mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-09 01:30:10 +08:00
commit
fc5a359aac
125
published/20180107 7 leadership rules for the DevOps age.md
Normal file
125
published/20180107 7 leadership rules for the DevOps age.md
Normal file
@ -0,0 +1,125 @@
|
||||
DevOps 时代的 7 个领导力准则
|
||||
======
|
||||
|
||||
> DevOps 是一种持续性的改变和提高:那么也准备改变你所珍视的领导力准则吧。
|
||||
|
||||

|
||||
|
||||
如果 [DevOps] 最终更多的是一种文化而非某种技术或者平台,那么请记住:它没有终点线。而是一种持续性的改变和提高——而且最高管理层并不及格。
|
||||
|
||||
然而,如果期望 DevOps 能够帮助获得更多的成果,领导者需要[修订他们的一些传统的方法][2]。让我们考虑 7 个在 DevOps 时代更有效的 IT 领导的想法。
|
||||
|
||||
### 1、 向失败说“是的”
|
||||
|
||||
“失败”这个词在 IT 领域中一直包含着非常具体的意义,而且通常是糟糕的意思:服务器失败、备份失败、硬盘驱动器失败——你的印象就是如此。
|
||||
|
||||
然而一个健康的 DevOps 文化取决于如何重新定义失败——IT 领导者应该在他们的字典里重新定义这个单词,使这个词的含义和“机会”对等起来。
|
||||
|
||||
“在 DevOps 之前,我们曾有一种惩罚失败者的文化,”[Datical][3] 的首席技术官兼联合创始人罗伯特·里夫斯说,“我们学到的仅仅是去避免错误。在 IT 领域避免错误的首要措施就是不要去改变任何东西:不要加速版本迭代的日程,不要迁移到云中,不要去做任何不同的事”
|
||||
|
||||
那是一个旧时代的剧本,里夫斯坦诚的说,它已经不起作用了,事实上,那种停滞实际上是失败。
|
||||
|
||||
“那些缓慢的发布周期并逃避云的公司被恐惧所麻痹——他们将会走向失败,”里夫斯说道。“IT 领导者必须拥抱失败,并把它当做成一个机遇。人们不仅仅从他们的过错中学习,也会从别人的错误中学习。开放和[安全心理][4]的文化促进学习和提高。”
|
||||
|
||||
**[相关文章:[为什么敏捷领导者谈论“失败”必须超越它本义][5]]**
|
||||
|
||||
### 2、 在管理层渗透开发运营的理念
|
||||
|
||||
尽管 DevOps 文化可以在各个方向有机的发展,那些正在从单体、孤立的 IT 实践中转变出来的公司,以及可能遭遇逆风的公司——需要高管层的全面支持。如果缺少了它,你就会传达模糊的信息,而且可能会鼓励那些宁愿被推着走的人,但这是我们一贯的做事方式。[改变文化是困难的][6];人们需要看到高管层完全投入进去并且知道改变已经实际发生了。
|
||||
|
||||
“高层管理必须全力支持 DevOps,才能成功的实现收益”,来自 [Rainforest QA][7] 的首席信息官德里克·蔡说道。
|
||||
|
||||
成为一个 DevOps 商店。德里克指出,涉及到公司的一切,从技术团队到工具到进程到规则和责任。
|
||||
|
||||
“没有高层管理的统一赞助支持,DevOps 的实施将很难成功,”德里克说道,“因此,在转变到 DevOps 之前在高层中保持一致是很重要的。”
|
||||
|
||||
### 3、 不要只是声明 “DevOps”——要明确它
|
||||
|
||||
即使 IT 公司也已经开始张开双臂拥抱 DevOps,也可能不是每个人都在同一个步调上。
|
||||
|
||||
**[参考我们的相关文章,[3 阐明了DevOps和首席技术官们必须在同一进程上][8]]**
|
||||
|
||||
造成这种脱节的一个根本原因是:人们对这个术语的有着不同的定义理解。
|
||||
|
||||
“DevOps 对不同的人可能意味着不同的含义,”德里克解释道,“对高管层和副总裁层来说,要执行明确的 DevOps 的目标,清楚地声明期望的成果,充分理解带来的成果将如何使公司的商业受益,并且能够衡量和报告成功的过程。”
|
||||
|
||||
事实上,在基线定义和远景之外,DevOps 要求正在进行频繁的交流,不是仅仅在小团队里,而是要贯穿到整个组织。IT 领导者必须将它设置为优先。
|
||||
|
||||
“不可避免的,将会有些阻碍,在商业中将会存在失败和破坏,”德里克说道,“领导者们需要清楚的将这个过程向公司的其他人阐述清楚,告诉他们他们作为这个过程的一份子能够期待的结果。”
|
||||
|
||||
### 4、 DevOps 对于商业和技术同样重要
|
||||
|
||||
IT 领导者们成功的将 DevOps 商店的这种文化和实践当做一项商业策略,以及构建和运营软件的方法。DevOps 是将 IT 从支持部门转向战略部门的推动力。
|
||||
|
||||
IT 领导者们必须转变他们的思想和方法,从成本和服务中心转变到驱动商业成果,而且 DevOps 的文化能够通过自动化和强大的协作加速这些成果,来自 [CYBRIC][9] 的首席技术官和联合创始人迈克·凯尔说道。
|
||||
|
||||
事实上,这是一个强烈的趋势,贯穿这些新“规则”,在 DevOps 时代走在前沿。
|
||||
|
||||
“促进创新并且鼓励团队成员去聪明的冒险是 DevOps 文化的一个关键部分,IT 领导者们需要在一个持续的基础上清楚的和他们交流”,凯尔说道。
|
||||
|
||||
“一个高效的 IT 领导者需要比以往任何时候都要积极的参与到业务中去,”来自 [West Monroe Partners][10] 的性能服务部门的主任埃文说道,“每年或季度回顾的日子一去不复返了——[你需要欢迎每两周一次的挤压整理][11],你需要有在年度水平上的思考战略能力,在冲刺阶段的互动能力,在商业期望满足时将会被给予一定的奖励。”
|
||||
|
||||
### 5、 改变妨碍 DevOps 目标的任何事情
|
||||
|
||||
虽然 DevOps 的老兵们普遍认为 DevOps 更多的是一种文化而不是技术,成功取决于通过正确的过程和工具激活文化。当你声称自己的部门是一个 DevOps 商店却拒绝对进程或技术做必要的改变,这就是你买了辆法拉利却使用了用了 20 年的引擎,每次转动钥匙都会冒烟。
|
||||
|
||||
展览 A: [自动化][12]。这是 DevOps 成功的重要并行策略。
|
||||
|
||||
“IT 领导者需要重点强调自动化,”卡伦德说,“这将是 DevOps 的前期投资,但是如果没有它,DevOps 将会很容易被低效吞噬,而且将会无法完整交付。”
|
||||
|
||||
自动化是基石,但改变不止于此。
|
||||
|
||||
“领导者们需要推动自动化、监控和持续交付过程。这意着对现有的实践、过程、团队架构以及规则的很多改变,” 德里克说。“领导者们需要改变一切会阻碍团队去实现完全自动化的因素。”
|
||||
|
||||
### 6、 重新思考团队架构和能力指标
|
||||
|
||||
当你想改变时……如果你桌面上的组织结构图和你过去大部分时候嵌入的名字都是一样的,那么你是时候该考虑改革了。
|
||||
|
||||
“在这个 DevOps 的新时代文化中,IT 执行者需要采取一个全新的方法来组织架构。”凯尔说,“消除组织的边界限制,它会阻碍团队间的合作,允许团队自我组织、敏捷管理。”
|
||||
|
||||
凯尔告诉我们在 DevOps 时代,这种反思也应该拓展应用到其他领域,包括你怎样衡量个人或者团队的成功,甚至是你和人们的互动。
|
||||
|
||||
“根据业务成果和总体的积极影响来衡量主动性,”凯尔建议。“最后,我认为管理中最重要的一个方面是:有同理心。”
|
||||
|
||||
注意很容易收集的到测量值不是 DevOps 真正的指标,[Red Hat] 的技术专家戈登·哈夫写到,“DevOps 应该把指标以某种形式和商业成果绑定在一起”,他指出,“你可能并不真正在乎开发者些了多少代码,是否有一台服务器在深夜硬件损坏,或者是你的测试是多么的全面。你甚至都不直接关注你的网站的响应情况或者是你更新的速度。但是你要注意的是这些指标可能和顾客放弃购物车去竞争对手那里有关,”参考他的文章,[DevOps 指标:你在测量什么?]
|
||||
|
||||
### 7、 丢弃传统的智慧
|
||||
|
||||
如果 DevOps 时代要求关于 IT 领导能力的新的思考方式,那么也就意味着一些旧的方法要被淘汰。但是是哪些呢?
|
||||
|
||||
“说实话,是全部”,凯尔说道,“要摆脱‘因为我们一直都是以这种方法做事的’的心态。过渡到 DevOps 文化是一种彻底的思维模式的转变,不是对瀑布式的过去和变革委员会的一些细微改变。”
|
||||
|
||||
事实上,IT 领导者们认识到真正的变革要求的不只是对旧方法的小小接触。它更多的是要求对之前的进程或者策略的一个重新启动。
|
||||
|
||||
West Monroe Partners 的卡伦德分享了一个阻碍 DevOps 的领导力的例子:未能拥抱 IT 混合模型和现代的基础架构比如说容器和微服务。
|
||||
|
||||
“我所看到的一个大的规则就是架构整合,或者认为在一个同质的环境下长期的维护会更便宜,”卡伦德说。
|
||||
|
||||
**领导者们,想要更多像这样的智慧吗?[注册我们的每周邮件新闻报道][15]。**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/1/7-leadership-rules-devops-age
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:https://enterprisersproject.com/tags/devops
|
||||
[2]:https://enterprisersproject.com/article/2017/7/devops-requires-dumping-old-it-leadership-ideas
|
||||
[3]:https://www.datical.com/
|
||||
[4]:https://rework.withgoogle.com/guides/understanding-team-effectiveness/steps/foster-psychological-safety/
|
||||
[5]:https://enterprisersproject.com/article/2017/10/why-agile-leaders-must-move-beyond-talking-about-failure?sc_cid=70160000000h0aXAAQ
|
||||
[6]:https://enterprisersproject.com/article/2017/10/how-beat-fear-and-loathing-it-change
|
||||
[7]:https://www.rainforestqa.com/
|
||||
[8]:https://enterprisersproject.com/article/2018/1/3-areas-where-devops-and-cios-must-get-same-page
|
||||
[9]:https://www.cybric.io/
|
||||
[10]:http://www.westmonroepartners.com/
|
||||
[11]:https://www.scrumalliance.org/community/articles/2017/february/product-backlog-grooming
|
||||
[12]:https://www.redhat.com/en/topics/automation?intcmp=701f2000000tjyaAAA
|
||||
[13]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
|
||||
[14]:https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters
|
||||
[15]:https://enterprisersproject.com/email-newsletter?intcmp=701f2000000tsjPAAQ
|
||||
@ -1,5 +1,5 @@
|
||||
如何使用 Android Things 和 TensorFlow 在物联网上应用机器学习
|
||||
============================================================
|
||||
=============================
|
||||
|
||||

|
||||
|
||||
@ -3,14 +3,11 @@
|
||||
|
||||
> 通过使用 `/etc/passwd` 文件,`getent` 命令,`compgen` 命令这三种方法查看系统中用户的信息
|
||||
|
||||
----------------
|
||||
大家都知道,Linux 系统中用户信息存放在 `/etc/passwd` 文件中。
|
||||
|
||||
这是一个包含每个用户基本信息的文本文件。
|
||||
这是一个包含每个用户基本信息的文本文件。当我们在系统中创建一个用户,新用户的详细信息就会被添加到这个文件中。
|
||||
|
||||
当我们在系统中创建一个用户,新用户的详细信息就会被添加到这个文件中。
|
||||
|
||||
`/etc/passwd` 文件将每个用户的基本信息记录为文件中的一行,一行中包含7个字段。
|
||||
`/etc/passwd` 文件将每个用户的基本信息记录为文件中的一行,一行中包含 7 个字段。
|
||||
|
||||
`/etc/passwd` 文件的一行代表一个单独的用户。该文件将用户的信息分为 3 个部分。
|
||||
|
||||
@ -18,11 +15,6 @@
|
||||
* 第 2 部分:系统定义的账号信息
|
||||
* 第 3 部分:真实用户的账户信息
|
||||
|
||||
** 建议阅读 : **
|
||||
**( # )** [ 如何在 Linux 上查看创建用户的日期 ][1]
|
||||
**( # )** [ 如何在 Linux 上查看 A 用户所属的群组 ][2]
|
||||
**( # )** [ 如何强制用户在下一次登录 Linux 系统时修改密码 ][3]
|
||||
|
||||
第一部分是 `root` 账户,这代表管理员账户,对系统的每个方面都有完全的权力。
|
||||
|
||||
第二部分是系统定义的群组和账户,这些群组和账号是正确安装和更新系统软件所必需的。
|
||||
@ -31,18 +23,24 @@
|
||||
|
||||
在创建新用户时,将修改以下 4 个文件。
|
||||
|
||||
* `/etc/passwd:` 用户账户的详细信息在此文件中更新。
|
||||
* `/etc/shadow:` 用户账户密码在此文件中更新。
|
||||
* `/etc/group:` 新用户群组的详细信息在此文件中更新。
|
||||
* `/etc/gshadow:` 新用户群组密码在此文件中更新。
|
||||
* `/etc/passwd`: 用户账户的详细信息在此文件中更新。
|
||||
* `/etc/shadow`: 用户账户密码在此文件中更新。
|
||||
* `/etc/group`: 新用户群组的详细信息在此文件中更新。
|
||||
* `/etc/gshadow`: 新用户群组密码在此文件中更新。
|
||||
|
||||
** 建议阅读 : **
|
||||
|
||||
- [ 如何在 Linux 上查看创建用户的日期 ][1]
|
||||
- [ 如何在 Linux 上查看 A 用户所属的群组 ][2]
|
||||
- [ 如何强制用户在下一次登录 Linux 系统时修改密码 ][3]
|
||||
|
||||
### 方法 1 :使用 `/etc/passwd` 文件
|
||||
|
||||
使用任何一个像 `cat`,`more`,`less` 等文件操作命令来打印 Linux 系统上创建的用户列表。
|
||||
使用任何一个像 `cat`、`more`、`less` 等文件操作命令来打印 Linux 系统上创建的用户列表。
|
||||
|
||||
`/etc/passwd` 是一个文本文件,其中包含了登录 Linux 系统所必需的每个用户的信息。它保存用户的有用信息,如用户名,密码,用户 ID,群组 ID,用户 ID 信息,用户的家目录和 Shell 。
|
||||
`/etc/passwd` 是一个文本文件,其中包含了登录 Linux 系统所必需的每个用户的信息。它保存用户的有用信息,如用户名、密码、用户 ID、群组 ID、用户 ID 信息、用户的家目录和 Shell 。
|
||||
|
||||
`/etc/passwd` 文件将每个用户的详细信息写为一行,其中包含七个字段,每个字段之间用冒号 “ :” 分隔:
|
||||
`/etc/passwd` 文件将每个用户的详细信息写为一行,其中包含七个字段,每个字段之间用冒号 `:` 分隔:
|
||||
|
||||
```
|
||||
# cat /etc/passwd
|
||||
@ -72,15 +70,15 @@ mageshm:x:506:507:2g Admin - Magesh M:/home/mageshm:/bin/bash
|
||||
```
|
||||
7 个字段的详细信息如下。
|
||||
|
||||
* **`Username ( magesh ):`** 已创建用户的用户名,字符长度 1 个到 12 个字符。
|
||||
* **`Password ( x ):`** 代表加密密码保存在 `/etc/shadow 文件中。
|
||||
* **`User ID ( UID-506 ):`** 代表用户 ID ,每个用户都要有一个唯一的 ID 。UID 号为 0 的是为 `root` 用户保留的,UID 号 1 到 99 是为系统用户保留的,UID 号100-999 是为系统账户和群组保留的。
|
||||
* **`Group ID ( GID-507 ):`** 代表组 ID ,每个群组都要有一个唯一的 GID ,保存在 `/etc/group` 文件中。
|
||||
* **`User ID Info ( 2g Admin - Magesh M):`** 代表命名字段,可以用来描述用户的信息。
|
||||
* **`Home Directory ( /home/mageshm ):`** 代表用户的家目录。
|
||||
* **`shell ( /bin/bash ):`** 代表用户使用的 shell种类。
|
||||
* **用户名** (`magesh`): 已创建用户的用户名,字符长度 1 个到 12 个字符。
|
||||
* **密码**(`x`):代表加密密码保存在 `/etc/shadow 文件中。
|
||||
* **用户 ID(`506`):代表用户的 ID 号,每个用户都要有一个唯一的 ID 。UID 号为 0 的是为 `root` 用户保留的,UID 号 1 到 99 是为系统用户保留的,UID 号 100-999 是为系统账户和群组保留的。
|
||||
* **群组 ID (`507`):代表群组的 ID 号,每个群组都要有一个唯一的 GID ,保存在 `/etc/group` 文件中。
|
||||
* **用户信息(`2g Admin - Magesh M`):代表描述字段,可以用来描述用户的信息(LCTT 译注:此处原文疑有误)。
|
||||
* **家目录(`/home/mageshm`):代表用户的家目录。
|
||||
* **Shell(`/bin/bash`):代表用户使用的 shell 类型。
|
||||
|
||||
你可以使用 **`awk`** 或 **`cut`** 命令仅打印出 Linux 系统中所有用户的用户名列表。显示的结果是相同的。
|
||||
你可以使用 `awk` 或 `cut` 命令仅打印出 Linux 系统中所有用户的用户名列表。显示的结果是相同的。
|
||||
|
||||
```
|
||||
# awk -F':' '{ print $1}' /etc/passwd
|
||||
@ -108,11 +106,10 @@ rpc
|
||||
2daygeek
|
||||
named
|
||||
mageshm
|
||||
|
||||
```
|
||||
### 方法 2 :使用 `getent` 命令
|
||||
|
||||
`getent` 命令显示 `Name Service Switch` 库支持的数据库中的条目。这些库的配置文件为 `/etc/nsswitch.conf`。
|
||||
`getent` 命令显示 Name Service Switch 库支持的数据库中的条目。这些库的配置文件为 `/etc/nsswitch.conf`。
|
||||
|
||||
`getent` 命令显示类似于 `/etc/passwd` 文件的用户详细信息,它将每个用户详细信息显示为包含七个字段的单行。
|
||||
|
||||
@ -140,49 +137,11 @@ rpc:x:32:32:Rpcbind Daemon:/var/cache/rpcbind:/sbin/nologin
|
||||
2daygeek:x:503:504::/home/2daygeek:/bin/bash
|
||||
named:x:25:25:Named:/var/named:/sbin/nologin
|
||||
mageshm:x:506:507:2g Admin - Magesh M:/home/mageshm:/bin/bash
|
||||
|
||||
```
|
||||
|
||||
7 个字段的详细信息如下。
|
||||
7 个字段的详细信息如上所述。(LCTT 译注:此处内容重复,删节)
|
||||
|
||||
* **`Username ( magesh ):`** 已创建用户的用户名,字符长度 1 个到 12 个字符。
|
||||
* **`Password ( x ):` 代表加密密码保存在 `/etc/shadow 文件中。
|
||||
* **`User ID ( UID-506 ):`** 代表用户 ID ,每个用户都要有一个唯一的 ID 。UID 号为 0 的是为 `root` 用户保留的,UID 号 1 到 99 是为系统用户保留的,UID 号100-999 是为系统账户和群组保留的。
|
||||
* **`Group ID ( GID-507 ):`** 代表组 ID ,每个群组都要有一个唯一的 GID ,保存在 `/etc/group` 文件中。
|
||||
* **`User ID Info ( 2g Admin - Magesh M):`** 代表命名字段,可以用来描述用户的信息。
|
||||
* **`Home Directory ( /home/mageshm ):`** 代表用户的家目录。
|
||||
* **`shell ( /bin/bash ):`** 代表用户使用的 shell种类。
|
||||
|
||||
你可以使用 **`awk`** 或 **`cut`** 命令仅打印出 Linux 系统中所有用户的用户名列表。显示的结果是相同的。
|
||||
|
||||
```
|
||||
# getent passwd | awk -F':' '{ print $1}'
|
||||
or
|
||||
# getent passwd | cut -d: -f1
|
||||
root
|
||||
bin
|
||||
daemon
|
||||
adm
|
||||
lp
|
||||
sync
|
||||
shutdown
|
||||
halt
|
||||
mail
|
||||
ftp
|
||||
postfix
|
||||
sshd
|
||||
tcpdump
|
||||
2gadmin
|
||||
apache
|
||||
zabbix
|
||||
mysql
|
||||
zend
|
||||
rpc
|
||||
2daygeek
|
||||
named
|
||||
mageshm
|
||||
|
||||
```
|
||||
你同样可以使用 `awk` 或 `cut` 命令仅打印出 Linux 系统中所有用户的用户名列表。显示的结果是相同的。
|
||||
|
||||
### 方法 3 :使用 `compgen` 命令
|
||||
|
||||
@ -212,7 +171,6 @@ rpc
|
||||
2daygeek
|
||||
named
|
||||
mageshm
|
||||
|
||||
```
|
||||
|
||||
------------------------
|
||||
@ -222,7 +180,7 @@ via: https://www.2daygeek.com/3-methods-to-list-all-the-users-in-linux-system/
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[SunWave](https://github.com/SunWave)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,21 +1,23 @@
|
||||
使用 Handbrake 转换视频
|
||||
======
|
||||
|
||||
> 这个开源工具可以很简单地将老视频转换为新格式。
|
||||
|
||||

|
||||
|
||||
最近,当我的儿子让我数字化他的高中篮球比赛的一些旧 DVD 时,我立刻知道我会使用 [Handbrake][1]。它是一个开源软件包,可轻松将视频转换为可在 MacOS、Windows、Linux、iOS、Android 和其他平台上播放的格式所需的所有工具。
|
||||
|
||||
Handbrake 是开源的,并在[ GPLv2 许可证][2]下分发。它很容易在 MacOS、Windows 和 Linux 包括 [Fedora][3] 和 [Ubuntu][4] 上安装。在 Linux 中,安装后就可以从命令行使用 `$ handbrake` 或从图形用户界面中选择它。(在我的例子中,是 GNOME 3)
|
||||
最近,当我的儿子让我数字化他的高中篮球比赛的一些旧 DVD 时,我马上就想到了 [Handbrake][1]。它是一个开源软件包,可轻松将视频转换为可在 MacOS、Windows、Linux、iOS、Android 和其他平台上播放的格式所需的所有工具。
|
||||
|
||||
Handbrake 是开源的,并在 [GPLv2 许可证][2]下分发。它很容易在 MacOS、Windows 和 Linux 包括 [Fedora][3] 和 [Ubuntu][4] 上安装。在 Linux 中,安装后就可以从命令行使用 `$ handbrake` 或从图形用户界面中选择它。(我的情况是 GNOME 3)
|
||||
|
||||

|
||||
|
||||
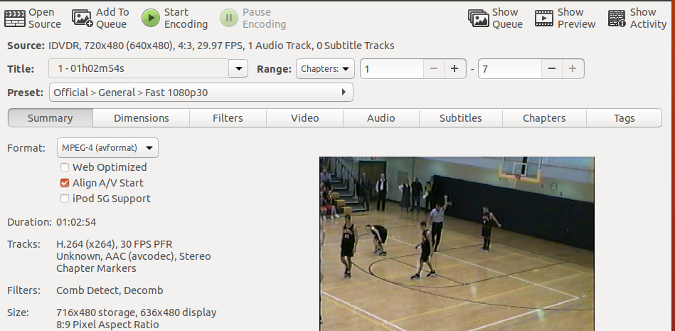
Handbrake 的菜单系统易于使用。单击 **Open Source** 选择要转换的视频源。对于我儿子的篮球视频,它是我的 Linux 笔记本中的 DVD 驱动器。将 DVD 插入驱动器后,软件会识别磁盘的内容。
|
||||
Handbrake 的菜单系统易于使用。单击 “Open Source” 选择要转换的视频源。对于我儿子的篮球视频,它是我的 Linux 笔记本中的 DVD 驱动器。将 DVD 插入驱动器后,软件会识别磁盘的内容。
|
||||
|
||||
|
||||
|
||||
正如你在上面截图中的 Source 旁边看到的那样,Handbrake 将其识别为 720x480 的 DVD,宽高比为 4:3,以每秒 29.97 帧的速度录制,有一个音轨。该软件还能预览视频。
|
||||
正如你在上面截图中的 “Source” 旁边看到的那样,Handbrake 将其识别为 720x480 的 DVD,宽高比为 4:3,以每秒 29.97 帧的速度录制,有一个音轨。该软件还能预览视频。
|
||||
|
||||
如果默认转换设置可以接受,只需按下 **Start Encoding** 按钮(一段时间后,根据处理器的速度),DVD 的内容将被转换并以默认格式 [M4V][5] 保存(可以改变)。
|
||||
如果默认转换设置可以接受,只需按下 “Start Encoding” 按钮(一段时间后,根据处理器的速度),DVD 的内容将被转换并以默认格式 [M4V][5] 保存(可以改变)。
|
||||
|
||||
如果你不喜欢文件名,很容易改变它。
|
||||
|
||||
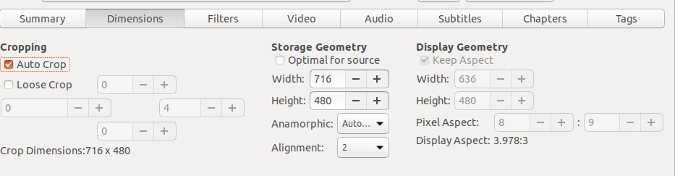
@ -25,7 +27,7 @@ Handbrake 有各种格式、大小和配置的输出选项。例如,它可以
|
||||
|
||||
|
||||
|
||||
你可以在 ”Dimensions“ 选项卡中更改视频输出大小。其他选项卡允许你应用过滤器、更改视频质量和编码、添加或修改音轨,包括字幕和修改章节。“Tags” 选项卡可让你识别输出视频文件中的作者、演员、导演、发布日期等。
|
||||
你可以在 “Dimensions” 选项卡中更改视频输出大小。其他选项卡允许你应用过滤器、更改视频质量和编码、添加或修改音轨,包括字幕和修改章节。“Tags” 选项卡可让你识别输出视频文件中的作者、演员、导演、发布日期等。
|
||||
|
||||
|
||||
|
||||
@ -44,7 +46,7 @@ via: https://opensource.com/article/18/7/handbrake
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating by ynmlml
|
||||
|
||||
Write Dumb Code
|
||||
======
|
||||
The best way you can contribute to an open source project is to remove lines of code from it. We should endeavor to write code that a novice programmer can easily understand without explanation or that a maintainer can understand without significant time investment.
