mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
johnhoow translating
This commit is contained in:
commit
fb74cc08d5
@ -1,12 +1,14 @@
|
|||||||
在逻辑卷管理中设置精简资源调配卷——第四部分
|
在LVM中设置精简资源调配卷(第四部分)
|
||||||
================================================================================
|
================================================================================
|
||||||
逻辑卷管理有许多特性,比如像快照和精简资源调配。在先前(第三部分中),我们已经介绍了如何为逻辑卷创建快照。在本文中,我们将了解如何在LVM中设置精简资源调配。
|
逻辑卷管理有许多特性,比如像快照和精简资源调配。在先前([第三部分][3]中),我们已经介绍了如何为逻辑卷创建快照。在本文中,我们将了解如何在LVM中设置精简资源调配。
|
||||||
|
|
||||||

|

|
||||||
在LVM中设置精简资源调配
|
|
||||||
|
*在LVM中设置精简资源调配*
|
||||||
|
|
||||||
### 精简资源调配是什么? ###
|
### 精简资源调配是什么? ###
|
||||||
精简资源调配用于lvm以在精简池中创建虚拟磁盘。我们假定我服务器上有**15GB**的存储容量,而我已经有2个客户各自占去了5GB存储空间。你是第三个客户,你也请求5GB的存储空间。在以前,我们会提供整个5GB的空间(富卷)。然而,你可能只使用5GB中的2GB,其它3GB以后再去填满它。
|
|
||||||
|
精简资源调配用于LVM以在精简池中创建虚拟磁盘。我们假定我服务器上有**15GB**的存储容量,而我已经有2个客户各自占去了5GB存储空间。你是第三个客户,你也请求5GB的存储空间。在以前,我们会提供整个5GB的空间(富卷)。然而,你可能只使用5GB中的2GB,其它3GB以后再去填满它。
|
||||||
|
|
||||||
而在精简资源调配中我们所做的是,在其中一个大卷组中定义一个精简池,再在精简池中定义一个精简卷。这样,不管你写入什么文件,它都会保存进去,而你的存储空间看上去就是5GB。然而,这所有5GB空间不会全部铺满整个硬盘。对其它客户也进行同样的操作,就像我说的,那儿已经有两个客户,你是第三个客户。
|
而在精简资源调配中我们所做的是,在其中一个大卷组中定义一个精简池,再在精简池中定义一个精简卷。这样,不管你写入什么文件,它都会保存进去,而你的存储空间看上去就是5GB。然而,这所有5GB空间不会全部铺满整个硬盘。对其它客户也进行同样的操作,就像我说的,那儿已经有两个客户,你是第三个客户。
|
||||||
|
|
||||||
@ -20,15 +22,13 @@
|
|||||||
|
|
||||||
在精简资源调配中,如果我为你定义了5GB空间,它就不会在定义卷时就将整个磁盘空间全部分配,它会根据你的数据写入而增长,希望你看懂了!跟你一样,其它客户也不会使用全部卷,所以还是有机会为一个新客户分配5GB空间的,这称之为过度资源调配。
|
在精简资源调配中,如果我为你定义了5GB空间,它就不会在定义卷时就将整个磁盘空间全部分配,它会根据你的数据写入而增长,希望你看懂了!跟你一样,其它客户也不会使用全部卷,所以还是有机会为一个新客户分配5GB空间的,这称之为过度资源调配。
|
||||||
|
|
||||||
但是,必须对各个卷的增长情况进行监控,否则结局会是个灾难。在过度资源调配完成后,如果所有4个客户都极度地写入数据到磁盘,你将碰到问题了。因为这个动作会填满15GB的存储空间,甚至溢出,从而导致这些卷下线。
|
但是,必须对各个卷的增长情况进行监控,否则结局会是个灾难。在过度资源调配完成后,如果所有4个客户都尽量写入数据到磁盘,你将碰到问题了。因为这个动作会填满15GB的存储空间,甚至溢出,从而导致这些卷下线。
|
||||||
|
|
||||||
### 需求 ###
|
### 前置阅读 ###
|
||||||
|
|
||||||
注:此三篇文章如果发布后可换成发布后链接,原文在前几天更新中
|
- [在Linux中使用LVM构建灵活的磁盘存储(第一部分)][1]
|
||||||
|
- [在Linux中扩展/缩减LVM(第二部分)][2]
|
||||||
- [使用LVM在Linux中创建逻辑卷——第一部分][1]
|
- [在 LVM中 录制逻辑卷快照并恢复(第三部分)][3]
|
||||||
- [在Linux中扩展/缩减LVM——第二部分][2]
|
|
||||||
- [在LVM中创建/恢复逻辑卷快照——第三部分][3]
|
|
||||||
|
|
||||||
#### 我的服务器设置 ####
|
#### 我的服务器设置 ####
|
||||||
|
|
||||||
@ -42,7 +42,8 @@
|
|||||||
# vgcreate -s 32M vg_thin /dev/sdb1
|
# vgcreate -s 32M vg_thin /dev/sdb1
|
||||||
|
|
||||||

|

|
||||||
列出卷组
|
|
||||||
|
*列出卷组*
|
||||||
|
|
||||||
接下来,在创建精简池和精简卷之前,检查逻辑卷有多少空间可用。
|
接下来,在创建精简池和精简卷之前,检查逻辑卷有多少空间可用。
|
||||||
|
|
||||||
@ -50,7 +51,8 @@
|
|||||||
# lvs
|
# lvs
|
||||||
|
|
||||||

|

|
||||||
检查逻辑卷
|
|
||||||
|
*检查逻辑卷*
|
||||||
|
|
||||||
我们可以在上面的lvs命令输出中看到,只显示了一些默认逻辑用于文件系统和交换分区。
|
我们可以在上面的lvs命令输出中看到,只显示了一些默认逻辑用于文件系统和交换分区。
|
||||||
|
|
||||||
@ -62,18 +64,20 @@
|
|||||||
|
|
||||||
- **-L** – 卷组大小
|
- **-L** – 卷组大小
|
||||||
- **–thinpool** – 创建精简池
|
- **–thinpool** – 创建精简池
|
||||||
- **tp_tecmint_poolThin** - 精简池名称
|
- **tp\_tecmint\_poolThin** - 精简池名称
|
||||||
- **vg_thin** – 我们需要创建精简池的卷组名称
|
- **vg\_thin** – 我们需要创建精简池的卷组名称
|
||||||
|
|
||||||

|

|
||||||
创建精简池
|
|
||||||
|
*创建精简池*
|
||||||
|
|
||||||
使用‘lvdisplay’命令来查看详细信息。
|
使用‘lvdisplay’命令来查看详细信息。
|
||||||
|
|
||||||
# lvdisplay vg_thin/tp_tecmint_pool
|
# lvdisplay vg_thin/tp_tecmint_pool
|
||||||
|
|
||||||

|

|
||||||
逻辑卷信息
|
|
||||||
|
*逻辑卷信息*
|
||||||
|
|
||||||
这里,我们还没有在该精简池中创建虚拟精简卷。在图片中,我们可以看到分配的精简池数据为**0.00%**。
|
这里,我们还没有在该精简池中创建虚拟精简卷。在图片中,我们可以看到分配的精简池数据为**0.00%**。
|
||||||
|
|
||||||
@ -83,16 +87,17 @@
|
|||||||
|
|
||||||
# lvcreate -V 5G --thin -n thin_vol_client1 vg_thin/tp_tecmint_pool
|
# lvcreate -V 5G --thin -n thin_vol_client1 vg_thin/tp_tecmint_pool
|
||||||
|
|
||||||
我已经在我的**vg_thin**卷组中的**tp_tecmint_pool**内创建了一个精简虚拟卷,取名为**thin_vol_client1**。现在,使用下面的命令来列出逻辑卷。
|
我已经在我的**vg_thin**卷组中的**tp\_tecmint\_pool**内创建了一个精简虚拟卷,取名为**thin\_vol\_client1**。现在,使用下面的命令来列出逻辑卷。
|
||||||
|
|
||||||
# lvs
|
# lvs
|
||||||
|
|
||||||

|

|
||||||
列出逻辑卷
|
|
||||||
|
*列出逻辑卷*
|
||||||
|
|
||||||
刚才,我们已经在上面创建了精简卷,这就是为什么没有数据,显示为**0.00%M**。
|
刚才,我们已经在上面创建了精简卷,这就是为什么没有数据,显示为**0.00%M**。
|
||||||
|
|
||||||
好吧,让我为其它2个客户再创建2个精简卷。这里,你可以看到在精简池(**tp_tecmint_pool**)下有3个精简卷了。所以,从这一点上看,我们开始明白,我已经使用所有15GB的精简池。
|
好吧,让我为其它2个客户再创建2个精简卷。这里,你可以看到在精简池(**tp\_tecmint\_pool**)下有3个精简卷了。所以,从这一点上看,我们开始明白,我已经使用所有15GB的精简池。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
@ -107,14 +112,16 @@
|
|||||||
# ls -l /mnt/
|
# ls -l /mnt/
|
||||||
|
|
||||||
|

|
||||||
创建挂载点
|
|
||||||
|
*创建挂载点*
|
||||||
|
|
||||||
使用‘mkfs’命令为这些创建的精简卷创建文件系统。
|
使用‘mkfs’命令为这些创建的精简卷创建文件系统。
|
||||||
|
|
||||||
# mkfs.ext4 /dev/vg_thin/thin_vol_client1 && mkfs.ext4 /dev/vg_thin/thin_vol_client2 && mkfs.ext4 /dev/vg_thin/thin_vol_client3
|
# mkfs.ext4 /dev/vg_thin/thin_vol_client1 && mkfs.ext4 /dev/vg_thin/thin_vol_client2 && mkfs.ext4 /dev/vg_thin/thin_vol_client3
|
||||||
|
|
||||||

|

|
||||||
创建文件系统
|
|
||||||
|
*创建文件系统*
|
||||||
|
|
||||||
使用‘mount’命令来挂载所有3个客户卷到创建的挂载点。
|
使用‘mount’命令来挂载所有3个客户卷到创建的挂载点。
|
||||||
|
|
||||||
@ -125,12 +132,14 @@
|
|||||||
# df -h
|
# df -h
|
||||||
|
|
||||||

|

|
||||||
打印挂载点
|
|
||||||
|
*显示挂载点*
|
||||||
|
|
||||||
这里,我们可以看到所有3个客户卷已经挂载了,而每个客户卷只使用了3%的数据空间。那么,让我们从桌面添加一些文件到这3个挂载点,以填充一些空间。
|
这里,我们可以看到所有3个客户卷已经挂载了,而每个客户卷只使用了3%的数据空间。那么,让我们从桌面添加一些文件到这3个挂载点,以填充一些空间。
|
||||||
|
|
||||||

|

|
||||||
添加文件到卷
|
|
||||||
|
*添加文件到卷*
|
||||||
|
|
||||||
现在列出挂载点,并查看每个精简卷使用的空间,然后列出精简池来查看池中已使用的大小。
|
现在列出挂载点,并查看每个精简卷使用的空间,然后列出精简池来查看池中已使用的大小。
|
||||||
|
|
||||||
@ -138,10 +147,12 @@
|
|||||||
# lvdisplay vg_thin/tp_tecmint_pool
|
# lvdisplay vg_thin/tp_tecmint_pool
|
||||||
|
|
||||||

|

|
||||||
检查挂载点大小
|
|
||||||
|
*检查挂载点大小*
|
||||||
|
|
||||||

|

|
||||||
检查精简池大小
|
|
||||||
|
*检查精简池大小*
|
||||||
|
|
||||||
上面的命令显示了3个挂载点及其使用大小百分比。
|
上面的命令显示了3个挂载点及其使用大小百分比。
|
||||||
|
|
||||||
@ -161,18 +172,20 @@
|
|||||||
# lvs
|
# lvs
|
||||||
|
|
||||||

|

|
||||||
创建精简存储
|
|
||||||
|
*创建精简存储*
|
||||||
|
|
||||||
在精简池中,我只有15GB大小的空间,但是我已经在精简池中创建了4个卷,其总量达到了20GB。如果4个客户都开始写入数据到他们的卷,并将空间填满,到那时我们将面对严峻的形势。如果不填满空间,那不会有问题。
|
在精简池中,我只有15GB大小的空间,但是我已经在精简池中创建了4个卷,其总量达到了20GB。如果4个客户都开始写入数据到他们的卷,并将空间填满,到那时我们将面对严峻的形势。如果不填满空间,那不会有问题。
|
||||||
|
|
||||||
现在,我已经创建在**thin_vol_client4**中创建了文件系统,然后挂载到了**/mnt/client4**下,并且拷贝了一些文件到里头。
|
现在,我已经创建在**thin\_vol\_client4**中创建了文件系统,然后挂载到了**/mnt/client4**下,并且拷贝了一些文件到里头。
|
||||||
|
|
||||||
# lvs
|
# lvs
|
||||||
|
|
||||||

|

|
||||||
验证精简存储
|
|
||||||
|
|
||||||
我们可以在上面的图片中看到,新创建的client 4总计使用空间达到了**89.34%**,而精简池的已用空间达到了**59.19**。如果所有这些用户不在过度对卷写入,那么它就不会溢出,下线。要避免溢出,我们需要扩展精简池大小。
|
*验证精简存储*
|
||||||
|
|
||||||
|
我们可以在上面的图片中看到,新创建的client 4总计使用空间达到了**89.34%**,而精简池的已用空间达到了**59.19**。如果所有这些用户不再过度对卷写入,那么它就不会溢出,下线。要避免溢出的话,我们需要扩展精简池大小。
|
||||||
|
|
||||||
**重要**:精简池只是一个逻辑卷,因此,如果我们需要对其进行扩展,我们可以使用和扩展逻辑卷一样的命令,但我们不能缩减精简池大小。
|
**重要**:精简池只是一个逻辑卷,因此,如果我们需要对其进行扩展,我们可以使用和扩展逻辑卷一样的命令,但我们不能缩减精简池大小。
|
||||||
|
|
||||||
@ -183,16 +196,18 @@
|
|||||||
# lvextend -L +15G /dev/vg_thin/tp_tecmint_pool
|
# lvextend -L +15G /dev/vg_thin/tp_tecmint_pool
|
||||||
|
|
||||||

|

|
||||||
扩展精简存储
|
|
||||||
|
*扩展精简存储*
|
||||||
|
|
||||||
接下来,列出精简池大小。
|
接下来,列出精简池大小。
|
||||||
|
|
||||||
# lvs
|
# lvs
|
||||||
|
|
||||||

