mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-03 23:40:14 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
fd01f71b69
@ -1,70 +1,58 @@
|
||||
最好的 Linux 工具献给老师和学生们
|
||||
=====
|
||||
|
||||
Linux是一个适合每个人的平台。如果你有一个商机,Linux 已经准备好满足或超过这个商机的需求,其中一个商机是教育。如果你是一名教师或一名学生,Linux 已经准备好帮助你在几乎任何级别的教育系统领域中畅游。从辅助学习,写作论文,管理课程,到管理整个机构,Linux 已经全部涵盖了。
|
||||
Linux 是一个适合每个人的平台。如果你有一份合适的工作,Linux 已经可以满足或超过它的需求,其中一个工作是教育。如果你是一名教师或一名学生,Linux 已经准备好帮助你在几乎任何级别的教育系统领域中畅游。从辅助学习、写作论文、管理课程,到管理整个机构,Linux 已经全部涵盖了。
|
||||
|
||||
如果你不确定,请让我介绍一下 Linux 准备好的一些工具。其中一些工具几乎不需要学习曲线,而另一些工具则需要一个全面的系统管理员来安装,设置和管理。我们将从简单开始,然后到复杂。
|
||||
如果你不确定,请让我介绍一下 Linux 准备好的一些工具。其中一些工具几乎没有学习曲线,而另一些工具则需要一个全面的系统管理员来安装、设置和管理。我们将从简单开始,然后到复杂。
|
||||
|
||||
### 学习辅助工具
|
||||
|
||||
每个人的学习方式都有所不同,每个班级都需要不同的学习类型和水平。幸运的是,Linux 有很多学习辅助工具。让我们来看几个例子:
|
||||
|
||||
闪存卡 [KWordQuiz][1](图1)是适用于 Linux 平台的许多闪存卡应用程序之一。KWordQuiz 使用 kvtml 文件格式,你可以下载大量预制的贡献文件在[这里][2]使用。 KWordQuiz 是 KDE 桌面环境的一部分,但可以安装在其他桌面上(KDE 依赖关系将与闪存卡应用程序一起安装)。
|
||||
闪卡 —— [KWordQuiz][1](图 1)是适用于 Linux 平台的许多闪卡应用程序之一。KWordQuiz 使用 kvtml 文件格式,你可以下载大量预制的、人们贡献的文件。 KWordQuiz 是 KDE 桌面环境的一部分,但可以安装在其他桌面上(KDE 依赖文件将与闪卡应用程序一起安装)。
|
||||
|
||||
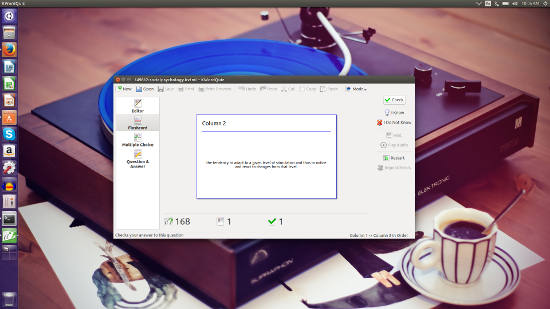
|
||||
|
||||
### 语言工具
|
||||
|
||||
由于全球化,外语已成为教育的重要组成部分。你会发现很多语言工具,包括 [Kiten][3](图2)KDE 桌面的汉字浏览器。
|
||||
由于全球化进程,外语已成为教育的重要组成部分。你会发现很多语言工具,包括 [Kiten][3](图 2)—— KDE 桌面的日语汉字浏览器。
|
||||
|
||||
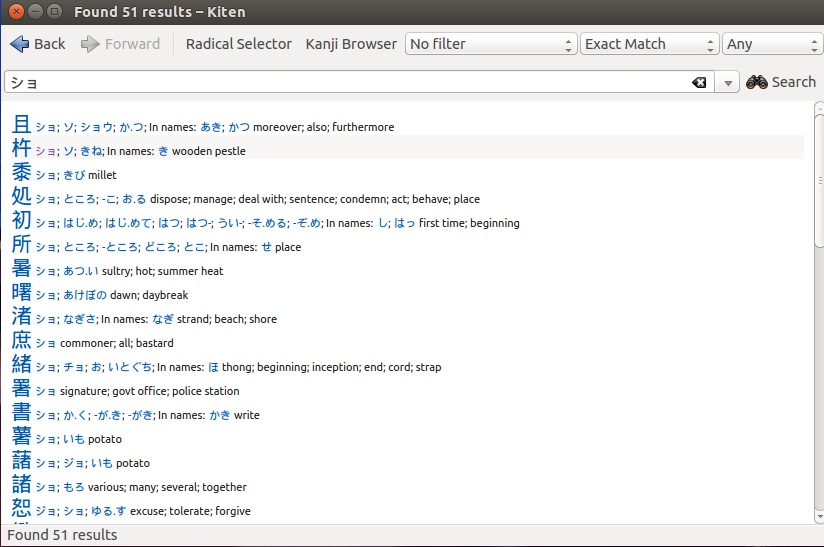
|
||||
|
||||
如果日文不是你的母语,你可以试试[Jargon Informatique][4]。这本词典完全是法文的,所以如果你对这门语言还不熟悉,你可能要需要 [Google 翻译][5]的帮助才能坚持下去。
|
||||
如果日文不是你的母语,你可以试试 [Jargon Informatique][4]。这本词典完全是法文的,所以如果你对这门语言还不熟悉,你可能要需要 [Google 翻译][5]的帮助才能坚持下去。
|
||||
|
||||
### Writing Aids/ Note Taking
|
||||
### Writing Aids / Note Taking
|
||||
|
||||
Linux 拥有你需要的所有东西比如记录一个主题,撰写那些学期论文。让我们从记笔记开始。如果你熟悉 Microsoft OneNote,你一定会喜欢 [BasKet Note Pads][6]。有了这个应用程序,你可以为主题创建 basket(to 校正者:我将其翻译为笔记本),并添加任何东西─注释,链接,图像,交叉引用(到其他 basket─图 3),应用程序启动器,从文件加载等等。
|
||||
Linux 拥有你需要的所有东西比如记录一个主题,撰写那些学期论文。让我们从记笔记开始。如果你熟悉 Microsoft OneNote,你一定会喜欢 [BasKet Note Pads][6]。有了这个应用程序,你可以为主题创建<ruby>笔记本<rt>basket</rt></ruby>,并添加任何东西——注释、链接、图像、交叉引用(到其他笔记本─图 3)、应用程序启动器、从文件加载等等。
|
||||
|
||||
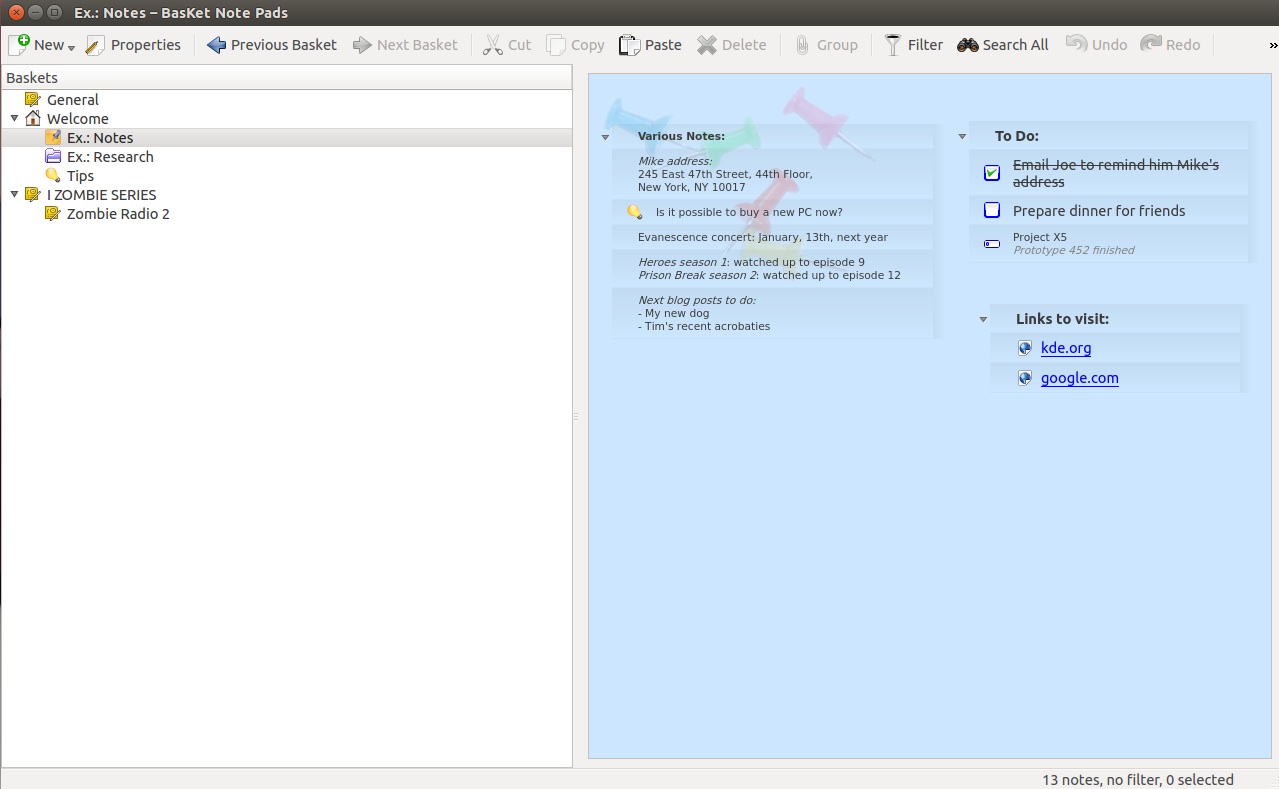
|
||||
|
||||
你可以创建任意形式的 basket,可以移动元素来满足你的需求。如果你更喜欢有序的感觉,那么创建一个表状的 basket 来保留那些封装的笔记。
|
||||
你可以创建任意形式的笔记本,可以移动元素来满足你的需求。如果你更喜欢有序的感觉,那么创建一个表状的 basket 来保留那些封装的笔记。
|
||||
|
||||
当然,所有 Linux 写作辅助工具都是由 [LibreOffice][7] 发展而来。LibreOffice 是大多数 Linux 发行版默认的办公套件,它能打开文本文档,电子表格,演示文稿,数据库,公式和绘图。
|
||||
当然,所有 Linux 写作辅助工具都是由 [LibreOffice][7] 发展而来。LibreOffice 是大多数 Linux 发行版默认的办公套件,它能打开文本文档、电子表格、演示文稿、数据库、公式和绘图。
|
||||
|
||||
在教育环境中使用 LibreOffice 的一个警告是,你很可能不得不将文档以 MS Office 格式保存。
|
||||
|
||||
### 为教育而生的发行版
|
||||
|
||||
所有这些都是关于 Linux 面向学生的应用程序,你可以看看专门为教育而开发的一个发行版。最好的是 [Edubuntu][8]。这种草根(to 校正者:草根这个词感觉不雅) Linux 发行版旨在让 Linux 进入学校,家庭和社区。Edubuntu 使用默认的 Ubuntu 桌面(Unity shell)并添加以下软件:
|
||||
所有这些都是关于 Linux 面向学生的应用程序,你可以看看专门为教育而开发的一个发行版。最好的是 [Edubuntu][8]。这种平易的 Linux 发行版旨在让 Linux 进入学校、家庭和社区。Edubuntu 使用默认的 Ubuntu 桌面(Unity shell)并添加以下软件:
|
||||
|
||||
+ KDE 教育套件
|
||||
|
||||
+ GCompris
|
||||
|
||||
+ Celestia
|
||||
|
||||
+ Tux4Kids
|
||||
|
||||
+ Epoptes
|
||||
|
||||
+ LTSP
|
||||
|
||||
+ GBrainy
|
||||
|
||||
+ 等等
|
||||
|
||||
Edubuntu 并不是唯一的发行版。如果你想测试其他特定于教育的 Linux 发行版,以下是简短列表:
|
||||
|
||||
+ Debian-Edu
|
||||
|
||||
+ Fedora Education Spin
|
||||
|
||||
+ Guadalinux-Edu
|
||||
|
||||
+ OpenSuse-Edu
|
||||
|
||||
+ Qimo
|
||||
|
||||
+ Uberstudent
|
||||
|
||||
### 课堂/机构管理
|
||||
@ -73,48 +61,35 @@ Edubuntu 并不是唯一的发行版。如果你想测试其他特定于教育
|
||||
|
||||
[iTalc][9] 是一个强大的课堂教学环境。借助此工具,教师可以查看和控制学生桌面(支持 Linux 和 Windows)。iTalc 系统允许教师查看学生桌面上发生了什么,控制他们的桌面,锁定他们的桌面,对桌面演示,打开或关闭桌面,向学生桌面发送文本消息等等。
|
||||
|
||||
[aTutor][10](图4)是一个开源的学习管理系统(LMS),专注于开发在线课程和电子学习内容。一个老师真正发挥的就是创建和管理在线考试和测验。当然,aTutor 不限于测试的目的,有了这个强大的软件,学生和老师可以享受:
|
||||
[aTutor][10](图 4)是一个开源的学习管理系统(LMS),专注于开发在线课程和电子学习内容。一个老师真正发挥的就是创建和管理在线考试和测验。当然,aTutor 不限于测试的目的,有了这个强大的软件,学生和老师可以享受:
|
||||
|
||||
* 社交网络
|
||||
|
||||
* 配置文件
|
||||
|
||||
* 消息
|
||||
|
||||
* 自适应导航
|
||||
|
||||
* 工作组
|
||||
|
||||
* 文件存储
|
||||
|
||||
* 小组博客
|
||||
|
||||
* 以及更多。
|
||||
|
||||
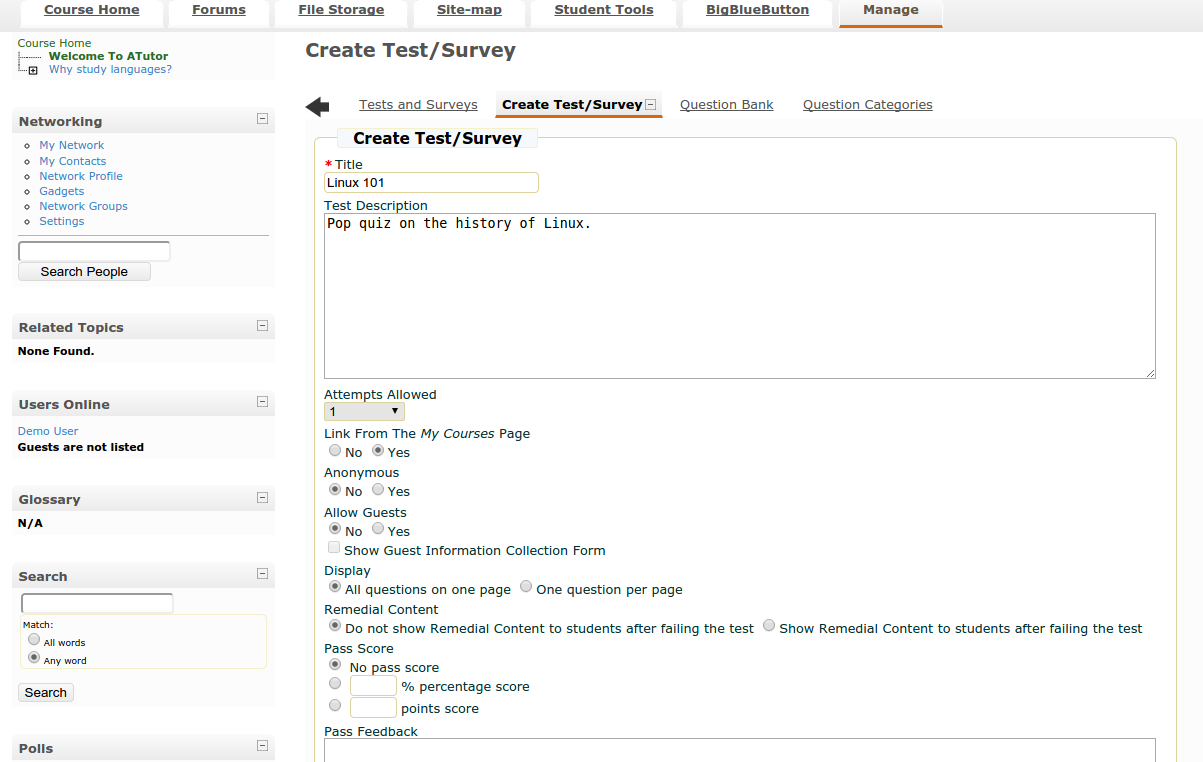
|
||||
|
||||
课程资料易于创建和部署(你甚至可以将考试/测验分配给特定的学习小组)。
|
||||
|
||||
[Moodle][11] 是目前使用最广泛的教育管理软件之一。通过 Moodle,你可以管理,教授,学习甚至参与孩子的教育。这个强大的软件为教师和学生,考试,日历,论坛,文件管理,课程管理(图5),通知,进度跟踪,大量注册,批量课程创建,考勤等提供协作工具。
|
||||
[Moodle][11] 是目前使用最广泛的教育管理软件之一。通过 Moodle,你可以管理、教授、学习甚至参与孩子的教育。这个强大的软件为教师和学生、考试、日历、论坛、文件管理、课程管理(图 5)、通知、进度跟踪、大量注册、批量课程创建、考勤等提供协作工具。
|
||||
|
||||
|
||||
|
||||
[OpenSIS][12] 代表开源学生信息系统,在管理你的教育机构方面做得很好。有一个免费的社区版,但即使使用付费版本,你也可以期待将学区的拥有成本降低高达 75%(与专有解决方案相比)。
|
||||
[OpenSIS][12] 意即开源学生信息系统,在管理你的教育机构方面做得很好。有一个免费的社区版,但即使使用付费版本,你也可以期待将学区的拥有成本降低高达 75%(与专有解决方案相比)。
|
||||
|
||||
OpenSIS 包括以下特点或模块:
|
||||
|
||||
* 出席情况(图6)
|
||||
|
||||
* 出席情况(图 6)
|
||||
* 联系信息
|
||||
|
||||
* 学生人口统计
|
||||
|
||||
* 成绩簿
|
||||
|
||||
* 计划
|
||||
|
||||
* 健康记录
|
||||
|
||||
* 报告卡
|
||||
|
||||
|
||||
@ -124,24 +99,18 @@ OpenSIS 有四个版本,在[这里][13]查看它们的功能比较。
|
||||
[vufind][14] 是一个优秀的图书馆管理系统,允许学生和教师轻松浏览图书馆资源,例如:
|
||||
|
||||
* 目录记录
|
||||
|
||||
* 本地缓存期刊
|
||||
|
||||
* 数字图书馆项目
|
||||
|
||||
* 机构知识库
|
||||
|
||||
* 机构书目
|
||||
|
||||
* 其他图书馆集合和资源
|
||||
|
||||
Vufind 系统允许用户登录,通过认证的用户可以节省资源以便快速回忆,并享受“更像这样”的结果。
|
||||
|
||||
这份列表仅仅触及了 Linux 在教育领域可用性的一点皮毛。而且,正如你所期望的那样,每个工具都是高度可定制且开放源代码的 - 所以如果软件不能精确地满足你的需求,那么你可以免费(在大多数情况下)修改源代码并进行更改。
|
||||
这份列表仅仅触及了 Linux 在教育领域可用性的一点皮毛。而且,正如你所期望的那样,每个工具都是高度可定制且开放源代码的 —— 所以如果软件不能精确地满足你的需求,那么你可以自由(在大多数情况下)修改源代码并进行更改。
|
||||
|
||||
Linux 在与教育齐头并进。无论你是老师,学生还是管理员,你都会找到大量工具来帮助教育机构开放,灵活和强大。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/best-linux-tools-teachers-and-students
|
||||
@ -149,7 +118,7 @@ via: https://www.linux.com/news/best-linux-tools-teachers-and-students
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,34 +1,36 @@
|
||||
5 个理由,开源助你求职成功
|
||||
======
|
||||
> 为开源项目工作可以给你或许从其他地方根本得不到的经验和人脉。
|
||||
|
||||

|
||||
|
||||
你正在在繁华的技术行业中寻找工作吗?无论你是寻找新挑战的技术团体老手,还是正在寻找第一份工作的毕业生,参加开源项目都是可以让你在众多应聘者中脱颖而出的好方法。以下是从事开源项目工作可以增强你求职竞争力的五个理由。
|
||||
|
||||
### 1. 获得项目经验
|
||||
### 1、 获得项目经验
|
||||
|
||||
或许从事开源项目工作能带给你的最明显的好处是提供了项目经验。如果你是一个学生,你可能没有很多实质上的项目在你的简历中展示。如果你还在工作,由于保密限制,或者你对正在完成的任务不感兴趣,你不能或者不能很详细的讨论你当前的项目。无论那种情况,找出并参加那些有吸引力的,而且又正好可以展现你的技能的开源项目,无疑对求职有帮助。这些项目不仅在众多简历中引人注目,而且可以是面试环节中完美的谈论主题。
|
||||
或许从事开源项目工作能带给你的最明显的好处是提供了项目经验。如果你是一个学生,你可能没有很多实质上的项目可以在你的简历中展示。如果你还在工作,由于保密限制,或者你对正在完成的任务不感兴趣,你不能或者不能很详细的讨论你当前的项目。无论那种情况,找出并参加那些有吸引力的,而且又正好可以展现你的技能的开源项目,无疑对求职有帮助。这些项目不仅在众多简历中引人注目,而且可以是面试环节中完美的谈论主题。
|
||||
|
||||
另外,很多开源项目托管在公共仓库(比如 [Github][1] )上,所以对任何想参与其中的任何人,获取这些项目的源代码都异常简单。同时,你对项目的公开代码贡献,也能很方便的被招聘单位或者潜在雇主找到。开源项目提供了一个可以让你以一种更实际的的方式展现你的技能,而不是仅仅在面试中纸上谈兵。
|
||||
|
||||
### 2. 学会提问
|
||||
### 2、 学会提问
|
||||
|
||||
开源项目团体的新成员总会有机会去学习大量的新技能。他们肯定会发现特定项目的多种交流方式,结构层次,文档格式,和其他的方方面面。在刚刚参与到项目中时,你需要问大量的问题,才能找准自己的定位。正如俗语说得好,没有愚蠢的问题。开源社区提倡好奇心,特别是在问题答案不容易找到的时候。
|
||||
开源项目团体的新成员总会有机会去学习大量的新技能。他们肯定会发现该项目独特的的多种交流方式、结构层次、文档格式和其他的方方面面。在刚刚参与到项目中时,你需要问大量的问题,才能找准自己的定位。正如俗语说得好,没有愚蠢的问题。开源社区提倡好奇心,特别是在问题答案不容易找到的时候。
|
||||
|
||||
在从事开源项目工作初期,对项目的不熟悉感会驱使个人去提问,去经常提问。这可以帮助参与者学会提问。学会去分辨问什么,怎么问,问谁。学会提问在找工作,[面试][2],甚至生活中都非常有用。解决问题和寻求帮助的能力在人才市场中都非常重要。
|
||||
在从事开源项目工作初期,对项目的不熟悉感会驱使个人去提问,去经常提问。这可以帮助参与者学会提问。学会去分辨问什么,怎么问,问谁。学会提问在找工作、[面试][2],甚至生活中都非常有用。解决问题和寻求帮助的能力在人才市场中都非常重要。
|
||||
|
||||
### 3. 获取新的技能与持续学习
|
||||
### 3、 获取新的技能与持续学习
|
||||
|
||||
大量的软件项目同时使用很多不同的技术。很少有贡献者可以熟悉项目中的所有技术。即使已经在项目中工作了一段时间后,很多人很可能也不能对项目中所用的所有技术都熟悉。
|
||||
大量的软件项目同时使用很多不同的技术。很少有贡献者可以熟悉项目中的所有技术。即使已经在项目中工作了一段时间后,很多人很可能不能对项目中所用的所有技术都熟悉。
|
||||
|
||||
虽然一个开源项目中的老手可能会对项目的一些特定的方面不熟悉,但是新手不熟悉的显然更多。这种情况产生了大量的学习机会。在一个人刚开始从事开源工作时,可能只是去提高项目中的一些小功能,甚至很可能是在他熟悉的领域。但是以后的旅程就大不相同了。
|
||||
|
||||
从事项目的某一方面的工作可能会把你带进一个不熟悉的领域,可能会驱使你开始新的学习。而从事开源项目的工作,可能会把你带向一个你以前可能从没用过的技术。这会激起新的激情,或者,至少促进你继续学习([这正是雇主渴望具备的能力][3])。
|
||||
|
||||
### 4.增加人脉
|
||||
### 4、增加人脉
|
||||
|
||||
开源项目被不同的社区维护和支持。一些人在他们的业余时间进行开源工作,他们都有各自的经历,兴趣和人脉。正如他们所说,“你了解什么人决定你成为什么人”。不通过开源项目,可能你永远不会遇到特定的人。或许你和世界各地的人一起工作,或许你和你的邻里有联系。但是,你不是知道谁能帮你找到下一份工作。参加开源项目扩展人脉的可能性将对你寻找下一份(或者第一份)工作极有帮助。
|
||||
开源项目被不同的社区维护和支持。一些人在他们的业余时间进行开源工作,他们都有各自的经历、兴趣和人脉。正如他们所说,“你了解什么人决定你成为什么人”。不通过开源项目,可能你永远不会遇到特定的人。或许你和世界各地的人一起工作,或许你和你的邻里有联系。但是,你不知道谁能帮你找到下一份工作。参加开源项目扩展人脉的可能性将对你寻找下一份(或者第一份)工作极有帮助。
|
||||
|
||||
### 5. 建立自信
|
||||
### 5、 建立自信
|
||||
|
||||
最后,参与开源项目可能给你新的自信。很多科技企业的新员工会有些[冒充者综合症][4]。由于没有完成重要工作,他们会感到没有归属感,好像自己是冒名顶替的那个人,认为自己配不上他们的新职位。在被雇佣前参加开源项目可以最小化这种问题。
|
||||
|
||||
@ -37,7 +39,8 @@
|
||||
这只是从事开源工作的一些好处。如果你知道更多的好处,请在下方评论区留言分享。
|
||||
|
||||
### 关于作者
|
||||
Sophie Polson;Sophie 一名研究计算机科学的杜克大学的学生。通过杜克大学 2017 秋季课程 “开源世界( Open Source World )”,开始了开源社区的冒险。对探索 [DevOps][5] 十分有兴趣。在 2018 春季毕业后,将成为一名软件工程师。
|
||||
|
||||
Sophie Polson :一名研究计算机科学的杜克大学的学生。通过杜克大学 2017 秋季课程 “开源世界( Open Source World )”,开始了开源社区的冒险。对探索 [DevOps][5] 十分有兴趣。在 2018 春季毕业后,将成为一名软件工程师。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -45,7 +48,7 @@ via: https://opensource.com/article/18/1/5-ways-turn-open-source-new-job
|
||||
|
||||
作者:[Sophie Polson][a]
|
||||
译者:[Lontow](https://github.com/lontow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
99
published/20180201 IT automation- How to make the case.md
Normal file
99
published/20180201 IT automation- How to make the case.md
Normal file
@ -0,0 +1,99 @@
|
||||
IT 自动化:如何去实现
|
||||
======
|
||||
|
||||
> 想要你的整个团队都登上 IT 自动化之旅吗? IT 执行者们分享了他们的战略。
|
||||
|
||||

