mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-25 00:50:15 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
fa711aad6b
@ -7,7 +7,7 @@
|
||||
|
||||

|
||||
|
||||
使用这种方式的明显好处就是你可以通过使用他们各自的官方应用访问你的各种云存储。目前,提供官方Linux客户端的服务提供商有[SpiderOak](1), [Dropbox](2), [Ubuntu One](3),[Copy](5)。[Ubuntu One](3)虽不出名但的确是[一个不错的云存储竞争着](4)。[Copy][5]则提供比Dropbox更多的空间,是[Dropbox的替代选择之一](6)。使用这些官方Linux客户端可以保持你的电脑与他们的服务器之间的通信,还可以让你进行属性设置,如选择性同步。
|
||||
使用这种方式的明显好处就是你可以通过使用他们各自的官方应用访问你的各种云存储。目前,提供官方Linux客户端的服务提供商有[SpiderOak][1], [Dropbox][2], [Ubuntu One][3],[Copy][5]。[Ubuntu One][3]虽不出名但的确是[一个不错的云存储竞争着][4]。[Copy][5]则提供比Dropbox更多的空间,是[Dropbox的替代选择之一][6]。使用这些官方Linux客户端可以保持你的电脑与他们的服务器之间的通信,还可以让你进行属性设置,如选择性同步。
|
||||
|
||||
对于普通桌面用户,使用官方客户端是最好的选择,因为官方客户端可以提供最多的功能和最好的兼容性。使用它们也很简单,只需要下载他们对应你的发行版的软件包,然后安装安装完后在运行一下就Ok了。安装客户端时,它一般会指导你完成这些简单的过程。
|
||||
|
||||
@ -25,9 +25,9 @@
|
||||
|
||||
当你运行最后一条命令后,脚本会提醒你这是你第一次运行这个脚本。它将告诉你去浏览一个Dropbox的特定网页以便访问你的账户。它还会告诉你所有你需要放入网站的信息,这是为了让Dropbox给你App Key和App Secret以及赋予这个脚本你给予的访问权限。现在脚本就拥有了访问你账户的合法授权了。
|
||||
|
||||
这些一旦完成,你就可以这个脚本执行各种任务了,例如上传、下载、删除、移动、复制、创建文件夹、查看文件、共享文件、查看文件信息和取消共享。对于全部的语法解释,你可以查看一下[这个页面](9)。
|
||||
这些一旦完成,你就可以这个脚本执行各种任务了,例如上传、下载、删除、移动、复制、创建文件夹、查看文件、共享文件、查看文件信息和取消共享。对于全部的语法解释,你可以查看一下[这个页面][9]。
|
||||
|
||||
###通过[Storage Made Easy](7)将SkyDrive带到Linux上
|
||||
###通过[Storage Made Easy][7]将SkyDrive带到Linux上
|
||||
|
||||
微软并没有提供SkyDrive的官方Linux客户端,这一点也不令人惊讶。但是你并不意味着你不能在Linux上访问SkyDrive,记住:SkyDrive的web版本是可用的。
|
||||
|
||||
@ -41,7 +41,7 @@
|
||||
|
||||
第一次启动时。它会要求你登录,还有询问你要把云存储挂载到什么地方。在你做完了这些后,你就可以浏览你选择的文件夹,你还可以访问你的Storage Made Easy空间以及你的SkyDrive空间了!这种方法对于那些想在Linux上使用SkyDrive的人来说非常好,对于想把他们的多个云存储服务整合到一个地方的人来说也很不错。这种方法的缺点是你无法使用他们各自官方客户端中可以使用的特殊功能。
|
||||
|
||||
因为现在在你的Linux桌面上也可以使用SkyDrive,接下来你可能需要阅读一下我写的[SkyDrive与Google Drive的比较](8)以便于知道究竟哪种更适合于你。
|
||||
因为现在在你的Linux桌面上也可以使用SkyDrive,接下来你可能需要阅读一下我写的[SkyDrive与Google Drive的比较][8]以便于知道究竟哪种更适合于你。
|
||||
|
||||
###结论
|
||||
|
||||
|
||||
125
published/20141223 Defending the Free Linux World.md
Normal file
125
published/20141223 Defending the Free Linux World.md
Normal file
@ -0,0 +1,125 @@
|
||||
守卫自由的 Linux 世界
|
||||
================================================================================
|
||||

|
||||
|
||||
**合作是开源的一部分。OIN 的 CEO Keith Bergelt 解释说,开放创新网络(Open Invention Network)模式允许众多企业和公司决定它们该在哪较量,在哪合作。随着开源的演变,“我们需要为合作创造渠道,否则我们将会有几百个团体把数十亿美元花费到同样的技术上。”**
|
||||
|
||||
[开放创新网络(Open Invention Network)][1],即 OIN,正在全球范围内开展让 Linux 远离专利诉讼的伤害的活动。它的努力得到了一千多个公司的热烈回应,它们的加入让这股力量成为了历史上最大的反专利管理组织。
|
||||
|
||||
开放创新网络以白帽子组织的身份创建于2005年,目的是保护 Linux 免受来自许可证方面的困扰。包括 Google、 IBM、 NEC、 Novell、 Philips、 [Red Hat][2] 和 Sony 这些成员的董事会给予了它可观的经济支持。世界范围内的多个组织通过签署自由 OIN 协议加入了这个社区。
|
||||
|
||||
创立开放创新网络的组织成员把它当作利用知识产权保护 Linux 的大胆尝试。它的商业模式非常的难以理解。它要求它的成员采用免版权许可证,并永远放弃由于 Linux 相关知识产权起诉其他成员的机会。
|
||||
|
||||
然而,从 Linux 收购风波——想想服务器和云平台——那时起,保护 Linux 知识产权的策略就变得越加的迫切。
|
||||
|
||||
在过去的几年里,Linux 的版图曾经历了一场变革。OIN 不必再向人们解释这个组织的定义,也不必再解释为什么 Linux 需要保护。据 OIN 的 CEO Keith Bergelt 说,现在 Linux 的重要性得到了全世界的关注。
|
||||
|
||||
“我们已经见到了一场人们了解到 OIN 如何让合作受益的文化变革,”他对 LinuxInsider 说。
|
||||
|
||||
### 如何运作 ###
|
||||
|
||||
开放创新网络使用专利权的方式创建了一个协作环境。这种方法有助于确保创新的延续。这已经使很多软件厂商、顾客、新型市场和投资者受益。
|
||||
|
||||
开放创新网络的专利证可以让任何公司、公共机构或个人免版权使用。这些权利的获得建立在签署者同意不会专为了维护专利而攻击 Linux 系统的基础上。
|
||||
|
||||
OIN 确保 Linux 的源代码保持开放的状态。这让编程人员、设备厂商、独立软件开发者和公共机构在投资和使用 Linux 时不用过多的担心知识产权的问题。这让对 Linux 进行重新打包、嵌入和使用的公司省了不少钱。
|
||||
|
||||
“随着版权许可证越来越广泛的使用,对 OIN 许可证的需求也变得更加的迫切。现在,人们正在寻找更加简单或更实用的解决方法”,Bergelt 说。
|
||||
|
||||
OIN 法律防御援助对成员是免费的。成员必须承诺不对 OIN 名单上的软件发起专利诉讼。为了保护他们的软件,他们也同意提供他们自己的专利。最终,这些保证将让几十万的交叉许可通过该网络相互连接起来,Bergelt 如此解释道。
|
||||
|
||||
### 填补法律漏洞 ###
|
||||
|
||||
“OIN 正在做的事情是非常必要的。它提供另一层 IP (知识产权)保护,”[休斯顿法律中心大学][3]的副教授 Greg R. Vetter 这样说道。
|
||||
|
||||
他回答 LinuxInsider 说,第二版 GPL 许可证被某些人认为提供了隐含的专利许可,但是律师们更喜欢明确的许可。
|
||||
|
||||
OIN 所提供的许可填补了这个空白。它还明确的覆盖了 Linux 内核。据 Vetter 说,明确的专利许可并不是 GPLv2 中的必要部分,但是这个部分被加入到了 GPLv3 中。(LCTT 译注:Linux 内核采用的是 GPLv2 的许可)
|
||||
|
||||
拿一个在 GPLv3 中写了10000行代码的代码编写者来说。随着时间推移,其他的代码编写者会贡献更多行的代码,也加入到了知识产权中。GPLv3 中的软件专利许可条款将基于所有参与的贡献者的专利,保护全部代码的使用,Vetter 如此说道。
|
||||
|
||||
### 并不完全一样 ###
|
||||
|
||||
专利权和许可证在法律结构上层层叠叠互相覆盖。弄清两者对开源软件的作用就像是穿越雷区。
|
||||
|
||||
Vetter 说“通常,许可证是授予建立在专利和版权法律上的额外权利的法律结构。许可证被认为是给予了人们做一些的可能会侵犯到其他人的知识产权权利的事的许可。”
|
||||
|
||||
Vetter 指出,很多自由开源许可证(例如 Mozilla 公共许可、GNU GPLv3 以及 Apache 软件许可)融合了某些互惠专利权的形式。Vetter 指出,像 BSD 和 MIT 这样旧的许可证不会提到专利。
|
||||
|
||||
一个软件的许可证让其他人可以在某种程度上使用这个编程人员创造的代码。版权对所属权的建立是自动的,只要某个人写或者画了某个原创的东西。然而,版权只覆盖了个别的表达方式和衍生的作品。他并没有涵盖代码的功能性或可用的想法。
|
||||
|
||||
专利涵盖了功能性。专利权还可以被许可。版权可能无法保护某人如何独立地开发对另一个人的代码的实现,但是专利填补了这个小瑕疵,Vetter 解释道。
|
||||
|
||||
### 寻找安全通道 ###
|
||||
|
||||
许可证和专利混合的法律性质可能会对开源开发者产生威胁。据 [Chaotic Moon Studios][4] 的创办者之一、 [IEEE][5] 计算机协会成员 William Hurley 说,对于某些人来说,即使是 GPL 也会成为威胁。
|
||||
|
||||
“在很久以前,开源是个完全不同的世界。被彼此间的尊重和把代码视为艺术而非资产的观点所驱动,那时的程序和代码比现在更加的开放。我相信很多为最好的愿景所做的努力几乎最后总是背负着意外的结果,”Hurley 这样告诉 LinuxInsider。
|
||||
|
||||
他暗示说,成员人数超越了1000人(的组织)可能会在知识产权保护重要性方面意见不一。这可能会继续搅混开源生态系统这滩浑水。
|
||||
|
||||
“最终,这些显现出了围绕着知识产权的常见的一些错误概念。拥有几千个开发者并不会减少风险——而是增加。给出了专利许可的开发者越多,它们看起来就越值钱,”Hurley 说。“它们看起来越值钱,有着类似专利的或者其他知识产权的人就越可能试图利用并从中榨取他们自己的经济利益。”
|
||||
|
||||
### 共享与竞争共存 ###
|
||||
|
||||
竞合策略是开源的一部分。OIN 模型让各个公司能够决定他们将在哪竞争以及在哪合作,Bergelt 解释道。
|
||||
|
||||
“开源演化中的许多改变已经把我们移到了另一个方向上。我们必须为合作创造渠道。否则我们将会有几百个团体把数十亿美元花费到同样的技术上,”他说。
|
||||
|
||||
手机产业的革新就是个很好的例子。各个公司放出了不同的标准。没有共享,没有合作,Bergelt 解释道。
|
||||
|
||||
他说:“这让我们在美国接触技术的能力落后了七到十年。我们接触设备的经验远远落后于世界其他地方的人。在我们用不上 CDMA (Code Division Multiple Access 码分多址访问通信技术)时对 GSM (Global System for Mobile Communications 全球移动通信系统) 还沾沾自喜。”
|
||||
|
||||
### 改变格局 ###
|
||||
|
||||
OIN 在去年经历了激增400个新许可的增长。这意味着着开源有了新趋势。
|
||||
|
||||
Bergelt 说:“市场到达了一个临界点,组织内的人们终于意识到直白地合作和竞争的需要。结果是两件事同时进行。这可能会变得复杂、费力。”
|
||||
|
||||
然而,这个由人们开始考虑合作和竞争的文化革新所驱动的转换过程是可以接受的。他解释说,这也是一个人们怎样拥抱开源的转变——尤其是在 Linux 这个开源社区的领导者项目。
|
||||
|
||||
还有一个迹象是,最具意义的新项目都没有在 GPLv3 许可下开发。
|
||||
|
||||
### 二个总比一个好 ###
|
||||
|
||||
“GPL 极为重要,但是事实是有一堆的许可模型正被使用着。在 Eclipse、Apache 和 Berkeley 许可中,专利问题的相对可解决性通常远远低于在 GPLv3 中的。”Bergelt 说。
|
||||
|
||||
GPLv3 对于解决专利问题是个自然的补充——但是 GPL 自身不足以独自解决围绕专利使用的潜在冲突。所以 OIN 的设计是以能够补充版权许可为目的的,他补充道。
|
||||
|
||||
然而,层层叠叠的专利和许可也许并没有带来多少好处。到最后,专利在几乎所有的案例中都被用于攻击目的——而不是防御目的,Bergelt 暗示说。
|
||||
|
||||
“如果你不准备对其他人采取法律行动,那么对于你的知识产权来说专利可能并不是最佳的法律保护方式”,他说。“我们现在生活在一个对软件——开放的和专有的——误会重重的世界里。这些软件还被错误而过时的专利系统所捆绑。我们每天在工业化和被扼杀的创新中挣扎”,他说。
|
||||
|
||||
### 法院是最后的手段###
|
||||
|
||||
想到 OIN 的出现抑制了诉讼的泛滥就感到十分欣慰,Bergelt 说,或者至少可以说 OIN 的出现扼制了特定的某些威胁。
|
||||
|
||||
“可以说我们让人们放下他们的武器。同时我们正在创建一种新的文化规范。一旦你入股这个模型中的非侵略专利,所产生的相关影响就是对合作的鼓励”,他说。
|
||||
|
||||
如果你愿意承诺合作,你的第一反应就会趋向于不急着起诉。相反的,你会想如何让我们允许你使用我们所拥有的东西并让它为你赚钱,而同时我们也能使用你所拥有的东西,Bergelt 解释道。
|
||||
|
||||
“OIN 是个多面的解决方式。它鼓励签署者创造双赢协议”,他说,“这让起诉成为最逼不得已的行为。那才是它的位置。”
|
||||
|
||||
### 底线###
|
||||
|
||||
Bergelt 坚信,OIN 的运作是为了阻止 Linux 受到专利伤害。在这个需要 Linux 的世界里没有诉讼的地方。
|
||||
|
||||
唯一临近的是与微软的移动之争,这关系到行业的发展前景(原文: The only thing that comes close are the mobile wars with Microsoft, which focus on elements high in the stack. 不太理解,请指正。)。那些来自法律的挑战可能是为了提高包括使用 Linux 产品的所属权的成本,Bergelt 说。
|
||||
|
||||
尽管如此“这些并不是有关 Linux 诉讼”,他说。“他们的重点并不在于 Linux 的核心。他们关注的是 Linux 系统里都有些什么。”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/Defending-the-Free-Linux-World-81512.html
|
||||
|
||||
作者:Jack M. Germain
|
||||
译者:[H-mudcup](https://github.com/H-mudcup)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.openinventionnetwork.com/
|
||||
[2]:http://www.redhat.com/
|
||||
[3]:http://www.law.uh.edu/
|
||||
[4]:http://www.chaoticmoon.com/
|
||||
[5]:http://www.ieee.org/
|
||||
@ -0,0 +1,348 @@
|
||||
Shilpa Nair 分享的 RedHat Linux 包管理方面的面试经验
|
||||
========================================================================
|
||||
**Shilpa Nair 刚于2015年毕业。她之后去了一家位于 Noida,Delhi 的国家新闻电视台,应聘实习生的岗位。在她去年毕业季的时候,常逛 Tecmint 寻求作业上的帮助。从那时开始,她就常去 Tecmint。**
|
||||
|
||||

|
||||
|
||||
*有关 RPM 方面的 Linux 面试题*
|
||||
|
||||
所有的问题和回答都是 Shilpa Nair 根据回忆重写的。
|
||||
|
||||
> “大家好!我是来自 Delhi 的Shilpa Nair。我不久前才顺利毕业,正寻找一个实习的机会。在大学早期的时候,我就对 UNIX 十分喜爱,所以我也希望这个机会能适合我,满足我的兴趣。我被提问了很多问题,大部分都是关于 RedHat 包管理的基础问题。”
|
||||
|
||||
下面就是我被问到的问题,和对应的回答。我仅贴出了与 RedHat GNU/Linux 包管理相关的,也是主要被提问的。
|
||||
|
||||
### 1,Linux 里如何查找一个包安装与否?假设你需要确认 ‘nano’ 有没有安装,你怎么做? ###
|
||||
|
||||
**回答**:为了确认 nano 软件包有没有安装,我们可以使用 rpm 命令,配合 -q 和 -a 选项来查询所有已安装的包
|
||||
|
||||
# rpm -qa nano
|
||||
或
|
||||
# rpm -qa | grep -i nano
|
||||
|
||||
nano-2.3.1-10.el7.x86_64
|
||||
|
||||
同时包的名字必须是完整的,不完整的包名会返回到提示符,不打印任何东西,就是说这包(包名字不全)未安装。下面的例子会更好理解些:
|
||||
|
||||
我们通常使用 vim 替代 vi 命令。当时如果我们查找安装包 vi/vim 的时候,我们就会看到标准输出上没有任何结果。
|
||||
|
||||
# vi
|
||||
# vim
|
||||
|
||||
尽管如此,我们仍然可以像上面一样运行 vi/vim 命令来清楚地知道包有没有安装。只是因为我们不知道它的完整包名才不能找到的。如果我们不确切知道完整的文件名,我们可以使用通配符:
|
||||
|
||||
# rpm -qa vim*
|
||||
|
||||
vim-minimal-7.4.160-1.el7.x86_64
|
||||
|
||||
通过这种方式,我们可以获得任何软件包的信息,安装与否。
|
||||
|
||||
### 2. 你如何使用 rpm 命令安装 XYZ 软件包? ###
|
||||
|
||||
**回答**:我们可以使用 rpm 命令安装任何的软件包(*.rpm),像下面这样,选项 -i(安装),-v(冗余或者显示额外的信息)和 -h(在安装过程中,打印#号显示进度)。
|
||||
|
||||
# rpm -ivh peazip-1.11-1.el6.rf.x86_64.rpm
|
||||
|
||||
Preparing... ################################# [100%]
|
||||
Updating / installing...
|
||||
1:peazip-1.11-1.el6.rf ################################# [100%]
|
||||
|
||||
如果要升级一个早期版本的包,应加上 -U 选项,选项 -v 和 -h 可以确保我们得到用 # 号表示的冗余输出,这增加了可读性。
|
||||
|
||||
### 3. 你已经安装了一个软件包(假设是 httpd),现在你想看看软件包创建并安装的所有文件和目录,你会怎么做? ###
|
||||
|
||||
**回答**:使用选项 -l(列出所有文件)和 -q(查询)列出 httpd 软件包安装的所有文件(Linux 哲学:所有的都是文件,包括目录)。
|
||||
|
||||
# rpm -ql httpd
|
||||
|
||||
/etc/httpd
|
||||
/etc/httpd/conf
|
||||
/etc/httpd/conf.d
|
||||
...
|
||||
|
||||
### 4. 假如你要移除一个软件包,叫 postfix。你会怎么做? ###
|
||||
|
||||
**回答**:首先我们需要知道什么包安装了 postfix。查找安装 postfix 的包名后,使用 -e(擦除/卸载软件包)和 -v(冗余输出)两个选项来实现。
|
||||
|
||||
# rpm -qa postfix*
|
||||
|
||||
postfix-2.10.1-6.el7.x86_64
|
||||
|
||||
然后移除 postfix,如下:
|
||||
|
||||
# rpm -ev postfix-2.10.1-6.el7.x86_64
|
||||
|
||||
Preparing packages...
|
||||
postfix-2:3.0.1-2.fc22.x86_64
|
||||
|
||||
### 5. 获得一个已安装包的具体信息,如版本,发行号,安装日期,大小,总结和一个简短的描述。 ###
|
||||
|
||||
**回答**:我们通过使用 rpm 的选项 -qi,后面接包名,可以获得关于一个已安装包的具体信息。
|
||||
|
||||
举个例子,为了获得 openssh 包的具体信息,我需要做的就是:
|
||||
|
||||
# rpm -qi openssh
|
||||
|
||||
[root@tecmint tecmint]# rpm -qi openssh
|
||||
Name : openssh
|
||||
Version : 6.8p1
|
||||
Release : 5.fc22
|
||||
Architecture: x86_64
|
||||
Install Date: Thursday 28 May 2015 12:34:50 PM IST
|
||||
Group : Applications/Internet
|
||||
Size : 1542057
|
||||
License : BSD
|
||||
....
|
||||
|
||||
### 6. 假如你不确定一个指定包的配置文件在哪,比如 httpd。你如何找到所有 httpd 提供的配置文件列表和位置。 ###
|
||||
|
||||
**回答**: 我们需要用选项 -c 接包名,这会列出所有配置文件的名字和他们的位置。
|
||||
|
||||
# rpm -qc httpd
|
||||
|
||||
/etc/httpd/conf.d/autoindex.conf
|
||||
/etc/httpd/conf.d/userdir.conf
|
||||
/etc/httpd/conf.d/welcome.conf
|
||||
/etc/httpd/conf.modules.d/00-base.conf
|
||||
/etc/httpd/conf/httpd.conf
|
||||
/etc/sysconfig/httpd
|
||||
|
||||
相似地,我们可以列出所有相关的文档文件,如下:
|
||||
|
||||
# rpm -qd httpd
|
||||
|
||||
/usr/share/doc/httpd/ABOUT_APACHE
|
||||
/usr/share/doc/httpd/CHANGES
|
||||
/usr/share/doc/httpd/LICENSE
|
||||
...
|
||||
|
||||
我们也可以列出所有相关的证书文件,如下:
|
||||
|
||||
# rpm -qL openssh
|
||||
|
||||
/usr/share/licenses/openssh/LICENCE
|
||||
|
||||
忘了说明上面的选项 -d 和 -L 分别表示 “文档” 和 “证书”,抱歉。
|
||||
|
||||
### 7. 你找到了一个配置文件,位于‘/usr/share/alsa/cards/AACI.conf’,现在你不确定该文件属于哪个包。你如何查找出包的名字? ###
|
||||
|
||||
**回答**:当一个包被安装后,相关的信息就存储在了数据库里。所以使用选项 -qf(-f 查询包拥有的文件)很容易追踪谁提供了上述的包。
|
||||
|
||||
# rpm -qf /usr/share/alsa/cards/AACI.conf
|
||||
alsa-lib-1.0.28-2.el7.x86_64
|
||||
|
||||
类似地,我们可以查找(谁提供的)关于任何子包,文档和证书文件的信息。
|
||||
|
||||
### 8. 你如何使用 rpm 查找最近安装的软件列表? ###
|
||||
|
||||
**回答**:如刚刚说的,每一样被安装的文件都记录在了数据库里。所以这并不难,通过查询 rpm 的数据库,找到最近安装软件的列表。
|
||||
|
||||
我们通过运行下面的命令,使用选项 -last(打印出最近安装的软件)达到目的。
|
||||
|
||||
# rpm -qa --last
|
||||
|
||||
上面的命令会打印出所有安装的软件,最近安装的软件在列表的顶部。
|
||||
|
||||
如果我们关心的是找出特定的包,我们可以使用 grep 命令从列表中匹配包(假设是 sqlite ),简单如下:
|
||||
|
||||
# rpm -qa --last | grep -i sqlite
|
||||
|
||||
sqlite-3.8.10.2-1.fc22.x86_64 Thursday 18 June 2015 05:05:43 PM IST
|
||||
|
||||
我们也可以获得10个最近安装的软件列表,简单如下:
|
||||
|
||||
# rpm -qa --last | head
|
||||
|
||||
我们可以重定义一下,输出想要的结果,简单如下:
|
||||
|
||||
# rpm -qa --last | head -n 2
|
||||
|
||||
上面的命令中,-n 代表数目,后面接一个常数值。该命令是打印2个最近安装的软件的列表。
|
||||
|
||||
### 9. 安装一个包之前,你如果要检查其依赖。你会怎么做? ###
|
||||
|
||||
**回答**:检查一个 rpm 包(XYZ.rpm)的依赖,我们可以使用选项 -q(查询包),-p(指定包名)和 -R(查询/列出该包依赖的包,嗯,就是依赖)。
|
||||
|
||||
# rpm -qpR gedit-3.16.1-1.fc22.i686.rpm
|
||||
|
||||
/bin/sh
|
||||
/usr/bin/env
|
||||
glib2(x86-32) >= 2.40.0
|
||||
gsettings-desktop-schemas
|
||||
gtk3(x86-32) >= 3.16
|
||||
gtksourceview3(x86-32) >= 3.16
|
||||
gvfs
|
||||
libX11.so.6
|
||||
...
|
||||
|
||||
### 10. rpm 是不是一个前端的包管理工具呢? ###
|
||||
|
||||
**回答**:**不是!**rpm 是一个后端管理工具,适用于基于 Linux 发行版的 RPM (此处指 Redhat Package Management)。
|
||||
|
||||
[YUM][1],全称 Yellowdog Updater Modified,是一个 RPM 的前端工具。YUM 命令自动完成所有工作,包括解决依赖和其他一切事务。
|
||||
|
||||
最近,[DNF][2](YUM命令升级版)在Fedora 22发行版中取代了 YUM。尽管 YUM 仍然可以在 RHEL 和 CentOS 平台使用,我们也可以安装 dnf,与 YUM 命令共存使用。据说 DNF 较于 YUM 有很多提高。
|
||||
|
||||
知道更多总是好的,保持自我更新。现在我们移步到前端部分来谈谈。
|
||||
|
||||
### 11. 你如何列出一个系统上面所有可用的仓库列表。 ###
|
||||
|
||||
**回答**:简单地使用下面的命令,我们就可以列出一个系统上所有可用的仓库列表。
|
||||
|
||||
# yum repolist
|
||||
或
|
||||
# dnf repolist
|
||||
|
||||
Last metadata expiration check performed 0:30:03 ago on Mon Jun 22 16:50:00 2015.
|
||||
repo id repo name status
|
||||
*fedora Fedora 22 - x86_64 44,762
|
||||
ozonos Repository for Ozon OS 61
|
||||
*updates Fedora 22 - x86_64 - Updates
|
||||
|
||||
上面的命令仅会列出可用的仓库。如果你需要列出所有的仓库,不管可用与否,可以这样做。
|
||||
|
||||
# yum repolist all
|
||||
或
|
||||
# dnf repolist all
|
||||
|
||||
Last metadata expiration check performed 0:29:45 ago on Mon Jun 22 16:50:00 2015.
|
||||
repo id repo name status
|
||||
*fedora Fedora 22 - x86_64 enabled: 44,762
|
||||
fedora-debuginfo Fedora 22 - x86_64 - Debug disabled
|
||||
fedora-source Fedora 22 - Source disabled
|
||||
ozonos Repository for Ozon OS enabled: 61
|
||||
*updates Fedora 22 - x86_64 - Updates enabled: 5,018
|
||||
updates-debuginfo Fedora 22 - x86_64 - Updates - Debug
|
||||
|
||||
### 12. 你如何列出一个系统上所有可用并且安装了的包? ###
|
||||
|
||||
**回答**:列出一个系统上所有可用的包,我们可以这样做:
|
||||
|
||||
# yum list available
|
||||
或
|
||||
# dnf list available
|
||||
|
||||
ast metadata expiration check performed 0:34:09 ago on Mon Jun 22 16:50:00 2015.
|
||||
Available Packages
|
||||
0ad.x86_64 0.0.18-1.fc22 fedora
|
||||
0ad-data.noarch 0.0.18-1.fc22 fedora
|
||||
0install.x86_64 2.6.1-2.fc21 fedora
|
||||
0xFFFF.x86_64 0.3.9-11.fc22 fedora
|
||||
2048-cli.x86_64 0.9-4.git20141214.723738c.fc22 fedora
|
||||
2048-cli-nocurses.x86_64 0.9-4.git20141214.723738c.fc22 fedora
|
||||
....
|
||||
|
||||
而列出一个系统上所有已安装的包,我们可以这样做。
|
||||
|
||||
# yum list installed
|
||||
或
|
||||
# dnf list installed
|
||||
|
||||
Last metadata expiration check performed 0:34:30 ago on Mon Jun 22 16:50:00 2015.
|
||||
Installed Packages
|
||||
GeoIP.x86_64 1.6.5-1.fc22 @System
|
||||
GeoIP-GeoLite-data.noarch 2015.05-1.fc22 @System
|
||||
NetworkManager.x86_64 1:1.0.2-1.fc22 @System
|
||||
NetworkManager-libnm.x86_64 1:1.0.2-1.fc22 @System
|
||||
aajohan-comfortaa-fonts.noarch 2.004-4.fc22 @System
|
||||
....
|
||||
|
||||
而要同时满足两个要求的时候,我们可以这样做。
|
||||
|
||||
# yum list
|
||||
或
|
||||
# dnf list
|
||||
|
||||
Last metadata expiration check performed 0:32:56 ago on Mon Jun 22 16:50:00 2015.
|
||||
Installed Packages
|
||||
GeoIP.x86_64 1.6.5-1.fc22 @System
|
||||
GeoIP-GeoLite-data.noarch 2015.05-1.fc22 @System
|
||||
NetworkManager.x86_64 1:1.0.2-1.fc22 @System
|
||||
NetworkManager-libnm.x86_64 1:1.0.2-1.fc22 @System
|
||||
aajohan-comfortaa-fonts.noarch 2.004-4.fc22 @System
|
||||
acl.x86_64 2.2.52-7.fc22 @System
|
||||
....
|
||||
|
||||
### 13. 你会怎么在一个系统上面使用 YUM 或 DNF 分别安装和升级一个包与一组包? ###
|
||||
|
||||
**回答**:安装一个包(假设是 nano),我们可以这样做,
|
||||
|
||||
# yum install nano
|
||||
|
||||
而安装一组包(假设是 Haskell),我们可以这样做,
|
||||
|
||||
# yum groupinstall 'haskell'
|
||||
|
||||
升级一个包(还是 nano),我们可以这样做,
|
||||
|
||||
# yum update nano
|
||||
|
||||
而为了升级一组包(还是 haskell),我们可以这样做,
|
||||
|
||||
# yum groupupdate 'haskell'
|
||||
|
||||
### 14. 你会如何同步一个系统上面的所有安装软件到稳定发行版? ###
|
||||
|
||||
**回答**:我们可以一个系统上(假设是 CentOS 或者 Fedora)的所有包到稳定发行版,如下,
|
||||
|
||||
# yum distro-sync [在 CentOS/ RHEL]
|
||||
或
|
||||
# dnf distro-sync [在 Fedora 20之后版本]
|
||||
|
||||
似乎来面试之前你做了相当不多的功课,很好!在进一步交谈前,我还想问一两个问题。
|
||||
|
||||
### 15. 你对 YUM 本地仓库熟悉吗?你尝试过建立一个本地 YUM 仓库吗?让我们简单看看你会怎么建立一个本地 YUM 仓库。 ###
|
||||
|
||||
**回答**:首先,感谢你的夸奖。回到问题,我必须承认我对本地 YUM 仓库十分熟悉,并且在我的本地主机上也部署过,作为测试用。
|
||||
|
||||
1、 为了建立本地 YUM 仓库,我们需要安装下面三个包:
|
||||
|
||||
# yum install deltarpm python-deltarpm createrepo
|
||||
|
||||
2、 新建一个目录(假设 /home/$USER/rpm),然后复制 RedHat/CentOS DVD 上的 RPM 包到这个文件夹下
|
||||
|
||||
# mkdir /home/$USER/rpm
|
||||
# cp /path/to/rpm/on/DVD/*.rpm /home/$USER/rpm
|
||||
|
||||
3、 新建基本的库头文件如下。
|
||||
|
||||
# createrepo -v /home/$USER/rpm
|
||||
|
||||
4、 在路径 /etc/yum.repo.d 下创建一个 .repo 文件(如 abc.repo):
|
||||
|
||||
cd /etc/yum.repos.d && cat << EOF abc.repo
|
||||
[local-installation]name=yum-local
|
||||
baseurl=file:///home/$USER/rpm
|
||||
enabled=1
|
||||
gpgcheck=0
|
||||
EOF
|
||||
|
||||
**重要**:用你的用户名替换掉 $USER。
|
||||
|
||||
以上就是创建一个本地 YUM 仓库所要做的全部工作。我们现在可以从这里安装软件了,相对快一些,安全一些,并且最重要的是不需要 Internet 连接。
|
||||
|
||||
好了!面试过程很愉快。我已经问完了。我会将你推荐给 HR。你是一个年轻且十分聪明的候选者,我们很愿意你加入进来。如果你有任何问题,你可以问我。
|
||||
|
||||
**我**:谢谢,这确实是一次愉快的面试,我感到今天非常幸运,可以搞定这次面试...
|
||||
|
||||
显然,不会在这里结束。我问了很多问题,比如他们正在做的项目。我会担任什么角色,负责什么,,,balabalabala
|
||||
|
||||
小伙伴们,这之后的 3 天会经过 HR 轮,到时候所有问题到时候也会被写成文档。希望我当时表现不错。感谢你们所有的祝福。
|
||||
|
||||
谢谢伙伴们和 Tecmint,花时间来编辑我的面试经历。我相信 Tecmint 好伙伴们做了很大的努力,必要要赞一个。当我们与他人分享我们的经历的时候,其他人从我们这里知道了更多,而我们自己则发现了自己的不足。
|
||||
|
||||
这增加了我们的信心。如果你最近也有任何类似的面试经历,别自己蔵着。分享出来!让我们所有人都知道。你可以使用如下的表单来与我们分享你的经历。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-rpm-package-management-interview-questions/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[2]:https://linux.cn/article-5718-1.html
|
||||
690
published/20150728 Process of the Linux kernel building.md
Normal file
690
published/20150728 Process of the Linux kernel building.md
Normal file
@ -0,0 +1,690 @@
|
||||
你知道 Linux 内核是如何构建的吗?
|
||||
================================================================================
|
||||
|
||||
###介绍
|
||||
|
||||
我不会告诉你怎么在自己的电脑上去构建、安装一个定制化的 Linux 内核,这样的[资料](https://encrypted.google.com/search?q=building+linux+kernel#q=building+linux+kernel+from+source+code)太多了,它们会对你有帮助。本文会告诉你当你在内核源码路径里敲下`make` 时会发生什么。
|
||||
|
||||
当我刚刚开始学习内核代码时,[Makefile](https://github.com/torvalds/linux/blob/master/Makefile) 是我打开的第一个文件,这个文件看起来真令人害怕 :)。那时候这个 [Makefile](https://en.wikipedia.org/wiki/Make_%28software%29) 还只包含了`1591` 行代码,当我开始写本文时,内核已经是[4.2.0的第三个候选版本](https://github.com/torvalds/linux/commit/52721d9d3334c1cb1f76219a161084094ec634dc) 了。
|
||||
|
||||
这个 makefile 是 Linux 内核代码的根 makefile ,内核构建就始于此处。是的,它的内容很多,但是如果你已经读过内核源代码,你就会发现每个包含代码的目录都有一个自己的 makefile。当然了,我们不会去描述每个代码文件是怎么编译链接的,所以我们将只会挑选一些通用的例子来说明问题。而你不会在这里找到构建内核的文档、如何整洁内核代码、[tags](https://en.wikipedia.org/wiki/Ctags) 的生成和[交叉编译](https://en.wikipedia.org/wiki/Cross_compiler) 相关的说明,等等。我们将从`make` 开始,使用标准的内核配置文件,到生成了内核镜像 [bzImage](https://en.wikipedia.org/wiki/Vmlinux#bzImage) 结束。
|
||||
|
||||
如果你已经很了解 [make](https://en.wikipedia.org/wiki/Make_%28software%29) 工具那是最好,但是我也会描述本文出现的相关代码。
|
||||
|
||||
让我们开始吧!
|
||||
|
||||
|
||||
###编译内核前的准备
|
||||
|
||||
在开始编译前要进行很多准备工作。最主要的就是找到并配置好配置文件,`make` 命令要使用到的参数都需要从这些配置文件获取。现在就让我们深入内核的根 `makefile` 吧
|
||||
|
||||
内核的根 `Makefile` 负责构建两个主要的文件:[vmlinux](https://en.wikipedia.org/wiki/Vmlinux) (内核镜像可执行文件)和模块文件。内核的 [Makefile](https://github.com/torvalds/linux/blob/master/Makefile) 从定义如下变量开始:
|
||||
|
||||
```Makefile
|
||||
VERSION = 4
|
||||
PATCHLEVEL = 2
|
||||
SUBLEVEL = 0
|
||||
EXTRAVERSION = -rc3
|
||||
NAME = Hurr durr I'ma sheep
|
||||
```
|
||||
|
||||
这些变量决定了当前内核的版本,并且被使用在很多不同的地方,比如同一个 `Makefile` 中的 `KERNELVERSION` :
|
||||
|
||||
```Makefile
|
||||
KERNELVERSION = $(VERSION)$(if $(PATCHLEVEL),.$(PATCHLEVEL)$(if $(SUBLEVEL),.$(SUBLEVEL)))$(EXTRAVERSION)
|
||||
```
|
||||
|
||||
接下来我们会看到很多`ifeq` 条件判断语句,它们负责检查传递给 `make` 的参数。内核的 `Makefile` 提供了一个特殊的编译选项 `make help` ,这个选项可以生成所有的可用目标和一些能传给 `make` 的有效的命令行参数。举个例子,`make V=1` 会在构建过程中输出详细的编译信息,第一个 `ifeq` 就是检查传递给 make 的 `V=n` 选项。
|
||||
|
||||
```Makefile
|
||||
ifeq ("$(origin V)", "command line")
|
||||
KBUILD_VERBOSE = $(V)
|
||||
endif
|
||||
ifndef KBUILD_VERBOSE
|
||||
KBUILD_VERBOSE = 0
|
||||
endif
|
||||
|
||||
ifeq ($(KBUILD_VERBOSE),1)
|
||||
quiet =
|
||||
Q =
|
||||
else
|
||||
quiet=quiet_
|
||||
Q = @
|
||||
endif
|
||||
|
||||
export quiet Q KBUILD_VERBOSE
|
||||
```
|
||||
如果 `V=n` 这个选项传给了 `make` ,系统就会给变量 `KBUILD_VERBOSE` 选项附上 `V` 的值,否则的话`KBUILD_VERBOSE` 就会为 `0`。然后系统会检查 `KBUILD_VERBOSE` 的值,以此来决定 `quiet` 和`Q` 的值。符号 `@` 控制命令的输出,如果它被放在一个命令之前,这条命令的输出将会是 `CC scripts/mod/empty.o`,而不是`Compiling .... scripts/mod/empty.o`(LCTT 译注:CC 在 makefile 中一般都是编译命令)。在这段最后,系统导出了所有的变量。
|
||||
|
||||
下一个 `ifeq` 语句检查的是传递给 `make` 的选项 `O=/dir`,这个选项允许在指定的目录 `dir` 输出所有的结果文件:
|
||||
|
||||
```Makefile
|
||||
ifeq ($(KBUILD_SRC),)
|
||||
|
||||
ifeq ("$(origin O)", "command line")
|
||||
KBUILD_OUTPUT := $(O)
|
||||
endif
|
||||
|
||||
ifneq ($(KBUILD_OUTPUT),)
|
||||
saved-output := $(KBUILD_OUTPUT)
|
||||
KBUILD_OUTPUT := $(shell mkdir -p $(KBUILD_OUTPUT) && cd $(KBUILD_OUTPUT) \
|
||||
&& /bin/pwd)
|
||||
$(if $(KBUILD_OUTPUT),, \
|
||||
$(error failed to create output directory "$(saved-output)"))
|
||||
|
||||
sub-make: FORCE
|
||||
$(Q)$(MAKE) -C $(KBUILD_OUTPUT) KBUILD_SRC=$(CURDIR) \
|
||||
-f $(CURDIR)/Makefile $(filter-out _all sub-make,$(MAKECMDGOALS))
|
||||
|
||||
skip-makefile := 1
|
||||
endif # ifneq ($(KBUILD_OUTPUT),)
|
||||
endif # ifeq ($(KBUILD_SRC),)
|
||||
```
|
||||
|
||||
系统会检查变量 `KBUILD_SRC`,它代表内核代码的顶层目录,如果它是空的(第一次执行 makefile 时总是空的),我们会设置变量 `KBUILD_OUTPUT` 为传递给选项 `O` 的值(如果这个选项被传进来了)。下一步会检查变量 `KBUILD_OUTPUT` ,如果已经设置好,那么接下来会做以下几件事:
|
||||
|
||||
* 将变量 `KBUILD_OUTPUT` 的值保存到临时变量 `saved-output`;
|
||||
* 尝试创建给定的输出目录;
|
||||
* 检查创建的输出目录,如果失败了就打印错误;
|
||||
* 如果成功创建了输出目录,那么就在新目录重新执行 `make` 命令(参见选项`-C`)。
|
||||
|
||||
下一个 `ifeq` 语句会检查传递给 make 的选项 `C` 和 `M`:
|
||||
|
||||
```Makefile
|
||||
ifeq ("$(origin C)", "command line")
|
||||
KBUILD_CHECKSRC = $(C)
|
||||
endif
|
||||
ifndef KBUILD_CHECKSRC
|
||||
KBUILD_CHECKSRC = 0
|
||||
endif
|
||||
|
||||
ifeq ("$(origin M)", "command line")
|
||||
KBUILD_EXTMOD := $(M)
|
||||
endif
|
||||
```
|
||||
|
||||
第一个选项 `C` 会告诉 `makefile` 需要使用环境变量 `$CHECK` 提供的工具来检查全部 `c` 代码,默认情况下会使用[sparse](https://en.wikipedia.org/wiki/Sparse)。第二个选项 `M` 会用来编译外部模块(本文不做讨论)。
|
||||
|
||||
系统还会检查变量 `KBUILD_SRC`,如果 `KBUILD_SRC` 没有被设置,系统会设置变量 `srctree` 为`.`:
|
||||
|
||||
```Makefile
|
||||
ifeq ($(KBUILD_SRC),)
|
||||
srctree := .
|
||||
endif
|
||||
|
||||
objtree := .
|
||||
src := $(srctree)
|
||||
obj := $(objtree)
|
||||
|
||||
export srctree objtree VPATH
|
||||
```
|
||||
|
||||
这将会告诉 `Makefile` 内核的源码树就在执行 `make` 命令的目录,然后要设置 `objtree` 和其他变量为这个目录,并且将这些变量导出。接着就是要获取 `SUBARCH` 的值,这个变量代表了当前的系统架构(LCTT 译注:一般都指CPU 架构):
|
||||
|
||||
```Makefile
|
||||
SUBARCH := $(shell uname -m | sed -e s/i.86/x86/ -e s/x86_64/x86/ \
|
||||
-e s/sun4u/sparc64/ \
|
||||
-e s/arm.*/arm/ -e s/sa110/arm/ \
|
||||
-e s/s390x/s390/ -e s/parisc64/parisc/ \
|
||||
-e s/ppc.*/powerpc/ -e s/mips.*/mips/ \
|
||||
-e s/sh[234].*/sh/ -e s/aarch64.*/arm64/ )
|
||||
```
|
||||
|
||||
如你所见,系统执行 [uname](https://en.wikipedia.org/wiki/Uname) 得到机器、操作系统和架构的信息。因为我们得到的是 `uname` 的输出,所以我们需要做一些处理再赋给变量 `SUBARCH` 。获得 `SUBARCH` 之后就要设置`SRCARCH` 和 `hfr-arch`,`SRCARCH` 提供了硬件架构相关代码的目录,`hfr-arch` 提供了相关头文件的目录:
|
||||
|
||||
```Makefile
|
||||
ifeq ($(ARCH),i386)
|
||||
SRCARCH := x86
|
||||
endif
|
||||
ifeq ($(ARCH),x86_64)
|
||||
SRCARCH := x86
|
||||
endif
|
||||
|
||||
hdr-arch := $(SRCARCH)
|
||||
```
|
||||
|
||||
注意:`ARCH` 是 `SUBARCH` 的别名。如果没有设置过代表内核配置文件路径的变量 `KCONFIG_CONFIG`,下一步系统会设置它,默认情况下就是 `.config` :
|
||||
|
||||
```Makefile
|
||||
KCONFIG_CONFIG ?= .config
|
||||
export KCONFIG_CONFIG
|
||||
```
|
||||
|
||||
以及编译内核过程中要用到的 [shell](https://en.wikipedia.org/wiki/Shell_%28computing%29)
|
||||
|
||||
```Makefile
|
||||
CONFIG_SHELL := $(shell if [ -x "$$BASH" ]; then echo $$BASH; \
|
||||
else if [ -x /bin/bash ]; then echo /bin/bash; \
|
||||
else echo sh; fi ; fi)
|
||||
```
|
||||
|
||||
接下来就要设置一组和编译内核的编译器相关的变量。我们会设置主机的 `C` 和 `C++` 的编译器及相关配置项:
|
||||
|
||||
```Makefile
|
||||
HOSTCC = gcc
|
||||
HOSTCXX = g++
|
||||
HOSTCFLAGS = -Wall -Wmissing-prototypes -Wstrict-prototypes -O2 -fomit-frame-pointer -std=gnu89
|
||||
HOSTCXXFLAGS = -O2
|
||||
```
|
||||
|
||||
接下来会去适配代表编译器的变量 `CC`,那为什么还要 `HOST*` 这些变量呢?这是因为 `CC` 是编译内核过程中要使用的目标架构的编译器,但是 `HOSTCC` 是要被用来编译一组 `host` 程序的(下面我们就会看到)。
|
||||
|
||||
然后我们就看到变量 `KBUILD_MODULES` 和 `KBUILD_BUILTIN` 的定义,这两个变量决定了我们要编译什么东西(内核、模块或者两者):
|
||||
|
||||
```Makefile
|
||||
KBUILD_MODULES :=
|
||||
KBUILD_BUILTIN := 1
|
||||
|
||||
ifeq ($(MAKECMDGOALS),modules)
|
||||
KBUILD_BUILTIN := $(if $(CONFIG_MODVERSIONS),1)
|
||||
endif
|
||||
```
|
||||
|
||||
在这我们可以看到这些变量的定义,并且,如果们仅仅传递了 `modules` 给 `make`,变量 `KBUILD_BUILTIN` 会依赖于内核配置选项 `CONFIG_MODVERSIONS`。
|
||||
|
||||
下一步操作是引入下面的文件:
|
||||
|
||||
```Makefile
|
||||
include scripts/Kbuild.include
|
||||
```
|
||||
|
||||
文件 [Kbuild](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/kbuild.txt) 或者又叫做 `Kernel Build System` 是一个用来管理构建内核及其模块的特殊框架。`kbuild` 文件的语法与 makefile 一样。文件[scripts/Kbuild.include](https://github.com/torvalds/linux/blob/master/scripts/Kbuild.include) 为 `kbuild` 系统提供了一些常规的定义。因为我们包含了这个 `kbuild` 文件,我们可以看到和不同工具关联的这些变量的定义,这些工具会在内核和模块编译过程中被使用(比如链接器、编译器、来自 [binutils](http://www.gnu.org/software/binutils/) 的二进制工具包 ,等等):
|
||||
|
||||
```Makefile
|
||||
AS = $(CROSS_COMPILE)as
|
||||
LD = $(CROSS_COMPILE)ld
|
||||
CC = $(CROSS_COMPILE)gcc
|
||||
CPP = $(CC) -E
|
||||
AR = $(CROSS_COMPILE)ar
|
||||
NM = $(CROSS_COMPILE)nm
|
||||
STRIP = $(CROSS_COMPILE)strip
|
||||
OBJCOPY = $(CROSS_COMPILE)objcopy
|
||||
OBJDUMP = $(CROSS_COMPILE)objdump
|
||||
AWK = awk
|
||||
...
|
||||
...
|
||||
...
|
||||
```
|
||||
|
||||
在这些定义好的变量后面,我们又定义了两个变量:`USERINCLUDE` 和 `LINUXINCLUDE`。他们包含了头文件的路径(第一个是给用户用的,第二个是给内核用的):
|
||||
|
||||
```Makefile
|
||||
USERINCLUDE := \
|
||||
-I$(srctree)/arch/$(hdr-arch)/include/uapi \
|
||||
-Iarch/$(hdr-arch)/include/generated/uapi \
|
||||
-I$(srctree)/include/uapi \
|
||||
-Iinclude/generated/uapi \
|
||||
-include $(srctree)/include/linux/kconfig.h
|
||||
|
||||
LINUXINCLUDE := \
|
||||
-I$(srctree)/arch/$(hdr-arch)/include \
|
||||
...
|
||||
```
|
||||
|
||||
以及给 C 编译器的标准标志:
|
||||
|
||||
```Makefile
|
||||
KBUILD_CFLAGS := -Wall -Wundef -Wstrict-prototypes -Wno-trigraphs \
|
||||
-fno-strict-aliasing -fno-common \
|
||||
-Werror-implicit-function-declaration \
|
||||
-Wno-format-security \
|
||||
-std=gnu89
|
||||
```
|
||||
|
||||
这并不是最终确定的编译器标志,它们还可以在其他 makefile 里面更新(比如 `arch/` 里面的 kbuild)。变量定义完之后,全部会被导出供其他 makefile 使用。
|
||||
|
||||
下面的两个变量 `RCS_FIND_IGNORE` 和 `RCS_TAR_IGNORE` 包含了被版本控制系统忽略的文件:
|
||||
|
||||
```Makefile
|
||||
export RCS_FIND_IGNORE := \( -name SCCS -o -name BitKeeper -o -name .svn -o \
|
||||
-name CVS -o -name .pc -o -name .hg -o -name .git \) \
|
||||
-prune -o
|
||||
export RCS_TAR_IGNORE := --exclude SCCS --exclude BitKeeper --exclude .svn \
|
||||
--exclude CVS --exclude .pc --exclude .hg --exclude .git
|
||||
```
|
||||
|
||||
这就是全部了,我们已经完成了所有的准备工作,下一个点就是如果构建`vmlinux`。
|
||||
|
||||
###直面内核构建
|
||||
|
||||
现在我们已经完成了所有的准备工作,根 makefile(注:内核根目录下的 makefile)的下一步工作就是和编译内核相关的了。在这之前,我们不会在终端看到 `make` 命令输出的任何东西。但是现在编译的第一步开始了,这里我们需要从内核根 makefile 的 [598](https://github.com/torvalds/linux/blob/master/Makefile#L598) 行开始,这里可以看到目标`vmlinux`:
|
||||
|
||||
```Makefile
|
||||
all: vmlinux
|
||||
include arch/$(SRCARCH)/Makefile
|
||||
```
|
||||
|
||||
不要操心我们略过的从 `export RCS_FIND_IGNORE.....` 到 `all: vmlinux.....` 这一部分 makefile 代码,他们只是负责根据各种配置文件(`make *.config`)生成不同目标内核的,因为之前我就说了这一部分我们只讨论构建内核的通用途径。
|
||||
|
||||
目标 `all:` 是在命令行如果不指定具体目标时默认使用的目标。你可以看到这里包含了架构相关的 makefile(在这里就指的是 [arch/x86/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile))。从这一时刻起,我们会从这个 makefile 继续进行下去。如我们所见,目标 `all` 依赖于根 makefile 后面声明的 `vmlinux`:
|
||||
|
||||
```Makefile
|
||||
vmlinux: scripts/link-vmlinux.sh $(vmlinux-deps) FORCE
|
||||
```
|
||||
|
||||
`vmlinux` 是 linux 内核的静态链接可执行文件格式。脚本 [scripts/link-vmlinux.sh](https://github.com/torvalds/linux/blob/master/scripts/link-vmlinux.sh) 把不同的编译好的子模块链接到一起形成了 vmlinux。
|
||||
|
||||
第二个目标是 `vmlinux-deps`,它的定义如下:
|
||||
|
||||
```Makefile
|
||||
vmlinux-deps := $(KBUILD_LDS) $(KBUILD_VMLINUX_INIT) $(KBUILD_VMLINUX_MAIN)
|
||||
```
|
||||
|
||||
它是由内核代码下的每个顶级目录的 `built-in.o` 组成的。之后我们还会检查内核所有的目录,`kbuild` 会编译各个目录下所有的对应 `$(obj-y)` 的源文件。接着调用 `$(LD) -r` 把这些文件合并到一个 `build-in.o` 文件里。此时我们还没有`vmlinux-deps`,所以目标 `vmlinux` 现在还不会被构建。对我而言 `vmlinux-deps` 包含下面的文件:
|
||||
|
||||
```
|
||||
arch/x86/kernel/vmlinux.lds arch/x86/kernel/head_64.o
|
||||
arch/x86/kernel/head64.o arch/x86/kernel/head.o
|
||||
init/built-in.o usr/built-in.o
|
||||
arch/x86/built-in.o kernel/built-in.o
|
||||
mm/built-in.o fs/built-in.o
|
||||
ipc/built-in.o security/built-in.o
|
||||
crypto/built-in.o block/built-in.o
|
||||
lib/lib.a arch/x86/lib/lib.a
|
||||
lib/built-in.o arch/x86/lib/built-in.o
|
||||
drivers/built-in.o sound/built-in.o
|
||||
firmware/built-in.o arch/x86/pci/built-in.o
|
||||
arch/x86/power/built-in.o arch/x86/video/built-in.o
|
||||
net/built-in.o
|
||||
```
|
||||
|
||||
下一个可以被执行的目标如下:
|
||||
|
||||
```Makefile
|
||||
$(sort $(vmlinux-deps)): $(vmlinux-dirs) ;
|
||||
$(vmlinux-dirs): prepare scripts
|
||||
$(Q)$(MAKE) $(build)=$@
|
||||
```
|
||||
|
||||
就像我们看到的,`vmlinux-dir` 依赖于两部分:`prepare` 和 `scripts`。第一个 `prepare` 定义在内核的根 `makefile` 中,准备工作分成三个阶段:
|
||||
|
||||
```Makefile
|
||||
prepare: prepare0
|
||||
prepare0: archprepare FORCE
|
||||
$(Q)$(MAKE) $(build)=.
|
||||
archprepare: archheaders archscripts prepare1 scripts_basic
|
||||
|
||||
prepare1: prepare2 $(version_h) include/generated/utsrelease.h \
|
||||
include/config/auto.conf
|
||||
$(cmd_crmodverdir)
|
||||
prepare2: prepare3 outputmakefile asm-generic
|
||||
```
|
||||
|
||||
第一个 `prepare0` 展开到 `archprepare` ,后者又展开到 `archheader` 和 `archscripts`,这两个变量定义在 `x86_64` 相关的 [Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile)。让我们看看这个文件。`x86_64` 特定的 makefile 从变量定义开始,这些变量都是和特定架构的配置文件 ([defconfig](https://github.com/torvalds/linux/tree/master/arch/x86/configs),等等)有关联。在定义了编译 [16-bit](https://en.wikipedia.org/wiki/Real_mode) 代码的编译选项之后,根据变量 `BITS` 的值,如果是 `32`, 汇编代码、链接器、以及其它很多东西(全部的定义都可以在[arch/x86/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile)找到)对应的参数就是 `i386`,而 `64` 就对应的是 `x86_84`。
|
||||
|
||||
第一个目标是 makefile 生成的系统调用列表(syscall table)中的 `archheaders` :
|
||||
|
||||
```Makefile
|
||||
archheaders:
|
||||
$(Q)$(MAKE) $(build)=arch/x86/entry/syscalls all
|
||||
```
|
||||
|
||||
第二个目标是 makefile 里的 `archscripts`:
|
||||
|
||||
```Makefile
|
||||
archscripts: scripts_basic
|
||||
$(Q)$(MAKE) $(build)=arch/x86/tools relocs
|
||||
```
|
||||
|
||||
我们可以看到 `archscripts` 是依赖于根 [Makefile](https://github.com/torvalds/linux/blob/master/Makefile)里的`scripts_basic` 。首先我们可以看出 `scripts_basic` 是按照 [scripts/basic](https://github.com/torvalds/linux/blob/master/scripts/basic/Makefile) 的 makefile 执行 make 的:
|
||||
|
||||
```Maklefile
|
||||
scripts_basic:
|
||||
$(Q)$(MAKE) $(build)=scripts/basic
|
||||
```
|
||||
|
||||
`scripts/basic/Makefile` 包含了编译两个主机程序 `fixdep` 和 `bin2` 的目标:
|
||||
|
||||
```Makefile
|
||||
hostprogs-y := fixdep
|
||||
hostprogs-$(CONFIG_BUILD_BIN2C) += bin2c
|
||||
always := $(hostprogs-y)
|
||||
|
||||
$(addprefix $(obj)/,$(filter-out fixdep,$(always))): $(obj)/fixdep
|
||||
```
|
||||
|
||||
第一个工具是 `fixdep`:用来优化 [gcc](https://gcc.gnu.org/) 生成的依赖列表,然后在重新编译源文件的时候告诉make。第二个工具是 `bin2c`,它依赖于内核配置选项 `CONFIG_BUILD_BIN2C`,并且它是一个用来将标准输入接口(LCTT 译注:即 stdin)收到的二进制流通过标准输出接口(即:stdout)转换成 C 头文件的非常小的 C 程序。你可能注意到这里有些奇怪的标志,如 `hostprogs-y` 等。这个标志用于所有的 `kbuild` 文件,更多的信息你可以从[documentation](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/makefiles.txt) 获得。在我们这里, `hostprogs-y` 告诉 `kbuild` 这里有个名为 `fixed` 的程序,这个程序会通过和 `Makefile` 相同目录的 `fixdep.c` 编译而来。
|
||||
|
||||
执行 make 之后,终端的第一个输出就是 `kbuild` 的结果:
|
||||
|
||||
```
|
||||
$ make
|
||||
HOSTCC scripts/basic/fixdep
|
||||
```
|
||||
|
||||
当目标 `script_basic` 被执行,目标 `archscripts` 就会 make [arch/x86/tools](https://github.com/torvalds/linux/blob/master/arch/x86/tools/Makefile) 下的 makefile 和目标 `relocs`:
|
||||
|
||||
```Makefile
|
||||
$(Q)$(MAKE) $(build)=arch/x86/tools relocs
|
||||
```
|
||||
|
||||
包含了[重定位](https://en.wikipedia.org/wiki/Relocation_%28computing%29) 的信息的代码 `relocs_32.c` 和 `relocs_64.c` 将会被编译,这可以在`make` 的输出中看到:
|
||||
|
||||
```Makefile
|
||||
HOSTCC arch/x86/tools/relocs_32.o
|
||||
HOSTCC arch/x86/tools/relocs_64.o
|
||||
HOSTCC arch/x86/tools/relocs_common.o
|
||||
HOSTLD arch/x86/tools/relocs
|
||||
```
|
||||
|
||||
在编译完 `relocs.c` 之后会检查 `version.h`:
|
||||
|
||||
```Makefile
|
||||
$(version_h): $(srctree)/Makefile FORCE
|
||||
$(call filechk,version.h)
|
||||
$(Q)rm -f $(old_version_h)
|
||||
```
|
||||
|
||||
我们可以在输出看到它:
|
||||
|
||||
```
|
||||
CHK include/config/kernel.release
|
||||
```
|
||||
|
||||
以及在内核的根 Makefiel 使用 `arch/x86/include/generated/asm` 的目标 `asm-generic` 来构建 `generic` 汇编头文件。在目标 `asm-generic` 之后,`archprepare` 就完成了,所以目标 `prepare0` 会接着被执行,如我上面所写:
|
||||
|
||||
```Makefile
|
||||
prepare0: archprepare FORCE
|
||||
$(Q)$(MAKE) $(build)=.
|
||||
```
|
||||
|
||||
注意 `build`,它是定义在文件 [scripts/Kbuild.include](https://github.com/torvalds/linux/blob/master/scripts/Kbuild.include),内容是这样的:
|
||||
|
||||
```Makefile
|
||||
build := -f $(srctree)/scripts/Makefile.build obj
|
||||
```
|
||||
|
||||
或者在我们的例子中,它就是当前源码目录路径:`.`:
|
||||
|
||||
```Makefile
|
||||
$(Q)$(MAKE) -f $(srctree)/scripts/Makefile.build obj=.
|
||||
```
|
||||
|
||||
脚本 [scripts/Makefile.build](https://github.com/torvalds/linux/blob/master/scripts/Makefile.build) 通过参数 `obj` 给定的目录找到 `Kbuild` 文件,然后引入 `kbuild` 文件:
|
||||
|
||||
```Makefile
|
||||
include $(kbuild-file)
|
||||
```
|
||||
|
||||
并根据这个构建目标。我们这里 `.` 包含了生成 `kernel/bounds.s` 和 `arch/x86/kernel/asm-offsets.s` 的 [Kbuild](https://github.com/torvalds/linux/blob/master/Kbuild) 文件。在此之后,目标 `prepare` 就完成了它的工作。 `vmlinux-dirs` 也依赖于第二个目标 `scripts` ,它会编译接下来的几个程序:`filealias`,`mk_elfconfig`,`modpost` 等等。之后,`scripts/host-programs` 就可以开始编译我们的目标 `vmlinux-dirs` 了。
|
||||
|
||||
首先,我们先来理解一下 `vmlinux-dirs` 都包含了那些东西。在我们的例子中它包含了下列内核目录的路径:
|
||||
|
||||
```
|
||||
init usr arch/x86 kernel mm fs ipc security crypto block
|
||||
drivers sound firmware arch/x86/pci arch/x86/power
|
||||
arch/x86/video net lib arch/x86/lib
|
||||
```
|
||||
|
||||
我们可以在内核的根 [Makefile](https://github.com/torvalds/linux/blob/master/Makefile) 里找到 `vmlinux-dirs` 的定义:
|
||||
|
||||
```Makefile
|
||||
vmlinux-dirs := $(patsubst %/,%,$(filter %/, $(init-y) $(init-m) \
|
||||
$(core-y) $(core-m) $(drivers-y) $(drivers-m) \
|
||||
$(net-y) $(net-m) $(libs-y) $(libs-m)))
|
||||
|
||||
init-y := init/
|
||||
drivers-y := drivers/ sound/ firmware/
|
||||
net-y := net/
|
||||
libs-y := lib/
|
||||
...
|
||||
...
|
||||
...
|
||||
```
|
||||
|
||||
这里我们借助函数 `patsubst` 和 `filter`去掉了每个目录路径里的符号 `/`,并且把结果放到 `vmlinux-dirs` 里。所以我们就有了 `vmlinux-dirs` 里的目录列表,以及下面的代码:
|
||||
|
||||
```Makefile
|
||||
$(vmlinux-dirs): prepare scripts
|
||||
$(Q)$(MAKE) $(build)=$@
|
||||
```
|
||||
|
||||
符号 `$@` 在这里代表了 `vmlinux-dirs`,这就表明程序会递归遍历从 `vmlinux-dirs` 以及它内部的全部目录(依赖于配置),并且在对应的目录下执行 `make` 命令。我们可以在输出看到结果:
|
||||
|
||||
```
|
||||
CC init/main.o
|
||||
CHK include/generated/compile.h
|
||||
CC init/version.o
|
||||
CC init/do_mounts.o
|
||||
...
|
||||
CC arch/x86/crypto/glue_helper.o
|
||||
AS arch/x86/crypto/aes-x86_64-asm_64.o
|
||||
CC arch/x86/crypto/aes_glue.o
|
||||
...
|
||||
AS arch/x86/entry/entry_64.o
|
||||
AS arch/x86/entry/thunk_64.o
|
||||
CC arch/x86/entry/syscall_64.o
|
||||
```
|
||||
|
||||
每个目录下的源代码将会被编译并且链接到 `built-io.o` 里:
|
||||
|
||||
```
|
||||
$ find . -name built-in.o
|
||||
./arch/x86/crypto/built-in.o
|
||||
./arch/x86/crypto/sha-mb/built-in.o
|
||||
./arch/x86/net/built-in.o
|
||||
./init/built-in.o
|
||||
./usr/built-in.o
|
||||
...
|
||||
...
|
||||
```
|
||||
|
||||
好了,所有的 `built-in.o` 都构建完了,现在我们回到目标 `vmlinux` 上。你应该还记得,目标 `vmlinux` 是在内核的根makefile 里。在链接 `vmlinux` 之前,系统会构建 [samples](https://github.com/torvalds/linux/tree/master/samples), [Documentation](https://github.com/torvalds/linux/tree/master/Documentation) 等等,但是如上文所述,我不会在本文描述这些。
|
||||
|
||||
```Makefile
|
||||
vmlinux: scripts/link-vmlinux.sh $(vmlinux-deps) FORCE
|
||||
...
|
||||
...
|
||||
+$(call if_changed,link-vmlinux)
|
||||
```
|
||||
|
||||
你可以看到,调用脚本 [scripts/link-vmlinux.sh](https://github.com/torvalds/linux/blob/master/scripts/link-vmlinux.sh) 的主要目的是把所有的 `built-in.o` 链接成一个静态可执行文件,和生成 [System.map](https://en.wikipedia.org/wiki/System.map)。 最后我们来看看下面的输出:
|
||||
|
||||
```
|
||||
LINK vmlinux
|
||||
LD vmlinux.o
|
||||
MODPOST vmlinux.o
|
||||
GEN .version
|
||||
CHK include/generated/compile.h
|
||||
UPD include/generated/compile.h
|
||||
CC init/version.o
|
||||
LD init/built-in.o
|
||||
KSYM .tmp_kallsyms1.o
|
||||
KSYM .tmp_kallsyms2.o
|
||||
LD vmlinux
|
||||
SORTEX vmlinux
|
||||
SYSMAP System.map
|
||||
```
|
||||
|
||||
`vmlinux` 和`System.map` 生成在内核源码树根目录下。
|
||||
|
||||
```
|
||||
$ ls vmlinux System.map
|
||||
System.map vmlinux
|
||||
```
|
||||
|
||||
这就是全部了,`vmlinux` 构建好了,下一步就是创建 [bzImage](https://en.wikipedia.org/wiki/Vmlinux#bzImage).
|
||||
|
||||
###制作bzImage
|
||||
|
||||
`bzImage` 就是压缩了的 linux 内核镜像。我们可以在构建了 `vmlinux` 之后通过执行 `make bzImage` 获得`bzImage`。同时我们可以仅仅执行 `make` 而不带任何参数也可以生成 `bzImage` ,因为它是在 [arch/x86/kernel/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile) 里预定义的、默认生成的镜像:
|
||||
|
||||
```Makefile
|
||||
all: bzImage
|
||||
```
|
||||
|
||||
让我们看看这个目标,它能帮助我们理解这个镜像是怎么构建的。我已经说过了 `bzImage` 是被定义在 [arch/x86/kernel/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile),定义如下:
|
||||
|
||||
```Makefile
|
||||
bzImage: vmlinux
|
||||
$(Q)$(MAKE) $(build)=$(boot) $(KBUILD_IMAGE)
|
||||
$(Q)mkdir -p $(objtree)/arch/$(UTS_MACHINE)/boot
|
||||
$(Q)ln -fsn ../../x86/boot/bzImage $(objtree)/arch/$(UTS_MACHINE)/boot/$@
|
||||
```
|
||||
|
||||
在这里我们可以看到第一次为 boot 目录执行 `make`,在我们的例子里是这样的:
|
||||
|
||||
```Makefile
|
||||
boot := arch/x86/boot
|
||||
```
|
||||
|
||||
现在的主要目标是编译目录 `arch/x86/boot` 和 `arch/x86/boot/compressed` 的代码,构建 `setup.bin` 和 `vmlinux.bin`,最后用这两个文件生成 `bzImage`。第一个目标是定义在 [arch/x86/boot/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/boot/Makefile) 的 `$(obj)/setup.elf`:
|
||||
|
||||
```Makefile
|
||||
$(obj)/setup.elf: $(src)/setup.ld $(SETUP_OBJS) FORCE
|
||||
$(call if_changed,ld)
|
||||
```
|
||||
|
||||
我们已经在目录 `arch/x86/boot` 有了链接脚本 `setup.ld`,和扩展到 `boot` 目录下全部源代码的变量 `SETUP_OBJS` 。我们可以看看第一个输出:
|
||||
|
||||
```Makefile
|
||||
AS arch/x86/boot/bioscall.o
|
||||
CC arch/x86/boot/cmdline.o
|
||||
AS arch/x86/boot/copy.o
|
||||
HOSTCC arch/x86/boot/mkcpustr
|
||||
CPUSTR arch/x86/boot/cpustr.h
|
||||
CC arch/x86/boot/cpu.o
|
||||
CC arch/x86/boot/cpuflags.o
|
||||
CC arch/x86/boot/cpucheck.o
|
||||
CC arch/x86/boot/early_serial_console.o
|
||||
CC arch/x86/boot/edd.o
|
||||
```
|
||||
|
||||
下一个源码文件是 [arch/x86/boot/header.S](https://github.com/torvalds/linux/blob/master/arch/x86/boot/header.S),但是我们不能现在就编译它,因为这个目标依赖于下面两个头文件:
|
||||
|
||||
```Makefile
|
||||
$(obj)/header.o: $(obj)/voffset.h $(obj)/zoffset.h
|
||||
```
|
||||
|
||||
第一个头文件 `voffset.h` 是使用 `sed` 脚本生成的,包含用 `nm` 工具从 `vmlinux` 获取的两个地址:
|
||||
|
||||
```C
|
||||
#define VO__end 0xffffffff82ab0000
|
||||
#define VO__text 0xffffffff81000000
|
||||
```
|
||||
|
||||
这两个地址是内核的起始和结束地址。第二个头文件 `zoffset.h` 在 [arch/x86/boot/compressed/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/boot/compressed/Makefile) 可以看出是依赖于目标 `vmlinux`的:
|
||||
|
||||
```Makefile
|
||||
$(obj)/zoffset.h: $(obj)/compressed/vmlinux FORCE
|
||||
$(call if_changed,zoffset)
|
||||
```
|
||||
|
||||
目标 `$(obj)/compressed/vmlinux` 依赖于 `vmlinux-objs-y` —— 说明需要编译目录 [arch/x86/boot/compressed](https://github.com/torvalds/linux/tree/master/arch/x86/boot/compressed) 下的源代码,然后生成 `vmlinux.bin`、`vmlinux.bin.bz2`,和编译工具 `mkpiggy`。我们可以在下面的输出看出来:
|
||||
|
||||
```Makefile
|
||||
LDS arch/x86/boot/compressed/vmlinux.lds
|
||||
AS arch/x86/boot/compressed/head_64.o
|
||||
CC arch/x86/boot/compressed/misc.o
|
||||
CC arch/x86/boot/compressed/string.o
|
||||
CC arch/x86/boot/compressed/cmdline.o
|
||||
OBJCOPY arch/x86/boot/compressed/vmlinux.bin
|
||||
BZIP2 arch/x86/boot/compressed/vmlinux.bin.bz2
|
||||
HOSTCC arch/x86/boot/compressed/mkpiggy
|
||||
```
|
||||
|
||||
`vmlinux.bin` 是去掉了调试信息和注释的 `vmlinux` 二进制文件,加上了占用了 `u32` (LCTT 译注:即4-Byte)的长度信息的 `vmlinux.bin.all` 压缩后就是 `vmlinux.bin.bz2`。其中 `vmlinux.bin.all` 包含了 `vmlinux.bin` 和`vmlinux.relocs`(LCTT 译注:vmlinux 的重定位信息),其中 `vmlinux.relocs` 是 `vmlinux` 经过程序 `relocs` 处理之后的 `vmlinux` 镜像(见上文所述)。我们现在已经获取到了这些文件,汇编文件 `piggy.S` 将会被 `mkpiggy` 生成、然后编译:
|
||||
|
||||
```Makefile
|
||||
MKPIGGY arch/x86/boot/compressed/piggy.S
|
||||
AS arch/x86/boot/compressed/piggy.o
|
||||
```
|
||||
|
||||
这个汇编文件会包含经过计算得来的、压缩内核的偏移信息。处理完这个汇编文件,我们就可以看到 `zoffset` 生成了:
|
||||
|
||||
```Makefile
|
||||
ZOFFSET arch/x86/boot/zoffset.h
|
||||
```
|
||||
|
||||
现在 `zoffset.h` 和 `voffset.h` 已经生成了,[arch/x86/boot](https://github.com/torvalds/linux/tree/master/arch/x86/boot/) 里的源文件可以继续编译:
|
||||
|
||||
```Makefile
|
||||
AS arch/x86/boot/header.o
|
||||
CC arch/x86/boot/main.o
|
||||
CC arch/x86/boot/mca.o
|
||||
CC arch/x86/boot/memory.o
|
||||
CC arch/x86/boot/pm.o
|
||||
AS arch/x86/boot/pmjump.o
|
||||
CC arch/x86/boot/printf.o
|
||||
CC arch/x86/boot/regs.o
|
||||
CC arch/x86/boot/string.o
|
||||
CC arch/x86/boot/tty.o
|
||||
CC arch/x86/boot/video.o
|
||||
CC arch/x86/boot/video-mode.o
|
||||
CC arch/x86/boot/video-vga.o
|
||||
CC arch/x86/boot/video-vesa.o
|
||||
CC arch/x86/boot/video-bios.o
|
||||
```
|
||||
|
||||
所有的源代码会被编译,他们最终会被链接到 `setup.elf` :
|
||||
|
||||
```Makefile
|
||||
LD arch/x86/boot/setup.elf
|
||||
```
|
||||
|
||||
或者:
|
||||
|
||||
```
|
||||
ld -m elf_x86_64 -T arch/x86/boot/setup.ld arch/x86/boot/a20.o arch/x86/boot/bioscall.o arch/x86/boot/cmdline.o arch/x86/boot/copy.o arch/x86/boot/cpu.o arch/x86/boot/cpuflags.o arch/x86/boot/cpucheck.o arch/x86/boot/early_serial_console.o arch/x86/boot/edd.o arch/x86/boot/header.o arch/x86/boot/main.o arch/x86/boot/mca.o arch/x86/boot/memory.o arch/x86/boot/pm.o arch/x86/boot/pmjump.o arch/x86/boot/printf.o arch/x86/boot/regs.o arch/x86/boot/string.o arch/x86/boot/tty.o arch/x86/boot/video.o arch/x86/boot/video-mode.o arch/x86/boot/version.o arch/x86/boot/video-vga.o arch/x86/boot/video-vesa.o arch/x86/boot/video-bios.o -o arch/x86/boot/setup.elf
|
||||
```
|
||||
|
||||
最后的两件事是创建包含目录 `arch/x86/boot/*` 下的编译过的代码的 `setup.bin`:
|
||||
|
||||
```
|
||||
objcopy -O binary arch/x86/boot/setup.elf arch/x86/boot/setup.bin
|
||||
```
|
||||
|
||||
以及从 `vmlinux` 生成 `vmlinux.bin` :
|
||||
|
||||
```
|
||||
objcopy -O binary -R .note -R .comment -S arch/x86/boot/compressed/vmlinux arch/x86/boot/vmlinux.bin
|
||||
```
|
||||
|
||||
最最后,我们编译主机程序 [arch/x86/boot/tools/build.c](https://github.com/torvalds/linux/blob/master/arch/x86/boot/tools/build.c),它将会用来把 `setup.bin` 和 `vmlinux.bin` 打包成 `bzImage`:
|
||||
|
||||
```
|
||||
arch/x86/boot/tools/build arch/x86/boot/setup.bin arch/x86/boot/vmlinux.bin arch/x86/boot/zoffset.h arch/x86/boot/bzImage
|
||||
```
|
||||
|
||||
实际上 `bzImage` 就是把 `setup.bin` 和 `vmlinux.bin` 连接到一起。最终我们会看到输出结果,就和那些用源码编译过内核的同行的结果一样:
|
||||
|
||||
```
|
||||
Setup is 16268 bytes (padded to 16384 bytes).
|
||||
System is 4704 kB
|
||||
CRC 94a88f9a
|
||||
Kernel: arch/x86/boot/bzImage is ready (#5)
|
||||
```
|
||||
|
||||
|
||||
全部结束。
|
||||
|
||||
###结论
|
||||
|
||||
这就是本文的结尾部分。本文我们了解了编译内核的全部步骤:从执行 `make` 命令开始,到最后生成 `bzImage`。我知道,linux 内核的 makefile 和构建 linux 的过程第一眼看起来可能比较迷惑,但是这并不是很难。希望本文可以帮助你理解构建 linux 内核的整个流程。
|
||||
|
||||
|
||||
###链接
|
||||
|
||||
* [GNU make util](https://en.wikipedia.org/wiki/Make_%28software%29)
|
||||
* [Linux kernel top Makefile](https://github.com/torvalds/linux/blob/master/Makefile)
|
||||
* [cross-compilation](https://en.wikipedia.org/wiki/Cross_compiler)
|
||||
* [Ctags](https://en.wikipedia.org/wiki/Ctags)
|
||||
* [sparse](https://en.wikipedia.org/wiki/Sparse)
|
||||
* [bzImage](https://en.wikipedia.org/wiki/Vmlinux#bzImage)
|
||||
* [uname](https://en.wikipedia.org/wiki/Uname)
|
||||
* [shell](https://en.wikipedia.org/wiki/Shell_%28computing%29)
|
||||
* [Kbuild](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/kbuild.txt)
|
||||
* [binutils](http://www.gnu.org/software/binutils/)
|
||||
* [gcc](https://gcc.gnu.org/)
|
||||
* [Documentation](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/makefiles.txt)
|
||||
* [System.map](https://en.wikipedia.org/wiki/System.map)
|
||||
* [Relocation](https://en.wikipedia.org/wiki/Relocation_%28computing%29)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/0xAX/linux-insides/blob/master/Misc/how_kernel_compiled.md
|
||||
|
||||
译者:[oska874](https://github.com/oska874)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,16 +1,17 @@
|
||||
如何在CentOS上安装iTOP(IT操作门户)
|
||||
如何在 CentOS 7 上安装开源 ITIL 门户 iTOP
|
||||
================================================================================
|
||||
iTOP简单来说是一个简单的基于网络的开源IT服务管理工具。它有所有的ITIL功能包括服务台、配置管理、事件管理、问题管理、更改管理和服务管理。iTOP依赖于Apache/IIS、MySQL和PHP,因此它可以运行在任何支持这些软件的操作系统中。因为iTOP是一个网络程序,因此你不必在用户的PC端任何客户端程序。一个简单的浏览器就足够每天的IT环境操作了。
|
||||
|
||||
iTOP是一个简单的基于Web的开源IT服务管理工具。它有所有的ITIL功能,包括服务台、配置管理、事件管理、问题管理、变更管理和服务管理。iTOP依赖于Apache/IIS、MySQL和PHP,因此它可以运行在任何支持这些软件的操作系统中。因为iTOP是一个Web程序,因此你不必在用户的PC端任何客户端程序。一个简单的浏览器就足够每天的IT环境操作了。
|
||||
|
||||
我们要在一台有满足基本需求的LAMP环境的CentOS 7上安装和配置iTOP。
|
||||
|
||||
### 下载 iTOP ###
|
||||
|
||||
iTOP的下载包现在在SOurceForge上,我们可以从这获取它的官方[链接][1]。
|
||||
iTOP的下载包现在在SourceForge上,我们可以从这获取它的官方[链接][1]。
|
||||
|
||||

|
||||
|
||||
我们从这里的连接用wget命令获取压缩文件
|
||||
我们从这里的连接用wget命令获取压缩文件。
|
||||
|
||||
[root@centos-007 ~]# wget http://downloads.sourceforge.net/project/itop/itop/2.1.0/iTop-2.1.0-2127.zip
|
||||
|
||||
@ -40,7 +41,7 @@ iTOP的下载包现在在SOurceForge上,我们可以从这获取它的官方[
|
||||
installation.xml itop-change-mgmt-itil itop-incident-mgmt-itil itop-request-mgmt-itil itop-tickets
|
||||
itop-attachments itop-config itop-knownerror-mgmt itop-service-mgmt itop-virtualization-mgmt
|
||||
|
||||
在解压的目录下,通过不同的数据模型用复制命令迁移需要的扩展从datamodels复制到web扩展目录下。
|
||||
在解压的目录下,使用如下的 cp 命令将不同的数据模型从web 下的 datamodels 目录下复制到 extensions 目录,来迁移需要的扩展。
|
||||
|
||||
[root@centos-7 2.x]# pwd
|
||||
/var/www/html/itop/web/datamodels/2.x
|
||||
@ -50,19 +51,19 @@ iTOP的下载包现在在SOurceForge上,我们可以从这获取它的官方[
|
||||
|
||||
大多数服务端设置和配置已经完成了。最后我们安装web界面来完成安装。
|
||||
|
||||
打开浏览器使用ip地址或者FQDN来访问WordPress web目录。
|
||||
打开浏览器使用ip地址或者完整域名来访问iTop 的 web目录。
|
||||
|
||||
http://servers_ip_address/itop/web/
|
||||
|
||||
你会被重定向到iTOP的web安装页面。让我们按照要求配置,就像在这篇教程中做的那样。
|
||||
|
||||
#### 先决要求验证 ####
|
||||
#### 验证先决要求 ####
|
||||
|
||||
这一步你就会看到验证完成的欢迎界面。如果你看到了一些警告信息,你需要先安装这些软件来解决这些问题。
|
||||
|
||||

|
||||
|
||||
这一步一个叫php mcrypt的可选包丢失了。下载下面的rpm包接着尝试安装php mcrypt包。
|
||||
这一步有一个叫php mcrypt的可选包丢失了。下载下面的rpm包接着尝试安装php mcrypt包。
|
||||
|
||||
[root@centos-7 ~]#yum localinstall php-mcrypt-5.3.3-1.el6.x86_64.rpm libmcrypt-2.5.8-9.el6.x86_64.rpm.
|
||||
|
||||
@ -76,7 +77,7 @@ iTOP的下载包现在在SOurceForge上,我们可以从这获取它的官方[
|
||||
|
||||
#### iTop 许可协议 ####
|
||||
|
||||
勾选同意iTOP所有组件的许可协议并点击“NEXT”。
|
||||
勾选接受 iTOP所有组件的许可协议,并点击“NEXT”。
|
||||
|
||||

|
||||
|
||||
@ -94,7 +95,7 @@ iTOP的下载包现在在SOurceForge上,我们可以从这获取它的官方[
|
||||
|
||||
#### 杂项参数 ####
|
||||
|
||||
让我们选择额外的参数来选择你是否需要安装一个演示内容或者使用全新的数据库,接着下一步。
|
||||
让我们选择额外的参数来选择你是否需要安装一个带有演示内容的数据库或者使用全新的数据库,接着下一步。
|
||||
|
||||

|
||||
|
||||
@ -118,7 +119,7 @@ iTOP的下载包现在在SOurceForge上,我们可以从这获取它的官方[
|
||||
|
||||
#### 改变管理选项 ####
|
||||
|
||||
选择不同的ticket类型以便管理可用选项中的IT设备更改。我们选择ITTL更改管理选项。
|
||||
选择不同的ticket类型以便管理可用选项中的IT设备变更。我们选择ITTL变更管理选项。
|
||||
|
||||

|
||||
|
||||
@ -166,7 +167,7 @@ via: http://linoxide.com/tools/setup-itop-centos-7/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
如何在 Docker 容器中运行支持 OData 的 JBoss 数据虚拟化 GA
|
||||
Howto Run JBoss Data Virtualization GA with OData in Docker Container
|
||||
================================================================================
|
||||
大家好,我们今天来学习如何在一个 Docker 容器中运行支持 OData(译者注:Open Data Protocol,开放数据协议) 的 JBoss 数据虚拟化 6.0.0 GA(译者注:GA,General Availability,具体定义可以查看[WIKI][4])。JBoss 数据虚拟化是数据提供和集成解决方案平台,有多种分散的数据源时,转换为一种数据源统一对待,在正确的时间将所需数据传递给任意的应用或者用户。JBoss 数据虚拟化可以帮助我们将数据快速组合和转换为可重用的商业友好的数据模型,通过开放标准接口简单可用。它提供全面的数据抽取、联合、集成、转换,以及传输功能,将来自一个或多个源的数据组合为可重复使用和共享的灵活数据。要了解更多关于 JBoss 数据虚拟化的信息,可以查看它的[官方文档][1]。Docker 是一个提供开放平台用于打包,装载和以轻量级容器运行任何应用的开源平台。使用 Docker 容器我们可以轻松处理和启用支持 OData 的 JBoss 数据虚拟化。
|
||||
|
||||
大家好,我们今天来学习如何在一个 Docker 容器中运行支持 OData(译者注:Open Data Protocol,开放数据协议) 的 JBoss 数据虚拟化 6.0.0 GA(译者注:GA,General Availability,具体定义可以查看[WIKI][4])。JBoss 数据虚拟化是数据提供和集成解决方案平台,将多种分散的数据源转换为一种数据源统一对待,在正确的时间将所需数据传递给任意的应用或者用户。JBoss 数据虚拟化可以帮助我们将数据快速组合和转换为可重用的商业友好的数据模型,通过开放标准接口简单可用。它提供全面的数据抽取、联合、集成、转换,以及传输功能,将来自一个或多个源的数据组合为可重复使用和共享的灵活数据。要了解更多关于 JBoss 数据虚拟化的信息,可以查看它的[官方文档][1]。Docker 是一个提供开放平台用于打包,装载和以轻量级容器运行任何应用的开源平台。使用 Docker 容器我们可以轻松处理和启用支持 OData 的 JBoss 数据虚拟化。
|
||||
|
||||
下面是该指南中在 Docker 容器中运行支持 OData 的 JBoss 数据虚拟化的简单步骤。
|
||||
|
||||
@ -78,7 +78,6 @@ Howto Run JBoss Data Virtualization GA with OData in Docker Container
|
||||
"LinkLocalIPv6PrefixLen": 0,
|
||||
|
||||
### 6. Web 界面 ###
|
||||
### 6. Web Interface ###
|
||||
|
||||
现在,如果一切如期望的那样进行,当我们用浏览器打开 http://container-ip:8080/ 和 http://container-ip:9990 时会看到支持 oData 的 JBoss 数据虚拟化登录界面和 JBoss 管理界面。管理验证的用户名和密码分别是 admin 和 redhat1!数据虚拟化验证的用户名和密码都是 user。之后,我们可以通过 web 界面在内容间导航。
|
||||
|
||||
@ -94,7 +93,7 @@ via: http://linoxide.com/linux-how-to/run-jboss-data-virtualization-ga-odata-doc
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,10 +1,9 @@
|
||||
|
||||
在 Linux 中怎样将 MySQL 迁移到 MariaDB 上
|
||||
================================================================================
|
||||
|
||||
自从甲骨文收购 MySQL 后,很多 MySQL 的开发者和用户放弃了 MySQL 由于甲骨文对 MySQL 的开发和维护更多倾向于闭门的立场。在社区驱动下,促使更多人移到 MySQL 的另一个分支中,叫 MariaDB。在原有 MySQL 开发人员的带领下,MariaDB 的开发遵循开源的理念,并确保 [它的二进制格式与 MySQL 兼容][1]。Linux 发行版如 Red Hat 家族(Fedora,CentOS,RHEL),Ubuntu 和Mint,openSUSE 和 Debian 已经开始使用,并支持 MariaDB 作为 MySQL 的简易替换品。
|
||||
自从甲骨文收购 MySQL 后,由于甲骨文对 MySQL 的开发和维护更多倾向于闭门的立场,很多 MySQL 的开发者和用户放弃了 MySQL。在社区驱动下,促使更多人移到 MySQL 的另一个叫 MariaDB 的分支。在原有 MySQL 开发人员的带领下,MariaDB 的开发遵循开源的理念,并确保[它的二进制格式与 MySQL 兼容][1]。Linux 发行版如 Red Hat 家族(Fedora,CentOS,RHEL),Ubuntu 和 Mint,openSUSE 和 Debian 已经开始使用,并支持 MariaDB 作为 MySQL 的直接替换品。
|
||||
|
||||
如果想要将 MySQL 中的数据库迁移到 MariaDB 中,这篇文章就是你所期待的。幸运的是,由于他们的二进制兼容性,MySQL-to-MariaDB 迁移过程是非常简单的。如果你按照下面的步骤,将 MySQL 迁移到 MariaDB 会是无痛的。
|
||||
如果你想要将 MySQL 中的数据库迁移到 MariaDB 中,这篇文章就是你所期待的。幸运的是,由于他们的二进制兼容性,MySQL-to-MariaDB 迁移过程是非常简单的。如果你按照下面的步骤,将 MySQL 迁移到 MariaDB 会是无痛的。
|
||||
|
||||
### 准备 MySQL 数据库和表 ###
|
||||
|
||||
@ -69,7 +68,7 @@
|
||||
|
||||
### 安装 MariaDB ###
|
||||
|
||||
在 CentOS/RHEL 7和Ubuntu(14.04或更高版本)上,最新的 MariaDB 包含在其官方源。在 Fedora 上,自19版本后 MariaDB 已经替代了 MySQL。如果你使用的是旧版本或 LTS 类型如 Ubuntu 13.10 或更早的,你仍然可以通过添加其官方仓库来安装 MariaDB。
|
||||
在 CentOS/RHEL 7和Ubuntu(14.04或更高版本)上,最新的 MariaDB 已经包含在其官方源。在 Fedora 上,自19 版本后 MariaDB 已经替代了 MySQL。如果你使用的是旧版本或 LTS 类型如 Ubuntu 13.10 或更早的,你仍然可以通过添加其官方仓库来安装 MariaDB。
|
||||
|
||||
[MariaDB 网站][2] 提供了一个在线工具帮助你依据你的 Linux 发行版中来添加 MariaDB 的官方仓库。此工具为 openSUSE, Arch Linux, Mageia, Fedora, CentOS, RedHat, Mint, Ubuntu, 和 Debian 提供了 MariaDB 的官方仓库.
|
||||
|
||||
@ -103,7 +102,7 @@
|
||||
|
||||
$ sudo yum install MariaDB-server MariaDB-client
|
||||
|
||||
安装了所有必要的软件包后,你可能会被要求为 root 用户创建一个新密码。设置 root 的密码后,别忘了恢复备份的 my.cnf 文件。
|
||||
安装了所有必要的软件包后,你可能会被要求为 MariaDB 的 root 用户创建一个新密码。设置 root 的密码后,别忘了恢复备份的 my.cnf 文件。
|
||||
|
||||
$ sudo cp /opt/my.cnf /etc/mysql/
|
||||
|
||||
@ -111,7 +110,7 @@
|
||||
|
||||
$ sudo service mariadb start
|
||||
|
||||
或者:
|
||||
或:
|
||||
|
||||
$ sudo systemctl start mariadb
|
||||
|
||||
@ -141,13 +140,13 @@
|
||||
|
||||
### 结论 ###
|
||||
|
||||
如你在本教程中看到的,MySQL-to-MariaDB 的迁移并不难。MariaDB 相比 MySQL 有很多新的功能,你应该知道的。至于配置方面,在我的测试情况下,我只是将我旧的 MySQL 配置文件(my.cnf)作为 MariaDB 的配置文件,导入过程完全没有出现任何问题。对于配置文件,我建议你在迁移之前请仔细阅读MariaDB 配置选项的文件,特别是如果你正在使用 MySQL 的特殊配置。
|
||||
如你在本教程中看到的,MySQL-to-MariaDB 的迁移并不难。你应该知道,MariaDB 相比 MySQL 有很多新的功能。至于配置方面,在我的测试情况下,我只是将我旧的 MySQL 配置文件(my.cnf)作为 MariaDB 的配置文件,导入过程完全没有出现任何问题。对于配置文件,我建议你在迁移之前请仔细阅读 MariaDB 配置选项的文件,特别是如果你正在使用 MySQL 的特定配置。
|
||||
|
||||
如果你正在运行更复杂的配置有海量的数据库和表,包括群集或主从复制,看一看 Mozilla IT 和 Operations 团队的 [更详细的指南][3] ,或者 [官方的 MariaDB 文档][4]。
|
||||
如果你正在运行有海量的表、包括群集或主从复制的数据库的复杂配置,看一看 Mozilla IT 和 Operations 团队的 [更详细的指南][3] ,或者 [官方的 MariaDB 文档][4]。
|
||||
|
||||
### 故障排除 ###
|
||||
|
||||
1.在运行 mysqldump 命令备份数据库时出现以下错误。
|
||||
1、 在运行 mysqldump 命令备份数据库时出现以下错误。
|
||||
|
||||
$ mysqldump --all-databases --user=root --password --master-data > backupdb.sql
|
||||
|
||||
@ -155,7 +154,7 @@
|
||||
|
||||
mysqldump: Error: Binlogging on server not active
|
||||
|
||||
通过使用 "--master-data",你要在导出的输出中包含二进制日志信息,这对于数据库的复制和恢复是有用的。但是,二进制日志未在 MySQL 服务器启用。要解决这个错误,修改 my.cnf 文件,并在 [mysqld] 部分添加下面的选项。
|
||||
通过使用 "--master-data",你可以在导出的输出中包含二进制日志信息,这对于数据库的复制和恢复是有用的。但是,二进制日志未在 MySQL 服务器启用。要解决这个错误,修改 my.cnf 文件,并在 [mysqld] 部分添加下面的选项。
|
||||
|
||||
log-bin=mysql-bin
|
||||
|
||||
@ -176,8 +175,8 @@
|
||||
via: http://xmodulo.com/migrate-mysql-to-mariadb-linux.html
|
||||
|
||||
作者:[Kristophorus Hadiono][a]
|
||||
译者:[strugglingyouth](https://github.com/译者ID)
|
||||
校对:[strugglingyouth](https://github.com/校对者ID)
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,5 +1,4 @@
|
||||
|
||||
Linux 有问必答 - 如何在 Linux 中统计一个进程的线程数
|
||||
Linux 有问必答:如何在 Linux 中统计一个进程的线程数
|
||||
================================================================================
|
||||
> **问题**: 我正在运行一个程序,它在运行时会派生出多个线程。我想知道程序在运行时会有多少线程。在 Linux 中检查进程的线程数最简单的方法是什么?
|
||||
|
||||
@ -7,11 +6,11 @@ Linux 有问必答 - 如何在 Linux 中统计一个进程的线程数
|
||||
|
||||
### 方法一: /proc ###
|
||||
|
||||
proc 伪文件系统,它驻留在 /proc 目录,这是最简单的方法来查看任何活动进程的线程数。 /proc 目录以可读文本文件形式输出,提供现有进程和系统硬件相关的信息如 CPU, interrupts, memory, disk, 等等.
|
||||
proc 伪文件系统,它驻留在 /proc 目录,这是最简单的方法来查看任何活动进程的线程数。 /proc 目录以可读文本文件形式输出,提供现有进程和系统硬件相关的信息如 CPU、中断、内存、磁盘等等.
|
||||
|
||||
$ cat /proc/<pid>/status
|
||||
|
||||
上面的命令将显示进程 <pid> 的详细信息,包括过程状态(例如, sleeping, running),父进程 PID,UID,GID,使用的文件描述符的数量,以及上下文切换的数量。输出也包括**进程创建的总线程数**如下所示。
|
||||
上面的命令将显示进程 \<pid> 的详细信息,包括过程状态(例如, sleeping, running),父进程 PID,UID,GID,使用的文件描述符的数量,以及上下文切换的数量。输出也包括**进程创建的总线程数**如下所示。
|
||||
|
||||
Threads: <N>
|
||||
|
||||
@ -23,11 +22,11 @@ Linux 有问必答 - 如何在 Linux 中统计一个进程的线程数
|
||||
|
||||
输出表明该进程有28个线程。
|
||||
|
||||
或者,你可以在 /proc/<pid>/task 中简单的统计目录的数量,如下所示。
|
||||
或者,你可以在 /proc/<pid>/task 中简单的统计子目录的数量,如下所示。
|
||||
|
||||
$ ls /proc/<pid>/task | wc
|
||||
|
||||
这是因为,对于一个进程中创建的每个线程,在 /proc/<pid>/task 中会创建一个相应的目录,命名为其线程 ID。由此在 /proc/<pid>/task 中目录的总数表示在进程中线程的数目。
|
||||
这是因为,对于一个进程中创建的每个线程,在 `/proc/<pid>/task` 中会创建一个相应的目录,命名为其线程 ID。由此在 `/proc/<pid>/task` 中目录的总数表示在进程中线程的数目。
|
||||
|
||||
### 方法二: ps ###
|
||||
|
||||
@ -35,7 +34,7 @@ Linux 有问必答 - 如何在 Linux 中统计一个进程的线程数
|
||||
|
||||
$ ps hH p <pid> | wc -l
|
||||
|
||||
如果你想监视一个进程的不同线程消耗的硬件资源(CPU & memory),请参阅[此教程][1]。(注:此文我们翻译过)
|
||||
如果你想监视一个进程的不同线程消耗的硬件资源(CPU & memory),请参阅[此教程][1]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -43,9 +42,9 @@ via: http://ask.xmodulo.com/number-of-threads-process-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://ask.xmodulo.com/view-threads-process-linux.html
|
||||
[1]:https://linux.cn/article-5633-1.html
|
||||
@ -1,14 +1,6 @@
|
||||
|
||||
Linux 有问必答--如何解决 Linux 桌面上的 Wireshark GUI 死机
|
||||
Linux 有问必答:如何解决 Linux 上的 Wireshark 界面僵死
|
||||
================================================================================
|
||||
> **问题**: 当我试图在 Ubuntu 上的 Wireshark 中打开一个 pre-recorded 数据包转储时,它的 UI 突然死机,在我发起 Wireshark 的终端出现了下面的错误和警告。我该如何解决这个问题?
|
||||
|
||||
Wireshark 是一个基于 GUI 的数据包捕获和嗅探工具。该工具被网络管理员普遍使用,网络安全工程师或开发人员对于各种任务的 packet-level 网络分析是必需的,例如在网络故障,漏洞测试,应用程序调试,或逆向协议工程是必需的。 Wireshark 允许记录存活数据包,并通过便捷的图形用户界面浏览他们的协议首部和有效负荷。
|
||||
|
||||

