mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-28 23:20:10 +08:00
commit
fc1c6938ef
@ -2,8 +2,6 @@
|
||||
================================================================================
|
||||

|
||||
|
||||
图片来源 : opensource.com
|
||||
|
||||
经过了一整天的Opensource.com[社区版主][1]年会,最后一项日程提了上来,内容只有“特邀嘉宾:待定”几个字。作为[Opensource.com][3]的项目负责人和社区管理员,[Jason Hibbets][2]起身解释道,“因为这个嘉宾有可能无法到场,因此我不想提前说是谁。在几个月前我问他何时有空过来,他给了我两个时间点,我选了其中一个。今天是这三周中Jim唯一能来的一天”。(译者注:Jim是指下文中提到的Jim Whitehurst,即红帽公司总裁兼首席执行官)
|
||||
|
||||
这句话在版主们(Moderators)中引起一阵轰动,他们从世界各地赶来参加此次的[拥抱开源大会(All Things Open Conference)][4]。版主们纷纷往前挪动椅子,仔细聆听。
|
||||
@ -14,7 +12,7 @@
|
||||
|
||||
“大家好!”,这个家伙开口了。他没穿正装,只是衬衫和休闲裤。
|
||||
|
||||
这时会场中第二高个子的人,红帽全球意识部门(Global Awareness)的高级主管[Jeff Mackanic][5],告诉他大部分社区版本今天都在场,然后让每个人开始作简单的自我介绍。
|
||||
这时会场中第二高个子的人,红帽全球意识部门(Global Awareness)的高级主管[Jeff Mackanic][5],告诉他大部分社区版主今天都在场,然后让每个人开始作简单的自我介绍。
|
||||
|
||||
“我叫[Jen Wike Huger][6],负责Opensource.com的内容管理,很高兴见到大家。”
|
||||
|
||||
@ -22,13 +20,13 @@
|
||||
|
||||
“我叫[Robin][9],从2013年开始参与版主项目。我在OSDC做了一些事情,工作是在[City of the Hague][10]维护[网站][11]。”
|
||||
|
||||
“我叫[Marcus Hanwell][12],来自英格兰,在[Kitware][13]工作。同时,我是FOSS科学软件的技术总监,和国家实验室在[Titan][14] Z和[Gpu programming][15]方面合作。我主要使用[Gentoo][16]和[KDE][17]。最后,我很激动能加入FOSS和开源科学。”
|
||||
“我叫[Marcus Hanwell][12],来自英格兰,在[Kitware][13]工作。同时,我是FOSS science software的技术总监,和国家实验室在[Titan][14] Z和[Gpu programming][15]方面合作。我主要使用[Gentoo][16]和[KDE][17]。最后,我很激动能参与到FOSS和开源科学。”
|
||||
|
||||
“我叫[Phil Shapiro][18],是华盛顿的一个小图书馆28个Linux工作站的管理员。我视各位为我的同事。非常高兴能一起交流分享,贡献力量。我主要关注FOSS和自豪感的关系,以及FOSS如何提升自豪感。”
|
||||
“我叫[Phil Shapiro][18],是华盛顿的一个小图书馆的28个Linux工作站的管理员。我视各位为我的同事。非常高兴能一起交流分享,贡献力量。我主要关注FOSS和自豪感的关系,以及FOSS如何提升自豪感。”
|
||||
|
||||
“我叫[Joshua Holm][19]。我大多数时间都在关注系统更新,以及帮助人们在网上找工作。”
|
||||
|
||||
“我叫[Mel Chernoff][20],在红帽工作,和[Jason Hibbets]和[Mark Bohannon]一起主要关注政府渠道方面。”
|
||||
“我叫[Mel Chernoff][20],在红帽工作,和[Jason Hibbets][22]和[Mark Bohannon][23]一起主要关注[政府][21]渠道方面。”
|
||||
|
||||
“我叫[Scott Nesbitt][24],写过很多东西,使用FOSS很久了。我是个普通人,不是系统管理员,也不是程序员,只希望能更加高效工作。我帮助人们在商业和生活中使用FOSS。”
|
||||
|
||||
@ -38,41 +36,41 @@
|
||||
|
||||
“你在[新FOSS Minor][30]教书?!”,Jim说道,“很酷!”
|
||||
|
||||
“我叫[Jason Baker][31]。我是红慢的一个云专家,主要做[OpenStack][32]方面的工作。”
|
||||
“我叫[Jason Baker][31]。我是红帽的一个云专家,主要做[OpenStack][32]方面的工作。”
|
||||
|
||||
“我叫[Mark Bohannan][33],是红帽全球开放协议的一员,在华盛顿外工作。和Mel一样,我花了相当多时间写作,也从法律和政府部门中找合作者。我做了一个很好的小册子来讨论正在发生在政府中的积极变化。”
|
||||
|
||||
“我叫[Jason Hibbets][34],我组织了这次会议。”
|
||||
“我叫[Jason Hibbets][34],我组织了这次讨论。”
|
||||
|
||||
会场中一片笑声。
|
||||
|
||||
“我也组织了这片讨论,可以这么说,”这个棕红色头发笑容灿烂的家伙说道。笑声持续一会逐渐平息。
|
||||
“我也组织了这个讨论,可以这么说,”这个棕红色头发笑容灿烂的家伙说道。笑声持续一会逐渐平息。
|
||||
|
||||
我当时在他左边,时不时从转录空隙中抬头看一眼,然后从眼神中注意到微笑背后暗示的那个自2008年1月起开始领导公司的人,红帽的CEO[Jim Whitehurst][35]。
|
||||
我当时在他左边,时不时从记录的间隙中抬头看一眼,我注意到淡淡微笑背后的那个令人瞩目的人,是自2008年1月起开始领导红帽公司的CEO [Jim Whitehurst][35]。
|
||||
|
||||
“我有世界上最好的工作,”稍稍向后靠、叉腿抱头,Whitehurst开始了演讲。“我开始领导红帽,在世界各地旅行到处看看情况。在这里的七年中,FOSS和广泛的开源创新所发生的美好的事情是开源已经脱离了条条框框。我现在认为,IT正处在FOSS之前所在的位置。我们可以预见FOSS从一个替代走向创新驱动力。”用户也看到了这一点。他们用FOSS并不是因为它便宜,而是因为它能提供和创新的解决方案。这也十一个全球现象。比如,我刚才还在印度,然后发现那里的用户拥抱开源的两个理由:一个是创新,另一个是那里的市场有些特殊,需要完全的控制。
|
||||
“我有世界上最好的工作,”稍稍向后靠、叉腿抱头,Whitehurst开始了演讲。“我开始领导红帽,在世界各地旅行到处看看情况。在这里的七年中,FOSS和广泛的开源创新所发生的最美好的事情是开源已经脱离了条条框框。我现在认为,信息技术正处在FOSS之前所在的位置。我们可以预见FOSS从一个替代品走向创新驱动力。我们的用户也看到了这一点。他们用FOSS并不是因为它便宜,而是因为它能带来可控和创新的解决方案。这也是个全球现象。比如,我刚才还在印度,然后发现那里的用户拥抱开源的两个理由:一个是创新,另一个是那里的市场有些特殊,需要完全的可控。”
|
||||
|
||||
“[孟买证券交易所][36]想得到源代码并加以控制,五年前这在证券交易领域闻所未闻。那时FOSS正在重复发明轮子。今天看来,FOSS正在做几乎所有的结合了大数据的事物。几乎所有的新框架,语言和方法论,包括流动(尽管不包括设备),都首先发生在开源世界。”
|
||||
“[孟买证券交易所][36]想得到源代码并加以控制,五年前这种事情在证券交易领域就没有听说过。那时FOSS正在重复发明轮子。今天看来,实际上大数据的每件事情都出现在FOSS领域。几乎所有的新框架,语言和方法论,包括移动通讯(尽管不包括设备),都首先发生在开源世界。”
|
||||
|
||||
“这是因为用户数量已经达到了相当的规模。这不只是红帽遇到的情况,[Google][37],[Amazon][38],[Facebook][39]等也出现这样的情况。他们想解决自己的问题,用开源的方式。忘掉协议吧,开源绝不仅如此。我们建立了一个交通工具,一套规则,例如[Hadoop][40],[Cassandra][41]和其他工具。事实上,开源驱动创新。例如,Hadoop在厂商们意识的规模带来的问题。他们实际上有足够的资和资源金来解决自己的问题。”开源是许多领域的默认技术方案。这在一个更加注重内容的世界中更是如此,例如[3D打印][42]和其他使用信息内容的物理产品。”
|
||||
“这是因为用户数量已经达到了相当的规模。这不只是红帽遇到的情况,[Google][37],[Amazon][38],[Facebook][39]等也出现这样的情况。他们想解决自己的问题,用开源的方式。忘掉许可协议吧,开源绝不仅如此。我们建立了一个交通工具,一套规则,例如[Hadoop][40],[Cassandra][41]和其他工具。事实上,开源驱动创新。例如,Hadoop是在厂商们意识到规模带来的问题时的一个解决方案。他们实际上有足够的资金和资源来解决自己的问题。开源是许多领域的默认技术方案。这在一个更加注重内容的世界中更是如此,例如[3D打印][42]和其他使用信息内容的实体产品。”
|
||||
|
||||
“源代码的开源确实很酷,但开源不应当仅限于此。在各行各业不同领域开源仍有可以用武之地。我们要问下自己:‘开源能够为教育,政府,法律带来什么?其它的呢?其它的领域如何能学习我们?’”
|
||||
|
||||
“还有内容的问题。内容在现在是免费的,当然我们可以投资更多的免费内容,不过我们也需要商业模式围绕的内容。这是我们更应该关注的。如果你相信开放的创新能带来更好,那么我们需要更多的商业模式。”
|
||||
“还有内容的问题。内容在现在是免费的,当然我们可以投资更多的免费内容,不过我们也需要商业模式围绕的内容。这是我们更应该关注的。如果你相信开放的创新更好,那么我们需要更多的商业模式。”
|
||||
|
||||
“教育让我担心其相比与‘社区’它更关注‘内容’。例如,无论我走到哪里,大学校长们都会说,‘等等,难道教育将会免费?!’对于下游来说FOSS免费很棒,但别忘了上游很强大。免费课程很棒,但我们同样需要社区来不断迭代和完善。这是很多人都在做的事情,Opensource.com是一个提供交流的社区。问题不是‘我们如何控制内容’,也不是‘如何建立和分发内容’,而是要确保它处在不断的完善当中,而且能给其他领域提供有价值的参考。”
|
||||
“教育让我担心,其相比与‘社区’它更关注‘内容’。例如,无论我走到哪里,大学的校长们都会说,‘等等,难道教育将会免费?!’对于下游来说FOSS免费很棒,但别忘了上游很强大。免费课程很棒,但我们同样需要社区来不断迭代和完善。这是很多人都在做的事情,Opensource.com是一个提供交流的社区。问题不是‘我们如何控制内容’,也不是‘如何建立和分发内容’,而是要确保它处在不断的完善当中,而且能给其他领域提供有价值的参考。”
|
||||
|
||||
“改变世界的潜力是无穷无尽的,我们已经取得了很棒的进步。”六年前我们痴迷于制定宣言,我们说‘我们是领导者’。我们用错词了,因为那潜在意味着控制。积极的参与者们同样也不能很好理解……[Máirín Duffy][43]提出了[催化剂][44]这个词。然后我们组成了红帽,不断地促进行动,指引方向。”
|
||||
|
||||
“Opensource.com也是其他领域的催化剂,而这正是它的本义所在,我希望你们也这样认为。当时的内容质量和现在比起来都令人难以置信。你可以看到每季度它都在进步。谢谢你们的时间!谢谢成为了催化剂!这是一个让世界变得更好的机会。我想听听你们的看法。”
|
||||
“Opensource.com也是其他领域的催化剂,而这正是它的本义所在,我希望你们也这样认为。当时的内容质量和现在比起来都令人难以置信。你可以看到每季度它都在进步。谢谢你们付出的时间!谢谢成为了催化剂!这是一个让世界变得更好的机会。我想听听你们的看法。”
|
||||
|
||||
我瞥了一下桌子,发现几个人眼中带泪。
|
||||
|
||||
然后Whitehurst又回顾了大会的开放教育议题。“极端一点看,如果你有一门[Ulysses][45]的公开课。在这里你能和一群人一起合作体验课堂。这样就和代码块一样的:大家一起努力,代码随着时间不断改进。”
|
||||
|
||||
在这一点上,我有发言权。当谈论其FOSS和学术团体之间的差异,向基础和可能的不调和这些词语都跳了出来。
|
||||
在这一点上,我有发言权。当谈论其FOSS和学术团体之间的差异,像“基础”和“可能不调和”这些词语都跳了出来。
|
||||
|
||||
**Remy**: “倒退带来死亡。如果你在论文或者发布的代码中烦了一个错误,有可能带来十分严重的后果。学校一直都是避免失败寻求正确答案的地方。复制意味着抄袭。轮子在一遍遍地教条地被发明。FOSS你能快速失败,但在学术界,你只能带来无效的结果。”
|
||||
**Remy**: “倒退带来死亡。如果你在论文或者发布的代码中犯了一个错误,有可能带来十分严重的后果。学校一直都是避免失败寻求正确答案的地方。复制意味着抄袭。轮子在一遍遍地教条地被发明。FOSS让你能快速失败,但在学术界,你只能带来无效的结果。”
|
||||
|
||||
**Nicole**: “学术界有太多自我的家伙,你们需要一个发布经理。”
|
||||
|
||||
@ -80,20 +78,21 @@
|
||||
|
||||
**Luis**: “团队和分享应该优先考虑,红帽可以多向它们强调这一点。”
|
||||
|
||||
**Jim**: “还有公司在其中扮演积极角色吗?”
|
||||
**Jim**: “还有公司在其中扮演积极角色了吗?”
|
||||
|
||||
[Phil Shapiro][46]: “我对FOSS的临界点感兴趣。联邦没有改用[LibreOffice][47]把我逼疯了。我们没有在软件上花税款,也不应当在字处理软件或者微软的Office上浪费税钱。”
|
||||
[Phil Shapiro][46]: “我对FOSS的临界点感兴趣。Fed没有改用[LibreOffice][47]把我逼疯了。我们没有在软件上花税款,也不应当在字处理软件或者微软的Office上浪费税钱。”
|
||||
|
||||
**Jim**: “我们经常提倡这一点。我们能做更多吗?这是个问题。首先,我们在我们的产品涉足的地方取得了进步。我们在政府中有坚实的专营权。我们比私有公司平均话费更多。银行和电信业都和政府挨着。我们在欧洲做的更好,我认为在那工作又更低的税。下一代计算就像‘终结者’,我们到处取得了进步,但仍然需要忧患意识。”
|
||||
**Jim**: “我们经常提倡这一点。我们能做更多吗?这是个问题。首先,我们在我们的产品涉足的地方取得了进步。我们在政府中有坚实的专营权。我们比私有公司平均花费更多。银行和电信业都和政府挨着。我们在欧洲做的更好,我认为在那工作有更低的税。下一代计算就像‘终结者’,我们到处取得了进步,但仍然需要忧患意识。”
|
||||
|
||||
突然,门开了。Jim转身向门口站着的执行助理点头。他要去参加下一场会了。他并拢双腿,站着向前微倾。然后,他再次向每个人的工作和奉献表示感谢,微笑着出了门……留给我们更多的激励。
|
||||
|
||||
突然,门开了。Jim转身向门口站着的执行助理点头。他要去参加下一场会了。他并拢双腿,站着向前微倾。然后,他再次向每个人的工作和奉献表示感谢,微笑着除了门……留给我们更多的激励。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/14/12/jim-whitehurst-inspiration-open-source
|
||||
|
||||
作者:[Remy][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[fyh](https://github.com/fyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,86 @@
|
||||
7 个驱动开源发展的社区
|
||||
================================================================================
|
||||
不久前,开源模式还被成熟的工业级厂商以怀疑的态度认作是叛逆小孩的玩物。如今,开源的促进会和基金会在一长列的供应商提供者的支持下正蓬勃发展,而他们将开源模式视作创新的关键。
|
||||
|
||||

|
||||
|
||||
### 技术的开放发展驱动着创新 ###
|
||||
|
||||
在过去的 20 几年间,技术的开源推进已被视作驱动创新的关键因素。即使那些以前将开源视作威胁的公司也开始接受这个观点 — 例如微软,如今它在一系列的开源的促进会中表现活跃。到目前为止,大多数的开源推进都集中在软件方面,但甚至这个也正在改变,因为社区已经开始向开源硬件倡议方面聚拢。这里介绍 7 个成功地在硬件和软件方面同时促进和发展开源技术的组织。
|
||||
|
||||
### OpenPOWER 基金会 ###
|
||||
|
||||

|
||||
|
||||
[OpenPOWER 基金会][2] 由 IBM, Google, Mellanox, Tyan 和 NVIDIA 于 2013 年共同创建,在与开源软件发展相同的精神下,旨在驱动开放协作硬件的发展,在过去的 20 几年间,开源软件发展已经找到了肥沃的土壤。
|
||||
|
||||
IBM 通过开放其基于 Power 架构的硬件和软件技术,向使用 Power IP 的独立硬件产品提供许可证等方式为基金会的建立播下种子。如今超过 70 个成员共同协作来为基于 Linux 的数据中心提供自定义的开放服务器,组件和硬件。
|
||||
|
||||
去年四月,在比最新基于 x86 系统快 50 倍的数据分析能力的新的 POWER8 处理器的服务器的基础上, OpenPOWER 推出了一个技术路线图。七月, IBM 和 Google 发布了一个固件堆栈。去年十月见证了 NVIDIA GPU 带来加速 POWER8 系统的能力和来自 Tyan 的第一个 OpenPOWER 参考服务器。
|
||||
|
||||
### Linux 基金会 ###
|
||||
|
||||

|
||||
|
||||
于 2000 年建立的 [Linux 基金会][2] 如今成为掌控着历史上最大的开源协同开发成果,它有着超过 180 个合作成员和许多独立成员及学生成员。它赞助 Linux 核心开发者的工作并促进、保护和推进 Linux 操作系统,并协调软件的协作开发。
|
||||
|
||||
它最为成功的协作项目包括 Code Aurora Forum (一个拥有为移动无线产业服务的企业财团),MeeGo (一个为移动设备和 IVI [注:指的是车载消息娱乐设备,为 In-Vehicle Infotainment 的简称] 构建一个基于 Linux 内核的操作系统的项目) 和 Open Virtualization Alliance (开放虚拟化联盟,它促进自由和开源软件虚拟化解决方案的采用)。
|
||||
|
||||
### 开放虚拟化联盟 ###
|
||||
|
||||

|
||||
|
||||
[开放虚拟化联盟(OVA)][3] 的存在目的为:通过提供使用案例和对具有互操作性的通用接口和 API 的发展提供支持,来促进自由、开源软件的虚拟化解决方案,例如 KVM 的采用。KVM 将 Linux 内核转变为一个虚拟机管理程序。
|
||||
|
||||
如今, KVM 已成为和 OpenStack 共同使用的最为常见的虚拟机管理程序。
|
||||
|
||||
### OpenStack 基金会 ###
|
||||
|
||||

|
||||
|
||||
原本作为一个 IaaS(基础设施即服务) 产品由 NASA 和 Rackspace 于 2010 年启动,[OpenStack 基金会][4] 已成为最大的开源项目聚居地之一。它拥有超过 200 家公司成员,其中包括 AT&T, AMD, Avaya, Canonical, Cisco, Dell 和 HP。
|
||||
|
||||
大约以 6 个月为一个发行周期,基金会的 OpenStack 项目开发用于通过一个基于 Web 的仪表盘,命令行工具或一个 RESTful 风格的 API 来控制或调配流经一个数据中心的处理存储池和网络资源。至今为止,基金会支持的协同开发已经孕育出了一系列 OpenStack 组件,其中包括 OpenStack Compute(一个云计算网络控制器,它是一个 IaaS 系统的主要部分),OpenStack Networking(一个用以管理网络和 IP 地址的系统) 和 OpenStack Object Storage(一个可扩展的冗余存储系统)。
|
||||
|
||||
### OpenDaylight ###
|
||||
|
||||

|
||||
|
||||
作为来自 Linux 基金会的另一个协作项目, [OpenDaylight][5] 是一个由诸如 Dell, HP, Oracle 和 Avaya 等行业厂商于 2013 年 4 月建立的联合倡议。它的任务是建立一个由社区主导、开源、有工业支持的针对软件定义网络( SDN: Software-Defined Networking)的包含代码和蓝图的框架。其思路是提供一个可直接部署的全功能 SDN 平台,而不需要其他组件,供应商可提供附件组件和增强组件。
|
||||
|
||||
### Apache 软件基金会 ###
|
||||
|
||||

|
||||
|
||||
[Apache 软件基金会 (ASF)][7] 是将近 150 个顶级项目的聚居地,这些项目涵盖从开源的企业级自动化软件到与 Apache Hadoop 相关的分布式计算的整个生态系统。这些项目分发企业级、可免费获取的软件产品,而 Apache 协议则是为了让无论是商业用户还是个人用户更方便地部署 Apache 的产品。
|
||||
|
||||
ASF 是 1999 年成立的一个会员制,非盈利公司,以精英为其核心 — 要成为它的成员,你必须首先在基金会的一个或多个协作项目中做出积极贡献。
|
||||
|
||||
### 开放计算项目 ###
|
||||
|
||||

|
||||
|
||||
作为 Facebook 重新设计其 Oregon 数据中心的副产物, [开放计算项目][7] 旨在发展针对数据中心的开源硬件解决方案。 OCP 是一个由廉价无浪费的服务器、针对 Open Rack(为数据中心设计的机架标准,来让机架集成到数据中心的基础设施中) 的模块化 I/O 存储和一个相对 "绿色" 的数据中心设计方案等构成。
|
||||
|
||||
OCP 董事会成员包括来自 Facebook,Intel,Goldman Sachs,Rackspace 和 Microsoft 的代表。
|
||||
|
||||
OCP 最近宣布了有两种可选的许可证: 一个类似 Apache 2.0 的允许衍生工作的许可证,和一个更规范的鼓励将更改回馈到原有软件的许可证。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.networkworld.com/article/2866074/opensource-subnet/7-communities-driving-open-source-development.html
|
||||
|
||||
作者:[Thor Olavsrud][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.networkworld.com/author/Thor-Olavsrud/
|
||||
[1]:http://openpowerfoundation.org/
|
||||
[2]:http://www.linuxfoundation.org/
|
||||
[3]:https://openvirtualizationalliance.org/
|
||||
[4]:http://www.openstack.org/foundation/
|
||||
[5]:http://www.opendaylight.org/
|
||||
[6]:http://www.apache.org/
|
||||
[7]:http://www.opencompute.org/
|
||||
@ -0,0 +1,150 @@
|
||||
在 Debian 中安装 OpenQRM 云计算平台
|
||||
================================================================================
|
||||
|
||||
### 简介 ###
|
||||
|
||||
**openQRM**是一个基于 Web 的开源云计算和数据中心管理平台,可灵活地与企业数据中心的现存组件集成。
|
||||
|
||||
它支持下列虚拟技术:
|
||||
|
||||
- KVM
|
||||
- XEN
|
||||
- Citrix XenServer
|
||||
- VMWare ESX
|
||||
- LXC
|
||||
- OpenVZ
|
||||
|
||||
openQRM 中的混合云连接器支持 **Amazon AWS**, **Eucalyptus** 或 **OpenStack** 等一系列的私有或公有云提供商,以此来按需扩展你的基础设施。它也可以自动地进行资源调配、 虚拟化、 存储和配置管理,且保证高可用性。集成的计费系统的自服务云门户可使终端用户按需请求新的服务器和应用堆栈。
|
||||
|
||||
openQRM 有两种不同风格的版本可获取:
|
||||
|
||||
- 企业版
|
||||
- 社区版
|
||||
|
||||
你可以在[这里][1]查看这两个版本间的区别。
|
||||
|
||||
### 特点 ###
|
||||
|
||||
- 私有/混合的云计算平台
|
||||
- 可管理物理或虚拟的服务器系统
|
||||
- 集成了所有主流的开源或商业的存储技术
|
||||
- 跨平台: Linux, Windows, OpenSolaris 和 BSD
|
||||
- 支持 KVM, XEN, Citrix XenServer, VMWare ESX(i), lxc, OpenVZ 和 VirtualBox
|
||||
- 支持使用额外的 Amazon AWS, Eucalyptus, Ubuntu UEC 等云资源来进行混合云设置
|
||||
- 支持 P2V, P2P, V2P, V2V 迁移和高可用性
|
||||
- 集成最好的开源管理工具 – 如 puppet, nagios/Icinga 或 collectd
|
||||
- 有超过 50 个插件来支持扩展功能并与你的基础设施集成
|
||||
- 针对终端用户的自服务门户
|
||||
- 集成了计费系统
|
||||
|
||||
### 安装 ###
|
||||
|
||||
在这里我们将在 Debian 7.5 上安装 openQRM。你的服务器必须至少满足以下要求:
|
||||
|
||||
- 1 GB RAM
|
||||
- 100 GB Hdd(硬盘驱动器)
|
||||
- 可选: Bios 支持虚拟化(Intel CPUs 的 VT 或 AMD CPUs AMD-V)
|
||||
|
||||
首先,安装 `make` 软件包来编译 openQRM 源码包:
|
||||
|
||||
sudo apt-get update
|
||||
sudo apt-get upgrade
|
||||
sudo apt-get install make
|
||||
|
||||
然后,逐次运行下面的命令来安装 openQRM。
|
||||
|
||||
从[这里][2]下载最新的可用版本:
|
||||
|
||||
wget http://sourceforge.net/projects/openqrm/files/openQRM-Community-5.1/openqrm-community-5.1.tgz
|
||||
|
||||
tar -xvzf openqrm-community-5.1.tgz
|
||||
|
||||
cd openqrm-community-5.1/src/
|
||||
|
||||
sudo make
|
||||
|
||||
sudo make install
|
||||
|
||||
sudo make start
|
||||
|
||||
安装期间,会要求你更新文件 `php.ini`
|
||||
|
||||

|
||||
|
||||
输入 mysql root 用户密码。
|
||||
|
||||

|
||||
|
||||
再次输入密码:
|
||||
|
||||

|
||||
|
||||
选择邮件服务器配置类型:
|
||||
|
||||

|
||||
|
||||
假如你不确定该如何选择,可选择 `Local only`。在我们的这个示例中,我选择了 **Local only** 选项。
|
||||
|
||||

|
||||
|
||||
输入你的系统邮件名称,并最后输入 Nagios 管理员密码。
|
||||
|
||||

|
||||
|
||||
根据你的网络连接状态,上面的命令可能将花费很长的时间来下载所有运行 openQRM 所需的软件包,请耐心等待。
|
||||
|
||||
最后你将得到 openQRM 配置 URL 地址以及相关的用户名和密码。
|
||||
|
||||

|
||||
|
||||
### 配置 ###
|
||||
|
||||
在安装完 openQRM 后,打开你的 Web 浏览器并转到 URL: **http://ip-address/openqrm**
|
||||
|
||||
例如,在我的示例中为 http://192.168.1.100/openqrm 。
|
||||
|
||||
默认的用户名和密码是: **openqrm/openqrm** 。
|
||||
|
||||

|
||||
|
||||
选择一个网卡来给 openQRM 管理网络使用。
|
||||
|
||||

|
||||
|
||||
选择一个数据库类型,在我们的示例中,我选择了 mysql。
|
||||
|
||||

|
||||
|
||||
现在,配置数据库连接并初始化 openQRM, 在这里,我使用 **openQRM** 作为数据库名称, **root** 作为用户的身份,并将 debian 作为数据库的密码。 请小心,你应该输入先前在安装 openQRM 时创建的 mysql root 用户密码。
|
||||
|
||||

|
||||
|
||||
祝贺你! openQRM 已经安装并配置好了。
|
||||
|
||||

|
||||
|
||||
### 更新 openQRM ###
|
||||
|
||||
在任何时候可以使用下面的命令来更新 openQRM:
|
||||
|
||||
cd openqrm/src/
|
||||
make update
|
||||
|
||||
到现在为止,我们做的只是在我们的 Debian 服务器中安装和配置 openQRM, 至于 创建、运行虚拟,管理存储,额外的系统集成和运行你自己的私有云等内容,我建议你阅读 [openQRM 管理员指南][3]。
|
||||
|
||||
就是这些了,欢呼吧!周末快乐!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/install-openqrm-cloud-computing-platform-debian/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/sk/
|
||||
[1]:http://www.openqrm-enterprise.com/products/edition-comparison.html
|
||||
[2]:http://sourceforge.net/projects/openqrm/files/?source=navbar
|
||||
[3]:http://www.openqrm-enterprise.com/fileadmin/Documents/Whitepaper/openQRM-Enterprise-Administrator-Guide-5.2.pdf
|
||||
@ -1,20 +1,20 @@
|
||||
如何在 Ubuntu 中管理和使用 LVM(Logical Volume Management,逻辑卷管理)
|
||||
如何在 Ubuntu 中管理和使用 逻辑卷管理 LVM
|
||||
================================================================================
|
||||

|
||||
|
||||
在我们之前的文章中,我们介绍了[什么是 LVM 以及能用 LVM 做什么][1],今天我们会给你介绍一些 LVM 的主要管理工具,使得你在设置和扩展安装时更游刃有余。
|
||||
|
||||
正如之前所述,LVM 是介于你的操作系统和物理硬盘驱动器之间的抽象层。这意味着你的物理硬盘驱动器和分区不再依赖于他们所在的硬盘驱动和分区。而是,你的操作系统所见的硬盘驱动和分区可以是由任意数目的独立硬盘驱动汇集而成或是一个软件磁盘阵列。
|
||||
正如之前所述,LVM 是介于你的操作系统和物理硬盘驱动器之间的抽象层。这意味着你的物理硬盘驱动器和分区不再依赖于他们所在的硬盘驱动和分区。而是你的操作系统所见的硬盘驱动和分区可以是由任意数目的独立硬盘汇集而成的或是一个软件磁盘阵列。
|
||||
|
||||
要管理 LVM,这里有很多可用的 GUI 工具,但要真正理解 LVM 配置发生的事情,最好要知道一些命令行工具。这当你在一个服务器或不提供 GUI 工具的发行版上管理 LVM 时尤为有用。
|
||||
|
||||
LVM 的大部分命令和彼此都非常相似。每个可用的命令都由以下其中之一开头:
|
||||
|
||||
- Physical Volume = pv
|
||||
- Volume Group = vg
|
||||
- Logical Volume = lv
|
||||
- Physical Volume (物理卷) = pv
|
||||
- Volume Group (卷组)= vg
|
||||
- Logical Volume (逻辑卷)= lv
|
||||
|
||||
物理卷命令用于在卷组中添加或删除硬盘驱动。卷组命令用于为你的逻辑卷操作更改显示的物理分区抽象集。逻辑卷命令会以分区形式显示卷组使得你的操作系统能使用指定的空间。
|
||||
物理卷命令用于在卷组中添加或删除硬盘驱动。卷组命令用于为你的逻辑卷操作更改显示的物理分区抽象集。逻辑卷命令会以分区形式显示卷组,使得你的操作系统能使用指定的空间。
|
||||
|
||||
### 可下载的 LVM 备忘单 ###
|
||||
|
||||
@ -26,7 +26,7 @@ LVM 的大部分命令和彼此都非常相似。每个可用的命令都由以
|
||||
|
||||
### 如何查看当前 LVM 信息 ###
|
||||
|
||||
你首先需要做的事情是检查你的 LVM 设置。s 和 display 命令和物理卷(pv)、卷组(vg)以及逻辑卷(lv)一起使用,是一个找出当前设置好的开始点。
|
||||
你首先需要做的事情是检查你的 LVM 设置。s 和 display 命令可以和物理卷(pv)、卷组(vg)以及逻辑卷(lv)一起使用,是一个找出当前设置的好起点。
|
||||
|
||||
display 命令会格式化输出信息,因此比 s 命令更易于理解。对每个命令你会看到名称和 pv/vg 的路径,它还会给出空闲和已使用空间的信息。
|
||||
|
||||
@ -40,17 +40,17 @@ display 命令会格式化输出信息,因此比 s 命令更易于理解。对
|
||||
|
||||
#### 创建物理卷 ####
|
||||
|
||||
我们会从一个完全新的没有任何分区和信息的硬盘驱动开始。首先找出你将要使用的磁盘。(/dev/sda, sdb, 等)
|
||||
我们会从一个全新的没有任何分区和信息的硬盘开始。首先找出你将要使用的磁盘。(/dev/sda, sdb, 等)
|
||||
|
||||
> 注意:记住所有的命令都要以 root 身份运行或者在命令前面添加 'sudo' 。
|
||||
|
||||
fdisk -l
|
||||
|
||||
如果之前你的硬盘驱动从没有格式化或分区,在 fdisk 的输出中你很可能看到类似下面的信息。这完全正常,因为我们会在下面的步骤中创建需要的分区。
|
||||
如果之前你的硬盘从未格式化或分区过,在 fdisk 的输出中你很可能看到类似下面的信息。这完全正常,因为我们会在下面的步骤中创建需要的分区。
|
||||
|
||||

|
||||
|
||||
我们的新磁盘位置是 /dev/sdb,让我们用 fdisk 命令在驱动上创建一个新的分区。
|
||||
我们的新磁盘位置是 /dev/sdb,让我们用 fdisk 命令在磁盘上创建一个新的分区。
|
||||
|
||||
这里有大量能创建新分区的 GUI 工具,包括 [Gparted][2],但由于我们已经打开了终端,我们将使用 fdisk 命令创建需要的分区。
|
||||
|
||||
@ -62,9 +62,9 @@ display 命令会格式化输出信息,因此比 s 命令更易于理解。对
|
||||
|
||||

|
||||
|
||||
以指定的顺序输入命令创建一个使用新硬盘驱动 100% 空间的主分区并为 LVM 做好了准备。如果你需要更改分区的大小或相应多个分区,我建议使用 GParted 或自己了解关于 fdisk 命令的使用。
|
||||
以指定的顺序输入命令创建一个使用新硬盘 100% 空间的主分区并为 LVM 做好了准备。如果你需要更改分区的大小或想要多个分区,我建议使用 GParted 或自己了解一下关于 fdisk 命令的使用。
|
||||
|
||||
**警告:下面的步骤会格式化你的硬盘驱动。确保在进行下面步骤之前你的硬盘驱动中没有任何信息。**
|
||||
**警告:下面的步骤会格式化你的硬盘驱动。确保在进行下面步骤之前你的硬盘驱动中没有任何有用的信息。**
|
||||
|
||||
- n = 创建新分区
|
||||
- p = 创建主分区
|
||||
@ -79,9 +79,9 @@ display 命令会格式化输出信息,因此比 s 命令更易于理解。对
|
||||
- t = 更改分区类型
|
||||
- 8e = 更改为 LVM 分区类型
|
||||
|
||||
核实并将信息写入硬盘驱动器。
|
||||
核实并将信息写入硬盘。
|
||||
|
||||
- p = 查看分区设置使得写入更改到磁盘之前可以回看
|
||||
- p = 查看分区设置使得在写入更改到磁盘之前可以回看
|
||||
- w = 写入更改到磁盘
|
||||
|
||||

|
||||
@ -102,7 +102,7 @@ display 命令会格式化输出信息,因此比 s 命令更易于理解。对
|
||||
|
||||

|
||||
|
||||
Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称,但建议标签以 vg 开头,以便后面你使用它时能意识到这是一个卷组。
|
||||
vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称,但建议标签以 vg 开头,以便后面你使用它时能意识到这是一个卷组。
|
||||
|
||||
#### 创建逻辑卷 ####
|
||||
|
||||
@ -112,7 +112,7 @@ Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称
|
||||
|
||||

|
||||
|
||||
-L 命令指定逻辑卷的大小,在该情况中是 3 GB,-n 命令指定卷的名称。 指定 vgpool 所以 lvcreate 命令知道从什么卷获取空间。
|
||||
-L 命令指定逻辑卷的大小,在该情况中是 3 GB,-n 命令指定卷的名称。 指定 vgpool 以便 lvcreate 命令知道从什么卷获取空间。
|
||||
|
||||
#### 格式化并挂载逻辑卷 ####
|
||||
|
||||
@ -131,7 +131,7 @@ Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称
|
||||
|
||||
#### 重新设置逻辑卷大小 ####
|
||||
|
||||
逻辑卷的一个好处是你能使你的共享物理变大或变小而不需要移动所有东西到一个更大的硬盘驱动。另外,你可以添加新的硬盘驱动并同时扩展你的卷组。或者如果你有一个不使用的硬盘驱动,你可以从卷组中移除它使得逻辑卷变小。
|
||||
逻辑卷的一个好处是你能使你的存储物理地变大或变小,而不需要移动所有东西到一个更大的硬盘。另外,你可以添加新的硬盘并同时扩展你的卷组。或者如果你有一个不使用的硬盘,你可以从卷组中移除它使得逻辑卷变小。
|
||||
|
||||
这里有三个用于使物理卷、卷组和逻辑卷变大或变小的基础工具。
|
||||
|
||||
@ -147,9 +147,9 @@ Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称
|
||||
|
||||
按照上面创建新分区并更改分区类型为 LVM(8e) 的步骤安装一个新硬盘驱动。然后用 pvcreate 命令创建一个 LVM 能识别的物理卷。
|
||||
|
||||
#### 添加新硬盘驱动到卷组 ####
|
||||
#### 添加新硬盘到卷组 ####
|
||||
|
||||
要添加新的硬盘驱动到一个卷组,你只需要知道你的新分区,在我们的例子中是 /dev/sdc1,以及想要添加到的卷组的名称。
|
||||
要添加新的硬盘到一个卷组,你只需要知道你的新分区,在我们的例子中是 /dev/sdc1,以及想要添加到的卷组的名称。
|
||||
|
||||
这会添加新物理卷到已存在的卷组中。
|
||||
|
||||
@ -189,7 +189,7 @@ Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称
|
||||
|
||||
1. 调整文件系统大小 (调整之前确保已经移动文件到硬盘驱动安全的地方)
|
||||
1. 减小逻辑卷 (除了 + 可以扩展大小,你也可以用 - 压缩大小)
|
||||
1. 用 vgreduce 从卷组中移除硬盘驱动
|
||||
1. 用 vgreduce 从卷组中移除硬盘
|
||||
|
||||
#### 备份逻辑卷 ####
|
||||
|
||||
@ -197,7 +197,7 @@ Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称
|
||||
|
||||

|
||||
|
||||
LVM 获取快照的时候,会有一张和逻辑卷完全相同的照片,该照片可以用于在不同的硬盘驱动上进行备份。生成一个备份的时候,任何需要添加到逻辑卷的新信息会如往常一样写入磁盘,但会跟踪更改使得原始快照永远不会损毁。
|
||||
LVM 获取快照的时候,会有一张和逻辑卷完全相同的“照片”,该“照片”可以用于在不同的硬盘上进行备份。生成一个备份的时候,任何需要添加到逻辑卷的新信息会如往常一样写入磁盘,但会跟踪更改使得原始快照永远不会损毁。
|
||||
|
||||
要创建一个快照,我们需要创建拥有足够空闲空间的逻辑卷,用于保存我们备份的时候会写入该逻辑卷的任何新信息。如果驱动并不是经常写入,你可以使用很小的一个存储空间。备份完成的时候我们只需要移除临时逻辑卷,原始逻辑卷会和往常一样。
|
||||
|
||||
@ -209,7 +209,7 @@ LVM 获取快照的时候,会有一张和逻辑卷完全相同的照片,该
|
||||
|
||||

|
||||
|
||||
这里我们创建了一个只有 512MB 的逻辑卷,因为驱动实际上并不会使用。512MB 的空间会保存备份时产生的任何新数据。
|
||||
这里我们创建了一个只有 512MB 的逻辑卷,因为该硬盘实际上并不会使用。512MB 的空间会保存备份时产生的任何新数据。
|
||||
|
||||
#### 挂载新快照 ####
|
||||
|
||||
@ -222,7 +222,7 @@ LVM 获取快照的时候,会有一张和逻辑卷完全相同的照片,该
|
||||
|
||||
#### 复制快照和删除逻辑卷 ####
|
||||
|
||||
你剩下需要做的是从 /mnt/lvstuffbackup/ 中复制所有文件到一个外部的硬盘驱动或者打包所有文件到一个文件。
|
||||
你剩下需要做的是从 /mnt/lvstuffbackup/ 中复制所有文件到一个外部的硬盘或者打包所有文件到一个文件。
|
||||
|
||||
**注意:tar -c 会创建一个归档文件,-f 要指出归档文件的名称和路径。要获取 tar 命令的帮助信息,可以在终端中输入 man tar。**
|
||||
|
||||
@ -230,7 +230,7 @@ LVM 获取快照的时候,会有一张和逻辑卷完全相同的照片,该
|
||||
|
||||

|
||||
|
||||
记住备份发生的时候写到 lvstuff 的所有文件都会在我们之前创建的临时逻辑卷中被跟踪。确保备份的时候你有足够的空闲空间。
|
||||
记住备份时候写到 lvstuff 的所有文件都会在我们之前创建的临时逻辑卷中被跟踪。确保备份的时候你有足够的空闲空间。
|
||||
|
||||
备份完成后,卸载卷并移除临时快照。
|
||||
|
||||
@ -259,10 +259,10 @@ LVM 获取快照的时候,会有一张和逻辑卷完全相同的照片,该
|
||||
via: http://www.howtogeek.com/howto/40702/how-to-manage-and-use-lvm-logical-volume-management-in-ubuntu/
|
||||
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.howtogeek.com/howto/36568/what-is-logical-volume-management-and-how-do-you-enable-it-in-ubuntu/
|
||||
[1]:https://linux.cn/article-5953-1.html
|
||||
[2]:http://www.howtogeek.com/howto/17001/how-to-format-a-usb-drive-in-ubuntu-using-gparted/
|
||||
[3]:http://www.howtogeek.com/howto/33552/htg-explains-which-linux-file-system-should-you-choose/
|
||||
@ -0,0 +1,131 @@
|
||||
如何通过反向 SSH 隧道访问 NAT 后面的 Linux 服务器
|
||||
================================================================================
|
||||
你在家里运行着一台 Linux 服务器,它放在一个 NAT 路由器或者限制性防火墙后面。现在你想在外出时用 SSH 登录到这台服务器。你如何才能做到呢?SSH 端口转发当然是一种选择。但是,如果你需要处理多级嵌套的 NAT 环境,端口转发可能会变得非常棘手。另外,在多种 ISP 特定条件下可能会受到干扰,例如阻塞转发端口的限制性 ISP 防火墙、或者在用户间共享 IPv4 地址的运营商级 NAT。
|
||||
|
||||
### 什么是反向 SSH 隧道? ###
|
||||
|
||||
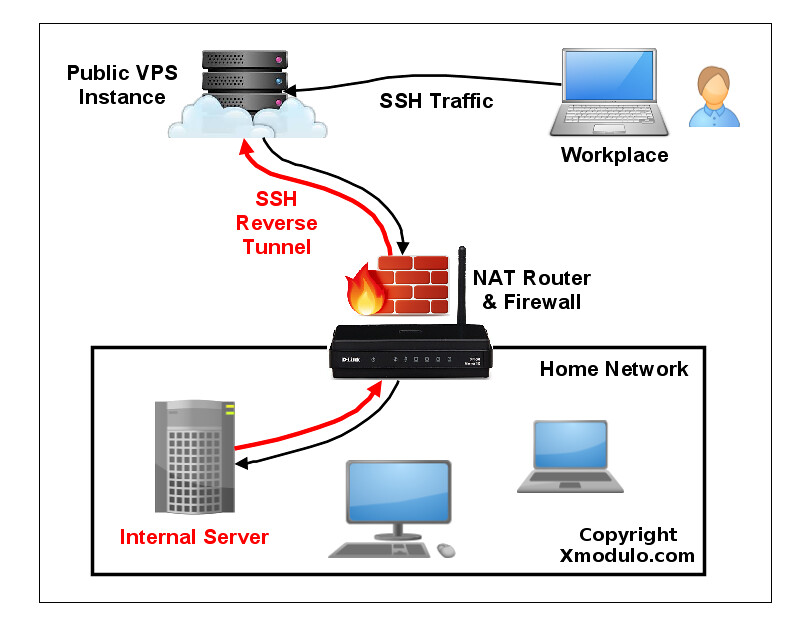
SSH 端口转发的一种替代方案是 **反向 SSH 隧道**。反向 SSH 隧道的概念非常简单。使用这种方案,在你的受限的家庭网络之外你需要另一台主机(所谓的“中继主机”),你能从当前所在地通过 SSH 登录到它。你可以用有公网 IP 地址的 [VPS 实例][1] 配置一个中继主机。然后要做的就是从你的家庭网络服务器中建立一个到公网中继主机的永久 SSH 隧道。有了这个隧道,你就可以从中继主机中连接“回”家庭服务器(这就是为什么称之为 “反向” 隧道)。不管你在哪里、你的家庭网络中的 NAT 或 防火墙限制多么严格,只要你可以访问中继主机,你就可以连接到家庭服务器。
|
||||
|
||||
|
||||
|
||||
### 在 Linux 上设置反向 SSH 隧道 ###
|
||||
|
||||
让我们来看看怎样创建和使用反向 SSH 隧道。我们做如下假设:我们会设置一个从家庭服务器(homeserver)到中继服务器(relayserver)的反向 SSH 隧道,然后我们可以通过中继服务器从客户端计算机(clientcomputer) SSH 登录到家庭服务器。本例中的**中继服务器** 的公网 IP 地址是 1.1.1.1。
|
||||
|
||||
在家庭服务器上,按照以下方式打开一个到中继服务器的 SSH 连接。
|
||||
|
||||
homeserver~$ ssh -fN -R 10022:localhost:22 relayserver_user@1.1.1.1
|
||||
|
||||
这里端口 10022 是任何你可以使用的端口数字。只需要确保中继服务器上不会有其它程序使用这个端口。
|
||||
|
||||
“-R 10022:localhost:22” 选项定义了一个反向隧道。它转发中继服务器 10022 端口的流量到家庭服务器的 22 号端口。
|
||||
|
||||
用 “-fN” 选项,当你成功通过 SSH 服务器验证时 SSH 会进入后台运行。当你不想在远程 SSH 服务器执行任何命令,就像我们的例子中只想转发端口的时候非常有用。
|
||||
|
||||
运行上面的命令之后,你就会回到家庭主机的命令行提示框中。
|
||||
|
||||
登录到中继服务器,确认其 127.0.0.1:10022 绑定到了 sshd。如果是的话就表示已经正确设置了反向隧道。
|
||||
|
||||
relayserver~$ sudo netstat -nap | grep 10022
|
||||
|
||||
----------
|
||||
|
||||
tcp 0 0 127.0.0.1:10022 0.0.0.0:* LISTEN 8493/sshd
|
||||
|
||||
现在就可以从任何其它计算机(客户端计算机)登录到中继服务器,然后按照下面的方法访问家庭服务器。
|
||||
|
||||
relayserver~$ ssh -p 10022 homeserver_user@localhost
|
||||
|
||||
需要注意的一点是你在上面为localhost输入的 SSH 登录/密码应该是家庭服务器的,而不是中继服务器的,因为你是通过隧道的本地端点登录到家庭服务器,因此不要错误输入中继服务器的登录/密码。成功登录后,你就在家庭服务器上了。
|
||||
|
||||
### 通过反向 SSH 隧道直接连接到网络地址变换后的服务器 ###
|
||||
|
||||
上面的方法允许你访问 NAT 后面的 **家庭服务器**,但你需要登录两次:首先登录到 **中继服务器**,然后再登录到**家庭服务器**。这是因为中继服务器上 SSH 隧道的端点绑定到了回环地址(127.0.0.1)。
|
||||
|
||||
事实上,有一种方法可以只需要登录到中继服务器就能直接访问NAT之后的家庭服务器。要做到这点,你需要让中继服务器上的 sshd 不仅转发回环地址上的端口,还要转发外部主机的端口。这通过指定中继服务器上运行的 sshd 的 **GatewayPorts** 实现。
|
||||
|
||||
打开**中继服务器**的 /etc/ssh/sshd_conf 并添加下面的行。
|
||||
|
||||
relayserver~$ vi /etc/ssh/sshd_conf
|
||||
|
||||
----------
|
||||
|
||||
GatewayPorts clientspecified
|
||||
|
||||
重启 sshd。
|
||||
|
||||
基于 Debian 的系统:
|
||||
|
||||
relayserver~$ sudo /etc/init.d/ssh restart
|
||||
|
||||
基于红帽的系统:
|
||||
|
||||
relayserver~$ sudo systemctl restart sshd
|
||||
|
||||
现在在家庭服务器中按照下面方式初始化一个反向 SSH 隧道。
|
||||
|
||||
homeserver~$ ssh -fN -R 1.1.1.1:10022:localhost:22 relayserver_user@1.1.1.1
|
||||
|
||||
登录到中继服务器然后用 netstat 命令确认成功建立的一个反向 SSH 隧道。
|
||||
|
||||
relayserver~$ sudo netstat -nap | grep 10022
|
||||
|
||||
----------
|
||||
|
||||
tcp 0 0 1.1.1.1:10022 0.0.0.0:* LISTEN 1538/sshd: dev
|
||||
|
||||
不像之前的情况,现在隧道的端点是 1.1.1.1:10022(中继服务器的公网 IP 地址),而不是 127.0.0.1:10022。这就意味着从外部主机可以访问隧道的另一端。
|
||||
|
||||
现在在任何其它计算机(客户端计算机),输入以下命令访问网络地址变换之后的家庭服务器。
|
||||
|
||||
clientcomputer~$ ssh -p 10022 homeserver_user@1.1.1.1
|
||||
|
||||
在上面的命令中,1.1.1.1 是中继服务器的公共 IP 地址,homeserver_user必须是家庭服务器上的用户账户。这是因为你真正登录到的主机是家庭服务器,而不是中继服务器。后者只是中继你的 SSH 流量到家庭服务器。
|
||||
|
||||
### 在 Linux 上设置一个永久反向 SSH 隧道 ###
|
||||
|
||||
现在你已经明白了怎样创建一个反向 SSH 隧道,然后把隧道设置为 “永久”,这样隧道启动后就会一直运行(不管临时的网络拥塞、SSH 超时、中继主机重启,等等)。毕竟,如果隧道不是一直有效,你就不能可靠的登录到你的家庭服务器。
|
||||
|
||||
对于永久隧道,我打算使用一个叫 autossh 的工具。正如名字暗示的,这个程序可以让你的 SSH 会话无论因为什么原因中断都会自动重连。因此对于保持一个反向 SSH 隧道非常有用。
|
||||
|
||||
第一步,我们要设置从家庭服务器到中继服务器的[无密码 SSH 登录][2]。这样的话,autossh 可以不需要用户干预就能重启一个损坏的反向 SSH 隧道。
|
||||
|
||||
下一步,在建立隧道的家庭服务器上[安装 autossh][3]。
|
||||
|
||||
在家庭服务器上,用下面的参数运行 autossh 来创建一个连接到中继服务器的永久 SSH 隧道。
|
||||
|
||||
homeserver~$ autossh -M 10900 -fN -o "PubkeyAuthentication=yes" -o "StrictHostKeyChecking=false" -o "PasswordAuthentication=no" -o "ServerAliveInterval 60" -o "ServerAliveCountMax 3" -R 1.1.1.1:10022:localhost:22 relayserver_user@1.1.1.1
|
||||
|
||||
“-M 10900” 选项指定中继服务器上的监视端口,用于交换监视 SSH 会话的测试数据。中继服务器上的其它程序不能使用这个端口。
|
||||
|
||||
“-fN” 选项传递给 ssh 命令,让 SSH 隧道在后台运行。
|
||||
|
||||
“-o XXXX” 选项让 ssh:
|
||||
|
||||
- 使用密钥验证,而不是密码验证。
|
||||
- 自动接受(未知)SSH 主机密钥。
|
||||
- 每 60 秒交换 keep-alive 消息。
|
||||
- 没有收到任何响应时最多发送 3 条 keep-alive 消息。
|
||||
|
||||
其余 SSH 隧道相关的选项和之前介绍的一样。
|
||||
|
||||
如果你想系统启动时自动运行 SSH 隧道,你可以将上面的 autossh 命令添加到 /etc/rc.local。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇博文中,我介绍了你如何能从外部通过反向 SSH 隧道访问限制性防火墙或 NAT 网关之后的 Linux 服务器。这里我介绍了家庭网络中的一个使用事例,但在企业网络中使用时你尤其要小心。这样的一个隧道可能被视为违反公司政策,因为它绕过了企业的防火墙并把企业网络暴露给外部攻击。这很可能被误用或者滥用。因此在使用之前一定要记住它的作用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/access-linux-server-behind-nat-reverse-ssh-tunnel.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/go/digitalocean
|
||||
[2]:https://linux.cn/article-5444-1.html
|
||||
[3]:https://linux.cn/article-5459-1.html
|
||||
199
published/20150518 How to set up a Replica Set on MongoDB.md
Normal file
199
published/20150518 How to set up a Replica Set on MongoDB.md
Normal file
@ -0,0 +1,199 @@
|
||||
如何配置 MongoDB 副本集
|
||||
================================================================================
|
||||
|
||||
MongoDB 已经成为市面上最知名的 NoSQL 数据库。MongoDB 是面向文档的,它的无模式设计使得它在各种各样的WEB 应用当中广受欢迎。最让我喜欢的特性之一是它的副本集(Replica Set),副本集将同一数据的多份拷贝放在一组 mongod 节点上,从而实现数据的冗余以及高可用性。
|
||||
|
||||
这篇教程将向你介绍如何配置一个 MongoDB 副本集。
|
||||
|
||||
副本集的最常见配置需要一个主节点以及多个副节点。这之后启动的复制行为会从这个主节点到其他副节点。副本集不止可以针对意外的硬件故障和停机事件对数据库提供保护,同时也因为提供了更多的节点从而提高了数据库客户端数据读取的吞吐量。
|
||||
|
||||
### 配置环境 ###
|
||||
|
||||
这个教程里,我们会配置一个包括一个主节点以及两个副节点的副本集。
|
||||
|
||||

|
||||
|
||||
为了达到这个目的,我们使用了3个运行在 VirtualBox 上的虚拟机。我会在这些虚拟机上安装 Ubuntu 14.04,并且安装 MongoDB 官方包。
|
||||
|
||||
我会在一个虚拟机实例上配置好所需的环境,然后将它克隆到其他的虚拟机实例上。因此,选择一个名为 master 的虚拟机,执行以下安装过程。
|
||||
|
||||
首先,我们需要给 apt 增加一个 MongoDB 密钥:
|
||||
|
||||
$ sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 7F0CEB10
|
||||
|
||||
然后,将官方的 MongoDB 仓库添加到 source.list 中:
|
||||
|
||||
$ sudo su
|
||||
# echo "deb http://repo.mongodb.org/apt/ubuntu "$(lsb_release -sc)"/mongodb-org/3.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-3.0.list
|
||||
|
||||
接下来更新 apt 仓库并且安装 MongoDB。
|
||||
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install -y mongodb-org
|
||||
|
||||
现在对 /etc/mongodb.conf 做一些更改
|
||||
|
||||
auth = true
|
||||
dbpath=/var/lib/mongodb
|
||||
logpath=/var/log/mongodb/mongod.log
|
||||
logappend=true
|
||||
keyFile=/var/lib/mongodb/keyFile
|
||||
replSet=myReplica
|
||||
|
||||
第一行的作用是表明我们的数据库需要验证才可以使用。keyfile 配置用于 MongoDB 节点间复制行为的密钥文件。replSet 为副本集设置一个名称。
|
||||
|
||||
接下来我们创建一个用于所有实例的密钥文件。
|
||||
|
||||
$ echo -n "MyRandomStringForReplicaSet" | md5sum > keyFile
|
||||
|
||||
这将会创建一个含有 MD5 字符串的密钥文件,但是由于其中包含了一些噪音,我们需要对他们清理后才能正式在 MongoDB 中使用。
|
||||
|
||||
$ echo -n "MyReplicaSetKey" | md5sum|grep -o "[0-9a-z]\+" > keyFile
|
||||
|
||||
grep 命令的作用的是把将空格等我们不想要的内容过滤掉之后的 MD5 字符串打印出来。
|
||||
|
||||
现在我们对密钥文件进行一些操作,让它真正可用。
|
||||
|
||||
$ sudo cp keyFile /var/lib/mongodb
|
||||
$ sudo chown mongodb:nogroup keyFile
|
||||
$ sudo chmod 400 keyFile
|
||||
|
||||
接下来,关闭此虚拟机。将其 Ubuntu 系统克隆到其他虚拟机上。
|
||||
|
||||

|
||||
|
||||
这是克隆后的副节点1和副节点2。确认你已经将它们的MAC地址重新初始化,并且克隆整个硬盘。
|
||||
|
||||

|
||||
|
||||
请注意,三个虚拟机示例需要在同一个网络中以便相互通讯。因此,我们需要它们弄到“互联网"上去。
|
||||
|
||||
这里推荐给每个虚拟机设置一个静态 IP 地址,而不是使用 DHCP。这样它们就不至于在 DHCP 分配IP地址给他们的时候失去连接。
|
||||
|
||||
像下面这样编辑每个虚拟机的 /etc/networks/interfaces 文件。
|
||||
|
||||
在主节点上:
|
||||
|
||||
auto eth1
|
||||
iface eth1 inet static
|
||||
address 192.168.50.2
|
||||
netmask 255.255.255.0
|
||||
|
||||
在副节点1上:
|
||||
|
||||
auto eth1
|
||||
iface eth1 inet static
|
||||
address 192.168.50.3
|
||||
netmask 255.255.255.0
|
||||
|
||||
在副节点2上:
|
||||
|
||||
auto eth1
|
||||
iface eth1 inet static
|
||||
address 192.168.50.4
|
||||
netmask 255.255.255.0
|
||||
|
||||
由于我们没有 DNS 服务,所以需要设置设置一下 /etc/hosts 这个文件,手工将主机名称放到此文件中。
|
||||
|
||||
在主节点上:
|
||||
|
||||
127.0.0.1 localhost primary
|
||||
192.168.50.2 primary
|
||||
192.168.50.3 secondary1
|
||||
192.168.50.4 secondary2
|
||||
|
||||
在副节点1上:
|
||||
|
||||
127.0.0.1 localhost secondary1
|
||||
192.168.50.2 primary
|
||||
192.168.50.3 secondary1
|
||||
192.168.50.4 secondary2
|
||||
|
||||
在副节点2上:
|
||||
|
||||
127.0.0.1 localhost secondary2
|
||||
192.168.50.2 primary
|
||||
192.168.50.3 secondary1
|
||||
192.168.50.4 secondary2
|
||||
|
||||
使用 ping 命令检查各个节点之间的连接。
|
||||
|
||||
$ ping primary
|
||||
$ ping secondary1
|
||||
$ ping secondary2
|
||||
|
||||
### 配置副本集 ###
|
||||
|
||||
验证各个节点可以正常连通后,我们就可以新建一个管理员用户,用于之后的副本集操作。
|
||||
|
||||
在主节点上,打开 /etc/mongodb.conf 文件,将 auth 和 replSet 两项注释掉。
|
||||
|
||||
dbpath=/var/lib/mongodb
|
||||
logpath=/var/log/mongodb/mongod.log
|
||||
logappend=true
|
||||
#auth = true
|
||||
keyFile=/var/lib/mongodb/keyFile
|
||||
#replSet=myReplica
|
||||
|
||||
在一个新安装的 MongoDB 上配置任何用户或副本集之前,你需要注释掉 auth 行。默认情况下,MongoDB 并没有创建任何用户。而如果在你创建用户前启用了 auth,你就不能够做任何事情。你可以在创建一个用户后再次启用 auth。
|
||||
|
||||
修改 /etc/mongodb.conf 之后,重启 mongod 进程。
|
||||
|
||||
$ sudo service mongod restart
|
||||
|
||||
现在连接到 MongoDB master:
|
||||
|
||||
$ mongo <master-ip-address>:27017
|
||||
|
||||
连接 MongoDB 后,新建管理员用户。
|
||||
|
||||
> use admin
|
||||
> db.createUser({
|
||||
user:"admin",
|
||||
pwd:"
|
||||
})
|
||||
|
||||
重启 MongoDB:
|
||||
|
||||
$ sudo service mongod restart
|
||||
|
||||
再次连接到 MongoDB,用以下命令将 副节点1 和副节点2节点添加到我们的副本集中。
|
||||
|
||||
> use admin
|
||||
> db.auth("admin","myreallyhardpassword")
|
||||
> rs.initiate()
|
||||
> rs.add ("secondary1:27017")
|
||||
> rs.add("secondary2:27017")
|
||||
|
||||
|
||||
现在副本集到手了,可以开始我们的项目了。参照 [官方驱动文档][1] 来了解如何连接到副本集。如果你想要用 Shell 来请求数据,那么你需要连接到主节点上来插入或者请求数据,副节点不行。如果你执意要尝试用副本集操作,那么以下错误信息就蹦出来招呼你了。
|
||||
|
||||
myReplica:SECONDARY>
|
||||
myReplica:SECONDARY> show databases
|
||||
2015-05-10T03:09:24.131+0000 E QUERY Error: listDatabases failed:{ "note" : "from execCommand", "ok" : 0, "errmsg" : "not master" }
|
||||
at Error ()
|
||||
at Mongo.getDBs (src/mongo/shell/mongo.js:47:15)
|
||||
at shellHelper.show (src/mongo/shell/utils.js:630:33)
|
||||
at shellHelper (src/mongo/shell/utils.js:524:36)
|
||||
at (shellhelp2):1:1 at src/mongo/shell/mongo.js:47
|
||||
|
||||
如果你要从 shell 连接到整个副本集,你可以安装如下命令。在副本集中的失败切换是自动的。
|
||||
|
||||
$ mongo primary,secondary1,secondary2:27017/?replicaSet=myReplica
|
||||
|
||||
如果你使用其它驱动语言(例如,JavaScript、Ruby 等等),格式也许不同。
|
||||
|
||||
希望这篇教程能对你有所帮助。你可以使用Vagrant来自动完成你的本地环境配置,并且加速你的代码。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/setup-replica-set-mongodb.html
|
||||
|
||||
作者:[Christopher Valerio][a]
|
||||
译者:[mr-ping](https://github.com/mr-ping)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/valerio
|
||||
[1]:http://docs.mongodb.org/ecosystem/drivers/
|
||||
183
published/20150522 Analyzing Linux Logs.md
Normal file
183
published/20150522 Analyzing Linux Logs.md
Normal file
@ -0,0 +1,183 @@
|
||||
如何分析 Linux 日志
|
||||
==============================================================================
|
||||

|
||||
|
||||
日志中有大量的信息需要你处理,尽管有时候想要提取并非想象中的容易。在这篇文章中我们会介绍一些你现在就能做的基本日志分析例子(只需要搜索即可)。我们还将涉及一些更高级的分析,但这些需要你前期努力做出适当的设置,后期就能节省很多时间。对数据进行高级分析的例子包括生成汇总计数、对有效值进行过滤,等等。
|
||||
|
||||
我们首先会向你展示如何在命令行中使用多个不同的工具,然后展示了一个日志管理工具如何能自动完成大部分繁重工作从而使得日志分析变得简单。
|
||||
|
||||
### 用 Grep 搜索 ###
|
||||
|
||||
搜索文本是查找信息最基本的方式。搜索文本最常用的工具是 [grep][1]。这个命令行工具在大部分 Linux 发行版中都有,它允许你用正则表达式搜索日志。正则表达式是一种用特殊的语言写的、能识别匹配文本的模式。最简单的模式就是用引号把你想要查找的字符串括起来。
|
||||
|
||||
#### 正则表达式 ####
|
||||
|
||||
这是一个在 Ubuntu 系统的认证日志中查找 “user hoover” 的例子:
|
||||
|
||||
$ grep "user hoover" /var/log/auth.log
|
||||
Accepted password for hoover from 10.0.2.2 port 4792 ssh2
|
||||
pam_unix(sshd:session): session opened for user hoover by (uid=0)
|
||||
pam_unix(sshd:session): session closed for user hoover
|
||||
|
||||
构建精确的正则表达式可能很难。例如,如果我们想要搜索一个类似端口 “4792” 的数字,它可能也会匹配时间戳、URL 以及其它不需要的数据。Ubuntu 中下面的例子,它匹配了一个我们不想要的 Apache 日志。
|
||||
|
||||
$ grep "4792" /var/log/auth.log
|
||||
Accepted password for hoover from 10.0.2.2 port 4792 ssh2
|
||||
74.91.21.46 - - [31/Mar/2015:19:44:32 +0000] "GET /scripts/samples/search?q=4972 HTTP/1.0" 404 545 "-" "-”
|
||||
|
||||
#### 环绕搜索 ####
|
||||
|
||||
另一个有用的小技巧是你可以用 grep 做环绕搜索。这会向你展示一个匹配前面或后面几行是什么。它能帮助你调试导致错误或问题的东西。`B` 选项展示前面几行,`A` 选项展示后面几行。举个例子,我们知道当一个人以管理员员身份登录失败时,同时他们的 IP 也没有反向解析,也就意味着他们可能没有有效的域名。这非常可疑!
|
||||
|
||||
$ grep -B 3 -A 2 'Invalid user' /var/log/auth.log
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12545]: reverse mapping checking getaddrinfo for 216-19-2-8.commspeed.net [216.19.2.8] failed - POSSIBLE BREAK-IN ATTEMPT!
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12545]: Received disconnect from 216.19.2.8: 11: Bye Bye [preauth]
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: Invalid user admin from 216.19.2.8
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: input_userauth_request: invalid user admin [preauth]
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: Received disconnect from 216.19.2.8: 11: Bye Bye [preauth]
|
||||
|
||||
#### Tail ####
|
||||
|
||||
你也可以把 grep 和 [tail][2] 结合使用来获取一个文件的最后几行,或者跟踪日志并实时打印。这在你做交互式更改的时候非常有用,例如启动服务器或者测试代码更改。
|
||||
|
||||
$ tail -f /var/log/auth.log | grep 'Invalid user'
|
||||
Apr 30 19:49:48 ip-172-31-11-241 sshd[6512]: Invalid user ubnt from 219.140.64.136
|
||||
Apr 30 19:49:49 ip-172-31-11-241 sshd[6514]: Invalid user admin from 219.140.64.136
|
||||
|
||||
关于 grep 和正则表达式的详细介绍并不在本指南的范围,但 [Ryan’s Tutorials][3] 有更深入的介绍。
|
||||
|
||||
日志管理系统有更高的性能和更强大的搜索能力。它们通常会索引数据并进行并行查询,因此你可以很快的在几秒内就能搜索 GB 或 TB 的日志。相比之下,grep 就需要几分钟,在极端情况下可能甚至几小时。日志管理系统也使用类似 [Lucene][4] 的查询语言,它提供更简单的语法来检索数字、域以及其它。
|
||||
|
||||
### 用 Cut、 AWK、 和 Grok 解析 ###
|
||||
|
||||
#### 命令行工具 ####
|
||||
|
||||
Linux 提供了多个命令行工具用于文本解析和分析。当你想要快速解析少量数据时非常有用,但处理大量数据时可能需要很长时间。
|
||||
|
||||
#### Cut ####
|
||||
|
||||
[cut][5] 命令允许你从有分隔符的日志解析字段。分隔符是指能分开字段或键值对的等号或逗号等。
|
||||
|
||||
假设我们想从下面的日志中解析出用户:
|
||||
|
||||
pam_unix(su:auth): authentication failure; logname=hoover uid=1000 euid=0 tty=/dev/pts/0 ruser=hoover rhost= user=root
|
||||
|
||||
我们可以像下面这样用 cut 命令获取用等号分割后的第八个字段的文本。这是一个 Ubuntu 系统上的例子:
|
||||
|
||||
$ grep "authentication failure" /var/log/auth.log | cut -d '=' -f 8
|
||||
root
|
||||
hoover
|
||||
root
|
||||
nagios
|
||||
nagios
|
||||
|
||||
#### AWK ####
|
||||
|
||||
另外,你也可以使用 [awk][6],它能提供更强大的解析字段功能。它提供了一个脚本语言,你可以过滤出几乎任何不相干的东西。
|
||||
|
||||
例如,假设在 Ubuntu 系统中我们有下面的一行日志,我们想要提取登录失败的用户名称:
|
||||
|
||||
Mar 24 08:28:18 ip-172-31-11-241 sshd[32701]: input_userauth_request: invalid user guest [preauth]
|
||||
|
||||
你可以像下面这样使用 awk 命令。首先,用一个正则表达式 /sshd.*invalid user/ 来匹配 sshd invalid user 行。然后用 { print $9 } 根据默认的分隔符空格打印第九个字段。这样就输出了用户名。
|
||||
|
||||
$ awk '/sshd.*invalid user/ { print $9 }' /var/log/auth.log
|
||||
guest
|
||||
admin
|
||||
info
|
||||
test
|
||||
ubnt
|
||||
|
||||
你可以在 [Awk 用户指南][7] 中阅读更多关于如何使用正则表达式和输出字段的信息。
|
||||
|
||||
#### 日志管理系统 ####
|
||||
|
||||
日志管理系统使得解析变得更加简单,使用户能快速的分析很多的日志文件。他们能自动解析标准的日志格式,比如常见的 Linux 日志和 Web 服务器日志。这能节省很多时间,因为当处理系统问题的时候你不需要考虑自己写解析逻辑。
|
||||
|
||||
下面是一个 sshd 日志消息的例子,解析出了每个 remoteHost 和 user。这是 Loggly 中的一张截图,它是一个基于云的日志管理服务。
|
||||
|
||||

|
||||
|
||||
你也可以对非标准格式自定义解析。一个常用的工具是 [Grok][8],它用一个常见正则表达式库,可以解析原始文本为结构化 JSON。下面是一个 Grok 在 Logstash 中解析内核日志文件的事例配置:
|
||||
|
||||
filter{
|
||||
grok {
|
||||
match => {"message" => "%{CISCOTIMESTAMP:timestamp} %{HOST:host} %{WORD:program}%{NOTSPACE} %{NOTSPACE}%{NUMBER:duration}%{NOTSPACE} %{GREEDYDATA:kernel_logs}"
|
||||
}
|
||||
}
|
||||
|
||||
下图是 Grok 解析后输出的结果:
|
||||
|
||||

|
||||
|
||||
### 用 Rsyslog 和 AWK 过滤 ###
|
||||
|
||||
过滤使得你能检索一个特定的字段值而不是进行全文检索。这使你的日志分析更加准确,因为它会忽略来自其它部分日志信息不需要的匹配。为了对一个字段值进行搜索,你首先需要解析日志或者至少有对事件结构进行检索的方式。
|
||||
|
||||
#### 如何对应用进行过滤 ####
|
||||
|
||||
通常,你可能只想看一个应用的日志。如果你的应用把记录都保存到一个文件中就会很容易。如果你需要在一个聚集或集中式日志中过滤一个应用就会比较复杂。下面有几种方法来实现:
|
||||
|
||||
1. 用 rsyslog 守护进程解析和过滤日志。下面的例子将 sshd 应用的日志写入一个名为 sshd-message 的文件,然后丢弃事件以便它不会在其它地方重复出现。你可以将它添加到你的 rsyslog.conf 文件中测试这个例子。
|
||||
|
||||
:programname, isequal, “sshd” /var/log/sshd-messages
|
||||
&~
|
||||
|
||||
2. 用类似 awk 的命令行工具提取特定字段的值,例如 sshd 用户名。下面是 Ubuntu 系统中的一个例子。
|
||||
|
||||
$ awk '/sshd.*invalid user/ { print $9 }' /var/log/auth.log
|
||||
guest
|
||||
admin
|
||||
info
|
||||
test
|
||||
ubnt
|
||||
|
||||
3. 用日志管理系统自动解析日志,然后在需要的应用名称上点击过滤。下面是在 Loggly 日志管理服务中提取 syslog 域的截图。我们对应用名称 “sshd” 进行过滤,如维恩图图标所示。
|
||||
|
||||

|
||||
|
||||
#### 如何过滤错误 ####
|
||||
|
||||
一个人最希望看到日志中的错误。不幸的是,默认的 syslog 配置不直接输出错误的严重性,也就使得难以过滤它们。
|
||||
|
||||
这里有两个解决该问题的方法。首先,你可以修改你的 rsyslog 配置,在日志文件中输出错误的严重性,使得便于查看和检索。在你的 rsyslog 配置中你可以用 pri-text 添加一个 [模板][9],像下面这样:
|
||||
|
||||
"<%pri-text%> : %timegenerated%,%HOSTNAME%,%syslogtag%,%msg%n"
|
||||
|
||||
这个例子会按照下面的格式输出。你可以看到该信息中指示错误的 err。
|
||||
|
||||
<authpriv.err> : Mar 11 18:18:00,hoover-VirtualBox,su[5026]:, pam_authenticate: Authentication failure
|
||||
|
||||
你可以用 awk 或者 grep 检索错误信息。在 Ubuntu 中,对这个例子,我们可以用一些语法特征,例如 . 和 >,它们只会匹配这个域。
|
||||
|
||||
$ grep '.err>' /var/log/auth.log
|
||||
<authpriv.err> : Mar 11 18:18:00,hoover-VirtualBox,su[5026]:, pam_authenticate: Authentication failure
|
||||
|
||||
你的第二个选择是使用日志管理系统。好的日志管理系统能自动解析 syslog 消息并抽取错误域。它们也允许你用简单的点击过滤日志消息中的特定错误。
|
||||
|
||||
下面是 Loggly 中一个截图,显示了高亮错误严重性的 syslog 域,表示我们正在过滤错误:
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.loggly.com/ultimate-guide/logging/analyzing-linux-logs/
|
||||
|
||||
作者:[Jason Skowronski][a],[Amy Echeverri][b],[ Sadequl Hussain][c]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linkedin.com/in/jasonskowronski
|
||||
[b]:https://www.linkedin.com/in/amyecheverri
|
||||
[c]:https://www.linkedin.com/pub/sadequl-hussain/14/711/1a7
|
||||
[1]:http://linux.die.net/man/1/grep
|
||||
[2]:http://linux.die.net/man/1/tail
|
||||
[3]:http://ryanstutorials.net/linuxtutorial/grep.php
|
||||
[4]:https://lucene.apache.org/core/2_9_4/queryparsersyntax.html
|
||||
[5]:http://linux.die.net/man/1/cut
|
||||
[6]:http://linux.die.net/man/1/awk
|
||||
[7]:http://www.delorie.com/gnu/docs/gawk/gawk_26.html#IDX155
|
||||
[8]:http://logstash.net/docs/1.4.2/filters/grok
|
||||
[9]:http://www.rsyslog.com/doc/v8-stable/configuration/templates.html
|
||||
@ -1,18 +1,18 @@
|
||||
Ubuntu 15.04上配置OpenVPN服务器-客户端
|
||||
在 Ubuntu 15.04 上配置 OpenVPN 服务器和客户端
|
||||
================================================================================
|
||||
虚拟专用网(VPN)是几种用于建立与其它网络连接的网络技术中常见的一个名称。它被称为虚拟网,因为各个节点的连接不是通过物理线路实现的。而由于没有网络所有者的正确授权是不能通过公共线路访问到网络,所以它是专用的。
|
||||
虚拟专用网(VPN)常指几种通过其它网络建立连接技术。它之所以被称为“虚拟”,是因为各个节点间的连接不是通过物理线路实现的,而“专用”是指如果没有网络所有者的正确授权是不能被公开访问到。
|
||||
|
||||

|
||||
|
||||
[OpenVPN][1]软件通过TUN/TAP驱动的帮助,使用TCP和UDP协议来传输数据。UDP协议和TUN驱动允许NAT后的用户建立到OpenVPN服务器的连接。此外,OpenVPN允许指定自定义端口。它提额外提供了灵活的配置,可以帮助你避免防火墙限制。
|
||||
[OpenVPN][1]软件借助TUN/TAP驱动使用TCP和UDP协议来传输数据。UDP协议和TUN驱动允许NAT后的用户建立到OpenVPN服务器的连接。此外,OpenVPN允许指定自定义端口。它提供了更多的灵活配置,可以帮助你避免防火墙限制。
|
||||
|
||||
OpenVPN中,由OpenSSL库和传输层安全协议(TLS)提供了安全和加密。TLS是SSL协议的一个改进版本。
|
||||
|
||||
OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示了如何配置OpenVPN的服务器端,以及如何预备使用带有公共密钥非对称加密和TLS协议基础结构(PKI)。
|
||||
OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示了如何配置OpenVPN的服务器端,以及如何配置使用带有公共密钥基础结构(PKI)的非对称加密和TLS协议。
|
||||
|
||||
### 服务器端配置 ###
|
||||
|
||||
首先,我们必须安装OpenVPN。在Ubuntu 15.04和其它带有‘apt’报管理器的Unix系统中,可以通过如下命令安装:
|
||||
首先,我们必须安装OpenVPN软件。在Ubuntu 15.04和其它带有‘apt’包管理器的Unix系统中,可以通过如下命令安装:
|
||||
|
||||
sudo apt-get install openvpn
|
||||
|
||||
@ -20,7 +20,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
sudo apt-get unstall easy-rsa
|
||||
|
||||
**注意**: 所有接下来的命令要以超级用户权限执行,如在“sudo -i”命令后;此外,你可以使用“sudo -E”作为接下来所有命令的前缀。
|
||||
**注意**: 所有接下来的命令要以超级用户权限执行,如在使用`sudo -i`命令后执行,或者你可以使用`sudo -E`作为接下来所有命令的前缀。
|
||||
|
||||
开始之前,我们需要拷贝“easy-rsa”到openvpn文件夹。
|
||||
|
||||
@ -32,15 +32,15 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
cd /etc/openvpn/easy-rsa/2.0
|
||||
|
||||
这里,我们开启了一个密钥生成进程。
|
||||
这里,我们开始密钥生成进程。
|
||||
|
||||
首先,我们编辑一个“var”文件。为了简化生成过程,我们需要在里面指定数据。这里是“var”文件的一个样例:
|
||||
首先,我们编辑一个“vars”文件。为了简化生成过程,我们需要在里面指定数据。这里是“vars”文件的一个样例:
|
||||
|
||||
export KEY_COUNTRY="US"
|
||||
export KEY_PROVINCE="CA"
|
||||
export KEY_CITY="SanFrancisco"
|
||||
export KEY_ORG="Fort-Funston"
|
||||
export KEY_EMAIL="my@myhost.mydomain"
|
||||
export KEY_COUNTRY="CN"
|
||||
export KEY_PROVINCE="BJ"
|
||||
export KEY_CITY="Beijing"
|
||||
export KEY_ORG="Linux.CN"
|
||||
export KEY_EMAIL="open@vpn.linux.cn"
|
||||
export KEY_OU=server
|
||||
|
||||
希望这些字段名称对你而言已经很清楚,不需要进一步说明了。
|
||||
@ -61,7 +61,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
./build-ca
|
||||
|
||||
在对话中,我们可以看到默认的变量,这些变量是我们先前在“vars”中指定的。我们可以检查以下,如有必要进行编辑,然后按回车几次。对话如下
|
||||
在对话中,我们可以看到默认的变量,这些变量是我们先前在“vars”中指定的。我们可以检查一下,如有必要进行编辑,然后按回车几次。对话如下
|
||||
|
||||
Generating a 2048 bit RSA private key
|
||||
.............................................+++
|
||||
@ -75,14 +75,14 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
For some fields there will be a default value,
|
||||
If you enter '.', the field will be left blank.
|
||||
-----
|
||||
Country Name (2 letter code) [US]:
|
||||
State or Province Name (full name) [CA]:
|
||||
Locality Name (eg, city) [SanFrancisco]:
|
||||
Organization Name (eg, company) [Fort-Funston]:
|
||||
Organizational Unit Name (eg, section) [MyOrganizationalUnit]:
|
||||
Common Name (eg, your name or your server's hostname) [Fort-Funston CA]:
|
||||
Country Name (2 letter code) [CN]:
|
||||
State or Province Name (full name) [BJ]:
|
||||
Locality Name (eg, city) [Beijing]:
|
||||
Organization Name (eg, company) [Linux.CN]:
|
||||
Organizational Unit Name (eg, section) [Tech]:
|
||||
Common Name (eg, your name or your server's hostname) [Linux.CN CA]:
|
||||
Name [EasyRSA]:
|
||||
Email Address [me@myhost.mydomain]:
|
||||
Email Address [open@vpn.linux.cn]:
|
||||
|
||||
接下来,我们需要生成一个服务器密钥
|
||||
|
||||
@ -102,14 +102,14 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
For some fields there will be a default value,
|
||||
If you enter '.', the field will be left blank.
|
||||
-----
|
||||
Country Name (2 letter code) [US]:
|
||||
State or Province Name (full name) [CA]:
|
||||
Locality Name (eg, city) [SanFrancisco]:
|
||||
Organization Name (eg, company) [Fort-Funston]:
|
||||
Organizational Unit Name (eg, section) [MyOrganizationalUnit]:
|
||||
Common Name (eg, your name or your server's hostname) [server]:
|
||||
Country Name (2 letter code) [CN]:
|
||||
State or Province Name (full name) [BJ]:
|
||||
Locality Name (eg, city) [Beijing]:
|
||||
Organization Name (eg, company) [Linux.CN]:
|
||||
Organizational Unit Name (eg, section) [Tech]:
|
||||
Common Name (eg, your name or your server's hostname) [Linux.CN server]:
|
||||
Name [EasyRSA]:
|
||||
Email Address [me@myhost.mydomain]:
|
||||
Email Address [open@vpn.linux.cn]:
|
||||
|
||||
Please enter the following 'extra' attributes
|
||||
to be sent with your certificate request
|
||||
@ -119,14 +119,14 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
Check that the request matches the signature
|
||||
Signature ok
|
||||
The Subject's Distinguished Name is as follows
|
||||
countryName :PRINTABLE:'US'
|
||||
stateOrProvinceName :PRINTABLE:'CA'
|
||||
localityName :PRINTABLE:'SanFrancisco'
|
||||
organizationName :PRINTABLE:'Fort-Funston'
|
||||
organizationalUnitName:PRINTABLE:'MyOrganizationalUnit'
|
||||
commonName :PRINTABLE:'server'
|
||||
countryName :PRINTABLE:'CN'
|
||||
stateOrProvinceName :PRINTABLE:'BJ'
|
||||
localityName :PRINTABLE:'Beijing'
|
||||
organizationName :PRINTABLE:'Linux.CN'
|
||||
organizationalUnitName:PRINTABLE:'Tech'
|
||||
commonName :PRINTABLE:'Linux.CN server'
|
||||
name :PRINTABLE:'EasyRSA'
|
||||
emailAddress :IA5STRING:'me@myhost.mydomain'
|
||||
emailAddress :IA5STRING:'open@vpn.linux.cn'
|
||||
Certificate is to be certified until May 22 19:00:25 2025 GMT (3650 days)
|
||||
Sign the certificate? [y/n]:y
|
||||
1 out of 1 certificate requests certified, commit? [y/n]y
|
||||
@ -143,7 +143,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
Generating DH parameters, 2048 bit long safe prime, generator 2
|
||||
This is going to take a long time
|
||||
................................+................<and many many dots>
|
||||
................................+................<许多的点>
|
||||
|
||||
在漫长的等待之后,我们可以继续生成最后的密钥了,该密钥用于TLS验证。命令如下:
|
||||
|
||||
@ -176,7 +176,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
### Unix的客户端配置 ###
|
||||
|
||||
假定我们有一台装有类Unix操作系统的设备,比如Ubuntu 15.04,并安装有OpenVPN。我们想要从先前的部分连接到OpenVPN服务器。首先,我们需要为客户端生成密钥。为了生成该密钥,请转到服务器上的目录中:
|
||||
假定我们有一台装有类Unix操作系统的设备,比如Ubuntu 15.04,并安装有OpenVPN。我们想要连接到前面建立的OpenVPN服务器。首先,我们需要为客户端生成密钥。为了生成该密钥,请转到服务器上的对应目录中:
|
||||
|
||||
cd /etc/openvpn/easy-rsa/2.0
|
||||
|
||||
@ -211,7 +211,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
dev tun
|
||||
proto udp
|
||||
|
||||
# IP and Port of remote host with OpenVPN server
|
||||
# 远程 OpenVPN 服务器的 IP 和 端口号
|
||||
remote 111.222.333.444 1194
|
||||
|
||||
resolv-retry infinite
|
||||
@ -243,7 +243,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
安卓设备上的OpenVPN配置和Unix系统上的十分类似,我们需要一个含有配置文件、密钥和证书的包。文件列表如下:
|
||||
|
||||
- configuration file (.ovpn),
|
||||
- 配置文件 (扩展名 .ovpn),
|
||||
- ca.crt,
|
||||
- dh2048.pem,
|
||||
- client.crt,
|
||||
@ -257,7 +257,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
dev tun
|
||||
proto udp
|
||||
|
||||
# IP and Port of remote host with OpenVPN server
|
||||
# 远程 OpenVPN 服务器的 IP 和 端口号
|
||||
remote 111.222.333.444 1194
|
||||
|
||||
resolv-retry infinite
|
||||
@ -274,21 +274,21 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
所有这些文件我们必须移动我们设备的SD卡上。
|
||||
|
||||
然后,我们需要安装[OpenVPN连接][2]。
|
||||
然后,我们需要安装一个[OpenVPN Connect][2] 应用。
|
||||
|
||||
接下来,配置过程很是简单:
|
||||
|
||||
open setting of OpenVPN and select Import options
|
||||
select Import Profile from SD card option
|
||||
in opened window go to folder with prepared files and select .ovpn file
|
||||
application offered us to create a new profile
|
||||
tap on the Connect button and wait a second
|
||||
- 打开 OpenVPN 并选择“Import”选项
|
||||
- 选择“Import Profile from SD card”
|
||||
- 在打开的窗口中导航到我们放置好文件的目录,并选择那个 .ovpn 文件
|
||||
- 应用会要求我们创建一个新的配置文件
|
||||
- 点击“Connect”按钮并稍等一下
|
||||
|
||||
搞定。现在,我们的安卓设备已经通过安全的VPN连接连接到我们的专用网。
|
||||
|
||||
### 尾声 ###
|
||||
|
||||
虽然OpenVPN初始配置花费不少时间,但是简易客户端配置为我们弥补了时间上的损失,也提供了从任何设备连接的能力。此外,OpenVPN提供了一个很高的安全等级,以及从不同地方连接的能力,包括位于NAT后面的客户端。因此,OpenVPN可以同时在家和在企业中使用。
|
||||
虽然OpenVPN初始配置花费不少时间,但是简易的客户端配置为我们弥补了时间上的损失,也提供了从任何设备连接的能力。此外,OpenVPN提供了一个很高的安全等级,以及从不同地方连接的能力,包括位于NAT后面的客户端。因此,OpenVPN可以同时在家和企业中使用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -296,7 +296,7 @@ via: http://linoxide.com/ubuntu-how-to/configure-openvpn-server-client-ubuntu-15
|
||||
|
||||
作者:[Ivan Zabrovskiy][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,205 @@
|
||||
关于Linux防火墙'iptables'的面试问答
|
||||
================================================================================
|
||||
Nishita Agarwal是Tecmint的用户,她将分享关于她刚刚经历的一家公司(印度的一家私人公司Pune)的面试经验。在面试中她被问及许多不同的问题,但她是iptables方面的专家,因此她想分享这些关于iptables的问题和相应的答案给那些以后可能会进行相关面试的人。
|
||||
|
||||