|

|
||||||
验证精简存储
|
|
||||||
|
|
||||||
前面,我们的**tp_tecmint_pool**大小为15GB,而在对第四个精简卷进行过度资源配置后达到了20GB。现在,它扩展到了30GB,所以我们的过度资源配置又回归常态,而精简卷也不会溢出,下线了。通过这种方式,我们可以添加更多的精简卷到精简池中。
|
*验证精简存储*
|
||||||
|
|
||||||
|
前面,我们的**tp_tecmint_pool**大小为15GB,而在对第四个精简卷进行过度资源配置后达到了20GB。现在,它扩展到了30GB,所以我们的过度资源配置又回归常态,而精简卷也不会溢出下线了。通过这种方式,我们可以添加更多的精简卷到精简池中。
|
||||||
|
|
||||||
在本文中,我们已经了解了怎样来使用一个大尺寸的卷组创建一个精简池,以及怎样通过过度资源配置在精简池中创建精简卷和扩着精简池。在下一篇文章中,我们将介绍怎样来移除逻辑卷。
|
在本文中,我们已经了解了怎样来使用一个大尺寸的卷组创建一个精简池,以及怎样通过过度资源配置在精简池中创建精简卷和扩着精简池。在下一篇文章中,我们将介绍怎样来移除逻辑卷。
|
||||||
|
|
||||||
@ -202,11 +217,11 @@ via: http://www.tecmint.com/setup-thin-provisioning-volumes-in-lvm/
|
|||||||
|
|
||||||
作者:[Babin Lonston][a]
|
作者:[Babin Lonston][a]
|
||||||
译者:[GOLinux](https://github.com/GOLinux)
|
译者:[GOLinux](https://github.com/GOLinux)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
[a]:http://www.tecmint.com/author/babinlonston/
|
[a]:http://www.tecmint.com/author/babinlonston/
|
||||||
[1]:http://www.tecmint.com/create-lvm-storage-in-linux/
|
[1]:http://linux.cn/article-3965-1.html
|
||||||
[2]:http://www.tecmint.com/extend-and-reduce-lvms-in-linux/
|
[2]:http://linux.cn/article-3974-1.html
|
||||||
[3]:http://www.tecmint.com/take-snapshot-of-logical-volume-and-restore-in-lvm/
|
[3]:http://linux.cn/article-4145-1.html
|
||||||
@ -1,6 +1,6 @@
|
|||||||
如何在Debian上安装配置ownCloud
|
如何在Debian上安装配置ownCloud
|
||||||
================================================================================
|
================================================================================
|
||||||
据其官方网站,ownCloud可以让你通过一个网络接口或者WebDAV访问你的文件。它还提供了一个平台,可以轻松地查看、编辑和同步您所有设备的通讯录、日历和书签。尽管ownCloud与广泛使用Dropbox非常相似,但主要区别在于ownCloud是免费的,开源的,从而可以自己的服务器上建立与Dropbox类似的云存储服务。使用ownCloud你可以完整地访问和控制您的私人数据而对存储空间没有限制(除了硬盘容量)或者连客户端的连接数量。
|
据其官方网站,ownCloud可以让你通过一个Web界面或者WebDAV访问你的文件。它还提供了一个平台,可以轻松地查看、编辑和同步您所有设备的通讯录、日历和书签。尽管ownCloud与广泛使用Dropbox非常相似,但主要区别在于ownCloud是免费的,开源的,从而可以自己的服务器上建立与Dropbox类似的云存储服务。使用ownCloud你可以完整地访问和控制您的私人数据,而对存储空间(除了硬盘容量)或客户端的连接数量没有限制。
|
||||||
|
|
||||||
ownCloud提供了社区版(免费)和企业版(面向企业的有偿支持)。预编译的ownCloud社区版可以提供了CentOS、Debian、Fedora、openSUSE、,SLE和Ubuntu版本。本教程将演示如何在Debian Wheezy上安装和在配置ownCloud社区版。
|
ownCloud提供了社区版(免费)和企业版(面向企业的有偿支持)。预编译的ownCloud社区版可以提供了CentOS、Debian、Fedora、openSUSE、,SLE和Ubuntu版本。本教程将演示如何在Debian Wheezy上安装和在配置ownCloud社区版。
|
||||||
|
|
||||||
@ -14,7 +14,7 @@ ownCloud提供了社区版(免费)和企业版(面向企业的有偿支持
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
在下一屏职工点击继续:
|
在下一屏中点击继续:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
@ -36,11 +36,11 @@ ownCloud提供了社区版(免费)和企业版(面向企业的有偿支持
|
|||||||
# aptitude update
|
# aptitude update
|
||||||
# aptitude install owncloud
|
# aptitude install owncloud
|
||||||
|
|
||||||
打开你的浏览器并定位到你的ownCloud实例中,地址是http://<server-ip>/owncloud:
|
打开你的浏览器并定位到你的ownCloud实例中,地址是 http://服务器 IP/owncloud:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
注意ownCloud可能会包一个Apache配置错误的警告。使用下面的步骤来解决这个错误来摆脱这些错误信息。
|
注意ownCloud可能会包一个Apache配置错误的警告。使用下面的步骤来解决这个错误来解决这些错误信息。
|
||||||
|
|
||||||
a) 编辑 the /etc/apache2/apache2.conf (设置 AllowOverride 为 All):
|
a) 编辑 the /etc/apache2/apache2.conf (设置 AllowOverride 为 All):
|
||||||
|
|
||||||
@ -70,7 +70,7 @@ d) 刷新浏览器,确认安全警告已经消失
|
|||||||
|
|
||||||
### 设置数据库 ###
|
### 设置数据库 ###
|
||||||
|
|
||||||
是时候为ownCloud设置数据库了。
|
这时可以为ownCloud设置数据库了。
|
||||||
|
|
||||||
首先登录本地的MySQL/MariaDB数据库:
|
首先登录本地的MySQL/MariaDB数据库:
|
||||||
|
|
||||||
@ -83,7 +83,7 @@ d) 刷新浏览器,确认安全警告已经消失
|
|||||||
mysql> GRANT ALL PRIVILEGES ON owncloud_DB.* TO ‘owncloud-web’@'localhost';
|
mysql> GRANT ALL PRIVILEGES ON owncloud_DB.* TO ‘owncloud-web’@'localhost';
|
||||||
mysql> FLUSH PRIVILEGES;
|
mysql> FLUSH PRIVILEGES;
|
||||||
|
|
||||||
通过http://<server-ip>/owncloud 进入ownCloud页面,并选择‘Storage & database’ 选项。输入所需的信息(MySQL/MariaDB用户名,密码,数据库和主机名),并点击完成按钮。
|
通过http://服务器 IP/owncloud 进入ownCloud页面,并选择‘Storage & database’ 选项。输入所需的信息(MySQL/MariaDB用户名,密码,数据库和主机名),并点击完成按钮。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
@ -101,7 +101,7 @@ d) 刷新浏览器,确认安全警告已经消失
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
编辑/etc/apache2/conf.d/owncloud.conf 启用HTTPS。对于余下的NC、R和L重写规则的意义,你可以参考[Apache 文档][2]:
|
编辑/etc/apache2/conf.d/owncloud.conf 启用HTTPS。对于重写规则中的NC、R和L的意义,你可以参考[Apache 文档][2]:
|
||||||
|
|
||||||
Alias /owncloud /var/www/owncloud
|
Alias /owncloud /var/www/owncloud
|
||||||
|
|
||||||
@ -197,7 +197,7 @@ via: http://xmodulo.com/2014/08/install-configure-owncloud-debian.html
|
|||||||
|
|
||||||
作者:[Gabriel Cánepa][a]
|
作者:[Gabriel Cánepa][a]
|
||||||
译者:[geekpi](https://github.com/geekpi)
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -1,9 +1,8 @@
|
|||||||
如何用Puppet和Augeas管理Linux配置
|
如何用Puppet和Augeas管理Linux配置
|
||||||
================================================================================
|
================================================================================
|
||||||
虽然[Puppet][1](注:此文原文原文中曾今做过,文件名:“20140808 How to install Puppet server and client on CentOS and RHEL.md”,如果翻译发布过,可修改此链接为发布地址)是一个非常独特的和有用的工具,在有些情况下你可以使用一点不同的方法。要修改的配置文件已经在几个不同的服务器上且它们在这时是互补相同的。Puppet实验室的人也意识到了这一点并集成了一个伟大的工具,称之为[Augeas][2],它是专为这种使用情况而设计的。
|
虽然[Puppet][1]是一个真正独特的有用工具,但在有些情况下你可以使用一点不同的方法来用它。比如,你要修改几个服务器上已有的配置文件,而且它们彼此稍有不同。Puppet实验室的人也意识到了这一点,他们在 Puppet 中集成了一个叫做[Augeas][2]的伟大的工具,它是专为这种使用情况而设计的。
|
||||||
|
|
||||||
|
Augeas可被认为填补了Puppet能力的空白,比如在其中一个指定对象的资源类型(例如用于维护/etc/hosts中的条目的主机资源)还不可用时。在这个文档中,您将学习如何使用Augeas来减轻你管理配置文件的负担。
|
||||||
Augeas可被认为填补了Puppet能力的缺陷,其中一个特定对象的资源类型(如主机资源来处理/etc/hosts中的条目)还不可用。在这个文档中,您将学习如何使用Augeas来减轻你管理配置文件的负担。
|
|
||||||
|
|
||||||
### Augeas是什么? ###
|
### Augeas是什么? ###
|
||||||
|
|
||||||
@ -11,13 +10,13 @@ Augeas基本上就是一个配置编辑工具。它以他们原生的格式解
|
|||||||
|
|
||||||
### 这篇教程要达成什么目的? ###
|
### 这篇教程要达成什么目的? ###
|
||||||
|
|
||||||
我们会安装并配置Augeas用于我们之前构建的Puppet服务器。我们会使用这个工具创建并测试几个不同的配置文件,并学习如何适当地使用它来管理我们的系统配置。
|
我们会针对[我们之前构建的Puppet服务器][1]安装并配置Augeas。我们会使用这个工具创建并测试几个不同的配置文件,并学习如何适当地使用它来管理我们的系统配置。
|
||||||
|
|
||||||
### 先决条件 ###
|
### 前置阅读 ###
|
||||||
|
|
||||||
我们需要一台工作的Puppet服务器和客户端。如果你还没有,请先按照我先前的教程来。
|
我们需要一台工作的Puppet服务器和客户端。如果你还没有,请先按照我先前的[教程][1]来。
|
||||||
|
|
||||||
Augeas安装包可以在标准CentOS/RHEL仓库中找到。不幸的是,Puppet用到的ruby封装的Augeas只在puppetlabs仓库中(或者[EPEL][4])中才有。如果你系统中还没有这个仓库,请使用下面的命令:
|
Augeas安装包可以在标准CentOS/RHEL仓库中找到。不幸的是,Puppet用到的Augeas的ruby封装只在puppetlabs仓库中(或者[EPEL][4])中才有。如果你系统中还没有这个仓库,请使用下面的命令:
|
||||||
|
|
||||||
在CentOS/RHEL 6.5上:
|
在CentOS/RHEL 6.5上:
|
||||||
|
|
||||||
@ -31,7 +30,7 @@ Augeas安装包可以在标准CentOS/RHEL仓库中找到。不幸的是,Puppet
|
|||||||
|
|
||||||
# yum install rubyaugeas
|
# yum install rubyaugeas
|
||||||
|
|
||||||
或者如果你是从我的上一篇教程中继续的,使用puppet的方法安装这个包。在/etc/puppet/manifests/site.pp中修改你的custom_utils类,在packages这行中加入“rubyaugeas”。
|
或者如果你是从我的[上一篇教程中继续][1]的,使用puppet的方法安装这个包。在/etc/puppet/manifests/site.pp中修改你的custom_utils类,在packages这行中加入“rubyaugeas”。
|
||||||
|
|
||||||
class custom_utils {
|
class custom_utils {
|
||||||
package { ["nmap","telnet","vimenhanced","traceroute","rubyaugeas"]:
|
package { ["nmap","telnet","vimenhanced","traceroute","rubyaugeas"]:
|
||||||
@ -54,7 +53,7 @@ Augeas安装包可以在标准CentOS/RHEL仓库中找到。不幸的是,Puppet
|
|||||||
|
|
||||||
1. 给wheel组加上sudo权限。
|
1. 给wheel组加上sudo权限。
|
||||||
|
|
||||||
这个例子会向你战士如何在你的GNU/Linux系统中为%wheel组加上sudo权限。
|
这个例子会向你展示如何在你的GNU/Linux系统中为%wheel组加上sudo权限。
|
||||||
|
|
||||||
# 安装sudo包
|
# 安装sudo包
|
||||||
package { 'sudo':
|
package { 'sudo':
|
||||||
@ -73,7 +72,7 @@ Augeas安装包可以在标准CentOS/RHEL仓库中找到。不幸的是,Puppet
|
|||||||
]
|
]
|
||||||
}
|
}
|
||||||
|
|
||||||
现在来解释这些代码做了什么:**spec**定义了/etc/sudoers中的用户段,**[user]**定义了数组中给定的用户,所有的定义的斜杠( / ) 后用户的子部分。因此在典型的配置中这个可以这么表达:
|
现在来解释这些代码做了什么:**spec**定义了/etc/sudoers中的用户段,**[user]**定义了数组中给定的用户,所有的定义放在该用户的斜杠( / ) 后那部分。因此在典型的配置中这个可以这么表达:
|
||||||
|
|
||||||
user host_group/host host_group/command host_group/command/runas_user
|
user host_group/host host_group/command host_group/command/runas_user
|
||||||
|
|
||||||
@ -83,7 +82,7 @@ Augeas安装包可以在标准CentOS/RHEL仓库中找到。不幸的是,Puppet
|
|||||||
|
|
||||||
2. 添加命令别称
|
2. 添加命令别称
|
||||||
|
|
||||||
下面这部分会向你展示如何定义命令别名,他可以在你的sudoer文件中使用。
|
下面这部分会向你展示如何定义命令别名,它可以在你的sudoer文件中使用。
|
||||||
|
|
||||||
# 创建新的SERVICE别名,包含了一些基本的特权命令。
|
# 创建新的SERVICE别名,包含了一些基本的特权命令。
|
||||||
augeas { 'sudo_cmdalias':
|
augeas { 'sudo_cmdalias':
|
||||||
@ -97,7 +96,7 @@ Augeas安装包可以在标准CentOS/RHEL仓库中找到。不幸的是,Puppet
|
|||||||
]
|
]
|
||||||
}
|
}
|
||||||
|
|
||||||
sudo命令别名的语法很简单:**Cmnd_Alias**定义了命令别名字段,**[alias/name]**绑定所有给定的别名,/alias/name **SERVICES** 定义真实的别名以及alias/command 是所有命令的数组,每条命令是这个别名的一部分。
|
sudo命令别名的语法很简单:**Cmnd_Alias**定义了命令别名字段,**[alias/name]**绑定所有给定的别名,/alias/name **SERVICES** 定义真实的别名,alias/command 是属于该别名的所有命令的数组。以上将被转换如下:
|
||||||
|
|
||||||
Cmnd_Alias SERVICES = /sbin/service , /sbin/chkconfig , /bin/hostname , /sbin/shutdown
|
Cmnd_Alias SERVICES = /sbin/service , /sbin/chkconfig , /bin/hostname , /sbin/shutdown
|
||||||
|
|
||||||
@ -105,12 +104,12 @@ sudo命令别名的语法很简单:**Cmnd_Alias**定义了命令别名字段
|
|||||||
|
|
||||||
#### 向一个组中加入用户 ####
|
#### 向一个组中加入用户 ####
|
||||||
|
|
||||||
要使用Augeas向组中添加用户,你有也许要添加一个新用户,无论是在gid字段后或者在最后一个用户后。我们在这个例子中使用组SVN。这可以通过下面的命令达成:
|
要使用Augeas向组中添加用户,你也许要添加一个新用户,不管是排在 gid 字段还是最后的用户 uid 之后。我们在这个例子中使用SVN组。这可以通过下面的命令达成:
|
||||||
|
|
||||||
在Puppet中:
|
在Puppet中:
|
||||||
|
|
||||||
augeas { 'augeas_mod_group:
|
augeas { 'augeas_mod_group:
|
||||||
context => '/files/etc/group', # The target file is /etc/group
|
context => '/files/etc/group', #目标文件是 /etc/group
|
||||||
changes => [
|
changes => [
|
||||||
"ins user after svn/*[self::gid or self::user][last()]",
|
"ins user after svn/*[self::gid or self::user][last()]",
|
||||||
"set svn/user[last()] john",
|
"set svn/user[last()] john",
|
||||||
@ -123,14 +122,14 @@ sudo命令别名的语法很简单:**Cmnd_Alias**定义了命令别名字段
|
|||||||
|
|
||||||
### 总结 ###
|
### 总结 ###
|
||||||
|
|
||||||
目前为止,你应该对如何在Puppet项目中使用Augeas有一个好想法了。随意地试一下,你肯定会经历官方的Augeas文档。这会帮助你了解如何在你的个人项目中正确地使用Augeas,并且它会想你展示你可以用它节省多少时间。
|
目前为止,你应该对如何在Puppet项目中使用Augeas有点明白了。随意地试一下,你肯定需要浏览官方的Augeas文档。这会帮助你了解如何在你的个人项目中正确地使用Augeas,并且它会让你知道可以用它节省多少时间。
|
||||||
|
|
||||||
如有任何问题,欢迎在下面的评论中发布,我会尽力解答和向你建议。
|
如有任何问题,欢迎在下面的评论中发布,我会尽力解答和向你建议。
|
||||||
|
|
||||||
### 有用的链接 ###
|
### 有用的链接 ###
|
||||||
|
|
||||||
- [http://www.watzmann.net/categories/augeas.html][6]: contains a lot of tutorials focused on Augeas usage.
|
- [http://www.watzmann.net/categories/augeas.html][6]: 包含许多关于 Augeas 使用的教程。
|
||||||
- [http://projects.puppetlabs.com/projects/1/wiki/puppet_augeas][7]: Puppet wiki with a lot of practical examples.
|
- [http://projects.puppetlabs.com/projects/1/wiki/puppet_augeas][7]: Puppet wiki 带有许多实例。
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
@ -138,12 +137,12 @@ via: http://xmodulo.com/2014/09/manage-configurations-linux-puppet-augeas.html
|
|||||||
|
|
||||||
作者:[Jaroslav Štěpánek][a]
|
作者:[Jaroslav Štěpánek][a]
|
||||||
译者:[geekpi](https://github.com/geekpi)
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
[a]:http://xmodulo.com/author/jaroslav
|
[a]:http://xmodulo.com/author/jaroslav
|
||||||
[1]:http://xmodulo.com/2014/08/install-puppet-server-client-centos-rhel.html
|
[1]:http://linux.cn/article-3959-1.html
|
||||||
[2]:http://augeas.net/
|
[2]:http://augeas.net/
|
||||||
[3]:http://xmodulo.com/manage-configurations-linux-puppet-augeas.html
|
[3]:http://xmodulo.com/manage-configurations-linux-puppet-augeas.html
|
||||||
[4]:http://xmodulo.com/2013/03/how-to-set-up-epel-repository-on-centos.html
|
[4]:http://xmodulo.com/2013/03/how-to-set-up-epel-repository-on-centos.html
|
||||||
@ -1,24 +1,24 @@
|
|||||||
Ansible和Docker的作用和用法
|
Ansible和Docker的作用和用法
|
||||||
================================================================================
|
================================================================================
|
||||||
在 [Docker][1] 和 [Ansible][2] 的技术社区内存在着很多好玩的东西,我希望在你阅读完这篇文章后也能获取到我们对它们的那种热爱。当然,你也会收获一些实践知识,那就是如何通过部署 Ansible 和 Docker 来为 Rails 应用搭建一个完整的服务器环境。
|
在 [Docker][1] 和 [Ansible][2] 的技术社区内存在着很多好玩的东西,我希望在你阅读完这篇文章后也能像我们一样热爱它们。当然,你也会收获一些实践知识,那就是如何通过部署 Ansible 和 Docker 来为 Rails 应用搭建一个完整的服务器环境。
|
||||||
|
|
||||||
也许有人会问:你怎么不去用 Heroku?首先,我可以在任何供应商提供的主机上运行 Docker 和 Ansible;其次,相比于方便性,我更偏向于喜欢灵活性。我可以在这种组合中运行任何程序,而不仅仅是 web 应用。最后,我骨子里是一个工匠,我非常理解如何把零件拼凑在一起工作。Heroku 的基础模块是 Linux Container,而 Docker 表现出来的多功能性也是基于这种技术。事实上,Docker 的其中一个座右铭是:容器化是新虚拟化技术。
|
也许有人会问:你怎么不去用 Heroku?首先,我可以在任何供应商提供的主机上运行 Docker 和 Ansible;其次,相比于方便性,我更偏向于喜欢灵活性。我可以在这种组合中运行任何程序,而不仅仅是 web 应用。最后,我骨子里是一个工匠,我非常了解如何把零件拼凑在一起工作。Heroku 的基础模块是 Linux Container,而 Docker 表现出来的多功能性也是基于这种技术。事实上,Docker 的其中一个座右铭是:容器化是新虚拟化技术。
|
||||||
|
|
||||||
### 为什么使用 Ansible? ###
|
### 为什么使用 Ansible? ###
|
||||||
|
|
||||||
我重度使用 Chef 已经有4年了(LCTT:Chef 是与 puppet 类似的配置管理工具),**基础设施即代码**的观念让我觉得非常无聊。我花费大量时间来管理代码,而不是管理基础设施本身。不论多小的改变,都需要相当大的努力来实现它。使用 [Ansible][3],你可以一手掌握拥有可描述性数据的基础架构,另一只手掌握不同组件之间的交互作用。这种更简单的操作模式让我把精力集中在如何将我的技术设施私有化,提高了我的工作效率。与 Unix 的模式一样,Ansible 提供大量功能简单的模块,我们可以组合这些模块,达到不同的工作要求。
|
我重度使用 Chef 已经有4年了(LCTT:Chef 是与 puppet 类似的配置管理工具),**基础设施即代码**的观念让我觉得非常无聊。我花费大量时间来管理代码,而不是管理基础设施本身。不论多小的改变,都需要相当大的努力来实现它。使用 [Ansible][3],你可以一手掌握拥有可描述性数据的基础架构,另一只手掌握不同组件之间的交互作用。这种更简单的操作模式让我把精力集中在如何将我的技术设施私有化,提高了我的工作效率。与 Unix 的模式一样,Ansible 提供大量功能简单的模块,我们可以组合这些模块,达到不同的工作要求。
|
||||||
|
|
||||||
除了 Python 和 SSH,Ansible 不再依赖其他软件,在它的远端主机上不需要部署代理,也不会留下任何运行痕迹。更厉害的是,它提供一套内建的、可扩展的模块库文件,通过它你可以控制所有:包管理器、云服务供应商、数据库等等等等。
|
除了 Python 和 SSH,Ansible 不再依赖其他软件,在它的远端主机上不需要部署代理,也不会留下任何运行痕迹。更厉害的是,它提供一套内建的、可扩展的模块库文件,通过它你可以控制所有的一切:包管理器、云服务供应商、数据库等等等等。
|
||||||
|
|
||||||
### 为什么要使用 Docker? ###
|
### 为什么要使用 Docker? ###
|
||||||
|
|
||||||
[Docker][4] 的定位是:提供最可靠、最方便的方式来部署服务。这些服务可以是 mysqld,可以是 redis,可以是 Rails 应用。先聊聊 git,它的快照功能让它可以以最有效的方式发布代码,Docker 的处理方法与它类似。它保证应用可以无视主机环境,随心所欲地跑起来。
|
[Docker][4] 的定位是:提供最可靠、最方便的方式来部署服务。这些服务可以是 mysqld,可以是 redis,可以是 Rails 应用。先聊聊 git 吧,它的快照功能让它可以以最有效的方式发布代码,Docker 的处理方法与它类似。它保证应用可以无视主机环境,随心所欲地跑起来。
|
||||||
|
|
||||||
一种最普遍的误解是人们总是把 Docker 容器看成是一个虚拟机,当然,我表示理解你们的误解。Docker 满足[单一功能原则][5],在一个容器里面只跑一个进程,所以一次修改只会影响一个进程,而这些进程可以被重用。这种模型参考了 Unix 的哲学思想,当前还处于试验阶段,并且正变得越来越稳定。
|
一种最普遍的误解是人们总是把 Docker 容器看成是一个虚拟机,当然,我表示理解你们的误解。Docker 满足[单一功能原则][5],在一个容器里面只跑一个进程,所以一次修改只会影响一个进程,而这些进程可以被重用。这种模型参考了 Unix 的哲学思想,当前还处于试验阶段,并且正变得越来越稳定。
|
||||||
|
|
||||||
### 设置选项 ###
|
### 设置选项 ###
|
||||||
|
|
||||||
不需要离开终端,我就可以使用 Ansible 来生成以下实例:Amazon Web Services,Linode,Rackspace 以及 DigitalOcean。如果想要更详细的信息,我于1分25秒内在位于阿姆斯特丹的2号数据中心上创建了一个 2GB 的 DigitalOcean 虚拟机。另外的1分50秒用于系统配置,包括设置 Docker 和其他个人选项。当我完成这些基本设定后,就可以部署我的应用了。值得一提的是这个过程中我没有配置任何数据库或程序开发语言,Docker 已经帮我把应用所需要的事情都安排好了。
|
不需要离开终端,我就可以使用 Ansible 来在这些云平台中生成实例:Amazon Web Services,Linode,Rackspace 以及 DigitalOcean。如果想要更详细的信息,我于1分25秒内在位于阿姆斯特丹的2号数据中心上创建了一个 2GB 的 DigitalOcean 虚拟机。另外的1分50秒用于系统配置,包括设置 Docker 和其他个人选项。当我完成这些基本设定后,就可以部署我的应用了。值得一提的是这个过程中我没有配置任何数据库或程序开发语言,Docker 已经帮我把应用所需要的事情都安排好了。
|
||||||
|
|
||||||
Ansible 通过 SSH 为远端主机发送命令。我保存在本地 ssh 代理上面的 SSH 密钥会通过 Ansible 提供的 SSH 会话分享到远端主机。当我把应用代码从远端 clone 下来,或者上传到远端时,我就不再需要提供 git 所需的证书了,我的 ssh 代理会帮我通过 git 主机的身份验证程序的。
|
Ansible 通过 SSH 为远端主机发送命令。我保存在本地 ssh 代理上面的 SSH 密钥会通过 Ansible 提供的 SSH 会话分享到远端主机。当我把应用代码从远端 clone 下来,或者上传到远端时,我就不再需要提供 git 所需的证书了,我的 ssh 代理会帮我通过 git 主机的身份验证程序的。
|
||||||
|
|
||||||
@ -65,13 +65,13 @@ CMD 这个步骤是在新的 web 应用容器启动后执行的。在测试环
|
|||||||
|
|
||||||
没有本地 Docker 镜像,从零开始部署一个中级规模的 Rails 应用大概需要100个 gems,进行100次整体测试,在使用2个核心实例和2GB内存的情况下,这些操作需要花费8分16秒。装上 Ruby、MySQL 和 Redis Docker 镜像后,部署应用花费了4分45秒。另外,如果从一个已存在的主应用镜像编译出一个新的 Docker 应用镜像出来,只需花费2分23秒。综上所述,部署一套新的 Rails 应用,解决其所有依赖关系(包括 MySQL 和 Redis),只需花我2分钟多一点的时间就够了。
|
没有本地 Docker 镜像,从零开始部署一个中级规模的 Rails 应用大概需要100个 gems,进行100次整体测试,在使用2个核心实例和2GB内存的情况下,这些操作需要花费8分16秒。装上 Ruby、MySQL 和 Redis Docker 镜像后,部署应用花费了4分45秒。另外,如果从一个已存在的主应用镜像编译出一个新的 Docker 应用镜像出来,只需花费2分23秒。综上所述,部署一套新的 Rails 应用,解决其所有依赖关系(包括 MySQL 和 Redis),只需花我2分钟多一点的时间就够了。
|
||||||
|
|
||||||
需要指出的一点是,我的应用上运行着一套完全测试套件,跑完测试需要花费额外1分钟时间。尽管是无意的,Docker 可以变成一套简单的持续集成环境,当测试失败后,Docker 会把“test-only”这个容器保留下来,用于分析出错原因。我可以在1分钟之内和我的客户一起验证新代码,保证不同版本的应用之间是完全隔离的,同操作系统也是隔离的。传统虚拟机启动系统时需要花费好几分钟,Docker 容器只花几秒。另外,一旦一个 Dockedr 镜像编译出来,并且针对我的某个版本的应用的测试都被通过,我就可以把这个镜像提交到 Docker 私服 Registry 上,可以被其他 Docker 主机下载下来并启动一个新的 Docker 容器,而这不过需要几秒钟时间。
|
需要指出的一点是,我的应用上运行着一套完全测试套件,跑完测试需要花费额外1分钟时间。尽管是无意的,Docker 可以变成一套简单的持续集成环境,当测试失败后,Docker 会把“test-only”这个容器保留下来,用于分析出错原因。我可以在1分钟之内和我的客户一起验证新代码,保证不同版本的应用之间是完全隔离的,同操作系统也是隔离的。传统虚拟机启动系统时需要花费好几分钟,Docker 容器只花几秒。另外,一旦一个 Dockedr 镜像编译出来,并且针对我的某个版本的应用的测试都被通过,我就可以把这个镜像提交到一个私有的 Docker Registry 上,可以被其他 Docker 主机下载下来并启动一个新的 Docker 容器,而这不过需要几秒钟时间。
|
||||||
|
|
||||||
### 总结 ###
|
### 总结 ###
|
||||||
|
|
||||||
Ansible 让我重新看到管理基础设施的乐趣。Docker 让我有充分的信心能稳定处理应用部署过程中最重要的步骤——交付环节。双剑合璧,威力无穷。
|
Ansible 让我重新看到管理基础设施的乐趣。Docker 让我有充分的信心能稳定处理应用部署过程中最重要的步骤——交付环节。双剑合璧,威力无穷。
|
||||||
|
|
||||||
从无到有搭建一个完整的 Rails 应用可以在12分钟内完成,这种速度放在任何场合都是令人印象深刻的。能获得一个免费的持续集成环境,可以查看不同版本的应用之间的区别,不会影响到同主机上已经在运行的应用,这些功能强大到难以置信,让我感到很兴奋。在文章的最后,我只希望你能感受到我的兴奋。
|
从无到有搭建一个完整的 Rails 应用可以在12分钟内完成,这种速度放在任何场合都是令人印象深刻的。能获得一个免费的持续集成环境,可以查看不同版本的应用之间的区别,不会影响到同主机上已经在运行的应用,这些功能强大到难以置信,让我感到很兴奋。在文章的最后,我只希望你能感受到我的兴奋!
|
||||||
|
|
||||||
我在2014年1月伦敦 Docker 会议上讲过这个主题,[已经分享到 Speakerdeck][7]了。
|
我在2014年1月伦敦 Docker 会议上讲过这个主题,[已经分享到 Speakerdeck][7]了。
|
||||||
|
|
||||||
@ -87,7 +87,7 @@ via: http://thechangelog.com/ansible-docker/
|
|||||||
|
|
||||||
作者:[Gerhard Lazu][a]
|
作者:[Gerhard Lazu][a]
|
||||||
译者:[bazz2](https://github.com/bazz2)
|
译者:[bazz2](https://github.com/bazz2)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -5,7 +5,7 @@
|
|||||||
|
|
||||||
Git教程往往不会解决这个问题,因为它集中篇幅来教你Git命令和概念,并且不认为你会使用GitHub。[GitHub帮助教程](https://help.github.com/)一定程度上弥补了这一缺陷,但是它每篇文章的关注点都较为狭隘,而且没有提供关于"Git vs GitHub"问题的概念性概述。
|
Git教程往往不会解决这个问题,因为它集中篇幅来教你Git命令和概念,并且不认为你会使用GitHub。[GitHub帮助教程](https://help.github.com/)一定程度上弥补了这一缺陷,但是它每篇文章的关注点都较为狭隘,而且没有提供关于"Git vs GitHub"问题的概念性概述。
|
||||||
|
|
||||||
**如果你是习惯于先理解概念,再着手代码的学习者**,而且你也是Git和GitHub的初学者,我建议你先理解清楚什么是fork,为什么?
|
**如果你是习惯于先理解概念,再着手代码的学习者**,而且你也是Git和GitHub的初学者,我建议你先理解清楚什么是fork。为什么呢 ?
|
||||||
|
|
||||||
1. Fork是在GitHub起步最普遍的方式。
|
1. Fork是在GitHub起步最普遍的方式。
|
||||||
2. Fork只需要很少的Git命令,但是起得作用却非常大。
|
2. Fork只需要很少的Git命令,但是起得作用却非常大。
|
||||||
@ -53,15 +53,19 @@ Joe和其余贡献者已经对这个项目做了一些修改,而你将在他
|
|||||||
|
|
||||||
### 结论
|
### 结论
|
||||||
|
|
||||||
我希望这是一篇关于GitHub和Git [fork](https://help.github.com/articles/fork-a-repo)有用概述。现在,你已经理解了那些概念,你将会更容易地在实际中执行你的代码。GitHub关于fork和[同步](https://help.github.com/articles/syncing-a-fork)的文章将会给你大部分你需要的代码。
|
我希望这是一篇关于GitHub和Git 的 [fork](https://help.github.com/articles/fork-a-repo)有用概述。现在,你已经理解了那些概念,你将会更容易地在实际中执行你的代码。GitHub关于fork和[同步](https://help.github.com/articles/syncing-a-fork)的文章将会给你大部分你需要的代码。
|
||||||
|
|
||||||
如果你是Git的初学者,而且你很喜欢这种学习方式,那么我极力推荐书籍[Pro Git](http://git-scm.com/book)的前两个章节,网上是可以免费查阅的。
|
如果你是Git的初学者,而且你很喜欢这种学习方式,那么我极力推荐书籍[Pro Git](http://git-scm.com/book)的前两个章节,网上是可以免费查阅的。
|
||||||
|
|
||||||
如果你喜欢视频学习,我创建了一个[11部分的视频系列](http://www.dataschool.io/git-and-github-videos-for-beginners/)(总共36分钟),来向初学者介绍Git和GitHub。
|
如果你喜欢视频学习,我创建了一个[11部分的视频系列](http://www.dataschool.io/git-and-github-videos-for-beginners/)(总共36分钟),来向初学者介绍Git和GitHub。
|
||||||
|
|
||||||
---
|
---
|
||||||
|
via: http://www.dataschool.io/simple-guide-to-forks-in-github-and-git/
|
||||||
|
|
||||||
|
作者:[Kevin Markham][a]
|
||||||
译者:[su-kaiyao](https://github.com/su-kaiyao)
|
译者:[su-kaiyao](https://github.com/su-kaiyao)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://disqus.com/home/user/justmarkham/
|
||||||
54
published/20141023 6 Minesweeper Clones for Linux.md
Normal file
54
published/20141023 6 Minesweeper Clones for Linux.md
Normal file
@ -0,0 +1,54 @@
|
|||||||
|
Linux下的6个扫雷游戏的翻版
|
||||||
|
================================================================================
|
||||||
|
Windows 下的扫雷游戏还没玩够么?那么来 Linux 下继续扫雷吧——这是一个雷的时代~~
|
||||||
|
|
||||||
|
### GNOME Mines ###
|
||||||
|
|
||||||
|
这是GNOME扫雷复制品,允许你从3个不同的预定义表大小(8×8, 16×16, 30×16)中选择其一,或者自定义行列的数量。它能以全屏模式运行,带有高分值、耗时和提示。游戏可以暂停和继续。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### ace-minesweeper ###
|
||||||
|
|
||||||
|
这是一个大的软件包中的游戏,此包中也包含有其它一些游戏,如ace-freecel,ace-solitaire或ace-spider。它有一个以小企鹅为特色的图形化界面,但好像不能调整表的大小。该包在Ubuntu中名为ace-of-penguins。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### XBomb ###
|
||||||
|
|
||||||
|
XBomb是针对X Windows系统扫雷游戏,它有三种不同的表尺寸和卡牌风格,包含有不同的外形:六角形、矩形(传统)或三角形。不幸的是,在Ubuntu 14.04中的版本会出现程序分段冲突,所以你可能需要安装另外一个版本。
|
||||||
|
[首页][1]。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
([图像来源][1])
|
||||||
|
|
||||||
|
### KMines ###
|
||||||
|
|
||||||
|
KMines是一个KDE游戏,和GNOME Mines类似,有三个内建表尺寸(简易、中等、困单),也可以自定义,支持主题和高分。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### freesweep ###
|
||||||
|
|
||||||
|
Freesweep是一个针对终端的扫雷复制品,它可以配置表行列、炸弹比例、颜色,也有一个高分表。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### xdemineur ###
|
||||||
|
|
||||||
|
另外一个针对X的图形化扫雷Xdemineur,和Ace-Minesweeper十分相像,带有一个预定义的表尺寸。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.tuxarena.com/2014/10/6-minesweeper-clones-for-linux/
|
||||||
|
|
||||||
|
作者:Craciun Dan
|
||||||
|
译者:[GOLinux](https://github.com/GOLinux)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[1]:http://www.gedanken.org.uk/software/xbomb/
|
||||||
@ -1,31 +1,30 @@
|
|||||||
不得不说的磁盘镜像工具
|
Linux 下易用的光盘镜像管理工具
|
||||||
================================================================================
|
================================================================================
|
||||||
磁盘镜像包括整个磁盘卷的文件或者是全部的存储设备的数据,比如说硬盘,光盘(DVD,CD,蓝光光碟),磁带机,USB闪存,软盘。一个完整的磁盘镜像应该像在原来的存储设备上一样完整、准确,包括数据和结构信息。
|
磁盘镜像包括了整个磁盘卷的文件或者是全部的存储设备的数据,比如说硬盘,光盘(DVD,CD,蓝光光碟),磁带机,USB闪存,软盘。一个完整的磁盘镜像应该包含与原来的存储设备上一样完整、准确,包括数据和结构信息。
|
||||||
|
|
||||||
磁盘镜像文件格式可以是开放的标准,像ISO格式的光盘镜像,或者是专有的特别的软件应用程序。"ISO"这个名字来源于用CD存储的ISO 9660文件系统。但是,当用户转向Linux的时候,经常遇到这样的问题,需要把专有的的镜像格式转换为开放的格式。
|
磁盘镜像文件格式可以是采用开放的标准,像ISO格式的光盘镜像,或者是专有的软件应用程序的特定格式。"ISO"这个名字来源于用CD存储的ISO 9660文件系统。但是,当用户转向Linux的时候,经常遇到这样的问题,需要把专有的的镜像格式转换为开放的格式。
|
||||||
|
|
||||||
磁盘镜像有很多不同的用处,像烧录光盘,系统备份,数据恢复,硬盘克隆,电子取证和提供操作系统(即LiveCD/DVDs)。
|
磁盘镜像有很多不同的用处,像烧录光盘,系统备份,数据恢复,硬盘克隆,电子取证和提供操作系统(即LiveCD/DVDs)。
|
||||||
|
|
||||||
有很多不同非方法可以把ISO镜像挂载到Linux系统下。强大的mount 命令给我们提供了一个简单的解决方案。但是如果你需要很多工具来操作磁盘镜像,你可以试一试下面的这些完美的开源工具。
|
有很多不同的方法可以把ISO镜像挂载到Linux系统下。强大的mount 命令给我们提供了一个简单的解决方案。但是如果你需要很多工具来操作磁盘镜像,你可以试一试下面的这些强大的开源工具。
|
||||||
|
|
||||||
很多工具还没有看到最新的版本,所以如果你正在寻找一个很好用的开源工具,你也可以加入,一起来为开源做出一点贡献。
|
很多工具还没有看到最新的版本,所以如果你正在寻找一个很好用的开源工具,你也可以加入,一起来为开源做出一点贡献。
|
||||||
|
|
||||||
----------
|
### Furius ISO Mount
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
Furius ISO Mount是一个简单易用的开源应用程序用来挂载镜像文件,它支持直接打开ISO,IMG,BIN,MDF和NRG格式的镜像而不用把他们烧录到磁盘。
|
Furius ISO Mount是一个简单易用的开源应用程序,可以用来挂载镜像文件,它支持直接打开ISO,IMG,BIN,MDF和NRG格式的镜像而不用把他们烧录到磁盘。
|
||||||
|
|
||||||
特性:
|
特性:
|
||||||
|
|
||||||
- 支持自动挂载ISO, IMG, BIN, MDF and NRG镜像文件
|
- 支持自动挂载ISO, IMG, BIN, MDF and NRG镜像文件
|
||||||
- 支持通过loop 挂载 UDF 镜像
|
- 支持通过 loop 方式挂载 UDF 镜像
|
||||||
- 自动在根目录创建挂载点
|
- 自动在根目录创建挂载点
|
||||||
- 自动解挂镜像文件
|
- 自动解挂镜像文件
|
||||||
- 自动删除挂载目录,并返回到主目录之前的状态
|
- 自动删除挂载目录,并返回到主目录之前的状态
|
||||||
- 自动存档最近10次挂载历史
|
- 自动记录最近10次挂载历史
|
||||||
- 支持挂载多个镜像文件
|
- 支持挂载多个镜像文件
|
||||||
- 支持烧录ISO文件及IMG文件到光盘
|
- 支持烧录ISO文件及IMG文件到光盘
|
||||||
- 支持MD5校验和SHA1校验
|
- 支持MD5校验和SHA1校验
|
||||||
@ -33,14 +32,14 @@ Furius ISO Mount是一个简单易用的开源应用程序用来挂载镜像文
|
|||||||
- 自动创建手动挂载和解挂的日志文件
|
- 自动创建手动挂载和解挂的日志文件
|
||||||
- 语言支持(目前支持保加利亚语,中文(简体),捷克语,荷兰语,法语,德语,匈牙利语,意大利语,希腊语,日语,波兰语,葡萄牙语,俄语,斯洛文尼亚语,西班牙语,瑞典语和土耳其语)
|
- 语言支持(目前支持保加利亚语,中文(简体),捷克语,荷兰语,法语,德语,匈牙利语,意大利语,希腊语,日语,波兰语,葡萄牙语,俄语,斯洛文尼亚语,西班牙语,瑞典语和土耳其语)
|
||||||
|
|
||||||
|
---
|
||||||
- 项目网址: [launchpad.net/furiusisomount/][1]
|
- 项目网址: [launchpad.net/furiusisomount/][1]
|
||||||
- 开发者: Dean Harris (Marcus Furius)
|
- 开发者: Dean Harris (Marcus Furius)
|
||||||
- 许可: GNU GPL v3
|
- 许可: GNU GPL v3
|
||||||
- 版本号: 0.11.3.1
|
- 版本号: 0.11.3.1
|
||||||
|
|
||||||
----------
|
|
||||||
|
|
||||||