|
||||
|
||||
在任何重要的项目或主动变更刚开始的时候,IT 的管理者在前进的道路上面临着普遍的抉择。
|
||||
|
||||
第一条路径看上去是提供了一个从 A 到 B 的最短路径:简单的把项目强制分配给每个人去执行,本质来说就是你要么按照要求去做要么就不要做了。
|
||||
|
||||
第二条路径可能看上去会不是很直接,因为要通过这条路径你需要花时间去解释项目背后的策略以及原因。你会沿着这条路线设置停靠站点而不是从起点到终点的马拉松:“这就是我们正在做的 —— 和为什么我们这么做。”
|
||||
|
||||
猜想一下哪条路径会赢得更好的结果?
|
||||
|
||||
如果你选的是路径 2,你肯定是以前都经历过这两条路径——而且经历了第一次的结局。让人们参与到重大变革中总会是最明智的选择。
|
||||
|
||||
IT 领导者也知道重大的变革总会带来严重的恐慌、怀疑,和其他的挑战。IT 自动化确实是很正确的改变。这个术语对某些人来说是很可怕的,而且容易被曲解。帮助人们理解你的公司需要 IT 自动化的必要性的原因以及如何去实现是达到你的目标和策略的重要步骤。
|
||||
|
||||
[**阅读我们的相关文章,**[**IT自动化最佳实践:持久成功的7个关键点**][2]。]
|
||||
|
||||
考虑到这一点,我们咨询了许多 IT 管理者关于如何在你的组织中实现 IT 自动化。
|
||||
|
||||
### 1、向人们展示它的优点
|
||||
|
||||
我们要面对的一点事实是:自我利益和自我保护是本能。利用人们的这种本能是一个吸引他们的好方法:向他们展示自动化策略将如何让他们和他们的工作获益。自动化将会是软件管道中的一个特定过程意味着将会减少在半夜呼叫团队同事来解决故障?它将能让一些人丢弃技术含量低的技能,用更有策略、高效的有序工作代替手工作业,这将会帮助他们的职业生涯更进一步?
|
||||
|
||||
“向他们传达他们能得到什么好处,自动化将会如何让他们的客户和公司受益,”来自 ADP 全球首席技术官 vipual Nagrath 的建议。“将现在的状态和未来光明的未来进行对比,展现公司将会变得如何稳定,敏捷,高效和安全。”
|
||||
|
||||
这样的方法同样适用于 IT 领域之外的其他领域;只要在向非技术领域的股东们解读利益的时候解释清楚一些术语即可,Nagrath 说道。
|
||||
|
||||
设置好前后的情景是一个不错的帮助人们理解的更透彻的故事机。
|
||||
|
||||
“你要描述一幅人们能够联想到的当前状态的画面,” Nagrath 说。“描述现在是什么工作,但也要重点强调是什么导致团队的工作效率不够敏捷。”然后再阐释自动化过程将如何提高现在的状态。
|
||||
|
||||
### 2、将自动化和特定的商业目标绑定在一起
|
||||
|
||||
一个强有力的案列的一部分要确保人们理解你不只是在追逐潮流趋势。如果只是为了自动化而自动化,人们会很快察觉到进而会更加抵制的——也许在 IT 界更是如此。
|
||||
|
||||
“自动化需要商业需求的驱动,例如收入和运营开销,” Cyxtera的副总裁和首席信息安全官 David Emerson 说道。“没有自动化的努力是自我辩护的,而且任何技术专长都不应该被当做一种手段,除非它是公司的一项核心能力。”
|
||||
|
||||
像 Nagrath 一样,Emerson 建议将达到自动化的商业目标和奖励措施挂钩,用迭代式的循序渐进的方式推进这些目标和相关的激励措施。
|
||||
|
||||
### 3、 将自动化计划分解为可管理的条目
|
||||
|
||||
即使你的自动化策略字面上是“一切都自动化”,对大多数组织来说那也是很艰难的,而且可能是没有灵活性的。你需要制定一个强有力的方案,将自动化目标分解为可管理的目标计划。而且这将能够创造很大的灵活性来适应之后漫长的道路。
|
||||
|
||||
“当制定一个自动化方案的时候,我建议详细的阐明推进自动化进程的奖励措施,而且允许迭代朝着目标前进来介绍和证明利益处于一个低风险水平,”Emerson 说道。
|
||||
|
||||
GA Connector 的创始人 Sergey Zuev 分享了一个为什么自动化如此重要的快节奏体验的报告——它将怎样为你的策略建立一个强壮持久的论点。Zuevz 应该知道:他的公司的自动化工具将公司的客户关系应用数据导入谷歌分析。但实际上是公司的内部经验使顾客培训进程自动化从而出现了一个闪耀的时刻。
|
||||
|
||||
“起初, 我们曾尝试去建立整个培训机制,结果这个项目搁浅了好几个月,”Zuev 说道。“认识到这将无法继续下去之后,我们决定挑选其中的一个能够有巨大的时效的领域,而且立即启动。结果我们只用了一周就实现了其中的电子邮件序列的目标,而且我们已经从被亵渎的体力劳动中获益。”
|
||||
|
||||
### 4、 出售主要部分也有好处
|
||||
|
||||
循序渐进的方法并不会阻碍构建一个宏伟的蓝图。就像以个人或者团队的水平来制定方案是一个好主意,帮助人们理解全公司的利益也是一个不错的主意。
|
||||
|
||||
“如果我们能够加速达到商业需求所需的时间,那么一切质疑将会平息。”
|
||||
|
||||
AHEAD 的首席技术官 Eric Kaplan 赞同通过小范围的胜利来展示自动化的价值是一个赢得人心的聪明策略。但是那些所谓的“小的”的价值揭示能够帮助你提高人们的整体形象。Kaplan 指出个人和组织间的价值是每个人都可以容易联系到的领域。
|
||||
|
||||
“最能展现的地方就是你能够节约多少时间,”Kaaplan 说。“如果我们能够加速达到商业需求所需的时间,那么一切质疑将会消失。”
|
||||
|
||||
时间和可伸缩性是业务和 IT 同事的强大优势,都复制业务的增长,可以把握。
|
||||
|
||||
“自动化的结果是灵活伸缩的——每个人只需较少的努力就能保持和改善你的 IT 环境”,红帽的全球服务副总裁 John Allessio 最近提到。“如果增加人力是提升你的商业的唯一途径,那么灵活伸缩就是白日梦。自动化减少了你的人力需求而且提供了 IT 演进所需的灵活性和韧性。”(详细内容请参考他的文章,[DevOps 团队对 CIO 的真正需求是什么。])
|
||||
|
||||
### 5、 推广你的成果。
|
||||
|
||||
在你自动化策略的开始时,你可能是在目标和要达到目标的预期利益上制定方案。但随着你的自动化策略的不断演进,没有什么能够比现实中的实际结果令人信服。
|
||||
|
||||
“眼见为实,”ADP 的首席技术官 Nagrath 说。“没有什么比追踪记录能够平息质疑。”
|
||||
|
||||
那意味着,不仅仅要达到你的目标,还要准时的完成——这是迭代的循序渐进的方法论的另一个不错的解释。
|
||||
|
||||
而量化的结果如比利润的提高或者成本的节省可以大声宣扬出来,Nagrath 建议他的 IT 领导者同行在讲述你们的自动化故事的时候不要仅仅止步于此。
|
||||
|
||||
为自动化提供案例也是一个定性的讨论,通过它我们能够促进问题的预防,归总商业的连续性,减伤失败或错误,而且能够在他们处理更有价值的任务时承担更多的责任。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/1/how-make-case-it-automation
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:https://enterprisersproject.com/article/2017/10/how-beat-fear-and-loathing-it-change
|
||||
[2]:https://enterprisersproject.com/article/2018/1/it-automation-best-practices-7-keys-long-term-success?sc_cid=70160000000h0aXAAQ
|
||||
[3]:https://www.adp.com/
|
||||
[4]:https://www.cyxtera.com/
|
||||
[5]:http://gaconnector.com/
|
||||
[6]:https://www.thinkahead.com/
|
||||
[7]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
|
||||
[8]:https://enterprisersproject.com/article/2017/12/what-devops-teams-really-need-cio
|
||||
[9]:https://enterprisersproject.com/email-newsletter?intcmp=701f2000000tsjPAAQ
|
||||
@ -1,49 +1,50 @@
|
||||
开始使用 Pidgin:Skype for Business 的开源替代品
|
||||
Pidgin:Skype for Business 的开源替代品
|
||||
======
|
||||
|
||||

|
||||
技术正处在一个有趣的十字路口,Linux 统治服务器领域,但微软统治企业桌面。 Office 365、Skype for Business、Microsoft Teams、OneDrive、Outlook ......等等,这些是支配企业工作空间的微软软件和服务。
|
||||
> 用可以和 Office 365 协同工作的开源软件换下你的专有化的沟通软件。
|
||||
|
||||
如果你可以使用免费和开源程序替换该专有软件,并使其与你别无选择,但只能使用的 Office 365 的后端一起工作?是的,因为这正是我们要用 Pidgin 做的,它是 Skype 的开源替代品。
|
||||

|
||||
|
||||
技术正处在一个有趣的十字路口,Linux 统治服务器领域,但微软统治企业桌面。 Office 365、Skype for Business、Microsoft Teams、OneDrive、Outlook ......等等,这些是支配企业工作空间的是微软软件和服务。
|
||||
|
||||
如果你可以使用自由和开源程序替换该专有软件,并使其与你别无选择,但只能使用的 Office 365 的后端一起工作?是的,因为这正是我们要用 Pidgin 做的,它是 Skype 的开源替代品。
|
||||
|
||||
### 安装 Pidgin 和 SIPE
|
||||
|
||||
微软的 Office Communicator 变成了 Microsoft Lync,它成为我们今天所知的 Skype for Business。现在有针对 Linux 的[付费软件][1]提供了与 Skype for Business 相同的功能,但 [Pidgin][2] 是 GNU GPL 授权的完全免费且开源的选择。
|
||||
微软的 Office Communicator 变成了 Microsoft Lync,它成为我们今天所知的 Skype for Business。现在有针对 Linux 的[付费软件][1]提供了与 Skype for Business 相同的功能,但 [Pidgin][2] 是 GNU GPL 授权的、完全自由开源的选择。
|
||||
|
||||
Pidgin 可以在几乎每个 Linux 发行版的仓库中找到,因此,使用它不应该是一个问题。唯一不能在 Pidgin 中使用的 Skype 功能是屏幕共享,并且文件共享可能会失败,但有办法解决这个问题。
|
||||
|
||||
你还需要一个 [SIPE][3] 插件,因为它是使 Pidgin 成为 Skype for Business 替代品的秘密武器的一部分。请注意,`sipe` 库在不同的发行版中有不同的名称。例如,库在 System76 的 Pop_OS! 中是 `pidgin-sipe`,而在 Solus 3 仓库中是 `sipe`。
|
||||
|
||||
有了先决条件,你可以开始配置 Pidgin。
|
||||
满足了先决条件,你可以开始配置 Pidgin。
|
||||
|
||||
### 配置 Pidgin
|
||||
|
||||
首次启动 Pidgin 时,点击 **Add** 添加一个新帐户。在基本选项卡(如下截图所示)中,选择 **Protocol** 下拉菜单中的 **Office Communicator**,然后在 **Username** 字段中输入你的**公司电子邮件地址**。
|
||||
首次启动 Pidgin 时,点击 “Add” 添加一个新帐户。在基本选项卡(如下截图所示)中,选择 “Protocol” 下拉菜单中的 “Office Communicator”,然后在 “Username” 字段中输入你的“公司电子邮件地址”。
|
||||
|
||||

|
||||
|
||||
接下来,点击高级选项卡。在 **Server[:Port]** 字段中输入 **sipdir.online.lync.com:443**,在 **User Agent** 中输入 **UCCAPI/16.0.6965.5308 OC/16.0.6965.2117**。
|
||||
接下来,点击高级选项卡。在 “Server[:Port]” 字段中输入 “sipdir.online.lync.com:443”,在 “User Agent” 中输入 “UCCAPI/16.0.6965.5308 OC/16.0.6965.2117”。
|
||||
|
||||
你的高级选项卡现在应该如下所示:
|
||||
|
||||

|
||||
|
||||
你不需要对“代理”选项卡或“语音和视频”选项卡进行任何更改。只要确定,请确保 **Proxy type** 设置为 **Use Global Proxy Settings**,并且在语音和视频选项卡中,**Use silence suppression** 复选框为**取消选中**。
|
||||
你不需要对“Proxy”选项卡或“Voice and Video”选项卡进行任何更改。只要确定,请确保 “Proxy type” 设置为 “Use Global Proxy Settings”,并且在“Voice and Video”选项卡中,“Use silence suppression” 复选框为**取消选中**。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
完成这些配置后,点击 **Add**,系统会提示你输入电子邮件帐户的密码。
|
||||
完成这些配置后,点击 “Add”,系统会提示你输入电子邮件帐户的密码。
|
||||
|
||||
### 添加联系人
|
||||
|
||||
要将联系人添加到好友列表,请点击**好友窗口**中的 **Manage Accounts**。将鼠标悬停在你的帐户上,然后选择 **Contact Search** 查找你的同事。如果您在使用姓氏和名字进行搜索时遇到任何问题,请尝试使用你同事的完整电子邮件地址进行搜索,你就会找到正确的人。
|
||||
要将联系人添加到好友列表,请点击**好友窗口**中的 “Manage Accounts”。将鼠标悬停在你的帐户上,然后选择 “Contact Search” 查找你的同事。如果您在使用姓氏和名字进行搜索时遇到任何问题,请尝试使用你同事的完整电子邮件地址进行搜索,你就会找到正确的人。
|
||||
|
||||
你现在已经开始使用 Skype for Business 替代产品,该产品可为你提供 98% 的功能,从你的桌面上消除专有软件。
|
||||
|
||||
Ray Shimko 将在 4 月 28 日至 29 日的 [LinuxFest NW][5] 上谈论[ Linux 在微软世界][4]。查看计划亮点或注册参加。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/pidgin-open-source-replacement-skype-business
|
||||
@ -51,7 +52,7 @@ via: https://opensource.com/article/18/4/pidgin-open-source-replacement-skype-bu
|
||||
作者:[Ray Shimko][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,15 +1,20 @@
|
||||
使用 Buildah 创建小体积的容器
|
||||
======
|
||||
|
||||
> 技术问题推动了开源协作的力量。
|
||||
|
||||

|
||||
|
||||
我最近加入了 Red Hat,在这之前我在另外一家科技公司工作了很多年。在我的上一份工作岗位上,我开发了不少不同类型的软件产品,这些产品是成功的,但都有版权保护。不仅法规限制了我们不能在公司外将软件共享,而且我们在公司内部也基本不进行共享。在那时,我觉得这很有道理:公司花费了时间、精力和预算用于开发软件,理应保护并要求软件涉及的利益。
|
||||
|
||||
时间如梭,去年我加入 Red Hat 并培养出一种完全不同的理念。[Buildah 项目][1]是我最早加入的项目之一,该项目用于构建 OCI (Open Container Initiative) 标准的镜像,特别擅长让你精简已创建镜像的体积。那时 Buildah 还处于非常早期的阶段,包含一些瑕疵,不适合用于生产环境。
|
||||
时间如梭,去年我加入 Red Hat 并培养出一种完全不同的理念。[Buildah 项目][1]是我最早加入的项目之一,该项目用于构建 OCI (Open Container Initiative) 标准的镜像,特别擅长让你精简创建好的镜像的体积。那时 Buildah 还处于非常早期的阶段,包含一些瑕疵,不适合用于生产环境。
|
||||
|
||||
刚接触项目不久,我做了一些小变更,然后询问公司内部 git 仓库地址,以便提交我做的变更。收到的回答是:没有内部仓库,直接将变更提交到 GitHub 上。这让我感到困惑,将我的变更提交到 GitHub 意味着:任何人都可以查看这部分代码并在他们自己的项目中使用。况且代码还有一些瑕疵,这样做简直有悖常理。但作为一个新人,我只是惊讶地摇了摇头并提交了变更。
|
||||
|
||||
一年后,我终于相信了开源软件的力量和价值。我仍为 Buildah 项目工作,我们最近遇到的一个主题很形象地说明了这种力量和价值。标题为 [Buildah 镜像体积并不小?][2] 的主题由 Tim Dudgeon (@tdudgeon) 提出。简而言之,他发现使用 Buildah 创建的镜像比使用 Docker 创建的镜像体积更大,而且 Buildah 镜像中并不包含一些额外应用,但 Docker 镜像中却包含它们。
|
||||
一年后,我终于相信了开源软件的力量和价值。我仍为 Buildah 项目工作,我们最近遇到的一个主题很形象地说明了这种力量和价值。这个标题为 [Buildah 镜像体积并不小?][2] 的工单由 Tim Dudgeon (@tdudgeon) 提出。简而言之,他发现使用 Buildah 创建的镜像比使用 Docker 创建的镜像体积更大,而且 Buildah 镜像中并不包含一些额外应用,但 Docker 镜像中却包含它们。
|
||||
|
||||
为了比较,他首先操作如下:
|
||||
|
||||
```
|
||||
$ docker pull centos:7
|
||||
$ docker images
|
||||
@ -18,6 +23,7 @@ docker.io/centos 7 2d194b392dd1
|
||||
```
|
||||
|
||||
他发现 Docker 镜像的体积为 195MB。Tim 接着使用 Buildah 创建了一个(基于 scratch 的)最小化镜像,仅仅将 `coreutils` 和 `bash` 软件包加入到镜像中,使用的脚本如下:
|
||||
|
||||
```
|
||||
$ cat ./buildah-base.sh
|
||||
#!/bin/bash
|
||||
@ -50,7 +56,8 @@ IMAGE ID IMAGE NAME
|
||||
|
||||
Tim 想知道为何 Buildah 镜像体积反而大 17MB,毕竟 `python` 和 `yum` 软件包都没有安装到 Buildah 镜像中,而这些软件已经安装到 Docker 镜像中。这个结果并不符合预期,在 Github 的相关主题中引发了广泛的讨论。
|
||||
|
||||
不仅 Red Hat 的员工参与了讨论,还有不少公司外人士也加入了讨论,这很有意义。值得一提的是,GitHub 用户 @pixdrift 主导了很多重要的讨论并提出很多发现,他指出在 Buildah 镜像中文档和语言包就占据了比 100MB 略多一点的空间。Pixdrift 建议在 yum 安装器中强制指定语言,据此提出如下修改过的 `buildah-bash.sh` 脚本:
|
||||
不仅 Red Hat 的员工参与了讨论,还有不少公司外人士也加入了讨论,这很有意义。值得一提的是,GitHub 用户 @pixdrift 主导了很多重要的讨论并提出很多发现,他指出在这个 Buildah 镜像中文档和语言包就占据了比 100MB 略多一点的空间。Pixdrift 建议在 yum 安装器中强制指定语言,据此提出如下修改过的 `buildah-bash.sh` 脚本:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
@ -74,7 +81,7 @@ buildah unmount $newcontainer
|
||||
buildah commit $newcontainer centos-base
|
||||
```
|
||||
|
||||
Tim 运行这个新脚本,得到的镜像体积缩减至 92MB,相比之前的 Buildah 镜像体积减少了 120MB,这比较接近我们的预期;然而,c出于工程师的天性,56% 的体积缩减不能让他们满足。讨论继续深入下去,涉及如何移除个人语言包以节省更多空间。如果想了解讨论细节,点击 [Buildah 镜像体积并不小?][2] 链接。说不定你也能给出有帮助的点子,甚至更进一步成为 Buildah 项目的贡献者。这个主题的解决从一个侧面告诉我们,Buildah 软件可以多么快速和容易地创建体积最小化的容器,该容器仅包含你高效运行任务所需的软件。额外的好处是,你无需运行一个守护进程。
|
||||
Tim 运行这个新脚本,得到的镜像体积缩减至 92MB,相比之前的 Buildah 镜像体积减少了 120MB,这比较接近我们的预期;然而,出于工程师的天性,56% 的体积缩减不能让他们满足。讨论继续深入下去,涉及如何移除个人语言包以节省更多空间。如果想了解讨论细节,点击 [Buildah 镜像体积并不小?][2] 这个链接。说不定你也能给出有帮助的点子,甚至更进一步成为 Buildah 项目的贡献者。这个主题的解决从一个侧面告诉我们,Buildah 软件可以多么快速和容易地创建体积最小化的容器,该容器仅包含你高效运行任务所需的软件。额外的好处是,你无需运行一个守护进程。
|
||||
|
||||
这个镜像体积缩减的主题让我意识到开源软件的力量。来自不同公司的大量开发者,在一天多的时间内,以开放讨论的形式进行合作解决问题。虽然解决这个具体问题并没有修改已有代码,但 Red Hat 公司外开发者对 Buildah 做了很多代码贡献,进而帮助项目变得更好。这些贡献也吸引了更多人才关注项目代码;如果像之前那样,代码作为版权保护软件的一部分放置在私有 git 仓库中,不会获得上述好处。我只用了一年的时间就转向拥抱 [开源方式][3],而且可能不会再转回去了。
|
||||
|
||||
@ -87,7 +94,7 @@ via: https://opensource.com/article/18/5/containers-buildah
|
||||
作者:[Tom Sweeney][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,8 @@
|
||||
使用 GNU Parallel 提高 Linux 命令行执行效率
|
||||
======
|
||||
|
||||
> 将您的计算机变成一个多任务的动力室。
|
||||
|
||||