|
||||
|
||||
所有的问题和相应的答案都基于Nishita Agarwal的记忆并经过了重写。
|
||||
|
||||
> “嗨,朋友!我叫**Nishita Agarwal**。我已经取得了理学学士学位,我的专业集中在UNIX和它的变种(BSD,Linux)。它们一直深深的吸引着我。我在存储方面有1年多的经验。我正在寻求职业上的变化,并将供职于印度的Pune公司。”
|
||||
|
||||
下面是我在面试中被问到的问题的集合。我已经把我记忆中有关iptables的问题和它们的答案记录了下来。希望这会对您未来的面试有所帮助。
|
||||
|
||||
### 1. 你听说过Linux下面的iptables和Firewalld么?知不知道它们是什么,是用来干什么的? ###
|
||||
|
||||
**答案** : iptables和Firewalld我都知道,并且我已经使用iptables好一段时间了。iptables主要由C语言写成,并且以GNU GPL许可证发布。它是从系统管理员的角度写的,最新的稳定版是iptables 1.4.21。iptables通常被用作类UNIX系统中的防火墙,更准确的说,可以称为iptables/netfilter。管理员通过终端/GUI工具与iptables打交道,来添加和定义防火墙规则到预定义的表中。Netfilter是内核中的一个模块,它执行包过滤的任务。
|
||||
|
||||
Firewalld是RHEL/CentOS 7(也许还有其他发行版,但我不太清楚)中最新的过滤规则的实现。它已经取代了iptables接口,并与netfilter相连接。
|
||||
|
||||
### 2. 你用过一些iptables的GUI或命令行工具么? ###
|
||||
|
||||
**答案** : 虽然我既用过GUI工具,比如与[Webmin][1]结合的Shorewall;以及直接通过终端访问iptables,但我必须承认通过Linux终端直接访问iptables能给予用户更高级的灵活性、以及对其背后工作更好的理解的能力。GUI适合初级管理员,而终端适合有经验的管理员。
|
||||
|
||||
### 3. 那么iptables和firewalld的基本区别是什么呢? ###
|
||||
|
||||
**答案** : iptables和firewalld都有着同样的目的(包过滤),但它们使用不同的方式。iptables与firewalld不同,在每次发生更改时都刷新整个规则集。通常iptables配置文件位于‘/etc/sysconfig/iptables‘,而firewalld的配置文件位于‘/etc/firewalld/‘。firewalld的配置文件是一组XML文件。以XML为基础进行配置的firewalld比iptables的配置更加容易,但是两者都可以完成同样的任务。例如,firewalld可以在自己的命令行界面以及基于XML的配置文件下使用iptables。
|
||||
|
||||
### 4. 如果有机会的话,你会在你所有的服务器上用firewalld替换iptables么? ###
|
||||
|
||||
**答案** : 我对iptables很熟悉,它也工作的很好。如果没有任何需求需要firewalld的动态特性,那么没有理由把所有的配置都从iptables移动到firewalld。通常情况下,目前为止,我还没有看到iptables造成什么麻烦。IT技术的通用准则也说道“为什么要修一件没有坏的东西呢?”。上面是我自己的想法,但如果组织愿意用firewalld替换iptables的话,我不介意。
|
||||
|
||||
### 5. 你看上去对iptables很有信心,巧的是,我们的服务器也在使用iptables。 ###
|
||||
|
||||
iptables使用的表有哪些?请简要的描述iptables使用的表以及它们所支持的链。
|
||||
|
||||
**答案** : 谢谢您的赞赏。至于您问的问题,iptables使用的表有四个,它们是:
|
||||
|
||||
- Nat 表
|
||||
- Mangle 表
|
||||
- Filter 表
|
||||
- Raw 表
|
||||
|
||||
Nat表 : Nat表主要用于网络地址转换。根据表中的每一条规则修改网络包的IP地址。流中的包仅遍历一遍Nat表。例如,如果一个通过某个接口的包被修饰(修改了IP地址),该流中其余的包将不再遍历这个表。通常不建议在这个表中进行过滤,由NAT表支持的链称为PREROUTING 链,POSTROUTING 链和OUTPUT 链。
|
||||
|
||||
Mangle表 : 正如它的名字一样,这个表用于校正网络包。它用来对特殊的包进行修改。它能够修改不同包的头部和内容。Mangle表不能用于地址伪装。支持的链包括PREROUTING 链,OUTPUT 链,Forward 链,Input 链和POSTROUTING 链。
|
||||
|
||||
Filter表 : Filter表是iptables中使用的默认表,它用来过滤网络包。如果没有定义任何规则,Filter表则被当作默认的表,并且基于它来过滤。支持的链有INPUT 链,OUTPUT 链,FORWARD 链。
|
||||
|
||||
Raw表 : Raw表在我们想要配置之前被豁免的包时被使用。它支持PREROUTING 链和OUTPUT 链。
|
||||
|
||||
### 6. 简要谈谈什么是iptables中的目标值(能被指定为目标),他们有什么用 ###
|
||||
|
||||
**答案** : 下面是在iptables中可以指定为目标的值:
|
||||
|
||||
- ACCEPT : 接受包
|
||||
- QUEUE : 将包传递到用户空间 (应用程序和驱动所在的地方)
|
||||
- DROP : 丢弃包
|
||||
- RETURN : 将控制权交回调用的链并且为当前链中的包停止执行下一调用规则
|
||||
|
||||
### 7. 让我们来谈谈iptables技术方面的东西,我的意思是说实际使用方面 ###
|
||||
|
||||
你怎么检测在CentOS中安装iptables时需要的iptables的rpm?
|
||||
|
||||
**答案** : iptables已经被默认安装在CentOS中,我们不需要单独安装它。但可以这样检测rpm:
|
||||
|
||||
# rpm -qa iptables
|
||||
|
||||
iptables-1.4.21-13.el7.x86_64
|
||||
|
||||
如果您需要安装它,您可以用yum来安装。
|
||||
|
||||
# yum install iptables-services
|
||||
|
||||
### 8. 怎样检测并且确保iptables服务正在运行? ###
|
||||
|
||||
**答案** : 您可以在终端中运行下面的命令来检测iptables的状态。
|
||||
|
||||
# service status iptables [On CentOS 6/5]
|
||||
# systemctl status iptables [On CentOS 7]
|
||||
|
||||
如果iptables没有在运行,可以使用下面的语句
|
||||
|
||||
---------------- 在CentOS 6/5下 ----------------
|
||||
# chkconfig --level 35 iptables on
|
||||
# service iptables start
|
||||
|
||||
---------------- 在CentOS 7下 ----------------
|
||||
# systemctl enable iptables
|
||||
# systemctl start iptables
|
||||
|
||||
我们还可以检测iptables的模块是否被加载:
|
||||
|
||||
# lsmod | grep ip_tables
|
||||
|
||||
### 9. 你怎么检查iptables中当前定义的规则呢? ###
|
||||
|
||||
**答案** : 当前的规则可以简单的用下面的命令查看:
|
||||
|
||||
# iptables -L
|
||||
|
||||
示例输出
|
||||
|
||||
Chain INPUT (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
|
||||
ACCEPT icmp -- anywhere anywhere
|
||||
ACCEPT all -- anywhere anywhere
|
||||
ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
|
||||
REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
|
||||
Chain FORWARD (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
|
||||
Chain OUTPUT (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
|
||||
### 10. 你怎样刷新所有的iptables规则或者特定的链呢? ###
|
||||
|
||||
**答案** : 您可以使用下面的命令来刷新一个特定的链。
|
||||
|
||||
# iptables --flush OUTPUT
|
||||
|
||||
要刷新所有的规则,可以用:
|
||||
|
||||
# iptables --flush
|
||||
|
||||
### 11. 请在iptables中添加一条规则,接受所有从一个信任的IP地址(例如,192.168.0.7)过来的包。 ###
|
||||
|
||||
**答案** : 上面的场景可以通过运行下面的命令来完成。
|
||||
|
||||
# iptables -A INPUT -s 192.168.0.7 -j ACCEPT
|
||||
|
||||
我们还可以在源IP中使用标准的斜线和子网掩码:
|
||||
|
||||
# iptables -A INPUT -s 192.168.0.7/24 -j ACCEPT
|
||||
# iptables -A INPUT -s 192.168.0.7/255.255.255.0 -j ACCEPT
|
||||
|
||||
### 12. 怎样在iptables中添加规则以ACCEPT,REJECT,DENY和DROP ssh的服务? ###
|
||||
|
||||
**答案** : 但愿ssh运行在22端口,那也是ssh的默认端口,我们可以在iptables中添加规则来ACCEPT ssh的tcp包(在22号端口上)。
|
||||
|
||||
# iptables -A INPUT -s -p tcp --dport 22 -j ACCEPT
|
||||
|
||||
REJECT ssh服务(22号端口)的tcp包。
|
||||
|
||||
# iptables -A INPUT -s -p tcp --dport 22 -j REJECT
|
||||
|
||||
DENY ssh服务(22号端口)的tcp包。
|
||||
|
||||
|
||||
# iptables -A INPUT -s -p tcp --dport 22 -j DENY
|
||||
|
||||
DROP ssh服务(22号端口)的tcp包。
|
||||
|
||||
|
||||
# iptables -A INPUT -s -p tcp --dport 22 -j DROP
|
||||
|
||||
### 13. 让我给你另一个场景,假如有一台电脑的本地IP地址是192.168.0.6。你需要封锁在21、22、23和80号端口上的连接,你会怎么做? ###
|
||||
|
||||
**答案** : 这时,我所需要的就是在iptables中使用‘multiport‘选项,并将要封锁的端口号跟在它后面。上面的场景可以用下面的一条语句搞定:
|
||||
|
||||
# iptables -A INPUT -s 192.168.0.6 -p tcp -m multiport --dport 22,23,80,8080 -j DROP
|
||||
|
||||
可以用下面的语句查看写入的规则。
|
||||
|
||||
# iptables -L
|
||||
|
||||
Chain INPUT (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
|
||||
ACCEPT icmp -- anywhere anywhere
|
||||
ACCEPT all -- anywhere anywhere
|
||||
ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
|
||||
REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
DROP tcp -- 192.168.0.6 anywhere multiport dports ssh,telnet,http,webcache
|
||||
|
||||
Chain FORWARD (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
|
||||
Chain OUTPUT (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
|
||||
**面试官** : 好了,我问的就是这些。你是一个很有价值的雇员,我们不会错过你的。我将会向HR推荐你的名字。如果你有什么问题,请问我。
|
||||
|
||||
作为一个候选人我不愿不断的问将来要做的项目的事以及公司里其他的事,这样会打断愉快的对话。更不用说HR轮会不会比较难,总之,我获得了机会。
|
||||
|
||||
同时我要感谢Avishek和Ravi(我的朋友)花时间帮我整理我的面试。
|
||||
|
||||
朋友!如果您有过类似的面试,并且愿意与数百万Tecmint读者一起分享您的面试经历,请将您的问题和答案发送到admin@tecmint.com。
|
||||
|
||||
谢谢!保持联系。如果我能更好的回答我上面的问题的话,请记得告诉我。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-firewall-iptables-interview-questions-and-answers/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/install-webmin-web-based-system-administration-tool-for-rhel-centos-fedora/
|
||||
@ -0,0 +1,95 @@
|
||||
Tickr:一个开源的 Linux 桌面 RSS 新闻速递应用
|
||||
================================================================================
|
||||

|
||||
|
||||
**最新的!最新的!阅读关于它的一切!**
|
||||
|
||||
好了,我们今天要推荐的应用程序可不是旧式报纸的二进制版本——它会以一种漂亮的方式将最新的新闻推送到你的桌面上。
|
||||
|
||||
Tickr 是一个基于 GTK 的 Linux 桌面新闻速递应用,能够以横条方式滚动显示最新头条新闻以及你最爱的RSS资讯文章标题,当然你可以放置在你桌面的任何地方。
|
||||
|
||||
请叫我 Joey Calamezzo;我把它放在底部,就像电视新闻台的滚动字幕一样。 (LCTT 译注: Joan Callamezzo 是 Pawnee Today 的主持人,一位 Pawnee 的本地新闻/脱口秀主持人。而本文作者是 Joey。)
|
||||
|
||||
“到你了,副标题”。
|
||||
|
||||
### RSS -还记得吗? ###
|
||||
|
||||
“谢谢,这段结束了。”
|
||||
|
||||
在一个充斥着推送通知、社交媒体、标题党,以及哄骗人们点击的清单体的时代,RSS看起来有一点过时了。
|
||||
|
||||
对我来说呢?恩,RSS是名副其实的真正简单的聚合(RSS : Really Simple Syndication)。这是将消息通知给我的最简单、最易于管理的方式。我可以在我愿意的时候,管理和阅读一些东西;没必要匆忙的去看,以防这条微博消失在信息流中,或者推送通知消失。
|
||||
|
||||
tickr的美在于它的实用性。你可以不断地有新闻滚动在屏幕的底部,然后不时地瞥一眼。
|
||||
|
||||

|
||||
|
||||
你不会有“阅读”或“标记所有为已读”的压力。当你看到一些你想读的东西,你只需点击它,将它在Web浏览器中打开。
|
||||
|
||||
### 开始设置 ###
|
||||
|
||||

|
||||
|
||||
尽管虽然tickr可以从Ubuntu软件中心安装,然而它已经很久没有更新了。当你打开笨拙的不直观的控制面板的时候,没有什么能够比这更让人感觉被遗弃的了。
|
||||
|
||||
要打开它:
|
||||
|
||||
1. 右键单击tickr条
|
||||
1. 转至编辑>首选项
|
||||
1. 调整各种设置
|
||||
|
||||
选项和设置行的后面,有些似乎是容易理解的。但是详细了解这些你才能够掌握一切,包括:
|
||||
|
||||
- 设置滚动速度
|
||||
- 选择鼠标经过时的行为
|
||||
- 资讯更新频率
|
||||
- 字体,包括字体大小和颜色
|
||||
- 消息分隔符(“delineator”)
|
||||
- tickr在屏幕上的位置
|
||||
- tickr条的颜色和不透明度
|
||||
- 选择每种资讯显示多少文章
|
||||
|
||||
有个值得一提的“怪癖”是,当你点击“应用”按钮,只会更新tickr的屏幕预览。当您退出“首选项”窗口时,请单击“确定”。
|
||||
|
||||
想要得到完美的显示效果, 你需要一点点调整,特别是在 Unity 上。
|
||||
|
||||
按下“全宽按钮”,能够让应用程序自动检测你的屏幕宽度。默认情况下,当放置在顶部或底部时,会留下25像素的间距(应用程序以前是在GNOME2.x桌面上创建的)。只需添加额外的25像素到输入框,来弥补这个问题。
|
||||
|
||||
其他可供选择的选项包括:选择文章在哪个浏览器打开;tickr是否以一个常规的窗口出现;是否显示一个时钟;以及应用程序多久检查一次文章资讯。
|
||||
|
||||
#### 添加资讯 ####
|
||||
|
||||
tickr自带的有超过30种不同的资讯列表,从技术博客到主流新闻服务。
|
||||
|
||||

|
||||
|
||||
你可以选择很多你想在屏幕上显示的新闻提要。如果你想添加自己的资讯,你可以:—
|
||||
|
||||
1. 右键单击tickr条
|
||||
1. 转至文件>打开资讯
|
||||
1. 输入资讯网址
|
||||
1. 点击“添加/更新”按钮
|
||||
1. 单击“确定”(选择)
|
||||
|
||||
如果想设置每个资讯在ticker中显示多少条文章,可以去另一个首选项窗口修改“每个资讯最大读取N条文章”
|
||||
|
||||
### 在Ubuntu 14.04 LTS或更高版本上安装Tickr ###
|
||||
|
||||
这就是 Tickr,它不会改变世界,但是它能让你知道世界上发生了什么。
|
||||
|
||||
在Ubuntu 14.04 LTS或更高版本中安装,点击下面的按钮转到Ubuntu软件中心。
|
||||
|
||||
- [点击此处进入Ubuntu软件中心安装tickr][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/06/tickr-open-source-desktop-rss-news-ticker
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[xiaoyu33](https://github.com/xiaoyu33)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:apt://tickr
|
||||
@ -0,0 +1,126 @@
|
||||
如何使用Docker Machine部署Swarm集群
|
||||
================================================================================
|
||||
|
||||
大家好,今天我们来研究一下如何使用Docker Machine部署Swarm集群。Docker Machine提供了标准的Docker API 支持,所以任何可以与Docker守护进程进行交互的工具都可以使用Swarm来(透明地)扩增到多台主机上。Docker Machine可以用来在个人电脑、云端以及的数据中心里创建Docker主机。它为创建服务器,安装Docker以及根据用户设定来配置Docker客户端提供了便捷化的解决方案。我们可以使用任何驱动来部署swarm集群,并且swarm集群将由于使用了TLS加密具有极好的安全性。
|
||||
|
||||
下面是我提供的简便方法。
|
||||
|
||||
### 1. 安装Docker Machine ###
|
||||
|
||||
Docker Machine 在各种Linux系统上都支持的很好。首先,我们需要从Github上下载最新版本的Docker Machine。我们使用curl命令来下载最先版本Docker Machine ie 0.2.0。
|
||||
|
||||
64位操作系统:
|
||||
|
||||
# curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-amd64 > /usr/local/bin/docker-machine
|
||||
|
||||
32位操作系统:
|
||||
|
||||
# curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-i386 > /usr/local/bin/docker-machine
|
||||
|
||||
下载了最先版本的Docker Machine之后,我们需要对 /usr/local/bin/ 目录下的docker-machine文件的权限进行修改。命令如下:
|
||||
|
||||
# chmod +x /usr/local/bin/docker-machine
|
||||
|
||||
在做完上面的事情以后,我们要确保docker-machine已经安装正确。怎么检查呢?运行`docker-machine -v`指令,该指令将会给出我们系统上所安装的docker-machine版本。
|
||||
|
||||
# docker-machine -v
|
||||
|
||||

|
||||
|
||||
为了让Docker命令能够在我们的机器上运行,必须还要在机器上安装Docker客户端。命令如下。
|
||||
|
||||
# curl -L https://get.docker.com/builds/linux/x86_64/docker-latest > /usr/local/bin/docker
|
||||
# chmod +x /usr/local/bin/docker
|
||||
|
||||
### 2. 创建Machine ###
|
||||
|
||||
在将Docker Machine安装到我们的设备上之后,我们需要使用Docker Machine创建一个machine。在这篇文章中,我们会将其部署在Digital Ocean Platform上。所以我们将使用“digitalocean”作为它的Driver API,然后将docker swarm运行在其中。这个Droplet会被设置为Swarm主控节点,我们还要创建另外一个Droplet,并将其设定为Swarm节点代理。
|
||||
|
||||
创建machine的命令如下:
|
||||
|
||||
# docker-machine create --driver digitalocean --digitalocean-access-token <API-Token> linux-dev
|
||||
|
||||
**备注**: 假设我们要创建一个名为“linux-dev”的machine。<API-Token>是用户在Digital Ocean Cloud Platform的Digital Ocean控制面板中生成的密钥。为了获取这个密钥,我们需要登录我们的Digital Ocean控制面板,然后点击API选项,之后点击Generate New Token,起个名字,然后在Read和Write两个选项上打钩。之后我们将得到一个很长的十六进制密钥,这个就是<API-Token>了。用其替换上面那条命令中的API-Token字段。
|
||||
|
||||
现在,运行下面的指令,将Machine 的配置变量加载进shell里。
|
||||
|
||||
# eval "$(docker-machine env linux-dev)"
|
||||
|
||||

|
||||
|
||||
然后,我们使用如下命令将我们的machine标记为ACTIVE状态。
|
||||
|
||||
# docker-machine active linux-dev
|
||||
|
||||
现在,我们检查它(指machine)是否被标记为了 ACTIVE "*"。
|
||||
|
||||
# docker-machine ls
|
||||
|
||||

|
||||
|
||||
### 3. 运行Swarm Docker镜像 ###
|
||||
|
||||
现在,在我们创建完成了machine之后。我们需要将swarm docker镜像部署上去。这个machine将会运行这个docker镜像,并且控制Swarm主控节点和从节点。使用下面的指令运行镜像:
|
||||
|
||||
# docker run swarm create
|
||||
|
||||

|
||||
|
||||
如果你想要在**32位操作系统**上运行swarm docker镜像。你需要SSH登录到Droplet当中。
|
||||
|
||||
# docker-machine ssh
|
||||
#docker run swarm create
|
||||
#exit
|
||||
|
||||
### 4. 创建Swarm主控节点 ###
|
||||
|
||||
在我们的swarm image已经运行在machine当中之后,我们将要创建一个Swarm主控节点。使用下面的语句,添加一个主控节点。
|
||||
|
||||
# docker-machine create \
|
||||
-d digitalocean \
|
||||
--digitalocean-access-token <DIGITALOCEAN-TOKEN>
|
||||
--swarm \
|
||||
--swarm-master \
|
||||
--swarm-discovery token://<CLUSTER-ID> \
|
||||
swarm-master
|
||||
|
||||

|
||||
|
||||
### 5. 创建Swarm从节点 ###
|
||||
|
||||
现在,我们将要创建一个swarm从节点,此节点将与Swarm主控节点相连接。下面的指令将创建一个新的名为swarm-node的droplet,其与Swarm主控节点相连。到此,我们就拥有了一个两节点的swarm集群了。
|
||||
|
||||
# docker-machine create \
|
||||
-d digitalocean \
|
||||
--digitalocean-access-token <DIGITALOCEAN-TOKEN>
|
||||
--swarm \
|
||||
--swarm-discovery token://<TOKEN-FROM-ABOVE> \
|
||||
swarm-node
|
||||
|
||||

|
||||
|
||||
### 6. 与Swarm主控节点连接 ###
|
||||
|
||||
现在,我们连接Swarm主控节点以便我们可以依照需求和配置文件在节点间部署Docker容器。运行下列命令将Swarm主控节点的Machine配置文件加载到环境当中。
|
||||
|
||||
# eval "$(docker-machine env --swarm swarm-master)"
|
||||
|
||||
然后,我们就可以跨节点地运行我们所需的容器了。在这里,我们还要检查一下是否一切正常。所以,运行**docker info**命令来检查Swarm集群的信息。
|
||||
|
||||
# docker info
|
||||
|
||||
### 总结 ###
|
||||
|
||||
我们可以用Docker Machine轻而易举地创建Swarm集群。这种方法有非常高的效率,因为它极大地减少了系统管理员和用户的时间消耗。在这篇文章中,我们以Digital Ocean作为驱动,通过创建一个主控节点和一个从节点成功地部署了集群。其他类似的驱动还有VirtualBox,Google Cloud Computing,Amazon Web Service,Microsoft Azure等等。这些连接都是通过TLS进行加密的,具有很高的安全性。如果你有任何的疑问,建议,反馈,欢迎在下面的评论框中注明以便我们可以更好地提高文章的质量!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/provision-swarm-clusters-using-docker-machine/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[DongShuaike](https://github.com/DongShuaike)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
@ -1,53 +1,54 @@
|
||||
Autojump – 一个高级的‘cd’命令用以快速浏览 Linux 文件系统
|
||||
Autojump:一个可以在 Linux 文件系统快速导航的高级 cd 命令
|
||||
================================================================================
|
||||
对于那些主要通过控制台或终端使用 Linux 命令行来工作的 Linux 用户来说,他们真切地感受到了 Linux 的强大。 然而在 Linux 的分层文件系统中进行浏览有时或许是一件头疼的事,尤其是对于那些新手来说。
|
||||
|
||||
对于那些主要通过控制台或终端使用 Linux 命令行来工作的 Linux 用户来说,他们真切地感受到了 Linux 的强大。 然而在 Linux 的分层文件系统中进行导航有时或许是一件头疼的事,尤其是对于那些新手来说。
|
||||
|
||||
现在,有一个用 Python 写的名为 `autojump` 的 Linux 命令行实用程序,它是 Linux ‘[cd][1]’命令的高级版本。
|
||||
|
||||

|
||||
|
||||
Autojump – 浏览 Linux 文件系统的最快方式
|
||||
*Autojump – Linux 文件系统导航的最快方式*
|
||||
|
||||
这个应用原本由 Joël Schaerer 编写,现在由 +William Ting 维护。
|
||||
|
||||
Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行更轻松的目录浏览。与传统的 `cd` 命令相比,autojump 能够更加快速地浏览至目的目录。
|
||||
Autojump 应用可以从用户那里学习并帮助用户在 Linux 命令行中进行更轻松的目录导航。与传统的 `cd` 命令相比,autojump 能够更加快速地导航至目的目录。
|
||||
|
||||
#### autojump 的特色 ####
|
||||
|
||||
- 免费且开源的应用,在 GPL V3 协议下发布。
|
||||
- 自主学习的应用,从用户的浏览习惯中学习。
|
||||
- 更快速地浏览。不必包含子目录的名称。
|
||||
- 对于大多数的标准 Linux 发行版本,能够在软件仓库中下载得到,它们包括 Debian (testing/unstable), Ubuntu, Mint, Arch, Gentoo, Slackware, CentOS, RedHat and Fedora。
|
||||
- 自由开源的应用,在 GPL V3 协议下发布。
|
||||
- 自主学习的应用,从用户的导航习惯中学习。
|
||||
- 更快速地导航。不必包含子目录的名称。
|
||||
- 对于大多数的标准 Linux 发行版本,能够在软件仓库中下载得到,它们包括 Debian (testing/unstable), Ubuntu, Mint, Arch, Gentoo, Slackware, CentOS, RedHat 和 Fedora。
|
||||
- 也能在其他平台中使用,例如 OS X(使用 Homebrew) 和 Windows (通过 Clink 来实现)
|
||||
- 使用 autojump 你可以跳至任何特定的目录或一个子目录。你还可以打开文件管理器来到达某个目录,并查看你在某个目录中所待时间的统计数据。
|
||||
- 使用 autojump 你可以跳至任何特定的目录或一个子目录。你还可以用文件管理器打开某个目录,并查看你在某个目录中所待时间的统计数据。
|
||||
|
||||
#### 前提 ####
|
||||
|
||||
- 版本号不低于 2.6 的 Python
|
||||
|
||||
### 第 1 步: 做一次全局系统升级 ###
|
||||
### 第 1 步: 做一次完整的系统升级 ###
|
||||
|
||||
1. 以 **root** 用户的身份,做一次系统更新或升级,以此保证你安装有最新版本的 Python。
|
||||
1、 以 **root** 用户的身份,做一次系统更新或升级,以此保证你安装有最新版本的 Python。
|
||||
|
||||
# apt-get update && apt-get upgrade && apt-get dist-upgrade [APT based systems]
|
||||
# yum update && yum upgrade [YUM based systems]
|
||||
# dnf update && dnf upgrade [DNF based systems]
|
||||
# apt-get update && apt-get upgrade && apt-get dist-upgrade [基于 APT 的系统]
|
||||
# yum update && yum upgrade [基于 YUM 的系统]
|
||||
# dnf update && dnf upgrade [基于 DNF 的系统]
|
||||
|
||||
**注** : 这里特别提醒,在基于 YUM 或 DNF 的系统中,更新和升级执行相同的行动,大多数时间里它们是通用的,这点与基于 APT 的系统不同。
|
||||
|
||||
### 第 2 步: 下载和安装 Autojump ###
|
||||
|
||||
2. 正如前面所言,在大多数的 Linux 发行版本的软件仓库中, autojump 都可获取到。通过包管理器你就可以安装它。但若你想从源代码开始来安装它,你需要克隆源代码并执行 python 脚本,如下面所示:
|
||||
2、 正如前面所言,在大多数的 Linux 发行版本的软件仓库中, autojump 都可获取到。通过包管理器你就可以安装它。但若你想从源代码开始来安装它,你需要克隆源代码并执行 python 脚本,如下面所示:
|
||||
|
||||
#### 从源代码安装 ####
|
||||
|
||||
若没有安装 git,请安装它。我们需要使用它来克隆 git 仓库。
|
||||
|
||||
# apt-get install git [APT based systems]
|
||||
# yum install git [YUM based systems]
|
||||
# dnf install git [DNF based systems]
|
||||
# apt-get install git [基于 APT 的系统]
|
||||
# yum install git [基于 YUM 的系统]
|
||||
# dnf install git [基于 DNF 的系统]
|
||||
|
||||
一旦安装完 git,以常规用户身份登录,然后像下面那样来克隆 autojump:
|
||||
一旦安装完 git,以普通用户身份登录,然后像下面那样来克隆 autojump:
|
||||
|
||||
$ git clone git://github.com/joelthelion/autojump.git
|
||||
|
||||
@ -55,29 +56,29 @@ Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行
|
||||
|
||||
$ cd autojump
|
||||
|
||||
下载,赋予脚本文件可执行权限,并以 root 用户身份来运行安装脚本。
|
||||
下载,赋予安装脚本文件可执行权限,并以 root 用户身份来运行安装脚本。
|
||||
|
||||
# chmod 755 install.py
|
||||
# ./install.py
|
||||
|
||||
#### 从软件仓库中安装 ####
|
||||
|
||||
3. 假如你不想麻烦,你可以以 **root** 用户身份从软件仓库中直接安装它:
|
||||
3、 假如你不想麻烦,你可以以 **root** 用户身份从软件仓库中直接安装它:
|
||||
|
||||
在 Debian, Ubuntu, Mint 及类似系统中安装 autojump :
|
||||
|
||||
# apt-get install autojump (注: 这里原文为 autojumo, 应该为 autojump)
|
||||
# apt-get install autojump
|
||||
|
||||
为了在 Fedora, CentOS, RedHat 及类似系统中安装 autojump, 你需要启用 [EPEL 软件仓库][2]。
|
||||
|
||||
# yum install epel-release
|
||||
# yum install autojump
|
||||
OR
|
||||
或
|
||||
# dnf install autojump
|
||||
|
||||
### 第 3 步: 安装后的配置 ###
|
||||
|
||||
4. 在 Debian 及其衍生系统 (Ubuntu, Mint,…) 中, 激活 autojump 应用是非常重要的。
|
||||
4、 在 Debian 及其衍生系统 (Ubuntu, Mint,…) 中, 激活 autojump 应用是非常重要的。
|
||||
|
||||
为了暂时激活 autojump 应用,即直到你关闭当前会话或打开一个新的会话之前让 autojump 均有效,你需要以常规用户身份运行下面的命令:
|
||||
|
||||
@ -89,7 +90,7 @@ Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行
|
||||
|
||||
### 第 4 步: Autojump 的预测试和使用 ###
|
||||
|
||||
5. 如先前所言, autojump 将只跳到先前 `cd` 命令到过的目录。所以在我们开始测试之前,我们要使用 `cd` 切换到一些目录中去,并创建一些目录。下面是我所执行的命令。
|
||||
5、 如先前所言, autojump 将只跳到先前 `cd` 命令到过的目录。所以在我们开始测试之前,我们要使用 `cd` 切换到一些目录中去,并创建一些目录。下面是我所执行的命令。
|
||||
|
||||
$ cd
|
||||
$ cd
|
||||
@ -120,45 +121,45 @@ Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行
|
||||
|
||||
现在,我们已经切换到过上面所列的目录,并为了测试创建了一些目录,一切准备就绪,让我们开始吧。
|
||||
|
||||
**需要记住的一点** : `j` 是 autojump 的一个包装,你可以使用 j 来代替 autojump, 相反亦可。
|
||||
**需要记住的一点** : `j` 是 autojump 的一个封装,你可以使用 j 来代替 autojump, 相反亦可。
|
||||
|
||||
6. 使用 -v 选项查看安装的 autojump 的版本。
|
||||
6、 使用 -v 选项查看安装的 autojump 的版本。
|
||||
|
||||
$ j -v
|
||||
or
|
||||
或
|
||||
$ autojump -v
|
||||
|
||||

|
||||
|
||||
查看 Autojump 的版本
|
||||
*查看 Autojump 的版本*
|
||||
|
||||
7. 跳到先前到过的目录 ‘/var/www‘。
|
||||
7、 跳到先前到过的目录 ‘/var/www‘。
|
||||
|
||||
$ j www
|
||||
|
||||
|
||||
|
||||
跳到目录
|
||||
*跳到目录*
|
||||
|
||||
8. 跳到先前到过的子目录‘/home/avi/autojump-test/b‘ 而不键入子目录的全名。
|
||||
8、 跳到先前到过的子目录‘/home/avi/autojump-test/b‘ 而不键入子目录的全名。
|
||||
|
||||
$ jc b
|
||||
|
||||

|
||||
|
||||
跳到子目录
|
||||
*跳到子目录*
|
||||
|
||||
9. 使用下面的命令,你就可以从命令行打开一个文件管理器,例如 GNOME Nautilus ,而不是跳到一个目录。
|
||||
9、 使用下面的命令,你就可以从命令行打开一个文件管理器,例如 GNOME Nautilus ,而不是跳到一个目录。
|
||||
|
||||
$ jo www
|
||||
|
||||
|
||||

|
||||
|
||||
跳到目录
|
||||
*打开目录*
|
||||
|
||||

|
||||
|
||||
在文件管理器中打开目录
|
||||
*在文件管理器中打开目录*
|
||||
|
||||
你也可以在一个文件管理器中打开一个子目录。
|
||||
|
||||
@ -166,19 +167,19 @@ Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行
|
||||
|
||||

|
||||
|
||||
打开子目录
|
||||
*打开子目录*
|
||||
|
||||

|
||||
|
||||
在文件管理器中打开子目录
|
||||
*在文件管理器中打开子目录*
|
||||
|
||||
10. 查看每个文件夹的关键权重和在所有目录权重中的总关键权重的相关统计数据。文件夹的关键权重代表在这个文件夹中所花的总时间。 目录权重是列表中目录的数目。(注: 在这一句中,我觉得原文中的 if 应该为 is)
|
||||
10、 查看每个文件夹的权重和全部文件夹计算得出的总权重的统计数据。文件夹的权重代表在这个文件夹中所花的总时间。 文件夹权重是该列表中目录的数字。(LCTT 译注: 在这一句中,我觉得原文中的 if 应该为 is)
|
||||
|
||||
$ j --stat
|
||||
|
||||

|
||||

|
||||
|
||||
查看目录统计数据
|
||||
*查看文件夹统计数据*
|
||||
|
||||
**提醒** : autojump 存储其运行日志和错误日志的地方是文件夹 `~/.local/share/autojump/`。千万不要重写这些文件,否则你将失去你所有的统计状态结果。
|
||||
|
||||
@ -186,15 +187,15 @@ Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行
|
||||
|
||||
|
||||
|
||||
Autojump 的日志
|
||||
*Autojump 的日志*
|
||||
|
||||
11. 假如需要,你只需运行下面的命令就可以查看帮助 :
|
||||
11、 假如需要,你只需运行下面的命令就可以查看帮助 :
|
||||
|
||||
$ j --help
|
||||
|
||||

|
||||
|
||||
Autojump 的帮助和选项
|
||||
*Autojump 的帮助和选项*
|
||||
|
||||
### 功能需求和已知的冲突 ###
|
||||
|
||||
@ -204,18 +205,19 @@ Autojump 的帮助和选项
|
||||
|
||||
### 结论: ###
|
||||
|
||||
假如你是一个命令行用户, autojump 是你必备的实用程序。它可以简化许多事情。它是一个在命令行中浏览 Linux 目录的绝佳的程序。请自行尝试它,并在下面的评论框中让我知晓你宝贵的反馈。保持联系,保持分享。喜爱并分享,帮助我们更好地传播。
|
||||
假如你是一个命令行用户, autojump 是你必备的实用程序。它可以简化许多事情。它是一个在命令行中导航 Linux 目录的绝佳的程序。请自行尝试它,并在下面的评论框中让我知晓你宝贵的反馈。保持联系,保持分享。喜爱并分享,帮助我们更好地传播。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/autojump-a-quickest-way-to-navigate-linux-filesystem/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/cd-command-in-linux/
|
||||
[2]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[2]:https://linux.cn/article-2324-1.html
|
||||
[3]:http://www.tecmint.com/manage-linux-filenames-with-special-characters/
|
||||
@ -0,0 +1,207 @@
|
||||
Syncthing: 一个在计算机之间同步文件/文件夹的私密安全同步工具
|
||||
================================================================================
|
||||
### 简介 ###
|
||||
|
||||
**Syncthing**是一个免费开源的工具,它能在你的各个网络计算机间同步文件/文件夹。它不像其它的同步工具,如**BitTorrent Sync**和**Dropbox**那样,它的同步数据是直接从一个系统中直接传输到另一个系统的,并且它是完全开源的,安全且私密的。你所有的珍贵数据都会被存储在你的系统中,这样你就能对你的文件和文件夹拥有全面的控制权,没有任何的文件或文件夹会被存储在第三方系统中。此外,你有权决定这些数据该存于何处,是否要分享到第三方,或这些数据在互联网上的传输方式。
|
||||
|
||||
所有的信息通讯都使用TLS进行加密,这样你的数据便能十分安全地逃离窥探。Syncthing有一个强大的响应式的网页管理界面(WebGUI,下同),它能够帮助用户简便地添加、删除和管理那些通过网络进行同步的文件夹。通过使用Syncthing,你可以在多个系统上一次同步多个文件夹。在安装和使用上,Syncthing是一个可移植的、简单而强大的工具。即然文件或文件夹是从一部计算机中直接传输到另一计算机中的,那么你就无需考虑向云服务供应商支付金钱来获取额外的云空间。你所需要的仅仅是非常稳定的LAN/WAN连接以及在你的系统中有足够的硬盘空间。它支持所有的现代操作系统,包括GNU/Linux, Windows, Mac OS X, 当然还有Android。
|
||||
|
||||
### 安装 ###
|
||||
|
||||
基于本文的目的,我们将使用两个系统,一个是Ubuntu 14.04 LTS, 一个是Ubuntu 14.10 server。为了简单辨别这两个系统,我们将分别称其为**系统1**和**系统2**。
|
||||
|
||||
### 系统1细节: ###
|
||||
|
||||
- **操作系统**: Ubuntu 14.04 LTS server;
|
||||
- **主机名**: **server1**.unixmen.local;
|
||||
- **IP地址**: 192.168.1.150.
|
||||
- **系统用户**: sk (你可以使用你自己的系统用户)
|
||||
- **同步文件夹**: /home/Sync/ (Syncthing会默认创建)
|
||||
|
||||
### 系统2细节 ###
|
||||
|
||||
- **操作系统**: Ubuntu 14.10 server;
|
||||
- **主机名**: **server**.unixmen.local;
|
||||
- **IP地址**: 192.168.1.151.
|
||||
- **系统用户**: sk (你可以使用你自己的系统用户)
|
||||
- **同步文件夹**: /home/Sync/ (Syncthing会默认创建)
|
||||
|
||||
### 在系统1和系统2上为Syncthing创建用户 ###
|
||||
|
||||
在两个系统上运行下面的命令来为Syncthing创建用户以及两系统间的同步文件夹。
|
||||
|
||||
sudo useradd sk
|
||||
sudo passwd sk
|
||||
|
||||
### 为系统1和系统2安装Syncthing ###
|
||||
|
||||
在系统1和系统2上遵循以下步骤进行操作。
|
||||
|
||||
从[官方下载页][1]上下载最新版本。我使用的是64位版本,因此下载64位版的软件包。
|
||||
|
||||
wget https://github.com/syncthing/syncthing/releases/download/v0.10.20/syncthing-linux-amd64-v0.10.20.tar.gz
|
||||
|
||||
解压缩下载的文件:
|
||||
|
||||
tar xzvf syncthing-linux-amd64-v0.10.20.tar.gz
|
||||
|
||||
切换到解压缩出来的文件夹:
|
||||
|
||||
cd syncthing-linux-amd64-v0.10.20/
|
||||
|
||||
复制可执行文件"syncthing"到**$PATH**:
|
||||
|
||||
sudo cp syncthing /usr/local/bin/
|
||||
|
||||
现在,执行下列命令来首次运行Syncthing:
|
||||
|
||||
syncthing
|
||||
|
||||
当你执行上述命令后,syncthing会生成一个配置以及一些配置键值,并且在你的浏览器上打开一个管理界面。
|
||||
|
||||
输入示例:
|
||||
|
||||
[monitor] 15:40:27 INFO: Starting syncthing
|
||||
15:40:27 INFO: Generating RSA key and certificate for syncthing...
|
||||
[BQXVO] 15:40:34 INFO: syncthing v0.10.20 (go1.4 linux-386 default) unknown-user@syncthing-builder 2015-01-13 16:27:47 UTC
|
||||
[BQXVO] 15:40:34 INFO: My ID: BQXVO3D-VEBIDRE-MVMMGJI-ECD2PC3-T5LT3JB-OK4Z45E-MPIDWHI-IRW3NAZ
|
||||
[BQXVO] 15:40:34 INFO: No config file; starting with empty defaults
|
||||
[BQXVO] 15:40:34 INFO: Edit /home/sk/.config/syncthing/config.xml to taste or use the GUI
|
||||
[BQXVO] 15:40:34 INFO: Starting web GUI on http://127.0.0.1:8080/
|
||||
[BQXVO] 15:40:34 INFO: Loading HTTPS certificate: open /home/sk/.config/syncthing/https-cert.pem: no such file or directory
|
||||
[BQXVO] 15:40:34 INFO: Creating new HTTPS certificate
|
||||
[BQXVO] 15:40:34 INFO: Generating RSA key and certificate for server1...
|
||||
[BQXVO] 15:41:01 INFO: Starting UPnP discovery...
|
||||
[BQXVO] 15:41:07 INFO: Starting local discovery announcements
|
||||
[BQXVO] 15:41:07 INFO: Starting global discovery announcements
|
||||
[BQXVO] 15:41:07 OK: Ready to synchronize default (read-write)
|
||||
[BQXVO] 15:41:07 INFO: Device BQXVO3D-VEBIDRE-MVMMGJI-ECD2PC3-T5LT3JB-OK4Z45E-MPIDWHI-IRW3NAZ is "server1" at [dynamic]
|
||||
[BQXVO] 15:41:07 INFO: Completed initial scan (rw) of folder default
|
||||
|
||||
Syncthing已经被成功地初始化了,网页管理接口也可以通过浏览器访问URL: **http://localhost:8080**。如上面输入所看到的,Syncthing在你的**home**目录中的Sync目录**下自动为你创建了一个名为**default**的文件夹。
|
||||
|
||||
默认情况下,Syncthing的网页管理界面只能在本地端口(localhost)中进行访问,要从远程进行访问,你需要在两个系统中进行以下操作:
|
||||
|
||||
首先,按下CTRL+C键来终止Syncthing初始化进程。现在你回到了终端界面。
|
||||
|
||||
编辑**config.xml**文件,
|
||||
|
||||
sudo nano ~/.config/syncthing/config.xml
|
||||
|
||||
找到下面的指令:
|
||||
|
||||
[...]
|
||||
<gui enabled="true" tls="false">
|
||||
<address>127.0.0.1:8080</address>
|
||||
<apikey>-Su9v0lW80JWybGjK9vNK00YDraxXHGP</apikey>
|
||||
</gui>
|
||||
[...]
|
||||
|
||||
在**<address>**区域中,把**127.0.0.1:8080**改为**0.0.0.0:8080**。结果,你的config.xml看起来会是这样的:
|
||||
|
||||
<gui enabled="true" tls="false">
|
||||
<address>0.0.0.0:8080</address>
|
||||
<apikey>-Su9v0lW80JWybGjK9vNK00YDraxXHGP</apikey>
|
||||
</gui>
|
||||
|
||||
保存并关闭文件。
|
||||
|
||||
在两个系统上再次执行下述命令:
|
||||
|
||||
syncthing
|
||||
|
||||
### 访问网页管理界面 ###
|
||||
|
||||
现在,在你的浏览器上打开**http://ip-address:8080/**。你会看到下面的界面:
|
||||
|
||||

|
||||
|
||||
网页管理界面分为两个窗格,在左窗格中,你应该可以看到同步的文件夹列表。如前所述,文件夹**default**在你初始化Syncthing时被自动创建。如果你想同步更多文件夹,点击**Add Folder**按钮。
|
||||
|
||||
在右窗格中,你可以看到已连接的设备数。现在这里只有一个,就是你现在正在操作的计算机。
|
||||
|
||||
### 网页管理界面上设置Syncthing ###
|
||||
|
||||
为了提高安全性,让我们启用TLS,并且设置访问网页管理界面的管理员用户和密码。要做到这点,点击右上角的齿轮按钮,然后选择**Settings**
|
||||
|
||||

|
||||
|
||||
输入管理员的帐户名/密码。我设置的是admin/Ubuntu。你应该使用一些更复杂的密码。
|
||||
|
||||

|
||||
|
||||
点击Save按钮,现在,你会被要求重启Syncthing使更改生效。点击Restart。
|
||||
|
||||

|
||||
|
||||
刷新你的网页浏览器。你可以看到一个像下面一样的SSL警告。点击显示**我了解风险(I understand the Risks)**的按钮。接着,点击“添加例外(Add Exception)“按钮把当前页面添加进浏览器的信任列表中。
|
||||
|
||||

|
||||
|
||||
输入前面几步设置的管理员用户和密码。我设置的是**admin/ubuntu**。
|
||||
|
||||

|
||||
|
||||
现在,我们提高了网页管理界面的安全性。别忘了两个系统都要执行上面同样的步骤。
|
||||
|
||||
### 连接到其它服务器 ###
|
||||
|
||||
要在各个系统之间同步文件,你必须各自告诉它们其它服务器的信息。这是通过交换设备IDs(device IDs)来实现的。你可以通过选择“齿轮菜单(gear menu)”(在右上角)中的”Show ID(显示ID)“来找到它。
|
||||
|
||||
例如,下面是我系统1的ID.
|
||||
|
||||

|
||||
|
||||
复制这个ID,然后到另外一个系统(系统2)的网页管理界面,在右边窗格点击Add Device按钮。
|
||||
|
||||

|
||||
|
||||
接着会出现下面的界面。在Device区域粘贴**系统1 ID **。输入设备名称(可选)。在地址区域,你可以输入其它系统( LCTT 译注:即粘贴的ID所属的系统,此应为系统1)的IP地址,或者使用默认值。默认值为**dynamic**。最后,选择要同步的文件夹。在我们的例子中,同步文件夹为**default**。
|
||||
|
||||

|
||||
|
||||
一旦完成了,点击save按钮。你会被要求重启Syncthing。点击Restart按钮重启使更改生效。
|
||||
|
||||
现在,我们到**系统1**的网页管理界面,你会看到来自系统2的连接和同步请求。点击**Add**按钮。现在,系统2会要求系统1分享和同步名为default的文件夹。
|
||||
|
||||

|
||||
|
||||
接着重启系统1的Syncthing服务使更改生效。
|
||||
|
||||

|
||||
|
||||
等待大概60秒,接着你会看到两个系统之间已成功连接并同步。
|
||||
|
||||
你可以在网页管理界面中的Add Device区域核实该情况。
|
||||
|
||||
添加系统2后,系统1网页管理界面中的控制窗口如下:
|
||||
|
||||

|
||||
|
||||
添加系统1后,系统2网页管理界面中的控制窗口如下:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
现在,在任一个系统中的“**default**”文件夹中放进任意文件或文件夹。你应该可以看到这些文件/文件夹被自动同步到其它系统。
|
||||
|
||||
本文完!祝同步愉快!
|
||||
|
||||
噢耶!!!
|
||||
|
||||
- [Syncthing网站][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/syncthing-private-secure-tool-sync-filesfolders-computers/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/sk/
|
||||
[1]:https://github.com/syncthing/syncthing/releases/tag/v0.10.20
|
||||
[2]:http://syncthing.net/
|
||||
@ -0,0 +1,89 @@
|
||||
修复Linux中的“提供类似行编辑的袖珍BASH...”的GRUB错误
|
||||
================================================================================
|
||||
|
||||
这两天我[安装了Elementary OS和Windows双系统][1],在启动的时候遇到了一个Grub错误。命令行中呈现如下信息:
|
||||
|
||||
**Minimal BASH like line editing is supported. For the first word, TAB lists possible command completions. anywhere else TAB lists possible device or file completions.**
|
||||
|
||||
**提供类似行编辑的袖珍 BASH。TAB键补全第一个词,列出可以使用的命令。除此之外,TAB键补全可以列出可用的设备或文件。**
|
||||
|
||||

|
||||
|
||||
事实上这并不是Elementary OS独有的错误。这是常见的[Grub][2]错误,会在Ubuntu,Fedora,Linux Mint等Linux操作系统上发生。
|
||||
|
||||
通过这篇文章里我们可以学到基于Linux系统**如何修复Ubuntu中出现的“minimal BASH like line editing is supported” Grub错误**。
|
||||
|
||||
> 你可以参阅这篇教程来修复类似的常见问题,[错误:分区未找到Linux grub救援模式][3]。
|
||||
|
||||
### 先决条件 ###
|
||||
|
||||
要修复这个问题,你需要达成以下的条件:
|
||||
|
||||
- 一个包含相同版本、相同OS的LiveUSB或磁盘
|
||||
- 当前会话的Internet连接正常工作
|
||||
|
||||
在确认了你拥有先决条件了之后,让我们看看如何修复Linux的死亡黑屏(如果我可以这样的称呼它的话 ;) )。
|
||||
|
||||
### 如何在基于Ubuntu的Linux中修复“minimal BASH like line editing is supported” Grub错误 ###
|
||||
|
||||
我知道你一定疑问这种Grub错误并不局限于在基于Ubuntu的Linux发行版上发生,那为什么我要强调在基于Ubuntu的发行版上呢?原因是,在这里我们将采用一个简单的方法,用个叫做**Boot Repair**的工具来修复我们的问题。我并不确定在其他的诸如Fedora的发行版中是否有这个工具可用。不再浪费时间,我们来看如何修复“minimal BASH like line editing is supported” Grub错误。
|
||||
|
||||
### 步骤 1: 引导进入lives会话 ###
|
||||
|
||||
插入live USB,引导进入live会话。
|
||||
|
||||
### 步骤 2: 安装 Boot Repair ###
|
||||
|
||||
等你进入了lives会话后,打开终端使用以下命令来安装Boot Repair:
|
||||
|
||||
sudo add-apt-repository ppa:yannubuntu/boot-repair
|
||||
sudo apt-get update
|
||||
sudo apt-get install boot-repair
|
||||
|
||||
注意:推荐这篇教程[如何修复 apt-get update 无法添加新的 CD-ROM 的错误][4],如果你在运行以上命令是遭遇同样的问题。
|
||||
|
||||
### 步骤 3: 使用Boot Repair修复引导 ###
|
||||
|
||||
装完Boot Repair后,在命令行运行如下命令启动:
|
||||
|
||||
boot-repair &
|
||||
|
||||
其实操作非常简单直接,你仅需按照Boot Repair工具提供的说明操作即可。首先,点击Boot Repair中的**Recommended repair**选项。
|
||||
|
||||

|
||||
|
||||
Boot Repair需要花费一些时间来分析引导和Grub中存在的问题。然后,它会提供一些可在命令行中直接运行的命令。将这些命令一个个在终端中执行。我这边屏幕上显示的是:
|
||||
|
||||

|
||||
|
||||
在输入了这些命令之后,它会执行执行一段时间:
|
||||
|
||||

|
||||
|
||||
在这一过程结束后,它会提供一个由boot repair的日志组成的网页网址。如果你的引导问题这样都没有修复,你就可以去社区或是发邮件给开发团队并提交该网址作为参考。很酷!不是吗?
|
||||
|
||||

|
||||
|
||||
在boot repair成功完成后,关闭你的电脑,移除USB并再次引导。我这就能成功的引导了,但是在Grub画面上会多出额外的两行。相比于看到系统能够再次正常引导的喜悦这些对我来说并不重要。
|
||||
|
||||

|
||||
|
||||
### 对你有效吗? ###
|
||||
|
||||
这就是我修复**Elementary OS Freya中的minimal BASH like line editing is supported Grub 错误**的方法。怎么样?是否对你也有效呢?请自由的在下方的评论区提出你的问题和建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/fix-minimal-bash-line-editing-supported-grub-error-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/guide-install-elementary-os-luna/
|
||||
[2]:http://www.gnu.org/software/grub/
|
||||
[3]:http://itsfoss.com/solve-error-partition-grub-rescue-ubuntu-linux/
|
||||
[4]:http://itsfoss.com/fix-failed-fetch-cdrom-aptget-update-add-cdroms/
|
||||
@ -0,0 +1,101 @@
|
||||
FreeBSD 和 Linux 有什么不同?
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
### 简介 ###
|
||||
|
||||
BSD最初从UNIX继承而来,目前,有许多的类Unix操作系统是基于BSD的。FreeBSD是使用最广泛的开源的伯克利软件发行版(即 BSD 发行版)。就像它隐含的意思一样,它是一个自由开源的类Unix操作系统,并且是公共服务器平台。FreeBSD源代码通常以宽松的BSD许可证发布。它与Linux有很多相似的地方,但我们得承认它们在很多方面仍有不同。
|
||||
|
||||
本文的其余部分组织如下:FreeBSD的描述在第一部分,FreeBSD和Linux的相似点在第二部分,它们的区别将在第三部分讨论,对他们功能的讨论和总结在最后一节。
|
||||
|
||||
### FreeBSD描述 ###
|
||||
|
||||
#### 历史 ####
|
||||
|
||||
- FreeBSD的第一个版本发布于1993年,它的第一张CD-ROM是FreeBSD1.0,发行于1993年12月。接下来,FreeBSD 2.1.0在1995年发布,并且获得了所有用户的青睐。实际上许多IT公司都使用FreeBSD并且很满意,我们可以列出其中的一些:IBM、Nokia、NetApp和Juniper Network。
|
||||
|
||||
#### 许可证 ####
|
||||
|
||||
- 关于它的许可证,FreeBSD以多种开源许可证进行发布,它的名为Kernel的最新代码以两句版BSD许可证进行了发布,给予使用和重新发布FreeBSD的绝对自由。其它的代码则以三句版或四句版BSD许可证进行发布,有些是以GPL和CDDL的许可证发布的。
|
||||
|
||||
(LCTT 译注:BSD 许可证与 GPL 许可证相比,相当简短,最初只有四句规则;1999年应 RMS 请求,删除了第三句,新的许可证称作“新 BSD”或三句版BSD;原来的 BSD 许可证称作“旧 BSD”、“修订的 BSD”或四句版BSD;也有一种删除了第三、第四两句的版本,称之为两句版 BSD,等价于 MIT 许可证。)
|
||||
|
||||
#### 用户 ####
|
||||
|
||||
- FreeBSD的重要特点之一就是它的用户多样性。实际上,FreeBSD可以作为邮件服务器、Web 服务器、FTP 服务器以及路由器等,您只需要在它上运行服务相关的软件即可。而且FreeBSD还支持ARM、PowerPC、MIPS、x86、x86-64架构。
|
||||
|
||||
### FreeBSD和Linux的相似处 ###
|
||||
|
||||
FreeBSD和Linux是两个自由开源的软件。实际上,它们的用户可以很容易的检查并修改源代码,用户拥有绝对的自由。而且,FreeBSD和Linux都是类Unix系统,它们的内核、内部组件、库程序都使用从历史上的AT&T Unix继承来的算法。FreeBSD从根基上更像Unix系统,而Linux是作为自由的类Unix系统发布的。许多工具应用都可以在FreeBSD和Linux中找到,实际上,他们几乎有同样的功能。
|
||||
|
||||
此外,FreeBSD能够运行大量的Linux应用。它可以安装一个Linux的兼容层,这个兼容层可以在编译FreeBSD时加入AAC Compact Linux得到,或通过下载已编译了Linux兼容层的FreeBSD系统,其中会包括兼容程序:aac_linux.ko。不同于FreeBSD的是,Linux无法运行FreeBSD的软件。
|
||||
|
||||
最后,我们注意到虽然二者有同样的目标,但二者还是有一些不同之处,我们在下一节中列出。
|
||||
|
||||
### FreeBSD和Linux的区别 ###
|
||||
|
||||
目前对于大多数用户来说并没有一个选择FreeBSD还是Linux的明确的准则。因为他们有着很多同样的应用程序,因为他们都被称作类Unix系统。
|
||||
|
||||
在这一章,我们将列出这两种系统的一些重要的不同之处。
|
||||
|
||||
#### 许可证 ####
|
||||
|
||||
- 两个系统的区别首先在于它们的许可证。Linux以GPL许可证发行,它为用户提供阅读、发行和修改源代码的自由,GPL许可证帮助用户避免仅仅发行二进制。而FreeBSD以BSD许可证发布,BSD许可证比GPL更宽容,因为其衍生著作不需要仍以该许可证发布。这意味着任何用户能够使用、发布、修改代码,并且不需要维持之前的许可证。
|
||||
- 您可以依据您的需求,在两种许可证中选择一种。首先是BSD许可证,由于其特殊的条款,它更受用户青睐。实际上,这个许可证使用户在保证源代码的封闭性的同时,可以售卖以该许可证发布的软件。再说说GPL,它需要每个使用以该许可证发布的软件的用户多加注意。
|
||||
- 如果想在以不同许可证发布的两种软件中做出选择,您需要了解他们各自的许可证,以及他们开发中的方法论,从而能了解他们特性的区别,来选择更适合自己需求的。
|
||||
|
||||
#### 控制 ####
|
||||
|
||||
- 由于FreeBSD和Linux是以不同的许可证发布的,Linus Torvalds控制着Linux的内核,而FreeBSD却与Linux不同,它并未被控制。我个人更倾向于使用FreeBSD而不是Linux,这是因为FreeBSD才是绝对自由的软件,没有任何控制许可证的存在。Linux和FreeBSD还有其他的不同之处,我建议您先不急着做出选择,等读完本文后再做出您的选择。
|
||||
|
||||
#### 操作系统 ####
|
||||
|
||||
- Linux主要指内核系统,这与FreeBSD不同,FreeBSD的整个系统都被维护着。FreeBSD的内核和一组由FreeBSD团队开发的软件被作为一个整体进行维护。实际上,FreeBSD开发人员能够远程且高效的管理核心操作系统。
|
||||
- 而Linux方面,在管理系统方面有一些困难。由于不同的组件由不同的源维护,Linux开发者需要将它们汇集起来,才能达到同样的功能。
|
||||
- FreeBSD和Linux都给了用户大量的可选软件和发行版,但他们管理的方式不同。FreeBSD是统一的管理方式,而Linux需要被分别维护。
|
||||
|
||||
#### 硬件支持 ####
|
||||
|
||||
- 说到硬件支持,Linux比FreeBSD做的更好。但这不意味着FreeBSD没有像Linux那样支持硬件的能力。他们只是在管理的方式不同,这通常还依赖于您的需求。因此,如果您在寻找最新的解决方案,FreeBSD更适应您;但如果您在寻找更多的普适性,那最好使用Linux。
|
||||
|
||||
#### 原生FreeBSD Vs 原生Linux ####
|
||||
|
||||
- 两者的原生系统的区别又有不同。就像我之前说的,Linux是一个Unix的替代系统,由Linux Torvalds编写,并由网络上的许多极客一起协助实现的。Linux有一个现代系统所需要的全部功能,诸如虚拟内存、共享库、动态加载、优秀的内存管理等。它以GPL许可证发布。
|
||||
- FreeBSD也继承了Unix的许多重要的特性。FreeBSD作为在加州大学开发的BSD的一种发行版。开发BSD的最重要的原因是用一个开源的系统来替代AT&T操作系统,从而给用户无需AT&T许可证便可使用的能力。
|
||||
- 许可证的问题是开发者们最关心的问题。他们试图提供一个最大化克隆Unix的开源系统。这影响了用户的选择,由于FreeBSD使用BSD许可证进行发布,因而相比Linux更加自由。
|
||||
|
||||
#### 支持的软件包 ####
|
||||
|
||||
- 从用户的角度来看,另一个二者不同的地方便是软件包以及从源码安装的软件的可用性和支持。Linux只提供了预编译的二进制包,这与FreeBSD不同,它不但提供预编译的包,而且还提供从源码编译和安装的构建系统。使用它的 ports 工具,FreeBSD给了您选择使用预编译的软件包(默认)和在编译时定制您软件的能力。(LCTT 译注:此处说明有误。Linux 也提供了源代码方式的包,并支持自己构建。)
|
||||
- 这些 ports 允许您构建所有支持FreeBSD的软件。而且,它们的管理还是层次化的,您可以在/usr/ports下找到源文件的地址以及一些正确使用FreeBSD的文档。
|
||||
- 这些提到的 ports给予你产生不同软件包版本的可能性。FreeBSD给了您通过源代码构建以及预编译的两种软件,而不是像Linux一样只有预编译的软件包。您可以使用两种安装方式管理您的系统。
|
||||
|
||||
#### FreeBSD 和 Linux 常用工具比较 ####
|
||||
|
||||
- 有大量的常用工具在FreeBSD上可用,并且有趣的是他们由FreeBSD的团队所拥有。相反的,Linux工具来自GNU,这就是为什么在使用中有一些限制。(LCTT 译注:这也是 Linux 正式的名称被称作“GNU/Linux”的原因,因为本质上 Linux 其实只是指内核。)
|
||||
- 实际上FreeBSD采用的BSD许可证非常有益且有用。因此,您有能力维护核心操作系统,控制这些应用程序的开发。有一些工具类似于它们的祖先 - BSD和Unix的工具,但不同于GNU的套件,GNU套件只想做到最小的向后兼容。
|
||||
|
||||
#### 标准 Shell ####
|
||||
|
||||
- FreeBSD默认使用tcsh。它是csh的评估版,由于FreeBSD以BSD许可证发行,因此不建议您在其中使用GNU的组件 bash shell。bash和tcsh的区别仅仅在于tcsh的脚本功能。实际上,我们更推荐在FreeBSD中使用sh shell,因为它更加可靠,可以避免一些使用tcsh和csh时出现的脚本问题。
|
||||
|
||||
#### 一个更加层次化的文件系统 ####
|
||||
|
||||
- 像之前提到的一样,使用FreeBSD时,基础操作系统以及可选组件可以被很容易的区别开来。这导致了一些管理它们的标准。在Linux下,/bin,/sbin,/usr/bin或者/usr/sbin都是存放可执行文件的目录。FreeBSD不同,它有一些附加的对其进行组织的规范。基础操作系统被放在/usr/local/bin或者/usr/local/sbin目录下。这种方法可以帮助管理和区分基础操作系统和可选组件。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
FreeBSD和Linux都是自由且开源的系统,他们有相似点也有不同点。上面列出的内容并不能说哪个系统比另一个更好。实际上,FreeBSD和Linux都有自己的特点和技术规格,这使它们与别的系统区别开来。那么,您有什么看法呢?您已经有在使用它们中的某个系统了么?如果答案为是的话,请给我们您的反馈;如果答案是否的话,在读完我们的描述后,您怎么看?请在留言处发表您的观点。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/comparative-introduction-freebsd-linux-users/
|
||||
|
||||
作者:[anismaj][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.unixmen.com/author/anis/
|
||||
@ -1,4 +1,4 @@
|
||||
ZMap 文档
|
||||
互联网扫描器 ZMap 完全手册
|
||||
================================================================================
|
||||
1. 初识 ZMap
|
||||
1. 最佳扫描习惯
|
||||
@ -21,7 +21,7 @@ ZMap 文档
|
||||
|
||||
### 初识 ZMap ###
|
||||
|
||||
ZMap被设计用来针对IPv4所有地址或其中的大部分实施综合扫描的工具。ZMap是研究者手中的利器,但在运行ZMap时,请注意,您很有可能正在以每秒140万个包的速度扫描整个IPv4地址空间 。我们建议用户在实施即使小范围扫描之前,也联系一下本地网络的管理员并参考我们列举的最佳扫描习惯。
|
||||
ZMap被设计用来针对整个IPv4地址空间或其中的大部分实施综合扫描的工具。ZMap是研究者手中的利器,但在运行ZMap时,请注意,您很有可能正在以每秒140万个包的速度扫描整个IPv4地址空间 。我们建议用户即使在实施小范围扫描之前,也联系一下本地网络的管理员并参考我们列举的[最佳扫描体验](#bestpractices)。
|
||||
|
||||
默认情况下,ZMap会对于指定端口实施尽可能大速率的TCP SYN扫描。较为保守的情况下,对10,000个随机的地址的80端口以10Mbps的速度扫描,如下所示:
|
||||
|
||||
@ -42,11 +42,13 @@ ZMap也可用于扫描特定子网或CIDR地址块。例如,仅扫描10.0.0.0/
|
||||
0% (1h50m left); send: 39676 535 Kp/s (555 Kp/s avg); recv: 1663 220 p/s (232 p/s avg); hits: 0.04%
|
||||
0% (1h50m left); send: 45372 570 Kp/s (557 Kp/s avg); recv: 1890 226 p/s (232 p/s avg); hits: 0.04%
|
||||
|
||||
这些更新信息提供了扫描的即时状态并表示成:完成进度% (剩余时间); send: 发出包的数量 即时速率 (平均发送速率); recv: 接收包的数量 接收率 (平均接收率); hits: 成功率
|
||||
这些更新信息提供了扫描的即时状态并表示成:
|
||||
|
||||
如果您不知道您所在网络支持的扫描速率,您可能要尝试不同的扫描速率和带宽限制直到扫描效果开始下降,借此找出当前网络能够支持的最快速度。
|
||||
完成进度% (剩余时间); send: 发出包的数量 即时速率 (平均发送速率); recv: 接收包的数量 接收率 (平均接收率); hits: 命中率
|
||||
|
||||
默认情况下,ZMap会输出不同IP地址的列表(例如,SYN ACK数据包的情况)像下面这样。还有几种附加的格式(如,JSON和Redis)作为其输出结果,以及生成程序可解析的扫描统计选项。 同样,可以指定附加的输出字段并使用输出过滤来过滤输出的结果。
|
||||
如果您不知道您所在网络能支持的扫描速率,您可能要尝试不同的扫描速率和带宽限制直到扫描效果开始下降,借此找出当前网络能够支持的最快速度。
|
||||
|
||||
默认情况下,ZMap会输出不同IP地址的列表(例如,根据SYN ACK数据包的情况),像下面这样。其[输出结果](#output)还有几种附加的格式(如,JSON和Redis),可以用作生成[程序可解析的扫描统计](#verbosity)。 同样,可以指定附加的[输出字段](#outputfields)并使用[输出过滤](#outputfilter)来过滤输出的结果。
|
||||
|
||||
115.237.116.119
|
||||
23.9.117.80
|
||||
@ -54,52 +56,49 @@ ZMap也可用于扫描特定子网或CIDR地址块。例如,仅扫描10.0.0.0/
|
||||
217.120.143.111
|
||||
50.195.22.82
|
||||
|
||||
我们强烈建议您使用黑名单文件,以排除预留的/未分配的IP地址空间(如,组播地址,RFC1918),以及网络中需要排除在您扫描之外的地址。默认情况下,ZMap将采用位于 `/etc/zmap/blacklist.conf`的这个简单的黑名单文件中所包含的预留和未分配地址。如果您需要某些特定设置,比如每次运行ZMap时的最大带宽或黑名单文件,您可以在文件`/etc/zmap/zmap.conf`中指定或使用自定义配置文件。
|
||||
我们强烈建议您使用[黑名单文件](#blacklisting),以排除预留的/未分配的IP地址空间(如,RFC1918 规定的私有地址、组播地址),以及网络中需要排除在您扫描之外的地址。默认情况下,ZMap将采用位于 `/etc/zmap/blacklist.conf`的这个简单的[黑名单文件](#blacklisting)中所包含的预留和未分配地址。如果您需要某些特定设置,比如每次运行ZMap时的最大带宽或[黑名单文件](#blacklisting),您可以在文件`/etc/zmap/zmap.conf`中指定或使用自定义[配置文件](#config)。
|
||||
|
||||
如果您正试图解决扫描的相关问题,有几个选项可以帮助您调试。首先,您可以通过添加`--dryrun`实施预扫,以此来分析包可能会发送到网络的何处。此外,还可以通过设置'--verbosity=n`来更改日志详细程度。
|
||||
如果您正试图解决扫描的相关问题,有几个选项可以帮助您调试。首先,您可以通过添加`--dryrun`实施[预扫](#dryrun),以此来分析包可能会发送到网络的何处。此外,还可以通过设置'--verbosity=n`来更改[日志详细程度](#verbosity)。
|
||||
|
||||
----------
|
||||
### 最佳扫描体验 ###
|
||||
<a name="bestpractices" ></a>
|
||||
|
||||
### 最佳扫描习惯 ###
|
||||
|
||||
我们为针对互联网进行扫描的研究者提供了一些建议,以此来引导养成良好的互联网合作氛围
|
||||
我们为针对互联网进行扫描的研究者提供了一些建议,以此来引导养成良好的互联网合作氛围。
|
||||
|
||||
- 密切协同本地的网络管理员,以减少风险和调查
|
||||
- 确认扫描不会使本地网络或上游供应商瘫痪
|
||||
- 标记出在扫描中呈良性的网页和DNS条目的源地址
|
||||
- 明确注明扫描中所有连接的目的和范围
|
||||
- 提供一个简单的退出方法并及时响应请求
|
||||
- 在发起扫描的源地址的网页和DNS条目中申明你的扫描是善意的
|
||||
- 明确解释你的扫描中所有连接的目的和范围
|
||||
- 提供一个简单的退出扫描的方法并及时响应请求
|
||||
- 实施扫描时,不使用比研究对象需求更大的扫描范围或更快的扫描频率
|
||||
- 如果可以通过时间或源地址来传播扫描流量
|
||||
- 如果可以,将扫描流量分布到不同的时间或源地址上
|
||||
|
||||
即使不声明,使用扫描的研究者也应该避免利用漏洞或访问受保护的资源,并遵守其辖区内任何特殊的法律规定。
|
||||
|
||||
----------
|
||||
|
||||
### 命令行参数 ###
|
||||
<a name="args" ></a>
|
||||
|
||||
#### 通用选项 ####
|
||||
|
||||
这些选项是实施简单扫描时最常用的选项。我们注意到某些选项取决于所使用的探测模块或输出模块(如,在实施ICMP Echo扫描时是不需要使用目的端口的)。
|
||||
|
||||
这些选项是实施简单扫描时最常用的选项。我们注意到某些选项取决于所使用的[探测模块](#probemodule)或[输出模块](#outputmodule)(如,在实施ICMP Echo扫描时是不需要使用目的端口的)。
|
||||
|
||||
**-p, --target-port=port**
|
||||
|
||||
用来扫描的TCP端口号(例如,443)
|
||||
要扫描的目标TCP端口号(例如,443)
|
||||
|
||||
**-o, --output-file=name**
|
||||
|
||||
使用标准输出将结果写入该文件。
|
||||
将结果写入该文件,使用`-`代表输出到标准输出。
|
||||
|
||||
**-b, --blacklist-file=path**
|
||||
|
||||
文件中被排除的子网使用CIDR表示法(如192.168.0.0/16),一个一行。建议您使用此方法排除RFC 1918地址,组播地址,IANA预留空间等IANA专用地址。在conf/blacklist.example中提供了一个以此为目的示例黑名单文件。
|
||||
文件中被排除的子网使用CIDR表示法(如192.168.0.0/16),一个一行。建议您使用此方法排除RFC 1918地址、组播地址、IANA预留空间等IANA专用地址。在conf/blacklist.example中提供了一个以此为目的示例黑名单文件。
|
||||
|
||||
#### 扫描选项 ####
|
||||
|
||||
**-n, --max-targets=n**
|
||||
|
||||
限制探测目标的数量。后面跟的可以是一个数字(例如'-n 1000`)或百分比(例如,`-n 0.1%`)当然都是针对可扫描地址空间而言的(不包括黑名单)
|
||||
限制探测目标的数量。后面跟的可以是一个数字(例如'-n 1000`),或可扫描地址空间的百分比(例如,`-n 0.1%`,不包括黑名单)
|
||||
|
||||
**-N, --max-results=n**
|
||||
|
||||
@ -111,7 +110,7 @@ ZMap也可用于扫描特定子网或CIDR地址块。例如,仅扫描10.0.0.0/
|
||||
|
||||
**-r, --rate=pps**
|
||||
|
||||
设置传输速率,以包/秒为单位
|
||||
设置发包速率,以包/秒为单位
|
||||
|
||||
**-B, --bandwidth=bps**
|
||||
|
||||
@ -119,7 +118,7 @@ ZMap也可用于扫描特定子网或CIDR地址块。例如,仅扫描10.0.0.0/
|
||||
|
||||
**-c, --cooldown-time=secs**
|
||||
|
||||
发送完成后多久继续接收(默认值= 8)
|
||||
发送完成后等待多久继续接收回包(默认值= 8)
|
||||
|
||||
**-e, --seed=n**
|
||||
|
||||
@ -127,7 +126,7 @@ ZMap也可用于扫描特定子网或CIDR地址块。例如,仅扫描10.0.0.0/
|
||||
|
||||
**--shards=n**
|
||||
|
||||
将扫描分片/区在使其可多个ZMap中执行(默认值= 1)。启用分片时,`--seed`参数是必需的。
|
||||
将扫描分片/区,使其可多个ZMap中执行(默认值= 1)。启用分片时,`--seed`参数是必需的。
|
||||
|
||||
**--shard=n**
|
||||
|
||||
@ -165,7 +164,7 @@ ZMap也可用于扫描特定子网或CIDR地址块。例如,仅扫描10.0.0.0/
|
||||
|
||||
#### 探测选项 ####
|
||||
|
||||
ZMap允许用户指定并添加自己所需要探测的模块。 探测模块的职责就是生成主机回复的响应包。
|
||||
ZMap允许用户指定并添加自己所需要的[探测模块](#probemodule)。 探测模块的职责就是生成要发送的探测包,并处理主机回复的响应包。
|
||||
|
||||
**--list-probe-modules**
|
||||
|
||||
@ -173,7 +172,7 @@ ZMap允许用户指定并添加自己所需要探测的模块。 探测模块的
|
||||
|
||||
**-M, --probe-module=name**
|
||||
|
||||
选择探探测模块(默认值= tcp_synscan)
|
||||
选择[探测模块](#probemodule)(默认值= tcp_synscan)
|
||||
|
||||
**--probe-args=args**
|
||||
|
||||
@ -185,7 +184,7 @@ ZMap允许用户指定并添加自己所需要探测的模块。 探测模块的
|
||||
|
||||
#### 输出选项 ####
|
||||
|
||||
ZMap允许用户选择指定的输出模块。输出模块负责处理由探测模块返回的字段,并将它们交给用户。用户可以指定输出的范围,并过滤相应字段。
|
||||
ZMap允许用户指定和编写他们自己的[输出模块](#outputmodule)。输出模块负责处理由探测模块返回的字段,并将它们输出给用户。用户可以指定输出的字段,并过滤相应字段。
|
||||
|
||||
**--list-output-modules**
|
||||
|
||||
@ -193,7 +192,7 @@ ZMap允许用户选择指定的输出模块。输出模块负责处理由探测
|
||||
|
||||
**-O, --output-module=name**
|
||||
|
||||
选择输出模块(默认值为csv)
|
||||
选择[输出模块](#outputmodule)(默认值为csv)
|
||||
|
||||
**--output-args=args**
|
||||
|
||||
@ -201,21 +200,21 @@ ZMap允许用户选择指定的输出模块。输出模块负责处理由探测
|
||||
|
||||
**-f, --output-fields=fields**
|
||||
|
||||
输出列表,以逗号分割
|
||||
输出的字段列表,以逗号分割
|
||||
|
||||
**--output-filter**
|
||||
|
||||
通过指定相应的探测模块来过滤输出字段
|
||||
指定输出[过滤器](#outputfilter)对[探测模块](#probemodule)定义字段进行过滤
|
||||
|
||||
#### 附加选项 ####
|
||||
|
||||
**-C, --config=filename**
|
||||
|
||||
加载配置文件,可以指定其他路径。
|
||||
加载[配置文件](#config),可以指定其他路径。
|
||||
|
||||
**-q, --quiet**
|
||||
|
||||
不再是每秒刷新输出
|
||||
不必每秒刷新输出
|
||||
|
||||
**-g, --summary**
|
||||
|
||||
@ -233,13 +232,12 @@ ZMap允许用户选择指定的输出模块。输出模块负责处理由探测
|
||||
|
||||
打印版本并退出
|
||||
|
||||
----------
|
||||
|
||||
### 附加信息 ###
|
||||
<a name="additional"></a>
|
||||
|
||||
#### TCP SYN 扫描 ####
|
||||
|
||||
在执行TCP SYN扫描时,ZMap需要指定一个目标端口和以供扫描的源端口范围。
|
||||
在执行TCP SYN扫描时,ZMap需要指定一个目标端口,也支持指定发起扫描的源端口范围。
|
||||
|
||||
**-p, --target-port=port**
|
||||
|
||||
@ -249,27 +247,27 @@ ZMap允许用户选择指定的输出模块。输出模块负责处理由探测
|
||||
|
||||
发送扫描数据包的源端口(例如 40000-50000)
|
||||
|
||||
**警示!** ZMAP基于Linux内核使用SYN/ACK包应答,RST包关闭扫描打开的连接。ZMap是在Ethernet层完成包的发送的,这样做时为了减少跟踪打开的TCP连接和路由寻路带来的内核开销。因此,如果您有跟踪连接建立的防火墙规则,如netfilter的规则类似于`-A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT`,将阻止SYN/ACK包到达内核。这不会妨碍到ZMap记录应答,但它会阻止RST包被送回,最终连接会在超时后断开。我们强烈建议您在执行ZMap时,选择一组主机上未使用且防火墙允许访问的端口,加在`-s`后(如 `-s '50000-60000' ` )。
|
||||
**警示!** ZMap基于Linux内核使用RST包来应答SYN/ACK包响应,以关闭扫描器打开的连接。ZMap是在Ethernet层完成包的发送的,这样做是为了减少跟踪打开的TCP连接和路由寻路带来的内核开销。因此,如果您有跟踪连接建立的防火墙规则,如类似于`-A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT`的netfilter规则,将阻止SYN/ACK包到达内核。这不会妨碍到ZMap记录应答,但它会阻止RST包被送回,最终被扫描主机的连接会一直打开,直到超时后断开。我们强烈建议您在执行ZMap时,选择一组主机上未使用且防火墙允许访问的端口,加在`-s`后(如 `-s '50000-60000' ` )。
|
||||
|
||||
#### ICMP Echo 请求扫描 ####
|
||||
|
||||
虽然在默认情况下ZMap执行的是TCP SYN扫描,但它也支持使用ICMP echo请求扫描。在这种扫描方式下ICMP echo请求包被发送到每个主机,并以收到ICMP 应答包作为答复。实施ICMP扫描可以通过选择icmp_echoscan扫描模块来执行,如下:
|
||||
虽然在默认情况下ZMap执行的是TCP SYN扫描,但它也支持使用ICMP echo请求扫描。在这种扫描方式下ICMP echo请求包被发送到每个主机,并以收到ICMP应答包作为答复。实施ICMP扫描可以通过选择icmp_echoscan扫描模块来执行,如下:
|
||||
|
||||
$ zmap --probe-module=icmp_echoscan
|
||||
|
||||
#### UDP 数据报扫描 ####
|
||||
|
||||
ZMap还额外支持UDP探测,它会发出任意UDP数据报给每个主机,并能在无论UDP或是ICMP任何一个不可达的情况下接受应答。ZMap支持通过使用--probe-args命令行选择四种不同的UDP payload方式。这些都有可列印payload的‘文本’,用于命令行的十六进制payload的‘hex’,外部文件中包含payload的‘file’,和需要动态区域生成的payload的‘template’。为了得到UDP响应,请使用-f参数确保您指定的“data”领域处于汇报范围。
|
||||
ZMap还额外支持UDP探测,它会发出任意UDP数据报给每个主机,并接收UDP或ICMP不可达的应答。ZMap可以通过使用--probe-args命令行选项来设置四种不同的UDP载荷。这些是:可在命令行设置可打印的ASCII 码的‘text’载荷和十六进制载荷的‘hex’,外部文件中包含载荷的‘file’,和通过动态字段生成的载荷的‘template’。为了得到UDP响应,请使用-f参数确保您指定的“data”字段处于输出范围。
|
||||
|
||||
下面的例子将发送两个字节'ST',即PC的'status'请求,到UDP端口5632。
|
||||
下面的例子将发送两个字节'ST',即PCAnwywhere的'status'请求,到UDP端口5632。
|
||||
|
||||
$ zmap -M udp -p 5632 --probe-args=text:ST -N 100 -f saddr,data -o -
|
||||
|
||||
下面的例子将发送字节“0X02”,即SQL服务器的 'client broadcast'请求,到UDP端口1434。
|
||||
下面的例子将发送字节“0X02”,即SQL Server的'client broadcast'请求,到UDP端口1434。
|
||||
|
||||
$ zmap -M udp -p 1434 --probe-args=hex:02 -N 100 -f saddr,data -o -
|
||||
|
||||
下面的例子将发送一个NetBIOS状态请求到UDP端口137。使用一个ZMap自带的payload文件。
|
||||
下面的例子将发送一个NetBIOS状态请求到UDP端口137。使用一个ZMap自带的载荷文件。
|
||||
|
||||
$ zmap -M udp -p 1434 --probe-args=file:netbios_137.pkt -N 100 -f saddr,data -o -
|
||||
|
||||
@ -277,9 +275,9 @@ ZMap还额外支持UDP探测,它会发出任意UDP数据报给每个主机,
|
||||
|
||||
$ zmap -M udp -p 1434 --probe-args=file:sip_options.tpl -N 100 -f saddr,data -o -
|
||||
|
||||
UDP payload 模板仍处于实验阶段。当您在更多的使用一个以上的发送线程(-T)时可能会遇到崩溃和一个明显的相比静态payload性能降低的表现。模板仅仅是一个由一个或多个使用$ {}将字段说明封装成序列构成的payload文件。某些协议,特别是SIP,需要payload来反射包中的源和目的地址。其他协议,如端口映射和DNS,包含范围伴随每一次请求随机生成或Zamp扫描的多宿主系统将会抛出危险警告。
|
||||
UDP载荷模板仍处于实验阶段。当您在更多的使用一个以上的发送线程(-T)时可能会遇到崩溃和一个明显的相比静态载荷性能降低的表现。模板仅仅是一个由一个或多个使用${}将字段说明封装成序列构成的载荷文件。某些协议,特别是SIP,需要载荷来反射包中的源和目的包。其他协议,如portmapper和DNS,每个请求包含的字段应该是随机的,或降低被Zamp扫描的多宿主系统的风险。
|
||||
|
||||
以下的payload模板将发送SIP OPTIONS请求到每一个目的地:
|
||||
以下的载荷模板将发送SIP OPTIONS请求到每一个目的地:
|
||||
|
||||
OPTIONS sip:${RAND_ALPHA=8}@${DADDR} SIP/2.0
|
||||
Via: SIP/2.0/UDP ${SADDR}:${SPORT};branch=${RAND_ALPHA=6}.${RAND_DIGIT=10};rport;alias
|
||||
@ -293,10 +291,9 @@ UDP payload 模板仍处于实验阶段。当您在更多的使用一个以上
|
||||
User-Agent: ${RAND_ALPHA=8}
|
||||
Accept: text/plain
|
||||
|
||||
就像在上面的例子中展示的那样,对于大多数SIP正常的实现会在在每行行末添加\r\n,并且在请求的末尾一定包含\r\n\r\n。一个可以使用的在ZMap的examples/udp-payloads目录下的例子 (sip_options.tpl).
|
||||
|
||||
下面的字段正在如今的模板中实施:
|
||||
就像在上面的例子中展示的那样,注意每行行末以\r\n结尾,请求以\r\n\r\n结尾,大多数SIP实现都可以正确处理它。一个可以工作的例子放在ZMap的examples/udp-payloads目录下 (sip_options.tpl).
|
||||
|
||||
当前实现了下面的模板字段:
|
||||
|
||||
- **SADDR**: 源IP地址的点分十进制格式
|
||||
- **SADDR_N**: 源IP地址的网络字节序格式
|
||||
@ -306,14 +303,15 @@ UDP payload 模板仍处于实验阶段。当您在更多的使用一个以上
|
||||
- **SPORT_N**: 源端口的网络字节序格式
|
||||
- **DPORT**: 目的端口的ascii格式
|
||||
- **DPORT_N**: 目的端口的网络字节序格式
|
||||
- **RAND_BYTE**: 随机字节(0-255),长度由=(长度) 参数决定
|
||||
- **RAND_DIGIT**: 随机数字0-9,长度由=(长度) 参数决定
|
||||
- **RAND_ALPHA**: 随机大写字母A-Z,长度由=(长度) 参数决定
|
||||
- **RAND_ALPHANUM**: 随机大写字母A-Z和随机数字0-9,长度由=(长度) 参数决定
|
||||
- **RAND_BYTE**: 随机字节(0-255),长度由=(length) 参数决定
|
||||
- **RAND_DIGIT**: 随机数字0-9,长度由=(length) 参数决定
|
||||
- **RAND_ALPHA**: 随机大写字母A-Z,长度由=(length) 参数决定
|
||||
- **RAND_ALPHANUM**: 随机大写字母A-Z和随机数字0-9,长度由=(length) 参数决定
|
||||
|
||||
### 配置文件 ###
|
||||
<a name="config"></a>
|
||||
|
||||
ZMap支持使用配置文件代替在命令行上指定所有的需求选项。配置中可以通过每行指定一个长名称的选项和对应的值来创建:
|
||||
ZMap支持使用配置文件来代替在命令行上指定所有要求的选项。配置中可以通过每行指定一个长名称的选项和对应的值来创建:
|
||||
|
||||
interface "eth1"
|
||||
source-ip 1.1.1.4-1.1.1.8
|
||||
@ -324,11 +322,12 @@ ZMap支持使用配置文件代替在命令行上指定所有的需求选项。
|
||||
quiet
|
||||
summary
|
||||
|
||||
然后ZMap就可以按照配置文件和一些必要的附加参数运行了:
|
||||
然后ZMap就可以按照配置文件并指定一些必要的附加参数运行了:
|
||||
|
||||
$ zmap --config=~/.zmap.conf --target-port=443
|
||||
|
||||
### 详细 ###
|
||||
<a name="verbosity" ></a>
|
||||
|
||||
ZMap可以在屏幕上生成多种类型的输出。默认情况下,Zmap将每隔1秒打印出相似的基本进度信息。可以通过设置`--quiet`来禁用。
|
||||
|
||||
@ -377,8 +376,9 @@ ZMap还支持在扫描之后打印出一个的可grep的汇总信息,类似于
|
||||
adv permutation-gen 4215763218
|
||||
|
||||
### 结果输出 ###
|
||||
<a name="output" />
|
||||
|
||||
ZMap可以通过**输出模块**生成不同格式的结果。默认情况下,ZMap只支持**csv**的输出,但是可以通过编译支持**redis**和**json** 。可以使用**输出过滤**来过滤这些发送到输出模块上的结果。输出模块的范围由用户指定。默认情况如果没有指定输出文件,ZMap将以csv格式返回结果,ZMap不会产生特定结果。也可以编写自己的输出模块;请参阅编写输出模块。
|
||||
ZMap可以通过**输出模块**生成不同格式的结果。默认情况下,ZMap只支持**csv**的输出,但是可以通过编译支持**redis**和**json** 。可以使用**输出过滤**来过滤这些发送到输出模块上的结果。输出模块输出的字段由用户指定。默认情况如果没有指定输出文件,ZMap将以csv格式返回结果,而不会生成特定结果。也可以编写自己的输出模块;请参阅[编写输出模块](#exteding)。
|
||||
|
||||
**-o, --output-file=p**
|
||||
|
||||
@ -388,14 +388,13 @@ ZMap可以通过**输出模块**生成不同格式的结果。默认情况下,
|
||||
|
||||
调用自定义输出模块
|
||||
|
||||
|
||||
**-f, --output-fields=p**
|
||||
|
||||
输出以逗号分隔各字段的列表
|
||||
以逗号分隔的输出的字段列表
|
||||
|
||||
**--output-filter=filter**
|
||||
|
||||
在给定的探测区域实施输出过滤
|
||||
对给定的探测指定字段输出过滤
|
||||
|
||||
**--list-output-modules**
|
||||
|
||||
@ -403,17 +402,17 @@ ZMap可以通过**输出模块**生成不同格式的结果。默认情况下,
|
||||
|
||||
**--list-output-fields**
|
||||
|
||||
列出可用的给定探测区域
|
||||
列出给定的探测的可用输出字段
|
||||
|
||||
#### 输出字段 ####
|
||||
|
||||
ZMap有很多区域,它可以基于IP地址输出。这些区域可以通过在给定探测模块上运行`--list-output-fields`来查看。
|
||||
除了IP地址之外,ZMap有很多字段。这些字段可以通过在给定探测模块上运行`--list-output-fields`来查看。
|
||||
|
||||
$ zmap --probe-module="tcp_synscan" --list-output-fields
|
||||
saddr string: 应答包中的源IP地址
|
||||
saddr-raw int: 网络提供的整形形式的源IP地址
|
||||
saddr-raw int: 网络字节格式的源IP地址
|
||||
daddr string: 应答包中的目的IP地址
|
||||
daddr-raw int: 网络提供的整形形式的目的IP地址
|
||||
daddr-raw int: 网络字节格式的目的IP地址
|
||||
ipid int: 应答包中的IP识别号
|
||||
ttl int: 应答包中的ttl(存活时间)值
|
||||
sport int: TCP 源端口
|
||||
@ -426,7 +425,7 @@ ZMap有很多区域,它可以基于IP地址输出。这些区域可以通过
|
||||
repeat int: 是否是来自主机的重复响应
|
||||
cooldown int: 是否是在冷却时间内收到的响应
|
||||
timestamp-str string: 响应抵达时的时间戳使用ISO8601格式
|
||||
timestamp-ts int: 响应抵达时的时间戳使用纪元开始的秒数
|
||||
timestamp-ts int: 响应抵达时的时间戳使用UNIX纪元开始的秒数
|
||||
timestamp-us int: 时间戳的微秒部分(例如 从'timestamp-ts'的几微秒)
|
||||
|
||||
可以通过使用`--output-fields=fields`或`-f`来选择选择输出字段,任意组合的输出字段可以被指定为逗号分隔的列表。例如:
|
||||
@ -435,31 +434,32 @@ ZMap有很多区域,它可以基于IP地址输出。这些区域可以通过
|
||||
|
||||
#### 过滤输出 ####
|
||||
|
||||
在传到输出模块之前,探测模块生成的结果可以先过滤。过滤被实施在探测模块的输出字段上。过滤使用简单的过滤语法写成,类似于SQL,通过ZMap的**--output-filter**选项来实施。输出过滤通常用于过滤掉重复的结果或仅传输成功的响应到输出模块。
|
||||
在传到输出模块之前,探测模块生成的结果可以先过滤。过滤是针对探测模块的输出字段的。过滤使用类似于SQL的简单过滤语法写成,通过ZMap的**--output-filter**选项来指定。输出过滤通常用于过滤掉重复的结果,或仅传输成功的响应到输出模块。
|
||||
|
||||
过滤表达式的形式为`<字段名> <操作> <值>`。`<值>`的类型必须是一个字符串或一串无符号整数并且匹配`<字段名>`类型。对于整数比较有效的操作是`= !=, <, >, <=, >=`。字符串比较的操作是=,!=。`--list-output-fields`会打印那些可供探测模块选择的字段和类型,然后退出。
|
||||
过滤表达式的形式为`<字段名> <操作符> <值>`。`<值>`的类型必须是一个字符串或一串无符号整数并且匹配`<字段名>`类型。对于整数比较有效的操作符是`= !=, <, >, <=, >=`。字符串比较的操作是=,!=。`--list-output-fields`可以打印那些可供探测模块选择的字段和类型,然后退出。
|
||||
|
||||
复合型的过滤操作,可以通过使用`&&`(逻辑与)和`||`(逻辑或)这样的运算符来组合出特殊的过滤操作。
|
||||
|
||||
**示例**
|
||||
|
||||
书写一则过滤仅显示成功,过滤重复应答
|
||||
书写一则过滤仅显示成功的、不重复的应答
|
||||
|
||||
--output-filter="success = 1 && repeat = 0"
|
||||
|
||||
过滤出包中含RST并且TTL大于10的分类,或者包中含SYNACK的分类
|
||||
过滤出RST分类并且TTL大于10的包,或者SYNACK分类的包
|
||||
|
||||
--output-filter="(classification = rst && ttl > 10) || classification = synack"
|
||||
|
||||
#### CSV ####
|
||||
|
||||
csv模块将会生成以逗号分隔各输出请求字段的文件。例如,以下的指令将生成下面的CSV至名为`output.csv`的文件。
|
||||
csv模块将会生成以逗号分隔各个要求输出的字段的文件。例如,以下的指令将生成名为`output.csv`的CSV文件。
|
||||
|
||||
$ zmap -p 80 -f "response,saddr,daddr,sport,seq,ack,in_cooldown,is_repeat,timestamp" -o output.csv
|
||||
|
||||
----------
|
||||
|
||||
响应, 源地址, 目的地址, 源端口, 目的端口, 序列号, 应答, 是否是冷却模式, 是否重复, 时间戳
|
||||
#响应, 源地址, 目的地址, 源端口, 目的端口, 序列号, 应答, 是否是冷却模式, 是否重复, 时间戳
|
||||
response, saddr, daddr, sport, dport, seq, ack, in_cooldown, is_repeat, timestamp
|
||||
synack, 159.174.153.144, 10.0.0.9, 80, 40555, 3050964427, 3515084203, 0, 0,2013-08-15 18:55:47.681
|
||||
rst, 141.209.175.1, 10.0.0.9, 80, 40136, 0, 3272553764, 0, 0,2013-08-15 18:55:47.683
|
||||
rst, 72.36.213.231, 10.0.0.9, 80, 56642, 0, 2037447916, 0, 0,2013-08-15 18:55:47.691
|
||||
@ -472,13 +472,20 @@ csv模块将会生成以逗号分隔各输出请求字段的文件。例如,
|
||||
|
||||
#### Redis ####
|
||||
|
||||
Redis的输出模块允许地址被添加到一个Redis的队列,不是被保存到文件,允许ZMap将它与之后的处理工具结合使用。
|
||||
Redis的输出模块允许地址被添加到一个Redis的队列,而不是保存到文件,允许ZMap将它与之后的处理工具结合使用。
|
||||
|
||||
**注意!** ZMap默认不会编译Redis功能。如果您想要将Redis功能编译进ZMap源码中,可以在CMake的时候加上`-DWITH_REDIS=ON`。
|
||||
**注意!** ZMap默认不会编译Redis功能。如果你从源码构建ZMap,可以在CMake的时候加上`-DWITH_REDIS=ON`来增加Redis支持。
|
||||
|
||||
#### JSON ####
|
||||
|
||||
JSON输出模块用起来类似于CSV模块,只是以JSON格式写入到文件。JSON文件能轻松地导入到其它可以读取JSON的程序中。
|
||||
|
||||
**注意!**,ZMap默认不会编译JSON功能。如果你从源码构建ZMap,可以在CMake的时候加上`-DWITH_JSON=ON`来增加JSON支持。
|
||||
|
||||
### 黑名单和白名单 ###
|
||||
<a name="blacklisting"></a>
|
||||
|
||||
ZMap同时支持对网络前缀做黑名单和白名单。如果ZMap不加黑名单和白名单参数,他将会扫描所有的IPv4地址(包括本地的,保留的以及组播地址)。如果指定了黑名单文件,那么在黑名单中的网络前缀将不再扫描;如果指定了白名单文件,只有那些网络前缀在白名单内的才会扫描。白名单和黑名单文件可以协同使用;黑名单运用于白名单上(例如:如果您在白名单中指定了10.0.0.0/8并在黑名单中指定了10.1.0.0/16,那么10.1.0.0/16将不会扫描)。白名单和黑名单文件可以在命令行中指定,如下所示:
|
||||
ZMap同时支持对网络前缀做黑名单和白名单。如果ZMap不加黑名单和白名单参数,他将会扫描所有的IPv4地址(包括本地的,保留的以及组播地址)。如果指定了黑名单文件,那么在黑名单中的网络前缀将不再扫描;如果指定了白名单文件,只有那些网络前缀在白名单内的才会扫描。白名单和黑名单文件可以协同使用;黑名单优先于白名单(例如:如果您在白名单中指定了10.0.0.0/8并在黑名单中指定了10.1.0.0/16,那么10.1.0.0/16将不会扫描)。白名单和黑名单文件可以在命令行中指定,如下所示:
|
||||
|
||||
**-b, --blacklist-file=path**
|
||||
|
||||
@ -488,7 +495,7 @@ ZMap同时支持对网络前缀做黑名单和白名单。如果ZMap不加黑名
|
||||
|
||||
文件用于记录限制扫描的子网,以CIDR的表示法,例如192.168.0.0/16
|
||||
|
||||
黑名单文件的每行都需要以CIDR的表示格式书写一个单一的网络前缀。允许使用`#`加以备注。例如:
|
||||
黑名单文件的每行都需要以CIDR的表示格式书写,一行单一的网络前缀。允许使用`#`加以备注。例如:
|
||||
|
||||
# IANA(英特网编号管理局)记录的用于特殊目的的IPv4地址
|
||||
# http://www.iana.org/assignments/iana-ipv4-special-registry/iana-ipv4-special-registry.xhtml
|
||||
@ -501,14 +508,14 @@ ZMap同时支持对网络前缀做黑名单和白名单。如果ZMap不加黑名
|
||||
169.254.0.0/16 # RFC3927: 本地链路地址
|
||||
172.16.0.0/12 # RFC1918: 私有地址
|
||||
192.0.0.0/24 # RFC6890: IETF协议预留
|
||||
192.0.2.0/24 # RFC5737: 测试地址
|
||||
192.88.99.0/24 # RFC3068: IPv6转换到IPv4的任意播
|
||||
192.0.2.0/24 # RFC5737: 测试地址1
|
||||
192.88.99.0/24 # RFC3068: IPv6转换到IPv4的任播
|
||||
192.168.0.0/16 # RFC1918: 私有地址
|
||||
192.18.0.0/15 # RFC2544: 检测地址
|
||||
198.51.100.0/24 # RFC5737: 测试地址
|
||||
203.0.113.0/24 # RFC5737: 测试地址
|
||||
198.51.100.0/24 # RFC5737: 测试地址2
|
||||
203.0.113.0/24 # RFC5737: 测试地址3
|
||||
240.0.0.0/4 # RFC1112: 预留地址
|
||||
255.255.255.255/32 # RFC0919: 广播地址
|
||||
255.255.255.255/32 # RFC0919: 限制广播地址
|
||||
|
||||
# IANA记录的用于组播的地址空间
|
||||
# http://www.iana.org/assignments/multicast-addresses/multicast-addresses.xhtml
|
||||
@ -516,13 +523,14 @@ ZMap同时支持对网络前缀做黑名单和白名单。如果ZMap不加黑名
|
||||
|
||||
224.0.0.0/4 # RFC5771: 组播/预留地址ed
|
||||
|
||||
如果您只是想扫描因特网中随机的一部分地址,使用采样检出,来代替使用白名单和黑名单。
|
||||
如果您只是想扫描因特网中随机的一部分地址,使用[抽样](#ratelimiting)检出,来代替使用白名单和黑名单。
|
||||
|
||||
**注意!**ZMap默认设置使用`/etc/zmap/blacklist.conf`作为黑名单文件,其中包含有本地的地址空间和预留的IP空间。通过编辑`/etc/zmap/zmap.conf`可以改变默认的配置。
|
||||
|
||||
### 速度限制与抽样 ###
|
||||
<a name="ratelimiting"></a>
|
||||
|
||||
默认情况下,ZMap将以您当前网络所能支持的最快速度扫描。以我们对于常用硬件的经验,这普遍是理论上Gbit以太网速度的95-98%,这可能比您的上游提供商可处理的速度还要快。ZMap是不会自动的根据您的上游提供商来调整发送速率的。您可能需要手动的调整发送速率来减少丢包和错误结果。
|
||||
默认情况下,ZMap将以您当前网卡所能支持的最快速度扫描。以我们对于常用硬件的经验,这通常是理论上Gbit以太网速度的95-98%,这可能比您的上游提供商可处理的速度还要快。ZMap是不会自动的根据您的上游提供商来调整发送速率的。您可能需要手动的调整发送速率来减少丢包和错误结果。
|
||||
|
||||
**-r, --rate=pps**
|
||||
|
||||
@ -530,9 +538,9 @@ ZMap同时支持对网络前缀做黑名单和白名单。如果ZMap不加黑名
|
||||
|
||||
**-B, --bandwidth=bps**
|
||||
|
||||
设置发送速率以比特/秒(支持G,M和K后缀)。也同样作用于--rate的参数。
|
||||
设置发送速率以比特/秒(支持G,M和K后缀)。这会覆盖--rate参数。
|
||||
|
||||
ZMap同样支持对IPv4地址空间进行指定最大目标数和/或最长运行时间的随机采样。由于针对主机的扫描是通过随机排序生成的实例,限制扫描的主机个数为N就会随机抽选N个主机。命令选项如下:
|
||||
ZMap同样支持对IPv4地址空间进行指定最大目标数和/或最长运行时间的随机采样。由于每次对主机的扫描是通过随机排序生成的,限制扫描的主机个数为N就会随机抽选N个主机。命令选项如下:
|
||||
|
||||
**-n, --max-targets=n**
|
||||
|
||||
@ -540,7 +548,7 @@ ZMap同样支持对IPv4地址空间进行指定最大目标数和/或最长运
|
||||
|
||||
**-N, --max-results=n**
|
||||
|
||||
结果上限数量(累积收到这么多结果后推出)
|
||||
结果上限数量(累积收到这么多结果后退出)
|
||||
|
||||
**-t, --max-runtime=s**
|
||||
|
||||
@ -554,48 +562,46 @@ ZMap同样支持对IPv4地址空间进行指定最大目标数和/或最长运
|
||||
|
||||
zmap -p 443 -s 3 -n 1000000 -o results
|
||||
|
||||
为了确定哪一百万主机将要被扫描,您可以执行预扫,只列印数据包而非发送,并非真的实施扫描。
|
||||
为了确定哪一百万主机将要被扫描,您可以执行预扫,只打印数据包而非发送,并非真的实施扫描。
|
||||
|
||||
zmap -p 443 -s 3 -n 1000000 --dryrun | grep daddr
|
||||
| awk -F'daddr: ' '{print $2}' | sed 's/ |.*//;'
|
||||
|
||||
### 发送多个数据包 ###
|
||||
|
||||
ZMap支持想每个主机发送多个扫描。增加这个数量既增加了扫描时间又增加了到达的主机数量。然而,我们发现,增加扫描时间(每个额外扫描的增加近100%)远远大于到达的主机数量(每个额外扫描的增加近1%)。
|
||||
ZMap支持向每个主机发送多个探测。增加这个数量既增加了扫描时间又增加了到达的主机数量。然而,我们发现,增加的扫描时间(每个额外扫描的增加近100%)远远大于到达的主机数量(每个额外扫描的增加近1%)。
|
||||
|
||||
**-P, --probes=n**
|
||||
|
||||
向每个IP发出的独立扫描个数(默认值=1)
|
||||
向每个IP发出的独立探测个数(默认值=1)
|
||||
|
||||
----------
|
||||
### 示例应用 ###
|
||||
|
||||
### 示例应用程序 ###
|
||||
|
||||
ZMap专为向大量主机发启连接并寻找那些正确响应而设计。然而,我们意识到许多用户需要执行一些后续处理,如执行应用程序级别的握手。例如,用户在80端口实施TCP SYN扫描可能只是想要实施一个简单的GET请求,还有用户扫描443端口可能是对TLS握手如何完成感兴趣。
|
||||
ZMap专为向大量主机发起连接并寻找那些正确响应而设计。然而,我们意识到许多用户需要执行一些后续处理,如执行应用程序级别的握手。例如,用户在80端口实施TCP SYN扫描也许想要实施一个简单的GET请求,还有用户扫描443端口可能希望完成TLS握手。
|
||||
|
||||
#### Banner获取 ####
|
||||
|
||||
我们收录了一个示例程序,banner-grab,伴随ZMap使用可以让用户从监听状态的TCP服务器上接收到消息。Banner-grab连接到服务上,任意的发送一个消息,然后打印出收到的第一个消息。这个工具可以用来获取banners例如HTTP服务的回复的具体指令,telnet登陆提示,或SSH服务的字符串。
|
||||
我们收录了一个示例程序,banner-grab,伴随ZMap使用可以让用户从监听状态的TCP服务器上接收到消息。Banner-grab连接到提供的服务器上,发送一个可选的消息,然后打印出收到的第一个消息。这个工具可以用来获取banner,例如HTTP服务的回复的具体指令,telnet登陆提示,或SSH服务的字符串。
|
||||
|
||||
这个例子寻找了1000个监听80端口的服务器,并向每个发送一个简单的GET请求,存储他们的64位编码响应至http-banners.out
|
||||
下面的例子寻找了1000个监听80端口的服务器,并向每个发送一个简单的GET请求,存储他们的64位编码响应至http-banners.out
|
||||
|
||||
$ zmap -p 80 -N 1000 -B 10M -o - | ./banner-grab-tcp -p 80 -c 500 -d ./http-req > out
|
||||
|
||||
如果想知道更多使用`banner-grab`的细节,可以参考`examples/banner-grab`中的README文件。
|
||||
|
||||
**注意!** ZMap和banner-grab(如例子中)同时运行可能会比较显著的影响对方的表现和精度。确保不让ZMap充满banner-grab-tcp的并发连接,不然banner-grab将会落后于标准输入的读入,导致屏蔽编写标准输出。我们推荐使用较慢扫描速率的ZMap,同时提升banner-grab-tcp的并发性至3000以内(注意 并发连接>1000需要您使用`ulimit -SHn 100000`和`ulimit -HHn 100000`来增加每个问进程的最大文件描述)。当然,这些参数取决于您服务器的性能,连接成功率(hit-rate);我们鼓励开发者在运行大型扫描之前先进行小样本的试验。
|
||||
**注意!** ZMap和banner-grab(如例子中)同时运行可能会比较显著的影响对方的表现和精度。确保不让ZMap占满banner-grab-tcp的并发连接,不然banner-grab将会落后于标准输入的读入,导致阻塞ZMap的输出写入。我们推荐使用较慢扫描速率的ZMap,同时提升banner-grab-tcp的并发性至3000以内(注意 并发连接>1000需要您使用`ulimit -SHn 100000`和`ulimit -HHn 100000`来增加每个进程的最大文件描述符数量)。当然,这些参数取决于您服务器的性能、连接成功率(hit-rate);我们鼓励开发者在运行大型扫描之前先进行小样本的试验。
|
||||
|
||||
#### 建立套接字 ####
|
||||
|
||||
我们也收录了另一种形式的banner-grab,就是forge-socket, 重复利用服务器发出的SYN-ACK,连接并最终取得banner。在`banner-grab-tcp`中,ZMap向每个服务器发送一个SYN,并监听服务器发回的带有SYN+ACK的应答。运行ZMap主机的内核接受应答后发送RST,因为有没有处于活动状态的连接与该包关联。程序banner-grab必须在这之后创建一个新的TCP连接到从服务器获取数据。
|
||||
我们也收录了另一种形式的banner-grab,就是forge-socket, 重复利用服务器发出的SYN-ACK,连接并最终取得banner。在`banner-grab-tcp`中,ZMap向每个服务器发送一个SYN,并监听服务器发回的带有SYN+ACK的应答。运行ZMap主机的内核接受应答后发送RST,这样就没有与该包关联活动连接。程序banner-grab必须在这之后创建一个新的TCP连接到从服务器获取数据。
|
||||
|
||||
在forge-socket中,我们以同样的名字利用内核模块,这使我们可以创建任意参数的TCP连接。这样可以抑制内核的RST包,并且通过创建套接字取代它可以重用SYN+ACK的参数,通过这个套接字收发数据和我们平时使用的连接套接字并没有什么不同。
|
||||
在forge-socket中,我们利用内核中同名的模块,使我们可以创建任意参数的TCP连接。可以通过抑制内核的RST包,并重用SYN+ACK的参数取代该包而创建套接字,通过这个套接字收发数据和我们平时使用的连接套接字并没有什么不同。
|
||||
|
||||
要使用forge-socket,您需要forge-socket内核模块,从[github][1]上可以获得。您需要git clone `git@github.com:ewust/forge_socket.git`至ZMap源码根目录,然后cd进入forge_socket 目录,运行make。以root身份安装带有`insmod forge_socket.ko` 的内核模块。
|
||||
要使用forge-socket,您需要forge-socket内核模块,从[github][1]上可以获得。您需要`git clone git@github.com:ewust/forge_socket.git`至ZMap源码根目录,然后cd进入forge_socket目录,运行make。以root身份运行`insmod forge_socket.ko` 来安装该内核模块。
|
||||
|
||||
您也需要告知内核不要发送RST包。一个简单的在全系统禁用RST包的方法是**iptables**。以root身份运行`iptables -A OUTPUT -p tcp -m tcp --tcp-flgas RST,RST RST,RST -j DROP`即可,当然您也可以加上一项--dport X将禁用局限于所扫描的端口(X)上。扫描完成后移除这项设置,以root身份运行`iptables -D OUTPUT -p tcp -m tcp --tcp-flags RST,RST RST,RST -j DROP`即可。
|
||||
您也需要告知内核不要发送RST包。一个简单的在全系统禁用RST包的方法是使用**iptables**。以root身份运行`iptables -A OUTPUT -p tcp -m tcp --tcp-flgas RST,RST RST,RST -j DROP`即可,当然您也可以加上一项`--dport X`将禁用局限于所扫描的端口(X)上。扫描完成后移除这项设置,以root身份运行`iptables -D OUTPUT -p tcp -m tcp --tcp-flags RST,RST RST,RST -j DROP`即可。
|
||||
|
||||
现在应该可以建立forge-socket的ZMap示例程序了。运行需要使用**extended_file**ZMap输出模块:
|
||||
现在应该可以建立forge-socket的ZMap示例程序了。运行需要使用**extended_file**ZMap[输出模块](#outputmodule):
|
||||
|
||||
$ zmap -p 80 -N 1000 -B 10M -O extended_file -o - | \
|
||||
./forge-socket -c 500 -d ./http-req > ./http-banners.out
|
||||
@ -605,8 +611,9 @@ ZMap专为向大量主机发启连接并寻找那些正确响应而设计。然
|
||||
----------
|
||||
|
||||
### 编写探测和输出模块 ###
|
||||
<a name="extending"></a>
|
||||
|
||||
ZMap可以通过**probe modules**扩展支持不同类型的扫描,通过**output modules**追加不同类型的输出结果。注册过的探测和输出模块可以在命令行中列出:
|
||||
ZMap可以通过**探测模块**来扩展支持不同类型的扫描,通过**输出模块**增加不同类型的输出结果。注册过的探测和输出模块可以在命令行中列出:
|
||||
|
||||
**--list-probe-modules**
|
||||
|
||||
@ -617,95 +624,95 @@ ZMap可以通过**probe modules**扩展支持不同类型的扫描,通过**out
|
||||
列出安装过的输出模块
|
||||
|
||||
#### 输出模块 ####
|
||||
<a name="outputmodule"></a>
|
||||
|
||||
ZMap的输出和输出后处理可以通过执行和注册扫描的**output modules**来扩展。输出模块在接收每一个应答包时都会收到一个回调。然而提供的默认模块仅提供简单的输出,这些模块同样支持扩展扫描后处理(例如:重复跟踪或输出AS号码来代替IP地址)
|
||||
ZMap的输出和输出后处理可以通过实现和注册扫描器的**输出模块**来扩展。输出模块在接收每一个应答包时都会收到一个回调。然而默认提供的模块仅提供简单的输出,这些模块同样支持更多的输出后处理(例如:重复跟踪或输出AS号码来代替IP地址)。
|
||||
|
||||
通过定义一个新的output_module机构体来创建输出模块,并在[output_modules.c][2]中注册:
|
||||
通过定义一个新的output_module结构来创建输出模块,并在[output_modules.c][2]中注册:
|
||||
|
||||
typedef struct output_module {
|
||||
const char *name; // 在命令行如何引出输出模块
|
||||
const char *name; // 在命令行如何引用输出模块
|
||||
unsigned update_interval; // 以秒为单位的更新间隔
|
||||
|
||||
output_init_cb init; // 在扫描初始化的时候调用
|
||||
output_update_cb start; // 在开始的扫描的时候调用
|
||||
output_init_cb init; // 在扫描器初始化的时候调用
|
||||
output_update_cb start; // 在扫描器开始的时候调用
|
||||
output_update_cb update; // 每次更新间隔调用,秒为单位
|
||||
output_update_cb close; // 扫描终止后调用
|
||||
|
||||
output_packet_cb process_ip; // 接收到应答时调用
|
||||
|
||||
const char *helptext; // 会在--list-output-modules时打印在屏幕啥
|
||||
const char *helptext; // 会在--list-output-modules时打印在屏幕上
|
||||
|
||||
} output_module_t;
|
||||
|
||||
输出模块必须有名称,通过名称可以在命令行、普遍实施的`success_ip`和常见的`other_ip`回调中使用模块。process_ip的回调由每个收到的或经由**probe module**过滤的应答包调用。应答是否被认定为成功并不确定(比如,他可以是一个TCP的RST)。这些回调必须定义匹配`output_packet_cb`定义的函数:
|
||||
输出模块必须有名称,通过名称可以在命令行调用,并且通常会实现`success_ip`和常见的`other_ip`回调。process_ip的回调由每个收到并经由**probe module**过滤的应答包调用。应答是否被认定为成功并不确定(比如,它可以是一个TCP的RST)。这些回调必须定义匹配`output_packet_cb`定义的函数:
|
||||
|
||||
int (*output_packet_cb) (
|
||||
|
||||
ipaddr_n_t saddr, // network-order格式的扫描主机IP地址
|
||||
ipaddr_n_t daddr, // network-order格式的目的IP地址
|
||||
ipaddr_n_t saddr, // 网络字节格式的发起扫描主机IP地址
|
||||
ipaddr_n_t daddr, // 网络字节格式的目的IP地址
|
||||
|
||||
const char* response_type, // 发送模块的数据包分类
|
||||
|
||||
int is_repeat, // {0: 主机的第一个应答, 1: 后续的应答}
|
||||
int in_cooldown, // {0: 非冷却状态, 1: 扫描处于冷却中}
|
||||
int in_cooldown, // {0: 非冷却状态, 1: 扫描器处于冷却中}
|
||||
|
||||
const u_char* packet, // 指向结构体iphdr中IP包的指针
|
||||
size_t packet_len // 包的长度以字节为单位
|
||||
const u_char* packet, // 指向IP包的iphdr结构体的指针
|
||||
size_t packet_len // 包的长度,以字节为单位
|
||||
);
|
||||
|
||||
输出模块还可以通过注册回调执行在扫描初始化的时候(诸如打开输出文件的任务),扫描开始阶段(诸如记录黑名单的任务),在常规间隔实施(诸如程序升级的任务)在关闭的时候(诸如关掉所有打开的文件描述符。这些回调提供完整的扫描配置入口和实时状态:
|
||||
输出模块还可以通过注册回调,执行在扫描初始化的时候(诸如打开输出文件的任务)、在扫描开始阶段(诸如记录黑名单的任务)、在扫描的常规间隔(诸如状态更新的任务)、在关闭的时候(诸如关掉所有打开的文件描述符)。提供的这些回调可以完整的访问扫描配置和当前状态:
|
||||
|
||||
int (*output_update_cb)(struct state_conf*, struct state_send*, struct state_recv*);
|
||||
|
||||
被定义在[output_modules.h][3]中。在[src/output_modules/module_csv.c][4]中有可用示例。
|
||||
这些定义在[output_modules.h][3]中。在[src/output_modules/module_csv.c][4]中有可用示例。
|
||||
|
||||
#### 探测模块 ####
|
||||
<a name="probemodule"></a>
|
||||
|
||||
数据包由探测模块构造,由此可以创建抽象包并对应答分类。ZMap默认拥有两个扫描模块:`tcp_synscan`和`icmp_echoscan`。默认情况下,ZMap使用`tcp_synscan`来发送TCP SYN包并对每个主机的并对每个主机的响应分类,如打开时(收到SYN+ACK)或关闭时(收到RST)。ZMap允许开发者编写自己的ZMap探测模块,使用如下的API:
|
||||
数据包由**探测模块**构造,它可以创建各种包和不同类型的响应。ZMap默认拥有两个扫描模块:`tcp_synscan`和`icmp_echoscan`。默认情况下,ZMap使用`tcp_synscan`来发送TCP SYN包并对每个主机的响应分类,如打开时(收到SYN+ACK)或关闭时(收到RST)。ZMap允许开发者编写自己的ZMap探测模块,使用如下的API:
|
||||
|
||||
任何类型的扫描的实施都需要在`send_module_t`结构体内开发和注册必要的回调:
|
||||
任何类型的扫描都必须通过开发和注册`send_module_t`结构中的回调来实现:
|
||||
|
||||
typedef struct probe_module {
|
||||
const char *name; // 如何在命令行调用扫描
|
||||
size_t packet_length; // 探测包有多长(必须是静态的)
|
||||
|
||||
const char *pcap_filter; // 对收到的响应实施PCAP过滤
|
||||
size_t pcap_snaplen; // maximum number of bytes for libpcap to capture
|
||||
|
||||
uint8_t port_args; // 设为1,如果需要使用ZMap的--target-port
|
||||
// 用户指定
|
||||
size_t pcap_snaplen; // libpcap 捕获的最大字节数
|
||||
uint8_t port_args; // 设为1,如果ZMap需要用户指定--target-port
|
||||
|
||||
probe_global_init_cb global_initialize; // 在扫描初始化会时被调用一次
|
||||
probe_thread_init_cb thread_initialize; // 每个包缓存区的线程中被调用一次
|
||||
probe_make_packet_cb make_packet; // 每个主机更新包的时候被调用一次
|
||||
probe_validate_packet_cb validate_packet; // 每收到一个包被调用一次,
|
||||
// 如果包无效返回0,
|
||||
// 非零则覆盖。
|
||||
// 非零则有效。
|
||||
|
||||
probe_print_packet_cb print_packet; // 如果在dry-run模式下被每个包都调用
|
||||
probe_classify_packet_cb process_packet; // 由区分响应的接收器调用
|
||||
probe_print_packet_cb print_packet; // 如果在预扫模式下被每个包都调用
|
||||
probe_classify_packet_cb process_packet; // 由区分响应的接收器调用
|
||||
probe_close_cb close; // 扫描终止后被调用
|
||||
|
||||
fielddef_t *fields // 该模块指定的区域的定义
|
||||
int numfields // 区域的数量
|
||||
fielddef_t *fields // 该模块指定的字段的定义
|
||||
int numfields // 字段的数量
|
||||
|
||||
} probe_module_t;
|
||||
|
||||
在扫描操作初始化时会调用一次`global_initialize`,可以用来实施一些必要的全局配置和初始化操作。然而,`global_initialize`并不能访问报缓冲区,那里由线程指定。用以代替的,`thread_initialize`在每个发送线程初始化的时候被调用,提供对于缓冲区的访问,可以用来构建探测包和全局的源和目的值。此回调应用于构建宿主不可知分组结构,甚至只有特定值(如:目的主机和校验和),需要随着每个主机更新。例如,以太网头部信息在交换时不会变更(减去校验和是由NIC硬件计算的)因此可以事先定义以减少扫描时间开销。
|
||||
在扫描操作初始化时会调用一次`global_initialize`,可以用来实施一些必要的全局配置和初始化操作。然而,`global_initialize`并不能访问包缓冲区,那里是线程特定的。代替的,`thread_initialize`在每个发送线程初始化的时候被调用,提供对于缓冲区的访问,可以用来构建探测包和全局的源和目的值。此回调应用于构建主机不可知的包结构,甚至只有特定值(如:目的主机和校验和),需要随着每个主机更新。例如,以太网头部信息在交换时不会变更(减去校验和是由NIC硬件计算的)因此可以事先定义以减少扫描时间开销。
|
||||
|
||||
调用回调参数`make_packet是为了让被扫描的主机允许**probe module**更新主机指定的值,同时提供IP地址、一个非透明的验证字符串和探测数目(如下所示)。探测模块负责在探测中放置尽可能多的验证字符串,以至于当服务器返回的应答为空时,探测模块也能验证它的当前状态。例如,针对TCP SYN扫描,tcp_synscan探测模块会使用TCP源端口和序列号的格式存储验证字符串。响应包(SYN+ACKs)将包含预期的值包含目的端口和确认号。
|
||||
调用回调参数`make_packet`是为了让被扫描的主机允许**探测模块**更新主机指定的值,同时提供IP地址、一个非透明的验证字符串和探测数目(如下所示)。探测模块负责在探测中放置尽可能多的验证字符串,即便当服务器返回的应答为空时,探测模块也能验证它的当前状态。例如,针对TCP SYN扫描,tcp_synscan探测模块会使用TCP源端口和序列号的格式存储验证字符串。响应包(SYN+ACK)将包含目的端口和确认号的预期值。
|
||||
|
||||
int make_packet(
|
||||
void *packetbuf, // 包的缓冲区
|
||||
ipaddr_n_t src_ip, // network-order格式源IP
|
||||
ipaddr_n_t dst_ip, // network-order格式目的IP
|
||||
uint32_t *validation, // 探测中的确认字符串
|
||||
ipaddr_n_t src_ip, // 网络字节格式源IP
|
||||
ipaddr_n_t dst_ip, // 网络字节格式目的IP
|
||||
uint32_t *validation, // 探测中的有效字符串
|
||||
int probe_num // 如果向每个主机发送多重探测,
|
||||
// 该值为对于主机我们
|
||||
// 正在实施的探测数目
|
||||
// 该值为我们对于该主机
|
||||
// 正在发送的探测数目
|
||||
);
|
||||
|
||||
扫描模块也应该定义`pcap_filter`、`validate_packet`和`process_packet`。只有符合PCAP过滤的包才会被扫描。举个例子,在一个TCP SYN扫描的情况下,我们只想要调查TCP SYN / ACK或RST TCP数据包,并利用类似`tcp && tcp[13] & 4 != 0 || tcp[13] == 18`的过滤方法。`validate_packet`函数将会被每个满足PCAP过滤条件的包调用。如果验证返回的值非零,将会调用`process_packet`函数,并使用包中被定义成的`fields`字段和数据填充字段集。如下代码为TCP synscan探测模块处理了一个数据包。
|
||||
扫描模块也应该定义`pcap_filter`、`validate_packet`和`process_packet`。只有符合PCAP过滤器的包才会被扫描。举个例子,在一个TCP SYN扫描的情况下,我们只想要调查TCP SYN / ACK或RST TCP数据包,并利用类似`tcp && tcp[13] & 4 != 0 || tcp[13] == 18`的过滤方法。`validate_packet`函数将会被每个满足PCAP过滤条件的包调用。如果验证返回的值非零,将会调用`process_packet`函数,并使用`fields`定义的字段和包中的数据填充字段集。举个例子,如下代码为TCP synscan探测模块处理了一个数据包。
|
||||
|
||||
void synscan_process_packet(const u_char *packet, uint32_t len, fieldset_t *fs)
|
||||
{
|
||||
@ -733,7 +740,7 @@ ZMap的输出和输出后处理可以通过执行和注册扫描的**output modu
|
||||
via: https://zmap.io/documentation.html
|
||||
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,80 +1,78 @@
|
||||
sevenot translating
|
||||
10 Top Distributions in Demand to Get Your Dream Job
|
||||
10 大帮助你获得理想的职业的操作系统技能
|
||||
================================================================================
|
||||
We are coming up with a series of five articles which aims at making you aware of the top skills which will help you in getting yours dream job. In this competitive world you can not rely on one skill. You need to have balanced set of skills. There is no measure of a balanced skill set except a few conventions and statistics which changes from time-to-time.
|
||||
我们用了5篇系列文章,来让人们意识到那些可以帮助他们获得理想职业的顶级技能。在这个充满竞争的社会里,你不能仅仅依赖一项仅能,你需要在多个职业技能上都有所涉猎。我们并不能权衡这些技能,但是我们可以参考这些几乎不变的惯例和统计数据。
|
||||
|
||||
The below article and remaining to follow is the result of close study of job boards, posting and requirements of various IT Companies across the globe of last three months. The statistics keeps on changing as the demand and market changes. We will try our best to update the list when there is any major changes.
|
||||
The Five articles of this series are…
|
||||
下面的文章和紧跟其后的内容,是针对全球各大IT公司上一季度对员工技能要求的详细调查报告。统计数据真实的反映了需求和市场的变化。我们会尽力让这份报告保持时效性,特别是有明显变化的时候。这五篇系列文章是:
|
||||
|
||||
- 10 Distributions in Demand to Get Your Dream Job
|
||||
- [10 Famous IT Skills in Demand That Will Get You Hired][1]
|
||||
- 10 Programming Skills That Will Help You to Get Dream Job
|
||||
- 10 IT Networking Protocols Skills to Land Your Dream Job
|
||||
- 10 Professional Certifications in Demand That Will Get You Hired
|
||||
- 10大帮助你获得理想的职业的需求分布
|
||||
- [10大帮助你获得职位的著名 IT 技能][1]
|
||||
- [10大帮助你获得理想职位的项目技能][2]
|
||||
- [10大帮助你赢得理想职位的网络技能][3]
|
||||
- [10大帮助你获得理想职位的个人认证][4]
|
||||
|
||||
### 1. Windows ###
|
||||
|
||||
The operating System developed by Microsoft not only dominates the PC market but it is also the most sought OS skill from job perspective irrespective of all the odds and criticism that follows. It has shown a growth in demand which equals to 0.1% in the last quarter.
|
||||
微软研发的windows操作系统不仅在PC市场上占据龙头地位,而且从职位视角来看也是最抢手的操作系统技能,不管你是赞成还是反对。有资料显示上一季度需求增长达到0.1%.
|
||||
|
||||
Latest Stable Release : Windows 8.1
|
||||
最新版本 : Windows 8.1
|
||||
|
||||
### 2. Red Hat Enterprise Linux ###
|
||||
|
||||
Red Hat Enterprise Linux is a commercial Linux Distribution developed by Red Hat Inc. It is one of the Most widely used Linux distribution specially in corporates and production. It comes at number two having a overall growth in demand which equals to 17% in the last quarter.
|
||||
Red Hat Enterprise Linux 是一个商业的Linux发行版本,它由红帽公司研发。它是世界上运用最广的Linux发行版本之一,特别是在生产环境和协同工作方面。上一季度其整体需求上涨17%,位列第二。
|
||||
|
||||
Latest Stable Release : RedHat Enterprise Linux 7.1
|
||||
最新版本 : RedHat Enterprise Linux 7.1
|
||||
|
||||
### 3. Solaris ###
|
||||
|
||||
The UNIX Operating System developed by Sun Microsystems and now owned by Oracle Inc. comes at number three. It has shown a growth in demand which equals to 14% in the last quarter.
|
||||
排在第三的是 Solaris UNIX操作系统,最初由Sun Microsystems公司研发,现由Oracle公司负责继续研发。在上一季度起需求率上涨14%.
|
||||
|
||||
Latest Stable Release : Oracle Solaris 10 1/13
|
||||
最新版本:Oracle Solaris 10 1/13
|
||||
|
||||
### 4. AIX ###
|
||||
|
||||
Advanced Interactive eXecutive is a Proprietary Unix Operating System by IBM stands at number four. It has shown a growth in demand which equals to 11% in the last quarter.
|
||||
排在第四的是AIX,这是一款由IBM研发的专用 Unix 操作系统。在上一季度需求率上涨11%。
|
||||
|
||||
Latest Stable Release : AIX 7
|
||||
最新版本 : AIX 7
|
||||
|
||||
### 5. Android ###
|
||||
|
||||
One of the most widely used open source operating system designed specially for mobile, tablet computers and wearable gadgets is now owned by Google Inc. comes at number five. It has shown a growth in demand which equals to 4% in the last quarter.
|
||||
排在第5的是谷歌公司研发的安卓系统,它是一款使用非常广泛的开源操作系统,专门为手机、平板电脑、可穿戴设备设计的。在上一季度需求率上涨4%。
|
||||
|
||||
Latest Stable Release : Android 5.1 aka Lollipop
|
||||
最新版本 : Android 5.1 aka Lollipop
|
||||
|
||||
### 6. CentOS ###
|
||||
|
||||
Community Enterprise Operating System is a Linux distribution derived from RedHat Enterprise Linux. It comes at sixth position in the list. Market has shown a growth in demand which is nearly 22% for CentOS, in the last quarter.
|
||||
排在第6的是 CentOS,它是从 RedHat Enterprise Linux 衍生出的一个发行版本。在上一季度需求率上涨接近22%。
|
||||
|
||||
Latest Stable Release : CentOS 7
|
||||
最新版本 : CentOS 7
|
||||
|
||||
### 7. Ubuntu ###
|
||||
|
||||
The Linux Operating System designed for Humans and designed by Canonicals Ltd. Ubuntu comes at position seventh. It has shown a growth in demand which equals to 11% in the last quarter.
|
||||
Latest Stable Release :
|
||||
排在第7的是Ubuntu,这是一款由Canonicals公司研发设计的Linux系统,旨在服务于个人。上一季度需求率上涨11%。
|
||||
|
||||
- Ubuntu 14.10 (9 months security and maintenance update).
|
||||
最新版本 :
|
||||
|
||||
- Ubuntu 14.10 (已有九个月的安全和维护更新).
|
||||
- Ubuntu 14.04.2 LTS
|
||||
|
||||
### 8. Suse ###
|
||||
|
||||
Suse is a Linux operating System owned by Novell. The Linux distribution is famous for YaST configuration tool. It comes at position eight. It has shown a growth in demand which equals to 8% in the last quarter.
|
||||
排在第8的是由Novell研发的 Suse,这款发行版本的Linux操作系统因为YaST 配置工具而闻名。其上一季度需求率上涨8%。
|
||||
|
||||
Latest Stable Release : 13.2
|
||||
最新版本 : 13.2
|
||||
|
||||
### 9. Debian ###
|
||||
|
||||
The very famous Linux Operating System, mother of 100’s of Distro and closest to GNU comes at number nine. It has shown a decline in demand which is nearly 9% in the last quarter.
|
||||
排在第9的是非常有名的 Linux 操作系统Debian,它是上百种Linux 发行版之母,非常接近GNU理念。其上一季度需求率上涨9%。
|
||||
|
||||
Latest Stable Release : Debian 7.8
|
||||
最新版本: Debian 7.8
|
||||
|
||||
### 10. HP-UX ###
|
||||
|
||||
The Proprietary UNIX Operating System designed by Hewlett-Packard comes at number ten. It has shown a decline in the last quarter by 5%.
|
||||
排在第10的是Hewlett-Packard公司研发的专用 Linux 操作系统HP-UX,上一季度需求率上涨5%。
|
||||
|
||||
Latest Stable Release : 11i v3 Update 13
|
||||
最新版本 : 11i v3 Update 13
|
||||
|
||||
注:表格数据--不需要翻译--开始
|
||||
<table border="0" cellspacing="0">
|
||||
<colgroup width="107"></colgroup>
|
||||
<colgroup width="92"></colgroup>
|
||||
@ -132,19 +130,21 @@ Latest Stable Release : 11i v3 Update 13
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
注:表格数据--不需要翻译--结束
|
||||
|
||||
That’s all for now. I’ll be coming up with the next article of this series very soon. Till then stay tuned and connected to Tecmint. Don’t forget to provide us with your valuable feedback in the comments below. Like and share us and help us get spread.
|
||||
以上便是全部信息,我会尽快推出下一篇系列文章,敬请关注Tecmint。不要忘了留下您宝贵的评论。如果您喜欢我们的文章并且与我们分享您的见解,这对我们的工作是一种鼓励。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/top-distributions-in-demand-to-get-your-dream-job/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[weychen](https://github.com/weychen)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[sevenot](https://github.com/sevenot)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/top-distributions-in-demand-to-get-your-dream-job/www.tecmint.com/famous-it-skills-in-demand-that-will-get-you-hired/
|
||||
[1]:http://www.tecmint.com/famous-it-skills-in-demand-that-will-get-you-hired/
|
||||
[2]:https://linux.cn/article-5303-1.html
|
||||
[3]:http://www.tecmint.com/networking-protocols-skills-to-land-your-dream-job/
|
||||
[4]:http://www.tecmint.com/professional-certifications-in-demand-that-will-get-you-hired/
|
||||
@ -1,13 +1,14 @@
|
||||
在Linux中使用‘Systemctl’管理‘Systemd’服务和单元
|
||||
systemctl 完全指南
|
||||
================================================================================
|
||||
Systemctl是一个systemd工具,主要负责控制systemd系统和服务管理器。
|
||||
|
||||
Systemd是一个系统管理守护进程、工具和库的集合,用于取代System V初始进程。Systemd的功能是用于集中管理和配置类UNIX系统。
|
||||
|
||||
在Linux生态系统中,Systemd被部署到了大多数的标准Linux发行版中,只有位数不多的几个尚未部署。Systemd通常是所有其它守护进程的父进程,但并非总是如此。
|
||||
在Linux生态系统中,Systemd被部署到了大多数的标准Linux发行版中,只有为数不多的几个发行版尚未部署。Systemd通常是所有其它守护进程的父进程,但并非总是如此。
|
||||
|
||||