|
###fuseiso
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
@ -50,44 +49,46 @@ fuseiso 是用来挂载ISO文件系统的一个开源的安全模块。
|
|||||||
|
|
||||||
特性:
|
特性:
|
||||||
|
|
||||||
- 支持读ISO,BIN和NRG镜像,包括ISO9660文件系统
|
- 支持读ISO,BIN和NRG镜像,包括ISO 9660文件系统
|
||||||
- 支持普通的ISO9660级别1和级别2
|
- 支持普通的ISO 9660级别1和级别2
|
||||||
- 支持一些常用的扩展,想Joliet,RockRidge和zisofs
|
- 支持一些常用的扩展,想Joliet,RockRidge和zisofs
|
||||||
- 支持非标准的镜像,包括CloneCD's IMGs 、Alcohol 120%'s MDFs 因为他们的格式看起来恰好像BIN镜像一样
|
- 支持非标准的镜像,包括CloneCD's IMGs 、Alcohol 120%'s MDFs 因为他们的格式看起来恰好像BIN镜像一样
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
- 项目网址: [sourceforge.net/projects/fuseiso][2]
|
- 项目网址: [sourceforge.net/projects/fuseiso][2]
|
||||||
- 开发者: Dmitry Morozhnikov
|
- 开发者: Dmitry Morozhnikov
|
||||||
- 许可: GNU GPL v2
|
- 许可: GNU GPL v2
|
||||||
- 版本号: 20070708
|
- 版本号: 20070708
|
||||||
|
|
||||||
----------
|
|
||||||
|
|
||||||

|
###iat
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
iat(Iso9660分析工具)是一个通用的开源工具,能够检测很多不同镜像格式文件的结构,包括BIN,MDF,PDI,CDI,NRG和B5I,并转化成ISO-9660格式.
|
iat(Iso 9660分析工具)是一个通用的开源工具,能够检测很多不同镜像格式文件的结构,包括BIN,MDF,PDI,CDI,NRG和B5I,并转化成ISO 9660格式.
|
||||||
|
|
||||||
特性:
|
特性:
|
||||||
|
|
||||||
- 支持读(输入)NRG,MDF,PDI,CDI,BIN,CUE 和B5I镜像
|
- 支持读取(输入)NRG,MDF,PDI,CDI,BIN,CUE 和B5I镜像
|
||||||
- 支持用cd 刻录机直接烧录光盘镜像
|
- 支持用 cd 刻录机直接烧录光盘镜像
|
||||||
- 输出信息包括:进度条,块大小,ECC扇形分区(大小),头分区(大小),镜像偏移地址等等
|
- 输出信息包括:进度条,块大小,ECC扇形分区(大小),头分区(大小),镜像偏移地址等等
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
- 项目网址: [sourceforge.net/projects/iat.berlios][3]
|
- 项目网址: [sourceforge.net/projects/iat.berlios][3]
|
||||||
- 开发者: Salvatore Santagati
|
- 开发者: Salvatore Santagati
|
||||||
- 许可: GNU GPL v2
|
- 许可: GNU GPL v2
|
||||||
- 版本号: 0.1.3
|
- 版本号: 0.1.3
|
||||||
|
|
||||||
----------
|
|
||||||
|
|
||||||

|
###AcetoneISO
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
AcetoneISO 是一个功能丰富的开源图形化应用程序,用来挂载和管理CD/DVD镜像。
|
AcetoneISO 是一个功能丰富的开源图形化应用程序,用来挂载和管理CD/DVD镜像。
|
||||||
|
|
||||||
当你打开这个程序,你就会看到一个图形化的文件管理器用来挂载镜像文件,包括专有的镜像格式,也包括像ISO, BIN, NRG, MDF, IMG 等等,并且允许您执行一系列的动作。
|
当你打开这个程序,你就会看到一个图形化的文件管理器用来挂载镜像文件,包括专有的镜像格式,也包括像ISO, BIN, NRG, MDF, IMG 等等,并且允许您执行一系列的操作。
|
||||||
|
|
||||||
AcetoneISO是用QT 4写的,也就是说,对于基于QT的桌面环境能很好的兼容,像KDE,LXQT或是Razor-qt。
|
AcetoneISO是用QT 4写的,也就是说,对于基于QT的桌面环境能很好的兼容,像KDE,LXQT或是Razor-qt。
|
||||||
|
|
||||||
@ -95,57 +96,60 @@ AcetoneISO是用QT 4写的,也就是说,对于基于QT的桌面环境能很
|
|||||||
|
|
||||||
特性:
|
特性:
|
||||||
|
|
||||||
- 支持挂载大多数windowns 镜像,在一个简洁易用的界面
|
- 支持挂载大多数windows 镜像,界面简洁易用
|
||||||
- 支持所有镜像格式转换到ISO,或者是从中提取内容。
|
- 可以将其所有支持镜像格式转换到ISO,或者是从中提取内容
|
||||||
- 支持加密,压缩,解压任何类型的镜像
|
- 加密,压缩,解压任何类型的镜像
|
||||||
- 支持转换DVD成xvid avi,支持任何格式的转换成xvid avi
|
- 转换DVD成xvid avi,支持将各种常规视频格式转换成xvid avi
|
||||||
- 支持从录像里提取声音
|
- 从视频里提取声音
|
||||||
- 支持从不同格式中提取镜像文件,包括bin mdf nrg img daa dmg cdi b5i bwi pdi
|
- 从不同格式中提取镜像中的文件,包括bin mdf nrg img daa dmg cdi b5i bwi pdi
|
||||||
- 支持用Kaffeine / VLC / SMplayer播放DVD镜像,可以从Amazon 自动下载。
|
- 用Kaffeine / VLC / SMplayer播放DVD镜像,可以从Amazon 自动下载封面。
|
||||||
- 支持从文件夹或者是CD/DVD生成ISO镜像
|
- 从文件夹或者是CD/DVD生成ISO镜像
|
||||||
- 支持文件MD5校验,或者是生成一个MD5校验码
|
- 可以做镜像的MD5校验,或者是生成镜像的MD5校验码
|
||||||
- 支持计算镜像的ShaSums,以128,256和384位的速度
|
- 计算镜像的ShaSums(128,256和384位)
|
||||||
- 支持加密,解密一个镜像文件
|
- 支持加密,解密一个镜像文件
|
||||||
- 支持以M字节的速度,分开、合并镜像
|
- 按兆数分拆和合并镜像
|
||||||
- 支持高比例压缩镜像成7z 格式
|
- 以高压缩比将镜像压缩成7z 格式
|
||||||
- 支持翻录PSX CD成BIN格式,以便在ePSXe/pSX模拟器里运行
|
- 翻录PSX CD成BIN格式,以便在ePSXe/pSX模拟器里运行
|
||||||
- 支持修复CUE文件为BIN和IMG格式
|
- 为BIN和IMG格式恢复丢失的 CUE 文件
|
||||||
- 支持把MAC OS的DMG镜像转换成可挂载的镜像
|
- 把MAC OS的DMG镜像转换成可挂载的镜像
|
||||||
- 支持从指定的文件夹中挂载镜像
|
- 从指定的文件夹中挂载镜像
|
||||||
- 支持创建数据库来管理一个大的镜像集合
|
- 创建数据库来管理一个大的镜像集合
|
||||||
- 支持从CD/DVD 或者是ISO镜像中提取启动文件
|
- 从CD/DVD 或者是ISO镜像中提取启动文件
|
||||||
- 支持备份CD成BIN镜像
|
- 备份CD成BIN镜像
|
||||||
- 支持简单快速的把DVD翻录成Xvid AVI
|
- 简单快速的把DVD翻录成Xvid AVI
|
||||||
- 支持简单快速的把常见的视频(avi, mpeg, mov, wmv, asf)转换成Xvid AVI
|
- 简单快速的把常见的视频(avi, mpeg, mov, wmv, asf)转换成Xvid AVI
|
||||||
- 支持简单快速的把FLV 换换成AVI 格式
|
- 简单快速的把FLV 换换成AVI 格式
|
||||||
- 支持从YouTube和一些视频网站下载视频
|
- 从YouTube和一些视频网站下载视频
|
||||||
- 支持提取一个有密码的RAR存档
|
- 提取一个有密码的RAR存档
|
||||||
- 支持转换任何的视频到索尼便携式PSP上
|
- 支持转换任何的视频到PSP上
|
||||||
- 国际化的语言支持支持(英语,意大利语,波兰语,西班牙语,罗马尼亚语,匈牙利语,德语,捷克语和俄语)
|
- 国际化的语言支持支持(英语,意大利语,波兰语,西班牙语,罗马尼亚语,匈牙利语,德语,捷克语和俄语)
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
- 项目网址: [sourceforge.net/projects/acetoneiso][4]
|
- 项目网址: [sourceforge.net/projects/acetoneiso][4]
|
||||||
- 开发者: Marco Di Antonio
|
- 开发者: Marco Di Antonio
|
||||||
- 许可: GNU GPL v3
|
- 许可: GNU GPL v3
|
||||||
- 版本号: 2.3
|
- 版本号: 2.3
|
||||||
|
|
||||||
----------
|
|
||||||
|
|
||||||