|
||||
|
||||
你是否有过这种感觉,你的主机运行速度没有预期的那么快?我也曾经有过这种感觉,直到我发现了 GNU Parallel。
|
||||
@ -11,16 +13,16 @@ GNU Parallel 是一个 shell 工具,可以并行执行任务。它可以解析
|
||||
|
||||
### 安装 GNU Parallel
|
||||
|
||||
GNU Parallel 很可能没有预装在你的 Linux 或 BSD 主机上,你可以从软件源(Linux 对应 repository,BSD 对应 ports collection)中安装。以 Fedora 为例:
|
||||
GNU Parallel 很可能没有预装在你的 Linux 或 BSD 主机上,你可以从软件源中安装。以 Fedora 为例:
|
||||
|
||||
```
|
||||
$ sudo dnf install parallel
|
||||
|
||||
```
|
||||
|
||||
对于 NetBSD:
|
||||
|
||||
```
|
||||
# pkg_add parallel
|
||||
|
||||
```
|
||||
|
||||
如果各种方式都不成功,请参考[项目主页][1]。
|
||||
@ -34,28 +36,28 @@ $ sudo dnf install parallel
|
||||
假设你有一个图片目录,你希望将目录中的图片从 JEEG 格式转换为 PNG 格式。有多种方法可以完成这个任务。可以手动用 GIMP 打开每个图片,输出成新格式,但这基本是最差的选择,费时费力。
|
||||
|
||||
上述方法有一个漂亮且简洁的变种,即基于 shell 的方案:
|
||||
|
||||
```
|
||||
$ convert 001.jpeg 001.png
|
||||
$ convert 002.jpeg 002.png
|
||||
$ convert 003.jpeg 003.png
|
||||
... 略 ...
|
||||
|
||||
```
|
||||
|
||||
对于初学者而言,这是一个不小的转变,而且看起来是个不小的改进。不再需要图像界面和不断的鼠标点击,但仍然是费力的。
|
||||
|
||||
进一步改进:
|
||||
|
||||
```
|
||||
$ for i in *jpeg; do convert $i $i.png ; done
|
||||
|
||||
```
|
||||
|
||||
至少,这一步设置好任务执行,让你节省时间去做更有价值的事情。但问题来了,这仍然是串行操作;一张图片转换完成后,队列中的下一张进行转换,依此类推直到全部完成。
|
||||
|
||||
使用 Parallel:
|
||||
|
||||
```
|
||||
$ find . -name "*jpeg" | parallel -I% --max-args 1 convert % %.png
|
||||
|
||||
```
|
||||
|
||||
这是两条命令的组合:`find` 命令,用于收集需要操作的对象;`parallel` 命令,用于对象排序并确保每个对象按需处理。
|
||||
@ -66,34 +68,34 @@ $ find . -name "*jpeg" | parallel -I% --max-args 1 convert % %.png
|
||||
* `--max-args 1` 给出 Parallel 从队列获取新对象的速率限制。考虑到 Parallel 运行的命令只需要一个文件输入,这里将速率限制设置为 1。假如你需要执行更复杂的命令,需要两个文件输入(例如 `cat 001.txt 002.txt > new.txt`),你需要将速率限制设置为 2。
|
||||
* `convert % %.png` 是你希望 Parallel 执行的命令。
|
||||
|
||||
|
||||
组合命令的执行效果如下:`find` 命令收集所有相关的文件信息并传递给 `parallel`,后者(使用当前参数)启动一个任务,(无需等待任务完成)立即获取参数行中的下一个参数(注:管道输出的每一行对应 `parallel` 的一个参数,所有参数构成参数行);只要你的主机没有瘫痪,Parallel 会不断做这样的操作。旧任务完成后,Parallel 会为分配新任务,直到所有数据都处理完成。不使用 Parallel 完成任务大约需要 10 分钟,使用后仅需 3 至 5 分钟。
|
||||
组合命令的执行效果如下:`find` 命令收集所有相关的文件信息并传递给 `parallel`,后者(使用当前参数)启动一个任务,(无需等待任务完成)立即获取参数行中的下一个参数(LCTT 译注:管道输出的每一行对应 `parallel` 的一个参数,所有参数构成参数行);只要你的主机没有瘫痪,Parallel 会不断做这样的操作。旧任务完成后,Parallel 会为分配新任务,直到所有数据都处理完成。不使用 Parallel 完成任务大约需要 10 分钟,使用后仅需 3 至 5 分钟。
|
||||
|
||||
### 多个输入
|
||||
|
||||
只要你熟悉 `find` 和 `xargs` (整体被称为 GNU 查找工具,或 `findutils`),`find` 命令是一个完美的 Parallel 数据提供者。它提供了灵活的接口,大多数 Linux 用户已经很习惯使用,即使对于初学者也很容易学习。
|
||||
只要你熟悉 `find` 和 `xargs` (整体被称为 GNU 查找工具,或 `findutils`),`find` 命令是一个完美的 Parallel 数据提供者。它提供了灵活的接口,大多数 Linux 用户已经很习惯使用,即使对于初学者也很容易学习。
|
||||
|
||||
`find` 命令十分直截了当:你向 `find` 提供搜索路径和待查找文件的一部分信息。可以使用通配符完成模糊搜索;在下面的例子中,星号匹配任何字符,故 `find` 定位(文件名)以字符 `searchterm` 结尾的全部文件:
|
||||
|
||||
```
|
||||
$ find /path/to/directory -name "*searchterm"
|
||||
|
||||
```
|
||||
|
||||
默认情况下,`find` 逐行返回搜索结果,每个结果对应 1 行:
|
||||
|
||||
```
|
||||
$ find ~/graphics -name "*jpg"
|
||||
/home/seth/graphics/001.jpg
|
||||
/home/seth/graphics/cat.jpg
|
||||
/home/seth/graphics/penguin.jpg
|
||||
/home/seth/graphics/IMG_0135.jpg
|
||||
|
||||
```
|
||||
|
||||
当使用管道将 `find` 的结果传递给 `parallel` 时,每一行中的文件路径被视为 `parallel` 命令的一个参数。另一方面,如果你需要使用命令处理多个参数,你可以改变队列数据传递给 `parallel` 的方式。
|
||||
|
||||
下面先给出一个不那么真实的例子,后续会做一些修改使其更加有意义。如果你安装了 GNU Parallel,你可以跟着这个例子操作。
|
||||
下面先给出一个不那么实际的例子,后续会做一些修改使其更加有意义。如果你安装了 GNU Parallel,你可以跟着这个例子操作。
|
||||
|
||||
假设你有 4 个文件,按照每行一个文件的方式列出,具体如下:
|
||||
|
||||
```
|
||||
$ echo ada > ada ; echo lovelace > lovelace
|
||||
$ echo richard > richard ; echo stallman > stallman
|
||||
@ -102,37 +104,38 @@ ada
|
||||
lovelace
|
||||
richard
|
||||
stallman
|
||||
|
||||
```
|
||||
|
||||
你需要将两个文件合并成第三个文件,后者同时包含前两个文件的内容。这种情况下,Parallel 需要访问两个文件,使用 `-I%` 变量的方式不符合本例的预期。
|
||||
|
||||
Parallel 默认情况下读取 1 个队列对象:
|
||||
|
||||
```
|
||||
$ ls -1 | parallel echo
|
||||
ada
|
||||
lovelace
|
||||
richard
|
||||
stallman
|
||||
|
||||
```
|
||||
|
||||
现在让 Parallel 每个任务使用 2 个队列对象:
|
||||
|
||||
```
|
||||
$ ls -1 | parallel --max-args=2 echo
|
||||
ada lovelace
|
||||
richard stallman
|
||||
|
||||
```
|
||||
|
||||
现在,我们看到行已经并合并;具体而言,`ls -1` 的两个查询结果会被同时传送给 Parallel。传送给 Parallel 的参数涉及了任务所需的 2 个文件,但目前还只是 1 个有效参数:(对于两个任务分别为)"ada lovelace" 和 "richard stallman"。你真正需要的是每个任务对应 2 个独立的参数。
|
||||
现在,我们看到行已经并合并;具体而言,`ls -1` 的两个查询结果会被同时传送给 Parallel。传送给 Parallel 的参数涉及了任务所需的 2 个文件,但目前还只是 1 个有效参数:(对于两个任务分别为)“ada lovelace” 和 “richard stallman”。你真正需要的是每个任务对应 2 个独立的参数。
|
||||
|
||||
值得庆幸的是,Parallel 本身提供了上述所需的解析功能。如果你将 `--max-args` 设置为 `2`,那么 `{1}` 和 `{2}` 这两个变量分别代表传入参数的第一和第二部分:
|
||||
|
||||
```
|
||||
$ ls -1 | parallel --max-args=2 cat {1} {2} ">" {1}_{2}.person
|
||||
|
||||
```
|
||||
|
||||
在上面的命令中,变量 `{1}` 值为 `ada` 或 `richard` (取决于你选取的任务),变量 `{2}` 值为 `lovelace` 或 `stallman`。通过使用重定向符号(放到引号中,防止被 Bash 识别,以便 Parallel 使用),(两个)文件的内容被分别重定向至新文件 `ada_lovelace.person` 和 `richard_stallman.person`。
|
||||
|
||||
```
|
||||
$ ls -1
|
||||
ada
|
||||
@ -146,12 +149,12 @@ $ cat ada_*person
|
||||
ada lovelace
|
||||
$ cat ri*person
|
||||
richard stallman
|
||||
|
||||
```
|
||||
|
||||
如果你整天处理大量几百 MB 大小的日志文件,那么(上述)并行处理文本的方法对你帮忙很大;否则,上述例子只是个用于上手的示例。
|
||||
|
||||
然而,这种处理方法对于很多文本处理之外的操作也有很大帮助。下面是来自电影产业的真实案例,其中需要将一个目录中的视频文件和(对应的)音频文件进行合并。
|
||||
|
||||
```
|
||||
$ ls -1
|
||||
12_LS_establishing-manor.avi
|
||||
@ -159,13 +162,12 @@ $ ls -1
|
||||
14_butler-dialogue-mixed.flac
|
||||
14_MS_butler.avi
|
||||
...略...
|
||||
|
||||
```
|
||||
|
||||
使用同样的方法,使用下面这个简单命令即可并行地合并文件:
|
||||
|
||||
```
|
||||
$ ls -1 | parallel --max-args=2 ffmpeg -i {1} -i {2} -vcodec copy -acodec copy {1}.mkv
|
||||
|
||||
```
|
||||
|
||||
### 简单粗暴的方式
|
||||
@ -173,6 +175,7 @@ $ ls -1 | parallel --max-args=2 ffmpeg -i {1} -i {2} -vcodec copy -acodec copy {
|
||||
上述花哨的输入输出处理不一定对所有人的口味。如果你希望更直接一些,可以将一堆命令甩给 Parallel,然后去干些其它事情。
|
||||
|
||||
首先,需要创建一个文本文件,每行包含一个命令:
|
||||
|
||||
```
|
||||
$ cat jobs2run
|
||||
bzip2 oldstuff.tar
|
||||
@ -182,16 +185,15 @@ convert bigfile.tiff small.jpeg
|
||||
ffmepg -i foo.avi -v:b 12000k foo.mp4
|
||||
xsltproc --output build/tmp.fo style/dm.xsl src/tmp.xml
|
||||
bzip2 archive.tar
|
||||
|
||||
```
|
||||
|
||||
接着,将文件传递给 Parallel:
|
||||
|
||||
```
|
||||
$ parallel --jobs 6 < jobs2run
|
||||
|
||||
```
|
||||
|
||||
现在文件中对应的全部任务都在被 Parallel 执行。如果任务数量超过允许的数目(译者注:应该是 --jobs 指定的数目或默认值),Parallel 会创建并维护一个队列,直到任务全部完成。
|
||||
现在文件中对应的全部任务都在被 Parallel 执行。如果任务数量超过允许的数目(LCTT 译注:应该是 `--jobs` 指定的数目或默认值),Parallel 会创建并维护一个队列,直到任务全部完成。
|
||||
|
||||
### 更多内容
|
||||
|
||||
@ -206,7 +208,7 @@ via: https://opensource.com/article/18/5/gnu-parallel
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
79
published/20180521 Linux vs. Unix- What-s the difference.md
Normal file
79
published/20180521 Linux vs. Unix- What-s the difference.md
Normal file
@ -0,0 +1,79 @@
|
||||
Linux vs. Unix:有什么不同?
|
||||
=====
|
||||
|
||||
> 深入了解这两个有许多共同的传统和相同的目标的操作系统之间的不同。
|
||||
|
||||

|
||||
|
||||
如果你是位二、三十岁的软件开发人员,那么你已经成长在一个由 Linux 主导的世界。数十年来,它一直是数据中心的重要参与者,尽管很难找到明确的操作系统市场份额报告,但 Linux 的数据中心操作系统份额可能高达 70%,而 Windows 及其变体几乎涵盖了所有剩余的百分比。使用任何主流公共云服务的开发人员都可以预期目标系统会运行 Linux。近些年来,随着 Android 和基于 Linux 的嵌入式系统在智能手机、电视、汽车和其他设备中的应用,Linux 已经随处可见。
|
||||
|
||||
即便如此,大多数软件开发人员,甚至是那些在这场历史悠久的 “Linux 革命”中长大的软件开发人员,也都听过说 Unix。它听起来与 Linux 相似,你可能已经听到人们互换使用这些术语。或者你也许听说过 Linux 被称为“类 Unix ”操作系统。
|
||||
|
||||
那么,Unix 是什么?漫画中提到了像巫师一样留着“灰胡子”,坐在发光的绿色屏幕后面,写着 C 代码和 shell 脚本,由老式的、滴灌的咖啡提供动力。但是,Unix 的历史比上世纪 70 年代那些留着胡子的 C 程序员要丰富得多。虽然详细介绍 Unix 历史和 “Unix 与 Linux” 比较的文章比比皆是,但本文将提供高级背景和列出这些互补世界之间的主要区别。
|
||||
|
||||
### Unix 的起源
|
||||
|
||||
Unix 的历史始于 20 世纪 60 年代后期的 AT&T 贝尔实验室,有一小组程序员希望为 PDP-7 编写一个多任务、多用户操作系统。这个贝尔实验室研究机构的团队中最著名的两名成员是 Ken Thompson 和 Dennis Ritchie。尽管 Unix 的许多概念都是其前身([Multics][1])的衍生物,但 Unix 团队早在 70 年代就决定用 C 语言重写这个小型操作系统,这是将 Unix 与其他操作系统区分开来的原因。当时,操作系统很少,更不要说可移植的操作系统。相反,由于它们的设计和底层语言的本质,操作系统与他们所编写的硬件平台紧密相关。而通过 C 语言重构 Unix、Unix 现在可以移植到许多硬件体系结构中。
|
||||
|
||||
除了这种新的可移植性,之所以使得 Unix 迅速扩展到贝尔实验室以外的其他研究和学术机构甚至商业用途,是因为操作系统设计原则的几个关键点吸引了用户和程序员们。首先是 Ken Thompson 的 [Unix 哲学][2]成为模块化软件设计和计算的强大模型。Unix 哲学推荐使用小型的、专用的程序组合起来完成复杂的整体任务。由于 Unix 是围绕文件和管道设计的,因此这种“管道”模式的输入和输出程序的组合成一组线性的输入操作,现在仍然流行。事实上,目前的云功能即服务(FaaS)或无服务器计算模型要归功于 Unix 哲学的许多传统。
|
||||
|
||||
### 快速增长和竞争
|
||||
|
||||
到 70 年代末和 80 年代,Unix 成为了一个操作系统家族的起源,它遍及了研究和学术机构以及日益增长的商业 Unix 操作系统业务领域。Unix 不是开源软件,Unix 源代码可以通过与它的所有者 AT&T 达成协议来获得许可。第一个已知的软件许可证于 1975 年出售给<ruby>伊利诺伊大学<rt>University of Illinois</rt></ruby>。
|
||||
|
||||
Unix 在学术界迅速发展,在 Ken Thompson 在上世纪 70 年代的学术假期间,伯克利成为一个重要的活动中心。通过在伯克利的各种有关 Unix 的活动,Unix 软件的一种新的交付方式诞生了:<ruby>伯克利软件发行版<rt>Berkeley Software Distribution</rt></ruby>(BSD)。最初,BSD 不是 AT&T Unix 的替代品,而是一种添加类似于附加软件和功能。在 1979 年, 2BSD(第二版伯克利软件发行版)出现时,伯克利研究生 Bill Joy 已经添加了现在非常有名的程序,例如 `vi` 和 C shell(`/bin/csh`)。
|
||||
|
||||
除了成为 Unix 家族中最受欢迎的分支之一的 BSD 之外,Unix 的商业产品的爆发贯穿了二十世纪八、九十年代,其中包括 HP-UX、IBM 的 AIX、 Sun 的 Solaris、 Sequent 和 Xenix 等。随着分支从根源头发展壮大,“[Unix 战争][3]”开始了,标准化成为社区的新焦点。POSIX 标准诞生于 1988 年,其他标准化后续工作也开始通过 The Open Group 在 90 年代到来。
|
||||
|
||||
在此期间,AT&T 和 Sun 发布了 System V Release 4(SVR4),许多商业供应商都采用了这一版本。另外,BSD 系列操作系统多年来一直在增长,最终一些开源的变体在现在熟悉的 [BSD许可证][4]下发布。这包括 FreeBSD、 OpenBSD 和 NetBSD,每个在 Unix 服务器行业的目标市场略有不同。这些 Unix 变体今天仍然有一些在使用,尽管人们已经看到它们的服务器市场份额缩小到个位数字(或更低)。在当今的所有 Unix 系统中,BSD 可能拥有最大的安装基数。另外,每台 Apple Mac 硬件设备从历史的角度看都可以算做是 BSD ,这是因为 OS X(现在是 macOS)操作系统是 BSD 衍生产品。
|
||||
|
||||
虽然 Unix 的全部历史及其学术和商业变体可能需要更多的篇幅,但为了我们文章的重点,让我们来讨论 Linux 的兴起。
|
||||
|
||||
### 进入 Linux
|
||||
|
||||
今天我们所说的 Linux 操作系统实际上是 90 年代初期的两个努力的结合。Richard Stallman 希望创建一个真正的自由而开放源代码的专有 Unix 系统的替代品。他正在以 GNU 的名义开发实用程序和程序,这是一种递归的说法,意思是“GNU‘s not Unix!”。虽然当时有一个内核项目正在进行,但事实证明这是一件很困难的事情,而且没有内核,自由和开源操作系统的梦想无法实现。而这是 Linus Torvald 的工作 —— 生产出一种可工作和可行的内核,他称之为 Linux -- 它将整个操作系统带入了生活。鉴于 Linus 使用了几个 GNU 工具(例如 GNU 编译器集合,即 [GCC][5]),GNU 工具和 Linux 内核的结合是完美的搭配。
|
||||
|
||||
Linux 发行版采用了 GNU 的组件、Linux 内核、MIT 的 X-Windows GUI 以及可以在开源 BSD 许可下使用的其它 BSD 组件。像 Slackware 和 Red Hat 这样的发行版早期的流行给了 20 世纪 90 年代的“普通 PC 用户”一个进入 Linux 操作系统的机会,并且让他们在工作和学术生活中可以使用许多 Unix 系统特有的功能和实用程序。
|
||||
|
||||
由于所有 Linux 组件都是自由和开放的源代码,任何人都可以通过一些努力来创建一个 Linux 发行版,所以不久后发行版的总数达到了数百个。今天,[distrowatch.com][6] 列出了 312 种各种形式的独特的 Linux 发行版。当然,许多开发人员通过云提供商或使用流行的免费发行版来使用 Linux,如 Fedora、 Canonical 的 Ubuntu、 Debian、 Arch Linux、 Gentoo 和许多其它变体。随着包括 IBM 在内的许多企业从专有 Unix 迁移到 Linux 上并提供了中间件和软件解决方案,商用 Linux 产品在自由和开源组件之上提供支持变得可行。红帽公司围绕 Red Hat Enterprise Linux(红帽企业版 Linux) 建立了商业支持模式,德国供应商 SUSE 使用 SUSE Linux Enterprise Server(SLES)也提供了这种模式。
|
||||
|
||||
### 比较 Unix 和 Linux
|
||||
|
||||
到目前为止,我们已经了解了 Unix 的历史以及 Linux 的兴起,以及 GNU/自由软件基金会对 Unix 的自由和开源替代品的支持。让我们来看看这两个操作系统之间的差异,它们有许多共同的传统和许多相同的目标。
|
||||
|
||||
从用户体验角度来看,两者差不多!Linux 的很大吸引力在于操作系统在许多硬件体系结构(包括现代 PC)上的可用性以及类似使用 Unix 系统管理员和用户熟悉的工具的能力。
|
||||
|
||||
由于 POSIX 的标准和合规性,在 Unix 上编写的软件可以针对 Linux 操作系统进行编译,通常只有少量的移植工作量。在很多情况下,Shell 脚本可以在 Linux 上直接使用。虽然一些工具在 Unix 和 Linux 之间有着略微不同的标志或命令行选项,但许多工具在两者上都是相同的。
|
||||
|
||||
一方面要注意的是,macOS 硬件和操作系统作为主要针对 Linux 的开发平台的流行可能归因于类 BSD 的 macOS 操作系统。许多用于 Linux 系统的工具和脚本可以在 macOS 终端内轻松工作。Linux 上的许多开源软件组件都可以通过 [Homebrew][7] 等工具轻松获得。
|
||||
|
||||
Linux 和 Unix 之间的其他差异主要与许可模式有关:开源与专有许可软件。另外,在 Unix 发行版中缺少一个影响软件和硬件供应商的通用内核。对于 Linux,供应商可以为特定的硬件设备创建设备驱动程序,并期望在合理的范围内它可以在大多数发行版上运行。由于 Unix 家族的商业和学术分支,供应商可能必须为 Unix 的变体编写不同的驱动程序,并且需要许可和其他相关的权限才能访问 SDK 或软件的分发模型,以跨越多个二进制设备驱动程序的 Unix 变体。
|
||||
|
||||
随着这两个社区在过去十年中的成熟,Linux 的许多优点已经在 Unix 世界中被采用。当开发人员需要来自不属于 Unix 的 GNU 程序的功能时,许多 GNU 实用程序可作为 Unix 系统的附件提供。例如,IBM 的 AIX 为 Linux 应用程序提供了一个 AIX Toolbox,其中包含数百个 GNU 软件包(如 Bash、 GCC、 OpenLDAP 和许多其他软件包),这些软件包可添加到 AIX 安装包中以简化 Linux 和基于 Unix 的 AIX 系统之间的过渡。
|
||||
|
||||
专有的 Unix 仍然活着而且还不错,许多主要供应商承诺支持其当前版本,直到 2020 年。不言而喻,Unix 还会在可预见的将来一直出现。此外,Unix 的 BSD 分支是开源的,而 NetBSD、 OpenBSD 和 FreeBSD 都有强大的用户基础和开源社区,它们可能不像 Linux 那样显眼或活跃,但在最近的服务器报告中,在 Web 服务等领域它们远高于专有 Unix 的数量。
|
||||
|
||||
Linux 已经显示出其超越 Unix 的显著优势在于其在大量硬件平台和设备上的可用性。<ruby>树莓派<rt>Raspberry Pi</rt></ruby>受到业余爱好者的欢迎,它是由 Linux 驱动的,为运行 Linux 的各种物联网设备打开了大门。我们已经提到了 Android 设备,汽车(包括 Automotive Grade Linux)和智能电视,其中 Linux 占有巨大的市场份额。这个星球上的每个云提供商都提供运行 Linux 的虚拟服务器,而且当今许多最受欢迎的原生云架构都是基于 Linux 的,无论你是在谈论容器运行时还是 Kubernetes,或者是许多正在流行的无服务器平台。
|
||||
|
||||
其中一个最显著的代表 Linux 的优势是近年来微软的转变。如果你十年前告诉软件开发人员,Windows 操作系统将在 2016 年“运行 Linux”,他们中的大多数人会歇斯底里地大笑。 但是 Windows Linux 子系统(WSL)的存在和普及,以及最近宣布的诸如 Docker 的 Windows 移植版,包括 LCOW(Windows 上的 Linux 容器)支持等功能都证明了 Linux 在整个软件世界中所产生的影响 —— 而且显然还会继续存在。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/differences-between-linux-and-unix
|
||||
|
||||
作者:[Phil Estes][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/estesp
|
||||
[1]:https://en.wikipedia.org/wiki/Multics
|
||||
[2]:https://en.wikipedia.org/wiki/Unix_philosophy
|
||||
[3]:https://en.wikipedia.org/wiki/Unix_wars
|
||||
[4]:https://en.wikipedia.org/wiki/BSD_licenses
|
||||
[5]:https://en.wikipedia.org/wiki/GNU_Compiler_Collection
|
||||
[6]:https://distrowatch.com/
|
||||
[7]:https://brew.sh/
|
||||
51
sources/talk/20180603 Let-s migrate away from GitHub.md
Normal file
51
sources/talk/20180603 Let-s migrate away from GitHub.md
Normal file
@ -0,0 +1,51 @@
|
||||
Let's migrate away from GitHub
|
||||
======
|
||||
As many of you heard today, [Microsoft is acquiring GitHub][1]. What this means for the future of GitHub is not yet clear, but [the folks at Gitlab][2] think Microsoft's end goal is to integrate GitHub in their Azure empire. To me, this makes a lot of sense.
|
||||
|
||||
Even though I still reluctantly use GitHub for some projects, I migrated all my personal repositories to Gitlab instances a while ago. Now is time for you to do the same and ditch GitHub.
|
||||
|
||||
![Microsft loven't Linux][3]
|
||||
|
||||
Some people might be fine with Microsoft's takeover, but to me it's the straw that breaks the camel's back. For a few years now, MS has been running a large marketing campaign on how they love Linux and suddenly decided to embrace Free Software in all of its forms. More like MS BS to me.
|
||||
|
||||
Let us take a moment to remind ourselves that:
|
||||
|
||||
* Windows is still a huge proprietary monster that rips billions of people from their privacy and rights every day.
|
||||
* Microsoft is known for spreading FUD about "the dangers" of Free Software in order to keep governments and schools from dropping Windows in favor of FOSS.
|
||||
* To secure their monopoly, Microsoft hooks up kids on Windows by giving out "free" licences to primary schools around the world. Drug dealers use the same tactics and give out free samples to secure new clients.
|
||||
* Microsoft's Azure platform - even though it can run Linux VMs - is still a giant proprietary hypervisor.
|
||||
|
||||
|
||||
|
||||
I know moving git repositories around can seem like a pain in the ass, but the folks at Gitlab are riding the wave of people leaving GitHub and made the the migration easy [by providing a GitHub importer][4].
|
||||
|
||||
If you don't want to use Gitlab's main instance ([gitlab.org][5]), here are two other alternative instances you can use for Free Software projects:
|
||||
|
||||
* The [Debian Gitlab instance][6] is available for every FOSS project and not only for Debian-related ones. As long as the project respects the [Debian Free Software Guidelines][7], you can use the instance and its CI runners.
|
||||
* Riseup maintains a Gitlab instance for radical projects named [0xacab][8]. If your [ethos aligns with Riseup's][9], chances are they'll be happy to host your projects there.
|
||||
|
||||
|
||||
|
||||
Friends don't let friends use GitHub anymore.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://veronneau.org/lets-migrate-away-from-github.html
|
||||
|
||||
作者:[Louis-Philippe Véronneau][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://veronneau.org/
|
||||
[1]:https://www.bloomberg.com/news/articles/2018-06-03/microsoft-is-said-to-have-agreed-to-acquire-coding-site-github
|
||||
[2]:https://about.gitlab.com/2018/06/03/microsoft-acquires-github/
|
||||
[3]:https://veronneau.org/media/blog/2018-06-03/ms-lovent-linux.png (Microsoft loven't Linux)
|
||||
[4]:https://docs.gitlab.com/ee/user/project/import/github.html
|
||||
[5]:https://gitlab.org
|
||||
[6]:https://salsa.debian.org
|
||||
[7]:https://en.wikipedia.org/wiki/Debian_Free_Software_Guidelines
|
||||
[8]:https://0xacab.org
|
||||
[9]:https://riseup.net/en/about-us/politics
|
||||
@ -0,0 +1,93 @@
|
||||
10 principles of resilience for women in tech
|
||||
======
|
||||
|
||||