|
||||
使用Systemctl管理Linux服务
|
||||
|
||||
*使用Systemctl管理Linux服务*
|
||||
|
||||
本文旨在阐明在运行systemd的系统上“如何控制系统和服务”。
|
||||
|
||||
@ -41,11 +42,9 @@ Systemd是一个系统管理守护进程、工具和库的集合,用于取代S
|
||||
root 555 1 0 16:27 ? 00:00:00 /usr/lib/systemd/systemd-logind
|
||||
dbus 556 1 0 16:27 ? 00:00:00 /bin/dbus-daemon --system --address=systemd: --nofork --nopidfile --systemd-activation
|
||||
|
||||
**注意**:systemd是作为父进程(PID=1)运行的。在上面带(-e)参数的ps命令输出中,选择所有进程,(-
|
||||
**注意**:systemd是作为父进程(PID=1)运行的。在上面带(-e)参数的ps命令输出中,选择所有进程,(-a)选择除会话前导外的所有进程,并使用(-f)参数输出完整格式列表(即 -eaf)。
|
||||
|
||||
a)选择除会话前导外的所有进程,并使用(-f)参数输出完整格式列表(如 -eaf)。
|
||||
|
||||
也请注意上例中后随的方括号和样例剩余部分。方括号表达式是grep的字符类表达式的一部分。
|
||||
也请注意上例中后随的方括号和例子中剩余部分。方括号表达式是grep的字符类表达式的一部分。
|
||||
|
||||
#### 4. 分析systemd启动进程 ####
|
||||
|
||||
@ -147,7 +146,7 @@ a)选择除会话前导外的所有进程,并使用(-f)参数输出完
|
||||
1 loaded units listed. Pass --all to see loaded but inactive units, too.
|
||||
To show all installed unit files use 'systemctl list-unit-files'.
|
||||
|
||||
#### 10. 检查某个单元(cron.service)是否启用 ####
|
||||
#### 10. 检查某个单元(如 cron.service)是否启用 ####
|
||||
|
||||
# systemctl is-enabled crond.service
|
||||
|
||||
@ -187,7 +186,7 @@ a)选择除会话前导外的所有进程,并使用(-f)参数输出完
|
||||
dbus-org.fedoraproject.FirewallD1.service enabled
|
||||
....
|
||||
|
||||
#### 13. Linux中如何启动、重启、停止、重载服务以及检查服务(httpd.service)状态 ####
|
||||
#### 13. Linux中如何启动、重启、停止、重载服务以及检查服务(如 httpd.service)状态 ####
|
||||
|
||||
# systemctl start httpd.service
|
||||
# systemctl restart httpd.service
|
||||
@ -214,15 +213,15 @@ a)选择除会话前导外的所有进程,并使用(-f)参数输出完
|
||||
Apr 28 17:21:30 tecmint systemd[1]: Started The Apache HTTP Server.
|
||||
Hint: Some lines were ellipsized, use -l to show in full.
|
||||
|
||||
**注意**:当我们使用systemctl的start,restart,stop和reload命令时,我们不会不会从终端获取到任何输出内容,只有status命令可以打印输出。
|
||||
**注意**:当我们使用systemctl的start,restart,stop和reload命令时,我们不会从终端获取到任何输出内容,只有status命令可以打印输出。
|
||||
|
||||
#### 14. 如何激活服务并在启动时启用或禁用服务(系统启动时自动启动服务) ####
|
||||
#### 14. 如何激活服务并在启动时启用或禁用服务(即系统启动时自动启动服务) ####
|
||||
|
||||
# systemctl is-active httpd.service
|
||||
# systemctl enable httpd.service
|
||||
# systemctl disable httpd.service
|
||||
|
||||
#### 15. 如何屏蔽(让它不能启动)或显示服务(httpd.service) ####
|
||||
#### 15. 如何屏蔽(让它不能启动)或显示服务(如 httpd.service) ####
|
||||
|
||||
# systemctl mask httpd.service
|
||||
ln -s '/dev/null' '/etc/systemd/system/httpd.service'
|
||||
@ -297,7 +296,7 @@ a)选择除会话前导外的所有进程,并使用(-f)参数输出完
|
||||
# systemctl enable tmp.mount
|
||||
# systemctl disable tmp.mount
|
||||
|
||||
#### 20. 在Linux中屏蔽(让它不能启动)或显示挂载点 ####
|
||||
#### 20. 在Linux中屏蔽(让它不能启用)或可见挂载点 ####
|
||||
|
||||
# systemctl mask tmp.mount
|
||||
|
||||
@ -375,7 +374,7 @@ a)选择除会话前导外的所有进程,并使用(-f)参数输出完
|
||||
|
||||
CPUShares=2000
|
||||
|
||||
**注意**:当你为某个服务设置CPUShares,会自动创建一个以服务名命名的目录(httpd.service),里面包含了一个名为90-CPUShares.conf的文件,该文件含有CPUShare限制信息,你可以通过以下方式查看该文件:
|
||||
**注意**:当你为某个服务设置CPUShares,会自动创建一个以服务名命名的目录(如 httpd.service),里面包含了一个名为90-CPUShares.conf的文件,该文件含有CPUShare限制信息,你可以通过以下方式查看该文件:
|
||||
|
||||
# vi /etc/systemd/system/httpd.service.d/90-CPUShares.conf
|
||||
|
||||
@ -528,13 +527,13 @@ a)选择除会话前导外的所有进程,并使用(-f)参数输出完
|
||||
#### 35. 启动运行等级5,即图形模式 ####
|
||||
|
||||
# systemctl isolate runlevel5.target
|
||||
OR
|
||||
或
|
||||
# systemctl isolate graphical.target
|
||||
|
||||
#### 36. 启动运行等级3,即多用户模式(命令行) ####
|
||||
|
||||
# systemctl isolate runlevel3.target
|
||||
OR
|
||||
或
|
||||
# systemctl isolate multiuser.target
|
||||
|
||||
#### 36. 设置多用户模式或图形模式为默认运行等级 ####
|
||||
@ -572,7 +571,7 @@ via: http://www.tecmint.com/manage-services-using-systemd-and-systemctl-in-linux
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,57 @@
|
||||
GNU、开源和 Apple 的那些黑历史
|
||||
==============================================================================
|
||||
> 自由软件/开源社区与 Apple 之间的争论可以回溯到上世纪80年代,当时 Linux 的创始人称 Mac OS X 的核心就是“一堆废物”。还有其他一些软件史上的轶事。
|
||||
|
||||

|
||||
|
||||
开源拥护者们与微软之间有着很长、而且摇摆的关系。每个人都知道这个。但是,在许多方面,自由或者开源软件的支持者们与 Apple 之间的争执则更加突出——尽管这很少受到媒体的关注。
|
||||
|
||||
需要说明的是,并不是所有的开源拥护者都厌恶苹果。从各种轶事中,我已经见过很多 Linux 的黑客玩耍 iPhone 和iPad。实际上,许多 Linux 用户是十分喜欢 Apple 的 OS X 系统的,以至于他们[创造了很多Linux的发行版][1],都设计得看起来像OS X。(顺便说下,[北朝鲜政府][2]就这样做了。)
|
||||
|
||||
但是 Mac 的信徒与企鹅的信徒——即 Linux 社区(不包括别的,仅指自由与开源软件世界中的这一小部分)之间的关系,并不一直是完全的和谐。并且这绝不是一个新的现象,在我研究Linux和自由软件基金会历史的时候就发现了。
|
||||
|
||||
### GNU vs. Apple ###
|
||||
|
||||
这场战争将回溯到至少上世纪80年代后期。1988年6月,Richard Stallman 发起了 [GNU][3] 项目,希望建立一个完全自由的类 Unix 操作系统,其源代码将会免费共享,[强烈指责][4] Apple 对 [Hewlett-Packard][5](HPQ)和 [Microsoft][6](MSFT)的诉讼,称Apple的声明中说别人对 Macintosh 操作系统的界面和体验的抄袭是不正确。如果 Apple 流行的话,GNU 警告到,这家公司“将会借助大众的新力量终结掉为取代商业软件而生的自由软件。”
|
||||
|
||||
那个时候,GNU 对抗 Apple 的诉讼(这意味着,十分讽刺的是,GNU 正在支持 Microsoft,尽管当时的情况不一样),通过发布[“让你的律师远离我的电脑”按钮][7]。同时呼吁 GNU 的支持者们抵制 Apple,警告虽然 Macintosh 看起来是不错的计算机,但 Apple 一旦赢得了诉讼就会给市场带来垄断,这会极大地提高计算机的售价。
|
||||
|
||||
Apple 最终[输掉了这场诉讼][8],但是直到1994年之后,GNU 才[撤销对 Apple 的抵制][9]。这期间,GNU 一直不断指责 Apple。在上世纪90年代早期甚至之后,GNU 开始发展 GNU 软件项目,可以在其他个人电脑平台包括 MS-DOS 计算机上使用。[GNU 宣称][10],除非 Apple 停止在计算机领域垄断的野心,让用户界面可以模仿 Macintosh 的一些东西,否则“我们不会提供任何对 Apple 机器的支持。”(因此讽刺的是 Apple 在90年代后期开发的类 UNIX 系统 OS X 有一大堆软件来自GNU。但是那是另外的故事了。)
|
||||
|
||||
### Torvalds 与 Jobs ###
|
||||
|
||||
除去他对大多数发行版比较自由放任的态度,Linux内核的创造者 Liuns Torvalds 相较于 Stallman 和 GNU 过去对Apple 的态度和善得多。在他 2001 年出版的书”Just For Fun: The Story of an Accidental Revolutionary“中,Torvalds 描述到与 Steve Jobs 的一次会面,大约是 1997 年收到后者的邀请去讨论 Mac OS X,当时 Apple 正在开发中,但还没有公开发布。
|
||||
|
||||
“基本上,Jobs 一开始就试图告诉我在桌面上的玩家就两个,Microsoft 和 Apple,而且他认为我能为 Linux 做的最好的事,就是从了 Apple,努力让开源用户去支持 Mac OS X” Torvalds 写道。
|
||||
|
||||
这次会谈显然让 Torvalds 很不爽。争吵的一点集中在 Torvalds 对 Mach 技术上的藐视,对于 Apple 正在用于构建新的 OS X 操作系统的内核,Torvalds 称其“一堆废物。它包含了所有你能做到的设计错误,并且甚至打算只弥补一小部分。”
|
||||
|
||||
但是更令人不快的是,显然是 Jobs 在开发 OS X 时入侵开源的方式(OS X 的核心里上有很多开源程序):“他有点贬低了结构的瑕疵:谁在乎基础操作系统这个真正的 low-core 东西是不是开源,如果你有 Mac 层在最上面,这不是开源?”
|
||||
|
||||
一切的一切,Torvalds 总结到,Jobs “并没有太多争论。他仅仅很简单地说着,胸有成竹地认为我会对与 Apple 合作感兴趣”。“他一无所知,不能去想像还会有人并不关心 Mac 市场份额的增长。我认为他真的感到惊讶了,当我表现出对 Mac 的市场有多大,或者 Microsoft 市场有多大的毫不关心时。”
|
||||
|
||||
当然,Torvalds 并没有对所有 Linux 用户说起过。他对于 OS X 和 Apple 的看法从 2001 年开始就渐渐软化了。但实际上,早在2000年,Linux 社区的领导角色表现出对 Apple 及其高层的傲慢的深深的鄙视,可以看出一些重要的东西,关于 Apple 世界和开源/自由软件世界的矛盾是多么的根深蒂固。
|
||||
|
||||
从以上两则历史上的花边新闻中,可以看到关于 Apple 产品价值的重大争议,即是否该公司致力于提升其创造的软硬件的质量,或者仅仅是借市场的小聪明获利,让Apple产品卖出更多的钱而不是创造等同其价值的功能。但是不管怎样,我会暂时置身讨论之外。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thevarguy.com/open-source-application-software-companies/051815/linux-better-os-x-gnu-open-source-and-apple-
|
||||
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://thevarguy.com/author/christopher-tozzi
|
||||
[1]:https://www.linux.com/news/software/applications/773516-the-mac-ifying-of-the-linux-desktop/
|
||||
[2]:http://thevarguy.com/open-source-application-software-companies/010615/north-koreas-red-star-linux-os-made-apples-image
|
||||
[3]:http://gnu.org/
|
||||
[4]:https://www.gnu.org/bulletins/bull5.html
|
||||
[5]:http://www.hp.com/
|
||||
[6]:http://www.microsoft.com/
|
||||
[7]:http://www.duntemann.com/AppleSnakeButton.jpg
|
||||
[8]:http://www.freibrun.com/articles/articl12.htm
|
||||
[9]:https://www.gnu.org/bulletins/bull18.html#SEC6
|
||||
[10]:https://www.gnu.org/bulletins/bull12.html
|
||||
@ -1,28 +1,29 @@
|
||||
如何在Fedora 22上面配置Apache的Docker容器
|
||||
=============================================================================
|
||||
在这篇文章中,我们将会学习关于Docker的一些知识,如何使用Docker部署Apache httpd服务,并且共享到Docker Hub上面去。首先,我们学习怎样拉取和使用Docker Hub里面的镜像,然后交互式地安装Apache到一个Fedora 22的镜像里去,之后我们将会学习如何用一个Dockerfile文件来制作一个镜像,以一种更快,更优雅的方式。最后,我们会在Docker Hub上公开我们创建地镜像,这样以后任何人都可以下载并使用它。
|
||||
|
||||
### 安装Docker,运行hello world ###
|
||||
在这篇文章中,我们将会学习关于Docker的一些知识,如何使用Docker部署Apache httpd服务,并且共享到Docker Hub上面去。首先,我们学习怎样拉取和使用Docker Hub里面的镜像,然后在一个Fedora 22的镜像上交互式地安装Apache,之后我们将会学习如何用一个Dockerfile文件来以一种更快,更优雅的方式制作一个镜像。最后,我们将我们创建的镜像发布到Docker Hub上,这样以后任何人都可以下载并使用它。
|
||||
|
||||
### 安装并初体验Docker ###
|
||||
|
||||
**要求**
|
||||
|
||||
运行Docker,里至少需要满足这些:
|
||||
运行Docker,你至少需要满足这些:
|
||||
|
||||
- 你需要一个64位的内核,版本3.10或者更高
|
||||
- Iptables 1.4 - Docker会用来做网络配置,如网络地址转换(NAT)
|
||||
- Iptables 1.4 - Docker会用它来做网络配置,如网络地址转换(NAT)
|
||||
- Git 1.7 - Docker会使用Git来与仓库交流,如Docker Hub
|
||||
- ps - 在大多数环境中这个工具都存在,在procps包里有提供
|
||||
- root - 防止一般用户可以通过TCP或者其他方式运行Docker,为了简化,我们会假定你就是root
|
||||
- root - 尽管一般用户可以通过TCP或者其他方式来运行Docker,但是为了简化,我们会假定你就是root
|
||||
|
||||
### 使用dnf安装docker ###
|
||||
#### 使用dnf安装docker ####
|
||||
|
||||
以下的命令会安装Docker
|
||||
|
||||
dnf update && dnf install docker
|
||||
|
||||
**注意**:在Fedora 22里,你仍然可以使用Yum命令,但是被DNF取代了,而且在纯净安装时不可用了。
|
||||
**注意**:在Fedora 22里,你仍然可以使用Yum命令,但是它被DNF取代了,而且在纯净安装时不可用了。
|
||||
|
||||
### 检查安装 ###
|
||||
#### 检查安装 ####
|
||||
|
||||
我们将要使用的第一个命令是docker info,这会输出很多信息给你:
|
||||
|
||||
@ -32,25 +33,29 @@
|
||||
|
||||
docker version
|
||||
|
||||
### 启动Dcoker为守护进程 ###
|
||||
#### 以守护进程方式启动Dcoker####
|
||||
|
||||
你应该启动一个docker实例,然后她会处理我们的请求。
|
||||
|
||||
docker -d
|
||||
|
||||
现在我们设置 docker 随系统启动,以便我们不需要每次重启都需要运行上述命令。
|
||||
|
||||
chkconfig docker on
|
||||
|
||||
让我们用Busybox来打印hello world:
|
||||
|
||||
dockr run -t busybox /bin/echo "hello world"
|
||||
|
||||
这个命令里,我们告诉Docker执行 /bin/echo "hello world",在Busybox镜像的一个实例/容器里。Busybox是一个小型的POSIX环境,将许多小工具都结合到了一个单独的可执行程序里。
|
||||
这个命令里,我们告诉Docker在Busybox镜像的一个实例/容器里执行 /bin/echo "hello world"。Busybox是一个小型的POSIX环境,将许多小工具都结合到了一个单独的可执行程序里。
|
||||
|
||||
如果Docker不能在你的系统里找到本地的Busybox镜像,她就会自动从Docker Hub里拉取镜像,正如你可以看下如下的快照:
|
||||
|
||||

|
||||
|
||||
Hello world with Busybox
|
||||
*Hello world with Busybox*
|
||||
|
||||
再次尝试相同的命令,这次由于Docker已经有了本地的Busybox镜像,所有你将会看到的就是echo的输出:
|
||||
再次尝试相同的命令,这次由于Docker已经有了本地的Busybox镜像,你将会看到的全部就是echo的输出:
|
||||
|
||||
docker run -t busybox /bin/echo "hello world"
|
||||
|
||||
@ -66,31 +71,31 @@ Hello world with Busybox
|
||||
|
||||
docker pull fedora:22
|
||||
|
||||
起一个容器在后台运行:
|
||||
启动一个容器在后台运行:
|
||||
|
||||
docker run -d -t fedora:22 /bin/bash
|
||||
|
||||
列出正在运行地容器,并用名字标识,如下
|
||||
列出正在运行地容器及其名字标识,如下
|
||||
|
||||
docker ps
|
||||
|
||||

|
||||
|
||||
使用docker ps列出,并使用docker attach进入一个容器里
|
||||
*使用docker ps列出,并使用docker attach进入一个容器里*
|
||||
|
||||
angry_noble是docker分配给我们容器的名字,所以我们来附上去:
|
||||
angry_noble是docker分配给我们容器的名字,所以我们来连接上去:
|
||||
|
||||
docker attach angry_noble
|
||||
|
||||
注意:每次你起一个容器,就会被给与一个新的名字,如果你的容器需要一个固定的名字,你应该在 docker run 命令里使用 -name 参数。
|
||||
注意:每次你启动一个容器,就会被给与一个新的名字,如果你的容器需要一个固定的名字,你应该在 docker run 命令里使用 -name 参数。
|
||||
|
||||
### 安装Apache ###
|
||||
#### 安装Apache ####
|
||||
|
||||
下面的命令会更新DNF的数据库,下载安装Apache(httpd包)并清理dnf缓存使镜像尽量小
|
||||
|
||||
dnf -y update && dnf -y install httpd && dnf -y clean all
|
||||
|
||||
配置Apache
|
||||
**配置Apache**
|
||||
|
||||
我们需要修改httpd.conf的唯一地方就是ServerName,这会使Apache停止抱怨
|
||||
|
||||
@ -98,7 +103,7 @@ angry_noble是docker分配给我们容器的名字,所以我们来附上去:
|
||||
|
||||
**设定环境**
|
||||
|
||||
为了使Apache运行为单机模式,你必须以环境变量的格式提供一些信息,并且你也需要在这些变量里的目录设定,所以我们将会用一个小的shell脚本干这个工作,当然也会启动Apache
|
||||
为了使Apache运行为独立模式,你必须以环境变量的格式提供一些信息,并且你也需要创建这些变量里的目录,所以我们将会用一个小的shell脚本干这个工作,当然也会启动Apache
|
||||
|
||||
vi /etc/httpd/run_apache_foreground
|
||||
|
||||
@ -106,7 +111,7 @@ angry_noble是docker分配给我们容器的名字,所以我们来附上去:
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
#set variables
|
||||
#设置环境变量
|
||||
APACHE_LOG_DI=R"/var/log/httpd"
|
||||
APACHE_LOCK_DIR="/var/lock/httpd"
|
||||
APACHE_RUN_USER="apache"
|
||||
@ -114,12 +119,12 @@ angry_noble是docker分配给我们容器的名字,所以我们来附上去:
|
||||
APACHE_PID_FILE="/var/run/httpd/httpd.pid"
|
||||
APACHE_RUN_DIR="/var/run/httpd"
|
||||
|
||||
#create directories if necessary
|
||||
#如果需要的话,创建目录
|
||||
if ! [ -d /var/run/httpd ]; then mkdir /var/run/httpd;fi
|
||||
if ! [ -d /var/log/httpd ]; then mkdir /var/log/httpd;fi
|
||||
if ! [ -d /var/lock/httpd ]; then mkdir /var/lock/httpd;fi
|
||||
|
||||
#run Apache
|
||||
#运行 Apache
|
||||
httpd -D FOREGROUND
|
||||
|
||||
**另外地**,你可以粘贴这个片段代码到容器shell里并运行:
|
||||
@ -130,11 +135,11 @@ angry_noble是docker分配给我们容器的名字,所以我们来附上去:
|
||||
|
||||
**保存你的容器状态**
|
||||
|
||||
你的容器现在可以运行Apache,是时候保存容器当前的状态为一个镜像,以备你需要的时候使用。
|
||||
你的容器现在准备好运行Apache,是时候保存容器当前的状态为一个镜像,以备你需要的时候使用。
|
||||
|
||||
为了离开容器环境,你必须顺序按下 **Ctrl+q** 和 **Ctrl+p**,如果你仅仅在shell执行exit,你同时也会停止容器,失去目前为止你做过的所有工作。
|
||||
|
||||
回到Docker主机,使用 **docker commit** 加容器和你期望的仓库名字/标签:
|
||||
回到Docker主机,使用 **docker commit** 及容器名和你想要的仓库名字/标签:
|
||||
|
||||
docker commit angry_noble gaiada/apache
|
||||
|
||||
@ -144,17 +149,15 @@ angry_noble是docker分配给我们容器的名字,所以我们来附上去:
|
||||
|
||||
**运行并测试你的镜像**
|
||||
|
||||
最后,从你的新镜像起一个容器,并且重定向80端口到容器:
|
||||
最后,从你的新镜像启动一个容器,并且重定向80端口到该容器:
|
||||
|
||||
docker run -p 80:80 -d -t gaiada/apache /etc/httpd/run_apache_foreground
|
||||
|
||||
|
||||
|
||||
到目前,你正在你的容器里运行Apache,打开你的浏览器访问该服务,在[http://localhost][2],你将会看到如下Apache默认的页面
|
||||
|
||||

|
||||
|
||||
在容器里运行的Apache默认页面
|
||||
*在容器里运行的Apache默认页面*
|
||||
|
||||
### 使用Dockerfile Docker化Apache ###
|
||||
|
||||
@ -190,21 +193,14 @@ angry_noble是docker分配给我们容器的名字,所以我们来附上去:
|
||||
|
||||
CMD ["/usr/sbin/httpd", "-D", "FOREGROUND"]
|
||||
|
||||
|
||||
|
||||
我们一起来看看Dockerfile里面有什么:
|
||||
|
||||
**FROM** - 这告诉docker,我们将要使用Fedora 22作为基础镜像
|
||||
|
||||
**MAINTAINER** 和 **LABLE** - 这些命令对镜像没有直接作用,属于标记信息
|
||||
|
||||
**RUN** - 自动完成我们之前交互式做的工作,安装Apache,新建目录并编辑httpd.conf
|
||||
|
||||
**ENV** - 设置环境变量,现在我们再不需要run_apache_foreground脚本
|
||||
|
||||
**EXPOSE** - 暴露80端口给外网
|
||||
|
||||
**CMD** - 设置默认的命令启动httpd服务,这样我们就不需要每次起一个新的容器都重复这个工作
|
||||
- **FROM** - 这告诉docker,我们将要使用Fedora 22作为基础镜像
|
||||
- **MAINTAINER** 和 **LABLE** - 这些命令对镜像没有直接作用,属于标记信息
|
||||
- **RUN** - 自动完成我们之前交互式做的工作,安装Apache,新建目录并编辑httpd.conf
|
||||
- **ENV** - 设置环境变量,现在我们再不需要run_apache_foreground脚本
|
||||
- **EXPOSE** - 暴露80端口给外网
|
||||
- **CMD** - 设置默认的命令启动httpd服务,这样我们就不需要每次起一个新的容器都重复这个工作
|
||||
|
||||
**建立该镜像**
|
||||
|
||||
@ -214,7 +210,7 @@ angry_noble是docker分配给我们容器的名字,所以我们来附上去:
|
||||
|
||||

|
||||
|
||||
docker完成创建
|
||||
*docker完成创建*
|
||||
|
||||
使用 **docker images** 列出本地镜像,查看是否存在你新建的镜像:
|
||||
|
||||
@ -226,7 +222,7 @@ docker完成创建
|
||||
|
||||
这就是Dockerfile的工作,使用这项功能会使得事情更加容易,快速并且可重复生成。
|
||||
|
||||
### 公开你的镜像 ###
|
||||
### 发布你的镜像 ###
|
||||
|
||||
直到现在,你仅仅是从Docker Hub拉取了镜像,但是你也可以推送你的镜像,以后需要也可以再次拉取他们。实际上,其他人也可以下载你的镜像,在他们的系统中使用它而不需要改变任何东西。现在我们将要学习如何使我们的镜像对世界上的其他人可用。
|
||||
|
||||
@ -236,7 +232,7 @@ docker完成创建
|
||||
|
||||

|
||||
|
||||
Docker Hub 注册页面
|
||||
*Docker Hub 注册页面*
|
||||
|
||||
**登录**
|
||||
|
||||
@ -256,11 +252,11 @@ Docker Hub 注册页面
|
||||
|
||||

|
||||
|
||||
Docker推送Apache镜像完成
|
||||
*Docker推送Apache镜像完成*
|
||||
|
||||
### 结论 ###
|
||||
|
||||
现在,你知道如何Docker化Apache,试一试包含其他一些组块,Perl,PHP,proxy,HTTPS,或者任何你需要的东西。我希望你们这些家伙喜欢她,并推送你们自己的镜像到Docker Hub。
|
||||
现在,你知道如何Docker化Apache,试一试包含其他一些组件,Perl,PHP,proxy,HTTPS,或者任何你需要的东西。我希望你们这些家伙喜欢她,并推送你们自己的镜像到Docker Hub。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -268,7 +264,7 @@ via: http://linoxide.com/linux-how-to/configure-apache-containers-docker-fedora-
|
||||
|
||||
作者:[Carlos Alberto][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,98 @@
|
||||
如何配置一个 Docker Swarm 原生集群
|
||||
================================================================================
|
||||
|
||||
嗨,大家好。今天我们来学一学Swarm相关的内容吧,我们将学习通过Swarm来创建Docker原生集群。[Docker Swarm][1]是用于Docker的原生集群项目,它可以将一个Docker主机池转换成单个的虚拟主机。Swarm工作于标准的Docker API,所以任何可以和Docker守护进程通信的工具都可以使用Swarm来透明地伸缩到多个主机上。就像其它Docker项目一样,Swarm遵循“内置电池,并可拆卸”的原则(LCTT 译注:batteries included,内置电池原来是 Python 圈里面对 Python 的一种赞誉,指自给自足,无需外求的丰富环境;but removable,并可拆卸应该指的是非强制耦合)。它附带有一个开箱即用的简单的后端调度程序,而且作为初始开发套件,也为其开发了一个可插拔不同后端的API。其目标在于为一些简单的使用情况提供一个平滑的、开箱即用的体验,并且它允许切换为更强大的后端,如Mesos,以用于大规模生产环境部署。Swarm配置和使用极其简单。
|
||||
|
||||
这里给大家提供Swarm 0.2开箱的即用一些特性。
|
||||
|
||||
1. Swarm 0.2.0大约85%与Docker引擎兼容。
|
||||
2. 它支持资源管理。
|
||||
3. 它具有一些带有限制和类同功能的高级调度特性。
|
||||
4. 它支持多个发现后端(hubs,consul,etcd,zookeeper)
|
||||
5. 它使用TLS加密方法进行安全通信和验证。
|
||||
|
||||
那么,我们来看一看Swarm的一些相当简单而简用的使用步骤吧。
|
||||
|
||||
### 1. 运行Swarm的先决条件 ###
|
||||
|
||||
我们必须在所有节点安装Docker 1.4.0或更高版本。虽然各个节点的IP地址不需要要公共地址,但是Swarm管理器必须可以通过网络访问各个节点。
|
||||
|
||||
**注意**:Swarm当前还处于beta版本,因此功能特性等还有可能发生改变,我们不推荐你在生产环境中使用。
|
||||
|
||||
### 2. 创建Swarm集群 ###
|
||||
|
||||
现在,我们将通过运行下面的命令来创建Swarm集群。各个节点都将运行一个swarm节点代理,该代理会注册、监控相关的Docker守护进程,并更新发现后端获取的节点状态。下面的命令会返回一个唯一的集群ID标记,在启动节点上的Swarm代理时会用到它。
|
||||
|
||||
在集群管理器中:
|
||||
|
||||
# docker run swarm create
|
||||
|
||||

|
||||
|
||||
### 3. 启动各个节点上的Docker守护进程 ###
|
||||
|
||||
我们需要登录进我们将用来创建集群的每个节点,并在其上使用-H标记启动Docker守护进程。它会保证Swarm管理器能够通过TCP访问到各个节点上的Docker远程API。要启动Docker守护进程,我们需要在各个节点内部运行以下命令。
|
||||
|
||||
# docker -H tcp://0.0.0.0:2375 -d
|
||||
|
||||

|
||||
|
||||
### 4. 添加节点 ###
|
||||
|
||||
在启用Docker守护进程后,我们需要添加Swarm节点到发现服务,我们必须确保节点IP可从Swarm管理器访问到。要完成该操作,我们需要运行以下命令。
|
||||
|
||||
# docker run -d swarm join --addr=<node_ip>:2375 token://<cluster_id>
|
||||
|
||||

|
||||
|
||||
**注意**:我们需要用步骤2中获取到的节点IP地址和集群ID替换这里的<node_ip>和<cluster_id>。
|
||||
|
||||
### 5. 开启Swarm管理器 ###
|
||||
|
||||
现在,由于我们已经获得了连接到集群的节点,我们将启动swarm管理器。我们需要在节点中运行以下命令。
|
||||
|
||||
# docker run -d -p <swarm_port>:2375 swarm manage token://<cluster_id>
|
||||
|
||||

|
||||
|
||||
### 6. 检查配置 ###
|
||||
|
||||
一旦管理运行起来后,我们可以通过运行以下命令来检查配置。
|
||||
|
||||
# docker -H tcp://<manager_ip:manager_port> info
|
||||
|
||||

|
||||
|
||||
**注意**:我们需要替换<manager_ip:manager_port>为运行swarm管理器的主机的IP地址和端口。
|
||||
|
||||
### 7. 使用docker CLI来访问节点 ###
|
||||
|
||||
在一切都像上面说得那样完美地完成后,这一部分是Docker Swarm最为重要的部分。我们可以使用Docker CLI来访问节点,并在节点上运行容器。
|
||||
|
||||
# docker -H tcp://<manager_ip:manager_port> info
|
||||
# docker -H tcp://<manager_ip:manager_port> run ...
|
||||
|
||||
### 8. 监听集群中的节点 ###
|
||||
|
||||
我们可以使用swarm list命令来获取所有运行中节点的列表。
|
||||
|
||||
# docker run --rm swarm list token://<cluster_id>
|
||||
|
||||

|
||||
|
||||
### 尾声 ###
|
||||
|
||||
Swarm真的是一个有着相当不错的功能的docker,它可以用于创建和管理集群。它相当易于配置和使用,当我们在它上面使用限制器和类同器时它更为出色。高级调度程序是一个相当不错的特性,它可以应用过滤器来通过端口、标签、健康状况来排除节点,并且它使用策略来挑选最佳节点。那么,如果你有任何问题、评论、反馈,请在下面的评论框中写出来吧,好让我们知道哪些材料需要补充或改进。谢谢大家了!尽情享受吧 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/configure-swarm-clustering-docker/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://docs.docker.com/swarm/
|
||||
@ -1,23 +1,22 @@
|
||||
Linux_Logo – 输出彩色 ANSI Linux 发行版徽标的命令行工具
|
||||
================================================================================
|
||||
linuxlogo 或 linux_logo 是一款在Linux命令行下生成附带系统信息的彩色 ANSI 发行版徽标的工具。
|
||||
|
||||
linuxlogo(或叫 linux_logo)是一款在Linux命令行下用彩色 ANSI 代码生成附带有系统信息的发行版徽标的工具。
|
||||
|
||||

|
||||
|
||||
Linux_Logo – 输出彩色 ANSI Linux 发行版徽标
|
||||
*Linux_Logo – 输出彩色 ANSI Linux 发行版徽标*
|
||||
|
||||
这个小工具可以从 /proc 文件系统中获取系统信息并可以显示包括主机发行版在内的其他很多发行版的徽标。
|
||||
这个小工具可以从 /proc 文件系统中获取系统信息并可以显示包括主机上安装的发行版在内的很多发行版的徽标。
|
||||
|
||||
与徽标一同显示的系统信息包括 – Linux 内核版本,最近一次编译Linux内核的时间,处理器/核心数量,速度,制造商,以及哪一代处理器。它还能显示总共的物理内存大小。
|
||||
与徽标一同显示的系统信息包括 : Linux 内核版本,最近一次编译Linux内核的时间,处理器/核心数量,速度,制造商,以及哪一代处理器。它还能显示总共的物理内存大小。
|
||||
|
||||
值得一提的是,screenfetch是一个拥有类似功能的工具,它也能显示发行版徽标,同时还提供更加详细美观的系统信息。我们之前已经介绍过这个工具,你可以参考一下链接:
|
||||
- [ScreenFetch – Generates Linux System Information][1]
|
||||
无独有偶,screenfetch是一个拥有类似功能的工具,它也能显示发行版徽标,同时还提供更加详细美观的系统信息。我们之前已经介绍过这个工具,你可以参考一下链接:
|
||||
|
||||
- [screenFetch: 命令行信息截图工具][1]
|
||||
|
||||
linux_logo 和 Screenfetch 并不能相提并论。尽管 screenfetch 的输出较为整洁并提供更多细节, linux_logo 则提供了更多的彩色 ANSI 图标, 并且提供了格式化输出的选项。
|
||||
linux\_logo 和 Screenfetch 并完全一样。尽管 screenfetch 的输出较为整洁并提供更多细节, 但 linux\_logo 则提供了更多的彩色 ANSI 图标, 并且提供了格式化输出的选项。
|
||||
|
||||
linux_logo 主要使用C语言编写并将 linux 徽标呈现在 X 窗口系统中因此需要安装图形界面 X11 或 X 系统。这个软件使用GNU 2.0协议。
|
||||
linux\_logo 主要使用C语言编写并将 linux 徽标呈现在 X 窗口系统中因此需要安装图形界面 X11 或 X 系统(LCTT 译注:此处应是错误的。按说不需要任何图形界面支持,并且译者从其官方站 http://www.deater.net/weave/vmwprod/linux_logo 也没找到任何相关 X11的信息)。这个软件使用GNU 2.0协议。
|
||||
|
||||
本文中,我们将使用以下环境测试 linux_logo 工具。
|
||||
|
||||
@ -26,7 +25,7 @@ linux_logo 主要使用C语言编写并将 linux 徽标呈现在 X 窗口系统
|
||||
|
||||
### 在 Linux 中安装 Linux Logo工具 ###
|
||||
|
||||
**1. linuxlogo软件包 ( 5.11 稳定版) 可通过如下方式使用 apt, yum,或 dnf 在所有发行版中使用默认的软件仓库进行安装**
|
||||
**1. linuxlogo软件包 ( 5.11 稳定版) 可通过如下方式使用 apt, yum 或 dnf 在所有发行版中使用默认的软件仓库进行安装**
|
||||
|
||||
# apt-get install linux_logo [用于基于 Apt 的系统] (译者注:Ubuntu中,该软件包名为linuxlogo)
|
||||
# yum install linux_logo [用于基于 Yum 的系统]
|
||||
@ -42,7 +41,7 @@ linux_logo 主要使用C语言编写并将 linux 徽标呈现在 X 窗口系统
|
||||
|
||||

|
||||
|
||||
获取默认系统徽标
|
||||
*获取默认系统徽标*
|
||||
|
||||
**3. 使用 `[-a]` 选项可以输出没有颜色的徽标。当在黑白终端里使用 linux_logo 时,这个选项会很有用。**
|
||||
|
||||
@ -50,7 +49,7 @@ linux_logo 主要使用C语言编写并将 linux 徽标呈现在 X 窗口系统
|
||||
|
||||

|
||||
|
||||
黑白 Linux 徽标
|
||||
*黑白 Linux 徽标*
|
||||
|
||||
**4. 使用 `[-l]` 选项可以仅输出徽标而不包含系统信息。**
|
||||
|
||||
@ -58,7 +57,7 @@ linux_logo 主要使用C语言编写并将 linux 徽标呈现在 X 窗口系统
|
||||
|
||||

|
||||
|
||||
输出发行版徽标
|
||||
*输出发行版徽标*
|
||||
|
||||
**5. `[-u]` 选项可以显示系统运行时间。**
|
||||
|
||||
@ -66,7 +65,7 @@ linux_logo 主要使用C语言编写并将 linux 徽标呈现在 X 窗口系统
|
||||
|
||||

|
||||
|
||||
输出系统运行时间
|
||||
*输出系统运行时间*
|
||||
|
||||
**6. 如果你对系统平均负载感兴趣,可以使用 `[-y]` 选项。你可以同时使用多个选项。**
|
||||
|
||||
@ -74,7 +73,7 @@ linux_logo 主要使用C语言编写并将 linux 徽标呈现在 X 窗口系统
|
||||
|
||||

|
||||
|
||||
输出系统平均负载
|
||||
*输出系统平均负载*
|
||||
|
||||
如需查看更多选项并获取相关帮助,你可以使用如下命令。
|
||||
|
||||
@ -82,7 +81,7 @@ linux_logo 主要使用C语言编写并将 linux 徽标呈现在 X 窗口系统
|
||||
|
||||

|
||||
|
||||
Linuxlogo选项及帮助
|
||||
*Linuxlogo选项及帮助*
|
||||
|
||||
**7. 此工具内置了很多不同发行版的徽标。你可以使用 `[-L list]` 选项查看在这些徽标的列表。**
|
||||
|
||||
@ -90,7 +89,7 @@ Linuxlogo选项及帮助
|
||||
|
||||

|
||||
|
||||
Linux 徽标列表
|
||||
*Linux 徽标列表*
|
||||
|
||||
如果你想输出这个列表中的任意徽标,可以使用 `-L NUM` 或 `-L NAME` 来显示想要选中的图标。
|
||||
|
||||
@ -105,7 +104,7 @@ Linux 徽标列表
|
||||
|
||||

|
||||
|
||||
输出 AIX 图标
|
||||
*输出 AIX 图标*
|
||||
|
||||
**注**: 命令中的使用 `-L 1` 是因为 AIX 徽标在列表中的编号是1,而使用 `-L aix` 则是因为 AIX 徽标在列表中的名称为 aix
|
||||
|
||||
@ -116,13 +115,13 @@ Linux 徽标列表
|
||||
|
||||

|
||||
|
||||
各种 Linux 徽标
|
||||
*各种 Linux 徽标*
|
||||
|
||||
你可以通过徽标对应的编号或名字使用任意徽标
|
||||
你可以通过徽标对应的编号或名字使用任意徽标。
|
||||
|
||||
### 一些使用 Linux_logo 的建议和提示###
|
||||
|
||||
**8. 你可以在登录界面输出你的 Linux 发行版徽标。要输出默认徽标,你可以在 ` ~/.bashrc`` 文件的最后添加以下内容。**
|
||||
**8. 你可以在登录界面输出你的 Linux 发行版徽标。要输出默认徽标,你可以在 ` ~/.bashrc` 文件的最后添加以下内容。**
|
||||
|
||||
if [ -f /usr/bin/linux_logo ]; then linux_logo; fi
|
||||
|
||||
@ -132,15 +131,15 @@ Linux 徽标列表
|
||||
|
||||

