mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
fb1c1d979b
@ -0,0 +1,249 @@
|
||||
探索 Linux 内核:Kconfig/kbuild 的秘密
|
||||
======
|
||||
|
||||
> 深入理解 Linux 配置/构建系统是如何工作的。
|
||||
|
||||

|
||||
|
||||
自从 Linux 内核代码迁移到 Git 以来,Linux 内核配置/构建系统(也称为 Kconfig/kbuild)已存在很长时间了。然而,作为支持基础设施,它很少成为人们关注的焦点;甚至在日常工作中使用它的内核开发人员也从未真正思考过它。
|
||||
|
||||
为了探索如何编译 Linux 内核,本文将深入介绍 Kconfig/kbuild 内部的过程,解释如何生成 `.config` 文件和 `vmlinux`/`bzImage` 文件,并介绍一个巧妙的依赖性跟踪技巧。
|
||||
|
||||
### Kconfig
|
||||
|
||||
构建内核的第一步始终是配置。Kconfig 有助于使 Linux 内核高度模块化和可定制。Kconfig 为用户提供了许多配置目标:
|
||||
|
||||
|
||||
| 配置目标 | 解释 |
|
||||
| ---------------- | --------------------------------------------------------- |
|
||||
| `config` | 利用命令行程序更新当前配置 |
|
||||
| `nconfig` | 利用基于 ncurses 菜单的程序更新当前配置 |
|
||||
| `menuconfig` | 利用基于菜单的程序更新当前配置 |
|
||||
| `xconfig` | 利用基于 Qt 的前端程序更新当前配置 |
|
||||
| `gconfig` | 利用基于 GTK+ 的前端程序更新当前配置 |
|
||||
| `oldconfig` | 基于提供的 `.config` 更新当前配置 |
|
||||
| `localmodconfig` | 更新当前配置,禁用没有载入的模块 |
|
||||
| `localyesconfig` | 更新当前配置,转换本地模块到核心 |
|
||||
| `defconfig` | 带有来自架构提供的 `defconcig` 默认值的新配置 |
|
||||
| `savedefconfig` | 保存当前配置为 `./defconfig`(最小配置) |
|
||||
| `allnoconfig` | 所有选项回答为 `no` 的新配置 |
|
||||
| `allyesconfig` | 所有选项回答为 `yes` 的新配置 |
|
||||
| `allmodconfig` | 尽可能选择所有模块的新配置 |
|
||||
| `alldefconfig` | 所有符号(选项)设置为默认值的新配置 |
|
||||
| `randconfig` | 所有选项随机选择的新配置 |
|
||||
| `listnewconfig` | 列出新选项 |
|
||||
| `olddefconfig` | 同 `oldconfig` 一样,但设置新符号(选项)为其默认值而无须提问 |
|
||||
| `kvmconfig` | 启用支持 KVM 访客内核模块的附加选项 |
|
||||
| `xenconfig` | 启用支持 xen 的 dom0 和 访客内核模块的附加选项 |
|
||||
| `tinyconfig` | 配置尽可能小的内核 |
|
||||
|
||||
我认为 `menuconfig` 是这些目标中最受欢迎的。这些目标由不同的<ruby>主程序<rt>host program</rt></ruby>处理,这些程序由内核提供并在内核构建期间构建。一些目标有 GUI(为了方便用户),而大多数没有。与 Kconfig 相关的工具和源代码主要位于内核源代码中的 `scripts/kconfig/` 下。从 `scripts/kconfig/Makefile` 中可以看到,这里有几个主程序,包括 `conf`、`mconf` 和 `nconf`。除了 `conf` 之外,每个都负责一个基于 GUI 的配置目标,因此,`conf` 处理大多数目标。
|
||||
|
||||
从逻辑上讲,Kconfig 的基础结构有两部分:一部分实现一种[新语言][1]来定义配置项(参见内核源代码下的 Kconfig 文件),另一部分解析 Kconfig 语言并处理配置操作。
|
||||
|
||||
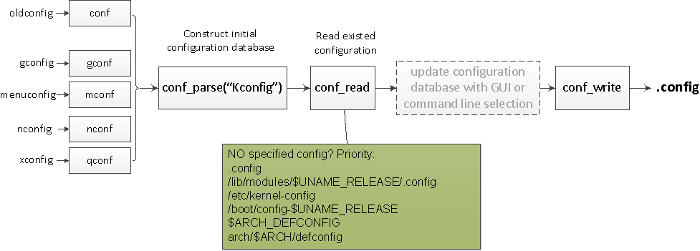
大多数配置目标具有大致相同的内部过程(如下所示):
|
||||
|
||||
|
||||
|
||||
请注意,所有配置项都具有默认值。
|
||||
|
||||
第一步读取源代码根目录下的 Kconfig 文件,构建初始配置数据库;然后它根据如下优先级读取现有配置文件来更新初始数据库:
|
||||
|
||||
1. `.config`
|
||||
2. `/lib/modules/$(shell,uname -r)/.config`
|
||||
3. `/etc/kernel-config`
|
||||
4. `/boot/config-$(shell,uname -r)`
|
||||
5. `ARCH_DEFCONFIG`
|
||||
6. `arch/$(ARCH)/defconfig`
|
||||
|
||||
如果你通过 `menuconfig` 进行基于 GUI 的配置或通过 `oldconfig` 进行基于命令行的配置,则根据你的自定义更新数据库。最后,该配置数据库被转储到 `.config` 文件中。
|
||||
|
||||
但 `.config` 文件不是内核构建的最终素材;这就是 `syncconfig` 目标存在的原因。`syncconfig`曾经是一个名为 `silentoldconfig` 的配置目标,但它没有做到其旧名称所说的工作,所以它被重命名。此外,因为它是供内部使用的(不适用于用户),所以它已从上述列表中删除。
|
||||
|
||||
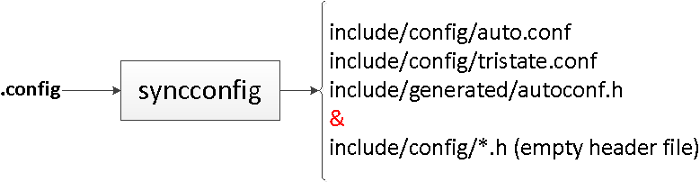
以下是 `syncconfig` 的作用:
|
||||
|
||||
|
||||
|
||||
`syncconfig` 将 `.config` 作为输入并输出许多其他文件,这些文件分为三类:
|
||||
|
||||
* `auto.conf` & `tristate.conf` 用于 makefile 文本处理。例如,你可以在组件的 makefile 中看到这样的语句:`obj-$(CONFIG_GENERIC_CALIBRATE_DELAY) += calibrate.o`。
|
||||
* `autoconf.h` 用于 C 语言的源文件。
|
||||
* `include/config/` 下空的头文件用于 kbuild 期间的配置依赖性跟踪。下面会解释。
|
||||
|
||||
配置完成后,我们将知道哪些文件和代码片段未编译。
|
||||
|
||||
### kbuild
|
||||
|
||||
组件式构建,称为*递归 make*,是 GNU `make` 管理大型项目的常用方法。kbuild 是递归 make 的一个很好的例子。通过将源文件划分为不同的模块/组件,每个组件都由其自己的 makefile 管理。当你开始构建时,顶级 makefile 以正确的顺序调用每个组件的 makefile、构建组件,并将它们收集到最终的执行程序中。
|
||||
|
||||
kbuild 指向到不同类型的 makefile:
|
||||
|
||||
* `Makefile` 位于源代码根目录的顶级 makefile。
|
||||
* `.config` 是内核配置文件。
|
||||
* `arch/$(ARCH)/Makefile` 是架构的 makefile,它用于补充顶级 makefile。
|
||||
* `scripts/Makefile.*` 描述所有的 kbuild makefile 的通用规则。
|
||||
* 最后,大约有 500 个 kbuild makefile。
|
||||
|
||||
顶级 makefile 会将架构 makefile 包含进去,读取 `.config` 文件,下到子目录,在 `scripts/ Makefile.*` 中定义的例程的帮助下,在每个组件的 makefile 上调用 `make`,构建每个中间对象,并将所有的中间对象链接为 `vmlinux`。内核文档 [Documentation/kbuild/makefiles.txt][2] 描述了这些 makefile 的方方面面。
|
||||
|
||||
作为一个例子,让我们看看如何在 x86-64 上生成 `vmlinux`:
|
||||
|
||||
![vmlinux overview][4]
|
||||
|
||||
(此插图基于 Richard Y. Steven 的[博客][5]。有过更新,并在作者允许的情况下使用。)
|
||||
|
||||
进入 `vmlinux` 的所有 `.o` 文件首先进入它们自己的 `built-in.a`,它通过变量`KBUILD_VMLINUX_INIT`、`KBUILD_VMLINUX_MAIN`、`KBUILD_VMLINUX_LIBS` 表示,然后被收集到 `vmlinux` 文件中。
|
||||
|
||||
在下面这个简化的 makefile 代码的帮助下,了解如何在 Linux 内核中实现递归 make:
|
||||
|
||||
```
|
||||
# In top Makefile
|
||||
vmlinux: scripts/link-vmlinux.sh $(vmlinux-deps)
|
||||
+$(call if_changed,link-vmlinux)
|
||||
|
||||
# Variable assignments
|
||||
vmlinux-deps := $(KBUILD_LDS) $(KBUILD_VMLINUX_INIT) $(KBUILD_VMLINUX_MAIN) $(KBUILD_VMLINUX_LIBS)
|
||||
|
||||
export KBUILD_VMLINUX_INIT := $(head-y) $(init-y)
|
||||
export KBUILD_VMLINUX_MAIN := $(core-y) $(libs-y2) $(drivers-y) $(net-y) $(virt-y)
|
||||
export KBUILD_VMLINUX_LIBS := $(libs-y1)
|
||||
export KBUILD_LDS := arch/$(SRCARCH)/kernel/vmlinux.lds
|
||||
|
||||
init-y := init/
|
||||
drivers-y := drivers/ sound/ firmware/
|
||||
net-y := net/
|
||||
libs-y := lib/
|
||||
core-y := usr/
|
||||
virt-y := virt/
|
||||
|
||||
# Transform to corresponding built-in.a
|
||||
init-y := $(patsubst %/, %/built-in.a, $(init-y))
|
||||
core-y := $(patsubst %/, %/built-in.a, $(core-y))
|
||||
drivers-y := $(patsubst %/, %/built-in.a, $(drivers-y))
|
||||
net-y := $(patsubst %/, %/built-in.a, $(net-y))
|
||||
libs-y1 := $(patsubst %/, %/lib.a, $(libs-y))
|
||||
libs-y2 := $(patsubst %/, %/built-in.a, $(filter-out %.a, $(libs-y)))
|
||||
virt-y := $(patsubst %/, %/built-in.a, $(virt-y))
|
||||
|
||||
# Setup the dependency. vmlinux-deps are all intermediate objects, vmlinux-dirs
|
||||
# are phony targets, so every time comes to this rule, the recipe of vmlinux-dirs
|
||||
# will be executed. Refer "4.6 Phony Targets" of `info make`
|
||||
$(sort $(vmlinux-deps)): $(vmlinux-dirs) ;
|
||||
|
||||
# Variable vmlinux-dirs is the directory part of each built-in.a
|
||||
vmlinux-dirs := $(patsubst %/,%,$(filter %/, $(init-y) $(init-m) \
|
||||
$(core-y) $(core-m) $(drivers-y) $(drivers-m) \
|
||||
$(net-y) $(net-m) $(libs-y) $(libs-m) $(virt-y)))
|
||||
|
||||
# The entry of recursive make
|
||||
$(vmlinux-dirs):
|
||||
$(Q)$(MAKE) $(build)=$@ need-builtin=1
|
||||
```
|
||||
|
||||
递归 make 的<ruby>配方<rt>recipe</rt></ruby>被扩展开是这样的:
|
||||
|
||||
```
|
||||
make -f scripts/Makefile.build obj=init need-builtin=1
|
||||
```
|
||||
|
||||
这意味着 `make` 将进入 `scripts/Makefile.build` 以继续构建每个 `built-in.a`。在`scripts/link-vmlinux.sh` 的帮助下,`vmlinux` 文件最终位于源根目录下。
|
||||
|
||||
#### vmlinux 与 bzImage 对比
|
||||
|
||||
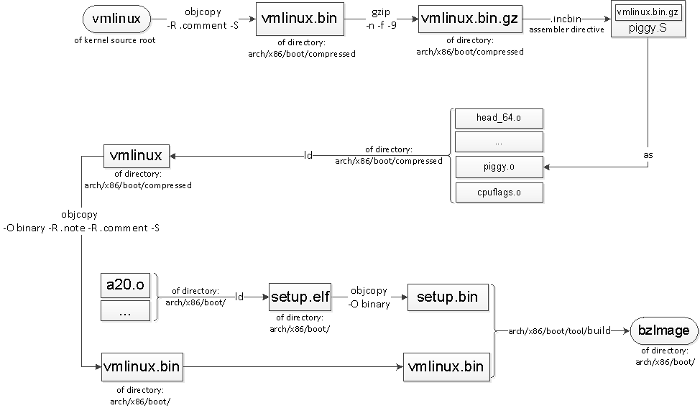
许多 Linux 内核开发人员可能不清楚 `vmlinux` 和 `bzImage` 之间的关系。例如,这是他们在 x86-64 中的关系:
|
||||
|
||||
|
||||
|
||||
源代码根目录下的 `vmlinux` 被剥离、压缩后,放入 `piggy.S`,然后与其他对等对象链接到 `arch/x86/boot/compressed/vmlinux`。同时,在 `arch/x86/boot` 下生成一个名为 `setup.bin` 的文件。可能有一个可选的第三个文件,它带有重定位信息,具体取决于 `CONFIG_X86_NEED_RELOCS` 的配置。
|
||||
|
||||
由内核提供的称为 `build` 的宿主程序将这两个(或三个)部分构建到最终的 `bzImage` 文件中。
|
||||
|
||||
#### 依赖跟踪
|
||||
|
||||
kbuild 跟踪三种依赖关系:
|
||||
|
||||
1. 所有必备文件(`*.c` 和 `*.h`)
|
||||
2. 所有必备文件中使用的 `CONFIG_` 选项
|
||||
3. 用于编译该目标的命令行依赖项
|
||||
|
||||
第一个很容易理解,但第二个和第三个呢? 内核开发人员经常会看到如下代码:
|
||||
|
||||
```
|
||||
#ifdef CONFIG_SMP
|
||||
__boot_cpu_id = cpu;
|
||||
#endif
|
||||
```
|
||||
|
||||
当 `CONFIG_SMP` 改变时,这段代码应该重新编译。编译源文件的命令行也很重要,因为不同的命令行可能会导致不同的目标文件。
|
||||
|
||||
当 `.c` 文件通过 `#include` 指令使用头文件时,你需要编写如下规则:
|
||||
|
||||
```
|
||||
main.o: defs.h
|
||||
recipe...