|
||||
|
||||
Being a woman in tech is pretty damn cool. For every headline about [what Silicon Valley thinks of women][1], there are tens of thousands of women building, innovating, and managing technology teams around the world. Women are helping build the future despite the hurdles they face, and the community of women and allies growing to support each other is stronger than ever. From [BetterAllies][2] to organizations like [Girls Who Code][3] and communities like the one I met recently at [Red Hat Summit][4], there are more efforts than ever before to create an inclusive community for women in tech.
|
||||
|
||||
But the tech industry has not always been this welcoming, nor is the experience for women always aligned with the aspiration. And so we're feeling the pain. Women in technology roles have dropped from its peak in 1991 at 36% to 25% today, [according to a report by NCWIT][5]. [Harvard Business Review estimates][6] that more than half of the women in tech will eventually leave due to hostile work conditions. Meanwhile, Ernst & Young recently shared [a study][7] and found that merely 11% of high school girls are planning to pursue STEM careers.
|
||||
|
||||
We have much work to do, lest we build a future that is less inclusive than the one we live in today. We need everyone at the table, in the lab, at the conference and in the boardroom.
|
||||
|
||||
I've been interviewing both women and men for more than a year now about their experiences in tech, all as part of [The Chasing Grace Project][8], a documentary series about women in tech. The purpose of the series is to help recruit and retain female talent for the tech industry and to give women a platform to be seen, heard, and acknowledged for their experiences. We believe that compelling story can begin to transform culture.
|
||||
|
||||
### What Chasing Grace taught me
|
||||
|
||||
What I've learned is that no matter the dismal numbers, women want to keep building and they collectively possess a resilience unmatched by anything I've ever seen. And this is inspiring me. I've found a power, a strength, and a beauty in every story I've heard that is the result of resilience. I recently shared with the attendees at the Red Hat Summit Women’s Leadership Luncheon the top 10 principles of resilience I've heard from throughout my interviews so far. I hope that by sharing them here the ideas and concepts can support and inspire you, too.
|
||||
|
||||
#### 1\. Practice optimism
|
||||
|
||||
When taken too far, optimism can give you blind spots. But a healthy dose of optimism allows you to see the best in people and situations and that positive energy comes back to you 100-fold. I haven’t met a woman yet as part of this project who isn’t an optimist.
|
||||
|
||||
#### 2\. Build mental toughness
|
||||
|
||||
I haven’t met a woman yet as part of this project who isn’t an optimist.
|
||||
|
||||
When I recently asked a 32-year-old tech CEO, who is also a single mom of three young girls, what being a CEO required she said _mental toughness_. It really summed up what I’d heard in other words from other women, but it connected with me on another level when she proceeded to tell me how caring for her daughter—who was born with a hole in heart—prepared her for what she would encounter as a tech CEO. Being mentally tough to her means fighting for what you love, persisting like a badass, and building your EQ as well as your IQ.
|
||||
|
||||
#### 3\. Recognize your power
|
||||
|
||||
When I recently asked a 32-year-old tech CEO, who is also a single mom of three young girls, what being a CEO required she said. It really summed up what I’d heard in other words from other women, but it connected with me on another level when she proceeded to tell me how caring for her daughter—who was born with a hole in heart—prepared her for what she would encounter as a tech CEO. Being mentally tough to her means fighting for what you love, persisting like a badass, and building your EQ as well as your IQ.
|
||||
|
||||
Most of the women I’ve interviewed don’t know their own power and so they give it away unknowingly. Too many women have told me that they willingly took on the housekeeping roles on their teams—picking up coffee, donuts, office supplies, and making the team dinner reservations. Usually the only woman on their teams, this put them in a position to be seen as less valuable than their male peers who didn’t readily volunteer for such tasks. All of us, men and women, have innate powers. Identify and know what your powers are and understand how to use them for good. You have so much more power than you realize. Know it, recognize it, use it strategically, and don’t give it away. It’s yours.
|
||||
|
||||
#### 4\. Know your strength
|
||||
|
||||
Not sure whether you can confront your boss about why you haven’t been promoted? You can. You don’t know your strength until you exercise it. Then, you’re unstoppable. Test your strength by pushing your fear aside and see what happens.
|
||||
|
||||
#### 5\. Celebrate vulnerability
|
||||
|
||||
Every single successful women I've interviewed isn't afraid to be vulnerable. She finds her strength in acknowledging where she is vulnerable and she looks to connect with others in that same place. Exposing, sharing, and celebrating each other’s vulnerabilities allows us to tap into something far greater than simply asserting strength; it actually builds strength—mental and emotional muscle. One women with whom we’ve talked shared how starting her own tech company made her feel like she was letting her husband down. She shared with us the details of that conversation with her husband. Honest conversations that share our doubts and our aspirations is what makes women uniquely suited to lead in many cases. Allow yourself to be seen and heard. It’s where we grow and learn.
|
||||
|
||||
#### 6\. Build community
|
||||
|
||||
If it doesn't exist, build it.
|
||||
|
||||
Building community seems like a no-brainer in the world of open source, right? But take a moment to think about how many minorities in tech, especially those outside the collaborative open source community, don’t always feel like part of the community. Many women in tech, for example, have told me they feel alone. Reach out and ask questions or answer questions in community forums, at meetups, and in IRC and Slack. When you see a woman alone at an event, consider engaging with her and inviting her into a conversation. Start a meetup group in your company or community for women in tech. I've been so pleased with the number of companies that host these groups. If it doesn't exists, build it.
|
||||
|
||||
#### 7\. Celebrate victories
|
||||
|
||||
Building community seems like a no-brainer in the world of open source, right? But take a moment to think about how many minorities in tech, especially those outside the collaborative open source community, don’t always feel like part of the community. Many women in tech, for example, have told me they feel alone. Reach out and ask questions or answer questions in community forums, at meetups, and in IRC and Slack. When you see a woman alone at an event, consider engaging with her and inviting her into a conversation. Start a meetup group in your company or community for women in tech. I've been so pleased with the number of companies that host these groups. If it doesn't exists, build it.
|
||||
|
||||
One of my favorite Facebook groups is [TechLadies][9] because of its recurring hashtag #YEPIDIDTHAT. It allows women to share their victories in a supportive community. No matter how big or small, don't let a victory go unrecognized. When you recognize your wins, you own them. They become a part of you and you build on top of each one.
|
||||
|
||||
#### 8\. Be curious
|
||||
|
||||
Being curious in the tech community often means asking questions: How does that work? What language is that written in? How can I make this do that? When I've managed teams over the years, my best employees have always been those who ask a lot of questions, those who are genuinely curious about things. But in this context, I mean be curious when your gut tells you something doesn't seem right. _The energy in the meeting was off. Did he/she just say what I think he said?_ Ask questions. Investigate. Communicate openly and clearly. It's the only way change happens.
|
||||
|
||||
#### 9\. Harness courage
|
||||
|
||||
One women told me a story about a meeting in which the women in the room kept being dismissed and talked over. During the debrief roundtable portion of the meeting, she called it out and asked if others noticed it, too. Being a 20-year tech veteran, she'd witnessed and experienced this many times but she had never summoned the courage to speak up about it. She told me she was incredibly nervous and was texting other women in the room to see if they agreed it should be addressed. She didn't want to be a "troublemaker." But this kind of courage results in an increased understanding by everyone in that room and can translate into other meetings, companies, and across the industry.
|
||||
|
||||
#### 10\. Share your story
|
||||
|
||||
When people connect to compelling story, they begin to change behaviors.
|
||||
|
||||
Share your experience with a friend, a group, a community, or an industry. Be empowered by the experience of sharing your experience. Stories change culture. When people connect to compelling story, they begin to change behaviors. When people act, companies and industries begin to transform.
|
||||
|
||||
Share your experience with a friend, a group, a community, or an industry. Be empowered by the experience of sharing your experience. Stories change culture. When people connect to compelling story, they begin to change behaviors. When people act, companies and industries begin to transform.
|
||||
|
||||
If you would like to support [The Chasing Grace Project][8], email Jennifer Cloer to learn more about how to get involved: [jennifer@wickedflicksproductions.com][10]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/being-woman-tech-10-principles-resilience
|
||||
|
||||
作者:[Jennifer Cloer][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jennifer-cloer
|
||||
[1]:http://www.newsweek.com/2015/02/06/what-silicon-valley-thinks-women-302821.html%E2%80%9D
|
||||
[2]:https://opensource.com/article/17/6/male-allies-tech-industry-needs-you%E2%80%9D
|
||||
[3]:https://twitter.com/GirlsWhoCode%E2%80%9D
|
||||
[4]:http://opensource.com/tags/red-hat-summit%E2%80%9D
|
||||
[5]:https://www.ncwit.org/sites/default/files/resources/womenintech_facts_fullreport_05132016.pdf%E2%80%9D
|
||||
[6]:Dhttp://www.latimes.com/business/la-fi-women-tech-20150222-story.html%E2%80%9D
|
||||
[7]:http://www.ey.com/us/en/newsroom/news-releases/ey-news-new-research-reveals-the-differences-between-boys-and-girls-career-and-college-plans-and-an-ongoing-need-to-engage-girls-in-stem%E2%80%9D
|
||||
[8]:https://www.chasinggracefilm.com/
|
||||
[9]:https://www.facebook.com/therealTechLadies/%E2%80%9D
|
||||
[10]:mailto:jennifer@wickedflicksproductions.com
|
||||
@ -1,82 +0,0 @@
|
||||
pinewall translating
|
||||
|
||||
Configuring local storage in Linux with Stratis
|
||||
======
|
||||
|
||||

|
||||
|
||||
Configuring local storage is something desktop Linux users do very infrequently—maybe only once, during installation. Linux storage tech moves slowly, and many storage tools used 20 years ago are still used regularly today. But some things have improved since then. Why aren't people taking advantage of these new capabilities?
|
||||
|
||||
This article is about Stratis, a new project that aims to bring storage advances to all Linux users, from the simple laptop single SSD to a hundred-disk array. Linux has the capabilities, but its lack of an easy-to-use solution has hindered widespread adoption. Stratis's goal is to make Linux's advanced storage features accessible.
|
||||
|
||||
### Simple, reliable access to advanced storage features
|
||||
|
||||
Stratis aims to make three things easier: initial configuration of storage; making later changes; and using advanced storage features like snapshots, thin provisioning, and even tiering.
|
||||
|
||||
### Stratis: a volume-managing filesystem
|
||||
|
||||
Stratis is a volume-managing filesystem (VMF) like [ZFS][1] and [Btrfs][2] . It starts with the central idea of a storage "pool," an idea common to VMFs and also standalone volume managers such as [LVM][3] . This pool is created from one or more local disks (or partitions), and volumes are created from the pool. Their exact layout is not specified by the user, unlike traditional disk partitioning using [fdisk][4] or [GParted][5]
|
||||
|
||||
VMFs take it a step further and integrate the filesystem layer. The user no longer picks a filesystem to put on the volume. The filesystem and volume are merged into a single thing—a conceptual tree of files (which ZFS calls a dataset, Btrfs a subvolume, and Stratis a filesystem) whose data resides in the pool but that has no size limit except for the pool's total size.
|
||||
|
||||
Another way of looking at this: Just as a filesystem abstracts the actual location of storage blocks that make up a single file within the filesystem, a VMF abstracts the actual storage blocks of a filesystem within the pool.
|
||||
|
||||
The pool enables other useful features. Some of these, like filesystem snapshots, occur naturally from the typical implementation of a VMF, where multiple filesystems can share physical data blocks within the pool. Others, like redundancy, tiering, and integrity, make sense because the pool is a central place to manage these features for all the filesystems on the system.
|
||||
|
||||
The result is that a VMF is simpler to set up and manage and easier to enable for advanced storage features than independent volume manager and filesystem layers.
|
||||
|
||||
### What makes Stratis different from ZFS or Btrfs?
|
||||
|
||||
Stratis is a new project, which gives it the benefit of learning from previous projects. What Stratis learned from ZFS, Btrfs, and LVM will be covered in depth in [Part 2][6], but to summarize, the differences in Stratis come from seeing what worked and what didn't work for others, from changes in how people use and automate computers, and changes in the underlying hardware.
|
||||
|
||||
First, Stratis focuses on being easy and safe to use. This is important for the individual user, who may go for long stretches of time between interactions with Stratis. If these interactions are unfriendly, especially if there's a possibility of losing data, most people will stick with the basics instead of using new features.
|
||||
|
||||
Second, APIs and DevOps-style automation are much more important today than they were even a few years ago. Stratis supports automation by providing a first-class API, so people and software tools alike can use Stratis directly.
|
||||
|
||||
Third, SSDs have greatly expanded in capacity as well as market share. Earlier filesystems went to great lengths to optimize for rotational media's slow access times, but flash-based media makes these efforts less important. Even if a pool's data is too big to use SSDs economically for the entire pool, an SSD caching tier is still an option and can give excellent results. Assuming good performance because of SSDs lets Stratis focus its pool design on flexibility and reliability.
|
||||
|
||||
Finally, Stratis has a very different implementation model from ZFS and Btrfs (I'll this discuss further in [Part 2][6]). This means some things are easier for Stratis, while other things are harder. It also increases Stratis's pace of development.
|
||||
|
||||
### Learn more
|
||||
|
||||
To learn more about Stratis, check out [Part 2][6] of this series. You'll also find a detailed [design document][7] on the [Stratis website][8].
|
||||
|
||||
### Get involved
|
||||
|
||||
To develop, test, or offer feedback on Stratis, subscribe to our [mailing list][9].
|
||||
|
||||
Development is on [GitHub][10] for both the [daemon][11] (written in [Rust][12]) and the [command-line tool][13] (written in [Python][14]).
|
||||
|
||||
Join us on the [Freenode][15] IRC network on channel #stratis-storage.
|
||||
|
||||
Andy Grover will be speaking at LinuxFest Northwest this year. See [program highlights][16] or [register to attend][17].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/stratis-easy-use-local-storage-management-linux
|
||||
|
||||
作者:[Andy Grover][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/agrover
|
||||
[1]:https://en.wikipedia.org/wiki/ZFS
|
||||
[2]:https://en.wikipedia.org/wiki/Btrfs
|
||||
[3]:https://en.wikipedia.org/wiki/Logical_Volume_Manager_(Linux)
|
||||
[4]:https://en.wikipedia.org/wiki/Fdisk
|
||||
[5]:https://gparted.org/
|
||||
[6]:https://opensource.com/article/18/4/stratis-lessons-learned
|
||||
[7]:https://stratis-storage.github.io/StratisSoftwareDesign.pdf
|
||||
[8]:https://stratis-storage.github.io/
|
||||
[9]:https://lists.fedoraproject.org/admin/lists/stratis-devel.lists.fedorahosted.org/
|
||||
[10]:https://github.com/stratis-storage/
|
||||
[11]:https://github.com/stratis-storage/stratisd
|
||||
[12]:https://www.rust-lang.org/
|
||||
[13]:https://github.com/stratis-storage/stratis-cli
|
||||
[14]:https://www.python.org/
|
||||
[15]:https://freenode.net/
|
||||
[16]:https://www.linuxfestnorthwest.org/conferences/lfnw18
|
||||
[17]:https://www.linuxfestnorthwest.org/conferences/lfnw18/register/new
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
A CLI Game To Learn Vim Commands
|
||||
======
|
||||
|
||||
|
||||
@ -1,171 +0,0 @@
|
||||
pinewall translating
|
||||
|
||||
A guide to Git branching
|
||||
======
|
||||
|
||||

|
||||
In my two previous articles in this series, we [started using Git][1] and learned how to [clone, modify, add, and delete][2] Git files. In this third installment, we'll explore Git branching and why and how it is used.
|
||||
|
||||
![tree branches][3]
|
||||
|
||||
Picture this tree as a Git repository. It has a lot of branches, long and short, stemming from the trunk and stemming from other branches. Let's say the tree's trunk represents a master branch of our repo. I will use `master` in this article as an alias for "master branch"—i.e., the central or first branch of a repo. To simplify things, let's assume that the `master` is a tree trunk and the other branches start from it.
|
||||
|
||||
### Why we need branches in a Git repo
|
||||
|
||||
* If you are creating a new feature for your project, there's a reasonable chance that adding it could break your working code. This would be very bad for active users of your project. It's better to start with a prototype, which you would want to design roughly in a different branch and see how it works, before you decide whether to add the feature to the repo's `master` for others to use.
|
||||
* Another, probably more important, reason is [Git was made][4] for collaboration. If everyone starts programming on top of your repo's `master` branch, it will cause a lot of confusion. Everyone has different knowledge and experience (in the programming language and/or the project); some people may write faulty/buggy code or simply the kind of code/feature you may not want in your project. Using branches allows you to verify contributions and select which to add to the project. (This assumes you are the only owner of the repo and want full control of what code is added to it. In real-life projects, there are multiple owners with the rights to merge code in a repo.)
|
||||
|
||||
|
||||
|
||||
### Adding a branch
|
||||
|
||||
The main reasons for having branches are:
|
||||
|
||||
Let's go back to the [previous article in this series][2] and see what branching in our Demo directory looks like. If you haven't yet done so, follow the instructions in that article to clone the repo from GitHub and navigate to Demo. Run the following commands:
|
||||
```
|
||||
pwd
|
||||
|
||||
git branch
|
||||
|
||||
ls -la
|
||||
|
||||
```
|
||||
|
||||
The `pwd` command (which stands for present working directory) reports which directory you're in (so you can check that you're in Demo), `git branch` lists all the branches on your computer in the Demo repository, and `ls -la` lists all the files in the PWD. Now your terminal will look like this:
|
||||
|
||||
![Terminal output][5]
|
||||
|
||||
There's only one file, `README.md`, on the branch master. (Kindly ignore the other directories and files listed.)
|
||||
|
||||
Next, run the following commands:
|
||||
```
|
||||
git status
|
||||
|
||||
git checkout -b myBranch
|
||||
|
||||
git status
|
||||
|
||||
```
|
||||
|
||||
The first command, `git status` reports you are currently on `branch master`, and (as you can see in the terminal screenshot below) it is up to date with `origin/master`, which means all the files you have on your local copy of the branch master are also present on GitHub. There is no difference between the two copies. All commits are identical on both the copies as well.
|
||||
|
||||
The next command, `git checkout -b myBranch`, `-b` tells Git to create a new branch and name it `myBranch`, and `checkout` switches us to the newly created branch. Enter the third line, `git status`, to verify you are on the new branch you just created.
|
||||
|
||||
As you can see below, `git status` reports you are on branch `myBranch` and there is nothing to commit. This is because there is neither a new file nor any modification in existing files.
|
||||
|
||||
![Terminal output][6]
|
||||
|
||||
If you want to see a visual representation of branches, run the command `gitk`. If the computer complains `bash: gitk: command not found…`, then install `gitk`. (See documentation for your operating system for the install instructions.)
|
||||
|
||||
The image below reports what we've done in Demo: Your last commit was `Delete file.txt` and there were three commits before that. The current commit is noted with a yellow dot, previous commits with blue dots, and the three boxes between the yellow dot and `Delete file.txt` tell you where each branch is (i.e., what is the last commit on each branch). Since you just created `myBranch`, it is on the same commit as `master` and the remote counterpart of `master`, namely `remotes/origin/master`. (A big thanks to [Peter Savage][7] from Red Hat who made me aware of `gitk`.)
|
||||
|
||||
![Gitk output][8]
|
||||
|
||||
Now let's create a new file on our branch `myBranch` and let's observe terminal output. **** Run the following commands:
|
||||
```
|
||||
echo "Creating a newFile on myBranch" > newFile
|
||||
|
||||
cat newFile
|
||||
|
||||
git status
|
||||
|
||||
```
|
||||
|
||||
The first command, `echo`, creates a file named `newFile`, and `cat newFile` shows what is written in it. `git status` tells you the current status of our branch `myBranch`. In the terminal screenshot below, Git reports there is a file called `newFile` on `myBranch` and `newFile` is currently `untracked`. That means Git has not been told to track any changes that happen to `newFile`.
|
||||
|
||||
![Terminal output][9]
|
||||
|
||||
The next step is to add, commit, and push `newFile` to `myBranch` (go back to the last article in this series for more details).
|
||||
```
|
||||
git add newFile
|
||||
|
||||
git commit -m "Adding newFile to myBranch"
|
||||
|
||||
git push origin myBranch
|
||||
|
||||
```
|
||||
|
||||
In these commands, the branch in the `push` command is `myBranch` instead of `master`. Git is taking `newFile`, pushing it to your Demo repository in GitHub, and telling you it's created a new branch on GitHub that is identical to your local copy of `myBranch`. The terminal screenshot below details the run of commands and its output.
|
||||
|
||||
![Terminal output][10]
|
||||
|
||||
If you go to GitHub, you can see there are two branches to pick from in the branch drop-down.
|
||||
|
||||
![GitHub][11]
|
||||
|
||||
Switch to `myBranch` by clicking on it, and you can see the file you added on that branch.
|
||||
|
||||
![GitHub][12]
|
||||
|
||||
Now there are two different branches; one, `master`, has a single file, `README.md`, and the other, `myBranch`, has two files.
|
||||
|
||||
Now that you know how to create a branch, let's create another branch. Enter the following commands:
|
||||
```
|
||||
git checkout master
|
||||
|
||||
git checkout -b myBranch2
|
||||
|
||||
touch newFile2
|
||||
|
||||
git add newFile2
|
||||
|
||||
git commit -m "Adding newFile2 to myBranch2"
|
||||
|
||||
git push origin myBranch2
|
||||
|
||||
```
|
||||
|
||||
I won't show this terminal output as I want you to try it yourself, but you are more than welcome to check out the [repository on GitHub][13].
|
||||
|
||||
### Deleting a branch
|
||||
|
||||
Since we've added two branches, let's delete one of them (`myBranch`) using a two-step process.
|
||||
|
||||
**1\. Delete the local copy of your branch:** Since you can't delete a branch you're on, switch to the `master` branch (or another one you plan to keep) by running the commands shown in the terminal image below:
|
||||
|
||||
`git branch` lists the available branches; `checkout` changes to the `master` branch and `git branch -D myBranch` removes that branch. Run `git branch` again to verify there are now only two branches (instead of three).
|
||||
|
||||
**2\. Delete the branch from GitHub:** Delete the remote copy of `myBranch` by running the following command:
|
||||
```
|
||||
git push origin :myBranch
|
||||
|
||||
```
|
||||
|
||||
![Terminal output][14]
|
||||
|
||||
The colon (`:`) before the branch name in the `push` command tells GitHub to delete the branch. Another option is:
|
||||
```
|
||||
git push -d origin myBranch
|
||||
|
||||
```
|
||||
|
||||
as `-d` (or `--delete`) also tells GitHub to remove your branch.
|
||||
|
||||
Now that we've learned about using Git branches, in the next article in this series we'll look at how to fetch and rebase branch operations. These are essential things to know when you are working on a project with multiple contributors.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/git-branching
|
||||
|
||||
作者:[Kedar Vijay Kulkarni][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/kkulkarn
|
||||
[1]:https://opensource.com/article/18/1/step-step-guide-git
|
||||
[2]:https://opensource.com/article/18/2/how-clone-modify-add-delete-git-files
|
||||
[3]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/tree-branches.jpg?itok=bQGpa5Uc (tree branches)
|
||||
[4]:https://en.wikipedia.org/wiki/Git
|
||||
[5]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/gitbranching_terminal1.png?itok=ZcAzRdlR (Terminal output)
|
||||
[6]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/gitbranching_terminal2.png?itok=nIcfy2Vh (Terminal output)
|
||||
[7]:https://opensource.com/users/psav
|
||||
[8]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/gitbranching_commit3.png?itok=GoP51yE4 (Gitk output)
|
||||
[9]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/gitbranching_terminal4.png?itok=HThID5aU (Terminal output)
|
||||
[10]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/gitbranching_terminal5.png?itok=rHVdrJ0m (Terminal output)
|
||||
[11]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/gitbranching_github6.png?itok=EyaKfCg2 (GitHub)
|
||||
[12]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/gitbranching_github7.png?itok=0ZSu0W2P (GitHub)
|
||||
[13]:https://github.com/kedark3/Demo/tree/myBranch2
|
||||
[14]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/gitbranching_terminal9.png?itok=B0vaRkyI (Terminal output)
|
||||
@ -1,3 +1,5 @@
|
||||
pinewall translating
|
||||
|
||||
4 Markdown-powered slide generators
|
||||
======
|
||||
|
||||
|
||||
@ -1,104 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
A Bittorrent Filesystem Based On FUSE
|
||||
======
|
||||
|
||||