|
||||
|
||||
在用户登录时输出徽标
|
||||
*在用户登录时输出徽标*
|
||||
|
||||
其实你也可以在登录后输出任意图标,只需加入以下内容
|
||||
其实你也可以在登录后输出任意图标,只需加入以下内容:
|
||||
|
||||
if [ -f /usr/bin/linux_logo ]; then linux_logo -L num; fi
|
||||
|
||||
**重要**: 不要忘了将 num 替换成你想使用的图标。
|
||||
|
||||
**10. You can also print your own logo by simply specifying the location of the logo as shown below.**
|
||||
**10. 你也能直接指定徽标所在的位置来显示你自己的徽标。**
|
||||
|
||||
# linux_logo -D /path/to/ASCII/logo
|
||||
|
||||
@ -152,12 +151,11 @@ Linux 徽标列表
|
||||
|
||||
# /usr/local/bin/linux_logo -a > /etc/issue.net
|
||||
|
||||
**12. 创建一个 Penguin 端口 - 用于回应连接的端口。要创建 Penguin 端口, 则需在 /etc/services 文件中加入以下内容 **
|
||||
**12. 创建一个 Linux 上的端口 - 用于回应连接的端口。要创建 Linux 端口, 则需在 /etc/services 文件中加入以下内容**
|
||||
|
||||
penguin 4444/tcp penguin
|
||||
|
||||
这里的 `4444` 是一个未被任何其他资源使用的空闲端口。你也可以使用其他端口。
|
||||
你还需要在 /etc/inetd.conf中加入以下内容
|
||||
这里的 `4444` 是一个未被任何其他资源使用的空闲端口。你也可以使用其他端口。你还需要在 /etc/inetd.conf中加入以下内容:
|
||||
|
||||
penguin stream tcp nowait root /usr/local/bin/linux_logo
|
||||
|
||||
@ -165,6 +163,8 @@ Linux 徽标列表
|
||||
|
||||
# killall -HUP inetd
|
||||
|
||||
(LCTT 译注:然后你就可以远程或本地连接到这个端口,并显示这个徽标了。)
|
||||
|
||||
linux_logo 还可以用做启动脚本来愚弄攻击者或对你朋友使用恶作剧。这是一个我经常在我的脚本中用来获取不同发行版输出的好工具。
|
||||
|
||||
试过一次后,你就不会忘记的。让我们知道你对这个工具的想法及它对你的作用吧。 不要忘记给评论、点赞或分享!
|
||||
@ -174,10 +174,10 @@ linux_logo 还可以用做启动脚本来愚弄攻击者或对你朋友使用恶
|
||||
via: http://www.tecmint.com/linux_logo-tool-to-print-color-ansi-logos-of-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[KevSJ](https://github.com/KevSJ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[KevinSJ](https://github.com/KevinSJ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/screenfetch-system-information-generator-for-linux/
|
||||
[1]:https://linux.cn/article-1947-1.html
|
||||
177
published/201507/20150616 LINUX 101--POWER UP YOUR SHELL.md
Normal file
177
published/201507/20150616 LINUX 101--POWER UP YOUR SHELL.md
Normal file
@ -0,0 +1,177 @@
|
||||
LINUX 101: 让你的 SHELL 更强大
|
||||
================================================================================
|
||||
> 在我们的关于 shell 基础的指导下, 得到一个更灵活,功能更强大且多彩的命令行界面
|
||||
|
||||
**为何要这样做?**
|
||||
|
||||
- 使得在 shell 提示符下过得更轻松,高效
|
||||
- 在失去连接后恢复先前的会话
|
||||
- Stop pushing around that fiddly rodent!
|
||||
|
||||
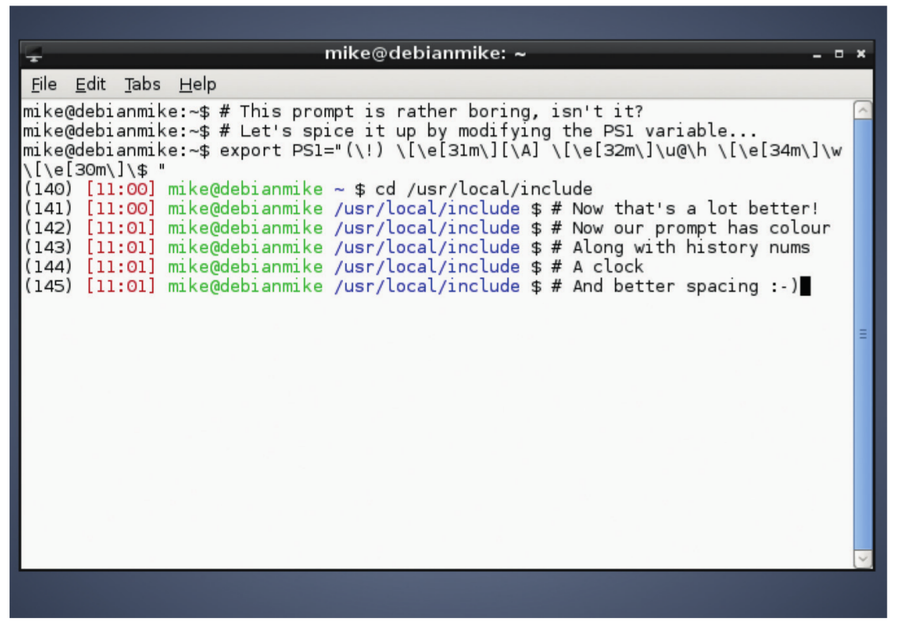
|
||||
|
||||
这是我的命令行提示符的设置。对于这个小的终端窗口来说,这或许有些长。但你可以根据你的喜好来调整它。
|
||||
|
||||
作为一个 Linux 用户, 你可能熟悉 shell (又名为命令行)。 或许你需要时不时的打开终端来完成那些不能在 GUI 下处理的必要任务,抑或是因为你处在一个将窗口铺满桌面的环境中,而 shell 是你与你的 linux 机器交互的主要方式。
|
||||
|
||||
在上面那些情况下,你可能正在使用你所使用的发行版本自带的 Bash 配置。 尽管对于大多数的任务而言,它足够好了,但它可以更加强大。 在本教程中,我们将向你展示如何使得你的 shell 提供更多有用信息、更加实用且更适合工作。 我们将对提示符进行自定义,让它比默认情况下提供更好的反馈,并向你展示如何使用炫酷的 `tmux` 工具来管理会话并同时运行多个程序。 并且,为了让眼睛舒服一点,我们还将关注配色方案。那么,进击吧,少女!
|
||||
|
||||
### 让提示符更美妙 ###
|
||||
|
||||
大多数的发行版本配置有一个非常简单的提示符,它们大多向你展示了一些基本信息, 但提示符可以为你提供更多的内容。例如,在 Debian 7 下,默认的提示符是这样的:
|
||||
|
||||
mike@somebox:~$
|
||||
|
||||
上面的提示符展示出了用户、主机名、当前目录和账户类型符号(假如你切换到 root 账户, **$** 会变为 **#**)。 那这些信息是在哪里存储的呢? 答案是:在 **PS1** 环境变量中。 假如你键入 `echo $PS1`, 你将会在这个命令的输出字符串的最后有如下的字符:
|
||||
|
||||
\u@\h:\w$
|
||||
|
||||
这看起来有一些丑陋,并在瞥见它的第一眼时,你可能会开始尖叫,认为它是令人恐惧的正则表达式,但我们不打算用这些复杂的字符来煎熬我们的大脑。这不是正则表达式,这里的斜杠是转义序列,它告诉提示符进行一些特别的处理。 例如,上面的 **u** 部分,告诉提示符展示用户名, 而 w 则展示工作路径.
|
||||
|
||||
下面是一些你可以在提示符中用到的字符的列表:
|
||||
|
||||
- d 当前的日期
|
||||
- h 主机名
|
||||
- n 代表换行的字符
|
||||
- A 当前的时间 (HH:MM)
|
||||
- u 当前的用户
|
||||
- w (小写) 整个工作路径的全称
|
||||
- W (大写) 工作路径的简短名称
|
||||
- $ 一个提示符号,对于 root 用户为 # 号
|
||||
- ! 当前命令在 shell 历史记录中的序号
|
||||
|
||||
下面解释 **w** 和 **W** 选项的区别: 对于前者,你将看到你所在的工作路径的完整地址,(例如 **/usr/local/bin**),而对于后者, 它则只显示 **bin** 这一部分。
|
||||
|
||||
现在,我们该怎样改变提示符呢? 你需要更改 **PS1** 环境变量的内容,试试下面这个:
|
||||
|
||||
export PS1="I am \u and it is \A $"
|
||||
|
||||
现在,你的提示符将会像下面这样:
|
||||
|
||||
I am mike and it is 11:26 $
|
||||
|
||||
从这个例子出发,你就可以按照你的想法来试验一下上面列出的其他转义序列。 但等等 – 当你登出后,你的这些努力都将消失,因为在你每次打开终端时,**PS1** 环境变量的值都会被重置。解决这个问题的最简单方式是打开 **.bashrc** 配置文件(在你的家目录下) 并在这个文件的最下方添加上完整的 `export` 命令。在每次你启动一个新的 shell 会话时,这个 **.bashrc** 会被 `Bash` 读取, 所以你的加强的提示符就可以一直出现。你还可以使用额外的颜色来装扮提示符。刚开始,这将有点棘手,因为你必须使用一些相当奇怪的转义序列,但结果是非常漂亮的。 将下面的字符添加到你的 **PS1**字符串中的某个位置,最终这将把文本变为红色:
|
||||
|
||||
\[\e[31m\]
|
||||
|
||||
你可以将这里的 31 更改为其他的数字来获得不同的颜色:
|
||||
|
||||
- 30 黑色
|
||||
- 32 绿色
|
||||
- 33 黄色
|
||||
- 34 蓝色
|
||||
- 35 洋红色
|
||||
- 36 青色
|
||||
- 37 白色
|
||||
|
||||
所以,让我们使用先前看到的转义序列和颜色来创造一个提示符,以此来结束这一小节的内容。深吸一口气,弯曲你的手指,然后键入下面这只“野兽”:
|
||||
|
||||
export PS1="(\!) \[\e[31m\] \[\A\] \[\e[32m\]\u@\h \[\e[34m\]\w \[\e[30m\]$"
|
||||
|
||||
上面的命令提供了一个 Bash 命令历史序号、当前的时间、彩色的用户或主机名组合、以及工作路径。假如你“野心勃勃”,利用一些惊人的组合,你还可以更改提示符的背景色和前景色。非常有用的 Arch wiki 有一个关于颜色代码的完整列表:[http://tinyurl.com/3gvz4ec][1]。
|
||||
|
||||
> **Shell 精要**
|
||||
>
|
||||
> 假如你是一个彻底的 Linux 新手并第一次阅读这份杂志,或许你会发觉阅读这些教程有些吃力。 所以这里有一些基础知识来让你熟悉一些 shell。 通常在你的菜单中, shell 指的是 Terminal、 XTerm 或 Konsole, 当你启动它后, 最为实用的命令有这些:
|
||||
>
|
||||
> **ls** (列出文件名); **cp one.txt two.txt** (复制文件); **rm file.txt** (移除文件); **mv old.txt new.txt** (移动或重命名文件);
|
||||
>
|
||||
> **cd /some/directory** (改变目录); **cd ..** (回到上级目录); **./program** (在当前目录下运行一个程序); **ls > list.txt** (重定向输出到一个文件)。
|
||||
>
|
||||
> 几乎每个命令都有一个手册页用来解释其选项(例如 **man ls** – 按 Q 来退出)。在那里,你可以知晓命令的选项,这样你就知道 **ls -la** 展示一个详细的列表,其中也列出了隐藏文件, 并且在键入一个文件或目录的名字的一部分后, 可以使用 Tab 键来自动补全。
|
||||
|
||||
### Tmux: 针对 shell 的窗口管理器 ###
|
||||
|
||||
在文本模式的环境中使用一个窗口管理器 – 这听起来有点不可思议, 是吧? 然而,你应该记得当 Web 浏览器第一次实现分页浏览的时候吧? 在当时, 这是在可用性上的一个重大进步,它减少了桌面任务栏的杂乱无章和繁多的窗口列表。 对于你的浏览器来说,你只需要一个按钮便可以在浏览器中切换到你打开的每个单独网站, 而不是针对每个网站都有一个任务栏或导航图标。 这个功能非常有意义。
|
||||
|
||||
若有时你同时运行着几个虚拟终端,你便会遇到相似的情况; 在这些终端之间跳转,或每次在任务栏或窗口列表中找到你所需要的那一个终端,都可能会让你觉得麻烦。 拥有一个文本模式的窗口管理器不仅可以让你像在同一个终端窗口中运行多个 shell 会话,而且你甚至还可以将这些窗口排列在一起。
|
||||
|
||||
另外,这样还有另一个好处:可以将这些窗口进行分离和重新连接。想要看看这是如何运行的最好方式是自己尝试一下。在一个终端窗口中,输入 `screen` (在大多数发行版本中,它已经默认安装了或者可以在软件包仓库中找到)。 某些欢迎的文字将会出现 – 只需敲击 Enter 键这些文字就会消失。 现在运行一个交互式的文本模式的程序,例如 `nano`, 并关闭这个终端窗口。
|
||||
|
||||
在一个正常的 shell 对话中, 关闭窗口将会终止所有在该终端中运行的进程 – 所以刚才的 Nano 编辑对话也就被终止了, 但对于 screen 来说,并不是这样的。打开一个新的终端并输入如下命令:
|
||||
|
||||
screen -r
|
||||
|
||||
瞧,你刚开打开的 Nano 会话又回来了!
|
||||
|
||||
当刚才你运行 **screen** 时, 它会创建了一个新的独立的 shell 会话, 它不与某个特定的终端窗口绑定在一起,所以可以在后面被分离并重新连接(即 **-r** 选项)。
|
||||
|
||||
当你正使用 SSH 去连接另一台机器并做着某些工作时, 但并不想因为一个脆弱的连接而影响你的进度,这个方法尤其有用。假如你在一个 **screen** 会话中做着某些工作,并且你的连接突然中断了(或者你的笔记本没电了,又或者你的电脑报废了——不是这么悲催吧),你只需重新连接或给电脑充电或重新买一台电脑,接着运行 **screen -r** 来重新连接到远程的电脑,并在刚才掉线的地方接着开始。
|
||||
|
||||
现在,我们都一直在讨论 GNU 的 **screen**,但这个小节的标题提到的是 tmux。 实质上, **tmux** (terminal multiplexer) 就像是 **screen** 的一个进阶版本,带有许多有用的额外功能,所以现在我们开始关注 tmux。 某些发行版本默认包含了 **tmux**; 在其他的发行版本上,通常只需要一个 **apt-get、 yum install** 或 **pacman -S** 命令便可以安装它。
|
||||
|
||||
一旦你安装了它过后,键入 **tmux** 来启动它。接着你将注意到,在终端窗口的底部有一条绿色的信息栏,它非常像传统的窗口管理器中的任务栏: 上面显示着一个运行着的程序的列表、机器的主机名、当前时间和日期。 现在运行一个程序,同样以 Nano 为例, 敲击 Ctrl+B 后接着按 C 键, 这将在 tmux 会话中创建一个新的窗口,你便可以在终端的底部的任务栏中看到如下的信息:
|
||||
|
||||
0:nano- 1:bash*
|
||||
|
||||
每一个窗口都有一个数字,当前呈现的程序被一个星号所标记。 Ctrl+B 是与 tmux 交互的标准方式, 所以若你敲击这个按键组合并带上一个窗口序号, 那么就会切换到对应的那个窗口。你也可以使用 Ctrl+B 再加上 N 或 P 来分别切换到下一个或上一个窗口 – 或者使用 Ctrl+B 加上 L 来在最近使用的两个窗口之间来进行切换(有点类似于桌面中的经典的 Alt+Tab 组合键的效果)。 若需要知道窗口列表,使用 Ctrl+B 再加上 W。
|
||||
|
||||
目前为止,一切都还好:现在你可以在一个单独的终端窗口中运行多个程序,避免混乱(尤其是当你经常与同一个远程主机保持多个 SSH 连接时)。 当想同时看两个程序又该怎么办呢?
|
||||
|
||||
针对这种情况, 可以使用 tmux 中的窗格。 敲击 Ctrl+B 再加上 % , 则当前窗口将分为两个部分:一个在左一个在右。你可以使用 Ctrl+B 再加上 O 来在这两个部分之间切换。 这尤其在你想同时看两个东西时非常实用, – 例如一个窗格看指导手册,另一个窗格里用编辑器看一个配置文件。
|
||||
|
||||
有时,你想对一个单独的窗格进行缩放,而这需要一定的技巧。 首先你需要敲击 Ctrl+B 再加上一个 :(冒号),这将使得位于底部的 tmux 栏变为深橙色。 现在,你进入了命令模式,在这里你可以输入命令来操作 tmux。 输入 **resize-pane -R** 来使当前窗格向右移动一个字符的间距, 或使用 **-L** 来向左移动。 对于一个简单的操作,这些命令似乎有些长,但请注意,在 tmux 的命令模式(前面提到的一个分号开始的模式)下,可以使用 Tab 键来补全命令。 另外需要提及的是, **tmux** 同样也有一个命令历史记录,所以若你想重复刚才的缩放操作,可以先敲击 Ctrl+B 再跟上一个分号,并使用向上的箭头来取回刚才输入的命令。
|
||||
|
||||
最后,让我们看一下分离和重新连接 - 即我们刚才介绍的 screen 的特色功能。 在 tmux 中,敲击 Ctrl+B 再加上 D 来从当前的终端窗口中分离当前的 tmux 会话。这使得这个会话的一切工作都在后台中运行、使用 `tmux a` 可以再重新连接到刚才的会话。但若你同时有多个 tmux 会话在运行时,又该怎么办呢? 我们可以使用下面的命令来列出它们:
|
||||
|
||||
tmux ls
|
||||
|
||||
这个命令将为每个会话分配一个序号; 假如你想重新连接到会话 1, 可以使用 `tmux a -t 1`. tmux 是可以高度定制的,你可以自定义按键绑定并更改配色方案, 所以一旦你适应了它的主要功能,请钻研指导手册以了解更多的内容。
|
||||
|
||||
|
||||
|
||||
|
||||
上图中, tmux 开启了两个窗格: 左边是 Vim 正在编辑一个配置文件,而右边则展示着指导手册页。
|
||||
|
||||
> **Zsh: 另一个 shell**
|
||||
>
|
||||
> 选择是好的,但标准同样重要。 你要知道几乎每个主流的 Linux 发行版本都默认使用 Bash shell – 尽管还存在其他的 shell。 Bash 为你提供了一个 shell 能够给你提供的几乎任何功能,包括命令历史记录,文件名补全和许多脚本编程的能力。它成熟、可靠并文档丰富 – 但它不是你唯一的选择。
|
||||
>
|
||||
> 许多高级用户热衷于 Zsh, 即 Z shell。 这是 Bash 的一个替代品并提供了 Bash 的几乎所有功能,另外还提供了一些额外的功能。 例如, 在 Zsh 中,你输入 **ls** ,并敲击 Tab 键可以得到 **ls** 可用的各种不同选项的一个大致描述。 而不需要再打开 man page 了!
|
||||
>
|
||||
> Zsh 还支持其他强大的自动补全功能: 例如,输入 **cd /u/lo/bi** 再敲击 Tab 键, 则完整的路径名 **/usr/local/bin** 就会出现(这里假设没有其他的路径包含 **u**, **lo** 和 **bi** 等字符)。 或者只输入 **cd** 再跟上 Tab 键,则你将看到着色后的路径名的列表 – 这比 Bash 给出的简单的结果好看得多。
|
||||
>
|
||||
> Zsh 在大多数的主要发行版本上都可以得到了; 安装它后并输入 **zsh** 便可启动它。 要将你的默认 shell 从 Bash 改为 Zsh, 可以使用 **chsh** 命令。 若需了解更多的信息,请访问 [www.zsh.org][2]。
|
||||
|
||||
### “未来”的终端 ###
|
||||
|
||||
你或许会好奇为什么包含你的命令行提示符的应用被叫做终端。 这需要追溯到 Unix 的早期, 那时人们一般工作在一个多用户的机器上,这个巨大的电脑主机将占据一座建筑中的一个房间, 人们通过某些线路,使用屏幕和键盘来连接到这个主机, 这些终端机通常被称为“哑终端”, 因为它们不能靠自己做任何重要的执行任务 – 它们只展示通过线路从主机传来的信息,并输送回从键盘的敲击中得到的输入信息。
|
||||
|
||||
今天,我们在自己的机器上执行几乎所有的实际操作,所以我们的电脑不是传统意义下的终端,这就是为什么诸如 **XTerm**、 Gnome Terminal、 Konsole 等程序被称为“终端模拟器” 的原因 – 他们提供了同昔日的物理终端一样的功能。事实上,在许多方面它们并没有改变多少。诚然,现在我们有了反锯齿字体,更好的颜色和点击网址的能力,但总的来说,几十年来我们一直以同样的方式在工作。
|
||||
|
||||
所以某些程序员正尝试改变这个状况。 **Terminology** ([http://tinyurl.com/osopjv9][3]), 它来自于超级时髦的 Enlightenment 窗口管理器背后的团队,旨在让终端步入到 21 世纪,例如带有在线媒体显示功能。你可以在一个充满图片的目录里输入 **ls** 命令,便可以看到它们的缩略图,或甚至可以直接在你的终端里播放视频。 这使得一个终端有点类似于一个文件管理器,意味着你可以快速地检查媒体文件的内容而不必用另一个应用来打开它们。
|
||||
|
||||
接着还有 Xiki ([www.xiki.org][4]),它自身的描述为“命令的革新”。它就像是一个传统的 shell、一个 GUI 和一个 wiki 之间的过渡;你可以在任何地方输入命令,并在后面将它们的输出存储为笔记以作为参考,并可以创建非常强大的自定义命令。用几句话是很能描述它的,所以作者们已经创作了一个视频来展示它的潜力是多么的巨大(请看 **Xiki** 网站的截屏视频部分)。
|
||||
|
||||
并且 Xiki 绝不是那种在几个月之内就消亡的昙花一现的项目,作者们成功地进行了一次 Kickstarter 众筹,在七月底已募集到超过 $84,000。 是的,你没有看错 – $84K 来支持一个终端模拟器。这可能是最不寻常的集资活动了,因为某些疯狂的家伙已经决定开始创办它们自己的 Linux 杂志 ......
|
||||
|
||||
### 下一代终端 ###
|
||||
|
||||
许多命令行和基于文本的程序在功能上与它们的 GUI 程序是相同的,并且常常更加快速和高效。我们的推荐有:
|
||||
**Irssi** (IRC 客户端); **Mutt** (mail 客户端); **rTorrent** (BitTorrent); **Ranger** (文件管理器); **htop** (进程监视器)。 若给定在终端的限制下来进行 Web 浏览, Elinks 确实做的很好,并且对于阅读那些以文字为主的网站例如 Wikipedia 来说。它非常实用。
|
||||
|
||||
> **微调配色方案**
|
||||
>
|
||||
> 在《Linux Voice》杂志社中,我们并不迷恋那些养眼的东西,但当你每天花费几个小时盯着屏幕看东西时,我们确实认识到美学的重要性。我们中的许多人都喜欢调整我们的桌面和窗口管理器来达到完美的效果,调整阴影效果、摆弄不同的配色方案,直到我们 100% 的满意(然后出于习惯,摆弄更多的东西)。
|
||||
>
|
||||
> 但我们倾向于忽视终端窗口,它理应也获得我们的喜爱,并且在 [http://ciembor.github.io/4bit][5] 你将看到一个极其棒的配色方案设计器,对于所有受欢迎的终端模拟器(**XTerm, Gnome Terminal, Konsole 和 Xfce4 Terminal 等都是支持的应用。**),它可以输出其设定。移动滑块直到你看到配色方案最佳, 然后点击位于该页面右上角的 `得到方案` 按钮。
|
||||
>
|
||||
> 相似的,假如你在一个文本编辑器,如 Vim 或 Emacs 上花费了很多的时间,使用一个精心设计的调色板也是非常值得的。 **Solarized** [http://ethanschoonover.com/solarized][6] 是一个卓越的方案,它不仅漂亮,而且因追求最大的可用性而设计,在其背后有着大量的研究和测试。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxvoice.com/linux-101-power-up-your-shell-8/
|
||||
|
||||
作者:[Ben Everard][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxvoice.com/author/ben_everard/
|
||||
[1]:http://tinyurl.com/3gvz4ec
|
||||
[2]:http://www.zsh.org/
|
||||
[3]:http://tinyurl.com/osopjv9
|
||||
[4]:http://www.xiki.org/
|
||||
[5]:http://ciembor.github.io/4bit
|
||||
[6]:http://ethanschoonover.com/solarized
|
||||
@ -1,16 +1,16 @@
|
||||
XBMC:自制遥控
|
||||
为 Kodi 自制遥控器
|
||||
================================================================================
|
||||
**通过运行在 Android 手机上的自制遥控器来控制你的家庭媒体播放器。**
|
||||
|
||||
**XBMC** 一款很优秀的软件,能够将几乎所有电脑变身成媒体中心。它可以播放音乐和视频,显示图片,甚至还能显示天气预报。为了在配置成家庭影院后方便使用,你可以通过手机 app 访问运行在已连接到 Wi-Fi 的 XBMC 机器上的服务来控制它。可以找到很多这种工具,几乎覆盖所有智能手机系统。
|
||||
**Kodi** 是一款很优秀的软件,能够将几乎所有电脑变身成媒体中心。它可以播放音乐和视频,显示图片,甚至还能显示天气预报。为了在配置成家庭影院后方便使用,你可以通过手机 app 访问运行在连接到 Wi-Fi 的 XBMC 机器上的服务来控制它。可以找到很多这种工具,几乎覆盖所有智能手机系统。
|
||||
|
||||
> ### Kodi ###
|
||||
> **XBMC**
|
||||
>
|
||||
> 在你阅读这篇文章的时候,**XBMC** 可能已经成为历史。因为法律原因(因为名字 **XBMC** 或 X**-Box Media Center** 里引用了不再支持的过时硬件)项目组决定使用新的名字 **Kodi**。不过,除了名字,其他的都会保持原样。或者说除开通常新版本中所期待的大量新改进。这一般不会影响到遥控软件,它应该能在已有的 **XBMC** 系统和新的 Kodi 系统上都能工作。
|
||||
> Kodi 原名叫做 XBMC,在你阅读这篇文章的时候,**XBMC** 已经成为历史。因为法律原因(因为名字 **XBMC** 或 X**-Box Media Center** 里引用了不再支持的过时硬件)项目组决定使用新的名字 **Kodi**。不过,除了名字,其他的都会保持原样。或者说除开通常新版本中所期待的大量新改进。这一般不会影响到遥控软件,它应该能在已有的 **XBMC** 系统和新的 Kodi 系统上都能工作。
|
||||
|
||||
我们目前配置了一个 **XBMC** 系统用于播放音乐,不过我们找到的所有 XBMC 遥控没一个好用的,特别是和媒体中心连接的电视没打开的时候。它们都有点太复杂了,集成了太多功能在手机的小屏幕上。我们希望能有这样的系统,从最开始就是设计成只用于访问音乐库和电台插件,所以我们决定自己实现一个。它不需要用到 XBMC 的所有功能,因为除了音乐以外的任务,我们可以简单地切换使用通用的 XBMC 遥控。我们的测试系统是一个刷了 RaspBMC 发行版的树莓派,但是我们要做的工具并不受限于树莓派或那个发行版,它应该可以匹配任何安装了相关插件的基于 Linux 的 XBMC 系统。
|
||||
我们目前已经配置好了一个用于播放音乐的 **Kodi** 系统,不过我们找到的所有 Kodi 遥控没一个好用的,特别是和媒体中心连接的电视没打开的时候。它们都有点太复杂了,集成了太多功能在手机的小屏幕上。我们希望能有这样的系统,从最开始就是设计成只用于访问音乐库和电台插件,所以我们决定自己实现一个。它不需要用到 Kodi 的所有功能,因为除了音乐以外的任务,我们可以简单地切换使用通用的 Kodi 遥控。我们的测试系统是一个刷了 RaspBMC 发行版的树莓派,但是我们要做的工具并不受限于树莓派或Kodi那个发行版,它应该可以匹配任何安装了相关插件的基于 Linux 的 Kodi 系统。
|
||||
|
||||
首先,遥控程序需要一个用户界面。大多数 XBMC 遥控程序都是独立的 app。不过对于我们要做的这个音乐控制程序,我们希望用户可以不用安装任何东西就可以使用。显然我们需要使用网页界面。XBMC 本身自带网页服务器,但是为了获得更多权限,我们还是使用了独立的网页框架。在同一台电脑上跑两个以上网页服务器没有问题,只不过它们不能使用相同的端口。
|
||||
首先,遥控程序需要一个用户界面。大多数 Kodi 遥控程序都是独立的 app。不过对于我们要做的这个音乐控制程序,我们希望用户可以不用安装任何东西就可以使用。显然我们需要使用网页界面。Kodi 本身自带网页服务器,但是为了获得更多权限,我们还是使用了独立的网页框架。在同一台电脑上跑两个以上网页服务器没有问题,只不过它们不能使用相同的端口。
|
||||
|
||||
有几个网页框架可以使用。而我们选用 Bottle 是因为它是一个简单高效的框架,而且我们也确实用不到任何高级功能。Bottle 是一个 Python 模块,所以这也将是我们编写服务器模块的语言。
|
||||
|
||||
@ -18,7 +18,7 @@ XBMC:自制遥控
|
||||
|
||||
sudo apt-get install python-bottle
|
||||
|
||||
遥控程序实际上只是连接用户和系统的中间层。Bottle 提供了和用户交互的方式,而我们将通过 JSON API 来和 **XBMC** 交互。这样可以让我们通过发送 JSON 格式消息的方式去控制媒体播放器。
|
||||
遥控程序实际上只是连接用户和系统的中间层。Bottle 提供了和用户交互的方式,而我们将通过 JSON API 来和 **Kodi** 交互。这样可以让我们通过发送 JSON 格式消息的方式去控制媒体播放器。
|
||||
|
||||
我们将用到一个叫做 xbmcjson 的简单 XBMC JASON API 封装。足够用来发送控制请求,而不需要关心实际的 JSON 格式以及和服务器通讯的无聊事。它没有包含在 PIP 包管理中,所以你得直接从 **GitHub** 安装:
|
||||
|
||||
@ -35,13 +35,13 @@ XBMC:自制遥控
|
||||
from xbmcjson import XBMC
|
||||
from bottle import route, run, template, redirect, static_file, request
|
||||
import os
|
||||
xbmc = XBMC(“http://192.168.0.5/jsonrpc”, “xbmc”, “xbmc”)
|
||||
@route(‘/hello/<name>’)
|
||||
xbmc = XBMC("http://192.168.0.5/jsonrpc", "xbmc", "xbmc")
|
||||
@route('/hello/<name>')
|
||||
def index(name):
|
||||
return template(‘<h1>Hello {{name}}!</h1>’, name=name)
|
||||
run(host=”0.0.0.0”, port=8000)
|
||||
return template('<h1>Hello {{name}}!</h1>', name=name)
|
||||
run(host="0.0.0.0", port=8000)
|
||||
|
||||
这样程序将连接到 **XBMC**(不过实际上用不到);然后 Bottle 会开始伺服网站。在我们的代码里,它将监听主机 0.0.0.0(意味着允许所有主机连接)的端口 8000。它只设定了一个站点,就是 /hello/XXXX,这里的 XXXX 可以是任何内容。不管 XXXX 是什么都将作为参数名传递给 index()。然后再替换进去 HTML 网页模版。
|
||||
这样程序将连接到 **Kodi**(不过实际上用不到);然后 Bottle 会开始提供网站服务。在我们的代码里,它将监听主机 0.0.0.0(意味着允许所有主机连接)的端口 8000。它只设定了一个站点,就是 /hello/XXXX,这里的 XXXX 可以是任何内容。不管 XXXX 是什么都将作为参数名传递给 index()。然后再替换进去 HTML 网页模版。
|
||||
|
||||
你可以先试着把上面内容写到一个文件(我们取的名字是 remote.py),然后用下面的命令启动:
|
||||
|
||||
@ -51,56 +51,56 @@ XBMC:自制遥控
|
||||
|
||||
@route() 用来设定网页服务器的路径,而函数 index() 会返回该路径的数据。通常是返回由模版生成的 HTML 页面,但是并不是说只能这样(后面会看到)。
|
||||
|
||||
随后,我们将给应用添加更多页面入口,让它变成一个全功能的 XBMC 遥控,但仍将采用相同代码结构。
|
||||
随后,我们将给应用添加更多页面入口,让它变成一个全功能的 Kodi 遥控,但仍将采用相同代码结构。
|
||||
|
||||
XBMC JSON API 接口可以从和 XBMC 机器同网段的任意电脑上访问。也就是说你可以在自己的笔记本上开发,然后再布置到媒体中心上,而不需要浪费时间上传每次改动。
|
||||
XBMC JSON API 接口可以从和 Kodi 机器同网段的任意电脑上访问。也就是说你可以在自己的笔记本上开发,然后再布置到媒体中心上,而不需要浪费时间上传每次改动。
|
||||
|
||||
模版 - 比如前面例子里的那个简单模版 - 是一种结合 Python 和 HTML 来控制输出的方式。理论上,这俩能做很多很多事,但是会非常混乱。我们将只是用它们来生成正确格式的数据。不过,在开始动手之前,我们先得准备点数据。
|
||||
|
||||
> ### Paste ###
|
||||
> **Paste**
|
||||
>
|
||||
> Bottle 自带网页服务器,就是我们用来测试遥控程序的。不过,我们发现它性能有时不够好。当我们的遥控程序正式上线时,我们希望页面能更快一点显示出来。Bottle 可以和很多不同的网页服务器配合工作,而我们发现 Paste 用起来非常不错。而要使用的话,只要简单地安装(Debian 系统里的 python-paste 包),然后修改一下代码里的 run 调用:
|
||||
> Bottle 自带网页服务器,我们用它来测试遥控程序。不过,我们发现它性能有时不够好。当我们的遥控程序正式上线时,我们希望页面能更快一点显示出来。Bottle 可以和很多不同的网页服务器配合工作,而我们发现 Paste 用起来非常不错。而要使用的话,只要简单地安装(Debian 系统里的 python-paste 包),然后修改一下代码里的 run 调用:
|
||||
>
|
||||
> run(host=hostname, port=hostport, server=”paste”)
|
||||
> run(host=hostname, port=hostport, server="paste")
|
||||
>
|
||||
> 你可以在 [http://bottlepy.org/docs/dev/deployment.html][1] 找到如何使用其他服务器的相关细节。
|
||||
|
||||
#### 从 XBMC 获取数据 ####
|
||||
#### 从 Kodi 获取数据 ####
|
||||
|
||||
XBMC JSON API 分成 14 个命名空间:JSONRPC, Player, Playlist, Files, AudioLibrary, VideoLibrary, Input, Application, System, Favourites, Profiles, Settings, Textures 和 XBMC。每个都可以通过 Python 的 XBMC 对象访问(Favourites 除外,明显是个疏忽)。每个命名空间都包含许多方法用于对程序的控制。例如,Playlist.GetItems() 可以用来获取某个特定播放列表的内容。服务器会返回给我们 JSON 格式的数据,但 xbmcjson 模块会为我们转化成 Python 词典。
|
||||
|
||||
我们需要用到 XBMC 里的两个组件来控制播放:播放器和播放列表。播放器带有播放列表并在每首歌结束时从列表里取下一首。为了查看当前正在播放的内容,我们需要获取正在工作的播放器的 ID,然后根据它找到当前播放列表的 ID。这个可以通过下面的代码来实现:
|
||||
我们需要用到 Kodi 里的两个组件来控制播放:播放器和播放列表。播放器处理播放列表并在每首歌结束时从列表里取下一首。为了查看当前正在播放的内容,我们需要获取正在工作的播放器的 ID,然后根据它找到当前播放列表的 ID。这个可以通过下面的代码来实现:
|
||||
|
||||
def get_playlistid():
|
||||
player = xbmc.Player.GetActivePlayers()
|
||||
if len(player[‘result’]) > 0:
|
||||
playlist_data = xbmc.Player.GetProperties({“playerid”:0, “properties”:[“playlistid”]})
|
||||
if len(playlist_data[‘result’]) > 0 and “playlistid” in playlist_data[‘result’].keys():
|
||||
return playlist_data[‘result’][‘playlistid’]
|
||||
if len(player['result']) > 0:
|
||||
playlist_data = xbmc.Player.GetProperties({"playerid":0, "properties":["playlistid"]})
|
||||
if len(playlist_data['result']) > 0 and "playlistid" in playlist_data['result'].keys():
|
||||
return playlist_data['result']['playlistid']
|
||||
return -1
|
||||
|
||||
如果当前没有播放器在工作(就是说,返回数据的结果部分的长度是 0),或者当前播放器不带播放列表,这样的话函数会返回 -1。其他时候,它会返回当前播放列表的数字 ID。
|
||||
如果当前没有播放器在工作(就是说,返回数据的结果部分的长度是 0),或者当前播放器没有处理播放列表,这样的话函数会返回 -1。其他时候,它会返回当前播放列表的数字 ID。
|
||||
|
||||
当我们拿到当前播放列表的 ID 后,就可以获取列表的细节内容。按照我们的需求,有两个重要的地方:播放列表里包含的项,以及当前播放所处的位置(已经播放过的项并不会从播放列表移除,只是移动当前播放位置)。
|
||||
当我们拿到当前播放列表的 ID 后,就可以获取该列表的细节内容。按照我们的需求,有两个重要的地方:播放列表里包含的项,以及当前播放所处的位置(已经播放过的项并不会从播放列表移除,只是移动当前播放位置)。
|
||||
|
||||
def get_playlist():
|
||||
playlistid = get_playlistid()
|
||||
if playlistid >= 0:
|
||||
data = xbmc.Playlist.GetItems({“playlistid”:playlistid, “properties”: [“title”, “album”, “artist”, “file”]})
|
||||
position_data = xbmc.Player.GetProperties({“playerid”:0, ‘properties’:[“position”]})
|
||||
position = int(position_data[‘result’][‘position’])
|
||||
return data[‘result’][‘items’][position:], position
|
||||
data = xbmc.Playlist.GetItems({"playlistid":playlistid, "properties": ["title", "album", "artist", "file"]})
|
||||
position_data = xbmc.Player.GetProperties({"playerid":0, 'properties':["position"]})
|
||||
position = int(position_data['result']['position'])
|
||||
return data['result']['items'][position:], position
|
||||
return [], -1
|
||||
|
||||
这样可以返回以正在播放的项开始的列表(因为我们并不关心已经播放过的内容),而且也包含了位置信息用来从列表里移除项。
|
||||
这样可以返回正在播放的项开始的列表(因为我们并不关心已经播放过的内容),而且也包含了用来从列表里移除项的位置信息。
|
||||
|
||||
|
||||
|
||||
API 文档在这里:[http://wiki.xbmc.org/?title=JSON-RPC_API/v6][2]。它列出了所有支持的函数,但是关于具体如何使用的描述有点太简单了。
|
||||
|
||||
> ### JSON ###
|
||||
> **JSON**
|
||||
>
|
||||
> JSON 是 JavaScript Object Notation 的缩写,开始设计用于 JavaScript 对象的序列化。目前仍然起到这个作用,但是它也是用来编码任意数据的一种很好用的方式。
|
||||
> JSON 是 JavaScript Object Notation 的缩写,最初设计用于 JavaScript 对象的序列化。目前仍然起到这个作用,但是它也是用来编码任意数据的一种很好用的方式。
|
||||
>
|
||||
> JSON 对象都是这样的格式:
|
||||
>
|
||||
@ -110,18 +110,18 @@ API 文档在这里:[http://wiki.xbmc.org/?title=JSON-RPC_API/v6][2]。它列
|
||||
>
|
||||
> 在字典数据结构里,值本身可以是另一个 JSON 对象,或者一个列表,所以下面的格式也是正确的:
|
||||
>
|
||||
> {“name”:“Ben”, “jobs”:[“cook”, “bottle-washer”], “appearance”: {“height”:195, “skin”:“fair”}}
|
||||
> {"name":"Ben", "jobs":["cook", "bottle-washer"], "appearance": {"height":195, "skin":"fair"}}
|
||||
>
|
||||
> JSON 通常在网络服务中用来发送和接收数据,并且大多数编程语言都能很好地支持,所以如果你熟悉 Python 的话,你应该可以使用你熟悉的编程语言调用相同的接口来轻松地控制 XBMC。
|
||||
> JSON 通常在网络服务中用来发送和接收数据,并且大多数编程语言都能很好地支持,所以如果你熟悉 Python 的话,你应该可以使用你熟悉的编程语言调用相同的接口来轻松地控制 Kodi。
|
||||
|
||||
#### 整合到一起 ####
|
||||
|
||||
把之前的功能连接到 HTML 页面很简单:
|
||||
|
||||
@route(‘/juke’)
|
||||
@route('/juke')
|
||||
def index():
|
||||
current_playlist, position = get_playlist()
|
||||
return template(‘list’, playlist=current_playlist, offset = position)
|
||||
return template('list', playlist=current_playlist, offset = position)
|
||||
|
||||
只需要抓取播放列表(调用我们之前定义的函数),然后将结果传递给负责显示的模版。
|
||||
|
||||
@ -131,57 +131,57 @@ API 文档在这里:[http://wiki.xbmc.org/?title=JSON-RPC_API/v6][2]。它列
|
||||
% if playlist is not None:
|
||||
% position = offset
|
||||
% for song in playlist:
|
||||
<strong> {{song[‘title’]}} </strong>
|
||||
% if song[‘type’] == ‘unknown’:
|
||||
<strong> {{song['title']}} </strong>
|
||||
% if song['type'] == 'unknown':
|
||||
Radio
|
||||
% else:
|
||||
{{song[‘artist’][0]}}
|
||||
{{song['artist'][0]}}
|
||||
% end
|
||||
% if position != offset:
|
||||
<a href=”/remove/{{position}}”>remove</a>
|
||||
<a href="/remove/{{position}}">remove</a>
|
||||
% else:
|
||||
<a href=”/skip/{{position}}”>skip</a>
|
||||
<a href="/skip/{{position}}">skip</a>
|
||||
% end
|
||||
<br>
|
||||
% position += 1
|
||||
% end
|
||||
|
||||
可以看到,模版大部分是用 HTML 写的,只有一小部分用来控制输出的其他代码。用两个括号括起来的变量是输出位置(像我们在第一个 ‘hello world’ 例子里看到的)。你也可以嵌入以百分号开头的 Python 代码。因为没有缩进,你需要用一个 % end 来结束当前的代码块(就像循环或 if 语句)。
|
||||
可以看到,模版大部分是用 HTML 写的,只有一小部分用来控制输出的其他代码。用两个大括号括起来的变量是输出位置(像我们在第一个 'hello world' 例子里看到的)。你也可以嵌入以百分号开头的 Python 代码。因为没有缩进,你需要用一个 `% end` 来结束当前的代码块(就像循环或 if 语句)。
|
||||
|
||||
这个模版首先检查列表是否为空,然后遍历里面的每一项。每一项会用粗体显示歌曲名字,然后是艺术家名字,然后是一个是否跳过(如果是当前正在播的歌曲)或从列表移除的链接。所有歌曲的类型都是 ‘song’,如果类型是 ‘unknown’,那就不是歌曲而是网络电台。
|
||||
这个模版首先检查列表是否为空,然后遍历里面的每一项。每一项会用粗体显示歌曲名字,然后是艺术家名字,然后是一个是否跳过(如果是当前正在播的歌曲)或从列表移除的链接。所有歌曲的类型都是 'song',如果类型是 'unknown',那就不是歌曲而是网络电台。
|
||||
|
||||
/remove/ 和 /skip/ 路径只是简单地封装了 XBMC 控制功能,在改动生效后重新加载 /juke:
|
||||
|
||||
@route(‘/skip/<position>’)
|
||||
@route('/skip/<position>')
|
||||
def index(position):
|
||||
print xbmc.Player.GoTo({‘playerid’:0, ‘to’:’next’})
|
||||
redirect(“/juke”)
|
||||
@route(‘/remove/<position>’)
|
||||
print xbmc.Player.GoTo({'playerid':0, 'to':'next'})
|
||||
redirect("/juke")
|
||||
@route('/remove/<position>')
|
||||
def index(position):
|
||||
playlistid = get_playlistid()
|
||||
if playlistid >= 0:
|
||||
xbmc.Playlist.Remove({‘playlistid’:int(playlistid), ‘position’:int(position)})
|
||||
redirect(“/juke”)
|
||||
xbmc.Playlist.Remove({'playlistid':int(playlistid), 'position':int(position)})
|
||||
redirect("/juke")
|
||||
|
||||
当然,如果不能往列表里添加歌曲的话那这个列表管理功能也不行。
|
||||
|
||||
因为一旦播放列表结束,它就消失了,所以你需要重新创建一个,这会让事情复杂一些。而且有点让人迷惑的是,播放列表是通过调用 Playlist.Clear() 方法来创建的。这个方法也还用来删除包含网络电台(类型是 unknown)的播放列表。另一个麻烦的地方是列表里的网络电台开始播放后就不会停,所以如果当前在播网络电台,也会需要清除播放列表。
|
||||
|
||||
这些页面包含了指向 /play/<songid> 的链接来播放歌曲。通过下面的代码处理:
|
||||
这些页面包含了指向 /play/\<songid> 的链接来播放歌曲。通过下面的代码处理:
|
||||
|
||||
@route(‘/play/<id>’)
|
||||
@route('/play/<id>')
|
||||
def index(id):
|
||||
playlistid = get_playlistid()
|
||||
playlist, not_needed= get_playlist()
|
||||
if playlistid < 0 or playlist[0][‘type’] == ‘unknown’:
|
||||
xbmc.Playlist.Clear({“playlistid”:0})
|
||||
xbmc.Playlist.Add({“playlistid”:0, “item”:{“songid”:int(id)}})
|
||||
xbmc.Player.open({“item”:{“playlistid”:0}})
|
||||
if playlistid < 0 or playlist[0]['type'] == 'unknown':
|
||||
xbmc.Playlist.Clear({"playlistid":0})
|
||||
xbmc.Playlist.Add({"playlistid":0, "item":{"songid":int(id)}})
|
||||
xbmc.Player.open({"item":{"playlistid":0}})
|
||||
playlistid = 0
|
||||
else:
|
||||
xbmc.Playlist.Add({“playlistid”:playlistid, “item”:{“songid”:int(id)}})
|
||||
xbmc.Playlist.Add({"playlistid":playlistid, "item":{"songid":int(id)}})
|
||||
remove_duplicates(playlistid)
|
||||
redirect(“/juke”)
|
||||
redirect("/juke")
|
||||
|
||||
最后一件事情是实现 remove_duplicates 调用。这并不是必须的 - 而且还有人并不喜欢这个 - 不过可以保证同一首歌不会多次出现在播放列表里。
|
||||
|
||||
@ -191,40 +191,40 @@ API 文档在这里:[http://wiki.xbmc.org/?title=JSON-RPC_API/v6][2]。它列
|
||||
|
||||
还需要处理一下 UI,不过功能已经有了。
|
||||
|
||||
> ### 日志 ###
|
||||
> **日志**
|
||||
>
|
||||
> 通常拿到 XBMC JSON API 并不清楚能用来做什么,而且它的文档也有点模糊。找出如何使用的一种方式是看别的遥控程序是怎么做的。如果打开日志功能,就可以在使用其他遥控程序的时候看到哪个 API 被调用了,然后就可以应用到在自己的代码里。
|
||||
>
|
||||
> 要打开日志功能,把 XBMC 媒体中心 接到显示器上,再依次进入设置 > 系统 > 调试,打开允许调试日志。在打开日志功能后,还需要登录到 XBMC 机器上(比如通过 SSH),然后就可以查看日志了。日志文件的位置应该显示在 XBMC 界面左上角。在 RaspBMC 系统里,文件位置是 /home/pi/.xbmc/temp/xbmc.log。你可以通过下面的命令实时监视哪个 API 接口被调用了:
|
||||
> 要打开日志功能,把 Kodi 媒体中心 接到显示器上,再依次进入设置 > 系统 > 调试,打开允许调试日志。在打开日志功能后,还需要登录到 Kodi 机器上(比如通过 SSH),然后就可以查看日志了。日志文件的位置应该显示在 Kodi 界面左上角。在 RaspBMC 系统里,文件位置是 /home/pi/.xbmc/temp/xbmc.log。你可以通过下面的命令实时监视哪个 API 接口被调用了:
|
||||
>
|
||||
> cd /home/pi/.xbmc/temp
|
||||
> tail -f xbmc.log | grep “JSON”
|
||||
> tail -f xbmc.log | grep "JSON"
|
||||
|
||||
#### 增加功能 ####
|
||||
|
||||
上面的代码都是用来播放 XBMC 媒体库里的歌曲的,但我们还希望能播放网络电台。每个插件都有自己的独立 URL 可以通过普通的 XBMC JSON 命令来获取信息。举个例子,要从电台插件里获取选中的电台,可以使用;
|
||||
上面的代码都是用来播放 Kodi 媒体库里的歌曲的,但我们还希望能播放网络电台。每个插件都有自己的独立 URL 可以通过普通的 XBMC JSON 命令来获取信息。举个例子,要从电台插件里获取选中的电台,可以使用;
|
||||
|
||||
@route(‘/radio/’)
|
||||
@route('/radio/')
|
||||
def index():
|
||||
my_stations = xbmc.Files.GetDirectory({“directory”:”plugin://plugin.audio.radio_de/stations/my/”, “properties”:
|
||||
[“title”,”thumbnail”,”playcount”,”artist”,”album”,”episode”,”season”,”showtitle”]})
|
||||
if ‘result’ in my_stations.keys():
|
||||
return template(‘radio’, stations=my_stations[‘result’][‘files’])
|
||||
my_stations = xbmc.Files.GetDirectory({"directory":"plugin://plugin.audio.radio_de/stations/my/", "properties":
|
||||
["title","thumbnail","playcount","artist","album","episode","season","showtitle"]})
|
||||
if 'result' in my_stations.keys():
|
||||
return template('radio', stations=my_stations['result']['files'])
|
||||
else:
|
||||
return template(‘error’, error=’radio’)
|
||||
return template('error', error='radio')
|
||||
|
||||
这样可以返回一个可以和歌曲一样能添加到播放列表的文件。不过,这些文件能一直播下去,所以(之前说过)在添加其他歌曲的时候需要重新创建列表。
|
||||
|
||||
#### 共享歌曲 ####
|
||||
|
||||
除了伺服页面模版,Bottle 还支持静态文件。方便用于那些不会因为用户输入而改变的内容。可以是 CSS 文件,一张图片或是一首 MP3 歌曲。在我们的简单遥控程序里(目前)还没有任何用来美化的 CSS 或图片,不过我们增加了一个下载歌曲的途径。这个可以让媒体中心变成一个存放歌曲的 NAS 盒子。在需要传输大量数据的时候,最好还是用类似 Samba 的功能,但只是下几首歌到手机上的话使用静态文件也是很好的方式。
|
||||
除了伺服页面模版,Bottle 还支持静态文件,方便用于那些不会因为用户输入而改变的内容。可以是 CSS 文件,一张图片或是一首 MP3 歌曲。在我们的简单遥控程序里(目前)还没有任何用来美化的 CSS 或图片,不过我们增加了一个下载歌曲的途径。这个可以让媒体中心变成一个存放歌曲的 NAS 盒子。在需要传输大量数据的时候,最好还是用类似 Samba 的功能,但只是下几首歌到手机上的话使用静态文件也是很好的方式。
|
||||
|
||||
通过歌曲 ID 来下载的 Bottle 代码:
|
||||
|
||||
@route(‘/download/<id>’)
|
||||
@route('/download/<id>')
|
||||
def index(id):
|
||||
data = xbmc.AudioLibrary.GetSongDetails({“songid”:int(id), “properties”:[“file”]})
|
||||
full_filename = data[‘result’][‘songdetails’][‘file’]
|
||||
data = xbmc.AudioLibrary.GetSongDetails({"songid":int(id), "properties":["file"]})
|
||||
full_filename = data['result']['songdetails']['file']
|
||||
path, filename = os.path.split(full_filename)
|
||||
return static_file(filename, root=path, download=True)
|
||||
|
||||
@ -232,13 +232,13 @@ API 文档在这里:[http://wiki.xbmc.org/?title=JSON-RPC_API/v6][2]。它列
|
||||
|
||||
我们已经把所有的代码过了一遍,不过还需要一点工作来把它们集合到一起。可以自己去 GitHub 页面 [https://github.com/ben-ev/xbmc-remote][3] 看下。
|
||||
|
||||
> ### 设置 ###
|
||||
> **设置**
|
||||
>
|
||||
> 我们的遥控程序已经开发完成,还需要保证让它在媒体中心每次开机的时候都能启动。有几种方式,最简单的是在 /etc/rc.local 里增加一行命令来启动。我们的文件位置在 /opt/xbmc-remote/remote.py,其他文件也和它一起。然后在 /etc/rc.local 最后的 exit 0 之前增加了下面一行。
|
||||
>
|
||||
> cd /opt/xbmc-remote && python remote.py &
|
||||
|
||||
> ### GitHub ###
|
||||
> **GitHub**
|
||||
>
|
||||
> 这个项目目前还只是个架子,但是 - 我们运营杂志就意味着没有太多自由时间来编程。不过,我们启动了一个 GitHub 项目,希望能持续完善, 而如果你觉得这个项目有用的话,欢迎做出贡献。
|
||||
>
|
||||
@ -252,7 +252,7 @@ via: http://www.linuxvoice.com/xbmc-build-a-remote-control/
|
||||
|
||||
作者:[Ben Everard][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,95 +1,92 @@
|
||||
用这些专用工具让你截图更简单
|
||||
================================================================================
|
||||
"一图胜过千万句",这句二十世纪早期在美国应运而生的名言,说的是一张单一的静止图片所蕴含的信息足以匹敌大量的描述性文字。本质上说,图片所传递的信息量的确是比文字更有效更高效。
|
||||
“一图胜千言”,这句二十世纪早期在美国应运而生的名言,说的是一张单一的静止图片所蕴含的信息足以匹敌大量的描述性文字。本质上说,图片所传递的信息量的确是比文字更有效更高效。
|
||||
|
||||
截图(或抓帧)是一种捕捉自计算机所录制可视化设备输出的快照或图片,屏幕捕捉软件能让计算机获取到截图。此类软件有很多用处,因为一张图片能很好地说明计算机软件的操作,截图在软件开发过程和文档中扮演了一个很重要的角色。或者,如果你的电脑有了个技术性问题,一张截图能让技术支持理解你碰到的这个问题。要写好计算机相关的文章、文档和教程,没有一款好的截图工具是几乎不可能的。如果你想在保存屏幕上任意一些零星的信息,特别是不方便打字时,截图也很有用。
|
||||
截图(或抓帧)是一种捕捉自计算机的快照或图片,用来记录可视设备的输出。屏幕捕捉软件能从计算机中获取到截图。此类软件有很多用处,因为一张图片能很好地说明计算机软件的操作,截图在软件开发过程和文档中扮演了一个很重要的角色。或者,如果你的电脑有了技术性问题,一张截图能让技术支持理解你碰到的这个问题。要写好计算机相关的文章、文档和教程,没有一款好的截图工具是几乎不可能的。如果你想保存你放在屏幕上的一些零星的信息,特别是不方便打字时,截图也很有用。
|
||||
|
||||
在开源世界,Linux有许多专注于截图功能的工具供选择,基于图形的和控制台的都有。如果要说一个功能丰富的专用截图工具,那就来看看Shutter吧。这款工具是小型开源工具的杰出代表,当然也有其它的选择。
|
||||
在开源世界,Linux有许多专注于截图功能的工具供选择,基于图形的和控制台的都有。如果要说一个功能丰富的专用截图工具,看起来没有能超过Shutter的。这款工具是小型开源工具的杰出代表,但是也有其它的不错替代品可以选择。
|
||||
|
||||
屏幕捕捉功能不仅仅只有专业的工具提供,GIMP和ImageMagick这两款主攻图像处理的工具,也能提供像样的屏幕捕捉功能。
|
||||
屏幕捕捉功能不仅仅只有专门的工具提供,GIMP和ImageMagick这两款主攻图像处理的工具,也能提供像样的屏幕捕捉功能。
|
||||
|
||||
----------
|
||||
|
||||
### Shutter ###
|
||||
|
||||

|
||||
|
||||
Shutter是一款功能丰富的截图软件。你可以给你的特殊区域、窗口、整个屏幕甚至是网站截图 - 在其中应用不用的效果,比如用高亮的点在上面绘图,然后上传至一个图片托管网站,一切尽在这个小窗口内。
|
||||
Shutter是一款功能丰富的截图软件。你可以对特定区域、窗口、整个屏幕甚至是网站截图 - 并为其应用不同的效果,比如用高亮的点在上面绘图,然后上传至一个图片托管网站,一切尽在这个小窗口内。
|
||||
|
||||
包含特性:
|
||||
|
||||
|
||||
- 截图范围:
|
||||
- 一块特殊区域
|
||||
- 一个特定区域
|
||||
- 窗口
|
||||
- 完整的桌面
|
||||
- 脚本生成的网页
|
||||
- 在截图中应用不同效果
|
||||
- 热键
|
||||
- 打印
|
||||
- 直接截图或指定一个延迟时间
|
||||
- 将截图保存至一个指定目录并用一个简便方法重命名它(用特殊的通配符)
|
||||
- 完成集成在GNOME桌面中(TrayIcon等等)
|
||||
- 当你截了一张图并以%设置了尺寸时,直接生成缩略图
|
||||
- Shutter会话选项:
|
||||
- 会话中保持所有截图的痕迹
|
||||
- 直接截图或指定延迟时间截图
|
||||
- 将截图保存至一个指定目录并用一个简便方法重命名它(用指定通配符)
|
||||
- 完全集成在GNOME桌面中(TrayIcon等等)
|
||||
- 当你截了一张图并根据尺寸的百分比直接生成缩略图
|
||||
- Shutter会话集:
|
||||
- 跟踪会话中所有的截图
|
||||
- 复制截图至剪贴板
|
||||
- 打印截图
|
||||
- 删除截图
|
||||
- 重命名文件
|
||||
- 直接上传你的文件至图像托管网站(比如http://ubuntu-pics.de),取回所有需要的图像并将它们与其他人分享
|
||||
- 直接上传你的文件至图像托管网站(比如 http://ubuntu-pics.de ),得到链接并将它们与其他人分享
|
||||
- 用内置的绘画工具直接编辑截图
|
||||
|
||||
---
|
||||
|
||||
- 主页: [shutter-project.org][1]
|
||||
- 开发者: Mario Kemper和Shutter团队
|
||||
- 许可证: GNU GPL v3
|
||||
- 版本号: 0.93.1
|
||||
|
||||
----------
|
||||
|
||||
### HotShots ###
|
||||
|
||||

|
||||
|
||||
HotShots是一款捕捉屏幕并能以各种图片格式保存的软件,同时也能添加注释和图形数据(箭头、行、文本, ...)。
|
||||
HotShots是一款捕捉屏幕并能以各种图片格式保存的软件,同时也能添加注释和图形数据(箭头、行、文本 ...)。
|
||||
|
||||
你也可以把你的作品上传到网上(FTP/一些web服务),HotShots是用Qt开发而成的。
|
||||
你也可以把你的作品上传到网上(FTP/一些web服务),HotShots是用Qt开发而成的。
|
||||
|
||||
HotShots无法从Ubuntu的Software Center中获取,不过用以下命令可以轻松地来安装它:
|
||||
|
||||
sudo add-apt-repository ppa:ubuntuhandbook1/apps
|
||||
|
||||
sudo add-apt-repository ppa:ubuntuhandbook1/apps
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install hotshots
|
||||
|
||||
包含特性:
|
||||
|
||||
- 简单易用
|
||||
- 全功能使用
|
||||
- 嵌入式编辑器
|
||||
- 功能完整
|
||||
- 内置编辑器
|
||||
- 热键
|
||||
- 内置放大功能
|
||||
- 徒手和多屏捕捉
|
||||
- 手动控制和多屏捕捉
|
||||
- 支持输出格式:Black & Whte (bw), Encapsulated PostScript (eps, epsf), Encapsulated PostScript Interchange (epsi), OpenEXR (exr), PC Paintbrush Exchange (pcx), Photoshop Document (psd), ras, rgb, rgba, Irix RGB (sgi), Truevision Targa (tga), eXperimental Computing Facility (xcf), Windows Bitmap (bmp), DirectDraw Surface (dds), Graphic Interchange Format (gif), Icon Image (ico), Joint Photographic Experts Group 2000 (jp2), Joint Photographic Experts Group (jpeg, jpg), Multiple-image Network Graphics (mng), Portable Pixmap (ppm), Scalable Vector Graphics (svg), svgz, Tagged Image File Format (tif, tiff), webp, X11 Bitmap (xbm), X11 Pixmap (xpm), and Khoros Visualization (xv)
|
||||
- 国际化支持:巴斯克语、中文、捷克语、法语、加利西亚语、德语、希腊语、意大利语、日语、立陶宛语、波兰语、葡萄牙语、罗马尼亚语、俄罗斯语、塞尔维亚语、僧伽罗语、斯洛伐克语、西班牙语、土耳其语、乌克兰语和越南语
|
||||
|
||||
---
|
||||
|
||||
- 主页: [thehive.xbee.net][2]
|
||||
- 开发者 xbee
|
||||
- 许可证: GNU GPL v2
|
||||
- 版本号: 2.2.0
|
||||
|
||||
----------
|
||||
|
||||
### ScreenCloud ###
|
||||
|
||||

|
||||
|
||||
ScreenCloud是一款易于使用的开源截图工具。
|
||||
|
||||
在这款软件中,用户可以用三个热键中的其中一个或只需点击ScreenCloud托盘图标就能进行截图,用户也可以自行选择保存截图的地址。
|
||||
在这款软件中,用户可以用三个热键之一或只需点击ScreenCloud托盘图标就能进行截图,用户也可以自行选择保存截图的地址。
|
||||
|
||||
如果你选择上传你的截图到screencloud主页,链接会自动复制到你的剪贴板上,你能通过email或在一个聊天对话框里和你的朋友同事分享它,他们肯定会点击这个链接来看你的截图的。
|
||||
如果你选择上传你的截图到screencloud网站,链接会自动复制到你的剪贴板上,你能通过email或在一个聊天对话框里和你的朋友同事分享它,他们肯定会点击这个链接来看你的截图的。
|
||||
|
||||
包含特性:
|
||||
|
||||
@ -106,18 +103,18 @@ ScreenCloud是一款易于使用的开源截图工具。
|
||||
- 插件支持:保存至Dropbox,Imgur等等
|
||||
- 支持上传至FTP和SFTP服务器
|
||||
|
||||
---
|
||||
|
||||
- 主页: [screencloud.net][3]
|
||||
- 开发者: Olav S Thoresen
|
||||
- 许可证: GNU GPL v2
|
||||
- 版本号: 1.2.1
|
||||
|
||||
----------
|
||||
|
||||
### KSnapshot ###
|
||||
|
||||

|
||||
|
||||
KSnapshot也是一款易于使用的截图工具,它能给整个桌面、一个单一窗口、窗口的一部分或一块所选区域捕捉图像。,图像能以各种不用的格式保存。
|
||||
KSnapshot也是一款易于使用的截图工具,它能给整个桌面、单一窗口、窗口的一部分或一块所选区域捕捉图像。图像能以各种不同格式保存。
|
||||
|
||||
KSnapshot也允许用户用热键来进行截图。除了保存截图之外,它也可以被复制到剪贴板或用任何与图像文件关联的程序打开。
|
||||
|
||||
@ -127,10 +124,12 @@ KSnapshot是KDE 4图形模块的一部分。
|
||||
|
||||
- 以多种格式保存截图
|
||||
- 延迟截图
|
||||
- 剔除窗口装饰图案
|
||||
- 剔除窗口装饰(边框、菜单等)
|
||||
- 复制截图至剪贴板
|
||||
- 热键
|
||||
- 能用它的D-Bus界面进行脚本化
|
||||
- 能用它的D-Bus接口进行脚本化
|
||||
|
||||
---
|
||||
|
||||
- 主页: [www.kde.org][4]
|
||||
- 开发者: KDE, Richard J. Moore, Aaron J. Seigo, Matthias Ettrich
|
||||
@ -142,7 +141,7 @@ KSnapshot是KDE 4图形模块的一部分。
|
||||
via: http://www.linuxlinks.com/article/2015062316235249/ScreenCapture.html
|
||||
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -4,7 +4,7 @@ Linux mkdir、tar 和 kill 命令的 4 个有用小技巧
|
||||
|
||||

|
||||
|
||||
4 个有用的 Linux 小技巧
|
||||
*4 个有用的 Linux 小技巧*
|
||||
|
||||
### 1. 假设你要创建一个类似于下面很长的/复杂的目录树。实现这最有效的方法是什么呢? ###
|
||||
|
||||
@ -37,9 +37,9 @@ Linux mkdir、tar 和 kill 命令的 4 个有用小技巧
|
||||
|
||||

|
||||
|
||||
检查目录结构
|
||||
*检查目录结构*
|
||||
|
||||
我们可以用上面的方式创建任意复制的目录树结构。注意这仅仅是一个普通的命令,但是用 ‘{}’ 来创建层级目录。需要的时候如果在 shell 脚本中使用是非常有用的。
|
||||
我们可以用上面的方式创建任意复杂的目录树结构。注意这仅仅是一个普通的命令,但是用 ‘{}’ 来创建层级目录。需要的时候如果在 shell 脚本中使用是非常有用的。
|
||||
|
||||
### 2. 在桌面(/home/$USER/Desktop)创建一个文件(例如 test)并填入以下内容。 ###
|
||||
|
||||
@ -109,7 +109,7 @@ c. 解压 tar 包。
|
||||
|
||||
我们也可以采用另外一种方式。
|
||||
|
||||
我们可以在 Tar 包所在位置解压并复制/移动解压后的文件到所需的目标位置,例如:
|
||||
我们也可以在 Tar 包所在位置解压并复制/移动解压后的文件到所需的目标位置,例如:
|
||||
|
||||
$ tar -jxvf firefox-37.0.2.tar.bz2
|
||||
$ cp -R firefox/ /opt/
|
||||
@ -122,7 +122,7 @@ c. 解压 tar 包。
|
||||
|
||||
-C 选项提取文件到指定目录(这里是 /opt/)。
|
||||
|
||||
这并不是关于选项(-C)的问题,而是习惯的问题。养成使用带 -C 选项 tar 命令的习惯。这会使你的工作更加轻松。从现在开始不要再移动归档文件或复制/移动解压后的文件了,在 Downloads 文件夹保存 tar 包并解压到你想要的任何地方吧。
|
||||
这并不是关于选项(-C)的问题,**而是习惯的问题**。养成使用带 -C 选项 tar 命令的习惯。这会使你的工作更加轻松。从现在开始不要再移动归档文件或复制/移动解压后的文件了,在 Downloads 文件夹保存 tar 包并解压到你想要的任何地方吧。
|
||||
|
||||
### 4. 常规方式我们怎样杀掉一个进程? ###
|
||||
|
||||
@ -132,7 +132,7 @@ c. 解压 tar 包。
|
||||
|
||||
#### 输出样例 ####
|
||||
|
||||
1006 ? 00:00:00 apache2
|
||||
1006 ? 00:00:00 apache2
|
||||
2702 ? 00:00:00 apache2
|
||||
2703 ? 00:00:00 apache2
|
||||
2704 ? 00:00:00 apache2
|
||||
@ -188,7 +188,7 @@ c. 解压 tar 包。
|
||||
|
||||
它没有输出任何东西并返回到窗口意味着没有名称中包含 apache2 的进程在运行。
|
||||
|
||||
这就是我要说的所有东西。上面讨论的点肯定远远不够,但也肯定对你有所帮助。我们不仅仅是介绍教程使你学到一些新的东西,更重要的是想告诉你 ‘在同样的情况下如何变得更有效率’。在下面的评论框中告诉我们你的反馈吧。保持联系,继续评论。
|
||||
这就是我要说的所有东西。上面讨论的点肯定远远不够,但也肯定对你有所帮助。我们不仅仅是介绍教程使你学到一些新的东西,更重要的是想告诉你 ‘**在同样的情况下如何变得更有效率**’。在下面的评论框中告诉我们你的反馈吧。保持联系,继续评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -196,7 +196,7 @@ via: http://www.tecmint.com/mkdir-tar-and-kill-commands-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,47 +1,46 @@
|
||||
使用去重加密工具来备份
|
||||
使用这些去重加密工具来备份你的数据
|
||||
================================================================================
|
||||
在体积和价值方面,数据都在增长。快速而可靠地备份和恢复数据正变得越来越重要。社会已经适应了技术的广泛使用,并懂得了如何依靠电脑和移动设备,但很少有人能够处理丢失重要数据的现实。在遭受数据损失的公司中,30% 的公司将在一年内损失一半市值,70% 的公司将在五年内停止交易。这更加凸显了数据的价值。
|
||||
|
||||
随着数据在体积上的增长,提高存储利用率尤为重要。In Computing(注:这里不知如何翻译),数据去重是一种特别的数据压缩技术,因为它可以消除重复数据的拷贝,所以这个技术可以提高存储利用率。
|
||||
无论是体积还是价值,数据都在不断增长。快速而可靠地备份和恢复数据正变得越来越重要。社会已经适应了技术的广泛使用,并懂得了如何依靠电脑和移动设备,但很少有人能够面对丢失重要数据的现实。在遭受数据损失的公司中,30% 的公司将在一年内损失一半市值,70% 的公司将在五年内停止交易。这更加凸显了数据的价值。
|
||||
|
||||
数据并不仅仅只有其创造者感兴趣。政府、竞争者、犯罪分子、偷窥者可能都热衷于获取你的数据。他们或许想偷取你的数据,从你那里进行敲诈,或看你正在做什么。对于保护你的数据,加密是非常必要的。
|
||||
随着数据在体积上的增长,提高存储利用率尤为重要。从计算机的角度说,数据去重是一种特别的数据压缩技术,因为它可以消除重复数据的拷贝,所以这个技术可以提高存储利用率。
|
||||
|
||||
所以,解决方法是我们需要一个去重加密备份软件。
|
||||
数据并不仅仅只有其创造者感兴趣。政府、竞争者、犯罪分子、偷窥者可能都热衷于获取你的数据。他们或许想偷取你的数据,从你那里进行敲诈,或看你正在做什么。因此,对于保护你的数据,加密是非常必要的。
|
||||
|
||||
对于所有的用户而言,做文件备份是一件非常必要的事,至今为止许多用户还没有采取足够的措施来保护他们的数据。一台电脑不论是工作在一个合作的环境中,还是供私人使用,机器的硬盘可能在没有任何警告的情况下挂掉。另外,有些数据丢失可能是人为的错误所引发的。如果没有做经常性的备份,数据也可能不可避免地失去掉,即使请了专业的数据恢复公司来帮忙。
|
||||
所以,解决方法是我们需要一个可以去重的加密备份软件。
|
||||
|
||||
对于所有的用户而言,做文件备份是一件非常必要的事,至今为止许多用户还没有采取足够的措施来保护他们的数据。一台电脑不论是工作在一个合作的环境中,还是供私人使用,机器的硬盘可能在没有任何警告的情况下挂掉。另外,有些数据丢失可能是人为的错误所引发的。如果没有做经常性的备份,数据也可能不可避免地丢失,即使请了专业的数据恢复公司来帮忙。
|
||||
|
||||
这篇文章将对 6 个去重加密备份工具进行简要的介绍。
|
||||
----------
|
||||
|
||||
### Attic ###
|
||||
|
||||
Attic 是一个可用于去重、加密,验证完整性的用 Python 写的压缩备份程序。Attic 的主要目标是提供一个高效且安全的方式来备份数据。Attic 使用的数据去重技术使得它适用于每日备份,因为只需存储改变的数据。
|
||||
Attic 是一个可用于去重、加密,验证完整性的压缩备份程序,它是用 Python 写的。Attic 的主要目标是提供一个高效且安全的方式来备份数据。Attic 使用的数据去重技术使得它适用于每日备份,因为只需存储改变的数据。
|
||||
|
||||
其特点有:
|
||||
|
||||
- 易用
|
||||
- 可高效利用存储空间,通过检查冗余的数据,数据块大小的去重被用来减少存储所用的空间
|
||||
- 可选的数据加密,使用 256 位的 AES 加密算法。数据的完整性和可靠性使用 HMAC-SHA256 来检查
|
||||
- 可高效利用存储空间,通过检查冗余的数据,对可变块大小的去重可以减少存储所用的空间
|
||||
- 可选的数据加密,使用 256 位的 AES 加密算法。数据的完整性和可靠性使用 HMAC-SHA256 来校验
|
||||
- 使用 SDSH 来进行离线备份
|
||||
- 备份可作为文件系统来挂载
|
||||
|
||||
网站: [attic-backup.org][1]
|
||||
|
||||
----------
|
||||
|
||||
### Borg ###
|
||||
|
||||
Borg 是 Attic 的分支。它是一个安全的开源备份程序,被设计用来高效地存储那些新的或修改过的数据。
|
||||
Borg 是 Attic 的一个分支。它是一个安全的开源备份程序,被设计用来高效地存储那些新的或修改过的数据。
|
||||
|
||||
Borg 的主要目标是提供一个高效、安全的方式来存储数据。Borg 使用的数据去重技术使得它适用于每日备份,因为只需存储改变的数据。认证加密使得它适用于不完全可信的目标的存储。
|
||||
Borg 的主要目标是提供一个高效、安全的方式来存储数据。Borg 使用的数据去重技术使得它适用于每日备份,因为只需存储改变的数据。认证加密使得它适用于存储在不完全可信的位置。
|
||||
|
||||
Borg 由 Python 写成。Borg 于 2015 年 5 月被创造出来,为了回应让新的代码或重大的改变带入 Attic 的困难。
|
||||
Borg 由 Python 写成。Borg 于 2015 年 5 月被创造出来,是为了解决让新的代码或重大的改变带入 Attic 的困难。
|
||||
|
||||
其特点包括:
|
||||
|
||||
- 易用
|
||||
- 可高效利用存储空间,通过检查冗余的数据,数据块大小的去重被用来减少存储所用的空间
|
||||
- 可选的数据加密,使用 256 位的 AES 加密算法。数据的完整性和可靠性使用 HMAC-SHA256 来检查
|
||||
- 可高效利用存储空间,通过检查冗余的数据,对可变块大小的去重被用来减少存储所用的空间
|
||||
- 可选的数据加密,使用 256 位的 AES 加密算法。数据的完整性和可靠性使用 HMAC-SHA256 来校验
|
||||
- 使用 SDSH 来进行离线备份
|
||||
- 备份可作为文件系统来挂载
|
||||
|
||||
@ -49,36 +48,32 @@ Borg 与 Attic 不兼容。
|
||||
|
||||
网站: [borgbackup.github.io/borgbackup][2]
|
||||
|
||||
----------
|
||||
|
||||
### Obnam ###
|
||||
|
||||
Obnam (OBligatory NAMe) 是一个易用、安全的基于 Python 的备份程序。备份可被存储在本地硬盘或通过 SSH SFTP 协议存储到网上。若使用了备份服务器,它并不需要任何特殊的软件,只需要使用 SSH 即可。
|
||||
|
||||
Obnam 通过将数据数据分成数据块,并单独存储它们来达到去重的目的,每次通过增量备份来生成备份,每次备份的生成就像是一次新的快照,但事实上是真正的增量备份。Obnam 由 Lars Wirzenius 开发。
|
||||
Obnam 通过将数据分成数据块,并单独存储它们来达到去重的目的,每次通过增量备份来生成备份,每次备份的生成就像是一次新的快照,但事实上是真正的增量备份。Obnam 由 Lars Wirzenius 开发。
|
||||
|
||||
其特点有:
|
||||
|
||||
- 易用
|
||||
- 快照备份
|
||||
- 数据去重,跨文件,生成备份
|
||||
- 数据去重,跨文件,然后生成备份
|
||||
- 可使用 GnuPG 来加密备份
|
||||
- 向一个单独的仓库中备份多个客户端的数据
|
||||
- 备份检查点 (创建一个保存点,以每 100MB 或其他容量)
|
||||
- 包含多个选项来调整性能,包括调整 lru-size 或 upload-queue-size
|
||||
- 支持 MD5 校验和算法来识别重复的数据块
|
||||
- 支持 MD5 校验算法来识别重复的数据块
|
||||
- 通过 SFTP 将备份存储到一个服务器上
|
||||
- 同时支持 push(即在客户端上运行) 和 pull(即在服务器上运行)
|
||||
|
||||
网站: [obnam.org][3]
|
||||
|
||||
----------
|
||||
|
||||
### Duplicity ###
|
||||
|
||||
Duplicity 持续地以 tar 文件格式备份文件和目录,并使用 GnuPG 来进行加密,同时将它们上传到远程(或本地)的文件服务器上。它可以使用 ssh/scp, 本地文件获取, rsync, ftp, 和 Amazon S3 等来传递数据。
|
||||
Duplicity 以 tar 文件格式增量备份文件和目录,并使用 GnuPG 来进行加密,同时将它们上传到远程(或本地)的文件服务器上。它可以使用 ssh/scp、本地文件获取、rsync、 ftp 和 Amazon S3 等来传递数据。
|
||||
|
||||
因为 duplicity 使用了 librsync, 增加的存档高效地利用了存储空间,且只记录自从上次备份依赖改变的那部分文件。由于该软件使用 GnuPG 来机密或对这些归档文件进行进行签名,这使得它们免于服务器的监视或修改。
|
||||
因为 duplicity 使用了 librsync, 增量存档可以高效地利用存储空间,且只记录自从上次备份依赖改变的那部分文件。由于该软件使用 GnuPG 来加密或对这些归档文件进行进行签名,这使得它们免于服务器的监视或修改。
|
||||
|
||||
当前 duplicity 支持备份删除的文件,全部的 unix 权限,目录,符号链接, fifo 等。
|
||||
|
||||
@ -101,39 +96,36 @@ duplicity 软件包还包含有 rdiffdir 工具。 Rdiffdir 是 librsync 的 rdi
|
||||
|
||||
网站: [duplicity.nongnu.org][4]
|
||||
|
||||
----------
|
||||
|
||||
### ZBackup ###
|
||||
|
||||
ZBackup 是一个通用的全局去重备份工具。
|
||||
|
||||
其特点包括:
|
||||
|
||||
- 存储数据的并行 LZMA 或 LZO 压缩,在一个仓库中,你还可以混合使用 LZMA 和 LZO
|
||||
- 对存储数据并行进行 LZMA 或 LZO 压缩,在一个仓库中,你还可以混合使用 LZMA 和 LZO
|
||||
- 内置对存储数据的 AES 加密
|
||||
- 可选择地删除旧的备份数据
|
||||
- 能够删除旧的备份数据
|
||||
- 可以使用 64 位的滚动哈希算法,使得文件冲突的数量几乎为零
|
||||
- Repository consists of immutable files. No existing files are ever modified ====
|
||||
- 仓库中存储的文件是不可修改的,已备份的文件不会被修改。
|
||||
- 用 C++ 写成,只需少量的库文件依赖
|
||||
- 在生成环境中可以安全使用
|
||||
- 可以在不同仓库中进行数据交换而不必再进行压缩
|
||||
- 可以使用 64 位改进型 Rabin-Karp 滚动哈希算法
|
||||
- 使用 64 位改进型 Rabin-Karp 滚动哈希算法
|
||||
|
||||
网站: [zbackup.org][5]
|
||||
|
||||
----------
|
||||
|
||||
### bup ###
|
||||
|
||||
bup 是一个用 Python 写的备份程序,其名称是 "backup" 的缩写。在 git packfile 文件的基础上, bup 提供了一个高效的方式来备份一个系统,提供快速的增量备份和全局去重(在文件中或文件里,甚至包括虚拟机镜像)。
|
||||
bup 是一个用 Python 写的备份程序,其名称是 "backup" 的缩写。基于 git packfile 文件格式, bup 提供了一个高效的方式来备份一个系统,提供快速的增量备份和全局去重(在文件中或文件里,甚至包括虚拟机镜像)。
|
||||
|
||||
bup 在 LGPL 版本 2 协议下发行。
|
||||
|
||||
其特点包括:
|
||||
|
||||
- 全局去重 (在文件中或文件里,甚至包括虚拟机镜像)
|
||||
- 全局去重 (在文件之间或文件内部,甚至包括虚拟机镜像)
|
||||
- 使用一个滚动的校验和算法(类似于 rsync) 来将大文件分为多个数据块
|
||||
- 使用来自 git 的 packfile 格式
|
||||
- 使用来自 git 的 packfile 文件格式
|
||||
- 直接写入 packfile 文件,以此提供快速的增量备份
|
||||
- 可以使用 "par2" 冗余来恢复冲突的备份
|
||||
- 可以作为一个 FUSE 文件系统来挂载你的 bup 仓库
|
||||
@ -145,7 +137,7 @@ bup 在 LGPL 版本 2 协议下发行。
|
||||
via: http://www.linuxlinks.com/article/20150628060000607/BackupTools.html
|
||||
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,24 +1,24 @@
|
||||
PHP 安全
|
||||
PHP 安全编程建议
|
||||
================================================================================
|
||||

|
||||
|
||||
### 简介 ###
|
||||
|
||||
为提供互联网服务,当你在开发代码的时候必须时刻保持安全意识。可能大部分 PHP 脚本都对安全问题不敏感;这很大程度上是因为有大量的无经验程序员在使用这门语言。但是,没有理由让你基于粗略估计你代码的影响性而有不一致的安全策略。当你在服务器上放任何经济相关的东西时,就有可能会有人尝试破解它。创建一个论坛程序或者任何形式的购物车,被攻击的可能性就上升到了无穷大。
|
||||
要提供互联网服务,当你在开发代码的时候必须时刻保持安全意识。可能大部分 PHP 脚本都对安全问题都不在意,这很大程度上是因为有大量的*无经验程序员*在使用这门语言。但是,没有理由让你因为对你的代码的不确定性而导致不一致的安全策略。当你在服务器上放任何涉及到钱的东西时,就有可能会有人尝试破解它。创建一个论坛程序或者任何形式的购物车,被攻击的可能性就上升到了无穷大。
|
||||
|
||||
### 背景 ###
|
||||
|
||||
为了确保你的 web 内容安全,这里有一些一般的安全准则:
|
||||
为了确保你的 web 内容安全,这里有一些常规的安全准则:
|
||||
|
||||
#### 别相信表单 ####
|
||||
|
||||
攻击表单很简单。通过使用一个简单的 JavaScript 技巧,你可以限制你的表单只允许在评分域中填写 1 到 5 的数字。如果有人关闭了他们浏览器的 JavaScript 功能或者提交自定义的表单数据,你客户端的验证就失败了。
|
||||
|
||||
用户主要通过表单参数和你的脚本交互,因此他们是最大的安全风险。你应该学到什么呢?总是要验证 PHP 脚本中传递到其它任何 PHP 脚本的数据。在本文中,我们向你演示了如何分析和防范跨站点脚本(XSS)攻击,它可能劫持用户凭据(甚至更严重)。你也会看到如何防止会玷污或毁坏你数据的 MySQL 注入攻击。
|
||||
用户主要通过表单参数和你的脚本交互,因此他们是最大的安全风险。你应该学到什么呢?在 PHP 脚本中,总是要验证 传递给任何 PHP 脚本的数据。在本文中,我们向你演示了如何分析和防范跨站脚本(XSS)攻击,它可能会劫持用户凭据(甚至更严重)。你也会看到如何防止会玷污或毁坏你数据的 MySQL 注入攻击。
|
||||
|
||||
#### 别相信用户 ####
|
||||
|
||||
假设你网站获取的每一份数据都充满了有害的代码。清理每一部分,就算你相信没有人会尝试攻击你的站点。
|
||||
假定你网站获取的每一份数据都充满了有害的代码。清理每一部分,即便你相信没有人会尝试攻击你的站点。
|
||||
|
||||
#### 关闭全局变量 ####
|
||||
|
||||
@ -32,9 +32,9 @@ PHP 安全
|
||||
|
||||
<input name="username" type="text" size="15" maxlength="64">
|
||||
|
||||
运行 process.php 的时候,启用了注册全局变量的 PHP 会为该参数赋值为 $username 变量。这会比通过 **$\_POST['username']** 或 **$\_GET['username']** 访问它节省敲击次数。不幸的是,这也会给你留下安全问题,因为 PHP 设置该变量的值为通过 GET 或 POST 参数发送到脚本的任何值,如果你没有显示地初始化该变量并且你不希望任何人去操作它,这就会有一个大问题。
|
||||
运行 process.php 的时候,启用了注册全局变量的 PHP 会将该参数赋值到 $username 变量。这会比通过 **$\_POST['username']** 或 **$\_GET['username']** 访问它节省击键次数。不幸的是,这也会给你留下安全问题,因为 PHP 会设置该变量的值为通过 GET 或 POST 的参数发送到脚本的任何值,如果你没有显示地初始化该变量并且你不希望任何人去操作它,这就会有一个大问题。
|
||||
|
||||
看下面的脚本,假如 $authorized 变量的值为 true,它会给用户显示验证数据。正常情况下,只有当用户正确通过了假想的 authenticated\_user() 函数验证,$authorized 变量的值才会被设置为真。但是如果你启用了 **register\_globals**,任何人都可以发送一个 GET 参数,例如 authorized=1 去覆盖它:
|
||||
看下面的脚本,假如 $authorized 变量的值为 true,它会给用户显示通过验证的数据。正常情况下,只有当用户正确通过了这个假想的 authenticated\_user() 函数验证,$authorized 变量的值才会被设置为真。但是如果你启用了 **register\_globals**,任何人都可以发送一个 GET 参数,例如 authorized=1 去覆盖它:
|
||||
|
||||
<?php
|
||||
// Define $authorized = true only if user is authenticated
|
||||
@ -45,7 +45,7 @@ PHP 安全
|
||||
|
||||
这个故事的寓意是,你应该从预定义的服务器变量中获取表单数据。所有通过 post 表单传递到你 web 页面的数据都会自动保存到一个称为 **$\_POST** 的大数组中,所有的 GET 数据都保存在 **$\_GET** 大数组中。文件上传信息保存在一个称为 **$\_FILES** 的特殊数据中。另外,还有一个称为 **$\_REQUEST** 的复合变量。
|
||||
|
||||
要从一个 POST 方法表单中访问 username 域,可以使用 **$\_POST['username']**。如果 username 在 URL 中就使用 **$\_GET['username']**。如果你不确定值来自哪里,用 **$\_REQUEST['username']**。
|
||||
要从一个 POST 方法表单中访问 username 字段,可以使用 **$\_POST['username']**。如果 username 在 URL 中就使用 **$\_GET['username']**。如果你不确定值来自哪里,用 **$\_REQUEST['username']**。
|
||||
|
||||
<?php
|
||||
$post_value = $_POST['post_value'];
|
||||
@ -61,12 +61,12 @@ $\_REQUEST 是 $\_GET、$\_POST、和 $\_COOKIE 数组的结合。如果你有
|
||||
|
||||
- **register\_globals** 设置为 off
|
||||
- **safe\_mode** 设置为 off
|
||||
- **error\_reporting** 设置为 off。如果出现错误了,这会向用户浏览器发送可见的错误报告信息。对于生产服务器,使用错误日志代替。开发服务器如果在防火墙后面就可以启用错误日志。
|
||||
- **error\_reporting** 设置为 off。如果出现错误了,这会向用户浏览器发送可见的错误报告信息。对于生产服务器,使用错误日志代替。开发服务器如果在防火墙后面就可以启用错误日志。(LCTT 译注:此处据原文逻辑和常识,应该是“开发服务器如果在防火墙后面就可以启用错误报告,即 on。”)
|
||||
- 停用这些函数:system()、exec()、passthru()、shell\_exec()、proc\_open()、和 popen()。
|
||||
- **open\_basedir** 为 /tmp(以便保存会话信息)目录和 web 根目录设置值,以便脚本不能访问选定区域外的文件。
|
||||
- **expose\_php** 设置为 off。该功能会向 Apache 头添加包含版本数字的 PHP 签名。
|
||||
- **allow\_url\_fopen** 设置为 off。如果你小心在你代码中访问文件的方式-也就是你验证所有输入参数,这并不严格需要。
|
||||
- **allow\_url\_include** 设置为 off。这实在没有明智的理由任何人会想要通过 HTTP 访问包含的文件。
|
||||
- **open\_basedir** 为 /tmp(以便保存会话信息)目录和 web 根目录,以便脚本不能访问这些选定区域外的文件。
|
||||
- **expose\_php** 设置为 off。该功能会向 Apache 头添加包含版本号的 PHP 签名。
|
||||
- **allow\_url\_fopen** 设置为 off。如果你能够注意你代码中访问文件的方式-也就是你验证所有输入参数,这并不严格需要。
|
||||
- **allow\_url\_include** 设置为 off。对于任何人来说,实在没有明智的理由会想要访问通过 HTTP 包含的文件。
|
||||
|
||||
一般来说,如果你发现想要使用这些功能的代码,你就不应该相信它。尤其要小心会使用类似 system() 函数的代码-它几乎肯定有缺陷。
|
||||
|
||||
@ -74,13 +74,13 @@ $\_REQUEST 是 $\_GET、$\_POST、和 $\_COOKIE 数组的结合。如果你有
|
||||
|
||||
### SQL 注入攻击 ###
|
||||
|
||||
由于 PHP 传递到 MySQL 数据库的查询语句是按照强大的 SQL 编程语言编写的,你就有某些人通过在 web 查询参数中使用 MySQL 语句尝试 SQL 注入攻击的风险。通过在参数中插入有害的 SQL 代码片段,攻击者会尝试进入(或破坏)你的服务器。
|
||||
由于 PHP 传递到 MySQL 数据库的查询语句是用强大的 SQL 编程语言编写的,就有了某些人通过在 web 查询参数中使用 MySQL 语句尝试 SQL 注入攻击的风险。通过在参数中插入有害的 SQL 代码片段,攻击者会尝试进入(或破坏)你的服务器。
|
||||
|
||||
假如说你有一个最终会放入变量 $product 的表单参数,你使用了类似下面的 SQL 语句:
|
||||
|
||||
$sql = "select * from pinfo where product = '$product'";
|
||||
|
||||
如果参数是直接从表单中获得的,使用 PHP 自带的数据库特定转义函数,类似:
|
||||
如果参数是直接从表单中获得的,应该使用 PHP 自带的数据库特定转义函数,类似:
|
||||
|
||||
$sql = 'Select * from pinfo where product = '"'
|
||||
mysql_real_escape_string($product) . '"';
|
||||
@ -89,7 +89,7 @@ $\_REQUEST 是 $\_GET、$\_POST、和 $\_COOKIE 数组的结合。如果你有
|
||||
|
||||
39'; DROP pinfo; SELECT 'FOO
|
||||
|
||||
$sql 的结果就是:
|
||||
那么 $sql 的结果就是:
|
||||
|
||||
select product from pinfo where product = '39'; DROP pinfo; SELECT 'FOO'
|
||||
|
||||
@ -110,15 +110,15 @@ $sql 的结果就是:
|
||||
|
||||
**注意:要自动转义任何表单数据,可以启用魔术引号(Magic Quotes)。**
|
||||
|
||||
一些 MySQL 破坏可以通过限制 MySQL 用户权限避免。任何 MySQL 账户可以限制为只允许对选定的表进行特定类型的查询。例如,你可以创建只能选择行的 MySQL 用户。但是,这对于动态数据并不十分有用,另外,如果你有敏感的用户信息,可能某些人能访问一些数据,但你并不希望如此。例如,一个访问账户数据的用户可能会尝试注入访问另一个账户号码的代码,而不是为当前会话指定的号码。
|
||||
一些 MySQL 破坏可以通过限制 MySQL 用户权限避免。任何 MySQL 账户可以限制为只允许对选定的表进行特定类型的查询。例如,你可以创建只能选择行的 MySQL 用户。但是,这对于动态数据并不十分有用,另外,如果你有敏感的用户信息,可能某些人能访问其中一些数据,但你并不希望如此。例如,一个访问账户数据的用户可能会尝试注入访问另一个人的账户号码的代码,而不是为当前会话指定的号码。
|
||||
|
||||
### 防止基本的 XSS 攻击 ###
|
||||
|
||||
XSS 表示跨站点脚本。不像大部分攻击,该漏洞发生在客户端。XSS 最常见的基本形式是在用户提交的内容中放入 JavaScript 以便偷取用户 cookie 中的数据。由于大部分站点使用 cookie 和 session 验证访客,偷取的数据可用于模拟该用于-如果是一个典型的用户账户就会深受麻烦,如果是管理员账户甚至是彻底的惨败。如果你不在站点中使用 cookie 和 session ID,你的用户就不容易被攻击,但你仍然应该明白这种攻击是如何工作的。
|
||||
XSS 表示跨站脚本。不像大部分攻击,该漏洞发生在客户端。XSS 最常见的基本形式是在用户提交的内容中放入 JavaScript 以便偷取用户 cookie 中的数据。由于大部分站点使用 cookie 和 session 验证访客,偷取的数据可用于模拟该用户-如果是一个常见的用户账户就会深受麻烦,如果是管理员账户甚至是彻底的惨败。如果你不在站点中使用 cookie 和 session ID,你的用户就不容易被攻击,但你仍然应该明白这种攻击是如何工作的。
|
||||
|
||||
不像 MySQL 注入攻击,XSS 攻击很难预防。Yahoo、eBay、Apple、以及 Microsoft 都曾经受 XSS 影响。尽管攻击不包含 PHP,你可以使用 PHP 来剥离用户数据以防止攻击。为了防止 XSS 攻击,你应该限制和过滤用户提交给你站点的数据。正是因为这个原因大部分在线公告板都不允许在提交的数据中使用 HTML 标签,而是用自定义的标签格式代替,例如 **[b]** 和 **[linkto]**。
|
||||
不像 MySQL 注入攻击,XSS 攻击很难预防。Yahoo、eBay、Apple、以及 Microsoft 都曾经受 XSS 影响。尽管攻击不包含 PHP,但你可以使用 PHP 来剥离用户数据以防止攻击。为了防止 XSS 攻击,你应该限制和过滤用户提交给你站点的数据。正是因为这个原因,大部分在线公告板都不允许在提交的数据中使用 HTML 标签,而是用自定义的标签格式代替,例如 **[b]** 和 **[linkto]**。
|
||||
|
||||
让我们来看一个如何防止这类攻击的简单脚本。对于更完善的解决办法,可以使用 SafeHHTML,本文的后面部分会讨论到。
|
||||
让我们来看一个如何防止这类攻击的简单脚本。对于更完善的解决办法,可以使用 SafeHTML,本文的后面部分会讨论到。
|
||||
|
||||
function transform_HTML($string, $length = null) {
|
||||
// Helps prevent XSS attacks
|
||||
@ -137,23 +137,21 @@ XSS 表示跨站点脚本。不像大部分攻击,该漏洞发生在客户端
|
||||
return $string;
|
||||
}
|
||||
|
||||
这个函数将 HTML 特定字符转换为 HTML 字面字符。一个浏览器对任何通过这个脚本的 HTML 以无标记的文本呈现。例如,考虑下面的 HTML 字符串:
|
||||
这个函数将 HTML 特定的字符转换为 HTML 字面字符。一个浏览器对任何通过这个脚本的 HTML 以非标记的文本呈现。例如,考虑下面的 HTML 字符串:
|
||||
|
||||
<STRONG>Bold Text</STRONG>
|
||||
|
||||
一般情况下,HTML 会显示为:
|
||||
一般情况下,HTML 会显示为:**Bold Text**
|
||||
|
||||
Bold Text
|
||||
|
||||
但是,通过 **transform\_HTML()** 后,它就像初始输入一样呈现。原因是处理的字符串中标签字符串是 HTML 条目。**transform\_HTML()** 结果字符串的纯文本看起来像下面这样:
|
||||
但是,通过 **transform\_HTML()** 后,它就像原始输入一样呈现。原因是处理的字符串中的标签字符串转换为 HTML 实体。**transform\_HTML()** 的结果字符串的纯文本看起来像下面这样:
|
||||
|
||||
<STRONG>Bold Text</STRONG>
|
||||
|
||||
该函数的实质是 htmlentities() 函数调用,它会将 <、>、和 & 转换为 **<**、**>**、和 **&**。尽管这会处理大部分的普通攻击,有经验的 XSS 攻击者有另一种把戏:用十六进制或 UTF-8 编码恶意脚本,而不是采用普通的 ASCII 文本,从而希望能饶过你的过滤器。他们可以在 URL 的 GET 变量中发送代码,例如,“这是十六进制代码,你能帮我运行吗?” 一个十六进制例子看起来像这样:
|
||||
该函数的实质是 htmlentities() 函数调用,它会将 <、>、和 & 转换为 **\<**、**\>**、和 **\&**。尽管这会处理大部分的普通攻击,但有经验的 XSS 攻击者有另一种把戏:用十六进制或 UTF-8 编码恶意脚本,而不是采用普通的 ASCII 文本,从而希望能绕过你的过滤器。他们可以在 URL 的 GET 变量中发送代码,告诉浏览器,“这是十六进制代码,你能帮我运行吗?” 一个十六进制例子看起来像这样:
|
||||
|
||||
<a href="http://host/a.php?variable=%22%3e %3c%53%43%52%49%50%54%3e%44%6f%73%6f%6d%65%74%68%69%6e%67%6d%61%6c%69%63%69%6f%75%73%3c%2f%53%43%52%49%50%54%3e">
|
||||
|
||||
浏览器渲染这信息的时候,结果就是:
|
||||
浏览器渲染这个信息的时候,结果就是:
|
||||
|
||||
<a href="http://host/a.php?variable="> <SCRIPT>Dosomethingmalicious</SCRIPT>
|
||||
|
||||
@ -163,20 +161,20 @@ XSS 表示跨站点脚本。不像大部分攻击,该漏洞发生在客户端
|
||||
|
||||
### 使用 SafeHTML ###
|
||||
|
||||
之前脚本的问题比较简单,它不允许任何类型的用户标记。不幸的是,这里有上百种方法能使 JavaScript 跳过用户的过滤器,从用户输入中剥离 HTML,没有方法可以防止这种情况。
|
||||
之前脚本的问题比较简单,它不允许任何类型的用户标记。不幸的是,这里有上百种方法能使 JavaScript 跳过用户的过滤器,并且要从用户输入中剥离全部 HTML,还没有方法可以防止这种情况。
|
||||
|
||||
当前,没有任何一个脚本能保证无法被破解,尽管有一些确实比大部分要好。有白名单和黑名单两种方法加固安全,白名单比较简单而且更加有效。
|
||||
|
||||
一个白名单解决方案是 PixelApes 的 SafeHTML 反跨站点脚本解析器。
|
||||
一个白名单解决方案是 PixelApes 的 SafeHTML 反跨站脚本解析器。
|
||||
|
||||
SafeHTML 能识别有效 HTML,能追踪并剥离任何危险标签。它用另一个称为 HTMLSax 的软件包进行解析。
|
||||
|
||||
按照下面步骤安装和使用 SafeHTML:
|
||||
|
||||
1. 到 [http://pixel-apes.com/safehtml/?page=safehtml][1] 下载最新版本的 SafeHTML。
|
||||
1. 把文件放到你服务器的类文件夹。该文件夹包括 SafeHTML 和 HTMLSax 起作用需要的所有东西。
|
||||
1. 在脚本中包含 SafeHTML 类文件(safehtml.php)。
|
||||
1. 创建称为 $safehtml 的新 SafeHTML 对象。
|
||||
1. 把文件放到你服务器的类文件夹。该文件夹包括 SafeHTML 和 HTMLSax 功能所需的所有东西。
|
||||
1. 在脚本中 `include` SafeHTML 类文件(safehtml.php)。
|
||||
1. 创建一个名为 $safehtml 的新 SafeHTML 对象。
|
||||
1. 用 $safehtml->parse() 方法清理你的数据。
|
||||
|
||||
这是一个完整的例子:
|
||||
@ -203,45 +201,45 @@ SafeHTML 能识别有效 HTML,能追踪并剥离任何危险标签。它用另
|
||||
|
||||
你可能犯的最大错误是假设这个类能完全避免 XSS 攻击。SafeHTML 是一个相当复杂的脚本,几乎能检查所有事情,但没有什么是能保证的。你仍然需要对你的站点做参数验证。例如,该类不能检查给定变量的长度以确保能适应数据库的字段。它也不检查缓冲溢出问题。
|
||||
|
||||
XSS 攻击者很有创造力,他们使用各种各样的方法来尝试达到他们的目标。可以阅读 RSnake 的 XSS 教程[http://ha.ckers.org/xss.html][2] 看一下这里有多少种方法尝试使代码跳过过滤器。SafeHTML 项目有很好的程序员一直在尝试阻止 XSS 攻击,但无法保证某些人不会想起一些奇怪和新奇的方法来跳过过滤器。
|
||||
XSS 攻击者很有创造力,他们使用各种各样的方法来尝试达到他们的目标。可以阅读 RSnake 的 XSS 教程[http://ha.ckers.org/xss.html][2] ,看一下这里有多少种方法尝试使代码跳过过滤器。SafeHTML 项目有很好的程序员一直在尝试阻止 XSS 攻击,但无法保证某些人不会想起一些奇怪和新奇的方法来跳过过滤器。
|
||||
|
||||
**注意:XSS 攻击严重影响的一个例子 [http://namb.la/popular/tech.html][3],其中显示了如何一步一步创建会超载 MySpace 服务器的 JavaScript XSS 蠕虫。**
|
||||
**注意:XSS 攻击严重影响的一个例子 [http://namb.la/popular/tech.html][3],其中显示了如何一步一步创建一个让 MySpace 服务器过载的 JavaScript XSS 蠕虫。**
|
||||
|
||||
### 用单向哈希保护数据 ###
|
||||
|
||||
该脚本对输入的数据进行单向转换-换句话说,它能对某人的密码产生哈希签名,但不能解码获得原始密码。为什么你希望这样呢?应用程序会存储密码。一个管理员不需要知道用户的密码-事实上,只有用户知道他的/她的密码是个好主意。系统(也仅有系统)应该能识别一个正确的密码;这是 Unix 多年来的密码安全模型。单向密码安全按照下面的方式工作:
|
||||
该脚本对输入的数据进行单向转换,换句话说,它能对某人的密码产生哈希签名,但不能解码获得原始密码。为什么你希望这样呢?应用程序会存储密码。一个管理员不需要知道用户的密码,事实上,只有用户知道他/她自己的密码是个好主意。系统(也仅有系统)应该能识别一个正确的密码;这是 Unix 多年来的密码安全模型。单向密码安全按照下面的方式工作:
|
||||
|
||||
1. 当一个用户或管理员创建或更改一个账户密码时,系统对密码进行哈希并保存结果。主机系统忽视明文密码。
|
||||
1. 当一个用户或管理员创建或更改一个账户密码时,系统对密码进行哈希并保存结果。主机系统会丢弃明文密码。
|
||||
2. 当用户通过任何方式登录到系统时,再次对输入的密码进行哈希。
|
||||
3. 主机系统抛弃输入的明文密码。
|
||||
3. 主机系统丢弃输入的明文密码。
|
||||
4. 当前新哈希的密码和之前保存的哈希相比较。
|
||||
5. 如果哈希的密码相匹配,系统就会授予访问权限。
|
||||
|
||||
主机系统完成这些并不需要知道原始密码;事实上,原始值完全不相关。一个副作用是,如果某人侵入系统并盗取了密码数据库,入侵者会获得很多哈希后的密码,但无法把它们反向转换为原始密码。当然,给足够时间、计算能力,以及弱用户密码,一个攻击者还是有可能采用字典攻击找出密码。因此,别轻易让人碰你的密码数据库,如果确实有人这样做了,让每个用户更改他们的密码。
|
||||
主机系统完成这些并不需要知道原始密码;事实上,原始密码完全无所谓。一个副作用是,如果某人侵入系统并盗取了密码数据库,入侵者会获得很多哈希后的密码,但无法把它们反向转换为原始密码。当然,给足够时间、计算能力,以及弱用户密码,一个攻击者还是有可能采用字典攻击找出密码。因此,别轻易让人碰你的密码数据库,如果确实有人这样做了,让每个用户更改他们的密码。
|
||||
|
||||
#### 加密 Vs 哈希 ####
|
||||
|
||||
技术上来来说,这过程并不是加密。哈希和加密是不相同的,这有两个理由:
|
||||
技术上来来说,哈希过程并不是加密。哈希和加密是不同的,这有两个理由:
|
||||
|
||||
不像加密,数据不能被解密。
|
||||
不像加密,哈希数据不能被解密。
|
||||
|
||||
是有可能(但很不常见)两个不同的字符串会产生相同的哈希。并不能保证哈希是唯一的,因此别像数据库中的唯一键那样使用哈希。
|
||||
是有可能(但非常罕见)两个不同的字符串会产生相同的哈希。并不能保证哈希是唯一的,因此别像数据库中的唯一键那样使用哈希。
|
||||
|
||||
function hash_ish($string) {
|
||||
return md5($string);
|
||||
}
|
||||
|
||||
md5() 函数基于 RSA 数据安全公司的消息摘要算法(即 MD5)返回一个由 32 个字符组成的十六进制串。然后你可以将那个 32 位字符串插入到数据库中,和另一个 md5 字符串相比较,或者就用这 32 个字符。
|
||||
上面的 md5() 函数基于 RSA 数据安全公司的消息摘要算法(即 MD5)返回一个由 32 个字符组成的十六进制串。然后你可以将那个 32 位字符串插入到数据库中和另一个 md5 字符串相比较,或者直接用这 32 个字符。
|
||||
|
||||
#### 破解脚本 ####
|
||||
|
||||
几乎不可能解密 MD5 数据。或者说很难。但是,你仍然需要好的密码,因为根据整个字典生成哈希数据库仍然很简单。这里有在线 MD5 字典,当你输入 **06d80eb0c50b49a509b49f2424e8c805** 后会得到结果 “dog”。因此,尽管技术上 MD5 不能被解密,这里仍然有漏洞-如果某人获得了你的密码数据库,你可以肯定他们肯定会使用 MD5 字典破译。因此,当你创建基于密码的系统的时候尤其要注意密码长度(最小 6 个字符,8 个或许会更好)和包括字母和数字。并确保字典中没有这个密码。
|
||||
几乎不可能解密 MD5 数据。或者说很难。但是,你仍然需要好的密码,因为用一整个字典生成哈希数据库仍然很简单。有一些在线 MD5 字典,当你输入 **06d80eb0c50b49a509b49f2424e8c805** 后会得到结果 “dog”。因此,尽管技术上 MD5 不能被解密,这里仍然有漏洞,如果某人获得了你的密码数据库,你可以肯定他们肯定会使用 MD5 字典破译。因此,当你创建基于密码的系统的时候尤其要注意密码长度(最小 6 个字符,8 个或许会更好)和包括字母和数字。并确保这个密码不在字典中。
|
||||
|
||||
### 用 Mcrypt 加密数据 ###
|
||||
|
||||
如果你不需要以可阅读形式查看密码,采用 MD5 就足够了。不幸的是,这里并不总是有可选项-如果你提供以加密形式存储某人的信用卡信息,你可能需要在后面的某个点进行解密。
|
||||
如果你不需要以可阅读形式查看密码,采用 MD5 就足够了。不幸的是,这里并不总是有可选项,如果你提供以加密形式存储某人的信用卡信息,你可能需要在后面的某个地方进行解密。
|
||||
|
||||
最早的一个解决方案是 Mcrypt 模块,用于允许 PHP 高速加密的附件。Mcrypt 库提供了超过 30 种计算方法用于加密,并且提供短语确保只有你(或者你的用户)可以解密数据。
|
||||
最早的一个解决方案是 Mcrypt 模块,这是一个用于允许 PHP 高速加密的插件。Mcrypt 库提供了超过 30 种用于加密的计算方法,并且提供口令确保只有你(或者你的用户)可以解密数据。
|
||||
|
||||
让我们来看看使用方法。下面的脚本包含了使用 Mcrypt 加密和解密数据的函数:
|
||||
|
||||
@ -282,21 +280,21 @@ md5() 函数基于 RSA 数据安全公司的消息摘要算法(即 MD5)返
|
||||
**mcrypt()** 函数需要几个信息:
|
||||
|
||||
- 需要加密的数据
|
||||
- 用于加密和解锁数据的短语,也称为键。
|
||||
- 用于加密和解锁数据的口令,也称为键。
|
||||
- 用于加密数据的计算方法,也就是用于加密数据的算法。该脚本使用了 **MCRYPT\_SERPENT\_256**,但你可以从很多算法中选择,包括 **MCRYPT\_TWOFISH192**、**MCRYPT\_RC2**、**MCRYPT\_DES**、和 **MCRYPT\_LOKI97**。
|
||||
- 加密数据的模式。这里有几个你可以使用的模式,包括电子密码本(Electronic Codebook) 和加密反馈(Cipher Feedback)。该脚本使用 **MCRYPT\_MODE\_CBC** 密码块链接。
|
||||
- 一个 **初始化向量**-也称为 IV,或着一个种子-用于为加密算法设置种子的额外二进制位。也就是使算法更难于破解的额外信息。
|
||||
- 键和 IV 字符串的长度,这可能随着加密和块而不同。使用 **mcrypt\_get\_key\_size()** 和 **mcrypt\_get\_block\_size()** 函数获取合适的长度;然后用 **substr()** 函数将键的值截取为合适的长度。(如果键的长度比要求的短,别担心-Mcrypt 会用 0 填充。)
|
||||
- 一个 **初始化向量**-也称为 IV 或者种子,用于为加密算法设置种子的额外二进制位。也就是使算法更难于破解的额外信息。
|
||||
- 键和 IV 字符串的长度,这可能随着加密和块而不同。使用 **mcrypt\_get\_key\_size()** 和 **mcrypt\_get\_block\_size()** 函数获取合适的长度;然后用 **substr()** 函数将键的值截取为合适的长度。(如果键的长度比要求的短,别担心,Mcrypt 会用 0 填充。)
|
||||
|
||||
如果有人窃取了你的数据和短语,他们只能一个个尝试加密算法直到找到正确的那一个。因此,在使用它之前我们通过对键使用 **md5()** 函数增加安全,就算他们获取了数据和短语,入侵者也不能获得想要的东西。
|
||||
|
||||
入侵者同时需要函数,数据和短语-如果真是如此,他们可能获得了对你服务器的完整访问,你只能大清洗了。
|
||||
入侵者同时需要函数,数据和口令,如果真是如此,他们可能获得了对你服务器的完整访问,你只能大清洗了。
|
||||
|
||||
这里还有一个数据存储格式的小问题。Mcrypt 以难懂的二进制形式返回加密后的数据,这使得当你将其存储到 MySQL 字段的时候可能出现可怕错误。因此,我们使用 **base64encode()** 和 **base64decode()** 函数转换为和 SQL 兼容的字母格式和检索行。
|
||||
这里还有一个数据存储格式的小问题。Mcrypt 以难懂的二进制形式返回加密后的数据,这使得当你将其存储到 MySQL 字段的时候可能出现可怕错误。因此,我们使用 **base64encode()** 和 **base64decode()** 函数转换为和 SQL 兼容的字母格式和可检索行。
|
||||
|
||||
#### 破解脚本 ####
|
||||
|
||||
除了实验多种加密方法,你还可以在脚本中添加一些便利。例如,不是每次都提供键和模式,而是在包含的文件中声明为全局常量。
|
||||
除了实验多种加密方法,你还可以在脚本中添加一些便利。例如,不用每次都提供键和模式,而是在包含的文件中声明为全局常量。
|
||||
|
||||
### 生成随机密码 ###
|
||||
|
||||
@ -331,8 +329,8 @@ md5() 函数基于 RSA 数据安全公司的消息摘要算法(即 MD5)返
|
||||
函数按照下面步骤工作:
|
||||
|
||||
- 函数确保 **$num\_chars** 是非零的正整数。
|
||||
- 函数初始化 **$accepted\_chars** 变量为密码可能包含的字符列表。该脚本使用所有小写字母和数字 0 到 9,但你可以使用你喜欢的任何字符集合。
|
||||
- 随机数生成器需要一个种子,从而获得一系列类随机值(PHP 4.2 及之后版本中并不严格要求)。
|
||||
- 函数初始化 **$accepted\_chars** 变量为密码可能包含的字符列表。该脚本使用所有小写字母和数字 0 到 9,但你可以使用你喜欢的任何字符集合。(LCTT 译注:有时候为了便于肉眼识别,你可以将其中的 0 和 O,1 和 l 之类的都去掉。)
|
||||
- 随机数生成器需要一个种子,从而获得一系列类随机值(PHP 4.2 及之后版本中并不需要,会自动播种)。
|
||||
- 函数循环 **$num\_chars** 次,每次迭代生成密码中的一个字符。
|
||||
- 对于每个新字符,脚本查看 **$accepted_chars** 的长度,选择 0 和长度之间的一个数字,然后添加 **$accepted\_chars** 中该数字为索引值的字符到 $password。
|
||||
- 循环结束后,函数返回 **$password**。
|
||||
@ -347,7 +345,7 @@ via: http://www.codeproject.com/Articles/363897/PHP-Security
|
||||
|
||||
作者:[SamarRizvi][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,83 @@
|
||||
监控 Linux 系统的 7 个命令行工具
|
||||
================================================================================
|
||||
**这里有一些基本的命令行工具,让你能更简单地探索和操作Linux。**
|
||||
|
||||