|
||||
```
|
||||
|
||||
管理大型项目时,需要大量的这些规则;把它们全部写下来会很乏味无聊。幸运的是,大多数现代 C 编译器都可以通过查看源文件中的 `#include` 行来为你编写这些规则。对于 GNU 编译器集合(GCC),只需添加一个命令行参数:`-MD depfile`
|
||||
|
||||
```
|
||||
# In scripts/Makefile.lib
|
||||
c_flags = -Wp,-MD,$(depfile) $(NOSTDINC_FLAGS) $(LINUXINCLUDE) \
|
||||
-include $(srctree)/include/linux/compiler_types.h \
|
||||
$(__c_flags) $(modkern_cflags) \
|
||||
$(basename_flags) $(modname_flags)
|
||||
```
|
||||
|
||||
这将生成一个 `.d` 文件,内容如下:
|
||||
|
||||
```
|
||||
init_task.o: init/init_task.c include/linux/kconfig.h \
|
||||
include/generated/autoconf.h include/linux/init_task.h \
|
||||
include/linux/rcupdate.h include/linux/types.h \
|
||||
...
|
||||
```
|
||||
|
||||
然后主程序 [fixdep][6] 通过将 depfile 文件和命令行作为输入来处理其他两个依赖项,然后以 makefile 格式输出一个 `.<target>.cmd` 文件,它记录命令行和目标的所有先决条件(包括配置)。 它看起来像这样:
|
||||
|
||||
```
|
||||
# The command line used to compile the target
|
||||
cmd_init/init_task.o := gcc -Wp,-MD,init/.init_task.o.d -nostdinc ...
|
||||
...
|
||||
# The dependency files
|
||||
deps_init/init_task.o := \
|
||||
$(wildcard include/config/posix/timers.h) \
|
||||
$(wildcard include/config/arch/task/struct/on/stack.h) \
|
||||
$(wildcard include/config/thread/info/in/task.h) \
|
||||
...
|
||||
include/uapi/linux/types.h \
|
||||
arch/x86/include/uapi/asm/types.h \
|
||||
include/uapi/asm-generic/types.h \
|
||||
...
|
||||
```
|
||||
|
||||
在递归 make 中,`.<target>.cmd` 文件将被包含,以提供所有依赖关系信息并帮助决定是否重建目标。
|
||||
|
||||
这背后的秘密是 `fixdep` 将解析 depfile(`.d` 文件),然后解析里面的所有依赖文件,搜索所有 `CONFIG_` 字符串的文本,将它们转换为相应的空的头文件,并将它们添加到目标的先决条件。每次配置更改时,相应的空的头文件也将更新,因此 kbuild 可以检测到该更改并重建依赖于它的目标。因为还记录了命令行,所以很容易比较最后和当前的编译参数。
|
||||
|
||||
### 展望未来
|
||||
|
||||
Kconfig/kbuild 在很长一段时间内没有什么变化,直到新的维护者 Masahiro Yamada 于 2017 年初加入,现在 kbuild 正在再次积极开发中。如果你不久后看到与本文中的内容不同的内容,请不要感到惊讶。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/kbuild-and-kconfig
|
||||
|
||||
作者:[Cao Jin][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/pinocchio
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/torvalds/linux/blob/master/Documentation/kbuild/kconfig-language.txt
|
||||
[2]: https://www.mjmwired.net/kernel/Documentation/kbuild/makefiles.txt
|
||||
[3]: https://opensource.com/file/411516
|
||||
[4]: https://opensource.com/sites/default/files/uploads/vmlinux_generation_process.png (vmlinux overview)
|
||||
[5]: https://blog.csdn.net/richardysteven/article/details/52502734
|
||||
[6]: https://github.com/torvalds/linux/blob/master/scripts/basic/fixdep.c
|
||||
@ -1,91 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Linux Smartphone Librem 5 is Available for Preorder)
|
||||
[#]: via: (https://itsfoss.com/librem-5-available/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Linux Smartphone Librem 5 is Available for Preorder
|
||||
======
|
||||
|
||||
Purism recently [announced][1] the final specs for its [Librem 5 smartphone][2]. This is not based on Android or iOS – but built on [PureOS][3], which is an [open-source alternative to Android][4].
|
||||
|
||||
Along with the announcement, the Librem 5 is also available for [pre-orders for $649][5] (as an early bird offer till 31st July) and it will go up by $50 following the date. It will start shipping from Q3 of 2019.
|
||||
|
||||
![][6]
|
||||
|
||||
Here’s what Purism mentioned about Librem 5 in its blog post:
|
||||
|
||||
_**We believe phones should not track you nor exploit your digital life.**_
|
||||
|
||||
_The Librem 5 represents the opportunity for you to take back control and protect your private information, your digital life through free and open source software, open governance, and transparency. The Librem 5 is_ **_a phone built on_ [_PureOS_][3]**_, a fully free, ethical and open-source operating system that is_ _**not based on Android or iOS**_ _(learn more about [why this is important][7])._
|
||||
|
||||
_We have successfully crossed our crowdfunding goals and will be delivering on our promise. The Librem 5’s hardware and software development is advancing [at a steady pace][8], and is scheduled for an initial release in Q3 2019. You can preorder the phone at $649 until shipping begins and regular pricing comes into effect. Kits with an external monitor, keyboard and mouse, are also available for preorder._
|
||||
|
||||
### Librem 5 Specifications
|
||||
|
||||
From what it looks like, Librem 5 definitely aims to provide better privacy and security. In addition to this, it tries to avoid using anything from Google or Apple.
|
||||
|
||||
While the idea is good enough – how does it hold up as a commercial smartphone under $700?
|
||||
|
||||
![Librem 5 Smartphone][9]
|
||||
|
||||
Let us take a look at the tech specs:
|
||||
|
||||
![Librem 5][10]
|
||||
|
||||
On paper the tech specs seems to be good enough. Not too great – not too bad. But, what about the performance? The user experience?
|
||||
|
||||
Well, we can’t be too sure about it – unless we use it. So, if you are pre-ordering it – take that into consideration.
|
||||
|
||||
[][11]
|
||||
|
||||
Suggested read Linux Games Get A Performance Boost for AMD GPUs Thanks to Valve's New Compiler
|
||||
|
||||
### Lifetime software updates for Librem 5
|
||||
|
||||
Of course, the specs aren’t very pretty when compared to the smartphones available at this price range.
|
||||
|
||||
However, with the promise of lifetime software updates – it does look like a decent offering for open source enthusiasts.
|
||||
|
||||
### Other Key Features
|
||||
|
||||
Purism also highlights the fact that Librem 5 will be the first-ever [Matrix][12]-powered smartphone. This means that it will support end-to-end decentralized encrypted communications for messaging and calling.
|
||||
|
||||
In addition to all these, the presence of headphone jack and a user-replaceable battery makes it a pretty solid deal.
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
Even though it is tough to compete with the likes of Android/iOS smartphones, having an alternative is always good. Librem 5 may not prove to be an ideal smartphone for every user – but if you are an open-source enthusiast and looking for a simple smartphone that respects privacy and security without utilizing Google/Apple services, this is for you.
|
||||
|
||||
Also the fact that it will receive lifetime software updates – makes it an interesting smartphone.
|
||||
|
||||
What do you think about Librem 5? Are you thinking to pre-order it? Let us know your thoughts in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/librem-5-available/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://puri.sm/posts/librem-5-smartphone-final-specs-announced/
|
||||
[2]: https://itsfoss.com/librem-linux-phone/
|
||||
[3]: https://pureos.net/
|
||||
[4]: https://itsfoss.com/open-source-alternatives-android/
|
||||
[5]: https://shop.puri.sm/shop/librem-5/
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/librem-5-linux-smartphone.jpg?resize=800%2C450&ssl=1
|
||||
[7]: https://puri.sm/products/librem-5/pureos-mobile/
|
||||
[8]: https://puri.sm/posts/tag/phones
|
||||
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/librem-5-smartphone.jpg?ssl=1
|
||||
[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/librem-5-specs.png?ssl=1
|
||||
[11]: https://itsfoss.com/linux-games-performance-boost-amd-gpu/
|
||||
[12]: http://matrix.org
|
||||
@ -1,257 +0,0 @@
|
||||
Exploring the Linux kernel: The secrets of Kconfig/kbuild
|
||||
======
|
||||
Dive into understanding how the Linux config/build system works.
|
||||
|
||||

|
||||
|
||||
The Linux kernel config/build system, also known as Kconfig/kbuild, has been around for a long time, ever since the Linux kernel code migrated to Git. As supporting infrastructure, however, it is seldom in the spotlight; even kernel developers who use it in their daily work never really think about it.
|
||||
|
||||
To explore how the Linux kernel is compiled, this article will dive into the Kconfig/kbuild internal process, explain how the .config file and the vmlinux/bzImage files are produced, and introduce a smart trick for dependency tracking.
|
||||
|
||||
### Kconfig
|
||||
|
||||
The first step in building a kernel is always configuration. Kconfig helps make the Linux kernel highly modular and customizable. Kconfig offers the user many config targets:
|
||||
| config | Update current config utilizing a line-oriented program |
|
||||
| nconfig | Update current config utilizing a ncurses menu-based program |
|
||||
| menuconfig | Update current config utilizing a menu-based program |
|
||||
| xconfig | Update current config utilizing a Qt-based frontend |
|
||||
| gconfig | Update current config utilizing a GTK+ based frontend |
|
||||
| oldconfig | Update current config utilizing a provided .config as base |
|
||||
| localmodconfig | Update current config disabling modules not loaded |
|
||||
| localyesconfig | Update current config converting local mods to core |
|
||||
| defconfig | New config with default from Arch-supplied defconfig |
|
||||
| savedefconfig | Save current config as ./defconfig (minimal config) |
|
||||
| allnoconfig | New config where all options are answered with 'no' |
|
||||
| allyesconfig | New config where all options are accepted with 'yes' |
|
||||
| allmodconfig | New config selecting modules when possible |
|
||||
| alldefconfig | New config with all symbols set to default |
|
||||
| randconfig | New config with a random answer to all options |
|
||||
| listnewconfig | List new options |
|
||||
| olddefconfig | Same as oldconfig but sets new symbols to their default value without prompting |
|
||||
| kvmconfig | Enable additional options for KVM guest kernel support |
|
||||
| xenconfig | Enable additional options for xen dom0 and guest kernel support |
|
||||
| tinyconfig | Configure the tiniest possible kernel |
|
||||
|
||||
I think **menuconfig** is the most popular of these targets. The targets are processed by different host programs, which are provided by the kernel and built during kernel building. Some targets have a GUI (for the user's convenience) while most don't. Kconfig-related tools and source code reside mainly under **scripts/kconfig/** in the kernel source. As we can see from **scripts/kconfig/Makefile** , there are several host programs, including **conf** , **mconf** , and **nconf**. Except for **conf** , each of them is responsible for one of the GUI-based config targets, so, **conf** deals with most of them.
|
||||
|
||||
Logically, Kconfig's infrastructure has two parts: one implements a [new language][1] to define the configuration items (see the Kconfig files under the kernel source), and the other parses the Kconfig language and deals with configuration actions.
|
||||
|
||||
Most of the config targets have roughly the same internal process (shown below):
|
||||
|
||||

|
||||
|
||||
Note that all configuration items have a default value.
|
||||
|
||||
The first step reads the Kconfig file under source root to construct an initial configuration database; then it updates the initial database by reading an existing configuration file according to this priority:
|
||||
|
||||
> .config
|
||||
> /lib/modules/$(shell,uname -r)/.config
|
||||
> /etc/kernel-config
|
||||
> /boot/config-$(shell,uname -r)
|
||||
> ARCH_DEFCONFIG
|
||||
> arch/$(ARCH)/defconfig
|
||||
|
||||
If you are doing GUI-based configuration via **menuconfig** or command-line-based configuration via **oldconfig** , the database is updated according to your customization. Finally, the configuration database is dumped into the .config file.
|
||||
|
||||
But the .config file is not the final fodder for kernel building; this is why the **syncconfig** target exists. **syncconfig** used to be a config target called **silentoldconfig** , but it doesn't do what the old name says, so it was renamed. Also, because it is for internal use (not for users), it was dropped from the list.
|
||||
|
||||
Here is an illustration of what **syncconfig** does:
|
||||
|
||||

|
||||
|
||||
**syncconfig** takes .config as input and outputs many other files, which fall into three categories:
|
||||
|
||||
* **auto.conf & tristate.conf** are used for makefile text processing. For example, you may see statements like this in a component's makefile:
|
||||
|
||||
```
|
||||
obj-$(CONFIG_GENERIC_CALIBRATE_DELAY) += calibrate.o
|
||||
```
|
||||
|
||||
* **autoconf.h** is used in C-language source files.
|
||||
|
||||
* Empty header files under **include/config/** are used for configuration-dependency tracking during kbuild, which is explained below.
|
||||
|
||||
|
||||
|
||||
|
||||
After configuration, we will know which files and code pieces are not compiled.
|
||||
|
||||
### kbuild
|
||||
|
||||
Component-wise building, called _recursive make_ , is a common way for GNU `make` to manage a large project. Kbuild is a good example of recursive make. By dividing source files into different modules/components, each component is managed by its own makefile. When you start building, a top makefile invokes each component's makefile in the proper order, builds the components, and collects them into the final executive.
|
||||
|
||||
Kbuild refers to different kinds of makefiles:
|
||||
|
||||
* **Makefile** is the top makefile located in source root.
|
||||
* **.config** is the kernel configuration file.
|
||||
* **arch/$(ARCH)/Makefile** is the arch makefile, which is the supplement to the top makefile.
|
||||
* **scripts/Makefile.*** describes common rules for all kbuild makefiles.
|
||||
* Finally, there are about 500 **kbuild makefiles**.
|
||||
|
||||
|
||||
|
||||
The top makefile includes the arch makefile, reads the .config file, descends into subdirectories, invokes **make** on each component's makefile with the help of routines defined in **scripts/Makefile.*** , builds up each intermediate object, and links all the intermediate objects into vmlinux. Kernel document [Documentation/kbuild/makefiles.txt][2] describes all aspects of these makefiles.
|
||||
|
||||
As an example, let's look at how vmlinux is produced on x86-64:
|
||||
|
||||
![vmlinux overview][4]
|
||||
|
||||
(The illustration is based on Richard Y. Steven's [blog][5]. It was updated and is used with the author's permission.)
|
||||
|
||||
All the **.o** files that go into vmlinux first go into their own **built-in.a** , which is indicated via variables **KBUILD_VMLINUX_INIT** , **KBUILD_VMLINUX_MAIN** , **KBUILD_VMLINUX_LIBS** , then are collected into the vmlinux file.