|
||||
The torrents have been around for a long time to share and download data from the Internet. There are plethora of GUI and CLI torrent clients available on the market. Sometimes, you just can not sit and wait for your download to complete. You might want to watch the content immediately. This is where **BTFS** , the bittorent filesystem, comes in handy. Using BTFS, you can mount the torrent file or magnet link as a directory and then use it as any read-only directory in your file tree. The contents of the files will be downloaded on-demand as they are read by applications. Since BTFS runs on top of FUSE, it does not require intervention into the Linux Kernel.
|
||||
|
||||
## BTFS – A Bittorrent Filesystem Based On FUSE
|
||||
|
||||
### Installing BTFS
|
||||
|
||||
BTFS is available in the default repositories of most Linux distributions.
|
||||
|
||||
On Arch Linux and its variants, run the following command to install BTFS.
|
||||
```
|
||||
$ sudo pacman -S btfs
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint:
|
||||
```
|
||||
$ sudo apt-get install btfs
|
||||
|
||||
```
|
||||
|
||||
On Gentoo:
|
||||
```
|
||||
# emerge -av btfs
|
||||
|
||||
```
|
||||
|
||||
BTFS can also be installed using [**Linuxbrew**][1] package manager.
|
||||
```
|
||||
$ brew install btfs
|
||||
|
||||
```
|
||||
|
||||
### Usage
|
||||
|
||||
BTFS usage is fairly simple. All you have to find the .torrent file or magnet link and mount it in a directory. The contents of the torrent file or magnet link will be mounted inside the directory of your choice. When a program tries to access the file for reading, the actual data will be downloaded on demand. Furthermore, tools like **ls** , **cat** and **cp** works as expected for manipulating the torrents. Applications like **vlc** and **mplayer** can also work without changes. The thing is the players don’t even know that the actual content is not physically present in the local disk and the content is collected in parts from peers on demand.
|
||||
|
||||
Create a directory to mount the torrent/magnet link:
|
||||
```
|
||||
$ mkdir mnt
|
||||
|
||||
```
|
||||
|
||||
Mount the torrent/magnet link:
|
||||
```
|
||||
$ btfs video.torrent mnt
|
||||
|
||||
```
|
||||
|
||||
[![][2]][3]
|
||||
|
||||
Cd to the directory:
|
||||
```
|
||||
$ cd mnt
|
||||
|
||||
```
|
||||
|
||||
And, start watching!
|
||||
```
|
||||
$ vlc <path-to-video.mp4>
|
||||
|
||||
```
|
||||
|
||||
Give BTFS a few moments to find and get the website tracker. Once the real data is loaded, BTFS won’t require the tracker any more.
|
||||
|
||||
![][4]
|
||||
|
||||
To unmount the BTFS filesystem, simply run the following command:
|
||||
```
|
||||
$ fusermount -u mnt
|
||||
|
||||
```
|
||||
|
||||
Now, the contents in the mounted directory will be gone. To access the contents again, you need to mount the torrent as described above.
|
||||
|
||||
The BTFS application will turn your VLC or Mplayer into Popcorn Time. Mount your favorite TV show or movie torrent file or magnet link and start watching without having to download the entire contents of the torrent or wait for your download to complete. The contents of the torrent or magnet link will be downloaded on demand when accessed by the applications.
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/btfs-a-bittorrent-filesystem-based-on-fuse/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/05/btfs.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/05/btfs-1.png
|
||||
@ -1,4 +1,4 @@
|
||||
translating---geekp
|
||||
translating---geekpi
|
||||
|
||||
The Source Code Line Counter And Analyzer
|
||||
======
|
||||
|
||||
@ -0,0 +1,173 @@
|
||||
8 basic Docker container management commands
|
||||
======
|
||||
Learn basic Docker container management with the help of these 8 commands. Useful guide for Docker beginners which includes sample command outputs.
|
||||
|
||||
![Docker container management commands][1]
|
||||
|
||||
In this article we will walk you through 6 basic Docker container commands which are useful in performing basic activities on Docker containers like run, list, stop, view logs, delete etc. If you are new to Docker concept then do check our [introduction guide][2] to know what is Docker & [how-to guide][3] to install Docker in Linux. Without further delay lets directly jump into commands :
|
||||
|
||||
### How to run Docker container?
|
||||
|
||||
As you know, Docker container is just a application process running on host OS. For Docker container, you need a image to run from. Docker image when runs as process called as Docker container. You can have Docker image available locally or you have to download it from Docker hub. Docker hub is a centralized repository which has public and private images stored to pull from. Docker’s official hub is at [hub.docker.com][4]. So whenever you instruct Docker engine to run a container, it looks for image locally and if not found it pulls it from Docker hub.
|
||||
|
||||
Let’s run a Docker container for Apache web-server i.e httpd process. You need to run command `docker container run`. Old command was just `docker run` but lately Docker added sub-command section so new versions supports below command –
|
||||
|
||||
```
|
||||
root@kerneltalks # docker container run -d -p 80:80 httpd
|
||||
Unable to find image 'httpd:latest' locally
|
||||
latest: Pulling from library/httpd
|
||||
3d77ce4481b1: Pull complete
|
||||
73674f4d9403: Pull complete
|
||||
d266646f40bd: Pull complete
|
||||
ce7b0dda0c9f: Pull complete
|
||||
01729050d692: Pull complete
|
||||
014246127c67: Pull complete
|
||||
7cd2e04cf570: Pull complete
|
||||
Digest: sha256:f4610c3a1a7da35072870625733fd0384515f7e912c6223d4a48c6eb749a8617
|
||||
Status: Downloaded newer image for httpd:latest
|
||||
c46f2e9e4690f5c28ee7ad508559ceee0160ac3e2b1688a61561ce9f7d99d682
|
||||
```
|
||||
|
||||
Docker `run` command takes image name as a mandatory argument along with many other optional ones. Commanly used arguments are –
|
||||
|
||||
* `-d` : Detach container from current shell
|
||||
* `-p X:Y` : Bind container port Y with host’s port X
|
||||
* `--name` : Name your container. If not used, it will be assigned randomly generated name
|
||||
* `-e` : Pass environmental variables and their values while starting container
|
||||
|
||||
|
||||
|
||||
In above output you can see, we supply `httpd` as a image name to run container from. Since, image was not locally found, Docker engine pulled it from Docker Hub. Now, observe it downloaded image **httpd:latest **where : is followed by version. That’s the naming convention of Docker container image. If you want specific version container to run from then you can provide version name along with image name. If not supplied, Docker engine will always pull latest one.
|
||||
|
||||
The very last line of output shown unique container ID of your newly running httpd container.
|
||||
|
||||
### How to list all running Docker containers?
|
||||
|
||||
Now, your container is running, you may want to check it or you want to list all running containers on your machine. You can list all running containers using `docker container ls` command. In old Docker version, `docker ps` does this task for you.
|
||||
|
||||
```
|
||||
root@kerneltalks # docker container ls
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
c46f2e9e4690 httpd "httpd-foreground" 11 minutes ago Up 11 minutes 0.0.0.0:80->80/tcp cranky_cori
|
||||
```
|
||||
|
||||
Listing output is presented in column-wise format. Where column-wise values are –
|
||||
|
||||
1. Container ID : First few digits of unique container ID
|
||||
2. Image : Name of image used to run container
|
||||
3. Command : Command ran by container after it ran
|
||||
4. Created : Time created
|
||||
5. Status : Current status of container
|
||||
6. Ports : Port binding details with host’s ports
|
||||
7. Names : Name of container (since we haven’t named our container you can see randomly generated name assigned to our container)
|
||||
|
||||
|
||||
|
||||
### How to view logs of Docker container?
|
||||
|
||||
Since during first step we used -d switch to detach container from current shell once it ran its running in background. In this case, we are clueless whats happening inside container. So to view logs of container, Docker provided `logs` command. It takes container name or ID as an argument.
|
||||
|
||||
```
|
||||
root@kerneltalks # docker container logs cranky_cori
|
||||
AH00558: httpd: Could not reliably determine the server's fully qualified domain name, using 172.17.0.2. Set the 'ServerName' directive globally to suppress this message
|
||||
AH00558: httpd: Could not reliably determine the server's fully qualified domain name, using 172.17.0.2. Set the 'ServerName' directive globally to suppress this message
|
||||
[Thu May 31 18:35:07.301158 2018] [mpm_event:notice] [pid 1:tid 139734285989760] AH00489: Apache/2.4.33 (Unix) configured -- resuming normal operations
|
||||
[Thu May 31 18:35:07.305153 2018] [core:notice] [pid 1:tid 139734285989760] AH00094: Command line: 'httpd -D FOREGROUND'
|
||||
```
|
||||
|
||||
I used container name in my command as argument. You can see Apache related log within our httpd container.
|
||||
|
||||
### How to identify Docker container process?
|
||||
|
||||
Container is a process which uses host resources to run. If its true, then you will be able to locate container process on host’s process table. Lets see how to check container process on host.
|
||||
|
||||
Docker used famous `top` command as its sub-command’s name to view processes spawned by container. It takes container name/ID as an argument. In old Docker version only `docker top` command works. In newer versions, `docker top` and `docker container top` both works.
|
||||
|
||||
```
|
||||
root@kerneltalks # docker container top cranky_cori
|
||||
UID PID PPID C STIME TTY TIME CMD
|
||||
root 15702 15690 0 18:35 ? 00:00:00 httpd -DFOREGROUND
|
||||
bin 15729 15702 0 18:35 ? 00:00:00 httpd -DFOREGROUND
|
||||
bin 15730 15702 0 18:35 ? 00:00:00 httpd -DFOREGROUND
|
||||
bin 15731 15702 0 18:35 ? 00:00:00 httpd -DFOREGROUND
|
||||
|
||||
root@kerneltalks # ps -ef |grep -i 15702
|
||||
root 15702 15690 0 18:35 ? 00:00:00 httpd -DFOREGROUND
|
||||
bin 15729 15702 0 18:35 ? 00:00:00 httpd -DFOREGROUND
|
||||
bin 15730 15702 0 18:35 ? 00:00:00 httpd -DFOREGROUND
|
||||
bin 15731 15702 0 18:35 ? 00:00:00 httpd -DFOREGROUND
|
||||
root 15993 15957 0 18:59 pts/0 00:00:00 grep --color=auto -i 15702
|
||||
```
|
||||
|
||||
In the first output, list of processes spawned by that container. It has all details like use, pid, ppid, start time, command etc. All those PID you can search in your host’s process table and you can find them there. That’s what we did in second command. So, this proves containers are indeed just processes on Host’s OS.
|
||||
|
||||
### How to stop Docker container?
|
||||
|
||||
Its simple `stop` command! Again it takes container name /ID as an argument.
|
||||
|
||||
```
|
||||
root@kerneltalks # docker container stop cranky_cori
|
||||
cranky_cori
|
||||
```
|
||||
|
||||
### How to list stopped or not running Docker containers?
|
||||
|
||||
Now we stopped our container if we try to list container using `ls` command, we wont be able to see it.
|
||||
|
||||
```
|
||||
root@kerneltalks # docker container ls
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
```
|
||||
|
||||
So in this case to view stopped or non running container you need to use `-a` switch along with `ls` command.
|
||||
|
||||
```
|
||||
root@kerneltalks # docker container ls -a
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
c46f2e9e4690 httpd "httpd-foreground" 33 minutes ago Exited (0) 2 minutes ago cranky_cori
|
||||
```
|
||||
|
||||
With `-a` switch we can see stopped container now. Notice status of this container is mentioned ‘Exited’. Since container is just a process its termed as ‘exited’ rather than stopped!
|
||||
|
||||
### How to start Docker container?
|
||||
|
||||
Now, we will start this stopped container. There is difference with running and starting a container. When you run a container, you are starting a command in fresh container. When you start a container, you are starting old stopped container which has old state saved in it. It will start it from that state forward.
|
||||
|
||||
```
|
||||
root@kerneltalks # docker container start c46f2e9e4690
|
||||
c46f2e9e4690
|
||||
|
||||
root@kerneltalks # docker container ls -a
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
c46f2e9e4690 httpd "httpd-foreground" 35 minutes ago Up 8 seconds 0.0.0.0:80->80/tcp cranky_cori
|
||||
```
|
||||
|
||||
### How to remove Docker container?
|
||||
|
||||
To remove container from your Docker engine use `rm` command. You can not remove running container. You have to first stop the container and then remove it. You can remove it forcefully using `-f` switch with `rm` command but that’s not recommended.
|
||||
|
||||
```
|
||||
root@kerneltalks # docker container rm cranky_cori
|
||||
cranky_cori
|
||||
root@kerneltalks # docker container ls -a
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
```
|
||||
|
||||
You can see once we remove container, its not visible in `ls -a` listing too.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/virtualization/8-basic-docker-container-management-commands/
|
||||
|
||||
作者:[Shrikant Lavhate][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kerneltalks.com
|
||||
[1]:https://a4.kerneltalks.com/wp-content/uploads/2018/06/basic-Docker-container-management-commands.png
|
||||
[2]:https://kerneltalks.com/virtualization/what-is-docker-introduction-guide-to-docker/
|
||||
[3]:https://kerneltalks.com/virtualization/how-to-install-docker-in-linux/
|
||||
[4]:https://hub.docker.com/
|
||||
@ -0,0 +1,120 @@
|
||||
Vim-plug : A Minimalist Vim Plugin Manager
|
||||
======
|
||||
|
||||

|
||||
|
||||
When there were no plugin managers, the Vim users had to manually download the Plugins distributed as tarballs and extract them in a directory called **~/.vim**. It was OK for few plugins. When they installed more plugins, it became a mess. All plugin files scattered in a single directory and the users couldn’t find which file belongs to which plugin. Further more, they could not find which file they should remove to uninstall a plugin. There is where Vim plugin managers comes in handy. The plugin managers saves the files of installed plugins in separate directory, so it is became very easy to manage all plugins. We already wrote about [**Vundle**][1] few months ago. Today, we will see yet another Vim plugin manager named **“Vim-plug”**.
|
||||
|
||||
Vim-plug is a free, open source, very fast, minimalist vim plugin manager. It can install or update plugins in parallel. You can also rollback the updates. It creates shallow clones to minimize disk space usage and download time. It supports on-demand plugin loading for faster startup time. Other notable features are branch/tag/commit support, post-update hooks, support for externally managed plugins etc.
|
||||
|
||||
### Vim-plug : A Minimalist Vim Plugin Manager
|
||||
|
||||
#### **Installation**
|
||||
|
||||
It is very easier to setup and use. All you have to do is to open your Terminal and run the following command:
|
||||
```
|
||||
$ curl -fLo ~/.vim/autoload/plug.vim --create-dirs https://raw.githubusercontent.com/junegunn/vim-plug/master/plug.vim
|
||||
|
||||
```
|
||||
|
||||
The Neovim users can install Vim-plug using the following command:
|
||||
```
|
||||
$ curl -fLo ~/.config/nvim/autoload/plug.vim --create-dirs https://raw.githubusercontent.com/junegunn/vim-plug/master/plug.vim
|
||||
|
||||
```
|
||||
|
||||
#### Usage
|
||||
|
||||
**Installing Plugins**
|
||||
|
||||
To install plugins, you must first declare them in Vim configuration file as shown below. The configuration file for ordinary Vim is **~/.vimrc** and the config file for Neovim is **~/.config/nvim/init.vim**. Please remember that when you declare the plugins in configuration file, the list should start with **call plug#begin(PLUGIN_DIRECTORY)** and end with call **plug#end()**.
|
||||
|
||||
For example, let us install “lightline.vim” plugin. To do so, add the following lines on top of your **~/.vimrc** file.
|
||||
```
|
||||
call plug#begin('~/.vim/plugged')
|
||||
Plug 'itchyny/lightline.vim'
|
||||
call plug#end()
|
||||
|
||||
```
|
||||
|
||||
After adding the above lines in vim configuration file, reload by entering the following:
|
||||
```
|
||||
:source ~/.vimrc
|
||||
|
||||
```
|
||||
|
||||
Or, simply reload the Vim editor.
|
||||
|
||||
Now, open vim editor:
|
||||
```
|
||||
$ vim
|
||||
|
||||
```
|
||||
|
||||
Check the status using command:
|
||||
```
|
||||
:PlugStatus
|
||||
|
||||
```
|
||||
|
||||
And type following command and hit ENTER to install the plugins that you have declared in the config file earlier.
|
||||
```
|
||||
:PlugInstall
|
||||
|
||||
```
|
||||
|
||||
**Update Plugins**
|
||||
|
||||
To update plugins, run:
|
||||
```
|
||||
:PlugUpdate
|
||||
|
||||
```
|
||||
|
||||
After updating the plugins, press **d** to review the changes. Or, you can do it later by typing **:PlugDiff**.
|
||||
|
||||
**Review Plugins**
|
||||
|
||||
Some times, the updated plugins may have new bugs or no longer work correctly. To fix this, you can simply rollback the problematic plugins. Type **:PlugDiff** command and hit ENTER to review the changes from the last **:PlugUpdate** and roll each plugin back to the previous state before the update by pressing **X** on each paragraph.
|
||||
|
||||
**Removing Plugins**
|
||||
|
||||
To remove a plugin delete or comment out the **plug** commands that you have added earlier in your vim configuration file. Then, run **:source ~/.vimrc** or restart Vim editor. Finally, run the following command to uninstall the plugins:
|
||||
```
|
||||
:PlugClean
|
||||
|
||||
```
|
||||
|
||||
This command will delete all undeclared plugins in your vim config file.
|
||||
|
||||
**Upgrade Vim-plug**
|
||||
|
||||
To upgrade vim-plug itself, type:
|
||||
```
|
||||
:PlugUpgrade
|
||||
|
||||
```
|
||||
|
||||
As you can see, managing plugins using Vim-plug is not a big deal. It simplifies the plugin management a lot easier. Now go and find out your favorite plugins and install them using Vim-plug.
|
||||
|
||||
**Suggested read:**
|
||||
|
||||
And, that’s all for now. I will be soon here with another interesting topic. Until then, stay tuned with OSTechNix.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/vim-plug-a-minimalist-vim-plugin-manager/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/manage-vim-plugins-using-vundle-linux/
|
||||
109
sources/tech/20180604 4 Firefox extensions worth checking out.md
Normal file
109
sources/tech/20180604 4 Firefox extensions worth checking out.md
Normal file
@ -0,0 +1,109 @@
|
||||
4 Firefox extensions worth checking out
|
||||
======
|
||||
|
||||

|
||||
|
||||
I've been a Firefox user since v2.0 came out about 12 years ago. There were times when it wasn't the best web browser out there, but still, I kept going back to it for one reason: My favorite extensions wouldn't work with anything else.
|
||||
|
||||
Today, I like the current state of Firefox itself for being fast, customizable, and open source, but I also appreciate extensions for manifesting ideas the original developers never thought of: What if you want to browse without a mouse? What if you don't like staring at bright light coming out of the monitor at night? What about using a dedicated media player for YouTube and other video hosting websites for better performance and extended playback controls? And what if you need a more sophisticated way to disable trackers and speed up loading pages?
|
||||
|
||||
Fortunately, there's an answer for each of these questions, and I'm going to give them to you in the form of my favorite extensions—all of which are free software or open source (i.e., distributed under the [GNU GPL][1], [MPL][2], or [Apache][3] license) and make an excellent browser even better.
|
||||
|
||||
Although the terms add-on and extension have slightly different meanings, I'll use them interchangeably in this article.
|
||||
|
||||
### Tridactyl
|
||||
|
||||
![Tridactyl screenshot][5]
|
||||
|
||||
Tridactyl's new tab page, showcasing link hinting.
|
||||
|
||||
[Tridactyl][6] enables you to use your keyboard for most of your browsing activities. It's inspired by the now-defunct [Vimperator][7] and [Pentadactyl][8], which were inspired by the default keybindings of [Vim][9]. Since I'm already used to Vim and other command-line applications, I find features like being able to navigate with the keys `h/j/k/l`, interact with hyperlinks with `f/F`, and create custom keybindings and commands very convenient.
|
||||
|
||||
Tridactyl's optional native messenger (for now, available only for GNU/Linux and Mac OSX), which was implemented recently, offers even more cool features to boot. With it, for example, you can hide some elements of the GUI of Firefox (à la Vimperator and Pentadactyl), open a link or the current page in an external program (I often use [mpv][10] and [youtube-dl][11] for videos) and edit the content of text areas with your favorite text editor by pressing `Ctrl-I` (or any key combination of your choice).
|
||||
|
||||
Having said that, keep in mind that it's a relatively young project and may still be rough around the edges. On the other hand, its development is very active, and when you look past its childhood illnesses, it can be a pleasure to use.
|
||||
|
||||
### Open With
|
||||
|
||||
![Open With Screenshot][13]
|
||||
|
||||
A context menu provided by Open With. I can open the current page with one of the external programs listed here.
|
||||
|
||||
Speaking of interaction with external programs, sometimes it's nice to have the ability to do that with the mouse. That's where [Open With][14] comes in.
|
||||
|
||||
Apart from the added context menu (shown in the screenshot), you can find your own defined commands by clicking on the extension's icon on the add-on bar. As its icon and the description on [its page on Mozilla Add-ons][14] suggest, it was primarily intended to work with other web browsers, but I can use it with mpv and youtube-dl with ease as well.
|
||||
|
||||
Keyboard shortcuts are available here, too, but they're severely limited. There are no more than three different combinations that can be selected in a drop-down list in the extension's settings. In contrast, Tridactyl lets me assign commands to virtually anything that isn't blocked by Firefox. Open With is currently for the mouse, really.
|
||||
|
||||
### Stylus
|
||||
|
||||
![Stylus Screenshot][16]
|
||||
|
||||
In this screenshot, I've just searched for and installed a dark theme for the site I'm currently on with Stylus. Even the popup has custom style (called Deepdark Stylus)!
|
||||
|
||||
[Stylus][17] is a userstyle manager, which means that by writing custom CSS rules and loading them with Stylus, you can change the appearance of any webpage. If you don't know CSS, there are a plethora of userstyles made by others on websites such as [userstyles.org][18].
|
||||
|
||||
Now, you may be asking, "Isn't that exactly what [Stylish][19] does?" You would be correct! You see, Stylus is based on Stylish and provides additional improvements: It respects your privacy by not containing any telemetry, all development is done in the open (although Stylish is still actively developed, I haven't been able to find the source code for recent versions), and it supports [UserCSS][20], among other things.
|
||||
|
||||
UserCSS is an interesting format, especially for developers. I've written several userstyles for various websites (mainly dark themes and tweaks for better readability), and while the internal editor of Stylus is excellent, I still prefer editing code with Neovim. For that, all I need to do is load a local file with its name ending with ".user.css" in Stylus, enable the option "Live Reload", and any changes will be applied as soon as I modify and save that file in Neovim. Remote UserCSS files are also supported, so whenever I push changes to GitHub or any git-based development platforms, they'll automatically become available for users. (I provide a link to the raw version of the file so that they can access it easily.)
|
||||
|
||||
### uMatrix
|
||||
|
||||
![uMatrix Screenshot][22]
|
||||
|
||||
The user interface of uMatrix, showing the current rules for the currently visited webpage.
|
||||
|
||||
Jeremy Garcia mentioned uBlock Origin in [his article][23] here on Opensource.com as an excellent blocker. I'd like to draw attention to another extension made by [gorhill][24]: uMatrix.
|
||||
|
||||
[uMatrix][25] allows you to set blocking rules for certain requests on a webpage, which can be toggled by clicking on the add-on's popup (seen in the screenshot above). These requests are distinguished by the categories of scripts, requests made by scripts, cookies, CSS rules, images, media content, frames, and anything else labeled as "other" by uMatrix. You can set up global rules to, for instance, allow all requests by default and add only particular ones to the blacklist (the more convenient approach), or block everything by default and whitelist certain requests manually (the safer approach). If you've been using NoScript or RequestPolicy, you can [import][26] your whitelist rules from them, too.
|
||||
|
||||
In addition, uMatrix supports [hosts files][27], which can be used to block requests from certain domains. These are not to be confused with the filter lists used by uBlock Origin, which use the same syntax as the filters set by Adblock Plus. By default, uMatrix blocks domains of servers known to distribute ads, trackers, and malware with the help of a few hosts files, and you can add more external sources if you want to.
|
||||
|
||||
So which one shall you choose—uBlock Origin or uMatrix? Personally, I use both on my desktop PC and only uMatrix on my Android phone. There's some overlap between the two, [according to gorhill][28], but they have a different target userbase and goals. If all you want is an easy way to block trackers and ads, uBlock Origin is a better choice. On the other hand, if you want granular control over what a webpage can or can't do inside your browser, even if it takes some time to configure and it can prevent sites from functioning as intended, uMatrix is the way to go.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Currently, these are my favorite extensions for Firefox. Tridactyl is for speeding up browsing navigation by relying on the keyboard and interacting with external programs; Open With is there if I need to open something in another program with the mouse; Stylus is the definitive userstyle manager, appealing to both users and developers alike; and uMatrix is essentially a firewall within Firefox for filtering out requests on unknown territories.
|
||||
|
||||
Even though I almost exclusively discussed the benefits of these add-ons, no software is ever perfect. If you like any of them and think they can be improved in any way, I recommend that you go to their GitHub page and look for their contribution guides. Usually, developers of free and open source software welcome bug reports and pull requests. Telling your friends about them or saying thanks are also excellent ways to help the developers, especially if they work on their projects in their spare time.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/firefox-open-source-extensions
|
||||
|
||||
作者:[Zsolt Szakács][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/zsolt
|
||||
[1]:https://www.gnu.org/licenses/gpl-3.0.en.html
|
||||
[2]:https://www.mozilla.org/en-US/MPL/
|
||||
[3]:https://www.apache.org/licenses/LICENSE-2.0
|
||||
[4]:/file/398411
|
||||
[5]:https://opensource.com/sites/default/files/uploads/tridactyl.png (Tridactyl's new tab page, showcasing link hinting)
|
||||
[6]:https://addons.mozilla.org/en-US/firefox/addon/tridactyl-vim/
|
||||
[7]:https://github.com/vimperator/vimperator-labs
|
||||
[8]:https://addons.mozilla.org/en-US/firefox/addon/pentadactyl/
|
||||
[9]:https://www.vim.org/
|
||||
[10]:https://mpv.io/
|
||||
[11]:https://rg3.github.io/youtube-dl/index.html
|
||||
[12]:/file/398416
|
||||
[13]:https://opensource.com/sites/default/files/uploads/openwith.png (A context menu provided by Open With. I can open the current page with one of the external programs listed here.)
|
||||
[14]:https://addons.mozilla.org/en-US/firefox/addon/open-with/
|
||||
[15]:/file/398421
|
||||
[16]:https://opensource.com/sites/default/files/uploads/stylus.png (In this screenshot, I've just searched for and installed a dark theme for the site I'm currently on with Stylus. Even the popup has custom style (called Deepdark Stylus)!)
|
||||
[17]:https://addons.mozilla.org/en-US/firefox/addon/styl-us/
|
||||
[18]:https://userstyles.org/
|
||||
[19]:https://addons.mozilla.org/en-US/firefox/addon/stylish/
|
||||
[20]:https://github.com/openstyles/stylus/wiki/Usercss
|
||||
[21]:/file/398426
|
||||
[22]:https://opensource.com/sites/default/files/uploads/umatrix.png (The user interface of uMatrix, showing the current rules for the currently visited webpage.)
|
||||
[23]:https://opensource.com/article/18/5/firefox-extensions
|
||||
[24]:https://addons.mozilla.org/en-US/firefox/user/gorhill/
|
||||
[25]:https://addons.mozilla.org/en-US/firefox/addon/umatrix
|
||||
[26]:https://github.com/gorhill/uMatrix/wiki/FAQ
|
||||
[27]:https://en.wikipedia.org/wiki/Hosts_(file)
|
||||
[28]:https://github.com/gorhill/uMatrix/issues/32#issuecomment-61372436
|
||||
@ -0,0 +1,80 @@
|
||||
4 cool new projects to try in COPR for June 2018
|
||||
======
|
||||
COPR is a [collection][1] of personal repositories for software that isn’t carried in Fedora. Some software doesn’t conform to standards that allow easy packaging. Or it may not meet other Fedora standards, despite being free and open source. COPR can offer these projects outside the Fedora set of packages. Software in COPR isn’t supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
|
||||
|
||||
Here’s a set of new and interesting projects in COPR.
|
||||
|
||||
### Ghostwriter
|
||||
|
||||
[Ghostwriter][2] is a text editor for [Markdown][3] format with a minimal interface. It provides a preview of the document in HTML and syntax highlighting for Markdown. It offers the option to highlight only the paragraph or sentence currently being written. In addition, Ghostwriter can export documents to several formats, including PDF and HTML. Finally, it has the so-called “Hemingway” mode, in which erasing is disabled, forcing the user to write now and edit later.![][4]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides Ghostwriter for Fedora 26, 27, 28, and Rawhide, and EPEL 7. To install Ghostwriter, use these commands:
|
||||
```
|
||||
sudo dnf copr enable scx/ghostwriter
|
||||
sudo dnf install ghostwriter
|
||||
|
||||
```
|
||||
|
||||
### Lector
|
||||
|
||||
[Lector][5] is a simple ebook reader application. Lector supports most common ebook formats, such as EPUB, MOBI, and AZW, as well as comic book archives CBZ and CBR. It’s easy to setup — just specify the directory containing your ebooks. You can browse books in Lector’s library using either a table or book covers. Among Lector’s features are bookmarks, user-defined tags, and a built-in dictionary.![][6]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides Lector for Fedora 26, 27, 28, and Rawhide. To install Lector, use these commands:
|
||||
```
|
||||
sudo dnf copr enable bugzy/lector
|
||||
sudo dnf install lector
|
||||
|
||||
```
|
||||
|
||||
### Ranger
|
||||
|
||||
Ranerger is a text-based file manager with Vim key bindings. It displays the directory structure in three columns. The left one shows the parent directory, the middle the contents of the current directory, and the right a preview of the selected file or directory. In the case of text files, Ranger shows actual contents of the file as a preview.![][7]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides Ranger for Fedora 27, 28, and Rawhide. To install Ranger, use these commands:
|
||||
```
|
||||
sudo dnf copr enable fszymanski/ranger
|
||||
sudo dnf install ranger
|
||||
|
||||
```
|
||||
|
||||
### PrestoPalette
|
||||
|
||||
PrestoPeralette is a tool that helps create balanced color palettes. A nice feature of PrestoPalette is the ability to use lighting to affect both lightness and saturation of the palette. You can export created palettes either as PNG or JSON.
|
||||
![][8]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides PrestoPalette for Fedora 26, 27, 28, and Rawhide, and EPEL 7. To install PrestoPalette, use these commands:
|
||||
```
|
||||
sudo dnf copr enable dagostinelli/prestopalette
|
||||
sudo dnf install prestopalette
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-try-copr-june-2018/
|
||||
|
||||
作者:[Dominik Turecek][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://copr.fedorainfracloud.org/
|
||||
[2]:http://wereturtle.github.io/ghostwriter/
|
||||
[3]:https://daringfireball.net/
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/05/ghostwriter.png
|
||||
[5]:https://github.com/BasioMeusPuga/Lector
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/05/lector.png
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2018/05/ranger.png
|
||||
[8]:https://fedoramagazine.org/wp-content/uploads/2018/05/prestopalette.png
|
||||
130
sources/tech/20180604 How to use the history command in Linux.md
Normal file
130
sources/tech/20180604 How to use the history command in Linux.md
Normal file
@ -0,0 +1,130 @@
|
||||
How to use the history command in Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
As I spend more and more time in terminal sessions, it feels like I'm continually finding new commands that make my daily tasks more efficient. The GNU `history` command is one that really changed my work day.
|
||||
|
||||
The GNU `history` command keeps a list of all the other commands that have been run from that terminal session, then allows you to replay or reuse those commands instead of retyping them. If you are an old greybeard, you know about the power of `history`, but for us dabblers or new sysadmin folks, `history` is an immediate productivity gain.
|
||||
|
||||
### History 101
|
||||
|
||||
To see `history` in action, open a terminal program on your Linux installation and type:
|
||||
```
|
||||
$ history
|
||||
|
||||
```
|
||||
|
||||
Here's the response I got:
|
||||
```
|
||||
1 clear
|
||||
|
||||
|
||||
|
||||
2 ls -al
|
||||
|
||||
|
||||
|
||||
3 sudo dnf update -y
|
||||
|
||||
|
||||
|
||||
4 history
|
||||
|
||||
```
|
||||
|
||||
The `history` command shows a list of the commands entered since you started the session. The joy of `history` is that now you can replay any of them by using a command such as:
|
||||
```
|
||||
$ !3
|
||||
|
||||
```
|
||||
|
||||
The `!3` command at the prompt tells the shell to rerun the command on line 3 of the history list. I could also access that command by entering:
|
||||
```
|
||||
linuser@my_linux_box: !sudo dnf
|
||||
|
||||
```
|
||||
|
||||
`history` will search for the last command that matches the pattern you provided and run it.
|
||||
|
||||
### Searching history
|
||||
|
||||
You can also use `history` to rerun the last command you entered by typing `!!`. And, by pairing it with `grep`, you can search for commands that match a text pattern or, by using it with `tail`, you can find the last few commands you executed. For example:
|
||||
```
|
||||
$ history | grep dnf
|
||||
|
||||
|
||||
|
||||
3 sudo dnf update -y
|
||||
|
||||
|
||||
|
||||
5 history | grep dnf
|
||||
|
||||
|
||||
|
||||
$ history | tail -n 3
|
||||
|
||||
|
||||
|
||||
4 history
|
||||
|
||||
|
||||
|
||||
5 history | grep dnf
|
||||
|
||||
|
||||
|
||||
6 history | tail -n 3
|
||||
|
||||
```
|
||||
|
||||
Another way to get to this search functionality is by typing `Ctrl-R` to invoke a recursive search of your command history. After typing this, the prompt changes to:
|
||||
```
|
||||
(reverse-i-search)`':
|
||||
|
||||
```
|
||||
|
||||
Now you can start typing a command, and matching commands will be displayed for you to execute by pressing Return or Enter.
|
||||
|
||||
### Changing an executed command
|
||||
|
||||
`history` also allows you to rerun a command with different syntax. For example, if I wanted to change my previous command `history | grep dnf` to `history | grep ssh`, I can execute the following at the prompt:
|
||||
```
|
||||
$ ^dnf^ssh^
|
||||
|
||||
```
|
||||
|
||||
`history` will rerun the command, but replace `dnf` with `ssh`, and execute it.
|
||||
|
||||
### Removing history
|
||||
|
||||
There may come a time that you want to remove some or all the commands in your history file. If you want to delete a particular command, enter `history -d <line number>`. To clear the entire contents of the history file, execute `history -c`.
|
||||
|
||||
The history file is stored in a file that you can modify, as well. Bash shell users will find it in their Home directory as `.bash_history`.
|
||||
|
||||
### Next steps
|
||||
|
||||
There are a number of other things that you can do with `history`:
|
||||
|
||||
* Set the size of your history buffer to a certain number of commands
|
||||
* Record the date and time for each line in history
|
||||
* Prevent certain commands from being recorded in history
|
||||
|
||||
|
||||
|
||||
For more information about the `history` command and other interesting things you can do with it, take a look at the [GNU Bash Manual][1].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/history-command
|
||||
|
||||
作者:[Steve Morris][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/smorris12
|
||||
[1]:https://www.gnu.org/software/bash/manual/
|
||||
138
sources/tech/20180605 How to use autofs to mount NFS shares.md
Normal file
138
sources/tech/20180605 How to use autofs to mount NFS shares.md
Normal file
@ -0,0 +1,138 @@
|
||||
How to use autofs to mount NFS shares
|
||||
======
|
||||
|
||||