|
||||
|
||||
110
sources/talk/20180731 How to be the lazy sysadmin.md
Normal file
110
sources/talk/20180731 How to be the lazy sysadmin.md
Normal file
@ -0,0 +1,110 @@
|
||||
How to be the lazy sysadmin
|
||||
======
|
||||

|
||||
|
||||
The job of a Linux SysAdmin is always complex and often fraught with various pitfalls and obstacles. Ranging from never having enough time to do everything, to having the Pointy-Haired Boss (PHB) staring over your shoulder while you try to work on the task that she or he just gave you, to having the most critical server in your care crash at the most inopportune time, problems and challenges abound. I have found that becoming the Lazy Sysadmin can help.
|
||||
|
||||
I discuss how to be a lazy SysAdmin in detail in my forthcoming book, [The Linux Philosophy for SysAdmins][1], (Apress), which is scheduled to be available in September. Parts of this article are taken from that book, especially Chapter 9, "Be a Lazy SysAdmin." Let's take a brief look at what it means to be a Lazy SysAdmin before we discuss how to do it.
|
||||
|
||||
### Real vs. fake productivity
|
||||
|
||||
#### Fake productivity
|
||||
|
||||
At one place I worked, the PHB believed in the management style called "management by walking around," the supposition being that anyone who wasn't typing something on their keyboard, or at least examining something on their display, was not being productive. This was a horrible place to work. It had high administrative walls between departments that created many, tiny silos, a heavy overburden of useless paperwork, and excruciatingly long wait times to obtain permission to do anything. For these and other reasons, it was impossible to do anything efficiently—if at all—so we were incredibly non-productive. To look busy, we all had our Look Busy Kits (LBKs), which were just short Bash scripts that showed some activity, or programs like `top`, `htop`, `iotop`, or any monitoring tool that constantly displayed some activity. The ethos of this place made it impossible to be truly productive, and I hated both the place and the fact that it was nearly impossible to accomplish anything worthwhile.
|
||||
|
||||
That horrible place was a nightmare for real SysAdmins. None of us was happy. It took four or five months to accomplish what took only a single morning in other places. We had little real work to do but spent a huge amount of time working to look busy. We had an unspoken contest going to create the best LBK, and that is where we spent most of our time. I only managed to last a few months at that job, but it seemed like a lifetime. If you looked only at the surface of that dungeon, you could say we were lazy because we accomplished almost zero real work.
|
||||
|
||||
This is an extreme example, and it is totally the opposite of what I mean when I say I am a Lazy SysAdmin and being a Lazy SysAdmin is a good thing.
|
||||
|
||||
#### Real productivity
|
||||
|
||||
I am fortunate to have worked for some true managers—they were people who understood that the productivity of a SysAdmin is not measured by how many hours per day are spent banging on a keyboard. After all, even a monkey can bang on a keyboard, but that is no indication of the value of the results.
|
||||
|
||||
As I say in my book:
|
||||
|
||||
> "I am a lazy SysAdmin and yet I am also a very productive SysAdmin. Those two seemingly contradictory statements are not mutually exclusive, rather they are complementary in a very positive way. …
|
||||
>
|
||||
> "A SysAdmin is most productive when thinking—thinking about how to solve existing problems and about how to avoid future problems; thinking about how to monitor Linux computers in order to find clues that anticipate and foreshadow those future problems; thinking about how to make their work more efficient; thinking about how to automate all of those tasks that need to be performed whether every day or once a year.
|
||||
>
|
||||
> "This contemplative aspect of the SysAdmin job is not well known or understood by those who are not SysAdmins—including many of those who manage the SysAdmins, the Pointy Haired Bosses. SysAdmins all approach the contemplative parts of their job in different ways. Some of the SysAdmins I have known found their best ideas at the beach, cycling, participating in marathons, or climbing rock walls. Others think best when sitting quietly or listening to music. Still others think best while reading fiction, studying unrelated disciplines, or even while learning more about Linux. The point is that we all stimulate our creativity in different ways, and many of those creativity boosters do not involve typing a single keystroke on a keyboard. Our true productivity may be completely invisible to those around the SysAdmin."
|
||||
|
||||
There are some simple secrets to being the Lazy SysAdmin—the SysAdmin who accomplishes everything that needs to be done and more, all the while keeping calm and collected while others are running around in a state of panic. Part of this is working efficiently, and part is about preventing problems in the first place.
|
||||
|
||||
### Ways to be the Lazy SysAdmin
|
||||
|
||||
#### Thinking
|
||||
|
||||
I believe the most important secret about being the Lazy SysAdmin is thinking. As in the excerpt above, great SysAdmins spend a significant amount of time thinking about things we can do to work more efficiently, locate anomalies before they become problems, and work smarter, all while considering how to accomplish all of those things and more.
|
||||
|
||||
For example, right now—in addition to writing this article—I am thinking about a project I intend to start as soon as the new parts arrive from Amazon and the local computer store. The motherboard on one of my less critical computers is going bad, and it has been crashing more frequently recently. But my very old and minimal server—the one that handles my email and external websites, as well as providing DHCP and DNS services for the rest of my network—isn't failing but has to deal with intermittent overloads due to external attacks of various types.
|
||||
|
||||
I started by thinking I would just replace the motherboard and its direct components—memory, CPU, and possibly the power supply—in the failing unit. But after thinking about it for a while, I decided I should put the new components into the server and move the old (but still serviceable) ones from the server into the failing system. This would work and take only an hour, or perhaps two, to remove the old components from the server and install the new ones. Then I could take my time replacing the components in the failing computer. Great. So I started generating a mental list of tasks to do to accomplish this.
|
||||
|
||||
However, as I worked the list, I realized that about the only components of the server I wouldn't replace were the case and the hard drive, and the two computers' cases are almost identical. After having this little revelation, I started thinking about replacing the failing computer's components with the new ones and making it my server. Then, after some testing, I would just need to remove the hard drive from my current server and install it in the case with all the new components, change a couple of network configuration items, change the hostname on the KVM switch port, and change the hostname labels on the case, and it should be good to go. This will produce far less server downtime and significantly less stress for me. Also, if something fails, I can simply move the hard drive back to the original server until I can fix the problem with the new one.
|
||||
|
||||
So now I have created a mental list of the tasks I need to do to accomplish this. And—I hope you were watching closely—my fingers never once touched the keyboard while I was working all of this out in my head. My new mental action plan is low risk and involves a much smaller amount of server downtime compared to my original plan.
|
||||
|
||||
When I worked for IBM, I used to see signs all over that said "THINK" in many languages. Thinking can save time and stress and is the main hallmark of a Lazy SysAdmin.
|
||||
|
||||
#### Doing preventative maintenance
|
||||
|
||||
In the mid-1970s, I was hired as a customer engineer at IBM, and my territory consisted of a fairly large number of [unit record machines][2]. That just means that they were heavily mechanical devices that processed punched cards—a few dated from the 1930s. Because these machines were primarily mechanical, their parts often wore out or became maladjusted. Part of my job was to fix them when they broke. The main part of my job—the most important part—was to prevent them from breaking in the first place. The preventative maintenance was intended to replace worn parts before they broke and to lubricate and adjust the moving components to ensure that they were working properly.
|
||||
|
||||
As I say in The Linux Philosophy for SysAdmins:
|
||||
|
||||
> "My managers at IBM understood that was only the tip of the iceberg; they—and I—knew my job was customer satisfaction. Although that usually meant fixing broken hardware, it also meant reducing the number of times the hardware broke. That was good for the customer because they were more productive when their machines were working. It was good for me because I received far fewer calls from those happier customers. I also got to sleep more due to the resultant fewer emergency off-hours callouts. I was being the Lazy [Customer Engineer]. By doing the extra work upfront, I had to do far less work in the long run.
|
||||
>
|
||||
> "This same tenet has become one of the functional tenets of the Linux Philosophy for SysAdmins. As SysAdmins, our time is best spent doing those tasks that minimize future workloads."
|
||||
|
||||
Looking for problems to fix in a Linux computer is the equivalent of project management. I review the system logs looking for hints of problems that might become critical later. If something appears to be a little amiss, or I notice my workstation or a server is not responding as it should, or if the logs show something unusual—all of these can be indicative of an underlying problem that has not generated symptoms obvious to users or the PHB.
|
||||
|
||||
I do frequent checks of the files in `/var/log/`, especially messages and security. One of my more common problems is the many script kiddies who try various types of attacks on my firewall system. And, no, I do not rely on the alleged firewall in the modem/router provided by my ISP. These logs contain a lot of information about the source of the attempted attack and can be very valuable. But it takes a lot of work to scan the logs on various hosts and put solutions into place. So I turn to automation.
|
||||
|
||||
#### Automating
|
||||
|
||||
I have found that a very large percentage of my work can be performed by some form of automation. One of the tenets of the Linux Philosophy for SysAdmins is "automate everything," and this includes boring, drudge tasks like scanning logfiles every day.
|
||||
|
||||
Programs like [Logwatch][3] can monitor your logfiles for anomalous entries and notify you when they occur. Logwatch usually runs as a cron job once a day and sends an email to root on the localhost. You can run Logwatch from the command line and view the results immediately on your display. Now I just need to look at the Logwatch email notification every day.
|
||||
|
||||
But the reality is just getting a notification is not enough, because we can't sit and watch for problems all the time. Sometimes an immediate response is required. Another program I like, one that does all of the work for me—see, this is the real Lazy Admin—is [Fail2Ban][4]. Fail2Ban scans designated logfiles for various types of hacking and intrusion attempts, and if it sees enough sustained activity of a specific type from a particular IP address, it adds an entry to the firewall that blocks any further hacking attempts from that IP address for a specified time. The defaults tend to be around 10 minutes, but I like to specify 12 or 24 hours for most types of attacks. Each type of hacking attack is configured separately, such as those trying to log in via SSH and those attacking a web server.
|
||||
|
||||
#### Writing scripts
|
||||
|
||||
Automation is one of the key components of the Philosophy. Everything that can be automated should be, and the rest should be automated as much as possible. So, I also write a lot of scripts to solve problems, which also means I write scripts to do most of my work for me.
|
||||
|
||||
My scripts save me huge amounts of time because they contain the commands to perform specific tasks, which significantly reduces the amount of typing I need to do. For example, I frequently restart my email server and my spam-fighting software (which needs restarted when configuration changes are made to SpamAssassin's `local.cf` file). Those services must be stopped and restarted in a specific order. So, I wrote a short script with a few commands and stored it in `/usr/local/bin`, where it is accessible. Now, instead of typing several commands and waiting for each to finish before typing the next one—not to mention remembering the correct sequence of commands and the proper syntax of each—I type in a three-character command and leave the rest to my script.
|
||||
|
||||
#### Reducing typing
|
||||
|
||||
Another way to be the Lazy SysAdmin is to reduce the amount of typing we need to do. Besides, my typing skills are really horrible (that is to say I have none—a few clumsy fingers at best). One possible cause for errors is my poor typing, so I try to keep typing to a minimum.
|
||||
|
||||
The vast majority of GNU and Linux core utilities have very short names. They are, however, names that have some meaning. Tools like `cd` for change directory, `ls` for list (the contents of a directory), and `dd` for disk dump are pretty obvious. Short names mean less typing and fewer opportunities for errors to creep in. I think the short names are usually easier to remember.
|
||||
|
||||
When I write shell scripts, I like to keep the names short but meaningful (to me at least) like `rsbu` for Rsync BackUp. In some cases, I like the names a bit longer, such as `doUpdates` to perform system updates. In the latter case, the longer name makes the script's purpose obvious. This saves time because it's easy to remember the script's name.
|
||||
|
||||
Other methods to reduce typing are command line aliases and command line recall and editing. Aliases are simply substitutions that are made by the Bash shell when you type a command. Type the `alias` command and look at the list of aliases that are configured by default. For example, when you enter the command `ls`, the entry `alias ls='ls –color=auto'` substitutes the longer command, so you only need to type two characters instead of 14 to get a listing with colors. You can also use the `alias` command to add your own aliases.
|
||||
|
||||
Command line recall allows you to use the keyboard's Up and Down arrow keys to scroll through your command history. If you need to use the same command again, you can just press the Enter key when you find the one you need. If you need to change the command once you have found it, you can use standard command line editing features to make the changes.
|
||||
|
||||
### Parting thoughts
|
||||
|
||||
It is actually quite a lot of work being the Lazy SysAdmin. But we work smart, rather than working hard. We spend time exploring the hosts we are responsible for and dealing with any little problems long before they become large problems. We spend a lot of time thinking about the best ways to resolve problems, and we think a lot about discovering new ways to work smarter at being the Lazy SysAdmin.
|
||||
|
||||
There are many other ways to be the Lazy SysAdmin besides the few described here. I'm sure you have some of your own; please share them with the rest of us in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/how-be-lazy-sysadmin
|
||||
|
||||
作者:[David Both][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://www.apress.com/us/book/9781484237298
|
||||
[2]:https://en.wikipedia.org/wiki/Unit_record_equipment
|
||||
[3]:https://www.techrepublic.com/article/how-to-install-and-use-logwatch-on-linux/
|
||||
[4]:https://www.fail2ban.org/wiki/index.php/Main_Page
|
||||
@ -1,254 +0,0 @@
|
||||
Translating by qhwdw
|
||||
How to reset, revert, and return to previous states in Git
|
||||
======
|
||||
|
||||

|
||||
|
||||
One of the lesser understood (and appreciated) aspects of working with Git is how easy it is to get back to where you were before—that is, how easy it is to undo even major changes in a repository. In this article, we'll take a quick look at how to reset, revert, and completely return to previous states, all with the simplicity and elegance of individual Git commands.
|
||||
|
||||
### Reset
|
||||
|
||||
Let's start with the Git command `reset`. Practically, you can think of it as a "rollback"—it points your local environment back to a previous commit. By "local environment," we mean your local repository, staging area, and working directory.
|
||||
|
||||
Take a look at Figure 1. Here we have a representation of a series of commits in Git. A branch in Git is simply a named, movable pointer to a specific commit. In this case, our branch master is a pointer to the latest commit in the chain.
|
||||
|
||||
![Local Git environment with repository, staging area, and working directory][2]
|
||||
|
||||
Fig. 1: Local Git environment with repository, staging area, and working directory
|
||||
|
||||
If we look at what's in our master branch now, we can see the chain of commits made so far.
|
||||
```
|
||||
$ git log --oneline
|
||||
b764644 File with three lines
|
||||
7c709f0 File with two lines
|
||||
9ef9173 File with one line
|
||||
```
|
||||
|
||||
`reset` command to do this for us. For example, if we want to reset master to point to the commit two back from the current commit, we could use either of the following methods:
|
||||
|
||||
What happens if we want to roll back to a previous commit. Simple—we can just move the branch pointer. Git supplies thecommand to do this for us. For example, if we want to reset master to point to the commit two back from the current commit, we could use either of the following methods:
|
||||
|
||||
`$ git reset 9ef9173` (using an absolute commit SHA1 value 9ef9173)
|
||||
|
||||
or
|
||||
|
||||
`$ git reset current~2` (using a relative value -2 before the "current" tag)
|
||||
|
||||
Figure 2 shows the results of this operation. After this, if we execute a `git log` command on the current branch (master), we'll see just the one commit.
|
||||
```
|
||||
$ git log --oneline
|
||||
|
||||
9ef9173 File with one line
|
||||
|
||||
```
|
||||
|
||||
![After reset][4]
|
||||
|
||||
Fig. 2: After `reset`
|
||||
|
||||
The `git reset` command also includes options to update the other parts of your local environment with the contents of the commit where you end up. These options include: `hard` to reset the commit being pointed to in the repository, populate the working directory with the contents of the commit, and reset the staging area; `soft` to only reset the pointer in the repository; and `mixed` (the default) to reset the pointer and the staging area.
|
||||
|
||||
Using these options can be useful in targeted circumstances such as `git reset --hard <commit sha1 | reference>``.` This overwrites any local changes you haven't committed. In effect, it resets (clears out) the staging area and overwrites content in the working directory with the content from the commit you reset to. Before you use the `hard` option, be sure that's what you really want to do, since the command overwrites any uncommitted changes.
|
||||
|
||||
### Revert
|
||||
|
||||
The net effect of the `git revert` command is similar to reset, but its approach is different. Where the `reset` command moves the branch pointer back in the chain (typically) to "undo" changes, the `revert` command adds a new commit at the end of the chain to "cancel" changes. The effect is most easily seen by looking at Figure 1 again. If we add a line to a file in each commit in the chain, one way to get back to the version with only two lines is to reset to that commit, i.e., `git reset HEAD~1`.
|
||||
|
||||
Another way to end up with the two-line version is to add a new commit that has the third line removed—effectively canceling out that change. This can be done with a `git revert` command, such as:
|
||||
```
|
||||
$ git revert HEAD
|
||||
|
||||
```
|
||||
|
||||
Because this adds a new commit, Git will prompt for the commit message:
|
||||
```
|
||||
Revert "File with three lines"
|
||||
|
||||
This reverts commit b764644bad524b804577684bf74e7bca3117f554.
|
||||
|
||||
# Please enter the commit message for your changes. Lines starting
|
||||
# with '#' will be ignored, and an empty message aborts the commit.
|
||||
# On branch master
|
||||
# Changes to be committed:
|
||||
# modified: file1.txt
|
||||
#
|
||||
```
|
||||
|
||||
Figure 3 (below) shows the result after the `revert` operation is completed.
|
||||
|
||||
If we do a `git log` now, we'll see a new commit that reflects the contents before the previous commit.
|
||||
```
|
||||
$ git log --oneline
|
||||
11b7712 Revert "File with three lines"
|
||||
b764644 File with three lines
|
||||
7c709f0 File with two lines
|
||||
9ef9173 File with one line
|
||||
```
|
||||
|
||||
Here are the current contents of the file in the working directory:
|
||||
```
|
||||
$ cat <filename>
|
||||
Line 1
|
||||
Line 2
|
||||
```
|
||||
|
||||
#### Revert or reset?
|
||||
|
||||
Why would you choose to do a `revert` over a `reset` operation? If you have already pushed your chain of commits to the remote repository (where others may have pulled your code and started working with it), a revert is a nicer way to cancel out changes for them. This is because the Git workflow works well for picking up additional commits at the end of a branch, but it can be challenging if a set of commits is no longer seen in the chain when someone resets the branch pointer back.
|
||||
|
||||
This brings us to one of the fundamental rules when working with Git in this manner: Making these kinds of changes in your local repository to code you haven't pushed yet is fine. But avoid making changes that rewrite history if the commits have already been pushed to the remote repository and others may be working with them.
|
||||
|
||||
In short, if you rollback, undo, or rewrite the history of a commit chain that others are working with, your colleagues may have a lot more work when they try to merge in changes based on the original chain they pulled. If you must make changes against code that has already been pushed and is being used by others, consider communicating before you make the changes and give people the chance to merge their changes first. Then they can pull a fresh copy after the infringing operation without needing to merge.
|
||||
|
||||
You may have noticed that the original chain of commits was still there after we did the reset. We moved the pointer and reset the code back to a previous commit, but it did not delete any commits. This means that, as long as we know the original commit we were pointing to, we can "restore" back to the previous point by simply resetting back to the original head of the branch:
|
||||
```
|
||||
git reset <sha1 of commit>
|
||||
|
||||
```
|
||||
|
||||
A similar thing happens in most other operations we do in Git when commits are replaced. New commits are created, and the appropriate pointer is moved to the new chain. But the old chain of commits still exists.
|
||||
|
||||
### Rebase
|
||||
|
||||
Now let's look at a branch rebase. Consider that we have two branches—master and feature—with the chain of commits shown in Figure 4 below. Master has the chain `C4->C2->C1->C0` and feature has the chain `C5->C3->C2->C1->C0`.
|
||||
|
||||
![Chain of commits for branches master and feature][6]
|
||||
|
||||
Fig. 4: Chain of commits for branches master and feature
|
||||
|
||||
If we look at the log of commits in the branches, they might look like the following. (The `C` designators for the commit messages are used to make this easier to understand.)
|
||||
```
|
||||
$ git log --oneline master
|
||||
6a92e7a C4
|
||||
259bf36 C2
|
||||
f33ae68 C1
|
||||
5043e79 C0
|
||||
|
||||
$ git log --oneline feature
|
||||
79768b8 C5
|
||||
000f9ae C3
|
||||
259bf36 C2
|
||||
f33ae68 C1
|
||||
5043e79 C0
|
||||
```
|
||||
|
||||
I tell people to think of a rebase as a "merge with history" in Git. Essentially what Git does is take each different commit in one branch and attempt to "replay" the differences onto the other branch.
|
||||
|
||||
So, we can rebase a feature onto master to pick up `C4` (e.g., insert it into feature's chain). Using the basic Git commands, it might look like this:
|
||||
```
|
||||
$ git checkout feature
|
||||
$ git rebase master
|
||||
|
||||
First, rewinding head to replay your work on top of it...
|
||||
Applying: C3
|
||||
Applying: C5
|
||||
```
|
||||
|
||||
Afterward, our chain of commits would look like Figure 5.
|
||||
|
||||
![Chain of commits after the rebase command][8]
|
||||
|
||||
Fig. 5: Chain of commits after the `rebase` command
|
||||
|
||||
Again, looking at the log of commits, we can see the changes.
|
||||
```
|
||||
$ git log --oneline master
|
||||
6a92e7a C4
|
||||
259bf36 C2
|
||||
f33ae68 C1
|
||||
5043e79 C0
|
||||
|
||||
$ git log --oneline feature
|
||||
c4533a5 C5
|
||||
64f2047 C3
|
||||
6a92e7a C4
|
||||
259bf36 C2
|
||||
f33ae68 C1
|
||||
5043e79 C0
|
||||
```
|
||||
|
||||
Notice that we have `C3'` and `C5'`—new commits created as a result of making the changes from the originals "on top of" the existing chain in master. But also notice that the "original" `C3` and `C5` are still there—they just don't have a branch pointing to them anymore.
|
||||
|
||||
If we did this rebase, then decided we didn't like the results and wanted to undo it, it would be as simple as:
|
||||
```
|
||||
$ git reset 79768b8
|
||||
|
||||
```
|
||||
|
||||
With this simple change, our branch would now point back to the same set of commits as before the `rebase` operation—effectively undoing it (Figure 6).
|
||||
|
||||
![After undoing rebase][10]
|
||||
|
||||
Fig. 6: After undoing the `rebase` operation
|
||||
|
||||
What happens if you can't recall what commit a branch pointed to before an operation? Fortunately, Git again helps us out. For most operations that modify pointers in this way, Git remembers the original commit for you. In fact, it stores it in a special reference named `ORIG_HEAD `within the `.git` repository directory. That path is a file containing the most recent reference before it was modified. If we `cat` the file, we can see its contents.