|
||||
|
||||
这是 Wireshark 的 UI,尤其是在 Ubuntu 桌面下运行,有时会挂起或冻结出现以下错误,而你是向上或向下滚动分组列表视图时,就开始加载一个 pre-recorded 包转储文件。
|
||||
|
||||
> **问题**: 当我试图在 Ubuntu 上的 Wireshark 中打开一个 pre-recorded 数据包转储时,它的界面突然死机,在我运行 Wireshark 的终端出现了下面的错误和警告。我该如何解决这个问题?
|
||||
|
||||
(wireshark:3480): GLib-GObject-WARNING **: invalid unclassed pointer in cast to 'GObject'
|
||||
(wireshark:3480): GLib-GObject-CRITICAL **: g_object_set_qdata_full: assertion 'G_IS_OBJECT (object)' failed
|
||||
@ -22,6 +14,15 @@ Wireshark 是一个基于 GUI 的数据包捕获和嗅探工具。该工具被
|
||||
(wireshark:3480): GLib-GObject-CRITICAL **: g_object_get_qdata: assertion 'G_IS_OBJECT (object)' failed
|
||||
(wireshark:3480): Gtk-CRITICAL **: gtk_widget_set_name: assertion 'GTK_IS_WIDGET (widget)' failed
|
||||
|
||||
|
||||
Wireshark 是一个基于 GUI 的数据包捕获和嗅探工具。该工具被网络管理员普遍使用,网络安全工程师或开发人员对于各种任务的数据包级的网络分析是必需的,例如在网络故障,漏洞测试,应用程序调试,或逆向协议工程是必需的。 Wireshark 允许实时记录数据包,并通过便捷的图形用户界面浏览他们的协议首部和有效负荷。
|
||||
|
||||

|
||||
|
||||
这是 Wireshark 的 UI,尤其是在 Ubuntu 桌面下运行时,当你向上或向下滚动分组列表视图时,或开始加载一个 pre-recorded 包转储文件时,有时会挂起或冻结,并出现以下错误。
|
||||
|
||||

|
||||
|
||||
显然,这个错误是由 Wireshark 和叠加滚动条之间的一些不兼容造成的,在最新的 Ubuntu 桌面还没有被解决(例如,Ubuntu 15.04 的桌面)。
|
||||
|
||||
一种避免 Wireshark 的 UI 卡死的办法就是 **暂时禁用叠加滚动条**。在 Wireshark 上有两种方法来禁用叠加滚动条,这取决于你在桌面上如何启动 Wireshark 的。
|
||||
@ -46,7 +47,7 @@ Wireshark 是一个基于 GUI 的数据包捕获和嗅探工具。该工具被
|
||||
|
||||
Exec=env LIBOVERLAY_SCROLLBAR=0 wireshark %f
|
||||
|
||||
虽然这种解决方法将有利于所有桌面用户的 system-wide,但它将无法升级 Wireshark。如果你想保留修改的 .desktop 文件,如下所示将它复制到你的主目录。
|
||||
虽然这种解决方法可以在系统级帮助到所有桌面用户,但升级 Wireshark 就没用了。如果你想保留修改的 .desktop 文件,如下所示将它复制到你的主目录。
|
||||
|
||||
$ cp /usr/share/applications/wireshark.desktop ~/.local/share/applications/
|
||||
|
||||
@ -56,7 +57,7 @@ via: http://ask.xmodulo.com/fix-wireshark-gui-freeze-linux-desktop.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,108 @@
|
||||
Debian GNU/Linux,22 年未完的美妙旅程
|
||||
================================================================================
|
||||
|
||||
在2015年8月16日, Debian项目组庆祝了 Debian 的22周年纪念日;这也是开源世界历史最悠久、热门的发行版之一。 Debian项目于1993年由Ian Murdock创立。彼时,Slackware 作为最早的 Linux 发行版已经名声在外。
|
||||
|
||||

|
||||
|
||||
*22岁生日快乐! Debian Linux!*
|
||||
|
||||
Ian Ashly Murdock, 一个美国职业软件工程师, 在他还是普渡大学的学生时构想出了 Debian 项目的计划。他把这个项目命名为 Debian 是由于这个名字组合了他彼时女友的名字 Debra Lynn 和他自己的名字 Ian。 他之后和 Lynn 结婚并在2008年1月离婚。
|
||||
|
||||

|
||||
|
||||
*Debian 创始人:Ian Murdock*
|
||||
|
||||
Ian 目前是 ExactTarget 的平台与开发社区的副总裁。
|
||||
|
||||
Debian (如同Slackware一样) 都是由于当时缺乏满足合乎标准的发行版才应运而生的。 Ian 在一次采访中说:“免费提供一流的产品会是 Debian 项目的唯一使命。 尽管过去的 Linux 发行版均不尽然可靠抑或是优秀。 我印象里...比如在不同的文件系统间移动文件, 处理大型文件经常会导致内核出错。 但是 Linux 其实是很可靠的, 自由的源代码让这个项目本质上很有前途。”
|
||||
|
||||
"我记得过去我像其他想解决问题的人一样, 想在家里运行一个像 UNIX 的东西。 但那是不可能的, 无论是经济上还是法律上或是别的什么角度。 然后我就听闻了 GNU 内核开发项目, 以及这个项目是如何没有任何法律纷争", Ian 补充到。 他早年在开发 Debian 时曾被自由软件基金会(FSF)资助, 这份资助帮助 Debian 取得了长足的发展; 尽管一年后由于学业原因 Ian 退出了 FSF 转而去完成他的学位。
|
||||
|
||||
### Debian开发历史 ###
|
||||
|
||||
- **Debian 0.01 – 0.09** : 发布于 1993 年八月 – 1993 年十二月。
|
||||
- **Debian 0.91** : 发布于 1994 年一月。 有了原始的包管理系统, 没有依赖管理机制。
|
||||
- **Debian 0.93 rc5** : 发布于 1995 年三月。 “现代”意义的 Debian 的第一次发布, 在基础系统安装后会使用dpkg 安装以及管理其他软件包。
|
||||
- **Debian 0.93 rc6**: 发布于 1995 年十一月。 最后一次 a.out 发布, deselect 机制第一次出现, 有60位开发者在彼时维护着软件包。
|
||||
- **Debian 1.1**: 发布于 1996 年六月。 项目代号 – Buzz, 软件包数量 – 474, 包管理器 dpkg, 内核版本 2.0, ELF 二进制。
|
||||
- **Debian 1.2**: 发布于 1996 年十二月。 项目代号 – Rex, 软件包数量 – 848, 开发者数量 – 120。
|
||||
- **Debian 1.3**: 发布于 1997 年七月。 项目代号 – Bo, 软件包数量 974, 开发者数量 – 200。
|
||||
- **Debian 2.0**: 发布于 1998 年七月。 项目代号 - Hamm, 支持构架 – Intel i386 以及 Motorola 68000 系列, 软件包数量: 1500+, 开发者数量: 400+, 内置了 glibc。
|
||||
- **Debian 2.1**: 发布于1999 年三月九日。 项目代号 – slink, 支持构架 - Alpha 和 Sparc, apt 包管理器开始成型, 软件包数量 – 2250。
|
||||
- **Debian 2.2**: 发布于 2000 年八月十五日。 项目代号 – Potato, 支持构架 – Intel i386, Motorola 68000 系列, Alpha, SUN Sparc, PowerPC 以及 ARM 构架。 软件包数量: 3900+ (二进制) 以及 2600+ (源代码), 开发者数量 – 450。 有一群人在那时研究并发表了一篇论文, 论文展示了自由软件是如何在被各种问题包围的情况下依然逐步成长为优秀的现代操作系统的。
|
||||
- **Debian 3.0**: 发布于 2002 年七月十九日。 项目代号 – woody, 支持构架新增 – HP, PA_RISC, IA-64, MIPS 以及 IBM, 首次以DVD的形式发布, 软件包数量 – 8500+, 开发者数量 – 900+, 支持加密。
|
||||
- **Debian 3.1**: 发布于 2005 年六月六日。 项目代号 – sarge, 支持构架 – 新增 AMD64(非官方渠道发布), 内核 – 2.4 以及 2.6 系列, 软件包数量: 15000+, 开发者数量 : 1500+, 增加了诸如 OpenOffice 套件, Firefox 浏览器, Thunderbird, Gnome 2.8, 支持: RAID, XFS, LVM, Modular Installer。
|
||||
- **Debian 4.0**: 发布于 2007 年四月八日。 项目代号 – etch, 支持构架 – 如前,包括 AMD64。 软件包数量: 18,200+ 开发者数量 : 1030+, 图形化安装器。
|
||||
- **Debian 5.0**: 发布于 2009 年二月十四日。 项目代号 – lenny, 支持构架 – 新增 ARM。 软件包数量: 23000+, 开发者数量: 1010+。
|
||||
- **Debian 6.0**: 发布于 2009 年七月二十九日。 项目代号 – squeeze, 包含的软件包: 内核 2.6.32, Gnome 2.3. Xorg 7.5, 同时包含了 DKMS, 基于依赖包支持。 支持构架 : 新增 kfreebsd-i386 以及 kfreebsd-amd64, 基于依赖管理的启动过程。
|
||||
- **Debian 7.0**: 发布于 2013 年五月四日。 项目代号: wheezy, 支持 Multiarch, 私有云工具, 升级了安装器, 移除了第三方软件依赖, 全功能多媒体套件-codec, 内核版本 3.2, Xen Hypervisor 4.1.4 ,软件包数量: 37400+。
|
||||
- **Debian 8.0**: 发布于 2015 年五月二十五日。 项目代号: Jessie, 将 Systemd 作为默认的初始化系统, 内核版本 3.16, 增加了快速启动(fast booting), service进程所依赖的 cgroups 使隔离部分 service 进程成为可能, 43000+ 软件包。 Sysvinit 初始化工具在 Jessie 中可用。
|
||||
|
||||
**注意**: Linux的内核第一次是在1991 年十月五日被发布, 而 Debian 的首次发布则在1993 年九月十三日。 所以 Debian 已经在只有24岁的 Linux 内核上运行了整整22年了。
|
||||
|
||||
### Debian 的那些事 ###
|
||||
|
||||
1994年管理和重整了 Debian 项目以使得其他开发者能更好地加入,所以在那一年并没有发布面向用户的更新, 当然, 内部版本肯定是有的。
|
||||
|
||||
Debian 1.0 从来就没有被发布过。 一家 CD-ROM 的生产商错误地把某个未发布的版本标注为了 1.0, 为了避免产生混乱, 原本的 Debian 1.0 以1.1的面貌发布了。 从那以后才有了所谓的官方CD-ROM的概念。
|
||||
|
||||
每个 Debian 新版本的代号都是玩具总动员里某个角色的名字哦。
|
||||
|
||||
Debian 有四种可用版本: 旧稳定版(old stable), 稳定版(stable), 测试版(testing) 以及 试验版(experimental)。 始终如此。
|
||||
|
||||
Debian 项目组一直工作在不稳定发行版上, 这个不稳定版本始终被叫做Sid(玩具总动员里那个邪恶的臭小孩)。 Sid是unstable版本的永久名称, 同时Sid也取自'Still In Development"(译者:还在开发中)的首字母。 Sid 将会成为下一个稳定版, 当前的稳定版本代号为 jessie。
|
||||
|
||||
Debian 的官方发行版只包含开源并且自由的软件, 绝无其他东西. 不过 contrib 和非自由软件包使得安装那些本身自由但是其依赖的软件包不自由(contrib)的软件和非自由软件成为了可能。
|
||||
|
||||
Debian 是一堆Linux 发行版之母。 举几个例子:
|
||||
|
||||
- Damn Small Linux
|
||||
- KNOPPIX
|
||||
- Linux Advanced
|
||||
- MEPIS
|
||||
- Ubuntu
|
||||
- 64studio (不再活跃开发)
|
||||
- LMDE
|
||||
|
||||
Debian 是世界上最大的非商业 Linux 发行版。它主要是由C编写的(32.1%), 一并的还有其他70多种语言。
|
||||
|
||||

|
||||
|
||||
*Debian 开发语言贡献表,图片来源: [Xmodulo][1]*
|
||||
|
||||
Debian 项目包含6,850万行代码, 以及 450万行空格和注释。
|
||||
|
||||
国际空间站放弃了 Windows 和红帽子, 进而换成了 Debian - 在上面的宇航员使用落后一个版本的稳定发行版, 目前是 squeeze; 这么做是为了稳定程度以及来自 Debian 社区的雄厚帮助支持。
|
||||
|
||||
感谢上帝! 我们差点就听到来自国际空间宇航员面对 Windows Metro 界面的尖叫了 :P
|
||||
|
||||
#### 黑色星期三 ####
|
||||
|
||||
2002 年十一月二十日, Twente 大学的网络运营中心(NOC)着火。 当地消防部门放弃了服务器区域。 NOC维护着satie.debian.org 的网站服务器, 这个网站包含了安全、非美国相关的存档、新维护者资料、数量报告、数据库等等;这一切都化为了灰烬。 之后这些服务由 Debian 重建了。
|
||||
|
||||
#### 未来版本 ####
|
||||
|
||||
下一个待发布版本是 Debian 9, 项目代号 – Stretch, 它会带来什么还是个未知数。 满心期待吧!
|
||||
|
||||
有很多发行版在 Linux 发行版的历史上出现过一瞬间然后很快消失了。 在多数情况下, 维护一个日渐庞大的项目是开发者们面临的挑战。 但这对 Debian 来说不是问题。 Debian 项目有全世界成百上千的开发者、维护者。 它在 Linux 诞生的之初起便一直存在。
|
||||
|
||||
Debian 在 Linux 生态环境中的贡献是难以用语言描述的。 如果 Debian 没有出现过, 那么 Linux 世界将不会像现在这样丰富和用户友好。 Debian 是为数不多可以被认为安全可靠又稳定的发行版,是作为网络服务器完美选择。
|
||||
|
||||
这仅仅是 Debian 的一个开始。 它走过了这么长的征程, 并将一直走下去。 未来即是现在! 世界近在眼前! 如果你到现在还从来没有使用过 Debian, 我只想问, 你还再等什么? 快去下载一份镜像试试吧, 我们会在此守候遇到任何问题的你。
|
||||
|
||||
- [Debian 主页][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/happy-birthday-to-debian-gnu-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[jerryling315](http://moelf.xyz)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://xmodulo.com/2013/08/interesting-facts-about-debian-linux.html
|
||||
[2]:https://www.debian.org/
|
||||
@ -1,6 +1,6 @@
|
||||
LinuxCon: 服务器操作系统的转型
|
||||
================================================================================
|
||||
来自西雅图。容器迟早要改变世界,以及改变操作系统的角色。这是 Wim Coekaerts 带来的 LinuxCon 演讲主题,Coekaerts 是 Oracle 公司 Linux 与虚拟化工程的高级副总裁。
|
||||
西雅图报道。容器迟早要改变世界,以及改变操作系统的角色。这是 Wim Coekaerts 带来的 LinuxCon 演讲主题,Coekaerts 是 Oracle 公司 Linux 与虚拟化工程的高级副总裁。
|
||||
|
||||

|
||||
|
||||
@ -8,7 +8,7 @@ Coekaerts 在开始演讲的时候拿出一张关于“桌面之年”的幻灯
|
||||
|
||||
“你需要操作系统做什么事情?”,Coekaerts 回答现场观众:“只需一件事:运行一个应用。操作系统负责管理硬件和资源,来让你的应用运行起来。”
|
||||
|
||||
Coakaerts 说在 Docker 容器的帮助下,我们的注意力再次集中在应用上,而在 Oracle,我们将注意力放在如何让应用更好地运行在操作系统上。
|
||||
Coakaerts 补充说,在 Docker 容器的帮助下,我们的注意力再次集中在应用上,而在 Oracle,我们将注意力放在如何让应用更好地运行在操作系统上。
|
||||
|
||||
“许多人过去常常需要繁琐地安装应用,而现在的年轻人只需要按一个按钮就能让应用在他们的移动设备上运行起来”。
|
||||
|
||||
@ -20,7 +20,6 @@ Docker 的出现不代表虚拟机的淘汰,容器化过程需要经过很长
|
||||
|
||||
在这段时间内,容器会与虚拟机共存,并且我们需要一些工具,将应用在容器和虚拟机之间进行转换迁移。Coekaerts 举例说 Oracle 的 VirtualBox 就可以用来帮助用户运行 Docker,而它原来是被广泛用在桌面系统上的一项开源技术。现在 Docker 的 Kitematic 项目将在 Mac 上使用 VirtualBox 运行 Docker。
|
||||
|
||||
### The Open Compute Initiative and Write Once, Deploy Anywhere for Containers ###
|
||||
### 容器的开放计算计划和一次写随处部署 ###
|
||||
|
||||
一个能让容器成功的关键是“一次写,随处部署”的概念。而在容器之间的互操作领域,Linux 基金会的开放计算计划(OCI)扮演一个非常关键的角色。
|
||||
@ -43,7 +42,7 @@ via: http://www.serverwatch.com/server-news/linuxcon-the-changing-role-of-the-se
|
||||
|
||||
作者:[Sean Michael Kerner][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,24 +1,24 @@
|
||||
Linux 内核的发展方向
|
||||
对 Linux 内核的发展方向的展望
|
||||
================================================================================
|
||||

|
||||
|
||||
**即将到来的 Linux 4.2 内核涉及到史上最多的贡献者数量,内核开发者 Jonathan Corbet 如是说。**
|
||||
** Linux 4.2 内核涉及到史上最多的贡献者数量,内核开发者 Jonathan Corbet 如是说。**
|
||||
|
||||
来自西雅图。Linux 内核持续增长:代码量在增加,代码贡献者数量也在增加。而随之而来的一些挑战需要处理一下。以上是 Jonathan Corbet 在今年的 LinuxCon 的内核年度报告上提出的主要观点。以下是他的主要演讲内容:
|
||||
西雅图报道。Linux 内核持续增长:代码量在增加,代码贡献者数量也在增加。而随之而来的一些挑战需要处理一下。以上是 Jonathan Corbet 在今年的 LinuxCon 的内核年度报告上提出的主要观点。以下是他的主要演讲内容:
|
||||
|
||||
Linux 4.2 内核依然处于开发阶段,预计在8月23号释出。Corbet 强调有 1569 名开发者为这个版本贡献了代码,其中 277 名是第一次提交代码。
|
||||
Linux 4.2 内核已经于上月底释出。Corbet 强调有 1569 名开发者为这个版本贡献了代码,其中 277 名是第一次提交代码。
|
||||
|
||||
越来越多的开发者的加入,内核更新非常快,Corbet 估计现在大概 63 天就能产生一个新的内核里程碑。
|
||||
|
||||
Linux 4.2 涉及多方面的更新。其中一个就是引进了 OverLayFS,这是一种只读型文件系统,它可以实现在一个容器之上再放一个容器。
|
||||
|
||||
网络系统对小包传输性能也有了提升,这对于高频传输领域如金融交易而言非常重要。提升的方面主要集中在减小处理数据包的时间的能耗。
|
||||
网络系统对小包传输性能也有了提升,这对于高频金融交易而言非常重要。提升的方面主要集中在减小处理数据包的时间的能耗。
|
||||
|
||||
依然有新的驱动中加入内核。在每个内核发布周期,平均会有 60 到 80 个新增或升级驱动中加入。
|
||||
|
||||
另一个主要更新是实时内核补丁,这个特性在 4.0 版首次引进,好处是系统管理员可以在生产环境中打上内核补丁而不需要重启系统。当补丁所需要的元素都已准备就绪,打补丁的过程会在后台持续而稳定地进行。
|
||||
|
||||
**Linux 安全, IoT 和其他关注点 **
|
||||
**Linux 安全, IoT 和其他关注点**
|
||||
|
||||
过去一年中,安全问题在开源社区是一个很热的话题,这都归因于那些引发高度关注的事件,比如 Heartbleed 和 Shellshock。
|
||||
|
||||
@ -26,9 +26,9 @@ Linux 4.2 涉及多方面的更新。其中一个就是引进了 OverLayFS,这
|
||||
|
||||
他强调说过去 10 年间有超过 3 百万行代码不再被开发者修改,而产生 Shellshock 漏洞的代码的年龄已经是 20 岁了,近年来更是无人问津。
|
||||
|
||||
另一个关注点是 2038 问题,Linux 界的“千年虫”,如果不解决,2000 年出现过的问题还会重现。2038 问题说的是在 2038 年一些 Linux 和 Unix 机器会死机(LCTT:32 位系统记录的时间,在2038年1月19日星期二晚上03:14:07之后的下一秒,会变成负数)。Corbet 说现在离 2038 年还有 23 年时间,现在部署的系统都会考虑 2038 问题。
|
||||
另一个关注点是 2038 问题,Linux 界的“千年虫”,如果不解决,2000 年出现过的问题还会重现。2038 问题说的是在 2038 年一些 Linux 和 Unix 机器会死机(LCTT译注:32 位系统记录的时间,在2038年1月19日星期二晚上03:14:07之后的下一秒,会变成负数)。Corbet 说现在离 2038 年还有 23 年时间,现在部署的系统都会考虑 2038 问题。
|
||||
|
||||
Linux 已经开始一些初步的方案来修复 2038 问题了,但做的还远远不够。“现在就要修复这个问题,而不是等 20 年后把这个头疼的问题留给下一代解决,我们却享受着退休的美好时光”。
|
||||
Linux 已经启动一些初步的方案来修复 2038 问题了,但做的还远远不够。“现在就要修复这个问题,而不是等 20 年后把这个头疼的问题留给下一代解决,我们却享受着退休的美好时光”。
|
||||
|
||||
物联网(IoT)也是 Linux 关注的领域,Linux 是物联网嵌入式操作系统的主要占有者,然而这并没有什么卵用。Corget 认为日渐臃肿的内核对于未来的物联网设备来说肯定过于庞大。
|
||||
|
||||
@ -42,7 +42,7 @@ via: http://www.eweek.com/enterprise-apps/a-look-at-whats-next-for-the-linux-ker
|
||||
|
||||
作者:[Sean Michael Kerner][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,13 +1,12 @@
|
||||
KevinSJ Translating
|
||||
四大开源版命令行邮件客户端
|
||||
4 个开源的命令行邮件客户端
|
||||
================================================================================
|
||||

|
||||
|
||||
无论你承认与否,email并没有消亡。对依赖命令行的 Linux 高级用户而言,离开 shell 转而使用传统的桌面或网页版邮件客户端并不合适。归根结底,命令行最善于处理文件,特别是文本文件,能使效率倍增。
|
||||
无论你承认与否,email并没有消亡。对那些对命令行至死不渝的 Linux 高级用户而言,离开 shell 转而使用传统的桌面或网页版邮件客户端并不适应。归根结底,命令行最善于处理文件,特别是文本文件,能使效率倍增。
|
||||
|
||||
幸运的是,也有不少的命令行邮件客户端,他们的用户大都乐于帮助你入门并回答你使用中遇到的问题。但别说我没警告过你:一旦你完全掌握了其中一个客户端,要再使用图基于图形界面的客户端将回变得很困难!
|
||||
幸运的是,也有不少的命令行邮件客户端,而它们的用户大都乐于帮助你入门并回答你使用中遇到的问题。但别说我没警告过你:一旦你完全掌握了其中一个客户端,你会发现很难回到基于图形界面的客户端!
|
||||
|
||||
要安装下述四个客户端中的任何一个是非常容易的;主要 Linux 发行版的软件仓库中都提供此类软件,并可通过包管理器进行安装。你也可以再其他的操作系统中寻找并安装这类客户端,但我并未尝试过也没有相关的经验。
|
||||
要安装下述四个客户端中的任何一个是非常容易的;主要的 Linux 发行版的软件仓库中都提供此类软件,并可通过包管理器进行安装。你也可以在其它的操作系统中寻找并安装这类客户端,但我并未尝试过也没有相关的经验。
|
||||
|
||||
### Mutt ###
|
||||
|
||||
@ -17,7 +16,7 @@ KevinSJ Translating
|
||||
|
||||
许多终端爱好者都听说过甚至熟悉 Mutt 和 Alpine, 他们已经存在多年。让我们先看看 Mutt。
|
||||
|
||||
Mutt 支持许多你所期望 email 系统支持的功能:会话,颜色区分,支持多语言,同时还有很多设置选项。它支持 POP3 和 IMAP, 两个主要的邮件传输协议,以及许多邮箱格式。自从1995年诞生以来, Mutt 即拥有一个活跃的开发社区,但最近几年,新版本更多的关注于修复问题和安全更新而非提供新功能。这对大多数 Mutt 用户而言并无大碍,他们钟爱这样的界面,并支持此项目的口号:“所有邮件客户端都很烂,只是这个烂的没那么彻底。”
|
||||
Mutt 支持许多你所期望 email 系统支持的功能:会话,颜色区分,支持多语言,同时还有很多设置选项。它支持 POP3 和 IMAP 这两个主要的邮件传输协议,以及许多邮箱格式。自从1995年诞生以来, Mutt 就拥有了一个活跃的开发社区,但最近几年,新版本更多的关注于修复问题和安全更新而非提供新功能。这对大多数 Mutt 用户而言并无大碍,他们钟爱这样的界面,并支持此项目的口号:“所有邮件客户端都很烂,只是这个烂的没那么彻底。”
|
||||
|
||||
### Alpine ###
|
||||
|
||||
@ -25,13 +24,13 @@ Mutt 支持许多你所期望 email 系统支持的功能:会话,颜色区
|
||||
- [源代码][5]
|
||||
- 授权协议: [Apache 2.0][6]
|
||||
|
||||
Alpine 是另一款知名的终端邮件客户端,它由华盛顿大学开发,初衷是作为 UW 开发的 Pine 的开源,支持unicode的替代版本。
|
||||
Alpine 是另一款知名的终端邮件客户端,它由华盛顿大学开发,设计初衷是作为一个开源的、支持 unicode 的 Pine (也来自华盛顿大学)的替代版本。
|
||||
|
||||
Alpine 不仅容易上手,还为高级用户提供了很多特性,它支持很多协议 —— IMAP, LDAP, NNTP, POP, SMTP 等,同时也支持不同的邮箱格式。Alpine 内置了一款名为 Pico 的可独立使用的简易文本编辑工具,但你也可以使用你常用的文本编辑器: vi, Emacs等。
|
||||
|
||||
尽管Alpine的升级并不频繁,名为re-alpine的分支为不同的开发者提供了开发此项目的机会。
|
||||
尽管 Alpine 的升级并不频繁,不过有个名为 re-alpine 的分支为不同的开发者提供了开发此项目的机会。
|
||||
|
||||
Alpine 支持再屏幕上显示上下文帮助,但一些用户回喜欢 Mutt 式的独立说明手册,但这两种提供了较好的说明。用户可以同时尝试 Mutt 和 Alpine,并由个人喜好作出决定,也可以尝试以下几个比较新颖的选项。
|
||||
Alpine 支持在屏幕上显示上下文帮助,但一些用户会喜欢 Mutt 式的独立说明手册,不过它们两个的文档都很完善。用户可以同时尝试 Mutt 和 Alpine,并由个人喜好作出决定,也可以尝试以下的几个新选择。
|
||||
|
||||
### Sup ###
|
||||
|
||||
@ -39,10 +38,9 @@ Alpine 支持再屏幕上显示上下文帮助,但一些用户回喜欢 Mutt
|
||||
- [源代码][8]
|
||||
- 授权协议: [GPLv2][9]
|
||||
|
||||
Sup 是我们列表中能被称为“大容量邮件客户端”的两个之一。自称“为邮件较多的人设计的命令行客户端”,Sup 的目标是提供一个支持层次化设计并允许再为会话添加标签进行简单整理的界面。
|
||||
Sup 是我们列表中能被称为“大容量邮件客户端”的二者之一。自称“为邮件较多的人设计的命令行客户端”,Sup 的目标是提供一个支持层次化设计并允许为会话添加标签进行简单整理的界面。
|
||||
|
||||
由于采用 Ruby 编写,Sup 能提供十分快速的搜索并能自动管理联系人列表,同时还允许自定义插件。对于使用 Gmail 作为网页邮件客户端的人们,这些功能都是耳熟能详的,这就使得 Sup 成为一种比较现代的命令行邮件管理方式。
|
||||
Written in Ruby, Sup provides exceptionally fast searching, manages your contact list automatically, and allows for custom extensions. For people who are used to Gmail as a webmail interface, these features will seem familiar, and Sup might be seen as a more modern approach to email on the command line.
|
||||
|
||||
### Notmuch ###
|
||||
|
||||
@ -52,16 +50,17 @@ Written in Ruby, Sup provides exceptionally fast searching, manages your contact
|
||||
|
||||
"Sup? Notmuch." Notmuch 作为 Sup 的回应,最初只是重写了 Sup 的一小部分来提高性能。最终,这个项目逐渐变大并成为了一个独立的邮件客户端。
|
||||
|
||||
Notmuch是一款相当精简的软件。它并不能独立的收发邮件,启用 Notmuch 的快速搜索功能的代码实际上是一个需要调用的独立库。但这样的模块化设计也使得你能使用你最爱的工具进行写信,发信和收信,集中精力做好一件事情并有效浏览和管理你的邮件。
|
||||
Notmuch 是一款相当精简的软件。它并不能独立的收发邮件,启用 Notmuch 的快速搜索功能的代码实际上是设计成一个程序可以调用的独立库。但这样的模块化设计也使得你能使用你最爱的工具进行写信,发信和收信,集中精力做好一件事情并有效浏览和管理你的邮件。
|
||||
|
||||
这个列表并不完整,还有很多 email 客户端,它们或许才是你的最佳选择。你喜欢什么客户端呢?
|
||||
|
||||
这个列表并不完整,还有很多 email 客户端,他们或许才是你的最佳选择。你喜欢什么客户端呢?
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://opensource.com/life/15/8/top-4-open-source-command-line-email-clients
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[KevinSJ](https://github.com/KevinSj)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,14 +1,15 @@
|
||||
网络管理命令行工具基础,Nmcli
|
||||
Nmcli 网络管理命令行工具基础
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
### 介绍 ###
|
||||
|
||||
在本教程中,我们会在CentOS / RHEL 7中讨论网络管理工具,也叫**nmcli**。那些使用**ifconfig**的用户应该在CentOS 7中避免使用这个命令。
|
||||
在本教程中,我们会在CentOS / RHEL 7中讨论网络管理工具(NetworkManager command line tool),也叫**nmcli**。那些使用**ifconfig**的用户应该在CentOS 7中避免使用**ifconfig** 了。
|
||||
|
||||
让我们用nmcli工具配置一些网络设置。
|
||||
|
||||
### 要得到系统中所有接口的地址信息 ###
|
||||
#### 要得到系统中所有接口的地址信息 ####
|
||||
|
||||
[root@localhost ~]# ip addr show
|
||||
|
||||
@ -27,13 +28,13 @@
|
||||
inet6 fe80::20c:29ff:fe67:2f4c/64 scope link
|
||||
valid_lft forever preferred_lft forever
|
||||
|
||||
#### 检索与连接的接口相关的数据包统计 ####
|
||||
#### 检索与已连接的接口相关的数据包统计 ####
|
||||
|
||||
[root@localhost ~]# ip -s link show eno16777736
|
||||
|
||||
**示例输出:**
|
||||
|
||||

|
||||

|
||||
|
||||
#### 得到路由配置 ####
|
||||
|
||||
@ -50,11 +51,11 @@
|
||||
|
||||
输出像traceroute,但是更加完整。
|
||||
|
||||

|
||||

|
||||
|
||||
### nmcli 工具 ###
|
||||
|
||||
**Nmcli** 是一个非常丰富和灵活的命令行工具。nmcli使用的情况有:
|
||||
**nmcli** 是一个非常丰富和灵活的命令行工具。nmcli使用的情况有:
|
||||
|
||||
- **设备** – 正在使用的网络接口
|
||||
- **连接** – 一组配置设置,对于一个单一的设备可以有多个连接,可以在连接之间切换。
|
||||
@ -63,7 +64,7 @@
|
||||
|
||||
[root@localhost ~]# nmcli connection show
|
||||
|
||||

|
||||

|
||||
|
||||
#### 得到特定连接的详情 ####
|
||||
|
||||
@ -71,7 +72,7 @@
|
||||
|
||||
**示例输出:**
|
||||
|
||||

|
||||

|
||||
|
||||
#### 得到网络设备状态 ####
|
||||
|
||||
@ -89,7 +90,7 @@
|
||||
|
||||
这里,
|
||||
|
||||
- **Connection add** – 添加新的连接
|
||||
- **connection add** – 添加新的连接
|
||||
- **con-name** – 连接名
|
||||
- **type** – 设备类型
|
||||
- **ifname** – 接口名
|
||||
@ -100,7 +101,7 @@
|
||||
|
||||
Connection 'dhcp' (163a6822-cd50-4d23-bb42-8b774aeab9cb) successfully added.
|
||||
|
||||
#### 不同过dhcp分配IP,使用“static”添加地址 ####
|
||||
#### 不通过dhcp分配IP,使用“static”添加地址 ####
|
||||
|
||||
[root@localhost ~]# nmcli connection add con-name "static" ifname eno16777736 autoconnect no type ethernet ip4 192.168.1.240 gw4 192.168.1.1
|
||||
|
||||
@ -112,25 +113,23 @@
|
||||
|
||||
[root@localhost ~]# nmcli connection up eno1
|
||||
|
||||
Again Check, whether ip address is changed or not.
|
||||
再检查一遍,ip地址是否已经改变
|
||||
|
||||
[root@localhost ~]# ip addr show
|
||||
|
||||

|
||||

|
||||
|
||||
#### 添加DNS设置到静态连接中 ####
|
||||
|
||||
[root@localhost ~]# nmcli connection modify "static" ipv4.dns 202.131.124.4
|
||||
|
||||
#### 添加额外的DNS值 ####
|
||||
#### 添加更多的DNS ####
|
||||
|
||||
[root@localhost ~]# nmcli connection modify "static" +ipv4.dns 8.8.8.8
|
||||
[root@localhost ~]# nmcli connection modify "static" +ipv4.dns 8.8.8.8
|
||||
|
||||
**注意**:要使用额外的**+**符号,并且要是**+ipv4.dns**,而不是**ip4.dns**。
|
||||
|
||||
|
||||
添加一个额外的ip地址:
|
||||
####添加一个额外的ip地址####
|
||||
|
||||
[root@localhost ~]# nmcli connection modify "static" +ipv4.addresses 192.168.200.1/24
|
||||
|
||||
@ -138,11 +137,11 @@ Again Check, whether ip address is changed or not.
|
||||
|
||||
[root@localhost ~]# nmcli connection up eno1
|
||||
|
||||

|
||||

|
||||
|
||||
你会看见,设置生效了。
|
||||
|
||||
完结
|
||||
完结。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -150,6 +149,6 @@ via: http://www.unixmen.com/basics-networkmanager-command-line-tool-nmcli/
|
||||
|
||||
作者:Rajneesh Upadhyay
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,44 +1,45 @@
|
||||
修复安装完 Ubuntu 后无可引导设备错误
|
||||
修复安装完 Ubuntu 后无可引导设备的错误
|
||||
================================================================================
|
||||
通常情况下,我启动 Ubuntu 和 Windows 双系统,但是这次我决定完全消除 Windows 纯净安装 Ubuntu。纯净安装 Ubuntu 完成后,结束时屏幕输出 **no bootable device found** 而不是进入 GRUB 界面。显然,安装搞砸了 UEFI 引导设置。
|
||||
|
||||
通常情况下,我会安装启动 Ubuntu 和 Windows 的双系统,但是这次我决定完全消除 Windows 纯净安装 Ubuntu。纯净安装 Ubuntu 完成后,结束时屏幕输出 **无可引导设备(no bootable device found)** 而不是进入 GRUB 界面。显然,安装搞砸了 UEFI 引导设置。
|
||||
|
||||

|
||||
|
||||
我会告诉你我是如何修复**在宏碁笔记本上安装 Ubuntu 后出现无可引导设备错误**。我声明了我使用的是宏碁灵越 R13,这很重要,因为我们需要更改固件设置,而这些设置可能因制造商和设备有所不同。
|
||||
我会告诉你我是如何修复**在宏碁笔记本上安装 Ubuntu 后出现无可引导设备错误**的。我声明了我使用的是宏碁灵越 R13,这很重要,因为我们需要更改固件设置,而这些设置可能因制造商和设备有所不同。
|
||||
|
||||
因此在你开始这里介绍的步骤之前,先看一下发生这个错误时我计算机的状态:
|
||||
|
||||
- 我的宏碁灵越 R13 预装了 Windows8.1 和 UEFI 引导管理器
|
||||
- 关闭了 Secure boot(我的笔记本刚维修过,维修人员又启用了它,直到出现了问题我才发现)。你可以阅读这篇博文了解[如何在宏碁笔记本中关闭 secure boot][1]
|
||||
- 我通过选择清除所有东西安装 Ubuntu,例如现有的 Windows 8.1,各种分区等。
|
||||
- 我的宏碁灵越 R13 预装了 Windows 8.1 和 UEFI 引导管理器
|
||||
- 安全引导( Secure boot)没有关闭,(我的笔记本刚维修过,维修人员又启用了它,直到出现了问题我才发现)。你可以阅读这篇博文了解[如何在宏碁笔记本中关闭安全引导(secure boot)][1]
|
||||
- 我选择了清除所有东西安装 Ubuntu,例如现有的 Windows 8.1,各种分区等
|
||||
- 安装完 Ubuntu 之后,从硬盘启动时我看到无可引导设备错误。但能从 USB 设备正常启动
|
||||
|
||||
在我看来,没有禁用 secure boot 可能是这个错误的原因。但是,我没有数据支撑我的观点。这仅仅是预感。有趣的是,双系统启动 Windows 和 Linux 经常会出现这两个 Grub 问题:
|
||||
在我看来,没有禁用安全引导(secure boot)可能是这个错误的原因。但是,我没有数据支撑我的观点。这仅仅是预感。有趣的是,双系统启动 Windows 和 Linux 经常会出现这两个 Grub 问题:
|
||||
|
||||
- [error: no such partition grub rescue][2]
|
||||
- [Minimal BASH like line editing is supported][3]
|
||||
- [错误:没有 grub 救援分区][2]
|
||||
- [支持最小化 BASH 式的行编辑][3]
|
||||
|
||||
如果你遇到类似的情况,你可以试试我的修复方法。
|
||||
|
||||
### 修复安装完 Ubuntu 后无可引导设备错误 ###
|
||||
|
||||
请原谅我没有丰富的图片。我的一加相机不能很好地拍摄笔记本屏幕。
|
||||
请原谅我的图片质量很差。我的一加相机不能很好地拍摄笔记本屏幕。
|
||||
|
||||
#### 第一步 ####
|
||||
|
||||
关闭电源并进入 boot 设置。我需要在宏碁灵越 R13 上快速地按 Fn+F2。如果你使用固态硬盘的话要按的非常快,因为固态硬盘启动速度很快。取决于你的制造商,你可能要用 Del 或 F10 或者 F12。
|
||||
关闭电源并进入引导设置。我需要在宏碁灵越 R13 上快速地按下 Fn+F2。如果你使用固态硬盘的话要按的非常快,因为固态硬盘启动速度很快。这取决于你的制造商,你可能要用 Del 或 F10 或者 F12。
|
||||
|
||||
#### 第二步 ####
|
||||
|
||||
在 boot 设置中,确保启用了 Secure Boot。它在 Boot 标签里。
|
||||
在引导设置中,确保启用了 Secure Boot。它在 Boot 标签里。
|
||||
|
||||
#### 第三步 ####
|
||||
|
||||
进入到 Security 标签,查找 “Select an UEFI file as trusted for executing” 并敲击回车。
|
||||
进入到 Security 标签,找到 “选择一个用于执行的可信任 UEFI 文件(Select an UEFI file as trusted for executing)” 并敲击回车。
|
||||
|
||||

|
||||
|
||||
特意说明,我们这一步是要在你的设备中添加 UEFI 设置文件(安装 Ubuntu 的时候生成)到可信 UEFI 启动。如果你记得的话,UEFI 启动的主要目的是提供安全性,由于(可能)没有禁用 Secure Boot,设备不会试图从新安装的操作系统中启动。添加它到类似白名单的可信列表,会使设备从 Ubuntu UEFI 文件启动。
|
||||
特意说明,我们这一步是要在你的设备中添加 UEFI 设置文件(安装 Ubuntu 的时候生成)到可信 UEFI 启动中。如果你记得的话,UEFI 启动的主要目的是提供安全性,由于(可能)没有禁用安全引导(Secure Boot),设备不会试图从新安装的操作系统中启动。添加它到类似白名单的可信列表,会使设备从 Ubuntu UEFI 文件启动。
|
||||
|
||||
#### 第四步 ####
|
||||
|
||||
@ -48,13 +49,13 @@
|
||||
|
||||
#### 第五步 ####
|
||||
|
||||
你应该可以看到 <EFI>,敲击回车。
|
||||
你应该可以看到 \<EFI> 了,敲击回车。
|
||||
|
||||

|
||||
|
||||
#### 第六步 ####
|
||||
|
||||
在下一个屏幕中你会看到 <Ubuntu>。耐心点,马上就好了。
|
||||
在下一个屏幕中你会看到 \<Ubuntu>。耐心点,马上就好了。
|
||||
|
||||

|
||||
|
||||
@ -71,7 +72,7 @@
|
||||
|
||||
#### 第八步 ####
|
||||
|
||||
当我们添加它到可信 EFI 文件并执行时,按 F10 保存并退出。
|
||||
当我们添加它到可信 EFI 文件并执行后,按 F10 保存并退出。
|
||||
|
||||

|
||||
|
||||
@ -87,7 +88,7 @@ via: http://itsfoss.com/no-bootable-device-found-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,17 +1,19 @@
|
||||
为Antergos与Arch Linux添加印度语和梵文支持
|
||||
也许你需要在 Antergos 与 Arch Linux 中查看印度语和梵文?
|
||||
================================================================================
|
||||

|
||||
|
||||
你们到目前或许知道,我最近一直在尝试体验[Antergos Linux][1]。在安装完[Antergos][2]后我所首先注意到的一些事情是在默认的Chromium浏览器中**没法正确显示印度语脚本**。
|
||||
你们到目前或许知道,我最近一直在尝试体验 [Antergos Linux][1]。在安装完[Antergos][2]后我所首先注意到的一些事情是在默认的 Chromium 浏览器中**没法正确显示印度语脚本**。
|
||||
|
||||
这是一件奇怪的事情,在我之前桌面Linux的体验中是从未遇到过的。起初,我认为是浏览器的问题,所以我安装了Firefox,然而问题依旧,Firefox也不能正确显示印度语。和Chromium不显示任何东西不同的是,Firefox确实显示了一些东西,但是毫无可读性。
|
||||
|
||||

|
||||
Chromium中的印度语显示
|
||||
|
||||
*Chromium中的印度语显示*
|
||||
|
||||
|
||||

|
||||
Firefox中的印度语显示
|
||||
|
||||
*Firefox中的印度语显示*
|
||||
|
||||
奇怪吧?那么,默认情况下基于Arch的Antergos Linux中没有印度语的支持吗?我没有去验证,但是我假设其它基于梵语脚本的印地语之类会产生同样的问题。
|
||||
|
||||
@ -37,7 +39,7 @@ via: http://itsfoss.com/display-hindi-arch-antergos/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,77 @@
|
||||
如何在 Ubuntu 15.04 下创建一个可供 Android/iOS 连接的 AP
|
||||
================================================================================
|
||||
我成功地在 Ubuntu 15.04 下用 Gnome Network Manager 创建了一个无线AP热点。接下来我要分享一下我的步骤。请注意:你必须要有一个可以用来创建AP热点的无线网卡。如果你不知道如何确认它的话,在终端(Terminal)里输入`iw list`。
|
||||
|
||||
如果你没有安装`iw`的话, 在Ubuntu下你可以使用`sudo apt-get install iw`进行安装.
|
||||
|
||||
在你键入`iw list`之后, 查看“支持的接口模式”, 你应该会看到类似下面的条目中看到 AP:
|
||||
|
||||
Supported interface modes:
|
||||
|
||||
* IBSS
|
||||
* managed
|
||||
* AP
|
||||
* AP/VLAN
|
||||
* monitor
|
||||
* mesh point
|
||||
|
||||
让我们一步步看:
|
||||
|
||||
1、 断开WIFI连接。使用有线网络接入你的笔记本。
|
||||
|
||||
2、 在顶栏面板里点击网络的图标 -> Edit Connections(编辑连接) -> 在弹出窗口里点击Add(新增)按钮。
|
||||
|
||||
3、 在下拉菜单内选择Wi-Fi。
|
||||
|
||||
4、 接下来:
|
||||
|
||||
a、 输入一个链接名 比如: Hotspot 1
|
||||
|
||||
b、 输入一个 SSID 比如: Hotspot 1
|
||||
|
||||
c、 选择模式(mode): Infrastructure (基础设施)
|
||||
|
||||
d、 设备 MAC 地址: 在下拉菜单里选择你的无线设备
|
||||
|
||||

|
||||
|
||||
5、 进入Wi-Fi安全选项卡,选择 WPA & WPA2 Personal 并且输入密码。
|
||||
6、 进入IPv4设置选项卡,在Method(方法)下拉菜单里,选择Shared to other computers(共享至其他电脑)。
|
||||
|
||||

|
||||
|
||||
7、 进入IPv6选项卡,在Method(方法)里设置为忽略ignore (只有在你不使用IPv6的情况下这么做)
|
||||
8、 点击 Save(保存) 按钮以保存配置。
|
||||
9、 从 menu/dash 里打开Terminal。
|
||||
10、 修改你刚刚使用 network settings 创建的连接。
|
||||
|
||||
使用 VIM 编辑器:
|
||||
|
||||
sudo vim /etc/NetworkManager/system-connections/Hotspot
|
||||
|
||||
或使用Gedit 编辑器:
|
||||
|
||||
gksu gedit /etc/NetworkManager/system-connections/Hotspot
|
||||
|
||||
把名字 Hotspot 用你在第4步里起的连接名替换掉。
|
||||
|
||||

|
||||
|
||||
a、 把 `mode=infrastructure` 改成 `mode=ap` 并且保存文件。
|
||||
b、 一旦你保存了这个文件,你应该能在 Wifi 菜单里看到你刚刚建立的AP了。(如果没有的话请再顶栏里 关闭/打开 Wifi 选项一次)
|
||||
|
||||

|
||||
|
||||
11、你现在可以把你的设备连上Wifi了。已经过 Android 5.0的小米4测试。(下载了1GB的文件以测试速度与稳定性)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxveda.com/2015/08/23/how-to-create-an-ap-in-ubuntu-15-04-to-connect-to-androidiphone/
|
||||
|
||||
作者:[Sayantan Das][a]
|
||||
译者:[jerryling315](https://github.com/jerryling315)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxveda.com/author/sayantan_das/
|
||||
@ -1,14 +1,15 @@
|
||||
Linux 界将出现一个新的文件系统:bcachefs
|
||||
Linux 上将出现一个新的文件系统:bcachefs
|
||||
================================================================================
|
||||
这个有 5 年历史,由 Kent Oberstreet 创建,过去属于谷歌的文件系统,最近完成了关键的组件。Bcachefs 文件系统自称其性能和稳定性与 ext4 和 xfs 相同,而其他方面的功能又可以与 btrfs 和 zfs 相媲美。主要特性包括校验、压缩、多设备支持、缓存、快照与其他好用的特性。
|
||||
|
||||
Bcachefs 来自 **bcache**,这是一个块级缓存层,从 bcaceh 到一个功能完整的[写时复制][1]文件系统,堪称是一项质的转变。
|
||||
这个有 5 年历史,由 Kent Oberstreet 创建,过去属于谷歌的文件系统,最近完成了全部关键组件。Bcachefs 文件系统自称其性能和稳定性与 ext4 和 xfs 相同,而其他方面的功能又可以与 btrfs 和 zfs 相媲美。主要特性包括校验、压缩、多设备支持、缓存、快照与其他“漂亮”的特性。
|
||||
|
||||
在自己提出问题“为什么要出一个新的文件系统”中,Kent Oberstreet 作了以下回答:当我还在谷歌的时候,我与其他在 bcache 上工作的同事在偶然的情况下意识到我们正在使用的东西可以成为一个成熟文件系统的功能块,我们可以用 bcache 创建一个拥有干净而优雅设计的文件系统,而最重要的一点是,bcachefs 的主要目的就是在性能和稳定性上能与 ext4 和 xfs 匹敌,同时拥有 btrfs 和 zfs 的特性。
|
||||
Bcachefs 来自 **bcache**,这是一个块级缓存层。从 bcaceh 到一个功能完整的[写时复制][1]文件系统,堪称是一项质的转变。
|
||||
|
||||
对自己的问题“为什么要出一个新的文件系统”中,Kent Oberstreet 自问自答道:当我还在谷歌的时候,我与其他在 bcache 上工作的同事在偶然的情况下意识到我们正在使用的东西可以成为一个成熟文件系统的功能块,我们可以用 bcache 创建一个拥有干净而优雅设计的文件系统,而最重要的一点是,bcachefs 的主要目的就是在性能和稳定性上能与 ext4 和 xfs 匹敌,同时拥有 btrfs 和 zfs 的特性。
|
||||
|
||||
Overstreet 邀请人们在自己的系统上测试 bcachefs,可以通过邮件列表[通告]获取 bcachefs 的操作指南。
|
||||
|
||||
Linux 生态系统中文件系统几乎处于一家独大状态,Fedora 在第 16 版的时候就想用 btrfs 换掉 ext4 作为其默认文件系统,但是到现在(LCTT:都出到 Fedora 22 了)还在使用 ext4。而几乎所有 Debian 系的发行版(Ubuntu、Mint、elementary OS 等)也使用 ext4 作为默认文件系统,并且这些主流的发生版都没有替换默认文件系统的意思。
|
||||
Linux 生态系统中文件系统几乎处于一家独大状态,Fedora 在第 16 版的时候就想用 btrfs 换掉 ext4 作为其默认文件系统,但是到现在(LCTT:都出到 Fedora 22 了)还在使用 ext4。而几乎所有 Debian 系的发行版(Ubuntu、Mint、elementary OS 等)也使用 ext4 作为默认文件系统,并且这些主流的发行版都没有替换默认文件系统的意思。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -16,7 +17,7 @@ via: http://www.linuxveda.com/2015/08/22/linux-gain-new-file-system-bcachefs/
|
||||
|
||||
作者:[Paul Hill][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
66
published/20150826 Five Super Cool Open Source Games.md
Normal file
66
published/20150826 Five Super Cool Open Source Games.md
Normal file
@ -0,0 +1,66 @@
|
||||
五大超酷的开源游戏
|
||||
================================================================================
|
||||
|
||||
在2014年和2015年,Linux 涌入了一堆流行的付费游戏,例如备受欢迎的无主之地(Borderlands)、巫师(Witcher)、死亡岛(Dead Island) 和 CS 系列游戏。虽然这是令人激动的消息,但玩家有这个支出预算吗?付费游戏很好,但更好的是由了解玩家喜好的开发者开发的免费的替代品。
|
||||
|
||||
前段时间,我偶然看到了一个三年前发布的 YouTube 视频,标题非常的有正能量 [5个不算糟糕的开源游戏][1]。虽然视频表扬了一些开源游戏,我还是更喜欢用一个更加热情的方式来切入这个话题,至少如标题所说。所以,下面是我的一份五大超酷开源游戏的清单。
|
||||
|
||||
### Tux Racer ###
|
||||
|
||||
|
||||
|
||||
*Tux Racer*
|
||||
|
||||
[《Tux Racer》][2]是这份清单上的第一个游戏,因为我对这个游戏很熟悉。最近,我的兄弟和我为了参加[玩电脑的孩子们][4]项目,在[去墨西哥的路途中][3],Tux Racer 是孩子和教师都喜欢玩的游戏之一。在这个游戏中,玩家使用 Linux 吉祥物——企鹅 Tux——在下山雪道上以计时赛的方式进行比赛。玩家们不断挑战他们自己的最佳纪录。目前还没有多玩家版本,但这是有可能改变的。它适用于 Linux、OS X、Windows 和 Android。
|
||||
|
||||
### Warsow ###
|
||||
|
||||

|
||||
|
||||
*Warsow*
|
||||
|
||||
[《Warsow》][5]网站介绍道:“设定是有未来感的卡通世界,Warsow 是个完全开放的适用于 Windows、Linux 和 Mac OS X平台的快节奏第一人称射击游戏(FPS)。Warsow 是跨网络的尊重和体育精神的的艺术。(Warsow is the Art of Respect and Sportsmanship Over the Web. 大写回文字母组成 Warsow。)” 我很不情愿的把 FPS 类放到了这个列表中,因为很多人玩过这类的游戏,但是我的确被 Warsow 打动了。它对很多动作进行了优先级排序,游戏节奏很快,一开始就有八个武器。卡通化的风格让玩的过程变得没有那么严肃,更加的休闲,非常适合和亲友一同玩。然而,它却以充满竞争的游戏自居,并且当我体验这个游戏时,我发现周围确实有一些专家级的玩家。它适用于 Linux、Windows 和 OS X。
|
||||
|
||||
### M.A.R.S——一个荒诞的射击游戏 ###
|
||||
|
||||

|
||||
|
||||
*M.A.R.S.——一个荒诞的射击游戏*
|
||||
|
||||
[《M.A.R.S——一个荒诞的射击游戏》][6]之所以吸引人是因为它充满活力的色彩和画风。支持两个玩家使用同一个键盘,而一个在线多玩家版本目前正在开发中——这意味着想要和朋友们一起玩暂时还要等等。不论如何,它是个可以使用几个不同飞船和武器的有趣的太空射击游戏。飞船的形状不同,从普通的枪、激光、散射枪到更有趣的武器(随机出来的飞船中有一个会对敌人发射泡泡,这为这款混乱的游戏增添了很多乐趣)。游戏有几种模式,比如标准模式和对方进行殊死搏斗以获得高分或先达到某个分数线,还有其他的模式,空间球(Spaceball)、坟坑(Grave-itation Pit)和保加农炮(Cannon Keep)。它适用于 Linux、Windows 和 OS X。
|
||||
|
||||
### Valyria Tear ###
|
||||
|
||||
|
||||
|
||||
*Valyria Tear*
|
||||
|
||||
[Valyria Tear][7] 类似近年来拥有众多粉丝的角色扮演游戏(RPG)。故事设定在奇幻游戏的通用年代,充满了骑士、王国和魔法,以及主要角色 Bronann。设计团队在这个世界的设计上做的非常棒,实现了玩家对这类游戏所有的期望:隐藏的宝藏、偶遇的怪物、非玩家操纵角色(NPC)的互动以及所有 RPG 不可或缺的——在低级别的怪物上刷经验直到可以面对大 BOSS。我在试玩的时候,时间不允许我太过深入到这个游戏故事中,但是感兴趣的人可以看 YouTube 上由 Yohann Ferriera 用户发的‘[Let’s Play][8]’系列视频。它适用于 Linux、Windows 和 OS X。
|
||||
|
||||
### SuperTuxKart ###
|
||||
|
||||

|
||||
|
||||
*SuperTuxKart*
|
||||
|
||||
最后一个同样好玩的游戏是 [SuperTuxKart][9],一个效仿 Mario Kart(马里奥卡丁车)但丝毫不逊色的好游戏。它在2000年-2004年间开始以 Tux Kart 开发,但是在成品中有错误,结果开发就停止了几年。从2006年开始重新开发时起,它就一直在改进,直到四个月前0.9版首次发布。在游戏里,我们的老朋友 Tux 与马里奥和其他一些开源吉祥物一同开始。其中一个熟悉的面孔是 Suzanne,这是 Blender 的那只吉祥物猴子。画面很给力,游戏很流畅。虽然在线游戏还在计划阶段,但是分屏多玩家游戏是可以的。一个电脑最多可以供四个玩家同时玩。它适用于 Linux、Windows、OS X、AmigaOS 4、AROS 和 MorphOS。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://fossforce.com/2015/08/five-super-cool-open-source-games/
|
||||
|
||||
作者:Hunter Banks
|
||||
译者:[H-mudcup](https://github.com/H-mudcup)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.youtube.com/watch?v=BEKVl-XtOP8
|
||||
[2]:http://tuxracer.sourceforge.net/download.html
|
||||
[3]:http://fossforce.com/2015/07/banks-family-values-texas-linux-fest/
|
||||
[4]:http://www.kidsoncomputers.org/an-amazing-week-in-oaxaca
|
||||
[5]:https://www.warsow.net/download
|
||||
[6]:http://mars-game.sourceforge.net/
|
||||
[7]:http://valyriatear.blogspot.com/
|
||||
[8]:https://www.youtube.com/channel/UCQ5KrSk9EqcT_JixWY2RyMA
|
||||
[9]:http://supertuxkart.sourceforge.net/
|
||||
@ -0,0 +1,110 @@
|
||||
mosh:一个基于 SSH 用于连接远程 Unix/Linux 系统的工具
|
||||
================================================================================
|
||||
Mosh 表示移动 Shell(Mobile Shell),是一个用于从客户端跨互联网连接远程服务器的命令行工具。它能用于 SSH 连接,但是比 Secure Shell 功能更多。它是一个类似于 SSH 而带有更多功能的应用。程序最初由 Keith Winstein 编写,用于类 Unix 的操作系统中,发布于GNU GPL v3协议下。
|
||||
|
||||

|
||||
|
||||
*Mosh Shell SSH 客户端*
|
||||
|
||||
#### Mosh的功能 ####
|
||||
|
||||
- 它是一个支持漫游的远程终端程序。
|
||||
- 在所有主流的类 Unix 版本中可用,如 Linux、FreeBSD、Solaris、Mac OS X 和 Android。
|
||||
- 支持不稳定连接
|
||||
- 支持智能的本地回显
|
||||
- 支持用户输入的行编辑
|
||||
- 响应式设计及在 wifi、3G、长距离连接下的鲁棒性
|
||||
- 在 IP 改变后保持连接。它使用 UDP 代替 TCP(在 SSH 中使用),当连接被重置或者获得新的 IP 后 TCP 会超时,但是 UDP 仍然保持连接。
|
||||
- 在很长的时候之后恢复会话时仍然保持连接。
|
||||
- 没有网络延迟。立即显示用户输入和删除而没有延迟
|
||||
- 像 SSH 那样支持一些旧的方式登录。
|
||||
- 包丢失处理机制
|
||||
|
||||
### Linux 中 mosh 的安装 ###
|
||||
|
||||
在 Debian、Ubuntu 和 Mint 类似的系统中,你可以很容易地用 [apt-get 包管理器][1]安装。
|
||||
|
||||
# apt-get update
|
||||
# apt-get install mosh
|
||||
|
||||
在基于 RHEL/CentOS/Fedora 的系统中,要使用 [yum 包管理器][3]安装 mosh,你需要打开第三方的 [EPEL][2]。
|
||||
|
||||
# yum update
|
||||
# yum install mosh
|
||||
|
||||
在 Fedora 22+的版本中,你需要使用 [dnf 包管理器][4]来安装 mosh。
|
||||
|
||||
# dnf install mosh
|
||||
|
||||
### 我该如何使用 mosh? ###
|
||||
|
||||
1、 让我们尝试使用 mosh 登录远程 Linux 服务器。
|
||||
|
||||
$ mosh root@192.168.0.150
|
||||
|
||||

|
||||
|
||||
*mosh远程连接*
|
||||
|
||||
**注意**:你有没有看到一个连接错误,因为我在 CentOS 7中还有打开这个端口。一个快速但是我并不建议的解决方法是:
|
||||
|
||||
# systemctl stop firewalld [在远程服务器上]
|
||||
|
||||
更好的方法是打开一个端口并更新防火墙规则。接着用 mosh 连接到预定义的端口中。至于更深入的细节,也许你会对下面的文章感兴趣。
|
||||
|
||||
- [如何配置 Firewalld][5]
|
||||
|
||||
2、 让我们假设把默认的 22 端口改到 70,这时使用 -p 选项来使用自定义端口。
|
||||
|
||||
$ mosh -p 70 root@192.168.0.150
|
||||
|
||||
3、 检查 mosh 的版本
|
||||
|
||||
$ mosh --version
|
||||
|
||||

|
||||
|
||||
*检查mosh版本*
|
||||
|
||||
4、 你可以输入`exit`来退出 mosh 会话。
|
||||
|
||||
$ exit
|
||||
|
||||
5、 mosh 支持很多选项,你可以用下面的方法看到:
|
||||
|
||||
$ mosh --help
|
||||
|
||||

|
||||
|
||||
*Mosh 选项*
|
||||
|
||||
#### mosh 的优缺点 ####
|
||||
|
||||
- mosh 有额外的需求,比如需要允许 UDP 直接连接,这在 SSH 不需要。
|
||||
- 动态分配的端口范围是 60000-61000。第一个打开的端口是分配好的。每个连接都需要一个端口。
|
||||
- 默认的端口分配是一个严重的安全问题,尤其是在生产环境中。
|
||||
- 支持 IPv6 连接,但是不支持 IPv6 漫游。
|
||||
- 不支持回滚
|
||||
- 不支持 X11 转发
|
||||
- 不支持 ssh-agent 转发
|
||||
|
||||
### 总结 ###
|
||||
|
||||
mosh是一款在大多数linux发行版的仓库中可以下载的一款小工具。虽然它有一些差异尤其是安全问题和额外的需求,它的功能,比如漫游后保持连接是一个加分点。我的建议是任何一个使用ssh的linux用户都应该试试这个程序,mosh值得一试。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-mosh-shell-ssh-client-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/useful-basic-commands-of-apt-get-and-apt-cache-for-package-management/
|
||||
[2]:https://linux.cn/article-2324-1.html
|
||||
[3]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[4]:http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
[5]:http://www.tecmint.com/configure-firewalld-in-centos-7/
|
||||
@ -1,4 +1,4 @@
|
||||
Xtreme下载管理器升级全新用户界面
|
||||
Xtreme 下载管理器升级带来全新用户界面
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -6,11 +6,11 @@ Xtreme下载管理器升级全新用户界面
|
||||
|
||||
Xtreme 下载管理器,也被称作 XDM 或 XDMAN,它是一个跨平台的下载管理器,可以用于 Linux、Windows 和 Mac OS X 系统之上。同时它兼容于主流的浏览器,如 Chrome, Firefox, Safari 等,因此当你从浏览器下载东西的时候可以直接使用 XDM 下载。
|
||||
|
||||
当你的网络连接超慢并且需要管理下载文件的时候,像 XDM 这种软件可以帮到你大忙。例如说你在一个慢的要死的网络速度下下载一个超大文件, XDM 可以帮助你暂停并且继续下载。
|
||||
当你的网络连接超慢并且需要管理下载文件的时候,像 XDM 这种软件可以帮到你大忙。例如说你在一个慢的要死的网络速度下下载一个超大文件,或者你想要暂停和恢复下载的话, XDM 可以帮助你。
|
||||
|
||||
XDM 的主要功能:
|
||||
|
||||
- 暂停和继续下载
|
||||
- 暂停和恢复下载
|
||||
- [从 YouTube 下载视频][3],其他视频网站同样适用
|
||||
- 强制聚合
|
||||
- 下载加速
|
||||
@ -23,11 +23,11 @@ XDM 的主要功能:
|
||||
|
||||

|
||||
|
||||
老版本XDM
|
||||
*老版本XDM*
|
||||
|
||||

|
||||
|
||||
新版本XDM
|
||||
*新版本XDM*
|
||||
|
||||
### 在基于 Ubuntu 的 Linux 发行版上安装 Xtreme下载管理器 ###
|
||||
|
||||
@ -48,15 +48,15 @@ XDM 的主要功能:
|
||||
|
||||
对于其他Linux发行版,可以通过以下连接下载:
|
||||
|
||||
- [Download Xtreme Download Manager][4]
|
||||
- [下载 Xtreme 下载管理器][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/xtreme-download-manager-install/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/mr-ping)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[mr-ping](https://github.com/mr-ping)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,22 +1,22 @@
|
||||
使用脚本便捷地在Ubuntu系统中安装最新的Linux内核
|
||||
使用脚本便捷地在 Ubuntu 中安装最新 Linux 内核
|
||||
================================================================================
|
||||

|
||||
|
||||
想要安装最新的Linux内核吗?一个简单的脚本就可以在Ubuntu系统中方便的完成这项工作。
|
||||
|
||||
Michael Murphy 写了一个脚本用来将最新的候选版、标准版、或者低延时版内核安装到 Ubuntu 系统中。这个脚本会在询问一些问题后从 [Ubuntu kernel mainline page][1] 下载安装最新的 Linux 内核包。
|
||||
Michael Murphy 写了一个脚本用来将最新的候选版、标准版、或者低延时版的内核安装到 Ubuntu 系统中。这个脚本会在询问一些问题后从 [Ubuntu 内核主线页面][1] 下载安装最新的 Linux 内核包。
|
||||
|
||||
### 通过脚本来安装、升级Linux内核: ###
|
||||
|
||||
1. 点击 [github page][2] 右上角的 “Download Zip” 来下载脚本。
|
||||
1. 点击这个 [github 页面][2] 右上角的 “Download Zip” 来下载该脚本。
|
||||
|
||||
2. 鼠标右键单击用户下载目录下的 Zip 文件,选择 “Extract Here” 将其解压到此处。
|
||||
2. 鼠标右键单击用户下载目录下的 Zip 文件,选择 “在此展开” 将其解压。
|
||||
|
||||
3. 右键点击解压后的文件夹,选择 “Open in Terminal” 在终端中导航到此文件夹下。
|
||||
3. 右键点击解压后的文件夹,选择 “在终端中打开” 到此文件夹下。
|
||||
|
||||
|
||||
|
||||
此时将会打开一个终端,并且自动导航到结果文件夹下。如果你找不到 “Open in Terminal” 选项的话,在 Ubuntu 软件中心搜索安装 `nautilus-open-terminal` ,然后重新登录系统即可(也可以再终端中运行 `nautilus -q` 来取代重新登录系统的操作)。
|
||||
此时将会打开一个终端,并且自动导航到目标文件夹下。如果你找不到 “在终端中打开” 选项的话,在 Ubuntu 软件中心搜索安装 `nautilus-open-terminal` ,然后重新登录系统即可(也可以再终端中运行 `nautilus -q` 来取代重新登录系统的操作)。
|
||||
4. 当进入终端后,运行以下命令来赋予脚本执行本次操作的权限。
|
||||
|
||||
chmod +x *
|
||||
@ -39,7 +39,7 @@ Michael Murphy 写了一个脚本用来将最新的候选版、标准版、或
|
||||
|
||||
### 如何移除旧的(或新的)内核: ###
|
||||
|
||||
1. 从Ubuntu软件中心安装 Synaptic Package Manager。
|
||||
1. 从 Ubuntu 软件中心安装 Synaptic Package Manager。
|
||||
|
||||
2. 打开 Synaptic Package Manager 然后如下操作:
|
||||
|
||||
@ -68,8 +68,8 @@ Michael Murphy 写了一个脚本用来将最新的候选版、标准版、或
|
||||
via: http://ubuntuhandbook.org/index.php/2015/08/install-latest-kernel-script/
|
||||
|
||||
作者:[Ji m][a]
|
||||
译者:[译者ID](https://github.com/mr-ping)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[mr-ping](https://github.com/mr-ping)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
63
published/20150901 Is Linux Right For You.md
Normal file
63
published/20150901 Is Linux Right For You.md
Normal file
@ -0,0 +1,63 @@
|
||||
Linux 系统是否适合于您?
|
||||
================================================================================
|
||||
> 并非人人都适合使用 Linux --对许多用户来说,Windows 或 OSX 会是更好的选择。
|
||||
|
||||
我喜欢使用 Linux 桌面系统,并不是因为软件的政治性质,也不是不喜欢其它操作系统。我喜欢 Linux 系统因为它能满足我的需求并且确实适合使用。
|
||||
|
||||
我的经验是,并非人人都适合切换至“Linux 的生活方式”。本文将帮助您通过分析使用 Linux 系统的利弊来供您自行判断使用 Linux 是否真正适合您。
|
||||
|
||||
### 什么时候更换系统? ###
|
||||
|
||||
当有充分的理由时,将系统切换到 Linux 系统是很有意义的。这对 Windows 用户将系统更换到 OSX 或类似的情况都同样适用。为让您的系统转变成功,您必须首先确定为什么要做这种转换。
|
||||
|
||||
对某些人来说,更换系统通常意味着他们不满于当前的系统操作平台。也许是最新的升级给了他们糟糕的用户体验,而他们也已准备好更换到别的系统,也许仅仅是因为对某个系统好奇。不管动机是什么,必须要有充分的理由支撑您做出更换操作系统的决定。如果没有一个充足的原因让您这样做,往往不会成功。
|
||||
|
||||
然而事事都有例外。如果您确实对 Linux 桌面非常感兴趣,或许可以选择一种折衷的方式。
|
||||
|
||||
### 放慢起步的脚步 ###
|
||||
|
||||
第一次尝试运行 Linux 系统后,我看到就有人开始批判 Windows 安装过程的费时,完全是因为他们20分钟就用闪存安装好 Ubuntu 的良好体验。但是伙伴们,这并不只是一次测验。相反,我有如下建议:
|
||||
|
||||
- 用一周的时间尝试在[虚拟机上运行 Linux 系统][1]。这意味着您将在该系统上执行所有的浏览器工作、邮箱操作和其它想要完成的任务。
|
||||
- 如果运行虚拟机资源消耗太大,您可以尝试用提供了[一些持久存储][2]的 USB 驱动器来运行 Linux,您的主操作系统将不受任何影响。与此同时,您仍可以运行 Linux 系统。
|
||||
- 运行 Linux 系统一周后,如果一切进展顺利,下一步您可以计算一下这周内登入 Windows 的次数。如果只是偶尔登录 Windows 系统,下一步就可以尝试运行 Windows 和 Linux 的[双系统][3]。对那些只运行了 Linux 系统的用户,可以考虑尝试将系统真正更换为 Linux 系统。
|
||||
- 在你完全删除 Windows 分区前,更应该购买一个新硬盘来安装 Linux 系统。这样有了充足的硬盘空间,您就可以使用双系统。如果必须要启动 Windows 系统做些事情的话,Windows 系统也是可以运行的。
|
||||
|
||||
### 使用 Linux 系统的好处是什么? ###
|
||||
|
||||
将系统更换到 Linux 有什么好处呢?一般而言,这种好处对大多数人来说可以归结到释放个性自由。在使用 Linux 系统的时候,如果您不喜欢某些设置,可以自行更改它们。同时使用 Linux 可以为用户节省大量的硬件升级开支和不必要的软件开支。另外,您不需再费力找寻已丢失的软件许可证密钥,而且如果您不喜欢即将发布的系统版本,大可轻松地更换到别的版本。
|
||||
|
||||
在 Linux 桌面方面可以选择的桌面种类是惊人的多,看起来对新手来说做这种选择非常困难。但是如果您发现了喜欢的一款 Linux 版本(Debian、Fedora、Arch等),最困难的工作其实已经完成了,您需要做的就是找到各版本的区别并选择出您最喜欢的系统版本环境。
|
||||
|
||||
如今我听到的最常见的抱怨之一是用户发现没有太多的软件能适用于 Linux 系统。然而,这并不是事实。尽管别的操作系统可能会提供更多软件,但是如今的 Linux 也已经提供了足够多应用程序满足您的各种需求,包括视频剪辑(家用和专业级)、摄影、办公管理软件、远程访问、音乐软件、等等等等。
|
||||
|
||||
### 使用 Linux 系统您会失去些什么? ###
|
||||
|
||||
虽然我喜欢使用 Linux,但我妻子的家庭办公依然依赖于 OS X。对于用 Linux 系统完成一些特定的任务她心满意足,但是她需要 OS X 来运行一些不支持 Linux 的软件。这是许多想要更换系统的用户会遇到的一个常见的问题。如果要更换系统,您需要考虑是否愿意失去一些关键的软件工具。
|
||||
|
||||
有时这个问题是因为软件的数据只能用该软件打开。别的情况下,是传统应用程序的工作流和功能并不适用于在 Linux 系统上可运行的软件。我自己并没有遇到过这类问题,但是我知道确实存在这些问题。许多 Linux 上的软件在其它操作系统上也都可以用。所以如果担心这类软件兼容问题,建议您先尝试在已有的系统上操作一下几款类似的应用程序。
|
||||
|
||||
更换成 Linux 系统后,另一件您可能会失去的是本地系统支持服务。人们通常会嘲笑这种愚蠢行径,但我知道,无数的新手在使用 Linux 时会发现解决 Linux 上各种问题的唯一资源就是来自网络另一端的陌生人提供的帮助。如果只是他们的 PC 遇到了一些问题,这将会比较麻烦。Windows 和 OS X 的用户已经习惯各城市遍布了支持他们操作系统的各项技术服务。
|
||||
|
||||
### 如何开启新旅程? ###
|
||||
|
||||
这里建议大家要记住最重要的就是总要有个回退方案。如果您将 Windows 10 从硬盘中擦除,您会发现重新安装它又会花费金钱。对那些从其它 Windows 发布版本升级的用户来说尤其会遇到这种情况。请接受这个建议,对新手来说使用闪存安装 Linux 或使用 Windows 和 Linux 双系统都是更值得提倡的做法。您也许会如鱼得水般使用 Linux系统,但是有了一份回退方案,您将高枕无忧。
|
||||
|
||||
相反,如果数周以来您一直依赖于使用双操作系统,但是已经准备好冒险去尝试一下单操作系统,那么就去做吧。格式化您的驱动器,重新安装您喜爱的 Linux 发行版。数年来我一直都是“全职” Linux 使用爱好者,这里可以确定地告诉您,使用 Linux 系统感觉棒极了。这种感觉会持续多久?我第一次的 Linux 系统使用经验还是来自早期的 Red Hat 系统,最终在2003年,我在自己的笔记本上整个安装了 Linux 系统。
|
||||
|
||||
Linux 爱好者们,你们什么时候开始使用 Linux 的?您在最初更换成 Linux 系统时是兴奋还是焦虑呢?欢迎点击评论分享你们的经验。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/is-linux-right-for-you.html
|
||||
|
||||
作者:[Matt Hartley][a]
|
||||
译者:[icybreaker](https://github.com/icybreaker)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]:http://www.psychocats.net/ubuntu/virtualbox
|
||||
[2]:http://www.howtogeek.com/howto/14912/create-a-persistent-bootable-ubuntu-usb-flash-drive/
|
||||
[3]:http://www.linuxandubuntu.com/home/dual-boot-ubuntu-15-04-14-10-and-windows-10-8-1-8-step-by-step-tutorial-with-screenshots
|
||||
@ -0,0 +1,53 @@
|
||||
在 Ubuntu 和 Elementary OS 上使用 NaSC 进行简单数学运算
|
||||
================================================================================
|
||||

|
||||
|
||||
[NaSC][1],Not a Soulver Clone 的缩写,是为 elementary 操作系统开发的第三方应用程序。正如名字暗示的那样,NaSC 的灵感来源于 [Soulver][2],后者是像普通人一样进行数学计算的 OS X 应用。
|
||||
|
||||
Elementary OS 它自己本身借鉴了 OS X,也就不奇怪它的很多第三方应用灵感都来自于 OS X 应用。
|
||||
|
||||
回到 NaSC,“像普通人一样进行数学计算”到底是什么意思呢?事实上,它意味着正如你想的那样去书写。按照该应用程序的介绍:
|
||||
|
||||
> “它能使你像平常那样进行计算。它允许你输入任何你想输入的,智能识别其中的数学部分并在右边面板打印出结果。然后你可以在后面的等式中使用这些结果,如果结果发生了改变,等式中使用的也会同样变化。”
|
||||
|
||||
还不相信?让我们来看一个截图。
|
||||
|
||||

|
||||
|
||||
现在,你明白什么是 “像普通人一样做数学” 了吗?坦白地说,我并不是这类应用程序的粉丝,但对你们中的某些人可能会有用。让我们来看看怎么在 Elementary OS、Ubuntu 和 Linux Mint 上安装 NaSC。
|
||||
|
||||
### 在 Ubuntu、Elementary OS 和 Mint 上安装 NaSC ###
|
||||
|
||||
安装 NaSC 有一个可用的 PPA。PPA 是 ‘每日’,意味着每日构建(意即,不稳定),但作为我的快速测试,并没什么影响。
|
||||
|
||||
打开一个终端并运行下面的命令:
|
||||
|
||||
sudo apt-add-repository ppa:nasc-team/daily
|
||||
sudo apt-get update
|
||||
sudo apt-get install nasc
|
||||
|
||||
这是 Ubuntu 15.04 中使用 NaSC 的一个截图:
|
||||
|
||||

|
||||
|
||||
如果你想卸载它,可以使用下面的命令:
|
||||
|
||||
sudo apt-get remove nasc
|
||||
sudo apt-add-repository --remove ppa:nasc-team/daily
|
||||
|
||||
如果你试用了这个软件,要分享你的经验哦。除此之外,你也可以在第三方 Elementary OS 应用中体验 [Vocal podcast app for Linux][3]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/math-ubuntu-nasc/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://parnold-x.github.io/nasc/
|
||||
[2]:http://www.acqualia.com/soulver/
|
||||
[3]:http://itsfoss.com/podcast-app-vocal-linux/
|
||||
@ -1,33 +1,35 @@
|
||||
|
||||
FISH - Linux 的一个智能、易用的SHELL
|
||||
FISH:Linux 的一个智能易用的 Shell
|
||||
================================================================================
|
||||
|
||||
FISH:友好的交互式shell。 fish 是一个用户友好的命令行shell,主要是用来进行交互式使用。shell 就是一个用来执行其他程序的程序。
|
||||
FISH(friendly interactive shell)是一个用户友好的命令行 shell,主要是用来进行交互式使用。shell 就是一个用来执行其他程序的程序。
|
||||
|
||||
### FISH 特性 ###
|
||||
|
||||
#### 自动建议 ####
|
||||
|
||||
fish 会根据你的历史输入和已经完成的命令来提供建议,方便输入,就像一个网络浏览器一样。注意了,就是Netscape Navigator 4.0!
|
||||
fish 会根据你的历史输入和补完来提供命令建议,就像一个网络浏览器一样。注意了,就是Netscape Navigator 4.0!
|
||||
|
||||

|
||||
|
||||
#### 漂亮的VGA 色彩 ####
|
||||
fish 原生支持term256, 它就是一个终端技术的艺术国度。 你将可以拥有一个难以置信的、256 色的shell 来使用。
|
||||
|
||||
fish 原生支持 term256, 它就是一个终端技术的艺术国度。 你将可以拥有一个难以置信的、256 色的shell 来使用。
|
||||
|
||||
#### 理智的脚本 ####
|
||||
|
||||
fish 是完全可以通过脚本控制的,而且它的语法又是那么的简单、干净,而且一致。你甚至不需要去重写。
|
||||
|
||||
#### 基于web 的配置 ####
|
||||
#### 基于 web 的配置 ####
|
||||
|
||||
对于少数能使用图形计算机的幸运儿, 你们可以在网页上配置你们自己的色彩方案,以及查看函数、变量和历史记录。
|
||||
|
||||
#### 帮助手册补全 ####
|
||||
|
||||
其它的shell 支持可配置的补全, 但是只有fish 可以通过自动转换你安装好的man 手册来实现补全功能。
|
||||
其它的 shell 支持可配置的补全, 但是只有 fish 可以通过自动转换你安装好的 man 手册来实现补全功能。
|
||||
|
||||
#### 开箱即用 ####
|
||||
|
||||
fish 将会通过tab 补全和语法高亮是你非常愉快的使用shell, 同时不需要太多的学习或者配置。
|
||||
fish 将会通过 tab 补全和语法高亮使你非常愉快的使用shell, 同时不需要太多的学习或者配置。
|
||||
|
||||
### 在ubuntu 15.04 上安装FISH
|
||||
|
||||
@ -37,12 +39,13 @@ fish 将会通过tab 补全和语法高亮是你非常愉快的使用shell,
|
||||
sudo apt-get update
|
||||
sudo apt-get install fish
|
||||
|
||||
**使用FISH**
|
||||
###使用FISH###
|
||||
|
||||
打开终端,运行下列命令来启动FISH:
|
||||
|
||||
fish
|
||||
|
||||
欢迎来到fish, 友好的交互式shell,输入指令help 来了解怎么使用fish。
|
||||
欢迎来到 fish,友好的交互式shell,输入指令 help 来了解怎么使用fish。
|
||||
|
||||
阅读[FISH 文档][1] ,掌握使用方法。
|
||||
|
||||
@ -51,8 +54,8 @@ fish 将会通过tab 补全和语法高亮是你非常愉快的使用shell,
|
||||
via: http://www.ubuntugeek.com/fish-a-smart-and-user-friendly-command-line-shell-for-linux.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[译者ID](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[oska874](https://github.com/oska874)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,65 @@
|
||||
在 Ubuntu 上安装类 Winamp 的音频播放器 Qmmp 0.9.0
|
||||
================================================================================
|
||||

|
||||
|
||||
Qmmp,一个基于 Qt 的音频播放器,与 Winamp 或 xmms 的用户界面类似,现在最新版本是0.9.0。PPA 已经在 Ubuntu 15.10,Ubuntu 15.04,Ubuntu 14.04,Ubuntu 12.04 和其衍生版本中已经更新了。
|
||||
|
||||
Qmmp 0.9.0 是一个较大的版本,有许多新的功能,有许多改进和新的转变。它添加了如下功能:
|
||||
|
||||
- 音频-信道序列转换器;
|
||||
- 9通道支持均衡器;
|
||||
- 支持艺术家专辑标签;
|
||||
- 异步排序;
|
||||
- 不用修改 qmmp.pri 来禁用插件(仅在 qmake 中)功能
|
||||
- 记住播放列表滚动位置功能;
|
||||
- 排除 cue 数据文件功能;
|
||||
- 更改用户代理功能;
|
||||
- 改变窗口标题功能;
|
||||
- 禁用 gme 插件淡出的功能;
|
||||
- 简单用户界面(QSUI)有以下变化:
|
||||
- 增加了多列的支持;
|
||||
- 增加了按艺术家专辑排序;
|
||||
- 增加了按文件的修改日期进行排序;
|
||||
- 增加了隐藏歌曲长度功能;
|
||||
- 增加了“Rename List”的默认热键;
|
||||
- 增加了“Save List”功能到标签菜单;
|
||||
- 增加了复位字体功能;
|
||||
- 增加了复位快捷键功能;
|
||||
- 改进了状态栏;
|
||||
|
||||
它还改进了播放列表的改变通知,播放列表容器,采样率转换器,cmake 构建脚本,标题格式化,在 mpeg 插件中支持 ape 标签,fileops 插件,降低了 cpu 占用率,改变默认的皮肤(炫光)和分离的播放列表。
|
||||
|
||||
|
||||
|
||||
### 在 Ubuntu 中安装 Qmmp 0.9.0 : ###
|
||||
|
||||
新版本已经制做了 PPA,适用于目前所有 Ubuntu 发行版和衍生版。
|
||||
|
||||
1、 添加 [Qmmp PPA][1].
|
||||
|
||||
从 Dash 中打开终端并启动应用,通过按 Ctrl+Alt+T 快捷键。当它打开时,运行命令:
|
||||
|
||||
sudo add-apt-repository ppa:forkotov02/ppa
|
||||
|
||||