|
||||
|
||||
Most Linux file systems are mounted at boot and remain mounted while the system is running. This is also true of any remote file systems that have been configured in the `fstab` file. However, there may be times when you prefer to have a remote file system mount only on demand—for example, to boost performance by reducing network bandwidth usage, or to hide or obfuscate certain directories for security reasons. The package [autofs][1] provides this feature. In this article, I'll describe how to get a basic automount configuration up and running.
|
||||
|
||||
`tree.mydatacenter.net` is up and running. Also assume a data directory named `ourfiles` and two user directories, for Carl and Sarah, are being shared by this server.
|
||||
|
||||
First, a few assumptions: Assume the NFS server namedis up and running. Also assume a data directory namedand two user directories, for Carl and Sarah, are being shared by this server.
|
||||
|
||||
A few best practices will make things work a bit better: It is a good idea to use the same user ID for your users on the server and any client workstations where they have an account. Also, your workstations and server should have the same domain name. Checking the relevant configuration files should confirm.
|
||||
```
|
||||
alan@workstation1:~$ sudo getent passwd carl sarah
|
||||
|
||||
[sudo] password for alan:
|
||||
|
||||
carl:x:1020:1020:Carl,,,:/home/carl:/bin/bash
|
||||
|
||||
sarah:x:1021:1021:Sarah,,,:/home/sarah:/bin/bash
|
||||
|
||||
|
||||
|
||||
alan@workstation1:~$ sudo getent hosts
|
||||
|
||||
127.0.0.1 localhost
|
||||
|
||||
127.0.1.1 workstation1.mydatacenter.net workstation1
|
||||
|
||||
10.10.1.5 tree.mydatacenter.net tree
|
||||
|
||||
```
|
||||
|
||||
As you can see, both the client workstation and the NFS server are configured in the `hosts` file. I’m assuming a basic home or even small office network that might lack proper internal domain name service (i.e., DNS).
|
||||
|
||||
### Install the packages
|
||||
|
||||
You need to install only two packages: `nfs-common` for NFS client functions, and `autofs` to provide the automount function.
|
||||
```
|
||||
alan@workstation1:~$ sudo apt-get install nfs-common autofs
|
||||
|
||||
```
|
||||
|
||||
You can verify that the autofs files have been placed in the `etc` directory:
|
||||
```
|
||||
alan@workstation1:~$ cd /etc; ll auto*
|
||||
|
||||
-rw-r--r-- 1 root root 12596 Nov 19 2015 autofs.conf
|
||||
|
||||
-rw-r--r-- 1 root root 857 Mar 10 2017 auto.master
|
||||
|
||||
-rw-r--r-- 1 root root 708 Jul 6 2017 auto.misc
|
||||
|
||||
-rwxr-xr-x 1 root root 1039 Nov 19 2015 auto.net*
|
||||
|
||||
-rwxr-xr-x 1 root root 2191 Nov 19 2015 auto.smb*
|
||||
|
||||
alan@workstation1:/etc$
|
||||
|
||||
```
|
||||
|
||||
### Configure autofs
|
||||
|
||||
Now you need to edit several of these files and add the file `auto.home`. First, add the following two lines to the file `auto.master`:
|
||||
```
|
||||
/mnt/tree /etc/auto.misc
|
||||
|
||||
/home/tree /etc/auto.home
|
||||
|
||||
```
|
||||
|
||||
Each line begins with the directory where the NFS shares will be mounted. Go ahead and create those directories:
|
||||
```
|
||||
alan@workstation1:/etc$ sudo mkdir /mnt/tree /home/tree
|
||||
|
||||
```
|
||||
|
||||
Second, add the following line to the file `auto.misc`:
|
||||
```
|
||||
ourfiles -fstype=nfs tree:/share/ourfiles
|
||||
|
||||
```
|
||||
|
||||
This line instructs autofs to mount the `ourfiles` share at the location matched in the `auto.master` file for `auto.misc`. As shown above, these files will be available in the directory `/mnt/tree/ourfiles`.
|
||||
|
||||
Third, create the file `auto.home` with the following line:
|
||||
```
|
||||
* -fstype=nfs tree:/home/&
|
||||
|
||||
```
|
||||
|
||||
This line instructs autofs to mount the users share at the location matched in the `auto.master` file for `auto.home`. In this case, Carl and Sarah's files will be available in the directories `/home/tree/carl` or `/home/tree/sarah`, respectively. The asterisk (referred to as a wildcard) makes it possible for each user's share to be automatically mounted when they log in. The ampersand also works as a wildcard representing the user's directory on the server side. Their home directory should be mapped accordingly in the `passwd` file. This doesn’t have to be done if you prefer a local home directory; instead, the user could use this as simple remote storage for specific files.
|
||||
|
||||
Finally, restart the `autofs` daemon so it will recognize and load these configuration file changes.
|
||||
```
|
||||
alan@workstation1:/etc$ sudo service autofs restart
|
||||
|
||||
```
|
||||
|
||||
### Testing autofs
|
||||
|
||||
If you change to one of the directories listed in the file `auto.master` and run the `ls` command, you won’t see anything immediately. For example, change directory `(cd)` to `/mnt/tree`. At first, the output of `ls` won’t show anything, but after running `cd ourfiles`, the `ourfiles` share directory will be automatically mounted. The `cd` command will also be executed and you will be placed into the newly mounted directory.
|
||||
```
|
||||
carl@workstation1:~$ cd /mnt/tree
|
||||
|
||||
carl@workstation1:/mnt/tree$ ls
|
||||
|
||||
carl@workstation1:/mnt/tree$ cd ourfiles
|
||||
|
||||
carl@workstation1:/mnt/tree/ourfiles$
|
||||
|
||||
```
|
||||
|
||||
To further confirm that things are working, the `mount` command will display the details of the mounted share.
|
||||
```
|
||||
carl@workstation1:~$ mount
|
||||
|
||||
tree:/mnt/share/ourfiles on /mnt/tree/ourfiles type nfs4 (rw,relatime,vers=4.0,rsize=131072,wsize=131072,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.10.1.22,local_lock=none,addr=10.10.1.5)
|
||||
|
||||
```
|
||||
|
||||
The `/home/tree` directory will work the same way for Carl and Sarah.
|
||||
|
||||
I find it useful to bookmark these directories in my file manager for quicker access.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/using-autofs-mount-nfs-shares
|
||||
|
||||
作者:[Alan Formy-Duval][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/alanfdoss
|
||||
[1]:https://wiki.archlinux.org/index.php/autofs
|
||||
@ -0,0 +1,165 @@
|
||||
MySQL without the MySQL: An introduction to the MySQL Document Store
|
||||
======
|
||||
|
||||

|
||||
|
||||
MySQL can act as a NoSQL JSON Document Store so programmers can save data without having to normalize data, set up schemas, or even have a clue what their data looks like before starting to code. Since MySQL version 5.7 and in MySQL 8.0, developers can store JSON documents in a column of a table. By adding the new X DevAPI, you can stop embedding nasty strings of structured query language in your code and replace them with API calls that support modern programming design.
|
||||
|
||||
Very few developers have any formal training in structured query language (SQL), relational theory, sets, or other foundations of relational databases. But they need a secure, reliable data store. Add in a dearth of available database administrators, and things can get very messy quickly.
|
||||
|
||||
The [MySQL Document Store][1] allows programmers to store data without having to create an underlying schema, normalize data, or any of the other tasks normally required to use a database. A JSON document collection is created and can then be used.
|
||||
|
||||
### JSON data type
|
||||
|
||||
This is all based on the JSON data type introduced a few years ago in MySQL 5.7. This provides a roughly 1GB column in a row of a table. The data has to be valid JSON or the server will return an error, but developers are free to use that space as they want.
|
||||
|
||||
### X DevAPI
|
||||
|
||||
The old MySQL protocol is showing its age after almost a quarter-century, so a new protocol was developed called [X DevAPI][2]. It includes a new high-level session concept that allows code to scale from one server to many with non-blocking, asynchronous I/O that follows common host-language programming patterns. The focus is put on using CRUD (create, replace, update, delete) patterns while following modern practices and coding styles. Or, to put it another way, you no longer have to embed ugly strings of SQL statements in your beautiful, pristine code.
|
||||
|
||||
### Coding examples
|
||||
|
||||
A new shell, creatively called the [MySQL Shell][3] , supports this new protocol. It can be used to set up high-availability clusters, check servers for upgrade readiness, and interact with MySQL servers. This interaction can be done in three modes: JavaScript, Python, and SQL.
|
||||
|
||||
The coding examples that follow are in the JavaScript mode of the MySQL Shell; it has a `JS>` prompt.
|
||||
|
||||
Here, we will log in as `dstokes` with the password `password` to the local system and a schema named `demo`. There is a pointer to the schema demo that is named `db`.
|
||||
```
|
||||
$ mysqlsh dstokes:password@localhost/demo
|
||||
|
||||
JS> db.createCollection("example")
|
||||
|
||||
JS> db.example.add(
|
||||
|
||||
{
|
||||
|
||||
Name: "Dave",
|
||||
|
||||
State: "Texas",
|
||||
|
||||
foo : "bar"
|
||||
|
||||
}
|
||||
|
||||
)
|
||||
|
||||
JS>
|
||||
|
||||
```
|
||||
|
||||
Above we logged into the server, connected to the `demo` schema, created a collection named `example`, and added a record, all without creating a table definition or using SQL. We can use or abuse this data as our whims desire. This is not an object-relational mapper, as there is no mapping the code to the SQL because the new protocol “speaks” at the server layer.
|
||||
|
||||
### Node.js supported
|
||||
|
||||
The new shell is pretty sweet; you can do a lot with it, but you will probably want to use your programming language of choice. The following example uses the `world_x` demo database to search for a record with the `_id` field matching "CAN." We point to the desired collection in the schema and issue a `find` command with the desired parameters. Again, there’s no SQL involved.
|
||||
```
|
||||
var mysqlx = require('@mysql/xdevapi');
|
||||
|
||||
mysqlx.getSession({ //Auth to server
|
||||
|
||||
host: 'localhost',
|
||||
|
||||
port: '33060',
|
||||
|
||||
dbUser: 'root',
|
||||
|
||||
dbPassword: 'password'
|
||||
|
||||
}).then(function (session) { // use world_x.country.info
|
||||
|
||||
var schema = session.getSchema('world_x');
|
||||
|
||||
var collection = schema.getCollection('countryinfo');
|
||||
|
||||
|
||||
|
||||
collection // Get row for 'CAN'
|
||||
|
||||
.find("$._id == 'CAN'")
|
||||
|
||||
.limit(1)
|
||||
|
||||
.execute(doc => console.log(doc))
|
||||
|
||||
.then(() => console.log("\n\nAll done"));
|
||||
|
||||
|
||||
|
||||
session.close();
|
||||
|
||||
})
|
||||
|
||||
```
|
||||
|
||||
Here is another example in PHP that looks for "USA":
|
||||
```
|
||||
<?PHP
|
||||
|
||||
// Connection parameters
|
||||
|
||||
$user = 'root';
|
||||
|
||||
$passwd = 'S3cret#';
|
||||
|
||||
$host = 'localhost';
|
||||
|
||||
$port = '33060';
|
||||
|
||||
$connection_uri = 'mysqlx://'.$user.':'.$passwd.'@'.$host.':'.$port;
|
||||
|
||||
echo $connection_uri . "\n";
|
||||
|
||||
|
||||
|
||||
// Connect as a Node Session
|
||||
|
||||
$nodeSession = mysql_xdevapi\getNodeSession($connection_uri);
|
||||
|
||||
// "USE world_x" schema
|
||||
|
||||
$schema = $nodeSession->getSchema("world_x");
|
||||
|
||||
// Specify collection to use
|
||||
|
||||
$collection = $schema->getCollection("countryinfo");
|
||||
|
||||
// SELECT * FROM world_x WHERE _id = "USA"
|
||||
|
||||
$result = $collection->find('_id = "USA"')->execute();
|
||||
|
||||
// Fetch/Display data
|
||||
|
||||
$data = $result->fetchAll();
|
||||
|
||||
var_dump($data);
|
||||
|
||||
?>#!/usr/bin/phpmysql_xdevapi\getNodeSession
|
||||
|
||||
```
|
||||
|
||||
Note that the `find` operator used in both examples looks pretty much the same between the two different languages. This consistency should help developers who hop between programming languages or those looking to reduce the learning curve with a new language.
|
||||
|
||||
Other supported languages include C, Java, Python, and JavaScript, and more are planned.
|
||||
|
||||
### Best of both worlds
|
||||
|
||||
Did I mention that the data entered in this NoSQL fashion is also available from the SQL side of MySQL? Or that the new NoSQL method can access relational data in old-fashioned relational tables? You now have the option to use your MySQL server as a SQL server, a NoSQL server, or both.
|
||||
|
||||
Dave Stokes will present "MySQL Without the SQL—Oh My!" at [Southeast LinuxFest][4], June 8-10, in Charlotte, N.C.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/mysql-document-store
|
||||
|
||||
作者:[Dave Stokes][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/davidmstokes
|
||||
[1]:https://www.mysql.com/products/enterprise/document_store.html
|
||||
[2]:https://dev.mysql.com/doc/x-devapi-userguide/en/
|
||||
[3]:https://dev.mysql.com/downloads/shell/
|
||||
[4]:http://www.southeastlinuxfest.org/
|
||||
@ -0,0 +1,103 @@
|
||||
Sound themes in Linux: What every user should know
|
||||
======
|
||||
|
||||

