
||||
[3]: https://www.2daygeek.com/how-to-check-all-running-services-in-linux/
|
||||
[4]: https://www.2daygeek.com/chkservice-a-tool-for-managing-systemd-units-from-linux-terminal/
|
||||
@ -0,0 +1,70 @@
|
||||
Convert Screenshots of Equations into LaTeX Instantly With This Nifty Tool
|
||||
======
|
||||
**Mathpix is a nifty little tool that allows you to take screenshots of complex mathematical equations and instantly converts it into LaTeX editable text.**
|
||||
|
||||
![Mathpix converts math equations images into LaTeX][1]
|
||||
|
||||
[LaTeX editors][2] are excellent when it comes to writing academic and scientific documentation.
|
||||
|
||||
There is a steep learning curved involved of course. And this learning curve becomes steeper if you have to write complex mathematical equations.
|
||||
|
||||
[Mathpix][3] is a nifty little tool that helps you in this regard.
|
||||
|
||||
Suppose you are reading a document that has mathematical equations. If you want to use those equations in your [LaTeX document][4], you need to use your ninja LaTeX skills and plenty of time.
|
||||
|
||||
But Mathpix solves this problem for you. With Mathpix, you take the screenshot of the mathematical equations, and it will instantly give you the LaTeX code. You can then use this code in your [favorite LaTeX editor][2].
|
||||
|
||||
See Mathpix in action in the video below:
|
||||
|
||||
<https://itsfoss.com/wp-content/uploads/2018/10/mathpix.mp4>
|
||||
|
||||
[Video credit][5]: Reddit User [kaitlinmcunningham][6]
|
||||
|
||||
Isn’t it super-cool? I guess the hardest part of writing LaTeX documents are those complicated equations. For lazy bums like me, Mathpix is a godsend.
|
||||
|
||||
### Getting Mathpix
|
||||
|
||||
Mathpix is available for Linux, macOS, Windows and iOS. There is no Android app for the moment.
|
||||
|
||||
Note: Mathpix is a free to use tool but it’s not open source.
|
||||
|
||||
On Linux, [Mathpix is available as a Snap package][7]. Which means [if you have Snap support enabled on your Linux distribution][8], you can install Mathpix with this simple command:
|
||||
|
||||
```
|
||||
sudo snap install mathpix-snipping-tool
|
||||
|
||||
```
|
||||
|
||||
Using Mathpix is simple. Once installed, open the tool. You’ll find it in the top panel. You can start taking the screenshot with Mathpix using the keyboard shortcut Ctrl+Alt+M.
|
||||
|
||||
It will instantly translate the image of equation into a LaTeX code. The code will be copied into clipboard and you can then paste it in a LaTeX editor.
|
||||
|
||||
Mathpix’s optical character recognition technology is [being used][9] by a number of companies like [WolframAlpha][10], Microsoft, Google, etc. to improve their tools’ image recognition capability while dealing with math symbols.
|
||||
|
||||
Altogether, it’s an awesome tool for students and academics. It’s free to use and I so wish that it was an open source tool. We cannot get everything in life, can we?
|
||||
|
||||
Do you use Mathpix or some other similar tool while dealing with mathematical symbols in LaTeX? What do you think of Mathpix? Share your views with us in the comment section.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/mathpix/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/10/mathpix-converts-equations-into-latex.jpeg
|
||||
[2]: https://itsfoss.com/latex-editors-linux/
|
||||
[3]: https://mathpix.com/
|
||||
[4]: https://www.latex-project.org/
|
||||
[5]: https://g.redditmedia.com/b-GL1rQwNezQjGvdlov9U_6vDwb1A7kEwGHYcQ1Ogtg.gif?fm=mp4&mp4-fragmented=false&s=39fd1816b43e2b544986d629f75a7a8e
|
||||
[6]: https://www.reddit.com/user/kaitlinmcunningham
|
||||
[7]: https://snapcraft.io/mathpix-snipping-tool
|
||||
[8]: https://itsfoss.com/install-snap-linux/
|
||||
[9]: https://mathpix.com/api.html
|
||||
[10]: https://www.wolframalpha.com/
|
||||
@ -0,0 +1,198 @@
|
||||
How To Create And Maintain Your Own Man Pages
|
||||
======
|
||||
|
||||

|
||||
|
||||
We already have discussed about a few [**good alternatives to Man pages**][1]. Those alternatives are mainly used for learning concise Linux command examples without having to go through the comprehensive man pages. If you’re looking for a quick and dirty way to easily and quickly learn a Linux command, those alternatives are worth trying. Now, you might be thinking – how can I create my own man-like help pages for a Linux command? This is where **“Um”** comes in handy. Um is a command line utility, used to easily create and maintain your own Man pages that contains only what you’ve learned about a command so far.
|
||||
|
||||
By creating your own alternative to man pages, you can avoid lots of unnecessary, comprehensive details in a man page and include only what is necessary to keep in mind. If you ever wanted to created your own set of man-like pages, Um will definitely help. In this brief tutorial, we will see how to install “Um” command line utility and how to create our own man pages.
|
||||
|
||||
### Installing Um
|
||||
|
||||
Um is available for Linux and Mac OS. At present, it can only be installed using **Linuxbrew** package manager in Linux systems. Refer the following link if you haven’t installed Linuxbrew yet.
|
||||
|
||||
Once Linuxbrew installed, run the following command to install Um utility.
|
||||
|
||||
```
|
||||
$ brew install sinclairtarget/wst/um
|
||||
|
||||
```
|
||||
|
||||
If you will see an output something like below, congratulations! Um has been installed and ready to use.
|
||||
|
||||
```
|
||||
[...]
|
||||
==> Installing sinclairtarget/wst/um
|
||||
==> Downloading https://github.com/sinclairtarget/um/archive/4.0.0.tar.gz
|
||||
==> Downloading from https://codeload.github.com/sinclairtarget/um/tar.gz/4.0.0
|
||||
-=#=# # #
|
||||
==> Downloading https://rubygems.org/gems/kramdown-1.17.0.gem
|
||||
######################################################################## 100.0%
|
||||
==> gem install /home/sk/.cache/Homebrew/downloads/d0a5d978120a791d9c5965fc103866815189a4e3939
|
||||
==> Caveats
|
||||
Bash completion has been installed to:
|
||||
/home/linuxbrew/.linuxbrew/etc/bash_completion.d
|
||||
==> Summary
|
||||
🍺 /home/linuxbrew/.linuxbrew/Cellar/um/4.0.0: 714 files, 1.3MB, built in 35 seconds
|
||||
==> Caveats
|
||||
==> openssl
|
||||
A CA file has been bootstrapped using certificates from the SystemRoots
|
||||
keychain. To add additional certificates (e.g. the certificates added in
|
||||
the System keychain), place .pem files in
|
||||
/home/linuxbrew/.linuxbrew/etc/openssl/certs
|
||||
|
||||
and run
|
||||
/home/linuxbrew/.linuxbrew/opt/openssl/bin/c_rehash
|
||||
==> ruby
|
||||
Emacs Lisp files have been installed to:
|
||||
/home/linuxbrew/.linuxbrew/share/emacs/site-lisp/ruby
|
||||
==> um
|
||||
Bash completion has been installed to:
|
||||
/home/linuxbrew/.linuxbrew/etc/bash_completion.d
|
||||
|
||||
```
|
||||
|
||||
Before going to use to make your man pages, you need to enable bash completion for Um.
|
||||
|
||||
To do so, open your **~/.bash_profile** file:
|
||||
|
||||
```
|
||||
$ nano ~/.bash_profile
|
||||
|
||||
```
|
||||
|
||||
And, add the following lines in it:
|
||||
|
||||
```
|
||||
if [ -f $(brew --prefix)/etc/bash_completion.d/um-completion.sh ]; then
|
||||
. $(brew --prefix)/etc/bash_completion.d/um-completion.sh
|
||||
fi
|
||||
|
||||
```
|
||||
|
||||
Save and close the file. Run the following commands to update the changes.
|
||||
|
||||
```
|
||||
$ source ~/.bash_profile
|
||||
|
||||
```
|
||||
|
||||
All done. let us go ahead and create our first man page.
|
||||
|
||||
### Create And Maintain Your Own Man Pages
|
||||
|
||||
Let us say, you want to create your own man page for “dpkg” command. To do so, run:
|
||||
|
||||
```
|
||||
$ um edit dpkg
|
||||
|
||||
```
|
||||
|
||||
The above command will open a markdown template in your default editor:
|
||||
|
||||
|
||||
|
||||
My default editor is Vi, so the above commands open it in the Vi editor. Now, start adding everything you want to remember about “dpkg” command in this template.
|
||||
|
||||
Here is a sample:
|
||||
|
||||

|
||||
|
||||
As you see in the above output, I have added Synopsis, description and two options for dpkg command. You can add as many as sections you want in the man pages. Make sure you have given proper and easily-understandable titles for each section. Once done, save and quit the file (If you use Vi editor, Press **ESC** key and type **:wq** ).
|
||||
|
||||
Finally, view your newly created man page using command:
|
||||
|
||||
```
|
||||
$ um dpkg
|
||||
|
||||
```
|
||||
|
||||

|
||||
|
||||
As you can see, the the dpkg man page looks exactly like the official man pages. If you want to edit and/or add more details in a man page, again run the same command and add the details.
|
||||
|
||||
```
|
||||
$ um edit dpkg
|
||||
|
||||
```
|
||||
|
||||
To view the list of newly created man pages using Um, run:
|
||||
|
||||
```
|
||||
$ um list
|
||||
|
||||
```
|
||||
|
||||
All man pages will be saved under a directory named**`.um`**in your home directory
|
||||
|
||||
Just in case, if you don’t want a particular page, simply delete it as shown below.
|
||||
|
||||
```
|
||||
$ um rm dpkg
|
||||
|
||||
```
|
||||
|
||||
To view the help section and all available general options, run:
|
||||
|
||||
```
|
||||
$ um --help
|
||||
usage: um <page name>
|
||||
um <sub-command> [ARGS...]
|
||||
|
||||
The first form is equivalent to `um read <page name>`.
|
||||
|
||||
Subcommands:
|
||||
um (l)ist List the available pages for the current topic.
|
||||
um (r)ead <page name> Read the given page under the current topic.
|
||||
um (e)dit <page name> Create or edit the given page under the current topic.
|
||||
um rm <page name> Remove the given page.
|
||||
um (t)opic [topic] Get or set the current topic.
|
||||
um topics List all topics.
|
||||
um (c)onfig [config key] Display configuration environment.
|
||||
um (h)elp [sub-command] Display this help message, or the help message for a sub-command.
|
||||
|
||||
```
|
||||
|
||||
### Configure Um
|
||||
|
||||
To view the current configuration, run:
|
||||
|
||||
```
|
||||
$ um config
|
||||
Options prefixed by '*' are set in /home/sk/.um/umconfig.
|
||||
editor = vi
|
||||
pager = less
|
||||
pages_directory = /home/sk/.um/pages
|
||||
default_topic = shell
|
||||
pages_ext = .md
|
||||
|
||||
```
|
||||
|
||||
In this file, you can edit and change the values for **pager** , **editor** , **default_topic** , **pages_directory** , and **pages_ext** options as you wish. Say for example, if you want to save the newly created Um pages in your **[Dropbox][2]** folder, simply change the value of **pages_directory** directive and point it to the Dropbox folder in **~/.um/umconfig** file.
|
||||
|
||||
```
|
||||
pages_directory = /Users/myusername/Dropbox/um
|
||||
|
||||
```
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-create-and-maintain-your-own-man-pages/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/3-good-alternatives-man-pages-every-linux-user-know/
|
||||
[2]: https://www.ostechnix.com/install-dropbox-in-ubuntu-18-04-lts-desktop/
|
||||
@ -0,0 +1,163 @@
|
||||
5 alerting and visualization tools for sysadmins
|
||||
======
|
||||
These open source tools help users understand system behavior and output, and provide alerts for potential problems.
|
||||
|
||||

|
||||
|
||||
You probably know (or can guess) what alerting and visualization tools are used for. Why would we discuss them as observability tools, especially since some systems include visualization as a feature?
|
||||
|
||||
Observability comes from control theory and describes our ability to understand a system based on its inputs and outputs. This article focuses on the output component of observability.
|
||||
|
||||
Alerting and visualization tools analyze the outputs of other systems and provide structured representations of these outputs. Alerts are basically a synthesized understanding of negative system outputs, and visualizations are disambiguated structured representations that facilitate user comprehension.
|
||||
|
||||
### Common types of alerts and visualizations
|
||||
|
||||
#### Alerts
|
||||
|
||||
Let’s first cover what alerts are _not_. Alerts should not be sent if the human responder can’t do anything about the problem. This includes alerts that are sent to multiple individuals with only a few who can respond, or situations where every anomaly in the system triggers an alert. This leads to alert fatigue and receivers ignoring all alerts within a specific medium until the system escalates to a medium that isn’t already saturated.
|
||||
|
||||
For example, if an operator receives hundreds of emails a day from the alerting system, that operator will soon ignore all emails from the alerting system. The operator will respond to a real incident only when he or she is experiencing the problem, emailed by a customer, or called by the boss. In this case, alerts have lost their meaning and usefulness.
|
||||
|
||||
Alerts are not a constant stream of information or a status update. They are meant to convey a problem from which the system can’t automatically recover, and they are sent only to the individual most likely to be able to recover the system. Everything that falls outside this definition isn’t an alert and will only damage your employees and company culture.
|
||||
|
||||
Everyone has a different set of alert types, so I won't discuss things like priority levels (P1-P5) or models that use words like "Informational," "Warning," and "Critical." Instead, I’ll describe the generic categories emergent in complex systems’ incident response.
|
||||
|
||||
You might have noticed I mentioned an “Informational” alert type right after I wrote that alerts shouldn’t be informational. Well, not everyone agrees, but I don’t consider something an alert if it isn’t sent to anyone. It is a data point that many systems refer to as an alert. It represents some event that should be known but not responded to. It is generally part of the visualization system of the alerting tool and not an event that triggers actual notifications. Mike Julian covers this and other aspects of alerting in his book [Practical Monitoring][1]. It's a must read for work in this area.
