mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
commit
fc3e5783b6
17
.travis.yml
17
.travis.yml
@ -1,18 +1,27 @@
|
||||
language: c
|
||||
language: minimal
|
||||
install:
|
||||
- sudo apt-get install jq
|
||||
- git clone --depth=1 -b gh-pages https://github.com/LCTT/TranslateProject/ build && rm -rf build/.git
|
||||
script:
|
||||
- 'if [ "$TRAVIS_PULL_REQUEST" != "false" ]; then sh ./scripts/check.sh; fi'
|
||||
- 'if [ "$TRAVIS_PULL_REQUEST" = "false" ]; then sh ./scripts/badge.sh; fi'
|
||||
- 'if [ "$TRAVIS_EVENT_TYPE" = "cron" ]; then sh ./scripts/status.sh; fi'
|
||||
|
||||
branches:
|
||||
only:
|
||||
- master
|
||||
- master
|
||||
# - status
|
||||
except:
|
||||
- gh-pages
|
||||
- gh-pages
|
||||
git:
|
||||
submodules: false
|
||||
depth: false
|
||||
deploy:
|
||||
provider: pages
|
||||
skip_cleanup: true
|
||||
github_token: $GITHUB_TOKEN
|
||||
local_dir: build
|
||||
on:
|
||||
branch: master
|
||||
branch:
|
||||
- master
|
||||
# - status
|
||||
|
||||
@ -1,4 +0,0 @@
|
||||
# Linux中国翻译规范
|
||||
1. 翻译中出现的专有名词,可参见Dict.md中的翻译。
|
||||
2. 英文人名,如无中文对应译名,一般不译。
|
||||
2. 缩写词,一般不须翻译,可考虑旁注中文全名。
|
||||
112
README.md
112
README.md
@ -1,44 +1,40 @@
|
||||
|
||||

|
||||

|
||||

|
||||

|
||||
[](https://lctt.github.io/new)
|
||||
[](https://lctt.github.io/translating)
|
||||
[](https://github.com/LCTT/TranslateProject/tree/master/translated)
|
||||
[](https://github.com/LCTT/TranslateProject/tree/master/published)
|
||||
|
||||
[](https://travis-ci.org/LCTT/TranslateProject)
|
||||
[](https://travis-ci.com/LCTT/TranslateProject)
|
||||
[](https://github.com/LCTT/TranslateProject/graphs/contributors)
|
||||
[](https://github.com/LCTT/TranslateProject/pulls?q=is%3Apr+is%3Aclosed)
|
||||
|
||||
简介
|
||||
-------------------------------
|
||||
|
||||
[LCTT](https://linux.cn/lctt/) 是“Linux中国”([https://linux.cn/](https://linux.cn/))的翻译组,负责从国外优秀媒体翻译 Linux 相关的技术、资讯、杂文等内容。
|
||||
[LCTT](https://linux.cn/lctt/) 是“Linux 中国”([https://linux.cn/](https://linux.cn/))的翻译组,负责从国外优秀媒体翻译 Linux 相关的技术、资讯、杂文等内容。
|
||||
|
||||
LCTT 已经拥有几百名活跃成员,并欢迎更多的 Linux 志愿者加入我们的团队。
|
||||
|
||||

|
||||

|
||||
|
||||
LCTT 的组成
|
||||
-------------------------------
|
||||
|
||||
**选题**,负责选择合适的内容,并将原文转换为 markdown 格式,提交到 LCTT 的 [TranslateProject](https://github.com/LCTT/TranslateProject) 库中。
|
||||
|
||||
**译者**,负责从选题中选择内容进行翻译。
|
||||
|
||||
**校对**,负责将初译的文章进行文字润色、技术校对等工作。
|
||||
|
||||
**发布**,负责将校对后的文章,排版进行发布。
|
||||
- LCTT 官网: [https://linux.cn/lctt/](https://linux.cn/lctt/)
|
||||
- LCTT 状态: [https://lctt.github.io/](https://lctt.github.io/)
|
||||
|
||||
加入我们
|
||||
-------------------------------
|
||||
|
||||
请首先加入翻译组的 QQ 群,群号是:198889102,加群时请说明是“志愿者”。加入后记得修改您的群名片为您的 GitHub 的 ID。
|
||||
请首先加入翻译组的 QQ 群,群号是:**198889102**,加群时请说明是“*志愿者*”。
|
||||
|
||||
加入的成员,请先阅读 [WIKI 如何开始](https://github.com/LCTT/TranslateProject/wiki/01-如何开始)。
|
||||
加入的成员,请:
|
||||
|
||||
1. 修改你的 QQ 群名片为“译者-您的_GitHub_ID”。
|
||||
2. 阅读 [WIKI](http://lctt.github.io/wiki) 了解如何开始。
|
||||
3. 遇到不解之处,请在群内发问。
|
||||
|
||||
如何开始
|
||||
-------------------------------
|
||||
|
||||
请阅读 [WIKI](https://github.com/LCTT/TranslateProject/wiki)。
|
||||
请阅读 [WIKI](http://lctt.github.io/wiki)。如需要协助,请在群内发问。
|
||||
|
||||
历史
|
||||
-------------------------------
|
||||
@ -79,44 +75,52 @@ LCTT 的组成
|
||||
* 2018/08/17 提升 pityonline 为核心成员,担任校对,并接受他的建议采用 PR 审核模式。
|
||||
* 2018/09/10 [LCTT 五周年](https://linux.cn/article-9999-1.html)。
|
||||
* 2018/10/25 重构了 CI,感谢 vizv、lujun9972、bestony。
|
||||
* 2018/11/13 [成立了项目管理委员会(PMC)](https://linux.cn/article-10279-1.html),初始成员为:@wxy (主席)、@oska874、@lujun9972、@bestony、@pityonline、@geekpi、@qhwdw。
|
||||
|
||||
核心成员
|
||||
|
||||
项目管理委员及核心成员
|
||||
-------------------------------
|
||||
|
||||
目前 LCTT 核心成员有:
|
||||
LCTT 现由项目管理委员会(PMC)进行管理,成员如下:
|
||||
|
||||
- 组长 @wxy,
|
||||
- 选题 @oska874,
|
||||
- 选题 @lujun9972,
|
||||
- 技术 @bestony,
|
||||
- 校对 @jasminepeng,
|
||||
- 校对 @pityonline,
|
||||
- 钻石译者 @geekpi,
|
||||
- 钻石译者 @qhwdw,
|
||||
- 钻石译者 @GOLinux,
|
||||
- 核心成员 @GHLandy,
|
||||
- 核心成员 @martin2011qi,
|
||||
- 核心成员 @ictlyh,
|
||||
- 核心成员 @strugglingyouth,
|
||||
- 核心成员 @FSSlc,
|
||||
- 核心成员 @zpl1025,
|
||||
- 核心成员 @runningwater,
|
||||
- 核心成员 @bazz2,
|
||||
- 核心成员 @Vic020,
|
||||
- 核心成员 @alim0x,
|
||||
- 核心成员 @tinyeyeser,
|
||||
- 核心成员 @Locez,
|
||||
- 核心成员 @ucasFL,
|
||||
- 核心成员 @rusking,
|
||||
- 核心成员 @MjSeven
|
||||
- 前任选题 @DeadFire,
|
||||
- 前任校对 @reinoir222,
|
||||
- 前任校对 @PurlingNayuki,
|
||||
- 前任校对 @carolinewuyan,
|
||||
- 功勋成员 @vito-L,
|
||||
- 功勋成员 @willqian,
|
||||
- 功勋成员 @vizv,
|
||||
- 功勋成员 @dongfengweixiao,
|
||||
- 🎩 主席 @wxy
|
||||
- 🎩 选题 @oska874
|
||||
- 🎩 选题 @lujun9972
|
||||
- 🎩 技术 @bestony
|
||||
- 🎩 校对 @pityonline
|
||||
- 🎩 译者 @geekpi
|
||||
- 🎩 译者 @qhwdw
|
||||
|
||||
目前 LCTT 核心成员有:
|
||||
|
||||
- ❤️ 核心成员 @vizv
|
||||
- ❤️ 核心成员 @zpl1025
|
||||
- ❤️ 核心成员 @runningwater
|
||||
- ❤️ 核心成员 @FSSlc
|
||||
- ❤️ 核心成员 @Vic020
|
||||
- ❤️ 核心成员 @alim0x
|
||||
- ❤️ 核心成员 @martin2011qi
|
||||
- ❤️ 核心成员 @Locez
|
||||
- ❤️ 核心成员 @ucasFL
|
||||
- ❤️ 核心成员 @MjSeven
|
||||
|
||||
曾经做出了巨大贡献的核心成员,被列入荣誉榜:
|
||||
|
||||
- 🏆 前任选题 @DeadFire
|
||||
- 🏆 前任校对 @reinoir222
|
||||
- 🏆 前任校对 @PurlingNayuki
|
||||
- 🏆 前任校对 @carolinewuyan
|
||||
- 🏆 前任校对 @jasminepeng
|
||||
- 🏆 功勋成员 @tinyeyeser
|
||||
- 🏆 功勋成员 @vito-L
|
||||
- 🏆 功勋成员 @willqian
|
||||
- 🏆 功勋成员 @GOLinux
|
||||
- 🏆 功勋成员 @bazz2
|
||||
- 🏆 功勋成员 @ictlyh
|
||||
- 🏆 功勋成员 @dongfengweixiao
|
||||
- 🏆 功勋成员 @strugglingyouth
|
||||
- 🏆 功勋成员 @GHLandy
|
||||
- 🏆 功勋成员 @rusking
|
||||
|
||||
全部成员列表请参见: https://linux.cn/lctt-list/ 。
|
||||
|
||||
|
||||
@ -0,0 +1,159 @@
|
||||
Linux 下如何避免重复性压迫损伤(RSI)
|
||||
======
|
||||
|
||||
![workrave-image][1]
|
||||
|
||||
<ruby>[重复性压迫损伤][2]<rt>Repetitive Strain Injury</rt></ruby>(RSI)是职业性损伤综合症,非特异性手臂疼痛或工作引起的上肢障碍。RSI 是由于过度使用双手从事重复性任务导致的,如打字、书写和使用鼠标. 不幸的是,大部分人不了解什么是 RSI 以及它的危害有多大。你可以使用名叫 Workrave 的开源软件轻松的预防 RSI。
|
||||
|
||||
### RSI 有哪些症状?
|
||||
|
||||
我从这个[页面][3]引用过来的,看看哪些你被说中了:
|
||||
|
||||
1. 疲惫缺乏忍耐力?
|
||||
2. 手掌及上肢乏力
|
||||
3. 疼痛麻木甚至失去知觉?
|
||||
4. 沉重:你有没有感觉手很沉?
|
||||
5. 笨拙: 你有没有感觉抓不紧东西?
|
||||
6. 你有没有感觉手上无力?很难打开罐子或切菜无力?
|
||||
7. 缺乏协调和控制?
|
||||
8. 手总是冰凉的?
|
||||
9. 健康意识有待提高?稍不注意身体就发现有毛病了。
|
||||
10. 是否过敏?
|
||||
11. 频繁的自我按摩(潜意识的)?
|
||||
12. 共鸣的疼痛?当别人在谈论手痛的时候,你是否也感觉到了手疼?
|
||||
|
||||
### 如何减少发展为 RSI 的风险
|
||||
|
||||
* 使用计算机的时候每隔 30 分钟间隔休息一下。借助软件如 workrave 预防 RSI。
|
||||
* 有规律的锻炼可以预防各种损伤,包括 RSI。
|
||||
* 使用合理的姿势。调整你的电脑桌和椅子使身体保持一个肌肉放松状态。
|
||||
|
||||
### Workrave
|
||||
|
||||
Workrave 是一款预防计算机用户发展为 RSI 或近视的自由开源软件。软件会定期锁屏为一个动画: “Workrave 小姐”,引导用户做各种伸展运动并敦促其休息一下。这个软件经常提醒你暂停休息一下,并限制你每天的限度。程序可以运行在 MS-Window、Linux 以及类 UNIX 操作系统下。
|
||||
|
||||
#### 安装 workrave
|
||||
|
||||
在 Debian/Ubuntu Linux 系统运行以下 [apt 命令][4]/[apt-get 命令][5]:
|
||||
|
||||
```
|
||||
$ sudo apt-get install workrave
|
||||
```
|
||||
|
||||
Fedora Linux 发行版用户运行以下 dnf 命令:
|
||||
|
||||
```
|
||||
$ sudo dnf install workrave
|
||||
```
|
||||
|
||||
RHEL/CentOS Linux 用户可以启动 EPEL 仓库并用 [yum 命令][6]安装:
|
||||
|
||||
```
|
||||
### [ **在CentOS/RHEL 7.x 及衍生版本上测试** ] ###
|
||||
$ sudo yum install epel-release
|
||||
$ sudo yum install https://rpms.remirepo.net/enterprise/remi-release-7.rpm
|
||||
$ sudo yum install workrave
|
||||
```
|
||||
|
||||
Arch Linux 用户运行以下 pacman 命令来安装:
|
||||
|
||||
```
|
||||
$ sudo pacman -S workrave
|
||||
```
|
||||
|
||||
FreeBSD 用户可用以下 pkg 命令安装:
|
||||
|
||||
```
|
||||
# pkg install workrave
|
||||
```
|
||||
|
||||
OpenBSD 用户可用以下 pkg_add 命令安装:
|
||||
|
||||
```
|
||||
$ doas pkg_add workrave
|
||||
```
|
||||
|
||||
#### 如何配置 workrave
|
||||
|
||||
Workrave 以一个小程序运行,它的用户界面位于面板中。你可以为 workrave 增加一个面板来控制软件的动作和外观。
|
||||
|
||||
增加一个新 workrave 对象到面板:
|
||||
|
||||
* 在面板空白区域右键,打开面板弹出菜单
|
||||
* 选择新增到面板
|
||||
* 新增面板对话框打开,在加载器顶部,可以看到可用的面板对象按照字母排列。选中 workrave 程序并单击新增。
|
||||
|
||||
![图 01:新增 workrave 对象到面板][7]
|
||||
|
||||
*图 01:新增 workrave 对象到面板*
|
||||
|
||||
如果修改 workrave 对象的属性,执行以下步骤:
|
||||
|
||||
* 右键 workrave 对象打开面板对象弹出
|
||||
* 选中偏好。使用属性对话框修改对应属性
|
||||
|
||||

|
||||
|
||||
*图 02:修改 Workrave 对象属性*
|
||||
|
||||
#### Workrave 运行展示
|
||||
|
||||
主窗口显示下一次提醒休息的剩余时间,这个窗口可以关闭,时间提示窗口会显示在面板上。
|
||||
|
||||
![图 03:时间计数器][8]
|
||||
|
||||
*图 03:时间计数器*
|
||||
|
||||
![图 04:Workrave 小姐 - 引导你做伸展运动的动画][9]
|
||||
|
||||
*图 04:Workrave 小姐 - 引导你做伸展运动的动画*
|
||||
|
||||
休息提示窗口,请求你暂停一下工作:
|
||||
|
||||
![图 05:休息提示倒计时][10]
|
||||
|
||||
*图 05:休息提示倒计时*
|
||||
|
||||
![图 06:你可以跳过休息][11]
|
||||
|
||||
*图 06:你可以跳过休息*
|
||||
|
||||
#### 参考链接:
|
||||
|
||||
1. [Workrave 项目][12] 主页
|
||||
2. [pokoy][13] 防止 RSI 和其他计算机压力的轻量级守护进程
|
||||
3. GNOME3 下的 [Pomodoro][14] 计数器
|
||||
4. [RSI][2] 的维基百科
|
||||
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 创始人,经验丰富的系统管理员,同时也是一个 Linux/Unix 系统下的 shell 脚本培训师。他曾服务于全球客户,并与多个行业合作包括 IT、教育、国防和航天研究,以及非盈利机构。可以在 [Twitter][15]、[Facebook][16]、[Google+][17] 上关注他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/repetitive-strain-injury-prevention-software.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[guevaraya](https://github.com/guevaraya)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz/
|
||||
[1]:https://www.cyberciti.biz/media/new/tips/2009/11/workrave-image.jpg
|
||||
[2]:https://en.wikipedia.org/wiki/Repetitive_strain_injury
|
||||
[3]:https://web.eecs.umich.edu/~cscott/rsi.html##symptoms
|
||||
[4]:https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/
|
||||
[5]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html
|
||||
[6]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/
|
||||
[7]:https://www.cyberciti.biz/media/new/tips/2009/11/add-workwave-to-panel.png
|
||||
[8]:https://www.cyberciti.biz/media/new/tips/2009/11/screenshot-workrave.png
|
||||
[9]:https://www.cyberciti.biz/media/new/tips/2009/11/miss-workrave.png
|
||||
[10]:https://www.cyberciti.biz/media/new/tips/2009/11/time-for-micro-pause.gif
|
||||
[11]:https://www.cyberciti.biz/media/new/tips/2009/11/Micro-break.png
|
||||
[12]:http://www.workrave.org/
|
||||
[13]:https://github.com/ttygde/pokoy
|
||||
[14]:http://gnomepomodoro.org
|
||||
[15]:https://twitter.com/nixcraft
|
||||
[16]:https://facebook.com/nixcraft
|
||||
[17]:https://plus.google.com/+CybercitiBiz
|
||||
@ -0,0 +1,358 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qhwdw)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10519-1.html)
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 3 OK03)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok03.html)
|
||||
[#]: author: (Robert Mullins http://www.cl.cam.ac.uk/~rdm34)
|
||||
|
||||
计算机实验室之树莓派:课程 3 OK03
|
||||
======
|
||||
|
||||
OK03 课程基于 OK02 课程来构建,它教你在汇编中如何使用函数让代码可复用和可读性更好。假设你已经有了 [课程 2:OK02][1] 的操作系统,我们将以它为基础。
|
||||
|
||||
### 1、可复用的代码
|
||||
|
||||
到目前为止,我们所写的代码都是以我们希望发生的事为顺序来输入的。对于非常小的程序来说,这种做法很好,但是如果我们以这种方式去写一个完整的系统,所写的代码可读性将非常差。我们应该去使用函数。
|
||||
|
||||
> 一个函数是一段可复用的代码片断,可以用于去计算某些答案,或执行某些动作。你也可以称它们为<ruby>过程<rt>procedure</rt></ruby>、<ruby>例程<rt>routine</rt></ruby>或<ruby>子例程<rt>subroutine</rt></ruby>。虽然它们都是不同的,但人们几乎都没有正确地使用这个术语。
|
||||
|
||||
> 你应该在数学上遇到了函数的概念。例如,余弦函数应用于一个给定的数时,会得到介于 -1 到 1 之间的另一个数,这个数就是角的余弦。一般我们写成 `cos(x)` 来表示应用到一个值 `x` 上的余弦函数。
|
||||
|
||||
> 在代码中,函数可以有多个输入(也可以没有输入),然后函数给出多个输出(也可以没有输出),并可能导致副作用。例如一个函数可以在一个文件系统上创建一个文件,第一个输入是它的名字,第二个输入是文件的长度。
|
||||
|
||||
> ![Function as black boxes][2]
|
||||
|
||||
> 函数可以认为是一个“黑匣子”。我们给它输入,然后它给我们输出,而我们不需要知道它是如何工作的。
|
||||
|
||||
在像 C 或 C++ 这样的高级代码中,函数是语言的组成部分。在汇编代码中,函数只是我们的创意。
|
||||
|
||||
理想情况下,我们希望能够在我们的寄存器中设置一些输入值,然后分支切换到某个地址,然后预期在某个时刻分支返回到我们代码,并通过代码来设置输出值到寄存器。这就是我们所设想的汇编代码中的函数。困难之处在于我们用什么样的方式去设置寄存器。如果我们只是使用平时所接触到的某种方法去设置寄存器,每个程序员可能使用不同的方法,这样你将会发现你很难理解其他程序员所写的代码。另外,编译器也不能像使用汇编代码那样轻松地工作,因为它们压根不知道如何去使用函数。为避免这种困惑,为每个汇编语言设计了一个称为<ruby>应用程序二进制接口<rt>Application Binary Interface</rt></ruby>(ABI)的标准,由它来规范函数如何去运行。如果每个人都使用相同的方法去写函数,这样每个人都可以去使用其他人写的函数。在这里,我将教你们这个标准,而从现在开始,我所写的函数将全部遵循这个标准。
|
||||
|
||||
该标准规定,寄存器 `r0`、`r1`、`r2` 和 `r3` 将被依次用于函数的输入。如果函数没有输入,那么它不会在意值是什么。如果只需要一个输入,那么它应该总是在寄存器 `r0` 中,如果它需要两个输入,那么第一个输入在寄存器 `r0` 中,而第二个输入在寄存器 `r1` 中,依此类推。输出值也总是在寄存器 `r0` 中。如果函数没有输出,那么 `r0` 中是什么值就不重要了。
|
||||
|
||||
另外,该标准要求当一个函数运行之后,寄存器 `r4` 到 `r12` 的值必须与函数启动时的值相同。这意味着当你调用一个函数时,你可以确保寄存器 `r4` 到 `r12` 中的值没有发生变化,但是不能确保寄存器 `r0` 到 `r3` 中的值也没有发生变化。
|
||||
|
||||
当一个函数运行完成后,它将返回到启动它的代码分支处。这意味着它必须知道启动它的代码的地址。为此,需要一个称为 `lr`(链接寄存器)的专用寄存器,它总是在保存调用这个函数的指令后面指令的地址。
|
||||
|
||||
表 1.1 ARM ABI 寄存器用法
|
||||
|
||||
| 寄存器 | 简介 | 保留 | 规则 |
|
||||
| ------ | --------- | ---- | ----------------- |
|
||||
| `r0` | 参数和结果 | 否 | `r0` 和 `r1` 用于给函数传递前两个参数,以及函数返回的结果。如果函数返回值不使用它,那么在函数运行之后,它们可以携带任何值。 |
|
||||
| `r1` | 参数和结果 | 否 | |
|
||||
| `r2` | 参数 | 否 | `r2` 和 `r3` 用去给函数传递后两个参数。在函数运行之后,它们可以携带任何值。 |
|
||||
| `r3` | 参数 | 否 | |
|
||||
| `r4` | 通用寄存器 | 是 | `r4` 到 `r12` 用于保存函数运行过程中的值,它们的值在函数调用之后必须与调用之前相同。 |
|
||||
| `r5` | 通用寄存器 | 是 | |
|
||||
| `r6` | 通用寄存器 | 是 | |
|
||||
| `r7` | 通用寄存器 | 是 | |
|
||||
| `r8` | 通用寄存器 | 是 | |
|
||||
| `r9` | 通用寄存器 | 是 | |
|
||||
| `r10` | 通用寄存器 | 是 | |
|
||||
| `r11` | 通用寄存器 | 是 | |
|
||||
| `r12` | 通用寄存器 | 是 | |
|
||||
| `lr` | 返回地址 | 否 | 当函数运行完成后,`lr` 中保存了分支的返回地址,但在函数运行完成之后,它将保存相同的地址。 |
|
||||
| `sp` | 栈指针 | 是 | `sp` 是栈指针,在下面有详细描述。它的值在函数运行完成后,必须是相同的。 |
|
||||
|
||||
通常,函数需要使用很多的寄存器,而不仅是 `r0` 到 `r3`。但是,由于 `r4` 到 `r12` 必须在函数完成之后值必须保持相同,因此它们需要被保存到某个地方。我们将它们保存到称为栈的地方。
|
||||
|
||||
> ![Stack diagram][3]
|
||||
|
||||
> 一个<ruby>栈<rt>stack</rt></ruby>就是我们在计算中用来保存值的一个很形象的方法。就像是摞起来的一堆盘子,你可以从上到下来移除它们,而添加它们时,你只能从下到上来添加。
|
||||
|
||||
> 在函数运行时,使用栈来保存寄存器值是个非常好的创意。例如,如果我有一个函数需要去使用寄存器 `r4` 和 `r5`,它将在一个栈上存放这些寄存器的值。最后用这种方式,它可以再次将它拿回来。更高明的是,如果为了运行完我的函数,需要去运行另一个函数,并且那个函数需要保存一些寄存器,在那个函数运行时,它将把寄存器保存在栈顶上,然后在结束后再将它们拿走。而这并不会影响我保存在寄存器 `r4` 和 `r5` 中的值,因为它们是在栈顶上添加的,拿走时也是从栈顶上取出的。
|
||||
|
||||
> 用来表示使用特定的方法将值放到栈上的专用术语,我们称之为那个方法的“<ruby>栈帧<rt>stack frame</rt></ruby>”。不是每种方法都使用一个栈帧,有些是不需要存储值的。
|
||||
|
||||
因为栈非常有用,它被直接实现在 ARMv6 的指令集中。一个名为 `sp`(栈指针)的专用寄存器用来保存栈的地址。当需要有值添加到栈上时,`sp` 寄存器被更新,这样就总是保证它保存的是栈上第一个值的地址。`push {r4,r5}` 将推送 `r4` 和 `r5` 中的值到栈顶上,而 `pop {r4,r5}` 将(以正确的次序)取回它们。
|
||||
|
||||
### 2、我们的第一个函数
|
||||
|
||||
现在,关于函数的原理我们已经有了一些概念,我们尝试来写一个函数。由于是我们的第一个很基础的例子,我们写一个没有输入的函数,它将输出 GPIO 的地址。在上一节课程中,我们就是写到这个值上,但将它写成函数更好,因为我们在真实的操作系统中经常需要用到它,而我们不可能总是能够记住这个地址。
|
||||
|
||||
复制下列代码到一个名为 `gpio.s` 的新文件中。就像在 `source` 目录中使用的 `main.s` 一样。我们将把与 GPIO 控制器相关的所有函数放到一个文件中,这样更好查找。
|
||||
|
||||
```assembly
|
||||
.globl GetGpioAddress
|
||||
GetGpioAddress:
|
||||
ldr r0,=0x20200000
|
||||
mov pc,lr
|
||||
```
|
||||
|
||||
> `.globl lbl` 使标签 `lbl` 从其它文件中可访问。
|
||||
|
||||
> `mov reg1,reg2` 复制 `reg2` 中的值到 `reg1` 中。
|
||||
|
||||
这就是一个很简单的完整的函数。`.globl GetGpioAddress` 命令是通知汇编器,让标签 `GetGpioAddress` 在所有文件中全局可访问。这意味着在我们的 `main.s` 文件中,我们可以使用分支指令到标签 `GetGpioAddress` 上,即便这个标签在那个文件中没有定义也没有问题。
|
||||
|
||||
你应该认得 `ldr r0,=0x20200000` 命令,它将 GPIO 控制器地址保存到 `r0` 中。由于这是一个函数,我们必须要让它输出到寄存器 `r0` 中,我们不能再像以前那样随意使用任意一个寄存器了。
|
||||
|
||||
`mov pc,lr` 将寄存器 `lr` 中的值复制到 `pc` 中。正如前面所提到的,寄存器 `lr` 总是保存着方法完成后我们要返回的代码的地址。`pc` 是一个专用寄存器,它总是包含下一个要运行的指令的地址。一个普通的分支命令只需要改变这个寄存器的值即可。通过将 `lr` 中的值复制到 `pc` 中,我们就可以将要运行的下一行命令改变成我们将要返回的那一行。
|
||||
|
||||
理所当然这里有一个问题,那就是我们如何去运行这个代码?我们将需要一个特殊的分支类型 `bl` 指令。它像一个普通的分支一样切换到一个标签,但它在切换之前先更新 `lr` 的值去包含一个在该分支之后的行的地址。这意味着当函数执行完成后,将返回到 `bl` 指令之后的那一行上。这就确保了函数能够像任何其它命令那样运行,它简单地运行,做任何需要做的事情,然后推进到下一行。这是理解函数最有用的方法。当我们使用它时,就将它们按“黑匣子”处理即可,不需要了解它是如何运行的,我们只了解它需要什么输入,以及它给我们什么输出即可。
|
||||
|
||||
到现在为止,我们已经明白了函数如何使用,下一节我们将使用它。
|
||||
|
||||
### 3、一个大的函数
|
||||
|
||||
现在,我们继续去实现一个更大的函数。我们的第一项任务是启用 GPIO 第 16 号针脚的输出。如果它是一个函数那就太好了。我们能够简单地指定一个针脚号和一个函数作为输入,然后函数将设置那个针脚的值。那样,我们就可以使用这个代码去控制任意的 GPIO 针脚,而不只是 LED 了。
|
||||
|
||||
将下列的命令复制到 `gpio.s` 文件中的 `GetGpioAddress` 函数中。
|
||||
|
||||
```assembly
|
||||
.globl SetGpioFunction
|
||||
SetGpioFunction:
|
||||
cmp r0,#53
|
||||
cmpls r1,#7
|
||||
movhi pc,lr
|
||||
```
|
||||
|
||||
> 带后缀 `ls` 的命令只有在上一个比较命令的结果是第一个数字小于或与第二个数字相同的情况下才会被运行。它是无符号的。
|
||||
|
||||
> 带后缀 `hi` 的命令只有上一个比较命令的结果是第一个数字大于第二个数字的情况下才会被运行。它是无符号的。
|
||||
|
||||
在写一个函数时,我们首先要考虑的事情就是输入,如果输入错了我们怎么办?在这个函数中,我们有一个输入是 GPIO 针脚号,而它必须是介于 0 到 53 之间的数字,因为只有 54 个针脚。每个针脚有 8 个函数,被编号为 0 到 7,因此函数编号也必须是 0 到 7 之间的数字。我们可以假设输入应该是正确的,但是当在硬件上使用时,这种做法是非常危险的,因为不正确的值将导致非常糟糕的副作用。所以,在这个案例中,我们希望确保输入值在正确的范围。
|
||||
|
||||
为了确保输入值在正确的范围,我们需要做一个检查,即 `r0` <= 53 并且 `r1` <= 7。首先我们使用前面看到的比较命令去将 `r0` 的值与 53 做比较。下一个指令 `cmpls` 仅在前一个比较指令结果是小于或与 53 相同时才会去运行。如果是这种情况,它将寄存器 `r1` 的值与 7 进行比较,其它的部分都和前面的是一样的。如果最后的比较结果是寄存器值大于那个数字,最后我们将返回到运行函数的代码处。
|
||||
|
||||
这正是我们所希望的效果。如果 `r0` 中的值大于 53,那么 `cmpls` 命令将不会去运行,但是 `movhi` 会运行。如果 `r0` 中的值 <= 53,那么 `cmpls` 命令会运行,它会将 `r1` 中的值与 7 进行比较,如果 `r1` > 7,`movhi` 会运行,函数结束,否则 `movhi` 不会运行,这样我们就确定 `r0` <= 53 并且 `r1` <= 7。
|
||||
|
||||
`ls`(低于或相同)与 `le`(小于或等于)有一些细微的差别,以及后缀 `hi`(高于)和 `gt`(大于)也一样有一些细微差别,我们在后面将会讲到。
|
||||
|
||||
将这些命令复制到上面的代码的下面位置。
|
||||
|
||||
```assembly
|
||||
push {lr}
|
||||
mov r2,r0
|
||||
bl GetGpioAddress
|
||||
```
|
||||
|
||||
> `push {reg1,reg2,...}` 复制列出的寄存器 `reg1`、`reg2`、... 到栈顶。该命令仅能用于通用寄存器和 `lr` 寄存器。
|
||||
|
||||
> `bl lbl` 设置 `lr` 为下一个指令的地址并切换到标签 `lbl`。
|
||||
|
||||
这三个命令用于调用我们第一个方法。`push {lr}` 命令复制 `lr` 中的值到栈顶,这样我们在后面可以获取到它。当我们调用 `GetGpioAddress` 时必须要这样做,我们将需要使用 `lr` 去保存我们函数要返回的地址。
|
||||
|
||||
如果我们对 `GetGpioAddress` 函数一无所知,我们必须假设它改变了 `r0`、`r1`、`r2` 和 `r3` 的值 ,并移动我们的值到 `r4` 和 `r5` 中,以在函数完成之后保持它们的值一样。幸运的是,我们知道 `GetGpioAddress` 做了什么,并且我们也知道它仅改变了 `r0` 为 GPIO 地址,它并没有影响 `r1`、`r2` 或 `r3` 的值。因此,我们仅去将 GPIO 针脚号从 `r0` 中移出,这样它就不会被覆盖掉,但我们知道,可以将它安全地移到 `r2` 中,因为 `GetGpioAddress` 并不去改变 `r2`。
|
||||
|
||||
最后我们使用 `bl` 指令去运行 `GetGpioAddress`。通常,运行一个函数,我们使用一个术语叫“调用”,从现在开始我们将一直使用这个术语。正如我们前面讨论过的,`bl` 调用一个函数是通过更新 `lr` 为下一个指令的地址并切换到该函数完成的。
|
||||
|
||||
当一个函数结束时,我们称为“返回”。当一个 `GetGpioAddress` 调用返回时,我们已经知道了 `r0` 中包含了 GPIO 的地址,`r1` 中包含了函数编号,而 `r2` 中包含了 GPIO 针脚号。
|
||||
|
||||
我前面说过,GPIO 函数每 10 个保存在一个块中,因此首先我们需要去判断我们的针脚在哪个块中。这似乎听起来像是要使用一个除法,但是除法做起来非常慢,因此对于这些比较小的数来说,不停地做减法要比除法更好。
|
||||
|
||||
将下面的代码复制到上面的代码中最下面的位置。
|
||||
|
||||
```assembly
|
||||
functionLoop$:
|
||||
|
||||
cmp r2,#9
|
||||
subhi r2,#10
|
||||
addhi r0,#4
|
||||
bhi functionLoop$
|
||||
```
|
||||
|
||||
> `add reg,#val` 将数字 `val` 加到寄存器 `reg` 的内容上。
|
||||
|
||||
这个简单的循环代码将针脚号(`r2`)与 9 进行比较。如果它大于 9,它将从针脚号上减去 10,并且将 GPIO 控制器地址加上 4,然后再次运行检查。
|
||||
|
||||
这样做的效果就是,现在,`r2` 中将包含一个 0 到 9 之间的数字,它是针脚号除以 10 的余数。`r0` 将包含这个针脚的函数所设置的 GPIO 控制器的地址。它就如同是 “GPIO 控制器地址 + 4 × (GPIO 针脚号 ÷ 10)”。
|
||||
|
||||
最后,将下面的代码复制到上面的代码中最下面的位置。
|
||||
|
||||
```assembly
|
||||
add r2, r2,lsl #1
|
||||
lsl r1,r2
|
||||
str r1,[r0]
|
||||
pop {pc}
|
||||
```
|
||||
|
||||
> 移位参数 `reg,lsl #val` 表示将寄存器 `reg` 中二进制表示的数逻辑左移 `val` 位之后的结果作为与前面运算的操作数。
|
||||
|
||||
> `lsl reg,amt` 将寄存器 `reg` 中的二进制数逻辑左移 `amt` 中的位数。
|
||||
|
||||
> `str reg,[dst]` 与 `str reg,[dst,#0]` 相同。
|
||||
|
||||
> `pop {reg1,reg2,...}` 从栈顶复制值到寄存器列表 `reg1`、`reg2`、... 仅有通用寄存器与 `pc` 可以这样弹出值。
|
||||
|
||||
这个代码完成了这个方法。第一行其实是乘以 3 的变体。乘法在汇编中是一个大而慢的指令,因为电路需要很长时间才能给出答案。有时使用一些能够很快给出答案的指令会让它变得更快。在本案例中,我们知道 `r2` × 3 与 `r2` × 2 + `r2` 是相同的。一个寄存器乘以 2 是非常容易的,因为它可以通过将二进制表示的数左移一位来很方便地实现。
|
||||
|
||||
ARMv6 汇编语言其中一个非常有用的特性就是,在使用它之前可以先移动参数所表示的位数。在本案例中,我将 `r2` 加上 `r2` 中二进制表示的数左移一位的结果。在汇编代码中,你可以经常使用这个技巧去更快更容易地计算出答案,但如果你觉得这个技巧使用起来不方便,你也可以写成类似 `mov r3,r2`; `add r2,r3`; `add r2,r3` 这样的代码。
|
||||
|
||||
现在,我们可以将一个函数的值左移 `r2` 中所表示的位数。大多数对数量的指令(比如 `add` 和 `sub`)都有一个可以使用寄存器而不是数字的变体。我们执行这个移位是因为我们想去设置表示针脚号的位,并且每个针脚有三个位。
|
||||
|
||||
然后,我们将函数计算后的值保存到 GPIO 控制器的地址上。我们在循环中已经算出了那个地址,因此我们不需要像 OK01 和 OK02 中那样在一个偏移量上保存它。
|
||||
|
||||
最后,我们从这个方法调用中返回。由于我们将 `lr` 推送到了栈上,因此我们 `pop pc`,它将复制 `lr` 中的值并将它推送到 `pc` 中。这个操作类似于 `mov pc,lr`,因此函数调用将返回到运行它的那一行上。
|
||||
|
||||
敏锐的人可能会注意到,这个函数其实并不能正确工作。虽然它将 GPIO 针脚函数设置为所要求的值,但它会导致在同一个块中的所有的 10 个针脚的函数都归 0!在一个大量使用 GPIO 针脚的系统中,这将是一个很恼人的问题。我将这个问题留给有兴趣去修复这个函数的人,以确保只设置相关的 3 个位而不去覆写其它位,其它的所有位都保持不变。关于这个问题的解决方案可以在本课程的下载页面上找到。你可能会发现非常有用的几个函数是 `and`,它是计算两个寄存器的布尔与函数,`mvns` 是计算布尔非函数,而 `orr` 是计算布尔或函数。
|
||||
|
||||
### 4、另一个函数
|
||||
|
||||
现在,我们已经有了能够管理 GPIO 针脚函数的函数。我们还需要写一个能够打开或关闭 GPIO 针脚的函数。我们不需要写一个打开的函数和一个关闭的函数,只需要一个函数就可以做这两件事情。
|
||||
|
||||
我们将写一个名为 `SetGpio` 的函数,它将 GPIO 针脚号作为第一个输入放入 `r0` 中,而将值作为第二个输入放入 `r1` 中。如果该值为 `0`,我们将关闭针脚,而如果为非零则打开针脚。
|
||||
|
||||
将下列的代码复制粘贴到 `gpio.s` 文件的结尾部分。
|
||||
|
||||
```assembly
|
||||
.globl SetGpio
|
||||
SetGpio:
|
||||
pinNum .req r0
|
||||
pinVal .req r1
|
||||
```
|
||||
|
||||
> `alias .req reg` 设置寄存器 `reg` 的别名为 `alias`。
|
||||
|
||||
我们再次需要 `.globl` 命令,标记它为其它文件可访问的全局函数。这次我们将使用寄存器别名。寄存器别名允许我们为寄存器使用名字而不仅是 `r0` 或 `r1`。到目前为止,寄存器别名还不是很重要,但随着我们后面写的方法越来越大,它将被证明非常有用,现在开始我们将尝试使用别名。当在指令中使用到 `pinNum .req r0` 时,它的意思是 `pinNum` 表示 `r0`。
|
||||
|
||||
将下面的代码复制粘贴到上述的代码下面位置。
|
||||
|
||||
```assembly
|
||||
cmp pinNum,#53
|
||||
movhi pc,lr
|
||||
push {lr}
|
||||
mov r2,pinNum
|
||||
.unreq pinNum
|
||||
pinNum .req r2
|
||||
bl GetGpioAddress
|
||||
gpioAddr .req r0
|
||||
```
|
||||
|
||||
> `.unreq alias` 删除别名 `alias`。
|
||||
|
||||
就像在函数 `SetGpio` 中所做的第一件事情是检查给定的针脚号是否有效一样。我们需要同样的方式去将 `pinNum`(`r0`)与 53 进行比较,如果它大于 53 将立即返回。一旦我们想要再次调用 `GetGpioAddress`,我们就需要将 `lr` 推送到栈上来保护它,将 `pinNum` 移动到 `r2` 中。然后我们使用 `.unreq` 语句来删除我们给 `r0` 定义的别名。因为针脚号现在保存在寄存器 `r2` 中,我们希望别名能够反映这个变化,因此我们从 `r0` 移走别名,重新定义到 `r2`。你应该每次在别名使用结束后,立即删除它,这样当它不再存在时,你就不会在后面的代码中因它而产生错误。
|
||||
|
||||
然后,我们调用了 `GetGpioAddress`,并且我们创建了一个指向 `r0`的别名以反映此变化。
|
||||
|
||||
将下面的代码复制粘贴到上述代码的后面位置。
|
||||
|
||||
```assembly
|
||||
pinBank .req r3
|
||||
lsr pinBank,pinNum,#5a
|
||||
lsl pinBank,#2
|
||||
add gpioAddr,pinBank
|
||||
.unreq pinBank
|
||||
```
|
||||
|
||||
> `lsr dst,src,#val` 将 `src` 中二进制表示的数右移 `val` 位,并将结果保存到 `dst`。
|
||||
|
||||
对于打开和关闭 GPIO 针脚,每个针脚在 GPIO 控制器上有两个 4 字节组。第一个 4 字节组每个位控制前 32 个针脚,而第二个 4 字节组控制剩下的 22 个针脚。为了判断我们要设置的针脚在哪个 4 字节组中,我们需要将针脚号除以 32。幸运的是,这很容易,因为它等价于将二进制表示的针脚号右移 5 位。因此,在本案例中,我们将 `r3` 命名为 `pinBank`,然后计算 `pinNum` ÷ 32。因为它是一个 4 字节组,我们需要将它与 4 相乘的结果。它与二进制表示的数左移 2 位相同,这就是下一行的命令。你可能想知道我们能否只将它右移 3 位呢,这样我们就不用先右移再左移。但是这样做是不行的,因为当我们做 ÷ 32 时答案有些位可能被舍弃,而如果我们做 ÷ 8 时却不会这样。
|
||||
|
||||
现在,`gpioAddr` 的结果有可能是 20200000<sub>16</sub>(如果针脚号介于 0 到 31 之间),也有可能是 20200004<sub>16</sub>(如果针脚号介于 32 到 53 之间)。这意味着如果加上 28<sub>10</sub>,我们将得到打开针脚的地址,而如果加上 40<sub>10</sub> ,我们将得到关闭针脚的地址。由于我们用完了 `pinBank` ,所以在它之后立即使用 `.unreq` 去删除它。
|
||||
|
||||
将下面的代码复制粘贴到上述代码的下面位置。
|
||||
|
||||
```assembly
|
||||
and pinNum,#31
|
||||
setBit .req r3
|
||||
mov setBit,#1
|
||||
lsl setBit,pinNum
|
||||
.unreq pinNum
|
||||
```
|
||||
|
||||
> `and reg,#val` 计算寄存器 `reg` 中的数与 `val` 的布尔与。
|
||||
|
||||
该函数的下一个部分是产生一个正确的位集合的数。至于 GPIO 控制器去打开或关闭针脚,我们在针脚号除以 32 的余数里设置了位的数。例如,设置 16 号针脚,我们需要第 16 位设置数字为 1 。设置 45 号针脚,我们需要设置第 13 位数字为 1,因为 45 ÷ 32 = 1 余数 13。
|
||||
|
||||
这个 `and` 命令计算我们需要的余数。它是这样计算的,在两个输入中所有的二进制位都是 1 时,这个 `and` 运算的结果就是 1,否则就是 0。这是一个很基础的二进制操作,`and` 操作非常快。我们给定的输入是 “pinNum and 31<sub>10</sub> = 11111<sub>2</sub>”。这意味着答案的后 5 位中只有 1,因此它肯定是在 0 到 31 之间。尤其是在 `pinNum` 的后 5 位的位置是 1 的地方它只有 1。这就如同被 32 整除的余数部分。就像 31 = 32 - 1 并不是巧合。
|
||||
|
||||
![binary division example][4]
|
||||
|
||||
代码的其余部分使用这个值去左移 1 位。这就有了创建我们所需要的二进制数的效果。
|
||||
|
||||
将下面的代码复制粘贴到上述代码的下面位置。
|
||||
|
||||
```assembly
|
||||
teq pinVal,#0
|
||||
.unreq pinVal
|
||||
streq setBit,[gpioAddr,#40]
|
||||
strne setBit,[gpioAddr,#28]
|
||||
.unreq setBit
|
||||
.unreq gpioAddr
|
||||
pop {pc}
|
||||
```
|
||||
|
||||
> `teq reg,#val` 检查寄存器 `reg` 中的数字与 `val` 是否相等。
|
||||
|
||||
这个代码结束了该方法。如前面所说,当 `pinVal` 为 0 时,我们关闭它,否则就打开它。`teq`(等于测试)是另一个比较操作,它仅能够测试是否相等。它类似于 `cmp` ,但它并不能算出哪个数大。如果你只是希望测试数字是否相同,你可以使用 `teq`。
|
||||
|
||||
如果 `pinVal` 是 0,我们将 `setBit` 保存在 GPIO 地址偏移 40 的位置,我们已经知道,这样会关闭那个针脚。否则将它保存在 GPIO 地址偏移 28 的位置,它将打开那个针脚。最后,我们通过弹出 `pc` 返回,这将设置它为我们推送链接寄存器时保存的值。
|
||||
|
||||
### 5、一个新的开始
|
||||
|
||||
在完成上述工作后,我们终于有了我们的 GPIO 函数。现在,我们需要去修改 `main.s` 去使用它们。因为 `main.s` 现在已经有点大了,也更复杂了。将它分成两节将是一个很好的设计。到目前为止,我们一直使用的 `.init` 应该尽可能的让它保持小。我们可以更改代码来很容易地反映出这一点。
|
||||
|
||||
将下列的代码插入到 `main.s` 文件中 `_start:` 的后面:
|
||||
|
||||
```
|
||||
b main
|
||||
|
||||
.section .text
|
||||
main:
|
||||
mov sp,#0x8000
|
||||
```
|
||||
|
||||
在这里重要的改变是引入了 `.text` 节。我设计了 `makefile` 和链接器脚本,它将 `.text` 节(它是默认节)中的代码放在地址为 8000<sub>16</sub> 的 `.init` 节之后。这是默认加载地址,并且它给我们提供了一些空间去保存栈。由于栈存在于内存中,它也有一个地址。栈向下增长内存,因此每个新值都低于前一个地址,所以,这使得栈顶是最低的一个地址。
|
||||
|
||||
![Layout diagram of operating system][5]
|
||||
|
||||
> 图中的 “ATAGs” 节的位置保存了有关树莓派的信息,比如它有多少内存,默认屏幕分辨率是多少。
|
||||
|
||||
用下面的代码替换掉所有设置 GPIO 函数针脚的代码:
|
||||
|
||||
```assembly
|
||||
pinNum .req r0
|
||||
pinFunc .req r1
|
||||
mov pinNum,#16
|
||||
mov pinFunc,#1
|
||||
bl SetGpioFunction
|
||||
.unreq pinNum
|
||||
.unreq pinFunc
|
||||
```
|
||||
|
||||
这个代码将使用针脚号 16 和函数编号 1 去调用 `SetGpioFunction`。它的效果就是启用了 OK LED 灯的输出。
|
||||
|
||||
用下面的代码去替换打开 OK LED 灯的代码:
|
||||
|
||||
```assembly
|
||||
pinNum .req r0
|
||||
pinVal .req r1
|
||||
mov pinNum,#16
|
||||
mov pinVal,#0
|
||||
bl SetGpio
|
||||
.unreq pinNum
|
||||
.unreq pinVal
|
||||
```
|
||||
|
||||
这个代码使用 `SetGpio` 去关闭 GPIO 第 16 号针脚,因此将打开 OK LED。如果我们(将第 4 行)替换成 `mov pinVal,#1` 它将关闭 LED 灯。用以上的代码去替换掉你关闭 LED 灯的旧代码。
|
||||
|
||||
### 6、继续向目标前进
|
||||
|
||||
但愿你能够顺利地在你的树莓派上测试我们所做的这一切。到目前为止,我们已经写了一大段代码,因此不可避免会出现错误。如果有错误,可以去查看我们的排错页面。
|
||||
|
||||
如果你的代码已经正常工作,恭喜你。虽然我们的操作系统除了做 [课程 2:OK02][1] 中的事情,还做不了别的任何事情,但我们已经学会了函数和格式有关的知识,并且我们现在可以更好更快地编写新特性了。现在,我们在操作系统上修改 GPIO 寄存器将变得非常简单,而它就是用于控制硬件的!
|
||||
|
||||
在 [课程 4:OK04][6] 中,我们将处理我们的 `wait` 函数,目前,它的时间控制还不精确,这样我们就可以更好地控制我们的 LED 灯了,进而最终控制所有的 GPIO 针脚。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok03.html
|
||||
|
||||
作者:[Robert Mullins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.cl.cam.ac.uk/~rdm34
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-10478-1.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/functions.png
|
||||
[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/stack.png
|
||||
[4]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/binary3.png
|
||||
[5]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/osLayout.png
|
||||
[6]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok04.html
|
||||
@ -0,0 +1,165 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qhwdw)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10526-1.html)
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 4 OK04)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok04.html)
|
||||
[#]: author: (Robert Mullins http://www.cl.cam.ac.uk/~rdm34)
|
||||
|
||||
计算机实验室之树莓派:课程 4 OK04
|
||||
======
|
||||
|
||||
OK04 课程在 OK03 的基础上进行构建,它教你如何使用定时器让 OK 或 ACT LED 灯按精确的时间间隔来闪烁。假设你已经有了 [课程 3:OK03][1] 的操作系统,我们将以它为基础来构建。
|
||||
|
||||
### 1、一个新设备
|
||||
|
||||
> 定时器是树莓派保持时间的唯一方法。大多数计算机都有一个电池供电的时钟,这样当计算机关机后仍然能保持时间。
|
||||
|
||||
到目前为止,我们仅看了树莓派硬件的一小部分,即 GPIO 控制器。我只是简单地告诉你做什么,然后它会发生什么事情。现在,我们继续看定时器,并继续带你去了解它的工作原理。
|
||||
|
||||
和 GPIO 控制器一样,定时器也有地址。在本案例中,定时器的基地址在 20003000<sub>16</sub>。阅读手册我们可以找到下面的表:
|
||||
|
||||
表 1.1 GPIO 控制器寄存器
|
||||
|
||||
| 地址 | 大小 / 字节 | 名字 | 描述 | 读或写 |
|
||||
| -------- | ------------ | ---------------- | ---------------------------------------------------------- | ---------------- |
|
||||
| 20003000 | 4 | Control / Status | 用于控制和清除定时器通道比较器匹配的寄存器 | RW |
|
||||
| 20003004 | 8 | Counter | 按 1 MHz 的频率递增的计数器 | R |
|
||||
| 2000300C | 4 | Compare 0 | 0 号比较器寄存器 | RW |
|
||||
| 20003010 | 4 | Compare 1 | 1 号比较器寄存器 | RW |
|
||||
| 20003014 | 4 | Compare 2 | 2 号比较器寄存器 | RW |
|
||||
| 20003018 | 4 | Compare 3 | 3 号比较器寄存器 | RW |
|
||||
|
||||
![Flowchart of the system timer's operation][2]
|
||||
|
||||
这个表只告诉我们一部分内容,在手册中描述了更多的字段。手册上解释说,定时器本质上是按每微秒将计数器递增 1 的方式来运行。每次它是这样做的,它将计数器的低 32 位(4 字节)与 4 个比较器寄存器进行比较,如果匹配它们中的任何一个,它更新 `Control/Status` 以反映出其中有一个是匹配的。
|
||||
|
||||
关于<ruby>位<rt>bit</rt></ruby>、<ruby>字节<rt>byte</rt></ruby>、<ruby>位字段<rt>bit field</rt></ruby>、以及数据大小的更多内容如下:
|
||||
|
||||
>
|
||||
> 一个位是一个单个的二进制数的名称。你可能还记得,一个单个的二进制数既可能是一个 1,也可能是一个 0。
|
||||
>
|
||||
> 一个字节是一个 8 位集合的名称。由于每个位可能是 1 或 0 这两个值的其中之一,因此,一个字节有 2^8 = 256 个不同的可能值。我们一般解释一个字节为一个介于 0 到 255(含)之间的二进制数。
|
||||
>
|
||||
> ![Diagram of GPIO function select controller register 0.][3]
|
||||
>
|
||||
> 一个位字段是解释二进制的另一种方式。二进制可以解释为许多不同的东西,而不仅仅是一个数字。一个位字段可以将二进制看做为一系列的 1(开) 或 0(关)的开关。对于每个小开关,我们都有一个意义,我们可以使用它们去控制一些东西。我们已经遇到了 GPIO 控制器使用的位字段,使用它设置一个针脚的开或关。位为 1 时 GPIO 针脚将准确地打开或关闭。有时我们需要更多的选项,而不仅仅是开或关,因此我们将几个开关组合到一起,比如 GPIO 控制器的函数设置(如上图),每 3 位为一组控制一个 GPIO 针脚的函数。
|
||||
|
||||
我们的目标是实现一个函数,这个函数能够以一个时间数量为输入来调用它,这个输入的时间数量将作为等待的时间,然后返回。想一想如何去做,想想我们都拥有什么。
|
||||
|
||||
我认为这将有两个选择:
|
||||
|
||||
1. 从计数器中读取一个值,然后保持分支返回到相同的代码,直到计数器的等待时间数量大于它。
|
||||
2. 从计数器中读取一个值,加上要等待的时间数量,将它保存到比较器寄存器,然后保持分支返回到相同的代码处,直到 `Control / Status` 寄存器更新。
|
||||
|
||||
这两种策略都工作的很好,但在本教程中,我们将只实现第一个。原因是比较器寄存器更容易出错,因为在增加等待时间并保存它到比较器的寄存器期间,计数器可能已经增加了,并因此可能会不匹配。如果请求的是 1 微秒(或更糟糕的情况是 0 微秒)的等待,这样可能导致非常长的意外延迟。
|
||||
|
||||
> 像这样存在被称为“并发问题”的问题,并且几乎无法解决。
|
||||
|
||||
### 2、实现
|
||||
|
||||
我将把这个创建完美的等待方法的挑战基本留给你。我建议你将所有与定时器相关的代码都放在一个名为 `systemTimer.s` 的文件中(理由很明显)。关于这个方法的复杂部分是,计数器是一个 8 字节值,而每个寄存器仅能保存 4 字节。所以,计数器值将分到 2 个寄存器中。
|
||||
|
||||
> 大型的操作系统通常使用等待函数来抓住机会在后台执行任务。
|
||||
|
||||
下列的代码块是一个示例。
|
||||
|
||||
```assembly
|
||||
ldrd r0,r1,[r2,#4]
|
||||
```
|
||||
|
||||
> `ldrd regLow,regHigh,[src,#val]` 从 `src` 中的数加上 `val` 之和的地址加载 8 字节到寄存器 `regLow` 和 `regHigh` 中。
|
||||
|
||||
上面的代码中你可以发现一个很有用的指令是 `ldrd`。它加载 8 字节的内存到两个寄存器中。在本案例中,这 8 字节内存从寄存器 `r2` 中的地址 + 4 开始,将被复制进寄存器 `r0` 和 `r1`。这种安排的稍微复杂之处在于 `r1` 实际上只持有了高位 4 字节。换句话说就是,如果如果计数器的值是 999,999,999,999<sub>10</sub> = 1110100011010100101001010000111111111111<sub>2</sub> ,那么寄存器 `r1` 中只有 11101000<sub>2</sub>,而寄存器 `r0` 中则是 11010100101001010000111111111111<sub>2</sub>。
|
||||
|
||||
实现它的更明智的方式应该是,去计算当前计数器值与来自方法启动后的那一个值的差,然后将它与要求的等待时间数量进行比较。除非恰好你希望的等待时间是占用 8 字节的,否则上面示例中寄存器 `r1` 中的值将会丢弃,而计数器仅需要使用低位 4 字节。
|
||||
|
||||
当等待开始时,你应该总是确保使用大于比较,而不是使用等于比较,因为如果你尝试去等待一个时间,而这个时间正好等于方法开始的时间与结束的时间之差,那么你就错过这个值而永远等待下去。
|
||||
|
||||
如果你不明白如何编写等待函数的代码,可以参考下面的指南。
|
||||
|
||||
>
|
||||
> 借鉴 GPIO 控制器的创意,第一个函数我们应该去写如何取得系统定时器的地址。示例如下:
|
||||
>
|
||||
> ```assembly
|
||||
> .globl GetSystemTimerBase
|
||||
> GetSystemTimerBase:
|
||||
> ldr r0,=0x20003000
|
||||
> mov pc,lr
|
||||
> ```
|
||||
>
|
||||
> 另一个被证明非常有用的函数是返回在寄存器 `r0` 和 `r1` 中的当前计数器值:
|
||||
>
|
||||
> ```assembly
|
||||
> .globl GetTimeStamp
|
||||
> GetTimeStamp:
|
||||
> push {lr}
|
||||
> bl GetSystemTimerBase
|
||||
> ldrd r0,r1,[r0,#4]
|
||||
> pop {pc}
|
||||
> ```
|
||||
>
|
||||
> 这个函数简单地使用了 `GetSystemTimerBase` 函数,并像我们前面学过的那样,使用 `ldrd` 去加载当前计数器值。
|
||||
>
|
||||
> 现在,我们可以去写我们的等待方法的代码了。首先,在该方法启动后,我们需要知道计数器值,我们可以使用 `GetTimeStamp` 来取得。
|
||||
>
|
||||
> ```assembly
|
||||
> delay .req r2
|
||||
> mov delay,r0
|
||||
> push {lr}
|
||||
> bl GetTimeStamp
|
||||
> start .req r3
|
||||
> mov start,r0
|
||||
> ```
|
||||
>
|
||||
> 这个代码复制了我们的方法的输入,将延迟时间的数量放到寄存器 `r2` 中,然后调用 `GetTimeStamp`,这个函数将会返回寄存器 `r0` 和 `r1` 中的当前计数器值。接着复制计数器值的低位 4 字节到寄存器 `r3` 中。
|
||||
>
|
||||
> 接下来,我们需要计算当前计数器值与读入的值的差,然后持续这样做,直到它们的差至少是 `delay` 的大小为止。
|
||||
>
|
||||
> ```assembly
|
||||
> loop$:
|
||||
>
|
||||
> bl GetTimeStamp
|
||||
> elapsed .req r1
|
||||
> sub elapsed,r0,start
|
||||
> cmp elapsed,delay
|
||||
> .unreq elapsed
|
||||
> bls loop$
|
||||
> ```
|
||||
>
|
||||
> 这个代码将一直等待,一直到等待到传递给它的时间数量为止。它从计数器中读取数值,减去最初从计数器中读取的值,然后与要求的延迟时间进行比较。如果过去的时间数量小于要求的延迟,它切换回 `loop$`。
|
||||
>
|
||||
> ```assembly
|
||||
> .unreq delay
|
||||
> .unreq start
|
||||
> pop {pc}
|
||||
> ```
|
||||
>
|
||||
> 代码完成后,函数返回。
|
||||
>
|
||||
|
||||
|
||||
### 3、另一个闪灯程序
|
||||
|
||||
你一旦明白了等待函数的工作原理,修改 `main.s` 去使用它。修改各处 `r0` 的等待设置值为某个很大的数量(记住它的单位是微秒),然后在树莓派上测试。如果函数不能正常工作,请查看我们的排错页面。
|
||||
|
||||
如果正常工作,恭喜你学会控制另一个设备了,会使用它,则时间由你控制。在下一节课程中,我们将完成 OK 系列课程的最后一节 [课程 5:OK05][4],我们将使用我们已经学习过的知识让 LED 按我们的模式进行闪烁。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok04.html
|
||||
|
||||
作者:[Robert Mullins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.cl.cam.ac.uk/~rdm34
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-10519-1.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/systemTimer.png
|
||||
[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/gpioControllerFunctionSelect.png
|
||||
[4]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok05.html
|
||||
@ -0,0 +1,100 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (oska874)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10530-1.html)
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 5 OK05)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok05.html)
|
||||
[#]: author: (Robert Mullins http://www.cl.cam.ac.uk/~rdm34)
|
||||
|
||||
计算机实验室之树莓派:课程 5 OK05
|
||||
======
|
||||
|
||||
OK05 课程构建于课程 OK04 的基础,使用它来闪烁摩尔斯电码的 SOS 序列(`...---...`)。这里假设你已经有了 [课程 4:OK04][1] 操作系统的代码作为基础。
|
||||
|
||||
### 1、数据
|
||||
|
||||
到目前为止,我们与操作系统有关的所有内容提供的都是指令。然而有时候,指令只是完成了一半的工作。我们的操作系统可能还需要数据。
|
||||
|
||||
> 一些早期的操作系统确实只允许特定文件中的特定类型的数据,但是这通常被认为限制太多了。现代方法确实可以使程序变得复杂的多。
|
||||
|
||||
通常,数据就是些很重要的值。你可能接受过培训,认为数据就是某种类型的,比如,文本文件包含文本,图像文件包含图片,等等。说实话,这只是你的想法而已。计算机上的全部数据都是二进制数字,重要的是我们选择用什么来解释这些数据。在这个例子中,我们会用一个闪灯序列作为数据保存下来。
|
||||
|
||||
在 `main.s` 结束处复制下面的代码:
|
||||
|
||||
```
|
||||
.section .data %定义 .data 段
|
||||
.align 2 %对齐
|
||||
pattern: %定义整形变量
|
||||
.int 0b11111111101010100010001000101010
|
||||
```
|
||||
|
||||
> `.align num` 确保下一行代码的地址是 2^num 的整数倍。
|
||||
|
||||
> `.int val` 输出数值 `val`。
|
||||
|
||||
要区分数据和代码,我们将数据都放在 `.data` 区域。我已经将该区域包含在操作系统的内存布局图。我选择将数据放到代码后面。将我们的指令和数据分开保存的原因是,如果最后我们在自己的操作系统上实现一些安全措施,我们就需要知道代码的那些部分是可以执行的,而那些部分是不行的。
|
||||
|
||||
我在这里使用了两个新命令 `.align` 和 `.int`。`.align` 保证接下来的数据是按照 2 的乘方对齐的。在这个里,我使用 `.align 2` ,意味着数据最终存放的地址是 2^2=4 的整数倍。这个操作是很重要的,因为我们用来读取内存的指令 `ldr` 要求内存地址是 4 的倍数。
|
||||
|
||||
命令 `.int` 直接复制它后面的常量到输出。这意味着 11111111101010100010001000101010<sub>2</sub> 将会被存放到输出,所以该标签模式实际是将这段数据标识为模式。
|
||||
|
||||
> 关于数据的一个挑战是寻找一个高效和有用的展示形式。这种保存一个开、关的时间单元的序列的方式,运行起来很容易,但是将很难编辑,因为摩尔斯电码的 `-` 或 `.` 样式丢失了。
|
||||
|
||||
如我提到的,数据可以代表你想要的所有东西。在这里我编码了摩尔斯电码的 SOS 序列,对于不熟悉的人,就是 `...---...`。我使用 0 表示一个时间单元的 LED 灭灯,而 1 表示一个时间单元的 LED 亮。这样,我们可以像这样编写一些代码在数据中显示一个序列,然后要显示不同序列,我们所有需要做的就是修改这段数据。下面是一个非常简单的例子,操作系统必须一直执行这段程序,解释和展示数据。
|
||||
|
||||
复制下面几行到 `main.s` 中的标记 `loop$` 之前。
|
||||
|
||||
```
|
||||
ptrn .req r4 %重命名 r4 为 ptrn
|
||||
ldr ptrn,=pattern %加载 pattern 的地址到 ptrn
|
||||
ldr ptrn,[ptrn] %加载地址 ptrn 所在内存的值
|
||||
seq .req r5 %重命名 r5 为 seq
|
||||
mov seq,#0 %seq 赋值为 0
|
||||
```
|
||||
|
||||
这段代码加载 `pattrern` 到寄存器 `r4`,并加载 0 到寄存器 `r5`。`r5` 将是我们的序列位置,所以我们可以追踪我们已经展示了多少个 `pattern`。
|
||||
|
||||
如果 `pattern` 的当前位置是 1 且仅有一个 1,下面的代码将非零值放入 `r1`。
|
||||
|
||||
```
|
||||
mov r1,#1 %加载1到 r1
|
||||
lsl r1,seq %对r1 的值逻辑左移 seq 次
|
||||
and r1,ptrn %按位与
|
||||
```
|
||||
|
||||
这段代码对你调用 `SetGpio` 很有用,它必须有一个非零值来关掉 LED,而一个 0 值会打开 LED。
|
||||
|
||||
现在修改 `main.s` 中你的全部代码,这样代码中每次循环会根据当前的序列数设置 LED,等待 250000 毫秒(或者其他合适的延时),然后增加序列数。当这个序列数到达 32 就需要返回 0。看看你是否能实现这个功能,作为额外的挑战,也可以试着只使用一条指令。
|
||||
|
||||
### 2、当你玩得开心时,时间过得很快
|
||||
|
||||
你现在准备好在树莓派上实验。应该闪烁一串包含 3 个短脉冲,3 个长脉冲,然后 3 个短脉冲的序列。在一次延时之后,这种模式应该重复。如果这不工作,请查看我们的问题页。
|
||||
|
||||
一旦它工作,祝贺你已经抵达 OK 系列教程的结束点。
|
||||
|
||||
在这个系列我们学习了汇编代码,GPIO 控制器和系统定时器。我们已经学习了函数和 ABI,以及几个基础的操作系统原理,已经关于数据的知识。
|
||||
|
||||
你现在已经可以准备学习下面几个更高级的课程的某一个。
|
||||
|
||||
* [Screen][2] 系列是接下来的,会教你如何通过汇编代码使用屏幕。
|
||||
* [Input][3] 系列教授你如何使用键盘和鼠标。
|
||||
|
||||
到现在,你已经有了足够的信息来制作操作系统,用其它方法和 GPIO 交互。如果你有任何机器人工具,你可能会想尝试编写一个通过 GPIO 管脚控制的机器人操作系统。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok05.html
|
||||
|
||||
作者:[Robert Mullins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[ezio](https://github.com/oska874)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.cl.cam.ac.uk/~rdm34
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-10526-1.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen01.html
|
||||
[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html
|
||||
115
published/20150513 XML vs JSON.md
Normal file
115
published/20150513 XML vs JSON.md
Normal file
@ -0,0 +1,115 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wwhio)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10515-1.html)
|
||||
[#]: subject: (XML vs JSON)
|
||||
[#]: via: (https://www.cs.tufts.edu/comp/150IDS/final_papers/tstras01.1/FinalReport/FinalReport.html)
|
||||
[#]: author: (TOM STRASSNER tomstrassner@gmail.com)
|
||||
|
||||
XML 与 JSON 优劣对比
|
||||
======
|
||||
|
||||
### 简介
|
||||
|
||||
XML 和 JSON 是现今互联网中最常用的两种数据交换格式。XML 格式由 W3C 于 1996 年提出。JSON 格式由 Douglas Crockford 于 2002 年提出。虽然这两种格式的设计目标并不相同,但它们常常用于同一个任务,也就是数据交换中。XML 和 JSON 的文档都很完善([RFC 7159][1]、[RFC 4825][2]),且都同时具有<ruby>人类可读性<rt>human-readable</rt></ruby>和<ruby>机器可读性<rt>machine-readable</rt></ruby>。这两种格式并没有哪一个比另一个更强,只是各自适用的领域不用。(LCTT 译注:W3C 是[互联网联盟](https://www.w3.org/),制定了各种 Web 相关的标准,如 HTML、CSS 等。Douglas Crockford 除了制定了 JSON 格式,还致力于改进 JavaScript,开发了 JavaScript 相关工具 [JSLint](http://jslint.com/) 和 [JSMin](http://www.crockford.com/javascript/jsmin.html))
|
||||
|
||||
### XML 的优点
|
||||
|
||||
XML 与 JSON 相比有很多优点。二者间最大的不同在于 XML 可以通过在标签中添加属性这一简单的方法来存储<ruby>元数据<rt>metadata</rt></ruby>。而使用 JSON 时需要创建一个对象,把元数据当作对象的成员来存储。虽然二者都能达到存储元数据的目的,但在这一情况下 XML 往往是更好的选择,因为 JSON 的表达形式会让客户端程序开发人员误以为要将数据转换成一个对象。举个例子,如果你的 C++ 程序需要使用 JSON 格式发送一个附带元数据的整型数据,需要创建一个对象,用对象中的一个<ruby>名称/值对<rt>name/value pair</rt></ruby>来记录整型数据的值,再为每一个附带的属性添加一个名称/值对。接收到这个 JSON 的程序在读取后很可能把它当成一个对象,可事实并不是这样。虽然这是使用 JSON 传递元数据的一种变通方法,但他违背了 JSON 的核心理念:“<ruby>JSON 的结构与常规的程序语言中的结构相对应,而无需修改。<rt>JSON's structures look like conventional programming language structures. No restructuring is necessary.</rt></ruby>”[^2]
|
||||
|
||||
虽然稍后我会说这也是 XML 的一个缺点,但 XML 中对命名冲突、<ruby>前缀<rt>prefix</rt></ruby>的处理机制赋予了它 JSON 所不具备的能力。程序员们可以通过前缀来把统一名称给予两个不同的实体。[^1] 当不同的实体在客户端中使用的名称相同时,这一特性会非常有用。
|
||||
|
||||
XML 的另一个优势在于大多数的浏览器可以把它以<ruby>具有高可读性和强组织性的方式<rt>highly readable and organized way</rt></ruby>展现给用户。XML 的树形结构让它易于结构化,浏览器也让用户可以自行展开或折叠树中的元素,这简直就是调试的福音。
|
||||
|
||||
XML 对比 JSON 有一个很重要的优势就是它可以记录<ruby>混合内容<rt>mixed content</rt></ruby>。例如在 XML 中处理包含结构化标记的字符串时,程序员们只要把带有标记的文本放在一个标签内就可以了。可因为 JSON 只包含数据,没有用于指明标签的简单方式,虽然可以使用处理元数据的解决方法,但这总有点滥用之嫌。
|
||||
|
||||
### JSON 的优点
|
||||
|
||||
JSON 自身也有很多优点。其中最显而易见的一点就是 JSON 比 XML 简洁得多。因为 XML 中需要打开和关闭标签,而 JSON 使用名称/值对表示数据,使用简单的 `{` 和 `}` 来标记对象,`[` 和 `]` 来标记数组,`,` 来表示数据的分隔,`:` 表示名称和值的分隔。就算是使用 gzip 压缩,JSON 还是比 XML 要小,而且耗时更少。[^6] 正如 Sumaray 和 Makki 在实验中指出的那样,JSON 在很多方面都比 XML 更具优势,得出同样结果的还有 Nurseitov、Paulson、Reynolds 和 Izurieta。首先,由于 JSON 文件天生的简洁性,与包含相同信息的 XML 相比,JSON 总是更小,这意味着更快的传输和处理速度。第二,在不考虑大小的情况下,两组研究 [^3] [^4] 表明使用 JSON 执行序列化和反序列化的速度显著优于使用 XML。第三,后续的研究指出 JSON 的处理在 CPU 资源的使用上也优于 XML。研究人员发现 JSON 在总体上使用的资源更少,其中更多的 CPU 资源消耗在用户空间,系统空间消耗的 CPU 资源较少。这一实验是在 RedHat 的设备上进行的,RedHat 表示更倾向于在用户空间使用 CPU 资源。[^3a] 不出意外,Sumaray 和 Makki 在研究里还说明了在移动设备上 JSON 的性能也优于 XML。[^4a] 这是有道理的,因为 JSON 消耗的资源更少,而移动设备的性能也更弱。
|
||||
|
||||
JSON 的另一个优点在于其对对象和数组的表述和<ruby>宿主语言<rt>host language</rt></ruby>中的数据结构相对应,例如<ruby>对象<rt>object</rt></ruby>、<ruby>记录<rt>record</rt></ruby>、<ruby>结构体<rt>struct</rt></ruby>、<ruby>字典<rt>dictionary</rt></ruby>、<ruby>哈希表<rt>hash table</rt></ruby>、<ruby>键值列表<rt>keyed list</rt></ruby>还有<ruby>数组<rt>array</rt></ruby>、<ruby>向量<rt>vector</rt></ruby>、<ruby>列表<rt>list</rt></ruby>,以及对象组成的数组等等。[^2a] 虽然 XML 里也能表达这些数据结构,也只需调用一个函数就能完成解析,而往往需要更多的代码才能正确的完成 XML 的序列化和反序列化处理。而且 XML 对于人类来说不如 JSON 那么直观,XML 标准缺乏对象、数组的标签的明确定义。当结构化的标记可以替代嵌套的标签时,JSON 的优势极为突出。JSON 中的花括号和中括号则明确表示了数据的结构,当然这一优势也包含前文中的问题,在表示元数据时 JSON 不如 XML 准确。
|
||||
|
||||
虽然 XML 支持<ruby>命名空间<rt>namespace</rt></ruby>与<ruby>前缀<rt>prefix</rt></ruby>,但这不代表 JSON 没有处理命名冲突的能力。比起 XML 的前缀,它处理命名冲突的方式更简洁,在程序中的处理也更自然。在 JSON 里,每一个对象都在它自己的命名空间中,因此不同对象内的元素名称可以随意重复。在大多数编程语言中,不同的对象中的成员可以包含相同的名字,所以 JSON 根据对象进行名称区分的规则在处理时更加自然。
|
||||
|
||||
也许 JSON 比 XML 更优的部分是因为 JSON 是 JavaScript 的子集,所以在 JavaScript 代码中对它的解析或封装都非常的自然。虽然这看起来对 JavaScript 程序非常有用,而其他程序则不能直接从中获益,可实际上这一问题已经被很好的解决了。现在 JSON 的网站的列表上展示了 64 种不同语言的 175 个工具,它们都实现了处理 JSON 所需的功能。虽然我不能评价大多数工具的质量,但它们的存在明确了开发者社区拥抱 JSON 这一现象,而且它们切实简化了在不同平台使用 JSON 的难度。
|
||||
|
||||
### 二者的动机
|
||||
|
||||
简单地说,XML 的目标是标记文档。这和 JSON 的目标想去甚远,所以只要用得到 XML 的地方就尽管用。它使用树形的结构和包含语义的文本来表达混合内容以实现这一目标。在 XML 中可以表示数据的结构,但这并不是它的长处。
|
||||
|
||||
JSON 的目标是用于数据交换的一种结构化表示。它直接使用对象、数组、数字、字符串、布尔值这些元素来达成这一目标。这完全不同于文档标记语言。正如上面说的那样,JSON 没有原生支持<ruby>混合内容<rt>mixed content</rt></ruby>的记录。
|
||||
|
||||
### 软件
|
||||
|
||||
这些主流的开放 API 仅提供 XML:<ruby>亚马逊产品广告 API<rt>Amazon Product Advertising API</rt></ruby>。
|
||||
|
||||
这些主流 API 仅提供 JSON:<ruby>脸书图 API<rt>Facebook Graph API</rt></ruby>、<ruby>谷歌地图 API<rt>Google Maps API</rt></ruby>、<ruby>推特 API<rt>Twitter API</rt></ruby>、AccuWeather API、Pinterest API、Reddit API、Foursquare API。
|
||||
|
||||
这些主流 API 同时提供 XML 和 JSON:<ruby>谷歌云存储<rt>Google Cloud Storage</rt></ruby>、<ruby>领英 API<rt>Linkedin API</rt></ruby>、Flickr API。
|
||||
|
||||
根据<ruby>可编程网络<rt>Programmable Web</rt></ruby> [^9] 的数据,最流行的 10 个 API 中只有一个是仅提供 XML 且不支持 JSON 的。其他的要么同时支持 XML 和 JSON,要么只支持 JSON。这表明了大多数应用开发者都更倾向于使用支持 JSON 的 API,原因大概是 JSON 更快的处理速度与良好口碑,加之与 XML 相比更加轻量。此外,大多数 API 只是传递数据而非文档,所以 JSON 更加合适。例如 Facebook 的重点在于用户的交流与帖子,谷歌地图则主要处理坐标和地图信息,AccuWeather 就只传递天气数据。总之,虽然不能说天气 API 在使用时究竟是 JSON 用的多还是 XML 用的多,但是趋势明确偏向了 JSON。[^10] [^11]
|
||||
|
||||
这些主流的桌面软件仍然只是用 XML:Microsoft Word、Apache OpenOffice、LibraOffice。
|
||||
|
||||
因为这些软件需要考虑引用、格式、存储等等,所以比起 JSON,XML 优势更大。另外,这三款程序都支持混合内容,而 JSON 在这一点上做得并不如 XML 好。举例说明,当用户使用 Microsoft Word 编辑一篇论文时,用户需要使用不同的文字字形、文字大小、文字颜色、页边距、段落格式等,而 XML 结构化的组织形式与标签属性生来就是为了表达这些信息的。
|
||||
|
||||
这些主流的数据库支持 XML:IBM DB2、Microsoft SQL Server、Oracle Database、PostgresSQL、BaseX、eXistDB、MarkLogic、MySQL。
|
||||
|
||||
这些是支持 JSON 的主流数据库:MongoDB、CouchDB、eXistDB、Elastisearch、BaseX、MarkLogic、OrientDB、Oracle Database、PostgreSQL、Riak。
|
||||
|
||||
在很长一段时间里,SQL 和关系型数据库统治着整个数据库市场。像<ruby>甲骨文<rt>Oracle</rt></ruby>和<ruby>微软<rt>Microsoft</rt></ruby>这样的软件巨头都提供这类数据库,然而近几年 NoSQL 数据库正逐步受到开发者的青睐。也许是正巧碰上了 JSON 的普及,大多数 NoSQL 数据库都支持 JSON,像 MongoDB、CouchDB 和 Riak 这样的数据库甚至使用 JSON 来存储数据。这些数据库有两个重要的特性是它们适用于现代网站:一是它们与关系型数据库相比<ruby>更容易扩展<rt>more scalable</rt></ruby>;二是它们设计的目标就是 web 运行所需的核心组件。[^10a] 由于 JSON 更加轻量,又是 JavaScript 的子集,所以很适合 NoSQL 数据库,并且让这两个品质更容易实现。此外,许多旧的关系型数据库增加了 JSON 支持,例如 Oracle Database 和 PostgreSQL。由于 XML 与 JSON 间的转换比较麻烦,所以大多数开发者会直接在他们的应用里使用 JSON,因此开发数据库的公司才有支持 JSON 的理由。(LCTT 译注:NoSQL 是对不同于传统的关系数据库的数据库管理系统的统称。[参考来源](https://zh.wikipedia.org/wiki/NoSQL)) [^7]
|
||||
|
||||
### 未来
|
||||
|
||||
对互联网的种种变革中,最让人期待的便是<ruby>物联网<rt>Internet of Things</rt></ruby>(IoT)。这会给互联网带来大量计算机之外的设备,例如手表、温度计、电视、冰箱等等。这一势头的发展良好,预期在不久的将来迎来爆发式的增长。据估计,到 2020 年时会有 260 亿 到 2000 亿的物联网设备被接入互联网。[^12] [^13] 几乎所有的物联网设备都是小型设备,因此性能比笔记本或台式电脑要弱很多,而且大多数都是嵌入式系统。因此,当它们需要与互联网上的系统交换数据时,更轻量、更快速的 JSON 自然比 XML 更受青睐。[^10b] 受益于 JSON 在 web 上的快速普及,与 XML 相比,这些新的物联网设备更有可能从使用 JSON 中受益。这是一个典型的梅特卡夫定律的例子,无论是 XML 还是 JSON,抑或是什么其他全新的格式,现存的设备和新的设备都会从支持最广泛使用的格式中受益。
|
||||
|
||||
Node.js 是一款服务器端的 JavaScript 框架,随着她的诞生与快速成长,与 MongoDB 等 NoSQL 数据库一起,让全栈使用 JavaScript 开发成为可能。这些都预示着 JSON 光明的未来,这些软件的出现让 JSON 运用在全栈开发的每一个环节成为可能,这将使应用更加轻量,响应更快。这也是任何应用的追求之一,所以,全栈使用 JavaScript 的趋势在不久的未来都不会消退。[^10c]
|
||||
|
||||
此外,另一个应用开发的趋势是从 SOAP 转向 REST。[^11a] [^15] [^16] XML 和 JSON 都可以用于 REST,可 SOAP 只能使用 XML。
|
||||
|
||||
从这些趋势中可以推断,JSON 的发展将统一 Web 的信息交换格式,XML 的使用率将继续降低。虽然不应该把 JSON 吹过头了,因为 XML 在 Web 中的使用依旧很广,而且它还是 SOAP 的唯一选择,可考虑到 SOAP 到 REST 的迁移,NoSQL 数据库和全栈 JavaScript 的兴起,JSON 卓越的性能,我相信 JSON 很快就会在 Web 开发中超过 XML。至于其他领域,XML 比 JSON 更好的情况并不多。
|
||||
|
||||
|
||||
### 角注
|
||||
|
||||
[^1]: [XML Tutorial](http://www.w3schools.com/xml/default.asp)
|
||||
[^2]: [Introducing JSON](http://www.json.org/)
|
||||
[^2a]: [Introducing JSON](http://www.json.org/)
|
||||
[^3]: [Comparison of JSON and XML Data Interchange Formats: A Case Study](http://www.cs.montana.edu/izurieta/pubs/caine2009.pdf)
|
||||
[^3a]: [Comparison of JSON and XML Data Interchange Formats: A Case Study](http://www.cs.montana.edu/izurieta/pubs/caine2009.pdf)
|
||||
[^4]: [A comparison of data serialization formats for optimal efficiency on a mobile platform](http://dl.acm.org/citation.cfm?id=2184810)
|
||||
[^4a]: [A comparison of data serialization formats for optimal efficiency on a mobile platform](http://dl.acm.org/citation.cfm?id=2184810)
|
||||
[^5]: [JSON vs. XML: The Debate](http://ajaxian.com/archives/json-vs-xml-the-debate)
|
||||
[^6]: [JSON vs. XML: Some hard numbers about verbosity](http://www.codeproject.com/Articles/604720/JSON-vs-XML-Some-hard-numbers-about-verbosity)
|
||||
[^7]: [How JSON sparked NoSQL -- and will return to the RDBMS fold](http://www.infoworld.com/article/2608293/nosql/how-json-sparked-nosql----and-will-return-to-the-rdbms-fold.html)
|
||||
[^8]: [Did You Say "JSON Support" in Oracle 12.1.0.2?](https://blogs.oracle.com/OTN-DBA-DEV-Watercooler/entry/did_you_say_json_support)
|
||||
[^9]: [Most Popular APIs: At Least One Will Surprise You](http://www.programmableweb.com/news/most-popular-apis-least-one-will-surprise-you/2014/01/23)
|
||||
[^10]: [Why JSON will continue to push XML out of the picture](https://www.centurylinkcloud.com/blog/post/why-json-will-continue-to-push-xml-out-of-the-picture/)
|
||||
[^10a]: [Why JSON will continue to push XML out of the picture](https://www.centurylinkcloud.com/blog/post/why-json-will-continue-to-push-xml-out-of-the-picture/)
|
||||
[^10b]: [Why JSON will continue to push XML out of the picture](https://www.centurylinkcloud.com/blog/post/why-json-will-continue-to-push-xml-out-of-the-picture/)
|
||||
[^10c]: [Why JSON will continue to push XML out of the picture](https://www.centurylinkcloud.com/blog/post/why-json-will-continue-to-push-xml-out-of-the-picture/)
|
||||
[^11]: [Thousands of APIs Paint a Bright Future for the Web](http://www.webmonkey.com/2011/03/thousand-of-apis-paint-a-bright-future-for-the-web/)
|
||||
[^11a]: [Thousands of APIs Paint a Bright Future for the Web](http://www.webmonkey.com/2011/03/thousand-of-apis-paint-a-bright-future-for-the-web/)
|
||||
[^12]: [A Simple Explanation Of 'The Internet Of Things’](http://www.forbes.com/sites/jacobmorgan/2014/05/13/simple-explanation-internet-things-that-anyone-can-understand/)
|
||||
[^13]: [Proofpoint Uncovers Internet of Things (IoT) Cyberattack](http://www.proofpoint.com/about-us/press-releases/01162014.php)
|
||||
[^14]: [The Internet of Things: New Threats Emerge in a Connected World](http://www.symantec.com/connect/blogs/internet-things-new-threats-emerge-connected-world)
|
||||
[^15]: [3,000 Web APIs: Trends From A Quickly Growing Directory](http://www.programmableweb.com/news/3000-web-apis-trends-quickly-growing-directory/2011/03/08)
|
||||
[^16]: [How REST replaced SOAP on the Web: What it means to you](http://www.infoq.com/articles/rest-soap)
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cs.tufts.edu/comp/150IDS/final_papers/tstras01.1/FinalReport/FinalReport.html
|
||||
|
||||
作者:[TOM STRASSNER][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wwhio](https://github.com/wwhio)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: tomstrassner@gmail.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://tools.ietf.org/html/rfc7159
|
||||
[2]: https://tools.ietf.org/html/rfc4825
|
||||
@ -0,0 +1,451 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qhwdw)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10540-1.html)
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 6 Screen01)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen01.html)
|
||||
[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
|
||||
|
||||
计算机实验室之树莓派:课程 6 屏幕01
|
||||
======
|
||||
|
||||
欢迎来到屏幕系列课程。在本系列中,你将学习在树莓派中如何使用汇编代码控制屏幕,从显示随机数据开始,接着学习显示一个固定的图像和显示文本,然后格式化数字为文本。假设你已经完成了 OK 系列课程的学习,所以在本系列中出现的有些知识将不再重复。
|
||||
|
||||
第一节的屏幕课程教你一些关于图形的基础理论,然后用这些理论在屏幕或电视上显示一个图案。
|
||||
|
||||
### 1、入门
|
||||
|
||||
预期你已经完成了 OK 系列的课程,以及那个系列课程中在 `gpio.s` 和 `systemTimer.s` 文件中调用的函数。如果你没有完成这些,或你喜欢完美的实现,可以去下载 `OK05.s` 解决方案。在这里也要使用 `main.s` 文件中从开始到包含 `mov sp,#0x8000` 的这一行之前的代码。请删除这一行以后的部分。
|
||||
|
||||
### 2、计算机图形
|
||||
|
||||
正如你所认识到的,从根本上来说,计算机是非常愚蠢的。它们只能执行有限数量的指令,仅仅能做一些数学,但是它们也能以某种方式来做很多很多的事情。而在这些事情中,我们目前想知道的是,计算机是如何将一个图像显示到屏幕上的。我们如何将这个问题转换成二进制?答案相当简单;我们为每个颜色设计一些编码方法,然后我们为在屏幕上的每个像素保存一个编码。一个像素就是你的屏幕上的一个非常小的点。如果你离屏幕足够近,你或许能够辨别出你的屏幕上的单个像素,能够看到每个图像都是由这些像素组成的。
|
||||
|
||||
> 将颜色表示为数字有几种方法。在这里我们专注于 RGB 方法,但 HSL 也是很常用的另一种方法。
|
||||
|
||||
随着计算机时代的进步,人们希望显示越来越复杂的图形,于是发明了图形卡的概念。图形卡是你的计算机上用来在屏幕上专门绘制图像的第二个处理器。它的任务就是将像素值信息转换成显示在屏幕上的亮度级别。在现代计算机中,图形卡已经能够做更多更复杂的事情了,比如绘制三维图形。但是在本系列教程中,我们只专注于图形卡的基本使用;从内存中取得像素然后把它显示到屏幕上。
|
||||
|
||||
不管使用哪种方法,现在马上出现的一个问题就是我们使用的颜色编码。这里有几种选择,每个产生不同的输出质量。为了完整起见,我在这里只是简单概述它们。
|
||||
|
||||
| 名字 | 唯一颜色数量 | 描述 | 示例 |
|
||||
| ----------- | --------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ---------------------------- |
|
||||
| 单色 | 2 | 每个像素使用 1 位去保存,其中 1 表示白色,0 表示黑色。 | ![Monochrome image of a bird][1] |
|
||||
| 灰度 | 256 | 每个像素使用 1 个字节去保存,使用 255 表示白色,0 表示黑色,介于这两个值之间的所有值表示这两个颜色的一个线性组合。 | ![Geryscale image of a bird][2] |
|
||||
| 8 色 | 8 | 每个像素使用 3 位去保存,第一位表示红色通道,第二位表示绿色通道,第三位表示蓝色通道。 | ![8 colour image of a bird][3] |
|
||||
| 低色值 | 256 | 每个像素使用 8 位去保存,前三位表示红色通道的强度,接下来的三位表示绿色通道的强度,最后两位表示蓝色通道的强度。 | ![Low colour image of a bird][4] |
|
||||
| 高色值 | 65,536 | 每个像素使用 16 位去保存,前五位表示红色通道的强度,接下来的六位表示绿色通道的强度,最后的五位表示蓝色通道的强度。 | ![High colour image of a bird][5] |
|
||||
| 真彩色 | 16,777,216 | 每个像素使用 24 位去保存,前八位表示红色通道,第二个八位表示绿色通道,最后八位表示蓝色通道。 | ![True colour image of a bird][6] |
|
||||
| RGBA32 | 16,777,216 带 256 级透明度 | 每个像素使用 32 位去保存,前八位表示红色通道,第二个八位表示绿色通道,第三个八位表示蓝色通道。只有一个图像绘制在另一个图像的上方时才考虑使用透明通道,值为 0 时表示下面图像的颜色,值为 255 时表示上面这个图像的颜色,介于这两个值之间的所有值表示这两个图像颜色的混合。 ||
|
||||
|
||||
> 不过这里的一些图像只用了很少的颜色,因为它们使用了一个叫空间抖动的技术。这允许它们以很少的颜色仍然能表示出非常好的图像。许多早期的操作系统就使用了这种技术。
|
||||
|
||||
在本教程中,我们将从使用高色值开始。这样你就可以看到图像的构成,它的形成过程清楚,图像质量好,又不像真彩色那样占用太多的空间。也就是说,显示一个比较小的 800x600 像素的图像,它只需要小于 1 MiB 的空间。它另外的好处是它的大小是 2 次幂的倍数,相比真彩色这将极大地降低了获取信息的复杂度。
|
||||
|
||||
树莓派和它的图形处理器有一种特殊而奇怪的关系。在树莓派上,首先运行的事实上是图形处理器,它负责启动主处理器。这是很不常见的。最终它不会有太大的差别,但在许多交互中,它经常给人感觉主处理器是次要的,而图形处理器才是主要的。在树莓派上这两者之间依靠一个叫 “邮箱” 的东西来通讯。它们中的每一个都可以为对方投放邮件,这个邮件将在未来的某个时刻被对方收集并处理。我们将使用这个邮箱去向图形处理器请求一个地址。这个地址将是一个我们在屏幕上写入像素颜色信息的位置,我们称为帧缓冲,图形卡将定期检查这个位置,然后更新屏幕上相应的像素。
|
||||
|
||||
> 保存<ruby>帧缓冲<rt>frame buffer</rt></ruby>给计算机带来了很大的内存负担。基于这种原因,早期计算机经常作弊,比如,保存一屏幕文本,在每次单独刷新时,它只绘制刷新了的字母。
|
||||
|
||||
### 3、编写邮差程序
|
||||
|
||||
接下来我们做的第一件事情就是编写一个“邮差”程序。它有两个方法:`MailboxRead`,从寄存器 `r0` 中的邮箱通道读取一个消息。而 `MailboxWrite`,将寄存器 `r0` 中的头 28 位的值写到寄存器 `r1` 中的邮箱通道。树莓派有 7 个与图形处理器进行通讯的邮箱通道。但仅第一个对我们有用,因为它用于协调帧缓冲。
|
||||
|
||||
> 消息传递是组件间通讯时使用的常见方法。一些操作系统在程序之间使用虚拟消息进行通讯。
|
||||
|
||||
下列的表和示意图描述了邮箱的操作。
|
||||
|
||||
表 3.1 邮箱地址
|
||||
|
||||
| 地址 | 大小 / 字节 | 名字 | 描述 | 读 / 写 |
|
||||
| ---- | ---------- | ------------ | -------------------- | ------ |
|
||||
| 2000B880 | 4 | Read | 接收邮件 | R |
|
||||
| 2000B890 | 4 | Poll | 不检索接收 | R |
|
||||
| 2000B894 | 4 | Sender |发送者信息 | R |
|
||||
| 2000B898 | 4 | Status | 信息 | R |
|
||||
| 2000B89C | 4 | Configuration | 设置 | RW |
|
||||
| 2000B8A0 | 4 | Write | 发送邮件 | W |
|
||||
|
||||
为了给指定的邮箱发送一个消息:
|
||||
|
||||
1. 发送者等待,直到 `Status` 字段的头一位为 0。
|
||||
2. 发送者写入到 `Write`,低 4 位是要发送到的邮箱,高 28 位是要写入的消息。
|
||||
|
||||
为了读取一个消息:
|
||||
|
||||
1. 接收者等待,直到 `Status` 字段的第 30 位为 0。
|
||||
2. 接收者读取消息。
|
||||
3. 接收者确认消息来自正确的邮箱,否则再次重试。
|
||||
|
||||
如果你觉得有信心,你现在已经有足够的信息去写出我们所需的两个方法。如果没有信心,请继续往下看。
|
||||
|
||||
与以前一样,我建议你实现的第一个方法是获取邮箱区域的地址。
|
||||
|
||||
```assembly
|
||||
.globl GetMailboxBase
|
||||
GetMailboxBase:
|
||||
ldr r0,=0x2000B880
|
||||
mov pc,lr
|
||||
```
|
||||
|
||||
发送程序相对简单一些,因此我们将首先去实现它。随着你的方法越来越复杂,你需要提前去规划它们。规划它们的一个好的方式是写出一个简单步骤列表,详细地列出你需要做的事情,像下面一样。
|
||||
|
||||
1. 我们的输入将要写什么(`r0`),以及写到什么邮箱(`r1`)。我们必须验证邮箱的真实性,以及它的低 4 位的值是否为 0。不要忘了验证输入。
|
||||
2. 使用 `GetMailboxBase` 去检索地址。
|
||||
3. 读取 `Status` 字段。
|
||||
4. 检查头一位是否为 0。如果不是,回到第 3 步。
|
||||
5. 将写入的值和邮箱通道组合到一起。
|
||||
6. 写入到 `Write`。
|
||||
|
||||
我们来按顺序写出它们中的每一步。
|
||||
|
||||
1. 这将实现我们验证 `r0` 和 `r1` 的目的。`tst` 是通过计算两个操作数的逻辑与来比较两个操作数的函数,然后将结果与 0 进行比较。在本案例中,它将检查在寄存器 `r0` 中的输入的低 4 位是否为全 0。
|
||||
|
||||
```assembly
|
||||
.globl MailboxWrite
|
||||
MailboxWrite:
|
||||
tst r0,#0b1111
|
||||
movne pc,lr
|
||||
cmp r1,#15
|
||||
movhi pc,lr
|
||||
```
|
||||
|
||||
> `tst reg,#val` 计算寄存器 `reg` 和 `#val` 的逻辑与,然后将计算结果与 0 进行比较。
|
||||
|
||||
2. 这段代码确保我们不会覆盖我们的值,或链接寄存器,然后调用 `GetMailboxBase`。
|
||||
|
||||
```assembly
|
||||
channel .req r1
|
||||
value .req r2
|
||||
mov value,r0
|
||||
push {lr}
|
||||
bl GetMailboxBase
|
||||
mailbox .req r0
|
||||
```
|
||||
|
||||
3. 这段代码加载当前状态。
|
||||
|
||||
```assembly
|
||||
wait1$:
|
||||
status .req r3
|
||||
ldr status,[mailbox,#0x18]
|
||||
```
|
||||
|
||||
4. 这段代码检查状态字段的头一位是否为 0,如果不为 0,循环回到第 3 步。
|
||||
|
||||
```assembly
|
||||
tst status,#0x80000000
|
||||
.unreq status
|
||||
bne wait1$
|
||||
```
|
||||
|
||||
5. 这段代码将通道和值组合到一起。
|
||||
|
||||
```assembly
|
||||
add value,channel
|
||||
.unreq channel
|
||||
```
|
||||
|
||||
6. 这段代码保存结果到写入字段。
|
||||
|
||||
```assembly
|
||||
str value,[mailbox,#0x20]
|
||||
.unreq value
|
||||
.unreq mailbox
|
||||
pop {pc}
|
||||
```
|
||||
|
||||
`MailboxRead` 的代码和它非常类似。
|
||||
|
||||
1. 我们的输入将从哪个邮箱读取(`r0`)。我们必须要验证邮箱的真实性。不要忘了验证输入。
|
||||
2. 使用 `GetMailboxBase` 去检索地址。
|
||||
3. 读取 `Status` 字段。
|
||||
4. 检查第 30 位是否为 0。如果不为 0,返回到第 3 步。
|
||||
5. 读取 `Read` 字段。
|
||||
6. 检查邮箱是否是我们所要的,如果不是返回到第 3 步。
|
||||
7. 返回结果。
|
||||
|
||||
我们来按顺序写出它们中的每一步。
|
||||
|
||||
1. 这一段代码来验证 `r0` 中的值。
|
||||
|
||||
```assembly
|
||||
.globl MailboxRead
|
||||
MailboxRead:
|
||||
cmp r0,#15
|
||||
movhi pc,lr
|
||||
```
|
||||
|
||||
2. 这段代码确保我们不会覆盖掉我们的值,或链接寄存器,然后调用 `GetMailboxBase`。
|
||||
|
||||
```assembly
|
||||
channel .req r1
|
||||
mov channel,r0
|
||||
push {lr}
|
||||
bl GetMailboxBase
|
||||
mailbox .req r0
|
||||
```
|
||||
|
||||
3. 这段代码加载当前状态。
|
||||
|
||||
```assembly
|
||||
rightmail$:
|
||||
wait2$:
|
||||
status .req r2
|
||||
ldr status,[mailbox,#0x18]
|
||||
```
|
||||
|
||||
4. 这段代码检查状态字段第 30 位是否为 0,如果不为 0,返回到第 3 步。
|
||||
|
||||
```assembly
|
||||
tst status,#0x40000000
|
||||
.unreq status
|
||||
bne wait2$
|
||||
```
|
||||
|
||||
5. 这段代码从邮箱中读取下一条消息。
|
||||
|
||||
```assembly
|
||||
mail .req r2
|
||||
ldr mail,[mailbox,#0]
|
||||
```
|
||||
|
||||
6. 这段代码检查我们正在读取的邮箱通道是否为提供给我们的通道。如果不是,返回到第 3 步。
|
||||
|
||||
```assembly
|
||||
inchan .req r3
|
||||
and inchan,mail,#0b1111
|
||||
teq inchan,channel
|
||||
.unreq inchan
|
||||
bne rightmail$
|
||||
.unreq mailbox
|
||||
.unreq channel
|
||||
```
|
||||
|
||||
7. 这段代码将答案(邮件的前 28 位)移动到寄存器 `r0` 中。
|
||||
|
||||
```assembly
|
||||
and r0,mail,#0xfffffff0
|
||||
.unreq mail
|
||||
pop {pc}
|
||||
```
|
||||
|
||||
### 4、我心爱的图形处理器
|
||||
|
||||
通过我们新的邮差程序,我们现在已经能够向图形卡上发送消息了。我们应该发送些什么呢?这对我来说可能是个很难找到答案的问题,因为它不是任何线上手册能够找到答案的问题。尽管如此,通过查找有关树莓派的 GNU/Linux,我们能够找出我们需要发送的内容。
|
||||
|
||||
消息很简单。我们描述我们想要的帧缓冲区,而图形卡要么接受我们的请求,给我们返回一个 0,然后用我们写的一个小的调查问卷来填充屏幕;要么发送一个非 0 值,我们知道那表示很遗憾(出错了)。不幸的是,我并不知道它返回的其它数字是什么,也不知道它意味着什么,但我们知道仅当它返回一个 0,才表示一切顺利。幸运的是,对于合理的输入,它总是返回一个 0,因此我们不用过于担心。
|
||||
|
||||
> 由于在树莓派的内存是在图形处理器和主处理器之间共享的,我们能够只发送可以找到我们信息的位置即可。这就是 DMA,许多复杂的设备使用这种技术去加速访问时间。
|
||||
|
||||
为简单起见,我们将提前设计好我们的请求,并将它保存到 `framebuffer.s` 文件的 `.data` 节中,它的代码如下:
|
||||
|
||||
```assembly
|
||||
.section .data
|
||||
.align 4
|
||||
.globl FrameBufferInfo
|
||||
FrameBufferInfo:
|
||||
.int 1024 /* #0 物理宽度 */
|
||||
.int 768 /* #4 物理高度 */
|
||||
.int 1024 /* #8 虚拟宽度 */
|
||||
.int 768 /* #12 虚拟高度 */
|
||||
.int 0 /* #16 GPU - 间距 */
|
||||
.int 16 /* #20 位深 */
|
||||
.int 0 /* #24 X */
|
||||
.int 0 /* #28 Y */
|
||||
.int 0 /* #32 GPU - 指针 */
|
||||
.int 0 /* #36 GPU - 大小 */
|
||||
```
|
||||
|
||||
这就是我们发送到图形处理器的消息格式。第一对两个关键字描述了物理宽度和高度。第二对关键字描述了虚拟宽度和高度。帧缓冲的宽度和高度就是虚拟的宽度和高度,而 GPU 按需要伸缩帧缓冲去填充物理屏幕。如果 GPU 接受我们的请求,接下来的关键字将是 GPU 去填充的参数。它们是帧缓冲每行的字节数,在本案例中它是 `2 × 1024 = 2048`。下一个关键字是每个像素分配的位数。使用了一个 16 作为值意味着图形处理器使用了我们上面所描述的高色值模式。值为 24 是真彩色,而值为 32 则是 RGBA32。接下来的两个关键字是 x 和 y 偏移量,它表示当将帧缓冲复制到屏幕时,从屏幕左上角跳过的像素数目。最后两个关键字是由图形处理器填写的,第一个表示指向帧缓冲的实际指针,第二个是用字节数表示的帧缓冲大小。
|
||||
|
||||
在这里我非常谨慎地使用了一个 `.align 4` 指令。正如前面所讨论的,这样确保了下一行地址的低 4 位是 0。所以,我们可以确保将被放到那个地址上的帧缓冲(`FrameBufferInfo`)是可以发送到图形处理器上的,因为我们的邮箱仅发送低 4 位全为 0 的值。
|
||||
|
||||
> 当设备使用 DMA 时,对齐约束变得非常重要。GPU 预期该消息都是 16 字节对齐的。
|
||||
|
||||
到目前为止,我们已经有了待发送的消息,我们可以写代码去发送它了。通讯将按如下的步骤进行:
|
||||
|
||||
1. 写入 `FrameBufferInfo + 0x40000000` 的地址到邮箱 1。
|
||||
2. 从邮箱 1 上读取结果。如果它是非 0 值,意味着我们没有请求一个正确的帧缓冲。
|
||||
3. 复制我们的图像到指针,这时图像将出现在屏幕上!
|
||||
|
||||
我在步骤 1 中说了一些以前没有提到的事情。我们在发送之前,在帧缓冲地址上加了 `0x40000000`。这其实是一个给 GPU 的特殊信号,它告诉 GPU 应该如何写到结构上。如果我们只是发送地址,GPU 将写到它的回复上,这样不能保证我们可以通过刷新缓存看到它。缓存是处理器使用的值在它们被发送到存储之前保存在内存中的片段。通过加上 `0x40000000`,我们告诉 GPU 不要将写入到它的缓存中,这样将确保我们能够看到变化。
|
||||
|
||||
因为在那里发生很多事情,因此最好将它实现为一个函数,而不是将它以代码的方式写入到 `main.s` 中。我们将要写一个函数 `InitialiseFrameBuffer`,由它来完成所有协调和返回指向到上面提到的帧缓冲数据的指针。为方便起见,我们还将帧缓冲的宽度、高度、位深作为这个方法的输入,这样就很容易地修改 `main.s` 而不必知道协调的细节了。
|
||||
|
||||
再一次,来写下我们要做的详细步骤。如果你有信心,可以略过这一步直接尝试去写函数。
|
||||
|
||||
1. 验证我们的输入。
|
||||
2. 写输入到帧缓冲。
|
||||
3. 发送 `frame buffer + 0x40000000` 的地址到邮箱。
|
||||
4. 从邮箱中接收回复。
|
||||
5. 如果回复是非 0 值,方法失败。我们应该返回 0 去表示失败。
|
||||
6. 返回指向帧缓冲信息的指针。
|
||||
|
||||
现在,我们开始写更多的方法。以下是上面其中一个实现。
|
||||
|
||||
1. 这段代码检查宽度和高度是小于或等于 4096,位深小于或等于 32。这里再次使用了条件运行的技巧。相信自己这是可行的。
|
||||
|
||||
```assembly
|
||||
.section .text
|
||||
.globl InitialiseFrameBuffer
|
||||
InitialiseFrameBuffer:
|
||||
width .req r0
|
||||
height .req r1
|
||||
bitDepth .req r2
|
||||
cmp width,#4096
|
||||
cmpls height,#4096
|
||||
cmpls bitDepth,#32
|
||||
result .req r0
|
||||
movhi result,#0
|
||||
movhi pc,lr
|
||||
```
|
||||
|
||||
2. 这段代码写入到我们上面定义的帧缓冲结构中。我也趁机将链接寄存器推入到栈上。
|
||||
|
||||
```assembly
|
||||
fbInfoAddr .req r3
|
||||
push {lr}
|
||||
ldr fbInfoAddr,=FrameBufferInfo
|
||||
str width,[fbInfoAddr,#0]
|
||||
str height,[fbInfoAddr,#4]
|
||||
str width,[fbInfoAddr,#8]
|
||||
str height,[fbInfoAddr,#12]
|
||||
str bitDepth,[fbInfoAddr,#20]
|
||||
.unreq width
|
||||
.unreq height
|
||||
.unreq bitDepth
|
||||
```
|
||||
|
||||
3. `MailboxWrite` 方法的输入是写入到寄存器 `r0` 中的值,并将通道写入到寄存器 `r1` 中。
|
||||
|
||||
```assembly
|
||||
mov r0,fbInfoAddr
|
||||
add r0,#0x40000000
|
||||
mov r1,#1
|
||||
bl MailboxWrite
|
||||
```
|
||||
|
||||
4. `MailboxRead` 方法的输入是写入到寄存器 `r0` 中的通道,而输出是值读数。
|
||||
|
||||
```assembly
|
||||
mov r0,#1
|
||||
bl MailboxRead
|
||||
```
|
||||
|
||||
5. 这段代码检查 `MailboxRead` 方法的结果是否为 0,如果不为 0,则返回 0。
|
||||
|
||||
```assembly
|
||||
teq result,#0
|
||||
movne result,#0
|
||||
popne {pc}
|
||||
```
|
||||
|
||||
6. 这是代码结束,并返回帧缓冲信息地址。
|
||||
|
||||
```assembly
|
||||
mov result,fbInfoAddr
|
||||
pop {pc}
|
||||
.unreq result
|
||||
.unreq fbInfoAddr
|
||||
```
|
||||
|
||||
### 5、在一帧中一行之内的一个像素
|
||||
|
||||
到目前为止,我们已经创建了与图形处理器通讯的方法。现在它已经能够给我们返回一个指向到帧缓冲的指针去绘制图形了。我们现在来绘制一个图形。
|
||||
|
||||
第一示例中,我们将在屏幕上绘制连续的颜色。它看起来并不漂亮,但至少能说明它在工作。我们如何才能在帧缓冲中设置每个像素为一个连续的数字,并且要持续不断地这样做。
|
||||
|
||||
将下列代码复制到 `main.s` 文件中,并放置在 `mov sp,#0x8000` 行之后。
|
||||
|
||||
```assembly
|
||||
mov r0,#1024
|
||||
mov r1,#768
|
||||
mov r2,#16
|
||||
bl InitialiseFrameBuffer
|
||||
```
|
||||
|
||||
这段代码使用了我们的 `InitialiseFrameBuffer` 方法,简单地创建了一个宽 1024、高 768、位深为 16 的帧缓冲区。在这里,如果你愿意可以尝试使用不同的值,只要整个代码中都一样就可以。如果图形处理器没有给我们创建好一个帧缓冲区,这个方法将返回 0,我们最好检查一下返回值,如果出现返回值为 0 的情况,我们打开 OK LED 灯。
|
||||
|
||||
```assembly
|
||||
teq r0,#0
|
||||
bne noError$
|
||||
|
||||
mov r0,#16
|
||||
mov r1,#1
|
||||
bl SetGpioFunction
|
||||
mov r0,#16
|
||||
mov r1,#0
|
||||
bl SetGpio
|
||||
|
||||
error$:
|
||||
b error$
|
||||
|
||||
noError$:
|
||||
fbInfoAddr .req r4
|
||||
mov fbInfoAddr,r0
|
||||
```
|
||||
|
||||
现在,我们已经有了帧缓冲信息的地址,我们需要取得帧缓冲信息的指针,并开始绘制屏幕。我们使用两个循环来做实现,一个走行,一个走列。事实上,树莓派中的大多数应用程序中,图片都是以从左到右然后从上到下的顺序来保存的,因此我们也按这个顺序来写循环。
|
||||
|
||||
```assembly
|
||||
render$:
|
||||
|
||||
fbAddr .req r3
|
||||
ldr fbAddr,[fbInfoAddr,#32]
|
||||
|
||||
colour .req r0
|
||||
y .req r1
|
||||
mov y,#768
|
||||
drawRow$:
|
||||
|
||||
x .req r2
|
||||
mov x,#1024
|
||||
drawPixel$:
|
||||
|
||||
strh colour,[fbAddr]
|
||||
add fbAddr,#2
|
||||
sub x,#1
|
||||
teq x,#0
|
||||
bne drawPixel$
|
||||
|
||||
sub y,#1
|
||||
add colour,#1
|
||||
teq y,#0
|
||||
bne drawRow$
|
||||
|
||||
b render$
|
||||
|
||||
.unreq fbAddr
|
||||
.unreq fbInfoAddr
|
||||
```
|
||||
|
||||
> `strh reg,[dest]` 将寄存器中的低位半个字保存到给定的 `dest` 地址上。
|
||||
|
||||
这是一个很长的代码块,它嵌套了三层循环。为了帮你理清头绪,我们将循环进行缩进处理,这就有点类似于高级编程语言,而汇编器会忽略掉这些用于缩进的 `tab` 字符。我们看到,在这里它从帧缓冲信息结构中加载了帧缓冲的地址,然后基于每行来循环,接着是每行上的每个像素。在每个像素上,我们使用一个 `strh`(保存半个字)命令去保存当前颜色,然后增加地址继续写入。每行绘制完成后,我们增加绘制的颜色号。在整个屏幕绘制完成后,我们跳转到开始位置。
|
||||
|
||||
### 6、看到曙光
|
||||
|
||||
现在,你已经准备好在树莓派上测试这些代码了。你应该会看到一个渐变图案。注意:在第一个消息被发送到邮箱之前,树莓派在它的四个角上一直显示一个渐变图案。如果它不能正常工作,请查看我们的排错页面。
|
||||
|
||||
如果一切正常,恭喜你!你现在可以控制屏幕了!你可以随意修改这些代码去绘制你想到的任意图案。你还可以做更精彩的渐变图案,可以直接计算每个像素值,因为每个像素包含了一个 Y 坐标和 X 坐标。在下一个 [课程 7:Screen 02][7] 中,我们将学习一个更常用的绘制任务:行。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen01.html
|
||||
|
||||
作者:[Alex Chadwick][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.cl.cam.ac.uk
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour1bImage.png
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour8gImage.png
|
||||
[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour3bImage.png
|
||||
[4]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour8bImage.png
|
||||
[5]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour16bImage.png
|
||||
[6]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour24bImage.png
|
||||
[7]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen02.html
|
||||
@ -0,0 +1,437 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qhwdw)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10551-1.html)
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 7 Screen02)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen02.html)
|
||||
[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
|
||||
|
||||
计算机实验室之树莓派:课程 7 屏幕02
|
||||
======
|
||||
|
||||
屏幕02 课程在屏幕01 的基础上构建,它教你如何绘制线和一个生成伪随机数的小特性。假设你已经有了 [课程 6:屏幕01][1] 的操作系统代码,我们将以它为基础来构建。
|
||||
|
||||
### 1、点
|
||||
|
||||
现在,我们的屏幕已经正常工作了,现在开始去创建一个更实用的图像,是水到渠成的事。如果我们能够绘制出更实用的图形那就更好了。如果我们能够在屏幕上的两点之间绘制一条线,那我们就能够组合这些线绘制出更复杂的图形了。
|
||||
|
||||
我们将尝试用汇编代码去实现它,但在开始时,我们确实需要使用一些其它的函数去辅助。我们需要一个这样的函数,我将调用 `SetPixel` 去修改指定像素的颜色,而在寄存器 `r0` 和 `r1` 中提供输入。如果我们写出的代码可以在任意内存中而不仅仅是屏幕上绘制图形,这将在以后非常有用,因此,我们首先需要一些控制真实绘制位置的方法。我认为实现上述目标的最好方法是,能够有一个内存片段用于保存将要绘制的图形。我应该最终得到的是一个存储地址,它通常指向到自上次的帧缓存结构上。我们将一直在我们的代码中使用这个绘制方法。这样,如果我们想在我们的操作系统的另一部分绘制一个不同的图像,我们就可以生成一个不同结构的地址值,而使用的是完全相同的代码。为简单起见,我们将使用另一个数据片段去控制我们绘制的颜色。
|
||||
|
||||
> 为了绘制出更复杂的图形,一些方法使用一个着色函数而不是一个颜色去绘制。每个点都能够调用着色函数来确定在那里用什么颜色去绘制。
|
||||
|
||||
复制下列代码到一个名为 `drawing.s` 的新文件中。
|
||||
|
||||
```assembly
|
||||
.section .data
|
||||
.align 1
|
||||
foreColour:
|
||||
.hword 0xFFFF
|
||||
|
||||
.align 2
|
||||
graphicsAddress:
|
||||
.int 0
|
||||
|
||||
.section .text
|
||||
.globl SetForeColour
|
||||
SetForeColour:
|
||||
cmp r0,#0x10000
|
||||
movhs pc,lr
|
||||
ldr r1,=foreColour
|
||||
strh r0,[r1]
|
||||
mov pc,lr
|
||||
|
||||
.globl SetGraphicsAddress
|
||||
SetGraphicsAddress:
|
||||
ldr r1,=graphicsAddress
|
||||
str r0,[r1]
|
||||
mov pc,lr
|
||||
```
|
||||
|
||||
这段代码就是我上面所说的一对函数以及它们的数据。我们将在 `main.s` 中使用它们,在绘制图像之前去控制在何处绘制什么内容。
|
||||
|
||||
我们的下一个任务是去实现一个 `SetPixel` 方法。它需要带两个参数,像素的 x 和 y 轴,并且它应该要使用 `graphicsAddress` 和 `foreColour`,我们只定义精确控制在哪里绘制什么图像即可。如果你认为你能立即实现这些,那么去动手实现吧,如果不能,按照我们提供的步骤,按示例去实现它。
|
||||
|
||||
> 构建一个通用方法,比如 `SetPixel`,我们将在它之上构建另一个方法是一个很好的想法。但我们必须要确保这个方法很快,因为我们要经常使用它。
|
||||
|
||||
1. 加载 `graphicsAddress`。
|
||||
2. 检查像素的 x 和 y 轴是否小于宽度和高度。
|
||||
3. 计算要写入的像素地址(提示:`frameBufferAddress +(x + y * 宽度)* 像素大小`)
|
||||
4. 加载 `foreColour`。
|
||||
5. 保存到地址。
|
||||
|
||||
上述步骤实现如下:
|
||||
|
||||
1、加载 `graphicsAddress`。
|
||||
|
||||
```assembly
|
||||
.globl DrawPixel
|
||||
DrawPixel:
|
||||
px .req r0
|
||||
py .req r1
|
||||
addr .req r2
|
||||
ldr addr,=graphicsAddress
|
||||
ldr addr,[addr]
|
||||
```
|
||||
|
||||
2、记住,宽度和高度被各自保存在帧缓冲偏移量的 0 和 4 处。如有必要可以参考 `frameBuffer.s`。
|
||||
|
||||
```assembly
|
||||
height .req r3
|
||||
ldr height,[addr,#4]
|
||||
sub height,#1
|
||||
cmp py,height
|
||||
movhi pc,lr
|
||||
.unreq height
|
||||
|
||||
width .req r3
|
||||
ldr width,[addr,#0]
|
||||
sub width,#1
|
||||
cmp px,width
|
||||
movhi pc,lr
|
||||
```
|
||||
|
||||
3、确实,这段代码是专用于高色值帧缓存的,因为我使用一个逻辑左移操作去计算地址。你可能希望去编写一个不需要专用的高色值帧缓冲的函数版本,记得去更新 `SetForeColour` 的代码。它实现起来可能更复杂一些。
|
||||
|
||||
```assembly
|
||||
ldr addr,[addr,#32]
|
||||
add width,#1
|
||||
mla px,py,width,px
|
||||
.unreq width
|
||||
.unreq py
|
||||
add addr, px,lsl #1
|
||||
.unreq px
|
||||
```
|
||||
|
||||
> `mla dst,reg1,reg2,reg3` 将寄存器 `reg1` 和 `reg2` 中的值相乘,然后将结果与寄存器 `reg3` 中的值相加,并将结果的低 32 位保存到 `dst` 中。
|
||||
|
||||
4、这是专用于高色值的。
|
||||
|
||||
```assembly
|
||||
fore .req r3
|
||||
ldr fore,=foreColour
|
||||
ldrh fore,[fore]
|
||||
```
|
||||
|
||||
5、这是专用于高色值的。
|
||||
|
||||
```assembly
|
||||
strh fore,[addr]
|
||||
.unreq fore
|
||||
.unreq addr
|
||||
mov pc,lr
|
||||
```
|
||||
|
||||
### 2、线
|
||||
|
||||
问题是,线的绘制并不是你所想像的那么简单。到目前为止,你必须认识到,编写一个操作系统时,几乎所有的事情都必须我们自己去做,绘制线条也不例外。我建议你们花点时间想想如何在任意两点之间绘制一条线。
|
||||
|
||||
我估计大多数的策略可能是去计算线的梯度,并沿着它来绘制。这看上去似乎很完美,但它事实上是个很糟糕的主意。主要问题是它涉及到除法,我们知道在汇编中,做除法很不容易,并且还要始终记录小数,这也很困难。事实上,在这里,有一个叫布鲁塞姆的算法,它非常适合汇编代码,因为它只使用加法、减法和位移运算。
|
||||
|
||||
> 在我们日常编程中,我们对像除法这样的运算通常懒得去优化。但是操作系统不同,它必须高效,因此我们要始终专注于如何让事情做的尽可能更好。
|
||||
|
||||
.
|
||||
|
||||
> 我们从定义一个简单的直线绘制算法开始,代码如下:
|
||||
>
|
||||
> ```matlab
|
||||
> /* 我们希望从 (x0,y0) 到 (x1,y1) 去绘制一条线,只使用一个函数 setPixel(x,y),它的功能是在给定的 (x,y) 上绘制一个点。 */
|
||||
>
|
||||
> if x1 > x0 then
|
||||
>
|
||||
> set deltax to x1 - x0
|
||||
> set stepx to +1
|
||||
>
|
||||
> otherwise
|
||||
>
|
||||
> set deltax to x0 - x1
|
||||
> set stepx to -1
|
||||
>
|
||||
> end if
|
||||
>
|
||||
> if y1 > y0 then
|
||||
>
|
||||
> set deltay to y1 - y0
|
||||
> set stepy to +1
|
||||
>
|
||||
> otherwise
|
||||
>
|
||||
> set deltay to y0 - y1
|
||||
> set stepy to -1
|
||||
>
|
||||
> end if
|
||||
>
|
||||
> if deltax > deltay then
|
||||
>
|
||||
> set error to 0
|
||||
> until x0 = x1 + stepx
|
||||
>
|
||||
> setPixel(x0, y0)
|
||||
> set error to error + deltax ÷ deltay
|
||||
> if error ≥ 0.5 then
|
||||
>
|
||||
> set y0 to y0 + stepy
|
||||
> set error to error - 1
|
||||
>
|
||||
> end if
|
||||
> set x0 to x0 + stepx
|
||||
>
|
||||
> repeat
|
||||
>
|
||||
> otherwise
|
||||
>
|
||||
> end if
|
||||
> ```
|
||||
>
|
||||
> 这个算法用来表示你可能想像到的那些东西。变量 `error` 用来记录你离实线的距离。沿着 x 轴每走一步,这个 `error` 的值都会增加,而沿着 y 轴每走一步,这个 `error` 值就会减 1 个单位。`error` 是用于测量距离 y 轴的距离。
|
||||
>
|
||||
> 虽然这个算法是有效的,但它存在一个重要的问题,很明显,我们使用了小数去保存 `error`,并且也使用了除法。所以,一个立即要做的优化将是去改变 `error` 的单位。这里并不需要用特定的单位去保存它,只要我们每次使用它时都按相同数量去伸缩即可。所以,我们可以重写这个算法,通过在所有涉及 `error` 的等式上都简单地乘以 `deltay`,从面让它简化。下面只展示主要的循环:
|
||||
>
|
||||
> ```matlab
|
||||
> set error to 0 × deltay
|
||||
> until x0 = x1 + stepx
|
||||
>
|
||||
> setPixel(x0, y0)
|
||||
> set error to error + deltax ÷ deltay × deltay
|
||||
> if error ≥ 0.5 × deltay then
|
||||
>
|
||||
> set y0 to y0 + stepy
|
||||
> set error to error - 1 × deltay
|
||||
>
|
||||
> end if
|
||||
> set x0 to x0 + stepx
|
||||
>
|
||||
> repeat
|
||||
> ```
|
||||
>
|
||||
> 它将简化为:
|
||||
>
|
||||
> ```matlab
|
||||
> cset error to 0
|
||||
> until x0 = x1 + stepx
|
||||
>
|
||||
> setPixel(x0, y0)
|
||||
> set error to error + deltax
|
||||
> if error × 2 ≥ deltay then
|
||||
>
|
||||
> set y0 to y0 + stepy
|
||||
> set error to error - deltay
|
||||
>
|
||||
> end if
|
||||
> set x0 to x0 + stepx
|
||||
>
|
||||
> repeat
|
||||
> ```
|
||||
>
|
||||
> 突然,我们有了一个更好的算法。现在,我们看一下如何完全去除所需要的除法运算。最好保留唯一的被 2 相乘的乘法运算,我们知道它可以通过左移 1 位来实现!现在,这是非常接近布鲁塞姆算法的,但还可以进一步优化它。现在,我们有一个 `if` 语句,它将导致产生两个代码块,其中一个用于 x 差异较大的线,另一个用于 y 差异较大的线。对于这两种类型的线,如果审查代码能够将它们转换成一个单语句,还是很值得去做的。
|
||||
>
|
||||
> 困难之处在于,在第一种情况下,`error` 是与 y 一起变化,而第二种情况下 `error` 是与 x 一起变化。解决方案是在一个变量中同时记录它们,使用负的 `error` 去表示 x 中的一个 `error`,而用正的 `error` 表示它是 y 中的。
|
||||
>
|
||||
> ```matlab
|
||||
> set error to deltax - deltay
|
||||
> until x0 = x1 + stepx or y0 = y1 + stepy
|
||||
>
|
||||
> setPixel(x0, y0)
|
||||
> if error × 2 > -deltay then
|
||||
>
|
||||
> set x0 to x0 + stepx
|
||||
> set error to error - deltay
|
||||
>
|
||||
> end if
|
||||
> if error × 2 < deltax then
|
||||
>
|
||||
> set y0 to y0 + stepy
|
||||
> set error to error + deltax
|
||||
>
|
||||
> end if
|
||||
>
|
||||
> repeat
|
||||
> ```
|
||||
>
|
||||
> 你可能需要一些时间来搞明白它。在每一步中,我们都认为它正确地在 x 和 y 中移动。我们通过检查来做到这一点,如果我们在 x 或 y 轴上移动,`error` 的数量会变低,那么我们就继续这样移动。
|
||||
>
|
||||
|
||||
.
|
||||
|
||||
> 布鲁塞姆算法是在 1962 年由 Jack Elton Bresenham 开发,当时他 24 岁,正在攻读博士学位。
|
||||
|
||||
用于画线的布鲁塞姆算法可以通过以下的伪代码来描述。以下伪代码是文本,它只是看起来有点像是计算机指令而已,但它却能让程序员实实在在地理解算法,而不是为机器可读。
|
||||
|
||||
```matlab
|
||||
/* 我们希望从 (x0,y0) 到 (x1,y1) 去绘制一条线,只使用一个函数 setPixel(x,y),它的功能是在给定的 (x,y) 上绘制一个点。 */
|
||||
|
||||
if x1 > x0 then
|
||||
set deltax to x1 - x0
|
||||
set stepx to +1
|
||||
otherwise
|
||||
set deltax to x0 - x1
|
||||
set stepx to -1
|
||||
end if
|
||||
|
||||
set error to deltax - deltay
|
||||
until x0 = x1 + stepx or y0 = y1 + stepy
|
||||
setPixel(x0, y0)
|
||||
if error × 2 ≥ -deltay then
|
||||
set x0 to x0 + stepx
|
||||
set error to error - deltay
|
||||
end if
|
||||
if error × 2 ≤ deltax then
|
||||
set y0 to y0 + stepy
|
||||
set error to error + deltax
|
||||
end if
|
||||
repeat
|
||||
```
|
||||
|
||||
与我们目前所使用的编号列表不同,这个算法的表示方式更常用。看看你能否自己实现它。我在下面提供了我的实现作为参考。
|
||||
|
||||
```assembly
|
||||
.globl DrawLine
|
||||
DrawLine:
|
||||
push {r4,r5,r6,r7,r8,r9,r10,r11,r12,lr}
|
||||
x0 .req r9
|
||||
x1 .req r10
|
||||
y0 .req r11
|
||||
y1 .req r12
|
||||
|
||||
mov x0,r0
|
||||
mov x1,r2
|
||||
mov y0,r1
|
||||
mov y1,r3
|
||||
|
||||
dx .req r4
|
||||
dyn .req r5 /* 注意,我们只使用 -deltay,因此为了速度,我保存它的负值。(因此命名为 dyn)*/
|
||||
sx .req r6
|
||||
sy .req r7
|
||||
err .req r8
|
||||
|
||||
cmp x0,x1
|
||||
subgt dx,x0,x1
|
||||
movgt sx,#-1
|
||||
suble dx,x1,x0
|
||||
movle sx,#1
|
||||
|
||||
cmp y0,y1
|
||||
subgt dyn,y1,y0
|
||||
movgt sy,#-1
|
||||
suble dyn,y0,y1
|
||||
movle sy,#1
|
||||
|
||||
add err,dx,dyn
|
||||
add x1,sx
|
||||
add y1,sy
|
||||
|
||||
pixelLoop$:
|
||||
|
||||
teq x0,x1
|
||||
teqne y0,y1
|
||||
popeq {r4,r5,r6,r7,r8,r9,r10,r11,r12,pc}
|
||||
|
||||
mov r0,x0
|
||||
mov r1,y0
|
||||
bl DrawPixel
|
||||
|
||||
cmp dyn, err,lsl #1
|
||||
addle err,dyn
|
||||
addle x0,sx
|
||||
|
||||
cmp dx, err,lsl #1
|
||||
addge err,dx
|
||||
addge y0,sy
|
||||
|
||||
b pixelLoop$
|
||||
|
||||
.unreq x0
|
||||
.unreq x1
|
||||
.unreq y0
|
||||
.unreq y1
|
||||
.unreq dx
|
||||
.unreq dyn
|
||||
.unreq sx
|
||||
.unreq sy
|
||||
.unreq err
|
||||
```
|
||||
|
||||
### 3、随机性
|
||||
|
||||
到目前,我们可以绘制线条了。虽然我们可以使用它来绘制图片及诸如此类的东西(你可以随意去做!),我想应该借此机会引入计算机中随机性的概念。我将这样去做,选择一对随机的坐标,然后从上一对坐标用渐变色绘制一条线到那个点。我这样做纯粹是认为它看起来很漂亮。
|
||||
|
||||
那么,总结一下,我们如何才能产生随机数呢?不幸的是,我们并没有产生随机数的一些设备(这种设备很罕见)。因此只能利用我们目前所学过的操作,需要我们以某种方式来发明“随机数”。你很快就会意识到这是不可能的。各种操作总是给出定义好的结果,用相同的寄存器运行相同的指令序列总是给出相同的答案。而我们要做的是推导出一个伪随机序列。这意味着数字在外人看来是随机的,但实际上它是完全确定的。因此,我们需要一个生成随机数的公式。其中有人可能会想到很垃圾的数学运算,比如:4x<sup>2</sup>! / 64,而事实上它产生的是一个低质量的随机数。在这个示例中,如果 x 是 0,那么答案将是 0。看起来很愚蠢,我们需要非常谨慎地选择一个能够产生高质量随机数的方程式。
|
||||
|
||||
> 硬件随机数生成器很少用在安全中,因为可预测的随机数序列可能影响某些加密的安全。
|
||||
|
||||
我将要教给你的方法叫“二次同余发生器”。这是一个非常好的选择,因为它能够在 5 个指令中实现,并且能够产生一个从 0 到 232-1 之间的看似很随机的数字序列。
|
||||
|
||||
不幸的是,对为什么使用如此少的指令能够产生如此长的序列的原因的研究,已经远超出了本课程的教学范围。但我还是鼓励有兴趣的人去研究它。它的全部核心所在就是下面的二次方程,其中 `xn` 是产生的第 `n` 个随机数。
|
||||
|
||||
> 这类讨论经常寻求一个问题,那就是我们所谓的随机数到底是什么?通常从统计学的角度来说的随机性是:一组没有明显模式或属性能够概括它的数的序列。
|
||||
|
||||
```
|
||||
x_(n+1) = ax_(n)^2 + bx_(n) + c mod 2^32
|
||||
```
|
||||
|
||||
这个方程受到以下的限制:
|
||||
|
||||
1. a 是偶数
|
||||
2. b = a + 1 mod 4
|
||||
3. c 是奇数
|
||||
|
||||
如果你之前没有见到过 `mod` 运算,我来解释一下,它的意思是被它后面的数相除之后的余数。比如 `b = a + 1 mod 4` 的意思是 `b` 是 `a + 1` 除以 `4` 的余数,因此,如果 `a` 是 12,那么 `b` 将是 `1`,因为 `a + 1` 是 13,而 `13` 除以 4 的结果是 3 余 1。
|
||||
|
||||
复制下列代码到名为 `random.s` 的文件中。
|
||||
|
||||
```assembly
|
||||
.globl Random
|
||||
Random:
|
||||
xnm .req r0
|
||||
a .req r1
|
||||
|
||||
mov a,#0xef00
|
||||
mul a,xnm
|
||||
mul a,xnm
|
||||
add a,xnm
|
||||
.unreq xnm
|
||||
add r0,a,#73
|
||||
|
||||
.unreq a
|
||||
mov pc,lr
|
||||
```
|
||||
|
||||
这是随机函数的一个实现,使用一个在寄存器 `r0` 中最后生成的值作为输入,而接下来的数字则是输出。在我的案例中,我使用 a = EF00<sub>16</sub>,b = 1, c = 73。这个选择是随意的,但是需要满足上述的限制。你可以使用任何数字代替它们,只要符合上述的规则就行。
|
||||
|
||||
### 4、Pi-casso
|
||||
|
||||
OK,现在我们有了所有我们需要的函数,我们来试用一下它们。获取帧缓冲信息的地址之后,按如下的要求修改 `main`:
|
||||
|
||||
1. 使用包含了帧缓冲信息地址的寄存器 `r0` 调用 `SetGraphicsAddress`。
|
||||
2. 设置四个寄存器为 0。一个将是最后的随机数,一个将是颜色,一个将是最后的 x 坐标,而最后一个将是最后的 y 坐标。
|
||||
3. 调用 `random` 去产生下一个 x 坐标,使用最后一个随机数作为输入。
|
||||
4. 调用 `random` 再次去生成下一个 y 坐标,使用你生成的 x 坐标作为输入。
|
||||
5. 更新最后的随机数为 y 坐标。
|
||||
6. 使用 `colour` 值调用 `SetForeColour`,接着增加 `colour` 值。如果它大于 FFFF~16~,确保它返回为 0。
|
||||
7. 我们生成的 x 和 y 坐标将介于 0 到 FFFFFFFF<sub>16</sub>。通过将它们逻辑右移 22 位,将它们转换为介于 0 到 1023<sub>10</sub> 之间的数。
|
||||
8. 检查 y 坐标是否在屏幕上。验证 y 坐标是否介于 0 到 767<sub>10</sub> 之间。如果不在这个区间,返回到第 3 步。
|
||||
9. 从最后的 x 坐标和 y 坐标到当前的 x 坐标和 y 坐标之间绘制一条线。
|
||||
10. 更新最后的 x 和 y 坐标去为当前的坐标。
|
||||
11. 返回到第 3 步。
|
||||
|
||||
一如既往,你可以在下载页面上找到这个解决方案。
|
||||
|
||||
在你完成之后,在树莓派上做测试。你应该会看到一系列颜色递增的随机线条以非常快的速度出现在屏幕上。它一直持续下去。如果你的代码不能正常工作,请查看我们的排错页面。
|
||||
|
||||
如果一切顺利,恭喜你!我们现在已经学习了有意义的图形和随机数。我鼓励你去使用它绘制线条,因为它能够用于渲染你想要的任何东西,你可以去探索更复杂的图案了。它们中的大多数都可以由线条生成,但这需要更好的策略?如果你愿意写一个画线程序,尝试使用 `SetPixel` 函数。如果不是去设置像素值而是一点点地增加它,会发生什么情况?你可以用它产生什么样的图案?在下一节课 [课程 8:屏幕 03][2] 中,我们将学习绘制文本的宝贵技能。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen02.html
|
||||
|
||||
作者:[Alex Chadwick][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.cl.cam.ac.uk
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-10540-1.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen03.html
|
||||
@ -0,0 +1,156 @@
|
||||
每个 Linux 游戏玩家都绝不想要的恼人体验
|
||||
===================
|
||||
|
||||
[][10]
|
||||
|
||||
(LCTT 译注:本文原文发表于 2016 年,可能有些信息已经过时。)
|
||||
|
||||
[在 Linux 平台上玩游戏][12] 并不是什么新鲜事,现在甚至有专门的 [Linux 游戏发行版][13],但是这不意味着在 Linux 上打游戏的体验和在 Windows 上一样顺畅。
|
||||
|
||||
为了确保我们和 Windows 用户同样地享受游戏乐趣,哪些问题是我们应该考虑的呢?
|
||||
|
||||
[Wine][14]、[PlayOnLinux][15] 和其它类似软件不总是能够让我们玩所有流行的 Windows 游戏。在这篇文章里,我想讨论一下为了拥有最好的 Linux 游戏体验所必须处理好的若干因素。
|
||||
|
||||
### #1 SteamOS 是开源平台,但 Steam for Linux 并不是
|
||||
|
||||
正如 [StemOS 主页][16]所说, 即便 SteamOS 是一个开源平台,但 Steam for Linux 仍然是专有的软件。如果 Steam for Linux 也开源,那么它从开源社区得到的支持将会是巨大的。既然它不是,那么 [Ascension 计划的诞生自然是不可避免的][17]:
|
||||
|
||||
- [Destination: Project Ascension • UI Design Mockups Reveal](https://youtu.be/07UiS5iAknA)
|
||||
|
||||
Ascension 是一个开源的游戏启动器,旨在能够启动从任何平台购买、下载的游戏。这些游戏可以是 Steam 平台的、[Origin 游戏][18]平台的、Uplay 平台的,以及直接从游戏开发者主页下载的,或者来自 DVD、CD-ROM 的。
|
||||
|
||||
Ascension 计划的开端是这样:[某个观点的分享][19]激发了一场与游戏社区读者之间有趣的讨论,在这场讨论中读者们纷纷发表了自己的观点并给出建议。
|
||||
|
||||
### #2 与 Windows 平台的性能比较
|
||||
|
||||
在 Linux 平台上运行 Windows 游戏并不总是一件轻松的任务。但是得益于一个叫做 [CSMT][20](多线程命令流)的特性,尽管离 Windows 级别的性能还有相当长的路要走,PlayOnLinux 现在依旧可以更好地解决这些性能方面的问题。
|
||||
|
||||
Linux 对游戏的原生支持在过去发行的游戏中从未尽如人意。
|
||||
|
||||
去年,有报道说 SteamOS 比 Windows 在游戏方面的表现要[差得多][21]。古墓丽影去年在 SteamOS 及 Steam for Linux 上发行,然而其基准测试的结果与 Windows 上的性能无法抗衡。
|
||||
|
||||
- [Destination: Tomb Raider benchmark video comparison, Linux vs Windows 10](https://youtu.be/nkWUBRacBNE)
|
||||
|
||||
这明显是因为游戏是基于 [DirectX][23] 而不是 [OpenGL][24] 开发的缘故。
|
||||
|
||||
古墓丽影是[第一个使用 TressFX 的游戏][25]。下面这个视频包涵了 TressFX 的比较:
|
||||
|
||||
- [Destination: Tomb Raider Benchmark - Ubuntu 15.10 vs Windows 8.1 + Ubuntu 16.04 vs Windows 10](https://youtu.be/-IeY5ZS-LlA)
|
||||
|
||||
下面是另一个有趣的比较,它显示出使用 Wine + CSMT 带来的游戏性能比 Steam 上原生的 Linux 版游戏带来的游戏性能要好得多!这就是开源的力量!
|
||||
|
||||
- [Destination: [LinuxBenchmark] Tomb Raider Linux vs Wine comparison](https://youtu.be/sCJkC6oJ08A)
|
||||
|
||||
以防 FPS 损失,TressFX 已经被关闭。
|
||||
|
||||
以下是另一个有关在 Linux 上最新发布的 “[Life is Strange][27]” 在 Linux 与 Windows 上的比较:
|
||||
|
||||
- [Destination: Life is Strange on radeonsi (Linux nine_csmt vs Windows 10)](https://youtu.be/Vlflu-pIgIY)
|
||||
|
||||
[Steam for Linux][28] 开始在这个新游戏上展示出比 Windows 更好的游戏性能,这是一件好事。
|
||||
|
||||
在发布任何 Linux 版的游戏前,开发者都应该考虑优化游戏,特别是基于 DirectX 并需要进行 OpenGL 转制的游戏。我们十分希望 Linux 上的<ruby>[杀出重围:人类分裂][29]<rt>Deus Ex: Mankind Divided</rt></ruby> 在正式发行时能有一个好的基准测试结果。由于它是基于 DirectX 的游戏,我们希望它能良好地移植到 Linux 上。[该游戏执行总监说过这样的话][30]。
|
||||
|
||||
### #3 专有的 NVIDIA 驱动
|
||||
|
||||
相比于 [NVIDIA][32],[AMD 对于开源的支持][31]绝对是值得称赞的。尽管 [AMD][33] 因其更好的开源驱动在 Linux 上的驱动支持挺不错,而 NVIDIA 显卡用户由于开源版本的 NVIDIA 显卡驱动 “Nouveau” 有限的能力,仍不得不用专有的 NVIDIA 驱动。
|
||||
|
||||
曾经,Linus Torvalds 大神也分享过他关于“来自 NVIDIA 的 Linux 支持完全不可接受”的想法。
|
||||
|
||||
- [Destination: Linus Torvalds Publicly Attacks NVidia for lack of Linux & Android Support](https://youtu.be/O0r6Pr_mdio)
|
||||
|
||||
你可以在这里观看完整的[谈话][35],尽管 NVIDIA 回应 [承诺更好的 Linux 平台支持][36],但其开源显卡驱动仍如之前一样毫无起色。
|
||||
|
||||
### #4 需要 Linux 平台上的 Uplay 和 Origin 的 DRM 支持
|
||||
|
||||
- [Destination: Uplay #1 Rayman Origins em Linux - como instalar - ago 2016](https://youtu.be/rc96NFwyxWU)
|
||||
|
||||
以上的视频描述了如何在 Linux 上安装 [Uplay][37] DRM。视频上传者还建议说并不推荐使用 Wine 作为 Linux 上的主要的应用和游戏支持软件。相反,更鼓励使用原生的应用。
|
||||
|
||||
以下视频是一个关于如何在 Linux 上安装 [Origin][38] DRM 的教程。
|
||||
|
||||
- [Destination: Install EA Origin in Ubuntu with PlayOnLinux (Updated)](https://youtu.be/ga2lNM72-Kw)
|
||||
|
||||
数字版权管理(DRM)软件给游戏运行又加了一层阻碍,使得在 Linux 上良好运行 Windows 游戏这一本就充满挑战性的任务更有难度。因此除了使游戏能够运行之外,W.I.N.E 不得不同时负责运行像 Uplay 或 Origin 之类的 DRM 软件。如果能像 Steam 一样,Linux 也能够有自己原生版本的 Uplay 和 Origin 那就好了。
|
||||
|
||||
### #5 DirectX 11 对于 Linux 的支持
|
||||
|
||||
尽管我们在 Linux 平台上有可以运行 Windows 应用的工具,每个游戏为了能在 Linux 上运行都带有自己的配套调整需求。尽管去年在 Code Weavers 有一篇关于 [DirectX 11 对于 Linux 的支持][40] 的公告,在 Linux 上畅玩新发大作仍是长路漫漫。
|
||||
|
||||
现在你可以[从 Codweavers 购买 Crossover][41] 以获得可得到的最佳 DirectX 11 支持。这个在 Arch Linux 论坛上的[频道][42]清楚展现了将这个梦想成真需要多少的努力。以下是一个 [Reddit 频道][44] 上的有趣 [发现][43]。这个发现提到了[来自 Codeweavers 的 DirectX 11 补丁][45],现在看来这无疑是好消息。
|
||||
|
||||
### #6 不是全部的 Steam 游戏都可跑在 Linux 上
|
||||
|
||||
随着 Linux 游戏玩家一次次错过主要游戏的发行,这是需要考虑的一个重点,因为大部分主要游戏都在 Windows 上发行。这是[如何在 Linux 上安装 Windows 版的 Steam 的教程][46]。
|
||||
|
||||
### #7 游戏发行商对 OpenGL 更好的支持
|
||||
|
||||
目前开发者和发行商主要着眼于用 DirectX 而不是 OpenGL 来开发游戏。现在随着 Steam 正式登录 Linux,开发者应该同样考虑在 OpenGL 下开发。
|
||||
|
||||
[Direct3D][47] 仅仅是为 Windows 平台而打造。而 OpenGL API 拥有开放性标准,并且它不仅能在 Windows 上同样也能在其它各种各样的平台上实现。
|
||||
|
||||
尽管是一篇很老的文章,但[这个很有价值的资源][48]分享了许多有关 OpenGL 和 DirectX 现状的很有想法的信息。其所提出的观点确实十分明智,基于按时间排序的事件也能给予读者启迪。
|
||||
|
||||
在 Linux 平台上发布大作的发行商绝不应该忽视一个事实:在 OpenGL 下直接开发游戏要比从 DirectX 移植到 OpenGL 合算得多。如果必须进行平台转制,移植必须被仔细优化并谨慎研究。发布游戏可能会有延迟,但这绝对值得。
|
||||
|
||||
有更多的烦恼要分享?务必在评论区让我们知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/linux-gaming-problems/
|
||||
|
||||
作者:[Avimanyu Bandyopadhyay][a]
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/avimanyu/
|
||||
[1]:https://itsfoss.com/author/avimanyu/
|
||||
[2]:https://itsfoss.com/linux-gaming-problems/#comments
|
||||
[3]:https://www.facebook.com/share.php?u=https%3A%2F%2Fitsfoss.com%2Flinux-gaming-problems%2F%3Futm_source%3Dfacebook%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[4]:https://twitter.com/share?original_referer=/&text=Annoying+Experiences+Every+Linux+Gamer+Never+Wanted%21&url=https://itsfoss.com/linux-gaming-problems/%3Futm_source%3Dtwitter%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare&via=itsfoss2
|
||||
[5]:https://plus.google.com/share?url=https%3A%2F%2Fitsfoss.com%2Flinux-gaming-problems%2F%3Futm_source%3DgooglePlus%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[6]:https://www.linkedin.com/cws/share?url=https%3A%2F%2Fitsfoss.com%2Flinux-gaming-problems%2F%3Futm_source%3DlinkedIn%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[7]:http://www.stumbleupon.com/submit?url=https://itsfoss.com/linux-gaming-problems/&title=Annoying+Experiences+Every+Linux+Gamer+Never+Wanted%21
|
||||
[8]:https://www.reddit.com/submit?url=https://itsfoss.com/linux-gaming-problems/&title=Annoying+Experiences+Every+Linux+Gamer+Never+Wanted%21
|
||||
[9]:https://itsfoss.com/wp-content/uploads/2016/09/Linux-Gaming-Problems.jpg
|
||||
[10]:https://itsfoss.com/wp-content/uploads/2016/09/Linux-Gaming-Problems.jpg
|
||||
[11]:http://pinterest.com/pin/create/bookmarklet/?media=https://itsfoss.com/wp-content/uploads/2016/09/Linux-Gaming-Problems.jpg&url=https://itsfoss.com/linux-gaming-problems/&is_video=false&description=Linux%20gamer%27s%20problem
|
||||
[12]:https://itsfoss.com/linux-gaming-guide/
|
||||
[13]:https://itsfoss.com/linux-gaming-distributions/
|
||||
[14]:https://itsfoss.com/use-windows-applications-linux/
|
||||
[15]:https://www.playonlinux.com/en/
|
||||
[16]:http://store.steampowered.com/steamos/
|
||||
[17]:http://www.ibtimes.co.uk/reddit-users-want-replace-steam-open-source-game-launcher-project-ascension-1498999
|
||||
[18]:https://www.origin.com/
|
||||
[19]:https://www.reddit.com/r/pcmasterrace/comments/33xcvm/we_hate_valves_monopoly_over_pc_gaming_why/
|
||||
[20]:https://github.com/wine-compholio/wine-staging/wiki/CSMT
|
||||
[21]:http://arstechnica.com/gaming/2015/11/ars-benchmarks-show-significant-performance-hit-for-steamos-gaming/
|
||||
[22]:https://www.gamingonlinux.com/articles/tomb-raider-benchmark-video-comparison-linux-vs-windows-10.7138
|
||||
[23]:https://en.wikipedia.org/wiki/DirectX
|
||||
[24]:https://en.wikipedia.org/wiki/OpenGL
|
||||
[25]:https://www.gamingonlinux.com/articles/tomb-raider-released-for-linux-video-thoughts-port-report-included-the-first-linux-game-to-use-tresfx.7124
|
||||
[26]:https://itsfoss.com/osu-new-linux/
|
||||
[27]:http://lifeisstrange.com/
|
||||
[28]:https://itsfoss.com/install-steam-ubuntu-linux/
|
||||
[29]:https://itsfoss.com/deus-ex-mankind-divided-linux/
|
||||
[30]:http://wccftech.com/deus-ex-mankind-divided-director-console-ports-on-pc-is-disrespectful/
|
||||
[31]:http://developer.amd.com/tools-and-sdks/open-source/
|
||||
[32]:http://nvidia.com/
|
||||
[33]:http://amd.com/
|
||||
[34]:http://www.makeuseof.com/tag/open-source-amd-graphics-now-awesome-heres-get/
|
||||
[35]:https://youtu.be/MShbP3OpASA
|
||||
[36]:https://itsfoss.com/nvidia-optimus-support-linux/
|
||||
[37]:http://uplay.com/
|
||||
[38]:http://origin.com/
|
||||
[39]:https://itsfoss.com/linux-foundation-head-uses-macos/
|
||||
[40]:http://www.pcworld.com/article/2940470/hey-gamers-directx-11-is-coming-to-linux-thanks-to-codeweavers-and-wine.html
|
||||
[41]:https://itsfoss.com/deal-run-windows-software-and-games-on-linux-with-crossover-15-66-off/
|
||||
[42]:https://bbs.archlinux.org/viewtopic.php?id=214771
|
||||
[43]:https://ghostbin.com/paste/sy3e2
|
||||
[44]:https://www.reddit.com/r/linux_gaming/comments/3ap3uu/directx_11_support_coming_to_codeweavers/
|
||||
[45]:https://www.codeweavers.com/about/blogs/caron/2015/12/10/directx-11-really-james-didnt-lie
|
||||
[46]:https://itsfoss.com/linux-gaming-guide/
|
||||
[47]:https://en.wikipedia.org/wiki/Direct3D
|
||||
[48]:http://blog.wolfire.com/2010/01/Why-you-should-use-OpenGL-and-not-DirectX
|
||||
119
published/20171215 Top 5 Linux Music Players.md
Normal file
119
published/20171215 Top 5 Linux Music Players.md
Normal file
@ -0,0 +1,119 @@
|
||||
Linux 上最好的五款音乐播放器
|
||||
======
|
||||
> Jack Wallen 盘点他最爱的五款 Linux 音乐播放器。
|
||||
|
||||