|
||||
|
||||
Like all modern operating systems, Linux has a set of specifications for sound themes. Sound themes are sets of similar sounds coordinated into themes that sound good together. They signal events such as switching to a different workspace, opening a new application, plugging and unplugging hardware, and alerting you when your battery is low or fully charged. The sounds that play is determined by which themes you have installed and which ones you’re currently using. If your desktop tries to play a sound your theme doesn’t have, it will play a sound from another sound theme if it can find one.
|
||||
|
||||
### How do I select a sound theme?
|
||||
|
||||
This is where things can get tricky. Most desktops make it easy to select a sound theme, but some are more challenging, and others can't do this at all. I’ll detail the steps for [MATE][1], my personal favorite desktop. If you use another desktop, consult your desktop’s help by pressing F1.
|
||||
|
||||
#### MATE
|
||||
|
||||
To select a sound theme in MATE, open the sound settings by either pressing Alt+F1, or right-arrowing to the Settings menu, down-arrowing to Preferences, right-arrowing twice to the Hardware menu and selecting the Sound menu item. If you have a Search menu installed, such as MATE menu or [Linux Mint][2] menu, simply open that menu, search for "Sound settings," and press Enter on the first result. Once the dialog is opened, tab over to the "Sound theme" combo box and select your sound theme. If you want sounds for windows and buttons to play, check the checkbox; if not, clear it. Then press Close.
|
||||
|
||||
### How many sound themes are available in Linux?
|
||||
|
||||
There are several sound theme options in Linux, but most are included only in select distros because those distro’s developers made the theme. There is only one theme available in all distros by default, as I'll discuss later in this article. If you want a sound theme that's not available in your distribution, you'll need to download it and copy it into the proper place. For all users, this folder is `/usr/share/sounds`; for your own personal use, it is `~/.local/share/sounds`. Most sound themes can legally be used in any Linux distribution, including the sound themes in the [Ubuntu][3], [Linux Mint][4], [elementary OS][5] and [Trisquel][6] distributions.
|
||||
|
||||
### Where can I get sound themes?
|
||||
|
||||
There are several websites dedicated to sound themes, desktop background themes, icon sets, and more. These include:
|
||||
|
||||
#### Gnome-look
|
||||
|
||||
In my opinion, [Gnome-look.org][7] is the best site in terms of selection and variety. It hosts a wide variety of sound themes, icon sets, desktop themes, desktop backgrounds, and so on. Its name is misleading; the site works for all desktops, not just GNOME.
|
||||
|
||||
#### Mate-Look
|
||||
|
||||
[Mate-Look.org][8], another site specific to the MATE desktop, offers a smaller but still respectable collection of sound themes, icon sets, backgrounds, and more.
|
||||
|
||||
#### Linux a11y sound theme
|
||||
|
||||
This is the main sound theme for the Linux accessibility organization, and I maintain the site, which you can find at [Linux-a11y-sound-theme][9]. All these sounds are free to use, and the entire sound theme is open source. It is a bit of a hodgepodge mixture, but it sounds decent.
|
||||
|
||||
#### Chihuahua sound theme
|
||||
|
||||
This theme is composed of various adorable sounds my chihuahua-Pekinese mix makes, recorded on GNU/Linux using various programs and converted into the proper formats. This sound theme can be cloned at `git://github.com/coffeeking/chihuahua-sound-theme`.
|
||||
|
||||
#### Free desktop sound theme
|
||||
|
||||
Available in all Linux distributions, this sound theme is usually installed along with your desktop of choice. I don’t have a link for this sound theme, but it is usually available in your package manager as "sound-theme-freedesktop" or something similar. This theme is meant to demonstrate what themes can do rather than as an all-inclusive theme.
|
||||
|
||||
### The bad
|
||||
|
||||
While the selection of sound themes is quite good, there are some problems—not with the sound themes themselves, but with the knowledge of how sound themes work and how to create them. A common problem concerns people using sounds they are not legally allowed to use, such as the sounds included in Microsoft Windows operating systems. These sounds, which are licensed (usually by Creative Commons), are legal for use only with Windows; using them with Linux is illegal.
|
||||
|
||||
To address this problem, websites that offer sound themes should include clear guidelines specifying what is and is not legal to post. They should also include credit guidelines so those who create sound themes receive credit when others use their sounds. Many users don't know where to find high-quality sounds, so they use what they know. The solution is to make accessible websites offering a wide selection of sounds with clear licenses so users understand how they can and can't use these sounds.
|
||||
|
||||
I’ve detailed two such sites below, but these are not the only ones.
|
||||
|
||||
#### SoundBible
|
||||
|
||||
[SoundBible][10] offers a plethora of good sounds, most of which are the right length for short clip tasks, like desktop sounds. All are free, though not all are free to use commercially—check the specific license that comes with a sound for details.
|
||||
|
||||
#### Freesound
|
||||
|
||||
[Freesound][11] also provides a wide variety of sound effects for desktop tasks and other uses. Both Freesound and SoundBible include clear licenses as well as author credits so users know who made the sound and what they can do with it. This cuts down on confusion and accidental (or deliberate) misuse of sounds.
|
||||
|
||||
### Theme and naming specifications
|
||||
|
||||
A big problem in open source is that many users do not know how sound themes work or how to create them. To address this, below I will link to two specifications: sound theme specifications, which explain what should be included in a sound themes index.theme file (mandatory for all sound themes), and sound-naming guidelines, which detail how sounds should be named for your desktop to find and play them.
|
||||
|
||||
#### Sound theme specs
|
||||
|
||||
[This specification][12] explains what’s in a sound theme’s index file, which is the file that describes the sound theme and lists the theme's name, what files it contains, and so on. Click on the `html` link under "The Sound Theme Spec" heading (ignore the "draft" comment; this specification is stable and has become standardized).
|
||||
|
||||
#### Sound-naming specs
|
||||
|
||||
[This specification][12] explains how sounds should be named for your desktop to find and play them. Click on the `html` link under the "The Sound Naming Spec" heading (this also has a "draft" comment, and this theme is also standardized). The site also details what file format sounds should be in. If you come across a file that is not in a proper format, you can easily convert it using applications like [SoundConverter][13] and [FFmpeg][14].
|
||||
|
||||
### Conclusion
|
||||
|
||||
Like most things in open source, sound themes generally get little attention; most users don’t even notice that they are there. But for us visually impaired people and others who prefer unique computer experiences, sound themes provide a nice touch. Along with icon themes and desktop backgrounds, they showcase the talent and variety for which open source is famous. But it's important for users to understand how sound themes work and what they can and cannot do with them.
|
||||
|
||||
I hope this article has been helpful. Looking forward to the next big sound theme!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/sound-themes-linux
|
||||
|
||||
作者:[Kendell Clark][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/kendell-clark
|
||||
[1]:https://mate-desktop.org/themes/
|
||||
[2]:https://linuxmint.com/
|
||||
[3]:http://www.ubuntu.com/
|
||||
[4]:http://www.Linuxmint.com/
|
||||
[5]:http://www.elementaryos.org/
|
||||
[6]:http://www.trisquel.info/
|
||||
[7]:http://www.gnome-look.org/
|
||||
[8]:http://www.mate-look.org/
|
||||
[9]:http://www.github.com/coffeeking/Linux-a11y-sound-theme
|
||||
[10]:http://www.soundbible.com/
|
||||
[11]:http://www.freesound.org/
|
||||
[12]:https://www.freedesktop.org/wiki/Specifications/sound-theme-spec/
|
||||
[13]:http://www.soundconverter.org/
|
||||
[14]:http://www.ffmpeg.org/
|
||||
@ -1,96 +0,0 @@
|
||||
IT自动化:如何去实现
|
||||
======
|
||||
|
||||
在任何重要的项目或变更刚开始的时候,TI的管理者在前进的道路上面临着普遍的抉择。
|
||||
|
||||
第一条路径看上去是提供了一个从A到B的最短路径:简单的把项目强制分配给每个人去执行,本质来说就是你要么按照要求去做要么就不要做了。
|
||||
|
||||
第二条路径可能看上去会不是很直接,因为要通过这条路径你要花时间去解释项目背后的策略以及原因。你会沿着这条路线设置停靠站点而不是从起点到终点的马拉松:
|
||||
“这就是我们正在做的-和为什么我们这么做。”
|
||||
|
||||
猜想一下哪条路径会赢得更好的结果?
|
||||
|
||||
如果你选的是路径2,你肯定是以前都经历过这两条路径-而且经历了第一次的结局。让人们参与到重大变革中总会是最明智的选择。
|
||||
|
||||
IT领导者也知道重大的变革总会带来严重的恐慌、怀疑,和其他的挑战。IT自动化确实是很正确的改变。这个术语对某些人来说是很可怕的,而且容易被曲解。帮助人们理解你的公司需要IT自动化的必要性的原因以及如何去实现是达到你的目标和策略的重要步骤。
|
||||
|
||||
[**阅读我们的相关文章,**[**IT自动化最佳实践:持久成功的7个关键点**][2]. ]
|
||||
|
||||
考虑到这一点,我们咨询了许多IT管理者关于如何在你的组织中实现IT自动化。
|
||||
|
||||
## 1. 向人们展示它的优点
|
||||
|
||||
我们要面对的一点事实是:自我利益和自我保护是本能。利用人们的这种本能是一个吸引他们的好方法:向他们展示自动化策略将如何让他们和他们的工作获益。自动化将会是软件管道中的一个特定过程意味着将会减少在半夜呼叫团队同事来解决故障?他将能让一些人丢弃技术含量低的技能,用更有策略,高效的有序工作代替手工作业,这将会帮助他们的职业生涯更进一步?
|
||||
|
||||
”向他们传达他们能得到什么好处,自动化将会如何让他们的客户和公司受益,“来自vipual的建议,ADP全球首席技术官。”将现在的状态和未来光明的未来进行对比,展现公司将会变得如何稳定,敏捷,高效和安全。“
|
||||
|
||||
这样的方法同样适用于IT领域之外的其他领域;只要在向非技术领域的股东们解读利益的时候解释清楚一些术语即可,Nagrath 说道。
|
||||
|
||||
设置好前后的情景是一个不错的帮助人们理解的更透彻的故事机。
|
||||
|
||||
“你要描述一幅人们能够联想到的当前状态的画面,”Nagrath 说。“描述现在是什么工作,但也要重点强调是什么导致团队的工作效率不够敏捷。”然后再阐释自动化过程将如何提高现在的状态。
|
||||
|
||||
## 2.将自动化和特定的商业目标绑定在一起
|
||||
|
||||
一个强有力的案列的一部分要确保人们理解你不只是在追逐潮流趋势。如果i只是为了自动化而自动化,人们会很快察觉到进而会更加抵制的-也许在IT界更是如此。
|
||||
|
||||
“自动化需要商业需求的驱动,列如收入和运营开销,” David说道,Cyxtera的副总裁和首席信息安全官。“没有自动化的努力是自我辩护的,而且任何技术专长都不应该被当做一种手段,除非它是公司的一项核心能力”
|
||||
|
||||
像Nagrath一样,Emerson建议将达到自动化的商业目标和奖励措施挂钩,用迭代式的循序渐进的方式推进这些目标和相关的激励措施。
|
||||
|
||||
## 3. 将自动化计划分解为可管理的条目
|
||||
|
||||
即使你的自动化策略字面上是“一切都自动化,”对大多数组织来说那也是很艰难的而且可能是没有灵活性的。你需要一个能够将自动化目标分解为可管理的目标的计划来制定一个强有力的方案。而且这将能够创造很大的灵活性来适应之后漫长的道路。
|
||||
|
||||
“当制定一个自动化方案的时候,我建议详细的阐明推进自动化进程的奖励措施,而且允许迭代朝着目标前进来介绍和证明利益处于一个低风险水平,”Emerson说道。
|
||||
|
||||
Sergey Zuev, GA Connector的创始人,分享了一个为什么自动化如此重要的快节奏体验的报告-它将如何帮助你的策略建立一个强壮持久的论点。Zuevz应该知道:他的公司的自动化工具将公司的客户关系应用数据导入谷歌分析。但实际上是公司的内部经验使顾客培训进程自动化从而出现了一个闪耀的时刻。
|
||||
|
||||
“起初, 我们曾尝试去建立整个培训机制,结果这个项目搁浅了好几个月,”Zuev说道。“认识到这将无法继续下去之后,我们决定挑选其中的一个能够有巨大的时效的领域,而且立即启动。结果我们只用了一周就实现了其中的电子邮件序列的目标,而且我们已经从被亵渎的体力劳动中获益。”
|
||||
|
||||
## 4. 出售主要部分也有好处
|
||||
|
||||
循序渐进的方法并不会阻碍构建一个宏伟的蓝图。就像以个人或者团队的水平来制定方案是一个好主意,帮助人们理解全公司的利益也是一个不错的主意。
|
||||
|
||||
“如果我们能够加速达到商业需求所需的时间,那么一切质疑将会平息。”
|
||||
|
||||
Eric Kaplan, AHEAD的首席技术官,赞同通过小范围的胜利来展示自动化的价值是一个赢得人心的聪明策略。但是那些所谓的“小的”的价值揭示能够帮助你提高人们的整体形象。Kaplan指出个人和组织间的价值是每个人都可以容易联系到的领域。
|
||||
|
||||
“最能展现的地方就是你能够在节约多少时间,”Kaaplan说。“如果我们能够加速达到商业需求所需的时间,那么一切质疑将会消失。”
|
||||
|
||||
时间和可伸缩性是业务和IT同事的强大优势,都被业务的增长控制,能够被控制。
|
||||
|
||||
“自动化的结果是伸缩灵活的-每个人只需较少的努力就能保持和改善你的IT环境”,红帽的全球服务副总裁John最近提到。“如果增加人力是提升你的商业的唯一途径,那么伸缩灵活就是白日梦。自动化减少了你的人力需求而且提供了IT演进所需的灵活性和韧性。”(详细内容请参考他的文章,[DevOps团队对CIO的真正需求是什么。])
|
||||
|
||||
## 5. 推广你的成果。
|
||||
|
||||
在你自动化策略的开始时,你可能是在目标和要达到目标的预期利益上制定方案。但随着你的自动化策略的不断演进,没有什么能够比现实中的实际结果令人信服。
|
||||
|
||||
“眼见为实,”ADP的首席技术官Nagrath说。“没有什么比追踪记录能够平息质疑。”
|
||||
|
||||
那意味着,不仅仅要达到你的目标,还要准时的完成-这是迭代的循序渐进的方法论的另一个不错的解释。
|
||||
|
||||
而量化的结果如比列的提高或者成本的节省可以大声宣扬出来,Nagrath建议他的IT领导者的同事们在讲述你们的自动化故事的时候不要仅仅止步于此。
|
||||
|
||||
为自动化提供案列也是一个定性的讨论,通过它我们能够促进问题的预防,归总商业的连续性,减伤失败或错误,而且能够在他们处理更有价值的任务时承担更多的责任。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/1/how-make-case-it-automation
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:https://enterprisersproject.com/article/2017/10/how-beat-fear-and-loathing-it-change
|
||||
[2]:https://enterprisersproject.com/article/2018/1/it-automation-best-practices-7-keys-long-term-success?sc_cid=70160000000h0aXAAQ
|
||||
[3]:https://www.adp.com/
|
||||
[4]:https://www.cyxtera.com/
|
||||
[5]:http://gaconnector.com/
|
||||
[6]:https://www.thinkahead.com/
|
||||
[7]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
|
||||
[8]:https://enterprisersproject.com/article/2017/12/what-devops-teams-really-need-cio
|
||||
[9]:https://enterprisersproject.com/email-newsletter?intcmp=701f2000000tsjPAAQ
|
||||
@ -1,76 +0,0 @@
|
||||
Linux vs Unix:有什么不同?
|
||||
=====
|
||||

|
||||
|
||||
如果你是 20 多岁或 30 多岁的软件开发人员,那么你已经成长在一个由 Linux 主导的世界。数十年来,它一直是数据中心的重要参与者,尽管很难找到明确的操作系统市场份额报告,但 Linux 的数据中心操作系统份额可能高达 70%,而 Windows 及其变体几乎涵盖了所有剩余的百分比。使用任何主要公共云的开发人员可以预期目标系统将运行 Linux。近些年来,随着 Android 和基于 Linux 的嵌入式系统在智能手机,电视,汽车和其他设备中的应用,Linux 已经随处可见。
|
||||
|
||||
即便如此,大多数软件开发人员,甚至是那些在这场历史悠久的 “Linux 革命”中长大的软件开发人员,至少听过说 Unix。它听起来与 Linux 相似,你可能已经听到人们互换使用这些术语。或者你也许听说过 Linux 被称为“类 Unix ”操作系统。
|
||||
|
||||
那么,Unix 是什么?漫画中提到了像巫师一样留着“灰胡子”,坐在发光的绿色屏幕后面,写着 C 代码和 shell 脚本,受老式的、滴灌的咖啡提供动力。但是,Unix 的历史比上世纪 70 年代那些留着胡子的 C 程序员要丰富得多。虽然详细介绍 Unix 历史和 “Unix 与 Linux” 比较的文章比比皆是,但本文将提供高级背景和这些互补世界之间的主要区别的列表。
|
||||
|
||||
### Unix 的起源
|
||||
|
||||
Unix 的历史始于 20 世纪 60 年代后期的 AT&T 贝尔实验室,有一小组程序员希望为 PDP-7 编写一个多任务、多用户操作系统。贝尔实验室研究机构中最著名的两名成员是 Ken Thompson 和 Dennis Ritchie。尽管 Unix 的许多概念都是其前身([Multics][1])的衍生物,但 Unix 团队早在 70 年代就决定用 C 语言重写这个小型操作系统,这是将 Unix 与其他分离开来的原因。当时,操作系统很少,如果有的话,protable(to 校正者,这个 protable 不知道怎样翻译才好)。相反,由于他们的设计和底层语言的本质,操作系统与他们所编写的硬件平台紧密相关。通过 C 语言重构 Unix,Unix 现在可以移植到许多硬件体系结构中。
|
||||
|
||||
除了这种新的可移植性,之所以使得 Unix 迅速扩展到贝尔实验室以外的其他研究,学术甚至商业用途,是因为操作系统设计原则的几个关键点对用户和程序员都很有吸引力。首先是 Ken Thompson 的 [Unix哲学][2]成为模块化软件设计和计算的强大模型。Unix 哲学推荐使用小型的、专用的程序组合起来完成复杂的整体任务。由于 Unix 是围绕文件和管道设计的,因此这种“管道”模式的输入和输出程序的组合成一组线性操作的输入操作,现在仍然流行。事实上,目前的云功能即服务(FaaS)或无服务器计算模型归功于 Unix 哲学的许多传统。
|
||||
|
||||
### 快速增长和竞争
|
||||
|
||||
到 70 年代末和 80 年代,Unix 成为了一个家族的起源,它扩展了研究,学术和日益增长的商业 Unix 操作系统业务。Unix 不是开源软件,Unix 源代码可以通过与它的所有者 AT&T 达成协议来获得许可。第一个已知的软件许可证于 1975 年出售给 University of Illinois(伊利诺伊大学)。
|
||||
|
||||
Unix 在学术界迅速发展,由于 Ken Thompson 在 70 年代的休假期间,伯克利成为一个重要的活动中心。通过在伯克利的所有有关 Unix 活动,Unix 软件的一种新的交付方式诞生了:Berkeley Software Distribution 或 BSD。最初,BSD 不是 AT&T Unix 的替代品,而是一种添加类似于附加软件和功能。在 1979 年, 2BSD(第二伯克利软件发行版)出现时,伯克利研究生 Bill Joy 已经添加了现在知名的程序,例如 `vi` 和 C shell(/bin/csh)。
|
||||
|
||||
除了成为 Unix 家族中最受欢迎的分支之一的 BSD 之外,Unix 的商业产品在 20 世纪 80 年代和 90 年代爆发,其中包括 HP-UX, IBM 的 AIX, Sun 的 Solaris, Sequent 和 Xenix 等。随着分支从根源头发展壮大,“ [Unix 战争][3]”开始了,标准化成为社区的新焦点。POSIX 标准诞生于 1988 年,在 90 年代后,其他标准化后续工作也开始通过 The Open Group (to 校正者:这里是开源组织吗)进入。
|
||||
|
||||
在此期间,AT&T 和 Sun 发布了 System V Release 4(SVR4),许多商业供应商都采用了这一版本。另外,BSD 系列操作系统多年来一直在增长,导致一些开源的变体在现在熟悉的 [BSD许可证][4]下发布。这包括 FreeBSD, OpenBSD 和 NetBSD,每个 Unix 服务器行业的目标市场略有不同。这些 Unix 变体今天仍然有一些在使用,尽管很多人已经看到他们的服务器市场份额缩小到个位数字(或更低)。在当今的所有 Unix 系统中,BSD 可能拥有最大的安装基数。另外,BSD 声称每台 Apple Mac 硬件设备都可以申请,因为其 OS X(现在是 macOS)操作系统是 BSD 衍生产品。
|
||||
|
||||
虽然 Unix 的全部历史及其学术和商业变体可能需要更多的页面,但为了我们文章的重点,让我们来讨论 Linux 的兴起。
|
||||
|
||||
### 进入 Linux
|
||||
|
||||
今天我们所说的 Linux 操作系统实际上是 90 年代初期的两个努力的结合。Richard Stallman 希望创建一个真正的免费和开放源代码的专有 Unix 系统。他正在以 GNU 的名义开发实用程序和程序,它是一种递归算法,意思是“ GNU 不是 Unix!”(to 校正者,这点不太理解)虽然当时有一个内核项目正在进行,但事实证明这是一件很困难的事情,而且没有内核,自由和开源操作系统的梦想无法实现。这是 Linus Torvald 的工作 - 生产出一种可工作和可行的内核,他称之为 Linux -- 它将整个操作系统带入了生活。鉴于 Linus 使用了几个 GNU 工具(例如 GNU 编译器集合或 [GCC][5]),GNU 工具和 Linux 内核的结合是完美的搭配。
|
||||
|
||||
Linux 发行版采用了 GNU 的组件,Linux 内核,MIT 的 X-Windows GUI 以及可以在开源 BSD 许可下使用的其他 BSD 组件。像 Slackware 和 Red Hat 这样的发行版早期的流行给了 20 世纪 90 年代的“普通 PC 用户”一个机会进入 Linux 操作系统,并且让他们在工作和学术生活中使用许多特有的 Unix 系统功能和实用程序。
|
||||
|
||||
由于所有 Linux 组件都有自由和开放的源代码,任何人都可以通过一些努力来创建一个 Linux 发行版,所以不久后发行版的总数达到了数百个。今天,[distrowatch.com][6] 列出了 312 种独特的 Linux 发行版。当然,许多开发人员通过云提供商或使用流行的免费发行版来使用 Linux,如 Fedora, Canonical 的 Ubuntu, Debian, Arch Linux, Gentoo 和许多其他变体。随着包括 IBM 在内的许多企业从专有 Unix 迁移到 Linux 上并提供中间件和软件解决方案,商用 Linux 产品在免费和开源组件之上提供支持变得可行。红帽公司围绕 Red Hat Enterprise Linux(红帽企业版 Linux) 建立了商业支持模式,德国供应商 SUSE 使用 SUSE Linux Enterprise Server(SLES)也提供了这种模式。
|
||||
|
||||
### 比较 Unix 和 Linux
|
||||
|
||||
到目前为止,我们已经了解了 Unix 的历史以及 Linux 的兴起,以及 GNU/自由软件基金会对 Unix 的免费和开源替代品的支持。让我们来看看这两个操作系统之间的差异,它们有许多共同的传统和许多相同的目标。
|
||||
|
||||
从用户体验角度来看,两者差不多!Linux 的很大吸引力在于操作系统在许多硬件体系结构(包括现代 PC)上的可用性以及类似使用 Unix 系统管理员和用户熟悉的工具的能力。
|
||||
|
||||
由于 POSIX 的标准和合规性,在 Unix 上编写的软件可以针对 Linux 操作系统进行编译,通常只有少量的移植工作量。在很多情况下,Shell 脚本可以在 Linux 上直接使用。虽然一些工具在 Unix 和 Linux 之间有着略微不同的标志或命令行选项,但许多工具在两者上都是相同的。
|
||||
|
||||
一方面要注意的是,macOS 硬件和操作系统作为主要针对 Linux 的开发平台的流行可能归因于类似 BSD 的 macOS 操作系统。许多用于 Linux 系统的工具和脚本可以在 macOS 终端内轻松工作。Linux 上的许多开源软件组件都可以通过 [Homebrew][7] 等工具轻松获得。
|
||||
|
||||
Linux 和 Unix 之间的其他差异主要与许可模式有关:开源与专有许可软件。另外,在 Unix 发行版中缺少一个通用内核对软件和硬件供应商有影响。对于 Linux,供应商可以为特定的硬件设备创建设备驱动程序,并期望在合理的范围内,它可以在大多数发行版上运行。由于 Unix 家族的商业和学术分支,供应商可能必须为 Unix 的变体编写不同的驱动程序,并且需要许可和其他相关的权限才能访问 SDK 或软件的分发模型,以跨越多个二进制设备驱动程序的 Unix 变体。
|
||||
|
||||
随着这两个社区在过去十年中的成熟,Linux 的许多优点已经在 Unix 世界中被采用。当开发人员需要来自不属于 Unix 的 GNU 程序的功能时,许多 GNU 实用程序可作为 Unix 系统的附件提供。例如,IBM 的AIX为 Linux 应用程序提供了一个 AIX Toolbox,其中包含数百个 GNU 软件包(如 Bash, GCC, OpenLDAP 和许多其他软件包),这些软件包可添加到 AIX 安装包中以简化基于 Linux 和基于 Unix 的 AIX 系统。
|
||||
|
||||
Unix 仍然活着而且还不错,许多主要供应商承诺支持其当前版本,直到 2020 年。不言而喻,Unix 还会在可预见的将来一直出现。此外,Unix 的 BSD 分支是开源的,而 NetBSD, OpenBSD 和 FreeBSD 都有强大的用户基础和开源社区,它们可能不像 Linux 那样明显或活跃,但在最近的服务器报告中,它们远高于 Web 服务等领域的专有 Unix 数量。
|
||||
|
||||
Linux 已经显示出超越 Unix 的显著优势在于其在大量硬件平台和设备上的可用性。Raspberry Pi(树莓派)受到业余爱好者的欢迎,它是由 Linux 驱动的,为运行 Linux 的各种物联网设备打开了大门。我们已经提到了 Android 设备,汽车(包括 Automotive Grade Linux)和智能电视,其中 Linux 占有巨大的市场份额。这个星球上的每个云提供商都提供运行 Linux 的虚拟服务器,而且当今许多最受欢迎的本地云(to 校正者:cloud-native 这个词需要斟酌以下)堆栈都是基于 Linux 的,无论你是在谈论容器运行时还是 Kubernetes,或者是许多正在流行的无服务器平台。
|
||||
|
||||
其中一个最显著的代表 Linux 的优势是近年来微软的转变。如果你十年前告诉软件开发人员,Windows 操作系统将在 2016 年“运行 Linux”,他们中的大多数人会歇斯底里地大笑。 但是 Windows Linux 子系统(WSL)的存在和普及,以及最近宣布的诸如 Docker 的 Windows 端口,包括 LCOW(Windows 上的 Linux 容器)支持等功能都证明了 Linux 在整个软件世界中所产生的影响 - 而且显然还会继续存在。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/differences-between-linux-and-unix
|
||||
|
||||
作者:[Phil Estes][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/estesp
|
||||
[1]:https://en.wikipedia.org/wiki/Multics
|
||||
[2]:https://en.wikipedia.org/wiki/Unix_philosophy
|
||||
[3]:https://en.wikipedia.org/wiki/Unix_wars
|
||||
[4]:https://en.wikipedia.org/wiki/BSD_licenses
|
||||
[5]:https://en.wikipedia.org/wiki/GNU_Compiler_Collection
|
||||
[6]:https://distrowatch.com/
|
||||
[7]:https://brew.sh/
|
||||
@ -0,0 +1,80 @@
|
||||
在 Linux 中使用 Stratis 配置本地存储
|
||||
======
|
||||
|
||||