|
||||
|
||||
### 深入 ###
|
||||
|
||||
关于Linux最棒的一件事之一是你能深入操作系统,来探索它是如何工作的,并寻找机会来微调性能或诊断问题。这里有一些基本的命令行工具,让你能更简单地探索和操作Linux。大多数的这些命令是在你的Linux系统中已经内建的,但假如它们没有的话,就用谷歌搜索命令名和你的发行版名吧,你会找到哪些包需要安装(注意,一些命令是和其它命令捆绑起来打成一个包的,你所找的包可能写的是其它的名字)。如果你知道一些你所使用的其它工具,欢迎评论。
|
||||
|
||||
|
||||
### 我们怎么开始 ###
|
||||
|
||||
|
||||
|
||||
须知: 本文中的截图取自一台[Debian Linux 8.1][1] (“Jessie”),其运行在[OS X 10.10.3][3] (“Yosemite”)操作系统下的[Oracle VirtualBox 4.3.28][2]中的一台虚拟机里。想要建立你的Debian虚拟机,可以看看我的这篇教程——“[如何在 VirtualBox VM 下安装 Debian][4]”。
|
||||
|
||||
|
||||
### Top ###
|
||||
|
||||
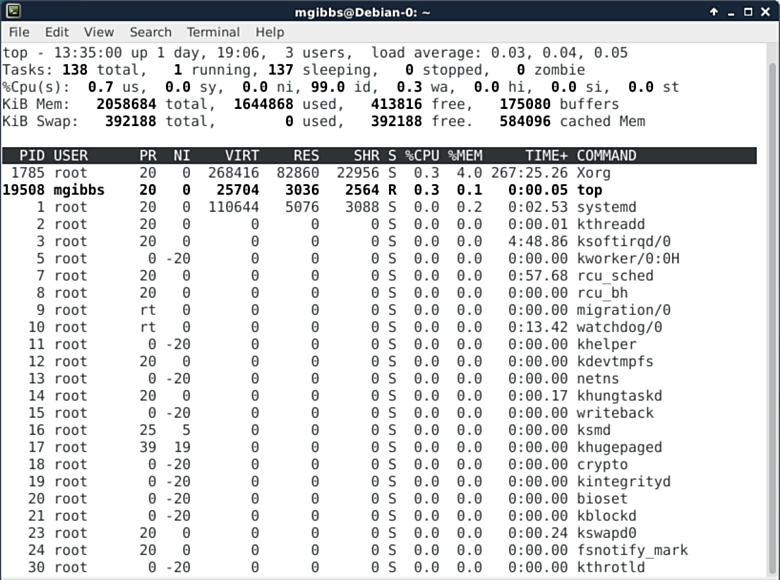
|
||||
|
||||
作为Linux系统监控工具中比较易用的一个,**top命令**能带我们一览Linux中的几乎每一处。以下这张图是它的默认界面,但是按“z”键可以切换不同的显示颜色。其它热键和命令则有其它的功能,例如显示概要信息和内存信息(第四行第二个),根据各种不一样的条件排序、终止进程任务等等(你可以在[这里][5]找到完整的列表)。
|
||||
|
||||
|
||||
### htop ###
|
||||
|
||||
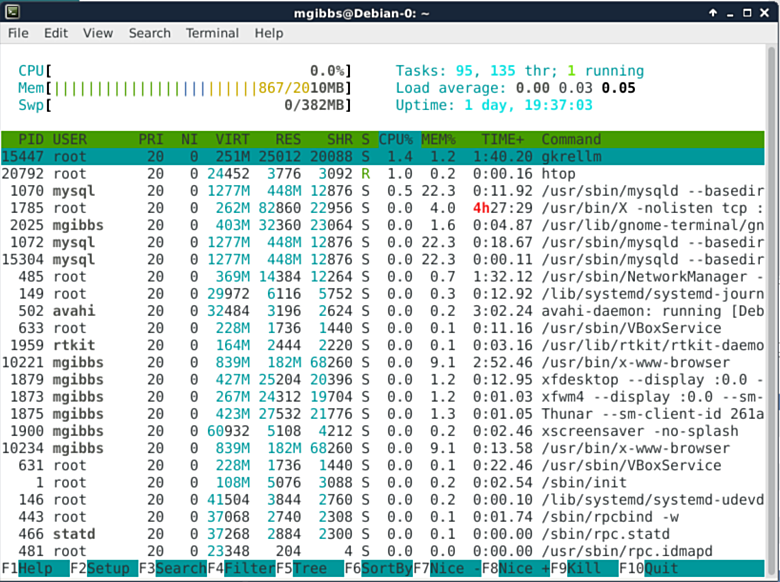
|
||||
|
||||
相比top,它的替代品Htop则更为精致。维基百科是这样描述的:“用户经常会部署htop以免Unix top不能提供关于系统进程的足够信息,比如说当你在尝试发现应用程序里的一个小的内存泄露问题,Htop一般也能作为一个系统监听器来使用。相比top,它提供了一个更方便的光标控制界面来向进程发送信号。” (想了解更多细节猛戳[这里][6])
|
||||
|
||||
|
||||
### Vmstat ###
|
||||
|
||||
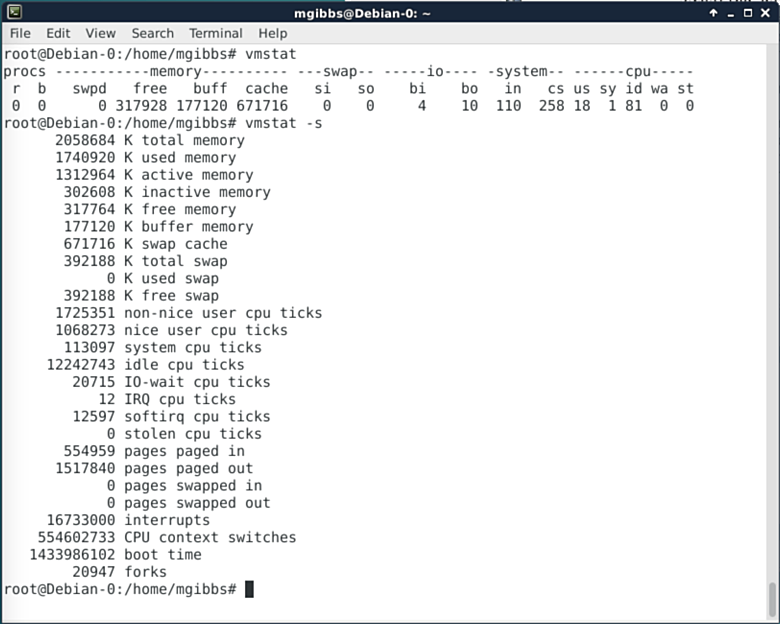
|
||||
|
||||
Vmstat是一款监控Linux系统性能数据的简易工具,这让它更合适使用在shell脚本中。使出你的正则表达式绝招,用vmstat和cron作业来做一些激动人心的事情吧。“后面的报告给出的是上一次系统重启之后的均值,另外一份报告给出的则是从前一个报告起间隔周期中的信息。其它的进程和内存报告是那个瞬态的情况”(猛戳[这里][7]获取更多信息)。
|
||||
|
||||
### ps ###
|
||||
|
||||
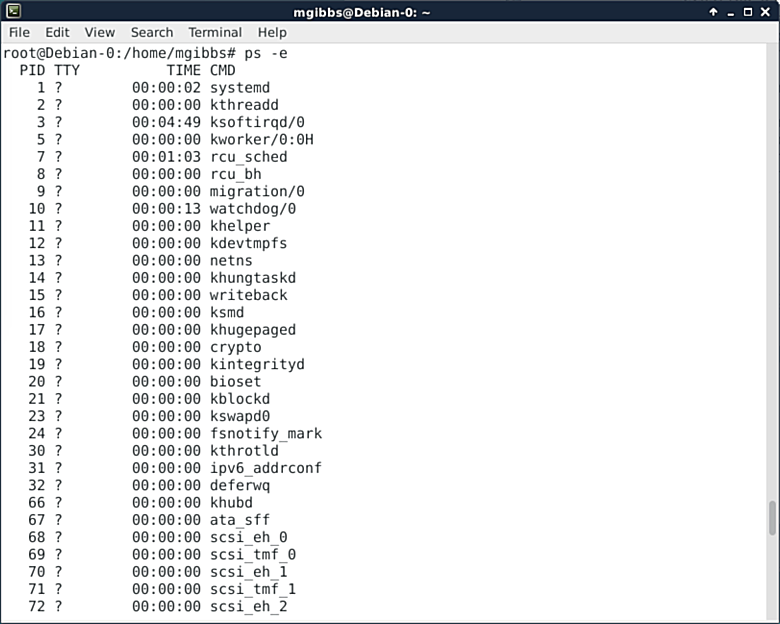
|
||||
|
||||
ps命令展现的是正在运行中的进程列表。在这种情况下,我们用“-e”选项来显示每个进程,也就是所有正在运行的进程了(我把列表滚动到了前面,否则列名就看不到了)。这个命令有很多选项允许你去按需格式化输出。只要使用上述一点点的正则表达式技巧,你就能得到一个强大的工具了。猛戳[这里][8]获取更多信息。
|
||||
|
||||
### Pstree ###
|
||||
|
||||
|
||||
|
||||
Pstree“以树状图显示正在运行中的进程。这个进程树是以某个 pid 为根节点的,如果pid被省略的话那树是以init为根节点的。如果指定用户名,那所有进程树都会以该用户所属的进程为父进程进行显示。”以树状图来帮你将进程之间的所属关系进行分类,这的确是个很有效的工具(戳[这里][9])。
|
||||
|
||||
### pmap ###
|
||||
|
||||
|
||||
|
||||
在调试过程中,理解一个应用程序如何使用内存是至关重要的,而pmap的作用就是当给出一个进程ID时显示出相关信息。上面的截图展示的是使用“-x”选项所产生的部分输出,你也可以用pmap的“-X”选项来获取更多的细节信息,但是前提是你要有个更宽的终端窗口。
|
||||
|
||||
### iostat ###
|
||||
|
||||
|
||||
|
||||
Linux系统的一个至关重要的性能指标是处理器和存储的使用率,它也是iostat命令所报告的内容。如同ps命令一样,iostat有很多选项允许你选择你需要的输出格式,除此之外还可以在某一段时间范围内的重复采样几次。详情请戳[这里][10]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.networkworld.com/article/2937219/linux/7-command-line-tools-for-monitoring-your-linux-system.html
|
||||
|
||||
作者:[Mark Gibbs][a]
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.networkworld.com/author/Mark-Gibbs/
|
||||
[1]:https://www.debian.org/releases/stable/
|
||||
[2]:https://www.virtualbox.org/
|
||||
[3]:http://www.apple.com/osx/
|
||||
[4]:http://www.networkworld.com/article/2937148/how-to-install-debian-linux-8-1-in-a-virtualbox-vm
|
||||
[5]:http://linux.die.net/man/1/top
|
||||
[6]:http://linux.die.net/man/1/htop
|
||||
[7]:http://linuxcommand.org/man_pages/vmstat8.html
|
||||
[8]:http://linux.die.net/man/1/ps
|
||||
[9]:http://linux.die.net/man/1/pstree
|
||||
[10]:http://linux.die.net/man/1/iostat
|
||||
@ -1,24 +1,25 @@
|
||||
在 Linux 中安装 Google 环聊桌面客户端
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
先前,我们已经介绍了如何[在 Linux 中安装 Facebook Messenger][1] 和[WhatsApp 桌面客户端][2]。这些应用都是非官方的应用。今天,我将为你推荐另一款非官方的应用,它就是 [Google 环聊][3]
|
||||
|
||||
当然,你可以在 Web 浏览器中使用 Google 环聊,但相比于此,使用桌面客户端会更加有趣。好奇吗?那就跟着我看看如何 **在 Linux 中安装 Google 环聊** 以及如何使用它把。
|
||||
当然,你可以在 Web 浏览器中使用 Google 环聊,但相比于此,使用桌面客户端会更加有趣。好奇吗?那就跟着我看看如何 **在 Linux 中安装 Google 环聊** 以及如何使用它吧。
|
||||
|
||||
### 在 Linux 中安装 Google 环聊 ###
|
||||
|
||||
我们将使用一个名为 [yakyak][4] 的开源项目,它是一个针对 Linux,Windows 和 OS X 平台的非官方 Google 环聊客户端。我将向你展示如何在 Ubuntu 中使用 yakyak,但我相信在其他的 Linux 发行版本中,你可以使用同样的方法来使用它。在了解如何使用它之前,让我们先看看 yakyak 的主要特点:
|
||||
|
||||
- 发送和接受聊天信息
|
||||
- 创建和更改对话 (重命名, 添加人物)
|
||||
- 创建和更改对话 (重命名, 添加参与者)
|
||||
- 离开或删除对话
|
||||
- 桌面提醒通知
|
||||
- 打开或关闭通知
|
||||
- 针对图片上传,支持拖放,复制粘贴或使用上传按钮
|
||||
- Hangupsbot 房间同步(实际的用户图片) (注: 这里翻译不到位,希望改善一下)
|
||||
- 对于图片上传,支持拖放,复制粘贴或使用上传按钮
|
||||
- Hangupsbot 房间同步(使用用户实际的图片)
|
||||
- 展示行内图片
|
||||
- 历史回放
|
||||
- 翻阅历史
|
||||
|
||||
听起来不错吧,你可以从下面的链接下载到该软件的安装文件:
|
||||
|
||||
@ -36,7 +37,7 @@
|
||||
|
||||

|
||||
|
||||
假如你想看看对话的配置图,你可以选择 `查看-> 展示对话缩略图`
|
||||
假如你想在联系人里面显示用户头像,你可以选择 `查看-> 展示对话缩略图`
|
||||
|
||||

|
||||
|
||||
@ -54,7 +55,7 @@ via: http://itsfoss.com/install-google-hangouts-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,10 +1,12 @@
|
||||
Linux有问必答-- 如何为在Linux中安装兄弟打印机
|
||||
Linux有问必答:如何为在Linux中安装兄弟牌打印机
|
||||
================================================================================
|
||||
> **提问**: 我有一台兄弟HL-2270DW激光打印机,我想从我的Linux机器上答应文档。我该如何在我的电脑上安装合适的驱动并使用它?
|
||||
> **提问**: 我有一台兄弟牌HL-2270DW激光打印机,我想从我的Linux机器上打印文档。我该如何在我的电脑上安装合适的驱动并使用它?
|
||||
|
||||
兄弟牌以买得起的[紧凑型激光打印机][1]而闻名。你可以用低于200美元的价格得到高质量的WiFi/双工激光打印机,而且价格还在下降。最棒的是,它们还提供良好的Linux支持,因此你可以在Linux中下载并安装它们的打印机驱动。我在一年前买了台[HL-2270DW][2],我对它的性能和可靠性都很满意。
|
||||
|
||||
下面是如何在Linux中安装和配置兄弟打印机驱动。本篇教程中,我会演示安装HL-2270DW激光打印机的USB驱动。首先通过USB线连接你的打印机到Linux上。
|
||||
下面是如何在Linux中安装和配置兄弟打印机驱动。本篇教程中,我会演示安装HL-2270DW激光打印机的USB驱动。
|
||||
|
||||
首先通过USB线连接你的打印机到Linux上。
|
||||
|
||||
### 准备 ###
|
||||
|
||||
@ -16,13 +18,13 @@ Linux有问必答-- 如何为在Linux中安装兄弟打印机
|
||||
|
||||
|
||||
|
||||
下一页,你会找到你打印机的LPR驱动和CUPS包装器驱动。前者是命令行驱动后者允许你通过网页管理和配置你的打印机。尤其是基于CUPS的GUI对(本地、远程)打印机维护非常有用。建议你安装这两个驱动。点击“Driver Install Tool”下载安装文件。
|
||||
下一页,你会找到你打印机的LPR驱动和CUPS包装器驱动。前者是命令行驱动,后者允许你通过网页管理和配置你的打印机。尤其是基于CUPS的图形界面对(本地、远程)打印机维护非常有用。建议你安装这两个驱动。点击“Driver Install Tool”下载安装文件。
|
||||
|
||||
|
||||
|
||||
运行安装文件之前,你需要在64位的Linux系统上做另外一件事情。
|
||||
|
||||
因为兄弟打印机驱动是为32位的Linux系统开发的,因此你需要按照下面的方法安装32位的库。
|
||||
因为兄弟打印机驱动是为32位的Linux系统开发的,因此你需要按照下面的方法安装32位的库。
|
||||
|
||||
在早期的Debian(6.0或者更早期)或者Ubuntu(11.04或者更早期),安装下面的包。
|
||||
|
||||
@ -54,7 +56,7 @@ Linux有问必答-- 如何为在Linux中安装兄弟打印机
|
||||
|
||||

|
||||
|
||||
同意GPL协议直呼,接受接下来的任何默认问题。
|
||||
同意GPL协议之后,接受接下来的任何默认问题。
|
||||
|
||||

|
||||
|
||||
@ -68,7 +70,7 @@ Linux有问必答-- 如何为在Linux中安装兄弟打印机
|
||||
|
||||
$ sudo netstat -nap | grep 631
|
||||
|
||||
打开一个浏览器输入http://localhost:631。你会下面的打印机管理界面。
|
||||
打开一个浏览器输入 http://localhost:631 。你会看到下面的打印机管理界面。
|
||||
|
||||

|
||||
|
||||
@ -98,7 +100,7 @@ via: http://ask.xmodulo.com/install-brother-printer-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -6,7 +6,7 @@
|
||||
|
||||
当监控服务器发送一个关于 MySQL 服务器存储的报警时,恐慌就开始了 —— 就是说磁盘快要满了。
|
||||
|
||||
一番调查后你意识到大多数地盘空间被 InnoDB 的共享表空间 ibdata1 使用。而你已经启用了 [innodb_file_per_table][2],所以问题是:
|
||||
一番调查后你意识到大多数地盘空间被 InnoDB 的共享表空间 ibdata1 使用。而你已经启用了 [innodb\_file\_per\_table][2],所以问题是:
|
||||
|
||||
### ibdata1存了什么? ###
|
||||
|
||||
@ -17,7 +17,7 @@
|
||||
- 双写缓冲区
|
||||
- 撤销日志
|
||||
|
||||
其中的一些在 [Percona 服务器][3]上可以被配置来避免增长过大的。例如你可以通过 [innodb_ibuf_max_size][4] 设置最大变更缓冲区,或设置 [innodb_doublewrite_file][5] 来将双写缓冲区存储到一个分离的文件。
|
||||
其中的一些在 [Percona 服务器][3]上可以被配置来避免增长过大的。例如你可以通过 [innodb\_ibuf\_max\_size][4] 设置最大变更缓冲区,或设置 [innodb\_doublewrite\_file][5] 来将双写缓冲区存储到一个分离的文件。
|
||||
|
||||
MySQL 5.6 版中你也可以创建外部的撤销表空间,所以它们可以放到自己的文件来替代存储到 ibdata1。可以看看这个[文档][6]。
|
||||
|
||||
@ -82,7 +82,7 @@ MySQL 5.6 版中你也可以创建外部的撤销表空间,所以它们可以
|
||||
|
||||
没有,目前还没有一个容易并且快速的方法。InnoDB 表空间从不收缩...参见[10 年之久的漏洞报告][10],最新更新自詹姆斯·戴(谢谢):
|
||||
|
||||
当你删除一些行,这个页被标为已删除稍后重用,但是这个空间从不会被回收。唯一的方法是使用新的 ibdata1 启动数据库。要做这个你应该需要使用 mysqldump 做一个逻辑全备份,然后停止 MySQL 并删除所有数据库、ib_logfile*、ibdata1* 文件。当你再启动 MySQL 的时候将会创建一个新的共享表空间。然后恢复逻辑备份。
|
||||
当你删除一些行,这个页被标为已删除稍后重用,但是这个空间从不会被回收。唯一的方法是使用新的 ibdata1 启动数据库。要做这个你应该需要使用 mysqldump 做一个逻辑全备份,然后停止 MySQL 并删除所有数据库、ib_logfile\*、ibdata1\* 文件。当你再启动 MySQL 的时候将会创建一个新的共享表空间。然后恢复逻辑备份。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
@ -1,10 +1,9 @@
|
||||
|
||||
如何修复ubuntu 14.04中检测到系统程序错误的问题
|
||||
如何修复 ubuntu 中检测到系统程序错误的问题
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
|
||||
在过去的几个星期,(几乎)每次都有消息 **Ubuntu 15.04在启动时检测到系统程序错误(system program problem detected on startup in Ubuntu 15.04)** 跑出来“欢迎”我。那时我是直接忽略掉它的,但是这种情况到了某个时刻,它就让人觉得非常烦人了!
|
||||
在过去的几个星期,(几乎)每次都有消息 **Ubuntu 15.04在启动时检测到系统程序错误** 跑出来“欢迎”我。那时我是直接忽略掉它的,但是这种情况到了某个时刻,它就让人觉得非常烦人了!
|
||||
|
||||
> 检测到系统程序错误(System program problem detected)
|
||||
>
|
||||
@ -18,15 +17,16 @@
|
||||
|
||||
#### 那么这个通知到底是关于什么的? ####
|
||||
|
||||
大体上讲,它是在告知你,你的系统的一部分崩溃了。可别因为“崩溃”这个词而恐慌。这不是一个严重的问题,你的系统还是完完全全可用的。只是在以前的某个时刻某个程序崩溃了,而Ubuntu想让你决定要不要把这个问题报告给开发者,这样他们就能够修复这个问题。
|
||||
大体上讲,它是在告知你,你的系统的一部分崩溃了。可别因为“崩溃”这个词而恐慌。这不是一个严重的问题,你的系统还是完完全全可用的。只是在之前的某个时刻某个程序崩溃了,而Ubuntu想让你决定要不要把这个问题报告给开发者,这样他们就能够修复这个问题。
|
||||
|
||||
#### 那么,我们点了“报告错误”的按钮后,它以后就不再显示了?####
|
||||
|
||||
不,不是的!即使你点了“报告错误”按钮,最后你还是会被一个如下的弹窗再次“欢迎”一下:
|
||||
|
||||
不,不是的!即使你点了“报告错误”按钮,最后你还是会被一个如下的弹窗再次“欢迎”:
|
||||

|
||||
|
||||
[对不起,Ubuntu发生了一个内部错误(Sorry, Ubuntu has experienced an internal error)][1]是一个Apport(Apport是Ubuntu中错误信息的收集报告系统,详见Ubuntu Wiki中的Apport篇,译者注),它将会进一步的打开网页浏览器,然后你可以通过登录或创建[Launchpad][2]帐户来填写一份漏洞(Bug)报告文件。你看,这是一个复杂的过程,它要花整整四步来完成.
|
||||
[对不起,Ubuntu发生了一个内部错误][1]是个Apport(LCTT 译注:Apport是Ubuntu中错误信息的收集报告系统,详见Ubuntu Wiki中的Apport篇),它将会进一步的打开网页浏览器,然后你可以通过登录或创建[Launchpad][2]帐户来填写一份漏洞(Bug)报告文件。你看,这是一个复杂的过程,它要花整整四步来完成。
|
||||
|
||||
#### 但是我想帮助开发者,让他们知道这个漏洞啊 !####
|
||||
|
||||
你这样想的确非常地周到体贴,而且这样做也是正确的。但是这样做的话,存在两个问题。第一,存在非常高的概率,这个漏洞已经被报告过了;第二,即使你报告了个这次崩溃,也无法保证你不会再看到它。
|
||||
@ -34,35 +34,38 @@
|
||||
#### 那么,你的意思就是说别报告这次崩溃了?####
|
||||
|
||||
对,也不对。如果你想的话,在你第一次看到它的时候报告它。你可以在上面图片显示的“显示细节(Show Details)”中,查看崩溃的程序。但是如果你总是看到它,或者你不想报告漏洞(Bug),那么我建议你还是一次性摆脱这个问题吧。
|
||||
|
||||
### 修复Ubuntu中“检测到系统程序错误”的错误 ###
|
||||
|
||||
这些错误报告被存放在Ubuntu中目录/var/crash中。如果你翻看这个目录的话,应该可以看到有一些以crash结尾的文件。
|
||||
|
||||

|
||||
|
||||
我的建议是删除这些错误报告。打开一个终端,执行下面的命令:
|
||||
|
||||
sudo rm /var/crash/*
|
||||
|
||||
这个操作会删除所有在/var/crash目录下的所有内容。这样你就不会再被这些报告以前程序错误的弹窗所扰。但是如果有一个程序又崩溃了,你就会再次看到“检测到系统程序错误”的错误。你可以再次删除这些报告文件,或者你可以禁用Apport来彻底地摆脱这个错误弹窗。
|
||||
这个操作会删除所有在/var/crash目录下的所有内容。这样你就不会再被这些报告以前程序错误的弹窗所扰。但是如果又有一个程序崩溃了,你就会再次看到“检测到系统程序错误”的错误。你可以再次删除这些报告文件,或者你可以禁用Apport来彻底地摆脱这个错误弹窗。
|
||||
|
||||
#### 彻底地摆脱Ubuntu中的系统错误弹窗 ####
|
||||
|
||||
如果你这样做,系统中任何程序崩溃时,系统都不会再通知你。如果你想问问我的看法的话,我会说,这不是一件坏事,除非你愿意填写错误报告。如果你不想填写错误报告,那么这些错误通知存不存在都不会有什么区别。
|
||||
|
||||
要禁止Apport,并且彻底地摆脱Ubuntu系统中的程序崩溃报告,打开一个终端,输入以下命令:
|
||||
|
||||
gksu gedit /etc/default/apport
|
||||
|
||||
这个文件的内容是:
|
||||
|
||||
# set this to 0 to disable apport, or to 1 to enable it
|
||||
# 设置0表示禁用Apportw,或者1开启它。译者注,下同。
|
||||
# you can temporarily override this with
|
||||
# 设置0表示禁用Apportw,或者1开启它。
|
||||
# 你可以用下面的命令暂时关闭它:
|
||||
# sudo service apport start force_start=1
|
||||
enabled=1
|
||||
|
||||
把**enabled=1**改为**enabled=0**.保存并关闭文件。完成之后你就再也不会看到弹窗报告错误了。很显然,如果我们想重新开启错误报告功能,只要再打开这个文件,把enabled设置为1就可以了。
|
||||
把**enabled=1**改为**enabled=0**。保存并关闭文件。完成之后你就再也不会看到弹窗报告错误了。很显然,如果我们想重新开启错误报告功能,只要再打开这个文件,把enabled设置为1就可以了。
|
||||
|
||||
#### 你的有效吗? ####
|
||||
|
||||
我希望这篇教程能够帮助你修复Ubuntu 14.04和Ubuntu 15.04中检测到系统程序错误的问题。如果这个小窍门帮你摆脱了这个烦人的问题,请让我知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -71,7 +74,7 @@ via: http://itsfoss.com/how-to-fix-system-program-problem-detected-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
140
published/201507/20150713 How to manage Vim plugins.md
Normal file
140
published/201507/20150713 How to manage Vim plugins.md
Normal file
@ -0,0 +1,140 @@
|
||||
如何管理 Vim 插件
|
||||
================================================================================
|
||||
|
||||
Vim是Linux上一个轻量级的通用文本编辑器。虽然它开始时的学习曲线对于一般的Linux用户来说可能很困难,但比起它的好处,这些付出完全是值得的。vim 可以通过完全可定制的插件来增加越来越多的功能。但是,由于它的功能配置比较难,你需要花一些时间去了解它的插件系统,然后才能够有效地去个性化定置Vim。幸运的是,我们已经有一些工具能够使我们在使用Vim插件时更加轻松。而我日常所使用的就是Vundle。
|
||||
|
||||
### 什么是Vundle ###
|
||||
|
||||
[Vundle][1]意即Vim Bundle,是一个vim插件管理器。Vundle能让你很简单地实现插件的安装、升级、搜索或者清除。它还能管理你的运行环境并且在标签方面提供帮助。在本教程中我们将展示如何安装和使用Vundle。
|
||||
|
||||
### 安装Vundle ###
|
||||
|
||||
首先,如果你的Linux系统上没有Git的话,先[安装Git][2]。
|
||||
|
||||
接着,创建一个目录,Vim的插件将会被下载并且安装在这个目录上。默认情况下,这个目录为~/.vim/bundle。
|
||||
|
||||
$ mkdir -p ~/.vim/bundle
|
||||
|
||||
现在,使用如下指令安装Vundle。注意Vundle本身也是一个vim插件。因此我们同样把vundle安装到之前创建的目录~/.vim/bundle下。
|
||||
|
||||
$ git clone https://github.com/gmarik/Vundle.vim.git ~/.vim/bundle/Vundle.vim
|
||||
|
||||
### 配置Vundle ###
|
||||
|
||||
现在配置你的.vimrc文件如下:
|
||||
|
||||
set nocompatible " 必需。
|
||||
filetype off " 必须。
|
||||
|
||||
" 在这里设置你的运行时环境的路径。
|
||||
set rtp+=~/.vim/bundle/Vundle.vim
|
||||
|
||||
" 初始化vundle
|
||||
call vundle#begin()
|
||||
|
||||
" 这一行应该永远放在开头。
|
||||
Plugin 'gmarik/Vundle.vim'
|
||||
|
||||
" 这个示范来自https://github.com/gmarik/Vundle.vim README
|
||||
Plugin 'tpope/vim-fugitive'
|
||||
|
||||
" 取自http://vim-scripts.org/vim/scripts.html的插件
|
||||
Plugin 'L9'
|
||||
|
||||
" 该Git插件没有放在GitHub上。
|
||||
Plugin 'git://git.wincent.com/command-t.git'
|
||||
|
||||
"本地计算机上的Git仓库路径 (例如,当你在开发你自己的插件时)
|
||||
Plugin 'file:///home/gmarik/path/to/plugin'
|
||||
|
||||
" vim脚本sparkup存放在这个名叫vim的仓库下的一个子目录中。
|
||||
" 将这个路径正确地设置为runtimepath。
|
||||
Plugin 'rstacruz/sparkup', {'rtp': 'vim/'}
|
||||
|
||||
" 避免与L9发生名字上的冲突
|
||||
Plugin 'user/L9', {'name': 'newL9'}
|
||||
|
||||
"所有的插件都应该在这一行之前。
|
||||
call vundle#end() " 必需。
|
||||
|
||||
容我简单解释一下上面的设置:默认情况下,Vundle将从github.com或者vim-scripts.org下载和安装vim插件。你也可以改变这个默认行为。
|
||||
|
||||
要从github安装插件:
|
||||
|
||||
Plugin 'user/plugin'
|
||||
|
||||
要从 http://vim-scripts.org/vim/scripts.html 处安装:
|
||||
|
||||
Plugin 'plugin_name'
|
||||
|
||||
要从另外一个git仓库中安装:
|
||||
|
||||
Plugin 'git://git.another_repo.com/plugin'
|
||||
|
||||
从本地文件中安装:
|
||||
|
||||
Plugin 'file:///home/user/path/to/plugin'
|
||||
|
||||
你同样可以定制其它东西,例如你的插件的运行时路径,当你自己在编写一个插件时,或者你只是想从其它目录——而不是~/.vim——中加载插件时,这样做就非常有用。
|
||||
|
||||
Plugin 'rstacruz/sparkup', {'rtp': 'another_vim_path/'}
|
||||
|
||||
如果你有同名的插件,你可以重命名你的插件,这样它们就不会发生冲突了。
|
||||
|
||||
Plugin 'user/plugin', {'name': 'newPlugin'}
|
||||
|
||||
### 使用Vum命令 ###
|
||||
|
||||
一旦你用vundle设置好你的插件,你就可以通过几个vundle命令来安装、升级、搜索插件,或者清除没有用的插件。
|
||||
|
||||
#### 安装一个新的插件 ####
|
||||
|
||||
`PluginInstall`命令将会安装所有列在你的.vimrc文件中的插件。你也可以通过传递一个插件名给它,来安装某个的特定插件。
|
||||
|
||||
:PluginInstall
|
||||
:PluginInstall <插件名>
|
||||
|
||||
|
||||
|
||||
#### 清除没有用的插件 ####
|
||||
|
||||
如果你有任何没有用到的插件,你可以通过`PluginClean`命令来删除它。
|
||||
|
||||
:PluginClean
|
||||
|
||||
|
||||
|
||||
#### 查找一个插件 ####
|
||||
|
||||
如果你想从提供的插件清单中安装一个插件,搜索功能会很有用。
|
||||
|
||||
:PluginSearch <文本>
|
||||
|
||||
|
||||
|
||||
在搜索的时候,你可以在交互式分割窗口中安装、清除、重新搜索或者重新加载插件清单。安装后的插件不会自动加载生效,要使其加载生效,可以将它们添加进你的.vimrc文件中。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
Vim是一个妙不可言的工具。它不单单是一个能够使你的工作更加顺畅高效的默认文本编辑器,同时它还能够摇身一变,成为现存的几乎任何一门编程语言的IDE。
|
||||
|
||||
注意,有一些网站能帮你找到适合的vim插件。猛击 [http://www.vim-scripts.org][3], Github或者 [http://www.vimawesome.com][4] 获取新的脚本或插件。同时记得使用为你的插件提供的帮助。
|
||||
|
||||
和你最爱的编辑器一起嗨起来吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/manage-vim-plugins.html
|
||||
|
||||
作者:[Christopher Valerio][a]
|
||||
译者:[XLCYun(袖里藏云)](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/valerio
|
||||
[1]:https://github.com/VundleVim/Vundle.vim
|
||||
[2]:http://ask.xmodulo.com/install-git-linux.html
|
||||
[3]:http://www.vim-scripts.org/
|
||||
[4]:http://www.vimawesome.com/
|
||||
|
||||
@ -0,0 +1,118 @@
|
||||
Ubuntu 下 CCleaner 的 4 个替代品
|
||||
================================================================================
|
||||

|
||||
|
||||
回首我使用 Windows 的那些日子,[CCleaner][1] 是我用来释放空间、删除垃圾文件和加速 Windows 的最喜爱的工具。我知道,当从 Windows 切换到 Linux 时,我并不是唯一期望 CCleaner 拥有 Linux 版本的人。假如你正在寻找 Linux 下 CCleaner 的替代品,我将在下面列举 4 个这样的应用,它们可以用来清理 Ubuntu 或基于 Ubuntu 的 Linux 发行版本。但在我们看这个清单之前,先让我们考虑一下 Linux 是否需要系统清理工具这个问题。
|
||||
|
||||
### Linux 需要像 CCleaner 那样的系统清理工具吗? ###
|
||||
|
||||
为了得到答案,让我们看看 CCleaner 做了什么。正如 [How-To Geek][2] 的这篇文章中所提到的那样:
|
||||
|
||||
> CCleaner 有两个主要的功能。一是:它扫描并删除无用的文件,释放磁盘空间。二是:它擦除隐私的数据,例如你的浏览记录和在各种软件中最近打开的文件列表。
|
||||
|
||||
所以,概括起来,它在系统范围内清理在你的浏览器或媒体播放器中的临时文件。你或许知道 Windows 有在系统中保存垃圾文件的喜好,那 Linux 呢?它是如何处理临时文件的呢?
|
||||
|
||||
与 Windows 不同, Linux 自动地清理所有的临时文件(在 `/tmp` 中存储)。在 Linux 中没有注册表,这进一步减轻了头痛。在最坏情况下,你可能会有一些损坏的不再需要的软件包,以及丢失一些网络浏览历史记录, cookies ,缓存等。
|
||||
|
||||
### 这意味着 Linux 不必需要系统清理工具了吗? ###
|
||||
|
||||
- 假如你可以运行某些命令来清理偶尔使用的软件包,手动删除浏览历史记录等,那么答案是:不需要;
|
||||
- 假如你不想不断地从一个地方跳到另一个地方来运行命令,并想用一个工具来删除所有可通过一次或多次点击所选择的东西,那么答案是:需要。
|
||||
|
||||
假如你的答案是“需要”,就让我们继续看看一些类似于 CCleaner 的工具,用它们清理你的 Ubuntu 系统。
|
||||
|
||||
### Ubuntu 下 CCleaner 的替代品 ###
|
||||
|
||||
请注意,我使用的系统是 Ubuntu,因为下面讨论的一些工具只存在于基于 Ubuntu 的 Linux 发行版本中,而另外一些在所有的 Linux 发行版本中都可使用。
|
||||
|
||||
#### 1. BleachBit ####
|
||||
|
||||

|
||||
|
||||
[BleachBit][3] 是一个跨平台的应用程序,在 Windows 和 Linux 平台下都可使用。它有一个很长的支持清理的程序的列表,这样可以让你选择性的清理缓存,cookies 和日志文件。让我们快速浏览它的特点:
|
||||
|
||||
- 简洁的图形界面确认框,你可以预览或删除
|
||||
- 支持多平台: Linux 和 Windows
|
||||
- 免费且开源
|
||||
- 粉碎文件以隐藏它们的内容并防止数据恢复
|
||||
- 重写空闲的磁盘空间来隐藏先前删除的文件内容
|
||||
- 也拥有命令行界面
|
||||
|
||||
默认情况下,在 Ubuntu 14.04 and 15.04 中都可以获取到 BleachBit,你可以在终端中使用下面的命令来安装:
|
||||
|
||||
sudo apt-get install bleachbit
|
||||
|
||||
对于所有主流的 Linux 发行版本, BleachBit 提供有二进制程序,你可以从下面的链接中下载到 BleachBit:
|
||||
|
||||
- [下载 BleachBit 的 Linux 版本][4]
|
||||
|
||||
#### 2. Sweeper ####
|
||||
|
||||

|
||||
|
||||
Sweeper 是一个系统清理工具,它是[KDE SC utilities][5] 模块的一部分。它的主要特点有:
|
||||
|
||||
- 移除与网络相关的痕迹: cookies, 历史,缓存等
|
||||
- 移除图形缩略图缓存
|
||||
- 清理应用和文件的历史记录
|
||||
|
||||
默认情况下,Sweeper 在 Ubuntu 的软件仓库中可以得到。可以在终端中使用下面的命令来安装 Sweeper:
|
||||
|
||||
sudo apt-get install sweeper
|
||||
|
||||
#### 3. Ubuntu Tweak ####
|
||||
|
||||

|
||||
|
||||
正如它的名称所说的那样,[Ubuntu Tweak][6] 是一个调整工具,而不仅仅是一个清理应用。除了调整诸如 compiz 设置,面板的配置,开机启动程序的控制,电源管理等,Ubuntu Tweak 还提供一个清理选项,它可以让你:
|
||||
|
||||
- 清理浏览器缓存
|
||||
- 清理 Ubuntu 软件中心缓存
|
||||
- 清理缩略图缓存
|
||||
- 清理 apt 仓库缓存
|
||||
- 清理旧的内核文件
|
||||
- 清理软件包配置
|
||||
|
||||
你可以从下面的链接中得到 Ubuntu Tweak 的 `.deb` 安装文件:
|
||||
|
||||
- [下载 Ubuntu Tweak][7]
|
||||
|
||||
#### 4. GCleaner (beta) ####
|
||||
|
||||

|
||||
|
||||
作为 elementary OS Freya 的第三方应用, GCleaner 旨在成为 GNU 世界的 CCleaner,其界面与 CCleaner 非常相似。它的一些主要特点有:
|
||||
|
||||
- 清理浏览器历史记录
|
||||
- 清理应用缓存
|
||||
- 清理软件包及其配置
|
||||
- 清理最近使用的文件历史记录
|
||||
- 清空垃圾箱
|
||||
|
||||
在书写本文时, GCleaner 仍处于开发阶段,你可以查看这个项目的网站,并得到源代码来编译和使用 GCleaner。
|
||||
|
||||
- [更多地了解 GCleaner][8]
|
||||
|
||||
### 你的选择呢? ###
|
||||
|
||||
我已经向你列举了一些可能选项,我让你选择决定使用哪个工具来清理 Ubuntu 14.04。但我可以肯定的是,若你正在寻找一个类似 CCleaner 的应用,你将在上面列举的 4 个工具中进行最后的选择。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/ccleaner-alternatives-ubuntu-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:https://www.piriform.com/ccleaner/download
|
||||
[2]:http://www.howtogeek.com/172820/beginner-geek-what-does-ccleaner-do-and-should-you-use-it/
|
||||
[3]:http://bleachbit.sourceforge.net/
|
||||
[4]:http://bleachbit.sourceforge.net/download/linux
|
||||
[5]:https://www.kde.org/applications/utilities/
|
||||
[6]:http://ubuntu-tweak.com/
|
||||
[7]:http://ubuntu-tweak.com/
|
||||
[8]:https://quassy.github.io/elementary-apps/GCleaner/
|
||||
@ -0,0 +1,162 @@
|
||||
|
||||
在 RHEL/CentOS 上为Web服务器架设 “XR”(Crossroads) 负载均衡器
|
||||
================================================================================
|
||||
Crossroads 是一个独立的服务,它是一个用于Linux和TCP服务的开源负载均衡和故障转移实用程序。它可用于HTTP,HTTPS,SSH,SMTP 和 DNS 等,它也是一个多线程的工具,在提供负载均衡服务时,它可以只使用一块内存空间以此来提高性能。
|
||||
|
||||
首先来看看 XR 是如何工作的。我们可以将 XR 放到网络客户端和服务器之间,它可以将客户端的请求分配到服务器上以平衡负载。
|
||||
|
||||
如果一台服务器宕机,XR 会转发客户端请求到另一个服务器,所以客户感觉不到停顿。看看下面的图来了解什么样的情况下,我们要使用 XR 处理。
|
||||
|
||||
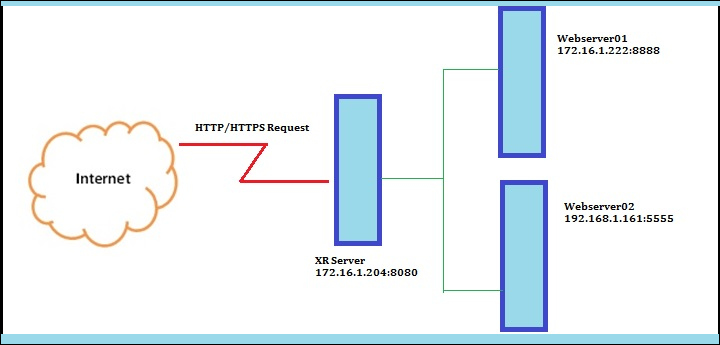
|
||||
|
||||
*安装 XR Crossroads 负载均衡器*
|
||||
|
||||
这里有两个 Web 服务器,一个网关服务器,我们将在网关服务器上安装和设置 XR 以接收客户端请求,并分发到服务器。
|
||||
|
||||
XR Crossroads 网关服务器:172.16.1.204
|
||||
|
||||
Web 服务器01:172.16.1.222
|
||||
|
||||
Web 服务器02:192.168.1.161
|
||||
|
||||
在上述情况下,我们网关服务器(即 XR Crossroads)的IP地址是172.16.1.222,webserver01 为172.16.1.222,它监听8888端口,webserver02 是192.168.1.161,它监听端口5555。
|
||||
|
||||
现在,我们需要的是均衡所有的请求,通过 XR 网关从网上接收请求然后分发它到两个web服务器已达到负载均衡。
|
||||
|
||||
### 第1步:在网关服务器上安装 XR Crossroads 负载均衡器 ###
|
||||
|
||||
**1. 不幸的是,没有为 crossroads 提供可用的 RPM 包,我们只能从源码安装。**
|
||||
|
||||
要编译 XR,你必须在系统上安装 C++ 编译器和 GNU make 组件,才能避免安装错误。
|
||||
|
||||
# yum install gcc gcc-c++ make
|
||||
|
||||
接下来,去他们的官方网站([https://crossroads.e-tunity.com] [1])下载此压缩包(即 crossroads-stable.tar.gz)。
|
||||
|
||||
或者,您可以使用 wget 去下载包然后解压在任何位置(如:/usr/src/),进入解压目录,并使用 “make install” 命令安装。
|
||||
|
||||
# wget https://crossroads.e-tunity.com/downloads/crossroads-stable.tar.gz
|
||||
# tar -xvf crossroads-stable.tar.gz
|
||||
# cd crossroads-2.74/
|
||||
# make install
|
||||
|
||||

|
||||
|
||||
*安装 XR Crossroads 负载均衡器*
|
||||
|
||||
安装完成后,二进制文件安装在 /usr/sbin 目录下,XR 的配置文件在 /etc 下名为 “xrctl.xml” 。
|
||||
|
||||
**2. 最后一个条件,你需要两个web服务器。为了方便使用,我在一台服务器中创建两个 Python SimpleHTTPServer 实例。**
|
||||
|
||||
要了解如何设置一个 python SimpleHTTPServer,请阅读我们此处的文章 [使用 SimpleHTTPServer 轻松创建两个 web 服务器][2].
|
||||
|
||||
正如我所说的,我们要使用两个web服务器,webserver01 通过8888端口运行在172.16.1.222上,webserver02 通过5555端口运行在192.168.1.161上。
|
||||
|
||||

|
||||
|
||||
*XR WebServer 01*
|
||||
|
||||

|
||||
|
||||
*XR WebServer 02*
|
||||
|
||||
### 第2步: 配置 XR Crossroads 负载均衡器 ###
|
||||
|
||||
**3. 所需都已经就绪。现在我们要做的就是配置`xrctl.xml` 文件并通过 XR 服务器接受来自互联网的请求分发到 web 服务器上。**
|
||||
|
||||
现在用 [vi/vim 编辑器][3]打开`xrctl.xml`文件。
|
||||
|
||||
# vim /etc/xrctl.xml
|
||||
|
||||
并作如下修改。
|
||||
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<configuration>
|
||||
<system>
|
||||
<uselogger>true</uselogger>
|
||||
<logdir>/tmp</logdir>
|
||||
</system>
|
||||
<service>
|
||||
<name>Tecmint</name>
|
||||
<server>
|
||||
<address>172.16.1.204:8080</address>
|
||||
<type>tcp</type>
|
||||
<webinterface>0:8010</webinterface>
|
||||
<verbose>yes</verbose>
|
||||
<clientreadtimeout>0</clientreadtimeout>
|
||||
<clientwritetimout>0</clientwritetimeout>
|
||||
<backendreadtimeout>0</backendreadtimeout>
|
||||
<backendwritetimeout>0</backendwritetimeout>
|
||||
</server>
|
||||
<backend>
|
||||
<address>172.16.1.222:8888</address>
|
||||
</backend>
|
||||
<backend>
|
||||
<address>192.168.1.161:5555</address>
|
||||
</backend>
|
||||
</service>
|
||||
</configuration>
|
||||
|
||||

|
||||
|
||||
*配置 XR Crossroads 负载均衡器*
|
||||
|
||||
在这里,你可以看到在 xrctl.xml 中配置了一个非常基本的 XR 。我已经定义了 XR 服务器在哪里,XR 的后端服务和端口及 XR 的 web 管理界面是什么。
|
||||
|
||||
**4. 现在,你需要通过以下命令来启动该 XR 守护进程。**
|
||||
|
||||
# xrctl start
|
||||
# xrctl status
|
||||
|
||||

|
||||
|
||||
*启动 XR Crossroads*
|
||||
|
||||
**5. 好的。现在是时候来检查该配置是否可以工作正常了。打开两个网页浏览器,输入 XR 服务器的 IP 地址和端口,并查看输出。**
|
||||
|
||||

|
||||
|
||||
*验证 Web 服务器负载均衡*
|
||||
|
||||
太棒了。它工作正常。是时候玩玩 XR 了。(LCTT 译注:可以看到两个请求分别分配到了不同服务器。)
|
||||
|
||||
**6. 现在可以通过我们配置的网络管理界面的端口来登录到 XR Crossroads 仪表盘。在浏览器输入你的 XR 服务器的 IP 地址和你配置在 xrctl.xml 中的管理端口。**
|
||||
|
||||
http://172.16.1.204:8010
|
||||
|
||||

|
||||
|
||||
*XR Crossroads 仪表盘*
|
||||
|
||||
看起来像上面一样。它容易理解,用户界面友好,易于使用。它在右上角显示每个服务器能容纳多少个连接,以及关于接收该请求的附加细节。你也可以设置每个服务器承担的负载量,最大连接数和平均负载等。
|
||||
|
||||
最大的好处是,即使没有配置文件 xrctl.xml,你也可以做到这一点。你唯一要做的就是运行以下命令,它就会把这一切搞定。
|
||||
|
||||
# xr --verbose --server tcp:172.16.1.204:8080 --backend 172.16.1.222:8888 --backend 192.168.1.161:5555
|
||||
|
||||
上面语法的详细说明:
|
||||
|
||||
- -verbose 将显示命令执行后的信息。
|
||||
- -server 定义你在安装包中的 XR 服务器。
|
||||
- -backend 定义你需要平衡分配到 Web 服务器的流量。
|
||||
- tcp 说明我们使用 TCP 服务。
|
||||
|
||||
欲了解更多详情,有关文件及 CROSSROADS 的配置,请访问他们的官方网站: [https://crossroads.e-tunity.com/][4].
|
||||
|
||||
XR Corssroads 使用许多方法来提高服务器性能,避免宕机,让你的管理任务更轻松,更简便。希望你喜欢此文章,并随时在下面发表你的评论和建议,方便与我们保持联系。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/setting-up-xr-crossroads-load-balancer-for-web-servers-on-rhel-centos/
|
||||
|
||||
作者:[Thilina Uvindasiri][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/thilidhanushka/
|
||||
[1]:https://crossroads.e-tunity.com/
|
||||
[2]:http://www.tecmint.com/python-simplehttpserver-to-create-webserver-or-serve-files-instantly/
|
||||
[3]:http://www.tecmint.com/vi-editor-usage/
|
||||
[4]:https://crossroads.e-tunity.com/
|
||||
@ -0,0 +1,201 @@
|
||||
在 Linux 命令行中使用和执行 PHP 代码(二):12 个 PHP 交互性 shell 的用法
|
||||
================================================================================
|
||||
在上一篇文章“[在 Linux 命令行中使用和执行 PHP 代码(一)][1]”中,我同时着重讨论了直接在Linux命令行中运行PHP代码以及在Linux终端中执行PHP脚本文件。
|
||||
|
||||

|
||||
|
||||
本文旨在让你了解一些相当不错的Linux终端中的PHP交互性 shell 的用法特性。
|
||||
|
||||
让我们先在PHP 的交互shell中来对`php.ini`设置进行一些配置吧。
|
||||
|
||||
**6. 设置PHP命令行提示符**
|
||||
|
||||
要设置PHP命令行提示,你需要在Linux终端中使用下面的php -a(启用PHP交互模式)命令开启一个PHP交互shell。
|
||||
|
||||
$ php -a
|
||||
|
||||
然后,设置任何东西(比如说Hi Tecmint ::)作为PHP交互shell的命令提示符,操作如下:
|
||||
|
||||
php > #cli.prompt=Hi Tecmint ::
|
||||
|
||||

|
||||
|
||||
*启用PHP交互Shell*
|
||||
|
||||
同时,你也可以设置当前时间作为你的命令行提示符,操作如下:
|
||||
|
||||
php > #cli.prompt=`echo date('H:m:s');` >
|
||||
|
||||
22:15:43 >
|
||||
|
||||
**7. 每次输出一屏**
|
||||
|
||||
在我们上一篇文章中,我们已经在原始命令中通过管道在很多地方使用了`less`命令。通过该操作,我们可以在那些不能一屏全部输出的地方获得分屏显示。但是,我们可以通过配置php.ini文件,设置pager的值为less以每次输出一屏,操作如下:
|
||||
|
||||
$ php -a
|
||||
php > #cli.pager=less
|
||||
|
||||

|
||||
|
||||
*限制PHP屏幕输出*
|
||||
|
||||
这样,下次当你运行一个命令(比如说条调试器`phpinfo();`)的时候,而该命令的输出内容又太过庞大而不能固定在一屏,它就会自动产生适合你当前屏幕的输出结果。
|
||||
|
||||
php > phpinfo();
|
||||
|
||||

|
||||
|
||||
*PHP信息输出*
|
||||
|
||||
**8. 建议和TAB补全**
|
||||
|
||||
PHP shell足够智能,它可以显示给你建议和进行TAB补全,你可以通过TAB键来使用该功能。如果对于你想要用TAB补全的字符串而言有多个选项,那么你需要使用两次TAB键来完成,其它情况则使用一次即可。
|
||||
|
||||
如果有超过一个的可能性,请使用两次TAB键。
|
||||
|
||||
php > ZIP [TAB] [TAB]
|
||||
|
||||
如果只有一个可能性,只要使用一次TAB键。
|
||||
|
||||
php > #cli.pager [TAB]
|
||||
|
||||
你可以一直按TAB键来获得建议的补全,直到该值满足要求。所有的行为都将记录到`~/.php-history`文件。
|
||||
|
||||
要检查你的PHP交互shell活动日志,你可以执行:
|
||||
|
||||
$ nano ~/.php_history | less
|
||||
|
||||

|
||||
|
||||
*检查PHP交互Shell日志*
|
||||
|
||||
**9. 你可以在PHP交互shell中使用颜色,你所需要知道的仅仅是颜色代码。**
|
||||
|
||||
使用echo来打印各种颜色的输出结果,类似这样:
|
||||
|
||||
php > echo "color_code1 TEXT second_color_code";
|
||||
|
||||
具体来说是:
|
||||
|
||||
php > echo "\033[0;31m Hi Tecmint \x1B[0m";
|
||||
|
||||

|
||||
|
||||
*在PHP Shell中启用彩色*
|
||||
|
||||
到目前为止,我们已经看到,按回车键意味着执行命令,然而PHP Shell中各个命令结尾的分号是必须的。
|
||||
|
||||
**10. 在PHP shell中用basename()输出路径中最后一部分**
|
||||
|
||||
PHP shell中的basename函数可以从给出的包含有到文件或目录路径的最后部分。
|
||||
|
||||
basename()样例#1和#2。
|
||||
|
||||
php > echo basename("/var/www/html/wp/wp-content/plugins");
|
||||
php > echo basename("www.tecmint.com/contact-us.html");
|
||||
|
||||
上述两个样例将输出:
|
||||
|
||||
plugins
|
||||
contact-us.html
|
||||
|
||||

|
||||
|
||||
*在PHP中打印基本名称*
|
||||
|
||||
**11. 你可以使用PHP交互shell在你的桌面创建文件(比如说test1.txt),就像下面这么简单**
|
||||
|
||||
php> touch("/home/avi/Desktop/test1.txt");
|
||||
|
||||
我们已经见识了PHP交互shell在数学运算中有多优秀,这里还有更多一些例子会令你吃惊。
|
||||
|
||||
**12. 使用PHP交互shell打印比如像tecmint.com这样的字符串的长度**
|
||||
|
||||
strlen函数用于获取指定字符串的长度。
|
||||
|
||||
php > echo strlen("tecmint.com");
|
||||
|
||||

|
||||
|
||||
*在PHP中打印字符串长度*
|
||||
|
||||
**13. PHP交互shell可以对数组排序,是的,你没听错**
|
||||
|
||||
声明变量a,并将其值设置为array(7,9,2,5,10)。
|
||||
|
||||
php > $a=array(7,9,2,5,10);
|
||||
|
||||
对数组中的数字进行排序。
|
||||
|
||||
php > sort($a);
|
||||
|
||||
以排序后的顺序打印数组中的数字,同时打印序号,第一个为[0]。
|
||||
|
||||
php > print_r($a);
|
||||
Array
|
||||
(
|
||||
[0] => 2
|
||||
[1] => 5
|
||||
[2] => 7
|
||||
[3] => 9
|
||||
[4] => 10
|
||||
)
|
||||
|
||||

|
||||
|
||||
*在PHP中对数组排序*
|
||||
|
||||
**14. 在PHP交互Shell中获取π的值**
|
||||
|
||||
php > echo pi();
|
||||
|
||||
3.1415926535898
|
||||
|
||||
**15. 打印某个数比如32的平方根**
|
||||
|
||||
php > echo sqrt(150);
|
||||
|
||||
12.247448713916
|
||||
|
||||
**16. 从0-10的范围内挑选一个随机数**
|
||||
|
||||
php > echo rand(0, 10);
|
||||
|
||||

|
||||
|
||||
*在PHP中获取随机数*
|
||||
|
||||
**17. 获取某个指定字符串的md5校验和sha1校验,例如,让我们在PHP Shell中检查某个字符串(比如说avi)的md5校验和sha1校验,并交叉校验bash shell生成的md5校验和sha1校验的结果。**
|
||||
|
||||
php > echo md5(avi);
|
||||
3fca379b3f0e322b7b7967bfcfb948ad
|
||||
|
||||
php > echo sha1(avi);
|
||||
8f920f22884d6fea9df883843c4a8095a2e5ac6f
|
||||
|
||||
----------
|
||||
|
||||
$ echo -n avi | md5sum
|
||||
3fca379b3f0e322b7b7967bfcfb948ad -
|
||||
|
||||
$ echo -n avi | sha1sum
|
||||
8f920f22884d6fea9df883843c4a8095a2e5ac6f -
|
||||
|
||||

|
||||
|
||||
*在PHP中检查md5校验和sha1校验*
|
||||
|
||||
这里只是PHP Shell中所能获取的功能和PHP Shell的交互特性的惊鸿一瞥,这些就是到现在为止我所讨论的一切。保持连线,在评论中为我们提供你有价值的反馈吧。为我们点赞并分享,帮助我们扩散哦。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/execute-php-codes-functions-in-linux-commandline/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:https://linux.cn/article-5906-1.html
|
||||
@ -0,0 +1,183 @@
|
||||
在 Linux 命令行中使用和执行 PHP 代码(一)
|
||||
================================================================================
|
||||
PHP是一个开源服务器端脚本语言,最初这三个字母代表的是“Personal Home Page”,而现在则代表的是“PHP:Hypertext Preprocessor”,它是个递归首字母缩写。它是一个跨平台脚本语言,深受C、C++和Java的影响。
|
||||
|
||||

|
||||
|
||||
*在 Linux 命令行中运行 PHP 代码*
|
||||
|
||||
PHP的语法和C、Java以及带有一些PHP特性的Perl变成语言中的语法十分相似,它当下大约正被2.6亿个网站所使用,当前最新的稳定版本是PHP版本5.6.10。
|
||||
|
||||
PHP是HTML的嵌入脚本,它便于开发人员快速写出动态生成的页面。PHP主要用于服务器端(而Javascript则用于客户端)以通过HTTP生成动态网页,然而,当你知道可以在Linux终端中不需要网页浏览器来执行PHP时,你或许会大为惊讶。
|
||||
|
||||
本文将阐述PHP脚本语言的命令行方面。
|
||||
|
||||
**1. 在安装完PHP和Apache2后,我们需要安装PHP命令行解释器。**
|
||||
|
||||
# apt-get install php5-cli [Debian 及类似系统]
|
||||
# yum install php-cli [CentOS 及类似系统]
|
||||
|
||||
接下来我们通常要做的是,在`/var/www/html`(这是 Apache2 在大多数发行版中的工作目录)这个位置创建一个内容为 `<?php phpinfo(); ?>`,名为 `infophp.php` 的文件来测试(PHP是否安装正确),执行以下命令即可。
|
||||
|
||||
# echo '<?php phpinfo(); ?>' > /var/www/html/infophp.php
|
||||
|
||||
然后,将浏览器访问 http://127.0.0.1/infophp.php ,这将会在网络浏览器中打开该文件。
|
||||
|
||||

|
||||
|
||||
*检查PHP信息*
|
||||
|
||||
不需要任何浏览器,在Linux终端中也可以获得相同的结果。在Linux命令行中执行`/var/www/html/infophp.php`,如:
|
||||
|
||||
# php -f /var/www/html/infophp.php
|
||||
|
||||

|
||||
|
||||
*从命令行检查PHP信息*
|
||||
|
||||
由于输出结果太大,我们可以通过管道将上述输出结果输送给 `less` 命令,这样就可以一次输出一屏了,命令如下:
|
||||
|
||||
# php -f /var/www/html/infophp.php | less
|
||||
|
||||

|
||||
|
||||
*检查所有PHP信息*
|
||||
|
||||
这里,‘-f‘选项解析并执行命令后跟随的文件。
|
||||
|
||||
**2. 我们可以直接在Linux命令行使用`phpinfo()`这个十分有价值的调试工具而不需要从文件来调用,只需执行以下命令:**
|
||||
|
||||
# php -r 'phpinfo();'
|
||||
|
||||

|
||||
|
||||
*PHP调试工具*
|
||||
|
||||
这里,‘-r‘ 选项会让PHP代码在Linux终端中不带`<`和`>`标记直接执行。
|
||||
|
||||
**3. 以交互模式运行PHP并做一些数学运算。这里,‘-a‘ 选项用于以交互模式运行PHP。**
|
||||
|
||||
# php -a
|
||||
|
||||
Interactive shell
|
||||
|
||||
php > echo 2+3;
|
||||
5
|
||||
php > echo 9-6;
|
||||
3
|
||||
php > echo 5*4;
|
||||
20
|
||||
php > echo 12/3;
|
||||
4
|
||||
php > echo 12/5;
|
||||
2.4
|
||||
php > echo 2+3-1;
|
||||
4
|
||||
php > echo 2+3-1*3;
|
||||
2
|
||||
php > exit
|
||||
|
||||
输入 ‘exit‘ 或者按下 ‘ctrl+c‘ 来关闭PHP交互模式。
|
||||
|
||||

|
||||
|
||||
*启用PHP交互模式*
|
||||
|
||||
**4. 你可以仅仅将PHP脚本作为shell脚本来运行。首先,创建在你当前工作目录中创建一个PHP样例脚本。**
|
||||
|
||||
# echo -e '#!/usr/bin/php\n<?php phpinfo(); ?>' > phpscript.php
|
||||
|
||||
注意,我们在该PHP脚本的第一行使用`#!/usr/bin/php`,就像在shell脚本中那样(`/bin/bash`)。第一行的`#!/usr/bin/php`告诉Linux命令行用 PHP 解释器来解析该脚本文件。
|
||||
|
||||
其次,让该脚本可执行:
|
||||
|
||||
# chmod 755 phpscript.php
|
||||
|
||||
接着来运行它,
|
||||
|
||||
# ./phpscript.php
|
||||
|
||||
**5. 你可以完全靠自己通过交互shell来创建简单函数,这你一定会被惊到了。下面是循序渐进的指南。**
|
||||
|
||||
开启PHP交互模式。
|
||||
|
||||
# php -a
|
||||
|
||||
创建一个函数,将它命名为 `addition`。同时,声明两个变量 `$a` 和 `$b`。
|
||||
|
||||
php > function addition ($a, $b)
|
||||
|
||||
使用花括号来在其间为该函数定义规则。
|
||||
|
||||
php > {
|
||||
|
||||
定义规则。这里,该规则讲的是添加这两个变量。
|
||||
|
||||
php { echo $a + $b;
|
||||
|
||||
所有规则定义完毕,通过闭合花括号来封装规则。
|
||||
|
||||
php {}
|
||||
|
||||
测试函数,添加数字4和3,命令如下:
|
||||
|
||||
php > var_dump (addition(4,3));
|
||||
|
||||
#### 样例输出 ####
|
||||
|
||||
7NULL
|
||||
|
||||
你可以运行以下代码来执行该函数,你可以测试不同的值,你想来多少次都行。将里头的 a 和 b 替换成你自己的值。
|
||||
|
||||
php > var_dump (addition(a,b));
|
||||
|
||||
----------
|
||||
|
||||
php > var_dump (addition(9,3.3));
|
||||
|
||||
#### 样例输出 ####
|
||||
|
||||
12.3NULL
|
||||
|
||||

|
||||
|
||||
*创建PHP函数*
|
||||
|
||||
你可以一直运行该函数,直至退出交互模式(ctrl+z)。同时,你也应该注意到了,上面输出结果中返回的数据类型为 NULL。这个问题可以通过要求 php 交互 shell用 return 代替 echo 返回结果来修复。
|
||||
|
||||
只需要在上面的函数的中 ‘echo‘ 声明用 ‘return‘ 来替换
|
||||
|
||||
替换
|
||||
|
||||
php { echo $a + $b;
|
||||
|
||||
为
|
||||
|
||||
php { return $a + $b;
|
||||
|
||||
剩下的东西和原理仍然一样。
|
||||
|
||||
这里是一个样例,在该样例的输出结果中返回了正确的数据类型。
|
||||
|
||||

|
||||
|
||||
*PHP函数*
|
||||
|
||||
永远都记住,用户定义的函数不会从一个shell会话保留到下一个shell会话,因此,一旦你退出交互shell,它就会丢失了。
|
||||
|
||||
希望你喜欢此次教程。保持连线,你会获得更多此类文章。保持关注,保持健康。请在下面的评论中为我们提供有价值的反馈。点赞并分享,帮助我们扩散。
|
||||
|
||||
还请阅读: [12个Linux终端中有用的的PHP命令行用法——第二部分][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/run-php-codes-from-linux-commandline/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/execute-php-codes-functions-in-linux-commandline/
|
||||
@ -0,0 +1,188 @@
|
||||
如何在 Ubuntu/CentOS7.1/Fedora22 上安装 Plex Media Server
|
||||
================================================================================
|
||||
在本文中我们将会向你展示如何容易地在主流的最新Linux发行版上安装Plex Media Server。在Plex安装成功后你将可以使用你的中央式家庭媒体播放系统,该系统能让多个Plex播放器App共享它的媒体资源,并且该系统允许你设置你的环境,增加你的设备以及设置一个可以一起使用Plex的用户组。让我们首先在Ubuntu15.04上开始Plex的安装。
|
||||
|
||||
### 基本的系统资源 ###
|
||||
|
||||
系统资源主要取决于你打算用来连接服务的设备类型和数量, 所以根据我们的需求我们将会在一个单独的服务器上使用以下系统资源。
|
||||
|
||||
<table width="666" style="height: 181px;">
|
||||
<tbody>
|
||||
<tr>
|
||||
<td width="670" colspan="2"><b>Plex Media Server</b></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="236"><b>基础操作系统</b></td>
|
||||
<td width="425">Ubuntu 15.04 / CentOS 7.1 / Fedora 22 Work Station</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="236"><b>Plex Media Server</b></td>
|
||||
<td width="425">Version 0.9.12.3.1173-937aac3</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="236"><b>RAM 和 CPU</b></td>
|
||||
<td width="425">1 GB , 2.0 GHZ</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="236"><b>硬盘</b></td>
|
||||
<td width="425">30 GB</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
### 在Ubuntu 15.04上安装Plex Media Server 0.9.12.3 ###
|
||||
|
||||
我们现在准备开始在Ubuntu上安装Plex Media Server,让我们从下面的步骤开始来让Plex做好准备。
|
||||
|
||||
#### 步骤 1: 系统更新 ####
|
||||
|
||||
用root权限登录你的服务器。确保你的系统是最新的,如果不是就使用下面的命令。
|
||||
|
||||
root@ubuntu-15:~#apt-get update
|
||||
|
||||
#### 步骤 2: 下载最新的Plex Media Server包 ####
|
||||
|
||||
创建一个新目录,用wget命令从[Plex官网](https://plex.tv/)下载为Ubuntu提供的.deb包并放入该目录中。
|
||||
|
||||
root@ubuntu-15:~# cd /plex/
|
||||
root@ubuntu-15:/plex#
|
||||
root@ubuntu-15:/plex# wget https://downloads.plex.tv/plex-media-server/0.9.12.3.1173-937aac3/plexmediaserver_0.9.12.3.1173-937aac3_amd64.deb
|
||||
|
||||
#### 步骤 3: 安装Plex Media Server的Debian包 ####
|
||||
|
||||
现在在相同的目录下执行下面的命令来开始debian包的安装, 然后检查plexmediaserver服务的状态。
|
||||
|
||||
root@ubuntu-15:/plex# dpkg -i plexmediaserver_0.9.12.3.1173-937aac3_amd64.deb
|
||||
|
||||
----------
|
||||
|
||||
root@ubuntu-15:~# service plexmediaserver status
|
||||
|
||||

|
||||
|
||||
### 在Ubuntu 15.04上设置Plex Media Web应用 ###
|
||||
|
||||
让我们在你的本地网络主机中打开web浏览器, 并用你的本地主机IP以及端口32400来打开Web界面,并完成以下步骤来配置Plex。
|
||||
|
||||
http://172.25.10.179:32400/web
|
||||
http://localhost:32400/web
|
||||
|
||||
#### 步骤 1: 登录前先注册 ####
|
||||
|
||||
在你访问到Plex Media Server的Web界面之后, 确保注册并填上你的用户名和密码来登录。
|
||||
|
||||

|
||||
|
||||
#### 输入你的PIN码来保护你的Plex Media用户####
|
||||
|
||||

|
||||
|
||||
现在你已经成功的在Plex Media下配置你的用户。
|
||||
|
||||

|
||||
|
||||
### 在设备上而不是本地服务器上打开Plex Web应用 ###
|
||||
|
||||
如我们在Plex Media主页看到的提示“你没有权限访问这个服务”。 这说明我们跟服务器计算机不在同个网络。
|
||||
|
||||

|
||||
|
||||
现在我们需要解决这个权限问题,以便我们通过设备访问服务器而不是只能在服务器上访问。通过完成下面的步骤完成。
|
||||
|
||||
### 设置SSH隧道使Windows系统可以访问到Linux服务器 ###
|
||||
|
||||
首先我们需要建立一条SSH隧道以便我们访问远程服务器资源,就好像资源在本地一样。 这仅仅是必要的初始设置。
|
||||
|
||||
如果你正在使用Windows作为你的本地系统,Linux作为服务器,那么我们可以参照下图通过Putty来设置SSH隧道。
|
||||
(LCTT译注: 首先要在Putty的Session中用Plex服务器IP配置一个SSH的会话,才能进行下面的隧道转发规则配置。
|
||||
然后点击“Open”,输入远端服务器用户名密码, 来保持SSH会话连接。)
|
||||
|
||||

|
||||
|
||||
**一旦你完成SSH隧道设置:**
|
||||
|
||||
打开你的Web浏览器窗口并在地址栏输入下面的URL。
|
||||
|
||||
http://localhost:8888/web
|
||||
|
||||
浏览器将会连接到Plex服务器并且加载与服务器本地功能一致的Plex Web应用。 同意服务条款并开始。
|
||||
|
||||

|
||||
|
||||
现在一个功能齐全的Plex Media Server已经准备好添加新的媒体库、频道、播放列表等资源。
|
||||
|
||||

|
||||
|
||||
### 在CentOS 7.1上安装Plex Media Server 0.9.12.3 ###
|
||||
|
||||
我们将会按照上述在Ubuntu15.04上安装Plex Media Server的步骤来将Plex安装到CentOS 7.1上。
|
||||
|
||||
让我们从安装Plex Media Server开始。
|
||||
|
||||
#### 步骤1: 安装Plex Media Server ####
|
||||
|
||||
为了在CentOS7.1上安装Plex Media Server,我们需要从Plex官网下载rpm安装包。 因此我们使用wget命令来将rpm包下载到一个新的目录下。
|
||||
|
||||
[root@linux-tutorials ~]# cd /plex
|
||||
[root@linux-tutorials plex]# wget https://downloads.plex.tv/plex-media-server/0.9.12.3.1173-937aac3/plexmediaserver-0.9.12.3.1173-937aac3.x86_64.rpm
|
||||
|
||||
#### 步骤2: 安装RPM包 ####
|
||||
|
||||
在完成安装包完整的下载之后, 我们将会使用rpm命令在相同的目录下安装这个rpm包。
|
||||
|
||||
[root@linux-tutorials plex]# ls
|
||||
plexmediaserver-0.9.12.3.1173-937aac3.x86_64.rpm
|
||||
[root@linux-tutorials plex]# rpm -i plexmediaserver-0.9.12.3.1173-937aac3.x86_64.rpm
|
||||
|
||||
#### 步骤3: 启动Plexmediaservice ####
|
||||
|
||||
我们已经成功地安装Plex Media Server, 现在我们只需要重启它的服务然后让它永久地启用。
|
||||
|
||||
[root@linux-tutorials plex]# systemctl start plexmediaserver.service
|
||||
[root@linux-tutorials plex]# systemctl enable plexmediaserver.service
|
||||
[root@linux-tutorials plex]# systemctl status plexmediaserver.service
|
||||
|
||||
### 在CentOS-7.1上设置Plex Media Web应用 ###
|
||||
|
||||
现在我们只需要重复在Ubuntu上设置Plex Web应用的所有步骤就可以了。 让我们在Web浏览器上打开一个新窗口并用localhost或者Plex服务器的IP来访问Plex Media Web应用。
|
||||
|
||||
http://172.20.3.174:32400/web
|
||||
http://localhost:32400/web
|
||||
|
||||
为了获取服务的完整权限你需要重复创建SSH隧道的步骤。 在你用新账户注册后我们将可以访问到服务的所有特性,并且可以添加新用户、添加新的媒体库以及根据我们的需求来设置它。
|
||||
|
||||

|
||||
|
||||
### 在Fedora 22工作站上安装Plex Media Server 0.9.12.3 ###
|
||||
|
||||
下载和安装Plex Media Server步骤基本跟在CentOS 7.1上安装的步骤一致。我们只需要下载对应的rpm包然后用rpm命令来安装它。
|
||||
|
||||

|
||||
|
||||
### 在Fedora 22工作站上配置Plex Media Web应用 ###
|
||||
|
||||
我们在(与Plex服务器)相同的主机上配置Plex Media Server,因此不需要设置SSH隧道。只要在你的Fedora 22工作站上用Plex Media Server的默认端口号32400打开Web浏览器并同意Plex的服务条款即可。
|
||||
|
||||