|
###ISO Master
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
ISO Master是一个开源、易用的、图形化CD 镜像编辑器,适用于Linux 和BSD 。可以从ISO 里提取文件,给ISO 添加文件,创建一个可引导的ISO,这些都是在一个可视化的用户界面完成的。可以打开ISO,NRG 和一些MDF文件,但是只能保存成ISO 格式。
|
ISO Master是一个开源、易用的、图形化CD 镜像编辑器,适用于Linux 和BSD 。可以从ISO 里提取文件,给ISO 里面添加文件,创建一个可引导的ISO,这些都是在一个可视化的用户界面完成的。可以打开ISO,NRG 和一些MDF文件,但是只能保存成ISO 格式。
|
||||||
|
|
||||||
ISO Master 是基于bkisofs 创建的,一个简单、稳定的阅读库,修改和编写ISO 镜像,支持Joliet, RockRidge 和EL Torito扩展,
|
ISO Master 是基于bkisofs 创建的,这是一个简单、稳定的阅读,修改和编写ISO 镜像的软件库,支持Joliet, RockRidge 和EL Torito扩展,
|
||||||
|
|
||||||
特性:
|
特性:
|
||||||
|
|
||||||
- 支持读ISO 格式文件(ISO9660, Joliet, RockRidge 和 El Torito),大多数的NRG 格式文件和一些单向的MDF文件,但是,只能保存成ISO 格式
|
- 支持读ISO 格式文件(ISO9660, Joliet, RockRidge 和 El Torito),大多数的NRG 格式文件和一些单轨道的MDF文件,但是,只能保存成ISO 格式
|
||||||
- 创建和修改一个CD/DVD 格式文件
|
- 创建和修改一个CD/DVD 格式文件
|
||||||
- 支持CD 格式文件的添加或删除文件和目录
|
- 支持CD 格式文件的添加或删除文件和目录
|
||||||
- 支持创建可引导的CD/DVD
|
- 支持创建可引导的CD/DVD
|
||||||
- 国际化的支持
|
- 国际化的支持
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
- 项目网址: [www.littlesvr.ca/isomaster/][5]
|
- 项目网址: [www.littlesvr.ca/isomaster/][5]
|
||||||
- 开发者: Andrew Smith
|
- 开发者: Andrew Smith
|
||||||
- 许可: GNU GPL v2
|
- 许可: GNU GPL v2
|
||||||
@ -157,7 +161,7 @@ via: http://www.linuxlinks.com/article/20141025082352476/DiskImageTools.html
|
|||||||
|
|
||||||
作者:Frazer Kline
|
作者:Frazer Kline
|
||||||
译者:[barney-ro](https://github.com/barney-ro)
|
译者:[barney-ro](https://github.com/barney-ro)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -1,6 +1,6 @@
|
|||||||
Linux 有问必答 -- 如何修复“hda-duplex not supported in this QEMU binary”(hda-duplex在此QEMU文件中不支持)
|
Linux 有问必答:如何修复“hda-duplex not supported in this QEMU binary”
|
||||||
================================================================================
|
================================================================================
|
||||||
> **提问**: 当我尝试在虚拟机中安装一个新的Linux时,虚拟机不能启动且报了下面这个错误:“不支持的配置:hda-duplex在此QEMU文件中不支持。” 我该如何修复?
|
> **提问**: 当我尝试在虚拟机中安装一个新的Linux时,虚拟机不能启动且报了下面这个错误:"unsupported configuration: hda-duplex not supported in this QEMU binary."(“不支持的配置:hda-duplex在此QEMU文件中不支持。”) 我该如何修复?
|
||||||
|
|
||||||
这个错误可能来自一个当默认声卡型号不能被识别时的一个qemu bug。
|
这个错误可能来自一个当默认声卡型号不能被识别时的一个qemu bug。
|
||||||
|
|
||||||
@ -20,7 +20,7 @@ Linux 有问必答 -- 如何修复“hda-duplex not supported in this QEMU binar
|
|||||||
|
|
||||||
### 方案二: Virsh ###
|
### 方案二: Virsh ###
|
||||||
|
|
||||||
如果你使用的是**virt-manager** 而不是**virt-manager**, 你可以编辑VM相应的配置文件。在<device>节点中查找**sound**节点,并按照下面的默认声卡型号改成**ac97**。
|
如果你使用的是**virsh** 而不是**virt-manager**, 你可以编辑VM相应的配置文件。在<device>节点中查找**sound**节点,并按照下面的默认声卡型号改成**ac97**。
|
||||||
|
|
||||||
<devices>
|
<devices>
|
||||||
. . .
|
. . .
|
||||||
@ -35,6 +35,6 @@ Linux 有问必答 -- 如何修复“hda-duplex not supported in this QEMU binar
|
|||||||
via: http://ask.xmodulo.com/hda-duplex-not-supported-in-this-qemu-binary.html
|
via: http://ask.xmodulo.com/hda-duplex-not-supported-in-this-qemu-binary.html
|
||||||
|
|
||||||
译者:[geekpi](https://github.com/geekpi)
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
@ -1,14 +1,15 @@
|
|||||||
修复了60个bug的LibreOffice 4.3.4正式发布,4.4版本开发工作有序进行中
|
修复了60个bug的LibreOffice 4.3.4正式发布
|
||||||
================================================================================
|
================================================================================
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
**[上两周][1], 文档基金会带着它的开源LibreOffice生产力套件的又一个次版本回来了。**
|
**[前一段时间][1], 文档基金会带着它的开源LibreOffice生产力套件的又一个小版本更新回来了。**
|
||||||
|
|
||||||
LibreOffice 4.3.4,新系列中的第四个次版本,是单独由修复好的bug构成的一个版本,不出乎意料地以点版本形式发行。
|
LibreOffice 4.3.4,新系列中的第四个次版本,该版本只包含 BUG 修复,按计划发布了。
|
||||||
|
|
||||||
除了增加了即视感,基金会所说的在developers’ butterfly net上被揪出来并且修复的bug数量大概有:60个左右。
|
可以看到的变化是,如基金会所说的在developers’ butterfly net上被揪出来并且修复的bug数量大概有:60个左右。
|
||||||
|
|
||||||
- 排序操作现在还是默认为旧的样式(Calc)
|
- 排序操作现在还是默认为旧式风格(Calc)
|
||||||
- 在预览后恢复焦点窗口(Impress)
|
- 在预览后恢复焦点窗口(Impress)
|
||||||
- 图表向导对话框不再是‘切除’式
|
- 图表向导对话框不再是‘切除’式
|
||||||
- 修复了记录改变时的字数统计问题 (Writer)
|
- 修复了记录改变时的字数统计问题 (Writer)
|
||||||
@ -28,13 +29,13 @@ LibreOffice 4.3.4,新系列中的第四个次版本,是单独由修复好的
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
来自LibreOffice 4.4的信息栏
|
*来自LibreOffice 4.4的信息栏*
|
||||||
|
|
||||||
LibreOffice 4.4应该给予大家多一点希望。
|
LibreOffice 4.4应该会让大家更多期望。
|
||||||
|
|
||||||
[维基上讲述了][4]正在进行中的不间断大范围GUI调整,包括一个新的颜色选择器,重新设计的段落行距选择器和一个在凸显部位表示该文件是否为只读模式的信息栏。
|
[维基上讲述了][4]正在进行中的不间断大范围GUI调整,包括一个新的颜色选择器,重新设计的段落行距选择器和一个在凸显部位表示该文件是否为只读模式的信息栏。
|
||||||
|
|
||||||
虽然以上大规模的界面变动我知道一些桌面社区的抗议声不断,但是他们还是朝着正确的方向稳步前进。
|
虽然我知道一些桌面社区对这些大规模的界面变动的抗议声不断,但是他们还是朝着正确的方向稳步前进。
|
||||||
|
|
||||||
要记住,在一些必要情况下,LibreOffice对于企业和机构来说是一款非常重要的软件。在外观和布局上有任何引人注目的修改都会引发一串连锁效应。
|
要记住,在一些必要情况下,LibreOffice对于企业和机构来说是一款非常重要的软件。在外观和布局上有任何引人注目的修改都会引发一串连锁效应。
|
||||||
|
|
||||||
@ -46,7 +47,7 @@ via: http://www.omgubuntu.co.uk/2014/11/libreoffice-4-3-4-arrives-bundle-bug-fix
|
|||||||
|
|
||||||
作者:[Joey-Elijah Sneddon][a]
|
作者:[Joey-Elijah Sneddon][a]
|
||||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -1,6 +1,6 @@
|
|||||||
使用GDB命令行调试器调试C/C++程序
|
使用GDB命令行调试器调试C/C++程序
|
||||||
============================================================
|
============================================================
|
||||||
没有调试器的情况下编写程序时最糟糕的状况是什么?编译时,跪着祈祷不要出错?用生命在运行可执行程序(blood offering不知道怎么翻译好...)?或者在每一行代码间添加printf("test")语句来定位错误点?如你所知,编写程序时不使用调试器的话是不利的。幸好,linux下调试还是很方便的。大多数人使用的IDE都集成了调试器,但linxu著名的调试器是命令行形式的C/C++调试器GDB。然而,与其他命令行工具一致,DGB需要一定的练习才能完全掌握。这里,我会告诉你GDB的基本情况及使用方法。
|
没有调试器的情况下编写程序时最糟糕的状况是什么?编译时跪着祈祷不要出错?用血祭召唤恶魔帮你运行可执行程序?或者在每一行代码间添加printf("test")语句来定位错误点?如你所知,编写程序时不使用调试器的话是不方便的。幸好,linux下调试还是很方便的。大多数人使用的IDE都集成了调试器,但 linux 最著名的调试器是命令行形式的C/C++调试器GDB。然而,与其他命令行工具一致,DGB需要一定的练习才能完全掌握。这里,我会告诉你GDB的基本情况及使用方法。
|
||||||
|
|
||||||
###安装GDB###
|
###安装GDB###
|
||||||
|
|
||||||
@ -18,11 +18,11 @@ Fedora,CentOS 或 RHEL:
|
|||||||
|
|
||||||
$sudo yum install gdb
|
$sudo yum install gdb
|
||||||
|
|
||||||
如果在仓库中找不到的话,可以从官网中下载[official page][1]
|
如果在仓库中找不到的话,可以从[官网中下载][1]。
|
||||||
|
|
||||||
###示例代码###
|
###示例代码###
|
||||||
|
|
||||||
当学习GDB时,最好有一份代码,动手试验。下列代码是我编写的简单例子,它可以很好的体现GDB的特性。将它拷贝下来并且进行实验。这是最好的方法。
|
当学习GDB时,最好有一份代码,动手试验。下列代码是我编写的简单例子,它可以很好的体现GDB的特性。将它拷贝下来并且进行实验——这是最好的方法。
|
||||||
|
|
||||||
#include <stdio.h>
|
#include <stdio.h>
|
||||||
#include <stdlib.h>
|
#include <stdlib.h>
|
||||||
@ -48,21 +48,21 @@ Fedora,CentOS 或 RHEL:
|
|||||||
|
|
||||||
$ gdb -tui [executable's name]
|
$ gdb -tui [executable's name]
|
||||||
|
|
||||||
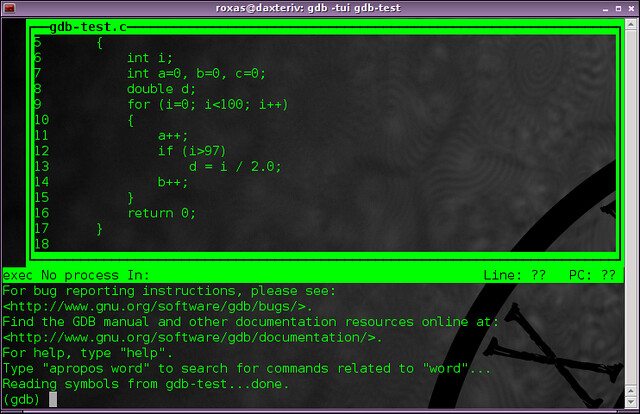
使用”-tui“选项可以将代码显示在一个窗口内(被称为”文本接口”),在这个窗口内可以使用光标来操控,同时在下面输入GDB shell命令。
|
使用”-tui“选项可以将代码显示在一个漂亮的交互式窗口内(所以被称为“文本用户界面 TUI”),在这个窗口内可以使用光标来操控,同时在下面的GDB shell中输入命令。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
现在我们可以在程序的任何地方设置断点。你可以通过下列命令来为当前源文件的某一行设置断点。
|
现在我们可以在程序的任何地方设置断点。你可以通过下列命令来为当前源文件的某一行设置断点。
|
||||||
|
|
||||||
break [line number]
|
break [行号]
|
||||||
|
|
||||||
或者为一个特定的函数设置断点:
|
或者为一个特定的函数设置断点:
|
||||||
|
|
||||||
break [function name]
|
break [函数名]
|
||||||
|
|
||||||
甚至可以设置条件断点
|
甚至可以设置条件断点
|
||||||
|
|
||||||
break [line number] if [condition]
|
break [行号] if [条件]
|
||||||
|
|
||||||
例如,在我们的示例代码中,可以设置如下:
|
例如,在我们的示例代码中,可以设置如下:
|
||||||
|
|
||||||
@ -74,23 +74,25 @@ Fedora,CentOS 或 RHEL:
|
|||||||
|
|
||||||
最后但也是很重要的是,我们可以设置一个“观察断点”,当这个被观察的变量发生变化时,程序会被停止。
|
最后但也是很重要的是,我们可以设置一个“观察断点”,当这个被观察的变量发生变化时,程序会被停止。
|
||||||
|
|
||||||
watch [variable]
|
watch [变量]
|
||||||
|
|
||||||
可以设置如下:
|
这里我们可以设置如下:
|
||||||
|
|
||||||
watch d
|
watch d
|
||||||
|
|
||||||
当d的值发生变化时程序会停止运行(例如,当i>97为真时)。
|
当d的值发生变化时程序会停止运行(例如,当i>97为真时)。
|
||||||
当设置后断点后,使用"run"命令开始运行程序,或按如下所示:
|
|
||||||
|
当设置断点后,使用"run"命令开始运行程序,或按如下所示:
|
||||||
|
|
||||||
r [程序的输入参数(如果有的话)]
|
r [程序的输入参数(如果有的话)]
|
||||||
|
|
||||||
gdb中,大多数的单词都可以简写为一个字母。
|
gdb中,大多数的命令单词都可以简写为一个字母。
|
||||||
|
|
||||||
不出意外,程序会停留在11行。这里,我们可以做些有趣的事情。下列命令:
|
不出意外,程序会停留在11行。这里,我们可以做些有趣的事情。下列命令:
|
||||||
|
|
||||||
bt
|
bt
|
||||||
|
|
||||||
回溯功能可以让我们知道程序如何到达这条语句的。
|
回溯功能(backtrace)可以让我们知道程序如何到达这条语句的。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
@ -98,16 +100,15 @@ gdb中,大多数的单词都可以简写为一个字母。
|
|||||||
|
|
||||||
这条语句会显示所有的局部变量以及它们的值(你可以看到,我没有为d设置初始值,所以它现在的值是任意值)。
|
这条语句会显示所有的局部变量以及它们的值(你可以看到,我没有为d设置初始值,所以它现在的值是任意值)。
|
||||||
|
|
||||||
当然
|
当然:
|
||||||
|
|
||||||
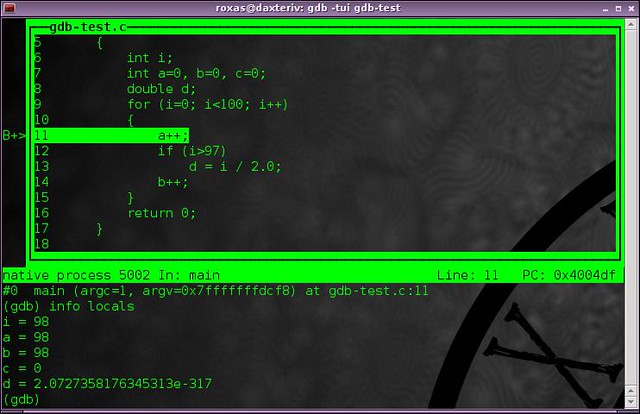
|

|
||||||
|
|
||||||
p [variable]
|
p [变量]
|
||||||
|
|
||||||
这可以显示特定变量的值,但是还有更好的:
|
这个命令可以显示特定变量的值,而更进一步:
|
||||||
|
|
||||||
ptype [variable]
|
|
||||||
|
|
||||||
|
ptype [变量]
|
||||||
|
|
||||||
可以显示变量的类型。所以这里可以确定d是double型。
|
可以显示变量的类型。所以这里可以确定d是double型。
|
||||||
|
|
||||||
@ -115,11 +116,11 @@ gdb中,大多数的单词都可以简写为一个字母。
|
|||||||
|
|
||||||
既然已经到这一步了,我么不妨这么做:
|
既然已经到这一步了,我么不妨这么做:
|
||||||
|
|
||||||
set var [variable] = [new value]
|
set var [变量] = [新的值]
|
||||||
|
|
||||||
这样会覆盖变量的值。不过需要注意,你不能创建一个新的变量或改变变量的类型。我们可以这样做:
|
这样会覆盖变量的值。不过需要注意,你不能创建一个新的变量或改变变量的类型。我们可以这样做:
|
||||||
|
|
||||||
set var a = 0
|
set var a = 0
|
||||||
|
|
||||||
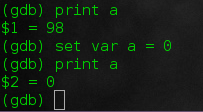
|

|
||||||
|
|
||||||
@ -127,17 +128,17 @@ gdb中,大多数的单词都可以简写为一个字母。
|
|||||||
|
|
||||||
step
|
step
|
||||||
|
|
||||||
使用如上命令,运行到下一条语句,也可以进入到一个函数里面。或者使用:
|
使用如上命令,运行到下一条语句,有可能进入到一个函数里面。或者使用:
|
||||||
|
|
||||||
next
|
next
|
||||||
|
|
||||||
这可以直接下一条语句,并且不进入子函数内部。
|
这可以直接运行下一条语句,而不进入子函数内部。
|
||||||
|
|
||||||
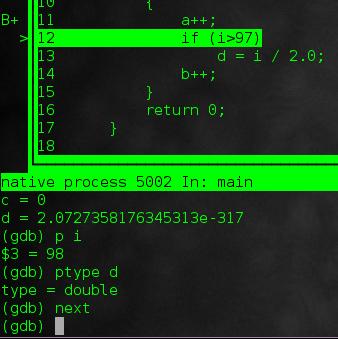
|

|
||||||
|
|
||||||
结束测试后,删除断点:
|
结束测试后,删除断点:
|
||||||
|
|
||||||
delete [line number]
|
delete [行号]
|
||||||
|
|
||||||
从当前断点继续运行程序:
|
从当前断点继续运行程序:
|
||||||
|
|
||||||
@ -147,7 +148,7 @@ gdb中,大多数的单词都可以简写为一个字母。
|
|||||||
|
|
||||||
quit
|
quit
|
||||||
|
|
||||||
总结,有了GDB,编译时不用祈祷上帝了,运行时不用血祭(?)了,再也不用printf(“test“)了。当然,这里所讲的并不完整,而且GDB的功能远不止这些。所以我强烈建议你自己更加深入的学习它。我现在感兴趣的是将GDB整合到Vim中。同时,这里有一个[备忘录][2]记录了GDB所有的命令行,以供查阅。
|
总之,有了GDB,编译时不用祈祷上帝了,运行时不用血祭了,再也不用printf(“test“)了。当然,这里所讲的并不完整,而且GDB的功能远远不止于此。所以我强烈建议你自己更加深入的学习它。我现在感兴趣的是将GDB整合到Vim中。同时,这里有一个[备忘录][2]记录了GDB所有的命令行,以供查阅。
|
||||||
|
|
||||||
你对GDB有什么看法?你会将它与图形调试器对比吗,它有什么优势呢?对于将GDB集成到Vim有什么看法呢?将你的想法写到评论里。
|
你对GDB有什么看法?你会将它与图形调试器对比吗,它有什么优势呢?对于将GDB集成到Vim有什么看法呢?将你的想法写到评论里。
|
||||||
|
|
||||||
@ -157,7 +158,7 @@ via: http://xmodulo.com/gdb-command-line-debugger.html
|
|||||||
|
|
||||||
作者:[Adrien Brochard][a]
|
作者:[Adrien Brochard][a]
|
||||||
译者:[SPccman](https://github.com/SPccman)
|
译者:[SPccman](https://github.com/SPccman)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -1,8 +1,7 @@
|
|||||||
如何将Ubuntu14.04安全的升级到14.10
|
如何将 Ubuntu14.04 安全的升级到14.10
|
||||||
================================================================================
|
================================================================================
|
||||||
本文将讨论如何将Ubuntu14.04升级到14.10的beta版。Ubuntu14.10的最终beta版已经发布了
|
|
||||||
|
|
||||||
如果想从Ubuntu14.04/13.10/13.04/12.10/12.04或者更老的版本升级到14.10,只要遵循下面给出的步骤。注意,你不能直接从13.10升级到14.10。你应该想将13.10升级到14.04在从14.04升级到14.10。下面是详细步骤。
|
如果想从Ubuntu14.04/13.10/13.04/12.10/12.04或者更老的版本升级到14.10,只要遵循下面给出的步骤。注意,你不能直接从13.10升级到14.10。你应该先将13.10升级到14.04在从14.04升级到14.10。下面是详细步骤。
|
||||||
|
|
||||||
下面的步骤不仅能用于14.10,也兼容于一些像Lubuntu14.10,Kubuntu14.10和Xubuntu14.10等的Ubuntu衍生版本
|
下面的步骤不仅能用于14.10,也兼容于一些像Lubuntu14.10,Kubuntu14.10和Xubuntu14.10等的Ubuntu衍生版本
|
||||||
|
|
||||||
@ -90,15 +89,15 @@
|
|||||||
|
|
||||||
sudo do-release-upgrade -d
|
sudo do-release-upgrade -d
|
||||||
|
|
||||||
直到屏幕提示你已完成
|
直到屏幕提示你已完成。
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
via: http://www.unixmen.com/upgrade-ubuntu-14-04-trusty-ubuntu-14-10-utopic/
|
via: http://www.unixmen.com/upgrade-ubuntu-14-04-trusty-ubuntu-14-10-utopic/
|
||||||
|
|
||||||
作者:SK
|
作者:SK
|
||||||
译者:[译者ID](https://github.com/johnhoow)
|
译者:[johnhoow](https://github.com/johnhoow)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -1,52 +0,0 @@
|
|||||||
6 Minesweeper Clones for Linux
|
|
||||||
================================================================================
|
|
||||||
### GNOME Mines ###
|
|
||||||
|
|
||||||
This is the GNOME Minesweeper clone, allowing you to choose from three different pre-defined table sizes (8×8, 16×16, 30×16) or a custom number of rows and columns. It can be ran in fullscreen mode, comes with highscores, elapsed time and hints. The game can be paused and resumed.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### ace-minesweeper ###
|
|
||||||
|
|
||||||
This is part of a package that contains some other games too, like ace-freecel, ace-solitaire or ace-spider. It has a graphical interface featuring Tux, but doesn’t seem to come with different table sizes. The package is called ace-of-penguins in Ubuntu.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### XBomb ###
|
|
||||||
|
|
||||||
XBomb is a mines game for the X Window System with three different table sizes and tiles which can take different shapes: hexagonal, rectangular (traditional) or triangular. Unfortunately the current version in Ubuntu 14.04 crashes with a segmentation fault, so you may need to install another version to make it work.
|
|
||||||
[Homepage][1]
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
([Image credit][1])
|
|
||||||
|
|
||||||
### KMines ###
|
|
||||||
|
|
||||||
KMines is the a KDE game, and just like GNOME Mines, there are three built-in table sizes (easy, medium, hard) and custom, support for themes and highscores.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### freesweep ###
|
|
||||||
|
|
||||||
Freesweep is a Minesweeper clone for the terminal which allows you to configure settings such as table rows and columns, percentage of bombs, colors and also has a highscores table.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### xdemineur ###
|
|
||||||
|
|
||||||
Another graphical Minesweeper clone for X, Xdemineur is very much alike Ace-Minesweeper, with one predefined table size.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: http://www.tuxarena.com/2014/10/6-minesweeper-clones-for-linux/
|
|
||||||
|
|
||||||
作者:Craciun Dan
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[1]:http://www.gedanken.org.uk/software/xbomb/
|
|
||||||
@ -1,47 +0,0 @@
|
|||||||
Qshutdown – An avanced shutdown tool
|
|
||||||
================================================================================
|
|
||||||
qshutdown is a Qt program to shutdown/reboot/suspend/hibernate the computer at a given time or after a certain number of minutes. It shows the time until the corresponding request is send to either the Gnome- or KDE-session-manager, to HAL or to DeviceKit and if none of these works the command ‘sudo shutdown -P now' is used. This program may be useful for people who want to work with the computer only for a certain time.
|
|
||||||
|
|
||||||
qshutdown will show it self 3 times as a warning if there are less than 70 seconds left. (if 1 Minute or local time +1 Minute was set it’ll appear only once.)
|
|
||||||
|
|
||||||
This program uses qdbus to send a shutdown/reboot/suspend/hibernate request to either the gnome- or kde-session-manager, to HAL or to DeviceKit and if none of these works, the command ’sudo shutdown’ will be used (note that when sending the request to HAL or DeviceKit, or the shutdown command is used, the Session will never be saved. If the shutdown command is used, the program will only be able to shutdown and reboot). So if nothing happens when the shutdown- or reboot-time is reached, it means that one lacks the rights for the shutdown command.
|
|
||||||
|
|
||||||
In this case one can do the following:
|
|
||||||
|
|
||||||
Post the following in a terminal: "EDITOR:nano sudo -E visudo" and add this line: "* ALL = NOPASSWD:/sbin/shutdown" whereas * replaces the username or %groupname.
|
|
||||||
|
|
||||||
Configurationfile qshutdown.conf
|
|
||||||
|
|
||||||
The maximum Number of countdown_minutes is 1440 (24 hours).The configurationfile (and logfile) is located at ~/.qshutdown
|
|
||||||
|
|
||||||
For admins:
|
|
||||||
|
|
||||||
With the option Lock_all in qshutdown.conf set to true the user won’t be able to change any settings. If you change the permissions of qshutdown.conf with "sudo chown root -R ~/.qshutdown" and "sudo chmod 744 ~/.qshutdown/qshutdown.conf", the user won’t be able to change anything in the configurationfile.
|
|
||||||
|
|
||||||
### Install Qshutdown in Ubuntu ###
|
|
||||||
|
|
||||||
Open the terminal and run the following command
|
|
||||||
|
|
||||||
sudo apt-get install qshutdown
|
|
||||||
|
|
||||||
### Screenshots ###
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: http://www.ubuntugeek.com/qshutdown-an-avanced-shutdown-tool.html
|
|
||||||
|
|
||||||
作者:[ruchi][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
|
||||||
@ -1,4 +1,4 @@
|
|||||||
[translating by KayGuoWhu]
|
[Translating by Stevearzh]
|
||||||
When hackers grow old
|
When hackers grow old
|
||||||
================================================================================
|
================================================================================
|
||||||
Lately I’ve been wrestling with various members of an ancient and venerable open-source development group which I am not going to name, though people who regularly follow my adventures will probably guess which one it is by the time I’m done venting.
|
Lately I’ve been wrestling with various members of an ancient and venerable open-source development group which I am not going to name, though people who regularly follow my adventures will probably guess which one it is by the time I’m done venting.
|
||||||
|
|||||||
@ -0,0 +1,55 @@
|
|||||||
|
Four ways Linux is headed for no-downtime kernel patching
|
||||||
|
================================================================================
|
||||||
|

|
||||||
|
Credit: Shutterstock
|
||||||
|
|
||||||
|
These technologies are competing to provide the best way to patch the Linux kernel without reboots or downtime
|
||||||
|
|
||||||
|
Nobody loves a reboot, especially not if it involves a late-breaking patch for a kernel-level issue that has to be applied stat.
|
||||||
|
|
||||||
|
To that end, three projects are in the works to provide a mechanism for upgrading the kernel in a running Linux instance without having to reboot anything.
|
||||||
|
|
||||||
|
### Ksplice ###
|
||||||
|
|
||||||
|
The first and original contender is Ksplice, courtesy of a company of the same name founded in 2008. The kernel being replaced does not have to be pre-modified; all it needs is a diff file listing the changes to be made to the kernel source. Ksplice, Inc. offered support for the (free) software as a paid service and supported most common Linux distributions used in production.
|
||||||
|
|
||||||
|
All that changed in 2011, when [Oracle purchased the company][1], rolled the feature into its own Linux distribution, and kept updates for the technology to itself. As a result, other intrepid kernel hackers have been looking for ways to pick up where Ksplice left off, without having to pay the associated Oracle tax.
|
||||||
|
|
||||||
|
### Kgraft ###
|
||||||
|
|
||||||
|
In February 2014, Suse provided the exact solution needed: [Kgraft][2], its kernel-update technology released under a mixed GPLv2/GPLv3 license and not kept close as a proprietary creation. It's since been [submitted][3] as a possible inclusion to the mainline Linux kernel, although Suse has rolled a version of the technology into [Suse Linux Enterprise Server 12][4].
|
||||||
|
|
||||||
|
Kgraft works roughly like Ksplice by using a set of diffs to figure out what parts of the kernel to replace. But unlike Ksplice, Kgraft doesn't need to stop the kernel entirely to replace it. Any running functions can be directed to their old or new kernel-level counterparts until the patching process is finished.
|
||||||
|
|
||||||
|
### Kpatch ###
|
||||||
|
|
||||||
|
Red Hat came up with its own no-reboot kernel-patch mechanism, too. Also introduced earlier this year -- right after Suse's work in that vein, no less -- [Kpatch][5] works in roughly the same manner as Kgraft.
|
||||||
|
|
||||||
|
The main difference, [as outlined][6] by Josh Poimboeuf of Red Hat, is that Kpatch doesn't redirect calls to old kernel functions. Rather, it waits until all function calls have stopped, then swaps in the new kernel. Red Hat's engineers consider this approach safer, with less code to maintain, albeit at the cost of more latency during the patch process.
|
||||||
|
|
||||||
|
Like Kgraft, Kpatch has been submitted for consideration as a possible kernel inclusion and can be used with Linux kernels other than Red Hat's. The bad news is that Kpatch isn't yet considered production-ready by Red Hat. It's included as part of Red Hat Enterprise Linux 7, but only in the form of a technology preview.
|
||||||
|
|
||||||
|
### ...or Kgraft + Kpatch? ###
|
||||||
|
|
||||||
|
A fourth solution [proposed by Red Hat developer Seth Jennings][7] early in November 2014 is a mix of both the Kgraft and Kpatch approaches, using patches built for either one of those solutions. This new approach, Jennings explained, "consists of a live patching 'core' that provides an interface for other 'patch' kernel modules to register patches with the core." This way, the patching process -- specifically, how to deal with any running kernel functions -- can be handled in a more orderly fashion.
|
||||||
|
|
||||||
|
The sheer newness of these proposals means it'll be a while before any of them are officially part of the Linux kernel, although Suse's chosen to move fast and made it a part of its latest enterprise offering. Let's see if Red Hat and Canonical choose to follow suit in the short run as well.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.infoworld.com/article/2851028/linux/four-ways-linux-is-headed-for-no-downtime-kernel-patching.html
|
||||||
|
|
||||||
|
作者:[Serdar Yegulalp][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.infoworld.com/author/Serdar-Yegulalp/
|
||||||
|
[1]:http://www.infoworld.com/article/2622437/open-source-software/oracle-buys-ksplice-for-linux--zero-downtime--tech.html
|
||||||
|
[2]:http://www.infoworld.com/article/2610749/linux/suse-open-sources-live-updater-for-linux-kernel.html
|
||||||
|
[3]:https://lwn.net/Articles/596854/
|
||||||
|
[4]:http://www.infoworld.com/article/2838421/linux/suse-linux-enterprise-12-goes-light-on-docker-heavy-on-reliability.html
|
||||||
|
[5]:https://github.com/dynup/kpatch
|
||||||
|
[6]:https://lwn.net/Articles/597123/
|
||||||
|
[7]:http://lkml.iu.edu/hypermail/linux/kernel/1411.0/04020.html
|
||||||
@ -1,78 +0,0 @@
|
|||||||
alim0x translating
|
|
||||||
|
|
||||||
The history of Android
|
|
||||||
================================================================================
|
|
||||||
|
|
||||||
The new Android Market—less black, more white and green.
|
|
||||||
Photo by Ron Amadeo
|
|
||||||
|
|
||||||
### Android 1.6, Donut—CDMA support brings Android to any carrier ###
|
|
||||||
|
|
||||||
The fourth version of Android—1.6, Donut—launched in September 2009, five months after Cupcake hit the market. Despite the myriad of updates, Google was still adding basic functionality to Android. Donut brought support for different screen sizes, CDMA support, and a text-to-speech engine.
|
|
||||||
|
|
||||||
Android 1.6 is a great example of an update that, today, would have little reason to exist as a separate point update. The major improvements basically boiled down to new versions of the Android Market, camera, and YouTube. In the years since, apps like this have been broken out of the OS and can be updated by Google at any time. Before all this modularization work, though, even seemingly minor app updates like this required a full OS update.
|
|
||||||
|
|
||||||
The other big improvement—CDMA support—demonstrated that, despite the version number, Google was still busy getting basic functionality into Android.
|
|
||||||
|
|
||||||
The Android Market was christened as version "1.6" and got a complete overhaul. The original all-black design was tossed in favor of a white app with green highlights—the Android designers were clearly using the Android mascot for inspiration.
|
|
||||||
|
|
||||||
The new market was definitely a new style of app design for Google. The top fifth of the screen was dedicated to a banner logo announcing that this app is indeed the “Android Market." Below the banner were buttons for Apps, Games, and Downloads, and a search button was placed to the right of the banner. Below the navigation was a thumbnail display of featured apps, which could be swiped through. Below that were even more featured apps in a vertically scrolling list.
|
|
||||||
|
|
||||||
|
|
||||||
The new Market design, showing an app page with screenshots, the apps categories page, an app top list, and the downloads section.
|
|
||||||
Photo by Ron Amadeo
|
|
||||||
|
|
||||||
The biggest addition to the market was the inclusion of app screenshots. Android users could finally see what an app looked like before installing it—previously they only had a brief description and user reviews to go on. Your personal star review and comment was given top billing, followed by the description, and then finally the screenshots. Viewing the screenshots would often require a bit of scrolling—if you were looking for a well-designed app, it was a lot of work.
|
|
||||||
|
|
||||||
Tapping on App or Games would bring up a category list, which you can see in the second picture, above. After picking a category, more navigation was shown at the top of the screen, where users could see "Top paid," "Top free," or "Just in" apps within a category. While these sorta looked like buttons that would load a new screen, they were really just a clunky tabbed interface. To denote which "tab" was currently active, there were little green lights next to each button. The nicest part of this interface was that the list of apps would scroll infinitely—once you hit the bottom, more apps would load in. This made it easy to look through the list of apps, but opening any app and coming back would lose your spot in the list—you’d be kicked to the top. The downloads section would do something the new Google Play Store still can't do: simply display a list of your purchased apps.
|
|
||||||
|
|
||||||
While the new Market definitely looked better than the old market, cohesion across apps was getting worse and worse. It seemed like each app was made by a different group with no communication about how all Android apps should look.
|
|
||||||
|
|
||||||