|
||||
|
||||
Non-informational alerts consist of types that can be responded to or require action. I group these into two categories: internal outage and external outage. (Most companies have more than two levels for prioritizing their response efforts.) Degraded system performance is considered an outage in this model, as the impact to each user is usually unknown.
|
||||
|
||||
Internal outages are a lower priority than external outages, but they still need to be responded to quickly. They often include internal systems that company employees use or components of applications that are visible only to company employees.
|
||||
|
||||
External outages consist of any system outage that would immediately impact a customer. These don’t include a system outage that prevents releasing updates to the system. They do include customer-facing application failures, database outages, and networking partitions that hurt availability or consistency if either can impact a user. They also include outages of tools that may not have a direct impact on users, as the application continues to run but this transparent dependency impacts performance. This is common when the system uses some external service or data source that isn’t necessary for full functionality but may cause delays as the application performs retries or handles errors from this external dependency.
|
||||
|
||||
### Visualizations
|
||||
|
||||
There are many visualization types, and I won’t cover them all here. It’s a fascinating area of research. On the data analytics side of my career, learning and applying that knowledge is a constant challenge. We need to provide simple representations of complex system outputs for the widest dissemination of information. [Google Charts][2] and [Tableau][3] have a wide selection of visualization types. We’ll cover the most common visualizations and some innovative solutions for quickly understanding systems.
|
||||
|
||||
#### Line chart
|
||||
|
||||
The line chart is probably the most common visualization. It does a pretty good job of producing an understanding of a system over time. A line chart in a metrics system would have a line for each unique metric or some aggregation of metrics. This can get confusing when there are a lot of metrics in the same dashboard (as shown below), but most systems can select specific metrics to view rather than having all of them visible. Also, anomalous behavior is easy to spot if it’s significant enough to escape the noise of normal operations. Below we can see purple, yellow, and light blue lines that might indicate anomalous behavior.
|
||||
|
||||
|
||||
|
||||
Another feature of a line chart is that you can often stack them to show relationships. For example, you might want to look at requests on each server individually, but also in aggregate. This allows you to understand the overall system as well as each instance in the same graph.
|
||||
|
||||
|
||||
|
||||
#### Heatmaps
|
||||
|
||||
Another common visualization is the heatmap. It is useful when looking at histograms. This type of visualization is similar to a bar chart but can show gradients within the bars representing the different percentiles of the overall metric. For example, suppose you’re looking at request latencies and you want to quickly understand the overall trend as well as the distribution of all requests. A heatmap is great for this, and it can use color to disambiguate the quantity of each section with a quick glance.
|
||||
|
||||
The heatmap below shows the higher concentration around the centerline of the graph with an easy-to-understand visualization of the distribution vertically for each time bucket. We might want to review a couple of points in time where the distribution gets wide while the others are fairly tight like at 14:00. This distribution might be a negative performance indicator.
|
||||
|
||||
|
||||
|
||||
#### Gauges
|
||||
|
||||
The last common visualization I’ll cover here is the gauge, which helps users understand a single metric quickly. Gauges can represent a single metric, like your speedometer represents your driving speed or your gas gauge represents the amount of gas in your car. Similar to the gas gauge, most monitoring gauges clearly indicate what is good and what isn’t. Often (as is shown below), good is represented by green, getting worse by orange, and “everything is breaking” by red. The middle row below shows traditional gauges.
|
||||
|
||||
|
||||
|
||||
This image shows more than just traditional gauges. The other gauges are single stat representations that are similar to the function of the classic gauge. They all use the same color scheme to quickly indicate system health with just a glance. Arguably, the bottom row is probably the best example of a gauge that allows you to glance at a dashboard and know that everything is healthy (or not). This type of visualization is usually what I put on a top-level dashboard. It offers a full, high-level understanding of system health in seconds.
|
||||
|
||||
#### Flame graphs
|
||||
|
||||
A less common visualization is the flame graph, introduced by [Netflix’s Brendan Gregg][4] in 2011. It’s not ideal for dashboarding or quickly observing high-level system concerns; it’s normally seen when trying to understand a specific application problem. This visualization focuses on CPU and memory and the associated frames. The X-axis lists the frames alphabetically, and the Y-axis shows stack depth. Each rectangle is a stack frame and includes the function being called. The wider the rectangle, the more it appears in the stack. This method is invaluable when trying to diagnose system performance at the application level and I urge everyone to give it a try.
|
||||
|
||||
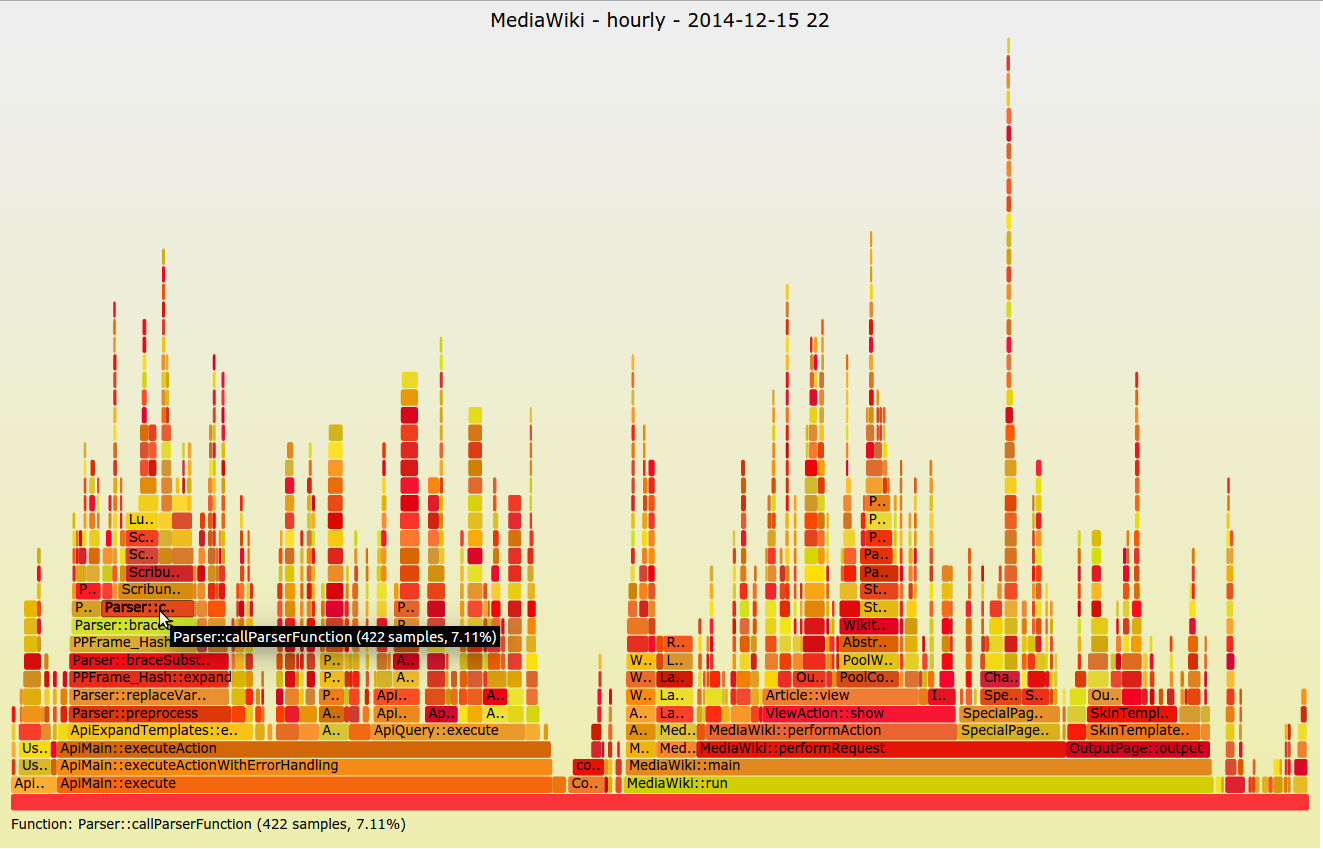
|
||||
|
||||
### Tool options
|
||||
|
||||
There are several commercial options for alerting, but since this is Opensource.com, I’ll cover only systems that are being used at scale by real companies that you can use at no cost. Hopefully, you’ll be able to contribute new and innovative features to make these systems even better.
|
||||
|
||||
### Alerting tools
|
||||
|
||||
#### Bosun
|
||||
|
||||
If you’ve ever done anything with computers and gotten stuck, the help you received was probably thanks to a Stack Exchange system. Stack Exchange runs many different websites around a crowdsourced question-and-answer model. [Stack Overflow][5] is very popular with developers, and [Super User][6] is popular with operations. However, there are now hundreds of sites ranging from parenting to sci-fi and philosophy to bicycles.
|
||||
|
||||
Stack Exchange open-sourced its alert management system, [Bosun][7], around the same time Prometheus and its [AlertManager][8] system were released. There were many similarities in the two systems, and that’s a really good thing. Like Prometheus, Bosun is written in Golang. Bosun’s scope is more extensive than Prometheus’ as it can interact with systems beyond metrics aggregation. It can also ingest data from log and event aggregation systems. It supports Graphite, InfluxDB, OpenTSDB, and Elasticsearch.
|
||||
|
||||
Bosun’s architecture consists of a single server binary, a backend like OpenTSDB, Redis, and [scollector agents][9]. The scollector agents automatically detect services on a host and report metrics for those processes and other system resources. This data is sent to a metrics backend. The Bosun server binary then queries the backends to determine if any alerts need to be fired. Bosun can also be used by tools like [Grafana][10] to query the underlying backends through one common interface. Redis is used to store state and metadata for Bosun.
|
||||
|
||||
A really neat feature of Bosun is that it lets you test your alerts against historical data. This was something I missed in Prometheus several years ago, when I had data for an issue I wanted alerts on but no easy way to test it. To make sure my alerts were working, I had to create and insert dummy data. This system alleviates that very time-consuming process.
|
||||
|
||||
Bosun also has the usual features like showing simple graphs and creating alerts. It has a powerful expression language for writing alerting rules. However, it only has email and HTTP notification configurations, which means connecting to Slack and other tools requires a bit more customization ([which its documentation covers][11]). Similar to Prometheus, Bosun can use templates for these notifications, which means they can look as awesome as you want them to. You can use all your HTML and CSS skills to create the baddest email alert anyone has ever seen.
|
||||
|
||||
#### Cabot
|
||||
|
||||
[Cabot][12] was created by a company called [Arachnys][13]. You may not know who Arachnys is or what it does, but you have probably felt its impact: It built the leading cloud-based solution for fighting financial crimes. That sounds pretty cool, right? At a previous company, I was involved in similar functions around [“know your customer"][14] laws. Most companies would consider it a very bad thing to be linked to a terrorist group, for example, funneling money through their systems. These solutions also help defend against less-atrocious offenders like fraudsters who could also pose a risk to the institution.
|
||||
|
||||
So why did Arachnys create Cabot? Well, it is kind of a Christmas present to everyone, as it was a Christmas project built because its developers couldn’t wrap their heads around [Nagios][15]. And really, who can blame them? Cabot was written with Django and Bootstrap, so it should be easy for most to contribute to the project. (Another interesting factoid: The name comes from the creator’s dog.)
|
||||
|
||||
The Cabot architecture is similar to Bosun in that it doesn’t collect any data. Instead, it accesses data through the APIs of the tools it is alerting for. Therefore, Cabot uses a pull (rather than a push) model for alerting. It reaches out into each system’s API and retrieves the information it needs to make a decision based on a specific check. Cabot stores the alerting data in a Postgres database and also has a cache using Redis.
|
||||
|
||||
Cabot natively supports [Graphite][16], but it also supports [Jenkins][17], which is rare in this area. [Arachnys][13] uses Jenkins like a centralized cron, but I like this idea of treating build failures like outages. Obviously, a build failure isn’t as critical as a production outage, but it could still alert the team and escalate if the failure isn’t resolved. Who actually checks Jenkins every time an email comes in about a build failure? Yeah, me too!
|
||||
|
||||
Another interesting feature is that Cabot can integrate with Google Calendar for on-call rotations. Cabot calls this feature Rota, which is a British term for a roster or rotation. This makes a lot of sense, and I wish other systems would take this idea further. Cabot doesn’t support anything more complex than primary and backup personnel, but there is certainly room for additional features. The docs say if you want something more advanced, you should look at a commercial option.
|
||||
|
||||
#### StatsAgg
|
||||
|
||||
[StatsAgg][18]? How did that make the list? Well, it’s not every day you come across a publishing company that has created an alerting platform. I think that deserves recognition. Of course, [Pearson][19] isn’t just a publishing company anymore; it has several web presences and a joint venture with [O’Reilly Media][20]. However, I still think of it as the company that published my schoolbooks and tests.
|
||||
|
||||
StatsAgg isn’t just an alerting platform; it’s also a metrics aggregation platform. And it’s kind of like a proxy for other systems. It supports Graphite, StatsD, InfluxDB, and OpenTSDB as inputs, but it can also forward those metrics to their respective platforms. This is an interesting concept, but potentially risky as loads increase on a central service. However, if the StatsAgg infrastructure is robust enough, it can still produce alerts even when a backend storage platform has an outage.
|
||||
|
||||
StatsAgg is written in Java and consists only of the main server and UI, which keeps complexity to a minimum. It can send alerts based on regular expression matching and is focused on alerting by service rather than host or instance. Its goal is to fill a void in the open source observability stack, and I think it does that quite well.
|
||||
|
||||
### Visualization tools
|
||||
|
||||
#### Grafana
|
||||
|
||||
Almost everyone knows about [Grafana][10], and many have used it. I have used it for years whenever I need a simple dashboard. The tool I used before was deprecated, and I was fairly distraught about that until Grafana made it okay. Grafana was gifted to us by Torkel Ödegaard. Like Cabot, Grafana was also created around Christmastime, and released in January 2014. It has come a long way in just a few years. It started life as a Kibana dashboarding system, and Torkel forked it into what became Grafana.