|
||||
|
||||
不管你做什么,你都有时会来一点背景音乐。不管你是开发、运维或是一个典型的电脑用户,享受美妙的音乐都可能是你在电脑上最想做的事情之一。同时随着即将到来的假期,你可能收到一些能让你买几首新歌的礼物卡。如果你所选的音乐是数字形式(我的恰好是唱片形式)而且你的平台是 Linux 的话,你会想要一个好的图形用户界面播放器来享受音乐。
|
||||
|
||||
幸运的是,Linux 不缺好的数字音乐播放器。事实上,Linux 上有不少播放器,大部分是开源并且可以免费获得的。让我们看看其中的几款,看哪个能满足你的需要。
|
||||
|
||||
### Clementine
|
||||
|
||||
我想从我用来许多年的默认选项的播放器开始。[Clementine][1] 可能是最好的平衡了易用性与灵活性的播放器。Clementine 是新停摆的 [Amarok][2] 音乐播放器的复刻,但它不仅限于 Linux; Clementine 在 Mac OS 和 Windows 平台上也可以获得。它的一系列特性十分惊艳,包括:
|
||||
|
||||
* 內建的均衡器
|
||||
* 可定制的界面(将现在的专辑封面显示成背景,见图一)
|
||||
* 播放本地音乐或者从 Spotify、Last.fm 等播放音乐
|
||||
* 便于库导航的侧边栏
|
||||
* 內建的音频转码(转成 MP3、OGG、Flac 等)
|
||||
* 通过 [安卓应用][3] 远程控制
|
||||
* 便利的搜索功能
|
||||
* 选项卡式播放列表
|
||||
* 简单创建常规和智能化的播放列表
|
||||
* 支持 CUE 文件
|
||||
* 支持标签
|
||||
|
||||
![Clementine][5]
|
||||
|
||||
*图一:Clementine 界面可能有一点老派,但是它不可思议得灵活好用。*
|
||||
|
||||
在所有我用过的音乐播放器中,Clementine 是目前为止功能最多也是最容易使用的。它同时也包含了你能在 Linux 音乐播放器中找到的最好的均衡器(有十个频带可以调)。尽管它的界面不够时髦,但它创建、操控播放列表的能力是无与伦比的。如果你的音乐集很大,同时你想完全操控你的音乐集的话,这就是你想要的播放器。
|
||||
|
||||
Clementine 可以在标准仓库中找到。它可以从你的发行版的软件中心或通过命令行来安装。
|
||||
|
||||
### Rhythmbox
|
||||
|
||||
[Rhythmbox][7] 是 GNOME 桌面的默认播放器,但是它在其它桌面工作得也很好。Rhythmbox 的界面比 Clementine 的界面稍微时尚一点,它的设计遵循极简的理念。这并不意味着它缺乏特性,相反 Rhythmbox 提供无间隔回放、支持 Soundcloud、专辑封面显示、从 Last.fm 和 Libre.fm 导入音频、支持 Jamendo、播客订阅(从 [Apple iTunes][8])、从网页远程控制等特性。
|
||||
|
||||
在 Rhythmbox 中发现的一个很好的特性是支持插件,这使得你可以使用像 DAAP 音乐分享、FM 电台、封面查找、通知、ReplayGain、歌词等特性。
|
||||
|
||||
Rhythmbox 播放列表特性不像 Clementine 的那么强大,但是将你的音乐整理进任何形式的快速播放列表还是很简单的。尽管 Rhythmbox 的界面(图二)比 Clementine 要时髦一点,但是它不像 Clementine 那样灵活。
|
||||
|
||||
![Rhythmbox][10]
|
||||
|
||||
*图二:Rhythmbox 界面简单直接。*
|
||||
|
||||
### VLC Media Player
|
||||
|
||||
对于部分人来说,[VLC][11] 在视频播放方面是无懈可击的。然而 VLC 不仅限于视频播放。事实上,VLC在播放音频文件方面做得也很好。对于 [KDE Neon][12] 用户来说,VLC 既是音乐也是视频的默认播放器。尽管 VLC 是 Linux 市场最好的视频播放器的之一(它是我的默认播放器),它在音频方面确实略有瑕疵 —— 缺少播放列表以及不能够连接到你网络中的远程仓库。但如果你是在寻找一种播放本地文件或者网络 mms/rtsp 的简单可靠的方式,VLC 是上佳之选。VLC 包括一个均衡器(图三)、一个压缩器以及一个空间音响。它同样也能够从捕捉到的设备录音。
|
||||
|
||||
![VLC][14]
|
||||
|
||||
*图三:运转中的 VLC 均衡器。*
|
||||
|
||||
### Audacious
|
||||
|
||||
如果你在寻找一个轻量级的音乐播放器,Audacious 完美地满足要求。这个音乐播放器相当的专一,但是它包括了一个均衡器和一小部分能够改善许多音频的声效(比如回声、消除默音、调节速度和音调、去除人声等,见图四)。
|
||||
|
||||
![Audacious][16]
|
||||
|
||||
*图四:Audacious 均衡器和插件。*
|
||||
|
||||
Audacious 也包括了一个十分简便的闹铃功能。它允许你设置一个能在用户选定的时间点和持续的时间段内播放选定乐段的闹铃。
|
||||
|
||||
### Spotify
|
||||
|
||||
我必须承认,我每天都用 Spotify。我是一个 Spotify 的订阅者并用它去发现、购买新的音乐 —— 这意味着我在不停地探索发现。幸运的是,Spotify 有一个我能按照 [Spotify官方 Linux 平台安装指导][17] 轻松安装的桌面客户端。在桌面客户端与 [安卓应用][18] 间无缝转换对我来说也大有帮助,这样我就永远不会错过我喜欢的音乐了。
|
||||
|
||||
![Spotify][16]
|
||||
|
||||
*图五:Linux 上的 Spotify 官方客户端。*
|
||||
|
||||
Spotify 界面十分易于使用,事实上它完胜网页端的播放器。不要在 Linux 上装 [Spotify 网页播放器][21] 因为桌面客户端在创建管理你的播放列表方面简便得多。如果你是 Spotify 重度用户,甚至没必要用其他桌面应用的內建流传输客户端支持 —— 一旦你用过 Spotify 桌面客户端,其它应用就根本没可比性。
|
||||
|
||||
### 选择在你
|
||||
|
||||
其它选择也是有的(查看你的桌面软件中心),但这五款客户端(在我看来)是最好的了。对我来说,Clementine 和 Spotify 的组合拳就已经让我美好得唱赞歌了。尝试它们看看哪个能更好地满足你的需要。
|
||||
|
||||
### 额外奖品
|
||||
|
||||
虽然这篇文章翻译于国外作者,但作为给中国的 Linux 用户看的文章,如果在一篇分享音乐播放器的文章中**不提及**网易云音乐,那一定会被猛烈吐槽(事实上,我们曾经被吐槽过好多次了,哈哈)。
|
||||
|
||||
网易云音乐是我见过的最好的音乐播放器之一,不只是在 Linux 上,它甚至还支持包括 Windows、Mac、 iOS、安卓等在内的 8 个操作系统平台。当前的 Linux 版本是 1.1.0 版,支持 64 位的深度 Linux 15 和 Ubuntu 16.04 及之后的版本。下载地址和截图就不在这里安利了,大家想必自己能找到的。
|
||||
|
||||
通过 edX 和 Linux Foundation 上免费的 ["Introduction to Linux" ][22] 课程学习更多有关 Linux 的知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/12/top-5-linux-music-players
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.clementine-player.org/
|
||||
[2]:https://en.wikipedia.org/wiki/Amarok_(software)
|
||||
[3]:https://play.google.com/store/apps/details?id=de.qspool.clementineremote
|
||||
[4]:https://www.linux.com/files/images/clementinejpg
|
||||
[5]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/clementine.jpg?itok=_k13MtM3 (Clementine)
|
||||
[6]:https://www.linux.com/licenses/category/used-permission
|
||||
[7]:https://wiki.gnome.org/Apps/Rhythmbox
|
||||
[8]:https://www.apple.com/itunes/
|
||||
[9]:https://www.linux.com/files/images/rhythmboxjpg
|
||||
[10]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/rhythmbox.jpg?itok=GOjs9vTv (Rhythmbox)
|
||||
[11]:https://www.videolan.org/vlc/index.html
|
||||
[12]:https://neon.kde.org/
|
||||
[13]:https://www.linux.com/files/images/vlcjpg
|
||||
[14]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/vlc.jpg?itok=hn7iKkmK (VLC)
|
||||
[15]:https://www.linux.com/files/images/audaciousjpg
|
||||
[16]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/audacious.jpg?itok=9YALPzOx (Audacious )
|
||||
[17]:https://www.spotify.com/us/download/linux/
|
||||
[18]:https://play.google.com/store/apps/details?id=com.spotify.music
|
||||
[19]:https://www.linux.com/files/images/spotifyjpg
|
||||
[20]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/spotify.jpg?itok=P3FLfcYt (Spotify)
|
||||
[21]:https://open.spotify.com/browse/featured
|
||||
[22]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,96 @@
|
||||
8 个在 KDE Plasma 桌面环境下提高生产力的技巧和提示
|
||||
======
|
||||
|
||||

|
||||
|
||||
众所周知,KDE 的 Plasma 是 Linux 下最强大的桌面环境之一。它是高度可定制的,并且看起来也很棒。当你完成所有的配置工作后,你才能体会到它的所有特性。
|
||||
|
||||
你能够轻松地配置 Plasma 桌面并且使用它大量方便且节省时间的特性来加速你的工作,拥有一个能够帮助你而非阻碍你的桌面环境。
|
||||
|
||||
以下这些提示并没有特定顺序,因此你无需按次序阅读。你只需要挑出最适合你的工作流的那几个即可。
|
||||
|
||||
**相关阅读**:[10 个你应该尝试的最佳 KDE Plasma 应用][1]
|
||||
|
||||
### 1、多媒体控制
|
||||
|
||||
这点不太算得上是一条提示,因为它是很容易被记在脑海里的。Plasma 可在各处进行多媒体控制。当你需要暂停、继续或跳过一首歌时,你不需要每次都打开你的媒体播放器。你能够通过将鼠标移至那个最小化窗口之上,甚至通过锁屏进行控制。当你需要切换歌曲或忘了暂停时,你也不必麻烦地登录再进行操作。
|
||||
|
||||
### 2、KRunner
|
||||
|
||||
![KDE Plasma KRunner][2]
|
||||
|
||||
KRunner 是 Plasma 桌面中一个经常受到赞誉的特性。大部分人习惯于穿过层层的应用启动菜单来找到想要启动的程序。当你使用 KRunner 时就不需要这么做。
|
||||
|
||||
为了使用 KRunner,确保你当前的活动焦点在桌面本身(点击桌面而不是窗口)。然后开始输入你想要启动的应用名称,KRunner 将会带着建议项从你的屏幕顶部自动下拉。在你寻找的匹配项上点击或敲击回车键。这比记住你每个应用所属的类别要更快。
|
||||
|
||||
### 3、跳转列表
|
||||
|
||||
![KDE Plasma 的跳转列表][3]
|
||||
|
||||
跳转列表功能是最近才被添加进 Plasma 桌面的。它允许你在启动应用时直接跳转至特定的区域或特性部分。
|
||||
|
||||
因此如果你在菜单栏上有一个应用启动图标,你可以通过右键得到可跳转位置的列表。选择你想要跳转的位置,然后就可以“起飞”了。
|
||||
|
||||
### 4、KDE Connect
|
||||
|
||||
![KDE Connect Android 客户端菜单][4]
|
||||
|
||||
如果你有一个安卓手机,那么 [KDE Connect][5] 会为你提供大量帮助。它可以将你的手机连接至你的桌面,由此你可以在两台设备间无缝地共享。
|
||||
|
||||
通过 KDE Connect,你能够在你的桌面上实时地查看 [Android 设备通知][6]。它同时也让你能够从 Plasma 中收发文字信息,甚至不需要拿起你的手机。
|
||||
|
||||
KDE Connect 也允许你在手机和电脑间发送文件或共享网页。你可以轻松地从一个设备转移至另一设备,而无需烦恼或打乱思绪。
|
||||
|
||||
### 5、Plasma Vaults
|
||||
|
||||
![KDE Plasma Vault][7]
|
||||
|
||||
Plasma Vaults 是 Plasma 桌面的另一个新功能。它的 KDE 为加密文件和文件夹提供的简单解决方案。如果你不使用加密文件,此项功能不会为你节省时间。如果你使用,Vaults 是一个更简单的途径。
|
||||
|
||||
Plasma Vaults 允许你以无 root 权限的普通用户创建加密目录,并通过你的任务栏来管理它们。你能够快速地挂载或卸载目录,而无需外部程序或附加权限。
|
||||
|
||||
### 6、Pager 控件
|
||||
|
||||
![KDE Plasma Pager][8]
|
||||
|
||||
配置你的桌面的 pager 控件。它允许你轻松地切换至另三个附加工作区,带来更大的屏幕空间。
|
||||
|
||||
将控件添加到你的菜单栏上,然后你就可以在多个工作区间滑动切换。每个工作区都与你原桌面的尺寸相同,因此你能够得到数倍于完整屏幕的空间。这就使你能够排布更多的窗口,而不必受到一堆混乱的最小化窗口的困扰。
|
||||
|
||||
### 7、创建一个 Dock
|
||||
|
||||
![KDE Plasma Dock][9]
|
||||
|
||||
Plasma 以其灵活性和可配置性出名,同时也是它的优势。如果你有常用的程序,你可以考虑将常用程序设置为 OS X 风格的 dock。你能够通过单击启动,而不必深入菜单或输入它们的名字。
|
||||
|
||||
### 8、为 Dolphin 添加文件树
|
||||
|
||||
![Plasma Dolphin 目录][10]
|
||||
|
||||
通过目录树来浏览文件夹会更加简单。Dolphin 作为 Plasma 的默认文件管理器,具有在文件夹窗口一侧,以树的形式展示目录列表的内置功能。
|
||||
|
||||
为了启用目录树,点击“控制”标签,然后“配置 Dolphin”、“显示模式”、“详细”,最后选择“可展开文件夹”。
|
||||
|
||||
记住这些仅仅是提示,不要强迫自己做阻碍自己的事情。你可能讨厌在 Dolphin 中使用文件树,你也可能从不使用 Pager,这都没关系。当然也可能会有你喜欢但是此处没列举出来的功能。选择对你有用处的,也就是说,这些技巧中总有一些能帮助你度过日常工作中的艰难时刻。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/kde-plasma-tips-tricks-improve-productivity/
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[cycoe](https://github.com/cycoe)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/nickcongleton/
|
||||
[1]:https://www.maketecheasier.com/10-best-kde-plasma-applications/ (10 of the Best KDE Plasma Applications You Should Try)
|
||||
[2]:https://www.maketecheasier.com/assets/uploads/2017/10/pe-krunner.jpg (KDE Plasma KRunner)
|
||||
[3]:https://www.maketecheasier.com/assets/uploads/2017/10/pe-jumplist.jpg (KDE Plasma Jump Lists)
|
||||
[4]:https://www.maketecheasier.com/assets/uploads/2017/05/kde-connect-menu-e1494899929112.jpg (KDE Connect Menu Android)
|
||||
[5]:https://www.maketecheasier.com/send-receive-sms-linux-kde-connect/
|
||||
[6]:https://www.maketecheasier.com/android-notifications-ubuntu-kde-connect/
|
||||
[7]:https://www.maketecheasier.com/assets/uploads/2017/10/pe-vault.jpg (KDE Plasma Vault)
|
||||
[8]:https://www.maketecheasier.com/assets/uploads/2017/10/pe-pager.jpg (KDE Plasma Pager)
|
||||
[9]:https://www.maketecheasier.com/assets/uploads/2017/10/pe-dock.jpg (KDE Plasma Dock)
|
||||
[10]:https://www.maketecheasier.com/assets/uploads/2017/10/pe-dolphin.jpg (Plasma Dolphin Directory)
|
||||
@ -0,0 +1,79 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10574-1.html)
|
||||
[#]: subject: (Get started with Org mode without Emacs)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tool-org-mode)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
|
||||
|
||||
开始使用 Org 模式吧,在没有 Emacs 的情况下
|
||||
======
|
||||
|
||||
> 不,你不需要 Emacs 也能用 Org,这是我开源工具系列的第 16 集,将会让你在 2019 年变得更加有生产率。
|
||||
|
||||

|
||||
|
||||
每到年初似乎总有这么一个疯狂的冲动来寻找提高生产率的方法。新年决心,正确地开始一年的冲动,以及“向前看”的态度都是这种冲动的表现。软件推荐通常都会选择闭源和专利软件。但这不是必须的。
|
||||
|
||||
这是我 2019 年改进生产率的 19 个新工具中的第 16 个。
|
||||
|
||||
### Org (非 Emacs)
|
||||
|
||||
[Org 模式][1] (或者就称为 Org) 并不是新鲜货,但依然有许多人没有用过。他们很乐意试用一下以体验 Org 是如何改善生产率的。但最大的障碍来自于 Org 是与 Emacs 相关联的,而且很多人都认为两者缺一不可。并不是这样的!一旦你理解了其基础,Org 就可以与各种其他工具和编辑器一起使用。
|
||||
|
||||
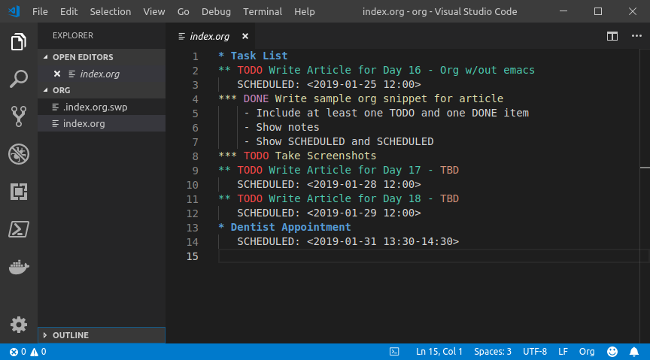
|
||||
|
||||
Org,本质上,是一个结构化的文本文件。它有标题、子标题,以及各种关键字,其他工具可以根据这些关键字将文件解析成日程表和代办列表。Org 文件可以被任何纯文本编辑器编辑(例如,[Vim][2]、[Atom][3] 或 [Visual Studio Code][4]),而且很多编辑器都有插件可以帮你创建和管理 Org 文件。
|
||||
|
||||
一个基础的 Org 文件看起来是这样的:
|
||||
|
||||
```
|
||||
* Task List
|
||||
** TODO Write Article for Day 16 - Org w/out emacs
|
||||
DEADLINE: <2019-01-25 12:00>
|
||||
*** DONE Write sample org snippet for article
|
||||
- Include at least one TODO and one DONE item
|
||||
- Show notes
|
||||
- Show SCHEDULED and DEADLINE
|
||||
*** TODO Take Screenshots
|
||||
** Dentist Appointment
|
||||
SCHEDULED: <2019-01-31 13:30-14:30>
|
||||
```
|
||||
|
||||
Org 是一种大纲格式,它使用 `*` 作为标识指明事项的级别。任何以 `TODO`(是的,全大些)开头的事项都是代办事项。标注为 `DONE` 的工作表示该工作已经完成。`SCHEDULED` 和 `DEADLINE` 标识与该事务相关的日期和时间。如何任何地方都没有时间,则该事务被视为全天活动。
|
||||
|
||||
使用正确的插件,你喜欢的文本编辑器可以成为一个充满生产率和组织能力的强大工具。例如,[vim-orgmode][5] 插件包括创建 Org 文件、语法高亮的功能,以及各种用来生成跨文件的日程和综合代办事项列表的关键命令。
|
||||
|
||||
|
||||
|
||||
Atom 的 [Organized][6] 插件可以在屏幕右边添加一个侧边栏,用来显示 Org 文件中的日程和代办事项。默认情况下它从配置项中设置的路径中读取多个 Org 文件。Todo 侧边栏允许你通过点击未完事项来将其标记为已完成,它会自动更新源 Org 文件。
|
||||
|
||||
|
||||
|
||||
还有一大堆 Org 工具可以帮助你保持生产率。使用 Python、Perl、PHP、NodeJS 等库,你可以开发自己的脚本和工具。当然,少不了 [Emacs][7],它的核心功能就包括支持 Org。
|
||||
|
||||
|
||||
|
||||
Org 模式是跟踪需要完成的工作和时间的最好工具之一。而且,与传闻相反,它无需 Emacs,任何一个文本编辑器都行。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/productivity-tool-org-mode
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney (Kevin Sonney)
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://orgmode.org/
|
||||
[2]: https://www.vim.org/
|
||||
[3]: https://atom.io/
|
||||
[4]: https://code.visualstudio.com/
|
||||
[5]: https://github.com/jceb/vim-orgmode
|
||||
[6]: https://atom.io/packages/organized
|
||||
[7]: https://www.gnu.org/software/emacs/
|
||||
@ -0,0 +1,76 @@
|
||||
采用 snaps 为 Linux 社区构建 Slack
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
作为一个被数以百万计用户使用的企业级软件平台,[Slack][2] 可以让各种规模的团队和企业有效地沟通。Slack 通过在一个单一集成环境中与其它软件工具无缝衔接,为一个组织内的通讯、信息和项目提供了一个易于接触的档案馆。尽管自从诞生后 Slack 就在过去四年中快速成长,但是他们负责该平台的 Windows、MacOS 和 Linux 桌面的工程师团队仅由四人组成。我们采访了这个团队的主任工程师 Felix Rieseberg(他负责追踪[上月首次发布的 Slack snap][3],LCTT 译注:原文发布于 2018.2),来了解更多有关该公司对于 Linux 社区的态度,以及他们决定构建一个 snap 软件包的原因。
|
||||
|
||||
- [安装 Slack snap][4]
|
||||
|
||||
### 你们能告诉我们更多关于已发布的 Slack snap 的信息吗?
|
||||
|
||||
作为发布给 Linux 社区的一种新形式,我们上月发布了我们的第一个 snap。在企业界,我们发现人们更倾向于以一种相对于个人消费者来说较慢的速度来采用新科技,因此我们将会在未来继续提供 .deb 形式的软件包。
|
||||
|
||||
### 你们觉得 Linux 社区会对 Slack 有多大的兴趣呢?
|
||||
|
||||
我很高兴在所有的平台上人们都对 Slack 的兴趣越来越大。因此,很难说来自 Linux 社区的兴趣和我们大体上所见到的兴趣有什么区别。当然,不管用户们在什么平台上面工作,满足他们对我们都是很重要的。我们有一个专门负责 Linux 的测试工程师,并且我们同时也会尽全力提供最好的用户体验。
|
||||
|
||||
只是我们发现总体相对于 Windows 来说,为 Linux 搭建 snap 略微有点难度,因为我们是在一个较难以预测的平台上工作——而这正是 Linux 社区之光照耀的领域。在汇报程序缺陷以及寻找程序崩溃原因方面,我们有相当多极有帮助的用户。
|
||||
|
||||
### 你们是如何得知 snap 的?
|
||||
|
||||
Canonical 公司的 Martin Wimpress 接触了我,并向我解释了 snap 的概念。说实话尽管我也用 Ubuntu 但最初我还是迟疑的,因为它看起来像需要搭建与维护的另一套标准。然而,一当我了解到其中的好处之后,我确信这是一笔值得的投入。
|
||||
|
||||
### snap 的什么方面吸引了你们并使你们决定投入其中?
|
||||
|
||||
毫无疑问,我们决定搭建 snap 最重要的原因是它的更新特性。在 Slack 上我们大量运用了网页技术,这些技术反过来也使得我们提供大量的特性——比如将 YouTube 视频或者 Spotify 播放列表集成在 Slack 中。与浏览器十分相似,这意味着我们需要频繁更新应用。
|
||||
|
||||
在 MacOS 和 Windows 上,我们已经有了一个专门的自动更新器,甚至无需用户关注更新。任何形式的中断都是一种我们需要避免的烦恼,哪怕是为了更新。因此通过 snap 自动化的更新就显得更加无缝和便捷。
|
||||
|
||||
### 相比于其它形式的打包方式,构建 snap 感觉如何?将它与现有的设施和流程集成在一起有多简便呢?
|
||||
|
||||
就 Linux 而言,我们尚未尝试其它的“新”打包方式,但我们迟早会的。鉴于我们的大多数用户都使用 Ubuntu,snap 是一个自然的选择。同时 snap 在其它发行版上同样也可以使用,这也是一个巨大的加分项。Canonical 正将 snap 做到跨发行版,而不是仅仅集中在 Ubuntu 上,这一点我认为是很好的。
|
||||
|
||||
搭建 snap 极其简单,我们有一个创建安装器和软件包的统一流程,我们的 snap 创建过程就是从一个 .deb 软件包炮制出一个 snap。对于其它技术而言,有时候我们为了支持构建链而先打造一个内部工具。但是 snapcraft 工具正是我们需要的东西。在整个过程中 Canonical 的团队非常有帮助,因为我们一路上确实碰到了一些问题。
|
||||
|
||||
### 你们觉得 snap 商店是如何改变用户们寻找、安装你们软件的方式的呢?
|
||||
|
||||
Slack 真正的独特之处在于人们不仅仅是碰巧发现它,他们从别的地方知道它并积极地试图找到它。因此尽管我们已经有了相当高的觉悟,我希望对于我们的用户来说,在商店中可以获得 snap 能够让安装过程变得简单一点。
|
||||
|
||||
我们总是尽力为用户服务。当我们觉得它比其他安装方式更好,我们就会向用户更多推荐它。
|
||||
|
||||
### 通过使用 snap 而不是为其它发行版打包,你期待或者已经看到的节省是什么?
|
||||
|
||||
我们希望 snap 可以给予我们的用户更多的便利,并确保他们能够更加喜欢使用 Slack。在我们看来,鉴于用户们不必被困在之前的版本,这自然而然地解决了许多问题,因此 snap 可以让我们在客户支持方面节约时间。snap 对我们来说也是一个额外的加分项,因为我们能有一个可供搭建的平台,而不是替换我们现有的东西。
|
||||
|
||||
### 如果存在的话,你们正使用或者准备使用边缘 (edge)、测试 (beta)、候选 (candidate)、稳定 (stable) 中的哪种发行频道?
|
||||
|
||||
我们开发中专门使用边缘 (edge) 频道以与 Canonical 团队合作。为 Linux 打造的 Slack 总体仍处于测试 (beta) 频道中。但是长远来看,拥有不同频道的选择十分有意思,同时能够提早一点为感兴趣的客户发布版本也肯定是有好处的。
|
||||
|
||||
### 你们如何认为将软件打包成一个 snap 能够帮助用户?你们从用户那边得到了什么反馈吗?
|
||||
|
||||
对我们的用户来说一个很大的好处是安装和更新总体来说都会变得简便一点。长远来看,问题是“那些安装 snap 的用户是不是比其它用户少碰到一些困难?”,我十分期望 snap 自带的依赖关系能够使其变成可能。
|
||||
|
||||
### 你们对刚使用 snap 的新用户们有什么建议或知识呢?
|
||||
|
||||
我会推荐从 Debian 软件包来着手搭建你们的 snap ——那出乎意料得简单。这同样也缩小了范围,避免变得不堪重负。这只需要投入相当少的时间,并且很大可能是一笔值得的投入。同样如果你们可以的话,尽量试着找到 Canonical 的人员来协作——他们拥有了不起的工程师。
|
||||
|
||||
### 对于开发来说,你们在什么地方看到了最大的机遇?
|
||||
|
||||
我们现在正一步步来,先是让人们接受 snap,再从那里开始搭建。正在使用 snap 的人们将会感到更加稳健,因为他们将会得益于最新的更新。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://insights.ubuntu.com/2018/02/06/building-slack-for-the-linux-community-and-adopting-snaps/
|
||||
|
||||
作者:[Sarah][a]
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/sarahfd/
|
||||
[1]:https://insights.ubuntu.com/wp-content/uploads/a115/Slack_linux_screenshot@2x-2.png
|
||||
[2]:https://slack.com/
|
||||
[3]:https://insights.ubuntu.com/2018/01/18/canonical-brings-slack-to-the-snap-ecosystem/
|
||||
[4]:https://snapcraft.io/slack/
|
||||
@ -0,0 +1,94 @@
|
||||
Pony 编程语言简介
|
||||
======
|
||||
|
||||
> Pony,一种“Rust 遇上 Erlang”的语言,让开发快捷、安全、高效、高并发的程序更简单。
|
||||
|
||||

|
||||
|
||||
在 [Wallaroo Labs][1],我是工程副总裁,我们正在构建一个用 [Pony][3] 编程语言编写的 [高性能分布式流处理器][2]。大多数人没有听说过 Pony,但它一直是 Wallaroo 的最佳选择,它也可能成为你的下一个项目的最佳选择。
|
||||
|
||||
> “一门编程语言只是另一种工具。与语法无关,与表达性无关,与范式或模型无关,仅与解决难题有关。” —Sylvan Clebsch,Pony 的创建者
|
||||
|
||||
我是 Pony 项目的贡献者,但在这里我要谈谈为什么 Pony 对于像 Wallaroo 这样的应用是个好选择,并分享我使用 Pony 的方式。如果你对我们为什么使用 Pony 来编写 Wallaroo 甚感兴趣,我们有一篇关于它的 [博文][4]。
|
||||
|
||||
### Pony 是什么?
|
||||
|
||||
你可以把 Pony 想象成某种“Rust 遇上 Erlang”的东西。Pony 有着最引人注目的特性,它们是:
|
||||
|
||||
* 类型安全
|
||||
* 存储安全
|
||||
* 异常安全
|
||||
* 无数据竞争
|
||||
* 无死锁
|
||||
|
||||
此外,它可以被编译为高效的本地代码,它是在开放的情况下开发的,在两句版 BSD 许可证下发布。
|
||||
|
||||
以上说的功能不少,但在这里我将重点关注那些对我们公司来说采用 Pony 至关重要的功能。
|
||||
|
||||
### 为什么使用 Pony?
|
||||
|
||||
使用大多数我们现有的工具编写快速、安全、高效、高并发的程序并非易事。“快速、高效、高并发”是可实现的目标,但加入“安全”之后,就困难了许多。对于 Wallaroo,我们希望同时实现四个目标,而 Pony 让实现它们更加简单。
|
||||
|
||||
#### 高并发
|
||||
|
||||
Pony 让并发变得简单。部分是通过提供一个固执的并发方式实现的。在 Pony 语言中,所有的并发都是通过 [Actor 模型][5] 进行的。
|
||||
|
||||
Actor 模型以在 Erlang 和 Akka 中的实现最为著名。Actor 模型出现于上世纪 70 年代,细节因实现方式而异。不变的是,所有计算都由通过异步消息进行通信的 actor 来执行。
|
||||
|
||||
你可以用这种方式来看待 Actor 模型:面向对象中的对象是状态 + 同步方法,而 actor 是状态 + 异步方法。
|
||||
|
||||
当一个 actor 收到一个消息时,它执行相应的方法。该方法可以在只有该 actor 可访问的状态下运行。Actor 模型允许我们以并发安全的方式使用可变状态。每个 actor 都是单线程的。一个 actor 中的两个方法绝不会并发运行。这意味着,在给定的 actor 中,数据更新不会引起数据竞争或通常与线程和可变状态相关的其他问题。
|
||||
|
||||
#### 快速高效
|
||||
|
||||
Pony actor 通过一个高效的工作窃取调度程序来调度。每个可用的 CPU 都有一个单独 Pony 调度程序。这种每个核心一个线程的并发模型是 Pony 尝试与 CPU 协同工作以尽可能高效运行的一部分。Pony 运行时尝试尽可能利用 CPU 缓存。代码越少干扰缓存,运行得越好。Pony 意在帮你的代码与 CPU 缓存友好相处。
|
||||
|
||||
Pony 的运行时还会有每个 actor 的堆,因此在垃圾收集期间,没有 “停止一切” 的垃圾收集步骤。这意味着你的程序总是至少能做一点工作。因此 Pony 程序最终具有非常一致的性能和可预测的延迟。
|
||||
|
||||
#### 安全
|
||||
|
||||
Pony 类型系统引入了一个新概念:引用能力,它使得数据安全成为类型系统的一部分。Pony 语言中每种变量的类型都包含了有关如何在 actor 之间分享数据的信息。Pony 编译器用这些信息来确认,在编译时,你的代码是无数据竞争和无死锁的。
|
||||
|
||||
如果这听起来有点像 Rust,那是因为本来就是这样的。Pony 的引用功能和 Rust 的借用检查器都提供数据安全性;它们只是以不同的方式来接近这个目标,并有不同的权衡。
|
||||
|
||||
### Pony 适合你吗?
|
||||
|
||||
决定是否要在一个非业余爱好的项目上使用一门新的编程语言是困难的。与其他方法想比,你必须权衡工具的适当性和不成熟度。那么,Pony 和你搭不搭呢?
|
||||
|
||||
如果你有一个困难的并发问题需要解决,那么 Pony 可能是一个好选择。解决并发应用问题是 Pony 之所以存在的理由。如果你能用一个单线程的 Python 脚本就完成所需操作,那你大概不需要它。如果你有一个困难的并发问题,你应该考虑 Pony 及其强大的无数据竞争、并发感知类型系统。
|
||||
|
||||
你将获得一个这样的编译器,它将阻止你引入许多与并发相关的错误,并在运行时为你提供出色的性能特征。
|
||||
|
||||
### 开始使用 Pony
|
||||
|
||||
如果你准备好开始使用 Pony,你需要先在 Pony 的网站上访问 [学习部分][6]。在这里你会找到安装 Pony 编译器的步骤和学习这门语言的资源。
|
||||
|
||||
如果你愿意为你正在使用的这个语言做出贡献,我们会在 GitHub 上为你提供一些 [初学者友好的问题][7]。
|
||||
|
||||
同时,我迫不及待地想在 [我们的 IRC 频道][8] 和 [Pony 邮件列表][9] 上与你交谈。
|
||||
|
||||
要了解更多有关 Pony 的消息,请参阅 Sean Allen 2018 年 7 月 16 日至 19 日在俄勒冈州波特兰举行的 [第 20 届 OSCON 会议][11] 上的演讲: [Pony,我如何学会停止担心并拥抱未经证实的技术][10]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/pony
|
||||
|
||||
作者:[Sean T Allen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[beamrolling](https://github.com/beamrolling)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/seantallen
|
||||
[1]:http://www.wallaroolabs.com/
|
||||
[2]:https://github.com/wallaroolabs/wallaroo
|
||||
[3]:https://www.ponylang.org/
|
||||
[4]:https://blog.wallaroolabs.com/2017/10/why-we-used-pony-to-write-wallaroo/
|
||||
[5]:https://en.wikipedia.org/wiki/Actor_model
|
||||
[6]:https://www.ponylang.org/learn/
|
||||
[7]:https://github.com/ponylang/ponyc/issues?q=is%3Aissue+is%3Aopen+label%3A%22complexity%3A+beginner+friendly%22
|
||||
[8]:https://webchat.freenode.net/?channels=%23ponylang
|
||||
[9]:https://pony.groups.io/g/user
|
||||
[10]:https://conferences.oreilly.com/oscon/oscon-or/public/schedule/speaker/213590
|
||||
[11]:https://conferences.oreilly.com/oscon/oscon-or
|
||||
@ -0,0 +1,124 @@
|
||||
Qalculate! :全宇宙最好的计算器软件
|
||||
======
|
||||
|
||||
十多年来,我一直都是 GNU-Linux 以及 [Debian][1] 的用户。随着我越来越频繁的使用桌面环境,我发现对我来说除了少数基于 web 的服务以外我的大多数需求都可以通过 Debian 软件库里自带的[桌面应用][2]解决。
|
||||
|
||||
我的需求之一就是进行单位换算。尽管有很多很多在线服务可以做这件事,但是我还是需要一个可以在桌面环境使用的应用。这主要是因为隐私问题以及我不想一而再再而三的寻找在线服务做事。为此我搜寻良久,直到找到 Qalculate!。
|
||||
|
||||
### Qalculate! 最强多功能计算器应用
|
||||
|
||||
![最佳计算器应用 Qalculator][3]
|
||||
|
||||
这是 aptitude 上关于 [Qalculate!][4] 的介绍,我没法总结的比他们更好了:
|
||||
|
||||
> 强大易用的桌面计算器 - GTK+ 版
|
||||
>
|
||||
> Qalculate! 是一款外表简单易用,内核强大且功能丰富的应用。其功能包含自定义函数、单位、高计算精度、作图以及可以输入一行表达式(有容错措施)的图形界面(也可以选择使用传统按钮)。
|
||||
|
||||
这款应用也发行过 KDE 的界面,但是至少在 Debian Testing 软件库里,只出现了 GTK+ 版的界面,你也可以在 GitHub 上的这个[仓库][5]里面看到。
|
||||
|
||||
不必多说,Qalculate! 在 Debian 的软件源内处于可用状态,因此可以使用 [apt][6] 命令或者是基于 Debian 的发行版比如 Ubuntu 提供的软件中心轻松安装。在 Windows 或者 macOS 上也可以使用这款软件。
|
||||
|
||||
#### Qalculate! 特性一览
|
||||
|
||||
列出全部的功能清单会有点长,请允许我只列出一部分功能并使用截图来展示极少数 Qalculate! 提供的功能。这么做是为了让你熟悉 Qalculate! 的基本功能,并在之后可以自由探索 Qalculate! 到底还能干什么。
|
||||
|
||||
* 代数
|
||||
* 微积分
|
||||
* 组合数学
|
||||
* 复数
|
||||
* 数据集
|
||||
* 日期与时间
|
||||
* 经济学
|
||||
* 对数和指数
|
||||
* 几何
|
||||
* 逻辑学
|
||||
* 向量和矩阵
|
||||
* 杂项
|
||||
* 数论
|
||||
* 统计学
|
||||
* 三角学
|
||||
|
||||
#### 使用 Qalculate!
|
||||
|
||||
Qalculate! 的使用不是很难。你甚至可以在里面写简单的英文。但是我还是推荐先[阅读手册][7]以便充分发挥 Qalculate! 的潜能。
|
||||
|
||||
![使用 Qalculate 进行字节到 GB 的换算][8]
|
||||
|
||||
![摄氏度到华氏度的换算][9]
|
||||
|
||||
#### qalc 是 Qalculate! 的命令行版
|
||||
|
||||
你也可以使用 Qalculate! 的命令行版 `qalc`:
|
||||
|
||||
```
|
||||
$ qalc 62499836 byte to gibibyte
|
||||
62499836 * byte = approx. 0.058207508 gibibyte
|
||||
|
||||
$ qalc 40 degree celsius to fahrenheit
|
||||
(40 * degree) * celsius = 104 deg*oF
|
||||
```
|
||||
|
||||
Qalculate! 的命令行界面可以让不喜欢 GUI 而是喜欢命令行界面(CLI)或者是使用无头结点(没有 GUI)的人可以使用 Qalculate!。这些人大多是在服务器环境下工作。
|
||||
|
||||
如果你想要在脚本里使用这一软件的话,我想 libqalculate 是最好的解决方案。看一看 `qalc` 以及 qalculate-gtk 是如何依赖于它工作的就足以知晓如何使用了。
|
||||
|
||||
再提一嘴,你还可以了解下如何根据一系列数据绘图,其他应用方式就留给你自己发掘了。不要忘记查看 `/usr/share/doc/qalculate/index.html` 以获取 Qalculate! 的全部功能。
|
||||
|
||||
注释:注意 Debian 更喜欢 [gnuplot][10],因为其输出的图片很精美。
|
||||
|
||||
#### 附加技巧:你可以通过在 Debian 下通过命令行感谢开发者
|
||||
|
||||
如果你使用 Debian 而且喜欢哪个包的话,你可以使用如下命令感谢 Debian 下这个软件包的开发者或者是维护者:
|
||||
|
||||
```
|
||||
reportbug --kudos $PACKAGENAME
|
||||
```
|
||||
|
||||
因为我喜欢 Qalculate!,我想要对 Debian 的开发者以及维护者 Vincent Legout 的卓越工作表示感谢:
|
||||
|
||||
```
|
||||
reportbug --kudos qalculate
|
||||
```
|
||||
|
||||
建议各位阅读我写的关于如何使用报错工具[在 Debian 中上报 BUG][11]的详细指南。
|
||||
|
||||
#### 一位高分子化学家对 Qalculate! 的评价
|
||||
|
||||
经由作者 [Philip Prado][12],我们联系上了 Timothy Meyers 先生,他目前是在高分子实验室工作的高分子化学家。
|
||||
|
||||
他对 Qaclulate! 的专业评价是:
|
||||
|
||||
> 看起来几乎任何科学家都可以使用这个软件,因为如果你知道指令以及如何使其生效的话,几乎任何数据计算都可以使用这个软件计算。
|
||||
|
||||
> 我觉得这个软件少了些物理常数,但我想不起来缺了哪些。我觉得它没有太多有关[流体动力学][13]的东西,再就是少了点部分化合物的[光吸收][14]系数,但这些东西只对我这个化学家来说比较重要,我不知道这些是不是对别人来说也是特别必要的。[自由能][15]可能也是。
|
||||
|
||||
最后,我分享的关于 Qalculate! 的介绍十分简陋,其实际功能与你的需要以及你的想象力有关系。希望你能喜欢 Qalculate!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/qalculate/
|
||||
|
||||
作者:[Shirish][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/shirish/
|
||||
[1]:https://www.debian.org/
|
||||
[2]:https://itsfoss.com/essential-linux-applications/
|
||||
[3]:https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/05/qalculate-app-featured-1.jpeg?w=800&ssl=1
|
||||
[4]:https://qalculate.github.io/
|
||||
[5]:https://github.com/Qalculate
|
||||
[6]:https://itsfoss.com/apt-command-guide/
|
||||
[7]:https://qalculate.github.io/manual/index.html
|
||||
[8]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/04/qalculate-byte-conversion.png?zoom=2&ssl=1
|
||||
[9]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/04/qalculate-gtk-weather-conversion.png?zoom=2&ssl=1
|
||||
[10]:http://www.gnuplot.info/
|
||||
[11]:https://itsfoss.com/bug-report-debian/
|
||||
[12]:https://itsfoss.com/author/phillip/
|
||||
[13]:https://en.wikipedia.org/wiki/Fluid_dynamics
|
||||
[14]:https://en.wikipedia.org/wiki/Absorption_(electromagnetic_radiation)
|
||||
[15]:https://en.wikipedia.org/wiki/Gibbs_free_energy
|
||||
@ -0,0 +1,591 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: subject: (An introduction to the Tornado Python web app framework)
|
||||
[#]: via: (https://opensource.com/article/18/6/tornado-framework)
|
||||
[#]: author: (Nicholas Hunt-Walker https://opensource.com/users/nhuntwalker)
|
||||
[#]: url: (https://linux.cn/article-10522-1.html)
|
||||
|
||||
Python Web 应用程序 Tornado 框架简介
|
||||
======
|
||||
|
||||
> 在比较 Python 框架的系列文章的第三部分中,我们来了解 Tornado,它是为处理异步进程而构建的。
|
||||
|
||||

|
||||
|
||||
在这个由四部分组成的系列文章的前两篇中,我们介绍了 [Pyramid][1] 和 [Flask][2] Web 框架。我们已经构建了两次相同的应用程序,看到了一个完整的 DIY 框架和包含了更多功能的框架之间的异同。
|
||||
|
||||
现在让我们来看看另一个稍微不同的选择:[Tornado 框架][3]。Tornado 在很大程度上与 Flask 一样简单,但有一个主要区别:Tornado 是专门为处理异步进程而构建的。在我们本系列所构建的应用程序中,这种特殊的酱料(LCTT 译注:这里意思是 Tornado 的异步功能)在我们构建的 app 中并不是非常有用,但我们将看到在哪里可以使用它,以及它在更一般的情况下是如何工作的。
|
||||
|
||||
让我们继续前两篇文章中模式,首先从处理设置和配置开始。
|
||||
|
||||
### Tornado 启动和配置
|
||||
|
||||
如果你一直关注这个系列,那么第一步应该对你来说习以为常。
|
||||
|
||||
```
|
||||
$ mkdir tornado_todo
|
||||
$ cd tornado_todo
|
||||
$ pipenv install --python 3.6
|
||||
$ pipenv shell
|
||||
(tornado-someHash) $ pipenv install tornado
|
||||
```
|
||||
|
||||
创建一个 `setup.py` 文件来安装我们的应用程序相关的东西:
|
||||
|
||||
```
|
||||
(tornado-someHash) $ touch setup.py
|
||||
# setup.py
|
||||
from setuptools import setup, find_packages
|
||||
|
||||
requires = [
|
||||
'tornado',
|
||||
'tornado-sqlalchemy',
|
||||
'psycopg2',
|
||||
]
|
||||
|
||||
setup(
|
||||
name='tornado_todo',
|
||||
version='0.0',
|
||||
description='A To-Do List built with Tornado',
|
||||
author='<Your name>',
|
||||
author_email='<Your email>',
|
||||
keywords='web tornado',
|
||||
packages=find_packages(),
|
||||
install_requires=requires,
|
||||
entry_points={
|
||||
'console_scripts': [
|
||||
'serve_app = todo:main',
|
||||
],
|
||||
},
|
||||
)
|
||||
```
|
||||
|
||||
因为 Tornado 不需要任何外部配置,所以我们可以直接编写 Python 代码来让程序运行。让我们创建 `todo` 目录,并用需要的前几个文件填充它。
|
||||
|
||||
```
|
||||
todo/
|
||||
__init__.py
|
||||
models.py
|
||||
views.py
|
||||
```
|
||||
|
||||
就像 Flask 和 Pyramid 一样,Tornado 也有一些基本配置,放在 `__init__.py` 中。从 `tornado.web` 中,我们将导入 `Application` 对象,它将处理路由和视图的连接,包括数据库(当我们谈到那里时再说)以及运行 Tornado 应用程序所需的其它额外设置。
|
||||
|
||||
```
|
||||
# __init__.py
|
||||
from tornado.web import Application
|
||||
|
||||
def main():
|
||||
"""Construct and serve the tornado application."""
|
||||
app = Application()
|
||||
```
|
||||
|
||||
像 Flask 一样,Tornado 主要是一个 DIY 框架。当构建我们的 app 时,我们必须设置该应用实例。因为 Tornado 用它自己的 HTTP 服务器来提供该应用,我们必须设置如何提供该应用。首先,在 `tornado.options.define` 中定义要监听的端口。然后我们实例化 Tornado 的 `HTTPServer`,将该 `Application` 对象的实例作为参数传递给它。
|
||||
|
||||
```
|
||||
# __init__.py
|
||||
from tornado.httpserver import HTTPServer
|
||||
from tornado.options import define, options
|
||||
from tornado.web import Application
|
||||
|
||||
define('port', default=8888, help='port to listen on')
|
||||
|
||||
def main():
|
||||
"""Construct and serve the tornado application."""
|
||||
app = Application()
|
||||
http_server = HTTPServer(app)
|
||||
http_server.listen(options.port)
|
||||
```
|
||||
|
||||
当我们使用 `define` 函数时,我们最终会在 `options` 对象上创建属性。第一个参数位置的任何内容都将是属性的名称,分配给 `default` 关键字参数的内容将是该属性的值。
|
||||
|
||||
例如,如果我们将属性命名为 `potato` 而不是 `port`,我们可以通过 `options.potato` 访问它的值。
|
||||
|
||||
在 `HTTPServer` 上调用 `listen` 并不会启动服务器。我们必须再做一步,找一个可以监听请求并返回响应的工作应用程序,我们需要一个输入输出循环。幸运的是,Tornado 以 `tornado.ioloop.IOLoop` 的形式提供了开箱即用的功能。
|
||||
|
||||
```
|
||||
# __init__.py
|
||||
from tornado.httpserver import HTTPServer
|
||||
from tornado.ioloop import IOLoop
|
||||
from tornado.options import define, options
|
||||
from tornado.web import Application
|
||||
|
||||
define('port', default=8888, help='port to listen on')
|
||||
|
||||
def main():
|
||||
"""Construct and serve the tornado application."""
|
||||
app = Application()
|
||||
http_server = HTTPServer(app)
|
||||
http_server.listen(options.port)
|
||||
print('Listening on http://localhost:%i' % options.port)
|
||||
IOLoop.current().start()
|
||||
```
|
||||
|
||||
我喜欢某种形式的 `print` 语句,来告诉我什么时候应用程序正在提供服务,这是我的习惯。如果你愿意,可以不使用 `print`。
|
||||
|
||||
我们以 `IOLoop.current().start()` 开始我们的 I/O 循环。让我们进一步讨论输入,输出和异步性。
|
||||
|
||||
### Python 中的异步和 I/O 循环的基础知识
|
||||
|
||||
请允许我提前说明,我绝对,肯定,一定并且放心地说不是异步编程方面的专家。就像我写的所有内容一样,接下来的内容源于我对这个概念的理解的局限性。因为我是人,可能有很深很深的缺陷。
|
||||
|
||||
异步程序的主要问题是:
|
||||
|
||||
* 数据如何进来?
|
||||
* 数据如何出去?
|
||||
* 什么时候可以在不占用我全部注意力情况下运行某个过程?
|
||||
|
||||
由于[全局解释器锁][4](GIL),Python 被设计为一种[单线程][5]语言。对于 Python 程序必须执行的每个任务,其线程执行的全部注意力都集中在该任务的持续时间内。我们的 HTTP 服务器是用 Python 编写的,因此,当接收到数据(如 HTTP 请求)时,服务器的唯一关心的是传入的数据。这意味着,在大多数情况下,无论是程序需要运行还是处理数据,程序都将完全消耗服务器的执行线程,阻止接收其它可能的数据,直到服务器完成它需要做的事情。
|
||||
|
||||
在许多情况下,这不是太成问题。典型的 Web 请求,响应周期只需要几分之一秒。除此之外,构建 HTTP 服务器的套接字可以维护待处理的传入请求的积压。因此,如果请求在该套接字处理其它内容时进入,则它很可能只是在处理之前稍微排队等待一会。对于低到中等流量的站点,几分之一秒的时间并不是什么大问题,你可以使用多个部署的实例以及 [NGINX][6] 等负载均衡器来为更大的请求负载分配流量。
|
||||
|
||||
但是,如果你的平均响应时间超过一秒钟,该怎么办?如果你使用来自传入请求的数据来启动一些长时间的过程(如机器学习算法或某些海量数据库查询),该怎么办?现在,你的单线程 Web 服务器开始累积一个无法寻址的积压请求,其中一些请求会因为超时而被丢弃。这不是一种选择,特别是如果你希望你的服务在一段时间内是可靠的。
|
||||
|
||||
异步 Python 程序登场。重要的是要记住因为它是用 Python 编写的,所以程序仍然是一个单线程进程。除非特别标记,否则在异步程序中仍然会阻塞执行。
|
||||
|
||||
但是,当异步程序结构正确时,只要你指定某个函数应该具有这样的能力,你的异步 Python 程序就可以“搁置”长时间运行的任务。然后,当搁置的任务完成并准备好恢复时,异步控制器会收到报告,只要在需要时管理它们的执行,而不会完全阻塞对新输入的处理。
|
||||
|
||||
这有点夸张,所以让我们用一个人类的例子来证明。
|
||||
|
||||
### 带回家吧
|
||||
|
||||
我经常发现自己在家里试图完成很多家务,但没有多少时间来做它们。在某一天,积压的家务可能看起来像:
|
||||
|
||||
* 做饭(20 分钟准备,40 分钟烹饪)
|
||||
* 洗碗(60 分钟)
|
||||
* 洗涤并擦干衣物(30 分钟洗涤,每次干燥 90 分钟)
|
||||
* 真空清洗地板(30 分钟)
|
||||
|
||||
如果我是一个传统的同步程序,我会亲自完成每项任务。在我考虑处理任何其他事情之前,每项任务都需要我全神贯注地完成。因为如果没有我的全力关注,什么事情都完成不了。所以我的执行顺序可能如下:
|
||||
|
||||
1. 完全专注于准备和烹饪食物,包括等待食物烹饪(60 分钟)
|
||||
2. 将脏盘子移到水槽中(65 分钟过去了)
|
||||
3. 清洗所有盘子(125 分钟过去了)
|
||||
4. 开始完全专注于洗衣服,包括等待洗衣机洗完,然后将衣物转移到烘干机,再等烘干机完成( 250 分钟过去了)
|
||||
5. 对地板进行真空吸尘(280 分钟了)
|
||||
|
||||
从头到尾完成所有事情花费了 4 小时 40 分钟。
|
||||
|
||||
我应该像异步程序一样聪明地工作,而不是努力工作。我的家里到处都是可以为我工作的机器,而不用我一直努力工作。同时,现在我可以将注意力转移真正需要的东西上。
|
||||
|
||||
我的执行顺序可能看起来像:
|
||||
|
||||
1. 将衣物放入洗衣机并启动它(5 分钟)
|
||||
2. 在洗衣机运行时,准备食物(25 分钟过去了)
|
||||
3. 准备好食物后,开始烹饪食物(30 分钟过去了)
|
||||
4. 在烹饪食物时,将衣物从洗衣机移到烘干机机中开始烘干(35 分钟过去了)
|
||||
5. 当烘干机运行中,且食物仍在烹饪时,对地板进行真空吸尘(65 分钟过去了)
|
||||
6. 吸尘后,将食物从炉子中取出并装盘子入洗碗机(70 分钟过去了)
|
||||
7. 运行洗碗机(130 分钟完成)
|
||||
|
||||
现在花费的时间下降到 2 小时 10 分钟。即使我允许在作业之间切换花费更多时间(总共 10-20 分钟)。如果我等待着按顺序执行每项任务,我花费的时间仍然只有一半左右。这就是将程序构造为异步的强大功能。
|
||||
|
||||
#### 那么 I/O 循环在哪里?
|
||||
|
||||
一个异步 Python 程序的工作方式是从某个外部源(输入)获取数据,如果某个进程需要,则将该数据转移到某个外部工作者(输出)进行处理。当外部进程完成时,Python 主程序会收到提醒,然后程序获取外部处理(输入)的结果,并继续这样其乐融融的方式。
|
||||
|
||||
当数据不在 Python 主程序手中时,主程序就会被释放来处理其它任何事情。包括等待全新的输入(如 HTTP 请求)和处理长时间运行的进程的结果(如机器学习算法的结果,长时间运行的数据库查询)。主程序虽仍然是单线程的,但成了事件驱动的,它对程序处理的特定事件会触发动作。监听这些事件并指示应如何处理它们的主要是 I/O 循环在工作。
|
||||
|
||||
我知道,我们走了很长的路才得到这个重要的解释,但我希望在这里传达的是,它不是魔术,也不是某种复杂的并行处理或多线程工作。全局解释器锁仍然存在,主程序中任何长时间运行的进程仍然会阻塞其它任何事情的进行,该程序仍然是单线程的。然而,通过将繁琐的工作外部化,我们可以将线程的注意力集中在它需要注意的地方。
|
||||
|
||||
这有点像我上面的异步任务。当我的注意力完全集中在准备食物上时,它就是我所能做的一切。然而,当我能让炉子帮我做饭,洗碗机帮我洗碗,洗衣机和烘干机帮我洗衣服时,我的注意力就会被释放出来,去做其它事情。当我被提醒,我的一个长时间运行的任务已经完成并准备再次处理时,如果我的注意力是空闲的,我可以获取该任务的结果,并对其做下一步需要做的任何事情。
|
||||
|
||||
### Tornado 路由和视图
|
||||
|
||||
尽管经历了在 Python 中讨论异步的所有麻烦,我们还是决定暂不使用它。先来编写一个基本的 Tornado 视图。
|
||||
|
||||
与我们在 Flask 和 Pyramid 实现中看到的基于函数的视图不同,Tornado 的视图都是基于类的。这意味着我们将不在使用单独的、独立的函数来规定如何处理请求。相反,传入的 HTTP 请求将被捕获并将其分配为我们定义的类的一个属性。然后,它的方法将处理相应的请求类型。
|
||||
|
||||
让我们从一个基本的视图开始,即在屏幕上打印 “Hello, World”。我们为 Tornado 应用程序构造的每个基于类的视图都必须继承 `tornado.web` 中的 `RequestHandler` 对象。这将设置我们需要(但不想写)的所有底层逻辑来接收请求,同时构造正确格式的 HTTP 响应。
|
||||
|
||||
```
|
||||
from tornado.web import RequestHandler
|
||||
|
||||
class HelloWorld(RequestHandler):
|
||||
"""Print 'Hello, world!' as the response body."""
|
||||
|
||||
def get(self):
|
||||
"""Handle a GET request for saying Hello World!."""
|
||||
self.write("Hello, world!")
|
||||
```
|
||||
|
||||
因为我们要处理 `GET` 请求,所以我们声明(实际上是重写)了 `get` 方法。我们提供文本或 JSON 可序列化对象,用 `self.write` 写入响应体。之后,我们让 `RequestHandler` 来做在发送响应之前必须完成的其它工作。
|
||||
|
||||
就目前而言,此视图与 Tornado 应用程序本身并没有实际连接。我们必须回到 `__init__.py`,并稍微更新 `main` 函数。以下是新的内容:
|
||||
|
||||
```
|
||||
# __init__.py
|
||||
from tornado.httpserver import HTTPServer
|
||||
from tornado.ioloop import IOLoop
|
||||
from tornado.options import define, options
|
||||
from tornado.web import Application
|
||||
from todo.views import HelloWorld
|
||||
|
||||
define('port', default=8888, help='port to listen on')
|
||||
|
||||
def main():
|
||||
"""Construct and serve the tornado application."""
|
||||
app = Application([
|
||||
('/', HelloWorld)
|
||||
])
|
||||
http_server = HTTPServer(app)
|
||||
http_server.listen(options.port)
|
||||
print('Listening on http://localhost:%i' % options.port)
|
||||
IOLoop.current().start()
|
||||
```
|
||||
|
||||
#### 我们做了什么
|
||||
|
||||
我们将 `views.py` 文件中的 `HelloWorld` 视图导入到脚本 `__init__.py` 的顶部。然后我们添加了一个路由-视图对应的列表,作为 `Application` 实例化的第一个参数。每当我们想要在应用程序中声明一个路由时,它必须绑定到一个视图。如果需要,可以对多个路由使用相同的视图,但每个路由必须有一个视图。
|
||||
|
||||
我们可以通过在 `setup.py` 中启用的 `serve_app` 命令来运行应用程序,从而确保这一切都能正常工作。查看 `http://localhost:8888/` 并看到它显示 “Hello, world!”。
|
||||
|
||||
当然,在这个领域中我们还能做更多,也将做更多,但现在让我们来讨论模型吧。
|
||||
|
||||
### 连接数据库
|
||||
|
||||
如果我们想要保留数据,就需要连接数据库。与 Flask 一样,我们将使用一个特定于框架的 SQLAchemy 变体,名为 [tornado-sqlalchemy][7]。
|
||||
|
||||
为什么要使用它而不是 [SQLAlchemy][8] 呢?好吧,其实 `tornado-sqlalchemy` 具有简单 SQLAlchemy 的所有优点,因此我们仍然可以使用通用的 `Base` 声明模型,并使用我们习以为常的所有列数据类型和关系。除了我们已经惯常了解到的,`tornado-sqlalchemy` 还为其数据库查询功能提供了一种可访问的异步模式,专门用于与 Tornado 现有的 I/O 循环一起工作。
|
||||
|
||||
我们通过将 `tornado-sqlalchemy` 和 `psycopg2` 添加到 `setup.py` 到所需包的列表并重新安装包来创建环境。在 `models.py` 中,我们声明了模型。这一步看起来与我们在 Flask 和 Pyramid 中已经看到的完全一样,所以我将跳过全部声明,只列出了 `Task` 模型的必要部分。
|
||||
|
||||
```
|
||||
# 这不是完整的 models.py, 但是足够看到不同点
|
||||
from tornado_sqlalchemy import declarative_base
|
||||
|
||||
Base = declarative_base
|
||||
|
||||
class Task(Base):
|
||||
# 等等,因为剩下的几乎所有的东西都一样 ...
|
||||
```
|
||||
|
||||
我们仍然需要将 `tornado-sqlalchemy` 连接到实际应用程序。在 `__init__.py` 中,我们将定义数据库并将其集成到应用程序中。
|
||||
|
||||
```
|
||||
# __init__.py
|
||||
from tornado.httpserver import HTTPServer
|
||||
from tornado.ioloop import IOLoop
|
||||
from tornado.options import define, options
|
||||
from tornado.web import Application
|
||||
from todo.views import HelloWorld
|
||||
|
||||
# add these
|
||||
import os
|
||||
from tornado_sqlalchemy import make_session_factory
|
||||
|
||||
define('port', default=8888, help='port to listen on')
|
||||
factory = make_session_factory(os.environ.get('DATABASE_URL', ''))
|
||||
|
||||
def main():
|
||||
"""Construct and serve the tornado application."""
|
||||
app = Application([
|
||||
('/', HelloWorld)
|
||||
],
|
||||
session_factory=factory
|
||||
)
|
||||
http_server = HTTPServer(app)
|
||||
http_server.listen(options.port)
|
||||
print('Listening on http://localhost:%i' % options.port)
|
||||
IOLoop.current().start()
|
||||
```
|
||||
|
||||
就像我们在 Pyramid 中传递的会话工厂一样,我们可以使用 `make_session_factory` 来接收数据库 URL 并生成一个对象,这个对象的唯一目的是为视图提供到数据库的连接。然后我们将新创建的 `factory` 传递给 `Application` 对象,并使用 `session_factory` 关键字参数将它绑定到应用程序中。
|
||||
|
||||
最后,初始化和管理数据库与 Flask 和 Pyramid 相同(即,单独的 DB 管理脚本,与 `Base` 对象一起工作等)。它看起来很相似,所以在这里我就不介绍了。
|
||||
|
||||
### 回顾视图
|
||||
|
||||
Hello,World 总是适合学习基础知识,但我们需要一些真实的,特定应用程序的视图。
|
||||
|
||||
让我们从 info 视图开始。
|
||||
|
||||
```
|
||||
# views.py
|
||||
import json
|
||||
from tornado.web import RequestHandler
|
||||
|
||||
class InfoView(RequestHandler):
|
||||
"""只允许 GET 请求"""
|
||||
SUPPORTED_METHODS = ["GET"]
|
||||
|
||||
def set_default_headers(self):
|
||||
"""设置默认响应头为 json 格式的"""
|
||||
self.set_header("Content-Type", 'application/json; charset="utf-8"')
|
||||
|
||||
def get(self):
|
||||
"""列出这个 API 的路由"""
|
||||
routes = {
|
||||
'info': 'GET /api/v1',
|
||||
'register': 'POST /api/v1/accounts',
|
||||
'single profile detail': 'GET /api/v1/accounts/<username>',
|
||||
'edit profile': 'PUT /api/v1/accounts/<username>',
|
||||
'delete profile': 'DELETE /api/v1/accounts/<username>',
|
||||
'login': 'POST /api/v1/accounts/login',
|
||||
'logout': 'GET /api/v1/accounts/logout',
|
||||
"user's tasks": 'GET /api/v1/accounts/<username>/tasks',
|
||||
"create task": 'POST /api/v1/accounts/<username>/tasks',
|
||||
"task detail": 'GET /api/v1/accounts/<username>/tasks/<id>',
|
||||
"task update": 'PUT /api/v1/accounts/<username>/tasks/<id>',
|
||||
"delete task": 'DELETE /api/v1/accounts/<username>/tasks/<id>'
|
||||
}
|
||||
self.write(json.dumps(routes))
|
||||
```
|
||||
|
||||
有什么改变吗?让我们从上往下看。
|
||||
|
||||
我们添加了 `SUPPORTED_METHODS` 类属性,它是一个可迭代对象,代表这个视图所接受的请求方法,其他任何方法都将返回一个 [405][9] 状态码。当我们创建 `HelloWorld` 视图时,我们没有指定它,主要是当时有点懒。如果没有这个类属性,此视图将响应任何试图绑定到该视图的路由的请求。
|
||||
|
||||
我们声明了 `set_default_headers` 方法,它设置 HTTP 响应的默认头。我们在这里声明它,以确保我们返回的任何响应都有一个 `"Content-Type"` 是 `"application/json"` 类型。
|
||||
|
||||
我们将 `json.dumps(some_object)` 添加到 `self.write` 的参数中,因为它可以很容易地构建响应主体的内容。
|
||||
|
||||
现在已经完成了,我们可以继续将它连接到 `__init__.py` 中的主路由。
|
||||
|
||||
```
|
||||
# __init__.py
|
||||
from tornado.httpserver import HTTPServer
|
||||
from tornado.ioloop import IOLoop
|
||||
from tornado.options import define, options
|
||||
from tornado.web import Application
|
||||
from todo.views import InfoView
|
||||
|
||||
# 添加这些
|
||||
import os
|
||||
from tornado_sqlalchemy import make_session_factory
|
||||
|
||||
define('port', default=8888, help='port to listen on')
|
||||
factory = make_session_factory(os.environ.get('DATABASE_URL', ''))
|
||||
|
||||
def main():
|
||||
"""Construct and serve the tornado application."""
|
||||
app = Application([
|
||||
('/', InfoView)
|
||||
],
|
||||
session_factory=factory
|
||||
)
|
||||
http_server = HTTPServer(app)
|
||||
http_server.listen(options.port)
|
||||
print('Listening on http://localhost:%i' % options.port)
|
||||
IOLoop.current().start()
|
||||
```
|
||||
|
||||
我们知道,还需要编写更多的视图和路由。每个都会根据需要放入 `Application` 路由列表中,每个视图还需要一个 `set_default_headers` 方法。在此基础上,我们还将创建 `send_response` 方法,它的作用是将响应与我们想要给响应设置的任何自定义状态码打包在一起。由于每个视图都需要这两个方法,因此我们可以创建一个包含它们的基类,这样每个视图都可以继承基类。这样,我们只需要编写一次。
|
||||
|
||||
```
|
||||
# views.py
|
||||
import json
|
||||
from tornado.web import RequestHandler
|
||||
|
||||
class BaseView(RequestHandler):
|
||||
"""Base view for this application."""
|
||||
|
||||
def set_default_headers(self):
|
||||
"""Set the default response header to be JSON."""
|
||||
self.set_header("Content-Type", 'application/json; charset="utf-8"')
|
||||
|
||||
def send_response(self, data, status=200):
|
||||
"""Construct and send a JSON response with appropriate status code."""
|
||||
self.set_status(status)
|
||||
self.write(json.dumps(data))
|
||||
```
|
||||
|
||||
对于我们即将编写的 `TaskListView` 这样的视图,我们还需要一个到数据库的连接。我们需要 `tornado_sqlalchemy` 中的 `SessionMixin` 在每个视图类中添加一个数据库会话。我们可以将它放在 `BaseView` 中,这样,默认情况下,从它继承的每个视图都可以访问数据库会话。
|
||||
|
||||
```
|
||||
# views.py
|
||||
import json
|
||||
from tornado_sqlalchemy import SessionMixin
|
||||
from tornado.web import RequestHandler
|
||||
|
||||
class BaseView(RequestHandler, SessionMixin):
|
||||
"""Base view for this application."""
|
||||
|
||||
def set_default_headers(self):
|
||||
"""Set the default response header to be JSON."""
|
||||
self.set_header("Content-Type", 'application/json; charset="utf-8"')
|
||||
|
||||
def send_response(self, data, status=200):
|
||||
"""Construct and send a JSON response with appropriate status code."""
|
||||
self.set_status(status)
|
||||
self.write(json.dumps(data))
|
||||
```
|
||||
|
||||
只要我们修改 `BaseView` 对象,在将数据发布到这个 API 时,我们就应该定位到这里。
|
||||
|
||||
当 Tornado(从 v.4.5 开始)使用来自客户端的数据并将其组织起来到应用程序中使用时,它会将所有传入数据视为字节串。但是,这里的所有代码都假设使用 Python 3,因此我们希望使用的唯一字符串是 Unicode 字符串。我们可以为这个 `BaseView` 类添加另一个方法,它的工作是将输入数据转换为 Unicode,然后再在视图的其他地方使用。
|
||||
|
||||
如果我们想要在正确的视图方法中使用它之前转换这些数据,我们可以重写视图类的原生 `prepare` 方法。它的工作是在视图方法运行前运行。如果我们重写 `prepare` 方法,我们可以设置一些逻辑来运行,每当收到请求时,这些逻辑就会执行字节串到 Unicode 的转换。
|
||||
|
||||
```
|
||||
# views.py
|
||||
import json
|
||||
from tornado_sqlalchemy import SessionMixin
|
||||
from tornado.web import RequestHandler
|
||||
|
||||
class BaseView(RequestHandler, SessionMixin):
|
||||
"""Base view for this application."""
|
||||
|
||||
def prepare(self):
|
||||
self.form_data = {
|
||||
key: [val.decode('utf8') for val in val_list]
|
||||
for key, val_list in self.request.arguments.items()
|
||||
}
|
||||
|
||||
def set_default_headers(self):
|
||||
"""Set the default response header to be JSON."""
|
||||
self.set_header("Content-Type", 'application/json; charset="utf-8"')
|
||||
|
||||
def send_response(self, data, status=200):
|
||||
"""Construct and send a JSON response with appropriate status code."""
|
||||
self.set_status(status)
|
||||
self.write(json.dumps(data))
|
||||
```
|
||||
|
||||
如果有任何数据进入,它将在 `self.request.arguments` 字典中找到。我们可以通过键访问该数据库,并将其内容(始终是列表)转换为 Unicode。因为这是基于类的视图而不是基于函数的,所以我们可以将修改后的数据存储为一个实例属性,以便以后使用。我在这里称它为 `form_data`,但它也可以被称为 `potato`。关键是我们可以存储提交给应用程序的数据。
|
||||
|
||||
### 异步视图方法
|
||||
|
||||
现在我们已经构建了 `BaseaView`,我们可以构建 `TaskListView` 了,它会继承 `BaseaView`。
|
||||
|
||||
正如你可以从章节标题中看到的那样,以下是所有关于异步性的讨论。`TaskListView` 将处理返回任务列表的 `GET` 请求和用户给定一些表单数据来创建新任务的 `POST` 请求。让我们首先来看看处理 `GET` 请求的代码。
|
||||
|
||||
```
|
||||
# all the previous imports
|
||||
import datetime
|
||||
from tornado.gen import coroutine
|
||||
from tornado_sqlalchemy import as_future
|
||||
from todo.models import Profile, Task
|
||||
|
||||
# the BaseView is above here
|
||||
class TaskListView(BaseView):
|
||||
"""View for reading and adding new tasks."""
|
||||
SUPPORTED_METHODS = ("GET", "POST",)
|
||||
|
||||
@coroutine
|
||||
def get(self, username):
|
||||
"""Get all tasks for an existing user."""
|
||||
with self.make_session() as session:
|
||||
profile = yield as_future(session.query(Profile).filter(Profile.username == username).first)
|
||||
if profile:
|
||||
tasks = [task.to_dict() for task in profile.tasks]
|
||||
self.send_response({
|
||||
'username': profile.username,
|
||||
'tasks': tasks
|
||||
})
|
||||
```
|
||||
|
||||
这里的第一个主要部分是 `@coroutine` 装饰器,它从 `tornado.gen` 导入。任何具有与调用堆栈的正常流程不同步的 Python 可调用部分实际上是“协程”,即一个可以与其它协程一起运行的协程。在我的家务劳动的例子中,几乎所有的家务活都是一个共同的例行协程。有些阻止了例行协程(例如,给地板吸尘),但这种例行协程只会阻碍我开始或关心其它任何事情的能力。它没有阻止已经启动的任何其他协程继续进行。
|
||||
|
||||
Tornado 提供了许多方法来构建一个利用协程的应用程序,包括允许我们设置函数调用锁,同步异步协程的条件,以及手动修改控制 I/O 循环的事件系统。
|
||||
|
||||
这里使用 `@coroutine` 装饰器的唯一条件是允许 `get` 方法将 SQL 查询作为后台进程,并在查询完成后恢复,同时不阻止 Tornado I/O 循环去处理其他传入的数据源。这就是关于此实现的所有“异步”:带外数据库查询。显然,如果我们想要展示异步 Web 应用程序的魔力和神奇,那么一个任务列表就不是好的展示方式。
|
||||
|
||||
但是,这就是我们正在构建的,所以让我们来看看方法如何利用 `@coroutine` 装饰器。`SessionMixin` 混合到 `BaseView` 声明中,为我们的视图类添加了两个方便的,支持数据库的属性:`session` 和 `make_session`。它们的名字相似,实现的目标也相当相似。
|
||||
|
||||
`self.session` 属性是一个关注数据库的会话。在请求-响应周期结束时,在视图将响应发送回客户端之前,任何对数据库的更改都被提交,并关闭会话。
|
||||
|
||||
`self.make_session` 是一个上下文管理器和生成器,可以动态构建和返回一个全新的会话对象。第一个 `self.session` 对象仍然存在。无论如何,反正 `make_session` 会创建一个新的。`make_session` 生成器还为其自身提供了一个功能,用于在其上下文(即缩进级别)结束时提交和关闭它创建的会话。
|
||||
|
||||
如果你查看源代码,则赋值给 `self.session` 的对象类型与 `self.make_session` 生成的对象类型之间没有区别,不同之处在于它们是如何被管理的。
|
||||
|
||||
使用 `make_session` 上下文管理器,生成的会话仅属于上下文,在该上下文中开始和结束。你可以使用 `make_session` 上下文管理器在同一个视图中打开,修改,提交以及关闭多个数据库会话。
|
||||
|
||||
`self.session` 要简单得多,当你进入视图方法时会话已经打开,在响应被发送回客户端之前会话就已提交。
|
||||
|
||||
虽然[读取文档片段][10]和 [PyPI 示例][11]都说明了上下文管理器的使用,但是没有说明 `self.session` 对象或由 `self.make_session` 生成的 `session` 本质上是不是异步的。当我们启动查询时,我们开始考虑内置于 `tornado-sqlalchemy` 中的异步行为。
|
||||
|
||||
`tornado-sqlalchemy` 包为我们提供了 `as_future` 函数。它的工作是装饰 `tornado-sqlalchemy` 会话构造的查询并 yield 其返回值。如果视图方法用 `@coroutine` 装饰,那么使用 `yield as_future(query)` 模式将使封装的查询成为一个异步后台进程。I/O 循环会接管等待查询的返回值和 `as_future` 创建的 `future` 对象的解析。
|
||||
|
||||
要访问 `as_future(query)` 的结果,你必须从它 `yield`。否则,你只能获得一个未解析的生成器对象,并且无法对查询执行任何操作。
|
||||
|
||||
这个视图方法中的其他所有内容都与之前课堂上的类似,与我们在 Flask 和 Pyramid 中看到的内容类似。
|
||||
|
||||
`post` 方法看起来非常相似。为了保持一致性,让我们看一下 `post` 方法以及它如何处理用 `BaseView` 构造的 `self.form_data`。
|
||||
|
||||
```
|
||||
@coroutine
|
||||
def post(self, username):
|
||||
"""Create a new task."""
|
||||
with self.make_session() as session:
|
||||
profile = yield as_future(session.query(Profile).filter(Profile.username == username).first)
|
||||
if profile:
|
||||
due_date = self.form_data['due_date'][0]
|
||||
task = Task(
|
||||
name=self.form_data['name'][0],
|
||||
note=self.form_data['note'][0],
|
||||
creation_date=datetime.now(),
|
||||
due_date=datetime.strptime(due_date, '%d/%m/%Y %H:%M:%S') if due_date else None,
|
||||
completed=self.form_data['completed'][0],
|
||||
profile_id=profile.id,
|
||||
profile=profile
|
||||
)
|
||||
session.add(task)
|
||||
self.send_response({'msg': 'posted'}, status=201)
|
||||
```
|
||||
|
||||
正如我所说,这是我们所期望的:
|
||||
|
||||
* 与我们在 `get` 方法中看到的查询模式相同
|
||||
* 构造一个新的 `Task` 对象的实例,用 `form_data` 的数据填充
|
||||
* 添加新的 `Task` 对象(但不提交,因为它由上下文管理器处理!)到数据库会话
|
||||
* 将响应发送给客户端
|
||||
|
||||
这样我们就有了 Tornado web 应用程序的基础。其他内容(例如,数据库管理和更多完整应用程序的视图)实际上与我们在 Flask 和 Pyramid 应用程序中看到的相同。
|
||||
|
||||
### 关于使用合适的工具完成合适的工作的一点想法
|
||||
|
||||
在我们继续浏览这些 Web 框架时,我们开始看到它们都可以有效地处理相同的问题。对于像这样的待办事项列表,任何框架都可以完成这项任务。但是,有些 Web 框架比其它框架更适合某些工作,这具体取决于对你来说什么“更合适”和你的需求。
|
||||
|
||||
虽然 Tornado 显然和 Pyramid 或 Flask 一样可以处理相同工作,但将它用于这样的应用程序实际上是一种浪费,这就像开车从家走一个街区(LCTT 译注:这里意思应该是从家开始走一个街区只需步行即可)。是的,它可以完成“旅行”的工作,但短途旅行不是你选择汽车而不是自行车或者使用双脚的原因。
|
||||
|
||||
根据文档,Tornado 被称为 “Python Web 框架和异步网络库”。在 Python Web 框架生态系统中很少有人喜欢它。如果你尝试完成的工作需要(或将从中获益)以任何方式、形状或形式的异步性,使用 Tornado。如果你的应用程序需要处理多个长期连接,同时又不想牺牲太多性能,选择 Tornado。如果你的应用程序是多个应用程序,并且需要线程感知以准确处理数据,使用 Tornado。这是它最有效的地方。
|
||||
|
||||
用你的汽车做“汽车的事情”,使用其他交通工具做其他事情。
|
||||
|
||||
### 向前看,进行一些深度检查
|
||||
|
||||
谈到使用合适的工具来完成合适的工作,在选择框架时,请记住应用程序的范围和规模,包括现在和未来。到目前为止,我们只研究了适用于中小型 Web 应用程序的框架。本系列的下一篇也是最后一篇将介绍最受欢迎的 Python 框架之一 Django,它适用于可能会变得更大的大型应用程序。同样,尽管它在技术上能够并且将会处理待办事项列表问题,但请记住,这不是它的真正用途。我们仍然会通过它来展示如何使用它来构建应用程序,但我们必须牢记框架的意图以及它是如何反映在架构中的:
|
||||
|
||||
* **Flask**: 适用于小型,简单的项目。它可以使我们轻松地构建视图并将它们快速连接到路由,它可以简单地封装在一个文件中。
|
||||
* **Pyramid**: 适用于可能增长的项目。它包含一些配置来启动和运行。应用程序组件的独立领域可以很容易地划分并构建到任意深度,而不会忽略中央应用程序。
|
||||
* **Tornado**: 适用于受益于精确和有意识的 I/O 控制的项目。它允许协程,并轻松公开可以控制如何接收请求或发送响应以及何时发生这些操作的方法。
|
||||
* **Django**:(我们将会看到)意味着可能会变得更大的东西。它有着非常庞大的生态系统,包括大量插件和模块。它非常有主见的配置和管理,以保持所有不同部分在同一条线上。
|
||||
|
||||
无论你是从本系列的第一篇文章开始阅读,还是稍后才加入的,都要感谢阅读!请随意留下问题或意见。下次再见时,我手里会拿着 Django。
|
||||
|
||||
### 感谢 Python BDFL
|
||||
|
||||
我必须把功劳归于它应得的地方,非常感谢 [Guido van Rossum][12],不仅仅是因为他创造了我最喜欢的编程语言。
|
||||
|
||||
在 [PyCascades 2018][13] 期间,我很幸运的不仅做了基于这个文章系列的演讲,而且还被邀请参加了演讲者的晚宴。整个晚上我都坐在 Guido 旁边,不停地问他问题。其中一个问题是,在 Python 中异步到底是如何工作的,但他没有一点大惊小怪,而是花时间向我解释,让我开始理解这个概念。他后来[推特给我][14]发了一条消息:是用于学习异步 Python 的广阔资源。我随后在三个月内阅读了三次,然后写了这篇文章。你真是一个非常棒的人,Guido!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/tornado-framework
|
||||
|
||||
作者:[Nicholas Hunt-Walker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/nhuntwalker
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/18/5/pyramid-framework
|
||||
[2]: https://opensource.com/article/18/4/flask
|
||||
[3]: https://tornado.readthedocs.io/en/stable/
|
||||
[4]: https://realpython.com/python-gil/
|
||||
[5]: https://en.wikipedia.org/wiki/Thread_(computing)
|
||||
[6]: https://www.nginx.com/
|
||||
[7]: https://tornado-sqlalchemy.readthedocs.io/en/latest/
|
||||
[8]: https://www.sqlalchemy.org/
|
||||
[9]: https://en.wikipedia.org/wiki/List_of_HTTP_status_codes#4xx_Client_errors
|
||||
[10]: https://tornado-sqlalchemy.readthedocs.io/en/latest/#usage
|
||||
[11]: https://pypi.org/project/tornado-sqlalchemy/#description
|
||||
[12]: https://www.twitter.com/gvanrossum
|
||||
[13]: https://www.pycascades.com
|
||||
[14]: https://twitter.com/gvanrossum/status/956186585493458944
|
||||
@ -0,0 +1,138 @@
|
||||
如何从 Linux 上连接到远程桌面
|
||||
======
|
||||
|
||||
> Remmina 的极简用户界面使得远程访问 Linux / Windows 10 变得轻松。
|
||||
|
||||