|
||||
|
||||
*欢迎来到Fedora 22工作站上的Plex Media Server*
|
||||
|
||||
让我们用你的Plex账户登录,并且开始将你喜欢的电影频道添加到媒体库、创建你的播放列表、添加你的图片以及享用更多其他的特性。
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
我们已经成功完成Plex Media Server在主流Linux发行版上安装和配置。Plex Media Server永远都是媒体管理的最佳选择。 它在跨平台上的设置是如此的简单,就像我们在Ubuntu,CentOS以及Fedora上的设置一样。它简化了你组织媒体内容的工作,并将媒体内容“流”向其他计算机以及设备以便你跟你的朋友分享媒体内容。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/tools/install-plex-media-server-ubuntu-centos-7-1-fedora-22/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[dingdongnigetou](https://github.com/dingdongnigetou)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
626
published/201507/PHP 7 upgrading.md
Normal file
626
published/201507/PHP 7 upgrading.md
Normal file
@ -0,0 +1,626 @@
|
||||
PHP 7.0 升级备注
|
||||
===============
|
||||
|
||||
1. 向后不兼容的变化
|
||||
2. 新功能
|
||||
3. SAPI 模块中的变化
|
||||
4. 废弃的功能
|
||||
5. 变化的功能
|
||||
6. 新功能
|
||||
7. 新的类和接口
|
||||
8. 移除的扩展和 SAPI
|
||||
9. 扩展的其它变化
|
||||
10. 新的全局常量
|
||||
11. INI 文件处理的变化
|
||||
12. Windows 支持
|
||||
13. 其它变化
|
||||
|
||||
|
||||
##1. 向后不兼容的变化
|
||||
|
||||
###语言变化
|
||||
|
||||
####变量处理的变化
|
||||
|
||||
* 间接变量、属性和方法引用现在以从左到右的语义进行解释。一些例子:
|
||||
|
||||
$$foo['bar']['baz'] // 解释做 ($$foo)['bar']['baz']
|
||||
$foo->$bar['baz'] // 解释做 ($foo->$bar)['baz']
|
||||
$foo->$bar['baz']() // 解释做 ($foo->$bar)['baz']()
|
||||
Foo::$bar['baz']() // 解释做 (Foo::$bar)['baz']()
|
||||
|
||||
要恢复以前的行为,需要显式地加大括号:
|
||||
|
||||
${$foo['bar']['baz']}
|
||||
$foo->{$bar['baz']}
|
||||
$foo->{$bar['baz']}()
|
||||
Foo::{$bar['baz']}()
|
||||
|
||||
* 全局关键字现在只接受简单变量。像以前的
|
||||
|
||||
global $$foo->bar;
|
||||
|
||||
现在要求如下写法:
|
||||
|
||||
global ${$foo->bar};
|
||||
|
||||
* 变量或函数调用的前后加上括号不再有任何影响。例如下列代码,函数调用结果以引用的方式传给一个函数
|
||||
|
||||
function getArray() { return [1, 2, 3]; }
|
||||
|
||||
$last = array_pop(getArray());
|
||||
// Strict Standards: 只有变量可以用引用方式传递
|
||||
$last = array_pop((getArray()));
|
||||
// Strict Standards: 只有变量可以用引用方式传递
|
||||
|
||||
现在无论是否使用括号,都会抛出一个严格标准错误。以前在第二种调用方式下不会有提示。
|
||||
|
||||
* 数组元素或对象属性自动安装引用顺序创建,现在的结果顺序将不同。例如:
|
||||
|
||||
$array = [];
|
||||
$array["a"] =& $array["b"];
|
||||
$array["b"] = 1;
|
||||
var_dump($array);
|
||||
|
||||
现在结果是 ["a" => 1, "b" => 1],而以前的结果是 ["b" => 1, "a" => 1]。
|
||||
|
||||
相关的 RFC:
|
||||
* https://wiki.php.net/rfc/uniform_variable_syntax
|
||||
* https://wiki.php.net/rfc/abstract_syntax_tree
|
||||
|
||||
####list() 的变化
|
||||
|
||||
* list() 不再以反序赋值,例如:
|
||||
|
||||
list($array[], $array[], $array[]) = [1, 2, 3];
|
||||
var_dump($array);
|
||||
|
||||
现在结果是 $array == [1, 2, 3] ,而不是 [3, 2, 1]。注意仅赋值**顺序**变化了,而赋值仍然一致(LCTT 译注:即以前的 list()行为是从后面的变量开始逐一赋值,这样对与上述用法就会产生 [3,2,1] 这样的结果了。)。例如,类似如下的常规用法
|
||||
|
||||
list($a, $b, $c) = [1, 2, 3];
|
||||
// $a = 1; $b = 2; $c = 3;
|
||||
|
||||
仍然保持当前的行为。
|
||||
|
||||
* 不再允许对空的 list() 赋值。如下全是无效的:
|
||||
|
||||
list() = $a;
|
||||
list(,,) = $a;
|
||||
list($x, list(), $y) = $a;
|
||||
|
||||
* list() 不再支持对字符串的拆分(以前也只在某些情况下支持)。如下代码:
|
||||
|
||||
$string = "xy";
|
||||
list($x, $y) = $string;
|
||||
|
||||
现在的结果是: $x == null 和 $y == null (没有提示),而以前的结果是:
|
||||
$x == "x" 和 $y == "y" 。此外, list() 现在总是可以处理实现了 ArrayAccess 的对象,例如:
|
||||
|
||||
list($a, $b) = (object) new ArrayObject([0, 1]);
|
||||
|
||||
现在的结果是: $a == 0 和 $b == 1。 以前 $a 和 $b 都是 null。
|
||||
|
||||
相关 RFC:
|
||||
* https://wiki.php.net/rfc/abstract_syntax_tree#changes_to_list
|
||||
* https://wiki.php.net/rfc/fix_list_behavior_inconsistency
|
||||
|
||||
####foreach 的变化
|
||||
|
||||
* foreach() 迭代不再影响数组内部指针,数组指针可通过 current()/next() 等系列的函数访问。例如:
|
||||
|
||||
$array = [0, 1, 2];
|
||||
foreach ($array as &$val) {
|
||||
var_dump(current($array));
|
||||
}
|
||||
|
||||
现在将指向值 int(0) 三次。以前的输出是 int(1)、int(2) 和 bool(false)。
|
||||
|
||||
* 在对数组按值迭代时,foreach 总是在对数组副本进行操作,在迭代中任何对数组的操作都不会影响到迭代行为。例如:
|
||||
|
||||
$array = [0, 1, 2];
|
||||
$ref =& $array; // Necessary to trigger the old behavior
|
||||
foreach ($array as $val) {
|
||||
var_dump($val);
|
||||
unset($array[1]);
|
||||
}
|
||||
|
||||
现在将打印出全部三个元素 (0 1 2),而以前第二个元素 1 会跳过 (0 2)。
|
||||
|
||||
* 在对数组按引用迭代时,对数组的修改将继续会影响到迭代。不过,现在 PHP 在使用数字作为键时可以更好的维护数组内的位置。例如,在按引用迭代过程中添加数组元素:
|
||||
|
||||
$array = [0];
|
||||
foreach ($array as &$val) {
|
||||
var_dump($val);
|
||||
$array[1] = 1;
|
||||
}
|
||||
|
||||
现在迭代会正确的添加了元素。如上代码输出是 "int(0) int(1)",而以前只是 "int(0)"。
|
||||
|
||||
* 对普通(不可遍历的)对象按值或按引用迭代的行为类似于对数组进行按引用迭代。这符合以前的行为,除了如上一点所述的更精确的位置管理的改进。
|
||||
|
||||
* 对可遍历对象的迭代行为保持不变。
|
||||
|
||||
相关 RFC: https://wiki.php.net/rfc/php7_foreach
|
||||
|
||||
####参数处理的变化
|
||||
|
||||
* 不能定义两个同名的函数参数。例如,下面的方法将会触发编译时错误:
|
||||
|
||||
public function foo($a, $b, $unused, $unused) {
|
||||
// ...
|
||||
}
|
||||
|
||||
如上的代码应该修改使用不同的参数名,如:
|
||||
|
||||
public function foo($a, $b, $unused1, $unused2) {
|
||||
// ...
|
||||
}
|
||||
|
||||
* func\_get\_arg() 和 func\_get\_args() 函数不再返回传递给参数的原始值,而是返回其当前值(也许会被修改)。例如:
|
||||
|
||||
function foo($x) {
|
||||
$x++;
|
||||
var_dump(func_get_arg(0));
|
||||
}
|
||||
foo(1);
|
||||
|
||||
将会打印 "2" 而不是 "1"。代码应该改成仅在调用 func\_get\_arg(s) 后进行修改操作。
|
||||
|
||||
function foo($x) {
|
||||
var_dump(func_get_arg(0));
|
||||
$x++;
|
||||
}
|
||||
|
||||
或者应该避免修改参数:
|
||||
|
||||
function foo($x) {
|
||||
$newX = $x + 1;
|
||||
var_dump(func_get_arg(0));
|
||||
}
|
||||
|
||||
* 类似的,异常回溯也不再显示传递给函数的原始值,而是修改后的值。例如:
|
||||
|
||||
function foo($x) {
|
||||
$x = 42;
|
||||
throw new Exception;
|
||||
}
|
||||
foo("string");
|
||||
|
||||
现在堆栈跟踪的结果是:
|
||||
|
||||
Stack trace:
|
||||
#0 file.php(4): foo(42)
|
||||
#1 {main}
|
||||
|
||||
而以前是:
|
||||
|
||||
Stack trace:
|
||||
#0 file.php(4): foo('string')
|
||||
#1 {main}
|
||||
|
||||
这并不会影响到你的代码的运行时行为,值得注意的是在调试时会有所不同。
|
||||
|
||||
同样的限制也会影响到 debug\_backtrace() 及其它检查函数参数的函数。
|
||||
|
||||
相关 RFC: https://wiki.php.net/phpng
|
||||
|
||||
####整数处理的变化
|
||||
|
||||
* 无效的八进制表示(包含大于7的数字)现在会产生编译错误。例如,下列代码不再有效:
|
||||
|
||||
$i = 0781; // 8 不是一个有效的八进制数字!
|
||||
|
||||
以前,无效的数字(以及无效数字后的任何数字)会简单的忽略。以前如上 $i 的值是 7,因为后两位数字会被悄悄丢弃。
|
||||
|
||||
* 二进制以负数镜像位移现在会抛出一个算术错误:
|
||||
|
||||
var_dump(1 >> -1);
|
||||
// ArithmeticError: 以负数进行位移
|
||||
|
||||
* 向左位移的位数超出了整型宽度时,结果总是 0。
|
||||
|
||||
var_dump(1 << 64); // int(0)
|
||||
|
||||
以前上述代码的结果依赖于所用的 CPU 架构。例如,在 x86(包括 x86-64) 上结果是 int(1),因为其位移操作数在范围内。
|
||||
|
||||
* 类似的,向右位移的位数超出了整型宽度时,其结果总是 0 或 -1 (依赖于符号):
|
||||
|
||||
var_dump(1 >> 64); // int(0)
|
||||
var_dump(-1 >> 64); // int(-1)
|
||||
|
||||
相关 RFC: https://wiki.php.net/rfc/integer_semantics
|
||||
|
||||
####字符串处理的变化
|
||||
|
||||
* 包含十六进制数字的字符串不会再被当做数字,也不会被特殊处理。参见例子中的新行为:
|
||||
|
||||
var_dump("0x123" == "291"); // bool(false) (以前是 true)
|
||||
var_dump(is_numeric("0x123")); // bool(false) (以前是 true)
|
||||
var_dump("0xe" + "0x1"); // int(0) (以前是 16)
|
||||
|
||||
var_dump(substr("foo", "0x1")); // string(3) "foo" (以前是 "oo")
|
||||
// 注意:遇到了一个非正常格式的数字
|
||||
|
||||
filter\_var() 可以用来检查一个字符串是否包含了十六进制数字,或这个字符串是否能转换为整数:
|
||||
|
||||
$str = "0xffff";
|
||||
$int = filter_var($str, FILTER_VALIDATE_INT, FILTER_FLAG_ALLOW_HEX);
|
||||
if (false === $int) {
|
||||
throw new Exception("Invalid integer!");
|
||||
}
|
||||
var_dump($int); // int(65535)
|
||||
|
||||
* 由于给双引号字符串和 HERE 文档增加了 Unicode 码点转义格式(Unicode Codepoint Escape Syntax), 所以带有无效序列的 "\u{" 现在会造成错误:
|
||||
|
||||
$str = "\u{xyz}"; // 致命错误:无效的 UTF-8 码点转义序列
|
||||
|
||||
要避免这种情况,需要转义开头的反斜杠:
|
||||
|
||||
$str = "\\u{xyz}"; // 正确
|
||||
|
||||
不过,不跟随 { 的 "\u" 不受影响。如下代码不会生成错误,和前面的一样工作:
|
||||
|
||||
$str = "\u202e"; // 正确
|
||||
|
||||
相关 RFC:
|
||||
* https://wiki.php.net/rfc/remove_hex_support_in_numeric_strings
|
||||
* https://wiki.php.net/rfc/unicode_escape
|
||||
|
||||
####错误处理的变化
|
||||
|
||||
* 现在有两个异常类: Exception 和 Error 。这两个类都实现了一个新接口: Throwable 。在异常处理代码中的类型指示也许需要修改来处理这种情况。
|
||||
|
||||
* 一些致命错误和可恢复的致命错误现在改为抛出一个 Error 。由于 Error 是一个独立于 Exception 的类,这些异常不会被已有的 try/catch 块捕获。
|
||||
|
||||
可恢复的致命错误被转换为一个异常,所以它们不能在错误处理里面悄悄的忽略。部分情况下,类型指示失败不再能忽略。
|
||||
|
||||
* 解析错误现在会生成一个 Error 扩展的 ParseError 。除了以前的基于返回值 / error_get_last() 的处理,对某些可能无效的代码的 eval() 的错误处理应该改为捕获 ParseError 。
|
||||
|
||||
* 内部类的构造函数在失败时总是会抛出一个异常。以前一些构造函数会返回 NULL 或一个不可用的对象。
|
||||
|
||||
* 一些 E_STRICT 提示的错误级别改变了。
|
||||
|
||||
相关 RFC:
|
||||
* https://wiki.php.net/rfc/engine_exceptions_for_php7
|
||||
* https://wiki.php.net/rfc/throwable-interface
|
||||
* https://wiki.php.net/rfc/internal_constructor_behaviour
|
||||
* https://wiki.php.net/rfc/reclassify_e_strict
|
||||
|
||||
####其它的语言变化
|
||||
|
||||
* 静态调用一个不兼容的 $this 上下文的非静态调用的做法不再支持。这种情况下,$this 是没有定义的,但是对它的调用是允许的,并带有一个废弃提示。例子:
|
||||
|
||||
class A {
|
||||
public function test() { var_dump($this); }
|
||||
}
|
||||
|
||||
// 注意:没有从类 A 进行扩展
|
||||
class B {
|
||||
public function callNonStaticMethodOfA() { A::test(); }
|
||||
}
|
||||
|
||||
(new B)->callNonStaticMethodOfA();
|
||||
|
||||
// 废弃:非静态方法 A::test() 不应该被静态调用
|
||||
// 提示:未定义的变量 $this
|
||||
NULL
|
||||
|
||||
注意,这仅出现在来自不兼容上下文的调用上。如果类 B 扩展自类 A ,调用会被允许,没有任何提示。
|
||||
|
||||
* 不能使用下列类名、接口名和特殊名(大小写敏感):
|
||||
|
||||
bool
|
||||
int
|
||||
float
|
||||
string
|
||||
null
|
||||
false
|
||||
true
|
||||
|
||||
这用于 class/interface/trait 声明、 class_alias() 和 use 语句中。
|
||||
|
||||
此外,下列类名、接口名和特殊名保留做将来使用,但是使用时尚不会抛出错误:
|
||||
|
||||
resource
|
||||
object
|
||||
mixed
|
||||
numeric
|
||||
|
||||
* yield 语句结构当用在一个表达式上下文时,不再要求括号。它现在是一个优先级在 “print” 和 “=>” 之间的右结合操作符。在某些情况下这会导致不同的行为,例如:
|
||||
|
||||
echo yield -1;
|
||||
// 以前被解释如下
|
||||
echo (yield) - 1;
|
||||
// 现在被解释如下
|
||||
echo yield (-1);
|
||||
|
||||
yield $foo or die;
|
||||
// 以前被解释如下
|
||||
yield ($foo or die);
|
||||
// 现在被解释如下
|
||||
(yield $foo) or die;
|
||||
|
||||
这种情况可以通过增加括号来解决。
|
||||
|
||||
* 移除了 ASP (\<%) 和 script (\<script language=php>) 标签。
|
||||
|
||||
RFC: https://wiki.php.net/rfc/remove_alternative_php_tags
|
||||
|
||||
* 不支持以引用的方式对 new 的结果赋值。
|
||||
|
||||
* 不支持对一个来自非兼容的 $this 上下文的非静态方法的域内调用。细节参见: https://wiki.php.net/rfc/incompat_ctx 。
|
||||
|
||||
* 不支持 ini 文件中的 # 风格的备注。使用 ; 风格的备注替代。
|
||||
|
||||
* $HTTP\_RAW\_POST\_DATA 不再可用,使用 php://input 流替代。
|
||||
|
||||
###标准库的变化
|
||||
|
||||
* call\_user\_method() 和 call\_user\_method\_array() 不再存在。
|
||||
|
||||
* 在一个输出缓冲区被创建在输出缓冲处理器里时, ob\_start() 不再发出 E\_ERROR,而是 E\_RECOVERABLE\_ERROR。
|
||||
|
||||
* 改进的 zend\_qsort (使用 hybrid 排序算法)性能更好,并改名为 zend\_sort。
|
||||
|
||||
* 增加静态排序算法 zend\_insert\_sort。
|
||||
|
||||
* 移除 fpm-fcgi 的 dl() 函数。
|
||||
|
||||
* setcookie() 如果 cookie 名为空会触发一个 WARNING ,而不是发出一个空的 set-cookie 头。
|
||||
|
||||
###其它
|
||||
|
||||
- Curl:
|
||||
- 去除对禁用 CURLOPT\_SAFE\_UPLOAD 选项的支持。所有的 curl 文件上载必须使用 curl\_file / CURLFile API。
|
||||
|
||||
- Date:
|
||||
- 从 mktime() 和 gmmktime() 中移除 $is\_dst 参数
|
||||
|
||||
- DBA
|
||||
- 如果键也没有出现在 inifile 处理器中,dba\_delete() 现在会返回 false。
|
||||
|
||||
- GMP
|
||||
- 现在要求 libgmp 版本 4.2 或更新。
|
||||
- gmp\_setbit() 和 gmp\_clrbit() 对于负指标返回 FALSE,和其它的 GMP 函数一致。
|
||||
|
||||
- Intl:
|
||||
- 移除废弃的别名 datefmt\_set\_timezone\_id() 和 IntlDateFormatter::setTimeZoneID()。替代使用 datefmt\_set\_timezone() 和 IntlDateFormatter::setTimeZone()。
|
||||
|
||||
- libxml:
|
||||
- 增加 LIBXML\_BIGLINES 解析器选项。从 libxml 2.9.0 开始可用,并增加了在错误报告中行号大于 16 位的支持。
|
||||
|
||||
- Mcrypt
|
||||
- 移除等同于 mcrypt\_generic\_deinit() 的废弃别名 mcrypt\_generic\_end()。
|
||||
- 移除废弃的 mcrypt\_ecb()、 mcrypt\_cbc()、 mcrypt\_cfb() 和 mcrypt\_ofb() 函数,它们等同于使用 MCRYPT\_MODE\_* 标志的 mcrypt\_encrypt() 和 mcrypt\_decrypt() 。
|
||||
|
||||
- Session
|
||||
- session\_start() 以数组方式接受所有的 INI 设置。例如, ['cache\_limiter'=>'private'] 会设置 session.cache\_limiter=private 。也支持 'read\_and\_close' 以在读取数据后立即关闭会话数据。
|
||||
- 会话保存处理器接受使用 validate\_sid() 和 update\_timestamp() 来校验会话 ID 是否存在、更新会话时间戳。对旧式的用户定义的会话保存处理器继续兼容。
|
||||
- 增加了 SessionUpdateTimestampHandlerInterface 。 validateSid()、 updateTimestamp()
|
||||
定义在接口里面。
|
||||
- session.lazy\_write(默认是 On) 的 INI 设置支持仅在会话数据更新时写入。
|
||||
|
||||
- Opcache
|
||||
- 移除 opcache.load\_comments 配置语句。现在文件内备注载入无成本,并且总是启用的。
|
||||
|
||||
- OpenSSL:
|
||||
- 移除 "rsa\_key\_size" SSL 上下文选项,按给出的协商的加密算法自动设置适当的大小。
|
||||
- 移除 "CN\_match" 和 "SNI\_server\_name" SSL 上下文选项。使用自动侦测或 "peer\_name" 选项替代。
|
||||
|
||||
- PCRE:
|
||||
- 移除对 /e (PREG\_REPLACE\_EVAL) 修饰符的支持,使用 preg\_replace\_callback() 替代。
|
||||
|
||||
- PDO\_pgsql:
|
||||
- 移除 PGSQL\_ATTR\_DISABLE\_NATIVE\_PREPARED\_STATEMENT 属性,等同于 ATTR\_EMULATE\_PREPARES。
|
||||
|
||||
- Standard:
|
||||
- 移除 setlocale() 中的字符串类目支持。使用 LC_* 常量替代。
|
||||
instead.
|
||||
- 移除 set\_magic\_quotes\_runtime() 及其别名 magic\_quotes\_runtime()。
|
||||
|
||||
- JSON:
|
||||
- 拒绝 json_decode 中的 RFC 7159 不兼容数字格式 - 顶层 (07, 0xff, .1, -.1) 和所有层的 ([1.], [1.e1])
|
||||
- 用一个参数调用 json\_decode 等价于用空的 PHP 字符串或值调用,转换为空字符串(NULL, FALSE)的结果是 JSON 格式错误。
|
||||
|
||||
- Stream:
|
||||
- 移除 set\_socket\_blocking() ,等同于其别名 stream\_set\_blocking()。
|
||||
|
||||
- XSL:
|
||||
- 移除 xsl.security\_prefs ini 选项,使用 XsltProcessor::setSecurityPrefs() 替代。
|
||||
|
||||
##2. 新功能
|
||||
|
||||
- Core
|
||||
- 增加了组式 use 声明。
|
||||
(RFC: https://wiki.php.net/rfc/group_use_declarations)
|
||||
- 增加了 null 合并操作符 (??)。
|
||||
(RFC: https://wiki.php.net/rfc/isset_ternary)
|
||||
- 在 64 位架构上支持长度 >= 2^31 字节的字符串。
|
||||
- 增加了 Closure::call() 方法(仅工作在用户侧的类)。
|
||||
- 在双引号字符串和 here 文档中增加了 \u{xxxxxx} Unicode 码点转义格式。
|
||||
- define() 现在支持数组作为常量值,修复了一个当 define() 还不支持数组常量值时的疏忽。
|
||||
- 增加了比较操作符 (<=>),即太空船操作符。
|
||||
(RFC: https://wiki.php.net/rfc/combined-comparison-operator)
|
||||
- 为委托生成器添加了类似协程的 yield from 操作符。
|
||||
(RFC: https://wiki.php.net/rfc/generator-delegation)
|
||||
- 保留的关键字现在可以用在几种新的上下文中。
|
||||
(RFC: https://wiki.php.net/rfc/context_sensitive_lexer)
|
||||
- 增加了标量类型的声明支持,并可以使用 declare(strict\_types=1) 的声明严格模式。
|
||||
(RFC: https://wiki.php.net/rfc/scalar_type_hints_v5)
|
||||
- 增加了对加密级安全的用户侧的随机数发生器的支持。
|
||||
(RFC: https://wiki.php.net/rfc/easy_userland_csprng)
|
||||
|
||||
- Opcache
|
||||
- 增加了基于文件的二级 opcode 缓存(实验性——默认禁用)。要启用它,PHP 需要使用 --enable-opcache-file 配置和构建,然后 opcache.file\_cache=\<DIR> 配置指令就可以设置在 php.ini 中。二级缓存也许可以提升服务器重启或 SHM 重置时的性能。此外,也可以设置 opcache.file\_cache\_only=1 来使用文件缓存而根本不用 SHM(也许对于共享主机有用);设置 opcache.file\_cache\_consistency\_checks=0 来禁用文件缓存一致性检查,以加速载入过程,有安全风险。
|
||||
|
||||
- OpenSSL
|
||||
- 当用 OpenSSL 1.0.2 及更新构建时,增加了 "alpn\_protocols" SSL 上下文选项来允许加密的客户端/服务器流使用 ALPN TLS 扩展去协商替代的协议。协商后的协议信息可以通过 stream\_get\_meta\_data() 输出访问。
|
||||
|
||||
- Reflection
|
||||
- 增加了一个 ReflectionGenerator 类(yield from Traces,当前文件/行等等)。
|
||||
- 增加了一个 ReflectionType 类来更好的支持新的返回类型和标量类型声明功能。新的 ReflectionParameter::getType() 和 ReflectionFunctionAbstract::getReturnType() 方法都返回一个 ReflectionType 实例。
|
||||
|
||||
- Stream
|
||||
- 添加了新的仅用于 Windows 的流上下文选项以允许阻塞管道读取。要启用该功能,当创建流上下文时,传递 array("pipe" => array("blocking" => true)) 。要注意的是,该选项会导致管道缓冲区的死锁,然而它在几个命令行场景中有用。
|
||||
|
||||
##3. SAPI 模块的变化
|
||||
|
||||
- FPM
|
||||
- 修复错误 #65933 (不能设置超过1024字节的配置行)。
|
||||
- Listen = port 现在监听在所有地址上(IPv6 和 IPv4 映射的)。
|
||||
|
||||
##4. 废弃的功能
|
||||
|
||||
- Core
|
||||
- 废弃了 PHP 4 风格的构建函数(即构建函数名必须与类名相同)。
|
||||
- 废弃了对非静态方法的静态调用。
|
||||
|
||||
- OpenSSL
|
||||
- 废弃了 "capture\_session\_meta" SSL 上下文选项。 在流资源上活动的加密相关的元数据可以通过 stream\_get\_meta\_data() 的返回值访问。
|
||||
|
||||
##5. 函数的变化
|
||||
|
||||
- parse\_ini\_file():
|
||||
- parse\_ini\_string():
|
||||
- 添加了扫描模式 INI_SCANNER_TYPED 来得到 yield 类型的 .ini 值。
|
||||
|
||||
- unserialize():
|
||||
- 给 unserialize 函数添加了第二个参数
|
||||
(RFC: https://wiki.php.net/rfc/secure_unserialize) 来指定可接受的类:
|
||||
unserialize($foo, ["allowed_classes" => ["MyClass", "MyClass2"]]);
|
||||
|
||||
- proc\_open():
|
||||
- 可以被 proc\_open() 使用的最大管道数以前被硬编码地限制为 16。现在去除了这个限制,只受限于 PHP 的可用内存大小。
|
||||
- 新添加的仅用于 Windows 的配置选项 "blocking\_pipes" 可以用于强制阻塞对子进程管道的读取。这可以用于几种命令行应用场景,但是它会导致死锁。此外,这与新的流的管道上下文选项相关。
|
||||
|
||||
- array_column():
|
||||
- 该函数现在支持把对象数组当做二维数组。只有公开属性会被处理,对象里面使用 \_\_get() 的动态属性必须也实现 \_\_isset() 才行。
|
||||
|
||||
- stream\_context\_create()
|
||||
- 现在可以接受一个仅 Windows 可用的配置 array("pipe" => array("blocking" => \<boolean>)) 来强制阻塞管道读取。该选项应该小心使用,该平台有可能导致管道缓冲区的死锁。
|
||||
|
||||
##6. 新函数
|
||||
|
||||
- GMP
|
||||
- 添加了 gmp\_random\_seed()。
|
||||
|
||||
- PCRE:
|
||||
- 添加了 preg\_replace\_callback\_array 函数。
|
||||
(RFC: https://wiki.php.net/rfc/preg_replace_callback_array)
|
||||
|
||||
- Standard
|
||||
. 添加了整数除法 intdiv() 函数。
|
||||
. 添加了重置错误状态的 error\_clear\_last() 函数。
|
||||
|
||||
- Zlib:
|
||||
. 添加了 deflate\_init()、 deflate\_add()、 inflate\_init()、 inflate\_add() 函数来运行递增和流的压缩/解压。
|
||||
|
||||
##7. 新的类和接口
|
||||
|
||||
(暂无)
|
||||
|
||||
##8. 移除的扩展和 SAPI
|
||||
|
||||
- sapi/aolserver
|
||||
- sapi/apache
|
||||
- sapi/apache_hooks
|
||||
- sapi/apache2filter
|
||||
- sapi/caudium
|
||||
- sapi/continuity
|
||||
- sapi/isapi
|
||||
- sapi/milter
|
||||
- sapi/nsapi
|
||||
- sapi/phttpd
|
||||
- sapi/pi3web
|
||||
- sapi/roxen
|
||||
- sapi/thttpd
|
||||
- sapi/tux
|
||||
- sapi/webjames
|
||||
- ext/mssql
|
||||
- ext/mysql
|
||||
- ext/sybase_ct
|
||||
- ext/ereg
|
||||
|
||||
更多细节参见:
|
||||
|
||||
- https://wiki.php.net/rfc/removal_of_dead_sapis_and_exts
|
||||
- https://wiki.php.net/rfc/remove_deprecated_functionality_in_php7
|
||||
|
||||
注意:NSAPI 没有在 RFC 中投票,不过它会在以后移除。这就是说,它相关的 SDK 今后不可用。
|
||||
|
||||
##9. 扩展的其它变化
|
||||
|
||||
- Mhash
|
||||
- Mhash 今后不是一个扩展了,使用 function\_exists("mhash") 来检查器是否可用。
|
||||
|
||||
##10. 新的全局常量
|
||||
|
||||
- Core
|
||||
. 添加 PHP\_INT\_MIN
|
||||
|
||||
- Zlib
|
||||
- 添加的这些常量用于控制新的增量deflate\_add() 和 inflate\_add() 函数的刷新行为:
|
||||
- ZLIB\_NO\_FLUSH
|
||||
- ZLIB\_PARTIAL\_FLUSH
|
||||
- ZLIB\_SYNC\_FLUSH
|
||||
- ZLIB\_FULL\_FLUSH
|
||||
- ZLIB\_BLOCK
|
||||
- ZLIB\_FINISH
|
||||
|
||||
- GD
|
||||
- 移除了 T1Lib 支持,这样由于对 T1Lib 的可选依赖,如下将来不可用:
|
||||
|
||||
函数:
|
||||
- imagepsbbox()
|
||||
- imagepsencodefont()
|
||||
- imagepsextendedfont()
|
||||
- imagepsfreefont()
|
||||
- imagepsloadfont()
|
||||
- imagepsslantfont()
|
||||
- imagepstext()
|
||||
|
||||
资源:
|
||||
- 'gd PS font'
|
||||
- 'gd PS encoding'
|
||||
|
||||
##11. INI 文件处理的变化
|
||||
|
||||
- Core
|
||||
- 移除了 asp\_tags ini 指令。如果启用它会导致致命错误。
|
||||
- 移除了 always\_populate\_raw\_post\_data ini 指令。
|
||||
|
||||
##12. Windows 支持
|
||||
|
||||
- Core
|
||||
- 在 64 位系统上支持原生的 64 位整数。
|
||||
- 在 64 位系统上支持大文件。
|
||||
- 支持 getrusage()。
|
||||
|
||||
- ftp
|
||||
- 所带的 ftp 扩展总是共享库的。
|
||||
- 对于 SSL 支持,取消了对 openssl 扩展的依赖,取而代之仅依赖 openssl 库。如果在编译时需要,会自动启用
|
||||
ftp\_ssl\_connect()。
|
||||
|
||||
- odbc
|
||||
- 所带的 odbc 扩展总是共享库的。
|
||||
|
||||
##13. 其它变化
|
||||
|
||||
- Core
|
||||
- NaN 和 Infinity 转换为整数时总是 0,而不是未定义和平台相关的。
|
||||
- 对非对象调用方法会触发一个可捕获错误,而不是致命错误;参见: https://wiki.php.net/rfc/catchable-call-to-member-of-non-object
|
||||
- zend\_parse\_parameters、类型提示和转换,现在总是用 "integer" 和 "float",而不是 "long" 和 "double"。
|
||||
- 如果 ignore\_user\_abort 设置为 true ,对应中断的连接,输出缓存会继续工作。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/php/php-src/blob/php-7.0.0beta1/UPGRADING
|
||||
|
||||
作者:[php][a]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/php
|
||||
@ -0,0 +1,56 @@
|
||||
一周 GNOME 之旅:品味它和 KDE 的是是非非(第一节 介绍)
|
||||
================================================================================
|
||||
|
||||
*作者声明: 如果你是因为某种神迹而在没看标题的情况下点开了这篇文章,那么我想再重申一些东西……这是一篇评论文章,文中的观点都是我自己的,不代表 Phoronix 网站和 Michael 的观点。它们完全是我自己的想法。*
|
||||
|
||||
另外,没错……这可能是一篇引战的文章。我希望 KDE 和 Gnome 社团变得更好一些,因为我想发起一个讨论并反馈给他们。为此,当我想指出(我所看到的)一个瑕疵时,我会尽量地做到具体而直接。这样,相关的讨论也能做到同样的具体和直接。再次声明:本文另一可选标题为“死于成千上万的[纸割][1]”(LCTT 译注:paper cuts——纸割,被纸片割伤——指易修复但烦人的缺陷。Ubuntu 从 9.10 开始,发起了 [One Hundred Papercuts][1] 项目,用于修复那些小而烦人的易用性问题)。
|
||||
|
||||
现在,重申完毕……文章开始。
|
||||
|
||||
|
||||
|
||||
当我把[《评价 Fedora 22 KDE 》][2]一文发给 Michael 时,感觉很不是滋味。不是因为我不喜欢 KDE,或者不待见 Fedora,远非如此。事实上,我刚开始想把我的 T450s 的系统换为 Arch Linux 时,马上又决定放弃了,因为我很享受 fedora 在很多方面所带来的便捷性。
|
||||
|
||||
我感觉很不是滋味的原因是 Fedora 的开发者花费了大量的时间和精力在他们的“工作站”产品上,但是我却一点也没看到。在使用 Fedora 时,我并没用采用那些主要开发者希望用户采用的那种使用方式,因此我也就体验不到所谓的“ Fedora 体验”。它感觉就像一个人评价 Ubuntu 时用的却是 Kubuntu,评价 OS X 时用的却是 Hackintosh,或者评价 Gentoo 时用的却是 Sabayon。根据论坛里大量读者对 Michael 的说法,他们在评价各种发行版时都是使用的默认设置——我也不例外。但是我还是认为这些评价应该在“真实”配置下完成,当然我也知道在给定的情况下评论某些东西也的确是有价值的——无论是好是坏。
|
||||
|
||||
正是在怀着这种态度的情况下,我决定跳到 Gnome 这个水坑里来泡泡澡。
|
||||
|
||||
但是,我还要在此多加一个声明……我在这里所看到的 KDE 和 Gnome 都是打包在 Fedora 中的。OpenSUSE、 Kubuntu、 Arch等发行版的各个桌面可能有不同的实现方法,使得我这里所说的具体的“痛点”跟你所用的发行版有所不同。还有,虽然用了这个标题,但这篇文章将会是一篇“很 KDE”的重量级文章。之所以这样称呼,是因为我在“使用” Gnome 之后,才知道 KDE 的“纸割”到底有多么的多。
|
||||
|
||||
### 登录界面 ###
|
||||
|
||||
|
||||
|
||||
我一般情况下都不会介意发行版带着它们自己的特别主题,因为一般情况下桌面看起来会更好看。可我今天可算是找到了一个例外。
|
||||
|
||||
第一印象很重要,对吧?那么,GDM(LCTT 译注: Gnome Display Manage:Gnome 显示管理器。)绝对干得漂亮。它的登录界面看起来极度简洁,每一部分都应用了一致的设计风格。使用通用图标而不是文本框为它的简洁加了分。
|
||||
|
||||

|
||||
|
||||
这并不是说 Fedora 22 KDE ——现在已经是 SDDM 而不是 KDM 了——的登录界面不好看,但是看起来绝对没有它这样和谐。
|
||||
|
||||
问题到底出来在哪?顶部栏。看看 Gnome 的截图——你选择一个用户,然后用一个很小的齿轮简单地选择想登入哪个会话。设计很简洁,一点都不碍事,实话讲,如果你没注意的话可能完全会看不到它。现在看看那蓝色( LCTT 译注:blue,有忧郁之意,一语双关)的 KDE 截图,顶部栏看起来甚至不像是用同一个工具渲染出来的,它的整个位置的安排好像是某人想着:“哎哟妈呀,我们需要把这个选项扔在哪个地方……”之后决定下来的。
|
||||
|
||||
对于右上角的重启和关机选项也一样。为什么不单单用一个电源按钮,点击后会下拉出一个菜单,里面包括重启,关机,挂起的功能?按钮的颜色跟背景色不同肯定会让它更加突兀和显眼……但我可不觉得这样子有多好。同样,这看起来可真像“苦思”后的决定。
|
||||
|
||||
从实用观点来看,GDM 还要远远实用的多,再看看顶部一栏。时间被列了出来,还有一个音量控制按钮,如果你想保持周围安静,你甚至可以在登录前设置静音,还有一个可用性按钮来实现高对比度、缩放、语音转文字等功能,所有可用的功能通过简单的一个开关按钮就能得到。
|
||||
|
||||
|
||||
|
||||
切换到上游(KDE 自带)的 Breeve 主题……突然间,我抱怨的大部分问题都被解决了。通用图标,所有东西都放在了屏幕中央,但不是那么重要的被放到了一边。因为屏幕顶部和底部都是同样的空白,在中间也就酝酿出了一种美好的和谐。还是有一个文本框来切换会话,但既然电源按钮被做成了通用图标,那么这点还算可以原谅。当前时间以一种漂亮的感觉呈现,旁边还有电量指示器。当然 gnome 还是有一些很好的附加物,例如音量小程序和可用性按钮,但 Breeze 总归要比 Fedora 的 KDE 主题进步。
|
||||
|
||||
到 Windows(Windows 8和10之前)或者 OS X 中去,你会看到类似的东西——非常简洁的,“不碍事”的锁屏与登录界面,它们都没有文本框或者其它分散视觉的小工具。这是一种有效的不分散人注意力的设计。Fedora……默认带有 Breeze 主题。VDG 在 Breeze 主题设计上干得不错。可别糟蹋了它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=1
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://wiki.ubuntu.com/One%20Hundred%20Papercuts
|
||||
[2]:http://www.phoronix.com/scan.php?page=article&item=fedora-22-kde&num=1
|
||||
[3]:https://launchpad.net/hundredpapercuts
|
||||
@ -0,0 +1,32 @@
|
||||
一周 GNOME 之旅:品味它和 KDE 的是是非非(第二节 GNOME桌面)
|
||||
================================================================================
|
||||
|
||||
### 桌面 ###
|
||||
|
||||
|
||||
|
||||
在我这一周的前五天中,我都是直接手动登录进 Gnome 的——没有打开自动登录功能。在第五天的晚上,每一次都要手动登录让我觉得很厌烦,所以我就到用户管理器中打开了自动登录功能。下一次我登录的时候收到了一个提示:“你的密钥链(keychain)未解锁,请输入你的密码解锁”。在这时我才意识到了什么……Gnome 以前一直都在自动解锁我的密钥链(KDE 中叫做我的钱包),每当我通过 GDM 登录时 !当我绕开 GDM 的登录程序时,Gnome 才不得不介入让我手动解锁。
|
||||
|
||||
现在,鄙人的陋见是如果你打开了自动登录功能,那么你的密钥链也应当自动解锁——否则,这功能还有何用?无论如何,你还是需要输入你的密码,况且在 GDM 登录界面你还有机会选择要登录的会话,如果你想换的话。
|
||||
|
||||
但是,这点且不提,也就是在那一刻,我意识到要让这桌面感觉就像它在**和我**一起工作一样是多么简单的一件事。当我通过 SDDM 登录 KDE 时?甚至连启动界面都还没加载完成,就有一个窗口弹出来遮挡了启动动画(因此启动动画也就被破坏了),它提示我解锁我的 KDE 钱包或 GPG 钥匙环。
|
||||
|
||||
如果当前还没有钱包,你就会收到一个创建钱包的提醒——就不能在创建用户的时候同时为我创建一个吗?接着它又让你在两种加密模式中选择一种,甚至还暗示我们其中一种(Blowfish)是不安全的,既然是为了安全,为什么还要我选择一个不安全的东西?作者声明:如果你安装了真正的 KDE spin 版本而不是仅仅安装了被 KDE 搞过的版本,那么在创建用户时,它就会为你创建一个钱包。但很不幸的是,它不会帮你自动解锁,并且它似乎还使用了更老的 Blowfish 加密模式,而不是更新而且更安全的 GPG 模式。
|
||||
|
||||
|
||||
|
||||
如果你选择了那个安全的加密模式(GPG),那么它会尝试加载 GPG 密钥……我希望你已经创建过一个了,因为如果你没有,那么你可又要被指责一番了。怎么样才能创建一个?额……它不帮你创建一个……也不告诉你怎么创建……假如你真的搞明白了你应该使用 KGpg 来创建一个密钥,接着在你就会遇到一层层的菜单和一个个的提示,而这些菜单和提示只能让新手感到困惑。为什么你要问我 GPG 的二进制文件在哪?天知道在哪!如果不止一个,你就不能为我选择一个最新的吗?如果只有一个,我再问一次,为什么你还要问我?
|
||||
|
||||
为什么你要问我要使用多大的密钥大小和加密算法?你既然默认选择了 2048 和 RSA/RSA,为什么不直接使用?如果你想让这些选项能够被修改,那就把它们扔在下面的“Expert mode(专家模式)” 按钮里去。这里不仅仅是说让配置可被用户修改的问题,而是说根本不需要默认把多余的东西扔在了用户面前。这种问题将会成为这篇文章剩下的主要内容之一……KDE 需要更理智的默认配置。配置是好的,我很喜欢在使用 KDE 时的配置,但它还需要知道什么时候应该,什么时候不应该去提示用户。而且它还需要知道“嗯,它是可配置的”不能做为默认配置做得不好的借口。用户最先接触到的就是默认配置,不好的默认配置注定要失去用户。
|
||||
|
||||
让我们抛开密钥链的问题,因为我想我已经表达出了我的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=2
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,66 @@
|
||||
一周 GNOME 之旅:品味它和 KDE 的是是非非(第三节 GNOME应用)
|
||||
================================================================================
|
||||
|
||||
### 应用 ###
|
||||
|
||||
|
||||
|
||||
这是一个基本扯平的方面。每一个桌面环境都有一些非常好的应用,也有一些不怎么样的。再次强调,Gnome 把那些 KDE 完全错失的小细节给做对了。我不是想说 KDE 中有哪些应用不好。他们都能工作,但仅此而已。也就是说:它们合格了,但确实还没有达到甚至接近100分。
|
||||
|
||||
Gnome 在左,KDE 在右。Dragon 播放器运行得很好,清晰的标出了播放文件、URL或和光盘的按钮,正如你在 Gnome Videos 中能做到的一样……但是在便利的文件名和用户的友好度方面,Gnome 多走了一小步。它默认显示了在你的电脑上检测到的所有影像文件,不需要你做任何事情。KDE 有 [Baloo][](正如之前的 [Nepomuk][2],LCTT 译注:这是 KDE 中一种文件索引服务框架)为什么不使用它们?它们能列出可读取的影像文件……但却没被使用。
|
||||
|
||||
下一步……音乐播放器
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
这两个应用,左边的是 Rhythmbox ,右边的是 Amarok,都是打开后没有做任何修改直接截屏的。看到差别了吗?Rhythmbox 看起来像个音乐播放器,直接了当,排序文件的方法也很清晰,它知道它应该是什么样的,它的工作是什么:就是播放音乐。
|
||||
|
||||
Amarok 感觉就像是某个人为了展示而把所有的扩展和选项都尽可能地塞进一个应用程序中去,而做出来的一个技术演示产品(tech demos),或者一个库演示产品(library demos)——而这些是不应该做为产品装进去的,它只应该展示其中一点东西。而 Amarok 给人的感觉却是这样的:好像是某个人想把每一个感觉可能很酷的东西都塞进一个媒体播放器里,甚至都不停下来想“我想写啥来着?一个播放音乐的应用?”
|
||||
|
||||
看看默认布局就行了。前面和中心都呈现了什么?一个可视化工具和集成了维基百科——占了整个页面最大和最显眼的区域。第二大的呢?播放列表。第三大,同时也是最小的呢?真正的音乐列表。这种默认设置对于一个核心应用来说,怎么可能称得上理智?
|
||||
|
||||
软件管理器!它在最近几年当中有很大的进步,而且接下来的几个月中,很可能只能看到它更大的进步。不幸的是,这是另一个 KDE 做得差一点点就能……但还是在终点线前以脸戗地了。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
Gnome 软件中心可能是我的新的最爱的软件中心,先放下牢骚等下再发。Muon, 我想爱上你,真的。但你就是个设计上的梦魇。当 VDG 给你画设计草稿时(草图如下),你看起来真漂亮。白色空间用得很好,设计简洁,类别列表也很好,你的整个“不要分开做成两个应用程序”的设计都很不错。
|
||||
|
||||
|
||||
|
||||
接着就有人为你写代码,实现真正的UI,但是,我猜这些家伙当时一定是喝醉了。
|
||||
|
||||
我们来看看 Gnome 软件中心。正中间是什么?软件,软件截图和软件描述等等。Muon 的正中心是什么?白白浪费的大块白色空间。Gnome 软件中心还有一个贴心便利特点,那就是放了一个“运行”的按钮在那儿,以防你已经安装了这个软件。便利性和易用性很重要啊,大哥。说实话,仅仅让 Muon 把东西都居中对齐了可能看起来的效果都要好得多。
|
||||
|
||||
Gnome 软件中心沿着顶部的东西是什么,像个标签列表?所有软件,已安装软件,软件升级。语言简洁,直接,直指要点。Muon,好吧,我们有个“发现”,这个语言表达上还算差强人意,然后我们又有一个“已安装软件”,然后,就没有然后了。软件升级哪去了?
|
||||
|
||||
好吧……开发者决定把升级独立分开成一个应用程序,这样你就得打开两个应用程序才能管理你的软件——一个用来安装,一个用来升级——自从有了新立得图形软件包管理器以来,首次有这种破天荒的设计,与任何已存的软件中心的设计范例相违背。
|
||||
|
||||
我不想贴上截图给你们看,因为我不想等下还得清理我的电脑,如果你进入 Muon 安装了什么,那么它就会在屏幕下方根据安装的应用名创建一个标签,所以如果你一次性安装很多软件的话,那么下面的标签数量就会慢慢的增长,然后你就不得不手动检查清除它们,因为如果你不这样做,当标签增长到超过屏幕显示时,你就不得不一个个找过去来才能找到最近正在安装的软件。想想:在火狐浏览器中打开50个标签是什么感受。太烦人,太不方便!
|
||||
|
||||
我说过我会给 Gnome 一点打击,我是认真的。Muon 有一点做得比 Gnome 软件中心做得好。在 Muon 的设置栏下面有个“显示技术包”,即:编辑器,软件库,非图形应用程序,无 AppData 的应用等等(LCTT 译注:AppData 是软件包中的一个特殊文件,用于专门存储软件的信息)。Gnome 则没有。如果你想安装其中任何一项你必须跑到终端操作。我想这是他们做得不对的一点。我完全理解他们推行 AppData 的心情,但我想他们太急了(LCTT 译注:推行所有软件包带有 AppData 是 Gnome 软件中心的目标之一)。我是在想安装 PowerTop,而 Gnome 不显示这个软件时我才发现这点的——因为它没有 AppData,也没有“显示技术包”设置。
|
||||
|
||||
更不幸的事实是,如果你在 KDE 下你不能说“用 [Apper][3] 就行了”,因为……
|
||||
|
||||
|
||||
|
||||
Apper 对安装本地软件包的支持大约在 Fedora 19 时就中止了,几乎两年了。我喜欢关注细节与质量。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=3
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://community.kde.org/Baloo
|
||||
[2]:http://www.ikde.org/tech/kde-tech-nepomuk/
|
||||
[3]:https://en.wikipedia.org/wiki/Apper
|
||||
@ -0,0 +1,52 @@
|
||||
一周 GNOME 之旅:品味它和 KDE 的是是非非(第四节 GNOME设置)
|
||||
================================================================================
|
||||
|
||||
### 设置 ###
|
||||
|
||||
在这我要挑一挑几个特定 KDE 控制模块的毛病,大部分原因是因为相比它们的对手GNOME来说,糟糕得太可笑,实话说,真是悲哀。
|
||||
|
||||
第一个接招的?打印机。
|
||||
|
||||
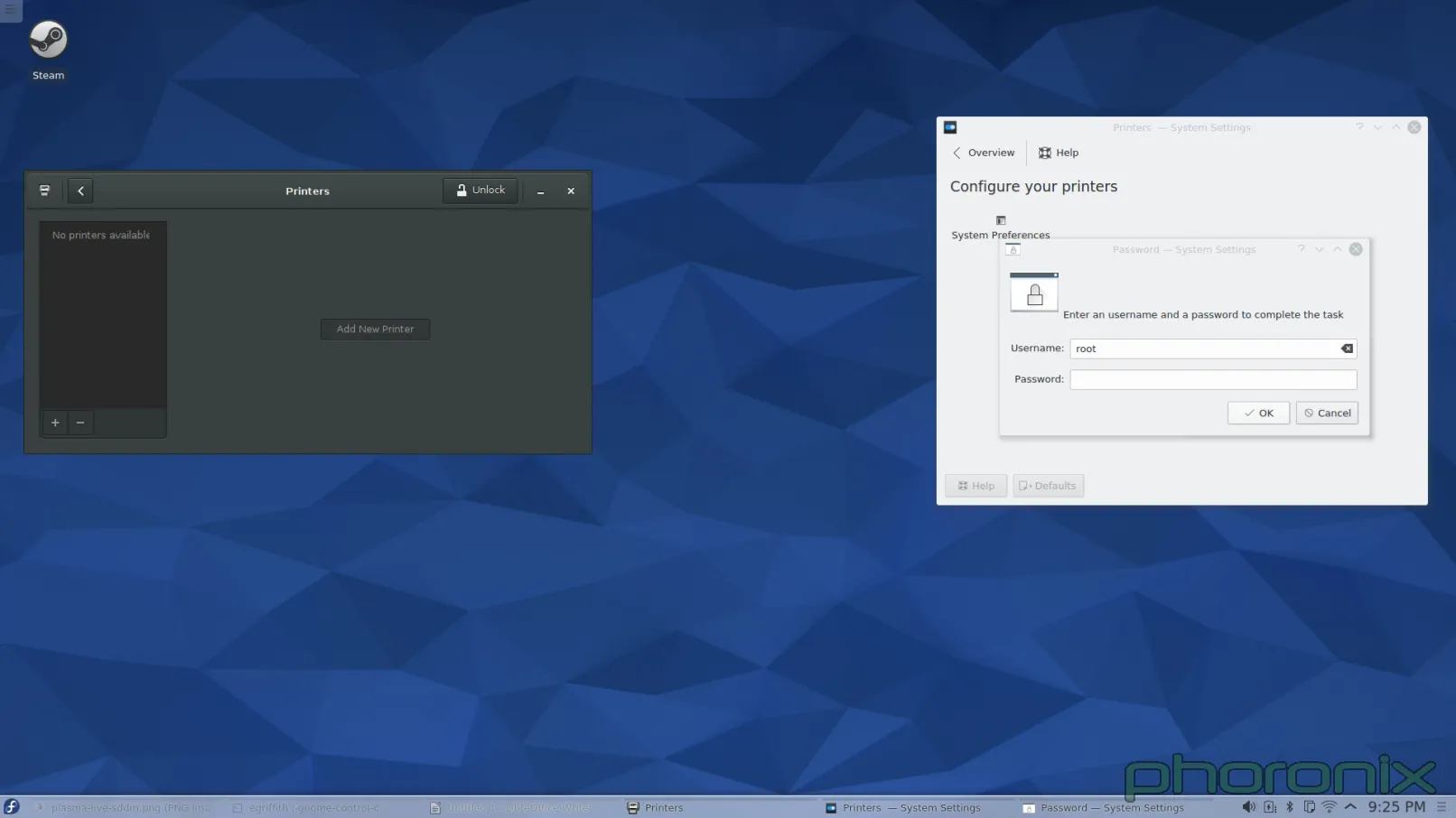
|
||||
|
||||
GNOME 在左,KDE 在右。你知道左边跟右边的打印程序有什么区别吗?当我在 GNOME 控制中心打开“打印机”时,程序窗口弹出来了,然后这样就可以使用了。而当我在 KDE 系统设置打开“打印机”时,我得到了一条密码提示。甚至我都没能看一眼打印机呢,我就必须先交出 ROOT 密码。
|
||||
|
||||
让我再重复一遍。在今天这个有了 PolicyKit 和 Logind 的日子里,对一个应该是 sudo 的操作,我依然被询问要求 ROOT 的密码。我安装系统的时候甚至都没设置 root 密码。所以我必须跑到 Konsole 去,接着运行 'sudo passwd root' 命令,这样我才能给 root 设一个密码,然后我才能回到系统设置中的打印程序,再交出 root 密码,然后仅仅是看一看哪些打印机可用。完成了这些工作后,当我点击“添加打印机”时,我再次得到请求 ROOT 密码的提示,当我解决了它后再选择一个打印机和驱动时,我再次得到请求 ROOT 密码的提示。仅仅是为了添加一个打印机到系统我就收到三次密码请求!
|
||||
|
||||
而在 GNOME 下添加打印机,在点击打印机程序中的“解锁”之前,我没有得到任何请求 SUDO 密码的提示。整个过程我只被请求过一次,仅此而已。KDE,求你了……采用 GNOME 的“解锁”模式吧。不到一定需要的时候不要发出提示。还有,不管是哪个库,只要它允许 KDE 应用程序绕过 PolicyKit/Logind(如果有的话)并直接请求 ROOT 权限……那就把它封进箱里吧。如果这是个多用户系统,那我要么必须交出 ROOT 密码,要么我必须时时刻刻待命,以免有一个用户需要升级、更改或添加一个新的打印机。而这两种情况都是完全无法接受的。
|
||||
|
||||
有还一件事……
|
||||
|
||||
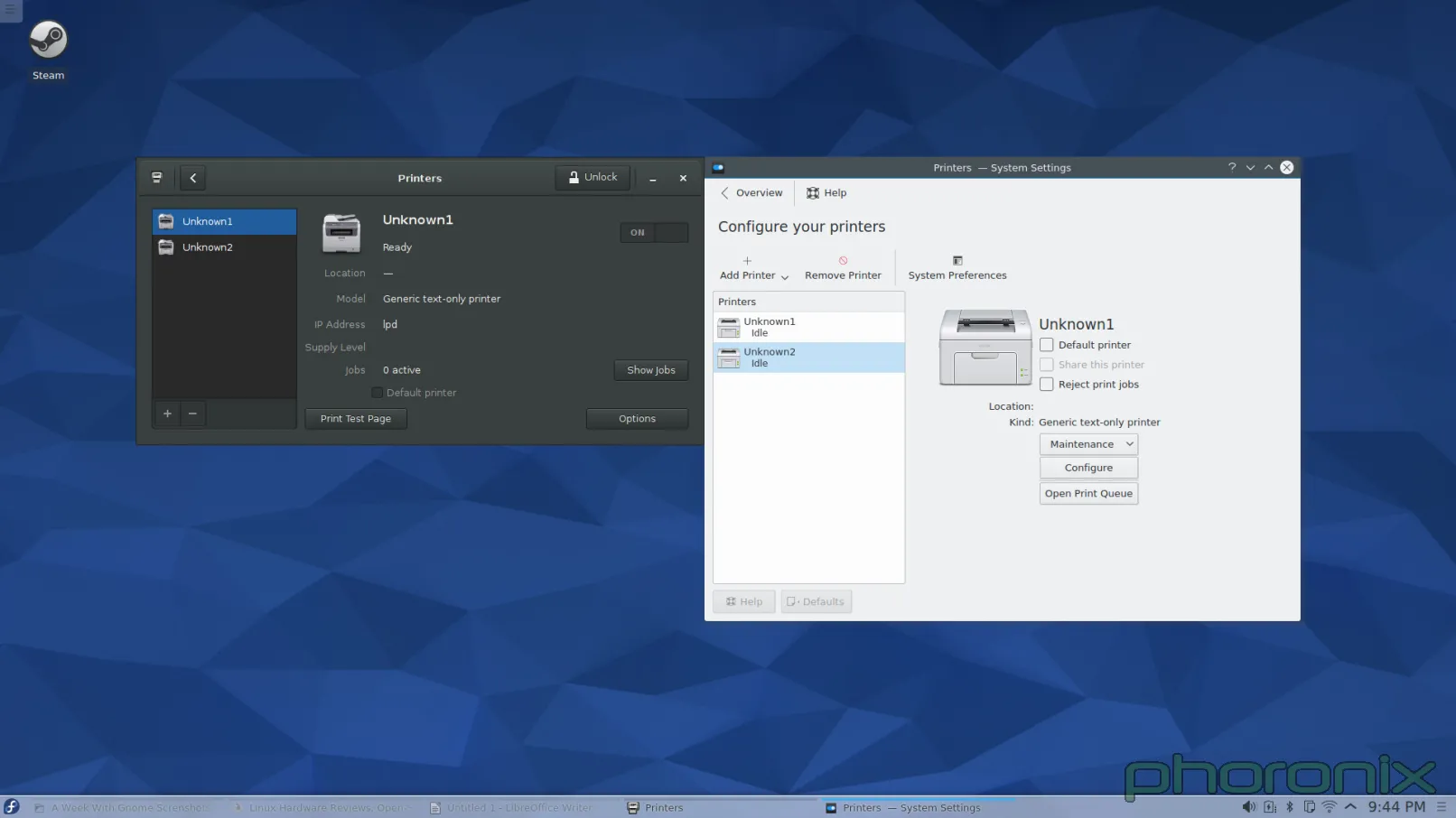
|
||||
|
||||
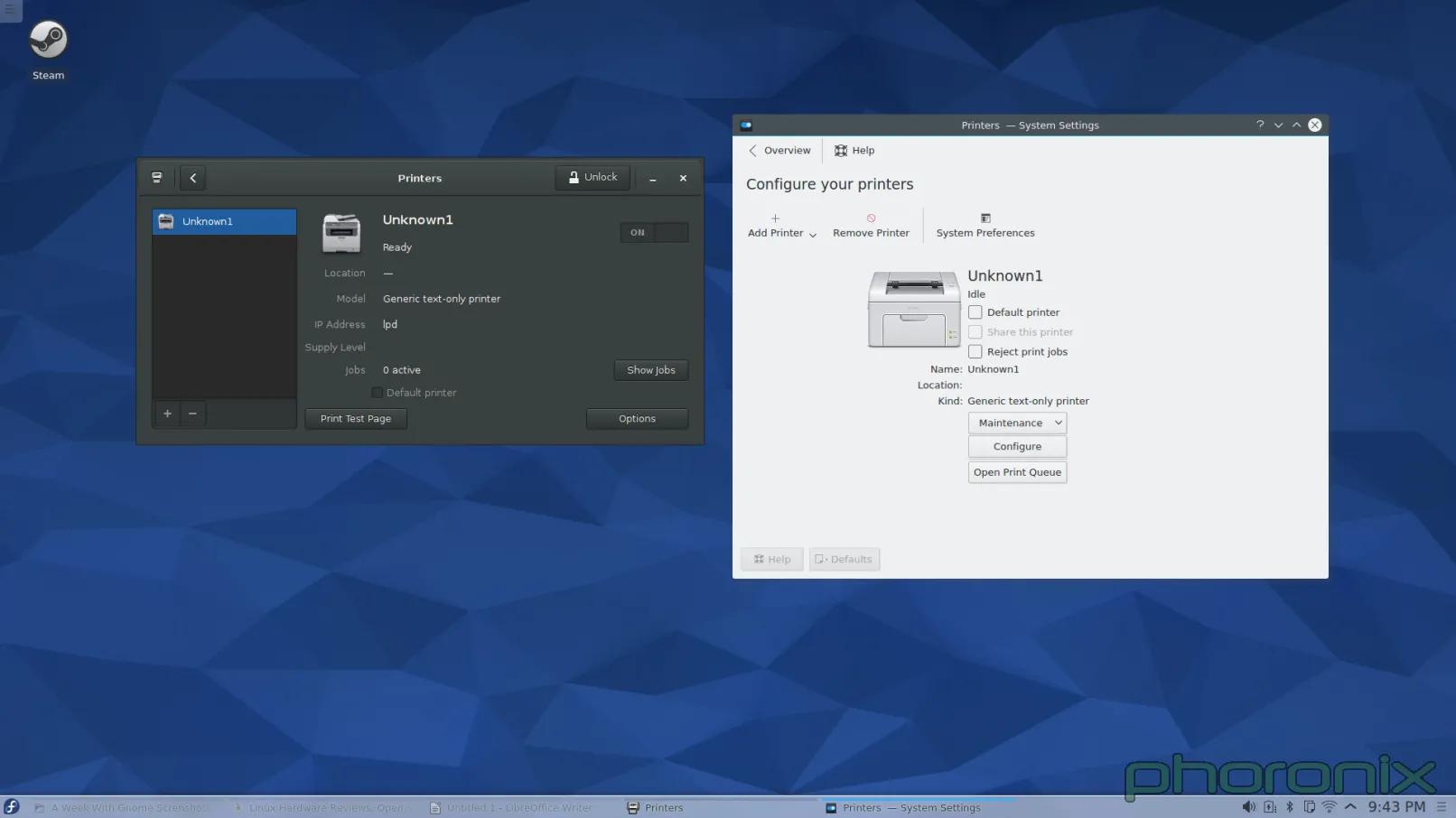
|
||||
|
||||
这个问题问大家:怎么样看起来更简洁?我在写这篇文章时意识到:当有任何附加的打印机准备好时,Gnome 打印机程序会把过程做得非常简洁,它们在左边上放了一个竖直栏来列出这些打印机。而我在 KDE 中添加第二台打印机时,它突然增加出一个左边栏来。而在添加之前,我脑海中已经有了一个恐怖的画面,它会像图片文件夹显示预览图一样直接在界面里插入另外一个图标。我很高兴也很惊讶的看到我是错的。但是事实是它直接“长出”另外一个从未存在的竖直栏,彻底改变了它的界面布局,而这样也称不上“好”。终究还是一种令人困惑,奇怪而又不直观的设计。
|
||||
|
||||
打印机说得够多了……下一个接受我公开石刑的 KDE 系统设置是?多媒体,即 Phonon。
|
||||
|
||||
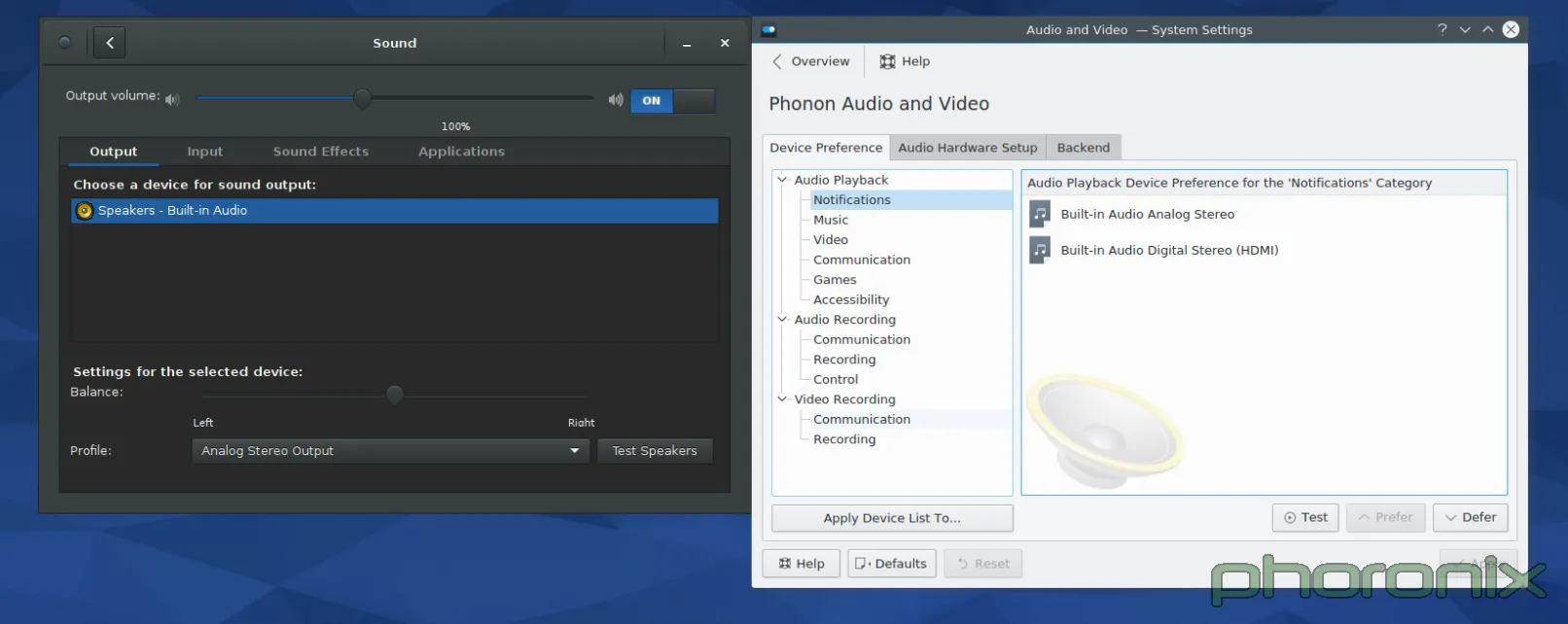
|
||||
|
||||
一如既往,GNOME 在左边,KDE 在右边。让我们先看看 GNOME 的系统设置先……眼睛移动是从左到右,从上到下,对吧?来吧,就这样做。首先:音量控制滑条。滑条中的蓝色条与空条百分百清晰地消除了哪边是“音量增加”的困惑。在音量控制条后马上就是一个 On/Off 开关,用来开关静音功能。Gnome 的再次得分在于静音后能记住当前设置的音量,而在点击音量增加按钮取消静音后能回到原来设置的音量中来。Kmixer,你个健忘的垃圾,我真的希望我能多讨论你一下。
|
||||
|
||||
继续!输入输出和应用程序的标签选项?每一个应用程序的音量随时可控?Gnome,每过一秒,我爱你越深。音量均衡选项、声音配置、和清晰地标上标志的“测试麦克风”选项。
|
||||
|
||||
我不清楚它能否以一种更干净更简洁的设计实现。是的,它只是一个 Gnome 化的 Pavucontrol,但我想这就是重要的地方。Pavucontrol 在这方面几乎完全做对了,Gnome 控制中心中的“声音”应用程序的改善使它向完美更进了一步。
|
||||
|
||||
Phonon,该你上了。但开始前我想说:我 TM 看到的是什么?!我知道我看到的是音频设备的优先级列表,但是它呈现的方式有点太坑。还有,那些用户可能关心的那些东西哪去了?拥有一个优先级列表当然很好,它也应该存在,但问题是优先级列表属于那种用户乱搞一两次之后就不会再碰的东西。它还不够重要,或者说不够常用到可以直接放在正中间位置的程度。音量控制滑块呢?对每个应用程序的音量控制功能呢?那些用户使用最频繁的东西呢?好吧,它们在 Kmix 中,一个分离的程序,拥有它自己的配置选项……而不是在系统设置下……这样真的让“系统设置”这个词变得有点用词不当。
|
||||
|
||||
|
||||
|
||||
上面展示的 Gnome 的网络设置。KDE 的没有展示,原因就是我接下来要吐槽的内容了。如果你进入 KDE 的系统设置里,然后点击“网络”区域中三个选项中的任何一个,你会得到一大堆的选项:蓝牙设置、Samba 分享的默认用户名和密码(说真的,“连通性(Connectivity)”下面只有两个选项:SMB 的用户名和密码。TMD 怎么就配得上“连通性”这么大的词?),浏览器身份验证控制(只有 Konqueror 能用……一个已经倒闭的项目),代理设置,等等……我的 wifi 设置哪去了?它们没在这。哪去了?好吧,它们在网络应用程序的设置里面……而不是在网络设置里……
|
||||
|
||||
KDE,你这是要杀了我啊,你有“系统设置”当凶器,拿着它动手吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=4
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,40 @@
|
||||
一周 GNOME 之旅:品味它和 KDE 的是是非非(第三节 总结)
|
||||
================================================================================
|
||||
|
||||
### 用户体验和最后想法 ###
|
||||
|
||||
当 Gnome 2.x 和 KDE 4.x 要正面交锋时……我在它们之间左右逢源。我对它们爱恨交织,但总的来说它们使用起来还算是一种乐趣。然后 Gnome 3.x 来了,带着一场 Gnome Shell 的戏剧。那时我就放弃了 Gnome,我尽我所能的避开它。当时它对用户是不友好的,而且不直观,它打破了原有的设计典范,只为平板的统治世界做准备……而根据平板下跌的销量来看,这样的未来不可能实现。
|
||||
|
||||
在 Gnome 3 后续发布了八个版本后,奇迹发生了。Gnome 变得对对用户友好了,变得直观了。它完美吗?当然不。我还是很讨厌它想推动的那种设计范例,我讨厌它总想给我强加一种工作流(work flow),但是在付出时间和耐心后,这两都能被接受。只要你能够回头去看看 Gnome Shell 那外星人一样的界面,然后开始跟 Gnome 的其它部分(特别是控制中心)互动,你就能发现 Gnome 绝对做对了:细节,对细节的关注!
|
||||
|
||||
人们能适应新的界面设计范例,能适应新的工作流—— iPhone 和 iPad 都证明了这一点——但真正让他们操心的一直是“纸割”——那些不完美的细节。
|
||||
|
||||
它带出了 KDE 和 Gnome 之间最重要的一个区别。Gnome 感觉像一个产品,像一种非凡的体验。你用它的时候,觉得它是完整的,你要的东西都触手可及。它让人感觉就像是一个拥有 Windows 或者 OS X 那样桌面体验的 Linux 桌面版:你要的都在里面,而且它是被同一个目标一致的团队中的同一个人写出来的。天,即使是一个应用程序发出的 sudo 请求都感觉是 Gnome 下的一个特意设计的部分,就像在 Windows 下的一样。而在 KDE 下感觉就是随便一个应用程序都能创建的那种各种外观的弹窗。它不像是以系统本身这样的正式身份停下来说“嘿,有个东西要请求管理员权限!你要给它吗?”。
|
||||
|
||||
KDE 让人体验不到有凝聚力的体验。KDE 像是在没有方向地打转,感觉没有完整的体验。它就像是一堆东西往不同的的方向移动,只不过恰好它们都有一个共同享有的工具包而已。如果开发者对此很开心,那么好吧,他们开心就好,但是如果他们想提供最好体验的话,那么就需要多关注那些小地方了。用户体验跟直观应当做为每一个应用程序的设计中心,应当有一个视野,知道 KDE 要提供什么——并且——知道它看起来应该是什么样的。
|
||||
|
||||
是不是有什么原因阻止我在 KDE 下使用 Gnome 磁盘管理? Rhythmbox 呢? Evolution 呢? 没有,没有,没有。但是这样说又错过了关键。Gnome 和 KDE 都称它们自己为“桌面环境”。那么它们就应该是完整的环境,这意味着他们的各个部件应该汇集并紧密结合在一起,意味着你应该使用它们环境下的工具,因为它们说“您在一个完整的桌面中需要的任何东西,我们都支持。”说真的?只有 Gnome 看起来能符合完整的要求。KDE 在“汇集在一起”这一方面感觉就像个半成品,更不用说提供“完整体验”中你所需要的东西。Gnome 磁盘管理没有相应的对手—— kpartionmanage 要求 ROOT 权限。KDE 不运行“首次用户注册”的过程(原文:No 'First Time User' run through。可能是指系统安装过程中KDE没有创建新用户的过程,译注) ,现在也不过是在 Kubuntu 下引入了一个用户管理器。老天,Gnome 甚至提供了地图、笔记、日历和时钟应用。这些应用都是百分百要紧的吗?不,当然不了。但是正是这些应用帮助 Gnome 推动“Gnome 是一种完整丰富的体验”的想法。
|
||||
|
||||
我吐槽的 KDE 问题并非不可能解决,决对不是这样的!但是它需要人去关心它。它需要开发者为他们的作品感到自豪,而不仅仅是为它们实现的功能而感到自豪——组织的价值可大了去了。别夺走用户设置选项的能力—— GNOME 3.x 就是因为缺乏配置选项的能力而为我所诟病,但别把“好吧,你想怎么设置就怎么设置”作为借口而不提供任何理智的默认设置。默认设置是用户将看到的东西,它们是用户从打开软件的第一刻开始进行评判的关键。给用户留个好印象吧。
|
||||
|
||||
我知道 KDE 开发者们知道设计很重要,这也是为什么VDG(Visual Design Group 视觉设计组)存在的原因,但是感觉好像他们没有让 VDG 充分发挥,所以 KDE 里存在组织上的缺陷。不是 KDE 没办法完整,不是它没办法汇集整合在一起然后解决衰败问题,只是开发者们没做到。他们瞄准了靶心……但是偏了。
|
||||
|
||||
还有,在任何人说这句话之前……千万别说“欢迎给我们提交补丁啊"。因为当我开心的为某个人提交补丁时,只要开发者坚持以他们喜欢的却不直观的方式干事,更多这样的烦人事就会不断发生。这不关 Muon 有没有中心对齐。也不关 Amarok 的界面太丑。也不关每次我敲下快捷键后,弹出的音量和亮度调节窗口占用了我一大块的屏幕“地皮”(说真的,有人会把这些东西缩小)。
|
||||
|
||||
这跟心态的冷漠有关,跟开发者们在为他们的应用设计 UI 时根本就不多加思考有关。KDE 团队做的东西都工作得很好。Amarok 能播放音乐。Dragon 能播放视频。Kwin 或 Qt 和 kdelibs 似乎比 Mutter/gtk 更有力更效率(仅根据我的电池电量消耗计算。非科学性测试)。这些都很好,很重要……但是它们呈现的方式也很重要。甚至可以说,呈现方式是最重要的,因为它是用户看到的并与之交互的东西。
|
||||
|
||||
KDE 应用开发者们……让 VDG 参与进来吧。让 VDG 审查并核准每一个“核心”应用,让一个 VDG 的 UI/UX 专家来设计应用的使用模式和使用流程,以此保证其直观性。真见鬼,不管你们在开发的是啥应用,仅仅把它的模型发到 VDG 论坛寻求反馈甚至都可能都能得到一些非常好的指点跟反馈。你有这么好的资源在这,现在赶紧用吧。
|
||||
|
||||
我不想说得好像我一点都不懂感恩。我爱 KDE,我爱那些志愿者们为了给 Linux 用户一个可视化的桌面而付出的工作与努力,也爱可供选择的 Gnome。正是因为我关心我才写这篇文章。因为我想看到更好的 KDE,我想看到它走得比以前更加遥远。而这样做需要每个人继续努力,并且需要人们不再躲避批评。它需要人们对系统互动及系统崩溃的地方都保持诚实。如果我们不能直言批评,如果我们不说“这真垃圾!”,那么情况永远不会变好。
|
||||
|
||||
这周后我会继续使用 Gnome 吗?可能不。应该不。Gnome 还在试着强迫我接受其工作流,而我不想追随,也不想遵循,因为我在使用它的时候感觉变得不够高效,因为它并不遵循我的思维模式。可是对于我的朋友们,当他们问我“我该用哪种桌面环境?”我可能会推荐 Gnome,特别是那些不大懂技术,只要求“能工作”就行的朋友。根据目前 KDE 的形势来看,这可能是我能说出的最狠毒的评估了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=article&item=gnome-week-editorial&num=5
|
||||
|
||||
作者:Eric Griffith
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,291 @@
|
||||
如何在 Ubuntu 上安装配置管理系统 Chef (大厨)
|
||||
================================================================================
|
||||
Chef是面对IT专业人员的一款配置管理和自动化工具,它可以配置和管理你的基础设施,无论它在本地还是在云上。它可以用于加速应用部署并协调多个系统管理员和开发人员的工作,这涉及到可支持大量的客户群的成百上千的服务器和程序。chef最有用的是让基础设施变成代码。一旦你掌握了Chef,你可以获得一流的网络IT支持来自动化管理你的云端基础设施或者终端用户。
|
||||
|
||||
下面是我们将要在本篇中要设置和配置Chef的主要组件。
|
||||
|
||||

|
||||
|
||||
### 安装Chef的要求和版本 ###
|
||||
|
||||
我们将在下面的基础环境下设置Chef配置管理系统。
|
||||
|
||||
|管理和配置工具:Chef||
|
||||
|-------------------------------|---|
|
||||
|基础操作系统|Ubuntu 14.04.1 LTS (x86_64)|
|
||||
|Chef Server|Version 12.1.0|
|
||||
|Chef Manage|Version 1.17.0|
|
||||
|Chef Development Kit|Version 0.6.2|
|
||||
|内存和CPU|4 GB , 2.0+2.0 GHz|
|
||||
|
||||
### Chef服务端的安装和配置 ###
|
||||
|
||||
Chef服务端是核心组件,它存储配置以及其他和工作站交互的配置数据。让我们在他们的官网下载最新的安装文件。
|
||||
|
||||
我使用下面的命令来下载和安装它。
|
||||
|
||||
####1) 下载Chef服务端
|
||||
|
||||
root@ubuntu-14-chef:/tmp# wget https://web-dl.packagecloud.io/chef/stable/packages/ubuntu/trusty/chef-server-core_12.1.0-1_amd64.deb
|
||||
|
||||
####2) 安装Chef服务端
|
||||
|
||||
root@ubuntu-14-chef:/tmp# dpkg -i chef-server-core_12.1.0-1_amd64.deb
|
||||
|
||||
####3) 重新配置Chef服务端
|
||||
|
||||
现在运行下面的命令来启动所有的chef服务端服务,这步也许会花费一些时间,因为它有许多不同一起工作的服务组成来创建一个正常运作的系统。
|
||||
|
||||
root@ubuntu-14-chef:/tmp# chef-server-ctl reconfigure
|
||||
|
||||
chef服务端启动命令'chef-server-ctl reconfigure'需要运行两次,这样就会在安装后看到这样的输出。
|
||||
|
||||
Chef Client finished, 342/350 resources updated in 113.71139964 seconds
|
||||
opscode Reconfigured!
|
||||
|
||||
####4) 重启系统
|
||||
|
||||
安装完成后重启系统使系统能最好的工作,不然我们或许会在创建用户的时候看到下面的SSL连接错误。
|
||||
|
||||
ERROR: Errno::ECONNRESET: Connection reset by peer - SSL_connect
|
||||
|
||||
####5) 创建新的管理员
|
||||
|
||||
运行下面的命令来创建一个新的管理员账户及其配置。创建过程中,用户的RSA私钥会自动生成,它需要保存到一个安全的地方。--file选项会保存RSA私钥到指定的路径下。
|
||||
|
||||
root@ubuntu-14-chef:/tmp# chef-server-ctl user-create kashi kashi kashi kashif.fareedi@gmail.com kashi123 --filename /root/kashi.pem
|
||||
|
||||
### Chef服务端的管理设置 ###
|
||||
|
||||
Chef Manage是一个针对企业Chef用户的管理控制台,它提供了可视化的web用户界面,可以管理节点、数据包、规则、环境、Cookbook 和基于角色的访问控制(RBAC)
|
||||
|
||||
####1) 下载Chef Manage
|
||||
|
||||
从官网复制链接并下载chef manage的安装包。
|
||||
|
||||
root@ubuntu-14-chef:~# wget https://web-dl.packagecloud.io/chef/stable/packages/ubuntu/trusty/opscode-manage_1.17.0-1_amd64.deb
|
||||
|
||||
####2) 安装Chef Manage
|
||||
|
||||
使用下面的命令在root的家目录下安装它。
|
||||
|
||||
root@ubuntu-14-chef:~# chef-server-ctl install opscode-manage --path /root
|
||||
|
||||
####3) 重启Chef Manage和服务端
|
||||
|
||||
安装完成后我们需要运行下面的命令来重启chef manage和服务端。
|
||||
|
||||
root@ubuntu-14-chef:~# opscode-manage-ctl reconfigure
|
||||
root@ubuntu-14-chef:~# chef-server-ctl reconfigure
|
||||
|
||||
### Chef Manage网页控制台 ###
|
||||
|
||||
我们可以使用localhost或它的全称域名来访问网页控制台,并用已经创建的管理员登录
|
||||
|
||||

|
||||
|
||||
####1) Chef Manage创建新的组织
|
||||
|
||||
你或许被要求创建新的组织,或者也可以接受其他组织的邀请。如下所示,使用缩写和全名来创建一个新的组织。
|
||||
|
||||

|
||||
|
||||
####2) 用命令行创建新的组织
|
||||
|
||||
我们同样也可以运行下面的命令来创建新的组织。
|
||||
|
||||
root@ubuntu-14-chef:~# chef-server-ctl org-create linux Linoxide Linux Org. --association_user kashi --filename linux.pem
|
||||
|
||||
### 设置工作站 ###
|
||||
|
||||
我们已经完成安装chef服务端,现在我们可以开始创建任何recipes([基础配置元素](https://docs.chef.io/recipes.html))、cookbooks([基础配置集](https://docs.chef.io/cookbooks.html))、attributes([节点属性](https://docs.chef.io/attributes.html))和其他任何的我们想要对Chef做的修改。
|
||||
|
||||
####1) 在Chef服务端上创建新的用户和组织
|
||||
|
||||
为了设置工作站,我们用命令行创建一个新的用户和组织。
|
||||
|
||||
root@ubuntu-14-chef:~# chef-server-ctl user-create bloger Bloger Kashif bloger.kashif@gmail.com bloger123 --filename bloger.pem
|
||||
|
||||
root@ubuntu-14-chef:~# chef-server-ctl org-create blogs Linoxide Blogs Inc. --association_user bloger --filename blogs.pem
|
||||
|
||||
####2) 下载工作站入门套件
|
||||
|
||||
在工作站的网页控制台中下载保存入门套件,它用于与服务端协同工作
|
||||
|
||||

|
||||
|
||||
####3) 下载套件后,点击"Proceed"
|
||||
|
||||

|
||||
|
||||
### 用于工作站的Chef开发套件设置 ###
|
||||
|
||||
Chef开发套件是一款包含开发chef所需的所有工具的软件包。它捆绑了由Chef开发的带Chef客户端的工具。
|
||||
|
||||
####1) 下载 Chef DK
|
||||
|
||||
我们可以从它的官网链接中下载开发包,并选择操作系统来下载chef开发包。
|
||||
|
||||

|
||||
|
||||
复制链接并用wget下载
|
||||
|
||||
root@ubuntu-15-WKS:~# wget https://opscode-omnibus-packages.s3.amazonaws.com/ubuntu/12.04/x86_64/chefdk_0.6.2-1_amd64.deb
|
||||
|
||||
####2) Chef开发套件安装
|
||||
|
||||
使用dpkg命令安装开发套件
|
||||
|
||||
root@ubuntu-15-WKS:~# dpkg -i chefdk_0.6.2-1_amd64.deb
|
||||
|
||||
####3) Chef DK 验证
|
||||
|
||||
使用下面的命令验证客户端是否已经正确安装。
|
||||
|
||||
root@ubuntu-15-WKS:~# chef verify
|
||||
|
||||
----------
|
||||
|
||||
Running verification for component 'berkshelf'
|
||||
Running verification for component 'test-kitchen'
|
||||
Running verification for component 'chef-client'
|
||||
Running verification for component 'chef-dk'
|
||||
Running verification for component 'chefspec'
|
||||
Running verification for component 'rubocop'
|
||||
Running verification for component 'fauxhai'
|
||||
Running verification for component 'knife-spork'
|
||||
Running verification for component 'kitchen-vagrant'
|
||||
Running verification for component 'package installation'
|
||||
Running verification for component 'openssl'
|
||||
..............
|
||||
---------------------------------------------
|
||||
Verification of component 'rubocop' succeeded.
|
||||
Verification of component 'knife-spork' succeeded.
|
||||
Verification of component 'openssl' succeeded.
|
||||
Verification of component 'berkshelf' succeeded.
|
||||
Verification of component 'chef-dk' succeeded.
|
||||
Verification of component 'fauxhai' succeeded.
|
||||
Verification of component 'test-kitchen' succeeded.
|
||||
Verification of component 'kitchen-vagrant' succeeded.
|
||||
Verification of component 'chef-client' succeeded.
|
||||
Verification of component 'chefspec' succeeded.
|
||||
Verification of component 'package installation' succeeded.
|
||||
|
||||
####4) 连接Chef服务端
|
||||
|
||||
我们将创建 ~/.chef并从chef服务端复制两个用户和组织的pem文件到chef的文件到这个目录下。
|
||||
|
||||
root@ubuntu-14-chef:~# scp bloger.pem blogs.pem kashi.pem linux.pem root@172.25.10.172:/.chef/
|
||||
|
||||
----------
|
||||
|
||||
root@172.25.10.172's password:
|
||||
bloger.pem 100% 1674 1.6KB/s 00:00
|
||||
blogs.pem 100% 1674 1.6KB/s 00:00
|
||||
kashi.pem 100% 1678 1.6KB/s 00:00
|
||||
linux.pem 100% 1678 1.6KB/s 00:00
|
||||
|
||||
####5) 编辑配置来管理chef环境
|
||||
|
||||
现在使用下面的内容创建"~/.chef/knife.rb"。
|
||||
|
||||
root@ubuntu-15-WKS:/.chef# vim knife.rb
|
||||
current_dir = File.dirname(__FILE__)
|
||||
|
||||
log_level :info
|
||||
log_location STDOUT
|
||||
node_name "kashi"
|
||||
client_key "#{current_dir}/kashi.pem"
|
||||
validation_client_name "kashi-linux"
|
||||
validation_key "#{current_dir}/linux.pem"
|
||||
chef_server_url "https://172.25.10.173/organizations/linux"
|
||||
cache_type 'BasicFile'
|
||||
cache_options( :path => "#{ENV['HOME']}/.chef/checksums" )
|
||||
cookbook_path ["#{current_dir}/../cookbooks"]
|
||||
|
||||
创建knife.rb中指定的“~/cookbooks”文件夹。
|
||||
|
||||
root@ubuntu-15-WKS:/# mkdir cookbooks
|
||||
|
||||
####6) 测试Knife配置
|
||||
|
||||
运行“knife user list”和“knife client list”来验证knife是否在工作。
|
||||
|
||||
root@ubuntu-15-WKS:/.chef# knife user list
|
||||
|
||||
第一次运行的时候可能会看到下面的错误,这是因为工作站上还没有chef服务端的SSL证书。
|
||||
|
||||
ERROR: SSL Validation failure connecting to host: 172.25.10.173 - SSL_connect returned=1 errno=0 state=SSLv3 read server certificate B: certificate verify failed
|
||||
ERROR: Could not establish a secure connection to the server.
|
||||
Use `knife ssl check` to troubleshoot your SSL configuration.
|
||||
If your Chef Server uses a self-signed certificate, you can use
|
||||
`knife ssl fetch` to make knife trust the server's certificates.
|
||||
|
||||
要从上面的命令中恢复,运行下面的命令来获取ssl证书,并重新运行knife user和client list,这时候应该就可以了。
|
||||
|
||||
root@ubuntu-15-WKS:/.chef# knife ssl fetch
|
||||
WARNING: Certificates from 172.25.10.173 will be fetched and placed in your trusted_cert
|
||||
directory (/.chef/trusted_certs).
|
||||
|
||||
knife没有办法验证这些是有效的证书。你应该在下载时候验证这些证书的真实性。
|
||||
|
||||
在/.chef/trusted_certs/ubuntu-14-chef_test_com.crt下面添加ubuntu-14-chef.test.com的证书。
|
||||
|
||||
在上面的命令取得ssl证书后,接着运行下面的命令。
|
||||
|
||||
root@ubuntu-15-WKS:/.chef#knife client list
|
||||
kashi-linux
|
||||
|
||||
### 配置与chef服务端交互的新节点 ###
|
||||
|
||||
节点是执行所有基础设施自动化的chef客户端。因此,在配置完chef-server和knife工作站后,通过配置新的与chef-server交互的节点,来添加新的服务端到我们的chef环境下。
|
||||
|
||||
我们使用下面的命令来添加新的节点与chef服务端工作。
|
||||
|
||||
root@ubuntu-15-WKS:~# knife bootstrap 172.25.10.170 --ssh-user root --ssh-password kashi123 --node-name mydns
|
||||
|
||||
----------
|
||||
|
||||
Doing old-style registration with the validation key at /.chef/linux.pem...
|
||||
Delete your validation key in order to use your user credentials instead
|
||||
|
||||
Connecting to 172.25.10.170
|
||||
172.25.10.170 Installing Chef Client...
|
||||
172.25.10.170 --2015-07-04 22:21:16-- https://www.opscode.com/chef/install.sh
|
||||
172.25.10.170 Resolving www.opscode.com (www.opscode.com)... 184.106.28.91
|
||||
172.25.10.170 Connecting to www.opscode.com (www.opscode.com)|184.106.28.91|:443... connected.
|
||||
172.25.10.170 HTTP request sent, awaiting response... 200 OK
|
||||
172.25.10.170 Length: 18736 (18K) [application/x-sh]
|
||||
172.25.10.170 Saving to: ‘STDOUT’
|
||||
172.25.10.170
|
||||
100%[======================================>] 18,736 --.-K/s in 0s
|
||||
172.25.10.170
|
||||
172.25.10.170 2015-07-04 22:21:17 (200 MB/s) - written to stdout [18736/18736]
|
||||
172.25.10.170
|
||||
172.25.10.170 Downloading Chef 12 for ubuntu...
|
||||
172.25.10.170 downloading https://www.opscode.com/chef/metadata?v=12&prerelease=false&nightlies=false&p=ubuntu&pv=14.04&m=x86_64
|
||||
172.25.10.170 to file /tmp/install.sh.26024/metadata.txt
|
||||
172.25.10.170 trying wget...
|
||||
|
||||
之后我们可以在knife节点列表下看到新创建的节点,它也会在新节点创建新的客户端。
|
||||
|
||||
root@ubuntu-15-WKS:~# knife node list
|
||||
mydns
|
||||
|
||||
相似地我们只要提供ssh证书通过上面的knife命令,就可以在chef设施上创建多个节点。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
本篇我们学习了chef管理工具并通过安装和配置设置基本了解了它的组件。我希望你在学习安装和配置Chef服务端以及它的工作站和客户端节点中获得乐趣。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/install-configure-chef-ubuntu-14-04-15-04/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
178
published/20150717 How to collect NGINX metrics - Part 2.md
Normal file
178
published/20150717 How to collect NGINX metrics - Part 2.md
Normal file
@ -0,0 +1,178 @@
|
||||
|
||||
如何收集 NGINX 指标(第二篇)
|
||||
================================================================================
|
||||

|
||||
|
||||
### 如何获取你所需要的 NGINX 指标 ###
|
||||
|
||||
如何获取需要的指标取决于你正在使用的 NGINX 版本以及你希望看到哪些指标。(参见 [如何监控 NGINX(第一篇)][1] 来深入了解NGINX指标。)自由开源的 NGINX 和商业版的 NGINX Plus 都有可以报告指标度量的状态模块,NGINX 也可以在其日志中配置输出特定指标:
|
||||
|
||||
**指标可用性**
|
||||
|
||||
| 指标 | [NGINX (开源)](https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source) | [NGINX Plus](https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#plus) | [NGINX 日志](https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#logs)|
|
||||
|-----|------|-------|-----|
|
||||
|accepts(接受) / accepted(已接受)|x|x| |
|
||||
|handled(已处理)|x|x| |
|
||||
|dropped(已丢弃)|x|x| |
|
||||
|active(活跃)|x|x| |
|
||||
|requests (请求数)/ total(全部请求数)|x|x| |
|
||||
|4xx 代码||x|x|
|
||||
|5xx 代码||x|x|
|
||||
|request time(请求处理时间)|||x|
|
||||
|
||||
#### 指标收集:NGINX(开源版) ####
|
||||
|
||||
开源版的 NGINX 会在一个简单的状态页面上显示几个与服务器状态有关的基本指标,它们由你启用的 HTTP [stub status module][2] 所提供。要检查该模块是否已启用,运行以下命令:
|
||||
|
||||
nginx -V 2>&1 | grep -o with-http_stub_status_module
|
||||
|
||||
如果你看到终端输出了 **http_stub_status_module**,说明该状态模块已启用。
|
||||
|
||||
如果该命令没有输出,你需要启用该状态模块。你可以在[从源代码构建 NGINX ][3]时使用 `--with-http_stub_status_module` 配置参数:
|
||||
|
||||
./configure \
|
||||
… \
|
||||
--with-http_stub_status_module
|
||||
make
|
||||
sudo make install
|
||||
|
||||
在验证该模块已经启用或你自己启用它后,你还需要修改 NGINX 配置文件,来给状态页面设置一个本地可访问的 URL(例如: /nginx_status):
|
||||
|
||||
server {
|
||||
location /nginx_status {
|
||||
stub_status on;
|
||||
|
||||
access_log off;
|
||||
allow 127.0.0.1;
|
||||
deny all;
|
||||
}
|
||||
}
|
||||
|
||||
注:nginx 配置中的 server 块通常并不放在主配置文件中(例如:/etc/nginx/nginx.conf),而是放在主配置会加载的辅助配置文件中。要找到主配置文件,首先运行以下命令:
|
||||
|
||||
nginx -t
|
||||
|
||||
打开列出的主配置文件,在以 http 块结尾的附近查找以 include 开头的行,如:
|
||||
|
||||
include /etc/nginx/conf.d/*.conf;
|
||||
|
||||
在其中一个包含的配置文件中,你应该会找到主 **server** 块,你可以如上所示配置 NGINX 的指标输出。更改任何配置后,通过执行以下命令重新加载配置文件:
|
||||
|
||||
nginx -s reload
|
||||
|
||||
现在,你可以浏览状态页看到你的指标:
|
||||
|
||||
Active connections: 24
|
||||
server accepts handled requests
|
||||
1156958 1156958 4491319
|
||||
Reading: 0 Writing: 18 Waiting : 6
|
||||
|
||||
请注意,如果你希望从远程计算机访问该状态页面,则需要将远程计算机的 IP 地址添加到你的状态配置文件的白名单中,在上面的配置文件中的白名单仅有 127.0.0.1。
|
||||
|
||||
NGINX 的状态页面是一种快速查看指标状况的简单方法,但当连续监测时,你需要按照标准间隔自动记录该数据。监控工具箱 [Nagios][4] 或者 [Datadog][5],以及收集统计信息的服务 [collectD][6] 已经可以解析 NGINX 的状态信息了。
|
||||
|
||||
#### 指标收集: NGINX Plus ####
|
||||
|
||||
商业版的 NGINX Plus 通过它的 ngx_http_status_module 提供了比开源版 NGINX [更多的指标][7]。NGINX Plus 以字节流的方式提供这些额外的指标,提供了关于上游系统和高速缓存的信息。NGINX Plus 也会报告所有的 HTTP 状态码类型(1XX,2XX,3XX,4XX,5XX)的计数。一个 NGINX Plus 状态报告例子[可在此查看][8]:
|
||||
|
||||