|
||||
|
||||
Grafana’s sole focus is presenting monitoring data in a more usable and pleasing way. It can natively gather data from Graphite, Elasticsearch, OpenTSDB, Prometheus, and InfluxDB. There’s an Enterprise version that uses plugins for more data sources, but there’s no reason those other data source plugins couldn’t be created as open source, as the Grafana plugin ecosystem already offers many other data sources.
|
||||
|
||||
What does Grafana do for me? It provides a central location for understanding my system. It is web-based, so anyone can access the information, although it can be restricted using different authentication methods. Grafana can provide knowledge at a glance using many different types of visualizations. However, it has started integrating alerting and other features that aren’t traditionally combined with visualizations.
|
||||
|
||||
Now you can set alerts visually. That means you can look at a graph, maybe even one showing where an alert should have triggered due to some degradation of the system, click on the graph where you want the alert to trigger, and then tell Grafana where to send the alert. That’s a pretty powerful addition that won’t necessarily replace an alerting platform, but it can certainly help augment it by providing a different perspective on alerting criteria.
|
||||
|
||||
Grafana has also introduced more collaboration features. Users have been able to share dashboards for a long time, meaning you don’t have to create your own dashboard for your [Kubernetes][21] cluster because there are several already available—with some maintained by Kubernetes developers and others by Grafana developers.
|
||||
|
||||
The most significant addition around collaboration is annotations. Annotations allow a user to add context to part of a graph. Other users can then use this context to understand the system better. This is an invaluable tool when a team is in the middle of an incident and communication and common understanding are critical. Having all the information right where you’re already looking makes it much more likely that knowledge will be shared across the team quickly. It’s also a nice feature to use during blameless postmortems when the team is trying to understand how the failure occurred and learn more about their system.
|
||||
|
||||
#### Vizceral
|
||||
|
||||
Netflix created [Vizceral][22] to understand its traffic patterns better when performing a traffic failover. Unlike Grafana, which is a more general tool, Vizceral serves a very specific use case. Netflix no longer uses this tool internally and says it is no longer actively maintained, but it still updates the tool periodically. I highlight it here primarily to point out an interesting visualization mechanism and how it can help solve a problem. It’s worth running it in a demo environment just to better grasp the concepts and witness what’s possible with these systems.
|
||||
|
||||
### What to read next
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/alerting-and-visualization-tools-sysadmins
|
||||
|
||||
作者:[Dan Barker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/barkerd427
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.practicalmonitoring.com/
|
||||
[2]: https://developers.google.com/chart/interactive/docs/gallery
|
||||
[3]: https://libguides.libraries.claremont.edu/c.php?g=474417&p=3286401
|
||||
[4]: http://www.brendangregg.com/flamegraphs.html
|
||||
[5]: https://stackoverflow.com/
|
||||
[6]: https://superuser.com/
|
||||
[7]: http://bosun.org/
|
||||
[8]: https://prometheus.io/docs/alerting/alertmanager/
|
||||
[9]: https://bosun.org/scollector/
|
||||
[10]: https://grafana.com/
|
||||
[11]: https://bosun.org/notifications
|
||||
[12]: https://cabotapp.com/
|
||||
[13]: https://www.arachnys.com/
|
||||
[14]: https://en.wikipedia.org/wiki/Know_your_customer
|
||||
[15]: https://www.nagios.org/
|
||||
[16]: https://graphiteapp.org/
|
||||
[17]: https://jenkins.io/
|
||||
[18]: https://github.com/PearsonEducation/StatsAgg
|
||||
[19]: https://www.pearson.com/us/
|
||||
[20]: https://www.oreilly.com/
|
||||
[21]: https://opensource.com/resources/what-is-kubernetes
|
||||
[22]: https://github.com/Netflix/vizceral
|
||||
@ -0,0 +1,457 @@
|
||||
An introduction to using tcpdump at the Linux command line
|
||||
======
|
||||
|
||||
This flexible, powerful command-line tool helps ease the pain of troubleshooting network issues.
|
||||
|
||||

|
||||
|
||||
In my experience as a sysadmin, I have often found network connectivity issues challenging to troubleshoot. For those situations, tcpdump is a great ally.
|
||||
|
||||
Tcpdump is a command line utility that allows you to capture and analyze network traffic going through your system. It is often used to help troubleshoot network issues, as well as a security tool.
|
||||
|
||||
A powerful and versatile tool that includes many options and filters, tcpdump can be used in a variety of cases. Since it's a command line tool, it is ideal to run in remote servers or devices for which a GUI is not available, to collect data that can be analyzed later. It can also be launched in the background or as a scheduled job using tools like cron.
|
||||
|
||||
In this article, we'll look at some of tcpdump's most common features.
|
||||
|
||||
### 1\. Installation on Linux
|
||||
|
||||
Tcpdump is included with several Linux distributions, so chances are, you already have it installed. Check if tcpdump is installed on your system with the following command:
|
||||
|
||||
```
|
||||
$ which tcpdump
|
||||
/usr/sbin/tcpdump
|
||||
```
|
||||
|
||||
If tcpdump is not installed, you can install it but using your distribution's package manager. For example, on CentOS or Red Hat Enterprise Linux, like this:
|
||||
|
||||
```
|
||||
$ sudo yum install -y tcpdump
|
||||
```
|
||||
|
||||
Tcpdump requires `libpcap`, which is a library for network packet capture. If it's not installed, it will be automatically added as a dependency.
|
||||
|
||||
You're ready to start capturing some packets.
|
||||
|
||||
### 2\. Capturing packets with tcpdump
|
||||
|
||||
To capture packets for troubleshooting or analysis, tcpdump requires elevated permissions, so in the following examples most commands are prefixed with `sudo`.
|
||||
|
||||
To begin, use the command `tcpdump -D` to see which interfaces are available for capture:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -D
|
||||
1.eth0
|
||||
2.virbr0
|
||||
3.eth1
|
||||
4.any (Pseudo-device that captures on all interfaces)
|
||||
5.lo [Loopback]
|
||||
```
|
||||
|
||||
In the example above, you can see all the interfaces available in my machine. The special interface `any` allows capturing in any active interface.
|
||||
|
||||
Let's use it to start capturing some packets. Capture all packets in any interface by running this command:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
|
||||
09:56:18.293641 IP rhel75.localdomain.ssh > 192.168.64.1.56322: Flags [P.], seq 3770820720:3770820916, ack 3503648727, win 309, options [nop,nop,TS val 76577898 ecr 510770929], length 196
|
||||
09:56:18.293794 IP 192.168.64.1.56322 > rhel75.localdomain.ssh: Flags [.], ack 196, win 391, options [nop,nop,TS val 510771017 ecr 76577898], length 0
|
||||
09:56:18.295058 IP rhel75.59883 > gateway.domain: 2486+ PTR? 1.64.168.192.in-addr.arpa. (43)
|
||||
09:56:18.310225 IP gateway.domain > rhel75.59883: 2486 NXDomain* 0/1/0 (102)
|
||||
09:56:18.312482 IP rhel75.49685 > gateway.domain: 34242+ PTR? 28.64.168.192.in-addr.arpa. (44)
|
||||
09:56:18.322425 IP gateway.domain > rhel75.49685: 34242 NXDomain* 0/1/0 (103)
|
||||
09:56:18.323164 IP rhel75.56631 > gateway.domain: 29904+ PTR? 1.122.168.192.in-addr.arpa. (44)
|
||||
09:56:18.323342 IP rhel75.localdomain.ssh > 192.168.64.1.56322: Flags [P.], seq 196:584, ack 1, win 309, options [nop,nop,TS val 76577928 ecr 510771017], length 388
|
||||
09:56:18.323563 IP 192.168.64.1.56322 > rhel75.localdomain.ssh: Flags [.], ack 584, win 411, options [nop,nop,TS val 510771047 ecr 76577928], length 0
|
||||
09:56:18.335569 IP gateway.domain > rhel75.56631: 29904 NXDomain* 0/1/0 (103)
|
||||
09:56:18.336429 IP rhel75.44007 > gateway.domain: 61677+ PTR? 98.122.168.192.in-addr.arpa. (45)
|
||||
09:56:18.336655 IP gateway.domain > rhel75.44007: 61677* 1/0/0 PTR rhel75. (65)
|
||||
09:56:18.337177 IP rhel75.localdomain.ssh > 192.168.64.1.56322: Flags [P.], seq 584:1644, ack 1, win 309, options [nop,nop,TS val 76577942 ecr 510771047], length 1060
|
||||
|
||||
---- SKIPPING LONG OUTPUT -----
|
||||
|
||||
09:56:19.342939 IP 192.168.64.1.56322 > rhel75.localdomain.ssh: Flags [.], ack 1752016, win 1444, options [nop,nop,TS val 510772067 ecr 76578948], length 0
|
||||
^C
|
||||
9003 packets captured
|
||||
9010 packets received by filter
|
||||
7 packets dropped by kernel
|
||||
$
|
||||
```
|
||||
|
||||
Tcpdump continues to capture packets until it receives an interrupt signal. You can interrupt capturing by pressing `Ctrl+C`. As you can see in this example, `tcpdump` captured more than 9,000 packets. In this case, since I am connected to this server using `ssh`, tcpdump captured all these packages. To limit the number of packets captured and stop `tcpdump`, use the `-c` option:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any -c 5
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
|
||||
11:21:30.242740 IP rhel75.localdomain.ssh > 192.168.64.1.56322: Flags [P.], seq 3772575680:3772575876, ack 3503651743, win 309, options [nop,nop,TS val 81689848 ecr 515883153], length 196
|
||||
11:21:30.242906 IP 192.168.64.1.56322 > rhel75.localdomain.ssh: Flags [.], ack 196, win 1443, options [nop,nop,TS val 515883235 ecr 81689848], length 0
|
||||
11:21:30.244442 IP rhel75.43634 > gateway.domain: 57680+ PTR? 1.64.168.192.in-addr.arpa. (43)
|
||||
11:21:30.244829 IP gateway.domain > rhel75.43634: 57680 NXDomain 0/0/0 (43)
|
||||
11:21:30.247048 IP rhel75.33696 > gateway.domain: 37429+ PTR? 28.64.168.192.in-addr.arpa. (44)
|
||||
5 packets captured
|
||||
12 packets received by filter
|
||||
0 packets dropped by kernel
|
||||
$
|
||||
```
|
||||
|
||||
In this case, `tcpdump` stopped capturing automatically after capturing five packets. This is useful in different scenarios—for instance, if you're troubleshooting connectivity and capturing a few initial packages is enough. This is even more useful when we apply filters to capture specific packets (shown below).
|
||||
|
||||
By default, tcpdump resolves IP addresses and ports into names, as shown in the previous example. When troubleshooting network issues, it is often easier to use the IP addresses and port numbers; disable name resolution by using the option `-n` and port resolution with `-nn`:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any -c5 -nn
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
|
||||
23:56:24.292206 IP 192.168.64.28.22 > 192.168.64.1.35110: Flags [P.], seq 166198580:166198776, ack 2414541257, win 309, options [nop,nop,TS val 615664 ecr 540031155], length 196
|
||||
23:56:24.292357 IP 192.168.64.1.35110 > 192.168.64.28.22: Flags [.], ack 196, win 1377, options [nop,nop,TS val 540031229 ecr 615664], length 0
|
||||
23:56:24.292570 IP 192.168.64.28.22 > 192.168.64.1.35110: Flags [P.], seq 196:568, ack 1, win 309, options [nop,nop,TS val 615664 ecr 540031229], length 372
|
||||
23:56:24.292655 IP 192.168.64.1.35110 > 192.168.64.28.22: Flags [.], ack 568, win 1400, options [nop,nop,TS val 540031229 ecr 615664], length 0
|
||||
23:56:24.292752 IP 192.168.64.28.22 > 192.168.64.1.35110: Flags [P.], seq 568:908, ack 1, win 309, options [nop,nop,TS val 615664 ecr 540031229], length 340
|
||||
5 packets captured
|
||||
6 packets received by filter
|
||||
0 packets dropped by kernel
|
||||
```
|
||||
|
||||
As shown above, the capture output now displays the IP addresses and port numbers. This also prevents tcpdump from issuing DNS lookups, which helps to lower network traffic while troubleshooting network issues.
|
||||
|
||||
Now that you're able to capture network packets, let's explore what this output means.
|
||||
|
||||
### 3\. Understanding the output format
|
||||
|
||||
Tcpdump is capable of capturing and decoding many different protocols, such as TCP, UDP, ICMP, and many more. While we can't cover all of them here, to help you get started, let's explore the TCP packet. You can find more details about the different protocol formats in tcpdump's [manual pages][1]. A typical TCP packet captured by tcpdump looks like this:
|
||||
|
||||
```
|
||||
08:41:13.729687 IP 192.168.64.28.22 > 192.168.64.1.41916: Flags [P.], seq 196:568, ack 1, win 309, options [nop,nop,TS val 117964079 ecr 816509256], length 372
|
||||
```
|
||||
|
||||
The fields may vary depending on the type of packet being sent, but this is the general format.
|
||||
|
||||
The first field, `08:41:13.729687,` represents the timestamp of the received packet as per the local clock.
|
||||
|
||||
Next, `IP` represents the network layer protocol—in this case, `IPv4`. For `IPv6` packets, the value is `IP6`.
|
||||
|
||||
The next field, `192.168.64.28.22`, is the source IP address and port. This is followed by the destination IP address and port, represented by `192.168.64.1.41916`.
|
||||
|
||||
After the source and destination, you can find the TCP Flags `Flags [P.]`. Typical values for this field include:
|
||||
|
||||
| Value | Flag Type | Description |
|
||||
|-------| --------- | ----------------- |
|
||||
| S | SYN | Connection Start |
|
||||
| F | FIN | Connection Finish |
|
||||
| P | PUSH | Data push |
|
||||
| R | RST | Connection reset |
|
||||
| . | ACK | Acknowledgment |
|
||||
|
||||
This field can also be a combination of these values, such as `[S.]` for a `SYN-ACK` packet.