|
||||
|
||||
2、 在添加 PPA 后,通过更新软件来升级 Qmmp 播放器。刷新系统缓存,并通过以下命令安装软件:
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install qmmp qmmp-plugin-pack
|
||||
|
||||
就是这样。尽情享受吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ubuntuhandbook.org/index.php/2015/09/qmmp-0-9-0-in-ubuntu/
|
||||
|
||||
作者:[Ji m][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ubuntuhandbook.org/index.php/about/
|
||||
[1]:https://launchpad.net/~forkotov02/+archive/ubuntu/ppa
|
||||
@ -0,0 +1,66 @@
|
||||
在 Ubuntu 里如何下载、安装和配置 Plank Dock
|
||||
=============================================================================
|
||||
一个众所周知的事实就是,Linux 是一个用户可以高度自定义的系统,有很多选项可以选择 —— 作为操作系统,有各种各样的发行版,而对于单个发行版来说,又有很多桌面环境可以选择。与其他操作系统的用户一样,Linux 用户也有不同的口味和喜好,特别是对于桌面来说。
|
||||
|
||||
一些用户并非很在意他们的桌面,而其他一些则非常关心,要确保他们的桌面看起来很酷,很有吸引力,对于这种情况,有很多不错的应用可以派上用场。有一个应用可以给你的桌面带来活力 —— 特别是当你常用一个全局菜单的时候 —— 这就是 dock 。Linux 上有很多 dock 应用可选用;如果你希望是一个最简洁的,那么就选择 [Plank][1] 吧,文章接下来就要讨论这个应用。
|
||||
|
||||
**注意**:接下提到的例子和命令都已在 Ubuntu(版本 14.10)和 Plank(版本 0.9.1.1383)上测试通过。
|
||||
|
||||
### Plank ###
|
||||
|
||||
官方的文档描述 Plank 是“这个星球上最简洁的 dock”。该项目的目的就是仅提供一个 dock 需要的功能,尽管这是很基础的一个库,却可以被扩展,创造其他的含更多高级功能的 dock 程序。
|
||||
|
||||
这里值得一提的就是,在 elementary OS 里,Plank 是预装的。并且 Plank 是 Docky 的基础,Docky 也是一个非常流行的 dock 应用,在功能上与 Mac OS X 的 Dock 非常相似。
|
||||
|
||||
### 下载和安装 ###
|
||||
|
||||
通过在终端里执行下面的命令,可以下载并安装 Plank:
|
||||
|
||||
sudo add-apt-repository ppa:docky-core/stable
|
||||
sudo apt-get update
|
||||
sudo apt-get install plank
|
||||
|
||||
安装成功后,你就可以在 Unity Dash(见下面图片)里通过输入 Plank 来打开该应用,或者从应用菜单里面打开,如果你没有使用 Unity 环境的话。
|
||||
|
||||

|
||||
|
||||
### 特性 ###
|
||||
|
||||
当 Plank 启用后,你会看见它停靠在你桌面的底部中间位置。
|
||||
|
||||

|
||||
|
||||
正如上面图片显示的那样,dock 包含许多带橙色标示的应用图标,这表明这些应用正处于运行状态。无需说,你可以点击一个图标来打开那个应用。同时,右击一个应用图标会给出更多的选项,你可能会感兴趣。举个例子,看下面的屏幕快照:
|
||||
|
||||

|
||||
|
||||
为了获得配置的选项,你需要右击一下 Plank 的图标(左数第一个),然后点击 Preferences 选项。这就会出现如下的窗口。
|
||||
|
||||

|
||||
|
||||
如你所见,Preferences 窗口包含两个标签:Apperance 和 Behavior,前者是默认选中的。Appearance 标签栏包含 Plank 主题相关的设置,dock 的位置,对齐,还有图标相关的,而 Behavior 标签栏包含 dock 本身相关的设定。
|
||||
|
||||

|
||||
|
||||
举个例子,我在 Appearance 里改变 dock 的位置为右侧,在 Behavior 里锁定图标(这表示右击选项中不再有 “Keep in Dock”)。
|
||||
|
||||

|
||||
|
||||
如你所见的上面屏幕快照一样,改变生效了。类似地,根据你个人需求,改变任何可用的设定。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
如我开始所说的那样,使用 dock 不是强制的。尽管如此,使用一个会让事情变得方便,特别是你习惯了 Mac,而最近由于一些原因切换到了 Linux 系统。就其本身而言,Plank 不仅提供简洁性,还有可信任和稳定性 —— 该项目一直被很好地维护着。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/download-install-configure-plank-dock-ubuntu/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/himanshu/
|
||||
[1]:https://launchpad.net/plank
|
||||
184
published/20150908 List Of 10 Funny Linux Commands.md
Normal file
184
published/20150908 List Of 10 Funny Linux Commands.md
Normal file
@ -0,0 +1,184 @@
|
||||
10 条真心有趣的 Linux 命令
|
||||
================================================================================
|
||||
|
||||
**在终端工作是一件很有趣的事情。今天,我们将会列举一些有趣得为你带来欢笑的Linux命令。**
|
||||
|
||||
### 1. rev ###
|
||||
|
||||
创建一个文件,在文件里面输入几个单词,rev命令会将你写的东西反转输出到控制台。
|
||||
|
||||
# rev <file name>
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### 2. fortune ###
|
||||
|
||||
这个命令没有被默认安装,用apt-get命令安装它,fortune命令会随机显示一些句子
|
||||
|
||||
crank@crank-System:~$ sudo apt-get install fortune
|
||||
|
||||

|
||||
|
||||
利用fortune命令的**_s** 选项,他会限制一个句子的输出长度。
|
||||
|
||||
# fortune -s
|
||||
|
||||

|
||||
|
||||
### 3. yes ###
|
||||
|
||||
# yes <string>
|
||||
|
||||
这个命令会不停打印字符串,直到用户把这进程给结束掉。
|
||||
|
||||
# yes unixmen
|
||||
|
||||

|
||||
|
||||
### 4. figlet ###
|
||||
|
||||
这个命令可以用apt-get安装,安装之后,在**/usr/share/figlet**可以看到一些ascii字体文件。
|
||||
|
||||
cd /usr/share/figlet
|
||||
|
||||
----------
|
||||
|
||||
#figlet -f <font> <string>
|
||||
#figlet -f big.flf unixmen
|
||||
|
||||

|
||||
|
||||
#figlet -f block.flf unixmen
|
||||
|
||||

|
||||
|
||||
当然,你也可以尝试使用其他的选项。
|
||||
|
||||
### 5. asciiquarium ###
|
||||
|
||||
这个命令会将你的终端变成一个海洋馆。
|
||||
|
||||
下载term animator:
|
||||
|
||||
# wget http://search.cpan.org/CPAN/authors/id/K/KB/KBAUCOM/Term-Animation-2.4.tar.gz
|
||||
|
||||
安装并且配置这个包:
|
||||
|
||||
# tar -zxvf Term-Animation-2.4.tar.gz
|
||||
# cd Term-Animation-2.4/
|
||||
# perl Makefile.PL && make && make test
|
||||
# sudo make install
|
||||
|
||||
接着安装下面这个包:
|
||||
|
||||
# apt-get install libcurses-perl
|
||||
|
||||
下载并且安装asciiquarium:
|
||||
|
||||
# wget http://www.robobunny.com/projects/asciiquarium/asciiquarium.tar.gz
|
||||
# tar -zxvf asciiquarium.tar.gz
|
||||
# cd asciiquarium_1.0/
|
||||
# cp asciiquarium /usr/local/bin/
|
||||
|
||||
执行如下命令:
|
||||
|
||||
# /usr/local/bin/asciiquarium
|
||||
|
||||

|
||||
|
||||
### 6. bb ###
|
||||
|
||||
# apt-get install bb
|
||||
# bb
|
||||
|
||||
看看会输出什么?
|
||||
|
||||

|
||||
|
||||
### 7. sl ###
|
||||
|
||||
有的时候你可能把 **ls** 误打成了 **sl**,其实 **sl** 也是一个命令,如果你打 sl的话,你会看到一个移动的火车头
|
||||
|
||||
# apt-get install sl
|
||||
|
||||
----------
|
||||
|
||||
# sl
|
||||
|
||||

|
||||
|
||||
### 8. cowsay ###
|
||||
|
||||
一个很常见的命令,它会用ascii显示你想说的话。
|
||||
|
||||
apt-get install cowsay
|
||||
|
||||
----------
|
||||
|
||||
# cowsay <string>
|
||||
|
||||

|
||||
|
||||
或者,你可以用其他的角色来取代默认角色来说这句话,这些角色都存储在**/usr/share/cowsay/cows**目录下
|
||||
|
||||
# cd /usr/share/cowsay/cows
|
||||
|
||||
----------
|
||||
|
||||
cowsay -f ghostbusters.cow unixmen
|
||||
|
||||

|
||||
|
||||
或者
|
||||
|
||||
# cowsay -f bud-frogs.cow Rajneesh
|
||||
|
||||

|
||||
|
||||
### 9. toilet ###
|
||||
|
||||
你没看错,这是个命令来的,他会将字符串以彩色的ascii字符串形式输出到终端
|
||||
|
||||
# apt-get install toilet
|
||||
|
||||
----------
|
||||
|
||||
# toilet --gay unixmen
|
||||
|
||||

|
||||
|
||||
toilet -F border -F gay unixmen
|
||||
|
||||

|
||||
|
||||
toilet -f mono12 -F metal unixmen
|
||||
|
||||

|
||||
|
||||
### 10. aafire ###
|
||||
|
||||
aafire能让你的终端燃起来。
|
||||
|
||||
# apt-get install libaa-bin
|
||||
|
||||
----------
|
||||
|
||||
# aafire
|
||||
|
||||

|
||||
|
||||
就这么多,祝你们在Linux终端玩得开心哈!!!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/list-10-funny-linux-commands/
|
||||
|
||||
作者:[Rajneesh Upadhyay][a]
|
||||
译者:[tnuoccalanosrep](https://github.com/tnuoccalanosrep)
|
||||
校对:[wxy](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/rajneesh/
|
||||
@ -0,0 +1,68 @@
|
||||
Linux有问必答:如何删除Ubuntu上不再使用的旧内核
|
||||
================================================================================
|
||||
> **提问**:过去我已经在我的Ubuntu上升级了几次内核。现在我想要删除这些旧的内核镜像来节省我的磁盘空间。如何用最简单的方法删除Ubuntu上先前版本的内核?
|
||||
|
||||
在Ubuntu上,有几个方法来升级内核。在Ubuntu桌面中,软件更新允许你每天检查并更新到最新的内核上。在Ubuntu服务器上,最为重要的安全更新项目之一就是 unattended-upgrades 软件包会自动更新内核。然而,你也可以手动用apt-get或者aptitude命令来更新。
|
||||
|
||||
随着时间的流逝,持续的内核更新会在系统中积聚大量的不再使用的内核,浪费你的磁盘空间。每个内核镜像和其相关联的模块/头文件会占用200-400MB的磁盘空间,因此由不再使用的内核而浪费的磁盘空间会快速地增加。
|
||||
|
||||
|
||||
|
||||
GRUB管理器为每个旧内核都维护了一个GRUB入口,以备你想要使用它们。
|
||||
|
||||
|
||||
|
||||
作为磁盘清理的一部分,如果你不再使用这些,你可以考虑清理掉这些镜像。
|
||||
|
||||
### 如何清理旧内核镜像 ###
|
||||
|
||||
在删除旧内核之前,记住最好留有2个最近的内核(最新的和上一个版本),以防主要的版本出错。现在就让我们看看如何在Ubuntu上清理旧内核。
|
||||
|
||||
在Ubuntu内核镜像包含了以下的包。
|
||||
|
||||
- **linux-image-<VERSION-NUMBER>**: 内核镜像
|
||||
- **linux-image-extra-<VERSION-NUMBER>**: 额外的内核模块
|
||||
- **linux-headers-<VERSION-NUMBER>**: 内核头文件
|
||||
|
||||
首先检查系统中安装的内核镜像。
|
||||
|
||||
$ dpkg --list | grep linux-image
|
||||
$ dpkg --list | grep linux-headers
|
||||
|
||||
在列出的内核镜像中,你可以移除一个特定的版本(比如3.19.0-15)。
|
||||
|
||||
$ sudo apt-get purge linux-image-3.19.0-15
|
||||
$ sudo apt-get purge linux-headers-3.19.0-15
|
||||
|
||||
上面的命令会删除内核镜像和它相关联的内核模块和头文件。
|
||||
|
||||
注意如果你还没有升级内核那么删除旧内核会自动触发安装新内核。这样在删除旧内核之后,GRUB配置会自动升级来移除GRUB菜单中相关GRUB入口。
|
||||
|
||||
如果你有很多没用的内核,你可以用shell表达式来一次性地删除多个内核。注意这个括号表达式只在bash或者兼容的shell中才有效。
|
||||
|
||||
$ sudo apt-get purge linux-image-3.19.0-{18,20,21,25}
|
||||
$ sudo apt-get purge linux-headers-3.19.0-{18,20,21,25}
|
||||
|
||||

|
||||
|
||||
上面的命令会删除4个内核镜像:3.19.0-18、3.19.0-20、3.19.0-21 和 3.19.0-25。
|
||||
|
||||
如果GRUB配置由于任何原因在删除旧内核后没有正确升级,你可以尝试手动用update-grub2命令来更新配置。
|
||||
|
||||
$ sudo update-grub2
|
||||
|
||||
现在就重启来验证GRUB菜单是否已经正确清理了。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/remove-kernel-images-ubuntu.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
@ -0,0 +1,248 @@
|
||||
RHCSA 系列(三): 如何管理 RHEL7 的用户和组
|
||||
================================================================================
|
||||
|
||||
和管理其它Linux服务器一样,管理一个 RHEL 7 服务器要求你能够添加、修改、暂停或删除用户帐户,并且授予他们执行其分配的任务所需的文件、目录、其它系统资源所必要的权限。
|
||||
|
||||

|
||||
|
||||
*RHCSA: 用户和组管理 – Part 3*
|
||||
|
||||
###管理用户帐户##
|
||||
|
||||
如果想要给RHEL 7 服务器添加账户,你需要以root用户执行如下两条命令之一:
|
||||
|
||||
# adduser [new_account]
|
||||
# useradd [new_account]
|
||||
|
||||
当添加新的用户帐户时,默认会执行下列操作。
|
||||
|
||||
- 它/她的主目录就会被创建(一般是"/home/用户名",除非你特别设置)
|
||||
- 一些隐藏文件 如`.bash_logout`, `.bash_profile` 以及 `.bashrc` 会被复制到用户的主目录,它们会为用户的回话提供环境变量。你可以进一步查看它们的相关细节。
|
||||
- 会为您的账号添加一个邮件池目录。
|
||||
- 会创建一个和用户名同样的组(LCTT 译注:除非你给新创建的用户指定了组)。
|
||||
|
||||
用户帐户的全部信息被保存在`/etc/passwd`文件。这个文件以如下格式保存了每一个系统帐户的所有信息(字段以“:”分割)
|
||||
|
||||
[username]:[x]:[UID]:[GID]:[Comment]:[Home directory]:[Default shell]
|
||||
|
||||
- `[username]` 和`[Comment]` 其意自明,就是用户名和备注
|
||||
- 第二个‘x’表示帐户的启用了密码保护(记录在`/etc/shadow`文件),密码用于登录`[username]`
|
||||
- `[UID]` 和`[GID]`是整数,它们表明了`[username]`的用户ID 和所属的主组ID
|
||||
|
||||
最后。
|
||||
|
||||
- `[Home directory]`显示`[username]`的主目录的绝对路径
|
||||
- `[Default shell]` 是当用户登录系统后使用的默认shell
|
||||
|
||||
另外一个你必须要熟悉的重要的文件是存储组信息的`/etc/group`。和`/etc/passwd`类似,也是每行一个记录,字段由“:”分割
|
||||
|
||||
[Group name]:[Group password]:[GID]:[Group members]
|
||||
|
||||
- `[Group name]` 是组名
|
||||
- 这个组是否使用了密码 (如果是"x"意味着没有)
|
||||
- `[GID]`: 和`/etc/passwd`中一样
|
||||
- `[Group members]`:用户列表,使用“,”隔开。里面包含组内的所有用户
|
||||
|
||||
添加过帐户后,任何时候你都可以通过 usermod 命令来修改用户账户信息,基本的语法如下:
|
||||
|
||||
# usermod [options] [username]
|
||||
|
||||
相关阅读
|
||||
|
||||
- [15 ‘useradd’ 命令示例][1]
|
||||
- [15 ‘usermod’ 命令示例][2]
|
||||
|
||||
#### 示例1 : 设置帐户的过期时间 ####
|
||||
|
||||
如果你的公司有一些短期使用的帐户或者你要在有限时间内授予访问,你可以使用 `--expiredate` 参数 ,后加YYYY-MM-DD 格式的日期。为了查看是否生效,你可以使用如下命令查看
|
||||
|
||||
# chage -l [username]
|
||||
|
||||
帐户更新前后的变动如下图所示
|
||||
|
||||
|
||||
|
||||
*修改用户信息*
|
||||
|
||||
#### 示例 2: 向组内追加用户 ####
|
||||
|
||||
除了创建用户时的主用户组,一个用户还能被添加到别的组。你需要使用 -aG或 -append -group 选项,后跟逗号分隔的组名。
|
||||
|
||||
#### 示例 3: 修改用户主目录或默认Shell ####
|
||||
|
||||
如果因为一些原因,你需要修改默认的用户主目录(一般为 /home/用户名),你需要使用 -d 或 -home 参数,后跟绝对路径来修改主目录。
|
||||
|
||||
如果有用户想要使用其它的shell来取代默认的bash(比如zsh)。使用 usermod ,并使用 -shell 的参数,后加新的shell的路径。
|
||||
|
||||
#### 示例 4: 展示组内的用户 ####
|
||||
|
||||
当把用户添加到组中后,你可以使用如下命令验证属于哪一个组
|
||||
|
||||
# groups [username]
|
||||
# id [username]
|
||||
|
||||
下面图片的演示了示例2到示例4
|
||||
|
||||

|
||||
|
||||
*添加用户到额外的组*
|
||||
|
||||
在上面的示例中:
|
||||
|
||||
# usermod --append --groups gacanepa,users --home /tmp --shell /bin/sh tecmint
|
||||
|
||||
如果想要从组内删除用户,取消 `--append` 选项,并使用 `--groups` 和你要用户属于的组的列表。
|
||||
|
||||
#### 示例 5: 通过锁定密码来停用帐户 ####
|
||||
|
||||
如果想要关闭帐户,你可以使用 -l(小写的L)或 -lock 选项来锁定用户的密码。这将会阻止用户登录。
|
||||
|
||||
#### 示例 6: 解锁密码 ####
|
||||
|
||||
当你想要重新启用帐户让它可以继续登录时,使用 -u 或 –unlock 选项来解锁用户的密码,就像示例5 介绍的那样
|
||||
|
||||
# usermod --unlock tecmint
|
||||
|
||||
下面的图片展示了示例5和示例6:
|
||||
|
||||

|
||||
|
||||
*锁定上锁用户*
|
||||
|
||||
#### 示例 7:删除组和用户 ####
|
||||
|
||||
如果要删除一个组,你需要使用 groupdel ,如果需要删除用户 你需要使用 userdel (添加 -r 可以删除主目录和邮件池的内容)。
|
||||
|
||||
# groupdel [group_name] # 删除组
|
||||
# userdel -r [user_name] # 删除用户,并删除主目录和邮件池
|
||||
|
||||
如果一些文件属于该组,删除组时它们不会也被删除。但是组拥有者的名字将会被设置为删除掉的组的GID。
|
||||
|
||||
### 列举,设置,并且修改标准 ugo/rwx 权限 ###
|
||||
|
||||
著名的 [ls 命令][3] 是管理员最好的助手. 当我们使用 -l 参数, 这个工具允许您以长格式(或详细格式)查看一个目录中的内容。
|
||||
|
||||
而且,该命令还可以用于单个文件中。无论哪种方式,在“ls”输出中的前10个字符表示每个文件的属性。
|
||||
|
||||
这10个字符序列的第一个字符用于表示文件类型:
|
||||
|
||||
- – (连字符): 一个标准文件
|
||||
- d: 一个目录
|
||||
- l: 一个符号链接
|
||||
- c: 字符设备(将数据作为字节流,例如终端)
|
||||
- b: 块设备(以块的方式处理数据,例如存储设备)
|
||||
|
||||
文件属性的接下来的九个字符,分为三个组,被称为文件模式,并注明读(r)、写(w)、和执行(x)权限授予文件的所有者、文件的所有组、和其它的用户(通常被称为“世界”)。
|
||||
|
||||
同文件上的读取权限允许文件被打开和读取一样,如果目录同时有执行权限时,就允许其目录内容被列出。此外,如果一个文件有执行权限,就允许它作为一个程序运行。
|
||||
|
||||
文件权限是通过chmod命令改变的,它的基本语法如下:
|
||||
|
||||
# chmod [new_mode] file
|
||||
|
||||
new_mode 是一个八进制数或表达式,用于指定新的权限。随意试试各种权限看看是什么效果。或者您已经有了一个更好的方式来设置文件的权限,你也可以用你自己的方式自由地试试。
|
||||
|
||||
八进制数可以基于二进制等价计算,可以从所需的文件权限的文件的所有者、所有组、和世界组合成。每种权限都等于2的幂(R = 2\^2,W = 2\^1,x = 2\^0),没有时即为0。例如:
|
||||
|
||||

|
||||
|
||||
*文件权限*
|
||||
|
||||
在八进制形式下设置文件的权限,如上图所示
|
||||
|
||||
# chmod 744 myfile
|
||||
|
||||
请用马上来对比一下我们以前的计算,在更改文件的权限后,我们的实际输出为:
|
||||
|
||||
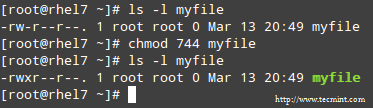
|
||||
|
||||
*长列表格式*
|
||||
|
||||
#### 示例 8: 寻找777权限的文件 ####
|
||||
|
||||
出于安全考虑,你应该确保在正常情况下,尽可能避免777权限(任何人可读、可写、可执行的文件)。虽然我们会在以后的教程中教你如何更有效地找到您的系统的具有特定权限的全部文件,你现在仍可以组合使用ls 和 grep来获取这种信息。
|
||||
|
||||
在下面的例子,我们会寻找 /etc 目录下的777权限文件。注意,我们要使用[第二章:文件和目录管理][4]中讲到的管道的知识:
|
||||
|
||||
# ls -l /etc | grep rwxrwxrwx
|
||||
|
||||

|
||||
|
||||
*查找所有777权限的文件*
|
||||
|
||||
#### 示例 9: 为所有用户指定特定权限 ####
|
||||
|
||||
shell脚本,以及一些二进制文件,所有用户都应该有权访问(不只是其相应的所有者和组),应该有相应的执行权限(我们会讨论特殊情况下的问题):
|
||||
|
||||
# chmod a+x script.sh
|
||||
|
||||
**注意**: 我们可以使用表达式设置文件模式,表示用户权限的字母如“u”,组所有者权限的字母“g”,其余的为“o” ,同时具有所有权限为“a”。权限可以通过`+` 或 `-` 来授予和收回。
|
||||
|
||||

|
||||
|
||||
*为文件设置执行权限*
|
||||
|
||||
长目录列表还用两列显示了该文件的所有者和所有组。此功能可作为系统中文件的第一级访问控制方法:
|
||||
|
||||
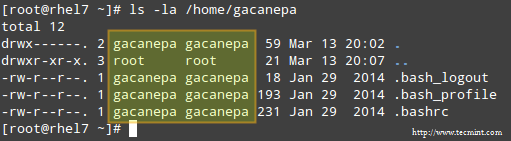
|
||||
|
||||
*检查文件的所有者和所有组*
|
||||
|
||||
改变文件的所有者,您应该使用chown命令。请注意,您可以在同时或分别更改文件的所有组:
|
||||
|
||||
# chown user:group file
|
||||
|
||||
你可以更改用户或组,或在同时更改两个属性,但是不要忘记冒号区分,如果你想要更新其它属性,让另外的部分为空:
|
||||
|
||||
# chown :group file # 仅改变所有组
|
||||
# chown user: file # 仅改变所有者
|
||||
|
||||
#### 示例 10:从一个文件复制权限到另一个文件####
|
||||
|
||||
|
||||
如果你想“克隆”一个文件的所有权到另一个,你可以这样做,使用–reference参数,如下:
|
||||
|
||||
# chown --reference=ref_file file
|
||||
|
||||
ref_file的所有信息会复制给 file
|
||||
|
||||

|
||||
|
||||
*复制文件属主信息*
|
||||
|
||||
### 设置 SETGID 协作目录 ###
|
||||
|
||||
假如你需要授予在一个特定的目录中拥有访问所有的文件的权限给一个特定的用户组,你有可能需要使用给目录设置setgid的方法。当setgid设置后,该真实用户的有效GID会变成属主的GID。
|
||||
|
||||
因此,任何访问该文件的用户会被授予该文件的属组的权限。此外,当setgid设置在一个目录中,新创建的文件继承组该目录的组,而且新创建的子目录也将继承父目录的setgid权限。
|
||||
|
||||
# chmod g+s [filename]
|
||||
|
||||
要以八进制形式设置 setgid,需要在基本权限前缀以2。
|
||||
|
||||
# chmod 2755 [directory]
|
||||
|
||||
### 总结 ###
|
||||
|
||||
扎实的用户和组管理知识,以及标准和特殊的 Linux权限管理,通过实践,可以帮你快速解决 RHEL 7 服务器的文件权限问题。
|
||||
|
||||
我向你保证,当你按照本文所概述的步骤和使用系统文档(在本系列的[第一章 回顾基础命令及系统文档][5]中讲到), 你将掌握基本的系统管理的能力。
|
||||
|
||||
请随时使用下面的评论框让我们知道你是否有任何问题或意见。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-manage-users-and-groups/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[xiqingongzi](https://github.com/xiqingongzi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/add-users-in-linux/
|
||||
[2]:http://www.tecmint.com/usermod-command-examples/
|
||||
[3]:http://linux.cn/article-5349-1.html
|
||||
[4]:https://www.linux.cn/article-6155-1.html
|
||||
[5]:http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
|
||||
@ -0,0 +1,209 @@
|
||||
RHCSA 系列(四): 编辑文本文件及分析文本
|
||||
================================================================================
|
||||
|
||||
作为系统管理员的日常职责的一部分,每个系统管理员都必须处理文本文件,这包括编辑已有文件(大多可能是配置文件),或创建新的文件。有这样一个说法,假如你想在 Linux 世界中挑起一场圣战,你可以询问系统管理员们,什么是他们最喜爱的编辑器以及为什么。在这篇文章中,我们并不打算那样做,但我们将向你呈现一些技巧,这些技巧对使用两款在 RHEL 7 中最为常用的文本编辑器: nano(由于其简单和易用,特别是对于新手来说)和 vi/m(由于其自身的几个特色使得它不仅仅是一个简单的编辑器)来说都大有裨益。我确信你可以找到更多的理由来使用其中的一个或另一个,或许其他的一些编辑器如 emacs 或 pico。这完全取决于你自己。
|
||||
|
||||

|
||||
|
||||
*RHCSA: 使用 Nano 和 Vim 编辑文本文件 – Part 4*
|
||||
|
||||
### 使用 Nano 编辑器来编辑文件 ###
|
||||
|
||||
要启动 nano,你可以在命令提示符下输入 `nano`,或可选地跟上一个文件名(在这种情况下,若文件存在,它将在编辑模式中被打开)。若文件不存在,或我们省略了文件名, nano 也将在编辑模式下开启,但将为我们开启一个空白屏以便开始输入:
|
||||
|
||||

|
||||
|
||||
*Nano 编辑器*
|
||||
|
||||
正如你在上一张图片中所见的那样, nano 在屏幕的底部呈现出一些可以通过指定的快捷键来触发的功能(\^,即插入记号,代指 Ctrl 键)。它们中的一些是:
|
||||
|
||||
- Ctrl + G: 触发一个帮助菜单,带有一个关于功能和相应的描述的完整列表;
|
||||
|
||||
|
||||
|
||||
*Nano 编辑器帮助菜单*
|
||||
|
||||
- Ctrl + O: 保存更改到一个文件。它可以让你用一个与源文件相同或不同的名称来保存该文件,然后按 Enter 键来确认。
|
||||
|
||||

|
||||
|
||||
*Nano 编辑器的保存更改模式*
|
||||
|
||||
- Ctrl + X: 离开当前文件,假如更改没有被保存,则它们将被丢弃;
|
||||
- Ctrl + R: 通过指定一个完整的文件路径,让你选择一个文件来将该文件的内容插入到当前文件中;
|
||||
|
||||
|
||||
|
||||
*Nano: 插入文件内容到主文件中*
|
||||
|
||||
上图的操作将把 `/etc/passwd` 的内容插入到当前文件中。
|
||||
|
||||
- Ctrl + K: 剪切当前行;
|
||||
- Ctrl + U: 粘贴;
|
||||
- Ctrl + C: 取消当前的操作并返回先前的屏幕;
|
||||
|
||||
为了轻松地在打开的文件中浏览, nano 提供了下面的功能:
|
||||
|
||||
- Ctrl + F 和 Ctrl + B 分别先前或向后移动光标;而 Ctrl + P 和 Ctrl + N 则分别向上或向下移动一行,功能与箭头键相同;
|
||||
- Ctrl + space 和 Alt + space 分别向前或向后移动一个单词;
|
||||
|
||||
最后,
|
||||
|
||||
- 假如你想将光标移动到文档中的特定位置,使用 Ctrl + _ (下划线) 并接着输入 X,Y 将准确地带你到 第 X 行,第 Y 列。
|
||||
|
||||

|
||||
|
||||
*在 nano 中定位到具体的行和列*
|
||||
|
||||
上面的例子将带你到当前文档的第 15 行,第 14 列。
|
||||
|
||||
假如你可以回忆起你早期的 Linux 岁月,特别是当你刚从 Windows 迁移到 Linux 中,你就可能会同意:对于一个新手来说,使用 nano 来开始学习是最好的方式。
|
||||
|
||||
### 使用 Vim 编辑器来编辑文件 ###
|
||||
|
||||
Vim 是 vi 的加强版本,它是 Linux 中一个著名的文本编辑器,可在所有兼容 POSIX 的 *nix 系统中获取到,例如在 RHEL 7 中。假如你有机会并可以安装 Vim,请继续;假如不能,这篇文章中的大多数(若不是全部)的提示也应该可以正常工作。
|
||||
|
||||
Vim 的一个出众的特点是可以在多个不同的模式中进行操作:
|
||||
|
||||
- 命令模式(Command Mode)将允许你在文件中跳转和输入命令,这些命令是由一个或多个字母组成的简洁且大小写敏感的组合。假如你想重复执行某个命令特定次数,你可以在这个命令前加上需要重复的次数(这个规则只有极少数例外)。例如, `yy`(或 `Y`,yank 的缩写)可以复制整个当前行,而 `4yy`(或 `4Y`)则复制整个从当前行到接下来的 3 行(总共 4 行)。
|
||||
- 我们总是可以通过敲击 `Esc` 键来进入命令模式(无论我们正工作在哪个模式下)。
|
||||
- 在末行模式(Ex Mode)中,你可以操作文件(包括保存当前文件和运行外部的程序或命令)。要进入末行模式,你必须从命令模式中(换言之,输入 `Esc` + `:`)输入一个冒号(`:`),再直接跟上你想使用的末行模式命令的名称。
|
||||
- 对于插入模式(Insert Mode),可以输入字母 `i` 进入,然后只需要输入文字即可。大多数的击键结果都将出现在屏幕中的文本中。
|
||||
|
||||
现在,让我们看看如何在 vim 中执行在上一节列举的针对 nano 的相同的操作。不要忘记敲击 Enter 键来确认 vim 命令。
|
||||
|
||||
为了从命令行中获取 vim 的完整手册,在命令模式下键入 `:help` 并敲击 Enter 键:
|
||||
|
||||
|
||||
|
||||
*vim 编辑器帮助菜单*
|
||||
|
||||
上面的部分呈现出一个内容列表,这些定义的小节则描述了 Vim 的特定话题。要浏览某一个小节,可以将光标放到它的上面,然后按 `Ctrl + ]` (闭方括号)。注意,底部的小节展示的是当前文件的内容。
|
||||
|
||||
1、 要保存更改到文件,在命令模式中运行下面命令中的任意一个,就可以达到这个目的:
|
||||
|
||||
```
|
||||
:wq!
|
||||
:x!
|
||||
ZZ (是的,两个 ZZ,前面无需添加冒号)
|
||||
```
|
||||
|
||||
2、 要离开并丢弃更改,使用 `:q!`。这个命令也将允许你离开上面描述过的帮助菜单,并返回到命令模式中的当前文件。
|
||||
|
||||
3、 剪切 N 行:在命令模式中键入 `Ndd`。
|
||||
|
||||
4、 复制 M 行:在命令模式中键入 `Myy`。
|
||||
|
||||
5、 粘贴先前剪贴或复制过的行:在命令模式中按 `P`键。
|
||||
|
||||
6、 要插入另一个文件的内容到当前文件:
|
||||
|
||||
:r filename
|
||||
|
||||
例如,插入 `/etc/fstab` 的内容,可以这样做:
|
||||
|
||||
[在 vi 编辑器中插入文件的内容](http://www.tecmint.com/wp-content/uploads/2015/03/Insert-Content-vi-Editor.png)
|
||||
|
||||
*在 vi 编辑器中插入文件的内容*
|
||||
|
||||
7、 插入一个命令的输出到当前文档:
|
||||
|
||||
:r! command
|
||||
|
||||
例如,要在光标所在的当前位置后面插入日期和时间:
|
||||
|
||||
|
||||
|
||||
*在 vi 编辑器中插入时间和日期*
|
||||
|
||||
在另一篇我写的文章中,([LFCS 系列(二)][1]),我更加详细地解释了在 vim 中可用的键盘快捷键和功能。或许你可以参考那个教程来查看如何使用这个强大的文本编辑器的更深入的例子。
|
||||
|
||||
### 使用 grep 和正则表达式来分析文本 ###
|
||||
|
||||
到现在为止,你已经学习了如何使用 nano 或 vim 创建和编辑文件。打个比方说,假如你成为了一个文本编辑器忍者 – 那又怎样呢? 在其他事情上,你也需要知道如何在文本中搜索正则表达式。
|
||||
|
||||
正则表达式(也称为 "regex" 或 "regexp") 是一种识别一个特定文本字符串或模式的方式,使得一个程序可以将这个模式和任意的文本字符串相比较。尽管利用 grep 来使用正则表达式值得用一整篇文章来描述,这里就让我们复习一些基本的知识:
|
||||
|
||||
**1、 最简单的正则表达式是一个由数字和字母构成的字符串(例如,单词 "svm") ,或者两个(在使用两个字符串时,你可以使用 `|`(或) 操作符):**
|
||||
|
||||
# grep -Ei 'svm|vmx' /proc/cpuinfo
|
||||
|
||||
上面命令的输出结果中若有这两个字符串之一的出现,则标志着你的处理器支持虚拟化:
|
||||
|
||||

|
||||
|
||||
*正则表达式示例*
|
||||
|
||||
**2、 第二种正则表达式是一个范围列表,由方括号包裹。**
|
||||
|
||||
例如, `c[aeiou]t` 匹配字符串 cat、cet、cit、cot 和 cut,而 `[a-z]` 和 `[0-9]` 则相应地匹配小写字母或十进制数字。假如你想重复正则表达式 X 次,在正则表达式的后面立即输入 `{X}`即可。
|
||||
|
||||
例如,让我们从 `/etc/fstab` 中析出存储设备的 UUID:
|
||||
|
||||
# grep -Ei '[0-9a-f]{8}-([0-9a-f]{4}-){3}[0-9a-f]{12}' -o /etc/fstab
|
||||
|
||||

|
||||
|
||||
*从一个文件中析出字符串*
|
||||
|
||||
方括号中的第一个表达式 `[0-9a-f]` 被用来表示小写的十六进制字符,`{8}`是一个量词,暗示前面匹配的字符串应该重复的次数(在一个 UUID 中的开头序列是一个 8 个字符长的十六进制字符串)。
|
||||
|
||||
在圆括号中,量词 `{4}`和连字符暗示下一个序列是一个 4 个字符长的十六进制字符串,接着的量词 `({3})`表示前面的表达式要重复 3 次。
|
||||
|
||||
最后,在 UUID 中的最后一个 12 个字符长的十六进制字符串可以由 `[0-9a-f]{12}` 取得, `-o` 选项表示只打印出在 `/etc/fstab`中匹配行中的匹配的(非空)部分。
|
||||
|
||||
**3、 POSIX 字符类**
|
||||
|
||||
|字符类|匹配 …|
|
||||
|-----|-----|
|
||||
| `[:alnum:]` | 任意字母或数字 [a-zA-Z0-9] |
|
||||
| `[:alpha:]` |任意字母 [a-zA-Z] |
|
||||
| `[:blank:]` |空格或制表符 |
|
||||
| `[:cntrl:]` |任意控制字符 (ASCII 码的 0 至 32) |
|
||||
| `[:digit:]` |任意数字 [0-9] |
|
||||
| `[:graph:]` |任意可见字符 |
|
||||
| `[:lower:]` |任意小写字母 [a-z] |
|
||||
| `[:print:]` |任意非控制字符 |
|
||||
| `[:space:]` |任意空格 |
|
||||
| `[:punct:]` |任意标点字符 |
|
||||
| `[:upper:]` |任意大写字母 [A-Z] |
|
||||
| `[:xdigit:]` |任意十六进制数字 [0-9a-fA-F] |
|
||||
| `[:word:]` |任意字母,数字和下划线 [a-zA-Z0-9_] |
|
||||
|
||||
例如,我们可能会对查找已添加到我们系统中给真实用户的 UID 和 GID(参考“[RHCSA 系列(二): 如何进行文件和目录管理][2]”来回忆起这些知识)感兴趣。那么,我们将在 `/etc/passwd` 文件中查找 4 个字符长的序列:
|
||||
|
||||
# grep -Ei [[:digit:]]{4} /etc/passwd
|
||||
|
||||

|
||||
|
||||
*在文件中查找一个字符串*
|
||||
|
||||
上面的示例可能不是真实世界中使用正则表达式的最好案例,但它清晰地启发了我们如何使用 POSIX 字符类来使用 grep 分析文本。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
|
||||
在这篇文章中,我们已经提供了一些技巧来最大地利用针对命令行用户的两个文本编辑器 nano 和 vim,这两个工具都有相关的扩展文档可供阅读,你可以分别查询它们的官方网站(链接在下面给出)以及使用“[RHCSA 系列(一): 回顾基础命令及系统文档][3]”中给出的建议。
|
||||
|
||||
#### 参考文件链接 ####
|
||||
|
||||
- [http://www.nano-editor.org/][4]
|
||||
- [http://www.vim.org/][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-how-to-use-nano-vi-editors/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/vi-editor-usage/
|
||||
[2]:https://linux.cn/article-6155-1.html
|
||||
[3]:https://linux.cn/article-6133-1-rel.html
|
||||
[4]:http://www.nano-editor.org/
|
||||
[5]:http://www.vim.org/
|
||||
[6]:http://www.tecmint.com/vi-editor-usage/
|
||||
@ -0,0 +1,152 @@
|
||||
RHCSA 系列(五): RHEL7 中的进程管理:开机,关机
|
||||
================================================================================
|
||||
我们将概括和简要地复习从你按开机按钮来打开你的 RHEL 7 服务器到呈现出命令行界面的登录屏幕之间所发生的所有事情,以此来作为这篇文章的开始。
|
||||
|
||||

|
||||
|
||||
*Linux 开机过程*
|
||||
|
||||
**请注意:**
|
||||
|
||||
1. 相同的基本原则也可以应用到其他的 Linux 发行版本中,但可能需要较小的更改,并且
|
||||
2. 下面的描述并不是旨在给出开机过程的一个详尽的解释,而只是介绍一些基础的东西
|
||||
|
||||
### Linux 开机过程 ###
|
||||
|
||||
1. 初始化 POST(加电自检)并执行硬件检查;
|
||||
|
||||
2. 当 POST 完成后,系统的控制权将移交给启动管理器的第一阶段(first stage),它存储在一个硬盘的引导扇区(对于使用 BIOS 和 MBR 的旧式的系统而言)或存储在一个专门的 (U)EFI 分区上。
|
||||
|
||||
3. 启动管理器的第一阶段完成后,接着进入启动管理器的第二阶段(second stage),通常大多数使用的是 GRUB(GRand Unified Boot Loader 的简称),它驻留在 `/boot` 中,然后开始加载内核和驻留在 RAM 中的初始化文件系统(被称为 initramfs,它包含执行必要操作所需要的程序和二进制文件,以此来最终挂载真实的根文件系统)。
|
||||
|
||||
4. 接着展示了闪屏(splash)过后,呈现在我们眼前的是类似下图的画面,它允许我们选择一个操作系统和内核来启动:
|
||||
|
||||

|
||||
|
||||
*启动菜单屏幕*
|
||||
|
||||
5. 内核会对接入到系统的硬件进行设置,当根文件系统被挂载后,接着便启动 PID 为 1 的进程,这个进程将开始初始化其他的进程并最终呈现给我们一个登录提示符界面。
|
||||
|
||||
注意:假如我们想在启动后查看这些信息,我们可以使用 [dmesg 命令][1],并使用这个系列里的上一篇文章中介绍过的工具(注:即 grep)来过滤它的输出。
|
||||
|
||||

|
||||
|
||||
*登录屏幕和进程的 PID*
|
||||
|
||||
在上面的例子中,我们使用了大家熟知的 `ps` 命令来显示在系统启动过程中的一系列当前进程的信息,它们的父进程(或者换句话说,就是那个开启这些进程的进程)为 systemd(大多数现代的 Linux 发行版本已经切换到的系统和服务管理器):
|
||||
|
||||
# ps -o ppid,pid,uname,comm --ppid=1
|
||||
|
||||
记住 `-o`(为 -format 的简写)选项允许你以一个自定义的格式来显示 ps 的输出,以此来满足你的需求;这个自定义格式使用 `man ps` 里 STANDARD FORMAT SPECIFIERS 一节中的特定关键词。
|
||||
|
||||
另一个你想自定义 ps 的输出而不是使用其默认输出的情形是:当你需要找到引起 CPU 或内存消耗过多的那些进程,并按照下列方式来对它们进行排序时:
|
||||
|
||||
# ps aux --sort=+pcpu # 以 %CPU 来排序(增序)
|
||||
# ps aux --sort=-pcpu # 以 %CPU 来排序(降序)
|
||||
# ps aux --sort=+pmem # 以 %MEM 来排序(增序)
|
||||
# ps aux --sort=-pmem # 以 %MEM 来排序(降序)
|
||||
# ps aux --sort=+pcpu,-pmem # 结合 %CPU (增序) 和 %MEM (降序)来排列
|
||||
|
||||

|
||||
|
||||
*自定义 ps 命令的输出*
|
||||
|
||||
### systemd 的一个介绍 ###
|
||||
|
||||
在 Linux 世界中,很少有能比在主流的 Linux 发行版本中采用 systemd 引起更多的争论的决定。systemd 的倡导者根据以下事实来表明其主要的优势:
|
||||
|
||||
1. 在系统启动期间,systemd 允许并发地启动更多的进程(相比于先前的 SysVinit,SysVinit 似乎总是表现得更慢,因为它一个接一个地启动进程,检查一个进程是否依赖于另一个进程,然后等待守护进程启动才可以启动的更多的服务),并且
|
||||
2. 在一个运行着的系统中,它用作一个动态的资源管理器。这样在启动期间,当一个服务被需要时,才启动它(以此来避免消耗系统资源)而不是在没有一个合理的原因的情况下启动额外的服务。
|
||||
3. 向后兼容 sysvinit 的脚本。
|
||||
|
||||
另外请阅读: ['init' 和 'systemd' 背后的故事][2]
|
||||
|
||||
systemd 由 systemctl 工具控制,假如你了解 SysVinit,你将会对以下的内容感到熟悉:
|
||||
|
||||
- service 工具,在旧一点的系统中,它被用来管理 SysVinit 脚本,以及
|
||||
- chkconfig 工具,为系统服务升级和查询运行级别信息
|
||||
- shutdown 你一定使用过几次来重启或关闭一个运行的系统。
|
||||
|
||||
下面的表格展示了使用传统的工具和 systemctl 之间的相似之处:
|
||||
|
||||
|
||||
| 旧式工具 | Systemctl 等价命令 | 描述 |
|
||||
|-------------|----------------------|-------------|
|
||||
| service name start | systemctl start name | 启动 name (这里 name 是一个服务) |
|
||||
| service name stop | systemctl stop name | 停止 name |
|
||||
| service name condrestart | systemctl try-restart name | 重启 name (如果它已经运行了) |
|
||||
| service name restart | systemctl restart name | 重启 name |
|
||||
| service name reload | systemctl reload name | 重载 name 的配置 |
|
||||
| service name status | systemctl status name | 显示 name 的当前状态 |
|
||||
| service - status-all | systemctl | 显示当前所有服务的状态 |
|
||||
| chkconfig name on | systemctl enable name | 通过一个特定的单元文件,让 name 可以在系统启动时运行(这个文件是一个符号链接)。启用或禁用一个启动时的进程,实际上是增加或移除一个到 /etc/systemd/system 目录中的符号链接。 |
|
||||
| chkconfig name off | systemctl disable name | 通过一个特定的单元文件,让 name 可以在系统启动时禁止运行(这个文件是一个符号链接)。 |
|
||||
| chkconfig -list name | systemctl is-enabled name | 确定 name (一个特定的服务)当前是否启用。|
|
||||
| chkconfig - list | systemctl - type=service | 显示所有的服务及其是否启用或禁用。 |
|
||||
| shutdown -h now | systemctl poweroff | 关机 |
|
||||
| shutdown -r now | systemctl reboot | 重启系统 |
|
||||
|
||||
systemd 也引进了单元(unit)(它可能是一个服务,一个挂载点,一个设备或者一个网络套接字)和目标(target)(它们定义了 systemd 如何去管理和同时开启几个相关的进程,可以认为它们与在基于 SysVinit 的系统中的运行级别等价,尽管事实上它们并不等价)的概念。
|
||||
|
||||
### 总结归纳 ###
|
||||
|
||||
其他与进程管理相关,但并不仅限于下面所列的功能的任务有:
|
||||
|
||||
**1. 在考虑到系统资源的使用上,调整一个进程的执行优先级:**
|
||||
|
||||
这是通过 `renice` 工具来完成的,它可以改变一个或多个正在运行着的进程的调度优先级。简单来说,调度优先级是一个允许内核(当前只支持 >= 2.6 的版本)根据某个给定进程被分配的执行优先级(即友善度(niceness),从 -20 到 19)来为其分配系统资源的功能。
|
||||
|
||||
`renice` 的基本语法如下:
|
||||
|
||||
# renice [-n] priority [-gpu] identifier
|
||||
|
||||
在上面的通用命令中,第一个参数是将要使用的优先级数值,而另一个参数可以是进程 ID(这是默认的设定),进程组 ID,用户 ID 或者用户名。一个常规的用户(即除 root 以外的用户)只可以更改他或她所拥有的进程的调度优先级,并且只能增加友善度的层次(这意味着占用更少的系统资源)。
|
||||
|
||||

|
||||
|
||||
*进程调度优先级*
|
||||
|
||||
**2. 按照需要杀死一个进程(或终止其正常执行):**
|
||||
|
||||
更精确地说,杀死一个进程指的是通过 [kill 或 pkill][3] 命令给该进程发送一个信号,让它优雅地(SIGTERM=15)或立即(SIGKILL=9)结束它的执行。
|
||||
|
||||
这两个工具的不同之处在于前一个被用来终止一个特定的进程或一个进程组,而后一个则允许你通过进程的名称和其他属性,执行相同的动作。
|
||||
|
||||
另外, pkill 与 pgrep 相捆绑,pgrep 提供将受符合的进程的 PID 给 pkill 来使用。例如,在运行下面的命令之前:
|
||||
|
||||
# pkill -u gacanepa
|
||||
|
||||
查看一眼由 gacanepa 所拥有的 PID 或许会带来点帮助:
|
||||
|
||||
# pgrep -l -u gacanepa
|
||||
|
||||
|
||||
|
||||
*找到用户拥有的 PID*
|
||||
|
||||
默认情况下,kill 和 pkiill 都发送 SIGTERM 信号给进程,如我们上面提到的那样,这个信号可以被忽略(即该进程可能会终止其自身的执行,也可能不终止),所以当你因一个合理的理由要真正地停止一个运行着的进程,则你将需要在命令行中带上特定的 SIGKILL 信号:
|
||||
|
||||
# kill -9 identifier # 杀死一个进程或一个进程组
|
||||
# kill -s SIGNAL identifier # 同上
|
||||
# pkill -s SIGNAL identifier # 通过名称或其他属性来杀死一个进程
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们解释了在 RHEL 7 系统中,有关开机启动过程的基本知识,并分析了一些可用的工具来帮助你通过使用一般的程序和 systemd 特有的命令来管理进程。
|
||||
|
||||
请注意,这个列表并不旨在涵盖有关这个话题的所有花哨的工具,请随意使用下面的评论栏来添加你自已钟爱的工具和命令。同时欢迎你的提问和其他的评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-boot-process-and-process-management/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:https://linux.cn/article-3587-1.html
|
||||
[2]:http://www.tecmint.com/systemd-replaces-init-in-linux/
|
||||
[3]:https://linux.cn/article-2116-1.html
|
||||
@ -1,28 +1,28 @@
|
||||
RHCSA 系列:使用 'Parted' 和 'SSM' 来配置和加密系统存储 – Part 6
|
||||
RHCSA 系列(六): 使用 Parted 和 SSM 来配置和加密系统存储
|
||||
================================================================================
|
||||
在本篇文章中,我们将讨论在 RHEL 7 中如何使用传统的工具来设置和配置本地系统存储,并介绍系统存储管理器(也称为 SSM),它将极大地简化上面的任务。
|
||||
在本篇文章中,我们将讨论在 RHEL 7 中如何使用传统的工具来设置和配置本地系统存储,并介绍系统存储管理器(也称为 SSM),它将极大地简化上面的任务。
|
||||
|
||||

|
||||
|
||||
RHCSA: 配置和加密系统存储 – Part 6
|
||||
*RHCSA: 配置和加密系统存储 – Part 6*
|
||||
|
||||
请注意,我们将在这篇文章中展开这个话题,但由于该话题的宽泛性,我们将在下一期(Part 7)中继续介绍有关它的描述和使用。
|
||||
请注意,我们将在这篇文章中展开这个话题,但由于该话题的宽泛性,我们将在下一期中继续介绍有关它的描述和使用。
|
||||
|
||||
### 在 RHEL 7 中创建和修改分区 ###
|
||||
|
||||
在 RHEL 7 中, parted 是默认的用来处理分区的程序,且它允许你:
|
||||
|
||||
- 展示当前的分区表
|
||||
- 操纵(增加或减少分区的大小)现有的分区
|
||||
- 操纵(扩大或缩小分区的大小)现有的分区
|
||||
- 利用空余的磁盘空间或额外的物理存储设备来创建分区
|
||||
|
||||
强烈建议你在试图增加一个新的分区或对一个现有分区进行更改前,你应当确保设备上没有任何一个分区正在使用(`umount /dev/partition`),且假如你正使用设备的一部分来作为 swap 分区,在进行上面的操作期间,你需要将它禁用(`swapoff -v /dev/partition`) 。
|
||||
强烈建议你在试图增加一个新的分区或对一个现有分区进行更改前,你应当确保该设备上没有任何一个分区正在使用(`umount /dev/分区`),且假如你正使用设备的一部分来作为 swap 分区,在进行上面的操作期间,你需要将它禁用(`swapoff -v /dev/分区`) 。
|
||||
|
||||
实施上面的操作的最简单的方法是使用一个安装介质例如一个 RHEL 7 安装 DVD 或 USB 以急救模式启动 RHEL(Troubleshooting → Rescue a Red Hat Enterprise Linux system),然后当让你选择一个选项来挂载现有的 Linux 安装时,选择'跳过'这个选项,接着你将看到一个命令行提示符,在其中你可以像下图显示的那样开始键入与在一个未被使用的物理设备上创建一个正常的分区时所用的相同的命令。
|
||||
实施上面的操作的最简单的方法是使用一个安装介质例如一个 RHEL 7 的 DVD 或 USB 安装盘以急救模式启动 RHEL(`Troubleshooting` → `Rescue a Red Hat Enterprise Linux system`),然后当让你选择一个选项来挂载现有的 Linux 安装时,选择“跳过”这个选项,接着你将看到一个命令行提示符,在其中你可以像下图显示的那样开始键入与在一个未被使用的物理设备上创建一个正常的分区时所用的相同的命令。
|
||||
|
||||

|
||||
|
||||
RHEL 7 急救模式
|
||||
*RHEL 7 急救模式*
|
||||
|
||||
要启动 parted,只需键入:
|
||||
|
||||
@ -32,17 +32,17 @@ RHEL 7 急救模式
|
||||
|
||||
|
||||
|
||||
创建新的分区
|
||||
*创建新的分区*
|
||||
|
||||
正如你所看到的那样,在这个例子中,我们正在使用一个 5 GB 的虚拟光驱。现在我们将要创建一个 4 GB 的主分区,然后将它格式化为 xfs 文件系统,它是 RHEL 7 中默认的文件系统。
|
||||
正如你所看到的那样,在这个例子中,我们正在使用一个 5 GB 的虚拟驱动器。现在我们将要创建一个 4 GB 的主分区,然后将它格式化为 xfs 文件系统,它是 RHEL 7 中默认的文件系统。
|
||||
|
||||
你可以从一系列的文件系统中进行选择。你将需要使用 mkpart 来手动地创建分区,接着和平常一样,用 mkfs.fstype 来对分区进行格式化,因为 mkpart 并不支持许多现代的文件系统以达到即开即用。
|
||||
你可以从一系列的文件系统中进行选择。你将需要使用 `mkpart` 来手动地创建分区,接着和平常一样,用 `mkfs.类型` 来对分区进行格式化,因为 `mkpart` 并不支持许多现代的文件系统的到即开即用。
|
||||
|
||||
在下面的例子中,我们将为设备设定一个标记,然后在 `/dev/sdb` 上创建一个主分区 `(p)`,它从设备的 0% 开始,并在 4000MB(4 GB) 处结束。
|
||||
|
||||
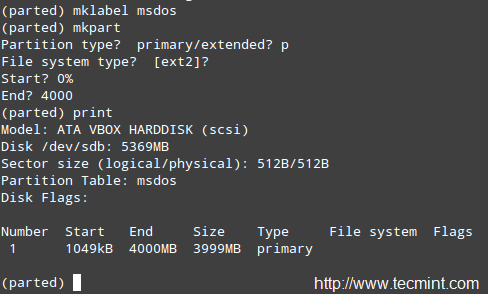
|
||||
|
||||
标记分区的名称
|
||||
*标记分区的名称*
|
||||
|
||||
接下来,我们将把分区格式化为 xfs 文件系统,然后再次打印出分区表,以此来确保更改已被应用。
|
||||
|
||||
@ -51,11 +51,11 @@ RHEL 7 急救模式
|
||||
|
||||

|
||||
|
||||
格式化分区为 XFS 文件系统
|
||||
*格式化分区为 XFS 文件系统*
|
||||
|
||||
对于旧一点的文件系统,在 parted 中你应该使用 `resize` 命令来改变分区的大小。不幸的是,这只适用于 ext2, fat16, fat32, hfs, linux-swap, 和 reiserfs (若 libreiserfs 已被安装)。
|
||||
对于旧一点的文件系统,在 parted 中你可以使用 `resize` 命令来改变分区的大小。不幸的是,这只适用于 ext2, fat16, fat32, hfs, linux-swap, 和 reiserfs (若 libreiserfs 已被安装)。
|
||||
|
||||
因此,改变分区大小的唯一方式是删除它然后再创建它(所以确保你对你的数据做了完整的备份!)。毫无疑问,在 RHEL 7 中默认的分区方案是基于 LVM 的。
|
||||
因此,改变分区大小的唯一方式是删除它然后再创建它(所以,确保你对你的数据做了完整的备份!)。毫无疑问,在 RHEL 7 中默认的分区方案是基于 LVM 的。
|
||||
|
||||
使用 parted 来移除一个分区,可以用:
|
||||
|
||||
@ -64,23 +64,23 @@ RHEL 7 急救模式
|
||||
|
||||

|
||||
|
||||
移除或删除分区
|
||||
*移除或删除分区*
|
||||
|
||||
### 逻辑卷管理(LVM) ###
|
||||
|
||||
一旦一个磁盘被分好了分区,再去更改分区的大小就是一件困难或冒险的事了。基于这个原因,假如我们计划在我们的系统上对分区的大小进行更改,我们应当考虑使用 LVM 的可能性,而不是使用传统的分区系统。这样多个物理设备可以组成一个逻辑组,以此来寄宿可自定义数目的逻辑卷,而逻辑卷的增大或减少不会带来任何麻烦。
|
||||
一旦一个磁盘被分好了分区,再去更改分区的大小就是一件困难或冒险的事了。基于这个原因,假如我们计划在我们的系统上对分区的大小进行更改,我们应当考虑使用 LVM 的可能性,而不是使用传统的分区系统。这样多个物理设备可以组成一个逻辑组,以此来存放任意数目的逻辑卷,而逻辑卷的增大或减少不会带来任何麻烦。
|
||||
|
||||
简单来说,你会发现下面的示意图对记住 LVM 的基础架构或许有用。
|
||||
|
||||

|
||||
|
||||
LVM 的基本架构
|
||||
*LVM 的基本架构*
|
||||
|
||||
#### 创建物理卷,卷组和逻辑卷 ####
|
||||
|
||||
遵循下面的步骤是为了使用传统的卷管理工具来设置 LVM。由于你可以通过阅读这个网站上的 LVM 系列来扩展这个话题,我将只是概要的介绍设置 LVM 的基本步骤,然后与使用 SSM 来实现相同功能做个比较。
|
||||
|
||||
**注**: 我们将使用整个磁盘 `/dev/sdb` 和 `/dev/sdc` 来作为 PVs (物理卷),但是否执行相同的操作完全取决于你。
|
||||
**注**: 我们将使用整个磁盘 `/dev/sdb` 和 `/dev/sdc` 来作为物理卷(PV),但是否执行相同的操作完全取决于你。
|
||||
|
||||
**1. 使用 /dev/sdb 和 /dev/sdc 中 100% 的可用磁盘空间来创建分区 `/dev/sdb1` 和 `/dev/sdc1`:**
|
||||
|
||||
@ -89,7 +89,7 @@ LVM 的基本架构
|
||||
|
||||
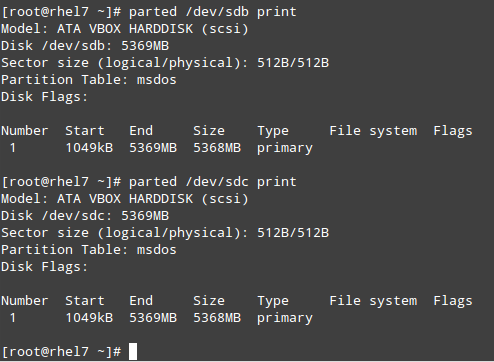
|
||||
|
||||
创建新分区
|
||||
*创建新分区*
|
||||
|
||||
**2. 分别在 /dev/sdb1 和 /dev/sdc1 上共创建 2 个物理卷。**
|
||||
|
||||
@ -98,21 +98,21 @@ LVM 的基本架构
|
||||
|
||||

|
||||
|
||||
创建两个物理卷
|
||||
*创建两个物理卷*
|
||||
|
||||
记住,你可以使用 pvdisplay /dev/sd{b,c}1 来显示有关新建的 PV 的信息。
|
||||
记住,你可以使用 pvdisplay /dev/sd{b,c}1 来显示有关新建的物理卷的信息。
|
||||
|
||||
**3. 在上一步中创建的 PV 之上创建一个 VG:**
|
||||
**3. 在上一步中创建的物理卷之上创建一个卷组(VG):**
|
||||
|
||||
# vgcreate tecmint_vg /dev/sd{b,c}1
|
||||
|
||||

|
||||
|
||||
创建卷组
|
||||
*创建卷组*
|
||||
|
||||
记住,你可使用 vgdisplay tecmint_vg 来显示有关新建的 VG 的信息。
|
||||
记住,你可使用 vgdisplay tecmint_vg 来显示有关新建的卷组的信息。
|
||||
|
||||
**4. 像下面那样,在 VG tecmint_vg 之上创建 3 个逻辑卷:**
|
||||
**4. 像下面那样,在卷组 tecmint_vg 之上创建 3 个逻辑卷(LV):**
|
||||
|
||||
# lvcreate -L 3G -n vol01_docs tecmint_vg [vol01_docs → 3 GB]
|
||||
# lvcreate -L 1G -n vol02_logs tecmint_vg [vol02_logs → 1 GB]
|
||||
@ -120,11 +120,11 @@ LVM 的基本架构
|
||||
|
||||

|
||||
|
||||
创建逻辑卷
|
||||
*创建逻辑卷*
|
||||
|
||||
记住,你可以使用 lvdisplay tecmint_vg 来显示有关在 VG tecmint_vg 之上新建的 LV 的信息。
|
||||
记住,你可以使用 lvdisplay tecmint_vg 来显示有关在 tecmint_vg 之上新建的逻辑卷的信息。
|
||||
|
||||
**5. 格式化每个逻辑卷为 xfs 文件系统格式(假如你计划在以后将要缩小卷的大小,请别使用 xfs 文件系统格式!):**
|
||||
**5. 格式化每个逻辑卷为 xfs 文件系统格式(假如你计划在以后将要缩小卷的大小,请别使用 xfs 文件系统格式!):**
|
||||
|
||||
# mkfs.xfs /dev/tecmint_vg/vol01_docs
|
||||
# mkfs.xfs /dev/tecmint_vg/vol02_logs
|
||||
@ -138,7 +138,7 @@ LVM 的基本架构
|
||||
|
||||
#### 移除逻辑卷,卷组和物理卷 ####
|
||||
|
||||
**7.现在我们将进行与刚才相反的操作并移除 LV,VG 和 PV:**
|
||||
**7.现在我们将进行与刚才相反的操作并移除逻辑卷、卷组和物理卷:**
|
||||
|
||||
# lvremove /dev/tecmint_vg/vol01_docs
|
||||
# lvremove /dev/tecmint_vg/vol02_logs
|
||||
@ -161,20 +161,20 @@ LVM 的基本架构
|
||||
- 初始化块设备来作为物理卷
|
||||
- 创建一个卷组
|
||||
- 创建逻辑卷
|
||||
- 格式化 LV 和
|
||||
- 格式化逻辑卷,以及
|
||||
- 只使用一个命令来挂载它们
|
||||
|
||||
**9. 现在,我们可以使用下面的命令来展示有关 PV,VG 或 LV 的信息:**
|
||||
**9. 现在,我们可以使用下面的命令来展示有关物理卷、卷组或逻辑卷的信息:**
|
||||
|
||||
# ssm list dev
|
||||
# ssm list pool
|
||||
# ssm list vol
|
||||
|
||||

|
||||

|
||||
|
||||
检查有关 PV, VG,或 LV 的信息
|
||||
*检查有关物理卷、卷组或逻辑卷的信息*
|
||||
|
||||
**10. 正如我们知道的那样, LVM 的一个显著的特点是可以在不停机的情况下更改(增大或缩小) 逻辑卷的大小:**
|
||||
**10. 正如我们知道的那样, LVM 的一个显著的特点是可以在不停机的情况下更改(增大或缩小)逻辑卷的大小:**
|
||||
|
||||
假定在 vol02_logs 上我们用尽了空间,而 vol03_homes 还留有足够的空间。我们将把 vol03_homes 的大小调整为 4 GB,并使用剩余的空间来扩展 vol02_logs:
|
||||
|
||||
@ -184,7 +184,7 @@ LVM 的基本架构
|
||||
|
||||
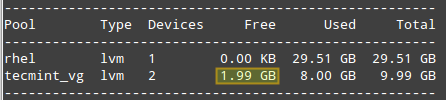
|
||||
|
||||
查看卷的大小
|
||||
*查看卷的大小*
|
||||
|
||||
然后执行:
|
||||
|
||||
@ -196,11 +196,11 @@ LVM 的基本架构
|
||||
|
||||
# ssm remove tecmint_vg
|
||||
|
||||
这个命令将返回一个提示,询问你是否确认删除 VG 和它所包含的 LV:
|
||||
这个命令将返回一个提示,询问你是否确认删除卷组和它所包含的逻辑卷:
|
||||
|
||||

|
||||
|
||||
移除逻辑卷和卷组
|
||||
*移除逻辑卷和卷组*
|
||||
|
||||
### 管理加密的卷 ###
|
||||
|
||||
@ -216,7 +216,7 @@ SSM 也给系统管理员提供了为新的或现存的卷加密的能力。首
|
||||
|
||||
我们的下一个任务是往 /etc/fstab 中添加条目来让这些逻辑卷在启动时可用,而不是使用设备识别编号(/dev/something)。
|
||||
|
||||
我们将使用每个 LV 的 UUID (使得当我们添加其他的逻辑卷或设备后,我们的设备仍然可以被唯一的标记),而我们可以使用 blkid 应用来找到它们的 UUID:
|
||||
我们将使用每个逻辑卷的 UUID (使得当我们添加其他的逻辑卷或设备后,我们的设备仍然可以被唯一的标记),而我们可以使用 blkid 应用来找到它们的 UUID:
|
||||
|
||||
# blkid -o value UUID /dev/tecmint_vg/vol01_docs
|
||||
# blkid -o value UUID /dev/tecmint_vg/vol02_logs
|
||||
@ -226,7 +226,7 @@ SSM 也给系统管理员提供了为新的或现存的卷加密的能力。首
|
||||
|
||||

|
||||
|
||||
找到逻辑卷的 UUID
|
||||
*找到逻辑卷的 UUID*
|
||||
|
||||
接着,使用下面的内容来创建 /etc/crypttab 文件(请更改 UUID 来适用于你的设置):
|
||||
|
||||
@ -243,11 +243,11 @@ SSM 也给系统管理员提供了为新的或现存的卷加密的能力。首
|
||||
# Logical volume vol03_homes
|
||||
/dev/mapper/homes /mnt/homes ext4 defaults 0 2
|
||||
|
||||
现在重启(systemctl reboot),则你将被要求为每个 LV 输入密码。随后,你可以通过检查相应的挂载点来确保挂载操作是否成功:
|
||||
现在重启(`systemctl reboot`),则你将被要求为每个逻辑卷输入密码。随后,你可以通过检查相应的挂载点来确保挂载操作是否成功:
|
||||
|
||||

|
||||
|
||||
确保逻辑卷挂载点
|
||||
*确保逻辑卷挂载点*
|
||||
|
||||
### 总结 ###
|
||||
|
||||
@ -261,7 +261,7 @@ via: http://www.tecmint.com/rhcsa-exam-create-format-resize-delete-and-encrypt-p
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,42 +1,40 @@
|
||||
RHCSA 系列:使用 ACL(访问控制列表) 和挂载 Samba/NFS 共享 – Part 7
|
||||
RHCSA 系列(六): 使用 ACL(访问控制列表) 和挂载 Samba/NFS 共享
|
||||
================================================================================
|
||||
在上一篇文章([RHCSA 系列 Part 6][1])中,我们解释了如何使用 parted 和 ssm 来设置和配置本地系统存储。
|
||||
在上一篇文章([RHCSA 系列(六)][1])中,我们解释了如何使用 parted 和 ssm 来设置和配置本地系统存储。
|
||||
|
||||

|
||||
|
||||
RHCSA Series: 配置 ACL 及挂载 NFS/Samba 共享 – Part 7
|
||||
*RHCSA 系列: 配置 ACL 及挂载 NFS/Samba 共享 – Part 7*
|
||||
|
||||
我们也讨论了如何创建和在系统启动时使用一个密码来挂载加密的卷。另外,我们告诫过你要避免在挂载的文件系统上执行苛刻的存储管理操作。记住了这点后,现在,我们将回顾在 RHEL 7 中最常使用的文件系统格式,然后将涵盖有关手动或自动挂载、使用和卸载网络文件系统(CIFS 和 NFS)的话题以及在你的操作系统上实现访问控制列表的使用。
|
||||
我们也讨论了如何创建和在系统启动时使用一个密码来挂载加密的卷。另外,我们告诫过你要避免在挂载的文件系统上执行危险的存储管理操作。记住了这点后,现在,我们将回顾在 RHEL 7 中最常使用的文件系统格式,然后将涵盖有关手动或自动挂载、使用和卸载网络文件系统(CIFS 和 NFS)的话题以及在你的操作系统上实现访问控制列表(Access Control List)的使用。
|
||||
|
||||
#### 前提条件 ####
|
||||
|
||||
在进一步深入之前,请确保你可使用 Samba 服务和 NFS 服务(注意在 RHEL 7 中 NFSv2 已不再被支持)。
|
||||
在进一步深入之前,请确保你可使用 Samba 服务和 NFS 服务(注意在 RHEL 7 中 NFSv2 已不再被支持)。
|
||||
|
||||
在本次指导中,我们将使用一个IP 地址为 192.168.0.10 且同时运行着 Samba 服务和 NFS 服务的机子来作为服务器,使用一个 IP 地址为 192.168.0.18 的 RHEL 7 机子来作为客户端。在这篇文章的后面部分,我们将告诉你在客户端上你需要安装哪些软件包。
|
||||
在本次指导中,我们将使用一个IP 地址为 192.168.0.10 且同时运行着 Samba 服务和 NFS 服务的机器来作为服务器,使用一个 IP 地址为 192.168.0.18 的 RHEL 7 机器来作为客户端。在这篇文章的后面部分,我们将告诉你在客户端上你需要安装哪些软件包。
|
||||
|
||||
### RHEL 7 中的文件系统格式 ###
|
||||
|
||||
从 RHEL 7 开始,由于 XFS 的高性能和可扩展性,它已经被引入所有的架构中来作为默认的文件系统。
|
||||
根据 Red Hat 及其合作伙伴在主流硬件上执行的最新测试,当前 XFS 已支持最大为 500 TB 大小的文件系统。
|
||||
从 RHEL 7 开始,由于 XFS 的高性能和可扩展性,它已经被作为所有的架构中的默认文件系统。根据 Red Hat 及其合作伙伴在主流硬件上执行的最新测试,当前 XFS 已支持最大为 500 TB 大小的文件系统。
|
||||
|
||||
另外, XFS 启用了 user_xattr(扩展用户属性) 和 acl(
|
||||
POSIX 访问控制列表)来作为默认的挂载选项,而不像 ext3 或 ext4(对于 RHEL 7 来说, ext2 已过时),这意味着当挂载一个 XFS 文件系统时,你不必显式地在命令行或 /etc/fstab 中指定这些选项(假如你想在后一种情况下禁用这些选项,你必须显式地使用 no_acl 和 no_user_xattr)。
|
||||
另外,XFS 启用了 `user_xattr`(扩展用户属性) 和 `acl`(POSIX 访问控制列表)来作为默认的挂载选项,而不像 ext3 或 ext4(对于 RHEL 7 来说,ext2 已过时),这意味着当挂载一个 XFS 文件系统时,你不必显式地在命令行或 /etc/fstab 中指定这些选项(假如你想在后一种情况下禁用这些选项,你必须显式地使用 `no_acl` 和 `no_user_xattr`)。
|
||||
|
||||
请记住扩展用户属性可以被指定到文件和目录中来存储任意的额外信息如 mime 类型,字符集或文件的编码,而用户属性中的访问权限由一般的文件权限位来定义。
|
||||
请记住扩展用户属性可以给文件和目录指定,用来存储任意的额外信息如 mime 类型,字符集或文件的编码,而用户属性中的访问权限由一般的文件权限位来定义。
|
||||
|
||||
#### 访问控制列表 ####
|
||||
|
||||
作为一名系统管理员,无论你是新手还是专家,你一定非常熟悉与文件和目录有关的常规访问权限,这些权限为所有者,所有组和"世界"(所有的其他人)指定了特定的权限(可读,可写及可执行)。但如若你需要稍微更新你的记忆,请随意参考 [RHCSA 系列的 Part 3][3].
|
||||
作为一名系统管理员,无论你是新手还是专家,你一定非常熟悉与文件和目录有关的常规访问权限,这些权限为所有者,所有组和“世界”(所有的其他人)指定了特定的权限(可读,可写及可执行)。但如若你需要稍微更新下你的记忆,请参考 [RHCSA 系列(三)][3].
|
||||
|
||||
但是,由于标准的 `ugo/rwx` 集合并不允许为不同的用户配置不同的权限,所以 ACL 便被引入了进来,为的是为文件和目录定义更加详细的访问权限,而不仅仅是这些特别指定的特定权限。
|
||||
|
||||
事实上, ACL 定义的权限是由文件权限位所特别指定的权限的一个超集。下面就让我们看看这个转换是如何在真实世界中被应用的吧。
|
||||
|
||||
1. 存在两种类型的 ACL:访问 ACL,可被应用到一个特定的文件或目录上,以及默认 ACL,只可被应用到一个目录上。假如目录中的文件没有 ACL,则它们将继承它们的父目录的默认 ACL 。
|
||||
1. 存在两种类型的 ACL:访问 ACL,可被应用到一个特定的文件或目录上;以及默认 ACL,只可被应用到一个目录上。假如目录中的文件没有 ACL,则它们将继承它们的父目录的默认 ACL 。
|
||||
|
||||
2. 从一开始, ACL 就可以为每个用户,每个组或不在文件所属组中的用户配置相应的权限。
|
||||
|
||||
3. ACL 可使用 `setfacl` 来设置(和移除),可相应地使用 -m 或 -x 选项。
|
||||
3. ACL 可使用 `setfacl` 来设置(和移除),可相应地使用 -m 或 -x 选项。
|
||||
|
||||
例如,让我们创建一个名为 tecmint 的组,并将用户 johndoe 和 davenull 加入该组:
|
||||
|
||||
@ -53,36 +51,32 @@ POSIX 访问控制列表)来作为默认的挂载选项,而不像 ext3 或 ext
|
||||
|
||||

|
||||
|
||||
检验用户
|
||||
*检验用户*
|
||||
|
||||
现在,我们在 /mnt 下创建一个名为 playground 的目录,并在该目录下创建一个名为 testfile.txt 的文件。我们将设定该文件的属组为 tecmint,并更改它的默认 ugo/rwx 权限为 770(即赋予该文件的属主和属组可读,可写和可执行权限):
|
||||
现在,我们在 /mnt 下创建一个名为 playground 的目录,并在该目录下创建一个名为 testfile.txt 的文件。我们将设定该文件的属组为 tecmint,并更改它的默认 `ugo/rwx` 权限为 770(即赋予该文件的属主和属组可读、可写和可执行权限):
|
||||
|
||||
# mkdir /mnt/playground
|
||||
# touch /mnt/playground/testfile.txt
|
||||
# chown :tecmint /mnt/playground/testfile.txt
|
||||
# chmod 770 /mnt/playground/testfile.txt
|
||||
|
||||
接着,依次切换为 johndoe 和 davenull 用户,并在文件中写入一些信息:
|
||||
|
||||
echo "My name is John Doe" > /mnt/playground/testfile.txt
|
||||
echo "My name is Dave Null" >> /mnt/playground/testfile.txt
|
||||
|
||||
到目前为止,一切正常。现在我们让用户 gacanepa 来向该文件执行写操作 – 则写操作将会失败,这是可以预料的。
|
||||
|
||||
但实际上我们需要用户 gacanepa(TA 不是组 tecmint 的成员)在文件 /mnt/playground/testfile.txt 上有写权限,那又该怎么办呢?首先映入你脑海里的可能是将该用户添加到组 tecmint 中。但那将使得他在所有该组具有写权限位的文件上均拥有写权限,但我们并不想这样,我们只想他能够在文件 /mnt/playground/testfile.txt 上有写权限。
|
||||
|
||||
# touch /mnt/playground/testfile.txt
|
||||
# chown :tecmint /mnt/playground/testfile.txt
|
||||
# chmod 777 /mnt/playground/testfile.txt
|
||||
# su johndoe
|
||||
$ echo "My name is John Doe" > /mnt/playground/testfile.txt
|
||||
$ su davenull
|
||||
$ echo "My name is Dave Null" >> /mnt/playground/testfile.txt
|
||||
|
||||
到目前为止,一切正常。现在我们让用户 gacanepa 来向该文件执行写操作 – 则写操作将会失败,这是可以预料的。
|
||||
|
||||
$ su gacanepa
|
||||
$ echo "My name is Gabriel Canepa" >> /mnt/playground/testfile.txt
|
||||
|
||||

|
||||
|
||||
管理用户的权限
|
||||
*管理用户的权限*
|
||||
|
||||
但实际上我们需要用户 gacanepa(他不是组 tecmint 的成员)在文件 /mnt/playground/testfile.txt 上有写权限,那又该怎么办呢?首先映入你脑海里的可能是将该用户添加到组 tecmint 中。但那将使得他在所有该组具有写权限位的文件上均拥有写权限,但我们并不想这样,我们只想他能够在文件 /mnt/playground/testfile.txt 上有写权限。
|
||||
|
||||
现在,让我们给用户 gacanepa 在 /mnt/playground/testfile.txt 文件上有读和写权限。
|
||||
|
||||
@ -90,7 +84,7 @@ POSIX 访问控制列表)来作为默认的挂载选项,而不像 ext3 或 ext
|
||||
|
||||
# setfacl -R -m u:gacanepa:rwx /mnt/playground
|
||||
|
||||
则你将成功地添加一条 ACL,运行 gacanepa 对那个测试文件可写。然后切换为 gacanepa 用户,并再次尝试向该文件写入一些信息:
|
||||
则你将成功地添加一条 ACL,允许 gacanepa 对那个测试文件可写。然后切换为 gacanepa 用户,并再次尝试向该文件写入一些信息:
|
||||
|
||||
$ echo "My name is Gabriel Canepa" >> /mnt/playground/testfile.txt
|
||||
|
||||
@ -100,9 +94,9 @@ POSIX 访问控制列表)来作为默认的挂载选项,而不像 ext3 或 ext
|
||||
|
||||

|
||||
|
||||
检查文件的 ACL
|
||||
*检查文件的 ACL*
|
||||
|
||||
要为目录设定默认 ACL(它的内容将被该目录下的文件继承,除非另外被覆写),在规则前添加 `d:`并特别指定一个目录名,而不是文件名:
|
||||
要为目录设定默认 ACL(它的内容将被该目录下的文件继承,除非另外被覆写),在规则前添加 `d:`并特别指定一个目录名,而不是文件名:
|
||||
|
||||
# setfacl -m d:o:r /mnt/playground
|
||||
|
||||
@ -111,7 +105,7 @@ POSIX 访问控制列表)来作为默认的挂载选项,而不像 ext3 或 ext
|
||||
|
||||

|
||||
|
||||
在 Linux 中设定默认 ACL
|
||||
*在 Linux 中设定默认 ACL*
|
||||
|
||||
[在官方的 RHEL 7 存储管理指导手册的第 20 章][3] 中提供了更多有关 ACL 的例子,我极力推荐你看一看它并将它放在身边作为参考。
|
||||
|
||||
@ -129,7 +123,7 @@ POSIX 访问控制列表)来作为默认的挂载选项,而不像 ext3 或 ext
|
||||
|
||||
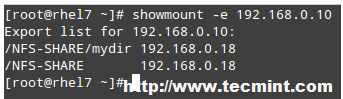
|
||||
|
||||
检查可用的 NFS 共享
|
||||
*检查可用的 NFS 共享*
|
||||
|
||||
要按照需求在本地客户端上使用命令行来挂载 NFS 网络共享,可使用下面的语法:
|
||||
|
||||
@ -139,7 +133,7 @@ POSIX 访问控制列表)来作为默认的挂载选项,而不像 ext3 或 ext
|
||||
|
||||
# mount -t nfs 192.168.0.10:/NFS-SHARE /mnt/nfs
|
||||
|
||||
若你得到如下的错误信息:“Job for rpc-statd.service failed. See “systemctl status rpc-statd.service”及“journalctl -xn” for details.”,请确保 `rpcbind` 服务被启用且已在你的系统中启动了。
|
||||
若你得到如下的错误信息:`Job for rpc-statd.service failed. See "systemctl status rpc-statd.service" and "journalctl -xn" for details.`,请确保 `rpcbind` 服务被启用且已在你的系统中启动了。
|
||||
|
||||
# systemctl enable rpcbind.socket
|
||||
# systemctl restart rpcbind.service
|
||||
@ -162,7 +156,7 @@ Samba 代表一个特别的工具,使得在由 *nix 和 Windows 机器组成
|
||||
|
||||

|
||||
|
||||
检查 Samba 共享
|
||||
*检查 Samba 共享*
|
||||
|
||||
要在本地客户端上挂载 Samba 网络共享,你需要已安装好 cifs-utils 软件包:
|
||||
|
||||
@ -176,14 +170,14 @@ Samba 代表一个特别的工具,使得在由 *nix 和 Windows 机器组成
|
||||
|
||||
# mount -t cifs -o credentials=~/.smbcredentials //192.168.0.10/gacanepa /mnt/samba
|
||||
|
||||
其中 `smbcredentials`
|
||||
其中 `.smbcredentials` 的内容是:
|
||||
|
||||
username=gacanepa
|
||||
password=XXXXXX
|
||||
|
||||
是一个位于 root 用户的家目录(/root/) 中的隐藏文件,其权限被设置为 600,所以除了该文件的属主外,其他人对该文件既不可读也不可写。
|
||||
它是一个位于 root 用户的家目录(/root/) 中的隐藏文件,其权限被设置为 600,所以除了该文件的属主外,其他人对该文件既不可读也不可写。
|
||||
|
||||
请注意 samba_share 是 Samba 分享的名称,由上面展示的 `smbclient -L remote_host` 所返回。
|
||||
请注意 samba_share 是 Samba 共享的名称,由上面展示的 `smbclient -L remote_host` 所返回。
|
||||
|
||||
现在,若你需要在系统启动时自动地使得 Samba 分享可用,可以向 /etc/fstab 文件添加一个像下面这样的有效条目:
|
||||
|
||||
@ -197,7 +191,7 @@ Samba 代表一个特别的工具,使得在由 *nix 和 Windows 机器组成
|
||||
|
||||
在这篇文章中,我们已经解释了如何在 Linux 中设置 ACL,并讨论了如何在一个 RHEL 7 客户端上挂载 CIFS 和 NFS 网络共享。
|
||||
|
||||
我建议你去练习这些概念,甚至混合使用它们(试着在一个挂载的网络共享上设置 ACL),直至你感觉舒适。假如你有问题或评论,请随时随意地使用下面的评论框来联系我们。另外,请随意通过你的社交网络分享这篇文章。
|
||||
我建议你去练习这些概念,甚至混合使用它们(试着在一个挂载的网络共享上设置 ACL),直至你感觉掌握了。假如你有问题或评论,请随时随意地使用下面的评论框来联系我们。另外,请随意通过你的社交网络分享这篇文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -205,11 +199,11 @@ via: http://www.tecmint.com/rhcsa-exam-configure-acls-and-mount-nfs-samba-shares
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/rhcsa-exam-create-format-resize-delete-and-encrypt-partitions-in-linux/
|
||||
[2]:http://www.tecmint.com/rhcsa-exam-manage-users-and-groups/
|
||||
[1]:https://linux.cn/article-6257-1.html
|
||||
[2]:https://linux.cn/article-6187-1.html
|
||||
[3]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Storage_Administration_Guide/ch-acls.html
|
||||
@ -1,26 +1,27 @@
|
||||
RHCSA 系列:安全 SSH,设定主机名及开启网络服务 – Part 8
|
||||
RHCSA 系列(八): 加固 SSH,设定主机名及启用网络服务
|
||||
================================================================================
|
||||
作为一名系统管理员,你将经常使用一个终端模拟器来登陆到一个远程的系统中,执行一系列的管理任务。你将很少有机会坐在一个真实的(物理)终端前,所以你需要设定好一种方法来使得你可以登陆到你被要求去管理的那台远程主机上。
|
||||
|
||||
事实上,当你必须坐在一台物理终端前的时候,就可能是你登陆到该主机的最后一种方法。基于安全原因,使用 Telnet 来达到以上目的并不是一个好主意,因为穿行在线缆上的流量并没有被加密,它们以文本方式在传送。
|
||||
作为一名系统管理员,你将经常使用一个终端模拟器来登录到一个远程的系统中,执行一系列的管理任务。你将很少有机会坐在一个真实的(物理)终端前,所以你需要设定好一种方法来使得你可以登录到你需要去管理的那台远程主机上。
|
||||
|
||||
事实上,当你必须坐在一台物理终端前的时候,就可能是你登录到该主机的最后一种方法了。基于安全原因,使用 Telnet 来达到以上目的并不是一个好主意,因为穿行在线缆上的流量并没有被加密,它们以明文方式在传送。
|
||||
|
||||
另外,在这篇文章中,我们也将复习如何配置网络服务来使得它在开机时被自动开启,并学习如何设置网络和静态或动态地解析主机名。
|
||||
|
||||

|
||||
|
||||
RHCSA: 安全 SSH 和开启网络服务 – Part 8
|
||||
*RHCSA: 安全 SSH 和开启网络服务 – Part 8*
|
||||
|
||||
### 安装并确保 SSH 通信安全 ###
|
||||
|
||||
对于你来说,要能够使用 SSH 远程登陆到一个 RHEL 7 机子,你必须安装 `openssh`,`openssh-clients` 和 `openssh-servers` 软件包。下面的命令不仅将安装远程登陆程序,也会安装安全的文件传输工具以及远程文件复制程序:
|
||||
对于你来说,要能够使用 SSH 远程登录到一个 RHEL 7 机子,你必须安装 `openssh`,`openssh-clients` 和 `openssh-servers` 软件包。下面的命令不仅将安装远程登录程序,也会安装安全的文件传输工具以及远程文件复制程序:
|
||||
|
||||
# yum update && yum install openssh openssh-clients openssh-servers
|
||||
|
||||
注意,安装上服务器所需的相应软件包是一个不错的主意,因为或许在某个时刻,你想使用同一个机子来作为客户端和服务器。
|
||||
注意,也安装上服务器所需的相应软件包是一个不错的主意,因为或许在某个时刻,你想使用同一个机子来作为客户端和服务器。
|
||||
|
||||
在安装完成后,如若你想安全地访问你的 SSH 服务器,你还需要考虑一些基本的事情。下面的设定应该在文件 `/etc/ssh/sshd_config` 中得以呈现。
|
||||
在安装完成后,如若你想安全地访问你的 SSH 服务器,你还需要考虑一些基本的事情。下面的设定应该出现在文件 `/etc/ssh/sshd_config` 中。
|
||||
|
||||
1. 更改 sshd 守护进程的监听端口,从 22(默认的端口值)改为一个更高的端口值(2000 或更大),但首先要确保所选的端口没有被占用。
|
||||
1、 更改 sshd 守护进程的监听端口,从 22(默认的端口值)改为一个更高的端口值(2000 或更大),但首先要确保所选的端口没有被占用。
|
||||
|
||||
例如,让我们假设你选择了端口 2500 。使用 [netstat][1] 来检查所选的端口是否被占用:
|
||||
|
||||
@ -30,17 +31,17 @@ RHCSA: 安全 SSH 和开启网络服务 – Part 8
|
||||
|
||||
Port 2500
|
||||
|
||||
2. 只允许协议 2:
|
||||
2、 只允许协议 2(LCTT 译注:SSHv1 已经被证明不安全,默认情况下 SSHv1 和 SSHv2 都支持,所以应该显示去掉如下配置行的注释,并只支持 SSHv2。):
|
||||
|
||||
Protocol 2
|
||||
|
||||
3. 配置验证超时的时间为 2 分钟,不允许以 root 身份登陆,并将允许通过 ssh 登陆的人数限制到最小:
|
||||
3、 配置验证超时的时间为 2 分钟,不允许以 root 身份登录,并将允许通过 ssh 登录的人数限制到最小:
|
||||
|
||||
LoginGraceTime 2m
|
||||
PermitRootLogin no
|
||||
AllowUsers gacanepa
|
||||
|
||||
4. 假如可能,使用基于公钥的验证方式而不是使用密码:
|
||||
4、 假如可能,使用基于公钥的验证方式而不是使用密码:
|
||||
|
||||
PasswordAuthentication no
|
||||
RSAAuthentication yes
|
||||
@ -48,13 +49,13 @@ RHCSA: 安全 SSH 和开启网络服务 – Part 8
|
||||
|
||||
这假设了你已经在你的客户端机子上创建了带有你的用户名的一个密钥对,并将公钥复制到了你的服务器上。
|
||||
|
||||
- [开启 SSH 无密码登陆][2]
|
||||
- [开启 SSH 无密码登录][2]
|
||||
|
||||
### 配置网络和名称的解析 ###
|
||||
|
||||
1. 每个系统管理员应该对下面这个系统配置文件非常熟悉:
|
||||
1、 每个系统管理员都应该对下面这个系统配置文件非常熟悉:
|
||||
|
||||
- /etc/hosts 被用来在小型网络中解析名称 <---> IP 地址。
|
||||
- /etc/hosts 被用来在小型网络中解析“名称” <---> “IP 地址”。
|
||||
|
||||
文件 `/etc/hosts` 中的每一行拥有如下的结构:
|
||||
|
||||
@ -64,7 +65,7 @@ RHCSA: 安全 SSH 和开启网络服务 – Part 8
|
||||
|
||||
192.168.0.10 laptop laptop.gabrielcanepa.com.ar
|
||||
|
||||
2. `/etc/resolv.conf` 特别指定 DNS 服务器的 IP 地址和搜索域,它被用来在没有提供域名后缀时,将一个给定的查询名称对应为一个全称域名。
|
||||
2、 `/etc/resolv.conf` 特别指定 DNS 服务器的 IP 地址和搜索域,它被用来在没有提供域名后缀时,将一个给定的查询名称对应为一个全称域名。
|
||||
|
||||
在正常情况下,你不必编辑这个文件,因为它是由系统管理的。然而,若你非要改变 DNS 服务器的 IP 地址,建议你在该文件的每一行中,都应该遵循下面的结构:
|
||||
|
||||
@ -74,7 +75,7 @@ RHCSA: 安全 SSH 和开启网络服务 – Part 8
|
||||
|
||||
nameserver 8.8.8.8
|
||||
|
||||
3. `/etc/host.conf` 特别指定在一个网络中主机名被解析的方法和顺序。换句话说,告诉名称解析器使用哪个服务,并以什么顺序来使用。
|
||||
3、 `/etc/host.conf` 特别指定在一个网络中主机名被解析的方法和顺序。换句话说,告诉名称解析器使用哪个服务,并以什么顺序来使用。
|
||||
|
||||
尽管这个文件由几个选项,但最为常见和基本的设置包含如下的一行:
|
||||
|
||||
@ -82,12 +83,12 @@ RHCSA: 安全 SSH 和开启网络服务 – Part 8
|
||||
|
||||
它意味着解析器应该首先查看 `resolv.conf` 中特别指定的域名服务器,然后到 `/etc/hosts` 文件中查找解析的名称。
|
||||
|
||||
4. `/etc/sysconfig/network` 包含了所有网络接口的路由和全局主机信息。下面的值可能会被使用:
|
||||
4、 `/etc/sysconfig/network` 包含了所有网络接口的路由和全局主机信息。下面的值可能会被使用:
|
||||
|
||||
NETWORKING=yes|no
|
||||
HOSTNAME=value
|
||||
|
||||
其中的 value 应该是全称域名(FQDN)。
|
||||
其中的 value 应该是全称域名(FQDN)。
|
||||
|
||||
GATEWAY=XXX.XXX.XXX.XXX
|
||||
|
||||
@ -97,7 +98,7 @@ RHCSA: 安全 SSH 和开启网络服务 – Part 8
|
||||
|
||||
在一个带有多个网卡的机器中, value 为网关设备名,例如 enp0s3。
|
||||
|
||||
5. 位于 `/etc/sysconfig/network-scripts` 中的文件(网络适配器配置文件)。
|
||||
5、 位于 `/etc/sysconfig/network-scripts` 中的文件(网络适配器配置文件)。
|
||||
|
||||
在上面提到的目录中,你将找到几个被命名为如下格式的文本文件。
|
||||
|
||||
@ -107,26 +108,27 @@ RHCSA: 安全 SSH 和开启网络服务 – Part 8
|
||||
|
||||