|
||||
```
|
||||
$ cat .git/ORIG_HEAD
|
||||
79768b891f47ce06f13456a7e222536ee47ad2fe
|
||||
```
|
||||
|
||||
We could use the `reset` command, as before, to point back to the original chain. Then the log would show this:
|
||||
```
|
||||
$ git log --oneline feature
|
||||
79768b8 C5
|
||||
000f9ae C3
|
||||
259bf36 C2
|
||||
f33ae68 C1
|
||||
5043e79 C0
|
||||
```
|
||||
|
||||
Another place to get this information is in the reflog. The reflog is a play-by-play listing of switches or changes to references in your local repository. To see it, you can use the `git reflog` command:
|
||||
```
|
||||
$ git reflog
|
||||
79768b8 HEAD@{0}: reset: moving to 79768b
|
||||
c4533a5 HEAD@{1}: rebase finished: returning to refs/heads/feature
|
||||
c4533a5 HEAD@{2}: rebase: C5
|
||||
64f2047 HEAD@{3}: rebase: C3
|
||||
6a92e7a HEAD@{4}: rebase: checkout master
|
||||
79768b8 HEAD@{5}: checkout: moving from feature to feature
|
||||
79768b8 HEAD@{6}: commit: C5
|
||||
000f9ae HEAD@{7}: checkout: moving from master to feature
|
||||
6a92e7a HEAD@{8}: commit: C4
|
||||
259bf36 HEAD@{9}: checkout: moving from feature to master
|
||||
000f9ae HEAD@{10}: commit: C3
|
||||
259bf36 HEAD@{11}: checkout: moving from master to feature
|
||||
259bf36 HEAD@{12}: commit: C2
|
||||
f33ae68 HEAD@{13}: commit: C1
|
||||
5043e79 HEAD@{14}: commit (initial): C0
|
||||
```
|
||||
|
||||
You can then reset to any of the items in that list using the special relative naming format you see in the log:
|
||||
```
|
||||
$ git reset HEAD@{1}
|
||||
|
||||
```
|
||||
|
||||
Once you understand that Git keeps the original chain of commits around when operations "modify" the chain, making changes in Git becomes much less scary. This is one of Git's core strengths: being able to quickly and easily try things out and undo them if they don't work.
|
||||
|
||||
Brent Laster will present [Power Git: Rerere, Bisect, Subtrees, Filter Branch, Worktrees, Submodules, and More][11] at the 20th annual [OSCON][12] event, July 16-19 in Portland, Ore. For more tips and explanations about using Git at any level, checkout Brent's book "[Professional Git][13]," available on Amazon.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/git-reset-revert-rebase-commands
|
||||
|
||||
作者:[Brent Laster][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bclaster
|
||||
[1]:/file/401126
|
||||
[2]:https://opensource.com/sites/default/files/uploads/gitcommands1_local-environment.png (Local Git environment with repository, staging area, and working directory)
|
||||
[3]:/file/401131
|
||||
[4]:https://opensource.com/sites/default/files/uploads/gitcommands2_reset.png (After reset)
|
||||
[5]:/file/401141
|
||||
[6]:https://opensource.com/sites/default/files/uploads/gitcommands4_commits-branches.png (Chain of commits for branches master and feature)
|
||||
[7]:/file/401146
|
||||
[8]:https://opensource.com/sites/default/files/uploads/gitcommands5_commits-rebase.png (Chain of commits after the rebase command)
|
||||
[9]:/file/401151
|
||||
[10]:https://opensource.com/sites/default/files/uploads/gitcommands6_rebase-undo.png (After undoing rebase)
|
||||
[11]:https://conferences.oreilly.com/oscon/oscon-or/public/schedule/detail/67142
|
||||
[12]:https://conferences.oreilly.com/oscon/oscon-or
|
||||
[13]:https://www.amazon.com/Professional-Git-Brent-Laster/dp/111928497X/ref=la_B01MTGIINQ_1_2?s=books&ie=UTF8&qid=1528826673&sr=1-2
|
||||
@ -1,128 +0,0 @@
|
||||
How to edit Adobe InDesign files with Scribus and Gedit
|
||||
======
|
||||
|
||||
|
||||
|
||||
To be a good graphic designer, you must be adept at using the profession's tools, which for most designers today are the ones in the proprietary Adobe Creative Suite.
|
||||
|
||||
However, there are times that open source tools will get you out of a jam. For example, imagine you're a commercial printer tasked with printing a file created in Adobe InDesign. You need to make a simple change (e.g., fixing a small typo) to the file, but you don't have immediate access to the Adobe suite. While these situations are admittedly rare, open source tools like desktop publishing software [Scribus][1] and text editor [Gedit][2] can save the day.
|
||||
|
||||
In this article, I'll show you how I edit Adobe InDesign files with Scribus and Gedit. Note that there are many open source graphic design solutions that can be used instead of or in conjunction with Adobe InDesign. For more on this subject, check out my articles: [Expensive tools aren't the only option for graphic design (and never were)][3] and [2 open][4][source][4][Adobe InDesign scripts][4].
|
||||
|
||||
When developing this solution, I read a few blogs on how to edit InDesign files with open source software but did not find what I was looking for. One suggestion I found was to create an EPS from InDesign and open it as an editable file in Scribus, but that did not work. Another suggestion was to create an IDML (an older InDesign file format) document from InDesign and open that in Scribus. That worked much better, so that's the workaround I used in the following examples.
|
||||
|
||||
### Editing a business card
|
||||
|
||||
Opening and editing my InDesign business card file in Scribus worked fairly well. The only issue I had was that the tracking (the space between letters) was a bit off and the upside-down "J" I used to create the lower-case "f" in "Jeff" was flipped. Otherwise, the styles and colors were all intact.
|
||||
|
||||
|
||||
![Business card in Adobe InDesign][6]
|
||||
|
||||
Business card designed in Adobe InDesign.
|
||||
|
||||
![InDesign IDML file opened in Scribus][8]
|
||||
|
||||
InDesign IDML file opened in Scribus.
|
||||
|
||||
### Deleting copy in a paginated book
|
||||
|
||||
The book conversion didn't go as well. The main body of the text was OK, but the table of contents and some of the drop caps and footers were messed up when I opened the InDesign file in Scribus. Still, it produced an editable document. One problem was some of my blockquotes defaulted to Arial font because a character style (apparently carried over from the original Word file) was on top of the paragraph style. This was simple to fix.
|
||||
|
||||
![Book layout in InDesign][10]
|
||||
|
||||
Book layout in InDesign.
|
||||
|
||||
![InDesign IDML file of book layout opened in Scribus][12]
|
||||
|
||||
InDesign IDML file of book layout opened in Scribus.
|
||||
|
||||
Trying to select and delete a page of text produced surprising results. I placed the cursor in the text and hit Command+A (the keyboard shortcut for "select all"). It looked like one page was highlighted. However, that wasn't really true.
|
||||
|
||||
![Selecting text in Scribus][14]
|
||||
|
||||
Selecting text in Scribus.
|
||||
|
||||
When I hit the Delete key, the entire text string (not just the highlighted page) disappeared.
|
||||
|
||||
![Both pages of text deleted in Scribus][16]
|
||||
|
||||
Both pages of text deleted in Scribus.
|
||||
|
||||
Then something even more interesting happened… I hit Command+Z to undo the deletion. When the text came back, the formatting was messed up.
|
||||
|
||||
![Undo delete restored the text, but with bad formatting.][18]
|
||||
|
||||
Command+Z (undo delete) restored the text, but the formatting was bad.
|
||||
|
||||
### Opening a design file in a text editor
|
||||
|
||||
If you open a Scribus file and an InDesign file in a standard text editor (e.g., TextEdit on a Mac), you will see that the Scribus file is very readable whereas the InDesign file is not.
|
||||
|
||||
You can use TextEdit to make changes to either type of file and save it, but the resulting file is useless. Here's the error I got when I tried re-opening the edited file in InDesign.
|
||||
|
||||
![InDesign error message][20]
|
||||
|
||||
InDesign error message.
|
||||
|
||||
I got much better results when I used Gedit on my Linux Ubuntu machine to edit the Scribus file. I launched Gedit from the command line and voilà, the Scribus file opened, and the changes I made in Gedit were retained.
|
||||
|
||||
![Editing Scribus file in Gedit][22]
|
||||
|
||||
Editing a Scribus file in Gedit.
|
||||
|
||||
![Result of the Gedit edit in Scribus][24]
|
||||
|
||||
Result of the Gedit edit opened in Scribus.
|
||||
|
||||
This could be very useful to a printer that receives a call from a client about a small typo in a project. Instead of waiting to get a new file, the printer could open the Scribus file in Gedit, make the change, and be good to go.
|
||||
|
||||
### Dropping images into a file
|
||||
|
||||
I converted an InDesign doc to an IDML file so I could try dropping in some PDFs using Scribus. It seems Scribus doesn't do this as well as InDesign, as it failed. Instead, I converted my PDFs to JPGs and imported them into Scribus. That worked great. However, when I exported my document as a PDF, I found that the files size was rather large.
|
||||
|
||||
![Huge PDF file][26]
|
||||
|
||||
Exporting Scribus to PDF produced a huge file.
|
||||
|
||||
I'm not sure why this happened—I'll have to investigate it later.
|
||||
|
||||
Do you have any tips for using open source software to edit graphics files? If so, please share them in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/adobe-indesign-open-source-tools
|
||||
|
||||
作者:[Jeff Macharyas][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rikki-endsley
|
||||
[1]:https://www.scribus.net/
|
||||
[2]:https://wiki.gnome.org/Apps/Gedit
|
||||
[3]:https://opensource.com/life/16/8/open-source-alternatives-graphic-design
|
||||
[4]:https://opensource.com/article/17/3/scripts-adobe-indesign
|
||||
[5]:/file/402516
|
||||
[6]:https://opensource.com/sites/default/files/uploads/1-business_card_designed_in_adobe_indesign_cc.png (Business card in Adobe InDesign)
|
||||
[7]:/file/402521
|
||||
[8]:https://opensource.com/sites/default/files/uploads/2-indesign_.idml_file_opened_in_scribus.png (InDesign IDML file opened in Scribus)
|
||||
[9]:/file/402531
|
||||
[10]:https://opensource.com/sites/default/files/uploads/3-book_layout_in_indesign.png (Book layout in InDesign)
|
||||
[11]:/file/402536
|
||||
[12]:https://opensource.com/sites/default/files/uploads/4-indesign_.idml_file_of_book_opened_in_scribus.png (InDesign IDML file of book layout opened in Scribus)
|
||||
[13]:/file/402541
|
||||
[14]:https://opensource.com/sites/default/files/uploads/5-command-a_in_the_scribus_file.png (Selecting text in Scribus)
|
||||
[15]:/file/402546
|
||||
[16]:https://opensource.com/sites/default/files/uploads/6-deleted_text_in_scribus.png (Both pages of text deleted in Scribus)
|
||||
[17]:/file/402551
|
||||
[18]:https://opensource.com/sites/default/files/uploads/7-command-z_in_scribus.png (Undo delete restored the text, but with bad formatting.)
|
||||
[19]:/file/402556
|
||||
[20]:https://opensource.com/sites/default/files/uploads/8-indesign_error_message.png (InDesign error message)
|
||||
[21]:/file/402561
|
||||
[22]:https://opensource.com/sites/default/files/uploads/9-scribus_edited_in_gedit_on_linux.png (Editing Scribus file in Gedit)
|
||||
[23]:/file/402566
|
||||
[24]:https://opensource.com/sites/default/files/uploads/10-scribus_opens_after_gedit_changes.png (Result of the Gedit edit in Scribus)
|
||||
[25]:/file/402571
|
||||
[26]:https://opensource.com/sites/default/files/uploads/11-large_pdf_size.png (Huge PDF file)
|
||||
@ -1,75 +0,0 @@
|
||||
[Moelf](https://github.com/Moelf) Translating
|
||||
Why is Arch Linux So Challenging and What are Its Pros & Cons?
|
||||
======
|
||||
|
||||

|
||||
|
||||
[Arch Linux][1] is among the most popular Linux distributions and it was first released in **2002** , being spear-headed by **Aaron Grifin**. Yes, it aims to provide simplicity, minimalism, and elegance to the OS user but its target audience is not the faint of hearts. Arch encourages community involvement and a user is expected to put in some effort to better comprehend how the system operates.
|
||||
|
||||
Many old-time Linux users know a good amount about **Arch Linux** but you probably don’t if you are new to it considering using it for your everyday computing tasks. I’m no authority on the distro myself but from my experience with it, here are the pros and cons you will experience while using it.
|
||||
|
||||
### 1\. Pro: Build Your Own Linux OS
|
||||
|
||||
Other popular Linux Operating Systems like **Fedora** and **Ubuntu** ship with computers, same as **Windows** and **MacOS**. **Arch** , on the other hand, allows you to develop your OS to your taste. If you are able to achieve this, you will end up with a system that will be able to do exactly as you wish.
|
||||
|
||||
#### Con: Installation is a Hectic Process
|
||||
|
||||
[Installing Arch Linux][2] is far from a walk in a park and since you will be fine-tuning the OS, it will take a while. You will need to have an understanding of various terminal commands and the components you will be working with since you are to pick them yourself. By now, you probably already know that this requires quite a bit of reading.
|
||||
|
||||
### 2\. Pro: No Bloatware and Unnecessary Services
|
||||
|
||||
Since **Arch** allows you to choose your own components, you no longer have to deal with a bunch of software you don’t want. In contrast, OSes like **Ubuntu** come with a huge number of pre-installed desktop and background apps which you may not need and might not be able to know that they exist in the first place, before going on to remove them.
|
||||
|
||||
To put simply, **Arch Linux** saves you post-installation time. **Pacman** , an awesome utility app, is the package manager Arch Linux uses by default. There is an alternative to **Pacman** , called [Pamac][3].
|
||||
|
||||
### 3\. Pro: No System Upgrades
|
||||
|
||||
**Arch Linux** uses the rolling release model and that is awesome. It means that you no longer have to worry about upgrading every now and then. Once you install Arch, say goodbye to upgrading to a new version as updates occur continuously. By default, you will always be using the latest version.
|
||||
|
||||
#### Con: Some Updates Can Break Your System
|
||||
|
||||
While updates flow in continuously, you have to consciously track what comes in. Nobody knows your software’s specific configuration and it’s not tested by anyone but you. So, if you are not careful, things on your machine could break.
|
||||
|
||||
### 4\. Pro: Arch is Community Based
|
||||
|
||||
Linux users generally have one thing in common: The need for independence. Although most Linux distros have less corporate ties, there are still a few you cannot ignore. For instance, a distro based on **Ubuntu** is influenced by whatever decisions Canonical makes.
|
||||
|
||||
If you are trying to become even more independent with the use of your computer, then **Arch Linux** is the way to go. Unlike most systems, Arch has no commercial influence and focuses on the community.
|
||||
|
||||
### 5\. Pro: Arch Wiki is Awesome
|
||||
|
||||
The [Arch Wiki][4] is a super library of everything you need to know about the installation and maintenance of every component in the Linux system. The great thing about this site is that even if you are using a different Linux distro from Arch, you would still find its information relevant. That’s simply because Arch uses the same components as many other Linux distros and its guides and fixes sometimes apply to all.
|
||||
|
||||
### 6\. Pro: Check Out the Arch User Repository
|
||||
|
||||
The [Arch User Repository (AUR)][5] is a huge collection of software packages from members of the community. If you are looking for a Linux program that is not yet available on Arch’s repositories, you can find it on the **AUR** for sure.
|
||||
|
||||
The **AUR** is maintained by users who compile and install packages from source. Users are also allowed to vote on packages which give them (the packages i.e.) higher rankings that make them more visible to potential users.
|
||||
|
||||
#### Ultimately: Is Arch Linux for You?
|
||||
|
||||
**Arch Linux** has way more **pros** than **cons** including the ones that aren’t on this list. The installation process is long and probably too technical for a non-Linux savvy user, but with enough time on your hands and the ability to maximize productivity using wiki guides and the like, you should be good to go.
|
||||
|
||||
**Arch Linux** is a great Linux distro – not in spite of its complexity, but because of it. And it appeals most to those who are ready to do what needs to be done – given that you will have to do your homework and exercise a good amount of patience.
|
||||
|
||||
By the time you build this Operating System from scratch, you would have learned many details about GNU/Linux and would never be ignorant of what’s going on with your PC again.
|
||||
|
||||
What are the **pros** and **cons** of using **Arch Linux** in your experience? And on the whole, why is using it so challenging? Drop your comments in the discussion section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.fossmint.com/why-is-arch-linux-so-challenging-what-are-pros-cons/
|
||||
|
||||
作者:[Martins D. Okoi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.fossmint.com/author/dillivine/
|
||||
[1]:https://www.archlinux.org/
|
||||
[2]:https://www.tecmint.com/arch-linux-installation-and-configuration-guide/
|
||||
[3]:https://www.fossmint.com/pamac-arch-linux-gui-package-manager/
|
||||
[4]:https://wiki.archlinux.org/
|
||||
[5]:https://wiki.archlinux.org/index.php/Arch_User_Repository
|
||||
362
sources/tech/20180719 Building tiny container images.md
Normal file
362
sources/tech/20180719 Building tiny container images.md
Normal file
@ -0,0 +1,362 @@
|
||||
Building tiny container images
|
||||
======
|
||||
|
||||
|
||||
|
||||
When [Docker][1] exploded onto the scene a few years ago, it brought containers and container images to the masses. Although Linux containers existed before then, Docker made it easy to get started with a user-friendly command-line interface and an easy-to-understand way to build images using the Dockerfile format. But while it may be easy to jump in, there are still some nuances and tricks to building container images that are usable, even powerful, but still small in size.
|
||||
|
||||
### First pass: Clean up after yourself
|
||||
|
||||
Some of these examples involve the same kind of cleanup you would use with a traditional server, but more rigorously followed. Smaller image sizes are critical for quickly moving images around, and storing multiple copies of unnecessary data on disk is a waste of resources. Consequently, these techniques should be used more regularly than on a server with lots of dedicated storage.
|
||||
|
||||
An example of this kind of cleanup is removing cached files from an image to recover space. Consider the difference in size between a base image with [Nginx][2] installed by `dnf` with and without the metadata and yum cache cleaned up:
|
||||
```
|
||||
# Dockerfile with cache
|
||||
|
||||
FROM fedora:28
|
||||
|
||||
LABEL maintainer Chris Collins <collins.christopher@gmail.com>
|
||||
|
||||
|
||||
|
||||
RUN dnf install -y nginx
|
||||
|
||||
|
||||
|
||||
-----
|
||||
|
||||
|
||||
|
||||
# Dockerfile w/o cache
|
||||
|
||||
FROM fedora:28
|
||||
|
||||
LABEL maintainer Chris Collins <collins.christopher@gmail.com>
|
||||
|
||||
|
||||
|
||||
RUN dnf install -y nginx \
|
||||
|
||||
&& dnf clean all \
|
||||
|
||||
&& rm -rf /var/cache/yum
|
||||
|
||||
|
||||
|
||||
-----
|
||||
|
||||
|
||||
|
||||
[chris@krang] $ docker build -t cache -f Dockerfile .
|
||||
|
||||
[chris@krang] $ docker images --format "{{.Repository}}: {{.Size}}"
|
||||
|
||||
| head -n 1
|
||||
|
||||
cache: 464 MB
|
||||
|
||||
|
||||
|
||||
[chris@krang] $ docker build -t no-cache -f Dockerfile-wo-cache .
|
||||
|
||||
[chris@krang] $ docker images --format "{{.Repository}}: {{.Size}}" | head -n 1
|
||||
|
||||
no-cache: 271 MB
|
||||
|
||||
```
|
||||
|
||||
That is a significant difference in size. The version with the `dnf` cache is almost twice the size of the image without the metadata and cache. Package manager cache, Ruby gem temp files, `nodejs` cache, even downloaded source tarballs are all perfect candidates for cleaning up.
|
||||
|
||||
### Layers—a potential gotcha
|
||||
|
||||
Unfortunately (or fortunately, as you’ll see later), based on the way layers work with containers, you cannot simply add a `RUN rm -rf /var/cache/yum` line to your Dockerfile and call it a day. Each instruction of a Dockerfile is stored in a layer, with changes between layers applied on top. So even if you were to do this:
|
||||
```
|
||||
RUN dnf install -y nginx
|
||||
|
||||
RUN dnf clean all
|
||||
|
||||
RUN rm -rf /var/cache/yum
|
||||
|
||||
```
|
||||
|
||||
...you’d still end up with three layers, one of which contains all the cache, and two intermediate layers that "remove" the cache from the image. But the cache is actually still there, just as when you mount a filesystem over the top of another one, the files are there—you just can’t see or access them.
|
||||
|
||||
You’ll notice that the example in the previous section chains the cache cleanup in the same Dockerfile instruction where the cache is generated:
|
||||
```
|
||||
RUN dnf install -y nginx \
|
||||
|
||||
&& dnf clean all \
|
||||
|
||||
&& rm -rf /var/cache/yum
|
||||
|
||||
```
|
||||
|
||||
This is a single instruction and ends up being a single layer within the image. You’ll lose a bit of the Docker (*ahem*) cache this way, making a rebuild of the image slightly longer, but the cached data will not end up in your final image. As a nice compromise, just chaining related commands (e.g., `yum install` and `yum clean all`, or downloading, extracting and removing a source tarball, etc.) can save a lot on your final image size while still allowing you to take advantage of the Docker cache for quicker development.
|
||||
|
||||
This layer "gotcha" is more subtle than it first appears, though. Because the image layers document the _changes_ to each layer, one upon another, it’s not just the existence of files that add up, but any change to the file. For example, _even changing the mode_ of the file creates a copy of that file in the new layer.
|
||||
|
||||
For example, the output of `docker images` below shows information about two images. The first, `layer_test_1`, was created by adding a single 1GB file to a base CentOS image. The second image, `layer_test_2`, was created `FROM layer_test_1` and did nothing but change the mode of the 1GB file with `chmod u+x`.
|
||||
```
|
||||
layer_test_2 latest e11b5e58e2fc 7 seconds ago 2.35 GB
|
||||
|
||||
layer_test_1 latest 6eca792a4ebe 2 minutes ago 1.27 GB
|
||||
|
||||
```
|
||||
|
||||
As you can see, the new image is more than 1GB larger than the first. Despite the fact that `layer_test_1` is only the first two layers of `layer_test_2`, there’s still an extra 1GB file floating around hidden inside the second image. This is true anytime you remove, move, or change any file during the image build process.
|
||||
|
||||
### Purpose-built images vs. flexible images
|
||||
|
||||
An anecdote: As my office heavily invested in [Ruby on Rails][3] applications, we began to embrace the use of containers. One of the first things we did was to create an official Ruby base image for all of our teams to use. For simplicity’s sake (and suffering under “this is the way we did it on our servers”), we used [rbenv][4] to install the latest four versions of Ruby into the image, allowing our developers to migrate all of their applications into containers using a single image. This resulted in a very large but flexible (we thought) image that covered all the bases of the various teams we were working with.
|
||||
|
||||
This turned out to be wasted work. The effort required to maintain separate, slightly modified versions of a particular image was easy to automate, and selecting a specific image with a specific version actually helped to identify applications approaching end-of-life before a breaking change was introduced, wreaking havoc downstream. It also wasted resources: When we started to split out the different versions of Ruby, we ended up with multiple images that shared a single base and took up very little extra space if they coexisted on a server, but were considerably smaller to ship around than a giant image with multiple versions installed.
|
||||
|
||||
That is not to say building flexible images is not helpful, but in this case, creating purpose-build images from a common base ended up saving both storage space and maintenance time, and each team could modify their setup however they needed while maintaining the benefit of the common base image.
|
||||
|
||||
### Start without the cruft: Add what you need to a blank image
|
||||
|
||||
As friendly and easy-to-use as the _Dockerfile_ is, there are tools available that offer the flexibility to create very small Docker-compatible container images without the cruft of a full operating system—even those as small as the standard Docker base images.
|
||||
|
||||
[I’ve written about Buildah before][5], and I’ll mention it again because it is flexible enough to create an image from scratch using tools from your host to install packaged software and manipulate the image. Those tools then never need to be included in the image itself.
|
||||
|
||||
Buildah replaces the `docker build` command. With it, you can mount the filesystem of your container image to your host machine and interact with it using tools from the host.
|
||||
|
||||
Let’s try Buildah with the Nginx example from above (ignoring caches for now):
|
||||
```
|
||||
#!/usr/bin/env bash
|
||||
|
||||
set -o errexit
|
||||
|
||||
|
||||
|
||||
# Create a container
|
||||
|
||||
container=$(buildah from scratch)
|
||||
|
||||
|
||||
|
||||
# Mount the container filesystem
|
||||
|
||||
mountpoint=$(buildah mount $container)
|
||||
|
||||
|
||||
|
||||
# Install a basic filesystem and minimal set of packages, and nginx
|
||||
|
||||
dnf install --installroot $mountpoint --releasever 28 glibc-minimal-langpack nginx --setopt install_weak_deps=false -y
|
||||
|
||||
|
||||
|
||||
# Save the container to an image
|
||||
|
||||
buildah commit --format docker $container nginx
|
||||
|
||||
|
||||
|
||||
# Cleanup
|
||||
|
||||
buildah unmount $container
|
||||
|
||||
|
||||
|
||||
# Push the image to the Docker daemon’s storage
|
||||
|
||||
buildah push nginx:latest docker-daemon:nginx:latest
|
||||
|
||||
```
|
||||
|
||||
You’ll notice we’re no longer using a Dockerfile to build the image, but a simple Bash script, and we’re building it from a scratch (or blank) image. The Bash script mounts the container’s root filesystem to a mount point on the host, and then uses the hosts’ command to install the packages. This way the package manager doesn’t even have to exist inside the container.