|
||||
|
||||
Next is the sequence number of the data contained in the packet. For the first packet captured, this is an absolute number. Subsequent packets use a relative number to make it easier to follow. In this example, the sequence is `seq 196:568,` which means this packet contains bytes 196 to 568 of this flow.
|
||||
|
||||
This is followed by the Ack Number: `ack 1`. In this case, it is 1 since this is the side sending data. For the side receiving data, this field represents the next expected byte (data) on this flow. For example, the Ack number for the next packet in this flow would be 568.
|
||||
|
||||
The next field is the window size `win 309`, which represents the number of bytes available in the receiving buffer, followed by TCP options such as the MSS (Maximum Segment Size) or Window Scale. For details about TCP protocol options, consult [Transmission Control Protocol (TCP) Parameters][2].
|
||||
|
||||
Finally, we have the packet length, `length 372`, which represents the length, in bytes, of the payload data. The length is the difference between the last and first bytes in the sequence number.
|
||||
|
||||
Now let's learn how to filter packages to narrow down results and make it easier to troubleshoot specific issues.
|
||||
|
||||
### 4\. Filtering packets
|
||||
|
||||
As mentioned above, tcpdump can capture too many packages, some of which are not even related to the issue you're troubleshooting. For example, if you're troubleshooting a connectivity issue with a web server you're not interested in the SSH traffic, so removing the SSH packets from the output makes it easier to work on the real issue.
|
||||
|
||||
One of tcpdump's most powerful features is its ability to filter the captured packets using a variety of parameters, such as source and destination IP addresses, ports, protocols, etc. Let's look at some of the most common ones.
|
||||
|
||||
#### Protocol
|
||||
|
||||
To filter packets based on protocol, specifying the protocol in the command line. For example, capture ICMP packets only by using this command:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any -c5 icmp
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
|
||||
```
|
||||
|
||||
In a different terminal, try to ping another machine:
|
||||
|
||||
```
|
||||
$ ping opensource.com
|
||||
PING opensource.com (54.204.39.132) 56(84) bytes of data.
|
||||
64 bytes from ec2-54-204-39-132.compute-1.amazonaws.com (54.204.39.132): icmp_seq=1 ttl=47 time=39.6 ms
|
||||
```
|
||||
|
||||
Back in the tcpdump capture, notice that tcpdump captures and displays only the ICMP-related packets. In this case, tcpdump is not displaying name resolution packets that were generated when resolving the name `opensource.com`:
|
||||
|
||||
```
|
||||
09:34:20.136766 IP rhel75 > ec2-54-204-39-132.compute-1.amazonaws.com: ICMP echo request, id 20361, seq 1, length 64
|
||||
09:34:20.176402 IP ec2-54-204-39-132.compute-1.amazonaws.com > rhel75: ICMP echo reply, id 20361, seq 1, length 64
|
||||
09:34:21.140230 IP rhel75 > ec2-54-204-39-132.compute-1.amazonaws.com: ICMP echo request, id 20361, seq 2, length 64
|
||||
09:34:21.180020 IP ec2-54-204-39-132.compute-1.amazonaws.com > rhel75: ICMP echo reply, id 20361, seq 2, length 64
|
||||
09:34:22.141777 IP rhel75 > ec2-54-204-39-132.compute-1.amazonaws.com: ICMP echo request, id 20361, seq 3, length 64
|
||||
5 packets captured
|
||||
5 packets received by filter
|
||||
0 packets dropped by kernel
|
||||
```
|
||||
|
||||
#### Host
|
||||
|
||||
Limit capture to only packets related to a specific host by using the `host` filter:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any -c5 -nn host 54.204.39.132
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
|
||||
09:54:20.042023 IP 192.168.122.98.39326 > 54.204.39.132.80: Flags [S], seq 1375157070, win 29200, options [mss 1460,sackOK,TS val 122350391 ecr 0,nop,wscale 7], length 0
|
||||
09:54:20.088127 IP 54.204.39.132.80 > 192.168.122.98.39326: Flags [S.], seq 1935542841, ack 1375157071, win 28960, options [mss 1460,sackOK,TS val 522713542 ecr 122350391,nop,wscale 9], length 0
|
||||
09:54:20.088204 IP 192.168.122.98.39326 > 54.204.39.132.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 122350437 ecr 522713542], length 0
|
||||
09:54:20.088734 IP 192.168.122.98.39326 > 54.204.39.132.80: Flags [P.], seq 1:113, ack 1, win 229, options [nop,nop,TS val 122350438 ecr 522713542], length 112: HTTP: GET / HTTP/1.1
|
||||
09:54:20.129733 IP 54.204.39.132.80 > 192.168.122.98.39326: Flags [.], ack 113, win 57, options [nop,nop,TS val 522713552 ecr 122350438], length 0
|
||||
5 packets captured
|
||||
5 packets received by filter
|
||||
0 packets dropped by kernel
|
||||
```
|
||||
|
||||
In this example, tcpdump captures and displays only packets to and from host `54.204.39.132`.
|
||||
|
||||
#### Port
|
||||
|
||||
To filter packets based on the desired service or port, use the `port` filter. For example, capture packets related to a web (HTTP) service by using this command:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any -c5 -nn port 80
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
|
||||
09:58:28.790548 IP 192.168.122.98.39330 > 54.204.39.132.80: Flags [S], seq 1745665159, win 29200, options [mss 1460,sackOK,TS val 122599140 ecr 0,nop,wscale 7], length 0
|
||||
09:58:28.834026 IP 54.204.39.132.80 > 192.168.122.98.39330: Flags [S.], seq 4063583040, ack 1745665160, win 28960, options [mss 1460,sackOK,TS val 522775728 ecr 122599140,nop,wscale 9], length 0
|
||||
09:58:28.834093 IP 192.168.122.98.39330 > 54.204.39.132.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 122599183 ecr 522775728], length 0
|
||||
09:58:28.834588 IP 192.168.122.98.39330 > 54.204.39.132.80: Flags [P.], seq 1:113, ack 1, win 229, options [nop,nop,TS val 122599184 ecr 522775728], length 112: HTTP: GET / HTTP/1.1
|
||||
09:58:28.878445 IP 54.204.39.132.80 > 192.168.122.98.39330: Flags [.], ack 113, win 57, options [nop,nop,TS val 522775739 ecr 122599184], length 0
|
||||
5 packets captured
|
||||
5 packets received by filter
|
||||
0 packets dropped by kernel
|
||||
```
|
||||
|
||||
#### Source IP/hostname
|
||||
|
||||
You can also filter packets based on the source or destination IP Address or hostname. For example, to capture packets from host `192.168.122.98`:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any -c5 -nn src 192.168.122.98
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
|
||||
10:02:15.220824 IP 192.168.122.98.39436 > 192.168.122.1.53: 59332+ A? opensource.com. (32)
|
||||
10:02:15.220862 IP 192.168.122.98.39436 > 192.168.122.1.53: 20749+ AAAA? opensource.com. (32)
|
||||
10:02:15.364062 IP 192.168.122.98.39334 > 54.204.39.132.80: Flags [S], seq 1108640533, win 29200, options [mss 1460,sackOK,TS val 122825713 ecr 0,nop,wscale 7], length 0
|
||||
10:02:15.409229 IP 192.168.122.98.39334 > 54.204.39.132.80: Flags [.], ack 669337581, win 229, options [nop,nop,TS val 122825758 ecr 522832372], length 0
|
||||
10:02:15.409667 IP 192.168.122.98.39334 > 54.204.39.132.80: Flags [P.], seq 0:112, ack 1, win 229, options [nop,nop,TS val 122825759 ecr 522832372], length 112: HTTP: GET / HTTP/1.1
|
||||
5 packets captured
|
||||
5 packets received by filter
|
||||
0 packets dropped by kernel
|
||||
```
|
||||
|
||||
Notice that tcpdumps captured packets with source IP address `192.168.122.98` for multiple services such as name resolution (port 53) and HTTP (port 80). The response packets are not displayed since their source IP is different.
|
||||
|
||||
Conversely, you can use the `dst` filter to filter by destination IP/hostname:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any -c5 -nn dst 192.168.122.98
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
|
||||
10:05:03.572931 IP 192.168.122.1.53 > 192.168.122.98.47049: 2248 1/0/0 A 54.204.39.132 (48)
|
||||
10:05:03.572944 IP 192.168.122.1.53 > 192.168.122.98.47049: 33770 0/0/0 (32)
|
||||
10:05:03.621833 IP 54.204.39.132.80 > 192.168.122.98.39338: Flags [S.], seq 3474204576, ack 3256851264, win 28960, options [mss 1460,sackOK,TS val 522874425 ecr 122993922,nop,wscale 9], length 0
|
||||
10:05:03.667767 IP 54.204.39.132.80 > 192.168.122.98.39338: Flags [.], ack 113, win 57, options [nop,nop,TS val 522874436 ecr 122993972], length 0
|
||||
10:05:03.672221 IP 54.204.39.132.80 > 192.168.122.98.39338: Flags [P.], seq 1:643, ack 113, win 57, options [nop,nop,TS val 522874437 ecr 122993972], length 642: HTTP: HTTP/1.1 302 Found
|
||||
5 packets captured
|
||||
5 packets received by filter
|
||||
0 packets dropped by kernel
|
||||
```
|
||||
|
||||
#### Complex expressions
|
||||
|
||||
You can also combine filters by using the logical operators `and` and `or` to create more complex expressions. For example, to filter packets from source IP address `192.168.122.98` and service HTTP only, use this command:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any -c5 -nn src 192.168.122.98 and port 80
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
|
||||
10:08:00.472696 IP 192.168.122.98.39342 > 54.204.39.132.80: Flags [S], seq 2712685325, win 29200, options [mss 1460,sackOK,TS val 123170822 ecr 0,nop,wscale 7], length 0
|
||||
10:08:00.516118 IP 192.168.122.98.39342 > 54.204.39.132.80: Flags [.], ack 268723504, win 229, options [nop,nop,TS val 123170865 ecr 522918648], length 0
|
||||
10:08:00.516583 IP 192.168.122.98.39342 > 54.204.39.132.80: Flags [P.], seq 0:112, ack 1, win 229, options [nop,nop,TS val 123170866 ecr 522918648], length 112: HTTP: GET / HTTP/1.1
|
||||
10:08:00.567044 IP 192.168.122.98.39342 > 54.204.39.132.80: Flags [.], ack 643, win 239, options [nop,nop,TS val 123170916 ecr 522918661], length 0
|
||||
10:08:00.788153 IP 192.168.122.98.39342 > 54.204.39.132.80: Flags [F.], seq 112, ack 643, win 239, options [nop,nop,TS val 123171137 ecr 522918661], length 0
|
||||
5 packets captured
|
||||
5 packets received by filter
|
||||
0 packets dropped by kernel
|
||||
```
|
||||
|
||||
You can create more complex expressions by grouping filter with parentheses. In this case, enclose the entire filter expression with quotation marks to prevent the shell from confusing them with shell expressions:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any -c5 -nn "port 80 and (src 192.168.122.98 or src 54.204.39.132)"
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
|
||||
10:10:37.602214 IP 192.168.122.98.39346 > 54.204.39.132.80: Flags [S], seq 871108679, win 29200, options [mss 1460,sackOK,TS val 123327951 ecr 0,nop,wscale 7], length 0
|
||||
10:10:37.650651 IP 54.204.39.132.80 > 192.168.122.98.39346: Flags [S.], seq 854753193, ack 871108680, win 28960, options [mss 1460,sackOK,TS val 522957932 ecr 123327951,nop,wscale 9], length 0
|
||||
10:10:37.650708 IP 192.168.122.98.39346 > 54.204.39.132.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 123328000 ecr 522957932], length 0
|
||||
10:10:37.651097 IP 192.168.122.98.39346 > 54.204.39.132.80: Flags [P.], seq 1:113, ack 1, win 229, options [nop,nop,TS val 123328000 ecr 522957932], length 112: HTTP: GET / HTTP/1.1
|
||||
10:10:37.692900 IP 54.204.39.132.80 > 192.168.122.98.39346: Flags [.], ack 113, win 57, options [nop,nop,TS val 522957942 ecr 123328000], length 0
|
||||
5 packets captured
|
||||
5 packets received by filter
|
||||
0 packets dropped by kernel
|
||||
```
|
||||
|
||||
In this example, we're filtering packets for HTTP service only (port 80) and source IP addresses `192.168.122.98` or `54.204.39.132`. This is a quick way of examining both sides of the same flow.
|
||||
|
||||
### 5\. Checking packet content
|
||||
|
||||
In the previous examples, we're checking only the packets' headers for information such as source, destinations, ports, etc. Sometimes this is all we need to troubleshoot network connectivity issues. Sometimes, however, we need to inspect the content of the packet to ensure that the message we're sending contains what we need or that we received the expected response. To see the packet content, tcpdump provides two additional flags: `-X` to print content in hex, and ASCII or `-A` to print the content in ASCII.
|
||||
|
||||
For example, inspect the HTTP content of a web request like this:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any -c10 -nn -A port 80
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
|
||||
13:02:14.871803 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [S], seq 2546602048, win 29200, options [mss 1460,sackOK,TS val 133625221 ecr 0,nop,wscale 7], length 0
|
||||
E..<..@.@.....zb6.'....P...@......r............
|
||||
............................
|
||||
13:02:14.910734 IP 54.204.39.132.80 > 192.168.122.98.39366: Flags [S.], seq 1877348646, ack 2546602049, win 28960, options [mss 1460,sackOK,TS val 525532247 ecr 133625221,nop,wscale 9], length 0
|
||||
E..<..@./..a6.'...zb.P..o..&...A..q a..........
|
||||
.R.W....... ................
|
||||
13:02:14.910832 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 133625260 ecr 525532247], length 0
|
||||
E..4..@.@.....zb6.'....P...Ao..'...........