|
||||
|
||||
根据维基百科,[远程桌面][1] 是一种“软件或者操作系统特性,它可以让个人电脑上的桌面环境在一个系统(通常是电脑,但是也可以是服务器)上远程运行,但在另一个分开的客户端设备显示”。
|
||||
|
||||
换句话说,远程桌面是用来访问在另一台电脑上运行的环境的。比如说 [ManageIQ/Integration tests][2] 仓库的拉取请求 (PR) 测试系统开放了一个虚拟网络计算 (VNC) 连接端口,使得我能够远程浏览正被实时测试的拉取请求。远程桌面也被用于帮助客户解决电脑问题:在客户的许可下,你可以远程建立 VNC 或者远程桌面协议(RDP)连接来查看或者交互式地访问该电脑以寻找并解决问题。
|
||||
|
||||
运用远程桌面连接软件可以建立这些连接。可供选择的软件有很多,我用 [Remmina][3],因为我喜欢它极简、好用的用户界面 (UI)。它是用 GTK+ 编写的,在 GNU GPL 许可证开源。
|
||||
|
||||
在这篇文章里,我会解释如何使用 Remmina 客户端从一台 Linux 电脑上远程连接到 Windows 10 系统 和 Red Hat 企业版 Linux 7 系统。
|
||||
|
||||
### 在 Linux 上安装 Remmina
|
||||
|
||||
首先,你需要在你用来远程访问其它电脑的的主机上安装 Remmina。如果你用的是 Fedora,你可以运行如下的命令来安装 Remmina:
|
||||
|
||||
```
|
||||
sudo dnf install -y remmina
|
||||
```
|
||||
|
||||
如果你想在一个不同的 Linux 平台上安装 Remmina,跟着 [安装教程][4] 走。然后你会发现 Remmina 正和你其它软件出现在一起(在这张图片里选中了 Remmina)。
|
||||
|
||||
|
||||
|
||||
点击图标运行 Remmina,你应该能看到像这样的屏幕:
|
||||
|
||||
|
||||
|
||||
Remmina 提供不同种类的连接,其中包括用来连接到 Windows 系统的 RDP 和用来连接到 Linux 系统的 VNC。如你在上图左上角所见的,Remmina 的默认设置是 RDP。
|
||||
|
||||
### 连接到 Windows 10
|
||||
|
||||
在你通过 RDP 连接到一台 Windows 10 电脑之前,你必须修改权限以允许分享远程桌面并通过防火墙建立连接。
|
||||
|
||||
- [注意: Windows 10 家庭版没有列入 RDP 特性][5]
|
||||
|
||||
要许可远程桌面分享,在“文件管理器”界面右击“我的电脑 → 属性 → 远程设置”,接着在跳出的窗口中,勾选“在这台电脑上允许远程连接”,再点击“应用”。
|
||||
|
||||
|
||||
|
||||
然后,允许远程连接通过你的防火墙。首先在“开始菜单”中查找“防火墙设置”,选择“允许应用通过防火墙”。
|
||||
|
||||
|
||||
|
||||
在打开的窗口中,在“允许的应用和特性”下找到“远程桌面”。根据你用来访问这个桌面的网络酌情勾选“隐私”和/或“公开”列的选框。点击“确定”。
|
||||
|
||||
|
||||
|
||||
回到你用来远程访问 Windows 主机的 Linux 电脑,打开 Remmina。输入你的 Windows 主机的 IP 地址,敲击回车键。(我怎么在 [Linux][6] 和 [Windws][7] 中确定我的 IP 地址?)看到提示后,输入你的用户名和密码,点击“确定”。
|
||||
|
||||
|
||||
|
||||
如果你被询问是否接受证书,点击“确定”。
|
||||
|
||||
|
||||
|
||||
你此时应能看到你的 Windows 10 主机桌面。
|
||||
|
||||
|
||||
|
||||
### 连接到 Red Hat 企业版 Linux 7
|
||||
|
||||
要在你的 RHEL7 电脑上允许远程访问,在 Linux 桌面上打开“所有设置”。
|
||||
|
||||
|
||||
|
||||
点击分享图标会打开如下的窗口:
|
||||
|
||||
|
||||
|
||||
如果“屏幕分享”处于关闭状态,点击一下。一个窗口会弹出,你可以滑动到“打开”的位置。如果你想允许远程控制桌面,将“允许远程控制”调到“打开”。你同样也可以在两种访问选项间选择:一个能够让电脑的主要用户接受或者否绝连接要求,另一个能用密码验证连接。在窗口底部,选择被允许连接的网络界面,最后关闭窗口。
|
||||
|
||||
接着,从“应用菜单 → 其它 → 防火墙”打开“防火墙设置”。
|
||||
|
||||
|
||||
|
||||
勾选 “vnc-server”旁边的选框(如下图所示)关闭窗口。接着直接到你远程电脑上的 Remmina,输入你想连接到的 Linux 桌面的 IP 地址,选择 VNC 作为协议,点击回车键。
|
||||
|
||||
|
||||
|
||||
如果你之前选择的验证选项是“新连接必须询问访问许可”,RHEL 系统用户会看到这样的一个弹窗:
|
||||
|
||||
|
||||
|
||||
点击“接受”以成功进行远程连接。
|
||||
|
||||
如果你选择用密码验证连接,Remmina 会向你询问密码。
|
||||
|
||||
|
||||
|
||||
输入密码然后“确认”,你应该能连接到远程电脑。
|
||||
|
||||
|
||||
|
||||
### 使用 Remmina
|
||||
|
||||
Remmina 提供如上图所示的标签化的 UI,就好像一个浏览器一样。在上图所示的左上角你可以看到两个标签:一个是之前建立的 WIndows 10 连接,另一个新的是 RHEL 连接。
|
||||
|
||||
在窗口的左侧,有一个有着“缩放窗口”、“全屏模式”、“偏好”、“截屏”、“断开连接”等选项的工具栏。你可以自己探索看那种适合你。
|
||||
|
||||
你也可以通过点击左上角的“+”号创建保存过的连接。根据你的连接情况填好表单点击“保存”。以下是一个 Windows 10 RDP 连接的示例:
|
||||
|
||||
|
||||
|
||||
下次你打开 Remmina 时连接就在那了。
|
||||
|
||||
|
||||
|
||||
点击一下它,你不用补充细节就可以建立连接了。
|
||||
|
||||
### 补充说明
|
||||
|
||||
当你使用远程桌面软件时,你所有的操作都在远程桌面上消耗资源 —— Remmina(或者其它类似软件)仅仅是一种与远程桌面交互的方式。你也可以通过 SSH 远程访问一台电脑,但那将会让你在那台电脑上局限于仅能使用文字的终端。
|
||||
|
||||
你也应当注意到当你允许你的电脑远程连接时,如果一名攻击者用这种方法获得你电脑的访问权同样会给你带来严重损失。因此当你不频繁使用远程桌面时,禁止远程桌面连接以及其在防火墙中相关的服务是很明智的做法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/linux-remote-desktop
|
||||
|
||||
作者:[Kedar Vijay Kulkarni][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/kkulkarn
|
||||
[1]:https://en.wikipedia.org/wiki/Remote_desktop_software
|
||||
[2]:https://github.com/ManageIQ/integration_tests
|
||||
[3]:https://www.remmina.org/wp/
|
||||
[4]:https://www.tecmint.com/remmina-remote-desktop-sharing-and-ssh-client/
|
||||
[5]:https://superuser.com/questions/1019203/remote-desktop-settings-missing#1019212
|
||||
[6]:https://opensource.com/article/18/5/how-find-ip-address-linux
|
||||
[7]:https://www.groovypost.com/howto/find-windows-10-device-ip-address/
|
||||
@ -0,0 +1,339 @@
|
||||
如何搜索一个包是否在你的 Linux 发行版中
|
||||
======
|
||||
|
||||
如果你知道包名称,那么你可以直接安装所需的包。
|
||||
|
||||
在某些情况下,如果你不知道确切的包名称或者你想搜索某些包,那么你可以在发行版的包管理器的帮助下轻松搜索该包。搜索会自动包括已安装和可用的包。结果的格式取决于选项。如果你的查询没有输出任何信息,那么意味着没有匹配条件的包。这可以通过发行版的包管理器的各种选项来完成。我已经在本文中添加了所有可能的选项,你可以选择最好的和最合适你的选项。
|
||||
|
||||
或者,我们可以通过 `whohas` 命令实现这一点。它会从所有的主流发行版(例如 Debian、Ubuntu、 Fedora 等)中搜索,而不仅仅是你自己的系统发行版。
|
||||
|
||||
建议阅读:
|
||||
|
||||
- [适用于 Linux 的命令行包管理器列表以及用法][1]
|
||||
- [Linux 包管理器的图形前端工具][2]
|
||||
|
||||
### 如何在 Debian/Ubuntu 中搜索一个包
|
||||
|
||||
我们可以使用 `apt`、`apt-cache` 和 `aptitude` 包管理器在基于 Debian 的发行版上查找给定的包。我为这个包管理器中包括了大量的选项。
|
||||
|
||||
我们可以在基于 Debian 的系统中使用三种方式完成此操作。
|
||||
|
||||
* `apt` 命令
|
||||
* `apt-cache` 命令
|
||||
* `aptitude` 命令
|
||||
|
||||
#### 如何使用 apt 命令搜索一个包
|
||||
|
||||
APT 代表<ruby>高级包管理工具<rt>Advanced Packaging Tool</rt></ruby>(APT),它取代了 `apt-get`。它有功能丰富的命令行工具,包括所有功能包含在一个命令(`apt`)里,包括 `apt-cache`、`apt-search`、`dpkg`、`apt-cdrom`、`apt-config`、`apt-key` 等,还有其他几个独特的功能。
|
||||
|
||||
APT 是一个强大的命令行工具,它可以访问 libapt-pkg 底层库的所有特性,它可以用于安装、下载、删除、搜索和管理以及查询包的信息,另外它还包含一些较少使用的与包管理相关的命令行实用程序。
|
||||
|
||||
```
|
||||
$ apt -q list nano vlc
|
||||
Listing...
|
||||
nano/artful,now 2.8.6-3 amd64 [installed]
|
||||
vlc/artful 2.2.6-6 amd64
|
||||
```
|
||||
|
||||
或者,我们可以使用以下格式搜索指定的包。
|
||||
|
||||
```
|
||||
$ apt search ^vlc
|
||||
Sorting... Done
|
||||
Full Text Search... Done
|
||||
vlc/artful 2.2.6-6 amd64
|
||||
multimedia player and streamer
|
||||
|
||||
vlc-bin/artful 2.2.6-6 amd64
|
||||
binaries from VLC
|
||||
|
||||
vlc-data/artful,artful 2.2.6-6 all
|
||||
Common data for VLC
|
||||
|
||||
vlc-l10n/artful,artful 2.2.6-6 all
|
||||
Translations for VLC
|
||||
|
||||
vlc-plugin-access-extra/artful 2.2.6-6 amd64
|
||||
multimedia player and streamer (extra access plugins)
|
||||
|
||||
vlc-plugin-base/artful 2.2.6-6 amd64
|
||||
multimedia player and streamer (base plugins)
|
||||
```
|
||||
|
||||
#### 如何使用 apt-cache 命令搜索一个包
|
||||
|
||||
`apt-cache` 会在 APT 的包缓存上执行各种操作。它会显示有关指定包的信息。`apt-cache` 不会改变系统的状态,但提供了从包的元数据中搜索和生成有趣输出的操作。
|
||||
|
||||
```
|
||||
$ apt-cache search nano | grep ^nano
|
||||
nano - small, friendly text editor inspired by Pico
|
||||
nano-tiny - small, friendly text editor inspired by Pico - tiny build
|
||||
nanoblogger - Small weblog engine for the command line
|
||||
nanoblogger-extra - Nanoblogger plugins
|
||||
nanoc - static site generator written in Ruby
|
||||
nanoc-doc - static site generator written in Ruby - documentation
|
||||
nanomsg-utils - nanomsg utilities
|
||||
nanopolish - consensus caller for nanopore sequencing data
|
||||
```
|
||||
|
||||
或者,我们可以使用以下格式搜索指定的包。
|
||||
|
||||
```
|
||||
$ apt-cache policy vlc
|
||||
vlc:
|
||||
Installed: (none)
|
||||
Candidate: 2.2.6-6
|
||||
Version table:
|
||||
2.2.6-6 500
|
||||
500 http://in.archive.ubuntu.com/ubuntu artful/universe amd64 Packages
|
||||
```
|
||||
|
||||
或者,我们可以使用以下格式搜索给定的包。
|
||||
|
||||
```
|
||||
$ apt-cache pkgnames vlc
|
||||
vlc-bin
|
||||
vlc-plugin-video-output
|
||||
vlc-plugin-sdl
|
||||
vlc-plugin-svg
|
||||
vlc-plugin-samba
|
||||
vlc-plugin-fluidsynth
|
||||
vlc-plugin-qt
|
||||
vlc-plugin-skins2
|
||||
vlc-plugin-visualization
|
||||
vlc-l10n
|
||||
vlc-plugin-notify
|
||||
vlc-plugin-zvbi
|
||||
vlc-plugin-vlsub
|
||||
vlc-plugin-jack
|
||||
vlc-plugin-access-extra
|
||||
vlc
|
||||
vlc-data
|
||||
vlc-plugin-video-splitter
|
||||
vlc-plugin-base
|
||||
```
|
||||
|
||||
#### 如何使用 aptitude 命令搜索一个包
|
||||
|
||||
`aptitude` 是一个基于文本的 Debian GNU/Linux 软件包系统的命令行界面。它允许用户查看包列表,并执行包管理任务,例如安装、升级和删除包,它可以从可视化界面或命令行执行操作。
|
||||
|
||||
```
|
||||
$ aptitude search ^vlc
|
||||
p vlc - multimedia player and streamer
|
||||
p vlc:i386 - multimedia player and streamer
|
||||
p vlc-bin - binaries from VLC
|
||||
p vlc-bin:i386 - binaries from VLC
|
||||
p vlc-data - Common data for VLC
|
||||
v vlc-data:i386 -
|
||||
p vlc-l10n - Translations for VLC
|
||||
v vlc-l10n:i386 -
|
||||
p vlc-plugin-access-extra - multimedia player and streamer (extra access plugins)
|
||||
p vlc-plugin-access-extra:i386 - multimedia player and streamer (extra access plugins)
|
||||
p vlc-plugin-base - multimedia player and streamer (base plugins)
|
||||
p vlc-plugin-base:i386 - multimedia player and streamer (base plugins)
|
||||
p vlc-plugin-fluidsynth - FluidSynth plugin for VLC
|
||||
p vlc-plugin-fluidsynth:i386 - FluidSynth plugin for VLC
|
||||
p vlc-plugin-jack - Jack audio plugins for VLC
|
||||
p vlc-plugin-jack:i386 - Jack audio plugins for VLC
|
||||
p vlc-plugin-notify - LibNotify plugin for VLC
|
||||
p vlc-plugin-notify:i386 - LibNotify plugin for VLC
|
||||
p vlc-plugin-qt - multimedia player and streamer (Qt plugin)
|
||||
p vlc-plugin-qt:i386 - multimedia player and streamer (Qt plugin)
|
||||
p vlc-plugin-samba - Samba plugin for VLC
|
||||
p vlc-plugin-samba:i386 - Samba plugin for VLC
|
||||
p vlc-plugin-sdl - SDL video and audio output plugin for VLC
|
||||
p vlc-plugin-sdl:i386 - SDL video and audio output plugin for VLC
|
||||
p vlc-plugin-skins2 - multimedia player and streamer (Skins2 plugin)
|
||||
p vlc-plugin-skins2:i386 - multimedia player and streamer (Skins2 plugin)
|
||||
p vlc-plugin-svg - SVG plugin for VLC
|
||||
p vlc-plugin-svg:i386 - SVG plugin for VLC
|
||||
p vlc-plugin-video-output - multimedia player and streamer (video output plugins)
|
||||
p vlc-plugin-video-output:i386 - multimedia player and streamer (video output plugins)
|
||||
p vlc-plugin-video-splitter - multimedia player and streamer (video splitter plugins)
|
||||
p vlc-plugin-video-splitter:i386 - multimedia player and streamer (video splitter plugins)
|
||||
p vlc-plugin-visualization - multimedia player and streamer (visualization plugins)
|
||||
p vlc-plugin-visualization:i386 - multimedia player and streamer (visualization plugins)
|
||||
p vlc-plugin-vlsub - VLC extension to download subtitles from opensubtitles.org
|
||||
p vlc-plugin-zvbi - VBI teletext plugin for VLC
|
||||
p vlc-plugin-zvbi:i386
|
||||
```
|
||||
|
||||
### 如何在 RHEL/CentOS 中搜索一个包
|
||||
|
||||
Yum(Yellowdog Updater Modified)是 Linux 操作系统中的包管理器实用程序之一。Yum 命令用于在一些基于 RedHat 的 Linux 发行版上,它用来安装、更新、搜索和删除软件包。
|
||||
|
||||
```
|
||||
# yum search ftpd
|
||||
Loaded plugins: fastestmirror, refresh-packagekit, security
|
||||
Loading mirror speeds from cached hostfile
|
||||
* base: centos.hyve.com
|
||||
* epel: mirrors.coreix.net
|
||||
* extras: centos.hyve.com
|
||||
* rpmforge: www.mirrorservice.org
|
||||
* updates: mirror.sov.uk.goscomb.net
|
||||
============================================================== N/S Matched: ftpd ===============================================================
|
||||
nordugrid-arc-gridftpd.x86_64 : ARC gridftp server
|
||||
pure-ftpd.x86_64 : Lightweight, fast and secure FTP server
|
||||
vsftpd.x86_64 : Very Secure Ftp Daemon
|
||||
|
||||
Name and summary matches only, use "search all" for everything.
|
||||
```
|
||||
|
||||
或者,我们可以使用以下命令搜索相同内容。
|
||||
|
||||
```
|
||||
# yum list ftpd
|
||||
```
|
||||
|
||||
### 如何在 Fedora 中搜索一个包
|
||||
|
||||
DNF 代表 Dandified yum。我们可以说 DNF 是下一代 yum 包管理器(Yum 的衍生品),它使用 hawkey/libsolv 库作为底层。Aleš Kozumplík 从 Fedora 18 开始开发 DNF,最终在 Fedora 22 中发布。
|
||||
|
||||
```
|
||||
# dnf search ftpd
|
||||
Last metadata expiration check performed 0:42:28 ago on Tue Jun 9 22:52:44 2018.
|
||||
============================== N/S Matched: ftpd ===============================
|
||||
proftpd-utils.x86_64 : ProFTPD - Additional utilities
|
||||
pure-ftpd-selinux.x86_64 : SELinux support for Pure-FTPD
|
||||
proftpd-devel.i686 : ProFTPD - Tools and header files for developers
|
||||
proftpd-devel.x86_64 : ProFTPD - Tools and header files for developers
|
||||
proftpd-ldap.x86_64 : Module to add LDAP support to the ProFTPD FTP server
|
||||
proftpd-mysql.x86_64 : Module to add MySQL support to the ProFTPD FTP server
|
||||
proftpd-postgresql.x86_64 : Module to add PostgreSQL support to the ProFTPD FTP
|
||||
: server
|
||||
vsftpd.x86_64 : Very Secure Ftp Daemon
|
||||
proftpd.x86_64 : Flexible, stable and highly-configurable FTP server
|
||||
owfs-ftpd.x86_64 : FTP daemon providing access to 1-Wire networks
|
||||
perl-ftpd.noarch : Secure, extensible and configurable Perl FTP server
|
||||
pure-ftpd.x86_64 : Lightweight, fast and secure FTP server
|
||||
pyftpdlib.noarch : Python FTP server library
|
||||
nordugrid-arc-gridftpd.x86_64 : ARC gridftp server
|
||||
```
|
||||
|
||||
或者,我们可以使用以下命令搜索相同的内容。
|
||||
|
||||
```
|
||||
# dnf list proftpd
|
||||
Failed to synchronize cache for repo 'heikoada-terminix', disabling.
|
||||
Last metadata expiration check: 0:08:02 ago on Tue 26 Jun 2018 04:30:05 PM IST.
|
||||
Available Packages
|
||||
proftpd.x86_64
|
||||
```
|
||||
|
||||
### 如何在 Arch Linux 中搜索一个包
|
||||
|
||||
pacman 代表包管理实用程序(pacman)。它是一个用于安装、构建、删除和管理 Arch Linux 软件包的命令行实用程序。pacman 使用 libalpm(Arch Linux Package Management(ALPM)库)作为底层来执行所有操作。
|
||||
|
||||
在本例中,我将要搜索 chromium 包。
|
||||
|
||||
```
|
||||
# pacman -Ss chromium
|
||||
extra/chromium 48.0.2564.116-1
|
||||
The open-source project behind Google Chrome, an attempt at creating a safer, faster, and more stable browser
|
||||
extra/qt5-webengine 5.5.1-9 (qt qt5)
|
||||
Provides support for web applications using the Chromium browser project
|
||||
community/chromium-bsu 0.9.15.1-2
|
||||
A fast paced top scrolling shooter
|
||||
community/chromium-chromevox latest-1
|
||||
Causes the Chromium web browser to automatically install and update the ChromeVox screen reader extention. Note: This
|
||||
package does not contain the extension code.
|
||||
community/fcitx-mozc 2.17.2313.102-1
|
||||
Fcitx Module of A Japanese Input Method for Chromium OS, Windows, Mac and Linux (the Open Source Edition of Google Japanese
|
||||
Input)
|
||||
```
|
||||
|
||||
默认情况下,`-s` 选项内置 ERE(扩展正则表达式)会导致很多不需要的结果。使用以下格式会仅匹配包名称。
|
||||
|
||||
```
|
||||
# pacman -Ss '^chromium-'
|
||||
```
|
||||
|
||||
`pkgfile` 是一个用于在 Arch Linux 官方仓库的包中搜索文件的工具。
|
||||
|
||||
```
|
||||
# pkgfile chromium
|
||||
```
|
||||
|
||||
### 如何在 openSUSE 中搜索一个包
|
||||
|
||||
Zypper 是 SUSE 和 openSUSE 发行版的命令行包管理器。它用于安装、更新、搜索和删除包以及管理仓库,执行各种查询等。Zypper 命令行对接到 ZYpp 系统管理库(libzypp)。
|
||||
|
||||
```
|
||||
# zypper search ftp
|
||||
or
|
||||
# zypper se ftp
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
S | Name | Summary | Type
|
||||
--+----------------+-----------------------------------------+--------
|
||||
| proftpd | Highly configurable GPL-licensed FTP -> | package
|
||||
| proftpd-devel | Development files for ProFTPD | package
|
||||
| proftpd-doc | Documentation for ProFTPD | package
|
||||
| proftpd-lang | Languages for package proftpd | package
|
||||
| proftpd-ldap | LDAP Module for ProFTPD | package
|
||||
| proftpd-mysql | MySQL Module for ProFTPD | package
|
||||
| proftpd-pgsql | PostgreSQL Module for ProFTPD | package
|
||||
| proftpd-radius | Radius Module for ProFTPD | package
|
||||
| proftpd-sqlite | SQLite Module for ProFTPD | package
|
||||
| pure-ftpd | A Lightweight, Fast, and Secure FTP S-> | package
|
||||
| vsftpd | Very Secure FTP Daemon - Written from-> | package
|
||||
```
|
||||
|
||||
### 如何使用 whohas 命令搜索一个包
|
||||
|
||||
`whohas` 命令是一个智能工具,从所有主流发行版中搜索指定包,如 Debian、Ubuntu、Gentoo、Arch、AUR、Mandriva、Fedora、Fink、FreeBSD 和 NetBSD。
|
||||
|
||||
```
|
||||
$ whohas nano
|
||||
Mandriva nano-debug 2.3.1-1mdv2010.2.x http://sophie.zarb.org/rpms/0b33dc73bca710749ad14bbc3a67e15a
|
||||
Mandriva nano-debug 2.2.4-1mdv2010.1.i http://sophie.zarb.org/rpms/d9dfb2567681e09287b27e7ac6cdbc05
|
||||
Mandriva nano-debug 2.2.4-1mdv2010.1.x http://sophie.zarb.org/rpms/3299516dbc1538cd27a876895f45aee4
|
||||
Mandriva nano 2.3.1-1mdv2010.2.x http://sophie.zarb.org/rpms/98421c894ee30a27d9bd578264625220
|
||||
Mandriva nano 2.3.1-1mdv2010.2.i http://sophie.zarb.org/rpms/cea07b5ef9aa05bac262fc7844dbd223
|
||||
Mandriva nano 2.2.4-1mdv2010.1.s http://sophie.zarb.org/rpms/d61f9341b8981e80424c39c3951067fa
|
||||
Mandriva spring-mod-nanoblobs 0.65-2mdv2010.0.sr http://sophie.zarb.org/rpms/74bb369d4cbb4c8cfe6f6028e8562460
|
||||
Mandriva nanoxml-lite 2.2.3-4.1.4mdv2010 http://sophie.zarb.org/rpms/287a4c37bc2a39c0f277b0020df47502
|
||||
Mandriva nanoxml-manual-lite 2.2.3-4.1.4mdv2010 http://sophie.zarb.org/rpms/17dc4f638e5e9964038d4d26c53cc9c6
|
||||
Mandriva nanoxml-manual 2.2.3-4.1.4mdv2010 http://sophie.zarb.org/rpms/a1b5092cd01fc8bb78a0f3ca9b90370b
|
||||
Gentoo nano 9999 http://packages.gentoo.org/package/app-editors/nano
|
||||
Gentoo nano 9999 http://packages.gentoo.org/package/app-editors/nano
|
||||
Gentoo nano 2.9.8 http://packages.gentoo.org/package/app-editors/nano
|
||||
Gentoo nano 2.9.7
|
||||
```
|
||||
|
||||
如果你希望只从当前发行版仓库中搜索指定包,使用以下格式:
|
||||
|
||||
```
|
||||
$ whohas -d Ubuntu vlc
|
||||
Ubuntu vlc 2.1.6-0ubuntu14.04 1M all http://packages.ubuntu.com/trusty/vlc
|
||||
Ubuntu vlc 2.1.6-0ubuntu14.04 1M all http://packages.ubuntu.com/trusty-updates/vlc
|
||||
Ubuntu vlc 2.2.2-5ubuntu0.16. 1M all http://packages.ubuntu.com/xenial/vlc
|
||||
Ubuntu vlc 2.2.2-5ubuntu0.16. 1M all http://packages.ubuntu.com/xenial-updates/vlc
|
||||
Ubuntu vlc 2.2.6-6 40K all http://packages.ubuntu.com/artful/vlc
|
||||
Ubuntu vlc 3.0.1-3build1 32K all http://packages.ubuntu.com/bionic/vlc
|
||||
Ubuntu vlc 3.0.2-0ubuntu0.1 32K all http://packages.ubuntu.com/bionic-updates/vlc
|
||||
Ubuntu vlc 3.0.3-1 33K all http://packages.ubuntu.com/cosmic/vlc
|
||||
Ubuntu browser-plugin-vlc 2.0.6-2 55K all http://packages.ubuntu.com/trusty/browser-plugin-vlc
|
||||
Ubuntu browser-plugin-vlc 2.0.6-4 47K all http://packages.ubuntu.com/xenial/browser-plugin-vlc
|
||||
Ubuntu browser-plugin-vlc 2.0.6-4 47K all http://packages.ubuntu.com/artful/browser-plugin-vlc
|
||||
Ubuntu browser-plugin-vlc 2.0.6-4 47K all http://packages.ubuntu.com/bionic/browser-plugin-vlc
|
||||
Ubuntu browser-plugin-vlc 2.0.6-4 47K all http://packages.ubuntu.com/cosmic/browser-plugin-vlc
|
||||
Ubuntu libvlc-bin 2.2.6-6 27K all http://packages.ubuntu.com/artful/libvlc-bin
|
||||
Ubuntu libvlc-bin 3.0.1-3build1 17K all http://packages.ubuntu.com/bionic/libvlc-bin
|
||||
Ubuntu libvlc-bin 3.0.2-0ubuntu0.1 17K all
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-search-if-a-package-is-available-on-your-linux-distribution-or-not/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/prakash/
|
||||
[1]:https://www.2daygeek.com/list-of-command-line-package-manager-for-linux/
|
||||
[2]:https://www.2daygeek.com/list-of-graphical-frontend-tool-for-linux-package-manager/
|
||||
@ -0,0 +1,267 @@
|
||||
|
||||
如何把 Google 云端硬盘当做虚拟磁盘一样挂载到 Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
[Google 云端硬盘][1] 是全球比较受欢迎的云存储平台. 直到 2017 年, 全球有超过 8 亿的活跃用户在使用它。即使用户数在持续增长,但直到现在 Google 还是没有发布一款可以在 Linux 平台使用的客户端。但这难不倒 Linux 社区。不时就有一些开发者给 Linux 操作系统带来一些客户端。下面我将会介绍三个用于 Linux 系统非官方开发的 Google 云端硬盘客户端。使用这些客户端,你能把 Google 云端硬盘像虚拟磁盘一样挂载到 Linux 系统。请继续阅读。
|
||||
|
||||
### 1、Google-drive-ocamlfuse
|
||||
|
||||
google-drive-ocamlfuse 把 Google 云端硬盘当做是一个 FUSE 类型的文件系统,它是用 OCam 语言写的。FUSE 意即<ruby>用户态文件系统<rt>Filesystem in Userspace</rt></ruby>,此项目允许非管理员用户在用户空间创建虚拟文件系统。google-drive-ocamlfuse 可以让你把 Google 云端硬盘当做磁盘一样挂载到 Linux 系统。支持对普通文件和目录的读写操作,支持对 Google dock、表单和演示稿的只读操作,支持多个 Googe 云端硬盘用户,重复文件处理,支持访问回收站等等。
|
||||
|
||||
#### 安装 google-drive-ocamlfuse
|
||||
|
||||
google-drive-ocamlfuse 能在 Arch 系统的 [AUR][2] 上直接找到,所以你可以使用 AUR 助手程序,如 [Yay][3] 来安装。
|
||||
|
||||
```
|
||||
$ yay -S google-drive-ocamlfuse
|
||||
```
|
||||
|
||||
在 Ubuntu 系统:
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:alessandro-strada/ppa
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install google-drive-ocamlfuse
|
||||
```
|
||||
|
||||
安装最新的测试版本:
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:alessandro-strada/google-drive-ocamlfuse-beta
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install google-drive-ocamlfuse
|
||||
```
|
||||
|
||||
#### 使用方法
|
||||
|
||||
安装完成后,直接在终端里面输入如下命令,就可以启动 google-drive-ocamlfuse 程序了:
|
||||
|
||||
```
|
||||
$ google-drive-ocamlfuse
|
||||
```
|
||||
|
||||
当你第一次运行该命令,程序会直接打开你的浏览器并要求你确认是否对 Google 云端硬盘的文件的操作进行授权。当你确认授权后,挂载 Google 云端硬盘所需要的配置文件和目录都会自动进行创建。
|
||||
|
||||
![][5]
|
||||
|
||||
当成功授权后,你会在终端里面看到如下的信息。
|
||||
|
||||
```
|
||||
Access token retrieved correctly.
|
||||
```
|
||||
|
||||
好了,我们可以进行下一步操作了。关闭浏览器并为我们的 Google 云端硬盘创建一个挂载点吧。
|
||||
|
||||
```
|
||||
$ mkdir ~/mygoogledrive
|
||||
|
||||
```
|
||||
|
||||
最后操作,使用如下命令挂载 Google 云端硬盘:
|
||||
|
||||
```
|
||||
$ google-drive-ocamlfuse ~/mygoogledrive
|
||||
```
|
||||
|
||||
恭喜你了!你可以使用终端或文件管理器来访问 Google 云端硬盘里面的文件了。
|
||||
|
||||
使用终端:
|
||||
|
||||
```
|
||||
$ ls ~/mygoogledrive
|
||||
```
|
||||
|
||||
使用文件管理器:
|
||||
|
||||
![][6]
|
||||
|
||||
如何你有不止一个账户,可以使用 `label` 命令对其进行区分不同的账户,就像下面一样:
|
||||
|
||||
```
|
||||
$ google-drive-ocamlfuse -label label [mountpoint]
|
||||
```
|
||||
|
||||
当操作完成后,你可以使用如下的命令卸载 Google 云端硬盘:
|
||||
|
||||
```
|
||||
$ fusermount -u ~/mygoogledrive
|
||||
```
|
||||
|
||||
获取更多信息,你可以参考 man 手册。
|
||||
|
||||
```
|
||||
$ google-drive-ocamlfuse --help
|
||||
```
|
||||
|
||||
当然你也可以看看[官方文档][7]和该项目的 [GitHub 项目][8]以获取更多内容。
|
||||
|
||||
### 2. GCSF
|
||||
|
||||
GCSF 是基于 Google 云端硬盘的 FUSE 文件系统,使用 Rust 语言编写。GCSF 得名于罗马尼亚语中的“ **G** oogle **C** onduce **S** istem de **F** ișiere”,翻译成英文就是“Google Drive Filesystem”(即 Google 云端硬盘文件系统)。使用 GCSF,你可以把 Google 云端硬盘当做虚拟磁盘一样挂载到 Linux 系统,可以通过终端和文件管理器对其进行操作。你肯定会很好奇,这到底与其它的 Google 云端硬盘 FUSE 项目有什么不同,比如 google-drive-ocamlfuse。GCSF 的开发者回应 [Reddit 上的类似评论][9]:“GCSF 意在某些方面更快(递归列举文件、从 Google 云端硬盘中读取大文件)。当文件被缓存后,在消耗更多的内存后,其缓存策略也能让读取速度更快(相对于 google-drive-ocamlfuse 4-7 倍的提升)”。
|
||||
|
||||
#### 安装 GCSF
|
||||
|
||||
GCSF 能在 [AUR][10] 上面找到,对于 Arch 用户来说直接使用 AUR 助手来安装就行了,例如[Yay][3]。
|
||||
|
||||
```
|
||||
$ yay -S gcsf-git
|
||||
```
|
||||
|
||||
对于其它的发行版,需要进行如下的操作来进行安装。
|
||||
|
||||
首先,你得确认系统中是否安装了Rust语言。
|
||||
|
||||
- [在 Linux 上安装 Rust](https://www.ostechnix.com/install-rust-programming-language-in-linux/)
|
||||
|
||||
确保 `pkg-config` 和 `fuse` 软件包是否安装了。它们在绝大多数的 Linux 发行版的默认仓库中都能找到。例如,在 Ubuntu 及其衍生版本中,你可以使用如下的命令进行安装:
|
||||
|
||||
```
|
||||
$ sudo apt-get install -y libfuse-dev pkg-config
|
||||
```
|
||||
|
||||
当所有的依赖软件安装完成后,你可以使用如下的命令来安装 GCSF:
|
||||
|
||||
```
|
||||
$ cargo install gcsf
|
||||
```
|
||||
|
||||
#### 使用方法
|
||||
|
||||
首先,我们需要对 Google 云端硬盘的操作进行授权,简单输入如下命令:
|
||||
|
||||
```
|
||||
$ gcsf login ostechnix
|
||||
```
|
||||
|
||||
你必须指定一个会话名称。请使用自己的会话名称来代 `ostechnix`。你会看到像下图的提示信息和Google 云端硬盘账户的授权验证连接。
|
||||
|
||||
![][11]
|
||||
|
||||
直接复制并用浏览器打开上述 URL,并点击 “allow” 来授权访问你的 Google 云端硬盘账户。当完成授权后,你的终端会显示如下的信息。
|
||||
|
||||
```
|
||||
Successfully logged in. Credentials saved to "/home/sk/.config/gcsf/ostechnix".
|
||||
```
|
||||
|
||||
GCSF 会把配置保存文件在 `$XDG_CONFIG_HOME/gcsf/gcsf.toml`,通常位于 `$HOME/.config/gcsf/gcsf.toml`。授权凭证也会保存在此目录当中。
|
||||
|
||||
下一步,创建一个用来挂载 Google 云端硬盘的目录。
|
||||
|
||||
```
|
||||
$ mkdir ~/mygoogledrive
|
||||
```
|
||||
|
||||
之后,修改 `/etc/fuse.conf` 文件:
|
||||
|
||||
```
|
||||
$ sudo vi /etc/fuse.conf
|
||||
```
|
||||
|
||||
注释掉以下的行,以允许非管理员用 `allow_other` 或 `allow_root` 挂载选项来挂载。
|
||||
|
||||
```
|
||||
user_allow_other
|
||||
```
|
||||
|
||||
保存并关闭文件。
|
||||
|
||||
最后一步,使用如下命令挂载 Google 云端硬盘:
|
||||
|
||||
```
|
||||
$ gcsf mount ~/mygoogledrive -s ostechnix
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
INFO gcsf > Creating and populating file system...
|
||||
INFO gcsf > File sytem created.
|
||||
INFO gcsf > Mounting to /home/sk/mygoogledrive
|
||||
INFO gcsf > Mounted to /home/sk/mygoogledrive
|
||||
INFO gcsf::gcsf::file_manager > Checking for changes and possibly applying them.
|
||||
INFO gcsf::gcsf::file_manager > Checking for changes and possibly applying them.
|
||||
```
|
||||
|
||||
重复一次,使用自己的会话名来更换 `ostechnix`。你可以使用如下的命令来查看已经存在的会话:
|
||||
|
||||
```
|
||||
$ gcsf list
|
||||
Sessions:
|
||||
- ostechnix
|
||||
```
|
||||
|
||||
你现在可以使用终端和文件管理器对 Google 云端硬盘进行操作了。
|
||||
|
||||
使用终端:
|
||||
|
||||
```
|
||||
$ ls ~/mygoogledrive
|
||||
```
|
||||
|
||||
使用文件管理器:
|
||||
|
||||
![][12]
|
||||
|
||||
如果你不知道自己把 Google 云端硬盘挂载到哪个目录了,可以使用 `df` 或者 `mount` 命令,就像下面一样。
|
||||
|
||||
```
|
||||
$ df -h
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
udev 968M 0 968M 0% /dev
|
||||
tmpfs 200M 1.6M 198M 1% /run
|
||||
/dev/sda1 20G 7.5G 12G 41% /
|
||||
tmpfs 997M 0 997M 0% /dev/shm
|
||||
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
|
||||
tmpfs 997M 0 997M 0% /sys/fs/cgroup
|
||||
tmpfs 200M 40K 200M 1% /run/user/1000
|
||||
GCSF 15G 857M 15G 6% /home/sk/mygoogledrive
|
||||
|
||||
$ mount | grep GCSF
|
||||
GCSF on /home/sk/mygoogledrive type fuse (rw,nosuid,nodev,relatime,user_id=1000,group_id=1000,allow_other)
|
||||
```
|
||||
|
||||
当操作完成后,你可以使用如下命令来卸载 Google 云端硬盘:
|
||||
|
||||
```
|
||||
$ fusermount -u ~/mygoogledrive
|
||||
```
|
||||
|
||||
浏览[GCSF GitHub 项目][13]以获取更多内容。
|
||||
|
||||
### 3、Tuxdrive
|
||||
|
||||
Tuxdrive 也是一个非官方 Linux Google 云端硬盘客户端。我们之前有写过一篇关于 Tuxdrive 比较详细的使用方法。可以查看如下链接:
|
||||
|
||||
- [Tuxdrive: 一个 Linux 下的 Google 云端硬盘客户端](https://www.ostechnix.com/tuxdrive-commandline-google-drive-client-linux/)
|
||||
|
||||
当然,之前还有过其它的非官方 Google 云端硬盘客户端,例如 Grive2、Syncdrive。但它们好像都已经停止开发了。当有更受欢迎的 Google 云端硬盘客户端出现,我会对这个列表进行持续的跟进。
|
||||
|
||||
谢谢你的阅读。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-mount-google-drive-locally-as-virtual-file-system-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[sndnvaps](https://github.com/sndnvaps)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.google.com/drive/
|
||||
[2]:https://aur.archlinux.org/packages/google-drive-ocamlfuse/
|
||||
[3]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[4]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/07/google-drive.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/07/google-drive-2.png
|
||||
[7]:https://github.com/astrada/google-drive-ocamlfuse/wiki/Configuration
|
||||
[8]:https://github.com/astrada/google-drive-ocamlfuse
|
||||
[9]:https://www.reddit.com/r/DataHoarder/comments/8vlb2v/google_drive_as_a_file_system/e1oh9q9/
|
||||
[10]:https://aur.archlinux.org/packages/gcsf-git/
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2018/07/google-drive-3.png
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2018/07/google-drive-4.png
|
||||
[13]:https://github.com/harababurel/gcsf
|
||||
@ -0,0 +1,87 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (oneforalone)
|
||||
[#]: reviewer: (acyanbird wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10510-1.html)
|
||||
[#]: subject: (Two Years With Emacs as a CEO (and now CTO))
|
||||
[#]: via: (https://www.fugue.co/blog/2018-08-09-two-years-with-emacs-as-a-cto.html)
|
||||
[#]: author: (Josh Stella https://www.fugue.co/blog/author/josh-stella)
|
||||
|
||||
作为 CEO 使用 Emacs 的两年经验之谈
|
||||
======
|
||||
|
||||
两年前,我写了一篇[博客][1],并取得了一些反响。这让我有点受宠若惊。那篇博客写的是我准备将 Emacs 作为我的主办公软件,当时我还是 CEO,现在已经是 CTO 了。现在回想起来,我发现我之前不是做程序员就是做软件架构师,而且那时我也喜欢用 Emacs 写代码。重新考虑使用 Emacs 是一次令我振奋的尝试,但我不太清楚这次行动会造成什么反响。在网上,那篇博客的评论也是褒贬不一,但是还是有数万的阅读量,所以总的来说,我写的是一个蛮有意思的题材。在 [Reddit][2] 和 [HackerNews][3] 上有些令人哭笑不得的回复,说我的手会变成鸡爪,或者说我会因白色的背景而近视。在这里我可以很高兴地回答,到目前为止并没有出现什么特别糟糕的后果,相反,我的手腕还因此变得更灵活了。还有一些人担心,说使用 Emacs 会耗费一个 CEO 的精力。把 Fugue 从一个在我家后院的灵感变成强大的产品,并有一大批忠实的顾客,我发现在做这种真正复杂之事的时候,Emacs 可以给你带来安慰。还有,我现在仍然在用白色的背景。
|
||||
|
||||
近段时间那篇博客又被翻出来了,并发到了 [HackerNews][4] 上。我收到了大量的跟帖者问我现在使用状况如何,所以我写了这篇博客来回应他们。在本文中,我还将重点讨论为什么 Emacs 和函数式编程有很高的关联性,以及我们是怎样使用 Emacs 来开发我们的产品 —— Fugue,一个使用函数式编程的自动化的云计算平台的。由于我收到了很多反馈,其众多细节和评论很有用,因此这篇博客比较长,而我确实也需要费点精力来解释我如此作为时的想法,但这篇文章的主要内容还是反映了我担任 CEO 时处理的事务。而我想在之后更频繁地用 Emacs 写代码,所以需要提前做一些准备。一如既往,本文因人而异,后果自负。
|
||||
|
||||
### 意外之喜
|
||||
|
||||
我大部分时间都在不断的处理公司内外沟通。交流是解决问题的唯一方法,但也是反思及思考困难或复杂问题的敌人。对我来说,作为创业公司的 CEO,最需要的是能专注工作而不被打扰的时间。一旦你决定投入时间来学习一些有用的命令,Emacs 就能帮助创造这种不被打扰的可贵环境。其他的应用会弹出提示,但是一个配置好了的 Emacs 可以完全不影响你 —— 无论是视觉上还是精神上。除非你想,否则的话它不会改变,况且没有比空白屏幕和漂亮的字体更干净的界面了。不断被打扰是我的日常状况,因此这种简洁让我能够专注于我在想的事情,而不是电脑本身。好的程序能够默默地操纵电脑,并且不会夺取你的注意力。
|
||||
|
||||
一些人指出,我原来的博客有太多对现代图形界面的批判和对 Emacs 的赞许。我既不赞同,也不否认。现代的界面,特别是那些以应用程序为中心的方法(相对于以内容为中心的方法),既不是以用户为中心的,也不是面向任务的。Emacs 避免了这种错误,这也是我如此喜欢它的部分原因,而它也带来了其他优点。Emacs 是带领你体会计算机魅力的传送门,一个值得跳下去的兔子洞(LCTT 译注:爱丽丝梦游仙境里的兔子洞,跳进去会有新世界)。它的核心是发现和创造属于自己的道路,对我来说这本身就是创造了。现代计算的悲哀之处在于,它很大程度上是由带有闪亮界面的黑盒组成的,这些黑盒提供的是瞬间的喜悦,而不是真正的满足感。这让我们变成了消费者,而不是技术的创造者。无论你是谁或者你的背景是什么;你都可以理解你的电脑,你可以用它创造事物。它很有趣,能令人满意,而且不是你想的那么难学!
|
||||
|
||||
我们常常低估了环境对我们心理的影响。Emacs 给人一种平静和自由的感觉,而不是紧迫感、烦恼或兴奋 —— 后者是思考和沉思的敌人。我喜欢那些持久的、不碍事的东西,当我花时间去关注它们的时候,它们会给我带来真知灼见。Emacs 满足我的所有这些标准。我每天都使用 Emacs 来工作,我也很高兴我很少需要注意到它。Emacs 确实有一个学习曲线,但不会比学自行车的学习曲线来的更陡,而且一旦你掌握了它,你会得到相应的回报,而且不必再去想它了。它赋予你一种其他工具所没有的自由感。这是一个优雅的工具,来自一个更加文明的计算时代。我很高兴我们步入了另一个文明的计算时代,我相信 Emacs 也将越来越受欢迎。
|
||||
|
||||
### 弃用 Org 模式处理日程和待办事项
|
||||
|
||||
在原来的文章中,我花了一些时间介绍如何使用 Org 模式来规划日程。不过现在我放弃了使用 Org 模式来处理待办事项一类的事物,因为我每天都有很多会议要开,很多电话要打,我也不能让其他人来适应我选的工具,而且也没有时间将事务转换或是自动移动到 Org 上。我们主要是 Mac 一族,使用谷歌日历等工具,而且原生的 Mac OS/iOS 工具可以很好的进行团队协作。我还有支老钢笔用来在会议中做笔记,因为我发现在会议中使用笔记本电脑或者说键盘记录很不礼貌,而且这也限制了我的聆听和思考。因此,我基本上放弃了用 Org 模式帮我规划日程或安排生活。当然,Org 模式对其他的方面也很有用,它是我编写文档的首选,包括本文。换句话说,我使用它的方式与其作者的想法背道而驰,但它的确做得很好。我也希望有一天也有人如此评价并使用我们的 Fugue。
|
||||
|
||||
### Emacs 已经在 Fugue 公司中扩散
|
||||
|
||||
我在上篇博客就有说,你可能会喜欢 Emacs,也可能不会。因此,当 Fugue 的文档组将 Emacs 作为标准工具时,我是有点担心的,因为我觉得他们可能是受了我的影响才做出这种选择。不过在两年后,我确信他们做出了正确的选择。文档组的组长是一个很聪明的程序员,但是另外两个编写文档的人却没有怎么接触过技术。我想,如果这是一个经理强迫员工使用错误工具的案例,我就会收到投诉要去解决它,因为 Fugue 有反威权文化,大家不怕挑战任何事和任何人。之前的组长在去年辞职了,但[文档组][5]现在有了一个灵活的集成的 CI/CD 工具链,并且文档组的人已经成为了 Emacs 的忠实用户。Emacs 有一条学习曲线,但即使在最陡的时候,也不至于多么困难,并且翻过顶峰后,对生产力和总体幸福感都得到了提升。这也提醒我们,学文科的人在技术方面和程序员一样聪明,一样能干,也许不那么容易受到技术崇拜与习俗产生的影响。
|
||||
|
||||
### 我的手腕感激我的决定
|
||||
|
||||
上世纪 80 年代中期以来,我每天花 12 个小时左右在电脑前工作,这给我的手腕(以及后背)造成了很大的损伤(因此我强烈安利 Tag Capisco 的椅子)。Emacs 和人机工程学键盘的结合让手腕的 [RSI][10](<ruby>重复性压迫损伤<rt>Repetitive Strain Injury</rt></ruby>)问题消失了,我已经一年多没有想过这种问题了。在那之前,我的手腕每天都会疼,尤其是右手。如果你也有这种问题,你就知道这疼痛很让人分心和忧虑。有几个人问过关于选购键盘和鼠标的问题,如果你也对此有兴趣,那么在过去两年里,我主要使用的是 Truly Ergonomic 键盘,不过我现在用的是[这款键盘][6]。我已经换成现在的键盘有几个星期,而且我爱死它了。大写键的形状很神奇,因为你不用看就能知道它在哪里。而人体工学的拇指键也设计的十分合理,尤其是对于 Emacs 用户而言,Control 和 Meta 是你的坚实伴侣,不要再需要用小指做高度重复的任务了!
|
||||
|
||||
我使用鼠标的次数比使用 Office 和 IDE 时要少得多,这对我的工作效率有很大帮助,但我还是需要一个鼠标。我一直在使用外观相当过时,但功能和人体工程学非常优秀的 Clearly Superior 轨迹球,恰如其名。
|
||||
|
||||
撇开具体的工具不谈,事实证明,一个很棒的键盘,再加上避免使用鼠标,在减少身体的磨损方面很有效。Emacs 是达成这方面的核心,因为我不需要在菜单上滑动鼠标来完成任务,而且导航键就在我的手指下面。我现在十分肯定,我的手离开标准打字位置会给我的肌腱造成很大的压力。不过这也因人而异,我不是医生不好下定论。
|
||||
|
||||
### 我并没有做太多配置……
|
||||
|
||||
有人说我会在界面配置上耗费很多的时间。我想验证下他们说的对不对,所以我特别留意了下。我不仅在很多程度上不用配置,关注这个问题还让我意识到,我使用的其他工具是多么的耗费我的精力和时间。Emacs 是我用过的维护成本最低的软件。Mac OS 和 Windows 一直要求我更新它,但在我看来,这远没有 Adobe 套件和 Office 的更新给我带来的困扰那么大。我只是偶尔更新 Emacs,但对我来说它也没什么变化,所以从我的个人观点而言,更新基本上是一个接近于零成本的操作,我高兴什么时候更新就什么时候更新。
|
||||
|
||||
有一点让你们失望了,因为许多人想知道我为跟上重新打造的 Emacs 社区的更新做了些什么,但是在过去的两年中,我只在配置中添加了少部分内容。我认为这也是一种成功,因为 Emacs 只是一个工具,而不是我的爱好。但即便如此,如果你想和我分享关于 Emacs 的新鲜事物,我很乐意聆听。
|
||||
|
||||
### 期望实现云端控制
|
||||
|
||||
在我们 Fugue 公司有很多 Emacs 的粉丝,所以我们有一段时间在用 [Ludwing 模式][7]。Ludwig 模式是我们用于自动化云基础设施和服务的声明式、功能性的 DSL。最近,Alex Schoof 利用在飞机上和晚上的时间来构建 fugue 模式,它在 Fugue CLI 上充当 Emacs 控制台。要是你不熟悉 Fugue,这是我们开发的一个云自动化和治理工具,它利用函数式编程为用户提供与云的 API 交互的良好体验。但它做的不止这些。fugue 模式很酷的原因有很多,它有一个不断报告云基础设施状态的缓冲区,由于我经常修改这些基础设施,这样我就可以快速看到代码的效果。Fugue 将云工作负载当成进程处理,fugue 模式非常类似于为云工作负载设计的 `top` 工具。它还允许我执行一些操作,比如创建新的设备或删除过期的东西,而且也不需要太多输入。Fugue 模式只是个雏形,但它非常方便,而我现在也经常使用它。
|
||||
|
||||
![fugue-mode-edited.gif][8]
|
||||
|
||||
### 模式及监控
|
||||
|
||||
我添加了一些模式和集成插件,但并不是真正用于工作或 CEO 职能。我喜欢在周末时写写 Haskell 和 Scheme 娱乐,所以我添加了 haskell 模式和 geiser。Emacs 很适合拥有 REPL 的语言,因为你可以在不同的窗口中运行不同的模式,包括 REPL 和 shell。geiser 和 Scheme 很配,要是你还没有用过 Scheme,那么阅读《计算机程序的构造和解释》(SICP)也不失为一种乐趣,在这个有很多货物崇拜编程(LCTT 译注:是一种计算机程序设计中的反模式,其特征为不明就里地、仪式性地使用代码或程序架构)例子的时代,阅读此书或许可以启发你。安装 MIT Scheme 和 geiser,你就会感觉有点像 lore 的符号环境。
|
||||
|
||||
这就引出了我在 2015 年的文章中没有提到的另一个话题:屏幕管理。我喜欢使用单独一个纵向模式的显示器来写作,我在家里和我的主要办公室都有这个配置。对于编程或混合使用,我喜欢我们提供给所有 Fugue 人的新型超宽显示器。对于它来说,我更喜欢将屏幕分成三列,中间是主编辑缓冲区,左边是水平分隔的 shell 和 fugue 模式缓冲区,右边是文档缓冲区或另外一、两个编辑缓冲区。这个很简单,首先按 `Ctl-x 3` 两次,然后使用 `Ctl-x =` 使窗口的宽度相等。这将提供三个相等的列,你也可以使用 `Ctl-x 2` 对分割之后的窗口再次进行水平分割。以下是我的截图。
|
||||
|
||||
![Emacs Screen Shot][9]
|
||||
|
||||
### 这将是最后一篇 CEO/Emacs 文章
|
||||
|
||||
首先是因为我现在是 Fugue 的 CTO 而并非 CEO,其次是我有好多要写的博客主题,而我现在刚好有时间。我还打算写些更深入的东西,比如说函数式编程、基础设施即代码的类型安全,以及我们即将推出的一些 Fugue 的新功能、关于 Fugue 在云上可以做什么的博文等等。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.fugue.co/blog/2018-08-09-two-years-with-emacs-as-a-cto.html
|
||||
|
||||
作者:[Josh Stella][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[oneforalone](https://github.com/oneforalone)
|
||||
校对:[acyanbird](https://github.com/acyanbird), [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.fugue.co/blog/author/josh-stella
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-10401-1.html
|
||||
[2]: https://www.reddit.com/r/emacs/comments/7efpkt/a_ceos_guide_to_emacs/
|
||||
[3]: https://news.ycombinator.com/item?id=10642088
|
||||
[4]: https://news.ycombinator.com/item?id=15753150
|
||||
[5]: https://docs.fugue.co/
|
||||
[6]: https://shop.keyboard.io/
|
||||
[7]: https://github.com/fugue/ludwig-mode
|
||||
[8]: https://www.fugue.co/hubfs/Imported_Blog_Media/fugue-mode-edited-1.gif
|
||||
[9]: https://www.fugue.co/hs-fs/hubfs/Emacs%20Screen%20Shot.png?width=929&name=Emacs%20Screen%20Shot.png
|
||||
[10]: https://baike.baidu.com/item/RSI/21509642
|
||||
@ -0,0 +1,230 @@
|
||||
Caffeinated 6.828:实验 2:内存管理
|
||||
======
|
||||
|
||||
### 简介
|
||||
|
||||
在本实验中,你将为你的操作系统写内存管理方面的代码。内存管理由两部分组成。
|
||||
|
||||
第一部分是内核的物理内存分配器,内核通过它来分配内存,以及在不需要时释放所分配的内存。分配器以<ruby>页<rt>page</rt></ruby>为单位分配内存,每个页的大小为 4096 字节。你的任务是去维护那个数据结构,它负责记录物理页的分配和释放,以及每个分配的页有多少进程共享它。本实验中你将要写出分配和释放内存页的全套代码。
|
||||
|
||||
第二个部分是虚拟内存的管理,它负责由内核和用户软件使用的虚拟内存地址到物理内存地址之间的映射。当使用内存时,x86 架构的硬件是由内存管理单元(MMU)负责执行映射操作来查阅一组页表。接下来你将要修改 JOS,以根据我们提供的特定指令去设置 MMU 的页表。
|
||||
|
||||
#### 预备知识
|
||||
|
||||
在本实验及后面的实验中,你将逐步构建你的内核。我们将会为你提供一些附加的资源。使用 Git 去获取这些资源、提交自[实验 1][1] 以来的改变(如有需要的话)、获取课程仓库的最新版本、以及在我们的实验 2 (`origin/lab2`)的基础上创建一个称为 `lab2` 的本地分支:
|
||||
|
||||
```c
|
||||
athena% cd ~/6.828/lab
|
||||
athena% add git
|
||||
athena% git pull
|
||||
Already up-to-date.
|
||||
athena% git checkout -b lab2 origin/lab2
|
||||
Branch lab2 set up to track remote branch refs/remotes/origin/lab2.
|
||||
Switched to a new branch "lab2"
|
||||
athena%
|
||||
```
|
||||
|
||||
上面的 `git checkout -b` 命令其实做了两件事情:首先它创建了一个本地分支 `lab2`,它跟踪给我们提供课程内容的远程分支 `origin/lab2` ,第二件事情是,它改变你的 `lab` 目录的内容以反映 `lab2` 分支上存储的文件的变化。Git 允许你在已存在的两个分支之间使用 `git checkout *branch-name*` 命令去切换,但是在你切换到另一个分支之前,你应该去提交那个分支上你做的任何有意义的变更。
|
||||
|
||||
现在,你需要将你在 `lab1` 分支中的改变合并到 `lab2` 分支中,命令如下:
|
||||
|
||||
```c
|
||||
athena% git merge lab1
|
||||
Merge made by recursive.
|
||||
kern/kdebug.c | 11 +++++++++--
|
||||
kern/monitor.c | 19 +++++++++++++++++++
|
||||
lib/printfmt.c | 7 +++----
|
||||
3 files changed, 31 insertions(+), 6 deletions(-)
|
||||
athena%
|
||||
```
|
||||
|
||||
在一些案例中,Git 或许并不知道如何将你的更改与新的实验任务合并(例如,你在第二个实验任务中变更了一些代码的修改)。在那种情况下,你使用 `git` 命令去合并,它会告诉你哪个文件发生了冲突,你必须首先去解决冲突(通过编辑冲突的文件),然后使用 `git commit -a` 去重新提交文件。
|
||||
|
||||
实验 2 包含如下的新源代码,后面你将逐个了解它们:
|
||||
|
||||
- `inc/memlayout.h`
|
||||
- `kern/pmap.c`
|
||||
- `kern/pmap.h`
|
||||
- `kern/kclock.h`
|
||||
- `kern/kclock.c`
|
||||
|
||||
`memlayout.h` 描述虚拟地址空间的布局,这个虚拟地址空间是通过修改 `pmap.c`、`memlayout.h` 和 `pmap.h` 所定义的 `PageInfo` 数据结构来实现的,这个数据结构用于跟踪物理内存页面是否被释放。`kclock.c` 和 `kclock.h` 维护 PC 上基于电池的时钟和 CMOS RAM 硬件,在此,BIOS 中记录了 PC 上安装的物理内存数量,以及其它的一些信息。在 `pmap.c` 中的代码需要去读取这个设备硬件,以算出在这个设备上安装了多少物理内存,但这部分代码已经为你完成了:你不需要知道 CMOS 硬件工作原理的细节。
|
||||
|
||||
特别需要注意的是 `memlayout.h` 和 `pmap.h`,因为本实验需要你去使用和理解的大部分内容都包含在这两个文件中。你或许还需要去看看 `inc/mmu.h` 这个文件,因为它也包含了本实验中用到的许多定义。
|
||||
|
||||
开始本实验之前,记得去添加 `exokernel` 以获取 QEMU 的 6.828 版本。
|
||||
|
||||
#### 实验过程
|
||||
|
||||
在你准备进行实验和写代码之前,先添加你的 `answers-lab2.txt` 文件到 Git 仓库,提交你的改变然后去运行 `make handin`。
|
||||
|
||||
```
|
||||
athena% git add answers-lab2.txt
|
||||
athena% git commit -am "my answer to lab2"
|
||||
[lab2 a823de9] my answer to lab2 4 files changed, 87 insertions(+), 10 deletions(-)
|
||||
athena% make handin
|
||||
```
|
||||
|
||||
正如前面所说的,我们将使用一个评级程序来分级你的解决方案,你可以在 `lab` 目录下运行 `make grade`,使用评级程序来测试你的内核。为了完成你的实验,你可以改变任何你需要的内核源代码和头文件。但毫无疑问的是,你不能以任何形式去改变或破坏评级代码。
|
||||
|
||||
### 第 1 部分:物理页面管理
|
||||
|
||||
操作系统必须跟踪物理内存页是否使用的状态。JOS 以“页”为最小粒度来管理 PC 的物理内存,以便于它使用 MMU 去映射和保护每个已分配的内存片段。
|
||||
|
||||
现在,你将要写内存的物理页分配器的代码。它将使用 `struct PageInfo` 对象的链表来保持对物理页的状态跟踪,每个对象都对应到一个物理内存页。在你能够编写剩下的虚拟内存实现代码之前,你需要先编写物理内存页面分配器,因为你的页表管理代码将需要去分配物理内存来存储页表。
|
||||
|
||||
> **练习 1**
|
||||
>
|
||||
> 在文件 `kern/pmap.c` 中,你需要去实现以下函数的代码(或许要按给定的顺序来实现)。
|
||||
>
|
||||
> - `boot_alloc()`
|
||||
> - `mem_init()`(只要能够调用 `check_page_free_list()` 即可)
|
||||
> - `page_init()`
|
||||
> - `page_alloc()`
|
||||
> - `page_free()`
|
||||
>
|
||||
> `check_page_free_list()` 和 `check_page_alloc()` 可以测试你的物理内存页分配器。你将需要引导 JOS 然后去看一下 `check_page_alloc()` 是否报告成功即可。如果没有报告成功,修复你的代码直到成功为止。你可以添加你自己的 `assert()` 以帮助你去验证是否符合你的预期。
|
||||
|
||||
本实验以及所有的 6.828 实验中,将要求你做一些检测工作,以便于你搞清楚它们是否按你的预期来工作。这个任务不需要详细描述你添加到 JOS 中的代码的细节。查找 JOS 源代码中你需要去修改的那部分的注释;这些注释中经常包含有技术规范和提示信息。你也可能需要去查阅 JOS 和 Intel 的技术手册、以及你的 6.004 或 6.033 课程笔记的相关部分。
|
||||
|
||||
### 第 2 部分:虚拟内存
|
||||
|
||||
在你开始动手之前,需要先熟悉 x86 内存管理架构的保护模式:即分段和页面转换。
|
||||
|
||||
> **练习 2**
|
||||
>
|
||||
> 如果你对 x86 的保护模式还不熟悉,可以查看 [Intel 80386 参考手册][2]的第 5 章和第 6 章。阅读这些章节(5.2 和 6.4)中关于页面转换和基于页面的保护。我们建议你也去了解关于段的章节;在虚拟内存和保护模式中,JOS 使用了分页、段转换、以及在 x86 上不能禁用的基于段的保护,因此你需要去理解这些基础知识。
|
||||
|
||||
#### 虚拟地址、线性地址和物理地址
|
||||
|
||||
在 x86 的专用术语中,一个<ruby>虚拟地址<rt>virtual address</rt></ruby>是由一个段选择器和在段中的偏移量组成。一个<ruby>线性地址<rt>linear address</rt></ruby>是在页面转换之前、段转换之后得到的一个地址。一个<ruby>物理地址<rt>physical address</rt></ruby>是段和页面转换之后得到的最终地址,它最终将进入你的物理内存中的硬件总线。
|
||||
|
||||

|
||||
|
||||
一个 C 指针是虚拟地址的“偏移量”部分。在 `boot/boot.S` 中我们安装了一个<ruby>全局描述符表<rt>Global Descriptor Table</rt></ruby>(GDT),它通过设置所有的段基址为 0,并且限制为 `0xffffffff` 来有效地禁用段转换。因此“段选择器”并不会生效,而线性地址总是等于虚拟地址的偏移量。在实验 3 中,为了设置权限级别,我们将与段有更多的交互。但是对于内存转换,我们将在整个 JOS 实验中忽略段,只专注于页转换。
|
||||
|
||||
回顾[实验 1][1] 中的第 3 部分,我们安装了一个简单的页表,这样内核就可以在 `0xf0100000` 链接的地址上运行,尽管它实际上是加载在 `0x00100000` 处的 ROM BIOS 的物理内存上。这个页表仅映射了 4MB 的内存。在实验中,你将要为 JOS 去设置虚拟内存布局,我们将从虚拟地址 `0xf0000000` 处开始扩展它,以映射物理内存的前 256MB,并映射许多其它区域的虚拟内存。
|
||||
|
||||
> **练习 3**
|
||||
>
|
||||
> 虽然 GDB 能够通过虚拟地址访问 QEMU 的内存,它经常用于在配置虚拟内存期间检查物理内存。在实验工具指南中复习 QEMU 的[监视器命令][3],尤其是 `xp` 命令,它可以让你去检查物理内存。要访问 QEMU 监视器,可以在终端中按 `Ctrl-a c`(相同的绑定返回到串行控制台)。
|
||||
>
|
||||
> 使用 QEMU 监视器的 `xp` 命令和 GDB 的 `x` 命令去检查相应的物理内存和虚拟内存,以确保你看到的是相同的数据。
|
||||
>
|
||||
> 我们的打过补丁的 QEMU 版本提供一个非常有用的 `info pg` 命令:它可以展示当前页表的一个具体描述,包括所有已映射的内存范围、权限、以及标志。原本的 QEMU 也提供一个 `info mem` 命令用于去展示一个概要信息,这个信息包含了已映射的虚拟内存范围和使用了什么权限。
|
||||
|
||||
在 CPU 上运行的代码,一旦处于保护模式(这是在 `boot/boot.S` 中所做的第一件事情)中,是没有办法去直接使用一个线性地址或物理地址的。所有的内存引用都被解释为虚拟地址,然后由 MMU 来转换,这意味着在 C 语言中的指针都是虚拟地址。
|
||||
|
||||
例如在物理内存分配器中,JOS 内存经常需要在不反向引用的情况下,去维护作为地址的一个很难懂的值或一个整数。有时它们是虚拟地址,而有时是物理地址。为便于在代码中证明,JOS 源文件中将它们区分为两种:类型 `uintptr_t` 表示一个难懂的虚拟地址,而类型 `physaddr_trepresents` 表示物理地址。这些类型其实不过是 32 位整数(`uint32_t`)的同义词,因此编译器不会阻止你将一个类型的数据指派为另一个类型!因为它们都是整数(而不是指针)类型,如果你想去反向引用它们,编译器将报错。
|
||||
|
||||
JOS 内核能够通过将它转换为指针类型的方式来反向引用一个 `uintptr_t` 类型。相反,内核不能反向引用一个物理地址,因为这是由 MMU 来转换所有的内存引用。如果你转换一个 `physaddr_t` 为一个指针类型,并反向引用它,你或许能够加载和存储最终结果地址(硬件将它解释为一个虚拟地址),但你并不会取得你想要的内存位置。
|
||||
|
||||
总结如下:
|
||||
|
||||
| C 类型 | 地址类型 |
|
||||
| ------------ | ------------ |
|
||||
| `T*` | 虚拟 |
|
||||
| `uintptr_t` | 虚拟 |
|
||||
| `physaddr_t` | 物理 |
|
||||
|
||||
> 问题:
|
||||
>
|
||||
> 1. 假设下面的 JOS 内核代码是正确的,那么变量 `x` 应该是什么类型?`uintptr_t` 还是 `physaddr_t` ?
|
||||
>
|
||||
> 
|
||||
>
|
||||
|
||||
JOS 内核有时需要去读取或修改它只知道其物理地址的内存。例如,添加一个映射到页表,可以要求分配物理内存去存储一个页目录,然后去初始化它们。然而,内核也和其它的软件一样,并不能跳过虚拟地址转换,内核并不能直接加载和存储物理地址。一个原因是 JOS 将重映射从虚拟地址 `0xf0000000` 处的物理地址 `0` 开始的所有的物理地址,以帮助内核去读取和写入它知道物理地址的内存。为转换一个物理地址为一个内核能够真正进行读写操作的虚拟地址,内核必须添加 `0xf0000000` 到物理地址以找到在重映射区域中相应的虚拟地址。你应该使用 `KADDR(pa)` 去做那个添加操作。
|
||||
|
||||
JOS 内核有时也需要能够通过给定的内核数据结构中存储的虚拟地址找到内存中的物理地址。内核全局变量和通过 `boot_alloc()` 分配的内存是在内核所加载的区域中,从 `0xf0000000` 处开始的这个所有物理内存映射的区域。因此,要转换这些区域中一个虚拟地址为物理地址时,内核能够只是简单地减去 `0xf0000000` 即可得到物理地址。你应该使用 `PADDR(va)` 去做那个减法操作。
|
||||
|
||||
#### 引用计数
|
||||
|
||||
在以后的实验中,你将会经常遇到多个虚拟地址(或多个环境下的地址空间中)同时映射到相同的物理页面上。你将在 `struct PageInfo` 数据结构中的 `pp_ref` 字段来记录一个每个物理页面的引用计数器。如果一个物理页面的这个计数器为 0,表示这个页面已经被释放,因为它不再被使用了。一般情况下,这个计数器应该等于所有页表中物理页面出现在 `UTOP` 之下的次数(`UTOP` 之上的映射大都是在引导时由内核设置的,并且它从不会被释放,因此不需要引用计数器)。我们也使用它去跟踪放到页目录页的指针数量,反过来就是,页目录到页表页的引用数量。
|
||||
|
||||
使用 `page_alloc` 时要注意。它返回的页面引用计数总是为 0,因此,一旦对返回页做了一些操作(比如将它插入到页表),`pp_ref` 就应该增加。有时这需要通过其它函数(比如,`page_instert`)来处理,而有时这个函数是直接调用 `page_alloc` 来做的。
|
||||
|
||||
#### 页表管理
|
||||
|
||||
现在,你将写一套管理页表的代码:去插入和删除线性地址到物理地址的映射表,并且在需要的时候去创建页表。
|
||||
|
||||
> **练习 4**
|
||||
>
|
||||
> 在文件 `kern/pmap.c` 中,你必须去实现下列函数的代码。
|
||||
>
|
||||
> - pgdir_walk()
|
||||
> - boot_map_region()
|
||||
> - page_lookup()
|
||||
> - page_remove()
|
||||
> - page_insert()
|
||||
>
|
||||
> `check_page()`,调用自 `mem_init()`,测试你的页表管理函数。在进行下一步流程之前你应该确保它成功运行。
|
||||
|
||||
### 第 3 部分:内核地址空间
|
||||
|
||||
JOS 分割处理器的 32 位线性地址空间为两部分:用户环境(进程),(我们将在实验 3 中开始加载和运行),它将控制其上的布局和低位部分的内容;而内核总是维护对高位部分的完全控制。分割线的定义是在 `inc/memlayout.h` 中通过符号 `ULIM` 来划分的,它为内核保留了大约 256MB 的虚拟地址空间。这就解释了为什么我们要在实验 1 中给内核这样的一个高位链接地址的原因:如是不这样做的话,内核的虚拟地址空间将没有足够的空间去同时映射到下面的用户空间中。
|
||||
|
||||
你可以在 `inc/memlayout.h` 中找到一个图表,它有助于你去理解 JOS 内存布局,这在本实验和后面的实验中都会用到。
|
||||
|
||||
#### 权限和故障隔离
|
||||
|
||||
由于内核和用户的内存都存在于它们各自环境的地址空间中,因此我们需要在 x86 的页表中使用权限位去允许用户代码只能访问用户所属地址空间的部分。否则,用户代码中的 bug 可能会覆写内核数据,导致系统崩溃或者发生各种莫名其妙的的故障;用户代码也可能会偷窥其它环境的私有数据。
|
||||
|
||||
对于 `ULIM` 以上部分的内存,用户环境没有任何权限,只有内核才可以读取和写入这部分内存。对于 `[UTOP,ULIM]` 地址范围,内核和用户都有相同的权限:它们可以读取但不能写入这个地址范围。这个地址范围是用于向用户环境暴露某些只读的内核数据结构。最后,低于 `UTOP` 的地址空间是为用户环境所使用的;用户环境将为访问这些内核设置权限。
|
||||
|
||||
#### 初始化内核地址空间
|
||||
|
||||
现在,你将去配置 `UTOP` 以上的地址空间:内核部分的地址空间。`inc/memlayout.h` 中展示了你将要使用的布局。我将使用函数去写相关的线性地址到物理地址的映射配置。
|
||||
|
||||
> **练习 5**
|
||||
>
|
||||
> 完成调用 `check_page()` 之后在 `mem_init()` 中缺失的代码。
|
||||
|
||||
现在,你的代码应该通过了 `check_kern_pgdir()` 和 `check_page_installed_pgdir()` 的检查。
|
||||
|
||||
> 问题:
|
||||
>
|
||||
> 1、在这个时刻,页目录中的条目(行)是什么?它们映射的址址是什么?以及它们映射到哪里了?换句话说就是,尽可能多地填写这个表:
|
||||
>
|
||||
> | 条目 | 虚拟地址基址 | 指向(逻辑上):|
|
||||
> | --- | ---------- | ------------- |
|
||||
> | 1023 | ? | 物理内存顶部 4MB 的页表 |
|
||||
> | 1022 | ? | ? |
|
||||
> | . | ? | ? |
|
||||
> | . | ? | ? |
|
||||
> | . | ? | ? |
|
||||
> | 2 | 0x00800000 | ? |
|
||||
> | 1 | 0x00400000 | ? |
|
||||
> | 0 | 0x00000000 | [参见下一问题] |
|
||||
>
|
||||
> 2、(来自课程 3) 我们将内核和用户环境放在相同的地址空间中。为什么用户程序不能去读取和写入内核的内存?有什么特殊机制保护内核内存?
|
||||
>
|
||||
> 3、这个操作系统能够支持的最大的物理内存数量是多少?为什么?
|
||||
>
|
||||
> 4、如果我们真的拥有最大数量的物理内存,有多少空间的开销用于管理内存?这个开销可以减少吗?
|
||||
>
|
||||
> 5、复习在 `kern/entry.S` 和 `kern/entrypgdir.c` 中的页表设置。一旦我们打开分页,EIP 仍是一个很小的数字(稍大于 1MB)。在什么情况下,我们转而去运行在 KERNBASE 之上的一个 EIP?当我们启用分页并开始在 KERNBASE 之上运行一个 EIP 时,是什么让我们能够一个很低的 EIP 上持续运行?为什么这种转变是必需的?
|
||||
|
||||
#### 地址空间布局的其它选择
|
||||
|
||||
在 JOS 中我们使用的地址空间布局并不是我们唯一的选择。一个操作系统可以在低位的线性地址上映射内核,而为用户进程保留线性地址的高位部分。然而,x86 内核一般并不采用这种方法,因为 x86 向后兼容模式之一(被称为“虚拟 8086 模式”)“不可改变地”在处理器使用线性地址空间的最下面部分,所以,如果内核被映射到这里是根本无法使用的。
|
||||
|
||||
虽然很困难,但是设计这样的内核是有这种可能的,即:不为处理器自身保留任何固定的线性地址或虚拟地址空间,而有效地允许用户级进程不受限制地使用整个 4GB 的虚拟地址空间 —— 同时还要在这些进程之间充分保护内核以及不同的进程之间相互受保护!
|
||||
|
||||
将内核的内存分配系统进行概括类推,以支持二次幂为单位的各种页大小,从 4KB 到一些你选择的合理的最大值。你务必要有一些方法,将较大的分配单位按需分割为一些较小的单位,以及在需要时,将多个较小的分配单位合并为一个较大的分配单位。想一想在这样的一个系统中可能会出现些什么样的问题。
|
||||
|
||||
这个实验做完了。确保你通过了所有的等级测试,并记得在 `answers-lab2.txt` 中写下你对上述问题的答案。提交你的改变(包括添加 `answers-lab2.txt` 文件),并在 `lab` 目录下输入 `make handin` 去提交你的实验。
|
||||
|
||||
------
|
||||
|
||||
via: https://sipb.mit.edu/iap/6.828/lab/lab2/
|
||||
|
||||
作者:[Mit](https://sipb.mit.edu/iap/6.828/lab/lab2/)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]: https://linux.cn/article-9740-1.html
|
||||
[2]: https://sipb.mit.edu/iap/6.828/readings/i386/toc.htm
|
||||
[3]: https://sipb.mit.edu/iap/6.828/labguide/#qemu
|
||||
@ -1,44 +1,43 @@
|
||||
2017 年 Linux 上最好的 9 个免费视频编辑软件
|
||||
Linux 上最好的 9 个免费视频编辑软件(2018)
|
||||
======
|
||||
**概要:这里介绍 Linux 上几个最好的视频编辑器,介绍他们的特性、利与弊,以及如何在你的 Linux 发行版上安装它们。**
|
||||
|
||||
![Linux 上最好的视频编辑器][1]
|
||||
|
||||
> 概要:这里介绍 Linux 上几个最好的视频编辑器,介绍它们的特性、利与弊,以及如何在你的 Linux 发行版上安装它们。
|
||||
|
||||
![Linux 上最好的视频编辑器][2]
|
||||
|
||||
我们曾经在一篇短文中讨论过[ Linux 上最好的照片管理应用][3],[Linux 上最好的代码编辑器][4]。今天我们将讨论 **Linux 上最好的视频编辑软件**。
|
||||
我们曾经在一篇短文中讨论过 [Linux 上最好的照片管理应用][3],[Linux 上最好的代码编辑器][4]。今天我们将讨论 **Linux 上最好的视频编辑软件**。
|
||||
|
||||
当谈到免费视频编辑软件,Windows Movie Maker 和 iMovie 是大部分人经常推荐的。
|
||||
|
||||
很不幸,上述两者在 GNU/Linux 上都不可用。但是不必担心,我们为你汇集了一个**最好的视频编辑器**清单。
|
||||
|
||||
## Linux 上最好的视频编辑器
|
||||
### Linux 上最好的视频编辑器
|
||||
|
||||
接下来让我们一起看看这些最好的视频编辑软件。如果你觉得文章读起来太长,这里有一个快速摘要。你可以点击链接跳转到文章的相关章节:
|
||||
接下来让我们一起看看这些最好的视频编辑软件。如果你觉得文章读起来太长,这里有一个快速摘要。
|
||||
|
||||
视频编辑器 主要用途 类型
|
||||
Kdenlive 通用视频编辑 免费开源
|
||||
OpenShot 通用视频编辑 免费开源
|
||||
Shotcut 通用视频编辑 免费开源
|
||||
Flowblade 通用视频编辑 免费开源
|
||||
Lightworks 专业级视频编辑 免费增值
|
||||
Blender 专业级三维编辑 免费开源
|
||||
Cinelerra 通用视频编辑 免费开源
|
||||
DaVinci 专业级视频处理编辑 免费增值
|
||||
VidCutter 简单视频拆分合并 免费开源
|
||||
| 视频编辑器 | 主要用途 | 类型 |
|
||||
|----------|---------|-----|
|
||||
| Kdenlive | 通用视频编辑 | 自由开源 |
|
||||
| OpenShot | 通用视频编辑 | 自由开源 |
|
||||
| Shotcut | 通用视频编辑 | 自由开源 |
|
||||
| Flowblade | 通用视频编辑 | 自由开源 |
|
||||
| Lightworks | 专业级视频编辑 | 免费增值 |
|
||||
| Blender | 专业级三维编辑 | 自由开源 |
|
||||
| Cinelerra | 通用视频编辑 | 自由开源 |
|
||||
| DaVinci | 专业级视频处理编辑 | 免费增值 |
|
||||
| VidCutter | 简单视频拆分合并 | 自由开源 |
|
||||
|
||||
### 1\. Kdenlive
|
||||
|
||||
![Kdenlive - Ubuntu 上的免费视频编辑器][1]
|
||||
### 1、 Kdenlive
|
||||
|
||||
![Kdenlive - Ubuntu 上的免费视频编辑器][5]
|
||||
[Kdenlive][6] 是 [KDE][8] 上的一个免费且[开源][7]的视频编辑软件,支持双视频监控,多轨时间线,剪辑列表,支持自定义布局,基本效果,以及基本过渡。
|
||||
|
||||
[Kdenlive][6] 是 [KDE][8] 上的一个自由且[开源][7]的视频编辑软件,支持双视频监控、多轨时间线、剪辑列表、自定义布局、基本效果,以及基本过渡效果。
|
||||
|
||||
它支持多种文件格式和多种摄像机、相机,包括低分辨率摄像机(Raw 和 AVI DV 编辑),Mpeg2,mpeg4 和 h264 AVCHD(小型相机和便携式摄像机),高分辨率摄像机文件,包括 HDV 和 AVCHD 摄像机,专业摄像机,包括 XDCAM-HD™ 流, IMX™ (D10) 流,DVCAM (D10),DVCAM,DVCPRO™,DVCPRO50™ 流以及 DNxHD™ 流。
|
||||
它支持多种文件格式和多种摄像机、相机,包括低分辨率摄像机(Raw 和 AVI DV 编辑)、mpeg2、mpeg4 和 h264 AVCHD(小型相机和便携式摄像机)、高分辨率摄像机文件(包括 HDV 和 AVCHD 摄像机)、专业摄像机(包括 XDCAM-HD™ 流、IMX™ (D10) 流、DVCAM (D10)、DVCAM、DVCPRO™、DVCPRO50™ 流以及 DNxHD™ 流)。
|
||||
|
||||
如果你正寻找 Linux 上 iMovie 的替代品,Kdenlive 会是你最好的选择。
|
||||
|
||||
#### Kdenlive 特性
|
||||
Kdenlive 特性:
|
||||
|
||||
* 多轨视频编辑
|
||||
* 多种音视频格式支持
|
||||
@ -51,50 +50,44 @@ VidCutter 简单视频拆分合并 免费开源
|
||||
* 广泛的硬件支持
|
||||
* 关键帧效果
|
||||
|
||||
|
||||
|
||||
#### 优点
|
||||
优点:
|
||||
|
||||
* 通用视频编辑器
|
||||
* 对于那些熟悉视频编辑的人来说并不太复杂
|
||||
|
||||
缺点:
|
||||
|
||||
|
||||
#### 缺点
|
||||
* 如果你想找的是极致简单的编辑软件,它可能还是令你有些困惑
|
||||
* KDE 应用程序以臃肿而臭名昭著
|
||||
|
||||
|
||||
|
||||
#### 安装 Kdenlive
|
||||
|
||||
Kdenlive 适用于所有主要的 Linux 发行版。你只需在软件中心搜索即可。[Kdenlive 网站的下载部分][9]提供了各种软件包。
|
||||
|
||||
命令行爱好者可以通过在 Debian 和基于 Ubuntu 的 Linux 发行版中运行以下命令从终端安装它:
|
||||
命令行爱好者可以通过在 Debian 和基于 Ubuntu 的 Linux 发行版中运行以下命令从终端安装它:
|
||||
|
||||
```
|
||||
sudo apt install kdenlive
|
||||
```
|
||||
|
||||
### 2\. OpenShot
|
||||
|
||||
![Openshot - ubuntu 上的免费视频编辑器][1]
|
||||
### 2、 OpenShot
|
||||
|
||||
![Openshot - ubuntu 上的免费视频编辑器][10]
|
||||
|
||||
[OpenShot][11] 是 Linux 上的另一个多用途视频编辑器。OpenShot 可以帮助你创建具有过渡和效果的视频。你还可以调整声音大小。当然,它支持大多数格式和编解码器。
|
||||
|
||||
你还可以将视频导出至 DVD,上传至 YouTube,Vimeo,Xbox 360 以及许多常见的视频格式。OpenShot 比 Kdenlive 要简单一些。因此,如果你需要界面简单的视频编辑器,OpenShot 是一个不错的选择。
|
||||
你还可以将视频导出至 DVD,上传至 YouTube、Vimeo、Xbox 360 以及许多常见的视频格式。OpenShot 比 Kdenlive 要简单一些。因此,如果你需要界面简单的视频编辑器,OpenShot 是一个不错的选择。
|
||||
|
||||
它还有个简洁的[开始使用 Openshot][12] 文档。
|
||||
|
||||
#### OpenShot 特性
|
||||
OpenShot 特性:
|
||||
|
||||
* 跨平台,可在Linux,macOS 和 Windows 上使用
|
||||
* 跨平台,可在 Linux、macOS 和 Windows 上使用
|
||||
* 支持多种视频,音频和图像格式
|
||||
* 强大的基于曲线的关键帧动画
|
||||
* 桌面集成与拖放支持
|
||||
* 不受限制的音视频轨道或图层
|
||||
* 可剪辑调整大小,缩放,修剪,捕捉,旋转和剪切
|
||||
* 可剪辑调整大小、缩放、修剪、捕捉、旋转和剪切
|
||||
* 视频转换可实时预览
|
||||
* 合成,图像层叠和水印
|
||||
* 标题模板,标题创建,子标题
|
||||
@ -107,96 +100,81 @@ sudo apt install kdenlive
|
||||
* 音频混合和编辑
|
||||
* 数字视频效果,包括亮度,伽玛,色调,灰度,色度键等
|
||||
|
||||
|
||||
|
||||
#### 优点
|
||||
优点:
|
||||
|
||||
* 用于一般视频编辑需求的通用视频编辑器
|
||||
* 可在 Windows 和 macOS 以及 Linux 上使用
|
||||
|
||||
|
||||
|
||||
#### 缺点
|
||||
缺点:
|
||||
|
||||
* 软件用起来可能很简单,但如果你对视频编辑非常陌生,那么肯定需要一个曲折学习的过程
|
||||
* 你可能仍然没有达到专业级电影制作编辑软件的水准
|
||||
|
||||
|
||||
|
||||
#### 安装 OpenShot
|
||||
|
||||
OpenShot 也可以在所有主流 Linux 发行版的软件仓库中使用。你只需在软件中心搜索即可。你也可以从[官方页面][13]中获取它。
|
||||
|
||||
在 Debian 和基于 Ubuntu 的 Linux 发行版中,我最喜欢运行以下命令来安装它:
|
||||
在 Debian 和基于 Ubuntu 的 Linux 发行版中,我最喜欢运行以下命令来安装它:
|
||||
|
||||
```
|
||||
sudo apt install openshot
|
||||
```
|
||||
|
||||
### 3\. Shotcut
|
||||
|
||||
![Shotcut Linux 视频编辑器][1]
|
||||
### 3、 Shotcut
|
||||
|
||||
![Shotcut Linux 视频编辑器][14]
|
||||
|
||||
[Shotcut][15] 是 Linux 上的另一个编辑器,可以和 Kdenlive 与 OpenShot 归为同一联盟。虽然它确实与上面讨论的其他两个软件有类似的功能,但 Shotcut 更先进的地方是支持4K视频。
|
||||
[Shotcut][15] 是 Linux 上的另一个编辑器,可以和 Kdenlive 与 OpenShot 归为同一联盟。虽然它确实与上面讨论的其他两个软件有类似的功能,但 Shotcut 更先进的地方是支持 4K 视频。
|
||||
|
||||
支持许多音频,视频格式,过渡和效果是 Shotcut 的众多功能中的一部分。它也支持外部监视器。
|
||||
支持许多音频、视频格式,过渡和效果是 Shotcut 的众多功能中的一部分。它也支持外部监视器。
|
||||
|
||||
这里有一系列视频教程让你[轻松上手 Shotcut][16]。它也可在 Windows 和 macOS 上使用,因此你也可以在其他操作系统上学习。
|
||||
|
||||
#### Shotcut 特性
|
||||
Shotcut 特性:
|
||||
|
||||
* 跨平台,可在 Linux,macOS 和 Windows 上使用
|
||||
* 跨平台,可在 Linux、macOS 和 Windows 上使用
|
||||
* 支持各种视频,音频和图像格式
|
||||
* 原生时间线编辑
|
||||
* 混合并匹配项目中的分辨率和帧速率
|
||||
* 音频滤波,混音和效果
|
||||
* 音频滤波、混音和效果
|
||||
* 视频转换和过滤
|
||||
* 具有缩略图和波形的多轨时间轴
|
||||
* 无限制撤消和重做播放列表编辑,包括历史记录视图
|
||||
* 剪辑调整大小,缩放,修剪,捕捉,旋转和剪切
|
||||
* 剪辑调整大小、缩放、修剪、捕捉、旋转和剪切
|
||||
* 使用纹波选项修剪源剪辑播放器或时间轴
|
||||
* 在额外系统显示/监视器上的外部监察
|
||||
* 硬件支持
|
||||
|
||||
|
||||
|
||||
你可以在[这里][17]阅它的更多特性。
|
||||
|
||||
#### 优点
|
||||
优点:
|
||||
|
||||
* 用于常见视频编辑需求的通用视频编辑器
|
||||
* 支持 4K 视频
|
||||
* 可在 Windows,macOS 以及 Linux 上使用
|
||||
|
||||
|
||||
|
||||
#### 缺点
|
||||
缺点:
|
||||
|
||||
* 功能太多降低了软件的易用性
|
||||
|
||||
|
||||
|
||||
#### 安装 Shotcut
|
||||
|
||||
Shotcut 以 [Snap][18] 格式提供。你可以在 Ubuntu 软件中心找到它。对于其他发行版,你可以从此[下载页面][19]获取可执行文件来安装。
|
||||
|
||||
### 4\. Flowblade
|
||||
|
||||
![Flowblade ubuntu 上的视频编辑器][1]
|
||||
### 4、 Flowblade
|
||||
|
||||
![Flowblade ubuntu 上的视频编辑器][20]
|
||||
|
||||
[Flowblade][21] 是 Linux 上的一个多轨非线性视频编辑器。与上面讨论的一样,这也是一个免费开源的软件。它具有时尚和现代化的用户界面。
|
||||
[Flowblade][21] 是 Linux 上的一个多轨非线性视频编辑器。与上面讨论的一样,这也是一个自由开源的软件。它具有时尚和现代化的用户界面。
|
||||
|
||||
用 Python 编写,它的设计初衷是快速且准确。Flowblade 专注于在 Linux 和其他免费平台上提供最佳体验。所以它没有在 Windows 和 OS X 上运行的版本。Linux 用户专享其实感觉也不错的。
|
||||
用 Python 编写,它的设计初衷是快速且准确。Flowblade 专注于在 Linux 和其他自由平台上提供最佳体验。所以它没有在 Windows 和 OS X 上运行的版本。Linux 用户专享其实感觉也不错的。
|
||||
|
||||
你也可以查看这个不错的[文档][22]来帮助你使用它的所有功能。
|
||||
|
||||
#### Flowblade 特性
|
||||
Flowblade 特性:
|
||||
|
||||
* 轻量级应用
|
||||
* 为简单的任务提供简单的界面,如拆分,合并,覆盖等
|
||||
* 为简单的任务提供简单的界面,如拆分、合并、覆盖等
|
||||
* 大量的音视频效果和过滤器
|
||||
* 支持[代理编辑][23]
|
||||
* 支持拖拽
|
||||
@ -206,39 +184,32 @@ Shotcut 以 [Snap][18] 格式提供。你可以在 Ubuntu 软件中心找到它
|
||||
* 视频转换和过滤器
|
||||
* 具有缩略图和波形的多轨时间轴
|
||||
|
||||
|
||||
|
||||
你可以在 [Flowblade 特性][24]里阅读关于它的更多信息。
|
||||
|
||||
#### 优点
|
||||
优点:
|
||||
|
||||
* 轻量
|
||||
* 适用于通用视频编辑
|
||||
|
||||
|
||||
|
||||
#### 缺点
|
||||
缺点:
|
||||
|
||||
* 不支持其他平台
|
||||
|
||||
|
||||
|
||||
#### 安装 Flowblade
|
||||
|
||||
Flowblade 应当在所有主流 Linux 发行版的软件仓库中都可以找到。你可以从软件中心安装它。也可以在[下载页面][25]查看更多信息。
|
||||
|
||||
另外,你可以在 Ubuntu 和基于 Ubuntu 的系统中使用一下命令安装 Flowblade:
|
||||
|
||||
```
|
||||
sudo apt install flowblade
|
||||
```
|
||||
|
||||
### 5\. Lightworks
|
||||
|
||||
![Lightworks 运行在 ubuntu 16.04][1]
|
||||
### 5、 Lightworks
|
||||
|
||||
![Lightworks 运行在 ubuntu 16.04][26]
|
||||
|
||||
如果你在寻找一个具有更多特性的视频编辑器,这就是你想要的。[Lightworks][27] 是一个跨平台的专业视频编辑器,可以在 Linux,Mac OS X 以及 Windows上使用。
|
||||
如果你在寻找一个具有更多特性的视频编辑器,这就是你想要的。[Lightworks][27] 是一个跨平台的专业视频编辑器,可以在 Linux、Mac OS X 以及 Windows上使用。
|
||||
|
||||
它是一款屡获殊荣的专业[非线性编辑][28](NLE)软件,支持高达 4K 的分辨率以及 SD 和 HD 格式的视频。
|
||||
|
||||
@ -249,13 +220,11 @@ Lightwokrs 有两个版本:
|
||||
* Lightworks 免费版
|
||||
* Lightworks 专业版
|
||||
|
||||
|
||||
|
||||
专业版有更多功能,比如支持更高的分辨率,支持 4K 和 蓝光视频等。
|
||||
专业版有更多功能,比如支持更高的分辨率,支持 4K 和蓝光视频等。
|
||||
|
||||
这个[页面][29]有广泛的可用文档。你也可以参考 [Lightworks 视频向导页][30]的视频。
|
||||
|
||||
#### Lightworks 特性
|
||||
Lightworks 特性:
|
||||
|
||||
* 跨平台
|
||||
* 简单直观的用户界面
|
||||
@ -267,27 +236,19 @@ Lightwokrs 有两个版本:
|
||||
* 支持拖拽
|
||||
* 各种音频和视频效果和滤镜
|
||||
|
||||
|
||||
|
||||
#### 优点
|
||||
优点:
|
||||
|
||||
* 专业,功能丰富的视频编辑器
|
||||
|
||||
|
||||
|
||||
#### 缺点
|
||||
缺点:
|
||||
|
||||
* 免费版有使用限制
|
||||
|
||||
|
||||
|
||||
#### 安装 Lightworks
|
||||
|
||||
Lightworks 为 Debian 和基于 Ubuntu 的 Linux 提供了 DEB 安装包,为基于 Fedora 的 Linux 发行版提供了RPM 安装包。你可以在[下载页面][31]找到安装包。
|
||||
|
||||
### 6\. Blender
|
||||
|
||||
![Blender 运行在 Ubuntu 16.04][1]
|
||||
### 6、 Blender
|
||||
|
||||
![Blender 运行在 Ubuntu 16.04][32]
|
||||
|
||||
@ -295,48 +256,40 @@ Lightworks 为 Debian 和基于 Ubuntu 的 Linux 提供了 DEB 安装包,为
|
||||
|
||||
虽然最初设计用于制作 3D 模型,但它也具有多种格式视频的编辑功能。
|
||||
|
||||
#### Blender 特性
|
||||
|
||||
* 实时预览,亮度波形,色度矢量显示和直方图显示
|
||||
* 音频混合,同步,擦洗和波形可视化
|
||||
* 最多32个轨道,用于添加视频,图像,音频,场景,面具和效果
|
||||
* 速度控制,调整图层,过渡,关键帧,过滤器等
|
||||
|
||||
Blender 特性:
|
||||
|
||||
* 实时预览、亮度波形、色度矢量显示和直方图显示
|
||||
* 音频混合、同步、擦洗和波形可视化
|
||||
* 最多32个轨道,用于添加视频、图像、音频、场景、面具和效果
|
||||
* 速度控制、调整图层、过渡、关键帧、过滤器等
|
||||
|
||||
你可以在[这里][34]阅读更多相关特性。
|
||||
|
||||
#### 优点
|
||||
优点:
|
||||
|
||||
* 跨平台
|
||||
* 专业级视频编辑
|
||||
|
||||
|
||||
|
||||
#### 缺点
|
||||
缺点:
|
||||
|
||||
* 复杂
|
||||
* 主要用于制作 3D 动画,不专门用于常规视频编辑
|
||||
|
||||
|
||||
|
||||
#### 安装 Blender
|
||||
|
||||
Blender 的最新版本可以从[下载页面][35]下载。
|
||||
|
||||
### 7\. Cinelerra
|
||||
|
||||
![Cinelerra Linux 上的视频编辑器][1]
|
||||
### 7、 Cinelerra
|
||||
|
||||
![Cinelerra Linux 上的视频编辑器][36]
|
||||
|
||||
[Cinelerra][37] 从 1998 年发布以来,已被下载超过500万次。它是 2003 年第一个在 64 位系统上提供非线性编辑的视频编辑器。当时它是Linux用户的首选视频编辑器,但随后一些开发人员丢弃了此项目,它也随之失去了光彩。
|
||||
[Cinelerra][37] 从 1998 年发布以来,已被下载超过 500 万次。它是 2003 年第一个在 64 位系统上提供非线性编辑的视频编辑器。当时它是 Linux 用户的首选视频编辑器,但随后一些开发人员丢弃了此项目,它也随之失去了光彩。
|
||||
|
||||
好消息是它正回到正轨并且良好地再次发展。
|
||||
|
||||
如果你想了解关于 Cinelerra 项目是如何开始的,这里有些[有趣的背景故事][38]。
|
||||
|
||||
#### Cinelerra 特性
|
||||
Cinelerra 特性:
|
||||
|
||||
* 非线性编辑
|
||||
* 支持 HD 视频
|
||||
@ -345,27 +298,20 @@ Blender 的最新版本可以从[下载页面][35]下载。
|
||||
* 不受限制的图层数量
|
||||
* 拆分窗格编辑
|
||||
|
||||
|
||||
|
||||
#### 优点
|
||||
优点:
|
||||
|
||||
* 通用视频编辑器
|
||||
|
||||
|
||||
|
||||
#### 缺点
|
||||
缺点:
|
||||
|
||||
* 不适用于新手
|
||||
* 没有可用的安装包
|
||||
|
||||
|
||||
|
||||
#### 安装 Cinelerra
|
||||
|
||||
你可以从 [SourceForge][39] 下载源码。更多相关信息请看[下载页面][40]。
|
||||
|
||||
### 8\. DaVinci Resolve
|
||||
|
||||
![DaVinci Resolve 视频编辑器][1]
|
||||
### 8、 DaVinci Resolve
|
||||
|
||||
![DaVinci Resolve 视频编辑器][41]
|
||||
|
||||
@ -375,10 +321,10 @@ DaVinci Resolve 不是常规的视频编辑器。它是一个成熟的编辑工
|
||||
|
||||
DaVinci Resolve 不开源。类似于 LightWorks,它也为 Linux 提供一个免费版本。专业版售价是 $300。
|
||||
|
||||
#### DaVinci Resolve 特性
|
||||
DaVinci Resolve 特性:
|
||||
|
||||
* 高性能播放引擎
|
||||
* 支持所有类型的编辑类型,如覆盖,插入,波纹覆盖,替换,适合填充,末尾追加
|
||||
* 支持所有类型的编辑类型,如覆盖、插入、波纹覆盖、替换、适合填充、末尾追加
|
||||
* 高级修剪
|
||||
* 音频叠加
|
||||
* Multicam Editing 可实现实时编辑来自多个摄像机的镜头
|
||||
@ -387,60 +333,48 @@ DaVinci Resolve 不开源。类似于 LightWorks,它也为 Linux 提供一个
|
||||
* 时间轴曲线编辑器
|
||||
* VFX 的非线性编辑
|
||||
|
||||
优点:
|
||||
|
||||
|
||||
#### 优点
|
||||
* 跨平台
|
||||
* 专业级视频编辑器
|
||||
|
||||
|
||||
|
||||
#### 缺点
|
||||
缺点:
|
||||
|
||||
* 不适用于通用视频编辑
|
||||
* 不开源
|
||||
* 免费版本中有些功能无法使用
|
||||
|
||||
|
||||
|
||||
#### 安装 DaVinci Resolve
|
||||
|
||||
你可以从[这个页面][42]下载 DaVinci Resolve。你需要注册,哪怕仅仅下载免费版。
|
||||
|
||||
### 9\. VidCutter
|
||||
|
||||
![VidCutter Linux 上的视频编辑器][1]
|
||||
### 9、 VidCutter
|
||||
|
||||
![VidCutter Linux 上的视频编辑器][43]
|
||||
|
||||
不像这篇文章讨论的其他视频编辑器,[VidCutter][44] 非常简单。除了分割和合并视频之外,它没有其他太多功能。但有时你正好需要 VidCutter 提供的这些功能。
|
||||
|
||||
#### VidCutter 特性
|
||||
VidCutter 特性:
|
||||
|
||||
* 适用于Linux,Windows 和 MacOS 的跨平台应用程序
|
||||
* 支持绝大多数常见视频格式,例如:AVI,MP4,MPEG 1/2,WMV,MP3,MOV,3GP,FLV 等等
|
||||
* 适用于Linux、Windows 和 MacOS 的跨平台应用程序
|
||||
* 支持绝大多数常见视频格式,例如:AVI、MP4、MPEG 1/2、WMV、MP3、MOV、3GP、FLV 等等
|
||||
* 界面简单
|
||||
* 修剪和合并视频,仅此而已
|
||||
|
||||
|
||||
|
||||
#### 优点
|
||||
|
||||
优点:
|
||||
|
||||
* 跨平台
|
||||
* 很适合做简单的视频分割和合并
|
||||
|
||||
|
||||
|
||||
#### 缺点
|
||||
缺点:
|
||||
|
||||
* 不适合用于通用视频编辑
|
||||
* 经常崩溃
|
||||
|
||||
|
||||
|
||||
#### 安装 VidCutter
|
||||
|
||||
如果你使用的是基于 Ubuntu 的 Linux 发行版,你可以使用这个官方 PPA(译者注:PPA,个人软件包档案,PersonalPackageArchives):
|
||||
如果你使用的是基于 Ubuntu 的 Linux 发行版,你可以使用这个官方 PPA(LCTT 译注:PPA,个人软件包档案,PersonalPackageArchives):
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:ozmartian/apps
|
||||
sudo apt-get update
|
||||
@ -457,17 +391,17 @@ Arch Linux 用户可以轻松的使用 AUR 安装它。对于其他 Linux 发行
|
||||
|
||||
如果你需要的不止这些,**OpenShot** 或者 **Kdenlive** 是不错的选择。他们有规格标准的系统,适用于初学者。
|
||||
|
||||
如果你拥有一台高端计算机并且需要高级功能,可以使用 **Lightworks** 或者 **DaVinci Resolve**。如果你在寻找更高级的工具用于制作 3D 作品,If you are looking for more advanced features for 3D works,**Blender** 就得到了你的支持。
|
||||
如果你拥有一台高端计算机并且需要高级功能,可以使用 **Lightworks** 或者 **DaVinci Resolve**。如果你在寻找更高级的工具用于制作 3D 作品,你肯定会支持选择 **Blender**。
|
||||
|
||||
这就是关于 **Linux 上最好的视频编辑软件**我所能表达的全部内容,像Ubuntu,Linux Mint,Elementary,以及其他 Linux 发行版。向我们分享你最喜欢的视频编辑器。
|
||||
这就是在 Ubuntu、Linux Mint、Elementary,以及其它发行版等 **Linux 上最好的视频编辑软件**的全部内容。向我们分享你最喜欢的视频编辑器。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-video-editing-software-linux/
|
||||
|
||||
作者:[It'S Foss Team][a]
|
||||
作者:[itsfoss][a]
|
||||
译者:[fuowang](https://github.com/fuowang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,80 @@
|
||||
让决策更透明的三步
|
||||
======
|
||||
|
||||
> 当您使用这种决策技巧时,可以使你作为一个开源领导人做出决策时更透明。
|
||||
|
||||

|
||||
|
||||
要让你的领导工作更加透明,其中一个最有效的方法就是将一个现有的流程开放给你的团队进行反馈,然后根据反馈去改变流程。下面这些练习能让透明度更加切实,并且它有助于让你在持续评估并调整你的工作的透明度时形成“肌肉记忆”。
|
||||
|
||||
我想说,你可以通过任何流程来完成这项工作 —— 即使有些流程看起来像是“禁区”流程,比如晋升或者调薪。但是如果第一次它对于初步实践来说太大了,那么你可能需要从一个不那么敏感的流程开始,比如旅行批准流程或者为你的团队寻找空缺候选人的系统。(举个例子,我在我们的招聘和晋升流程中使用了这种方式)
|
||||
|
||||
开放流程并使其更加透明可以建立你的信誉并增强团队成员对你的信任。它会使你以一种可能超乎你设想和舒适程度的方式“走在透明的路上”。以这种方式工作确实会产生额外的工作,尤其是在过程的开始阶段 —— 但是,最终这种方法对于让管理者(比如我)对团队成员更具责任,而且它会更加相容。
|
||||
|
||||
### 阶段一:选择一个流程
|
||||
|
||||
**第一步** 想想你的团队使用的一个普通的或常规的流程,但是这个流程通常不需要仔细检查。下面有一些例子:
|
||||
|
||||
* 招聘:如何创建职位描述、如何挑选面试团队、如何筛选候选人以及如何做出最终的招聘决定。
|
||||
* 规划:你的团队或组织如何确定年度或季度目标。
|
||||
* 升职:你如何选择并考虑升职候选人,并决定谁升职。
|
||||
* 经理绩效评估:谁有机会就经理绩效提供反馈,以及他们是如何反馈。
|
||||
* 旅游:旅游预算如何分配,以及你如何决定是否批准旅行(或提名某人是否旅行)。
|
||||
|
||||
上面的某个例子可能会引起你的共鸣,或者你可能会发现一些你觉得更合适的流程。也许你已经收到了关于某个特定流程的问题,又或者你发现自己屡次解释某个特定决策的逻辑依据。选择一些你能够控制或影响的东西 —— 一些你认为你的成员所关心的东西。
|
||||
|
||||
**第二步** 现在回答以下关于这个流程的问题:
|
||||
|
||||
* 该流程目前是否记录在一个所有成员都知道并可以访问的地方?如果没有,现在就开始创建文档(不必太详细;只需要解释这个流程的不同步骤以及它是如何工作的)。你可能会发现这个过程不够清晰或一致,无法记录到文档。在这种情况下,用你*认为*理想情况下所应该的方式去记录它。
|
||||
* 完成流程的文档是否说明了在不同的点上是如何做出决定?例如,在旅行批准流程中,它是否解释了如何批准或拒绝请求。
|
||||
* 流程的*输入信息*是什么?例如,在确定部门年度目标时,哪些数据用于关键绩效指标,查找或者采纳谁的反馈,谁有机会审查或“签字”。
|
||||
* 这个过程会做出什么*假设*?例如,在升职决策中,你是否认为所有的晋升候选人都会在适当的时间被他们的经理提出。
|
||||
* 流程的*输出物*是什么?例如,在评估经理的绩效时,评估的结果是否会与经理共享,该审查报告的任何方面是否会与经理的直接报告更广泛地共享(例如,改进的领域)?
|
||||
|
||||
回答上述问题时,避免作出判断。如果这个流程不能清楚地解释一个决定是如何做出的,那也可以接受。这些问题只是评估现状的一个机会。
|
||||
|
||||
接下来,修改流程的文档,直到你对它充分说明了流程并预测潜在的问题感到满意。
|
||||
|
||||
### 阶段二:收集反馈
|
||||
|
||||
下一个阶段涉及到与你的成员分享这个流程并要求反馈。分享说起来容易做起来难。
|
||||
|
||||
**第一步** 鼓励人们提供反馈。考虑一下实现此目的的各种机制:
|
||||
|
||||
* 把这个流程公布在人们可以在内部找到的地方,并提示他们可以在哪里发表评论或提供反馈。谷歌文档可以很好地评论特定的文本或直接提议文本中的更改。
|
||||
* 通过电子邮件分享过程文档,邀请反馈。
|
||||
* 提及流程文档,在团队会议或一对一的谈话时要求反馈。
|
||||
* 给人们一个他们可以提供反馈的时间窗口,并在此窗口内定期发送提醒。
|
||||
|
||||
如果你得不到太多的反馈,不要认为沉默就等于认可。你可以试着直接询问人们,他们为什么没有反馈。是因为他们太忙了吗?这个过程对他们来说不像你想的那么重要吗?你清楚地表达了你的要求吗?
|
||||
|
||||
**第二步** 迭代。当你获得关于流程的反馈时,鼓励团队对流程进行修改和迭代。加入改进的想法和建议,并要求确认预期的反馈已经被应用。如果你不同意某个建议,那就接受讨论,问问自己为什么不同意,以及一种方法和另一种方法的优点是什么。
|
||||
|
||||
设置一个收集反馈和迭代的时间窗口有助于向前推进。一旦收集和审查了反馈,你应当讨论和应用它,并且发布最终的流程供团队审查。
|
||||
|
||||
### 阶段三:实现
|
||||
|
||||
实现一个流程通常是计划中最困难的阶段。但如果你在修改过程中考虑了反馈意见,人们应该已经预料到了,并且可能会更支持你。从上面迭代过程中获得的文档是一个很好的工具,可以让你对实现负责。
|
||||
|
||||
**第一步** 审查实施需求。许多可以从提高透明度中获益的流程只需要做一点不同的事情,但是你确实需要检查你是否需要其他支持(例如工具)。
|
||||
|
||||
**第二步** 设置实现的时间表。与成员一起回顾时间表,这样他们就知道会发生什么。如果新流程需要对其他流程进行更改,请确保为人们提供足够的时间去适应新方式,并提供沟通和提醒。
|
||||
|
||||
**第三步** 跟进。在使用该流程 3-6 个月后,与你的成员联系,看看进展如何。新流程是否更加透明、更有效、更可预测?你有什么经验教训可以用来进一步改进这个流程吗?
|
||||
|
||||
### 关于作者
|
||||
|
||||
Sam Knuth —— 我有幸在 Red Hat 领导客户内容服务团队;我们生成提供给我们的客户的所有文档。我们的目标是为客户提供他们在企业中使用开源技术取得成功所需要的洞察力。在 Twitter 上与我联系([@samfw][1])。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/17/9/exercise-in-transparent-decisions
|
||||
|
||||
作者:[Sam Knuth][a]
|
||||
译者:[MarineFish](https://github.com/MarineFish)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/samfw
|
||||
[1]: https://twitter.com/samfw
|
||||
@ -0,0 +1,260 @@
|
||||
在 Ubuntu 和 Debian 上启用双因子身份验证的三种备选方案
|
||||
=====
|
||||
|
||||
> 如何为你的 SSH 服务器安装三种不同的双因子身份验证方案。
|
||||
|
||||
如今,安全比以往更加重要,保护 SSH 服务器是作为系统管理员可以做的最为重要的事情之一。传统地,这意味着禁用密码身份验证而改用 SSH 密钥。无疑这是你首先应该做的,但这并不意味着 SSH 无法变得更加安全。
|
||||
|
||||
双因子身份验证就是指需要两种身份验证才能登录。可以是密码和 SSH 密钥,也可以是密钥和第三方服务,比如 Google。这意味着单个验证方法的泄露不会危及服务器。
|
||||
|
||||
以下指南是为 SSH 启用双因子验证的三种方式。
|
||||
|
||||
当你修改 SSH 配置时,总是要确保有一个连接到服务器的第二终端。第二终端意味着你可以修复你在 SSH 配置中犯的任何错误。打开的终端将一直保持,即便 SSH 服务重启。
|
||||
|
||||
### SSH 密钥和密码
|
||||
|
||||
SSH 支持对登录要求不止一个身份验证方法。
|
||||
|
||||
在 `/etc/sh/sshd_config` 中的 SSH 服务器配置文件中的 `AuthenticationMethods` 选项中设置了身份验证方法。
|
||||
|
||||
当在 `/etc/ssh/sshd_config` 中添加下一行时,SSH 需要提交一个 SSH 密钥,然后提示输入密码:
|
||||
|
||||
```
|
||||
AuthenticationMethods "publickey,password"
|
||||
```
|
||||
|
||||
如果你想要根据使用情况设置这些方法,那么请使用以下附加配置:
|
||||
|
||||
```
|
||||
Match User jsmith
|
||||
AuthenticationMethods "publickey,password"
|
||||
```
|
||||
|
||||
当你已经编辑或保存了新的 `sshd_config` 文件,你应该通过运行以下程序来确保你没有犯任何错误:
|
||||
|
||||
```
|
||||
sshd -t
|
||||
```
|
||||
|
||||
任何导致 SSH 不能启动的语法或其他错误都将在这里标记出来。当 `ssh-t` 运行时没有错误,使用 `systemctl` 重新启动 SSH:
|
||||
|
||||
```
|
||||
systemctl restart sshd
|
||||
```
|
||||
|
||||
现在,你可以使用新终端登录,以核实你会被提示输入密码并需要 SSH 密钥。如果你用 `ssh-v`,例如:
|
||||
|
||||
```
|
||||
ssh -v jsmith@example.com
|
||||
```
|
||||
|
||||
你将可以看到登录的每一步。
|
||||
|
||||
注意,如果你确实将密码设置成必需的身份验证方法,你要确保将 `PasswordAuthentication` 选项设置成 `yes`。
|
||||
|
||||
### 使用 Google Authenticator 的 SSH
|
||||
|
||||
Google 在 Google 自己的产品上使用的双因子身份验证系统可以集成到你的 SSH 服务器中。如果你已经使用了Google Authenticator,那么此方法将非常方便。
|
||||
|
||||
虽然 libpam-google-authenticator 是由 Google 编写的,但它是[开源][1]的。此外,Google Authenticator 是由 Google 编写的,但并不需要 Google 帐户才能工作。多亏了 [Sitaram Chamarty][2] 的贡献。
|
||||
|
||||
如果你还没有在手机上安装和配置 Google Authenticator,请参阅 [这里][3]的说明。
|
||||
|
||||
首先,我们需要在服务器上安装 Google Authenticatior 安装包。以下命令将更新你的系统并安装所需的软件包:
|
||||
|
||||
```
|
||||
apt-get update
|
||||
apt-get upgrade
|
||||
apt-get install libpam-google-authenticator
|
||||
```
|
||||
|
||||
现在,我们需要在你的手机上使用 Google Authenticatior APP 注册服务器。这是通过首先运行我们刚刚安装的程序完成的:
|
||||
|
||||
```
|
||||
google-authenticator
|
||||
```
|
||||
|
||||
运行这个程序时,会问到几个问题。你应该以适合你的设置的方式回答,然而,最安全的选项是对每个问题回答 `y`。如果以后需要更改这些选项,您可以简单地重新运行 `google-authenticator` 并选择不同的选项。
|
||||
|
||||
当你运行 `google-authenticator` 时,一个二维码会被打印到终端上,有些代码看起来像这样:
|
||||
|
||||
```
|
||||
Your new secret key is: VMFY27TYDFRDNKFY
|
||||
Your verification code is 259652
|
||||
Your emergency scratch codes are:
|
||||
96915246
|
||||
70222983
|
||||
31822707
|
||||
25181286
|
||||
28919992
|
||||
```
|
||||
|
||||
你应该将所有这些代码记录到一个像密码管理器一样安全的位置。“scratch codes” 是单一的使用代码,即使你的手机不可用,它总是允许你访问。
|
||||
|
||||
要将服务器注册到 Authenticator APP 中,只需打开应用程序并点击右下角的红色加号即可。然后选择扫描条码选项,扫描打印到终端的二维码。你的服务器和应用程序现在连接。
|
||||
|
||||
回到服务器上,我们现在需要编辑用于 SSH 的 PAM (可插入身份验证模块),以便它使用我们刚刚安装的身份验证器安装包。PAM 是独立系统,负责 Linux 服务器上的大多数身份验证。
|
||||
|
||||
需要修改的 SSH PAM 文件位于 `/etc/pam.d/sshd` ,用以下命令编辑:
|
||||
|
||||
```
|
||||
nano /etc/pam.d/sshd
|
||||
```
|
||||
|
||||
在文件顶部添加以下行:
|
||||
|
||||
```
|
||||
auth required pam_google_authenticator.so
|
||||
```
|
||||
|
||||
此外,我们还需要注释掉一行,这样 PAM 就不会提示输入密码。改变这行:
|
||||
|
||||
```
|
||||
# Standard Un*x authentication.
|
||||
@include common-auth
|
||||
```
|
||||
|
||||
为如下:
|
||||
|
||||
```
|
||||
# Standard Un*x authentication.
|
||||
# @include common-auth
|
||||
```
|
||||
|
||||
接下来,我们需要编辑 SSH 服务器配置文件:
|
||||
|
||||
```
|
||||
nano /etc/ssh/sshd_config
|
||||
```
|
||||
|
||||
改变这一行:
|
||||
|
||||
```
|
||||
ChallengeResponseAuthentication no
|
||||
```
|
||||
|
||||
为:
|
||||
|
||||
```
|
||||
ChallengeResponseAuthentication yes
|
||||
```
|
||||
|
||||
接下来,添加以下代码行来启用两个身份验证方案:SSH 密钥和谷歌认证器(键盘交互):
|
||||
|
||||
```
|
||||
AuthenticationMethods "publickey,keyboard-interactive"
|
||||
```
|
||||
|
||||
在重新加载 SSH 服务器之前,最好检查一下在配置中没有出现任何错误。执行以下命令:
|
||||
|
||||
```
|
||||
sshd -t
|
||||
```
|
||||
|
||||
如果没有标识出任何错误,用新的配置重载 SSH:
|
||||
|
||||
```
|
||||
systemctl reload sshd.service
|
||||
```
|
||||
|
||||
现在一切都应该开始工作了。现在,当你登录到你的服务器时,你将需要使用 SSH 密钥,并且当你被提示输入:
|
||||
|
||||
```
|
||||
Verification code:
|
||||
```
|
||||
|
||||
打开 Authenticator APP 并输入为您的服务器显示的 6 位代码。
|
||||
|
||||
### Authy
|
||||
|
||||
[Authy][4] 是一个双重身份验证服务,与 Google 一样,它提供基于时间的代码。然而,Authy 不需要手机,因为它提供桌面和平板客户端。它们还支持离线身份验证,不需要 Google 帐户。
|
||||
|
||||
你需要从应用程序商店安装 Authy 应用程序,或 Authy [下载页面][5]所链接的桌面客户端。
|
||||
|
||||
安装完应用程序后,需要在服务器上使用 API 密钥。这个过程需要几个步骤:
|
||||
|
||||
1. 在[这里][6]注册一个账户。
|
||||
2. 向下滚动到 “Authy” 部分。
|
||||
3. 在帐户上启用双因子认证(2FA)。
|
||||
4. 回 “Authy” 部分。
|
||||
5. 为你的服务器创建一个新的应用程序。
|
||||
6. 从新应用程序的 “General Settings” 页面顶部获取 API 密钥。你需要 “PRODUCTION API KEY”旁边的眼睛符号来显示密钥。如图:
|
||||
|
||||

|
||||
|
||||
在某个安全的地方记下 API 密钥。
|
||||
|
||||
现在,回到服务器,以 root 身份运行以下命令:
|
||||
|
||||
```
|
||||
curl -O 'https://raw.githubusercontent.com/authy/authy-ssh/master/authy-ssh'
|
||||
bash authy-ssh install /usr/local/bin
|
||||
```
|
||||
|
||||
当提示时输入 API 键。如果输入错误,你始终可以编辑 `/usr/local/bin/authy-ssh` 再添加一次。
|
||||
|
||||
Authy 现已安装。但是,在为用户启用它之前,它不会开始工作。启用 Authy 的命令有以下形式:
|
||||
|
||||
```
|
||||
/usr/local/bin/authy-ssh enable <system-user> <your-email> <your-phone-country-code> <your-phone-number>
|
||||
```
|
||||
|
||||
root 登录的一些示例细节:
|
||||
|
||||
```
|
||||
/usr/local/bin/authy-ssh enable root john@example.com 44 20822536476
|
||||
```
|
||||
|
||||
如果一切顺利,你会看到:
|
||||
|
||||
```
|
||||
User was registered
|
||||
```
|
||||
|
||||
现在可以通过运行以下命令来测试 Authy:
|
||||
|
||||
```
|
||||
authy-ssh test
|
||||
```
|
||||
|
||||
最后,重载 SSH 实现新的配置:
|
||||
|
||||
```
|
||||
systemctl reload sshd.service
|
||||
```
|
||||
|
||||
Authy 现在正在工作,SSH 需要它才能登录。
|
||||
|
||||
现在,当你登录时,你将看到以下提示:
|
||||
|
||||
```
|
||||
Authy Token (type 'sms' to request a SMS token):
|
||||
```
|
||||
|
||||
你可以输入手机或桌面客户端的 Authy APP 上的代码。或者你可以输入 `sms`, Authy 会给你发送一条带有登录码的短信。
|
||||
|
||||
可以通过运行以下命令卸载 Authy:
|
||||
|
||||
```
|
||||
/usr/local/bin/authy-ssh uninstall
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://bash-prompt.net/guides/ssh-2fa/
|
||||
|
||||
作者:[Elliot Cooper][a]
|
||||
译者:[cielllll](https://github.com/cielllll)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://bash-prompt.net
|
||||
[1]:https://github.com/google/google-authenticator-libpam
|
||||
[2]:https://plus.google.com/115609618223925128756
|
||||
[3]:https://support.google.com/accounts/answer/1066447?hl=en
|
||||
[4]:https://authy.com/
|
||||
[5]:https://authy.com/download/
|
||||
[6]:https://www.authy.com/signup
|
||||
[7]:/images/guides/2FA/twilio-authy-api.png
|
||||
|
||||
@ -0,0 +1,65 @@
|
||||
使用 SonarQube 追踪代码问题
|
||||
======
|
||||
> 通过不断分析代码以了解潜在的质量问题,开源的 SonarQube 项目支持了 DevOps 的“尽早发布和经常发布” 的思维模式。
|
||||
|
||||

|
||||
|
||||
越来越多的组织正在实施 [DevOps][1] 以便在通过中间开发和测试环境以后更快更好的将新代码引入到生产环境。虽然版本控制、持续集成和部署以及自动化测试都属于 DevOps 的范畴,但仍然存在一个关键问题:组织如何量化代码质量,而不仅仅是部署的速度?
|
||||
|
||||
[SonarQube][2] 是用来填补这个空隙的一种选择。它是一个开源平台,通过代码的自动化静态分析不断的检查代码质量。 SonarQube 支持 20 多种语言的分析,并在各种类型的项目中输出和存储问题。
|
||||
|
||||
SonarQube 同时也提供了一个可同时维护和管理不同项目、不同代码的集中的环境。可以为每个项目定制规则。持续的检查和分析代码的健康轨迹。
|
||||
|
||||
SonarQube 还可以集成到可持续集成和开发(CI/CD)流程中,协助和自动确定代码是否为生产环境做好了准备的过程。
|
||||
|
||||
### 它可以衡量什么
|
||||
|
||||
开箱即用,SonarQube 可以测量的关键指标,包括代码错误、<ruby>代码异味<rt>code smells</rt></ruby>、安全漏洞和重复的代码。
|
||||
|
||||
* **代码错误** 是代码中的一部分不正确或无法正常运行、可能会导致错误的结果,是指那些在代码发布到生产环境之前应该被修复的明显的错误。
|
||||
* [代码异味][3] 不同于代码错误,被检测到的代码是可能能正确执行并符合预期。然而,它不容易被修复,也不能被单元测试覆盖,却可能会导致一些未知的错误,或是一些其它的问题。从长期的可维护性来讲,立即修复代码异味是明智之举。通常在编写代码的时候,代码异味并不容易被发现,而 SonarQube 的静态分析是一种发现它们的很好的方式。
|
||||
* **安全漏洞** 正如听起来的一样:指的是现在的代码中可能存在的安全问题的缺陷。这些缺陷应该立即修复来防止黑客利用它们。
|
||||
* **重复的代码** 也和听起来的一样:指的是源代码中重复的部分。代码重复在软件设计中是一种很不好的做法。总的来说,如果对一部分代码进行更改而另一部分没有,则会导致一些维护性的问题。例如,识别重复的代码可以很容易的将重复的代码打包成一个库来重复的使用。
|
||||
|
||||
### 可自定义的选项
|
||||
|
||||
因为它是开源的,所以 SonarQube 鼓励用户开发和提供可定制的选项。目前有超过 60 个[插件][4] 可用于增强 SonarQube 开箱即用的分析功能。
|
||||
|
||||
大多数的插件是为了增加 SonarQube 可以分析的编程语言的数量。另一些插件可以分析一些额外的指标甚至包括一些显示的仪表盘视图。实际上,如果组织需要检查一些自定义指标,或是想要在自己的仪表盘和以特定的方式查看分析数据,或使用 SonarQube 不支持的编程语言,则可能存在一些自定义的选项可以使用。如果你想要的功能并不支持,SonarQube 源码的开放也为你自己开发新的功能提供了可能性。
|
||||
|
||||
用户还可以定制适用于每种特定编程语言分析器的规则。通过 SonarQube 用户界面,可以按语言和按项目选择和取消规则。这些为特定的项目指定的规则,可以很好的在一个集中的位置维护所有的数据和配置。
|
||||
|
||||
### 为什么它那么重要
|
||||
|
||||
SonarQube 为组织提供了一个集中的位置来管理和跟踪多个项目代码中的问题。它还可以把持续的检查与质量门限相结合。一旦项目分析过一次以后,更进一步的分析会参考软件最新的修改来更新原始的统计信息,以反映最新的变化。这些跟踪可以让用户看到问题解决的程度和速度。这与 “尽早发布并经常发布”不谋而合。
|
||||
|
||||
另外,SonarQube 可使用 [可持续集成流程][5],比如像 [Hudson][6] 和 [Jenkins][7] 这样的工具。这个质量门限可以很好的反映代码的整体运行状况,并且通过 Jenkins 等集成工具,在发布代码到生产环境时担任一个重要的角色。
|
||||
|
||||
本着 DevOps 的精神, SonarQube 可以量化代码质量,来达到组织内部的要求。为了加快代码生产和发布的周期,组织必须意识到它们自己的技术债务和软件问题。通过发现这些信息, SonarQube 可以帮助组织更快的生成高质量的软件。
|
||||
|
||||
### 想要了解更多吗?
|
||||
|
||||
SonarQube 基于 GUN 通用公共许可证发布,它的源码可以在 [GitHub][8] 上查看。越来越多的用户对 SonarQube 的特性和功能感兴趣。 [Twitter][9] 和 [Google][10] 上有活跃的社区。这些社区以及 [SonarQube 博客][11] 对任何有兴趣开始和使用 SonarQube 的人有很有帮助。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/sonarqube
|
||||
|
||||
作者:[Sophie Polson][a]
|
||||
译者:[Jamkr](https://github.com/Jamkr)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/sophiepolson
|
||||
[1]:https://en.wikipedia.org/wiki/DevOps
|
||||
[2]:https://www.sonarqube.org/
|
||||
[3]:https://en.wikipedia.org/wiki/Code_smell
|
||||
[4]:https://docs.sonarqube.org/display/PLUG/Plugin+Library
|
||||
[5]:https://jenkins.io/blog/2017/04/18/continuousdelivery-devops-sonarqube/
|
||||
[6]:https://en.wikipedia.org/wiki/Hudson_(software)
|
||||
[7]:https://en.wikipedia.org/wiki/Jenkins_(software)
|
||||
[8]:https://github.com/SonarSource/sonarqube
|
||||
[9]:https://twitter.com/SonarQube
|
||||
[10]:https://groups.google.com/forum/#!forum/sonarqube
|
||||
[11]:https://blog.sonarsource.com/
|
||||
@ -0,0 +1,212 @@
|
||||
Bash 脚本中如何使用 here 文档将数据写入文件
|
||||
======
|
||||
|
||||
<ruby>here 文档<rt>here document</rt></ruby> (LCTT 译注:here 文档又称作 heredoc )不是什么特殊的东西,只是一种 I/O 重定向方式,它告诉 bash shell 从当前源读取输入,直到读取到只有分隔符的行。
|
||||
|
||||
![redirect output of here document to a text file][1]
|
||||
|
||||
这对于向 ftp、cat、echo、ssh 和许多其他有用的 Linux/Unix 命令提供指令很有用。 此功能适用于 bash 也适用于 Bourne、Korn、POSIX 这三种 shell。
|
||||
|
||||
### here 文档语法
|
||||
|
||||
语法是:
|
||||
|
||||
```
|
||||
command <<EOF
|
||||
cmd1
|
||||
cmd2 arg1
|
||||
EOF
|
||||
```
|
||||
|
||||
或者允许 shell 脚本中的 here 文档使用 `EOF<<-` 以自然的方式缩进:
|
||||
|
||||
```
|
||||
command <<-EOF
|
||||
msg1
|
||||
msg2
|
||||
$var on line
|
||||
EOF
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
```
|
||||
command <<'EOF'
|
||||
cmd1
|
||||
cmd2 arg1
|
||||
$var won't expand as parameter substitution turned off
|
||||
by single quoting
|
||||
EOF
|
||||
```
|
||||
|
||||
或者 **重定向并将其覆盖** 到名为 `my_output_file.txt` 的文件中:
|
||||
|
||||
```
|
||||
command <<EOF > my_output_file.txt
|
||||
mesg1
|
||||
msg2
|
||||
msg3
|
||||
$var on $foo
|
||||
EOF
|
||||
```
|
||||
|
||||
或**重定向并将其追加**到名为 `my_output_file.txt` 的文件中:
|
||||
|
||||
```
|
||||
command <<EOF >> my_output_file.txt
|
||||
mesg1
|
||||
msg2
|
||||
msg3
|
||||
$var on $foo
|
||||
EOF
|
||||
```
|
||||
|
||||
### 示例
|
||||
|
||||
以下脚本将所需内容写入名为 `/tmp/output.txt` 的文件中:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
OUT=/tmp/output.txt
|
||||
|
||||
echo "Starting my script..."
|
||||
echo "Doing something..."
|
||||
|
||||
cat <<EOF >$OUT
|
||||
Status of backup as on $(date)
|
||||
Backing up files $HOME and /etc/
|
||||
EOF
|
||||
|
||||
echo "Starting backup using rsync..."
|
||||
```
|
||||
|
||||
你可以使用[cat命令][3]查看/tmp/output.txt文件:
|
||||
|
||||
```
|
||||
$ cat /tmp/output.txt
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Status of backup as on Thu Nov 16 17:00:21 IST 2017
|
||||
Backing up files /home/vivek and /etc/
|
||||
```
|
||||
|
||||
### 禁用路径名/参数/变量扩展、命令替换、算术扩展
|
||||
|
||||
像 `$HOME` 这类变量和像 `$(date)` 这类命令在脚本中会被解释为替换。 要禁用它,请使用带有 `'EOF'` 这样带有单引号的形式,如下所示:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
OUT=/tmp/output.txt
|
||||
|
||||
echo "Starting my script..."
|
||||
echo "Doing something..."
|
||||
# No parameter and variable expansion, command substitution, arithmetic expansion, or pathname expansion is performed on word.
|
||||
# If any part of word is quoted, the delimiter is the result of quote removal on word, and the lines in the here-document
|
||||
# are not expanded. So EOF is quoted as follows
|
||||
cat <<'EOF' >$OUT
|
||||
Status of backup as on $(date)
|
||||
Backing up files $HOME and /etc/
|
||||
EOF
|
||||
|
||||
echo "Starting backup using rsync..."
|
||||
```
|
||||
|
||||
你可以使用 [cat 命令][3]查看 `/tmp/output.txt` 文件:
|
||||
|
||||
```
|
||||
$ cat /tmp/output.txt
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Status of backup as on $(date)
|
||||
Backing up files $HOME and /etc/
|
||||
|
||||
```
|
||||
|
||||
### 关于 tee 命令的使用
|
||||
|
||||
语法是:
|
||||
|
||||
```
|
||||
tee /tmp/filename <<EOF >/dev/null
|
||||
line 1
|
||||
line 2
|
||||
line 3
|
||||
$(cmd)
|
||||
$var on $foo
|
||||
EOF
|
||||
```
|
||||
|
||||
或者通过在单引号中引用 `EOF` 来禁用变量替换和命令替换:
|
||||
|
||||
```
|
||||
tee /tmp/filename <<'EOF' >/dev/null
|
||||
line 1
|
||||
line 2
|
||||
line 3
|
||||
$(cmd)
|
||||
$var on $foo
|
||||
EOF
|
||||
```
|
||||
|
||||
这是我更新的脚本:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
OUT=/tmp/output.txt
|
||||
|
||||
echo "Starting my script..."
|
||||
echo "Doing something..."
|
||||
|
||||
tee $OUT <<EOF >/dev/null
|
||||
Status of backup as on $(date)
|
||||
Backing up files $HOME and /etc/
|
||||
EOF
|
||||
|
||||
echo "Starting backup using rsync..."
|
||||
```
|
||||
|
||||
### 关于内存 here 文档的使用
|
||||
|
||||
这是我更新的脚本:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
OUT=/tmp/output.txt
|
||||
|
||||
## in memory here docs
|
||||
## thanks https://twitter.com/freebsdfrau
|
||||
exec 9<<EOF
|
||||
Status of backup as on $(date)
|
||||
Backing up files $HOME and /etc/
|
||||
EOF
|
||||
|
||||
## continue
|
||||
echo "Starting my script..."
|
||||
echo "Doing something..."
|
||||
|
||||
## do it
|
||||
cat <&9 >$OUT
|
||||
|
||||
echo "Starting backup using rsync..."
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/using-heredoc-rediection-in-bash-shell-script-to-write-to-file/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.cyberciti.biz
|
||||
[1]: https://www.cyberciti.biz/media/new/faq/2017/11/redirect-output-of-here-document-to-a-text-file.jpg
|
||||
[2]: https://bash.cyberciti.biz/guide/Here_documents
|
||||
[3]: https//www.cyberciti.biz/faq/linux-unix-appleosx-bsd-cat-command-examples/
|
||||
71
published/201811/20171229 Excellent Free Roguelike Games.md
Normal file
71
published/201811/20171229 Excellent Free Roguelike Games.md
Normal file
@ -0,0 +1,71 @@
|
||||
最棒的免费 Roguelike 游戏
|
||||
======
|
||||
|
||||

|
||||
|
||||
Roguelike 属于角色扮演游戏的一个子流派,它从字面上理解就是“类 Rogue 游戏”。Rogue 是一个地牢探索视频游戏,第一个版本由开发者 Michel Toy、Glenn Wichman 和 Ken Arnold 在 1980 年发布,由于其极易上瘾使得它从一众游戏中脱颖而出。整个游戏的目标是深入第 26 层,取回 Yendor 的护身符并回到地面,所有设定都基于龙与地下城的世界观。
|
||||
|
||||
Rogue 被认为是一个经典、极其困难并且让人废寝忘食的游戏。虽然它在大学校园中非常受欢迎,但并不十分畅销。在 Rogue 发布时,它并没有使用开源许可证,导致了爱好者们开发了许多克隆版本。
|
||||
|
||||
对于 Roguelike 游戏并没有一个明确的定义,但是此类游戏会拥有下述的典型特征:
|
||||
|
||||
* 高度魔幻的叙事背景;
|
||||
* 程序化生成关卡。游戏世界中的大部分地图在每次开始游戏时重新生成,也就意味着鼓励多周目;
|
||||
* 回合制的地牢探险和战斗;
|
||||
* 基于图块随机生成的图形;
|
||||
* 随机的战斗结果;
|
||||
* 永久死亡——死亡实际起作用,一旦死亡你就需要重新开始
|
||||
* 高难度
|
||||
|
||||
此篇文章收集了大量 Linux 平台可玩的 Roguelike 游戏。如果你享受提供真实紧张感的上瘾游戏体验,我衷心推荐你下载这些游戏。不要被其中很多游戏的原始画面吓退,一旦你沉浸其中你会很快忽略简陋的画面。记住,在 Roguelike 游戏中应是游戏机制占主导,画面只是一个加分项而不是必需项。
|
||||
|
||||
此处推荐 16 款游戏。所有的游戏都可免费下载,并且大部分采用开源许可证发布。
|
||||
|
||||
| Roguelike 游戏 | |
|
||||
| --- | --- |
|
||||
| [Dungeon Crawl Stone Soup][1] | Linley 的 Dungeon Crawl 的续作 |
|
||||
| [Prospector][2] | 基于科幻小说世界观的 Roguelike 游戏 |
|
||||
| [Dwarf Fortress][3] | 冒险和侏儒塔防 |
|
||||
| [NetHack][4] | 非常怪诞并且令人上瘾的龙与地下城风格冒险游戏 |
|
||||
| [Angband][5] | 沿着 Rogue 和 NetHack 的路线,它源于游戏 Moria 和 Umoria |
|
||||
| [Ancient Domains of Mystery][6] | 非常成熟的 Roguelike 游戏 |
|
||||
| [Tales of Maj’Eyal][7] | 特色的策略回合制战斗与先进的角色培养系统 |
|
||||
| [UnNetHack][8] | NetHack 的创新复刻 |
|
||||
| [Hydra Slayer][9] | 基于数学谜题的 Roguelike 游戏 |
|
||||
| [Cataclysm DDA][10] | 后启示录风格 Roguelike 游戏,设定于虚构的新英格兰乡下|
|
||||
| [Brogue][11] | Rogue 的正统续作 |
|
||||
| [Goblin Hack][12] | 受 NetHack 启发的游戏, 但密钥更少游戏流程更快 |
|
||||
| [Ascii Sector][13] | 拥有 Roguelike 动作系统的 2D 版贸易和太空飞行模拟器 |
|
||||
| [SLASH'EM][14] | Super Lotsa Added Stuff Hack - Extended Magic |
|
||||
| [Everything Is Fodder][15] | Seven Day Roguelike 比赛入口 |
|
||||
| [Woozoolike][16] | 7DRL 2017 比赛中一款简单的太空探索 Roguelike 游戏 |
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxlinks.com/excellent-free-roguelike-games/
|
||||
|
||||
作者:[Steve Emms][a]
|
||||
译者:[cycoe](https://github.com/cycoe)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxlinks.com/author/linuxlinks/
|
||||
[1]:https://www.linuxlinks.com/dungeoncrawlstonesoup/
|
||||
[2]:https://www.linuxlinks.com/Prospector-roguelike/
|
||||
[3]:https://www.linuxlinks.com/dwarffortress/
|
||||
[4]:https://www.linuxlinks.com/nethack/
|
||||
[5]:https://www.linuxlinks.com/angband/
|
||||
[6]:https://www.linuxlinks.com/ADOM/
|
||||
[7]:https://www.linuxlinks.com/talesofmajeyal/
|
||||
[8]:https://www.linuxlinks.com/unnethack/
|
||||
[9]:https://www.linuxlinks.com/hydra-slayer/
|
||||
[10]:https://www.linuxlinks.com/cataclysmdda/
|
||||
[11]:https://www.linuxlinks.com/brogue/
|
||||
[12]:https://www.linuxlinks.com/goblin-hack/
|
||||
[13]:https://www.linuxlinks.com/asciisector/
|
||||
[14]:https://www.linuxlinks.com/slashem/
|
||||
[15]:https://www.linuxlinks.com/everything-is-fodder/
|
||||
[16]:https://www.linuxlinks.com/Woozoolike/
|
||||
[17]:https://i2.wp.com/www.linuxlinks.com/wp-content/uploads/2017/12/dungeon.jpg?resize=300%2C200&ssl=1
|
||||
@ -1,67 +1,71 @@
|
||||
在 Linux 上使用 Lutries 管理你的游戏
|
||||
======
|
||||
|
||||
|
||||
|
||||
让我们用游戏开始 2018 的第一天吧!今天我们要讨论的是 **Lutris**,一个 Linux 上的开源游戏平台。你可以使用 Lutries 安装、移除、配置、启动和管理你的游戏。它可以以一个界面帮你管理你的 Linux 游戏、Windows 游戏、仿真控制台游戏和浏览器游戏。它还包含社区编写的安装脚本,使得游戏的安装过程更加简单。
|
||||
今天我们要讨论的是 **Lutris**,一个 Linux 上的开源游戏平台。你可以使用 Lutries 安装、移除、配置、启动和管理你的游戏。它可以在一个单一界面中帮你管理你的 Linux 游戏、Windows 游戏、仿真控制台游戏和浏览器游戏。它还包含社区编写的安装脚本,使得游戏的安装过程更加简单。
|
||||
|
||||
Lutries 自动安装(或者你可以单击点击安装)了超过 20 个模拟器,它提供了从七十年代到现在的大多数游戏系统。目前支持的游戏系统如下:
|
||||
|
||||
* Native Linux
|
||||
* Linux 原生
|
||||
* Windows
|
||||
* Steam (Linux and Windows)
|
||||
* Steam (Linux 和 Windows)
|
||||
* MS-DOS
|
||||
* 街机
|
||||
* Amiga 电脑
|
||||
* Atari 8 和 16 位计算机和控制器
|
||||
* 浏览器 (Flash 或者 HTML5 游戏)
|
||||
* Commmodore 8 位计算机
|
||||
* 基于 SCUMM 的游戏和其他点击冒险游戏
|
||||
* Magnavox Odyssey², Videopac+
|
||||
* 基于 SCUMM 的游戏和其他点击式冒险游戏
|
||||
* Magnavox Odyssey²、Videopac+
|
||||
* Mattel Intellivision
|
||||
* NEC PC-Engine Turbographx 16, Supergraphx, PC-FX
|
||||
* Nintendo NES, SNES, Game Boy, Game Boy Advance, DS
|
||||
* Game Cube and Wii
|
||||
* Sega Master Sytem, Game Gear, Genesis, Dreamcast
|
||||
* SNK Neo Geo, Neo Geo Pocket
|
||||
* NEC PC-Engine Turbographx 16、Supergraphx、PC-FX
|
||||
* Nintendo NES、SNES、Game Boy、Game Boy Advance、DS
|
||||
* Game Cube 和 Wii
|
||||
* Sega Master Sytem、Game Gear、Genesis、Dreamcast
|
||||
* SNK Neo Geo、Neo Geo Pocket
|
||||
* Sony PlayStation
|
||||
* Sony PlayStation 2
|
||||
* Sony PSP
|
||||
* 像 Zork 这样的 Z-Machine 游戏
|
||||
* 还有更多
|
||||
|
||||
|
||||
|
||||
### 安装 Lutris
|
||||
|
||||
就像 Steam 一样,Lutries 包含两部分:网站和客户端程序。从网站你可以浏览可用的游戏,添加最喜欢的游戏到个人库,以及使用安装链接安装他们。
|
||||
|
||||
首先,我们还是来安装客户端。它目前支持 Arch Linux、Debian、Fedroa、Gentoo、openSUSE 和 Ubuntu。
|
||||
|
||||
对于 Arch Linux 和它的衍生版本,像是 Antergos, Manjaro Linux,都可以在 [**AUR**][1] 中找到。因此,你可以使用 AUR 帮助程序安装它。
|
||||
对于 **Arch Linux** 和它的衍生版本,像是 Antergos, Manjaro Linux,都可以在 [AUR][1] 中找到。因此,你可以使用 AUR 帮助程序安装它。
|
||||
|
||||
使用 [Pacaur][2]:
|
||||
|
||||
使用 [**Pacaur**][2]:
|
||||
```
|
||||
pacaur -S lutris
|
||||
```
|
||||
|
||||
使用 **[Packer][3]** :
|
||||
使用 [Packer][3]:
|
||||
|
||||
```
|
||||
packer -S lutris
|
||||
```
|
||||
|
||||
使用 [**Yaourt**][4]:
|
||||
使用 [Yaourt][4]:
|
||||
|
||||
```
|
||||
yaourt -S lutris
|
||||
```
|
||||
|
||||
使用 [**Yay**][5]:
|
||||
使用 [Yay][5]:
|
||||
|
||||
```
|
||||
yay -S lutris
|
||||
```
|
||||
|
||||
**Debian:**
|
||||
|
||||
在 **Debian 9.0** 上以 **root** 身份运行以下命令:
|
||||
在 **Debian 9.0** 上以 **root** 身份运行以下命令:
|
||||
|
||||
```
|
||||
echo 'deb http://download.opensuse.org/repositories/home:/strycore/Debian_9.0/ /' > /etc/apt/sources.list.d/lutris.list
|
||||
wget -nv https://download.opensuse.org/repositories/home:strycore/Debian_9.0/Release.key -O Release.key
|
||||
@ -71,6 +75,7 @@ apt-get install lutris
|
||||
```
|
||||
|
||||
在 **Debian 8.0** 上以 **root** 身份运行以下命令:
|
||||
|
||||
```
|
||||
echo 'deb http://download.opensuse.org/repositories/home:/strycore/Debian_8.0/ /' > /etc/apt/sources.list.d/lutris.list
|
||||
wget -nv https://download.opensuse.org/repositories/home:strycore/Debian_8.0/Release.key -O Release.key
|
||||
@ -79,19 +84,22 @@ apt-get update
|
||||
apt-get install lutris
|
||||
```
|
||||
|
||||
在 **Fedora 27** 上以 **root** 身份运行以下命令: r
|
||||
在 **Fedora 27** 上以 **root** 身份运行以下命令:
|
||||
|
||||
```
|
||||
dnf config-manager --add-repo https://download.opensuse.org/repositories/home:strycore/Fedora_27/home:strycore.repo
|
||||
dnf install lutris
|
||||
```
|
||||
|
||||
在 **Fedora 26** 上以 **root** 身份运行以下命令:
|
||||
在 **Fedora 26** 上以 **root** 身份运行以下命令:
|
||||
|
||||
```
|
||||
dnf config-manager --add-repo https://download.opensuse.org/repositories/home:strycore/Fedora_26/home:strycore.repo
|
||||
dnf install lutris
|
||||
```
|
||||
|
||||
在 **openSUSE Tumbleweed** 上以 **root** 身份运行以下命令:
|
||||
|
||||
```
|
||||
zypper addrepo https://download.opensuse.org/repositories/home:strycore/openSUSE_Tumbleweed/home:strycore.repo
|
||||
zypper refresh
|
||||
@ -99,13 +107,15 @@ zypper install lutris
|
||||
```
|
||||
|
||||
在 **openSUSE Leap 42.3** 上以 **root** 身份运行以下命令:
|
||||
|
||||
```
|
||||
zypper addrepo https://download.opensuse.org/repositories/home:strycore/openSUSE_Leap_42.3/home:strycore.repo
|
||||
zypper refresh
|
||||
zypper install lutris
|
||||
```
|
||||
|
||||
**Ubuntu 17.10**:
|
||||
**Ubuntu 17.10**:
|
||||
|
||||
```
|
||||
sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/strycore/xUbuntu_17.10/ /' > /etc/apt/sources.list.d/lutris.list"
|
||||
wget -nv https://download.opensuse.org/repositories/home:strycore/xUbuntu_17.10/Release.key -O Release.key
|
||||
@ -114,7 +124,8 @@ sudo apt-get update
|
||||
sudo apt-get install lutris
|
||||
```
|
||||
|
||||
**Ubuntu 17.04**:
|
||||
**Ubuntu 17.04**:
|
||||
|
||||
```
|
||||
sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/strycore/xUbuntu_17.04/ /' > /etc/apt/sources.list.d/lutris.list"
|
||||
wget -nv https://download.opensuse.org/repositories/home:strycore/xUbuntu_17.04/Release.key -O Release.key
|
||||
@ -123,7 +134,8 @@ sudo apt-get update
|
||||
sudo apt-get install lutris
|
||||
```
|
||||
|
||||
**Ubuntu 16.10**:
|
||||
**Ubuntu 16.10**:
|
||||
|
||||
```
|
||||
sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/strycore/xUbuntu_16.10/ /' > /etc/apt/sources.list.d/lutris.list"
|
||||
wget -nv https://download.opensuse.org/repositories/home:strycore/xUbuntu_16.10/Release.key -O Release.key
|
||||
@ -132,7 +144,8 @@ sudo apt-get update
|
||||
sudo apt-get install lutris
|
||||
```
|
||||
|
||||
**Ubuntu 16.04**:
|
||||
**Ubuntu 16.04**:
|
||||
|
||||
```
|
||||
sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/strycore/xUbuntu_16.04/ /' > /etc/apt/sources.list.d/lutris.list"
|
||||
wget -nv https://download.opensuse.org/repositories/home:strycore/xUbuntu_16.04/Release.key -O Release.key
|
||||
@ -141,71 +154,75 @@ sudo apt-get update
|
||||
sudo apt-get install lutris
|
||||
```
|
||||
|
||||
对于其他平台,参考 [**Lutris 下载链接**][6].
|
||||
对于其他平台,参考 [Lutris 下载链接][6]。
|
||||
|
||||
### 使用 Lutris 管理你的游戏
|
||||
|
||||
安装完成后,从菜单或者应用启动器里打开 Lutries。首次启动时,Lutries 的默认界面像下面这样:
|
||||
|
||||
[![][7]][8]
|
||||
![][8]
|
||||
|
||||
**登录你的 Lutris.net 账号**
|
||||
#### 登录你的 Lutris.net 账号
|
||||
|
||||
为了能同步你个人库中的游戏,下一步你需要在客户端中登录你的 Lutris.net 账号。如果你没有,先 [**注册一个新的账号**][9]。然后点击 **"连接到你的 Lutirs.net 账号同步你的库 "** 连接到 Lutries 客户端。
|
||||
为了能同步你个人库中的游戏,下一步你需要在客户端中登录你的 Lutris.net 账号。如果你没有,先 [注册一个新的账号][9]。然后点击 “Connecting to your Lutirs.net account to sync your library” 连接到 Lutries 客户端。
|
||||
|
||||
输入你的账号信息然后点击 **继续**。
|
||||
输入你的账号信息然后点击 “Connect”。
|
||||
|
||||
[![][7]][10]
|
||||
![][10]
|
||||
|
||||
现在你已经连接到你的 Lutries.net 账号了。
|
||||
|
||||
[![][7]][11]**Browse Games**
|
||||
![][11]
|
||||
|
||||
#### 浏览游戏
|
||||
|
||||
点击工具栏里的浏览图标(游戏控制器图标)可以搜索任何游戏。它会自动定向到 Lutries 网站的游戏页。你可以以字母顺序查看所有可用的游戏。Lutries 现在已经有了很多游戏,而且还有更多的不断添加进来。
|
||||
|
||||
[![][7]][12]
|
||||
![][12]
|
||||
|
||||
任选一个游戏,添加到你的库中。
|
||||
|
||||
[![][7]][13]
|
||||
![][13]
|
||||
|
||||
然后返回到你的 Lutries 客户端,点击 **菜单 - > Lutris -> 同步库**。现在你可以在本地的 Lutries 客户端中看到所有在库中的游戏了。
|
||||
然后返回到你的 Lutries 客户端,点击 “Menu -> Lutris -> Synchronize library”。现在你可以在本地的 Lutries 客户端中看到所有在库中的游戏了。
|
||||
|
||||
[![][7]][14]
|
||||
![][14]
|
||||
|
||||
如果你没有看到游戏,只需要重启一次。
|
||||
|
||||
**安装游戏**
|
||||
#### 安装游戏
|
||||
|
||||
安装游戏,只需要点击游戏,然后点击 **安装** 按钮。例如,我想在我的系统安装 [**2048**][15],就像你在底下的截图中看到的,它要求我选择一个版本去安装。因为它只有一个版本(例如,在线),它就会自动选择这个版本。点击 **继续**。
|
||||
安装游戏,只需要点击游戏,然后点击 “Install” 按钮。例如,我想在我的系统安装 [2048][15],就像你在底下的截图中看到的,它要求我选择一个版本去安装。因为它只有一个版本(例如,在线),它就会自动选择这个版本。点击 “Continue”。
|
||||
|
||||
[![][7]][16]Click Install:
|
||||
![][16]
|
||||
|
||||
[![][7]][17]
|
||||
点击“Install”:
|
||||
|
||||
![][17]
|
||||
|
||||
安装完成之后,你可以启动新安装的游戏或是关闭这个窗口,继续从你的库中安装其他游戏。
|
||||
|
||||
**导入 Steam 库**
|
||||
#### 导入 Steam 库
|
||||
|
||||
你也可以导入你的 Steam 库。在你的头像处点击 **"通过 Steam 登录"** 按钮。接下来你将被重定向到 Steam,输入你的账号信息。填写正确后,你的 Steam 账号将被连接到 Lutries 账号。请注意,为了同步库中的游戏,这里你的 Steam 账号将被公开。你可以在同步完成之后将其重新设为私密状态。
|
||||
你也可以导入你的 Steam 库。在你的头像处点击 “Sign in through Steam” 按钮。接下来你将被重定向到 Steam,输入你的账号信息。填写正确后,你的 Steam 账号将被连接到 Lutries 账号。请注意,为了同步库中的游戏,这里你的 Steam 账号将被公开。你可以在同步完成之后将其重新设为私密状态。
|
||||
|
||||
**手动添加游戏**
|
||||
#### 手动添加游戏
|
||||
|
||||
Lutries 有手动添加游戏的选项。在工具栏中点击 + 号登录。
|
||||
Lutries 有手动添加游戏的选项。在工具栏中点击 “+” 号登录。
|
||||
|
||||
[![][7]][18]
|
||||
![][18]
|
||||
|
||||
在下一个窗口,输入游戏名,在游戏信息栏选择一个运行器。运行器是指 Linux 上类似 wine,Steam 之类的程序,它们可以帮助你启动这个游戏。你可以从 菜单 -> 管理运行器 中安装运行器。
|
||||
在下一个窗口,输入游戏名,在游戏信息栏选择一个运行器。运行器是指 Linux 上类似 wine、Steam 之类的程序,它们可以帮助你启动这个游戏。你可以从 “Menu -> Manage” 中安装运行器。
|
||||
|
||||
[![][7]][19]
|
||||
![][19]
|
||||
|
||||
然后在下一栏中选择可执行文件或者 ISO。最后点击保存。有一个好消息是,你可以添加一个游戏的多个版本。
|
||||
|
||||
**移除游戏**
|
||||
#### 移除游戏
|
||||
|
||||
移除任何已安装的游戏,只需在 Lutries 客户端的本地库中点击对应的游戏。选择 **移除** 然后 **应用**。
|
||||
移除任何已安装的游戏,只需在 Lutries 客户端的本地库中点击对应的游戏。选择 “Remove” 然后 “Apply”。
|
||||
|
||||
[![][7]][20]
|
||||
![][20]
|
||||
|
||||
Lutries 就像 Steam。只是从网站向你的库中添加游戏,并在客户端中为你安装它们。
|
||||
|
||||
@ -215,15 +232,13 @@ Lutries 就像 Steam。只是从网站向你的库中添加游戏,并在客户
|
||||
|
||||
:)
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/manage-games-using-lutris-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -234,17 +249,16 @@ via: https://www.ostechnix.com/manage-games-using-lutris-linux/
|
||||
[4]:https://www.ostechnix.com/install-yaourt-arch-linux/
|
||||
[5]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[6]:https://lutris.net/downloads/
|
||||
[7]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-1-1.png ()
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-1-1.png
|
||||
[9]:https://lutris.net/user/register/
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-2.png ()
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-3.png ()
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-15-1.png ()
|
||||
[13]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-16.png ()
|
||||
[14]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-6.png ()
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-2.png
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-3.png
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-15-1.png
|
||||
[13]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-16.png
|
||||
[14]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-6.png
|
||||
[15]:https://www.ostechnix.com/let-us-play-2048-game-terminal/
|
||||
[16]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-12.png ()
|
||||
[17]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-13.png ()
|
||||
[18]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-18-1.png ()
|
||||
[19]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-19.png ()
|
||||
[20]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-14-1.png ()
|
||||
[16]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-12.png
|
||||
[17]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-13.png
|
||||
[18]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-18-1.png
|
||||
[19]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-19.png
|
||||
[20]:http://www.ostechnix.com/wp-content/uploads/2018/01/Lutris-14-1.png
|
||||
@ -0,0 +1,104 @@
|
||||
使用 Docker 企业版搭建自己的私有注册服务器
|
||||
======
|
||||
|
||||
![docker trusted registry][1]
|
||||
|
||||
Docker 真的很酷,特别是和使用虚拟机相比,转移 Docker 镜像十分容易。如果你已准备好使用 Docker,那你肯定已从 [Docker Hub][2] 上拉取过完整的镜像。Docker Hub 是 Docker 的云端注册服务器服务,它包含成千上万个供选择的 Docker 镜像。如果你开发了自己的软件包并创建了自己的 Docker 镜像,那么你会想有自己私有的注册服务器。如果你有搭配着专有许可的镜像,或想为你的构建系统提供复杂的持续集成(CI)过程,则更应该拥有自己的私有注册服务器。
|
||||
|
||||
Docker 企业版包括 <ruby>Docker 可信注册服务器<rt>Docker Trusted Registry</rt></ruby>(DTR)。这是一个具有安全镜像管理功能的高可用的注册服务器,为在你自己的数据中心或基于云端的架构上运行而构建。在接下来,我们将了解到 DTR 是提供安全、可重用且连续的[软件供应链][3]的一个关键组件。你可以通过我们的[免费托管小样][4]立即开始使用,或者通过下载安装进行 30 天的免费试用。下面是开始自己安装的步骤。
|
||||
|
||||
### 配置 Docker 企业版
|
||||
|
||||
DTR 运行于通用控制面板(UCP)之上,所以开始前要安装一个单节点集群。如果你已经有了自己的 UCP 集群,可以跳过这一步。在你的 docker 托管主机上,运行以下命令:
|
||||
|
||||
```
|
||||
# 拉取并安装 UCP
|
||||
docker run -it -rm -v /var/run/docker.sock:/var/run/docker.sock -name ucp docker/ucp:latest install
|
||||
```
|
||||
|
||||
当 UCP 启动并运行后,在安装 DTR 之前你还有几件事要做。针对刚刚安装的 UCP 实例,打开浏览器。在日志输出的末尾应该有一个链接。如果你已经有了 Docker 企业版的许可证,那就在这个界面上输入它吧。如果你还没有,可以访问 [Docker 商店][5]获取 30 天的免费试用版。
|
||||
|
||||
准备好许可证后,你可能会需要改变一下 UCP 运行的端口。因为这是一个单节点集群,DTR 和 UCP 可能会以相同的端口运行它们的 web 服务。如果你拥有不只一个节点的 UCP 集群,这就不是问题,因为 DTR 会寻找有所需空闲端口的节点。在 UCP 中,点击“管理员设置 -> 集群配置”并修改控制器端口,比如 5443。
|
||||
|
||||
### 安装 DTR
|
||||
|
||||
我们要安装一个简单的、单节点的 DTR 实例。如果你要安装实际生产用途的 DTR,那么你会将其设置为高可用(HA)模式,即需要另一种存储介质,比如基于云端的对象存储或者 NFS(LCTT 译注:Network File System,网络文件系统)。因为目前安装的是一个单节点实例,我们依然使用默认的本地存储。
|
||||
|
||||
首先我们需要拉取 DTR 的 bootstrap 镜像。boostrap 镜像是一个微小的独立安装程序,包括了连接到 UCP 以及设置和启动 DTR 所需的所有容器、卷和逻辑网络。
|
||||
|
||||
使用命令:
|
||||
|
||||
```
|
||||
# 拉取并运行 DTR 引导程序
|
||||
docker run -it -rm docker/dtr:latest install -ucp-insecure-tls
|
||||
```
|
||||
|
||||
注意:默认情况下,UCP 和 DTR 都有自己的证书,系统无法识别。如果你已使用系统信任的 TLS 证书设置 UCP,则可以省略 `-ucp-insecure-tls` 选项。另外,你可以使用 `-ucp-ca` 选项来直接指定 UCP 的 CA 证书。
|
||||
|
||||
然后 DTR bootstrap 镜像会让你确定几项设置,比如 UCP 安装的 URL 地址以及管理员的用户名和密码。从拉取所有的 DTR 镜像到设置全部完成,只需要一到两分钟的时间。
|
||||
|
||||
### 保证一切安全
|
||||
|
||||
一切都准备好后,就可以向注册服务器推送或者从中拉取镜像了。在做这一步之前,让我们设置 TLS 证书,以便与 DTR 安全地通信。
|
||||
|
||||
在 Linux 上,我们可以使用以下命令(只需确保更改了 `DTR_HOSTNAME` 变量,来正确映射我们刚刚设置的 DTR):
|
||||
|
||||
```
|
||||
# 从 DTR 拉取 CA 证书(如果 curl 不可用,你可以使用 wget)
|
||||
DTR_HOSTNAME=< DTR 主机名>
|
||||
curl -k https://$(DTR_HOSTNAME)/ca > $(DTR_HOSTNAME).crt
|
||||
sudo mkdir /etc/docker/certs.d/$(DTR_HOSTNAME)
|
||||
sudo cp $(DTR_HOSTNAME) /etc/docker/certs.d/$(DTR_HOSTNAME)
|
||||
# 重启 docker 守护进程(在 Ubuntu 14.04 上,使用 `sudo service docker restart` 命令)
|
||||
sudo systemctl restart docker
|
||||
```
|
||||
|
||||
对于 Mac 和 Windows 版的 Docker,我们会以不同的方式安装客户端。转入“设置 -> 守护进程”,在“不安全的注册服务器”部分,输入你的 DTR 主机名。点击“应用”,docker 守护进程应在重启后可以良好使用。
|
||||
|
||||
### 推送和拉取镜像
|
||||
|
||||
现在我们需要设置一个仓库来存放镜像。这和 Docker Hub 有一点不同,如果你做的 docker 推送仓库中不存在,它会自动创建一个。要创建一个仓库,在浏览器中打开 `https://<Your DTR hostname>` 并在出现登录提示时使用你的管理员凭据登录。如果你向 UCP 添加了许可证,则 DTR 会自动获取该许可证。如果没有,请现在确认上传你的许可证。
|
||||
|
||||
进入刚才的网页之后,点击“新建仓库”按钮来创建新的仓库。
|
||||
|
||||
我们会创建一个用于存储 Alpine linux 的仓库,所以在名字输入处键入 “alpine”,点击“保存”(在 DTR 2.5 及更高版本中叫“创建”)。
|
||||
|
||||
现在我们回到 shell 界面输入以下命令:
|
||||
|
||||
```
|
||||
# 拉取 Alpine Linux 的最新版
|
||||
docker pull alpine:latest
|
||||
# 登入新的 DTR 实例
|
||||
docker login <Your DTR hostname>
|
||||
# 标记上 Alpine 使能推送其至你的 DTR
|
||||
docker tag alpine:latest <Your DTR hostname>/admin/alpine:latest
|
||||
# 向 DTR 推送镜像
|
||||
docker push <Your DTR hostname>/admin/alpine:latest
|
||||
```
|
||||
|
||||
就是这样!我们刚刚推送了最新的 Alpine Linux 的一份拷贝,重新打了标签以便将其存储到 DTR 中,并将其推送到我们的私有注册服务器。如果你想将镜像拉取至不同的 Docker 引擎中,按如上所示设置你的 DTR 证书,然后执行以下命令:
|
||||
|
||||
```
|
||||
# 从 DTR 中拉取镜像
|
||||
docker pull <Your DTR hostname>/admin/alpine:latest
|
||||
```
|
||||
|
||||
DTR 具有许多优秀的镜像管理功能,例如镜像的缓存、映像、扫描、签名甚至自动化供应链策略。这些功能我们在后期的博客文章中更详细的探讨。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.docker.com/2018/01/dtr/
|
||||
|
||||
作者:[Patrick Devine][a]
|
||||
译者:[fuowang](https://github.com/fuowang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.docker.com/author/pdevine/
|
||||
[1]:https://i1.wp.com/blog.docker.com/wp-content/uploads/ccd278d2-29c2-4866-8285-c2fe60b4bd5e-1.jpg?resize=965%2C452&ssl=1
|
||||
[2]:https://hub.docker.com/
|
||||
[3]:https://blog.docker.com/2016/08/securing-enterprise-software-supply-chain-using-docker/
|
||||
[4]:https://www.docker.com/trial
|
||||
[5]:https://store.docker.com/search?offering=enterprise&page=1&q=&type=edition
|
||||
53
published/201811/20180127 Write Dumb Code.md
Normal file
53
published/201811/20180127 Write Dumb Code.md
Normal file
@ -0,0 +1,53 @@
|
||||
写直白的代码
|
||||
====
|
||||
|
||||
为开源项目作贡献最好的方式是为它减少代码,我们应致力于写出让新手程序员无需注释就容易理解的代码,让维护者也无需花费太多精力就能着手维护。
|
||||
|
||||
在学生时代,我们会更多地用复杂巧妙的技术去挑战新的难题。首先我们会学习循环,然后是函数啊,类啊,等等。当我们到达一定高的程度,能用更高级的技术写更长的程序,我们会因此受到称赞。此刻我们发现老司机们用 monads 而新手们用 loop 作循环。
|
||||
|
||||
之后我们毕业找了工作,或者和他人合作开源项目。我们用在学校里学到的各种炫技寻求并骄傲地给出解决方案的代码实现。
|
||||
|
||||
*哈哈,我能扩展这个项目,并实现某牛 X 功能啦,我这里能用继承啦,我太聪明啦!*
|
||||
|
||||
我们实现了某个小的功能,并以充分的理由觉得自己做到了。现实项目中的编程却不是针对某某部分的功能而言。以我个人的经验而言,以前我很开心的去写代码,并骄傲地向世界展示我所知道的事情。有例为证,作为对某种编程技术的偏爱,这是用另一种元编程语言构建的一个 [线性代数语言][1],注意,这么多年以来一直没人愿意碰它。
|
||||
|
||||
在维护了更多的代码后,我的观点发生了变化。
|
||||
|
||||
1. 我们不应去刻意探求如何构建软件。软件是我们为解决问题所付出的代价,那才是我们真实的目的。我们应努力为了解决问题而构建较小的软件。
|
||||
2. 我们应使用尽可能简单的技术,那么更多的人就越可能会使用,并且无需理解我们所知的高级技术就能扩展软件的功能。当然,在我们不知道如何使用简单技术去实现时,我们也可以使用高级技术。
|
||||
|
||||
所有的这些例子都不是听来的故事。我遇到的大部分人会认同某些部分,但不知为什么,当我们向一个新项目贡献代码时又会忘掉这个初衷。直觉里用复杂技术去构建的念头往往会占据上风。
|
||||
|
||||
### 软件是种投入
|
||||
|
||||
你写的每行代码都要花费人力。写代码当然是需要时间的,也许你会认为只是你个人在奉献,然而这些代码在被审阅的时候也需要花时间理解,对于未来维护和开发人员来说,他们在维护和修改代码时同样要花费时间。否则他们完全可以用这时间出去晒晒太阳,或者陪伴家人。
|
||||
|
||||
所以,当你向某个项目贡献代码时,请心怀谦恭。就像是,你正和你的家人进餐时,餐桌上却没有足够的食物,你只索取你所需的部分,别人对你的自我约束将肃然起敬。以更少的代码去解决问题是很难的,你肩负重任的同时自然减轻了别人的重负。
|
||||
|
||||
### 技术越复杂越难维护
|
||||
|
||||
作为学生,逐渐使用高端技术证明了自己的价值。这体现在,首先我们有能力在开源项目中使用函数,接着是类,然后是高阶函数,monads 等等。我们向同行显示自己的解决方案时,常因自己所用技术高低而感到自豪或卑微。
|
||||
|
||||
而在现实中,和团队去解决问题时,情况发生了逆转。现在,我们致力于尽可能使用简单的代码去解决问题。简单方式解决问题使新手程序员能够以此扩展并解决其他问题。简单的代码让别人容易上手,效果立竿见影。我们藉以只用简单的技术去解决难题,从而展示自己的价值。
|
||||
|
||||
*看,我用循环替代了递归函数并且一样达到了我们的需求。当然我明白这是不够聪明的做法,不过我注意到新手同事在这里会遇上麻烦,我觉得这种改变将有所帮助吧。*
|
||||
|
||||
如果你是个好的程序员,你不需要证明你知道很多炫技。相应的,你可以通过用一个简单的方法解决一个问题来显示你的价值,并激发你的团队在未来的时间里去完善它。
|
||||
|
||||
### 当然,也请保持节制
|
||||
|
||||
话虽如此,过于遵循 “用简单的工具去构建” 的教条也会降低生产力。通常用递归会比用循环解决问题更简单,用类或 monad 才是正确的途径。还有两种情况另当别论,一是只是只为满足自我而创建的系统,或者是别人毫无构建经验的系统。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://matthewrocklin.com/blog/work/2018/01/27/write-dumb-code
|
||||
|
||||
作者:[Matthew Rocklin][a]
|
||||
译者:[plutoid](https://github.com/plutoid)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://matthewrocklin.com
|
||||
[1]:https://github.com/mrocklin/matrix-algebra
|
||||
@ -0,0 +1,211 @@
|
||||
使用 Redis 和 Python 构建一个共享单车的应用程序
|
||||
======
|
||||
|
||||
> 学习如何使用 Redis 和 Python 构建一个位置感知的应用程序。
|
||||
|
||||