|
|
||||||
The Camera viewfinder, photo review screen, and menu.
|
|
||||||
Photo by Ron Amadeo
|
|
||||||
|
|
||||||
For instance, the camera app was changed from a full-screen, minimal design to a boxed viewfinder with controls on the side. With the new camera app, Google tried its hand at skeuomorphism, wrapping the whole app in a leather texture roughly replicating the exterior of a classic camera. Switching between the camera and camcorder was done with a literal switch, and below that was the on-screen shutter button.
|
|
||||||
|
|
||||||
Tapping on the previous picture thumbnail no longer launched the gallery, but a custom image viewer that was built in to the camera app. When viewing a picture the leather control area changed the camera controls to picture controls, where you could delete, share a picture, or set the picture as a wallpaper or contact image. There was still no swiping between pictures—that was still done with arrows on either side of the image.
|
|
||||||
|
|
||||||
This second picture shows one of the first examples of designers reducing dependence on the menu button, which the Android team slowly started to realize functioned terribly for discoverability. Many app designers (including those within Google) used the menu as a dumping ground for all sorts of controls and navigational elements. Most users didn't think to hit the menu button, though, and never saw the commands.
|
|
||||||
|
|
||||||
A common theme for future versions of Android would be moving things out of the menu and on to the main screen, making the whole OS more user-friendly. The menu button was completely killed in Android 4.0, and it's only supported in Android for legacy apps.
|
|
||||||
|
|
||||||
|
|
||||||
The battery and TTS settings.
|
|
||||||
Photo by Ron Amadeo
|
|
||||||
|
|
||||||
Donut was the first Android version to keep track of battery usage. Buried in the "About phone" menu was an option called "Battery use," which would display battery usage by app and hardware function as a percentage. Tapping on an item would bring up a separate page with relevant stats. Hardware items had buttons to jump directly to their settings, so for instance, you could change the display timeout if you felt the display battery usage was too high.
|
|
||||||
|
|
||||||
Android 1.6 was also the first version to support text-to-speech (TTS) engines, meaning the OS and apps would be able to talk back to you in a robot voice. The “Speech synthesizer controls" would allow you to set the language, choose the speech rate, and (critically) install the voice data from the Android market. Today, Google has its own TTS engine that ships with Android, but it seems Donut was hard coded to accept one specific TTS engine made by SVOX. But SVOX’s engine didn’t ship with Donut, so tapping on “install voice data" linked to an app in the Android Market. (In the years since Donut’s heyday, the app has been taken down. It seems Android 1.6 will never speak again.)
|
|
||||||
|
|
||||||
|
|
||||||
From left to right: new widgets, the search bar UI, the new notification clear button, and the new gallery controls.
|
|
||||||
Photo by Ron Amadeo
|
|
||||||
|
|
||||||
There was more work on the widget front. Donut brought an entirely new widget called "Power control." This comprised on/off switches for common power-hungry features: Wi-FI, Bluetooth, GPS, Sync (to Google's servers), and brightness.
|
|
||||||
|
|
||||||
The search widget was redesigned to be much slimmer looking, and it had an embedded microphone button for voice search. It now had some actual UI to it and did find-as-you-type live searching, which searched not only the Internet, but your applications and history too.
|
|
||||||
|
|
||||||
The "Clear notifications" button has shrunk down considerably and lost the "notifications" text. In later Android versions it would be reduced to just a square button. The Gallery continues the trend of taking functionality out of the menu and putting it in front of the user—the individual picture view gained buttons for "Set as," "Share," and "Delete."
|
|
||||||
|
|
||||||
----------
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
[Ron Amadeo][a] / Ron is the Reviews Editor at Ars Technica, where he specializes in Android OS and Google products. He is always on the hunt for a new gadget and loves to rip things apart to see how they work.
|
|
||||||
|
|
||||||
[@RonAmadeo][t]
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/9/
|
|
||||||
|
|
||||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:http://arstechnica.com/author/ronamadeo
|
|
||||||
[t]:https://twitter.com/RonAmadeo
|
|
||||||
@ -1,155 +0,0 @@
|
|||||||
翻译中 by coloka
|
|
||||||
How to Debug CPU Regressions Using Flame Graphs
|
|
||||||
================================================================================
|
|
||||||
How quickly can you debug a CPU performance regression? If your environment is complex and changing quickly, this becomes challenging with existing tools. If it takes a week to root cause a regression, the code may have changed multiple times, and now you have new regressions to debug.
|
|
||||||
|
|
||||||
Debugging CPU usage is easy in most cases, thanks to [CPU flame graphs][1]. To debug regressions, I would load before and after flame graphs in separate browser tabs, and then blink between them like searching for [Pluto][2]. It got the job done, but I wondered about a better way.
|
|
||||||
|
|
||||||
Introducing **red/blue differential flame graphs**:
|
|
||||||
|
|
||||||
<p><object data="http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-diff.svg" type="image/svg+xml" width=720 height=296>
|
|
||||||
<img src="http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-diff.svg" width=720 />
|
|
||||||
</object></p>
|
|
||||||
|
|
||||||
This is an interactive SVG (direct [link][3]). The color shows **red for growth**, and **blue for reductions**.
|
|
||||||
|
|
||||||
The size and shape of the flame graph is the same as a CPU flame graph for the second profile (y-axis is stack depth, x-axis is population, and the width of each frame is proportional to its presence in the profile; the top edge is what's actually running on CPU, and everything beneath it is ancestry.)
|
|
||||||
|
|
||||||
In this example, a workload saw a CPU increase after a system update. Here's the CPU flame graph ([SVG][4]):
|
|
||||||
|
|
||||||
<p><object data="http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-after.svg" type="image/svg+xml" width=720 height=296>
|
|
||||||
<img src="http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-after.svg" width=720 />
|
|
||||||
</object></p>
|
|
||||||
|
|
||||||
Normally, the colors are picked at random to differentiate frames and towers. Red/blue differential flame graphs use color to show the difference between two profiles.
|
|
||||||
|
|
||||||
The deflate_slow() code and children were running more in the second profile, highlighted earlier as red frames. The cause was that ZFS compression was enabled in the system update, which it wasn't previously.
|
|
||||||
|
|
||||||
While this makes for a clear example, I didn't really need a differential flame graph for this one. Imagine tracking down subtle regressions, of less than 5%, and where the code is also more complex.
|
|
||||||
|
|
||||||
### Red/Blue Differential Flame Graphs ###
|
|
||||||
|
|
||||||
I've had many discussions about this for years, and finally wrote an implementation that I hope makes sense. It works like this:
|
|
||||||
|
|
||||||
1. Take stack profile 1.
|
|
||||||
1. Take stack profile 2.
|
|
||||||
1. Generate a flame graph using 2. (This sets the width of all frames using profile 2.)
|
|
||||||
1. Colorize the flame graph using the "2 - 1" delta. If a frame appeared more times in 2, it is red, less times, it is blue. The saturation is relative to the delta.
|
|
||||||
|
|
||||||
The intent is for use with before & after profiles, such as for **non-regression testing** or benchmarking code changes. The flame graph is drawn using the "after" profile (such that the frame widths show the current CPU consumption), and then colorized by the delta to show how we got there.
|
|
||||||
|
|
||||||
The colors show the difference that function directly contributed (eg, being on-CPU), not its children.
|
|
||||||
|
|
||||||
### Generation ###
|
|
||||||
|
|
||||||
I've pushed a simple implementation to github (see [FlameGraph][5]), which includes a new program, difffolded.pl. To show how it works, here are the steps using Linux [perf_events][6] (you can use other profilers).
|
|
||||||
|
|
||||||
#### Collect profile 1: ####
|
|
||||||
|
|
||||||
# perf record -F 99 -a -g -- sleep 30
|
|
||||||
# perf script > out.stacks1
|
|
||||||
|
|
||||||
#### Some time later (or after a code change), collect profile 2: ####
|
|
||||||
|
|
||||||
# perf record -F 99 -a -g -- sleep 30
|
|
||||||
# perf script > out.stacks2
|
|
||||||
|
|
||||||
#### Now fold these profile files, and generate a differential flame graph: ####
|
|
||||||
|
|
||||||
$ git clone --depth 1 http://github.com/brendangregg/FlameGraph
|
|
||||||
$ cd FlameGraph
|
|
||||||
$ ./stackcollapse-perf.pl ../out.stacks1 > out.folded1
|
|
||||||
$ ./stackcollapse-perf.pl ../out.stacks2 > out.folded2
|
|
||||||
$ ./difffolded.pl out.folded1 out.folded2 | ./flamegraph.pl > diff2.svg
|
|
||||||
|
|
||||||
difffolded.pl operates on the "folded" style of stack profiles, which are generated by the stackcollapse collection of tools (see the files in [FlameGraph][7]). It emits a three column output, with the folded stack trace and two value columns, one for each profile. Eg:
|
|
||||||
|
|
||||||
func_a;func_b;func_c 31 33
|
|
||||||
[...]
|
|
||||||
|
|
||||||
This would mean the stack composed of "func_a()->func_b()->func_c()" was seen 31 times in profile 1, and in 33 times in profile 2. If flamegraph.pl is handed this three column input, it will automatically generate a red/blue differential flame graph.
|
|
||||||
|
|
||||||
### Options ###
|
|
||||||
|
|
||||||
Some options you'll want to know about:
|
|
||||||
|
|
||||||
**difffolded.pl -n**: This normalizes the first profile count to match the second. If you don't do this, and take profiles at different times of day, then all the stack counts will naturally differ due to varied load. Everything will look red if the load increased, or blue if load decreased. The -n option balances the first profile, so you get the full red/blue spectrum.
|
|
||||||
|
|
||||||
**difffolded.pl -x**: This strips hex addresses. Sometimes profilers can't translate addresses into symbols, and include raw hex addresses. If these addresses differ between profiles, then they'll be shown as differences, when in fact the executed function was the same. Fix with -x.
|
|
||||||
|
|
||||||
**flamegraph.pl --negate**: Inverts the red/blue scale. See the next section.
|
|
||||||
|
|
||||||
### Negation ###
|
|
||||||
|
|
||||||
While my red/blue differential flame graphs are useful, there is a problem: if code paths vanish completely in the second profile, then there's nothing to color blue. You'll be looking at the current CPU usage, but missing information on how we got there.
|
|
||||||
|
|
||||||
One solution is to reverse the order of the profiles and draw a negated flame graph differential. Eg:
|
|
||||||
|
|
||||||
<p><object data="http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-negated.svg" type="image/svg+xml" width=720 height=296>
|
|
||||||
<img src="http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-negated.svg" width=720 />
|
|
||||||
</object></p>
|
|
||||||
|
|
||||||
Now the widths show the first profile, and the colors show what will happen. The blue highlighting on the right shows we're about to spend a lot less time in the CPU idle path. (Note that I usually filter out cpu_idle from the folded files, by including a grep -v cpu_idle.)
|
|
||||||
|
|
||||||
This also highlights the vanishing code problem (or rather, doesn't highlight), as since compression wasn't enabled in the "before" profile, there is nothing to color red.
|
|
||||||
|
|
||||||
This was generated using:
|
|
||||||
|
|
||||||
$ ./difffolded.pl out.folded2 out.folded1 | ./flamegraph.pl --negate > diff1.svg
|
|
||||||
|
|
||||||
Which, along with the earlier diff2.svg, gives us:
|
|
||||||
|
|
||||||
- **diff1.svg**: widths show the before profile, colored by what WILL happen
|
|
||||||
- **diff2.svg**: widths show the after profile, colored by what DID happen
|
|
||||||
|
|
||||||
If I were to automate this for non-regression testing, I'd generate and show both side by side.
|
|
||||||
|
|
||||||
### CPI Flame Graphs ###
|
|
||||||
|
|
||||||
I first used this code for my [CPI flame graphs][8], where instead of doing a difference between two profiles, I showed the difference between CPU cycles and stall cycles, which highlights what the CPUs were doing.
|
|
||||||
|
|
||||||
### Other Differential Flame Graphs ###
|
|
||||||
|
|
||||||
[][9]
|
|
||||||
|
|
||||||
There's other ways flame graph differentials can be done. [Robert Mustacchi][10] experimented with [differentials][11] a while ago, and used an approach similar to a colored code review: only the difference is shown, colored red for added (increased) code paths, and blue for removed (decreased) code paths. The key difference is that the frame widths are now relative to the size of the difference only. An example is on the right. It's a good idea, but in practice I found it a bit weird, and hard to follow without the bigger picture context: a standard flame graph showing the full profile.
|
|
||||||
|
|
||||||
[][12]
|
|
||||||
|
|
||||||
Cor-Paul Bezemer has created [flamegraphdiff][13], which shows the profile difference using three flame graphs at the same time: the standard before and after flame graphs, and then a differential flame graph where the widths show the difference. See the [example][14]. You can mouse-over frames in the differential, which highlights frames in all profiles. This solves the context problem, since you can see the standard flame graph profiles.
|
|
||||||
|
|
||||||
My red/blue flame graphs, Robert's hue differential, and Cor-Paul's triple-view, all have their strengths. These could be combined: the top two flame graphs in Cor-Paul's view could be my diff1.svg and diff2.svg. Then the bottom flame graph colored using Robert's approach. For consistency, the bottom flame graph could use the same palette range as mine: blue->white->red.
|
|
||||||
|
|
||||||
Flame graphs are spreading, and are now used by many companies. I wouldn't be surprised if there were already other implementations of flame graph differentials I didn't know about. (Leave a comment!)
|
|
||||||
|
|
||||||
### Conclusion ###
|
|
||||||
|
|
||||||
If you have problems with performance regressions, red/blue differential flame graphs may be the quickest way to find the root cause. These take a normal flame graph and then use colors to show the difference between two profiles: red for greater samples, and blue for fewer. The size and shape of the flame graph shows the current ("after") profile, so that you can easily see where the samples are based on the widths, and then the colors show how we got there: the profile difference.
|
|
||||||
|
|
||||||
These differential flame graphs could also be generated by a nightly non-regression test suite, so that performance regressions can be quickly debugged after the fact.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: http://www.brendangregg.com/blog/2014-11-09/differential-flame-graphs.html
|
|
||||||
|
|
||||||
作者:[Brendan Gregg][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:http://www.linux.com/community/forums/person/60160
|
|
||||||
[1]:http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html
|
|
||||||
[2]:http://en.wikipedia.org/wiki/Planets_beyond_Neptune#Discovery_of_Pluto
|
|
||||||
[3]:http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-diff.svg
|
|
||||||
[4]:http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-after.svg
|
|
||||||
[5]:https://github.com/brendangregg/FlameGraph
|
|
||||||
[6]:http://www.brendangregg.com/perf.html
|
|
||||||
[7]:https://github.com/brendangregg/FlameGraph
|
|
||||||
[8]:http://www.brendangregg.com/blog/2014-10-31/cpi-flame-graphs.html
|
|
||||||
[9]:http://www.slideshare.net/brendangregg/blazing-performance-with-flame-graphs/167
|
|
||||||
[10]:http://dtrace.org/blogs/rm
|
|
||||||
[11]:http://www.slideshare.net/brendangregg/blazing-performance-with-flame-graphs/167
|
|
||||||
[12]:https://github.com/corpaul/flamegraphdiff
|
|
||||||
[13]:http://corpaul.github.io/flamegraphdiff/
|
|
||||||
[14]:http://corpaul.github.io/flamegraphdiff/demos/dispersy/dispersy_diff.html
|
|
||||||
@ -1,3 +1,4 @@
|
|||||||
|
翻译中 by coloka
|
||||||
Restricting process CPU usage using nice, cpulimit, and cgroups
|
Restricting process CPU usage using nice, cpulimit, and cgroups
|
||||||
================================================================================
|
================================================================================
|
||||||
注:本文中的图片似乎都需要翻墙后才能看到,发布的时候注意
|
注:本文中的图片似乎都需要翻墙后才能看到,发布的时候注意
|
||||||
|
|||||||
@ -1,3 +1,4 @@
|
|||||||
|
Translating by ZTinoZ
|
||||||
Linux FAQs with Answers--How to install phpMyAdmin on CentOS
|
Linux FAQs with Answers--How to install phpMyAdmin on CentOS
|
||||||
================================================================================
|
================================================================================
|
||||||
> **Question**: I am running a MySQL/MariaDB server on CentOS, and I would like to manage its databases via web-based interface using phpMyAdmin. What is a proper way to install phpMyAdmin on CentOS?
|
> **Question**: I am running a MySQL/MariaDB server on CentOS, and I would like to manage its databases via web-based interface using phpMyAdmin. What is a proper way to install phpMyAdmin on CentOS?
|
||||||
@ -176,4 +177,4 @@ via: http://ask.xmodulo.com/install-phpmyadmin-centos.html
|
|||||||
[17]:
|
[17]:
|
||||||
[18]:
|
[18]:
|
||||||
[19]:
|
[19]:
|
||||||
[20]:
|
[20]:
|
||||||
|
|||||||
@ -1,88 +0,0 @@
|
|||||||
johnhoow translating...
|
|
||||||
How to visualize memory usage on Linux
|
|
||||||
================================================================================
|
|
||||||
Lack of sufficient physical memory can significantly hamper the performance of Linux desktop and server environments. When your desktop is sluggish, one of the first things to do is to free up RAMs. Memory usage is even more critical in multi-user shared hosting or mission-critical server environments, where different users or application threads constantly compete for more memory.
|
|
||||||
|
|
||||||
When it comes to monitoring any type of system resources such as memory or CPUs, visualization is an effective means to help understand quickly how they are consumed by different processes and users. In this tutorial, I describe **how to visualize memory usage in Linux environment** using a command-line tool called [smem][1].
|
|
||||||
|
|
||||||
### Physical Memory Usage: RSS vs. PSS vs. USS ###
|
|
||||||
|
|
||||||
In the presence of virtual memory abstraction, accurately quantifying physical memory usage of a process is actually not straightforward. The virtual memory size of a process is not meaningful because it does not tell how much of it is actually allocated physical memory.
|
|
||||||
|
|
||||||
**Resident set size (RSS)**, reported by top command, is one popular metric which captures what portion of a process' reported memory is residing in RAM. However, aggregating RSS of existing processes can easily overestimate the overall physical memory usage of the Linux system because the same physical memory page can be shared by different processes. **Proportional set size (PSS)** is a more accurate measurement of effective memory usage of Linux processes since PSS properly discounts the memory page shared by more than one process. **Unique set size (USS)** of a process is a subset of the process' PSS, which is not shared by any other processes.
|
|
||||||
|
|
||||||
### Install Smem on Linux ###
|
|
||||||
|
|
||||||
The command-line tool smem can generate a variety of reports related to memory PSS/USS usage by pulling information from /proc. It comes with built-in graphical chart generation capabilities, so one can easily visualize overall memory consumption status.
|
|
||||||
|
|
||||||
#### Install Smem on Debian, Ubuntu or Linux Mint ####
|
|
||||||
|
|
||||||
$ sudo apt-get install smem
|
|
||||||
|
|
||||||
#### Install Smem on Fedora or CentOS/RHEL ####
|
|
||||||
|
|
||||||
On CentOS/RHEL, you need to [enable][2] EPEL repository first.
|
|
||||||
|
|
||||||
$ sudo yum install smem python-matplotlib
|
|
||||||
|
|
||||||
### Check Memory Usage with Smem ###
|
|
||||||
|
|
||||||
When you run smem as a unprivileged user, it will report physical memory usage of every process launched by the current user, in an increasing order of PSS.
|
|
||||||
|
|
||||||
$ smem
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
If you want to check the overall system memory usage for all users, run smem as the root.
|
|
||||||
|
|
||||||
$ sudo smem
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
To view per-user memory usage:
|
|
||||||
|
|
||||||
$ sudo smem -u
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
smem allows you to filter memory usage results based on mapping, processes or users in the following format:
|
|
||||||
|
|
||||||
- -M <mapping-filtering-regular-expression>
|
|
||||||
- -P <process-filtering-regular-expression>
|
|
||||||
- -U <user-filtering-regular-expression>
|
|
||||||
|
|
||||||
For a complete usage of smem, refer to its man page.
|
|
||||||
|
|
||||||
### Visualize Memory Usage with Smem ###
|
|
||||||
|
|
||||||
Visualized reports are often easier to read to identify the memory hogs of your system quickly. smem supports two kinds of graphical reports for memory usage visualization: bar and pie graphs.
|
|
||||||
|
|
||||||
Here are examples of memory usage visualization.
|
|
||||||
|
|
||||||
The following command will generate a bar graph that visualizes the PSS/USS memory usage of a user alice.
|
|
||||||
|
|
||||||
$ sudo smem --bar name -c "pss uss" -U alice
|
|
||||||
|
|
||||||
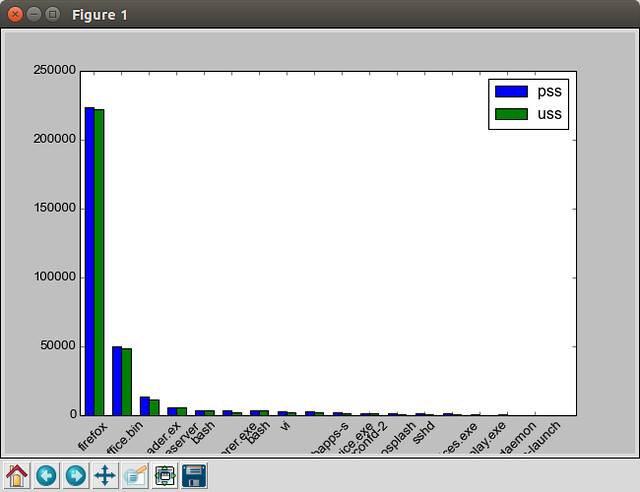
|
|
||||||
|
|
||||||
The next command will plot a pie graph of the overall PSS memory usage of different processes.
|
|
||||||
|
|
||||||
$ sudo smem --pie name -c "pss"
|
|
||||||
|
|
||||||
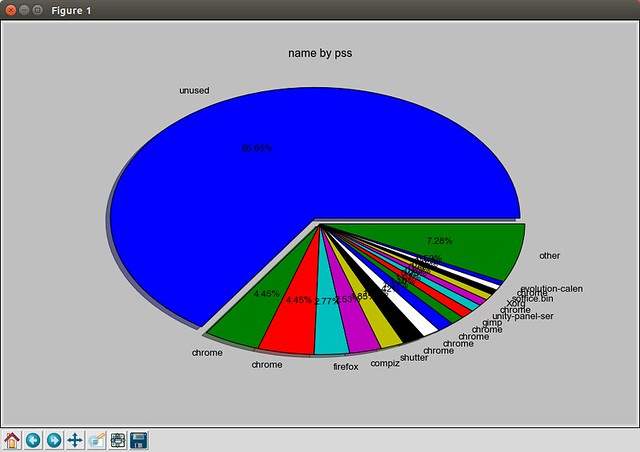
|
|
||||||
|
|
||||||
As a summary, smem is a simple and effective memory analysis tool that comes in handy in various circumstances. Using its formatted output, you can run smem to identify any memory issues and take an action in an automatic fashion. If you know of any good memory monitoring tool, share it in the comment.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: http://xmodulo.com/visualize-memory-usage-linux.html
|
|
||||||
|
|
||||||
作者:[Dan Nanni][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:http://xmodulo.com/author/nanni
|
|
||||||
[1]:http://www.selenic.com/smem/
|
|
||||||
[2]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
|
||||||
@ -0,0 +1,265 @@
|
|||||||
|
15 ‘pwd’ (Print Working Directory) Command Examples in Linux
|
||||||
|
================================================================================
|
||||||
|
For those working with Linux command Line, command ‘**pwd**‘ is very helpful, which tells where you are – in which directory, starting from the root (**/**). Specially for Linux newbies, who may get lost amidst of directories in command Line Interface while navigation, command ‘**pwd**‘ comes to rescue.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
15 pwd Command Examples
|
||||||
|
|
||||||
|
### What is pwd? ###
|
||||||
|
|
||||||
|
‘**pwd**‘ stands for ‘**Print Working Directory**‘. As the name states, command ‘**pwd**‘ prints the current working directory or simply the directory user is, at present. It prints the current directory name with the complete path starting from root (**/**). This command is built in shell command and is available on most of the shell – bash, Bourne shell, ksh,zsh, etc.
|
||||||
|
|
||||||
|
#### Basic syntax of pwd: ####
|
||||||
|
|
||||||
|
# pwd [OPTION]
|
||||||
|
|
||||||
|
#### Options used with pwd ####
|
||||||
|
|
||||||
|
<table border="0" cellspacing="0">
|
||||||
|
<colgroup width="126"></colgroup>
|
||||||
|
<colgroup width="450"></colgroup>
|
||||||
|
<tbody>
|
||||||
|
<tr>
|
||||||
|
<td height="21" align="LEFT" style="border: 1px solid #000000;"><b><span style="font-size: small;"> Options</span></b></td>
|
||||||
|
<td align="LEFT" style="border: 1px solid #000000;"><b><span style="font-size: small;"> Description</span></b></td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td height="19" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Liberation Serif,Times New Roman; font-size: small;"> -L (logical)</span></td>
|
||||||
|
<td align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Liberation Serif,Times New Roman; font-size: small;"> Use PWD from environment, even if it contains symbolic links</span></td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td height="19" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Liberation Serif,Times New Roman; font-size: small;"> -P (physical)</span></td>
|
||||||
|
<td align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Liberation Serif,Times New Roman; font-size: small;"> Avoid all symbolic links</span></td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td height="19" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Liberation Serif,Times New Roman; font-size: small;"> –help </span></td>
|
||||||
|
<td align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Liberation Serif,Times New Roman; font-size: small;"> Display this help and exit</span></td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td height="19" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Liberation Serif,Times New Roman; font-size: small;"> –version</span></td>
|
||||||
|
<td align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Liberation Serif,Times New Roman; font-size: small;"> Output version information and exit</span></td>
|
||||||
|
</tr>
|
||||||
|
</tbody>
|
||||||
|
</table>
|
||||||
|
|
||||||
|
If both ‘**-L**‘ and ‘**-P**‘ options are used, option ‘**L**‘ is taken into priority. If no option is specified at the prompt, pwd will avoid all symlinks, i.e., take option ‘**-P**‘ into account.
|
||||||
|
|
||||||
|
Exit status of command pwd:
|
||||||
|
|
||||||
|
<table border="0" cellspacing="0">
|
||||||
|
<colgroup width="128"></colgroup>
|
||||||
|
<colgroup width="151"></colgroup>
|
||||||
|
<tbody>
|
||||||
|
<tr>
|
||||||
|
<td height="19" align="CENTER" style="border: 1px solid #000000;"><span style="font-size: small;">0</span></td>
|
||||||
|
<td align="CENTER" style="border: 1px solid #000000;"><span style="font-size: small;">Success</span></td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td height="19" align="CENTER" style="border: 1px solid #000000;"><span style="font-size: small;">Non-zero</span></td>
|
||||||
|
<td align="CENTER" style="border: 1px solid #000000;"><span style="font-size: small;">Failure</span></td>
|
||||||
|
</tr>
|
||||||
|
</tbody>
|
||||||
|
</table>
|
||||||
|
|
||||||
|
This article aims at providing you a deep insight of Linux command ‘**pwd**‘ with practical examples.
|
||||||
|
|
||||||
|
**1.** Print your current working directory.
|
||||||
|
|
||||||
|
avi@tecmint:~$ /bin/pwd
|
||||||
|
|
||||||
|
/home/avi
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Print Working Directory
|
||||||
|
|
||||||
|
**2.** Create a symbolic link of a folder (say **/var/www/html** into your home directory as **htm**). Move to the newly created directory and print working directory with symbolic links and without symbolic links.
|
||||||
|
|
||||||
|
Create a symbolic link of folder /var/www/html as htm in your home directory and move to it.
|
||||||
|
|
||||||
|
avi@tecmint:~$ ln -s /var/www/html/ htm
|
||||||
|
avi@tecmint:~$ cd htm
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Create Symbolic Link
|
||||||
|
|
||||||
|
**3.** Print working directory from environment even if it contains symlinks.
|
||||||
|
|
||||||
|
avi@tecmint:~$ /bin/pwd -L
|
||||||
|
|
||||||
|
/home/avi/htm
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Print Current Working Directory
|
||||||
|
|
||||||
|
**4.** Print actual physical current working directory by resolving all symbolic links.
|
||||||
|
|
||||||
|
avi@tecmint:~$ /bin/pwd -P
|
||||||
|
|
||||||
|
/var/www/html
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Print Physical Working Directory
|
||||||
|
|
||||||
|
**5.** Check if the output of command “**pwd**” and “**pwd -P**” are same or not i.e., if no options are given at run-time does “**pwd**” takes option **-P** into account or not, automatically.
|
||||||
|
|
||||||
|
avi@tecmint:~$ /bin/pwd
|
||||||
|
|
||||||
|
/var/www/html
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Check pwd Output
|
||||||
|
|
||||||
|
**Result:** It’s clear from the above output of example 4 and 5 (both result are same) thus, when no options are specified with command “**pwd**”, it automatically takes option “**-P**” into account.
|
||||||
|
|
||||||
|
**6.** Print version of your ‘pwd’ command.
|
||||||
|
|
||||||
|
avi@tecmint:~$ /bin/pwd --version
|
||||||
|
|
||||||
|
pwd (GNU coreutils) 8.23
|
||||||
|
Copyright (C) 2014 Free Software Foundation, Inc.
|
||||||
|
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>.
|
||||||
|
This is free software: you are free to change and redistribute it.
|
||||||
|
There is NO WARRANTY, to the extent permitted by law.
|
||||||
|
|
||||||
|
Written by Jim Meyering.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Check pwd Version
|
||||||
|
|
||||||
|
**Note:** A ‘pwd’ command is often used without options and never used with arguments.
|
||||||
|
|
||||||
|
**Important:** You might have noticed that we are executing the above command as “**/bin/pwd**” and not “**pwd**”.
|
||||||
|
|
||||||
|
So what’s the difference? Well “**pwd**” alone means shell built-in pwd. Your shell may have different version of pwd. Please refer manual. When we are using **/bin/pwd**, we are calling the binary version of that command. Both the shell and the binary version of command Prints Current Working Directory, though the binary version have more options.
|
||||||
|
|
||||||
|
**7.** Print all the locations containing executable named pwd.
|
||||||
|
|
||||||
|
avi@tecmint:~$ type -a pwd
|
||||||
|
|
||||||
|
pwd is a shell builtin
|
||||||
|
pwd is /bin/pwd
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Print Executable Locations
|
||||||
|
|
||||||
|
**8.** Store the value of “**pwd**” command in variable (say **a**), and print its value from the variable (important for shell scripting perspective).
|
||||||
|
|
||||||
|
avi@tecmint:~$ a=$(pwd)
|
||||||
|
avi@tecmint:~$ echo "Current working directory is : $a"
|
||||||
|
|
||||||
|
Current working directory is : /home/avi
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Store Pwd Value in Variable
|
||||||
|
|
||||||
|
Alternatively, we can use **printf**, in the above example.
|
||||||
|
|
||||||
|
**9.** Change current working directory to anything (say **/home**) and display it in command line prompt. Execute a command (say ‘**ls**‘) to verify is everything is **OK**.
|
||||||
|
|
||||||
|
avi@tecmint:~$ cd /home
|
||||||
|
avi@tecmint:~$ PS1='$pwd> ' [Notice single quotes in the example]
|
||||||
|
> ls
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Change Current Working Directory
|
||||||
|
|
||||||
|
**10.** Set multi-line command line prompt (say something like below).
|
||||||
|
|
||||||
|
/home
|
||||||
|
123#Hello#!
|
||||||
|
|
||||||
|
And then execute a command (say **ls**) to check is everything is **OK**.
|
||||||
|
|
||||||
|
avi@tecmint:~$ PS1='
|
||||||
|
> $PWD
|
||||||
|
$ 123#Hello#!
|
||||||
|
$ '
|
||||||
|
|
||||||
|
/home
|
||||||
|
123#Hello#!
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Set Multi Commandline Prompt
|
||||||
|
|
||||||
|
**11.** Check the current working directory and previous working directory in one GO!
|
||||||
|
|
||||||
|
avi@tecmint:~$ echo “$PWD $OLDPWD”
|
||||||
|
|
||||||
|
/home /home/avi
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Check Present Previous Working Directory
|
||||||
|
|
||||||
|
**12.** What is the absolute path (starting from **/**) of the pwd binary file.
|
||||||
|
|
||||||
|
/bin/pwd
|
||||||
|
|
||||||
|
**13.** What is the absolute path (starting from **/**) of the pwd source file.
|
||||||
|
|
||||||
|
/usr/include/pwd.h
|
||||||
|
|
||||||
|
**14.** Print the absolute path (starting from **/**) of the pwd manual pages file.
|
||||||
|
|
||||||
|
/usr/share/man/man1/pwd.1.gz
|
||||||
|
|
||||||
|
**15.** Write a shell script analyses current directory (say **tecmint**) in your home directory. If you are under directory **tecmint** it output “**Well! You are in tecmint directory**” and then print “**Good Bye**” else create a directory **tecmint** under your home directory and ask you to cd to it.
|
||||||
|
|
||||||
|
Let’s first create a ‘tecmint’ directory, under it create a following shell script file with name ‘pwd.sh’.
|
||||||
|
|
||||||
|
avi@tecmint:~$ mkdir tecmint
|
||||||
|
avi@tecmint:~$ cd tecmint
|
||||||
|
avi@tecmint:~$ nano pwd.sh
|
||||||
|
|
||||||
|
Next, add the following script to the pwd.sh file.
|
||||||
|
|
||||||
|
#!/bin/bash
|
||||||
|
|
||||||
|
x="$(pwd)"
|
||||||
|
if [ "$x" == "/home/$USER/tecmint" ]
|
||||||
|
then
|
||||||
|
{
|
||||||
|
echo "Well you are in tecmint directory"
|
||||||
|
echo "Good Bye"
|
||||||
|
}
|
||||||
|
else
|
||||||
|
{
|
||||||
|
mkdir /home/$USER/tecmint
|
||||||
|
echo "Created Directory tecmint you may now cd to it"
|
||||||
|
}
|
||||||
|
fi
|
||||||
|
|
||||||
|
Give execute permission and run it.
|
||||||
|
|
||||||
|
avi@tecmint:~$ chmod 755 pwd.sh
|
||||||
|
avi@tecmint:~$ ./pwd.sh
|
||||||
|
|
||||||
|
Well you are in tecmint directory
|
||||||
|
Good Bye
|
||||||
|
|
||||||
|
#### Conclusion ####
|
||||||
|
|
||||||
|
**pwd** is one of the simplest yet most popular and most widely used command. A good command over pwd is basic to use Linux terminal. That’s all for now. I’ll be here again with another interesting article soon, till then stay tuned and connected to Tecmint.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.tecmint.com/pwd-command-examples/
|
||||||
|
|
||||||
|
作者:[Avishek Kumar][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.tecmint.com/author/avishek/
|
||||||
@ -0,0 +1,189 @@
|
|||||||
|
johnhoow translating...
|
||||||
|
Important 10 Linux ps command Practical Examples
|
||||||
|
================================================================================
|
||||||
|
As an Operating System which inspired from Unix, Linux has a built-in tool to capture current processes on the system. This tool is available in command line interface.
|
||||||
|
|
||||||
|
### What is PS Command ###
|
||||||
|
|
||||||
|
From its manual page, PS gives a snapshots of the current process. It will “capture” the system condition at a single time. If you want to have a repetitive updates in a real time, we can use top command.
|
||||||
|
|
||||||
|
PS support three (3) type of usage syntax style.
|
||||||
|
|
||||||
|
1. UNIX style, which may be grouped and **must** be preceded by a dash
|
||||||
|
2. BSD style, which may be grouped and **must not be** used with a dash
|
||||||
|
3. GNU long options, which are preceded by two dash
|
||||||
|
|
||||||
|
We can mix those style, but conflicts can appear. In this article, will use UNIX style. Here’s are some examples of PS command in a daily use.
|
||||||
|
|
||||||
|
### 1. Run ps without any options ###
|
||||||
|
|
||||||
|
This is a very basic **ps** usage. Just type ps on your console to see its result.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
By default, it will show us 4 columns of information.
|
||||||
|
|
||||||
|
- PID is a Process ID of the running command (CMD)
|
||||||
|
- TTY is a place where the running command runs
|
||||||
|
- TIME tell about how much time is used by CPU while running the command
|
||||||
|
- CMD is a command that run as current process
|
||||||
|
|
||||||
|
This information is displayed in unsorted result.
|
||||||
|
|
||||||
|
### 2. Show all current processes ###
|
||||||
|
|
||||||
|
To do this, we can use **-a** options. As we can guess, **-a is stand for “all”**. While x will show all process even the current process is not associated with any TTY (terminal)
|
||||||
|
|
||||||
|
$ ps -ax
|
||||||
|
|
||||||
|
This result might be long result. To make it more easier to read, combine it with less command.
|
||||||
|
|
||||||
|
$ ps -ax | less
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 3. Filter processes by its user ###
|
||||||
|
|
||||||
|
For some situation we may want to filter processes by user. To do this, we can use **-u** option. Let say we want to see what processes which run by user pungki. So the command will be like below
|
||||||
|
|
||||||
|
$ ps -u pungki
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 4. Filter processes by CPU or memory usage ###
|
||||||
|
|
||||||
|
Another thing that you might want to see is filter the result by CPU or memory usage. With this, you can grab information about which processes that consume your resource. To do this, we can use **aux options**. Here’s an example of it :
|
||||||
|
|
||||||
|
$ ps -aux | less
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Since the result can be in a long list, we can **pipe** less command into ps command.
|
||||||
|
By default, the result will be in unsorted form. If we want to sort by particular column, we can add **--sort** option into ps command.
|
||||||
|
|
||||||
|
Sort by the highest **CPU utilization** in ascending order
|
||||||
|
|
||||||
|
$ ps -aux --sort -pcpu | less
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Sort by the highest **Memory utilization** in ascending order
|
||||||
|
|
||||||
|
$ ps -aux --sort -pmem | less
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Or we can combine itu a single command and display only the top ten of the result :
|
||||||
|
|
||||||
|
$ ps -aux --sort -pcpu,+pmem | head -n 10
|
||||||
|
|
||||||
|
### 5. Filter processes by its name or process ID ###
|
||||||
|
|
||||||
|
To to this, we can use **-C option** followed by the keyword. Let say, we want to show processes named getty. We can type :
|
||||||
|
|
||||||
|
$ ps -C getty
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
If we want to show more detail about the result, we can add -f option to show it on full format listing. The above command will looks like below :
|
||||||
|
|
||||||
|
$ ps -f -C getty
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 6. Filter processes by thread of process ###
|
||||||
|
|
||||||
|
If we need to know the thread of a particular process, we can use **-L option** followed by its Process ID (PID). Here’s an example of **-L option** in action :
|
||||||
|
|
||||||
|
$ ps -L 1213
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
As we can see, the PID remain the same value, but the LWP which shows numbers of thread show different values.
|
||||||
|
|
||||||
|
### 7. Show processes in hierarchy ###
|
||||||
|
|
||||||
|
Sometime we want to see the processes in hierarchical form. To do this, we can use **-axjf** options.
|
||||||
|
|
||||||
|
$ps -axjf
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Or, another command which we can use is pstree.
|
||||||
|
|
||||||
|
$ pstree
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 8. Show security information ###
|
||||||
|
|
||||||
|
If we want to see who is currently logged on into your server, we can see it using the ps command. There are some options that we can use to fulfill our needs. Here’s some examples :
|
||||||
|
|
||||||
|
$ ps -eo pid,user,args
|
||||||
|
|
||||||
|
**Option -e** will show you all processes while **-o option** will control the output. **Pid**, **User and Args** will show you the **Process ID**, **the User who run the application** and **the running application**.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
The keyword / user-defined format that can be used with **-e option** are **args, cmd, comm, command, fname, ucmd, ucomm, lstart, bsdstart and start**.
|
||||||
|
|
||||||
|
### 9. Show every process running as root (real & effecitve ID) in user format ###
|
||||||
|
|
||||||
|
System admin may want to see what processes are being run by root and other information related to it. Using ps command, we can do by this simple command :
|
||||||
|
|
||||||
|
$ ps -U root -u root u
|
||||||
|
|
||||||
|
The **-U parameter** will select by **real user ID (RUID)**. It selects the processes whose real user name or ID is in the userlist list. The real User ID identifies the user who created the process.
|
||||||
|
|
||||||
|
While the **-u paramater** will select by effective user ID (EUID)
|
||||||
|
|
||||||
|
The last **u** paramater, will display the output in user-oriented format which contains **User, PID, %CPU, %MEM, VSZ, RSS, TTY, STAT, START, TIME and COMMAND** columns.
|
||||||
|
|
||||||
|
Here’s the output of the above command.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 10. Use PS in a realtime process viewer ###
|
||||||
|
|
||||||
|
ps will display a report of what happens in your system. The result will be a static report.
|
||||||
|
Let say, we want to filter processes by CPU and Memory usage as on the point 4 above. And we want the report is updated every 1 second. We can do it by **combining ps command with watch command** on Linux.
|
||||||
|
|
||||||
|
Here’s the command :
|
||||||
|
|
||||||
|
$ watch -n 1 ‘ps -aux --sort -pmem, -pcpu’
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
If you feel the report is too long, **we can limit it** by - let say - the top 20 processes. We can add **head** command to do it.
|
||||||
|
|
||||||
|
$ watch -n 1 ‘ps -aux --sort -pmem, -pcpu | head 20’
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
This live reporter **is not** like top or htop of course. **But the advantage of using ps** to make live report is that you can custom the field. You can choose which field you want to see.
|
||||||
|
|
||||||
|
For example, **if you need only the pungki user shown**, then you can change the command to become like this :
|
||||||
|
|
||||||
|
$ watch -n 1 ‘ps -aux -U pungki u --sort -pmem, -pcpu | head 20’
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### Conclusion ###
|
||||||
|
|
||||||
|
You may use **ps** on your daily usage to monitor about what happens your Linux system. But actually, you can generate various types of report using **ps** command with the use of appropriate paramaters.
|
||||||
|
|
||||||
|
**Another ps advantage** is that **ps** are installed by default in any kind of Linux. So you can just start to use it.
|
||||||
|
|
||||||
|
Don't forget to see **ps documentation** by typing **man ps** on you Linux console to explore more options.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://linoxide.com/how-tos/linux-ps-command-examples/
|
||||||
|
|
||||||
|
作者:[Pungki Arianto][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://linoxide.com/author/pungki/
|
||||||
@ -0,0 +1,110 @@
|
|||||||
|
Linux blkid Command to Find Block Devices Details
|
||||||
|
================================================================================
|
||||||
|
Today we will show you how to use **lsblk** and **blkid** utilities to find out information about block devices and we are using a CentOS 7.0 installed machine.
|
||||||
|
|
||||||
|
**lsblk** is a Linux utility that will display information about all the available block devices on your system. It reads and gathers from them from [the sysfs filesystem][1]. The utility will display information about all block devices (with the exception of RAM disks) in a tree-like format by default.
|
||||||
|
|
||||||
|
### Lsblk default output ###
|
||||||
|
|
||||||
|
By default lsblk will display a tree-like format of the block devices:
|
||||||
|
|
||||||
|
**NAME**
|
||||||
|
|
||||||
|
– the device name
|
||||||
|
|
||||||
|
**MAJ:MIN**
|
||||||
|
|
||||||
|
- Every device on a Linux operating system is represented by a file, for block (disk) devices, they describe the device using major and minor device numbers.
|
||||||
|
|
||||||
|
**RM**
|
||||||
|
|
||||||
|
– removable device – shows 1 if this is a removable device and 0 if it’s not
|
||||||
|
|
||||||
|
**TYPE**
|
||||||
|
|
||||||
|
– the device type
|
||||||
|
|
||||||
|
**MOUNTPOINT**
|
||||||
|
|
||||||
|
- the location where the device is mounted
|
||||||
|
|
||||||
|
**RO**
|
||||||
|
|
||||||
|
– it will display 1 for read-only filesystems and 0 for those that are not read-only
|
||||||
|
|
||||||
|
**SIZE**
|
||||||
|
|
||||||
|
– the size of the device
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### Display the owner of the devices ###
|
||||||
|
|
||||||
|
To display information about the owenership of the device, the user and group that own the file and the mode that the filesystem has been mounted with you can use the –m option like this:
|
||||||
|
|
||||||
|
lsblk –m
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### List the device blocks ###
|
||||||
|
|
||||||
|
If you wish to just list the devices and not show them as a tree you can use the –l option:
|
||||||
|
|
||||||
|
lsblk –l
|
||||||
|
|
||||||
|
### Use in scripts ###
|
||||||
|
|
||||||
|
Advanced tip: if you wish to use this in a script and don’t want to have the heading displayed you can use the –n flag like so:
|
||||||
|
|
||||||
|
lsblk –ln
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
The **blkid** program is a command-line utility that displays information about available block devices. It can determine the type of content (e.g. filesystem, swap) a block device holds and also attributes (tokens, NAME=value pairs) from the content metadata (e.g. LABEL or UUID fields). It has two main forms of operation: either searching for a device with a specific NAME=value pair or displaying NAME=value pairs for one or more devices.
|
||||||
|
|
||||||
|
### blkid usage ###
|
||||||
|
|
||||||
|
Simply running blkid without any argument will list all the available devices with their Universally Unique Identifier (UUID), the TYPE of the file-system and the LABEL if it's set.
|
||||||
|
|
||||||
|
# blkid
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### Listing devices based on name or UUID ###
|
||||||
|
|
||||||
|
If you wish to have information displayed only for a specific device you can use the device name as an option after blkid to do so:
|
||||||
|
|
||||||
|
# blkid /dev/sda1
|
||||||
|
|
||||||
|
Also if you know the UUID of a device but don't know the device name and wish to find it out you can use the 0-U option like this:
|
||||||
|
|
||||||
|
# blkid -U d3b1dcc2-e3b0-45b0-b703-d6d0d360e524
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### Detailed information ###
|
||||||
|
|
||||||
|
If you wish to obtain mode detailed information you can use the -p and -o udev option to have it display in a nice format like this:
|
||||||
|
|
||||||
|
# blkid -po udev /dev/sda1
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### Reset cache ###
|
||||||
|
|
||||||
|
Sometimes the device list might not be updated, if you think this is the case you can use the -g option that will perform a garbage collection pass on the blkid cache to remove devices which no longer exist.
|
||||||
|
|
||||||
|
# blkid -g
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://linoxide.com/linux-command/linux-command-lsblk-blkid/
|
||||||
|
|
||||||
|
作者:[Adrian Dinu][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://linoxide.com/author/adriand/
|
||||||
|
[1]:https://www.kernel.org/doc/Documentation/filesystems/sysfs.txt
|
||||||
@ -0,0 +1,129 @@
|
|||||||
|
How to install Cacti (Monitoring tool) on ubuntu 14.10 server
|
||||||
|
================================================================================
|
||||||
|
Cacti is a complete network graphing solution designed to harness the power of RRDTool's data storage and graphing functionality. Cacti provides a fast poller, advanced graph templating, multiple data acquisition methods, and user management features out of the box. All of this is wrapped in an intuitive, easy to use interface that makes sense for LAN-sized installations up to complex networks with hundreds of devices.
|
||||||
|
|
||||||
|
### Features ###
|
||||||
|
|
||||||
|
#### Graphs ####
|
||||||
|
|
||||||
|
Unlimited number of graph items can be defined for each graph optionally utilizing CDEFs or data sources from within cacti.
|
||||||
|
|
||||||
|
Automatic grouping of GPRINT graph items to AREA, STACK, and LINE[1-3] to allow for quick re-sequencing of graph items.
|
||||||
|
|
||||||
|
Auto-Padding support to make sure graph legend text lines up.
|
||||||
|
|
||||||
|
Graph data can be manipulated using the CDEF math functions built into RRDTool. These CDEF functions can be defined in cacti and can be used globally on each graph.
|
||||||
|
|
||||||
|
Support for all of RRDTool's graph item types including AREA, STACK, LINE[1-3], GPRINT, COMMENT, VRULE, and HRULE.
|
||||||
|
|
||||||
|
#### Data Sources ####
|
||||||
|
|
||||||
|
Data sources can be created that utilize RRDTool's "create" and "update" functions. Each data source can be used to gather local or remote data and placed on a graph.
|
||||||
|
|
||||||
|
Supports RRD files with more than one data source and can use an RRD file stored anywhere on the local file system.
|
||||||
|
Round robin archive (RRA) settings can be customized giving the user the ability to gather data on non-standard timespans while store varying amounts of data.
|
||||||
|
|
||||||
|
#### Data Gathering ####
|
||||||
|
|
||||||
|
Contains a "data input" mechanism which allows users to define custom scripts that can be used to gather data. Each script can contain arguments that must be entered for each data source created using the script (such as an IP address).
|
||||||
|
|
||||||
|
Built in SNMP support that can use php-snmp, ucd-snmp, or net-snmp.
|
||||||
|
|
||||||
|
Ability to retrieve data using SNMP or a script with an index. An example of this would be populating a list with IP interfaces or mounted partitions on a server. Integration with graph templates can be defined to enable one click graph creation for hosts.
|
||||||
|
|
||||||
|
A PHP-based poller is provided to execute scripts, retrieve SNMP data, and update your RRD files.
|
||||||
|
|
||||||
|
#### Templates ####
|
||||||
|
|
||||||
|
Graph templates enable common graphs to be grouped together by templating. Every field for a normal graph can be templated or specified on a per-graph basis.
|
||||||
|
|
||||||
|
Data source templates enable common data source types to be grouped together by templating. Every field for a normal data source can be templated or specified on a per-data source basis.
|
||||||
|
|
||||||
|
Host templates are a group of graph and data source templates that allow you to define common host types. Upon the creation of a host, it will automatically take on the properties of its template.
|
||||||
|
|
||||||
|
#### Graph Display ####
|
||||||
|
|
||||||
|
The tree view allows users to create "graph hierarchies" and place graphs on the tree. This is an easy way to manage/organize a large number of graphs.
|
||||||
|
|
||||||
|
The list view lists the title of each graph in one large list which links the user to the actual graph.
|
||||||
|
The preview view displays all of the graphs in one large list format. This is similar to the default view for the 14all cgi script for RRDTool/MRTG.
|
||||||
|
|
||||||
|
#### User Management ####
|
||||||
|
|
||||||
|
User based management allows administrators to create users and assign different levels of permissions to the cacti interface.
|
||||||
|
|
||||||
|
Permissions can be specified per-graph for each user, making cacti suitable for co location situations.
|
||||||
|
Each user can keep their own graph settings for varying viewing preferences.
|
||||||
|
|
||||||
|
#### Preparing your system ####
|
||||||
|
|
||||||
|
Before installing cacti you need to make sure you have installed [Ubuntu 14.10 LAMP server][1].
|
||||||
|
|
||||||
|
#### Install Cacti on ubuntu 14.10 server ####
|
||||||
|
|
||||||
|
Open the terminal and run the following command
|
||||||
|
|
||||||
|
sudo apt-get install cacti-spine
|
||||||
|
|
||||||
|
The above command starts the cacti installation and you should see the first as php path change select ok and press enter
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Now select the webserver you want to use (in my case it is apache2)
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Cacti database configurations select yes
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Enter database admin user password
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Mysql application password for cacti
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
confirm the password
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Now that Cacti is installed, we can start the configuration process on it.
|
||||||
|
|
||||||
|
#### Configuring cacti ####
|
||||||
|
|
||||||
|
Point your web browser towards http://YOURSERVERIP/cacti/install/ to start the initial setup and click next
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Select new install option and click next
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
In the following screen you need to make sure you have all the required paths are correct and click on finish
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Now login to Cacti with the default admin/admin, and change the password to something more sensible
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
After login in to Cacti you should see similar to the following screen
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.ubuntugeek.com/how-to-install-cacti-monitoring-tool-on-ubuntu-14-10-server.html
|
||||||
|
|
||||||
|
作者:[ruchi][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||||
|
[1]:http://www.ubuntugeek.com/www.ubuntugeek.com/step-by-step-ubuntu-14-10-utopic-unicorn-lamp-server-setup.html
|
||||||
@ -0,0 +1,67 @@
|
|||||||
|
Linux FAQs with Answers--How to access a NAT guest from host with VirtualBox
|
||||||
|
================================================================================
|
||||||
|
> **Question**: I have a guest VM running on VirtualBox, which uses NAT networking. So the guest VM is getting a private IP address (10.x.x.x) assigned by VirtualBox. If I want to SSH to the guest VM from the host machine, how can I do that?
|
||||||
|
|
||||||
|
VirtualBox supports several networking options for guest VMs, one of them being NAT networking. When NAT networking is enabled for a guest VM, VirtualBox automatically performs network address translation between the guest VM and host's network stack, so that you do not have to configure anything on the host machine and local network for the guest VM's networking to work. The implication of such NAT, however, is that the guest VM is not reachable or visible from external networks as well as from the local host itself. This is a problem if you want to access the guest VM from the host machine for some reason (e.g., SSH).
|
||||||
|
|
||||||
|
If you want to access a NAT guest from the host on VirtualBox, you can enable port forwarding for VirtualBox NAT, either from the GUI or from the command line. This tutorial demonstrates **how to SSH a NAT guest from the host** by enabling port forwarding for port 22. If you want to access HTTP of a NAT guest instead, replace port 22 with port 80.
|
||||||
|
|
||||||
|
### Configure VirtualBox Port Forwarding from the GUI ###
|
||||||
|
|
||||||
|
On VirtualBox, choose the guest VM you want to access, and open "Settings" window of the VM. Click on "Network" menu on the left, click on "Advanced" to show additional network adapter options.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Click on a button labeled "Port Forwarding."
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
You will see a window where you can configure port forwarding rules. Click on "Add" icon in the upper right corner.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Add a new port forwarding rule with the following detail.
|
||||||
|
|
||||||
|
- **Name**: SSH (any arbitrary unique name)
|
||||||
|
- **Protocol**: TCP
|
||||||
|
- **Host IP**: 127.0.0.1
|
||||||
|
- **Host Port**: 2222 (any unused port higher than 1024)
|
||||||
|
- **Guest IP**: IP address of the guest VM
|
||||||
|
- **Guest Port**: 22 (SSH port)
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Port forwarding configured for the guest VM will be enabled automatically when you power on the guest VM. For verification, check that port 2222 is opened by VirtualBox after you launch the guest VM:
|
||||||
|
|
||||||
|
$ sudo netstat -nap | grep 2222
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Now that port forwarding is in place, you can SSH to the guest VM bs follows.
|
||||||
|
|
||||||
|
$ ssh -p 2222 <login>@127.0.0.1
|
||||||
|
|
||||||
|
An SSH login request sent to 127.0.0.1:2222 will automatically be translated into 10.0.2.15:22 by VirtualBox, allowing you to SSH to the guest VM.
|
||||||
|
|
||||||
|
### Configure VirtualBox Port Forwarding from the Command Line ###
|
||||||
|
|
||||||
|
VirtualBox comes with a command-line management interface called VBoxManage. Using this command-line tool, you can also set up port forwarding for your guest VM.
|
||||||
|
|
||||||
|
The following command creates a port forwarding rule for guest VM named "centos7" with IP address 10.0.2.15 and SSH port 22, mapped to local host at port 2222. The name of the rule ("SSH" in this example) must be unique.
|
||||||
|
|
||||||
|
$ VBoxManage modifyvm "centos7" --natpf1 "SSH,tcp,127.0.0.1,2222,10.0.2.15,22"
|
||||||
|
|
||||||
|
Once the rule is created, you can verify that by using the command below.
|
||||||
|
|
||||||
|
$ VBoxManage showvminfo "centos7" | grep NIC
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://ask.xmodulo.com/access-nat-guest-from-host-virtualbox.html
|
||||||
|
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
@ -0,0 +1,47 @@
|
|||||||
|
Qshutdown – 一个先进的关机神器
|
||||||
|
================================================================================
|
||||||
|
qshutdown是一个QT程序,用于让计算机在指定时间或者在几分钟后关机/重启/挂起/睡眠。它会一直显示时间,直到相应的请求被发送到Gnome或KDE会话管理器,或者发送到HAL或DeviceKit。而如果这一切都没有发生,将会使用‘sudo shutdown -P now’进行关机。对于那些只在特定时间使用计算机工作的人而言,可能很有用。
|
||||||
|
|
||||||
|
qshutdown将在最后70秒时显示3次警告提醒。(如果设置了1分钟或者本地时间+1,它只会显示一次。)
|
||||||
|
|
||||||
|
该程序使用qdbus来发送关机/重启/挂起/睡眠请求到gnome或kde会话管理器,或者到HAL或DeviceKit,而如果这些都没有工作,那么就会使用‘sudo shutdown’命令进行关机(注意,但发送请求到HAL或DeviceKit,或者使用shutdown命令时,会话不会被保存。如果使用shutdown命令,该程序只会被关机或重启)。所以,如果在shutdown或reboot时间到时什么都没发生,这就意味着用户缺少使用shutdown命令的权限。
|
||||||
|
|
||||||
|
在这种情况下,你可以进行以下操作:
|
||||||
|
|
||||||
|
粘贴以下信息到终端:“EDITOR:nano sudo -E visudo”并添加此行:“* ALL = NOPASSWD:/sbin/shutdown”这里*替换username或%groupname。
|
||||||
|
|
||||||
|
配置文件qshutdown.conf
|
||||||
|
|
||||||
|
倒计时最大计数为1440分钟(24小时)。配置文件(和日志文件)位于~/.qshutdown。
|
||||||
|
|
||||||
|
对于管理员:
|
||||||
|
|
||||||
|
在将qshutdonw.conf中的Lock_all选项设置为true后,用户将不能修改设置。如果你使用“sudo chown root -R ~/.qshutdown”和“sudo chmod 744 ~/.qshutdown/qshutdown.conf”命令修改qshutdown.conf的权限后,用户将不能修改配置文件。
|
||||||
|
|
||||||
|
### Ubuntu中安装Qshutdown ###
|
||||||
|
|
||||||
|
打开终端,然后运行以下命令
|
||||||
|
|
||||||
|
sudo apt-get install qshutdown
|
||||||
|
|
||||||
|
### 屏幕截图 ###
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.ubuntugeek.com/qshutdown-an-avanced-shutdown-tool.html
|
||||||
|
|
||||||
|
作者:[ruchi][a]
|
||||||
|
译者:[GOLinux](https://github.com/GOLinux)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||||
@ -4,7 +4,7 @@ Ubuntu也许能在中国给Windows以致命打击
|
|||||||
|
|
||||||
**Windows操作系统将退出中国的前门,而它的位置将由一个Linux发行版替代,用于官方和政府部门。问题是目前还没有一个真正的可替代系统,尽管还是有一款操作系统也许已经准备接下这个任务,它就是Ubuntu Kylin。**
|
**Windows操作系统将退出中国的前门,而它的位置将由一个Linux发行版替代,用于官方和政府部门。问题是目前还没有一个真正的可替代系统,尽管还是有一款操作系统也许已经准备接下这个任务,它就是Ubuntu Kylin。**
|
||||||
|
|
||||||
至少可以这么说,中国政府和微软目前的关系很紧张。[就像今天新闻里说的][1],一个用Linux类似系统在全国逐步替换Windows的计划已经在准备了。还不清楚具体会采用哪个系统,因为情况很复杂而且这是一个非常大的国家。
|
至少可以这么说,中国政府和微软目前的关系很紧张。[就像新闻里说的][1],一个用Linux类似系统在全国逐步替换Windows的计划已经在准备了。还不清楚具体会采用哪个系统,因为情况很复杂而且这是一个非常大的国家。
|
||||||
|
|
||||||
通常,这种问题没有一个普适的解决方案,而且中国的行动确实看起来有点呆板。不管怎样,这为Ubuntu Keylin打开了一扇巨大的机会之窗,它是一个基于Ubuntu由中国开发者和Canonical共同开发的发行版。它已经稳定一段时间了,而且已经发布了几个连续版本。
|
通常,这种问题没有一个普适的解决方案,而且中国的行动确实看起来有点呆板。不管怎样,这为Ubuntu Keylin打开了一扇巨大的机会之窗,它是一个基于Ubuntu由中国开发者和Canonical共同开发的发行版。它已经稳定一段时间了,而且已经发布了几个连续版本。
|
||||||
|
|
||||||
@ -12,13 +12,13 @@ Ubuntu也许能在中国给Windows以致命打击
|
|||||||
|
|
||||||
有趣的是,在这个关于中国意图的新闻冒出来的同一天里,发布了一篇对国防科技大学(NUDT)副教授Dr. Jonas Zhang的采访,关于[最新的14.10分支开发计划][2]。
|
有趣的是,在这个关于中国意图的新闻冒出来的同一天里,发布了一篇对国防科技大学(NUDT)副教授Dr. Jonas Zhang的采访,关于[最新的14.10分支开发计划][2]。
|
||||||
|
|
||||||
“在这次的14.10版本中,有许多很好的功能。比如,新手也可以轻松地通过Ubuntu Kylin软件中心找到Windows软件的替代;用户可以使用Ubuntu Kylin的SSO(Ubuntu Kylin的单一登录系统,我们叫它UKID)来登陆到Ubuntu Kylin的软件和社区;Sogou输入法(一款世界知名的中文输入法,上个月已经在苹果的应用市场上线了)减少了40%的CPU和内存占用。”
|
“在这次的14.10版本中,有许多很好的功能。比如,新手也可以轻松地通过Ubuntu Kylin软件中心找到Windows软件的替代;用户可以使用Ubuntu Kylin的SSO(Ubuntu Kylin的单一登录系统,我们叫它UKID)来登录到Ubuntu Kylin的软件和社区;Sogou输入法(一款世界知名的中文输入法,上个月已经在苹果的应用市场上线了)减少了40%的CPU和内存占用。”
|
||||||
|
|
||||||
“来自CSIP(中国政府的一个部门),Canonical和NUDT(国防科技大学)的超过50个项目经理,工程师和社区管理员在为Ubuntu Kylin工作。大部分全职工程师来自NUDT。许多来自Ubuntu,Debian和其他社区的开发者也参与到Ubuntu Kylin的开发中了。”Dr. Jonas Zhang[说][2]。
|
“来自CSIP(中国政府的一个部门),超过50个 Canonical 和 NUDT(国防科技大学)的项目经理、工程师和社区管理员在为 Ubuntu Kylin 工作。大部分全职工程师来自NUDT。许多来自Ubuntu,Debian和其他社区的开发者也参与到Ubuntu Kylin的开发中了。”Dr. Jonas Zhang[说][2]。
|
||||||
|
|
||||||
中国政府也许自己也正想办法搭建另一个Linux发行版(不是第一次尝试了),但是目前看来已经有一个很好的用来替代Windows的候选者了。这对于Canonical也是很好的商机,至少从被承认这个角度看。
|
中国政府也许自己也正想办法搭建另一个Linux发行版(不是第一次尝试了),但是目前看来已经有一个很好的用来替代Windows的候选者了。这对于Canonical也是很好的商机,至少从被承认这个角度看。
|
||||||
|
|
||||||
如果Ubuntu,通过它和Kylin的联系,想在像中国这样一个大国里取代Windows,对这家公司是巨大的促进。让我们拭目以待,开发者们让Ubuntu Kylin变成一个有竞争力的操作系统的努力是不是白费力气。
|
如果Ubuntu,通过它和Kylin的联系,想在像中国这样的大国里取代Windows,对这家公司将会是个巨大的促进。让我们拭目以待,看看开发者们让Ubuntu Kylin变成一个有竞争力的操作系统所花费的努力是不是白费力气。
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
@ -26,7 +26,7 @@ via: http://news.softpedia.com/news/Ubuntu-Could-Give-a-Fatal-Blow-to-Windows-in
|
|||||||
|
|
||||||
作者:[Silviu Stahie][a]
|
作者:[Silviu Stahie][a]
|
||||||
译者:[zpl1025](https://github.com/zpl1025)
|
译者:[zpl1025](https://github.com/zpl1025)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[Caroline](https://github.com/carolinewuyan)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
|||||||
@ -0,0 +1,75 @@
|
|||||||
|
安卓编年史
|
||||||
|
================================================================================
|
||||||
|