|
||||
.....R.W................
|
||||
13:02:14.911808 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [P.], seq 1:113, ack 1, win 229, options [nop,nop,TS val 133625261 ecr 525532247], length 112: HTTP: GET / HTTP/1.1
|
||||
E.....@.@..1..zb6.'....P...Ao..'...........
|
||||
.....R.WGET / HTTP/1.1
|
||||
User-Agent: Wget/1.14 (linux-gnu)
|
||||
Accept: */*
|
||||
Host: opensource.com
|
||||
Connection: Keep-Alive
|
||||
|
||||
................
|
||||
13:02:14.951199 IP 54.204.39.132.80 > 192.168.122.98.39366: Flags [.], ack 113, win 57, options [nop,nop,TS val 525532257 ecr 133625261], length 0
|
||||
E..4.F@./.."6.'...zb.P..o..'.......9.2.....
|
||||
.R.a....................
|
||||
13:02:14.955030 IP 54.204.39.132.80 > 192.168.122.98.39366: Flags [P.], seq 1:643, ack 113, win 57, options [nop,nop,TS val 525532258 ecr 133625261], length 642: HTTP: HTTP/1.1 302 Found
|
||||
E....G@./...6.'...zb.P..o..'.......9.......
|
||||
.R.b....HTTP/1.1 302 Found
|
||||
Server: nginx
|
||||
Date: Sun, 23 Sep 2018 17:02:14 GMT
|
||||
Content-Type: text/html; charset=iso-8859-1
|
||||
Content-Length: 207
|
||||
X-Content-Type-Options: nosniff
|
||||
Location: https://opensource.com/
|
||||
Cache-Control: max-age=1209600
|
||||
Expires: Sun, 07 Oct 2018 17:02:14 GMT
|
||||
X-Request-ID: v-6baa3acc-bf52-11e8-9195-22000ab8cf2d
|
||||
X-Varnish: 632951979
|
||||
Age: 0
|
||||
Via: 1.1 varnish (Varnish/5.2)
|
||||
X-Cache: MISS
|
||||
Connection: keep-alive
|
||||
|
||||
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
|
||||
<html><head>
|
||||
<title>302 Found</title>
|
||||
</head><body>
|
||||
<h1>Found</h1>
|
||||
<p>The document has moved <a href="https://opensource.com/">here</a>.</p>
|
||||
</body></html>
|
||||
................
|
||||
13:02:14.955083 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [.], ack 643, win 239, options [nop,nop,TS val 133625304 ecr 525532258], length 0
|
||||
E..4..@.@.....zb6.'....P....o..............
|
||||
.....R.b................
|
||||
13:02:15.195524 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [F.], seq 113, ack 643, win 239, options [nop,nop,TS val 133625545 ecr 525532258], length 0
|
||||
E..4..@.@.....zb6.'....P....o..............
|
||||
.....R.b................
|
||||
13:02:15.236592 IP 54.204.39.132.80 > 192.168.122.98.39366: Flags [F.], seq 643, ack 114, win 57, options [nop,nop,TS val 525532329 ecr 133625545], length 0
|
||||
E..4.H@./.. 6.'...zb.P..o..........9.I.....
|
||||
.R......................
|
||||
13:02:15.236656 IP 192.168.122.98.39366 > 54.204.39.132.80: Flags [.], ack 644, win 239, options [nop,nop,TS val 133625586 ecr 525532329], length 0
|
||||
E..4..@.@.....zb6.'....P....o..............
|
||||
.....R..................
|
||||
10 packets captured
|
||||
10 packets received by filter
|
||||
0 packets dropped by kernel
|
||||
```
|
||||
|
||||
This is helpful for troubleshooting issues with API calls, assuming the calls are using plain HTTP. For encrypted connections, this output is less useful.
|
||||
|
||||
### 6\. Saving captures to a file
|
||||
|
||||
Another useful feature provided by tcpdump is the ability to save the capture to a file so you can analyze the results later. This allows you to capture packets in batch mode overnight, for example, and verify the results in the morning. It also helps when there are too many packets to analyze since real-time capture can occur too fast.
|
||||
|
||||
To save packets to a file instead of displaying them on screen, use the option `-w`:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any -c10 -nn -w webserver.pcap port 80
|
||||
[sudo] password for ricardo:
|
||||
tcpdump: listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
|
||||
10 packets captured
|
||||
10 packets received by filter
|
||||
0 packets dropped by kernel
|
||||
```
|
||||
|
||||
This command saves the output in a file named `webserver.pcap`. The `.pcap` extension stands for "packet capture" and is the convention for this file format.
|
||||
|
||||
As shown in this example, nothing gets displayed on-screen, and the capture finishes after capturing 10 packets, as per the option `-c10`. If you want some feedback to ensure packets are being captured, use the option `-v`.
|
||||
|
||||
Tcpdump creates a file in binary format so you cannot simply open it with a text editor. To read the contents of the file, execute tcpdump with the `-r` option:
|
||||
|
||||
```
|
||||
$ tcpdump -nn -r webserver.pcap
|
||||
reading from file webserver.pcap, link-type LINUX_SLL (Linux cooked)
|
||||
13:36:57.679494 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [S], seq 3709732619, win 29200, options [mss 1460,sackOK,TS val 135708029 ecr 0,nop,wscale 7], length 0
|
||||
13:36:57.718932 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [S.], seq 1999298316, ack 3709732620, win 28960, options [mss 1460,sackOK,TS val 526052949 ecr 135708029,nop,wscale 9], length 0
|
||||
13:36:57.719005 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 135708068 ecr 526052949], length 0
|
||||
13:36:57.719186 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [P.], seq 1:113, ack 1, win 229, options [nop,nop,TS val 135708068 ecr 526052949], length 112: HTTP: GET / HTTP/1.1
|
||||
13:36:57.756979 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [.], ack 113, win 57, options [nop,nop,TS val 526052959 ecr 135708068], length 0
|
||||
13:36:57.760122 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [P.], seq 1:643, ack 113, win 57, options [nop,nop,TS val 526052959 ecr 135708068], length 642: HTTP: HTTP/1.1 302 Found
|
||||
13:36:57.760182 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [.], ack 643, win 239, options [nop,nop,TS val 135708109 ecr 526052959], length 0
|
||||
13:36:57.977602 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [F.], seq 113, ack 643, win 239, options [nop,nop,TS val 135708327 ecr 526052959], length 0
|
||||
13:36:58.022089 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [F.], seq 643, ack 114, win 57, options [nop,nop,TS val 526053025 ecr 135708327], length 0
|
||||
13:36:58.022132 IP 192.168.122.98.39378 > 54.204.39.132.80: Flags [.], ack 644, win 239, options [nop,nop,TS val 135708371 ecr 526053025], length 0
|
||||
$
|
||||
```
|
||||
|
||||
Since you're no longer capturing the packets directly from the network interface, `sudo` is not required to read the file.
|
||||
|
||||
You can also use any of the filters we've discussed to filter the content from the file, just as you would with real-time data. For example, inspect the packets in the capture file from source IP address `54.204.39.132` by executing this command:
|
||||
|
||||
```
|
||||
$ tcpdump -nn -r webserver.pcap src 54.204.39.132
|
||||
reading from file webserver.pcap, link-type LINUX_SLL (Linux cooked)
|
||||
13:36:57.718932 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [S.], seq 1999298316, ack 3709732620, win 28960, options [mss 1460,sackOK,TS val 526052949 ecr 135708029,nop,wscale 9], length 0
|
||||
13:36:57.756979 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [.], ack 113, win 57, options [nop,nop,TS val 526052959 ecr 135708068], length 0
|
||||
13:36:57.760122 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [P.], seq 1:643, ack 113, win 57, options [nop,nop,TS val 526052959 ecr 135708068], length 642: HTTP: HTTP/1.1 302 Found
|
||||
13:36:58.022089 IP 54.204.39.132.80 > 192.168.122.98.39378: Flags [F.], seq 643, ack 114, win 57, options [nop,nop,TS val 526053025 ecr 135708327], length 0
|
||||
```
|
||||
|
||||
### What's next?
|
||||
|
||||
These basic features of tcpdump will help you get started with this powerful and versatile tool. To learn more, consult the [tcpdump website][3] and [man pages][4].
|
||||
|
||||
The tcpdump command line interface provides great flexibility for capturing and analyzing network traffic. If you need a graphical tool to understand more complex flows, look at [Wireshark][5].
|
||||
|
||||
One benefit of Wireshark is that it can read `.pcap` files captured by tcpdump. You can use tcpdump to capture packets in a remote machine that does not have a GUI and analyze the result file with Wireshark, but that is a topic for another day.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/introduction-tcpdump
|
||||
|
||||
作者:[Ricardo Gerardi][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rgerardi
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://www.tcpdump.org/manpages/tcpdump.1.html#lbAG
|
||||
[2]: https://www.iana.org/assignments/tcp-parameters/tcp-parameters.xhtml
|
||||
[3]: http://www.tcpdump.org/#
|
||||
[4]: http://www.tcpdump.org/manpages/tcpdump.1.html
|
||||
[5]: https://www.wireshark.org/
|
||||
@ -0,0 +1,197 @@
|
||||
Cloc – Count The Lines Of Source Code In Many Programming Languages
|
||||
======
|
||||
|
||||

|
||||
|
||||
As a developer, you may need to share the progress and statistics of your code to your boss or colleagues. Your boss might want to analyze the code and give any additional inputs. In such cases, there are few programs, as far as I know, available to analyze the source code. One such program is [**Ohcount**][1]. Today, I came across yet another similar utility namely **“Cloc”**. Using the Cloc, you can easily count the lines of source code in several programming languages. It counts the blank lines, comment lines, and physical lines of source code and displays the result in a neat tabular-column format. Cloc is free, open source and cross-platform utility entirely written in **Perl** programming language.
|
||||
|
||||
### Features
|
||||
|
||||
Cloc ships with numerous advantages including the following:
|
||||
|
||||
* Easy to install/use. Requires no dependencies.
|
||||
* Portable
|
||||
* It can produce results in a variety of formats, such as plain text, SQL, JSON, XML, YAML, comma separated values.
|
||||
* Can count your git commits.
|
||||
* Count the code in directories and sub-directories.
|
||||
* Count codes count code within compressed archives like tar balls, Zip files, Java .ear files etc.
|
||||
* Open source and cross platform.
|
||||
|
||||
|
||||
|
||||
### Installing Cloc
|
||||
|
||||
The Cloc utility is available in the default repositories of most Unix-like operating systems. So, you can install it using the default package manager as shown below.
|
||||
|
||||
On Arch Linux and its variants:
|
||||
|
||||
```
|
||||
$ sudo pacman -S cloc
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu:
|
||||
|
||||
```
|
||||
$ sudo apt-get install cloc
|
||||
|
||||
```
|
||||
|
||||
On CentOS, Red Hat, Scientific Linux:
|
||||
|
||||
```
|
||||
$ sudo yum install cloc
|
||||
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
|
||||
```
|
||||
$ sudo dnf install cloc
|
||||
|
||||
```
|
||||
|
||||
On FreeBSD:
|
||||
|
||||
```
|
||||
$ sudo pkg install cloc
|
||||
|
||||
```
|
||||
|
||||
It can also installed using third-party package manager like [**NPM**][2] as well.
|
||||
|
||||
```
|
||||
$ npm install -g cloc
|
||||
|
||||
```
|
||||
|
||||
### Count The Lines Of Source Code In Many Programming Languages
|
||||
|
||||
Let us start with a simple example. I have a “hello world” program written in C in my current working directory.
|
||||
|
||||
```
|
||||
$ cat hello.c
|
||||
#include <stdio.h>
|
||||
int main()
|
||||
{
|
||||
// printf() displays the string inside quotation
|
||||
printf("Hello, World!");
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
To count the lines of code in the hello.c program, simply run:
|
||||
|
||||
```
|
||||
$ cloc hello.c
|
||||
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||

|
||||
|
||||
The first column specifies the **name of programming languages that the source code consists of**. As you can see in the above output, the source code of “hello world” program is written using **C** programming language.
|
||||
|
||||
The second column displays the **number of files in each programming languages**. So, our code contains **1 file** in total.
|
||||
|
||||
The third column displays the **total number of blank lines**. We have zero blank files in our code.
|
||||
|
||||
The fourth column displays **number of comment lines**.
|
||||
|
||||
And the final and fifth column displays **total physical lines of given source code**.