|
||||
|
||||
检查网络连接状态
|
||||
*检查网络连接状态*
|
||||
|
||||
例如:
|
||||
|
||||
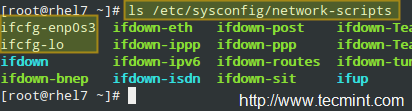
|
||||
|
||||
网络文件
|
||||
*网络文件*
|
||||
|
||||
除了环回接口,你还可以为你的网卡进行一个相似的配置。注意,假如设定了某些变量,它们将为这个特别的接口,覆盖掉 `/etc/sysconfig/network` 中定义的值。在这篇文章中,为了能够解释清楚,每行都被加上了注释,但在实际的文件中,你应该避免加上注释:
|
||||
除了环回接口(loopback),你还可以为你的网卡指定相似的配置。注意,假如设定了某些变量,它们将为这个指定的接口覆盖掉 `/etc/sysconfig/network` 中定义的默认值。在这篇文章中,为了能够解释清楚,每行都被加上了注释,但在实际的文件中,你应该避免加上注释:
|
||||
|
||||
HWADDR=08:00:27:4E:59:37 # The MAC address of the NIC
|
||||
TYPE=Ethernet # Type of connection
|
||||
BOOTPROTO=static # This indicates that this NIC has been assigned a static IP. If this variable was set to dhcp, the NIC will be assigned an IP address by a DHCP server and thus the next two lines should not be present in that case.
|
||||
HWADDR=08:00:27:4E:59:37 ### 网卡的 MAC 地址
|
||||
TYPE=Ethernet ### 连接类型
|
||||
BOOTPROTO=static ### 这代表着该网卡指定了一个静态地址。
|
||||
### 如果这个值指定为 dhcp,这个网卡会从 DHCP 服务器获取 IP 地址,并且就不应该出现以下两行。
|
||||
IPADDR=192.168.0.18
|
||||
NETMASK=255.255.255.0
|
||||
GATEWAY=192.168.0.1
|
||||
NM_CONTROLLED=no # Should be added to the Ethernet interface to prevent NetworkManager from changing the file.
|
||||
NM_CONTROLLED=no ### 应该给以太网卡设置,以便可以让 NetworkManager 可以修改这个文件。
|
||||
NAME=enp0s3
|
||||
UUID=14033805-98ef-4049-bc7b-d4bea76ed2eb
|
||||
ONBOOT=yes # The operating system should bring up this NIC during boot
|
||||
ONBOOT=yes ### 操作系统会在启动时打开这个网卡。
|
||||
|
||||
### 设定主机名 ###
|
||||
|
||||
@ -138,7 +140,7 @@ RHCSA: 安全 SSH 和开启网络服务 – Part 8
|
||||
|
||||
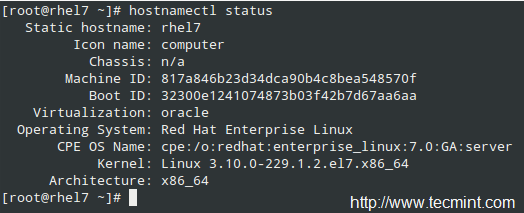
|
||||
|
||||
检查系统的主机名
|
||||
*检查系统的主机名*
|
||||
|
||||
要更改主机名,使用
|
||||
|
||||
@ -148,13 +150,13 @@ RHCSA: 安全 SSH 和开启网络服务 – Part 8
|
||||
|
||||
# hostnamectl set-hostname cinderella
|
||||
|
||||
要想使得更改生效,你需要重启 hostnamed 守护进程(这样你就不必因为要应用更改而登出系统并再登陆系统):
|
||||
要想使得更改生效,你需要重启 hostnamed 守护进程(这样你就不必因为要应用更改而登出并再登录系统):
|
||||
|
||||
# systemctl restart systemd-hostnamed
|
||||
|
||||

|
||||
|
||||
设定系统主机名
|
||||
*设定系统主机名*
|
||||
|
||||
另外, RHEL 7 还包含 `nmcli` 工具,它可被用来达到相同的目的。要展示主机名,运行:
|
||||
|
||||
@ -170,13 +172,13 @@ RHCSA: 安全 SSH 和开启网络服务 – Part 8
|
||||
|
||||

|
||||
|
||||
使用 nmcli 命令来设定主机名
|
||||
*使用 nmcli 命令来设定主机名*
|
||||
|
||||
### 在开机时开启网络服务 ###
|
||||
|
||||
作为本文的最后部分,就让我们看看如何确保网络服务在开机时被自动开启。简单来说,这个可通过创建符号链接到某些由服务的配置文件中的 [Install] 小节中指定的文件来实现。
|
||||
作为本文的最后部分,就让我们看看如何确保网络服务在开机时被自动开启。简单来说,这个可通过创建符号链接到某些由服务的配置文件中的 `[Install]` 小节中指定的文件来实现。
|
||||
|
||||
以 firewalld(/usr/lib/systemd/system/firewalld.service) 为例:
|
||||
以 firewalld(/usr/lib/systemd/system/firewalld.service) 为例:
|
||||
|
||||
[Install]
|
||||
WantedBy=basic.target
|
||||
@ -192,11 +194,11 @@ RHCSA: 安全 SSH 和开启网络服务 – Part 8
|
||||
|
||||

|
||||
|
||||
在开机时开启服务
|
||||
*在开机时开启服务*
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇文章中,我们总结了如何安装 SSH 及使用它安全地连接到一个 RHEL 服务器,如何改变主机名,并在最后如何确保在系统启动时开启服务。假如你注意到某个服务启动失败,你可以使用 `systemctl status -l [service]` 和 `journalctl -xn` 来进行排错。
|
||||
在这篇文章中,我们总结了如何安装 SSH 及使用它安全地连接到一个 RHEL 服务器;如何改变主机名,并在最后如何确保在系统启动时开启服务。假如你注意到某个服务启动失败,你可以使用 `systemctl status -l [service]` 和 `journalctl -xn` 来进行排错。
|
||||
|
||||
请随意使用下面的评论框来让我们知晓你对本文的看法。提问也同样欢迎。我们期待着你的反馈!
|
||||
|
||||
@ -206,10 +208,10 @@ via: http://www.tecmint.com/rhcsa-series-secure-ssh-set-hostname-enable-network-
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/20-netstat-commands-for-linux-network-management/
|
||||
[2]:http://www.tecmint.com/ssh-passwordless-login-using-ssh-keygen-in-5-easy-steps/
|
||||
[2]:https://linux.cn/article-5444-1.html
|
||||
@ -1,66 +0,0 @@
|
||||
Translating by H-mudcup
|
||||
Five Super Cool Open Source Games
|
||||
================================================================================
|
||||
In 2014 and 2015, Linux became home to a list of popular commercial titles such as the popular Borderlands, Witcher, Dead Island, and Counter Strike series of games. While this is exciting news, what of the gamer on a budget? Commercial titles are good, but even better are free-to-play alternatives made by developers who know what players like.
|
||||
|
||||
Some time ago, I came across a three year old YouTube video with the ever optimistic title [5 Open Source Games that Don’t Suck][1]. Although the video praises some open source games, I’d prefer to approach the subject with a bit more enthusiasm, at least as far as the title goes. So, here’s my list of five super cool open source games.
|
||||
|
||||
### Tux Racer ###
|
||||
|
||||

|
||||
|
||||
Tux Racer
|
||||
|
||||
[Tux Racer][2] is the first game on this list because I’ve had plenty of experience with it. On a [recent trip to Mexico][3] that my brother and I took with [Kids on Computers][4], Tux Racer was one of the games that kids and teachers alike enjoyed. In this game, players use the Linux mascot, the penguin Tux, to race on downhill ski slopes in time trials in which players challenge their own personal bests. Currently there’s no multiplayer version available, but that could be subject to change. Available for Linux, OS X, Windows, and Android.
|
||||
|
||||
### Warsow ###
|
||||
|
||||

|
||||
|
||||
Warsow
|
||||
|
||||
The [Warsow][5] website explains: “Set in a futuristic cartoonish world, Warsow is a completely free fast-paced first-person shooter (FPS) for Windows, Linux and Mac OS X. Warsow is the Art of Respect and Sportsmanship Over the Web.” I was reluctant to include games from the FPS genre on this list, because many have played games in this genre, but I was amused by Warsow. It prioritizes lots of movement and the game is fast paced with a set of eight weapons to start with. The cartoonish style makes playing feel less serious and more casual, something for friends and family to play together. However, it boasts competitive play, and when I experienced the game I found there were, indeed, some expert players around. Available for Linux, Windows and OS X.
|
||||
|
||||
### M.A.R.S – A ridiculous shooter ###
|
||||
|
||||

|
||||
|
||||
M.A.R.S. – A ridiculous shooter
|
||||
|
||||
[M.A.R.S – A ridiculous shooter][6] is appealing because of it’s vibrant coloring and style. There is support for two players on the same keyboard, but an online multiplayer version is currently in the works — meaning plans to play with friends have to wait for now. Regardless, it’s an entertaining space shooter with a few different ships and weapons to play as. There are different shaped ships, ranging from shotguns, lasers, scattered shots and more (one of the random ships shot bubbles at my opponents, which was funny amid the chaotic gameplay). There are a few modes of play, such as the standard death match against opponents to score a certain limit or score high, along with other modes called Spaceball, Grave-itation Pit and Cannon Keep. Available for Linux, Windows and OS X.
|
||||
|
||||
### Valyria Tear ###
|
||||
|
||||

|
||||
|
||||
Valyria Tear
|
||||
|
||||
[Valyria Tear][7] resembles many fan favorite role-playing games (RPGs) spanning the years. The story is set in the usual era of fantasy games, full of knights, kingdoms and wizardry, and follows the main character Bronann. The design team did great work in designing the world and gives players everything expected from the genre: hidden chests, random monster encounters, non-player character (NPC) interaction, and something no RPG would be complete without: grinding for experience on lower level slime monsters until you’re ready for the big bosses. When I gave it a try, time didn’t permit me to play too far into the campaign, but for those interested there is a ‘[Let’s Play][8]‘ series by YouTube user Yohann Ferriera. Available for Linux, Windows and OS X.
|
||||
|
||||
### SuperTuxKart ###
|
||||
|
||||

|
||||
|
||||
SuperTuxKart
|
||||
|
||||
Last but not least is [SuperTuxKart][9], a clone of Mario Kart that is every bit as fun as the original. It started development around 2000-2004 as Tux Kart, but there were errors in its production which led to a cease in development for a few years. Since development picked up again in 2006, it’s been improving, with version 0.9 debuting four months ago. In the game, our old friend Tux starts in the role of Mario and a few other open source mascots. One recognizable face among them is Suzanne, the monkey mascot for Blender. The graphics are solid and gameplay is fluent. While online play is in the planning stages, split screen multiplayer action is available, with up to four players supported on a single computer. Available for Linux, Windows, OS X, AmigaOS 4, AROS and MorphOS.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://fossforce.com/2015/08/five-super-cool-open-source-games/
|
||||
|
||||
作者:Hunter Banks
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.youtube.com/watch?v=BEKVl-XtOP8
|
||||
[2]:http://tuxracer.sourceforge.net/download.html
|
||||
[3]:http://fossforce.com/2015/07/banks-family-values-texas-linux-fest/
|
||||
[4]:http://www.kidsoncomputers.org/an-amazing-week-in-oaxaca
|
||||
[5]:https://www.warsow.net/download
|
||||
[6]:http://mars-game.sourceforge.net/
|
||||
[7]:http://valyriatear.blogspot.com/
|
||||
[8]:https://www.youtube.com/channel/UCQ5KrSk9EqcT_JixWY2RyMA
|
||||
[9]:http://supertuxkart.sourceforge.net/
|
||||
@ -1,110 +0,0 @@
|
||||
Mosh Shell – A SSH Based Client for Connecting Remote Unix/Linux Systems
|
||||
================================================================================
|
||||
Mosh, which stands for Mobile Shell is a command-line application which is used for connecting to the server from a client computer, over the Internet. It can be used as SSH and contains more feature than Secure Shell. It is an application similar to SSH, but with additional features. The application is written originally by Keith Winstein for Unix like operating system and released under GNU GPL v3.
|
||||
|
||||

|
||||
|
||||
Mosh Shell SSH Client
|
||||
|
||||
#### Features of Mosh ####
|
||||
|
||||
- It is a remote terminal application that supports roaming.
|
||||
- Available for all major UNIX-like OS viz., Linux, FreeBSD, Solaris, Mac OS X and Android.
|
||||
- Intermittent Connectivity supported.
|
||||
- Provides intelligent local echo.
|
||||
- Line editing of user keystrokes supported.
|
||||
- Responsive design and Robust Nature over wifi, cellular and long-distance links.
|
||||
- Remain Connected even when IP changes. It usages UDP in place of TCP (used by SSH). TCP time out when connect is reset or new IP assigned but UDP keeps the connection open.
|
||||
- The Connection remains intact when you resume the session after a long time.
|
||||
- No network lag. Shows users typed key and deletions immediately without network lag.
|
||||
- Same old method to login as it was in SSH.
|
||||
- Mechanism to handle packet loss.
|
||||
|
||||
### Installation of Mosh Shell in Linux ###
|
||||
|
||||
On Debian, Ubuntu and Mint alike systems, you can easily install the Mosh package with the help of [apt-get package manager][1] as shown.
|
||||
|
||||
# apt-get update
|
||||
# apt-get install mosh
|
||||
|
||||
On RHEL/CentOS/Fedora based distributions, you need to turn on third party repository called [EPEL][2], in order to install mosh from this repository using [yum package manager][3] as shown.
|
||||
|
||||
# yum update
|
||||
# yum install mosh
|
||||
|
||||
On Fedora 22+ version, you need to use [dnf package manager][4] to install mosh as shown.
|
||||
|
||||
# dnf install mosh
|
||||
|
||||
### How do I use Mosh Shell? ###
|
||||
|
||||
1. Let’s try to login into remote Linux server using mosh shell.
|
||||
|
||||
$ mosh root@192.168.0.150
|
||||
|
||||

|
||||
|
||||
Mosh Shell Remote Connection
|
||||
|
||||
**Note**: Did you see I got an error in connecting since the port was not open in my remote CentOS 7 box. A quick but not recommended solution I performed was:
|
||||
|
||||
# systemctl stop firewalld [on Remote Server]
|
||||
|
||||
The preferred way is to open a port and update firewall rules. And then connect to mosh on a predefined port. For in-depth details on firewalld you may like to visit this post.
|
||||
|
||||
- [How to Configure Firewalld][5]
|
||||
|
||||
2. Let’s assume that the default SSH port 22 was changed to port 70, in this case you can define custom port with the help of ‘-p‘ switch with mosh.
|
||||
|
||||
$ mosh -p 70 root@192.168.0.150
|
||||
|
||||
3. Check the version of installed Mosh.
|
||||
|
||||
$ mosh --version
|
||||
|
||||

|
||||
|
||||
Check Mosh Version
|
||||
|
||||
4. You can close mosh session type ‘exit‘ on the prompt.
|
||||
|
||||
$ exit
|
||||
|
||||
5. Mosh supports a lot of options, which you may see as:
|
||||
|
||||
$ mosh --help
|
||||
|
||||

|
||||
|
||||
Mosh Shell Options
|
||||
|
||||
#### Cons of Mosh Shell ####
|
||||
|
||||
- Mosh requires additional prerequisite for example, allow direct connection via UDP, which was not required by SSH.
|
||||
- Dynamic port allocation in the range of 60000-61000. The first open fort is allocated. It requires one port per connection.
|
||||
- Default port allocation is a serious security concern, especially in production.
|
||||
- IPv6 connections supported, but roaming on IPv6 not supported.
|
||||
- Scrollback not supported.
|
||||
- No X11 forwarding supported.
|
||||
- No support for ssh-agent forwarding.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Mosh is a nice small utility which is available for download in the repository of most of the Linux Distributions. Though it has a few discrepancies specially security concern and additional requirement it’s features like remaining connected even while roaming is its plus point. My recommendation is Every Linux-er who deals with SSH should try this application and mind it, Mosh is worth a try.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-mosh-shell-ssh-client-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/useful-basic-commands-of-apt-get-and-apt-cache-for-package-management/
|
||||
[2]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[3]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[4]:http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
[5]:http://www.tecmint.com/configure-firewalld-in-centos-7/
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by H-mudcup
|
||||
5 best open source board games to play online
|
||||
================================================================================
|
||||
I have always had a fascination with board games, in part because they are a device of social interaction, they challenge the mind and, most importantly, they are great fun to play. In my misspent youth, myself and a group of friends gathered together to escape the horrors of the classroom, and indulge in a little escapism. The time provided an outlet for tension and rivalry. Board games help teach diplomacy, how to make and break alliances, bring families and friends together, and learn valuable lessons.
|
||||
|
||||
@ -0,0 +1,44 @@
|
||||
Meet The New Ubuntu 15.10 Default Wallpaper
|
||||
================================================================================
|
||||
**The brand new default wallpaper for Ubuntu 15.10 Wily Werewolf has been unveiled. **
|
||||
|
||||
At first glance you may find little has changed from the origami-inspired ‘Suru’ design shipped with April’s release of Ubuntu 15.04. But look closer and you’ll see that the new default background does feature some subtle differences.
|
||||
|
||||
For one it looks much lighter, helped by an orange glow emanating from the upper-left of the image. The angular folds and sections remain, but with the addition of blocky, rectangular sections.
|
||||
|
||||
The new background has been designed by Canonical Design Team member Alex Milazzo.
|
||||
|
||||

|
||||
|
||||
The Ubuntu 15.10 default desktop wallpaper
|
||||
|
||||
And just to show that there is a change, here is the Ubuntu 15.04 default wallpaper for comparison:
|
||||
|
||||

|
||||
|
||||
The Ubuntu 15.04 default desktop wallpaper
|
||||
|
||||
### Download Ubuntu 15.10 Wallpaper ###
|
||||
|
||||
If you’re running daily builds of Ubuntu 15.10 Wily Werewolf and don’t yet see this as your default wallpaper you’ve no broken anything: the design has been unveiled but is, as of writing, yet to be packaged and uploaded to Wily itself.
|
||||
|
||||
You don’t have to wait until October to use the new design as your desktop background. You can download the wallpaper in a huge HiDPI display friendly 4096×2304 resolution by hitting the button below.
|
||||
|
||||
- [Download Ubuntu the new 15.10 Default Wallpaper][1]
|
||||
|
||||
Finally, as we say this every time there’s a new wallpaper, you don’t have to care about the minutiae of distribution branding and design. If the new wallpaper is not to your tastes or you never keep it you can, as ever, easily change it — this isn’t the Ubuntu Phone after all!
|
||||
|
||||
**Are you a fan of the refreshed look? Let us know in the comments below. **
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/09/ubuntu-15-10-wily-werewolf-default-wallpaper
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://launchpadlibrarian.net/218258177/Wolf_Wallpaper_Desktop_4096x2304_Purple_PNG-24.png
|
||||
@ -1,126 +0,0 @@
|
||||
How learning data structures and algorithms make you a better developer
|
||||
================================================================================
|
||||
|
||||
> "I'm a huge proponent of designing your code around the data, rather than the other way around, and I think it's one of the reasons git has been fairly successful […] I will, in fact, claim that the difference between a bad programmer and a good one is whether he considers his code or his data structures more important."
|
||||
-- Linus Torvalds
|
||||
|
||||
---
|
||||
|
||||
> "Smart data structures and dumb code works a lot better than the other way around."
|
||||
-- Eric S. Raymond, The Cathedral and The Bazaar
|
||||
|
||||
Learning about data structures and algorithms makes you a stonking good programmer.
|
||||
|
||||
**Data structures and algorithms are patterns for solving problems.** The more of them you have in your utility belt, the greater variety of problems you'll be able to solve. You'll also be able to come up with more elegant solutions to new problems than you would otherwise be able to.
|
||||
|
||||
You'll understand, ***in depth***, how your computer gets things done. This informs any technical decisions you make, regardless of whether or not you're using a given algorithm directly. Everything from memory allocation in the depths of your operating system, to the inner workings of your RDBMS to how your networking stack manages to send data from one corner of Earth to another. All computers rely on fundamental data structures and algorithms, so understanding them better makes you understand the computer better.
|
||||
|
||||
Cultivate a broad and deep knowledge of algorithms and you'll have stock solutions to large classes of problems. Problem spaces that you had difficulty modelling before often slot neatly into well-worn data structures that elegantly handle the known use-cases. Dive deep into the implementation of even the most basic data structures and you'll start seeing applications for them in your day-to-day programming tasks.
|
||||
|
||||
You'll also be able to come up with novel solutions to the somewhat fruitier problems you're faced with. Data structures and algorithms have the habit of proving themselves useful in situations that they weren't originally intended for, and the only way you'll discover these on your own is by having a deep and intuitive knowledge of at least the basics.
|
||||
|
||||
But enough with the theory, have a look at some examples
|
||||
|
||||
###Figuring out the fastest way to get somewhere###
|
||||
Let's say we're creating software to figure out the shortest distance from one international airport to another. Assume we're constrained to following routes:
|
||||
|
||||

|
||||
|
||||
graph of destinations and the distances between them, how can we find the shortest distance say, from Helsinki to London? **Dijkstra's algorithm** is the algorithm that will definitely get us the right answer in the shortest time.
|
||||
|
||||
In all likelihood, if you ever came across this problem and knew that Dijkstra's algorithm was the solution, you'd probably never have to implement it from scratch. Just ***knowing*** about it would point you to a library implementation that solves the problem for you.
|
||||
|
||||
If you did dive deep into the implementation, you'd be working through one of the most important graph algorithms we know of. You'd know that in practice it's a little resource intensive so an extension called A* is often used in it's place. It gets used everywhere from robot guidance to routing TCP packets to GPS pathfinding.
|
||||
|
||||
###Figuring out the order to do things in###
|
||||
Let's say you're trying to model courses on a new Massive Open Online Courses platform (like Udemy or Khan Academy). Some of the courses depend on each other. For example, a user has to have taken Calculus before she's eligible for the course on Newtonian Mechanics. Courses can have multiple dependencies. Here's are some examples of what that might look like written out in YAML:
|
||||
|
||||
# Mapping from course name to requirements
|
||||
#
|
||||
# If you're a physcist or a mathematicisn and you're reading this, sincere
|
||||
# apologies for the completely made-up dependency tree :)
|
||||
courses:
|
||||
arithmetic: []
|
||||
algebra: [arithmetic]
|
||||
trigonometry: [algebra]
|
||||
calculus: [algebra, trigonometry]
|
||||
geometry: [algebra]
|
||||
mechanics: [calculus, trigonometry]
|
||||
atomic_physics: [mechanics, calculus]
|
||||
electromagnetism: [calculus, atomic_physics]
|
||||
radioactivity: [algebra, atomic_physics]
|
||||
astrophysics: [radioactivity, calculus]
|
||||
quantumn_mechanics: [atomic_physics, radioactivity, calculus]
|
||||
|
||||
Given those dependencies, as a user, I want to be able to pick any course and have the system give me an ordered list of courses that I would have to take to be eligible. So if I picked `calculus`, I'd want the system to return the list:
|
||||
|
||||
arithmetic -> algebra -> trigonometry -> calculus
|
||||
|
||||
Two important constraints on this that may not be self-evident:
|
||||
|
||||
- At every stage in the course list, the dependencies of the next course must be met.
|
||||
- We don't want any duplicate courses in the list.
|
||||
|
||||
This is an example of resolving dependencies and the algorithm we're looking for to solve this problem is called topological sort (tsort). Tsort works on a dependency graph like we've outlined in the YAML above. Here's what that would look like in a graph (where each arrow means `requires`):
|
||||
|
||||

|
||||
|
||||
topological sort does is take a graph like the one above and find an ordering in which all the dependencies are met at each stage. So if we took a sub-graph that only contained `radioactivity` and it's dependencies, then ran tsort on it, we might get the following ordering:
|
||||
|
||||
arithmetic
|
||||
algebra
|
||||
trigonometry
|
||||
calculus
|
||||
mechanics
|
||||
atomic_physics
|
||||
radioactivity
|
||||
|
||||
This meets the requirements set out by the use case we described above. A user just has to pick `radioactivity` and they'll get an ordered list of all the courses they have to work through before they're allowed to.
|
||||
|
||||
We don't even need to go into the details of how topological sort works before we put it to good use. In all likelihood, your programming language of choice probably has an implementation of it in the standard library. In the worst case scenario, your Unix probably has the `tsort` utility installed by default, run man `tsort` and have a play with it.
|
||||
|
||||
###Other places tsort get's used###
|
||||
|
||||
- **Tools like** `make` allow you to declare task dependencies. Topological sort is used under the hood to figure out what order the tasks should be executed in.
|
||||
- **Any programming language that has a `require` directive**, indicating that the current file requires the code in a different file to be run first. Here topological sort can be used to figure out what order the files should be loaded in so that each is only loaded once and all dependencies are met.
|
||||
- **Project management tools with Gantt charts**. A Gantt chart is a graph that outlines all the dependencies of a given task and gives you an estimate of when it will be complete based on those dependencies. I'm not a fan of Gantt charts, but it's highly likely that tsort will be used to draw them.
|
||||
|
||||
###Squeezing data with Huffman coding###
|
||||
[Huffman coding](http://en.wikipedia.org/wiki/Huffman_coding) is an algorithm used for lossless data compression. It works by analyzing the data you want to compress and creating a binary code for each character. More frequently occurring characters get smaller codes, so `e` might be encoded as `111` while `x` might be `10010`. The codes are created so that they can be concatenated without a delimeter and still be decoded accurately.
|
||||
|
||||
Huffman coding is used along with LZ77 in the DEFLATE algorithm which is used by gzip to compress things. gzip is used all over the place, in particular for compressing files (typically anything with a `.gz` extension) and for http requests/responses in transit.
|
||||
|
||||
Knowing how to implement and use Huffman coding has a number of benefits:
|
||||
|
||||
- You'll know why a larger compression context results in better compression overall (e.g. the more you compress, the better the compression ratio). This is one of the proposed benefits of SPDY: that you get better compression on multiple HTTP requests/responses.
|
||||
- You'll know that if you're compressing your javascript/css in transit anyway, it's completely pointless to run a minifier on them. Sames goes for PNG files, which use DEFLATE internally for compression already.
|
||||
- If you ever find yourself trying to forcibly decipher encrypted information , you may realize that since repeating data compresses better, the compression ratio of a given bit of ciphertext will help you determine it's [block cipher mode of operation](http://en.wikipedia.org/wiki/Block_cipher_mode_of_operation).
|
||||
|
||||
###Picking what to learn next is hard###
|
||||
Being a programmer involves learning constantly. To operate as a web developer you need to know markup languages, high level languages like ruby/python, regular expressions, SQL and JavaScript. You need to know the fine details of HTTP, how to drive a unix terminal and the subtle art of object oriented programming. It's difficult to navigate that landscape effectively and choose what to learn next.
|
||||
|
||||
I'm not a fast learner so I have to choose what to spend time on very carefully. As much as possible, I want to learn skills and techniques that are evergreen, that is, won't be rendered obsolete in a few years time. That means I'm hesitant to learn the javascript framework of the week or untested programming languages and environments.
|
||||
|
||||
As long as our dominant model of computation stays the same, data structures and algorithms that we use today will be used in some form or another in the future. You can safely spend time on gaining a deep and thorough knowledge of them and know that they will pay dividends for your entire career as a programmer.
|
||||
|
||||
###Sign up to the Happy Bear Software List###
|
||||
Find this article useful? For a regular dose of freshly squeezed technical content delivered straight to your inbox, **click on the big green button below to sign up to the Happy Bear Software mailing list.**
|
||||
|
||||
We'll only be in touch a few times per month and you can unsubscribe at any time.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.happybearsoftware.com/how-learning-data-structures-and-algorithms-makes-you-a-better-developer
|
||||
|
||||
作者:[Happy Bear][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.happybearsoftware.com/
|
||||
[1]:http://en.wikipedia.org/wiki/Huffman_coding
|
||||
[2]:http://en.wikipedia.org/wiki/Block_cipher_mode_of_operation
|
||||
|
||||
|
||||
|
||||
@ -1,63 +0,0 @@
|
||||
Is Linux Right For You?
|
||||
================================================================================
|
||||
> Not everyone should opt for Linux -- for many users, remaining with Windows or OSX is the better choice.
|
||||
|
||||
I enjoy using Linux on the desktop. Not because of software politics or because I despise other operating systems. I simply like Linux because it just works.
|
||||
|
||||
It's been my experience that not everyone is cut out for the Linux lifestyle. In this article, I'll help you run through the pros and cons of making the switch to Linux so you can determine if switching is right for you.
|
||||
|
||||
### When to make the switch ###
|
||||
|
||||
Switching to Linux makes sense when there is a decisive reason to do so. The same can be said about moving from Windows to OS X or vice versa. In order to have success with switching, you must be able to identify your reason for jumping ship in the first place.
|
||||
|
||||
For some people, the reason for switching is frustration with their current platform. Maybe the latest upgrade left them with a lousy experience and they're ready to chart new horizons. In other instances, perhaps it's simply a matter of curiosity. Whatever the motivation, you must have a good reason for switching operating systems. If you're pushing yourself in this direction without a good reason, then no one wins.
|
||||
|
||||
However, there are exceptions to every rule. And if you're really interested in trying Linux on the desktop, then maybe coming to terms with a workable compromise is the way to go.
|
||||
|
||||
### Starting off slow ###
|
||||
|
||||
After trying Linux for the first time, I've seen people blast their Windows installation to bits because they had a good experience with Ubuntu on a flash drive for 20 minutes. Folks, this isn't a test. Instead I'd suggest the following:
|
||||
|
||||
- Run the [Linux distro in a virtual machine][1] for a week. This means you are committing to running that distro for all browser work, email and other tasks you might otherwise do on that machine.
|
||||
- If running a VM for a week is too resource intensive, try doing the same with a USB drive running Linux that offers [some persistent storage][2]. This will allow you to leave your main OS alone and intact. At the same time, you'll still be able to "live inside" of your Linux distribution for a week.
|
||||
- If you find that everything is successful after a week of running Linux, the next step is to examine how many times you booted into Windows that week. If only occasionally, then the next step is to look into [dual-booting Windows][3] and Linux. For those of you that only found themselves using their Linux distro, it might be worth considering making the switch full time.
|
||||
- Before you hose your Windows partition completely, it might make more sense to purchase a second hard drive to install Linux onto instead. This allows you to dual-boot, but to do so with ample hard drive space. It also makes Windows available to you if something should come up.
|
||||
|
||||
### What do you gain adopting Linux? ###
|
||||
|
||||
So what does one gain by switching to Linux? Generally it comes down to personal freedom for most people. With Linux, if something isn't to your liking, you're free to change it. Using Linux also saves users oodles of money in avoiding hardware upgrades and unnecessary software expenses. Additionally, you're not burdened with tracking down lost license keys for software. And if you dislike the direction a particular distribution is headed, you can switch to another distribution with minimal hassle.
|
||||
|
||||
The sheer volume of desktop choice on the Linux desktop is staggering. This level of choice might even seem overwhelming to the newcomer. But if you find a distro base (Debian, Fedora, Arch, etc) that you like, the hard work is already done. All you need to do now is find a variation of the distro and the desktop environment you prefer.
|
||||
|
||||
Now one of the most common complaints I hear is that there isn't much in the way of software for Linux. However, this isn't accurate at all. While other operating systems may have more of it, today's Linux desktop has applications to do just about anything you can think of. Video editing (home and pro-level), photography, office management, remote access, music (listening and creation), plus much, much more.
|
||||
|
||||
### What you lose adopting Linux? ###
|
||||
|
||||
As much as I enjoy using Linux, my wife's home office relies on OS X. She's perfectly content using Linux for some tasks, however she relies on OS X for specific software not available for Linux. This is a common problem that many people face when first looking at making the switch. You must decide whether or not you're going to be losing out on critical software if you make the switch.
|
||||
|
||||
Sometimes the issue is because the software has content locked down with it. In other cases, it's a workflow and functionality that was found with the legacy applications and not with the software available for Linux. I myself have never experienced this type of challenge, but I know those who have. Many of the software titles available for Linux are also available for other operating systems. So if there is a concern about such things, I encourage you to try out comparable apps on your native OS first.
|
||||
|
||||
Another thing you might lose by switching to Linux is the luxury of local support when you need it. People scoff at this, but I know of countless instances where a newcomer to Linux was dismayed to find their only recourse for solving Linux challenges was from strangers on the Web. This is especially problematic if their only PC is the one having issues. Windows and OS X users are spoiled in that there are endless support techs in cities all over the world that support their platform(s).
|
||||
|
||||
### How to proceed from here ###
|
||||
|
||||
Perhaps the single biggest piece of advice to remember is always have a fallback plan. Remember, once you wipe that copy of Windows 10 from your hard drive, you may find yourself spending money to get it reinstalled. This is especially true for those of you who upgrade from other Windows releases. Accepting this, persistent flash drives with Linux or dual-booting Windows and Linux is always a preferable way forward for newcomers. Odds are that you may be just fine and take to Linux like a fish to water. But having that fallback plan in place just means you'll sleep better at night.
|
||||
|
||||
If instead you've been relying on a dual-boot installation for weeks and feel ready to take the plunge, then by all means do it. Wipe your drive and start off with a clean installation of your favorite Linux distribution. I've been a full time Linux enthusiast for years and I can tell you for certain, it's a great feeling. How long? Let's just say my first Linux experience was with early Red Hat. I finally installed a dedicated installation on my laptop by 2003.
|
||||
|
||||
Existing Linux enthusiasts, where did you first get started? Was your switch an exciting one or was it filled with angst? Hit the Comments and share your experiences.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/is-linux-right-for-you.html
|
||||
|
||||
作者:[Matt Hartley][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]:http://www.psychocats.net/ubuntu/virtualbox
|
||||
[2]:http://www.howtogeek.com/howto/14912/create-a-persistent-bootable-ubuntu-usb-flash-drive/
|
||||
[3]:http://www.linuxandubuntu.com/home/dual-boot-ubuntu-15-04-14-10-and-windows-10-8-1-8-step-by-step-tutorial-with-screenshots
|
||||
@ -0,0 +1,389 @@
|
||||
Superclass: 15 of the world’s best living programmers
|
||||
================================================================================
|
||||
When developers discuss who the world’s top programmer is, these names tend to come up a lot.
|
||||
|
||||

|
||||
|
||||
Image courtesy [tom_bullock CC BY 2.0][1]
|
||||
|
||||
It seems like there are lots of programmers out there these days, and lots of really good programmers. But which one is the very best?
|
||||
|
||||
Even though there’s no way to really say who the best living programmer is, that hasn’t stopped developers from frequently kicking the topic around. ITworld has solicited input and scoured coder discussion forums to see if there was any consensus. As it turned out, a handful of names did frequently get mentioned in these discussions.
|
||||
|
||||
Use the arrows above to read about 15 people commonly cited as the world’s best living programmer.
|
||||
|
||||

|
||||
|
||||
Image courtesy [NASA][2]
|
||||
|
||||
### Margaret Hamilton ###
|
||||
|
||||
**Main claim to fame: The brains behind Apollo’s flight control software**
|
||||
|
||||
Credentials: As the Director of the Software Engineering Division at Charles Stark Draper Laboratory, she headed up the team which [designed and built][3] the on-board [flight control software for NASA’s Apollo][4] and Skylab missions. Based on her Apollo work, she later developed the [Universal Systems Language][5] and [Development Before the Fact][6] paradigm. Pioneered the concepts of [asynchronous software, priority scheduling, and ultra-reliable software design][7]. Coined the term “[software engineering][8].” Winner of the [Augusta Ada Lovelace Award][9] in 1986 and [NASA’s Exceptional Space Act Award in 2003][10].
|
||||
|
||||
Quotes: “Hamilton invented testing , she pretty much formalised Computer Engineering in the US.” [ford_beeblebrox][11]
|
||||
|
||||
“I think before her (and without disrespect including Knuth) computer programming was (and to an extent remains) a branch of mathematics. However a flight control system for a spacecraft clearly moves programming into a different paradigm.” [Dan Allen][12]
|
||||
|
||||
“... she originated the term ‘software engineering’ — and offered a great example of how to do it.” [David Hamilton][13]
|
||||
|
||||
“What a badass” [Drukered][14]
|
||||
|
||||

|
||||
|
||||
Image courtesy [vonguard CC BY-SA 2.0][15]
|
||||
|
||||
### Donald Knuth ###
|
||||
|
||||
**Main claim to fame: Author of The Art of Computer Programming**
|
||||
|
||||
Credentials: Wrote the [definitive book on the theory of programming][16]. Created the TeX digital typesetting system. [First winner of the ACM’s Grace Murray Hopper Award][17] in 1971. Winner of the ACM’s [A. M. Turing][18] Award in 1974, the [National Medal of Science][19] in 1979 and the IEEE’s [John von Neumann Medal][20] in 1995. Named a [Fellow at the Computer History Museum][21] in 1998.
|
||||
|
||||
Quotes: “... wrote The Art of Computer Programming which is probably the most comprehensive work on computer programming ever.” [Anonymous][22]
|
||||
|
||||
“There is only one large computer program I have used in which there are to a decent approximation 0 bugs: Don Knuth's TeX. That's impressive.” [Jaap Weel][23]
|
||||
|
||||
“Pretty awesome if you ask me.” [Mitch Rees-Jones][24]
|
||||
|
||||

|
||||
|
||||
Image courtesy [Association for Computing Machinery][25]
|
||||
|
||||
### Ken Thompson ###
|
||||
|
||||
**Main claim to fame: Creator of Unix**
|
||||
|
||||
Credentials: Co-creator, [along with Dennis Ritchie][26], of Unix. Creator of the [B programming language][27], the [UTF-8 character encoding scheme][28], the ed [text editor][29], and co-developer of the Go programming language. Co-winner (along with Ritchie) of the [A.M. Turing Award][30] in 1983, [IEEE Computer Pioneer Award][31] in 1994, and the [National Medal of Technology][32] in 1998. Inducted as a [fellow of the Computer History Museum][33] in 1997.
|
||||
|
||||
Quotes: “... probably the most accomplished programmer ever. Unix kernel, Unix tools, world-champion chess program Belle, Plan 9, Go Language.” [Pete Prokopowicz][34]
|
||||
|
||||
“Ken's contributions, more than anyone else I can think of, were fundamental and yet so practical and timeless they are still in daily use.“ [Jan Jannink][35]
|
||||
|
||||

|
||||
|
||||
Image courtesy Jiel Beaumadier CC BY-SA 3.0
|
||||
|
||||
### Richard Stallman ###
|
||||
|
||||
**Main claim to fame: Creator of Emacs, GCC**
|
||||
|
||||
Credentials: Founded the [GNU Project][36] and created many of its core tools, such as [Emacs, GCC, GDB][37], and [GNU Make][38]. Also founded the [Free Software Foundation][39]. Winner of the ACM's [Grace Murray Hopper Award][40] in 1990 and the [EFF's Pioneer Award in 1998][41].
|
||||
|
||||
Quotes: “... there was the time when he single-handedly outcoded several of the best Lisp hackers around, in the Symbolics vs LMI fight.” [Srinivasan Krishnan][42]
|
||||
|
||||
“Through his amazing mastery of programming and force of will, he created a whole sub-culture in programming and computers.” [Dan Dunay][43]
|
||||
|
||||
“I might disagree on many things with the great man, but he is still one of the most important programmers, alive or dead” [Marko Poutiainen][44]
|
||||
|
||||
“Try to imagine Linux without the prior work on the GNu project. Stallman's the bomb, yo.” [John Burnette][45]
|
||||
|
||||

|
||||
|
||||
Image courtesy [D.Begley CC BY 2.0][46]
|
||||
|
||||
### Anders Hejlsberg ###
|
||||
|
||||
**Main claim to fame: Creator of Turbo Pascal**
|
||||
|
||||
Credentials: [The original author of what became Turbo Pascal][47], one of the most popular Pascal compilers and the first integrated development environment. Later, [led the building of Delphi][48], Turbo Pascal’s successor. [Chief designer and architect of C#][49]. Winner of [Dr. Dobb's Excellence in Programming Award][50] in 2001.
|
||||
|
||||
Quotes: “He wrote the [Pascal] compiler in assembly language for both of the dominant PC operating systems of the day (DOS and CPM). It was designed to compile, link and run a program in seconds rather than minutes.” [Steve Wood][51]
|
||||
|
||||
“I revere this guy - he created the development tools that were my favourite through three key periods along my path to becoming a professional software engineer.” [Stefan Kiryazov][52]
|
||||
|
||||

|
||||
|
||||
Image courtesy [vonguard CC BY-SA 2.0][53]
|
||||
|
||||
### Doug Cutting ###
|
||||
|
||||
**Main claim to fame: Creator of Lucene**
|
||||
|
||||
Credentials: [Developed the Lucene search engine, as well as Nutch][54], a web crawler, and [Hadoop][55], a set of tools for distributed processing of large data sets. A strong proponent of open-source (Lucene, Nutch and Hadoop are all open-source). Currently [a former director of the Apache Software Foundation][56].
|
||||
|
||||
Quotes: “... he is the same guy who has written an exceptional search framework(lucene/solr) and opened the big-data gateway to the world(hadoop).” [Rajesh Rao][57]
|
||||
|
||||
“His creation/work on Lucene and Hadoop (among other projects) has created a tremendous amount of wealth and employment for folks in the world….” [Amit Nithianandan][58]
|
||||
|
||||

|
||||
|
||||
Image courtesy [Association for Computing Machinery][59]
|
||||
|
||||
### Sanjay Ghemawat ###
|
||||
|
||||
**Main claim to fame: Key Google architect**
|
||||
|
||||
Credentials: [Helped to design and implement some of Google’s large distributed systems][60], including MapReduce, BigTable, Spanner and Google File System. [Created Unix’s ical][61] calendaring system. Elected to the [National Academy of Engineering][62] in 2009. Winner of the [ACM-Infosys Foundation Award in the Computing Sciences][63] in 2012.
|
||||
|
||||
Quote: “Jeff Dean's wingman.” [Ahmet Alp Balkan][64]
|
||||
|
||||

|
||||
|
||||
Image courtesy [Google][65]
|
||||
|
||||
### Jeff Dean ###
|
||||
|
||||
**Main claim to fame: The brains behind Google search indexing**
|
||||
|
||||
Credentials: Helped to design and implement [many of Google’s large-scale distributed systems][66], including website crawling, indexing and searching, AdSense, MapReduce, BigTable and Spanner. Elected to the [National Academy of Engineering][67] in 2009. 2012 winner of the ACM’s [SIGOPS Mark Weiser Award][68] and the [ACM-Infosys Foundation Award in the Computing Sciences][69].
|
||||
|
||||
Quotes: “... for bringing breakthroughs in data mining( GFS, Map and Reduce, Big Table ).” [Natu Lauchande][70]
|
||||
|
||||
“... conceived, built, and deployed MapReduce and BigTable, among a bazillion other things” [Erik Goldman][71]
|
||||
|
||||

|
||||
|
||||
Image courtesy [Krd CC BY-SA 4.0][72]
|
||||
|
||||
### Linus Torvalds ###
|
||||
|
||||
**Main claim to fame: Creator of Linux**
|
||||
|
||||
Credentials: Created the [Linux kernel][73] and [Git][74], an open source version control system. Winner of numerous awards and honors, including the [EFF Pioneer Award][75] in 1998, the [British Computer Society’s Lovelace Medal][76] in 2000, the [Millenium Technology Prize][77] in 2012 and the [IEEE Computer Society’s Computer Pioneer Award][78] in 2014. Also inducted into the [Computer History Museum’s Hall of Fellows][79] in 2008 and the [Internet Hall of Fame][80] in 2012.
|
||||
|
||||
Quotes: “To put into prospective what an achievement this is, he wrote the Linux kernel in a few years while the GNU Hurd (a GNU-developed kernel) has been under development for 25 years and has still yet to release a production-ready example.” [Erich Ficker][81]
|
||||
|
||||
“Torvalds is probably the programmer's programmer.” [Dan Allen][82]
|
||||
|
||||
“He's pretty darn good.” [Alok Tripathy][83]
|
||||
|
||||

|
||||
|
||||
Image courtesy [QuakeCon CC BY 2.0][84]
|
||||
|
||||
### John Carmack ###
|
||||
|
||||
**Main claim to fame: Creator of Doom**
|
||||
|
||||
Credentials: Cofounded id Software and [created such influential FPS games][85] as Wolfenstein 3D, Doom and Quake. Pioneered such ground-breaking computer graphic techniques [adaptive tile refresh][86], [binary space partitioning][87], and surface caching. Inducted into the [Academy of Interactive Arts and Sciences Hall of Fame][88] in 2001, [won Emmy awards][89] in the Engineering & Technology category in 2007 and 2008, and given a lifetime achievement award by the [Game Developers Choice Awards][90] in 2010.
|
||||
|
||||
Quotes: “He wrote his first rendering engine before he was 20 years old. The guy's a genius. I wish I were a quarter a programmer he is.” [Alex Dolinsky][91]
|
||||
|
||||
“... Wolfenstein 3D, Doom and Quake were revolutionary at the time and have influenced a generation of game designers.” [dniblock][92]
|
||||
|
||||
“He can write basically anything in a weekend....” [Greg Naughton][93]
|
||||
|
||||
“He is the Mozart of computer coding….” [Chris Morris][94]
|
||||
|
||||

|
||||
|
||||
Image courtesy [Duff][95]
|
||||
|
||||
### Fabrice Bellard ###
|
||||
|
||||
**Main claim to fame: Creator of QEMU**
|
||||
|
||||
Credentials: Created a [variety of well-known open-source software programs][96], including QEMU, a platform for hardware emulation and virtualization, FFmpeg, for handling multimedia data, the Tiny C Compiler and LZEXE, an executable file compressor. [Winner of the Obfuscated C Code Contest][97] in 2000 and 2001 and the [Google-O'Reilly Open Source Award][98] in 2011. Former world record holder for [calculating the most number of digits in Pi][99].
|
||||
|
||||
Quotes: “I find Fabrice Bellard's work remarkable and impressive.” [raphinou][100]
|
||||
|
||||
“Fabrice Bellard is the most productive programmer in the world....” [Pavan Yara][101]
|
||||
|
||||
“Hes like the Nikola Tesla of sofware engineering.” [Michael Valladolid][102]
|
||||
|
||||
“He's a prolific serial achiever since the 1980s.” M[ichael Biggins][103]
|
||||
|
||||

|
||||
|
||||
Image courtesy [Craig Murphy CC BY 2.0][104]
|
||||
|
||||
### Jon Skeet ###
|
||||
|
||||
**Main claim to fame: Legendary Stack Overflow contributor**
|
||||
|
||||
Credentials: Google engineer and author of [C# in Depth][105]. Holds [highest reputation score of all time on Stack Overflow][106], answering, on average, 390 questions per month.
|
||||
|
||||
Quotes: “Jon Skeet doesn't need a debugger, he just stares down the bug until the code confesses” [Steven A. Lowe][107]
|
||||
|
||||
“When Jon Skeet's code fails to compile the compiler apologises.” [Dan Dyer][108]
|
||||
|
||||
“Jon Skeet's code doesn't follow a coding convention. It is the coding convention.” [Anonymous][109]
|
||||
|
||||

|
||||
|
||||
Image courtesy [Philip Neustrom CC BY 2.0][110]
|
||||
|
||||
### Adam D'Angelo ###
|
||||
|
||||
**Main claim to fame: Co-founder of Quora**
|
||||
|
||||
Credentials: As an engineer at Facebook, [built initial infrastructure for its news feed][111]. Went on to become CTO and VP of engineering at Facebook, before leaving to co-found Quora. [Eighth place finisher at the USA Computing Olympiad][112] as a high school student in 2001. Member of [California Institute of Technology’s silver medal winning team][113] at the ACM International Collegiate Programming Contest in 2004. [Finalist in the Algorithm Coding Competition][114] of Topcoder Collegiate Challenge in 2005.
|
||||
|
||||
Quotes: “An "All-Rounder" Programmer.” [Anonymous][115]
|
||||
|
||||
"For every good thing I make he has like six." [Mark Zuckerberg][116]
|
||||
|
||||

|
||||
|
||||
Image courtesy [Facebook][117]
|
||||
|
||||
### Petr Mitrechev ###
|
||||
|
||||
**Main claim to fame: One of the top competitive programmers of all time**
|
||||
|
||||
Credentials: [Two-time gold medal winner][118] in the International Olympiad in Informatics (2000, 2002). In 2006, [won the Google Code Jam][119] and was also the [TopCoder Open Algorithm champion][120]. Also, two-time winner of the Facebook Hacker Cup ([2011][121], [2013][122]). At the time of this writing, [the second ranked algorithm competitor on TopCoder][123] (handle: Petr) and also [ranked second by Codeforces][124]
|
||||
|
||||
Quote: “He is an idol in competitive programming even here in India…” [Kavish Dwivedi][125]
|
||||
|
||||

|
||||
|
||||
Image courtesy [Ishandutta2007 CC BY-SA 3.0][126]
|
||||
|
||||
### Gennady Korotkevich ###
|
||||
|
||||
**Main claim to fame: Competitive programming prodigy**
|
||||
|
||||
Credentials: Youngest participant ever (age 11) and [6 time gold medalist][127] (2007-2012) in the International Olympiad in Informatics. Part of [the winning team][128] at the ACM International Collegiate Programming Contest in 2013 and winner of the [2014 Facebook Hacker Cup][129]. At the time of this writing, [ranked first by Codeforces][130] (handle: Tourist) and [first among algorithm competitors by TopCoder][131].
|
||||
|
||||
Quotes: “A programming prodigy!” [Prateek Joshi][132]
|
||||
|
||||
“Gennady is definitely amazing, and visible example of why I have a large development team in Belarus.” [Chris Howard][133]
|
||||
|
||||
“Tourist is genius” [Nuka Shrinivas Rao][134]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.itworld.com/article/2823547/enterprise-software/158256-superclass-14-of-the-world-s-best-living-programmers.html#slide1
|
||||
|
||||
作者:[Phil Johnson][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.itworld.com/author/Phil-Johnson/
|
||||
[1]:https://www.flickr.com/photos/tombullock/15713223772
|
||||
[2]:https://commons.wikimedia.org/wiki/File:Margaret_Hamilton_in_action.jpg
|
||||
[3]:http://klabs.org/home_page/hamilton.htm
|
||||
[4]:https://www.youtube.com/watch?v=DWcITjqZtpU&feature=youtu.be&t=3m12s
|
||||
[5]:http://www.htius.com/Articles/r12ham.pdf
|
||||
[6]:http://www.htius.com/Articles/Inside_DBTF.htm
|
||||
[7]:http://www.nasa.gov/home/hqnews/2003/sep/HQ_03281_Hamilton_Honor.html
|
||||
[8]:http://www.nasa.gov/50th/50th_magazine/scientists.html
|
||||
[9]:https://books.google.com/books?id=JcmV0wfQEoYC&pg=PA321&lpg=PA321&dq=ada+lovelace+award+1986&source=bl&ots=qGdBKsUa3G&sig=bkTftPAhM1vZ_3VgPcv-38ggSNo&hl=en&sa=X&ved=0CDkQ6AEwBGoVChMI3paoxJHWxwIVA3I-Ch1whwPn#v=onepage&q=ada%20lovelace%20award%201986&f=false
|
||||
[10]:http://history.nasa.gov/alsj/a11/a11Hamilton.html
|
||||
[11]:https://www.reddit.com/r/pics/comments/2oyd1y/margaret_hamilton_with_her_code_lead_software/cmrswof
|
||||
[12]:http://qr.ae/RFEZLk
|
||||
[13]:http://qr.ae/RFEZUn
|
||||
[14]:https://www.reddit.com/r/pics/comments/2oyd1y/margaret_hamilton_with_her_code_lead_software/cmrv9u9
|
||||
[15]:https://www.flickr.com/photos/44451574@N00/5347112697
|
||||
[16]:http://cs.stanford.edu/~uno/taocp.html
|
||||
[17]:http://awards.acm.org/award_winners/knuth_1013846.cfm
|
||||
[18]:http://amturing.acm.org/award_winners/knuth_1013846.cfm
|
||||
[19]:http://www.nsf.gov/od/nms/recip_details.jsp?recip_id=198
|
||||
[20]:http://www.ieee.org/documents/von_neumann_rl.pdf
|
||||
[21]:http://www.computerhistory.org/fellowawards/hall/bios/Donald,Knuth/
|
||||
[22]:http://www.quora.com/Who-are-the-best-programmers-in-Silicon-Valley-and-why/answers/3063
|
||||
[23]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Jaap-Weel
|
||||
[24]:http://qr.ae/RFE94x
|
||||
[25]:http://amturing.acm.org/photo/thompson_4588371.cfm
|
||||
[26]:https://www.youtube.com/watch?v=JoVQTPbD6UY
|
||||
[27]:https://www.bell-labs.com/usr/dmr/www/bintro.html
|
||||
[28]:http://doc.cat-v.org/bell_labs/utf-8_history
|
||||
[29]:http://c2.com/cgi/wiki?EdIsTheStandardTextEditor
|
||||
[30]:http://amturing.acm.org/award_winners/thompson_4588371.cfm
|
||||
[31]:http://www.computer.org/portal/web/awards/cp-thompson
|
||||
[32]:http://www.uspto.gov/about/nmti/recipients/1998.jsp
|
||||
[33]:http://www.computerhistory.org/fellowawards/hall/bios/Ken,Thompson/
|
||||
[34]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Pete-Prokopowicz-1
|
||||
[35]:http://qr.ae/RFEWBY
|
||||
[36]:https://groups.google.com/forum/#!msg/net.unix-wizards/8twfRPM79u0/1xlglzrWrU0J
|
||||
[37]:http://www.emacswiki.org/emacs/RichardStallman
|
||||
[38]:https://www.gnu.org/gnu/thegnuproject.html
|
||||
[39]:http://www.emacswiki.org/emacs/FreeSoftwareFoundation
|
||||
[40]:http://awards.acm.org/award_winners/stallman_9380313.cfm
|
||||
[41]:https://w2.eff.org/awards/pioneer/1998.php
|
||||
[42]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Greg-Naughton/comment/4146397
|
||||
[43]:http://qr.ae/RFEaib
|
||||
[44]:http://www.quora.com/Software-Engineering/Who-are-some-of-the-greatest-currently-active-software-architects-in-the-world/answer/Marko-Poutiainen
|
||||
[45]:http://qr.ae/RFEUqp
|
||||
[46]:https://www.flickr.com/photos/begley/2979906130
|
||||
[47]:http://www.taoyue.com/tutorials/pascal/history.html
|
||||
[48]:http://c2.com/cgi/wiki?AndersHejlsberg
|
||||
[49]:http://www.microsoft.com/about/technicalrecognition/anders-hejlsberg.aspx
|
||||
[50]:http://www.drdobbs.com/windows/dr-dobbs-excellence-in-programming-award/184404602
|
||||
[51]:http://qr.ae/RFEZrv
|
||||
[52]:http://www.quora.com/Software-Engineering/Who-are-some-of-the-greatest-currently-active-software-architects-in-the-world/answer/Stefan-Kiryazov
|
||||
[53]:https://www.flickr.com/photos/vonguard/4076389963/
|
||||
[54]:http://www.wizards-of-os.org/archiv/sprecher/a_c/doug_cutting.html
|
||||
[55]:http://hadoop.apache.org/
|
||||
[56]:https://www.linkedin.com/in/cutting
|
||||
[57]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Shalin-Shekhar-Mangar/comment/2293071
|
||||
[58]:http://www.quora.com/Who-are-the-best-programmers-in-Silicon-Valley-and-why/answer/Amit-Nithianandan
|
||||
[59]:http://awards.acm.org/award_winners/ghemawat_1482280.cfm
|
||||
[60]:http://research.google.com/pubs/SanjayGhemawat.html
|
||||
[61]:http://www.quora.com/Google/Who-is-Sanjay-Ghemawat
|
||||
[62]:http://www8.nationalacademies.org/onpinews/newsitem.aspx?RecordID=02062009
|
||||
[63]:http://awards.acm.org/award_winners/ghemawat_1482280.cfm
|
||||
[64]:http://www.quora.com/Google/Who-is-Sanjay-Ghemawat/answer/Ahmet-Alp-Balkan
|
||||
[65]:http://research.google.com/people/jeff/index.html
|
||||
[66]:http://research.google.com/people/jeff/index.html
|
||||
[67]:http://www8.nationalacademies.org/onpinews/newsitem.aspx?RecordID=02062009
|
||||
[68]:http://news.cs.washington.edu/2012/10/10/uw-cse-ph-d-alum-jeff-dean-wins-2012-sigops-mark-weiser-award/
|
||||
[69]:http://awards.acm.org/award_winners/dean_2879385.cfm
|
||||
[70]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Natu-Lauchande
|
||||
[71]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Cosmin-Negruseri/comment/28399
|
||||
[72]:https://commons.wikimedia.org/wiki/File:LinuxCon_Europe_Linus_Torvalds_05.jpg
|
||||
[73]:http://www.linuxfoundation.org/about/staff#torvalds
|
||||
[74]:http://git-scm.com/book/en/Getting-Started-A-Short-History-of-Git
|
||||
[75]:https://w2.eff.org/awards/pioneer/1998.php
|
||||
[76]:http://www.bcs.org/content/ConWebDoc/14769
|
||||
[77]:http://www.zdnet.com/blog/open-source/linus-torvalds-wins-the-tech-equivalent-of-a-nobel-prize-the-millennium-technology-prize/10789
|
||||
[78]:http://www.computer.org/portal/web/pressroom/Linus-Torvalds-Named-Recipient-of-the-2014-IEEE-Computer-Society-Computer-Pioneer-Award
|
||||
[79]:http://www.computerhistory.org/fellowawards/hall/bios/Linus,Torvalds/
|
||||
[80]:http://www.internethalloffame.org/inductees/linus-torvalds
|
||||
[81]:http://qr.ae/RFEeeo
|
||||
[82]:http://qr.ae/RFEZLk
|
||||
[83]:http://www.quora.com/Software-Engineering/Who-are-some-of-the-greatest-currently-active-software-architects-in-the-world/answer/Alok-Tripathy-1
|
||||
[84]:https://www.flickr.com/photos/quakecon/9434713998
|
||||
[85]:http://doom.wikia.com/wiki/John_Carmack
|
||||
[86]:http://thegamershub.net/2012/04/gaming-gods-john-carmack/
|
||||
[87]:http://www.shamusyoung.com/twentysidedtale/?p=4759
|
||||
[88]:http://www.interactive.org/special_awards/details.asp?idSpecialAwards=6
|
||||
[89]:http://www.itworld.com/article/2951105/it-management/a-fly-named-for-bill-gates-and-9-other-unusual-honors-for-tech-s-elite.html#slide8
|
||||
[90]:http://www.gamechoiceawards.com/archive/lifetime.html
|
||||
[91]:http://qr.ae/RFEEgr
|
||||
[92]:http://www.itworld.com/answers/topic/software/question/whos-best-living-programmer#comment-424562
|
||||
[93]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Greg-Naughton
|
||||
[94]:http://money.cnn.com/2003/08/21/commentary/game_over/column_gaming/
|
||||
[95]:http://dufoli.wordpress.com/2007/06/23/ammmmaaaazing-night/
|
||||
[96]:http://bellard.org/
|
||||
[97]:http://www.ioccc.org/winners.html#B
|
||||
[98]:http://www.oscon.com/oscon2011/public/schedule/detail/21161
|
||||
[99]:http://bellard.org/pi/pi2700e9/
|
||||
[100]:https://news.ycombinator.com/item?id=7850797
|
||||
[101]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Erik-Frey/comment/1718701
|
||||
[102]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Erik-Frey/comment/2454450
|
||||
[103]:http://qr.ae/RFEjhZ
|
||||
[104]:https://www.flickr.com/photos/craigmurphy/4325516497
|
||||
[105]:http://www.amazon.co.uk/gp/product/1935182471?ie=UTF8&tag=developetutor-21&linkCode=as2&camp=1634&creative=19450&creativeASIN=1935182471
|
||||
[106]:http://stackexchange.com/leagues/1/alltime/stackoverflow
|
||||
[107]:http://meta.stackexchange.com/a/9156
|
||||
[108]:http://meta.stackexchange.com/a/9138
|
||||
[109]:http://meta.stackexchange.com/a/9182
|
||||
[110]:https://www.flickr.com/photos/philipn/5326344032
|
||||
[111]:http://www.crunchbase.com/person/adam-d-angelo
|
||||
[112]:http://www.exeter.edu/documents/Exeter_Bulletin/fall_01/oncampus.html
|
||||
[113]:http://icpc.baylor.edu/community/results-2004
|
||||
[114]:https://www.topcoder.com/tc?module=Static&d1=pressroom&d2=pr_022205
|
||||
[115]:http://qr.ae/RFfOfe
|
||||
[116]:http://www.businessinsider.com/in-new-alleged-ims-mark-zuckerberg-talks-about-adam-dangelo-2012-9#ixzz369FcQoLB
|
||||
[117]:https://www.facebook.com/hackercup/photos/a.329665040399024.91563.133954286636768/553381194694073/?type=1
|
||||
[118]:http://stats.ioinformatics.org/people/1849
|
||||
[119]:http://googlepress.blogspot.com/2006/10/google-announces-winner-of-global-code_27.html
|
||||
[120]:http://community.topcoder.com/tc?module=SimpleStats&c=coder_achievements&d1=statistics&d2=coderAchievements&cr=10574855
|
||||
[121]:https://www.facebook.com/notes/facebook-hacker-cup/facebook-hacker-cup-finals/208549245827651
|
||||
[122]:https://www.facebook.com/hackercup/photos/a.329665040399024.91563.133954286636768/553381194694073/?type=1
|
||||
[123]:http://community.topcoder.com/tc?module=AlgoRank
|
||||
[124]:http://codeforces.com/ratings
|
||||
[125]:http://www.quora.com/Respected-Software-Engineers/Who-are-some-of-the-best-programmers-in-the-world/answer/Venkateswaran-Vicky/comment/1960855
|
||||
[126]:http://commons.wikimedia.org/wiki/File:Gennady_Korot.jpg
|
||||
[127]:http://stats.ioinformatics.org/people/804
|
||||
[128]:http://icpc.baylor.edu/regionals/finder/world-finals-2013/standings
|
||||
[129]:https://www.facebook.com/hackercup/posts/10152022955628845
|
||||
[130]:http://codeforces.com/ratings
|
||||
[131]:http://community.topcoder.com/tc?module=AlgoRank
|
||||
[132]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Prateek-Joshi
|
||||
[133]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Prateek-Joshi/comment/4720779
|
||||
[134]:http://www.quora.com/Computer-Programming/Who-is-the-best-programmer-in-the-world-right-now/answer/Prateek-Joshi/comment/4880549
|
||||
@ -0,0 +1,149 @@
|
||||
The Free Software Foundation: 30 years in
|
||||
================================================================================
|
||||

|
||||
|
||||
Welcome back, folks, to a new Six Degrees column. As usual, please send your thoughts on this piece to the comment box and your suggestions for future columns to [my inbox][1].
|
||||
|
||||
Now, I have to be honest with you all, this column went a little differently than I expected.
|
||||
|
||||
A few weeks ago when thinking what to write, I mused over the notion of a piece about the [Free Software Foundation][2] celebrating its 30 year anniversary and how relevant and important its work is in today's computing climate.
|
||||
|
||||
To add some meat I figured I would interview [John Sullivan][3], executive director of the FSF. My plan was typical of many of my pieces: thread together an interesting narrative and quote pieces of the interview to give it color.
|
||||
|
||||
Well, that all went out the window when John sent me a tremendously detailed, thoughtful, and descriptive interview. I decided therefore to present it in full as the main event, and to add some commentary throughout. Thus, this is quite a long column, but I think it paints a fascinating picture of a fascinating organization. I recommend you grab a cup of something delicious and settle in for a solid read.
|
||||
|
||||
### The sands of change ###
|
||||
|
||||
The Free Software Foundation was founded in 1985. To paint a picture of what computing was like back then, the [Amiga 1000][4] was released, C++ was becoming a dominant language, [Aldus PageMaker][5] was announced, and networking was just starting to grow. Oh, and that year [Careless Whisper][6] by Wham! was a major hit.
|
||||
|
||||
Things have changed a lot in 30 years. Back in 1985 the FSF was primarily focused on building free pieces of software that were primarily useful to nerdy computer people. These days we have software, services, social networks, and more to consider.
|
||||
|
||||
I first wanted to get a sense of what John feels are most prominent risks to software freedom today.
|
||||
|
||||
"I think there's widespread agreement on the biggest risks for computer user freedom today, but maybe not on the names for them."
|
||||
|
||||
"The first is what we might as well just call 'tiny computers everywhere.' The free software movement has succeeded to the point where laptops, desktops, and servers can run fully free operating systems doing anything users of proprietary systems can do. There are still a few holes, but they'll be closed. The challenge that remains in this area is to cut through the billion dollar marketing budgets and legal regimes working against us to actually get the systems into users hands."
|
||||
|
||||
"However, we have a serious problem on the set of computers whose primary common trait is that they are very small. Even though a car is not especially small, the computers in it are, so I include that form factor in this category, along with phones, tablets, glasses, watches, and so on. While these computers often have a basis in free software—for example, using the kernel Linux along with other free software like Android or GNU—their primary uses are to run proprietary applications and be shims for services that replace local computing with computing done on a server over which the user has no control. Since these devices serve vital functions, with some being primary means of communication for huge populations, some sitting very close to our bodies and our actual vital functions, some bearing responsibility for our physical safety, it is imperative that they run fully free systems under their users' control. Right now, they don't."
|
||||
|
||||
John feels the risk here is not just the platforms and form factors, but the services integrates into them.
|
||||
|
||||
"The services many of these devices talk to are the second major threat we face. It does us little good booting into a free system if we do our actual work and entertainment on companies' servers running software we have no access to at all. The point of free software is that we can see, modify, and share code. The existence of those freedoms even for nontechnical users provides a shield that prevents companies from controlling us. None of these freedoms exist for users of Facebook or Salesforce or Google Docs. Even more worrisome, we see a trend where people are accepting proprietary restrictions imposed on their local machines in order to have access to certain services. Browsers—including Firefox—are now automatically installing a DRM plugin in order to appease Netflix and other video giants. We need to work harder at developing free software decentralized replacements for media distribution that can actually empower users, artists, and user-artists, and for other services as well. For Facebook we have GNU social, pump.io, Diaspora, Movim, and others. For Salesforce, we have CiviCRM. For Google Docs, we have Etherpad. For media, we have GNU MediaGoblin. But all of these projects need more help, and many services don't have any replacement contenders yet."
|
||||
|
||||
It is interesting that John mentions finding free software equivalents for common applications and services today. The FSF maintains a list of "High Priority Projects" that are designed to fill this gap. Unfortunately the capabilities of these projects varies tremendously and in an age where social media is so prominent, the software is only part of the problem: the real challenge is getting people to use it.
|
||||
|
||||
This all begs the question of where the FSF fit in today's modern computing world. I am a fan of the FSF. I think the work they do is valuable and I contribute financially to support it too. They are an important organization for building an open computing culture, but all organizations need to grow, adjust, and adapt, particularly ones in the technology space.
|
||||
|
||||
I wanted to get a better sense of what the FSF is doing today that it wasn't doing at it's inception.
|
||||
|
||||
"We're speaking to a much larger audience than we were 30 years ago, and to a much broader audience. It's no longer just hackers and developers and researchers that need to know about free software. Everyone using a computer does, and it's quickly becoming the case that everyone uses a computer."
|
||||
|
||||
John went on to provide some examples of these efforts.
|
||||
|
||||
"We're doing coordinated public advocacy campaigns on issues of concern to the free software movement. Earlier in our history, we expressed opinions on these things, and took action on a handful, but in the last ten years we've put more emphasis on formulating and carrying out coherent campaigns. We've made especially significant noise in the area of Digital Restrictions Management (DRM) with Defective by Design, which I believe played a role in getting iTunes music off DRM (now of course, Apple is bringing DRM back with Apple Music). We've made attractive and useful introductory materials for people new to free software, like our [User Liberation animated video][7] and our [Email Self-Defense Guide][8].
|
||||
|
||||
We're also endorsing hardware that [respects users' freedoms][9]. Hardware distributors whose devices have been certified by the FSF to contain and require only free software can display a logo saying so. Expanding the base of free software users and the free software movement has two parts: convincing people to care, and then making it possible for them to act on that. Through this initiative, we encourage manufacturers and distributors to do the right thing, and we make it easy for users who have started to care about free software to buy what they need without suffering through hours and hours of research. We've certified a home WiFi router, 3D printers, laptops, and USB WiFi adapters, with more on the way.
|
||||
|
||||
We're collecting all of the free software we can find in our [Free Software Directory][10]. We still have a long way to go on this—we're at only about 15,500 packages right now, and we can imagine many improvements to the design and function of the site—but I think this resource has great potential for helping users find the free software they need, especially users who aren't yet using a full GNU/Linux system. With the dangers inherent in downloading random programs off the Internet, there is a definite need for a curated collection like this. It also happens to provide a wealth of machine-readable data of use to researchers.
|
||||
|
||||
We're acting as the fiscal sponsor for several specific free software projects, enabling them to raise funds for development. Most of these projects are part of GNU (which we continue to provide many kinds of infrastructure for), but we also sponsor [Replicant][11], a fully free fork of Android designed to give users the free-est mobile devices currently possible.
|
||||
|
||||
We're helping developers use free software licenses properly, and we're following up on complaints about companies that aren't following the terms of the GPL. We help them fix their mistakes and distribute properly. RMS was in fact doing similar work with the precursors of the GPL very early on, but it's now an ongoing part of our work.
|
||||
|
||||
Most of the specific things the FSF does now it wasn't doing 30 years ago, but the vision is little changed from the original paperwork—we aim to create a world where everything users want to do on any computer can be done using free software; a world where users control their computers and not the other way around."
|
||||
|
||||
### A cult of personality ###
|
||||
|
||||
There is little doubt in anyone's minds about the value the FSF brings. As John just highlighted, its efforts span not just the creation and licensing of free software, but also recognizing, certifying, and advocating a culture of freedom in technology.
|
||||
|
||||
The head of the FSF is the inimitable Richard M. Stallman, commonly referred to as RMS.
|
||||
|
||||
RMS is a curious character. He has demonstrated an unbelievable level of commitment to his ideas, philosophy, and ethical devotion to freedom in software.
|
||||
|
||||
While he is sometimes mocked online for his social awkwardness, be it things said in his speeches, his bizarre travel requirements, or other sometimes cringeworthy moments, RMS's perspectives on software and freedom are generally rock-solid. He takes a remarkably consistent approach to his perspectives and he is clearly a careful thinker about not just his own thoughts but the wider movement he is leading. My only criticism is that I think from time to time he somewhat over-eggs the pudding with the voracity of his words. But hey, given his importance in our world, I would rather take an extra egg than no pudding for anyone. O.K., I get that the whole pudding thing here was strained...
|
||||
|
||||
So RMS is a key part of the FSF, but the organization is also much more than that. There are employees, a board, and many contributors. I was curious to see how much of a role RMS plays these days in the FSF. John shared this with me.
|
||||
|
||||
"RMS is the FSF's President, and does that work without receiving a salary from the FSF. He continues his grueling global speaking schedule, advocating for free software and computer user freedom in dozens of countries each year. In the course of that, he meets with government officials as well as local activists connected with all varieties of social movements. He also raises funds for the FSF and inspires many people to volunteer."
|
||||
|
||||
"In between engagements, he does deep thinking on issues facing the free software movement, and anticipates new challenges. Often this leads to new articles—he wrote a 3-part series for Wired earlier this year about free software and free hardware designs—or new ideas communicated to the FSF's staff as the basis for future projects."
|
||||
|
||||
As we delved into the cult of personality, I wanted to tap John's perspectives on how wide the free software movement has grown.
|
||||
|
||||
I remember being at the [Open Source Think Tank][12] (an event that brings together execs from various open source organizations) and there was a case study where attendees were asked to recommend license choice for a particular project. The vast majority of break-out groups recommended the Apache Software License (APL) over the GNU Public License (GPL).
|
||||
|
||||
This stuck in my mind as since then I have noticed that many companies seem to have opted for open licenses other than the GPL. I was curious to see if John had noticed a trend towards the APL as opposed to the GPL.
|
||||
|
||||
"Has there been? I'm not so sure. I gave a presentation at FOSDEM a few years ago called 'Is Copyleft Being Framed?' that showed some of the problems with the supposed data behind claims of shifts in license adoption. I'll be publishing an article soon on this, but here's some of the major problems:
|
||||
|
||||
|
||||
- Free software license choices do not exist in a vacuum. The number of people choosing proprietary software licenses also needs to be considered in order to draw the kinds of conclusions that people want to draw. I find it much more likely that lax permissive license choices (such as the Apache License or 3-clause BSD) are trading off with proprietary license choices, rather than with the GPL.
|
||||
- License counters often, ironically, don't publish the software they use to collect that data as free software. That means we can't inspect their methods or reproduce their results. Some people are now publishing the code they use, but certainly any that don't should be completely disregarded. Science has rules.
|
||||
- What counts as a thing with a license? Are we really counting an app under the APL that makes funny noises as 1:1 with GNU Emacs under GPLv3? If not, how do we decide which things to treat as equals? Are we only looking at software that actually works? Are we making sure not to double- and triple- count programs that exist on multiple hosting sites, and what about ports for different OSes?
|
||||
|
||||
The question is interesting to ponder, but every conclusion I've seen so far has been extremely premature in light of the actual data. I'd much rather see a survey of developers asking about why they chose particular licenses for their projects than any more of these attempts to programmatically ascertain the license of programs and then ascribe human intentions on to patterns in that data.
|
||||
|
||||
Copyleft is as vital as it ever was. Permissively licensed software is still free software and on-face a good thing, but it is contingent and needs an accompanying strong social commitment to not incorporate it in proprietary software. If free software's major long-term impact is enabling businesses to more efficiently make products that restrict us, then we have achieved nothing for computer user freedom."
|
||||
|
||||
### Rising to new challenges ###
|
||||
|
||||
30 years is an impressive time for any organization to be around, and particularly one with such important goals that span so many different industries, professions, governments, and cultures.
|
||||
|
||||
As I started to wrap up the interview I wanted to get a better sense of what the FSF's primary function is today, 30 years after the mission started.
|
||||
|
||||
"I think the FSF is in a very interesting position of both being a steady rock and actively pushing the envelope."
|
||||
|
||||
"We have core documents like the [Free Software Definition][13], the [GNU General Public License][14], and the [list we maintain of free and nonfree software licenses][15], which have been keystones in the construction of the world of free software we have today. People place a great deal of trust in us to stay true to the principles outlined in those documents, and to apply them correctly and wisely in our assessments of new products or practices in computing. In this role, we hold the ladder for others to climb. As a 501(c)(3) charity held legally accountable to the public interest, and about 85% funded by individuals, we have the right structure for this."
|
||||
|
||||
"But we also push the envelope. We take on challenges that others say are too hard. I guess that means we also build ladders? Or maybe I should stop with the metaphors."
|
||||
|
||||
While John may not be great with metaphors (like I am one to talk), the FSF is great at setting a mission and demonstrating a devout commitment to it. This mission starts with a belief that free software should be everywhere.
|
||||
|
||||
"We are not satisfied with the idea that you can get a laptop that works with free software except for a few components. We're not satisfied that you can have a tablet that runs a lot of free software, and just uses proprietary software to communicate with networks and to accelerate video and to take pictures and to check in on your flight and to call an Über and to.. Well, we are happy about some such developments for sure, but we are also unhappy about the suggestion that we should be fully content with them. Any proprietary software on a system is both an injustice to the user and inherently a threat to users' security. These almost-free things can be stepping stones on the way to a free world, but only if we keep our feet moving."
|
||||
|
||||
In the early years of the FSF, we actually had to get a free operating system written. This has now been done by GNU and Linux and many collaborators, although there is always more software to write and bugs to fix. So while the FSF does still sponsor free software development in specific areas, there are thankfully many other organizations also doing this."
|
||||
|
||||
A key part of the challenge John is referring to is getting the right hardware into the hands of the right people.
|
||||
|
||||
"What we have been focusing on now are the challenges I highlighted in the first question. We are in desperate need of hardware in several different areas that fully supports free software. We have been talking a lot at the FSF about what we can do to address this, and I expect us to be making some significant moves to both increase our support for some of the projects already out there—as we having been doing to some extent through our Respects Your Freedom certification program—and possibly to launch some projects of our own. The same goes for the network service problem. I think we need to tackle them together, because having full control over the mobile components has great potential for changing how we relate to services, and decentralizing more and more services will in turn shape the mobile components."
|
||||
|
||||
I hope folks will support the FSF as we work to grow and tackle these challenges. Hardware is expensive and difficult, as is making usable, decentralized, federated replacements for network services. We're going to need the resources and creativity of a lot of people. But, 30 years ago, a community rallied around RMS and the concept of copyleft to write an entire operating system. I've spent my last 12 years at the FSF because I believe we can rise to the new challenges in the same way."
|
||||
|
||||
### Final thoughts ###
|
||||
|
||||
In reading John's thoughtful responses to my questions, and in knowing various FSF members, the one sense that resonates for me is the sheer level of passion that is alive and kicking in the FSF. This is not an organization that has got bored or disillusioned with its mission. Its passion and commitment is as voracious as it has ever been.
|
||||
|
||||
While I don't always agree with the FSF and I sometimes think its approach is a little one-dimensional at times, I have been and will continue to be a huge fan and supporter of its work. The FSF represent the ethical heartbeat of much of the free software and open source work that happens across the world. It represents a world view that is pretty hard to the left, but I believe its passion and conviction helps to bring people further to the right a little closer to the left too.
|
||||
|
||||
Sure, RMS can be odd, somewhat hardline, and a little sensational, but he is precisely the kind of leader that is valuable in a movement that encapsulates a mixture of technology, ethics, and culture. We need an RMS in much the same way we need a Torvalds, a Shuttleworth, a Whitehurst, and a Zemlin. These different people bring together mixture of perspectives that ultimately maps to technology that can be adaptable to almost any set of use cases, ethics, and ambitions.
|
||||
|
||||
So, in closing, I want to thank the FSF for its tremendous efforts, and I wish the FSF and its fearless leaders, one Richard M. Stallman and one John Sullivan, another 30 years of fighting the good fight. Go get 'em!
|
||||
|
||||
> This article is part of Jono Bacon's Six Degrees column, where he shares his thoughts and perspectives on culture, communities, and trends in open source.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://opensource.com/business/15/9/free-software-foundation-30-years
|
||||
|
||||
作者:[Jono Bacon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://opensource.com/users/jonobacon
|
||||
[1]:Welcome back, folks, to a new Six Degrees column. As usual, please send your thoughts on this piece to the comment box and your suggestions for future columns to my inbox.
|
||||
[2]:http://www.fsf.org/
|
||||
[3]:http://twitter.com/johns_fsf/
|
||||
[4]:https://en.wikipedia.org/wiki/Amiga_1000
|
||||
[5]:https://en.wikipedia.org/wiki/Adobe_PageMaker
|
||||
[6]:https://www.youtube.com/watch?v=izGwDsrQ1eQ
|
||||
[7]:http://fsf.org/
|
||||
[8]:http://emailselfdefense.fsf.org/
|
||||
[9]:http://fsf.org/ryf
|
||||
[10]:http://directory.fsf.org/
|
||||
[11]:http://www.replicant.us/
|
||||
[12]:http://www.osthinktank.com/
|
||||
[13]:http://www.fsf.org/about/what-is-free-software
|
||||
[14]:http://www.gnu.org/licenses/gpl-3.0.en.html
|
||||
[15]:http://www.gnu.org/licenses/licenses.en.html
|
||||
@ -0,0 +1,30 @@
|
||||
Italy's Ministry of Defense to Drop Microsoft Office in Favor of LibreOffice
|
||||
================================================================================
|
||||
>**LibreItalia's Italo Vignoli [reports][1] that the Italian Ministry of Defense is about to migrate to the LibreOffice open-source software for productivity and adopt the Open Document Format (ODF), while moving away from proprietary software products.**
|
||||
|
||||
The movement comes in the form of a [collaboration][1] between Italy's Ministry of Defense and the LibreItalia Association. Sonia Montegiove, President of the LibreItalia Association, and Ruggiero Di Biase, Rear Admiral and General Executive Manager of Automated Information Systems of the Ministry of Defense in Italy signed an agreement for a collaboration to adopt the LibreOffice office suite in all of the Ministry's offices.
|
||||
|
||||
While the LibreItalia non-profit organization promises to help the Italian Ministry of Defense with trainers for their offices across the country, the Ministry will start the implementation of the LibreOffice software on October 2015 with online training courses for their staff. The entire transition process is expected to be completed by the end of year 2016\. An Italian law lets officials find open source software alternatives to well-known commercial software.
|
||||
|
||||
"Under the agreement, the Italian Ministry of Defense will develop educational content for a series of online training courses on LibreOffice, which will be released to the community under Creative Commons, while the partners, LibreItalia, will manage voluntarily the communication and training of trainers in the Ministry," says Italo Vignoli, Honorary President of LibreItalia.
|
||||
|
||||
### The Ministry of Defense will adopt the Open Document Format (ODF)
|
||||
|
||||
The initiative will allow the Italian Ministry of Defense to be independent from proprietary software applications, which are aimed at individual productivity, and adopt open source document format standards like Open Document Format (ODF), which is used by default in the LibreOffice office suite. The project follows similar movements already made by governments of other European countries, including United Kingdom, France, Spain, Germany, and Holland.
|
||||
|
||||
It would appear that numerous other public institutions all over Italy are using open source alternatives, including the Italian Region Emilia Romagna, Galliera Hospital in Genoa, Macerata, Cremona, Trento and Bolzano, Perugia, the municipalities of Bologna, ASL 5 of Veneto, Piacenza and Reggio Emilia, and many others. AGID (Agency for Digital Italy) welcomes this project and hopes that other public institutions will do the same.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/italy-s-ministry-of-defense-to-drop-microsoft-office-in-favor-of-libreoffice-491850.shtml
|
||||
|
||||
作者:[Marius Nestor][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/marius-nestor
|
||||
[1]:http://www.libreitalia.it/accordo-di-collaborazione-tra-associazione-libreitalia-onlus-e-difesa-per-ladozione-del-prodotto-libreoffice-quale-pacchetto-di-produttivita-open-source-per-loffice-automation/
|
||||
[2]:http://www.libreitalia.it/chi-siamo/
|
||||
@ -0,0 +1,72 @@
|
||||
14 tips for teaching open source development
|
||||
================================================================================
|
||||
Academia is an excellent platform for training and preparing the open source developers of tomorrow. In research, we occasionally open source software we write. We do this for two reasons. One, to promote the use of the tools we produce. And two, to learn more about the impact and issues other people face when using them. With this background of writing research software, I was tasked with redesigning the undergraduate software engineering course for second-year students at the University of Bradford.
|
||||
|
||||
It was a challenge, as I was faced with 80 students coming for different degrees, including IT, business computing, and software engineering, all in the same course. The hardest part was working with students with a wide range of programming experience levels. Traditionally, the course had involved allowing students to choose their own teams, tasking them with building a garage database system and then submitting a report in the end as part of the assessment.
|
||||
|
||||
I decided to redesign the course to give students insight into the process of working on real-world software teams. I divided the students into teams of five or six, based on their degrees and programming skills. The aim was to have an equal distribution of skills across the teams to prevent any unfair advantage of one team over another.
|
||||
|
||||
### The core lessons ###
|
||||
|
||||
The course format was updated to have both lectures and lab sessions. However, the lab session functioned as mentoring sessions, where instructors visited each team to ask for updates and see how the teams were progressing with the clients and the products. There were traditional lectures on project management, software testing, requirements engineering, and similar topics, supplemented by lab sessions and mentor meetings. These meetings allowed us to check up on students' progress and monitor whether they were following the software engineering methodologies taught in the lecture portion. Topics we taught this year included:
|
||||
|
||||
- Requirements engineering
|
||||
- How to interact with clients and other team members
|
||||
- Software methodologies, such as agile and extreme programming approaches
|
||||
- How to use different software engineering approaches and work through sprints
|
||||
- Team meetings and documentations
|
||||
- Project management and Gantt charts
|
||||
- UML diagrams and system descriptions
|
||||
- Code revisioning using Git
|
||||
- Software testing and bug tracking
|
||||
- Using open source libraries for their tools
|
||||
- Open source licenses and which one to use
|
||||
- Software delivery
|
||||
|
||||
Along with these lectures, we had a few guest speakers from the corporate world talk about their practices in software product deliveries. We also managed to get the university’s intellectual property lawyer to come and talk about IP issues surrounding software in the UK, and how to handle any intellectual properties issues in software.
|
||||
|
||||
### Collaboration tools ###
|
||||
|
||||
To make all of the above possible, a number of tools were introduced. Students were trained on how to use them for their projects. These included:
|
||||
|
||||
- Google Drive folders shared within the team and the tutor, to maintain documents and spreadsheets for project descriptions, requirements gathering, meeting minutes, and time tracking of the project. This was an extremely efficient way to monitor and also provide feedback straight into the folders for each team.
|
||||
- [Basecamp][1] for document sharing as well, and later in the course we considered this as a possible replacement for Google Drive.
|
||||
- Bug reporting tools such as [Mantis][2] again have a limited users for free reporting. Later Git itself was being used for bug reports n any tools by the testers in the teams
|
||||
- Remote videoconferencing tools were used as a number of clients were off-campus, and sometimes not even in the same city. The students were regularly using Skype to communicate with them, documenting their meetings and sometimes even recording them for later use.
|
||||
- A number of open source tool kits were also used for students' projects. The students were allowed to choose their own tool kits and languages based on the requirements of the projects. The only condition was that these have to be open source and could be installed in the university labs, which the technical staff was extremely supportive of.
|
||||
- In the end all teams had to deliver their projects to the client, including complete working version of the software, documentation, and open source licenses of their own choosing. Most of the teams chose the GPL version 3 license.
|
||||
|
||||
### Tips and lessons learned ###
|
||||
|
||||
In the end, it was a fun year and nearly all students did very well. Here are some of the lessons I learned which may help improve the course next year:
|
||||
|
||||
1. Give the students a wide variety of choice in projects that are interesting, such as game development or mobile application development, and projects with goals. Working with mundane database systems is not going to keep most students interested. Working with interesting projects, most students became self-learners, and were also helping others in their teams and outside to solve some common issues. The course also had a message list, where students were posting any issues they were encountering, in hopes of receiving advice from others. However, there was a drawback to this approach. The external examiners have advised us to go back to a style of one type of project, and one type of language to help narrow the assessment criteria for the students.
|
||||
1. Give students regular feedback on their performance at every stage. This could be done during the mentoring meetings with the teams, or at other stages, to help them improve the work for next time.
|
||||
1. Students are more than willing to work with clients from outside university! They look forward to working with external company representatives or people outside the university, just because of the new experience. They were all able to display professional behavior when interacting with their mentors, which put the instructors at ease.
|
||||
1. A lot of teams left developing unit testing until the end of the project, which from an extreme programming methodology standpoint was a serious no-no. Maybe testing should be included at the assessments of the various stages to help remind students that they need to be developing unit tests in parallel with the software.
|
||||
1. In the class of 80, there were only four girls, each working in different teams. I observed that boys were very ready to take on roles as team leads, assigning the most interesting code pieces to themselves and the girls were mostly following instructions or doing documentation. For some reason, the girls choose not to show authority or preferred not to code even when they were encouraged by a female instructor. This is still a major issue that needs to be addressed.
|
||||
1. There are different styles of documentation such as using UML, state diagrams, and others. Allow students to learn them all and merge with other courses during the year to improve their learning experience.
|
||||
1. Some students were very good developers, but some doing business computing had very little coding experience. The teams were encouraged to work together to prevent the idea that developer would get better marks than other team members if they were only doing meeting minutes or documentations. Roles were also encouraged to be rotated during mentoring sessions to see that everyone was getting a chance to learn how to program.
|
||||
1. Allowing the team to meet with the mentor every week was helpful in monitoring team activities. It also showed who was doing the most work. Usually students who were not participating in their groups would not come to meetings, and could be identified by the work being presented by other members every week.
|
||||
1. We encouraged students to attach licenses to their work and identify intellectual property issues when working with external libraries and clients. This allowed students to think out of the box and learn about real-world software delivery problems.
|
||||
1. Give students room to choose their own technologies.
|
||||
1. Having teaching assistants is key. Managing 80 students was very difficult, especially on the weeks when they were being assessed. Next year I would definitely have teaching assistants helping me with the teams.
|
||||
1. A supportive tech support for the lab is very important. The university tech support was extremely supportive of the course. Next year, they are talking about having virtual machines assigned to teams, so the teams can install any software on their own virtual machine as needed.
|
||||
1. Teamwork helps. Most teams exhibited a supportive nature to other team members, and mentoring also helped.
|
||||
1. Additional support from other staff members is a plus. As a new academic, I needed to learn from experience and also seek advice at multiple points on how to handle certain students and teams if I was confused on how to engage them with the course. Support from senior staff members was very encouraging to me.
|
||||
|
||||
In the end, it was a fun course—not only for the me as an instructor, but for the students as well. There were some issues with learning objectives and traditional grading schemes that still need to be ironed out to reduce the workload it produced on the instructors. For next year, I plan to keep this same format, but hope to come up with a better grading scheme and introduce more software tools that can help monitor project activities and code revisions.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://opensource.com/education/15/9/teaching-open-source-development-undergraduates
|
||||
|
||||
作者:[Mariam Kiran][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://opensource.com/users/mariamkiran
|
||||
[1]:https://basecamp.com/
|
||||
[2]:https://www.mantisbt.org/
|
||||
@ -1,85 +0,0 @@
|
||||
alim0x translating
|
||||
|
||||
The history of Android
|
||||
================================================================================
|
||||