|
||||||
|
新版安卓市场——黑色比重减少,白色和绿色增多。
|
||||||
|
Ron Amadeo供图
|
||||||
|
|
||||||
|
###安卓1.6,Donut——CDMA支持将安卓带给了各个运营商###
|
||||||
|
|
||||||
|
安卓的第四个版本——1.6,甜甜圈——在2009年9月发布,这时是在纸杯蛋糕面世的5个月后。尽管有无数更新,谷歌仍然在给安卓添加基本的功能。甜甜圈带来了对不同屏幕尺寸和CDMA的支持,还有一个文本语音转换引擎。
|
||||||
|
|
||||||
|
安卓1.6是个很好的更新例子,要在今天的话,它将没什么理由作为一个独立更新存在。主要的改进基本上可以总结为新版安卓市场,相机以及YouTube。从这一年起,像这样的应用已经从系统分离开来,并且谷歌任何时候都能升级它们。然而在完成所有的这些模块化功能工作之前,看起来甚至是一个微小的应用更新似乎都需要完整的系统更新。
|
||||||
|
|
||||||
|
另一个重大改进——CDMA支持——也表明了除了版本号之外,谷歌仍然在忙于将基本功能带到安卓上来。
|
||||||
|
|
||||||
|
安卓市场被标注为版本“1.6”,并且得到了一个彻底的改进。原本的全黑设计被抛弃,转向带有绿色高亮的白色应用设计——安卓的设计师很明显使用了安卓吉祥物来获得灵感。
|
||||||
|
|
||||||
|
新的市场对谷歌来说一定是个新的应用设计风格。屏幕顶部的五分之一用于显示横幅logo,表明了这个应用确实是“安卓市场”。在横幅之下是应用,游戏以及下载按钮,一个搜索按钮被安置在横幅的右侧。在导航键下面显示这特色应用的快照,可以在它们之间滑动。再下面是个垂直滚动列表,显示了更多的特色应用。
|
||||||
|
|
||||||
|