|
||||
|
||||
注:NGINX Plus 在状态仪表盘中的“Active”连接的定义和开源 NGINX 通过 stub_status_module 收集的“Active”连接指标略有不同。在 NGINX Plus 指标中,“Active”连接不包括Waiting状态的连接(即“Idle”连接)。
|
||||
|
||||
NGINX Plus 也可以输出 [JSON 格式的指标][9],可以用于集成到其他监控系统。在 NGINX Plus 中,你可以看到 [给定的上游服务器组][10]的指标和健康状况,或者简单地从上游服务器的[单个服务器][11]得到响应代码的计数:
|
||||
|
||||
{"1xx":0,"2xx":3483032,"3xx":0,"4xx":23,"5xx":0,"total":3483055}
|
||||
|
||||
要启动 NGINX Plus 指标仪表盘,你可以在 NGINX 配置文件的 http 块内添加状态 server 块。 (参见上一节,为收集开源版 NGINX 指标而如何查找相关的配置文件的说明。)例如,要设置一个状态仪表盘 (http://your.ip.address:8080/status.html)和一个 JSON 接口(http://your.ip.address:8080/status),可以添加以下 server 块来设定:
|
||||
|
||||
server {
|
||||
listen 8080;
|
||||
root /usr/share/nginx/html;
|
||||
|
||||
location /status {
|
||||
status;
|
||||
}
|
||||
|
||||
location = /status.html {
|
||||
}
|
||||
}
|
||||
|
||||
当你重新加载 NGINX 配置后,状态页就可以用了:
|
||||
|
||||
nginx -s reload
|
||||
|
||||
关于如何配置扩展状态模块,官方 NGINX Plus 文档有 [详细介绍][13] 。
|
||||
|
||||
#### 指标收集:NGINX 日志 ####
|
||||
|
||||
NGINX 的 [日志模块][14] 会把可自定义的访问日志写到你配置的指定位置。你可以通过[添加或移除变量][15]来自定义日志的格式和包含的数据。要存储详细的日志,最简单的方法是添加下面一行在你配置文件的 server 块中(参见上上节,为收集开源版 NGINX 指标而如何查找相关的配置文件的说明。):
|
||||
|
||||
access_log logs/host.access.log combined;
|
||||
|
||||
更改 NGINX 配置文件后,执行如下命令重新加载配置文件:
|
||||
|
||||
nginx -s reload
|
||||
|
||||
默认包含的 “combined” 的日志格式,会包括[一系列关键的数据][17],如实际的 HTTP 请求和相应的响应代码。在下面的示例日志中,NGINX 记录了请求 /index.html 时的 200(成功)状态码和访问不存在的请求文件 /fail 的 404(未找到)错误。
|
||||
|
||||
127.0.0.1 - - [19/Feb/2015:12:10:46 -0500] "GET /index.html HTTP/1.1" 200 612 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari 537.36"
|
||||
|
||||
127.0.0.1 - - [19/Feb/2015:12:11:05 -0500] "GET /fail HTTP/1.1" 404 570 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari/537.36"
|
||||
|
||||
你可以通过在 NGINX 配置文件中的 http 块添加一个新的日志格式来记录请求处理时间:
|
||||
|
||||
log_format nginx '$remote_addr - $remote_user [$time_local] '
|
||||
'"$request" $status $body_bytes_sent $request_time '
|
||||
'"$http_referer" "$http_user_agent"';
|
||||
|
||||
并修改配置文件中 **server** 块的 access_log 行:
|
||||
|
||||
access_log logs/host.access.log nginx;
|
||||
|
||||
重新加载配置文件后(运行 `nginx -s reload`),你的访问日志将包括响应时间,如下所示。单位为秒,精度到毫秒。在这个例子中,服务器接收到一个对 /big.pdf 的请求时,发送 33973115 字节后返回 206(成功)状态码。处理请求用时 0.202 秒(202毫秒):
|
||||
|
||||
127.0.0.1 - - [19/Feb/2015:15:50:36 -0500] "GET /big.pdf HTTP/1.1" 206 33973115 0.202 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari/537.36"
|
||||
|
||||
你可以使用各种工具和服务来解析和分析 NGINX 日志。例如,[rsyslog][18] 可以监视你的日志,并将其传递给多个日志分析服务;你也可以使用自由开源工具,比如 [logstash][19] 来收集和分析日志;或者你可以使用一个统一日志记录层,如 [Fluentd][20] 来收集和解析你的 NGINX 日志。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
监视 NGINX 的哪一项指标将取决于你可用的工具,以及监控指标所提供的信息是否满足你们的需要。举例来说,错误率的收集是否足够重要到需要你们购买 NGINX Plus ,还是架设一个可以捕获和分析日志的系统就够了?
|
||||
|
||||
在 Datadog 中,我们已经集成了 NGINX 和 NGINX Plus,这样你就可以以最小的设置来收集和监控所有 Web 服务器的指标。[在本文中][21]了解如何用 NGINX Datadog 来监控 ,并开始 [Datadog 的免费试用][22]吧。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
|
||||
作者:K Young
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.datadoghq.com/blog/how-to-monitor-nginx/
|
||||
[2]:http://nginx.org/en/docs/http/ngx_http_stub_status_module.html
|
||||
[3]:http://wiki.nginx.org/InstallOptions
|
||||
[4]:https://exchange.nagios.org/directory/Plugins/Web-Servers/nginx
|
||||
[5]:http://docs.datadoghq.com/integrations/nginx/
|
||||
[6]:https://collectd.org/wiki/index.php/Plugin:nginx
|
||||
[7]:http://nginx.org/en/docs/http/ngx_http_status_module.html#data
|
||||
[8]:http://demo.nginx.com/status.html
|
||||
[9]:http://demo.nginx.com/status
|
||||
[10]:http://demo.nginx.com/status/upstreams/demoupstreams
|
||||
[11]:http://demo.nginx.com/status/upstreams/demoupstreams/0/responses
|
||||
[12]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source
|
||||
[13]:http://nginx.org/en/docs/http/ngx_http_status_module.html#example
|
||||
[14]:http://nginx.org/en/docs/http/ngx_http_log_module.html
|
||||
[15]:http://nginx.org/en/docs/http/ngx_http_log_module.html#log_format
|
||||
[16]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source
|
||||
[17]:http://nginx.org/en/docs/http/ngx_http_log_module.html#log_format
|
||||
[18]:http://www.rsyslog.com/
|
||||
[19]:https://www.elastic.co/products/logstash
|
||||
[20]:http://www.fluentd.org/
|
||||
[21]:https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/
|
||||
[22]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#sign-up
|
||||
[23]:https://github.com/DataDog/the-monitor/blob/master/nginx/how_to_collect_nginx_metrics.md
|
||||
[24]:https://github.com/DataDog/the-monitor/issues
|
||||
146
published/20150717 How to monitor NGINX with Datadog - Part 3.md
Normal file
146
published/20150717 How to monitor NGINX with Datadog - Part 3.md
Normal file
@ -0,0 +1,146 @@
|
||||
如何使用 Datadog 监控 NGINX(第三篇)
|
||||
================================================================================
|
||||

|
||||
|
||||
如果你已经阅读了前面的[如何监控 NGINX][1],你应该知道从你网络环境的几个指标中可以获取多少信息。而且你也看到了从 NGINX 特定的基础中收集指标是多么容易的。但要实现全面,持续的监控 NGINX,你需要一个强大的监控系统来存储并将指标可视化,当异常发生时能提醒你。在这篇文章中,我们将向你展示如何使用 Datadog 安装 NGINX 监控,以便你可以在定制的仪表盘中查看这些指标:
|
||||
|
||||

|
||||
|
||||
Datadog 允许你以单个主机、服务、流程和度量来构建图形和警告,或者使用它们的几乎任何组合构建。例如,你可以监控你的所有主机,或者某个特定可用区域的所有NGINX主机,或者您可以监视具有特定标签的所有主机的一个关键指标。本文将告诉您如何:
|
||||
|
||||
- 在 Datadog 仪表盘上监控 NGINX 指标,就像监控其他系统一样
|
||||
- 当一个关键指标急剧变化时设置自动警报来通知你
|
||||
|
||||
### 配置 NGINX ###
|
||||
|
||||
为了收集 NGINX 指标,首先需要确保 NGINX 已启用 status 模块和一个 报告 status 指标的 URL。一步步的[配置开源 NGINX][2] 和 [NGINX Plus][3] 请参见之前的相关文章。
|
||||
|
||||
### 整合 Datadog 和 NGINX ###
|
||||
|
||||
#### 安装 Datadog 代理 ####
|
||||
|
||||
Datadog 代理是[一个开源软件][4],它能收集和报告你主机的指标,这样就可以使用 Datadog 查看和监控他们。安装这个代理通常[仅需要一个命令][5]
|
||||
|
||||
只要你的代理启动并运行着,你会看到你主机的指标报告[在你 Datadog 账号下][6]。
|
||||
|
||||

|
||||
|
||||
#### 配置 Agent ####
|
||||
|
||||
接下来,你需要为代理创建一个简单的 NGINX 配置文件。在你系统中代理的配置目录应该[在这儿][7]找到。
|
||||
|
||||
在目录里面的 conf.d/nginx.yaml.example 中,你会发现[一个简单的配置文件][8],你可以编辑并提供 status URL 和可选的标签为每个NGINX 实例:
|
||||
|
||||
init_config:
|
||||
|
||||
instances:
|
||||
|
||||
- nginx_status_url: http://localhost/nginx_status/
|
||||
tags:
|
||||
- instance:foo
|
||||
|
||||
当你提供了 status URL 和任意 tag,将配置文件保存为 conf.d/nginx.yaml。
|
||||
|
||||
#### 重启代理 ####
|
||||
|
||||
你必须重新启动代理程序来加载新的配置文件。重新启动命令[在这里][9],根据平台的不同而不同。
|
||||
|
||||
#### 检查配置文件 ####
|
||||
|
||||
要检查 Datadog 和 NGINX 是否正确整合,运行 Datadog 的 info 命令。每个平台使用的命令[看这儿][10]。
|
||||
|
||||
如果配置是正确的,你会看到这样的输出:
|
||||
|
||||
Checks
|
||||
======
|
||||
|
||||
[...]
|
||||
|
||||
nginx
|
||||
-----
|
||||
- instance #0 [OK]
|
||||
- Collected 8 metrics & 0 events
|
||||
|
||||
#### 安装整合 ####
|
||||
|
||||
最后,在你的 Datadog 帐户打开“Nginx 整合”。这非常简单,你只要在 [NGINX 整合设置][11]中点击“Install Integration”按钮。
|
||||
|
||||

|
||||
|
||||
### 指标! ###
|
||||
|
||||
一旦代理开始报告 NGINX 指标,你会看到[一个 NGINX 仪表盘][12]出现在在你 Datadog 可用仪表盘的列表中。
|
||||
|
||||
基本的 NGINX 仪表盘显示有用的图表,囊括了几个[我们的 NGINX 监控介绍][13]中的关键指标。 (一些指标,特别是请求处理时间要求进行日志分析,Datadog 不支持。)
|
||||
|
||||
你可以通过增加 NGINX 之外的重要指标的图表来轻松创建一个全面的仪表盘,以监控你的整个网站设施。例如,你可能想监视你 NGINX 的主机级的指标,如系统负载。要构建一个自定义的仪表盘,只需点击靠近仪表盘的右上角的选项并选择“Clone Dash”来克隆一个默认的 NGINX 仪表盘。
|
||||
|
||||

|
||||
|
||||
你也可以使用 Datadog 的[主机地图][14]在更高层面监控你的 NGINX 实例,举个例子,用颜色标示你所有的 NGINX 主机的 CPU 使用率来辨别潜在热点。
|
||||
|
||||

|
||||
|
||||
### NGINX 指标警告 ###
|
||||
|
||||
一旦 Datadog 捕获并可视化你的指标,你可能会希望建立一些监控自动地密切关注你的指标,并当有问题提醒你。下面将介绍一个典型的例子:一个提醒你 NGINX 吞吐量突然下降时的指标监控器。
|
||||
|
||||
#### 监控 NGINX 吞吐量 ####
|
||||
|
||||
Datadog 指标警报可以是“基于吞吐量的”(当指标超过设定值会警报)或“基于变化幅度的”(当指标的变化超过一定范围会警报)。在这个例子里,我们会采取后一种方式,当每秒传入的请求急剧下降时会提醒我们。下降往往意味着有问题。
|
||||
|
||||
1. **创建一个新的指标监控**。从 Datadog 的“Monitors”下拉列表中选择“New Monitor”。选择“Metric”作为监视器类型。
|
||||
|
||||

|
||||
|
||||
2. **定义你的指标监视器**。我们想知道 NGINX 每秒总的请求量下降的数量,所以我们在基础设施中定义我们感兴趣的 nginx.net.request_per_s 之和。
|
||||
|
||||

|
||||
|
||||
3. **设置指标警报条件**。我们想要在变化时警报,而不是一个固定的值,所以我们选择“Change Alert”。我们设置监控为无论何时请求量下降了30%以上时警报。在这里,我们使用一个一分钟的数据窗口来表示 “now” 指标的值,对横跨该间隔内的平均变化和之前 10 分钟的指标值作比较。
|
||||
|
||||

|
||||
|
||||
4. **自定义通知**。如果 NGINX 的请求量下降,我们想要通知我们的团队。在这个例子中,我们将给 ops 团队的聊天室发送通知,并给值班工程师发送短信。在“Say what’s happening”中,我们会为监控器命名,并添加一个伴随该通知的短消息,建议首先开始调查的内容。我们会 @ ops 团队使用的 Slack,并 @pagerduty [将警告发给短信][15]。
|
||||
|
||||

|
||||
|
||||
5. **保存集成监控**。点击页面底部的“Save”按钮。你现在在监控一个关键的 NGINX [工作指标][16],而当它快速下跌时会给值班工程师发短信。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们谈到了通过整合 NGINX 与 Datadog 来可视化你的关键指标,并当你的网络基础架构有问题时会通知你的团队。
|
||||
|
||||
如果你一直使用你自己的 Datadog 账号,你现在应该可以极大的提升你的 web 环境的可视化,也有能力对你的环境、你所使用的模式、和对你的组织最有价值的指标创建自动监控。
|
||||
|
||||
如果你还没有 Datadog 帐户,你可以注册[免费试用][17],并开始监视你的基础架构,应用程序和现在的服务。
|
||||
|
||||
------------------------------------------------------------
|
||||
|
||||
via: https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/
|
||||
|
||||
作者:K Young
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://linux.cn/article-5970-1.html
|
||||
[2]:https://linux.cn/article-5985-1.html#open-source
|
||||
[3]:https://linux.cn/article-5985-1.html#plus
|
||||
[4]:https://github.com/DataDog/dd-agent
|
||||
[5]:https://app.datadoghq.com/account/settings#agent
|
||||
[6]:https://app.datadoghq.com/infrastructure
|
||||
[7]:http://docs.datadoghq.com/guides/basic_agent_usage/
|
||||
[8]:https://github.com/DataDog/dd-agent/blob/master/conf.d/nginx.yaml.example
|
||||
[9]:http://docs.datadoghq.com/guides/basic_agent_usage/
|
||||
[10]:http://docs.datadoghq.com/guides/basic_agent_usage/
|
||||
[11]:https://app.datadoghq.com/account/settings#integrations/nginx
|
||||
[12]:https://app.datadoghq.com/dash/integration/nginx
|
||||
[13]:https://linux.cn/article-5970-1.html
|
||||
[14]:https://www.datadoghq.com/blog/introducing-host-maps-know-thy-infrastructure/
|
||||
[15]:https://www.datadoghq.com/blog/pagerduty/
|
||||
[16]:https://www.datadoghq.com/blog/monitoring-101-collecting-data/#metrics
|
||||
[17]:https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/#sign-up
|
||||
[18]:https://github.com/DataDog/the-monitor/blob/master/nginx/how_to_monitor_nginx_with_datadog.md
|
||||
[19]:https://github.com/DataDog/the-monitor/issues
|
||||
231
published/20150717 How to monitor NGINX- Part 1.md
Normal file
231
published/20150717 How to monitor NGINX- Part 1.md
Normal file
@ -0,0 +1,231 @@
|
||||
如何监控 NGINX(第一篇)
|
||||
================================================================================
|
||||

|
||||
|
||||
### NGINX 是什么? ###
|
||||
|
||||
[NGINX][1] (发音为 “engine X”) 是一种流行的 HTTP 和反向代理服务器。作为一个 HTTP 服务器,NGINX 可以使用较少的内存非常高效可靠地提供静态内容。作为[反向代理][2],它可以用作多个后端服务器或类似缓存和负载平衡这样的其它应用的单一访问控制点。NGINX 是一个自由开源的产品,并有一个具备更全的功能的叫做 NGINX Plus 的商业版。
|
||||
|
||||
NGINX 也可以用作邮件代理和通用的 TCP 代理,但本文并不直接讨论 NGINX 的那些用例的监控。
|
||||
|
||||
### NGINX 主要指标 ###
|
||||
|
||||
通过监控 NGINX 可以 捕获到两类问题:NGINX 本身的资源问题,和出现在你的基础网络设施的其它问题。大多数 NGINX 用户会用到以下指标的监控,包括**每秒请求数**,它提供了一个由所有最终用户活动组成的上层视图;**服务器错误率** ,这表明你的服务器已经多长没有处理看似有效的请求;还有**请求处理时间**,这说明你的服务器处理客户端请求的总共时长(并且可以看出性能降低或当前环境的其他问题)。
|
||||
|
||||
更一般地,至少有三个主要的指标类别来监视:
|
||||
|
||||
- 基本活动指标
|
||||
- 错误指标
|
||||
- 性能指标
|
||||
|
||||
下面我们将分析在每个类别中最重要的 NGINX 指标,以及用一个相当普遍但是值得特别提到的案例来说明:使用 NGINX Plus 作反向代理。我们还将介绍如何使用图形工具或可选择的监控工具来监控所有的指标。
|
||||
|
||||
本文引用指标术语[来自我们的“监控 101 系列”][3],,它提供了一个指标收集和警告框架。
|
||||
|
||||
#### 基本活跃指标 ####
|
||||
|
||||
无论你在怎样的情况下使用 NGINX,毫无疑问你要监视服务器接收多少客户端请求和如何处理这些请求。
|
||||
|
||||
NGINX Plus 上像开源 NGINX 一样可以报告基本活跃指标,但它也提供了略有不同的辅助模块。我们首先讨论开源的 NGINX,再来说明 NGINX Plus 提供的其他指标的功能。
|
||||
|
||||
**NGINX**
|
||||
|
||||
下图显示了一个客户端连接的过程,以及开源版本的 NGINX 如何在连接过程中收集指标。
|
||||
|
||||

|
||||
|
||||
Accepts(接受)、Handled(已处理)、Requests(请求)是一直在增加的计数器。Active(活跃)、Waiting(等待)、Reading(读)、Writing(写)随着请求量而增减。
|
||||
|
||||
| 名称 | 描述| [指标类型](https://www.datadoghq.com/blog/monitoring-101-collecting-data/)|
|
||||
|-----------|-----------------|-------------------------------------------------------------------------------------------------------------------------|
|
||||
| Accepts | NGINX 所接受的客户端连接数 | 资源: 功能 |
|
||||
| Handled | 成功的客户端连接数 | 资源: 功能 |
|
||||
| Active | 当前活跃的客户端连接数| 资源: 功能 |
|
||||
| Dropped(已丢弃,计算得出)| 丢弃的连接数(接受 - 已处理)| 工作:错误*|
|
||||
| Requests | 客户端请求数 | 工作:吞吐量 |
|
||||
|
||||
|
||||
_*严格的来说,丢弃的连接是 [一个资源饱和指标](https://www.datadoghq.com/blog/monitoring-101-collecting-data/#resource-metrics),但是因为饱和会导致 NGINX 停止服务(而不是延后该请求),所以,“已丢弃”视作 [一个工作指标](https://www.datadoghq.com/blog/monitoring-101-collecting-data/#work-metrics) 比较合适。_
|
||||
|
||||
NGINX worker 进程接受 OS 的连接请求时 **Accepts** 计数器增加,而**Handled** 是当实际的请求得到连接时(通过建立一个新的连接或重新使用一个空闲的)。这两个计数器的值通常都是相同的,如果它们有差别则表明连接被**Dropped**,往往这是由于资源限制,比如已经达到 NGINX 的[worker_connections][4]的限制。
|
||||
|
||||
一旦 NGINX 成功处理一个连接时,连接会移动到**Active**状态,在这里对客户端请求进行处理:
|
||||
|
||||
Active状态
|
||||
|
||||
- **Waiting**: 活跃的连接也可以处于 Waiting 子状态,如果有在此刻没有活跃请求的话。新连接可以绕过这个状态并直接变为到 Reading 状态,最常见的是在使用“accept filter(接受过滤器)” 和 “deferred accept(延迟接受)”时,在这种情况下,NGINX 不会接收 worker 进程的通知,直到它具有足够的数据才开始响应。如果连接设置为 keep-alive ,那么它在发送响应后将处于等待状态。
|
||||
|
||||
- **Reading**: 当接收到请求时,连接离开 Waiting 状态,并且该请求本身使 Reading 状态计数增加。在这种状态下 NGINX 会读取客户端请求首部。请求首部是比较小的,因此这通常是一个快速的操作。
|
||||
|
||||
- **Writing**: 请求被读取之后,其使 Writing 状态计数增加,并保持在该状态,直到响应返回给客户端。这意味着,该请求在 Writing 状态时, 一方面 NGINX 等待来自上游系统的结果(系统放在 NGINX “后面”),另外一方面,NGINX 也在同时响应。请求往往会在 Writing 状态花费大量的时间。
|
||||
|
||||
通常,一个连接在同一时间只接受一个请求。在这种情况下,Active 连接的数目 == Waiting 的连接 + Reading 请求 + Writing 。然而,较新的 SPDY 和 HTTP/2 协议允许多个并发请求/响应复用一个连接,所以 Active 可小于 Waiting 的连接、 Reading 请求、Writing 请求的总和。 (在撰写本文时,NGINX 不支持 HTTP/2,但预计到2015年期间将会支持。)
|
||||
|
||||
**NGINX Plus**
|
||||
|
||||
正如上面提到的,所有开源 NGINX 的指标在 NGINX Plus 中是可用的,但另外也提供其他的指标。本节仅说明了 NGINX Plus 可用的指标。
|
||||
|
||||
|
||||

|
||||
|
||||
Accepted (已接受)、Dropped,总数是不断增加的计数器。Active、 Idle(空闲)和处于 Current(当前)处理阶段的各种状态下的连接或请求的当前数量随着请求量而增减。
|
||||
|
||||
| 名称 | 描述| [指标类型](https://www.datadoghq.com/blog/monitoring-101-collecting-data/)|
|
||||
|-----------|-----------------|-------------------------------------------------------------------------------------------------------------------------|
|
||||
| Accepted | NGINX 所接受的客户端连接数 | 资源: 功能 |
|
||||
| Dropped |丢弃的连接数(接受 - 已处理)| 工作:错误*|
|
||||
| Active | 当前活跃的客户端连接数| 资源: 功能 |
|
||||
| Idle | 没有当前请求的客户端连接| 资源: 功能 |
|
||||
| Total(全部) | 客户端请求数 | 工作:吞吐量 |
|
||||
|
||||
_*严格的来说,丢弃的连接是 [一个资源饱和指标](https://www.datadoghq.com/blog/monitoring-101-collecting-data/#resource-metrics),但是因为饱和会导致 NGINX 停止服务(而不是延后该请求),所以,“已丢弃”视作 [一个工作指标](https://www.datadoghq.com/blog/monitoring-101-collecting-data/#work-metrics) 比较合适。_
|
||||
|
||||
当 NGINX Plus worker 进程接受 OS 的连接请求时 **Accepted** 计数器递增。如果 worker 进程为请求建立连接失败(通过建立一个新的连接或重新使用一个空闲),则该连接被丢弃, **Dropped** 计数增加。通常连接被丢弃是因为资源限制,如 NGINX Plus 的[worker_connections][4]的限制已经达到。
|
||||
|
||||
**Active** 和 **Idle** 和[如上所述][5]的开源 NGINX 的“active” 和 “waiting”状态是相同的,但是有一点关键的不同:在开源 NGINX 上,“waiting”状态包括在“active”中,而在 NGINX Plus 上“idle”的连接被排除在“active” 计数外。**Current** 和开源 NGINX 是一样的也是由“reading + writing” 状态组成。
|
||||
|
||||
**Total** 为客户端请求的累积计数。请注意,单个客户端连接可涉及多个请求,所以这个数字可能会比连接的累计次数明显大。事实上,(total / accepted)是每个连接的平均请求数量。
|
||||
|
||||
**开源 和 Plus 之间指标的不同**
|
||||
|
||||
|NGINX (开源) |NGINX Plus|
|
||||
|-----------------------|----------------|
|
||||
| accepts | accepted |
|
||||
| dropped 通过计算得来| dropped 直接得到 |
|
||||
| reading + writing| current|
|
||||
| waiting| idle|
|
||||
| active (包括 “waiting”状态) | active (排除 “idle” 状态)|
|
||||
| requests| total|
|
||||
|
||||
**提醒指标: 丢弃连接**
|
||||
|
||||
被丢弃的连接数目等于 Accepts 和 Handled 之差(NGINX 中),或是可直接得到标准指标(NGINX Plus 中)。在正常情况下,丢弃连接数应该是零。如果在每个单位时间内丢弃连接的速度开始上升,那么应该看看是否资源饱和了。
|
||||
|
||||

|
||||
|
||||
**提醒指标: 每秒请求数**
|
||||
|
||||
按固定时间间隔采样你的请求数据(开源 NGINX 的**requests**或者 NGINX Plus 中**total**) 会提供给你单位时间内(通常是分钟或秒)所接受的请求数量。监测这个指标可以查看进入的 Web 流量尖峰,无论是合法的还是恶意的,或者突然的下降,这通常都代表着出现了问题。每秒请求数若发生急剧变化可以提醒你的环境出现问题了,即使它不能告诉你确切问题的位置所在。请注意,所有的请求都同样计数,无论 URL 是什么。
|
||||
|
||||

|
||||
|
||||
**收集活跃指标**
|
||||
|
||||
开源的 NGINX 提供了一个简单状态页面来显示基本的服务器指标。该状态信息以标准格式显示,实际上任何图形或监控工具可以被配置去解析这些相关数据,以用于分析、可视化、或提醒。NGINX Plus 提供一个 JSON 接口来供给更多的数据。阅读相关文章“[NGINX 指标收集][6]”来启用指标收集的功能。
|
||||
|
||||
#### 错误指标 ####
|
||||
|
||||
| 名称 | 描述| [指标类型](https://www.datadoghq.com/blog/monitoring-101-collecting-data/)| 可用于 |
|
||||
|-----------|-----------------|--------------------------------------------------------------------------------------------------------|----------------|
|
||||
| 4xx 代码 | 客户端错误计数 | 工作:错误 | NGINX 日志, NGINX Plus|
|
||||
| 5xx 代码| 服务器端错误计数 | 工作:错误 | NGINX 日志, NGINX Plus|
|
||||
|
||||
NGINX 错误指标告诉你服务器是否经常返回错误而不是正常工作。客户端错误返回4XX状态码,服务器端错误返回5XX状态码。
|
||||
|
||||
**提醒指标: 服务器错误率**
|
||||
|
||||
服务器错误率等于在单位时间(通常为一到五分钟)内5xx错误状态代码的总数除以[状态码][7](1XX,2XX,3XX,4XX,5XX)的总数。如果你的错误率随着时间的推移开始攀升,调查可能的原因。如果突然增加,可能需要采取紧急行动,因为客户端可能收到错误信息。
|
||||
|
||||

|
||||
|
||||
关于客户端错误的注意事项:虽然监控4XX是很有用的,但从该指标中你仅可以捕捉有限的信息,因为它只是衡量客户的行为而不捕捉任何特殊的 URL。换句话说,4xx出现的变化可能是一个信号,例如网络扫描器正在寻找你的网站漏洞时。
|
||||
|
||||
**收集错误度量**
|
||||
|
||||
虽然开源 NGINX 不能马上得到用于监测的错误率,但至少有两种方法可以得到:
|
||||
|
||||
- 使用商业支持的 NGINX Plus 提供的扩展状态模块
|
||||
- 配置 NGINX 的日志模块将响应码写入访问日志
|
||||
|
||||
关于这两种方法,请阅读相关文章“[NGINX 指标收集][6]”。
|
||||
|
||||
#### 性能指标 ####
|
||||
|
||||
| 名称 | 描述| [指标类型](https://www.datadoghq.com/blog/monitoring-101-collecting-data/)| 可用于 |
|
||||
|-----------|-----------------|--------------------------------------------------------------------------------------------------------|----------------|
|
||||
| request time (请求处理时间)| 处理每个请求的时间,单位为秒 | 工作:性能 | NGINX 日志|
|
||||
|
||||
**提醒指标: 请求处理时间**
|
||||
|
||||
请求处理时间指标记录了 NGINX 处理每个请求的时间,从读到客户端的第一个请求字节到完成请求。较长的响应时间说明问题在上游。
|
||||
|
||||
**收集处理时间指标**
|
||||
|
||||
NGINX 和 NGINX Plus 用户可以通过添加 $request_time 变量到访问日志格式中来捕捉处理时间数据。关于配置日志监控的更多细节在[NGINX指标收集][6]。
|
||||
|
||||
#### 反向代理指标 ####
|
||||
|
||||
| 名称 | 描述| [指标类型](https://www.datadoghq.com/blog/monitoring-101-collecting-data/)| 可用于 |
|
||||
|-----------|-----------------|--------------------------------------------------------------------------------------------------------|----------------|
|
||||
| 上游服务器的活跃链接 | 当前活跃的客户端连接 | 资源:功能 | NGINX Plus |
|
||||
| 上游服务器的 5xx 错误代码| 服务器错误 | 工作:错误 | NGINX Plus |
|
||||
| 每个上游组的可用服务器 | 服务器传递健康检查 | 资源:可用性| NGINX Plus
|
||||
|
||||
[反向代理][9]是 NGINX 最常见的使用方法之一。商业支持的 NGINX Plus 显示了大量有关后端(或“上游 upstream”)的服务器指标,这些与反向代理设置相关的。本节重点介绍了几个 NGINX Plus 用户可用的关键上游指标。
|
||||
|
||||
NGINX Plus 首先将它的上游指标按组分开,然后是针对单个服务器的。因此,例如,你的反向代理将请求分配到五个上游的 Web 服务器上,你可以一眼看出是否有单个服务器压力过大,也可以看出上游组中服务器的健康状况,以确保良好的响应时间。
|
||||
|
||||
**活跃指标**
|
||||
|
||||
**每上游服务器的活跃连接**的数量可以帮助你确认反向代理是否正确的分配工作到你的整个服务器组上。如果你正在使用 NGINX 作为负载均衡器,任何一台服务器处理的连接数的明显偏差都可能表明服务器正在努力消化请求,或者是你配置使用的负载均衡的方法(例如[round-robin 或 IP hashing][10])不是最适合你流量模式的。
|
||||
|
||||
**错误指标**
|
||||
|
||||
错误指标,上面所说的高于5XX(服务器错误)状态码,是监控指标中有价值的一个,尤其是响应码部分。 NGINX Plus 允许你轻松地提取**每个上游服务器的 5xx 错误代码**的数量,以及响应的总数量,以此来确定某个特定服务器的错误率。
|
||||
|
||||
**可用性指标**
|
||||
|
||||
对于 web 服务器的运行状况,还有另一种角度,NGINX 可以通过**每个组中当前可用服务器的总量**很方便监控你的上游组的健康。在一个大的反向代理上,你可能不会非常关心其中一个服务器的当前状态,就像你只要有可用的服务器组能够处理当前的负载就行了。但监视上游组内的所有工作的服务器总量可为判断 Web 服务器的健康状况提供一个更高层面的视角。
|
||||
|
||||
**收集上游指标**
|
||||
|
||||
NGINX Plus 上游指标显示在内部 NGINX Plus 的监控仪表盘上,并且也可通过一个JSON 接口来服务于各种外部监控平台。在我们的相关文章“[NGINX指标收集][6]”中有个例子。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们已经谈到了一些有用的指标,你可以使用表格来监控 NGINX 服务器。如果你是刚开始使用 NGINX,监控下面提供的大部分或全部指标,可以让你很好的了解你的网络基础设施的健康和活跃程度:
|
||||
|
||||
- [已丢弃的连接][12]
|
||||
- [每秒请求数][13]
|
||||
- [服务器错误率][14]
|
||||
- [请求处理数据][15]
|
||||
|
||||
最终,你会学到更多,更专业的衡量指标,尤其是关于你自己基础设施和使用情况的。当然,监控哪一项指标将取决于你可用的工具。参见相关的文章来[逐步指导你的指标收集][6],不管你使用 NGINX 还是 NGINX Plus。
|
||||
|
||||
在 Datadog 中,我们已经集成了 NGINX 和 NGINX Plus,这样你就可以以最少的设置来收集和监控所有 Web 服务器的指标。 [在本文中][17]了解如何用 NGINX Datadog来监控,并开始[免费试用 Datadog][18]吧。
|
||||
|
||||
### 诚谢 ###
|
||||
|
||||
在文章发表之前非常感谢 NGINX 团队审阅这篇,并提供重要的反馈和说明。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.datadoghq.com/blog/how-to-monitor-nginx/
|
||||
|
||||
作者:K Young
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://nginx.org/en/
|
||||
[2]:http://nginx.com/resources/glossary/reverse-proxy-server/
|
||||
[3]:https://www.datadoghq.com/blog/monitoring-101-collecting-data/
|
||||
[4]:http://nginx.org/en/docs/ngx_core_module.html#worker_connections
|
||||
[5]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#active-state
|
||||
[6]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[7]:http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html
|
||||
[8]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[9]:https://en.wikipedia.org/wiki/Reverse_proxy
|
||||
[10]:http://nginx.com/blog/load-balancing-with-nginx-plus/
|
||||
[11]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[12]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#dropped-connections
|
||||
[13]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#requests-per-second
|
||||
[14]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#server-error-rate
|
||||
[15]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#request-processing-time
|
||||
[16]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[17]:https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/
|
||||
[18]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#sign-up
|
||||
[19]:https://github.com/DataDog/the-monitor/blob/master/nginx/how_to_monitor_nginx.md
|
||||
[20]:https://github.com/DataDog/the-monitor/issues
|
||||
@ -0,0 +1,189 @@
|
||||
如何在 Fedora 22 上配置 Proftpd 服务器
|
||||
================================================================================
|
||||
在本文中,我们将了解如何在运行 Fedora 22 的电脑或服务器上使用 Proftpd 架设 FTP 服务器。[ProFTPD][1] 是一款基于 GPL 授权的自由开源 FTP 服务器软件,是 Linux 上的主流 FTP 服务器。它的主要设计目标是提供许多高级功能以及给用户提供丰富的配置选项以轻松实现定制。它具备许多在其他一些 FTP 服务器软件里仍然没有的配置选项。最初它是被开发作为 wu-ftpd 服务器的一个更安全更容易配置的替代。
|
||||
|
||||
FTP 服务器是这样一个软件,用户可以通过 FTP 客户端从安装了它的远端服务器上传或下载文件和目录。下面是一些 ProFTPD 服务器的主要功能,更详细的资料可以访问 [http://www.proftpd.org/features.html][2]。
|
||||
|
||||
- 每个目录都可以包含 ".ftpaccess" 文件用于访问控制,类似 Apache 的 ".htaccess"
|
||||
- 支持多个虚拟 FTP 服务器以及多用户登录和匿名 FTP 服务。
|
||||
- 可以作为独立进程启动服务或者通过 inetd/xinetd 启动
|
||||
- 它的文件/目录属性、属主和权限是基于 UNIX 方式的。
|
||||
- 它可以独立运行,保护系统避免 root 访问可能带来的损坏。
|
||||
- 模块化的设计让它可以轻松扩展其他模块,比如 LDAP 服务器,SSL/TLS 加密,RADIUS 支持,等等。
|
||||
- ProFTPD 服务器还支持 IPv6.
|
||||
|
||||
下面是如何在运行 Fedora 22 操作系统的计算机上使用 ProFTPD 架设 FTP 服务器的一些简单步骤。
|
||||
|
||||
### 1. 安装 ProFTPD ###
|
||||
|
||||
首先,我们将在运行 Fedora 22 的机器上安装 Proftpd 软件。因为 yum 包管理器已经被抛弃了,我们将使用最新最好的包管理器 dnf。DNF 很容易使用,是 Fedora 22 上采用的非常人性化的包管理器。我们将用它来安装 proftpd 软件。这需要在终端或控制台里用 sudo 模式运行下面的命令。
|
||||
|
||||
$ sudo dnf -y install proftpd proftpd-utils
|
||||
|
||||
### 2. 配置 ProFTPD ###
|
||||
|
||||
现在,我们将修改软件的一些配置。要配置它,我们需要用文本编辑器编辑 /etc/proftpd.conf 文件。**/etc/proftpd.conf** 文件是 ProFTPD 软件的主要配置文件,所以,这个文件的任何改动都会影响到 FTP 服务器。在这里,是我们在初始步骤里做出的改动。
|
||||
|
||||
$ sudo vi /etc/proftpd.conf
|
||||
|
||||
之后,在用文本编辑器打开这个文件后,我们会想改下 ServerName 以及 ServerAdmin,分别填入自己的域名和 email 地址。下面是我们改的。
|
||||
|
||||
ServerName "ftp.linoxide.com"
|
||||
ServerAdmin arun@linoxide.com
|
||||
|
||||
在这之后,我们将把下面的设定加到配置文件里,这样可以让服务器将访问和授权记录到相应的日志文件里。
|
||||
|
||||
ExtendedLog /var/log/proftpd/access.log WRITE,READ default
|
||||
ExtendedLog /var/log/proftpd/auth.log AUTH auth
|
||||
|
||||

|
||||
|
||||
### 3. 添加 FTP 用户 ###
|
||||
|
||||
在设定好了基本的配置文件后,我们很自然地希望添加一个以特定目录为根目录的 FTP 用户。目前登录的用户自动就可以使用 FTP 服务,可以用来登录到 FTP 服务器。但是,在这篇教程里,我们将创建一个以 ftp 服务器上指定目录为主目录的新用户。
|
||||
|
||||
下面,我们将建立一个名字是 ftpgroup 的新用户组。
|
||||
|
||||
$ sudo groupadd ftpgroup
|
||||
|
||||
然后,我们将以目录 /ftp-dir/ 作为主目录增加一个新用户 arunftp 并加入这个组中。
|
||||
|
||||
$ sudo useradd -G ftpgroup arunftp -s /sbin/nologin -d /ftp-dir/
|
||||
|
||||
在创建好用户并加入用户组后,我们将为用户 arunftp 设置一个密码。
|
||||
|
||||
$ sudo passwd arunftp
|
||||
|
||||
Changing password for user arunftp.
|
||||
New password:
|
||||
Retype new password:
|
||||
passwd: all authentication tokens updated successfully.
|
||||
|
||||
现在,我们将通过下面命令为这个 ftp 用户设定主目录的读写权限(LCTT 译注:这是SELinux 相关设置,如果未启用 SELinux,可以不用)。
|
||||
|
||||
$ sudo setsebool -P allow_ftpd_full_access=1
|
||||
$ sudo setsebool -P ftp_home_dir=1
|
||||
|
||||
然后,我们会设定不允许其他用户移动或重命名这个目录以及里面的内容。
|
||||
|
||||
$ sudo chmod -R 1777 /ftp-dir/
|
||||
|
||||
### 4. 打开 TLS 支持 ###
|
||||
|
||||
目前 FTP 所用的加密手段并不安全,任何人都可以通过监听网卡来读取 FTP 传输的数据。所以,我们将为自己的服务器打开 TLS 加密支持。这样的话,需要编辑 /etc/proftpd.conf 配置文件。在这之前,我们先备份一下当前的配置文件,可以保证在改出问题后还可以恢复。
|
||||
|
||||
$ sudo cp /etc/proftpd.conf /etc/proftpd.conf.bak
|
||||
|
||||
然后,我们可以用自己喜欢的文本编辑器修改配置文件。
|
||||
|
||||
$ sudo vi /etc/proftpd.conf
|
||||
|
||||
然后,把下面几行附加到我们在第 2 步中所增加内容的后面。
|
||||
|
||||
TLSEngine on
|
||||
TLSRequired on
|
||||
TLSProtocol SSLv23
|
||||
TLSLog /var/log/proftpd/tls.log
|
||||
TLSRSACertificateFile /etc/pki/tls/certs/proftpd.pem
|
||||
TLSRSACertificateKeyFile /etc/pki/tls/certs/proftpd.pem
|
||||
|
||||

|
||||
|
||||
完成上面的设定后,保存退出。
|
||||
|
||||
然后,我们需要生成 SSL 凭证 proftpd.pem 并放到 **/etc/pki/tls/certs/** 目录里。这样的话,首先需要在 Fedora 22 上安装 openssl。
|
||||
|
||||
$ sudo dnf install openssl
|
||||
|
||||
然后,可以通过执行下面的命令生成 SSL 凭证。
|
||||
|
||||
$ sudo openssl req -x509 -nodes -newkey rsa:2048 -keyout /etc/pki/tls/certs/proftpd.pem -out /etc/pki/tls/certs/proftpd.pem
|
||||
|
||||
系统会询问一些将写入凭证里的基本信息。在填完资料后,就会生成一个 2048 位的 RSA 私钥。
|
||||
|
||||
Generating a 2048 bit RSA private key
|
||||
...................+++
|
||||
...................+++
|
||||
writing new private key to '/etc/pki/tls/certs/proftpd.pem'
|
||||
-----
|
||||
You are about to be asked to enter information that will be incorporated
|
||||
into your certificate request.
|
||||
What you are about to enter is what is called a Distinguished Name or a DN.
|
||||
There are quite a few fields but you can leave some blank
|
||||
For some fields there will be a default value,
|
||||
If you enter '.', the field will be left blank.
|
||||
-----
|
||||
Country Name (2 letter code) [XX]:NP
|
||||
State or Province Name (full name) []:Narayani
|
||||
Locality Name (eg, city) [Default City]:Bharatpur
|
||||
Organization Name (eg, company) [Default Company Ltd]:Linoxide
|
||||
Organizational Unit Name (eg, section) []:Linux Freedom
|
||||
Common Name (eg, your name or your server's hostname) []:ftp.linoxide.com
|
||||
Email Address []:arun@linoxide.com
|
||||
|
||||
在这之后,我们要改变所生成凭证文件的权限以增加安全性。
|
||||
|
||||
$ sudo chmod 600 /etc/pki/tls/certs/proftpd.pem
|
||||
|
||||
### 5. 允许 FTP 通过 Firewall ###
|
||||
|
||||
现在,需要允许 ftp 端口,一般默认被防火墙阻止了。就是说,需要允许 ftp 端口能通过防火墙访问。
|
||||
|
||||
如果 **打开了 TLS/SSL 加密**,执行下面的命令。
|
||||
|
||||
$ sudo firewall-cmd --add-port=1024-65534/tcp
|
||||
$ sudo firewall-cmd --add-port=1024-65534/tcp --permanent
|
||||
|
||||
如果 **没有打开 TLS/SSL 加密**,执行下面的命令。
|
||||
|
||||
$ sudo firewall-cmd --permanent --zone=public --add-service=ftp
|
||||
|
||||
success
|
||||
|
||||
然后,重新加载防火墙设定。
|
||||
|
||||
$ sudo firewall-cmd --reload
|
||||
|
||||
success
|
||||
|
||||
### 6. 启动并激活 ProFTPD ###
|
||||
|
||||
全部设定好后,最后就是启动 ProFTPD 并试一下。可以运行下面的命令来启动 proftpd ftp 守护程序。
|
||||
|
||||
$ sudo systemctl start proftpd.service
|
||||
|
||||
然后,我们可以设定开机启动。
|
||||
|
||||
$ sudo systemctl enable proftpd.service
|
||||
|
||||
Created symlink from /etc/systemd/system/multi-user.target.wants/proftpd.service to /usr/lib/systemd/system/proftpd.service.
|
||||
|
||||
### 7. 登录到 FTP 服务器 ###
|
||||
|
||||
现在,如果都是按照本教程设置好的,我们一定可以连接到 ftp 服务器并使用以上设置的信息登录上去。在这里,我们将配置一下 FTP 客户端 filezilla,使用 **服务器的 IP 或名称 **作为主机名,协议选择 **FTP**,用户名填入 **arunftp**,密码是在上面第 3 步中设定的密码。如果你按照第 4 步中的方式打开了 TLS 支持,还需要在加密类型中选择 **要求显式的基于 TLS 的 FTP**,如果没有打开,也不想使用 TLS 加密,那么加密类型选择 **简单 FTP**。
|
||||
|
||||

|
||||
|
||||
要做上述设定,需要打开菜单里的文件,点击站点管理器,然后点击新建站点,再按上面的方式设置。
|
||||
|
||||

|
||||
|
||||
随后系统会要求允许 SSL 凭证,点确定。之后,就可以从我们的 FTP 服务器上传下载文件和文件夹了。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
最后,我们成功地在 Fedora 22 机器上安装并配置好了 Proftpd FTP 服务器。Proftpd 是一个超级强大,能高度定制和扩展的 FTP 守护软件。上面的教程展示了如何配置一个采用 TLS 加密的安全 FTP 服务器。强烈建议设置 FTP 服务器支持 TLS 加密,因为它允许使用 SSL 凭证加密数据传输和登录。本文中,我们也没有配置 FTP 的匿名访问,因为一般受保护的 FTP 系统不建议这样做。 FTP 访问让人们的上传和下载变得非常简单也更高效。我们还可以改变用户端口增加安全性。好吧,如果你有任何疑问,建议,反馈,请在下面评论区留言,这样我们就能够改善并更新文章内容。谢谢!玩的开心 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/configure-ftp-proftpd-fedora-22/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://www.proftpd.org/
|
||||
[2]:http://www.proftpd.org/features.html
|
||||
@ -0,0 +1,113 @@
|
||||
如何在 Ubuntu 中管理开机启动应用
|
||||
================================================================================
|
||||

|
||||
|
||||
你曾经考虑过 **在 Ubuntu 中管理开机启动应用** 吗?如果在开机时,你的 Ubuntu 系统启动得非常缓慢,那么你就需要考虑这个问题了。
|
||||
|
||||
每当你开机进入一个操作系统,一系列的应用将会自动启动。这些应用被称为‘开机启动应用’ 或‘开机启动程序’。随着时间的推移,当你在系统中安装了足够多的应用时,你将发现有太多的‘开机启动应用’在开机时自动地启动了,它们吃掉了很多的系统资源,并将你的系统拖慢。这可能会让你感觉卡顿,我想这种情况并不是你想要的。
|
||||
|
||||
让 Ubuntu 变得更快的方法之一是对这些开机启动应用进行控制。 Ubuntu 为你提供了一个 GUI 工具来让你找到这些开机启动应用,然后完全禁止或延迟它们的启动,这样就可以不让每个应用在开机时同时运行。
|
||||
|
||||
在这篇文章中,我们将看到 **在 Ubuntu 中,如何控制开机启动应用,如何让一个应用在开机时启动以及如何发现隐藏的开机启动应用。**这里提供的指导对所有的 Ubuntu 版本均适用,例如 Ubuntu 12.04, Ubuntu 14.04 和 Ubuntu 15.04。
|
||||
|
||||
### 在 Ubuntu 中管理开机启动应用 ###
|
||||
|
||||
默认情况下, Ubuntu 提供了一个`Startup Applications`工具来供你使用,你不必再进行安装。只需到 Unity 面板中就可以查找到该工具。
|
||||
|
||||

|
||||
|
||||
点击它来启动。下面是我的`Startup Applications`的样子:
|
||||
|
||||

|
||||
|
||||
### 在 Ubuntu 中移除开机启动应用 ###
|
||||
|
||||
现在由你来发现哪个程序对你用处不大,对我来说,是 [Caribou][1] 这个软件,它是一个屏幕键盘程序,在开机时它并没有什么用处,所以我想将它移除出开机启动程序的列表中。
|
||||
|
||||
你可以选择阻止某个程序在开机时启动,而在开机启动程序列表中保留该选项以便以后再进行激活。点击 `关闭`按钮来保留你的偏好设置。
|
||||
|
||||

|
||||
|
||||
要将一个程序从开机启动程序列表中移除,选择对应的选项然后从窗口右边的面板中点击`移除`按钮来保留你的偏好设置。
|
||||
|
||||

|
||||
|
||||
需要提醒的是,这并不会将该程序卸载掉,只是让该程序不再在每次开机时自动启动。你可以对所有你不喜欢的程序做类似的处理。
|
||||
|
||||
### 让开机启动程序延迟启动 ###
|
||||
|
||||
若你并不想在开机启动列表中移除掉程序,但同时又忧虑着系统性能的问题,那么你所需要做的是给程序添加一个延迟启动命令,这样所有的程序就不会在开机时同时启动。
|
||||
|
||||
选择一个程序然后点击 `编辑` 按钮。
|
||||
|
||||

|
||||
|
||||
这将展示出运行这个特定的程序所需的命令。
|
||||
|
||||

|
||||
|
||||
所有你需要做的就是在程序运行命令前添加一句 `sleep XX;` 。这样就为实际运行该命令来启动的对应程序添加了 `XX` 秒的延迟。例如,假如我想让 Variety [壁纸管理应用][2] 延迟启动 2 分钟,我就需要像下面那样在命令前添加 `sleep 120;`
|
||||
|
||||

|
||||
|
||||
保存并关闭设置。你将在下一次启动时看到效果。
|
||||
|
||||
### 增添一个程序到开机启动应用列表中 ###
|
||||
|
||||
这对于新手来说需要一点技巧。我们知道,在 Linux 的底层都是一些命令,在上一节我们看到这些开机启动程序只是在每次开机时运行一些命令。假如你想在开机启动列表中添加一个新的程序,你需要知道运行该应用所需的命令。
|
||||
|
||||
#### 第 1 步:如何查找运行一个程序所需的命令? ####
|
||||
|
||||
首先来到 Unity Dash 面板然后搜索 `Main Menu`:
|
||||
|
||||

|
||||
|
||||
这将展示出在各种类别下你安装的所有程序。在 Ubuntu 的低版本中,你将看到一个相似的菜单,通过它来选择并运行应用。
|
||||
|
||||

|
||||
|
||||
在各种类别下找到你找寻的应用,然后点击 `属性` 按钮来查看运行该应用所需的命令。例如,我想在开机时运行 `Transmission Torrent 客户端`。
|
||||
|
||||

|
||||
|
||||
这就会向我给出运行 `Transmission` 应用的命令:
|
||||
|
||||

|
||||
|
||||
接着,我将用相同的信息来将 `Transmission` 应用添加到开机启动列表中。
|
||||
|
||||
#### 第 2 步: 添加一个程序到开机启动列表中 ####
|
||||
|
||||
再次来到开机启动应用工具中并点击 `添加` 按钮。这将让你输入一个应用的名称,对应的命令和相关的描述。其中命令最为重要,你可以使用任何你想用的名称和描述。使用上一步得到的命令然后点击 `添加` 按钮。
|
||||
|
||||

|
||||
|
||||
就这样,你将在下一次开机时看到这个程序会自动运行。这就是在 Ubuntu 中你能做的关于开机启动应用的所有事情。
|
||||
|
||||
到现在为止,我们已经讨论在开机时可见到的应用,但仍有更多的服务,守护进程和程序并不在`开机启动应用工具`中可见。下一节中,我们将看到如何在 Ubuntu 中查看这些隐藏的开机启动程序。
|
||||
|
||||
### 在 Ubuntu 中查看隐藏的开机启动程序 ###
|
||||
|
||||
要查看在开机时哪些服务在运行,可以打开一个终端并使用下面的命令:
|
||||
|
||||
sudo sed -i 's/NoDisplay=true/NoDisplay=false/g' /etc/xdg/autostart/*.desktop
|
||||
|
||||
上面的命令是一个快速查找和替换命令,它将在所有自动启动的程序里的 `NoDisplay=false` 改为 `NoDisplay=true` ,一旦执行了这个命令后,再次打开`开机启动应用工具`,现在你应该可以看到更多的程序:
|
||||
|
||||

|
||||
|
||||
你可以像先前我们讨论的那样管理这些开机启动应用。我希望这篇教程可以帮助你在 Ubuntu 中控制开机启动程序。任何的问题或建议总是欢迎的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/manage-startup-applications-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:https://wiki.gnome.org/action/show/Projects/Caribou?action=show&redirect=Caribou
|
||||
[2]:http://itsfoss.com/applications-manage-wallpapers-ubuntu/
|
||||
@ -0,0 +1,92 @@
|
||||
无忧之道:Docker中容器的备份、恢复和迁移
|
||||
================================================================================
|
||||
今天,我们将学习如何快速地对docker容器进行快捷备份、恢复和迁移。[Docker][1]是一个开源平台,用于自动化部署应用,以通过快捷的途径在称之为容器的轻量级软件层下打包、发布和运行这些应用。它使得应用平台独立,因为它扮演了Linux上一个额外的操作系统级虚拟化的自动化抽象层。它通过其组件cgroups和命名空间利用Linux内核的资源分离特性,达到避免虚拟机开销的目的。它使得用于部署和扩展web应用、数据库和后端服务的大规模构建组件无需依赖于特定的堆栈或供应者。
|
||||
|
||||
所谓的容器,就是那些创建自Docker镜像的软件层,它包含了独立的Linux文件系统和开箱即用的应用程序。如果我们有一个在机器中运行着的Docker容器,并且想要备份这些容器以便今后使用,或者想要迁移这些容器,那么,本教程将帮助你掌握在Linux操作系统中备份、恢复和迁移Docker容器的方法。
|
||||
|
||||
我们怎样才能在Linux中备份、恢复和迁移Docker容器呢?这里为您提供了一些便捷的步骤。
|
||||
|
||||
### 1. 备份容器 ###
|
||||
|
||||
首先,为了备份Docker中的容器,我们会想看看我们想要备份的容器列表。要达成该目的,我们需要在我们运行着Docker引擎,并已创建了容器的Linux机器中运行 docker ps 命令。
|
||||
|
||||
# docker ps
|
||||
|
||||

|
||||
|
||||
在此之后,我们要选择我们想要备份的容器,然后去创建该容器的快照。我们可以使用 docker commit 命令来创建快照。
|
||||
|
||||
# docker commit -p 30b8f18f20b4 container-backup
|
||||
|
||||

|
||||
|
||||
该命令会生成一个作为Docker镜像的容器快照,我们可以通过运行 `docker images` 命令来查看Docker镜像,如下。
|
||||
|
||||
# docker images
|
||||
|
||||

|
||||
|
||||
正如我们所看见的,上面做的快照已经作为Docker镜像保存了。现在,为了备份该快照,我们有两个选择,一个是我们可以登录进Docker注册中心,并推送该镜像;另一个是我们可以将Docker镜像打包成tar包备份,以供今后使用。
|
||||
|
||||
如果我们想要在[Docker注册中心][2]上传或备份镜像,我们只需要运行 docker login 命令来登录进Docker注册中心,然后推送所需的镜像即可。
|
||||
|
||||
# docker login
|
||||
|
||||

|
||||
|
||||
# docker tag a25ddfec4d2a arunpyasi/container-backup:test
|
||||
# docker push arunpyasi/container-backup
|
||||
|
||||

|
||||
|
||||
如果我们不想备份到docker注册中心,而是想要将此镜像保存在本地机器中,以供日后使用,那么我们可以将其作为tar包备份。要完成该操作,我们需要运行以下 `docker save` 命令。
|
||||
|
||||
# docker save -o ~/container-backup.tar container-backup
|
||||
|
||||

|
||||
|
||||
要验证tar包是否已经生成,我们只需要在保存tar包的目录中运行 ls 命令即可。
|
||||
|
||||
### 2. 恢复容器 ###
|
||||
|
||||
接下来,在我们成功备份了我们的Docker容器后,我们现在来恢复这些制作了Docker镜像快照的容器。如果我们已经在注册中心推送了这些Docker镜像,那么我们仅仅需要把那个Docker镜像拖回并直接运行即可。
|
||||
|
||||
# docker pull arunpyasi/container-backup:test
|
||||
|
||||

|
||||
|
||||
但是,如果我们将这些Docker镜像作为tar包文件备份到了本地,那么我们只要使用 docker load 命令,后面加上tar包的备份路径,就可以加载该Docker镜像了。
|
||||
|
||||
# docker load -i ~/container-backup.tar
|
||||
|
||||
现在,为了确保这些Docker镜像已经加载成功,我们来运行 docker images 命令。
|
||||
|
||||
# docker images
|
||||
|
||||
在镜像被加载后,我们将用加载的镜像去运行Docker容器。
|
||||
|
||||
# docker run -d -p 80:80 container-backup
|
||||
|
||||

|
||||
|
||||
### 3. 迁移Docker容器 ###
|
||||
|
||||
迁移容器同时涉及到了上面两个操作,备份和恢复。我们可以将任何一个Docker容器从一台机器迁移到另一台机器。在迁移过程中,首先我们将把容器备份为Docker镜像快照。然后,该Docker镜像或者是被推送到了Docker注册中心,或者被作为tar包文件保存到了本地。如果我们将镜像推送到了Docker注册中心,我们简单地从任何我们想要的机器上使用 docker run 命令来恢复并运行该容器。但是,如果我们将镜像打包成tar包备份到了本地,我们只需要拷贝或移动该镜像到我们想要的机器上,加载该镜像并运行需要的容器即可。
|
||||
|
||||
### 尾声 ###
|
||||
|
||||
最后,我们已经学习了如何快速地备份、恢复和迁移Docker容器,本教程适用于各个可以成功运行Docker的操作系统平台。真的,Docker是一个相当简单易用,然而功能却十分强大的工具。它的命令相当易记,这些命令都非常短,带有许多简单而强大的标记和参数。上面的方法让我们备份容器时很是安逸,使得我们可以在日后很轻松地恢复它们。这会帮助我们恢复我们的容器和镜像,即便主机系统崩溃,甚至意外地被清除。如果你还有很多问题、建议、反馈,请在下面的评论框中写出来吧,可以帮助我们改进或更新我们的内容。谢谢大家!享受吧 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/backup-restore-migrate-containers-docker/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://docker.com/
|
||||
[2]:https://registry.hub.docker.com/
|
||||
@ -0,0 +1,53 @@
|
||||
如何修复:There is no command installed for 7-zip archive files
|
||||
================================================================================
|
||||
### 问题 ###
|
||||
|
||||
我试着在Ubuntu中安装Emerald图标主题,而这个主题被打包成了.7z归档包。和以往一样,我试着通过在GUI中右击并选择“提取到这里”来将它解压缩。但是Ubuntu 15.04却并没有解压文件,取而代之的,却是丢给了我一个下面这样的错误信息:
|
||||
|
||||
> Could not open this file
|
||||
>
|
||||
> 无法打开该文件
|
||||
>
|
||||
> There is no command installed for 7-zip archive files. Do you want to search for a command to open this file?
|
||||
>
|
||||
> 没有安装用于7-zip归档文件的命令。你是否想要搜索用于来打开该文件的命令?
|
||||
|
||||
错误信息看上去是这样的:
|
||||
|
||||

|
||||
|
||||
### 原因 ###
|
||||
|
||||
发生该错误的原因从错误信息本身来看就十分明了。7Z,称之为[7-zip][1]更好,该程序没有安装,因此7Z压缩文件就无法解压缩。这也暗示着Ubuntu默认不支持7-zip文件。
|
||||
|
||||
### 解决方案:在Ubuntu中安装 7zip ###
|
||||
|
||||
要解决该问题也十分简单,在Ubuntu中安装7-Zip包即可。现在,你也许想知道如何在Ubuntu中安装 7Zip吧?好吧,在前面的错误对话框中,如果你右击“Search Command”搜索命令,它会查找可用的 p7zip 包。只要点击“Install”安装,如下图:
|
||||
|
||||

|
||||
|
||||
### 可选方案:在终端中安装 7Zip ###
|
||||
|
||||
如果偏好使用终端,你可以使用以下命令在终端中安装 7zip:
|
||||
|
||||
sudo apt-get install p7zip-full
|
||||
|
||||
注意:在Ubuntu中,你会发现有3个7zip包:p7zip,p7zip-full 和 p7zip-rar。p7zip和p7zip-full的区别在于,p7zip是一个更轻量化的版本,仅仅提供了对 .7z 和 .7za 文件的支持,而完整版则提供了对更多(用于音频文件等的) 7z 压缩算法的支持。对于 p7zip-rar,它除了对 7z 文件的支持外,也提供了对 .rar 文件的支持。
|
||||
|
||||
事实上,相同的错误也会发生在[Ubuntu中的RAR文件][2]身上。解决方案也一样,安装正确的程序即可。
|
||||
|
||||
希望这篇快文帮助你解决了**Ubuntu 14.04中如何打开 7zip**的谜团。如有任何问题或建议,我们将无任欢迎。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/fix-there-is-no-command-installed-for-7-zip-archive-files/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://www.7-zip.org/
|
||||
[2]:http://itsfoss.com/fix-there-is-no-command-installed-for-rar-archive-files/
|
||||
@ -0,0 +1,120 @@
|
||||
如何更新 Linux 内核来提升系统性能
|
||||
================================================================================
|
||||

|
||||
|
||||
目前的 [Linux 内核][1]的开发速度是前所未有的,大概每2到3个月就会有一个主要的版本发布。每个发布都带来几个的新的功能和改进,可以让很多人的处理体验更快、更有效率、或者其它的方面更好。
|
||||
|
||||
问题是,你不能在这些内核发布的时候就用它们,你要等到你的发行版带来新内核的发布。我们先前讲到[定期更新内核的好处][2],所以你不必等到那时。让我们来告诉你该怎么做。
|
||||
|
||||
> 免责声明: 我们先前的一些文章已经提到过,升级内核有(很小)的风险可能会破坏你系统。如果发生这种情况,通常可以通过使用旧内核来使系统保持工作,但是有时还是不行。因此我们对系统的任何损坏都不负责,你得自己承担风险!
|
||||
|
||||
### 预备工作 ###
|
||||
|
||||
要更新你的内核,你首先要确定你使用的是32位还是64位的系统。打开终端并运行:
|
||||
|
||||
uname -a
|
||||
|
||||
检查一下输出的是 x86\_64 还是 i686。如果是 x86\_64,你就运行64位的版本,否则就运行32位的版本。千万记住这个,这很重要。
|
||||
|
||||

|
||||
|
||||
接下来,访问[官方的 Linux 内核网站][3],它会告诉你目前稳定内核的版本。愿意的话,你可以尝试下发布预选版(RC),但是这比稳定版少了很多测试。除非你确定想要需要发布预选版,否则就用稳定内核。
|
||||
|
||||

|
||||
|
||||
### Ubuntu 指导 ###
|
||||
|
||||
对 Ubuntu 及其衍生版的用户而言升级内核非常简单,这要感谢 Ubuntu 主线内核 PPA。虽然,官方把它叫做 PPA,但是你不能像其他 PPA 一样将它添加到你软件源列表中,并指望它自动升级你的内核。实际上,它只是一个简单的网页,你应该浏览并下载到你想要的内核。
|
||||
|
||||

|
||||
|
||||
现在,访问这个[内核 PPA 网页][4],并滚到底部。列表的最下面会含有最新发布的预选版本(你可以在名字中看到“rc”字样),但是这上面就可以看到最新的稳定版(说的更清楚些,本文写作时最新的稳定版是4.1.2。LCTT 译注:这里虽然 4.1.2 是当时的稳定版,但是由于尚未进入 Ubuntu 发行版中,所以文件夹名称为“-unstable”)。点击文件夹名称,你会看到几个选择。你需要下载 3 个文件并保存到它们自己的文件夹中(如果你喜欢的话可以放在下载文件夹中),以便它们与其它文件相隔离:
|
||||
|
||||
1. 针对架构的含“generic”(通用)的头文件(我这里是64位,即“amd64”)
|
||||
2. 放在列表中间,在文件名末尾有“all”的头文件
|
||||
3. 针对架构的含“generic”内核文件(再说一次,我会用“amd64”,但是你如果用32位的,你需要使用“i686”)
|
||||
|
||||
你还可以在下面看到含有“lowlatency”(低延时)的文件。但最好忽略它们。这些文件相对不稳定,并且只为那些通用文件不能满足像音频录制这类任务想要低延迟的人准备的。再说一次,首选通用版,除非你有特定的任务需求不能很好地满足。一般的游戏和网络浏览不是使用低延时版的借口。
|
||||
|
||||
你把它们放在各自的文件夹下,对么?现在打开终端,使用`cd`命令切换到新创建的文件夹下,如
|
||||
|
||||
cd /home/user/Downloads/Kernel
|
||||
|
||||
接着运行:
|
||||
|
||||
sudo dpkg -i *.deb
|
||||
|
||||
这个命令会标记文件夹中所有的“.deb”文件为“待安装”,接着执行安装。这是推荐的安装方法,因为不可以很简单地选择一个文件安装,它总会报出依赖问题。这这样一起安装就可以避免这个问题。如果你不清楚`cd`和`sudo`是什么。快速地看一下 [Linux 基本命令][5]这篇文章。
|
||||
|
||||

|
||||
|
||||
安装完成后,**重启**你的系统,这时应该就会运行刚安装的内核了!你可以在命令行中使用`uname -a`来检查输出。
|
||||
|
||||
### Fedora 指导 ###
|
||||
|
||||
如果你使用的是 Fedora 或者它的衍生版,过程跟 Ubuntu 很类似。不同的是文件获取的位置不同,安装的命令也不同。
|
||||
|
||||

|
||||
|
||||
查看 [最新 Fedora 内核构建][6]列表。选取列表中最新的稳定版并翻页到下面选择 i686 或者 x86_64 版。这取决于你的系统架构。这时你需要下载下面这些文件并保存到它们对应的目录下(比如“Kernel”到下载目录下):
|
||||
|
||||
- kernel
|
||||
- kernel-core
|
||||
- kernel-headers
|
||||
- kernel-modules
|
||||
- kernel-modules-extra
|
||||
- kernel-tools
|
||||
- perf 和 python-perf (可选)
|
||||
|
||||
如果你的系统是 i686(32位)同时你有 4GB 或者更大的内存,你需要下载所有这些文件的 PAE 版本。PAE 是用于32位系统上的地址扩展技术,它允许你使用超过 3GB 的内存。
|
||||
|
||||
现在使用`cd`命令进入文件夹,像这样
|
||||
|
||||
cd /home/user/Downloads/Kernel
|
||||
|
||||
接着运行下面的命令来安装所有的文件
|
||||
|
||||
yum --nogpgcheck localinstall *.rpm
|
||||
|
||||
最后**重启**你的系统,这样你就可以运行新的内核了!
|
||||
|
||||
#### 使用 Rawhide ####
|
||||
|
||||
另外一个方案是,Fedora 用户也可以[切换到 Rawhide][7],它会自动更新所有的包到最新版本,包括内核。然而,Rawhide 经常会破坏系统(尤其是在早期的开发阶段中),它**不应该**在你日常使用的系统中用。
|
||||
|
||||
### Arch 指导 ###
|
||||
|
||||
[Arch 用户][8]应该总是使用的是最新和最棒的稳定版(或者相当接近的版本)。如果你想要更接近最新发布的稳定版,你可以启用测试库提前2到3周获取到主要的更新。
|
||||
|
||||
要这么做,用[你喜欢的编辑器][9]以`sudo`权限打开下面的文件
|
||||
|
||||
/etc/pacman.conf
|
||||
|
||||
接着取消注释带有 testing 的三行(删除行前面的#号)。如果你启用了 multilib 仓库,就把 multilib-testing 也做相同的事情。如果想要了解更多参考[这个 Arch 的 wiki 界面][10]。
|
||||
|
||||
升级内核并不简单(有意这么做的),但是这会给你带来很多好处。只要你的新内核不会破坏任何东西,你可以享受它带来的性能提升,更好的效率,更多的硬件支持和潜在的新特性。尤其是你正在使用相对较新的硬件时,升级内核可以帮助到你。
|
||||
|
||||
|
||||
**怎么升级内核这篇文章帮助到你了么?你认为你所喜欢的发行版对内核的发布策略应该是怎样的?**。在评论栏让我们知道!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.makeuseof.com/tag/update-linux-kernel-improved-system-performance/
|
||||
|
||||
作者:[Danny Stieben][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.makeuseof.com/tag/author/danny/
|
||||
[1]:http://www.makeuseof.com/tag/linux-kernel-explanation-laymans-terms/
|
||||
[2]:http://www.makeuseof.com/tag/5-reasons-update-kernel-linux/
|
||||
[3]:http://www.kernel.org/
|
||||
[4]:http://kernel.ubuntu.com/~kernel-ppa/mainline/
|
||||
[5]:http://www.makeuseof.com/tag/an-a-z-of-linux-40-essential-commands-you-should-know/
|
||||
[6]:http://koji.fedoraproject.org/koji/packageinfo?packageID=8
|
||||
[7]:http://www.makeuseof.com/tag/bleeding-edge-linux-fedora-rawhide/
|
||||
[8]:http://www.makeuseof.com/tag/arch-linux-letting-you-build-your-linux-system-from-scratch/
|
||||
[9]:http://www.makeuseof.com/tag/nano-vs-vim-terminal-text-editors-compared/
|
||||
[10]:https://wiki.archlinux.org/index.php/Pacman#Repositories
|
||||
@ -0,0 +1,138 @@
|
||||
一些 Linux 小技巧
|
||||
================================================================================
|
||||
我已经写过 [Linux 提示和技巧][1] 系列的一篇文章。写这篇文章的目的是让你知道这些小技巧可以有效地管理你的系统/服务器。
|
||||
|
||||

|
||||
|
||||
*在Linux中创建 Cdrom ISO 镜像和监控用户*
|
||||
|
||||
在这篇文章中,我们将看到如何使用 CD/DVD 驱动器中载入的碟片来创建 ISO 镜像;打开随机手册页学习;看到登录用户的详细情况和查看浏览器内存使用量,而所有这些完全使用本地工具/命令,无需任何第三方应用程序/组件。让我们开始吧……
|
||||
|
||||
### 用 CD 碟片创建 ISO 映像 ###
|
||||
|
||||
我们经常需要备份/复制 CD/DVD 的内容。如果你是在 Linux 平台上,不需要任何额外的软件。所有需要的是进入 Linux 终端。
|
||||
|
||||
要从 CD/DVD 上创建 ISO 镜像,你需要做两件事。第一件事就是需要找到CD/DVD 驱动器的名称。要找到 CD/DVD 驱动器的名称,可以使用以下三种方法。
|
||||
|
||||
**1. 从终端/控制台上运行 lsblk 命令(列出块设备)**
|
||||
|
||||
$ lsblk
|
||||
|
||||

|
||||
|
||||
*找块设备*
|
||||
|
||||
从上图可以看到,sr0 就是你的 cdrom (即 /dev/sr0 )。
|
||||
|
||||
**2. 要查看有关 CD-ROM 的信息,可以使用以下命令**
|
||||
|
||||
$ less /proc/sys/dev/cdrom/info
|
||||
|
||||

|
||||
|
||||
*检查 Cdrom 信息*
|
||||
|
||||
从上图可以看到, 设备名称是 sr0 (即 /dev/sr0)。
|
||||
|
||||
**3. 使用 [dmesg 命令][2] 也会得到相同的信息,并使用 egrep 来自定义输出。**
|
||||
|
||||
命令 ‘dmesg‘ 命令的输出/控制内核缓冲区信息。‘egrep‘ 命令输出匹配到的行。egrep 使用选项 -i 和 -color 时会忽略大小写,并高亮显示匹配的字符串。
|
||||
|
||||
$ dmesg | egrep -i --color 'cdrom|dvd|cd/rw|writer'
|
||||
|
||||

|
||||
|
||||
*查找设备信息*
|
||||
|
||||
从上图可以看到,设备名称是 sr0 (即 /dev/sr0)。
|
||||
|
||||
一旦知道 CD/DVD 的名称后,在 Linux 上你可以用下面的命令来创建 ISO 镜像(你看,只需要 cat 即可!)。
|
||||
|
||||
$ cat /dev/sr0 > /path/to/output/folder/iso_name.iso
|
||||
|
||||
这里的‘sr0‘是我的 CD/DVD 驱动器的名称。你应该用你的 CD/DVD 名称来代替。这将帮你创建 ISO 镜像并备份 CD/DVD 的内容无需任何第三方应用程序。
|
||||
|
||||

|
||||
|
||||
*创建 CDROM 的 ISO 映像*
|
||||
|
||||
### 随机打开一个手册页 ###
|
||||
|
||||
如果你是 Linux 新人并想学习使用命令行开关,这个技巧就是给你的。把下面的代码行添加在`〜/ .bashrc`文件的末尾。
|
||||
|
||||
/use/bin/man $(ls /bin | shuf | head -1)
|
||||
|
||||
记得把上面一行脚本添加在用户的`.bashrc`文件中,而不是根目录的 .bashrc 文件。所以,当你下次登录本地或远程使用 SSH 时,你会看到一个随机打开的手册页供你阅读。对于想要学习命令行开关的新手,这被证明是有益的。
|
||||
|
||||
下面是在终端登录两次分别看到的。
|
||||
|
||||

|
||||
|
||||
*LoadKeys 手册页*
|
||||
|
||||

|
||||
|
||||
*Zgrep 手册页*
|
||||
|
||||
希望你知道如何退出手册页浏览——如果你已经厌烦了每次都看到手册页,你可以删除你添加到 `.bashrc`文件中的那几行。
|
||||
|
||||
### 查看登录用户的状态 ###
|
||||
|
||||
了解其他用户正在共享服务器上做什么。
|
||||
|
||||
一般情况下,你是共享的 Linux 服务器的用户或管理员的。如果你担心自己服务器的安全并想要查看哪些用户在做什么,你可以使用命令 `w`。
|
||||
|
||||
这个命令可以让你知道是否有人在执行恶意代码或篡改服务器,让他停下或使用其他方法。'w' 是查看登录用户状态的首选方式。
|
||||
|
||||
要查看登录的用户正在做什么,从终端运行命令“w”,最好是 root 用户。
|
||||
|
||||
# w
|
||||
|
||||

|
||||
|
||||
*检查 Linux 用户状态*
|
||||
|
||||
### 查看浏览器的内存使用状况 ###
|
||||
|
||||
最近有不少谈论关于 Google-chrome 的内存使用量。如要检查浏览器的内存使用情况,只需在地址栏输入 “about:memory”,不要带引号。
|
||||
|
||||
我已经在 Google-Chrome 和 Mozilla 的 Firefox 网页浏览器进行了测试。你可以查看任何浏览器,如果它工作得很好,你可能会承认我们在下面的评论。你也可以杀死浏览器进程在 Linux 终端的进程/服务中。
|
||||
|
||||
在 Google Chrome 中,在地址栏输入 `about:memory`,你应该得到类似下图的东西。
|
||||
|
||||

|
||||
|
||||
*查看 Chrome 内存使用状况*
|
||||
|
||||
在Mozilla Firefox浏览器,在地址栏输入 `about:memory`,你应该得到类似下图的东西。
|
||||
|
||||

|
||||
|
||||
*查看 Firefox 内存使用状况*
|
||||
|
||||
如果你已经了解它是什么,除了这些选项。要检查内存用量,你也可以点击最左边的 ‘Measure‘ 选项。
|
||||
|
||||

|
||||
|
||||
*Firefox 主进程*
|
||||
|
||||
它将通过浏览器树形展示进程内存使用量。
|
||||
|
||||
目前为止就这样了。希望上述所有的提示将会帮助你。如果你有一个(或多个)技巧,分享给我们,将帮助 Linux 用户更有效地管理他们的 Linux 系统/服务器。
|
||||
|
||||
我会很快在这里发帖,到时候敬请关注。请在下面的评论里提供你的宝贵意见。喜欢请分享并帮助我们传播。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/creating-cdrom-iso-image-watch-user-activity-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/tag/linux-tricks/
|
||||
[2]:http://www.tecmint.com/dmesg-commands/
|
||||
@ -0,0 +1,118 @@
|
||||
轻松使用“Explain Shell”脚本来理解 Shell 命令
|
||||
================================================================================
|
||||
我们在Linux上工作时,每个人都会遇到需要查找shell命令的帮助信息的时候。 尽管内置的帮助像man pages、whatis命令有所助益, 但man pages的输出非常冗长, 除非是个有linux经验的人,不然从大量的man pages中获取帮助信息是非常困难的,而whatis命令的输出很少超过一行, 这对初学者来说是不够的。
|
||||
|
||||

|
||||
|
||||
*在Linux Shell中解释Shell命令*
|
||||
|
||||
有一些第三方应用程序, 像我们在[Linux 用户的命令行速查表][1]提及过的'cheat'命令。cheat是个优秀的应用程序,即使计算机没有联网也能提供shell命令的帮助, 但是它仅限于预先定义好的命令。
|
||||
|
||||
Jackson写了一小段代码,它能非常有效地在bash shell里面解释shell命令,可能最美之处就是你不需要安装第三方包了。他把包含这段代码的的文件命名为“explain.sh”。
|
||||
|
||||
#### explain.sh工具的特性 ####
|
||||
|
||||
- 易嵌入代码。
|
||||
- 不需要安装第三方工具。
|
||||
- 在解释过程中输出恰到好处的信息。
|
||||
- 需要网络连接才能工作。
|
||||
- 纯命令行工具。
|
||||
- 可以解释bash shell里面的大部分shell命令。
|
||||
- 无需使用root账户。
|
||||
|
||||
**先决条件**
|
||||
|
||||
唯一的条件就是'curl'包了。 在如今大多数Linux发行版里面已经预安装了curl包, 如果没有你可以按照下面的命令来安装。
|
||||
|
||||
# apt-get install curl [On Debian systems]
|
||||
# yum install curl [On CentOS systems]
|
||||
|
||||
### 在Linux上安装explain.sh工具 ###
|
||||
|
||||
我们要将下面这段代码插入'~/.bashrc'文件(LCTT译注: 若没有该文件可以自己新建一个)中。我们要为每个用户以及对应的'.bashrc'文件插入这段代码,但是建议你不要加在root用户下。
|
||||
|
||||
我们注意到.bashrc文件的第一行代码以(#)开始, 这个是可选的并且只是为了区分余下的代码。
|
||||
|
||||
\# explain.sh 标记代码的开始, 我们将代码插入.bashrc文件的底部。
|
||||
|
||||
# explain.sh begins
|
||||
explain () {
|
||||
if [ "$#" -eq 0 ]; then
|
||||
while read -p "Command: " cmd; do
|
||||
curl -Gs "https://www.mankier.com/api/explain/?cols="$(tput cols) --data-urlencode "q=$cmd"
|
||||
done
|
||||
echo "Bye!"
|
||||
elif [ "$#" -eq 1 ]; then
|
||||
curl -Gs "https://www.mankier.com/api/explain/?cols="$(tput cols) --data-urlencode "q=$1"
|
||||
else
|
||||
echo "Usage"
|
||||
echo "explain interactive mode."
|
||||
echo "explain 'cmd -o | ...' one quoted command to explain it."
|
||||
fi
|
||||
}
|
||||
|
||||
### explain.sh工具的使用 ###
|
||||
|
||||
在插入代码并保存之后,你必须退出当前的会话然后重新登录来使改变生效(LCTT译注:你也可以直接使用命令`source~/.bashrc` 来让改变生效)。每件事情都是交由‘curl’命令处理, 它负责将需要解释的命令以及命令选项传送给mankier服务,然后将必要的信息打印到Linux命令行。不必说的就是使用这个工具你总是需要连接网络。
|
||||
|
||||
让我们用explain.sh脚本测试几个笔者不懂的命令例子。
|
||||
|
||||
**1.我忘了‘du -h’是干嘛用的, 我只需要这样做:**
|
||||
|
||||
$ explain 'du -h'
|
||||
|
||||

|
||||
|
||||
*获得du命令的帮助*
|
||||
|
||||
**2.如果你忘了'tar -zxvf'的作用,你可以简单地如此做:**
|
||||
|
||||
$ explain 'tar -zxvf'
|
||||
|
||||

|
||||
|
||||
*Tar命令帮助*
|
||||
|
||||
**3.我的一个朋友经常对'whatis'以及'whereis'命令的使用感到困惑,所以我建议他:**
|
||||
|
||||
在终端简单的地敲下explain命令进入交互模式。
|
||||
|
||||
$ explain
|
||||
|
||||
然后一个接着一个地输入命令,就能在一个窗口看到他们各自的作用:
|
||||
|
||||
Command: whatis
|
||||
Command: whereis
|
||||
|
||||

|
||||
|
||||
*Whatis/Whereis命令的帮助*
|
||||
|
||||
你只需要使用“Ctrl+c”就能退出交互模式。
|
||||
|
||||
**4. 你可以通过管道来请求解释更多的命令。**
|
||||
|
||||
$ explain 'ls -l | grep -i Desktop'
|
||||
|
||||

|
||||
|
||||
*获取多条命令的帮助*
|
||||
|
||||
同样地,你可以请求你的shell来解释任何shell命令。 前提是你需要一个可用的网络。输出的信息是基于需要解释的命令,从服务器中生成的,因此输出的结果是不可定制的。
|
||||
|
||||
对于我来说这个工具真的很有用,并且它已经荣幸地添加在我的.bashrc文件中。你对这个项目有什么想法?它对你有用么?它的解释令你满意吗?请让我知道吧!
|
||||
|
||||
请在下面评论为我们提供宝贵意见,喜欢并分享我们以及帮助我们得到传播。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/explain-shell-commands-in-the-linux-shell/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[dingdongnigetou](https://github.com/dingdongnigetou)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/cheat-command-line-cheat-sheet-for-linux-users/
|
||||
@ -0,0 +1,71 @@
|
||||
什么是逻辑分区管理 LVM ,如何在Ubuntu中使用?
|
||||
================================================================================
|
||||
|
||||
> 逻辑分区管理(LVM)是每一个主流Linux发行版都含有的磁盘管理选项。无论是你需要设置存储池,还是只想动态创建分区,那么LVM就是你正在寻找的。
|
||||
|
||||
### 什么是 LVM? ###
|
||||
|
||||
逻辑分区管理是一个存在于磁盘/分区和操作系统之间的一个抽象层。在传统的磁盘管理中,你的操作系统寻找有哪些磁盘可用(/dev/sda、/dev/sdb等等),并且这些磁盘有哪些可用的分区(如/dev/sda1、/dev/sda2等等)。
|
||||
|
||||
在LVM下,磁盘和分区可以抽象成一个含有多个磁盘和分区的设备。你的操作系统将不会知道这些区别,因为LVM只会给操作系统展示你设置的卷组(磁盘)和逻辑卷(分区)
|
||||
|
||||
因为卷组和逻辑卷并不物理地对应到影片,因此可以很容易地动态调整和创建新的磁盘和分区。除此之外,LVM带来了你的文件系统所不具备的功能。比如,ext3不支持实时快照,但是如果你正在使用LVM你可以不卸载磁盘的情况下做一个逻辑卷的快照。
|
||||
|
||||
### 你什么时候该使用LVM? ###
|
||||
|
||||
在使用LVM之前首先得考虑的一件事是你要用你的磁盘和分区来做什么。注意,一些发行版如Fedora已经默认安装了LVM。
|
||||
|
||||
如果你使用的是一台只有一块磁盘的Ubuntu笔记本电脑,并且你不需要像实时快照这样的扩展功能,那么你或许不需要LVM。如果你想要轻松地扩展或者想要将多块磁盘组成一个存储池,那么LVM或许正是你所寻找的。
|
||||
|
||||
### 在Ubuntu中设置LVM ###
|
||||
|
||||
使用LVM首先要了解的一件事是,没有一个简单的方法可以将已有的传统分区转换成逻辑卷。可以将数据移到一个使用LVM的新分区下,但是这并不会在本篇中提到;在这里,我们将全新安装一台Ubuntu 10.10来设置LVM。(LCTT 译注:本文针对的是较老的版本,新的版本已经不需如此麻烦了)
|
||||
|
||||
要使用LVM安装Ubuntu你需要使用另外的安装CD。从下面的链接中下载并烧录到CD中或者[使用unetbootin创建一个USB盘][1]。
|
||||
|
||||

|
||||
|
||||
从安装盘启动你的电脑,并在磁盘选择界面选择整个磁盘并设置LVM。
|
||||
|
||||
*注意:这会格式化你的整个磁盘,因此如果正在尝试双启动或者其他的安装选择,选择手动。*
|
||||
|
||||

|
||||
|
||||
选择你想用的主磁盘,最典型的是使用你最大的磁盘,接着进入下一步。
|
||||
|
||||

|
||||
|
||||
你马上会将改变写入磁盘所以确保此时你选择的是正确的磁盘接着才写入设置。
|
||||
|
||||

|
||||
|
||||
选择第一个逻辑卷的大小并继续。
|
||||
|
||||

|
||||
|
||||
确认你的磁盘分区并继续安装。
|
||||
|
||||

|
||||
|
||||
最后一步将GRUB的bootloader写到磁盘中。重点注意的是GRUB不能作为一个LVM分区因为计算机BIOS不能直接从逻辑卷中读取数据。Ubuntu将自动创建一个255MB的ext2分区用于bootloder。
|
||||
|
||||

|
||||
|
||||
安装完成之后。重启电脑并如往常一样进入Ubuntu。使用这种方式安装之后应该就感受不到LVM和传统磁盘管理之间的区别了。
|
||||
|
||||