|
||||
Yet another Android Market redesign dips its toe into the "cards" interface that would become a Google staple.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
The Android Market released its fourth new design in Android's two-and-a-half years on the market. This new design was hugely important as it came really close to Google's "cards" interface. By displaying Apps or other content in little blocks, Google could seamlessly transition its app design between screens of various sizes with minimal effort. Content could be displayed just like photos in a gallery app—feed the layout renderer a big list of content blocks, enable screen wrapping, and you were done. Bigger screens saw more blocks of content, and smaller screens only saw a few at a time. With the content display out of the way, Google added a "Categories" fragment to the right side and a big featured app carousel at the top.
|
||||
|
||||
While the design was ready for an easily configurable interface, the functionality was not. The original shipping version of the market was locked to a landscape orientation and was Honeycomb-exclusive.
|
||||
|
||||
|
||||
The app page and "My Apps" interface.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
This new market sold not only apps, but brought Books and Movies rentals into the fold as well. Google was selling books since 2010; it was only ever through a Website. The new market unified all of Google's content sales in a single location and brought it one step closer to taking on Apple's iTunes juggernaut, though selling all of these items under the "Android Market" was a bit of a branding snafu, as much of the content didn't require Android to use.
|
||||
|
||||
|
||||
The browser did its best to look like Chrome, and Contacts used a two-pane interface.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
The new Browser added an honest-to-goodness tabs strip at the top of the interface. While this browser wasn't Chrome, it aped a lot of Chrome's design and features. Besides the pioneering tabs-on-top interface, it added Incognito tabs, which kept no history or autocomplete records. There was also an option to have a Chrome-style new tab page consisting of thumbnails of your most-viewed webpages.
|
||||
|
||||
The new Browser even synced with Chrome. After signing in to the browser, it would download your Chrome bookmarks and automatically sign in to Google Web pages with your account. Bookmarking a page was as easy as tapping on the star icon in the address bar. Just like Google Maps, the browser dumped the zoom buttons and went with all gesture controls.
|
||||
|
||||
The contacts app was finally removed from the phone app and broken out into a standalone app. The previous contacts/dialer hybrid was far too phone-centric for how people use a modern smartphone. Contacts housed information for e-mails, IM, texting, addresses, birthdays, and social networks, so tying it to the phone app makes just as much sense as trying it to Google Maps. With the telephony requirements out of the way, contacts could be simplified to a tab-less list of people. Honeycomb went with a dual pane view showing the full contact list on the left and contacts on the right. This again made use of a Fragments API; a hypothetical phone version of this app could show each panel as a single screen.
|
||||
|
||||
The Honeycomb version of Contacts was the first version to have a quick scroll feature. When grabbing the left scroll bar, you could quickly scroll up and down, and a letter preview showed your current spot in the list.
|
||||
|
||||
|
||||
The new YouTube app looked like something out of the Matrix.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
YouTube thankfully dumped the "unique" design Google came up with for 2.3 and gave the video service a cohesive design that looked like it belonged in Android. The main screen was a horizontally scrolling curved wall of video thumbnails that showed a most popular or (when signed in) personalized selection of videos. While Google never brought this design to phones, it could be considered an easily reconfigurable card interface. The action bar shined here as a reconfigurable toolbar. When not signed it, the action bar was filled with a search bar. When you were signed in, search shrank down to a button, and tabs for "Home," "Browse," and "Your Channel" were shown.
|
||||
|
||||
|
||||
Honeycomb really liked to drive home that it was a computer interface with blue scaffolding. Movie Studio completes the Tron look with an orange theme.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
The lone new app in Honeycomb was "Movie Studio," which was not a self-explanatory app and arrived with no explanations or instructions. As far as we could tell, you could import video clips, cut them up, and add text and scene transitions. Editing video—one of the most time consuming, difficult, and processor-intensive things you can do on a computer—on a tablet felt just a little too ambitious, and Google would completely remove this app in later versions. Our favorite part of Movie Studio was that it really completed the Tron theme. While the rest of the OS used blue highlights, this was all orange. (Movie Studio is an evil program!)
|
||||
|
||||
|
||||
Widgets!
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Honeycomb brought a new widget framework that allowed for scrolling widgets, and the Gmail, Email, and Calendar widgets were upgraded to support it. YouTube and Books used a new widget that auto-scrolled through cards of content. By flicking up or down on the widget, you could scroll through the cards. We're not sure what the point of being constantly reminded of your book collection was, but it's there if you want it. While all of these widgets worked great on a 10-inch screen, Google never redesigned them for phones, making them practically useless on Android's most popular form factor. All the widgets had massive identifying headers and usually took up half the screen to show only a few items.
|
||||
|
||||
|
||||
The scrollable Recent Apps and resizable widgets in Android 3.1.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Later versions of Honeycomb would fix many of the early problems 3.0 had. Android 3.1 was released three months after the first version of Honeycomb, and it brought several improvements. Resizable widgets were one of the biggest features added. After long pressing on a widget, a blue outline with grabbable handles would pop up around it, and dragging the handles around would resize the widget. The Recent Apps panel could now scroll vertically and held many more apps. The only feature missing from it at this point was the ability to swipe away apps.
|
||||
|
||||
Today, an 0.1 upgrade is a major release, but in Honeycomb, point releases were considerably smaller. Besides the few UI tweaks, 3.1 added support for gamepads, keyboards, mice, and other input devices over USB and Bluetooth. It also offered a few more developer APIs.
|
||||
|
||||
|
||||
Android 3.2's compatibility zoom and a typical stretched-out app on an Android tablet.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Android 3.2 launched two months after 3.1, adding support for smaller sized tablets in the seven- to eight-inch range. It finally enabled SD card support, which the Xoom carried like a vestigial limb for the first five months of its life.
|
||||
|
||||
Honeycomb was rushed out the door in order to be an ecosystem builder. No one will want an Android tablet if the tablet-specific apps aren't there, and Google knew it needed to get something in the hands of developers ASAP. At this early stage of Android's tablet ecosystem, the apps just weren't there. It was the biggest problem people had with the Xoom.
|
||||
|
||||
3.2 added "Compatibility Zoom," which gave users a new option of stretching apps to the screen (as shown in the right picture) or zooming the normal app layout to fit the screen. Neither option was ideal, and without the app ecosystem to support it, Honeycomb devices sold pretty poorly. Google's tablet moves would eventually pay off though. Today, Android tablets have [taken the market share crown from iOS][1].
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||
[Ron Amadeo][a] / Ron is the Reviews Editor at Ars Technica, where he specializes in Android OS and Google products. He is always on the hunt for a new gadget and loves to rip things apart to see how they work.
|
||||
|
||||
[@RonAmadeo][t]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/18/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://techcrunch.com/2014/03/03/gartner-195m-tablets-sold-in-2013-android-grabs-top-spot-from-ipad-with-62-share/
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
@ -0,0 +1,84 @@
|
||||
(translating by runningwater)
|
||||
Best command line tools for linux performance monitoring
|
||||
================================================================================
|
||||
Sometimes a system can be slow and many reasons can be the root cause. To identify the process that is consuming memory, disk I/O or processor capacity you need to use tools to see what is happening in an operation system.
|
||||
|
||||
There are many tools to monitor a GNU/Linux server. In this article, I am providing 7 monitoring tools and i hope it will help you.
|
||||
|
||||
###Htop
|
||||
Htop is an alternative of top command but it provides interactive system-monitor process-viewer and more user friendly output than top.
|
||||
|
||||
htop also provides a better way to navigate to any process using keyboard Up/Down keys as well as we can also operate it using mouse.
|
||||
|
||||
For Check our previous post:[How to install and use htop on RHEL/Centos and Fedora linux][1]
|
||||
|
||||
###dstat
|
||||
Dstat is a versatile replacement for vmstat, iostat, netstat and ifstat. Dstat overcomes some of their limitations and adds some extra features, more counters and flexibility. Dstat is handy for monitoring systems during performance tuning tests, benchmarks or troubleshooting.
|
||||
|
||||
Dstat allows you to view all of your system resources in real-time, you can eg. compare disk utilization in combination with interrupts from your IDE controller, or compare the network bandwidth numbers directly with the disk throughput (in the same interval).
|
||||
Dstat gives you detailed selective information in columns and clearly indicates in what magnitude and unit the output is displayed. Less confusion, less mistakes. And most importantly, it makes it very easy to write plugins to collect your own counters and extend in ways you never expected.
|
||||
|
||||
Dstat’s output by default is designed for being interpreted by humans in real-time, however you can export details to CSV output to a file to be imported later into Gnumeric or Excel to generate graphs.
|
||||
Check our previous post:[How to install and use dstat on RHEL/CentOS,Fedora and Debian/Ubuntu based distribution][2]
|
||||
|
||||
###Collectl
|
||||
Collectl is a light-weight performance monitoring tool capable of reporting interactively as well as logging to disk. It reports statistics on cpu, disk, infiniband, lustre, memory, network, nfs, process, quadrics, slabs and more in easy to read format.
|
||||
In this article i will show you how to install and sample usage Collectl on Debian/Ubuntu and RHEL/Centos and Fedora linux.
|
||||
|
||||
Check our previous post:[Collectl-Monitoring system resources][3]
|
||||
|
||||
|
||||
###Nmon
|
||||
nmon is a beutiful tool to monitor linux system performance. It works on Linux, IBM AIX Unix, Power,x86, amd64 and ARM based system such as Raspberry Pi. The nmon command displays and recordslocal system information. The command can run either in interactive or recording mode.
|
||||
|
||||
Check our previous post: [Nmon – linux monitoring tools][4]
|
||||
|
||||
###Saidar
|
||||
Saidar is a curses-based application to display system statistics. It use the libstatgrab library, which provides cross platform access to statistics about the system on which it’s run. Reported statistics includeCPU, load, processes, memory, swap, network input and output and disks activities along with their free space.
|
||||
|
||||
Check our previous post:[Saidar – system monitoring tool][5]
|
||||
|
||||
###Sar
|
||||
The sar utility, which is part of the systat package, can be used to review history performance data on your server. System resource utilization can be seen for given time frames to help troubleshoot performance issues, or to optimize performance.
|
||||
|
||||
Check our previous post:[Using Sar To Monitor System Performance][6]
|
||||
|
||||
|
||||
###Glances
|
||||
Glances is a cross-platform curses-based command line monitoring tool writen in Python which use the psutil library to grab informations from the system. Glance monitoring CPU, Load Average, Memory, Network Interfaces, Disk I/O, Processesand File System spaces utilization.
|
||||
|
||||
Glances can adapt dynamically the displayed information depending on the terminal siwrize. It can also work in a client/server mode for remote monitoring.
|
||||
|
||||
Check our previous post: [Glances – Real Time System Monitoring Tool for Linux][7]
|
||||
|
||||
|
||||
###Atop
|
||||
[Atop](http://www.atoptool.nl/) is an interactive monitor to view the load on a Linux system. It shows the occupation of the most critical hardware resources on system level, i.e. cpu, memory, disk and network. It also shows which processes are responsible for the indicated load with respect to cpu- and memory load on process level. Disk load is shown if per process “storage accounting” is active in the kernel or if the kernel patch ‘cnt’ has been installed. Network load is only shown per process if the kernel patch ‘cnt’ has been installed.
|
||||
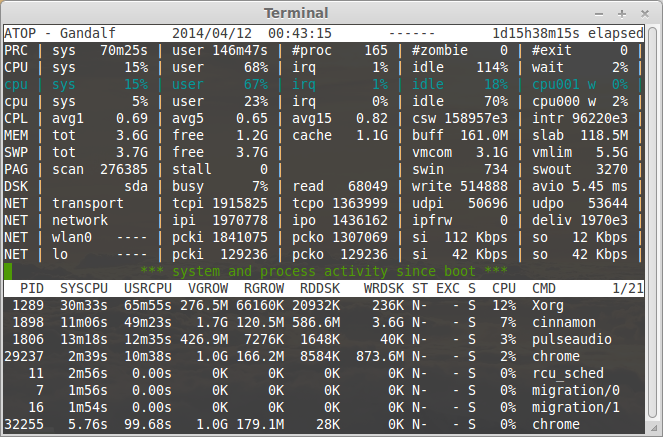
|
||||
For more about Atop check next post:[Atop - monitor system resources in linux][8]
|
||||
So, if you come across any other similar tool then let us know in the comment box below.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://lintut.com/best-command-line-tools-for-linux-performance-monitring/
|
||||
|
||||
作者:[rasho][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[1]:http://lintut.com/install-htop-in-rhel-centos-fedora-linux/
|
||||
[2]:http://lintut.com/dstat-linux-monitoring-tools/
|
||||
[3]:http://lintut.com/collectl-monitoring-system-resources/
|
||||
[4]:http://lintut.com/nmon-linux-monitoring-tools/
|
||||
[5]:http://lintut.com/saidar-system-monitoring-tool/
|
||||
[6]:http://lintut.com/using-sar-to-monitor-system-performance/
|
||||
[7]:http://lintut.com/glances-an-eye-on-your-system/
|
||||
[8]:http://lintut.com/atop-linux-system-resource-monitor/
|
||||
@ -1,54 +0,0 @@
|
||||
ictlyh Translating
|
||||
Do Simple Math In Ubuntu And elementary OS With NaSC
|
||||
================================================================================
|
||||

|
||||
|
||||
[NaSC][1], abbreviation Not a Soulver Clone, is a third party app developed for elementary OS. Whatever the name suggests, NaSC is heavily inspired by [Soulver][2], an OS X app for doing maths like a normal person.
|
||||
|
||||
elementary OS itself draws from OS X and it is not a surprise that a number of the third party apps it has got, are also inspired by OS X apps.
|
||||
|
||||
Coming back to NaSC, what exactly it means by “maths like a normal person “? Well, it means to write like how you think in your mind. As per the description of the app:
|
||||
|
||||
> “Its an app where you do maths like a normal person. It lets you type whatever you want and smartly figures out what is math and spits out an answer on the right pane. Then you can plug those answers in to future equations and if that answer changes, so does the equations its used in.”
|
||||
|
||||
Still not convinced? Here, take a look at this screenshot.
|
||||
|
||||

|
||||
|
||||
Now, you see what is ‘math for normal person’? Honestly, I am not a fan of such apps but it might be useful for some of you perhaps. Let’s see how can you install NaSC in elementary OS, Ubuntu and Linux Mint.
|
||||
|
||||
### Install NaSC in Ubuntu, elementary OS and Mint ###
|
||||
|
||||
There is a PPA available for installing NaSC. The PPA says ‘daily’ which could mean daily build (i.e. unstable) but in my quick test, it worked just fine.
|
||||
|
||||
Open a terminal and use the following commands:
|
||||
|
||||
sudo apt-add-repository ppa:nasc-team/daily
|
||||
sudo apt-get update
|
||||
sudo apt-get install nasc
|
||||
|
||||
Here is a screenshot of NaSC in Ubuntu 15.04:
|
||||
|
||||

|
||||
|
||||
If you want to remove it, you can use the following commands:
|
||||
|
||||
sudo apt-get remove nasc
|
||||
sudo apt-add-repository --remove ppa:nasc-team/daily
|
||||
|
||||
If you try it, do share your experience with it. In addition to this, you can also try [Vocal podcast app for Linux][3] from third party elementary OS apps.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/math-ubuntu-nasc/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://parnold-x.github.io/nasc/
|
||||
[2]:http://www.acqualia.com/soulver/
|
||||
[3]:http://itsfoss.com/podcast-app-vocal-linux/
|
||||
@ -1,117 +0,0 @@
|
||||
ictlyh Translating
|
||||
How To Manage Log Files With Logrotate On Ubuntu 12.10
|
||||
================================================================================
|
||||
#### About Logrotate ####
|
||||
|
||||
Logrotate is a utility/tool that manages activities like automatic rotation, removal and compression of log files in a system. This is an excellent tool to manage your logs conserve precious disk space. By having a simple yet powerful configuration file, different parameters of logrotation can be controlled. This gives complete control over the way logs can be automatically managed and need not necessitate manual intervention.
|
||||
|
||||
### Prerequisites ###
|
||||
|
||||
As a prerequisite, we are assuming that you have gone through the article on how to set up your droplet or VPS. If not, you can find the article [here][1]. This tutorial requires you to have a VPS up and running and have you log into it.
|
||||
|
||||
#### Setup Logrotate ####
|
||||
|
||||
### Step 1—Update System and System Packages ###
|
||||
|
||||
Run the following command to update the package lists from apt-get and get the information on the newest versions of packages and their dependencies.
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
### Step 2—Install Logrotate ###
|
||||
|
||||
If logrotate is not already on your VPS, install it now through apt-get.
|
||||
|
||||
sudo apt-get install logrotate
|
||||
|
||||
### Step 3 — Confirmation ###
|
||||
|
||||
To verify that logrotate was successfully installed, run this in the command prompt.
|
||||
|
||||
logrotate
|
||||
|
||||
Since the logrotate utility is based on configuration files, the above command will not rotate any files and will show you a brief overview of the usage and the switch options available.
|
||||
|
||||
### Step 4—Configure Logrotate ###
|
||||
|
||||
Configurations and default options for the logrotate utility are present in:
|
||||
|
||||
/etc/logrotate.conf
|
||||
|
||||
Some of the important configuration settings are : rotation-interval, log-file-size, rotation-count and compression.
|
||||
|
||||
Application-specific log file information (to override the defaults) are kept at:
|
||||
|
||||
/etc/logrotate.d/
|
||||
|
||||
We will have a look at a few examples to understand the concept better.
|
||||
|
||||
### Step 5—Example ###
|
||||
|
||||
An example application configuration setting would be the dpkg (Debian package management system), that is stored in /etc/logrotate.d/dpkg. One of the entries in this file would be:
|
||||
|
||||
/var/log/dpkg.log {
|
||||
monthly
|
||||
rotate 12
|
||||
compress
|
||||
delaycompress
|
||||
missingok
|
||||
notifempty
|
||||
create 644 root root
|
||||
}
|
||||
|
||||
What this means is that:
|
||||
|
||||
- the logrotation for dpkg monitors the /var/log/dpkg.log file and does this on a monthly basis this is the rotation interval.
|
||||
- 'rotate 12' signifies that 12 days worth of logs would be kept.
|
||||
- logfiles can be compressed using the gzip format by specifying 'compress' and 'delaycompress' delays the compression process till the next log rotation. 'delaycompress' will work only if 'compress' option is specified.
|
||||
- 'missingok' avoids halting on any error and carries on with the next log file.
|
||||
- 'notifempty' avoid log rotation if the logfile is empty.
|
||||
- 'create <mode> <owner> <group>' creates a new empty file with the specified properties after log-rotation.
|
||||
|
||||
Though missing in the above example, 'size' is also an important setting if you want to control the sizing of the logs growing in the system.
|
||||
|
||||
A configuration setting of around 100MB would look like:
|
||||
|
||||
size 100M
|
||||
|
||||
Note that If both size and rotation interval are set, then size is taken as a higher priority. That is, if a configuration file has the following settings:
|
||||
|
||||
monthly
|
||||
size 100M
|
||||
|
||||
then the logs are rotated once the file size reaches 100M and this need not wait for the monthly cycle.
|
||||
|
||||
### Step 6—Cron Job ###
|
||||
|
||||
You can also set the logrotation as a cron so that the manual process can be avoided and this is taken care of automatically. By specifying an entry in /etc/cron.daily/logrotate , the rotation is triggered daily.
|
||||
|
||||
### Step 7—Status Check and Verification ###
|
||||
|
||||
To verify if a particular log is indeed rotating or not and to check the last date and time of its rotation, check the /var/lib/logrotate/status file. This is a neatly formatted file that contains the log file name and the date on which it was last rotated.
|
||||
|
||||
cat /var/lib/logrotate/status
|
||||
|
||||
A few entries from this file, for example:
|
||||
|
||||
"/var/log/lpr.log" 2013-4-11
|
||||
"/var/log/dpkg.log" 2013-4-11
|
||||
"/var/log/pm-suspend.log" 2013-4-11
|
||||
"/var/log/syslog" 2013-4-11
|
||||
"/var/log/mail.info" 2013-4-11
|
||||
"/var/log/daemon.log" 2013-4-11
|
||||
"/var/log/apport.log" 2013-4-11
|
||||
|
||||
Congratulations! You have logrotate installed in your system. Now, change the configuration settings as per your requirements.
|
||||
|
||||
Try 'man logrotate' or 'logrotate -?' for more details.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.digitalocean.com/community/tutorials/how-to-manage-log-files-with-logrotate-on-ubuntu-12-10
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.digitalocean.com/community/articles/initial-server-setup-with-ubuntu-12-04
|
||||
@ -1,103 +0,0 @@
|
||||
translating by cvsher
|
||||
How To Set Up Your FTP Server In Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
In this lesson, I will explain to you how to Set up your FTP server. But first, let me quickly tell you what is FTP.
|
||||
|
||||
### What is FTP? ###
|
||||
|
||||
[FTP][1] is an acronym for File Transfer Protocol. As the name suggests, FTP is used to transfer files between computers on a network. You can use FTP to exchange files between computer accounts, transfer files between an account and a desktop computer, or access online software archives. Keep in mind, however, that many FTP sites are heavily used and require several attempts before connecting.
|
||||
|
||||
An FTP address looks a lot like an HTTP or website address except it uses the prefix ftp:// instead of http://.
|
||||
|
||||
### What is an FTP Server? ###
|
||||
|
||||
Typically, a computer with an FTP address is dedicated to receive an FTP connection. A computer dedicated to receiving an FTP connection is referred to as an FTP server or FTP site.
|
||||
|
||||
Now, let’s begin a special adventure. We will make FTP server to share files with friends and family. I will use [vsftpd][2] for this purpose.
|
||||
|
||||
VSFTPD is an FTP server software which claims to be the most secure FTP software. In fact, the first two letters in VSFTPD, stand for “very secure”. The software was built around the vulnerabilities of the FTP protocol.
|
||||
|
||||
Nevertheless, you should always remember that there are better solutions for secure transfer and management of files such as SFTP (uses [OpenSSH][3]). The FTP protocol is particularly useful for sharing non-sensitive data and is very reliable at that.
|
||||
|
||||
#### Installing VSFTPD in rpm distributions: ####
|
||||
|
||||
You can quickly install VSFTPD on your server through the command line interface with:
|
||||
|
||||
dnf -y install vsftpd
|
||||
|
||||
#### Installing VSFTPD in deb distributions: ####
|
||||
|
||||
You can quickly install VSFTPD on your server through the command line interface with:
|
||||
|
||||
sudo apt-get install vsftpd
|
||||
|
||||
#### Installing VSFTPD in Arch distribution: ####
|
||||
|
||||
You can quickly install VSFTPD on your server through the command line interface with:
|
||||
|
||||
sudo pacman -S vsftpd
|
||||
|
||||
#### Configuring FTP server ####
|
||||
|
||||
Most VSFTPD’s configuration takes place in /etc/vsftpd.conf. The file itself is well-documented, so this section only highlights some important changes you may want to make. For all available options and basic documentation see the man pages:
|
||||
|
||||
man vsftpd.conf
|
||||
|
||||
Files are served by default from /srv/ftp as per the Filesystem Hierarchy Standard.
|
||||
|
||||
**Enable Uploading:**
|
||||
|
||||
The “write_enable” flag must be set to YES in order to allow changes to the filesystem, such as uploading:
|
||||
|
||||
write_enable=YES
|
||||
|
||||
**Allow Local Users to Login:**
|
||||
|
||||
In order to allow users in /etc/passwd to login, the “local_enable” directive must look like this:
|
||||
|
||||
local_enable=YES
|
||||
|
||||
**Anonymous Login**
|
||||
|
||||
The following lines control whether anonymous users can login:
|
||||
|
||||
# Allow anonymous login
|
||||
|
||||
anonymous_enable=YES
|
||||
# No password is required for an anonymous login (Optional)
|
||||
no_anon_password=YES
|
||||
# Maximum transfer rate for an anonymous client in Bytes/second (Optional)
|
||||
anon_max_rate=30000
|
||||
# Directory to be used for an anonymous login (Optional)
|
||||
anon_root=/example/directory/
|
||||
|
||||
**Chroot Jail**
|
||||
|
||||
It is possible to set up a chroot environment, which prevents the user from leaving his home directory. To enable this, add/change the following lines in the configuration file:
|
||||
|
||||
chroot_list_enable=YES chroot_list_file=/etc/vsftpd.chroot_list
|
||||
|
||||
The “chroot_list_file” variable specifies the file in which the jailed users are contained to.
|
||||
|
||||
In the end you must restart your ftp server. Type in your command line
|
||||
|
||||
sudo systemctl restart vsftpd
|
||||
|
||||
That’s it. Your FTP server is up and running.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/set-ftp-server-linux/
|
||||
|
||||
作者:[alimiracle][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/ali/
|
||||
[1]:https://en.wikipedia.org/wiki/File_Transfer_Protocol
|
||||
[2]:https://security.appspot.com/vsftpd.html
|
||||
[3]:http://www.openssh.com/
|
||||
@ -1,113 +0,0 @@
|
||||
How to Install QGit Viewer in Ubuntu 14.04
|
||||
================================================================================
|
||||
QGit is a free and Open Source GUI git viewer written on Qt and C++ by Marco Costalba. It is a better git viewer which provides us the ability to browse revisions history, view commits and patches applied to the files under a simple GUI environment. It utilizes git command line to process execute the commands and to display the output. It has some common features like to view revisions, diffs, files history, files annotation, archive tree. We can format and apply patch series with the selected commits, drag and drop commits between two instances and more with QGit Viewer. It allows us to create custom buttons with which we can add more buttons to execute a specific command when pressed using its builtin Action Builder.
|
||||
|
||||
Here are some easy steps on how we can compile and install QGit Viewer from its source code in Ubuntu 14.04 LTS "Trusty".
|
||||
|
||||
### 1. Installing QT4 Libraries ###
|
||||
|
||||
First of all, we'll need have QT4 Libraries installed in order to run QGit viewer in our ubuntu machine. As apt is the default package manager of ubuntu and QT4 packages is available in the official repository of ubutnu, we'll gonna install qt4-default using apt-get command as shown below.
|
||||
|
||||
$ sudo apt-get install qt4-default
|
||||
|
||||
### 2. Downloading QGit Tarball ###
|
||||
|
||||
After installing Qt4 libraries, we'll gonna install git so that we can clone the Git repository of QGit Viewer for Qt 4 . To do so, we'll run the following apt-get command.
|
||||
|
||||
$ sudo apt-get install git
|
||||
|
||||
Now, we'll clone the repository using git command as shown below.
|
||||
|
||||
$ git clone git://repo.or.cz/qgit4/redivivus.git
|
||||
|
||||
Cloning into 'redivivus'...
|
||||
remote: Counting objects: 7128, done.
|
||||
remote: Compressing objects: 100% (2671/2671), done.
|
||||
remote: Total 7128 (delta 5464), reused 5711 (delta 4438)
|
||||
Receiving objects: 100% (7128/7128), 2.39 MiB | 470.00 KiB/s, done.
|
||||
Resolving deltas: 100% (5464/5464), done.
|
||||
Checking connectivity... done.
|
||||
|
||||
### 3. Compiling QGit ###
|
||||
|
||||
After we have cloned the repository, we'll now enter into the directory named redivivus and create the makefile which we'll require to compile qgit viewer. So, to enter into the directory, we'll run the following command.
|
||||
|
||||
$ cd redivivus
|
||||
|
||||
Next, we'll run the following command in order to generate a new Makefile from qmake project file ie qgit.pro.
|
||||
|
||||
$ qmake qgit.pro
|
||||
|
||||
After the Makefile has been generated, we'll now finally compile the source codes of qgit and get the binary as output. To do so, first we'll need to install make and g++ package so that we can compile, as it is a program written in C++ .
|
||||
|
||||
$ sudo apt-get install make g++
|
||||
|
||||
Now, we'll gonna compile the codes using make command.
|
||||
|
||||
$ make
|
||||
|
||||
### 4. Installing QGit ###
|
||||
|
||||
As we have successfully compiled the source code of QGit viewer, now we'll surely wanna install it in our Ubuntu 14.04 machine so that we can execute it from our system. To do so, we'll run the following command.
|
||||
|
||||
$ sudo make install
|
||||
|
||||
cd src/ && make -f Makefile install
|
||||
make[1]: Entering directory `/home/arun/redivivus/src'
|
||||
make -f Makefile.Release install
|
||||
make[2]: Entering directory `/home/arun/redivivus/src'
|
||||
install -m 755 -p "../bin/qgit" "/usr/lib/x86_64-linux-gnu/qt4/bin/qgit"
|
||||
strip "/usr/lib/x86_64-linux-gnu/qt4/bin/qgit"
|
||||
make[2]: Leaving directory `/home/arun/redivivus/src'
|
||||
make[1]: Leaving directory `/home/arun/redivivus/src'
|
||||
|
||||
Next, we'll need to copy the built qgit binary file from bin directory to /usr/bin/ directory so that it will be available as global command.
|
||||
|
||||
$ sudo cp bin/qgit /usr/bin/
|
||||
|
||||
### 5. Creating Desktop File ###
|
||||
|
||||
As we have successfully installed qgit in our Ubuntu box, we'll now go for create a desktop file so that QGit will be available under Menu or Launcher of our Desktop Environment. To do so, we'll need to create a new file named qgit.desktop under /usr/share/applications/ directory.
|
||||
|
||||
$ sudo nano /usr/share/applications/qgit.desktop
|
||||
|
||||
Then, we'll need to paste the following lines into the file.
|
||||
|
||||
[Desktop Entry]
|
||||
Name=qgit
|
||||
GenericName=git GUI viewer
|
||||
Exec=qgit
|
||||
Icon=qgit
|
||||
Type=Application
|
||||
Comment=git GUI viewer
|
||||
Terminal=false
|
||||
MimeType=inode/directory;
|
||||
Categories=Qt;Development;RevisionControl;
|
||||
|
||||
After done, we'll simply save the file and exit.
|
||||
|
||||
### 6. Running QGit Viewer ###
|
||||
|
||||
After QGit is installed successfully in our Ubuntu box, we can now run it from any launcher or application menu. In order to run QGit from the terminal, we'll need to run as follows.
|
||||
|
||||
$ qgit
|
||||
|
||||
This will open the Qt4 Framework based QGit Viewer in GUI mode.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
QGit is really an awesome QT based git viewer. It is available on all three platforms Linux, Mac OSX and Microsoft Windows. It helps us to easily navigate to the history, revisions, branches and more from the available git repository. It reduces the need of running git command line for the common stuffs like viewing revisions, history, diff, etc as graphical interface of it makes easy to do tasks. The latest version of qgit is also available in the default repository of ubuntu which we can install using **apt-get install qgit** command. So, qgit makes our work pretty fast and easy to do with its simple GUI.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/install-qgit-viewer-ubuntu-14-04/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
@ -1,72 +0,0 @@
|
||||
Install Qmmp 0.9.0 Winamp-like Audio Player in Ubuntu
|
||||
================================================================================
|
||||

|
||||
|
||||
Qmmp, Qt-based audio player with winamp or xmms like user interface, now is at 0.9.0 release. PPA updated for Ubuntu 15.10, Ubuntu 15.04, Ubuntu 14.04, Ubuntu 12.04 and derivatives.
|
||||
|
||||
Qmmp 0.9.0 is a big release with many new features, improvements and some translation updates. It added:
|
||||
|
||||
- audio-channel sequence converter;
|
||||
- 9 channels support to equalizer;
|
||||
- album artist tag support;
|
||||
- asynchronous sorting;
|
||||
- sorting by file modification date;
|
||||
- sorting by album artist;
|
||||
- multiple column support;
|
||||
- feature to hide track length;
|
||||
- feature to disable plugins without qmmp.pri modification (qmake only)
|
||||
- feature to remember playlist scroll position;
|
||||
- feature to exclude cue data files;
|
||||
- feature to change user agent;
|
||||
- feature to change window title;
|
||||
- feature to reset fonts;
|
||||
- feature to restore default shortcuts;
|
||||
- default hotkey for the “Rename List” action;
|
||||
- feature to disable fadeout in the gme plugin;
|
||||
- Simple User Interface (QSUI) with the following changes:
|
||||
- added multiple column support;
|
||||
- added sorting by album artist;
|
||||
- added sorting by file modification date;
|
||||
- added feature to hide song length;
|
||||
- added default hotkey for the “Rename List” action;
|
||||
- added “Save List” action to the tab menu;
|
||||
- added feature to reset fonts;
|
||||
- added feature to reset shortcuts;
|
||||
- improved status bar;
|
||||
|
||||
It also improved playlist changes notification, playlist container, sample rate converter, cmake build scripts, title formatter, ape tags support in the mpeg plugin, fileops plugin, reduced cpu usage, changed default skin (to Glare) and playlist separator.
|
||||
|
||||

|
||||
|
||||
### Install Qmmp 0.9.0 in Ubuntu: ###
|
||||
|
||||
New release has been made into PPA, available for all current Ubuntu releases and derivatives.
|
||||
|
||||
1. To add the [Qmmp PPA][1].
|
||||
|
||||
Open terminal from the Dash, App Launcher, or via Ctrl+Alt+T shortcut keys. When it opens, run command:
|
||||
|
||||
sudo add-apt-repository ppa:forkotov02/ppa
|
||||
|
||||

|
||||
|
||||
2. After adding the PPA, upgrade Qmmp player through Software Updater. Or refresh system cache and install the software via below commands:
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install qmmp qmmp-plugin-pack
|
||||
|
||||
That’s it. Enjoy!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ubuntuhandbook.org/index.php/2015/09/qmmp-0-9-0-in-ubuntu/
|
||||
|
||||
作者:[Ji m][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ubuntuhandbook.org/index.php/about/
|
||||
[1]:https://launchpad.net/~forkotov02/+archive/ubuntu/ppa
|
||||
@ -1,451 +0,0 @@
|
||||
translation by strugglingyouth
|
||||
nstalling NGINX and NGINX Plus With Ansible
|
||||
================================================================================
|
||||
Coming from a production operations background, I have learned to love all things related to automation. Why do something by hand if a computer can do it for you? But creating and implementing automation can be a difficult task given an ever-changing infrastructure and the various technologies surrounding your environments. This is why I love [Ansible][1]. Ansible is an open source tool for IT configuration management, deployment, and orchestration that is extremely easy to use.
|
||||
|
||||
One of my favorite features of Ansible is that it is completely clientless. To manage a system, a connection is made over SSH, using either [Paramiko][2] (a Python library) or native [OpenSSH][3]. Another attractive feature of Ansible is its extensive selection of modules. These modules can be used to perform some of the common tasks of a system administrator. In particular, they make Ansible a powerful tool for installing and configuring any application across multiple servers, environments, and operating systems, all from one central location.
|
||||
|
||||
In this tutorial I will walk you through the steps for using Ansible to install and deploy the open source [NGINX][4] software and [NGINX Plus][5], our commercial product. I’m showing deployment onto a [CentOS][6] server, but I have included details about deploying on Ubuntu servers in [Creating an Ansible Playbook for Installing NGINX and NGINX Plus on Ubuntu][7] below.
|
||||
|
||||
For this tutorial I will be using Ansible version 1.9.2 and performing the deployment from a server running CentOS 7.1.
|
||||
|
||||
$ ansible --version
|
||||
ansible 1.9.2
|
||||
|
||||
$ cat /etc/redhat-release
|
||||
CentOS Linux release 7.1.1503 (Core)
|
||||
|
||||
If you don’t already have Ansible, you can get instructions for installing it [at the Ansible site][8].
|
||||
|
||||
If you are using CentOS, installing Ansible is easy as typing the following command. If you want to compile from source or for other distributions, see the instructions at the Ansible link provided just above.
|
||||
|
||||
$ sudo yum install -y epel-release && sudo yum install -y ansible
|
||||
|
||||
Depending on your environment, some of the commands in this tutorial might require sudo privileges. The path to the files, usernames, and destination servers are all values that will be specific to your environment.
|
||||
|
||||
### Creating an Ansible Playbook for Installing NGINX (CentOS) ###
|
||||
|
||||
First we create a working directory for our NGINX deployment, along with subdirectories and deployment configuration files. I usually recommend creating the directory in your home directory and show that in all examples in this tutorial.
|
||||
|
||||
$ cd $HOME
|
||||
$ mkdir -p ansible-nginx/tasks/
|
||||
$ touch ansible-nginx/deploy.yml
|
||||
$ touch ansible-nginx/tasks/install_nginx.yml
|
||||
|
||||
The directory structure now looks like this. You can check by using the tree command.
|
||||
|
||||
$ tree $HOME/ansible-nginx/
|
||||
/home/kjones/ansible-nginx/
|
||||
├── deploy.yml
|
||||
└── tasks
|
||||
└── install_nginx.yml
|
||||
|
||||
1 directory, 2 files
|
||||
|
||||
If you do not have tree installed, you can do so using the following command.
|
||||
|
||||
$ sudo yum install -y tree
|
||||
|
||||
#### Creating the Main Deployment File ####
|
||||
|
||||
Next we open **deploy.yml** in a text editor. I prefer vim for editing configuration files on the command line, and will use it throughout the tutorial.
|
||||
|
||||
$ vim $HOME/ansible-nginx/deploy.yml
|
||||
|
||||
The **deploy.yml** file is our main Ansible deployment file, which we’ll reference when we run the ansible‑playbook command in [Running Ansible to Deploy NGINX][9]. Within this file we specify the inventory for Ansible to use along with any other configuration files to include at runtime.
|
||||
|
||||
In my example I use the [include][10] module to specify a configuration file that has the steps for installing NGINX. While it is possible to create a playbook in one very large file, I recommend that you separate the steps into smaller included files to keep things organized. Sample use cases for an include are copying static content, copying configuration files, or assigning variables for a more advanced deployment with configuration logic.
|
||||
|
||||
Type the following lines into the file. I include the filename at the top in a comment for reference.
|
||||
|
||||
# ./ansible-nginx/deploy.yml
|
||||
|
||||
- hosts: nginx
|
||||
tasks:
|
||||
- include: 'tasks/install_nginx.yml'
|
||||
|
||||
The hosts statement tells Ansible to deploy to all servers in the **nginx** group, which is defined in **/etc/ansible/hosts**. We’ll edit this file in [Creating the List of NGINX Servers below][11].
|
||||
|
||||
The include statement tells Ansible to read in and execute the contents of the **install_nginx.yml** file from the **tasks** directory during deployment. The file includes the steps for downloading, installing, and starting NGINX. We’ll create this file in the next section.
|
||||
|
||||
#### Creating the Deployment File for NGINX ####
|
||||
|
||||
Now let’s save our work to **deploy.yml** and open up **install_nginx.yml** in the editor.
|
||||
|
||||
$ vim $HOME/ansible-nginx/tasks/install_nginx.yml
|
||||
|
||||
The file is going to contain the instructions – written in [YAML][12] format – for Ansible to follow when installing and configuring our NGINX deployment. Each section (step in the process) starts with a name statement (preceded by hyphen) that describes the step. The string following name: is written to stdout during the Ansible deployment and can be changed as you wish. The next line of a section in the YAML file is the module that will be used during that deployment step. In the configuration below, both the [yum][13] and [service][14] modules are used. The yum module is used to install packages on CentOS. The service module is used to manage UNIX services. The final line or lines in a section specify any parameters for the module (in the example, these lines start with name and state).
|
||||
|
||||
Type the following lines into the file. As with **deploy.yml**, the first line in our file is a comment that names the file for reference. The first section tells Ansible to install the **.rpm** file for CentOS 7 from the NGINX repository. This directs the package manager to install the most recent stable version of NGINX directly from NGINX. Modify the pathname as necessary for your CentOS version. A list of available packages can be found on the [open source NGINX website][15]. The next two sections tell Ansible to install the latest NGINX version using the yum module and then start NGINX using the service module.
|
||||
|
||||
**Note:** In the first section, the pathname to the CentOS package appears on two lines only for space reasons. Type the entire path on a single line.
|
||||
|
||||
# ./ansible-nginx/tasks/install_nginx.yml
|
||||
|
||||
- name: NGINX | Installing NGINX repo rpm
|
||||
yum:
|
||||
name: http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.noarch.rpm
|
||||
|
||||
- name: NGINX | Installing NGINX
|
||||
yum:
|
||||
name: nginx
|
||||
state: latest
|
||||
|
||||
- name: NGINX | Starting NGINX
|
||||
service:
|
||||
name: nginx
|
||||
state: started
|
||||
|
||||
#### Creating the List of NGINX Servers ####
|
||||
|
||||
Now that we have our Ansible deployment configuration files all set up, we need to tell Ansible exactly which servers to deploy to. We specify this in the Ansible **hosts** file I mentioned earlier. Let’s make a backup of the existing file and create a new one just for our deployment.
|
||||
|
||||
$ sudo mv /etc/ansible/hosts /etc/ansible/hosts.backup
|
||||
$ sudo vim /etc/ansible/hosts
|
||||
|
||||
Type (or edit) the following lines in the file to create a group called **nginx** and list the servers to install NGINX on. You can designate servers by hostname, IP address, or in an array such as **server[1-3].domain.com**. Here I designate one server by its IP address.
|
||||
|
||||
# /etc/ansible/hosts
|
||||
|
||||
[nginx]
|
||||
172.16.239.140
|
||||
|
||||
#### Setting Up Security ####
|
||||
|
||||
We are almost all set, but before deployment we need to ensure that Ansible has authorization to access our destination server over SSH.
|
||||
|
||||
The preferred and most secure method is to add the Ansible deployment server’s RSA SSH key to the destination server’s **authorized_keys** file, which gives Ansible unrestricted SSH permissions on the destination server. To learn more about this configuration, see [Securing OpenSSH][16] on wiki.centos.org. This way you can automate your deployments without user interaction.
|
||||
|
||||
Alternatively, you can request the password interactively during deployment. I strongly recommend that you use this method during testing only, because it is insecure and there is no way to track changes to a destination host’s fingerprint. If you want to do this, change the value of StrictHostKeyChecking from the default yes to no in the **/etc/ssh/ssh_config** file on each of your destination hosts. Then add the --ask-pass flag on the ansible-playbook command to have Ansible prompt for the SSH password.
|
||||
|
||||
Here I illustrate how to edit the **ssh_config** file to disable strict host key checking on the destination server. We manually SSH into the server to which we’ll deploy NGINX and change the value of StrictHostKeyChecking to no.
|
||||
|
||||
$ ssh kjones@172.16.239.140
|
||||
kjones@172.16.239.140's password:***********
|
||||
|
||||
[kjones@nginx ]$ sudo vim /etc/ssh/ssh_config
|
||||
|
||||
After you make the change, save **ssh_config**, and connect to your Ansible server via SSH. The setting should look as below before you save your work.
|
||||
|
||||
# /etc/ssh/ssh_config
|
||||
|
||||
StrictHostKeyChecking no
|
||||
|
||||
#### Running Ansible to Deploy NGINX ####
|
||||
|
||||
If you have followed the steps in this tutorial, you can run the following command to have Ansible deploy NGINX. (Again, if you have set up RSA SSH key authentication, then the --ask-pass flag is not needed.) Run the command on the Ansible server with the configuration files we created above.
|
||||
|
||||
$ sudo ansible-playbook --ask-pass $HOME/ansible-nginx/deploy.yml
|
||||
|
||||
Ansible prompts for the SSH password and produces output like the following. A recap that reports failed=0 like this one indicates that deployment succeeded.
|
||||
|
||||
$ sudo ansible-playbook --ask-pass $HOME/ansible-nginx/deploy.yml
|
||||
SSH password:
|
||||
|
||||
PLAY [all] ********************************************************************
|
||||
|
||||
GATHERING FACTS ***************************************************************
|
||||
ok: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX | Installing NGINX repo rpm] *************************************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX | Installing NGINX] **********************************************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX | Starting NGINX] ************************************************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
PLAY RECAP ********************************************************************
|
||||
172.16.239.140 : ok=4 changed=3 unreachable=0 failed=0
|
||||
|
||||
If you didn’t get a successful play recap, you can try running the ansible-playbook command again with the -vvvv flag (verbose with connection debugging) to troubleshoot the deployment process.
|
||||
|
||||
When deployment succeeds (as it did for us on the first try), you can verify that NGINX is running on the remote server by running the following basic [cURL][17] command. Here it returns 200 OK. Success! We have successfully installed NGINX using Ansible.
|
||||
|
||||
$ curl -Is 172.16.239.140 | grep HTTP
|
||||
HTTP/1.1 200 OK
|
||||
|
||||
### Creating an Ansible Playbook for Installing NGINX Plus (CentOS) ###
|
||||
|
||||
Now that I’ve shown you how to install the open source version of NGINX, I’ll walk you through the steps for installing NGINX Plus. This requires some additional changes to the deployment configuration and showcases some of Ansible’s other features.
|
||||
|
||||
#### Copying the NGINX Plus Certificate and Key to the Ansible Server ####
|
||||
|
||||
To install and configure NGINX Plus with Ansible, we first need to copy the key and certificate for our NGINX Plus subscription from the [NGINX Plus Customer Portal][18] to the standard location on the Ansible deployment server.
|
||||
|
||||
Access to the NGINX Plus Customer Portal is available for customers who have purchased NGINX Plus or are evaluating it. If you are interested in evaluating NGINX Plus, you can request a 30-day free trial [here][19]. You will receive a link to your trial certificate and key shortly after you sign up.
|
||||
|
||||
On a Mac or Linux host, use the [scp][20] utility as I show here. On a Microsoft Windows host, you can use [WinSCP][21]. For this tutorial, I downloaded the files to my Mac laptop, then used scp to copy them to the Ansible server. These commands place both the key and certificate in my home directory.
|
||||
|
||||
$ cd /path/to/nginx-repo-files/
|
||||
$ scp nginx-repo.* user@destination-server:.
|
||||
|
||||
Next we SSH to the Ansible server, make sure the SSL directory for NGINX Plus exists, and move the files there.
|
||||
|
||||
$ ssh user@destination-server
|
||||
$ sudo mkdir -p /etc/ssl/nginx/
|
||||
$ sudo mv nginx-repo.* /etc/ssl/nginx/
|
||||
|
||||
Verify that your **/etc/ssl/nginx** directory contains both the certificate (**.crt**) and key (**.key**) files. You can check by using the tree command.
|
||||
|
||||
$ tree /etc/ssl/nginx
|
||||
/etc/ssl/nginx
|
||||
├── nginx-repo.crt
|
||||
└── nginx-repo.key
|
||||
|
||||
0 directories, 2 files
|
||||
|
||||
If you do not have tree installed, you can do so using the following command.
|
||||
|
||||
$ sudo yum install -y tree
|
||||
|
||||
#### Creating the Ansible Directory Structure ####
|
||||
|
||||
The remaining steps are very similar to the ones for open source NGINX that we performed in [Creating an Ansible Playbook for Installing NGINX (CentOS)][22]. First we set up a working directory for our NGINX Plus deployment. Again I prefer creating it as a subdirectory of my home directory.
|
||||
|
||||
$ cd $HOME
|
||||
$ mkdir -p ansible-nginx-plus/tasks/
|
||||
$ touch ansible-nginx-plus/deploy.yml
|
||||
$ touch ansible-nginx-plus/tasks/install_nginx_plus.yml
|
||||
|
||||
The directory structure now looks like this.
|
||||
|
||||
$ tree $HOME/ansible-nginx-plus/
|
||||
/home/kjones/ansible-nginx-plus/
|
||||
├── deploy.yml
|
||||
└── tasks
|
||||
└── install_nginx_plus.yml
|
||||
|
||||
1 directory, 2 files
|
||||
|
||||
#### Creating the Main Deployment File ####
|
||||
|
||||
Next we use vim to create the **deploy.yml** file as for open source NGINX.
|
||||
|
||||
$ vim ansible-nginx-plus/deploy.yml
|
||||
|
||||
The only difference from the open source NGINX deployment is that we change the name of the included file to **install_nginx_plus.yml**. As a reminder, the file tells Ansible to deploy NGINX Plus on all servers in the **nginx** group (which is defined in **/etc/ansible/hosts**), and to read in and execute the contents of the **install_nginx_plus.yml** file from the **tasks** directory during deployment.
|
||||
|
||||
# ./ansible-nginx-plus/deploy.yml
|
||||
|
||||
- hosts: nginx
|
||||
tasks:
|
||||
- include: 'tasks/install_nginx_plus.yml'
|
||||
|
||||
If you have not done so already, you also need to create the hosts file as detailed in [Creating the List of NGINX Servers][23] above.
|
||||
|
||||
#### Creating the Deployment File for NGINX Plus ####
|
||||
|
||||
Open **install_nginx_plus.yml** in a text editor. The file is going to contain the instructions for Ansible to follow when installing and configuring your NGINX Plus deployment. The commands and modules are specific to CentOS and some are unique to NGINX Plus.
|
||||
|
||||
$ vim ansible-nginx-plus/tasks/install_nginx_plus.yml
|
||||
|
||||
The first section uses the [file][24] module, telling Ansible to create the SSL directory for NGINX Plus as specified by the path and state arguments, set the ownership to root, and change the mode to 0700.
|
||||
|
||||
# ./ansible-nginx-plus/tasks/install_nginx_plus.yml
|
||||
|
||||
- name: NGINX Plus | Creating NGINX Plus ssl cert repo directory
|
||||
file: path=/etc/ssl/nginx state=directory group=root mode=0700
|
||||
|
||||
The next two sections use the [copy][25] module to copy the NGINX Plus certificate and key from the Ansible deployment server to the NGINX Plus server during the deployment, again setting ownership to root and the mode to 0700.
|
||||
|
||||
- name: NGINX Plus | Copying NGINX Plus repository certificate
|
||||
copy: src=/etc/ssl/nginx/nginx-repo.crt dest=/etc/ssl/nginx/nginx-repo.crt owner=root group=root mode=0700
|
||||
|
||||
- name: NGINX Plus | Copying NGINX Plus repository key
|
||||
copy: src=/etc/ssl/nginx/nginx-repo.key dest=/etc/ssl/nginx/nginx-repo.key owner=root group=root mode=0700
|
||||
|
||||
Next we tell Ansible to use the [get_url][26] module to download the CA certificate from the NGINX Plus repository at the remote location specified by the url argument, put it in the directory specified by the dest argument, and set the mode to 0700.
|
||||
|
||||
- name: NGINX Plus | Downloading NGINX Plus CA certificate
|
||||
get_url: url=https://cs.nginx.com/static/files/CA.crt dest=/etc/ssl/nginx/CA.crt mode=0700
|
||||
|
||||
Similarly, we tell Ansible to download the NGINX Plus repo file using the get_url module and copy it to the **/etc/yum.repos.d** directory on the NGINX Plus server.
|
||||
|
||||
- name: NGINX Plus | Downloading yum NGINX Plus repository
|
||||
get_url: url=https://cs.nginx.com/static/files/nginx-plus-7.repo dest=/etc/yum.repos.d/nginx-plus-7.repo mode=0700
|
||||
|
||||
The final two name sections tell Ansible to install and start NGINX Plus using the yum and service modules.
|
||||
|
||||
- name: NGINX Plus | Installing NGINX Plus
|
||||
yum:
|
||||
name: nginx-plus
|
||||
state: latest
|
||||
|
||||
- name: NGINX Plus | Starting NGINX Plus
|
||||
service:
|
||||
name: nginx
|
||||
state: started
|
||||
|
||||
#### Running Ansible to Deploy NGINX Plus ####
|
||||
|
||||
After saving the **install_nginx_plus.yml** file, we run the ansible-playbook command to deploy NGINX Plus. Again here we include the --ask-pass flag to have Ansible prompt for the SSH password and pass it to each NGINX Plus server, and specify the path to the main Ansible **deploy.yml** file.
|
||||
|
||||
$ sudo ansible-playbook --ask-pass $HOME/ansible-nginx-plus/deploy.yml
|
||||
|
||||
PLAY [nginx] ******************************************************************
|
||||
|
||||
GATHERING FACTS ***************************************************************
|
||||
ok: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX Plus | Creating NGINX Plus ssl cert repo directory] **************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX Plus | Copying NGINX Plus repository certificate] ****************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX Plus | Copying NGINX Plus repository key] ************************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX Plus | Downloading NGINX Plus CA certificate] ********************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX Plus | Downloading yum NGINX Plus repository] ********************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX Plus | Installing NGINX Plus] ************************************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX Plus | Starting NGINX Plus] **************************************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
PLAY RECAP ********************************************************************
|
||||
172.16.239.140 : ok=8 changed=7 unreachable=0 failed=0
|
||||
|
||||
The playbook recap was successful. Now we can run a quick curl command to verify that NGINX Plus is running. Great, we get 200 OK! Success! We have successfully installed NGINX Plus with Ansible.
|
||||
|
||||
$ curl -Is http://172.16.239.140 | grep HTTP
|
||||
HTTP/1.1 200 OK
|
||||
|
||||
### Creating an Ansible Playbook for Installing NGINX and NGINX Plus on Ubuntu ###
|
||||
|
||||
The process for deploying NGINX and NGINX Plus on [Ubuntu servers][27] is pretty similar to the process on CentOS, so instead of providing step-by-step instructions I’ll show the complete deployment files and and point out the slight differences from CentOS.
|
||||
|
||||
First create the Ansible directory structure and the main Ansible deployment file, as for CentOS. Also create the **/etc/ansible/hosts** file as described in [Creating the List of NGINX Servers][28]. For NGINX Plus, you need to copy over the key and certificate as described in [Copying the NGINX Plus Certificate and Key to the Ansible Server][29].
|
||||
|
||||
Here’s the **install_nginx.yml** deployment file for open source NGINX. In the first section, we use the [apt_key][30] module to import the NGINX signing key. The next two sections use the [lineinfile][31] module to add the package URLs for Ubuntu 14.04 to the **sources.list** file. Lastly we use the [apt][32] module to update the cache and install NGINX (apt replaces the yum module we used for deploying to CentOS).
|
||||
|
||||
# ./ansible-nginx/tasks/install_nginx.yml
|
||||
|
||||
- name: NGINX | Adding NGINX signing key
|
||||
apt_key: url=http://nginx.org/keys/nginx_signing.key state=present
|
||||
|
||||
- name: NGINX | Adding sources.list deb url for NGINX
|
||||
lineinfile: dest=/etc/apt/sources.list line="deb http://nginx.org/packages/mainline/ubuntu/ trusty nginx"
|
||||
|
||||
- name: NGINX Plus | Adding sources.list deb-src url for NGINX
|
||||
lineinfile: dest=/etc/apt/sources.list line="deb-src http://nginx.org/packages/mainline/ubuntu/ trusty nginx"
|
||||
|
||||
- name: NGINX | Updating apt cache
|
||||
apt:
|
||||
update_cache: yes
|
||||
|
||||
- name: NGINX | Installing NGINX
|
||||
apt:
|
||||
pkg: nginx
|
||||
state: latest
|
||||
|
||||
- name: NGINX | Starting NGINX
|
||||
service:
|
||||
name: nginx
|
||||
state: started
|
||||
|
||||
Here’s the **install_nginx.yml** deployment file for NGINX Plus. The first four sections set up the NGINX Plus key and certificate. Then we use the apt_key module to import the signing key as for open source NGINX, and the get_url module to download the apt configuration file for NGINX Plus. The [shell][33] module evokes a printf command that writes its output to the **nginx-plus.list** file in the **sources.list.d** directory. The final name modules are the same as for open source NGINX.
|
||||
|
||||
# ./ansible-nginx-plus/tasks/install_nginx_plus.yml
|
||||
|
||||
- name: NGINX Plus | Creating NGINX Plus ssl cert repo directory
|
||||
file: path=/etc/ssl/nginx state=directory group=root mode=0700
|
||||
|
||||
- name: NGINX Plus | Copying NGINX Plus repository certificate
|
||||
copy: src=/etc/ssl/nginx/nginx-repo.crt dest=/etc/ssl/nginx/nginx-repo.crt owner=root group=root mode=0700
|
||||
|
||||
- name: NGINX Plus | Copying NGINX Plus repository key
|
||||
copy: src=/etc/ssl/nginx/nginx-repo.key dest=/etc/ssl/nginx/nginx-repo.key owner=root group=root mode=0700
|
||||
|
||||
- name: NGINX Plus | Downloading NGINX Plus CA certificate
|
||||
get_url: url=https://cs.nginx.com/static/files/CA.crt dest=/etc/ssl/nginx/CA.crt mode=0700
|
||||
|
||||
- name: NGINX Plus | Adding NGINX Plus signing key
|
||||
apt_key: url=http://nginx.org/keys/nginx_signing.key state=present
|
||||
|
||||
- name: NGINX Plus | Downloading Apt-Get NGINX Plus repository
|
||||
get_url: url=https://cs.nginx.com/static/files/90nginx dest=/etc/apt/apt.conf.d/90nginx mode=0700
|
||||
|
||||
- name: NGINX Plus | Adding sources.list url for NGINX Plus
|
||||
shell: printf "deb https://plus-pkgs.nginx.com/ubuntu `lsb_release -cs` nginx-plus\n" >/etc/apt/sources.list.d/nginx-plus.list
|
||||
|
||||
- name: NGINX Plus | Running apt-get update
|
||||
apt:
|
||||
update_cache: yes
|
||||
|
||||
- name: NGINX Plus | Installing NGINX Plus via apt-get
|
||||
apt:
|
||||
pkg: nginx-plus
|
||||
state: latest
|
||||
|
||||
- name: NGINX Plus | Start NGINX Plus
|
||||
service:
|
||||
name: nginx
|
||||
state: started
|
||||
|
||||
We’re now ready to run the ansible-playbook command:
|
||||
|
||||
$ sudo ansible-playbook --ask-pass $HOME/ansible-nginx-plus/deploy.yml
|
||||
|
||||
You should get a successful play recap. If you did not get a success, you can use the verbose flag to help troubleshoot your deployment as described in [Running Ansible to Deploy NGINX][34].
|
||||
|
||||
### Summary ###
|
||||
|
||||
What I demonstrated in this tutorial is just the beginning of what Ansible can do to help automate your NGINX or NGINX Plus deployment. There are many useful modules ranging from user account management to custom configuration templates. If you are interested in learning more about these, please visit the extensive [Ansible documentation][35 site.
|
||||
|
||||
To learn more about Ansible, come hear my talk on deploying NGINX Plus with Ansible at [NGINX.conf 2015][36], September 22–24 in San Francisco.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/
|
||||
|
||||
作者:[Kevin Jones][a]
|
||||
译者:[struggling](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.nginx.com/blog/author/kjones/
|
||||
[1]:http://www.ansible.com/
|
||||
[2]:http://www.paramiko.org/
|
||||
[3]:http://www.openssh.com/
|
||||
[4]:http://nginx.org/en/
|
||||
[5]:https://www.nginx.com/products/
|
||||
[6]:http://www.centos.org/
|
||||
[7]:https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/#ubuntu
|
||||
[8]:http://docs.ansible.com/ansible/intro_installation.html#installing-the-control-machine
|
||||
[9]:https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/#deploy-nginx
|
||||
[10]:http://docs.ansible.com/ansible/playbooks_roles.html#task-include-files-and-encouraging-reuse
|
||||
[11]:https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/#list-nginx
|
||||
[12]:http://docs.ansible.com/ansible/YAMLSyntax.html
|
||||
[13]:http://docs.ansible.com/ansible/yum_module.html
|
||||
[14]:http://docs.ansible.com/ansible/service_module.html
|
||||
[15]:http://nginx.org/en/linux_packages.html
|
||||
[16]:http://wiki.centos.org/HowTos/Network/SecuringSSH
|
||||
[17]:http://curl.haxx.se/
|
||||
[18]:https://cs.nginx.com/
|
||||
[19]:https://www.nginx.com/#free-trial
|
||||
[20]:http://linux.die.net/man/1/scp
|
||||
[21]:https://winscp.net/eng/download.php
|
||||
[22]:https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/#playbook-nginx
|
||||
[23]:https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/#list-nginx
|
||||
[24]:http://docs.ansible.com/ansible/file_module.html
|
||||
[25]:http://docs.ansible.com/ansible/copy_module.html
|
||||
[26]:http://docs.ansible.com/ansible/get_url_module.html
|
||||
[27]:http://www.ubuntu.com/
|
||||
[28]:https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/#list-nginx
|
||||
[29]:https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/#copy-cert-key
|
||||
[30]:http://docs.ansible.com/ansible/apt_key_module.html
|
||||
[31]:http://docs.ansible.com/ansible/lineinfile_module.html
|
||||
[32]:http://docs.ansible.com/ansible/apt_module.html
|
||||
[33]:http://docs.ansible.com/ansible/shell_module.html
|
||||
[34]:https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/#deploy-nginx
|
||||
[35]:http://docs.ansible.com/
|
||||
[36]:https://www.nginx.com/nginxconf/
|
||||
@ -1,63 +0,0 @@
|
||||
ictlyh Translating
|
||||
Make Math Simple in Ubuntu / Elementary OS via NaSC
|
||||
================================================================================
|
||||

|
||||
|
||||
NaSC (Not a Soulver Clone) is an open source software designed for Elementary OS to do arithmetics. It’s kinda similar to the Mac app [Soulver][1].
|
||||
|
||||
> Its an app where you do maths like a normal person. It lets you type whatever you want and smartly figures out what is math and spits out an answer on the right pane. Then you can plug those answers in to future equations and if that answer changes, so does the equations its used in.
|
||||
|
||||
With NaSC you can for example:
|
||||
|
||||
- Perform calculations with strangers you can define yourself
|
||||
- Change the units and values (in m cm, dollar euro …)
|
||||
- Knowing the surface area of a planet
|
||||
- Solve of second-degree polynomial
|
||||
- and more …
|
||||
|
||||
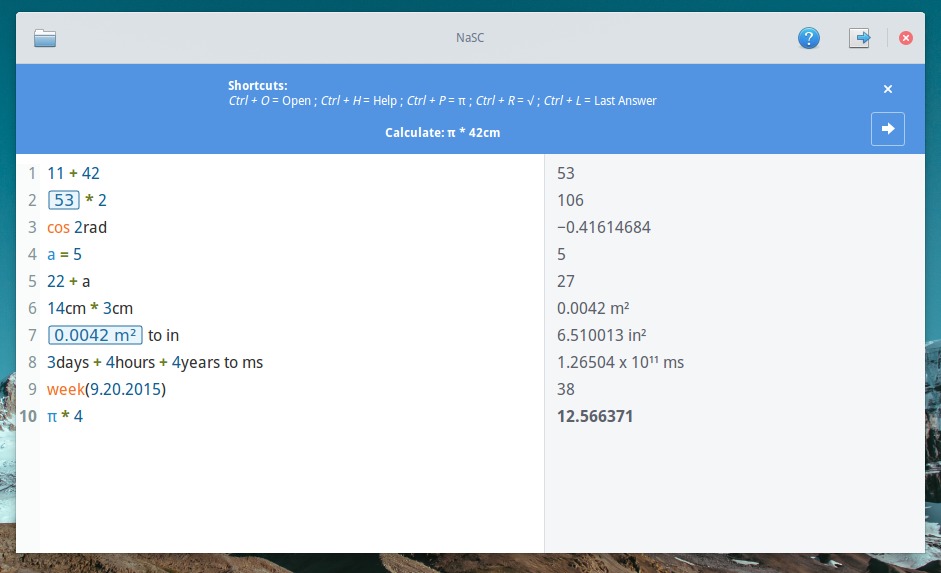
|
||||
|
||||
At the first launch, NaSC offers a tutorial that details possible features. You can later click the help icon on headerbar to get more.
|
||||
|
||||
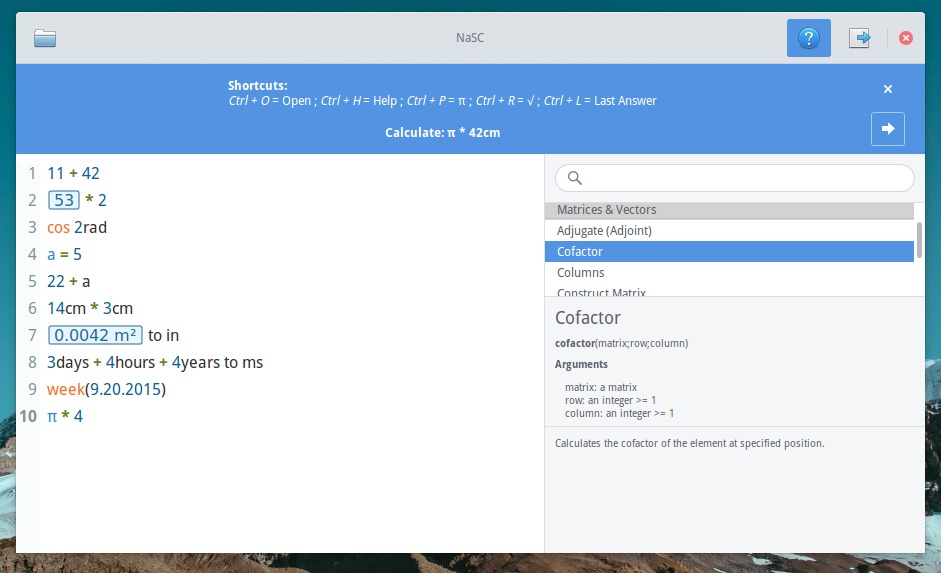
|
||||
|
||||
In addition, the software allows to save your file in order to continue the work. It can be also shared on Pastebin with a defined time.
|
||||
|
||||
### Install NaSC in Ubuntu / Elementary OS Freya: ###
|
||||
|
||||
For Ubuntu 15.04, Ubuntu 15.10, Elementary OS Freya, open terminal from the Dash, App Launcher and run below commands one by one:
|
||||
|
||||
1. Add the [NaSC PPA][2] via command:
|
||||
|
||||
sudo apt-add-repository ppa:nasc-team/daily
|
||||
|
||||
|
||||
|
||||
2. If you’ve installed Synaptic Package Manager, search for and install `nasc` via it after clicking Reload button.
|
||||
|
||||
Or run below commands to update system cache and install the software:
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install nasc
|
||||
|
||||
3. **(Optional)** To remove the software as well as NaSC, run:
|
||||
|
||||
sudo apt-get remove nasc && sudo add-apt-repository -r ppa:nasc-team/daily
|
||||
|
||||
For those who don’t want to add PPA, grab the .deb package directly from [this page][3].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ubuntuhandbook.org/index.php/2015/09/make-math-simple-in-ubuntu-elementary-os-via-nasc/
|
||||
|
||||
作者:[Ji m][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ubuntuhandbook.org/index.php/about/
|
||||
[1]:http://www.acqualia.com/soulver/
|
||||
[2]:https://launchpad.net/~nasc-team/+archive/ubuntu/daily/
|
||||
[3]:http://ppa.launchpad.net/nasc-team/daily/ubuntu/pool/main/n/nasc/
|
||||
@ -0,0 +1,96 @@
|
||||
How to Run ISO Files Directly From the HDD with GRUB2
|
||||
================================================================================
|
||||

|
||||
|
||||
Most Linux distros offer a live environment, which you can boot up from a USB drive, for you to test the system without installing. You can either use it to evaluate the distro or as a disposable OS. While it is easy to copy these onto a USB disk, in certain cases one might want to run the same ISO image often or run different ones regularly. GRUB 2 can be configured so that you do not need to burn the ISOs to disk or use a USB drive, but need to run a live environment directly form the boot menu.
|
||||
|
||||
### Obtaining and checking bootable ISO images ###
|
||||
|
||||
To obtain an ISO image, you should usually visit the website of the desired distribution and download any image that is compatible with your setup. If the image can be started from a USB, it should be able to start from the GRUB menu as well.
|
||||
|
||||
Once the image has finished downloading, you should check its integrity by running a simple md5 check on it. This will output a long combination of numbers and alphanumeric characters
|
||||
|
||||

|
||||
|
||||
which you can compare against the MD5 checksum provided on the download page. The two should be identical.
|
||||
|
||||
### Setting up GRUB 2 ###
|
||||
|
||||
ISO images contain full systems. All you need to do is direct GRUB2 to the appropriate file, and tell it where it can find the kernel and the initramdisk or initram filesystem (depending on which one your distribution uses).
|
||||
|
||||
In this example, a Kubuntu 15.04 live environment will be set up to run on an Ubuntu 14.04 box as a Grub menu item. It should work for most newer Ubuntu-based systems and derivatives. If you have a different system or want to achieve something else, you can get some ideas on how to do this from one of [these files][1], although it will require a little experience with GRUB.
|
||||
|
||||
In this example the file `kubuntu-15.04-desktop-amd64.iso`
|
||||
|
||||
lives in `/home/maketecheasier/TempISOs/` on `/dev/sda1`.
|
||||
|
||||
To make GRUB2 look for it in the right place, you need to edit the
|
||||
|
||||
/etc/grub.d40-custom
|
||||
|
||||

|
||||
|
||||
To start Kubuntu from the above location, add the following code (after adjusting it to your needs) below the commented section, without modifying the original content.
|
||||
|
||||
menuentry "Kubuntu 15.04 ISO" {
|
||||
set isofile="/home/maketecheasier/TempISOs/kubuntu-15.04-desktop-amd64.iso"
|
||||
loopback loop (hd0,1)$isofile
|
||||
echo "Starting $isofile..."
|
||||
linux (loop)/casper/vmlinuz.efi boot=casper iso-scan/filename=${isofile} quiet splash
|
||||
initrd (loop)/casper/initrd.lz
|
||||
}
|
||||
|
||||

|
||||
|
||||
### Breaking down the above code ###
|
||||
|
||||
First set up a variable named `$menuentry`. This is where the ISO file is located. If you want to change to a different ISO, you need to change the bit where it says set `isofile="/path/to/file/name-of-iso-file-.iso"`.
|
||||
|
||||
The next line is where you specify the loopback device; you also need to give it the right partition number. This is the bit where it says
|
||||
|
||||
loopback loop (hd0,1)$isofile
|
||||
|
||||
Note the hd0,1 bit; it is important. This means first HDD, first partition (`/dev/sda1`).
|
||||
|
||||
GRUB’s naming here is slightly confusing. For HDDs, it starts counting from “0”, making the first HDD #0, the second one #1, the third one #2, etc. However, for partitions, it will start counting from 1. First partition is #1, second is #2, etc. There might be a good reason for this but not necessarily a sane one (UX-wise it is a disaster, to be sure)..
|
||||
|
||||
This makes fist disk, first partition, which in Linux would usually look something like `/dev/sda1` become `hd0,1` in GRUB2. The second disk, third partition would be `hd1,3`, and so on.
|
||||
|
||||
The next important line is
|
||||
|
||||
linux (loop)/casper/vmlinuz.efi boot=casper iso-scan/filename=${isofile} quiet splash
|
||||
|
||||
It will load the kernel image. On newer Ubuntu Live CDs, this would be in the `/casper` directory and called `vmlinuz.efi`. If you use a different system, your kernel might be missing the `.efi` extension or be located somewhere else entirely (You can easily check this by opening the ISO file with an archive manager and looking inside `/casper.`). The last options, `quiet splash`, would be your regular GRUB options, if you care to change them.
|
||||
|
||||
Finally
|
||||
|
||||
initrd (loop)/casper/initrd.lz
|
||||
|
||||
will load `initrd`, which is responsible to load a RAMDisk into memory for bootup.
|
||||
|
||||
### Booting into your live system ###
|
||||
|
||||
To make it all work, you will only need to update GRUB2
|
||||
|
||||
sudo update-grub
|
||||
|
||||

|
||||
|
||||
When you reboot your system, you should be presented with a new GRUB entry which will allow you to load into the ISO image you’ve just set up.
|
||||
|
||||

|
||||
|
||||
Selecting the new entry should boot you into the live environment, just like booting from a DVD or USB would.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/run-iso-files-hdd-grub2/
|
||||
|
||||
作者:[Attila Orosz][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/attilaorosz/
|
||||
[1]:http://git.marmotte.net/git/glim/tree/grub2
|
||||
@ -0,0 +1,250 @@
|
||||
10 Useful Linux Command Line Tricks for Newbies – Part 2
|
||||
================================================================================
|
||||
I remember when I first started using Linux and I was used to the graphical interface of Windows, I truly hated the Linux terminal. Back then I was finding the commands hard to remember and proper use of each one of them. With time I realised the beauty, flexibility and usability of the Linux terminal and to be honest a day doesn’t pass without using. Today, I would like to share some useful tricks and tips for Linux new comers to ease their transition to Linux or simply help them learn something new (hopefully).
|
||||
|
||||

|
||||
|
||||
10 Linux Commandline Tricks – Part 2
|
||||
|
||||
- [5 Interesting Command Line Tips and Tricks in Linux – Part 1][1]
|
||||
- [5 Useful Commands to Manage Linux File Types – Part 3][2]
|
||||
|
||||
This article intends to show you some useful tricks how to use the Linux terminal like a pro with minimum amount of skills. All you need is a Linux terminal and some free time to test these commands.
|
||||
|
||||
### 1. Find the right command ###
|
||||
|
||||
Executing the right command can be vital for your system. However in Linux there are so many different command lines that they are often hard to remember. So how do you search for the right command you need? The answer is apropos. All you need to run is:
|
||||
|
||||
# apropos <description>
|
||||
|
||||
Where you should change the “description” with the actual description of the command you are looking for. Here is a good example:
|
||||
|
||||
# apropos "list directory"
|
||||
|
||||
dir (1) - list directory contents
|
||||
ls (1) - list directory contents
|
||||
ntfsls (8) - list directory contents on an NTFS filesystem
|
||||
vdir (1) - list directory contents
|
||||
|
||||
On the left you can see the commands and on the right their description.
|
||||
|
||||
### 2. Execute Previous Command ###
|
||||
|
||||
Many times you will need to execute the same command over and over again. While you can repeatedly press the Up key on your keyboard, you can use the history command instead. This command will list all commands you entered since you launched the terminal:
|
||||
|
||||
# history
|
||||
|
||||
1 fdisk -l
|
||||
2 apt-get install gnome-paint
|
||||
3 hostname tecmint.com
|
||||
4 hostnamectl tecmint.com
|
||||
5 man hostnamectl
|
||||
6 hostnamectl --set-hostname tecmint.com
|
||||
7 hostnamectl -set-hostname tecmint.com
|
||||
8 hostnamectl set-hostname tecmint.com
|
||||
9 mount -t "ntfs" -o
|
||||
10 fdisk -l
|
||||
11 mount -t ntfs-3g /dev/sda5 /mnt
|
||||
12 mount -t rw ntfs-3g /dev/sda5 /mnt
|
||||
13 mount -t -rw ntfs-3g /dev/sda5 /mnt
|
||||
14 mount -t ntfs-3g /dev/sda5 /mnt
|
||||
15 mount man
|
||||
16 man mount
|
||||
17 mount -t -o ntfs-3g /dev/sda5 /mnt
|
||||
18 mount -o ntfs-3g /dev/sda5 /mnt
|
||||
19 mount -ro ntfs-3g /dev/sda5 /mnt
|
||||
20 cd /mnt
|
||||
...
|
||||
|
||||
As you will see from the output above, you will receive a list of all commands that you have ran. On each line you have number indicating the row in which you have entered the command. You can recall that command by using:
|
||||
|
||||
!#
|
||||
|
||||
Where # should be changed with the actual number of the command. For better understanding, see the below example:
|
||||
|
||||
!501
|
||||
|
||||
Is equivalent to:
|
||||
|
||||
# history
|
||||
|
||||
### 3. Use midnight Commander ###
|
||||
|
||||
If you are not used to using commands such cd, cp, mv, rm than you can use the midnight command. It is an easy to use visual shell in which you can also use mouse:
|
||||
|
||||
|
||||
|
||||
Midnight Commander in Action
|
||||
|
||||
Thanks to the F1 – F12 keys, you can easy perform different tasks. Simply check the legend at the bottom. To select a file or folder click the “Insert” button.
|
||||
|
||||
In short the midnight command is called “mc“. To install mc on your system simply run:
|
||||
|
||||
$ sudo apt-get install mc [On Debian based systems]
|
||||
|
||||
----------
|
||||
|
||||
# yum install mc [On Fedora based systems]
|
||||
|
||||
Here is a simple example of using midnight commander. Open mc by simply typing:
|
||||
|
||||
# mc
|
||||
|
||||
Now use the TAB button to switch between windows – left and right. I have a LibreOffice file that I will move to “Software” folder:
|
||||
|
||||

|
||||
|
||||
Midnight Commander Move Files
|
||||
|
||||
To move the file in the new directory press F6 button on your keyboard. MC will now ask you for confirmation:
|
||||
|
||||

|
||||
|
||||
Move Files to New Directory
|
||||
|
||||
Once confirmed, the file will be moved in the new destination directory.
|
||||
|
||||
Read More: [How to Use Midnight Commander File Manager in Linux][4]
|
||||
|
||||
### 4. Shutdown Computer at Specific Time ###
|
||||
|
||||
Sometimes you will need to shutdown your computer some hours after your work hours have ended. You can configure your computer to shut down at specific time by using:
|
||||
|
||||
$ sudo shutdown 21:00
|
||||
|
||||
This will tell your computer to shut down at the specific time you have provided. You can also tell the system to shutdown after specific amount of minutes:
|
||||
|
||||
$ sudo shutdown +15
|
||||
|
||||
That way the system will shut down in 15 minutes.
|
||||
|
||||
### 5. Show Information about Known Users ###
|
||||
|
||||
You can use a simple command to list your Linux system users and some basic information about them. Simply use:
|
||||
|
||||
# lslogins
|
||||
|
||||
This should bring you the following output:
|
||||
|
||||
UID USER PWD-LOCK PWD-DENY LAST-LOGIN GECOS
|
||||
0 root 0 0 Apr29/11:35 root
|
||||
1 bin 0 1 bin
|
||||
2 daemon 0 1 daemon
|
||||
3 adm 0 1 adm
|
||||
4 lp 0 1 lp
|
||||
5 sync 0 1 sync
|
||||
6 shutdown 0 1 Jul19/10:04 shutdown
|
||||
7 halt 0 1 halt
|
||||
8 mail 0 1 mail
|
||||
10 uucp 0 1 uucp
|
||||
11 operator 0 1 operator
|
||||
12 games 0 1 games
|
||||
13 gopher 0 1 gopher
|
||||
14 ftp 0 1 FTP User
|
||||
23 squid 0 1
|
||||
25 named 0 1 Named
|
||||
27 mysql 0 1 MySQL Server
|
||||
47 mailnull 0 1
|
||||
48 apache 0 1 Apache
|
||||
...
|
||||
|
||||
### 6. Search for Files ###
|
||||
|
||||
Searching for files can sometimes be not as easy as you think. A good example for searching for files is:
|
||||
|
||||
# find /home/user -type f
|
||||
|
||||
This command will search for all files located in /home/user. The find command is extremely powerful one and you can pass more options to it to make your search even more detailed. If you want to search for files larger than given size, you can use:
|
||||
|
||||
# find . -type f -size 10M
|
||||
|
||||
The above command will search from current directory for all files that are larger than 10 MB. Make sure not to run the command from the root directory of your Linux system as this may cause high I/O on your machine.
|
||||
|
||||
One of the most frequently used combinations that I use find with is “exec” option, which basically allows you to run some actions on the results of the find command.
|
||||
|
||||
For example, lets say that we want to find all files in a directory and change their permissions. This can be easily done with:
|
||||
|
||||
# find /home/user/files/ -type f -exec chmod 644 {} \;
|
||||
|
||||
The above command will search for all files in the specified directory recursively and will executed chmod command on the found files. I am sure you will find many more uses on this command in future, for now read [35 Examples of Linux ‘find’ Command and Usage][5].
|
||||
|
||||
### 7. Build Directory Trees with one Command ###
|
||||
|
||||
You probably know that you can create new directories by using the mkdir command. So if you want to create a new folder you will run something like this:
|
||||
|
||||
# mkdir new_folder
|
||||
|
||||
But what, if you want to create 5 subfolders within that folder? Running mkdir 5 times in a row is not a good solution. Instead you can use -p option like that:
|
||||
|
||||
# mkdir -p new_folder/{folder_1,folder_2,folder_3,folder_4,folder_5}
|
||||
|
||||
In the end you should have 5 folders located in new_folder:
|
||||
|
||||
# ls new_folder/
|
||||
|
||||
folder_1 folder_2 folder_3 folder_4 folder_5
|
||||
|
||||
### 8. Copy File into Multiple Directories ###
|
||||
|
||||
File copying is usually performed with the cp command. Copying a file usually looks like this:
|
||||
|
||||
# cp /path-to-file/my_file.txt /path-to-new-directory/
|
||||
|
||||
Now imagine that you need to copy that file in multiple directories:
|
||||
|
||||
# cp /home/user/my_file.txt /home/user/1
|
||||
# cp /home/user/my_file.txt /home/user/2
|
||||
# cp /home/user/my_file.txt /home/user/3
|
||||
|
||||
This is a bit absurd. Instead you can solve the problem with a simple one line command:
|
||||
|
||||
# echo /home/user/1/ /home/user/2/ /home/user/3/ | xargs -n 1 cp /home/user/my_file.txt
|
||||
|
||||
### 9. Deleting Larger Files ###
|
||||
|
||||
Sometimes files can grow extremely large. I have seen cases where a single log file went over 250 GB large due to poor administrating skills. Removing the file with rm utility might not be sufficient in such cases due to the fact that there is extremely large amount of data that needs to be removed. The operation will be a “heavy” one and should be avoided. Instead, you can go with a really simple solution:
|
||||
|
||||
# > /path-to-file/huge_file.log
|
||||
|
||||
Where of course you will need to change the path and the file names with the exact ones to match your case. The above command will simply write an empty output to the file. In more simpler words it will empty the file without causing high I/O on your system.
|
||||
|
||||
### 10. Run Same Command on Multiple Linux Servers ###
|
||||
|
||||
Recently one of our readers asked in our [LinuxSay forum][6], how to execute single command to multiple Linux boxes at once using SSH. He had his machines IP addresses looking like this:
|
||||
|
||||
10.0.0.1
|
||||
10.0.0.2
|
||||
10.0.0.3
|
||||
10.0.0.4
|
||||
10.0.0.5
|
||||
|
||||
So here is a simple solution of this issue. Collect the IP addresses of the servers in a one file called list.txt one under other just as shown above. Then you can run:
|
||||
|
||||
# for in $i(cat list.txt); do ssh user@$i 'bash command'; done
|
||||
|
||||
In the above example you will need to change “user” with the actual user with which you will be logging and “bash command” with the actual bash command you wish to execute. The method is better working when you are [using passwordless authentication with SSH key][7] to your machines as that way you will not need to enter the password for your user over and over again.
|
||||
|
||||
Note that you may need to pass some additional parameters to the SSH command depending on your Linux boxes setup.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
The above examples are really simple ones and I hope they have helped you to find some of the beauty of Linux and how you can easily perform different operations that can take much more time on other operating systems.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/10-useful-linux-command-line-tricks-for-newbies/
|
||||
|
||||
作者:[Marin Todorov][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/marintodorov89/
|
||||
[1]:http://www.tecmint.com/5-linux-command-line-tricks/
|
||||
[2]:http://www.tecmint.com/manage-file-types-and-set-system-time-in-linux/
|
||||
[3]:http://www.tecmint.com/history-command-examples/
|
||||
[4]:http://www.tecmint.com/midnight-commander-a-console-based-file-manager-for-linux/
|
||||
[5]:http://www.tecmint.com/35-practical-examples-of-linux-find-command/
|
||||
[6]:http://www.linuxsay.com/
|
||||
[7]:http://www.tecmint.com/ssh-passwordless-login-using-ssh-keygen-in-5-easy-steps/
|
||||
@ -0,0 +1,280 @@
|
||||
ictlyh Translating
|
||||
5 Useful Commands to Manage File Types and System Time in Linux – Part 3
|
||||
================================================================================
|
||||
Adapting to using the command line or terminal can be very hard for beginners who want to learn Linux. Because the terminal gives more control over a Linux system than GUIs programs, one has to get a used to running commands on the terminal. Therefore to memorize different commands in Linux, you should use the terminal on a daily basis to understand how commands are used with different options and arguments.
|
||||
|
||||