|
||||
|
||||
Without extra cruft—all the extra stuff in the base image, like `dnf`, for example—the image weighs in at only 304 MB, more than 100 MB smaller than the Nginx image built with a Dockerfile above.
|
||||
```
|
||||
[chris@krang] $ docker images |grep nginx
|
||||
|
||||
docker.io/nginx buildah 2505d3597457 4 minutes ago 304 MB
|
||||
|
||||
```
|
||||
|
||||
_Note: The image name has`docker.io` appended to it due to the way the image is pushed into the Docker daemon’s namespace, but it is still the image built locally with the build script above._
|
||||
|
||||
That 100 MB is already a huge savings when you consider a base image is already around 300 MB on its own. Installing Nginx with a package manager brings in a ton of dependencies, too. For something compiled from source using tools from the host, the savings can be even greater because you can choose the exact dependencies and not pull in any extra files you don’t need.
|
||||
|
||||
If you’d like to try this route, [Tom Sweeney][6] wrote a much more in-depth article, [Creating small containers with Buildah][7], which you should check out.
|
||||
|
||||
Using Buildah to build images without a full operating system and included build tools can enable much smaller images than you would otherwise be able to create. For some types of images, we can take this approach even further and create images with _only_ the application itself included.
|
||||
|
||||
### Create images with only statically linked binaries
|
||||
|
||||
Following the same philosophy that leads us to ditch administrative and build tools inside images, we can go a step further. If we specialize enough and abandon the idea of troubleshooting inside of production containers, do we need Bash? Do we need the [GNU core utilities][8]? Do we _really_ need the basic Linux filesystem? You can do this with any compiled language that allows you to create binaries with [statically linked libraries][9]—where all the libraries and functions needed by the program are copied into and stored within the binary itself.
|
||||
|
||||
This is a relatively popular way of doing things within the [Golang][10] community, so we’ll use a Go application to demonstrate.
|
||||
|
||||
The Dockerfile below takes a small Go Hello-World application and compiles it in an image `FROM golang:1.8`:
|
||||
```
|
||||
FROM golang:1.8
|
||||
|
||||
|
||||
|
||||
ENV GOOS=linux
|
||||
|
||||
ENV appdir=/go/src/gohelloworld
|
||||
|
||||
|
||||
|
||||
COPY ./ /go/src/goHelloWorld
|
||||
|
||||
WORKDIR /go/src/goHelloWorld
|
||||
|
||||
|
||||
|
||||
RUN go get
|
||||
|
||||
RUN go build -o /goHelloWorld -a
|
||||
|
||||
|
||||
|
||||
CMD ["/goHelloWorld"]
|
||||
|
||||
```
|
||||
|
||||
The resulting image, containing the binary, the source code, and the base image layer comes in at 716 MB. The only thing we actually need for our application is the compiled binary, however. Everything else is unused cruft that gets shipped around with our image.
|
||||
|
||||
If we disable `cgo` with `CGO_ENABLED=0` when we compile, we can create a binary that doesn’t wrap C libraries for some of its functions:
|
||||
```
|
||||
GOOS=linux CGO_ENABLED=0 go build -a goHelloWorld.go
|
||||
|
||||
```
|
||||
|
||||
The resulting binary can be added to an empty, or "scratch" image:
|
||||
```
|
||||
FROM scratch
|
||||
|
||||
COPY goHelloWorld /
|
||||
|
||||
CMD ["/goHelloWorld"]
|
||||
|
||||
```
|
||||
|
||||
Let’s compare the difference in image size between the two:
|
||||
```
|
||||
[ chris@krang ] $ docker images
|
||||
|
||||
REPOSITORY TAG IMAGE ID CREATED SIZE
|
||||
|
||||
goHello scratch a5881650d6e9 13 seconds ago 1.55 MB
|
||||
|
||||
goHello builder 980290a100db 14 seconds ago 716 MB
|
||||
|
||||
```
|
||||
|
||||
That’s a huge difference. The image built from `golang:1.8` with the `goHelloWorld` binary in it (tagged "builder" above) is _460_ times larger than the scratch image with just the binary. The entirety of the scratch image with the binary is only 1.55 MB. That means we’d be shipping around 713 MB of unnecessary data if we used the builder image.
|
||||
|
||||
As mentioned above, this method of creating small images is used often in the Golang community, and there is no shortage of blog posts on the subject. [Kelsey Hightower][11] wrote [an article on the subject][12] that goes into more detail, including dealing with dependencies other than just C libraries.
|
||||
|
||||
### Consider squashing, if it works for you
|
||||
|
||||
There’s an alternative to chaining all the commands into layers in an attempt to save space: Squashing your image. When you squash an image, you’re really exporting it, removing all the intermediate layers, and saving a single layer with the current state of the image. This has the advantage of reducing that image to a much smaller size.
|
||||
|
||||
Squashing layers used to require some creative workarounds to flatten an image—exporting the contents of a container and re-importing it as a single layer image, or using tools like `docker-squash`. Starting in version 1.13, Docker introduced a handy flag, `--squash`, to accomplish the same thing during the build process:
|
||||
```
|
||||
FROM fedora:28
|
||||
|
||||
LABEL maintainer Chris Collins <collins.christopher@gmail.com>
|
||||
|
||||
|
||||
|
||||
RUN dnf install -y nginx
|
||||
|
||||
RUN dnf clean all
|
||||
|
||||
RUN rm -rf /var/cache/yum
|
||||
|
||||
|
||||
|
||||
[chris@krang] $ docker build -t squash -f Dockerfile-squash --squash .
|
||||
|
||||
[chris@krang] $ docker images --format "{{.Repository}}: {{.Size}}" | head -n 1
|
||||
|
||||
squash: 271 MB
|
||||
|
||||
```
|
||||
|
||||
Using `docker squash` with this multi-layer Dockerfile, we end up with another 271MB image, as we did with the chained instruction example. This works great for this use case, but there’s a potential gotcha.
|
||||
|
||||
“What? ANOTHER gotcha?”
|
||||
|
||||
Well, sort of—it’s the same issue as before, causing problems in another way.
|
||||
|
||||
### Going too far: Too squashed, too small, too specialized
|
||||
|
||||
Images can share layers. The base may be _x_ megabytes in size, but it only needs to be pulled/stored once and each image can use it. The effective size of all the images sharing layers is the base layers plus the diff of each specific change on top of that. In this way, thousands of images may take up only a small amount more than a single image.
|
||||
|
||||
This is a drawback with squashing or specializing too much. When you squash an image into a single layer, you lose any opportunity to share layers with other images. Each image ends up being as large as the total size of its single layer. This might work well for you if you use only a few images and run many containers from them, but if you have many diverse images, it could end up costing you space in the long run.
|
||||
|
||||
Revisiting the Nginx squash example, we can see it’s not a big deal for this case. We end up with Fedora, Nginx installed, no cache, and squashing that is fine. Nginx by itself is not incredibly useful, though. You generally need customizations to do anything interesting—e.g., configuration files, other software packages, maybe some application code. Each of these would end up being more instructions in the Dockerfile.
|
||||
|
||||
With a traditional image build, you would have a single base image layer with Fedora, a second layer with Nginx installed (with or without cache), and then each customization would be another layer. Other images with Fedora and Nginx could share these layers.
|
||||
|
||||
Need an image:
|
||||
```
|
||||
[ App 1 Layer ( 5 MB) ] [ App 2 Layer (6 MB) ]
|
||||
|
||||
[ Nginx Layer ( 21 MB) ] ------------------^
|
||||
|
||||
[ Fedora Layer (249 MB) ]
|
||||
|
||||
```
|
||||
|
||||
But if you squash the image, then even the Fedora base layer is squashed. Any squashed image based on Fedora has to ship around its own Fedora content, adding another 249 MB for _each image!_
|
||||
```
|
||||
[ Fedora + Nginx + App 1 (275 MB)] [ Fedora + Nginx + App 2 (276 MB) ]
|
||||
|
||||
```
|
||||
|
||||
This also becomes a problem if you build lots of highly specialized, super-tiny images.
|
||||
|
||||
As with everything in life, moderation is key. Again, thanks to how layers work, you will find diminishing returns as your container images become smaller and more specialized and can no longer share base layers with other related images.
|
||||
|
||||
Images with small customizations can share base layers. As explained above, the base may be _x_ megabytes in size, but it only needs to be pulled/stored once and each image can use it. The effective size of all the images is the base layers plus the diff of each specific change on top of that. In this way, thousands of images may take up only a small amount more than a single image.
|
||||
```
|
||||
[ specific app ] [ specific app 2 ]
|
||||
|
||||
[ customizations ]--------------^
|
||||
|
||||
[ base layer ]
|
||||
|
||||
```
|
||||
|
||||
If you go too far with your image shrinking and you have too many variations or specializations, you can end up with many images, none of which share base layers and all of which take up their own space on disk.
|
||||
```
|
||||
[ specific app 1 ] [ specific app 2 ] [ specific app 3 ]
|
||||
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
There are a variety of different ways to reduce the amount of storage space and bandwidth you spend working with container images, but the most effective way is to reduce the size of the images themselves. Whether you simply clean up your caches (avoiding leaving them orphaned in intermediate layers), squash all your layers into one, or add only static binaries in an empty image, it’s worth spending some time looking at where bloat might exist in your container images and slimming them down to an efficient size.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/building-container-images
|
||||
|
||||
作者:[Chris Collins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/clcollins
|
||||
[1]:https://www.docker.com/
|
||||
[2]:https://www.nginx.com/
|
||||
[3]:https://rubyonrails.org/
|
||||
[4]:https://github.com/rbenv/rbenv
|
||||
[5]:https://opensource.com/article/18/6/getting-started-buildah
|
||||
[6]:https://twitter.com/TSweeneyRedHat
|
||||
[7]:https://opensource.com/article/18/5/containers-buildah
|
||||
[8]:https://www.gnu.org/software/coreutils/coreutils.html
|
||||
[9]:https://en.wikipedia.org/wiki/Static_library
|
||||
[10]:https://golang.org/
|
||||
[11]:https://twitter.com/kelseyhightower
|
||||
[12]:https://medium.com/@kelseyhightower/optimizing-docker-images-for-static-binaries-b5696e26eb07
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
4 open source media conversion tools for the Linux desktop
|
||||
======
|
||||
|
||||
|
||||
@ -1,42 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Textricator: Data extraction made simple
|
||||
======
|
||||
|
||||

|
||||
|
||||
You probably know the feeling: You ask for data and get a positive response, only to open the email and find a whole bunch of PDFs attached. Data, interrupted.
|
||||
|
||||
We understand your frustration, and we’ve done something about it: Introducing [Textricator][1], our first open source product.
|
||||
|
||||
We’re Measures for Justice, a criminal justice research and transparency organization. Our mission is to provide data transparency for the entire justice system, from arrest to post-conviction. We do this by producing a series of up to 32 performance measures covering the entire criminal justice system, county by county. We get our data in many ways—all legal, of course—and while many state and county agencies are data-savvy, giving us quality, formatted data in CSVs, the data is often bundled inside software with no simple way to get it out. PDF reports are the best they can offer.
|
||||
|
||||
Developers Joe Hale and Stephen Byrne have spent the past two years developing Textricator to extract tens of thousands of pages of data for our internal use. Textricator can process just about any text-based PDF format—not just tables, but complex reports with wrapping text and detail sections generated from tools like Crystal Reports. Simply tell Textricator the attributes of the fields you want to collect, and it chomps through the document, collecting and writing out your records.
|
||||
|
||||
Not a software engineer? Textricator doesn’t require programming skills; rather, the user describes the structure of the PDF and Textricator handles the rest. Most users run it via the command line; however, a browser-based GUI is available.
|
||||
|
||||
We evaluated other great open source solutions like [Tabula][2], but they just couldn’t handle the structure of some of the PDFs we needed to scrape. “Textricator is both flexible and powerful and has cut the time we spend to process large datasets from days to hours,” says Andrew Branch, director of technology.
|
||||
|
||||
At MFJ, we’re committed to transparency and knowledge-sharing, which includes making our software available to anyone, especially those trying to free and share data publicly. Textricator is available on [GitHub][3] and released under [GNU Affero General Public License Version 3][4].
|
||||
|
||||
You can see the results of our work, including data processed via Textricator, on our free [online data portal][5]. Textricator is an essential part of our process and we hope civic tech and government organizations alike can unlock more data with this new tool.
|
||||
|
||||
If you use Textricator, let us know how it helped solve your data problem. Want to improve it? Submit a pull request.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/textricator
|
||||
|
||||
作者:[Stephen Byrne][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[1]:https://textricator.mfj.io/
|
||||
[2]:https://tabula.technology/
|
||||
[3]:https://github.com/measuresforjustice/textricator
|
||||
[4]:https://www.gnu.org/licenses/agpl-3.0.en.html
|
||||
[5]:https://www.measuresforjustice.org/portal/
|
||||
@ -0,0 +1,221 @@
|
||||
Download Subtitles Via Right Click From File Manager Or Command Line With OpenSubtitlesDownload.py
|
||||
======
|
||||
**If you're looking for a quick way to download subtitles from OpenSubtitles.org from your Linux desktop or server, give[OpenSubtitlesDownload.py][1] a try. This neat Python tool can be used as a Nautilus, Nemo or Caja script, or from the command line.**
|
||||
|
||||
|
||||
|
||||
The Python script **searches for subtitles on OpenSubtitles.org using the video hash sum to find exact matches** , and thus avoid out of sync subtitles. In case no match is found, it then tries to perform a search based on the video file name, although such subtitles may not always be in sync.
|
||||
|
||||
OpenSubtitlesDownload.py has quite a few cool features, including **support for more than 60 languages,** and it can query both multiple subtitle languages and videos in the same time (so it **supports mass subtitle search and download** ).
|
||||
|
||||
The **optional graphical user interface** (uses Zenity for Gnome and Kdialog for KDE) can display multiple subtitle matches and by digging into its settings you can enable the display of some extra information, like the subtitles download count, rating, language, and more.
|
||||
|
||||
Other OpenSubtitlesDownload.py features include:
|
||||
|
||||
* Option to download subtitles automatically if only one is available, choose the one you want otherwise.
|
||||
* Option to rename downloaded subtitles to match source video file. Possibility to append the language code to the file name (ex: movie_en.srt).
|
||||
|
||||
|
||||
|
||||
The Python tool does not yet support downloading subtitles for movies within a directory recursively, but this is a planned feature.
|
||||
|
||||
In case you encounter errors when downloading a large number of subtitles, you should be aware that OpenSubtitles has a daily subtitle download limit (it appears it was 200 subtitles downloads / day a while back, I'm not sure if it changed). For VIP users it's 1000 subtitles per day, but OpenSubtitlesDownload.py does not allow logging it to an OpenSubtitles account and thus, you can't take advantage of a VIP account while using this tool.
|
||||
|
||||
### Installing and using OpenSubtitlesDownload.py as a Nautilus, Nemo or Caja script
|
||||
|
||||
The instructions below explain how to install OpenSubtitlesDownload.py as a script for Caja, Nemo or Nautilus file managers. Thanks to this you'll be able to right click (context menu) one or multiple video files in your file manager, select `Scripts > OpenSubtitlesDownload.py` and the script will search for and download subtitles from OpenSubtitles.org for your video files.
|
||||
|
||||
This is OpenSubtitlesDownload.py used as a Nautilus script:
|
||||
|
||||
|
||||
|
||||
And as a Nemo script:
|
||||
|
||||
|
||||
|
||||
To install OpenSubtitlesDownload.py as a Nautilus, Nemo or Caja script, see the instructions below.
|
||||
|
||||
1\. Install the dependencies required by OpenSubtitlesDownload.py
|
||||
|
||||
You'll need to install `gzip` , `wget` and `zenity` before using OpenSubtitlesDownload.py. The instructions below assume you already have Python (both Python 2 and 3 will do it), as well as `ps` and `grep` available.
|
||||
|
||||
In Debian, Ubuntu, or Linux Mint, install `gzip` , `wget` and `zenity` using this command:
|
||||
```
|
||||
sudo apt install gzip wget zenity
|
||||
|
||||
```
|
||||
|
||||
2\. Now you can download the OpenSubtitlesDownload.py
|
||||
```
|
||||
wget https://raw.githubusercontent.com/emericg/OpenSubtitlesDownload/master/OpenSubtitlesDownload.py
|
||||
|
||||
```
|
||||
|
||||
3\. Use the commands below to move the downloaded OpenSubtitlesDownload.py script to the file manager scripts folder and make it executable (use the commands for your current file manager - Nautilus, Nemo or Caja):
|
||||
|
||||
* Nautilus (default Gnome, Unity and Solus OS file manager):
|
||||
|
||||
|
||||
```
|
||||
mkdir -p ~/.local/share/nautilus/scripts
|
||||
mv OpenSubtitlesDownload.py ~/.local/share/nautilus/scripts/
|
||||
chmod u+x ~/.local/share/nautilus/scripts/OpenSubtitlesDownload.py
|
||||
|
||||
```
|
||||
|
||||
* Nemo (default Cinnamon file manager):
|
||||
|
||||
|
||||
```
|
||||
mkdir -p ~/.local/share/nemo/scripts
|
||||
mv OpenSubtitlesDownload.py ~/.local/share/nemo/scripts/
|
||||
chmod u+x ~/.local/share/nemo/scripts/OpenSubtitlesDownload.py
|
||||
|
||||
```
|
||||
|
||||
* Caja (default MATE file manager):
|
||||
|
||||
|
||||
```
|
||||
mkdir -p ~/.config/caja/scripts
|
||||
mv OpenSubtitlesDownload.py ~/.config/caja/scripts/
|
||||
chmod u+x ~/.config/caja/scripts/OpenSubtitlesDownload.py
|
||||
|
||||
```
|
||||
|
||||
4\. Configure OpenSubtitlesDownload.py
|
||||
|
||||
Since it's running as a file manager script, without any arguments, you'll need to modify the script if you want to change some of its settings, like enabling the GUI, changing the subtitles language, and so on. These are optional of course, and you can use it directly to automatically download subtitles using its default settings.
|
||||
|
||||
To Configure OpenSubtitlesDownload.py, you'll need to open it with a text editor. The script path should now be:
|
||||
|
||||
* Nautilus:
|
||||
|
||||
`~/.local/share/nautilus/scripts`
|
||||
|
||||
* Nemo:
|
||||
|
||||
`~/.local/share/nemo/scripts`
|
||||
|
||||
* Caja:
|
||||
|
||||
`~/.config/caja/scripts`
|
||||
|
||||
|
||||
|
||||
|
||||
Navigate to that folder using your file manager and open the OpenSubtitlesDownload.py file with a text editor.
|
||||
|
||||
Here's what you may want to change in this file:
|
||||
|
||||
* To change the subtitle language, search for `opt_languages = ['eng']` and change the language from `['eng']` (English) to `['fre']` (French), or whatever language you want to use. The ISO codes for each language supported by OpenSubtitles.org are available on [this][2] page (use the code in the first column).
|
||||
|
||||
* If you want a GUI to present you with all subtitles options and let you choose which to download, find the `opt_selection_mode = 'default'` setting and change it to `'manual'` . You'll not want to change this to 'manual' (or better yet, change it to 'auto') if you want to download multiple subtitles in the same time and avoid having a window popup for each video!
|
||||
|
||||
* To force the Gnome GUI to be used, search for `opt_gui = 'auto'` and change `'auto'` to `'gnome'`
|
||||
|
||||
* You can also enable multiple info columns in the GUI:
|
||||
|
||||
* Search for `opt_selection_rating = 'off'` and change it to `'auto'` to display user ratings if available
|
||||
|
||||
* Search for `opt_selection_count = 'off'` and change it to `'auto'` to display the subtitle number of downloads if available
|
||||
|
||||
|
||||
**You can find a list of OpenSubtitlesDownload.py settings with explanations by visiting[this page][3].**
|
||||
|
||||
And you're done. OpenSubtitlesDownload.py should now appear in Nautilus, Nemo or Caja, when right clicking a file and selecting Scripts. Clicking OpenSubtitlesDownload.py should search and download subtitles for the selected video(s).
|
||||
|
||||
### Installing and using OpenSubtitlesDownload.py from the command line
|
||||
|
||||
1\. Install the dependencies required by OpenSubtitlesDownload.py (command line only)
|
||||
|
||||
You'll need to install `gzip` and `wget` . On Debian, Ubuntu or Linux Mint you can install these packages by using this command:
|
||||
```
|
||||
sudo apt install wget gzip
|
||||
|
||||
```
|
||||
|
||||
2\. Install the `/usr/local/bin/` and set it so it uses the command line interface by default:
|
||||
```
|
||||
wget https://raw.githubusercontent.com/emericg/OpenSubtitlesDownload/master/OpenSubtitlesDownload.py -O opensubtitlesdownload
|
||||
sed -i "s/opt_gui = 'auto'/opt_gui = 'cli'/" opensubtitlesdownload
|
||||
sudo install opensubtitlesdownload /usr/local/bin/
|
||||
|
||||
```
|
||||
|
||||
Now you can start using it. To use the script with automatic selection and download of the best available subtitle, type:
|
||||
```
|
||||
opensubtitlesdownload --auto /path/to/video.mkv
|
||||
|
||||
```
|
||||
|
||||
You can specify the language by appending `--lang LANG` , where `LANG` is the ISO code for a language supported by OpenSubtitles.org, available on
|
||||
```
|
||||
opensubtitlesdownload --lang SPA /home/logix/Videos/Sintel.2010.720p.mkv
|
||||
|
||||
```
|
||||
|
||||
Which provides this output (it allows you to choose the best subtitle since we didn't use `--auto` only, nor did we append `--select manual` to allow manual selection):
|
||||
```
|
||||
>> Title: Sintel
|
||||
>> Filename: Sintel.2010.720p.mkv
|
||||
>> Available subtitles:
|
||||
[1] "Sintel (2010).spa.srt" > "Language: Spanish"
|
||||
[2] "sintel_es.srt" > "Language: Spanish"
|
||||
[3] "Sintel.2010.720p.x264-VODO-spa.srt" > "Language: Spanish"
|
||||
[0] Cancel search
|
||||
>> Enter your choice (0-3): 1
|
||||
>> Downloading 'Spanish' subtitles for 'Sintel'
|
||||
2018-07-27 14:37:04 URL:http://dl.opensubtitles.org/en/download/src-api/vrf-19c10c57/sid-8rL5O0xhUw2BgKG6lvsVBM0p00f/filead/1955318590.gz [936/936] -> "-" [1]
|
||||
|
||||
```
|
||||
|
||||
These are all the available options:
|
||||
```
|
||||
$ opensubtitlesdownload --help
|
||||
usage: OpenSubtitlesDownload.py [-h] [-g GUI] [--cli] [-s SEARCH] [-t SELECT]
|
||||
[-a] [-v] [-l [LANG]]
|
||||
filePathListArg [filePathListArg ...]
|
||||
|
||||
This software is designed to help you find and download subtitles for your favorite videos!
|
||||
|
||||
|
||||
-h, --help show this help message and exit
|
||||
-g GUI, --gui GUI Select the GUI you want from: auto, kde, gnome, cli (default: auto)
|
||||
--cli Force CLI mode
|
||||
-s SEARCH, --search SEARCH
|
||||
Search mode: hash, filename, hash_then_filename, hash_and_filename (default: hash_then_filename)
|
||||
-t SELECT, --select SELECT
|
||||
Selection mode: manual, default, auto
|
||||
-a, --auto Force automatic selection and download of the best subtitles found
|
||||
-v, --verbose Force verbose output
|
||||
-l [LANG], --lang [LANG]
|
||||
Specify the language in which the subtitles should be downloaded (default: eng).
|
||||
Syntax:
|
||||
-l eng,fre: search in both language
|
||||
-l eng -l fre: download both language
|
||||
|
||||
```
|
||||
|
||||
**The theme used for the screenshots in this article is called[Canta][4].**
|
||||
|
||||
**You may also be interested in:[How To Replace Nautilus With Nemo File Manager On Ubuntu 18.04 Gnome Desktop (Complete Guide)][5]**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/07/download-subtitles-via-right-click-from.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://emericg.github.io/OpenSubtitlesDownload/
|
||||
[2]:http://www.opensubtitles.org/addons/export_languages.php
|
||||
[3]:https://github.com/emericg/OpenSubtitlesDownload/wiki/Adjust-settings
|
||||
[4]:https://www.linuxuprising.com/2018/04/canta-is-amazing-material-design-gtk.html
|
||||
[5]:https://www.linuxuprising.com/2018/07/how-to-replace-nautilus-with-nemo-file.html
|
||||
[6]:https://raw.githubusercontent.com/emericg/OpenSubtitlesDownload/master/OpenSubtitlesDownload.py
|
||||
@ -0,0 +1,121 @@
|
||||
7 Python libraries for more maintainable code
|
||||
======
|
||||
|
||||

|
||||
|
||||
> Readability counts.
|
||||
> — [The Zen of Python][1], Tim Peters
|
||||
|
||||
It's easy to let readability and coding standards fall by the wayside when a software project moves into "maintenance mode." (It's also easy to never establish those standards in the first place.) But maintaining consistent style and testing standards across a codebase is an important part of decreasing the maintenance burden, ensuring that future developers are able to quickly grok what's happening in a new-to-them project and safeguarding the health of the app over time.