|
||||
|
||||
我经常出差。但不是一个汽车狂热分子,所以当我有空闲时,我更喜欢在城市中散步或者骑单车。我参观过的许多城市都有共享单车系统,你可以租个单车用几个小时。大多数系统都有一个应用程序来帮助用户定位和租用他们的单车,但对于像我这样的用户来说,在一个地方可以获得可租赁的城市中所有单车的信息会更有帮助。
|
||||
|
||||
为了解决这个问题并且展示开源的强大还有为 Web 应用程序添加位置感知的功能,我组合了可用的公开的共享单车数据、[Python][1] 编程语言以及开源的 [Redis][2] 内存数据结构服务,用来索引和查询地理空间数据。
|
||||
|
||||
由此诞生的共享单车应用程序包含来自很多不同的共享系统的数据,包括纽约市的 [Citi Bike][3] 共享单车系统(LCTT 译注:Citi Bike 是纽约市的一个私营公共单车系统。在 2013 年 5 月 27 日正式营运,是美国最大的公共单车系统。Citi Bike 的名称有两层意思。Citi 是计划赞助商花旗银行(CitiBank)的名字。同时,Citi 和英文中“城市(city)”一词的读音相同)。它利用了花旗单车系统提供的 <ruby>通用共享单车数据流<rt>General Bikeshare Feed</rt></ruby>,并利用其数据演示了一些使用 Redis 地理空间数据索引的功能。 花旗单车数据可按照 [花旗单车数据许可协议][4] 提供。
|
||||
|
||||
### 通用共享单车数据流规范
|
||||
|
||||
<ruby>通用共享单车数据流规范<rt>General Bikeshare Feed Specification</rt></ruby>(GBFS)是由 [北美共享单车协会][6] 开发的 [开放数据规范][5],旨在使地图程序和运输程序更容易的将共享单车系统添加到对应平台中。 目前世界上有 60 多个不同的共享系统使用该规范。
|
||||
|
||||
Feed 流由几个简单的 [JSON][7] 数据文件组成,其中包含系统状态的信息。 Feed 流以一个顶级 JSON 文件开头,其引用了子数据流的 URL:
|
||||
|
||||
```
|
||||
{
|
||||
"data": {
|
||||
"en": {
|
||||
"feeds": [
|
||||
{
|
||||
"name": "system_information",
|
||||
"url": "https://gbfs.citibikenyc.com/gbfs/en/system_information.json"
|
||||
},
|
||||
{
|
||||
"name": "station_information",
|
||||
"url": "https://gbfs.citibikenyc.com/gbfs/en/station_information.json"
|
||||
},
|
||||
. . .
|
||||
]
|
||||
}
|
||||
},
|
||||
"last_updated": 1506370010,
|
||||
"ttl": 10
|
||||
}
|
||||
```
|
||||
|
||||
第一步是使用 `system_information` 和 `station_information` 的数据将共享单车站的信息加载到 Redis 中。
|
||||
|
||||
`system_information` 提供系统 ID,系统 ID 是一个简短编码,可用于为 Redis 键名创建命名空间。 GBFS 规范没有指定系统 ID 的格式,但确保它是全局唯一的。许多共享单车数据流使用诸如“coast_bike_share”,“boise_greenbike” 或者 “topeka_metro_bikes” 这样的短名称作为系统 ID。其他的使用常见的有地理缩写,例如 NYC 或者 BA,并且使用通用唯一标识符(UUID)。 这个共享单车应用程序使用该标识符作为前缀来为指定系统构造唯一键。
|
||||
|
||||
`station_information` 数据流提供组成整个系统的共享单车站的静态信息。车站由具有多个字段的 JSON 对象表示。车站对象中有几个必填字段,用于提供物理单车站的 ID、名称和位置。还有几个可选字段提供有用的信息,例如最近的十字路口、可接受的付款方式。这是共享单车应用程序这一部分的主要信息来源。
|
||||
|
||||
### 建立数据库
|
||||
|
||||
我编写了一个示例应用程序 [load_station_data.py][8],它模仿后端进程中从外部源加载数据时会发生什么。
|
||||
|
||||
### 查找共享单车站
|
||||
|
||||
从 [GitHub 上 GBFS 仓库][5]中的 [systems.csv][9] 文件开始加载共享单车数据。
|
||||
|
||||
仓库中的 [systems.csv][9] 文件提供已注册的共享单车系统及可用的 GBFS 数据流的<ruby>发现 URL<rt>discovery URL</rt></ruby>。 这个发现 URL 是处理共享单车信息的起点。
|
||||
|
||||
`load_station_data` 程序获取系统文件中找到的每个发现 URL,并使用它来查找两个子数据流的 URL:系统信息和车站信息。 系统信息提供提供了一条关键信息:系统的唯一 ID。 (注意:系统 ID 也在 `systems.csv` 文件中提供,但文件中的某些标识符与数据流中的标识符不匹配,因此我总是从数据流中获取标识符。)系统上的详细信息,比如共享单车 URL、电话号码和电子邮件, 可以在程序的后续版本中添加,因此使用 `${system_id}:system_info` 这个键名将数据存储在 Redis 中。
|
||||
|
||||
### 载入车站数据
|
||||
|
||||
车站信息提供系统中每个车站的数据,包括该系统的位置。`load_station_data` 程序遍历车站数据流中的每个车站,并使用 `${system_id}:station:${station_id}` 形式的键名将每个车站的数据存储到 Redis 中。 使用 `GEOADD` 命令将每个车站的位置添加到共享单车的地理空间索引中。
|
||||
|
||||
### 更新数据
|
||||
|
||||
在后续运行中,我不希望代码从 Redis 中删除所有 Feed 数据并将其重新加载到空的 Redis 数据库中,因此我仔细考虑了如何处理数据的原地更新。
|
||||
|
||||
代码首先加载所有需要系统在内存中处理的共享单车站的信息数据集。 当加载了一个车站的信息时,该站就会按照 Redis 键名从内存中的车站集合中删除。 加载完所有车站数据后,我们就剩下一个包含该系统所有必须删除的车站数据的集合。
|
||||
|
||||
程序迭代处理该数据集,并创建一个事务删除车站的信息,从地理空间索引中删除该车站的键名,并从系统的车站列表中删除该车站。
|
||||
|
||||
### 代码重点
|
||||
|
||||
在[示例代码][8]中有一些值得注意的地方。 首先,使用 `GEOADD` 命令将所有数据项添加到地理空间索引中,而使用 `ZREM` 命令将其删除。 由于地理空间类型的底层实现使用了有序集合,因此需要使用 ZREM 删除数据项。 需要注意的是:为简单起见,示例代码演示了如何在单个 Redis 节点工作; 为了在集群环境中运行,需要重新构建事务块。
|
||||
|
||||
如果你使用的是 Redis 4.0(或更高版本),则可以在代码中使用 `DELETE` 和 `HMSET` 命令。 Redis 4.0 提供 `UNLINK` 命令作为 `DELETE` 命令的异步版本的替代。 `UNLINK` 命令将从键空间中删除键,但它会在另外的线程中回收内存。 在 Redis 4.0 中 [HMSET 命令已经被弃用了而且 HSET 命令现在接收可变参数][12](即,它接受的参数个数不定)。
|
||||
|
||||
### 通知客户端
|
||||
|
||||
处理结束时,会向依赖我们数据的客户端发送通知。 使用 Redis 发布/订阅机制,通知将通过 `geobike:station_changed` 通道和系统 ID 一起发出。
|
||||
|
||||
### 数据模型
|
||||
|
||||
在 Redis 中构建数据时,最重要的考虑因素是如何查询信息。 共享单车程序需要支持的两个主要查询是:
|
||||
|
||||
- 找到我们附近的车站
|
||||
- 显示车站相关的信息
|
||||
|
||||
Redis 提供了两种主要数据类型用于存储数据:哈希和有序集。 [哈希类型][13]很好地映射到表示车站的 JSON 对象;由于 Redis 哈希不使用固定的数据结构,因此它们可用于存储可变的车站信息。
|
||||
|
||||
当然,在地理位置上寻找站点需要地理空间索引来搜索相对于某些坐标的站点。 Redis 提供了[几个][14]使用[有序集][15]数据结构构建地理空间索引的命令。
|
||||
|
||||
我们使用 `${system_id}:station:${station_id}` 这种格式的键名存储车站相关的信息,使用 `${system_id}:stations:location` 这种格式的键名查找车站的地理空间索引。
|
||||
|
||||
### 获取用户位置
|
||||
|
||||
构建应用程序的下一步是确定用户的当前位置。 大多数应用程序通过操作系统提供的内置服务来实现此目的。 操作系统可以基于设备内置的 GPS 硬件为应用程序提供定位,或者从设备的可用 WiFi 网络提供近似的定位。
|
||||
|
||||
### 查找车站
|
||||
|
||||
找到用户的位置后,下一步是找到附近的共享单车站。 Redis 的地理空间功能可以返回用户当前坐标在给定距离内的所有车站信息。 以下是使用 Redis 命令行界面的示例。
|
||||
|
||||
|
||||
|
||||
想象一下,我正在纽约市第五大道的苹果零售店,我想要向市中心方向前往位于西 37 街的 MOOD 布料店,与我的好友 [Swatch][16] 相遇。 我可以坐出租车或地铁,但我更喜欢骑单车。 附近有没有我可以使用的单车共享站呢?
|
||||
|
||||
苹果零售店位于 40.76384,-73.97297。 根据地图显示,在零售店 500 英尺半径范围内(地图上方的蓝色)有两个单车站,分别是陆军广场中央公园南单车站和东 58 街麦迪逊单车站。
|
||||
|
||||
我可以使用 Redis 的 `GEORADIUS` 命令查询 500 英尺半径范围内的车站的 `NYC` 系统索引:
|
||||
|
||||
```
|
||||
127.0.0.1:6379> GEORADIUS NYC:stations:location -73.97297 40.76384 500 ft
|
||||
1) "NYC:station:3457"
|
||||
2) "NYC:station:281"
|
||||
```
|
||||
|
||||
Redis 使用地理空间索引中的元素作为特定车站的元数据的键名,返回在该半径内找到的两个共享单车站。 下一步是查找两个站的名称:
|
||||
|
||||
```
|
||||
127.0.0.1:6379> hget NYC:station:281 name
|
||||
"Grand Army Plaza & Central Park S"
|
||||
|
||||
127.0.0.1:6379> hget NYC:station:3457 name
|
||||
"E 58 St & Madison Ave"
|
||||
```
|
||||
|
||||
这些键名对应于上面地图上标识的车站。 如果需要,可以在 `GEORADIUS` 命令中添加更多标志来获取元素列表,每个元素的坐标以及它们与当前点的距离:
|
||||
|
||||
```
|
||||
127.0.0.1:6379> GEORADIUS NYC:stations:location -73.97297 40.76384 500 ft WITHDIST WITHCOORD ASC
|
||||
1) 1) "NYC:station:281"
|
||||
2) "289.1995"
|
||||
3) 1) "-73.97371262311935425"
|
||||
2) "40.76439830559216659"
|
||||
2) 1) "NYC:station:3457"
|
||||
2) "383.1782"
|
||||
3) 1) "-73.97209256887435913"
|
||||
2) "40.76302702144496237"
|
||||
```
|
||||
|
||||
查找与这些键名关联的名称会生成一个我可以从中选择的车站的有序列表。 Redis 不提供方向和路线的功能,因此我使用设备操作系统的路线功能绘制从当前位置到所选单车站的路线。
|
||||
|
||||
`GEORADIUS` 函数可以很轻松的在你喜欢的开发框架的 API 里实现,这样就可以向应用程序添加位置功能了。
|
||||
|
||||
### 其他的查询命令
|
||||
|
||||
除了 `GEORADIUS` 命令外,Redis 还提供了另外三个用于查询索引数据的命令:`GEOPOS`、`GEODIST` 和 `GEORADIUSBYMEMBER`。
|
||||
|
||||
`GEOPOS` 命令可以为 <ruby>地理哈希<rt>geohash</rt></ruby> 中的给定元素提供坐标(LCTT 译注:geohash 是一种将二维的经纬度编码为一位的字符串的一种算法,常用于基于距离的查找算法和推荐算法)。 例如,如果我知道西 38 街 8 号有一个共享单车站,ID 是 523,那么该站的元素名称是 `NYC:station:523`。 使用 Redis,我可以找到该站的经度和纬度:
|
||||
|
||||
```
|
||||
127.0.0.1:6379> geopos NYC:stations:location NYC:station:523
|
||||
1) 1) "-73.99138301610946655"
|
||||
2) "40.75466497634030105"
|
||||
```
|
||||
|
||||
`GEODIST` 命令提供两个索引元素之间的距离。 如果我想找到陆军广场中央公园南单车站与东 58 街麦迪逊单车站之间的距离,我会使用以下命令:
|
||||
|
||||
```
|
||||
127.0.0.1:6379> GEODIST NYC:stations:location NYC:station:281 NYC:station:3457 ft
|
||||
"671.4900"
|
||||
```
|
||||
|
||||
最后,`GEORADIUSBYMEMBER` 命令与 `GEORADIUS` 命令类似,但该命令不是采用一组坐标,而是采用索引的另一个成员的名称,并返回以该成员为中心的给定半径内的所有成员。 要查找陆军广场中央公园南单车站 1000 英尺范围内的所有车站,请输入以下内容:
|
||||
|
||||
```
|
||||
127.0.0.1:6379> GEORADIUSBYMEMBER NYC:stations:location NYC:station:281 1000 ft WITHDIST
|
||||
1) 1) "NYC:station:281"
|
||||
2) "0.0000"
|
||||
2) 1) "NYC:station:3132"
|
||||
2) "793.4223"
|
||||
3) 1) "NYC:station:2006"
|
||||
2) "911.9752"
|
||||
4) 1) "NYC:station:3136"
|
||||
2) "940.3399"
|
||||
5) 1) "NYC:station:3457"
|
||||
2) "671.4900"
|
||||
```
|
||||
|
||||
虽然此示例侧重于使用 Python 和 Redis 来解析数据并构建共享单车系统位置的索引,但可以很容易地衍生为定位餐馆、公共交通或者是开发人员希望帮助用户找到的任何其他类型的场所。
|
||||
|
||||
本文基于今年我在北卡罗来纳州罗利市的开源 101 会议上的[演讲][17]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/building-bikesharing-application-open-source-tools
|
||||
|
||||
作者:[Tague Griffith][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/tague
|
||||
[1]: https://www.python.org/
|
||||
[2]: https://redis.io/
|
||||
[3]: https://www.citibikenyc.com/
|
||||
[4]: https://www.citibikenyc.com/data-sharing-policy
|
||||
[5]: https://github.com/NABSA/gbfs
|
||||
[6]: http://nabsa.net/
|
||||
[7]: https://www.json.org/
|
||||
[8]: https://gist.github.com/tague/5a82d96bcb09ce2a79943ad4c87f6e15
|
||||
[9]: https://github.com/NABSA/gbfs/blob/master/systems.csv
|
||||
[10]: https://redis.io/commands/unlink
|
||||
[11]: https://redis.io/commands/hmset
|
||||
[12]: https://raw.githubusercontent.com/antirez/redis/4.0/00-RELEASENOTES
|
||||
[13]: https://redis.io/topics/data-types#Hashes
|
||||
[14]: https://redis.io/commands#geo
|
||||
[15]: https://redis.io/topics/data-types-intro#redis-sorted-sets
|
||||
[16]: https://twitter.com/swatchthedog
|
||||
[17]: http://opensource101.com/raleigh/talks/building-location-aware-apps-open-source-tools/
|
||||
@ -0,0 +1,78 @@
|
||||
Emacs 系列(一):抛掉一切,投入 Emacs 和 Org 模式的怀抱
|
||||
======
|
||||
|
||||
我必须承认,在使用了几十年的 vim 后, 我被 [Emacs][1] 吸引了。
|
||||
|
||||
长期以来,我一直对如何组织安排事情感到沮丧。我也有用过 [GTD][2] 和 [ZTD][3] 之类的方法,但是像邮件或是大型文件这样的事务真的很难来组织安排。
|
||||
|
||||
我一直在用 Asana 处理任务,用 Evernote 做笔记,用 Thunderbird 处理邮件,把 ikiwiki 和其他的一些项目组合作为个人知识库,而且还在电脑的归档了各种文件。当我的新工作需要将 Slack 也加入进来时,我终于忍无可忍了。
|
||||
|
||||
许多 TODO 管理工具与电子邮件集成的很差。当你想做“提醒我在一周内回复这个邮件”之类的事时,很多时候是不可能的,因为这个工具不能以一种能够轻松回复的方式存储邮件。而这个问题在 Slack 上更为严重。
|
||||
|
||||
就在那时,我偶然发现了 [Carsten Dominik 在 Google Talk 上关于 Org 模式的讲话][4]。Carsten 是 Org 模式的作者,即便是这个讲话已经有 10 年了,但它仍然很具有参考价值。
|
||||
|
||||
我之前有用过 [Org 模式][5],但是每次我都没有真正的深入研究它,
|
||||
因为我当时的反应是“一个大纲编辑器?但我需要的是待办事项列表”。我就这么错过了它。但实际上 Org 模式就是我所需要的。
|
||||
|
||||
### 什么是 Emacs?什么是 Org 模式?
|
||||
|
||||
Emacs 最初是一个文本编辑器,现在依然是一个文本编辑器,而且这种传统无疑贯穿始终。但是说 Emacs 是个编辑器是很不公平的。
|
||||
|
||||
Emacs 更像一个平台或是工具包。你不仅可以用它来编辑源代码,而且配置 Emacs 本身也是编程,里面有很多模式。就像编写一个 Firefox 插件一样简单,只要几行代码,然后,模式里的操作就改变了。
|
||||
|
||||
Org 模式也一样。确实,它是一个大纲编辑器,但它真正所包含的不止如此。它是一个信息组织平台。它的网站上写着,“你可以用纯文本来记录你的生活:你可以用 Org 模式来记笔记,处理待办事项,规划项目和使用快速有效的纯文本系统编写文档。”
|
||||
|
||||
### 捕获
|
||||
|
||||
如果你读过基于 GTD 的生产力指南,那么他们强调的一件事就是毫不费力地获取项目。这个想法是,当某件事突然出现在你的脑海里时,把它迅速输入一个受信任的系统,这样你就可以继续做你正在做的事情。Org 模式有一个专门的捕获系统。我可以在 Emacs 的任何地方按下 `C-c c` 键,它就会空出一个位置来记录我的笔记。最关键的是,自动嵌入到笔记中的链接可以链接到我按下 `C-c c` 键时正在编辑的那一行。如果我正在编辑文件,它会链回到那个文件和我所在的行。如果我正在浏览邮件,它就会链回到那封邮件(通过邮件的 Message-Id,这样它就可以在任何一个文件夹中找到邮件)。聊天时也一样,甚至是当你在另一个 Org 模式中也可也这样。
|
||||
|
||||
这样我就可以做一个笔记,它会提醒我在一周内回复某封邮件,当我点击这个笔记中的链接时,它会在我的邮件阅读器中弹出这封邮件 —— 即使我随后将它从收件箱中存档。
|
||||
|
||||
没错,这正是我要找的!
|
||||
|
||||
### 工具套件
|
||||
|
||||
一旦你开始使用 Org 模式,很快你就会想将所有的事情都集成到里面。有可以从网络上捕获内容的浏览器插件,也有多个 Emacs 邮件或新闻阅读器与之集成,ERC(IRC 客户端)也不错。所以我将自己从 Thunderbird 和 mairix + mutt (用于邮件归档)换到了 mu4e,从 xchat + slack 换到了 ERC。
|
||||
|
||||
你可能不明白,我喜欢这些基于 Emacs 的工具,而不是具有相同功能的单独的工具。
|
||||
|
||||
一个小花絮:我又在使用离线 IMAP 了!我甚至在很久以前就用过 GNUS。
|
||||
|
||||
### 用一个 Emacs 进程来管理
|
||||
|
||||
我以前也经常使用 Emacs,那时,Emacs 是一个“大”的程序(现在显示电源状态的小程序占用的内存要比 Emacs 多)。当时存在在启动时间过长的问题,但是现在已经有连接到一个正在运行的 Emacs 进程的解决方法。
|
||||
|
||||
我喜欢用 Mod-p(一个 [xmonad][6] 中 [dzen][7] 菜单栏的快捷方式,但是在大多数传统的桌面环境中该功能的快捷键是 `Alt-F2`)来启动程序(LCTT 译注:xmonad 是一种平铺桌面;dzen 是 X11 窗口下管理消息、提醒和菜单的程序)。这个设置在不运行多个<ruby>[emacs 们](https://www.emacswiki.org/emacs/Emacsen)<rt>emacsen</rt></ruby>时很方便,因为这样就不会在试图捕获另一个打开的文件时出问题。这中方法很简单:创建一个叫 `em` 的脚本并将它放到我自己的环境变量中。就像这样:
|
||||
|
||||
```
|
||||
#!/bin/bash exec emacsclient -c -a "" "$@"
|
||||
```
|
||||
|
||||
如果没有 emacs 进程存在的话,就会创建一个新的 emacs 进程,否则的话就直接使用已存在的进程。这样做还有一个好处:`-nw` 之类的参数工作的很好,它实际上就像在 shell 提示符下输入 `emacs` 一样。它很适合用于设置 `EDITOR` 环境变量。
|
||||
|
||||
### 下一篇
|
||||
|
||||
接下来我将讨论我的使用情况,并展示以下的配置:
|
||||
|
||||
* Org 模式,包括计算机之间的同步、捕获、日程和待办事项、文件、链接、关键字和标记、各种导出(幻灯片)等。
|
||||
* mu4e,用于电子邮件,包括多个账户,bbdb 集成
|
||||
* ERC,用于 IRC 和即时通讯
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://changelog.complete.org/archives/9861-emacs-1-ditching-a-bunch-of-stuff-and-moving-to-emacs-and-org-mode
|
||||
|
||||
作者:[John Goerzen][a]
|
||||
译者:[oneforalone](https://github.com/oneforalone)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://changelog.complete.org/archives/author/jgoerzen
|
||||
[1]:https://www.gnu.org/software/emacs/
|
||||
[2]:https://gettingthingsdone.com/
|
||||
[3]:https://zenhabits.net/zen-to-done-the-simple-productivity-e-book/
|
||||
[4]:https://www.youtube.com/watch?v=oJTwQvgfgMM
|
||||
[5]:https://orgmode.org/
|
||||
[6]:https://wiki.archlinux.org/index.php/Xmonad_(%E7%AE%80%E4%BD%93%E4%B8%AD%E6%96%87)
|
||||
[7]:http://robm.github.io/dzen/
|
||||
@ -1,118 +1,101 @@
|
||||
Python 数据科学入门
|
||||
======
|
||||
|
||||
> 不需要昂贵的工具即可领略数据科学的力量,从这些开源工具起步即可。
|
||||
|
||||

|
||||
|
||||
无论你是一个具有数学或计算机科学背景的数据科学爱好者,还是一个其它领域的专家,数据科学提供的可能性都在你力所能及的范围内,而且你不需要昂贵的,高度专业化的企业软件。本文中讨论的开源工具就是你入门时所需的全部内容。
|
||||
无论你是一个具有数学或计算机科学背景的资深数据科学爱好者,还是一个其它领域的专家,数据科学提供的可能性都在你力所能及的范围内,而且你不需要昂贵的,高度专业化的企业级软件。本文中讨论的开源工具就是你入门时所需的全部内容。
|
||||
|
||||
[Python][1],其机器学习和数据科学库([pandas][2], [Keras][3], [TensorFlow][4], [scikit-learn][5], [SciPy][6], [NumPy][7] 等),以及大量可视化库([Matplotlib][8], [pyplot][9], [Plotly][10] 等)对于初学者和专家来说都是优秀的 FOSS(译注:全称为 Free and Open Source Software)工具。它们易于学习,很受欢迎且受到社区支持,并拥有为数据科学开发的最新技术和算法。它们是你在开始学习时可以获得的最佳工具集之一。
|
||||
[Python][1],其机器学习和数据科学库([pandas][2]、 [Keras][3]、 [TensorFlow][4]、 [scikit-learn][5]、 [SciPy][6]、 [NumPy][7] 等),以及大量可视化库([Matplotlib][8]、[pyplot][9]、 [Plotly][10] 等)对于初学者和专家来说都是优秀的自由及开源软件工具。它们易于学习,很受欢迎且受到社区支持,并拥有为数据科学而开发的最新技术和算法。它们是你在开始学习时可以获得的最佳工具集之一。
|
||||
|
||||
许多 Python 库都是建立在彼此之上的(称为依赖项),其基础是 [NumPy][7] 库。NumPy 专门为数据科学设计,经常用于在其 ndarray 数据类型中存储数据集的相关部分。ndarray 是一种方便的数据类型,用于将关系表中的记录存储为 `cvs` 文件或其它任何格式,反之亦然。将 scikit 功能应用于多维数组时,它特别方便。SQL 非常适合查询数据库,但是对于执行复杂和资源密集型的数据科学操作,在 ndarray 中存储数据可以提高效率和速度(确保在处理大量数据集时有足够的 RAM)。当你使用 pandas 进行知识提取和分析时,pandas 中的 DataFrame 数据类型和 NumPy 中的 ndarray 之间的无缝转换分别为提取和计算密集型操作创建了一个强大的组合。
|
||||
许多 Python 库都是建立在彼此之上的(称为依赖项),其基础是 [NumPy][7] 库。NumPy 专门为数据科学设计,经常被用于在其 ndarray 数据类型中存储数据集的相关部分。ndarray 是一种方便的数据类型,用于将关系表中的记录存储为 `cvs` 文件或其它任何格式,反之亦然。将 scikit 函数应用于多维数组时,它特别方便。SQL 非常适合查询数据库,但是对于执行复杂和资源密集型的数据科学操作,在 ndarray 中存储数据可以提高效率和速度(但请确保在处理大量数据集时有足够的 RAM)。当你使用 pandas 进行知识提取和分析时,pandas 中的 DataFrame 数据类型和 NumPy 中的 ndarray 之间的无缝转换分别为提取和计算密集型操作创建了一个强大的组合。
|
||||
|
||||
作为快速演示,让我们启动 Python shell 并在 pandas DataFrame 变量中加载来自巴尔的摩的犯罪统计数据的开放数据集,并查看加载的一部分 DataFrame:
|
||||
|
||||
为了快速演示,让我们启动 Python shel 并在 pandas DataFrame 变量中加载来自巴尔的摩(Baltimore)的犯罪统计数据的开放数据集,并查看加载 frame 的一部分:
|
||||
```
|
||||
>>> import pandas as pd
|
||||
|
||||
>>> crime_stats = pd.read_csv('BPD_Arrests.csv')
|
||||
|
||||
>>> crime_stats.head()
|
||||
```
|
||||
|
||||

|
||||
|
||||
我们现在可以在这个 pandas DataFrame 上执行大多数查询就像我们可以在数据库中使用 SQL。例如,要获取 "Description"属性的所有唯一值,SQL 查询是:
|
||||
我们现在可以在这个 pandas DataFrame 上执行大多数查询,就像我们可以在数据库中使用 SQL 一样。例如,要获取 `Description` 属性的所有唯一值,SQL 查询是:
|
||||
|
||||
```
|
||||
$ SELECT unique(“Description”) from crime_stats;
|
||||
|
||||
```
|
||||
|
||||
利用 pandas DataFrame 编写相同的查询如下所示:
|
||||
|
||||
```
|
||||
>>> crime_stats['Description'].unique()
|
||||
|
||||
['COMMON ASSAULT' 'LARCENY' 'ROBBERY - STREET' 'AGG. ASSAULT'
|
||||
|
||||
'LARCENY FROM AUTO' 'HOMICIDE' 'BURGLARY' 'AUTO THEFT'
|
||||
|
||||
'ROBBERY - RESIDENCE' 'ROBBERY - COMMERCIAL' 'ROBBERY - CARJACKING'
|
||||
|
||||
'ASSAULT BY THREAT' 'SHOOTING' 'RAPE' 'ARSON']
|
||||
|
||||
>>> crime_stats['Description'].unique()
|
||||
['COMMON ASSAULT' 'LARCENY' 'ROBBERY - STREET' 'AGG. ASSAULT'
|
||||
'LARCENY FROM AUTO' 'HOMICIDE' 'BURGLARY' 'AUTO THEFT'
|
||||
'ROBBERY - RESIDENCE' 'ROBBERY - COMMERCIAL' 'ROBBERY - CARJACKING'
|
||||
'ASSAULT BY THREAT' 'SHOOTING' 'RAPE' 'ARSON']
|
||||
```
|
||||
|
||||
它返回的是一个 NumPy 数组(ndarray 类型):
|
||||
|
||||
```
|
||||
>>> type(crime_stats['Description'].unique())
|
||||
|
||||
<class 'numpy.ndarray'>
|
||||
|
||||
>>> type(crime_stats['Description'].unique())
|
||||
<class 'numpy.ndarray'>
|
||||
```
|
||||
|
||||
接下来让我们将这些数据输入神经网络,看看它能多准确地预测使用的武器类型,给出的数据包括犯罪事件,犯罪类型以及发生的地点:
|
||||
|
||||
```
|
||||
>>> from sklearn.neural_network import MLPClassifier
|
||||
|
||||
>>> import numpy as np
|
||||
|
||||
>>> from sklearn.neural_network import MLPClassifier
|
||||
>>> import numpy as np
|
||||
>>>
|
||||
|
||||
>>> prediction = crime_stats[[‘Weapon’]]
|
||||
|
||||
>>> predictors = crime_stats['CrimeTime', ‘CrimeCode’, ‘Neighborhood’]
|
||||
|
||||
>>> prediction = crime_stats[[‘Weapon’]]
|
||||
>>> predictors = crime_stats['CrimeTime', ‘CrimeCode’, ‘Neighborhood’]
|
||||
>>>
|
||||
|
||||
>>> nn_model = MLPClassifier(solver='lbfgs', alpha=1e-5, hidden_layer_sizes=(5,2), random_state=1)
|
||||
|
||||
>>> nn_model = MLPClassifier(solver='lbfgs', alpha=1e-5, hidden_layer_sizes=(5,
|
||||
2), random_state=1)
|
||||
>>>
|
||||
|
||||
>>>predict_weapon = nn_model.fit(prediction, predictors)
|
||||
|
||||
>>>predict_weapon = nn_model.fit(prediction, predictors)
|
||||
```
|
||||
|
||||
现在学习模型准备就绪,我们可以执行一些测试来确定其质量和可靠性。对于初学者,让我们输入一个训练集数据(用于训练模型的原始数据集的一部分,不包括在创建模型中):
|
||||
```
|
||||
>>> predict_weapon.predict(training_set_weapons)
|
||||
|
||||
array([4, 4, 4, ..., 0, 4, 4])
|
||||
|
||||
```
|
||||
|
||||
如你所见,它返回一个列表,每个数字预测训练集中每个记录的武器。我们之所以看到的是数字而不是武器名称,是因为大多数分类算法都是用数字优化的。对于分类数据,有一些技术可以将属性转换为数字表示。在这种情况下,使用的技术是 Label Encoder,使用 sklearn 预处理库中的 LabelEncoder 函数:`preprocessing.LabelEncoder()`。它能够对一个数据和其对应的数值表示来进行变换和逆变换。在这个例子中,我们可以使用 LabelEncoder() 的 `inverse_transform` 函数来查看武器 0 和 4 是什么:
|
||||
>>> predict_weapon.predict(training_set_weapons)
|
||||
array([4, 4, 4, ..., 0, 4, 4])
|
||||
```
|
||||
>>> preprocessing.LabelEncoder().inverse_transform(encoded_weapons)
|
||||
|
||||
array(['HANDS', 'FIREARM', 'HANDS', ..., 'FIREARM', 'FIREARM', 'FIREARM']
|
||||
如你所见,它返回一个列表,每个数字预测训练集中每个记录的武器。我们之所以看到的是数字而不是武器名称,是因为大多数分类算法都是用数字优化的。对于分类数据,有一些技术可以将属性转换为数字表示。在这种情况下,使用的技术是标签编码,使用 sklearn 预处理库中的 `LabelEncoder` 函数:`preprocessing.LabelEncoder()`。它能够对一个数据和其对应的数值表示来进行变换和逆变换。在这个例子中,我们可以使用 `LabelEncoder()` 的 `inverse_transform` 函数来查看武器 0 和 4 是什么:
|
||||
|
||||
```
|
||||
>>> preprocessing.LabelEncoder().inverse_transform(encoded_weapons)
|
||||
array(['HANDS', 'FIREARM', 'HANDS', ..., 'FIREARM', 'FIREARM', 'FIREARM']
|
||||
```
|
||||
|
||||
这很有趣,但为了了解这个模型的准确程度,我们将几个分数计算为百分比:
|
||||
```
|
||||
>>> nn_model.score(X, y)
|
||||
|
||||
```
|
||||
>>> nn_model.score(X, y)
|
||||
0.81999999999999995
|
||||
|
||||
```
|
||||
|
||||
这表明我们的神经网络模型准确度约为 82%。这个结果似乎令人印象深刻,但用于不同的犯罪数据集时,检查其有效性非常重要。还有其它测试来做这个,如相关性,混淆,矩阵等。尽管我们的模型有很高的准确率,但它对于一般犯罪数据集并不是非常有用,因为这个特定数据集具有不成比例的行数,其列出 ‘FIREARM’ 作为使用的武器。除非重新训练,否则我们的分类器最有可能预测 ‘FIREARM’,即使输入数据集有不同的分布。
|
||||
这表明我们的神经网络模型准确度约为 82%。这个结果似乎令人印象深刻,但用于不同的犯罪数据集时,检查其有效性非常重要。还有其它测试来做这个,如相关性、混淆、矩阵等。尽管我们的模型有很高的准确率,但它对于一般犯罪数据集并不是非常有用,因为这个特定数据集具有不成比例的行数,其列出 `FIREARM` 作为使用的武器。除非重新训练,否则我们的分类器最有可能预测 `FIREARM`,即使输入数据集有不同的分布。
|
||||
|
||||
在对数据进行分类之前清洗数据并删除异常值和畸形数据非常重要。预处理越好,我们的见解准确性就越高。此外,为模型或分类器提供过多数据(通常超过 90%)以获得更高的准确度是一个坏主意,因为它看起来准确但由于[过度拟合][11]而无效。
|
||||
|
||||
[Jupyter notebooks][12] 相对于命令行来说是一个很好的交互式替代品。虽然 CLI 对大多数事情都很好,但是当你想要运行代码片段以生成可视化时,Jupyter 会很出色。它比终端更好地格式化数据。
|
||||
[Jupyter notebooks][12] 相对于命令行来说是一个很好的交互式替代品。虽然 CLI 对于大多数事情都很好,但是当你想要运行代码片段以生成可视化时,Jupyter 会很出色。它比终端更好地格式化数据。
|
||||
|
||||
[这篇文章][13] 列出了一些最好的机器学习免费资源,但是还有很多其它的指导和教程。根据你的兴趣和爱好,你还会发现许多开放数据集可供使用。作为起点,由 [Kaggle][14] 维护的数据集,以及在州政府网站上提供的数据集是极好的资源。
|
||||
|
||||
(to 校正:最后这句话不知该如何理解)
|
||||
Payal Singh 将出席今年 3 月 8 日至 11 日在 California(加利福尼亚)的 Pasadena(帕萨迪纳)举行的 SCaLE16x。要参加并获得 50% 的门票优惠,[注册][15]使用优惠码**OSDC**。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/getting-started-data-science
|
||||
|
||||
作者:[Payal Singh][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,26 +1,34 @@
|
||||
DevOps应聘者应该准备回答的20个问题
|
||||
DevOps 应聘者应该准备回答的 20 个问题
|
||||
======
|
||||
|
||||
> 想要建立一个积极,富有成效的工作环境? 在招聘过程中要专注于寻找契合点。
|
||||
|
||||

|
||||
聘请一个不合适的人代价是很高的。根据Link人力资源的首席执行官Jörgen Sundberg的统计,招聘,雇佣一名新员工将会花费公司$240,000之多,当你进行了一次不合适的招聘:
|
||||
* 你失去了他们所知道的。
|
||||
* 你失去了他们认识的人
|
||||
|
||||
聘请一个不合适的人[代价是很高的][1]。根据 Link 人力资源的首席执行官 Jörgen Sundberg 的统计,招聘、雇佣一名新员工将会花费公司$240,000 之多,当你进行了一次不合适的招聘:
|
||||
|
||||
* 你失去了他们的知识技能。
|
||||
* 你失去了他们的人脉。
|
||||
* 你的团队将可能进入到一个组织发展的震荡阶段
|
||||
* 你的公司将会面临组织破裂的风险
|
||||
|
||||
当你失去一名员工的时候,你就像丢失了公司图谱中的一块。同样值得一提的是另一端的疼痛。应聘到一个错误工作岗位的员工会感受到很大的压力以及整个身心的不满意,甚至是健康问题。
|
||||
当你失去一名员工的时候,你就像丢失了公司版图中的一块。同样值得一提的是另一端的痛苦。应聘到一个错误工作岗位的员工会感受到很大的压力以及整个身心的不满意,甚至是健康问题。
|
||||
|
||||
另外一方面,当你招聘到合适的人时,新的员工将会:
|
||||
* 丰富公司现有的文化,使你的组织成为一个更好的工作场所。研究表明一个积极的工作文化能够帮助驱动一个更长久的财务业绩,而且如果你在一个欢快的环境中工 作,你更有可能在生活中做的更好。
|
||||
|
||||
* 丰富公司现有的文化,使你的组织成为一个更好的工作场所。研究表明一个积极的工作文化能够帮助更长久推动财务业绩增长,而且如果你在一个欢快的环境中工作,你更有可能在生活中做的更好。
|
||||
* 热爱和你的组织在一起工作。当人们热爱他们所在做的,他们会趋向于做的更好。
|
||||
|
||||
招聘适合的或者加强现有的文化在DevOps和敏捷团多中是必不可少的。也就是说雇佣到一个能够鼓励积极合作的人,以便来自不同背景,有着不同目标和工作方式的团队能够在一起有效的工作。你新雇佣的员工因应该能够帮助团队合作来充分发挥放大他们的价值同时也能够增加员工的满意度以及平衡组织目标的冲突。他或者她应该能够通过明智的选择工具和工作流来促进你的组织,文化就是一切。
|
||||
招聘以适合或加强现有的文化在 DevOps 和敏捷团多中是必不可少的。也就是说雇佣到一个能够鼓励积极合作的人,以便来自不同背景,有着不同目标和工作方式的团队能够在一起有效的工作。你新雇佣的员工应该能够帮助团队合作来充分发挥放大他们的价值,同时也能够增加员工的满意度以及平衡组织目标的冲突。他或者她应该能够通过明智的选择工具和工作流来促进你的组织,文化就是一切。
|
||||
|
||||
作为我们 2017 年 11 月发布的一篇文章 [DevOps 的招聘经理应该准备回答的 20 个问题][4] 的回应,这篇文章将会重点关注在如何招聘最适合的人。
|
||||
|
||||
作为我们2017年11月发布的一篇文章,[DevOps的招聘经理应该准备回答的20个问题][4],这篇文章将会重点关注在如何招聘最适合的人。
|
||||
### 为什么招聘走错了方向
|
||||
很多公司现在在用的典型的雇佣策略是基于人才过剩的基础上:
|
||||
|
||||
* 职位公告栏。
|
||||
* 关注和所需才能符合的应聘者。
|
||||
很多公司现在用的典型的雇佣策略是基于人才过剩的基础上:
|
||||
|
||||
* 在职位公告栏发布招聘。
|
||||
* 关注具有所需才能的应聘者。
|
||||
* 尽可能找多的候选者。
|
||||
* 通过面试淘汰弱者。
|
||||
* 通过正式的面试淘汰更多的弱者。
|
||||
@ -30,37 +38,48 @@ DevOps应聘者应该准备回答的20个问题
|
||||

|
||||
|
||||
职位公告栏是有成千上万失业者人才过剩的经济大萧条时期发明的。在今天的求职市场上已经没有人才过剩了,然而我们仍然在使用基于此的招聘策略。
|
||||
|
||||

|
||||
|
||||
### 雇佣最合适的人员:运用文化和情感
|
||||
在人才过剩雇佣策略背后的思想是去设计工作岗位然后将人员安排进去。
|
||||
相反,做相反的事情:寻找将会积极融入你的商业文化的人才,然后为他们寻找他们热爱的最合适的岗位。要想如此实现,你必须能够围绕他们热情为他们创造工作岗位。
|
||||
**谁正在寻找一份工作?** 根据一份2016年对美国50,000名开发者的调查显示,[85.7%的受访对象][5]要么对新的机会不感兴趣,要么对于寻找新工作没有积极性。在寻找工作的那部分中,有将近[28.3%的求职者][5]来自于朋友的推荐。如果你只是在那些在找工作的人中寻找人才,你将会错过高端的人才。
|
||||
**运用团队力量去发现和寻找潜力的雇员**。列如,戴安娜是你的团队中的一名开发者,她所提供的机会即使她已经从事编程很多年而且在期间已经结识了很多从事热爱他们所从事的工作的人。难道你不认为她所推荐的潜在员工在技能,知识和智慧上要比HR所寻找的要优秀吗?在要求戴安娜分享她同伴之前,通知她即将到来的使命任务,向她阐明你要雇佣潜在有探索精神的团队,描述在将来会需要的知识领域。
|
||||
**雇员想要什么?**一份来自千禧年,婴儿潮实时期出生的人的对比综合性研究显示,20% 的人所想要的是相同的:
|
||||
|
||||
在人才过剩雇佣策略背后的思想是设计工作岗位然后将人员安排进去。
|
||||
|
||||
反而应该反过来:寻找将会积极融入你的商业文化的人才,然后为他们寻找他们热爱的最合适的岗位。要想实现这样的目标,你必须能够围绕他们热情为他们创造工作岗位。
|
||||
|
||||
**谁正在寻找一份工作?** 根据一份 2016 年对美国 50000 名开发者的调查显示,[85.7% 的受访对象][5]要么对新的机会不感兴趣,要么对于寻找新工作没有积极性。在寻找工作的那部分中,有将近 [28.3% 的求职者][5]来自于朋友的推荐。如果你只是在那些在找工作的人中寻找人才,你将会错过高端的人才。
|
||||
|
||||
**运用团队力量去发现和寻找潜力的雇员**。例如,戴安娜是你的团队中的一名开发者,她所能提供的机会是,她已经[从事编程很多年][6]而且在期间已经结识了很多从事热爱他们所从事的工作的人。难道你不认为她所推荐的潜在员工在技能、知识和智慧上要比 HR 所寻找的要优秀吗?在要求戴安娜分享她同伴之前,通知她即将到来的使命任务,向她阐明你要雇佣潜在有探索精神的团队,描述在将来会需要的知识领域。
|
||||
|
||||
**雇员想要什么?**一份来自千禧年婴儿潮时期出生的人的对比综合性研究显示,20% 的人所想要的是相同的:
|
||||
|
||||
1. 对组织产生积极的影响
|
||||
2. 帮助解决社交或者环境上的挑战
|
||||
3. 和一群有动力的人一起工作
|
||||
|
||||
### 面试的挑战
|
||||
面试应该是招聘者和应聘者双方为了寻找最合适的人才进行的一次双方之间的对话。将面试聚焦在企业文化和情感对话两个问题上:这个应聘者将会丰富你的企业文化并且会热爱和你在一起工作吗?你能够在工作中帮他们取得成功吗?
|
||||
**对于招聘经理来说:** 每一次的面试都是你学习如何将自己的组织变得对未来的团队成员更有吸引力,并且每次积极的面试多都可能是你发现人才(即使你不会雇佣)的机会。每个人都将会记得积极有效的面试的经历。即使他们不会被雇佣,他们将会和他们的朋友谈论这次经历,你竟会得到一个被推荐的机会。这又很大的好处:如果你无法吸引到这个人才,你也将会从中学习吸取经验并且改善。
|
||||
**对面试者来说**:每次的面试都是你释放激情的机会
|
||||
|
||||
### 助你释放潜在雇员激情的20个问题
|
||||
面试应该是招聘者和应聘者双方为了寻找最合适的人才进行的一次双方之间的对话。将面试聚焦在企业文化和情感对话两个问题上:这个应聘者将会丰富你的企业文化并且会热爱和你在一起工作吗?你能够在工作中帮他们取得成功吗?
|
||||
|
||||
**对于招聘经理来说:** 每一次的面试都是你学习如何将自己的组织变得对未来的团队成员更有吸引力,并且每次积极的面试都可能是你发现人才(即使你不会雇佣)的机会。每个人都将会记得积极有效的面试的经历。即使他们不会被雇佣,他们将会和他们的朋友谈论这次经历,你会得到一个被推荐的机会。这有很大的好处:如果你无法吸引到这个人才,你也将会从中学习吸取经验并且改善。
|
||||
|
||||
**对面试者来说**:每次的面试都是你释放激情的机会。
|
||||
|
||||
### 助你释放潜在雇员激情的 20 个问题
|
||||
|
||||
1. 你热爱什么?
|
||||
2. “今天早晨我已经迫不及待的要去工作”你怎么看待这句话?
|
||||
2. “今天早晨我已经迫不及待的要去工作”,你怎么看待这句话?
|
||||
3. 你曾经最快乐的是什么?
|
||||
4. 你曾经解决问题的最典型的例子是什么,你是如何解决的?
|
||||
5. 你如何看待配对学习?
|
||||
6. 你到达办公室和离开办公室心里最先想到的是什么?
|
||||
7. 你如果你有一次改变你之前或者现在的共工作的一件事的机会,将会是什么事?
|
||||
8. 当你在这工作的时候,你最兴奋去学习什么?
|
||||
7. 你如果你有一次改变你之前或者现在的工作中的一件事的机会,将会是什么事?
|
||||
8. 当你在工作的时候,你最乐于去学习什么?
|
||||
9. 你的梦想是什么,你如何去实现?
|
||||
10. 你在学会如何去实现你的追求的时候想要或者需要什么?
|
||||
11. 你的价值观是什么?
|
||||
12. 你是如何坚守自己的价值观的?
|
||||
13. 平衡在你的生活中意味着什么?
|
||||
13. 在你的生活中平衡意味着什么?
|
||||
14. 你最引以为傲的工作交流能力是什么?为什么?
|
||||
15. 你最喜欢营造什么样的环境?
|
||||
16. 你喜欢别人怎样对待你?
|
||||
@ -70,14 +89,13 @@ DevOps应聘者应该准备回答的20个问题
|
||||
20. 如果你正在雇佣我,你将会问我什么问题?
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/questions-devops-employees-should-answer
|
||||
|
||||
作者:[Catherine Louis][a]
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,447 @@
|
||||
17 种查看 Linux 物理内存的方法
|
||||
=======
|
||||
|
||||
大多数系统管理员在遇到性能问题时会检查 CPU 和内存利用率。Linux 中有许多实用程序可以用于检查物理内存。这些命令有助于我们检查系统中存在的物理内存,还允许用户检查各种方面的内存利用率。
|
||||
|
||||
我们大多数人只知道很少的命令,在本文中我们试图包含所有可能的命令。
|
||||
|
||||
你可能会想,为什么我想知道所有这些命令,而不是知道一些特定的和例行的命令呢。
|
||||
|
||||
不要觉得没用或对此有负面的看法,因为每个人都有不同的需求和看法,所以,对于那些在寻找其它目的的人,这对于他们非常有帮助。
|
||||
|
||||
### 什么是 RAM
|
||||
|
||||
计算机内存是能够临时或永久存储信息的物理设备。RAM 代表随机存取存储器,它是一种易失性存储器,用于存储操作系统,软件和硬件使用的信息。
|
||||
|
||||
有两种类型的内存可供选择:
|
||||
|
||||
* 主存
|
||||
* 辅助内存
|
||||
|
||||
主存是计算机的主存储器。CPU 可以直接读取或写入此内存。它固定在电脑的主板上。
|
||||
|
||||
* **RAM**:随机存取存储器是临时存储。关闭计算机后,此信息将消失。
|
||||
* **ROM**: 只读存储器是永久存储,即使系统关闭也能保存数据。
|
||||
|
||||
### 方法-1:使用 free 命令
|
||||
|
||||
`free` 显示系统中空闲和已用的物理内存和交换内存的总量,以及内核使用的缓冲区和缓存。它通过解析 `/proc/meminfo` 来收集信息。
|
||||
|
||||
**建议阅读:** [free – 在 Linux 系统中检查内存使用情况统计(空闲和已用)的标准命令][1]
|
||||
|
||||
```
|
||||
$ free -m
|
||||
total used free shared buff/cache available
|
||||
Mem: 1993 1681 82 81 228 153
|
||||
Swap: 12689 1213 11475
|
||||
|
||||
$ free -g
|
||||
total used free shared buff/cache available
|
||||
Mem: 1 1 0 0 0 0
|
||||
Swap: 12 1 11
|
||||
```
|
||||
|
||||
### 方法-2:使用 /proc/meminfo 文件
|
||||
|
||||
`/proc/meminfo` 是一个虚拟文本文件,它包含有关系统 RAM 使用情况的大量有价值的信息。
|
||||
|
||||
它报告系统上的空闲和已用内存(物理和交换)的数量。
|
||||
|
||||
```
|
||||
$ grep MemTotal /proc/meminfo
|
||||
MemTotal: 2041396 kB
|
||||
|
||||
$ grep MemTotal /proc/meminfo | awk '{print $2 / 1024}'
|
||||
1993.55
|
||||
|
||||
$ grep MemTotal /proc/meminfo | awk '{print $2 / 1024 / 1024}'
|
||||
1.94683
|
||||
```
|
||||
|
||||
### 方法-3:使用 top 命令
|
||||
|
||||
`top` 命令是 Linux 中监视实时系统进程的基本命令之一。它显示系统信息和运行的进程信息,如正常运行时间、平均负载、正在运行的任务、登录的用户数、CPU 数量和 CPU 利用率,以及内存和交换信息。运行 `top` 命令,然后按下 `E` 来使内存利用率以 MB 为单位显示。
|
||||
|
||||
**建议阅读:** [TOP 命令示例监视服务器性能][2]
|
||||
|
||||
```
|
||||
$ top
|
||||
|
||||
top - 14:38:36 up 1:59, 1 user, load average: 1.83, 1.60, 1.52
|
||||
Tasks: 223 total, 2 running, 221 sleeping, 0 stopped, 0 zombie
|
||||
%Cpu(s): 48.6 us, 11.2 sy, 0.0 ni, 39.3 id, 0.3 wa, 0.0 hi, 0.5 si, 0.0 st
|
||||
MiB Mem : 1993.551 total, 94.184 free, 1647.367 used, 252.000 buff/cache
|
||||
MiB Swap: 12689.58+total, 11196.83+free, 1492.750 used. 306.465 avail Mem
|
||||
|
||||
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
||||
9908 daygeek 20 0 2971440 649324 39700 S 55.8 31.8 11:45.74 Web Content
|
||||
21942 daygeek 20 0 2013760 308700 69272 S 35.0 15.1 4:13.75 Web Content
|
||||
4782 daygeek 20 0 3687116 227336 39156 R 14.5 11.1 16:47.45 gnome-shell
|
||||
```
|
||||
|
||||
### 方法-4:使用 vmstat 命令
|
||||
|
||||
`vmstat` 是一个漂亮的标准工具,它报告 Linux 系统的虚拟内存统计信息。`vmstat` 报告有关进程、内存、分页、块 IO、陷阱和 CPU 活动的信息。它有助于 Linux 管理员在故障检修时识别系统瓶颈。
|
||||
|
||||
**建议阅读:** [vmstat – 一个报告虚拟内存统计信息的标准且漂亮的工具][3]
|
||||
|
||||
```
|
||||
$ vmstat -s | grep "total memory"
|
||||
2041396 K total memory
|
||||
|
||||
$ vmstat -s -S M | egrep -ie 'total memory'
|
||||
1993 M total memory
|
||||
|
||||
$ vmstat -s | awk '{print $1 / 1024 / 1024}' | head -1
|
||||
1.94683
|
||||
|
||||
```
|
||||
|
||||
### 方法-5:使用 nmon 命令
|
||||
|
||||
`nmon` 是另一个很棒的工具,用于在 Linux 终端上监视各种系统资源,如 CPU、内存、网络、磁盘、文件系统、NFS、top 进程、Power 的微分区和资源(Linux 版本和处理器)。
|
||||
|
||||
只需按下 `m` 键,即可查看内存利用率统计数据(缓存、活动、非活动、缓冲、空闲,以 MB 和百分比为单位)。
|
||||
|
||||
**建议阅读:** [nmon – Linux 中一个监视系统资源的漂亮的工具][4]
|
||||
|
||||
```
|
||||
┌nmon─14g──────[H for help]───Hostname=2daygeek──Refresh= 2secs ───07:24.44─────────────────┐
|
||||
│ Memory Stats ─────────────────────────────────────────────────────────────────────────────│
|
||||
│ RAM High Low Swap Page Size=4 KB │
|
||||
│ Total MB 32079.5 -0.0 -0.0 20479.0 │
|
||||
│ Free MB 11205.0 -0.0 -0.0 20479.0 │
|
||||
│ Free Percent 34.9% 100.0% 100.0% 100.0% │
|
||||
│ MB MB MB │
|
||||
│ Cached= 19763.4 Active= 9617.7 │
|
||||
│ Buffers= 172.5 Swapcached= 0.0 Inactive = 10339.6 │
|
||||
│ Dirty = 0.0 Writeback = 0.0 Mapped = 11.0 │
|
||||
│ Slab = 636.6 Commit_AS = 118.2 PageTables= 3.5 │
|
||||
│───────────────────────────────────────────────────────────────────────────────────────────│
|
||||
│ │
|
||||
│ │
|
||||
│ │
|
||||
│ │
|
||||
│ │
|
||||
│ │
|
||||
└───────────────────────────────────────────────────────────────────────────────────────────┘
|
||||
```
|
||||
|
||||
### 方法-6:使用 dmidecode 命令
|
||||
|
||||
`dmidecode` 是一个读取计算机 DMI 表内容的工具,它以人类可读的格式显示系统硬件信息。(DMI 意即桌面管理接口,也有人说是读取的是 SMBIOS —— 系统管理 BIOS)
|
||||
|
||||
此表包含系统硬件组件的描述,以及其它有用信息,如序列号、制造商信息、发布日期和 BIOS 修改等。
|
||||
|
||||
**建议阅读:** [Dmidecode – 获取 Linux 系统硬件信息的简便方法][5]
|
||||
|
||||
```
|
||||
# dmidecode -t memory | grep Size:
|
||||
Size: 8192 MB
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: 8192 MB
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: 8192 MB
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: 8192 MB
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
Size: No Module Installed
|
||||
```
|
||||
|
||||
只打印已安装的 RAM 模块。
|
||||
|
||||
```
|
||||
# dmidecode -t memory | grep Size: | grep -v "No Module Installed"
|
||||
Size: 8192 MB
|
||||
Size: 8192 MB
|
||||
Size: 8192 MB
|
||||
Size: 8192 MB
|
||||
```
|
||||
|
||||
汇总所有已安装的 RAM 模块。
|
||||
|
||||
```
|
||||
# dmidecode -t memory | grep Size: | grep -v "No Module Installed" | awk '{sum+=$2}END{print sum}'
|
||||
32768
|
||||
```
|
||||
|
||||
### 方法-7:使用 hwinfo 命令
|
||||
|
||||
`hwinfo` 意即硬件信息,它是另一个很棒的实用工具,用于探测系统中存在的硬件,并以人类可读的格式显示有关各种硬件组件的详细信息。
|
||||
|
||||
它报告有关 CPU、RAM、键盘、鼠标、图形卡、声音、存储、网络接口、磁盘、分区、BIOS 和网桥等的信息。
|
||||
|
||||
**建议阅读:** [hwinfo(硬件信息)– 一个在 Linux 系统上检测系统硬件信息的好工具][6]
|
||||
|
||||
```
|
||||
$ hwinfo --memory
|
||||
01: None 00.0: 10102 Main Memory
|
||||
[Created at memory.74]
|
||||
Unique ID: rdCR.CxwsZFjVASF
|
||||
Hardware Class: memory
|
||||
Model: "Main Memory"
|
||||
Memory Range: 0x00000000-0x7a4abfff (rw)
|
||||
Memory Size: 1 GB + 896 MB
|
||||
Config Status: cfg=new, avail=yes, need=no, active=unknown
|
||||
```
|
||||
|
||||
### 方法-8:使用 lshw 命令
|
||||
|
||||
`lshw`(代表 Hardware Lister)是一个小巧的工具,可以生成机器上各种硬件组件的详细报告,如内存配置、固件版本、主板配置、CPU 版本和速度、缓存配置、USB、网卡、显卡、多媒体、打印机、总线速度等。
|
||||
|
||||
它通过读取 `/proc` 目录和 DMI 表中的各种文件来生成硬件信息。
|
||||
|
||||
**建议阅读:** [LSHW (Hardware Lister) – 一个在 Linux 上获取硬件信息的好工具][7]
|
||||
|
||||
```
|
||||
$ sudo lshw -short -class memory
|
||||
[sudo] password for daygeek:
|
||||
H/W path Device Class Description
|
||||
==================================================
|
||||
/0/0 memory 128KiB BIOS
|
||||
/0/1 memory 1993MiB System memory
|
||||
```
|
||||
|
||||
### 方法-9:使用 inxi 命令
|
||||
|
||||
`inxi` 是一个很棒的工具,它可以检查 Linux 上的硬件信息,并提供了大量的选项来获取 Linux 系统上的所有硬件信息,这些特性是我在 Linux 上的其它工具中从未发现的。它是从 locsmif 编写的古老的但至今看来都异常灵活的 infobash 演化而来的。
|
||||
|
||||
`inxi` 是一个脚本,它可以快速显示系统硬件、CPU、驱动程序、Xorg、桌面、内核、GCC 版本、进程、RAM 使用情况以及各种其它有用的信息,还可以用于论坛技术支持和调试工具。
|
||||
|
||||
**建议阅读:** [inxi – 一个检查 Linux 上硬件信息的好工具][8]
|
||||
|
||||
```
|
||||
$ inxi -F | grep "Memory"
|
||||
Info: Processes: 234 Uptime: 3:10 Memory: 1497.3/1993.6MB Client: Shell (bash) inxi: 2.3.37
|
||||
```
|
||||
|
||||
### 方法-10:使用 screenfetch 命令
|
||||
|
||||
`screenfetch` 是一个 bash 脚本。它将自动检测你的发行版,并在右侧显示该发行版标识的 ASCII 艺术版本和一些有价值的信息。
|
||||
|
||||
**建议阅读:** [ScreenFetch – 以 ASCII 艺术标志在终端显示 Linux 系统信息][9]
|
||||
|
||||
```
|
||||
$ screenfetch
|
||||
./+o+- daygeek@ubuntu
|
||||
yyyyy- -yyyyyy+ OS: Ubuntu 17.10 artful
|
||||
://+//////-yyyyyyo Kernel: x86_64 Linux 4.13.0-37-generic
|
||||
.++ .:/++++++/-.+sss/` Uptime: 44m
|
||||
.:++o: /++++++++/:--:/- Packages: 1831
|
||||
o:+o+:++.`..`` `.-/oo+++++/ Shell: bash 4.4.12
|
||||
.:+o:+o/. `+sssoo+/ Resolution: 1920x955
|
||||
.++/+:+oo+o:` /sssooo. DE: GNOME
|
||||
/+++//+:`oo+o /::--:. WM: GNOME Shell
|
||||
\+/+o+++`o++o ++////. WM Theme: Adwaita
|
||||
.++.o+++oo+:` /dddhhh. GTK Theme: Azure [GTK2/3]
|
||||
.+.o+oo:. `oddhhhh+ Icon Theme: Papirus-Dark
|
||||
\+.++o+o``-````.:ohdhhhhh+ Font: Ubuntu 11
|
||||
`:o+++ `ohhhhhhhhyo++os: CPU: Intel Core i7-6700HQ @ 2x 2.592GHz
|
||||
.o:`.syhhhhhhh/.oo++o` GPU: llvmpipe (LLVM 5.0, 256 bits)
|
||||
/osyyyyyyo++ooo+++/ RAM: 1521MiB / 1993MiB
|
||||
````` +oo+++o\:
|
||||
`oo++.
|
||||
```
|
||||
|
||||
### 方法-11:使用 neofetch 命令
|
||||
|
||||
`neofetch` 是一个跨平台且易于使用的命令行(CLI)脚本,它收集你的 Linux 系统信息,并将其作为一张图片显示在终端上,也可以是你的发行版徽标,或者是你选择的任何 ascii 艺术。
|
||||
|
||||
**建议阅读:** [Neofetch – 以 ASCII 分发标志来显示 Linux 系统信息][10]
|
||||
|
||||
```
|
||||
$ neofetch
|
||||
.-/+oossssoo+/-. daygeek@ubuntu
|
||||
`:+ssssssssssssssssss+:` --------------
|
||||
-+ssssssssssssssssssyyssss+- OS: Ubuntu 17.10 x86_64
|
||||
.ossssssssssssssssssdMMMNysssso. Host: VirtualBox 1.2
|
||||
/ssssssssssshdmmNNmmyNMMMMhssssss/ Kernel: 4.13.0-37-generic
|
||||
+ssssssssshmydMMMMMMMNddddyssssssss+ Uptime: 47 mins
|
||||
/sssssssshNMMMyhhyyyyhmNMMMNhssssssss/ Packages: 1832
|
||||
.ssssssssdMMMNhsssssssssshNMMMdssssssss. Shell: bash 4.4.12
|
||||
+sssshhhyNMMNyssssssssssssyNMMMysssssss+ Resolution: 1920x955
|
||||
ossyNMMMNyMMhsssssssssssssshmmmhssssssso DE: ubuntu:GNOME
|
||||
ossyNMMMNyMMhsssssssssssssshmmmhssssssso WM: GNOME Shell
|
||||
+sssshhhyNMMNyssssssssssssyNMMMysssssss+ WM Theme: Adwaita
|
||||
.ssssssssdMMMNhsssssssssshNMMMdssssssss. Theme: Azure [GTK3]
|
||||
/sssssssshNMMMyhhyyyyhdNMMMNhssssssss/ Icons: Papirus-Dark [GTK3]
|
||||
+sssssssssdmydMMMMMMMMddddyssssssss+ Terminal: gnome-terminal
|
||||
/ssssssssssshdmNNNNmyNMMMMhssssss/ CPU: Intel i7-6700HQ (2) @ 2.591GHz
|
||||
.ossssssssssssssssssdMMMNysssso. GPU: VirtualBox Graphics Adapter
|
||||
-+sssssssssssssssssyyyssss+- Memory: 1620MiB / 1993MiB
|
||||
`:+ssssssssssssssssss+:`
|
||||
.-/+oossssoo+/-.
|
||||
```
|
||||
|
||||
### 方法-12:使用 dmesg 命令
|
||||
|
||||
`dmesg`(代表显示消息或驱动消息)是大多数类 Unix 操作系统上的命令,用于打印内核的消息缓冲区。
|
||||
|
||||
```
|
||||
$ dmesg | grep "Memory"
|
||||
[ 0.000000] Memory: 1985916K/2096696K available (12300K kernel code, 2482K rwdata, 4000K rodata, 2372K init, 2368K bss, 110780K reserved, 0K cma-reserved)
|
||||
[ 0.012044] x86/mm: Memory block size: 128MB
|
||||
```
|
||||
|
||||
### 方法-13:使用 atop 命令
|
||||
|
||||
`atop` 是一个用于 Linux 的 ASCII 全屏系统性能监视工具,它能报告所有服务器进程的活动(即使进程在间隔期间已经完成)。
|
||||
|
||||
它记录系统和进程活动以进行长期分析(默认情况下,日志文件保存 28 天),通过使用颜色等来突出显示过载的系统资源。它结合可选的内核模块 netatop 显示每个进程或线程的网络活动。
|
||||
|
||||
**建议阅读:** [Atop – 实时监控系统性能,资源,进程和检查资源利用历史][11]
|
||||
|
||||
```
|
||||
$ atop -m
|
||||
|
||||
ATOP - ubuntu 2018/03/31 19:34:08 ------------- 10s elapsed
|
||||
PRC | sys 0.47s | user 2.75s | | | #proc 219 | #trun 1 | #tslpi 802 | #tslpu 0 | #zombie 0 | clones 7 | | | #exit 4 |
|
||||
CPU | sys 7% | user 22% | irq 0% | | | idle 170% | wait 0% | | steal 0% | guest 0% | | curf 2.59GHz | curscal ?% |
|
||||
cpu | sys 3% | user 11% | irq 0% | | | idle 85% | cpu001 w 0% | | steal 0% | guest 0% | | curf 2.59GHz | curscal ?% |
|
||||
cpu | sys 4% | user 11% | irq 0% | | | idle 85% | cpu000 w 0% | | steal 0% | guest 0% | | curf 2.59GHz | curscal ?% |
|
||||
CPL | avg1 1.98 | | avg5 3.56 | avg15 3.20 | | | csw 14894 | | intr 6610 | | | numcpu 2 | |
|
||||
MEM | tot 1.9G | free 101.7M | cache 244.2M | dirty 0.2M | buff 6.9M | slab 92.9M | slrec 35.6M | shmem 97.8M | shrss 21.0M | shswp 3.2M | vmbal 0.0M | hptot 0.0M | hpuse 0.0M |
|
||||
SWP | tot 12.4G | free 11.6G | | | | | | | | | vmcom 7.9G | | vmlim 13.4G |
|
||||
PAG | scan 0 | steal 0 | | stall 0 | | | | | | | swin 3 | | swout 0 |
|
||||
DSK | sda | busy 0% | | read 114 | write 37 | KiB/r 21 | KiB/w 6 | | MBr/s 0.2 | MBw/s 0.0 | avq 6.50 | | avio 0.26 ms |
|
||||
NET | transport | tcpi 11 | tcpo 17 | udpi 4 | udpo 8 | tcpao 3 | tcppo 0 | | tcprs 3 | tcpie 0 | tcpor 0 | udpnp 0 | udpie 0 |
|
||||
NET | network | ipi 20 | | ipo 33 | ipfrw 0 | deliv 20 | | | | | icmpi 5 | | icmpo 0 |
|
||||
NET | enp0s3 0% | pcki 11 | pcko 28 | sp 1000 Mbps | si 1 Kbps | so 1 Kbps | | coll 0 | mlti 0 | erri 0 | erro 0 | drpi 0 | drpo 0 |
|
||||
NET | lo ---- | pcki 9 | pcko 9 | sp 0 Mbps | si 0 Kbps | so 0 Kbps | | coll 0 | mlti 0 | erri 0 | erro 0 | drpi 0 | drpo 0 |
|
||||
|
||||
PID TID MINFLT MAJFLT VSTEXT VSLIBS VDATA VSTACK VSIZE RSIZE PSIZE VGROW RGROW SWAPSZ RUID EUID MEM CMD 1/1
|
||||
2536 - 941 0 188K 127.3M 551.2M 144K 2.3G 281.2M 0K 0K 344K 6556K daygeek daygeek 14% Web Content
|
||||
2464 - 75 0 188K 187.7M 680.6M 132K 2.3G 226.6M 0K 0K 212K 42088K daygeek daygeek 11% firefox
|
||||
2039 - 4199 6 16K 163.6M 423.0M 132K 3.5G 220.2M 0K 0K 2936K 109.6M daygeek daygeek 11% gnome-shell
|
||||
10822 - 1 0 4K 16680K 377.0M 132K 3.4G 193.4M 0K 0K 0K 0K root root 10% java
|
||||
```
|
||||
|
||||
### 方法-14:使用 htop 命令
|
||||
|
||||
`htop` 是由 Hisham 用 ncurses 库开发的用于 Linux 的交互式进程查看器。与 `top` 命令相比,`htop` 有许多特性和选项。
|
||||
|
||||
**建议阅读:** [使用 Htop 命令监视系统资源][12]
|
||||
|
||||
```
|
||||
$ htop
|
||||
|
||||
1 [||||||||||||| 13.0%] Tasks: 152, 587 thr; 1 running
|
||||
2 [||||||||||||||||||||||||| 25.0%] Load average: 0.91 2.03 2.66
|
||||
Mem[||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||1.66G/1.95G] Uptime: 01:14:53
|
||||
Swp[|||||| 782M/12.4G]
|
||||
|
||||
PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command
|
||||
2039 daygeek 20 0 3541M 214M 46728 S 36.6 10.8 22:36.77 /usr/bin/gnome-shell
|
||||
2045 daygeek 20 0 3541M 214M 46728 S 10.3 10.8 3:02.92 /usr/bin/gnome-shell
|
||||
2046 daygeek 20 0 3541M 214M 46728 S 8.3 10.8 3:04.96 /usr/bin/gnome-shell
|
||||
6080 daygeek 20 0 807M 37228 24352 S 2.1 1.8 0:11.99 /usr/lib/gnome-terminal/gnome-terminal-server
|
||||
2880 daygeek 20 0 2205M 164M 17048 S 2.1 8.3 7:16.50 /usr/lib/firefox/firefox -contentproc -childID 6 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51:0|57:128|58:10000|63:0|65:400|66
|
||||
6125 daygeek 20 0 1916M 159M 92352 S 2.1 8.0 2:09.14 /usr/lib/firefox/firefox -contentproc -childID 7 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51:0|57:128|58:10000|63:0|65:400|66
|
||||
2536 daygeek 20 0 2335M 243M 26792 S 2.1 12.2 6:25.77 /usr/lib/firefox/firefox -contentproc -childID 1 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51:0|57:128|58:10000|63:0|65:400|66
|
||||
2653 daygeek 20 0 2237M 185M 20788 S 1.4 9.3 3:01.76 /usr/lib/firefox/firefox -contentproc -childID 4 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51:0|57:128|58:10000|63:0|65:400|66
|
||||
```
|
||||
|
||||
### 方法-15:使用 corefreq 实用程序
|
||||
|
||||
CoreFreq 是为 Intel 64 位处理器设计的 CPU 监控软件,支持的架构有 Atom、Core2、Nehalem、SandyBridge 和 superior,AMD 家族 0F。
|
||||
|
||||
CoreFreq 提供了一个框架来以高精确度检索 CPU 数据。
|
||||
|
||||
**建议阅读:** [CoreFreq – 一个用于 Linux 系统的强大的 CPU 监控工具][13]
|
||||
|
||||
```
|
||||
$ ./corefreq-cli -k
|
||||
Linux:
|
||||
|- Release [4.13.0-37-generic]
|
||||
|- Version [#42-Ubuntu SMP Wed Mar 7 14:13:23 UTC 2018]
|
||||
|- Machine [x86_64]
|
||||
Memory:
|
||||
|- Total RAM 2041396 KB
|
||||
|- Shared RAM 99620 KB
|
||||
|- Free RAM 108428 KB
|
||||
|- Buffer RAM 8108 KB
|
||||
|- Total High 0 KB
|
||||
|- Free High 0 KB
|
||||
```
|
||||
|
||||
### 方法-16:使用 glances 命令
|
||||
|
||||
Glances 是用 Python 编写的跨平台基于 curses(LCTT 译注:curses 是一个 Linux/Unix 下的图形函数库)的系统监控工具。我们可以说它一应俱全,就像在最小的空间含有最大的信息。它使用 psutil 库从系统中获取信息。
|
||||
|
||||
Glances 可以监视 CPU、内存、负载、进程列表、网络接口、磁盘 I/O、Raid、传感器、文件系统(和文件夹)、Docker、监视器、警报、系统信息、正常运行时间、快速预览(CPU、内存、负载)等。
|
||||
|
||||
**建议阅读:** [Glances (一应俱全)– 一个 Linux 的高级的实时系
|
||||
统性能监控工具][14]
|
||||
|
||||
```
|
||||
$ glances
|
||||
|
||||
ubuntu (Ubuntu 17.10 64bit / Linux 4.13.0-37-generic) - IP 192.168.1.6/24 Uptime: 1:08:40
|
||||
|
||||
CPU [|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 90.6%] CPU - 90.6% nice: 0.0% ctx_sw: 4K MEM \ 78.4% active: 942M SWAP - 5.9% LOAD 2-core
|
||||
MEM [||||||||||||||||||||||||||||||||||||||||||||||||||||||||| 78.0%] user: 55.1% irq: 0.0% inter: 1797 total: 1.95G inactive: 562M total: 12.4G 1 min: 4.35
|
||||
SWAP [|||| 5.9%] system: 32.4% iowait: 1.8% sw_int: 897 used: 1.53G buffers: 14.8M used: 749M 5 min: 4.38
|
||||
idle: 7.6% steal: 0.0% free: 431M cached: 273M free: 11.7G 15 min: 3.38
|
||||
|
||||
NETWORK Rx/s Tx/s TASKS 211 (735 thr), 4 run, 207 slp, 0 oth sorted automatically by memory_percent, flat view
|
||||
docker0 0b 232b
|
||||
enp0s3 12Kb 4Kb Systemd 7 Services loaded: 197 active: 196 failed: 1
|
||||
lo 616b 616b
|
||||
_h478e48e 0b 232b CPU% MEM% VIRT RES PID USER NI S TIME+ R/s W/s Command
|
||||
63.8 18.9 2.33G 377M 2536 daygeek 0 R 5:57.78 0 0 /usr/lib/firefox/firefox -contentproc -childID 1 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
|
||||
DefaultGateway 83ms 78.5 10.9 3.46G 217M 2039 daygeek 0 S 21:07.46 0 0 /usr/bin/gnome-shell
|
||||
8.5 10.1 2.32G 201M 2464 daygeek 0 S 8:45.69 0 0 /usr/lib/firefox/firefox -new-window
|
||||
DISK I/O R/s W/s 1.1 8.5 2.19G 170M 2653 daygeek 0 S 2:56.29 0 0 /usr/lib/firefox/firefox -contentproc -childID 4 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
|
||||
dm-0 0 0 1.7 7.2 2.15G 143M 2880 daygeek 0 S 7:10.46 0 0 /usr/lib/firefox/firefox -contentproc -childID 6 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
|
||||
sda1 9.46M 12K 0.0 4.9 1.78G 97.2M 6125 daygeek 0 S 1:36.57 0 0 /usr/lib/firefox/firefox -contentproc -childID 7 -isForBrowser -intPrefs 6:50|7:-1|19:0|34:1000|42:20|43:5|44:10|51
|
||||
```
|
||||
|
||||
### 方法-17 : 使用 Gnome 系统监视器
|
||||
|
||||
Gnome 系统监视器是一个管理正在运行的进程和监视系统资源的工具。它向你显示正在运行的程序以及耗费的处理器时间,内存和磁盘空间。
|
||||
|
||||
![][16]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/easy-ways-to-check-size-of-physical-memory-ram-in-linux/
|
||||
|
||||
作者:[Ramya Nuvvula][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/ramya/
|
||||
[1]:https://www.2daygeek.com/free-command-to-check-memory-usage-statistics-in-linux/
|
||||
[2]:https://www.2daygeek.com/top-command-examples-to-monitor-server-performance/
|
||||
[3]:https://www.2daygeek.com/linux-vmstat-command-examples-tool-report-virtual-memory-statistics/
|
||||
[4]:https://www.2daygeek.com/nmon-system-performance-monitor-system-resources-on-linux/
|
||||
[5]:https://www.2daygeek.com/dmidecode-get-print-display-check-linux-system-hardware-information/
|
||||
[6]:https://www.2daygeek.com/hwinfo-check-display-detect-system-hardware-information-linux/
|
||||
[7]:https://www.2daygeek.com/lshw-find-check-system-hardware-information-details-linux/
|
||||
[8]:https://www.2daygeek.com/inxi-system-hardware-information-on-linux/
|
||||
[9]:https://www.2daygeek.com/screenfetch-display-linux-systems-information-ascii-distribution-logo-terminal/
|
||||
[10]:https://www.2daygeek.com/neofetch-display-linux-systems-information-ascii-distribution-logo-terminal/
|
||||
[11]:https://www.2daygeek.com/atop-system-process-performance-monitoring-tool/
|
||||
[12]:https://www.2daygeek.com/htop-command-examples-to-monitor-system-resources/
|
||||
[13]:https://www.2daygeek.com/corefreq-linux-cpu-monitoring-tool/
|
||||
[14]:https://www.2daygeek.com/install-glances-advanced-real-time-linux-system-performance-monitoring-tool-on-centos-fedora-ubuntu-debian-opensuse-arch-linux/
|
||||
[15]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[16]:https://www.2daygeek.com/wp-content/uploads/2018/03/check-memory-information-using-gnome-system-monitor.png
|
||||
@ -0,0 +1,101 @@
|
||||
构建满足用户需求的云环境的五个步骤
|
||||
======
|
||||
> 在投入时间和资金开发你的云环境之前,确认什么是你的用户所需要的。
|
||||
|
||||

|
||||
|
||||
无论你如何定义,云就是你的用户展现其在组织中的价值的另一个工具。当谈论新的范例或者技术(云是两者兼有)的时候很容易被它的新特性所分心。由一系列无止境的问题引发的对话能够很快的被发展为功能愿景清单,所有下面的这些都是你可能已经考虑到的:
|
||||
|
||||
* 是公有云、私有云还是混合云?
|
||||
* 会使用虚拟机还是容器,或者是两者?
|
||||
* 会提供自助服务吗?
|
||||
* 从开发到生产是完全自动的,还是它将需要手动操作?
|
||||
* 我们能以多块的速度做到?
|
||||
* 关于某某工具?
|
||||
|
||||
这样的清单还可以列举很多。
|
||||
|
||||
当开始 IT 现代化,或者数字转型,无论你是如何称呼的,通常方法是开始回答更高管理层的一些高层次问题,这种方法的结果是可以预想到的:失败。经过大范围的调研并且花费了数月的时间(如果不是几年的话)部署了这个最炫的新技术,而这个新的云技术却从未被使用过,而且陷入了荒废,直到它最终被丢弃或者遗忘在数据中心的一角和预算之中。
|
||||
|
||||
这是因为无论你交付的是什么工具,都不是用户所想要或者需要的。更加糟糕的是,它可能是一个单一的工具,而用户真正需要的是一系列工具 —— 能够随着时间推移,更换升级为更新的、更漂亮的工具,以更好地满足其需求。
|
||||
|
||||
### 专注于重要的事情
|
||||
|
||||
问题在于关注,传统上一直是关注于工具。但工具并不是要增加到组织价值中的东西;终端用户利用它做什么才是目的。你需要将你的注意力从创建云(例如技术和工具)转移到你的人员和用户身上。
|
||||
|
||||
事实上,除了使用工具的用户(而不是工具本身)是驱动价值的因素之外,聚焦注意力在用户身上也是有其它原因的。工具是给用户使用去解决他们的问题并允许他们创造价值的,所以这就导致了如果那些工具不能满足那些用户的需求,那么那些工具将不会被使用。如果你交付给你的用户的工具并不是他们喜欢的,他们将不会使用,这就是人类的人性行为。
|
||||
|
||||
数十年来,IT 产业只为用户提供一种解决方案,因为仅有一个或两个选择,用户是没有权力去改变的。现在情况已经不同了。我们现在生活在一个技术选择的世界中。不给用户一个选择的机会的情况将不会被接受的;他们在个人的科技生活中有选择,同时希望在工作中也有选择。现在的用户都是受过教育的并且知道将会有比你所提供的更好选择。
|
||||
|
||||
因此,在物理上的最安全的地点之外,没有能够阻止他们只做他们自己想要的东西的方法,我们称之为“影子 IT”。如果你的组织有如此严格的安全策略和承诺策略而不允许影子 IT,许多员工将会感到灰心丧气并且会离职去其他能提供更好机会的公司。
|
||||
|
||||
基于以上所有的原因,你必须牢记要首先和你的最终用户设计你的昂贵又费时的云项目。
|
||||
|
||||
### 创建满足用户需求的云五个步骤的过程
|
||||
|
||||
既然我们已经知道了为什么,接下来我们来讨论一下怎么做。你如何去为终端用户创建一个云?你怎样重新将你的注意力从技术转移到使用技术的用户身上?
|
||||
|
||||
根据以往的经验,我们知道最好的方法中包含两件重要的事情:从你的用户中得到及时的反馈,在创建中和用户进行更多的互动。
|
||||
|
||||
你的云环境将继续随着你的组织不断发展。下面的五个步骤将会帮助你创建满足用户需求的云环境。
|
||||
|
||||
#### 1、识别谁将是你的用户
|
||||
|
||||
在你开始询问用户问题之前,你首先必须识别谁将是你的新的云环境的用户。他们可能包括将在云上创建开发应用的开发者;也可能是运营、维护或者或者创建该云的运维团队;还可能是保护你的组织的安全团队。在第一次迭代时,将你的用户数量缩小至人数较少的小组防止你被大量的反馈所淹没,让你识别的每个小组指派两个代表(一个主要的一个辅助的)。这将使你的第一次交付在规模和时间上都很小。
|
||||
|
||||
#### 2、和你的用户面对面的交谈来收获有价值的输入。
|
||||
|
||||
获得反馈的最佳途径是和用户直接交谈。群发的邮件会自行挑选出受访者——如果你能收到回复的话。小组讨论会很有帮助的,但是当人们有个私密的、专注的对话者时,他们会比较的坦诚。
|
||||
|
||||
和你的第一批用户安排个面对面的个人的会谈,并且向他们询问以下的问题:
|
||||
|
||||
* 为了完成你的任务,你需要什么?
|
||||
* 为了完成你的任务,你想要什么?
|
||||
* 你现在最头疼的技术痛点是什么?
|
||||
* 你现在最头疼的政策或者流程痛点是哪个?
|
||||
* 关于解决你的需求、希望或痛点,你有什么建议?
|
||||
|
||||
这些问题只是指导性的,并不一定适合每个组织。你不应该只询问这些问题,他们应该导向更深层次的讨论。确保告诉用户他们任何所说的和被问的都被视作反馈,所有的反馈都是有帮助的,无论是消极的还是积极的。这些对话将会帮助你设置你的开发优先级。
|
||||
|
||||
收集这种个性化的反馈是保持初始用户群较小的另一个原因:这将会花费你大量的时间来和每个用户交流,但是我们已经发现这是相当值得付出的投入。
|
||||
|
||||
#### 3、设计并交付你的解决方案的第一个版本
|
||||
|
||||
一旦你收到初始用户的反馈,就是时候开始去设计并交付一部分的功能了。我们不推荐尝试一次性交付整个解决方案。设计和交付的时期要短;这可以避免你花费一年的时间去构建一个你*认为*正确的解决方案,而只会让你的用户拒绝它,因为对他们来说毫无用处。创建你的云所需要的工具取决于你的组织和它的特殊需求。只需确保你的解决方案是建立在用户的反馈的基础上的,你将功能小块化的交付并且要经常的去征求用户的反馈。
|
||||
|
||||
#### 4、询问用户对第一个版本的反馈
|
||||
|
||||
太棒了,现在你已经设计并向你的用户交付了你的炫酷的新的云环境的第一个版本!你并不是花费一整年去完成它而是将它处理成小的模块。为什么将其分为小的模块如此重要呢?因为你要回到你的用户组并且向他们收集关于你的设计和交付的功能。他们喜欢什么?不喜欢什么?你正确的处理了他们所关注的吗?是技术功能上很厉害,但系统进程或者策略方面仍然欠缺吗?
|
||||
|
||||
再重申一次,你要问的问题取决于你的组织;这里的关键是继续前一个阶段的讨论。毕竟你正在为用户创建云环境,所以确保它对用户来说是有用的并且能够有效利用每个人的时间。
|
||||
|
||||
#### 5、回到第一步。
|
||||
|
||||
这是一个迭代的过程。你的首次交付应该是快速而小规模的,而且以后的迭代也应该是这样的。不要期待仅仅按照这个流程完成了一次、两次甚至是三次就能完成。一旦你持续的迭代,你将会吸引更多的用户从而能够在这个过程中得到更好的回报。你将会从用户那里得到更多的支持。你能够迭代的更迅速并且更可靠。到最后,你将会通过改变你的流程来满足用户的需求。
|
||||
|
||||
用户是这个过程中最重要的一部分,但迭代是第二重要的因为它让你能够回到用户中进行持续沟通从而得到更多有用的信息。在每个阶段,记录哪些是有效的哪些没有起到应有的效果。要自省,要对自己诚实。我们所花费的时间提供了最有价值的了吗?如果不是,在下一个阶段尝试些不同的。在每次循环中不要花费太多时间的最重要的部分是,如果某部分在这次不起作用,你能够很容易的在下一次中调整它,直到你找到能够在你组织中起作用的方法。
|
||||
|
||||
### 这仅仅是开始
|
||||
|
||||
通过许多客户约见,从他们那里收集反馈,以及在这个领域的同行的经验,我们一次次的发现在创建云的时候最重要事就是和你的用户交谈。这似乎是很明显的,但很让人惊讶的是很多组织却偏离了这个方向去花费数月或者数年的时间去创建,然后最终发现它对终端用户甚至一点用处都没有。
|
||||
|
||||
现在你已经知道为什么你需要将你的注意力集中到终端用户身上并且在中心节点和用户一起的互动创建云。剩下的是我们所喜欢的部分,你自己去做的部分。
|
||||
|
||||
这篇文章是基于一篇作者在 [Red Hat Summit 2018][3] 上发表的文章“[为终端用户设计混合云,要么失败]”。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/5-steps-building-your-cloud-correctly
|
||||
|
||||
作者:[Cameron Wyatt][a], [Ian Teksbury][1]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/cameronmwyatt
|
||||
[1]:https://opensource.com/users/itewk
|
||||
[2]:https://agenda.summit.redhat.com/SessionDetail.aspx?id=154225
|
||||
[3]:https://www.redhat.com/en/summit/2018
|
||||
@ -0,0 +1,214 @@
|
||||
如何使用 Emacs 创建 LaTeX 文档
|
||||
======
|
||||
> 这篇教程将带你遍历在 Emacs 使用强大的开源排版系统 LaTex 来创建文档的全过程。
|
||||
|
||||

|
||||
|
||||
一篇由 Aaron Cocker 写的很棒的文章 “[在 LaTeX 中创建文件的介绍][1]” 中,介绍了 [LaTeX 排版系统][3] 并描述了如何使用 [TeXstudio][4] 来创建 LaTeX 文档。同时,他也列举了一些很多用户觉得创建 LaTeX 文档很方便的编辑器。
|
||||
|
||||
[Greg Pittman][5] 对这篇文章的评论吸引了我:“当你第一次开始使用 LaTeX 时,他似乎是个很差劲的排版……” 事实也确实如此。LaTeX 包含了多种排版字体和调试,如果你漏了一个特殊的字符比如说感叹号,这会让很多用户感到沮丧,尤其是新手。在本文中,我将介绍如何使用 [GNU Emacs][6] 来创建 LaTeX 文档。
|
||||
|
||||
### 创建你的第一个文档
|
||||
|
||||
启动 Emacs:
|
||||
|
||||
```
|
||||
emacs -q --no-splash helloworld.org
|
||||
```
|
||||
|
||||
参数 `-q` 确保 Emacs 不会加载其他的初始化配置。参数 `--no-splash-screen` 防止 Emacs 打开多个窗口,确保只打开一个窗口,最后的参数 `helloworld.org` 表示你要创建的文件名为 `helloworld.org` 。
|
||||
|
||||
![Emacs startup screen][8]
|
||||
|
||||
*GNU Emacs 打开文件名为 helloworld.org 的窗口时的样子。*
|
||||
|
||||
现在让我们用 Emacs 添加一些 LaTeX 的标题吧:在菜单栏找到 “Org” 选项并选择 “Export/Publish”。
|
||||
|
||||
![template_flow.png][10]
|
||||
|
||||
*导入一个默认的模板*
|
||||
|
||||
在下一个窗口中,Emacs 同时提供了导入和导出一个模板。输入 `#`(“[#] Insert template”)来导入一个模板。这将会使光标跳转到一个带有 “Options category:” 提示的 mini-buffer 中。第一次你可能不知道这个类型的名字,但是你可以使用 `Tab` 键来查看所有的补全。输入 “default” 然后按回车,之后你就能看到如下的内容被插入了:
|
||||
|
||||
```
|
||||
#+TITLE: helloworld
|
||||
#+DATE: <2018-03-12 Mon>
|
||||
#+AUTHOR:
|
||||
#+EMAIL: makerpm@nubia
|
||||
#+OPTIONS: ':nil *:t -:t ::t <:t H:3 \n:nil ^:t arch:headline
|
||||
#+OPTIONS: author:t c:nil creator:comment d:(not "LOGBOOK") date:t
|
||||
#+OPTIONS: e:t email:nil f:t inline:t num:t p:nil pri:nil stat:t
|
||||
#+OPTIONS: tags:t tasks:t tex:t timestamp:t toc:t todo:t |:t
|
||||
#+CREATOR: Emacs 25.3.1 (Org mode 8.2.10)
|
||||
#+DESCRIPTION:
|
||||
#+EXCLUDE_TAGS: noexport
|
||||
#+KEYWORDS:
|
||||
#+LANGUAGE: en
|
||||
#+SELECT_TAGS: export
|
||||
```
|
||||
|
||||
根据自己的需求修改标题、日期、作者和 email。我自己的话是下面这样的:
|
||||
|
||||
```
|
||||
#+TITLE: Hello World! My first LaTeX document
|
||||
#+DATE: \today
|
||||
#+AUTHOR: Sachin Patil
|
||||
#+EMAIL: psachin@redhat.com
|
||||
```
|
||||
|
||||
我们目前还不想创建一个目录,所以要将 `toc` 的值由 `t` 改为 `nil`,具体如下:
|
||||
|
||||
```
|
||||
#+OPTIONS: tags:t tasks:t tex:t timestamp:t toc:nil todo:t |:t
|
||||
```
|
||||
|
||||
现在让我们添加一个章节和段落吧。章节是由一个星号(`*`)开头。我们从 Aaron 的贴子(来自 [Lipsum Lorem Ipsum 生成器][11])复制一些文本过来:
|
||||
|
||||
```
|
||||
* Introduction
|
||||
|
||||
\paragraph{}
|
||||
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Cras lorem
|
||||
nisi, tincidunt tempus sem nec, elementum feugiat ipsum. Nulla in
|
||||
diam libero. Nunc tristique ex a nibh egestas sollicitudin.
|
||||
|
||||
\paragraph{}
|
||||
Mauris efficitur vitae ex id egestas. Vestibulum ligula felis,
|
||||
pulvinar a posuere id, luctus vitae leo. Sed ac imperdiet orci, non
|
||||
elementum leo. Nullam molestie congue placerat. Phasellus tempor et
|
||||
libero maximus commodo.
|
||||
```
|
||||
|
||||
|
||||
![helloworld_file.png][13]
|
||||
|
||||
*helloworld.org 文件*
|
||||
|
||||
|
||||
将内容修改好后,我们要把它导出为 PDF 格式。再次在 “Org” 的菜单选项中选择 “Export/Publish”,但是这次,要输入 `l`(“export to LaTeX”),紧跟着输入 `o`(“as PDF file and open”)。这次操作不止会打开 PDF 文件让你浏览,同时也会将文件保存为 `helloworld.pdf`,并保存在与 `helloworld.org` 的同一个目录下。
|
||||
|
||||
![org_to_pdf.png][15]
|
||||
|
||||
*将 helloworld.org 导出为 helloworld.pdf*
|
||||
|
||||
![org_and_pdf_file.png][17]
|
||||
|
||||
*打开 helloworld.pdf 文件*
|
||||
|
||||
你也可以按下 `Alt + x` 键,然后输入 `org-latex-export-to-pdf` 来将 org 文件导出为 PDF 文件。可以使用 `Tab` 键来自动补全命令。
|
||||
|
||||
Emacs 也会创建 `helloworld.tex` 文件来让你控制具体的内容。
|
||||
|
||||
![org_tex_pdf.png][19]
|
||||
|
||||
*Emacs 在三个不同的窗口中分别打开 LaTeX,org 和 PDF 文档。*
|
||||
|
||||
你可以使用命令来将 `.tex` 文件转换为 `.pdf` 文件:
|
||||
|
||||
```
|
||||
pdflatex helloworld.tex
|
||||
```
|
||||
|
||||
你也可以将 `.org` 文件输出为 HTML 或是一个简单的文本格式的文件。我最喜欢 `.org` 文件的原因是他们可以被推送到 [GitHub][20] 上,然后同 markdown 一样被渲染。
|
||||
|
||||
### 创建一个 LaTeX 的 Beamer 简报
|
||||
|
||||
现在让我们更进一步,通过少量的修改上面的文档来创建一个 LaTeX [Beamer][21] 简报,如下所示:
|
||||
|
||||
```
|
||||
#+TITLE: LaTeX Beamer presentation
|
||||
#+DATE: \today
|
||||
#+AUTHOR: Sachin Patil
|
||||
#+EMAIL: psachin@redhat.com
|
||||
#+OPTIONS: ':nil *:t -:t ::t <:t H:3 \n:nil ^:t arch:headline
|
||||
#+OPTIONS: author:t c:nil creator:comment d:(not "LOGBOOK") date:t
|
||||
#+OPTIONS: e:t email:nil f:t inline:t num:t p:nil pri:nil stat:t
|
||||
#+OPTIONS: tags:t tasks:t tex:t timestamp:t toc:nil todo:t |:t
|
||||
#+CREATOR: Emacs 25.3.1 (Org mode 8.2.10)
|
||||
#+DESCRIPTION:
|
||||
#+EXCLUDE_TAGS: noexport
|
||||
#+KEYWORDS:
|
||||
#+LANGUAGE: en
|
||||
#+SELECT_TAGS: export
|
||||
#+LATEX_CLASS: beamer
|
||||
#+BEAMER_THEME: Frankfurt
|
||||
#+BEAMER_INNER_THEME: rounded
|
||||
|
||||
|
||||
* Introduction
|
||||
*** Programming
|
||||
- Python
|
||||
- Ruby
|
||||
|
||||
*** Paragraph one
|
||||
|
||||
Lorem ipsum dolor sit amet, consectetur adipiscing
|
||||
elit. Cras lorem nisi, tincidunt tempus sem nec, elementum feugiat
|
||||
ipsum. Nulla in diam libero. Nunc tristique ex a nibh egestas
|
||||
sollicitudin.
|
||||
|
||||
*** Paragraph two
|
||||
|
||||
Mauris efficitur vitae ex id egestas. Vestibulum
|
||||
ligula felis, pulvinar a posuere id, luctus vitae leo. Sed ac
|
||||
imperdiet orci, non elementum leo. Nullam molestie congue
|
||||
placerat. Phasellus tempor et libero maximus commodo.
|
||||
|
||||
* Thanks
|
||||
*** Links
|
||||
- Link one
|
||||
- Link two
|
||||
```
|
||||
|
||||
我们给标题增加了三行:
|
||||
|
||||
```
|
||||
#+LATEX_CLASS: beamer
|
||||
#+BEAMER_THEME: Frankfurt
|
||||
#+BEAMER_INNER_THEME: rounded
|
||||
```
|
||||
|
||||
导出为 PDF,按下 `Alt + x` 键后输入 `org-beamer-export-to-pdf`。
|
||||
|
||||
![latex_beamer_presentation.png][23]
|
||||
|
||||
*用 Emacs 和 Org 模式创建的 Latex Beamer 简报*
|
||||
|
||||
希望你会爱上使用 Emacs 来创建 LaTex 和 Beamer 文档(注意:使用快捷键比用鼠标更快些)。Emacs 的 Org 模式提供了比我在这篇文章中说的更多的功能,你可以在 [orgmode.org][24] 获取更多的信息.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/how-create-latex-documents-emacs
|
||||
|
||||
作者:[Sachin Patil][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[oneforalone](https://github.com/oneforalone)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/psachin
|
||||
[1]:https://opensource.com/article/17/6/introduction-latex
|
||||
[2]:https://opensource.com/users/aaroncocker
|
||||
[3]:https://www.latex-project.org
|
||||
[4]:http://www.texstudio.org/
|
||||
[5]:https://opensource.com/users/greg-p
|
||||
[6]:https://www.gnu.org/software/emacs/
|
||||
[7]:/file/392261
|
||||
[8]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/emacs_startup.png?itok=UnT4PgK5 (Emacs startup screen)
|
||||
[9]:/file/392266
|
||||
[10]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/insert_template_flow.png?itok=V_c2KipO (template_flow.png)
|
||||
[11]:https://www.lipsum.com/feed/html
|
||||
[12]:/file/392271
|
||||
[13]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/helloworld_file.png?itok=o8IX0TsJ (helloworld_file.png)
|
||||
[14]:/file/392276
|
||||
[15]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/org_to_pdf.png?itok=fNnC1Y-L (org_to_pdf.png)
|
||||
[16]:/file/392281
|
||||
[17]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/org_and_pdf_file.png?itok=HEhtw-cu (org_and_pdf_file.png)
|
||||
[18]:/file/392286
|
||||
[19]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/org_tex_pdf.png?itok=poZZV_tj (org_tex_pdf.png)
|
||||
[20]:https://github.com
|
||||
[21]:https://www.sharelatex.com/learn/Beamer
|
||||
[22]:/file/392291
|
||||
[23]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/latex_beamer_presentation.png?itok=rsPSeIuM (latex_beamer_presentation.png)
|
||||
[24]:https://orgmode.org/worg/org-tutorials/org-latex-export.html
|
||||
@ -0,0 +1,139 @@
|
||||
如何在终端中浏览 Stack Overflow
|
||||
======
|
||||
|
||||

|
||||
|
||||
前段时间,我们写了一篇关于 [SoCLI][1] 的文章,它是一个从命令行搜索和浏览 Stack Overflow 网站的 python 脚本。今天,我们将讨论一个名为 “how2” 的类似工具。它是一个命令行程序,可以从终端浏览 Stack Overflow。你可以如你在 [Google 搜索][2]中那样直接用英语查询,然后它会使用 Google 和 Stackoverflow API 来搜索给定的查询。它是使用 NodeJS 编写的自由开源程序。
|
||||
|
||||
### 使用 how2 从终端浏览 Stack Overflow
|
||||
|
||||
由于 `how2` 是一个 NodeJS 包,我们可以使用 Npm 包管理器安装它。如果你尚未安装 Npm 和 NodeJS,请参考以下指南。
|
||||
|
||||
在安装 Npm 和 NodeJS 后,运行以下命令安装 how2。
|
||||
|
||||
```
|
||||
$ npm install -g how2
|
||||
```
|
||||
|
||||
现在让我们看下如何使用这个程序浏览 Stack Overflow。使用 `how2` 搜索 Stack Overflow 站点的典型用法是:
|
||||
|
||||
```
|
||||
$ how2 <search-query>
|
||||
```
|
||||
|
||||
例如,我将搜索如何创建 tgz 存档。
|
||||
|
||||
```
|
||||
$ how2 create archive tgz
|
||||
```
|
||||
|
||||
哎呀!我收到以下错误。
|
||||
|
||||
```
|
||||
/home/sk/.nvm/versions/node/v9.11.1/lib/node_modules/how2/node_modules/devnull/transports/transport.js:59
|
||||
Transport.prototype.__proto__ = EventEmitter.prototype;
|
||||
^
|
||||
|
||||
TypeError: Cannot read property 'prototype' of undefined
|
||||
at Object.<anonymous> (/home/sk/.nvm/versions/node/v9.11.1/lib/node_modules/how2/node_modules/devnull/transports/transport.js:59:46)
|
||||
at Module._compile (internal/modules/cjs/loader.js:654:30)
|
||||
at Object.Module._extensions..js (internal/modules/cjs/loader.js:665:10)
|
||||
at Module.load (internal/modules/cjs/loader.js:566:32)
|
||||
at tryModuleLoad (internal/modules/cjs/loader.js:506:12)
|
||||
at Function.Module._load (internal/modules/cjs/loader.js:498:3)
|
||||
at Module.require (internal/modules/cjs/loader.js:598:17)
|
||||
at require (internal/modules/cjs/helpers.js:11:18)
|
||||
at Object.<anonymous> (/home/sk/.nvm/versions/node/v9.11.1/lib/node_modules/how2/node_modules/devnull/transports/stream.js:8:17)
|
||||
at Module._compile (internal/modules/cjs/loader.js:654:30)
|
||||
|
||||
```
|
||||
|
||||
我可能遇到了一个 bug。我希望它在未来版本中得到修复。但是,我在[这里][3]找到了一个临时方法。
|
||||
|
||||
|
||||
要临时修复此错误,你需要使用以下命令编辑 `transport.js`:
|
||||
|
||||
```
|
||||
$ vi /home/sk/.nvm/versions/node/v9.11.1/lib/node_modules/how2/node_modules/devnull/transports/transport.js
|
||||
```
|
||||
|
||||
此文件的实际路径将显示在错误输出中。用你自己的文件路径替换上述文件路径。然后找到以下行:
|
||||
|
||||
```
|
||||
var EventEmitter = process.EventEmitter;
|
||||
```
|
||||
|
||||
并用以下行替换它:
|
||||
|
||||
```
|
||||
var EventEmitter = require('events');
|
||||
```
|
||||
|
||||
按 `ESC` 并输入 `:wq` 以保存并退出文件。
|
||||
|
||||
现在再次搜索查询。
|
||||
|
||||
```
|
||||
$ how2 create archive tgz
|
||||
```
|
||||
|
||||
这是我的 Ubuntu 系统的示例输出。
|
||||
|
||||
![][5]
|
||||
|
||||
如果你要查找的答案未显示在上面的输出中,请按**空格键**键开始交互式搜索,你可以通过它查看 Stack Overflow 站点中的所有建议问题和答案。
|
||||
|
||||
![][6]
|
||||
|
||||
使用向上/向下箭头在结果之间移动。得到正确的答案/问题后,点击空格键或回车键在终端中打开它。
|
||||
|
||||
![][7]
|
||||
|
||||
要返回并退出,请按 `ESC`。
|
||||
|
||||
**搜索特定语言的答案**
|
||||
|
||||
如果你没有指定语言,它**默认为 Bash** unix 命令行,并立即为你提供最可能的答案。你还可以将结果缩小到特定语言,例如 perl、python、c、Java 等。
|
||||
|
||||
例如,使用 `-l` 标志仅搜索与 “Python” 语言相关的查询,如下所示。
|
||||
|
||||
```
|
||||
$ how2 -l python linked list
|
||||
```
|
||||
|
||||
![][8]
|
||||
|
||||
要获得快速帮助,请输入:
|
||||
|
||||
```
|
||||
$ how2 -h
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
`how2` 是一个基本的命令行程序,它可以快速搜索 Stack Overflow 中的问题和答案,而无需离开终端,并且它可以很好地完成这项工作。但是,它只是 Stack overflow 的 CLI 浏览器。对于一些高级功能,例如搜索投票最多的问题,使用多个标签搜索查询,彩色界面,提交新问题和查看问题统计信息等,**SoCLI** 做得更好。
|
||||
|
||||
就是这些了。希望这篇文章有用。我将很快写一篇新的指南。在此之前,请继续关注!
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-browse-stack-overflow-from-terminal/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/search-browse-stack-overflow-website-commandline/
|
||||
[2]:https://www.ostechnix.com/google-search-navigator-enhance-keyboard-navigation-in-google-search/
|
||||
[3]:https://github.com/santinic/how2/issues/79
|
||||
[4]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/04/stack-overflow-1.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/04/stack-overflow-2.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/04/stack-overflow-3.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/04/stack-overflow-4.png
|
||||
@ -0,0 +1,53 @@
|
||||
关于安全,开发人员需要知道的
|
||||
======
|
||||
> 开发人员不需要成为安全专家, 但他们确实需要摆脱将安全视为一些不幸障碍的心态。
|
||||
|
||||

|
||||
|
||||
DevOps 并不意味着每个人都需要成为开发和运维方面的专家。尤其在大型组织中,其中角色往往更加专业化。相反,DevOps 思想在某种程度上更多地是关注问题的分离。在某种程度上,运维团队可以为开发人员(无论是在本地云还是在公共云中)部署平台,并且不受影响,这对两个团队来说都是好消息。开发人员可以获得高效的开发环境和自助服务,运维人员可以专注于保持基础管道运行和维护平台。
|
||||
|
||||
这是一种约定。开发者期望从运维人员那里得到一个稳定和实用的平台,运维人员希望开发者能够自己处理与开发应用相关的大部分任务。
|
||||
|
||||
也就是说,DevOps 还涉及更好的沟通、合作和透明度。如果它不仅仅是一种介于开发和运维之间的新型壁垒,它的效果会更好。运维人员需要对开发者想要和需要的工具类型以及他们通过监视和日志记录来编写更好应用程序所需的可见性保持敏感。另一方面,开发人员需要了解如何才能更有效地使用底层基础设施,以及什么能够使运维在夜间(字面上)保持运行。
|
||||
|
||||
同样的原则也适用于更广泛的 DevSecOps,这个术语明确地提醒我们,安全需要嵌入到整个 DevOps 管道中,从获取内容到编写应用程序、构建应用程序、测试应用程序以及在生产环境中运行它们。开发人员(和运维人员)除了他们已有的角色不需要突然成为安全专家。但是,他们通常可以从对安全最佳实践(这可能不同于他们已经习惯的)的更高认识中获益,并从将安全视为一些不幸障碍的心态中转变出来。
|
||||
|
||||
以下是一些观察结果。
|
||||
|
||||
<ruby>开放式 Web 应用程序安全项目<rt>Open Web Application Security Project</rt></ruby>([OWASP][1])[Top 10 列表]提供了一个窗口,可以了解 Web 应用程序中的主要漏洞。列表中的许多条目对 Web 程序员来说都很熟悉。跨站脚本(XSS)和注入漏洞是最常见的。但令人震惊的是,2007 年列表中的许多漏洞仍在 2017 年的列表中([PDF][3])。无论是培训还是工具,都有问题,许多同样的编码漏洞一再出现。
|
||||
|
||||
新的平台技术加剧了这种情况。例如,虽然容器不一定要求应用程序以不同的方式编写,但是它们与新模式(例如[微服务][4])相吻合,并且可以放大某些对于安全实践的影响。例如,我的同事 [Dan Walsh][5]([@rhatdan][6])写道:“计算机领域最大的误解是需要 root 权限来运行应用程序,问题是并不是所有开发者都认为他们需要 root,而是他们将这种假设构建到他们建设的服务中,即服务无法在非 root 情况下运行,而这降低了安全性。”
|
||||
|
||||
默认使用 root 访问是一个好的实践吗?并不是。但它可能(也许)是一个可以防御的应用程序和系统,否则就会被其它方法完全隔离。但是,由于所有东西都连接在一起,没有真正的边界,多用户工作负载,拥有许多不同级别访问权限的用户,更不用说更加危险的环境了,那么快捷方式的回旋余地就更小了。
|
||||
|
||||
[自动化][7]应该是 DevOps 不可分割的一部分。自动化需要覆盖整个过程中,包括安全和合规性测试。代码是从哪里来的?是否涉及第三方技术、产品或容器镜像?是否有已知的安全勘误表?是否有已知的常见代码缺陷?机密信息和个人身份信息是否被隔离?如何进行身份认证?谁被授权部署服务和应用程序?
|
||||
|
||||
你不是自己在写你的加密代码吧?
|
||||
|
||||
尽可能地自动化渗透测试。我提到过自动化没?它是使安全性持续的一个重要部分,而不是偶尔做一次的检查清单。
|
||||
|
||||
这听起来很难吗?可能有点。至少它是不同的。但是,一名 [DevOpsDays OpenSpaces][8] 伦敦论坛的参与者对我说:“这只是技术测试。它既不神奇也不神秘。”他接着说,将安全作为一种更广泛地了解整个软件生命周期的方法(这是一种不错的技能)来参与进来并不难。他还建议参加事件响应练习或[夺旗练习][9]。你会发现它们很有趣。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/what-developers-need-know-about-security
|
||||
|
||||
作者:[Gordon Haff][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ghaff
|
||||
[1]:https://www.owasp.org/index.php/Main_Page
|
||||
[2]:https://www.owasp.org/index.php/Category:OWASP_Top_Ten_Project
|
||||
[3]:https://www.owasp.org/images/7/72/OWASP_Top_10-2017_%28en%29.pdf.pdf
|
||||
[4]:https://opensource.com/tags/microservices
|
||||
[5]:https://opensource.com/users/rhatdan
|
||||
[6]:https://twitter.com/rhatdan
|
||||
[7]:https://opensource.com/tags/automation
|
||||
[8]:https://www.devopsdays.org/open-space-format/
|
||||
[9]:https://dev.to/_theycallmetoni/capture-the-flag-its-a-game-for-hacki-mean-security-professionals
|
||||
[10]:https://agenda.summit.redhat.com/SessionDetail.aspx?id=154677
|
||||
[11]:https://www.redhat.com/en/summit/2018
|
||||
@ -1,10 +1,9 @@
|
||||
9 个提升开发者与设计师协作的方法
|
||||
======
|
||||
> 抛开成见,设计师和开发者的命运永远交织在一起。 以下是如何让每个人都在同一页面上。
|
||||
|
||||