|
||||||
|
新的市场设计,展示了:带有截图的应用页面,应用分类页面,应用榜,下载。
|
||||||
|
Ron Amadeo供图
|
||||||
|
|
||||||
|
市场最大的新增内容是包含应用截图。安卓用户终于可以在安装之前看到应用长什么样子——之前他们只能看到简短的描述和用户评论。你的个人星级评价和评论被放在显著位置,随后是描述,最后是截图。查看截图常常需要一点点滚动来查看——如果你想要找个设计尚佳的应用,那可要费一番功夫了。
|
||||||
|
|
||||||
|
点击应用或游戏按钮会打开一个分类列表,就像你在上面第二张图看到的那样。选择一个类别之后,更多的导航显示在了屏幕顶部,用户可以看到“热门付费”,“热门免费”,或“热门新品”分类里看到各自的应用。尽管这些看起来像是会加载出新页面的按钮,实际上它们仅仅是个笨拙的标签页。每个按钮边有个绿色小灯指示现在哪个标签处于活跃状态。这个界面最赞的地方是应用列表是无穷滚动的(滚动加载)——一旦你到达列表底部的时候,它将加载更多应用。这个特性使得查看应用列表变得轻松,但是你点开任意一个应用再返回的话将会丢失你在列表里的位置——你得从头开始查看。下载部分可以做一些连新的Google Play商店都做不到的事:不过是显示一个已购买应用列表而已。
|
||||||
|
|
||||||
|
尽管新的市场看起来无疑比旧的好多了,但应用间的一致性更糟糕了。看起来就像是每个应用都是由不同团队制作的,但他们之间从没沟通过所有的安卓应用应该有的样子。
|
||||||
|
|
||||||
|

|
||||||
|
相机取景窗,照片回看界面,菜单。
|
||||||
|
Ron Amadeo供图
|
||||||
|
|
||||||
|
举个例子,相机应用从全屏,最小化设计变成一个盒状的边缘带控制的取景窗。在相机应用中,谷歌着手引入拟物化,将应用包装成一个大致复刻皮革纹经典相机的样子。在相机和摄像机之间切换通过一个缺乏想象力的开关完成,下面是个触摸快门按钮。
|
||||||
|
|
||||||
|
点击最近照片快照不再会打开相册,但一个定制的照片查看器内建在了相机应用内。当你查看照片的时候,皮革质感的控制区从相机操作键变成图片操作键,你可以在这里删除,共享照片,或者把照片设置成壁纸或联系人图像。这里图片之间依然没有滑动操作——切换照片还是要通过照片两侧的箭头按钮完成。
|
||||||
|
|
||||||
|
第二张截图展示的是设计师减少对菜单按钮依赖的例子之一,因为安卓团队慢慢开始意识到其在可发现性上的糟糕表现。许多的应用设计者(包括那些在谷歌的)使用菜单作为所有种类的控制和导航元素的集中处。但大多数用户没想过点击菜单按钮,也从没看到这些指令。
|
||||||
|
|
||||||
|
未来版本的安卓的共有主题会将选项从菜单移到主要屏幕上,使得整个系统对用户更加友好。菜单按钮在安卓4.0中被完全移除,并且它只在传统应用中被支持。
|
||||||
|
|
||||||
|