|
||||
|
||||
对桌面 Linux 用户而言,极少或仅在安装系统时配置本地存储。Linux 存储技术进展比较慢,以至于 20 年前的很多存储工具仍在今天广泛使用。但从那之后,存储技术已经提升了不少,我们为何不享受新特性带来的好处呢?
|
||||
|
||||
本文介绍 Startis,这是一个新项目,试图让所有 Linux 用户从存储技术进步中受益,适用场景可以是仅有一块 SSD 的单台笔记本,也可以是包含上百块硬盘的存储阵列。Linux 支持新特性,但由于缺乏易于使用的解决方案,使其没有被广泛采用。Stratis 的目标就是让 Linux 的高级存储特性更加可用。
|
||||
|
||||
### 简单可靠地使用高级存储特性
|
||||
|
||||
Stratis 希望让如下三件事变得更加容易:存储初始化配置;做后续变更;使用高级存储特性,包括<ruby>快照<rt>snapshots</rt></ruby>、<ruby>精简配置<rt>thin provisioning</rt></ruby>,甚至<ruby>分层<rt>tiering</rt></ruby>。
|
||||
|
||||
### Stratis:一个卷管理文件系统
|
||||
|
||||
Stratis 是一个<ruby>卷管理文件系统<rt>volume-managing filesystem, VMF</rt></ruby>,类似于 [ZFS][1] 和 [Btrfs][2]。它使用了存储“池”的核心思想,该思想被各种 VMFs 和 形如 [LVM][3] 的独立卷管理器采用。使用一个或多个硬盘(或分区)创建存储池,然后在存储池中创建<ruby>卷<rt>volumes</rt></ruby>。与使用 [fdisk][4] 或 [GParted][5] 执行的传统硬盘分区不同,存储池中的卷分布无需用户指定。
|
||||
|
||||
VMF 更进一步与文件系统层结合起来。用户无需在卷上部署选取的文件系统,因为文件系统和卷已经被合并在一起,成为一个概念上的文件树(ZFS 称之为<ruby>数据集<rt>dataset</rt></ruby>,Brtfs 称之为<ruby>子卷<rt>subvolume</rt></ruby>,Stratis 称之为文件系统),文件数据位于存储池中,但文件大小仅受存储池整体容量限制。
|
||||
|
||||
换一个角度来看:正如文件系统对其中单个文件的真实存储块的实际位置做了一层<ruby>抽象<rt>abstract</rt></ruby>,VMF 对存储池中单个文件系统的真实存储块的实际位置做了一层抽象。
|
||||
|
||||
基于存储池,我们可以启用其它有用的特性。特性中的一部分理所当然地来自典型的 VMF <ruby>实现<rt>implementation</rt></ruby>,例如文件系统快照,毕竟存储池中的多个文件系统可以共享<ruby>物理数据块<rt>physical data blocks</rt></ruby>;<ruby>冗余<rt>redundancy</rt></ruby>,分层,<ruby>完整性<rt>integrity</rt></ruby>等其它特性也很符合逻辑,因为存储池是操作系统中管理所有文件系统上述特性的重要场所。
|
||||
|
||||
上述结果表明,相比独立的卷管理器和文件系统层,VMF 的搭建和管理更简单,启用高级存储特性也更容易。
|
||||
|
||||
### Stratis 与 ZFS 和 Btrfs 有哪些不同?
|
||||
|
||||
作为新项目,Stratis 可以从已有项目中吸取经验,我们将在[第二部分][6]深入介绍 Stratis 采用了 ZFS,Brtfs 和 LVM 的哪些设计。总结一下,Stratis 与其不同之处来自于对功能特性支持的观察,来自于个人使用及计算机自动化运行方式的改变,以及来自于底层硬件的改变。
|
||||
|
||||
首先,Stratis 强调易用性和安全性。对个人用户而言,这很重要,毕竟他们与 Stratis 交互的时间间隔可能很长。如果交互不那么友好,尤其是有丢数据的可能性,大部分人宁愿放弃使用新特性,继续使用功能比较基础的文件系统。
|
||||
|
||||
第二,当前 API 和 <ruby>DevOps 式<rt>Devops-style</rt></ruby>自动化的重要性远高于早些年。通过提供<ruby>极好的<rt>first-class</rt></ruby> API,Stratis 支持自动化,这样人们可以直接通过自动化工具使用 Stratis。
|
||||
|
||||
第三,SSD 的容量和市场份额都已经显著提升。早期的文件系统中很多代码用于优化机械<ruby>介质<rt>media</rt></ruby>访问速度慢的问题,但对于基于闪存的介质,这些优化变得不那么重要。即使当存储池过大不适合使用 SSD 的情况,仍可以考虑使用 SSD 充当<ruby>缓存层<rt>caching tier</rt></ruby>,可以提供不错的性能提升。考虑到 SSD 的优良性能,Stratis 主要聚焦存储池设计方面的<ruby>灵活性<rt>flexibility</rt></ruby>和<ruby>可靠性<rt>reliability</rt></ruby>。
|
||||
|
||||
最后,与 ZFS 和 Btrfs 相比,Stratis 具有明显不一样的<ruby>实现模型<rt>implementation model</rt></ruby>(我会在[第二部分][6]进一步分析)。这意味着对 Stratis 而言,虽然一些功能较难实现,但一些功能较容易实现。这也加快了 Stratis 的开发进度。
|
||||
|
||||
### 了解更多
|
||||
|
||||
如果希望更多了解 Stratis,可以查看本系列的[第二部分][6]。你还可以在 [Stratis 官网][8] 找到详细的[设计文档][7]。
|
||||
|
||||
### 如何参与
|
||||
|
||||
如果希望参与开发、测试 Stratis 或给出反馈,请订阅我们的[邮件列表][9]。
|
||||
|
||||
[GitHub][10] 上的开发项目包括 [守护进程][11] (使用 [Rust][12] 开发)和 [命令行工具][13] (使用 [Python][14] 开发)两部分。
|
||||
|
||||
可以在 [Freenode][15] IRC 网络的 #stratis-storage 频道加入我们。
|
||||
|
||||
Andy Grover 将在今年的 LinuxFest Northwest 会议上演讲。查看[会议安排][16] 或 [注册参会][17]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/stratis-easy-use-local-storage-management-linux
|
||||
|
||||
作者:[Andy Grover][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/agrover
|
||||
[1]:https://en.wikipedia.org/wiki/ZFS
|
||||
[2]:https://en.wikipedia.org/wiki/Btrfs
|
||||
[3]:https://en.wikipedia.org/wiki/Logical_Volume_Manager_(Linux)
|
||||
[4]:https://en.wikipedia.org/wiki/Fdisk
|
||||
[5]:https://gparted.org/
|
||||
[6]:https://opensource.com/article/18/4/stratis-lessons-learned
|
||||
[7]:https://stratis-storage.github.io/StratisSoftwareDesign.pdf
|
||||
[8]:https://stratis-storage.github.io/
|
||||
[9]:https://lists.fedoraproject.org/admin/lists/stratis-devel.lists.fedorahosted.org/
|
||||
[10]:https://github.com/stratis-storage/
|
||||
[11]:https://github.com/stratis-storage/stratisd
|
||||
[12]:https://www.rust-lang.org/
|
||||
[13]:https://github.com/stratis-storage/stratis-cli
|
||||
[14]:https://www.python.org/
|
||||
[15]:https://freenode.net/
|
||||
[16]:https://www.linuxfestnorthwest.org/conferences/lfnw18
|
||||
[17]:https://www.linuxfestnorthwest.org/conferences/lfnw18/register/new
|
||||
155
translated/tech/20180516 A guide to Git branching.md
Normal file
155
translated/tech/20180516 A guide to Git branching.md
Normal file
@ -0,0 +1,155 @@
|
||||
Git 分支操作介绍
|
||||
======
|
||||
|
||||

|
||||
在本系列的前两篇文章中,我们[开始使用 Git][1],学会如何[克隆项目,修改、增加和删除内容][2]。在这第三篇文章中,我将介绍 Git 分支,为何以及如何使用分支。
|
||||
|
||||
![树枝][3]
|
||||
|
||||
不妨用树来描绘 Git 仓库。图中的树有很多分支,或长或短,或从树干延伸或从其它分支延伸。在这里,我们用树干比作仓库的 master 分支,其中 `master` 代指 ”master branch",Git 仓库的中心分支或第一个分支。为简单起见,我们假设 `master` 是树干,其它分支都是从该分支分出的。
|
||||
|
||||
### 为何在 Git 仓库中使用分支
|
||||
|
||||
* 如果你希望为项目增加新特性,但很可能会影响当前可正常工作的代码。对于项目的活跃用户而言,这是很糟糕的事情。与其将特性加入到其它人正在使用的 `master` 分支,更好的方法是在仓库的其它分支中变更代码,下面给出具体的工作方式。
|
||||
* 更重要的是,[Git 被设计][4]用于协作。如果所有人都在你代码仓库的 `master` 分支上操作,会引发很多混乱。对编程语言或项目的知识和阅历因人而异;有些人可能编写有错误或缺陷的代码,也可能编写你觉得不适合该项目的代码。使用分支可以让你核验他人的贡献并选择适合的加入到项目中。(这里假设你是代码库唯一的所有者,希望对增加到项目中的代码有完全的控制。在真实的项目中,代码库有多个具有合并代码权限的所有者)
|
||||
|
||||
### 创建分支
|
||||
|
||||
使用分支的主要理由为:
|
||||
|
||||
让我们回顾[本系列上一篇文章][2],看一下在我们的 Demo 目录中分支是怎样的。如果你没有完成上述操作,请按照文章中的指示从 GitHub 克隆代码并进入 Demo 目录。运行如下命令:
|
||||
```
|
||||
pwd
|
||||
git branch
|
||||
ls -la
|
||||
```
|
||||
|
||||
`pwd` 命令(是当前工作目录的英文缩写)返回当前你所处的目录(以便确认你在 Demo 目录中),`git branch` 列出 Demo 项目在你主机上的全部分支,`ls -la` 列出当前目录下的所有文件。你的终端输出类似于:
|
||||
|
||||
![终端输出][5]
|
||||
|
||||
在 master 分支中,只有一个文件 `README.md`。(Git 会友好地忽略掉其它目录和文件。)
|
||||
|
||||
接下来,运行如下命令:
|
||||
```
|
||||
git status
|
||||
git checkout -b myBranch
|
||||
git status
|
||||
|
||||
```
|
||||
|
||||
第一条命令 `git status` 告知你当前处于 `branch master`,(就像在终端中看到的那样)与 `origin/master` 处于同步状态,意味着 master 分支本地副本中的全部文件也出现在 GitHub 中。两份副本没有差异,所有的提交也是一致的。
|
||||
|
||||
下一条命令 `git checkout -b myBranch` 中的 `-b` 告知 Git 创建一个名为 `myBranch` 的新分支,然后 `checkout` 将我们切换到新创建的分支。运行第三条命令 `git status` 确保你已经位于刚创建的分支下。
|
||||
|
||||
如你所见,`git status` 告知你当前处于 `myBranch` 分支,没有变更需要提交。这是因为我们既没有增加新文件,也没有修改已有文件。
|
||||
|
||||
![终端输出][6]
|
||||
|
||||
如果希望以可视化的方式查看分支,可以运行 `gitk` 命令。如果遇到报错 `bash: gitk: command not found…`,请先安装 `gitk` 软件包(找到你操作系统对应的安装文档,以获得安装方式)。
|
||||
|
||||
(LCTT 译注:需要在有 X 服务器的终端运行 `gitk`,否则会报错)
|
||||
|
||||
下图展示了我们在 Demo 项目中的所作所为:你最后一次提交(对应的信息)是 `Delete file.txt`,在此之前有三次提交。当前的提交用黄点标注,之前的提交用蓝点标注,黄点和 `Delete file.txt` 之间的三个方块展示每个分支所在的位置(或者说每个分支中的最后一次提交的位置)。由于 `myBranch` 刚创建,提交状态与 `master` 分支及其对应的记为 `remotes/origin/master` 的远程 `master` 分支保持一致。(非常感谢来自 Red Hat 的 [Peter Savage][7] 让我知道 `gitk` 这个工具)
|
||||
|
||||
![Gitk 输出][8]
|
||||
|
||||
下面让我们在 `myBranch` 分支下创建一个新文件并观察终端输出。运行如下命令:
|
||||
```
|
||||
echo "Creating a newFile on myBranch" > newFile
|
||||
cat newFile
|
||||
git status
|
||||
|
||||
```
|
||||
|
||||
第一条命令中的 `echo` 创建了名为 `newFile` 的文件,接着 `cat newFile` 打印出文件内容,最后 `git status` 告知你我们 `myBranch` 分支的当前状态。在下面的终端输出中,Git 告知 `myBranch` 分支下有一个名为 `newFile` 的文件当前处于 `untracked` 状态。这表明我们没有让 Git 追踪发生在文件 `newFile` 上的变更。
|
||||
|
||||
![终端输出][9]
|
||||
|
||||
下一步是增加文件,提交变更并将 `newFile` 文件推送至 `myBranch` 分支(请回顾本系列上一篇文章获得更多细节)。
|
||||
```
|
||||
git add newFile
|
||||
git commit -m "Adding newFile to myBranch"
|
||||
git push origin myBranch
|
||||
|
||||
```
|
||||
|
||||
在上述命令中,`push` 命令使用的分支参数为 `myBranch` 而不是 `master`。Git 添加 `newFile` 并将变更推送到你 GitHub 账号下的 Demo 仓库中,告知你在 GitHub 上创建了一个与你本地副本分支 `myBranch` 一样的新分支。终端输出截图给出了运行命令的细节及命令输出。
|
||||
|
||||
![终端输出][10]
|
||||
|
||||
当你访问 GitHub 时,在分支选择的下拉列表中可以发现两个可供选择的分支。
|
||||
|
||||
![GitHub][11]
|
||||
|
||||
点击 `myBranch` 切换到 `myBranch` 分支,你可以看到在此分支上新增的文件。
|
||||
|
||||
![GitHub][12]
|
||||
|
||||
截至目前,我们有两个分支:一个是 `master` 分支,只有一个 `README.md` 文件;另一个是 `myBranch` 分支,有两个文件。
|
||||
|
||||
你已经知道如何创建分支了,下面我们再创建一个分支。输入如下命令:
|
||||
```
|
||||
git checkout master
|
||||
git checkout -b myBranch2
|
||||
touch newFile2
|
||||
git add newFile2
|
||||
git commit -m "Adding newFile2 to myBranch2"
|
||||
git push origin myBranch2
|
||||
|
||||
```
|
||||
|
||||
我不再给出终端输出,需要你自己尝试,但你可以在 [GitHub 代码库][13] 中验证你的结果。
|
||||
|
||||
### 删除分支
|
||||
|
||||
由于我们增加了两个分支,下面删除其中的一个(`myBranch`),包括两步:
|
||||
|
||||
**1\. 删除本地分支** 你不能删除正在操作的分支,故切换到 `master` 分支 (或其它你希望保留的分支),命令及终端输出如下:
|
||||
|
||||
`git branch` 可以列出可用的分支,使用 `checkout` 切换到 `master` 分支,然后使用 `git branch -D myBranch` 删除该分支。再次运行 `git branch` 检查是否只剩下两个分支(而不是三个)。
|
||||
|
||||
**2\. 删除 GitHub 上的分支** 使用如下命令删除 `myBranch` 的远程分支:
|
||||
```
|
||||
git push origin :myBranch
|
||||
|
||||
```
|
||||
|
||||
![Terminal output][14]
|
||||
|
||||
上面 `push` 命令中分支名称前面的冒号(`:`)告知 GitHub 删除分支。另一种写法为:
|
||||
```
|
||||
git push -d origin myBranch
|
||||
|
||||
```
|
||||
|
||||
其中 `-d` (也可以用 `--delete`) 也用于告知 GitHub 删除你的分支。
|
||||
|
||||
我们学习了 Git 分支的使用,在本系列的下一篇文章中,我们将介绍如何执行 fetch 和 rebase 操作,对于多人同时的贡献的项目而言,这是很必须学会的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/git-branching
|
||||
|
||||
作者:[Kedar Vijay Kulkarni][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/kkulkarn
|
||||
[1]:https://opensource.com/article/18/1/step-step-guide-git
|
||||
[2]:https://opensource.com/article/18/2/how-clone-modify-add-delete-git-files
|
||||
[3]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/tree-branches.jpg?itok=bQGpa5Uc (tree branches)
|
||||
[4]:https://en.wikipedia.org/wiki/Git
|
||||
[5]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/gitbranching_terminal1.png?itok=ZcAzRdlR (Terminal output)
|
||||
[6]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/gitbranching_terminal2.png?itok=nIcfy2Vh (Terminal output)
|
||||
[7]:https://opensource.com/users/psav
|
||||
[8]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/gitbranching_commit3.png?itok=GoP51yE4 (Gitk output)
|
||||
[9]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/gitbranching_terminal4.png?itok=HThID5aU (Terminal output)
|
||||
[10]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/gitbranching_terminal5.png?itok=rHVdrJ0m (Terminal output)
|
||||
[11]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/gitbranching_github6.png?itok=EyaKfCg2 (GitHub)
|
||||
[12]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/gitbranching_github7.png?itok=0ZSu0W2P (GitHub)
|
||||
[13]:https://github.com/kedark3/Demo/tree/myBranch2
|
||||
[14]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/gitbranching_terminal9.png?itok=B0vaRkyI (Terminal output)
|
||||
@ -0,0 +1,102 @@
|
||||
基于 FUSE 的 Bittorrent 文件系统
|
||||
======
|
||||
|
||||

|
||||
Bittorrent 已经存在了很长时间,它可以从互联网上共享和下载数据。市场上有大量的 GUI 和 CLI 的 Bittorrent 客户端。有时,你不能坐下来等待你的下载完成。你可能想要立即观看内容。这就是 **BTFS**这个不起眼的文件系统派上用场的地方。使用 BTFS,你可以将种子文件或磁力链接挂载为目录,然后在文件树中作为只读目录。这些文件的内容将在程序读取时按需下载。由于 BTFS 在 FUSE 之上运行,因此不需要干预 Linux 内核。
|
||||
|
||||
## BTFS – 基于 FUSE 的 Bittorrent 文件系统
|
||||
|
||||
### 安装 BTFS
|
||||
|
||||
BTFS 存在于大多数 Linux 发行版的默认参仓库中。
|
||||
|
||||
在 Arch Linux 及其变体上,运行以下命令来安装 BTFS。
|
||||
```
|
||||
$ sudo pacman -S btfs
|
||||
|
||||
```
|
||||
|
||||
在Debian、Ubuntu、Linux Mint 上:
|
||||
```
|
||||
$ sudo apt-get install btfs
|
||||
|
||||
```
|
||||
|
||||
在 Gentoo 上:
|
||||
```
|
||||
# emerge -av btfs
|
||||
|
||||
```
|
||||
|
||||
BTFS 也可以使用 [**Linuxbrew**][1] 包管理器进行安装。
|
||||
```
|
||||
$ brew install btfs
|
||||
|
||||
```
|
||||
|
||||
### 用法
|
||||
|
||||
BTFS 的使用非常简单。你所要做的就是找到 .torrent 文件或磁力链接,并将其挂载到一个目录中。种子文件或磁力链接的内容将被挂载到你选择的目录内。当一个程序试图访问该文件进行读取时,实际的数据将按需下载。此外,像 **ls** 、**cat** 和 **cp**这样的工具能按照预期的方式来操作种子。像 **vlc** 和 **mplayer** 这样的程序也可以不加修改地工作。玩家甚至不知道实际内容并非物理存在于本地磁盘中,而是根据需要从 peer 中收集。
|
||||
|
||||
创建一个目录来挂载 torrent/magnet 链接:
|
||||
```
|
||||
$ mkdir mnt
|
||||
|
||||
```
|
||||
|
||||
挂载 torrent/magnet 链接:
|
||||
```
|
||||
$ btfs video.torrent mnt
|
||||
|
||||
```
|
||||
|
||||
[![][2]][3]
|
||||
|
||||
cd 到目录:
|
||||
```
|
||||
$ cd mnt
|
||||
|
||||
```
|
||||
|
||||
然后,开始观看!
|
||||
```
|
||||
$ vlc <path-to-video.mp4>
|
||||
|
||||
```
|
||||
|
||||
给 BTFS 一些时间来找到并获取网站 tracker。一旦加载了真实数据,BTFS 将不再需要 tracker。
|
||||
|
||||
![][4]
|
||||
|
||||
要卸载 BTFS 文件系统,只需运行以下命令:
|
||||
```
|
||||
$ fusermount -u mnt
|
||||
|
||||
```
|
||||
|
||||
现在,挂载目录中的内容将消失。要再次访问内容,你需要按照上面的描述挂载 torrent。
|
||||
|
||||
BTFS 会将你的 VLC 或 Mplayer 变成爆米花时间。挂载你最喜爱的电视节目或电影的种子文件或磁力链接,然后开始观看,无需下载整个种子内容或等待下载完成。种子或磁力链接的内容将在程序访问时按需下载。
|
||||
|
||||
就是这些了。希望这些有用。还会有更好的东西。敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/btfs-a-bittorrent-filesystem-based-on-fuse/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/05/btfs.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/05/btfs-1.png
|
||||
Loading…
Reference in New Issue
Block a user