|
||||
|
||||
Manage File Types and Set Time in Linux – Part 3
|
||||
|
||||
Please go through our previous parts of this [Linux Tricks][1] series.
|
||||
|
||||
- [5 Interesting Command Line Tips and Tricks in Linux – Part 1][2]
|
||||
- [ Useful Commandline Tricks for Newbies – Part 2][3]
|
||||
|
||||
In this article, we are going to look at some tips and tricks of using 10 commands to work with files and time on the terminal.
|
||||
|
||||
### File Types in Linux ###
|
||||
|
||||
In Linux, everything is considered as a file, your devices, directories and regular files are all considered as files.
|
||||
|
||||
There are different types of files in a Linux system:
|
||||
|
||||
- Regular files which may include commands, documents, music files, movies, images, archives and so on.
|
||||
- Device files: which are used by the system to access your hardware components.
|
||||
|
||||
There are two types of device files block files that represent storage devices such as harddisks, they read data in blocks and character files read data in a character by character manner.
|
||||
|
||||
- Hardlinks and softlinks: they are used to access files from any where on a Linux filesystem.
|
||||
- Named pipes and sockets: allow different processes to communicate with each other.
|
||||
|
||||
#### 1. Determining the type of a file using ‘file’ command ####
|
||||
|
||||
You can determine the type of a file by using the file command as follows. The screenshot below shows different examples of using the file command to determine the types of different files.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ dir
|
||||
BACKUP master.zip
|
||||
crossroads-stable.tar.gz num.txt
|
||||
EDWARD-MAYA-2011-2012-NEW-REMIX.mp3 reggea.xspf
|
||||
Linux-Security-Optimization-Book.gif tmp-link
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ file BACKUP/
|
||||
BACKUP/: directory
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ file master.zip
|
||||
master.zip: Zip archive data, at least v1.0 to extract
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ file crossroads-stable.tar.gz
|
||||
crossroads-stable.tar.gz: gzip compressed data, from Unix, last modified: Tue Apr 5 15:15:20 2011
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ file Linux-Security-Optimization-Book.gif
|
||||
Linux-Security-Optimization-Book.gif: GIF image data, version 89a, 200 x 259
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ file EDWARD-MAYA-2011-2012-NEW-REMIX.mp3
|
||||
EDWARD-MAYA-2011-2012-NEW-REMIX.mp3: Audio file with ID3 version 2.3.0, contains: MPEG ADTS, layer III, v1, 192 kbps, 44.1 kHz, JntStereo
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ file /dev/sda1
|
||||
/dev/sda1: block special
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ file /dev/tty1
|
||||
/dev/tty1: character special
|
||||
|
||||
#### 2. Determining the file type using ‘ls’ and ‘dir’ commands ####
|
||||
|
||||
Another way of determining the type of a file is by performing a long listing using the ls and [dir][4] commands.
|
||||
|
||||
Using ls -l to determine the type of a file.
|
||||
|
||||
When you view the file permissions, the first character shows the file type and the other charcters show the file permissions.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ ls -l
|
||||
total 6908
|
||||
drwxr-xr-x 2 tecmint tecmint 4096 Sep 9 11:46 BACKUP
|
||||
-rw-r--r-- 1 tecmint tecmint 1075620 Sep 9 11:47 crossroads-stable.tar.gz
|
||||
-rwxr----- 1 tecmint tecmint 5916085 Sep 9 11:49 EDWARD-MAYA-2011-2012-NEW-REMIX.mp3
|
||||
-rw-r--r-- 1 tecmint tecmint 42122 Sep 9 11:49 Linux-Security-Optimization-Book.gif
|
||||
-rw-r--r-- 1 tecmint tecmint 17627 Sep 9 11:46 master.zip
|
||||
-rw-r--r-- 1 tecmint tecmint 5 Sep 9 11:48 num.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 0 Sep 9 11:46 reggea.xspf
|
||||
-rw-r--r-- 1 tecmint tecmint 5 Sep 9 11:47 tmp-link
|
||||
|
||||
Using ls -l to determine block and character files.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ ls -l /dev/sda1
|
||||
brw-rw---- 1 root disk 8, 1 Sep 9 10:53 /dev/sda1
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ ls -l /dev/tty1
|
||||
crw-rw---- 1 root tty 4, 1 Sep 9 10:54 /dev/tty1
|
||||
|
||||
Using dir -l to determine the type of a file.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ dir -l
|
||||
total 6908
|
||||
drwxr-xr-x 2 tecmint tecmint 4096 Sep 9 11:46 BACKUP
|
||||
-rw-r--r-- 1 tecmint tecmint 1075620 Sep 9 11:47 crossroads-stable.tar.gz
|
||||
-rwxr----- 1 tecmint tecmint 5916085 Sep 9 11:49 EDWARD-MAYA-2011-2012-NEW-REMIX.mp3
|
||||
-rw-r--r-- 1 tecmint tecmint 42122 Sep 9 11:49 Linux-Security-Optimization-Book.gif
|
||||
-rw-r--r-- 1 tecmint tecmint 17627 Sep 9 11:46 master.zip
|
||||
-rw-r--r-- 1 tecmint tecmint 5 Sep 9 11:48 num.txt
|
||||
-rw-r--r-- 1 tecmint tecmint 0 Sep 9 11:46 reggea.xspf
|
||||
-rw-r--r-- 1 tecmint tecmint 5 Sep 9 11:47 tmp-link
|
||||
|
||||
#### 3. Counting number of files of a specific type ####
|
||||
|
||||
Next we shall look at tips on counting number of files of a specific type in a given directory using the ls, [grep][5] and [wc][6] commands. Communication between the commands is achieved through named piping.
|
||||
|
||||
- grep – command to search according to a given pattern or regular expression.
|
||||
- wc – command to count lines, words and characters.
|
||||
|
||||
Counting number of regular files
|
||||
|
||||
In Linux, regular files are represented by the `–` symbol.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ ls -l | grep ^- | wc -l
|
||||
7
|
||||
|
||||
**Counting number of directories**
|
||||
|
||||
In Linux, directories are represented by the `d` symbol.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ ls -l | grep ^d | wc -l
|
||||
1
|
||||
|
||||
**Counting number of symbolic and hard links**
|
||||
|
||||
In Linux, symblic and hard links are represented by the l symbol.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ ls -l | grep ^l | wc -l
|
||||
0
|
||||
|
||||
**Counting number of block and character files**
|
||||
|
||||
In Linux, block and character files are represented by the `b` and `c` symbols respectively.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ ls -l /dev | grep ^b | wc -l
|
||||
37
|
||||
tecmint@tecmint ~/Linux-Tricks $ ls -l /dev | grep ^c | wc -l
|
||||
159
|
||||
|
||||
#### 4. Finding files on a Linux system ####
|
||||
|
||||
Next we shall look at some commands one can use to find files on a Linux system, these include the locate, find, whatis and which commands.
|
||||
|
||||
**Using the locate command to find files**
|
||||
|
||||
In the output below, I am trying to locate the [Samba server configuration][7] for my system.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ locate samba.conf
|
||||
/usr/lib/tmpfiles.d/samba.conf
|
||||
/var/lib/dpkg/info/samba.conffiles
|
||||
|
||||
**Using the find command to find files**
|
||||
|
||||
To learn how to use the find command in Linux, you can read our following article that shows more than 30+ practical examples and usage of find command in Linux.
|
||||
|
||||
- [35 Examples of ‘find’ Command in Linux][8]
|
||||
|
||||
**Using the whatis command to locate commands**
|
||||
|
||||
The whatis command is mostly used to locate commands and it is special because it gives information about a command, it also finds configurations files and manual entries for a command.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ whatis bash
|
||||
bash (1) - GNU Bourne-Again SHell
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ whatis find
|
||||
find (1) - search for files in a directory hierarchy
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ whatis ls
|
||||
ls (1) - list directory contents
|
||||
|
||||
**Using which command to locate commands**
|
||||
|
||||
The which command is used to locate commands on the filesystem.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ which mkdir
|
||||
/bin/mkdir
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ which bash
|
||||
/bin/bash
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ which find
|
||||
/usr/bin/find
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ $ which ls
|
||||
/bin/ls
|
||||
|
||||
#### 5. Working with time on your Linux system ####
|
||||
|
||||
When working in a networked environment, it is a good practice to keep the correct time on your Linux system. There are certain services on Linux systems that require correct time to work efficiently on a network.
|
||||
|
||||
We shall look at commands you can use to manage time on your machine. In Linux, time is managed in two ways: system time and hardware time.
|
||||
|
||||
The system time is managed by a system clock and the hardware time is managed by a hardware clock.
|
||||
|
||||
To view your system time, date and timezone, use the date command as follows.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ date
|
||||
Wed Sep 9 12:25:40 IST 2015
|
||||
|
||||
Set your system time using date -s or date –set=”STRING” as follows.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ sudo date -s "12:27:00"
|
||||
Wed Sep 9 12:27:00 IST 2015
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ sudo date --set="12:27:00"
|
||||
Wed Sep 9 12:27:00 IST 2015
|
||||
|
||||
You can also set time and date as follows.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ sudo date 090912302015
|
||||
Wed Sep 9 12:30:00 IST 2015
|
||||
|
||||
Viewing current date from a calendar using cal command.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ cal
|
||||
September 2015
|
||||
Su Mo Tu We Th Fr Sa
|
||||
1 2 3 4 5
|
||||
6 7 8 9 10 11 12
|
||||
13 14 15 16 17 18 19
|
||||
20 21 22 23 24 25 26
|
||||
27 28 29 30
|
||||
|
||||
View hardware clock time using the hwclock command.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ sudo hwclock
|
||||
Wednesday 09 September 2015 06:02:58 PM IST -0.200081 seconds
|
||||
|
||||
To set the hardware clock time, use hwclock –set –date=”STRING” as follows.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ sudo hwclock --set --date="09/09/2015 12:33:00"
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ sudo hwclock
|
||||
Wednesday 09 September 2015 12:33:11 PM IST -0.891163 seconds
|
||||
|
||||
The system time is set by the hardware clock during booting and when the system is shutting down, the hardware time is reset to the system time.
|
||||
|
||||
Therefore when you view system time and hardware time, they are the same unless when you change the system time. Your hardware time may be incorrect when the CMOS battery is weak.
|
||||
|
||||
You can also set your system time using time from the hardware clock as follows.
|
||||
|
||||
$ sudo hwclock --hctosys
|
||||
|
||||
It is also possible to set hardware clock time using the system clock time as follows.
|
||||
|
||||
$ sudo hwclock --systohc
|
||||
|
||||
To view how long your Linux system has been running, use the uptime command.
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ uptime
|
||||
12:36:27 up 1:43, 2 users, load average: 1.39, 1.34, 1.45
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ uptime -p
|
||||
up 1 hour, 43 minutes
|
||||
|
||||
tecmint@tecmint ~/Linux-Tricks $ uptime -s
|
||||
2015-09-09 10:52:47
|
||||
|
||||
### Summary ###
|
||||
|
||||
Understanding file types is Linux is a good practice for begginers, and also managing time is critical especially on servers to manage services reliably and efficiently. Hope you find this guide helpful. If you have any additional information, do not forget to post a comment. Stay connected to Tecmint.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/manage-file-types-and-set-system-time-in-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/tag/linux-tricks/
|
||||
[2]:http://www.tecmint.com/free-online-linux-learning-guide-for-beginners/
|
||||
[3]:http://www.tecmint.com/10-useful-linux-command-line-tricks-for-newbies/
|
||||
[4]:http://www.tecmint.com/linux-dir-command-usage-with-examples/
|
||||
[5]:http://www.tecmint.com/12-practical-examples-of-linux-grep-command/
|
||||
[6]:http://www.tecmint.com/wc-command-examples/
|
||||
[7]:http://www.tecmint.com/setup-samba-file-sharing-for-linux-windows-clients/
|
||||
[8]:http://www.tecmint.com/35-practical-examples-of-linux-find-command/
|
||||
@ -0,0 +1,227 @@
|
||||
Display Awesome Linux Logo With Basic Hardware Info Using screenfetch and linux_logo Tools
|
||||
================================================================================
|
||||
Do you want to display a super cool logo of your Linux distribution along with basic hardware information? Look no further try awesome screenfetch and linux_logo utilities.
|
||||
|
||||
### Say hello to screenfetch ###
|
||||
|
||||
screenFetch is a CLI bash script to show system/theme info in screenshots. It runs on a Linux, OS X, FreeBSD and many other Unix-like system. From the man page:
|
||||
|
||||
> This handy Bash script can be used to generate one of those nifty terminal theme information + ASCII distribution logos you see in everyone's screenshots nowadays. It will auto-detect your distribution and display an ASCII version of that distribution's logo and some valuable information to the right.
|
||||
|
||||
#### Installing screenfetch on Linux ####
|
||||
|
||||
Open the Terminal application. Simply type the following [apt-get command][1] on a Debian or Ubuntu or Mint Linux based system:
|
||||
|
||||
$ sudo apt-get install screenfetch
|
||||
|
||||
|
||||
|
||||
Fig.01: Installing screenfetch using apt-get
|
||||
|
||||
#### Installing screenfetch Mac OS X ####
|
||||
|
||||
Type the following command:
|
||||
|
||||
$ brew install screenfetch
|
||||
|
||||

|
||||
|
||||
Fig.02: Installing screenfetch using brew command
|
||||
|
||||
#### Installing screenfetch on FreeBSD ####
|
||||
|
||||
Type the following pkg command:
|
||||
|
||||
$ sudo pkg install sysutils/screenfetch
|
||||
|
||||
|
||||
|
||||
Fig.03: FreeBSD install screenfetch using pkg
|
||||
|
||||
#### Installing screenfetch on Fedora Linux ####
|
||||
|
||||
Type the following dnf command:
|
||||
|
||||
$ sudo dnf install screenfetch
|
||||
|
||||
|
||||
|
||||
Fig.04: Fedora Linux 22 install screenfetch using dnf
|
||||
|
||||
#### How do I use screefetch utility? ####
|
||||
|
||||
Simply type the following command:
|
||||
|
||||
$ screenfetch
|
||||
|
||||
Here is the output from various operating system:
|
||||
|
||||
|
||||
|
||||
Screenfetch on Fedora
|
||||
|
||||
|
||||
|
||||
Screenfetch on OS X
|
||||
|
||||
|
||||
|
||||
Screenfetch on FreeBSD
|
||||
|
||||
|
||||
|
||||
Screenfetch on Debian Linux
|
||||
|
||||
#### Take screenshot ####
|
||||
|
||||
To take a screenshot and to save a file, enter:
|
||||
|
||||
$ screenfetch -s
|
||||
|
||||
You will see a screenshot file at ~/Desktop/screenFetch-*.jpg. To take a screenshot and upload to imgur directly, enter:
|
||||
|
||||
$ screenfetch -su imgur
|
||||
|
||||
**Sample outputs:**
|
||||
|
||||
-/+:. veryv@Viveks-MacBook-Pro
|
||||
:++++. OS: 64bit Mac OS X 10.10.5 14F27
|
||||
/+++/. Kernel: x86_64 Darwin 14.5.0
|
||||
.:-::- .+/:-``.::- Uptime: 3d 1h 36m
|
||||
.:/++++++/::::/++++++/:` Packages: 56
|
||||
.:///////////////////////:` Shell: bash 3.2.57
|
||||
////////////////////////` Resolution: 2560x1600 1920x1200
|
||||
-+++++++++++++++++++++++` DE: Aqua
|
||||
/++++++++++++++++++++++/ WM: Quartz Compositor
|
||||
/sssssssssssssssssssssss. WM Theme: Blue
|
||||
:ssssssssssssssssssssssss- Font: Not Found
|
||||
osssssssssssssssssssssssso/` CPU: Intel Core i5-4288U CPU @ 2.60GHz
|
||||
`syyyyyyyyyyyyyyyyyyyyyyyy+` GPU: Intel Iris
|
||||
`ossssssssssssssssssssss/ RAM: 6405MB / 8192MB
|
||||
:ooooooooooooooooooo+.
|
||||
`:+oo+/:-..-:/+o+/-
|
||||
|
||||
Taking shot in 3.. 2.. 1.. 0.
|
||||
==> Uploading your screenshot now...your screenshot can be viewed at http://imgur.com/HKIUznn
|
||||
|
||||
You can visit [http://imgur.com/HKIUznn][2] to see uploaded screenshot.
|
||||
|
||||
### Say hello to linux_logo ###
|
||||
|
||||
The linux_logo program generates a color ANSI picture of a penguin which includes some system information obtained from the /proc filesystem.
|
||||
|
||||
#### Installation ####
|
||||
|
||||
Simply type the following command as per your Linux distro.
|
||||
|
||||
#### Debian/Ubutnu/Mint ####
|
||||
|
||||
# apt-get install linux_logo
|
||||
|
||||
#### CentOS/RHEL/Older Fedora ####
|
||||
|
||||
# yum install linux_logo
|
||||
|
||||
#### Fedora Linux v22+ or newer ####
|
||||
|
||||
# dnf install linux_logo
|
||||
|
||||
#### Run it ####
|
||||
|
||||
Simply type the following command:
|
||||
|
||||
$ linux_logo
|
||||
|
||||
|
||||
|
||||
linux_logo in action
|
||||
|
||||
#### But wait, there's more! ####
|
||||
|
||||
You can see a list of compiled in logos using:
|
||||
|
||||
$ linux_logo -f -L list
|
||||
|
||||
**Sample outputs:**
|
||||
|
||||
Available Built-in Logos:
|
||||
Num Type Ascii Name Description
|
||||
1 Classic Yes aix AIX Logo
|
||||
2 Banner Yes bsd_banner FreeBSD Logo
|
||||
3 Classic Yes bsd FreeBSD Logo
|
||||
4 Classic Yes irix Irix Logo
|
||||
5 Banner Yes openbsd_banner OpenBSD Logo
|
||||
6 Classic Yes openbsd OpenBSD Logo
|
||||
7 Banner Yes solaris The Default Banner Logos
|
||||
8 Banner Yes banner The Default Banner Logo
|
||||
9 Banner Yes banner-simp Simplified Banner Logo
|
||||
10 Classic Yes classic The Default Classic Logo
|
||||
11 Classic Yes classic-nodots The Classic Logo, No Periods
|
||||
12 Classic Yes classic-simp Classic No Dots Or Letters
|
||||
13 Classic Yes core Core Linux Logo
|
||||
14 Banner Yes debian_banner_2 Debian Banner 2
|
||||
15 Banner Yes debian_banner Debian Banner (white)
|
||||
16 Classic Yes debian Debian Swirl Logos
|
||||
17 Classic Yes debian_old Debian Old Penguin Logos
|
||||
18 Classic Yes gnu_linux Classic GNU/Linux
|
||||
19 Banner Yes mandrake Mandrakelinux(TM) Banner
|
||||
20 Banner Yes mandrake_banner Mandrake(TM) Linux Banner
|
||||
21 Banner Yes mandriva Mandriva(TM) Linux Banner
|
||||
22 Banner Yes pld PLD Linux banner
|
||||
23 Classic Yes raspi An ASCII Raspberry Pi logo
|
||||
24 Banner Yes redhat RedHat Banner (white)
|
||||
25 Banner Yes slackware Slackware Logo
|
||||
26 Banner Yes sme SME Server Banner Logo
|
||||
27 Banner Yes sourcemage_ban Source Mage GNU/Linux banner
|
||||
28 Banner Yes sourcemage Source Mage GNU/Linux large
|
||||
29 Banner Yes suse SUSE Logo
|
||||
30 Banner Yes ubuntu Ubuntu Logo
|
||||
|
||||
Do "linux_logo -L num" where num is from above to get the appropriate logo.
|
||||
Remember to also use -a to get ascii version.
|
||||
|
||||
To see aix logo, enter:
|
||||
|
||||
$ linux_logo -f -L aix
|
||||
|
||||
To see openbsd logo:
|
||||
|
||||
$ linux_logo -f -L openbsd
|
||||
|
||||
Or just see some random Linux logo:
|
||||
|
||||
$ linux_logo -f -L random_xy
|
||||
|
||||
You [can combine bash for loop as follows to display various logos][3], enter:
|
||||
|
||||

|
||||
|
||||
Gif 01: linux_logo and bash for loop for fun and profie
|
||||
|
||||
### Getting help ###
|
||||
|
||||
Simply type the following command:
|
||||
|
||||
$ screefetch -h
|
||||
$ linux_logo -h
|
||||
|
||||
**References**
|
||||
|
||||
- [screenFetch home page][4]
|
||||
- [linux_logo home page][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/hardware/howto-display-linux-logo-in-bash-terminal-using-screenfetch-linux_logo/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html
|
||||
[2]:http://imgur.com/HKIUznn
|
||||
[3]:http://www.cyberciti.biz/faq/bash-for-loop/
|
||||
[4]:https://github.com/KittyKatt/screenFetch
|
||||
[5]:https://github.com/deater/linux_logo
|
||||
@ -0,0 +1,202 @@
|
||||
A Repository with 44 Years of Unix Evolution
|
||||
================================================================================
|
||||
### Abstract ###
|
||||
|
||||
The evolution of the Unix operating system is made available as a version-control repository, covering the period from its inception in 1972 as a five thousand line kernel, to 2015 as a widely-used 26 million line system. The repository contains 659 thousand commits and 2306 merges. The repository employs the commonly used Git system for its storage, and is hosted on the popular GitHub archive. It has been created by synthesizing with custom software 24 snapshots of systems developed at Bell Labs, Berkeley University, and the 386BSD team, two legacy repositories, and the modern repository of the open source FreeBSD system. In total, 850 individual contributors are identified, the early ones through primary research. The data set can be used for empirical research in software engineering, information systems, and software archaeology.
|
||||
|
||||
### 1 Introduction ###
|
||||
|
||||
The Unix operating system stands out as a major engineering breakthrough due to its exemplary design, its numerous technical contributions, its development model, and its widespread use. The design of the Unix programming environment has been characterized as one offering unusual simplicity, power, and elegance [[1][1]]. On the technical side, features that can be directly attributed to Unix or were popularized by it include [[2][2]]: the portable implementation of the kernel in a high level language; a hierarchical file system; compatible file, device, networking, and inter-process I/O; the pipes and filters architecture; virtual file systems; and the shell as a user-selectable regular process. A large community contributed software to Unix from its early days [[3][3]], [[4][4],pp. 65-72]. This community grew immensely over time and worked using what are now termed open source software development methods [[5][5],pp. 440-442]. Unix and its intellectual descendants have also helped the spread of the C and C++ programming languages, parser and lexical analyzer generators (*yacc, lex*), document preparation tools (*troff, eqn, tbl*), scripting languages (*awk, sed, Perl*), TCP/IP networking, and configuration management systems (*SCCS, RCS, Subversion, Git*), while also forming a large part of the modern internet infrastructure and the web.
|
||||
|
||||
Luckily, important Unix material of historical importance has survived and is nowadays openly available. Although Unix was initially distributed with relatively restrictive licenses, the most significant parts of its early development have been released by one of its right-holders (Caldera International) under a liberal license. Combining these parts with software that was developed or released as open source software by the University of California, Berkeley and the FreeBSD Project provides coverage of the system's development over a period ranging from June 20th 1972 until today.
|
||||
|
||||
Curating and processing available snapshots as well as old and modern configuration management repositories allows the reconstruction of a new synthetic Git repository that combines under a single roof most of the available data. This repository documents in a digital form the detailed evolution of an important digital artefact over a period of 44 years. The following sections describe the repository's structure and contents (Section [II][6]), the way it was created (Section [III][7]), and how it can be used (Section [IV][8]).
|
||||
|
||||
### 2 Data Overview ###
|
||||
|
||||
The 1GB Unix history Git repository is made available for cloning on [GitHub][9].[1][10] Currently[2][11] the repository contains 659 thousand commits and 2306 merges from about 850 contributors. The contributors include 23 from the Bell Labs staff, 158 from Berkeley's Computer Systems Research Group (CSRG), and 660 from the FreeBSD Project.
|
||||
|
||||
The repository starts its life at a tag identified as *Epoch*, which contains only licensing information and its modern README file. Various tag and branch names identify points of significance.
|
||||
|
||||
- *Research-VX* tags correspond to six research editions that came out of Bell Labs. These start with *Research-V1* (4768 lines of PDP-11 assembly) and end with *Research-V7* (1820 mostly C files, 324kLOC).
|
||||
- *Bell-32V* is the port of the 7th Edition Unix to the DEC/VAX architecture.
|
||||
- *BSD-X* tags correspond to 15 snapshots released from Berkeley.
|
||||
- *386BSD-X* tags correspond to two open source versions of the system, with the Intel 386 architecture kernel code mainly written by Lynne and William Jolitz.
|
||||
- *FreeBSD-release/X* tags and branches mark 116 releases coming from the FreeBSD project.
|
||||
|
||||
In addition, branches with a *-Snapshot-Development* suffix denote commits that have been synthesized from a time-ordered sequence of a snapshot's files, while tags with a *-VCS-Development* suffix mark the point along an imported version control history branch where a particular release occurred.
|
||||
|
||||
The repository's history includes commits from the earliest days of the system's development, such as the following.
|
||||
|
||||
commit c9f643f59434f14f774d61ee3856972b8c3905b1
|
||||
Author: Dennis Ritchie <research!dmr>
|
||||
Date: Mon Dec 2 18:18:02 1974 -0500
|
||||
Research V5 development
|
||||
Work on file usr/sys/dmr/kl.c
|
||||
|
||||
Merges between releases that happened along the system's evolution, such as the development of BSD 3 from BSD 2 and Unix 32/V, are also correctly represented in the Git repository as graph nodes with two parents.
|
||||
|
||||
More importantly, the repository is constructed in a way that allows *git blame*, which annotates source code lines with the version, date, and author associated with their first appearance, to produce the expected code provenance results. For example, checking out the *BSD-4* tag, and running git blame on the kernel's *pipe.c* file will show lines written by Ken Thompson in 1974, 1975, and 1979, and by Bill Joy in 1980. This allows the automatic (though computationally expensive) detection of the code's provenance at any point of time.
|
||||
|
||||
|
||||
|
||||
Figure 1: Code provenance across significant Unix releases.
|
||||
|
||||
As can be seen in Figure [1][12], a modern version of Unix (FreeBSD 9) still contains visible chunks of code from BSD 4.3, BSD 4.3 Net/2, and FreeBSD 2.0. Interestingly, the Figure shows that code developed during the frantic dash to create an open source operating system out of the code released by Berkeley (386BSD and FreeBSD 1.0) does not seem to have survived. The oldest code in FreeBSD 9 appears to be an 18-line sequence in the C library file timezone.c, which can also be found in the 7th Edition Unix file with the same name and a time stamp of January 10th, 1979 - 36 years ago.
|
||||
|
||||
### 3 Data Collection and Processing ###
|
||||
|
||||
The goal of the project is to consolidate data concerning the evolution of Unix in a form that helps the study of the system's evolution, by entering them into a modern revision repository. This involves collecting the data, curating them, and synthesizing them into a single Git repository.
|
||||
|
||||
|
||||
|
||||
Figure 2: Imported Unix snapshots, repositories, and their mergers.
|
||||
|
||||
The project is based on three types of data (see Figure [2][13]). First, snapshots of early released versions, which were obtained from the [Unix Heritage Society archive][14],[3][15] the [CD-ROM images][16] containing the full source archives of CSRG,[4][17] the [OldLinux site][18],[5][19] and the [FreeBSD archive][20].[6][21] Second, past and current repositories, namely the CSRG SCCS [[6][22]] repository, the FreeBSD 1 CVS repository, and the [Git mirror of modern FreeBSD development][23].[7][24] The first two were obtained from the same sources as the corresponding snapshots.
|
||||
|
||||
The last, and most labour intensive, source of data was **primary research**. The release snapshots do not provide information regarding their ancestors and the contributors of each file. Therefore, these pieces of information had to be determined through primary research. The authorship information was mainly obtained by reading author biographies, research papers, internal memos, and old documentation scans; by reading and automatically processing source code and manual page markup; by communicating via email with people who were there at the time; by posting a query on the Unix *StackExchange* site; by looking at the location of files (in early editions the kernel source code was split into `usr/sys/dmr` and `/usr/sys/ken`); and by propagating authorship from research papers and manual pages to source code and from one release to others. (Interestingly, the 1st and 2nd Research Edition manual pages have an "owner" section, listing the person (e.g. *ken*) associated with the corresponding system command, file, system call, or library function. This section was not there in the 4th Edition, and resurfaced as the "Author" section in BSD releases.) Precise details regarding the source of the authorship information are documented in the project's files that are used for mapping Unix source code files to their authors and the corresponding commit messages. Finally, information regarding merges between source code bases was obtained from a [BSD family tree maintained by the NetBSD project][25].[8][26]
|
||||
|
||||
The software and data files that were developed as part of this project, are [available online][27],[9][28] and, with appropriate network, CPU and disk resources, they can be used to recreate the repository from scratch. The authorship information for major releases is stored in files under the project's `author-path` directory. These contain lines with a regular expressions for a file path followed by the identifier of the corresponding author. Multiple authors can also be specified. The regular expressions are processed sequentially, so that a catch-all expression at the end of the file can specify a release's default authors. To avoid repetition, a separate file with a `.au` suffix is used to map author identifiers into their names and emails. One such file has been created for every community associated with the system's evolution: Bell Labs, Berkeley, 386BSD, and FreeBSD. For the sake of authenticity, emails for the early Bell Labs releases are listed in UUCP notation (e.g. `research!ken`). The FreeBSD author identifier map, required for importing the early CVS repository, was constructed by extracting the corresponding data from the project's modern Git repository. In total the commented authorship files (828 rules) comprise 1107 lines, and there are another 640 lines mapping author identifiers to names.
|
||||
|
||||
The curation of the project's data sources has been codified into a 168-line `Makefile`. It involves the following steps.
|
||||
|
||||
**Fetching** Copying and cloning about 11GB of images, archives, and repositories from remote sites.
|
||||
|
||||
**Tooling** Obtaining an archiver for old PDP-11 archives from 2.9 BSD, and adjusting it to compile under modern versions of Unix; compiling the 4.3 BSD *compress* program, which is no longer part of modern Unix systems, in order to decompress the 386BSD distributions.
|
||||
|
||||
**Organizing** Unpacking archives using tar and *cpio*; combining three 6th Research Edition directories; unpacking all 1 BSD archives using the old PDP-11 archiver; mounting CD-ROM images so that they can be processed as file systems; combining the 8 and 62 386BSD floppy disk images into two separate files.
|
||||
|
||||
**Cleaning** Restoring the 1st Research Edition kernel source code files, which were obtained from printouts through optical character recognition, into a format close to their original state; patching some 7th Research Edition source code files; removing metadata files and other files that were added after a release, to avoid obtaining erroneous time stamp information; patching corrupted SCCS files; processing the early FreeBSD CVS repository by removing CVS symbols assigned to multiple revisions with a custom Perl script, deleting CVS *Attic* files clashing with live ones, and converting the CVS repository into a Git one using *cvs2svn*.
|
||||
|
||||
An interesting part of the repository representation is how snapshots are imported and linked together in a way that allows *git blame* to perform its magic. Snapshots are imported into the repository as sequential commits based on the time stamp of each file. When all files have been imported the repository is tagged with the name of the corresponding release. At that point one could delete those files, and begin the import of the next snapshot. Note that the *git blame* command works by traversing backwards a repository's history, and using heuristics to detect code moving and being copied within or across files. Consequently, deleted snapshots would create a discontinuity between them, and prevent the tracing of code between them.
|
||||
|
||||
Instead, before the next snapshot is imported, all the files of the preceding snapshot are moved into a hidden look-aside directory named `.ref` (reference). They remain there, until all files of the next snapshot have been imported, at which point they are deleted. Because every file in the `.ref` directory matches exactly an original file, *git blame* can determine how source code moves from one version to the next via the `.ref` file, without ever displaying the `.ref` file. To further help the detection of code provenance, and to increase the representation's realism, each release is represented as a merge between the branch with the incremental file additions (*-Development*) and the preceding release.
|
||||
|
||||
For a period in the 1980s, only a subset of the files developed at Berkeley were under SCCS version control. During that period our unified repository contains imports of both the SCCS commits, and the snapshots' incremental additions. At the point of each release, the SCCS commit with the nearest time stamp is found and is marked as a merge with the release's incremental import branch. These merges can be seen in the middle of Figure [2][29].
|
||||
|
||||
The synthesis of the various data sources into a single repository is mainly performed by two scripts. A 780-line Perl script (`import-dir.pl`) can export the (real or synthesized) commit history from a single data source (snapshot directory, SCCS repository, or Git repository) in the *Git fast export* format. The output is a simple text format that Git tools use to import and export commits. Among other things, the script takes as arguments the mapping of files to contributors, the mapping between contributor login names and their full names, the commit(s) from which the import will be merged, which files to process and which to ignore, and the handling of "reference" files. A 450-line shell script creates the Git repository and calls the Perl script with appropriate arguments to import each one of the 27 available historical data sources. The shell script also runs 30 tests that compare the repository at specific tags against the corresponding data sources, verify the appearance and disappearance of look-aside directories, and look for regressions in the count of tree branches and merges and the output of *git blame* and *git log*. Finally, *git* is called to garbage-collect and compress the repository from its initial 6GB size down to the distributed 1GB.
|
||||
|
||||
### 4 Data Uses ###
|
||||
|
||||
The data set can be used for empirical research in software engineering, information systems, and software archeology. Through its unique uninterrupted coverage of a period of more than 40 years, it can inform work on software evolution and handovers across generations. With thousandfold increases in processing speed and million-fold increases in storage capacity during that time, the data set can also be used to study the co-evolution of software and hardware technology. The move of the software's development from research labs, to academia, and to the open source community can be used to study the effects of organizational culture on software development. The repository can also be used to study how notable individuals, such as Turing Award winners (Dennis Ritchie and Ken Thompson) and captains of the IT industry (Bill Joy and Eric Schmidt), actually programmed. Another phenomenon worthy of study concerns the longevity of code, either at the level of individual lines, or as complete systems that were at times distributed with Unix (Ingres, Lisp, Pascal, Ratfor, Snobol, TMG), as well as the factors that lead to code's survival or demise. Finally, because the data set stresses Git, the underlying software repository storage technology, to its limits, it can be used to drive engineering progress in the field of revision management systems.
|
||||
|
||||
|
||||
|
||||
Figure 3: Code style evolution along Unix releases.
|
||||
|
||||
Figure [3][30], which depicts trend lines (obtained with R's local polynomial regression fitting function) of some interesting code metrics along 36 major releases of Unix, demonstrates the evolution of code style and programming language use over very long timescales. This evolution can be driven by software and hardware technology affordances and requirements, software construction theory, and even social forces. The dates in the Figure have been calculated as the average date of all files appearing in a given release. As can be seen in it, over the past 40 years the mean length of identifiers and file names has steadily increased from 4 and 6 characters to 7 and 11 characters, respectively. We can also see less steady increases in the number of comments and decreases in the use of the *goto* statement, as well as the virtual disappearance of the *register* type modifier.
|
||||
|
||||
### 5 Further Work ###
|
||||
|
||||
Many things can be done to increase the repository's faithfulness and usefulness. Given that the build process is shared as open source code, it is easy to contribute additions and fixes through GitHub pull requests. The most useful community contribution would be to increase the coverage of imported snapshot files that are attributed to a specific author. Currently, about 90 thousand files (out of a total of 160 thousand) are getting assigned an author through a default rule. Similarly, there are about 250 authors (primarily early FreeBSD ones) for which only the identifier is known. Both are listed in the build repository's unmatched directory, and contributions are welcomed. Furthermore, the BSD SCCS and the FreeBSD CVS commits that share the same author and time-stamp can be coalesced into a single Git commit. Support can be added for importing the SCCS file comment fields, in order to bring into the repository the corresponding metadata. Finally, and most importantly, more branches of open source systems can be added, such as NetBSD OpenBSD, DragonFlyBSD, and *illumos*. Ideally, current right holders of other important historical Unix releases, such as System III, System V, NeXTSTEP, and SunOS, will release their systems under a license that would allow their incorporation into this repository for study.
|
||||
|
||||
#### Acknowledgements ####
|
||||
|
||||
The author thanks the many individuals who contributed to the effort. Brian W. Kernighan, Doug McIlroy, and Arnold D. Robbins helped with Bell Labs login identifiers. Clem Cole, Era Eriksson, Mary Ann Horton, Kirk McKusick, Jeremy C. Reed, Ingo Schwarze, and Anatole Shaw helped with BSD login identifiers. The BSD SCCS import code is based on work by H. Merijn Brand and Jonathan Gray.
|
||||
|
||||
This research has been co-financed by the European Union (European Social Fund - ESF) and Greek national funds through the Operational Program "Education and Lifelong Learning" of the National Strategic Reference Framework (NSRF) - Research Funding Program: Thalis - Athens University of Economics and Business - Software Engineering Research Platform.
|
||||
|
||||
### References ###
|
||||
|
||||
[[1]][31]
|
||||
M. D. McIlroy, E. N. Pinson, and B. A. Tague, "UNIX time-sharing system: Foreword," *The Bell System Technical Journal*, vol. 57, no. 6, pp. 1899-1904, July-August 1978.
|
||||
|
||||
[[2]][32]
|
||||
D. M. Ritchie and K. Thompson, "The UNIX time-sharing system," *Bell System Technical Journal*, vol. 57, no. 6, pp. 1905-1929, July-August 1978.
|
||||
|
||||
[[3]][33]
|
||||
D. M. Ritchie, "The evolution of the UNIX time-sharing system," *AT&T Bell Laboratories Technical Journal*, vol. 63, no. 8, pp. 1577-1593, Oct. 1984.
|
||||
|
||||
[[4]][34]
|
||||
P. H. Salus, *A Quarter Century of UNIX*. Boston, MA: Addison-Wesley, 1994.
|
||||
|
||||
[[5]][35]
|
||||
E. S. Raymond, *The Art of Unix Programming*. Addison-Wesley, 2003.
|
||||
|
||||
[[6]][36]
|
||||
M. J. Rochkind, "The source code control system," *IEEE Transactions on Software Engineering*, vol. SE-1, no. 4, pp. 255-265, 1975.
|
||||
|
||||
----------
|
||||
|
||||
#### Footnotes: ####
|
||||
|
||||
[1][37] - [https://github.com/dspinellis/unix-history-repo][38]
|
||||
|
||||
[2][39] - Updates may add or modify material. To ensure replicability the repository's users are encouraged to fork it or archive it.
|
||||
|
||||
[3][40] - [http://www.tuhs.org/archive_sites.html][41]
|
||||
|
||||
[4][42] - [https://www.mckusick.com/csrg/][43]
|
||||
|
||||
[5][44] - [http://www.oldlinux.org/Linux.old/distributions/386BSD][45]
|
||||
|
||||
[6][46] - [http://ftp-archive.freebsd.org/pub/FreeBSD-Archive/old-releases/][47]
|
||||
|
||||
[7][48] - [https://github.com/freebsd/freebsd][49]
|
||||
|
||||
[8][50] - [http://ftp.netbsd.org/pub/NetBSD/NetBSD-current/src/share/misc/bsd-family-tree][51]
|
||||
|
||||
[9][52] - [https://github.com/dspinellis/unix-history-make][53]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#MPT78
|
||||
[2]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#RT78
|
||||
[3]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#Rit84
|
||||
[4]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#Sal94
|
||||
[5]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#Ray03
|
||||
[6]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#sec:data
|
||||
[7]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#sec:dev
|
||||
[8]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#sec:use
|
||||
[9]:https://github.com/dspinellis/unix-history-repo
|
||||
[10]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAB
|
||||
[11]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAC
|
||||
[12]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#fig:provenance
|
||||
[13]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#fig:branches
|
||||
[14]:http://www.tuhs.org/archive_sites.html
|
||||
[15]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAD
|
||||
[16]:https://www.mckusick.com/csrg/
|
||||
[17]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAE
|
||||
[18]:http://www.oldlinux.org/Linux.old/distributions/386BSD
|
||||
[19]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAF
|
||||
[20]:http://ftp-archive.freebsd.org/pub/FreeBSD-Archive/old-releases/
|
||||
[21]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAG
|
||||
[22]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#SCCS
|
||||
[23]:https://github.com/freebsd/freebsd
|
||||
[24]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAH
|
||||
[25]:http://ftp.netbsd.org/pub/NetBSD/NetBSD-current/src/share/misc/bsd-family-tree
|
||||
[26]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAI
|
||||
[27]:https://github.com/dspinellis/unix-history-make
|
||||
[28]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAJ
|
||||
[29]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#fig:branches
|
||||
[30]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#fig:metrics
|
||||
[31]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITEMPT78
|
||||
[32]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITERT78
|
||||
[33]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITERit84
|
||||
[34]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITESal94
|
||||
[35]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITERay03
|
||||
[36]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITESCCS
|
||||
[37]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAB
|
||||
[38]:https://github.com/dspinellis/unix-history-repo
|
||||
[39]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAC
|
||||
[40]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAD
|
||||
[41]:http://www.tuhs.org/archive_sites.html
|
||||
[42]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAE
|
||||
[43]:https://www.mckusick.com/csrg/
|
||||
[44]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAF
|
||||
[45]:http://www.oldlinux.org/Linux.old/distributions/386BSD
|
||||
[46]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAG
|
||||
[47]:http://ftp-archive.freebsd.org/pub/FreeBSD-Archive/old-releases/
|
||||
[48]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAH
|
||||
[49]:https://github.com/freebsd/freebsd
|
||||
[50]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAI
|
||||
[51]:http://ftp.netbsd.org/pub/NetBSD/NetBSD-current/src/share/misc/bsd-family-tree
|
||||
[52]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAJ
|
||||
[53]:https://github.com/dspinellis/unix-history-make
|
||||
250
sources/tech/20150921 Configure PXE Server In Ubuntu 14.04.md
Normal file
250
sources/tech/20150921 Configure PXE Server In Ubuntu 14.04.md
Normal file
@ -0,0 +1,250 @@
|
||||
translation by strugglingyouth
|
||||
Configure PXE Server In Ubuntu 14.04
|
||||
================================================================================
|
||||

|
||||
|
||||
PXE (Preboot Execution Environment) Server allows the user to boot a Linux distribution from a network and install it on hundreds of PCs at a time without any Linux iso images. If your client’s computers don’t have CD/DVD or USB drives, or if you want to set up multiple computers at the same time in a large enterprise, then PXE server can be used to save money and time.
|
||||
|
||||
In this article we will show you how you can configure a PXE server in Ubuntu 14.04.
|
||||
|
||||
### Configure Networking ###
|
||||
|
||||
To get started, you need to first set up your PXE server to use a static IP. To set up a static IP address in your system, you need to edit the “/etc/network/interfaces” file.
|
||||
|
||||
1. Open the “/etc/network/interfaces” file.
|
||||
|
||||
sudo nano /etc/network/interfaces
|
||||
|
||||
Add/edit as described below:
|
||||
|
||||
# The loopback network interface
|
||||
auto lo
|
||||
iface lo inet loopback
|
||||
# The primary network interface
|
||||
auto eth0
|
||||
iface eth0 inet static
|
||||
address 192.168.1.20
|
||||
netmask 255.255.255.0
|
||||
gateway 192.168.1.1
|
||||
dns-nameservers 8.8.8.8
|
||||
|
||||
Save the file and exit. This will set its IP address to “192.168.1.20”. Restart the network service.
|
||||
|
||||
sudo /etc/init.d/networking restart
|
||||
|
||||
### Install DHCP, TFTP and NFS: ###
|
||||
|
||||
DHCP, TFTP and NFS are essential components for configuring a PXE server. First you need to update your system and install all necessary packages.
|
||||
|
||||
For this, run the following commands:
|
||||
|
||||
sudo apt-get update
|
||||
sudo apt-get install isc-dhcp-Server inetutils-inetd tftpd-hpa syslinux nfs-kernel-Server
|
||||
|
||||
### Configure DHCP Server: ###
|
||||
|
||||
DHCP stands for Dynamic Host Configuration Protocol, and it is used mainly for dynamically distributing network configuration parameters such as IP addresses for interfaces and services. A DHCP server in PXE environment allow clients to request and receive an IP address automatically to gain access to the network servers.
|
||||
|
||||
1. Edit the “/etc/default/dhcp3-server” file.
|
||||
|
||||
sudo nano /etc/default/dhcp3-server
|
||||
|
||||
Add/edit as described below:
|
||||
|
||||
INTERFACES="eth0"
|
||||
|
||||
Save (Ctrl + o) and exit (Ctrl + x) the file.
|
||||
|
||||
2. Edit the “/etc/dhcp3/dhcpd.conf” file:
|
||||
|
||||
sudo nano /etc/dhcp/dhcpd.conf
|
||||
|
||||
Add/edit as described below:
|
||||
|
||||
default-lease-time 600;
|
||||
max-lease-time 7200;
|
||||
subnet 192.168.1.0 netmask 255.255.255.0 {
|
||||
range 192.168.1.21 192.168.1.240;
|
||||
option subnet-mask 255.255.255.0;
|
||||
option routers 192.168.1.20;
|
||||
option broadcast-address 192.168.1.255;
|
||||
filename "pxelinux.0";
|
||||
next-Server 192.168.1.20;
|
||||
}
|
||||
|
||||
Save the file and exit.
|
||||
|
||||
3. Start the DHCP service.
|
||||
|
||||
sudo /etc/init.d/isc-dhcp-server start
|
||||
|
||||
### Configure TFTP Server: ###
|
||||
|
||||
TFTP is a file-transfer protocol which is similar to FTP. It is used where user authentication and directory visibility are not required. The TFTP server is always listening for PXE clients on the network. When it detects any network PXE client asking for PXE services, then it provides a network package that contains the boot menu.
|
||||
|
||||
1. To configure TFTP, edit the “/etc/inetd.conf” file.
|
||||
|
||||
sudo nano /etc/inetd.conf
|
||||
|
||||
Add/edit as described below:
|
||||
|
||||
tftp dgram udp wait root /usr/sbin/in.tftpd /usr/sbin/in.tftpd -s /var/lib/tftpboot
|
||||
|
||||
Save and exit the file.
|
||||
|
||||
2. Edit the “/etc/default/tftpd-hpa” file.
|
||||
|
||||
sudo nano /etc/default/tftpd-hpa
|
||||
|
||||
Add/edit as described below:
|
||||
|
||||
TFTP_USERNAME="tftp"
|
||||
TFTP_DIRECTORY="/var/lib/tftpboot"
|
||||
TFTP_ADDRESS="[:0.0.0.0:]:69"
|
||||
TFTP_OPTIONS="--secure"
|
||||
RUN_DAEMON="yes"
|
||||
OPTIONS="-l -s /var/lib/tftpboot"
|
||||
|
||||
Save and exit the file.
|
||||
|
||||
3. Enable boot service for `inetd` to automatically start after every system reboot and start tftpd service.
|
||||
|
||||
sudo update-inetd --enable BOOT
|
||||
sudo service tftpd-hpa start
|
||||
|
||||
4. Check status.
|
||||
|
||||
sudo netstat -lu
|
||||
|
||||
It will show the following output:
|
||||
|
||||
Proto Recv-Q Send-Q Local Address Foreign Address State
|
||||
udp 0 0 *:tftp *:*
|
||||
|
||||
### Configure PXE boot files ###
|
||||
|
||||
Now you need the PXE boot file “pxelinux.0” to be present in the TFTP root directory. Make a directory structure for TFTP, and copy all the bootloader files provided by syslinux from the “/usr/lib/syslinux/” to the “/var/lib/tftpboot/” path by issuing the following commands:
|
||||
|
||||
sudo mkdir /var/lib/tftpboot
|
||||
sudo mkdir /var/lib/tftpboot/pxelinux.cfg
|
||||
sudo mkdir -p /var/lib/tftpboot/Ubuntu/14.04/amd64/
|
||||
sudo cp /usr/lib/syslinux/vesamenu.c32 /var/lib/tftpboot/
|
||||
sudo cp /usr/lib/syslinux/pxelinux.0 /var/lib/tftpboot/
|
||||
|
||||
#### Set up PXELINUX configuration file ####
|
||||
|
||||
The PXE configuration file defines the boot menu displayed to the PXE client when it boots up and contacts the TFTP server. By default, when a PXE client boots up, it will use its own MAC address to specify which configuration file to read, so we need to create that default file that contains the list of kernels which are available to boot.
|
||||
|
||||
Edit the PXE Server configuration file with valid installation options.
|
||||
|
||||
To edit “/var/lib/tftpboot/pxelinux.cfg/default,”
|
||||
|
||||
sudo nano /var/lib/tftpboot/pxelinux.cfg/default
|
||||
|
||||
Add/edit as described below:
|
||||
|
||||
DEFAULT vesamenu.c32
|
||||
TIMEOUT 100
|
||||
PROMPT 0
|
||||
MENU INCLUDE pxelinux.cfg/PXE.conf
|
||||
NOESCAPE 1
|
||||
LABEL Try Ubuntu 14.04 Desktop
|
||||
MENU LABEL Try Ubuntu 14.04 Desktop
|
||||
kernel Ubuntu/vmlinuz
|
||||
append boot=casper netboot=nfs nfsroot=192.168.1.20:/var/lib/tftpboot/Ubuntu/14.04/amd64
|
||||
initrd=Ubuntu/initrd.lz quiet splash
|
||||
ENDTEXT
|
||||
LABEL Install Ubuntu 14.04 Desktop
|
||||
MENU LABEL Install Ubuntu 14.04 Desktop
|
||||
kernel Ubuntu/vmlinuz
|
||||
append boot=casper automatic-ubiquity netboot=nfs nfsroot=192.168.1.20:/var/lib/tftpboot/Ubuntu/14.04/amd64
|
||||
initrd=Ubuntu/initrd.lz quiet splash
|
||||
ENDTEXT
|
||||
|
||||
Save and exit the file.
|
||||
|
||||
Edit the “/var/lib/tftpboot/pxelinux.cfg/pxe.conf” file.
|
||||
|
||||
sudo nano /var/lib/tftpboot/pxelinux.cfg/pxe.conf
|
||||
|
||||
Add/edit as described below:
|
||||
|
||||
MENU TITLE PXE Server
|
||||
NOESCAPE 1
|
||||
ALLOWOPTIONS 1
|
||||
PROMPT 0
|
||||
MENU WIDTH 80
|
||||
MENU ROWS 14
|
||||
MENU TABMSGROW 24
|
||||
MENU MARGIN 10
|
||||
MENU COLOR border 30;44 #ffffffff #00000000 std
|
||||
|
||||
Save and exit the file.
|
||||
|
||||
### Add Ubuntu 14.04 Desktop Boot Images to PXE Server ###
|
||||
|
||||
For this, Ubuntu kernel and initrd files are required. To get those files, you need the Ubuntu 14.04 Desktop ISO Image. You can download the Ubuntu 14.04 ISO image in the /mnt folder by issuing the following command:
|
||||
|
||||
sudo cd /mnt
|
||||
sudo wget http://releases.ubuntu.com/14.04/ubuntu-14.04.3-desktop-amd64.iso
|
||||
|
||||
**Note**: the download URL might change as the ISO image is updated. Check out this website for the latest download link if the above URL is not working.
|
||||
|
||||
Mount the ISO file, and copy all the files to the TFTP folder by issuing the following commands:
|
||||
|
||||
sudo mount -o loop /mnt/ubuntu-14.04.3-desktop-amd64.iso /media/
|
||||
sudo cp -r /media/* /var/lib/tftpboot/Ubuntu/14.04/amd64/
|
||||
sudo cp -r /media/.disk /var/lib/tftpboot/Ubuntu/14.04/amd64/
|
||||
sudo cp /media/casper/initrd.lz /media/casper/vmlinuz /var/lib/tftpboot/Ubuntu/
|
||||
|
||||
### Configure NFS Server to Export ISO Contents ###
|
||||
|
||||
Now you need to setup Installation Source Mirrors via NFS protocol. You can also use http and ftp for Installation Source Mirrors. Here I have used NFS to export ISO contents.
|
||||
|
||||
To configure the NFS server, you need to edit the “/etc/exports” file.
|
||||
|
||||
sudo nano /etc/exports
|
||||
|
||||
Add/edit as described below:
|
||||
|
||||
/var/lib/tftpboot/Ubuntu/14.04/amd64 *(ro,async,no_root_squash,no_subtree_check)
|
||||
|
||||
Save and exit the file. For the changes to take effect, export and start NFS service.
|
||||
|
||||
sudo exportfs -a
|
||||
sudo /etc/init.d/nfs-kernel-server start
|
||||
|
||||
Now your PXE Server is ready.
|
||||
|
||||
### Configure Network Boot PXE Client ###
|
||||
|
||||
A PXE client can be any computer system with a PXE network boot enable option. Now your clients can boot and install Ubuntu 14.04 Desktop by enabling “Boot From Network” options from their systems BIOS.
|
||||
|
||||
You’re now ready to go – start your PXE Client Machine with the network boot enable option, and you should now see a sub-menu showing for your Ubuntu 14.04 Desktop that we created.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Configuring network boot installation using PXE server is efficient and a time-saving method. You can install hundreds of client at a time in your local network. All you need is a PXE server and PXE enabled clients. Try it out, and let us know if this works for you.
|
||||
|
||||
Reference:
|
||||
- [PXE Server wiki][1]
|
||||
- [PXE Server Ubuntu][2]
|
||||
|
||||
Image credit: [fupsol_unl_20][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/configure-pxe-server-ubuntu/
|
||||
|
||||
作者:[Hitesh Jethva][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/hiteshjethva/
|
||||
[1]:https://en.wikipedia.org/wiki/Preboot_Execution_Environment
|
||||
[2]:https://help.ubuntu.com/community/PXEInstallServer
|
||||
[3]:https://www.flickr.com/photos/jhcalderon/3681926417/
|
||||
@ -0,0 +1,89 @@
|
||||
How to Setup IonCube Loaders on Ubuntu 14.04 / 15.04
|
||||
================================================================================
|
||||
IonCube Loaders is an encryption/decryption utility for PHP applications which assists in speeding up the pages that are served. It also protects your website's PHP code from being viewed and ran on unlicensed computers. Using ionCube encoded and secured PHP files requires a file called ionCube Loader to be installed on the web server and made available to PHP which is often required for a lot of PHP based applications. It handles the reading and execution of encoded files at run time. PHP can use the loader with one line added to a PHP configuration file that ‘php.ini’.
|
||||
|
||||
### Prerequisites ###
|
||||
|
||||
In this article we will setup the installation of Ioncube Loader on Ubuntu 14.04/15.04, so that it can be used in all PHP Modes. The only requirement for this tutorial is to have "php.ini" file exists in your system with LEMP stack installed on the server.
|
||||
|
||||
### Download IonCube Loader ###
|
||||
|
||||
Login to your ubuntu server to download the latest IonCube loader package according to your operating system architecture whether your are using a 32 Bit or 64 Bit OS. You can get its package by issuing the following command with super user privileges or root user.
|
||||
|
||||
# wget http://downloads3.ioncube.com/loader_downloads/ioncube_loaders_lin_x86-64.tar.gz
|
||||
|
||||

|
||||
|
||||
After Downloading unpack the archive into the "/usr/local/src/" folder by issuing the following command.
|
||||
|
||||
# tar -zxvf ioncube_loaders_lin_x86-64.tar.gz -C /usr/local/src/
|
||||
|
||||

|
||||
|
||||
After extracting the archive, we can see the list of all modules present in it. But we needs only the relevant with the version of PHP installed on our system.
|
||||
|
||||
To check your PHP version, you can run the below command to find the relevant modules.
|
||||
|
||||
# php -v
|
||||
|
||||

|
||||
|
||||
With reference to the output of above command we came to know that the PHP version installed on the system is 5.6.4, so we need to copy the appropriate module to the PHP modules folder.
|
||||
|
||||
To do so we will create a new folder with name "ioncube" within the "/usr/local/" directory and copy the required ioncube loader modules into it.
|
||||
|
||||
root@ubuntu-15:/usr/local/src/ioncube# mkdir /usr/local/ioncube
|
||||
root@ubuntu-15:/usr/local/src/ioncube# cp ioncube_loader_lin_5.6.so ioncube_loader_lin_5.6_ts.so /usr/local/ioncube/
|
||||
|
||||
### PHP Configuration ###
|
||||
|
||||
Now we need to put the following line into the configuration file of PHP file "php.ini" which is located in "/etc/php5/cli/" folder then restart your web server’s services and php module.
|
||||
|
||||
# vim /etc/php5/cli/php.ini
|
||||
|
||||

|
||||
|
||||
In our scenario we have Nginx web server installed, so we will run the following commands to start its services.
|
||||
|
||||
# service php5-fpm restart
|
||||
# service nginx restart
|
||||
|
||||

|
||||
|
||||
### Testing IonCube Loader ###
|
||||
|
||||
To test the ioncube loader in the PHP configuration for your website, create a test file called "info.php" with the following content and place it into the web directory of your web server.
|
||||
|
||||
# vim /usr/share/nginx/html/info.php
|
||||
|
||||
Then save the changes after placing phpinfo script and access "info.php" in your browser with your domain name or server’s IP address after reloading the web server services.
|
||||
|
||||
You will be able to see the below section at the bottom of your php modules information.
|
||||
|
||||

|
||||
|
||||
From the terminal issue the following command to verify the php version that shows the ionCube PHP Loader is Enabled.
|
||||
|
||||
# php -v
|
||||
|
||||

|
||||
|
||||
The output shown in the PHP version's command clearly indicated that IonCube loader has been successfully integrated with PHP.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
At the end of this tutorial you learnt about the installation and configuration of ionCube Loader on Ubuntu with Nginx web server there will be no such difference if you are using any other web server. So, installing Loaders is simple when its done correctly, and on most servers its installation will work without a problem. However there is no such thing as a "standard PHP installation", and servers can be setup in many different ways, and with different features enabled or disabled.
|
||||
|
||||
If you are on a shared server, then make sure that you have run the ioncube-loader-helper.php script, and click the link to test run time installation. If you still face as such issue while doing your setup, feel free to contact us and leave us a comment.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/setup-ioncube-loaders-ubuntu-14-04-15-04/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
@ -0,0 +1,102 @@
|
||||
How to Setup Node JS v4.0.0 on Ubuntu 14.04 / 15.04
|
||||
================================================================================
|
||||
Hi everyone, Node.JS Version 4.0.0 has been out, the popular server-side JavaScript platform has combines the Node.js and io.js code bases. This release represents the combined efforts encapsulated in both the Node.js project and the io.js project that are now combined in a single codebase. The most important change is this Node.js is ships with version 4.5 of Google's V8 JavaScript engine, which is the same version that ships with the current Chrome browser. So, being able to more closely track V8’s releases means Node.js runs JavaScript faster, more securely, and with the ability to use many desirable ES6 language features.
|
||||
|
||||

|
||||
|
||||
Node.js 4.0.0 aims to provide an easy update path for current users of io.js and node as there are no major API changes. Let’s see how you can easily get it installed and setup on Ubuntu server by following this simple article.
|
||||
|
||||
### Basic System Setup ###
|
||||
|
||||
Node works perfectly on Linux, Macintosh, and Solaris operating systems and among the Linux operating systems it has the best results using Ubuntu OS. That's why we are to setup it Ubuntu 15.04 while the same steps can be followed using Ubuntu 14.04.
|
||||
|
||||
**1) System Resources**
|
||||
|
||||
The basic system resources for Node depend upon the size of your infrastructure requirements. So, here in this tutorial we will setup Node with 1 GB RAM, 1 GHz Processor and 10 GB of available disk space with minimal installation packages installed on the server that is no web or database server packages are installed.
|
||||
|
||||
**2) System Update**
|
||||
|
||||
It always been recommended to keep your system upto date with latest patches and updates, so before we move to the installation on Node, let's login to your server with super user privileges and run update command.
|
||||
|
||||
# apt-get update
|
||||
|
||||
**3) Installing Dependencies**
|
||||
|
||||
Node JS only requires some basic system and software utilities to be present on your server, for its successful installation like 'make' 'gcc' and 'wget'. Let's run the below command to get them installed if they are not already present.
|
||||
|
||||
# apt-get install python gcc make g++ wget
|
||||
|
||||
### Download Latest Node JS v4.0.0 ###
|
||||
|
||||
Let's download the latest Node JS version 4.0.0 by following this link of [Node JS Download Page][1].
|
||||
|
||||

|
||||
|
||||
We will copy the link location of its latest package and download it using 'wget' command as shown.
|
||||
|
||||
# wget https://nodejs.org/download/rc/v4.0.0-rc.1/node-v4.0.0-rc.1.tar.gz
|
||||
|
||||
Once download completes, unpack using 'tar' command as shown.
|
||||
|
||||
# tar -zxvf node-v4.0.0-rc.1.tar.gz
|
||||
|
||||

|
||||
|
||||
### Installing Node JS v4.0.0 ###
|
||||
|
||||
Now we have to start the installation of Node JS from its downloaded source code. So, change your directory and configure the source code by running its configuration script before compiling it on your ubuntu server.
|
||||
|
||||
root@ubuntu-15:~/node-v4.0.0-rc.1# ./configure
|
||||
|
||||

|
||||
|
||||
Now run the 'make install' command to compile the Node JS installation package as shown.
|
||||
|
||||
root@ubuntu-15:~/node-v4.0.0-rc.1# make install
|
||||
|
||||
The make command will take a couple of minutes while compiling its binaries so after executinf above command, wait for a while and keep calm.
|
||||
|
||||
### Testing Node JS Installation ###
|
||||
|
||||
Once the compilation process is complete, we will test it if every thing went fine. Let's run the following command to confirm the installed version of Node JS.
|
||||
|
||||
root@ubuntu-15:~# node -v
|
||||
v4.0.0-pre
|
||||
|
||||
By executing 'node' without any arguments from the command-line you will be dropped into the REPL (Read-Eval-Print-Loop) that has simplistic emacs line-editing where you can interactively run JavaScript and see the results.
|
||||
|
||||

|
||||
|
||||
### Writing Test Program ###
|
||||
|
||||
We can also try out a very simple console program to test the successful installation and proper working of Node JS. To do so we will create a file named "test.js" and write the following code into it and save the changes made in the file as shown.
|
||||
|
||||
root@ubuntu-15:~# vim test.js
|
||||
var util = require("util");
|
||||
console.log("Hello! This is a Node Test Program");
|
||||
:wq!
|
||||
|
||||
Now in order to run the above program, from the command prompt run the below command.
|
||||
|
||||
root@ubuntu-15:~# node test.js
|
||||
|
||||

|
||||
|
||||
So, upon successful installation we will get the output as shown in the screen, where as in the above program it loads the "util" class into a variable "util" and then uses the "util" object to perform the console tasks. While the console.log is a command similar to the cout in C++.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
That’s it. Hope this gives you a good idea of Node.js going with Node.js on Ubuntu. If you are new to developing applications with Node.js. After all we can say that we can expect significant performance gains with Node JS Version 4.0.0.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/setup-node-js-4-0-ubuntu-14-04-15-04/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
[1]:https://nodejs.org/download/rc/v4.0.0-rc.1/
|
||||
@ -0,0 +1,155 @@
|
||||
Learn with Linux: Learning Music
|
||||
================================================================================
|
||||

|
||||
|
||||
This article is part of the [Learn with Linux][1] series:
|
||||
|
||||
- [Learn with Linux: Learning to Type][2]
|
||||
- [Learn with Linux: Physics Simulation][3]
|
||||
- [Learn with Linux: Learning Music][4]
|
||||
- [Learn with Linux: Two Geography Apps][5]
|
||||
- [Learn with Linux: Master Your Math with These Linux Apps][6]
|
||||
|
||||
Linux offers great educational software and many excellent tools to aid students of all grades and ages in learning and practicing a variety of topics, often interactively. The “Learn with Linux” series of articles offers an introduction to a variety of educational apps and software.
|
||||
|
||||
Learning music is a great pastime. Training your ears to identify scales and chords and mastering an instrument or your own voice requires lots of practise and could become difficult. Music theory is extensive. There is much to memorize, and to turn it into a “skill” you will need diligence. Linux offers exceptional software to help you along your musical journey. They will not help you become a professional musician instantly but could ease the process of learning, being a great aide and reference point.
|
||||
|
||||
### Gnu Solfège ###
|
||||
|
||||
[Solfège][7] is a popular music education method that is used in all levels of music education all around the world. Many popular methods (like the Kodály method) use Solfège as their basis. GNU Solfège is a great software aimed more at practising Solfège than learning it. It assumes the student has already acquired the basics and wishes to practise what they have learned.
|
||||
|
||||
As the developer states on the GNU website:
|
||||
|
||||
> “When you study music on high school, college, music conservatory, you usually have to do ear training. Some of the exercises, like sight singing, is easy to do alone [sic]. But often you have to be at least two people, one making questions, the other answering. […] GNU Solfège tries to help out with this. With Solfege you can practise the more simple and mechanical exercises without the need to get others to help you. Just don’t forget that this program only touches a part of the subject.”
|
||||
|
||||
The software delivers its promise; you can practise essentially everything with audible and visual aids.
|
||||
|
||||
GNU solfege is in the Debian (therefore Ubuntu) repositories. To get it just type the following command into a terminal:
|
||||
|
||||
sudo apt-get install solfege
|
||||
|
||||
When it loads, you find yourself on a simple starting screen/
|
||||
|
||||

|
||||
|
||||
The number of options is almost overwhelming. Most of the links will open sub-categories
|
||||
|
||||

|
||||
|
||||
from where you can select individual exercises.
|
||||
|
||||

|
||||
|
||||
There are practice sessions and tests. Both will be able to play the tones through any connected MIDI device or just your sound card’s MIDI player. The exercises often have visual notation and the ability to play back the sequence slowly.
|
||||
|
||||
One important note about Solfège is that under Ubuntu you might not be able to hear anything with the default setup (unless you have a MIDI device connected). If that is the case, head over to “File -> Preferences,” select sound setup and choose the appropriate option for your system (choosing ALSA would probably work in most cases).
|
||||
|
||||

|
||||
|
||||
Solfège could be very helpful for your daily practise. Use it regularly and you will have trained your ear before you can sing do-re-mi.
|
||||
|
||||
### Tete (ear trainer) ###
|
||||
|
||||
[Tete][8] (This ear trainer ‘ere) is a Java application for simple, yet efficient, [ear training][9]. It helps you identify a variety of scales by playing thhm back under various circumstances, from different roots and on different MIDI sounds. [Download it from SourceForge][10]. You then need to unzip the downloaded file.
|
||||
|
||||
unzip Tete-*
|
||||
|
||||
Enter the unpacked directory:
|
||||
|
||||
cd Tete-*
|
||||
|
||||
Assuming you have Java installed in your system, you can run the java file with
|
||||
|
||||
java -jar Tete-[your version]
|
||||
|
||||
(To autocomplete the above command, just press the Tab key after typing “Tete-“.)
|
||||
|
||||
Tete has a simple, one-page interface with everything on it.
|
||||
|
||||

|
||||
|
||||
You can choose to play scales (see above), chords,
|
||||
|
||||

|
||||
|
||||
or intervals.
|
||||
|
||||

|
||||
|
||||
You can “fine tune” your experience with various options including the midi instrument’s sound, what note to start from, ascending or descending scales, and how slow/fast the playback should be. Tete’s SourceForge page includes a very useful tutorial that explains most aspects of the software.
|
||||
|
||||
### JalMus ###
|
||||
|
||||
Jalmus is a Java-based keyboard note reading trainer. It works with attached MIDI keyboards or with the on-screen virtual keyboard. It has many simple lessons and exercises to train in music reading. Unfortunately, its development has been discontinued since 2013, but the software appears to still be functional.
|
||||
|
||||
To get Jalmus, head over to the [sourceforge page][11] of its last version (2.3) to get the Java installer, or just type the following command into a terminal:
|
||||
|
||||
wget http://garr.dl.sourceforge.net/project/jalmus/Jalmus-2.3/installjalmus23.jar
|
||||
|
||||
Once the download finishes, load the installer with
|
||||
|
||||
java -jar installjalmus23.jar
|
||||
|
||||
You will be guided through a simple Java-based installer that was made for cross-platform installation.
|
||||
|
||||
Jalmus’s main screen is plain.
|
||||
|
||||

|
||||
|
||||
You can find lessons of varying difficulty in the Lessons menu. It ranges from very simple ones, where one notes swims in from the left, and the corresponding key lights up on the on screen keyboard …
|
||||
|
||||

|
||||
|
||||
… to difficult ones with many notes swimming in from the right, and you are required to repeat the sequence on your keyboard.
|
||||
|
||||

|
||||
|
||||
Jalmus also includes exercises of note reading single notes, which are very similar to the lessons, only without the visual hints, where your score will be displayed after you finished. It also aids rhythm reading of varying difficulty, where the rhythm is both audible and visually marked. A metronome (audible and visual) aids in the understanding
|
||||
|
||||

|
||||
|
||||
and score reading where multiple notes will be played
|
||||
|
||||

|
||||
|
||||
All these options are configurable; you can switch features on and off as you like.
|
||||
|
||||
All things considered, Jalmus probably works best for rhythm training. Although it was not necessarily its intended purpose, the software really excelled in this particular use-case.
|
||||
|
||||
### Notable mentions ###
|
||||
|
||||
#### TuxGuitar ####
|
||||
|
||||
For guitarists, [TuxGuitar][12] works much like Guitar Pro on Windows (and it can also read guitar-pro files).
|
||||
PianoBooster
|
||||
|
||||
[Piano Booster][13] can help with piano skills. It is designed to play MIDI files, which you can play along with on an attached keyboard, watching the core roll past on the screen.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Linux offers many great tools for learning, and if your particular interest is music, your will not be left without software to aid your practice. Surely there are many more excellent software tools available for music students than were mentioned above. Do you know of any? Please let us know in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/linux-learning-music/
|
||||
|
||||
作者:[Attila Orosz][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/attilaorosz/
|
||||
[1]:https://www.maketecheasier.com/series/learn-with-linux/
|
||||
[2]:https://www.maketecheasier.com/learn-to-type-in-linux/
|
||||
[3]:https://www.maketecheasier.com/linux-physics-simulation/
|
||||
[4]:https://www.maketecheasier.com/linux-learning-music/
|
||||
[5]:https://www.maketecheasier.com/linux-geography-apps/
|
||||
[6]:https://www.maketecheasier.com/learn-linux-maths/
|
||||
[7]:https://en.wikipedia.org/wiki/Solf%C3%A8ge
|
||||
[8]:http://tete.sourceforge.net/index.shtml
|
||||
[9]:https://en.wikipedia.org/wiki/Ear_training
|
||||
[10]:http://sourceforge.net/projects/tete/files/latest/download
|
||||
[11]:http://sourceforge.net/projects/jalmus/files/Jalmus-2.3/
|
||||
[12]:http://tuxguitar.herac.com.ar/
|
||||
[13]:http://www.linuxlinks.com/article/20090517041840856/PianoBooster.html
|
||||
@ -0,0 +1,121 @@
|
||||
Learn with Linux: Learning to Type
|
||||
================================================================================
|
||||

|
||||
|
||||
This article is part of the [Learn with Linux][1] series:
|
||||
|
||||
- [Learn with Linux: Learning to Type][2]
|
||||
- [Learn with Linux: Physics Simulation][3]
|
||||
- [Learn with Linux: Learning Music][4]
|
||||
- [Learn with Linux: Two Geography Apps][5]
|
||||
- [Learn with Linux: Master Your Math with These Linux Apps][6]
|
||||
|
||||
Linux offers great educational software and many excellent tools to aid students of all grades and ages in learning and practicing a variety of topics, often interactively. The “Learn with Linux” series of articles offers an introduction to a variety of educational apps and software.
|
||||
|
||||
Typing is taken for granted by many people; today being keyboard savvy often comes as second nature. Yet how many of us still type with two fingers, even if ever so fast? Once typing was taught in schools, but slowly the art of ten-finger typing is giving way to two thumbs.
|
||||
|
||||
The following two applications can help you master the keyboard so that your next thought does not get lost while your fingers catch up. They were chosen for their simplicity and ease of use. While there are some more flashy or better looking typing apps out there, the following two will get the basics covered and offer the easiest way to start out.
|
||||
|
||||
### TuxType (or TuxTyping) ###
|
||||
|
||||
TuxType is for children. Young students can learn how to type with ten fingers with simple lessons and practice their newly-acquired skills in fun games.
|
||||
|
||||
Debian and derivatives (therefore all Ubuntu derivatives) should have TuxType in their standard repositories. To install simply type
|
||||
|
||||
sudo apt-get install tuxtype
|
||||
|
||||
The application starts with a simple menu screen featuring Tux and some really bad midi music (Fortunately the sound can be turned off easily with the icon in the lower left corner.).
|
||||
|
||||

|
||||
|
||||
The top two choices, “Fish Cascade” and “Comet Zap,” represent typing games, but to start learning you need to head over to the lessons.
|
||||
|
||||
There are forty simple built-in lessons to choose from. Each one of these will take a letter from the keyboard and make the student practice while giving visual hints, such as which finger to use.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
For more advanced practice, phrase typing is also available, although for some reason this is hidden under the options menu.
|
||||
|
||||

|
||||
|
||||
The games are good for speed and accuracy as the player helps Tux catch falling fish
|
||||
|
||||

|
||||
|
||||
or zap incoming asteroids by typing the words written over them.
|
||||
|
||||

|
||||
|
||||
Besides being a fun way to practice, these games teach spelling, speed, and eye-to-hand coordination, as you must type while also watching the screen, building a foundation for touch typing, if taken seriously.
|
||||
|
||||
### GNU typist (gtype) ###
|
||||
|
||||
For adults and more experienced typists, there is GNU Typist, a console-based application developed by the GNU project.
|
||||
|
||||
GNU Typist will also be carried by most Debian derivatives’ main repos. Installing it is as easy as typing
|
||||
|
||||
sudo apt-get install gtype
|
||||
|
||||
You will probably not find it in the Applications menu; insteaad you should start it from a terminal window.
|
||||
|
||||
gtype
|
||||
|
||||
The main menu is simple, no-nonsense and frill-free, yet it is evident how much the software has to offer. Typing lessons of all levels are immediately accessible.
|
||||
|
||||

|
||||
|
||||
The lessons are straightforward and detailed.
|
||||
|
||||

|
||||
|
||||
The interactive practice sessions offer little more than highlighting your mistakes. Instead of flashy visuals you have to chance to focus on practising. At the end of each lesson you get some simple statistics of how you’ve been doing. If you make too many mistakes, you cannot proceed until you can pass the level.
|
||||
|
||||

|
||||
|
||||
While the basic lessons only require you to repeat some characters, more advanced drills will have the practitioner type either whole sentences,
|
||||
|
||||

|
||||
|
||||
where of course the three percent error margin means you are allowed even fewer mistakes,
|
||||
|
||||

|
||||
|
||||
or some drills aiming to achieve certain goals, as in the “Balanced keyboard drill.”
|
||||
|
||||

|
||||
|
||||
Simple speed drills have you type quotes,
|
||||
|
||||

|
||||
|
||||
while more advanced ones will make you write longer texts taken from classics.
|
||||
|
||||

|
||||
|
||||
If you’d prefer a different language, more lessons can also be loaded as command line arguments.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
If you care to hone your typing skills, Linux has great software to offer. The two basic, yet feature-rich, applications discussed above will cater to most aspiring typists’ needs. If you use or know of another great typing application, please don’t hesitate to let us know below in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/learn-to-type-in-linux/
|
||||
|
||||
作者:[Attila Orosz][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/attilaorosz/
|
||||
[1]:https://www.maketecheasier.com/series/learn-with-linux/
|
||||
[2]:https://www.maketecheasier.com/learn-to-type-in-linux/
|
||||
[3]:https://www.maketecheasier.com/linux-physics-simulation/
|
||||
[4]:https://www.maketecheasier.com/linux-learning-music/
|
||||
[5]:https://www.maketecheasier.com/linux-geography-apps/
|
||||
[6]:https://www.maketecheasier.com/learn-linux-maths/
|
||||
@ -0,0 +1,128 @@
|
||||
Translating by KnightJoker
|
||||
|
||||
Learn with Linux: Master Your Math with These Linux Apps
|
||||
================================================================================
|
||||

|
||||
|
||||
This article is part of the [Learn with Linux][1] series:
|
||||
|
||||
- [Learn with Linux: Learning to Type][2]
|
||||
- [Learn with Linux: Physics Simulation][3]
|
||||
- [Learn with Linux: Learning Music][4]
|
||||
- [Learn with Linux: Two Geography Apps][5]
|
||||
- [Learn with Linux: Master Your Math with These Linux Apps][6]
|
||||
|
||||
Linux offers great educational software and many excellent tools to aid students of all grades and ages in learning and practicing a variety of topics, often interactively. The “Learn with Linux” series of articles offers an introduction to a variety of educational apps and software.
|
||||
|
||||
Mathematics is the core of computing. If one would expect a great operating system, such as GNU/Linux, to excel in and discipline, it would be Math. If you seek mathematical applications, you will not be disappointed. Linux offers many excellent tools that will make Mathematics look as intimidating as it ever did, but at least they will simplify your way of using it.
|
||||
|
||||
### Gnuplot ###
|
||||
|
||||
Gnuplot is a command-line scriptable and versatile graphing utility for different platforms. Despite its name, it is not part of the GNU operating system. Although it is not freely licensed, it’s free-ware (meaning it’s copyrighted but free to use).
|
||||
|
||||
To install `gnuplot` on an Ubuntu (or derivative) system, type
|
||||
|
||||
sudo apt-get install gnuplot gnuplot-x11
|
||||
|
||||
into a terminal window. To start the program, type
|
||||
|
||||
gnuplot
|
||||
|
||||
You will be presented with a simple command line interface
|
||||
|
||||

|
||||
|
||||
into which you can start typing functions directly. The plot command will draw a graph.
|
||||
|
||||
Typing, for instance,
|
||||
|
||||
plot sin(x)/x
|
||||
|
||||
into the `gnuplot` prompt, will open another window, wherein the graph is presented.
|
||||
|
||||

|
||||
|
||||
You can also set different attributes of the graphs in-line. For example, specifying “title” will give them just that.
|
||||
|
||||
plot sin(x) title 'Sine Function', tan(x) title 'Tangent'
|
||||
|
||||

|
||||
|
||||
You can give things a bit more depth and draw 3D graphs with the `splot` command.
|
||||
|
||||
splot sin(x*y/20)
|
||||
|
||||

|
||||
|
||||
The plot window has a few basic configuration options,
|
||||
|
||||

|
||||
|
||||
but the true power of `gnuplot` lies within its command line and scripting capabilities. The extensive full documentation of `gnuplot` can be found [here][7] with a great tutorial for the previous version [on the Duke University’s website][8].
|
||||
|
||||
### Maxima ###
|
||||
|
||||
[Maxima][9] is a computer algebra system developed from the original sources of Macsyma. According to its SourceForge page,
|
||||
|
||||
> “Maxima is a system for the manipulation of symbolic and numerical expressions, including differentiation, integration, Taylor series, Laplace transforms, ordinary differential equations, systems of linear equations, polynomials, sets, lists, vectors, matrices and tensors. Maxima yields high precision numerical results by using exact fractions, arbitrary-precision integers and variable-precision floating-point numbers. Maxima can plot functions and data in two and three dimensions.”
|
||||
|
||||
You will have binary packages for Maxima in most Ubuntu derivatives as well as the Maxima graphical interface. To install them all, type
|
||||
|
||||
sudo apt-get install maxima xmaxima wxmaxima
|
||||
|
||||
into a terminal window. Maxima is a command line utility with not much of a UI, but if you start `wxmaxima`, you’ll get into a simple, yet powerful GUI.
|
||||
|
||||

|
||||
|
||||
You can start using this by simply starting to type. (Hint: Enter will add more lines; if you want to evaluate an expression, use “Shift + Enter.”)
|
||||
|
||||
Maxima can be used for very simple problems, as it also acts as a calculator,
|
||||
|
||||

|
||||
|
||||
and much more complex ones as well.
|
||||
|
||||

|
||||
|
||||
It uses `gnuplot` to draw simple
|
||||
|
||||

|
||||
|
||||
and more elaborate graphs.
|
||||
|
||||

|
||||
|
||||
(It needs the `gnuplot-x11` package to display them.)
|
||||
|
||||
Besides beautifying the expressions, Maxima makes it possible to export them in latex format, or do some operations on the highlighted functions with a right-click context menu,
|
||||
|
||||

|
||||
|
||||
while its main menus offer an overwhelming amount of functionality. Of course, Maxima is capable of much more than this. It has an extensive documentation [available online][10].
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Mathematics is not an easy subject, and the excellent math software on Linux does not make it look easier, yet these applications make using Mathematics much more straightforward and productive. The above two applications are just an introduction to what Linux has to offer. If you are seriously engaged in math and need even more functionality with great documentation, you should check out the [Mathbuntu project][11].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/learn-linux-maths/
|
||||
|
||||
作者:[Attila Orosz][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/attilaorosz/
|
||||
[1]:https://www.maketecheasier.com/series/learn-with-linux/
|
||||
[2]:https://www.maketecheasier.com/learn-to-type-in-linux/
|
||||
[3]:https://www.maketecheasier.com/linux-physics-simulation/
|
||||
[4]:https://www.maketecheasier.com/linux-learning-music/
|
||||
[5]:https://www.maketecheasier.com/linux-geography-apps/
|
||||
[6]:https://www.maketecheasier.com/learn-linux-maths/
|
||||
[7]:http://www.gnuplot.info/documentation.html
|
||||
[8]:http://people.duke.edu/~hpgavin/gnuplot.html
|
||||
[9]:http://maxima.sourceforge.net/
|
||||
[10]:http://maxima.sourceforge.net/documentation.html
|
||||
[11]:http://www.mathbuntu.org/
|
||||
@ -0,0 +1,107 @@
|
||||
Learn with Linux: Physics Simulation
|
||||
================================================================================
|
||||

|
||||
|
||||
This article is part of the [Learn with Linux][1] series:
|
||||
|
||||
- [Learn with Linux: Learning to Type][2]
|
||||
- [Learn with Linux: Physics Simulation][3]
|
||||
- [Learn with Linux: Learning Music][4]
|
||||
- [Learn with Linux: Two Geography Apps][5]
|
||||
- [Learn with Linux: Master Your Math with These Linux Apps][6]
|
||||
|
||||
Linux offers great educational software and many excellent tools to aid students of all grades and ages in learning and practicing a variety of topics, often interactively. The “Learn with Linux” series of articles offers an introduction to a variety of educational apps and software.
|
||||
|
||||
Physics is an interesting subject, and arguably the most enjoyable part of any Physics class/lecture are the demonstrations. It is really nice to see physics in action, yet the experiments do not need to be restricted to the classroom. While Linux offers many great tools for scientists to support or conduct experiments, this article will concern a few that would make learning physics easier or more fun.
|
||||
|
||||
### 1. Step ###
|
||||
|
||||
[Step][7] is an interactive physics simulator, part of [KDEEdu, the KDE Education Project][8]. Nobody could better describe what Step does than the people who made it. According to the project webpage, “[Step] works like this: you place some bodies on the scene, add some forces such as gravity or springs, then click “Simulate” and Step shows you how your scene will evolve according to the laws of physics. You can change every property of bodies/forces in your experiment (even during simulation) and see how this will change the outcome of the experiment. With Step, you can not only learn but feel how physics works!”
|
||||
|
||||
While of course it requires Qt and loads of KDE-specific dependencies to work, projects like this (and KDEEdu itself) are part of the reason why KDE is such an awesome environment (if you don’t mind running a heavier desktop, of course).
|
||||
|
||||
Step is in the Debian repositories; to install it on derivatives, simply type
|
||||
|
||||
sudo apt-get install step
|
||||
|
||||
into a terminal. On a KDE system it should have minimal dependencies and install in seconds.
|
||||
|
||||
Step has a simple interface, and it lets you jump right into simulations.
|
||||
|
||||

|
||||
|
||||
You will find all available objects on the left-hand side. You can have different particles, gas, shaped objects, springs, and different forces in action. (1) If you select an object, a short description of it will appear on the right-hand side (2). On the right you will also see an overview of the “world” you have created (the objects it contains) (3), the properties of the currently selected object (4), and the steps you have taken so far (5).
|
||||
|
||||

|
||||
|
||||
Once you have placed all you wanted on the canvas, just press “Simulate,” and watch the events unfold as the objects interact with each other.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
To get to know Step better you only need to press F1. The KDE Help Center offers a great and detailed Step handbook.
|
||||
|
||||
### 2. Lightspeed ###
|
||||
|
||||
Lightspeed is a simple GTK+ and OpenGL based simulator that is meant to demonstrate the effect of how one might observe a fast moving object. Lightspeed will simulate these effects based on Einstein’s special relativity. According to [their sourceforge page][9] “When an object accelerates to more than a few million meters per second, it begins to appear warped and discolored in strange and unusual ways, and as it approaches the speed of light (299,792,458 m/s) the effects become more and more bizarre. In addition, the manner in which the object is distorted varies drastically with the viewpoint from which it is observed.”
|
||||
|
||||
These effects which come into play at relative velocities are:
|
||||
|
||||
- **The Lorentz contraction** – causes the object to appear shorter
|
||||
- **The Doppler red/blue shift** – alters the hues of color observed
|
||||
- **The headlight effect** – brightens or darkens the object
|
||||
- **Optical aberration** – deforms the object in unusual ways
|
||||
|
||||
Lightspeed is in the Debian repositories; to install it, simply type:
|
||||
|
||||
sudo apt-get install lightspeed
|
||||
|
||||
The user interface is very simple. You get a shape (more can be downloaded from sourceforge) which would move along the x-axis (animation can be started by processing “A” or by selecting it from the object menu).
|
||||
|
||||

|
||||
|
||||
You control the speed of its movement with the right-hand side slider and watch how it deforms.
|
||||
|
||||

|
||||
|
||||
Some simple controls will allow you to add more visual elements
|
||||
|
||||

|
||||
|
||||
The viewing angles can be adjusted by pressing either the left, middle or right button and dragging the mouse or from the Camera menu that also offers some other adjustments like background colour or graphics mode.
|
||||
|
||||
### Notable mention: Physion ###
|
||||
|
||||
Physion looks like an interesting project and a great looking software to simulate physics in a much more colorful and fun way than the above examples would allow. Unfortunately, at the time of writing, the [official website][10] was experiencing problems, and the download page was unavailable.
|
||||
|
||||
Judging from their Youtube videos, Physion must be worth installing once a download line becomes available. Until then we can just enjoy the this video demo.
|
||||
|
||||
注:youtube 视频
|
||||
<iframe frameborder="0" src="//www.youtube.com/embed/P32UHa-3BfU?autoplay=1&autohide=2&border=0&wmode=opaque&enablejsapi=1&controls=0&showinfo=0" id="youtube-iframe"></iframe>
|
||||
|
||||
Do you have another favorite physics simulation/demonstration/learning applications for Linux? Please share with us in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/linux-physics-simulation/
|
||||
|
||||
作者:[Attila Orosz][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/attilaorosz/
|
||||
[1]:https://www.maketecheasier.com/series/learn-with-linux/
|
||||
[2]:https://www.maketecheasier.com/learn-to-type-in-linux/
|
||||
[3]:https://www.maketecheasier.com/linux-physics-simulation/
|
||||
[4]:https://www.maketecheasier.com/linux-learning-music/
|
||||
[5]:https://www.maketecheasier.com/linux-geography-apps/
|
||||
[6]:https://www.maketecheasier.com/learn-linux-maths/
|
||||
[7]:https://edu.kde.org/applications/all/step
|
||||
[8]:https://edu.kde.org/
|
||||
[9]:http://lightspeed.sourceforge.net/
|
||||
[10]:http://www.physion.net/
|
||||
@ -0,0 +1,103 @@
|
||||
Learn with Linux: Two Geography Apps
|
||||
================================================================================
|
||||

|
||||
|
||||
This article is part of the [Learn with Linux][1] series:
|
||||
|
||||
- [Learn with Linux: Learning to Type][2]
|
||||
- [Learn with Linux: Physics Simulation][3]
|
||||
- [Learn with Linux: Learning Music][4]
|
||||
- [Learn with Linux: Two Geography Apps][5]
|
||||
- [Learn with Linux: Master Your Math with These Linux Apps][6]
|
||||
|
||||
Linux offers great educational software and many excellent tools to aid students of all grades and ages in learning and practicing a variety of topics, often interactively. The “Learn with Linux” series of articles offers an introduction to a variety of educational apps and software.
|
||||
|
||||
Geography is an interesting subject, used by many of us day to day, often without realizing. But when you fire up GPS, SatNav, or just Google maps, you are using the geographical data provided by this software with the maps drawn by cartographists. When you hear about a certain country in the news or hear financial data being recited, these all fall under the umbrella of geography. And you have some great Linux software to study and practice these, whether it is for school or your own improvement.
|
||||
|
||||
### Kgeography ###
|
||||
|
||||
There are only two geography-related applications readily available in most Linux repositories, and both of these are KDE applications, in fact part of the KDE Educatonal project. Kgeography uses simple color-coded maps of any selected country.
|
||||
|
||||
To install kegeography just type
|
||||
|
||||
sudo apt-get install kgeography
|
||||
|
||||
into a terminal window of any Ubuntu-based distribution.
|
||||
|
||||
The interface is very basic. You are first presented with a picker menu that lets you choose an area map.
|
||||
|
||||

|
||||
|
||||
On the map you can display the name and capital of any given territory by clicking on it,
|
||||
|
||||

|
||||
|
||||
and test your knowledge in different quizzes.
|
||||
|
||||

|
||||
|
||||
It is an interactive way to test your basic geographical knowledge and could be an excellent tool to help you prepare for exams.
|
||||
|
||||
### Marble ###
|
||||
|
||||
Marble is a somewhat more advanced software, offering a global view of the world without the need of 3D acceleration.
|
||||
|
||||

|
||||
|
||||
To get Marble, type
|
||||
|
||||
sudo apt-get install marble
|
||||
|
||||
into a terminal window of any Ubuntu-based distribution.
|
||||
|
||||
Marble focuses on cartography, its main view being that of an atlas.
|
||||
|
||||

|
||||
|
||||
You can have different projections, like Globe or Mercator displayed as defaults, with flat and other exotic views available from a drop-down menu. The surfaces include the basic Atlas view, a full-fledged offline map powered by OpenStreetMap,
|
||||
|
||||

|
||||
|
||||
satellite view (by NASA),
|
||||
|
||||

|
||||
|
||||
and political and even historical maps of the world, among others.
|
||||
|
||||

|
||||
|
||||
Besides providing great offline maps with different skins and varying amount of data, Marble offers other types of information as well. You can switch on and off various offline info-boxes
|
||||
|
||||

|
||||
|
||||
and online services from the menu.
|
||||
|
||||

|
||||
|
||||
An interesting online service is Wikipedia integration. Clicking on the little Wiki logos will bring up a pop-up featuring detailed information about the selected places.
|
||||
|
||||

|
||||
|
||||
The software also includes options for location tracking, route planning, and searching for locations, among other great and useful features. If you enjoy cartography, Marble offers hours of fun exploring and learning.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Linux offers many great educational applications, and the subject of geography is no exception. With the above two programs you can learn a lot about our globe and test your knowledge in a fun and interactive manner.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/linux-geography-apps/
|
||||
|
||||
作者:[Attila Orosz][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/attilaorosz/
|
||||
[1]:https://www.maketecheasier.com/series/learn-with-linux/
|
||||
[2]:https://www.maketecheasier.com/learn-to-type-in-linux/
|
||||
[3]:https://www.maketecheasier.com/linux-physics-simulation/
|
||||
[4]:https://www.maketecheasier.com/linux-learning-music/
|
||||
[5]:https://www.maketecheasier.com/linux-geography-apps/
|
||||
[6]:https://www.maketecheasier.com/learn-linux-maths/
|
||||
@ -1,198 +0,0 @@
|
||||
[xiqingongzi translating]
|
||||
RHCSA Series: Yum Package Management, Automating Tasks with Cron and Monitoring System Logs – Part 10
|
||||
================================================================================
|
||||
In this article we will review how to install, update, and remove packages in Red Hat Enterprise Linux 7. We will also cover how to automate tasks using cron, and will finish this guide explaining how to locate and interpret system logs files with the focus of teaching you why all of these are essential skills for every system administrator.
|
||||
|
||||

|
||||
|
||||
RHCSA: Yum Package Management, Cron Job Scheduling and Log Monitoring – Part 10
|
||||
|
||||
### Managing Packages Via Yum ###
|
||||
|
||||
To install a package along with all its dependencies that are not already installed, you will use:
|
||||
|
||||
# yum -y install package_name(s)
|
||||
|
||||
Where package_name(s) represent at least one real package name.
|
||||
|
||||
For example, to install httpd and mlocate (in that order), type.
|
||||
|
||||
# yum -y install httpd mlocate
|
||||
|
||||
**Note**: That the letter y in the example above bypasses the confirmation prompts that yum presents before performing the actual download and installation of the requested programs. You can leave it out if you want.
|
||||
|
||||
By default, yum will install the package with the architecture that matches the OS architecture, unless overridden by appending the package architecture to its name.
|
||||
|
||||
For example, on a 64 bit system, yum install package will install the x86_64 version of package, whereas yum install package.x86 (if available) will install the 32-bit one.
|
||||
|
||||
There will be times when you want to install a package but don’t know its exact name. The search all or search options can search the currently enabled repositories for a certain keyword in the package name and/or in its description as well, respectively.
|
||||
|
||||
For example,
|
||||
|
||||
# yum search log
|
||||
|
||||
will search the installed repositories for packages with the word log in their names and summaries, whereas
|
||||
|
||||
# yum search all log
|
||||
|
||||
will look for the same keyword in the package description and url fields as well.
|
||||
|
||||
Once the search returns a package listing, you may want to display further information about some of them before installing. That is when the info option will come in handy:
|
||||
|
||||
# yum info logwatch
|
||||
|
||||

|
||||
|
||||
Search Package Information
|
||||
|
||||
You can regularly check for updates with the following command:
|
||||
|
||||
# yum check-update
|
||||
|
||||
The above command will return all the installed packages for which an update is available. In the example shown in the image below, only rhel-7-server-rpms has an update available:
|
||||
|
||||

|
||||
|
||||
Check For Package Updates
|
||||
|
||||
You can then update that package alone with,
|
||||
|
||||
# yum update rhel-7-server-rpms
|
||||
|
||||
If there are several packages that can be updated, yum update will update all of them at once.
|
||||
|
||||
Now what happens when you know the name of an executable, such as ps2pdf, but don’t know which package provides it? You can find out with `yum whatprovides “*/[executable]”`:
|
||||
|
||||
# yum whatprovides “*/ps2pdf”
|
||||
|
||||
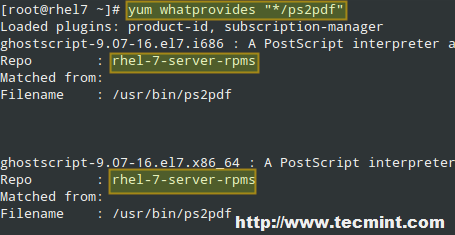
|
||||
|
||||
Find Package Belongs to Which Package
|
||||
|
||||
Now, when it comes to removing a package, you can do so with yum remove package. Easy, huh? This goes to show that yum is a complete and powerful package manager.
|
||||
|
||||
# yum remove httpd
|
||||
|
||||
Read Also: [20 Yum Commands to Manage RHEL 7 Package Management][1]
|
||||
|
||||
### Good Old Plain RPM ###
|
||||
|
||||
RPM (aka RPM Package Manager, or originally RedHat Package Manager) can also be used to install or update packages when they come in form of standalone `.rpm` packages.
|
||||
|
||||
It is often utilized with the `-Uvh` flags to indicate that it should install the package if it’s not already present or attempt to update it if it’s installed `(-U)`, producing a verbose output `(-v)` and a progress bar with hash marks `(-h)` while the operation is being performed. For example,
|
||||
|
||||
# rpm -Uvh package.rpm
|
||||
|
||||
Another typical use of rpm is to produce a list of currently installed packages with code>rpm -qa (short for query all):
|
||||
|
||||
# rpm -qa
|
||||
|
||||

|
||||
|
||||
Query All RPM Packages
|
||||
|
||||
Read Also: [20 RPM Commands to Install Packages in RHEL 7][2]
|
||||
|
||||
### Scheduling Tasks using Cron ###
|
||||
|
||||
Linux and other Unix-like operating systems include a tool called cron that allows you to schedule tasks (i.e. commands or shell scripts) to run on a periodic basis. Cron checks every minute the /var/spool/cron directory for files which are named after accounts in /etc/passwd.
|
||||
|
||||
When executing commands, any output is mailed to the owner of the crontab (or to the user specified in the MAILTO environment variable in the /etc/crontab, if it exists).
|
||||
|
||||
Crontab files (which are created by typing crontab -e and pressing Enter) have the following format:
|
||||
|
||||