|
||||
|
||||
Take a look at how recursive make is implemented in the Linux kernel, with the help of simplified makefile code:
|
||||
|
||||
```
|
||||
# In top Makefile
|
||||
vmlinux: scripts/link-vmlinux.sh $(vmlinux-deps)
|
||||
+$(call if_changed,link-vmlinux)
|
||||
|
||||
# Variable assignments
|
||||
vmlinux-deps := $(KBUILD_LDS) $(KBUILD_VMLINUX_INIT) $(KBUILD_VMLINUX_MAIN) $(KBUILD_VMLINUX_LIBS)
|
||||
|
||||
export KBUILD_VMLINUX_INIT := $(head-y) $(init-y)
|
||||
export KBUILD_VMLINUX_MAIN := $(core-y) $(libs-y2) $(drivers-y) $(net-y) $(virt-y)
|
||||
export KBUILD_VMLINUX_LIBS := $(libs-y1)
|
||||
export KBUILD_LDS := arch/$(SRCARCH)/kernel/vmlinux.lds
|
||||
|
||||
init-y := init/
|
||||
drivers-y := drivers/ sound/ firmware/
|
||||
net-y := net/
|
||||
libs-y := lib/
|
||||
core-y := usr/
|
||||
virt-y := virt/
|
||||
|
||||
# Transform to corresponding built-in.a
|
||||
init-y := $(patsubst %/, %/built-in.a, $(init-y))
|
||||
core-y := $(patsubst %/, %/built-in.a, $(core-y))
|
||||
drivers-y := $(patsubst %/, %/built-in.a, $(drivers-y))
|
||||
net-y := $(patsubst %/, %/built-in.a, $(net-y))
|
||||
libs-y1 := $(patsubst %/, %/lib.a, $(libs-y))
|
||||
libs-y2 := $(patsubst %/, %/built-in.a, $(filter-out %.a, $(libs-y)))
|
||||
virt-y := $(patsubst %/, %/built-in.a, $(virt-y))
|
||||
|
||||
# Setup the dependency. vmlinux-deps are all intermediate objects, vmlinux-dirs
|
||||
# are phony targets, so every time comes to this rule, the recipe of vmlinux-dirs
|
||||
# will be executed. Refer "4.6 Phony Targets" of `info make`
|
||||
$(sort $(vmlinux-deps)): $(vmlinux-dirs) ;
|
||||
|
||||
# Variable vmlinux-dirs is the directory part of each built-in.a
|
||||
vmlinux-dirs := $(patsubst %/,%,$(filter %/, $(init-y) $(init-m) \
|
||||
$(core-y) $(core-m) $(drivers-y) $(drivers-m) \
|
||||
$(net-y) $(net-m) $(libs-y) $(libs-m) $(virt-y)))
|
||||
|
||||
# The entry of recursive make
|
||||
$(vmlinux-dirs):
|
||||
$(Q)$(MAKE) $(build)=$@ need-builtin=1
|
||||
```
|
||||
|
||||
The recursive make recipe is expanded, for example:
|
||||
|
||||
```
|
||||
make -f scripts/Makefile.build obj=init need-builtin=1
|
||||
```
|
||||
|
||||
This means **make** will go into **scripts/Makefile.build** to continue the work of building each **built-in.a**. With the help of **scripts/link-vmlinux.sh** , the vmlinux file is finally under source root.
|
||||
|
||||
#### Understanding vmlinux vs. bzImage
|
||||
|
||||
Many Linux kernel developers may not be clear about the relationship between vmlinux and bzImage. For example, here is their relationship in x86-64:
|
||||
|
||||

|
||||
|
||||
The source root vmlinux is stripped, compressed, put into **piggy.S** , then linked with other peer objects into **arch/x86/boot/compressed/vmlinux**. Meanwhile, a file called setup.bin is produced under **arch/x86/boot**. There may be an optional third file that has relocation info, depending on the configuration of **CONFIG_X86_NEED_RELOCS**.
|
||||
|
||||
A host program called **build** , provided by the kernel, builds these two (or three) parts into the final bzImage file.
|
||||
|
||||
#### Dependency tracking
|
||||
|
||||
Kbuild tracks three kinds of dependencies:
|
||||
|
||||
1. All prerequisite files (both * **.c** and * **.h** )
|
||||
2. **CONFIG_** options used in all prerequisite files
|
||||
3. Command-line dependencies used to compile the target
|
||||
|
||||
|
||||
|
||||
The first one is easy to understand, but what about the second and third? Kernel developers often see code pieces like this:
|
||||
|
||||
```
|
||||
#ifdef CONFIG_SMP
|
||||
__boot_cpu_id = cpu;
|
||||
#endif
|
||||
```
|
||||
|
||||
When **CONFIG_SMP** changes, this piece of code should be recompiled. The command line for compiling a source file also matters, because different command lines may result in different object files.
|
||||
|
||||
When a **.c** file uses a header file via a **#include** directive, you need write a rule like this:
|
||||
|
||||
```
|
||||
main.o: defs.h
|
||||
recipe...
|
||||
```
|
||||
|
||||
When managing a large project, you need a lot of these kinds of rules; writing them all would be tedious and boring. Fortunately, most modern C compilers can write these rules for you by looking at the **#include** lines in the source file. For the GNU Compiler Collection (GCC), it is just a matter of adding a command-line parameter: **-MD depfile**
|
||||
|
||||
```
|
||||
# In scripts/Makefile.lib
|
||||
c_flags = -Wp,-MD,$(depfile) $(NOSTDINC_FLAGS) $(LINUXINCLUDE) \
|
||||
-include $(srctree)/include/linux/compiler_types.h \
|
||||
$(__c_flags) $(modkern_cflags) \
|
||||
$(basename_flags) $(modname_flags)
|
||||
```
|
||||
|
||||
This would generate a **.d** file with content like:
|
||||
|
||||
```
|
||||
init_task.o: init/init_task.c include/linux/kconfig.h \
|
||||
include/generated/autoconf.h include/linux/init_task.h \
|
||||
include/linux/rcupdate.h include/linux/types.h \
|
||||
...
|
||||
```
|
||||
|
||||
Then the host program **[fixdep][6]** takes care of the other two dependencies by taking the **depfile** and command line as input, then outputting a **. <target>.cmd** file in makefile syntax, which records the command line and all the prerequisites (including the configuration) for a target. It looks like this:
|
||||
|
||||
```
|
||||
# The command line used to compile the target
|
||||
cmd_init/init_task.o := gcc -Wp,-MD,init/.init_task.o.d -nostdinc ...
|
||||
...
|
||||
# The dependency files
|
||||
deps_init/init_task.o := \
|
||||
$(wildcard include/config/posix/timers.h) \
|
||||
$(wildcard include/config/arch/task/struct/on/stack.h) \
|
||||
$(wildcard include/config/thread/info/in/task.h) \
|
||||
...
|
||||
include/uapi/linux/types.h \
|
||||
arch/x86/include/uapi/asm/types.h \
|
||||
include/uapi/asm-generic/types.h \
|
||||
...
|
||||
```
|
||||
|
||||
A **. <target>.cmd** file will be included during recursive make, providing all the dependency info and helping to decide whether to rebuild a target or not.
|
||||
|
||||
The secret behind this is that **fixdep** will parse the **depfile** ( **.d** file), then parse all the dependency files inside, search the text for all the **CONFIG_** strings, convert them to the corresponding empty header file, and add them to the target's prerequisites. Every time the configuration changes, the corresponding empty header file will be updated, too, so kbuild can detect that change and rebuild the target that depends on it. Because the command line is also recorded, it is easy to compare the last and current compiling parameters.
|
||||
|
||||
### Looking ahead
|
||||
|
||||
Kconfig/kbuild remained the same for a long time until the new maintainer, Masahiro Yamada, joined in early 2017, and now kbuild is under active development again. Don't be surprised if you soon see something different from what's in this article.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/kbuild-and-kconfig
|
||||
|
||||
作者:[Cao Jin][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/pinocchio
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/torvalds/linux/blob/master/Documentation/kbuild/kconfig-language.txt
|
||||
[2]: https://www.mjmwired.net/kernel/Documentation/kbuild/makefiles.txt
|
||||
[3]: https://opensource.com/file/411516
|
||||
[4]: https://opensource.com/sites/default/files/uploads/vmlinux_generation_process.png (vmlinux overview)
|
||||
[5]: https://blog.csdn.net/richardysteven/article/details/52502734
|
||||
[6]: https://github.com/torvalds/linux/blob/master/scripts/basic/fixdep.c
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (zianglei)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (zmaster-zhang)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,109 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Add ‘New Document’ Option In Right Click Context Menu In Ubuntu 18.04)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-add-new-document-option-in-right-click-context-menu-in-ubuntu-18-04/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
How To Add ‘New Document’ Option In Right Click Context Menu In Ubuntu 18.04
|
||||
======
|
||||
|
||||
![Add 'New Document' Option In Right Click Context Menu In Ubuntu 18.04 GNOME desktop][1]
|
||||
|
||||
The other day, I was collecting reference notes for [**Linux package managers**][2] on various online sources. When I tried to create a text file to save those notes, I noticed that the ‘New document’ option is missing in my Ubuntu 18.04 LTS desktop. I thought somehow the option is gone in my system. After googling a bit, It turns out to be the “new document” option is not included in Ubuntu GNOME editions. Luckily, I have found an easy solution to add ‘New Document’ option in right click context menu in Ubuntu 18.04 LTS desktop.
|
||||
|
||||
As you can see in the following screenshot, the “New Doucment” option is missing in the right-click context menu of Nautilus file manager.
|
||||
|
||||
![][3]
|
||||
|
||||
new document option is missing in right-click context menu ubuntu 18.04
|
||||
|
||||
If you want to add this option, just follow the steps given below.
|
||||
|
||||
### Add ‘New Document’ Option In Right Click Context Menu In Ubuntu
|
||||
|
||||
First, make sure you have **~/Templates** directory in your system. If it is not available create one like below.
|
||||
|
||||
```
|
||||
$ mkdir ~/Templates
|
||||
```
|
||||
|
||||
Next open the Terminal application and cd into the **~/Templates** folder using command:
|
||||
|
||||
```
|
||||
$ cd ~/Templates
|
||||
```
|
||||
|
||||
Create an empty file:
|
||||
|
||||
```
|
||||
$ touch Empty\ Document
|
||||
```
|
||||
|
||||
Or,
|
||||
|
||||
```
|
||||
$ touch "Empty Document"
|
||||
```
|
||||
|
||||
![][4]
|
||||
|
||||
Now open your Nautilus file manager and check if “New Doucment” option is added in context menu.
|
||||
|
||||
![][5]
|
||||
|
||||
Add ‘New Document’ Option In Right Click Context Menu In Ubuntu 18.04
|
||||
|
||||
As you can see in the above screenshot, the “New Document” option is back again.
|
||||
|
||||
You can also additionally add options for different files types like below.
|
||||
|
||||
```
|
||||
$ cd ~/Templates
|
||||
|
||||
$ touch New\ Word\ Document.docx
|
||||
$ touch New\ PDF\ Document.pdf
|
||||
$ touch New\ Text\ Document.txt
|
||||
$ touch New\ PyScript.py
|
||||
```
|
||||
|
||||
![][6]
|
||||
|
||||
Add options for different files types in New Document sub-menu
|
||||
|
||||
Please note that all files should be created inside the **~/Templates** directory.
|
||||
|
||||
Now, open the Nautilus and check if the newly created file types are present in “New Document” sub-menu.
|
||||
|
||||
![][7]
|
||||
|
||||
If you want to remove any file type from the sub-menu, simply remove the appropriate file from the Templates directory.
|
||||
|
||||
```
|
||||
$ rm ~/Templates/New\ Word\ Document.docx
|
||||
```
|
||||
|
||||
I am wondering why this option has been removed in recent Ubuntu GNOME editions. I use it frequently. However, it is easy to re-enable this option in couple minutes.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-add-new-document-option-in-right-click-context-menu-in-ubuntu-18-04/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/07/Add-New-Document-Option-In-Right-Click-Context-Menu-1-720x340.png
|
||||
[2]: https://www.ostechnix.com/linux-package-managers-compared-appimage-vs-snap-vs-flatpak/
|
||||
[3]: https://www.ostechnix.com/wp-content/uploads/2019/07/new-document-option-missing.png
|
||||
[4]: https://www.ostechnix.com/wp-content/uploads/2019/07/Create-empty-document-in-Templates-directory.png
|
||||
[5]: https://www.ostechnix.com/wp-content/uploads/2019/07/Add-New-Document-Option-In-Right-Click-Context-Menu-In-Ubuntu.png
|
||||
[6]: https://www.ostechnix.com/wp-content/uploads/2019/07/Add-options-for-different-files-types.png
|
||||
[7]: https://www.ostechnix.com/wp-content/uploads/2019/07/Add-New-Document-Option-In-Right-Click-Context-Menu.png
|
||||
@ -1,91 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Get Linux Kernel 5.0 in Ubuntu 18.04 LTS)
|
||||
[#]: via: (https://itsfoss.com/ubuntu-hwe-kernel/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
How to Get Linux Kernel 5.0 in Ubuntu 18.04 LTS
|
||||
======
|
||||
|
||||
_**The recently released Ubuntu 18.04.3 includes Linux Kernel 5.0 among several new features and improvements but you won’t get it by default. This tutorial demonstrates how to get Linux Kernel 5 in Ubuntu 18.04 LTS.**_
|
||||
|
||||
[Subscribe to It’s FOSS YouTube Channel for More Videos][1]
|
||||
|
||||
The [third point release of Ubuntu 18.04 is here][2] and it brings new stable versions of GNOME component, livepatch desktop integration and kernel 5.0.
|
||||
|
||||
But wait! What is a point release? Let me explain it to you first.
|
||||
|
||||
### Ubuntu LTS point release
|
||||
|
||||
Ubuntu 18.04 was released in April 2018 and since it’s a long term support (LTS) release, it will be supported till 2023. There have been a number of bug fixes, security updates and software upgrades since then. If you download Ubuntu 18.04 today, you’ll have to install all those updates as one of the first [things to do after installing Ubuntu 18.04][3].
|
||||
|
||||
That, of course, is not an ideal situation. This is why Ubuntu provides these “point releases”. A point release consists of all the feature and security updates along with the bug fixes that has been added since the initial release of the LTS version. If you download Ubuntu today, you’ll get Ubuntu 18.04.3 instead of Ubuntu 18.04. This saves the trouble of downloading and installing hundreds of updates on a newly installed Ubuntu system.
|
||||
|
||||
Okay! So now you know the concept of point release. How do you upgrade to these point releases? The answer is simple. Just [update your Ubuntu system][4] like you normally do and you’ll be already on the latest point release.
|
||||
|
||||
You can [check Ubuntu version][5] to see which point release you are using. I did a check and since I was on Ubuntu 18.04.3, I assumed that I would have gotten Linux kernel 5 as well. When I [check the Linux kernel version][6], it was still the base kernel 4.15.
|
||||
|
||||
![Ubuntu Version And Linux Kernel Version Check][7]
|
||||
|
||||
Why is that? If Ubuntu 18.04.3 has Linux kernel 5.0 then why does it still have Linux Kernel 4.15? It’s because you have to manually ask for installing the new kernel in Ubuntu LTS by opting for LTS Enablement Stack popularly known as HWE.
|
||||
|
||||
[][8]
|
||||
|
||||
Suggested read Canonical Announces Ubuntu Edge!
|
||||
|
||||
### Get Linux Kernel 5.0 in Ubuntu 18.04 with Hardware Enablement Stack
|
||||
|
||||
By default, Ubuntu LTS release stay on the same Linux kernel they were released with. The [hardware enablement stack][9] (HWE) provides newer kernel and xorg support for existing Ubuntu LTS release.