|
||||
|
||||
It is just a 6 line code program, so counting the lines in the code is not a big deal. What about the some big source code file? Have a look at the following example:
|
||||
|
||||
```
|
||||
$ cloc file.tar.gz
|
||||
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
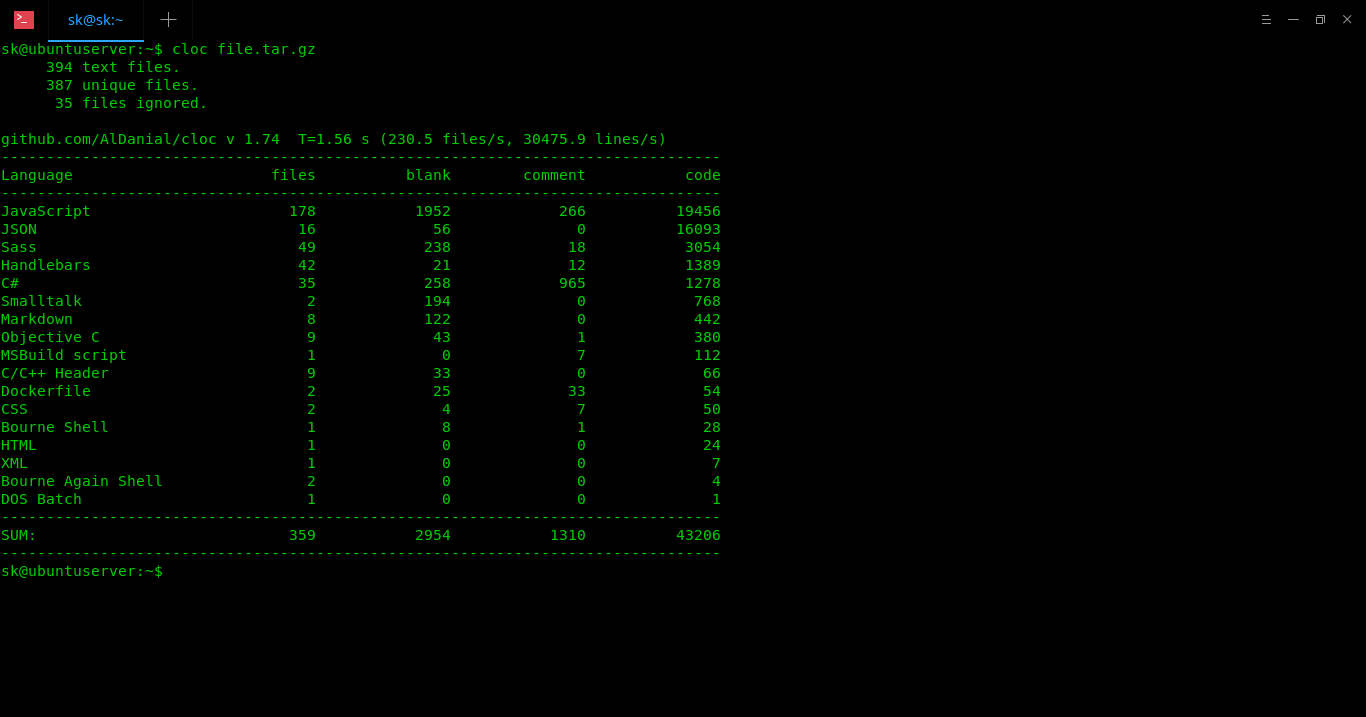
|
||||
|
||||
As per the above output, it is quite difficult to manually find exact count of code. But, Cloc displays the result in seconds with nice tabular-column format. You can view the gross total of each section at the end which is quite handy when it comes to analyze the source code of a program.
|
||||
|
||||
Cloc not only counts the individual source code files, but also files inside directories and sub-directories, archives, and even in specific git commits etc.
|
||||
|
||||
**Count the lines of codes in a directory:**
|
||||
|
||||
```
|
||||
$ cloc dir/
|
||||
|
||||
```
|
||||
|
||||
![][4]
|
||||
|
||||
**Sub-directory:**
|
||||
|
||||
```
|
||||
$ cloc dir/cloc/tests
|
||||
|
||||
```
|
||||
|
||||
![][5]
|
||||
|
||||
**Count the lines of codes in archive file:**
|
||||
|
||||
```
|
||||
$ cloc archive.zip
|
||||
|
||||
```
|
||||
|
||||
![][6]
|
||||
|
||||
You can also count lines in a git repository, using a specific commit like below.
|
||||
|
||||
```
|
||||
$ git clone https://github.com/AlDanial/cloc.git
|
||||
|
||||
$ cd cloc
|
||||
|
||||
$ cloc 157d706
|
||||
|
||||
```
|
||||
|
||||
![][7]
|
||||
|
||||
Cloc can recognize several programming languages. To view the complete list of recognized languages, run:
|
||||
|
||||
```
|
||||
$ cloc --show-lang
|
||||
|
||||
```
|
||||
|
||||
For more details, refer the help section.
|
||||
|
||||
```
|
||||
$ cloc --help
|
||||
|
||||
```
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/cloc-count-the-lines-of-source-code-in-many-programming-languages/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/ohcount-the-source-code-line-counter-and-analyzer/
|
||||
[2]: https://www.ostechnix.com/install-node-js-linux/
|
||||
[3]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[4]: http://www.ostechnix.com/wp-content/uploads/2018/10/cloc-2-1.png
|
||||
[5]: http://www.ostechnix.com/wp-content/uploads/2018/10/cloc-4.png
|
||||
[6]: http://www.ostechnix.com/wp-content/uploads/2018/10/cloc-3.png
|
||||
[7]: http://www.ostechnix.com/wp-content/uploads/2018/10/cloc-5.png
|
||||
@ -0,0 +1,131 @@
|
||||
Linux vs Mac: Linux 比 Mac 好的七个原因
|
||||
======
|
||||
最近我们谈论了一些[为什么 Linux 比 Windows 好][1]的原因。毫无疑问, Linux 是个非常优秀的平台。但是它和其他的操作系统一样也会有缺点。对于某些专门的领域,像是游戏, Windows 当然更好。 而对于视频编辑等任务, Mac 系统可能更为方便。这一切都取决于你的爱好,以及你想用你的系统做些什么。在这篇文章中,我们将会介绍一些 Linux 相对于 Mac 更好的一些地方。
|
||||
|
||||
如果你已经在用 Mac 或者打算买一台 Mac 电脑,我们建议你仔细考虑一下,看看是改为使用 Linux 还是继续使用 Mac 。
|
||||
|
||||
### Linux 比 Mac 好的 7 个原因
|
||||
|
||||
![Linux vs Mac: 为什么 Linux 更好][2]
|
||||
|
||||
Linux 和 macOS 都是类 Unix 操作系统,并且都支持 Unix 命令行、 bash 和其他一些命令行工具,相比于 Windows ,他们所支持的应用和游戏比较少。但缺点也仅仅如此。
|
||||
|
||||
平面设计师和视频剪辑师更加倾向于使用 Mac 系统,而 Linux 更加适合做开发、系统管理、运维的工程师。
|
||||
|
||||
那要不要使用 Linux 呢,为什么要选择 Linux 呢?下面是根据实际经验和理性分析给出的一些建议。
|
||||
|
||||
#### 1\. 价格
|
||||
|
||||
![Linux vs Mac: 为什么 Linux 更好][3]
|
||||
|
||||
假设你只是需要浏览文件、看电影、下载图片、写文档、制作报表或者做一些类似的工作,并且你想要一个更加安全的系统。
|
||||
|
||||
那在这种情况下,你觉得花费几百块买个系统完成这项工作,或者花费更多直接买个 Macbook 划算吗?当然,最终的决定权还是在你。
|
||||
|
||||
买个装好 Mac 系统的电脑还是买个便宜的电脑,然后自己装上免费的 Linux 系统,这个要看你自己的偏好。就我个人而言,除了音视频剪辑创作之外,Linux 都非常好地用,而对于音视频方面,我更倾向于使用 Final Cut Pro (专业的视频编辑软件) 和 Logic Pro X (专业的音乐制作软件)(这两款软件都是苹果公司推出的)。
|
||||
|
||||
#### 2\. 硬件支持
|
||||
|
||||
![Linux vs Mac: 为什么 Linux 更好][4]
|
||||
|
||||
Linux 支持多种平台. 无论你的电脑配置如何,你都可以在上面安装 Linux,无论性能好或者差,Linux 都可以运行。[即使你的电脑已经使用很久了, 你仍然可以通过选择安装合适的发行版让 Linux 在你的电脑上流畅的运行][5].
|
||||
|
||||
而 Mac 不同,它是苹果机专用系统。如果你希望买个便宜的电脑,然后自己装上 Mac 系统,这几乎是不可能的。一般来说 Mac 都是和苹果设备连在一起的。
|
||||
|
||||
这是[在非苹果系统上安装 Mac OS 的教程][6]. 这里面需要用到的专业技术以及可能遇到的一些问题将会花费你许多时间,你需要想好这样做是否值得。
|
||||
|
||||
总之,Linux 所支持的硬件平台很广泛,而 MacOS 相对而言则非常少。
|
||||
|
||||
#### 3\. 安全性
|
||||
|
||||
![Linux vs Mac: 为什么 Linux 更好][7]
|
||||
|
||||
很多人都说 ios 和 Mac 是非常安全的平台。的确,相比于 Windows ,它确实比较安全,可并不一定有 Linux 安全。
|
||||
|
||||
我不是在危言耸听。 Mac 系统上也有不少恶意软件和广告,并且[数量与日俱增][8]。我认识一些不太懂技术的用户 使用着非常缓慢的 Mac 电脑并且为此苦苦挣扎。一项快速调查显示[浏览器恶意劫持软件][9]是罪魁祸首.
|
||||
|
||||
从来没有绝对安全的操作系统,Linux 也不例外。 Linux 也有漏洞,但是 Linux 发行版提供的及时更新弥补了这些漏洞。另外,到目前为止在 Linux 上还没有自动运行的病毒或浏览器劫持恶意软件的案例发生。
|
||||
|
||||
这可能也是一个你应该选择 Linux 而不是 Mac 的原因。
|
||||
|
||||
#### 4\. 可定制性与灵活性
|
||||
|
||||
![Linux vs Mac: 为什么 Linux 更好][10]
|
||||
|
||||
如果你有不喜欢的东西,自己定制或者修改它都行。
|
||||
|
||||
举个例子,如果你不喜欢 Ubuntu 18.04.1 的 [Gnome 桌面环境][11],你可以换成 [KDE Plasma][11]。 你也可以尝试一些 [Gnome 扩展][12]丰富你的桌面选择。这种灵活性和可定制性在 Mac OS 是不可能有的。
|
||||
|
||||
除此之外你还可以根据需要修改一些操作系统的代码(但是可能需要一些专业知识)以创造出适合你的系统。这个在 Mac OS 上可以做吗?
|
||||
|
||||
另外你可以根据需要从一系列的 Linux 发行版进行选择。比如说,如果你想喜欢 Mac OS上的工作流, [Elementary OS][13] 可能是个不错的选择。你想在你的旧电脑上装上一个轻量级的 Linux 发行版系统吗?这里是一个[轻量级 Linux 发行版列表][5]。相比较而言, Mac OS 缺乏这种灵活性。
|
||||
|
||||
#### 5\. 使用 Linux 有助于你的职业生涯 [针对 IT 行业和科学领域的学生]
|
||||
|
||||
![Linux vs Mac: 为什么 Linux 更好][14]
|
||||
|
||||
对于 IT 领域的学生和求职者而言,这是有争议的但是也是有一定的帮助的。使用 Linux 并不会让你成为一个优秀的人,也不一定能让你得到任何与 IT 相关的工作。
|
||||
|
||||
但是当你开始使用 Linux 并且开始探索如何使用的时候,你将会获得非常多的经验。作为一名技术人员,你迟早会接触终端,学习通过命令行实现文件系统管理以及应用程序安装。你可能不会知道这些都是一些 IT 公司的新职员需要培训的内容。
|
||||
|
||||
除此之外,Linux 在就业市场上还有很大的发展空间。 Linux 相关的技术有很多( Cloud 、 Kubernetes 、Sysadmin 等),您可以学习,获得证书并获得一份相关的高薪的工作。要学习这些,你必须使用 Linux 。
|
||||
|
||||
#### 6\. 可靠
|
||||
|
||||
![Linux vs Mac: 为什么 Linux 更好][15]
|
||||
|
||||
想想为什么服务器上用的都是 Linux 系统,当然是因为它可靠。
|
||||
|
||||
但是它为什么可靠呢,相比于 Mac OS ,它的可靠体现在什么方面呢?
|
||||
|
||||
答案很简单——给用户更多的控制权,同时提供更好的安全性。在 Mac OS 上,你并不能完全控制它,这样做是为了让操作变得更容易,同时提高你的用户体验。使用 Linux ,你可以做任何你想做的事情——这可能会导致(对某些人来说)糟糕的用户体验——但它确实使其更可靠。
|
||||
|
||||
#### 7\. 开源
|
||||
|
||||
![Linux vs Mac: 为什么 Linux 更好][16]
|
||||
|
||||
开源并不是每个人都关心的。但对我来说,Linux 最重要的优势在于它的开源特性。下面讨论的大多数观点都是开源软件的直接优势。
|
||||
|
||||
简单解释一下,如果是开源软件,你可以自己查看或者修改它。但对 Mac 来说,苹果拥有独家控制权。即使你有足够的技术知识,也无法查看 Mac OS 的源代码。
|
||||
|
||||
形象点说,Mac 驱动的系统可以让你得到一辆车,但缺点是你不能打开引擎盖看里面是什么。那可能非常糟糕!
|
||||
|
||||
如果你想深入了解开源软件的优势,可以在 OpenSource.com 上浏览一下 [Ben Balter 的文章][17]。
|
||||
|
||||
### 总结
|
||||
|
||||
现在你应该知道为什么 Linux 比 Mac 好了吧,你觉得呢?上面的这些原因可以说服你选择 Linux 吗?如果不行的话那又是为什么呢?
|
||||
|
||||
在下方评论让我们知道你的想法。
|
||||
|
||||
Note: 这里的图片是以企鹅俱乐部为原型的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/linux-vs-mac/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Ryze-Borgia](https://github.com/Ryze-Borgia)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[1]: https://itsfoss.com/linux-better-than-windows/
|
||||
[2]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/Linux-vs-mac-featured.png
|
||||
[3]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-1.jpeg
|
||||
[4]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-4.jpeg
|
||||
[5]: https://itsfoss.com/lightweight-linux-beginners/
|
||||
[6]: https://hackintosh.com/
|
||||
[7]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-2.jpeg
|
||||
[8]: https://www.computerworld.com/article/3262225/apple-mac/warning-as-mac-malware-exploits-climb-270.html
|
||||
[9]: https://www.imore.com/how-to-remove-browser-hijack
|
||||
[10]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-3.jpeg
|
||||
[11]: https://www.gnome.org/
|
||||
[12]: https://itsfoss.com/best-gnome-extensions/
|
||||
[13]: https://elementary.io/
|
||||
[14]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-5.jpeg
|
||||
[15]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-6.jpeg
|
||||
[16]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/linux-vs-mac-7.jpeg
|
||||
[17]: https://opensource.com/life/15/12/why-open-source
|
||||
@ -1,139 +0,0 @@
|
||||
我应该使用哪些稳定版内核?