|
||||
|
||||
Crontab Entries
|
||||
|
||||
Thus, if we want to update the local file database (which is used by locate to find files by name or pattern) every second day of the month at 2:15 am, we need to add the following crontab entry:
|
||||
|
||||
15 02 2 * * /bin/updatedb
|
||||
|
||||
The above crontab entry reads, “Run /bin/updatedb on the second day of the month, every month of the year, regardless of the day of the week, at 2:15 am”. As I’m sure you already guessed, the star symbol is used as a wildcard character.
|
||||
|
||||
After adding a cron job, you can see that a file named root was added inside /var/spool/cron, as we mentioned earlier. That file lists all the tasks that the crond daemon should run:
|
||||
|
||||
# ls -l /var/spool/cron
|
||||
|
||||

|
||||
|
||||
Check All Cron Jobs
|
||||
|
||||
In the above image, the current user’s crontab can be displayed either using cat /var/spool/cron/root or,
|
||||
|
||||
# crontab -l
|
||||
|
||||
If you need to run a task on a more fine-grained basis (for example, twice a day or three times each month), cron can also help you to do that.
|
||||
|
||||
For example, to run /my/script on the 1st and 15th of each month and send any output to /dev/null, you can add two crontab entries as follows:
|
||||
|
||||
01 00 1 * * /myscript > /dev/null 2>&1
|
||||
01 00 15 * * /my/script > /dev/null 2>&1
|
||||
|
||||
But in order for the task to be easier to maintain, you can combine both entries into one:
|
||||
|
||||
01 00 1,15 * * /my/script > /dev/null 2>&1
|
||||
|
||||
Following the previous example, we can run /my/other/script at 1:30 am on the first day of the month every three months:
|
||||
|
||||
30 01 1 1,4,7,10 * /my/other/script > /dev/null 2>&1
|
||||
|
||||
But when you have to repeat a certain task every “x” minutes, hours, days, or months, you can divide the right position by the desired frequency. The following crontab entry has the exact same meaning as the previous one:
|
||||
|
||||
30 01 1 */3 * /my/other/script > /dev/null 2>&1
|
||||
|
||||
Or perhaps you need to run a certain job on a fixed frequency or after the system boots, for example. You can use one of the following string instead of the five fields to indicate the exact time when you want your job to run:
|
||||
|
||||
@reboot Run when the system boots.
|
||||
@yearly Run once a year, same as 00 00 1 1 *.
|
||||
@monthly Run once a month, same as 00 00 1 * *.
|
||||
@weekly Run once a week, same as 00 00 * * 0.
|
||||
@daily Run once a day, same as 00 00 * * *.
|
||||
@hourly Run once an hour, same as 00 * * * *.
|
||||
|
||||
Read Also: [11 Commands to Schedule Cron Jobs in RHEL 7][3]
|
||||
|
||||
### Locating and Checking Logs ###
|
||||
|
||||
System logs are located (and rotated) inside the /var/log directory. According to the Linux Filesystem Hierarchy Standard, this directory contains miscellaneous log files, which are written to it or an appropriate subdirectory (such as audit, httpd, or samba in the image below) by the corresponding daemons during system operation:
|
||||
|
||||
# ls /var/log
|
||||
|
||||

|
||||
|
||||
Linux Log Files Location
|
||||
|
||||
Other interesting logs are [dmesg][4] (contains all messages from kernel ring buffer), secure (logs connection attempts that require user authentication), messages (system-wide messages) and wtmp (records of all user logins and logouts).
|
||||
|
||||
Logs are very important in that they allow you to have a glimpse of what is going on at all times in your system, and what has happened in the past. They represent a priceless tool to troubleshoot and monitor a Linux server, and thus are often used with the `tail -f command` to display events, in real time, as they happen and are recorded in a log.
|
||||
|
||||
For example, if you want to display kernel-related events, type the following command:
|
||||
|
||||
# tail -f /var/log/dmesg
|
||||
|
||||
Same if you want to view access to your web server:
|
||||
|
||||
# tail -f /var/log/httpd/access.log
|
||||
|
||||
### Summary ###
|
||||
|
||||
If you know how to efficiently manage packages, schedule tasks, and where to look for information about the current and past operation of your system you can rest assure that you will not run into surprises very often. I hope this article has helped you learn or refresh your knowledge about these basic skills.
|
||||
|
||||
Don’t hesitate to drop us a line using the contact form below if you have any questions or comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/yum-package-management-cron-job-scheduling-monitoring-linux-logs/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[2]:http://www.tecmint.com/20-practical-examples-of-rpm-commands-in-linux/
|
||||
[3]:http://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
|
||||
[4]:http://www.tecmint.com/dmesg-commands/
|
||||
@ -1,144 +0,0 @@
|
||||
FSSlc translating
|
||||
|
||||
RHCSA Series: Automate RHEL 7 Installations Using ‘Kickstart’ – Part 12
|
||||
================================================================================
|
||||
Linux servers are rarely standalone boxes. Whether it is in a datacenter or in a lab environment, chances are that you have had to install several machines that will interact one with another in some way. If you multiply the time that it takes to install Red Hat Enterprise Linux 7 manually on a single server by the number of boxes that you need to set up, this can lead to a rather lengthy effort that can be avoided through the use of an unattended installation tool known as kickstart.
|
||||
|
||||
In this article we will show what you need to use kickstart utility so that you can forget about babysitting servers during the installation process.
|
||||
|
||||

|
||||
|
||||
RHCSA: Automatic Kickstart Installation of RHEL 7
|
||||
|
||||
#### Introducing Kickstart and Automated Installations ####
|
||||
|
||||
Kickstart is an automated installation method used primarily by Red Hat Enterprise Linux (and other Fedora spin-offs, such as CentOS, Oracle Linux, etc.) to execute unattended operating system installation and configuration. Thus, kickstart installations allow system administrators to have identical systems, as far as installed package groups and system configuration are concerned, while sparing them the hassle of having to manually install each of them.
|
||||
|
||||
### Preparing for a Kickstart Installation ###
|
||||
|
||||
To perform a kickstart installation, we need to follow these steps:
|
||||
|
||||
1. Create a Kickstart file, a plain text file with several predefined configuration options.
|
||||
|
||||
2. Make the Kickstart file available on removable media, a hard drive or a network location. The client will use the rhel-server-7.0-x86_64-boot.iso file, whereas you will need to make the full ISO image (rhel-server-7.0-x86_64-dvd.iso) available from a network resource, such as a HTTP of FTP server (in our present case, we will use another RHEL 7 box with IP 192.168.0.18).
|
||||
|
||||
3. Start the Kickstart installation
|
||||
|
||||
To create a kickstart file, login to your Red Hat Customer Portal account, and use the [Kickstart configuration tool][1] to choose the desired installation options. Read each one of them carefully before scrolling down, and choose what best fits your needs:
|
||||
|
||||

|
||||
|
||||
Kickstart Configuration Tool
|
||||
|
||||
If you specify that the installation should be performed either through HTTP, FTP, or NFS, make sure the firewall on the server allows those services.
|
||||
|
||||
Although you can use the Red Hat online tool to create a kickstart file, you can also create it manually using the following lines as reference. You will notice, for example, that the installation process will be in English, using the latin american keyboard layout and the America/Argentina/San_Luis time zone:
|
||||
|
||||
lang en_US
|
||||
keyboard la-latin1
|
||||
timezone America/Argentina/San_Luis --isUtc
|
||||
rootpw $1$5sOtDvRo$In4KTmX7OmcOW9HUvWtfn0 --iscrypted
|
||||
#platform x86, AMD64, or Intel EM64T
|
||||
text
|
||||
url --url=http://192.168.0.18//kickstart/media
|
||||
bootloader --location=mbr --append="rhgb quiet crashkernel=auto"
|
||||
zerombr
|
||||
clearpart --all --initlabel
|
||||
autopart
|
||||
auth --passalgo=sha512 --useshadow
|
||||
selinux --enforcing
|
||||
firewall --enabled
|
||||
firstboot --disable
|
||||
%packages
|
||||
@base
|
||||
@backup-server
|
||||
@print-server
|
||||
%end
|
||||
|
||||
In the online configuration tool, use 192.168.0.18 for HTTP Server and `/kickstart/tecmint.bin` for HTTP Directory in the Installation section after selecting HTTP as installation source. Finally, click the Download button at the right top corner to download the kickstart file.
|
||||
|
||||
In the kickstart sample file above, you need to pay careful attention to.
|
||||
|
||||
url --url=http://192.168.0.18//kickstart/media
|
||||
|
||||
That directory is where you need to extract the contents of the DVD or ISO installation media. Before doing that, we will mount the ISO installation file in /media/rhel as a loop device:
|
||||
|
||||
# mount -o loop /var/www/html/kickstart/rhel-server-7.0-x86_64-dvd.iso /media/rhel
|
||||
|
||||

|
||||
|
||||
Mount RHEL ISO Image
|
||||
|
||||
Next, copy all the contents of /media/rhel to /var/www/html/kickstart/media:
|
||||
|
||||
# cp -R /media/rhel /var/www/html/kickstart/media
|
||||
|
||||
When you’re done, the directory listing and disk usage of /var/www/html/kickstart/media should look as follows:
|
||||
|
||||

|
||||
|
||||
Kickstart Media Files
|
||||
|
||||
Now we’re ready to kick off the kickstart installation.
|
||||
|
||||
Regardless of how you choose to create the kickstart file, it’s always a good idea to check its syntax before proceeding with the installation. To do that, install the pykickstart package.
|
||||
|
||||
# yum update && yum install pykickstart
|
||||
|
||||
And then use the ksvalidator utility to check the file:
|
||||
|
||||
# ksvalidator /var/www/html/kickstart/tecmint.bin
|
||||
|
||||
If the syntax is correct, you will not get any output, whereas if there’s an error in the file, you will get a warning notice indicating the line where the syntax is not correct or unknown.
|
||||
|
||||
### Performing a Kickstart Installation ###
|
||||
|
||||
To start, boot your client using the rhel-server-7.0-x86_64-boot.iso file. When the initial screen appears, select Install Red Hat Enterprise Linux 7.0 and press the Tab key to append the following stanza and press Enter:
|
||||
|
||||
# inst.ks=http://192.168.0.18/kickstart/tecmint.bin
|
||||
|
||||

|
||||
|
||||
RHEL Kickstart Installation
|
||||
|
||||
Where tecmint.bin is the kickstart file created earlier.
|
||||
|
||||
When you press Enter, the automated installation will begin, and you will see the list of packages that are being installed (the number and the names will differ depending on your choice of programs and package groups):
|
||||
|
||||
|
||||
|
||||
Automatic Kickstart Installation of RHEL 7
|
||||
|
||||
When the automated process ends, you will be prompted to remove the installation media and then you will be able to boot into your newly installed system:
|
||||
|
||||

|
||||
|
||||
RHEL 7 Boot Screen
|
||||
|
||||
Although you can create your kickstart files manually as we mentioned earlier, you should consider using the recommended approach whenever possible. You can either use the online configuration tool, or the anaconda-ks.cfg file that is created by the installation process in root’s home directory.
|
||||
|
||||
This file actually is a kickstart file, so you may want to install the first box manually with all the desired options (maybe modify the logical volumes layout or the file system on top of each one) and then use the resulting anaconda-ks.cfg file to automate the installation of the rest.
|
||||
|
||||
In addition, using the online configuration tool or the anaconda-ks.cfg file to guide future installations will allow you to perform them using an encrypted root password out-of-the-box.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Now that you know how to create kickstart files and how to use them to automate the installation of Red Hat Enterprise Linux 7 servers, you can forget about babysitting the installation process. This will give you time to do other things, or perhaps some leisure time if you’re lucky.
|
||||
|
||||
Either way, let us know what you think about this article using the form below. Questions are also welcome!
|
||||
|
||||
Read Also: [Automated Installations of Multiple RHEL/CentOS 7 Distributions using PXE and Kickstart][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/automatic-rhel-installations-using-kickstart/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:https://access.redhat.com/labs/kickstartconfig/
|
||||
[2]:http://www.tecmint.com/multiple-centos-installations-using-kickstart/
|
||||
@ -1,176 +0,0 @@
|
||||
RHCSA Series: Mandatory Access Control Essentials with SELinux in RHEL 7 – Part 13
|
||||
================================================================================
|
||||
During this series we have explored in detail at least two access control methods: standard ugo/rwx permissions ([Manage Users and Groups – Part 3][1]) and access control lists ([Configure ACL’s on File Systems – Part 7][2]).
|
||||
|
||||

|
||||
|
||||
RHCSA Exam: SELinux Essentials and Control FileSystem Access
|
||||
|
||||
Although necessary as first level permissions and access control mechanisms, they have some limitations that are addressed by Security Enhanced Linux (aka SELinux for short).
|
||||
|
||||
One of such limitations is that a user can expose a file or directory to a security breach through a poorly elaborated chmod command and thus cause an unexpected propagation of access rights. As a result, any process started by that user can do as it pleases with the files owned by the user, where finally a malicious or otherwise compromised software can achieve root-level access to the entire system.
|
||||
|
||||
With those limitations in mind, the United States National Security Agency (NSA) first devised SELinux, a flexible mandatory access control method, to restrict the ability of processes to access or perform other operations on system objects (such as files, directories, network ports, etc) to the least permission model, which can be modified later as needed. In few words, each element of the system is given only the access required to function.
|
||||
|
||||
In RHEL 7, SELinux is incorporated into the kernel itself and is enabled in Enforcing mode by default. In this article we will explain briefly the basic concepts associated with SELinux and its operation.
|
||||
|
||||
### SELinux Modes ###
|
||||
|
||||
SELinux can operate in three different ways:
|
||||
|
||||
- Enforcing: SELinux denies access based on SELinux policy rules, a set of guidelines that control the security engine.
|
||||
- Permissive: SELinux does not deny access, but denials are logged for actions that would have been denied if running in enforcing mode.
|
||||
- Disabled (self-explanatory).
|
||||
|
||||
The `getenforce` command displays the current mode of SELinux, whereas `setenforce` (followed by a 1 or a 0) is used to change the mode to Enforcing or Permissive, respectively, during the current session only.
|
||||
|
||||
In order to achieve persistence across logouts and reboots, you will need to edit the `/etc/selinux/config` file and set the SELINUX variable to either enforcing, permissive, or disabled:
|
||||
|
||||
# getenforce
|
||||
# setenforce 0
|
||||
# getenforce
|
||||
# setenforce 1
|
||||
# getenforce
|
||||
# cat /etc/selinux/config
|
||||
|
||||

|
||||
|
||||
Set SELinux Mode
|
||||
|
||||
Typically you will use setenforce to toggle between SELinux modes (enforcing to permissive and back) as a first troubleshooting step. If SELinux is currently set to enforcing while you’re experiencing a certain problem, and the same goes away when you set it to permissive, you can be confident you’re looking at a SELinux permissions issue.
|
||||
|
||||
### SELinux Contexts ###
|
||||
|
||||
A SELinux context consists of an access control environment where decisions are made based on SELinux user, role, and type (and optionally a level):
|
||||
|
||||
- A SELinux user complements a regular Linux user account by mapping it to a SELinux user account, which in turn is used in the SELinux context for processes in that session, in order to explicitly define their allowed roles and levels.
|
||||
- The concept of role acts as an intermediary between domains and SELinux users in that it defines which process domains and file types can be accessed. This will shield your system against vulnerability to privilege escalation attacks.
|
||||
- A type defines an SELinux file type or an SELinux process domain. Under normal circumstances, processes are prevented from accessing files that other processes use, and and from accessing other processes, thus access is only allowed if a specific SELinux policy rule exists that allows it.
|
||||
|
||||
Let’s see how all of that works through the following examples.
|
||||
|
||||
**EXAMPLE 1: Changing the default port for the sshd daemon**
|
||||
|
||||
In [Securing SSH – Part 8][3] we explained that changing the default port where sshd listens on is one of the first security measures to secure your server against external attacks. Let’s edit the `/etc/ssh/sshd_config` file and set the port to 9999:
|
||||
|
||||
Port 9999
|
||||
|
||||
Save the changes, and restart sshd:
|
||||
|
||||
# systemctl restart sshd
|
||||
# systemctl status sshd
|
||||
|
||||

|
||||
|
||||
Restart SSH Service
|
||||
|
||||
As you can see, sshd has failed to start. But what happened?
|
||||
|
||||
A quick inspection of `/var/log/audit/audit.log` indicates that sshd has been denied permissions to start on port 9999 (SELinux log messages include the word “AVC” so that they might be easily identified from other messages) because that is a reserved port for the JBoss Management service:
|
||||
|
||||
# cat /var/log/audit/audit.log | grep AVC | tail -1
|
||||
|
||||

|
||||
|
||||
Inspect SSH Logs
|
||||
|
||||
At this point you could disable SELinux (but don’t!) as explained earlier and try to start sshd again, and it should work. However, the semanage utility can tell us what we need to change in order for us to be able to start sshd in whatever port we choose without issues.
|
||||
|
||||
Run,
|
||||
|
||||
# semanage port -l | grep ssh
|
||||
|
||||
to get a list of the ports where SELinux allows sshd to listen on.
|
||||
|
||||

|
||||
|
||||
Semanage Tool
|
||||
|
||||
So let’s change the port in /etc/ssh/sshd_config to Port 9998, add the port to the ssh_port_t context, and then restart the service:
|
||||
|
||||
# semanage port -a -t ssh_port_t -p tcp 9998
|
||||
# systemctl restart sshd
|
||||
# systemctl is-active sshd
|
||||
|
||||

|
||||
|
||||
Semanage Add Port
|
||||
|
||||
As you can see, the service was started successfully this time. This example illustrates the fact that SELinux controls the TCP port number to its own port type internal definitions.
|
||||
|
||||
**EXAMPLE 2: Allowing httpd to send access sendmail**
|
||||
|
||||
This is an example of SELinux managing a process accessing another process. If you were to implement mod_security and mod_evasive along with Apache in your RHEL 7 server, you need to allow httpd to access sendmail in order to send a mail notification in the wake of a (D)DoS attack. In the following command, omit the -P flag if you do not want the change to be persistent across reboots.
|
||||
|
||||
# semanage boolean -1 | grep httpd_can_sendmail
|
||||
# setsebool -P httpd_can_sendmail 1
|
||||
# semanage boolean -1 | grep httpd_can_sendmail
|
||||
|
||||

|
||||
|
||||
Allow Apache to Send Mails
|
||||
|
||||
As you can tell from the above example, SELinux boolean settings (or just booleans) are true / false rules embedded into SELinux policies. You can list all the booleans with `semanage boolean -l`, and alternatively pipe it to grep in order to filter the output.
|
||||
|
||||
**EXAMPLE 3: Serving a static site from a directory other than the default one**
|
||||
|
||||
Suppose you are serving a static website using a different directory than the default one (`/var/www/html`), say /websites (this could be the case if you’re storing your web files in a shared network drive, for example, and need to mount it at /websites).
|
||||
|
||||
a). Create an index.html file inside /websites with the following contents:
|
||||
|
||||
<html>
|
||||
<h2>SELinux test</h2>
|
||||
</html>
|
||||
|
||||
If you do,
|
||||
|
||||
# ls -lZ /websites/index.html
|
||||
|
||||
you will see that the index.html file has been labeled with the default_t SELinux type, which Apache can’t access:
|
||||
|
||||

|
||||
|
||||
Check SELinux File Permission
|
||||
|
||||
b). Change the DocumentRoot directive in `/etc/httpd/conf/httpd.conf` to /websites and don’t forget to update the corresponding Directory block. Then, restart Apache.
|
||||
|
||||
c). Browse to `http://<web server IP address>`, and you should get a 503 Forbidden HTTP response.
|
||||
|
||||
d). Next, change the label of /websites, recursively, to the httpd_sys_content_t type in order to grant Apache read-only access to that directory and its contents:
|
||||
|
||||
# semanage fcontext -a -t httpd_sys_content_t "/websites(/.*)?"
|
||||
|
||||
e). Finally, apply the SELinux policy created in d):
|
||||
|
||||
# restorecon -R -v /websites
|
||||
|
||||
Now restart Apache and browse to `http://<web server IP address>` again and you will see the html file displayed correctly:
|
||||
|
||||

|
||||
|
||||
Verify Apache Page
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this article we have gone through the basics of SELinux. Note that due to the vastness of the subject, a full detailed explanation is not possible in a single article, but we believe that the principles outlined in this guide will help you to move on to more advanced topics should you wish to do so.
|
||||
|
||||
If I may, let me recommend two essential resources to start with: the [NSA SELinux page][4] and the [RHEL 7 SELinux User’s and Administrator’s][5] guide.
|
||||
|
||||
Don’t hesitate to let us know if you have any questions or comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/selinux-essentials-and-control-filesystem-access/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/rhcsa-exam-manage-users-and-groups
|
||||
[2]:http://www.tecmint.com/rhcsa-exam-configure-acls-and-mount-nfs-samba-shares/
|
||||
[3]:http://www.tecmint.com/rhcsa-series-secure-ssh-set-hostname-enable-network-services-in-rhel-7/
|
||||
[4]:https://www.nsa.gov/research/selinux/index.shtml
|
||||
[5]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/SELinux_Users_and_Administrators_Guide/part_I-SELinux.html
|
||||
@ -1,66 +0,0 @@
|
||||
Translated by H-mudcup
|
||||
五大超酷的开源游戏
|
||||
================================================================================
|
||||
在2014年和2015年,Linux 成了一堆流行商业品牌的家,例如备受欢迎的 Borderlands、Witcher、Dead Island 和 CS系列游戏。虽然这是令人激动的消息,但这跟玩家的预算有什么关系?商业品牌很好,但更好的是由了解玩家喜好的开发者开发的免费的替代品。
|
||||
|
||||
前段时间,我偶然看到了一个三年前发布的 YouTube 视频,标题非常的有正能量[5个不算糟糕的开源游戏][1]。虽然视频表扬了一些开源游戏,我还是更喜欢用一个更加热情的方式来切入这个话题,至少如标题所说。所以,下面是我的一份五大超酷开源游戏的清单。
|
||||
|
||||
### Tux Racer ###
|
||||
|
||||

|
||||
|
||||
Tux Racer
|
||||
|
||||
[《Tux Racer》][2]是这份清单上的第一个游戏,因为我对这个游戏很熟悉。我和兄弟与[电脑上的孩子们][4]项目在[最近一次去墨西哥的路途中][3] Tux Racer 是孩子和教师都喜欢玩的游戏之一。在这个游戏中,玩家使用 Linux 吉祥物,企鹅 Tux,在下山雪道上以计时赛的方式进行比赛。玩家们不断挑战他们自己的最佳纪录。目前还没有多玩家版本,但这是有可能改变的。适用于 Linux、OS X、Windows 和 Android。
|
||||
|
||||
### Warsow ###
|
||||
|
||||

|
||||
|
||||
Warsow
|
||||
|
||||
[《Warsow》][5]网站解释道:“设定是有未来感的卡通世界,Warsow 是个完全开放的适用于 Windows、Linux 和 Mac OS X平台的快节奏第一人称射击游戏(FPS)。Warsow 是尊重的艺术和网络中的体育精神。(Warsow is the Art of Respect and Sportsmanship Over the Web.大写字母组成Warsow。)” 我很不情愿的把 FPS 类放到了这个列表中,因为很多人玩过这类的游戏,但是我的确被 Warsow 打动了。它对很多动作进行了优先级排序,游戏节奏很快,一开始就有八个武器。卡通化的风格让玩的过程变得没有那么严肃,更加的休闲,非常适合可以和亲友一同玩。然而,他却以充满竞争的游戏自居,并且当我体验这个游戏时,我发现周围确实有一些专家级的玩家。适用于 Linux、Windows 和 OS X。
|
||||
|
||||
### M.A.R.S——一个荒诞的射击游戏 ###
|
||||
|
||||

|
||||
|
||||
M.A.R.S.——一个荒诞的射击游戏
|
||||
|
||||
[《M.A.R.S——一个荒诞的射击游戏》][6]之所以吸引人是因为他充满活力的色彩和画风。支持两个玩家使用同一个键盘,而一个在线多玩家版本目前正在开发中——这意味着想要和朋友们一起玩暂时还要等等。不论如何,它是个可以使用几个不同飞船和武器的有趣的太空射击游戏。飞船的形状不同,从普通的枪、激光、散射枪到更有趣的武器(随机出来的飞船中有一个会对敌人发射泡泡,这为这款混乱的游戏增添了很多乐趣)。游戏几种模式,比如标准模式和对方进行殊死搏斗以获得高分或先达到某个分数线,还有其他的模式,空间球(Spaceball)、坟坑(Grave-itation Pit)和保加农炮(Cannon Keep)。适用于 Linux、Windows 和 OS X。
|
||||
|
||||
### Valyria Tear ###
|
||||
|
||||

|
||||
|
||||
Valyria Tear
|
||||
|
||||
[Valyria Tear][7] 类似几年来拥有众多粉丝的角色扮演游戏(RPG)。故事设定在梦幻游戏的通用年代,充满了骑士、王国和魔法,以及主要角色 Bronann。设计团队做的非常棒,在设计这个世界和实现玩家对这类游戏所有的期望:隐藏的宝藏、偶遇的怪物、非玩家操纵角色(NPC)的互动以及所有 RPG 不可或缺的:在低级别的怪物上刷经验直到可以面对大 BOSS。我在试玩的时候,时间不允许我太过深入到这个游戏故事中,但是感兴趣的人可以看 YouTube 上由 Yohann Ferriera 用户发的‘[Let’s Play][8]’系列视频。适用于 Linux、Windows 和 OS X。
|
||||
|
||||
### SuperTuxKart ###
|
||||
|
||||

|
||||
|
||||
SuperTuxKart
|
||||
|
||||
最后一个同样好玩的游戏是 [SuperTuxKart][9],一个效仿 Mario Kart(马里奥卡丁车)但丝毫不必原作差的好游戏。它在2000年-2004年间开始以 Tux Kart 开发,但是在成品中有错误,结果开发就停止了几年。从2006年开始重新开发时起,它就一直在改进,直到四个月前0.9版首次发布。在游戏里,我们的老朋友 Tux 与马里奥和其他一些开源吉祥物一同开始。其中一个熟悉的面孔是 Suzanne,Blender 的那只吉祥物猴子。画面很给力,游戏很流畅。虽然在线游戏还在计划阶段,但是分屏多玩家游戏是可以的。一个电脑最多可以四个玩家同时玩。适用于 Linux、Windows、OS X、AmigaOS 4、AROS 和 MorphOS。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://fossforce.com/2015/08/five-super-cool-open-source-games/
|
||||
|
||||
作者:Hunter Banks
|
||||
译者:[H-mudcup](https://github.com/H-mudcup)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.youtube.com/watch?v=BEKVl-XtOP8
|
||||
[2]:http://tuxracer.sourceforge.net/download.html
|
||||
[3]:http://fossforce.com/2015/07/banks-family-values-texas-linux-fest/
|
||||
[4]:http://www.kidsoncomputers.org/an-amazing-week-in-oaxaca
|
||||
[5]:https://www.warsow.net/download
|
||||
[6]:http://mars-game.sourceforge.net/
|
||||
[7]:http://valyriatear.blogspot.com/
|
||||
[8]:https://www.youtube.com/channel/UCQ5KrSk9EqcT_JixWY2RyMA
|
||||
[9]:http://supertuxkart.sourceforge.net/
|
||||
@ -1,127 +0,0 @@
|
||||
Translating by H-mudcup
|
||||
|
||||
守卫自由的Linux世界
|
||||
================================================================================
|
||||

|
||||
|
||||
**"合作是开源的一部分。OIN的CEO Keith Bergelt解释说,开放创新网络(Open Invention Network)模式允许众多企业和公司决定它们该在哪较量,在哪合作。随着开源的演变,“我们需要为合作创造渠道。否则我们将会有几百个团体把数十亿美元花费到同样的技术上。”**
|
||||
|
||||
[开放创新网络(Open Invention Network)][1],既OIN,正在全球范围内开展让 Linux 远离专利诉讼的伤害的活动。它的努力得到了一千多个公司的热烈回应,它们的加入让这股力量成为了历史上最大的反专利管理组织。
|
||||
|
||||
开放创新网络以白帽子组织的身份创建于2005年,目的是保护 Linux 免受来自许可证方面的困扰。包括Google、 IBM、 NEC、 Novell、 Philips、 [Red Hat][2] 和 Sony这些成员的董事会给予了它可观的经济支持。世界范围内的多个组织通过签署自由 OIN 协议加入了这个社区。
|
||||
|
||||
创立开放创新网络的组织成员把它当作利用知识产权保护 Linux 的大胆尝试。它的商业模式非常的难以理解。它要求它的成员持无专利证并永远放弃由于 Linux 相关知识产权起诉其他成员的机会。
|
||||
|
||||
然而,从 Linux 收购风波——想想服务器和云平台——那时起,保护 Linux 知识产权的策略就变得越加的迫切。
|
||||
|
||||
在过去的几年里,Linux 的版图曾经历了一场变革。OIN 不必再向人们解释这个组织的定义,也不必再解释为什么 Linux 需要保护。据 OIN 的 CEO Keith Bergelt 说,现在 Linux 的重要性得到了全世界的关注。
|
||||
|
||||
“我们已经见到了一场人们了解到OIN如何让合作受益的文化变革,”他对 LinuxInsider 说。
|
||||
|
||||
### 如何运作 ###
|
||||
|
||||
开放创新网络使用专利权的方式创建了一个协作环境。这种方法有助于确保创新的延续。这已经使很多软件商贩、顾客、新型市场和投资者受益。
|
||||
|
||||
开放创新网络的专利证可以让任何公司、公共机构或个人免版权使用。这些权利的获得建立在签署者同意不会专为了维护专利而攻击 Linux 系统的基础上。
|
||||
|
||||
OIN 确保 Linux 的源代码保持开放的状态。这让编程人员、设备出售人员、独立软件开发者和公共机构在投资和使用 Linux 时不用过多的担心知识产权的问题。这让对 Linux 进行重新装配、嵌入和使用的公司省了不少钱。
|
||||
|
||||
“随着版权许可证越来越广泛的使用,对 OIN 许可证的需求也变得更加的迫切。现在,人们正在寻找更加简单或更功利的解决方法”,Bergelt 说。
|
||||
|
||||
OIN 法律防御援助对成员是免费的。成员必须承诺不对 OIN 名单带上的软件发起专利诉讼。为了保护该软件,他们也同意提供他们自己的专利。最终,这些保证将导致几十万的交叉许可通过网络连接,Bergelt 如此解释道。
|
||||
|
||||
### 填补法律漏洞 ###
|
||||
|
||||
“OIN 正在做的事情是非常必要的。它提供额另一层 IP 保护,”[休斯顿法律中心大学][3]的副教授 Greg R. Vetter 这样说道。
|
||||
|
||||
他回答 LinuxInsider 说,某些人设想的第二版 GPL 许可证会隐含的提供专利许可,但是律师们更喜欢明确的许可。
|
||||
|
||||
OIN 所提供的许可填补了这个空白。它还明确的覆盖了 Linux 核心。据 Vetter 说,明确的专利许可并不是 GPLv2 中的必要部分,但是这个部分曾在 GPLv3 中。
|
||||
|
||||
拿一个在 GPLv3 中写了10000行代码的代码编写者来说。随着时间推移,其他的代码编写者会贡献更多行的代码到 IP 中。GPLv3 中的软件专利许可条款将保护所有基于参与其中的贡献者的专利的全部代码的使用,Vetter 如此说道。
|
||||
|
||||
### 并不完全一样 ###
|
||||
|
||||
专利权和许可证在法律结构上层层叠叠互相覆盖。弄清两者对开源软件的作用就像是穿越雷区。
|
||||
|
||||
Vetter 说“许可证是授予通常是建立在专利和版权法律上的额外权利的法律结构。许可证被认为是给予了人们做一些的可能会侵犯到其他人的 IP 权利的事的许可。”
|
||||
|
||||
Vetter 指出,很多自由开源许可证(例如 Mozilla 公共许可、GNU、GPLv3 以及 Apache 软件许可)融合了某些互惠专利权的形式。Vetter 指出,像 BSD 和 MIT 这样旧的许可证不会提到专利。
|
||||
|
||||
一个软件的许可证让其他人可以在某种程度上使用这个编程人员创造的代码。版权对所属权的建立是自动的,只要某个人写或者画了某个原创的东西。然而,版权只覆盖了个别的表达方式和衍生的作品。他并没有涵盖代码的功能性或可用的想法。
|
||||
|
||||
专利涵盖了功能性。专利权还可以成为许可证。版权可能无法保护某人如何独立的对另一个人的代码的实现的开发,但是专利填补了这个小瑕疵,Vetter 解释道。
|
||||
|
||||
### 寻找安全通道 ###
|
||||
|
||||
许可证和专利混合的法律性质可能会对开源开发者产生威胁。据 [Chaotic Moon Studios][4] 的创办者之一、 [IEEE][5] 计算机协会成员 William Hurley 说,对于某些人来说即使是 GPL 也会成为威胁。
|
||||
|
||||
"在很久以前,开源是个完全不同的世界。被彼此间的尊重和把代码视为艺术而非资产的观点所驱动,那时的程序和代码比现在更加的开放。我相信很多为最好的意图所做的努力几乎最后总是背负着意外的结果,"Hurley 这样告诉 LinuxInsider。
|
||||
|
||||
他暗示说,成员人数超越了1000人可能带来了一个关于知识产权保护重要性的混乱信息。这可能会继续搅混开源生态系统这滩浑水。
|
||||
|
||||
“最终,这些显现出了围绕着知识产权的常见的一些错误概念。拥有几千个开发者并不会减少风险——而是增加。给专利许可的开发者越多,它们看起来就越值钱,”Hurley 说。“它们看起来越值钱,有着类似专利的或者其他知识产权的人就越可能试图利用并从中榨取他们自己的经济利益。”
|
||||
|
||||
### 共享与竞争共存 ###
|
||||
|
||||
竞合策略是开源的一部分。OIN 模型让各个公司能够决定他们将在哪竞争以及在哪合作,Bergelt 解释道。
|
||||
|
||||
“开源演化中的许多改变已经把我们移到了另一个方向上。我们必须为合作创造渠道。否则我们将会有几百个团体把数十亿美元花费到同样的技术上,”他说。
|
||||
|
||||
手机产业的革新就是个很好的例子。各个公司放出了不同的标准。没有共享,没有合作,Bergelt 解释道。
|
||||
|
||||
他说:“这让我们在美国接触技术的能力落后了七到五年。我们接触设备的经验远远落后于世界其他地方的人。在我们等待 CDMA (Code Division Multiple Access 码分多址访问通信技术)时自满于 GSM (Global System for Mobile Communications 全球移动通信系统)。”
|
||||
|
||||
### 改变格局 ###
|
||||
|
||||
OIN 在去年经历了增长了400个新许可的浪潮。这意味着着开源有了新趋势。
|
||||
|
||||
Bergelt 说:“市场到达了一个临界点,组织内的人们终于意识到直白地合作和竞争的需要。结果是两件事同时进行。这可能会变得复杂、费力。”
|
||||
|
||||
然而,这个由人们开始考虑合作和竞争的文化革新所驱动的转换过程是可以忍受的。他解释说,这也是人们在以把开源作为开源社区的最重要的工程的方式拥抱开源——尤其是 Linux——的转变。
|
||||
|
||||
还有一个迹象是,最具意义的新工程都没有在 GPLv3 许可下开发。
|
||||
|
||||
### 二个总比一个好 ###
|
||||
|
||||
“GPL 极为重要,但是事实是有一堆的许可模型正被使用着。在Eclipse、Apache 和 Berkeley 许可中,专利问题的相对可解决性通常远远低于在 GPLv3 中的。”Bergelt 说。
|
||||
|
||||
GPLv3 对于解决专利问题是个自然的补充——但是 GPL 自身不足以独自解决围绕专利使用的潜在冲突。所以 OIN 的设计是以能够补充版权许可为目的的,他补充道。
|
||||
|
||||
然而,层层叠叠的专利和许可也许并没有带来多少好处。到最后,专利在几乎所有的案例中都被用于攻击目的——而不是防御目的,Bergelt 暗示说。
|
||||
|
||||
“如果你不准备对其他人采取法律行动,那么对于你的知识财产来说专利可能并不是最佳的法律保护方式”,他说。“我们现在生活在一个对软件——开放和专有——误会重重的世界里。这些软件还被错误并过时的专利系统所捆绑。我们每天在工业化的被窒息的创新中挣扎”,他说。
|
||||
|
||||
### 法院是最后的手段###
|
||||
|
||||
想到 OIN 的出现抑制了诉讼的泛滥就感到十分欣慰,Bergelt 说,或者至少可以说 OIN 的出现扼制了特定的某些威胁。
|
||||
|
||||
“可以说我们让人们放下它们了的武器。同时我们正在创建一种新的文化规范。一旦你入股这个模型中的非侵略专利,所产生的相关影响就是对合作的鼓励”,他说。
|
||||
|
||||
如果你愿意承诺合作,你的第一反应就会趋向于不急着起诉。相反的,你会想如何让我们允许你使用我们所拥有的东西并让它为你赚钱,而同时我们也能使用你所拥有的东西,Bergelt 解释道。
|
||||
|
||||
“OIN 是个多面的解决方式。他鼓励签署者创造双赢协议”,他说。“这让起诉成为最逼不得已的行为。那才是它的位置。”
|
||||
|
||||
### 底线###
|
||||
|
||||
Bergelt 坚信,OIN 的运作是为了阻止 Linux 受到专利伤害。在 Linux 的世界里没有诉讼的地方。
|
||||
|
||||
唯一临近的是和微软的移动大战,这主要关系到堆栈中高的元素。那些来自法律的挑战可能是为了提高包括使用 Linux 产品的所属权的成本,Bergelt 说。
|
||||
|
||||
尽管如此“这些并不是有关 Linux 诉讼”,他说。“他们的重点并不在于 Linux 的核心。他们关注的是 Linux 系统里都有些什么。”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/Defending-the-Free-Linux-World-81512.html
|
||||
|
||||
作者:Jack M. Germain
|
||||
译者:[H-mudcup](https://github.com/H-mudcup)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.openinventionnetwork.com/
|
||||
[2]:http://www.redhat.com/
|
||||
[3]:http://www.law.uh.edu/
|
||||
[4]:http://www.chaoticmoon.com/
|
||||
[5]:http://www.ieee.org/
|
||||
@ -1,109 +0,0 @@
|
||||
Debian GNU/Linux 生日: 22年未完的美妙旅程.
|
||||
================================================================================
|
||||
在2015年8月16日, Debian项目组庆祝了 Debian 的22周年纪念日; 这也是开源世界历史最悠久, 热门的发行版之一. Debian项目于1993年由Ian Murdock创立. 彼时, Slackware 作为最早的 Linux 发行版已经名声在外.
|
||||
|
||||

|
||||
|
||||
22岁生日快乐! Debian Linux!
|
||||
|
||||
Ian Ashly Murdock, 一个美国职业软件工程师, 在他还是普渡大学的学生时构想出了 Debia n项目的计划. 他把这个项目命名为 Debian 是由于这个名字组合了他彼时女友的名字, Debra Lynn, 和他自己的名字(译者: Ian). 他之后和Lynn顺利结婚并在2008年1月离婚.
|
||||
|
||||

|
||||
|
||||
Debian 创始人:Ian Murdock
|
||||
|
||||
Ian 目前是 ExactTarget 下 Platform and Development Community 的副总裁.
|
||||
|
||||
Debian (如同Slackware一样) 都是由于当时缺乏满足作者标准的发行版才应运而生的. Ian 在一次采访中说:"免费提供一流的产品会是Debian项目的唯一使命. 尽管过去的 Linux 发行版均不尽然可靠抑或是优秀. 我印象里...比如在不同的文件系统间移动文件, 处理大型文件经常会导致内核出错. 但是 Linux 其实是很可靠的, 免费的源代码让这个项目本质上很有前途.
|
||||
|
||||
"我记得过去我也像其他人一样想解决问题, 想在家里运营一个像 UNIX 的东西. 但那是不可能的, 无论是经济上还是法律上或是别的什么角度. 然后我就听闻了GNU内核开发项目, 以及这个项目是如何没有任何法律纷争", Ian 补充到. 他早年在开发 Debian 时曾被自由软件基金会(FSF)资助, 这份资助帮助 Debian 向前迈了一大步; 尽管一年后由于学业原因 Ian 退出了 FSF 转而去完成他的学位.
|
||||
|
||||
### Debian开发历史 ###
|
||||
|
||||
- **Debian 0.01 – 0.09** : 发布于 1993 八月 – 1993 十二月.
|
||||
- **Debian 0.91 ** – 发布于 1994 一月. 有了原始的包管理系统, 没有依赖管理机制.
|
||||
- **Debian 0.93 rc5** : 发布于 1995 三月. "现代"意义的 Debian 的第一次发布, dpkg 会在系统安装后被用作安装以及管理其他软件包.
|
||||
- **Debian 0.93 rc6**: 发布于1995 十一月. 最后一次a.out发布, deselect机制第一次出现, 有60位开发者在彼时维护着软件包.
|
||||
- **Debian 1.1**: 发布于1996 六月. 项目代号 – Buzz, 软件包数量 – 474, 包管理器 dpkg, 内核版本 2.0, ELF.
|
||||
- **Debian 1.2**: 发布于1996 十二月. 项目代号 – Rex, 软件包数量 – 848, 开发者数量 – 120.
|
||||
- **Debian 1.3**: 发布于1997 七月. 项目代号 – Bo, 软件包数量 974, 开发者数量 – 200.
|
||||
- **Debian 2.0**: 发布于1998 七月. 项目代号 - Hamm, 支持构架 – Intel i386 以及 Motorola 68000 系列, 软件包数量: 1500+, 开发者数量: 400+, 内置了 glibc.
|
||||
- **Debian 2.1**: 发布于1999 三月九日. 项目代号 – slink, 支持构架 - Alpha 和 Sparc, apt 包管理器开始成型, 软件包数量 – 2250.
|
||||
- **Debian 2.2**: 发布于2000 八月十五日. 项目代号 – Potato, 支持构架 – Intel i386, Motorola 68000 系列, Alpha, SUN Sparc, PowerPC 以及 ARM 构架. 软件包数量: 3900+ (二进制) 以及 2600+ (源代码), 开发者数量 – 450. 有一群人在那时研究并发表了一篇论文, 论文展示了自由软件是如何在被各种问题包围的情况下依然逐步成长为优秀的现代操作系统的.
|
||||
- **Debian 3.0**: 发布于2002 七月十九日. 项目代号 – woody, 支持构架新增– HP, PA_RISC, IA-64, MIPS 以及 IBM, 首次以DVD的形式发布, 软件包数量 – 8500+, 开发者数量 – 900+, 支持加密.
|
||||
- **Debian 3.1**: 发布于2005 六月六日. 项目代号 – sarge, 支持构架 – 不变基础上新增 AMD64 – 非官方渠道发布, 内核 – 2.4 以及 2.6 系列, 软件包数量: 15000+, 开发者数量 : 1500+, 增加了诸如 – OpenOffice 套件, Firefox 浏览器, Thunderbird, Gnome 2.8, 内核版本 3.3 先进地支持了: RAID, XFS, LVM, Modular Installer.
|
||||
- **Debian 4.0**: 发布于2007 四月八日. 项目代号 – etch, 支持构架 – 不变基础上新增 AMD64. 软件包数量: 18,200+ 开发者数量 : 1030+, 图形化安装器.
|
||||
- **Debian 5.0**: Released on February 14th, 发布于2009. 项目代号 – lenny, 支持构架 – 保不变基础上新增 ARM. 软件包数量: 23000+, 开发者数量: 1010+.
|
||||
- **Debian 6.0**: 发布于2009 七月二十九日. 项目代号 – squeeze, 包含的软件包: 内核 2.6.32, Gnome 2.3. Xorg 7.5, 同时包含了 DKMS, 基于依赖包支持. 支持构架 : 不变基础上新增 kfreebsd-i386 以及 kfreebsd-amd64, 基于依赖管理的启动过程.
|
||||
- **Debian 7.0**: 发布于2013 五月四日. 项目代号: wheezy, 支持 Multiarch, 私人云工具, 升级了安装器, 移除了第三方软件依赖, 万能的多媒体套件-codec, 内核版本 3.2, Xen Hypervisor 4.1.4 软件包数量: 37400+.
|
||||
- **Debian 8.0**: 发布于2015 五月二十五日. 项目代号: Jessie, 将 Systemd 作为默认的启动加载器, 内核版本 3.16, 增加了快速启动(fast booting), service进程所依赖的 cgroups 使隔离部分 service 进程成为可能, 43000+ packages. Sysvinit 初始化工具首次在 Jessie 中可用.
|
||||
|
||||
**注意**: Linux的内核第一次是在1991 十月五日被发布, 而 Debian 的首次发布则在1993 九月十三日. 所以 Debian 已经在只有24岁的 Linux 内核上运行了整整22年了.
|
||||
|
||||
### 有关 Debian 的小知识 ###
|
||||
|
||||
1994年被用来管理和重整 Debian 项目以使得其他开发者能更好地加入. 所以在那一年并没有面向用户的更新被发布, 当然, 内部版本肯定是有的.
|
||||
|
||||
Debian 1.0 从来就没有被发布过. 一家 CD-ROM 的生产商错误地把某个未发布的版本标注为了 1.0, 为了避免产生混乱, 原本的 Debian 1.0 以1.1的面貌发布了. 从那以后才有了所谓的官方CD-ROM的概念.
|
||||
|
||||
每个 Debian 新版本的代号都是玩具总动员里某个角色的名字哦.
|
||||
|
||||
Debian 有四种可用版本: 旧稳定版(old stable), 稳定版, 测试版 以及 试验版(experimental). 始终如此.
|
||||
|
||||
Debian 项目组一直致力于开发写一代发行版的不稳定版本, 这个不稳定版本始终被叫做Sid(玩具总动员里那个邪恶的臭小孩). Sid是unstable版本的永久名称, 同时Sid也取自'Still In Development"(译者:还在开发中)的首字母. Sid 将会成为下一个稳定版, 此时的下一个稳定版本代号为 jessie.
|
||||
|
||||
Debian 的官方发行版只包含开源并且免费的软件, 绝无其他东西. 不过contrib 和 不免费的软件包使得安装那些本身免费但是依赖的软件包不免费的软件成为了可能. 那些依赖包本身的证书可能不属于自由/免费软件.
|
||||
|
||||
Debian 是一堆Linux 发行版的母亲. 举几个例子:
|
||||
|
||||
- Damn Small Linux
|
||||
- KNOPPIX
|
||||
- Linux Advanced
|
||||
- MEPIS
|
||||
- Ubuntu
|
||||
- 64studio (不再活跃开发)
|
||||
- LMDE
|
||||
|
||||
Debian 是世界上最大的非商业Linux 发行版.他主要是由C书写的(32.1%), 一并的还有其他70多种语言.
|
||||
|
||||

|
||||
|
||||
Debian Contribution
|
||||
|
||||
图片来源: [Xmodulo][1]
|
||||
|
||||
Debian 项目包含6,850万行代码, 以及, 450万行空格和注释.
|
||||
|
||||
国际空间站放弃了 Windows 和红帽子, 进而换成了Debian - 在上面的宇航员使用落后一个版本的稳定发行版, 目前是squeeze; 这么做是为了稳定程度以及来自 Debian 社区的雄厚帮助支持.
|
||||
|
||||
感谢上帝! 我们差点就听到来自国际空间宇航员面对 Windows Metro 界面的尖叫了 :P
|
||||
|
||||
#### 黑色星期三 ####
|
||||
|
||||
2002 十一月而是日, Twente 大学的 Network Operation Center 着火 (NOC). 当地消防部门放弃了服务器区域. NOC维护了satie.debian.org的网站服务器, 这个网站包含了安全, 非美国相关的存档, 新维护者资料, 数量报告, 数据库; 这一切都化为了灰烬. 之后这些服务被使用 Debian 重新实现了.
|
||||
|
||||
#### 未来版本 ####
|
||||
|
||||
下一个待发布版本是 Debian 9, 项目代号 – Stretch, 它会带来什么还是个未知数. 满心期待吧!
|
||||
|
||||
有很多发行版在 Linux 发行版的历史上出现过一瞬然后很快消失了. 在多数情况下, 维护一个日渐庞大的项目是开发者们面临的挑战. 但这对 Debian 来说不是问题. Debian 项目有全世界成百上千的开发者, 维护者. 它在 Linux 诞生的之初起便一直存在.
|
||||
|
||||
Debian 在 Linux 生态环境中的贡献是难以用语言描述的. 如果 Debian 没有出现过, 那么 Linux 世界将不会像现在这样丰富, 用户友好. Debian 是为数不多可以被认为安全可靠又稳定, 是作为网络服务器完美选择的发行版.
|
||||
|
||||
这仅仅是 Debian 的一个开始. 它从远古时代一路走到今天, 并将一直走下去. 未来即是现在! 世界近在眼前! 如果你到现在还从来没有使用过 Debian, 我只想问, 你还再等什么? 快去下载一份镜像试试吧, 我们会在此守候遇到任何问题的你.
|
||||
|
||||
- [Debian 主页][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/happy-birthday-to-debian-gnu-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[jerryling315](http://moelf.xyz)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://xmodulo.com/2013/08/interesting-facts-about-debian-linux.html
|
||||
[2]:https://www.debian.org/
|
||||
@ -0,0 +1,123 @@
|
||||
学习数据结构与算法分析如何帮助您成为更优秀的开发人员?
|
||||
================================================================================
|
||||
|
||||
> "相较于其它方式,我一直热衷于推崇围绕数据设计代码,我想这也是Git能够如此成功的一大原因[…]在我看来,区别程序员优劣的一大标准就在于他是否认为自己设计的代码或数据结构更为重要。"
|
||||
-- Linus Torvalds
|
||||
|
||||
---
|
||||
|
||||
> "优秀的数据结构与简陋的代码组合远比倒过来的组合方式更好。"
|
||||
-- Eric S. Raymond, The Cathedral and The Bazaar
|
||||
|
||||
学习数据结构与算法分析会让您成为一名出色的程序员。
|
||||
|
||||
**数据结构与算法分析是一种解决问题的思维模式** 在您的个人知识库中,数据结构与算法分析的相关知识储备越多,您将具备应对并解决越多各类繁杂问题的能力。掌握了这种思维模式,您还将有能力针对新问题提出更多以前想不到的漂亮的解决方案。
|
||||
|
||||
您将***更深入地***了解,计算机如何完成各项操作。无论您是否是直接使用给定的算法,它都影响着您作出的各种技术决定。从计算机操作系统的内存分配到RDBMS的内在工作机制,以及网络堆栈如何实现将数据从地球的一个角落发送至另一个角落这些大大小小的工作的完成,都离不开基础的数据结构与算法,理解并掌握它将会让您更了解计算机的运作机理。
|
||||
|
||||
对算法广泛深入的学习能让为您应对大体系的问题储备解决方案。之前建模困难时遇到的问题如今通常都能融合进经典的数据结构中得到很好地解决。即使是最基础的数据结构,只要对它进行足够深入的钻研,您将会发现在每天的编程任务中都能经常用到这些知识。
|
||||
|
||||
有了这种思维模式,在遇到磨棱两可的问题时,您会具备想出新的解决方案的能力。即使最初并没有打算用数据结构与算法解决相应问题的情况,当真正用它们解决这些问题时您会发现它们将非常有用。要意识到这一点,您至少要对数据结构与算法分析的基础知识有深入直观的认识。
|
||||
|
||||
理论认识就讲到这里,让我们一起看看下面几个例子。
|
||||
|
||||
###最短路径问题###
|
||||
|
||||
我们想要开发一个计算从一个国际机场出发到另一个国际机场的最短距离的软件。假设我们受限于以下路线:
|
||||
|
||||

|
||||
|
||||
从这张画出机场各自之间的距离以及目的地的图中,我们如何才能找到最短距离,比方说从赫尔辛基到伦敦?**Dijkstra算法**是能让我们在最短的时间得到正确答案的适用算法。
|
||||
|
||||
在所有可能的解法中,如果您曾经遇到过这类问题,知道可以用Dijkstra算法求解,您大可不必从零开始实现它,只需***知道***该算法能指向固定的代码库帮助您解决相关的实现问题。
|
||||
|
||||
实现了该算法,您将深入理解一项著名的重要图论算法。您会发现实际上该算法太集成化,因此名为A*的扩展包经常会代替该算法使用。这个算法应用广泛,从机器人指引的功能实现到TCP数据包路由,以及GPS寻径问题都能应用到这个算法。
|
||||
|
||||
###先后排序问题###
|
||||
|
||||
您想要在开放式在线课程平台上(如Udemy或Khan学院)学习某课程,有些课程之间彼此依赖。例如,用户学习牛顿力学机制课程前必须先修微积分课程,课程之间可以有多种依赖关系。用YAML表述举例如下:
|
||||
|
||||
# Mapping from course name to requirements
|
||||
#
|
||||
# If you're a physcist or a mathematicisn and you're reading this, sincere
|
||||
# apologies for the completely made-up dependency tree :)
|
||||
courses:
|
||||
arithmetic: []
|
||||
algebra: [arithmetic]
|
||||
trigonometry: [algebra]
|
||||
calculus: [algebra, trigonometry]
|
||||
geometry: [algebra]
|
||||
mechanics: [calculus, trigonometry]
|
||||
atomic_physics: [mechanics, calculus]
|
||||
electromagnetism: [calculus, atomic_physics]
|
||||
radioactivity: [algebra, atomic_physics]
|
||||
astrophysics: [radioactivity, calculus]
|
||||
quantumn_mechanics: [atomic_physics, radioactivity, calculus]
|
||||
|
||||
鉴于以上这些依赖关系,作为一名用户,我希望系统能帮我列出必修课列表,让我在之后可以选择任意一门课程学习。如果我选择了`微积分`课程,我希望系统能返回以下列表:
|
||||
|
||||
arithmetic -> algebra -> trigonometry -> calculus
|
||||
|
||||
这里有两个潜在的重要约束条件:
|
||||
|
||||
- 返回的必修课列表中,每门课都与下一门课存在依赖关系
|
||||
- 必修课列表中不能有重复项
|
||||
|
||||
这是解决数据间依赖关系的例子,解决该问题的排序算法称作拓扑排序算法(tsort)。它适用于解决上述我们用YAML列出的依赖关系图的情况,以下是在图中显示的相关结果(其中箭头代表`需要先修的课程`):
|
||||
|
||||

|
||||
|
||||
拓扑排序算法的实现就是从如上所示的图中找到满足各层次要求的依赖关系。因此如果我们只列出包含`radioactivity`和与它有依赖关系的子图,运行tsort排序,会得到如下的顺序表:
|
||||
|
||||
arithmetic
|
||||
algebra
|
||||
trigonometry
|
||||
calculus
|
||||
mechanics
|
||||
atomic_physics
|
||||
radioactivity
|
||||
|
||||
这符合我们上面描述的需求,用户只需选出`radioactivity`,就能得到在此之前所有必修课程的有序列表。
|
||||
|
||||
在运用该排序算法之前,我们甚至不需要深入了解算法的实现细节。一般来说,选择不同的编程语言在其标准库中都会有相应的算法实现。即使最坏的情况,Unix也会默认安装`tsort`程序,运行`tsort`程序,您就可以实现该算法。
|
||||
|
||||
###其它拓扑排序适用场合###
|
||||
|
||||
- **工具** 使用诸如`make`的工具您可以声明任务之间的依赖关系,这里拓扑排序算法将从底层实现具有依赖关系的任务顺序执行的功能。
|
||||
- **有`require`指令的编程语言**,适用于要运行当前文件需先运行另一个文件的情况。这里拓扑排序用于识别文件运行顺序以保证每个文件只加载一次,且满足所有文件间的依赖关系要求。
|
||||
- **包含甘特图的项目管理工具**.甘特图能直观列出给定任务的所有依赖关系,在这些依赖关系之上能提供给用户任务完成的预估时间。我不常用到甘特图,但这些绘制甘特图的工具很可能会用到拓扑排序算法。
|
||||
|
||||
###霍夫曼编码实现数据压缩###
|
||||
[霍夫曼编码](http://en.wikipedia.org/wiki/Huffman_coding)是一种用于无损数据压缩的编码算法。它的工作原理是先分析要压缩的数据,再为每个字符创建一个二进制编码。字符出现的越频繁,编码赋值越小。因此在一个数据集中`e`可能会编码为`111`,而`x`会编码为`10010`。创建了这种编码模式,就可以串联无定界符,也能正确地进行解码。
|
||||
|
||||
在gzip中使用的DEFLATE算法就结合了霍夫曼编码与LZ77一同用于实现数据压缩功能。gzip应用领域很广,特别适用于文件压缩(以`.gz`为扩展名的文件)以及用于数据传输中的http请求与应答。
|
||||
|
||||
学会实现并使用霍夫曼编码有如下益处:
|
||||
|
||||
- 您会理解为什么较大的压缩文件会获得较好的整体压缩效果(如压缩的越多,压缩率也越高)。这也是SPDY协议得以推崇的原因之一:在复杂的HTTP请求/响应过程数据有更好的压缩效果。
|
||||
- 您会了解数据传输过程中如果想要压缩JavaScript/CSS文件,运行压缩软件是完全没有意义的。PNG文件也是类似,因为它们已经使用DEFLATE算法完成了压缩。
|
||||
- 如果您试图强行破译加密的信息,您可能会发现重复数据压缩质量越好,给定的密文单位bit的数据压缩将帮助您确定相关的[分组密码模式](http://en.wikipedia.org/wiki/Block_cipher_mode_of_operation).
|
||||
|
||||
###下一步选择学习什么是困难的###
|
||||
作为一名程序员应当做好持续学习的准备。为成为一名web开发人员,您需要了解标记语言以及Ruby/Python,正则表达式,SQL,JavaScript等高级编程语言,还需要了解HTTP的工作原理,如何运行UNIX终端以及面向对象的编程艺术。您很难有效地预览到未来的职业全景,因此选择下一步要学习哪些知识是困难的。
|
||||
|
||||
我没有快速学习的能力,因此我不得不在时间花费上非常谨慎。我希望尽可能地学习到有持久生命力的技能,即不会在几年内就过时的技术。这意味着我也会犹豫这周是要学习JavaScript框架还是那些新的编程语言。
|
||||
|
||||
只要占主导地位的计算模型体系不变,我们如今使用的数据结构与算法在未来也必定会以另外的形式继续适用。您可以放心地将时间投入到深入掌握数据结构与算法知识中,它们将会成为您作为一名程序员的职业生涯中一笔长期巨大的财富。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.happybearsoftware.com/how-learning-data-structures-and-algorithms-makes-you-a-better-developer
|
||||
|
||||
作者:[Happy Bear][a]
|
||||
译者:[icybreaker](https://github.com/icybreaker)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.happybearsoftware.com/
|
||||
[1]:http://en.wikipedia.org/wiki/Huffman_coding
|
||||
[2]:http://en.wikipedia.org/wiki/Block_cipher_mode_of_operation
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,41 @@
|
||||
基于Linux的Ubuntu开源操作系统在中国42%的Dell PC上运行
|
||||
================================================================================
|
||||
> Dell称它在中国市场出售的42%的PC运行的是Kylin,一款Canonical帮助创建的基于Ubuntu的操作系统。
|
||||
|
||||
让开源粉丝欢喜的是:Linux桌面年来了。或者说中国正在接近这个目标,[Dell][1]报告称超过40%售卖的PC机运行的是 [Canonical][3]帮助开发的[Ubuntu Linux][2]。
|
||||
|
||||
特别地,Dell称42%的中国电脑运行NeoKylin,一款中国本土倾力打造的用于替代[Microsoft][4] (MSFT) Windows的操作系统。它也简称麒麟,一款从2013年出来的基于Ubuntu的操作系统,也是这年开始Canonical公司与中国政府合作来建立一个专为中国市场Ubuntu变种。
|
||||
|
||||
2001年左右早期版本的麒麟,都是基于其他操作系统,包括FreeBSD,一个开放源码的区别于Linux的类Unix操作系统。
|
||||
|
||||
Ubuntu的麒麟的外观和感觉很像Ubuntu的现代版本。它拥有的[Unity][5]界面,并运行标准开源套件,以及专门的如Youker助理程序,它是一个图形化的前端,帮助用户管理的基本计算任务。但是麒麟的默认主题使得它看起来有点像Windows而不是Ubuntu。
|
||||
|
||||
鉴于桌面Linux PC市场在世界上大多数国家的相对停滞,戴尔的宣布是惊人的。并结合中国对现代windows的轻微[敌意][6],这个消息并不预示着微软在中国市场的前景。
|
||||
|
||||
在Dell公司[宣布][7]在华投资1.25亿美元很快之后一位行政官给华尔街杂志的评论中提到了Dell在中国市场上PC的销售。
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://thevarguy.com/open-source-application-software-companies/091515/ubuntu-linux-based-open-source-os-runs-42-percent-dell-pc
|
||||
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[geekpi](https://github.com/geeekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://thevarguy.com/author/christopher-tozzi
|
||||
[1]:http://dell.com/
|
||||
[2]:http://ubuntu.com/
|
||||
[3]:http://canonical.com/
|
||||
[4]:http://microsoft.com/
|
||||
[5]:http://unity.ubuntu.com/
|
||||
[6]:http://www.wsj.com/articles/windows-8-faces-new-criticism-in-china-1401882772
|
||||
[7]:http://thevarguy.com/business-technology-solution-sales/091415/dell-125-million-directed-china-jobs-new-business-and-innovation
|
||||
@ -0,0 +1,83 @@
|
||||
安卓编年史
|
||||
================================================================================
|
||||

|
||||
安卓市场的新设计试水“卡片式”界面,这将成为谷歌的主要风格。
|
||||
Ron Amadeo 供图
|
||||
|
||||
安卓推向市场已经有两年半时间了,安卓市场放出了它的第四版设计。这个新设计十分重要,因为它已经很接近谷歌的“卡片式”界面了。通过在小方块中显示应用或其他内容,谷歌可以使其设计在不同尺寸屏幕下无缝过渡而不受影响。内容可以像一个相册应用里的照片一样显示——给布局渲染填充一个内容块列表,加上屏幕包装,就完成了。更大的屏幕一次可以看到更多的内容块,小点的屏幕一次看到的内容就少。内容用了不一样的方式显示,谷歌还在右边新增了一个“分类”板块,顶部还有个巨大的热门应用滚动显示。
|
||||
|
||||
虽然设计上为更容易配置界面准备好准备好了,但功能上还没有。最初发布的市场版本锁定为横屏模式,而且还是蜂巢独占的。
|
||||
|
||||

|
||||
应用详情页和“我的应用”界面。
|
||||
Ron Amadeo 供图
|
||||
|
||||
新的市场不仅出售应用,还加入了书籍和电影租借。谷歌从2010年开始出售图书;之前只通过网站出售。新的市场将谷歌所有的内容销售聚合到了一处,进一步向苹果 iTunes 的主宰展开较量。虽然在“安卓市场”出售这些东西有点品牌混乱,因为大部分内容都不依赖于安卓才能使用。
|
||||
|
||||

|
||||
浏览器看起来非常像 Chrome,联系人使用了双面板界面。
|
||||
Ron Amadeo 供图
|
||||
|
||||
新浏览器界面顶部添加了标签页栏。尽管这个浏览器并不是 Chrome ,它模仿了许多 Chrome 的设计和特性。除了这个探索性的顶部标签页界面,浏览器还加入了隐身标签,在浏览网页时不保存历史记录和自动补全记录。它还有个选项可以让你拥有一个 Chrome 风格的新标签页,页面上包含你最经常访问的网页略缩图。
|
||||
|
||||
新浏览器甚至还能和 Chrome 同步。在浏览器登录后,它会下载你的 Chrome 书签并且自动登录你的谷歌账户。收藏一个页面只需点击地址栏的星形标志即可,和谷歌地图一样,浏览器抛弃了缩放按钮,完全改用手势控制。
|
||||
|
||||
联系人应用最终从电话应用中移除,并且独立为一个应用。之前的联系人/拨号混合式设计相对于人们使用现代智能手机的方式来说,过于以电话为中心了。联系人中存有电子邮件,IM,短信,地址,生日,以及社交网络等信息,所以将它们捆绑在电话应用里的意义和将它们放进谷歌地图里差不多。抛开了电话通讯功能,联系人能够简化成没有标签页的联系人列表。蜂巢采用了双面板视图,在左侧显示完整的联系人列表,右侧是联系人详情。应用利用了 Fragments API,通过它应用可以在同一屏显示多个面板界面。
|
||||
|
||||
蜂巢版本的联系人应用是第一个拥有快速滚动功能的版本。当按住左侧滚动条的时候,你可以快速上下拖动,应用会显示列表当前位置的首字母预览。
|
||||
|
||||

|
||||
新 Youtube 应用看起来像是来自黑客帝国。
|
||||
Ron Amadeo 供图
|
||||
|
||||
谢天谢地 Youtube 终于抛弃了自安卓 2.3 以来的谷歌给予这个视频服务的“独特”设计,新界面设计与系统更加一体化。主界面是一个水平滚动的曲面墙,上面显示着最热门或者(登录之后)个人关注的视频。虽然谷歌从来没有将这个设计带到手机上,但它可以被认为是一个易于重新配置的卡片界面。操作栏在这里是个可配置的工具栏。没有登录时,操作栏由一个搜索栏填满。当你登录后,搜索缩小为一个按钮,“首页”,“浏览”和“你的频道”标签将会显示出来。
|
||||
|
||||

|
||||
蜂巢用一个蓝色框架的电脑界面来驱动主屏。电影工作室完全采用橙色电子风格主题。
|
||||
Ron Amadeo 供图
|
||||
|
||||
蜂巢新增的应用“电影工作室”,这不是一个不言自明的应用,而且没有任何的解释或说明。就我们所知,你可以导入视频,剪切它们,添加文本和场景过渡。编辑视频——电脑上你可以做的最耗时,困难,以及处理器密集型任务之一——在平板上完成感觉有点野心过大了,谷歌在之后的版本里将其完全移除了。电影工作室里我们最喜欢的部分是它完全的电子风格主题。虽然系统的其它部分使用蓝色高亮,在这里是橙色的。(电影工作室是个邪恶的程序!)
|
||||
|
||||

|
||||
小部件!
|
||||
Ron Amadeo 供图
|
||||
|
||||
蜂巢带来了新的部件框架,允许部件滚动,Gmail,Email 以及日历部件都升级了以支持改功能。Youtube 和书籍使用了新的部件,内容卡片可以自动滚动切换。在小部件上轻轻向上或向下滑动可以切换卡片。我们不确定你的书籍中哪些书会被显示出来,但如果你想要的话它就在那儿。尽管所有的这些小部件在10英寸屏幕上运行良好,谷歌从未将它们重新设计给手机,这让它们在安卓最流行的规格上几乎毫无用处。所有的小部件有个大块的标识标题栏,而且通常占据大半屏幕只显示很少的内容。
|
||||
|
||||

|
||||
安卓3.1中可滚动的最近应用以及可自定义大小的小部件。
|
||||
Ron Amadeo 供图
|
||||
|
||||
蜂巢后续的版本修复了3.0早期的一些问题。安卓3.1在蜂巢的第一个版本之后三个月放出,并带来了一些改进。小部件自定义大小是添加的最大特性之一。长按小部件之后,一个带有拖拽按钮的蓝色外框会显示出来,拖动按钮可以改变小部件尺寸。最近应用界面现在可以垂直滚动并且承载更多应用。这个版本唯一缺失的功能是滑动关闭应用。
|
||||
|
||||
在今天,一个0.1版本的升级是个主要更新,但是在蜂巢,那只是个小更新。除了一些界面调整,3.1添加了对游戏手柄,键盘,鼠标以及其它USB和蓝牙输入设备的支持。它还提供了更多的开发者API。
|
||||
|
||||

|
||||
安卓3.2的兼容性缩放和一个安卓平板上典型的展开视图应用。
|
||||
Ron Amadeo 供图
|
||||
|
||||
安卓3.2在3.1发布后两个月放出,添加了七到八英寸的小尺寸平板支持。3.2终于启用了SD卡支持,Xoom 在生命最初的五个月像是抱着个不完整的肢体一样。
|
||||
|
||||
蜂巢匆匆问世是为了成为一个生态系统建设者。如果应用没有平板版本,没人会想要一个安卓平板的,所以谷歌知道需要尽快将东西送到开发者手中。在这个安卓平板生态的早期阶段,应用还没有到齐。这是拥有 Xoom 的人们所面临的最大的问题。
|
||||
|
||||
3.2添加了“兼容缩放”,给了用户一个新选项,可以将应用拉伸适应屏幕(如右侧图片显示的那样)或缩放成正常的应用布局来适应屏幕。这些选项都不是很理想,没有应用生态来支持平板,蜂巢设备销售状况惨淡。但谷歌的平板决策最终还是会得到回报。今天,安卓平板已经[取代 iOS 占据了最大的市场份额][1]。
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||
[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
|
||||
|
||||
[@RonAmadeo][t]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/18/
|
||||
|
||||
译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://techcrunch.com/2014/03/03/gartner-195m-tablets-sold-in-2013-android-grabs-top-spot-from-ipad-with-62-share/
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
@ -1,348 +0,0 @@
|
||||
Shilpa Nair 分享了她面试 RedHat Linux 包管理方面的经验
|
||||
========================================================================
|
||||
**Shilpa Nair 刚于2015年毕业。她之后去了一家位于 Noida,Delhi 的国家新闻电视台,应聘实习生的岗位。在她去年毕业季的时候,常逛 Tecmint 寻求作业上的帮助。从那时开始,她就常去 Tecmint。**
|
||||
|
||||