|
||||
|
||||
本文由我与 [Jason Porter][1] 共同完成。
|
||||
|
||||
在任何软件项目中,设计至关重要。设计师不像开发团队那样熟悉其内部工作,但迟早都要知道开发人员写代码的意图。
|
||||
|
||||
两边都有自己的成见。工程师经常认为设计师们古怪不理性,而设计师也认为工程师们死板要求高。在一天的工作快要结束时,情况会变得更加微妙。设计师和开发者们的命运永远交织在一起。
|
||||
@ -53,7 +52,7 @@
|
||||
|
||||
via: https://opensource.com/article/18/5/9-ways-improve-collaboration-developers-designers
|
||||
|
||||
作者:[Jason Brock][a]
|
||||
作者:[Jason Brock][a], [Jason Porter][1]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[LuuMing](https://github.com/LuuMing)
|
||||
校对:[pityonline](https://github.com/pityonline)
|
||||
@ -0,0 +1,431 @@
|
||||
如何在 CentOS 中添加、启用和禁用一个仓库
|
||||
======
|
||||
|
||||
在基于 RPM 的系统上,例如 RHEL、CentOS 等,我们中的许多人使用 yum 包管理器来管理软件的安装、删除、更新、搜索等。
|
||||
|
||||
Linux 发行版的大部分软件都来自发行版官方仓库。官方仓库包含大量免费和开源的应用和软件。它很容易安装和使用。
|
||||
|
||||
由于一些限制和专有问题,基于 RPM 的发行版在其官方仓库中没有提供某些包。另外,出于稳定性考虑,它不会提供最新版本的核心包。
|
||||
|
||||
为了克服这种情况,我们需要安装或启用需要的第三方仓库。对于基于 RPM 的系统,有许多第三方仓库可用,但所建议使用的仓库很少,因为这些不会替换大量的基础包。
|
||||
|
||||
建议阅读:
|
||||
|
||||
- [在 RHEL/CentOS 系统中使用 YUM 命令管理包][1]
|
||||
- [在 Fedora 系统中使用 DNF (YUM 的分支) 命令来管理包][2]
|
||||
- [命令行包管理器和用法列表][3]
|
||||
- [Linux 包管理器的图形化工具][4]
|
||||
|
||||
这可以在基于 RPM 的系统上完成,比如 RHEL, CentOS, OEL, Fedora 等。
|
||||
|
||||
* Fedora 系统使用 `dnf config-manager [options] [section …]`
|
||||
* 其它基于 RPM 的系统使用 `yum-config-manager [options] [section …]`
|
||||
|
||||
### 如何列出启用的仓库
|
||||
|
||||
只需运行以下命令即可检查系统上启用的仓库列表。
|
||||
|
||||
对于 CentOS/RHEL/OLE 系统:
|
||||
|
||||
```
|
||||
# yum repolist
|
||||
Loaded plugins: fastestmirror, security
|
||||
Loading mirror speeds from cached hostfile
|
||||
repo id repo name status
|
||||
base CentOS-6 - Base 6,706
|
||||
extras CentOS-6 - Extras 53
|
||||
updates CentOS-6 - Updates 1,255
|
||||
repolist: 8,014
|
||||
```
|
||||
|
||||
对于 Fedora 系统:
|
||||
|
||||
```
|
||||
# dnf repolist
|
||||
```
|
||||
|
||||
### 如何在系统中添加一个新仓库
|
||||
|
||||
每个仓库通常都提供自己的 `.repo` 文件。要将此类仓库添加到系统中,使用 root 用户运行以下命令。在我们的例子中将添加 EPEL 仓库 和 IUS 社区仓库,见下文。
|
||||
|
||||
但是没有 `.repo` 文件可用于这些仓库。因此,我们使用以下方法进行安装。
|
||||
|
||||
对于 EPEL 仓库,因为它可以从 CentOS 额外仓库获得,所以运行以下命令来安装它。
|
||||
|
||||
```
|
||||
# yum install epel-release -y
|
||||
```
|
||||
|
||||
对于 IUS 社区仓库,运行以下 bash 脚本来安装。
|
||||
|
||||
```
|
||||
# curl 'https://setup.ius.io/' -o setup-ius.sh
|
||||
# sh setup-ius.sh
|
||||
```
|
||||
|
||||
如果你有 `.repo` 文件,在 RHEL/CentOS/OEL 中,只需运行以下命令来添加一个仓库。
|
||||
|
||||
```
|
||||
# yum-config-manager --add-repo http://www.example.com/example.repo
|
||||
|
||||
Loaded plugins: product-id, refresh-packagekit, subscription-manager
|
||||
adding repo from: http://www.example.com/example.repo
|
||||
grabbing file http://www.example.com/example.repo to /etc/yum.repos.d/example.repo
|
||||
example.repo | 413 B 00:00
|
||||
repo saved to /etc/yum.repos.d/example.repo
|
||||
```
|
||||
|
||||
对于 Fedora 系统,运行以下命令来添加一个仓库:
|
||||
|
||||
```
|
||||
# dnf config-manager --add-repo http://www.example.com/example.repo
|
||||
adding repo from: http://www.example.com/example.repo
|
||||
```
|
||||
|
||||
如果在添加这些仓库之后运行 `yum repolist` 命令,你就可以看到新添加的仓库了。Yes,我看到了。
|
||||
|
||||
注意:每当运行 `yum repolist` 命令时,该命令会自动从相应的仓库获取更新,并将缓存保存在本地系统中。
|
||||
|
||||
```
|
||||
# yum repolist
|
||||
|
||||
Loaded plugins: fastestmirror, security
|
||||
Loading mirror speeds from cached hostfile
|
||||
epel/metalink | 6.1 kB 00:00
|
||||
* epel: epel.mirror.constant.com
|
||||
* ius: ius.mirror.constant.com
|
||||
ius | 2.3 kB 00:00
|
||||
repo id repo name status
|
||||
base CentOS-6 - Base 6,706
|
||||
epel Extra Packages for Enterprise Linux 6 - x86_64 12,505
|
||||
extras CentOS-6 - Extras 53
|
||||
ius IUS Community Packages for Enterprise Linux 6 - x86_64 390
|
||||
updates CentOS-6 - Updates 1,255
|
||||
repolist: 20,909
|
||||
```
|
||||
|
||||
每个仓库都有多个渠道,比如测试(Testing)、开发(Dev)和存档(Archive)等。通过导航到仓库文件位置,你可以更好地理解这一点。
|
||||
|
||||
```
|
||||
# ls -lh /etc/yum.repos.d
|
||||
total 64K
|
||||
-rw-r--r-- 1 root root 2.0K Apr 12 02:44 CentOS-Base.repo
|
||||
-rw-r--r-- 1 root root 647 Apr 12 02:44 CentOS-Debuginfo.repo
|
||||
-rw-r--r-- 1 root root 289 Apr 12 02:44 CentOS-fasttrack.repo
|
||||
-rw-r--r-- 1 root root 630 Apr 12 02:44 CentOS-Media.repo
|
||||
-rw-r--r-- 1 root root 916 May 18 11:07 CentOS-SCLo-scl.repo
|
||||
-rw-r--r-- 1 root root 892 May 18 10:36 CentOS-SCLo-scl-rh.repo
|
||||
-rw-r--r-- 1 root root 6.2K Apr 12 02:44 CentOS-Vault.repo
|
||||
-rw-r--r-- 1 root root 7.9K Apr 12 02:44 CentOS-Vault.repo.rpmnew
|
||||
-rw-r--r-- 1 root root 957 May 18 10:41 epel.repo
|
||||
-rw-r--r-- 1 root root 1.1K Nov 4 2012 epel-testing.repo
|
||||
-rw-r--r-- 1 root root 1.2K Feb 23 2017 ius-archive.repo
|
||||
-rw-r--r-- 1 root root 1.2K Feb 23 2017 ius-dev.repo
|
||||
-rw-r--r-- 1 root root 1.1K May 18 10:41 ius.repo
|
||||
-rw-r--r-- 1 root root 1.2K Feb 23 2017 ius-testing.repo
|
||||
```
|
||||
|
||||
### 如何在系统中启用一个仓库
|
||||
|
||||
当你在默认情况下添加一个新仓库时,它将启用它们的稳定仓库,这就是为什么我们在运行 `yum repolist` 命令时获取了仓库信息。在某些情况下,如果你希望启用它们的测试、开发或存档仓库,使用以下命令。另外,我们还可以使用此命令启用任何禁用的仓库。
|
||||
|
||||
为了验证这一点,我们将启用 `epel-testing.repo`,运行下面的命令:
|
||||
|
||||
```
|
||||
# yum-config-manager --enable epel-testing
|
||||
|
||||
Loaded plugins: fastestmirror
|
||||
==================================================================================== repo: epel-testing =====================================================================================
|
||||
[epel-testing]
|
||||
bandwidth = 0
|
||||
base_persistdir = /var/lib/yum/repos/x86_64/6
|
||||
baseurl =
|
||||
cache = 0
|
||||
cachedir = /var/cache/yum/x86_64/6/epel-testing
|
||||
cost = 1000
|
||||
enabled = 1
|
||||
enablegroups = True
|
||||
exclude =
|
||||
failovermethod = priority
|
||||
ftp_disable_epsv = False
|
||||
gpgcadir = /var/lib/yum/repos/x86_64/6/epel-testing/gpgcadir
|
||||
gpgcakey =
|
||||
gpgcheck = True
|
||||
gpgdir = /var/lib/yum/repos/x86_64/6/epel-testing/gpgdir
|
||||
gpgkey = file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6
|
||||
hdrdir = /var/cache/yum/x86_64/6/epel-testing/headers
|
||||
http_caching = all
|
||||
includepkgs =
|
||||
keepalive = True
|
||||
mdpolicy = group:primary
|
||||
mediaid =
|
||||
metadata_expire = 21600
|
||||
metalink =
|
||||
mirrorlist = https://mirrors.fedoraproject.org/metalink?repo=testing-epel6&arch=x86_64
|
||||
mirrorlist_expire = 86400
|
||||
name = Extra Packages for Enterprise Linux 6 - Testing - x86_64
|
||||
old_base_cache_dir =
|
||||
password =
|
||||
persistdir = /var/lib/yum/repos/x86_64/6/epel-testing
|
||||
pkgdir = /var/cache/yum/x86_64/6/epel-testing/packages
|
||||
proxy = False
|
||||
proxy_dict =
|
||||
proxy_password =
|
||||
proxy_username =
|
||||
repo_gpgcheck = False
|
||||
retries = 10
|
||||
skip_if_unavailable = False
|
||||
ssl_check_cert_permissions = True
|
||||
sslcacert =
|
||||
sslclientcert =
|
||||
sslclientkey =
|
||||
sslverify = True
|
||||
throttle = 0
|
||||
timeout = 30.0
|
||||
username =
|
||||
```
|
||||
|
||||
运行 `yum repolist` 命令来检查是否启用了 “epel-testing”。它被启用了,我可以从列表中看到它。
|
||||
|
||||
```
|
||||
# yum repolist
|
||||
Loaded plugins: fastestmirror, security
|
||||
Determining fastest mirrors
|
||||
epel/metalink | 18 kB 00:00
|
||||
epel-testing/metalink | 17 kB 00:00
|
||||
* epel: mirror.us.leaseweb.net
|
||||
* epel-testing: mirror.us.leaseweb.net
|
||||
* ius: mirror.team-cymru.com
|
||||
base | 3.7 kB 00:00
|
||||
centos-sclo-sclo | 2.9 kB 00:00
|
||||
epel | 4.7 kB 00:00
|
||||
epel/primary_db | 6.0 MB 00:00
|
||||
epel-testing | 4.7 kB 00:00
|
||||
epel-testing/primary_db | 368 kB 00:00
|
||||
extras | 3.4 kB 00:00
|
||||
ius | 2.3 kB 00:00
|
||||
ius/primary_db | 216 kB 00:00
|
||||
updates | 3.4 kB 00:00
|
||||
updates/primary_db | 8.1 MB 00:00 ...
|
||||
repo id repo name status
|
||||
base CentOS-6 - Base 6,706
|
||||
centos-sclo-sclo CentOS-6 - SCLo sclo 495
|
||||
epel Extra Packages for Enterprise Linux 6 - x86_64 12,509
|
||||
epel-testing Extra Packages for Enterprise Linux 6 - Testing - x86_64 809
|
||||
extras CentOS-6 - Extras 53
|
||||
ius IUS Community Packages for Enterprise Linux 6 - x86_64 390
|
||||
updates CentOS-6 - Updates 1,288
|
||||
repolist: 22,250
|
||||
```
|
||||
|
||||
如果你想同时启用多个仓库,使用以下格式。这个命令将启用 epel、epel-testing 和 ius 仓库:
|
||||
|
||||
```
|
||||
# yum-config-manager --enable epel epel-testing ius
|
||||
```
|
||||
|
||||
对于 Fedora 系统,运行下面的命令来启用仓库:
|
||||
|
||||
```
|
||||
# dnf config-manager --set-enabled epel-testing
|
||||
```
|
||||
|
||||
### 如何在系统中禁用一个仓库
|
||||
|
||||
无论何时你在默认情况下添加一个新的仓库,它都会启用它们的稳定仓库,这就是为什么我们在运行 `yum repolist` 命令时获取了仓库信息。如果你不想使用仓库,那么可以通过下面的命令来禁用它。
|
||||
|
||||
为了验证这点,我们将要禁用 `epel-testing.repo` 和 `ius.repo`,运行以下命令:
|
||||
|
||||
```
|
||||
# yum-config-manager --disable epel-testing ius
|
||||
|
||||
Loaded plugins: fastestmirror
|
||||
==================================================================================== repo: epel-testing =====================================================================================
|
||||
[epel-testing]
|
||||
bandwidth = 0
|
||||
base_persistdir = /var/lib/yum/repos/x86_64/6
|
||||
baseurl =
|
||||
cache = 0
|
||||
cachedir = /var/cache/yum/x86_64/6/epel-testing
|
||||
cost = 1000
|
||||
enabled = 0
|
||||
enablegroups = True
|
||||
exclude =
|
||||
failovermethod = priority
|
||||
ftp_disable_epsv = False
|
||||
gpgcadir = /var/lib/yum/repos/x86_64/6/epel-testing/gpgcadir
|
||||
gpgcakey =
|
||||
gpgcheck = True
|
||||
gpgdir = /var/lib/yum/repos/x86_64/6/epel-testing/gpgdir
|
||||
gpgkey = file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6
|
||||
hdrdir = /var/cache/yum/x86_64/6/epel-testing/headers
|
||||
http_caching = all
|
||||
includepkgs =
|
||||
keepalive = True
|
||||
mdpolicy = group:primary
|
||||
mediaid =
|
||||
metadata_expire = 21600
|
||||
metalink =
|
||||
mirrorlist = https://mirrors.fedoraproject.org/metalink?repo=testing-epel6&arch=x86_64
|
||||
mirrorlist_expire = 86400
|
||||
name = Extra Packages for Enterprise Linux 6 - Testing - x86_64
|
||||
old_base_cache_dir =
|
||||
password =
|
||||
persistdir = /var/lib/yum/repos/x86_64/6/epel-testing
|
||||
pkgdir = /var/cache/yum/x86_64/6/epel-testing/packages
|
||||
proxy = False
|
||||
proxy_dict =
|
||||
proxy_password =
|
||||
proxy_username =
|
||||
repo_gpgcheck = False
|
||||
retries = 10
|
||||
skip_if_unavailable = False
|
||||
ssl_check_cert_permissions = True
|
||||
sslcacert =
|
||||
sslclientcert =
|
||||
sslclientkey =
|
||||
sslverify = True
|
||||
throttle = 0
|
||||
timeout = 30.0
|
||||
username =
|
||||
|
||||
========================================================================================= repo: ius =========================================================================================
|
||||
[ius]
|
||||
bandwidth = 0
|
||||
base_persistdir = /var/lib/yum/repos/x86_64/6
|
||||
baseurl =
|
||||
cache = 0
|
||||
cachedir = /var/cache/yum/x86_64/6/ius
|
||||
cost = 1000
|
||||
enabled = 0
|
||||
enablegroups = True
|
||||
exclude =
|
||||
failovermethod = priority
|
||||
ftp_disable_epsv = False
|
||||
gpgcadir = /var/lib/yum/repos/x86_64/6/ius/gpgcadir
|
||||
gpgcakey =
|
||||
gpgcheck = True
|
||||
gpgdir = /var/lib/yum/repos/x86_64/6/ius/gpgdir
|
||||
gpgkey = file:///etc/pki/rpm-gpg/IUS-COMMUNITY-GPG-KEY
|
||||
hdrdir = /var/cache/yum/x86_64/6/ius/headers
|
||||
http_caching = all
|
||||
includepkgs =
|
||||
keepalive = True
|
||||
mdpolicy = group:primary
|
||||
mediaid =
|
||||
metadata_expire = 21600
|
||||
metalink =
|
||||
mirrorlist = https://mirrors.iuscommunity.org/mirrorlist?repo=ius-centos6&arch=x86_64&protocol=http
|
||||
mirrorlist_expire = 86400
|
||||
name = IUS Community Packages for Enterprise Linux 6 - x86_64
|
||||
old_base_cache_dir =
|
||||
password =
|
||||
persistdir = /var/lib/yum/repos/x86_64/6/ius
|
||||
pkgdir = /var/cache/yum/x86_64/6/ius/packages
|
||||
proxy = False
|
||||
proxy_dict =
|
||||
proxy_password =
|
||||
proxy_username =
|
||||
repo_gpgcheck = False
|
||||
retries = 10
|
||||
skip_if_unavailable = False
|
||||
ssl_check_cert_permissions = True
|
||||
sslcacert =
|
||||
sslclientcert =
|
||||
sslclientkey =
|
||||
sslverify = True
|
||||
throttle = 0
|
||||
timeout = 30.0
|
||||
username =
|
||||
```
|
||||
|
||||
运行 `yum repolist` 命令检查 “epel-testing” 和 “ius” 仓库是否被禁用。它被禁用了,我不能看到那些仓库,除了 “epel”。
|
||||
|
||||
```
|
||||
# yum repolist
|
||||
Loaded plugins: fastestmirror, security
|
||||
Loading mirror speeds from cached hostfile
|
||||
* epel: mirror.us.leaseweb.net
|
||||
repo id repo name status
|
||||
base CentOS-6 - Base 6,706
|
||||
centos-sclo-sclo CentOS-6 - SCLo sclo 495
|
||||
epel Extra Packages for Enterprise Linux 6 - x86_64 12,505
|
||||
extras CentOS-6 - Extras 53
|
||||
updates CentOS-6 - Updates 1,288
|
||||
repolist: 21,051
|
||||
```
|
||||
|
||||
或者,我们可以运行以下命令查看详细信息:
|
||||
|
||||
```
|
||||
# yum repolist all | grep "epel*\|ius*"
|
||||
* epel: mirror.steadfast.net
|
||||
epel Extra Packages for Enterprise Linux 6 enabled: 12,509
|
||||
epel-debuginfo Extra Packages for Enterprise Linux 6 disabled
|
||||
epel-source Extra Packages for Enterprise Linux 6 disabled
|
||||
epel-testing Extra Packages for Enterprise Linux 6 disabled
|
||||
epel-testing-debuginfo Extra Packages for Enterprise Linux 6 disabled
|
||||
epel-testing-source Extra Packages for Enterprise Linux 6 disabled
|
||||
ius IUS Community Packages for Enterprise disabled
|
||||
ius-archive IUS Community Packages for Enterprise disabled
|
||||
ius-archive-debuginfo IUS Community Packages for Enterprise disabled
|
||||
ius-archive-source IUS Community Packages for Enterprise disabled
|
||||
ius-debuginfo IUS Community Packages for Enterprise disabled
|
||||
ius-dev IUS Community Packages for Enterprise disabled
|
||||
ius-dev-debuginfo IUS Community Packages for Enterprise disabled
|
||||
ius-dev-source IUS Community Packages for Enterprise disabled
|
||||
ius-source IUS Community Packages for Enterprise disabled
|
||||
ius-testing IUS Community Packages for Enterprise disabled
|
||||
ius-testing-debuginfo IUS Community Packages for Enterprise disabled
|
||||
ius-testing-source IUS Community Packages for Enterprise disabled
|
||||
```
|
||||
|
||||
对于 Fedora 系统,运行以下命令来启用一个仓库:
|
||||
|
||||
```
|
||||
# dnf config-manager --set-disabled epel-testing
|
||||
```
|
||||
|
||||
或者,可以通过手动编辑适当的 repo 文件来完成。为此,打开相应的 repo 文件并将值从 `enabled=0` 改为 `enabled=1`(启用仓库)或从 `enabled=1` 变为 `enabled=0`(禁用仓库)。
|
||||
|
||||
即从:
|
||||
|
||||
```
|
||||
[epel]
|
||||
name=Extra Packages for Enterprise Linux 6 - $basearch
|
||||
#baseurl=http://download.fedoraproject.org/pub/epel/6/$basearch
|
||||
mirrorlist=https://mirrors.fedoraproject.org/metalink?repo=epel-6&arch=$basearch
|
||||
failovermethod=priority
|
||||
enabled=0
|
||||
gpgcheck=1
|
||||
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6
|
||||
```
|
||||
改为:
|
||||
|
||||
```
|
||||
[epel]
|
||||
name=Extra Packages for Enterprise Linux 6 - $basearch
|
||||
#baseurl=http://download.fedoraproject.org/pub/epel/6/$basearch
|
||||
mirrorlist=https://mirrors.fedoraproject.org/metalink?repo=epel-6&arch=$basearch
|
||||
failovermethod=priority
|
||||
enabled=1
|
||||
gpgcheck=1
|
||||
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-add-enable-disable-a-repository-dnf-yum-config-manager-on-linux/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/prakash/
|
||||
[1]:https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[2]:https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[3]:https://www.2daygeek.com/list-of-command-line-package-manager-for-linux/
|
||||
[4]:https://www.2daygeek.com/list-of-graphical-frontend-tool-for-linux-package-manager/
|
||||
File diff suppressed because it is too large
Load Diff
@ -0,0 +1,159 @@
|
||||
对 C++ 的忧虑?C++创始人警告:关于 C++ 的某些未来计划十分危险
|
||||
======
|
||||
|
||||

|
||||
|
||||
今年早些时候,我们对 Bjarne Stroustrup 进行了采访。他是 C++ 语言的创始人,摩根士丹利技术部门的董事总经理,美国哥伦比亚大学计算机科学的客座教授。他写了[一封信][1],请那些关注编程语言进展的人去“想想瓦萨号!”
|
||||
|
||||
这句话对于丹麦人来说,毫无疑问,很容易理解。而那些对于 17 世纪的斯堪的纳维亚历史了解不多的人,还需要详细说明一下。瓦萨号是一艘瑞典军舰,由国王 Gustavus Adolphus 定做。它是当时波罗的海国家中最强大的军舰,但在 1628 年 8 月 10 日首航没几分钟之后就沉没了。
|
||||
|
||||
巨大的瓦萨号有一个难以解决的设计缺陷:头重脚轻,以至于它被[一阵狂风刮翻了][2]。通过援引这艘沉船的历史,Stroustrup 警示了 C++ 所面临的风险 —— 现在越来越多的特性被添加到了 C++ 中。
|
||||
|
||||
我们现在已经发现了好些能导致头重脚轻的特性。Stroustrup 在他的信中引用了 43 个提议。他认为那些参与 C++ 语言 ISO 标准演进的人(即所谓的 [WG21 小组][3])正在努力推进语言发展,但成员们的努力方向却并不一致。
|
||||
|
||||
在他的信中,他写道:
|
||||
|
||||
> 分开来看,许多提议都很有道理。但将它们综合到一起,这些提议是很愚蠢的,将危害 C++ 的未来。
|
||||
|
||||
他明确表示,他用瓦萨号作为比喻并不是说他认为不断提升会带来毁灭。我们应该吸取瓦萨号的教训,构建一个坚实的基础,从错误中学习并对新版本做彻底的测试。
|
||||
|
||||
在瑞士<ruby>拉普斯威尔<rt>Rapperswill</rt></ruby>召开 C++ 标准化委员会会议之后,本月早些时候,Stroustrup 接受了 *The Register* 的采访,回答了有关 C++ 语言下一步发展方向的几个问题。(最新版是去年刚发布的 C++17;下一个版本是 C++20,预计于 2020 年发布。)
|
||||
|
||||
*Register:*在您的信件《想想瓦萨号!》中,您写道:
|
||||
|
||||
> 在 C++11 开始的基础建设尚未完成,而 C++17 基本没有在使基础更加稳固、规范和完整方面做出改善。相反,却增加了重要接口的复杂度(原文为 surface complexity,直译“表面复杂度”),让人们需要学习的特性数量越来越多。C++ 可能在这种不成熟的提议的重压之下崩溃。我们不应该花费大量的时间为专家级用户们(比如我们自己)去创建越来越复杂的东西。~~(还要考虑普通用户的学习曲线,越复杂的东西越不易普及。)~~
|
||||
|
||||
**对新人来说,C++ 过难了吗?如果是这样,您认为怎样的特性让新人更易理解?**
|
||||
|
||||
*Stroustrup:*C++ 的有些东西对于新人来说确实很具有挑战性。
|
||||
|
||||
另一方面而言,C++ 中有些东西对于新人来说,比起 C 或上世纪九十年代的 C++ 更容易理解了。而难点是让大型社区专注于这些部分,并且帮助新手和非专业的 C++ 用户去规避那些对高级库实现提供支持的部分。
|
||||
|
||||
我建议使用 [C++ 核心准则][4]作为实现上述目标的一个辅助。
|
||||
|
||||
此外,我的“C++ 教程”也可以帮助人们在使用现代 C++ 时走上正确的方向,而不会迷失在自上世纪九十年代以来的复杂性中,或困惑于只有专家级用户才能理解的东西中。这本即将出版的第二版的“C++ 教程”涵盖了 C++17 和部分 C++20 的内容。
|
||||
|
||||
我和其他人给没有编程经验的大一新生教过 C++,只要你不去深入编程语言的每个晦涩难懂的角落,把注意力集中到 C++ 中最主流的部分,就可以在三个月内学会 C++。
|
||||
|
||||
“让简单的东西保持简单”是我长期追求的目标。比如 C++11 的 `range-for` 循环:
|
||||
|
||||
```
|
||||
for (int& x : v) ++x; // increment each element of the container v
|
||||
```
|
||||
|
||||
`v` 的位置可以是任何容器。在 C 和 C 风格的 C++ 中,它可能看起来是这样:
|
||||
|
||||
```
|
||||
for (int i=0; i<MAX; i++) ++v[i]; // increment each element of the array v
|
||||
```
|
||||
|
||||
一些人抱怨说添加了 `range-for` 循环让 C++ 变得更复杂了,很显然,他们是正确的,因为它添加了一个新特性。但它却让 C++ 用起来更简单,而且同时它还消除了使用传统 `for` 循环时会出现的一些常见错误。
|
||||
|
||||
另一个例子是 C++11 的<ruby>标准线程库<rt>standard thread library</rt></ruby>。它比起使用 POSIX 或直接使用 Windows 的 C API 来说更简单,并且更不易出错。
|
||||
|
||||
*Register:***您如何看待 C++ 现在的状况?**
|
||||
|
||||
*Stroustrup:*C++11 中作出了许多重大改进,并且我们在 C++14 上全面完成了改进工作。C++17 添加了相当多的新特性,但是没有提供对新技术的很多支持。C++20 目前看上去可能会成为一个重大改进版。编译器的状况非常好,标准库实现得也很优秀,非常接近最新的标准。C++17 现在已经可以使用,对于工具的支持正在逐步推进。已经有了许多第三方的库和好些新工具。然而,不幸的是,这些东西不太好找到。
|
||||
|
||||
我在《想想瓦萨号!》一文中所表达的担忧与标准化过程有关,对新东西的过度热情与完美主义的组合推迟了重大改进。“追求完美往往事与愿违”。在六月份拉普斯威尔的会议上有 160 人参与;在这样一个数量庞大且多样化的人群中很难取得一致意见。专家们也本来就有只为自己设计语言的倾向,这让他们不会时常在设计时考虑整个社区的需求。
|
||||
|
||||
*Register:***C++ 是否有一个理想的状态,或者与之相反,您只是为了程序员们的期望而努力,随时适应并且努力满足程序员们的需要?**
|
||||
|
||||
*Stroustrup:*二者都有。我很乐意看到 C++ 支持彻底保证<ruby>类型安全<rt>type-safe</rt></ruby>和<ruby>资源安全<rt>resource-safe</rt></ruby>的编程方式。这不应该通过限制适用性或增加性能损耗来实现,而是应该通过改进的表达能力和更好的性能来实现。通过让程序员使用更好的(和更易用的)语言工具可以达到这个目标,我们可以做到的。
|
||||
|
||||
终极目标不会马上实现,也不会单靠语言设计来实现。为了实现这一目标,我们需要改进语言特性、提供更好的库和静态分析,并且设立提升编程效率的规则。C++ 核心准则是我为了提升 C++ 代码质量而实行的广泛而长期的计划的一部分。
|
||||
|
||||
*Register:***目前 C++ 是否面临着可以预见的风险?如果有,它是以什么形式出现的?(如,迭代过于缓慢,新兴低级语言,等等……据您的观点来看,似乎是提出的提议过多。)**
|
||||
|
||||
*Stroustrup:*就是这样。今年我们已经收到了 400 篇文章。当然了,它们并不都是新提议。许多提议都与规范语言和标准库这一必需而乏味的工作相关,但是量大到难以管理。你可以在 [WG21 网站][6]上找到所有这些文章。
|
||||
|
||||
我写了《想想瓦萨号!》这封信作为一个呼吁,因为这种为了解决即刻需求(或者赶时髦)而不断增添语言特性,却对巩固语言基础(比如,改善<ruby>静态类型系统<rt>static type system</rt></ruby>)不管不问的倾向让我感到震惊。增加的任何新东西,无论它多小都会产生成本,比如实现、学习、工具升级。重大的特性改变能够改变我们对编程的想法,而它们才是我们必须关注的东西。
|
||||
|
||||
委员会已经设立了一个“指导小组”,这个小组由在语言、标准库、实现、以及工程实践领域中拥有不错履历的人组成。我是其中的成员之一。我们负责为重点领域写[一些关于发展方向、设计理念和建议重点发展领域的东西][7]。
|
||||
|
||||
对于 C++20,我们建议去关注:
|
||||
|
||||
* 概念
|
||||
* 模块(适度地模块化并带来编译时的显著改进)
|
||||
* Ranges(包括一些无限序列的扩展)
|
||||
* 标准库中的网络概念
|
||||
|
||||
在拉普斯威尔会议之后,这些都有了实现的机会,虽然模块和网络化都不是会议的重点讨论对象。我是一个乐观主义者,并且委员会的成员们都非常努力。
|
||||
|
||||
我并不担心其它语言或新语言会取代它。我喜欢编程语言。如果一门新的语言提供了独一无二的、非常有用的东西,那它就是我们的榜样,我们可以向它学习。当然,每门语言本身都有一些问题。C++ 的许多问题都与它广泛的应用领域、大量的使用人群和过度的热情有关。大多数语言的社区都会有这样的问题。
|
||||
|
||||
*Register:***关于 C++ 您是否重新考虑过任何架构方面的决策?**
|
||||
|
||||
*Stroustrup:*当我着手规划新版本时,我经常反思原来的决策和设计。关于这些,可以看我的《编程的历史》论文第 [1][8]、[2][9] 部分。
|
||||
|
||||
并没有让我觉得很后悔的重大决策。如果我必须重新做一次,我觉得和以前做的不会有太大的不同。
|
||||
|
||||
与以前一样,能够直接处理硬件加上零开销的抽象是设计的指导思想。使用<ruby>构造函数<rt>constructor</rt></ruby>和<ruby>析构函数<rt>destructor</rt></ruby>去处理资源是关键(<ruby>资源获取即初始化<rt>Resource Acquisition Is Initialization</rt><ruby>,RAII);<ruby>标准模板库<rt>Standard Template Library</rt></ruby>(STL) 就是解释 C++ 库能够做什么的一个很好的例子。
|
||||
|
||||
*Register:***在 2011 年被采纳的每三年发布一个新版本的节奏是否仍然有效?我之所以这样问是因为 Java 已经决定更快地迭代。**
|
||||
|
||||
*Stroustrup:*我认为 C++20 将会按时发布(就像 C++14 和 C++17 那样),并且主流的编译器也会立即采用它。我也希望 C++20 基于 C++17 能有重大的改进。
|
||||
|
||||
对于其它语言如何管理它们的版本,我并不十分关心。C++ 是由一个遵循 ISO 规则的委员会来管理的,而不是由某个大公司或某种“<ruby>终生的仁慈独裁者<rt>Beneficial Dictator Of Life</rt></ruby>(BDOL)”来管理。这一点不会改变。C++ 每三年发布一次的周期在 ISO 标准中是一个引人注目的创举。通常而言,周期应该是 5 或 10 年。
|
||||
|
||||
*Register:***在您的信中您写道:**
|
||||
|
||||
> 我们需要一个能够被“普通程序员”使用的,条理还算清楚的编程语言。他们主要关心的是,能否按时高质量地交付他们的应用程序。
|
||||
|
||||
改进语言能够解决这个问题吗?或者,我们还需要更容易获得的工具和教育支持?
|
||||
|
||||
*Stroustrup:*我尽力宣传我关于 C++ 的实质和使用方式的[理念][10],并且我鼓励其他人也和我采取相同的行动。
|
||||
|
||||
特别是,我鼓励讲师和作者们向 C++ 程序员们提出有用的建议,而不是去示范复杂的示例和技术来展示他们自己有多高明。我在 2017 年的 CppCon 大会上的演讲主题就是“学习和传授 C++”,并且也指出,我们需要更好的工具。
|
||||
|
||||
我在演讲中提到了构建技术支持和包管理器,这些历来都是 C++ 的弱项。标准化委员会现在有一个工具研究小组,或许不久的将来也会组建一个教育研究小组。
|
||||
|
||||
C++ 的社区以前是十分无组织性的,但是在过去的五年里,为了满足社区对新闻和技术支持的需要,出现了很多集会和博客。CppCon、isocpp.org、以及 Meeting++ 就是一些例子。
|
||||
|
||||
在一个庞大的委员会中做语言标准设计是很困难的。但是,对于所有的大型项目来说,委员会又是必不可少的。我很忧虑,但是关注它们并且面对问题是成功的必要条件。
|
||||
|
||||
*Register:***您如何看待 C++ 社区的流程?在沟通和决策方面你希望看到哪些变化?**
|
||||
|
||||
*Stroustrup:*C++ 并没有企业管理一般的“社区流程”;它所遵循的是 ISO 标准流程。我们不能对 ISO 的条例做大的改变。理想的情况是,我们设立一个小型的、全职的“秘书处”来做最终决策和方向管理,但这种理想情况是不会出现的。相反,我们有成百上千的人在线讨论,大约有 160 人在技术问题上进行投票,大约有 70 组织和 11 个国家的人在最终提议上正式投票。这样很混乱,但是有些时候它的确能发挥作用。
|
||||
|
||||
*Register:***在最后,您认为那些即将推出的 C++ 特性中,对 C++ 用户最有帮助的是哪些?**
|
||||
|
||||
*Stroustrup:*
|
||||
|
||||
* 那些能让编程显著变简单的概念。
|
||||
* <ruby>并行算法<rt>Parallel algorithms</rt></ruby> —— 如果要使用现代硬件的并发特性的话,这方法再简单不过了。
|
||||
* <ruby>协程<rt>Coroutines</rt></ruby>,如果委员会能够确定在 C++20 上推出。
|
||||
* 改进了组织源代码方式的,并且大幅改善了编译时间的模块。我希望能有这样的模块,但是还没办法确定我们能不能在 C++20 上推出。
|
||||
* 一个标准的网络库,但是还没办法确定我们能否在 C++20 上推出。
|
||||
|
||||
此外:
|
||||
|
||||
* Contracts(运行时检查的先决条件、后置条件、和断言)可能对许多人都非常重要。
|
||||
* date 和 time-zone 支持库可能对许多人(行业)非常重要。
|
||||
|
||||
*Register:***您还有想对读者们说的话吗?**
|
||||
|
||||
*Stroustrup:*如果 C++ 标准化委员会能够专注于重大问题,去解决重大问题,那么 C++20 将会非常优秀。但是在 C++20 推出之前,我们还有 C++17;无论如何,它仍然远超许多人对 C++ 的旧印象。®
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.theregister.co.uk/2018/06/18/bjarne_stroustrup_c_plus_plus/
|
||||
|
||||
作者:[Thomas Claburn][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[thecyanbird](https://github.com/thecyanbird)、[Northurland](https://github.com/Northurland)、[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.theregister.co.uk/Author/3190
|
||||
[1]: http://open-std.org/JTC1/SC22/WG21/docs/papers/2018/p0977r0.pdf
|
||||
[2]: https://www.vasamuseet.se/en/vasa-history/disaster
|
||||
[3]: http://open-std.org/JTC1/SC22/WG21/
|
||||
[4]: https://github.com/isocpp/CppCoreGuidelines/blob/master/CppCoreGuidelines.md
|
||||
[5]: https://go.theregister.co.uk/tl/1755/shttps://continuouslifecycle.london/
|
||||
[6]: http://www.open-std.org/jtc1/sc22/wg21/docs/papers/
|
||||
[7]: http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2018/p0939r0.pdf
|
||||
[8]: http://www.stroustrup.com/hopl-almost-final.pdf
|
||||
[9]: http://www.stroustrup.com/hopl2.pdf
|
||||
[10]: http://www.stroustrup.com/papers.html
|
||||
77
published/201811/20180626 8 great pytest plugins.md
Normal file
77
published/201811/20180626 8 great pytest plugins.md
Normal file
@ -0,0 +1,77 @@
|
||||
8 个很棒的 pytest 插件
|
||||
======
|
||||
|
||||
> Python 测试工具最好的一方面是其强大的生态系统。这里列出了八个最好的插件。
|
||||
|
||||

|
||||
|
||||
我们是 [pytest][1] 的忠实粉丝,并将其作为工作和开源项目的默认 Python 测试工具。在本月的 Python 专栏中,我们分享了为什么我们喜欢 `pytest` 以及一些让 `pytest` 测试工作更有趣的插件。
|
||||
|
||||
### 什么是 pytest?
|
||||
|
||||
正如该工具的网站所说,“pytest 框架可以轻松地编写小型测试,也能进行扩展以支持应用和库的复杂功能测试。”
|
||||
|
||||
`pytest` 允许你在任何名为 `test_*.py` 的文件中定义测试,并将其定义为以 `test_*` 开头的函数。然后,pytest 将在整个项目中查找所有测试,并在控制台中运行 `pytest` 时自动运行这些测试。pytest 接受[标志和参数][2],它们可以在测试运行器停止时更改,这些包含如何输出结果,运行哪些测试以及输出中包含哪些信息。它还包括一个 `set_trace()` 函数,它可以进入到你的测试中。它会暂停您的测试, 并允许你与变量进行交互,不然你只能在终端中“四处翻弄”来调试你的项目。
|
||||
|
||||
`pytest` 最好的一方面是其强大的插件生态系统。因为 `pytest` 是一个非常流行的测试库,所以多年来创建了许多插件来扩展、定制和增强其功能。这八个插件是我们的最爱。
|
||||
|
||||
### 8 个很棒的插件
|
||||
|
||||
#### 1、pytest-sugar
|
||||
|
||||
[pytest-sugar][3] 改变了 `pytest` 的默认外观,添加了一个进度条,并立即显示失败的测试。它不需要配置,只需 `pip install pytest-sugar`,用 `pytest` 运行测试,来享受更漂亮、更有用的输出。
|
||||
|
||||
#### 2、pytest-cov
|
||||
|
||||
[pytest-cov][4] 在 `pytest` 中增加了覆盖率支持,来显示哪些代码行已经测试过,哪些还没有。它还将包括项目的测试覆盖率。
|
||||
|
||||
#### 3、pytest-picked
|
||||
|
||||
[pytest-picked][5] 对你已经修改但尚未提交 `git` 的代码运行测试。安装库并运行 `pytest --picked` 来仅测试自上次提交后已更改的文件。
|
||||
|
||||
#### 4、pytest-instafail
|
||||
|
||||
[pytest-instafail][6] 修改 `pytest` 的默认行为来立即显示失败和错误,而不是等到 `pytest` 完成所有测试。
|
||||
|
||||
#### 5、pytest-tldr
|
||||
|
||||
一个全新的 `pytest` 插件,可以将输出限制为你需要的东西。`pytest-tldr`(`tldr` 代表 “too long, didn't read” —— 太长,不想读),就像 pytest-sugar 一样,除基本安装外不需要配置。不像 pytest 的默认输出那么详细,[pytest-tldr][7] 将默认输出限制为失败测试的回溯信息,并忽略了一些令人讨厌的颜色编码。添加 `-v` 标志会为喜欢它的人返回更详细的输出。
|
||||
|
||||
#### 6、pytest-xdist
|
||||
|
||||
[pytest-xdist][8] 允许你通过 `-n` 标志并行运行多个测试:例如,`pytest -n 2` 将在两个 CPU 上运行你的测试。这可以显著加快你的测试速度。它还包括 `--looponfail` 标志,它将自动重新运行你的失败测试。
|
||||
|
||||
#### 7、pytest-django
|
||||
|
||||
[pytest-django][9] 为 Django 应用和项目添加了 `pytest` 支持。具体来说,`pytest-django` 引入了使用 pytest fixture 测试 Django 项目的能力,而省略了导入 `unittest` 和复制/粘贴其他样板测试代码的需要,并且比标准的 Django 测试套件运行得更快。
|
||||
|
||||
#### 8、django-test-plus
|
||||
|
||||
[django-test-plus][10] 并不是专门为 `pytest` 开发,但它现在支持 `pytest`。它包含自己的 `TestCase` 类,你的测试可以继承该类,并使你能够使用较少的按键来输出频繁的测试案例,例如检查特定的 HTTP 错误代码。
|
||||
|
||||
我们上面提到的库绝不是你扩展 `pytest` 的唯一选择。有用的 pytest 插件的前景是广阔的。查看 [pytest 插件兼容性][11]页面来自行探索。你最喜欢哪些插件?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/pytest-plugins
|
||||
|
||||
作者:[Jeff Triplett][a1], [Lacery Williams Henschel][a2]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a1]:https://opensource.com/users/jefftriplett
|
||||
[a2]:https://opensource.com/users/laceynwilliams
|
||||
[1]:https://docs.pytest.org/en/latest/
|
||||
[2]:https://docs.pytest.org/en/latest/usage.html
|
||||
[3]:https://github.com/Frozenball/pytest-sugar
|
||||
[4]:https://github.com/pytest-dev/pytest-cov
|
||||
[5]:https://github.com/anapaulagomes/pytest-picked
|
||||
[6]:https://github.com/pytest-dev/pytest-instafail
|
||||
[7]:https://github.com/freakboy3742/pytest-tldr
|
||||
[8]:https://github.com/pytest-dev/pytest-xdist
|
||||
[9]:https://pytest-django.readthedocs.io/en/latest/
|
||||
[10]:https://django-test-plus.readthedocs.io/en/latest/
|
||||
[11]:https://plugincompat.herokuapp.com/
|
||||
@ -0,0 +1,103 @@
|
||||
如何在 Anbox 上安装 Google Play 商店及启用 ARM 支持
|
||||
======
|
||||
|
||||
|
||||
|
||||
[Anbox][1] (Anroid in a Box)是一个自由开源工具,它允许你在 Linux 上运行 Android 应用程序。它的工作原理是在 LXC 容器中运行 Android 运行时环境,重新创建 Android 的目录结构作为可挂载的 loop 镜像,同时使用本机 Linux 内核来执行应用。
|
||||
|
||||
据其网站所述,它的主要特性是安全性、性能、集成和趋同(不同外形尺寸缩放)。
|
||||
|
||||
使用 Anbox,每个 Android 应用或游戏就像系统应用一样都在一个单独的窗口中启动,它们的行为或多或少类似于常规窗口,显示在启动器中,可以平铺等等。
|
||||
|
||||
默认情况下,Anbox 没有 Google Play 商店或 ARM 应用支持。要安装应用,你必须下载每个应用的 APK 并使用 `adb` 手动安装。此外,默认情况下不能使用 Anbox 安装 ARM 应用或游戏 —— 尝试安装 ARM 应用会显示以下错误:
|
||||
|
||||
```
|
||||
Failed to install PACKAGE.NAME.apk: Failure [INSTALL_FAILED_NO_MATCHING_ABIS: Failed to extract native libraries, res=-113]
|
||||
|
||||
```
|
||||
|
||||
你可以在 Anbox 中手动设置 Google Play 商店和 ARM 应用支持(通过 libhoudini),但这是一个非常复杂的过程。为了更容易地在 Anbox 上安装 Google Play 商店和 Google Play 服务,并让它支持 ARM 应用程序和游戏(使用 libhoudini),[geeks-r-us.de][2](文章是德语)上的人创建了一个自动执行这些任务的脚本。
|
||||
|
||||
在使用之前,我想明确指出,即使在集成 libhoudini 来支持 ARM 后,也并非所有 Android 应用和游戏都能在 Anbox 中运行。某些 Android 应用和游戏可能根本不会出现在 Google Play 商店中,而一些应用和游戏可能可以安装但无法使用。此外,某些应用可能无法使用某些功能。
|
||||
|
||||
### 安装 Google Play 商店并在 Anbox 上启用 ARM 应用/游戏支持
|
||||
|
||||
如果你的 Linux 桌面上尚未安装 Anbox,这些说明显然不起作用。如果你还没有,请按照[此处][7]的安装说明安装 Anbox。此外,请确保在安装 Anbox 之后,使用此脚本之前至少运行一次 `anbox.appmgr`,以避免遇到问题。另外,确保在执行下面的脚本时 Anbox 没有运行(我怀疑这是导致评论中提到的这个[问题][8]的原因)。
|
||||
|
||||
1、 安装所需的依赖项(wget、lzip、unzip 和 squashfs-tools)。
|
||||
|
||||
在 Debian、Ubuntu 或 Linux Mint 中,使用此命令安装所需的依赖项:
|
||||
|
||||
```
|
||||
sudo apt install wget lzip unzip squashfs-tools
|
||||
```
|
||||
|
||||
2、 下载并运行脚本,在 Anbox 上自动下载并安装 Google Play 商店(和 Google Play 服务)和 libhoudini(用于 ARM 应用/游戏支持)。
|
||||
|
||||
**警告:永远不要在不知道它做什么的情况下运行不是你写的脚本。在运行此脚本之前,请查看其[代码][4]。**
|
||||
|
||||
要下载脚本,使其可执行并在 Linux 桌面上运行,请在终端中使用以下命令:
|
||||
|
||||
```
|
||||
wget https://raw.githubusercontent.com/geeks-r-us/anbox-playstore-installer/master/install-playstore.sh
|
||||
chmod +x install-playstore.sh
|
||||
sudo ./install-playstore.sh
|
||||
```
|
||||
|
||||
3、要让 Google Play 商店在 Anbox 中运行,你需要启用 Google Play 商店和 Google Play 服务的所有权限
|
||||
|
||||
为此,请运行Anbox:
|
||||
|
||||
```
|
||||
anbox.appmgr
|
||||
```
|
||||
|
||||
然后进入“设置 > 应用 > Google Play 服务 > 权限”并启用所有可用权限。对 Google Play 商店也一样!
|
||||
|
||||
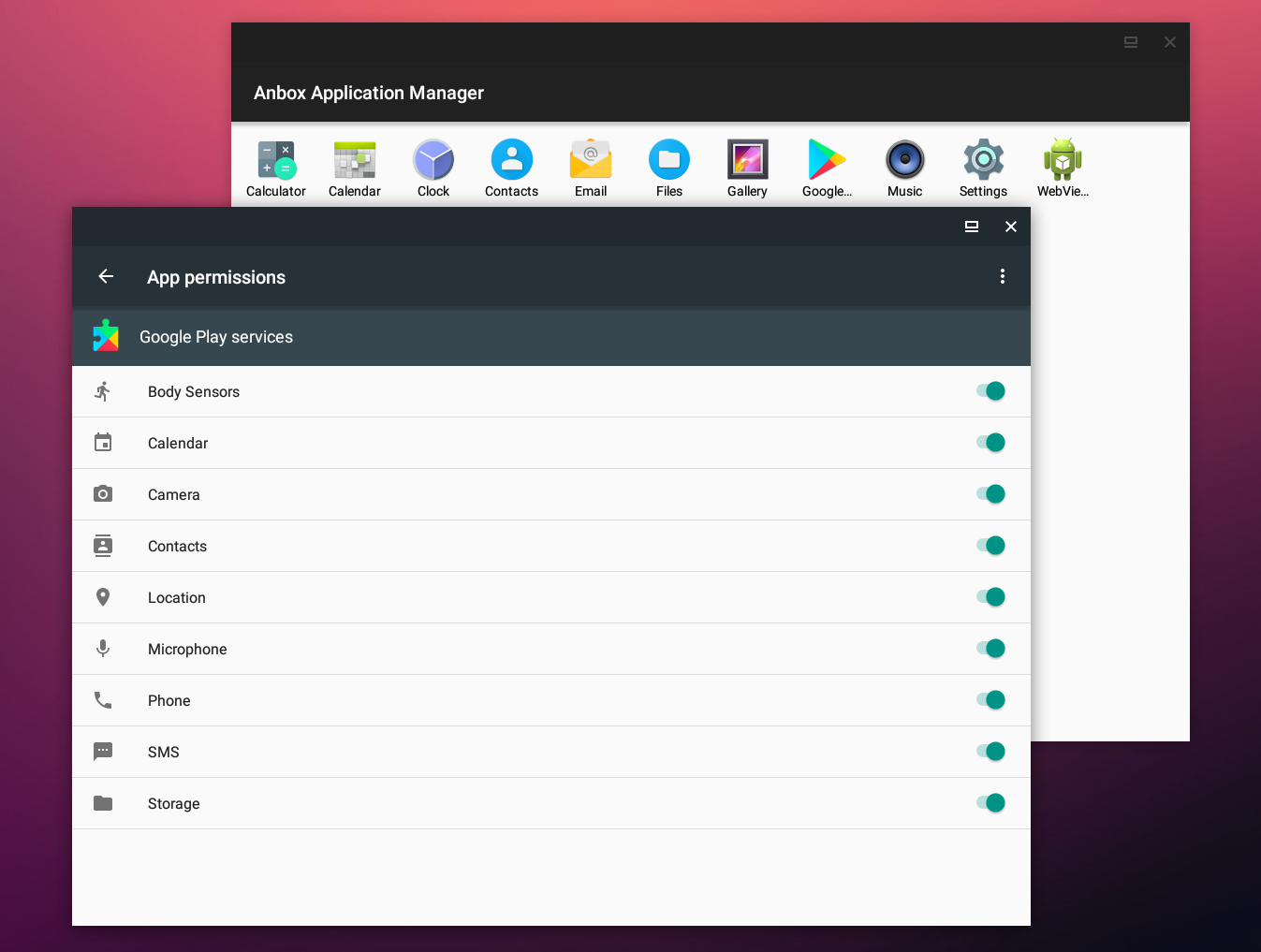
|
||||
|
||||
你现在应该可以使用 Google 帐户登录 Google Play 商店了。
|
||||
|
||||
如果未启用 Google Play 商店和 Google Play 服务的所有权限,你可能会在尝试登录 Google 帐户时可能会遇到问题,并显示以下错误消息:“Couldn't sign in. There was a problem communicating with Google servers. Try again later“,如你在下面的截图中看到的那样:
|
||||
|
||||
|
||||
|
||||
登录后,你可以停用部分 Google Play 商店/Google Play 服务权限。
|
||||
|
||||
**如果你在 Anbox 上登录 Google 帐户时遇到一些连接问题**,请确保 `anbox-bride.sh` 正在运行:
|
||||
|
||||
启动它:
|
||||
|
||||
```
|
||||
sudo /snap/anbox/current/bin/anbox-bridge.sh start
|
||||
```
|
||||
重启它:
|
||||
|
||||
```
|
||||
sudo /snap/anbox/current/bin/anbox-bridge.sh restart
|
||||
```
|
||||
|
||||
根据[此用户][9]的说法,如果 Anbox 仍然存在连接问题,你可能还需要安装 dnsmasq 包。但是在我的 Ubuntu 18.04 桌面上不需要这样做。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/07/anbox-how-to-install-google-play-store.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://anbox.io/
|
||||
[2]:https://geeks-r-us.de/2017/08/26/android-apps-auf-dem-linux-desktop/
|
||||
[3]:https://github.com/geeks-r-us/anbox-playstore-installer/
|
||||
[4]:https://github.com/geeks-r-us/anbox-playstore-installer/blob/master/install-playstore.sh
|
||||
[5]:https://docs.anbox.io/userguide/install.html
|
||||
[6]:https://github.com/anbox/anbox/issues/118#issuecomment-295270113
|
||||
[7]:https://github.com/anbox/anbox/blob/master/docs/install.md
|
||||
[8]:https://www.linuxuprising.com/2018/07/anbox-how-to-install-google-play-store.html?showComment=1533506821283#c4415289781078860898
|
||||
[9]:https://github.com/anbox/anbox/issues/118#issuecomment-295270113
|
||||
@ -3,17 +3,18 @@
|
||||
|
||||

|
||||
|
||||
如你所知,Linux 支持非常多的文件系统,例如 Ext4、ext3、ext2、sysfs、securityfs、FAT16、FAT32、NTFS 等等,当前被使用最多的文件系统是 Ext4。你曾经疑惑过你的 Linux 系统使用的是什么类型的文件系统吗?没有疑惑过?不用担心!我们将帮助你。本指南将解释如何在类 Unix 的操作系统中查看已挂载的文件系统类型。
|
||||
如你所知,Linux 支持非常多的文件系统,例如 ext4、ext3、ext2、sysfs、securityfs、FAT16、FAT32、NTFS 等等,当前被使用最多的文件系统是 ext4。你曾经疑惑过你的 Linux 系统使用的是什么类型的文件系统吗?没有疑惑过?不用担心!我们将帮助你。本指南将解释如何在类 Unix 的操作系统中查看已挂载的文件系统类型。
|
||||
|
||||
### 在 Linux 中查看已挂载的文件系统类型
|
||||
|
||||
有很多种方法可以在 Linux 中查看已挂载的文件系统类型,下面我将给出 8 种不同的方法。那现在就让我们开始吧!
|
||||
|
||||
#### 方法 1 – 使用 `findmnt` 命令
|
||||
#### 方法 1 – 使用 findmnt 命令
|
||||
|
||||
这是查出文件系统类型最常使用的方法。**findmnt** 命令将列出所有已挂载的文件系统或者搜索出某个文件系统。`findmnt` 命令能够在 `/etc/fstab`、`/etc/mtab` 或 `/proc/self/mountinfo` 这几个文件中进行搜索。
|
||||
这是查出文件系统类型最常使用的方法。`findmnt` 命令将列出所有已挂载的文件系统或者搜索出某个文件系统。`findmnt` 命令能够在 `/etc/fstab`、`/etc/mtab` 或 `/proc/self/mountinfo` 这几个文件中进行搜索。
|
||||
|
||||
`findmnt` 预装在大多数的 Linux 发行版中,因为它是 `util-linux` 包的一部分。如果 `findmnt` 命令不可用,你可以安装这个软件包。例如,你可以使用下面的命令在基于 Debian 的系统中安装 `util-linux` 包:
|
||||
|
||||
`findmnt` 预装在大多数的 Linux 发行版中,因为它是 **util-linux** 包的一部分。为了防止 `findmnt` 命令不可用,你可以安装这个软件包。例如,你可以使用下面的命令在基于 Debian 的系统中安装 **util-linux** 包:
|
||||
```
|
||||
$ sudo apt install util-linux
|
||||
```
|
||||
@ -21,24 +22,27 @@ $ sudo apt install util-linux
|
||||
下面让我们继续看看如何使用 `findmnt` 来找出已挂载的文件系统。
|
||||
|
||||
假如你只敲 `findmnt` 命令而不带任何的参数或选项,它将像下面展示的那样以树状图形式列举出所有已挂载的文件系统。
|
||||
|
||||
```
|
||||
$ findmnt
|
||||
```
|
||||
|
||||
**示例输出:**
|
||||
示例输出:
|
||||
|
||||
![][2]
|
||||
|
||||
正如你看到的那样,`findmnt` 展示出了目标挂载点(TARGET)、源设备(SOURCE)、文件系统类型(FSTYPE)以及相关的挂载选项(OPTIONS),例如文件系统是否是可读可写或者只读的。以我的系统为例,我的根(`/`)文件系统的类型是 EXT4 。
|
||||
正如你看到的那样,`findmnt` 展示出了目标挂载点(`TARGET`)、源设备(`SOURCE`)、文件系统类型(`FSTYPE`)以及相关的挂载选项(`OPTIONS`),例如文件系统是否是可读可写或者只读的。以我的系统为例,我的根(`/`)文件系统的类型是 EXT4 。
|
||||
|
||||
假如你不想以树状图的形式来展示输出,可以使用 `-l` 选项来以简单平凡的形式来展示输出:
|
||||
|
||||
假如你不想以树状图的形式来展示输出,可以使用 **-l** 选项来以简单平凡的形式来展示输出:
|
||||
```
|
||||
$ findmnt -l
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
你还可以使用 **-t** 选项来列举出特定类型的文件系统,例如下面展示的 **ext4** 文件系统类型:
|
||||
你还可以使用 `-t` 选项来列举出特定类型的文件系统,例如下面展示的 `ext4` 文件系统类型:
|
||||
|
||||
```
|
||||
$ findmnt -t ext4
|
||||
TARGET SOURCE FSTYPE OPTIONS
|
||||
@ -47,15 +51,18 @@ TARGET SOURCE FSTYPE OPTIONS
|
||||
```
|
||||
|
||||
`findmnt` 还可以生成 `df` 类型的输出,使用命令
|
||||
|
||||
```
|
||||
$ findmnt --df
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
```
|
||||
$ findmnt -D
|
||||
```
|
||||
|
||||
**示例输出:**
|
||||
示例输出:
|
||||
|
||||
```
|
||||
SOURCE FSTYPE SIZE USED AVAIL USE% TARGET
|
||||
@ -75,6 +82,7 @@ gvfsd-fuse fuse.gvfsd-fuse 0 0 0 - /run/user/1000/gvfs
|
||||
你还可以展示某个特定设备或者挂载点的文件系统类型。
|
||||
|
||||
查看某个特定的设备:
|
||||
|
||||
```
|
||||
$ findmnt /dev/sda1
|
||||
TARGET SOURCE FSTYPE OPTIONS
|
||||
@ -82,6 +90,7 @@ TARGET SOURCE FSTYPE OPTIONS
|
||||
```
|
||||
|
||||
查看某个特定的挂载点:
|
||||
|
||||
```
|
||||
$ findmnt /
|
||||
TARGET SOURCE FSTYPE OPTIONS
|
||||
@ -89,34 +98,38 @@ TARGET SOURCE FSTYPE OPTIONS
|
||||
```
|
||||
|
||||
你甚至还可以查看某个特定标签的文件系统的类型:
|
||||
|
||||
```
|
||||
$ findmnt LABEL=Storage
|
||||
```
|
||||
|
||||
更多详情,请参考其 man 手册。
|
||||
|
||||
```
|
||||
$ man findmnt
|
||||
```
|
||||
|
||||
`findmnt` 命令已足够完成在 Linux 中查看已挂载文件系统类型的任务,这个命令就是为了这个特定任务而生的。然而,还存在其他方法来查看文件系统的类型,假如你感兴趣的话,请接着让下看。
|
||||
`findmnt` 命令已足够完成在 Linux 中查看已挂载文件系统类型的任务,这个命令就是为了这个特定任务而生的。然而,还存在其他方法来查看文件系统的类型,假如你感兴趣的话,请接着往下看。
|
||||
|
||||
#### 方法 2 – 使用 `blkid` 命令
|
||||
#### 方法 2 – 使用 blkid 命令
|
||||
|
||||
**blkid** 命令被用来查找和打印块设备的属性。它也是 **util-linux** 包的一部分,所以你不必再安装它。
|
||||
`blkid` 命令被用来查找和打印块设备的属性。它也是 `util-linux` 包的一部分,所以你不必再安装它。
|
||||
|
||||
为了使用 `blkid` 命令来查看某个文件系统的类型,可以运行:
|
||||
|
||||
```
|
||||
$ blkid /dev/sda1
|
||||
```
|
||||
|
||||
#### 方法 3 – 使用 `df` 命令
|
||||
#### 方法 3 – 使用 df 命令
|
||||
|
||||
在类 Unix 的操作系统中,`df` 命令被用来报告文件系统的磁盘空间使用情况。为了查看所有已挂载文件系统的类型,只需要运行:
|
||||
|
||||
在类 Unix 的操作系统中, **df** 命令被用来报告文件系统的磁盘空间使用情况。为了查看所有已挂载文件系统的类型,只需要运行:
|
||||
```
|
||||
$ df -T
|
||||
```
|
||||
|
||||
**示例输出:**
|
||||
示例输出:
|
||||
|
||||
![][4]
|
||||
|
||||
@ -125,15 +138,17 @@ $ df -T
|
||||
- [针对新手的 df 命令教程](https://www.ostechnix.com/the-df-command-tutorial-with-examples-for-beginners/)
|
||||
|
||||
同样也可以参考其 man 手册:
|
||||
|
||||
```
|
||||
$ man df
|
||||
```
|
||||
|
||||
#### 方法 4 – 使用 `file` 命令
|
||||
#### 方法 4 – 使用 file 命令
|
||||
|
||||
**file** 命令可以判读出某个特定文件的类型,即便该文件没有文件后缀名也同样适用。
|
||||
`file` 命令可以判读出某个特定文件的类型,即便该文件没有文件后缀名也同样适用。
|
||||
|
||||
运行下面的命令来找出某个特定分区的文件系统类型:
|
||||
|
||||
```
|
||||
$ sudo file -sL /dev/sda1
|
||||
[sudo] password for sk:
|
||||
@ -141,13 +156,14 @@ $ sudo file -sL /dev/sda1
|
||||
```
|
||||
|
||||
查看其 man 手册可以知晓更多细节:
|
||||
|
||||
```
|
||||
$ man file
|
||||
```
|
||||
|
||||
#### 方法 5 – 使用 `fsck` 命令
|
||||
#### 方法 5 – 使用 fsck 命令
|
||||
|
||||
**fsck** 命令被用来检查某个文件系统是否健全或者修复它。你可以像下面那样通过将分区名字作为 `fsck` 的参数来查看该分区的文件系统类型:
|
||||
`fsck` 命令被用来检查某个文件系统是否健全或者修复它。你可以像下面那样通过将分区名字作为 `fsck` 的参数来查看该分区的文件系统类型:
|
||||
|
||||
```
|
||||
$ fsck -N /dev/sda1
|
||||
@ -156,15 +172,17 @@ fsck from util-linux 2.32
|
||||
```
|
||||
|
||||
如果想知道更多的内容,请查看其 man 手册:
|
||||
|
||||
```
|
||||
$ man fsck
|
||||
```
|
||||
|
||||
#### 方法 6 – 使用 `fstab` 命令
|
||||
#### 方法 6 – 使用 fstab 命令
|
||||
|
||||
**fstab** 是一个包含文件系统静态信息的文件。这个文件通常包含了挂载点、文件系统类型和挂载选项等信息。
|
||||
`fstab` 是一个包含文件系统静态信息的文件。这个文件通常包含了挂载点、文件系统类型和挂载选项等信息。
|
||||
|
||||
要查看某个文件系统的类型,只需要运行:
|
||||
|
||||
```
|
||||
$ cat /etc/fstab
|
||||
```
|
||||
@ -172,15 +190,17 @@ $ cat /etc/fstab
|
||||
![][5]
|
||||
|
||||
更多详情,请查看其 man 手册:
|
||||
|
||||
```
|
||||
$ man fstab
|
||||
```
|
||||
|
||||
#### 方法 7 – 使用 `lsblk` 命令
|
||||
#### 方法 7 – 使用 lsblk 命令
|
||||
|
||||
**lsblk** 命令可以展示设备的信息。
|
||||
`lsblk` 命令可以展示设备的信息。
|
||||
|
||||
要展示已挂载文件系统的信息,只需运行:
|
||||
|
||||
```
|
||||
$ lsblk -f
|
||||
NAME FSTYPE LABEL UUID MOUNTPOINT
|
||||
@ -193,15 +213,17 @@ sr0
|
||||
```
|
||||
|
||||
更多细节,可以参考它的 man 手册:
|
||||
|
||||
```
|
||||
$ man lsblk
|
||||
```
|
||||
|
||||
#### 方法 8 – 使用 `mount` 命令
|
||||
#### 方法 8 – 使用 mount 命令
|
||||
|
||||
**mount** 被用来在类 Unix 系统中挂载本地或远程的文件系统。
|
||||
`mount` 被用来在类 Unix 系统中挂载本地或远程的文件系统。
|
||||
|
||||
要使用 `mount` 命令查看文件系统的类型,可以像下面这样做:
|
||||
|
||||
```
|
||||
$ mount | grep "^/dev"
|
||||
/dev/sda2 on / type ext4 (rw,relatime,commit=360)
|
||||
@ -209,6 +231,7 @@ $ mount | grep "^/dev"
|
||||
```
|
||||
|
||||
更多详情,请参考其 man 手册的内容:
|
||||
|
||||
```
|
||||
$ man mount
|
||||
```
|
||||
@ -224,7 +247,7 @@ via: https://www.ostechnix.com/how-to-find-the-mounted-filesystem-type-in-linux/
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,19 +1,20 @@
|
||||
在 Linux 上使用 systemd 设置定时器
|
||||
======
|
||||
> 学习使用 systemd 创建启动你的游戏服务器的定时器。
|
||||
|
||||

|
||||
|
||||
之前,我们看到了如何[手动的][1]、[在开机与关机时][2]、[在启用某个设备时][3]、[在文件系统发生改变时][4]启用与禁用 systemd 服务。
|
||||
之前,我们看到了如何[手动的][1]、[在开机与关机时][2]、[在启用某个设备时][3]、[在文件系统发生改变时][4] 启用与禁用 systemd 服务。
|
||||
|
||||
定时器增加了另一种启动服务的方式,基于...时间。尽管与定时任务很相似,但 systemd 定时器稍微地灵活一些。让我们看看它是怎么工作的。
|
||||
定时器增加了另一种启动服务的方式,基于……时间。尽管与定时任务很相似,但 systemd 定时器稍微地灵活一些。让我们看看它是怎么工作的。
|
||||
|
||||
### “定时运行”
|
||||
|
||||
让我们展开[本系列前两篇文章][2]中[你所设置的 ][1] [Minetest][5] 服务器作为如何使用定时器单元的第一个例子。如果你还没有读过那几篇文章,可以现在去看看。
|
||||
让我们展开[本系列前两篇文章][2]中[你所设置的][1] [Minetest][5] 服务器作为如何使用定时器单元的第一个例子。如果你还没有读过那几篇文章,可以现在去看看。
|
||||
|
||||
你将通过创建一个定时器来改进 Minetest 服务器,使得在定时器启动 1 分钟后运行游戏服务器而不是立即运行。这样做的原因可能是,在启动之前可能会用到其他的服务,例如发邮件给其他玩家告诉他们游戏已经准备就绪,你要确保其他的服务(例如网络)在开始前完全启动并运行。
|
||||
你将通过创建一个定时器来“改进” Minetest 服务器,使得在服务器启动 1 分钟后运行游戏服务器而不是立即运行。这样做的原因可能是,在启动之前可能会用到其他的服务,例如发邮件给其他玩家告诉他们游戏已经准备就绪,你要确保其他的服务(例如网络)在开始前完全启动并运行。
|
||||
|
||||
跳到最底下,你的 `_minetest.timer_` 单元看起来就像这样:
|
||||
最终,你的 `minetest.timer` 单元看起来就像这样:
|
||||
|
||||
```
|
||||
# minetest.timer
|
||||
@ -26,23 +27,22 @@ Unit=minetest.service
|
||||
|
||||
[Install]
|
||||
WantedBy=basic.target
|
||||
|
||||
```
|
||||
|
||||
一点也不难吧。
|
||||
|
||||
通常,开头是 `[Unit]` 和一段描述单元作用的信息,这儿没什么新东西。`[Timer]` 这一节是新出现的,但它的作用不言自明:它包含了何时启动服务,启动哪个服务的信息。在这个例子当中,`OnBootSec` 是告诉 systemd 在系统启动后运行服务的指令。
|
||||
如以往一般,开头是 `[Unit]` 和一段描述单元作用的信息,这儿没什么新东西。`[Timer]` 这一节是新出现的,但它的作用不言自明:它包含了何时启动服务,启动哪个服务的信息。在这个例子当中,`OnBootSec` 是告诉 systemd 在系统启动后运行服务的指令。
|
||||
|
||||
其他的指令有:
|
||||
|
||||
* `OnActiveSec=`,告诉 systemd 在定时器启动后多长时间运行服务。
|
||||
* `OnStartupSec=`,同样的,它告诉 systemd 在 systemd 进程启动后多长时间运行服务。
|
||||
* `OnUnitActiveSec=`,告诉 systemd 在上次由定时器激活的服务启动后多长时间运行服务。
|
||||
* `OnUnitInactiveSec=`,告诉 systemd 在上次由定时器激活的服务停用后多长时间运行服务。
|
||||
* `OnActiveSec=`,告诉 systemd 在定时器启动后多长时间运行服务。
|
||||
* `OnStartupSec=`,同样的,它告诉 systemd 在 systemd 进程启动后多长时间运行服务。
|
||||
* `OnUnitActiveSec=`,告诉 systemd 在上次由定时器激活的服务启动后多长时间运行服务。
|
||||
* `OnUnitInactiveSec=`,告诉 systemd 在上次由定时器激活的服务停用后多长时间运行服务。
|
||||
|
||||
继续 `_minetest.timer_` 单元,`basic.target` 通常用作<ruby>后期引导服务<rt>late boot services</rt></ruby>的<ruby>同步点<rt>synchronization point</rt></ruby>。这就意味着它可以让 `_minetest.timer_` 单元运行在安装完<ruby>本地挂载点<rt>local mount points</rt></ruby>或交换设备,套接字、定时器、路径单元和其他基本的初始化进程之后。就像在[第二篇文章中 systemd 单元][2]里解释的那样,`_targets_` 就像<ruby>旧的运行等级<rt>old run levels</rt></ruby>,可以将你的计算机置于某个状态,或像这样告诉你的服务在达到某个状态后开始运行。
|
||||
继续 `minetest.timer` 单元,`basic.target` 通常用作<ruby>后期引导服务<rt>late boot services</rt></ruby>的<ruby>同步点<rt>synchronization point</rt></ruby>。这就意味着它可以让 `minetest.timer` 单元运行在安装完<ruby>本地挂载点<rt>local mount points</rt></ruby>或交换设备,套接字、定时器、路径单元和其他基本的初始化进程之后。就像在[第二篇文章中 systemd 单元][2]里解释的那样,`targets` 就像<ruby>旧的运行等级<rt>old run levels</rt></ruby>一样,可以将你的计算机置于某个状态,或像这样告诉你的服务在达到某个状态后开始运行。
|
||||
|
||||
在前两篇文章中你配置的`_minetest.service_`文件[最终][2]看起来就像这样:
|
||||
在前两篇文章中你配置的 `minetest.service` 文件[最终][2]看起来就像这样:
|
||||
|
||||
```
|
||||
# minetest.service
|
||||
@ -64,10 +64,9 @@ ExecStop= /bin/kill -2 $MAINPID
|
||||
|
||||
[Install]
|
||||
WantedBy= multi-user.target
|
||||
|
||||
```
|
||||
|
||||
这儿没什么需要修改的。但是你需要将 `_mtsendmail.sh_`(发送你的 email 的脚本)从:
|
||||
这儿没什么需要修改的。但是你需要将 `mtsendmail.sh`(发送你的 email 的脚本)从:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
@ -75,7 +74,6 @@ WantedBy= multi-user.target
|
||||
sleep 20
|
||||
echo $1 | mutt -F /home/<username>/.muttrc -s "$2" my_minetest@mailing_list.com
|
||||
sleep 10
|
||||
|
||||
```
|
||||
|
||||
改成:
|
||||
@ -84,40 +82,37 @@ sleep 10
|
||||
#!/bin/bash
|
||||
# mtsendmail.sh
|
||||
echo $1 | mutt -F /home/paul/.muttrc -s "$2" pbrown@mykolab.com
|
||||
|
||||
```
|
||||
|
||||
你做的事是去除掉 Bash 脚本中那些蹩脚的停顿。Systemd 现在正在等待。
|
||||
你做的事是去除掉 Bash 脚本中那些蹩脚的停顿。Systemd 现在来做等待。
|
||||
|
||||
### 让它运行起来
|
||||
|
||||
确保一切运作正常,禁用 `_minetest.service_`:
|
||||
确保一切运作正常,禁用 `minetest.service`:
|
||||
|
||||
```
|
||||
sudo systemctl disable minetest
|
||||
|
||||
```
|
||||
|
||||
这使得系统启动时它不会一同启动;然后,相反地,启用 `_minetest.timer_`:
|
||||
这使得系统启动时它不会一同启动;然后,相反地,启用 `minetest.timer`:
|
||||
|
||||
```
|
||||
sudo systemctl enable minetest.timer
|
||||
|
||||
```
|
||||
|
||||
现在你就可以重启服务器了,当运行`sudo journalctl -u minetest.*`后,你就会看到 `_minetest.timer_` 单元执行后大约一分钟,`_minetest.service_` 单元开始运行。
|
||||
现在你就可以重启服务器了,当运行 `sudo journalctl -u minetest.*` 后,你就会看到 `minetest.timer` 单元执行后大约一分钟,`minetest.service` 单元开始运行。
|
||||
|
||||
![minetest timer][7]
|
||||
|
||||
图 1:minetest.timer 运行大约 1 分钟后 minetest.service 开始运行
|
||||
|
||||
[经许可使用][8]
|
||||
*图 1:minetest.timer 运行大约 1 分钟后 minetest.service 开始运行*
|
||||
|
||||
### 时间的问题
|
||||
|
||||
`_minetest.timer_` 在 systemd 的日志里显示的启动时间为 09:08:33 而 `_minetest.service` 启动时间是 09:09:18,它们之间少于 1 分钟,关于这件事有几点需要说明一下:首先,请记住我们说过 `OnBootSec=` 指令是从引导完成后开始计算服务启动的时间。当 `_minetest.timer_` 的时间到来时,引导已经在几秒之前完成了。
|
||||
`minetest.timer` 在 systemd 的日志里显示的启动时间为 09:08:33 而 `minetest.service` 启动时间是 09:09:18,它们之间少于 1 分钟,关于这件事有几点需要说明一下:首先,请记住我们说过 `OnBootSec=` 指令是从引导完成后开始计算服务启动的时间。当 `minetest.timer` 的时间到来时,引导已经在几秒之前完成了。
|
||||
|
||||
另一件事情是 systemd 给自己设置了一个<ruby>误差幅度<rt>margin of error</rt></ruby>(默认是 1 分钟)来运行东西。这有助于在多个<ruby>资源密集型进程<rt>resource-intensive processes</rt></ruby>同时运行时分配负载:通过分配 1 分钟的时间,systemd 可以等待某些进程关闭。这也意味着 `_minetest.service_`会在引导完成后的 1~2 分钟之间启动。但精确的时间谁也不知道。
|
||||
另一件事情是 systemd 给自己设置了一个<ruby>误差幅度<rt>margin of error</rt></ruby>(默认是 1 分钟)来运行东西。这有助于在多个<ruby>资源密集型进程<rt>resource-intensive processes</rt></ruby>同时运行时分配负载:通过分配 1 分钟的时间,systemd 可以等待某些进程关闭。这也意味着 `minetest.service` 会在引导完成后的 1~2 分钟之间启动。但精确的时间谁也不知道。
|
||||
|
||||
作为记录,你可以用 `AccuracySec=` 指令[修改误差幅度][9]。
|
||||
顺便一提,你可以用 `AccuracySec=` 指令[修改误差幅度][9]。
|
||||
|
||||
你也可以检查系统上所有的定时器何时运行或是上次运行的时间:
|
||||
|
||||
@ -127,9 +122,7 @@ systemctl list-timers --all
|
||||
|
||||
![check timer][11]
|
||||
|
||||
图 2:检查定时器何时运行或上次运行的时间
|
||||
|
||||
[经许可使用][8]
|
||||
*图 2:检查定时器何时运行或上次运行的时间*
|
||||
|
||||
最后一件值得思考的事就是你应该用怎样的格式去表示一段时间。Systemd 在这方面非常灵活:`2 h`,`2 hours` 或 `2hr` 都可以用来表示 2 个小时。对于“秒”,你可以用 `seconds`,`second`,`sec` 和 `s`。“分”也是同样的方式:`minutes`,`minute`,`min` 和 `m`。你可以检查 `man systemd.time` 来查看 systemd 能够理解的所有时间单元。
|
||||
|
||||
@ -148,13 +141,13 @@ via: https://www.linux.com/blog/learn/intro-to-linux/2018/7/setting-timer-system
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[LuuMing](https://github.com/LuuMing)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/bro66
|
||||
[1]:https://www.linux.com/blog/learn/intro-to-linux/2018/5/writing-systemd-services-fun-and-profit
|
||||
[2]:https://www.linux.com/blog/learn/2018/5/systemd-services-beyond-starting-and-stopping
|
||||
[1]:https://linux.cn/article-9700-1.html
|
||||
[2]:https://linux.cn/article-9703-1.html
|
||||
[3]:https://www.linux.com/blog/intro-to-linux/2018/6/systemd-services-reacting-change
|
||||
[4]:https://www.linux.com/blog/learn/intro-to-linux/2018/6/systemd-services-monitoring-files-and-directories
|
||||
[5]:https://www.minetest.net/
|
||||
@ -0,0 +1,67 @@
|
||||
一个用于家庭项目的单用户、轻量级操作系统
|
||||
======
|
||||
> 业余爱好者应该了解一下 RISC OS 的五个原因。
|
||||
|
||||

|
||||
|
||||
究竟什么是 RISC OS?嗯,它不是一种新的 Linux。它也不是有些人认为的 Windows。事实上,它发布于 1987 年,它比它们任何一个都要古老。但你看到它时不一定会意识到这一点。
|
||||
|
||||
其点击式图形用户界面在底部为活动的程序提供一个固定面板和一个图标栏。因此,它看起来像 Windows 95,并且比它早了 8 年。
|
||||
|
||||
这个操作系统最初是为 [Acorn Archimedes][1] 编写的。这台机器中的 Acorn RISC Machines CPU 是全新的硬件,因此需要在其上运行全新的软件。这是最早的 ARM 芯片上的系统,早于任何人想到的 Android 或 [Armbian][2] 之前。
|
||||
|
||||
虽然 Acorn 桌面最终消失了,但 ARM 芯片继续征服世界。在这里,RISC OS 一直有一个优点 —— 通常在嵌入式设备中,你从来没有真正地意识到它。RISC OS 过去长期以来一直是一个完全专有的操作系统。但近年来,该抄系统的所有者已经开始将源代码发布到一个名为 [RISC OS Open][3] 的项目中。
|
||||
|
||||
### 1、你可以将它安装在树莓派上
|
||||
|
||||
树莓派的官方操作系统 [Raspbian][4] 实际上非常棒(如果你对摆弄不同技术上新奇的东西不感兴趣,那么你可能最初也不会选择树莓派)。由于 RISC OS 是专门为 ARM 编写的,因此它可以在各种小型计算机上运行,包括树莓派的各个型号。
|
||||
|
||||
### 2、它超轻量级
|
||||
|
||||
我的树莓派上安装的 RISC 系统占用了几百兆 —— 这是在我加载了数十个程序和游戏之后。它们大多数时候不超过 1 兆。
|
||||
|
||||
如果你真的节俭,RISC OS Pico 可用在 16MB SD 卡上。如果你要在嵌入式系统或物联网项目中鼓捣某些东西,这是很完美的。当然,16MB 实际上比压缩到 512KB 的老 Archimedes 的 ROM 要多得多。但我想 30 年间内存技术的发展,我们可以稍微放宽一下了。
|
||||
|
||||
### 3、它非常适合复古游戏
|
||||
|
||||
当 Archimedes 处于鼎盛时期时,ARM CPU 的速度比 Apple Macintosh 和 Commodore Amiga 中的 Motorola 68000 要快几倍,它也完全吸了新的 386 技术。这使得它成为对游戏开发者有吸引力的一个平台,他们希望用这个星球上最强大的桌面计算机来支撑他们的东西。
|
||||
|
||||
那些游戏的许多拥有者都非常慷慨,允许业余爱好者免费下载他们的老作品。虽然 RISC OS 和硬件已经发展了,但只需要进行少量的调整就可以让它们运行起来。
|
||||
|
||||
如果你有兴趣探索这个,[这里有一个指南][5]让这些游戏在你的树莓派上运行。
|
||||
|
||||
### 4、它有 BBC BASIC
|
||||
|
||||
就像过去一样,按下 `F12` 进入命令行,输入 `*BASIC`,就可以看到一个完整的 BBC BASIC 解释器。
|
||||
|
||||
对于那些在 80 年代没有接触过它的人,请让我解释一下:BBC BASIC 是当时我们很多人的第一个编程语言,因为它专门教孩子如何编码。当时有大量的书籍和杂志文章教我们编写自己的简单但高度可玩的游戏。
|
||||
|
||||
几十年后,对于一个想要在学校假期做点什么的有技术头脑的孩子而言,在 BBC BASIC 上编写自己的游戏仍然是一个很棒的项目。但很少有孩子在家里有 BBC micro。那么他们应该怎么做呢?
|
||||
|
||||
当然,你可以在每台家用电脑上运行解释器,但是当别人需要使用它时就不能用了。那么为什么不使用装有 RISC OS 的树莓派呢?
|
||||
|
||||
### 5、它是一个简单的单用户操作系统
|
||||
|
||||
RISC OS 不像 Linux 一样有自己的用户和超级用户访问权限。它有一个用户并可以完全访问整个机器。因此,它可能不是跨企业部署的最佳日常驱动,甚至不适合给老人家做银行业务。但是,如果你正在寻找可以用来修改和鼓捣的东西,那绝对是太棒了。你和机器之间没有那么多障碍,所以你可以直接闯进去。
|
||||
|
||||
### 扩展阅读
|
||||
|
||||
如果你想了解有关此操作系统的更多信息,请查看 [RISC OS Open][3],或者将镜像烧到闪存到卡上并开始使用它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/gentle-intro-risc-os
|
||||
|
||||
作者:[James Mawson][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dxmjames
|
||||
[1]:https://en.wikipedia.org/wiki/Acorn_Archimedes
|
||||
[2]:https://www.armbian.com/
|
||||
[3]:https://www.riscosopen.org/content/
|
||||
[4]:https://www.raspbian.org/
|
||||
[5]:https://www.riscosopen.org/wiki/documentation/show/Introduction%20to%20RISC%20OS
|
||||
@ -0,0 +1,86 @@
|
||||
2018 年 5 款最好的 Linux 游戏
|
||||
======
|
||||
|
||||

|
||||
|
||||
Linux 可能不会很快成为游戏玩家选择的平台 —— Valve Steam Machines 的失败似乎是对这一点的深刻提醒 —— 但这并不意味着该平台没有稳定增长,并且拥有相当多的优秀游戏。
|
||||
|
||||
从独立单机到辉煌的 RPG(角色扮演),2018 年已经可以称得上是 Linux 游戏的丰收年,在这里,我们将列出迄今为止最喜欢的五款。
|
||||
|
||||
你是否在寻找优秀的 Linux 游戏却又不想挥霍金钱?来看看我们的最佳 [免费 Linux 游戏][1] 名单吧!
|
||||
|
||||
### 1、<ruby>永恒之柱 2:死亡之火<rt>Pillars of Eternity II: Deadfire</rt></ruby>
|
||||
|
||||
![best-linux-games-2018-pillars-of-eternity-2-deadfire][2]
|
||||
|
||||
其中一款最能代表近年来 cRPG 的复兴,它让传统的 Bethesda RPG 看起来更像是轻松的动作冒险游戏。在磅礴的《<ruby>永恒之柱<rt>Pillars of Eternity</rt></ruby>》系列的最新作品中,当你和船员在充满冒险和危机的岛屿周围航行时,你会发现自己更像是一个海盗。
|
||||
|
||||
在混合了海战元素的基础上,《死亡之火》延续了前作丰富的游戏剧情和出色的文笔,同时在美丽的画面和手绘背景的基础上更进一步。
|
||||
|
||||
这是一款毫无疑问的令人印象深刻的硬核 RPG ,可能会让一些人对它产生抵触情绪,不过那些接受它的人会投入几个月的时间沉迷其中。
|
||||
|
||||
### 2、<ruby>杀戮尖塔<rt>Slay the Spire</rt></ruby>
|
||||
|
||||
![best-linux-games-2018-slay-the-spire][3]
|
||||
|
||||
《杀戮尖塔》仍处于早期阶段,却已经成为年度最佳游戏之一,它是一款采用 deck-building 玩法的卡牌游戏,由充满活力的视觉风格和 rogue-like 机制加以点缀,即便在一次次令人愤怒的(但可能是应受的)死亡之后,你还会再次投入其中。
|
||||
|
||||
每次游戏都有无尽的卡牌组合和不同的布局,《杀戮尖塔》就像是近年来所有令人震撼的独立游戏的最佳具现 —— 卡牌游戏和永久死亡冒险模式合二为一。
|
||||
|
||||
再强调一次,它仍处于早期阶段,所以它只会变得越来越好!
|
||||
|
||||
### 3、<ruby>战斗机甲<rt>Battletech</rt></ruby>
|
||||
|
||||
![best-linux-games-2018-battletech][4]
|
||||
|
||||
这是我们榜单上像“大片”一样的游戏,《战斗机甲》是一款星际战争游戏(基于桌面游戏),你将装载一个机甲战队并引导它们进行丰富的回合制战斗。
|
||||
|
||||
战斗发生在一系列的地形上,从寒冷的荒地到阳光普照的地带,你将用巨大的热武器装备你的四人小队,与对手小队作战。如果你觉得这听起来有点“机械战士”的味道,那么你想的没错,只不过这次更注重战术安排而不是直接行动。
|
||||
|
||||
除了让你在宇宙冲突中指挥的战役外,多人模式也可能会耗费你数不清的时间。
|
||||
|
||||
### 4、<ruby>死亡细胞<rt>Dead Cells</rt></ruby>
|
||||
|
||||
![best-linux-games-2018-dead-cells][5]
|
||||
|
||||
这款游戏称得上是年度最佳平台动作游戏。Roguelike 游戏《死亡细胞》将你带入一个黑暗(却色彩绚丽)的世界,在那里进行攻击和躲避以通过程序生成的关卡。它有点像 2D 的《<ruby>黑暗之魂<rt>Dark Souls</rt></ruby>》,如果《黑暗之魂》也充满五彩缤纷的颜色的话。
|
||||
|
||||
《死亡细胞》是无情的,只有精确而灵敏的控制才会让你避开死亡,而在两次运行期间的升级系统又会确保你总是有一些进步的成就感。
|
||||
|
||||
《死亡细胞》的像素风、动画效果和游戏机制都达到了巅峰,它及时地提醒我们,在没有 3D 图形的过度使用下游戏可以制作成什么样子。
|
||||
|
||||
|
||||
### 5、<ruby>叛逆机械师<rt>Iconoclasts</rt></ruby>
|
||||
|
||||
![best-linux-games-2018-iconoclasts][6]
|
||||
|
||||
这款游戏不像上面提到的几款那样为人所知,它是一款可爱风格的游戏,可以看作是《死亡细胞》不那么惊悚、更可爱的替代品。玩家将扮演成罗宾,一个发现自己处于政治扭曲的外星世界后开始了逃亡的女孩。
|
||||
|
||||
尽管你的角色将在非线性的关卡中行动,游戏却有着扣人心弦的游戏剧情,罗宾会获得各种各样充满想象力的提升,其中最重要的是她的扳手,从发射炮弹到解决巧妙的环境问题,你几乎可以用它来做任何事。
|
||||
|
||||
《叛逆机械师》是一个充满快乐与活力的平台游戏,融合了《<ruby>洛克人<rt>Megaman</rt></ruby>》的战斗和《<ruby>银河战士<rt>Metroid</rt></ruby>》的探索。如果你借鉴了那两部伟大的作品,可能不会比它做得更好。
|
||||
|
||||
### 总结
|
||||
|
||||
以上就是我们选出的 2018 年最佳的 Linux 游戏。有哪些我们错过的游戏精华?请在评论区告诉我们!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/best-linux-games/
|
||||
|
||||
作者:[Robert Zak][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[seriouszyx](https://github.com/seriouszyx)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.maketecheasier.com/author/robzak/
|
||||
[1]:https://www.maketecheasier.com/open-source-linux-games/
|
||||
[2]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-pillars-of-eternity-2-deadfire.jpg (best-linux-games-2018-pillars-of-eternity-2-deadfire)
|
||||
[3]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-slay-the-spire.jpg (best-linux-games-2018-slay-the-spire)
|
||||
[4]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-battletech.jpg (best-linux-games-2018-battletech)
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-dead-cells.jpg (best-linux-games-2018-dead-cells)
|
||||
[6]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-iconoclasts.jpg (best-linux-games-2018-iconoclasts)
|
||||
|
||||
|
||||
@ -1,39 +1,41 @@
|
||||
SDKMAN – A CLI Tool To Easily Manage Multiple Software Development Kits
|
||||
SDKMAN:轻松管理多个软件开发套件 (SDK) 的命令行工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
Are you a developer who often install and test applications on different SDKs? I’ve got a good news for you! Say hello to **SDKMAN** , a CLI tool that helps you to easily manage multiple software development kits. It provides a convenient way to install, switch, list and remove candidates. Using SDKMAN, you can now manage parallel versions of multiple SDKs easily on any Unix-like operating system. It allows the developers to install Software Development Kits for the JVM such as Java, Groovy, Scala, Kotlin and Ceylon. Ant, Gradle, Grails, Maven, SBT, Spark, Spring Boot, Vert.x and many others are also supported. SDKMAN is free, light weight, open source and written in **Bash**.
|
||||
你是否是一个经常在不同的 SDK 下安装和测试应用的开发者?我有一个好消息要告诉你!给你介绍一下 **SDKMAN**,一个可以帮你轻松管理多个 SDK 的命令行工具。它为安装、切换、列出和移除 SDK 提供了一个简便的方式。有了 SDKMAN,你可以在任何类 Unix 的操作系统上轻松地并行管理多个 SDK 的多个版本。它允许开发者为 JVM 安装不同的 SDK,例如 Java、Groovy、Scala、Kotlin 和 Ceylon、Ant、Gradle、Grails、Maven、SBT、Spark、Spring Boot、Vert.x,以及许多其他支持的 SDK。SDKMAN 是免费、轻量、开源、使用 **Bash** 编写的程序。
|
||||
|
||||
### Installing SDKMAN
|
||||
### 安装 SDKMAN
|
||||
|
||||
安装 SDKMAN 很简单。首先,确保你已经安装了 `zip` 和 `unzip` 这两个应用。它们在大多数的 Linux 发行版的默认仓库中。
|
||||
例如,在基于 Debian 的系统上安装 unzip,只需要运行:
|
||||
|
||||
Installing SDKMAN is trivial. First, make sure you have installed **zip** and **unzip** applications. It is available in the default repositories of most Linux distributions. For instance, to install unzip on Debian-based systems, simply run:
|
||||
```
|
||||
$ sudo apt-get install zip unzip
|
||||
|
||||
```
|
||||
|
||||
Then, install SDKMAN using command:
|
||||
然后使用下面的命令安装 SDKMAN:
|
||||
|
||||
```
|
||||
$ curl -s "https://get.sdkman.io" | bash
|
||||
|
||||
```
|
||||
|
||||
It’s that simple. Once the installation is completed, run the following command:
|
||||
在安装完成之后,运行以下命令:
|
||||
|
||||
```
|
||||
$ source "$HOME/.sdkman/bin/sdkman-init.sh"
|
||||
|
||||
```
|
||||
|
||||
If you want to install it in a custom location of your choice other than **$HOME/.sdkman** , for example **/usr/local/** , do:
|
||||
如果你希望自定义安装到其他位置,例如 `/usr/local/`,你可以这样做:
|
||||
|
||||
```
|
||||
$ export SDKMAN_DIR="/usr/local/sdkman" && curl -s "https://get.sdkman.io" | bash
|
||||
|
||||
```
|
||||
|
||||
Make sure your user has full access rights to this folder.
|
||||
确保你的用户有足够的权限访问这个目录。
|
||||
|
||||
最后,在安装完成后使用下面的命令检查一下:
|
||||
|
||||
Finally, check if the installation is succeeded using command:
|
||||
```
|
||||
$ sdk version
|
||||
==== BROADCAST =================================================================
|
||||
@ -43,20 +45,20 @@ $ sdk version
|
||||
================================================================================
|
||||
|
||||
SDKMAN 5.7.2+323
|
||||
|
||||
```
|
||||
|
||||
Congratulations! SDKMAN has been installed. Let us go ahead and see how to install and manage SDKs.
|
||||
恭喜你!SDKMAN 已经安装完成了。让我们接下来看如何安装和管理 SDKs 吧。
|
||||
|
||||
### Manage Multiple Software Development Kits
|
||||
### 管理多个 SDK
|
||||
|
||||
查看可用的 SDK 清单,运行:
|
||||
|
||||
To view the list of available candidates(SDKs), run:
|
||||
```
|
||||
$ sdk list
|
||||
|
||||
```
|
||||
|
||||
Sample output would be:
|
||||
将会输出:
|
||||
|
||||
```
|
||||
================================================================================
|
||||
Available Candidates
|
||||
@ -78,18 +80,18 @@ used to pilot any type of process which can be described in terms of targets and
|
||||
tasks.
|
||||
|
||||
: $ sdk install ant
|
||||
|
||||
```
|
||||
|
||||
As you can see, SDKMAN list one candidate at a time along with the description of the candidate and it’s official website and the installation command. Press ENTER key to list the next candidates.
|
||||
就像你看到的,SDK 每次列出众多 SDK 中的一个,以及该 SDK 的描述信息、官方网址和安装命令。按回车键继续下一个。
|
||||
|
||||
安装一个新的 SDK,例如 Java JDK,运行:
|
||||
|
||||
To install a SDK, for example Java JDK, run:
|
||||
```
|
||||
$ sdk install java
|
||||
|
||||
```
|
||||
|
||||
Sample output:
|
||||
将会输出:
|
||||
|
||||
```
|
||||
Downloading: java 8.0.172-zulu
|
||||
|
||||
@ -105,30 +107,30 @@ Installing: java 8.0.172-zulu
|
||||
Done installing!
|
||||
|
||||
Setting java 8.0.172-zulu as default.
|
||||
|
||||
```
|
||||
|
||||
If you have multiple SDKs, it will prompt if you want the currently installed version to be set as **default**. Answering **Yes** will set the currently installed version as default.
|
||||
如果你安装了多个 SDK,它将会提示你是否想要将当前安装的版本设置为 **默认版本**。回答 `Yes` 将会把当前版本设置为默认版本。
|
||||
|
||||
使用以下命令安装一个 SDK 的其他版本:
|
||||
|
||||
To install particular version of a SDK, do:
|
||||
```
|
||||
$ sdk install ant 1.10.1
|
||||
|
||||
```
|
||||
|
||||
If you already have local installation of a specific candidate, you can set it as local version like below.
|
||||
如果你之前已经在本地安装了一个 SDK,你可以像下面这样设置它为本地版本。
|
||||
|
||||
```
|
||||
$ sdk install groovy 3.0.0-SNAPSHOT /path/to/groovy-3.0.0-SNAPSHOT
|
||||
|
||||
```
|
||||
|
||||
To list a particular candidates versions:
|
||||
列出一个 SDK 的多个版本:
|
||||
|
||||
```
|
||||
$ sdk list ant
|
||||
|
||||
```
|
||||
|
||||
Sample output:
|
||||
将会输出:
|
||||
|
||||
```
|
||||
================================================================================
|
||||
Available Ant Versions
|
||||
@ -144,32 +146,31 @@ Available Ant Versions
|
||||
* - installed
|
||||
> - currently in use
|
||||
================================================================================
|
||||
|
||||
```
|
||||
|
||||
Like I already said, If you have installed multiple versions, SDKMAN will prompt you if you want the currently installed version to be set as **default**. You can answer Yes to set it as default. Also, you can do that later by using the following command:
|
||||
像我之前说的,如果你安装了多个版本,SDKMAN 会提示你是否想要设置当前安装的版本为 **默认版本**。你可以回答 Yes 设置它为默认版本。当然,你也可以在稍后使用下面的命令设置:
|
||||
|
||||
```
|
||||
$ sdk default ant 1.9.9
|
||||
|
||||
```
|
||||
|
||||
The above command will set Apache Ant version 1.9.9 as default.
|
||||
上面的命令将会设置 Apache Ant 1.9.9 为默认版本。
|
||||
|
||||
你可以根据自己的需要选择使用任何已安装的 SDK 版本,仅需运行以下命令:
|
||||
|
||||
You can choose which version of an installed candidate to use by using the following command:
|
||||
```
|
||||
$ sdk use ant 1.9.9
|
||||
|
||||
```
|
||||
|
||||
To check what is currently in use for a Candidate, for example Java, run:
|
||||
检查某个具体 SDK 当前的版本号,例如 Java,运行:
|
||||
|
||||
```
|
||||
$ sdk current java
|
||||
|
||||
Using java version 8.0.172-zulu
|
||||
|
||||
```
|
||||
|
||||
To check what is currently in use for all Candidates, for example Java, run:
|
||||
检查所有当下在使用的 SDK 版本号,运行:
|
||||
|
||||
```
|
||||
$ sdk current
|
||||
|
||||
@ -177,36 +178,35 @@ Using:
|
||||
|
||||
ant: 1.10.1
|
||||
java: 8.0.172-zulu
|
||||
|
||||
```
|
||||
|
||||
To upgrade an outdated candidate, do:
|
||||
升级过时的 SDK,运行:
|
||||
|
||||
```
|
||||
$ sdk upgrade scala
|
||||
|
||||
```
|
||||
|
||||
You can also check what is outdated for all Candidates as well.
|
||||
你也可以检查所有的 SDK 中还有哪些是过时的。
|
||||
|
||||
```
|
||||
$ sdk upgrade
|
||||
|
||||
```
|
||||
|
||||
SDKMAN has offline mode feature that allows the SDKMAN to function when working offline. You can enable or disable the offline mode at any time by using the following commands:
|
||||
SDKMAN 有离线模式,可以让 SDKMAN 在离线时也正常运作。你可以使用下面的命令在任何时间开启或者关闭离线模式:
|
||||
|
||||
```
|
||||
$ sdk offline enable
|
||||
|
||||
$ sdk offline disable
|
||||
|
||||
```
|
||||
|
||||
To remove an installed SDK, run:
|
||||
要移除已安装的 SDK,运行:
|
||||
|
||||
```
|
||||
$ sdk uninstall ant 1.9.9
|
||||
|
||||
```
|
||||
|
||||
For more details, check the help section.
|
||||
要了解更多的细节,参阅帮助章节。
|
||||
|
||||
```
|
||||
$ sdk help
|
||||
|
||||
@ -230,69 +230,67 @@ update
|
||||
flush <broadcast|archives|temp>
|
||||
|
||||
candidate : the SDK to install: groovy, scala, grails, gradle, kotlin, etc.
|
||||
use list command for comprehensive list of candidates
|
||||
eg: $ sdk list
|
||||
use list command for comprehensive list of candidates
|
||||
eg: $ sdk list
|
||||
|
||||
version : where optional, defaults to latest stable if not provided
|
||||
eg: $ sdk install groovy
|
||||
|
||||
eg: $ sdk install groovy
|
||||
```
|
||||
|
||||
### Update SDKMAN
|
||||
### 更新 SDKMAN
|
||||
|
||||
如果有可用的新版本,可以使用下面的命令安装:
|
||||
|
||||
The following command installs a new version of SDKMAN if it is available.
|
||||
```
|
||||
$ sdk selfupdate
|
||||
|
||||
```
|
||||
|
||||
SDKMAN will also periodically check for any updates and let you know with instruction on how to update.
|
||||
SDKMAN 会定期检查更新,并给出让你了解如何更新的指令。
|
||||
|
||||
```
|
||||
WARNING: SDKMAN is out-of-date and requires an update.
|
||||
|
||||
$ sdk update
|
||||
Adding new candidates(s): scala
|
||||
|
||||
```
|
||||
|
||||
### Remove cache
|
||||
### 清除缓存
|
||||
|
||||
建议时不时的清理缓存(包括那些下载的 SDK 的二进制文件)。仅需运行下面的命令就可以了:
|
||||
|
||||
It is recommended to clean the cache that contains the downloaded SDK binaries for time to time. To do so, simply run:
|
||||
```
|
||||
$ sdk flush archives
|
||||
|
||||
```
|
||||
|
||||
It is also good to clean temporary folder to save up some space:
|
||||
它也可以用于清理空的文件夹,节省一点空间:
|
||||
|
||||
```
|
||||
$ sdk flush temp
|
||||
|
||||
```
|
||||
|
||||
### Uninstall SDKMAN
|
||||
### 卸载 SDKMAN
|
||||
|
||||
如果你觉得不需要或者不喜欢 SDKMAN,可以使用下面的命令删除。
|
||||
|
||||
If you don’t need SDKMAN or don’t like it, remove as shown below.
|
||||
```
|
||||
$ tar zcvf ~/sdkman-backup_$(date +%F-%kh%M).tar.gz -C ~/ .sdkman
|
||||
$ rm -rf ~/.sdkman
|
||||
|
||||
```
|
||||
最后打开你的 `.bashrc`、`.bash_profile` 和/或者 `.profile`,找到并删除下面这几行。
|
||||
|
||||
Finally, open your **.bashrc** , **.bash_profile** and/or **.profile** files and find and remove the following lines.
|
||||
```
|
||||
#THIS MUST BE AT THE END OF THE FILE FOR SDKMAN TO WORK!!!
|
||||
export SDKMAN_DIR="/home/sk/.sdkman"
|
||||
[[ -s "/home/sk/.sdkman/bin/sdkman-init.sh" ]] && source "/home/sk/.sdkman/bin/sdkman-init.sh"
|
||||
|
||||
```
|
||||
|
||||
If you use ZSH, remove the above line from the **.zshrc** file.
|
||||
如果你使用的是 ZSH,就从 `.zshrc` 中删除上面这一行。
|
||||
|
||||
And, that’s all for today. I hope you find SDKMAN useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
这就是所有的内容了。我希望 SDKMAN 可以帮到你。还有更多的干货即将到来。敬请期待!
|
||||
|
||||
祝近祺!
|
||||
|
||||
:)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -300,8 +298,8 @@ via: https://www.ostechnix.com/sdkman-a-cli-tool-to-easily-manage-multiple-softw
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,109 @@
|
||||
i3 窗口管理器使 Linux 更美好
|
||||
======
|
||||
|
||||
> 通过键盘操作的 i3 平铺窗口管理器使用 Linux 桌面。
|
||||
|
||||

|
||||
|
||||
Linux(和一般的开源软件)最美好的一点是自由 —— 可以在不同的替代方案中进行选择以满足我们的需求。
|
||||
|
||||
我使用 Linux 已经很长时间了,但我从来没有对可选用的桌面环境完全满意过。直到去年,[Xfce][1] 还是我认为在功能和性能之间的平和最接近满意的一个桌面环境。然后我发现了 [i3][2],这是一个改变了我的生活的惊人的软件。
|
||||
|
||||
i3 是一个平铺窗口管理器。窗口管理器的目标是控制窗口系统中窗口的外观和位置。窗口管理器通常用作功能齐全的桌面环境 (如 GONME 或 Xfce ) 的一部分,但也有一些可以用作独立的应用程序。
|
||||
|
||||
平铺式窗口管理器会自动排列窗口,以不重叠的方式占据整个屏幕。其他流行的平铺式窗口管理器还有 [wmii][3] 和 [xmonad][4] 。
|
||||
|
||||
![i3 tiled window manager screenshot][6]
|
||||
|
||||
*带有三个的 i3 屏幕截图*
|
||||
|
||||
为了获得更好的 Linux 桌面体验,以下是我使用和推荐 i3 窗口管理器的五个首要原因。
|
||||
|
||||
### 1、极简艺术
|
||||
|
||||
i3 速度很快。它既不冗杂、也不花哨。它的设计简单而高效。作为开发人员,我重视这些功能,因为我可以使用更多的功能以丰富我最喜欢的开发工具,或者使用容器或虚拟机在本地测试内容。
|
||||
|
||||
此外, i3 是一个窗口管理器,与功能齐全的桌面环境不同,它并不规定您应该使用的应用程序。您是否想使用 Xfce 的 Thunar 作为文件管理器?GNOME 的 gedit 去编辑文本? i3 并不在乎。选择对您的工作流最有意义的工具,i3 将以相同的方式管理它们。
|
||||
|
||||
### 2、屏幕实际使用面积
|
||||
|
||||
作为平铺式窗口管理器,i3 将自动 “平铺”,以不重叠的方式定位窗口,类似于在墙上放置瓷砖。因为您不需要担心窗口定位,i3 一般会更好地利用您的屏幕空间。它还可以让您更快地找到您需要的东西。
|
||||
|
||||
对于这种情况有很多有用的例子。例如,系统管理员可以打开多个终端来同时监视或在不同的远程系统上工作;开发人员可以使用他们最喜欢的 IDE 或编辑器和几个终端来测试他们的程序。
|
||||
|
||||
此外,i3 具有灵活性。如果您需要为特定窗口提供更多空间,请启用全屏模式或切换到其他布局,如堆叠或选项卡式(标签式)。
|
||||
|
||||
### 3、键盘式工作流程
|
||||
|
||||
i3 广泛使用键盘快捷键来控制环境的不同方面。其中包括打开终端和其他程序、调整大小和定位窗口、更改布局,甚至退出 i3。当您开始使用 i3 时,您需要记住其中的一些快捷方式才能使用,随着时间的推移,您会使用更多的快捷方式。
|
||||
|
||||
主要好处是,您不需要经常在键盘和鼠标之间切换。通过练习,您将提高工作流程的速度和效率。
|
||||
|
||||
例如, 要打开新的终端,请按 `<SUPER>+<ENTER>`。由于窗口是自动定位的,您可以立即开始键入命令。结合一个很好的终端文本编辑器(如 Vim)和一个以面向键盘的浏览器,形成一个完全由键盘驱动的工作流程。
|
||||
|
||||
在 i3 中,您可以为所有内容定义快捷方式。下面是一些示例:
|
||||
|
||||
* 打开终端
|
||||
* 打开浏览器
|
||||
* 更改布局
|
||||
* 调整窗口大小
|
||||
* 控制音乐播放器
|
||||
* 切换工作区
|
||||
|
||||
现在我已经习惯了这个工作形式,我已无法回到了常规的桌面环境。
|
||||
|
||||
### 4、灵活
|
||||
|
||||
i3 力求极简,使用很少的系统资源,但这并不意味着它不能变漂亮。i3 是灵活且可通过多种方式进行自定义以改善视觉体验。因为 i3 是一个窗口管理器,所以它没有提供启用自定义的工具,你需要外部工具来实现这一点。一些例子:
|
||||
|
||||
* 用 `feh` 定义桌面的背景图片。
|
||||
* 使用合成器管理器,如 `compton` 以启用窗口淡入淡出和透明度等效果。
|
||||
* 用 `dmenu` 或 `rofi` 以启用可从键盘快捷方式启动的可自定义菜单。
|
||||
* 用 `dunst` 用于桌面通知。
|
||||
|
||||
i3 是可完全配置的,您可以通过更新默认配置文件来控制它的各个方面。从更改所有键盘快捷键,到重新定义工作区的名称,再到修改状态栏,您都可以使 i3 以任何最适合您需要的方式运行。
|
||||
|
||||
![i3 with rofi menu and dunst desktop notifications][8]
|
||||
|
||||
*i3 与 `rofi` 菜单和 `dunst` 桌面通知。*
|
||||
|
||||
最后,对于更高级的用户,i3 提供了完整的进程间通信([IPC][9])接口,允许您使用偏好的语言来开发脚本或程序,以实现更多的自定义选项。
|
||||
|
||||
### 5、工作空间
|
||||
|
||||
在 i3 中,工作区是对窗口进行分组的一种简单方法。您可以根据您的工作流以不同的方式对它们进行分组。例如,您可以将浏览器放在一个工作区上,终端放在另一个工作区上,将电子邮件客户端放在第三个工作区上等等。您甚至可以更改 i3 的配置,以便始终将特定应用程序分配给它们自己的工作区。
|
||||
|
||||
切换工作区既快速又简单。像 i3 中的惯例,使用键盘快捷方式执行此操作。按 `<SUPER>+num` 切换到工作区 `num` 。如果您养成了始终将应用程序组的窗口分配到同一个工作区的习惯,则可以在它们之间快速切换,这使得工作区成为非常有用的功能。
|
||||
|
||||
此外,还可以使用工作区来控制多监视器环境,其中每个监视器都有个初始工作区。如果切换到该工作区,则切换到该监视器,而无需让手离开键盘。
|
||||
|
||||
最后,i3 中还有另一种特殊类型的工作空间:the scratchpad(便笺簿)。它是一个不可见的工作区,通过按快捷方式显示在其他工作区的中间。这是一种访问您经常使用的窗口或程序的方便方式,如电子邮件客户端或音乐播放器。
|
||||
|
||||
### 尝试一下吧
|
||||
|
||||
如果您重视简洁和效率,并且不惮于使用键盘,i3 就是您的窗口管理器。有人说是为高级用户准备的,但情况不一定如此。你需要学习一些基本的快捷方式来度过开始的阶段,不久就会越来越自然并且不假思索地使用它们。
|
||||
|
||||
这篇文章只是浅浅谈及了 i3 能做的事情。欲了解更多详情,请参阅 [i3 的文档][10]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/i3-tiling-window-manager
|
||||
|
||||
作者:[Ricardo Gerardi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[lixinyuxx](https://github.com/lixinyuxx)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rgerardi
|
||||
[1]:https://xfce.org/
|
||||
[2]:https://i3wm.org/
|
||||
[3]:https://code.google.com/archive/p/wmii/
|
||||
[4]:https://xmonad.org/
|
||||
[5]:/file/406476
|
||||
[6]:https://opensource.com/sites/default/files/uploads/i3_screenshot.png "i3 tiled window manager screenshot"
|
||||
[7]:/file/405161
|
||||
[8]:https://opensource.com/sites/default/files/uploads/rofi_dunst.png "i3 with rofi menu and dunst desktop notifications"
|
||||
[9]:https://i3wm.org/docs/ipc.html
|
||||
[10]:https://i3wm.org/docs/userguide.html
|
||||
@ -0,0 +1,180 @@
|
||||
如何在 Linux 中快速地通过 HTTP 提供文件访问服务
|
||||
======
|
||||
|
||||

|
||||
|
||||
如今,我有很多方法来通过 Web 浏览器为局域网中的其他系统提供单个文件或整个目录的访问。我在我的 Ubuntu 测试机上测试了这些方法,它们如下面描述的那样运行正常。如果你想知道如何在类 Unix 操作系统中通过 HTTP 轻松快速地提供文件和文件夹的访问服务,以下方法之一肯定会有所帮助。
|
||||
|
||||
### 在 Linux 中通过 HTTP 访问文件和文件夹
|
||||
|
||||
**免责声明:**此处给出的所有方法适用于安全的局域网。由于这些方法没有任何安全机制,因此**不建议在生产环境中使用它们**。你注意了!
|
||||
|
||||
#### 方法 1 - 使用 simpleHTTPserver(Python)
|
||||
|
||||
我们写了一篇简要的指南来设置一个简单的 http 服务器,以便在以下链接中即时共享文件和目录。如果你有一个安装了 Python 的系统,这个方法非常方便。
|
||||
|
||||
- [如何使用 simpleHTTPserver 设置一个简单的文件服务器](https://www.ostechnix.com/how-to-setup-a-file-server-in-minutes-using-python/)
|
||||
|
||||
#### 方法 2 - 使用 Quickserve(Python)
|
||||
|
||||
此方法针对 Arch Linux 及其衍生版。有关详细信息,请查看下面的链接。
|
||||
|
||||
- [如何在 Arch Linux 中即时共享文件和文件夹](https://www.ostechnix.com/instantly-share-files-folders-arch-linux/)
|
||||
|
||||
#### 方法 3 - 使用 Ruby
|
||||
|
||||
在此方法中,我们使用 Ruby 在类 Unix 系统中通过 HTTP 提供文件和文件夹访问。按照以下链接中的说明安装 Ruby 和 Rails。
|
||||
|
||||
- [在 CentOS 和 Ubuntu 中安装 Ruby on Rails](https://www.ostechnix.com/install-ruby-rails-ubuntu-16-04/)
|
||||
|
||||
安装 Ruby 后,进入要通过网络共享的目录,例如 ostechnix:
|
||||
|
||||
```
|
||||
$ cd ostechnix
|
||||
```
|
||||
|
||||
并运行以下命令:
|
||||
|
||||
```
|
||||
$ ruby -run -ehttpd . -p8000
|
||||
[2018-08-10 16:02:55] INFO WEBrick 1.4.2
|
||||
[2018-08-10 16:02:55] INFO ruby 2.5.1 (2018-03-29) [x86_64-linux]
|
||||
[2018-08-10 16:02:55] INFO WEBrick::HTTPServer#start: pid=5859 port=8000
|
||||
```
|
||||
|
||||
确保在路由器或防火墙中打开端口 8000。如果该端口已被其他一些服务使用,那么请使用不同的端口。
|
||||
|
||||
现在你可以使用 URL 从任何远程系统访问此文件夹的内容 - `http:// <ip-address>:8000`。
|
||||
|
||||
|
||||
|
||||
要停止共享,请按 `CTRL+C`。
|
||||
|
||||
#### 方法 4 - 使用 Http-server(NodeJS)
|
||||
|
||||
[Http-server][1] 是一个用 NodeJS 编写的简单的可用于生产环境的命令行 http 服务器。它不需要配置,可用于通过 Web 浏览器即时共享文件和目录。
|
||||
|
||||
按如下所述安装 NodeJS。
|
||||
|
||||
- [如何在 Linux 上安装 NodeJS](https://www.ostechnix.com/install-node-js-linux/)
|
||||
|
||||
安装 NodeJS 后,运行以下命令安装 http-server。
|
||||
|
||||
```
|
||||
$ npm install -g http-server
|
||||
```
|
||||
|
||||
现在进入任何目录并通过 HTTP 共享其内容,如下所示。
|
||||
|
||||
```
|
||||
$ cd ostechnix
|
||||
|
||||
$ http-server -p 8000
|
||||
Starting up http-server, serving ./
|
||||
Available on:
|
||||
http://127.0.0.1:8000
|
||||
http://192.168.225.24:8000
|
||||
http://192.168.225.20:8000
|
||||
Hit CTRL-C to stop the server
|
||||
```
|
||||
|
||||
现在你可以使用 URL 从任何远程系统访问此文件夹的内容 - `http:// <ip-address>:8000`。
|
||||
|
||||

|
||||
|
||||
要停止共享,请按 `CTRL+C`。
|
||||
|
||||
#### 方法 5 - 使用 Miniserve(Rust)
|
||||
|
||||
[**Miniserve**][2] 是另一个命令行程序,它允许你通过 HTTP 快速访问文件。它是一个非常快速、易于使用的跨平台程序,它用 Rust 编程语言编写。与上面的程序/方法不同,它提供身份验证支持,因此你可以为共享设置用户名和密码。
|
||||
|
||||
按下面的链接在 Linux 系统中安装 Rust。
|
||||
|
||||
- [在 Linux 上安装 Rust 编程语言](https://www.ostechnix.com/install-rust-programming-language-in-linux/)
|
||||
|
||||
安装 Rust 后,运行以下命令安装 miniserve:
|
||||
|
||||
```
|
||||
$ cargo install miniserve
|
||||
```
|
||||
|
||||
或者,你可以在其[发布页][3]下载二进制文件并使其可执行。
|
||||
|
||||
```
|
||||
$ chmod +x miniserve-linux
|
||||
```
|
||||
|
||||
然后,你可以使用命令运行它(假设 miniserve 二进制文件下载到当前的工作目录中):
|
||||
|
||||
```
|
||||
$ ./miniserve-linux <path-to-share>
|
||||
```
|
||||
|
||||
**用法**
|
||||
|
||||
要提供目录访问:
|
||||
|
||||
```
|
||||
$ miniserve <path-to-directory>
|
||||
```
|
||||
|
||||
**示例:**
|
||||
|
||||
```
|
||||
$ miniserve /home/sk/ostechnix/
|
||||
miniserve v0.2.0
|
||||
Serving path /home/sk/ostechnix at http://[::]:8080, http://localhost:8080
|
||||
Quit by pressing CTRL-C
|
||||
```
|
||||
|
||||
现在,你可以在本地系统使用 URL – `http://localhost:8080` 访问共享,或者在远程系统使用 URL – `http://<ip-address>:8080` 访问。
|
||||
|
||||
要提供单个文件访问:
|
||||
|
||||
```
|
||||
$ miniserve <path-to-file>
|
||||
```
|
||||
|
||||
**示例:**
|
||||
|
||||
```
|
||||
$ miniserve ostechnix/file.txt
|
||||
```
|
||||
|
||||
带用户名和密码提供文件/文件夹访问:
|
||||
|
||||
```
|
||||
$ miniserve --auth joe:123 <path-to-share>
|
||||
```
|
||||
|
||||
绑定到多个接口:
|
||||
|
||||
```
|
||||
$ miniserve -i 192.168.225.1 -i 10.10.0.1 -i ::1 -- <path-to-share>
|
||||
```
|
||||
|
||||
如你所见,我只给出了 5 种方法。但是,本指南末尾附带的链接中还提供了几种方法。也去测试一下它们。此外,收藏并时不时重新访问它来检查将来是否有新的方法。
|
||||
|
||||
今天就是这些。希望这篇文章有用。还有更多的好东西。敬请期待!
|
||||
|
||||
干杯!
|
||||
|
||||
### 资源
|
||||
|
||||
- [单行静态 http 服务器大全](https://gist.github.com/willurd/5720255)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-quickly-serve-files-and-folders-over-http-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.npmjs.com/package/http-server
|
||||
[2]:https://github.com/svenstaro/miniserve
|
||||
[3]:https://github.com/svenstaro/miniserve/releases
|
||||
@ -0,0 +1,74 @@
|
||||
Dropbox 在 Linux 上终止除了 Ext4 之外所有文件系统的同步支持
|
||||
======
|
||||
|
||||
> Dropbox 正考虑将同步支持限制为少数几种文件系统类型:Windows 的 NTFS、macOS 的 HFS+/APFS 和 Linux 的 Ext4。
|
||||
|
||||
![Dropbox ends support for various file system types][1]
|
||||
|
||||
[Dropbox][2] 是最受欢迎的 [Linux 中的云服务][3]之一。很多人都在使用 Linux 下的 Dropbox 同步客户端。但是,最近,一些用户在他们的 Dropbox Linux 桌面客户端上收到一条警告说:
|
||||
|
||||
> “移动 Dropbox 文件夹位置,
|
||||
> Dropbox 将在 11 月停止同步“
|
||||
|
||||
### Dropbox 将仅支持少量文件系统
|
||||
|
||||
一个 [Reddit 主题][4]强调了一位用户在 [Dropbox 论坛][5]上查询了该消息后的公告,该消息被社区管理员标记为意外新闻。这是[回复][6]中的内容:
|
||||
|
||||
> “大家好,在 2018 年 11 月 7 日,我们会结束 Dropbox 在某些不常见文件系统的同步支持。支持的文件系统是 Windows 的 NTFS、macOS 的 HFS+ 或 APFS,以及Linux 的 Ext4。
|
||||
>
|
||||
> [Dropbox 官方论坛][6]
|
||||
|
||||
![Dropbox official confirmation over limitation on supported file systems][7]
|
||||
|
||||
*Dropbox 官方确认支持文件系统的限制*
|
||||
|
||||
此举旨在提供稳定和一致的体验。Dropbox 还更新了其[桌面要求][8]。
|
||||
|
||||
### 那你该怎么办?
|
||||
|
||||
如果你在不受支持的文件系统上使用 Dropbox 进行同步,那么应该考虑更改位置。
|
||||
|
||||
Linux 仅支持 Ext4 文件系统。但这并不是一个令人担忧的新闻,因为你可能已经在使用 Ext4 文件系统了。
|
||||
|
||||
在 Ubuntu 或其他基于 Ubuntu 的发行版上,打开磁盘应用并查看 Linux 系统所在分区的文件系统。
|
||||
|
||||
![Check file system type on Ubuntu][9]
|
||||
|
||||
*检查 Ubuntu 上的文件系统类型*
|
||||
|
||||
如果你的系统上没有安装磁盘应用,那么可以[使用命令行了解文件系统类型][10]。
|
||||
|
||||
如果你使用的是 Ext4 文件系统并仍然收到来自 Dropbox 的警告,请检查你是否有可能收到通知的非活动计算机/设备。如果是,[将该系统与你的 Dropbox 帐户取消连接][11]。
|
||||
|
||||
### Dropbox 也不支持加密的 Ext4 吗?
|
||||
|
||||
一些用户还报告说他们在加密 Ext4 文件系统同步时也收到了警告。那么,这是否意味着 Linux 的 Dropbox 客户端只支持未加密的 Ext4 文件系统?这方面 Dropbox 没有官方声明。
|
||||
|
||||
你使用的是什么文件系统?你也收到了警告吗?如果你在收到警告后仍不确定该怎么做,你应该前往该方案的[官方帮助中心页面][12]。
|
||||
|
||||
请在下面的评论中告诉我们你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/dropbox-linux-ext4-only/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[1]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/08/dropbox-filesystem-support-featured.png?w=800&ssl=1
|
||||
[2]: https://www.dropbox.com/
|
||||
[3]: https://itsfoss.com/cloud-services-linux/
|
||||
[4]: https://www.reddit.com/r/linux/comments/966xt0/linux_dropbox_client_will_stop_syncing_on_any/
|
||||
[5]: https://www.dropboxforum.com/t5/Syncing-and-uploads/
|
||||
[6]: https://www.dropboxforum.com/t5/Syncing-and-uploads/Linux-Dropbox-client-warn-me-that-it-ll-stop-syncing-in-Nov-why/m-p/290065/highlight/true#M42255
|
||||
[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/08/dropbox-stopping-file-system-supports.jpeg?w=800&ssl=1
|
||||
[8]: https://www.dropbox.com/help/desktop-web/system-requirements#desktop
|
||||
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/08/check-file-system-type-ubuntu.jpg?w=800&ssl=1
|
||||
[10]: https://www.thegeekstuff.com/2011/04/identify-file-system-type/
|
||||
[11]: https://www.dropbox.com/help/mobile/unlink-relink-computer-mobile
|
||||
[12]: https://www.dropbox.com/help/desktop-web/cant-establish-secure-connection#location
|
||||
@ -0,0 +1,100 @@
|
||||
顶级 Linux 开发者推荐的编程书籍
|
||||
======
|
||||
|
||||

|
||||
|
||||
> 毫无疑问,Linux 是由那些拥有深厚计算机知识背景而且才华横溢的程序员发明的。让那些大名鼎鼎的 Linux 程序员向如今的开发者分享一些曾经带领他们登堂入室的好书和技术参考资料吧,你会不会也读过其中几本呢?
|
||||
|
||||
Linux,毫无争议的属于 21 世纪的操作系统。虽然 Linus Torvalds 在建立开源社区这件事上做了很多工作和社区决策,不过那些网络专家和开发者愿意接受 Linux 的原因还是因为它卓越的代码质量和高可用性。Torvalds 是个编程天才,同时必须承认他还是得到了很多其他同样极具才华的开发者的无私帮助。
|
||||
|
||||
就此我咨询了 Torvalds 和其他一些顶级 Linux 开发者,有哪些书籍帮助他们走上了成为顶级开发者的道路,下面请听我一一道来。
|
||||
|
||||
### 熠熠生辉的 C 语言
|
||||
|
||||
Linux 是在大约上世纪 90 年代开发出来的,与它一起问世的还有其他一些完成基础功能的开源软件。与此相应,那时的开发者使用的工具和语言反映了那个时代的印记,也就是说 C 语言。可能 [C 语言不再流行了][1],可对于很多已经建功立业的开发者来说,C 语言是他们的第一个在实际开发中使用的语言,这一点也在他们推选的对他们有着深远影响的书单中反映出来。
|
||||
|
||||
Torvalds 说,“你不应该再选用我那个时代使用的语言或者开发方式”,他的开发道路始于 BASIC,然后转向机器码(“甚至都不是汇编语言,而是真真正正的‘二进制’机器码”,他解释道),再然后转向汇编语言和 C 语言。
|
||||
|
||||
“任何人都不应该再从这些语言开始进入开发这条路了”,他补充道。“这些语言中的一些今天已经没有什么意义(如 BASIC 和机器语言)。尽管 C 还是一个主流语言,我也不推荐你从它开始。”
|
||||
|
||||
并不是他不喜欢 C。不管怎样,Linux 是用 [GNU C 语言][2]写就的。“我始终认为 C 是一个伟大的语言,它有着非常简单的语法,对于很多方向的开发都很合适,但是我怀疑你会遇到重重挫折,从你的第一个‘Hello World’程序开始到你真正能开发出能用的东西当中有很大一步要走”。他认为,用现在的标准,如果作为入门语言的话,从 C 语言开始的代价太大。
|
||||
|
||||
在他那个时代,Torvalds 的唯一选择的书就只能是 Brian W. Kernighan 和 Dennis M. Ritchie 合著的《<ruby>[C 编程语言,第二版][3]<rt>C Programming Language, 2nd Edition</rt></ruby>》,它在编程圈内也被尊称为 K&R。“这本书简单精炼,但是你要先有编程的背景才能欣赏它”,Torvalds 说到。
|
||||
|
||||
Torvalds 并不是唯一一个推荐 K&R 的开源开发者。以下几位也同样引用了这本他们认为值得推荐的书籍,他们有:Linux 和 Oracle 虚拟化开发副总裁 Wim Coekaerts;Linux 开发者 Alan Cox;Google 云 CTO Brian Stevens;Canonical 技术运营部副总裁 Pete Graner。
|
||||
|
||||
如果你今日还想同 C 语言较量一番的话,Samba 的共同创始人 Jeremy Allison 推荐《<ruby>[C 程序设计新思维][4]<rt>21st Century C: C Tips from the New School</rt></ruby>》。他还建议,同时也去阅读一本比较旧但是写的更详细的《<ruby>[C 专家编程][5]<rt>Expert C Programming: Deep C Secrets</rt></ruby>》和有着 20 年历史的《<ruby>[POSIX 多线程编程][6]<rt>Programming with POSIX Threads</rt></ruby>》。
|
||||
|
||||
### 如果不选 C 语言, 那选什么?
|
||||
|
||||
Linux 开发者推荐的书籍自然都是他们认为适合今时今日的开发项目的语言工具。这也折射了开发者自身的个人偏好。例如,Allison 认为年轻的开发者应该在《<ruby>[Go 编程语言][7]<rt>The Go Programming Language</rt></ruby>》和《<ruby>[Rust 编程][8]<rt>Rust with Programming Rust</rt></ruby>》的帮助下去学习 Go 语言和 Rust 语言。
|
||||
|
||||
但是超越编程语言来考虑问题也不无道理(尽管这些书传授了你编程技巧)。今日要做些有意义的开发工作的话,"要从那些已经完成了 99% 显而易见工作的框架开始,然后你就能围绕着它开始写脚本了", Torvalds 推荐了这种做法。
|
||||
|
||||
“坦率来说,语言本身远远没有围绕着它的基础架构重要”,他继续道,“可能你会从 Java 或者 Kotlin 开始,但那是因为你想为自己的手机开发一个应用,因此安卓 SDK 成为了最佳的选择,又或者,你对游戏开发感兴趣,你选择了一个游戏开发引擎来开始,而通常它们有着自己的脚本语言”。
|
||||
|
||||
这里提及的基础架构包括那些和操作系统本身相关的编程书籍。
|
||||
Garner 在读完了大名鼎鼎的 K&R 后又拜读了 W. Richard Steven 的《<ruby>[Unix 网络编程][10]<rt>Unix Network Programming</rt></ruby>》。特别是,Steven 的《<ruby>[TCP/IP 详解,卷1:协议][11]<rt>TCP/IP Illustrated, Volume 1: The Protocols</rt></ruby>》在出版了 30 年之后仍然被认为是必读之书。因为 Linux 开发很大程度上和[和网络基础架构有关][12],Garner 也推荐了很多 O'Reilly 在 [Sendmail][13]、[Bash][14]、[DNS][15] 以及 [IMAP/POP][16] 等方面的书。
|
||||
|
||||
Coekaerts 也是 Maurice Bach 的《<ruby>[UNIX 操作系统设计][17]<rt>The Design of the Unix Operation System</rt></ruby>》的书迷之一。James Bottomley 也是这本书的推崇者,作为一个 Linux 内核开发者,当 Linux 刚刚问世时 James 就用 Bach 的这本书所传授的知识将它研究了个底朝天。
|
||||
|
||||
### 软件设计知识永不过时
|
||||
|
||||
尽管这样说有点太局限在技术领域。Stevens 还是说到,“所有的开发者都应该在开始钻研语法前先研究如何设计,《<ruby>[设计心理学][18]<rt>The Design of Everyday Things</rt></ruby>》是我的最爱”。
|
||||
|
||||
Coekaerts 喜欢 Kernighan 和 Rob Pike 合著的《<ruby>[程序设计实践][19]<rt>The Practic of Programming</rt></ruby>》。这本关于设计实践的书当 Coekaerts 还在学校念书的时候还未出版,他说道,“但是我把它推荐给每一个人”。
|
||||
|
||||
不管何时,当你问一个长期从事于开发工作的开发者他最喜欢的计算机书籍时,你迟早会听到一个名字和一本书:Donald Knuth 和他所著的《<ruby>[计算机程序设计艺术(1-4A)][20]<rt>The Art of Computer Programming, Volumes 1-4A</rt></ruby>》。VMware 首席开源官 Dirk Hohndel,认为这本书尽管有永恒的价值,但他也承认,“今时今日并非极其有用”。(LCTT 译注:不代表译者观点)
|
||||
|
||||
### 读代码。大量的读。
|
||||
|
||||
编程书籍能教会你很多,也请别错过另外一个在开源社区特有的学习机会:《<ruby>[代码阅读方法与实践][21]<rt>Code Reading: The Open Source Perspective</rt></ruby>》。那里有不可计数的代码例子阐述如何解决编程问题(以及如何让你陷入麻烦……)。Stevens 说,谈到磨炼编程技巧,在他的书单里排名第一的“书”是 Unix 的源代码。
|
||||
|
||||
“也请不要忽略从他人身上学习的各种机会。” Cox 道,“我是在一个计算机俱乐部里和其他人一起学的 BASIC,在我看来,这仍然是一个学习的最好办法”,他从《<ruby>[精通 ZX81 机器码][22]<rt>Mastering machine code on your ZX81</rt></ruby>》这本书和 Honeywell L66 B 编译器手册里学习到了如何编写机器码,但是学习技术这点来说,单纯阅读和与其他开发者在工作中共同学习仍然有着很大的不同。
|
||||
|
||||
Cox 说,“我始终认为最好的学习方法是和一群人一起试图去解决你们共同关心的一些问题并从中找到快乐,这和你是 5 岁还是 55 岁无关”。
|
||||
|
||||
最让我吃惊的是这些顶级 Linux 开发者都是在非常底层级别开始他们的开发之旅的,甚至不是从汇编语言或 C 语言,而是从机器码开始开发。毫无疑问,这对帮助开发者理解计算机在非常微观的底层级别是怎么工作的起了非常大的作用。
|
||||
|
||||
那么现在你准备好尝试一下硬核 Linux 开发了吗?Greg Kroah-Hartman,这位 Linux 内核稳定分支的维护者,推荐了 Steve Oualline 的《<ruby>[实用 C 语言编程][23]<rt>Practical C Programming</rt></ruby>》和 Samuel harbison 与 Guy Steels 合著的《<ruby>[C 语言参考手册][24]<rt>C: A Reference Manual</rt></ruby>》。接下来请阅读<ruby>[如何进行 Linux 内核开发][25]<rt>HOWTO do Linux kernel development</rt></ruby>,到这时,就像 Kroah-Hartman 所说,你已经准备好启程了。
|
||||
|
||||
于此同时,还请你刻苦学习并大量编码,最后祝你在跟随顶级 Linux 开发者脚步的道路上好运相随。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.hpe.com/us/en/insights/articles/top-linux-developers-recommended-programming-books-1808.html
|
||||
|
||||
作者:[Steven Vaughan-Nichols][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[DavidChenLiang](https://github.com/DavidChenLiang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.hpe.com/us/en/insights/contributors/steven-j-vaughan-nichols.html
|
||||
[1]:https://www.codingdojo.com/blog/7-most-in-demand-programming-languages-of-2018/
|
||||
[2]:https://www.gnu.org/software/gnu-c-manual/
|
||||
[3]:https://amzn.to/2nhyjEO
|
||||
[4]:https://amzn.to/2vsL8k9
|
||||
[5]:https://amzn.to/2KBbWn9
|
||||
[6]:https://amzn.to/2M0rfeR
|
||||
[7]:https://amzn.to/2nhyrnMe
|
||||
[8]:http://shop.oreilly.com/product/0636920040385.do
|
||||
[9]:https://www.hpe.com/us/en/resources/storage/containers-for-dummies.html?jumpid=in_510384402_linuxbooks_containerebook0818
|
||||
[10]:https://amzn.to/2MfpbyC
|
||||
[11]:https://amzn.to/2MpgrTn
|
||||
[12]:https://www.hpe.com/us/en/insights/articles/how-to-see-whats-going-on-with-your-linux-system-right-now-1807.html
|
||||
[13]:http://shop.oreilly.com/product/9780596510299.do
|
||||
[14]:http://shop.oreilly.com/product/9780596009656.do
|
||||
[15]:http://shop.oreilly.com/product/9780596100575.do
|
||||
[16]:http://shop.oreilly.com/product/9780596000127.do
|
||||
[17]:https://amzn.to/2vsCJgF
|
||||
[18]:https://amzn.to/2APzt3Z
|
||||
[19]:https://www.amazon.com/Practice-Programming-Addison-Wesley-Professional-Computing/dp/020161586X/ref=as_li_ss_tl?ie=UTF8&linkCode=sl1&tag=thegroovycorpora&linkId=e6bbdb1ca2182487069bf9089fc8107e&language=en_US
|
||||
[20]:https://amzn.to/2OknFsJ
|
||||
[21]:https://amzn.to/2M4VVL3
|
||||
[22]:https://amzn.to/2OjccJA
|
||||
[23]:http://shop.oreilly.com/product/9781565923065.do
|
||||
[24]:https://amzn.to/2OjzgrT
|
||||
[25]:https://www.kernel.org/doc/html/v4.16/process/howto.html
|
||||
File diff suppressed because it is too large
Load Diff
@ -1,34 +1,32 @@
|
||||
如何在 Ubuntu 服务器中禁用终端欢迎消息中的广告
|
||||
如何禁用 Ubuntu 服务器中终端欢迎消息中的广告
|
||||
======
|
||||
|
||||
如果你正在使用最新的 Ubuntu 服务器版本,你可能已经注意到欢迎消息中有一些与 Ubuntu 服务器平台无关的促销链接。你可能已经知道 **MOTD**,即 **M**essage **O**f **T**he **D**ay 的开头首字母,在 Linux 系统每次登录时都会显示欢迎信息。通常,欢迎消息包含操作系统版本,基本系统信息,官方文档链接以及有关最新安全更新等的链接。这些是我们每次通过 SSH 或本地登录时通常会看到的内容。但是,最近在终端欢迎消息中出现了一些其他链接。我已经几次注意到这些链接,但我并在意,也从未点击过。以下是我的 Ubuntu 18.04 LTS 服务器上显示的终端欢迎消息。
|
||||
|
||||
|
||||
|
||||
正如你在上面截图中所看到的,欢迎消息中有一个 bit.ly 链接和 Ubuntu wiki 链接。有些人可能会惊讶并想知道这是什么。其实欢迎信息中的链接无需担心。它可能看起来像广告,但并不是商业广告。链接实际上指的是 [**Ubuntu 官方博客**][1] 和 [**Ubuntu wiki**][2]。正如我之前所说,其中的一个链接是不相关的,没有任何与 Ubuntu 服务器相关的细节,这就是为什么我开头称它们为广告。
|
||||
(to 校正:这里是其中一个链接不相关还是两个链接都不相关)
|
||||
正如你在上面截图中所看到的,欢迎消息中有一个 bit.ly 链接和 Ubuntu wiki 链接。有些人可能会惊讶并想知道这是什么。其实欢迎信息中的链接无需担心。它可能看起来像广告,但并不是商业广告。链接实际上指向到了 [Ubuntu 官方博客][1] 和 [Ubuntu wiki][2]。正如我之前所说,其中的一个链接是不相关的,没有任何与 Ubuntu 服务器相关的细节,这就是为什么我开头称它们为广告。
|
||||
|
||||
虽然我们大多数人都不会访问 bit.ly 链接,但是有些人可能出于好奇去访问这些链接,结果失望地发现它只是指向一个外部链接。你可以使用任何 URL 短网址服务,例如 unshorten.it,在访问真正链接之前,查看它会指向哪里。或者,你只需在 bit.ly 链接的末尾输入加号(**+**)即可查看它们的实际位置以及有关链接的一些统计信息。
|
||||
虽然我们大多数人都不会访问 bit.ly 链接,但是有些人可能出于好奇去访问这些链接,结果失望地发现它只是指向一个外部链接。你可以使用任何 URL 去短网址服务,例如 unshorten.it,在访问真正链接之前,查看它会指向哪里。或者,你只需在 bit.ly 链接的末尾输入加号(`+`)即可查看它们的实际位置以及有关链接的一些统计信息。
|
||||
|
||||