|
||||
|
||||
Things have been changed recently. If you downloaded Ubuntu 18.04.2 or newer desktop version, HWE is enabled for you and you’ll get the new kernel along with the regular updates by default.
|
||||
|
||||
For server versions and people who downloaded 18.04 and 18.04.1, you’ll have to install the HWE kernel. Once you do that, you’ll get the newer kernel releases provided by Ubuntu to the LTS version.
|
||||
|
||||
To install HWE kernel in Ubuntu desktop along with newer xorg, you can use this command in the terminal:
|
||||
|
||||
```
|
||||
sudo apt install --install-recommends linux-generic-hwe-18.04 xserver-xorg-hwe-18.04
|
||||
```
|
||||
|
||||
If you are using Ubuntu Server edition, you won’t have the xorg option. So just install the HWE kernel in Ubutnu server:
|
||||
|
||||
```
|
||||
sudo apt-get install --install-recommends linux-generic-hwe-18.04
|
||||
```
|
||||
|
||||
Once you finish installing the HWE kernel, restart your system. Now you should have the newer Linux kernel.
|
||||
|
||||
**Are you getting kernel 5.0 in Ubuntu 18.04?**
|
||||
|
||||
Do note that HWE is enabled for people who downloaded and installed Ubuntu 18.04.2. So these users will get Kernel 5.0 without any trouble.
|
||||
|
||||
Should you go by the trouble of enabling HWE kernel in Ubuntu? It’s entirely up to you. [Linux Kernel 5.0][10] has several performance improvement and better hardware support. You’ll get the benefit of the new kernel.
|
||||
|
||||
What do you think? Will you install kernel 5.0 or will you rather stay on the kernel 4.15?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/ubuntu-hwe-kernel/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.youtube.com/channel/UCEU9D6KIShdLeTRyH3IdSvw
|
||||
[2]: https://ubuntu.com/blog/enhanced-livepatch-desktop-integration-available-with-ubuntu-18-04-3-lts
|
||||
[3]: https://itsfoss.com/things-to-do-after-installing-ubuntu-18-04/
|
||||
[4]: https://itsfoss.com/update-ubuntu/
|
||||
[5]: https://itsfoss.com/how-to-know-ubuntu-unity-version/
|
||||
[6]: https://itsfoss.com/find-which-kernel-version-is-running-in-ubuntu/
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/ubuntu-version-and-kernel-version-check.png?resize=800%2C300&ssl=1
|
||||
[8]: https://itsfoss.com/canonical-announces-ubuntu-edge/
|
||||
[9]: https://wiki.ubuntu.com/Kernel/LTSEnablementStack
|
||||
[10]: https://itsfoss.com/linux-kernel-5/
|
||||
@ -0,0 +1,121 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (4 misconceptions about ethics and bias in AI)
|
||||
[#]: via: (https://opensource.com/article/19/8/4-misconceptions-ethics-and-bias-ai)
|
||||
[#]: author: (Rachel Thomas https://opensource.com/users/rachel-thomas)
|
||||
|
||||
4 misconceptions about ethics and bias in AI
|
||||
======
|
||||
As artificial intelligence increasingly affects our lives, we must
|
||||
consider how algorithms affect real people. Join us at PyBay 2019 to
|
||||
continue the conversation.
|
||||
![A brain design in a head][1]
|
||||
|
||||
At [PyBay 2019][2] in August, I will continue a conversation I started at PyBay 2018 about the importance of ethics in the artificial intelligence (AI) we're developing, especially as it gains more and more influence in our everyday lives. In last year's keynote, I dug into how we're overlooking the essential role humans play in AI's future.
|
||||
|
||||
Ethical discussions around technology are more and more common, and I come to them from my first love, math. Math usually gives us a sense of certainty, but I have found that the more challenging, human parts of my work offer me the greatest potential to improve the world. If you're curious about the more technical side, here's a list of resources I put together:
|
||||
|
||||
> Deep Learning: <https://t.co/MhwV37J54I>
|
||||
> NLP: <https://t.co/zC31JstaF1>
|
||||
> Comp Linear Algebra: <https://t.co/CY7Gu90yLz>
|
||||
> Bias, Ethics, & AI: <https://t.co/ThSz3bnZ4k>
|
||||
> Debunk Pipeline Myth: <https://t.co/qIW64edWiQ>
|
||||
> AI Needs You: <https://t.co/xUAv2eIatU>
|
||||
> 67 Questions: <https://t.co/8m7JK57Aaq>
|
||||
>
|
||||
> — Rachel Thomas (@math_rachel) [July 9, 2019][3]
|
||||
|
||||
Misconceptions about the impact of all types and parts of technology have been common for a long time, but they are hitting home ever harder as AI systems gain increasing popularity and influence over our everyday lives. In this article, I'll walk through some common misconceptions about AI ethics then offer some healthy principles we can use to make AI work with us toward a better future.
|
||||
|
||||
### 1\. Misconception: Engineers are only responsible for the code
|
||||
|
||||
There is an idea that engineers are only responsible for their code, not how the code is used nor the quality of the outcomes it produces. The problem is that in complicated, real-world systems, which involve a mixture of software and various administrative processes, often nobody feels responsible for the outcome. For example, a software program that had bugs decreased essential healthcare services to people with serious disabilities, including cerebral palsy and diabetes, as reported in [The Verge][4]. In this case, the creator of the algorithm blamed state officials for their process, and state officials could blame the team that implemented the software, and so on, with nobody taking responsibility.
|
||||
|
||||
Systems where nobody feels responsible and there is no accountability do not lead to good outcomes. I don't bring up responsibility in order to point fingers, but because I want to help ensure good outcomes. Our code often interacts with very messy, real-world systems and can accidentally amplify those problems in an undesirable way.
|
||||
|
||||
### 2\. Misconception: Humans and computers are interchangeable
|
||||
|
||||
People often talk about human and computer decision makers as though they are plug-and-play interchangeable, or have the mindset of building machines to replicate exactly what humans do. However, humans and computers are typically used in different ways in practice.
|
||||
|
||||
One powerful example pertains to AI's value proposition—the idea that companies could scale services with AI that would be unaffordable if humans did all the work. Whether it's faster health insurance signups or recommending items on consumer sites, AI is meant to make life simpler for us and cheaper for service providers. The Trojan horse hiding here is that algorithms may be implemented in such a way that the outcome is a dead end with no appeals process and no way to catch or address mistakes. This can be incredibly harmful if a person is [fired from a job][5] or [denied needed healthcare][4] based on an algorithm without explanation or recourse.
|
||||
|
||||
People remain at risk even when we add humans back into the equation. Studies show that when given an option to override a harmful AI conclusion, people are likely to assume the code is objective or error-free and are reluctant to override "the system." In many cases, AI is being used because it is cheap, not because it is more accurate or leads to better outcomes. As [Cathy O'Neil][6] puts it, we are creating a world where "the privileged are processed by people; the poor are processed by algorithms."
|
||||
|
||||
> The privileged are processed by people; the poor are processed by algorithms. - [@mathbabedotorg][7] [pic.twitter.com/ZMEDTEPOvK][8]
|
||||
>
|
||||
> — Rachel Thomas (@math_rachel) [December 16, 2016][9]
|
||||
|
||||
Another angle posits that humans and computers are at odds with one another. That's fun in a story like competing in chess or Go, but the better issue is figuring out how machines can augment and complement human goals. Ultimately, algorithms are designed by human beings with human ends in mind.
|
||||
|
||||
### 3\. Misconception: We can't regulate the tech industry
|
||||
|
||||
I regularly hear that the tech industry is too hard to regulate and regulation won't be effective. It reminds me of a [99% Invisible podcast episode][10] about the early days of the automobile. When cars came out, there were no speed limits, licenses, or drunk driving laws, and they were made with a lot of sharp metal and shatterable glass. At the time, the idea of making cars safer was a tough conversation. People would argue that cars are inherently dangerous because the people driving them were dangerous, and that danger had nothing to do with the vehicle. At the time, the idea of making cars safer was a tough conversation, and car companies were strongly resistent to anyone discussing safety. People argued that cars were inherently dangerous because the people driving them were dangerous, and that the danger had nothing to do with the vehicle. Consumer safety advocates worked for decades to change the mindset and laws around car safety, addressing many of these previous issues.
|
||||
|
||||
Consider a case study on what is effective at spurring action: people warned executives of a large social media company for years (beginning as early as 2013) of how their platform was being used to incite ethnic violence in Myanmar, and executives took little action. After the UN determined in 2018 that the site had played a "determining role" in the Myanmar genocide, the company said they would hire "dozens" of additional moderators. Contrast this to when Germany passed a hate speech law with significant finacial penalties, and that same social media site hired 1,200 moderators in under a year to avoid being fined. The different orders of magnitude in response to [a potential fine vs a genocide][11] may provide insight into the potential effectiveness of regulation.
|
||||
|
||||
### 4\. Misconception: Tech is only about optimizing metrics
|
||||
|
||||
It can be easy to think of our job in tech being to optimize metrics and respond to consumer demand.
|
||||
|
||||
> _"Recommendation systems and collaborative filtering are never neutral; they are always ranking one video, pin, or group against another when they're deciding what to show you."_
|
||||
> –Renee Diresta, _[Wired][12]_
|
||||
|
||||
Metrics are just a proxy for the things we truly care about, and over-emphasizing metrics can lead to unintended consequences. When optimizing for viewing time, a popular video site was found to be pushing the most controversial, conspiracy-centric videos because they were the ones people on the site watched for the longest time. That metrics-only perspective resulted, for example, in people interested in lawnmower reviews being recommended extremist, white supremacist conspiracy theories.
|
||||
|
||||
We can choose to not just optimize for metrics, but also to consider desired outcomes. [Evan Estola][13] discussed what that looked like for his team at [Meetup.com][14], in his 2016 Machine Learning Conference presentation [When Recommendations Systems Go Bad][15]. Meetup's data showed that fewer women than men were going to technology-focused meetups. There was a risk that they could create an algorithm that recommended fewer tech meetups to women, which would cause fewer women to find out about tech meetups, decreasing attendance further, and then recommending even fewer tech meetups to women. That feedback loop would result in even fewer women going to tech events. Meetup decided to short-circuit that feedback loop before it was created.
|
||||
|
||||
Technology impacts the world and exposes us to new ideas. We need to think more about the values we stand for and the broader systems we want to build rather than solely optimizing for metrics.
|
||||
|
||||
### Better principles for AI
|
||||
|
||||
I share these misconceptions so we can move past them and make the world a better place. We can improve our world through the ethical use of AI.Keep the following ideas in mind to create a better future with AI:
|
||||
|
||||
* We have a responsibility to think about the whole system.
|
||||
* We need to work with domain experts and with those impacted by AI.
|
||||
* We have to find ways to leverage the strengths of computers and humans and bring them together for the best outcomes.
|
||||
* We must acknowledge regulation is both possible and has been impactful in the past.
|
||||
* We can't be afraid of hard and messy problems.
|
||||
* We can choose to optimize for impact on the world, not just for metrics.
|
||||
|
||||
|
||||
|
||||
By internalizing these concepts in our work and our daily lives, we can make the future a better place for everyone.
|
||||
|
||||
* * *
|
||||
|
||||
_Rachel Thomas will present [Getting Specific About Algorithmic Bias][16] at [PyBay 2019][17] August 17–18 in San Francisco. Use the [OpenSource35][18] discount code when purchasing tickets._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/4-misconceptions-ethics-and-bias-ai
|
||||
|
||||
作者:[Rachel Thomas][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rachel-thomas
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/LAW_patents4abstract_B.png?itok=6RHeRaYh (A brain design in a head)
|
||||
[2]: http://pybay.com/
|
||||
[3]: https://twitter.com/math_rachel/status/1148385754982363136?ref_src=twsrc%5Etfw
|
||||
[4]: https://www.theverge.com/2018/3/21/17144260/healthcare-medicaid-algorithm-arkansas-cerebral-palsy
|
||||
[5]: https://www.washingtonpost.com/local/education/creative--motivating-and-fired/2012/02/04/gIQAwzZpvR_story.html
|
||||
[6]: https://twitter.com/math_rachel/status/809810694065385472
|
||||
[7]: https://twitter.com/mathbabedotorg?ref_src=twsrc%5Etfw
|
||||
[8]: https://t.co/ZMEDTEPOvK
|
||||
[9]: https://twitter.com/math_rachel/status/809810694065385472?ref_src=twsrc%5Etfw
|
||||
[10]: https://99percentinvisible.org/episode/nut-behind-wheel/
|
||||
[11]: https://www.fast.ai/2018/04/19/facebook/#myanmar
|
||||
[12]: https://www.wired.com/story/creating-ethical-recommendation-engines/
|
||||
[13]: https://mlconf.com/speakers/evan-estola/
|
||||
[14]: http://meetup.com/
|
||||
[15]: https://mlconf.com/sessions/when-recommendations-systems-go-bad-machine-learn/
|
||||
[16]: https://pybay.com/speaker/rachel-thomas/
|
||||
[17]: https://pybay.com/
|
||||
[18]: https://ti.to/sf-python/pybay2019/discount/OpenSource35
|
||||
@ -0,0 +1,266 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (9 open source cloud native projects to consider)
|
||||
[#]: via: (https://opensource.com/article/19/8/cloud-native-projects)
|
||||
[#]: author: (Bryant Son https://opensource.com/users/brsonhttps://opensource.com/users/marcobravo)
|
||||
|
||||
9 open source cloud native projects to consider
|
||||
======
|
||||
Work with containers? Get familiar with these projects from the Cloud
|
||||
Native Computing Foundation
|
||||
![clouds in the sky with blue pattern][1]
|
||||
|
||||
As the practice of developing applications with containers is getting more popular, [cloud-native applications][2] are also on the rise. By [definition][3]:
|
||||
|
||||
> "Cloud-native technologies are used to develop applications built with services packaged in containers, deployed as microservices, and managed on elastic infrastructure through agile DevOps processes and continuous delivery workflows."
|
||||
|
||||
This description includes four elements that are integral to cloud-native applications:
|
||||
|
||||
1. Container
|
||||
2. Microservice
|
||||
3. DevOps
|
||||
4. Continuous integration and continuous delivery (CI/CD)
|
||||
|
||||
|
||||
|
||||
Although these technologies have very distinct histories, they complement each other well and have led to surprisingly exponential growth of cloud-native applications and toolsets in a short time. This [Cloud Native Computing Foundation][4] (CNCF) infographic shows the size and breadth of the cloud-native application ecosystem today.
|
||||
|
||||
![Cloud-Native Computing Foundation applications ecosystem][5]
|
||||
|
||||
Cloud-Native Computing Foundation projects
|
||||
|
||||
I mean, just look at that! And this is just a start. Just as NodeJS’s creation sparked the explosion of endless JavaScript tools, the popularity of container technology started the exponential growth of cloud-native applications.