|
||||
|
||||
### Check your code style
|
||||
|
||||
A great way to protect the future maintainability of a project is to use external libraries to check your code health for you. These are a few of our favorite libraries for [linting code][2] (checking for PEP 8 and other style errors), enforcing a consistent style, and ensuring acceptable test coverage as a project reaches maturity.
|
||||
|
||||
[PEP 8][3] is the Python code style guide, and it sets out rules for things like line length, indentation, multi-line expressions, and naming conventions. Your team might also have your own style rules that differ slightly from PEP 8. The goal of any code style guide is to enforce consistent standards across a codebase to make it more readable, and thus more maintainable. Here are three libraries to help prettify your code.
|
||||
|
||||
#### 1\. Pylint
|
||||
|
||||
[Pylint][4] is a library that checks for PEP 8 style violations and common errors. It integrates well with several popular [editors and IDEs][5] and can also be run from the command line.
|
||||
|
||||
To install, run `pip install pylint`.
|
||||
|
||||
To use Pylint from the command line, run `pylint [options] path/to/dir` or `pylint [options] path/to/module.py`. Pylint will output warnings about style violations and other errors to the console.
|
||||
|
||||
You can customize what errors Pylint checks for with a [configuration file][6] called `pylintrc`.
|
||||
|
||||
#### 2\. Flake8
|
||||
|
||||
[Flake8][7] is a "Python tool that glues together PEP8, Pyflakes (similar to Pylint), McCabe (code complexity checker), and third-party plugins to check the style and quality of some Python code."
|
||||
|
||||
To use Flake8, run `pip install flake8`. Then run `flake8 [options] path/to/dir` or `flake8 [options] path/to/module.py` to see its errors and warnings.
|
||||
|
||||
Like Pylint, Flake8 permits some customization for what it checks for with a [configuration file][8]. It has very clear docs, including some on useful [commit hooks][9] to automatically check your code as part of your development workflow.
|
||||
|
||||
Flake8 integrates with popular editors and IDEs, but those instructions generally aren't found in the docs. To integrate Flake8 with your favorite editor or IDE, search online for plugins (for example, [Flake8 plugin for Sublime Text][10]).
|
||||
|
||||
#### 3\. Isort
|
||||
|
||||
[Isort][11] is a library that sorts your imports alphabetically and breaks them up into [appropriate sections][12] (e.g., standard library imports, third-party library imports, imports from your own project, etc.). This increases readability and makes it easier to locate imports if you have a lot of them in your module.
|
||||
|
||||
Install isort with `pip install isort`, and run it with `isort path/to/module.py`. More configuration options are in the [documentation][13]. For example, you can [configure][14] how isort handles multi-line imports from one library in an `.isort.cfg` file.
|
||||
|
||||
Like Flake8 and Pylint, isort also provides plugins that integrate it with popular [editors and IDEs][15].
|
||||
|
||||
### Outsource your code style
|
||||
|
||||
Remembering to run linters manually from the command line for each file you change is a pain, and you might not like how a particular plugin behaves with your IDE. Also, your colleagues might prefer different linters or might not have plugins for their favorite editors, or you might be less meticulous about always running the linter and correcting the warnings. Over time, the codebase you all share will get messy and harder to read.
|
||||
|
||||
A great solution is to use a library that automatically reformats your code into something that passes PEP 8 for you. The three libraries we recommend all have different levels of customization and different defaults for how they format code. Some of these are more opinionated than others, so like with Pylint and Flake8, you'll want to test these out to see which offers the customizations you can't live without… and the unchangeable defaults you can live with.
|
||||
|
||||
#### 4\. Autopep8
|
||||
|
||||
[Autopep8][16] automatically formats the code in the module you specify. It will re-indent lines, fix indentation, remove extraneous whitespace, and refactor common comparison mistakes (like with booleans and `None`). See a full [list of corrections][17] in the docs.
|
||||
|
||||
To install, run `pip install --upgrade autopep8`. To reformat code in place, run `autopep8 --in-place --aggressive --aggressive <filename>`. The `aggressive` flags (and the number of them) indicate how much control you want to give autopep8 over your code style. Read more about [aggressive][18] options.
|
||||
|
||||
#### 5\. Yapf
|
||||
|
||||
[Yapf][19] is yet another option for reformatting code that comes with its own list of [configuration options][20]. It differs from autopep8 in that it doesn't just address PEP 8 violations. It also reformats code that doesn't violate PEP 8 specifically but isn't styled consistently or could be formatted better for readability.
|
||||
|
||||
To install, run `pip install yapf`. To reformat code, run, `yapf [options] path/to/dir` or `yapf [options] path/to/module.py`. There is also a full list of [customization options][20].
|
||||
|
||||
#### 6\. Black
|
||||
|
||||
[Black][21] is the new kid on the block for linters that reformat code in place. It's similar to autopep8 and Yapf, but way more opinionated. It has very few options for customization, which is kind of the point. The idea is that you shouldn't have to make decisions about code style; the only decision to make is to let Black decide for you. You can read about [limited customization options][22] and instructions on [storing them in a configuration file][23].
|
||||
|
||||
Black requires Python 3.6+ but can format Python 2 code. To use, run `pip install black`. To prettify your code, run: `black path/to/dir` or `black path/to/module.py`.
|
||||
|
||||
### Check your test coverage
|
||||
|
||||
You're writing tests, right? Then you will want to make sure new code committed to your codebase is tested and doesn't drop your overall amount of test coverage. While percentage of test coverage is not the only metric you should use to measure the effectiveness and sufficiency of your tests, it is one way to ensure basic testing standards are being followed in your project. For measuring test coverage, we have one recommendation: Coverage.
|
||||
|
||||
#### 7\. Coverage
|
||||
|
||||
[Coverage][24] has several options for the way it reports your test coverage to you, including outputting results to the console or to an HTML page and indicating which line numbers are missing test coverage. You can set up a [configuration file][25] to customize what Coverage checks for and make it easier to run.
|
||||
|
||||
To install, run `pip install coverage`. To run a program and see its output, run `coverage run [path/to/module.py] [args]`, and you will see your program's output. To see a report of which lines of code are missing coverage, run `coverage report -m`.
|
||||
|
||||
Continuous integration (CI) is a series of processes you can run to automatically check for linter errors and test coverage minimums before you merge and deploy code. There are lots of free or paid tools to automate this process, and a thorough walkthrough is beyond the scope of this article. But because setting up a CI process is an important step in removing blocks to more readable and maintainable code, you should investigate continuous integration tools in general; check out [Travis CI][26] and [Jenkins][27] in particular.
|
||||
|
||||
These are only a handful of the libraries available to check your Python code. If you have a favorite that's not on this list, please share it in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/7-python-libraries-more-maintainable-code
|
||||
|
||||
作者:[Jeff Triplett][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/laceynwilliams
|
||||
[1]:https://www.python.org/dev/peps/pep-0020/
|
||||
[2]:https://en.wikipedia.org/wiki/Lint_(software)
|
||||
[3]:https://www.python.org/dev/peps/pep-0008/
|
||||
[4]:https://www.pylint.org/
|
||||
[5]:https://pylint.readthedocs.io/en/latest/user_guide/ide-integration.html
|
||||
[6]:https://pylint.readthedocs.io/en/latest/user_guide/run.html#command-line-options
|
||||
[7]:http://flake8.pycqa.org/en/latest/
|
||||
[8]:http://flake8.pycqa.org/en/latest/user/configuration.html#configuration-locations
|
||||
[9]:http://flake8.pycqa.org/en/latest/user/using-hooks.html
|
||||
[10]:https://github.com/SublimeLinter/SublimeLinter-flake8
|
||||
[11]:https://github.com/timothycrosley/isort
|
||||
[12]:https://github.com/timothycrosley/isort#how-does-isort-work
|
||||
[13]:https://github.com/timothycrosley/isort#using-isort
|
||||
[14]:https://github.com/timothycrosley/isort#configuring-isort
|
||||
[15]:https://github.com/timothycrosley/isort/wiki/isort-Plugins
|
||||
[16]:https://github.com/hhatto/autopep8
|
||||
[17]:https://github.com/hhatto/autopep8#id4
|
||||
[18]:https://github.com/hhatto/autopep8#id5
|
||||
[19]:https://github.com/google/yapf
|
||||
[20]:https://github.com/google/yapf#usage
|
||||
[21]:https://github.com/ambv/black
|
||||
[22]:https://github.com/ambv/black#command-line-options
|
||||
[23]:https://github.com/ambv/black#pyprojecttoml
|
||||
[24]:https://coverage.readthedocs.io/en/latest/
|
||||
[25]:https://coverage.readthedocs.io/en/latest/config.html
|
||||
[26]:https://travis-ci.org/
|
||||
[27]:https://jenkins.io/
|
||||
@ -0,0 +1,65 @@
|
||||
A single-user, lightweight OS for your next home project | Opensource.com
|
||||
======
|
||||

|
||||
|
||||
What on earth is RISC OS? Well, it's not a new kind of Linux. And it's not someone's take on Windows. In fact, released in 1987, it's older than either of these. But you wouldn't necessarily realize it by looking at it.
|
||||
|
||||
The point-and-click graphic user interface features a pinboard and an icon bar across the bottom for your active applications. So, it looks eerily like Windows 95, eight years before it happened.
|
||||
|
||||
This OS was originally written for the [Acorn Archimedes][1] . The Acorn RISC Machines CPU in this computer was completely new hardware that needed completely new software to run on it. This was the original operating system for the ARM chip, long before anyone had thought of Android or [Armbian][2]
|
||||
|
||||
And while the Acorn desktop eventually faded to obscurity, the ARM chip went on to conquer the world. And here, RISC OS has always had a niche—often in embedded devices, where you'd never actually know it was there. RISC OS was, for a long time, a completely proprietary operating system. But in recent years, the owners have started releasing the source code to a project called [RISC OS Open][3].
|
||||
|
||||
### 1\. You can install it on your Raspberry Pi
|
||||
|
||||
The Raspberry Pi's official operating system, [Raspbian][4], is actually pretty great (but if you aren't interested in tinkering with novel and different things in tech, you probably wouldn't be fiddling with a Raspberry Pi in the first place). Because RISC OS is written specifically for ARM, it can run on all kinds of small-board computers, including every model of Raspberry Pi.
|
||||
|
||||
### 2\. It's super lightweight
|
||||
|
||||
The RISC OS installation on my Raspberry Pi takes up a few hundred megabytes—and that's after I've loaded dozens of utilities and games. Most of these are well under a megabyte.
|
||||
|
||||
If you're really on a diet, the RISC OS Pico will fit on a 16MB SD card. This is perfect if you're hacking something to go in an embedded system or IoT project. Of course, 16MB is actually a fair bit more than the 512KB ROM chip squeezed into the old Archimedes. But I guess with 30 years of progress in memory technology, it's okay to stretch your legs just a little a bit.
|
||||
|
||||
### 3\. It's excellent for retro gaming
|
||||
|
||||
When the Archimedes was in its prime, the ARM CPU was several times faster than the Motorola 68000 in the Apple Macintosh and Commodore Amiga, and it totally smoked that new 386, too. This made it an attractive platform for game developers who wanted to strut their stuff with the most powerful desktop computer on the planet.
|
||||
|
||||
Many of the rights holders to these games have been generous enough to give permission for hobbyists to download their old work for free. And while RISC OS and the hardware has moved on, with a very small amount of fiddling you can get them to run.
|
||||
|
||||
If you're interested in exploring this, [here's a guide][5] to getting these games working on your Raspberry Pi.
|
||||
|
||||
### 4\. It's got BBC BASIC
|
||||
|
||||
Press F12 to go to the command line, type `*BASIC`, and you get a full BBC BASIC interpreter, just like the old days.
|
||||
|
||||
For those who weren't around for it in the 80s, let me explain: BBC BASIC was the first ever programming language for so many of us back in the day, for the excellent reason that it was specifically designed to teach children how to code. There were mountains of books and magazine articles that taught us to code our own simple but highly playable games.
|
||||
|
||||
Decades later, coding your own game in BBC BASIC is still a great project for a technically minded kid who wants something to do during school holidays. But few kids have a BBC micro at home anymore. So what should they run it on?
|
||||
|
||||
Well, there are interpreters you can run on just about every home computer, but that's not helpful when someone else needs to use it. So why not a Raspberry Pi with RISC OS installed?
|
||||
|
||||
### 5\. It's a simple, single-user operating system
|
||||
|
||||
RISC OS is not like Linux, with its user and superuser access. It has one user who has full access to the whole machine. So it's probably not the best daily driver to deploy across an enterprise, or even to give to granddad to do his banking. But if you're looking for something to hack and tinker with, it's absolutely fantastic. There isn't all that much between you and the bare metal, so you can just tuck right in.
|
||||
|
||||
### Further reading
|
||||
|
||||
If you want to learn more about this operating system, check out [RISC OS Open][3], or just flash an image to a card and start using it.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/gentle-intro-risc-os
|
||||
|
||||
作者:[James Mawson][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dxmjames
|
||||
[1]:https://en.wikipedia.org/wiki/Acorn_Archimedes
|
||||
[2]:https://www.armbian.com/
|
||||
[3]:https://www.riscosopen.org/content/
|
||||
[4]:https://www.raspbian.org/
|
||||
[5]:https://www.riscosopen.org/wiki/documentation/show/Introduction%20to%20RISC%20OS
|
||||
197
sources/tech/20180731 A sysadmin-s guide to Bash.md
Normal file
197
sources/tech/20180731 A sysadmin-s guide to Bash.md
Normal file
@ -0,0 +1,197 @@
|
||||
A sysadmin's guide to Bash
|
||||
======
|
||||
|
||||

|
||||
|
||||
Each trade has a tool that masters in that trade wield most often. For many sysadmins, that tool is their [shell][1]. On the majority of Linux and other Unix-like systems out there, the default shell is Bash.
|
||||
|
||||
Bash is a fairly old program—it originated in the late 1980s—but it builds on much, much older shells, like the C shell ([csh][2]), which is easily 10 years its senior. Because the concept of a shell is that old, there is an enormous amount of arcane knowledge out there waiting to be consumed to make any sysadmin guy's or gal's life a lot easier.
|
||||
|
||||
Let's take a look at some of the basics.
|
||||
|
||||
Who has, at some point, unintentionally ran a command as root and caused some kind of issue? raises hand
|
||||
|
||||
I'm pretty sure a lot of us have been that guy or gal at one point. Very painful. Here are some very simple tricks to prevent you from hitting that stone a second time.
|
||||
|
||||
### Use aliases
|
||||
|
||||
First, set up aliases for commands like **`mv`** and **`rm`** that point to `mv -I` and `rm -I`. This will make sure that running `rm -f /boot` at least asks you for confirmation. In Red Hat Enterprise Linux, these aliases are set up by default if you use the root account.
|
||||
|
||||
If you want to set those aliases for your normal user account as well, just drop these two lines into a file called .bashrc in your home directory (these will also work with sudo):
|
||||
```
|
||||
alias mv='mv -i'
|
||||
|
||||
alias rm='rm -i'
|
||||
|
||||
```
|
||||
|
||||
### Make your root prompt stand out
|
||||
|
||||
Another thing you can do to prevent mishaps is to make sure you are aware when you are using the root account. I usually do that by making the root prompt stand out really well from the prompt I use for my normal, everyday work.
|
||||
|
||||
If you drop the following into the .bashrc file in root's home directory, you will have a root prompt that is red on black, making it crystal clear that you (or anyone else) should tread carefully.
|
||||
```
|
||||
export PS1="\[$(tput bold)$(tput setab 0)$(tput setaf 1)\]\u@\h:\w # \[$(tput sgr0)\]"
|
||||
|
||||
```
|
||||
|
||||
In fact, you should refrain from logging in as root as much as possible and instead run the majority of your sysadmin commands through sudo, but that's a different story.
|
||||
|
||||
Having implemented a couple of minor tricks to help prevent "unintentional side-effects" of using the root account, let's look at a couple of nice things Bash can help you do in your daily work.
|
||||
|
||||
### Control your history
|
||||
|
||||
You probably know that when you press the Up arrow key in Bash, you can see and reuse all (well, many) of your previous commands. That is because those commands have been saved to a file called .bash_history in your home directory. That history file comes with a bunch of settings and commands that can be very useful.
|
||||
|
||||
First, you can view your entire recent command history by typing **`history`** , or you can limit it to your last 30 commands by typing **`history 30`**. But that's pretty vanilla. You have more control over what Bash saves and how it saves it.
|
||||
|
||||
For example, if you add the following to your .bashrc, any commands that start with a space will not be saved to the history list:
|
||||
```
|
||||
HISTCONTROL=ignorespace
|
||||
|
||||
```
|
||||
|
||||
This can be useful if you need to pass a password to a command in plaintext. (Yes, that is horrible, but it still happens.)
|
||||
|
||||
If you don't want a frequently executed command to show up in your history, use:
|
||||
```
|
||||
HISTCONTROL=ignorespace:erasedups
|
||||
|
||||
```
|
||||
|
||||
With this, every time you use a command, all its previous occurrences are removed from the history file, and only the last invocation is saved to your history list.
|
||||
|
||||
A history setting I particularly like is the **`HISTTIMEFORMAT`** setting. This will prepend all entries in your history file with a timestamp. For example, I use:
|
||||
```
|
||||
HISTTIMEFORMAT="%F %T "
|
||||
|
||||
```
|
||||
|
||||
When I type **`history 5`** , I get nice, complete information, like this:
|
||||
```
|
||||
1009 2018-06-11 22:34:38 cat /etc/hosts
|
||||
|
||||
1010 2018-06-11 22:34:40 echo $foo
|
||||
|
||||
1011 2018-06-11 22:34:42 echo $bar
|
||||
|
||||
1012 2018-06-11 22:34:44 ssh myhost
|
||||
|
||||
1013 2018-06-11 22:34:55 vim .bashrc
|
||||
|
||||
```
|
||||
|
||||
That makes it a lot easier to browse my command history and find the one I used two days ago to set up an SSH tunnel to my home lab (which I forget again, and again, and again…).
|
||||
|
||||
### Best Bash practices
|
||||
|
||||
I'll wrap this up with my top 11 list of the best (or good, at least; I don't claim omniscience) practices when writing Bash scripts.
|
||||
|
||||
11. Bash scripts can become complicated and comments are cheap. If you wonder whether to add a comment, add a comment. If you return after the weekend and have to spend time figuring out what you were trying to do last Friday, you forgot to add a comment.
|
||||
|
||||
|
||||
10. Wrap all your variable names in curly braces, like **`${myvariable}`**. Making this a habit makes things like `${variable}_suffix` possible and improves consistency throughout your scripts.
|
||||
|
||||
|
||||
9. Do not use backticks when evaluating an expression; use the **`$()`** syntax instead. So use:
|
||||
```
|
||||
for file in $(ls); do
|
||||
```
|
||||
|
||||
|
||||
not
|
||||
```
|
||||
for file in `ls`; do
|
||||
|
||||
```
|
||||
|
||||
The former option is nestable, more easily readable, and keeps the general sysadmin population happy. Do not use backticks.
|
||||
|
||||
|
||||
|
||||
8. Consistency is good. Pick one style of doing things and stick with it throughout your script. Obviously, I would prefer if people picked the **`$()`** syntax over backticks and wrapped their variables in curly braces. I would prefer it if people used two or four spaces—not tabs—to indent, but even if you choose to do it wrong, do it wrong consistently.
|
||||
|
||||
|
||||
7. Use the proper shebang for a Bash script. As I'm writing Bash scripts with the intention of only executing them with Bash, I most often use **`#!/usr/bin/bash`** as my shebang. Do not use **`#!/bin/sh`** or **`#!/usr/bin/sh`**. Your script will execute, but it'll run in compatibility mode—potentially with lots of unintended side effects. (Unless, of course, compatibility mode is what you want.)
|
||||
|
||||
|
||||
6. When comparing strings, it's a good idea to quote your variables in if-statements, because if your variable is empty, Bash will throw an error for lines like these:
|
||||
```
|
||||
if [ ${myvar} == "foo" ]; then
|
||||
|
||||
echo "bar"
|
||||
|
||||
fi
|
||||
|
||||
```
|
||||
|
||||
And will evaluate to false for a line like this:
|
||||
```
|
||||
if [ "${myvar}" == "foo" ]; then
|
||||
|
||||
echo "bar"
|
||||
|
||||
fi
|
||||
```
|
||||
|
||||
Also, if you are unsure about the contents of a variable (e.g., when you are parsing user input), quote your variables to prevent interpretation of some special characters and make sure the variable is considered a single word, even if it contains whitespace.
|
||||
|
||||
|
||||
|
||||
5. This is a matter of taste, I guess, but I prefer using the double equals sign ( **`==`** ) even when comparing strings in Bash. It's a matter of consistency, and even though—for string comparisons only—a single equals sign will work, my mind immediately goes "single equals is an assignment operator!"
|
||||
|
||||
|
||||
4. Use proper exit codes. Make sure that if your script fails to do something, you present the user with a written failure message (preferably with a way to fix the problem) and send a non-zero exit code:
|
||||
```
|
||||
# we have failed
|
||||
|
||||
echo "Process has failed to complete, you need to manually restart the whatchamacallit"
|
||||
|
||||
exit 1
|
||||
|
||||
```
|
||||
|
||||
This makes it easier to programmatically call your script from yet another script and verify its successful completion.
|
||||
|
||||
|
||||
|
||||
3. Use Bash's built-in mechanisms to provide sane defaults for your variables or throw errors if variables you expect to be defined are not defined:
|
||||
```
|
||||
# this sets the value of $myvar to redhat, and prints 'redhat'
|
||||
|
||||
echo ${myvar:=redhat}
|
||||
|
||||
# this throws an error reading 'The variable myvar is undefined, dear reader' if $myvar is undefined
|
||||
|
||||
${myvar:?The variable myvar is undefined, dear reader}
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
2. Especially if you are writing a large script, and especially if you work on that large script with others, consider using the **`local`** keyword when defining variables inside functions. The **`local`** keyword will create a local variable, that is one that's visible only within that function. This limits the possibility of clashing variables.
|
||||
|
||||
|
||||
1. Every sysadmin must do it sometimes: debug something on a console, either a real one in a data center or a virtual one through a virtualization platform. If you have to debug a script that way, you will thank yourself for remembering this: Do not make the lines in your scripts too long!
|
||||
|
||||
On many systems, the default width of a console is still 80 characters. If you need to debug a script on a console and that script has very long lines, you'll be a sad panda. Besides, a script with shorter lines—the default is still 80 characters—is a lot easier to read and understand in a normal editor, too!