|
||||
|
||||
### 什么是 MOTD 以及它是如何工作的?
|
||||
|
||||
2009 年,来自 Canonical 的 **Dustin Kirkland** 在 Ubuntu 中引入了 MOTD 的概念。它是一个灵活的框架,使管理员或发行包能够在 /etc/update-motd.d/* 位置添加可执行脚本,目的是生成在登录时显示有益的,有趣的消息。它最初是为 Landscape(Canonical 的商业服务)实现的,但是其它发行版维护者发现它很有用,并且在他们自己的发行版中也采用了这个特性。
|
||||
2009 年,来自 Canonical 的 Dustin Kirkland 在 Ubuntu 中引入了 MOTD 的概念。它是一个灵活的框架,使管理员或发行包能够在 `/etc/update-motd.d/` 位置添加可执行脚本,目的是生成在登录时显示有益的、有趣的消息。它最初是为 Landscape(Canonical 的商业服务)实现的,但是其它发行版维护者发现它很有用,并且在他们自己的发行版中也采用了这个特性。
|
||||
|
||||
如果你在 Ubuntu 系统中查看 **/etc/update-motd.d/**,你会看到一组脚本。一个是打印通用的 “ Welcome” 横幅。下一个打印 3 个链接,显示在哪里可以找到操作系统的帮助。另一个计算并显示本地系统包可以更新的数量。另一个脚本告诉你是否需要重新启动等等。
|
||||
如果你在 Ubuntu 系统中查看 `/etc/update-motd.d/`,你会看到一组脚本。一个是打印通用的 “欢迎” 横幅。下一个打印 3 个链接,显示在哪里可以找到操作系统的帮助。另一个计算并显示本地系统包可以更新的数量。另一个脚本告诉你是否需要重新启动等等。
|
||||
|
||||
从 Ubuntu 17.04 起,开发人员添加了 **/etc/update-motd.d/50-motd-news**,这是一个脚本用来在欢迎消息中包含一些附加信息。这些附加信息是:
|
||||
|
||||
1. 重要的关键信息,例如 ShellShock, Heartbleed 等
|
||||
从 Ubuntu 17.04 起,开发人员添加了 `/etc/update-motd.d/50-motd-news`,这是一个脚本用来在欢迎消息中包含一些附加信息。这些附加信息是:
|
||||
|
||||
1. 重要的关键信息,例如 ShellShock、Heartbleed 等
|
||||
2. 生命周期(EOL)消息,新功能可用性等
|
||||
|
||||
3. 在 Ubuntu 官方博客和其他有关 Ubuntu 的新闻中发布的一些有趣且有益的帖子
|
||||
|
||||
另一个特点是异步,启动后约 60 秒,systemd 计时器运行 “/etc/update-motd.d/50-motd-news –force” 脚本。它提供了 /etc/default/motd-news 脚本中定义的 3 个配置变量。默认值为:ENABLED=1, URLS=”<https://motd.ubuntu.com”>, WAIT=”5″。
|
||||
另一个特点是异步,启动后约 60 秒,systemd 计时器运行 `/etc/update-motd.d/50-motd-news –force` 脚本。它提供了 `/etc/default/motd-news` 脚本中定义的 3 个配置变量。默认值为:`ENABLED=1, URLS="https://motd.ubuntu.com", WAIT="5"`。
|
||||
|
||||
以下是 `/etc/default/motd-news` 文件的内容:
|
||||
|
||||
以下是 /etc/default/motd-news 文件的内容:
|
||||
```
|
||||
$ cat /etc/default/motd-news
|
||||
# Enable/disable the dynamic MOTD news service
|
||||
@ -50,20 +48,20 @@ URLS="https://motd.ubuntu.com"
|
||||
# Note that news messages are fetched in the background by
|
||||
# a systemd timer, so this should never block boot or login
|
||||
WAIT=5
|
||||
|
||||
```
|
||||
|
||||
好事情是 MOTD 是完全可定制的,所以你可以彻底禁用它(ENABLED=0),根据你的意愿更改或添加脚本,并以秒为单位更改等待时间。
|
||||
好事情是 MOTD 是完全可定制的,所以你可以彻底禁用它(`ENABLED=0`)、根据你的意愿更改或添加脚本、以秒为单位更改等待时间等等。
|
||||
|
||||
如果启用了 MOTD,那么 systemd 计时器作业将循环遍历每个 URL,将它们缩减到每行 80 个字符,最多 10 行,并将它们连接(to 校正:也可能是链接?)到 /var/cache/motd-news 中的缓存文件。此 systemd 计时器作业将每隔 12 小时运行并更新 /var/cache/motd-news。用户登录后,/var/cache/motd-news 的内容会打印到屏幕上。这就是 MOTD 的工作原理。
|
||||
如果启用了 MOTD,那么 systemd 计时器作业将循环遍历每个 URL,将它们的内容缩减到每行 80 个字符、最多 10 行,并将它们连接到 `/var/cache/motd-news` 中的缓存文件。此 systemd 计时器作业将每隔 12 小时运行并更新 `/var/cache/motd-news`。用户登录后,`/var/cache/motd-news` 的内容会打印到屏幕上。这就是 MOTD 的工作原理。
|
||||
|
||||
此外,`/etc/update-motd.d/50-motd-news` 文件中包含自定义的用户代理字符串,以报告有关计算机的信息。如果你查看 `/etc/update-motd.d/50-motd-news` 文件,你会看到:
|
||||
|
||||
此外,**/etc/update-motd.d/50-motd-news** 文件中包含自定义用户代理字符串,以报告有关计算机的信息。如果你查看 **/etc/update-motd.d/50-motd-news** 文件,你会看到
|
||||
```
|
||||
# Piece together the user agent
|
||||
USER_AGENT="curl/$curl_ver $lsb $platform $cpu $uptime"
|
||||
```
|
||||
|
||||
这意味着,MOTD 检索器将向 Canonical 报告你的**操作系统版本**,**硬件平台**,**CPU 类型**和**正常运行时间**。
|
||||
这意味着,MOTD 检索器将向 Canonical 报告你的操作系统版本、硬件平台、CPU 类型和正常运行时间。
|
||||
|
||||
到这里,希望你对 MOTD 有了一个基本的了解。
|
||||
|
||||
@ -72,11 +70,13 @@ USER_AGENT="curl/$curl_ver $lsb $platform $cpu $uptime"
|
||||
### 在 Ubuntu 服务器中禁用终端欢迎消息中的广告
|
||||
|
||||
要禁用这些广告,编辑文件:
|
||||
|
||||
```
|
||||
$ sudo vi /etc/default/motd-news
|
||||
```
|
||||
|
||||
找到以下行并将其值设置为 0(零)。
|
||||
找到以下行并将其值设置为 `0`(零)。
|
||||
|
||||
```
|
||||
[...]
|
||||
ENABLED=0
|
||||
@ -101,7 +101,7 @@ via: https://www.ostechnix.com/how-to-disable-ads-in-terminal-welcome-message-in
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,72 @@
|
||||
Joplin:开源加密笔记及待办事项应用
|
||||
======
|
||||
|
||||
> [Joplin][1] 是一个自由开源的笔记和待办事项应用,可用于 Linux、Windows、macOS、Android 和 iOS。它的主要功能包括端到端加密,Markdown 支持以及通过 NextCloud、Dropbox、OneDrive 或 WebDAV 等第三方服务进行同步。
|
||||
|
||||
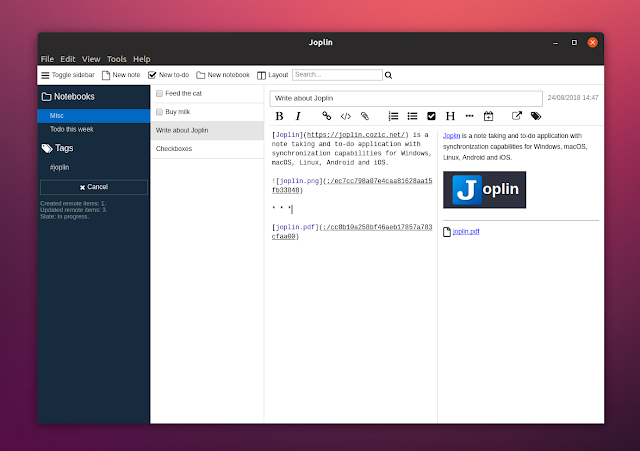
|
||||
|
||||
在 Joplin 中你可以用 Markdown 格式(支持数学符号和复选框)记笔记,桌面程序有 3 种视图:Markdown 代码、Markdown 预览或两者并排。你可以在笔记中添加附件(使用图像预览)或在外部 Markdown 编辑器中编辑它们并在每次保存文件时自动在 Joplin 中更新它们。
|
||||
|
||||
这个应用应该可以很好地处理大量笔记,它允许你将笔记组织到笔记本中、添加标签和搜索。你还可以按更新日期、创建日期或标题对笔记进行排序。每个笔记本可以包含笔记、待办事项或两者,你可以轻松添加其他笔记的链接(在桌面应用中右键单击笔记并选择 “Copy Markdown link”,然后在笔记中添加链接)。
|
||||
|
||||
Joplin 中的待办事项支持警报,但在 Ubuntu 18.04 上,此功能我无法使用。
|
||||
|
||||
其他 Joplin 功能包括:
|
||||
|
||||
* Firefox 和 Chrome 中可选的 Web Clipper 扩展(在 Joplin 桌面应用中进入 “Tools > Web clipper options” 以启用剪切服务并找到 Chrome/Firefox 扩展程序的下载链接),它可以剪切简单或完整的页面、剪切选中的区域或者截图。
|
||||
* 可选命令行客户端。
|
||||
* 导入 Enex 文件(Evernote 导出格式)和 Markdown 文件。
|
||||
* 导出 JEX 文件(Joplin 导出格式)、PDF 和原始文件。
|
||||
* 离线优先,因此即使没有互联网连接,所有数据也始终可在设备上查看。
|
||||
* 地理位置支持。
|
||||
|
||||
[![Joplin notes checkboxes link to other note][2]][3]
|
||||
|
||||
*Joplin 带有显示复选框和指向另一个笔记链接的隐藏侧边栏*
|
||||
|
||||
虽然它没有提供与 Evernote 一样多的功能,但 Joplin 是一个强大的开源 Evernote 替代品。Joplin 包含所有基本功能,除了它是开源软件之外,它还包括加密支持,你还可以选择用于同步的服务。
|
||||
|
||||
该应用实际上被设计为 Evernote 替代品,因此它可以导入完整的 Evernote 笔记本、笔记、标签、附件和笔记元数据,如作者、创建和更新时间或地理位置。
|
||||
|
||||
Joplin 开发重点关注的另一个方面是避免与特定公司或服务挂钩。这就是为什么该应用提供多种同步方案,如 NextCloud、Dropbox、oneDrive 和 WebDav,同时也容易支持新的服务。如果你改变主意,也很容易从一种服务切换到另一种服务。
|
||||
|
||||
我注意到 Joplin 默认情况下不使用加密,你必须在设置中启用此功能。进入 “Tools> Encryption options” 并在这里启用 Joplin 端到端加密。
|
||||
|
||||
### 下载 Joplin
|
||||
|
||||
- [下载 Joplin][7]
|
||||
|
||||
Joplin 适用于 Linux、Windows、macOS、Android 和 iOS。在 Linux 上,还有 AppImage 和 Aur 包。
|
||||
|
||||
要在 Linux 上运行 Joplin AppImage,请双击它并选择 “Make executable and run”(如果文件管理器支持这个)。如果不支持,你需要使用你的文件管理器使它可执行(应该类似这样:“右键单击>属性>权限>允许作为程序执行”,但这可能会因你使用的文件管理器而有所不同),或者从命令行:
|
||||
|
||||
```
|
||||
chmod +x /path/to/Joplin-*-x86_64.AppImage
|
||||
```
|
||||
|
||||
用你下载 Joplin 的路径替换 `/path/to/`。现在,你可以双击 Joplin Appimage 文件来启动它。
|
||||
|
||||
提示:如果你将 Joplin 集成到你的菜单中,而它的图标没有显示在你 dock 或应用切换器中,你可以打开 Joplin 的桌面文件(如果你使用 appimagekit 集成,它应该在 `~/.local/share/applications/appimagekit-joplin.desktop`)并在文件末尾添加 `StartupWMClass=Joplin` 其他不变来修复。
|
||||
|
||||
Joplin 有一个命令行客户端,它可以[使用 npm 安装][5](对于 Debian、Ubuntu 或 Linux Mint,请参阅[如何安装和配置 Node.js 和 npm][6])。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/08/joplin-encrypted-open-source-note.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://joplin.cozic.net/
|
||||
[2]:https://3.bp.blogspot.com/-y9JKL1F89Vo/W3_0dkZjzQI/AAAAAAAABcI/hQI7GAx6i_sMcel4mF0x4uxBrMO88O59wCLcBGAs/s640/joplin-notes-markdown.png (Joplin notes checkboxes link to other note)
|
||||
[3]:https://3.bp.blogspot.com/-y9JKL1F89Vo/W3_0dkZjzQI/AAAAAAAABcI/hQI7GAx6i_sMcel4mF0x4uxBrMO88O59wCLcBGAs/s1600/joplin-notes-markdown.png
|
||||
[4]:https://github.com/laurent22/joplin/issues/338
|
||||
[5]:https://joplin.cozic.net/terminal/
|
||||
[6]:https://www.linuxuprising.com/2018/04/how-to-install-and-configure-nodejs-and.html
|
||||
|
||||
[7]: https://joplin.cozic.net/#installation
|
||||
103
published/201811/20180827 Top 10 Raspberry Pi blogs to follow.md
Normal file
103
published/201811/20180827 Top 10 Raspberry Pi blogs to follow.md
Normal file
@ -0,0 +1,103 @@
|
||||
10 个最值得关注的树莓派博客
|
||||
======
|
||||
|
||||
> 如果你正在计划你的下一个树莓派项目,那么这些博客或许有帮助。
|
||||
|
||||

|
||||
|
||||
网上有很多很棒的树莓派爱好者网站、教程、代码仓库、YouTube 频道和其他资源。以下是我最喜欢的十大树莓派博客,排名不分先后。
|
||||
|
||||
### 1、Raspberry Pi Spy
|
||||
|
||||
树莓派粉丝 Matt Hawkins 从很早开始就在他的网站 [Raspberry Pi Spy][4] 上撰写了大量全面且信息丰富的教程。我从这个网站上直接学到了很多东西,而且 Matt 似乎也总是涵盖到众多主题的第一个人。在我学习使用树莓派的前三年里,多次在这个网站得到帮助。
|
||||
|
||||
值得庆幸的是,这个不断采用新技术的网站仍然很强大。我希望看到它继续存在下去,让新社区成员在需要时得到帮助。
|
||||
|
||||
### 2、Adafruit
|
||||
|
||||
[Adafruit][1] 是硬件黑客中知名品牌之一。该公司制作和销售漂亮的硬件,并提供由员工、社区成员,甚至 Lady Ada 女士自己编写的优秀教程。
|
||||
|
||||
除了网上商店,Adafruit 还经营一个博客,这个博客充满了来自世界各地的精彩内容。在博客上可以查看树莓派的类别,特别是在工作日的最后一天,会在 Adafruit Towers 举办名为 [Friday is Pi Day][1] 的活动。
|
||||
|
||||
### 3、Recantha 的 Raspberry Pi Pod
|
||||
|
||||
Mike Horne(Recantha)是英国一位重要的树莓派社区成员,负责 [CamJam 和 Potton Pi&Pint][2](剑桥的两个树莓派社团)以及 [Pi Wars][3] (一年一度的树莓派机器人竞赛)。他为其他人建立树莓派社团提供建议,并且总是有时间帮助初学者。Horne 和他的共同组织者 Tim Richardson 一起开发了 CamJam Edu Kit (一系列小巧且价格合理的套件,适合初学者使用 Python 学习物理计算)。
|
||||
|
||||
除此之外,他还运营着 [Pi Pod][18],这是一个包含了世界各地树莓派相关内容的博客。它可能是这个列表中更新最频繁的树莓派博客,所以这是一个把握树莓派社区动向的极好方式。
|
||||
|
||||
### 4. Raspberry Pi 官方博客
|
||||
|
||||
必须提一下[树莓派基金会][19]的官方博客,这个博客涵盖了基金会的硬件、软件、教育、社区、慈善和青年编码俱乐部的一系列内容。博客上的大型主题是家庭数字化、教育授权,以及硬件版本和软件更新的官方新闻。
|
||||
|
||||
该博客自 [2011 年][5] 运行至今,并提供了自那时以来所有 1800 多个帖子的 [存档][6] 。你也可以在 Twitter 上关注[@raspberrypi_otd][7],这是我用 [Python][8] 创建的机器人(教程在这里:[Opensource.com][9])。Twitter 机器人推送来自博客存档的过去几年同一天的树莓派帖子。
|
||||
|
||||
### 5、RasPi.tv
|
||||
|
||||
另一位开创性的树莓派社区成员是 Alex Eames,通过他的博客和 YouTube 频道 [RasPi.tv][20],他很早就加入了树莓派社区。他的网站为很多创客项目提供高质量、精心制作的视频教程和书面指南。
|
||||
|
||||
Alex 的网站 [RasP.iO][10] 制作了一系列树莓派附加板和配件,包括方便的 GPIO 端口引脚、电路板测量尺等等。他的博客也拓展到了 [Arduino][11]、[WEMO][12] 以及其他小网站。
|
||||
|
||||
### 6、pyimagesearch
|
||||
|
||||
虽然不是严格的树莓派博客(名称中的“py”是“Python”,而不是“树莓派”),但该网站的 [树莓派栏目][13] 有着大量内容。 Adrian Rosebrock 获得了计算机视觉和机器学习领域的博士学位,他的博客旨在分享他在学习和制作自己的计算机视觉项目时所学到的机器学习技巧。
|
||||
|
||||
如果你想使用树莓派的相机模块学习面部或物体识别,来这个网站就对了。Adrian 在图像识别领域的深度学习和人工智能知识和实际应用是首屈一指的,而且他编写了自己的项目,这样任何人都可以进行尝试。
|
||||
|
||||
### 7、Raspberry Pi Roundup
|
||||
|
||||
这个[博客][21]由英国官方树莓派经销商之一 The Pi Hut 进行维护,会有每周的树莓派新闻。这是另一个很好的资源,可以紧跟树莓派社区的最新资讯,而且之前的文章也值得回顾。
|
||||
|
||||
### 8、Dave Akerman
|
||||
|
||||
[Dave Akerman][22] 是研究高空热气球的一流专家,他分享使用树莓派以最低的成本进行热气球发射方面的知识和经验。他会在一张由热气球拍摄的平流层照片下面对本次发射进行评论,也会对个人发射树莓派热气球给出自己的建议。
|
||||
|
||||
查看 Dave 的[博客][22],了解精彩的临近空间摄影作品。
|
||||
|
||||
### 9、Pimoroni
|
||||
|
||||
[Pimoroni][23] 是一家世界知名的树莓派经销商,其总部位于英国谢菲尔德。这家经销商制作了著名的 [树莓派彩虹保护壳][14],并推出了许多极好的定制附加板和配件。
|
||||
|
||||
Pimoroni 的博客布局与其硬件设计和品牌推广一样精美,博文内容非常适合创客和业余爱好者在家进行创作,并且可以在有趣的 YouTube 频道 [Bilge Tank][15] 上找到。
|
||||
|
||||
### 10、Stuff About Code
|
||||
|
||||
Martin O'Hanlon 以树莓派社区成员的身份转为了树莓派基金会的员工,他起初出于乐趣在树莓派上开发“我的世界”作弊器,最近作为内容编辑加入了树莓派基金会。幸运的是,马丁的新工作并没有阻止他更新[博客][24]并与世界分享有益的趣闻。
|
||||
|
||||
除了“我的世界”的很多内容,你还可以在 Python 库、[Blue Dot][16] 和 [guizero][17] 上找到 Martin O'Hanlon 的贡献,以及一些总结性的树莓派技巧。
|
||||
|
||||
------
|
||||
|
||||
via: https://opensource.com/article/18/8/top-10-raspberry-pi-blogs-follow
|
||||
|
||||
作者:[Ben Nuttall][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[jlztan](https://github.com/jlztan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bennuttall
|
||||
[1]: https://blog.adafruit.com/category/raspberry-pi/
|
||||
[2]: https://camjam.me/?page_id=753
|
||||
[3]: https://piwars.org/
|
||||
[4]: https://www.raspberrypi-spy.co.uk/
|
||||
[5]: https://www.raspberrypi.org/blog/first-post/
|
||||
[6]: https://www.raspberrypi.org/blog/archive/
|
||||
[7]: https://twitter.com/raspberrypi_otd
|
||||
[8]: https://github.com/bennuttall/rpi-otd-bot/blob/master/src/bot.py
|
||||
[9]: https://opensource.com/article/17/8/raspberry-pi-twitter-bot
|
||||
[10]: https://rasp.io/
|
||||
[11]: https://www.arduino.cc/
|
||||
[12]: http://community.wemo.com/
|
||||
[13]: https://www.pyimagesearch.com/category/raspberry-pi/
|
||||
[14]: https://shop.pimoroni.com/products/pibow-for-raspberry-pi-3-b-plus
|
||||
[15]: https://www.youtube.com/channel/UCuiDNTaTdPTGZZzHm0iriGQ
|
||||
[16]: https://bluedot.readthedocs.io/en/latest/#
|
||||
[17]: https://lawsie.github.io/guizero/
|
||||
[18]: https://www.recantha.co.uk/blog/
|
||||
[19]: https://www.raspberrypi.org/blog/
|
||||
[20]: https://rasp.tv/
|
||||
[21]: https://thepihut.com/blogs/raspberry-pi-roundup
|
||||
[22]: http://www.daveakerman.com/
|
||||
[23]: https://blog.pimoroni.com/
|
||||
[24]: https://www.stuffaboutcode.com/
|
||||
@ -0,0 +1,162 @@
|
||||
用 Python 和 Conu 测试容器
|
||||
======
|
||||
|
||||

|
||||
|
||||
越来越多的开发人员使用容器开发和部署他们的应用。这意味着可以轻松地测试容器也变得很重要。[Conu][1] (container utilities 的简写) 是一个 Python 库,让你编写容器测试变得简单。本文向你介绍如何使用它测试容器。
|
||||
|
||||
### 开始吧
|
||||
|
||||
首先,你需要一个容器程序来测试。为此,以下命令创建一个包含一个容器的 Dockerfile 和一个被容器伺服的 Flask 应用程序的文件夹。
|
||||
|
||||
```bash
|
||||
$ mkdir container_test
|
||||
$ cd container_test
|
||||
$ touch Dockerfile
|
||||
$ touch app.py
|
||||
```
|
||||
|
||||
将以下代码复制到 `app.py` 文件中。这是惯常的基本 Flask 应用,它返回字符串 “Hello Container World!”。
|
||||
|
||||
```python
|
||||
from flask import Flask
|
||||
app = Flask(__name__)
|
||||
|
||||
@app.route('/')
|
||||
def hello_world():
|
||||
return 'Hello Container World!'
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.run(debug=True,host='0.0.0.0')
|
||||
```
|
||||
|
||||
### 创建和构建测试容器
|
||||
|
||||
为了构建测试容器,将以下指令添加到 Dockerfile。
|
||||
|
||||
```dockerfile
|
||||
FROM registry.fedoraproject.org/fedora-minimal:latest
|
||||
RUN microdnf -y install python3-flask && microdnf clean all
|
||||
ADD ./app.py /srv
|
||||
CMD ["python3", "/srv/app.py"]
|
||||
```
|
||||
|
||||
然后使用 Docker CLI 工具构建容器。
|
||||
|
||||
```bash
|
||||
$ sudo dnf -y install docker
|
||||
$ sudo systemctl start docker
|
||||
$ sudo docker build . -t flaskapp_container
|
||||
```
|
||||
|
||||
提示:只有在系统上未安装 Docker 时才需要前两个命令。
|
||||
|
||||
构建之后使用以下命令运行容器。
|
||||
|
||||
```bash
|
||||
$ sudo docker run -p 5000:5000 --rm flaskapp_container
|
||||
* Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
|
||||
* Restarting with stat
|
||||
* Debugger is active!
|
||||
* Debugger PIN: 473-505-51
|
||||
```
|
||||
|
||||
最后,使用 `curl` 检查 Flask 应用程序是否在容器内正确运行:
|
||||
|
||||
```bash
|
||||
$ curl http://127.0.0.1:5000
|
||||
Hello Container World!
|
||||
```
|
||||
|
||||
现在,flaskapp_container 正在运行并准备好进行测试,你可以使用 `Ctrl+C` 将其停止。
|
||||
|
||||
### 创建测试脚本
|
||||
|
||||
在编写测试脚本之前,必须安装 `conu`。在先前创建的 `container_test` 目录中,运行以下命令。
|
||||
|
||||
```bash
|
||||
$ python3 -m venv .venv
|
||||
$ source .venv/bin/activate
|
||||
(.venv)$ pip install --upgrade pip
|
||||
(.venv)$ pip install conu
|
||||
$ touch test_container.py
|
||||
```
|
||||
|
||||
然后将以下脚本复制并保存在 `test_container.py` 文件中。
|
||||
|
||||
```python
|
||||
import conu
|
||||
|
||||
PORT = 5000
|
||||
|
||||
with conu.DockerBackend() as backend:
|
||||
image = backend.ImageClass("flaskapp_container")
|
||||
options = ["-p", "5000:5000"]
|
||||
container = image.run_via_binary(additional_opts=options)
|
||||
|
||||
try:
|
||||
# Check that the container is running and wait for the flask application to start.
|
||||
assert container.is_running()
|
||||
container.wait_for_port(PORT)
|
||||
|
||||
# Run a GET request on / port 5000.
|
||||
http_response = container.http_request(path="/", port=PORT)
|
||||
|
||||
# Check the response status code is 200
|
||||
assert http_response.ok
|
||||
|
||||
# Get the response content
|
||||
response_content = http_response.content.decode("utf-8")
|
||||
|
||||
# Check that the "Hello Container World!" string is served.
|
||||
assert "Hello Container World!" in response_content
|
||||
|
||||
# Get the logs from the container
|
||||
logs = [line for line in container.logs()]
|
||||
# Check the the Flask application saw the GET request.
|
||||
assert b'"GET / HTTP/1.1" 200 -' in logs[-1]
|
||||
|
||||
finally:
|
||||
container.stop()
|
||||
container.delete()
|
||||
```
|
||||
|
||||
#### 测试设置
|
||||
|
||||
这个脚本首先设置 `conu` 使用 Docker 作为后端来运行容器。然后它设置容器镜像以使用你在本教程第一部分中构建的 flaskapp_container。
|
||||
|
||||
下一步是配置运行容器所需的选项。在此示例中,Flask 应用在端口5000上提供内容。于是你需要暴露此端口并将其映射到主机上的同一端口。
|
||||
|
||||
最后,用这个脚本启动容器,现在可以测试了。
|
||||
|
||||
#### 测试方法
|
||||
|
||||
在测试容器之前,检查容器是否正在运行并准备就绪。示范脚本使用 `container.is_running` 和 `container.wait_for_port`。这些方法可确保容器正在运行,并且服务在预设端口上可用。
|
||||
|
||||
`container.http_request` 是 [request][2] 库的包装器,可以方便地在测试期间发送 HTTP 请求。这个方法返回[requests.Responseobject][3],因此可以轻松地访问响应的内容以进行测试。
|
||||
|
||||
`conu` 还可以访问容器日志。又一次,这在测试期间非常有用。在上面的示例中,`container.logs` 方法返回容器日志。你可以使用它们断言打印了特定日志,或者,例如在测试期间没有异常被引发。
|
||||
|
||||
`conu` 提供了许多与容器接合的有用方法。[文档][4]中提供了完整的 API 列表。你还可以参考 [GitHub][5] 上提供的示例。
|
||||
|
||||
运行本教程所需的所有代码和文件也可以在 [GitHub][6] 上获得。 对于想要进一步采用这个例子的读者,你可以看看使用 [pytest][7] 来运行测试并构建一个容器测试套件。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/test-containers-python-conu/
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[GraveAccent](https://github.com/GraveAccent)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/cverna/
|
||||
[1]: https://github.com/user-cont/conu
|
||||
[2]: http://docs.python-requests.org/en/master/
|
||||
[3]: http://docs.python-requests.org/en/master/api/#requests.Response
|
||||
[4]: https://conu.readthedocs.io/en/latest/index.html
|
||||
[5]: https://github.com/user-cont/conu/tree/master/docs/source/examples
|
||||
[6]: https://github.com/cverna/container_test_script
|
||||
[7]: https://docs.pytest.org/en/latest/
|
||||
@ -1,13 +1,13 @@
|
||||
Gifski – 一个跨平台的高质量 GIF 编码器
|
||||
Gifski:一个跨平台的高质量 GIF 编码器
|
||||
======
|
||||
|
||||

|
||||
|
||||
作为一名文字工作者,我需要在我的文章中添加图片。有时为了更容易讲清楚某个概念,我还会添加视频或者 gif 动图,相比于文字,通过视频或者 gif 格式的输出,读者可以更容易地理解我的指导。前些天,我已经写了篇文章来介绍针对 Linux 的功能丰富的强大截屏工具 [**Flameshot**][1]。今天,我将向你展示如何从一段视频或者一些图片来制作高质量的 gif 动图。这个工具就是 **Gifski**,一个跨平台、开源、基于 **Pngquant** 的高质量命令行 GIF 编码器。
|
||||
作为一名文字工作者,我需要在我的文章中添加图片。有时为了更容易讲清楚某个概念,我还会添加视频或者 gif 动图,相比于文字,通过视频或者 gif 格式的输出,读者可以更容易地理解我的指导。前些天,我已经写了篇文章来介绍针对 Linux 的功能丰富的强大截屏工具 [Flameshot][1]。今天,我将向你展示如何从一段视频或者一些图片来制作高质量的 gif 动图。这个工具就是 **Gifski**,一个跨平台、开源、基于 **Pngquant** 的高质量命令行 GIF 编码器。
|
||||
|
||||
对于那些好奇 pngquant 是什么的读者,简单来说 pngquant 是一个针对 PNG 图片的无损压缩命令行工具。相信我,pngquant 是我使用过的最好的 PNG 无损压缩工具。它可以将 PNG 图片最高压缩 **70%** 而不会损失图片的原有质量并保存了所有的阿尔法透明度。经过压缩的图片可以在所有的网络浏览器和系统中使用。而 Gifski 是基于 Pngquant 的,它使用 pngquant 的功能来创建高质量的 GIF 动图。Gifski 能够创建每帧包含上千种颜色的 GIF 动图。Gifski 也需要 **ffmpeg** 来将视频转换为 PNG 图片。
|
||||
|
||||
### **安装 Gifski**
|
||||
### 安装 Gifski
|
||||
|
||||
首先需要确保你安装了 FFMpeg 和 Pngquant。
|
||||
|
||||
@ -15,31 +15,34 @@ FFmpeg 在大多数的 Linux 发行版的默认软件仓库中都可以获取到
|
||||
|
||||
- [在 Linux 中如何安装 FFmpeg](https://www.ostechnix.com/install-ffmpeg-linux/)
|
||||
|
||||
Pngquant 可以从 [**AUR**][2] 中获取到。要在基于 Arch 的系统安装它,使用任意一个 AUR 帮助程序即可,例如下面示例中的 [**Yay**][3]:
|
||||
Pngquant 可以从 [AUR][2] 中获取到。要在基于 Arch 的系统安装它,使用任意一个 AUR 帮助程序即可,例如下面示例中的 [Yay][3]:
|
||||
|
||||
```
|
||||
$ yay -S pngquant
|
||||
```
|
||||
|
||||
在基于 Debian 的系统中,运行:
|
||||
|
||||
```
|
||||
$ sudo apt install pngquant
|
||||
```
|
||||
|
||||
假如在你使用的发行版中没有 pngquant,你可以从源码编译并安装它。为此你还需要安装 **`libpng-dev`** 包。
|
||||
假如在你使用的发行版中没有 pngquant,你可以从源码编译并安装它。为此你还需要安装 `libpng-dev` 包。
|
||||
|
||||
```
|
||||
$ git clone --recursive https://github.com/kornelski/pngquant.git
|
||||
|
||||
$ make
|
||||
|
||||
$ sudo make install
|
||||
```
|
||||
|
||||
安装完上述依赖后,再安装 Gifski。假如你已经安装了 [**Rust**][4] 编程语言,你可以使用 **cargo** 来安装它:
|
||||
安装完上述依赖后,再安装 Gifski。假如你已经安装了 [Rust][4] 编程语言,你可以使用 **cargo** 来安装它:
|
||||
|
||||
```
|
||||
$ cargo install gifski
|
||||
```
|
||||
|
||||
另外,你还可以使用 [**Linuxbrew**][5] 包管理器来安装它:
|
||||
另外,你还可以使用 [Linuxbrew][5] 包管理器来安装它:
|
||||
|
||||
```
|
||||
$ brew install gifski
|
||||
```
|
||||
@ -49,6 +52,7 @@ $ brew install gifski
|
||||
### 使用 Gifski 来创建高质量的 GIF 动图
|
||||
|
||||
进入你保存 PNG 图片的目录,然后运行下面的命令来从这些图片创建 GIF 动图:
|
||||
|
||||
```
|
||||
$ gifski -o file.gif *.png
|
||||
```
|
||||
@ -64,12 +68,13 @@ Gifski 还有其他的特性,例如:
|
||||
* 以给定顺序来编码图片,而不是以排序的结果来编码
|
||||
|
||||
为了创建特定大小的 GIF 动图,例如宽为 800,高为 400,可以使用下面的命令:
|
||||
|
||||
```
|
||||
$ gifski -o file.gif -W 800 -H 400 *.png
|
||||
|
||||
```
|
||||
|
||||
你可以设定 GIF 动图在每秒钟展示多少帧,默认值是 **20**。为此,可以运行下面的命令:
|
||||
|
||||
```
|
||||
$ gifski -o file.gif --fps 1 *.png
|
||||
```
|
||||
@ -77,42 +82,49 @@ $ gifski -o file.gif --fps 1 *.png
|
||||
在上面的例子中,我指定每秒钟展示 1 帧。
|
||||
|
||||
我们还能够以特定质量(1-100 范围内)来编码。显然,更低的质量将生成更小的文件,更高的质量将生成更大的 GIF 动图文件。
|
||||
|
||||
```
|
||||
$ gifski -o file.gif --quality 50 *.png
|
||||
```
|
||||
|
||||
当需要编码大量图片时,Gifski 将会花费更多时间。如果想要编码过程加快到通常速度的 3 倍左右,可以运行:
|
||||
|
||||
```
|
||||
$ gifski -o file.gif --fast *.png
|
||||
```
|
||||
|
||||
请注意上面的命令产生的 GIF 动图文件将减少 10% 的质量并且文件大小也会更大。
|
||||
请注意上面的命令产生的 GIF 动图文件将减少 10% 的质量,并且文件大小也会更大。
|
||||
|
||||
如果想让图片以某个给定的顺序(而不是通过排序)精确地被编码,可以使用 `--nosort` 选项。
|
||||
|
||||
如果想让图片以某个给定的顺序(而不是通过排序)精确地被编码,可以使用 **`--nosort`** 选项。
|
||||
```
|
||||
$ gifski -o file.gif --nosort *.png
|
||||
```
|
||||
|
||||
假如你不想让 GIF 循环播放,只需要使用 **`--once`** 选项即可:
|
||||
假如你不想让 GIF 循环播放,只需要使用 `--once` 选项即可:
|
||||
|
||||
```
|
||||
$ gifski -o file.gif --once *.png
|
||||
```
|
||||
|
||||
**从视频创建 GIF 动图**
|
||||
### 从视频创建 GIF 动图
|
||||
|
||||
有时或许你想从一个视频创建 GIF 动图。这也是可以做到的,这时候 FFmpeg 便能提供帮助。首先像下面这样,将视频转换成一系列的 PNG 图片:
|
||||
|
||||
```
|
||||
$ ffmpeg -i video.mp4 frame%04d.png
|
||||
```
|
||||
|
||||
上面的命令将会从 `video.mp4` 这个视频文件创建名为“frame0001.png”、“frame0002.png”、“frame0003.png”等等形式的图片(其中的 `%04d` 代表帧数),然后将这些图片保存在当前的工作目录。
|
||||
上面的命令将会从 `video.mp4` 这个视频文件创建名为 “frame0001.png”、“frame0002.png”、“frame0003.png” 等等形式的图片(其中的 `%04d` 代表帧数),然后将这些图片保存在当前的工作目录。
|
||||
|
||||
转换好图片后,只需要运行下面的命令便可以制作 GIF 动图了:
|
||||
|
||||
```
|
||||
$ gifski -o file.gif *.png
|
||||
```
|
||||
|
||||
想知晓更多的细节,请参考它的帮助部分:
|
||||
|
||||
```
|
||||
$ gifski -h
|
||||
```
|
||||
@ -129,17 +141,17 @@ $ gifski -h
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/gifski-a-cross-platform-high-quality-gif-encoder/
|
||||
via: https://www.ostechnix.com/gifski-a-cross-platform-high-quality-gif-encoder/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.ostechnix.com/flameshot-a-simple-yet-powerful-feature-rich-screenshot-tool/
|
||||
[1]: https://linux.cn/article-10180-1.html
|
||||
[2]: https://aur.archlinux.org/packages/pngquant/
|
||||
[3]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[4]: https://www.ostechnix.com/install-rust-programming-language-in-linux/
|
||||
@ -0,0 +1,251 @@
|
||||
在 Linux 中怎么运行 MS-DOS 游戏和程序
|
||||
======
|
||||
|
||||

|
||||
|
||||
你是否想过尝试一些经典的 MS-DOS 游戏和像 Turbo C++ 这样的废弃的 C++ 编译器?这篇教程将会介绍如何使用 DOSBox 在 Linux 环境下运行 MS-DOS 的游戏和程序。DOSBox 是一个 x86 平台的 DOS 模拟器,可以用来运行经典的 DOS 游戏和程序。 DOSBox 可以模拟带有声音、图形、鼠标、操纵杆和调制解调器等的因特尔 x86 电脑,它允许你运行许多旧的 MS-DOS 游戏和程序,这些游戏和程序根本无法在任何现代 PC 和操作系统上运行,例如 Microsoft Windows XP 及更高版本、Linux 和FreeBSD。 DOSBox 是免费的,使用 C++ 编程语言编写并在 GPL 下分发。
|
||||
|
||||
### 在 Linux 上安装 DOSBox
|
||||
|
||||
DOSBox 在大多数 Linux 发行版的默认仓库中都能找的到。
|
||||
|
||||
在 Arch Linux 及其衍生版如 Antergos、Manjaro Linux 上:
|
||||
|
||||
```
|
||||
$ sudo pacman -S dosbox
|
||||
```
|
||||
|
||||
在 Debian、Ubuntu、Linux Mint 上:
|
||||
|
||||
```
|
||||
$ sudo apt-get install dosbox
|
||||
```
|
||||
|
||||
在 Fedora 上:
|
||||
|
||||
```
|
||||
$ sudo dnf install dosbox
|
||||
```
|
||||
|
||||
### 配置 DOSBox
|
||||
|
||||
DOSBox 是一个开箱即用的软件,它不需要进行初始化配置。它的配置文件位于 `~/.dosbox` 文件夹中,名为 `dosbox-x.xx.conf`。 在此配置文件中,你可以编辑/修改各种设置,例如以全屏模式启动 DOSBox,全屏使用双缓冲,设置首选分辨率,鼠标灵敏度,启用或禁用声音,扬声器,操纵杆等等。如前所述,默认设置即可正常工作。你可以不用进行任何更改。
|
||||
|
||||
### 在 Linux 中运行 MS-DOS 上的游戏和程序
|
||||
|
||||
在终端运行以下命令启动 DOSBox:
|
||||
|
||||
```
|
||||
$ dosbox
|
||||
```
|
||||
|
||||
下图就是 DOSBox 的界面
|
||||
|
||||
|
||||
|
||||
正如你所看到的,DOSBox 带有自己的类似 DOS 的命令提示符和一个虚拟的 `Z:\` 的驱动器,如果你熟悉 MS-DOS 的话,你会发现在 DOSBox 环境下工作不会有任何问题。
|
||||
|
||||
这是 `dir` 命令(在 Linux 中等同于 `ls` 命令)的输出:
|
||||
|
||||
|
||||
|
||||
如果你是第一次使用 DOSBox,你可以通过在 DOSBox 提示符中输入以下命令来查看关于 DOSBox 的简介:
|
||||
|
||||
```
|
||||
intro
|
||||
```
|
||||
|
||||
在介绍部分按回车进入下一页。
|
||||
|
||||
要查看 DOS 中最常用命令的列表,请使用此命令:
|
||||
|
||||
```
|
||||
help
|
||||
```
|
||||
|
||||
要查看 DOSBox 中所有支持的命令的列表,请键入:
|
||||
|
||||
```
|
||||
help /all
|
||||
```
|
||||
|
||||
记好了这些命令应该在 DOSBox 提示符中使用,而不是在 Linux 终端中使用。
|
||||
|
||||
DOSBox 还支持一些实用的键盘组合键。下图是能有效使用 DOSBox 的默认键盘快捷键。
|
||||
|
||||
|
||||
|
||||
要退出 DOSBox,只需键入如下命令并按回车:
|
||||
|
||||
```
|
||||
exit
|
||||
```
|
||||
|
||||
默认情况下,DOSBox 开始运行时的正常屏幕窗口大小如上所示。
|
||||
|
||||
要直接在全屏启动 DOSBox,请编辑 `dosbox-x.xx.conf` 文件并将`fullscreen` 变量的值设置为 `enable`。 之后,DOSBox 将以全屏模式启动。 如果要返回正常屏幕,请按 `ALT+ENTER`。
|
||||
|
||||
希望你掌握了 DOSBox 的这些基本用法。
|
||||
|
||||
让我们继续安装一些 DOS 程序和游戏。
|
||||
|
||||
首先,我们需要在 Linux 系统中创建目录来保存程序和游戏。我将创建两个名为 `~/dosprograms` 和 `~/dosgames` 的目录,第一个用于存储程序,后者用于存储游戏。
|
||||
|
||||
```
|
||||
$ mkdir ~/dosprograms ~/dosgames
|
||||
```
|
||||
|
||||
出于本指南的目的,我将向你展示如何安装 Turbo C++ 程序和 Mario 游戏。我们首先将看到如何安装 Turbo。
|
||||
|
||||
下载最后版本的 Turbo C++ 编译器并将其解压到 `~/dosprograms` 目录中。 我已经将 Turbo C++ 保存在在我的 `~/dosprograms/TC/` 目录中了。
|
||||
|
||||
```
|
||||
$ ls dosprograms/tc/
|
||||
|
||||
BGI BIN CLASSLIB DOC EXAMPLES FILELIST.DOC INCLUDE LIB README README.COM
|
||||
```
|
||||
|
||||
运行 DOSBox:
|
||||
|
||||
```
|
||||
$ dosbox
|
||||
```
|
||||
|
||||
将 `~/dosprograms` 目录挂载为 DOSBox 中的虚拟驱动器 `C:\`
|
||||
|
||||
```
|
||||
Z:\>mount c ~/dosprograms
|
||||
```
|
||||
|
||||
你会看到类似下面的输出:
|
||||
|
||||
```
|
||||
Drive C is mounted as local directory /home/sk/dosprograms.
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
现在,使用命令切换到 C 盘:
|
||||
|
||||
```
|
||||
Z:\>c:
|
||||
```
|
||||
|
||||
然后切换到 `tc/bin` 目录:
|
||||
|
||||
```
|
||||
Z:\>cd tc/bin
|
||||
```
|
||||
|
||||
最后,运行 Turbo C++ 可执行文件:
|
||||
|
||||
```
|
||||
Z:\>tc.exe
|
||||
```
|
||||
|
||||
**备注:**只需输入前几个字母,然后按回车键可以自动填充文件名。
|
||||
|
||||

|
||||
|
||||
你现在将进入 Turbo C++ 控制台。
|
||||
|
||||
|
||||
|
||||
创建新文件(`ATL + F`)并开始编程:
|
||||
|
||||
|
||||
|
||||
你可以同样安装和运行其他经典 DOS 程序。
|
||||
|
||||
**故障排除:**
|
||||
|
||||
运行 Turbo C++ 或其他任何 DOS 程序时,你可能会遇到以下错误:
|
||||
|
||||
```
|
||||
DOSBox switched to max cycles, because of the setting: cycles=auto. If the game runs too fast try a fixed cycles amount in DOSBox's options. Exit to error: DRC64:Unhandled memory reference
|
||||
```
|
||||
|
||||
要解决此问题,编辑 `~/.dosbox/dosbox-x.xx.conf` 文件:
|
||||
|
||||
```
|
||||
$ nano ~/.dosbox/dosbox-0.74.conf
|
||||
```
|
||||
|
||||
找到以下变量:
|
||||
|
||||
```
|
||||
core=auto
|
||||
```
|
||||
|
||||
并更改其值为:
|
||||
|
||||
```
|
||||
core=normal
|
||||
```
|
||||
|
||||
现在,让我们看看如何运行基于DOS的游戏,例如 **Mario Bros VGA**。
|
||||
|
||||
从 [这里][1] 下载 Mario 游戏,并将其解压到 Linux 中的 `~/dosgames` 目录。
|
||||
|
||||
运行 DOSBox:
|
||||
|
||||
```
|
||||
$ dosbox
|
||||
```
|
||||
|
||||
我们刚才使用了虚拟驱动器 `C:` 来运行 DOS 程序。现在让我们使用 `D:` 作为虚拟驱动器来运行游戏。
|
||||
|
||||
在 DOSBox 提示符下,运行以下命令将 `~/dosgames` 目录挂载为虚拟驱动器 `D`:
|
||||
|
||||
```
|
||||
Z:\>mount d ~/dosgames
|
||||
```
|
||||
|
||||
进入驱动器 `D:`:
|
||||
|
||||
```
|
||||
Z:\>d:
|
||||
```
|
||||
|
||||
然后进入 mario 游戏目录并运行 `mario.exe` 文件来启动游戏。
|
||||
|
||||
```
|
||||
D:\>cd mario
|
||||
D:\>mario.exe
|
||||
```
|
||||
|
||||
|
||||
|
||||
开始玩游戏:
|
||||
|
||||

|
||||
|
||||
你可以同样像上面所说的那样运行任何基于 DOS 的游戏。 [点击这里] [2]查看可以使用 DOSBox 运行的游戏的完整列表。
|
||||
|
||||
### 总结
|
||||
|
||||
尽管 DOSBox 并不能作为 MS-DOS 的完全替代品,并且还缺少 MS-DOS 中的许多功能,但它足以安装和运行大多数的 DOS 游戏和程序。
|
||||
|
||||
有关更多详细信息,请参阅官方 [DOSBox手册][3]。
|
||||
|
||||
这就是全部内容。希望这对你有用。更多优秀指南即将到来。 敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-run-ms-dos-games-and-programs-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[way-ww](https://github.com/way-ww)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.dosgames.com/game/mario-bros-vga
|
||||
[2]: https://www.dosbox.com/comp_list.php
|
||||
[3]: https://www.dosbox.com/DOSBoxManual.html
|
||||
@ -0,0 +1,68 @@
|
||||
6 个用于写书的开源工具
|
||||
======
|
||||
> 这些多能、免费的工具可以满足你撰写、编辑和生成你自己的书籍的全部需求。
|
||||
|
||||

|
||||
|
||||
我在 1993 年首次使用并贡献了免费和开源软件,从那时起我一直是一名开源软件的开发人员和布道者。尽管我被记住的一个项目是 [FreeDOS 项目][1],这是一个 DOS 操作系统的开源实现,但我已经编写或者贡献了数十个开源软件项目。
|
||||
|
||||
我最近写了一本关于 FreeDOS 的书。《[使用 FreeDOS][2]》是我庆祝 FreeDOS 出现 24 周年而撰写的。它是关于安装和使用 FreeDOS、关于我最喜欢的 DOS 程序,以及 DOS 命令行和 DOS 批处理编程的快速参考指南的集合。在一位出色的专业编辑的帮助下,我在过去的几个月里一直在编写这本书。
|
||||
|
||||
《使用 FreeDOS》 可在知识共享署名(cc-by)国际公共许可证下获得。你可以从 [FreeDOS 电子书][2]网站免费下载 EPUB 和 PDF 版本。(我也计划为那些喜欢纸质的人提供印刷版本。)
|
||||
|
||||
这本书几乎完全是用开源软件制作的。我想分享一下对用来创建、编辑和生成《使用 FreeDOS》的工具的看法。
|
||||
|
||||
### Google 文档
|
||||
|
||||
[Google 文档][3]是我使用的唯一不是开源软件的工具。我将我的第一份草稿上传到 Google 文档,这样我就能与编辑器进行协作。我确信有开源协作工具,但 Google 文档能够让两个人同时编辑同一个文档、发表评论、编辑建议和更改跟踪 —— 更不用说它使用段落样式和能够下载完成的文档 —— 这使其成为编辑过程中有价值的一部分。
|
||||
|
||||
### LibreOffice
|
||||
|
||||
我开始使用的是 [LibreOffice][4] 6.0,但我最终使用 LibreOffice 6.1 完成了这本书。我喜欢 LibreOffice 对样式的丰富支持。段落样式可以轻松地为标题、页眉、正文、示例代码和其他文本应用样式。字符样式允许我修改段落中文本的外观,例如内联示例代码或用不同的样式代表文件名。图形样式让我可以将某些样式应用于截图和其他图像。页面样式允许我轻松修改页面的布局和外观。
|
||||
|
||||
### GIMP
|
||||
|
||||
我的书包括很多 DOS 程序截图、网站截图和 FreeDOS 的 logo。我用 [GIMP][5] 修改这本书的图像。通常,只是裁剪或调整图像大小,但在我准备本书的印刷版时,我使用 GIMP 创建了一些更适于打印布局的图像。
|
||||
|
||||
### Inkscape
|
||||
|
||||
大多数 FreeDOS 的 logo 和小鱼吉祥物都是 SVG 格式,我使用 [Inkscape][6] 来调整它们。在准备电子书的 PDF 版本时,我想在页面顶部放置一个简单的蓝色横幅,角落里有 FreeDOS 的 logo。实验后,我发现在 Inkscape 中创建一个我想要的横幅 SVG 图案更容易,然后我将其粘贴到页眉中。
|
||||
|
||||
### ImageMagick
|
||||
|
||||
虽然使用 GIMP 来完成这项工作也很好,但有时在一组图像上运行 [ImageMagick][7] 命令会更快,例如转换为 PNG 格式或调整图像大小。
|
||||
|
||||
### Sigil
|
||||
|
||||
LibreOffice 可以直接导出到 EPUB 格式,但它不是个好的转换器。我没有尝试使用 LibreOffice 6.1 创建 EPUB,但在 LibreOffice 6.0 中没有包含我的图像。它还以奇怪的方式添加了样式。我使用 [Sigil][8] 来调整 EPUB 并使一切看起来正常。Sigil 甚至还有预览功能,因此你可以看到 EPUB 的样子。
|
||||
|
||||
### QEMU
|
||||
|
||||
因为本书是关于安装和运行 FreeDOS 的,所以我需要实际运行 FreeDOS。你可以在任何 PC 模拟器中启动 FreeDOS,包括 VirtualBox、QEMU、GNOME Boxes、PCem 和 Bochs。但我喜欢 [QEMU][9] 的简单性。QEMU 控制台允许你以 PPM 格式转储屏幕,这非常适合抓取截图来包含在书中。
|
||||
|
||||
当然,我不得不提到在 [Linux][11] 上运行 [GNOME][10]。我使用 Linux 的 [Fedora][12] 发行版。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/writing-book-open-source-tools
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jim-hall
|
||||
[1]: http://www.freedos.org/
|
||||
[2]: http://www.freedos.org/ebook/
|
||||
[3]: https://www.google.com/docs/about/
|
||||
[4]: https://www.libreoffice.org/
|
||||
[5]: https://www.gimp.org/
|
||||
[6]: https://inkscape.org/
|
||||
[7]: https://www.imagemagick.org/
|
||||
[8]: https://sigil-ebook.com/
|
||||
[9]: https://www.qemu.org/
|
||||
[10]: https://www.gnome.org/
|
||||
[11]: https://www.kernel.org/
|
||||
[12]: https://getfedora.org/
|
||||
222
published/201811/20180907 6.828 lab tools guide.md
Normal file
222
published/201811/20180907 6.828 lab tools guide.md
Normal file
@ -0,0 +1,222 @@
|
||||
Caffeinated 6.828:实验工具指南
|
||||
======
|
||||
|
||||
熟悉你的环境对高效率的开发和调试来说是至关重要的。本文将为你简单概述一下 JOS 环境和非常有用的 GDB 和 QEMU 命令。话虽如此,但你仍然应该去阅读 GDB 和 QEMU 手册,来理解这些强大的工具如何使用。
|
||||
|
||||
### 调试小贴士
|
||||
|
||||
#### 内核
|
||||
|
||||
GDB 是你的朋友。使用 `qemu-gdb target`(或它的变体 `qemu-gdb-nox`)使 QEMU 等待 GDB 去绑定。下面在调试内核时用到的一些命令,可以去查看 GDB 的资料。
|
||||
|
||||
如果你遭遇意外的中断、异常、或三重故障,你可以使用 `-d` 参数要求 QEMU 去产生一个详细的中断日志。
|
||||
|
||||
调试虚拟内存问题时,尝试 QEMU 的监视命令 `info mem`(提供内存高级概述)或 `info pg`(提供更多细节内容)。注意,这些命令仅显示**当前**页表。
|
||||
|
||||
(在实验 4 以后)去调试多个 CPU 时,使用 GDB 的线程相关命令,比如 `thread` 和 `info threads`。
|
||||
|
||||
#### 用户环境(在实验 3 以后)
|
||||
|
||||
GDB 也可以去调试用户环境,但是有些事情需要注意,因为 GDB 无法区分开多个用户环境或区分开用户环境与内核环境。
|
||||
|
||||
你可以使用 `make run-name`(或编辑 `kern/init.c` 目录)来指定 JOS 启动的用户环境,为使 QEMU 等待 GDB 去绑定,使用 `run-name-gdb` 的变体。
|
||||
|
||||
你可以符号化调试用户代码,就像调试内核代码一样,但是你要告诉 GDB,哪个符号表用到符号文件命令上,因为它一次仅能够使用一个符号表。提供的 `.gdbinit` 用于加载内核符号表 `obj/kern/kernel`。对于一个用户环境,这个符号表在它的 ELF 二进制文件中,因此你可以使用 `symbol-file obj/user/name` 去加载它。不要从任何 `.o` 文件中加载符号,因为它们不会被链接器迁移进去(库是静态链接进 JOS 用户二进制文件中的,因此这些符号已经包含在每个用户二进制文件中了)。确保你得到了正确的用户二进制文件;在不同的二进制文件中,库函数被链接为不同的 EIP,而 GDB 并不知道更多的内容!
|
||||
|
||||
(在实验 4 以后)因为 GDB 绑定了整个虚拟机,所以它可以将时钟中断看作为一种控制转移。这使得从底层上不可能实现步进用户代码,因为一个时钟中断无形中保证了片刻之后虚拟机可以再次运行。因此可以使用 `stepi` 命令,因为它阻止了中断,但它仅可以步进一个汇编指令。断点一般来说可以正常工作,但要注意,因为你可能在不同的环境(完全不同的一个二进制文件)上遇到同一个 EIP。
|
||||
|
||||
### 参考
|
||||
|
||||
#### JOS makefile
|
||||
|
||||
JOS 的 GNUmakefile 包含了在各种方式中运行的 JOS 的许多假目标。所有这些目标都配置 QEMU 去监听 GDB 连接(`*-gdb` 目标也等待这个连接)。要在运行中的 QEMU 上启动它,只需要在你的实验目录中简单地运行 `gdb ` 即可。我们提供了一个 `.gdbinit` 文件,它可以在 QEMU 中自动指向到 GDB、加载内核符号文件、以及在 16 位和 32 位模式之间切换。退出 GDB 将关闭 QEMU。
|
||||
|
||||
* `make qemu`
|
||||
|
||||
在一个新窗口中构建所有的东西并使用 VGA 控制台和你的终端中的串行控制台启动 QEMU。想退出时,既可以关闭 VGA 窗口,也可以在你的终端中按 `Ctrl-c` 或 `Ctrl-a x`。
|
||||
* `make qemu-nox`
|
||||
|
||||
和 `make qemu` 一样,但仅使用串行控制台来运行。想退出时,按下 `Ctrl-a x`。这种方式在通过 SSH 拨号连接到 Athena 上时非常有用,因为 VGA 窗口会占用许多带宽。
|
||||
* `make qemu-gdb`
|
||||
|
||||
和 `make qemu` 一样,但它与任意时间被动接受 GDB 不同,而是暂停第一个机器指令并等待一个 GDB 连接。
|
||||
* `make qemu-nox-gdb`
|
||||
|
||||
它是 `qemu-nox` 和 `qemu-gdb` 目标的组合。
|
||||
* `make run-nam`
|
||||
|
||||
(在实验 3 以后)运行用户程序 _name_。例如,`make run-hello` 运行 `user/hello.c`。
|
||||
* `make run-name-nox`,`run-name-gdb`, `run-name-gdb-nox`
|
||||
|
||||
(在实验 3 以后)与 `qemu` 目标变量对应的 `run-name` 的变体。
|
||||
|
||||
makefile 也接受几个非常有用的变量:
|
||||
|
||||
* `make V=1 …`
|
||||
|
||||
详细模式。输出正在运行的每个命令,包括参数。
|
||||
* `make V=1 grade`
|
||||
|
||||
在评级测试失败后停止,并将 QEMU 的输出放入 `jos.out` 文件中以备检查。
|
||||
* `make QEMUEXTRA=' _args_ ' …`
|
||||
|
||||
指定传递给 QEMU 的额外参数。
|
||||
|
||||
#### JOS obj/
|
||||
|
||||
在构建 JOS 时,makefile 也产生一些额外的输出文件,这些文件在调试时非常有用:
|
||||
|
||||
* `obj/boot/boot.asm`、`obj/kern/kernel.asm`、`obj/user/hello.asm`、等等。
|
||||
|
||||
引导加载器、内核、和用户程序的汇编代码列表。
|
||||
* `obj/kern/kernel.sym`、`obj/user/hello.sym`、等等。
|
||||
|
||||
内核和用户程序的符号表。
|
||||
* `obj/boot/boot.out`、`obj/kern/kernel`、`obj/user/hello`、等等。
|
||||
|
||||
内核和用户程序链接的 ELF 镜像。它们包含了 GDB 用到的符号信息。
|
||||
|
||||
#### GDB
|
||||
|
||||
完整的 GDB 命令指南请查看 [GDB 手册][1]。下面是一些在 6.828 课程中非常有用的命令,它们中的一些在操作系统开发之外的领域几乎用不到。
|
||||
|
||||
* `Ctrl-c`
|
||||
|
||||
在当前指令处停止机器并打断进入到 GDB。如果 QEMU 有多个虚拟的 CPU,所有的 CPU 都会停止。
|
||||
* `c`(或 `continue`)
|
||||
|
||||
继续运行,直到下一个断点或 `Ctrl-c`。
|
||||
* `si`(或 `stepi`)
|
||||
|
||||
运行一个机器指令。
|
||||
* `b function` 或 `b file:line`(或 `breakpoint`)
|
||||
|
||||
在给定的函数或行上设置一个断点。
|
||||
* `b * addr`(或 `breakpoint`)
|
||||
|
||||
在 EIP 的 addr 处设置一个断点。
|
||||
* `set print pretty`
|
||||
|
||||
启用数组和结构的美化输出。
|
||||
* `info registers`
|
||||
|
||||
输出通用寄存器 `eip`、`eflags`、和段选择器。更多更全的机器寄存器状态转储,查看 QEMU 自己的 `info registers` 命令。
|
||||
* `x/ N x addr`
|
||||
|
||||
以十六进制显示虚拟地址 addr 处开始的 N 个词的转储。如果 N 省略,默认为 1。addr 可以是任何表达式。
|
||||
* `x/ N i addr`
|
||||
|
||||
显示从 addr 处开始的 N 个汇编指令。使用 `$eip` 作为 addr 将显示当前指令指针寄存器中的指令。
|
||||
* `symbol-file file`
|
||||
|
||||
(在实验 3 以后)切换到符号文件 file 上。当 GDB 绑定到 QEMU 后,它并不是虚拟机中进程边界内的一部分,因此我们要去告诉它去使用哪个符号。默认情况下,我们配置 GDB 去使用内核符号文件 `obj/kern/kernel`。如果机器正在运行用户代码,比如是 `hello.c`,你就需要使用 `symbol-file obj/user/hello` 去切换到 hello 的符号文件。
|
||||
|
||||
QEMU 将每个虚拟 CPU 表示为 GDB 中的一个线程,因此你可以使用 GDB 中所有的线程相关的命令去查看或维护 QEMU 的虚拟 CPU。
|
||||
|
||||
* `thread n`
|
||||
|
||||
GDB 在一个时刻只关注于一个线程(即:CPU)。这个命令将关注的线程切换到 n,n 是从 0 开始编号的。
|
||||
* `info threads`
|
||||
|
||||
列出所有的线程(即:CPU),包括它们的状态(活动还是停止)和它们在什么函数中。
|
||||
|
||||
|
||||
#### QEMU
|
||||
|
||||
QEMU 包含一个内置的监视器,它能够有效地检查和修改机器状态。想进入到监视器中,在运行 QEMU 的终端中按入 `Ctrl-a c` 即可。再次按下 `Ctrl-a c` 将切换回串行控制台。
|
||||
|
||||
监视器命令的完整参考资料,请查看 [QEMU 手册][2]。下面是 6.828 课程中用到的一些有用的命令:
|
||||
|
||||
* `xp/ N x paddr`
|
||||
|
||||
显示从物理地址 paddr 处开始的 N 个词的十六进制转储。如果 N 省略,默认为 1。这是 GDB 的 `x` 命令模拟的物理内存。
|
||||
* `info registers`
|
||||
|
||||
显示机器内部寄存器状态的一个完整转储。实践中,对于段选择器,这将包含机器的 _隐藏_ 段状态和局部、全局、和中断描述符表加任务状态寄存器。隐藏状态是在加载段选择器后,虚拟的 CPU 从 GDT/LDT 中读取的信息。下面是实验 1 中 JOS 内核处于运行中时的 CS 信息和每个字段的含义:
|
||||
|
||||
```c
|
||||
CS =0008 10000000 ffffffff 10cf9a00 DPL=0 CS32 [-R-]
|
||||
```
|
||||
|
||||
* `CS =0008`
|
||||
|
||||
代码选择器可见部分。我们使用段 0x8。这也告诉我们参考全局描述符表(0x8&4=0),并且我们的 CPL(当前权限级别)是 0x8&3=0。
|
||||
* `10000000`
|
||||
|
||||
这是段基址。线性地址 = 逻辑地址 + 0x10000000。
|
||||
* `ffffffff`
|
||||
|
||||
这是段限制。访问线性地址 0xffffffff 以上将返回段违规异常。
|
||||
* `10cf9a00`
|
||||
|
||||
段的原始标志,QEMU 将在接下来的几个字段中解码这些对我们有用的标志。
|
||||
* `DPL=0`
|
||||
|
||||
段的权限级别。一旦代码以权限 0 运行,它将就能够加载这个段。
|
||||
* `CS32`
|
||||
|
||||
这是一个 32 位代码段。对于数据段(不要与 DS 寄存器混淆了),另外的值还包括 `DS`,而对于本地描述符表是 `LDT`。
|
||||
* `[-R-]`
|
||||
|
||||
这个段是只读的。
|
||||
|
||||
* `info mem`
|
||||
|
||||
(在实验 2 以后)显示映射的虚拟内存和权限。比如:
|
||||
|
||||
```
|
||||
ef7c0000-ef800000 00040000 urw
|
||||
efbf8000-efc00000 00008000 -rw
|
||||
```
|
||||
|
||||
这告诉我们从 0xef7c0000 到 0xef800000 的 0x00040000 字节的内存被映射为读取/写入/用户可访问,而映射在 0xefbf8000 到 0xefc00000 之间的内存权限是读取/写入,但是仅限于内核可访问。
|
||||
|
||||
* `info pg`
|
||||
|
||||
(在实验 2 以后)显示当前页表结构。它的输出类似于 `info mem`,但与页目录条目和页表条目是有区别的,并且为每个条目给了单独的权限。重复的 PTE 和整个页表被折叠为一个单行。例如:
|
||||
|
||||
```
|
||||
VPN range Entry Flags Physical page
|
||||
[00000-003ff] PDE[000] -------UWP
|
||||
[00200-00233] PTE[200-233] -------U-P 00380 0037e 0037d 0037c 0037b 0037a ..
|
||||
[00800-00bff] PDE[002] ----A--UWP
|
||||
[00800-00801] PTE[000-001] ----A--U-P 0034b 00349
|
||||
[00802-00802] PTE[002] -------U-P 00348
|
||||
```
|
||||
|
||||
这里各自显示了两个页目录条目、虚拟地址范围 0x00000000 到 0x003fffff 以及 0x00800000 到 0x00bfffff。 所有的 PDE 都存在于内存中、可写入、并且用户可访问,而第二个 PDE 也是可访问的。这些页表中的第二个映射了三个页、虚拟地址范围 0x00800000 到 0x00802fff,其中前两个页是存在于内存中的、可写入、并且用户可访问的,而第三个仅存在于内存中,并且用户可访问。这些 PTE 的第一个条目映射在物理页 0x34b 处。
|
||||
|
||||
QEMU 也有一些非常有用的命令行参数,使用 `QEMUEXTRA` 变量可以将参数传递给 JOS 的 makefile。
|
||||
|
||||
* `make QEMUEXTRA='-d int' ...`
|
||||
|
||||
记录所有的中断和一个完整的寄存器转储到 `qemu.log` 文件中。你可以忽略前两个日志条目、“SMM: enter” 和 “SMM: after RMS”,因为这些是在进入引导加载器之前生成的。在这之后的日志条目看起来像下面这样:
|
||||
|
||||
```
|
||||
4: v=30 e=0000 i=1 cpl=3 IP=001b:00800e2e pc=00800e2e SP=0023:eebfdf28 EAX=00000005
|
||||
EAX=00000005 EBX=00001002 ECX=00200000 EDX=00000000
|
||||
ESI=00000805 EDI=00200000 EBP=eebfdf60 ESP=eebfdf28
|
||||
...
|
||||
```
|
||||
|
||||
第一行描述了中断。`4:` 只是一个日志记录计数器。`v` 提供了十六进程的向量号。`e` 提供了错误代码。`i=1` 表示它是由一个 `int` 指令(相对一个硬件产生的中断而言)产生的。剩下的行的意思很明显。对于一个寄存器转储而言,接下来看到的就是寄存器信息。
|
||||
|
||||
注意:如果你运行的是一个 0.15 版本之前的 QEMU,日志将写入到 `/tmp` 目录,而不是当前目录下。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://pdos.csail.mit.edu/6.828/2018/labguide.html
|
||||
|
||||
作者:[csail.mit][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://pdos.csail.mit.edu
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://sourceware.org/gdb/current/onlinedocs/gdb/
|
||||
[2]: http://wiki.qemu.org/download/qemu-doc.html#pcsys_005fmonitor
|
||||
233
published/201811/20180911 Tools Used in 6.828.md
Normal file
233
published/201811/20180911 Tools Used in 6.828.md
Normal file
@ -0,0 +1,233 @@
|
||||
Caffeinated 6.828:使用的工具
|
||||
======
|
||||
|
||||
在这个课程中你将使用两套工具:一个是 x86 模拟器 QEMU,它用来运行你的内核;另一个是编译器工具链,包括汇编器、链接器、C 编译器,以及调试器,它们用来编译和测试你的内核。本文有你需要去下载和安装你自己的副本相关信息。本课程假定你熟悉所有出现的 Unix 命令的用法。
|
||||
|
||||
我们强烈推荐你使用一个 Debathena 机器去做你的实验,比如 athena.dialup.mit.edu。如果你使用运行在 Linux 上的 MIT Athena 机器,那么本课程所需要的所有软件工具都在 6.828 的存储中:只需要输入 `add -f 6.828` 就可以访问它们。
|
||||
|
||||
如果你不使用 Debathena 机器,我们建议你使用一台 Linux 虚拟机。如果是这样,你可以在你的 Linux 虚拟机上构建和安装工具。我们将在下面介绍如何在 Linux 和 MacOS 计算上来构建和安装工具。
|
||||
|
||||
在 [Cygwin][1] 的帮助下,在 Windows 中运行这个开发环境也是可行的。安装 cygwin,并确保安装了 flex 和 bison 包(它们在开发 header 软件包分类下面)。
|
||||
|
||||
对于 6.828 中使用的工具中的有用的命令,请参考[实验工具指南][2]。
|
||||
|
||||
### 编译器工具链
|
||||
|
||||
“编译器工具链“ 是一套程序,包括一个 C 编译器、汇编器和链接器,使用它们来将代码转换成可运行的二进制文件。你需要一个能够生成在 32 位 Intel 架构(x86 架构)上运行的 ELF 二进制格式程序的编译器工具链。
|
||||
|
||||
#### 测试你的编译器工具链
|
||||
|
||||
现代的 Linux 和 BSD UNIX 发行版已经为 6.828 提供了一个合适的工具链。去测试你的发行版,可以输入如下的命令:
|
||||
|
||||
```
|
||||
% objdump -i
|
||||
```
|
||||
|
||||
第二行应该是 `elf32-i386`。
|
||||
|
||||
```
|
||||
% gcc -m32 -print-libgcc-file-name
|
||||
```
|
||||
|
||||
这个命令应该会输出如 `/usr/lib/gcc/i486-linux-gnu/version/libgcc.a` 或 `/usr/lib/gcc/x86_64-linux-gnu/version/32/libgcc.a` 这样的东西。
|
||||
|
||||
如果这些命令都运行成功,说明你的工具链都已安装,你不需要去编译你自己的工具链。
|
||||
|
||||
如果 `gcc` 命令失败,你可能需要去安装一个开发环境。在 Ubuntu Linux 上,输入如下的命令:
|
||||
|
||||
```
|
||||
% sudo apt-get install -y build-essential gdb
|
||||
```
|
||||
|
||||
在 64 位的机器上,你可能需要去安装一个 32 位的支持库。链接失败的表现是有一个类似于 “`__udivdi3` not found” 和 “`__muldi3` not found” 的错误信息。在 Ubuntu Linux 上,输入如下的命令去尝试修复这个问题:
|
||||
|
||||
```
|
||||
% sudo apt-get install gcc-multilib
|
||||
```
|
||||
|
||||
#### 使用一个虚拟机
|
||||
|
||||
获得一个兼容的工具链的最容易的另外的方法是,在你的计算机上安装一个现代的 Linux 发行版。使用虚拟化平台,Linux 可以与你正常的计算环境和平共处。安装一个 Linux 虚拟机共有两步。首先,去下载一个虚拟化平台。
|
||||
|
||||
* [VirtualBox][3](对 Mac、Linux、Windows 免费)— [下载地址][3]
|
||||
* [VMware Player][4](对 Linux 和 Windows 免费,但要求注册)
|
||||
* [VMware Fusion][5](可以从 IS&T 免费下载)。
|
||||
|
||||
VirtualBox 有点慢并且灵活性欠佳,但它免费!
|
||||
|
||||
虚拟化平台安装完成后,下载一个你选择的 Linux 发行版的引导磁盘镜像。
|
||||
|
||||
* 我们使用的是 [Ubuntu 桌面版][6]。
|
||||
|
||||
这将下载一个命名类似于 `ubuntu-10.04.1-desktop-i386.iso` 的文件。启动你的虚拟化平台并创建一个新(32 位)的虚拟机。使用下载的 Ubuntu 镜像作为一个引导磁盘;安装过程在不同的虚拟机上有所不同,但都很简单。就像上面一样输入 `objdump -i`,去验证你的工具是否已安装。你将在虚拟机中完成你的工作。
|
||||
|
||||
#### 构建你自己的编译器工具链
|
||||
|
||||
你需要花一些时间来设置,但是比起一个虚拟机来说,它的性能要稍好一些,并且让你工作在你熟悉的环境中(Unix/MacOS)。对于 MacOS 命令,你可以快进到文章的末尾部分去看。
|
||||
|
||||
##### Linux
|
||||
|
||||
通过将下列行添加到 `conf/env.mk` 中去使用你自己的工具链:
|
||||
|
||||
```
|
||||
GCCPREFIX=
|
||||
```
|
||||
|
||||
我们假设你将工具链安装到了 `/usr/local` 中。你将需要大量的空间(大约 1 GB)去编译工具。如果你空间不足,在它的 `make install` 步骤之后删除它们的目录。
|
||||
|
||||
下载下列包:
|
||||
|
||||
+ ftp://ftp.gmplib.org/pub/gmp-5.0.2/gmp-5.0.2.tar.bz2
|
||||
+ https://www.mpfr.org/mpfr-3.1.2/mpfr-3.1.2.tar.bz2
|
||||
+ http://www.multiprecision.org/downloads/mpc-0.9.tar.gz
|
||||
+ http://ftpmirror.gnu.org/binutils/binutils-2.21.1.tar.bz2
|
||||
+ http://ftpmirror.gnu.org/gcc/gcc-4.6.4/gcc-core-4.6.4.tar.bz2
|
||||
+ http://ftpmirror.gnu.org/gdb/gdb-7.3.1.tar.bz2
|
||||
|
||||
(你可能也在使用这些包的最新版本。)解包并构建。安装到 `/usr/local` 中,它是我们建议的。要安装到不同的目录,如 `$PFX`,注意相应修改。如果有问题,可以看下面。
|
||||
|
||||
```c
|
||||
export PATH=$PFX/bin:$PATH
|
||||
export LD_LIBRARY_PATH=$PFX/lib:$LD_LIBRARY_PATH
|
||||
|
||||
tar xjf gmp-5.0.2.tar.bz2
|
||||
cd gmp-5.0.2
|
||||
./configure --prefix=$PFX
|
||||
make
|
||||
make install # This step may require privilege (sudo make install)
|
||||
cd ..
|
||||
|
||||
tar xjf mpfr-3.1.2.tar.bz2
|
||||
cd mpfr-3.1.2
|
||||
./configure --prefix=$PFX --with-gmp=$PFX
|
||||
make
|
||||
make install # This step may require privilege (sudo make install)
|
||||
cd ..
|
||||
|
||||
tar xzf mpc-0.9.tar.gz
|
||||
cd mpc-0.9
|
||||
./configure --prefix=$PFX --with-gmp=$PFX --with-mpfr=$PFX
|
||||
make
|
||||
make install # This step may require privilege (sudo make install)
|
||||
cd ..
|
||||
|
||||
|
||||
tar xjf binutils-2.21.1.tar.bz2
|
||||
cd binutils-2.21.1
|
||||
./configure --prefix=$PFX --target=i386-jos-elf --disable-werror
|
||||
make
|
||||
make install # This step may require privilege (sudo make install)
|
||||
cd ..
|
||||
|
||||
i386-jos-elf-objdump -i
|
||||
# Should produce output like:
|
||||
# BFD header file version (GNU Binutils) 2.21.1
|
||||
# elf32-i386
|
||||
# (header little endian, data little endian)
|
||||
# i386...
|
||||
|
||||
|
||||
tar xjf gcc-core-4.6.4.tar.bz2
|
||||
cd gcc-4.6.4
|
||||
mkdir build # GCC will not compile correctly unless you build in a separate directory
|
||||
cd build
|
||||
../configure --prefix=$PFX --with-gmp=$PFX --with-mpfr=$PFX --with-mpc=$PFX \
|
||||
--target=i386-jos-elf --disable-werror \
|
||||
--disable-libssp --disable-libmudflap --with-newlib \
|
||||
--without-headers --enable-languages=c MAKEINFO=missing
|
||||
make all-gcc
|
||||
make install-gcc # This step may require privilege (sudo make install-gcc)
|
||||
make all-target-libgcc
|
||||
make install-target-libgcc # This step may require privilege (sudo make install-target-libgcc)
|
||||
cd ../..
|
||||
|
||||
i386-jos-elf-gcc -v
|
||||
# Should produce output like:
|
||||
# Using built-in specs.
|
||||
# COLLECT_GCC=i386-jos-elf-gcc
|
||||
# COLLECT_LTO_WRAPPER=/usr/local/libexec/gcc/i386-jos-elf/4.6.4/lto-wrapper
|
||||
# Target: i386-jos-elf
|
||||
|
||||
|
||||
tar xjf gdb-7.3.1.tar.bz2
|
||||
cd gdb-7.3.1
|
||||
./configure --prefix=$PFX --target=i386-jos-elf --program-prefix=i386-jos-elf- \
|
||||
--disable-werror
|
||||
make all
|
||||
make install # This step may require privilege (sudo make install)
|
||||
cd ..
|
||||
```
|
||||
|
||||
**Linux 排错:**
|
||||
|
||||
Q:我不能运行 `make install`,因为我在这台机器上没有 root 权限。
|
||||
|
||||
A:我们的指令假定你是安装到了 `/usr/local` 目录中。但是,在你的环境中可能并不是这样做的。如果你仅能够在你的家目录中安装代码。那么在上面的命令中,使用 `--prefix=$HOME` 去替换 `--prefix=/usr/local`。你也需要修改你的 `PATH` 和 `LD_LIBRARY_PATH` 环境变量,以通知你的 shell 这个工具的位置。例如:
|
||||
|
||||
```
|
||||
export PATH=$HOME/bin:$PATH
|
||||
export LD_LIBRARY_PATH=$HOME/lib:$LD_LIBRARY_PATH
|
||||
```
|
||||
|
||||
在你的 `~/.bashrc` 文件中输入这些行,以便于你登入后不需要每次都输入它们。
|
||||
|
||||
Q:我构建失败了,错误信息是 “library not found”。
|
||||
|
||||
A:你需要去设置你的 `LD_LIBRARY_PATH`。环境变量必须包含 `PREFIX/lib` 目录(例如 `/usr/local/lib`)。
|
||||
|
||||
##### MacOS
|
||||
|
||||
首先从 Mac OSX 上安装开发工具开始:`xcode-select --install` 。
|
||||
|
||||
你可以从 homebrew 上安装 qemu 的依赖,但是不能去安装 qemu,因为我们需要安装打了 6.828 补丁的 qemu。
|
||||
|
||||
```
|
||||
brew install $(brew deps qemu)
|
||||
```
|
||||
|
||||
gettext 工具并不能把它已安装的二进制文件添加到路径中,因此你需要去运行:
|
||||
|
||||
```
|
||||
PATH=${PATH}:/usr/local/opt/gettext/bin make install
|
||||
```
|
||||
|
||||
完成后,开始安装 qemu。
|
||||
|
||||
### QEMU 模拟器
|
||||
|
||||
[QEMU][8] 是一个现代化的、并且速度非常快的 PC 模拟器。QEMU 的 2.3.0 版本是设置在 Athena 上的 6.828 中的 x86 机器存储中的(`add -f 6.828`)。
|
||||
|
||||
不幸的是,QEMU 的调试功能虽然很强大,但是有点不成熟,因此我们强烈建议你使用我们打过 6.828 补丁的版本,而不是发行版自带的版本。这个安装在 Athena 上的 QEMU 版本已经打过补丁了。构建你自己的、打 6.828 补丁的 QEMU 版本的过程如下:
|
||||
|
||||
1. 克隆 IAP 6.828 QEMU 的 git 仓库:`git clone https://github.com/mit-pdos/6.828-qemu.git qemu`。
|
||||
2. 在 Linux 上,你或许需要安装几个库。我们成功地在 Debian/Ubuntu 16.04 上构建 6.828 版的 QEMU 需要安装下列的库:libsdl1.2-dev、libtool-bin、libglib2.0-dev、libz-dev 和 libpixman-1-dev。
|
||||
3. 配置源代码(方括号中是可选参数;用你自己的真实路径替换 `PFX`)
|
||||
1. Linux:`./configure --disable-kvm --disable-werror [--prefix=PFX] [--target-list="i386-softmmu x86_64-softmmu"]`。
|
||||
2. OS X:`./configure --disable-kvm --disable-werror --disable-sdl [--prefix=PFX] [--target-list="i386-softmmu x86_64-softmmu"]`。`prefix` 参数指定安装 QEMU 的位置;如果不指定,将缺省安装 QEMU 到 `/usr/local` 目录中。`target-list` 参数将简单地简化 QEMU 所支持的架构。
|
||||
4. 运行 `make && make install`。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://pdos.csail.mit.edu/6.828/2018/tools.html
|
||||
|
||||
作者:[csail.mit][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://pdos.csail.mit.edu
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://www.cygwin.com
|
||||
[2]: labguide.html
|
||||
[3]: http://www.oracle.com/us/technologies/virtualization/oraclevm/
|
||||
[4]: http://www.vmware.com/products/player/
|
||||
[5]: http://www.vmware.com/products/fusion/
|
||||
[6]: http://www.ubuntu.com/download/desktop
|
||||
[8]: http://www.nongnu.org/qemu/
|
||||
[9]: mailto:6828-staff@lists.csail.mit.edu
|
||||
[10]: https://i.creativecommons.org/l/by/3.0/us/88x31.png
|
||||
[11]: https://creativecommons.org/licenses/by/3.0/us/
|
||||
[12]: https://pdos.csail.mit.edu/6.828/2018/index.html
|
||||
@ -0,0 +1,388 @@
|
||||
在命令行使用 Pandoc 进行文件转换
|
||||
======
|
||||
|
||||
> 这篇指南介绍如何使用 Pandoc 将文档转换为多种不同的格式。
|
||||
|
||||

|
||||
|
||||
Pandoc 是一个命令行工具,用于将文件从一种标记语言转换为另一种标记语言。标记语言使用标签来标记文档的各个部分。常用的标记语言包括 Markdown、ReStructuredText、HTML、LaTex、ePub 和 Microsoft Word DOCX。
|
||||
|
||||
简单来说,[Pandoc][1] 允许你将一些文件从一种标记语言转换为另一种标记语言。典型的例子包括将 Markdown 文件转换为演示文稿、LaTeX,PDF 甚至是 ePub。
|
||||
|
||||
本文将解释如何使用 Pandoc 从单一标记语言(在本文中为 Markdown)生成多种格式的文档,引导你完成从 Pandoc 安装,到展示如何创建多种类型的文档,再到提供有关如何编写易于移植到其他格式的文档的提示。
|
||||
|
||||
文中还将解释使用元信息文件对文档内容和元信息(例如,作者姓名、使用的模板、书目样式等)进行分离的意义。
|
||||
|
||||
### Pandoc 安装和要求
|
||||
|
||||
Pandoc 默认安装在大多数 Linux 发行版中。本教程使用 pandoc-2.2.3.2 和 pandoc-citeproc-0.14.3。如果不打算生成 PDF,那么这两个包就足够了。但是,我建议也安装 texlive,这样就可以选择生成 PDF 了。
|
||||
|
||||
通过以下命令在 Linux 上安装这些程序:
|
||||
|
||||
```
|
||||
sudo apt-get install pandoc pandoc-citeproc texlive
|
||||
```
|
||||
|
||||
您可以在 Pandoc 的网站上找到其他平台的 [安装说明][2]。
|
||||
|
||||
我强烈建议安装 [pandoc-crossref][3],这是一个“用于对图表,方程式,表格和交叉引用进行编号的过滤器”。最简单的安装方式是下载 [预构建的可执行文件][4],但也可以通过以下命令从 Haskell 的软件包管理器 cabal 安装它:
|
||||
|
||||
```
|
||||
cabal update
|
||||
cabal install pandoc-crossref
|
||||
```
|
||||
|
||||
如果需要额外的 Haskell [安装信息][5],请参考 pandoc-crossref 的 GitHub 仓库。
|
||||
|
||||
### 几个例子
|
||||
|
||||
我将通过解释如何生成三种类型的文档来演示 Pandoc 的工作原理:
|
||||
|
||||
- 由包含数学公式的 LaTeX 文件创建的网页
|
||||
- 由 Markdown 文件生成的 Reveal.js 幻灯片
|
||||
- 混合 Markdown 和 LaTeX 的合同文件
|
||||
|
||||
#### 创建一个包含数学公式的网站
|
||||
|
||||
Pandoc 的优势之一是以不同的输出文件格式显示数学公式。例如,我们可以从包含一些数学符号(用 LaTeX 编写)的 LaTeX 文档(名为 `math.tex`)生成一个网页。
|
||||
|
||||
`math.tex` 文档如下所示:
|
||||
|
||||
```
|
||||
% Pandoc math demos
|
||||
|
||||
$a^2 + b^2 = c^2$
|
||||
|
||||
$v(t) = v_0 + \frac{1}{2}at^2$
|
||||
|
||||
$\gamma = \frac{1}{\sqrt{1 - v^2/c^2}}$
|
||||
|
||||
$\exists x \forall y (Rxy \equiv Ryx)$
|
||||
|
||||
$p \wedge q \models p$
|
||||
|
||||
$\Box\diamond p\equiv\diamond p$
|
||||
|
||||
$\int_{0}^{1} x dx = \left[ \frac{1}{2}x^2 \right]_{0}^{1} = \frac{1}{2}$
|
||||
|
||||
$e^x = \sum_{n=0}^\infty \frac{x^n}{n!} = \lim_{n\rightarrow\infty} (1+x/n)^n$
|
||||
```
|
||||
|
||||
通过输入以下命令将 LaTeX 文档转换为名为 `mathMathML.html` 的网站:
|
||||
|
||||
```
|
||||
pandoc math.tex -s --mathml -o mathMathML.html
|
||||
```
|
||||
|
||||
参数 `-s` 告诉 Pandoc 生成一个独立的网页(而不是网页片段,因此它将包括 HTML 中的 head 和 body 标签),`-mathml` 参数强制 Pandoc 将 LaTeX 中的数学公式转换成 MathML,从而可以由现代浏览器进行渲染。
|
||||
|
||||
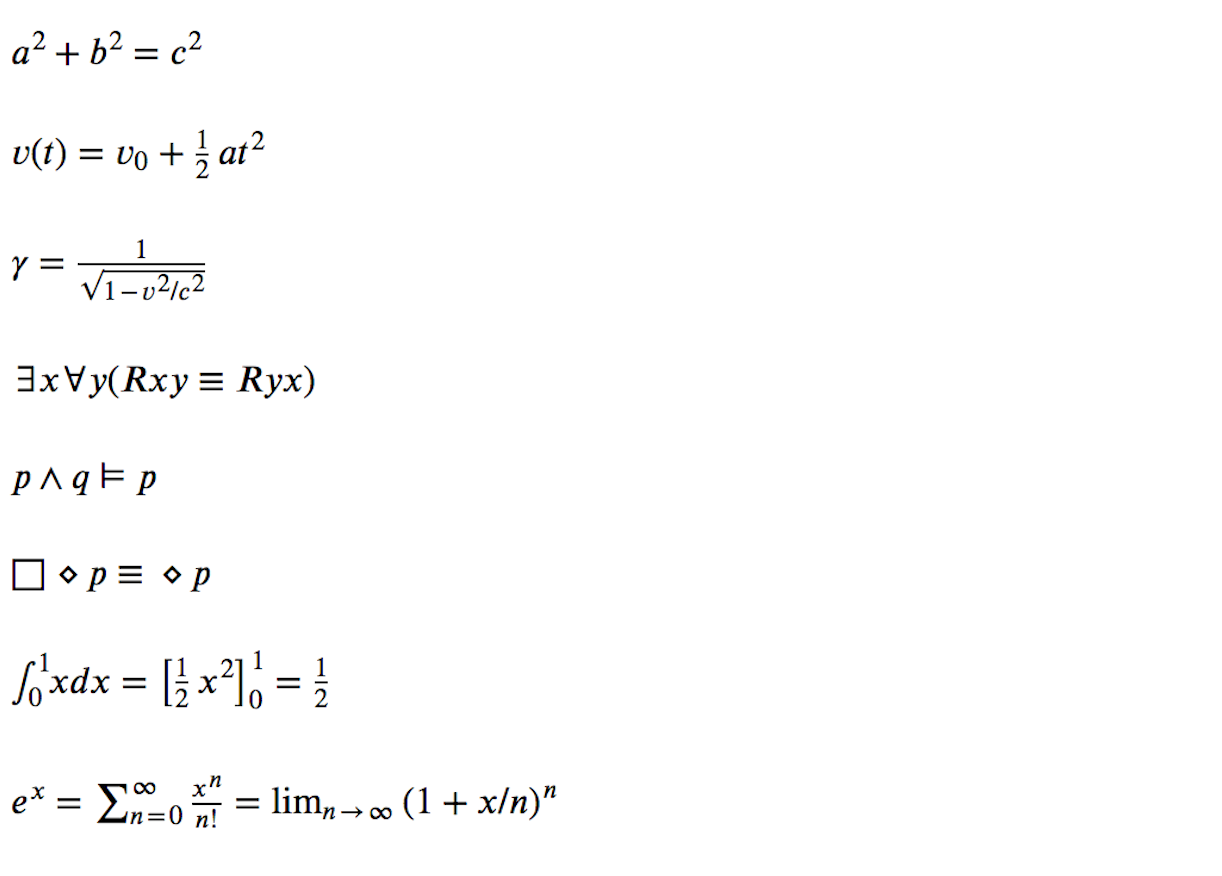
|
||||
|
||||
看一下 [网页效果][6] 和 [代码][7],代码仓库中的 Makefile 使得运行更加简单。
|
||||
|
||||
#### 制作一个 Reveal.js 幻灯片
|
||||
|
||||
使用 Pandoc 从 Markdown 文件生成简单的演示文稿很容易。幻灯片包含顶级幻灯片和下面的嵌套幻灯片。可以通过键盘控制演示文稿,从一个顶级幻灯片跳转到下一个顶级幻灯片,或者显示顶级幻灯片下面的嵌套幻灯片。 这种结构在基于 HTML 的演示文稿框架中很常见。
|
||||
|
||||
创建一个名为 `SLIDES` 的幻灯片文档(参见 [代码仓库][8])。首先,在 `%` 后面添加幻灯片的元信息(例如,标题、作者和日期):
|
||||
|
||||
```
|
||||
% Case Study
|
||||
% Kiko Fernandez Reyes
|
||||
% Sept 27, 2017
|
||||
```
|
||||
|
||||
这些元信息同时也创建了第一张幻灯片。要添加更多幻灯片,使用 Markdown 的一级标题(在下面例子中的第5行,参考 [Markdown 的一级标题][9] )生成顶级幻灯片。
|
||||
|
||||
例如,可以通过以下命令创建一个标题为 “Case Study”、顶级幻灯片名为 “Wine Management System” 的演示文稿:
|
||||
|
||||
```
|
||||
% Case Study
|
||||
% Kiko Fernandez Reyes
|
||||
% Sept 27, 2017
|
||||
|
||||
# Wine Management System
|
||||
```
|
||||
|
||||
使用 Markdown 的二级标题将内容(比如包含一个新管理系统的说明和实现的幻灯片)放入刚刚创建的顶级幻灯片。下面添加另外两张幻灯片(在下面例子中的第 7 行和 14 行 ,参考 [Markdown 的二级标题][9] )。
|
||||
|
||||
- 第一个二级幻灯片的标题为 “Idea”,并显示瑞士国旗的图像
|
||||
- 第二个二级幻灯片的标题为 “Implementation”
|
||||
|
||||
```
|
||||
% Case Study
|
||||
% Kiko Fernandez Reyes
|
||||
% Sept 27, 2017
|
||||
|
||||
# Wine Management System
|
||||
|
||||
## <img src="img/SwissFlag.png" style="vertical-align:middle"/> Idea
|
||||
|
||||
## Implementation
|
||||
```
|
||||
|
||||
我们现在有一个顶级幻灯片(`#Wine Management System`),其中包含两张幻灯片(`## Idea` 和 `## Implementation`)。
|
||||
|
||||
通过创建一个由符号 `>` 开头的 Markdown 列表,在这两张幻灯片中添加一些内容。在上面代码的基础上,在第一张幻灯片中添加两个项目(第 9-10 行),第二张幻灯片中添加五个项目(第 16-20 行):
|
||||
|
||||
```
|
||||
% Case Study
|
||||
% Kiko Fernandez Reyes
|
||||
% Sept 27, 2017
|
||||
|
||||
# Wine Management System
|
||||
|
||||
## <img src="img/SwissFlag.png" style="vertical-align:middle"/> Idea
|
||||
|
||||
>- Swiss love their **wine** and cheese
|
||||
>- Create a *simple* wine tracker system
|
||||
|
||||

|
||||
|
||||
## Implementation
|
||||
|
||||
>- Bottles have a RFID tag
|
||||
>- RFID reader (emits and read signal)
|
||||
>- **Raspberry Pi**
|
||||
>- **Server (online shop)**
|
||||
>- Mobile app
|
||||
```
|
||||
|
||||
上面的代码添加了马特洪峰的图像,也可以使用纯 Markdown 语法或添加 HTML 标签来改进幻灯片。
|
||||
|
||||
要生成幻灯片,Pandoc 需要引用 Reveal.js 库,因此它必须与 `SLIDES` 文件位于同一文件夹中。生成幻灯片的命令如下所示:
|
||||
|
||||
```
|
||||
pandoc -t revealjs -s --self-contained SLIDES \
|
||||
-V theme=white -V slideNumber=true -o index.html
|
||||
```
|
||||
|
||||

|
||||
|
||||
上面的 Pandoc 命令使用了以下参数:
|
||||
|
||||
- `-t revealjs` 表示将输出一个 revealjs 演示文稿
|
||||
- `-s` 告诉 Pandoc 生成一个独立的文档
|
||||
- `--self-contained` 生成没有外部依赖关系的 HTML 文件
|
||||
- `-V` 设置以下变量:
|
||||
- `theme=white` 将幻灯片的主题设为白色
|
||||
- `slideNumber=true` 显示幻灯片编号
|
||||
- `-o index.html` 在名为 `index.html` 的文件中生成幻灯片
|
||||
|
||||
为了简化操作并避免键入如此长的命令,创建以下 Makefile:
|
||||
|
||||
```
|
||||
all: generate
|
||||
|
||||
generate:
|
||||
pandoc -t revealjs -s --self-contained SLIDES \
|
||||
-V theme=white -V slideNumber=true -o index.html
|
||||
|
||||
clean: index.html
|
||||
rm index.html
|
||||
|
||||
.PHONY: all clean generate
|
||||
```
|
||||
|
||||
可以在 [这个仓库][8] 中找到所有代码。
|
||||
|
||||
#### 制作一份多种格式的合同
|
||||
|
||||
假设你正在准备一份文件,并且(这样的情况现在很常见)有些人想用 Microsoft Word 格式,其他人使用自由软件,想要 ODT 格式,而另外一些人则需要 PDF。你不必使用 OpenOffice 或 LibreOffice 来生成 DOCX 或 PDF 格式的文件,可以用 Markdown 创建一份文档(如果需要高级格式,可以使用一些 LaTeX 语法),并生成任何这些文件类型。
|
||||
|
||||
和以前一样,首先声明文档的元信息(标题、作者和日期):
|
||||
|
||||
```
|
||||
% Contract Agreement for Software X
|
||||
% Kiko Fernandez-Reyes
|
||||
% August 28th, 2018
|
||||
```
|
||||
|
||||
然后在 Markdown 中编写文档(如果需要高级格式,则添加 LaTeX)。例如,创建一个固定间隔的表格(在 LaTeX 中用 `\hspace{3cm}` 声明)以及客户端和承包商应填写的行(在 LaTeX 中用 `\hrulefill` 声明)。之后,添加一个用 Markdown 编写的表格。
|
||||
|
||||
创建的文档如下所示:
|
||||
|
||||
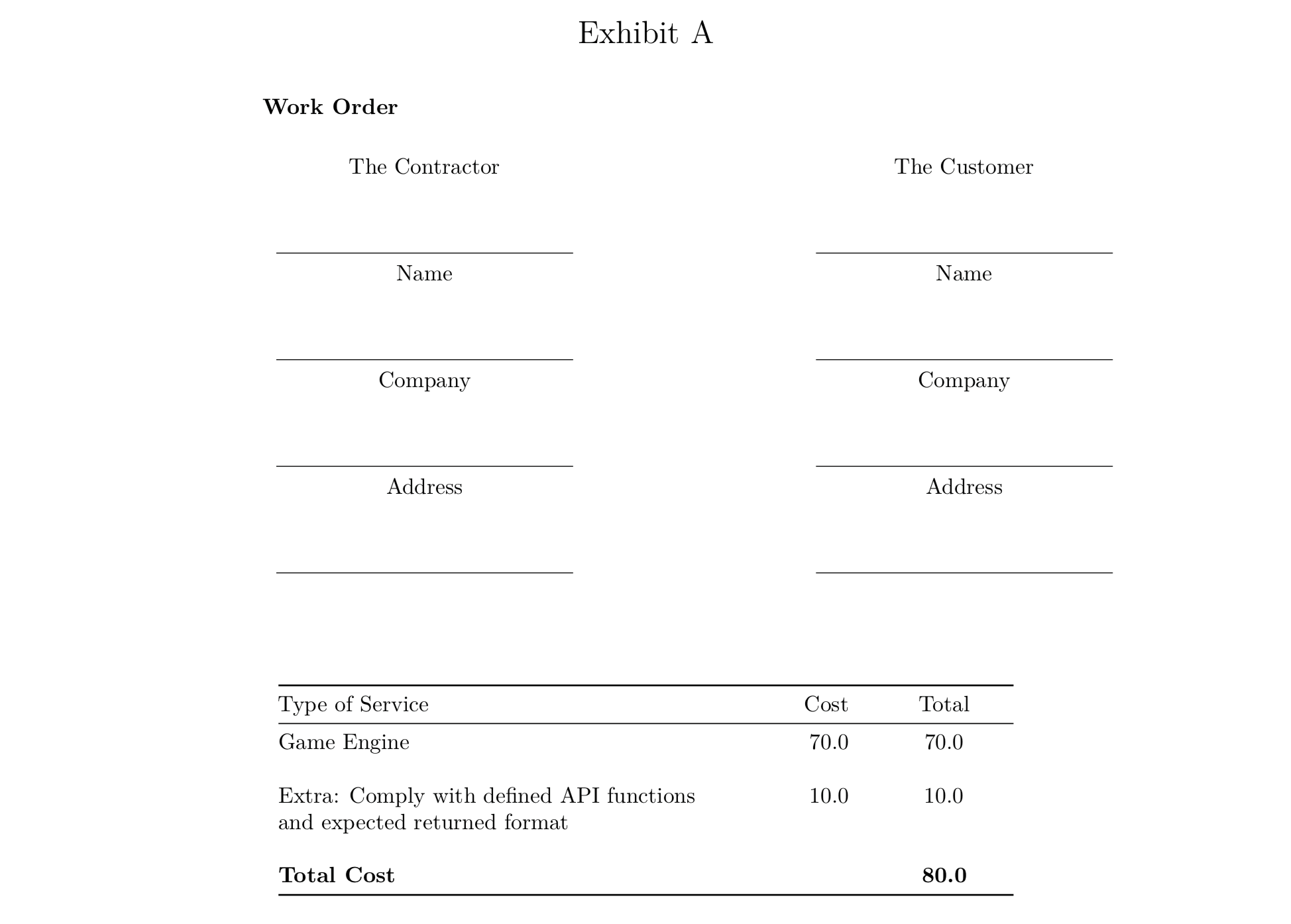
|
||||
|
||||
创建此文档的代码如下:
|
||||
|
||||
```
|
||||
% Contract Agreement for Software X
|
||||
% Kiko Fernandez-Reyes
|
||||
% August 28th, 2018
|
||||
|
||||
...
|
||||
|
||||
### Work Order
|
||||
|
||||
\begin{table}[h]
|
||||
\begin{tabular}{ccc}
|
||||
The Contractor & \hspace{3cm} & The Customer \\
|
||||
& & \\
|
||||
& & \\
|
||||
\hrulefill & \hspace{3cm} & \hrulefill \\
|
||||
%
|
||||
Name & \hspace{3cm} & Name \\
|
||||
& & \\
|
||||
& & \\
|
||||
\hrulefill & \hspace{3cm} & \hrulefill \\
|
||||
...
|
||||
\end{tabular}
|
||||
\end{table}
|
||||
|
||||
\vspace{1cm}
|
||||
|
||||
+--------------------------------------------|----------|-------------+
|
||||
| Type of Service | Cost | Total |
|
||||
+:===========================================+=========:+:===========:+
|
||||
| Game Engine | 70.0 | 70.0 |
|
||||
| | | |
|
||||
+--------------------------------------------|----------|-------------+
|
||||
| | | |
|
||||
+--------------------------------------------|----------|-------------+
|
||||
| Extra: Comply with defined API functions | 10.0 | 10.0 |
|
||||
| and expected returned format | | |
|
||||
+--------------------------------------------|----------|-------------+
|
||||
| | | |
|
||||
+--------------------------------------------|----------|-------------+
|
||||
| **Total Cost** | | **80.0** |
|
||||
+--------------------------------------------|----------|-------------+
|
||||
```
|
||||
|
||||
要生成此文档所需的三种不同输出格式,编写如下的 Makefile:
|
||||
|
||||
```
|
||||
DOCS=contract-agreement.md
|
||||
|
||||
all: $(DOCS)
|
||||
pandoc -s $(DOCS) -o $(DOCS:md=pdf)
|
||||
pandoc -s $(DOCS) -o $(DOCS:md=docx)
|
||||
pandoc -s $(DOCS) -o $(DOCS:md=odt)
|
||||
|
||||
clean:
|
||||
rm *.pdf *.docx *.odt
|
||||
|
||||
.PHONY: all clean
|
||||
```
|
||||
|
||||
4 到 7 行是生成三种不同输出格式的具体命令:
|
||||
|
||||
如果有多个 Markdown 文件并想将它们合并到一个文档中,需要按照希望它们出现的顺序编写命令。例如,在撰写本文时,我创建了三个文档:一个介绍文档、三个示例和一些高级用法。以下命令告诉 Pandoc 按指定的顺序将这些文件合并在一起,并生成一个名为 document.pdf 的 PDF 文件。
|
||||
|
||||
```
|
||||
pandoc -s introduction.md examples.md advanced-uses.md -o document.pdf
|
||||
```
|
||||
|
||||
### 模板和元信息
|
||||
|
||||
编写复杂的文档并非易事,你需要遵循一系列独立于内容的规则,例如使用特定的模板、编写摘要、嵌入特定字体,甚至可能要声明关键字。所有这些都与内容无关:简单地说,它就是元信息。
|
||||
|
||||
Pandoc 使用模板生成不同的输出格式。例如,有一个 LaTeX 的模板,还有一个 ePub 的模板,等等。这些模板的元信息中有未赋值的变量。使用以下命令找出 Pandoc 模板中可用的元信息:
|
||||
|
||||
```
|
||||
pandoc -D FORMAT
|
||||
```
|
||||
|
||||
例如,LaTex 的模版是:
|
||||
|
||||
```
|
||||
pandoc -D latex
|
||||
```
|
||||
|
||||
按照以下格式输出:
|
||||
|
||||
```
|
||||
$if(title)$
|
||||
\title{$title$$if(thanks)$\thanks{$thanks$}$endif$}
|
||||
$endif$
|
||||
$if(subtitle)$
|
||||
\providecommand{\subtitle}[1]{}
|
||||
\subtitle{$subtitle$}
|
||||
$endif$
|
||||
$if(author)$
|
||||
\author{$for(author)$$author$$sep$ \and $endfor$}
|
||||
$endif$
|
||||
$if(institute)$
|
||||
\providecommand{\institute}[1]{}
|
||||
\institute{$for(institute)$$institute$$sep$ \and $endfor$}
|
||||
$endif$
|
||||
\date{$date$}
|
||||
$if(beamer)$
|
||||
$if(titlegraphic)$
|
||||
\titlegraphic{\includegraphics{$titlegraphic$}}
|
||||
$endif$
|
||||
$if(logo)$
|
||||
\logo{\includegraphics{$logo$}}
|
||||
$endif$
|
||||
$endif$
|
||||
|
||||
\begin{document}
|
||||
```
|
||||
|
||||
如你所见,输出的内容中有标题、致谢、作者、副标题和机构模板变量(还有许多其他可用的变量)。可以使用 YAML 元区块轻松设置这些内容。 在下面例子的第 1-5 行中,我们声明了一个 YAML 元区块并设置了一些变量(使用上面合同协议的例子):
|
||||
|
||||
```
|
||||
---
|
||||
title: Contract Agreement for Software X
|
||||
author: Kiko Fernandez-Reyes
|
||||
date: August 28th, 2018
|
||||
---
|
||||
|
||||
(continue writing document as in the previous example)
|
||||
```
|
||||
|
||||
这样做非常奏效,相当于以前的代码:
|
||||
|
||||
```
|
||||
% Contract Agreement for Software X
|
||||
% Kiko Fernandez-Reyes
|
||||
% August 28th, 2018
|
||||
```
|
||||
|
||||
然而,这样做将元信息与内容联系起来,也即 Pandoc 将始终使用此信息以新格式输出文件。如果你将要生成多种文件格式,最好要小心一点。例如,如果你需要以 ePub 和 HTML 的格式生成合同,并且 ePub 和 HTML 需要不同的样式规则,该怎么办?
|
||||
|
||||
考虑一下这些情况:
|
||||
|
||||
- 如果你只是尝试嵌入 YAML 变量 `css:style-epub.css`,那么将从 HTML 版本中移除该变量。这不起作用。
|
||||
- 复制文档显然也不是一个好的解决方案,因为一个版本的更改不会与另一个版本同步。
|
||||
- 你也可以像下面这样将变量添加到 Pandoc 命令中:
|
||||
|
||||
```
|
||||
pandoc -s -V css=style-epub.css document.md document.epub
|
||||
pandoc -s -V css=style-html.css document.md document.html
|
||||
```
|
||||
|
||||
我的观点是,这样做很容易从命令行忽略这些变量,特别是当你需要设置数十个变量时(这可能出现在编写复杂文档的情况中)。现在,如果将它们放在同一文件中(`meta.yaml` 文件),则只需更新或创建新的元信息文件即可生成所需的输出格式。然后你会编写这样的命令:
|
||||
|
||||
```
|
||||
pandoc -s meta-pub.yaml document.md document.epub
|
||||
pandoc -s meta-html.yaml document.md document.html
|
||||
```
|
||||
|
||||
这是一个更简洁的版本,你可以从单个文件更新所有元信息,而无需更新文档的内容。
|
||||
|
||||
### 结语
|
||||
|
||||
通过以上的基本示例,我展示了 Pandoc 在将 Markdown 文档转换为其他格式方面是多么出色。
|
||||
|
||||
------
|
||||
|
||||
via: https://opensource.com/article/18/9/intro-pandoc
|
||||
|
||||
作者:[Kiko Fernandez-Reyes][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[jlztan](https://github.com/jlztan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/kikofernandez
|
||||
[1]: https://pandoc.org/
|
||||
[2]: http://pandoc.org/installing.html
|
||||
[3]: https://hackage.haskell.org/package/pandoc-crossref
|
||||
[4]: https://github.com/lierdakil/pandoc-crossref/releases/tag/v0.3.2.1
|
||||
[5]: https://github.com/lierdakil/pandoc-crossref#installation
|
||||
[6]: http://pandoc.org/demo/mathMathML.html
|
||||
[7]: https://github.com/kikofernandez/pandoc-examples/tree/master/math
|
||||
[8]: https://github.com/kikofernandez/pandoc-examples/tree/master/slides
|
||||
[9]: https://daringfireball.net/projects/markdown/syntax#header
|
||||
@ -0,0 +1,67 @@
|
||||
IssueHunt:一个新的开源软件打赏平台
|
||||
======
|
||||
|
||||
![IssueHunt][4]
|
||||
|
||||
许多开源开发者和公司都在努力解决的问题之一就是资金问题。社区中有一种假想,甚至是期望,必须免费提供自由开源软件(FOSS)。但即使是 FOSS 也需要资金来继续开发。如果我们不建立让软件持续开发的系统,我们怎能期待更高质量的软件?
|
||||
|
||||
我们已经写了一篇关于[开源资金平台][1]的文章来试图解决这个缺点,截至今年 7 月,市场上出现了一个新的竞争者,旨在帮助填补这个空白:[IssueHunt][2]。
|
||||
|
||||
### IssueHunt: 开源软件打赏平台
|
||||
|
||||
![IssueHunt website][3]
|
||||
|
||||
IssueHunt 提供了一种服务,对自由开发者的开源代码贡献进行支付。它通过所谓的赏金来实现:给予解决特定问题的任何人财务奖励。这些奖励的资金来自任何愿意捐赠以修复任何特定 bug 或添加功能的人。
|
||||
|
||||
如果你想修复的某个开源软件存在问题,你可以根据自己选择的方式提供奖励金额。
|
||||
|
||||
想要自己的产品被争抢解决么?在 IssueHunt 上向任何解决问题的人提供奖金就好了。就这么简单。
|
||||
|
||||
如果你是程序员,则可以浏览未解决的问题。解决这个问题(如果你可以的话),在 GitHub 存储库上提交拉取请求,如果你的拉取请求被合并,那么你就会得到了钱。
|
||||
|
||||
#### IssueHunt 最初是 Boostnote 的内部项目
|
||||
|
||||
当笔记应用 [Boostnote][5] 背后的开发人员联系社区为他们的产品做出贡献时,该产品出现了。
|
||||
|
||||
在使用 IssueHunt 的前两年,Boostnote 通过数百名贡献者和压倒性的捐款收到了超过 8,400 个 Github star。
|
||||
|
||||
该产品非常成功,团队决定将其开放给社区的其他成员。
|
||||
|
||||
如今,[列表中在使用这个服务的项目][6]提供了数千美元的赏金。
|
||||
|
||||
Boostnote 号称有 [$2,800 的总赏金][7],而 Settings Sync,以前称为 Visual Studio Code Settings Sync,提供了[超过 $1,600 的赏金][8]。
|
||||
|
||||
还有其他服务提供类似于 IssueHunt 在此提供的内容。也许最引人注目的是 [Bountysource][9],它提供与 IssueHunt 类似的赏金服务,同时还提供类似于 [Librepay][10] 的订阅支付处理。
|
||||
|
||||
#### 你怎么看待 IssueHunt?
|
||||
|
||||
在撰写本文时,IssueHunt 还处于起步阶段,但我非常高兴看到这个项目在这些年里的成果。
|
||||
|
||||
我不知道你会怎么看,但我非常乐意为 FOSS 付款。如果产品质量高,并为我的生活增添价值,那么我很乐意向开发者支付产品费用。特别是 FOSS 的开发者正在创造尊重我自由的产品。
|
||||
|
||||
话虽如此,我一定会关注 IssueHunt 的继续前进,我可以用自己的钱或者在需要贡献的地方传播这个它来支持社区。
|
||||
|
||||
但你怎么看?你是否同意我的看法,或者你认为软件应该免费提供,并且应该在志愿者的基础上做出贡献?请在下面的评论中告诉我们你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/issuehunt/
|
||||
|
||||
作者:[Phillip Prado][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/phillip/
|
||||
[1]: https://itsfoss.com/open-source-funding-platforms/
|
||||
[2]: https://issuehunt.io
|
||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/09/issuehunt-website.png?w=799&ssl=1
|
||||
[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/09/issuehunt.jpg?w=800&ssl=1
|
||||
[5]: https://itsfoss.com/boostnote-linux-review/
|
||||
[6]: https://issuehunt.io/repos
|
||||
[7]: https://issuehunt.io/repos/53266139
|
||||
[8]: https://issuehunt.io/repos/47984369
|
||||
[9]: https://www.bountysource.com/
|
||||
[10]: https://liberapay.com/
|
||||
@ -1,17 +1,17 @@
|
||||
将 Grails 与 jQuery 和 DataTables 一起使用
|
||||
在 Grails 中使用 jQuery 和 DataTables
|
||||
======
|
||||
|
||||
本文介绍如何构建一个基于 Grails 的数据浏览器来可视化复杂的表格数据。
|
||||
> 本文介绍如何构建一个基于 Grails 的数据浏览器来可视化复杂的表格数据。
|
||||
|
||||