|
||||
======
|
||||
很多人都问我这样的问题,在他们的产品/设备/笔记本/服务器等上面应该使用什么样的稳定版内核。一直以来,尤其是那些现在已经延长支持时间的内核,都是由我和其他人提供支持,因此,给出这个问题的答案并不是件容易的事情。因此这篇文章我将尝试去给出我在这个问题上的看法。当然,你可以任意选用任何一个你想去使用的内核版本,这里只是我的建议。
|
||||
|
||||
和以前一样,在这里给出的这些看法只代表我个人的意见。
|
||||
|
||||
### 可选择的内核有哪些
|
||||
|
||||
下面列出了我建议你应该去使用的内核的列表,从最好的到最差的都有。我在下面将详细介绍,但是如果你只想得到一个结论,它就是你想要的:
|
||||
|
||||
建议你使用的内核的分级,从最佳的方案到最差的方案如下:
|
||||
|
||||
* 你最喜欢的 Linux 发行版支持的内核
|
||||
* 最新的稳定版
|
||||
* 最新的 LTS 发行版
|
||||
* 仍然处于维护状态的老的 LTS 发行版
|
||||
|
||||
|
||||
|
||||
绝对不要去使用的内核:
|
||||
|
||||
* 不再维护的内核发行版
|
||||
|
||||
|
||||
|
||||
给上面的列表给出具体的数字,今天是 2018 年 8 月 24 日,kernel.org 页面上可以看到是这样:
|
||||
|
||||
![][1]
|
||||
|
||||
因此,基于上面的列表,那它应该是:
|
||||
|
||||
* 4.18.5 是最新的稳定版
|
||||
* 4.14.67 是最新的 LTS 发行版
|
||||
* 4.9.124、4.4.152、以及 3.16.57 是仍然处于维护状态的老的 LTS 发行版
|
||||
* 4.17.19 和 3.18.119 是过去 60 天内 “生命周期终止” 的内核版本,它们仍然保留在 kernel.org 站点上,是为了仍然想去使用它们的那些人。
|
||||
|
||||
|
||||
|
||||
非常容易,对吗?
|
||||
|
||||
Ok,现在我给出这样选择的一些理由:
|
||||
|
||||
### Linux 发行版内核
|
||||
|
||||
对于大多数 Linux 用户来说,最好的方案就是使用你喜欢的 Linux 发行版的内核。就我本人而言,我比较喜欢基于社区的、内核不断滚动升级的用最新内核的 Linux 发行版,并且它也是由开发者社区来支持的。这种类型的发行版有 Fedora、openSUSE、Arch、Gentoo、CoreOS、以及其它的。
|
||||
|
||||
所有这些发行版都使用了上游的最新的稳定版内核,并且确保定期打了需要的 bug 修复补丁。当它拥有了最新的修复之后([记住所有的修复都是安全修复][2]),这就是你可以使用的最安全、最好的内核之一。
|
||||
|
||||
有些社区的 Linux 发行版需要很长的时间才发行一个新内核的发行版,但是最终发行的版本和所支持的内核都是非常好的。这些也都非常好用,Debian 和 Ubuntu 就是这样的例子。
|
||||
|
||||
我没有在这里列出你所喜欢的发行版,并不是意味着它们的内核不够好。查看这些发行版的网站,确保它们的内核包是不断应用最新的安全补丁进行升级过的,那么它就应该是很好的。
|
||||
|
||||
许多人好像喜欢旧的、“传统” 模式的发行版,以及使用 RHEL、SLES、CentOS 或者 “LTS” Ubuntu 发行版。这些发行版挑选一个特定的内核版本,然后使用好几年,而不是几十年。他们移植了最新的 bug 修复,有时也有一些内核的新特性,所有的只是追求堂吉诃德式的保持版本号不变而已,尽管他们已经在那个旧的内核版本上做了成千上万的变更。这其实是一个吃力不讨好的工作,开发者分配去做这些任务,看上去做的很不错,其实就是为了实现这些目标。如果你从来没有看到你的内核版本号发生过变化,而仍然在使用这些发行版。他们通常会为使用而付出一些成本,当发生错误时能够从这些公司得到一些支持,那就是值得的。
|
||||
|
||||
所以,你能使用的最好的内核是你可以求助于别人,而别人可以为你提供支持的内核。使用那些支持,你通常都已经为它支付过费用了(对于企业发行版),而这些公司也知道他们职责是什么。
|
||||
|
||||
但是,如果你不希望去依赖别人,而是希望你自己管理你的内核,或者你有发行版不支持的硬件,那么你应该去使用最新的稳定版:
|
||||
|
||||
### 最新的稳定版
|
||||
|
||||
最新的稳定版内核是 Linux 内核开发者社区宣布为“稳定版”的最新的一个内核。大约每三个月,社区发行一个包含了对所有新硬件支持的、新的稳定版内核,最新版的内核不但改善内核性能,同时还包含内核各部分的 bug 修复。再经过三个月之后,进入到下一个内核版本的 bug 修复将被移植进入这个稳定版内核中,因此,使用这个内核版本的用户将确保立即得到这些修复。
|
||||
|
||||
最新的稳定版内核通常也是主流社区发行版使用的较好的内核,因此你可以确保它是经过测试和拥有大量用户使用的内核。另外,内核社区(全部开发者超过 4000 人)也将帮助这个发行版提供对用户的支持,因为这是他们做的最新的一个内核。
|
||||
|
||||
三个月之后,将发行一个新的稳定版内核,你应该去更新到它以确保你的内核始终是最新的稳定版,当最新的稳定版内核发布之后,对你的当前稳定版内核的支持通常会落后几周时间。
|
||||
|
||||
如果你在上一个 LTS 版本发布之后购买了最新的硬件,为了能够支持最新的硬件,你几乎是绝对需要去运行这个最新的稳定版内核。对于台式机或新的服务器,它们通常需要运行在它们推荐的内核版本上。
|
||||
|
||||
### 最新的 LTS 发行版
|
||||
|
||||
如果你的硬件为了保证正常运行(像大多数的嵌入式设备),需要依赖供应商的源码树外的补丁,那么对你来说,最好的内核版本是最新的 LTS 发行版。这个发行版拥有所有进入稳定版内核的最新 bug 修复,以及大量的用户测试和使用。
|
||||
|
||||
请注意,这个最新的 LTS 发行版没有新特性,并且也几乎不会增加对新硬件的支持,因此,如果你需要使用一个新设备,那你的最佳选择就是最新的稳定版内核,而不是最新的 LTS 版内核。
|
||||
|
||||
另外,对于这个 LTS 发行版内核的用户来说,他也不用担心每三个月一次的“重大”升级。因此,他们将一直坚持使用这个 LTS 内核发行版,并每年升级一次,这是一个很好的实践。
|
||||
|
||||
使用这个 LTS 发行版的不利方面是,你没法得到在最新版本内核上实现的内核性能提升,除非在未来的一年中,你升级到下一个 LTS 版内核。
|
||||
|
||||
另外,如果你使用的这个内核版本有问题,你所做的第一件事情就是向任意一位内核开发者报告发生的问题,并向他们询问,“最新的稳定版内核中是否也存在这个问题?”并且,你将意识到,对它的支持不会像使用最新的稳定版内核那样容易得到。
|
||||
|
||||
现在,如果你坚持使用一个有大量的补丁集的内核,并且不希望升级到每年一次的新 LTS 内核版本上,那么,或许你应该去使用老的 LTS 发行版内核:
|
||||
|
||||
### 老的 LTS 发行版
|
||||
|
||||
这些发行版传统上都由社区提供 2 年时间的支持,有时候当一个重要的 Linux 发行版(像 Debian 或 SLES 一样)依赖它时,这个支持时间会更长。然而在过去一年里,感谢 Google、Linaro、Linaro 成员公司、[kernelci.org][3]、以及其它公司在测试和基础设施上的大量投入,使得这些老的 LTS 发行版内核得到更长时间的支持。
|
||||
|
||||
这是最新的 LTS 发行版,它们将被支持多长时间,这是 2018 年 8 月 24 日显示在 [kernel.org/category/releases.html][4] 上的信息:
|
||||
|
||||
![][5]
|
||||
|
||||
Google 和其它公司希望这些内核使用的时间更长的原因是,由于现在几乎所有的 SoC 芯片的疯狂(也有人说是打破常规)的开发模型。这些设备在芯片发行前几年就启动了他们的开发生命周期,而那些代码从来不会合并到上游,最终结果是始终在一个分支中,新的芯片基于一个 2 年以前的老内核发布。这些 SoC 的代码树通常增加了超过 200 万行的代码,这使得它们成为我们前面称之为“类 Linux 内核“的东西。
|
||||
|
||||
如果在 2 年后,这个 LTS 发行版停止支持,那么来自社区的支持将立即停止,并且没有人对它再进行 bug 修复。这导致了在全球各地数以百万计的不安全设备仍然在使用中,这对任何生态系统来说都不是什么好事情。
|
||||
|
||||
由于这种依赖,这些公司现在要求新设备不断更新到最新的 LTS 发行版,而这些特定的发行版(即每个 4.9.y 发行版)就是为它们发行的。其中一个这样的例子就是新 Android 设备对内核版本的要求,这些新设备的 “O” 版本和现在的 “P” 版本指定了最低允许使用的内核版本,并且在设备上越来越频繁升级的、安全的 Android 发行版开始要求使用这些 “.y” 发行版。
|
||||
|
||||
我注意到一些生产商现在已经在做这些事情。Sony 是其中一个非常好的例子,在他们的大多数新手机上,通过他们每季度的安全发行版,将设备更新到最新的 4.4.y 发行版上。另一个很好的例子是一家小型公司 Essential,他们持续跟踪 4.4.y 发行版,据我所知,他们发布新版本的速度比其它公司都快。
|
||||
|
||||
当使用这种很老的内核时有个重大警告。移植到这种内核中的 bug 修复比起最新版本的 LTS 内核来说数量少很多,因为这些使用很老的 LTS 内核的传统设备型号要远少于现在的用户使用的型号。如果你打算将它们用在有不可信的用户或虚拟机的地方,那么这些内核将不再被用于任何”通用计算“的模型中,因为对于这些内核不会去做像最近的 Spectre 这样的修复,如果在一些分支中存在这样的 bug,那么将极大地降低安全性。
|
||||
|
||||
因此,仅当在你能够完全控制的设备中使用老的 LTS 发行版,或者是使用在有一个非常强大的安全模型(像 Android 一样强制使用 SELinux 和应用程序隔离)去限制的情况下。绝对不要在有不可信用户、程序、或虚拟机的服务器上使用这些老的 LTS 发行版内核。
|
||||
|
||||
此外,如果社区对它有支持的话,社区对这些老的 LTS 内核发行版相比正常的 LTS 内核发行版的支持要少的多。如果你使用这些内核,那么你只能是一个人在战斗,你需要有能力去独自支持这些内核,或者依赖你的 SoC 供应商为你提供支持(需要注意的是,对于大部分供应商来说是不会为你提供支持的,因此,你要特别注意 …)。
|
||||
|
||||
### 不再维护的内核发行版
|
||||
|
||||
更让人感到惊讶的事情是,许多公司只是随便选一个内核发行版,然后将它封装到它们的产品里,并将它毫不犹豫地承载到数十万的部件中。其中一个这样的糟糕例子是 Lego Mindstorm 系统,不知道是什么原因在它们的设备上随意选取了一个 `-rc` 的内核发行版。`-rc` 的发行版是开发中的版本,Linux 内核开发者认为它根本就不适合任何人使用,更不用说是数百万的用户了。
|
||||
|
||||
当然,如果你愿意,你可以随意地使用它,但是需要注意的是,可能真的就只有你一个人在使用它。社区不会为你提供支持,因为他们不可能关注所有内核版本的特定问题,因此如果出现错误,你只能独自去解决它。对于一些公司和系统来说,这么做可能还行,但是如果没有为此有所规划,那么要当心因此而产生的”隐性“成本。
|
||||
|
||||
### 总结
|
||||
|
||||
基于以上原因,下面是一个针对不同类型设备的简短列表,这些设备我推荐适用的内核如下:
|
||||
|
||||
* 笔记本 / 台式机:最新的稳定版内核
|
||||
* 服务器:最新的稳定版内核或最新的 LTS 版内核
|
||||
* 嵌入式设备:最新的 LTS 版内核或老的 LTS 版内核(如果使用的安全模型非常强大和严格)
|
||||
|
||||
|
||||
|
||||
至于我,在我的机器上运行什么样的内核?我的笔记本运行的是最新的开发版内核(即 Linus 的开发树)再加上我正在做修改的内核,我的服务器上运行的是最新的稳定版内核。因此,尽管我负责 LTS 发行版的支持工作,但我自己并不使用 LTS 版内核,除了在测试系统上。我依赖于开发版和最新的稳定版内核,以确保我的机器运行的是目前我们所知道的最快的也是最安全的内核版本。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://kroah.com/log/blog/2018/08/24/what-stable-kernel-should-i-use/
|
||||
|
||||
作者:[Greg Kroah-Hartman][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://kroah.com
|
||||
[1]:https://s3.amazonaws.com/kroah.com/images/kernel.org_2018_08_24.png
|
||||
[2]:http://kroah.com/log/blog/2018/02/05/linux-kernel-release-model/
|
||||
[3]:https://kernelci.org/
|
||||
[4]:https://www.kernel.org/category/releases.html
|
||||
[5]:https://s3.amazonaws.com/kroah.com/images/kernel.org_releases_2018_08_24.png
|
||||
@ -1,104 +0,0 @@
|
||||
一款免费且安全的在线PDF转换软件
|
||||
======
|
||||
|
||||

|
||||
|
||||
我们总在寻找一个更好用且更高效的解决方案,来我们的生活理加方便。 比方说,在处理PDF文档时,你会迫切地想拥有一款工具,它能够在任何情形下都显得快速可靠。在这,我们想向你推荐**EasyPDF**——一款可以胜任所有场合的在线PDF软件。通过大量的测试,我们可以保证:这款工具能够让你的PDF文档管理更加容易。
|
||||
|
||||
不过,关于EasyPDF有一些十分重要的事情,你必须知道。
|
||||
|
||||
* EasyPDF是免费的、匿名的在线PDF转换软件。
|
||||
* 能够将PDF文档转换成Word、Excel、PowerPoint、AutoCAD、JPG, GIF和Text等格式格式的文档。
|
||||
* 能够从ord、Excel、PowerPoint等其他格式的文件创建PDF文件。
|
||||
* 能够进行PDF文档的合并、分割和压缩。
|
||||
* 能够识别扫描的PDF和图片中的内容。
|
||||
* 可以从你的设备或者云存储(Google Drive 和 DropBox)中上传文档。
|
||||
* 可以在Windows、Linux、Mac和智能手机上通过浏览器来操作。
|
||||
* 支持多种语言。
|
||||
|
||||
### EasyPDF的用户界面
|
||||
|
||||

|
||||
|
||||
EasyPDF最吸引你眼球的就是平滑的用户界面,营造一种整洁的环境,这会让使用者感觉更加舒服。由于网站完全没有一点广告,EasyPDF的整体使用体验相比以前会好很多。
|
||||
|
||||
每种不同类型的转换都有它们专门的菜单,只需要简单地向其中添加文件,你并不需要知道太多知识来进行操作。
|
||||
|
||||
许多类似网站没有做好相关的优化,使得在手机上的使用体验并不太友好。然而,EasyPDF突破了这一个瓶颈。在智能手机上,EasyPDF几乎可以秒开,并且可以顺畅的操作。你也通过Chrome app的**three dots menu**把EasyPDF添加到手机的主屏幕上。
|
||||
|
||||

|
||||
|
||||
### 特性
|
||||
|
||||
除了好看的界面,EasyPDF还非常易于使用。为了使用它,你 **不需要注册一个账号** 或者**留下一个邮箱**,它是完全匿名的。另外,EasyPDF也不会对要转换的文件进行数量或者大小的限制,完全不需要安装!酷极了,不是吗?