|
||||
|
||||
|
||||
|
||||
|
||||
I truly love Bash. I can spend hours writing about it or exchanging nice tricks with fellow enthusiasts. Make sure you drop your favorites in the comments!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/admin-guide-bash
|
||||
|
||||
作者:[Maxim Burgerhout][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/wzzrd
|
||||
[1]:http://www.catb.org/jargon/html/S/shell.html
|
||||
[2]:https://en.wikipedia.org/wiki/C_shell
|
||||
@ -1,119 +0,0 @@
|
||||
DevOps时代的7个领导准则
|
||||
======
|
||||
|
||||

|
||||
|
||||
如果[DevOps]最终更多的是关于文化而不是任何其他的技术或者平台,那么请记住:没有终点线。而是继续改变和提高--而且最高管理层并没有通过。
|
||||
|
||||
然而,如果期望DevOps能够帮助获得更多的成果,领导者需要[修订他们的一些传统的方法][2]让我们考虑7个在DevOps时代更有效的IT领导的想法。
|
||||
|
||||
### 1. 向失败说“是的”
|
||||
|
||||
“失败”这个词在IT领域中一直包含着特殊的内涵,而且通常是糟糕的意思:服务器失败,备份失败,硬盘驱动器失败-你得了解这些情况。
|
||||
|
||||
然而一种健康的DevOps文化取决于重新定义失败-IT领导者在他们的字典里应该重新定义这个单词将它的含义和“机会”对等起来。
|
||||
|
||||
“在DevOps之前,我们曾有一种惩罚失败者的文化,”罗伯特·里夫斯说,[Datical][3]的首席技术官兼联合创始人。“我们学到的仅仅是去避免错误。在IT领域避免错误的首要措施就是不要去改变任何东西:不要加速版本迭代的日程,不要迁移到云中,不要去做任何不同的事”
|
||||
|
||||
那是过去的一个时代的剧本,里夫斯坦诚的说,它已经不起作用了,事实上,那种停滞是失败的。
|
||||
|
||||
“那些缓慢的释放并逃避云的公司被恐惧所麻痹-他们将会走向失败,”里夫斯说道。“IT领导者必须拥抱失败并把它当做成一个机遇。人们不仅仅从他们的过错中学习,也会从其他的错误中学习。一种开放和[安全心里][4]的文化促进学习和提高”
|
||||
**[相关文章:[为什么敏捷领导者谈论“失败”必须超越它本义]]
|
||||
### 2. 在管理层渗透开发运营的理念
|
||||
|
||||
尽管DevOps文化可以在各个方向有机的发展,那些正在从整体中转变,孤立的IT实践,而且可能遭遇逆风的公司-需要执行领导层的全面支持。你正在传达模糊的信息
|
||||
而且可能会鼓励那些愿意推一把的人,这是我们一贯的做事方式。[改变文化是困难的][6];人们需要看到领导层完全投入进去并且知道改变已经实际发生了。
|
||||
|
||||
“为了成功的实现利益的兑现高层管理必须全力支持DevOps,”来自[Rainforest QA][7]的首席技术官说道。
|
||||
|
||||
成为一个DevOps商店。德里克指出,涉及到公司的一切,从技术团队到工具到进程到规则和责任。
|
||||
|
||||
"没有高层管理的统一赞助支持,DevOps的实施将很难成功,"德里克说道。"因此,在转变到DevOps之前在高层中有支持的领导同盟是很重要的。"
|
||||
|
||||
### 3. 不要只是声明“DevOps”-要明确它
|
||||
即使IT公司也已经开始拥抱欢迎DevOps,每个人可能不是在同一个进程上。
|
||||
**[参考我们的相关文章,**][**3 阐明了DevOps和首席技术官们必须在同一进程上**][8] **.]**
|
||||
|
||||
造成这种脱节的一个根本原因是:人们对这个术语的有着不同的定义理解。
|
||||
|
||||
“DevOps 对不同的人可能意味着不同的含义,”德里克解释道。“对高管层和副总裁层来说,执行明确的DevOps的目标,清楚的声明期望的成果,充分理解带来的成果将如何使公司的商业受益并且能够衡量和报告成功的过程。”
|
||||
|
||||
事实上,在基线和视野之上,DevOps要求正在进行频繁的交流,不是仅仅在小团队里,而是要贯穿到整个组织。IT领导者必须为它设置优先级。
|
||||
|
||||
“不可避免的,将会有些阻碍,在商业中将会存在失败和破坏,”德里克说道。“领导者名需要清楚的将这个过程向公司的其他人阐述清楚告诉他们他们作为这个过程的一份子能够期待的结果。”
|
||||
|
||||
### 4. DevOps和技术同样重要
|
||||
|
||||
IT领导者们成功的将DevOps商店的这种文化和实践当做一项商业策略,与构建和运营软件的方法相结合。DevOps是将IT从支持部门转向战略部门的推动力。
|
||||
|
||||
IT领导者们必须转变他们的思想和方法,从成本和服务中心转变到驱动商业成果,而且DevOps的文化能够通过自动化和强大的协作加速收益。来自[CYBRIC][9]的首席技术官和联合创始人迈克说道。
|
||||
|
||||
事实上,这是一个强烈的趋势通过更多的这些规则在DevOps时代走在前沿。
|
||||
|
||||
“促进创新并且鼓励团队成员去聪明的冒险是DevOps文化的一个关键部分,IT领导者们需要在一个持续的基础上清楚的和他们交流,”凯尔说道。
|
||||
|
||||
“一个高效的IT领导者需要比以往任何时候都要积极的参与到商业中去,”来自[West Monroe Partners][10]的性能服务部门的主任埃文说道。“每年或季度回顾的日子一去不复返了-你需要欢迎每两周一次的待办事项。[11]你需要有在年度水平上的思考战略能力,在冲刺阶段的互动能力,在商业期望满足时将会被给予一定的奖励。”
|
||||
|
||||
### 5. 改变妨碍DevOps目标的任何事情
|
||||
|
||||
虽然DevOps的老兵们普遍认为DevOps更多的是一种文化而不是技术,成功取决于通过正确的过程和工具激活文化。当你声称自己的部门是一个DevOps商店却拒绝对进程或技术做必要的改变,这就是你买了辆法拉利却使用了用过20年的引擎,每次转动钥匙都会冒烟。
|
||||
|
||||
展览 A: [自动化][12].这是DevOps成功的重要并行策略。
|
||||
|
||||
“IT领导者需要重点强调自动化,”卡伦德说。“这将是DevOps的前期投资,但是如果没有它,DevOps将会很容易被低效吞噬自己而且将会无法完整交付。”
|
||||
|
||||
自动化是基石,但改变不止于此。
|
||||
|
||||
“领导者们需要推动自动化,监控和持续的交付过程。这意着对现有的实践,过程,团队架构以及规则的很多改变,”Choy说。“领导者们需要改变一切会阻碍隐藏团队去全利实现自动化的因素。”
|
||||
|
||||
### 6. 重新思考团队架构和能力指标
|
||||
|
||||
当你想改变时...如果你桌面上的组织结构图和你过去大部分时候嵌入的名字都是一样的,那么你是时候该考虑改革了。
|
||||
|
||||
“在这个DevOps的新时代文化中,IT执行者需要采取一个全新的方法来组织架构。”Kail说。“消除组织的边界限制,它会阻碍团队间的合作,允许团队自我组织,敏捷管理。”
|
||||
|
||||
Kail告诉我们在DevOps时代,这种反思也应该拓展应用到其他领域,包括你怎样衡量个人或者团队的成功,甚至是你和人们的互动。
|
||||
|
||||
“根据业务成果和总体的积极影响来衡量主动性,”Kail建议。“最后,我认为管理中最重要的一个方面是:有同理心。”
|
||||
|
||||
注意很容易收集的到测量值不是DevOps真正的指标,[Red Hat]的技术专员Gardon Half写到,“DevOps应该把指标以某种形式和商业成果绑定在一起,”他指出。“你可能真的不在乎开发者些了多少代码,是否有一台服务器在深夜硬件损坏,或者是你的测试是多么的全面。你甚至都不直接关注你的网站的响应情况或者是你更新的速度。但是你要注意的是这些指标可能和顾客放弃购物车去竞争对手那里有关,”参考他的文章,[DevOps 指标:你在测量什么?]
|
||||
|
||||
### 7. 丢弃传统的智慧
|
||||
|
||||
如果DevOps时代要求关于IT领导能力的新的思考方式,那么也就意味着一些旧的方法要被淘汰。但是是哪些呢?
|
||||
|
||||
“是实话,是全部,”Kail说道。“要摆脱‘因为我们一直都是以这种方法做事的’的心态。过渡到DevOps文化是一种彻底的思维模式的转变,不是对瀑布式的过去和变革委员会的一些细微改变。”
|
||||
|
||||
事实上,IT领导者们认识到真正的变革要求的不只是对旧方法的小小接触。它更多的是要求对之前的进程或者策略的一个重新启动。
|
||||
|
||||
West Monroe Partners的卡伦德分享了一个阻碍DevOps的领导力的例子:未能拥抱IT混合模型和现代的基础架构比如说容器和微服务
|
||||
|
||||
“我所看到的一个大的规则就是架构整合,或者认为在一个同质的环境下长期的维护会更便宜,”卡伦德说。
|
||||
|
||||
**想要更多像这样的智慧吗?[注册我们的每周邮件新闻报道][15].**
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/1/7-leadership-rules-devops-age
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[译者FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:https://enterprisersproject.com/tags/devops
|
||||
[2]:https://enterprisersproject.com/article/2017/7/devops-requires-dumping-old-it-leadership-ideas
|
||||
[3]:https://www.datical.com/
|
||||
[4]:https://rework.withgoogle.com/guides/understanding-team-effectiveness/steps/foster-psychological-safety/
|
||||
[5]:https://enterprisersproject.com/article/2017/10/why-agile-leaders-must-move-beyond-talking-about-failure?sc_cid=70160000000h0aXAAQ
|
||||
[6]:https://enterprisersproject.com/article/2017/10/how-beat-fear-and-loathing-it-change
|
||||
[7]:https://www.rainforestqa.com/
|
||||
[8]:https://enterprisersproject.com/article/2018/1/3-areas-where-devops-and-cios-must-get-same-page
|
||||
[9]:https://www.cybric.io/
|
||||
[10]:http://www.westmonroepartners.com/
|
||||
[11]:https://www.scrumalliance.org/community/articles/2017/february/product-backlog-grooming
|
||||
[12]:https://www.redhat.com/en/topics/automation?intcmp=701f2000000tjyaAAA
|
||||
[13]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
|
||||
[14]:https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters
|
||||
[15]:https://enterprisersproject.com/email-newsletter?intcmp=701f2000000tsjPAAQ
|
||||
@ -0,0 +1,253 @@
|
||||
如何在 Git 中重置、恢复、和返回到以前的状态
|
||||
======
|
||||
|
||||

|
||||
|
||||
使用 Git 工作时其中一个鲜为人知(和没有意识到)的方面就是,如何很容易地返回到你以前的位置 —— 也就是说,在仓库中如何很容易地去撤销那怕是重大的变更。在本文中,我们将带你了解如何去重置、恢复、和完全回到以前的状态,做到这些只需要几个简单而优雅的 Git 命令。
|
||||
|
||||
### reset
|
||||
|
||||
我们从 Git 的 `reset` 命令开始。确实,你应该能够想到它就是一个 "回滚" — 它将你本地环境返回到前面的提交。这里的 "本地环境" 一词,我们指的是你的本地仓库、暂存区、以及工作目录。
|
||||
|
||||
先看一下图 1。在这里我们有一个在 Git 中表示一系列状态的提交。在 Git 中一个分支就是简单的一个命名的、可移动指针到一个特定的提交。在这种情况下,我们的 master 分支是链中指向最新提交的一个指针。
|
||||
|
||||
![Local Git environment with repository, staging area, and working directory][2]
|
||||
|
||||
图 1:有仓库、暂存区、和工作目录的本地环境
|
||||
|
||||
如果看一下我们的 master 分支是什么,可以看一下到目前为止我们产生的提交链。
|
||||
```
|
||||
$ git log --oneline
|
||||
b764644 File with three lines
|
||||
7c709f0 File with two lines
|
||||
9ef9173 File with one line
|
||||
```
|
||||
|
||||
如果我们想回滚到前一个提交会发生什么呢?很简单 —— 我们只需要移动分支指针即可。Git 提供了为我们做这个动作的命令。例如,如果我们重置 master 为当前提交回退两个提交的位置,我们可以使用如下之一的方法:
|
||||
|
||||
`$ git reset 9ef9173`(使用一个绝对的提交 SHA1 值 9ef9173)
|
||||
|
||||
或
|
||||
|
||||
`$ git reset current~2`(在 “current” 标签之前,使用一个相对值 -2)
|
||||
|
||||
图 2 展示了操作的结果。在这之后,如果我们在当前分支(master)上运行一个 `git log` 命令,我们将看到只有一个提交。
|
||||
```
|
||||
$ git log --oneline
|
||||
|
||||
9ef9173 File with one line
|
||||
|
||||
```
|
||||
|
||||
![After reset][4]
|
||||
|
||||
图 2:在 `reset` 之后
|
||||
|
||||
`git reset` 命令也包含使用一个你最终满意的提交内容去更新本地环境的其它部分的选项。这些选项包括:`hard` 在仓库中去重置指向的提交,用提交的内容去填充工作目录,并重置暂存区;`soft` 仅重置仓库中的指针;而 `mixed`(默认值)将重置指针和暂存区。
|
||||
|
||||
这些选项在特定情况下非常有用,比如,`git reset --hard <commit sha1 | reference>` 这个命令将覆盖本地任何未提交的更改。实际上,它重置了(清除掉)暂存区,并用你重置的提交内容去覆盖了工作区中的内容。在你使用 `hard` 选项之前,一定要确保这是你真正地想要做的操作,因为这个命令会覆盖掉任何未提交的更改。
|
||||
|
||||
### revert
|
||||
|
||||
`git revert` 命令的实际结果类似于 `reset`,但它的方法不同。`reset` 命令是在(默认)链中向后移动分支的指针去“撤销”更改,`revert` 命令是在链中添加一个新的提交去“取消”更改。再次查看图 1 可以非常轻松地看到这种影响。如果我们在链中的每个提交中向文件添加一行,一种方法是使用 `reset` 使那个提交返回到仅有两行的那个版本,如:`git reset HEAD~1`。
|
||||
|
||||
另一个方法是添加一个新的提交去删除第三行,以使最终结束变成两行的版本 — 实际效果也是取消了那个更改。使用一个 `git revert` 命令可以实现上述目的,比如:
|
||||
```
|
||||
$ git revert HEAD
|
||||
|
||||
```
|
||||
|
||||
因为它添加了一个新的提交,Git 将提示如下的提交信息:
|
||||
```
|
||||
Revert "File with three lines"
|
||||
|
||||
This reverts commit b764644bad524b804577684bf74e7bca3117f554.
|
||||
|
||||
# Please enter the commit message for your changes. Lines starting
|
||||
# with '#' will be ignored, and an empty message aborts the commit.
|
||||
# On branch master
|
||||
# Changes to be committed:
|
||||
# modified: file1.txt
|
||||
#
|
||||
```
|
||||
|
||||
图 3(在下面)展示了 `revert` 操作完成后的结果。
|
||||
|
||||
如果我们现在运行一个 `git log` 命令,我们将看到前面的提交之前的一个新提交。
|
||||
```
|
||||
$ git log --oneline
|
||||
11b7712 Revert "File with three lines"
|
||||
b764644 File with three lines
|
||||
7c709f0 File with two lines
|
||||
9ef9173 File with one line
|
||||
```
|
||||
|
||||
这里是工作目录中这个文件当前的内容:
|
||||
```
|
||||
$ cat <filename>
|
||||
Line 1
|
||||
Line 2
|
||||
```
|
||||
|
||||
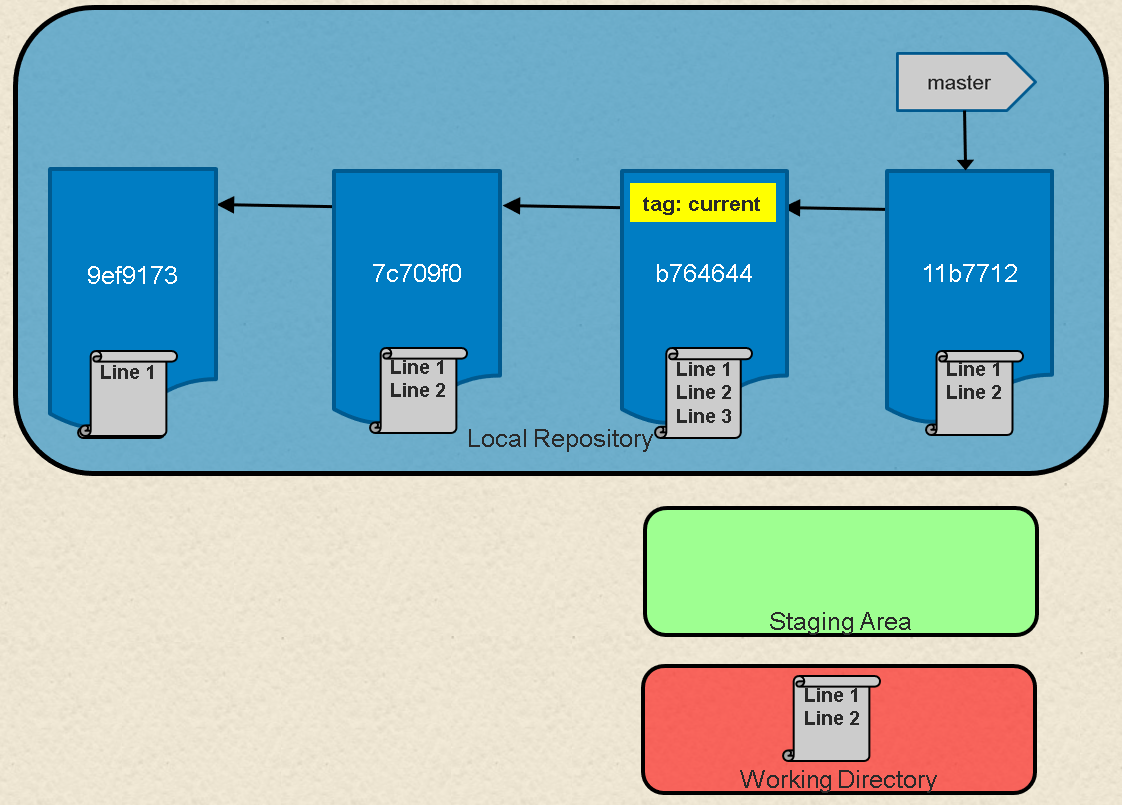
|
||||
|
||||
#### Revert 或 reset 如何选择?
|
||||
|
||||
为什么要优先选择 `revert` 而不是 `reset` 操作?如果你已经将你的提交链推送到远程仓库(其它人可以已经拉取了你的代码并开始工作),一个 `revert` 操作是让他们去获得更改的非常友好的方式。这是因为 Git 工作流可以非常好地在分支的末端添加提交,但是当有人 `reset` 分支指针之后,一组提交将再也看不见了,这可能会是一个挑战。
|
||||
|
||||
当我们以这种方式使用 Git 工作时,我们的基本规则之一是:在你的本地仓库中使用这种方式去更改还没有推送的代码是可以的。如果提交已经推送到了远程仓库,并且可能其它人已经使用它来工作了,那么应该避免这些重写提交历史的更改。
|
||||
|
||||
总之,如果你想回滚、撤销、或者重写其它人已经在使用的一个提交链的历史,当你的同事试图将他们的更改合并到他们拉取的原始链上时,他们可能需要做更多的工作。如果你必须对已经推送并被其他人正在使用的代码做更改,在你做更改之前必须要与他们沟通,让他们先合并他们的更改。然后在没有需要去合并的侵入操作之后,他们再拉取最新的副本。
|
||||
|
||||
你可能注意到了,在我们做了 `reset` 操作之后,原始的链仍然在那个位置。我们移动了指针,然后 `reset` 代码回到前一个提交,但它并没有删除任何提交。换句话说就是,只要我们知道我们所指向的原始提交,我们能够通过简单的返回到分支的原始头部来“恢复”指针到前面的位置:
|
||||
```
|
||||
git reset <sha1 of commit>
|
||||
|
||||
```
|
||||
|
||||
当提交被替换之后,我们在 Git 中做的大量其它操作也会发生类似的事情。新提交被创建,有关的指针被移动到一个新的链,但是老的提交链仍然存在。
|
||||
|
||||
### Rebase
|
||||
|
||||
现在我们来看一个分支变基。假设我们有两个分支 — master 和 feature — 提交链如下图 4 所示。Master 的提交链是 `C4->C2->C1->C0` 和 feature 的提交链是 `C5->C3->C2->C1->C0`.
|
||||
|
||||
![Chain of commits for branches master and feature][6]
|
||||
|
||||
图 4:master 和 feature 分支的提交链
|
||||
|
||||
如果我们在分支中看它的提交记录,它们看起来应该像下面的这样。(为了易于理解,`C` 表示提交信息)
|
||||
```
|
||||
$ git log --oneline master
|
||||
6a92e7a C4
|
||||
259bf36 C2
|
||||
f33ae68 C1
|
||||
5043e79 C0
|
||||
|
||||
$ git log --oneline feature
|
||||
79768b8 C5
|
||||
000f9ae C3
|
||||
259bf36 C2
|
||||
f33ae68 C1
|
||||
5043e79 C0
|
||||
```
|
||||
|
||||
我给人讲,在 Git 中,可以将 `rebase` 认为是 “将历史合并”。从本质上来说,Git 将一个分支中的每个不同提交尝试“重放”到另一个分支中。
|
||||
|
||||
因此,我们使用基本的 Git 命令,可以 rebase 一个 feature 分支进入到 master 中,并将它拼入到 `C4` 中(比如,将它插入到 feature 的链中)。操作命令如下:
|
||||
```
|
||||
$ git checkout feature
|
||||
$ git rebase master
|
||||
|
||||
First, rewinding head to replay your work on top of it...
|
||||
Applying: C3
|
||||
Applying: C5
|
||||
```
|
||||
|
||||
完成以后,我们的提交链将变成如下图 5 的样子。
|
||||
|
||||
![Chain of commits after the rebase command][8]
|
||||
|
||||
图 5:`rebase` 命令完成后的提交链
|
||||
|
||||
接着,我们看一下提交历史,它应该变成如下的样子。
|
||||
```
|
||||
$ git log --oneline master
|
||||
6a92e7a C4
|
||||
259bf36 C2
|
||||
f33ae68 C1
|
||||
5043e79 C0
|
||||
|
||||
$ git log --oneline feature
|
||||
c4533a5 C5
|
||||
64f2047 C3
|
||||
6a92e7a C4
|
||||
259bf36 C2
|
||||
f33ae68 C1
|
||||
5043e79 C0
|
||||
```
|
||||
|
||||
注意那个 `C3'` 和 `C5'`— 在 master 分支上已处于提交链的“顶部”,由于产生了更改而创建了新提交。但是也要注意的是,rebase 后“原始的” `C3` 和 `C5` 仍然在那里 — 只是再没有一个分支指向它们而已。
|
||||
|
||||
如果我们做了这个 rebase,然后确定这不是我们想要的结果,希望去撤销它,我们可以做下面示例所做的操作:
|
||||
```
|
||||
$ git reset 79768b8
|
||||
|
||||
```
|
||||
|
||||
由于这个简单的变更,现在我们的分支将重新指向到做 `rebase` 操作之前一模一样的位置 —— 完全等效于撤销操作(图 6)。
|
||||
|
||||
![After undoing rebase][10]
|
||||
|
||||
图 6:撤销 `rebase` 操作之后
|
||||
|
||||
如果你想不起来之前一个操作指向的一个分支上提交了什么内容怎么办?幸运的是,Git 命令依然可以帮助你。用这种方式可以修改大多数操作的指针,Git 会记住你的原始提交。事实上,它是在 `.git` 仓库目录下,将它保存为一个特定的名为 `ORIG_HEAD ` 的文件中。在它被修改之前,那个路径是一个包含了大多数最新引用的文件。如果我们 `cat` 这个文件,我们可以看到它的内容。
|
||||
```
|
||||
$ cat .git/ORIG_HEAD
|
||||
79768b891f47ce06f13456a7e222536ee47ad2fe
|
||||
```
|
||||
|
||||
我们可以使用 `reset` 命令,正如前面所述,它返回指向到原始的链。然后它的历史将是如下的这样:
|
||||
```
|
||||
$ git log --oneline feature
|
||||
79768b8 C5
|
||||
000f9ae C3
|
||||
259bf36 C2
|
||||
f33ae68 C1
|
||||
5043e79 C0
|
||||
```
|
||||
|
||||
在 reflog 中是获取这些信息的另外一个地方。这个 reflog 是你本地仓库中相关切换或更改的详细描述清单。你可以使用 `git reflog` 命令去查看它的内容:
|
||||
```
|
||||
$ git reflog
|
||||
79768b8 HEAD@{0}: reset: moving to 79768b
|
||||
c4533a5 HEAD@{1}: rebase finished: returning to refs/heads/feature
|
||||
c4533a5 HEAD@{2}: rebase: C5
|
||||
64f2047 HEAD@{3}: rebase: C3
|
||||
6a92e7a HEAD@{4}: rebase: checkout master
|
||||
79768b8 HEAD@{5}: checkout: moving from feature to feature
|
||||
79768b8 HEAD@{6}: commit: C5
|
||||
000f9ae HEAD@{7}: checkout: moving from master to feature
|
||||
6a92e7a HEAD@{8}: commit: C4
|
||||
259bf36 HEAD@{9}: checkout: moving from feature to master
|
||||
000f9ae HEAD@{10}: commit: C3
|
||||
259bf36 HEAD@{11}: checkout: moving from master to feature
|
||||
259bf36 HEAD@{12}: commit: C2
|
||||
f33ae68 HEAD@{13}: commit: C1
|
||||
5043e79 HEAD@{14}: commit (initial): C0
|
||||
```
|
||||
|
||||
你可以使用日志中列出的、你看到的相关命名格式,去 reset 任何一个东西:
|
||||
```
|
||||
$ git reset HEAD@{1}
|
||||
|
||||
```
|
||||
|
||||
一旦你理解了当“修改”链的操作发生后,Git 是如何跟踪原始提交链的基本原理,那么在 Git 中做一些更改将不再是那么可怕的事。这就是强大的 Git 的核心能力之一:能够很快速、很容易地尝试任何事情,并且如果不成功就撤销它们。
|
||||
|
||||
Brent Laster 将在 7 月 16 日至 19 日在俄勒冈州波特兰举行的第 20 届 OSCON 年度活动上,展示 [强大的 Git:Rerere, Bisect, Subtrees, Filter Branch, Worktrees, Submodules, 等等][11]。想了解在任何水平上使用 Git 的一些技巧和缘由,请查阅 Brent 的书 ——"[Professional Git][13]",它在 Amazon 上有售。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/git-reset-revert-rebase-commands
|
||||
|
||||
作者:[Brent Laster][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bclaster
|
||||
[1]:/file/401126
|
||||
[2]:https://opensource.com/sites/default/files/uploads/gitcommands1_local-environment.png "Local Git environment with repository, staging area, and working directory"
|
||||
[3]:/file/401131
|
||||
[4]:https://opensource.com/sites/default/files/uploads/gitcommands2_reset.png "After reset"
|
||||
[5]:/file/401141
|
||||
[6]:https://opensource.com/sites/default/files/uploads/gitcommands4_commits-branches.png "Chain of commits for branches master and feature"
|
||||
[7]:/file/401146
|
||||
[8]:https://opensource.com/sites/default/files/uploads/gitcommands5_commits-rebase.png "Chain of commits after the rebase command"
|
||||
[9]:/file/401151
|
||||
[10]:https://opensource.com/sites/default/files/uploads/gitcommands6_rebase-undo.png "After undoing rebase"
|
||||
[11]:https://conferences.oreilly.com/oscon/oscon-or/public/schedule/detail/67142
|
||||
[12]:https://conferences.oreilly.com/oscon/oscon-or
|
||||
[13]:https://www.amazon.com/Professional-Git-Brent-Laster/dp/111928497X/ref=la_B01MTGIINQ_1_2?s=books&ie=UTF8&qid=1528826673&sr=1-2
|
||||
@ -0,0 +1,127 @@
|
||||
# 如何用 Scribus 和 Gedit 编辑 Adobe InDesign 文件
|
||||
|
||||

|
||||
|
||||
要想成为一名优秀的平面设计师,您必须善于使用各种各样专业的工具。现在,对大多数设计师来说,最常用的工具是 Adobe 全家桶。
|
||||
|
||||
但是,有时候使用开源工具能够帮您摆脱困境。比如,您正在使用一台公共打印机打印一份用 Adobe InDesign 创建的文件。这时,您需要对文件做一些简单的改动(比如,改正一个错别字),但您无法立刻使用 Adobe 套件。虽然这种情况很少见,但电子杂志制作软件 [Scribus][1] 和文本编辑器 [Gedit][2] 等开源工具可以节约您的时间。
|
||||
|
||||
在本文中,我将向您展示如何使用 Scribus 和 Gedit 编辑 Adobe InDesign 文件。请注意,还有许多其他开源平面设计软件可以用来代替 Adobe InDesign 或者结合使用。详情请查看我的文章:[昂贵的工具(从来!)不是平面设计的唯一选择][3] 以及 [开源 Adobe InDesign 脚本][4].