|
||||
|
||||
我是 [Grails][1] 的忠实粉丝。当然,我主要是热衷于利用命令行工具来探索和分析数据的数据人。数据人经常需要_查看_数据,这也意味着他们通常拥有优秀的数据浏览器。利用 Grails,[jQuery][2],以及 [DataTables jQuery 插件][3],我们可以制作出非常友好的表格数据浏览器。
|
||||
我是 [Grails][1] 的忠实粉丝。当然,我主要是热衷于利用命令行工具来探索和分析数据的数据从业人员。数据从业人员经常需要*查看*数据,这也意味着他们通常拥有优秀的数据浏览器。利用 Grails、[jQuery][2],以及 [DataTables jQuery 插件][3],我们可以制作出非常友好的表格数据浏览器。
|
||||
|
||||
[DataTables 网站][3]提供了许多“食谱风格”的教程文档,展示了如何组合一些优秀的示例应用程序,这些程序包含了完成一些非常漂亮的东西所必要的 JavaScript,HTML,以及偶尔出现的 [PHP][4]。但对于那些宁愿使用 Grails 作为后端的人来说,有必要进行一些说明示教。此外,样本程序中使用的数据是虚构公司的员工的单个平面表数据,因此处理这些复杂的表关系可以作为读者的一个练习项目。
|
||||
[DataTables 网站][3]提供了许多“食谱式”的教程文档,展示了如何组合一些优秀的示例应用程序,这些程序包含了完成一些非常漂亮的东西所必要的 JavaScript、HTML,以及偶尔出现的 [PHP][4]。但对于那些宁愿使用 Grails 作为后端的人来说,有必要进行一些说明示教。此外,样本程序中使用的数据是一个虚构公司的员工的单个平面表格数据,因此处理这些复杂的表关系可以作为读者的一个练习项目。
|
||||
|
||||
本文中,我们将创建具有略微复杂的数据结构和 DataTables 浏览器的 Grails 应用程序。我们将介绍 Grails 标准 [Groovy][5]-fied Java Hibernate 标准。我已将代码托管在 [GitHub][6] 上方便大家访问,因此本文主要是对代码细节的解读。
|
||||
本文中,我们将创建具有略微复杂的数据结构和 DataTables 浏览器的 Grails 应用程序。我们将介绍 Grails 标准,它是 [Groovy][5] 式的 Java Hibernate 标准。我已将代码托管在 [GitHub][6] 上方便大家访问,因此本文主要是对代码细节的解读。
|
||||
|
||||
首先,你需要配置 Java,Groovy,Grails 的使用环境。对于 Grails,我倾向于使用终端窗口和 [Vim][7],本文也使用它们。为获得现代 Java,建议下载并安装 Linux 发行版提供的 [Open Java Development Kit][8] (OpenJDK)(应该是 Java 8,9,10或11,撰写本文时,我正在使用 Java 8)。从我的角度来看,获取最新的 Groovy 和 Grails 的最佳方法是使用 [SKDMAN!][9]。
|
||||
首先,你需要配置 Java、Groovy、Grails 的使用环境。对于 Grails,我倾向于使用终端窗口和 [Vim][7],本文也使用它们。为获得现代的 Java 环境,建议下载并安装 Linux 发行版提供的 [Open Java Development Kit][8] (OpenJDK)(应该是 Java 8、9、10 或 11 之一,撰写本文时,我正在使用 Java 8)。从我的角度来看,获取最新的 Groovy 和 Grails 的最佳方法是使用 [SDKMAN!][9]。
|
||||
|
||||
从未尝试过 Grails 的读者可能需要做一些背景资料阅读。作为初学者,推荐文章 [创建你的第一个 Grails 应用程序][10]。
|
||||
|
||||
@ -34,7 +34,7 @@ grails create-domain-class com.nuevaconsulting.embrow.Employeecd embrowgrails cr
|
||||
|
||||
这种方式构建的域类没有属性,因此必须按如下方式编辑它们:
|
||||
|
||||
Position 域类:
|
||||
`Position` 域类:
|
||||
|
||||
```
|
||||
package com.nuevaconsulting.embrow
|
||||
@ -51,7 +51,7 @@ class Position {
|
||||
}com.Stringint startingstatic constraintsnullableblankstarting nullable
|
||||
```
|
||||
|
||||
Office 域类:
|
||||
`Office` 域类:
|
||||
|
||||
```
|
||||
package com.nuevaconsulting.embrow
|
||||
@ -72,7 +72,7 @@ class Office {
|
||||
}
|
||||
```
|
||||
|
||||
Enployee 域类:
|
||||
`Enployee` 域类:
|
||||
|
||||
```
|
||||
package com.nuevaconsulting.embrow
|
||||
@ -98,7 +98,7 @@ class Employee {
|
||||
}
|
||||
```
|
||||
|
||||
请注意,虽然 Position 和 Office 域类使用了预定义的 Groovy 类型 String 以及 int,但 Employee 域类定义了 Position 和 Office 字段(以及预定义的 Date)。这会导致创建数据库表,其中存储的 Employee 实例中包含了指向存储 Position 和 Office 实例表的引用或者外键。
|
||||
请注意,虽然 `Position` 和 `Office` 域类使用了预定义的 Groovy 类型 `String` 以及 `int`,但 `Employee` 域类定义了 `Position` 和 `Office` 字段(以及预定义的 `Date`)。这会导致创建数据库表,其中存储的 `Employee` 实例中包含了指向存储 `Position` 和 `Office` 实例表的引用或者外键。
|
||||
|
||||
现在你可以生成控制器,视图,以及其他各种测试组件:
|
||||
|
||||
@ -108,7 +108,7 @@ grails generate-all com.nuevaconsulting.embrow.Office
|
||||
grails generate-all com.nuevaconsulting.embrow.Employeegrails generateall com.grails generateall com.grails generateall com.
|
||||
```
|
||||
|
||||
此时,你已经准备好基本的 create-read-update-delete(CRUD)应用程序。我在**grails-app/init/com/nuevaconsulting/BootStrap.groovy**中包含了一些基础数据来填充表格。
|
||||
此时,你已经准备好了一个基本的增删改查(CRUD)应用程序。我在 `grails-app/init/com/nuevaconsulting/BootStrap.groovy` 中包含了一些基础数据来填充表格。
|
||||
|
||||
如果你用如下命令来启动应用程序:
|
||||
|
||||
@ -116,43 +116,44 @@ grails generate-all com.nuevaconsulting.embrow.Employeegrails generateall com.gr
|
||||
grails run-app
|
||||
```
|
||||
|
||||
在浏览器输入**<http://localhost:8080/:>**,你将会看到如下界面:
|
||||
在浏览器输入 `http://localhost:8080/`,你将会看到如下界面:
|
||||
|
||||
![Embrow home screen][12]
|
||||
|
||||
Embrow 应用程序主界面。
|
||||
*Embrow 应用程序主界面。*
|
||||
|
||||
单击 OfficeController,会跳转到如下界面:
|
||||
单击 “OfficeController” 链接,会跳转到如下界面:
|
||||
|
||||
![Office list][14]
|
||||
|
||||
Office 列表
|
||||
*Office 列表*
|
||||
|
||||
注意,此表由 **OfficeController index** 生成,并由视图 `office/index.gsp` 显示。
|
||||
注意,此表由 `OfficeController` 的 `index` 方式生成,并由视图 `office/index.gsp` 显示。
|
||||
|
||||
同样,单击 **EmployeeController** 跳转到如下界面:
|
||||
同样,单击 “EmployeeController” 链接 跳转到如下界面:
|
||||
|
||||
![Employee controller][16]
|
||||
|
||||
employee controller
|
||||
*employee 控制器*
|
||||
|
||||
好吧,这很丑陋: Position 和 Office 链接是什么?
|
||||
|
||||
上面的命令 `generate-all` 生成的视图创建了一个叫 **index.gsp** 的文件,它使用 Grails <f:table/> 标签,该标签默认会显示类名(**com.nuevaconsulting.embrow.Position**)和持久化示例标识符(**30**)。这个操作可以自定义用来产生更好看的东西,并且自动生成链接,自动生成分页以及自动生成可拍序列的一些非常简洁直观的东西。
|
||||
上面的命令 `generate-all` 生成的视图创建了一个叫 `index.gsp` 的文件,它使用 Grails `<f:table/>` 标签,该标签默认会显示类名(`com.nuevaconsulting.embrow.Position`)和持久化示例标识符(`30`)。这个操作可以自定义用来产生更好看的东西,并且自动生成链接,自动生成分页以及自动生成可排序列的一些非常简洁直观的东西。
|
||||
|
||||
但该员工信息浏览器功能也是有限的。例如,如果想查找 position 信息中包含 “dev” 的员工该怎么办?如果要组合排序,以姓氏为主排序关键字,office 为辅助排序关键字,该怎么办?或者,你需要将已排序的数据导出到电子表格或 PDF 文档以便通过电子邮件发送给无法访问浏览器的人,该怎么办?
|
||||
但该员工信息浏览器功能也是有限的。例如,如果想查找 “position” 信息中包含 “dev” 的员工该怎么办?如果要组合排序,以姓氏为主排序关键字,“office” 为辅助排序关键字,该怎么办?或者,你需要将已排序的数据导出到电子表格或 PDF 文档以便通过电子邮件发送给无法访问浏览器的人,该怎么办?
|
||||
|
||||
jQuery DataTables 插件提供了这些所需的功能。允许你创建一个完成的表格数据浏览器。
|
||||
|
||||
### 创建员工信息浏览器视图和控制器的方法
|
||||
|
||||
要基于 jQuery DataTables 创建员工信息浏览器,你必须先完成以下两个任务:
|
||||
1. 创建 Grails 视图,其中包含启用 DataTable 所需的 HTML 和 JavaScript
|
||||
|
||||
1. 创建 Grails 视图,其中包含启用 DataTable 所需的 HTML 和 JavaScript
|
||||
2. 给 Grails 控制器增加一个方法来控制新视图。
|
||||
|
||||
#### 员工信息浏览器视图
|
||||
|
||||
在目录 **embrow/grails-app/views/employee** 中,首先复制 **index.gsp** 文件,重命名为 **browser.gsp**:
|
||||
在目录 `embrow/grails-app/views/employee` 中,首先复制 `index.gsp` 文件,重命名为 `browser.gsp`:
|
||||
|
||||
```
|
||||
cd Projects
|
||||
@ -160,7 +161,7 @@ cd embrow/grails-app/views/employee
|
||||
cp gsp browser.gsp
|
||||
```
|
||||
|
||||
此刻,你自定义新的 **browser.gsp** 文件来添加相关的 jQuery DataTables 代码。
|
||||
此刻,你自定义新的 `browser.gsp` 文件来添加相关的 jQuery DataTables 代码。
|
||||
|
||||
通常,在可能的时候,我喜欢从内容提供商处获得 JavaScript 和 CSS;在下面这行后面:
|
||||
|
||||
@ -185,7 +186,7 @@ cp gsp browser.gsp
|
||||
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/buttons/1.5.1/js/buttons.print.min.js "></script>
|
||||
```
|
||||
|
||||
然后删除 **index.gsp** 中提供数据分页的代码:
|
||||
然后删除 `index.gsp` 中提供数据分页的代码:
|
||||
|
||||
```
|
||||
<div id="list-employee" class="content scaffold-list" role="main">
|
||||
@ -253,7 +254,7 @@ $(this).html('<input type="text" size="15" placeholder="' + title + '?" />');
|
||||
});titletitletitletitletitle
|
||||
```
|
||||
|
||||
接下来,定义表模型。 这是提供所有表选项的地方,包括界面的滚动,而不是分页,根据 dom 字符串提供的装饰,将数据导出为 CSV 和其他格式的能力,以及建立与服务器的 Ajax 连接。 请注意,使用 Groovy GString 调用 Grails **createLink()** 的方法创建 URL,在 **EmployeeController** 中指向 **browserLister** 操作。同样有趣的是表格列的定义。此信息将发送到后端,后端查询数据库并返回相应的记录。
|
||||
接下来,定义表模型。这是提供所有表选项的地方,包括界面的滚动,而不是分页,根据 DOM 字符串提供的装饰,将数据导出为 CSV 和其他格式的能力,以及建立与服务器的 AJAX 连接。 请注意,使用 Groovy GString 调用 Grails `createLink()` 的方法创建 URL,在 `EmployeeController` 中指向 `browserLister` 操作。同样有趣的是表格列的定义。此信息将发送到后端,后端查询数据库并返回相应的记录。
|
||||
|
||||
```
|
||||
var table = $('#employee_dt').DataTable( {
|
||||
@ -302,7 +303,7 @@ that.search(this.value).draw();
|
||||
|
||||
|
||||
|
||||
这是另一个屏幕截图,显示了过滤和多列排序(寻找 position 包括字符 “dev” 的员工,先按 office 排序,然后按姓氏排序):
|
||||
这是另一个屏幕截图,显示了过滤和多列排序(寻找 “position” 包括字符 “dev” 的员工,先按 “office” 排序,然后按姓氏排序):
|
||||
|
||||
|
||||
|
||||
@ -314,37 +315,37 @@ that.search(this.value).draw();
|
||||
|
||||
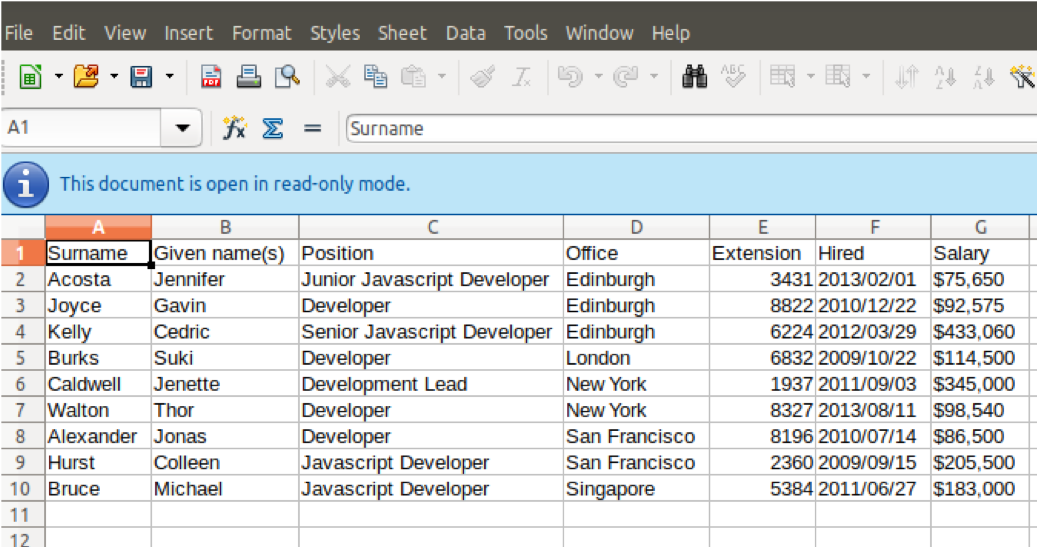
|
||||
|
||||
好的,视图部分看起来非常简单; 因此,控制器必须做所有繁重的工作,对吧? 让我们来看看…
|
||||
好的,视图部分看起来非常简单;因此,控制器必须做所有繁重的工作,对吧? 让我们来看看……
|
||||
|
||||
#### 控制器 browserLister 操作
|
||||
|
||||
回想一下,我们看到过这个字符串
|
||||
回想一下,我们看到过这个字符串:
|
||||
|
||||
```
|
||||
"${createLink(controller: 'employee', action: 'browserLister')}"
|
||||
```
|
||||
|
||||
对于从 DataTables 模型中调用 Ajax 的 URL,是在 Grails 服务器上动态创建 HTML 链接,其 Grails 标记背后通过调用 [createLink()][17] 的方法实现的。这会最终产生一个指向 **EmployeeController** 的链接,位于:
|
||||
对于从 DataTables 模型中调用 AJAX 的 URL,是在 Grails 服务器上动态创建 HTML 链接,其 Grails 标记背后通过调用 [createLink()][17] 的方法实现的。这会最终产生一个指向 `EmployeeController` 的链接,位于:
|
||||
|
||||
```
|
||||
embrow/grails-app/controllers/com/nuevaconsulting/embrow/EmployeeController.groovy
|
||||
```
|
||||
|
||||
特别是控制器方法 **browserLister()**。我在代码中留了一些 print 语句,以便在运行时能够在终端看到中间结果。
|
||||
特别是控制器方法 `browserLister()`。我在代码中留了一些 `print` 语句,以便在运行时能够在终端看到中间结果。
|
||||
|
||||
```
|
||||
def browserLister() {
|
||||
// Applies filters and sorting to return a list of desired employees
|
||||
```
|
||||
|
||||
首先,打印出传递给 **browserLister()** 的参数。我通常使用此代码开始构建控制器方法,以便我完全清楚我的控制器正在接收什么。
|
||||
首先,打印出传递给 `browserLister()` 的参数。我通常使用此代码开始构建控制器方法,以便我完全清楚我的控制器正在接收什么。
|
||||
|
||||
```
|
||||
println "employee browserLister params $params"
|
||||
println()
|
||||
```
|
||||
|
||||
接下来,处理这些参数以使它们更加有用。首先,jQuery DataTables 参数,一个名为 **jqdtParams**的 Groovy 映射:
|
||||
接下来,处理这些参数以使它们更加有用。首先,jQuery DataTables 参数,一个名为 `jqdtParams` 的 Groovy 映射:
|
||||
|
||||
```
|
||||
def jqdtParams = [:]
|
||||
@ -363,7 +364,7 @@ println "employee dataTableParams $jqdtParams"
|
||||
println()
|
||||
```
|
||||
|
||||
接下来,列数据,一个名为 **columnMap**的 Groovy 映射:
|
||||
接下来,列数据,一个名为 `columnMap` 的 Groovy 映射:
|
||||
|
||||
```
|
||||
def columnMap = jqdtParams.columns.collectEntries { k, v ->
|
||||
@ -386,7 +387,7 @@ println "employee columnMap $columnMap"
|
||||
println()
|
||||
```
|
||||
|
||||
接下来,从 **columnMap** 中检索的所有列表,以及在视图中应如何排序这些列表,Groovy 列表分别称为 **allColumnList**和 **orderList**:
|
||||
接下来,从 `columnMap` 中检索的所有列表,以及在视图中应如何排序这些列表,Groovy 列表分别称为 `allColumnList` 和 `orderList` :
|
||||
|
||||
```
|
||||
def allColumnList = columnMap.keySet() as List
|
||||
@ -395,7 +396,7 @@ def orderList = jqdtParams.order.collect { k, v -> [allColumnList[v.column as In
|
||||
println "employee orderList $orderList"
|
||||
```
|
||||
|
||||
我们将使用 Grails 的 Hibernate 标准实现来实际选择要显示的元素以及它们的排序和分页。标准要求过滤器关闭; 在大多数示例中,这是作为标准实例本身的创建的一部分给出的,但是在这里我们预先定义过滤器闭包。请注意,在这种情况下,“date hired” 过滤器的相对复杂的解释被视为一年并应用于建立日期范围,并使用 **createAlias** 以允许我们进入相关类别 Position 和 Office:
|
||||
我们将使用 Grails 的 Hibernate 标准实现来实际选择要显示的元素以及它们的排序和分页。标准要求过滤器关闭;在大多数示例中,这是作为标准实例本身的创建的一部分给出的,但是在这里我们预先定义过滤器闭包。请注意,在这种情况下,“date hired” 过滤器的相对复杂的解释被视为一年并应用于建立日期范围,并使用 `createAlias` 以允许我们进入相关类别 `Position` 和 `Office`:
|
||||
|
||||
```
|
||||
def filterer = {
|
||||
@ -424,14 +425,14 @@ def filterer = {
|
||||
}
|
||||
```
|
||||
|
||||
是时候应用上述内容了。第一步是获取分页代码所需的所有 Employee 实例的总数:
|
||||
是时候应用上述内容了。第一步是获取分页代码所需的所有 `Employee` 实例的总数:
|
||||
|
||||
```
|
||||
def recordsTotal = Employee.count()
|
||||
println "employee recordsTotal $recordsTotal"
|
||||
```
|
||||
|
||||
接下来,将过滤器应用于 Employee 实例以获取过滤结果的计数,该结果将始终小于或等于总数(同样,这是针对分页代码):
|
||||
接下来,将过滤器应用于 `Employee` 实例以获取过滤结果的计数,该结果将始终小于或等于总数(同样,这是针对分页代码):
|
||||
|
||||
```
|
||||
def c = Employee.createCriteria()
|
||||
@ -467,7 +468,7 @@ def filterer = {
|
||||
|
||||
要完全清楚,JTable 中的分页代码管理三个计数:数据集中的记录总数,应用过滤器后得到的数字,以及要在页面上显示的数字(显示是滚动还是分页)。 排序应用于所有过滤的记录,并且分页应用于那些过滤的记录的块以用于显示目的。
|
||||
|
||||
接下来,处理命令返回的结果,在每行中创建指向 Employee,Position 和 Office 实例的链接,以便用户可以单击这些链接以获取相关实例的所有详细信息:
|
||||
接下来,处理命令返回的结果,在每行中创建指向 `Employee`、`Position` 和 `Office` 实例的链接,以便用户可以单击这些链接以获取相关实例的所有详细信息:
|
||||
|
||||
```
|
||||
def dollarFormatter = new DecimalFormat('$##,###.##')
|
||||
@ -490,14 +491,15 @@ def filterer = {
|
||||
}
|
||||
```
|
||||
|
||||
大功告成
|
||||
大功告成。
|
||||
|
||||
如果你熟悉 Grails,这可能看起来比你原先想象的要多,但这里没有火箭式的一步到位方法,只是很多分散的操作步骤。但是,如果你没有太多接触 Grails(或 Groovy),那么需要了解很多新东西 - 闭包,代理和构建器等等。
|
||||
|
||||
在那种情况下,从哪里开始? 最好的地方是了解 Groovy 本身,尤其是 [Groovy closures][18] 和 [Groovy delegates and builders][19]。然后再去阅读上面关于 Grails 和 Hibernate 条件查询的建议阅读文章。
|
||||
|
||||
### 结语
|
||||
|
||||
jQuery DataTables 为 Grails 制作了很棒的表格数据浏览器。对视图进行编码并不是太棘手,但DataTables 文档中提供的 PHP 示例提供的功能仅到此位置。特别是,它们不是用 Grails 程序员编写的,也不包含探索使用引用其他类(实质上是查找表)的元素的更精细的细节。
|
||||
jQuery DataTables 为 Grails 制作了很棒的表格数据浏览器。对视图进行编码并不是太棘手,但 DataTables 文档中提供的 PHP 示例提供的功能仅到此位置。特别是,它们不是用 Grails 程序员编写的,也不包含探索使用引用其他类(实质上是查找表)的元素的更精细的细节。
|
||||
|
||||
我使用这种方法制作了几个数据浏览器,允许用户选择要查看和累积记录计数的列,或者只是浏览数据。即使在相对适度的 VPS 上的百万行表中,性能也很好。
|
||||
|
||||
@ -512,7 +514,7 @@ via: https://opensource.com/article/18/9/using-grails-jquery-and-datatables
|
||||
作者:[Chris Hermansen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[jrg](https://github.com/jrglinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -528,11 +530,11 @@ via: https://opensource.com/article/18/9/using-grails-jquery-and-datatables
|
||||
[9]: http://sdkman.io/
|
||||
[10]: http://guides.grails.org/creating-your-first-grails-app/guide/index.html
|
||||
[11]: https://opensource.com/file/410061
|
||||
[12]: https://opensource.com/sites/default/files/uploads/screen_1.png "Embrow home screen"
|
||||
[12]: https://opensource.com/sites/default/files/uploads/screen_1.png
|
||||
[13]: https://opensource.com/file/410066
|
||||
[14]: https://opensource.com/sites/default/files/uploads/screen_2.png "Office list screenshot"
|
||||
[14]: https://opensource.com/sites/default/files/uploads/screen_2.png
|
||||
[15]: https://opensource.com/file/410071
|
||||
[16]: https://opensource.com/sites/default/files/uploads/screen3.png "Employee controller screenshot"
|
||||
[16]: https://opensource.com/sites/default/files/uploads/screen3.png
|
||||
[17]: https://gsp.grails.org/latest/ref/Tags/createLink.html
|
||||
[18]: http://groovy-lang.org/closures.html
|
||||
[19]: http://groovy-lang.org/dsls.html
|
||||
@ -0,0 +1,98 @@
|
||||
容器技术对 DevOps 的一些启发
|
||||
======
|
||||
|
||||
> 容器技术的使用支撑了目前 DevOps 三大主要实践:工作流、及时反馈、持续学习。
|
||||
|
||||
|
||||
|
||||
有人说容器技术与 DevOps 二者在发展的过程中是互相促进的关系。得益于 DevOps 设计理念的流行,容器生态系统在设计上与组件选择上也有相应发展。同时,由于容器技术在生产环境中的使用,反过来也促进了 DevOps 三大主要实践:[支撑 DevOps 的三个实践][1]。
|
||||
|
||||
### 工作流
|
||||
|
||||
#### 容器中的工作流
|
||||
|
||||
每个容器都可以看成一个独立的运行环境,对于容器内部,不需要考虑外部的宿主环境、集群环境,以及其它基础设施。在容器内部,每个功能看起来都是以传统的方式运行。从外部来看,容器内运行的应用一般作为整个应用系统架构的一部分:比如 web API、web app 用户界面、数据库、任务执行、缓存系统、垃圾回收等。运维团队一般会限制容器的资源使用,并在此基础上建立完善的容器性能监控服务,从而降低其对基础设施或者下游其他用户的影响。
|
||||
|
||||
#### 现实中的工作流
|
||||
|
||||
那些跟“容器”一样业务功能独立的团队,也可以借鉴这种容器思维。因为无论是在现实生活中的工作流(代码发布、构建基础设施,甚至制造 [《杰森一家》中的斯贝斯利太空飞轮][2] 等),还是技术中的工作流(开发、测试、运维、发布)都使用了这样的线性工作流,一旦某个独立的环节或者工作团队出现了问题,那么整个下游都会受到影响,虽然使用这种线性的工作流有效降低了工作耦合性。
|
||||
|
||||
#### DevOps 中的工作流
|
||||
|
||||
DevOps 中的第一条原则,就是掌控整个执行链路的情况,努力理解系统如何协同工作,并理解其中出现的问题如何对整个过程产生影响。为了提高流程的效率,团队需要持续不断的找到系统中可能存在的性能浪费以及问题,并最终修复它们。
|
||||
|
||||
> 践行这样的工作流后,可以避免将一个已知缺陷带到工作流的下游,避免局部优化导致可能的全局性能下降,要不断探索如何优化工作流,持续加深对于系统的理解。
|
||||
|
||||
> —— Gene Kim,《[支撑 DevOps 的三个实践][3]》,IT 革命,2017.4.25
|
||||
|
||||
### 反馈
|
||||
|
||||
#### 容器中的反馈
|
||||
|
||||
除了限制容器的资源,很多产品还提供了监控和通知容器性能指标的功能,从而了解当容器工作不正常时,容器内部处于什么样的状态。比如目前[流行的][5] [Prometheus][4],可以用来收集容器和容器集群中相应的性能指标数据。容器本身特别适用于分隔应用系统,以及打包代码和其运行环境,但同时也带来了不透明的特性,这时,从中快速收集信息来解决其内部出现的问题就显得尤为重要了。
|
||||
|
||||
#### 现实中的反馈
|
||||
|
||||
在现实中,从始至终同样也需要反馈。一个高效的处理流程中,及时的反馈能够快速地定位事情发生的时间。反馈的关键词是“快速”和“相关”。当一个团队被淹没在大量不相关的事件时,那些真正需要快速反馈的重要信息很容易被忽视掉,并向下游传递形成更严重的问题。想象下[如果露西和埃塞尔][6]能够很快地意识到:传送带太快了,那么制作出的巧克力可能就没什么问题了(尽管这样就不那么搞笑了)。(LCTT 译注:露西和埃塞尔是上世纪 50 年代的著名黑白情景喜剧《我爱露西》中的主角)
|
||||
|
||||
#### DevOps 中的反馈
|
||||
|
||||
DevOps 中的第二条原则,就是快速收集所有相关的有用信息,这样在问题影响到其它开发流程之前就可以被识别出。DevOps 团队应该努力去“优化下游”,以及快速解决那些可能会影响到之后团队的问题。同工作流一样,反馈也是一个持续的过程,目标是快速的获得重要的信息以及当问题出现后能够及时地响应。
|
||||
|
||||
> 快速的反馈对于提高技术的质量、可用性、安全性至关重要。
|
||||
|
||||
> —— Gene Kim 等人,《DevOps 手册:如何在技术组织中创造世界级的敏捷性,可靠性和安全性》,IT 革命,2016
|
||||
|
||||
### 持续学习
|
||||
|
||||
#### 容器中的持续学习
|
||||
|
||||
践行第三条原则“持续学习”是一个不小的挑战。在不需要掌握太多边缘的或难以理解的东西的情况下,容器技术让我们的开发工程师和运营团队依然可以安全地进行本地和生产环境的测试,这在之前是难以做到的。即便是一些激进的实验,容器技术仍然让我们轻松地进行版本控制、记录和分享。
|
||||
|
||||
#### 现实中的持续学习
|
||||
|
||||
举个我自己的例子:多年前,作为一个年轻、初出茅庐的系统管理员(仅仅工作三周),我被安排对一个运行着某个大学核心 IT 部门网站的 Apache 虚拟主机配置进行更改。由于没有方便的测试环境,我直接在生产站点上修改配置,当时觉得配置没问题就发布了,几分钟后,我无意中听到了隔壁同事说:
|
||||
|
||||
“等会,网站挂了?”
|
||||
|
||||
“没错,怎么回事?”
|
||||
|
||||
很多人蒙圈了……
|
||||
|
||||
在被嘲讽之后(真实的嘲讽),我一头扎在工作台上,赶紧撤销我之前的更改。当天下午晚些时候,部门主管 —— 我老板的老板的老板 —— 来到我的工位询问发生了什么事。“别担心,”她告诉我。“我们不会责怪你,这是一个错误,现在你已经学会了。”
|
||||
|
||||
而在容器中,这种情形在我的笔记本上就很容易测试了,并且也很容易在部署生产环境之前,被那些经验老道的团队成员发现。
|
||||
|
||||
#### DevOps 中的持续学习
|
||||
|
||||
持续学习文化的一部分是我们每个人都希望通过一些改变从而能够提高一些东西,并勇敢地通过实验来验证我们的想法。对于 DevOps 团队来说,失败无论对团队还是个人来说都是成长而不是惩罚,所以不要畏惧失败。团队中的每个成员不断学习、共享,也会不断提升其所在团队与组织的水平。
|
||||
|
||||
随着系统越来越被细分,我们更需要将注意力集中在具体的点上:上面提到的两条原则主要关注整体流程,而持续学习关注的则是整个项目、人员、团队、组织的未来。它不仅对流程产生了影响,还对流程中的每个人产生影响。
|
||||
|
||||
> 实验和冒险让我们能够不懈地改进我们的工作,但也要求我们尝试之前未用过的工作方式。
|
||||
|
||||
> —— Gene Kim 等人,《[凤凰计划:让你了解 IT、DevOps 以及如何取得商业成功][7]》,IT 革命,2013
|
||||
|
||||
### 容器技术带给 DevOps 的启迪
|
||||
|
||||
有效地应用容器技术可以学习 DevOps 的三条原则:工作流,反馈以及持续学习。从整体上看应用程序和基础设施,而不是对容器外的东西置若罔闻,教会我们考虑到系统的所有部分,了解其上游和下游影响,打破隔阂,并作为一个团队工作,以提升整体表现和深度了解整个系统。通过努力提供及时准确的反馈,我们可以在组织内部创建有效的反馈机制,以便在问题发生影响之前发现问题。最后,提供一个安全的环境来尝试新的想法并从中学习,教会我们创造一种文化,在这种文化中,失败一方面促进了我们知识的增长,另一方面通过有根据的猜测,可以为复杂的问题带来新的、优雅的解决方案。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/containers-can-teach-us-devops
|
||||
|
||||
作者:[Chris Hermansen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[littleji](https://github.com/littleji)
|
||||
校对:[pityonline](https://github.com/pityonline), [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/clhermansen
|
||||
[1]: https://itrevolution.com/the-three-ways-principles-underpinning-devops/
|
||||
[2]: https://en.wikipedia.org/wiki/The_Jetsons
|
||||
[3]: http://itrevolution.com/the-three-ways-principles-underpinning-devops
|
||||
[4]: https://prometheus.io/
|
||||
[5]: https://opensource.com/article/18/9/prometheus-operational-advantage
|
||||
[6]: https://www.youtube.com/watch?v=8NPzLBSBzPI
|
||||
[7]: https://itrevolution.com/book/the-phoenix-project/
|
||||
@ -0,0 +1,259 @@
|
||||
使用 Pandoc 将你的书转换成网页和电子书
|
||||
======
|
||||
|
||||
> 通过 Markdown 和 Pandoc,可以做到编写一次,发布两次。
|
||||
|
||||

|
||||
|
||||
Pandoc 是一个命令行工具,用于将文件从一种标记语言转换为另一种标记语言。在我 [对 Pandoc 的简介][1] 一文中,我演示了如何把 Markdown 编写的文本转换为网页、幻灯片和 PDF。
|
||||
|
||||
在这篇后续文章中,我将深入探讨 [Pandoc][2],展示如何从同一个 Markdown 源文件生成网页和 ePub 格式的电子书。我将使用我即将发布的电子书《[面向对象思想的 GRASP 原则][3]》为例进行讲解,这本电子书正是通过以下过程创建的。
|
||||
|
||||
首先,我将解释这本书使用的文件结构,然后介绍如何使用 Pandoc 生成网页并将其部署在 GitHub 上;最后,我演示了如何生成对应的 ePub 格式电子书。
|
||||
|
||||
你可以在我的 GitHub 仓库 [Programming Fight Club][4] 中找到相应代码。
|
||||
|
||||
### 设置图书结构
|
||||
|
||||
我用 Markdown 语法完成了所有的写作,你也可以使用 HTML 标记,但是当 Pandoc 将 Markdown 转换为 ePub 文档时,引入的 HTML 标记越多,出现问题的风险就越高。我的书按照每章一个文件的形式进行组织,用 Markdown 的 `H1` 标记(`#`)声明每章的标题。你也可以在每个文件中放置多个章节,但将它们放在单独的文件中可以更轻松地查找内容并在以后进行更新。
|
||||
|
||||
元信息遵循类似的模式,每种输出格式都有自己的元信息文件。元信息文件定义有关文档的信息,例如要添加到 HTML 中的文本或 ePub 的许可证。我将所有 Markdown 文档存储在名为 `parts` 的文件夹中(这对于用来生成网页和 ePub 的 Makefile 非常重要)。下面以一个例子进行说明,让我们看一下目录,前言和关于本书(分为 `toc.md`、`preface.md` 和 `about.md` 三个文件)这三部分,为清楚起见,我们将省略其余的章节。
|
||||
|
||||
关于本书这部分内容的开头部分类似:
|
||||
|
||||
```
|
||||
# About this book {-}
|
||||
|
||||
## Who should read this book {-}
|
||||
|
||||
Before creating a complex software system one needs to create a solid foundation.
|
||||
General Responsibility Assignment Software Principles (GRASP) are guidelines to assign
|
||||
responsibilities to software classes in object-oriented programming.
|
||||
```
|
||||
|
||||
每一章完成后,下一步就是添加元信息来设置网页和 ePub 的格式。
|
||||
|
||||
### 生成网页
|
||||
|
||||
#### 创建 HTML 元信息文件
|
||||
|
||||
我创建的网页的元信息文件(`web-metadata.yaml`)是一个简单的 YAML 文件,其中包含 `<head> ` 标签中的作者、标题、和版权等信息,以及 HTML 文件中开头和结尾的内容。
|
||||
|
||||
我建议(至少)包括 `web-metadata.yaml` 文件中的以下字段:
|
||||
|
||||
```
|
||||
---
|
||||
title: <a href="/grasp-principles/toc/">GRASP principles for the Object-oriented mind</a>
|
||||
author: Kiko Fernandez-Reyes
|
||||
rights: 2017 Kiko Fernandez-Reyes, CC-BY-NC-SA 4.0 International
|
||||
header-includes:
|
||||
- |
|
||||
```{=html}
|
||||
<link href="https://fonts.googleapis.com/css?family=Inconsolata" rel="stylesheet">
|
||||
<link href="https://fonts.googleapis.com/css?family=Gentium+Basic|Inconsolata" rel="stylesheet">
|
||||
```
|
||||
include-before:
|
||||
- |
|
||||
```{=html}
|
||||
<p>If you like this book, please consider
|
||||
spreading the word or
|
||||
<a href="https://www.buymeacoffee.com/programming">
|
||||
buying me a coffee
|
||||
</a>
|
||||
</p>
|
||||
```
|
||||
include-after:
|
||||
- |
|
||||
```{=html}
|
||||
<div class="footnotes">
|
||||
<hr>
|
||||
<div class="container">
|
||||
<nav class="pagination" role="pagination">
|
||||
<ul>
|
||||
<p>
|
||||
<span class="page-number">Designed with</span> ❤️ <span class="page-number"> from Uppsala, Sweden</span>
|
||||
</p>
|
||||
<p>
|
||||
<a rel="license" href="http://creativecommons.org/licenses/by-nc-sa/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png" /></a>
|
||||
</p>
|
||||
</ul>
|
||||
</nav>
|
||||
</div>
|
||||
</div>
|
||||
```
|
||||
---
|
||||
```
|
||||
|
||||
下面几个变量需要注意一下:
|
||||
|
||||
- `header-includes` 变量包含将要嵌入 `<head>` 标签的 HTML 文本。
|
||||
- 调用变量后的下一行必须是 `- |`。再往下一行必须以与 `|` 对齐的三个反引号开始,否则 Pandoc 将无法识别。`{= html}` 告诉 Pandoc 其中的内容是原始文本,不应该作为 Markdown 处理。(为此,需要检查 Pandoc 中的 `raw_attribute` 扩展是否已启用。要进行此检查,键入 `pandoc --list-extensions | grep raw` 并确保返回的列表包含名为 `+ raw_html` 的项目,加号表示已启用。)
|
||||
- 变量 `include-before` 在网页开头添加一些 HTML 文本,此处我请求读者帮忙宣传我的书或给我打赏。
|
||||
- `include-after` 变量在网页末尾添加原始 HTML 文本,同时显示我的图书许可证。
|
||||
|
||||
这些只是其中一部分可用的变量,查看 HTML 中的模板变量(我的文章 [Pandoc简介][1] 中介绍了如何查看 LaTeX 的模版变量,查看 HTML 模版变量的过程是相同的)对其余变量进行了解。
|
||||
|
||||
#### 将网页分成多章
|
||||
|
||||
网页可以作为一个整体生成,这会产生一个包含所有内容的长页面;也可以分成多章,我认为这样会更容易阅读。我将解释如何将网页划分为多章,以便读者不会被长网页吓到。
|
||||
|
||||
为了使网页易于在 GitHub Pages 上部署,需要创建一个名为 `docs` 的根文件夹(这是 GitHub Pages 默认用于渲染网页的根文件夹)。然后我们需要为 `docs` 下的每一章创建文件夹,将 HTML 内容放在各自的文件夹中,将文件内容放在名为 `index.html` 的文件中。
|
||||
|
||||
例如,`about.md` 文件将转换成名为 `index.html` 的文件,该文件位于名为 `about`(`about/index.html`)的文件夹中。这样,当用户键入 `http://<your-website.com>/about/` 时,文件夹中的 `index.html` 文件将显示在其浏览器中。
|
||||
|
||||
下面的 `Makefile` 将执行上述所有操作:
|
||||
|
||||
```
|
||||
# Your book files
|
||||
DEPENDENCIES= toc preface about
|
||||
|
||||
# Placement of your HTML files
|
||||
DOCS=docs
|
||||
|
||||
all: web
|
||||
|
||||
web: setup $(DEPENDENCIES)
|
||||
@cp $(DOCS)/toc/index.html $(DOCS)
|
||||
|
||||
|
||||
# Creation and copy of stylesheet and images into
|
||||
# the assets folder. This is important to deploy the
|
||||
# website to Github Pages.
|
||||
setup:
|
||||
@mkdir -p $(DOCS)
|
||||
@cp -r assets $(DOCS)
|
||||
|
||||
|
||||
# Creation of folder and index.html file on a
|
||||
# per-chapter basis
|
||||
|
||||
$(DEPENDENCIES):
|
||||
@mkdir -p $(DOCS)/$@
|
||||
@pandoc -s --toc web-metadata.yaml parts/$@.md \
|
||||
-c /assets/pandoc.css -o $(DOCS)/$@/index.html
|
||||
|
||||
clean:
|
||||
@rm -rf $(DOCS)
|
||||
|
||||
.PHONY: all clean web setup
|
||||
```
|
||||
|
||||
选项 `- c /assets/pandoc.css` 声明要使用的 CSS 样式表,它将从 `/assets/pandoc.cs` 中获取。也就是说,在 `<head>` 标签内,Pandoc 会添加这样一行:
|
||||
|
||||
```
|
||||
<link rel="stylesheet" href="/assets/pandoc.css">
|
||||
```
|
||||
|
||||
使用下面的命令生成网页:
|
||||
|
||||
```
|
||||
make
|
||||
```
|
||||
|
||||
根文件夹现在应该包含如下所示的文件结构:
|
||||
|
||||
```
|
||||
.---parts
|
||||
| |--- toc.md
|
||||
| |--- preface.md
|
||||
| |--- about.md
|
||||
|
|
||||
|---docs
|
||||
|--- assets/
|
||||
|--- index.html
|
||||
|--- toc
|
||||
| |--- index.html
|
||||
|
|
||||
|--- preface
|
||||
| |--- index.html
|
||||
|
|
||||
|--- about
|
||||
|--- index.html
|
||||
|
||||
```
|
||||
|
||||
#### 部署网页
|
||||
|
||||
通过以下步骤将网页部署到 GitHub 上:
|
||||
|
||||
1. 创建一个新的 GitHub 仓库
|
||||
2. 将内容推送到新创建的仓库
|
||||
3. 找到仓库设置中的 GitHub Pages 部分,选择 `Source` 选项让 GitHub 使用主分支的内容
|
||||
|
||||
你可以在 [GitHub Pages][5] 的网站上获得更多详细信息。
|
||||
|
||||
[我的书的网页][6] 便是通过上述过程生成的,可以在网页上查看结果。
|
||||
|
||||
### 生成电子书
|
||||
|
||||
#### 创建 ePub 格式的元信息文件
|
||||
|
||||
ePub 格式的元信息文件 `epub-meta.yaml` 和 HTML 元信息文件是类似的。主要区别在于 ePub 提供了其他模板变量,例如 `publisher` 和 `cover-image` 。ePub 格式图书的样式表可能与网页所用的不同,在这里我使用一个名为 `epub.css` 的样式表。
|
||||
|
||||
```
|
||||
---
|
||||
title: 'GRASP principles for the Object-oriented Mind'
|
||||
publisher: 'Programming Language Fight Club'
|
||||
author: Kiko Fernandez-Reyes
|
||||
rights: 2017 Kiko Fernandez-Reyes, CC-BY-NC-SA 4.0 International
|
||||
cover-image: assets/cover.png
|
||||
stylesheet: assets/epub.css
|
||||
...
|
||||
```
|
||||
|
||||
将以下内容添加到之前的 `Makefile` 中:
|
||||
|
||||
```
|
||||
epub:
|
||||
@pandoc -s --toc epub-meta.yaml \
|
||||
$(addprefix parts/, $(DEPENDENCIES:=.md)) -o $(DOCS)/assets/book.epub
|
||||
```
|
||||
|
||||
用于产生 ePub 格式图书的命令从 HTML 版本获取所有依赖项(每章的名称),向它们添加 Markdown 扩展,并在它们前面加上每一章的文件夹路径,以便让 Pandoc 知道如何进行处理。例如,如果 `$(DEPENDENCIES` 变量只包含 “前言” 和 “关于本书” 两章,那么 `Makefile` 将会这样调用:
|
||||
|
||||
```
|
||||
@pandoc -s --toc epub-meta.yaml \
|
||||
parts/preface.md parts/about.md -o $(DOCS)/assets/book.epub
|
||||
```
|
||||
|
||||
Pandoc 将提取这两章的内容,然后进行组合,最后生成 ePub 格式的电子书,并放在 `Assets` 文件夹中。
|
||||
|
||||
这是使用此过程创建 ePub 格式电子书的一个 [示例][7]。
|
||||
|
||||
### 过程总结
|
||||
|
||||
从 Markdown 文件创建网页和 ePub 格式电子书的过程并不困难,但有很多细节需要注意。遵循以下大纲可能使你更容易使用 Pandoc。
|
||||
|
||||
- HTML 图书:
|
||||
- 使用 Markdown 语法创建每章内容
|
||||
- 添加元信息
|
||||
- 创建一个 `Makefile` 将各个部分组合在一起
|
||||
- 设置 GitHub Pages
|
||||
- 部署
|
||||
- ePub 电子书:
|
||||
- 使用之前创建的每一章内容
|
||||
- 添加新的元信息文件
|
||||
- 创建一个 `Makefile` 以将各个部分组合在一起
|
||||
- 设置 GitHub Pages
|
||||
- 部署
|
||||
|
||||
|
||||
------
|
||||
|
||||
via: https://opensource.com/article/18/10/book-to-website-epub-using-pandoc
|
||||
|
||||
作者:[Kiko Fernandez-Reyes][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[jlztan](https://github.com/jlztan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/kikofernandez
|
||||
[1]: https://linux.cn/article-10228-1.html
|
||||
[2]: https://pandoc.org/
|
||||
[3]: https://www.programmingfightclub.com/
|
||||
[4]: https://github.com/kikofernandez/programmingfightclub
|
||||
[5]: https://pages.github.com/
|
||||
[6]: https://www.programmingfightclub.com/grasp-principles/
|
||||
[7]: https://github.com/kikofernandez/programmingfightclub/raw/master/docs/web_assets/demo.epub
|
||||
@ -1,22 +1,23 @@
|
||||
适用于小型企业的 4 个开源发票工具
|
||||
======
|
||||
用基于 web 的发票软件管理你的账单,完成收款,十分简单。
|
||||
|
||||
> 用基于 web 的发票软件管理你的账单,轻松完成收款,十分简单。
|
||||
|
||||

|
||||
|
||||
无论您开办小型企业的原因是什么,保持业务发展的关键是可以盈利。收款也就意味着向客户提供发票。
|
||||
|
||||
使用 LibreOffice Writer 或 LibreOffice Calc 提供发票很容易,但有时候你需要的不止这些。从更专业的角度看。一种跟进发票的方法。提醒你何时跟进你发出的发票。
|
||||
使用 LibreOffice Writer 或 LibreOffice Calc 提供发票很容易,但有时候你需要的不止这些。从更专业的角度看,一种跟进发票的方法,可以提醒你何时跟进你发出的发票。
|
||||
|
||||
在这里有各种各样的商业闭源发票管理工具。但是开源界的产品和相对应的闭源商业工具比起来,并不差,没准还更灵活。
|
||||
在这里有各种各样的商业闭源的发票管理工具。但是开源的产品和相对应的闭源商业工具比起来,并不差,没准还更灵活。
|
||||
|
||||
让我们一起了解这 4 款基于 web 的开源发票工具,它们很适用于预算紧张的自由职业者和小型企业。2014 年,我在本文的[早期版本][1]中提到了其中两个工具。这 4 个工具用起来都很简单,并且你可以在任何设备上使用它们。
|
||||
|
||||
### Invoice Ninja
|
||||
|
||||
我不是很喜欢 ninja 这个词。尽管如此,我喜欢 [Invoice Ninja][2]。非常喜欢。它将功能融合在一个简单的界面,其中包含一组功能,可让创建,管理和向客户、消费者发送发票。
|
||||
我不是很喜欢 ninja (忍者)这个词。尽管如此,我喜欢 [Invoice Ninja][2]。非常喜欢。它将功能融合在一个简单的界面,其中包含一组可让你创建、管理和向客户、消费者发送发票的功能。
|
||||
|
||||
您可以轻松配置多个客户端,跟进付款和未结清的发票,生成报价并用电子邮件发送发票。Invoice Ninja 与其竞争对手不同,它[集成][3]了超过 40 个流行支付方式,包括 PayPal,Stripe,WePay 以及 Apple Pay。
|
||||
您可以轻松配置多个客户端,跟进付款和未结清的发票,生成报价并用电子邮件发送发票。Invoice Ninja 与其竞争对手不同,它[集成][3]了超过 40 个流行支付方式,包括 PayPal、Stripe、WePay 以及 Apple Pay。
|
||||
|
||||
[下载][4]一个可以安装到自己服务器上的版本,或者获取一个[托管版][5]的账户,都可以使用 Invoice Ninja。它有免费版,也有每月 8 美元的收费版。
|
||||
|
||||
@ -34,7 +35,7 @@ InvoicePlane 不仅可以生成或跟进发票。你还可以为任务或商品
|
||||
|
||||
[OpenSourceBilling][9] 被它的开发者称赞为“非常简单的计费软件”,当之无愧。它拥有最简洁的交互界面,配置使用起来轻而易举。
|
||||
|
||||
OpenSourceBilling 因它的商业智能仪表盘脱颖而出,它可以跟进跟进你当前和以前的发票,以及任何没有支付的款项。它以图表的形式整理信息,使之很容易阅读。
|
||||
OpenSourceBilling 因它的商业智能仪表盘脱颖而出,它可以跟进你当前和以前的发票,以及任何没有支付的款项。它以图表的形式整理信息,使之很容易阅读。
|
||||
|
||||
你可以在发票上配置很多信息。只需点几下鼠标按几下键盘,即可添加项目、税率、客户名称以及付款条件。OpenSourceBilling 将这些信息保存在你所有的发票当中,不管新发票还是旧发票。
|
||||
|
||||
@ -57,7 +58,7 @@ via: https://opensource.com/article/18/10/open-source-invoicing-tools
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[fuowang](https://github.com/fuowang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,70 @@
|
||||
|
||||
Greg Kroah-Hartman 解释内核社区是如何使 Linux 安全的
|
||||
============
|
||||
|
||||

|
||||
|
||||
> 内核维护者 Greg Kroah-Hartman 谈论内核社区如何保护 Linux 不遭受损害。
|
||||
|
||||
由于 Linux 使用量持续扩大,内核社区去提高这个世界上使用最广泛的技术 —— Linux 内核的安全性的重要性越来越高。安全不仅对企业客户很重要,它对消费者也很重要,因为 80% 的移动设备都使用了 Linux。在本文中,Linux 内核维护者 Greg Kroah-Hartman 带我们了解内核社区如何应对威胁。
|
||||
|
||||
### bug 不可避免
|
||||
|
||||

|
||||
|
||||
*Greg Kroah-Hartman [Linux 基金会][1]*
|
||||
|
||||
正如 Linus Torvalds 曾经说过的,大多数安全问题都是 bug 造成的,而 bug 又是软件开发过程的一部分。是软件就有 bug。
|
||||
|
||||
Kroah-Hartman 说:“就算是 bug,我们也不知道它是安全的 bug 还是不安全的 bug。我修复的一个著名 bug,在三年后才被 Red Hat 认定为安全漏洞“。
|
||||
|
||||
在消除 bug 方面,内核社区没有太多的办法,只能做更多的测试来寻找 bug。内核社区现在已经有了自己的安全团队,它们是由熟悉内核核心的内核开发者组成。
|
||||
|
||||
Kroah-Hartman 说:”当我们收到一个报告时,我们就让参与这个领域的核心开发者去修复它。在一些情况下,他们可能是同一个人,让他们进入安全团队可以更快地解决问题“。但他也强调,内核所有部分的开发者都必须清楚地了解这些问题,因为内核是一个可信环境,它必须被保护起来。
|
||||
|
||||
Kroah-Hartman 说:”一旦我们修复了它,我们就将它放到我们的栈分析规则中,以便于以后不再重新出现这个 bug。“
|
||||
|
||||
除修复 bug 之外,内核社区也不断加固内核。Kroah-Hartman 说:“我们意识到,我们需要一些主动的缓减措施,因此我们需要加固内核。”
|
||||
|
||||
Kees Cook 和其他一些人付出了巨大的努力,带来了一直在内核之外的加固特性,并将它们合并或适配到内核中。在每个内核发行后,Cook 都对所有新的加固特性做一个总结。但是只加固内核是不够的,供应商们必须要启用这些新特性来让它们充分发挥作用,但他们并没有这么做。
|
||||
|
||||
Kroah-Hartman [每周发布一个稳定版内核][5],而为了长期的支持,公司们只从中挑选一个,以便于设备制造商能够利用它。但是,Kroah-Hartman 注意到,除了 Google Pixel 之外,大多数 Android 手机并不包含这些额外的安全加固特性,这就意味着,所有的这些手机都是有漏洞的。他说:“人们应该去启用这些加固特性”。
|
||||
|
||||
Kroah-Hartman 说:“我购买了基于 Linux 内核 4.4 的所有旗舰级手机,去查看它们中哪些确实升级了新特性。结果我发现只有一家公司升级了它们的内核。……我在整个供应链中努力去解决这个问题,因为这是一个很棘手的问题。它涉及许多不同的组织 —— SoC 制造商、运营商等等。关键点是,需要他们把我们辛辛苦苦设计的内核去推送给大家。”
|
||||
|
||||
好消息是,与消费电子产品不一样,像 Red Hat 和 SUSE 这样的大供应商,在企业环境中持续对内核进行更新。使用容器、pod 和虚拟化的现代系统做到这一点更容易了。无需停机就可以毫不费力地更新和重启。事实上,现在来保证系统安全相比过去容易多了。
|
||||
|
||||
### Meltdown 和 Spectre
|
||||
|
||||
没有任何一个关于安全的讨论能够避免提及 Meltdown 和 Spectre 缺陷。内核社区一直致力于修改新发现的和已查明的安全漏洞。不管怎样,Intel 已经因为这些事情改变了它们的策略。
|
||||
|
||||
Kroah-Hartman 说:“他们已经重新研究如何处理安全 bug,以及如何与社区合作,因为他们知道他们做错了。内核已经修复了几乎所有大的 Spectre 问题,但是还有一些小问题仍在处理中”。
|
||||
|
||||
好消息是,这些 Intel 漏洞使得内核社区正在变得更好。Kroah-Hartman 说:“我们需要做更多的测试。对于最新一轮的安全补丁,在它们被发布之前,我们自己花了四个月时间来测试它们,因为我们要防止这个安全问题在全世界扩散。而一旦这些漏洞在真实的世界中被利用,将让我们认识到我们所依赖的基础设施是多么的脆弱,我们多年来一直在做这种测试,这确保了其它人不会遭到这些 bug 的伤害。所以说,Intel 的这些漏洞在某种程度上让内核社区变得更好了”。
|
||||
|
||||
对安全的日渐关注也为那些有才华的人创造了更多的工作机会。由于安全是个极具吸引力的领域,那些希望在内核空间中有所建树的人,安全将是他们一个很好的起点。
|
||||
|
||||
Kroah-Hartman 说:“如果有人想从事这方面的工作,我们有大量的公司愿意雇佣他们。我知道一些开始去修复 bug 的人已经被他们雇佣了。”
|
||||
|
||||
你可以在下面链接的视频上查看更多的内容:
|
||||
|
||||
[视频](https://youtu.be/jkGVabyMh1I)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/10/greg-kroah-hartman-explains-how-kernel-community-securing-linux-0
|
||||
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
选题:[oska874][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[b]:https://github.com/oska874
|
||||
[1]:https://www.linux.com/licenses/category/linux-foundation
|
||||
[2]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[3]:https://www.linux.com/files/images/greg-k-hpng
|
||||
[4]:https://www.linux.com/files/images/kernel-securityjpg-0
|
||||
[5]:https://www.kernel.org/category/releases.html
|
||||
@ -0,0 +1,191 @@
|
||||
Python 函数式编程:不可变数据结构
|
||||
======
|
||||
|
||||
> 不可变性可以帮助我们更好地理解我们的代码。下面我将讲述如何在不牺牲性能的条件下来实现它。
|
||||
|
||||

|
||||
|
||||
在这个由两篇文章构成的系列中,我将讨论如何将函数式编程方法论中的思想引入至 Python 中,来充分发挥这两个领域的优势。
|
||||
|
||||
本文(也就是第一篇文章)中,我们将探讨不可变数据结构的优势。第二部分会探讨如何在 `toolz` 库的帮助下,用 Python 实现高层次的函数式编程理念。
|
||||
|
||||
为什么要用函数式编程?因为变化的东西更难推理。如果你已经确信变化会带来麻烦,那很棒。如果你还没有被说服,在文章结束时,你会明白这一点的。
|
||||
|
||||
我们从思考正方形和矩形开始。如果我们抛开实现细节,单从接口的角度考虑,正方形是矩形的子类吗?
|
||||
|
||||
子类的定义基于[里氏替换原则][1]。一个子类必须能够完成超类所做的一切。
|
||||
|
||||
如何为矩形定义接口?
|
||||
|
||||
```
|
||||
from zope.interface import Interface
|
||||
|
||||
class IRectangle(Interface):
|
||||
def get_length(self):
|
||||
"""正方形能做到"""
|
||||
def get_width(self):
|
||||
"""正方形能做到"""
|
||||
def set_dimensions(self, length, width):
|
||||
"""啊哦"""
|
||||
```
|
||||
|
||||
如果我们这么定义,那正方形就不能成为矩形的子类:如果长度和宽度不等,它就无法对 `set_dimensions` 方法做出响应。
|
||||
|
||||
另一种方法,是选择将矩形做成不可变对象。
|
||||
|
||||
```
|
||||
class IRectangle(Interface):
|
||||
def get_length(self):
|
||||
"""正方形能做到"""
|
||||
def get_width(self):
|
||||
"""正方形能做到"""
|
||||
def with_dimensions(self, length, width):
|
||||
"""返回一个新矩形"""
|
||||
```
|
||||
|
||||
现在,我们可以将正方形视为矩形了。在调用 `with_dimensions` 时,它可以返回一个新的矩形(它不一定是个正方形),但它本身并没有变,依然是一个正方形。
|
||||
|
||||
这似乎像是个学术问题 —— 直到我们认为正方形和矩形可以在某种意义上看做一个容器的侧面。在理解了这个例子以后,我们会处理更传统的容器,以解决更现实的案例。比如,考虑一下随机存取数组。
|
||||
|
||||
我们现在有 `ISquare` 和 `IRectangle`,而且 `ISequere` 是 `IRectangle` 的子类。
|
||||
|
||||
我们希望把矩形放进随机存取数组中:
|
||||
|
||||
```
|
||||
class IArrayOfRectangles(Interface):
|
||||
def get_element(self, i):
|
||||
"""返回一个矩形"""
|
||||
def set_element(self, i, rectangle):
|
||||
"""'rectangle' 可以是任意 IRectangle 对象"""
|
||||
```
|
||||
|
||||
我们同样希望把正方形放进随机存取数组:
|
||||
|
||||
```
|
||||
class IArrayOfSquare(Interface):
|
||||
def get_element(self, i):
|
||||
"""返回一个正方形"""
|
||||
def set_element(self, i, square):
|
||||
"""'square' 可以是任意 ISquare 对象"""
|
||||
```
|
||||
|
||||
尽管 `ISquare` 是 `IRectangle` 的子集,但没有任何一个数组可以同时实现 `IArrayOfSquare` 和 `IArrayOfRectangle`.
|
||||
|
||||
为什么不能呢?假设 `bucket` 实现了这两个类的功能。
|
||||
|
||||
```
|
||||
>>> rectangle = make_rectangle(3, 4)
|
||||
>>> bucket.set_element(0, rectangle) # 这是 IArrayOfRectangle 中的合法操作
|
||||
>>> thing = bucket.get_element(0) # IArrayOfSquare 要求 thing 必须是一个正方形
|
||||
>>> assert thing.height == thing.width
|
||||
Traceback (most recent call last):
|
||||
File "<stdin>", line 1, in <module>
|
||||
AssertionError
|
||||
```
|
||||
|
||||
无法同时实现这两类功能,意味着这两个类无法构成继承关系,即使 `ISquare` 是 `IRectangle` 的子类。问题来自 `set_element` 方法:如果我们实现一个只读的数组,那 `IArrayOfSquare` 就可以是 `IArrayOfRectangle` 的子类了。
|
||||
|
||||
在可变的 `IRectangle` 和可变的 `IArrayOf*` 接口中,可变性都会使得对类型和子类的思考变得更加困难 —— 放弃变换的能力,意味着我们的直觉所希望的类型间关系能够成立了。
|
||||
|
||||
可变性还会带来作用域方面的影响。当一个共享对象被两个地方的代码改变时,这种问题就会发生。一个经典的例子是两个线程同时改变一个共享变量。不过在单线程程序中,即使在两个相距很远的地方共享一个变量,也是一件简单的事情。从 Python 语言的角度来思考,大多数对象都可以从很多位置来访问:比如在模块全局变量,或在一个堆栈跟踪中,或者以类属性来访问。
|
||||
|
||||
如果我们无法对共享做出约束,那我们可能要考虑对可变性来进行约束了。
|
||||
|
||||
这是一个不可变的矩形,它利用了 [attr][2] 库:
|
||||
|
||||
```
|
||||
@attr.s(frozen=True)
|
||||
class Rectange(object):
|
||||
length = attr.ib()
|
||||
width = attr.ib()
|
||||
@classmethod
|
||||
def with_dimensions(cls, length, width):
|
||||
return cls(length, width)
|
||||
```
|
||||
|
||||
这是一个正方形:
|
||||
|
||||
```
|
||||
@attr.s(frozen=True)
|
||||
class Square(object):
|
||||
side = attr.ib()
|
||||
@classmethod
|
||||
def with_dimensions(cls, length, width):
|
||||
return Rectangle(length, width)
|
||||
```
|
||||
|
||||
使用 `frozen` 参数,我们可以轻易地使 `attrs` 创建的类成为不可变类型。正确实现 `__setitem__` 方法的工作都交给别人完成了,对我们是不可见的。
|
||||
|
||||
修改对象仍然很容易;但是我们不可能改变它的本质。
|
||||
|
||||
```
|
||||
too_long = Rectangle(100, 4)
|
||||
reasonable = attr.evolve(too_long, length=10)
|
||||
```
|
||||
|
||||
[Pyrsistent][3] 能让我们拥有不可变的容器。
|
||||
|
||||
```
|
||||
# 由整数构成的向量
|
||||
a = pyrsistent.v(1, 2, 3)
|
||||
# 并非由整数构成的向量
|
||||
b = a.set(1, "hello")
|
||||
```
|
||||
|
||||
尽管 `b` 不是一个由整数构成的向量,但没有什么能够改变 `a` 只由整数构成的性质。
|
||||
|
||||
如果 `a` 有一百万个元素呢?`b` 会将其中的 999999 个元素复制一遍吗?`Pyrsistent` 具有“大 O”性能保证:所有操作的时间复杂度都是 `O(log n)`. 它还带有一个可选的 C 语言扩展,以在“大 O”性能之上进行提升。
|
||||
|
||||
修改嵌套对象时,会涉及到“变换器”的概念:
|
||||
|
||||
```
|
||||
blog = pyrsistent.m(
|
||||
title="My blog",
|
||||
links=pyrsistent.v("github", "twitter"),
|
||||
posts=pyrsistent.v(
|
||||
pyrsistent.m(title="no updates",
|
||||
content="I'm busy"),
|
||||
pyrsistent.m(title="still no updates",
|
||||
content="still busy")))
|
||||
new_blog = blog.transform(["posts", 1, "content"],
|
||||
"pretty busy")
|
||||
```
|
||||
|
||||
`new_blog` 现在将是如下对象的不可变等价物:
|
||||
|
||||
```
|
||||
{'links': ['github', 'twitter'],
|
||||
'posts': [{'content': "I'm busy",
|
||||
'title': 'no updates'},
|
||||
{'content': 'pretty busy',
|
||||
'title': 'still no updates'}],
|
||||
'title': 'My blog'}
|
||||
```
|
||||
|
||||
不过 `blog` 依然不变。这意味着任何拥有旧对象引用的人都没有受到影响:转换只会有局部效果。
|
||||
|
||||
当共享行为猖獗时,这会很有用。例如,函数的默认参数:
|
||||
|
||||
```
|
||||
def silly_sum(a, b, extra=v(1, 2)):
|
||||
extra = extra.extend([a, b])
|
||||
return sum(extra)
|
||||
```
|
||||
|
||||
在本文中,我们了解了为什么不可变性有助于我们来思考我们的代码,以及如何在不带来过大性能负担的条件下实现它。下一篇,我们将学习如何借助不可变对象来实现强大的程序结构。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/functional-programming-python-immutable-data-structures
|
||||
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[StdioA](https://github.com/StdioA)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez
|
||||
[1]: https://en.wikipedia.org/wiki/Liskov_substitution_principle
|
||||
[2]: https://www.attrs.org/en/stable/
|
||||
[3]: https://pyrsistent.readthedocs.io/en/latest/
|
||||
@ -0,0 +1,159 @@
|
||||
Terminalizer:一个记录您终端活动并且生成 Gif 图像的工具
|
||||
====
|
||||
|
||||
今天我们要讨论一个广为人知的主题,我们也围绕这个主题写过许多的文章,因此我不会针对这个如何记录终端会话流程给出太多具体的资料。
|
||||
|
||||
我们可以使用脚本命令来记录 Linux 的终端会话,这也是大家公认的一种办法。不过今天我们将来介绍一个能起到相同作用的工具 —— Terminalizer。
|
||||
|
||||
这个工具可以帮助我们记录用户的终端活动,以帮助我们从输出的文件中找到有用的信息。
|
||||
|
||||
### 什么是 Terminlizer
|
||||
|
||||
用户可以用 Terminlizer 记录他们的终端活动并且生成一个 Gif 图像。它是一个允许高度定制的 CLI 工具。用户可以在网络播放器、在线播放器上用链接分享他们记录下的文件。
|
||||
|
||||
**推荐阅读:**
|
||||
|
||||
- [Script – 一个记录您终端对话的简单工具][1]
|
||||
- [在 Linux 上自动记录/捕捉所有用户的终端对话][2]
|
||||
- [Teleconsole – 一个能立即与任何人分享您终端对话的工具][3]
|
||||
- [tmate – 立即与任何人分享您的终端对话][4]
|
||||
- [Peek – 在 Linux 里制造一个 Gif 记录器][5]
|
||||
- [Kgif – 一个能生成 Gif 图片,以记录窗口活动的简单 Shell 脚本][6]
|
||||
- [Gifine – 在 Ubuntu/Debian 里快速制造一个 Gif 视频][7]
|
||||
|
||||
目前没有发行版拥有官方软件包来安装此实用程序,不过我们可以用 Node.js 来安装它。
|
||||
|
||||
### 如何在 Linux 上安装 Node.js
|
||||
|
||||
安装 Node.js 有许多种方法。我们在这里将会教您一个常用的方法。
|
||||
|
||||
在 Ubuntu/LinuxMint 上可以使用 [APT-GET 命令][8] 或者 [APT 命令][9] 来安装 Node.js。
|
||||
|
||||
```
|
||||
$ curl -sL https://deb.nodesource.com/setup_8.x | sudo -E bash -
|
||||
$ sudo apt-get install -y nodejs
|
||||
```
|
||||
|
||||
在 Debian 上使用 [APT-GET 命令][8] 或者 [APT 命令][9] 来安装 Node.js。
|
||||
|
||||
```
|
||||
# curl -sL https://deb.nodesource.com/setup_8.x | bash -
|
||||
# apt-get install -y nodejs
|
||||
```
|
||||
|
||||
在 RHEL/CentOS 上,使用 [YUM 命令][10] 来安装。
|
||||
|
||||
```
|
||||
$ sudo curl --silent --location https://rpm.nodesource.com/setup_8.x | sudo bash -
|
||||
$ sudo yum install epel-release
|
||||
$ sudo yum -y install nodejs
|
||||
```
|
||||
|
||||
在 Fedora 上,用 [DNF 命令][11] 来安装 tmux。
|
||||
|
||||
```
|
||||
$ sudo dnf install nodejs
|
||||
```
|
||||
|
||||
在 Arch Linux 上,用 [Pacman 命令][12] 来安装 tmux。
|
||||
|
||||
```
|
||||
$ sudo pacman -S nodejs npm
|
||||
```
|
||||
|
||||
在 openSUSE 上,用 [Zypper Command][13] 来安装 tmux。
|
||||
|
||||
```
|
||||
$ sudo zypper in nodejs6
|
||||
```
|
||||
|
||||
### 如何安装 Terminalizer
|
||||
|
||||
您已经安装了 Node.js 这个先决软件包,现在是时候在您的系统上安装 Terminalizer 了。简单执行如下的 `npm` 命令即可安装。
|
||||
|
||||
```
|
||||
$ sudo npm install -g terminalizer
|
||||
```
|
||||
|
||||
### 如何使用 Terminalizer
|
||||
|
||||
您只需要执行如下的命令,即可使用 Terminalizer 记录您的终端会话活动。您可以敲击 `CTRL+D` 来结束并且保存记录。
|
||||
|
||||
```
|
||||
# terminalizer record 2g-session
|
||||
|
||||
defaultConfigPath
|
||||
The recording session is started
|
||||
Press CTRL+D to exit and save the recording
|
||||
```
|
||||
|
||||
这将会将您记录的会话保存成一个 YAML 文件,在这个例子里,我的文件名将会是 2g-session-activity.yml。
|
||||
|
||||
![][15]
|
||||
|
||||
```
|
||||
# logout
|
||||
Successfully Recorded
|
||||
The recording data is saved into the file:
|
||||
/home/daygeek/2g-session.yml
|
||||
You can edit the file and even change the configurations.
|
||||
```
|
||||
|
||||
![][16]
|
||||
|
||||
### 如何播放记录下来的文件
|
||||
|
||||
使用以下命令来播放您记录的 YAML 文件。在以下操作中,请确保您已经用了您的文件名来替换 “2g-session”。
|
||||
|
||||
```
|
||||
# terminalizer play 2g-session
|
||||
```
|
||||
|
||||
将记录的文件渲染成 Gif 图像。
|
||||
|
||||
```
|
||||
# terminalizer render 2g-session
|
||||
```
|
||||
|
||||
注意: 以下的两个命令在此版本尚且不可用,或许在下一版本这两个命令将会付诸使用。
|
||||
|
||||
如果您想要将记录的文件分享给其他人,您可以将您的文件上传到在线播放器,并且将链接分享给对方。
|
||||
|
||||
```
|
||||
terminalizer share 2g-session
|
||||
```
|
||||
|
||||
为记录的文件生成一个网络播放器。
|
||||
|
||||
```
|
||||
# terminalizer generate 2g-session
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/terminalizer-a-tool-to-record-your-terminal-and-generate-animated-gif-images/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[thecyanbird](https://github.com/thecyanbird)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[1]: https://www.2daygeek.com/script-command-record-save-your-terminal-session-activity-linux/
|
||||
[2]: https://www.2daygeek.com/automatically-record-all-users-terminal-sessions-activity-linux-script-command/
|
||||
[3]: https://www.2daygeek.com/teleconsole-share-terminal-session-instantly-to-anyone-in-seconds/
|
||||
[4]: https://www.2daygeek.com/tmate-instantly-share-your-terminal-session-to-anyone-in-seconds/
|
||||
[5]: https://www.2daygeek.com/peek-create-animated-gif-screen-recorder-capture-arch-linux-mint-fedora-ubuntu/
|
||||
[6]: https://www.2daygeek.com/kgif-create-animated-gif-file-active-window-screen-recorder-capture-arch-linux-mint-fedora-ubuntu-debian-opensuse-centos/
|
||||
[7]: https://www.2daygeek.com/gifine-create-animated-gif-vedio-recorder-linux-mint-debian-ubuntu/
|
||||
[8]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[9]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[10]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[11]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[12]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[13]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
[14]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[15]: https://www.2daygeek.com/wp-content/uploads/2018/10/terminalizer-record-2g-session-1.gif
|
||||
[16]: https://www.2daygeek.com/wp-content/uploads/2018/10/terminalizer-play-2g-session.gif
|
||||
@ -0,0 +1,118 @@
|
||||
服务器的 LinuxBoot:告别 UEFI、拥抱开源
|
||||
============
|
||||
|
||||
[LinuxBoot][13] 是私有的 [UEFI][15] 固件的开源 [替代品][14]。它发布于去年,并且现在已经得到主流的硬件生产商的认可成为他们产品的默认固件。去年,LinuxBoot 已经被 Linux 基金会接受并[纳入][16]开源家族。
|
||||
|
||||
这个项目最初是由 Ron Minnich 在 2017 年 1 月提出,它是 LinuxBIOS 的创造人,并且在 Google 领导 [coreboot][17] 的工作。
|
||||
|
||||
Google、Facebook、[Horizon Computing Solutions][18]、和 [Two Sigma][19] 共同合作,在运行 Linux 的服务器上开发 [LinuxBoot 项目][20](以前叫 [NERF][21])。
|
||||
|
||||
它的开放性允许服务器用户去很容易地定制他们自己的引导脚本、修复问题、构建他们自己的 [运行时环境][22] 和用他们自己的密钥去 [刷入固件][23],而不需要等待供应商的更新。
|
||||
|
||||
下面是第一次使用 NERF BIOS 去引导 [Ubuntu Xenial][24] 的视频:
|
||||
|
||||
[点击看视频](https://youtu.be/HBkZAN3xkJg)
|
||||
|
||||
我们来讨论一下它与 UEFI 相比在服务器硬件方面的其它优势。
|
||||
|
||||
### LinuxBoot 超越 UEFI 的优势
|
||||
|
||||

|
||||
|
||||
下面是一些 LinuxBoot 超越 UEFI 的主要优势:
|
||||
|
||||
#### 启动速度显著加快
|
||||
|
||||
它能在 20 秒钟以内完成服务器启动,而 UEFI 需要几分钟的时间。
|
||||
|
||||
#### 显著的灵活性
|
||||
|
||||
LinuxBoot 可以用在 Linux 支持的各种设备、文件系统和协议上。
|
||||
|
||||
#### 更加安全
|
||||
|
||||
相比 UEFI 而言,LinuxBoot 在设备驱动程序和文件系统方面进行更加严格的检查。
|
||||
|
||||
我们可能争辩说 UEFI 是使用 [EDK II][25] 而部分开源的,而 LinuxBoot 是部分闭源的。但有人[提出][26],即便有像 EDK II 这样的代码,但也没有做适当的审查级别和像 [Linux 内核][27] 那样的正确性检查,并且在 UEFI 的开发中还大量使用闭源组件。
|
||||
|
||||
另一方面,LinuxBoot 有非常小的二进制文件,它仅用了大约几百 KB,相比而言,而 UEFI 的二进制文件有 32 MB。
|
||||
|
||||
严格来说,LinuxBoot 与 UEFI 不一样,更适合于[可信计算基础][28]。
|
||||
|
||||
LinuxBoot 有一个基于 [kexec][30] 的引导加载器,它不支持启动 Windows/非 Linux 内核,但这影响并不大,因为主流的云都是基于 Linux 的服务器。
|
||||
|
||||
### LinuxBoot 的采用者
|
||||
|
||||
自 2011 年, [Facebook][32] 发起了[开源计算项目(OCP)][31],它的一些服务器是基于[开源][33]设计的,目的是构建的数据中心更加高效。LinuxBoot 已经在下面列出的几个开源计算硬件上做了测试:
|
||||
|
||||
* Winterfell
|
||||
* Leopard
|
||||
* Tioga Pass
|
||||
|
||||
更多 [OCP][34] 硬件在[这里][35]有一个简短的描述。OCP 基金会通过[开源系统固件][36]运行一个专门的固件项目。
|
||||
|
||||
支持 LinuxBoot 的其它一些设备有:
|
||||
|
||||
* [QEMU][9] 仿真的 [Q35][10] 系统
|
||||
* [Intel S2600wf][11]
|
||||
* [Dell R630][12]
|
||||
|
||||
上个月底(2018 年 9 月 24 日),[Equus 计算解决方案][37] [宣布][38] 发行它的 [白盒开放式™][39] M2660 和 M2760 服务器,作为它们的定制的、成本优化的、开放硬件服务器和存储平台的一部分。它们都支持 LinuxBoot 灵活定制服务器的 BIOS,以提升安全性和设计一个非常快的纯净的引导体验。
|
||||
|
||||
### 你认为 LinuxBoot 怎么样?
|
||||
|
||||
LinuxBoot 在 [GitHub][40] 上有很丰富的文档。你喜欢它与 UEFI 不同的特性吗?由于 LinuxBoot 的开放式开发和未来,你愿意使用 LinuxBoot 而不是 UEFI 去启动你的服务器吗?请在下面的评论区告诉我们吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/linuxboot-uefi/
|
||||
|
||||
作者:[Avimanyu Bandyopadhyay][a]
|
||||
选题:[oska874][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/avimanyu/
|
||||
[b]:https://github.com/oska874
|
||||
[1]:https://itsfoss.com/linuxboot-uefi/#
|
||||
[2]:https://itsfoss.com/linuxboot-uefi/#
|
||||
[3]:https://itsfoss.com/linuxboot-uefi/#
|
||||
[4]:https://itsfoss.com/linuxboot-uefi/#
|
||||
[5]:https://itsfoss.com/linuxboot-uefi/#
|
||||
[6]:https://itsfoss.com/linuxboot-uefi/#
|
||||
[7]:https://itsfoss.com/author/avimanyu/
|
||||
[8]:https://itsfoss.com/linuxboot-uefi/#comments
|
||||
[9]:https://en.wikipedia.org/wiki/QEMU
|
||||
[10]:https://wiki.qemu.org/Features/Q35
|
||||
[11]:https://trmm.net/S2600
|
||||
[12]:https://trmm.net/NERF#Installing_on_a_Dell_R630
|
||||
[13]:https://www.linuxboot.org/
|
||||
[14]:https://www.phoronix.com/scan.php?page=news_item&px=LinuxBoot-OSFC-2018-State
|
||||
[15]:https://itsfoss.com/check-uefi-or-bios/
|
||||
[16]:https://www.linuxfoundation.org/blog/2018/01/system-startup-gets-a-boost-with-new-linuxboot-project/
|
||||
[17]:https://en.wikipedia.org/wiki/Coreboot
|
||||
[18]:http://www.horizon-computing.com/
|
||||
[19]:https://www.twosigma.com/
|
||||
[20]:https://trmm.net/LinuxBoot_34c3
|
||||
[21]:https://trmm.net/NERF
|
||||
[22]:https://trmm.net/LinuxBoot_34c3#Runtimes
|
||||
[23]:http://www.tech-faq.com/flashing-firmware.html
|
||||
[24]:https://itsfoss.com/features-ubuntu-1604/
|
||||
[25]:https://www.tianocore.org/
|
||||
[26]:https://media.ccc.de/v/34c3-9056-bringing_linux_back_to_server_boot_roms_with_nerf_and_heads
|
||||
[27]:https://medium.com/@bhumikagoyal/linux-kernel-development-cycle-52b4c55be06e
|
||||
[28]:https://en.wikipedia.org/wiki/Trusted_computing_base
|
||||
[29]:https://itsfoss.com/adobe-alternatives-linux/
|
||||
[30]:https://en.wikipedia.org/wiki/Kexec
|
||||
[31]:https://en.wikipedia.org/wiki/Open_Compute_Project
|
||||
[32]:https://github.com/facebook
|
||||
[33]:https://github.com/opencomputeproject
|
||||
[34]:https://www.networkworld.com/article/3266293/lan-wan/what-is-the-open-compute-project.html
|
||||
[35]:http://hyperscaleit.com/ocp-server-hardware/
|
||||
[36]:https://www.opencompute.org/projects/open-system-firmware
|
||||
[37]:https://www.equuscs.com/
|
||||
[38]:http://www.dcvelocity.com/products/Software_-_Systems/20180924-equus-compute-solutions-introduces-whitebox-open-m2660-and-m2760-servers/
|
||||
[39]:https://www.equuscs.com/servers/whitebox-open/
|
||||
[40]:https://github.com/linuxboot/linuxboot
|
||||
@ -1,12 +1,13 @@
|
||||
推动 DevOps 变革的三个方面
|
||||
======
|
||||
推动大规模的组织变革是一个痛苦的过程。对于 DevOps 来说,尽管也有阵痛,但变革带来的价值则相当可观。
|
||||
|
||||
> 推动大规模的组织变革是一个痛苦的过程。对于 DevOps 来说,尽管也有阵痛,但变革带来的价值则相当可观。
|
||||
|
||||

|
||||
|
||||
避免痛苦是一种强大的动力。一些研究表明,[植物也会通过遭受疼痛的过程][1]以采取措施来保护自己。我们人类有时也会刻意让自己受苦——在剧烈运动之后,身体可能会发生酸痛,但我们仍然坚持运动。那是因为当人认为整个过程利大于弊时,几乎可以忍受任何事情。
|
||||
|
||||
推动大规模的组织变革得过程确实是痛苦的。有人可能会因难以改变价值观和行为而感到痛苦,有人可能会因难以带领团队而感到痛苦,也有人可能会因难以开展工作而感到痛苦。但就 DevOps 而言,我可以说这些痛苦都是值得的。
|
||||
推动大规模的组织变革的过程确实是痛苦的。有人可能会因难以改变价值观和行为而感到痛苦,有人可能会因难以带领团队而感到痛苦,也有人可能会因难以开展工作而感到痛苦。但就 DevOps 而言,我可以说这些痛苦都是值得的。
|
||||
|
||||
我也曾经关注过一个团队耗费大量时间优化技术流程的过程,在这个过程中,团队逐渐将流程进行自动化改造,并最终获得了成功。
|
||||
|
||||
@ -14,60 +15,64 @@
|
||||
|
||||
图片来源:Lee Eason. CC BY-SA 4.0
|
||||
|
||||
这张图表充分表明了变革的价值。一家公司在我主导实行了 DevOps 转型之后,60 多个团队每月提交了超过 900 个发布请求。这些工作量的原耗时高达每个月 350 天,而这么多的工作量对于任何公司来说都是不可忽视的。除此以外,他们每月的部署次数从 100 次增加到了 9000 次,高危 bug 减少了 24%,工程师们更轻松了,<ruby>净推荐值<rt>Net Promoter Score</rt></ruby>(NPS)也提高了,而 NPS 提高反过来也让团队的 DevOps 转型更加顺利。正如 [Puppet 发布的 DevOps 报告][4]所预测的,用在技术流程改进上的投资可以在业务成果上明显地体现出来。
|
||||
这张图表充分表明了变革的价值。一家公司在我主导实行了 DevOps 转型之后,60 多个团队每月提交了超过 900 个发布请求。这些工作量的原耗时高达每个月 350 人/天,而这么多的工作量对于任何公司来说都是不可忽视的。除此以外,他们每月的部署次数从 100 次增加到了 9000 次,高危 bug 减少了 24%,工程师们更轻松了,<ruby>净推荐值<rt>Net Promoter Score</rt></ruby>(NPS)也提高了,而 NPS 提高反过来也让团队的 DevOps 转型更加顺利。正如 [Puppet 发布的 DevOps 报告][4]所预测的,用在技术流程改进上的投入可以在业务成果上明显地体现出来。
|
||||
|
||||
而 DevOps 主导者在推动变革是必须关注这三个方面:团队管理,团队文化和团队活力。
|
||||
而 DevOps 主导者在推动变革时必须关注这三个方面:团队管理,团队文化和团队活力。
|
||||
|
||||
### 团队管理
|
||||
|
||||
最重要的是,改进对技术流程的投入可以转化为更好的业务成果。
|
||||
|
||||
组织架构越大,业务领导与一线员工之间的距离就会越大,当然发生误解的可能性也会越大。而且各种技术工具和实际应用都在以日新月异的速度变化,这就导致业务领导几乎不可能对 DevOps 或敏捷开发的转型方向有一个亲身的了解。
|
||||
|
||||
DevOps 主导者必须和管理层密切合作,在进行决策的时候给出相关的意见,以帮助他们做出正确的决策。
|
||||
|
||||
公司的管理层只是知道 DevOps 会对产品部署的方式进行改进,而并不了解其中的具体过程。当管理层发现你在和软件团队执行自动化部署失败时,就会想要了解这件事情的细节。如果管理层了解到进行部署的是软件团队而不是专门的发布管理团队,就可能会坚持使用传统的变更流程来保证业务的正常运作。你可能会失去团队的信任,团队也可能不愿意作出进一步的改变。
|
||||
公司的管理层只是知道 DevOps 会对产品部署的方式进行改进,而并不了解其中的具体过程。假设你正在帮助一个软件开发团队实现自动化部署,当管理层得知某次部署失败时(这种情况是有的),就会想要了解这件事情的细节。如果管理层了解到进行部署的是软件团队而不是专门的发布管理团队,就可能会坚持使用传统的变更流程来保证业务的正常运作。你可能会失去团队的信任,团队也可能不愿意做出进一步的改变。
|
||||
|
||||
如果没有和管理层做好心理上的预期,一旦发生意外的生产事件,都会对你和管理层之间的信任造成难以消除的影响。所以,最好事先和管理层之间在各方面协调好,这会让你在后续的工作中避免很多麻烦。
|
||||
如果没有和管理层做好心理上的预期,一旦发生意外的生产事件,重建管理层的信任并得到他们的支持比事先对他们进行教育需要更长的时间。所以,最好事先和管理层在各方面协调好,这会让你在后续的工作中避免很多麻烦。
|
||||
|
||||
对于和管理层之间的协调,这里有两条建议:
|
||||
|
||||
* 一是**重视所有规章制度**。如果管理层对合同、安全等各方面有任何疑问,你都可以向法务或安全负责人咨询,这样做可以避免犯下后果严重的错误。
|
||||
* 二是**将管理层的重点关注的方面输出为量化指标**。举个例子,如果公司的目标是减少客户流失,而你调查得出计划外的停机是造成客户流失的主要原因,那么就可以让团队对故障的<ruby>平均检测时间<rt>Mean Time To Detection</rt></ruby>(MTTD)和<ruby>平均解决时间<rt>Mean Time To Resolution</rt></ruby>(MTTR)实行重点优化。你可以使用这些关键指标来量化团队的工作成果,而管理层对此也可以有一个直观的了解。
|
||||
|
||||
|
||||
* 一是**重视所有规章制度**。如果管理层对合同、安全等各方面有任何疑问,你都可以向法务或安全负责人咨询,这样做可以避免犯下后果严重的错误。
|
||||
* 二是**将管理层重点关注的方面输出为量化指标**。举个例子,如果公司的目标是减少客户流失,而你调查得出计划外的服务宕机是造成客户流失的主要原因,那么就可以让团队对故障的<ruby>平均排查时间<rt>Mean Time To Detection</rt></ruby>(MTTD)和<ruby>平均解决时间<rt>Mean Time To Resolution</rt></ruby>(MTTR)实行重点优化。你可以使用这些关键指标来量化团队的工作成果,而管理层对此也可以有一个直观的了解。
|
||||
|
||||
### 团队文化
|
||||
|
||||
DevOps 是一种专注于持续改进代码、构建、部署和操作流程的文化,而团队文化代表了团队的价值观和行为。从本质上说,团队文化是要塑造团队成员的行为方式,而这并不是一件容易的事。
|
||||
|
||||
我推荐一本叫做《[披着狼皮的 CIO][5]》的书。另外,研究心理学、阅读《[Drive][6]》、观看 Daniel Pink 的 [TED 演讲][7]、阅读《[千面英雄][7]》、了解每个人的心路历程,以上这些都是你推动公司技术变革所应该尝试去做的事情。
|
||||
我推荐一本叫做《[披着狼皮的 CIO][5]》的书。另外,研究心理学、阅读《[Drive][6]》、观看 Daniel Pink 的 [TED 演讲][7]、阅读《[千面英雄][7]》、了解每个人的心路历程,以上这些都是你推动公司技术变革所应该尝试去做的事情。如果这些你都没兴趣,说明你不是那个推动公司变革的人。如果你想成为那个人,那就开始学习吧!
|
||||
|
||||
理性的人大多都按照自己的价值观工作,然而团队通常没有让每个人都能达成共识的明确价值观。因此,你需要明确团队目前的价值观,包括价值观的形成过程和价值观的目标导向。也不能将这些价值观强加到团队成员身上,只需要让团队成员在目前的硬件条件下力所能及地做到最好就可以了
|
||||
从本质上说,改变一个人真不是件容易的事。
|
||||
|
||||
同时需要向团队成员阐明,公司正在发生组织上的变化,团队的价值观也随之改变,最好也厘清整个过程中将会作出什么变化。例如,公司以往或许是由于资金有限,一直将节约成本的原则放在首位,在研发新产品的时候,基础架构团队不得不通过共享数据库集群或服务器,从而导致了服务之间的紧密耦合。然而随着时间的推移,这种做法会产生难以维护的混乱,即使是一个小小的变化也可能造成无法预料的后果。这就导致交付团队难以执行变更控制流程,进而令变更停滞不前。
|
||||
理性的人大多都按照自己的价值观工作,然而团队通常没有让每个人都能达成共识的明确价值观。因此,你需要明确团队目前的价值观,包括价值观的形成过程和价值观的目标导向。但不能将这些价值观强加到团队成员身上,只需要让团队成员在现有条件下力所能及地做到最好就可以了。
|
||||
|
||||
如果这种状况持续多年,最终的结果将会是毫无创新、技术老旧、问题繁多以及产品品质低下,公司的发展到达了瓶颈,原本的价值观已经不再适用。所以,工作效率的优先级必须高于节约成本。
|
||||
同时需要向团队成员阐明,公司正在发生组织和团队目标的变化,团队的价值观也随之改变,最好也厘清整个过程中将会作出什么变化。例如,公司以往或许是由于资金有限,一直将节约成本的原则放在首位,在研发新产品的时候,基础架构团队不得不共享数据库集群或服务器,从而导致了服务之间的紧密耦合。然而随着时间的推移,这种做法会产生难以维护的混乱,即使是一个小小的变化也可能造成无法预料的后果。这就导致交付团队难以执行变更控制流程,进而令变更停滞不前。
|
||||
|
||||
你必须强调团队的价值观。每当团队按照价值观取得了一定的工作进展,都应该对团队作出激励。在团队部署出现失败时,鼓励他们承担风险、继续学习,同时指导团队如何改进他们的工作并表示支持。长此下来,团队成员就会对你产生信任,并逐渐切合团队的价值观。
|
||||
如果这种状况持续几年,最终的结果将会是毫无创新、技术老旧、问题繁多以及产品品质低下,公司的发展到达了瓶颈,原本的价值观已经不再适用。所以,工作效率的优先级必须高于节约成本。如果一个选择能让团队运作更好,另一个选择只是短期来看成本便宜,那你应该选择前者。
|
||||
|
||||
你必须反复强调团队的价值观。每当团队取得了一定的工作进展(即使探索创新时出现一些小的失误),都应该对团队作出激励。在团队部署出现失败时,鼓励他们承担风险、吸取教训,同时指导团队如何改进他们的工作并表示支持。长此下来,团队成员就会对你产生信任,不再顾虑为切合团队的价值观而做出改变。
|
||||
|
||||
### 团队活力
|
||||
|
||||
你有没有在会议上听过类似这样的话?“在张三度假回来之前,我们无法对这件事情做出评估。他是唯一一个了解代码的人”,或者是“我们完成不了这项任务,它在网络上需要跨团队合作,而防火墙管理员刚好请病假了”,又或者是“张三最清楚这个系统最好,他说是怎么样,通常就是怎么样”。那么如果团队在处理工作时,谁才是主力?就是张三。而且也一直会是他。
|
||||
你有没有在会议上听过类似这样的话?“在张三度假回来之前,我们无法对这件事情做出评估。他是唯一一个了解代码的人”,或者是“我们完成不了这项任务,它在网络上需要跨团队合作,而防火墙管理员刚好请病假了”,又或者是“张三最清楚这个系统,他说是怎么样,通常就是怎么样”。那么如果团队在处理工作时,谁才是主力?就是张三。而且也一直会是他。
|
||||
|
||||
我们一直都认为这就是软件开发的本质。但是如果我们不作出改变,这种循环就会一直保持下去。
|
||||
我们一直都认为这就是软件开发的自带属性。但是如果我们不作出改变,这种循环就会一直持续下去。
|
||||
|
||||
熵的存在会让团队自发地变得混乱和缺乏活力,团队的成员和主导者的都有责任控制这个熵并保持团队的活力。DevOps、敏捷开发、上云、代码重构这些行为都会令熵增加速,这是因为转型让团队需要学习更多新技能和专业知识以开展新工作。
|
||||
熵的存在会让团队自发地变得混乱和缺乏活力,团队的成员和主导者的都有责任控制这个熵并保持团队的活力。DevOps、敏捷开发、上云、代码重构这些行为都会令熵加速增长,这是因为转型让团队需要学习更多新技能和专业知识以开展新工作。
|
||||
|
||||
我们来看一个产品团队重构遗留代码的例子。像往常一样,他们在 AWS 上构建新的服务。而传统的系统则在数据中心部署,并由 IT 部门进行监控和备份。IT 部门会确保在基础架构的层面上满足应用的安全需求、进行灾难恢复测试、系统补丁、安装配置了入侵检测和防病毒代理,而且 IT 部门还保留了年度审计流程所需的变更控制记录。
|
||||
我们来看一个产品团队重构历史代码的例子。像往常一样,他们在 AWS 上构建新的服务。而传统的系统则在数据中心部署,并由 IT 部门进行监控和备份。IT 部门会确保在基础架构的层面上满足应用的安全需求、进行灾难恢复测试、系统补丁、安装配置了入侵检测和防病毒代理,而且 IT 部门还保留了年度审计流程所需的变更控制记录。
|
||||
|
||||
产品团队经常会犯一个致命的错误,就是认为 IT 部门是需要突破的瓶颈。他们希望脱离已有的 IT 部门并使用公有云,但实际上是他们忽视了 IT 部门提供的关键服务。迁移到云上只是以不同的方式实现这些关键服务,因为 AWS 也是一个数据中心,团队即使使用 AWS 也需要完成 IT 运维任务。
|
||||
产品团队经常会犯一个致命的错误,就是认为 IT 是消耗资源的部门,是需要突破的瓶颈。他们希望脱离已有的 IT 部门并使用公有云,但实际上是他们忽视了 IT 部门提供的关键服务。迁移到云上只是以不同的方式实现这些关键服务,因为 AWS 也是一个数据中心,团队即使使用 AWS 也需要完成 IT 运维任务。
|
||||
|
||||
实际上,产品团队在迁移到云时候也必须学习如何使用这些 IT 服务。因此,当产品团队开始重构遗留的代码并部署到云上时,也需要学习大量的技能才能正常运作。这些技能不会无师自通,必须自行学习或者聘用相关的人员,团队的主导者也必须积极进行管理。
|
||||
实际上,产品团队在向云迁移的时候也必须学习如何使用这些 IT 服务。因此,当产品团队开始重构历史代码并部署到云上时,也需要学习大量的技能才能正常运作。这些技能不会无师自通,必须自行学习或者聘用相关的人员,团队的主导者也必须积极进行管理。
|
||||
|
||||
在带领团队时,我找不到任何适合我的工具,因此我建立了 [Tekita.io][9] 这个项目。Tekata 免费而且容易使用。但相比起来,把注意力集中在人员和流程上更为重要,你需要不断学习,持续关注团队的弱项,因为它们会影响团队的交付能力,而修补这些弱项往往需要学习大量的新知识,这就需要团队成员之间有一个很好的协作。因此 76% 的年轻人都认为个人发展机会是公司文化[最重要的的一环][10]。
|
||||
在带领团队时,我找不到任何适合我的工具,因此我建立了 [Tekita.io][9] 这个项目。Tekata 免费而且容易使用。但相比起来,把注意力集中在人员和流程上更为重要,你需要不断学习,持续关注团队的短板,因为它们会影响团队的交付能力,而弥补这些短板往往需要学习大量的新知识,这就需要团队成员之间有一个很好的协作。因此 76% 的年轻人都认为个人发展机会是公司文化[最重要的的一环][10]。
|
||||
|
||||
### 效果就是最好的证明
|
||||
|
||||
DevOps 转型会改变团队的工作方式和文化,这需要得到管理层的支持和理解。同时,工作方式的改变意味着新技术的引入,所以在管理上也必须谨慎。但转型的最终结果是团队变得更高效、成员变得更积极、产品变得更优质,客户也变得更快乐。
|
||||
DevOps 转型会改变团队的工作方式和文化,这需要得到管理层的支持和理解。同时,工作方式的改变意味着新技术的引入,所以在管理上也必须谨慎。但转型的最终结果是团队变得更高效、成员变得更积极、产品变得更优质,客户也变得更满意。
|
||||
|
||||
Lee Eason 将于 10 月 21-23 日在北卡罗来纳州 Raleigh 举行的 [All Things Open][12] 上讲述 [DevOps 转型的故事][11]。
|
||||
|
||||
免责声明:本文中的内容仅为 Lee Eason 的个人立场,不代表 Ipreo 或 IHS Markit。
|
||||
|
||||
@ -78,7 +83,7 @@ via: https://opensource.com/article/18/10/tales-devops-transformation
|
||||
作者:[Lee Eason][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -96,4 +101,3 @@ via: https://opensource.com/article/18/10/tales-devops-transformation
|
||||
[10]: https://www.execu-search.com/~/media/Resources/pdf/2017_Hiring_Outlook_eBook
|
||||
[11]: https://allthingsopen.org/talk/tales-from-a-devops-transformation/
|
||||
[12]: https://allthingsopen.org/
|
||||
|
||||
@ -0,0 +1,102 @@
|
||||
KeeWeb:一个开源且跨平台的密码管理工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
如果你长时间使用互联网,那很可能在很多网站上都有很多帐户。所有这些帐户都必须有密码,而且必须记住所有的密码,或者把它们写下来。在纸上写下密码可能不安全,如果有多个密码,记住它们实际上是不可能的。这就是密码管理工具在过去几年中大受欢迎的原因。密码管理工具就像一个中央存储库,你可以在其中存储所有帐户的所有密码,并为它设置一个主密码。使用这种方法,你唯一需要记住的只有主密码。
|
||||
|
||||
**KeePass** 就是一个这样的开源密码管理工具,它有一个官方客户端,但功能非常简单。也有许多 PC 端和手机端的其他密码管理工具,并且与 KeePass 存储加密密码的文件格式兼容。其中一个就是 **KeeWeb**。
|
||||
|
||||
KeeWeb 是一个开源、跨平台的密码管理工具,具有云同步,键盘快捷键和插件等功能。KeeWeb使用 Electron 框架,这意味着它可以在 Windows、Linux 和 Mac OS 上运行。
|
||||
|
||||
### KeeWeb 的使用
|
||||
|
||||
有两种方式可以使用 KeeWeb。第一种无需安装,直接在网页上使用,第二中就是在本地系统中安装 KeeWeb 客户端。
|
||||
|
||||
#### 在网页上使用 KeeWeb
|
||||
|
||||
如果不想在系统中安装应用,可以去 [https://app.keeweb.info/][1] 使用KeeWeb。
|
||||
|
||||
|
||||
|
||||
网页端具有桌面客户端的所有功能,当然也需要联网才能进行使用。
|
||||
|
||||
#### 在计算机中安装 KeeWeb
|
||||
|
||||
如果喜欢客户端的舒适性和离线可用性,也可以将其安装在系统中。
|
||||
|
||||
如果使用 Ubuntu/Debian,你可以去 [发布页][2] 下载 KeeWeb 最新的 .deb 文件,然后通过下面的命令进行安装:
|
||||
|
||||
```
|
||||
$ sudo dpkg -i KeeWeb-1.6.3.linux.x64.deb
|
||||
```
|
||||
|
||||
如果用的是 Arch,在 [AUR][3] 上也有 KeeWeb,可以使用任何 AUR 助手进行安装,例如 [Yay][4]:
|
||||
|
||||
```
|
||||
$ yay -S keeweb
|
||||
```
|
||||
|
||||
安装后,从菜单中或应用程序启动器启动 KeeWeb。默认界面如下:
|
||||
|
||||
|
||||
|
||||
### 总体布局
|
||||
|
||||
KeeWeb 界面主要显示所有密码的列表,在左侧展示所有标签。单击标签将对密码进行筛选,只显示带有那个标签的密码。在右侧,显示所选帐户的所有字段。你可以设置用户名、密码、网址,或者添加自定义的备注。你甚至可以创建自己的字段并将其标记为安全字段,这在存储信用卡信息等内容时非常有用。你只需单击即可复制密码。 KeeWeb 还显示账户的创建和修改日期。已删除的密码会保留在回收站中,可以在其中还原或永久删除。
|
||||
|
||||

|
||||
|
||||
### KeeWeb 功能
|
||||
|
||||
#### 云同步
|
||||
|
||||
KeeWeb 的主要功能之一是支持各种远程位置和云服务。除了加载本地文件,你可以从以下位置打开文件:
|
||||
|
||||
1. WebDAV Servers
|
||||
2. Google Drive
|
||||
3. Dropbox
|
||||
4. OneDrive
|
||||
|
||||
这意味着如果你使用多台计算机,就可以在它们之间同步密码文件,因此不必担心某台设备无法访问所有密码。
|
||||
|
||||
#### 密码生成器
|
||||
|
||||
|
||||
|
||||
除了对密码进行加密之外,为每个帐户创建新的强密码也很重要。这意味着,如果你的某个帐户遭到入侵,攻击者将无法使用相同的密码进入其他帐户。
|
||||
|
||||
为此,KeeWeb 有一个内置密码生成器,可以生成特定长度、包含指定字符的自定义密码。
|
||||
|
||||
#### 插件
|
||||
|
||||
|
||||
|
||||
你可以使用插件扩展 KeeWeb 的功能。其中一些插件用于更改界面语言,而其他插件则添加新功能,例如访问 https://haveibeenpwned.com 以查看密码是否暴露。
|
||||
|
||||
#### 本地备份
|
||||
|
||||
|
||||
|
||||
无论密码文件存储在何处,你都应该在计算机上保留一份本地备份。幸运的是,KeeWeb 内置了这个功能。你可以备份到特定路径,并将其设置为定期备份,或者只在文件更改时进行备份。
|
||||
|
||||
### 结论
|
||||
|
||||
我实际使用 KeeWeb 已经好几年了,它完全改变了我存储密码的方式。云同步是我长期使用 KeeWeb 的主要功能,这样我不必担心在多个设备上保存多个不同步的文件。如果你想要一个具有云同步功能的密码管理工具,KeeWeb 就是你应该关注的东西。
|
||||
|
||||
------
|
||||
|
||||
via: https://www.ostechnix.com/keeweb-an-open-source-cross-platform-password-manager/
|
||||
|
||||
作者:[EDITOR][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[jlztan](https://github.com/jlztan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[1]: https://app.keeweb.info/
|
||||
[2]: https://github.com/keeweb/keeweb/releases/latest
|
||||
[3]: https://aur.archlinux.org/packages/keeweb/
|
||||
[4]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
@ -1,9 +1,9 @@
|
||||
在 Fedora 上使用 Steam play 和 Proton 来玩 Windows 游戏
|
||||
在 Fedora 上使用 Steam play 和 Proton 来玩 Windows 游戏
|
||||
======
|
||||
|
||||

|
||||
|
||||
几周前,Steam 宣布要给 Steam Play 增加一个新组件,用于支持在 Linux 平台上使用 Proton 来玩 Windows 的游戏,这个组件是 WINE 的一个分支。这个功能仍然处于测试阶段,且并非对所有游戏都有效。这里有一些关于 Steam 和 Proton 的细节。
|
||||
之前,Steam [宣布][1]要给 Steam Play 增加一个新组件,用于支持在 Linux 平台上使用 Proton 来玩 Windows 的游戏,这个组件是 WINE 的一个分支。这个功能仍然处于测试阶段,且并非对所有游戏都有效。这里有一些关于 Steam 和 Proton 的细节。
|
||||
|
||||
据 Steam 网站称,测试版本中有以下这些新功能:
|
||||
|
||||
@ -13,29 +13,27 @@
|
||||
* 改进了对游戏控制器的支持,游戏自动识别所有 Steam 支持的控制器,比起游戏的原始版本,能够获得更多开箱即用的控制器兼容性。
|
||||
* 和 vanilla WINE 比起来,游戏的多线程性能得到了极大的提高。
|
||||
|
||||
|
||||
|
||||
### 安装
|
||||
|
||||
如果你有兴趣,想尝试一下 Steam 和 Proton。请按照下面这些简单的步骤进行操作。(请注意,如果你已经安装了最新版本的 Steam,可以忽略启用 Steam 测试版这个第一步。在这种情况下,你不再需要通过 Steam 测试版来使用 Proton。)
|
||||
|
||||
打开 Steam 并登陆到你的帐户,这个截屏示例显示的是在使用 Proton 之前仅支持22个游戏。
|
||||
打开 Steam 并登陆到你的帐户,这个截屏示例显示的是在使用 Proton 之前仅支持 22 个游戏。
|
||||
|
||||
![][3]
|
||||
|
||||
现在点击客户端顶部的 Steam 选项,这会显示一个下拉菜单。然后选择设置。
|
||||
现在点击客户端顶部的 “Steam” 选项,这会显示一个下拉菜单。然后选择“设置”。
|
||||
|
||||
![][4]
|
||||
|
||||
现在弹出了设置窗口,选择账户选项,并在 Beta participation 旁边,点击更改。
|
||||
现在弹出了设置窗口,选择“账户”选项,并在 “参与 Beta 测试” 旁边,点击“更改”。
|
||||
|
||||
![][5]
|
||||
|
||||
现在将 None 更改为 Steam Beta Update。
|
||||
现在将 “None” 更改为 “Steam Beta Update”。
|
||||
|
||||
![][6]
|
||||
|
||||
点击确定,然后系统会提示你重新启动。
|
||||
点击“确定”,然后系统会提示你重新启动。
|
||||
|
||||
![][7]
|
||||
|
||||
@ -43,11 +41,11 @@
|
||||
|
||||
![][8]
|
||||
|
||||
在重新启动之后,返回到上面的设置窗口。这次你会看到一个新选项。确定有为提供支持的游戏使用 Stream Play 这个复选框,让所有的游戏都使用 Steam Play 进行运行,而不是 steam 中游戏特定的选项。兼容性工具应该是 Proton。
|
||||
在重新启动之后,返回到上面的设置窗口。这次你会看到一个新选项。确定勾选了“为提供支持的游戏使用 Stream Play” 、“让所有的游戏都使用 Steam Play 运行”,“使用这个工具替代 Steam 中游戏特定的选项”。这个兼容性工具应该就是 Proton。
|
||||
|
||||
![][9]
|
||||
|
||||
Steam 客户端会要求你重新启动,照做,然后重新登陆你的 Steam 账户,你的 Linux 的游戏库就能得到扩展了。
|
||||
Steam 客户端会要求你重新启动,照做,然后重新登录你的 Steam 账户,你的 Linux 的游戏库就能得到扩展了。
|
||||
|
||||
![][10]
|
||||
|
||||
@ -69,7 +67,7 @@ Steam 客户端会要求你重新启动,照做,然后重新登陆你的 Stea
|
||||
|
||||
![][16]
|
||||
|
||||
一些游戏可能会受到 Proton 测试性质的影响,在下面这个叫 Chantelise 游戏中,没有了声音并且帧率很低。请记住这个功能仍然在测试阶段,Fedora 不会对结果负责。如果你想要了解更多,社区已经创建了一个 Google 文档,这个文档里有已经测试过的游戏的列表。
|
||||
一些游戏可能会受到 Proton 测试性质的影响,在这个叫 Chantelise 游戏中,没有了声音并且帧率很低。请记住这个功能仍然在测试阶段,Fedora 不会对结果负责。如果你想要了解更多,社区已经创建了一个 Google 文档,这个文档里有已经测试过的游戏的列表。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -79,25 +77,25 @@ via: https://fedoramagazine.org/play-windows-games-steam-play-proton/
|
||||
作者:[Francisco J. Vergara Torres][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/patxi/
|
||||
[1]: https://steamcommunity.com/games/221410/announcements/detail/1696055855739350561
|
||||
[2]: https://fedoramagazine.org/third-party-repositories-fedora/
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2018/09/listOfGamesLinux-300x197.png
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2018/09/1-300x169.png
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2018/09/2-300x196.png
|
||||
[6]: https://fedoramagazine.org/wp-content/uploads/2018/09/4-300x272.png
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2018/09/6-300x237.png
|
||||
[8]: https://fedoramagazine.org/wp-content/uploads/2018/09/7-300x126.png
|
||||
[9]: https://fedoramagazine.org/wp-content/uploads/2018/09/10-300x237.png
|
||||
[10]: https://fedoramagazine.org/wp-content/uploads/2018/09/12-300x196.png
|
||||
[11]: https://fedoramagazine.org/wp-content/uploads/2018/09/13-300x196.png
|
||||
[12]: https://fedoramagazine.org/wp-content/uploads/2018/09/14-300x195.png
|
||||
[13]: https://fedoramagazine.org/wp-content/uploads/2018/09/15-300x196.png
|
||||
[14]: https://fedoramagazine.org/wp-content/uploads/2018/09/16-300x195.png
|
||||
[15]: https://fedoramagazine.org/wp-content/uploads/2018/09/Screenshot-from-2018-08-30-15-14-59-300x169.png
|
||||
[16]: https://fedoramagazine.org/wp-content/uploads/2018/09/Screenshot-from-2018-08-30-15-19-34-300x169.png
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2018/09/listOfGamesLinux-768x505.png
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2018/09/1-768x432.png
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2018/09/2-768x503.png
|
||||
[6]: https://fedoramagazine.org/wp-content/uploads/2018/09/4.png
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2018/09/6.png
|
||||
[8]: https://fedoramagazine.org/wp-content/uploads/2018/09/7.png
|
||||
[9]: https://fedoramagazine.org/wp-content/uploads/2018/09/10.png
|
||||
[10]: https://fedoramagazine.org/wp-content/uploads/2018/09/12-768x503.png
|
||||
[11]: https://fedoramagazine.org/wp-content/uploads/2018/09/13-768x501.png
|
||||
[12]: https://fedoramagazine.org/wp-content/uploads/2018/09/14-768x498.png
|
||||
[13]: https://fedoramagazine.org/wp-content/uploads/2018/09/15-768x501.png
|
||||
[14]: https://fedoramagazine.org/wp-content/uploads/2018/09/16-768x500.png
|
||||
[15]: https://fedoramagazine.org/wp-content/uploads/2018/09/Screenshot-from-2018-08-30-15-14-59-768x432.png
|
||||
[16]: https://fedoramagazine.org/wp-content/uploads/2018/09/Screenshot-from-2018-08-30-15-19-34-768x432.png
|
||||
[17]: https://docs.google.com/spreadsheets/d/1DcZZQ4HL_Ol969UbXJmFG8TzOHNnHoj8Q1f8DIFe8-8/edit#gid=1003113831
|
||||
@ -0,0 +1,163 @@
|
||||
5 个适合系统管理员使用的告警可视化工具
|
||||
======
|
||||
|
||||
> 这些开源的工具能够通过输出帮助用户了解系统的运行状况,并对可能发生的潜在问题作出告警。
|
||||
|
||||

|
||||
|
||||
你大概已经知道(或猜到)<ruby>告警可视化<rt>alerting and visualization</rt></ruby>工具是用来做什么的了。下面我们就要来说一下,为什么要讨论这样的工具,甚至某些系统专门将可视化作为特有的功能。
|
||||
|
||||
<ruby>可观察性<rt>Observability</rt></ruby>的概念来自<ruby>控制理论<rt>control theory</ruby>,这个概念描述了我们通过对系统的输入和输出来了解其的能力。本文将重点介绍具有可观察性的输出组件。
|
||||
|
||||
告警可视化工具可以对其它系统的输出进行分析,进而对输出的信息进行结构化表示。告警实际上是对系统异常状态的描述,而可视化则是让用户能够直观理解的结构化表示。
|
||||
|
||||
### 常见的可视化告警
|
||||
|
||||
#### 告警
|
||||
|
||||
首先要明确一下<ruby>告警<rt>alert</rt></ruby>的含义。在人员无法响应告警内容情况下,不应该发送告警 —— 包括那些发给多个人但只有其中少数人可以响应的告警,以及系统中的每个异常都触发的告警。因为这样会产生告警疲劳,告警接收者也往往会对这些过多的告警采取忽视的态度 —— 直到系统恶化到以少见的方式告警。
|
||||
|
||||
例如,如果管理员每天都会收到告警系统发来的数百封告警邮件,他就很容易会忽略告警系统的所有邮件。除非他真的看到问题发生,或者受到了客户或上级的询问时,管理员才会重新重视告警信息。在这种情况下,告警已经失去了原有的意义和用途。
|
||||
|
||||
告警不是一个持续的信息流或者状态更新。告警的目的在于暴露系统无法自动恢复的问题,而且告警应该只发送给最有可能解决问题的人员。超出这个定义的内容都不应该作为告警,否则将会对实际工作造成不良的影响。
|
||||
|
||||
不同的告警体系都会有各自的告警类型,因此不能用优先级(P1-P5)或者诸如“信息”、“警告”、“严重”之类的字眼来一概而论,下面我会介绍一些新兴的复杂系统的事件响应中出现的通用分类方式。
|
||||
|
||||
刚才我提到了一个“信息”这个告警类型,但实际上告警不应该是一个信息,尽管有些人可能会不这样认为。但我觉得如果一个告警没有发送给任何一个人,它就不应该是警报,而只是一些在许多系统中被视为警报的数据点,代表了一些应该知晓但不需要响应的事件。它更应该作为告警可视化工具的一部分,而不是会导致触发告警的事件。《[实用监控][1]》是这个领域的必读书籍,其作者 Mike Julian 在书中就介绍了他自己关于告警的看法。
|
||||
|
||||
而非信息警报则代表告警需要被响应以及需要相关的操作。我将这些告警大致分为内部故障和外部故障两种类型,而对于大多数公司来说,通常会有两个以上的级别来确定响应告警的优先级。系统性能下降就是一种故障,因为其对用户的影响通常都是未知的。
|
||||
|
||||
内部故障比外部故障的优先级低,但也需要快速响应。内部故障通常包括公司员工使用的内部系统或仅对公司员工可见的应用故障。
|
||||
|
||||
外部故障则包括任何马上会产生业务影响的系统故障,但不包括影响系统更新的故障。外部故障一般包括客户所面临的应用故障、数据库故障和导致系统可用性或一致性失效的网络故障,这些都会影响用户的正常使用。对于不直接影响用户的依赖组件故障也属于外部故障,随着应用程序的不断运行,一旦依赖组件发生故障,系统的性能也会受到波及。这种情况对于使用某些外部服务或数据源的系统来说很常见,尽管这些外部服务或数据源对于可能不涉及到系统的主要功能,但是当系统在处理相关依赖组件的错误时可能会出现较明显的延迟。
|
||||
|
||||
### 可视化
|
||||
|
||||
可视化的种类有很多,我就不一一赘述了。这是一个有趣的研究领域,在我这些年的数据分析经历当中,学习和应用可视化方面的知识可以说是相当有挑战性。我们需要将复杂的系统输出通过直观的方式来向他人展示,才能有效地把信息传播出去。[Google Charts][2] 和 [Tableau][3] 都提供了很多可视化方面的工具。下面将会介绍一些最常见的可视化创新解决方案。
|
||||
|
||||
#### 折线图
|
||||
|
||||
折线图可能是最常见的可视化方式了,它可以让用户很直观地按照时间维度了解系统的情况。系统中每个单一或聚合的指标都会以一条折线在图表中体现。但当同一个图表中同时存在多条折线时,就可能会对阅读有所影响(如下图所示),所以大多数情况下都可以选择仅查看其中的少数几条折线,而不是让所有折线同时显示。如果某个指标的数值产生了大于正常范围的波动,就会很容易发现。例如下图中异常的紫线、黄线、浅蓝线。
|
||||
|
||||
|
||||
|
||||
折线图的另一个用法是可以将多条折线堆叠起来以显示它们之间的关系。例如对于通过折线图反映服务器的请求数量,可以单独看到每台服务器上的请求,也可以聚合在一起看。这就可以在同一个图表中灵活查看整个系统以及每个实例的情况了。
|
||||
|
||||
|
||||
|
||||
#### 热力图
|
||||
|
||||
另一种常见的可视化方式是热力图。热力图与条形图比较类似,还可以在条形图的基础上显示某部分在整体中占比的变化情况。例如在查看网络请求延时的时候,就可以使用热力图快速查看到所有网络请求的总体趋势和分布情况,另外,它可以使用不同颜色来表示不同部分的数值。
|
||||
|
||||
在以下这个热力图中,通过竖直方向上每个时间段的色块数量分布,可以清楚地看到大部分数据集中在整个范围的中心位置。我们还可以发现,大多数时间段的色块分布都是比较宽松的,而 14:00 到 15:00 这一段则分布得很密集,这样的分布有可能意味着一种不健康的状态。
|
||||
|
||||
|
||||
|
||||
#### 仪表图
|
||||
|
||||
还有一种常见的可视化方式是仪表图,用户可以通过仪表图快速了解单个指标。仪表一般用于单个指标的显示,例如车速表代表汽车的行驶速度、油量表代表油箱中的汽油量等等。大多数的仪表图都有一个共通点,就是会划分出所示指标的对应状态。如下图所示,绿色表示正常的状态,橙色表示不良的状态,而红色则表示极差的状态。下图中间一行模拟了真实仪表的显示情况。
|
||||
|
||||
|
||||
|
||||
上面图表中,除了常规仪表样式的显示方式之外,还有较为直接的数据显示方式,配合相同的配色方案,一眼就可以看出各个指标所处的状态,这一点与和仪表的特点类似。所以,最下面一行可能是仪表图的最佳显示方式,用户不需要仔细阅读,就可以大致了解各个指标的不同状态。这种类型的可视化是我最常用的类型,在数秒钟之间,我就可以全面地总览系统各方面地运行情况。
|
||||
|
||||
#### 火焰图
|
||||
|
||||
由 [Netflix 的 Brendan Gregg][4] 在 2011 年开始使用的火焰图是一种较为少见地可视化方式。它不像仪表图那样可以从图表中快速得到关键信息,通常只会在需要解决某个应用的问题的时候才会用到这种图表。火焰图主要用于 CPU、内存和相关帧方面的表示,X 轴按字母顺序将帧一一列出,而 Y 轴则表示堆栈的深度。图中每个矩形都是一个标明了调用的函数的堆栈帧。矩形越宽,就表示它在堆栈中出现越频繁。在分析系统性能问题的时候,火焰图能够起到很大的作用,大家不妨尝试一下。
|
||||
|
||||
|
||||
|
||||
### 工具的选择
|
||||
|
||||
在告警工具方面,有几个商用的工具相当不错。但由于这是一篇介绍开源技术的文章,我只会介绍那些已经被广泛使用的免费工具。希望你也能够为这些工具贡献你自己的代码,让它们更加完善。
|
||||
|
||||
### 告警工具
|
||||
|
||||
#### Bosun
|
||||
|
||||
如果你的电脑出现问题,得多亏 Stack Exchange 你才能在网上查到解决办法。Stack Exchange 以众包问答的模式运营着很多不同类型的网站。其中就有广受开发者欢迎的 [Stack Overflow][5],以及运维方面有名的 [Super User][6]。除此以外,从育儿经验到科幻小说、从哲学讨论到单车论坛,Stack Exchange 都有涉猎。
|
||||
|
||||
Stack Exchange 开源了它的告警管理系统 [Bosun][7],同时也发布了 Prometheus 及其 [AlertManager][8] 系统。这两个系统有共通点。Bosun 和 Prometheus 一样使用 Golang 开发,但 Bosun 比 Prometheus 更为强大,因为它可以使用<ruby>指标聚合<rt>metrics aggregation</rt></ruby>以外的方式与系统交互。Bosun 还可以从日志和事件收集系统中提取数据,并且支持 Graphite、InfluxDB、OpenTSDB 和 Elasticsearch。
|
||||
|
||||
Bosun 的架构包括一个单一的服务器的二进制文件,一个诸如 OpenTSDB 的后端、Redis 以及 [scollector 代理][9]。 scollector 代理会自动检测主机上正在运行的服务,并反馈这些进程和其它的系统资源的情况。这些数据将发送到后端。随后 Bosun 的二进制服务文件会向后端发起查询,确定是否需要触发告警。也可以通过 [Grafana][10] 这些工具通过一个通用接口查询 Bosun 的底层后端。而 Redis 则用于存储 Bosun 的状态信息和元数据。
|
||||
|
||||
Bosun 有一个非常巧妙的功能,就是可以根据历史数据来测试告警。这是我几年前在使用 Prometheus 的时候就非常需要的功能,当时我有一个异常的数据需要产生告警,但没有一个可以用于测试的简便方法。为了确保告警能够正常触发,我不得不造出对应的数据来进行测试。而 Bosun 让这个步骤的耗时大大缩短。
|
||||
|
||||
Bosun 更是涵盖了所有常用过的功能,包括简单的图形化表示和告警的创建。它还带有强大的用于编写告警规则的表达式语言。但 Bosun 默认只带有电子邮件通知配置和 HTTP 通知配置,因此如果需要连接到 Slack 或其它工具,就需要对配置作出更大程度的定制化([其文档中有][11])。类似于 Prometheus,Bosun 还可以使用模板通知,你可以使用 HTML 和 CSS 来创建你所需要的电子邮件通知。
|
||||
|
||||
#### Cabot
|
||||
|
||||
[Cabot][12] 由 [Arachnys][13] 公司开发。你或许对 Arachnys 公司并不了解,但它很有影响力:Arachnys 公司构建了一个基于云的先进解决方案,用于防范金融犯罪。在之前的公司时,我也曾经参与过类似“[了解你的客户][14](KYC)”的工作。大多数公司都认为与恐怖组织产生联系会造成相当不好的影响,因为恐怖组织可能会利用自己的系统来筹集资金。而这些解决方案将有助于防范欺诈类犯罪,尽管这类犯罪情节相对较轻,但仍然也会对机构产生风险。
|
||||
|
||||
Arachnys 公司为什么要开发 Cabot 呢?其实只是因为 Arachnys 的开发人员对 [Nagios][15] 不太熟悉。Cabot 的出现对很多人来说都是一个好消息,它基于 Django 和 Bootstrap 开发,因此如果想对这个项目做出自己的贡献,门槛并不高。(另外值得一提的是,Cabot 这个名字来源于开发者的狗。)
|
||||
|
||||
与 Bosun 类似,Cabot 也不对数据进行收集,而是使用监控对象的 API 提供的数据。因此,Cabot 告警的模式是拉取而不是推送。它通过访问每个监控对象的 API,根据特定的指标检索所需的数据,然后将告警数据使用 Redis 缓存,进而持久化存储到 Postgres 数据库。
|
||||
|
||||
Cabot 的一个较为少见的特点是,它原生支持 [Graphite][16],同时也支持 [Jenkins][17]。Jenkins 在这里被视为一个集中式的定时任务,它会以对待故障的方式去对待构建失败的状况。构建失败当然没有系统故障那么紧急,但一旦出现构建失败,还是需要团队采取措施去处理,毕竟并不是每个人在收到构建失败的电子邮件时都会亲自去检查 Jenkins。
|
||||
|
||||
Cabot 另一个有趣的功能是它可以接入 Google 日历安排值班人员,这个称为 Rota 的功能用处很大,希望其它告警系统也能加入类似的功能。Cabot 目前仅支持安排主备联系人,但还有继续改进的空间。它自己的文档也提到,如果需要全面的功能,更应该考虑付费的解决方案。
|
||||
|
||||
#### StatsAgg
|
||||
|
||||
[Pearson][19] 作为一家开发了 [StatsAgg][18] 告警平台的出版公司,这是极为罕见的,当然也很值得敬佩。除此以外,Pearson 还运营着另外几个网站以及和 [O'Reilly Media][20] 合资的企业。但我仍然会将它视为出版教学书籍的公司。
|
||||
|
||||
StatsAgg 除了是一个告警平台,还是一个指标聚合平台,甚至也有点类似其它系统的代理。StatsAgg 支持通过 Graphite、StatsD、InfluxDB 和 OpenTSDB 输入数据,也支持将其转发到各种平台。但随着中心服务的负载不断增加,风险也不断增大。尽管如此,如果 StatsAgg 的基础架构足够强壮,即使后端存储平台出现故障,也不会对它产生告警的过程造成影响。
|
||||
|
||||
StatsAgg 是用 Java 开发的,为了尽可能降低复杂性,它仅包括主服务和一个 UI。StatsAgg 支持基于正则表达式匹配来发送告警,而且它更注重于服务方面的告警,而不是服务器基础告警。我认为它填补了开源监控工具方面的空白,而这正式它自己的目标。
|
||||
|
||||
### 可视化工具
|
||||
|
||||
#### Grafana
|
||||
|
||||
[Grafana][10] 的知名度很高,它也被广泛采用。每当我需要用到数据面板的时候,我总是会想到它,因为它比我使用过的任何一款类似的产品都要好。Grafana 由 Torkel Ödegaard 开发的,像 Cabot 一样,也是在圣诞节期间开发的,并在 2014 年 1 月发布。在短短几年之间,它已经有了长足的发展。Grafana 基于 Kibana 开发,Torkel 开启了新的分支并将其命名为 Grafana。
|
||||
|
||||
Grafana 着重体现了实用性以及数据呈现的美观性。它天生就可以从 Graphite、Elasticsearch、OpenTSDB、Prometheus 和 InfluxDB 收集数据。此外有一个 Grafana 商用版插件可以从更多数据源获取数据,但是其他数据源插件也并非没有开源版本,Grafana 的插件生态系统已经提供了各种数据源。
|
||||
|
||||
Grafana 能做什么呢?Grafana 提供了一个中心化的了解系统的方式。它通过 web 来展示数据,任何人都有机会访问到相关信息,当然也可以使用身份验证来对访问进行限制。Grafana 使用各种可视化方式来提供对系统一目了然的了解。Grafana 还支持不同类型的可视化方式,包括集成告警可视化的功能。
|
||||
|
||||
现在你可以更直观地设置告警了。通过 Grafana,可以查看图表,还可以查看由于系统性能下降而触发告警的位置,单击要触发报警的位置,并告诉 Grafana 将告警发送何处。这是一个对告警平台非常强大的补充。告警平台不一定会因此而被取代,但告警系统一定会由此得到更多启发和发展。
|
||||
|
||||
Grafana 还引入了很多团队协作的功能。不同用户之间能够共享数据面板,你不再需要为 [Kubernetes][21] 集群创建独立的数据面板,因为由 Kubernetes 开发者和 Grafana 开发者共同维护的一些数据面板已经可用了。
|
||||
|
||||
团队协作过程中一个重要的功能是注释。注释功能允许用户将上下文添加到图表当中,其他用户就可以通过上下文更直观地理解图表。当团队成员在处理某个事件,并且需要沟通和理解时,这个功能就十分重要了。将所有相关信息都放在需要的位置,可以让整个团队中快速达成共识。在团队需要调查故障原因和定位事件责任时,这个功能就可以发挥作用了。
|
||||
|
||||
#### Vizceral
|
||||
|
||||
[Vizceral][22] 由 Netflix 开发,用于在故障发生时更有效地了解流量的情况。Grafana 是一种通用性更强的工具,而 Vizceral 则专用于某些领域。 尽管 Netflix 表示已经不再在内部使用 Vizceral,也不再主动对其展开维护,但 Vizceral 仍然会定期更新。我在这里介绍这个工具,主要是为了介绍它的的可视化机制,以及如何利用它来协助解决问题。你可以在样例环境中用它来更好地掌握这一类系统的特性。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/alerting-and-visualization-tools-sysadmins
|
||||
|
||||
作者:[Dan Barker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/barkerd427
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.practicalmonitoring.com/
|
||||
[2]: https://developers.google.com/chart/interactive/docs/gallery
|
||||
[3]: https://libguides.libraries.claremont.edu/c.php?g=474417&p=3286401
|
||||
[4]: http://www.brendangregg.com/flamegraphs.html
|
||||
[5]: https://stackoverflow.com/
|
||||
[6]: https://superuser.com/
|
||||
[7]: http://bosun.org/
|
||||
[8]: https://prometheus.io/docs/alerting/alertmanager/
|
||||
[9]: https://bosun.org/scollector/
|
||||
[10]: https://grafana.com/
|
||||
[11]: https://bosun.org/notifications
|
||||
[12]: https://cabotapp.com/
|
||||
[13]: https://www.arachnys.com/
|
||||
[14]: https://en.wikipedia.org/wiki/Know_your_customer
|
||||
[15]: https://www.nagios.org/
|
||||
[16]: https://graphiteapp.org/
|
||||
[17]: https://jenkins.io/
|
||||
[18]: https://github.com/PearsonEducation/StatsAgg
|
||||
[19]: https://www.pearson.com/us/
|
||||
[20]: https://www.oreilly.com/
|
||||
[21]: https://opensource.com/resources/what-is-kubernetes
|
||||
[22]: https://github.com/Netflix/vizceral
|
||||
|
||||
@ -1,41 +1,41 @@
|
||||
Linux 命令行中使用 tcpdump 抓包
|
||||
在 Linux 命令行中使用 tcpdump 抓包
|
||||
======
|
||||
|
||||
Tcpdump 是一款灵活、功能强大的抓包工具,能有效地帮助排查网络故障问题。
|
||||
> `tcpdump` 是一款灵活、功能强大的抓包工具,能有效地帮助排查网络故障问题。
|
||||
|
||||