|
||||
|
||||
The good news is that there are several organizations that oversee and connect these dots together. One is the [**Open Containers Initiative (OCI)**][6], which is a lightweight, open governance structure (or project), "formed under the auspices of the Linux Foundation for the express purpose of creating open industry standards around container formats and runtime." The other is the **CNCF**, "an open source software foundation dedicated to making cloud native computing universal and sustainable."
|
||||
|
||||
In addition to building a community around cloud-native applications generally, CNCF also helps projects set up structured governance around their cloud-native applications. CNCF created the concept of maturity levels—Sandbox, Incubating, or Graduated—which correspond to the Innovators, Early Adopters, and Early Majority tiers on the diagram below.
|
||||
|
||||
![CNCF project maturity levels][7]
|
||||
|
||||
CNCF project maturity levels
|
||||
|
||||
The CNCF has detailed [criteria][8] for each maturity level (included below for readers’ convenience). A two-thirds supermajority of the Technical Oversight Committee (TOC) is required for a project to be Incubating or Graduated.
|
||||
|
||||
### Sandbox stage
|
||||
|
||||
> To be accepted in the sandbox, a project must have at least two TOC sponsors. See the CNCF Sandbox Guidelines v1.0 for the detailed process.
|
||||
|
||||
### Incubating stage
|
||||
|
||||
> Note: The incubation level is the point at which we expect to perform full due diligence on projects.
|
||||
>
|
||||
> To be accepted to incubating stage, a project must meet the sandbox stage requirements plus:
|
||||
>
|
||||
> * Document that it is being used successfully in production by at least three independent end users which, in the TOC’s judgement, are of adequate quality and scope.
|
||||
> * Have a healthy number of committers. A committer is defined as someone with the commit bit; i.e., someone who can accept contributions to some or all of the project.
|
||||
> * Demonstrate a substantial ongoing flow of commits and merged contributions.
|
||||
> * Since these metrics can vary significantly depending on the type, scope, and size of a project, the TOC has final judgement over the level of activity that is adequate to meet these criteria
|
||||
>
|
||||
|
||||
|
||||
### Graduated stage
|
||||
|
||||
> To graduate from sandbox or incubating status, or for a new project to join as a graduated project, a project must meet the incubating stage criteria plus:
|
||||
>
|
||||
> * Have committers from at least two organizations.
|
||||
> * Have achieved and maintained a Core Infrastructure Initiative Best Practices Badge.
|
||||
> * Have completed an independent and third party security audit with results published of similar scope and quality as the following example (including critical vulnerabilities addressed): <https://github.com/envoyproxy/envoy#security-audit> and all critical vulnerabilities need to be addressed before graduation.
|
||||
> * Adopt the CNCF Code of Conduct.
|
||||
> * Explicitly define a project governance and committer process. This preferably is laid out in a GOVERNANCE.md file and references an OWNERS.md file showing the current and emeritus committers.
|
||||
> * Have a public list of project adopters for at least the primary repo (e.g., ADOPTERS.md or logos on the project website).
|
||||
> * Receive a supermajority vote from the TOC to move to graduation stage. Projects can attempt to move directly from sandbox to graduation, if they can demonstrate sufficient maturity. Projects can remain in an incubating state indefinitely, but they are normally expected to graduate within two years.
|
||||
>
|
||||
|
||||
|
||||
## 9 projects to consider
|
||||
|
||||
While it’s impossible to cover all of the CNCF projects in this article, I’ll describe are nine of most interesting Graduated and Incubating open source projects.
|
||||
|
||||
Name | License | What It Is
|
||||
---|---|---
|
||||
[Kubernetes][9] | Apache 2.0 | Orchestration platform for containers
|
||||
[Prometheus][10] | Apache 2.0 | Systems and service monitoring tool
|
||||
[Envoy][11] | Apache 2.0 | Edge and service proxy
|
||||
[rkt][12] | Apache 2.0 | Pod-native container engine
|
||||
[Jaeger][13] | Apache 2.0 | Distributed tracing system
|
||||
[Linkerd][14] | Apache 2.0 | Transparent service mesh
|
||||
[Helm][15] | Apache 2.0 | Kubernetes package manager
|
||||
[Etcd][16] | Apache 2.0 | Distributed key-value store
|
||||
[CRI-O][17] | Apache 2.0 | Lightweight runtime for Kubernetes
|
||||
|
||||
I also created this video tutorial to walk through these projects.
|
||||
|
||||
## Graduated projects
|
||||
|
||||
Graduated projects are considered mature—adopted by many organizations—and must adhere to the CNCF’s guidelines. Following are three of the most popular open source CNCF Graduated projects. (Note that some of these descriptions are adapted and reused from the projects' websites.)
|
||||
|
||||
### Kubernetes
|
||||
|
||||
Ah, Kubernetes. How can we talk about cloud-native applications without mentioning Kubernetes? Invented by Google, Kubernetes is undoubtedly the most famous container-orchestration platform for container-based applications, and it is also an open source tool.
|
||||
|
||||
What is a container orchestration platform? Basically, a container engine on its own may be okay for managing a few containers. However, when you are talking about thousands of containers and hundreds of services, managing those containers becomes super complicated. This is where the container engine comes in. The container-orchestration engine helps scale containers by automating the deployment, management, networking, and availability of containers.
|
||||
|
||||
Docker Swarm and Mesosphere Marathon are other container-orchestration engines, but it is safe to say that Kubernetes has won the race (at least for now). Kubernetes also gave birth to Container-as-a-Service (CaaS) platforms like [OKD][18], the Origin community distribution of Kubernetes that powers [Red Hat OpenShift][19].
|
||||
|
||||
To get started, visit the [Kubernetes GitHub repository][9], and access its documentation and learning resources from the [Kubernetes documentation][20] page.
|
||||
|
||||
### Prometheus
|
||||
|
||||
Prometheus is an open source system monitoring and alerting toolkit built at SoundCloud in 2012. Since then, many companies and organizations have adopted Prometheus, and the project has a very active developer and user community. It is now a standalone open source project that is maintained independently of the company.
|
||||
|
||||
![Prometheus’ architecture][21]
|
||||
|
||||
Prometheus’ architecture
|
||||
|
||||
The easiest way to think about Prometheus is to visualize a production system that needs to be up 24 hours a day and 365 days a year. No system is perfect, and there are techniques to reduce failures (called fault-tolerant systems). However, if an issue occurs, the most important thing is to identify it as soon as possible. That is where a monitoring tool like Prometheus comes in handy. Prometheus is more than a container-monitoring tool, but it is most popular among cloud-native application companies. In addition, other open source monitoring tools, including [Grafana][22], leverage Prometheus.
|
||||
|
||||
The best way to get started with Prometheus is to check out its [GitHub repo][10]. Running Prometheus locally is easy, but you need to have a container engine installed. You can access detailed documentation on [Prometheus’ website][23].
|
||||
|
||||
### Envoy
|
||||
|
||||
Envoy (or Envoy Proxy) is an open source edge and service proxy designed for cloud-native applications. Created at Lyft, Envoy is a high-performance, C++, distributed proxy designed for single services and applications, as well as a communications bus and a universal data plane designed for large microservice service mesh architectures. Built on the learnings of solutions such as Nginx, HAProxy, hardware load balancers, and cloud load balancers, Envoy runs alongside every application and abstracts the network by providing common features in a platform-agnostic manner.
|
||||
|
||||
When all service traffic in an infrastructure flows through an Envoy mesh, it becomes easy to visualize problem areas via consistent observability, tune overall performance, and add substrate features in a single place. Basically, Envoy Proxy is a service mesh tool that helps organizations build a fault-tolerant system for production environments.
|
||||
|
||||
There are numerous alternatives for service mesh applications, such as Uber’s [Linkerd][24] (discussed below) and [Istio][25]. Istio extends Envoy Proxy by deploying as a [Sidecar][26] and leveraging the [Mixer][27] configuration model. Notable Envoy features are:
|
||||
|
||||
* All the "table stakes" features (when paired with a control plane, like Istio) are included
|
||||
* Low, 99th percentile latencies at scale when running under load
|
||||
* Acts as an L3/L4 filter at its core with many L7 filters provided out of the box
|
||||
* Support for gRPC and HTTP/2 (upstream/downstream)
|
||||
* It’s API-driven and supports dynamic configuration and hot reloads
|
||||
* Has a strong focus on metric collection, tracing, and overall observability
|
||||
|
||||
|
||||
|
||||
Understanding Envoy, proving its capabilities, and realizing its full benefits require extensive experience with running production-level environments. You can learn more in its [detailed documentation][28] and by accessing its [GitHub][11] repository.
|
||||
|
||||
## Incubating projects
|
||||
|
||||
Following are six of the most popular open source CNCF Incubating projects.
|
||||
|
||||
### rkt
|
||||
|
||||
rkt, pronounced "rocket," is a pod-native container engine. It has a command-line interface (CLI) for running containers on Linux. In a sense, it is similar to other containers, like [Podman][29], Docker, and CRI-O.
|
||||
|
||||
rkt was originally developed by CoreOS (later acquired by Red Hat), and you can find detailed [documentation][30] on its website and access the source code on [GitHub][12].
|
||||
|
||||
### Jaeger
|
||||
|
||||
Jaeger is an open source, end-to-end distributed tracing system for cloud-native applications. In one way, it is a monitoring solution like Prometheus. Yet it is different because its use cases extend into:
|
||||
|
||||
* Distributed transaction monitoring
|
||||
* Performance and latency optimization
|
||||
* Root-cause analysis
|
||||
* Service dependency analysis
|
||||
* Distributed context propagation
|
||||
|
||||
|
||||
|
||||
Jaeger is an open source technology built by Uber. You can find [detailed documentation][31] on its website and its [source code][13] on GitHub.
|
||||
|
||||
### Linkerd
|
||||
|
||||
Like Lyft with Envoy Proxy, Uber developed Linkerd as an open source solution to maintain its service at the production level. In some ways, Linkerd is just like Envoy, as both are service mesh tools designed to give platform-wide observability, reliability, and security without requiring configuration or code changes.
|
||||
|
||||
However, there are some subtle differences between the two. While Envoy and Linkerd function as proxies and can report over services that are connected, Envoy isn’t designed to be a Kubernetes Ingress controller, as Linkerd is. Notable features of Linkerd include:
|
||||
|
||||
* Support for multiple platforms (Docker, Kubernetes, DC/OS, Amazon ECS, or any stand-alone machine)
|
||||
* Built-in service discovery abstractions to unite multiple systems
|
||||
* Support for gRPC, HTTP/2, and HTTP/1.x requests plus all TCP traffic
|
||||
|
||||
|
||||
|
||||
You can read more about it on [Linkerd’s website][32] and access its source code on [GitHub][14].
|
||||
|
||||
### Helm
|
||||
|
||||
Helm is basically the package manager for Kubernetes. If you’ve used Apache Maven, Maven Nexus, or a similar service, you will understand Helm’s purpose. Helm helps you manage your Kubernetes application. It uses "Helm Charts" to define, install, and upgrade even the most complex Kubernetes applications. Helm isn’t the only method for this; another concept becoming popular is [Kubernetes Operators][33], which are used by Red Hat OpenShift 4.
|
||||
|
||||
You can try Helm by following the [quickstart guide][34] in its documentation or its [GitHub guide][15].
|
||||
|
||||
### Etcd
|
||||
|
||||
Etcd is a distributed, reliable key-value store for the most critical data in a distributed system. Its key features are:
|
||||
|
||||
* Well-defined, user-facing API (gRPC)
|
||||
* Automatic TLS with optional client certificate authentication
|
||||
* Speed (benchmarked at 10,000 writes per second)
|
||||
* Reliability (distributed using Raft)
|
||||
|
||||
|
||||
|
||||
Etcd is used as a built-in default data storage for Kubernetes and many other technologies. That said, it is rarely run independently or as a separate service; instead, it utilizes the one integrated into Kubernetes, OKD/OpenShift, or another service. There is also an [etcd Operator][35] to manage its lifecycle and unlock its API management capabilities:
|
||||
|
||||
You can learn more in [etcd’s documentation][36] and access its [source code][16] on GitHub.
|
||||
|
||||
### CRI-O
|
||||
|
||||
CRI-O is an Open Container Initiative (OCI)-compliant implementation of the Kubernetes runtime interface. CRI-O is used for various functions including:
|
||||
|
||||
* Runtime using runc (or any OCI runtime-spec implementation) and OCI runtime tools
|
||||
* Image management using containers/image
|
||||
* Storage and management of image layers using containers/storage
|
||||
* Networking support through the Container Network Interface (CNI)
|
||||
|
||||
|
||||
|
||||
CRI-O provides plenty of [documentation][37], including guides, tutorials, articles, and even podcasts, and you can also access its [GitHub page][17].
|
||||
|
||||
* * *
|
||||
|
||||
Did I miss an interesting open source cloud-native project? Please let me know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/cloud-native-projects
|
||||
|
||||
作者:[Bryant Son][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/brsonhttps://opensource.com/users/marcobravo
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003601_05_mech_osyearbook2016_cloud_cc.png?itok=XSV7yR9e (clouds in the sky with blue pattern)
|
||||
[2]: https://opensource.com/article/18/7/what-are-cloud-native-apps
|
||||
[3]: https://thenewstack.io/10-key-attributes-of-cloud-native-applications/
|
||||
[4]: https://www.cncf.io
|
||||
[5]: https://opensource.com/sites/default/files/uploads/cncf_1.jpg (Cloud-Native Computing Foundation applications ecosystem)
|
||||
[6]: https://www.opencontainers.org
|
||||
[7]: https://opensource.com/sites/default/files/uploads/cncf_2.jpg (CNCF project maturity levels)
|
||||
[8]: https://github.com/cncf/toc/blob/master/process/graduation_criteria.adoc
|
||||
[9]: https://github.com/kubernetes/kubernetes
|
||||
[10]: https://github.com/prometheus/prometheus
|
||||
[11]: https://github.com/envoyproxy/envoy
|
||||
[12]: https://github.com/rkt/rkt
|
||||
[13]: https://github.com/jaegertracing/jaeger
|
||||
[14]: https://github.com/linkerd/linkerd
|
||||
[15]: https://github.com/helm/helm
|
||||
[16]: https://github.com/etcd-io/etcd
|
||||
[17]: https://github.com/cri-o/cri-o
|
||||
[18]: https://www.okd.io/
|
||||
[19]: https://www.openshift.com
|
||||
[20]: https://kubernetes.io/docs/home
|
||||
[21]: https://opensource.com/sites/default/files/uploads/cncf_3.jpg (Prometheus’ architecture)
|
||||
[22]: https://grafana.com
|
||||
[23]: https://prometheus.io/docs/introduction/overview
|
||||
[24]: https://linkerd.io/
|
||||
[25]: https://istio.io/
|
||||
[26]: https://istio.io/docs/reference/config/networking/v1alpha3/sidecar
|
||||
[27]: https://istio.io/docs/reference/config/policy-and-telemetry
|
||||
[28]: https://www.envoyproxy.io/docs/envoy/latest
|
||||
[29]: https://podman.io
|
||||
[30]: https://coreos.com/rkt/docs/latest
|
||||
[31]: https://www.jaegertracing.io/docs/1.13
|
||||
[32]: https://linkerd.io/2/overview
|
||||
[33]: https://coreos.com/operators
|
||||
[34]: https://helm.sh/docs
|
||||
[35]: https://github.com/coreos/etcd-operator
|
||||
[36]: https://etcd.io/docs/v3.3.12
|
||||
[37]: https://github.com/cri-o/cri-o/blob/master/awesome.md
|
||||
203
sources/tech/20190814 How to install Python on Windows.md
Normal file
203
sources/tech/20190814 How to install Python on Windows.md
Normal file
@ -0,0 +1,203 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to install Python on Windows)
|
||||
[#]: via: (https://opensource.com/article/19/8/how-install-python-windows)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/sethhttps://opensource.com/users/greg-p)
|
||||
|
||||
How to install Python on Windows
|
||||
======
|
||||
Install Python, run an IDE, and start coding right from your Microsoft
|
||||
Windows desktop.