|
||||
|
||||
在编写本文的时候,我阅读了一些关于如何使用开源软件编辑 InDesign 文件的博客,但没有找到有用的文章。我尝试了两个解决方案。一个是:创建一个 EPS 并在文本编辑器 Scribus 中将其打开为可编辑文件,但这不起作用。另一个是:从 InDesign 中创建一个 IDML(一种旧的 InDesign 文件格式)文件,并在 Scribus 中打开它。第二种方法效果更好,也是我在下文中使用的解决方法。
|
||||
|
||||
### 编辑个人名片
|
||||
|
||||
我尝试在 Scribus 中打开和编辑 InDesign 名片文件的效果很好。唯一的问题是字母间的间距有些偏移,以及 “Jeff” 中的 ‘f’ 被翻转、‘J’ 被上下颠倒。其他部分,像样式和颜色等都完好无损。
|
||||
|
||||
![Business card in Adobe InDesign][6]
|
||||
|
||||
图:在 Adobe InDesign 中编辑个人名片。
|
||||
|
||||
![InDesign IDML file opened in Scribus][8]
|
||||
|
||||
图:在 Scribus 中打开 InDesign IDML 文件。
|
||||
|
||||
### 删除书籍中的文本
|
||||
|
||||
这本书籍的更改并不顺利。书籍的正文还 OK,但当我用 Scribus 打开 InDesign 文件,目录、页脚和一些首字下沉的段落都出现问题。不过至少,它是一个可编辑的文档。其中一个问题是一些文本框中的文字变成了默认的 Arial 字体,这是因为字体样式的优先级比段落样式高。这个问题容易解决。
|
||||
|
||||
![Book layout in InDesign][10]
|
||||
|
||||
图:InDesign 中的书籍布局。
|
||||
|
||||
![InDesign IDML file of book layout opened in Scribus][12]
|
||||
|
||||
图:用 Scribus 打开 InDesign IDML 文件的书籍布局。
|
||||
|
||||
当我试图选择并删除一页文本的时候,发生了奇异事件。我把光标放在文本中,按下 ``Command + A``(“全选”的快捷键)。表面看起来一整页文本都高亮显示了,但事实并非如此!
|
||||
|
||||
![Selecting text in Scribus][14]
|
||||
|
||||
图:Scribus 中被选中的文本。
|
||||
|
||||
当我按下“删除”键,整个文本(不只是高亮的部分)都消失了。
|
||||
|
||||
![Both pages of text deleted in Scribus][16]
|
||||
|
||||
图:两页文本都被删除了。
|
||||
|
||||
然后,更奇异的事情发生了……我按下 ``Command + Z`` 键来撤回删除操作,文本恢复,但文本格式全乱套了。
|
||||
|
||||
![Undo delete restored the text, but with bad formatting.][18]
|
||||
|
||||
图:Command+Z (撤回删除操作) 恢复了文本,但格式乱套了。
|
||||
|
||||
### 用文本编辑器打开 InDesign 文件
|
||||
|
||||
当您用记事本(比如,Mac 中的 TextEdit)分别打开 Scribus 文件和 InDesign 文件,会发现 Scribus 文件是可读的,而 InDesign 文件全是乱码。
|
||||
|
||||
您可以用 TextEdit 对两者进行更改并成功保存,但得到的文件是损坏的。下图是当我用 InDesign 打开编辑后的文件时的报错。
|
||||
|
||||
![InDesign error message][20]
|
||||
|
||||
图:InDesign 的报错。
|
||||
|
||||
我在 Ubuntu 系统上用文本编辑器 Gedit 编辑 Scribus 时得到了更好的结果。我从命令行启动了 Gedit,然后打开并编辑 Scribus 文件,保存后,再次使用 Scribus 打开文件时,我在 Gedit 中所做的更改都成功显示在 Scribus 中。
|
||||
|
||||
![Editing Scribus file in Gedit][22]
|
||||
|
||||
图:用 Gedit 编辑 Scribus 文件。
|
||||
|
||||
![Result of the Gedit edit in Scribus][24]
|
||||
|
||||
图:用 Scribus 打开 Gedit 编辑过的文件。
|
||||
|
||||
当您正准备打印的时候,客户打来电话说有一个错别字需要更改,此时您不需要苦等客户爸爸发来新的文件,只需要用 Gedit 打开 Scribus 文件,改正错别字,继续打印。
|
||||
|
||||
### 把图像拖拽到 ID 文件中
|
||||
|
||||
我将 InDesign 文档另存为 IDML 文件,这样我就可以用 Scribus 往其中拖进一些 PDF 文档。似乎 Scribus 并不能像 InDesign 一样把 PDF 文档 拖拽进去。于是,我把 PDF 文档转换成 JPG 格式的图片然后导入到 Scribus 中,成功了。但这么做的结果是,将 IDML 文档转换成 PDF 格式后,文件大小非常大。
|
||||
|
||||
![Huge PDF file][26]
|
||||
|
||||
图:把 Scribus 转换成 PDF 时得到一个非常大的文件。
|
||||
|
||||
我不确定为什么会这样——这个坑留着以后再填吧。
|
||||
|
||||
您是否有使用开源软件编辑平面图形文件的技巧?如果有,请在评论中分享哦。
|
||||
|
||||
------
|
||||
|
||||
via: https://opensource.com/article/18/7/adobe-indesign-open-source-tools
|
||||
|
||||
作者:[Jeff Macharyas][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[XiatianSummer](https://github.com/XiatianSummer)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rikki-endsley
|
||||
[1]: https://www.scribus.net/
|
||||
[2]: https://wiki.gnome.org/Apps/Gedit
|
||||
[3]: https://opensource.com/life/16/8/open-source-alternatives-graphic-design
|
||||
[4]: https://opensource.com/article/17/3/scripts-adobe-indesign
|
||||
[5]: /file/402516
|
||||
[6]: https://opensource.com/sites/default/files/uploads/1-business_card_designed_in_adobe_indesign_cc.png "Business card in Adobe InDesign"
|
||||
[7]: /file/402521
|
||||
[8]: https://opensource.com/sites/default/files/uploads/2-indesign_.idml_file_opened_in_scribus.png "InDesign IDML file opened in Scribus"
|
||||
[9]: /file/402531
|
||||
[10]: https://opensource.com/sites/default/files/uploads/3-book_layout_in_indesign.png "Book layout in InDesign"
|
||||
[11]: /file/402536
|
||||
[12]: https://opensource.com/sites/default/files/uploads/4-indesign_.idml_file_of_book_opened_in_scribus.png "InDesign IDML file of book layout opened in Scribus"
|
||||
[13]: /file/402541
|
||||
[14]: https://opensource.com/sites/default/files/uploads/5-command-a_in_the_scribus_file.png "Selecting text in Scribus"
|
||||
[15]: /file/402546
|
||||
[16]: https://opensource.com/sites/default/files/uploads/6-deleted_text_in_scribus.png "Both pages of text deleted in Scribus"
|
||||
[17]: /file/402551
|
||||
[18]: https://opensource.com/sites/default/files/uploads/7-command-z_in_scribus.png "Undo delete restored the text, but with bad formatting."
|
||||
[19]: /file/402556
|
||||
[20]: https://opensource.com/sites/default/files/uploads/8-indesign_error_message.png "InDesign error message"
|
||||
[21]: /file/402561
|
||||
[22]: https://opensource.com/sites/default/files/uploads/9-scribus_edited_in_gedit_on_linux.png "Editing Scribus file in Gedit"
|
||||
[23]: /file/402566
|
||||
[24]: https://opensource.com/sites/default/files/uploads/10-scribus_opens_after_gedit_changes.png "Result of the Gedit edit in Scribus"
|
||||
[25]: /file/402571
|
||||
[26]: https://opensource.com/sites/default/files/uploads/11-large_pdf_size.png "Huge PDF file"
|
||||
|
||||
@ -0,0 +1,73 @@
|
||||
为什么 Arch Linux 如此'难弄'又有何优劣?
|
||||
======
|
||||
|
||||

|
||||
[Arch Linux][1] 于**2002**年发布,由** Aaron Grifin** 领头,是当下最热门的 Linux 发行版之一。从设计上说,Arch Linux 试图给用户提供简单,最小化且优雅的体验,但他的目标用户群可不是怕事儿多的用户。Arch 鼓励参与社区建设,并且从设计上期待用户自己有学习操作系统的能力。
|
||||
|
||||
很多 Linux 老鸟对于 **Arch Linux** 会更了解,但电脑前的你可能只是刚开始打算把 Arch 当作日常操作系统来使用。虽然我也不是权威人士,但下面几点优劣是我认为你总会在使用中慢慢发现的。
|
||||
|
||||
### 1\. Pro: 定制属于你自己的 Linux 操作系统
|
||||
|
||||
大多数热门的 Linux 发行版(比如**Ubuntu** 和 **Fedora**) 很像一般我们会看到的预装系统,和**Windows** 或者 **MacOS** 一样。但 Arch 则会更鼓励你去把操作系统配置到符合你的胃口。如果你能顺利做到这点的话,你会得到一个每一个细节都如你所想的操作系统。
|
||||
|
||||
#### Con: 安装过程让人头疼
|
||||
|
||||
[安装 Arch Linux][2] 是主流发行版里的一支独苗——因为你要花些时间来微调你的操作系统。你会在过程中学到不少终端命令,和组成你系统的各种软件模块——毕竟你要自己挑选安装什么。当然,你也知道这个过程少不了阅读一些文档/教程。
|
||||
|
||||
### 2\. Pro: 没有预装垃圾
|
||||
|
||||
介于 **Arch** 允许你在安装时选择你想要的系统部件,你再也不用烦恼怎么处理你不想要的一堆预装软件。作为对比,**Ubuntu** 会预装大量的软件和桌面应用——很多你不需要甚至卸载之前都不知道他们存在的东西。
|
||||
|
||||
长话短说,**Arch Linux* 能省去大量的系统安装后时间。**Pacman**,是 Arch Linux 默认使用的优秀包管理组件。或者你也可以选择 [Pamac][3] 作为替代。
|
||||
|
||||
### 3\. Pro: 无需繁琐系统升级
|
||||
|
||||
**Arch Linux** 采用滚动升级模型,妙极了。这意味着你不需要担心老是被升级打断。一旦你用上了 Arch,连续地更新体验会让你和一会儿一个版本的升级说再见。只要你记得‘滚’更新(Arch 用语),你就一直会使用最新的软件包们。
|
||||
|
||||
#### Con: 一些升级可能会滚坏你的系统
|
||||
|
||||
虽然升级过程是完全连续的,你有时得留意一下你在更新什么。没人能知道所有软件的细节配置,也没人能替你来测试你的情况。所以如果你盲目更新,有时候你会滚坏你的系统。(译者:别担心,你可以回滚)
|
||||
|
||||
### 4\. Pro: Arch 有一个社区基因
|
||||
|
||||
所有 Linux 用户通常有一个共同点:对独立自由的追求。虽然大多数 Linux 发行版和公司企业等挂钩极少,但有时候也不是不存在的。比如 基于 **Ubuntu** 的变化版本们不得不受到 Canonical 公司决策的影响。
|
||||
|
||||
如果你想让你的电脑更独立,那么 Arch Linux 是你的伙伴。不像大多数操作系统,Arch 完全没有商业集团的影响,完全由社区驱动。
|
||||
|
||||
### 5\. Pro: Arch Wiki 无敌
|
||||
|
||||
[Arch Wiki][4] 是一个无敌文档库,几乎涵盖了所有关于安装和维护 Arch 以及关于操作系统本身的知识。Arch Wiki 最厉害的一点可能是,不管你在用什么发行版,你多多少少可能都在 Arch Wiki 的页面里找到过有用信息。这是因为 Arch 用户也会用别的发行版用户会用的东西,所以一些技巧和知识得以泛化。
|
||||
|
||||
### 6\. Pro: 别忘了 Arch 用户软件库 (AUR)
|
||||
|
||||
[Arch User Repository (AUR)][5] 是一个来自社区的超大软件仓库。如果你找一个还没有 Arch 的官方仓库里出现的软件,你肯定能在 AUR 里找到社区为你准备好的包。
|
||||
|
||||
AUR 是由用户自发编译和维护的。Arch 用户也可以给每个包投票,这样后来者就能找到最有用的那些软件包了。
|
||||
|
||||
#### 最后: Arch Linux 适合你吗?
|
||||
|
||||
**Arch Linux** 优点多于缺点,也有很多优缺点我无法在此一一叙述。安装过程很长,对非 Linux 用户来说也可能偏有些技术,但只要你投入一些时间和善用 Wiki,你肯定能迈过这道坎。
|
||||
|
||||
**Arch Linux** 是一个非常优秀的发行版——尽管它有一些复杂性。同时它也很受那些知道自己想要什么的用户的欢迎——只要你肯做点功课,有些耐心。
|
||||
|
||||
当你从0搭安装完 Arch 的时候,你会掌握很多 GNU/Linux 的内部细节,也再也不会对你的电脑内部运作方式一无所知了。
|
||||
|
||||
欢迎读者们在评论区讨论你使用 Arch Linux 的优缺点?以及你曾经遇到过的一些挑战。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.fossmint.com/why-is-arch-linux-so-challenging-what-are-pros-cons/
|
||||
|
||||
作者:[Martins D. Okoi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Moelf](https://github.com/Moelf)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.fossmint.com/author/dillivine/
|
||||
[1]:https://www.archlinux.org/
|
||||
[2]:https://www.tecmint.com/arch-linux-installation-and-configuration-guide/
|
||||
[3]:https://www.fossmint.com/pamac-arch-linux-gui-package-manager/
|
||||
[4]:https://wiki.archlinux.org/
|
||||
[5]:https://wiki.archlinux.org/index.php/Arch_User_Repository
|
||||
@ -1,41 +1,38 @@
|
||||
FSSlc is translating
|
||||
|
||||
4 Essential and Practical Usage of Cut Command in Linux
|
||||
Linux 下 cut 命令的 4 个本质且实用的示例
|
||||
============================================================
|
||||
|
||||
The cut command is the canonical tool to remove “columns” from a text file. In this context, a “column” can be defined as a range of characters or bytes identified by their physical position on the line, or a range of fields delimited by a separator.
|
||||
`cut` 命令是用来从文本文件中移除“某些列”的经典工具。在本文中的“一列”可以被定义为按照一行中位置区分的一系列字符串或者字节, 或者是以某个分隔符为间隔的某些域。
|
||||
|
||||
I have written about [using AWK commands][13] earlier. In this detailed guide, I’ll explain four essential and practical examples of cut command in Linux that will help you big time.
|
||||
先前我已经介绍了[如何使用 AWK 命令][13]。在本文中,我将解释 linux 下 `cut` 命令的 4 个本质且实用的例子,有时这些例子将帮你节省很多时间。
|
||||
|
||||

|
||||

|
||||
|
||||
### 4 Practical examples of Cut command in Linux
|
||||
### Linux 下 cut 命令的 4 个实用示例
|
||||
|
||||
If you prefer, you can watch this video explaining the same practical examples of cut command that I have listed in the article.
|
||||
假如你想,你可以观看下面的视频,视频中解释了本文中我列举的 cut 命令的使用例子。
|
||||
|
||||
目录:
|
||||
|
||||
Table of Contents:
|
||||
* [作用在一系列字符上][8]
|
||||
* [范围如何定义?][1]
|
||||
|
||||
* [Working with character ranges][8]
|
||||
* [What’s a range?][1]
|
||||
* [作用在一系列字节上][9]
|
||||
* [作用在多字节编码的字符上][2]
|
||||
|
||||
* [Working with byte ranges][9]
|
||||
* [Working with multibyte characters][2]
|
||||
* [作用在域上][10]
|
||||
* [处理不包含分隔符的行][3]
|
||||
|
||||
* [Working with fields][10]
|
||||
* [Handling lines not containing the delimiter][3]
|
||||
* [改变输出的分隔符][4]
|
||||
|
||||
* [Changing the output delimiter][4]
|
||||
* [非 POSIX GNU 扩展][11]
|
||||
|
||||
* [Non-POSIX GNU extensions][11]
|
||||
### 1\. 作用在一系列字符上
|
||||
|
||||
### 1\. Working with character ranges
|
||||
当启用 `-c` 命令行选项时,cut 命令将移除一系列字符。
|
||||
|
||||
When invoked with the `-c` command line option, the cut command will remove characterranges.
|
||||
和其他的过滤器类似, cut 命令不会就地改变输入的文件,它将复制已修改的数据到它的标准输出里去。你可以通过重定向命令的结果到一个文件中来保存修改后的结果,或者使用管道将结果送到另一个命令的输入中,这些都由你来负责。
|
||||
|
||||
Like any other filter, the cut command does not change the input file in place but it will copy the modified data to its standard output. It is your responsibility to redirect the command output to a file to save the result or to use a pipe to send it as input to another command.
|
||||
|
||||
If you’ve downloaded the [sample test files][26] used in the video above, you can see the `BALANCE.txt` data file, coming straight out of an accounting software my wife is using at her work:
|
||||
假如你已经下载了上面视频中的[示例测试文件][26],你将看到一个名为 `BALANCE.txt` 的数据文件,这些数据是直接从我妻子在她工作中使用的某款会计软件中导出的:
|
||||
|
||||
```
|
||||
sh$ head BALANCE.txt
|
||||
@ -51,9 +48,9 @@ ACCDOC ACCDOCDATE ACCOUNTNUM ACCOUNTLIB ACCDOCLIB
|
||||
6 1012017 623795 TOURIST GUIDE BOOK FACT FA00006253 - BIT QUIROBEN 00000001531,00
|
||||
```
|
||||
|
||||
This is a fixed-width text file since the data fields are padded with a variable number of spaces to ensure they are displayed as a nicely aligned table.
|
||||
上述文件是一个固定宽度的文本文件,因为对于每一项数据,都使用了不定长的空格做填充,使得它看起来是一个对齐的列表。
|
||||
|
||||
As a corollary, a data column always starts and ends at the same character position on each line. There is a little pitfall though: despite its name, the `cut` command actually requires you to specify the range of data you want to _keep_ , not the range you want to _remove_ . So, if I need _only_ the `ACCOUNTNUM` and `ACCOUNTLIB` columns in the data file above, I would write that:
|
||||
这样一来,每一列数据开始和结束的位置都是一致的。从 cut 命令的字面意思去理解会给我们带来一个小陷阱:`cut` 命令实际上需要你指出你想_保留_的数据范围,而不是你想_移除_的范围。所以,假如我_只_需要上面文件中的 `ACCOUNTNUM` 和 `ACCOUNTLIB` 列,我需要这么做:
|
||||
|
||||
```
|
||||
sh$ cut -c 25-59 BALANCE.txt | head
|
||||
@ -69,38 +66,38 @@ ACCOUNTNUM ACCOUNTLIB
|
||||
623795 TOURIST GUIDE BOOK
|
||||
```
|
||||
|
||||
#### What’s a range?
|
||||
#### 范围如何定义?
|
||||
|
||||
As we have just seen it, the cut command requires we specify the _range_ of data we want to keep. So, let’s introduce more formally what is a range: for the `cut` command, a range is defined by a starting and ending position separated by a hyphen. Ranges are 1-based, that is the first item of the line is the item number 1, not 0\. Ranges are inclusive: the start and end will be preserved in the output, as well as all characters between them. It is an error to specify a range whose ending position is before (“lower”) than its starting position. As a shortcut, you can omit the start _or_ end value as described in the table below:
|
||||
正如我们上面看到的那样, cut 命令需要我们特别指定需要保留的数据的_范围_。所以,下面我将更正式地介绍如何定义范围:对于 `cut` 命令来说,范围是由连字符(`-`)分隔的起始和结束位置组成,范围是基于 1 计数的,即每行的第一项是从 1 开始计数的,而不是从 0 开始。范围是一个闭区间,开始和结束位置都将包含在结果之中,正如它们之间的所有字符那样。如果范围中的结束位置比起始位置小,则这种表达式是错误的。作为快捷方式,你可以省略起始_或_结束值,正如下面的表格所示:
|
||||
|
||||
|
||||
|||
|
||||
|--|--|
|
||||
| `a-b` | the range between a and b (inclusive) |
|
||||
|`a` | equivalent to the range `a-a` |
|
||||
| `-b` | equivalent to `1-a` |
|
||||
| `b-` | equivalent to `b-∞` |
|
||||
| `a-b` | a 和 b 之间的范围(闭区间) |
|
||||
|`a` | 与范围 `a-a` 等价 |
|
||||
| `-b` | 与范围 `1-a` 等价 |
|
||||
| `b-` | 与范围 `b-∞` 等价 |
|
||||
|
||||
The cut commands allow you to specify several ranges by separating them with a comma. Here are a couple of examples:
|
||||
cut 命令允许你通过逗号分隔多个范围,下面是一些示例:
|
||||
|
||||
```
|
||||
# Keep characters from 1 to 24 (inclusive)
|
||||
# 保留 1 到 24 之间(闭区间)的字符
|
||||
cut -c -24 BALANCE.txt
|
||||
|
||||
# Keep characters from 1 to 24 and 36 to 59 (inclusive)
|
||||
# 保留 1 到 24(闭区间)以及 36 到 59(闭区间)之间的字符
|
||||
cut -c -24,36-59 BALANCE.txt
|
||||
|
||||
# Keep characters from 1 to 24, 36 to 59 and 93 to the end of the line (inclusive)
|
||||
# 保留 1 到 24(闭区间)、36 到 59(闭区间)和 93 到该行末尾之间的字符
|
||||
cut -c -24,36-59,93- BALANCE.txt
|
||||
```
|
||||
|
||||
One limitation (or feature, depending on the way you see it) of the `cut` command is it will _never reorder the data_ . So the following command will produce exactly the same result as the previous one, despite the ranges being specified in a different order:
|
||||
`cut` 命令的一个限制(或者是特性,取决于你如何看待它)是它将 _不会对数据进行重排_。所以下面的命令和先前的命令将产生相同的结果,尽管范围的顺序做了改变:
|
||||
|
||||
```
|
||||
cut -c 93-,-24,36-59 BALANCE.txt
|
||||
```
|
||||
|
||||
You can check that easily using the `diff` command:
|
||||
你可以轻易地使用 `diff` 命令来验证:
|
||||
|
||||
```
|
||||
diff -s <(cut -c -24,36-59,93- BALANCE.txt) \
|
||||
@ -108,7 +105,7 @@ diff -s <(cut -c -24,36-59,93- BALANCE.txt) \
|
||||
Files /dev/fd/63 and /dev/fd/62 are identical
|
||||
```
|
||||
|
||||
Similarly, the `cut` command _never duplicates data_ :
|
||||
类似的,`cut` 命令 _不会重复数据_:
|
||||
|
||||
```
|
||||
# One might expect that could be a way to repeat
|
||||
@ -121,15 +118,15 @@ ACCDOC
|
||||
5
|
||||
```
|
||||
|
||||
Worth mentioning there was a proposal for a `-o` option to lift those two last limitations, allowing the `cut` utility to reorder or duplicate data. But this was [rejected by the POSIX committee][14] _“because this type of enhancement is outside the scope of the IEEE P1003.2b draft standard.”_
|
||||
值得提及的是,曾经有一个提议,建议使用 `-o` 选项来实现上面提到的两个限制,使得 `cut` 工具可以重排或者重复数据。但这个提议被 [POSIX 委员会拒绝了][14],_“因为这类增强不属于 IEEE P1003.2b 草案标准的范围”_。
|
||||
|
||||
As of myself, I don’t know any cut version implementing that proposal as an extension. But if you do, please, share that with us using the comment section!