|
||||
|
||||
根据我作为管理员的经验,在网络连接中经常遇到十分难以排查的故障问题。对于这类情况,tcpdump 便能派上用场。
|
||||
以我作为管理员的经验,在网络连接中经常遇到十分难以排查的故障问题。对于这类情况,`tcpdump` 便能派上用场。
|
||||
|
||||
Tcpdump 是一个命令行实用工具,允许你抓取和分析经过系统的流量数据包。它通常被用作于网络故障分析工具以及安全工具。
|
||||
`tcpdump` 是一个命令行实用工具,允许你抓取和分析经过系统的流量数据包。它通常被用作于网络故障分析工具以及安全工具。
|
||||
|
||||
Tcpdump 是一款强大的工具,支持多种选项和过滤规则,适用场景十分广泛。由于它是命令行工具,因此适用于在远程服务器或者没有图形界面的设备中收集数据包以便于事后分析。它可以在后台启动,也可以用 cron 等定时工具创建定时任务启用它。
|
||||
`tcpdump` 是一款强大的工具,支持多种选项和过滤规则,适用场景十分广泛。由于它是命令行工具,因此适用于在远程服务器或者没有图形界面的设备中收集数据包以便于事后分析。它可以在后台启动,也可以用 cron 等定时工具创建定时任务启用它。
|
||||
|
||||
本文中,我们将讨论 tcpdump 最常用的一些功能。
|
||||
本文中,我们将讨论 `tcpdump` 最常用的一些功能。
|
||||
|
||||
### 1\. 在 Linux 中安装 tcpdump
|
||||
### 1、在 Linux 中安装 tcpdump
|
||||
|
||||
Tcpdump 支持多种 Linux 发行版,所以你的系统中很有可能已经安装了它。用下面的命令检查一下是否已经安装了 tcpdump:
|
||||
`tcpdump` 支持多种 Linux 发行版,所以你的系统中很有可能已经安装了它。用下面的命令检查一下是否已经安装了 `tcpdump`:
|
||||
|
||||
```
|
||||
$ which tcpdump
|
||||
/usr/sbin/tcpdump
|
||||
```
|
||||
|
||||
如果还没有安装 tcpdump,你可以用软件包管理器安装它。
|
||||
例如,在 CentOS 或者 Red Hat Enterprise 系统中,用如下命令安装 tcpdump:
|
||||
如果还没有安装 `tcpdump`,你可以用软件包管理器安装它。
|
||||
例如,在 CentOS 或者 Red Hat Enterprise 系统中,用如下命令安装 `tcpdump`:
|
||||
|
||||
```
|
||||
$ sudo yum install -y tcpdump
|
||||
```
|
||||
|
||||
Tcpdump 依赖于 `libpcap`,该库文件用于捕获网络数据包。如果该库文件也没有安装,系统会根据依赖关系自动安装它。
|
||||
`tcpdump` 依赖于 `libpcap`,该库文件用于捕获网络数据包。如果该库文件也没有安装,系统会根据依赖关系自动安装它。
|
||||
|
||||
现在你可以开始抓包了。
|
||||
|
||||
### 2\. 用 tcpdump 抓包
|
||||
### 2、用 tcpdump 抓包
|
||||
|
||||
使用 tcpdump 抓包,需要管理员权限,因此下面的示例中绝大多数命令都是以 `sudo` 开头。
|
||||
使用 `tcpdump` 抓包,需要管理员权限,因此下面的示例中绝大多数命令都是以 `sudo` 开头。
|
||||
|
||||
首先,先用 `tcpdump -D` 命令列出可以抓包的网络接口:
|
||||
|
||||
@ -80,7 +80,7 @@ listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
|
||||
$
|
||||
```
|
||||
|
||||
Tcpdump 会持续抓包直到收到中断信号。你可以按 `Ctrl+C` 来停止抓包。正如上面示例所示,`tcpdump` 抓取了超过 9000 个数据包。在这个示例中,由于我是通过 `ssh` 连接到服务器,所以 tcpdump 也捕获了所有这类数据包。`-c` 选项可以用于限制 tcpdump 抓包的数量:
|
||||
`tcpdump` 会持续抓包直到收到中断信号。你可以按 `Ctrl+C` 来停止抓包。正如上面示例所示,`tcpdump` 抓取了超过 9000 个数据包。在这个示例中,由于我是通过 `ssh` 连接到服务器,所以 `tcpdump` 也捕获了所有这类数据包。`-c` 选项可以用于限制 `tcpdump` 抓包的数量:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any -c 5
|
||||
@ -97,9 +97,9 @@ listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
|
||||
$
|
||||
```
|
||||
|
||||
如上所示,`tcpdump` 在抓取 5 个数据包后自动停止了抓包。这在有些场景中十分有用——比如你只需要抓取少量的数据包用于分析。当我们需要使用过滤规则抓取特定的数据包(如下所示)时,`-c` 的作用就十分突出了。
|
||||
如上所示,`tcpdump` 在抓取 5 个数据包后自动停止了抓包。这在有些场景中十分有用 —— 比如你只需要抓取少量的数据包用于分析。当我们需要使用过滤规则抓取特定的数据包(如下所示)时,`-c` 的作用就十分突出了。
|
||||
|
||||
在上面示例中,tcpdump 默认是将 IP 地址和端口号解析为对应的接口名以及服务协议名称。而通常在网络故障排查中,使用 IP 地址和端口号更便于分析问题;用 `-n` 选项显示 IP 地址,`-nn` 选项显示端口号:
|
||||
在上面示例中,`tcpdump` 默认是将 IP 地址和端口号解析为对应的接口名以及服务协议名称。而通常在网络故障排查中,使用 IP 地址和端口号更便于分析问题;用 `-n` 选项显示 IP 地址,`-nn` 选项显示端口号:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any -c5 -nn
|
||||
@ -115,13 +115,13 @@ listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
|
||||
0 packets dropped by kernel
|
||||
```
|
||||
|
||||
如上所示,抓取的数据包中显示 IP 地址和端口号。这样还可以阻止 tcpdump 发出 DNS 查找,有助于在网络故障排查中减少数据流量。
|
||||
如上所示,抓取的数据包中显示 IP 地址和端口号。这样还可以阻止 `tcpdump` 发出 DNS 查找,有助于在网络故障排查中减少数据流量。
|
||||
|
||||
现在你已经会抓包了,让我们来分析一下这些抓包输出的含义吧。
|
||||
|
||||
### 3\. 理解抓取的报文
|
||||
### 3、理解抓取的报文
|
||||
|
||||
Tcpdump 能够抓取并解码多种协议类型的数据报文,如 TCP,UDP,ICMP 等等。虽然这里我们不可能介绍所有的数据报文类型,但可以分析下 TCP 类型的数据报文,来帮助你入门。更多有关 tcpdump 的详细介绍可以参考其 [帮助手册][1]。Tcpdump 抓取的 TCP 报文看起来如下:
|
||||
`tcpdump` 能够抓取并解码多种协议类型的数据报文,如 TCP、UDP、ICMP 等等。虽然这里我们不可能介绍所有的数据报文类型,但可以分析下 TCP 类型的数据报文,来帮助你入门。更多有关 `tcpdump` 的详细介绍可以参考其 [帮助手册][1]。`tcpdump` 抓取的 TCP 报文看起来如下:
|
||||
|
||||
```
|
||||
08:41:13.729687 IP 192.168.64.28.22 > 192.168.64.1.41916: Flags [P.], seq 196:568, ack 1, win 309, options [nop,nop,TS val 117964079 ecr 816509256], length 372
|
||||
@ -137,7 +137,7 @@ Tcpdump 能够抓取并解码多种协议类型的数据报文,如 TCP,UDP
|
||||
|
||||
在源 IP 和目的 IP 之后,可以看到是 TCP 报文标记段 `Flags [P.]`。该字段通常取值如下:
|
||||
|
||||
| Value | Flag Type | Description |
|
||||
| 值 | 标志类型 | 描述 |
|
||||
| ----- | --------- | ----------------- |
|
||||
| S | SYN | Connection Start |
|
||||
| F | FIN | Connection Finish |
|
||||
@ -149,19 +149,19 @@ Tcpdump 能够抓取并解码多种协议类型的数据报文,如 TCP,UDP
|
||||
|
||||
接下来是该数据包中数据的序列号。对于抓取的第一个数据包,该字段值是一个绝对数字,后续包使用相对数值,以便更容易查询跟踪。例如此处 `seq 196:568` 代表该数据包包含该数据流的第 196 到 568 字节。
|
||||
|
||||
接下来是 ack 值:`ack 1`。该数据包是数据发送方,ack 值为1。在数据接收方,该字段代表数据流上的下一个预期字节数据,例如,该数据流中下一个数据包的 ack 值应该是 568。
|
||||
接下来是 ack 值:`ack 1`。该数据包是数据发送方,ack 值为 1。在数据接收方,该字段代表数据流上的下一个预期字节数据,例如,该数据流中下一个数据包的 ack 值应该是 568。
|
||||
|
||||
接下来字段是接收窗口大小 `win 309`,它表示接收缓冲区中可用的字节数,后跟 TCP 选项如 MSS(最大段大小)或者窗口比例值。更详尽的 TCP 协议内容请参考 [Transmission Control Protocol(TCP) Parameters][2]。
|
||||
|
||||
最后,`length 372`代表数据包有效载荷字节长度。这个长度和 seq 序列号中字节数值长度是不一样的。
|
||||
最后,`length 372` 代表数据包有效载荷字节长度。这个长度和 seq 序列号中字节数值长度是不一样的。
|
||||
|
||||
现在让我们学习如何过滤数据报文以便更容易的分析定位问题。
|
||||
|
||||
### 4\. 过滤数据包
|
||||
### 4、过滤数据包
|
||||
|
||||
正如上面所提,tcpdump 可以抓取很多种类型的数据报文,其中很多可能和我们需要查找的问题并没有关系。举个例子,假设你正在定位一个与 web 服务器连接的网络问题,就不必关系 SSH 数据报文,因此在抓包结果中过滤掉 SSH 报文可能更便于你分析问题。
|
||||
正如上面所提,`tcpdump` 可以抓取很多种类型的数据报文,其中很多可能和我们需要查找的问题并没有关系。举个例子,假设你正在定位一个与 web 服务器连接的网络问题,就不必关系 SSH 数据报文,因此在抓包结果中过滤掉 SSH 报文可能更便于你分析问题。
|
||||
|
||||
Tcpdump 有很多参数选项可以设置数据包过滤规则,例如根据源 IP 以及目的 IP 地址,端口号,协议等等规则来过滤数据包。下面就介绍一些最常用的过滤方法。
|
||||
`tcpdump` 有很多参数选项可以设置数据包过滤规则,例如根据源 IP 以及目的 IP 地址,端口号,协议等等规则来过滤数据包。下面就介绍一些最常用的过滤方法。
|
||||
|
||||
#### 协议
|
||||
|
||||
@ -181,7 +181,7 @@ PING opensource.com (54.204.39.132) 56(84) bytes of data.
|
||||
64 bytes from ec2-54-204-39-132.compute-1.amazonaws.com (54.204.39.132): icmp_seq=1 ttl=47 time=39.6 ms
|
||||
```
|
||||
|
||||
回到运行 tcpdump 命令的终端中,可以看到它筛选出了 ICMP 报文。这里 tcpdump 并没有显示有关 `opensource.com`的域名解析数据包:
|
||||
回到运行 `tcpdump` 命令的终端中,可以看到它筛选出了 ICMP 报文。这里 `tcpdump` 并没有显示有关 `opensource.com` 的域名解析数据包:
|
||||
|
||||
```
|
||||
09:34:20.136766 IP rhel75 > ec2-54-204-39-132.compute-1.amazonaws.com: ICMP echo request, id 20361, seq 1, length 64
|
||||
@ -215,7 +215,7 @@ listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
|
||||
|
||||
#### 端口号
|
||||
|
||||
Tcpdump 可以根据服务类型或者端口号来筛选数据包。例如,抓取和 HTTP 服务相关的数据包:
|
||||
`tcpdump` 可以根据服务类型或者端口号来筛选数据包。例如,抓取和 HTTP 服务相关的数据包:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any -c5 -nn port 80
|
||||
@ -303,11 +303,11 @@ listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
|
||||
|
||||
该例子中我们只抓取了来自源 IP 为 `192.168.122.98` 或者 `54.204.39.132` 的 HTTP (端口号80)的数据包。使用该方法就很容易抓取到数据流中交互双方的数据包了。
|
||||
|
||||
### 5\. 检查数据包内容
|
||||
### 5、检查数据包内容
|
||||
|
||||
在以上的示例中,我们只按数据包头部的信息来建立规则筛选数据包,例如源地址、目的地址、端口号等等。有时我们需要分析网络连接问题,可能需要分析数据包中的内容来判断什么内容需要被发送、什么内容需要被接收等。Tcpdump 提供了两个选项可以查看数据包内容,`-X` 以十六进制打印出数据报文内容,`-A` 打印数据报文的 ASCII 值。
|
||||
在以上的示例中,我们只按数据包头部的信息来建立规则筛选数据包,例如源地址、目的地址、端口号等等。有时我们需要分析网络连接问题,可能需要分析数据包中的内容来判断什么内容需要被发送、什么内容需要被接收等。`tcpdump` 提供了两个选项可以查看数据包内容,`-X` 以十六进制打印出数据报文内容,`-A` 打印数据报文的 ASCII 值。
|
||||
|
||||
例如,HTTP request 报文内容如下:
|
||||
例如,HTTP 请求报文内容如下:
|
||||
|
||||
```
|
||||
$ sudo tcpdump -i any -c10 -nn -A port 80
|
||||
@ -379,9 +379,9 @@ E..4..@.@.....zb6.'....P....o..............
|
||||
|
||||
这对定位一些普通 HTTP 调用 API 接口的问题很有用。当然如果是加密报文,这个输出也就没多大用了。
|
||||
|
||||
### 6\. 保存抓包数据
|
||||
### 6、保存抓包数据
|
||||
|
||||
Tcpdump 提供了保存抓包数据的功能以便后续分析数据包。例如,你可以夜里让它在那里抓包,然后早上起来再去分析它。同样当有很多数据包时,显示过快也不利于分析,将数据包保存下来,更有利于分析问题。
|
||||
`tcpdump` 提供了保存抓包数据的功能以便后续分析数据包。例如,你可以夜里让它在那里抓包,然后早上起来再去分析它。同样当有很多数据包时,显示过快也不利于分析,将数据包保存下来,更有利于分析问题。
|
||||
|
||||
使用 `-w` 选项来保存数据包而不是在屏幕上显示出抓取的数据包:
|
||||
|
||||
@ -398,7 +398,7 @@ tcpdump: listening on any, link-type LINUX_SLL (Linux cooked), capture size 2621
|
||||
|
||||
正如示例中所示,保存数据包到文件中时屏幕上就没有任何有关数据报文的输出,其中 `-c10` 表示抓取到 10 个数据包后就停止抓包。如果想有一些反馈来提示确实抓取到了数据包,可以使用 `-v` 选项。
|
||||
|
||||
Tcpdump 将数据包保存在二进制文件中,所以不能简单的用文本编辑器去打开它。使用 `-r` 选项参数来阅读该文件中的报文内容:
|
||||
`tcpdump` 将数据包保存在二进制文件中,所以不能简单的用文本编辑器去打开它。使用 `-r` 选项参数来阅读该文件中的报文内容:
|
||||
|
||||
```
|
||||
$ tcpdump -nn -r webserver.pcap
|
||||
@ -418,7 +418,7 @@ $
|
||||
|
||||
这里不需要管理员权限 `sudo` 了,因为此刻并不是在网络接口处抓包。
|
||||
|
||||
你还可以使用我们讨论过的任何过滤规则来过滤文件中的内容,就像使用实时数据一样。 例如,通过执行以下命令从源 IP 地址`54.204.39.132` 检查文件中的数据包:
|
||||
你还可以使用我们讨论过的任何过滤规则来过滤文件中的内容,就像使用实时数据一样。 例如,通过执行以下命令从源 IP 地址 `54.204.39.132` 检查文件中的数据包:
|
||||
|
||||
```
|
||||
$ tcpdump -nn -r webserver.pcap src 54.204.39.132
|
||||
@ -431,11 +431,11 @@ reading from file webserver.pcap, link-type LINUX_SLL (Linux cooked)
|
||||
|
||||
### 下一步做什么?
|
||||
|
||||
以上的基本功能已经可以帮助你使用强大的 tcpdump 抓包工具了。更多的内容请参考 [tcpdump网页][3] 以及它的 [帮助文件][4]。
|
||||
以上的基本功能已经可以帮助你使用强大的 `tcpdump` 抓包工具了。更多的内容请参考 [tcpdump 网站][3] 以及它的 [帮助文件][4]。
|
||||
|
||||
Tcpdump 命令行工具为分析网络流量数据包提供了强大的灵活性。如果需要使用图形工具来抓包请参考 [Wireshark][5]。
|
||||
`tcpdump` 命令行工具为分析网络流量数据包提供了强大的灵活性。如果需要使用图形工具来抓包请参考 [Wireshark][5]。
|
||||
|
||||
Wireshark 还可以用来读取 tcpdump 保存的 `pcap` 文件。你可以使用 tcpdump 命令行在没有 GUI 界面的远程机器上抓包然后在 Wireshark 中分析数据包。
|
||||
Wireshark 还可以用来读取 `tcpdump` 保存的 pcap 文件。你可以使用 `tcpdump` 命令行在没有 GUI 界面的远程机器上抓包然后在 Wireshark 中分析数据包。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -444,7 +444,7 @@ via: https://opensource.com/article/18/10/introduction-tcpdump
|
||||
作者:[Ricardo Gerardi][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[jrg](https://github.com/jrglinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,186 @@
|
||||
Lisp 是怎么成为上帝的编程语言的
|
||||
======
|
||||
|
||||
当程序员们谈论各类编程语言的相对优势时,他们通常会采用相当平淡的措词,就好像这些语言是一条工具带上的各种工具似的 —— 有适合写操作系统的,也有适合把其它程序黏在一起来完成特殊工作的。这种讨论方式非常合理;不同语言的能力不同。不声明特定用途就声称某门语言比其他语言更优秀只能导致侮辱性的无用争论。
|
||||
|
||||
但有一门语言似乎受到和用途无关的特殊尊敬:那就是 Lisp。即使是恨不得给每个说出形如“某某语言比其他所有语言都好”这类话的人都来一拳的键盘远征军们,也会承认 Lisp 处于另一个层次。 Lisp 超越了用于评判其他语言的实用主义标准,因为普通程序员并不使用 Lisp 编写实用的程序 —— 而且,多半他们永远也不会这么做。然而,人们对 Lisp 的敬意是如此深厚,甚至于到了这门语言会时而被加上神话属性的程度。
|
||||
|
||||
大家都喜欢的网络漫画合集 xkcd 就至少在两组漫画中如此描绘过 Lisp:[其中一组漫画][1]中,某人得到了某种 Lisp 启示,而这好像使他理解了宇宙的基本构架。
|
||||
|
||||

|
||||
|
||||
在[另一组漫画][2]中,一个穿着长袍的老程序员给他的徒弟递了一沓圆括号,说这是“文明时代的优雅武器”,暗示着 Lisp 就像原力那样拥有各式各样的神秘力量。
|
||||
|
||||

|
||||
|
||||
另一个绝佳例子是 Bob Kanefsky 的滑稽剧插曲,《上帝就在人间》。这部剧叫做《永恒之火》,撰写于 1990 年代中期;剧中描述了上帝必然是使用 Lisp 创造世界的种种原因。完整的歌词可以在 [GNU 幽默合集][3]中找到,如下是一段摘抄:
|
||||
|
||||
> 因为上帝用祂的 Lisp 代码
|
||||
|
||||
> 让树叶充满绿意。
|
||||
|
||||
> 分形的花儿和递归的根:
|
||||
|
||||
> 我见过的奇技淫巧之中没什么比这更可爱。
|
||||
|
||||
> 当我对着雪花深思时,
|
||||
|
||||
> 从未见过两片相同的,
|
||||
|
||||
> 我知道,上帝偏爱那一门
|
||||
|
||||
> 名字是四个字母的语言。
|
||||
|
||||
(LCTT 译注:参见 “四个字母”,参见:[四字神名](https://zh.wikipedia.org/wiki/%E5%9B%9B%E5%AD%97%E7%A5%9E%E5%90%8D),致谢 [no1xsyzy](https://github.com/LCTT/TranslateProject/issues/11320))
|
||||
|
||||
以下这句话我实在不好在人前说;不过,我还是觉得,这样一种 “Lisp 是奥术魔法”的文化模因实在是有史以来最奇异、最迷人的东西。Lisp 是象牙塔的产物,是人工智能研究的工具;因此,它对于编程界的俗人而言总是陌生的,甚至是带有神秘色彩的。然而,当今的程序员们[开始怂恿彼此,“在你死掉之前至少试一试 Lisp”][4],就像这是一种令人恍惚入迷的致幻剂似的。尽管 Lisp 是广泛使用的编程语言中第二古老的(只比 Fortran 年轻一岁)[^1] ,程序员们也仍旧在互相怂恿。想象一下,如果你的工作是为某种组织或者团队推广一门新的编程语言的话,忽悠大家让他们相信你的新语言拥有神力难道不是绝佳的策略吗?—— 但你如何能够做到这一点呢?或者,换句话说,一门编程语言究竟是如何变成人们口中“隐晦知识的载体”的呢?
|
||||
|
||||
Lisp 究竟是怎么成为这样的?
|
||||
|
||||
![Byte 杂志封面,1979年八月。][5]
|
||||
|
||||
*Byte 杂志封面,1979年八月。*
|
||||
|
||||
### 理论 A :公理般的语言
|
||||
|
||||
Lisp 的创造者<ruby>约翰·麦卡锡<rt>John McCarthy</rt></ruby>最初并没有想过把 Lisp 做成优雅、精炼的计算法则结晶。然而,在一两次运气使然的深谋远虑和一系列优化之后,Lisp 的确变成了那样的东西。 <ruby>保罗·格雷厄姆<rt>Paul Graham</rt></ruby>(我们一会儿之后才会聊到他)曾经这么写道, 麦卡锡通过 Lisp “为编程作出的贡献就像是欧几里得对几何学所做的贡献一般” [^2]。人们可能会在 Lisp 中看出更加隐晦的含义 —— 因为麦卡锡创造 Lisp 时使用的要素实在是过于基础,基础到连弄明白他到底是创造了这门语言、还是发现了这门语言,都是一件难事。
|
||||
|
||||
最初, 麦卡锡产生要造一门语言的想法,是在 1956 年的<ruby>达特茅斯人工智能夏季研究项目<rt>Darthmouth Summer Research Project on Artificial Intelligence</rt></ruby>上。夏季研究项目是个持续数周的学术会议,直到现在也仍旧在举行;它是此类会议之中最早开始举办的会议之一。 麦卡锡当初还是个达特茅斯的数学助教,而“<ruby>人工智能<rt>artificial intelligence</rt></ruby>(AI)”这个词事实上就是他建议举办该会议时发明的 [^3]。在整个会议期间大概有十人参加 [^4]。他们之中包括了<ruby>艾伦·纽厄尔<rt>Allen Newell</rt></ruby>和<ruby>赫伯特·西蒙<rt>Herbert Simon</rt></ruby>,两名隶属于<ruby>兰德公司<rt>RAND Corporation</rt></ruby>和<ruby>卡内基梅隆大学<rt>Carnegie Mellon</rt></ruby>的学者。这两人不久之前设计了一门语言,叫做 IPL。
|
||||
|
||||
当时,纽厄尔和西蒙正试图制作一套能够在命题演算中生成证明的系统。两人意识到,用电脑的原生指令集编写这套系统会非常困难;于是他们决定创造一门语言——他们的原话是“<ruby>伪代码<rt>pseudo-code</rt></ruby>”,这样,他们就能更加轻松自然地表达这台“<ruby>逻辑理论机器<rt>Logic Theory Machine</rt></ruby>”的底层逻辑了 [^5]。这门语言叫做 IPL,即“<ruby>信息处理语言<rt>Information Processing Language</rt></ruby>”;比起我们现在认知中的编程语言,它更像是一种高层次的汇编语言方言。 纽厄尔和西蒙提到,当时人们开发的其它“伪代码”都抓着标准数学符号不放 —— 也许他们指的是 Fortran [^6];与此不同的是,他们的语言使用成组的符号方程来表示命题演算中的语句。通常,用 IPL 写出来的程序会调用一系列的汇编语言宏,以此在这些符号方程列表中对表达式进行变换和求值。
|
||||
|
||||
麦卡锡认为,一门实用的编程语言应该像 Fortran 那样使用代数表达式;因此,他并不怎么喜欢 IPL [^7]。然而,他也认为,在给人工智能领域的一些问题建模时,符号列表会是非常好用的工具 —— 而且在那些涉及演绎的问题上尤其有用。麦卡锡的渴望最终被诉诸行动;他要创造一门代数的列表处理语言 —— 这门语言会像 Fortran 一样使用代数表达式,但拥有和 IPL 一样的符号列表处理能力。
|
||||
|
||||
当然,今日的 Lisp 可不像 Fortran。在会议之后的几年中,麦卡锡关于“理想的列表处理语言”的见解似乎在逐渐演化。到 1957 年,他的想法发生了改变。他那时候正在用 Fortran 编写一个能下国际象棋的程序;越是长时间地使用 Fortran ,麦卡锡就越确信其设计中存在不当之处,而最大的问题就是尴尬的 `IF` 声明 [^8]。为此,他发明了一个替代品,即条件表达式 `true`;这个表达式会在给定的测试通过时返回子表达式 `A` ,而在测试未通过时返回子表达式 `B` ,*而且*,它只会对返回的子表达式进行求值。在 1958 年夏天,当麦卡锡设计一个能够求导的程序时,他意识到,他发明的 `true` 条件表达式让编写递归函数这件事变得更加简单自然了 [^9]。也是这个求导问题让麦卡锡创造了 `maplist` 函数;这个函数会将其它函数作为参数并将之作用于指定列表的所有元素 [^10]。在给项数多得叫人抓狂的多项式求导时,它尤其有用。
|
||||
|
||||
然而,以上的所有这些,在 Fortran 中都是没有的;因此,在 1958 年的秋天,麦卡锡请来了一群学生来实现 Lisp。因为他那时已经成了一名麻省理工助教,所以,这些学生可都是麻省理工的学生。当麦卡锡和学生们最终将他的主意变为能运行的代码时,这门语言得到了进一步的简化。这之中最大的改变涉及了 Lisp 的语法本身。最初,麦卡锡在设计语言时,曾经试图加入所谓的 “M 表达式”;这是一层语法糖,能让 Lisp 的语法变得类似于 Fortran。虽然 M 表达式可以被翻译为 S 表达式 —— 基础的、“用圆括号括起来的列表”,也就是 Lisp 最著名的特征 —— 但 S 表达式事实上是一种给机器看的低阶表达方法。唯一的问题是,麦卡锡用方括号标记 M 表达式,但他的团队在麻省理工使用的 IBM 026 键盘打孔机的键盘上根本没有方括号 [^11]。于是 Lisp 团队坚定不移地使用着 S 表达式,不仅用它们表示数据列表,也拿它们来表达函数的应用。麦卡锡和他的学生们还作了另外几样改进,包括将数学符号前置;他们也修改了内存模型,这样 Lisp 实质上就只有一种数据类型了 [^12]。
|
||||
|
||||
到 1960 年,麦卡锡发表了他关于 Lisp 的著名论文,《用符号方程表示的递归函数及它们的机器计算》。那时候,Lisp 已经被极大地精简,而这让麦卡锡意识到,他的作品其实是“一套优雅的数学系统”,而非普通的编程语言 [^13]。他后来这么写道,对 Lisp 的许多简化使其“成了一种描述可计算函数的方式,而且它比图灵机或者一般情况下用于递归函数理论的递归定义更加简洁” [^14]。在他的论文中,他不仅使用 Lisp 作为编程语言,也将它当作一套用于研究递归函数行为方式的表达方法。
|
||||
|
||||
通过“从一小撮规则中逐步实现出 Lisp”的方式,麦卡锡将这门语言介绍给了他的读者。后来,保罗·格雷厄姆在短文《<ruby>[Lisp 之根][6]<rt>The Roots of Lisp</rt></ruby>》中用更易读的语言回顾了麦卡锡的步骤。格雷厄姆只用了七种原始运算符、两种函数写法,以及使用原始运算符定义的六个稍微高级一点的函数来解释 Lisp。毫无疑问,Lisp 的这种只需使用极少量的基本规则就能完整说明的特点加深了其神秘色彩。格雷厄姆称麦卡锡的论文为“使计算公理化”的一种尝试 [^15]。我认为,在思考 Lisp 的魅力从何而来时,这是一个极好的切入点。其它编程语言都有明显的人工构造痕迹,表现为 `While`,`typedef`,`public static void` 这样的关键词;而 Lisp 的设计却简直像是纯粹计算逻辑的鬼斧神工。Lisp 的这一性质,以及它和晦涩难懂的“递归函数理论”的密切关系,使它具备了获得如今声望的充分理由。
|
||||
|
||||
### 理论 B:属于未来的机器
|
||||
|
||||
Lisp 诞生二十年后,它成了著名的《<ruby>[黑客词典][7]<rt>Hacker’s Dictionary</rt></ruby>》中所说的,人工智能研究的“母语”。Lisp 在此之前传播迅速,多半是托了语法规律的福 —— 不管在怎么样的电脑上,实现 Lisp 都是一件相对简单直白的事。而学者们之后坚持使用它乃是因为 Lisp 在处理符号表达式这方面有巨大的优势;在那个时代,人工智能很大程度上就意味着符号,于是这一点就显得十分重要。在许多重要的人工智能项目中都能见到 Lisp 的身影。这些项目包括了 [SHRDLU 自然语言程序][8]、[Macsyma 代数系统][9] 和 [ACL2 逻辑系统][10]。
|
||||
|
||||
然而,在 1970 年代中期,人工智能研究者们的电脑算力开始不够用了。PDP-10 就是一个典型。这个型号在人工智能学界曾经极受欢迎;但面对这些用 Lisp 写的 AI 程序,它的 18 位地址空间一天比一天显得吃紧 [^16]。许多的 AI 程序在设计上可以与人互动。要让这些既极度要求硬件性能、又有互动功能的程序在分时系统上优秀发挥,是很有挑战性的。麻省理工的<ruby>彼得·杜奇<rt>Peter Deutsch</rt></ruby>给出了解决方案:那就是针对 Lisp 程序来特别设计电脑。就像是我那[关于 Chaosnet 的上一篇文章][11]所说的那样,这些<ruby>Lisp 计算机<rt>Lisp machines</rt></ruby>会给每个用户都专门分配一个为 Lisp 特别优化的处理器。到后来,考虑到硬核 Lisp 程序员的需求,这些计算机甚至还配备上了完全由 Lisp 编写的开发环境。在当时那样一个小型机时代已至尾声而微型机的繁盛尚未完全到来的尴尬时期,Lisp 计算机就是编程精英们的“高性能个人电脑”。
|
||||
|
||||
有那么一会儿,Lisp 计算机被当成是未来趋势。好几家公司雨后春笋般出现,追着赶着要把这项技术商业化。其中最成功的一家叫做 Symbolics,由麻省理工 AI 实验室的前成员创立。上世纪八十年代,这家公司生产了所谓的 3600 系列计算机,它们当时在 AI 领域和需要高性能计算的产业中应用极广。3600 系列配备了大屏幕、位图显示、鼠标接口,以及[强大的图形与动画软件][12]。它们都是惊人的机器,能让惊人的程序运行起来。例如,之前在推特上跟我聊过的机器人研究者 Bob Culley,就能用一台 1985 年生产的 Symbolics 3650 写出带有图形演示的寻路算法。他向我解释说,在 1980 年代,位图显示和面向对象编程(能够通过 [Flavors 扩展][13]在 Lisp 计算机上使用)都刚刚出现。Symbolics 站在时代的最前沿。
|
||||
|
||||
![Bob Culley 的寻路程序。][14]
|
||||
|
||||
*Bob Culley 的寻路程序。*
|
||||
|
||||
而以上这一切导致 Symbolics 的计算机奇贵无比。在 1983 年,一台 Symbolics 3600 能卖 111,000 美金 [^16]。所以,绝大部分人只可能远远地赞叹 Lisp 计算机的威力和操作员们用 Lisp 编写程序的奇妙技术。不止他们赞叹,从 1979 年到 1980 年代末,Byte 杂志曾经多次提到过 Lisp 和 Lisp 计算机。在 1979 年八月发行的、关于 Lisp 的一期特别杂志中,杂志编辑激情洋溢地写道,麻省理工正在开发的计算机配备了“大坨大坨的内存”和“先进的操作系统” [^17];他觉得,这些 Lisp 计算机的前途是如此光明,以至于它们的面世会让 1978 和 1977 年 —— 诞生了 Apple II、Commodore PET 和 TRS-80 的两年 —— 显得黯淡无光。五年之后,在 1985 年,一名 Byte 杂志撰稿人描述了为“复杂精巧、性能强悍的 Symbolics 3670”编写 Lisp 程序的体验,并力劝读者学习 Lisp,称其为“绝大数人工智能工作者的语言选择”,和将来的通用编程语言 [^18]。
|
||||
|
||||
我问过<ruby>保罗·麦克琼斯<rt>Paul McJones</rt></ruby>(他在<ruby>山景城<rt>Mountain View<rt></ruby>的<ruby>计算机历史博物馆<rt>Computer History Museum</rt></ruby>做了许多 Lisp 的[保护工作][15]),人们是什么时候开始将 Lisp 当作高维生物的赠礼一样谈论的呢?他说,这门语言自有的性质毋庸置疑地促进了这种现象的产生;然而,他也说,Lisp 上世纪六七十年代在人工智能领域得到的广泛应用,很有可能也起到了作用。当 1980 年代到来、Lisp 计算机进入市场时,象牙塔外的某些人由此接触到了 Lisp 的能力,于是传说开始滋生。时至今日,很少有人还记得 Lisp 计算机和 Symbolics 公司;但 Lisp 得以在八十年代一直保持神秘,很大程度上要归功于它们。
|
||||
|
||||
### 理论 C:学习编程
|
||||
|
||||
1985 年,两位麻省理工的教授,<ruby>哈尔·阿伯尔森<rt>Harold "Hal" Abelson</rt></ruby>和<ruby>杰拉尔德·瑟斯曼<rt>Gerald Sussman</rt></ruby>,外加瑟斯曼的妻子<ruby>朱莉·瑟斯曼<rt>Julie Sussman</rt></ruby>,出版了一本叫做《<ruby>计算机程序的构造和解释<rt>Structure and Interpretation of Computer Programs</rt></ruby>》的教科书。这本书用 Scheme(一种 Lisp 方言)向读者们示范了如何编程。它被用于教授麻省理工入门编程课程长达二十年之久。出于直觉,我认为 SICP(这本书的名字通常缩写为 SICP)倍增了 Lisp 的“神秘要素”。SICP 使用 Lisp 描绘了深邃得几乎可以称之为哲学的编程理念。这些理念非常普适,可以用任意一种编程语言展现;但 SICP 的作者们选择了 Lisp。结果,这本阴阳怪气、卓越不凡、吸引了好几代程序员(还成了一种[奇特的模因][16])的著作臭名远扬之后,Lisp 的声望也顺带被提升了。Lisp 已不仅仅是一如既往的“麦卡锡的优雅表达方式”;它现在还成了“向你传授编程的不传之秘的语言”。
|
||||
|
||||
SICP 究竟有多奇怪这一点值得好好说;因为我认为,时至今日,这本书的古怪之处和 Lisp 的古怪之处是相辅相成的。书的封面就透着一股古怪。那上面画着一位朝着桌子走去,准备要施法的巫师或者炼金术士。他的一只手里抓着一副测径仪 —— 或者圆规,另一只手上拿着个球,上书“eval”和“apply”。他对面的女人指着桌子;在背景中,希腊字母 λ (lambda)漂浮在半空,释放出光芒。
|
||||
|
||||
![SICP 封面上的画作][17]
|
||||
|
||||
*SICP 封面上的画作。*
|
||||
|
||||
说真的,这上面画的究竟是怎么一回事?为什么桌子会长着动物的腿?为什么这个女人指着桌子?墨水瓶又是干什么用的?我们是不是该说,这位巫师已经破译了宇宙的隐藏奥秘,而所有这些奥秘就蕴含在 eval/apply 循环和 Lambda 演算之中?看似就是如此。单单是这张图片,就一定对人们如今谈论 Lisp 的方式产生了难以计量的影响。
|
||||
|
||||
然而,这本书的内容通常并不比封面正常多少。SICP 跟你读过的所有计算机科学教科书都不同。在引言中,作者们表示,这本书不只教你怎么用 Lisp 编程 —— 它是关于“现象的三个焦点:人的心智、复数的计算机程序,和计算机”的作品 [^19]。在之后,他们对此进行了解释,描述了他们对如下观点的坚信:编程不该被当作是一种计算机科学的训练,而应该是“<ruby>程序性认识论<rt>procedural epistemology</rt></ruby>”的一种新表达方式 [^20]。程序是将那些偶然被送入计算机的思想组织起来的全新方法。这本书的第一章简明地介绍了 Lisp,但是之后的绝大部分都在讲述更加抽象的概念。其中包括了对不同编程范式的讨论,对于面向对象系统中“时间”和“一致性”的讨论;在书中的某一处,还有关于通信的基本限制可能会如何带来同步问题的讨论 —— 而这些基本限制在通信中就像是光速不变在相对论中一样关键 [^21]。都是些高深难懂的东西。
|
||||
|
||||
以上这些并不是说这是本糟糕的书;这本书其实棒极了。在我读过的所有作品中,这本书对于重要的编程理念的讨论是最为深刻的;那些理念我琢磨了很久,却一直无力用文字去表达。一本入门编程教科书能如此迅速地开始描述面向对象编程的根本缺陷,和函数式语言“将可变状态降到最少”的优点,实在是一件让人印象深刻的事。而这种描述之后变为了另一种震撼人心的讨论:某种(可能类似于今日的 [RxJS][18] 的)流范式能如何同时具备两者的优秀特性。SICP 用和当初麦卡锡的 Lisp 论文相似的方式提纯出了高级程序设计的精华。你读完这本书之后,会立即想要将它推荐给你的程序员朋友们;如果他们找到这本书,看到了封面,但最终没有阅读的话,他们就只会记住长着动物腿的桌子上方那神秘的、根本的、给予魔法师特殊能力的、写着 eval/apply 的东西。话说回来,书上这两人的鞋子也让我印象颇深。
|
||||
|
||||
然而,SICP 最重要的影响恐怕是,它将 Lisp 由一门怪语言提升成了必要的教学工具。在 SICP 面世之前,人们互相推荐 Lisp,以学习这门语言为提升编程技巧的途径。1979 年的 Byte 杂志 Lisp 特刊印证了这一事实。之前提到的那位编辑不仅就麻省理工的新 Lisp 计算机大书特书,还说,Lisp 这门语言值得一学,因为它“代表了分析问题的另一种视角” [^22]。但 SICP 并未只把 Lisp 作为其它语言的陪衬来使用;SICP 将其作为*入门*语言。这就暗含了一种论点,那就是,Lisp 是最能把握计算机编程基础的语言。可以认为,如今的程序员们彼此怂恿“在死掉之前至少试试 Lisp”的时候,他们很大程度上是因为 SICP 才这么说的。毕竟,编程语言 [Brainfuck][19] 想必同样也提供了“分析问题的另一种视角”;但人们学习 Lisp 而非学习 Brainfuck,那是因为他们知道,前者的那种 Lisp 视角在二十年中都被看作是极其有用的,有用到麻省理工在给他们的本科生教其它语言之前,必然会先教 Lisp。
|
||||
|
||||
### Lisp 的回归
|
||||
|
||||
在 SICP 出版的同一年,<ruby>本贾尼·斯特劳斯特卢普<rt>Bjarne Stroustrup</rt></ruby>发布了 C++ 语言的首个版本,它将面向对象编程带到了大众面前。几年之后,Lisp 计算机的市场崩盘,AI 寒冬开始了。在下一个十年的变革中, C++ 和后来的 Java 成了前途无量的语言,而 Lisp 被冷落,无人问津。
|
||||
|
||||
理所当然地,确定人们对 Lisp 重新燃起热情的具体时间并不可能;但这多半是保罗·格雷厄姆发表他那几篇声称 Lisp 是首选入门语言的短文之后的事了。保罗·格雷厄姆是 Y-Combinator 的联合创始人和《Hacker News》的创始者,他这几篇短文有很大的影响力。例如,在短文《<ruby>[胜于平庸][20]<rt>Beating the Averages</rt></ruby>》中,他声称 Lisp 宏使 Lisp 比其它语言更强。他说,因为他在自己创办的公司 Viaweb 中使用 Lisp,他得以比竞争对手更快地推出新功能。至少,[一部分程序员][21]被说服了。然而,庞大的主流程序员群体并未换用 Lisp。
|
||||
|
||||
实际上出现的情况是,Lisp 并未流行,但越来越多 Lisp 式的特性被加入到广受欢迎的语言中。Python 有了列表推导式。C# 有了 Linq。Ruby……嗯,[Ruby 是 Lisp 的一种][22]。就如格雷厄姆之前在 2001 年提到的那样,“在一系列常用语言中所体现出的‘默认语言’正越发朝着 Lisp 的方向演化” [^23]。尽管其它语言变得越来越像 Lisp,Lisp 本身仍然保留了其作为“很少人了解但是大家都该学的神秘语言”的特殊声望。在 1980 年,Lisp 的诞生二十周年纪念日上,麦卡锡写道,Lisp 之所以能够存活这么久,是因为它具备“编程语言领域中的某种近似局部最优” [^24]。这句话并未充分地表明 Lisp 的真正影响力。Lisp 能够存活超过半个世纪之久,并非因为程序员们一年年地勉强承认它就是最好的编程工具;事实上,即使绝大多数程序员根本不用它,它还是存活了下来。多亏了它的起源和它的人工智能研究用途,说不定还要多亏 SICP 的遗产,Lisp 一直都那么让人着迷。在我们能够想象上帝用其它新的编程语言创造世界之前,Lisp 都不会走下神坛。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
[^1]: John McCarthy, “History of Lisp”, 14, Stanford University, February 12, 1979, accessed October 14, 2018, http://jmc.stanford.edu/articles/lisp/lisp.pdf
|
||||
|
||||
[^2]: Paul Graham, “The Roots of Lisp”, 1, January 18, 2002, accessed October 14, 2018, http://languagelog.ldc.upenn.edu/myl/llog/jmc.pdf.
|
||||
|
||||
[^3]: Martin Childs, “John McCarthy: Computer scientist known as the father of AI”, The Independent, November 1, 2011, accessed on October 14, 2018, https://www.independent.co.uk/news/obituaries/john-mccarthy-computer-scientist-known-as-the-father-of-ai-6255307.html.
|
||||
|
||||
[^4]: Lisp Bulletin History. http://www.artinfo-musinfo.org/scans/lb/lb3f.pdf
|
||||
|
||||
[^5]: Allen Newell and Herbert Simon, “Current Developments in Complex Information Processing,” 19, May 1, 1956, accessed on October 14, 2018, http://bitsavers.org/pdf/rand/ipl/P-850_Current_Developments_In_Complex_Information_Processing_May56.pdf.
|
||||
|
||||
[^6]: ibid.
|
||||
|
||||
[^7]: Herbert Stoyan, “Lisp History”, 43, Lisp Bulletin #3, December 1979, accessed on October 14, 2018, http://www.artinfo-musinfo.org/scans/lb/lb3f.pdf
|
||||
|
||||
[^8]: McCarthy, “History of Lisp”, 5.
|
||||
|
||||
[^9]: ibid.
|
||||
|
||||
[^10]: McCarthy “History of Lisp”, 6.
|
||||
|
||||
[^11]: Stoyan, “Lisp History”, 45
|
||||
|
||||
[^12]: McCarthy, “History of Lisp”, 8.
|
||||
|
||||
[^13]: McCarthy, “History of Lisp”, 2.
|
||||
|
||||
[^14]: McCarthy, “History of Lisp”, 8.
|
||||
|
||||
[^15]: Graham, “The Roots of Lisp”, 11.
|
||||
|
||||
[^16]: Guy Steele and Richard Gabriel, “The Evolution of Lisp”, 22, History of Programming Languages 2, 1993, accessed on October 14, 2018, http://www.dreamsongs.com/Files/HOPL2-Uncut.pdf. 2
|
||||
|
||||
[^17]: Carl Helmers, “Editorial”, Byte Magazine, 154, August 1979, accessed on October 14, 2018, https://archive.org/details/byte-magazine-1979-08/page/n153.
|
||||
|
||||
[^18]: Patrick Winston, “The Lisp Revolution”, 209, April 1985, accessed on October 14, 2018, https://archive.org/details/byte-magazine-1985-04/page/n207.
|
||||
|
||||
[^19]: Harold Abelson, Gerald Jay. Sussman, and Julie Sussman, Structure and Interpretation of Computer Programs (Cambridge, Mass: MIT Press, 2010), xiii.
|
||||
|
||||
[^20]: Abelson, xxiii.
|
||||
|
||||
[^21]: Abelson, 428.
|
||||
|
||||
[^22]: Helmers, 7.
|
||||
|
||||
[^23]: Paul Graham, “What Made Lisp Different”, December 2001, accessed on October 14, 2018, http://www.paulgraham.com/diff.html.
|
||||
|
||||
[^24]: John McCarthy, “Lisp—Notes on its past and future”, 3, Stanford University, 1980, accessed on October 14, 2018, http://jmc.stanford.edu/articles/lisp20th/lisp20th.pdf.
|
||||
|
||||
via: https://twobithistory.org/2018/10/14/lisp.html
|
||||
|
||||
作者:[Two-Bit History][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Northurland](https://github.com/Northurland)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twobithistory.org
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://xkcd.com/224/
|
||||
[2]: https://xkcd.com/297/
|
||||
[3]: https://www.gnu.org/fun/jokes/eternal-flame.en.html
|
||||
[4]: https://www.reddit.com/r/ProgrammerHumor/comments/5c14o6/xkcd_lisp/d9szjnc/
|
||||
[5]: https://twobithistory.org/images/byte_lisp.jpg
|
||||
[6]: http://languagelog.ldc.upenn.edu/myl/llog/jmc.pdf
|
||||
[7]: https://en.wikipedia.org/wiki/Jargon_File
|
||||
[8]: https://hci.stanford.edu/winograd/shrdlu/
|
||||
[9]: https://en.wikipedia.org/wiki/Macsyma
|
||||
[10]: https://en.wikipedia.org/wiki/ACL2
|
||||
[11]: https://twobithistory.org/2018/09/30/chaosnet.html
|
||||
[12]: https://youtu.be/gV5obrYaogU?t=201
|
||||
[13]: https://en.wikipedia.org/wiki/Flavors_(programming_language)
|
||||
[14]: https://twobithistory.org/images/symbolics.jpg
|
||||
[15]: http://www.softwarepreservation.org/projects/LISP/
|
||||
[16]: https://knowyourmeme.com/forums/meme-research/topics/47038-structure-and-interpretation-of-computer-programs-hugeass-image-dump-for-evidence
|
||||
[17]: https://twobithistory.org/images/sicp.jpg
|
||||
[18]: https://rxjs-dev.firebaseapp.com/
|
||||
[19]: https://en.wikipedia.org/wiki/Brainfuck
|
||||
[20]: http://www.paulgraham.com/avg.html
|
||||
[21]: https://web.archive.org/web/20061004035628/http://wiki.alu.org/Chris-Perkins
|
||||
[22]: http://www.randomhacks.net/2005/12/03/why-ruby-is-an-acceptable-lisp/
|
||||
@ -0,0 +1,247 @@
|
||||
如何使用 chkconfig 和 systemctl 命令启用或禁用 Linux 服务
|
||||
======
|
||||
|
||||
对于 Linux 管理员来说这是一个重要(美妙)的话题,所以每个人都必须知道,并练习怎样才能更高效的使用它们。
|
||||
|
||||
在 Linux 中,无论何时当你安装任何带有服务和守护进程的包,系统默认会把这些服务的初始化及 systemd 脚本添加进去,不过此时它们并没有被启用。
|
||||
|
||||
我们需要手动的开启或者关闭那些服务。Linux 中有三个著名的且一直在被使用的初始化系统。
|
||||
|
||||
### 什么是初始化系统?
|
||||
|
||||
在以 Linux/Unix 为基础的操作系统上,`init` (初始化的简称) 是内核引导系统启动过程中第一个启动的进程。
|
||||
|
||||
`init` 的进程 id (pid)是 1,除非系统关机否则它将会一直在后台运行。
|
||||
|
||||
`init` 首先根据 `/etc/inittab` 文件决定 Linux 运行的级别,然后根据运行级别在后台启动所有其他进程和应用程序。
|
||||
|
||||
BIOS、MBR、GRUB 和内核程序在启动 `init` 之前就作为 Linux 的引导程序的一部分开始工作了。
|
||||
|
||||
下面是 Linux 中可以使用的运行级别(从 0~6 总共七个运行级别):
|
||||
|
||||
* `0`:关机
|
||||
* `1`:单用户模式
|
||||
* `2`:多用户模式(没有NFS)
|
||||
* `3`:完全的多用户模式
|
||||
* `4`:系统未使用
|
||||
* `5`:图形界面模式
|
||||
* `6`:重启
|
||||
|
||||
下面是 Linux 系统中最常用的三个初始化系统:
|
||||
|
||||
* System V(Sys V)
|
||||
* Upstart
|
||||
* systemd
|
||||
|
||||
### 什么是 System V(Sys V)?
|
||||
|
||||
System V(Sys V)是类 Unix 系统第一个也是传统的初始化系统。`init` 是内核引导系统启动过程中第一支启动的程序,它是所有程序的父进程。
|
||||
|
||||
大部分 Linux 发行版最开始使用的是叫作 System V(Sys V)的传统的初始化系统。在过去的几年中,已经发布了好几个初始化系统以解决标准版本中的设计限制,例如:launchd、Service Management Facility、systemd 和 Upstart。
|
||||
|
||||
但是 systemd 已经被几个主要的 Linux 发行版所采用,以取代传统的 SysV 初始化系统。
|
||||
|
||||
### 什么是 Upstart?
|
||||
|
||||
Upstart 是一个基于事件的 `/sbin/init` 守护进程的替代品,它在系统启动过程中处理任务和服务的启动,在系统运行期间监视它们,在系统关机的时候关闭它们。
|
||||
|
||||
它最初是为 Ubuntu 而设计,但是它也能够完美的部署在其他所有 Linux系统中,用来代替古老的 System-V。
|
||||
|
||||
Upstart 被用于 Ubuntu 从 9.10 到 Ubuntu 14.10 和基于 RHEL 6 的系统,之后它被 systemd 取代。
|
||||
|
||||
### 什么是 systemd?
|
||||
|
||||
systemd 是一个新的初始化系统和系统管理器,它被用于所有主要的 Linux 发行版,以取代传统的 SysV 初始化系统。
|
||||
|
||||
systemd 兼容 SysV 和 LSB 初始化脚本。它可以直接替代 SysV 初始化系统。systemd 是被内核启动的第一个程序,它的 PID 是 1。
|
||||
|
||||
systemd 是所有程序的父进程,Fedora 15 是第一个用 systemd 取代 upstart 的发行版。`systemctl` 用于命令行,它是管理 systemd 的守护进程/服务的主要工具,例如:(开启、重启、关闭、启用、禁用、重载和状态)
|
||||
|
||||
systemd 使用 .service 文件而不是 bash 脚本(SysVinit 使用的)。systemd 将所有守护进程添加到 cgroups 中排序,你可以通过浏览 `/cgroup/systemd` 文件查看系统等级。
|
||||
|
||||
### 如何使用 chkconfig 命令启用或禁用引导服务?
|
||||
|
||||
`chkconfig` 实用程序是一个命令行工具,允许你在指定运行级别下启动所选服务,以及列出所有可用服务及其当前设置。
|
||||
|
||||
此外,它还允许我们从启动中启用或禁用服务。前提是你有超级管理员权限(root 或者 `sudo`)运行这个命令。
|
||||
|
||||
所有的服务脚本位于 `/etc/rd.d/init.d`文件中
|
||||
|
||||
### 如何列出运行级别中所有的服务
|
||||
|
||||
`--list` 参数会展示所有的服务及其当前状态(启用或禁用服务的运行级别):
|
||||
|
||||
```
|
||||
# chkconfig --list
|
||||
NetworkManager 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
abrt-ccpp 0:off 1:off 2:off 3:on 4:off 5:on 6:off
|
||||
abrtd 0:off 1:off 2:off 3:on 4:off 5:on 6:off
|
||||
acpid 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
atd 0:off 1:off 2:off 3:on 4:on 5:on 6:off
|
||||
auditd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
.
|
||||
.
|
||||
```
|
||||
|
||||
### 如何查看指定服务的状态
|
||||
|
||||
如果你想查看运行级别下某个服务的状态,你可以使用下面的格式匹配出需要的服务。
|
||||
|
||||
比如说我想查看运行级别中 `auditd` 服务的状态
|
||||
|
||||
```
|
||||
# chkconfig --list| grep auditd
|
||||
auditd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
```
|
||||
|
||||
### 如何在指定运行级别中启用服务
|
||||
|
||||
使用 `--level` 参数启用指定运行级别下的某个服务,下面展示如何在运行级别 3 和运行级别 5 下启用 `httpd` 服务。
|
||||
|
||||
|
||||
```
|
||||
# chkconfig --level 35 httpd on
|
||||
```
|
||||
|
||||
### 如何在指定运行级别下禁用服务
|
||||
|
||||
同样使用 `--level` 参数禁用指定运行级别下的服务,下面展示的是在运行级别 3 和运行级别 5 中禁用 `httpd` 服务。
|
||||
|
||||
```
|
||||
# chkconfig --level 35 httpd off
|
||||
```
|
||||
|
||||
### 如何将一个新服务添加到启动列表中
|
||||
|
||||
`-–add` 参数允许我们添加任何新的服务到启动列表中,默认情况下,新添加的服务会在运行级别 2、3、4、5 下自动开启。
|
||||
|
||||
```
|
||||
# chkconfig --add nagios
|
||||
```
|
||||
|
||||
### 如何从启动列表中删除服务
|
||||
|
||||
可以使用 `--del` 参数从启动列表中删除服务,下面展示的是如何从启动列表中删除 Nagios 服务。
|
||||
|
||||
```
|
||||
# chkconfig --del nagios
|
||||
```
|
||||
|
||||
### 如何使用 systemctl 命令启用或禁用开机自启服务?
|
||||
|
||||
`systemctl` 用于命令行,它是一个用来管理 systemd 的守护进程/服务的基础工具,例如:(开启、重启、关闭、启用、禁用、重载和状态)。
|
||||
|
||||
所有服务创建的 unit 文件位与 `/etc/systemd/system/`。
|
||||
|
||||
### 如何列出全部的服务
|
||||
|
||||
使用下面的命令列出全部的服务(包括启用的和禁用的)。
|
||||
|
||||
```
|
||||
# systemctl list-unit-files --type=service
|
||||
UNIT FILE STATE
|
||||
arp-ethers.service disabled
|
||||
auditd.service enabled
|
||||
autovt@.service enabled
|
||||
blk-availability.service disabled
|
||||
brandbot.service static
|
||||
chrony-dnssrv@.service static
|
||||
chrony-wait.service disabled
|
||||
chronyd.service enabled
|
||||
cloud-config.service enabled
|
||||
cloud-final.service enabled
|
||||
cloud-init-local.service enabled
|
||||
cloud-init.service enabled
|
||||
console-getty.service disabled
|
||||
console-shell.service disabled
|
||||
container-getty@.service static
|
||||
cpupower.service disabled
|
||||
crond.service enabled
|
||||
.
|
||||
.
|
||||
150 unit files listed.
|
||||
```
|
||||
|
||||
使用下面的格式通过正则表达式匹配出你想要查看的服务的当前状态。下面是使用 `systemctl` 命令查看 `httpd` 服务的状态。
|
||||
|
||||
```
|
||||
# systemctl list-unit-files --type=service | grep httpd
|
||||
httpd.service disabled
|
||||
```
|
||||
|
||||
### 如何让指定的服务开机自启
|
||||
|
||||
使用下面格式的 `systemctl` 命令启用一个指定的服务。启用服务将会创建一个符号链接,如下可见:
|
||||
|
||||
```
|
||||
# systemctl enable httpd
|
||||
Created symlink from /etc/systemd/system/multi-user.target.wants/httpd.service to /usr/lib/systemd/system/httpd.service.
|
||||
```
|
||||
|
||||
运行下列命令再次确认服务是否被启用。
|
||||
|
||||
```
|
||||
# systemctl is-enabled httpd
|
||||
enabled
|
||||
```
|
||||
|
||||
### 如何禁用指定的服务
|
||||
|
||||
运行下面的命令禁用服务将会移除你启用服务时所创建的符号链接。
|
||||
|
||||
```
|
||||
# systemctl disable httpd
|
||||
Removed symlink /etc/systemd/system/multi-user.target.wants/httpd.service.
|
||||
```
|
||||
|
||||
运行下面的命令再次确认服务是否被禁用。
|
||||
|
||||
```
|
||||
# systemctl is-enabled httpd
|
||||
disabled
|
||||
```
|
||||
|
||||
### 如何查看系统当前的运行级别
|
||||
|
||||
使用 `systemctl` 命令确认你系统当前的运行级别,`runlevel` 命令仍然可在 systemd 下工作,不过,运行级别对于 systemd 来说是一个历史遗留的概念。所以我建议你全部使用 `systemctl` 命令。
|
||||
|
||||
我们当前处于运行级别 3, 它等同于下面显示的 `multi-user.target`。
|
||||
|
||||
```
|
||||
# systemctl list-units --type=target
|
||||
UNIT LOAD ACTIVE SUB DESCRIPTION
|
||||
basic.target loaded active active Basic System
|
||||
cloud-config.target loaded active active Cloud-config availability
|
||||
cryptsetup.target loaded active active Local Encrypted Volumes
|
||||
getty.target loaded active active Login Prompts
|
||||
local-fs-pre.target loaded active active Local File Systems (Pre)
|
||||
local-fs.target loaded active active Local File Systems
|
||||
multi-user.target loaded active active Multi-User System
|
||||
network-online.target loaded active active Network is Online
|
||||
network-pre.target loaded active active Network (Pre)
|
||||
network.target loaded active active Network
|
||||
paths.target loaded active active Paths
|
||||
remote-fs.target loaded active active Remote File Systems
|
||||
slices.target loaded active active Slices
|
||||
sockets.target loaded active active Sockets
|
||||
swap.target loaded active active Swap
|
||||
sysinit.target loaded active active System Initialization
|
||||
timers.target loaded active active Timers
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: https://www.2daygeek.com/how-to-enable-or-disable-services-on-boot-in-linux-using-chkconfig-and-systemctl-command/
|
||||
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[way-ww](https://github.com/way-ww)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -1,71 +1,74 @@
|
||||
Kali Linux:在开始使用之前你必须知道的 – FOSS Post
|
||||
在你开始使用 Kali Linux 之前必须知道的事情
|
||||
======
|
||||
|
||||

|
||||
|
||||
Kali Linux 在渗透测试和白帽子方面,是业界领先的 Linux 发行版。默认情况下,该发行版附带了大量黑客和渗透工具和软件,并且在全世界都得到了广泛认可。即使在那些甚至可能不知道 Linux 是什么的 Windows 用户中也是如此。
|
||||
Kali Linux 在渗透测试和白帽子方面是业界领先的 Linux 发行版。默认情况下,该发行版附带了大量入侵和渗透的工具和软件,并且在全世界都得到了广泛认可。即使在那些甚至可能不知道 Linux 是什么的 Windows 用户中也是如此。
|
||||
|
||||
由于后者的原因,许多人都试图单独使用 Kali Linux,尽管他们甚至不了解 Linux 系统的基础知识。原因可能各不相同,有的为了玩乐,有的是为了取悦女友而伪装成黑客,有的仅仅是试图破解邻居的 WiFi 网络以免费上网。如果你打算使用 Kali Linux,所有的这些都是不好的事情。
|
||||
由于后者的原因(LCTT 译注:Windows 用户),许多人都试图单独使用 Kali Linux,尽管他们甚至不了解 Linux 系统的基础知识。原因可能各不相同,有的为了玩乐,有的是为了取悦女友而伪装成黑客,有的仅仅是试图破解邻居的 WiFi 网络以免费上网。如果你打算使用 Kali Linux,记住,所有的这些都是不好的事情。
|
||||
|
||||
在计划使用 Kali Linux 之前,你应该了解一些提示。
|
||||
|
||||
### Kali Linux 不适合初学者
|
||||
|
||||

|
||||
Kali Linux 默认 GNOME 桌面
|
||||
|
||||
如果你是几个月前刚开始使用 Linux 的人,或者你认为自己的知识水平低于平均水平,那么 Kali Linux 就不适合你。如果你打算问“如何在 Kali 上安装 Stream?如何让我的打印机在 Kali 上工作?如何解决 Kali 上的 APT 源错误?”这些东西,那么 Kali Linux 并不适合你。
|
||||
*Kali Linux 默认 GNOME 桌面*
|
||||
|
||||
Kali Linux 主要面向想要运行渗透测试的专家或想要学习成为白帽子和数字取证的人。但即使你来自后者,普通的 Kali Linux 用户在日常使用时也会遇到很多麻烦。他还被要求以非常谨慎的方式使用工具和软件,而不仅仅是“让我们安装并运行一切”。每一个工具必须小心使用,你安装的每一个软件都必须仔细检查。
|
||||
如果你是几个月前刚开始使用 Linux 的人,或者你认为自己的知识水平低于平均水平,那么 Kali Linux 就不适合你。如果你打算问“如何在 Kali 上安装 Steam?如何让我的打印机在 Kali 上工作?如何解决 Kali 上的 APT 源错误?”这些东西,那么 Kali Linux 并不适合你。
|
||||
|
||||
**建议阅读:** [Linux 系统的组件是什么?][1]
|
||||
Kali Linux 主要面向想要运行渗透测试套件的专家或想要学习成为白帽子和数字取证的人。但即使你属于后者,普通的 Kali Linux 用户在日常使用时也会遇到很多麻烦。他还被要求以非常谨慎的方式使用工具和软件,而不仅仅是“让我们安装并运行一切”。每一个工具必须小心使用,你安装的每一个软件都必须仔细检查。
|
||||
|
||||
普通 Linux 用户无法做正常的事情。(to 校正:这里什么意思呢?)一个更好的方法是花几周时间学习 Linux 及其守护进程,服务,软件,发行版及其工作方式,然后观看几十个关于白帽子攻击的视频和课程,然后再尝试使用 Kali 来应用你学习到的东西。
|
||||
**建议阅读:** [Linux 系统的组件有什么?][1]
|
||||
|
||||
普通 Linux 用户都无法自如地使用它。一个更好的方法是花几周时间学习 Linux 及其守护进程、服务、软件、发行版及其工作方式,然后观看几十个关于白帽子攻击的视频和课程,然后再尝试使用 Kali 来应用你学习到的东西。
|
||||
|
||||
### 它会让你被黑客攻击
|
||||
|
||||

|
||||
Kali Linux 入侵和测试工具
|
||||
|
||||
*Kali Linux 入侵和测试工具*
|
||||
|
||||
在普通的 Linux 系统中,普通用户有一个账户,而 root 用户也有一个单独的账号。但在 Kali Linux 中并非如此。Kali Linux 默认使用 root 账户,不提供普通用户账户。这是因为 Kali 中几乎所有可用的安全工具都需要 root 权限,并且为了避免每分钟要求你输入 root 密码,所以这样设计。
|
||||
|
||||
当然,你可以简单地创建一个普通用户账户并开始使用它。但是,这种方式仍然不推荐,因为这不是 Kali Linux 系统设计的工作方式。然后,在使用程序,打开端口,调试软件时,你会遇到很多问题,你会发现为什么这个东西不起作用,最终却发现它是一个奇怪的权限错误。另外每次在系统上做任何事情时,你会被每次运行工具都要求输入密码而烦恼。
|
||||
当然,你可以简单地创建一个普通用户账户并开始使用它。但是,这种方式仍然不推荐,因为这不是 Kali Linux 系统设计的工作方式。使用普通用户在使用程序,打开端口,调试软件时,你会遇到很多问题,你会发现为什么这个东西不起作用,最终却发现它是一个奇怪的权限错误。另外每次在系统上做任何事情时,你会被每次运行工具都要求输入密码而烦恼。
|
||||
|
||||
现在,由于你被迫以 root 用户身份使用它,因此你在系统上运行的所有软件也将以 root 权限运行。如果你不知道自己在做什么,那么这很糟糕,因为如果 Firefox 中存在漏洞,并且你访问了一个受感染的网站,那么黑客能够在你的 PC 上获得全部 root 权限并入侵你。如果你使用的是普通用户账户,则会收到限制。此外,你安装和使用的某些工具可能会在你不知情的情况下打开端口并泄露信息,因此如果你不是非常小心,人们可能会以你尝试入侵他们的方式入侵你。
|
||||
现在,由于你被迫以 root 用户身份使用它,因此你在系统上运行的所有软件也将以 root 权限运行。如果你不知道自己在做什么,那么这很糟糕,因为如果 Firefox 中存在漏洞,并且你访问了一个受感染的网站,那么黑客能够在你的 PC 上获得全部 root 权限并入侵你。如果你使用的是普通用户账户,则会受到限制。此外,你安装和使用的某些工具可能会在你不知情的情况下打开端口并泄露信息,因此如果你不是非常小心,人们可能会以你尝试入侵他们的方式入侵你。
|
||||
|
||||
如果你在一些情况下访问于与 Kali Linux 相关的 Facebook 群组,你会发现这些群组中几乎有四分之一的帖子是人们在寻求帮助,因为有人入侵了他们。
|
||||
如果你曾经访问过与 Kali Linux 相关的 Facebook 群组,你会发现这些群组中几乎有四分之一的帖子是人们在寻求帮助,因为有人入侵了他们。
|
||||
|
||||
### 它可以让你入狱
|
||||
|
||||
Kali Linux 仅提供软件。那么,如何使用它们完全是你自己的责任。
|
||||
Kali Linux 只是提供了软件。那么,如何使用它们完全是你自己的责任。
|
||||
|
||||
在世界上大多数发达国家,使用针对公共 WiFi 网络或其他设备的渗透测试工具很容易让你入狱。现在不要以为你使用了 Kali 就无法被跟踪,许多系统都配置了复杂的日志记录设备来简单地跟踪试图监听或入侵其网络的人,你可能无意间成为其中的一个,那么它会毁掉你的生活。
|
||||
|
||||
永远不要对不属于你的设备或网络使用 Kali Linux 系统,也不要明确允许对它们进行入侵。如果你说你不知道你在做什么,在法庭上它不会被当作借口来接受。
|
||||
|
||||
### 修改了内核和软件
|
||||
### 修改了的内核和软件
|
||||
|
||||
Kali [基于][2] Debian(测试分支,这意味着 Kali Linux 使用滚动发布模型),因此它使用了 Debian 的大部分软件体系结构,你会发现 Kali Linux 中的大部分软件跟 Debian 中的没什么区别。
|
||||
Kali [基于][2] Debian(“测试”分支,这意味着 Kali Linux 使用滚动发布模型),因此它使用了 Debian 的大部分软件体系结构,你会发现 Kali Linux 中的大部分软件跟 Debian 中的没什么区别。
|
||||
|
||||
但是,Kali 修改了一些包来加强安全性并修复了一些可能的漏洞。例如,Kali 使用的 Linux 内核被打了补丁,允许在各种设备上进行无线注入。这些补丁通常在普通内核中不可用。此外,Kali Linux 不依赖于 Debian 服务器和镜像,而是通过自己的服务器构建软件包。以下是最新版本中的默认软件源:
|
||||
|
||||
```
|
||||
deb http://http.kali.org/kali kali-rolling main contrib non-free
|
||||
deb-src http://http.kali.org/kali kali-rolling main contrib non-free
|
||||
deb http://http.kali.org/kali kali-rolling main contrib non-free
|
||||
deb-src http://http.kali.org/kali kali-rolling main contrib non-free
|
||||
```
|
||||
|
||||
这就是为什么,对于某些特定的软件,当你在 Kali Linux 和 Fedora 中使用相同的程序时,你会发现不同的行为。你可以从 [git.kali.org][3] 中查看 Kali Linux 软件的完整列表。你还可以在 Kali Linux(GNOME)上找到我们[自己生成的已安装包列表][4]。
|
||||
|
||||
更重要的是,Kali Linux 官方文档极力建议不要添加任何其他第三方软件仓库,因为 Kali Linux 是一个滚动发行版,并且依赖于 Debian 测试,由于依赖关系冲突和包钩子,所以你很可能只是添加一个新的仓库源就会破坏系统。
|
||||
更重要的是,Kali Linux 官方文档极力建议不要添加任何其他第三方软件仓库,因为 Kali Linux 是一个滚动发行版,并且依赖于 Debian 测试分支,由于依赖关系冲突和包钩子,所以你很可能只是添加一个新的仓库源就会破坏系统。
|
||||
|
||||
### 不要安装 Kali Linux
|
||||
|
||||

|
||||
|
||||
使用 Kali Linux 在 fosspost.org 上运行 wpscan
|
||||
*使用 Kali Linux 在 fosspost.org 上运行 wpscan*
|
||||
|
||||
我在极少数情况下使用 Kali Linux 来测试我部署的软件和服务器。但是,我永远不敢安装它并将其用作主系统。
|
||||
|
||||
如果你要将其用作主系统,那么你必须保留自己的个人文件,密码,数据以及系统上的所有内容。你还需要安装大量日常使用的软件,以解放你的生活。但正如我们上面提到的,使用 Kali Linux 是非常危险的,应该非常小心地进行,如果你被入侵了,你将丢失所有数据,并且可能会暴露给更多的人。如果你在做一些不合法的事情,你的个人信息也可用于跟踪你。如果你不小心使用这些工具,那么你甚至可能会毁掉自己的数据。
|
||||
如果你要将其用作主系统,那么你必须保留自己的个人文件、密码、数据以及系统上的所有内容。你还需要安装大量日常使用的软件,以解放你的生活。但正如我们上面提到的,使用 Kali Linux 是非常危险的,应该非常小心地进行,如果你被入侵了,你将丢失所有数据,并且可能会暴露给更多的人。如果你在做一些不合法的事情,你的个人信息也可用于跟踪你。如果你不小心使用这些工具,那么你甚至可能会毁掉自己的数据。
|
||||
|
||||
即使是专业的白帽子也不建议将其作为主系统安装,而是通过 USB 使用它来进行渗透测试工作,然后再回到普通的 Linux 发行版。
|
||||
|
||||
@ -83,7 +86,7 @@ via: https://fosspost.org/articles/must-know-before-using-kali-linux
|
||||
作者:[M.Hanny Sabbagh][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,9 +1,11 @@
|
||||
使用极简浏览器 Min 浏览网页
|
||||
======
|
||||
|
||||
> 并非所有 web 浏览器都要做到无所不能,Min 就是一个极简主义风格的浏览器。
|
||||
|
||||

|
||||
|
||||
现在还有开发新的网络浏览器的需要吗?即使现在浏览器领域已经成为了寡头市场,但仍然不断涌现出各种前所未有的浏览器产品。
|
||||
现在还有开发新的 Web 浏览器的需要吗?即使现在浏览器领域已经成为了寡头市场,但仍然不断涌现出各种前所未有的浏览器产品。
|
||||
|
||||
[Min][1] 就是其中一个。顾名思义,Min 是一个小的浏览器,也是一个极简主义的浏览器。但它麻雀虽小五脏俱全,而且还是一个开源的浏览器,它的 Apache 2.0 许可证引起了我的注意。
|
||||
|
||||
@ -29,7 +31,7 @@ Min 号称是更智能、更快速的浏览器。经过尝试以后,我觉得
|
||||
|
||||
Min 和其它浏览器一样,支持页面选项卡。它还有一个称为 Tasks 的功能,可以对打开的选项卡进行分组。
|
||||
|
||||
[DuckDuckGo][6]是我最喜欢的搜索引擎,而 Min 的默认搜索引擎恰好就是它,这正合我意。当然,如果你喜欢另一个搜索引擎,也可以在 Min 的偏好设置中配置你喜欢的搜索引擎作为默认搜索引擎。
|
||||
[DuckDuckGo][6] 是我最喜欢的搜索引擎,而 Min 的默认搜索引擎恰好就是它,这正合我意。当然,如果你喜欢另一个搜索引擎,也可以在 Min 的偏好设置中配置你喜欢的搜索引擎作为默认搜索引擎。
|
||||
|
||||
Min 没有使用类似 AdBlock 这样的插件来过滤你不想看到的内容,而是使用了一个名为 [EasyList][7] 的内置的广告拦截器,你可以使用它来屏蔽脚本和图片。另外 Min 还带有一个内置的防跟踪软件。
|
||||
|
||||
@ -54,7 +56,7 @@ Min 确实也有自己的缺点,例如它无法将网站添加为书签。替
|
||||
### 总结
|
||||
|
||||
Min 算是一个中规中矩的浏览器,它可以凭借轻量、快速的优点吸引很多极简主义的用户。但是对于追求多功能的用户来说,Min 就显得相当捉襟见肘了。
|
||||
.
|
||||
|
||||
所以,如果你想摆脱当今多功能浏览器的束缚,我觉得可以试用一下 Min。
|
||||
|
||||
|
||||
@ -65,7 +67,7 @@ via: https://opensource.com/article/18/10/min-web-browser
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,49 +1,49 @@
|
||||
Chrony – An Alternative NTP Client And Server For Unix-like Systems
|
||||
Chrony:一个类 Unix 系统上 NTP 客户端和服务器替代品
|
||||
======
|
||||
|
||||

|
||||
|
||||
In this tutorial, we will be discussing how to install and configure **Chrony** , an alternative NTP client and server for Unix-like systems. Chrony can synchronise the system clock faster with better time accuracy and it can be particularly useful for the systems which are not online all the time. Chrony is free, open source and supports GNU/Linux and BSD variants such as FreeBSD, NetBSD, macOS, and Solaris.
|
||||
在这个教程中,我们会讨论如何安装和配置 **Chrony**,一个类 Unix 系统上 NTP 客户端和服务器的替代品。Chrony 可以更快的同步系统时钟,具有更好的时钟准确度,并且它对于那些不是一直在线的系统很有帮助。Chrony 是自由开源的,并且支持 GNU/Linux 和 BSD 衍生版(比如 FreeBSD、NetBSD)、macOS 和 Solaris 等。
|
||||
|
||||
### Installing Chrony
|
||||
### 安装 Chrony
|
||||
|
||||
Chrony is available in the default repositories of most Linux distributions. If you’re on Arch Linux, run the following command to install it:
|
||||
Chrony 可以从大多数 Linux 发行版的默认软件库中获得。如果你使用的是 Arch Linux,运行下面的命令来安装它:
|
||||
|
||||
```
|
||||
$ sudo pacman -S chrony
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint:
|
||||
在 Debian、Ubuntu、Linux Mint 上:
|
||||
|
||||
```
|
||||
$ sudo apt-get install chrony
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
在 Fedora 上:
|
||||
|
||||
```
|
||||
$ sudo dnf install chrony
|
||||
```
|
||||
|
||||
Once installed, start **chronyd.service** daemon if it is not started already:
|
||||
当安装完成后,如果之前没有启动过的话需启动 `chronyd.service` 守护进程:
|
||||
|
||||
```
|
||||
$ sudo systemctl start chronyd.service
|
||||
```
|
||||
|
||||
Make it to start automatically on every reboot using command:
|
||||
使用下面的命令让它每次重启系统后自动运行:
|
||||
|
||||
```
|
||||
$ sudo systemctl enable chronyd.service
|
||||
```
|
||||
|
||||
To verify if the Chronyd.service has been started, run:
|
||||
为了确认 `chronyd.service` 已经启动,运行:
|
||||
|
||||
```
|
||||
$ sudo systemctl status chronyd.service
|
||||
```
|
||||
|
||||
If everything is OK, you will see an output something like below.
|
||||
如果一切正常,你将看到类似下面的输出:
|
||||
|
||||
```
|
||||
● chrony.service - chrony, an NTP client/server
|
||||
@ -67,13 +67,13 @@ Oct 17 10:35:03 ubuntuserver chronyd[2482]: Selected source 91.189.89.199
|
||||
Oct 17 10:35:06 ubuntuserver chronyd[2482]: Selected source 106.10.186.200
|
||||
```
|
||||
|
||||
As you can see, Chrony service is started and working!
|
||||
可以看到,Chrony 服务已经启动并且正在工作!
|
||||
|
||||
### Configure Chrony
|
||||
### 配置 Chrony
|
||||
|
||||
The NTP clients needs to know which NTP servers it should contact to get the current time. We can specify the NTP servers in the **server** or **pool** directive in the NTP configuration file. Usually, the default configuration file is **/etc/chrony/chrony.conf** or **/etc/chrony.conf** depending upon the Linux distribution version. For better reliability, it is recommended to specify at least three servers.
|
||||
NTP 客户端需要知道它要连接到哪个 NTP 服务器来获取当前时间。我们可以直接在该 NTP 配置文件中的 `server` 或者 `pool` 项指定 NTP 服务器。通常,默认的配置文件位于 `/etc/chrony/chrony.conf` 或者 `/etc/chrony.conf`,取决于 Linux 发行版版本。为了更可靠的同步时间,建议指定至少三个服务器。
|
||||
|
||||
The following lines are just an example taken from my Ubuntu 18.04 LTS server.
|
||||
下面几行是我的 Ubuntu 18.04 LTS 服务器上的一个示例。
|
||||
|
||||
```
|
||||
[...]
|
||||
@ -87,22 +87,19 @@ pool 2.ubuntu.pool.ntp.org iburst maxsources 2
|
||||
[...]
|
||||
```
|
||||
|
||||
As you see in the above output, [**NTP Pool Project**][1] has been set as the default time server. For those wondering, NTP pool project is the cluster of time servers that provides NTP service for tens of millions clients across the world. It is the default time server for Ubuntu and most of the other major Linux distributions.
|
||||
从上面的输出中你可以看到,[NTP 服务器池项目][1] 已经被设置成为了默认的时间服务器。对于那些好奇的人,NTP 服务器池项目是一个时间服务器集群,用来为全世界千万个客户端提供 NTP 服务。它是 Ubuntu 以及其他主流 Linux 发行版的默认时间服务器。
|
||||
|
||||
Here,
|
||||
在这里,
|
||||
* `iburst` 选项用来加速初始的同步过程
|
||||
* `maxsources` 代表 NTP 源的最大数量
|
||||
|
||||
* the **iburst** option is used to speed up the initial synchronisation.
|
||||
* the **maxsources** refers the maximum number of NTP sources.
|
||||
请确保你选择的 NTP 服务器是同步的、稳定的、离你的位置较近的,以便使用这些 NTP 源来提升时间准确度。
|
||||
|
||||
### 在命令行中管理 Chronyd
|
||||
|
||||
chrony 有一个命令行工具叫做 `chronyc` 用来控制和监控 chrony 守护进程(`chronyd`)。
|
||||
|
||||
Please make sure that the NTP servers you have chosen are well synchronised, stable and close to your location to improve the accuracy of the time with NTP sources.
|
||||
|
||||
### Manage Chronyd from command line
|
||||
|
||||
Chrony has a command line utility named **chronyc** to control and monitor the **chrony** daemon (chronyd).
|
||||
|
||||
To check if **chrony** is synchronized, we can use the **tracking** command as shown below.
|
||||
为了检查是否 chrony 已经同步,我们可以使用下面展示的 `tracking` 命令。
|
||||
|
||||
```
|
||||
$ chronyc tracking
|
||||
@ -121,7 +118,7 @@ Update interval : 515.1 seconds
|
||||
Leap status : Normal
|
||||
```
|
||||
|
||||
We can verify the current time sources that chrony uses with command:
|
||||
我们可以使用命令确认现在 chrony 使用的时间源:
|
||||
|
||||
```
|
||||
$ chronyc sources
|
||||
@ -138,7 +135,7 @@ MS Name/IP address Stratum Poll Reach LastRx Last sample
|
||||
^- ns2.pulsation.fr 2 10 377 311 -75ms[ -73ms] +/- 250ms
|
||||
```
|
||||
|
||||
Chronyc utility can find the statistics of each sources, such as drift rate and offset estimation process, using **sourcestats** command.
|
||||
`chronyc` 工具可以对每个源进行统计,比如使用 `sourcestats` 命令获得漂移速率和进行偏移估计。
|
||||
|
||||
```
|
||||
$ chronyc sourcestats
|
||||
@ -155,7 +152,7 @@ sin1.m-d.net 29 13 83m +0.049 6.060 -8466us 9940us
|
||||
ns2.pulsation.fr 32 17 88m +0.784 9.834 -62ms 22ms
|
||||
```
|
||||
|
||||
If your system is not connected to Internet, you need to notify Chrony that the system is not connected to the Internet. To do so, run:
|
||||
如果你的系统没有连接到互联网,你需要告知 Chrony 系统没有连接到 互联网。为了这样做,运行:
|
||||
|
||||
```
|
||||
$ sudo chronyc offline
|
||||
@ -163,7 +160,7 @@ $ sudo chronyc offline
|
||||
200 OK
|
||||
```
|
||||
|
||||
To verify the status of your NTP sources, simply run:
|
||||
为了确认你的 NTP 源的状态,只需要运行:
|
||||
|
||||
```
|
||||
$ chronyc activity
|
||||
@ -175,16 +172,16 @@ $ chronyc activity
|
||||
0 sources with unknown address
|
||||
```
|
||||
|
||||
As you see, all my NTP sources are down at the moment.
|
||||
可以看到,我的所有源此时都是离线状态。
|
||||
|
||||
Once you’re connected to the Internet, just notify Chrony that your system is back online using command:
|
||||
一旦你连接到互联网,只需要使用命令告知 Chrony 你的系统已经回到在线状态:
|
||||
|
||||
```
|
||||
$ sudo chronyc online
|
||||
200 OK
|
||||
```
|
||||
|
||||
To view the status of NTP source(s), run:
|
||||
为了查看 NTP 源的状态,运行:
|
||||
|
||||
```
|
||||
$ chronyc activity
|
||||
@ -196,18 +193,16 @@ $ chronyc activity
|
||||
0 sources with unknown address
|
||||
```
|
||||
|
||||
For more detailed explanation of all options and parameters, refer the man pages.
|
||||
所有选项和参数的详细解释,请参考其帮助手册。
|
||||
|
||||
```
|
||||
$ man chronyc
|
||||
|
||||
$ man chronyd
|
||||
```
|
||||
|
||||
And, that’s all for now. Hope this was useful. In the subsequent tutorials, we will see how to setup a local NTP server using Chrony and configure the clients to use it to synchronise time.
|
||||
|
||||
Stay tuned!
|
||||
这就是文章的所有内容。希望对你有所帮助。在随后的教程中,我们会看到如何使用 Chrony 启动一个本地的 NTP 服务器并且配置客户端来使用这个服务器同步时间。
|
||||
|
||||
保持关注!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -216,8 +211,8 @@ via: https://www.ostechnix.com/chrony-an-alternative-ntp-client-and-server-for-u
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[zianglei](https://github.com/zianglei)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
设计更快的网页(二):图片替换
|
||||
======
|
||||

|
||||
|
||||

|
||||
|
||||
欢迎回到我们为了构建更快网页所写的系列文章。上一篇[文章][1]讨论了只通过图片压缩实现这个目标的方法。这个例子从一开始有 1.2MB 的“浏览器脂肪”,然后它减轻到了 488.9KB 的大小。但这还不够快!那么本文继续来给浏览器“减肥”。你可能在这个过程中会认为我们所做的事情有点疯狂,但一旦完成,你就会明白为什么要这么做了。
|
||||
|
||||
@ -21,17 +21,15 @@ $ sudo dnf install inkscape
|
||||
|
||||
![Getfedora 的页面,对其中的图片做了标记][5]
|
||||
|
||||
这次分析更好地以图形方式完成,这也就是它从屏幕截图开始的原因。上面的截图标记了页面中的所有图形元素。Fedora 网站团队已经针对两种情况措施(也有可能是四种,这样更好)来替换图像了。社交媒体的图标变成了字体的字形,而语言选择器变成了 SVG.
|
||||
这次分析以图形方式完成更好,这也就是它从屏幕截图开始的原因。上面的截图标记了页面中的所有图形元素。Fedora 网站团队已经针对两种情况措施(也有可能是四种,这样更好)来替换图像了。社交媒体的图标变成了字体的字形,而语言选择器变成了 SVG.
|
||||
|
||||
我们有几个可以替换的选择:
|
||||
|
||||
|
||||
+ CSS3
|
||||
+ 字体
|
||||
+ SVG
|
||||
+ HTML5 Canvas
|
||||
|
||||
|
||||
#### HTML5 Canvas
|
||||
|
||||
简单来说,HTML5 Canvas 是一种 HTML 元素,它允许你借助脚本语言(通常是 JavaScript)在上面绘图,不过它现在还没有被广泛使用。因为它可以使用脚本语言来绘制,所以这个元素也可以用来做动画。这里有一些使用 HTML Canvas 实现的实例,比如[三角形模式][6]、[动态波浪][7]和[字体动画][8]。不过,在这种情况下,似乎这也不是最好的选择。
|
||||
@ -42,7 +40,7 @@ $ sudo dnf install inkscape
|
||||
|
||||
#### 字体
|
||||
|
||||
另外一种方式是使用字体来装饰网页,[Fontawesome][9] 在这方面很流行。比如,在这个例子中你可以使用字体来替换“风味”和“旋转”的图标。这种方法有一个负面影响,但解决起来很容易,我们会在本系列的下一部分中来介绍。
|
||||
另外一种方式是使用字体来装饰网页,[Fontawesome][9] 在这方面很流行。比如,在这个例子中你可以使用字体来替换“Flavor”和“Spin”的图标。这种方法有一个负面影响,但解决起来很容易,我们会在本系列的下一部分中来介绍。
|
||||
|
||||
#### SVG
|
||||
|
||||
@ -94,13 +92,13 @@ inkscape:connector-curvature="0" />
|
||||
|
||||
![Inkscape - 激活节点工具][10]
|
||||
|
||||
这个例子中有五个不必要的节点——就是直线中间的那些。要删除它们,你可以使用已激活的节点工具依次选中它们,并按下 **Del** 键。然后,选中这条线的定义节点,并使用工具栏的工具把它们重新做成角。
|
||||
这个例子中有五个不必要的节点——就是直线中间的那些。要删除它们,你可以使用已激活的节点工具依次选中它们,并按下 `Del` 键。然后,选中这条线的定义节点,并使用工具栏的工具把它们重新做成角。
|
||||
|
||||
![Inkscape - 将节点变成角的工具][11]
|
||||
|
||||
如果不修复这些角,我们还有方法可以定义这条曲线,这条曲线会被保存,也就会增加文件体积。你可以手动清理这些节点,因为它无法有效的自动完成。现在,你已经为下一阶段做好了准备。
|
||||
|
||||
使用_另存为_功能,并选择_优化的 SVG_。这会弹出一个窗口,你可以在里面选择移除或保留哪些成分。
|
||||
使用“另存为”功能,并选择“优化的 SVG”。这会弹出一个窗口,你可以在里面选择移除或保留哪些成分。
|
||||
|
||||
![Inkscape - “另存为”“优化的 SVG”][12]
|
||||
|
||||
@ -121,7 +119,7 @@ insgesamt 928K
|
||||
-rw-rw-r--. 1 user user 112K 19. Feb 19:05 greyscale-pattern-opti.svg.gz
|
||||
```
|
||||
|
||||
这是我为可视化这个主题所做的一个小测试的输出。你可能应该看到光栅图形——PNG——已经被压缩,不能再被压缩了。而 SVG,一个 XML 文件正相反。它是文本文件,所以可被压缩至原来的四分之一不到。因此,现在它的体积要比 PNG 小 50 KB 左右。
|
||||
这是我为可视化这个主题所做的一个小测试的输出。你可能应该看到光栅图形——PNG——已经被压缩,不能再被压缩了。而 SVG,它是一个 XML 文件正相反。它是文本文件,所以可被压缩至原来的四分之一不到。因此,现在它的体积要比 PNG 小 50 KB 左右。
|
||||
|
||||
现代浏览器可以以原生方式处理压缩文件。所以,许多 Web 服务器都打开了 mod_deflate (Apache) 和 gzip (Nginx) 模式。这样我们就可以在传输过程中节省空间。你可以在[这儿][13]看看你的服务器是不是启用了它。
|
||||
|
||||
@ -129,18 +127,16 @@ insgesamt 928K
|
||||
|
||||
首先,没有人希望每次都要用 Inkscape 来优化 SVG. 你可以在命令行中脱离 GUI 来运行 Inkscape,但你找不到选项来将 Inkscape SVG 转换成优化的 SVG. 用这种方式只能导出光栅图像。但是我们替代品:
|
||||
|
||||
* SVGO (看起来开发过程已经不活跃了)
|
||||
* Scour
|
||||
* SVGO (看起来开发过程已经不活跃了)
|
||||
* Scour
|
||||
|
||||
|
||||
|
||||
本例中我们使用 scour 来进行优化。先来安装它:
|
||||
本例中我们使用 `scour` 来进行优化。先来安装它:
|
||||
|
||||
```
|
||||
$ sudo dnf install scour
|
||||
```
|
||||
|
||||
要想自动优化 SVG 文件,请运行 scour,就像这样:
|
||||
要想自动优化 SVG 文件,请运行 `scour`,就像这样:
|
||||
|
||||
```
|
||||
[user@localhost ]$ scour INPUT.svg OUTPUT.svg -p 3 --create-groups --renderer-workaround --strip-xml-prolog --remove-descriptive-elements --enable-comment-stripping --disable-embed-rasters --no-line-breaks --enable-id-stripping --shorten-ids
|
||||
@ -156,13 +152,13 @@ via: https://fedoramagazine.org/design-faster-web-pages-part-2-image-replacement
|
||||
作者:[Sirko Kemter][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[StdioA](https://github.com/StdioA)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/gnokii/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://wp.me/p3XX0v-5fJ
|
||||
[1]: https://linux.cn/article-10166-1.html
|
||||
[2]: https://fedoramagazine.org/howto-use-sudo/
|
||||
[3]: https://fedoramagazine.org/?s=Inkscape
|
||||
[4]: https://getfedora.org
|
||||
@ -0,0 +1,120 @@
|
||||
如何弄清 Linux 系统运行何种系统管理程序
|
||||
======
|
||||
|
||||
虽然我们经常听到<ruby>系统管理器<rt>System Manager</rt></ruby>这词,但很少有人深究其确切意义。现在我们将向你展示其区别。
|
||||
|
||||
我会尽自己所能来解释清楚一切。我们大多都知道 System V 和 systemd 两种系统管理器。 System V (简写 SysV) 是老式系统所使用的古老且传统的初始化系统及系统管理器。
|
||||
|
||||
Systemd 是全新的初始化系统及系统管理器,并且已被大部分主流 Linux 发行版所采用。
|
||||
|
||||
Linux 系统中主要有三种有名而仍在使用的初始化系统。大多数 Linux 发行版都使用其中之一。
|
||||
|
||||
### 什么是初始化系统管理器?
|
||||
|
||||
在基于 Linux/Unix 的操作系统中,`init` (初始化的简称) 是内核启动系统时开启的第一个进程。
|
||||
|
||||
它持有的进程 ID(PID)号为 1,其在后台一直运行着,直到关机。
|
||||
|
||||
`init` 会查找 `/etc/inittab` 文件中相应配置信息来确定系统的运行级别,然后根据运行级别在后台启动所有的其它进程和应用。
|
||||
|
||||
作为 Linux 启动过程的一部分,BIOS、MBR、GRUB 和内核进程在此进程之前就被激活了。
|
||||
|
||||
下面列出的是 Linux 的可用运行级别(存在七个运行级别,从 0 到 6)。
|
||||
|
||||
* `0`:停机
|
||||
* `1`:单用户模式
|
||||
* `2`:多用户,无 NFS(LCTT 译注:NFS 即 Network File System,网络文件系统)
|
||||
* `3`:全功能多用户模式
|
||||
* `4`:未使用
|
||||
* `5`:X11(GUI – 图形用户界面)
|
||||
* `6`:重启
|
||||
|
||||
下面列出的是 Linux 系统中广泛使用的三种初始化系统。
|
||||
|
||||
* System V (Sys V):是类 Unix 操作系统传统的也是首款初始化系统。
|
||||
* Upstart:基于事件驱动,是 `/sbin/init` 守护进程的替代品。
|
||||
* Systemd:是一款全新的初始化系统及系统管理器,它被所有主流的 Linux 发行版实现/采用,以替代传统的 SysV 初始化系统。
|
||||
|
||||
### 什么是 System V (Sys V)?
|
||||
|
||||
System V(Sys V)是类 Unix 操作系统传统的也是首款初始化系统。`init` 是系统由内核启动期间启动的第一个进程,它是所有进程的父进程。
|
||||
|
||||
起初,大多数 Linux 发行版都使用名为 System V(SysV)的传统的初始化系统。多年来,为了解决标准版本中的设计限制,发布了几个替代的初始化系统,例如 launchd、Service Management Facility、systemd 和 Upstart。
|
||||
|
||||
但只有 systemd 最终被几个主流 Linux 发行版所采用,以替代传统的 SysV。
|
||||
|
||||
### 什么是 Upstart?
|
||||
|
||||
Upstart 基于事件驱动,是 `/sbin/init` 守护进程的替代品。用来在启动期间控制任务和服务的启动,在关机期间停止它们,及在系统运行过程中监视它们。
|
||||
|
||||
它最初是为 Ubuntu 发行版开发的,但也可以在所有的 Linux 发行版中部署运行,以替代古老的 System V 初始化系统。
|
||||
|
||||
它用于 Ubuntu 9.10 到 14.10 版本和基于 RHEL 6 的系统中,之后的被 systemd 取代了。
|
||||
|
||||
### 什么是 systemd?
|
||||
|
||||
systemd 是一款全新的初始化系统及系统管理器,它被所有主流的 Linux 发行版实现/采用,以替代传统的 SysV 初始化系统。
|
||||
|
||||
systemd 与 SysV 和 LSB(LCTT 译注:Linux Standards Base) 初始化脚本兼容。它可以作为 SysV 初始化系统的直接替代品。其是内核启动的第一个进程并占有数字 1 的 PID,它是所有进程的父进程。
|
||||
|
||||
Fedora 15 是第一个采用 systemd 而不是 upstart 的发行版。[systemctl][3] 是一款命令行工具,它是管理 systemd 守护进程/服务(如 `start`、`restart`、`stop`、`enable`、`disable`、`reload` 和 `status`)的主要工具。
|
||||
|
||||
systemd 使用 `.service` 文件而不是(SysV 初始化系统使用的) bash 脚本。systemd 把所有守护进程按顺序排列到自己 Cgroups (LCTT 译注:Cgroups 是 control groups 的缩写,是 Linux 内核提供的一种可以限制、记录、隔离进程组所使用的物理资源,如:cpu、memory、IO 等的机制。最初由 Google 的工程师提出,后来被整合进 Linux 内核。Cgroups 也是 LXC 为实现虚拟化所使用的资源管理手段,可以说没有 cgroups 就没有 LXC)中,所以通过查看 `/cgroup/systemd` 文件就可以查看系统层次结构。
|
||||
|
||||
### 在 Linux 上如何识别出系统管理器
|
||||
|
||||
在系统上运行如下命令来查看运行着什么系统管理器:
|
||||
|
||||
(LCTT 译注:原文繁冗啰嗦,翻译时进行了裁剪整理。)
|
||||
|
||||
#### 方法 1:使用 ps 命令
|
||||
|
||||
`ps` – 显示当前进程快照。`ps` 会显示选定的活动进程的信息。其输出不能确切区分出是 System V(SysV) 还是 upstart,所以我建议使用其它方法。
|
||||
|
||||
```
|
||||
# ps -p1 | grep "init\|upstart\|systemd"
|
||||
1 ? 00:00:00 init
|
||||
```
|
||||
|
||||
#### 方法 2:使用 rpm 命令
|
||||
|
||||
RPM 即 Red Hat Package Manager (红帽包管理),是一款功能强大的[安装包管理][1]命令行工具,在基于 Red Hat 的发行版中使用,如 RHEL、CentOS、Fedora、openSUSE 和 Mageia。此工具可以在系统/服务上对软件进行安装、更新、删除、查询及验证等操作。通常 RPM 文件都带有 `.rpm` 后缀。
|
||||
|
||||
RPM 会使用必要的库和依赖库来构建软件,并且不会与系统上安装的其它包冲突。
|
||||
|
||||
```
|
||||
# rpm -qf /sbin/init
|
||||
SysVinit-2.86-17.el5
|
||||
```
|
||||
|
||||
#### 方法 3:使用 /sbin/init 文件
|
||||
|
||||
`/sbin/init` 程序会将根文件系统从内存加载或切换到磁盘。
|
||||
|
||||
这是启动过程的主要部分。这个进程开始时的运行级别为 “N”(无)。`/sbin/init` 程序会按照 `/etc/inittab` 配制文件的描述来初始化系统。
|
||||
|
||||
```
|
||||
# /sbin/init --version
|
||||
init (upstart 0.6.5)
|
||||
Copyright (C) 2010 Canonical Ltd.
|
||||
|
||||
This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-determine-which-init-system-manager-is-running-on-linux-system/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/category/package-management/
|
||||
[2]: https://www.2daygeek.com/rpm-command-examples/
|
||||
[3]: https://www.2daygeek.com/how-to-check-all-running-services-in-linux/
|
||||
@ -1,10 +1,11 @@
|
||||
在 Fedora 上使用 Pitivi 编辑你的视频
|
||||
在 Fedora 上使用 Pitivi 编辑视频
|
||||
======
|
||||
|
||||

|
||||
想制作一部你本周末冒险的视频吗?视频编辑有很多选择。但是,如果你在寻找一个容易上手的视频编辑器,并且也可以在官方 Fedora 仓库中找到,请尝试一下[Pitivi][1]。
|
||||
|
||||
Pitivi 是一个使用 GStreamer 框架的开源非线性视频编辑器。在 Fedora 下开箱即用,Pitivi 支持 OGG、WebM 和一系列其他格式。此外,通过 gstreamer 插件可以获得更多视频格式支持。Pitivi 也与 GNOME 桌面紧密集成,因此相比其他新的程序,它的 UI 在 Fedora Workstation 上会感觉很熟悉。
|
||||
想制作一部你本周末冒险的视频吗?视频编辑有很多选择。但是,如果你在寻找一个容易上手的视频编辑器,并且也可以在官方 Fedora 仓库中找到,请尝试一下 [Pitivi][1]。
|
||||
|
||||
Pitivi 是一个使用 GStreamer 框架的开源非线性视频编辑器。在 Fedora 下开箱即用,Pitivi 支持 OGG、WebM 和一系列其他格式。此外,通过 GStreamer 插件可以获得更多视频格式支持。Pitivi 也与 GNOME 桌面紧密集成,因此相比其他新的程序,它的 UI 在 Fedora Workstation 上会感觉很熟悉。
|
||||
|
||||
### 在 Fedora 上安装 Pitivi
|
||||
|
||||
@ -20,7 +21,7 @@ sudo dnf install pitivi
|
||||
|
||||
### 基本编辑
|
||||
|
||||
Pitivi 内置了多种工具,可以快速有效地编辑剪辑。只需将视频、音频和图像导入 Pitivi 媒体库,然后将它们拖到时间线上即可。此外,除了时间线上的简单淡入淡出过渡之外,pitivi 还允许你轻松地将剪辑的各个部分分割、修剪和分组。
|
||||
Pitivi 内置了多种工具,可以快速有效地编辑剪辑。只需将视频、音频和图像导入 Pitivi 媒体库,然后将它们拖到时间线上即可。此外,除了时间线上的简单淡入淡出过渡之外,Pitivi 还允许你轻松地将剪辑的各个部分分割、修剪和分组。
|
||||
|
||||
![][3]
|
||||
|
||||
@ -40,7 +41,7 @@ via: https://fedoramagazine.org/edit-your-videos-with-pitivi-on-fedora/
|
||||
作者:[Ryan Lerch][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,15 +1,15 @@
|
||||
什么是 SRE?它和 DevOps 是怎么关联的?
|
||||
=====
|
||||
|
||||
大型企业里 SRE 角色比较常见,不过小公司也需要 SRE。
|
||||
> 大型企业里 SRE 角色比较常见,不过小公司也需要 SRE。
|
||||
|
||||

|
||||
|
||||
虽然站点可靠性工程师(SRE)角色在近几年变得流行起来,但是很多人 —— 甚至是软件行业里的 —— 还不知道 SRE 是什么或者 SRE 都干些什么。为了搞清楚这些问题,这篇文章解释了 SRE 的含义,还有 SRE 怎样关联 DevOps,以及在工程师团队规模不大的组织里 SRE 该如何工作。
|
||||
虽然<ruby>站点可靠性工程师<rt>site reliability engineer</rt></ruby>(SRE)角色在近几年变得流行起来,但是很多人 —— 甚至是软件行业里的 —— 还不知道 SRE 是什么或者 SRE 都干些什么。为了搞清楚这些问题,这篇文章解释了 SRE 的含义,还有 SRE 怎样关联 DevOps,以及在工程师团队规模不大的组织里 SRE 该如何工作。
|
||||
|
||||
### 什么是站点可靠性工程?
|
||||
|
||||
谷歌的几个工程师写的《 [SRE:谷歌运维解密][1]》被认为是站点可靠性工程的权威书籍。谷歌的工程副总裁 Ben Treynor Sloss 在二十一世纪初[创造了这个术语][2]。他是这样定义的:“当你让软件工程师设计运维功能时,SRE 就产生了。”
|
||||
谷歌的几个工程师写的《[SRE:谷歌运维解密][1]》被认为是站点可靠性工程的权威书籍。谷歌的工程副总裁 Ben Treynor Sloss 在二十一世纪初[创造了这个术语][2]。他是这样定义的:“当你让软件工程师设计运维功能时,SRE 就产生了。”
|
||||
|
||||
虽然系统管理员从很久之前就在写代码,但是过去的很多时候系统管理团队是手动管理机器的。当时他们管理的机器可能有几十台或者上百台,不过当这个数字涨到了几千甚至几十万的时候,就不能简单的靠人去解决问题了。规模如此大的情况下,很明显应该用代码去管理机器(以及机器上运行的软件)。
|
||||
|
||||
@ -19,13 +19,13 @@
|
||||
|
||||
### SRE 和 DevOps
|
||||
|
||||
站点可靠性工程的核心,就是对 DevOps 范例的实践。[DevOps 的定义][3]有很多种方式。开发团队(“devs”)和运维(“ops”)团队相互分离的传统模式下,写代码的团队在服务交付给用户使用之后就不再对服务状态负责了。开发团队“把代码扔到墙那边”让运维团队去部署和支持。
|
||||
站点可靠性工程的核心,就是对 DevOps 范例的实践。[DevOps 的定义][3]有很多种方式。开发团队(“dev”)和运维(“ops”)团队相互分离的传统模式下,写代码的团队在将服务交付给用户使用之后就不再对服务状态负责了。开发团队“把代码扔到墙那边”让运维团队去部署和支持。
|
||||
|
||||
这种情况会导致大量失衡。开发和运维的目标总是不一致 —— 开发希望用户体验到“最新最棒”的代码,但是运维想要的是变更尽量少的稳定系统。运维是这样假定的,任何变更都可能引发不稳定,而不做任何变更的系统可以一直保持稳定。(减少软件的变更次数并不是避免故障的唯一因素,认识到这一点很重要。例如,虽然你的 web 应用保持不变,但是当用户数量涨到十倍时,服务可能就会以各种方式出问题。)
|
||||
|
||||
DevOps 理念认为通过合并这两个岗位就能够消灭争论。如果开发团队时刻都想把新代码部署上线,那么他们也必须对新代码引起的故障负责。就像亚马逊的 [Werner Vogels 说的][4]那样,“谁开发,谁运维”(生产环境)。但是开发人员已经有一大堆问题了。他们不断的被推动着去开发老板要的产品功能。再让他们去了解基础设施,包括如何部署、配置还有监控服务,这对他们的要求有点太多了。所以就需要 SRE 了。
|
||||
|
||||
开发一个 web 应用的时候经常是很多人一起参与。有用户界面设计师,图形设计师,前端工程师,后端工程师,还有许多其他工种(视技术选型的具体情况而定)。如何管理写好的代码也是需求之一(例如部署,配置,监控)—— 这是 SRE 的专业领域。但是,就像前端工程师受益于后端领域的知识一样(例如从数据库获取数据的方法),SRE 理解部署系统的工作原理,知道如何满足特定的代码或者项目的具体需求。
|
||||
开发一个 web 应用的时候经常是很多人一起参与。有用户界面设计师、图形设计师、前端工程师、后端工程师,还有许多其他工种(视技术选型的具体情况而定)。如何管理写好的代码也是需求之一(例如部署、配置、监控)—— 这是 SRE 的专业领域。但是,就像前端工程师受益于后端领域的知识一样(例如从数据库获取数据的方法),SRE 理解部署系统的工作原理,知道如何满足特定的代码或者项目的具体需求。
|
||||
|
||||
所以 SRE 不仅仅是“写代码的运维工程师”。相反,SRE 是开发团队的成员,他们有着不同的技能,特别是在发布部署、配置管理、监控、指标等方面。但是,就像前端工程师必须知道如何从数据库中获取数据一样,SRE 也不是只负责这些领域。为了提供更容易升级、管理和监控的产品,整个团队共同努力。
|
||||
|
||||
@ -37,7 +37,7 @@ DevOps 理念认为通过合并这两个岗位就能够消灭争论。如果开
|
||||
|
||||
让开发人员做 SRE 最显著的优点是,团队规模变大的时候也能很好的扩展。而且,开发人员将会全面地了解应用的特性。但是,许多初创公司的基础设施包含了各种各样的 SaaS 产品,这种多样性在基础设施上体现的最明显,因为连基础设施本身也是多种多样。然后你们在某个基础设施上引入指标系统、站点监控、日志分析、容器等等。这些技术解决了一部分问题,也增加了复杂度。开发人员除了要了解应用程序的核心技术(比如开发语言),还要了解上述所有技术和服务。最终,掌握所有的这些技术让人无法承受。
|
||||
|
||||
另一种方案是聘请专家专职做 SRE。他们专注于发布部署、配置管理、监控和指标,可以节省开发人员的时间。这种方案的缺点是,SRE 的时间必须分配给多个不同的应用(就是说 SRE 需要贯穿整个工程部门)。 这可能意味着 SRE 没时间对任何应用深入学习,然而他们可以站在一个能看到服务全貌的高度,知道各个部分是怎么组合在一起的。 这个“ 三万英尺高的视角”可以帮助 SRE 从系统整体上考虑,哪些薄弱环节需要优先修复。
|
||||
另一种方案是聘请专家专职做 SRE。他们专注于发布部署、配置管理、监控和指标,可以节省开发人员的时间。这种方案的缺点是,SRE 的时间必须分配给多个不同的应用(就是说 SRE 需要贯穿整个工程部门)。 这可能意味着 SRE 没时间对任何应用深入学习,然而他们可以站在一个能看到服务全貌的高度,知道各个部分是怎么组合在一起的。 这个“三万英尺高的视角”可以帮助 SRE 从系统整体上考虑,哪些薄弱环节需要优先修复。
|
||||
|
||||
有一个关键信息我还没提到:其他的工程师。他们可能很渴望了解发布部署的原理,也很想尽全力学会使用指标系统。而且,雇一个 SRE 可不是一件简单的事儿。因为你要找的是一个既懂系统管理又懂软件工程的人。(我之所以明确地说软件工程而不是说“能写代码”,是因为除了写代码之外软件工程还包括很多东西,比如编写良好的测试或文档。)
|
||||
|
||||
@ -54,7 +54,7 @@ via: https://opensource.com/article/18/10/sre-startup
|
||||
作者:[Craig Sebenik][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[BeliteX](https://github.com/belitex)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,10 +1,11 @@
|
||||
正确选择开源数据库的 5 个技巧
|
||||
======
|
||||
|
||||
> 对关键应用的选择不容许丝毫错误。
|
||||
|
||||

|
||||
|
||||
你或许会遇到需要选择适合的开源数据库的情况。但这无论对于开源方面的老手或是新手,都是一项艰巨的任务。
|
||||
你或许会遇到需要选择合适的开源数据库的情况。但这无论对于开源方面的老手或是新手,都是一项艰巨的任务。
|
||||
|
||||
在过去的几年中,采用开源技术的企业越来越多。面对这样的趋势,众多开源应用公司都纷纷承诺自己提供的解决方案能够各种问题、适应各种负载。但这些承诺不能轻信,在开源应用上的选择是重要而艰难的,尤其是数据库这种关键的应用。
|
||||
|
||||
@ -20,7 +21,7 @@
|
||||
|
||||
### 了解你的工作负载
|
||||
|
||||
尽管开源数据库技术的功能越来越丰富,但这些新加入的功能都不太具有普适性。譬如 MongoDB 新增了事务的支持、MySQL 新增了 JSON 存储的功能等等。目前开源数据库的普遍趋势是不断加入新的功能,但很多人的误区却在于没有选择最适合的工具来完成自己的工作——这样的人或许是一个自大的开发者,又或许是一个视野狭窄的主管——最终导致公司业务上的损失。最致命的是,在业务初期,使用了不适合的工具往往也可以顺利地完成任务,但随着业务的增长,很快就会到达瓶颈,尽管这个时候还可以替换更合适的工具,但成本就比较高了。
|
||||
尽管开源数据库技术的功能越来越丰富,但这些新加入的功能都不太具有普适性。譬如 MongoDB 新增了事务的支持、MySQL 新增了 JSON 存储的功能等等。目前开源数据库的普遍趋势是不断加入新的功能,但很多人的误区却在于没有选择最适合的工具来完成自己的工作 —— 这样的人或许是一个自大的开发者,又或许是一个视野狭窄的主管 —— 最终导致公司业务上的损失。最致命的是,在业务初期,使用了不适合的工具往往也可以顺利地完成任务,但随着业务的增长,很快就会到达瓶颈,尽管这个时候还可以替换更合适的工具,但成本就比较高了。
|
||||
|
||||
例如,如果你需要的是数据分析仓库,关系数据库可能不是一个适合的选择;如果你处理事务的应用要求严格的数据完整性和一致性,就不要考虑 NoSQL 了。
|
||||
|
||||
@ -30,7 +31,7 @@
|
||||
|
||||
Battery Ventures 是一家专注于技术的投资公司,最近推出了一个用于跟踪最受欢迎开源项目的 [BOSS 指数][2] 。它提供了对一些被广泛采用的开源项目和活跃的开源项目的详细情况。其中,数据库技术毫无悬念地占据了榜单的主导地位,在前十位之中占了一半。这个 BOSS 指数对于刚接触开源数据库领域的人来说,这是一个很好的切入点。当然,开源技术的提供者也会针对很多常见的典型问题给出对应的解决方案。
|
||||
|
||||
我认为,你想要做的事情很可能已经有人解决过了。即使这些先行者的解决方案不一定完全契合你的需求,但也可以从他们成功或失败案例中根据你自己的需求修改得出合适的解决方案。
|
||||
我认为,你想要做的事情很可能已经有人解决过了。即使这些先行者的解决方案不一定完全契合你的需求,但也可以从他们成功或失败的案例中根据你自己的需求修改得出合适的解决方案。
|
||||
|
||||
如果你采用了一个最前沿的技术,这就是你探索的好机会了。如果你的工作负载刚好适合新的开源数据库技术,放胆去尝试吧。第一个吃螃蟹的人总是会得到意外的挑战和收获。
|
||||
|
||||
@ -46,7 +47,7 @@ Battery Ventures 是一家专注于技术的投资公司,最近推出了一个
|
||||
|
||||
### 有疑问,找专家
|
||||
|
||||
如果你仍然不确定数据库选择得是否合适,可以在论坛、网站或者与软件的提供者处商讨。研究各种开源数据库是否满足自己的需求是一件很有意义的事,因为总会发现你从不知道的技术。而开源社区就是分享这些信息的地方。
|
||||
如果你仍然不确定数据库选择的是否合适,可以在论坛、网站或者与软件的提供者处商讨。研究各种开源数据库是否满足自己的需求是一件很有意义的事,因为总会发现你从不知道的技术。而开源社区就是分享这些信息的地方。
|
||||
|
||||
当你接触到开源软件和软件提供者时,有一件重要的事情需要注意。很多公司都有开放的核心业务模式,鼓励采用他们的数据库软件。你可以只接受他们的部分建议和指导,然后用你自己的能力去研究和探索替代方案。
|
||||
|
||||
@ -62,7 +63,7 @@ via: https://opensource.com/article/18/10/tips-choosing-right-open-source-databa
|
||||
作者:[Barrett Chambers][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,38 +1,39 @@
|
||||
如何在 Rasspberry Pi 上搭建 WordPress
|
||||
如何在树莓派上搭建 WordPress
|
||||
======
|
||||
|
||||
这篇简单的教程可以让你在 Rasspberry Pi 上运行你的 WordPress 网站。
|
||||
> 这篇简单的教程可以让你在树莓派上运行你的 WordPress 网站。
|
||||
|
||||

|
||||
|
||||
WordPress 是一个非常受欢迎的开源博客平台和内容管理平台(CMS)。它很容易搭建,而且还有一个活跃的开发者社区构建网站、创建主题和插件供其他人使用。
|
||||
|
||||
虽然通过一键式 WordPress 设置获得托管包很容易,但通过命令行就可以在 Linux 服务器上设置自己的托管包,而且 Raspberry Pi 是一种用来尝试它并顺便学习一些东西的相当好的途径。
|
||||
虽然通过一键式 WordPress 设置获得托管包很容易,但也可以简单地通过命令行在 Linux 服务器上设置自己的托管包,而且树莓派是一种用来尝试它并顺便学习一些东西的相当好的途径。
|
||||
|
||||
使用一个 web 堆栈的四个部分是 Linux、Apache、MySQL 和 PHP。这里是你对它们每一个需要了解的。
|
||||
一个经常使用的 Web 套件的四个部分是 Linux、Apache、MySQL 和 PHP。这里是你对它们每一个需要了解的。
|
||||
|
||||
### Linux
|
||||
|
||||
Raspberry Pi 上运行的系统是 Raspbian,这是一个基于 Debian,优化地可以很好的运行在 Raspberry Pi 硬件上的 Linux 发行版。你有两个选择:桌面版或是精简版。桌面版有一个熟悉的桌面还有很多教育软件和编程工具,像是 LibreOffice 套件、Mincraft,还有一个 web 浏览器。精简版本没有桌面环境,因此它只有命令行以及一些必要的软件。
|
||||
树莓派上运行的系统是 Raspbian,这是一个基于 Debian,为运行在树莓派硬件上而优化的很好的 Linux 发行版。你有两个选择:桌面版或是精简版。桌面版有一个熟悉的桌面还有很多教育软件和编程工具,像是 LibreOffice 套件、Mincraft,还有一个 web 浏览器。精简版本没有桌面环境,因此它只有命令行以及一些必要的软件。
|
||||
|
||||
这篇教程在两个版本上都可以使用,但是如果你使用的是精简版,你必须要有另外一台电脑去访问你的站点。
|
||||
|
||||
### Apache
|
||||
|
||||
Apache 是一个受欢迎的 web 服务器应用,你可以安装在你的 Raspberry Pi 上伺服你的 web 页面。就其自身而言,Apache 可以通过 HTTP 提供静态 HTML 文件。使用额外的模块,它也可以使用像是 PHP 的脚本语言提供动态网页。
|
||||
Apache 是一个受欢迎的 web 服务器应用,你可以安装在你的树莓派上伺服你的 web 页面。就其自身而言,Apache 可以通过 HTTP 提供静态 HTML 文件。使用额外的模块,它也可以使用像是 PHP 的脚本语言提供动态网页。
|
||||
|
||||
安装 Apache 非常简单。打开一个终端窗口,然后输入下面的命令:
|
||||
|
||||
```
|
||||
sudo apt install apache2 -y
|
||||
```
|
||||
Apache 默认放了一个测试文件在一个 web 目录中,你可以从你的电脑或是你网络中的其他计算机进行访问。只需要打开 web 浏览器,然后输入地址 **<http://localhost>**。或者(特别是你使用的是 Raspbian Lite 的话)输入你的 Pi 的 IP 地址代替 **localhost**。你应该会在你的浏览器窗口中看到这样的内容:
|
||||
|
||||
Apache 默认放了一个测试文件在一个 web 目录中,你可以从你的电脑或是你网络中的其他计算机进行访问。只需要打开 web 浏览器,然后输入地址 `<http://localhost>`。或者(特别是你使用的是 Raspbian Lite 的话)输入你的树莓派的 IP 地址代替 `localhost`。你应该会在你的浏览器窗口中看到这样的内容:
|
||||
|
||||
|
||||
|
||||
这意味着你的 Apache 已经开始工作了!
|
||||
|
||||
这个默认的网页仅仅是你文件系统里的一个文件。它在你本地的 **/var/www/html/index/html**。你可以使用 [Leafpad][2] 文本编辑器写一些 HTML 去替换这个文件的内容。
|
||||
这个默认的网页仅仅是你文件系统里的一个文件。它在你本地的 `/var/www/html/index/html`。你可以使用 [Leafpad][2] 文本编辑器写一些 HTML 去替换这个文件的内容。
|
||||
|
||||
```
|
||||
cd /var/www/html/
|
||||
@ -43,27 +44,27 @@ sudo leafpad index.html
|
||||
|
||||
### MySQL
|
||||
|
||||
MySQL (显然是 "my S-Q-L" 或者 "my sequel") 是一个很受欢迎的数据库引擎。就像 PHP,它被非常广泛的应用于网页服务,这也是为什么像 WordPress 一样的项目选择了它,以及这些项目是为何如此受欢迎。
|
||||
MySQL(读作 “my S-Q-L” 或者 “my sequel”)是一个很受欢迎的数据库引擎。就像 PHP,它被非常广泛的应用于网页服务,这也是为什么像 WordPress 一样的项目选择了它,以及这些项目是为何如此受欢迎。
|
||||
|
||||
在一个终端窗口中输入以下命令安装 MySQL 服务:
|
||||
在一个终端窗口中输入以下命令安装 MySQL 服务(LCTT 译注:实际上安装的是 MySQL 分支 MariaDB):
|
||||
|
||||
```
|
||||
sudo apt-get install mysql-server -y
|
||||
```
|
||||
|
||||
WordPress 使用 MySQL 存储文章、页面、用户数据、还有许多其他的内容。
|
||||
WordPress 使用 MySQL 存储文章、页面、用户数据、还有许多其他的内容。
|
||||
|
||||
### PHP
|
||||
|
||||
PHP 是一个预处理器:它是在服务器通过网络浏览器接受网页请求是运行的代码。它解决那些需要展示在网页上的内容,然后发送这些网页到浏览器上。,不像静态的 HTML,PHP 能在不同的情况下展示不同的内容。PHP 是一个在 web 上非常受欢迎的语言;很多像 Facebook 和 Wikipedia 的项目都使用 PHP 编写。
|
||||
PHP 是一个预处理器:它是在服务器通过网络浏览器接受网页请求是运行的代码。它解决那些需要展示在网页上的内容,然后发送这些网页到浏览器上。不像静态的 HTML,PHP 能在不同的情况下展示不同的内容。PHP 是一个在 web 上非常受欢迎的语言;很多像 Facebook 和 Wikipedia 的项目都使用 PHP 编写。
|
||||
|
||||
安装 PHP 和 MySQL 的插件:
|
||||
安装 PHP 和 MySQL 的插件:
|
||||
|
||||
```
|
||||
sudo apt-get install php php-mysql -y
|
||||
```
|
||||
|
||||
删除 **index.html**,然后创建 **index.php**:
|
||||
删除 `index.html`,然后创建 `index.php`:
|
||||
|
||||
```
|
||||
sudo rm index.html
|
||||
@ -82,16 +83,16 @@ sudo leafpad index.php
|
||||
|
||||
### WordPress
|
||||
|
||||
你可以使用 **wget** 命令从 [wordpress.org][3] 下载 WordPress。最新的 WordPress 总是使用 [wordpress.org/latest.tar.gz][4] 这个网址,所以你可以直接抓取这些文件,而无需到网页里面查看,现在的版本是 4.9.8。
|
||||
你可以使用 `wget` 命令从 [wordpress.org][3] 下载 WordPress。最新的 WordPress 总是使用 [wordpress.org/latest.tar.gz][4] 这个网址,所以你可以直接抓取这些文件,而无需到网页里面查看,现在的版本是 4.9.8。
|
||||
|
||||
确保你在 **/var/www/html** 目录中,然后删除里面的所有内容:
|
||||
确保你在 `/var/www/html` 目录中,然后删除里面的所有内容:
|
||||
|
||||
```
|
||||
cd /var/www/html/
|
||||
sudo rm *
|
||||
```
|
||||
|
||||
使用 **wget** 下载 WordPress,然后提取里面的内容,并移动提取的 WordPress 目录中的内容移动到 **html** 目录下:
|
||||
使用 `wget` 下载 WordPress,然后提取里面的内容,并移动提取的 WordPress 目录中的内容移动到 `html` 目录下:
|
||||
|
||||
```
|
||||
sudo wget http://wordpress.org/latest.tar.gz
|
||||
@ -99,13 +100,13 @@ sudo tar xzf latest.tar.gz
|
||||
sudo mv wordpress/* .
|
||||
```
|
||||
|
||||
现在可以删除压缩包和空的 **wordpress** 目录:
|
||||
现在可以删除压缩包和空的 `wordpress` 目录了:
|
||||
|
||||
```
|
||||
sudo rm -rf wordpress latest.tar.gz
|
||||
```
|
||||
|
||||
运行 **ls** 或者 **tree -L 1** 命令显示 WordPress 项目下包含的内容:
|
||||
运行 `ls` 或者 `tree -L 1` 命令显示 WordPress 项目下包含的内容:
|
||||
|
||||
```
|
||||
.
|
||||
@ -132,9 +133,9 @@ sudo rm -rf wordpress latest.tar.gz
|
||||
3 directories, 16 files
|
||||
```
|
||||
|
||||
这是 WordPress 的默认安装源。在 **wp-content** 目录中,你可以编辑你的自定义安装。
|
||||
这是 WordPress 的默认安装源。在 `wp-content` 目录中,你可以编辑你的自定义安装。
|
||||
|
||||
你现在应该把所有文件的所有权改为 Apache 用户:
|
||||
你现在应该把所有文件的所有权改为 Apache 的运行用户 `www-data`:
|
||||
|
||||
```
|
||||
sudo chown -R www-data: .
|
||||
@ -152,24 +153,27 @@ sudo mysql_secure_installation
|
||||
|
||||
你将会被问到一系列的问题。这里原来没有设置密码,但是在下一步你应该设置一个。确保你记住了你输入的密码,后面你需要使用它去连接你的 WordPress。按回车确认下面的所有问题。
|
||||
|
||||
当它完成之后,你将会看到 "All done!" 和 "Thanks for using MariaDB!" 的信息。
|
||||
当它完成之后,你将会看到 “All done!” 和 “Thanks for using MariaDB!” 的信息。
|
||||
|
||||
在终端窗口运行 **mysql** 命令:
|
||||
在终端窗口运行 `mysql` 命令:
|
||||
|
||||
```
|
||||
sudo mysql -uroot -p
|
||||
```
|
||||
输入你创建的 root 密码。你将看到 “Welcome to the MariaDB monitor.” 的欢迎信息。在 **MariaDB [(none)] >** 提示处使用以下命令,为你 WordPress 的安装创建一个数据库:
|
||||
|
||||
输入你创建的 root 密码(LCTT 译注:不是 Linux 系统的 root 密码,是 MySQL 的 root 密码)。你将看到 “Welcome to the MariaDB monitor.” 的欢迎信息。在 “MariaDB [(none)] >” 提示处使用以下命令,为你 WordPress 的安装创建一个数据库:
|
||||
|
||||
```
|
||||
create database wordpress;
|
||||
```
|
||||
|
||||
注意声明最后的分号,如果命令执行成功,你将看到下面的提示:
|
||||
|
||||
```
|
||||
Query OK, 1 row affected (0.00 sec)
|
||||
```
|
||||
把 数据库权限交给 root 用户在声明的底部输入密码:
|
||||
|
||||
把数据库权限交给 root 用户在声明的底部输入密码:
|
||||
|
||||
```
|
||||
GRANT ALL PRIVILEGES ON wordpress.* TO 'root'@'localhost' IDENTIFIED BY 'YOURPASSWORD';
|
||||
@ -181,13 +185,13 @@ GRANT ALL PRIVILEGES ON wordpress.* TO 'root'@'localhost' IDENTIFIED BY 'YOURPAS
|
||||
FLUSH PRIVILEGES;
|
||||
```
|
||||
|
||||
按 **Ctrl+D** 退出 MariaDB 提示,返回到 Bash shell。
|
||||
按 `Ctrl+D` 退出 MariaDB 提示符,返回到 Bash shell。
|
||||
|
||||
### WordPress 配置
|
||||
|
||||
在你的 Raspberry Pi 打开网页浏览器,地址栏输入 **<http://localhost>**。选择一个你想要在 WordPress 使用的语言,然后点击 **继续**。你将会看到 WordPress 的欢迎界面。点击 **让我们开始吧** 按钮。
|
||||
在你的 树莓派 打开网页浏览器,地址栏输入 `http://localhost`。选择一个你想要在 WordPress 使用的语言,然后点击“Continue”。你将会看到 WordPress 的欢迎界面。点击 “Let's go!” 按钮。
|
||||
|
||||
按照下面这样填写基本的站点信息:
|
||||
按照下面这样填写基本的站点信息:
|
||||
|
||||
```
|
||||
Database Name: wordpress
|
||||
@ -197,22 +201,23 @@ Database Host: localhost
|
||||
Table Prefix: wp_
|
||||
```
|
||||
|
||||
点击 **提交** 继续,然后点击 **运行安装**。
|
||||
点击 “Submit” 继续,然后点击 “Run the install”。
|
||||
|
||||
|
||||
|
||||
按下面的格式填写:为你的站点设置一个标题、创建一个用户名和密码、输入你的 email 地址。点击 **安装 WordPress** 按钮,然后使用你刚刚创建的账号登录,你现在已经登录,而且你的站点已经设置好了,你可以在浏览器地址栏输入 **<http://localhost/wp-admin>** 查看你的网站。
|
||||
按下面的格式填写:为你的站点设置一个标题、创建一个用户名和密码、输入你的 email 地址。点击 “Install WordPress” 按钮,然后使用你刚刚创建的账号登录,你现在已经登录,而且你的站点已经设置好了,你可以在浏览器地址栏输入 `http://localhost/wp-admin` 查看你的网站。
|
||||
|
||||
### 永久链接
|
||||
|
||||
更改你的永久链接,使得你的 URLs 更加友好是一个很好的想法。
|
||||
更改你的永久链接设置,使得你的 URL 更加友好是一个很好的想法。
|
||||
|
||||
要这样做,首先登录你的 WordPress ,进入仪表盘。进入 **设置**,**永久链接**。选择 **文章名** 选项,然后点击 **保存更改**。接着你需要开启 Apache 的 **改写** 模块。
|
||||
要这样做,首先登录你的 WordPress ,进入仪表盘。进入 “Settings”,“Permalinks”。选择 “Post name” 选项,然后点击 “Save Changes”。接着你需要开启 Apache 的 `rewrite` 模块。
|
||||
|
||||
```
|
||||
sudo a2enmod rewrite
|
||||
```
|
||||
你还需要告诉虚拟托管服务,站点允许改写请求。为你的虚拟主机编辑 Apache 配置文件
|
||||
|
||||
你还需要告诉虚拟托管服务,站点允许改写请求。为你的虚拟主机编辑 Apache 配置文件:
|
||||
|
||||
```
|
||||
sudo leafpad /etc/apache2/sites-available/000-default.conf
|
||||
@ -226,7 +231,7 @@ sudo leafpad /etc/apache2/sites-available/000-default.conf
|
||||
</Directory>
|
||||
```
|
||||
|
||||
确保其中有像这样的内容 **< VirtualHost \*:80>**
|
||||
确保其中有像这样的内容 `<VirtualHost *:80>`:
|
||||
|
||||
```
|
||||
<VirtualHost *:80>
|
||||
@ -244,17 +249,16 @@ sudo systemctl restart apache2
|
||||
|
||||
### 下一步?
|
||||
|
||||
WordPress 是可以高度自定义的。在网站顶部横幅处点击你的站点名,你就会进入仪表盘,。在这里你可以修改主题、添加页面和文章、编辑菜单、添加插件、以及许多其他的事情。
|
||||
WordPress 是可以高度自定义的。在网站顶部横幅处点击你的站点名,你就会进入仪表盘。在这里你可以修改主题、添加页面和文章、编辑菜单、添加插件、以及许多其他的事情。
|
||||
|
||||
这里有一些你可以在 Raspberry Pi 的网页服务上尝试的有趣的事情:
|
||||
这里有一些你可以在树莓派的网页服务上尝试的有趣的事情:
|
||||
|
||||
* 添加页面和文章到你的网站
|
||||
* 从外观菜单安装不同的主题
|
||||
* 自定义你的网站主题或是创建你自己的
|
||||
* 使用你的网站服务向你的网络上的其他人显示有用的信息
|
||||
|
||||
|
||||
不要忘记,Raspberry Pi 是一台 Linux 电脑。你也可以使用相同的结构在运行着 Debian 或者 Ubuntu 的服务器上安装 WordPress。
|
||||
不要忘记,树莓派是一台 Linux 电脑。你也可以使用相同的结构在运行着 Debian 或者 Ubuntu 的服务器上安装 WordPress。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -263,7 +267,7 @@ via: https://opensource.com/article/18/10/setting-wordpress-raspberry-pi
|
||||
作者:[Ben Nuttall][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
使用Python的toolz库开始函数式编程
|
||||
使用 Python 的 toolz 库开始函数式编程
|
||||
======
|
||||
|
||||
toolz库允许你操作函数,使其更容易理解,更容易测试代码。
|
||||
> toolz 库允许你操作函数,使其更容易理解,更容易测试代码。
|
||||
|
||||

|
||||
|
||||
@ -20,7 +20,11 @@ def add_one_word(words, word):
|
||||
|
||||
这个函数假设它的第一个参数是一个不可变的类似字典的对象,它返回一个新的类似字典的在相关位置递增的对象:这就是一个简单的频率计数器。
|
||||
|
||||
但是,只有将它应用于单词流并做归纳时才有用。 我们可以使用内置模块 `functools` 中的归纳器。 `functools.reduce(function, stream, initializer)`
|
||||
但是,只有将它应用于单词流并做*归纳*时才有用。 我们可以使用内置模块 `functools` 中的归纳器。
|
||||
|
||||
```
|
||||
functools.reduce(function, stream, initializer)
|
||||
```
|
||||
|
||||
我们想要一个函数,应用于流,并且能能返回频率计数。
|
||||
|
||||
@ -30,14 +34,12 @@ def add_one_word(words, word):
|
||||
add_all_words = curry(functools.reduce, add_one_word)
|
||||
```
|
||||
|
||||
使用此版本,我们需要提供初始化程序。 但是,我们不能只将 `pyrsistent.m` 函数添加到 `curry` 函数中中; 因为这个顺序是错误的。
|
||||
使用此版本,我们需要提供初始化程序。但是,我们不能只将 `pyrsistent.m` 函数添加到 `curry` 函数中; 因为这个顺序是错误的。
|
||||
|
||||
```
|
||||
add_all_words_flipped = flip(add_all_words)
|
||||
```
|
||||
|
||||
The `flip` higher-level function returns a function that calls the original, with arguments flipped.
|
||||
|
||||
`flip` 这个高阶函数返回一个调用原始函数的函数,并且翻转参数顺序。
|
||||
|
||||
```
|
||||
@ -46,7 +48,7 @@ get_all_words = add_all_words_flipped(pyrsistent.m())
|
||||
|
||||
我们利用 `flip` 自动调整其参数的特性给它一个初始值:一个空字典。
|
||||
|
||||
现在我们可以执行 `get_all_words(word_stream)` 这个函数来获取频率字典。 但是,我们如何获得一个单词流呢? Python文件是行流的。
|
||||
现在我们可以执行 `get_all_words(word_stream)` 这个函数来获取频率字典。 但是,我们如何获得一个单词流呢? Python 文件是按行供流的。
|
||||
|
||||
```
|
||||
def to_words(lines):
|
||||
@ -60,9 +62,9 @@ def to_words(lines):
|
||||
words_from_file = toolz.compose(get_all_words, to_words)
|
||||
```
|
||||
|
||||
在这种情况下,组合只是使两个函数很容易阅读:首先将文件的行流应用于 `to_words`,然后将 `get_all_words` 应用于 `to_words` 的结果。 散文似乎与代码相反。
|
||||
在这种情况下,组合只是使两个函数很容易阅读:首先将文件的行流应用于 `to_words`,然后将 `get_all_words` 应用于 `to_words` 的结果。 但是文字上读起来似乎与代码执行相反。
|
||||
|
||||
当我们开始认真对待可组合性时,这很重要。 有时可以将代码编写为一个单元序列,单独测试每个单元,最后将它们全部组合。 如果有几个组合元素时,组合的顺序可能就很难理解。
|
||||
当我们开始认真对待可组合性时,这很重要。有时可以将代码编写为一个单元序列,单独测试每个单元,最后将它们全部组合。如果有几个组合元素时,组合的顺序可能就很难理解。
|
||||
|
||||
`toolz` 库借用了 Unix 命令行的做法,并使用 `pipe` 作为执行相同操作的函数,但顺序相反。
|
||||
|
||||
@ -70,17 +72,13 @@ words_from_file = toolz.compose(get_all_words, to_words)
|
||||
words_from_file = toolz.pipe(to_words, get_all_words)
|
||||
```
|
||||
|
||||
Now it reads more intuitively: Pipe the input into `to_words`, and pipe the results into `get_all_words`. On a command line, the equivalent would look like this:
|
||||
|
||||
现在读起来更直观了:将输入传递到 `to_words`,并将结果传递给 `get_all_words`。 在命令行上,等效写法如下所示:
|
||||
|
||||
```
|
||||
$ cat files | to_words | get_all_words
|
||||
```
|
||||
|
||||
The `toolz` library allows us to manipulate functions, slicing, dicing, and composing them to make our code easier to understand and to test.
|
||||
|
||||
`toolz` 库允许我们操作函数,切片,分割和组合,以使我们的代码更容易理解和测试。
|
||||
`toolz` 库允许我们操作函数,切片、分割和组合,以使我们的代码更容易理解和测试。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -89,10 +87,10 @@ via: https://opensource.com/article/18/10/functional-programming-python-toolz
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/18/10/functional-programming-python-immutable-data-structures
|
||||
[1]: https://linux.cn/article-10222-1.html
|
||||
@ -0,0 +1,77 @@
|
||||
COPR 仓库中 4 个很酷的新软件(2018.10)
|
||||
======
|
||||
|
||||

|
||||
|
||||
COPR 是软件的个人存储库的[集合] [1],它包含那些不在标准的 Fedora 仓库中的软件。某些软件不符合允许轻松打包的标准。或者它可能不符合其他 Fedora 标准,尽管它是自由开源的。COPR 可以在标准的 Fedora 包之外提供这些项目。COPR 中的软件不受 Fedora 基础设施的支持,或者是由项目自己背书的。但是,它是尝试新的或实验性软件的一种很好的方法。
|
||||
|
||||
这是 COPR 中一组新的有趣项目。
|
||||
|
||||
[编者按:这些项目里面有一个兵不适合通过 COPR 分发,所以从本文中 也删除了。相关的评论也删除了,以免误导读者。对此带来的不便,我们深表歉意。]
|
||||
|
||||
(LCTT 译注:本文后来移除了对“GitKraken”项目的介绍。)
|
||||
|
||||
### Music On Console
|
||||
|
||||
[Music On Console][4] 播放器(简称 mocp)是一个简单的控制台音频播放器。它有一个类似于 “Midnight Commander” 的界面,并且很容易使用。你只需进入包含音乐的目录,然后选择要播放的文件或目录。此外,mocp 提供了一组命令,允许直接从命令行进行控制。
|
||||
|
||||
![][5]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
该仓库目前为 Fedora 28 和 29 提供 Music On Console 播放器。要安装 mocp,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable Krzystof/Moc
|
||||
sudo dnf install moc
|
||||
```
|
||||
|
||||
### cnping
|
||||
|
||||
[Cnping][6] 是小型的图形化 ping IPv4 工具,可用于可视化显示 RTT 的变化。它提供了一个选项来控制每个数据包之间的间隔以及发送的数据大小。除了显示的图表外,cnping 还提供 RTT 和丢包的基本统计数据。
|
||||
|
||||
![][7]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
该仓库目前为 Fedora 27、28、29 和 Rawhide 提供 cnping。要安装 cnping,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable dreua/cnping
|
||||
sudo dnf install cnping
|
||||
```
|
||||
|
||||
### Pdfsandwich
|
||||
|
||||
[Pdfsandwich][8] 是将文本添加到图像形式的文本 PDF 文件 (如扫描书籍) 的工具。它使用光学字符识别 (OCR) 创建一个额外的图层, 包含了原始页面已识别的文本。这对于复制和处理文本很有用。
|
||||
|
||||
#### 安装说明
|
||||
|
||||
该仓库目前为 Fedora 27、28、29、Rawhide 以及 EPEL 7 提供 pdfsandwich。要安装 pdfsandwich,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable merlinm/pdfsandwich
|
||||
sudo dnf install pdfsandwich
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-cool-new-projects-try-copr-october-2018/
|
||||
|
||||
作者:[Dominik Turecek][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://copr.fedorainfracloud.org/
|
||||
[2]: https://www.gitkraken.com/git-client
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2018/10/copr-gitkraken.png
|
||||
[4]: http://moc.daper.net/
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2018/10/copr-mocp.png
|
||||
[6]: https://github.com/cnlohr/cnping
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2018/10/copr-cnping.png
|
||||
[8]: http://www.tobias-elze.de/pdfsandwich/
|
||||
@ -1,11 +1,11 @@
|
||||
使用 Calcurse 在 Linux 命令行中组织任务
|
||||
======
|
||||
|
||||
使用 Calcurse 了解你的日历和待办事项列表。
|
||||
> 使用 Calcurse 了解你的日历和待办事项列表。
|
||||
|
||||

|
||||
|
||||
你是否需要复杂,功能丰富的图形或 Web 程序才能保持井井有条?我不这么认为。正确的命令行工具可以完成工作并且做得很好。
|
||||
你是否需要复杂、功能丰富的图形或 Web 程序才能保持井井有条?我不这么认为。合适的命令行工具可以完成工作并且做得很好。
|
||||
|
||||
当然,说出命令行这个词可能会让一些 Linux 用户感到害怕。对他们来说,命令行是未知领域。
|
||||
|
||||
@ -15,54 +15,51 @@
|
||||
|
||||
### 获取软件
|
||||
|
||||
如果你喜欢编译代码(我通常不喜欢),你可以从[Calcurse 网站][1]获取源码。否则,根据你的 Linux 发行版获取[二进制安装程序][2]。你甚至可以从 Linux 发行版的软件包管理器中获取 Calcurse。检查一下不会有错的。
|
||||
如果你喜欢编译代码(我通常不喜欢),你可以从 [Calcurse 网站][1]获取源码。否则,根据你的 Linux 发行版获取[二进制安装程序][2]。你甚至可以从 Linux 发行版的软件包管理器中获取 Calcurse。检查一下不会有错的。
|
||||
|
||||
编译或安装 Calcurse 后(两者都不用太长时间),你就可以开始使用了。
|
||||
|
||||
### 使用 Calcurse
|
||||
|
||||
打开终端并输入 **calcurse**。
|
||||
打开终端并输入 `calcurse`。
|
||||
|
||||
|
||||
|
||||
Calcurse 的界面由三个面板组成:
|
||||
|
||||
* 预约(屏幕左侧)
|
||||
* 日历(右上角)
|
||||
* 待办事项清单(右下角)
|
||||
* <ruby>预约<rt>Appointments</rt></ruby>(屏幕左侧)
|
||||
* <ruby>日历<rt>Calendar</rt></ruby>(右上角)
|
||||
* <ruby>待办事项清单<rt>TODO</rt></ruby>(右下角)
|
||||
|
||||
按键盘上的 `Tab` 键在面板之间移动。要在面板添加新项目,请按下 `a`。Calcurse 将指导你完成添加项目所需的操作。
|
||||
|
||||
一个有趣的地方地是预约和日历面板配合工作。你选中日历面板并添加一个预约。在那里,你选择一个预约的日期。完成后,你回到预约面板,你就看到了。
|
||||
|
||||
|
||||
按键盘上的 Tab 键在面板之间移动。要在面板添加新项目,请按下 **a**。Calcurse 将指导你完成添加项目所需的操作。
|
||||
|
||||
一个有趣的地方地预约和日历面板一起生效。你选中日历面板并添加一个预约。在那里,你选择一个预约的日期。完成后,你回到预约面板。我知道。。。
|
||||
|
||||
按下 **a** 设置开始时间,持续时间(以分钟为单位)和预约说明。开始时间和持续时间是可选的。Calcurse 在它们到期的那天显示预约。
|
||||
按下 `a` 设置开始时间、持续时间(以分钟为单位)和预约说明。开始时间和持续时间是可选的。Calcurse 在它们到期的那天显示预约。
|
||||
|
||||
|
||||
|
||||
一天的预约看起来像:
|
||||
一天的预约看起来像这样:
|
||||
|
||||
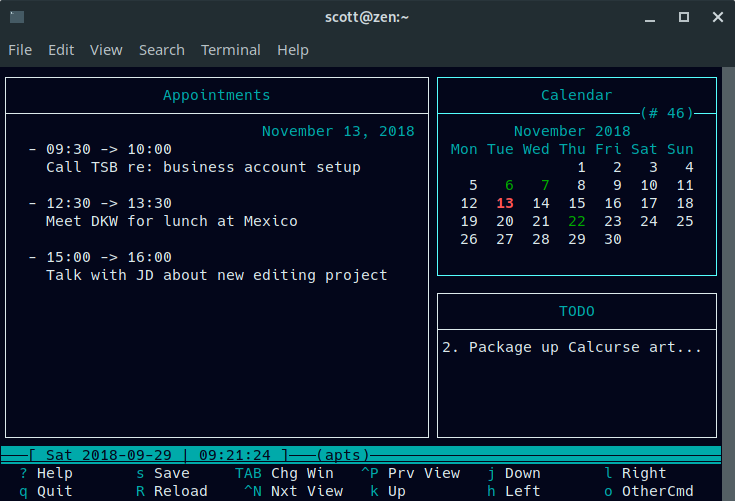
|
||||
|
||||
待办事项列表独立运作。选中待办面板并(再次)按下 **a**。输入任务的描述,然后设置优先级(1 表示最高,9 表示最低)。Calcurse 会在待办事项面板中列出未完成的任务。
|
||||
待办事项列表独立运作。选中待办面板并(再次)按下 `a`。输入任务的描述,然后设置优先级(1 表示最高,9 表示最低)。Calcurse 会在待办事项面板中列出未完成的任务。
|
||||
|
||||
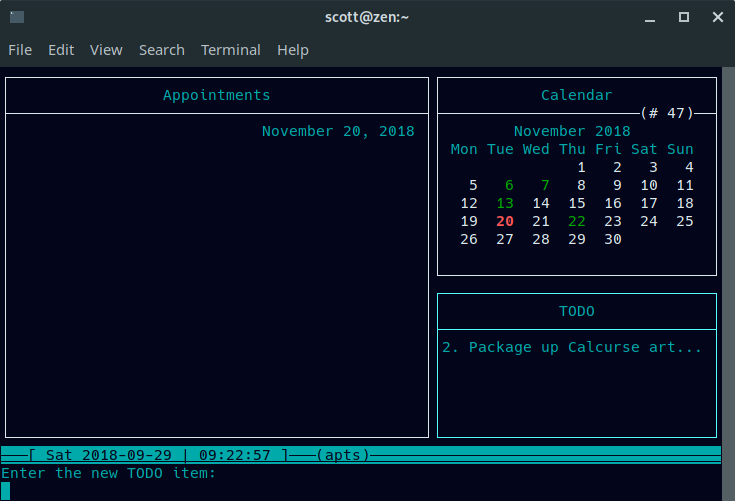
|
||||
|
||||
如果你的任务有很长的描述,那么 Calcurse 会截断它。你可以使用键盘上的向上或向下箭头键浏览任务,然后按下 **v** 查看描述。
|
||||
如果你的任务有很长的描述,那么 Calcurse 会截断它。你可以使用键盘上的向上或向下箭头键浏览任务,然后按下 `v` 查看描述。
|
||||
|
||||
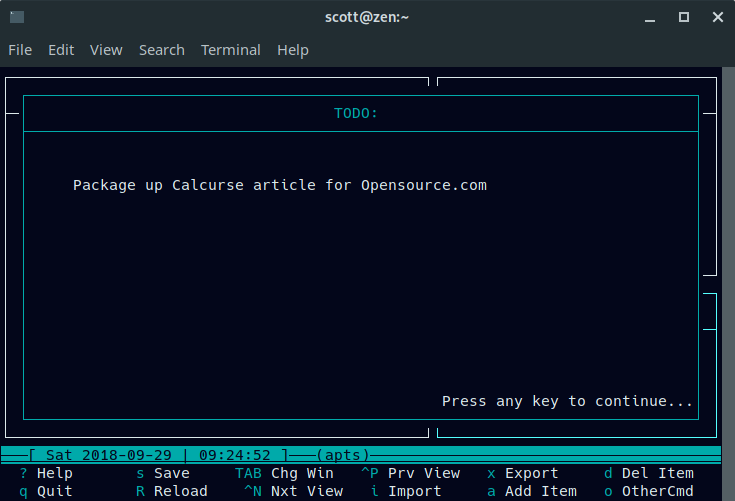
|
||||
|
||||
Calcurse 将其信息以文本形式保存在你的主目录下名为 **.calcurse** 的隐藏文件夹中,例如 **/home/scott/.calcurse**。如果 Calcurse 停止工作,那也很容易找到你的信息。
|
||||
Calcurse 将其信息以文本形式保存在你的主目录下名为 `.calcurse` 的隐藏文件夹中,例如 `/home/scott/.calcurse`。如果 Calcurse 停止工作,那也很容易找到你的信息。
|
||||
|
||||
### 其他有用的功能
|
||||
|
||||
Calcurse 其他的功能包括设置重复预约的功能。要执行此操作,找出要重复的预约,然后在预约面板中按下 **r**。系统会要求你设置频率(例如,每天或每周)以及你希望重复预约的时间。
|
||||
Calcurse 其他的功能包括设置重复预约的功能。要执行此操作,找出要重复的预约,然后在预约面板中按下 `r`。系统会要求你设置频率(例如,每天或每周)以及你希望重复预约的时间。
|
||||
|
||||
你还可以导入 [ICAL][3] 格式的日历或以 ICAL 或 [PCAL][4] 格式导出数据。使用 ICAL,你可以与其他日历程序共享数据。使用 PCAL,你可以生成日历的 Postscript 版本。
|
||||
|
||||
你还可以将许多命令行参数传递给 Calcurse。你可以[在文档中][5]阅读它们。
|
||||
你还可以将许多命令行参数传递给 Calcurse。你可以[在文档中][5]了解它们。
|
||||
|
||||
虽然很简单,但 Calcurse 可以帮助你保持井井有条。你需要更加关注自己的任务和预约,但是你将能够更好地关注你需要做什么以及你需要做的方向。
|
||||
|
||||
@ -73,7 +70,7 @@ via: https://opensource.com/article/18/10/calcurse
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,84 @@
|
||||
监测数据库的健康和行为:有哪些重要指标?
|
||||
======
|
||||
|
||||
> 对数据库的监测可能过于困难或者没有找到关键点。本文将讲述如何正确的监测数据库。
|
||||
|
||||

|
||||
|
||||
我们没有对数据库讨论过多少。在这个充满监测仪器的时代,我们监测我们的应用程序、基础设施、甚至我们的用户,但有时忘记我们的数据库也值得被监测。这很大程度是因为数据库表现的很好,以至于我们单纯地信任它能把任务完成的很好。信任固然重要,但能够证明它的表现确实如我们所期待的那样就更好了。
|
||||
|
||||

|
||||
|
||||
### 为什么监测你的数据库?
|
||||
|
||||
监测数据库的原因有很多,其中大多数原因与监测系统的任何其他部分的原因相同:了解应用程序的各个组件中发生的什么,会让你成为更了解情况的,能够做出明智决策的开发人员。
|
||||
|
||||

|
||||
|
||||
更具体地说,数据库是系统健康和行为的重要标志。数据库中的异常行为能够指出应用程序中出现问题的区域。另外,当应用程序中有异常行为时,你可以利用数据库的指标来迅速完成排除故障的过程。
|
||||
|
||||
### 问题
|
||||
|
||||
最轻微的调查揭示了监测数据库的一个问题:数据库有很多指标。说“很多”只是轻描淡写,如果你是<ruby>史高治<rt>Scrooge McDuck</rt></ruby>(LCTT 译注:史高治,唐老鸭的舅舅,以一毛不拔著称),你不会放过任何一个可用的指标。如果这是<ruby>摔角狂热<rt>Wrestlemania</rt></ruby> 比赛,那么指标就是折叠椅。监测所有指标似乎并不实用,那么你如何决定要监测哪些指标?
|
||||
|
||||

|
||||
|
||||
### 解决方案
|
||||
|
||||
开始监测数据库的最好方式是认识一些基础的数据库指标。这些指标为理解数据库的行为创造了良好的开端。
|
||||
|
||||
### 吞吐量:数据库做了多少?
|
||||
|
||||
开始检测数据库的最好方法是跟踪它所接到请求的数量。我们对数据库有较高期望;期望它能稳定的存储数据,并处理我们抛给它的所有查询,这些查询可能是一天一次大规模查询,或者是来自用户一天到晚的数百万次查询。吞吐量可以告诉我们数据库是否如我们期望的那样工作。
|
||||
|
||||
你也可以将请求按照类型(读、写、服务器端、客户端等)分组,以开始分析流量。
|
||||
|
||||
### 执行时间:数据库完成工作需要多长时间?
|
||||
|
||||
这个指标看起来很明显,但往往被忽视了。你不仅想知道数据库收到了多少请求,还想知道数据库在每个请求上花费了多长时间。 然而,参考上下文来讨论执行时间非常重要:像 InfluxDB 这样的时间序列数据库中的慢与像 MySQL 这样的关系型数据库中的慢不一样。InfluxDB 中的慢可能意味着毫秒,而 MySQL 的 `SLOW_QUERY` 变量的默认值是 10 秒。
|
||||
|
||||

|
||||
|
||||
监测执行时间和提高执行时间不一样,所以如果你的应用程序中有其他问题需要修复,那么请注意在优化上花费时间的诱惑。
|
||||
|
||||
### 并发性:数据库同时做了多少工作?
|
||||
|
||||
一旦你知道数据库正在处理多少请求以及每个请求需要多长时间,你就需要添加一层复杂性以开始从这些指标中获得实际值。
|
||||
|
||||
如果数据库接收到十个请求,并且每个请求需要十秒钟来完成,那么数据库是忙碌了 100 秒、10 秒,还是介于两者之间?并发任务的数量改变了数据库资源的使用方式。当你考虑连接和线程的数量等问题时,你将开始对数据库指标有更全面的了解。
|
||||
|
||||
并发性还能影响延迟,这不仅包括任务完成所需的时间(执行时间),还包括任务在处理之前需要等待的时间。
|
||||
|
||||
### 利用率:数据库繁忙的时间百分比是多少?
|
||||
|
||||
利用率是由吞吐量、执行时间和并发性的峰值所确定的数据库可用的频率,或者数据库太忙而不能响应请求的频率。
|
||||
|
||||

|
||||
|
||||
该指标对于确定数据库的整体健康和性能特别有用。如果只能在 80% 的时间内响应请求,则可以重新分配资源、进行优化工作,或者进行更改以更接近高可用性。
|
||||
|
||||
### 好消息
|
||||
|
||||
监测和分析似乎非常困难,特别是因为我们大多数人不是数据库专家,我们可能没有时间去理解这些指标。但好消息是,大部分的工作已经为我们做好了。许多数据库都有一个内部性能数据库(Postgres:`pg_stats`、CouchDB:`Runtime_Statistics`、InfluxDB:`_internal` 等),数据库工程师设计该数据库来监测与该特定数据库有关的指标。你可以看到像慢速查询的数量一样广泛的内容,或者像数据库中每个事件的平均微秒一样详细的内容。
|
||||
|
||||
### 结论
|
||||
|
||||
数据库创建了足够的指标以使我们需要长时间研究,虽然内部性能数据库充满了有用的信息,但并不总是使你清楚应该关注哪些指标。从吞吐量、执行时间、并发性和利用率开始,它们为你提供了足够的信息,使你可以开始了解你的数据库中的情况。
|
||||
|
||||

|
||||
|
||||
你在监视你的数据库吗?你发现哪些指标有用?告诉我吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/database-metrics-matter
|
||||
|
||||
作者:[Katy Farmer][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[ChiZelin](https://github.com/ChiZelin)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/thekatertot
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -0,0 +1,95 @@
|
||||
理解 Linux 链接(二)
|
||||
======
|
||||
> 我们继续这个系列,来看一些你所不知道的微妙之处。
|
||||
|
||||

|
||||
|
||||
在[本系列的第一篇文章中][1],我们认识了硬链接、软链接,知道在很多时候链接是非常有用的。链接看起来比较简单,但是也有一些不易察觉的奇怪的地方需要注意。这就是我们这篇文章中要讲的。例如,像一下我们在前一篇文章中创建的指向 `libblah` 的链接。请注意,我们是如何从目标文件夹中创建链接的。
|
||||
|
||||
```
|
||||
cd /usr/local/lib
|
||||
ln -s /usr/lib/libblah
|
||||
```
|
||||
|
||||
这样是可以工作的,但是下面的这个例子却是不行的。
|
||||
|
||||
```
|
||||
cd /usr/lib
|
||||
ln -s libblah /usr/local/lib
|
||||
```
|
||||
|
||||
也就是说,从原始文件夹内到目标文件夹之间的链接将不起作用。
|
||||
|
||||
出现这种情况的原因是 `ln` 会把它当作是你在 `/usr/local/lib` 中创建一个到 `/usr/local/lib` 的链接,并在 `/usr/local/lib` 中创建了从 `libblah` 到 `libblah` 的一个链接。这是因为所有链接文件获取的是文件的名称(`libblah),而不是文件的路径,最终的结果将会产生一个坏的链接。
|
||||
|
||||
然而,请看下面的这种情况。
|
||||
|
||||
```
|
||||
cd /usr/lib
|
||||
ln -s /usr/lib/libblah /usr/local/lib
|
||||
```
|
||||
|
||||
是可以工作的。奇怪的事情又来了,不管你在文件系统的任何位置执行这个指令,它都可以好好的工作。使用绝对路径,也就是说,指定整个完整的路径,从根目录(`/`)开始到需要的文件或者是文件夹,是最好的实现方式。
|
||||
|
||||
其它需要注意的事情是,只要 `/usr/lib` 和 `/usr/local/lib` 在一个分区上,做一个如下的硬链接:
|
||||
|
||||
```
|
||||
cd /usr/lib
|
||||
ln libblah /usr/local/lib
|
||||
```
|
||||
|
||||
也是可以工作的,因为硬链接不依赖于指向文件系统内的文件来工作。
|
||||
|
||||
如果硬链接不起作用,那么可能是你想跨分区之间建立一个硬链接。就比如说,你有分区 A 上有文件 `fileA` ,并且把这个分区挂载到 `/path/to/partitionA/directory` 目录,而你又想从 `fileA` 链接到分区 B 上 `/path/to/partitionB/directory` 目录,这样是行不通的。
|
||||
|
||||
```
|
||||
ln /path/to/partitionA/directory/file /path/to/partitionB/directory
|
||||
```
|
||||
|
||||
正如我们之前说的一样,硬链接是分区表中指向的是同一个分区的数据的条目,你不能把一个分区表的条目指向另一个分区上的数据,这种情况下,你只能选择创建一个软链接:
|
||||
|
||||
```
|
||||
ln -s /path/to/partitionA/directory/file /path/to/partitionB/directory
|
||||
```
|
||||
|
||||
另一个软链接能做到,而硬链接不能的是链接到一个目录。
|
||||
|
||||
```
|
||||
ln -s /path/to/some/directory /path/to/some/other/directory
|
||||
```
|
||||
|
||||
这将在 `/path/to/some/other/directory` 中创建 `/path/to/some/directory` 的链接,没有任何问题。
|
||||
|
||||
当你使用硬链接做同样的事情的时候,会提示你一个错误,说不允许那么做。而不允许这么做的原因量会导致无休止的递归:如果你在目录 A 中有一个目录 B,然后你在目录 B 中链接 A,就会出现同样的情况,在目录 A 中,目录 A 包含了目录 B,而在目录 B 中又包含了 A,然后又包含了 B,等等无穷无尽。
|
||||
|
||||
当然你可以在递归中使用软链接,但你为什么要那样做呢?
|
||||
|
||||
### 我应该使用硬链接还是软链接呢?
|
||||
|
||||
通常,你可以在任何地方使用软链接做任何事情。实际上,在有些情况下你只能使用软链接。话说回来,硬链接的效率要稍高一些:它们占用的磁盘空间更少,访问速度更快。在大多数的机器上,你可以忽略这一点点的差异,因为:在磁盘空间越来越大,访问速度越来越快的今天,空间和速度的差异可以忽略不计。不过,如果你是在一个有小存储和低功耗的处理器上使用嵌入式系统上使用 Linux, 则可能需要考虑使用硬链接。
|
||||
|
||||
另一个使用硬链接的原因是硬链接不容易损坏。假设你有一个软链接,而你意外的移动或者删除了它指向的文件,那么你的软链接将会损坏,并指向了一个不存在的东西。这种情况是不会发生在硬链接中的,因为硬链接直接指向的是磁盘上的数据。实际上,磁盘上的空间不会被标记为空闲,除非最后一个指向它的硬链接把它从文件系统中擦除掉。
|
||||
|
||||
软链接,在另一方面比硬链接可以做更多的事情,而且可以指向任何东西,可以是文件或目录。它也可以指向不在同一个分区上的文件和目录。仅这两个不同,我们就可以做出唯一的选择了。
|
||||
|
||||
### 下期
|
||||
|
||||
现在我们已经介绍了文件和目录以及操作它们的工具,你是否已经准备好转到这些工具,可以浏览目录层次结构,可以查找文件中的数据,也可以检查目录。这就是我们下一期中要做的事情。下期见。
|
||||
|
||||
你可以通过 Linux 基金会和 edX “[Linux 简介][2]”了解更多关于 Linux 的免费课程。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/10/understanding-linux-links-part-2
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Jamkr](https://github.com/Jamkr)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/bro66
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-10173-1.html
|
||||
[2]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user