|
||||
|
||||
要使用LVM的全部功能,静待我们的下篇关于管理LVM的文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.howtogeek.com/howto/36568/what-is-logical-volume-management-and-how-do-you-enable-it-in-ubuntu/
|
||||
|
||||
作者:[How-To Geek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/+howtogeek?prsrc=5
|
||||
[1]:http://www.howtogeek.com/howto/13379/create-a-bootable-ubuntu-9.10-usb-flash-drive/
|
||||
48
published/20150730 Compare PDF Files on Ubuntu.md
Normal file
48
published/20150730 Compare PDF Files on Ubuntu.md
Normal file
@ -0,0 +1,48 @@
|
||||
如何在 Ubuntu 上比较 PDF 文件
|
||||
================================================================================
|
||||
|
||||
如果你想要对PDF文件进行比较,你可以使用下面工具之一。
|
||||
|
||||
### Comparepdf ###
|
||||
|
||||
comparepdf是一个命令行应用,用于将两个PDF文件进行对比。默认对比模式是文本模式,该模式会对各对相关页面进行文字对比。只要一检测到差异,该程序就会终止,并显示一条信息(除非设置了-v0)和一个指示性的返回码。
|
||||
|
||||
用于文本模式对比的选项有 -ct 或 --compare=text(默认),用于视觉对比(这对图标或其它图像发生改变时很有用)的选项有 -ca 或 --compare=appearance。而 -v=1 或 --verbose=1 选项则用于报告差异(或者对匹配文件不作任何回应);使用 -v=0 选项取消报告,或者 -v=2 来同时报告不同的和匹配的文件。
|
||||
|
||||
#### 安装comparepdf到Ubuntu ####
|
||||
|
||||
打开终端,然后运行以下命令
|
||||
|
||||
sudo apt-get install comparepdf
|
||||
|
||||
**Comparepdf 语法**
|
||||
|
||||
comparepdf [OPTIONS] file1.pdf file2.pdf
|
||||
|
||||
###Diffpdf###
|
||||
|
||||
DiffPDF是一个图形化应用程序,用于对两个PDF文件进行对比。默认情况下,它只会对比两个相关页面的文字,但是也支持对图形化页面进行对比(例如,如果图表被修改过,或者段落被重新格式化过)。它也可以对特定的页面或者页面范围进行对比。例如,如果同一个PDF文件有两个版本,其中一个有页面1-12,而另一个则有页面1-13,因为这里添加了一个额外的页面4,它们可以通过指定两个页面范围来进行对比,第一个是1-12,而1-3,5-13则可以作为第二个页面范围。这将使得DiffPDF成对地对比这些页面(1,1),(2,2),(3,3),(4,5),(5,6),以此类推,直到(12,13)。
|
||||
|
||||
#### 安装 diffpdf 到 ubuntu ####
|
||||
|
||||
打开终端,然后运行以下命令
|
||||
|
||||
sudo apt-get install diffpdf
|
||||
|
||||
#### 截图 ####
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/compare-pdf-files-on-ubuntu.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
186
published/20150730 Must-Know Linux Commands For New Users.md
Normal file
186
published/20150730 Must-Know Linux Commands For New Users.md
Normal file
@ -0,0 +1,186 @@
|
||||
新手应知应会的Linux命令
|
||||
================================================================================
|
||||
|
||||
|
||||
*在Fedora上通过命令行使用dnf来管理系统更新*
|
||||
|
||||
基于Linux的系统最美妙的一点,就是你可以在终端中使用命令行来管理整个系统。使用命令行的优势在于,你可以使用相同的知识和技能来管理随便哪个Linux发行版。
|
||||
|
||||
对于各个发行版以及桌面环境(DE)而言,要一致地使用图形化用户界面(GUI)却几乎是不可能的,因为它们都提供了各自的用户界面。要明确的是,有些情况下在不同的发行版上需要使用不同的命令来执行某些特定的任务,但是,基本来说它们的思路和目的是一致的。
|
||||
|
||||
在本文中,我们打算讨论Linux用户应当掌握的一些基本命令。我将给大家演示怎样使用命令行来更新系统、管理软件、操作文件以及切换到root,这些操作将在三个主要发行版上进行:Ubuntu(也包括其定制版和衍生版,还有Debian),openSUSE,以及Fedora。
|
||||
|
||||
*让我们开始吧!*
|
||||
|
||||
### 保持系统安全和最新 ###
|
||||
|
||||
Linux是基于安全设计的,但事实上是,任何软件都有缺陷,会导致安全漏洞。所以,保持你的系统更新到最新是十分重要的。这么想吧:运行过时的操作系统,就像是你坐在全副武装的坦克里头,而门却没有锁。武器会保护你吗?任何人都可以进入开放的大门,对你造成伤害。同样,在你的系统中也有没有打补丁的漏洞,这些漏洞会危害到你的系统。开源社区,不像专利世界,在漏洞补丁方面反应是相当快的,所以,如果你保持系统最新,你也获得了安全保证。
|
||||
|
||||
留意新闻站点,了解安全漏洞。如果发现了一个漏洞,了解它,然后在补丁出来的第一时间更新。不管怎样,在生产环境上,你每星期必须至少运行一次更新命令。如果你运行着一台复杂的服务器,那么就要额外当心了。仔细阅读变更日志,以确保更新不会搞坏你的自定义服务。
|
||||
|
||||
**Ubuntu**:牢记一点:你在升级系统或安装不管什么软件之前,都必须要刷新仓库(也就是repos)。在Ubuntu上,你可以使用下面的命令来更新系统,第一个命令用于刷新仓库:
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
仓库更新后,现在你可以运行系统更新命令了:
|
||||
|
||||
sudo apt-get upgrade
|
||||
|
||||
然而,这个命令不会更新内核和其它一些包,所以你也必须要运行下面这个命令:
|
||||
|
||||
sudo apt-get dist-upgrade
|
||||
|
||||
**openSUSE**:如果你是在openSUSE上,你可以使用以下命令来更新系统(照例,第一个命令的意思是更新仓库):
|
||||
|
||||
sudo zypper refresh
|
||||
sudo zypper up
|
||||
|
||||
**Fedora**:如果你是在Fedora上,你可以使用'dnf'命令,它是zypper和apt-get的'同类':
|
||||
|
||||
sudo dnf update
|
||||
sudo dnf upgrade
|
||||
|
||||
### 软件安装与移除 ###
|
||||
|
||||
你只可以安装那些你系统上启用的仓库中可用的包,各个发行版默认都附带有并启用了一些官方或者第三方仓库。
|
||||
|
||||
**Ubuntu**:要在Ubuntu上安装包,首先更新仓库,然后使用下面的语句:
|
||||
|
||||
sudo apt-get install [package_name]
|
||||
|
||||
样例:
|
||||
|
||||
sudo apt-get install gimp
|
||||
|
||||
**openSUSE**:命令是这样的:
|
||||
|
||||
sudo zypper install [package_name]
|
||||
|
||||
**Fedora**:Fedora已经丢弃了'yum',现在换成了'dnf',所以命令是这样的:
|
||||
|
||||
sudo dnf install [package_name]
|
||||
|
||||
移除软件的过程也一样,只要把'install'改成'remove'。
|
||||
|
||||
**Ubuntu**:
|
||||
|
||||
sudo apt-get remove [package_name]
|
||||
|
||||
**openSUSE**:
|
||||
|
||||
sudo zypper remove [package_name]
|
||||
|
||||
**Fedora**:
|
||||
|
||||
sudo dnf remove [package_name]
|
||||
|
||||
### 如何管理第三方软件? ###
|
||||
|
||||
在一个庞大的开发者社区中,这些开发者们为用户提供了许多的软件。不同的发行版有不同的机制来将这些第三方软件提供给用户。当然,同时也取决于开发者怎样将这些软件提供给用户,有些开发者会提供二进制包,而另外一些开发者则将软件发布到仓库中。
|
||||
|
||||
Ubuntu很多地方都用到PPA(个人包归档),但是,不幸的是,它却没有提供一个内建工具来帮助用于搜索这些PPA仓库。在安装软件前,你将需要通过Google搜索PPA,然后手工添加该仓库。下面就是添加PPA到系统的方法:
|
||||
|
||||
sudo add-apt-repository ppa:<repository-name>
|
||||
|
||||
样例:比如说,我想要添加LibreOffice PPA到我的系统中。我应该Google该PPA,然后从Launchpad获得该仓库的名称,在本例中它是"libreoffice/ppa"。然后,使用下面的命令来添加该PPA:
|
||||
|
||||
sudo add-apt-repository ppa:libreoffice/ppa
|
||||
|
||||
它会要你按下回车键来导入密钥。完成后,使用'update'命令来刷新仓库,然后安装该包。
|
||||
|
||||
openSUSE拥有一个针对第三方应用的优雅的解决方案。你可以访问software.opensuse.org,一键点击搜索并安装相应包,它会自动将对应的仓库添加到你的系统中。如果你想要手工添加仓库,可以使用该命令:
|
||||
|
||||
sudo zypper ar -f url_of_the_repo name_of_repo
|
||||
sudo zypper ar -f http://download.opensuse.org/repositories/LibreOffice:Factory/openSUSE_13.2/LibreOffice:Factory.repo LOF
|
||||
|
||||
然后,刷新仓库并安装软件:
|
||||
|
||||
sudo zypper refresh
|
||||
sudo zypper install libreoffice
|
||||
|
||||
Fedora用户只需要添加RPMFusion(包括自由软件和非自由软件仓库),该仓库包含了大量的应用。如果你需要添加该仓库,命令如下:
|
||||
|
||||
dnf config-manager --add-repo http://www.example.com/example.repo
|
||||
|
||||
### 一些基本命令 ###
|
||||
|
||||
我已经写了一些关于使用CLI来管理你系统上的文件的[文章][1],下面介绍一些基本命令,这些命令在所有发行版上都经常会用到。
|
||||
|
||||
拷贝文件或目录到一个新的位置:
|
||||
|
||||
cp path_of_file_1 path_of_the_directory_where_you_want_to_copy/
|
||||
|
||||
将某个目录中的所有文件拷贝到一个新的位置(注意斜线和星号,它指的是该目录下的所有文件):
|
||||
|
||||
cp path_of_files/* path_of_the_directory_where_you_want_to_copy/
|
||||
|
||||
将一个文件从某个位置移动到另一个位置(尾斜杠是说放在该目录中):
|
||||
|
||||
mv path_of_file_1 path_of_the_directory_where_you_want_to_move/
|
||||
|
||||
将所有文件从一个位置移动到另一个位置:
|
||||
|
||||
mv path_of_directory_where_files_are/* path_of_the_directory_where_you_want_to_move/
|
||||
|
||||
删除一个文件:
|
||||
|
||||
rm path_of_file
|
||||
|
||||
删除一个目录:
|
||||
|
||||
rm -r path_of_directory
|
||||
|
||||
移除目录中所有内容,完整保留目录文件夹:
|
||||
|
||||
rm -r path_of_directory/*
|
||||
|
||||
### 创建新目录 ###
|
||||
|
||||
要创建一个新目录,首先进入到你要创建该目录的位置。比如说,你想要在你的Documents目录中创建一个名为'foundation'的文件夹。让我们使用 cd (即change directory,改变目录)命令来改变目录:
|
||||
|
||||
cd /home/swapnil/Documents
|
||||
|
||||
(替换'swapnil'为你系统中的用户名)
|
||||
|
||||
然后,使用 mkdir 命令来创建该目录:
|
||||
|
||||
mkdir foundation
|
||||
|
||||
你也可以从任何地方创建一个目录,通过指定该目录的路径即可。例如:
|
||||
|
||||
mdkir /home/swapnil/Documents/foundation
|
||||
|
||||
如果你想要连父目录一起创建,那么可以使用 -p 选项。它会在指定路径中创建所有目录:
|
||||
|
||||
mdkir -p /home/swapnil/Documents/linux/foundation
|
||||
|
||||
### 成为root ###
|
||||
|
||||
你或许需要成为root,或者具有sudo权力的用户,来实施一些管理任务,如管理软件包或者对根目录或其下的文件进行一些修改。其中一个例子就是编辑'fstab'文件,该文件记录了挂载的硬盘驱动器。它在'etc'目录中,而该目录又在根目录中,你只能作为超级用户来修改该文件。在大多数的发行版中,你可以通过'su'来成为root。比如说,在openSUSE上,我想要成为root,因为我要在根目录中工作,你可以使用下面的命令之一:
|
||||
|
||||
sudo su -
|
||||
|
||||
或
|
||||
|
||||
su -
|
||||
|
||||
该命令会要求输入密码,然后你就具有root特权了。记住一点:千万不要以root用户来运行系统,除非你知道你正在做什么。另外重要的一点需要注意的是,你以root什么对目录或文件进行修改后,会将它们的拥有关系从该用户或特定的服务改变为root。你必须恢复这些文件的拥有关系,否则该服务或用户就不能访问或写入到那些文件。要改变用户,命令如下:
|
||||
|
||||
sudo chown -R 用户:组 文件或目录名
|
||||
|
||||
当你将其它发行版上的分区挂载到系统中时,你可能经常需要该操作。当你试着访问这些分区上的文件时,你可能会碰到权限拒绝错误,你只需要改变这些分区的拥有关系就可以访问它们了。需要额外当心的是,不要改变根目录的权限或者拥有关系。
|
||||
|
||||
这些就是Linux新手们需要的基本命令。如果你有任何问题,或者如果你想要我们涵盖一个特定的话题,请在下面的评论中告诉我们吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/learn/tutorials/842251-must-know-linux-commands-for-new-users
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linux.com/community/forums/person/61003
|
||||
[1]:http://www.linux.com/learn/tutorials/828027-how-to-manage-your-files-from-the-command-line
|
||||
@ -0,0 +1,65 @@
|
||||
使用 Find 命令来帮你找到那些需要清理的文件
|
||||
================================================================================
|
||||

|
||||
|
||||
*Credit: Sandra H-S*
|
||||
|
||||
有一个问题几乎困扰着所有的文件系统 -- 包括 Unix 和其他的 -- 那就是文件的不断积累。几乎没有人愿意花时间清理掉他们不再使用的文件和整理文件系统,结果,文件变得很混乱,很难找到有用的东西,要使它们运行良好、维护备份、易于管理,这将是一种持久的挑战。
|
||||
|
||||
我见过的一种解决问题的方法是建议使用者将所有的数据碎屑创建一个文件集合的总结报告或"概况",来报告诸如所有的文件数量;最老的,最新的,最大的文件;并统计谁拥有这些文件等数据。如果有人看到五年前的一个包含五十万个文件的文件夹,他们可能会去删除哪些文件 -- 或者,至少会归档和压缩。主要问题是太大的文件夹会使人担心误删一些重要的东西。如果有一个描述文件夹的方法能帮助显示文件的性质,那么你就可以去清理它了。
|
||||
|
||||
当我准备做 Unix 文件系统的总结报告时,几个有用的 Unix 命令能提供一些非常有用的统计信息。要计算目录中的文件数,你可以使用这样一个 find 命令。
|
||||
|
||||
$ find . -type f | wc -l
|
||||
187534
|
||||
|
||||
虽然查找最老的和最新的文件是比较复杂,但还是相当方便的。在下面的命令,我们使用 find 命令再次查找文件,以文件时间排序并按年-月-日的格式显示,在列表顶部的显然是最老的。
|
||||
|
||||
在第二个命令,我们做同样的,但打印的是最后一行,这是最新的。
|
||||
|
||||
$ find -type f -printf '%T+ %p\n' | sort | head -n 1
|
||||
2006-02-03+02:40:33 ./skel/.xemacs/init.el
|
||||
$ find -type f -printf '%T+ %p\n' | sort | tail -n 1
|
||||
2015-07-19+14:20:16 ./.bash_history
|
||||
|
||||
printf 命令输出 %T(文件日期和时间)和 %P(带路径的文件名)参数。
|
||||
|
||||
如果我们在查找家目录时,无疑会发现,history 文件(如 .bash_history)是最新的,这并没有什么用。你可以通过 "un-grepping" 来忽略这些文件,也可以忽略以.开头的文件,如下图所示的。
|
||||
|
||||
$ find -type f -printf '%T+ %p\n' | grep -v "\./\." | sort | tail -n 1
|
||||
2015-07-19+13:02:12 ./isPrime
|
||||
|
||||
寻找最大的文件使用 %s(大小)参数,包括文件名(%f),因为这就是我们想要在报告中显示的。
|
||||
|
||||
$ find -type f -printf '%s %f \n' | sort -n | uniq | tail -1
|
||||
20183040 project.org.tar
|
||||
|
||||
统计文件的所有者,使用%u(所有者)
|
||||
|
||||
$ find -type f -printf '%u \n' | grep -v "\./\." | sort | uniq -c
|
||||
180034 shs
|
||||
7500 jdoe
|
||||
|
||||
如果文件系统能记录上次的访问日期,也将是非常有用的,可以用来看该文件有没有被访问过,比方说,两年之内没访问过。这将使你能明确分辨这些文件的价值。这个最后访问(%a)参数这样使用:
|
||||
|
||||
$ find -type f -printf '%a+ %p\n' | sort | head -n 1
|
||||
Fri Dec 15 03:00:30 2006+ ./statreport
|
||||
|
||||
当然,如果大多数最近访问的文件也是在很久之前的,这看起来你需要处理更多文件了。
|
||||
|
||||
$ find -type f -printf '%a+ %p\n' | sort | tail -n 1
|
||||
Wed Nov 26 03:00:27 2007+ ./my-notes
|
||||
|
||||
要想层次分明,可以为一个文件系统或大目录创建一个总结报告,显示这些文件的日期范围、最大的文件、文件所有者们、最老的文件和最新访问时间,可以帮助文件拥有者判断当前有哪些文件夹是重要的哪些该清理了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.itworld.com/article/2949898/linux/profiling-your-file-systems.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.itworld.com/author/Sandra-Henry_Stocker/
|
||||
88
published/20150803 Linux Logging Basics.md
Normal file
88
published/20150803 Linux Logging Basics.md
Normal file
@ -0,0 +1,88 @@
|
||||
Linux 日志基础
|
||||
================================================================================
|
||||
首先,我们将描述有关 Linux 日志是什么,到哪儿去找它们,以及它们是如何创建的基础知识。如果你已经知道这些,请随意跳至下一节。
|
||||
|
||||
### Linux 系统日志 ###
|
||||
|
||||
许多有价值的日志文件都是由 Linux 自动地为你创建的。你可以在 `/var/log` 目录中找到它们。下面是在一个典型的 Ubuntu 系统中这个目录的样子:
|
||||
|
||||

|
||||
|
||||
一些最为重要的 Linux 系统日志包括:
|
||||
|
||||
- `/var/log/syslog` 或 `/var/log/messages` 存储所有的全局系统活动数据,包括开机信息。基于 Debian 的系统如 Ubuntu 在 `/var/log/syslog` 中存储它们,而基于 RedHat 的系统如 RHEL 或 CentOS 则在 `/var/log/messages` 中存储它们。
|
||||
- `/var/log/auth.log` 或 `/var/log/secure` 存储来自可插拔认证模块(PAM)的日志,包括成功的登录,失败的登录尝试和认证方式。Ubuntu 和 Debian 在 `/var/log/auth.log` 中存储认证信息,而 RedHat 和 CentOS 则在 `/var/log/secure` 中存储该信息。
|
||||
- `/var/log/kern` 存储内核的错误和警告数据,这对于排除与定制内核相关的故障尤为实用。
|
||||
- `/var/log/cron` 存储有关 cron 作业的信息。使用这个数据来确保你的 cron 作业正成功地运行着。
|
||||
|
||||
Digital Ocean 有一个关于这些文件的完整[教程][1],介绍了 rsyslog 如何在常见的发行版本如 RedHat 和 CentOS 中创建它们。
|
||||
|
||||
应用程序也会在这个目录中写入日志文件。例如像 Apache,Nginx,MySQL 等常见的服务器程序可以在这个目录中写入日志文件。其中一些日志文件由应用程序自己创建,其他的则通过 syslog (具体见下文)来创建。
|
||||
|
||||
### 什么是 Syslog? ###
|
||||
|
||||
Linux 系统日志文件是如何创建的呢?答案是通过 syslog 守护程序,它在 syslog 套接字 `/dev/log` 上监听日志信息,然后将它们写入适当的日志文件中。
|
||||
|
||||
单词“syslog” 代表几个意思,并经常被用来简称如下的几个名称之一:
|
||||
|
||||
1. **Syslog 守护进程** — 一个用来接收、处理和发送 syslog 信息的程序。它可以[远程发送 syslog][2] 到一个集中式的服务器或写入到一个本地文件。常见的例子包括 rsyslogd 和 syslog-ng。在这种使用方式中,人们常说“发送到 syslog”。
|
||||
1. **Syslog 协议** — 一个指定日志如何通过网络来传送的传输协议和一个针对 syslog 信息(具体见下文) 的数据格式的定义。它在 [RFC-5424][3] 中被正式定义。对于文本日志,标准的端口是 514,对于加密日志,端口是 6514。在这种使用方式中,人们常说“通过 syslog 传送”。
|
||||
1. **Syslog 信息** — syslog 格式的日志信息或事件,它包括一个带有几个标准字段的消息头。在这种使用方式中,人们常说“发送 syslog”。
|
||||
|
||||
Syslog 信息或事件包括一个带有几个标准字段的消息头,可以使分析和路由更方便。它们包括时间戳、应用程序的名称、在系统中信息来源的分类或位置、以及事件的优先级。
|
||||
|
||||
下面展示的是一个包含 syslog 消息头的日志信息,它来自于控制着到该系统的远程登录的 sshd 守护进程,这个信息描述的是一次失败的登录尝试:
|
||||
|
||||
<34>1 2003-10-11T22:14:15.003Z server1.com sshd - - pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=10.0.2.2
|
||||
|
||||
### Syslog 格式和字段 ###
|
||||
|
||||
每条 syslog 信息包含一个带有字段的信息头,这些字段是结构化的数据,使得分析和路由事件更加容易。下面是我们使用的用来产生上面的 syslog 例子的格式,你可以将每个值匹配到一个特定的字段的名称上。
|
||||
|
||||
<%pri%>%protocol-version% %timestamp:::date-rfc3339% %HOSTNAME% %app-name% %procid% %msgid% %msg%n
|
||||
|
||||
下面,你将看到一些在查找或排错时最常使用的 syslog 字段:
|
||||
|
||||
#### 时间戳 ####
|
||||
|
||||
[时间戳][4] (上面的例子为 2003-10-11T22:14:15.003Z) 暗示了在系统中发送该信息的时间和日期。这个时间在另一系统上接收该信息时可能会有所不同。上面例子中的时间戳可以分解为:
|
||||
|
||||
- **2003-10-11** 年,月,日。
|
||||
- **T** 为时间戳的必需元素,它将日期和时间分隔开。
|
||||
- **22:14:15.003** 是 24 小时制的时间,包括进入下一秒的毫秒数(**003**)。
|
||||
- **Z** 是一个可选元素,指的是 UTC 时间,除了 Z,这个例子还可以包括一个偏移量,例如 -08:00,这意味着时间从 UTC 偏移 8 小时,即 PST 时间。
|
||||
|
||||
#### 主机名 ####
|
||||
|
||||
[主机名][5] 字段(在上面的例子中对应 server1.com) 指的是主机的名称或发送信息的系统.
|
||||
|
||||
#### 应用名 ####
|
||||
|
||||
[应用名][6] 字段(在上面的例子中对应 sshd:auth) 指的是发送信息的程序的名称.
|
||||
|
||||
#### 优先级 ####
|
||||
|
||||
优先级字段或缩写为 [pri][7] (在上面的例子中对应 <34>) 告诉我们这个事件有多紧急或多严峻。它由两个数字字段组成:设备字段和紧急性字段。紧急性字段从代表 debug 类事件的数字 7 一直到代表紧急事件的数字 0 。设备字段描述了哪个进程创建了该事件。它从代表内核信息的数字 0 到代表本地应用使用的 23 。
|
||||
|
||||
Pri 有两种输出方式。第一种是以一个单独的数字表示,可以这样计算:先用设备字段的值乘以 8,再加上紧急性字段的值:(设备字段)(8) + (紧急性字段)。第二种是 pri 文本,将以“设备字段.紧急性字段” 的字符串格式输出。后一种格式更方便阅读和搜索,但占据更多的存储空间。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.loggly.com/ultimate-guide/logging/linux-logging-basics/
|
||||
|
||||
作者:[Jason Skowronski][a1],[Amy Echeverri][a2],[Sadequl Hussain][a3]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a1]:https://www.linkedin.com/in/jasonskowronski
|
||||
[a2]:https://www.linkedin.com/in/amyecheverri
|
||||
[a3]:https://www.linkedin.com/pub/sadequl-hussain/14/711/1a7
|
||||
[1]:https://www.digitalocean.com/community/tutorials/how-to-view-and-configure-linux-logs-on-ubuntu-and-centos
|
||||
[2]:https://docs.google.com/document/d/11LXZxWlkNSHkcrCWTUdnLRf_CiZz9kK0cr3yGM_BU_0/edit#heading=h.y2e9tdfk1cdb
|
||||
[3]:https://tools.ietf.org/html/rfc5424
|
||||
[4]:https://tools.ietf.org/html/rfc5424#section-6.2.3
|
||||
[5]:https://tools.ietf.org/html/rfc5424#section-6.2.4
|
||||
[6]:https://tools.ietf.org/html/rfc5424#section-6.2.5
|
||||
[7]:https://tools.ietf.org/html/rfc5424#section-6.2.1
|
||||
@ -0,0 +1,75 @@
|
||||
选择成为软件开发工程师的5个原因
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
这个星期我将给本地一所高中做一次有关于程序猿是怎样工作的演讲。我是志愿(由 [Transfer][1] 组织的)来到这所学校谈论我的工作的。这个学校本周将有一个技术主题日,并且他们很想听听科技行业是怎样工作的。因为我是从事软件开发的,这也是我将和学生们讲的内容。演讲的其中一部分是我为什么觉得软件开发是一个很酷的职业。主要原因如下:
|
||||
|
||||
### 5个原因 ###
|
||||
|
||||
**1、创造性**
|
||||
|
||||
如果你问别人创造性的工作有哪些,别人通常会说像作家,音乐家或者画家那样的(工作)。但是极少有人知道软件开发也是一项非常具有创造性的工作。它是最符合创造性定义的了,因为你创造了一个以前没有的新功能。这种解决方案可以在整体和细节上以很多形式来展现。我们经常会遇到一些需要做权衡的场景(比如说运行速度与内存消耗的权衡)。当然前提是这种解决方案必须是正确的。这些所有的行为都是需要强大的创造性的。
|
||||
|
||||
**2、协作性**
|
||||
|
||||
另外一个表象是程序猿们独自坐在他们的电脑前,然后撸一天的代码。但是软件开发事实上通常总是一个团队努力的结果。你会经常和你的同事讨论编程问题以及解决方案,并且和产品经理、测试人员、客户讨论需求以及其他问题。
|
||||
经常有人说,结对编程(2个开发人员一起在一个电脑上编程)是一种流行的最佳实践。
|
||||
|
||||
**3、高需性**
|
||||
|
||||
世界上越来越多的人在用软件,正如 [Marc Andreessen](https://en.wikipedia.org/wiki/Marc_Andreessen) 所说 " [软件正在吞噬世界][2] "。虽然程序猿现在的数量非常巨大(在斯德哥尔摩,程序猿现在是 [最普遍的职业][3] ),但是,需求量一直处于供不应求的局面。据软件公司说,他们最大的挑战之一就是 [找到优秀的程序猿][4] 。我也经常接到那些想让我跳槽的招聘人员打来的电话。我知道至少除软件行业之外的其他行业的雇主不会那么拼(的去招聘)。
|
||||
|
||||
**4、高酬性**
|
||||
|
||||
软件开发可以带来不菲的收入。卖一份你已经开发好的软件的额外副本是没有 [边际成本][5] 的。这个事实与对程序猿的高需求意味着收入相当可观。当然还有许多更捞金的职业,但是相比一般人群,我认为软件开发者确实“日进斗金”(知足吧!骚年~~)。
|
||||
|
||||
**5、前瞻性**
|
||||
|
||||
有许多工作岗位消失,往往是由于它们可以被计算机和软件代替。但是所有这些新的程序依然需要开发和维护,因此,程序猿的前景还是相当好的。
|
||||
|
||||
### 但是...###
|
||||
|
||||
**外包又是怎么一回事呢?**
|
||||
|
||||
难道所有外包到其他国家的软件开发的薪水都很低吗?这是一个理想丰满,现实骨感的例子(有点像 [瀑布开发模型][6] )。软件开发基本上跟设计的工作一样,是一个探索发现的工作。它受益于强有力的合作。更进一步说,特别当你的主打产品是软件的时候,你所掌握的开发知识是绝对的优势。知识在整个公司中分享的越容易,那么公司的发展也将越来越好。
|
||||
|
||||
换一种方式去看待这个问题。软件外包已经存在了相当一段时间了。但是对本土程序猿的需求量依旧非常高。因为许多软件公司看到了雇佣本土程序猿的带来的收益要远远超过了相对较高的成本(其实还是赚了)。
|
||||
|
||||
### 如何成为人生大赢家 ###
|
||||
|
||||
虽然我有许多我认为软件开发是一件非常有趣的事情的理由 (详情见: [为什么我热爱编程][7] )。但是这些理由,并不适用于所有人。幸运的是,尝试编程是一件非常容易的事情。在互联网上有数不尽的学习编程的资源。例如,[Coursera][8] 和 [Udacity][9] 都拥有很好的入门课程。如果你从来没有撸过码,可以尝试其中一个免费的课程,找找感觉。
|
||||
|
||||
寻找一个既热爱又能谋生的事情至少有2个好处。首先,由于你天天去做,工作将比你简单的只为谋生要有趣的多。其次,如果你真的非常喜欢,你将更好的擅长它。我非常喜欢下面一副关于伟大工作组成的韦恩图(作者 [@eskimon)][10]) 。因为编码的薪水确实相当不错,我认为如果你真的喜欢它,你将有一个很好的机会,成为人生的大赢家!
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://henrikwarne.com/2014/12/08/5-reasons-why-software-developer-is-a-great-career-choice/
|
||||
|
||||
作者:[Henrik Warne][a]
|
||||
译者:[mousycoder](https://github.com/mousycoder)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[a]:http://henrikwarne.com/
|
||||
[1]:http://www.transfer.nu/omoss/transferinenglish.jspx?pageId=23
|
||||
[2]:http://www.wsj.com/articles/SB10001424053111903480904576512250915629460
|
||||
[3]:http://www.di.se/artiklar/2014/6/12/jobbet-som-tar-over-landet/
|
||||
[4]:http://computersweden.idg.se/2.2683/1.600324/examinationstakten-racker-inte-for-branschens-behov
|
||||
[5]:https://en.wikipedia.org/wiki/Marginal_cost
|
||||
[6]:https://en.wikipedia.org/wiki/Waterfall_model
|
||||
[7]:http://henrikwarne.com/2012/06/02/why-i-love-coding/
|
||||
[8]:https://www.coursera.org/
|
||||
[9]:https://www.udacity.com/
|
||||
[10]:https://eskimon.wordpress.com/about/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,50 @@
|
||||
Linux有问必答:如何修复“ImportError: No module named wxversion”错误
|
||||
================================================================================
|
||||
|
||||
> **问题** 我试着在[某某 Linux 发行版]上运行一个 Python 应用,但是我得到了这个错误“ImportError: No module named wxversion.”。我怎样才能解决 Python 程序中的这个错误呢?
|
||||
|
||||
Looking for python... 2.7.9 - Traceback (most recent call last):
|
||||
File "/home/dev/playonlinux/python/check_python.py", line 1, in
|
||||
import os, wxversion
|
||||
ImportError: No module named wxversion
|
||||
failed tests
|
||||
|
||||
该错误表明,你的Python应用是基于GUI的,依赖于一个名为wxPython的缺失模块。[wxPython][1]是一个用于wxWidgets GUI库的Python扩展模块,普遍被C++程序员用来设计GUI应用。该wxPython扩展允许Python开发者在任何Python应用中方便地设计和整合GUI。
|
||||
|
||||
摇解决这个 import 错误,你需要在你的 Linux 上安装 wxPython,如下:
|
||||
|
||||
### 安装wxPython到Debian,Ubuntu或Linux Mint ###
|
||||
|
||||
$ sudo apt-get install python-wxgtk2.8
|
||||
|
||||
### 安装wxPython到Fedora ###
|
||||
|
||||
$ sudo yum install wxPython
|
||||
|
||||
### 安装wxPython到CentOS/RHEL ###
|
||||
|
||||
wxPython可以在CentOS/RHEL的EPEL仓库中获取到,而基本仓库中则没有。因此,首先要在你的系统中[启用EPEL仓库][2],然后使用yum命令来安装。
|
||||
|
||||
$ sudo yum install wxPython
|
||||
|
||||
### 安装wxPython到Arch Linux ###
|
||||
|
||||
$ sudo pacman -S wxpython
|
||||
|
||||
### 安装wxPython到Gentoo ###
|
||||
|
||||
$ emerge wxPython
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/importerror-no-module-named-wxversion.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://wxpython.org/
|
||||
[2]:https://linux.cn/article-2324-1.html
|
||||
@ -0,0 +1,75 @@
|
||||
Linux有问必答:如何在Linux上安装Git
|
||||
================================================================================
|
||||
|
||||
> **问题:** 我尝试从一个Git公共仓库克隆项目,但出现了这样的错误提示:“git: command not found”。 请问我该如何在某某发行版上安装Git?
|
||||
|
||||
Git是一个流行的开源版本控制系统(VCS),最初是为Linux环境开发的。跟CVS或者SVN这些版本控制系统不同的是,Git的版本控制被认为是“分布式的”,某种意义上,git的本地工作目录可以作为一个功能完善的仓库来使用,它具备完整的历史记录和版本追踪能力。在这种工作模型之下,各个协作者将内容提交到他们的本地仓库中(与之相对的会总是提交到核心仓库),如果有必要,再有选择性地推送到核心仓库。这就为Git这个版本管理系统带来了大型协作系统所必须的可扩展能力和冗余能力。
|
||||
|
||||
|
||||
|
||||
### 使用包管理器安装Git ###
|
||||
|
||||
Git已经被所有的主流Linux发行版所支持。所以安装它最简单的方法就是使用各个Linux发行版的包管理器。
|
||||
|
||||
**Debian, Ubuntu, 或 Linux Mint**
|
||||
|
||||
$ sudo apt-get install git
|
||||
|
||||
**Fedora, CentOS 或 RHEL**
|
||||
|
||||
$ sudo yum install git
|
||||
或
|
||||
$ sudo dnf install git
|
||||
|
||||
**Arch Linux**
|
||||
|
||||
$ sudo pacman -S git
|
||||
|
||||
**OpenSUSE**
|
||||
|
||||
$ sudo zypper install git
|
||||
|
||||
**Gentoo**
|
||||
|
||||
$ emerge --ask --verbose dev-vcs/git
|
||||
|
||||
### 从源码安装Git ###
|
||||
|
||||
如果由于某些原因,你希望从源码安装Git,按照如下介绍操作。
|
||||
|
||||
**安装依赖包**
|
||||
|
||||
在构建Git之前,先安装它的依赖包。
|
||||
|
||||
**Debian, Ubuntu 或 Linux Mint**
|
||||
|
||||
$ sudo apt-get install libcurl4-gnutls-dev libexpat1-dev gettext libz-dev libssl-dev asciidoc xmlto docbook2x
|
||||
|
||||
**Fedora, CentOS 或 RHEL**
|
||||
|
||||
$ sudo yum install curl-devel expat-devel gettext-devel openssl-devel zlib-devel asciidoc xmlto docbook2x
|
||||
|
||||
#### 从源码编译Git ####
|
||||
|
||||
从 [https://github.com/git/git/releases][1] 下载最新版本的Git。然后在/usr下构建和安装。
|
||||
|
||||
注意,如果你打算安装到其他目录下(例如:/opt),那就把"--prefix=/usr"这个配置命令使用其他路径替换掉。
|
||||
|
||||
$ cd git-x.x.x
|
||||
$ make configure
|
||||
$ ./configure --prefix=/usr
|
||||
$ make all doc info
|
||||
$ sudo make install install-doc install-html install-info
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/install-git-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[mr-ping](https://github.com/mr-ping)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:https://github.com/git/git/releases
|
||||
@ -0,0 +1,98 @@
|
||||
如何在 Linux 上运行命令前临时清空 Bash 环境变量
|
||||
================================================================================
|
||||
我是个 bash shell 用户。我想临时清空 bash shell 环境变量。但我不想删除或者 unset 一个输出的环境变量。我怎样才能在 bash 或 ksh shell 的临时环境中运行程序呢?
|
||||
|
||||
你可以在 Linux 或类 Unix 系统中使用 env 命令设置并打印环境。env 命令可以按命令行指定的变量来修改环境,之后再执行程序。
|
||||
|
||||
### 如何显示当前环境? ###
|
||||
|
||||
打开终端应用程序并输入下面的其中一个命令:
|
||||
|
||||
printenv
|
||||
|
||||
或
|
||||
|
||||
env
|
||||
|
||||
输出样例:
|
||||
|
||||
|
||||
|
||||
*Fig.01: Unix/Linux: 列出所有环境变量*
|
||||
|
||||
### 统计环境变量数目 ###
|
||||
|
||||
输入下面的命令:
|
||||
|
||||
env | wc -l
|
||||
printenv | wc -l # 或者
|
||||
|
||||
输出样例:
|
||||
|
||||
20
|
||||
|
||||
### 在干净的 bash/ksh/zsh 环境中运行程序 ###
|
||||
|
||||
语法如下所示:
|
||||
|
||||
env -i your-program-name-here arg1 arg2 ...
|
||||
|
||||
例如,要在不使用 http_proxy 和/或任何其它环境变量的情况下运行 wget 程序。临时清除所有 bash/ksh/zsh 环境变量并运行 wget 程序:
|
||||
|
||||
env -i /usr/local/bin/wget www.cyberciti.biz
|
||||
env -i wget www.cyberciti.biz # 或者
|
||||
|
||||
这当你想忽视任何已经设置的环境变量来运行命令时非常有用。我每天都会多次使用这个命令,以便忽视 http_proxy 和其它我设置的环境变量。
|
||||
|
||||
#### 例子:使用 http_proxy ####
|
||||
|
||||
$ wget www.cyberciti.biz
|
||||
--2015-08-03 23:20:23-- http://www.cyberciti.biz/
|
||||
Connecting to 10.12.249.194:3128... connected.
|
||||
Proxy request sent, awaiting response... 200 OK
|
||||
Length: unspecified [text/html]
|
||||
Saving to: 'index.html'
|
||||
index.html [ <=> ] 36.17K 87.0KB/s in 0.4s
|
||||
2015-08-03 23:20:24 (87.0 KB/s) - 'index.html' saved [37041]
|
||||
|
||||
#### 例子:忽视 http_proxy ####
|
||||
|
||||
$ env -i /usr/local/bin/wget www.cyberciti.biz
|
||||
--2015-08-03 23:25:17-- http://www.cyberciti.biz/
|
||||
Resolving www.cyberciti.biz... 74.86.144.194
|
||||
Connecting to www.cyberciti.biz|74.86.144.194|:80... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: unspecified [text/html]
|
||||
Saving to: 'index.html.1'
|
||||
index.html.1 [ <=> ] 36.17K 115KB/s in 0.3s
|
||||
2015-08-03 23:25:18 (115 KB/s) - 'index.html.1' saved [37041]
|
||||
|
||||
-i 选项使 env 命令完全忽视它继承的环境。但是,它并不会阻止你的命令(例如 wget 或 curl)设置新的变量。同时,也要注意运行 bash/ksh shell 的副作用:
|
||||
|
||||
env -i env | wc -l ## 空的 ##
|
||||
# 现在运行 bash ##
|
||||
env -i bash
|
||||
## bash 设置了新的环境变量 ##
|
||||
env | wc -l
|
||||
|
||||
#### 例子:设置一个环境变量 ####
|
||||
|
||||
语法如下:
|
||||
|
||||
env var=value /path/to/command arg1 arg2 ...
|
||||
## 或 ##
|
||||
var=value /path/to/command arg1 arg2 ...
|
||||
|
||||
例如设置 http_proxy:
|
||||
|
||||
env http_proxy="http://USER:PASSWORD@server1.cyberciti.biz:3128/" /usr/local/bin/wget www.cyberciti.biz
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/linux-unix-temporarily-clearing-environment-variables-command/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
61
published/20150810 For Linux, Supercomputers R Us.md
Normal file
61
published/20150810 For Linux, Supercomputers R Us.md
Normal file
@ -0,0 +1,61 @@
|
||||
有了 Linux,你就可以搭建自己的超级计算机
|
||||
================================================================================
|
||||
|
||||
> 几乎所有超级计算机上运行的系统都是 Linux,其中包括那些由树莓派(Raspberry Pi)板卡和 PlayStation 3游戏机组成的计算机。
|
||||
|
||||

|
||||
|
||||
*题图来源:By Michel Ngilen,[ CC BY 2.0 ], via Wikimedia Commons*
|
||||
|
||||
超级计算机是一种严肃的工具,做的都是高大上的计算。它们往往从事于严肃的用途,比如原子弹模拟、气候模拟和高等物理学。当然,它们的花费也很高大上。在最新的超级计算机 [Top500][1] 排名中,中国国防科技大学研制的天河 2 号位居第一,而天河 2 号的建造耗资约 3.9 亿美元!
|
||||
|
||||
但是,也有一个超级计算机,是由博伊西州立大学电气和计算机工程系的一名在读博士 Joshua Kiepert [用树莓派构建完成][2]的,其建造成本低于2000美元。
|
||||
|
||||
不,这不是我编造的。它一个真实的超级计算机,由超频到 1GHz 的 [B 型树莓派][3]的 ARM11 处理器与 VideoCore IV GPU 组成。每个都配备了 512MB 的内存、一对 USB 端口和 1 个 10/100 BaseT 以太网端口。
|
||||
|
||||
那么天河 2 号和博伊西州立大学的超级计算机有什么共同点吗?它们都运行 Linux 系统。世界最快的超级计算机[前 500 强中有 486][4] 个也同样运行的是 Linux 系统。这是从 20 多年前就开始的格局。而现在的趋势是超级计算机开始由廉价单元组成,因为 Kiepert 的机器并不是唯一一个无所谓预算的超级计算机。
|
||||
|
||||
麻省大学达特茅斯分校的物理学副教授 Gaurav Khanna 创建了一台超级计算机仅用了[不足 200 台的 PlayStation3 视频游戏机][5]。
|
||||
|
||||
PlayStation 游戏机由一个 3.2 GHz 的基于 PowerPC 的 Power 处理器所驱动。每个都配有 512M 的内存。你现在仍然可以花 200 美元买到一个,尽管索尼将在年底逐步淘汰它们。Khanna 仅用了 16 个 PlayStation 3 构建了他第一台超级计算机,所以你也可以花费不到 4000 美元就拥有你自己的超级计算机。
|
||||
|
||||
这些机器可能是用玩具建成的,但他们不是玩具。Khanna 已经用它做了严肃的天体物理学研究。一个白帽子黑客组织使用了类似的 [PlayStation 3 超级计算机在 2008 年破解了 SSL 的 MD5 哈希算法][6]。
|
||||
|
||||
两年后,美国空军研究实验室研制的 [Condor Cluster,使用了 1760 个索尼的 PlayStation 3 的处理器][7]和168 个通用的图形处理单元。这个低廉的超级计算机,每秒运行约 500 TFLOP ,即每秒可进行 500 万亿次浮点运算。
|
||||
|
||||
其他的一些便宜且适用于构建家庭超级计算机的构件包括,专业并行处理板卡,比如信用卡大小的 [99 美元的 Parallella 板卡][8],以及高端显卡,比如 [Nvidia 的 Titan Z][9] 和 [ AMD 的 FirePro W9100][10]。这些高端板卡的市场零售价约 3000 美元,一些想要一台梦幻般的机器的玩家为此参加了[英特尔极限大师赛:英雄联盟世界锦标赛][11],要是甚至有机会得到了第一名的话,能获得超过 10 万美元奖金。另一方面,一个能够自己提供超过 2.5TFLOPS 计算能力的计算机,对于科学家和研究人员来说,这为他们提供了一个可以拥有自己专属的超级计算机的经济的方法。
|
||||
|
||||
而超级计算机与 Linux 的连接,这一切都始于 1994 年戈达德航天中心的第一个名为 [Beowulf 超级计算机][13]。
|
||||
|
||||
按照我们的标准,Beowulf 不能算是最优越的。但在那个时期,作为第一台自制的超级计算机,它的 16 个英特尔486DX 处理器和 10Mbps 的以太网总线,是个伟大的创举。[Beowulf 是由美国航空航天局的承建商 Don Becker 和 Thomas Sterling 所设计的][14],是第一台“创客”超级计算机。它的“计算部件” 486DX PC,成本仅有几千美元。尽管它的速度只有个位数的 GFLOPS (吉拍,每秒10亿次)浮点运算,[Beowulf][15] 表明了你可以用商用现货(COTS)硬件和 Linux 创建超级计算机。
|
||||
|
||||
我真希望我参与创建了一部分,但是我 1994 年就离开了戈达德,开始了作为一名全职的科技记者的职业生涯。该死。
|
||||
|
||||
但是尽管我只是使用笔记本的记者,我依然能够体会到 COTS 和开源软件是如何永远的改变了超级计算机。我希望现在读这篇文章的你也能。因为,无论是 Raspberry Pi 集群,还是超过 300 万个英特尔的 Ivy Bridge 和 Xeon Phi 芯片的庞然大物,几乎所有当代的超级计算机都可以追溯到 Beowulf。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworld.com/article/2960701/linux/for-linux-supercomputers-r-us.html
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[xiaoyu33](https://github.com/xiaoyu33)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworld.com/author/Steven-J.-Vaughan_Nichols/
|
||||
[1]:http://www.top500.org/
|
||||
[2]:http://www.zdnet.com/article/build-your-own-supercomputer-out-of-raspberry-pi-boards/
|
||||
[3]:https://www.raspberrypi.org/products/model-b/
|
||||
[4]:http://www.zdnet.com/article/linux-still-rules-supercomputing/
|
||||
[5]:http://www.nytimes.com/2014/12/23/science/an-economical-way-to-save-progress.html?smid=fb-nytimes&smtyp=cur&bicmp=AD&bicmlukp=WT.mc_id&bicmst=1409232722000&bicmet=1419773522000&_r=4
|
||||
[6]:http://www.computerworld.com/article/2529932/cybercrime-hacking/researchers-hack-verisign-s-ssl-scheme-for-securing-web-sites.html
|
||||
[7]:http://phys.org/news/2010-12-air-playstation-3s-supercomputer.html
|
||||
[8]:http://www.zdnet.com/article/parallella-the-99-linux-supercomputer/
|
||||
[9]:http://blogs.nvidia.com/blog/2014/03/25/titan-z/
|
||||
[10]:http://www.amd.com/en-us/press-releases/Pages/amd-flagship-professional-2014apr7.aspx
|
||||
[11]:http://en.intelextrememasters.com/news/check-out-the-intel-extreme-masters-katowice-prize-money-distribution/
|
||||
|
||||
[13]:http://www.beowulf.org/overview/history.html
|
||||
[14]:http://yclept.ucdavis.edu/Beowulf/aboutbeowulf.html
|
||||
[15]:http://www.beowulf.org/
|
||||
@ -0,0 +1,64 @@
|
||||
在 Linux 中安装 Darkstat:基于网页的流量分析器
|
||||
================================================================================
|
||||
|
||||
Darkstat是一个简易的,基于网页的流量分析程序。它可以在主流的操作系统如Linux、Solaris、MAC、AIX上工作。它以守护进程的形式持续工作在后台,不断地嗅探网络数据,以简单易懂的形式展现在它的网页上。它可以为主机生成流量报告,识别特定的主机上哪些端口是打开的,它兼容IPv6。让我们看下如何在Linux中安装和配置它。
|
||||
|
||||
### 在Linux中安装配置Darkstat ###
|
||||
|
||||
** 在Fedora/CentOS/RHEL中安装Darkstat:**
|
||||
|
||||
要在Fedora/RHEL和CentOS中安装,运行下面的命令。
|
||||
|
||||
sudo yum install darkstat
|
||||
|
||||
**在Ubuntu/Debian中安装Darkstat:**
|
||||
|
||||
运行下面的命令在Ubuntu和Debian中安装。
|
||||
|
||||
sudo apt-get install darkstat
|
||||
|
||||
恭喜你,Darkstat已经在你的Linux中安装了。
|
||||
|
||||
### 配置 Darkstat ###
|
||||
|
||||
为了正确运行这个程序,我们需要执行一些基本的配置。运行下面的命令用gedit编辑器打开/etc/darkstat/init.cfg文件。
|
||||
|
||||
sudo gedit /etc/darkstat/init.cfg
|
||||
|
||||

|
||||
|
||||
*编辑 Darkstat*
|
||||
|
||||
修改START_DARKSTAT这个参数为yes,并在“INTERFACE”中提供你的网络接口。确保取消了DIR、PORT、BINDIP和LOCAL这些参数的注释。如果你希望绑定Darkstat到特定的IP,在BINDIP参数中提供它。
|
||||
|
||||
### 启动Darkstat守护进程 ###
|
||||
|
||||
安装并配置完Darkstat后,运行下面的命令启动它的守护进程。
|
||||
|
||||
sudo /etc/init.d/darkstat start
|
||||
|
||||

|
||||
|
||||
你可以用下面的命令来在开机时启动Darkstat:
|
||||
|
||||
chkconfig darkstat on
|
||||
|
||||
打开浏览器并打开**http://localhost:666**,它会显示Darkstat的网页界面。使用这个工具来分析你的网络流量。
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
它是一个占用很少内存的轻量级工具。这个工具流行的原因是简易、易于配置使用。这是一个对系统管理员而言必须拥有的程序。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxpitstop.com/install-darkstat-on-ubuntu-linux/
|
||||
|
||||
作者:[Aun][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxpitstop.com/author/aun/
|
||||
@ -0,0 +1,100 @@
|
||||
如何在 Linux 上从 Google Play 商店里下载 apk 文件
|
||||
================================================================================
|
||||
|
||||
假设你想在你的 Android 设备中安装一个 Android 应用,然而由于某些原因,你不能在 Andord 设备上访问 Google Play 商店(LCTT 译注:显然这对于我们来说是常态)。接着你该怎么做呢?在不访问 Google Play 商店的前提下安装应用的一种可能的方法是,使用其他的手段下载该应用的 APK 文件,然后手动地在 Android 设备上 [安装 APK 文件][1]。
|
||||
|
||||
在非 Android 设备如常规的电脑和笔记本电脑上,有着几种方式来从 Google Play 商店下载到官方的 APK 文件。例如,使用浏览器插件(例如,针对 [Chrome][2] 或针对 [Firefox][3] 的插件) 或利用允许你使用浏览器下载 APK 文件的在线的 APK 存档等。假如你不信任这些闭源的插件或第三方的 APK 仓库,这里有另一种手动下载官方 APK 文件的方法,它使用一个名为 [GooglePlayDownloader][4] 的开源 Linux 应用。
|
||||
|
||||
GooglePlayDownloader 是一个基于 Python 的 GUI 应用,它可以让你从 Google Play 商店上搜索和下载 APK 文件。由于它是完全开源的,你可以放心地使用它。在本篇教程中,我将展示如何在 Linux 环境下,使用 GooglePlayDownloader 来从 Google Play 商店下载 APK 文件。
|
||||
|
||||
### Python 需求 ###
|
||||
|
||||
GooglePlayDownloader 需要使用带有 SNI(Server Name Indication 服务器名称指示)的 Python 来支持 SSL/TLS 通信,该功能由 Python 2.7.9 或更高版本引入。这使得一些旧的发行版本如 Debian 7 Wheezy 及早期版本,Ubuntu 14.04 及早期版本或 CentOS/RHEL 7 及早期版本均不能满足该要求。这里假设你已经有了一个带有 Python 2.7.9 或更高版本的发行版本,可以像下面这样接着安装 GooglePlayDownloader。
|
||||
|
||||
### 在 Ubuntu 上安装 GooglePlayDownloader ###
|
||||
|
||||
在 Ubuntu 上,你可以使用官方构建的 deb 包。有一个条件是你可能需要手动地安装一个必需的依赖。
|
||||
|
||||
#### 在 Ubuntu 14.10 上 ####
|
||||
|
||||
下载 [python-ndg-httpsclient][5] deb 软件包,这是一个较旧的 Ubuntu 发行版本中缺失的依赖。同时还要下载 GooglePlayDownloader 的官方 deb 软件包。
|
||||
|
||||
$ wget http://mirrors.kernel.org/ubuntu/pool/main/n/ndg-httpsclient/python-ndg-httpsclient_0.3.2-1ubuntu4_all.deb
|
||||
$ wget http://codingteam.net/project/googleplaydownloader/download/file/googleplaydownloader_1.7-1_all.deb
|
||||
|
||||
如下所示,我们将使用 [gdebi 命令][6] 来安装这两个 deb 文件。 gedbi 命令将自动地处理任何其他的依赖。
|
||||
|
||||
$ sudo apt-get install gdebi-core
|
||||
$ sudo gdebi python-ndg-httpsclient_0.3.2-1ubuntu4_all.deb
|
||||
$ sudo gdebi googleplaydownloader_1.7-1_all.deb
|
||||
|
||||
#### 在 Ubuntu 15.04 或更新的版本上 ####
|
||||
|
||||
最近的 Ubuntu 发行版本上已经配备了所有需要的依赖,所以安装过程可以如下面那样直接进行。
|
||||
|
||||
$ wget http://codingteam.net/project/googleplaydownloader/download/file/googleplaydownloader_1.7-1_all.deb
|
||||
$ sudo apt-get install gdebi-core
|
||||
$ sudo gdebi googleplaydownloader_1.7-1_all.deb
|
||||
|
||||
### 在 Debian 上安装 GooglePlayDownloader ###
|
||||
|
||||
由于其 Python 需求, Googleplaydownloader 不能被安装到 Debian 7 Wheezy 或早期版本上,除非你升级了它自备的 Python 版本。
|
||||
|
||||
#### 在 Debian 8 Jessie 及更高版本上: ####
|
||||
|
||||
$ wget http://codingteam.net/project/googleplaydownloader/download/file/googleplaydownloader_1.7-1_all.deb
|
||||
$ sudo apt-get install gdebi-core
|
||||
$ sudo gdebi googleplaydownloader_1.7-1_all.deb
|
||||
|
||||
### 在 Fedora 上安装 GooglePlayDownloader ###
|
||||
|
||||
由于 GooglePlayDownloader 原本是针对基于 Debian 的发行版本所开发的,假如你想在 Fedora 上使用它,你需要从它的源码开始安装。
|
||||
|
||||
首先安装必需的依赖。
|
||||
|
||||
$ sudo yum install python-pyasn1 wxPython python-ndg_httpsclient protobuf-python python-requests
|
||||
|
||||
然后像下面这样安装它。
|
||||
|
||||
$ wget http://codingteam.net/project/googleplaydownloader/download/file/googleplaydownloader_1.7.orig.tar.gz
|
||||
$ tar -xvf googleplaydownloader_1.7.orig.tar.gz
|
||||
$ cd googleplaydownloader-1.7
|
||||
$ chmod o+r -R .
|
||||
$ sudo python setup.py install
|
||||
$ sudo sh -c "echo 'python /usr/lib/python2.7/site-packages/googleplaydownloader-1.7-py2.7.egg/googleplaydownloader/googleplaydownloader.py' > /usr/bin/googleplaydownloader"
|
||||
|
||||
### 使用 GooglePlayDownloader 从 Google Play 商店下载 APK 文件 ###
|
||||
|
||||
一旦你安装好 GooglePlayDownloader 后,你就可以像下面那样从 Google Play 商店下载 APK 文件。(LCTT 译注:显然你需要让你的 Linux 能爬梯子)
|
||||
|
||||
首先通过输入下面的命令来启动该应用:
|
||||
|
||||
$ googleplaydownloader
|
||||
|
||||

|
||||
|
||||
在搜索栏中,输入你想从 Google Play 商店下载的应用的名称。
|
||||
|
||||
|
||||
|
||||
一旦你从搜索列表中找到了该应用,就选择该应用,接着点击 “下载选定的 APK 文件” 按钮。最后你将在你的家目录中找到下载的 APK 文件。现在,你就可以将下载到的 APK 文件转移到你所选择的 Android 设备上,然后手动安装它。
|
||||
|
||||
希望这篇教程对你有所帮助。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/download-apk-files-google-play-store.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/how-to-install-apk-file-on-android-phone-or-tablet.html
|
||||
[2]:https://chrome.google.com/webstore/detail/apk-downloader/cgihflhdpokeobcfimliamffejfnmfii
|
||||
[3]:https://addons.mozilla.org/en-us/firefox/addon/apk-downloader/
|
||||
[4]:http://codingteam.net/project/googleplaydownloader
|
||||
[5]:http://packages.ubuntu.com/vivid/python-ndg-httpsclient
|
||||
[6]:http://xmodulo.com/how-to-install-deb-file-with-dependencies.html
|
||||
@ -0,0 +1,70 @@
|
||||
如何在 Linux 终端中知道你的公有 IP
|
||||
================================================================================
|
||||

|
||||
|
||||
公有地址由 InterNIC 分配并由基于类的网络 ID 或基于 CIDR 的地址块构成(被称为 CIDR 块),并保证了在全球互联网中的唯一性。当公有地址被分配时,其路由将会被记录到互联网中的路由器中,这样访问公有地址的流量就能顺利到达。访问目标公有地址的流量可经由互联网抵达。比如,当一个 CIDR 块被以网络 ID 和子网掩码的形式分配给一个组织时,对应的 [网络 ID,子网掩码] 也会同时作为路由储存在互联网中的路由器中。目标是 CIDR 块中的地址的 IP 封包会被导向对应的位置。
|
||||
|
||||
在本文中我将会介绍在几种在 Linux 终端中查看你的公有 IP 地址的方法。这对普通用户来说并无意义,但 Linux 服务器(无GUI或者作为只能使用基本工具的用户登录时)会很有用。无论如何,从 Linux 终端中获取公有 IP 在各种方面都很意义,说不定某一天就能用得着。
|
||||
|
||||
以下是我们主要使用的两个命令,curl 和 wget。你可以换着用。
|
||||
|
||||
### Curl 纯文本格式输出: ###
|
||||
|
||||
curl icanhazip.com
|
||||
curl ifconfig.me
|
||||
curl curlmyip.com
|
||||
curl ip.appspot.com
|
||||
curl ipinfo.io/ip
|
||||
curl ipecho.net/plain
|
||||
curl www.trackip.net/i
|
||||
|
||||
### curl JSON格式输出: ###
|
||||
|
||||
curl ipinfo.io/json
|
||||
curl ifconfig.me/all.json
|
||||
curl www.trackip.net/ip?json (有点丑陋)
|
||||
|
||||
### curl XML格式输出: ###
|
||||
|
||||
curl ifconfig.me/all.xml
|
||||
|
||||
### curl 得到所有IP细节 (挖掘机)###
|
||||
|
||||
curl ifconfig.me/all
|
||||
|
||||
### 使用 DYDNS (当你使用 DYDNS 服务时有用)###
|
||||
|
||||
curl -s 'http://checkip.dyndns.org' | sed 's/.*Current IP Address: \([0-9\.]*\).*/\1/g'
|
||||
curl -s http://checkip.dyndns.org/ | grep -o "[[:digit:].]\+"
|
||||
|
||||
### 使用 Wget 代替 Curl ###
|
||||
|
||||
wget http://ipecho.net/plain -O - -q ; echo
|
||||
wget http://observebox.com/ip -O - -q ; echo
|
||||
|
||||
### 使用 host 和 dig 命令 ###
|
||||
|
||||
如果有的话,你也可以直接使用 host 和 dig 命令。
|
||||
|
||||
host -t a dartsclink.com | sed 's/.*has address //'
|
||||
dig +short myip.opendns.com @resolver1.opendns.com
|
||||
|
||||
### bash 脚本示例: ###
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
PUBLIC_IP=`wget http://ipecho.net/plain -O - -q ; echo`
|
||||
echo $PUBLIC_IP
|
||||
|
||||
简单易用。
|
||||
|
||||
我实际上是在写一个用于记录每日我的路由器中所有 IP 变化并保存到一个文件的脚本。我在搜索过程中找到了这些很好用的命令。希望某天它能帮到其他人。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.blackmoreops.com/2015/06/14/how-to-get-public-ip-from-linux-terminal/
|
||||
|
||||
译者:[KevinSJ](https://github.com/KevinSJ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,63 @@
|
||||
Ubuntu 有望让你安装最新 Nvidia Linux 驱动更简单
|
||||
================================================================================
|
||||

|
||||
|
||||
*Ubuntu 上的游戏玩家在增长——因而需要最新版驱动*
|
||||
|
||||
**在 Ubuntu 上安装上游的 NVIDIA 图形驱动即将变得更加容易。**
|
||||
|
||||
Ubuntu 开发者正在考虑构建一个全新的'官方' PPA,以便为桌面用户分发最新的闭源 NVIDIA 二进制驱动。
|
||||
|
||||
该项改变会让 Ubuntu 游戏玩家收益,并且*不会*给其它人造成 OS 稳定性方面的风险。
|
||||
|
||||
**仅**当用户明确选择它时,新的上游驱动将通过这个新 PPA 安装并更新。其他人将继续得到并使用更近的包含在 Ubuntu 归档中的稳定版 NVIDIA Linux 驱动快照。
|
||||
|
||||
### 为什么需要该项目? ###
|
||||
|
||||
|
||||
|
||||
*Ubuntu 提供了驱动——但是它们不是最新的*
|
||||
|
||||
可以从归档中(使用命令行、synaptic,或者通过额外驱动工具)安装到 Ubuntu 上的闭源 NVIDIA 图形驱动在大多数情况下都能工作得很好,并且可以轻松地处理 Unity 桌面外壳的混染。
|
||||
|
||||
但对于游戏需求而言,那完全是另外一码事儿。
|
||||
|
||||
如果你想要将最高帧率和 HD 纹理从最新流行的 Steam 游戏中压榨出来,你需要最新的二进制驱动文件。
|
||||
|
||||
驱动越新,越可能支持最新的特性和技术,或者带有预先打包的游戏专门的优化和漏洞修复。
|
||||
|
||||
问题在于,在 Ubuntu 上安装最新 Nvidia Linux 驱动不是件容易的事儿,而且也不具安全保证。
|
||||
|
||||
要填补这个空白,许多由热心人维护的第三方 PPA 就出现了。由于许多这些 PPA 也发布了其它实验性的或者前沿软件,它们的使用**并不是毫无风险的**。添加一个前沿的 PPA 通常是搞崩整个系统的最快的方式!
|
||||
|
||||
一个解决方法是,让 Ubuntu 用户安装最新的专有图形驱动以满足对第三方 PPA 的需要,**但是**提供一个安全机制,如果有需要,你可以回滚到稳定版本。
|
||||
|
||||
### ‘对全新驱动的需求难以忽视’ ###
|
||||
|
||||
> '一个让Ubuntu用户安全地获得最新硬件驱动的解决方案出现了。'
|
||||
|
||||
‘在快速发展的市场中,对全新驱动的需求正变得难以忽视,用户将想要最新的上游软件,’卡斯特罗在一封给 Ubuntu 桌面邮件列表的电子邮件中解释道。
|
||||
|
||||
‘[NVIDIA] 可以毫不费力为 [Windows 10] 用户带来了不起的体验。直到我们可以说服 NVIDIA 在 Ubuntu 中做了同样的工作,这样我们就可以搞定这一切了。’
|
||||
|
||||
卡斯特罗的“官方的” NVIDIA PPA 方案就是最实现这一目的的最容易的方式。
|
||||
|
||||
游戏玩家将可以在 Ubuntu 的默认专有软件驱动工具中选择接收来自该 PPA 的新驱动,再也不需要它们从网站或维基页面拷贝并粘贴终端命令了。
|
||||
|
||||
该 PPA 内的驱动将由一个选定的社区成员组成的团队打包并维护,并受惠于一个名为**自动化测试**的半官方方式。
|
||||
|
||||
就像卡斯特罗自己说的那样:'人们想要最新的闪光的东西,而不管他们想要做什么。我们也许也要在其周围放置一个框架,因此人们可以获得他们所想要的,而不必破坏他们的计算机。'
|
||||
|
||||
**你想要使用这个 PPA 吗?你怎样来评估 Ubuntu 上默认 Nvidia 驱动的性能呢?在评论中分享你的想法吧,伙计们!**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/08/ubuntu-easy-install-latest-nvidia-linux-drivers
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
@ -0,0 +1,66 @@
|
||||
Ubuntu NVIDIA 显卡驱动 PPA 已经做好准备
|
||||
================================================================================
|
||||

|
||||
|
||||
加速你的帧率!
|
||||
|
||||
**嘿,各位,稍安勿躁,很快就好。**
|
||||
|
||||
就在提议开发一个[新的 PPA][1] 来给 Ubuntu 用户们提供最新的 NVIDIA 显卡驱动后不久,ubuntu 社区的人们又集结起来了,就是为了这件事。
|
||||
|
||||
顾名思义,‘**Graphics Drivers PPA**’ 包含了最新的 NVIDIA Linux 显卡驱动发布,已经打包好可供用户升级使用,没有让人头疼的二进制运行时文件!
|
||||
|
||||
这个 PPA 被设计用来让玩家们尽可能方便地在 Ubuntu 上运行最新款的游戏。
|
||||
|
||||
#### 万事俱备,只欠东风 ####
|
||||
|
||||
Jorge Castro 开发一个包含 NVIDIA 最新显卡驱动的 PPA 神器的想法得到了 Ubuntu 用户和广大游戏开发者的热烈响应。
|
||||
|
||||
就连那些致力于将“Steam平台”上的知名大作移植到 Linux 上的人们,也给了不少建议。
|
||||
|
||||
Edwin Smith,Feral Interactive 公司(‘Shadow of Mordor’) 的产品总监,对于“让用户更方便地更新驱动”的倡议表示非常欣慰。
|
||||
|
||||
### 如何使用最新的 Nvidia Drivers PPA###
|
||||
|
||||
虽然新的“显卡PPA”已经开发出来,但是现在还远远达不到成熟。开发者们提醒到:
|
||||
|
||||
> “这个 PPA 还处于测试阶段,在你使用它之前最好有一些打包的经验。请大家稍安勿躁,再等几天。”
|
||||
|
||||
将 PPA 试发布给 Ubuntu desktop 邮件列表的 Jorge,也强调说,使用现行的一些 PPA(比如 xorg-edgers)的玩家可能发现不了什么区别(因为现在的驱动只不过是把内容从其他那些现存驱动拷贝过来了)
|
||||
|
||||
“新驱动发布的时候,好戏才会上演呢,”他说。
|
||||
|
||||
截至写作本文时为止,这个 PPA 囊括了从 Ubuntu 12.04.1 到 15.10 各个版本的 Nvidia 驱动。注意这些驱动对所有的发行版都适用。
|
||||
|
||||
> **毫无疑问,除非你清楚自己在干些什么,并且知道如果出了问题应该怎么撤销,否则就不要进行下面的操作。**
|
||||
|
||||
新打开一个终端窗口,运行下面的命令加入 PPA:
|
||||
|
||||
sudo add-apt-repository ppa:graphics-drivers/ppa
|
||||
|
||||
安装或更新到最新的 Nvidia 显卡驱动:
|
||||
|
||||
sudo apt-get update && sudo apt-get install nvidia-355
|
||||
|
||||
记住:如果PPA把你的系统弄崩了,你可得自己去想办法,我们提醒过了哦。(译者注:切记!)
|
||||
|
||||
如果想要撤销对PPA的改变,使用 `ppa-purge` 命令。
|
||||
|
||||
有什么意见,想法,或者指正,就在下面的评论栏里写下来吧。(我没有 NVIDIA 的硬件来为我自己验证上面的这些东西,如果你可以验证的话,那就太感谢了。)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/08/ubuntu-nvidia-graphics-drivers-ppa-is-ready-for-action
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[DongShuaike](https://github.com/DongShuaike)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://linux.cn/article-6030-1.html
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,158 @@
|
||||
shellinabox:一款使用 AJAX 的基于 Web 的终端模拟器
|
||||
================================================================================
|
||||
|
||||
### shellinabox简介 ###
|
||||
|
||||
通常情况下,我们在访问任何远程服务器时,会使用常见的通信工具如OpenSSH和Putty等。但是,有可能我们在防火墙后面不能使用这些工具访问远程系统,或者防火墙只允许HTTPS流量才能通过。不用担心!即使你在这样的防火墙后面,我们依然有办法来访问你的远程系统。而且,你不需要安装任何类似于OpenSSH或Putty的通讯工具。你只需要有一个支持JavaScript和CSS的现代浏览器,并且你不用安装任何插件或第三方应用软件。
|
||||
|
||||
这个 **Shell In A Box**,发音是**shellinabox**,是由**Markus Gutschke**开发的一款自由开源的基于Web的Ajax的终端模拟器。它使用AJAX技术,通过Web浏览器提供了类似原生的 Shell 的外观和感受。
|
||||
|
||||
这个**shellinaboxd**守护进程实现了一个Web服务器,能够侦听指定的端口。其Web服务器可以发布一个或多个服务,这些服务显示在用 AJAX Web 应用实现的VT100模拟器中。默认情况下,端口为4200。你可以更改默认端口到任意选择的任意端口号。在你的远程服务器安装shellinabox以后,如果你想从本地系统接入,打开Web浏览器并导航到:**http://IP-Address:4200/**。输入你的用户名和密码,然后就可以开始使用你远程系统的Shell。看起来很有趣,不是吗?确实 有趣!
|
||||
|
||||
**免责声明**:
|
||||
|
||||
shellinabox不是SSH客户端或任何安全软件。它仅仅是一个应用程序,能够通过Web浏览器模拟一个远程系统的Shell。同时,它和SSH没有任何关系。这不是可靠的安全地远程控制您的系统的方式。这只是迄今为止最简单的方法之一。无论如何,你都不应该在任何公共网络上运行它。
|
||||
|
||||
### 安装shellinabox ###
|
||||
|
||||
#### 在Debian / Ubuntu系统上: ####
|
||||
|
||||
shellinabox在默认库是可用的。所以,你可以使用命令来安装它:
|
||||
|
||||
$ sudo apt-get install shellinabox
|
||||
|
||||
#### 在RHEL / CentOS系统上: ####
|
||||
|
||||
首先,使用命令安装EPEL仓库:
|
||||
|
||||
# yum install epel-release
|
||||
|
||||
然后,使用命令安装shellinabox:
|
||||
|
||||
# yum install shellinabox
|
||||
|
||||
完成!
|
||||
|
||||
### 配置shellinabox ###
|
||||
|
||||
正如我之前提到的,shellinabox侦听端口默认为**4200**。你可以将此端口更改为任意数字,以防别人猜到。
|
||||
|
||||
在Debian/Ubuntu系统上shellinabox配置文件的默认位置是**/etc/default/shellinabox**。在RHEL/CentOS/Fedora上,默认位置在**/etc/sysconfig/shellinaboxd**。
|
||||
|
||||
如果要更改默认端口,
|
||||
|
||||
在Debian / Ubuntu:
|
||||
|
||||
$ sudo vi /etc/default/shellinabox
|
||||
|
||||
在RHEL / CentOS / Fedora:
|
||||
|
||||
# vi /etc/sysconfig/shellinaboxd
|
||||
|
||||
更改你的端口到任意数字。因为我在本地网络上测试它,所以我使用默认值。
|
||||
|
||||
# Shell in a box daemon configuration
|
||||
# For details see shellinaboxd man page
|
||||
|
||||
# Basic options
|
||||
USER=shellinabox
|
||||
GROUP=shellinabox
|
||||
CERTDIR=/var/lib/shellinabox
|
||||
PORT=4200
|
||||
OPTS="--disable-ssl-menu -s /:LOGIN"
|
||||
|
||||
# Additional examples with custom options:
|
||||
|
||||
# Fancy configuration with right-click menu choice for black-on-white:
|
||||
# OPTS="--user-css Normal:+black-on-white.css,Reverse:-white-on-black.css --disable-ssl-menu -s /:LOGIN"
|
||||
|
||||
# Simple configuration for running it as an SSH console with SSL disabled:
|
||||
# OPTS="-t -s /:SSH:host.example.com"
|
||||
|
||||
重启shelinabox服务。
|
||||
|
||||
**在Debian/Ubuntu:**
|
||||
|
||||
$ sudo systemctl restart shellinabox
|
||||
|
||||
或者
|
||||
|
||||
$ sudo service shellinabox restart
|
||||
|
||||
在RHEL/CentOS系统,运行下面的命令能在每次重启时自动启动shellinaboxd服务
|
||||
|
||||
# systemctl enable shellinaboxd
|
||||
|
||||
或者
|
||||
|
||||
# chkconfig shellinaboxd on
|
||||
|
||||
如果你正在运行一个防火墙,记得要打开端口**4200**或任何你指定的端口。
|
||||
|
||||
例如,在RHEL/CentOS系统,你可以如下图所示允许端口。
|
||||
|
||||
# firewall-cmd --permanent --add-port=4200/tcp
|
||||
|
||||
----------
|
||||
|
||||
# firewall-cmd --reload
|
||||
|
||||
### 使用 ###
|
||||
|
||||
现在,在你的客户端系统,打开Web浏览器并导航到:**https://ip-address-of-remote-servers:4200**。
|
||||
|
||||
**注意**:如果你改变了端口,请填写修改后的端口。
|
||||
|
||||
你会得到一个证书问题的警告信息。接受该证书并继续。
|
||||
|
||||

|
||||
|
||||
输入远程系统的用户名和密码。现在,您就能够从浏览器本身访问远程系统的外壳。
|
||||
|
||||

|
||||
|
||||
右键点击你浏览器的空白位置。你可以得到一些有很有用的额外菜单选项。
|
||||
|
||||

|
||||
|
||||
从现在开始,你可以通过本地系统的Web浏览器在你的远程服务器随意操作。
|
||||
|
||||
当你完成工作时,记得输入`exit`退出。
|
||||
|
||||
当再次连接到远程系统时,单击**连接**按钮,然后输入远程服务器的用户名和密码。
|
||||
|
||||

|
||||
|
||||
如果想了解shellinabox更多细节,在你的终端键入下面的命令:
|
||||
|
||||
# man shellinabox
|
||||
|
||||
或者
|
||||
|
||||
# shellinaboxd -help
|
||||
|
||||
同时,参考[shellinabox 在wiki页面的介绍][1],来了解shellinabox的综合使用细节。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
正如我之前提到的,如果你在服务器运行在防火墙后面,那么基于web的SSH工具是非常有用的。有许多基于web的SSH工具,但shellinabox是非常简单而有用的工具,可以从的网络上的任何地方,模拟一个远程系统的Shell。因为它是基于浏览器的,所以你可以从任何设备访问您的远程服务器,只要你有一个支持JavaScript和CSS的浏览器。
|
||||
|
||||
就这些啦。祝你今天有个好心情!
|
||||
|
||||
#### 参考链接: ####
|
||||
|
||||
- [shellinabox website][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/shellinabox-a-web-based-ajax-terminal-emulator/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[xiaoyu33](https://github.com/xiaoyu33)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/sk/
|
||||
[1]:https://code.google.com/p/shellinabox/wiki/shellinaboxd_man
|
||||
[2]:https://code.google.com/p/shellinabox/
|
||||
115
published/20150817 Top 5 Torrent Clients For Ubuntu Linux.md
Normal file
115
published/20150817 Top 5 Torrent Clients For Ubuntu Linux.md
Normal file
@ -0,0 +1,115 @@
|
||||
Ubuntu 下五个最好的 BT 客户端
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
在寻找 **Ubuntu 中最好的 BT 客户端**吗?事实上,Linux 桌面平台中有许多 BT 客户端,但是它们中的哪些才是**最好的 Ubuntu 客户端**呢?
|
||||
|
||||
我将会列出 Linux 上最好的五个 BT 客户端,它们都拥有着体积轻盈,功能强大的特点,而且还有令人印象深刻的用户界面。自然,易于安装和使用也是特性之一。
|
||||
|
||||
### Ubuntu 下最好的 BT 客户端 ###
|
||||
|
||||
考虑到 Ubuntu 默认安装了 Transmission,所以我将会从这个列表中排除了 Transmission。但是这并不意味着 Transmission 没有资格出现在这个列表中,事实上,Transmission 是一个非常好的BT客户端,这也正是它被包括 Ubuntu 在内的多个发行版默认安装的原因。
|
||||
|
||||
### Deluge ###
|
||||
|
||||

|
||||
|
||||
[Deluge][1] 被 Lifehacker 评选为 Linux 下最好的 BT 客户端,这说明了 Deluge 是多么的有用。而且,并不仅仅只有 Lifehacker 是 Deluge 的粉丝,纵观多个论坛,你都会发现不少 Deluge 的忠实拥趸。
|
||||
|
||||
快速,时尚而直观的界面使得 Deluge 成为 Linux 用户的挚爱。
|
||||
|
||||
Deluge 可在 Ubuntu 的仓库中获取,你能够在 Ubuntu 软件中心中安装它,或者使用下面的命令:
|
||||
|
||||
sudo apt-get install deluge
|
||||
|
||||
### qBittorrent ###
|
||||
|
||||

|
||||
|
||||
正如它的名字所暗示的,[qBittorrent][2] 是著名的 [Bittorrent][3] 应用的 Qt 版本。如果曾经使用过它,你将会看到和 Windows 下的 Bittorrent 相似的界面。同样轻巧并且有着 BT 客户端的所有标准功能, qBittorrent 也可以在 Ubuntu 的默认仓库中找到。
|
||||
|
||||
它可以通过 Ubuntu 软件仓库安装,或者使用下面的命令:
|
||||
|
||||
sudo apt-get install qbittorrent
|
||||
|
||||
|
||||
### Tixati ###
|
||||
|
||||

|
||||
|
||||
[Tixati][4] 是另一个不错的 Ubuntu 下的 BT 客户端。它有着一个默认的黑暗主题,尽管很多人喜欢,但是我例外。它拥有着一切你能在 BT 客户端中找到的功能。
|
||||
|
||||
除此之外,它还有着数据分析的额外功能。你可以在美观的图表中分析流量以及其它数据。
|
||||
|
||||
- [下载 Tixati][5]
|
||||
|
||||
|
||||
|
||||
### Vuze ###
|
||||
|
||||

|
||||
|
||||
[Vuze][6] 是许多 Linux 以及 Windows 用户最喜欢的 BT 客户端。除了标准的功能,你可以直接在应用程序中搜索种子,也可以订阅系列片源,这样就无需再去寻找新的片源了,因为你可以在侧边栏中的订阅看到它们。
|
||||
|
||||
它还配备了一个视频播放器,可以播放带有字幕的高清视频等等。但是我不认为你会用它来代替那些更好的视频播放器,比如 VLC。
|
||||
|
||||
Vuze 可以通过 Ubuntu 软件中心安装或者使用下列命令:
|
||||
|
||||
sudo apt-get install vuze
|
||||
|
||||
|
||||
|
||||
### Frostwire ###
|
||||
|
||||

|
||||
|
||||
[Frostwire][7] 是一个你应该试一下的应用。它不仅仅是一个简单的 BT 客户端,它还可以应用于安卓,你可以用它通过 Wifi 来共享文件。
|
||||
|
||||
你可以在应用中搜索种子并且播放他们。除了下载文件,它还可以浏览本地的影音文件,并且将它们有条理的呈现在播放器中。这同样适用于安卓版本。
|
||||
|
||||
还有一个特点是:Frostwire 提供了独立音乐人的[合法音乐下载][13]。你可以下载并且欣赏它们,免费而且合法。
|
||||
|
||||
- [下载 Frostwire][8]
|
||||
|
||||
|
||||
|
||||
### 荣誉奖 ###
|
||||
|
||||
在 Windows 中,uTorrent(发音:mu torrent)是我最喜欢的 BT 应用。尽管 uTorrent 可以在 Linux 下运行,但是我还是特意忽略了它。因为在 Linux 下使用 uTorrent 不仅困难,而且无法获得完整的应用体验(运行在浏览器中)。
|
||||
|
||||
可以[在这里][9]阅读 Ubuntu下uTorrent 的安装教程。
|
||||
|
||||
#### 快速提示: ####
|
||||
|
||||
大多数情况下,BT 应用不会默认自动启动。如果想改变这一行为,请阅读[如何管理 Ubuntu 下的自启动程序][10]来学习。
|
||||
|
||||
### 你最喜欢的是什么? ###
|
||||
|
||||
这些是我对于 Ubuntu 下最好的 BT 客户端的意见。你最喜欢的是什么呢?请发表评论。也可以查看与本主题相关的[Ubuntu 最好的下载管理器][11]。如果使用 Popcorn Time,试试 [Popcorn Time 技巧][12]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/best-torrent-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[Xuanwo](https://github.com/Xuanwo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://deluge-torrent.org/
|
||||
[2]:http://www.qbittorrent.org/
|
||||
[3]:http://www.bittorrent.com/
|
||||
[4]:http://www.tixati.com/
|
||||
[5]:http://www.tixati.com/download/
|
||||
[6]:http://www.vuze.com/
|
||||
[7]:http://www.frostwire.com/
|
||||
[8]:http://www.frostwire.com/downloads
|
||||
[9]:http://sysads.co.uk/2014/05/install-utorrent-3-3-ubuntu-14-04-13-10/
|
||||
[10]:http://itsfoss.com/manage-startup-applications-ubuntu/
|
||||
[11]:http://itsfoss.com/4-best-download-managers-for-linux/
|
||||
[12]:http://itsfoss.com/popcorn-time-tips/
|
||||
[13]:http://www.frostclick.com/wp/
|
||||
|
||||
@ -0,0 +1,100 @@
|
||||
Linux中通过命令行监控股票报价
|
||||
================================================================================
|
||||
|
||||
如果你是那些股票投资者或者交易者中的一员,那么监控证券市场将是你的日常工作之一。最有可能的是你会使用一个在线交易平台,这个平台有着一些漂亮的实时图表和全部种类的高级股票分析和交易工具。虽然这种复杂的市场研究工具是任何严肃的证券投资者了解市场的必备工具,但是监控最新的股票报价来构建有利可图的投资组合仍然有很长一段路要走。
|
||||
|
||||
如果你是一位长久坐在终端前的全职系统管理员,而证券交易又成了你日常生活中的业余兴趣,那么一个简单地显示实时股票报价的命令行工具会是给你的恩赐。
|
||||
|
||||
在本教程中,让我来介绍一个灵巧而简洁的命令行工具,它可以让你在Linux上从命令行监控股票报价。
|
||||
|
||||
这个工具叫做[Mop][1]。它是用GO编写的一个轻量级命令行工具,可以极其方便地跟踪来自美国市场的最新股票报价。你可以很轻松地自定义要监控的证券列表,它会在一个基于ncurses的便于阅读的界面显示最新的股票报价。
|
||||
|
||||
**注意**:Mop是通过雅虎金融API获取最新的股票报价的。你必须意识到,他们的的股票报价已知会有15分钟的延时。所以,如果你正在寻找0延时的“实时”股票报价,那么Mop就不是你的菜了。这种“现场”股票报价订阅通常可以通过向一些不开放的私有接口付费获取。了解这些之后,让我们来看看怎样在Linux环境下使用Mop吧。
|
||||
|
||||
### 安装 Mop 到 Linux ###
|
||||
|
||||
由于Mop是用Go实现的,你首先需要安装Go语言。如果你还没有安装Go,请参照[此指南][2]将Go安装到你的Linux平台中。请确保按指南中所讲的设置GOPATH环境变量。
|
||||
|
||||
安装完Go后,继续像下面这样安装Mop。
|
||||
|
||||
**Debian,Ubuntu 或 Linux Mint**
|
||||
|
||||
$ sudo apt-get install git
|
||||
$ go get github.com/michaeldv/mop
|
||||
$ cd $GOPATH/src/github.com/michaeldv/mop
|
||||
$ make install
|
||||
|
||||
**Fedora,CentOS,RHEL**
|
||||
|
||||
$ sudo yum install git
|
||||
$ go get github.com/michaeldv/mop
|
||||
$ cd $GOPATH/src/github.com/michaeldv/mop
|
||||
$ make install
|
||||
|
||||
上述命令将安装Mop到$GOPATH/bin。
|
||||
|
||||
现在,编辑你的.bashrc,将$GOPATH/bin写到你的PATH变量中。
|
||||
|
||||
export PATH="$PATH:$GOPATH/bin"
|
||||
|
||||
----------
|
||||
|
||||
$ source ~/.bashrc
|
||||
|
||||
### 使用Mop来通过命令行监控股票报价 ###
|
||||
|
||||
要启动Mop,只需运行名为cmd的命令(LCTT 译注:这名字实在是……)。
|
||||
|
||||
$ cmd
|
||||
|
||||
首次启动,你将看到一些Mop预配置的证券行情自动收录器。
|
||||
|
||||

|
||||
|
||||
报价显示了像最新价格、交易百分比、每日低/高、52周低/高、股息以及年收益率等信息。Mop从[CNN][3]获取市场总览信息,从[雅虎金融][4]获得个股报价,股票报价信息它自己会在终端内周期性更新。
|
||||
|
||||
### 自定义Mop中的股票报价 ###
|
||||
|
||||
让我们来试试自定义证券列表吧。对此,Mop提供了易于记忆的快捷键:‘+’用于添加一只新股,而‘-’则用于移除一只股票。
|
||||
|
||||
要添加新股,请按‘+’,然后输入股票代码来添加(如MSFT)。你可以通过输入一个由逗号分隔的交易代码列表来一次添加多个股票(如”MSFT, AMZN, TSLA”)。
|
||||
|
||||

|
||||
|
||||
从列表中移除股票可以类似地按‘-’来完成。
|
||||
|
||||
### 对Mop中的股票报价排序 ###
|
||||
|
||||
你可以基于任何栏目对股票报价列表进行排序。要排序,请按‘o’,然后使用左/右键来选择排序的基准栏目。当选定了一个特定栏目后,你可以按回车来对列表进行升序排序,或者降序排序。
|
||||
|
||||
|
||||
|
||||
通过按‘g’,你可以根据股票当日的涨或跌来分组。涨的情况以绿色表示,跌的情况以白色表示。
|
||||
|
||||

|
||||
|
||||
如果你想要访问帮助页,只需要按‘?’。
|
||||
|
||||

|
||||
|
||||
### 尾声 ###
|
||||
|
||||
正如你所见,Mop是一个轻量级的,然而极其方便的证券监控工具。当然,你可以很轻松地从其它别的什么地方,从在线站点,你的智能手机等等访问到股票报价信息。然而,如果你在整天使用终端环境,Mop可以很容易地适应你的工作环境,希望没有让你过多地从你的工作流程中分心。只要让它在你其中一个终端中运行并保持市场日期持续更新,那就够了。
|
||||
|
||||
交易快乐!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/monitor-stock-quotes-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://github.com/michaeldv/mop
|
||||
[2]:http://ask.xmodulo.com/install-go-language-linux.html
|
||||
[3]:http://money.cnn.com/data/markets/
|
||||
[4]:http://finance.yahoo.com/
|
||||
@ -0,0 +1,52 @@
|
||||
Linux无极限:IBM发布LinuxONE大型机
|
||||
================================================================================
|
||||

|
||||
|
||||
LinuxONE Emperor MainframeGood的Ubuntu服务器团队今天发布了一条消息关于[IBM发布了LinuxONE][1],一种只支持Linux的大型机,也可以运行Ubuntu。
|
||||
|
||||
IBM发布的最大的LinuxONE系统称作‘Emperor’,它可以扩展到8000台虚拟机或者上万台容器- 对任何一台Linux系统都可能的记录。
|
||||
|
||||
LinuxONE被IBM称作‘游戏改变者’,它‘释放了Linux的商业潜力’。
|
||||
|
||||
IBM和Canonical正在一起协作为LinuxONE和其他IBM z系统创建Ubuntu发行版。Ubuntu将会在IBM z加入RedHat和SUSE作为首屈一指的Linux发行版。
|
||||
|
||||
随着IBM ‘Emperor’发布的还有LinuxONE Rockhopper,一个为中等规模商业或者组织小一点的大型机。
|
||||
|
||||
IBM是大型机中的领导者,并且占有大型机市场中90%的份额。
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="750" height="422" frameborder="0" allowfullscreen="" src="https://www.youtube.com/embed/2ABfNrWs-ns?feature=oembed"></iframe>
|
||||
|
||||
### 大型机用于什么? ###
|
||||
|
||||
你阅读这篇文章所使用的电脑在一个‘大铁块’一样的大型机前会显得很矮小。它们是巨大的,笨重的机柜里面充满了高端的组件、自己设计的技术和眼花缭乱的大量存储(就是数据存储,没有空间放钢笔和尺子)。
|
||||
|
||||
大型机被大型机构和商业用来处理和存储大量数据,通过统计来处理数据和处理大规模的事务处理。
|
||||
|
||||
### ‘世界最快的处理器’ ###
|
||||
|
||||
IBM已经与Canonical Ltd组成了团队来在LinuxONE和其他IBM z系统中使用Ubuntu。
|
||||
|
||||
LinuxONE Emperor使用IBM z13处理器。发布于一月的芯片声称是时间上最快的微处理器。它可以在几毫秒内响应事务。
|
||||
|
||||
但是也可以很好地处理高容量的移动事务,z13中的LinuxONE系统也是一个理想的云系统。
|
||||
|
||||
每个核心可以处理超过50个虚拟服务器,总共可以超过8000台虚拟服务器么,这使它以更便宜,更环保、更高效的方式扩展到云。
|
||||
|
||||
**在阅读这篇文章时你不必是一个CIO或者大型机巡查员。LinuxONE提供的可能性足够清晰。**
|
||||
|
||||
来源: [Reuters (h/t @popey)][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/08/ibm-linuxone-mainframe-ubuntu-partnership
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://www-03.ibm.com/systems/z/announcement.html
|
||||
[2]:http://www.reuters.com/article/2015/08/17/us-ibm-linuxone-idUSKCN0QM09P20150817
|
||||
@ -0,0 +1,53 @@
|
||||
Ubuntu Linux 来到 IBM 大型机
|
||||
================================================================================
|
||||
最终来到了。在 [LinuxCon][1] 上,IBM 和 [Canonical][2] 宣布 [Ubuntu Linux][3] 不久就会运行在 IBM 大型机 [LinuxONE][1] 上,这是一种只支持 Linux 的大型机,现在也可以运行 Ubuntu 了。
|
||||
|
||||
这个 IBM 发布的最大的 LinuxONE 系统称作‘Emperor’,它可以扩展到 8000 台虚拟机或者上万台容器,这可能是单独一台 Linux 系统的记录。
|
||||
|
||||
LinuxONE 被 IBM 称作‘游戏改变者’,它‘释放了 Linux 的商业潜力’。
|
||||
|
||||

|
||||
|
||||
*很快你就可以在你的 IBM 大型机上安装 Ubuntu Linux orange 啦*
|
||||
|
||||
根据 IBM z 系统的总经理 Ross Mauri 以及 Canonical 和 Ubuntu 的创立者 Mark Shuttleworth 所言,这是因为客户需要。十多年来,IBM 大型机只支持 [红帽企业版 Linux (RHEL)][4] 和 [SUSE Linux 企业版 (SLES)][5] Linux 发行版。
|
||||
|
||||
随着 Ubuntu 越来越成熟,更多的企业把它作为企业级 Linux,也有更多的人希望它能运行在 IBM 大型机上。尤其是银行希望如此。不久,金融 CIO 们就可以满足他们的需求啦。
|
||||
|
||||
在一次采访中 Shuttleworth 说 Ubuntu Linux 在 2016 年 4 月下一次长期支持版 Ubuntu 16.04 中就可以用到大型机上。而在 2014 年底 Canonical 和 IBM 将 [Ubuntu 带到 IBM 的 POWER][6] 架构中就迈出了第一步。
|
||||
|
||||
在那之前,Canonical 和 IBM 差点签署了协议 [在 2011 年实现 Ubuntu 支持 IBM 大型机][7],但最终也没有实现。这次,真的发生了。
|
||||
|
||||
Canonical 的 CEO Jane Silber 解释说 “[把 Ubuntu 平台支持扩大][8]到 [IBM z 系统][9] 是因为认识到需要 z 系统运行其业务的客户数量以及混合云市场的成熟。”
|
||||
|
||||
**Silber 还说:**
|
||||
|
||||
> 由于 z 系统的支持,包括 [LinuxONE][10],Canonical 和 IBM 的关系进一步加深,构建了对 POWER 架构的支持和 OpenPOWER 生态系统。正如 Power 系统的客户受益于 Ubuntu 的可扩展能力,我们的敏捷开发过程也使得类似 POWER8 CAPI (Coherent Accelerator Processor Interface,一致性加速器接口)得到了市场支持,z 系统的客户也可以期望技术进步能快速部署,并从 [Juju][11] 和我们的其它云工具中获益,使得能快速向端用户提供新服务。另外,我们和 IBM 的合作包括实现扩展部署很多 IBM 和 Juju 的软件解决方案。大型机客户对于能通过 Juju 将丰富‘迷人的’ IBM 解决方案、其它软件供应商的产品、开源解决方案部署到大型机上感到高兴。
|
||||
|
||||
Shuttleworth 期望 z 系统上的 Ubuntu 能取得巨大成功。它发展很快,由于对 OpenStack 的支持,希望有卓越云性能的人会感到非常高兴。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/ubuntu-linux-is-coming-to-the-mainframe/
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/08/ibm-linuxone-mainframe-ubuntu-partnership
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a],[Joey-Elijah Sneddon][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh),[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]:http://events.linuxfoundation.org/events/linuxcon-north-america
|
||||
[2]:http://www.canonical.com/
|
||||
[3]:http://www.ubuntu.comj/
|
||||
[4]:http://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[5]:https://www.suse.com/products/server/
|
||||
[6]:http://www.zdnet.com/article/ibm-doubles-down-on-linux/
|
||||
[7]:http://www.zdnet.com/article/mainframe-ubuntu-linux/
|
||||
[8]:https://insights.ubuntu.com/2015/08/17/ibm-and-canonical-plan-ubuntu-support-on-ibm-z-systems-mainframe/
|
||||
[9]:http://www-03.ibm.com/systems/uk/z/
|
||||
[10]:http://www.zdnet.com/article/linuxone-ibms-new-linux-mainframes/
|
||||
[11]:https://jujucharms.com/
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user