|
||||
![Hands programming][1]
|
||||
|
||||
So you want to learn to program? One of the most common languages to start with is [Python][2], popular for its unique blend of [object-oriented][3] structure and simple syntax. Python is also an _interpreted_ _language_, meaning you don't need to learn how to compile code into machine language: Python does that for you, allowing you to test your programs sometimes instantly and, in a way, while you write your code.
|
||||
|
||||
Just because Python is easy to learn doesn't mean you should underestimate its potential power. Python is used by [movie][4] [studios][5], financial institutions, IT houses, video game studios, makers, hobbyists, [artists][6], teachers, and many others.
|
||||
|
||||
On the other hand, Python is also a serious programming language, and learning it takes dedication and practice. Then again, you don't have to commit to anything just yet. You can install and try Python on nearly any computing platform, so if you're on Windows, this article is for you.
|
||||
|
||||
If you want to try Python on a completely open source operating system, you can [install Linux][7] and then [try Python][8].
|
||||
|
||||
### Get Python
|
||||
|
||||
Python is available from its website, [Python.org][9]. Once there, hover your mouse over the **Downloads** menu, then over the **Windows** option, and then click the button to download the latest release.
|
||||
|
||||
![Downloading Python on Windows][10]
|
||||
|
||||
Alternatively, you can click the **Downloads** menu button and select a specific version from the downloads page.
|
||||
|
||||
### Install Python
|
||||
|
||||
Once the package is downloaded, open it to start the installer.
|
||||
|
||||
It is safe to accept the default install location, and it's vital to add Python to PATH. If you don't add Python to your PATH, then Python applications won't know where to find Python (which they require in order to run). This is _not_ selected by default, so activate it at the bottom of the install window before continuing!
|
||||
|
||||
![Select "Add Python 3 to PATH"][11]
|
||||
|
||||
Before Windows allows you to install an application from a publisher other than Microsoft, you must give your approval. Click the **Yes** button when prompted by the **User Account Control** system.
|
||||
|
||||
![Windows UAC][12]
|
||||
|
||||
Wait patiently for Windows to distribute the files from the Python package into the appropriate locations, and when it's finished, you're done installing Python.
|
||||
|
||||
Time to play.
|
||||
|
||||
### Install an IDE
|
||||
|
||||
To write programs in Python, all you really need is a text editor, but it's convenient to have an integrated development environment (IDE). An IDE integrates a text editor with some friendly and helpful Python features. IDLE 3 and NINJA-IDE are two options to consider.
|
||||
|
||||
#### IDLE 3
|
||||
|
||||
Python comes with an IDE called IDLE. You can write code in any text editor, but using an IDE provides you with keyword highlighting to help detect typos, a **Run** button to test code quickly and easily, and other code-specific features that a plain text editor like [Notepad++][13] normally doesn't have.
|
||||
|
||||
To start IDLE, click the **Start** (or **Window**) menu and type **python** for matches. You may find a few matches, since Python provides more than one interface, so make sure you launch IDLE.
|
||||
|
||||
![IDLE 3 IDE][14]
|
||||
|
||||
If you don't see Python in the Start menu, launch the Windows command prompt by typing **cmd** in the Start menu, then type:
|
||||
|
||||
|
||||
```
|
||||
`C:\Windows\py.exe`
|
||||
```
|
||||
|
||||
If that doesn't work, try reinstalling Python. Be sure to select **Add Python to PATH** in the install wizard. Refer to the [Python docs][15] for detailed instructions.
|
||||
|
||||
#### Ninja-IDE
|
||||
|
||||
If you already have some coding experience and IDLE seems too simple for you, try [Ninja-IDE][16]. Ninja-IDE is an excellent Python IDE. It has keyword highlighting to help detect typos, quotation and parenthesis completion to avoid syntax errors, line numbers (helpful when debugging), indentation markers, and a **Run** button to test code quickly and easily.
|
||||
|
||||
![Ninja-IDE][17]
|
||||
|
||||
To install it, visit the Ninja-IDE website and [download the Windows installer][18]. The process is the same as with Python: start the installer, allow Windows to install a non-Microsoft application, and wait for the installer to finish.
|
||||
|
||||
Once Ninja-IDE is installed, double-click the Ninja-IDE icon on your desktop or select it from the Start menu.
|
||||
|
||||
### Tell Python what to do
|
||||
|
||||
Keywords tell Python what you want it to do. In either IDLE or Ninja-IDE, go to the File menu and create a new file.
|
||||
|
||||
Ninja users: Do not create a new project, just a new file.
|
||||
|
||||
In your new, empty file, type this into IDLE or Ninja-IDE:
|
||||
|
||||
|
||||
```
|
||||
`print("Hello world.")`
|
||||
```
|
||||
|
||||
* If you are using IDLE, go to the Run menu and select the Run Module option.
|
||||
* If you are using Ninja, click the Run File button in the left button bar.
|
||||
|
||||
|
||||
|
||||
![Running code in Ninja-IDE][19]
|
||||
|
||||
Any time you run code, your IDE prompts you to save the file you're working on. Do that before continuing.
|
||||
|
||||
The keyword **print** tells Python to print out whatever text you give it in parentheses and quotes.
|
||||
|
||||
That's not very exciting, though. At its core, Python has access to only basic keywords like **print** and **help**, basic math functions, and so on.
|
||||
|
||||
Use the **import** keyword to load more keywords. Start a new file in IDLE or Ninja and name it **pen.py**.
|
||||
|
||||
**Warning**: Do not call your file **turtle.py**, because **turtle.py** is the name of the file that contains the turtle program you are controlling. Naming your file **turtle.py** confuses Python because it thinks you want to import your own file.
|
||||
|
||||
Type this code into your file and run it:
|
||||
|
||||
|
||||
```
|
||||
`import turtle`
|
||||
```
|
||||
|
||||
[Turtle][20] is a fun module to use. Add this code to your file:
|
||||
|
||||
|
||||
```
|
||||
turtle.begin_fill()
|
||||
turtle.forward(100)
|
||||
turtle.left(90)
|
||||
turtle.forward(100)
|
||||
turtle.left(90)
|
||||
turtle.forward(100)
|
||||
turtle.left(90)
|
||||
turtle.forward(100)
|
||||
turtle.end_fill()
|
||||
```
|
||||
|
||||
See what shapes you can draw with the turtle module.
|
||||
|
||||
To clear your turtle drawing area, use the **turtle.clear()** keyword. What do you think the keyword **turtle.color("blue")** does?
|
||||
|
||||
Try more complex code:
|
||||
|
||||
|
||||
```
|
||||
import turtle as t
|
||||
import time
|
||||
|
||||
t.color("blue")
|
||||
t.begin_fill()
|
||||
|
||||
counter = 0
|
||||
|
||||
while counter < 4:
|
||||
t.forward(100)
|
||||
t.left(90)
|
||||
counter = counter+1
|
||||
|
||||
t.end_fill()
|
||||
time.sleep(2)
|
||||
```
|
||||
|
||||
As a challenge, try changing your script to get this result:
|
||||
|
||||
![Example Python turtle output][21]
|
||||
|
||||
Once you complete that script, you're ready to move on to more exciting modules. A good place to start is this [introductory dice game][22].
|
||||
|
||||
### Stay Pythonic
|
||||
|
||||
Python is a fun language with modules for practically anything you can think to do with it. As you can see, it's easy to get started with Python, and as long as you're patient with yourself, you may find yourself understanding and writing Python code with the same fluidity as you write your native language. Work through some [Python articles][23] here on Opensource.com, try scripting some small tasks for yourself, and see where Python takes you. To really integrate Python with your daily workflow, you might even try Linux, which is natively scriptable in ways no other operating system is. You might find yourself, given enough time, using the applications you create!
|
||||
|
||||
Good luck, and stay Pythonic.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/how-install-python-windows
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/sethhttps://opensource.com/users/greg-p
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/programming-code-keyboard-laptop.png?itok=pGfEfu2S (Hands programming)
|
||||
[2]: https://www.python.org/
|
||||
[3]: https://opensource.com/article/19/7/get-modular-python-classes
|
||||
[4]: https://github.com/edniemeyer/weta_python_db
|
||||
[5]: https://www.python.org/about/success/ilm/
|
||||
[6]: https://opensource.com/article/19/7/rgb-cube-python-scribus
|
||||
[7]: https://opensource.com/article/19/7/ways-get-started-linux
|
||||
[8]: https://opensource.com/article/17/10/python-101
|
||||
[9]: https://www.python.org/downloads/
|
||||
[10]: https://opensource.com/sites/default/files/uploads/win-python-install.jpg (Downloading Python on Windows)
|
||||
[11]: https://opensource.com/sites/default/files/uploads/win-python-path.jpg (Select "Add Python 3 to PATH")
|
||||
[12]: https://opensource.com/sites/default/files/uploads/win-python-publisher.jpg (Windows UAC)
|
||||
[13]: https://notepad-plus-plus.org/
|
||||
[14]: https://opensource.com/sites/default/files/uploads/idle3.png (IDLE 3 IDE)
|
||||
[15]: http://docs.python.org/3/using/windows.html
|
||||
[16]: http://ninja-ide.org/
|
||||
[17]: https://opensource.com/sites/default/files/uploads/win-python-ninja.jpg (Ninja-IDE)
|
||||
[18]: http://ninja-ide.org/downloads/
|
||||
[19]: https://opensource.com/sites/default/files/uploads/ninja_run.png (Running code in Ninja-IDE)
|
||||
[20]: https://opensource.com/life/15/8/python-turtle-graphics
|
||||
[21]: https://opensource.com/sites/default/files/uploads/win-python-idle-turtle.jpg (Example Python turtle output)
|
||||
[22]: https://opensource.com/article/17/10/python-101#python-101-dice-game
|
||||
[23]: https://opensource.com/sitewide-search?search_api_views_fulltext=Python
|
||||
80
sources/tech/20190814 Taz Brown- How Do You Fedora.md
Normal file
80
sources/tech/20190814 Taz Brown- How Do You Fedora.md
Normal file
@ -0,0 +1,80 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Taz Brown: How Do You Fedora?)
|
||||
[#]: via: (https://fedoramagazine.org/taz-brown-how-do-you-fedora/)
|
||||
[#]: author: (Charles Profitt https://fedoramagazine.org/author/cprofitt/)
|
||||
|
||||
Taz Brown: How Do You Fedora?
|
||||
======
|
||||
|
||||
![Taz Brown: How Do You Fedora?][1]
|
||||
|
||||
We recently interviewed Taz Brown on how she uses Fedora. This is part of a series on the Fedora Magazine. The series profiles Fedora users and how they use Fedora to get things done. Contact us on the [feedback][2] form to express your interest in becoming a interviewee.
|
||||
|
||||
Taz Brown is a seasoned IT professional with over 15 years of experience. “I have worked as a systems administrator, senior Linux administrator, DevOps engineer and I now work as a senior Ansible automation consultant at Red Hat with the Automation Practice Team.” Originally Taz started using Ubuntu, but she started using CentOS, Red Hat Enterprise Linux and Fedora as a Linux administrator in the IT industry.
|
||||
|
||||
Taz is relatively new to contributing to open source, but she found that code was not the only way to contribute. “I prefer to contribute through documentation as I am not a software developer or engineer. I found that there was more than one way to contribute to open source than just through code.”
|
||||
|
||||
### All about Taz
|
||||
|
||||
Her childhood hero is Wonder Woman. Her favorite movie is Hackers. “My favorite scene is the beginning of the movie,” Taz tells the Magazine. “The movie starts with a group of special agents breaking into a house to catch the infamous hacker, Zero Cool. We soon discover that Zero Cool is actually 11-year-old Dade Murphy, who managed to crash 1,507 computer systems in one day. He is charged for his crimes and his family is fined $45,000. Additionally, he is banned from using computers or touch-tone telephones until he is 18.”
|
||||
|
||||
Her favorite character in the movie is Paul Cook. “Paul Cook, Lord Nikon, played by Laurence Mason was my favorite character. One of the main reasons is that I never really saw a hacker movie that had characters that looked like me so I was fascinated by his portrayal. He was enigmatic. It was refreshing to see and it made me real proud that I was passionate about IT and that I was a geek of sorts.”
|
||||
|
||||
Taz is an amateur photographer and uses a Nikon D3500. “I definitely like vintage things so I am looking to add a new one to my collection soon.” She also enjoys 3D printing, and drawing. “I use open source tools in my hobbies such as Wekan, which is an open-source kanban utility.”
|
||||
|
||||
![][3]
|
||||
|
||||
### The Fedora community
|
||||
|
||||
Taz first started using Linux about 8 years ago. “I started using Ubuntu and then graduated to Fedora and its community and I was hooked. I have been using Fedora now for about 5 years.”
|
||||
|
||||
When she became a Linux Administrator, Linux turned into a passion. “I was trying to find my way in terms of contributing to open source. I didn’t know where to go so I wondered if I could truly be an open source enthusiast and influencer because the community is so vast, but once I found a few people who embraced my interests and could show me the way, I was able to open up and ask questions and learn from the community.”
|
||||
|
||||
Taz first became involved with the Fedora community through her work as a Linux systems engineer while working at Mastercard. “My first impressions of the Fedora community was one of true collaboration, respect and sharing.”
|
||||
|
||||
When Brown talked about the Fedora Project she gave an excellent analogy. “America is an melting pot and that’s how I see open source projects like the Fedora Project. There is plenty of room for diverse contributions to the Fedora Project. There are so many ways in which to get and stay involved and there is also room for new ideas.”
|
||||
|
||||
When we asked Brown about what she would like to see improved in the Fedora community, she commented on making others more aware of the opportunities. “I wish those who are typically underrepresented in tech were more aware of the amazing commitment that the Fedora Project has to diversity and inclusion in open source and in the Fedora community.”
|
||||
|
||||
Next Taz had some advice for people looking to join the Fedora Community. “It’s a great decision and one that you likely will not regret joining. Fedora is a project with a very large supportive community and if you’re new to open source, it’s definitely a great place to start. There is a lot of cool stuff in Fedora. I believe there are limitless opportunities for The Fedora Project.”