|
||||
据我所知,我还没有见过哪个版本的 cut 程序实现了上面的提议,以此来作为扩展,假如你知道某些例外,请使用下面的评论框分享给大家!
|
||||
|
||||
### 2\. Working with byte ranges
|
||||
### 2\. 作用在一系列字节上
|
||||
|
||||
When invoked with the `-b` command line option, the cut command will remove byte ranges.
|
||||
当使用 `-b` 命令行选项时,cut 命令将移除字节范围。
|
||||
|
||||
At first sight, there is no obvious difference between _character_ and _byte_ ranges:
|
||||
咋一看,使用_字符_范围和使用_字节_没有什么明显的不同:
|
||||
|
||||
```
|
||||
sh$ diff -s <(cut -b -24,36-59,93- BALANCE.txt) \
|
||||
@ -137,18 +134,18 @@ sh$ diff -s <(cut -b -24,36-59,93- BALANCE.txt) \
|
||||
Files /dev/fd/63 and /dev/fd/62 are identical
|
||||
```
|
||||
|
||||
That’s because my sample data file is using the [US-ASCII character encoding][27] (“charset”) as the `file -i` command can correctly guess it:
|
||||
这是因为我们的示例数据文件使用的是 [US-ASCII 编码][27](字符集),使用 `file -i` 便可以正确地猜出来:
|
||||
|
||||
```
|
||||
sh$ file -i BALANCE.txt
|
||||
BALANCE.txt: text/plain; charset=us-ascii
|
||||
```
|
||||
|
||||
In that character encoding, there is a one-to-one mapping between characters and bytes. Using only one byte, you can theoretically encode up to 256 different characters (digits, letters, punctuations, symbols, … ) In practice, that number is much lower since character encodings make provision for some special values (like the 32 or 65 [control characters][28]generally found). Anyway, even if we could use the full byte range, that would be far from enough to store the variety of human writing. So, today, the one-to-one mapping between characters and byte is more the exception than the norm and is almost always replaced by the ubiquitous UTF-8 multibyte encoding. Let’s see now how the cut command could handle that.
|
||||
在 US-ASCII 编码中,字符和字节是一一对应的。理论上,你只需要使用一个字节就可以表示 256 个不同的字符(数字、字母、标点符号和某些符号等)。实际上,你能表达的字符数比 256 要更少一些,因为字符编码中为某些特定值做了规定(例如 32 或 65 就是[控制字符][28])。即便我们能够使用上述所有的字节范围,但对于存储种类繁多的人类手写符号来说,256 是远远不够的。所以如今字符和字节间的一一对应更像是某种例外,并且几乎总是被无处不在的 UTF-8 多字节编码所取代。下面让我们看看如何来处理多字节编码的情形。
|
||||
|
||||
#### Working with multibyte characters
|
||||
#### 作用在多字节编码的字符上
|
||||
|
||||
As I said previously, the sample data files used as examples for that article are coming from an accounting software used by my wife. It appends she updated that software recently and, after that, the exported text files were subtlely different. I let you try spotting the difference by yourself:
|
||||
正如我前面提到的那样,示例数据文件来源于我妻子使用的某款会计软件。最近好像她升级了那个软件,然后呢,导出的文本就完全不同了,你可以试试和上面的数据文件相比,找找它们之间的区别:
|
||||
|
||||
```
|
||||
sh$ head BALANCE-V2.txt
|
||||
@ -164,7 +161,7 @@ ACCDOC ACCDOCDATE ACCOUNTNUM ACCOUNTLIB ACCDOCLIB
|
||||
6 1012017 623795 TOURIST GUIDE BOOK FACT FA00006253 - BIT QUIROBEN 00000001531,00
|
||||
```
|
||||
|
||||
The title of this section might help you in finding what has changed. But, found or not, let see now the consequences of that change:
|
||||
上面的标题栏或许能够帮助你找到什么被改变了,但无论你找到与否,现在让我们看看上面的更改过后的结果:
|
||||
|
||||
```
|
||||
sh$ cut -c 93-,-24,36-59 BALANCE-V2.txt
|
||||
@ -200,23 +197,23 @@ ACCDOC ACCDOCDATE ACCOUNTLIB DEBIT CREDIT
|
||||
36 1012017 VAT BS/ENC 00000000013,83
|
||||
```
|
||||
|
||||
I have copied above the command output _in-extenso_ so it should be obvious something has gone wrong with the column alignment.
|
||||
我已经_毫无删减地_复制了上面命令的输出。所以可以很明显地看出列对齐那里有些问题。
|
||||
|
||||
The explanation is the original data file contained only US-ASCII characters (symbol, punctuations, numbers and Latin letters without any diacritical marks)
|
||||
对此我的解释是原来的数据文件只包含 US-ASCII 编码的字符(符号、标点符号、数字和没有发音符号的拉丁字母)。
|
||||
|
||||
But if you look closely at the file produced after the software update, you can see that new export data file now preserves accented letters. For example, the company named “ALNÉENRE” is now properly spelled whereas it was previously exported as “ALNEENRE” (no accent)
|
||||
但假如你仔细地查看经软件升级后产生的文件,你可以看到新导出的数据文件保留了带发音符号的字母。例如名为“ALNÉENRE”的公司现在被合理地记录了,而不是先前的 “ALNEENRE”(没有发音符号)。
|
||||
|
||||
The `file -i` utility did not miss that change since it reports now the file as being [UTF-8 encoded][15]:
|
||||
`file -i` 正确地识别出了改变,因为它报告道现在这个文件是 [UTF-8 编码][15] 的。
|
||||
|
||||
```
|
||||
sh$ file -i BALANCE-V2.txt
|
||||
BALANCE-V2.txt: text/plain; charset=utf-8
|
||||
```
|
||||
|
||||
To see how are encoded accented letters in an UTF-8 file, we can use the `[hexdump][12]` utility that allows us to look directly at the bytes in a file:
|
||||
如果想看看 UTF-8 文件中那些带发音符号的字母是如何编码的,我们可以使用 `[hexdump][12]`,它可以让我们直接以字节形式查看文件:
|
||||
|
||||
```
|
||||
# To reduce clutter, let's focus only on the second line of the file
|
||||
# 为了减少输出,让我们只关注文件的第 2 行
|
||||
sh$ sed '2!d' BALANCE-V2.txt
|
||||
4 1012017 623477 TIDE SCHEDULE ALNÉENRE-4701-LOC 00000001615,00
|
||||
sh$ sed '2!d' BALANCE-V2.txt | hexdump -C
|
||||
@ -231,32 +228,31 @@ sh$ sed '2!d' BALANCE-V2.txt | hexdump -C
|
||||
0000007c
|
||||
```
|
||||
|
||||
On the line 00000030 of the `hexdump` output, after a bunch of spaces (byte `20`), you can see:
|
||||
在 `hexdump` 输出的 00000030 那行,在一系列的空格(字节 `20`)之后,你可以看到:
|
||||
|
||||
* the letter `A` is encoded as the byte `41`,
|
||||
* 字母 `A` 被编码为 `41`,
|
||||
|
||||
* the letter `L` is encoded a the byte `4c`,
|
||||
* 字母 `L` 被编码为 `4c`,
|
||||
|
||||
* and the letter `N` is encoded as the byte `4e`.
|
||||
* 字母 `N` 被编码为 `4e`。
|
||||
|
||||
But, the uppercase [LATIN CAPITAL LETTER E WITH ACUTE][16] (as it is the official name of the letter _É_ in the Unicode standard) is encoded using the _two_ bytes `c3 89`
|
||||
但对于大写的[带有注音的拉丁大写字母 E][16] (这是它在 Unicode 标准中字母 _É_ 的官方名称),则是使用 _2_ 个字节 `c3 89` 来编码的。
|
||||
|
||||
And here is the problem: using the `cut` command with ranges expressed as byte positions works well for fixed length encodings, but not for variable length ones like UTF-8 or [Shift JIS][17]. This is clearly explained in the following [non-normative extract of the POSIX standard][18]:
|
||||
这样便出现问题了:对于使用固定宽度编码的文件, 使用字节位置来表示范围的 `cut` 命令工作良好,但这并不适用于使用变长编码的 UTF-8 或者 [Shift JIS][17] 编码。这种情况在下面的 [POSIX标准的非规范性摘录][18] 中被明确地解释过:
|
||||
|
||||
> Earlier versions of the cut utility worked in an environment where bytes and characters were considered equivalent (modulo <backspace> and <tab> processing in some implementations). In the extended world of multi-byte characters, the new -b option has been added.
|
||||
> 先前版本的 cut 程序将字节和字符视作等同的环境下运作(正如在某些实现下对 退格键<backspace> 和制表键<tab> 的处理)。在针对多字节字符的情况下,特别增加了 `-b` 选项。
|
||||
|
||||
Hey, wait a minute! I wasn’t using the `-b` option in the “faulty” example above, but the `-c`option. So, _shouldn’t_ that have worked?!?
|
||||
嘿,等一下!我并没有在上面“有错误”的例子中使用 '-b' 选项,而是 `-c` 选项呀!所以,难道_不应该_能够成功处理了吗!?
|
||||
|
||||
Yes, it _should_ : it is unfortunate, but we are in 2018 and despite that, as of GNU Coreutils 8.30, the GNU implementation of the cut utility still does not handle multi-byte characters properly. To quote the [GNU documentation][19], the `-c` option is _“The same as -b for now, but internationalization will change that[… ]”_ — a mention that is present since more than 10 years now!
|
||||
是的,确实_应该_:但是很不幸,即便我们现在已身处 2018 年,GNU Coreutils 的版本为 8.30 了,cut 程序的 GNU 版本实现仍然不能很好地处理多字节字符。引用 [GNU 文档][19] 的话说,_`-c` 选项“现在和 `-b` 选项是相同的,但对于国际化的情形将有所不同[...]”_。需要提及的是,这个问题距今已有 10 年之久了!
|
||||
|
||||
On the other hand, the [OpenBSD][20] implementation of the cut utility is POSIX compliant, and will honor the current locale settings to handle multi-byte characters properly:
|
||||
另一方面,[OpenBSD][20] 的实现版本和 POSIX 相吻合,这将归功于当前的本地化(locale) 设定来合理地处理多字节字符:
|
||||
|
||||
```
|
||||
# Ensure subseauent commands will know we are using UTF-8 encoded
|
||||
# text files
|
||||
# 确保随后的命令知晓我们现在处理的是 UTF-8 编码的文本文件
|
||||
openbsd-6.3$ export LC_CTYPE=en_US.UTF-8
|
||||
|
||||
# With the `-c` option, cut works properly with multi-byte characters
|
||||
# 使用 `-c` 选项, cut 能够合理地处理多字节字符
|
||||
openbsd-6.3$ cut -c -24,36-59,93- BALANCE-V2.txt
|
||||
ACCDOC ACCDOCDATE ACCOUNTLIB DEBIT CREDIT
|
||||
4 1012017 TIDE SCHEDULE 00000001615,00
|
||||
@ -290,7 +286,7 @@ ACCDOC ACCDOCDATE ACCOUNTLIB DEBIT CREDIT
|
||||
36 1012017 VAT BS/ENC 00000000013,83
|
||||
```
|
||||
|
||||
As expected, when using the `-b` byte mode instead of the `-c` character mode, the OpenBSD cut implementation behave like the legacy `cut`:
|
||||
正如期望的那样,当使用 `-b` 选项而不是 `-c` 选项后, OpenBSD 版本的 cut 实现和传统的 `cut` 表现是类似的:
|
||||
|
||||
```
|
||||
openbsd-6.3$ cut -b -24,36-59,93- BALANCE-V2.txt
|
||||
@ -326,11 +322,11 @@ ACCDOC ACCDOCDATE ACCOUNTLIB DEBIT CREDIT
|
||||
36 1012017 VAT BS/ENC 00000000013,83
|
||||
```
|
||||
|
||||
### 3\. Working with fields
|
||||
### 3\. 作用在域上
|
||||
|
||||
In some sense, working with fields in a delimited text file is easier for the `cut` utility, since it will only have to locate the (one byte) field delimiters on each row, copying then verbatim the field content to the output without bothering with any encoding issues.
|
||||
从某种意义上说,使用 `cut` 来处理用特定分隔符隔开的文本文件要更加容易一些,因为只需要确定好每行中域之间的分隔符,然后复制域的内容到输出就可以了,而不需要烦恼任何与编码相关的问题。
|
||||
|
||||
Here is a sample delimited text file:
|
||||
下面是一个用分隔符隔开的示例文本文件:
|
||||
|
||||
```
|
||||
sh$ head BALANCE.csv
|
||||
@ -346,9 +342,9 @@ ACCDOC;ACCDOCDATE;ACCOUNTNUM;ACCOUNTLIB;ACCDOCLIB;DEBIT;CREDIT
|
||||
6;1012017;623795;TOURIST GUIDE BOOK;FACT FA00006253 - BIT QUIROBEN;00000001531,00;
|
||||
```
|
||||
|
||||
You may know that file format as [CSV][29] (for Comma-separated Value), even if the field separator is not always a comma. For example, the semi-colon (`;`) is frequently encountered as a field separator, and it is often the default choice when exporting data as “CSV” in countries already using the comma as the [decimal separator][30] (like we do in France — hence the choice of that character in my sample file). Another popular variant uses a [tab character][31] as the field separator, producing what is sometimes called a [tab-separated values][32] file. Finally, in the Unix and Linux world, the colon (`:`) is yet another relatively common field separator you may find, for example, in the standard `/etc/passwd` and `/etc/group` files.
|
||||
你可能知道上面文件是一个 [CSV][29] 格式的文件(它以逗号来分隔),即便有时候域分隔符不是逗号。例如分号(`;`)也常被用来作为分隔符,并且对于那些总使用逗号作为 [十进制分隔符][30]的国家(例如法国,所以上面我的示例文件中选用了他们国家的字符),当导出数据为 "CSV" 格式时,默认将使用分号来分隔数据。另一种常见的情况是使用 [tab 键][32] 来作为分隔符,从而生成叫做 [tab 分隔数值][32] 的文件。最后,在 Unix 和 Linux 领域,冒号 (`:`) 是另一种你能找到的常见分隔符号,例如在标准的 `/etc/passwd` 和 `/etc/group` 这两个文件里。
|
||||
|
||||
When using a delimited text file format, you provide to the cut command the range of fields to keep using the `-f` option, and you have to specify the delimiter using the `-d` option (without the `-d` option, the cut utility defaults to a tab character for the separator):
|
||||
当处理使用分隔符隔开的文本文件格式时,你可以向带有 `-f` 选项的 cut 命令提供需要保留的域的范围,并且你也可以使用 `-d` 选项来制定分隔符(当没有使用 `-d` 选项时,默认以 tab 字符来作为分隔符):
|
||||
|
||||
```
|
||||
sh$ cut -f 5- -d';' BALANCE.csv | head
|
||||
@ -364,11 +360,11 @@ FACT FA00006253 - BIT QUIROBEN;00000000306,20;
|
||||
FACT FA00006253 - BIT QUIROBEN;00000001531,00;
|
||||
```
|
||||
|
||||
#### Handling lines not containing the delimiter
|
||||
#### 处理不包含分隔符的行
|
||||
|
||||
But what if some line in the input file does not contain the delimiter? It is tempting to imagine that as a row containing only the first field. But this is _not_ what the cut utility does.
|
||||
但要是输入文件中的某些行没有分隔符又该怎么办呢?很容易地认为可以将这样的行视为只包含第一个域。但 cut 程序并 _不是_ 这样做的。
|
||||
|
||||
By default, when using the `-f` option, the cut utility will always output verbatim a line that does not contain the delimiter (probably assuming this is a non-data row like a header or comment of some sort):
|
||||
默认情况下,当使用 `-f` 选项时, cut 将总是原样输出不包含分隔符的那一行(可能假设它是非数据行,就像表头或注释等):
|
||||
|
||||
```
|
||||
sh$ (echo "# 2018-03 BALANCE"; cat BALANCE.csv) > BALANCE-WITH-HEADER.csv
|
||||
@ -381,7 +377,7 @@ DEBIT;CREDIT
|
||||
;00000001938,00
|
||||
```
|
||||
|
||||
Using the `-s` option, you can reverse that behavior, so `cut` will always ignore such line:
|
||||
使用 `-s` 选项,你可以做出相反的行为,这样 `cut` 将总是忽略这些行:
|
||||
|
||||
```
|
||||
sh$ cut -s -f 6,7 -d';' BALANCE-WITH-HEADER.csv | head -5
|
||||
@ -392,16 +388,17 @@ DEBIT;CREDIT
|
||||
00000001333,00;
|
||||
```
|
||||
|
||||
If you are in a hackish mood, you can exploit that feature as a relatively obscure way to keep only lines containing a given character:
|
||||
假如你好奇心强,你还可以探索这种特性,来作为一种相对
|
||||
隐晦的方式去保留那些只包含给定字符的行:
|
||||
|
||||
```
|
||||
# Keep lines containing a `e`
|
||||
# 保留含有一个 `e` 的行
|
||||
sh$ printf "%s\n" {mighty,bold,great}-{condor,monkey,bear} | cut -s -f 1- -d'e'
|
||||
```
|
||||
|
||||
#### Changing the output delimiter
|
||||
#### 改变输出的分隔符
|
||||
|
||||
As an extension, the GNU implementation of cut allows to use a different field separator for the output using the `--output-delimiter` option:
|
||||
作为一种扩展, GNU 版本实现的 cut 允许通过使用 `--output-delimiter` 选项来为结果指定一个不同的域分隔符:
|
||||
|
||||
```
|
||||
sh$ cut -f 5,6- -d';' --output-delimiter="*" BALANCE.csv | head
|
||||
@ -417,32 +414,31 @@ FACT FA00006253 - BIT QUIROBEN*00000000306,20*
|
||||
FACT FA00006253 - BIT QUIROBEN*00000001531,00*
|
||||
```
|
||||
|
||||
Notice, in that case, all occurrences of the field separator are replaced, and not only those at the boundary of the ranges specified on the command line arguments.
|
||||
需要注意的是,在上面这个例子中,所有出现域分隔符的地方都被替换掉了,而不仅仅是那些在命令行中指定的作为域范围边界的分隔符。
|
||||
|
||||
### 4\. Non-POSIX GNU extensions
|
||||
### 4\. 非 POSIX GNU 扩展
|
||||
|
||||
Speaking of non-POSIX GNU extension, a couple of them that can be particularly useful. Worth mentioning the following extensions work equally well with the byte, character (for what that means in the current GNU implementation) or field ranges:
|
||||
说到非 POSIX GNU 扩展,它们中的某些特别有用。特别需要提及的是下面的扩展也同样对字节、字符或者域范围工作良好(相对于当前的 GNU 实现来说)。
|
||||
|
||||
Think of that option like the exclamation mark in a sed address (`!`); instead of keeping the data matching the given range, `cut` will keep data NOT matching the range
|
||||
想想在 sed 地址中的感叹符号(`!`),使用它,`cut` 将只保存**没有**被匹配到的范围:
|
||||
|
||||
```
|
||||
# Keep only field 5
|
||||
# 只保留第 5 个域
|
||||
sh$ cut -f 5 -d';' BALANCE.csv |head -3
|
||||
ACCDOCLIB
|
||||
ALNEENRE-4701-LOC
|
||||
ALNEENRE-4701-LOC
|
||||
|
||||
# Keep all but field 5
|
||||
# 保留除了第 5 个域之外的内容
|
||||
sh$ cut --complement -f 5 -d';' BALANCE.csv |head -3
|
||||
ACCDOC;ACCDOCDATE;ACCOUNTNUM;ACCOUNTLIB;DEBIT;CREDIT
|
||||
4;1012017;623477;TIDE SCHEDULE;00000001615,00;
|
||||
4;1012017;445452;VAT BS/ENC;00000000323,00;
|
||||
```
|
||||
|
||||
use the [NUL character][6] as the line terminator instead of the [newline character][7]. The `-z`option is particularly useful when your data may contain embedded newline characters, like when working with filenames (since newline is a valid character in a filename, but NUL isn’t).
|
||||
使用 [NUL 字符][6] 来作为行终止符,而不是 [新行(newline)字符][7]。当你的数据包含 新行 字符时, `-z` 选项就特别有用了,例如当处理文件名的时候(因为在文件名中 新行 字符是可以使用的,而 NUL 则不可以)。
|
||||
|
||||
|
||||
To show you how the `-z` option works, let’s make a little experiment. First, we will create a file whose name contains embedded new lines:
|
||||
为了展示 `-z` 选项,让我们先做一点实验。首先,我们将创建一个文件名中包含换行符的文件:
|
||||
|
||||
```
|
||||
bash$ touch $'EMPTY\nFILE\nWITH FUNKY\nNAME'.txt
|
||||
@ -452,7 +448,7 @@ BALANCE-V2.txt
|
||||
EMPTY?FILE?WITH FUNKY?NAME.txt
|
||||
```
|
||||
|
||||
Let’s now assume I want to display the first 5 characters of each `*.txt` file name. A naive solution will miserably fail here:
|
||||
现在假设我想展示每个 `*.txt` 文件的前 5 个字符。一个想当然的解法将会失败:
|
||||
|
||||
```
|
||||
sh$ ls -1 *.txt | cut -c 1-5
|
||||
@ -464,7 +460,7 @@ WITH
|
||||
NAME.
|
||||
```
|
||||
|
||||
You may have already read `[ls][21]` was designed for [human consumption][33], and using it in a command pipeline is an anti-pattern (it is indeed). So let’s use the `[find][22]` command instead:
|
||||
你可以已经知道 `[ls][21]` 是为了[方便人类使用][33]而特别设计的,并且在一个命令管道中使用它是一个反模式(确实是这样的)。所以让我们用 `[find][22]` 来替换它:
|
||||
|
||||
```
|
||||
sh$ find . -name '*.txt' -printf "%f\n" | cut -c 1-5
|
||||
@ -476,33 +472,32 @@ NAME.
|
||||
BALAN
|
||||
```
|
||||
|
||||
and … that produced basically the same erroneous result as before (although in a different order because `ls` implicitly sorts the filenames, something the `find` command does not do)
|
||||
上面的命令基本上产生了与先前类似的结果(尽管以不同的次序,因为 `ls` 会隐式地对文件名做排序,而 `find` 则不会)。
|
||||
|
||||
The problem is in both cases, the `cut` command can’t make the distinction between a newline character being part of a data field (the filename), and a newline character used as an end of record marker. But, using the NUL byte (`\0`) as the line terminator clears the confusion so we can finally obtain the expected result:
|
||||
在上面的两个例子中,都有一个相同的问题,`cut` 命令不能区分 新行 字符是数据域的一部分(即文件名),还是作为最后标记的 新行 记号。但使用 NUL 字节(`\0`)来作为行终止符就将排除掉这种混淆的情况,使得我们最后可以得到期望的结果:
|
||||
|
||||
```
|
||||
# I was told (?) some old versions of tr require using \000 instead of \0
|
||||
# to denote the NUL character (let me know if you needed that change!)
|
||||
# 我被告知在某些旧版的 `tr` 程序中需要使用 `\000` 而不是 `\0` 来代表 NUL 字符(假如你需要这种改变请让我知晓!)
|
||||
sh$ find . -name '*.txt' -printf "%f\0" | cut -z -c 1-5| tr '\0' '\n'
|
||||
BALAN
|
||||
EMPTY
|
||||
BALAN
|
||||
```
|
||||
|
||||
With that latest example, we are moving away from the core of this article that was the `cut`command. So, I will let you try to figure by yourself the meaning of the funky `"%f\0"` after the `-printf` argument of the `find` command or why I used the `[tr][23]` command at the end of the pipeline.
|
||||
通过上面最后的例子,我们就达到了本文的最后部分了,所以我将让你自己试试 `-printf` 后面那个有趣的 `"%f\0"` 参数或者理解为什么我在管道的最后使用了 `[tr][23]` 命令。
|
||||
|
||||
### A lot more can be done with Cut command
|
||||
### 使用 cut 命令可以实现更多功能
|
||||
|
||||
I just showed the most common and in my opinion the most essential usage of Cut command. You can apply the command in even more practical ways. It depends on your logical reasoning and imagination.
|
||||
我只是列举了 cut 命令的最常见且在我眼中最实质的使用方式。你甚至可以将它以更加实用的方式加以运用,这取决于你的逻辑和想象。
|
||||
|
||||
Don’t hesitate to use the comment section below to post your findings. And, as always, if you like this article, don’t forget to share it on your favorite websites and social media!
|
||||
不要再犹豫了,请使用下面的评论框贴出你的发现。最后一如既往的,假如你喜欢这篇文章,请不要忘记将它分享到你最喜爱网站和社交媒体中!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxhandbook.com/cut-command/
|
||||
|
||||
作者:[Sylvain Leroux ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user