|
||||||
|
电池以及文本语音转换引擎设置。
|
||||||
|
Ron Amadeo供图
|
||||||
|
|
||||||
|
甜甜圈是第一个持续追踪电池使用量的安卓版本。在“关于手机”菜单里有个选项“电池使用”,它会以百分比的方式显示应用以及硬件功能的电池用量。点击一项会打开一个单独的相关状态页面。硬件项目有个按钮可以直接跳转到它们的设置界面,所以,举个例子,如果你觉得显示的电池用量太高你可以更改显示的屏幕超时。
|
||||||
|
|
||||||
|
安卓1.6同样是第一个支持文本语音转换引擎(TTS)的版本,这意味着系统以及应用能够用机器合成声音来回应你。“语音合成器”选项允许你设置语言,选择语速,以及从安卓市场安装语音数据(慎重)。今天,谷歌在安卓上部署它自己的TTS引擎,但是似乎甜甜圈是通过硬编码的方式使用了来自SVOX的TTS引擎。但SVOX的引擎并未部署在甜甜圈上,所以点击“安装语音数据”会链接到安卓市场的一个应用。(甜甜圈的全盛期几年后,这个应用已被撤下。看起来似乎安卓1.6再也不能说话了。)
|
||||||
|
|
||||||
|

|
||||||
|
从左到右:新的小部件,搜索栏界面,新清除通知按钮,新相册控件。
|
||||||
|
Ron Amadeo供图
|
||||||
|
|
||||||
|
前端小部件部分花了更多的功夫。甜甜圈带来了全新的叫做“电量控制”小部件。它包含了常见耗电功能的开关:Wi-Fi,蓝牙,GPS,同步(同谷歌服务器之间),以及亮度。
|
||||||
|
|
||||||
|
搜索小部件同样经过了重新设计,变得更加纤细,并且内置了一个麦克风按钮用于语音搜索。它现在有了些实质界面并且够实时搜索,不仅仅是搜索互联网,还能搜索你的应用和历史。
|
||||||
|
|
||||||
|
“清除通知”按钮大幅缩水并且去掉了“通知”字样。在稍晚些的安卓后续版本总它还会缩减成仅仅是个方形按钮。相册继续遵循了把功能从菜单里拿出来的趋势,并且将它们放在用户面前——单张图片查看界面得到了“设置为”,“分享”,以及“删除”按钮。
|
||||||
|
|
||||||
|
----------
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
|
||||||
|
[@RonAmadeo][t]
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/9/
|
||||||
|
|
||||||
|
译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://arstechnica.com/author/ronamadeo
|
||||||
|
[t]:https://twitter.com/RonAmadeo
|
||||||
@ -0,0 +1,149 @@
|
|||||||
|
使用火焰图分析CPU性能回退问题
|
||||||
|
================================================================================
|
||||||
|
你能快速定位CPU性能回退的问题么? 如果你的工作环境非常复杂且变化快速,那么使用现有的工具是来定位这类问题是很具有挑战性的。当你花掉数周时间把根因找到时,代码已经又变更了好几轮,新的性能问题又冒了出来。
|
||||||
|
|
||||||
|
辛亏有了[CPU火焰图][1](flame graphs),CPU使用率的问题一般都比较好定位。但要处理性能回退问题,就要在修改前后的火焰图间,不断切换对比,来找出问题所在,这感觉就是像在太阳系中搜寻冥王星。虽然,这种方法可以解决问题,但我觉得应该会有更好的办法。
|
||||||
|
|
||||||
|
所以,下面就隆重介绍**红/蓝差分火焰图(red/blue differential flame graphs)**:
|
||||||
|
|
||||||
|
<p><object data="http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-diff.svg" type="image/svg+xml" width=720 height=296>
|
||||||
|
<img src="http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-diff.svg" width=720 />
|
||||||
|
</object></p>
|
||||||
|
|
||||||
|
上面是一副交互式SVG格式图片([链接][3])。图中使用了两种颜色来表示状态,**红色表示增长**,**蓝色表示衰减**。
|
||||||
|
|
||||||
|
这张火焰图中各火焰的形状和大小都是和第二次抓取的profile文件对应的CPU火焰图是相同的。(其中,y轴表示栈的深度,x轴表示样本的总数,栈帧的宽度表示了profile文件中该函数出现的比例,最顶层表示正在运行的函数,再往下就是调用它的栈)
|
||||||
|
|
||||||
|
在下面这个案例展示了,在系统升级后,一个工作负载的CPU使用率上升了。 下面是对应的CPU火焰图([SVG格式][4])
|
||||||
|
|
||||||
|
<p><object data="http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-after.svg" type="image/svg+xml" width=720 height=296>
|
||||||
|
<img src="http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-after.svg" width=720 />
|
||||||
|
</object></p>
|
||||||
|
|
||||||
|
通常,在标准的火焰图中栈帧和栈塔的颜色是随机选择的。 而在红/蓝差分火焰图中,使用不同的颜色来表示两个profile文件中的差异部分。
|
||||||
|
|
||||||
|
在第二个profile中deflate_slow()函数以及它后续调用的函数运行的次数要比前一次更多,所以在上图中这个栈帧被标为了红色。可以看出问题的原因是ZFS的压缩功能被使能了,而在系统升级前这项功能是关闭的。
|
||||||
|
|
||||||
|
这个例子过于简单,我甚至可以不用差分火焰图也能分析出来。但想象一下,如果是在分析一个微小的性能下降,比如说小于5%,而且代码也更加复杂的时候,问题就为那么好处理了。
|
||||||
|
|
||||||
|
### 红/蓝差分火焰图 ###
|
||||||
|
|
||||||
|
这个事情我已经讨论了好几年了,最终我自己编写了一个我个人认为有价值的实现。它的工作原理是这样的:
|
||||||
|
|
||||||
|
1. 抓取修改前的堆栈profile1文件
|
||||||
|
1. 抓取修改后的堆栈profile2文件
|
||||||
|
1. 使用profile2来生成火焰图。(这样栈帧的宽度就是以profile2文件为基准的)
|
||||||
|
1. 使用“2 - 1”的差异来对火焰图重新上色。上色的原则是,如果栈帧在profile2中出现出现的次数更多,则标为红色,否则标为蓝色。色彩是根据修改前后的差异来填充的。
|
||||||
|
|
||||||
|
这样做的目的是,同时使用了修改前后的profile文件进行对比,在进行功能验证测试或者评估代码修改对性能的影响时,会非常有用。新的火焰图是基于修改后的profile文件生成(所以栈帧的宽度仍然显示了当前的CPU消耗),通过颜色的对比,就可以了解到系统性能差异的原因。
|
||||||
|
|
||||||
|
只有对性能产生直接影响的函数才会标注颜色(比如说,正在运行的函数),它所调用的子函数不会重复标注。
|
||||||
|
|
||||||
|
### 生成红/蓝差分火焰图 ###
|
||||||
|
|
||||||
|
我已经把一个简单的代码实现推送到github上(见[火焰图][5]),其中新增了一个程序脚本,difffolded.pl。为了展示工具是如何工作的,用Linux [perf_events][6] 来演示一下操作步骤。(你也可以使用其他profiler)
|
||||||
|
|
||||||
|
#### 抓取修改前的profile 1文件: ####
|
||||||
|
|
||||||
|
# perf record -F 99 -a -g -- sleep 30
|
||||||
|
# perf script > out.stacks1
|
||||||
|
|
||||||
|
#### 一段时间后 (或者程序代码修改后), 抓取profile 2文件: ####
|
||||||
|
|
||||||
|
# perf record -F 99 -a -g -- sleep 30
|
||||||
|
# perf script > out.stacks2
|
||||||
|
|
||||||
|
#### 现在将 profile 文件进行折叠(fold), 再生成差分火焰图: ####
|
||||||
|
|
||||||
|
$ git clone --depth 1 http://github.com/brendangregg/FlameGraph
|
||||||
|
$ cd FlameGraph
|
||||||
|
$ ./stackcollapse-perf.pl ../out.stacks1 > out.folded1
|
||||||
|
$ ./stackcollapse-perf.pl ../out.stacks2 > out.folded2
|
||||||
|
$ ./difffolded.pl out.folded1 out.folded2 | ./flamegraph.pl > diff2.svg
|
||||||
|
|
||||||
|
difffolded.p只能对“折叠”过的堆栈profile文件进行操作,折叠操作是由前面的stackcollapse系列脚本完成的。(见链接[火焰图][7])。 脚本共输出3列数据,其中一列代表折叠的调用栈,另两列为修改前后profile文件的统计数据。
|
||||||
|
|
||||||
|
func_a;func_b;func_c 31 33
|
||||||
|
[...]
|
||||||
|
|
||||||
|
在上面的例子中"func_a()->func_b()->func_c()" 代表调用栈,这个调用栈在profile1文件中共出现了31次,在profile2文件中共出现了33次。然后,使用flamegraph.pl脚本处理这3列数据,会自动生成一张红/蓝差分火焰图。
|
||||||
|
|
||||||
|
### 其他选项 ###
|
||||||
|
再介绍一些有用的选项:
|
||||||
|
**difffolded.pl -n**:这个选项会把两个profile文件中的数据规范化,使其能相互匹配上。如果你不这样做,抓取到所有栈的统计值肯定会不相同,因为抓取的时间和CPU负载都不同。这样的话,看上去要么就是一片红(负载增加),要么就是一片蓝(负载下降)。-n选项对第一个profile文件进行了平衡,这样你就可以得到完整红/蓝图谱。
|
||||||
|
|
||||||
|
**difffolded.pl -x**: 这个选项会把16进制的地址删掉。 profiler时常会无法将地址转换为符号,这样的话栈里就会有16进制地址。如果这个地址在两个profile文件中不同,这两个栈就会认为是不同的栈,而实际上它们是相同的。遇到这样的问题就用-x选项搞定。
|
||||||
|
|
||||||
|
**flamegraph.pl --negate**: 用于颠倒红/蓝配色。 在下面的章节中,会用到这个功能。
|
||||||
|
|
||||||
|
### 不足之处 ###
|
||||||
|
虽然我的红/蓝差分火焰图很有用,但实际上还是有一个问题:如果一个代码执行路径完全消失了,那么在火焰图中就找不到地方来标注蓝色。你只能看到当前的CPU使用情况,而不知道为什么会变成这样。
|
||||||
|
|
||||||
|
一个办法是,将对比顺序颠倒,画一个相反的差分火焰图。例如:
|
||||||
|
|
||||||
|
<p><object data="http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-negated.svg" type="image/svg+xml" width=720 height=296>
|
||||||
|
<img src="http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-negated.svg" width=720 />
|
||||||
|
</object></p>
|
||||||
|
|
||||||
|
上面的火焰图是以修改前的profile文件为基准,颜色表达了将要发生的情况。右边使用蓝色高亮显示的部分,从中可以看出修改后CPU Idle消耗的CPU时间会变少。(其实,我通常会把cpu_idle给过滤掉,使用命令行grep -v cpu_idle)
|
||||||
|
|
||||||
|
图中把消失的代码也突显了出来(或者应该是说,没有突显),因为修改前并没有使能压缩功能,所以它没有出现在修改前的profile文件了,也就没有了被表为红色的部分。
|
||||||
|
|
||||||
|
下面是对应的命令行:
|
||||||
|
|
||||||
|
$ ./difffolded.pl out.folded2 out.folded1 | ./flamegraph.pl --negate > diff1.svg
|
||||||
|
|
||||||
|
这样,把前面生成diff2.svg一并使用,我们就能得到:
|
||||||
|
|
||||||
|
- **diff1.svg**: 宽度是以修改前profile文件为基准, 颜色表明将要发生的情况
|
||||||
|
- **diff2.svg**: 宽度以修改后的profile文件为基准,颜色表明已经发生的情况
|
||||||
|
|
||||||
|
如果是在做功能验证测试,我会同时生成这两张图。
|
||||||
|
|
||||||
|
### CPI 火焰图 ###
|
||||||
|
这些脚本开始是被使用在[CPI火焰图][8]的分析上。与比较修改前后的profile文件不同,在分析CPI火焰图时,可以分析CPU工作周期与停顿周期的差异变化,这样可以凸显出CPU的工作状态来。
|
||||||
|
|
||||||
|
### 其他的差分火焰图 ###
|
||||||
|
|
||||||
|
[][9]
|
||||||
|
|
||||||
|
也有其他人做过类似的工作。[Robert Mustacchi][10]在不久前也做了一些尝试,他使用的方法类似于代码检视时的标色风格:只显示了差异的部分,红色表示新增(上升)的代码路径,蓝色表示删除(下降)的代码路径。一个关键的差别是栈帧的宽度只体现了差异的样本数。右边是一个例子。这个是个很好的主意,但在实际使用中会感觉有点奇怪,因为缺失了完整profile文件的上下文作为背景,这张图显得有些难以理解。
|
||||||
|
|
||||||
|
[][12]
|
||||||
|
Cor-Paul Bezemer也制作了一种差分显示方法[flamegraphdiff][13],他同时将3张火焰图放在同一张图中,修改前后的标准火焰图各一张,下面再补充了一张差分火焰图,但栈帧宽度也是差异的样本数。 上图是一个[例子][14]。在差分图中将鼠标移到栈帧上,3张图中同一栈帧都会被高亮显示。这种方法中补充了两张标准的火焰图,因此解决了上下文的问题。
|
||||||
|
|
||||||
|
我们3人的差分火焰图,都各有所长。三者可以结合起来使用:Cor-Paul方法中上方的两张图,可以用我的diff1.svg 和 diff2.svg。下方的火焰图可以用Robert的方式。为保持一致性,下方的火焰图可以用我的着色方式:蓝->白->红。
|
||||||
|
|
||||||
|
火焰图正在广泛传播中,现在很多公司都在使用它。如果大家知道有其他的实现差分火焰图的方式,我也不会感到惊讶。(请在评论中告诉我)
|
||||||
|
|
||||||
|
### 结论 ###
|
||||||
|
|
||||||
|
如果你遇到了性能回退问题,红/蓝差分火焰图是找到根因的最快方式。这种方式抓取了两张普通的火焰图,然后进行对比,并对差异部分进行标色:红色表示上升,蓝色表示下降。 差分火焰图是以当前(“修改后”)的profile文件作为基准,形状和大小都保持不变。因此你通过色彩的差异就能够很直观的找到差异部分,且可以看出为什么会有这样的差异。
|
||||||
|
|
||||||
|
差分火焰图可以应用到项目的每日构建中,这样性能回退的问题就可以及时地被发现和修正。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.brendangregg.com/blog/2014-11-09/differential-flame-graphs.html
|
||||||
|
|
||||||
|
作者:[Brendan Gregg][a]
|
||||||
|
译者:[coloka](https://github.com/coloka)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.linux.com/community/forums/person/60160
|
||||||
|
[1]:http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html
|
||||||
|
[2]:http://en.wikipedia.org/wiki/Planets_beyond_Neptune#Discovery_of_Pluto
|
||||||
|
[3]:http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-diff.svg
|
||||||
|
[4]:http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-after.svg
|
||||||
|
[5]:https://github.com/brendangregg/FlameGraph
|
||||||
|
[6]:http://www.brendangregg.com/perf.html
|
||||||
|
[7]:https://github.com/brendangregg/FlameGraph
|
||||||
|
[8]:http://www.brendangregg.com/blog/2014-10-31/cpi-flame-graphs.html
|
||||||
|
[9]:http://www.slideshare.net/brendangregg/blazing-performance-with-flame-graphs/167
|
||||||
|
[10]:http://dtrace.org/blogs/rm
|
||||||
|
[11]:http://www.slideshare.net/brendangregg/blazing-performance-with-flame-graphs/167
|
||||||
|
[12]:https://github.com/corpaul/flamegraphdiff
|
||||||
|
[13]:http://corpaul.github.io/flamegraphdiff/
|
||||||
|
[14]:http://corpaul.github.io/flamegraphdiff/demos/dispersy/dispersy_diff.html
|
||||||
@ -0,0 +1,87 @@
|
|||||||
|
图形化显示Linux内存使用情况
|
||||||
|
================================================================================
|
||||||
|
物理内存不足对Linux桌面系统和服务器系统的性能影响都很大。当你的电脑变慢时,要做的第一件事就是释放内存。尤其是在多用户环境以及执行关键任务的服务器环境下,内存消耗会变得更加关键,因为多个用户和应用线程会同时争用更多的内存空间。
|
||||||
|
|
||||||
|
如果要监测系统内各种资源的使用情况(比如说CPU或内存),图形化显示是一种高效的方法,通过图形界面可以快速分析各用户和进程的资源消耗情况。本教程将给大家介绍**在linux下图形化分析内存使用情况**的方法,使用到命令行工具是[smem][1].
|
||||||
|
|
||||||
|
### 物理内存使用情况: RSS vs. PSS vs. USS ###
|
||||||
|
|
||||||
|
由于Linux使用到了虚拟内存(virtual memory),因此要准确的计算一个进程实际使用的物理内存就不是那么简单。 只知道进程的虚拟内存大小也并没有太大的用处,因为还是无法获取到实际分配的物理内存大小。
|
||||||
|
|
||||||
|
**RSS(Resident set size)**,使用top命令可以查询到,是最常用的内存指标,表示进程占用的物理内存大小。但是,将各进程的RSS值相加,通常会超出整个系统的内存消耗,这是因为RSS中包含了各进程间共享的内存。**PSS(Proportional set size)**会更准确一些,它将共享内存的大小进行平均后,再分摊到各进程上去。**USS(Unique set size )**是PSS的自己,它只计算了进程独自占用的内存大小,不包含任何共享的部分。
|
||||||
|
|
||||||
|
### 安装Smem ###
|
||||||
|
|
||||||
|
smem是一个能够生成多种内存耗用报告的命令行工具,它从/proc文件系统中提取各进程的PSS/USS信息,并进行汇总输出。它还内建了图表的生成能力,所以能够方便地分析整个系统的内存使用情况。
|
||||||
|
|
||||||
|
#### 在Debian, Ubuntu 或 Linux Mint 上安装smem ####
|
||||||
|
|
||||||
|
$ sudo apt-get install smem
|
||||||
|
|
||||||
|
#### 在Fedora 或 CentOS/RHEL上安装Smem ####
|
||||||
|
|
||||||
|
在CentOS/RHEL上,你首先得[使能][2]EPEL仓。
|
||||||
|
|
||||||
|
$ sudo yum install smem python-matplotlib
|
||||||
|
|
||||||
|
### 使用smem检查内存使用情况 ###
|
||||||
|
|
||||||
|
你可以在非特权模式下使用smem,它能够显示当前用户运行的所有进程的内存使用情况,并按照PSS的大小进行排序。
|
||||||
|
|
||||||
|
$ smem
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
如有你想得到整个系统中所有用户的内存使用情况,就需要使用root权限来运行smem。
|
||||||
|
|
||||||
|
$ sudo smem
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
也可以按用户维度来输出报告:
|
||||||
|
|
||||||
|
$ sudo smem -u
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
smem提供了以下选项来对输出结果进行筛选,支持按映射方式(mapping),进程和用户三个维度的筛选:
|
||||||
|
|
||||||
|
- -M <mapping-filtering-regular-expression>
|
||||||
|
- -P <process-filtering-regular-expression>
|
||||||
|
- -U <user-filtering-regular-expression>
|
||||||
|
|
||||||
|
想了解smem更多的使用方式,可以查询用户手册(man page)。
|
||||||
|
|
||||||
|
### 使用smem图形化显示内存使用情况 ###
|
||||||
|
|
||||||
|
图形化的报告使用起来会更加方便快捷。smem支持支持两种格式的图形显示方式:直方图和饼图。
|
||||||
|
|
||||||
|
下面是一些图形化显示的实例。
|
||||||
|
|
||||||
|
下面的命令行会基于PSS/RSS值,生成直方图,以用户alice为例。
|
||||||
|
|
||||||
|
$ sudo smem --bar name -c "pss uss" -U alice
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
这个例子会生成一张饼图,图中显示了系统中各进程的PSS内存使用量:
|
||||||
|
|
||||||
|
$ sudo smem --pie name -c "pss"
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
概括来说,smem是一个方便易用的内存分析工具。利用smem的格式化输出,你可以对内存使用报告进行自动化分析,并执行一些自动化的处理措施。如果你还知道其他的一些优秀的内存检测工具,请在留言区告诉我。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://xmodulo.com/visualize-memory-usage-linux.html
|
||||||
|
|
||||||
|
作者:[Dan Nanni][a]
|
||||||
|
译者:[coloka](https://github.com/coloka)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://xmodulo.com/author/nanni
|
||||||
|
[1]:http://www.selenic.com/smem/
|
||||||
|
[2]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||||
@ -0,0 +1,54 @@
|
|||||||
|
Linux有问必答——如何检查Linux上的glibc版本
|
||||||
|
================================================================================
|
||||||
|
> **问题**:我需要找出我的Linux系统上的GNU C库(glibc)的版本,我怎样才能检查Linux上的glibc版本呢?
|
||||||
|
|
||||||
|
GNU C库(glibc)是标准C库的GNU实现。glibc是GNU工具链的关键组件,用于和二进制工具和编译器一起使用,为目标架构生成用户空间应用程序。
|
||||||
|
|
||||||
|
当从源码进行构建时,一些Linux程序可能需要链接到某个特定版本的glibc。在这种情况下,你可能想要检查已安装的glibc信息以查看是否满足依赖关系。
|
||||||
|
|
||||||
|
这里介绍几种简单的方法,方便你检查Linux上的glibc版本。
|
||||||
|
|
||||||
|
### 方法一 ###
|
||||||
|
|
||||||
|
下面给出了命令行下检查GNU C库的简单命令。
|
||||||
|
|
||||||
|
$ ldd --version
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在本例中,**glibc**版本是**2.19**。
|
||||||
|
|
||||||
|
### 方法二 ###
|
||||||
|
|
||||||
|
另一个方法是在命令行“输入”**glibc library**(如,libc.so.6),就像命令一样。
|
||||||
|
|
||||||
|
输出结果会显示更多关于**glibc库**的详细信息,包括glibc的版本以及使用的GNU编译器,也提供了glibc扩展的信息。glibc变量的位置取决于Linux版本和处理器架构。
|
||||||
|
|
||||||
|
在基于Debian的64位系统上:
|
||||||
|
|
||||||
|
$ /lib/x86_64-linux-gnu/libc.so.6
|
||||||
|
|
||||||
|
在基于Debian的32位系统上:
|
||||||
|
|
||||||
|
$ /lib/i386-linux-gnu/libc.so.6
|
||||||
|
|
||||||
|
在基于Red Hat的64位系统上:
|
||||||
|
|
||||||
|
$ /lib64/libc.so.6
|
||||||
|
|
||||||
|
在基于Red Hat的32位系统上:
|
||||||
|
|
||||||
|
$ /lib/libc.so.6
|
||||||
|
|
||||||
|
下图中是输入glibc库后的输出结果样例。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://ask.xmodulo.com/check-glibc-version-linux.html
|
||||||
|
|
||||||
|
译者:[GOLinux](https://github.com/GOLinux)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
@ -0,0 +1,39 @@
|
|||||||
|
Linux有问必答——如何修复“ImportError: No module named scapy.all”
|
||||||
|
================================================================================
|
||||||
|
> **问题**:当我运行一个Python应用程序时,出现了这个提示消息“ImportError: No module named scapy.all”。我怎样才能修复这个导入错误呢?
|
||||||
|
|
||||||
|
[Scapy][1]是一个用Python写的灵活包生成和嗅探程序。使用Scapy,你可以完成创建专有包,发送上线,从线上或转储文件中读取包,转换包等工作。使用Scapy的通用包处理能力,你可以很容易地完成像SYN扫描、TCP路由跟踪以及OS指纹打印之类的工作。你也可以通过导入,将Scapy整合到其它工具中。
|
||||||
|
|
||||||
|
该导入错误表明:你还没有在你的Linux系统上安装Scapy。下面介绍安装方法。
|
||||||
|
### 安装Scapy到Debian, Ubuntu或Linux Mint ###
|
||||||
|
|
||||||
|
$ sudo apt-get install python-scapy
|
||||||
|
|
||||||
|
### 安装Scapy到Fedora或CentOS/RHEL ###
|
||||||
|
|
||||||
|
在CentOS/RHEL上,你首先需要[启用EPEL仓库][2]。
|
||||||
|
|
||||||
|
$ sudo yum install scapy
|
||||||
|
|
||||||
|
### 源码安装Scapy ###
|
||||||
|
|
||||||
|
如果你的Linux版本没有提供Scapy包,或者你想要试试最新的Scapy,你可以手工使用源码包安装。
|
||||||
|
|
||||||
|
下载[最新版的Scapy][3],然后按照以下步骤安装。
|
||||||
|
|
||||||
|
$ unzip scapy-latest.zip
|
||||||
|
$ cd scapy-2.*
|
||||||
|
$ sudo python setup.py install
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://ask.xmodulo.com/importerror-no-module-named-scapy-all.html
|
||||||
|
|
||||||
|
译者:[GOLinux](https://github.com/GOLinux)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[1]:http://www.secdev.org/projects/scapy/
|
||||||
|
[2]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||||
|
[3]:http://scapy.net/
|
||||||
Loading…
Reference in New Issue
Block a user