|
||||
|
||||
### What hardware?
|
||||
|
||||
Taz uses an Lenovo Thinkserver TS140 with 64 GB of ram, 4 1 TB SSDs and a 1 TB HD for data storage. The server is currently running Fedora 30. She also has a Synology NAS with 164 TB of storage using a RAID 5 configuration. Taz also has a Logitech MX Master and MX Master 2S. “For my keyboard, I use a Kinesis Advantage 2.” She also uses two 38 inch LG ultrawide curved monitors and a single 34 inch LG ultrawide monitor.
|
||||
|
||||
She owns a System76 laptop. “I use the 16.1-inch Oryx Pro by System76 with IPS Display with i7 processor with 6 cores and 12 threads.” It has 6 GB GDDR6 RTX 2060 w/ 1920 CUDA Cores and also 64 GB of DDR4 RAM and a total of 4 TB of SSD storage. “I love the way Fedora handles my peripherals and like my mouse and keyboard. Everything works seamlessly. Plug and play works as it should and performance never suffers.”
|
||||
|
||||
![][4]
|
||||
|
||||
### What software?
|
||||
|
||||
Brown is currently running Fedora 30. She has a variety of software in her everyday work flow. “I use Wekan, which is an open-source kanban, which I use to manage my engagements and projects. My favorite editor is [Atom][5], though I use to use Sublime at one point in time.”
|
||||
|
||||
And as for terminals? “I use Terminator as my go-to terminal because of grid arrangement as well as it’s many keyboard shortcuts and its tab formation.” Taz continues, “I love using neofetch which comes up with a nifty fedora logo and system information every time I log in to the terminal. I also have my terminal pimped out using [powerline][6] and powerlevel9k and vim-powerline as well.”
|
||||
|
||||
![][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/taz-brown-how-do-you-fedora/
|
||||
|
||||
作者:[Charles Profitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/cprofitt/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/07/header-use-this-816x345.png
|
||||
[2]: https://fedoramag.wpengine.com/submit-an-idea-or-tip/
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2019/08/Image-1.png
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2019/08/20190517_171809-1-1024x768.jpg
|
||||
[5]: https://fedoramagazine.org/install-atom-fedora/
|
||||
[6]: https://fedoramagazine.org/add-power-terminal-powerline/
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2019/08/screens-1024x421.jpg
|
||||
@ -0,0 +1,140 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Clementine Music Player for All Your Audio Needs)
|
||||
[#]: via: (https://itsfoss.com/clementine-music-player/)
|
||||
[#]: author: (John Paul https://itsfoss.com/author/john/)
|
||||
|
||||
Clementine Music Player for All Your Audio Needs
|
||||
======
|
||||
|
||||
[VLC][1] is a mainstay for most fans of FOSS technology and most Linux distros. It’s a great little player, don’t get me wrong, but if you have a large library of audio files, some times you need something more powerful.
|
||||
|
||||
The [Clementine Music Player][2] is a full-service audio player with all the tools you need to keep track of your audio library. According to the [project’s website][3], Clementine “inspired by Amarok 1.4, focusing on a fast and easy-to-use interface for searching and playing your music.”
|
||||
|
||||
![Clementine Music Player][4]
|
||||
|
||||
Clementine contains the following features:
|
||||
|
||||
* Search and play your local music library
|
||||
* Listen to internet radio from Spotify, Grooveshark, SomaFM, Magnatune, Jamendo, SKY.fm, Digitally Imported, JAZZRADIO.com, Soundcloud, Icecast and Subsonic servers
|
||||
* Search and play songs you’ve uploaded to Box, Dropbox, Google Drive, and OneDrive
|
||||
* Create smart playlists and dynamic playlists
|
||||
* Tabbed playlists, import and export M3U, XSPF, PLS and ASX
|
||||
* CUE sheet support
|
||||
* Play audio CDs
|
||||
* Visualizations from projectM.
|
||||
* Lyrics and artist biographies and photos
|
||||
* Transcode music into MP3, Ogg Vorbis, Ogg Speex, FLAC or AAC
|
||||
* Edit tags on MP3 and OGG files, organize your music
|
||||
* Fetch missing tags from MusicBrainz
|
||||
* Discover and download Podcasts
|
||||
* Download missing album cover art from Last.fm and Amazon
|
||||
* Cross-platform – works on Windows, Mac OS X and Linux
|
||||
* Native desktop notifications on Linux (libnotify) and Mac OS X (Growl)
|
||||
* Remote control using an [Android device][5], a Wii Remote, MPRIS or the command-line
|
||||
* Copy music to your iPod, iPhone, MTP or mass-storage USB player. Queue manager
|
||||
|
||||
|
||||
|
||||
Clementine is released under the GPL v3. The most recent version of Clementine (1.3.1) was released in April of 2016.
|
||||
|
||||
### Installing Clementine music player in Linux
|
||||
|
||||
Now let’s take a look at how you can install Clementine on your system. Clementine is a popular application and is available in almost all major Linux distributions.
|
||||
|
||||
You can search for it on your distribution’s software center:
|
||||
|
||||
![Clementine in Ubuntu Software Center][6]
|
||||
|
||||
If you are feeling a little geeky, you can always hop on the terminal train and use your distribution’s package manger to install Clementine.
|
||||
|
||||
[][7]
|
||||
|
||||
Suggested read Clementine Version 1.3 Released After 2 Years
|
||||
|
||||
In Ubuntu, Clementine is available in the [Universe repository][8]. You can [use the apt command][9] in this fashion:
|
||||
|
||||
```
|
||||
sudo apt install clementine
|
||||
```
|
||||
|
||||
In Fedora, you can use this command:
|
||||
|
||||
```
|
||||
sudo dnf clementine
|
||||
```
|
||||
|
||||
In Manjaro or other Arch-based distributions, you can use:
|
||||
|
||||
```
|
||||
sudo pacman -S clementine
|
||||
```
|
||||
|
||||
You can find a list of Linux distros that have Clementine in their repos [here][10]. You can also download packages directly from the [Clementine site][11].
|
||||
|
||||
If you have a Windows system, you can download a .exe from the [project’s download page][11].
|
||||
|
||||
### Experience with Clementine music player
|
||||
|
||||
I have installed Clementine on multiple Linux and Windows systems. I have a large collection of Old Time Radio shows, audio drama, and some music. Clementine does a good job of keeping it all organized.
|
||||
|
||||
![Clementine Library][12]
|
||||
|
||||
I also used it to download and listen to podcasts. It worked well for that. However, I did not use that part very much.
|
||||
|
||||
I didn’t use the cloud options because I don’t trust the cloud with my audio stuff.
|
||||
|
||||
![Clementine Cloud Settings][13]
|
||||
|
||||
### Final Thoughts on Clementine
|
||||
|
||||
I like Clementine. I installed it on multiple systems. I only used a small portion of the wide range of tools it offers and they worked great.
|
||||
|
||||
The only thing that concerns me is that the developers haven’t updated the project in three years. The [project’s GitHub page][14] has almost 2,000 open issues and 40 pending pull requests. I can understand that the developers might think that the project is stable and mature, but it looks like some users are having issues that are not being addressed.
|
||||
|
||||
I guess this is the reason why Clementine has been forked into [Strawberry music player][15].
|
||||
|
||||
If you are looking for an audio management program that is updated regularly, you may check out [Sayonara music player][16].
|
||||
|
||||
Have you ever used Clementine? What is your favorite music player/manager? Please let us know in the comments below.
|
||||
|
||||
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][17].
|
||||
|
||||
[][18]
|
||||
|
||||
Suggested read UberWriter: Uber Cool Markdown Editor for Linux
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/clementine-music-player/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/install-latest-vlc/
|
||||
[2]: https://www.clementine-player.org/
|
||||
[3]: https://www.clementine-player.org/about
|
||||
[4]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/clementine-music-player.jpg?ssl=1
|
||||
[5]: https://play.google.com/store/apps/details?id=de.qspool.clementineremote
|
||||
[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/clementine-ubuntu-software-center.jpg?resize=800%2C391&ssl=1
|
||||
[7]: https://itsfoss.com/clementine-version-1-3-released/
|
||||
[8]: https://itsfoss.com/ubuntu-repositories/
|
||||
[9]: https://itsfoss.com/apt-command-guide/
|
||||
[10]: https://repology.org/project/clementine-player/versions
|
||||
[11]: https://www.clementine-player.org/downloads
|
||||
[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/clementine-library.png?resize=800%2C579&ssl=1
|
||||
[13]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/07/clementine-cloud-settings.png?resize=800%2C488&ssl=1
|
||||
[14]: https://github.com/clementine-player/Clementine
|
||||
[15]: https://itsfoss.com/strawberry-music-player/
|
||||
[16]: https://itsfoss.com/sayonara-music-player/
|
||||
[17]: http://reddit.com/r/linuxusersgroup
|
||||
[18]: https://itsfoss.com/uberwriter/
|
||||
@ -0,0 +1,168 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Set up Automatic Security Update (Unattended Upgrades) on Debian/Ubuntu?)
|
||||
[#]: via: (https://www.2daygeek.com/automatic-security-update-unattended-upgrades-ubuntu-debian/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
How To Set up Automatic Security Update (Unattended Upgrades) on Debian/Ubuntu?
|
||||
======
|
||||
|
||||
One of an important task for Linux admins to make the system up-to-date.
|
||||
|
||||
It’s keep your system more stable and avoid unwanted access and attack.
|
||||
|
||||
Installing a package in Linux is a piece of cake.
|
||||
|
||||
In the similar way we can update security patches as well.
|
||||
|
||||
This is a simple tutorial that will show you to configure your system to receive automatic security updates.
|
||||
|
||||
There are some security risks involved when you running an automatic security package upgrades without inspection, but there are also benefits.
|
||||
|
||||
If you don’t want to miss security patches and would like to stay up-to-date with the latest security patches.
|
||||
|
||||
Then you should set up an automatic security update with help of unattended upgrades utility.
|
||||
|
||||
You can **[manually install Security Updates on Debian & Ubuntu systems][1]** if you don’t want to go for automatic security update.
|
||||
|
||||
There are many ways that we can automate this. However, we are going with an official method and later we will cover other ways too.
|
||||
|
||||
### How to Install unattended-upgrades package in Debian/Ubuntu?
|
||||
|
||||
By default unattended-upgrades package should be installed on your system. But in case if it’s not installed use the following command to install it.
|
||||
|
||||
Use **[APT-GET Command][2]** or **[APT Command][3]** to install unattended-upgrades package.
|
||||
|
||||
```
|
||||
$ sudo apt-get install unattended-upgrades
|
||||
```
|
||||
|
||||
The below two files are allows you to customize this utility.
|
||||
|
||||
```
|
||||
/etc/apt/apt.conf.d/50unattended-upgrades
|
||||
/etc/apt/apt.conf.d/20auto-upgrades
|
||||
```
|
||||
|
||||
### Make necessary changes in 50unattended-upgrades file
|
||||
|
||||
By default only minimal required options were enabled for security updates. It’s not limited and you can configure many option in this to make this utility more useful.
|
||||
|
||||
I have trimmed the file and added only the enabled lines for better clarifications.
|
||||
|
||||
```
|
||||
# vi /etc/apt/apt.conf.d/50unattended-upgrades
|
||||
|
||||
Unattended-Upgrade::Allowed-Origins {
|
||||
"${distro_id}:${distro_codename}";
|
||||
"${distro_id}:${distro_codename}-security";
|
||||
"${distro_id}ESM:${distro_codename}";
|
||||
};
|
||||
Unattended-Upgrade::DevRelease "false";
|
||||
```
|
||||
|
||||
There are three origins are enabled and the details are below.
|
||||
|
||||
* **`${distro_id}:${distro_codename}:`**` ` It is necessary because security updates may pull in new dependencies from non-security sources.
|
||||
* **`${distro_id}:${distro_codename}-security:`**` ` It is used to get a security updates from sources.
|
||||
* **`${distro_id}ESM:${distro_codename}:`**` ` It is used to get a security updates for ESM (Extended Security Maintenance) users.
|
||||
|
||||
|
||||
|
||||
**Enable Email Notification:** If you would like to receive email notifications after every security update, then modify the following line (uncomment it and add your email id).
|
||||
|
||||
From:
|
||||
|
||||
```
|
||||
//Unattended-Upgrade::Mail "root";
|
||||
```
|
||||
|
||||
To:
|
||||
|
||||
```
|
||||
Unattended-Upgrade::Mail "[email protected]";
|
||||
```
|
||||
|
||||
**Auto Remove Unused Dependencies:** You may need to run “sudo apt autoremove” command after every update to remove unused dependencies from the system.
|
||||
|
||||
We can automate this task by making the changes in the following line (uncomment it and change “false” to “true”).
|
||||
|
||||
From:
|
||||
|
||||
```
|
||||
//Unattended-Upgrade::Remove-Unused-Dependencies "false";
|
||||
```
|
||||
|
||||
To:
|
||||
|
||||
```
|
||||
Unattended-Upgrade::Remove-Unused-Dependencies "true";
|
||||
```
|
||||
|
||||
**Enable Automatic Reboot:** You may need to reboot your system when a security updates installed for kernel. To do so, make the following changes in the following line.
|
||||
|
||||
From:
|
||||
|
||||
```
|
||||
//Unattended-Upgrade::Automatic-Reboot "false";
|
||||
```
|
||||
|
||||
To: Uncomment it and change “false” to “true” to enable automatic reboot.
|
||||
|
||||
```
|
||||
Unattended-Upgrade::Automatic-Reboot "true";
|
||||
```
|
||||
|
||||
**Enable Automatic Reboot at The Specific Time:** If automatic reboot is enabled and you would like to perform the reboot at the specific time, then make the following changes.
|
||||
|
||||
From:
|
||||
|
||||
```
|
||||
//Unattended-Upgrade::Automatic-Reboot-Time "02:00";
|
||||
```
|
||||
|
||||
To: Uncomment it and change the time as per your requirement. I set it to reboot at 5 AM.
|
||||
|
||||
```
|
||||
Unattended-Upgrade::Automatic-Reboot-Time "05:00";
|
||||
```
|
||||
|
||||
### How to Enable Automatic Security Update?
|
||||
|
||||
Now, we have configured the necessary options. Once you are done.
|
||||
|
||||
Open the following file and verify it, both the values are set up correctly or not? It should not be a zero’s. (1=enabled, 0=disabled).
|
||||
|
||||
```
|
||||
# vi /etc/apt/apt.conf.d/20auto-upgrades
|
||||
|
||||
APT::Periodic::Update-Package-Lists "1";
|
||||
APT::Periodic::Unattended-Upgrade "1";
|
||||
```
|
||||
|
||||
**Details:**
|
||||
|
||||
* The first line makes apt to perform “apt-get update” automatically every day.