|
||||
|
||||
首先,你需要选择一种想要进行的格式转换,比如,将PDF转换成Word。然后,选择你想要转换的PDF文件。你可以通过两种方式来上传文件:直接拖拉或者从设备上的文件夹进行选择。还可以选择从[**Google Drive**][1] 或 [**Dropbox**][2]来上传文件。
|
||||
|
||||
选择要进行格式转换的文件后,点击Convert按钮开始转换过程。转换过程会在一分钟内完成,你并不需要等待太长时间。如果你还有对其他文件进行格式转换,在接着转换前,不要忘了将前面已经转换完成的文件下载保存。不然的话,你将会丢失前面的文件。
|
||||
|
||||

|
||||
|
||||
要进行其他类型的格式转换,直接返回到主页。
|
||||
|
||||
目前支持的几种格式转换类型如下:
|
||||
|
||||
* **PDF to Word** – 将 PDF 文档 转换成 Word 文档
|
||||
|
||||
* **PDF 转换成 PowerPoint** – 将 PDF 文档 转换成 PowerPoint 演示讲稿
|
||||
|
||||
* **PDF 转换成 Excel** – 将 PDF 文档 转换成 Excel 文档
|
||||
|
||||
* **PDF 创建** – 从一些其他类型的文件(如, text, doc, odt)来创建PDF文档
|
||||
|
||||
* **Word 转换成 PDF** – 将 Word 文档 转换成 PDF 文档
|
||||
|
||||
* **JPG 转换成 PDF** – 将 JPG images 转换成 PDF 文档
|
||||
|
||||
* **PDF 转换成 Au转换成CAD** – 将 PDF 文档 转换成 .dwg 格式 (DWG 是 CAD 文件的原生的格式)
|
||||
|
||||
* **PDF 转换成 Text** – 将 PDF 文档 转换成 Text 文档
|
||||
|
||||
* **PDF 分割** – 把 PDF 文件分割成多个部分
|
||||
|
||||
* **PDF 合并** – 把多个PDF文件合并成一个文件
|
||||
|
||||
* **PDF 压缩** – 将 PDF 文档进行压缩
|
||||
|
||||
* **PDF 转换成 JPG** – 将 PDF 文档 转换成 JPG 图片
|
||||
|
||||
* **PDF 转换成 PNG** – 将 PDF 文档 转换成 PNG 图片
|
||||
|
||||
* **PDF 转换成 GIF** – 将 PDF 文档 转换成 GIF 文件
|
||||
|
||||
* **在线文字内容识别** – 将扫描的纸质文档转换成能够进行编辑的文件(如,Word,Excel,Text)
|
||||
|
||||
想试一试吗?好极了!点击下面的链接,然后开始格式转换吧!
|
||||
|
||||
[][https://easypdf.com/]
|
||||
|
||||
### 总结
|
||||
|
||||
EasyPDF 名符其实,能够让PDF 管理更加容易。就我测试过的 EasyPDF 服务而言,它提供了**完全免费**的简单易用的转换功能。它十分快速、安全和可靠。你会对它的服务质量感到非常满意,因为它不用支付任何费用,也不用留下像邮箱这样的个人信息。值得一试,也许你会找到你自己更喜欢的 PDF 工具。
|
||||
|
||||
好吧,我就说这些。更多的好东西还在后后面,请继续关注!
|
||||
|
||||
加油!
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/easypdf-a-free-and-secure-online-pdf-conversion-suite/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/zhousiyu325)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.ostechnix.com/how-to-mount-google-drive-locally-as-virtual-file-system-in-linux/
|
||||
[2]: https://www.ostechnix.com/install-dropbox-in-ubuntu-18-04-lts-desktop/
|
||||
@ -0,0 +1,105 @@
|
||||
容器技术对指导我们 DevOps 的一些启发
|
||||
======
|
||||
|
||||
容器技术的使用支撑了目前 DevOps 三大主要实践:流水线,及时反馈,持续实验与学习以改进。
|
||||
|
||||

|
||||
|
||||
容器技术与 DevOps 二者在发展的过程中是互相促进的关系。得益于 DevOps 的设计理念愈发先进,容器生态系统在设计上与组件选择上也有相应发展。同时,由于容器技术在生产环境中的使用,反过来也促进了 DevOps 三大主要实践:[支撑DevOps的三个实践][1].
|
||||
|
||||
|
||||
### 工作流
|
||||
|
||||
**容器中的工作流**
|
||||
|
||||
每个容器都可以看成一个独立的封闭仓库,当你置身其中,不需要管外部的系统环境、集群环境、以及其他基础设施,不管你在里面如何折腾,只要对外提供正常的功能就好。一般来说,容器内运行的应用,一般作为整个应用系统架构的一部分:比如 web API,数据库,任务执行,缓存系统,垃圾回收器等。运维团队一般会限制容器的资源使用,并在此基础上建立完善的容器性能监控服务,从而降低其对基础设施或者下游其他用户的影响。
|
||||
|
||||
**现实中的工作流**
|
||||
|
||||
那些跟“容器”一样独立工作的团队,也可以借鉴这种限制容器占用资源的策略。因为无论是在现实生活中的工作流(代码发布、构建基础设施,甚至制造[Spacely’s Sprockets][2]等),还是技术中的工作流(开发、测试、试运行、发布)都使用了这样的线性工作流,一旦某个独立的环节或者工作团队出现了问题,那么整个下游都会受到影响,虽然使用我们这种线性的工作流有效降低了工作耦合性。
|
||||
|
||||
**DevOps 中的工作流**
|
||||
|
||||
DevOps 中的第一条原则,就是掌控整个执行链路的情况,努力理解系统如何协同工作,并理解其中出现的问题如何对整个过程产生影响。为了提高流程的效率,团队需要持续不断的找到系统中可能存在的性能浪费以及忽视的点,并最终修复它们。
|
||||
|
||||
|
||||
> “践行这样的工作流后,可以避免传递一个已知的缺陷到工作流的下游,避免产生一个可能会导致全局性能退化的局部优化,持续优化工作流的性能,持续加深对于系统的理解”
|
||||
|
||||
–Gene Kim, [支撑DevOps的三个实践][3], IT 革命, 2017.4.25
|
||||
|
||||
### 反馈
|
||||
|
||||
**容器中的反馈**
|
||||
|
||||
除了限制容器的资源,很多产品还提供了监控和通知容器性能指标的功能,从而了解当容器工作不正常时,容器内部处于什么样的工作状态。比如 目前[流行的][5][Prometheus][4],可以用来从容器和容器集群中收集相应的性能指标数据。容器本身特别适用于分隔应用系统,以及打包代码和其运行环境,但也同时带来不透明的特性,这时从中快速的收集信息,从而解决发生在其内部出现的问题,就显得尤为重要了。
|
||||
|
||||
**现实中的反馈**
|
||||
|
||||
在现实中,从始至终同样也需要反馈。一个高效的处理流程中,及时的反馈能够快速的定位事情发生的时间。反馈的关键词是“快速”和“相关”。当一个团队处理大量不相关的事件时,那些真正需要快速反馈的重要信息,很容易就被忽视掉,并向下游传递形成更严重的问题。想象下[如果露西和埃塞尔][6]能够很快的意识到:传送带太快了,那么制作出的巧克力可能就没什么问题了(尽管这样就不太有趣了)。
|
||||
|
||||
**DevOps and feedback**
|
||||
|
||||
DevOps 中的第二条原则,就是快速收集所有的相关有用信息,这样在出现的问题影响到其他开发进程之前,就可以被识别出。DevOps 团队应该努力去“优化下游“,以及快速解决那些可能会影响到之后团队的问题。同工作流一样,反馈也是一个持续的过程,目标是快速的获得重要的信息以及当问题出现后能够及时的响应。
|
||||
|
||||
> "快速的反馈对于提高技术的质量、可用性、安全性至关重要。"
|
||||
|
||||
–Gene Kim, et al., DevOps 手册:如何在技术组织中创造世界级的敏捷性,可靠性和安全性, IT 革命, 2016
|
||||
|
||||
### 持续实验与学习
|
||||
|
||||
**容器中的持续实验与学习**
|
||||
|
||||
如何让”持续的实验与学习“更具操作性是一个不小的挑战。容器让我们的开发工程师和运营团队,在不需要掌握太多边缘或难以理解的东西情况下,依然可以安全地进行本地和生产环境的测试,这在之前是难以做到的。即便是一些激进的实验,容器技术仍然让我们轻松地进行版本控制、记录、分享。
|
||||
|
||||
**现实中的持续实验与学习**
|
||||
|
||||
举个我自己的例子:多年前,作为一个年轻、初出茅庐的系统管理员(仅仅工作三周),我被要求对一个运行某个大学核心IT部门网站的Apache虚拟主机进行更改。由于没有易于使用的测试环境,我直接在生产的站点上进行了配置修改,当时觉得配置没问题就发布了,几分钟后,我隔壁无意中听到了同事说:
|
||||
|
||||
”等会,网站挂了?“
|
||||
|
||||
“没错,怎么回事?”
|
||||
|
||||
很多人蒙圈了……
|
||||
|
||||
在被嘲讽之后(真实的嘲讽),我一头扎在工作台上,赶紧撤销我之前的更改。当天下午晚些时候,部门主管 - 我老板的老板的老板来到我的工位上,问发生了什么事。
|
||||
“别担心,”她告诉我。“我们不会生你的气,这是一个错误,现在你已经学会了。“
|
||||
|
||||
而在容器中,这种情形很容易的进行测试,并且也很容易在部署生产环境之前,被那些经验老道的团队成员发现。
|
||||
|
||||
**DevOps 中的持续实验与学习**
|
||||
|
||||
做实验的初衷是我们每个人都希望通过一些改变从而能够提高一些东西,并勇敢地通过实验来验证我们的想法。对于 DevOps 团队来说,失败无论对团队还是个人来说都是经验,所要不要担心失败。团队中的每个成员不断学习、共享,也会不断提升其所在团队与组织的水平。
|
||||
|
||||
随着系统变得越来越琐碎,我们更需要将注意力发在特殊的点上:上面提到的两条原则主要关注的是流程的目前全貌,而持续的学习则是关注的则是整个项目、人员、团队、组织的未来。它不仅对流程产生了影响,还对流程中的每个人产生影响。
|
||||
|
||||
> "无风险的实验让我们能够不懈的改进我们的工作,但也要求我们使用之前没有用过的工作方式"
|
||||
|
||||
–Gene Kim, et al., [凤凰计划:让你了解 IT、DevOps以及如何取得商业成功][7], IT 革命, 2013
|
||||
|
||||
### 容器技术给我们 DevOps 上的启迪
|
||||
|
||||
学习如何有效地使用容器可以学习DevOps的三条原则:工作流,反馈以及持续实验和学习。从整体上看应用程序和基础设施,而不是对容器外的东西置若罔闻,教会我们考虑到系统的所有部分,了解其上游和下游影响,打破孤岛,并作为一个团队工作,以提高全局性能和深度
|
||||
了解整个系统。通过努力提供及时准确的反馈,我们可以在组织内部创建有效的反馈模式,以便在问题发生影响之前发现问题。
|
||||
最后,提供一个安全的环境来尝试新的想法并从中学习,教会我们创造一种文化,在这种文化中,失败一方面促进了我们知识的增长,另一方面通过有根据的猜测,可以为复杂的问题带来新的、优雅的解决方案。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/containers-can-teach-us-devops
|
||||
|
||||
作者:[Chris Hermansen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/littleji)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/clhermansen
|
||||
[1]: https://itrevolution.com/the-three-ways-principles-underpinning-devops/
|
||||
[2]: https://en.wikipedia.org/wiki/The_Jetsons
|
||||
[3]: http://itrevolution.com/the-three-ways-principles-underpinning-devops
|
||||
[4]: https://prometheus.io/
|
||||
[5]: https://opensource.com/article/18/9/prometheus-operational-advantage
|
||||
[6]: https://www.youtube.com/watch?v=8NPzLBSBzPI
|
||||
[7]: https://itrevolution.com/book/the-phoenix-project/
|
||||
Loading…
Reference in New Issue
Block a user