|
||||
* The second line makes apt to install security updates automatically every day.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/automatic-security-update-unattended-upgrades-ubuntu-debian/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/manually-install-security-updates-ubuntu-debian/
|
||||
[2]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[3]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
@ -0,0 +1,92 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (scvoet)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Linux Smartphone Librem 5 is Available for Preorder)
|
||||
[#]: via: (https://itsfoss.com/librem-5-available/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
基于 Linux 的智能手机 Librem 5 开启预售
|
||||
======
|
||||
|
||||
Purism 近期[宣布][1]了 [Librem 5 智能手机][2]的最终规格。这不再是基于 Android 或 iOS 了,它基于 [Android 的开源替代品][4]--[PureOS][3]上。
|
||||
|
||||
随着这一消息的宣布,Librem 5 也正式[以 649 美元的价格开启预售][5](7 月 31 日前可以享受早鸟价),在那以后价格将会上涨 5 美元,产品将会于 2019 年第三季度发货。
|
||||
|
||||
![][6]
|
||||
|
||||
以下是 Purism 博客文章中关于 Librem 5 的信息:
|
||||
|
||||
_**我们认为手机不应该跟踪你,也不应该利用你的数字生活。**_
|
||||
|
||||
_Librem 5 表示您将会有机会收回对私人信息的管理权和控制权,通过免费的开源软件,开放、透明地治理你的数字生活。Librem 5 是_ **_一个基于_ [_PureOS_][3] 的手机**_,一个完全免费、符合道德的_**不基于 Androidd 或 iOS**_ 的开源操作系统(了解更多关于[为什么这很重要]的信息[7])。_
|
||||
|
||||
_我们已成功超过了众筹计划,我们将会一一去实现我们的承诺。Librem 5 的硬件和软件开发正在[稳步前进][8],它计划在 2019 年的第三季度发行初始版本。您可以用 649 美元的价格预购直到产品出仓或确定正式价格和时间。现在附赠外接显示器、键盘和鼠标的套餐也可以预购了。_
|
||||
|
||||
### Librem 5 说明书
|
||||
|
||||
从它的预览来看,Librem 5 旨在提供更好的隐私保护和安全性。除此之外,它试图拒绝使用 Google 或 Apple 的服务。
|
||||
|
||||
虽然这个想法够好,它是如何成为一款低于 700 美元的商用智能手机?
|
||||
|
||||
![Librem 5 智能手机][9]
|
||||
|
||||
让我们来看一下它的配置:
|
||||
|
||||
![Librem 5][10]
|
||||
|
||||
从数据上讲它的配置已经足够高了。不是特别好,也不是特别坏。但是,性能呢?用户体验呢?
|
||||
|
||||
我们并不能够确切地了解到它的信息,除非我们正在使用它。所以,如果你打算预购,应该要考虑到这一点。
|
||||
|
||||
[][11]
|
||||
|
||||
推荐阅读 Linux Games Get A Performance Boost for AMD GPUs Thanks to Valve's New Compiler
|
||||
|
||||
### Librem 5 提供终身软件更新支持
|
||||
|
||||
当然,和同价位的智能手机相比,它的这些配置并不是很优秀。
|
||||
|
||||
然而,随着他们做出终身软件更新支持的承诺后,它看起来确实像被开源爱好者所钟情的一个好产品。不。
|
||||
|
||||
### 其他关键特性
|
||||
|
||||
Purism 还强调 Librem 5 将成为有史以来第一款以 [Matrix][12] 为动力的智能手机。这意味着它将支持短信、电话的端到端、分布式的加密交流。
|
||||
|
||||
除了这些,耳机接口和用户可以自行更换电池使它成为一个可靠的产品。
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
虽然它很难与 Android 或 iOS 智能手机竞争,但多一种选择方式总是好的。 Librem 5 不可能成为每个用户都喜欢的智能手机,但如果您是一个开源爱好者,而且正在寻找一款尊重隐私和安全,不使用 Google 和 Apple 服务的简单智能手机,那么这就很适合您。
|
||||
|
||||
另外,它提供终身的软件更新支持,这让它成为了一个优秀的智能手机。
|
||||
|
||||
您如何看待 Librem 5?你有在考虑预购吗?请在下方的评论中将您的想法告诉我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/librem-5-available/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Scvoet][c]
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[c]: https://github.com/scvoet
|
||||
[1]: https://puri.sm/posts/librem-5-smartphone-final-specs-announced/
|
||||
[2]: https://itsfoss.com/librem-linux-phone/
|
||||
[3]: https://pureos.net/
|
||||
[4]: https://itsfoss.com/open-source-alternatives-android/
|
||||
[5]: https://shop.puri.sm/shop/librem-5/
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/librem-5-linux-smartphone.jpg?resize=800%2C450&ssl=1
|
||||
[7]: https://puri.sm/products/librem-5/pureos-mobile/
|
||||
[8]: https://puri.sm/posts/tag/phones
|
||||
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/librem-5-smartphone.jpg?ssl=1
|
||||
[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/librem-5-specs.png?ssl=1
|
||||
[11]: https://itsfoss.com/linux-games-performance-boost-amd-gpu/
|
||||
[12]: http://matrix.org
|
||||
@ -0,0 +1,110 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Scvoet)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How To Add ‘New Document’ Option In Right Click Context Menu In Ubuntu 18.04)
|
||||
[#]: via: ((https://www.ostechnix.com/how-to-add-new-document-option-in-right-click-context-menu-in-ubuntu-18-04/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
如何在 Ubuntu 18.04 的右键单击菜单中添加“新建文档”按钮
|
||||
======
|
||||
|
||||
![Add 'New Document' Option In Right Click Context Menu In Ubuntu 18.04 GNOME desktop][1]
|
||||
|
||||
前几天,我在各种在线资源站点上收集关于 [**Linux 包管理**][2] 的参考资料。在我想创建一个用于保存笔记的文件,我突然发现我的 Ubuntu 18.04 LTS 桌面并没有“创建文件”的按钮了,它好像离奇失踪了。在谷歌一下后,我发现原来“新建文档”按钮不再被集成在 Ubuntu GNOME 版本中了。庆幸的是,我找到了一个在 Ubuntu 18.04 LTS 桌面的右键单击菜单中添加“新建文档”按钮的简易解决方案。
|
||||
|
||||
就像你在下方截图中看到的一样,Nautilus 文件管理器的右键单击菜单中并没有“新建文件”按钮。
|
||||
|
||||
![][3]
|
||||
|
||||
Ubuntu 18.04 移除了右键点击菜单中的“新建文件”的选项。
|
||||
|
||||
如果你想添加此一按钮,请按照以下步骤进行操作。
|
||||
|
||||
### 在 Ubuntu 的右键单击菜单中添加“新建文件”按钮
|
||||
|
||||
首先,你需要确保您的系统中有 **~/Templates** 文件夹。如果没有的话,可以按照下面的命令进行创建。
|
||||
|
||||
```
|
||||
$ mkdir ~/Templates
|
||||
```
|
||||
|
||||
然后打开终端应用并使用 cd 命令进入 **~/Templates** 文件夹:
|
||||
|
||||
```
|
||||
$ cd ~/Templates
|
||||
```
|
||||
|
||||
创建一个空文件:
|
||||
|
||||
```
|
||||
$ touch Empty\ Document
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
```
|
||||
$ touch "Empty Document"
|
||||
```
|
||||
|
||||
![][4]
|
||||
|
||||
新开一个 Nautilus 文件管理器,然后检查一下右键单击菜单中是否成功添加了“新建文档”按钮。
|
||||
|
||||
![][5]
|
||||
|
||||
在 Ubuntu 18.04 的右键单击菜单中添加“新建文件”按钮
|
||||
|
||||
如上图所示,我们重新启用了“新建文件”的按钮。
|
||||
|
||||
你还可以为不同文件类型添加按钮。
|
||||
|
||||
```
|
||||
$ cd ~/Templates
|
||||
|
||||
$ touch New\ Word\ Document.docx
|
||||
$ touch New\ PDF\ Document.pdf
|
||||
$ touch New\ Text\ Document.txt
|
||||
$ touch New\ PyScript.py
|
||||
```
|
||||
|
||||
![][6]
|
||||
|
||||
在“新建文件”子菜单中给不同的文件类型添加按钮
|
||||
|
||||
注意,所有文件都应该创建在 **~/Templates** 文件夹下。
|
||||
|
||||
现在,打开 Nautilus 并检查“新建文件” 菜单中是否有相应的新建文件按钮。
|
||||
|
||||
![][7]
|
||||
|
||||
如果你要从子菜单中删除任一文件类型,只需在 Templates 目录中移除相应的文件即可。
|
||||
|
||||
```
|
||||
$ rm ~/Templates/New\ Word\ Document.docx
|
||||
```
|
||||
|
||||
我十分好奇为什么最新的 Ubuntu GNOME 版本将这个常用选项移除了。不过,重新启用这个按钮也十分简单,只需要几分钟。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-add-new-document-option-in-right-click-context-menu-in-ubuntu-18-04/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID][c]
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux 中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[c]: https://github.com/scvoet
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/07/Add-New-Document-Option-In-Right-Click-Context-Menu-1-720x340.png
|
||||
[2]: https://www.ostechnix.com/linux-package-managers-compared-appimage-vs-snap-vs-flatpak/
|
||||
[3]: https://www.ostechnix.com/wp-content/uploads/2019/07/new-document-option-missing.png
|
||||
[4]: https://www.ostechnix.com/wp-content/uploads/2019/07/Create-empty-document-in-Templates-directory.png
|
||||
[5]: https://www.ostechnix.com/wp-content/uploads/2019/07/Add-New-Document-Option-In-Right-Click-Context-Menu-In-Ubuntu.png
|
||||
[6]: https://www.ostechnix.com/wp-content/uploads/2019/07/Add-options-for-different-files-types.png
|
||||
[7]: https://www.ostechnix.com/wp-content/uploads/2019/07/Add-New-Document-Option-In-Right-Click-Context-Menu.png
|
||||
@ -0,0 +1,86 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Get Linux Kernel 5.0 in Ubuntu 18.04 LTS)
|
||||
[#]: via: (https://itsfoss.com/ubuntu-hwe-kernel/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
如何在 Ubuntu 18.04 LTS 中获取 Linux 5.0 内核
|
||||
======
|
||||
|
||||
_ **最近发布的 Ubuntu 18.04.3 包括 Linux 5.0 内核中的几个新功能和改进,但默认情况下没有安装。本教程演示了如何在 Ubuntu 18.04 LTS 中获取 Linux 5 内核。** _
|
||||
|
||||
[Subscribe to It’s FOSS YouTube Channel for More Videos][1]
|
||||
|
||||
[Ubuntu 18.04 的第三个“点发布版”在这里][2],它带来了新的稳定版本的 GNOME 组件、livepatch 桌面集成和内核 5.0。
|
||||
|
||||
可是等等!什么是“点发布版”(point release)?让我先解释一下。
|
||||
|
||||
### Ubuntu LTS 点发布版
|
||||
|
||||
Ubuntu 18.04 于 2018 年 4 月发布,由于它是一个长期支持 (LTS) 版本,它将一直支持到 2023 年。从那时起,已经有许多 bug 修复,安全更新和软件升级。如果你今天下载 Ubuntu 18.04,你需要在[在安装 Ubuntu 后首先安装这些更新][3]。
|
||||
|
||||
当然,这不是一种理想情况。这就是 Ubuntu 提供这些“点发布版”的原因。点发布版包含所有功能和安全更新以及自 LTS 版本首次发布以来添加的 bug 修复。如果你今天下载 Ubuntu,你会得到 Ubuntu 18.04.3 而不是 Ubuntu 18.04。这节省了在新安装的 Ubuntu 系统上下载和安装数百个更新的麻烦。
|
||||
|
||||
好了!现在你知道“点发布版”的概念了。你如何升级到这些点发布版?答案很简单。只需要像平时一样[更新你的 Ubuntu 系统][4],这样你将在最新的点发布版上了。
|
||||
|
||||
你可以[查看 Ubuntu 版本][5]来了解正在使用的版本。我检查了一下,因为我用的是 Ubuntu 18.04.3,我以为我的内核会是 5。当我[查看 Linux 内核版本][6]时,它仍然是基本内核 4.15。
|
||||
|
||||
![Ubuntu Version And Linux Kernel Version Check][7]
|
||||
|
||||
这是为什么?如果 Ubuntu 18.04.3 有 Linux 5.0 内核,为什么它仍然使用 Linux 4.15 内核?这是因为你必须通过选择 LTS 支持栈(通常称为 HWE)手动请求在 Ubuntu LTS 中安装新内核。
|
||||
|
||||
### 使用 HWE 在Ubuntu 18.04 中获取 Linux 5.0 内核
|
||||
|
||||
默认情况下,Ubuntu LTS 将保持在最初发布的 Linux 内核上。 [硬件支持栈][9](HWE)为现有的 Ubuntu LTS 版本提供了更新的内核和 xorg 支持。
|
||||
|
||||
最近发生了一些变化。如果你下载了 Ubuntu 18.04.2 或更新的桌面版本,那么就会为你启用 HWE,默认情况下你将获得新内核以及常规更新。
|
||||
|
||||
对于服务器版本以及下载了 18.04 和 18.04.1 的人员,你需要安装 HWE 内核。完成后,你将获得 Ubuntu 提供的更新的 LTS 版本内核。
|
||||
|
||||
要在 Ubuntu 桌面上安装 HWE 内核以及更新的 xorg,你可以在终端中使用此命令:
|
||||
|
||||
```
|
||||
sudo apt install --install-recommends linux-generic-hwe-18.04 xserver-xorg-hwe-18.04
|
||||
```
|
||||
|
||||
如果你使用的是 Ubuntu 服务器版,那么就不会有 xorg 选项。所以只需在 Ubutnu 服务器版中安装 HWE 内核:
|
||||
|
||||
```
|
||||
sudo apt-get install --install-recommends linux-generic-hwe-18.04
|
||||
```
|
||||
|
||||
完成 HWE 内核的安装后,重启系统。现在你应该拥有更新的 Linux 内核了。
|
||||
|
||||
**你在 Ubuntu 18.04 中获取 5.0 内核了么?**
|
||||
|
||||
请注意,下载并安装了 Ubuntu 18.04.2 的用户已经启用了 HWE。所以这些用户将能轻松获取 5.0 内核。
|
||||
|
||||
在 Ubuntu 中启用 HWE 内核遇到困难了么?这完全取决于你。[Linux 5.0 内核][10]有几项性能改进和更好的硬件支持。你将从新内核获益。
|
||||
|
||||
你怎么看?你会安装 5.0 内核还是宁愿留在 4.15 内核上?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/ubuntu-hwe-kernel/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.youtube.com/channel/UCEU9D6KIShdLeTRyH3IdSvw
|
||||
[2]: https://ubuntu.com/blog/enhanced-livepatch-desktop-integration-available-with-ubuntu-18-04-3-lts
|
||||
[3]: https://itsfoss.com/things-to-do-after-installing-ubuntu-18-04/
|
||||
[4]: https://itsfoss.com/update-ubuntu/
|
||||
[5]: https://itsfoss.com/how-to-know-ubuntu-unity-version/
|
||||
[6]: https://itsfoss.com/find-which-kernel-version-is-running-in-ubuntu/
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/ubuntu-version-and-kernel-version-check.png?resize=800%2C300&ssl=1
|
||||
[9]: https://wiki.ubuntu.com/Kernel/LTSEnablementStack
|
||||
[10]: https://itsfoss.com/linux-kernel-5/
|
||||
Loading…
Reference in New Issue
Block a user