|
||||
|
||||
有关 RPM 方面的 Linux 面试题
|
||||
|
||||
所有的问题和回答都是 Shilpa Nair 根据回忆重写的。
|
||||
|
||||
> “大家好!我是来自 Delhi 的Shilpa Nair。我不久前才顺利毕业,正寻找一个实习的机会。在大学早期的时候,我就对 UNIX 十分喜爱,所以我也希望这个机会能适合我,满足我的兴趣。我被提问了很多问题,大部分都是关于 RedHat 包管理的基础问题。”
|
||||
|
||||
下面就是我被问到的问题,和对应的回答。我仅贴出了与 RedHat GNU/Linux 包管理相关的,也是主要被提问的。
|
||||
|
||||
### 1,里如何查找一个包安装与否?假设你需要确认 ‘nano’ 有没有安装,你怎么做? ###
|
||||
|
||||
> **回答**:为了确认 nano 软件包有没有安装,我们可以使用 rpm 命令,配合 -q 和 -a 选项来查询所有已安装的包
|
||||
>
|
||||
> # rpm -qa nano
|
||||
> OR
|
||||
> # rpm -qa | grep -i nano
|
||||
>
|
||||
> nano-2.3.1-10.el7.x86_64
|
||||
>
|
||||
> 同时包的名字必须是完成的,不完整的包名返回提示,不打印任何东西,就是说这包(包名字不全)未安装。下面的例子会更好理解些:
|
||||
>
|
||||
> 我们通常使用 vim 替代 vi 命令。当时如果我们查找安装包 vi/vim 的时候,我们就会看到标准输出上没有任何结果。
|
||||
>
|
||||
> # vi
|
||||
> # vim
|
||||
>
|
||||
> 尽管如此,我们仍然可以通过使用 vi/vim 命令来清楚地知道包有没有安装。Here is ... name(这句不知道)。如果我们不确切知道完整的文件名,我们可以使用通配符:
|
||||
>
|
||||
> # rpm -qa vim*
|
||||
>
|
||||
> vim-minimal-7.4.160-1.el7.x86_64
|
||||
>
|
||||
> 通过这种方式,我们可以获得任何软件包的信息,安装与否。
|
||||
|
||||
### 2. 你如何使用 rpm 命令安装 XYZ 软件包? ###
|
||||
|
||||
> **回答**:我们可以使用 rpm 命令安装任何的软件包(*.rpm),像下面这样,选项 -i(install),-v(冗余或者显示额外的信息)和 -h(打印#号显示进度,在安装过程中)。
|
||||
>
|
||||
> # rpm -ivh peazip-1.11-1.el6.rf.x86_64.rpm
|
||||
>
|
||||
> Preparing... ################################# [100%]
|
||||
> Updating / installing...
|
||||
> 1:peazip-1.11-1.el6.rf ################################# [100%]
|
||||
>
|
||||
> 如果要升级一个早期版本的包,应加上 -U 选项,选项 -v 和 -h 可以确保我们得到用 # 号表示的冗余输出,这增加了可读性。
|
||||
|
||||
### 3. 你已经安装了一个软件包(假设是 httpd),现在你想看看软件包创建并安装的所有文件和目录,你会怎么做? ###
|
||||
|
||||
> **回答**:使用选项 -l(列出所有文件)和 -q(查询)列出 httpd 软件包安装的所有文件(Linux哲学:所有的都是文件,包括目录)。
|
||||
>
|
||||
> # rpm -ql httpd
|
||||
>
|
||||
> /etc/httpd
|
||||
> /etc/httpd/conf
|
||||
> /etc/httpd/conf.d
|
||||
> ...
|
||||
|
||||
### 4. 假如你要移除一个软件包,叫 postfix。你会怎么做? ###
|
||||
|
||||
> **回答**:首先我们需要知道什么包安装了 postfix。查找安装 postfix 的包名后,使用 -e(擦除/卸载软件包)和 -v(冗余输出)两个选项来实现。
|
||||
>
|
||||
> # rpm -qa postfix*
|
||||
>
|
||||
> postfix-2.10.1-6.el7.x86_64
|
||||
>
|
||||
> 然后移除 postfix,如下:
|
||||
>
|
||||
> # rpm -ev postfix-2.10.1-6.el7.x86_64
|
||||
>
|
||||
> Preparing packages...
|
||||
> postfix-2:3.0.1-2.fc22.x86_64
|
||||
|
||||
### 5. 获得一个已安装包的具体信息,如版本,发行号,安装日期,大小,总结和一个间短的描述。 ###
|
||||
|
||||
> **回答**:我们通过使用 rpm 的选项 -qi,后面接包名,可以获得关于一个已安装包的具体信息。
|
||||
>
|
||||
> 举个例子,为了获得 openssh 包的具体信息,我需要做的就是:
|
||||
>
|
||||
> # rpm -qi openssh
|
||||
>
|
||||
> [root@tecmint tecmint]# rpm -qi openssh
|
||||
> Name : openssh
|
||||
> Version : 6.8p1
|
||||
> Release : 5.fc22
|
||||
> Architecture: x86_64
|
||||
> Install Date: Thursday 28 May 2015 12:34:50 PM IST
|
||||
> Group : Applications/Internet
|
||||
> Size : 1542057
|
||||
> License : BSD
|
||||
> ....
|
||||
|
||||
### 6. 假如你不确定一个指定包的配置文件在哪,比如 httpd。你如何找到所有 httpd 提供的配置文件列表和位置。 ###
|
||||
|
||||
> **回答**: 我们需要用选项 -c 接包名,这会列出所有配置文件的名字和他们的位置。
|
||||
>
|
||||
> # rpm -qc httpd
|
||||
>
|
||||
> /etc/httpd/conf.d/autoindex.conf
|
||||
> /etc/httpd/conf.d/userdir.conf
|
||||
> /etc/httpd/conf.d/welcome.conf
|
||||
> /etc/httpd/conf.modules.d/00-base.conf
|
||||
> /etc/httpd/conf/httpd.conf
|
||||
> /etc/sysconfig/httpd
|
||||
>
|
||||
> 相似地,我们可以列出所有相关的文档文件,如下:
|
||||
>
|
||||
> # rpm -qd httpd
|
||||
>
|
||||
> /usr/share/doc/httpd/ABOUT_APACHE
|
||||
> /usr/share/doc/httpd/CHANGES
|
||||
> /usr/share/doc/httpd/LICENSE
|
||||
> ...
|
||||
>
|
||||
> 我们也可以列出所有相关的证书文件,如下:
|
||||
>
|
||||
> # rpm -qL openssh
|
||||
>
|
||||
> /usr/share/licenses/openssh/LICENCE
|
||||
>
|
||||
> 忘了说明上面的选项 -d 和 -L 分别表示 “文档” 和 “证书”,抱歉。
|
||||
|
||||
### 7. 你进入了一个配置文件,位于‘/usr/share/alsa/cards/AACI.conf’,现在你不确定该文件属于哪个包。你如何查找出包的名字? ###
|
||||
|
||||
> **回答**:当一个包被安装后,相关的信息就存储在了数据库里。所以使用选项 -qf(-f 查询包拥有的文件)很容易追踪谁提供了上述的包。
|
||||
>
|
||||
> # rpm -qf /usr/share/alsa/cards/AACI.conf
|
||||
> alsa-lib-1.0.28-2.el7.x86_64
|
||||
>
|
||||
> 类似地,我们可以查找(谁提供的)关于任何子包,文档和证书文件的信息。
|
||||
|
||||
### 8. 你如何使用 rpm 查找最近安装的软件列表? ###
|
||||
|
||||
> **回答**:如刚刚说的,每一样被安装的文件都记录在了数据库里。所以这并不难,通过查询 rpm 的数据库,找到最近安装软件的列表。
|
||||
>
|
||||
> 我们通过运行下面的命令,使用选项 -last(打印出最近安装的软件)达到目的。
|
||||
>
|
||||
> # rpm -qa --last
|
||||
>
|
||||
> 上面的命令会打印出所有安装的软件,最近一次安装的软件在列表的顶部。
|
||||
>
|
||||
> 如果我们关心的是找出特定的包,我们可以使用 grep 命令从列表中匹配包(假设是 sqlite ),简单如下:
|
||||
>
|
||||
> # rpm -qa --last | grep -i sqlite
|
||||
>
|
||||
> sqlite-3.8.10.2-1.fc22.x86_64 Thursday 18 June 2015 05:05:43 PM IST
|
||||
>
|
||||
> 我们也可以获得10个最近安装的软件列表,简单如下:
|
||||
>
|
||||
> # rpm -qa --last | head
|
||||
>
|
||||
> 我们可以重定义一下,输出想要的结果,简单如下:
|
||||
>
|
||||
> # rpm -qa --last | head -n 2
|
||||
>
|
||||
> 上面的命令中,-n 代表数目,后面接一个常数值。该命令是打印2个最近安装的软件的列表。
|
||||
|
||||
### 9. 安装一个包之前,你如果要检查其依赖。你会怎么做? ###
|
||||
|
||||
> **回答**:检查一个 rpm 包(XYZ.rpm)的依赖,我们可以使用选项 -q(查询包),-p(指定包名)和 -R(查询/列出该包依赖的包,嗯,就是依赖)。
|
||||
>
|
||||
> # rpm -qpR gedit-3.16.1-1.fc22.i686.rpm
|
||||
>
|
||||
> /bin/sh
|
||||
> /usr/bin/env
|
||||
> glib2(x86-32) >= 2.40.0
|
||||
> gsettings-desktop-schemas
|
||||
> gtk3(x86-32) >= 3.16
|
||||
> gtksourceview3(x86-32) >= 3.16
|
||||
> gvfs
|
||||
> libX11.so.6
|
||||
> ...
|
||||
|
||||
### 10. rpm 是不是一个前端的包管理工具呢? ###
|
||||
|
||||
> **回答**:不是!rpm 是一个后端管理工具,适用于基于 Linux 发行版的 RPM (此处指 Redhat Package Management)。
|
||||
>
|
||||
> [YUM][1],全称 Yellowdog Updater Modified,是一个 RPM 的前端工具。YUM 命令自动完成所有工作,包括解决依赖和其他一切事务。
|
||||
>
|
||||
> 最近,[DNF][2](YUM命令升级版)在Fedora 22发行版中取代了 YUM。尽管 YUM 仍然可以在 RHEL 和 CentOS 平台使用,我们也可以安装 dnf,与 YUM 命令共存使用。据说 DNF 较于 YUM 有很多提高。
|
||||
>
|
||||
> 知道更多总是好的,保持自我更新。现在我们移步到前端部分来谈谈。
|
||||
|
||||
### 11. 你如何列出一个系统上面所有可用的仓库列表。 ###
|
||||
|
||||
> **回答**:简单地使用下面的命令,我们就可以列出一个系统上所有可用的仓库列表。
|
||||
>
|
||||
> # yum repolist
|
||||
> 或
|
||||
> # dnf repolist
|
||||
>
|
||||
> Last metadata expiration check performed 0:30:03 ago on Mon Jun 22 16:50:00 2015.
|
||||
> repo id repo name status
|
||||
> *fedora Fedora 22 - x86_64 44,762
|
||||
> ozonos Repository for Ozon OS 61
|
||||
> *updates Fedora 22 - x86_64 - Updates
|
||||
>
|
||||
> 上面的命令仅会列出可用的仓库。如果你需要列出所有的仓库,不管可用与否,可以这样做。
|
||||
>
|
||||
> # yum repolist all
|
||||
> or
|
||||
> # dnf repolist all
|
||||
>
|
||||
> Last metadata expiration check performed 0:29:45 ago on Mon Jun 22 16:50:00 2015.
|
||||
> repo id repo name status
|
||||
> *fedora Fedora 22 - x86_64 enabled: 44,762
|
||||
> fedora-debuginfo Fedora 22 - x86_64 - Debug disabled
|
||||
> fedora-source Fedora 22 - Source disabled
|
||||
> ozonos Repository for Ozon OS enabled: 61
|
||||
> *updates Fedora 22 - x86_64 - Updates enabled: 5,018
|
||||
> updates-debuginfo Fedora 22 - x86_64 - Updates - Debug
|
||||
|
||||
### 12. 你如何列出一个系统上所有可用并且安装了的包? ###
|
||||
|
||||
> **回答**:列出一个系统上所有可用的包,我们可以这样做:
|
||||
>
|
||||
> # yum list available
|
||||
> 或
|
||||
> # dnf list available
|
||||
>
|
||||
> ast metadata expiration check performed 0:34:09 ago on Mon Jun 22 16:50:00 2015.
|
||||
> Available Packages
|
||||
> 0ad.x86_64 0.0.18-1.fc22 fedora
|
||||
> 0ad-data.noarch 0.0.18-1.fc22 fedora
|
||||
> 0install.x86_64 2.6.1-2.fc21 fedora
|
||||
> 0xFFFF.x86_64 0.3.9-11.fc22 fedora
|
||||
> 2048-cli.x86_64 0.9-4.git20141214.723738c.fc22 fedora
|
||||
> 2048-cli-nocurses.x86_64 0.9-4.git20141214.723738c.fc22 fedora
|
||||
> ....
|
||||
>
|
||||
> 而列出一个系统上所有已安装的包,我们可以这样做。
|
||||
>
|
||||
> # yum list installed
|
||||
> or
|
||||
> # dnf list installed
|
||||
>
|
||||
> Last metadata expiration check performed 0:34:30 ago on Mon Jun 22 16:50:00 2015.
|
||||
> Installed Packages
|
||||
> GeoIP.x86_64 1.6.5-1.fc22 @System
|
||||
> GeoIP-GeoLite-data.noarch 2015.05-1.fc22 @System
|
||||
> NetworkManager.x86_64 1:1.0.2-1.fc22 @System
|
||||
> NetworkManager-libnm.x86_64 1:1.0.2-1.fc22 @System
|
||||
> aajohan-comfortaa-fonts.noarch 2.004-4.fc22 @System
|
||||
> ....
|
||||
>
|
||||
> 而要同时满足两个要求的时候,我们可以这样做。
|
||||
>
|
||||
> # yum list
|
||||
> 或
|
||||
> # dnf list
|
||||
>
|
||||
> Last metadata expiration check performed 0:32:56 ago on Mon Jun 22 16:50:00 2015.
|
||||
> Installed Packages
|
||||
> GeoIP.x86_64 1.6.5-1.fc22 @System
|
||||
> GeoIP-GeoLite-data.noarch 2015.05-1.fc22 @System
|
||||
> NetworkManager.x86_64 1:1.0.2-1.fc22 @System
|
||||
> NetworkManager-libnm.x86_64 1:1.0.2-1.fc22 @System
|
||||
> aajohan-comfortaa-fonts.noarch 2.004-4.fc22 @System
|
||||
> acl.x86_64 2.2.52-7.fc22 @System
|
||||
> ....
|
||||
|
||||
### 13. 你会怎么分别安装和升级一个包与一组包,在一个系统上面使用 YUM/DNF? ###
|
||||
|
||||
> **回答**:安装一个包(假设是 nano),我们可以这样做,
|
||||
>
|
||||
> # yum install nano
|
||||
>
|
||||
> 而安装一组包(假设是 Haskell),我们可以这样做,
|
||||
>
|
||||
> # yum groupinstall 'haskell'
|
||||
>
|
||||
> 升级一个包(还是 nano),我们可以这样做,
|
||||
>
|
||||
> # yum update nano
|
||||
>
|
||||
> 而为了升级一组包(还是 haskell),我们可以这样做,
|
||||
>
|
||||
> # yum groupupdate 'haskell'
|
||||
|
||||
### 14. 你会如何同步一个系统上面的所有安装软件到稳定发行版? ###
|
||||
|
||||
> **回答**:我们可以一个系统上(假设是 CentOS 或者 Fedora)的所有包到稳定发行版,如下,
|
||||
>
|
||||
> # yum distro-sync [On CentOS/ RHEL]
|
||||
> 或
|
||||
> # dnf distro-sync [On Fedora 20之后版本]
|
||||
|
||||
似乎来面试之前你做了相当不多的功课,很好!在进一步交谈前,我还想问一两个问题。
|
||||
|
||||
### 15. 你对 YUM 本地仓库熟悉吗?你尝试过建立一个本地 YUM 仓库吗?让我们简单看看你会怎么建立一个本地 YUM 仓库。 ###
|
||||
|
||||
> **回答**:首先,感谢你的夸奖。回到问题,我必须承认我对本地 YUM 仓库十分熟悉,并且在我的本地主机上也部署过,作为测试用。
|
||||
>
|
||||
> 1. 为了建立本地 YUM 仓库,我们需要安装下面三个包:
|
||||
>
|
||||
> # yum install deltarpm python-deltarpm createrepo
|
||||
>
|
||||
> 2. 新建一个目录(假设 /home/$USER/rpm),然后复制 RedHat/CentOS DVD 上的 RPM 包到这个文件夹下
|
||||
>
|
||||
> # mkdir /home/$USER/rpm
|
||||
> # cp /path/to/rpm/on/DVD/*.rpm /home/$USER/rpm
|
||||
>
|
||||
> 3. 新建基本的库头文件如下。
|
||||
>
|
||||
> # createrepo -v /home/$USER/rpm
|
||||
>
|
||||
> 4. 在路径 /etc/yum.repo.d 下创建一个 .repo 文件(如 abc.repo):
|
||||
>
|
||||
> cd /etc/yum.repos.d && cat << EOF > abc.repo
|
||||
> [local-installation]name=yum-local
|
||||
> baseurl=file:///home/$USER/rpm
|
||||
> enabled=1
|
||||
> gpgcheck=0
|
||||
> EOF
|
||||
|
||||
**重要**:用你的用户名替换掉 $USER。
|
||||
|
||||
以上就是创建一个本地 YUM 仓库所要做的全部工作。我们现在可以从这里安装软件了,相对快一些,安全一些,并且最重要的是不需要 Internet 连接。
|
||||
|
||||
好了!面试过程很愉快。我已经问完了。我会将你推荐给 HR。你是一个年轻且十分聪明的候选者,我们很愿意你加入进来。如果你有任何问题,你可以问我。
|
||||
|
||||
**我**:谢谢,这确实是一次愉快的面试,我感到非常幸运今天,然后这次面试就毁了。。。
|
||||
|
||||
显然,不会在这里结束。我问了很多问题,比如他们正在做的项目。我会担任什么角色,负责什么,,,balabalabala
|
||||
|
||||
小伙伴们,3天以前 HR 轮的所有问题到时候也会被写成文档。希望我当时表现不错。感谢你们所有的祝福。
|
||||
|
||||
谢谢伙伴们和 Tecmint,花时间来编辑我的面试经历。我相信 Tecmint 好伙伴们做了很大的努力,必要要赞一个。当我们与他人分享我们的经历的时候,其他人从我们这里知道了更多,而我们自己则发现了自己的不足。
|
||||
|
||||
这增加了我们的信心。如果你最近也有任何类似的面试经历,别自己蔵着。分享出来!让我们所有人都知道。你可以使用如下的格式来与我们分享你的经历。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-rpm-package-management-interview-questions/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[2]:http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
@ -1,674 +0,0 @@
|
||||
如何构建Linux 内核
|
||||
================================================================================
|
||||
介绍
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
我不会告诉你怎么在自己的电脑上去构建、安装一个定制化的Linux 内核,这样的[资料](https://encrypted.google.com/search?q=building+linux+kernel#q=building+linux+kernel+from+source+code) 太多了,它们会对你有帮助。本文会告诉你当你在内核源码路径里敲下`make` 时会发生什么。当我刚刚开始学习内核代码时,[Makefile](https://github.com/torvalds/linux/blob/master/Makefile) 是我打开的第一个文件,这个文件看起来真令人害怕 :)。那时候这个[Makefile](https://en.wikipedia.org/wiki/Make_%28software%29) 还只包含了`1591` 行代码,当我开始写本文是,这个[Makefile](https://github.com/torvalds/linux/commit/52721d9d3334c1cb1f76219a161084094ec634dc) 已经是第三个候选版本了。
|
||||
|
||||
这个makefile 是Linux 内核代码的根makefile ,内核构建就始于此处。是的,它的内容很多,但是如果你已经读过内核源代码,你就会发现每个包含代码的目录都有一个自己的makefile。当然了,我们不会去描述每个代码文件是怎么编译链接的。所以我们将只会挑选一些通用的例子来说明问题,而你不会在这里找到构建内核的文档、如何整洁内核代码、[tags](https://en.wikipedia.org/wiki/Ctags) 的生成和[交叉编译](https://en.wikipedia.org/wiki/Cross_compiler) 相关的说明,等等。我们将从`make` 开始,使用标准的内核配置文件,到生成了内核镜像[bzImage](https://en.wikipedia.org/wiki/Vmlinux#bzImage) 结束。
|
||||
|
||||
如果你已经很了解[make](https://en.wikipedia.org/wiki/Make_%28software%29) 工具那是最好,但是我也会描述本文出现的相关代码。
|
||||
|
||||
让我们开始吧
|
||||
|
||||
|
||||
编译内核前的准备
|
||||
---------------------------------------------------------------------------------
|
||||
|
||||
在开始编译前要进行很多准备工作。最主要的就是找到并配置好配置文件,`make` 命令要使用到的参数都需要从这些配置文件获取。现在就让我们深入内核的根`makefile` 吧
|
||||
|
||||
内核的根`Makefile` 负责构建两个主要的文件:[vmlinux](https://en.wikipedia.org/wiki/Vmlinux) (内核镜像可执行文件)和模块文件。内核的 [Makefile](https://github.com/torvalds/linux/blob/master/Makefile) 从此处开始:
|
||||
|
||||
```Makefile
|
||||
VERSION = 4
|
||||
PATCHLEVEL = 2
|
||||
SUBLEVEL = 0
|
||||
EXTRAVERSION = -rc3
|
||||
NAME = Hurr durr I'ma sheep
|
||||
```
|
||||
|
||||
这些变量决定了当前内核的版本,并且被使用在很多不同的地方,比如`KERNELVERSION` :
|
||||
|
||||
```Makefile
|
||||
KERNELVERSION = $(VERSION)$(if $(PATCHLEVEL),.$(PATCHLEVEL)$(if $(SUBLEVEL),.$(SUBLEVEL)))$(EXTRAVERSION)
|
||||
```
|
||||
|
||||
接下来我们会看到很多`ifeq` 条件判断语句,它们负责检查传给`make` 的参数。内核的`Makefile` 提供了一个特殊的编译选项`make help` ,这个选项可以生成所有的可用目标和一些能传给`make` 的有效的命令行参数。举个例子,`make V=1` 会在构建过程中输出详细的编译信息,第一个`ifeq` 就是检查传递给make的`V=n` 选项。
|
||||
|
||||
```Makefile
|
||||
ifeq ("$(origin V)", "command line")
|
||||
KBUILD_VERBOSE = $(V)
|
||||
endif
|
||||
ifndef KBUILD_VERBOSE
|
||||
KBUILD_VERBOSE = 0
|
||||
endif
|
||||
|
||||
ifeq ($(KBUILD_VERBOSE),1)
|
||||
quiet =
|
||||
Q =
|
||||
else
|
||||
quiet=quiet_
|
||||
Q = @
|
||||
endif
|
||||
|
||||
export quiet Q KBUILD_VERBOSE
|
||||
```
|
||||
|
||||
如果`V=n` 这个选项传给了`make` ,系统就会给变量`KBUILD_VERBOSE` 选项附上`V` 的值,否则的话`KBUILD_VERBOSE` 就会为`0`。然后系统会检查`KBUILD_VERBOSE` 的值,以此来决定`quiet` 和`Q` 的值。符号`@` 控制命令的输出,如果它被放在一个命令之前,这条命令的执行将会是`CC scripts/mod/empty.o`,而不是`Compiling .... scripts/mod/empty.o`(注:CC 在makefile 中一般都是编译命令)。最后系统仅仅导出所有的变量。下一个`ifeq` 语句检查的是传递给`make` 的选项`O=/dir`,这个选项允许在指定的目录`dir` 输出所有的结果文件:
|
||||
|
||||
```Makefile
|
||||
ifeq ($(KBUILD_SRC),)
|
||||
|
||||
ifeq ("$(origin O)", "command line")
|
||||
KBUILD_OUTPUT := $(O)
|
||||
endif
|
||||
|
||||
ifneq ($(KBUILD_OUTPUT),)
|
||||
saved-output := $(KBUILD_OUTPUT)
|
||||
KBUILD_OUTPUT := $(shell mkdir -p $(KBUILD_OUTPUT) && cd $(KBUILD_OUTPUT) \
|
||||
&& /bin/pwd)
|
||||
$(if $(KBUILD_OUTPUT),, \
|
||||
$(error failed to create output directory "$(saved-output)"))
|
||||
|
||||
sub-make: FORCE
|
||||
$(Q)$(MAKE) -C $(KBUILD_OUTPUT) KBUILD_SRC=$(CURDIR) \
|
||||
-f $(CURDIR)/Makefile $(filter-out _all sub-make,$(MAKECMDGOALS))
|
||||
|
||||
skip-makefile := 1
|
||||
endif # ifneq ($(KBUILD_OUTPUT),)
|
||||
endif # ifeq ($(KBUILD_SRC),)
|
||||
```
|
||||
|
||||
系统会检查变量`KBUILD_SRC`,如果他是空的(第一次执行makefile 时总是空的),并且变量`KBUILD_OUTPUT` 被设成了选项`O` 的值(如果这个选项被传进来了),那么这个值就会用来代表内核源码的顶层目录。下一步会检查变量`KBUILD_OUTPUT` ,如果之前设置过这个变量,那么接下来会做以下几件事:
|
||||
|
||||
* 将变量`KBUILD_OUTPUT` 的值保存到临时变量`saved-output`;
|
||||
* 尝试创建输出目录;
|
||||
* 检查创建的输出目录,如果失败了就打印错误;
|
||||
* 如果成功创建了输出目录,那么就在新目录重新执行`make` 命令(参见选项`-C`)。
|
||||
|
||||
下一个`ifeq` 语句会检查传递给make 的选项`C` 和`M`:
|
||||
|
||||
```Makefile
|
||||
ifeq ("$(origin C)", "command line")
|
||||
KBUILD_CHECKSRC = $(C)
|
||||
endif
|
||||
ifndef KBUILD_CHECKSRC
|
||||
KBUILD_CHECKSRC = 0
|
||||
endif
|
||||
|
||||
ifeq ("$(origin M)", "command line")
|
||||
KBUILD_EXTMOD := $(M)
|
||||
endif
|
||||
```
|
||||
|
||||
第一个选项`C` 会告诉`makefile` 需要使用环境变量`$CHECK` 提供的工具来检查全部`c` 代码,默认情况下会使用[sparse](https://en.wikipedia.org/wiki/Sparse)。第二个选项`M` 会用来编译外部模块(本文不做讨论)。因为设置了这两个变量,系统还会检查变量`KBUILD_SRC`,如果`KBUILD_SRC` 没有被设置,系统会设置变量`srctree` 为`.`:
|
||||
|
||||
```Makefile
|
||||
ifeq ($(KBUILD_SRC),)
|
||||
srctree := .
|
||||
endif
|
||||
|
||||
objtree := .
|
||||
src := $(srctree)
|
||||
obj := $(objtree)
|
||||
|
||||
export srctree objtree VPATH
|
||||
```
|
||||
|
||||
这将会告诉`Makefile` 内核的源码树就在执行make 命令的目录。然后要设置`objtree` 和其他变量为执行make 命令的目录,并且将这些变量导出。接着就是要获取`SUBARCH` 的值,这个变量代表了当前的系统架构(注:一般都指CPU 架构):
|
||||
|
||||
```Makefile
|
||||
SUBARCH := $(shell uname -m | sed -e s/i.86/x86/ -e s/x86_64/x86/ \
|
||||
-e s/sun4u/sparc64/ \
|
||||
-e s/arm.*/arm/ -e s/sa110/arm/ \
|
||||
-e s/s390x/s390/ -e s/parisc64/parisc/ \
|
||||
-e s/ppc.*/powerpc/ -e s/mips.*/mips/ \
|
||||
-e s/sh[234].*/sh/ -e s/aarch64.*/arm64/ )
|
||||
```
|
||||
|
||||
如你所见,系统执行[uname](https://en.wikipedia.org/wiki/Uname) 得到机器、操作系统和架构的信息。因为我们得到的是`uname` 的输出,所以我们需要做一些处理在赋给变量`SUBARCH` 。获得`SUBARCH` 之后就要设置`SRCARCH` 和`hfr-arch`,`SRCARCH`提供了硬件架构相关代码的目录,`hfr-arch` 提供了相关头文件的目录:
|
||||
|
||||
```Makefile
|
||||
ifeq ($(ARCH),i386)
|
||||
SRCARCH := x86
|
||||
endif
|
||||
ifeq ($(ARCH),x86_64)
|
||||
SRCARCH := x86
|
||||
endif
|
||||
|
||||
hdr-arch := $(SRCARCH)
|
||||
```
|
||||
|
||||
注意:`ARCH` 是`SUBARCH` 的别名。如果没有设置过代表内核配置文件路径的变量`KCONFIG_CONFIG`,下一步系统会设置它,默认情况下就是`.config` :
|
||||
|
||||
```Makefile
|
||||
KCONFIG_CONFIG ?= .config
|
||||
export KCONFIG_CONFIG
|
||||
```
|
||||
以及编译内核过程中要用到的[shell](https://en.wikipedia.org/wiki/Shell_%28computing%29)
|
||||
|
||||
```Makefile
|
||||
CONFIG_SHELL := $(shell if [ -x "$$BASH" ]; then echo $$BASH; \
|
||||
else if [ -x /bin/bash ]; then echo /bin/bash; \
|
||||
else echo sh; fi ; fi)
|
||||
```
|
||||
|
||||
接下来就要设置一组和编译内核的编译器相关的变量。我们会设置主机的`C` 和`C++` 的编译器及相关配置项:
|
||||
|
||||
```Makefile
|
||||
HOSTCC = gcc
|
||||
HOSTCXX = g++
|
||||
HOSTCFLAGS = -Wall -Wmissing-prototypes -Wstrict-prototypes -O2 -fomit-frame-pointer -std=gnu89
|
||||
HOSTCXXFLAGS = -O2
|
||||
```
|
||||
|
||||
下一步会去适配代表编译器的变量`CC`,那为什么还要`HOST*` 这些选项呢?这是因为`CC` 是编译内核过程中要使用的目标架构的编译器,但是`HOSTCC` 是要被用来编译一组`host` 程序的(下面我们就会看到)。然后我们就看看变量`KBUILD_MODULES` 和`KBUILD_BUILTIN` 的定义,这两个变量决定了我们要编译什么东西(内核、模块还是其他):
|
||||
|
||||
```Makefile
|
||||
KBUILD_MODULES :=
|
||||
KBUILD_BUILTIN := 1
|
||||
|
||||
ifeq ($(MAKECMDGOALS),modules)
|
||||
KBUILD_BUILTIN := $(if $(CONFIG_MODVERSIONS),1)
|
||||
endif
|
||||
```
|
||||
|
||||
在这我们可以看到这些变量的定义,并且,如果们仅仅传递了`modules` 给`make`,变量`KBUILD_BUILTIN` 会依赖于内核配置选项`CONFIG_MODVERSIONS`。下一步操作是引入下面的文件:
|
||||
|
||||
```Makefile
|
||||
include scripts/Kbuild.include
|
||||
```
|
||||
|
||||
文件`kbuild` ,[Kbuild](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/kbuild.txt) 或者又叫做 `Kernel Build System`是一个用来管理构建内核和模块的特殊框架。`kbuild` 文件的语法与makefile 一样。文件[scripts/Kbuild.include](https://github.com/torvalds/linux/blob/master/scripts/Kbuild.include) 为`kbuild` 系统同提供了一些原生的定义。因为我们包含了这个`kbuild` 文件,我们可以看到和不同工具关联的这些变量的定义,这些工具会在内核和模块编译过程中被使用(比如链接器、编译器、二进制工具包[binutils](http://www.gnu.org/software/binutils/),等等):
|
||||
|
||||
```Makefile
|
||||
AS = $(CROSS_COMPILE)as
|
||||
LD = $(CROSS_COMPILE)ld
|
||||
CC = $(CROSS_COMPILE)gcc
|
||||
CPP = $(CC) -E
|
||||
AR = $(CROSS_COMPILE)ar
|
||||
NM = $(CROSS_COMPILE)nm
|
||||
STRIP = $(CROSS_COMPILE)strip
|
||||
OBJCOPY = $(CROSS_COMPILE)objcopy
|
||||
OBJDUMP = $(CROSS_COMPILE)objdump
|
||||
AWK = awk
|
||||
...
|
||||
...
|
||||
...
|
||||
```
|
||||
|
||||
在这些定义好的变量后面,我们又定义了两个变量:`USERINCLUDE` 和`LINUXINCLUDE`。他们包含了头文件的路径(第一个是给用户用的,第二个是给内核用的):
|
||||
|
||||
```Makefile
|
||||
USERINCLUDE := \
|
||||
-I$(srctree)/arch/$(hdr-arch)/include/uapi \
|
||||
-Iarch/$(hdr-arch)/include/generated/uapi \
|
||||
-I$(srctree)/include/uapi \
|
||||
-Iinclude/generated/uapi \
|
||||
-include $(srctree)/include/linux/kconfig.h
|
||||
|
||||
LINUXINCLUDE := \
|
||||
-I$(srctree)/arch/$(hdr-arch)/include \
|
||||
...
|
||||
```
|
||||
|
||||
以及标准的C 编译器标志:
|
||||
```Makefile
|
||||
KBUILD_CFLAGS := -Wall -Wundef -Wstrict-prototypes -Wno-trigraphs \
|
||||
-fno-strict-aliasing -fno-common \
|
||||
-Werror-implicit-function-declaration \
|
||||
-Wno-format-security \
|
||||
-std=gnu89
|
||||
```
|
||||
|
||||
这并不是最终确定的编译器标志,他们还可以在其他makefile 里面更新(比如`arch/` 里面的kbuild)。变量定义完之后,全部会被导出供其他makefile 使用。下面的两个变量`RCS_FIND_IGNORE` 和 `RCS_TAR_IGNORE` 包含了被版本控制系统忽略的文件:
|
||||
|
||||
```Makefile
|
||||
export RCS_FIND_IGNORE := \( -name SCCS -o -name BitKeeper -o -name .svn -o \
|
||||
-name CVS -o -name .pc -o -name .hg -o -name .git \) \
|
||||
-prune -o
|
||||
export RCS_TAR_IGNORE := --exclude SCCS --exclude BitKeeper --exclude .svn \
|
||||
--exclude CVS --exclude .pc --exclude .hg --exclude .git
|
||||
```
|
||||
|
||||
这就是全部了,我们已经完成了所有的准备工作,下一个点就是如果构建`vmlinux`.
|
||||
|
||||
直面构建内核
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
现在我们已经完成了所有的准备工作,根makefile(注:内核根目录下的makefile)的下一步工作就是和编译内核相关的了。在我们执行`make` 命令之前,我们不会在终端看到任何东西。但是现在编译的第一步开始了,这里我们需要从内核根makefile的的[598](https://github.com/torvalds/linux/blob/master/Makefile#L598) 行开始,这里可以看到目标`vmlinux`:
|
||||
|
||||
```Makefile
|
||||
all: vmlinux
|
||||
include arch/$(SRCARCH)/Makefile
|
||||
```
|
||||
|
||||
不要操心我们略过的从`export RCS_FIND_IGNORE.....` 到`all: vmlinux.....` 这一部分makefile 代码,他们只是负责根据各种配置文件生成不同目标内核的,因为之前我就说了这一部分我们只讨论构建内核的通用途径。
|
||||
|
||||
目标`all:` 是在命令行如果不指定具体目标时默认使用的目标。你可以看到这里包含了架构相关的makefile(在这里就指的是[arch/x86/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile))。从这一时刻起,我们会从这个makefile 继续进行下去。如我们所见,目标`all` 依赖于根makefile 后面声明的`vmlinux`:
|
||||
|
||||
```Makefile
|
||||
vmlinux: scripts/link-vmlinux.sh $(vmlinux-deps) FORCE
|
||||
```
|
||||
|
||||
`vmlinux` 是linux 内核的静态链接可执行文件格式。脚本[scripts/link-vmlinux.sh](https://github.com/torvalds/linux/blob/master/scripts/link-vmlinux.sh) 把不同的编译好的子模块链接到一起形成了vmlinux。第二个目标是`vmlinux-deps`,它的定义如下:
|
||||
|
||||
```Makefile
|
||||
vmlinux-deps := $(KBUILD_LDS) $(KBUILD_VMLINUX_INIT) $(KBUILD_VMLINUX_MAIN)
|
||||
```
|
||||
|
||||
它是由内核代码下的每个顶级目录的`built-in.o` 组成的。之后我们还会检查内核所有的目录,`kbuild` 会编译各个目录下所有的对应`$obj-y` 的源文件。接着调用`$(LD) -r` 把这些文件合并到一个`build-in.o` 文件里。此时我们还没有`vmloinux-deps`, 所以目标`vmlinux` 现在还不会被构建。对我而言`vmlinux-deps` 包含下面的文件
|
||||
|
||||
```
|
||||
arch/x86/kernel/vmlinux.lds arch/x86/kernel/head_64.o
|
||||
arch/x86/kernel/head64.o arch/x86/kernel/head.o
|
||||
init/built-in.o usr/built-in.o
|
||||
arch/x86/built-in.o kernel/built-in.o
|
||||
mm/built-in.o fs/built-in.o
|
||||
ipc/built-in.o security/built-in.o
|
||||
crypto/built-in.o block/built-in.o
|
||||
lib/lib.a arch/x86/lib/lib.a
|
||||
lib/built-in.o arch/x86/lib/built-in.o
|
||||
drivers/built-in.o sound/built-in.o
|
||||
firmware/built-in.o arch/x86/pci/built-in.o
|
||||
arch/x86/power/built-in.o arch/x86/video/built-in.o
|
||||
net/built-in.o
|
||||
```
|
||||
|
||||
下一个可以被执行的目标如下:
|
||||
|
||||
```Makefile
|
||||
$(sort $(vmlinux-deps)): $(vmlinux-dirs) ;
|
||||
$(vmlinux-dirs): prepare scripts
|
||||
$(Q)$(MAKE) $(build)=$@
|
||||
```
|
||||
|
||||
就像我们看到的,`vmlinux-dir` 依赖于两部分:`prepare` 和`scripts`。第一个`prepare` 定义在内核的根`makefile` ,准备工作分成三个阶段:
|
||||
|
||||
```Makefile
|
||||
prepare: prepare0
|
||||
prepare0: archprepare FORCE
|
||||
$(Q)$(MAKE) $(build)=.
|
||||
archprepare: archheaders archscripts prepare1 scripts_basic
|
||||
|
||||
prepare1: prepare2 $(version_h) include/generated/utsrelease.h \
|
||||
include/config/auto.conf
|
||||
$(cmd_crmodverdir)
|
||||
prepare2: prepare3 outputmakefile asm-generic
|
||||
```
|
||||
|
||||
第一个`prepare0` 展开到`archprepare` ,后者又展开到`archheader` 和`archscripts`,这两个变量定义在`x86_64` 相关的[Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile)。让我们看看这个文件。`x86_64` 特定的makefile从变量定义开始,这些变量都是和特定架构的配置文件 ([defconfig](https://github.com/torvalds/linux/tree/master/arch/x86/configs),等等)有关联。变量定义之后,这个makefile 定义了编译[16-bit](https://en.wikipedia.org/wiki/Real_mode)代码的编译选项,根据变量`BITS` 的值,如果是`32`, 汇编代码、链接器、以及其它很多东西(全部的定义都可以在[arch/x86/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile)找到)对应的参数就是`i386`,而`64`就对应的是`x86_84`。生成的系统调用列表(syscall table)的makefile 里第一个目标就是`archheaders` :
|
||||
|
||||
```Makefile
|
||||
archheaders:
|
||||
$(Q)$(MAKE) $(build)=arch/x86/entry/syscalls all
|
||||
```
|
||||
|
||||
这个makefile 里第二个目标就是`archscripts`:
|
||||
|
||||
```Makefile
|
||||
archscripts: scripts_basic
|
||||
$(Q)$(MAKE) $(build)=arch/x86/tools relocs
|
||||
```
|
||||
|
||||
我们可以看到`archscripts` 是依赖于根[Makefile](https://github.com/torvalds/linux/blob/master/Makefile)里的`scripts_basic` 。首先我们可以看出`scripts_basic` 是按照[scripts/basic](https://github.com/torvalds/linux/blob/master/scripts/basic/Makefile) 的mekefile 执行make 的:
|
||||
|
||||
```Maklefile
|
||||
scripts_basic:
|
||||
$(Q)$(MAKE) $(build)=scripts/basic
|
||||
```
|
||||
|
||||
`scripts/basic/Makefile`包含了编译两个主机程序`fixdep` 和`bin2` 的目标:
|
||||
|
||||
```Makefile
|
||||
hostprogs-y := fixdep
|
||||
hostprogs-$(CONFIG_BUILD_BIN2C) += bin2c
|
||||
always := $(hostprogs-y)
|
||||
|
||||
$(addprefix $(obj)/,$(filter-out fixdep,$(always))): $(obj)/fixdep
|
||||
```
|
||||
|
||||
第一个工具是`fixdep`:用来优化[gcc](https://gcc.gnu.org/) 生成的依赖列表,然后在重新编译源文件的时候告诉make。第二个工具是`bin2c`,他依赖于内核配置选项`CONFIG_BUILD_BIN2C`,并且它是一个用来将标准输入接口(注:即stdin)收到的二进制流通过标准输出接口(即:stdout)转换成C 头文件的非常小的C 程序。你可以注意到这里有些奇怪的标志,如`hostprogs-y`等。这些标志使用在所有的`kbuild` 文件,更多的信息你可以从[documentation](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/makefiles.txt) 获得。在我们的用例`hostprogs-y` 中,他告诉`kbuild` 这里有个名为`fixed` 的程序,这个程序会通过和`Makefile` 相同目录的`fixdep.c` 编译而来。执行make 之后,终端的第一个输出就是`kbuild` 的结果:
|
||||
|
||||
```
|
||||
$ make
|
||||
HOSTCC scripts/basic/fixdep
|
||||
```
|
||||
|
||||
当目标`script_basic` 被执行,目标`archscripts` 就会make [arch/x86/tools](https://github.com/torvalds/linux/blob/master/arch/x86/tools/Makefile) 下的makefile 和目标`relocs`:
|
||||
|
||||
```Makefile
|
||||
$(Q)$(MAKE) $(build)=arch/x86/tools relocs
|
||||
```
|
||||
|
||||
代码`relocs_32.c` 和`relocs_64.c` 包含了[重定位](https://en.wikipedia.org/wiki/Relocation_%28computing%29) 的信息,将会被编译,者可以在`make` 的输出中看到:
|
||||
|
||||
```Makefile
|
||||
HOSTCC arch/x86/tools/relocs_32.o
|
||||
HOSTCC arch/x86/tools/relocs_64.o
|
||||
HOSTCC arch/x86/tools/relocs_common.o
|
||||
HOSTLD arch/x86/tools/relocs
|
||||
```
|
||||
|
||||
在编译完`relocs.c` 之后会检查`version.h`:
|
||||
|
||||
```Makefile
|
||||
$(version_h): $(srctree)/Makefile FORCE
|
||||
$(call filechk,version.h)
|
||||
$(Q)rm -f $(old_version_h)
|
||||
```
|
||||
|
||||
我们可以在输出看到它:
|
||||
|
||||
```
|
||||
CHK include/config/kernel.release
|
||||
```
|
||||
|
||||
以及在内核根Makefiel 使用`arch/x86/include/generated/asm`的目标`asm-generic` 来构建`generic` 汇编头文件。在目标`asm-generic` 之后,`archprepare` 就会被完成,所以目标`prepare0` 会接着被执行,如我上面所写:
|
||||
|
||||
```Makefile
|
||||
prepare0: archprepare FORCE
|
||||
$(Q)$(MAKE) $(build)=.
|
||||
```
|
||||
|
||||
注意`build`,它是定义在文件[scripts/Kbuild.include](https://github.com/torvalds/linux/blob/master/scripts/Kbuild.include),内容是这样的:
|
||||
|
||||
```Makefile
|
||||
build := -f $(srctree)/scripts/Makefile.build obj
|
||||
```
|
||||
|
||||
或者在我们的例子中,他就是当前源码目录路径——`.`:
|
||||
```Makefile
|
||||
$(Q)$(MAKE) -f $(srctree)/scripts/Makefile.build obj=.
|
||||
```
|
||||
|
||||
参数`obj` 会告诉脚本[scripts/Makefile.build](https://github.com/torvalds/linux/blob/master/scripts/Makefile.build) 那些目录包含`kbuild` 文件,脚本以此来寻找各个`kbuild` 文件:
|
||||
|
||||
```Makefile
|
||||
include $(kbuild-file)
|
||||
```
|
||||
|
||||
然后根据这个构建目标。我们这里`.` 包含了[Kbuild](https://github.com/torvalds/linux/blob/master/Kbuild),就用这个文件来生成`kernel/bounds.s` 和`arch/x86/kernel/asm-offsets.s`。这样目标`prepare` 就完成了它的工作。`vmlinux-dirs` 也依赖于第二个目标——`scripts` ,`scripts`会编译接下来的几个程序:`filealias`,`mk_elfconfig`,`modpost`等等。`scripts/host-programs` 编译完之后,我们的目标`vmlinux-dirs` 就可以开始编译了。第一步,我们先来理解一下`vmlinux-dirs` 都包含了那些东西。在我们的例子中它包含了接下来要使用的内核目录的路径:
|
||||
|
||||
```
|
||||
init usr arch/x86 kernel mm fs ipc security crypto block
|
||||
drivers sound firmware arch/x86/pci arch/x86/power
|
||||
arch/x86/video net lib arch/x86/lib
|
||||
```
|
||||
|
||||
我们可以在内核的根[Makefile](https://github.com/torvalds/linux/blob/master/Makefile) 里找到`vmlinux-dirs` 的定义:
|
||||
|
||||
```Makefile
|
||||
vmlinux-dirs := $(patsubst %/,%,$(filter %/, $(init-y) $(init-m) \
|
||||
$(core-y) $(core-m) $(drivers-y) $(drivers-m) \
|
||||
$(net-y) $(net-m) $(libs-y) $(libs-m)))
|
||||
|
||||
init-y := init/
|
||||
drivers-y := drivers/ sound/ firmware/
|
||||
net-y := net/
|
||||
libs-y := lib/
|
||||
...
|
||||
...
|
||||
...
|
||||
```
|
||||
|
||||
这里我们借助函数`patsubst` 和`filter`去掉了每个目录路径里的符号`/`,并且把结果放到`vmlinux-dirs` 里。所以我们就有了`vmlinux-dirs` 里的目录的列表,以及下面的代码:
|
||||
|
||||
```Makefile
|
||||
$(vmlinux-dirs): prepare scripts
|
||||
$(Q)$(MAKE) $(build)=$@
|
||||
```
|
||||
|
||||
符号`$@` 在这里代表了`vmlinux-dirs`,这就表明程序会递归遍历从`vmlinux-dirs` 以及它内部的全部目录(依赖于配置),并且在对应的目录下执行`make` 命令。我们可以在输出看到结果:
|
||||
|
||||
```
|
||||
CC init/main.o
|
||||
CHK include/generated/compile.h
|
||||
CC init/version.o
|
||||
CC init/do_mounts.o
|
||||
...
|
||||
CC arch/x86/crypto/glue_helper.o
|
||||
AS arch/x86/crypto/aes-x86_64-asm_64.o
|
||||
CC arch/x86/crypto/aes_glue.o
|
||||
...
|
||||
AS arch/x86/entry/entry_64.o
|
||||
AS arch/x86/entry/thunk_64.o
|
||||
CC arch/x86/entry/syscall_64.o
|
||||
```
|
||||
|
||||
每个目录下的源代码将会被编译并且链接到`built-io.o` 里:
|
||||
|
||||
```
|
||||
$ find . -name built-in.o
|
||||
./arch/x86/crypto/built-in.o
|
||||
./arch/x86/crypto/sha-mb/built-in.o
|
||||
./arch/x86/net/built-in.o
|
||||
./init/built-in.o
|
||||
./usr/built-in.o
|
||||
...
|
||||
...
|
||||
```
|
||||
|
||||
好了,所有的`built-in.o` 都构建完了,现在我们回到目标`vmlinux` 上。你应该还记得,目标`vmlinux` 是在内核的根makefile 里。在链接`vmlinux` 之前,系统会构建[samples](https://github.com/torvalds/linux/tree/master/samples), [Documentation](https://github.com/torvalds/linux/tree/master/Documentation)等等,但是如上文所述,我不会在本文描述这些。
|
||||
|
||||
```Makefile
|
||||
vmlinux: scripts/link-vmlinux.sh $(vmlinux-deps) FORCE
|
||||
...
|
||||
...
|
||||
+$(call if_changed,link-vmlinux)
|
||||
```
|
||||
|
||||
你可以看到,`vmlinux` 的调用脚本[scripts/link-vmlinux.sh](https://github.com/torvalds/linux/blob/master/scripts/link-vmlinux.sh) 的主要目的是把所有的`built-in.o` 链接成一个静态可执行文件、生成[System.map](https://en.wikipedia.org/wiki/System.map)。 最后我们来看看下面的输出:
|
||||
|
||||
```
|
||||
LINK vmlinux
|
||||
LD vmlinux.o
|
||||
MODPOST vmlinux.o
|
||||
GEN .version
|
||||
CHK include/generated/compile.h
|
||||
UPD include/generated/compile.h
|
||||
CC init/version.o
|
||||
LD init/built-in.o
|
||||
KSYM .tmp_kallsyms1.o
|
||||
KSYM .tmp_kallsyms2.o
|
||||
LD vmlinux
|
||||
SORTEX vmlinux
|
||||
SYSMAP System.map
|
||||
```
|
||||
|
||||
以及内核源码树根目录下的`vmlinux` 和`System.map`
|
||||
|
||||
```
|
||||
$ ls vmlinux System.map
|
||||
System.map vmlinux
|
||||
```
|
||||
|
||||
这就是全部了,`vmlinux` 构建好了,下一步就是创建[bzImage](https://en.wikipedia.org/wiki/Vmlinux#bzImage).
|
||||
|
||||
制作bzImage
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
`bzImage` 就是压缩了的linux 内核镜像。我们可以在构建了`vmlinux` 之后通过执行`make bzImage` 获得`bzImage`。同时我们可以仅仅执行`make` 而不带任何参数也可以生成`bzImage` ,因为它是在[arch/x86/kernel/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile) 里预定义的、默认生成的镜像:
|
||||
|
||||
```Makefile
|
||||
all: bzImage
|
||||
```
|
||||
|
||||
让我们看看这个目标,他能帮助我们理解这个镜像是怎么构建的。我已经说过了`bzImage` 师被定义在[arch/x86/kernel/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/Makefile),定义如下:
|
||||
|
||||
```Makefile
|
||||
bzImage: vmlinux
|
||||
$(Q)$(MAKE) $(build)=$(boot) $(KBUILD_IMAGE)
|
||||
$(Q)mkdir -p $(objtree)/arch/$(UTS_MACHINE)/boot
|
||||
$(Q)ln -fsn ../../x86/boot/bzImage $(objtree)/arch/$(UTS_MACHINE)/boot/$@
|
||||
```
|
||||
|
||||
在这里我们可以看到第一次为boot 目录执行`make`,在我们的例子里是这样的:
|
||||
|
||||
```Makefile
|
||||
boot := arch/x86/boot
|
||||
```
|
||||
|
||||
现在的主要目标是编译目录`arch/x86/boot` 和`arch/x86/boot/compressed` 的代码,构建`setup.bin` 和`vmlinux.bin`,然后用这两个文件生成`bzImage`。第一个目标是定义在[arch/x86/boot/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/boot/Makefile) 的`$(obj)/setup.elf`:
|
||||
|
||||
```Makefile
|
||||
$(obj)/setup.elf: $(src)/setup.ld $(SETUP_OBJS) FORCE
|
||||
$(call if_changed,ld)
|
||||
```
|
||||
|
||||
我们已经在目录`arch/x86/boot`有了链接脚本`setup.ld`,并且将变量`SETUP_OBJS` 扩展到`boot` 目录下的全部源代码。我们可以看看第一个输出:
|
||||
|
||||
```Makefile
|
||||
AS arch/x86/boot/bioscall.o
|
||||
CC arch/x86/boot/cmdline.o
|
||||
AS arch/x86/boot/copy.o
|
||||
HOSTCC arch/x86/boot/mkcpustr
|
||||
CPUSTR arch/x86/boot/cpustr.h
|
||||
CC arch/x86/boot/cpu.o
|
||||
CC arch/x86/boot/cpuflags.o
|
||||
CC arch/x86/boot/cpucheck.o
|
||||
CC arch/x86/boot/early_serial_console.o
|
||||
CC arch/x86/boot/edd.o
|
||||
```
|
||||
|
||||
下一个源码文件是[arch/x86/boot/header.S](https://github.com/torvalds/linux/blob/master/arch/x86/boot/header.S),但是我们不能现在就编译它,因为这个目标依赖于下面两个头文件:
|
||||
|
||||
```Makefile
|
||||
$(obj)/header.o: $(obj)/voffset.h $(obj)/zoffset.h
|
||||
```
|
||||
|
||||
第一个头文件`voffset.h` 是使用`sed` 脚本生成的,包含用`nm` 工具从`vmlinux` 获取的两个地址:
|
||||
|
||||
```C
|
||||
#define VO__end 0xffffffff82ab0000
|
||||
#define VO__text 0xffffffff81000000
|
||||
```
|
||||
|
||||
这两个地址是内核的起始和结束地址。第二个头文件`zoffset.h` 在[arch/x86/boot/compressed/Makefile](https://github.com/torvalds/linux/blob/master/arch/x86/boot/compressed/Makefile) 可以看出是依赖于目标`vmlinux`的:
|
||||
|
||||
```Makefile
|
||||
$(obj)/zoffset.h: $(obj)/compressed/vmlinux FORCE
|
||||
$(call if_changed,zoffset)
|
||||
```
|
||||
|
||||
目标`$(obj)/compressed/vmlinux` 依赖于变量`vmlinux-objs-y` —— 说明需要编译目录[arch/x86/boot/compressed](https://github.com/torvalds/linux/tree/master/arch/x86/boot/compressed) 下的源代码,然后生成`vmlinux.bin`, `vmlinux.bin.bz2`, 和编译工具 - `mkpiggy`。我们可以在下面的输出看出来:
|
||||
|
||||
```Makefile
|
||||
LDS arch/x86/boot/compressed/vmlinux.lds
|
||||
AS arch/x86/boot/compressed/head_64.o
|
||||
CC arch/x86/boot/compressed/misc.o
|
||||
CC arch/x86/boot/compressed/string.o
|
||||
CC arch/x86/boot/compressed/cmdline.o
|
||||
OBJCOPY arch/x86/boot/compressed/vmlinux.bin
|
||||
BZIP2 arch/x86/boot/compressed/vmlinux.bin.bz2
|
||||
HOSTCC arch/x86/boot/compressed/mkpiggy
|
||||
```
|
||||
|
||||
`vmlinux.bin` 是去掉了调试信息和注释的`vmlinux` 二进制文件,加上了占用了`u32` (注:即4-Byte)的长度信息的`vmlinux.bin.all` 压缩后就是`vmlinux.bin.bz2`。其中`vmlinux.bin.all` 包含了`vmlinux.bin` 和`vmlinux.relocs`(注:vmlinux 的重定位信息),其中`vmlinux.relocs` 是`vmlinux` 经过程序`relocs` 处理之后的`vmlinux` 镜像(见上文所述)。我们现在已经获取到了这些文件,汇编文件`piggy.S` 将会被`mkpiggy` 生成、然后编译:
|
||||
|
||||
```Makefile
|
||||
MKPIGGY arch/x86/boot/compressed/piggy.S
|
||||
AS arch/x86/boot/compressed/piggy.o
|
||||
```
|
||||
|
||||
这个汇编文件会包含经过计算得来的、压缩内核的偏移信息。处理完这个汇编文件,我们就可以看到`zoffset` 生成了:
|
||||
|
||||
```Makefile
|
||||
ZOFFSET arch/x86/boot/zoffset.h
|
||||
```
|
||||
|
||||
现在`zoffset.h` 和`voffset.h` 已经生成了,[arch/x86/boot](https://github.com/torvalds/linux/tree/master/arch/x86/boot/) 里的源文件可以继续编译:
|
||||
|
||||
```Makefile
|
||||
AS arch/x86/boot/header.o
|
||||
CC arch/x86/boot/main.o
|
||||
CC arch/x86/boot/mca.o
|
||||
CC arch/x86/boot/memory.o
|
||||
CC arch/x86/boot/pm.o
|
||||
AS arch/x86/boot/pmjump.o
|
||||
CC arch/x86/boot/printf.o
|
||||
CC arch/x86/boot/regs.o
|
||||
CC arch/x86/boot/string.o
|
||||
CC arch/x86/boot/tty.o
|
||||
CC arch/x86/boot/video.o
|
||||
CC arch/x86/boot/video-mode.o
|
||||
CC arch/x86/boot/video-vga.o
|
||||
CC arch/x86/boot/video-vesa.o
|
||||
CC arch/x86/boot/video-bios.o
|
||||
```
|
||||
|
||||
所有的源代码会被编译,他们最终会被链接到`setup.elf` :
|
||||
|
||||
```Makefile
|
||||
LD arch/x86/boot/setup.elf
|
||||
```
|
||||
|
||||
|
||||
或者:
|
||||
|
||||
```
|
||||
ld -m elf_x86_64 -T arch/x86/boot/setup.ld arch/x86/boot/a20.o arch/x86/boot/bioscall.o arch/x86/boot/cmdline.o arch/x86/boot/copy.o arch/x86/boot/cpu.o arch/x86/boot/cpuflags.o arch/x86/boot/cpucheck.o arch/x86/boot/early_serial_console.o arch/x86/boot/edd.o arch/x86/boot/header.o arch/x86/boot/main.o arch/x86/boot/mca.o arch/x86/boot/memory.o arch/x86/boot/pm.o arch/x86/boot/pmjump.o arch/x86/boot/printf.o arch/x86/boot/regs.o arch/x86/boot/string.o arch/x86/boot/tty.o arch/x86/boot/video.o arch/x86/boot/video-mode.o arch/x86/boot/version.o arch/x86/boot/video-vga.o arch/x86/boot/video-vesa.o arch/x86/boot/video-bios.o -o arch/x86/boot/setup.elf
|
||||
```
|
||||
|
||||
最后两件事是创建包含目录`arch/x86/boot/*` 下的编译过的代码的`setup.bin`:
|
||||
|
||||
```
|
||||
objcopy -O binary arch/x86/boot/setup.elf arch/x86/boot/setup.bin
|
||||
```
|
||||
|
||||
以及从`vmlinux` 生成`vmlinux.bin` :
|
||||
|
||||
```
|
||||
objcopy -O binary -R .note -R .comment -S arch/x86/boot/compressed/vmlinux arch/x86/boot/vmlinux.bin
|
||||
```
|
||||
|
||||
最后,我们编译主机程序[arch/x86/boot/tools/build.c](https://github.com/torvalds/linux/blob/master/arch/x86/boot/tools/build.c),它将会用来把`setup.bin` 和`vmlinux.bin` 打包成`bzImage`:
|
||||
|
||||
```
|
||||
arch/x86/boot/tools/build arch/x86/boot/setup.bin arch/x86/boot/vmlinux.bin arch/x86/boot/zoffset.h arch/x86/boot/bzImage
|
||||
```
|
||||
|
||||
实际上`bzImage` 就是把`setup.bin` 和`vmlinux.bin` 连接到一起。最终我们会看到输出结果,就和那些用源码编译过内核的同行的结果一样:
|
||||
|
||||
```
|
||||
Setup is 16268 bytes (padded to 16384 bytes).
|
||||
System is 4704 kB
|
||||
CRC 94a88f9a
|
||||
Kernel: arch/x86/boot/bzImage is ready (#5)
|
||||
```
|
||||
|
||||
|
||||
全部结束。
|
||||
|
||||
结论
|
||||
================================================================================
|
||||
|
||||
这就是本文的最后一节。本文我们了解了编译内核的全部步骤:从执行`make` 命令开始,到最后生成`bzImage`。我知道,linux 内核的makefiles 和构建linux 的过程第一眼看起来可能比较迷惑,但是这并不是很难。希望本文可以帮助你理解构建linux 内核的整个流程。
|
||||
|
||||
|
||||
链接
|
||||
================================================================================
|
||||
|
||||
* [GNU make util](https://en.wikipedia.org/wiki/Make_%28software%29)
|
||||
* [Linux kernel top Makefile](https://github.com/torvalds/linux/blob/master/Makefile)
|
||||
* [cross-compilation](https://en.wikipedia.org/wiki/Cross_compiler)
|
||||
* [Ctags](https://en.wikipedia.org/wiki/Ctags)
|
||||
* [sparse](https://en.wikipedia.org/wiki/Sparse)
|
||||
* [bzImage](https://en.wikipedia.org/wiki/Vmlinux#bzImage)
|
||||
* [uname](https://en.wikipedia.org/wiki/Uname)
|
||||
* [shell](https://en.wikipedia.org/wiki/Shell_%28computing%29)
|
||||
* [Kbuild](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/kbuild.txt)
|
||||
* [binutils](http://www.gnu.org/software/binutils/)
|
||||
* [gcc](https://gcc.gnu.org/)
|
||||
* [Documentation](https://github.com/torvalds/linux/blob/master/Documentation/kbuild/makefiles.txt)
|
||||
* [System.map](https://en.wikipedia.org/wiki/System.map)
|
||||
* [Relocation](https://en.wikipedia.org/wiki/Relocation_%28computing%29)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/0xAX/linux-insides/blob/master/Misc/how_kernel_compiled.md
|
||||
|
||||
译者:[译者ID](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,74 +0,0 @@
|
||||
如何在 Ubuntu 15.04 下创建连接至 Android/iOS 的 AP
|
||||
================================================================================
|
||||
我成功地在 Ubuntu 15.04 下用 Gnome Network Manager 创建了一个无线AP热点. 接下来我要分享一下我的步骤. 请注意: 你必须要有一个可以用来创建AP热点的无线网卡. 如果你不知道如何找到连上了的设备的话, 在终端(Terminal)里输入`iw list`.
|
||||
|
||||
如果你没有安装`iw`的话, 在Ubuntu下你可以使用`udo apt-get install iw`进行安装.
|
||||
|
||||
在你键入`iw list`之后, 寻找可用的借口, 你应该会看到类似下列的条目:
|
||||
|
||||
Supported interface modes:
|
||||
|
||||
* IBSS
|
||||
* managed
|
||||
* AP
|
||||
* AP/VLAN
|
||||
* monitor
|
||||
* mesh point
|
||||
|
||||
让我们一步步看
|
||||
|
||||
1. 断开WIFI连接. 使用有线网络接入你的笔记本.
|
||||
1. 在顶栏面板里点击网络的图标 -> Edit Connections(编辑连接) -> 在弹出窗口里点击Add(新增)按钮.
|
||||
1. 在下拉菜单内选择Wi-Fi.
|
||||
1. 接下来,
|
||||
|
||||
a. 输入一个链接名 比如: Hotspot
|
||||
|
||||
b. 输入一个 SSID 比如: Hotspot
|
||||
|
||||
c. 选择模式(mode): Infrastructure
|
||||
|
||||
d. 设备 MAC 地址: 在下拉菜单里选择你的无线设备
|
||||
|
||||

|
||||
|
||||
1. 进入Wi-Fi安全选项卡, 选择 WPA & WPA2 Personal 并且输入密码.
|
||||
1. 进入IPv4设置选项卡, 在Method(方法)下拉菜单里, 选择Shared to other computers(共享至其他电脑).
|
||||
|
||||

|
||||
|
||||
1. 进入IPv6选项卡, 在Method(方法)里设置为忽略ignore (只有在你不使用IPv6的情况下这么做)
|
||||
1. 点击 Save(保存) 按钮以保存配置.
|
||||
1. 从 menu/dash 里打开Terminal.
|
||||
1. 修改你刚刚使用 network settings 创建的连接.
|
||||
|
||||
使用 VIM 编辑器:
|
||||
|
||||
sudo vim /etc/NetworkManager/system-connections/Hotspot
|
||||
|
||||
使用Gedit 编辑器:
|
||||
|
||||
gksu gedit /etc/NetworkManager/system-connections/Hotspot
|
||||
|
||||
把名字 Hotspot 用你在第4步里起的连接名替换掉.
|
||||
|
||||

|
||||
|
||||
1. 把 `mode=infrastructure` 改成 `mode=ap` 并且保存文件
|
||||
1. 一旦你保存了这个文件, 你应该能在 Wifi 菜单里看到你刚刚建立的AP了. (如果没有的话请再顶栏里 关闭/打开 Wifi 选项一次)
|
||||
|
||||

|
||||
|
||||
1. 你现在可以把你的设备连上Wifi了. 已经过 Android 5.0的小米4测试.(下载了1GB的文件以测试速度与稳定性)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxveda.com/2015/08/23/how-to-create-an-ap-in-ubuntu-15-04-to-connect-to-androidiphone/
|
||||
|
||||
作者:[Sayantan Das][a]
|
||||
译者:[jerryling315](https://github.com/jerryling315)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxveda.com/author/sayantan_das/
|
||||
@ -0,0 +1,105 @@
|
||||
如何在linux中搭建FTP服务
|
||||
=====================================================================
|
||||

|
||||
|
||||
在本教程中,我将会解释如何搭建你自己的FTP服务。但是,首先我们应该来的学习一下FTP是什么。
|
||||
|
||||
###FTP是什么?###
|
||||
|
||||
[FTP][1] 是文件传输协议(File Transfer Protocol)的缩写。顾名思义,FTP是用于计算机之间通过网络进行文件传输。你可以通过FTP在计算机账户间进行文件传输,也可以在账户和桌面计算机之间传输文件,或者访问在线软件文档。但是,需要注意的是多数的FTP站点的使用率非常高,并且在连接前需要进行多次尝试。
|
||||
|
||||
FTP地址和HTTP地址(即网页地址)非常相似,只是FTP地址使用ftp://前缀而不是http://
|
||||
|
||||
###FTP服务器是什么?###
|
||||
|
||||
通常,拥有FTP地址的计算机是专用于接收FTP连接请求的。一台专用于接收FTP连接请求的计算机即为FTP服务器或者FTP站点。
|
||||
|
||||
现在,我们来开始一个特别的冒险,我们将会搭建一个FTP服务用于和家人、朋友进行文件共享。在本教程,我们将以[vsftpd][2]作为ftp服务。
|
||||
|
||||
VSFTPD是一个自称为最安全的FTP服务端软件。事实上VSFTPD的前两个字母表示“非常安全的(very secure)”。该软件的构建绕开了FTP协议的漏洞。
|
||||
|
||||
尽管如此,你应该知道还有更安全的方法进行文件管理和传输,如:SFTP(使用[OpenSSH][3])。FTP协议对于共享非敏感数据是非常有用和可靠的。
|
||||
|
||||
####在rpm distributions中安装VSFTPD:####
|
||||
|
||||
你可以使用如下命令在命令行界面中快捷的安装VSFTPD:
|
||||
|
||||
dnf -y install vsftpd
|
||||
|
||||
####在deb distributions中安装VSFTPD:####
|
||||
|
||||
你可以使用如下命令在命令行界面中快捷的安装VSFTPD:
|
||||
|
||||
sudo apt-get install vsftpd
|
||||
|
||||
####在Arch distribution中安装VSFTPD:####
|
||||
|
||||
你可以使用如下命令在命令行界面中快捷的安装VSFTPD:
|
||||
|
||||
sudo apt-get install vsftpd
|
||||
|
||||
####配置FTP服务####
|
||||
|
||||
多数的VSFTPD配置项都在/etc/vsftpd.conf配置文件中。这个文件本身已经有非常良好的文档说明了,因此,在本节中,我只强调一些你可能进行修改的重要选项。使用man页面查看所有可用的选项和基本的 文档说明:
|
||||
|
||||
man vsftpd.conf
|
||||
|
||||
根据文件系统层级标准,FTP共享文件默认位于/srv/ftp目录中。
|
||||
|
||||
**允许上传:**
|
||||
|
||||
为了允许ftp用户可以修改文件系统的内容,如上传文件等,“write_enable”标志必须设置为 YES。
|
||||
|
||||
write_enable=YES
|
||||
|
||||
**允许本地用户登陆:**
|
||||
|
||||
为了允许文件/etc/passwd中记录的用户可以登陆ftp服务,“local_enable”标记必须设置为YES。
|
||||
|
||||
local_enable=YES
|
||||
|
||||
**匿名用户登陆**
|
||||
|
||||
下面配置内容控制匿名用户是否允许登陆:
|
||||
|
||||
# Allow anonymous login
|
||||
anonymous_enable=YES
|
||||
# No password is required for an anonymous login (Optional)
|
||||
no_anon_password=YES
|
||||
# Maximum transfer rate for an anonymous client in Bytes/second (Optional)
|
||||
anon_max_rate=30000
|
||||
# Directory to be used for an anonymous login (Optional)
|
||||
anon_root=/example/directory/
|
||||
|
||||
**根目录限制(Chroot Jail)**
|
||||
|
||||
(译者注:chroot jail是类unix系统中的一种安全机制,用于修改进程运行的根目录环境,限制该线程不能感知到其根目录树以外的其他目录结构和文件的存在。详情参看[chroot jail][4])
|
||||
|
||||
有时我们需要设置根目录(chroot)环境来禁止用户离开他们的家(home)目录。在配置文件中增加/修改下面配置开启根目录限制(Chroot Jail):
|
||||
|
||||
chroot_list_enable=YES
|
||||
chroot_list_file=/etc/vsftpd.chroot_list
|
||||
|
||||
“chroot_list_file”变量指定根目录监狱所包含的文件/目录(译者注:即用户只能访问这些文件/目录)
|
||||
|
||||
最后你必须重启ftp服务,在命令行中输入以下命令:
|
||||
|
||||
sudo systemctl restart vsftpd
|
||||
|
||||
到此为止,你的ftp服务已经搭建完成并且启动了
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/set-ftp-server-linux/
|
||||
|
||||
作者:[alimiracle][a]
|
||||
译者:[cvsher](https://github.com/cvsher)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/ali/
|
||||
[1]:https://en.wikipedia.org/wiki/File_Transfer_Protocol
|
||||
[2]:https://security.appspot.com/vsftpd.html
|
||||
[3]:http://www.openssh.com/
|
||||
[4]:https://zh.wikipedia.org/wiki/Chroot
|
||||
@ -0,0 +1,113 @@
|
||||
如何在Ubuntu中安装QGit浏览器
|
||||
================================================================================
|
||||
QGit是一款Marco Costalba用Qt和C++写的开源GUI Git浏览器。它是一款在GUI环境下更好地提供浏览历史记录、提交记录和文件补丁的浏览器。它利用git命令行来执行并显示输出。它有一些常规的功能像浏览历史、比较、文件历史、文件标注、档案树。我们可以格式化并用选中的提交应用补丁,在两个实例之间拖拽并提交等等。它允许我们创建自定义的按钮来用它内置的生成器来执行特定的命令。
|
||||
|
||||
这里有简单的几步在Ubuntu 14.04 LTS "Trusty"中编译并安装QGit浏览器。
|
||||
|
||||
### 1. 安装 QT4 库 ###
|
||||
|
||||
首先在ubuntu中运行QGit需要先安装QT4库。由于apt是ubuntu默认的包管理器,同时qt4也在官方的仓库中,因此我们直接用下面的apt-get命令来安装qt4。
|
||||
|
||||
$ sudo apt-get install qt4-default
|
||||
|
||||
### 2. 下载QGit压缩包 ###
|
||||
|
||||
安装完Qt4之后,我们要安装git,这样我们才能在QGit中克隆git仓库。运行下面的apt-get命令。
|
||||
|
||||
$ sudo apt-get install git
|
||||
|
||||
现在,我们要使用下面的git命令来克隆仓库。
|
||||
|
||||
$ git clone git://repo.or.cz/qgit4/redivivus.git
|
||||
|
||||
Cloning into 'redivivus'...
|
||||
remote: Counting objects: 7128, done.
|
||||
remote: Compressing objects: 100% (2671/2671), done.
|
||||
remote: Total 7128 (delta 5464), reused 5711 (delta 4438)
|
||||
Receiving objects: 100% (7128/7128), 2.39 MiB | 470.00 KiB/s, done.
|
||||
Resolving deltas: 100% (5464/5464), done.
|
||||
Checking connectivity... done.
|
||||
|
||||
### 3. 编译 QGit ###
|
||||
|
||||
克隆之后,我们现在进入redivivus的目录,并创建我们编译需要的makefile文件。因此,要进入目录,我们要运行下面的命令。
|
||||
|
||||
$ cd redivivus
|
||||
|
||||
接下来,我们运行下面的命令从qmake项目也就是qgit.pro来生成新的Makefile。
|
||||
|
||||
$ qmake qgit.pro
|
||||
|
||||
生成Makefile之后,我们现在终于要编译qgit的源代码并得到二进制的输出。首先我们要安装make和g++包用于编译,因为这是一个用C++写的程序。
|
||||
|
||||
$ sudo apt-get install make g++
|
||||
|
||||
现在,我们要用make命令来编译代码了
|
||||
|
||||
$ make
|
||||
|
||||
### 4. 安装 QGit ###
|
||||
|
||||
成功编译QGit的源码之后,我们就要在Ubuntu 14.04中安装它了,这样就可以在系统中执行它。因此我们将运行下面的命令、
|
||||
|
||||
$ sudo make install
|
||||
|
||||
cd src/ && make -f Makefile install
|
||||
make[1]: Entering directory `/home/arun/redivivus/src'
|
||||
make -f Makefile.Release install
|
||||
make[2]: Entering directory `/home/arun/redivivus/src'
|
||||
install -m 755 -p "../bin/qgit" "/usr/lib/x86_64-linux-gnu/qt4/bin/qgit"
|
||||
strip "/usr/lib/x86_64-linux-gnu/qt4/bin/qgit"
|
||||
make[2]: Leaving directory `/home/arun/redivivus/src'
|
||||
make[1]: Leaving directory `/home/arun/redivivus/src'
|
||||
|
||||
接下来,我们需要从bin目录下复制qgit的二进制文件到/usr/bin/,这样我们就可以全局运行它了。
|
||||
|
||||
$ sudo cp bin/qgit /usr/bin/
|
||||
|
||||
### 5. 创建桌面文件 ###
|
||||
|
||||
既然我们已经在ubuntu中成功安装了qgit,我们来创建一个桌面文件,这样QGit就可以在我们桌面环境中的菜单或者启动器中找到了。要做到这点,我们要在/usr/share/applications/创建一个新文件叫qgit.desktop。
|
||||
|
||||
$ sudo nano /usr/share/applications/qgit.desktop
|
||||
|
||||
接下来复制下面的行到文件中。
|
||||
|
||||
[Desktop Entry]
|
||||
Name=qgit
|
||||
GenericName=git GUI viewer
|
||||
Exec=qgit
|
||||
Icon=qgit
|
||||
Type=Application
|
||||
Comment=git GUI viewer
|
||||
Terminal=false
|
||||
MimeType=inode/directory;
|
||||
Categories=Qt;Development;RevisionControl;
|
||||
|
||||
完成之后,保存并退出。
|
||||
|
||||
### 6. 运行 QGit 浏览器 ###
|
||||
|
||||
QGit安装完成之后,我们现在就可以从任何启动器或者程序菜单中启动它了。要在终端下面运行QGit,我们可以像下面那样。
|
||||
|
||||
$ qgit
|
||||
|
||||
这会打开基于Qt4框架GUI模式的QGit。
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
QGit是一个很棒的基于QT的git浏览器。它可以在Linux、MAC OSX和 Microsoft Windows所有这三个平台中运行。它帮助我们很容易地浏览历史、版本、分支等等git仓库提供的信息。它减少了使用命令行的方式去执行诸如浏览版本、历史、比较功能的需求,并用图形化的方式来简化了这些任务。最新的qgit版本也在默认仓库中,你可以使用 **apt-get install qgit** 命令来安装。因此。qgit用它简单的GUI使得我们的工作更加简单和快速。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/install-qgit-viewer-ubuntu-14-04/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
@ -0,0 +1,452 @@
|
||||
translation by strugglingyouth
|
||||
nstalling NGINX and NGINX Plus With Ansible
|
||||
================================================================================
|
||||
在生产环境中,我会更喜欢做与自动化相关的所有事情。如果计算机能完成你的任务,何必需要你亲自动手呢?但是,在不断变化并存在多种技术的环境中,创建和实施自动化是一项艰巨的任务。这就是为什么我喜欢[Ansible][1]。Ansible是免费的,开源的,对于 IT 配置管理,部署和业务流程,使用起来非常方便。
|
||||
|
||||
|
||||
我最喜欢 Ansible 的一个特点是,它是完全无客户端。要管理一个系统,通过 SSH 建立连接,也使用了[Paramiko][2](一个 Python 库)或本地的 [OpenSSH][3]。Ansible 另一个吸引人的地方是它有许多可扩展的模块。这些模块可被系统管理员用于执行一些的相同任务。特别是,它们使用 Ansible 这个强有力的工具可以安装和配置任何程序在多个服务器上,环境或操作系统,只需要一个控制节点。
|
||||
|
||||
在本教程中,我将带你使用 Ansible 完成安装和部署开源[NGINX][4] 和 [NGINX Plus][5],我们的商业产品。我将在 [CentOS][6] 服务器上演示,但我也写了一个详细的教程关于在 Ubuntu 服务器上部署[在 Ubuntu 上创建一个 Ansible Playbook 来安装 NGINX 和 NGINX Plus][7] 。
|
||||
|
||||
在本教程中我将使用 Ansible 1.9.2 版本的,并在 CentOS 7.1 服务器上部署运行。
|
||||
|
||||
$ ansible --version
|
||||
ansible 1.9.2
|
||||
|
||||
$ cat /etc/redhat-release
|
||||
CentOS Linux release 7.1.1503 (Core)
|
||||
|
||||
如果你还没有 Ansible,可以在 [Ansible 网站][8] 查看说明并安装它。
|
||||
|
||||
如果你使用的是 CentOS,安装 Ansible 十分简单,只要输入以下命令。如果你想使用源码编译安装或使用其他发行版,请参阅上面 Ansible 链接中的说明。
|
||||
|
||||
|
||||
$ sudo yum install -y epel-release && sudo yum install -y ansible
|
||||
|
||||
根据环境的不同,在本教程中的命令有的可能需要 sudo 权限。文件路径,用户名,目标服务器的值取决于你的环境中。
|
||||
|
||||
### 创建一个 Ansible Playbook 来安装 NGINX (CentOS) ###
|
||||
|
||||
首先,我们为 NGINX 的部署创建一个工作目录,以及子目录和部署配置文件目录。我通常建议在主目录中创建目录,在文章的所有例子中都会有说明。
|
||||
|
||||
$ cd $HOME
|
||||
$ mkdir -p ansible-nginx/tasks/
|
||||
$ touch ansible-nginx/deploy.yml
|
||||
$ touch ansible-nginx/tasks/install_nginx.yml
|
||||
|
||||
目录结构看起来是这样的。你可以使用 tree 命令来查看。
|
||||
|
||||
$ tree $HOME/ansible-nginx/
|
||||
/home/kjones/ansible-nginx/
|
||||
├── deploy.yml
|
||||
└── tasks
|
||||
└── install_nginx.yml
|
||||
|
||||
1 directory, 2 files
|
||||
|
||||
如果你没有安装 tree 命令,使用以下命令去安装。
|
||||
|
||||
$ sudo yum install -y tree
|
||||
|
||||
#### 创建主部署文件 ####
|
||||
|
||||
接下来,我们在文本编辑器中打开 **deploy.yml**。我喜欢在命令行上使用 vim 来编辑配置文件,在整个教程中也都将使用它。
|
||||
|
||||
$ vim $HOME/ansible-nginx/deploy.yml
|
||||
|
||||
**deploy.yml** 文件是 Ansible 部署的主要文件,[ 在使用 Ansible 部署 NGINX][9] 时,我们将运行 ansible‑playbook 命令执行此文件。在这个文件中,我们指定运行时 Ansible 使用的库以及其它配置文件。
|
||||
|
||||
在这个例子中,我使用 [include][10] 模块来指定配置文件一步一步来安装NGINX。虽然可以创建一个非常大的 playbook 文件,我建议你将其分割为小文件,以保证其可靠性。示例中的包括复制静态内容,复制配置文件,为更高级的部署使用逻辑配置设定变量。
|
||||
|
||||
在文件中输入以下行。包括顶部参考注释中的文件名。
|
||||
|
||||
# ./ansible-nginx/deploy.yml
|
||||
|
||||
- hosts: nginx
|
||||
tasks:
|
||||
- include: 'tasks/install_nginx.yml'
|
||||
|
||||
hosts 语句说明 Ansible 部署 **nginx** 组的所有服务器,服务器在 **/etc/ansible/hosts** 中指定。我们将编辑此文件来 [创建 NGINX 服务器的列表][11]。
|
||||
|
||||
include 语句说明 Ansible 在部署过程中从 **tasks** 目录下读取并执行 **install_nginx.yml** 文件中的内容。该文件包括以下几步:下载,安装,并启动 NGINX。我们将创建此文件在下一节。
|
||||
|
||||
#### 为 NGINX 创建部署文件 ####
|
||||
|
||||
现在,先保存 **deploy.yml** 文件,并在编辑器中打开 **install_nginx.yml** 。
|
||||
|
||||
$ vim $HOME/ansible-nginx/tasks/install_nginx.yml
|
||||
|
||||
该文件包含的说明有 - 以 [YAML][12] 格式写入 - 使用 Ansible 安装和配置 NGINX。每个部分(步骤中的过程)起始于一个 name 声明(前面连字符)描述此步骤。下面的 name 字符串:是 Ansible 部署过程中写到标准输出的,可以根据你的意愿来改变。YAML 文件中的下一个部分是在部署过程中将使用的模块。在下面的配置中,[yum][13] 和 [service][14] 模块使将被用。yum 模块用于在 CentOS 上安装软件包。service 模块用于管理 UNIX 的服务。在这部分的最后一行或几行指定了几个模块的参数(在本例中,这些行以 name 和 state 开始)。
|
||||
|
||||
在文件中输入以下行。对于 **deploy.yml**,在我们文件的第一行是关于文件名的注释。第一部分说明 Ansible 从 NGINX 仓库安装 **.rpm** 文件在CentOS 7 上。这说明软件包管理器直接从 NGINX 仓库安装最新最稳定的版本。需要在你的 CentOS 版本上修改路径。可使用包的列表可以在 [开源 NGINX 网站][15] 上找到。接下来的两节说明 Ansible 使用 yum 模块安装最新的 NGINX 版本,然后使用 service 模块启动 NGINX。
|
||||
|
||||
**注意:** 在第一部分中,CentOS 包中的路径名是连着的两行。在一行上输入其完整路径。
|
||||
|
||||
# ./ansible-nginx/tasks/install_nginx.yml
|
||||
|
||||
- name: NGINX | Installing NGINX repo rpm
|
||||
yum:
|
||||
name: http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.noarch.rpm
|
||||
|
||||
- name: NGINX | Installing NGINX
|
||||
yum:
|
||||
name: nginx
|
||||
state: latest
|
||||
|
||||
- name: NGINX | Starting NGINX
|
||||
service:
|
||||
name: nginx
|
||||
state: started
|
||||
|
||||
#### 创建 NGINX 服务器列表 ####
|
||||
|
||||
现在,我们有 Ansible 部署所有配置的文件,我们需要告诉 Ansible 部署哪个服务器。我们需要在 Ansible 中指定 **hosts** 文件。先备份现有的文件,并新建一个新文件来部署。
|
||||
|
||||
$ sudo mv /etc/ansible/hosts /etc/ansible/hosts.backup
|
||||
$ sudo vim /etc/ansible/hosts
|
||||
|
||||
在文件中输入以下行来创建一个名为 **nginx** 的组并列出安装 NGINX 的服务器。你可以指定服务器通过主机名,IP 地址,或者在一个区域,例如 **server[1-3].domain.com**。在这里,我指定一台服务器通过 IP 地址。
|
||||
|
||||
# /etc/ansible/hosts
|
||||
|
||||
[nginx]
|
||||
172.16.239.140
|
||||
|
||||
#### 设置安全性 ####
|
||||
|
||||
在部署之前,我们需要确保 Ansible 已通过 SSH 授权能访问我们的目标服务器。
|
||||
|
||||
首选并且最安全的方法是添加 Ansible 所要部署服务器的 RSA SSH 密钥到目标服务器的 **authorized_keys** 文件中,这给 Ansible 在目标服务器上的 SSH 权限不受限制。要了解更多关于此配置,请参阅 [安全的 OpenSSH][16] 在 wiki.centos.org。这样,你就可以自动部署而无需用户交互。
|
||||
|
||||
另外,你也可以在部署过程中需要输入密码。我强烈建议你只在测试过程中使用这种方法,因为它是不安全的,没有办法判断目标主机的身份。如果你想这样做,将每个目标主机 **/etc/ssh/ssh_config** 文件中 StrictHostKeyChecking 的默认值 yes 改为 no。然后在 ansible-playbook 命令中添加 --ask-pass参数来表示 Ansible 会提示输入 SSH 密码。
|
||||
|
||||
在这里,我将举例说明如何编辑 **ssh_config** 文件来禁用在目标服务器上严格的主机密钥检查。我们手动 SSH 到我们将部署 NGINX 的服务器并将StrictHostKeyChecking 的值更改为 no。
|
||||
|
||||
$ ssh kjones@172.16.239.140
|
||||
kjones@172.16.239.140's password:***********
|
||||
|
||||
[kjones@nginx ]$ sudo vim /etc/ssh/ssh_config
|
||||
|
||||
当你更改后,保存 **ssh_config**,并通过 SSH 连接到你的 Ansible 服务器。保存后的设置应该如下图所示。
|
||||
|
||||
# /etc/ssh/ssh_config
|
||||
|
||||
StrictHostKeyChecking no
|
||||
|
||||
#### 运行 Ansible 部署 NGINX ####
|
||||
|
||||
如果你一直照本教程的步骤来做,你可以运行下面的命令来使用 Ansible 部署NGINX。(同样,如果你设置了 RSA SSH 密钥认证,那么--ask-pass 参数是不需要的。)在 Ansible 服务器运行命令,并使用我们上面创建的配置文件。
|
||||
|
||||
$ sudo ansible-playbook --ask-pass $HOME/ansible-nginx/deploy.yml
|
||||
|
||||
Ansible 提示输入 SSH 密码,输出如下。recap 中显示 failed=0 这条信息,意味着部署成功了。
|
||||
|
||||
$ sudo ansible-playbook --ask-pass $HOME/ansible-nginx/deploy.yml
|
||||
SSH password:
|
||||
|
||||
PLAY [all] ********************************************************************
|
||||
|
||||
GATHERING FACTS ***************************************************************
|
||||
ok: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX | Installing NGINX repo rpm] *************************************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX | Installing NGINX] **********************************************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX | Starting NGINX] ************************************************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
PLAY RECAP ********************************************************************
|
||||
172.16.239.140 : ok=4 changed=3 unreachable=0 failed=0
|
||||
|
||||
如果你没有得到一个成功的 play recap,你可以尝试用 -vvvv 参数(带连接调试的详细信息)再次运行 ansible-playbook 命令来解决部署过程的问题。
|
||||
|
||||
当部署成功(因为我们不是第一次部署)后,你可以验证 NGINX 在远程服务器上运行基本的 [cURL][17] 命令。在这里,它会返回 200 OK。Yes!我们使用Ansible 成功安装了 NGINX。
|
||||
|
||||
$ curl -Is 172.16.239.140 | grep HTTP
|
||||
HTTP/1.1 200 OK
|
||||
|
||||
### 创建 Ansible Playbook 来安装 NGINX Plus (CentOS) ###
|
||||
|
||||
现在,我已经展示了如何安装 NGINX 的开源版本,我将带你完成安装 NGINX Plus。这需要更改一些额外的部署配置,并展示了一些 Ansible 的其他功能。
|
||||
|
||||
#### 复制 NGINX Plus 上的证书和密钥到 Ansible 服务器 ####
|
||||
|
||||
使用 Ansible 安装和配置 NGINX Plus 时,首先我们需要将 [NGINX Plus Customer Portal][18] 的密钥和证书复制到部署 Ansible 服务器上的标准位置。
|
||||
|
||||
购买了 NGINX Plus 或正在试用的客户也可以访问 NGINX Plus Customer Portal。如果你有兴趣测试 NGINX Plus,你可以申请免费试用30天[点击这里][19]。在你注册后不久你将收到一个试用证书和密钥的链接。
|
||||
|
||||
在 Mac 或 Linux 主机上,我在这里演示使用 [scp][20] 工具。在 Microsoft Windows 主机,可以使用 [WinSCP][21]。在本教程中,先下载文件到我的 Mac 笔记本电脑上,然后使用 scp 将其复制到 Ansible 服务器。密钥和证书的位置都在我的家目录下。
|
||||
|
||||
$ cd /path/to/nginx-repo-files/
|
||||
$ scp nginx-repo.* user@destination-server:.
|
||||
|
||||
接下来,我们通过 SSH 连接到 Ansible 服务器,确保 NGINX Plus 的 SSL 目录存在,移动文件到这儿。
|
||||
|
||||
$ ssh user@destination-server
|
||||
$ sudo mkdir -p /etc/ssl/nginx/
|
||||
$ sudo mv nginx-repo.* /etc/ssl/nginx/
|
||||
|
||||
验证你的 **/etc/ssl/nginx** 目录包含证书(**.crt**)和密钥(**.key**)文件。你可以使用 tree 命令检查。
|
||||
|
||||
$ tree /etc/ssl/nginx
|
||||
/etc/ssl/nginx
|
||||
├── nginx-repo.crt
|
||||
└── nginx-repo.key
|
||||
|
||||
0 directories, 2 files
|
||||
|
||||
如果你没有安装 tree,可以使用下面的命令去安装。
|
||||
|
||||
$ sudo yum install -y tree
|
||||
|
||||
#### 创建 Ansible 目录结构 ####
|
||||
|
||||
以下执行的步骤将和开源 NGINX 的非常相似在[创建安装 NGINX 的 Ansible Playbook 中(CentOS)][22]。首先,我们建一个工作目录为部署 NGINX Plus 使用。我喜欢将它创建为我主目录的子目录。
|
||||
|
||||
$ cd $HOME
|
||||
$ mkdir -p ansible-nginx-plus/tasks/
|
||||
$ touch ansible-nginx-plus/deploy.yml
|
||||
$ touch ansible-nginx-plus/tasks/install_nginx_plus.yml
|
||||
|
||||
目录结构看起来像这样。
|
||||
|
||||
$ tree $HOME/ansible-nginx-plus/
|
||||
/home/kjones/ansible-nginx-plus/
|
||||
├── deploy.yml
|
||||
└── tasks
|
||||
└── install_nginx_plus.yml
|
||||
|
||||
1 directory, 2 files
|
||||
|
||||
#### 创建主部署文件 ####
|
||||
|
||||
接下来,我们使用 vim 为开源的 NGINX 创建 **deploy.yml** 文件。
|
||||
|
||||
$ vim ansible-nginx-plus/deploy.yml
|
||||
|
||||
和开源 NGINX 的部署唯一的区别是,我们将包含文件的名称修改为**install_nginx_plus.yml**。该文件告诉 Ansible 在 **nginx** 组中的所有服务器(**/etc/ansible/hosts** 中定义的)上部署 NGINX Plus ,然后在部署过程中从 **tasks** 目录读取并执行 **install_nginx_plus.yml** 的内容。
|
||||
|
||||
# ./ansible-nginx-plus/deploy.yml
|
||||
|
||||
- hosts: nginx
|
||||
tasks:
|
||||
- include: 'tasks/install_nginx_plus.yml'
|
||||
|
||||
如果你还没有这样做的话,你需要创建 hosts 文件,详细说明在上面的 [创建 NGINX 服务器的列表][23]。
|
||||
|
||||
#### 为 NGINX Plus 创建部署文件 ####
|
||||
|
||||
在文本编辑器中打开 **install_nginx_plus.yml**。该文件在部署过程中使用 Ansible 来安装和配置 NGINX Plus。这些命令和模块仅针对 CentOS,有些是 NGINX Plus 独有的。
|
||||
|
||||
$ vim ansible-nginx-plus/tasks/install_nginx_plus.yml
|
||||
|
||||
第一部分使用 [文件][24] 模块,告诉 Ansible 使用指定的路径和状态参数为 NGINX Plus 创建特定的 SSL 目录,设置根目录的权限,将权限更改为0700。
|
||||
|
||||
# ./ansible-nginx-plus/tasks/install_nginx_plus.yml
|
||||
|
||||
- name: NGINX Plus | 创建 NGINX Plus ssl 证书目录
|
||||
file: path=/etc/ssl/nginx state=directory group=root mode=0700
|
||||
|
||||
接下来的两节使用 [copy][25] 模块从部署 Ansible 的服务器上将 NGINX Plus 的证书和密钥复制到 NGINX Plus 服务器上,再修改权根,将权限设置为0700。
|
||||
|
||||
- name: NGINX Plus | 复制 NGINX Plus repo 证书
|
||||
copy: src=/etc/ssl/nginx/nginx-repo.crt dest=/etc/ssl/nginx/nginx-repo.crt owner=root group=root mode=0700
|
||||
|
||||
- name: NGINX Plus | 复制 NGINX Plus 密钥
|
||||
copy: src=/etc/ssl/nginx/nginx-repo.key dest=/etc/ssl/nginx/nginx-repo.key owner=root group=root mode=0700
|
||||
|
||||
接下来,我们告诉 Ansible 使用 [get_url][26] 模块从 NGINX Plus 仓库下载 CA 证书在 url 参数指定的远程位置,通过 dest 参数把它放在指定的目录,并设置权限为 0700。
|
||||
|
||||
- name: NGINX Plus | 下载 NGINX Plus CA 证书
|
||||
get_url: url=https://cs.nginx.com/static/files/CA.crt dest=/etc/ssl/nginx/CA.crt mode=0700
|
||||
|
||||
同样,我们告诉 Ansible 使用 get_url 模块下载 NGINX Plus repo 文件,并将其复制到 **/etc/yum.repos.d** 目录下在 NGINX Plus 服务器上。
|
||||
|
||||
- name: NGINX Plus | 下载 yum NGINX Plus 仓库
|
||||
get_url: url=https://cs.nginx.com/static/files/nginx-plus-7.repo dest=/etc/yum.repos.d/nginx-plus-7.repo mode=0700
|
||||
|
||||
最后两节的 name 告诉 Ansible 使用 yum 和 service 模块下载并启动 NGINX Plus。
|
||||
|
||||
- name: NGINX Plus | 安装 NGINX Plus
|
||||
yum:
|
||||
name: nginx-plus
|
||||
state: latest
|
||||
|
||||
- name: NGINX Plus | 启动 NGINX Plus
|
||||
service:
|
||||
name: nginx
|
||||
state: started
|
||||
|
||||
#### 运行 Ansible 来部署 NGINX Plus ####
|
||||
|
||||
在保存 **install_nginx_plus.yml** 文件后,然后运行 ansible-playbook 命令来部署 NGINX Plus。同样在这里,我们使用 --ask-pass 参数使用 Ansible 提示输入 SSH 密码并把它传递给每个 NGINX Plus 服务器,指定路径在 **deploy.yml** 文件中。
|
||||
|
||||
$ sudo ansible-playbook --ask-pass $HOME/ansible-nginx-plus/deploy.yml
|
||||
|
||||
PLAY [nginx] ******************************************************************
|
||||
|
||||
GATHERING FACTS ***************************************************************
|
||||
ok: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX Plus | Creating NGINX Plus ssl cert repo directory] **************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX Plus | Copying NGINX Plus repository certificate] ****************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX Plus | Copying NGINX Plus repository key] ************************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX Plus | Downloading NGINX Plus CA certificate] ********************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX Plus | Downloading yum NGINX Plus repository] ********************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX Plus | Installing NGINX Plus] ************************************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
TASK: [NGINX Plus | Starting NGINX Plus] **************************************
|
||||
changed: [172.16.239.140]
|
||||
|
||||
PLAY RECAP ********************************************************************
|
||||
172.16.239.140 : ok=8 changed=7 unreachable=0 failed=0
|
||||
|
||||
playbook 的 recap 是成功的。现在,使用 curl 命令来验证 NGINX Plus 是否在运行。太好了,我们得到的是 200 OK!成功了!我们使用 Ansible 成功地安装了 NGINX Plus。
|
||||
|
||||
$ curl -Is http://172.16.239.140 | grep HTTP
|
||||
HTTP/1.1 200 OK
|
||||
|
||||
### 在 Ubuntu 上创建一个 Ansible Playbook 来安装 NGINX 和 NGINX Plus ###
|
||||
|
||||
此过程在 [Ubuntu 服务器][27] 上部署 NGINX 和 NGINX Plus 与 CentOS 很相似,我将一步一步的指导来完成整个部署文件,并指出和 CentOS 的细微差异。
|
||||
|
||||
首先和 CentOS 一样,创建 Ansible 目录结构和主要的 Ansible 部署文件。也创建 **/etc/ansible/hosts** 文件来描述 [创建 NGINX 服务器的列表][28]。对于 NGINX Plus,你也需要复制证书和密钥在此步中 [复制 NGINX Plus 证书和密钥到 Ansible 服务器][29]。
|
||||
|
||||
下面是开源 NGINX 的 **install_nginx.yml** 部署文件。在第一部分,我们使用 [apt_key][30] 模块导入 Nginx 的签名密钥。接下来的两节使用[lineinfile][31] 模块来添加 URLs 到 **sources.list** 文件中。最后,我们使用 [apt][32] 模块来更新缓存并安装 NGINX(apt 取代了我们在 CentOS 中部署时的 yum 模块)。
|
||||
|
||||
# ./ansible-nginx/tasks/install_nginx.yml
|
||||
|
||||
- name: NGINX | 添加 NGINX 签名密钥
|
||||
apt_key: url=http://nginx.org/keys/nginx_signing.key state=present
|
||||
|
||||
- name: NGINX | 为 NGINX 添加 sources.list deb url
|
||||
lineinfile: dest=/etc/apt/sources.list line="deb http://nginx.org/packages/mainline/ubuntu/ trusty nginx"
|
||||
|
||||
- name: NGINX Plus | 为 NGINX 添加 sources.list deb-src url
|
||||
lineinfile: dest=/etc/apt/sources.list line="deb-src http://nginx.org/packages/mainline/ubuntu/ trusty nginx"
|
||||
|
||||
- name: NGINX | 更新 apt 缓存
|
||||
apt:
|
||||
update_cache: yes
|
||||
|
||||
- name: NGINX | 安装 NGINX
|
||||
apt:
|
||||
pkg: nginx
|
||||
state: latest
|
||||
|
||||
- name: NGINX | 启动 NGINX
|
||||
service:
|
||||
name: nginx
|
||||
state: started
|
||||
下面是 NGINX Plus 的部署文件 **install_nginx.yml**。前四节设置了 NGINX Plus 密钥和证书。然后,我们用 apt_key 模块为开源的 NGINX 导入签名密钥,get_url 模块为 NGINX Plus 下载 apt 配置文件。[shell][33] 模块使用 printf 命令写下输出到 **nginx-plus.list** 文件中在**sources.list.d** 目录。最终的 name 模块是为开源 NGINX 的。
|
||||
|
||||
# ./ansible-nginx-plus/tasks/install_nginx_plus.yml
|
||||
|
||||
- name: NGINX Plus | 创建 NGINX Plus ssl 证书 repo 目录
|
||||
file: path=/etc/ssl/nginx state=directory group=root mode=0700
|
||||
|
||||
- name: NGINX Plus | 复制 NGINX Plus 仓库证书
|
||||
copy: src=/etc/ssl/nginx/nginx-repo.crt dest=/etc/ssl/nginx/nginx-repo.crt owner=root group=root mode=0700
|
||||
|
||||
- name: NGINX Plus | 复制 NGINX Plus 仓库密钥
|
||||
copy: src=/etc/ssl/nginx/nginx-repo.key dest=/etc/ssl/nginx/nginx-repo.key owner=root group=root mode=0700
|
||||
|
||||
- name: NGINX Plus | 安装 NGINX Plus CA 证书
|
||||
get_url: url=https://cs.nginx.com/static/files/CA.crt dest=/etc/ssl/nginx/CA.crt mode=0700
|
||||
|
||||
- name: NGINX Plus | 添加 NGINX Plus 签名密钥
|
||||
apt_key: url=http://nginx.org/keys/nginx_signing.key state=present
|
||||
|
||||
- name: NGINX Plus | 安装 Apt-Get NGINX Plus 仓库
|
||||
get_url: url=https://cs.nginx.com/static/files/90nginx dest=/etc/apt/apt.conf.d/90nginx mode=0700
|
||||
|
||||
- name: NGINX Plus | 为 NGINX Plus 添加 sources.list url
|
||||
shell: printf "deb https://plus-pkgs.nginx.com/ubuntu `lsb_release -cs` nginx-plus\n" >/etc/apt/sources.list.d/nginx-plus.list
|
||||
|
||||
- name: NGINX Plus | 运行 apt-get update
|
||||
apt:
|
||||
update_cache: yes
|
||||
|
||||
- name: NGINX Plus | 安装 NGINX Plus 通过 apt-get
|
||||
apt:
|
||||
pkg: nginx-plus
|
||||
state: latest
|
||||
|
||||
- name: NGINX Plus | 启动 NGINX Plus
|
||||
service:
|
||||
name: nginx
|
||||
state: started
|
||||
|
||||
现在我们已经准备好运行 ansible-playbook 命令:
|
||||
|
||||
$ sudo ansible-playbook --ask-pass $HOME/ansible-nginx-plus/deploy.yml
|
||||
|
||||
你应该得到一个成功的 play recap。如果你没有成功,你可以使用 verbose 参数,以帮助你解决在 [运行 Ansible 来部署 NGINX][34] 中出现的问题。
|
||||
|
||||
### 小结 ###
|
||||
|
||||
我在这个教程中演示是什么是 Ansible,可以做些什么来帮助你自动部署 NGINX 或 NGINX Plus,这仅仅是个开始。还有许多有用的模块,用户账号管理,自定义配置模板等。如果你有兴趣了解更多关于这些,请访问 [Ansible 官方文档][35]。
|
||||
|
||||
要了解更多关于 Ansible,来听我讲用 Ansible 部署 NGINX Plus 在[NGINX.conf 2015][36],9月22-24日在旧金山。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/
|
||||
|
||||
作者:[Kevin Jones][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.nginx.com/blog/author/kjones/
|
||||
[1]:http://www.ansible.com/
|
||||
[2]:http://www.paramiko.org/
|
||||
[3]:http://www.openssh.com/
|
||||
[4]:http://nginx.org/en/
|
||||
[5]:https://www.nginx.com/products/
|
||||
[6]:http://www.centos.org/
|
||||
[7]:https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/#ubuntu
|
||||
[8]:http://docs.ansible.com/ansible/intro_installation.html#installing-the-control-machine
|
||||
[9]:https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/#deploy-nginx
|
||||
[10]:http://docs.ansible.com/ansible/playbooks_roles.html#task-include-files-and-encouraging-reuse
|
||||
[11]:https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/#list-nginx
|
||||
[12]:http://docs.ansible.com/ansible/YAMLSyntax.html
|
||||
[13]:http://docs.ansible.com/ansible/yum_module.html
|
||||
[14]:http://docs.ansible.com/ansible/service_module.html
|
||||
[15]:http://nginx.org/en/linux_packages.html
|
||||
[16]:http://wiki.centos.org/HowTos/Network/SecuringSSH
|
||||
[17]:http://curl.haxx.se/
|
||||
[18]:https://cs.nginx.com/
|
||||
[19]:https://www.nginx.com/#free-trial
|
||||
[20]:http://linux.die.net/man/1/scp
|
||||
[21]:https://winscp.net/eng/download.php
|
||||
[22]:https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/#playbook-nginx
|
||||
[23]:https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/#list-nginx
|
||||
[24]:http://docs.ansible.com/ansible/file_module.html
|
||||
[25]:http://docs.ansible.com/ansible/copy_module.html
|
||||
[26]:http://docs.ansible.com/ansible/get_url_module.html
|
||||
[27]:http://www.ubuntu.com/
|
||||
[28]:https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/#list-nginx
|
||||
[29]:https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/#copy-cert-key
|
||||
[30]:http://docs.ansible.com/ansible/apt_key_module.html
|
||||
[31]:http://docs.ansible.com/ansible/lineinfile_module.html
|
||||
[32]:http://docs.ansible.com/ansible/apt_module.html
|
||||
[33]:http://docs.ansible.com/ansible/shell_module.html
|
||||
[34]:https://www.nginx.com/blog/installing-nginx-nginx-plus-ansible/#deploy-nginx
|
||||
[35]:http://docs.ansible.com/
|
||||
[36]:https://www.nginx.com/nginxconf/
|
||||
@ -0,0 +1,150 @@
|
||||
使用tuptime工具查看Linux服务器系统历史开机时间统计
|
||||
================================================================================
|
||||
你们可以使用下面的工具来查看Linux或者类Unix系统运行了多长时间:
|
||||
- uptime : 告诉你服务器运行了多长的时间。
|
||||
- lastt : 显示重启和关机时间。
|
||||
- tuptime : 报告系统的历史运行时间和统计运行时间,这是指重启之间的运行时间。和uptime命令类似,不过输出结果更有意思。
|
||||
|
||||
#### 找出系统上次重启时间和日期 ####
|
||||
|
||||
你[可以使用下面的命令来获取Linux操作系统的上次重启和关机时间及日期][1](在OSX/类Unix系统上也可以用):
|
||||
|
||||
## Just show system reboot and shutdown date and time ###
|
||||
who -b
|
||||
last reboot
|
||||
last shutdown
|
||||
## Uptime info ##
|
||||
uptime
|
||||
cat /proc/uptime
|
||||
awk '{ print "up " $1 /60 " minutes"}' /proc/uptime
|
||||
w
|
||||
|
||||
**样例输出:**
|
||||
|
||||
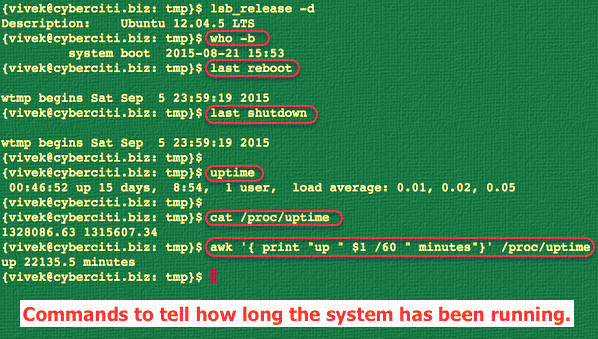
|
||||
|
||||
图像01:用于找出服务器开机时间的多个Linux命令
|
||||
|
||||
**跟tuptime问打个招呼吧**
|
||||
|
||||
tuptime命令行工具可以报告基于Linux的系统上的下列信息:
|
||||
1. 系统启动次数统计
|
||||
2. 注册首次启动时间(也就是安装时间)
|
||||
1. 正常关机和意外关机统计
|
||||
1. 平均开机时间和故障停机时间
|
||||
1. 当前开机时间
|
||||
1. 首次启动以来的开机和故障停机率
|
||||
1. 累积系统开机时间、故障停机时间和合计
|
||||
1. 报告每次启动、开机时间、关机和故障停机时间
|
||||
|
||||
#### 安装 ####
|
||||
|
||||
输入[下面的命令来克隆git仓库到Linux系统中][2]:
|
||||
|
||||
$ cd /tmp
|
||||
$ git clone https://github.com/rfrail3/tuptime.git
|
||||
$ ls
|
||||
$ cd tuptime
|
||||
$ ls
|
||||
|
||||
**样例输出:**
|
||||
|
||||
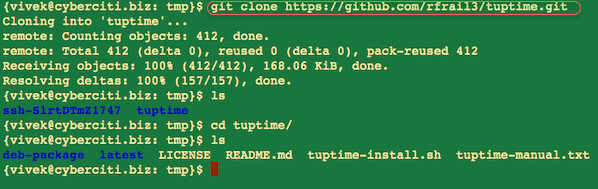
|
||||
|
||||
图像02:克隆git仓库
|
||||
|
||||
确保你随sys,optparse,os,re,string,sqlite3,datetime,disutils安装了Python v2.7和本地模块。
|
||||
|
||||
你可以像下面这样来安装:
|
||||
|
||||
$ sudo tuptime-install.sh
|
||||
|
||||
或者,可以手工安装(根据基于systemd或非systemd的Linux的推荐方法):
|
||||
|
||||
$ sudo cp /tmp/tuptime/latest/cron.d/tuptime /etc/cron.d/tuptime
|
||||
|
||||
如果系统是systemd的,拷贝服务文件并启用:
|
||||
|
||||
$ sudo cp /tmp/tuptime/latest/systemd/tuptime.service /lib/systemd/system/
|
||||
$ sudo systemctl enable tuptime.service
|
||||
|
||||
如果系统不是systemd的,拷贝初始化文件:
|
||||
|
||||
$ sudo cp /tmp/tuptime/latest/init.d/tuptime.init.d-debian7 /etc/init.d/tuptime
|
||||
$ sudo update-rc.d tuptime defaults
|
||||
|
||||
**运行**
|
||||
|
||||
只需输入以下命令:
|
||||
|
||||
$ sudo tuptime
|
||||
|
||||
**样例输出:**
|
||||
|
||||
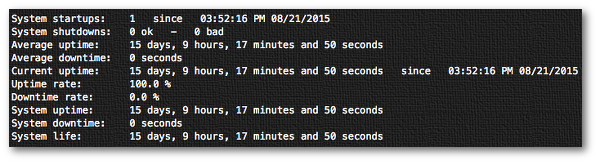
|
||||
|
||||
图像03:tuptime工作中
|
||||
|
||||
在更新内核后,我重启了系统,然后再次输入了同样的命令:
|
||||
|
||||
$ sudo tuptime
|
||||
System startups: 2 since 03:52:16 PM 08/21/2015
|
||||
System shutdowns: 1 ok - 0 bad
|
||||
Average uptime: 7 days, 16 hours, 48 minutes and 3 seconds
|
||||
Average downtime: 2 hours, 30 minutes and 5 seconds
|
||||
Current uptime: 5 minutes and 28 seconds since 06:23:06 AM 09/06/2015
|
||||
Uptime rate: 98.66 %
|
||||
Downtime rate: 1.34 %
|
||||
System uptime: 15 days, 9 hours, 36 minutes and 7 seconds
|
||||
System downtime: 5 hours, 0 minutes and 11 seconds
|
||||
System life: 15 days, 14 hours, 36 minutes and 18 seconds
|
||||
|
||||
你可以像下面这样修改日期和时间格式:
|
||||
|
||||
$ sudo tuptime -d '%H:%M:%S %m-%d-%Y'
|
||||
|
||||
**样例输出:**
|
||||
|
||||
System startups: 1 since 15:52:16 08-21-2015
|
||||
System shutdowns: 0 ok - 0 bad
|
||||
Average uptime: 15 days, 9 hours, 21 minutes and 19 seconds
|
||||
Average downtime: 0 seconds
|
||||
Current uptime: 15 days, 9 hours, 21 minutes and 19 seconds since 15:52:16 08-21-2015
|
||||
Uptime rate: 100.0 %
|
||||
Downtime rate: 0.0 %
|
||||
System uptime: 15 days, 9 hours, 21 minutes and 19 seconds
|
||||
System downtime: 0 seconds
|
||||
System life: 15 days, 9 hours, 21 minutes and 19 seconds
|
||||
|
||||
计算每次启动、开机时间、关机和故障停机时间:
|
||||
|
||||
$ sudo tuptime -e
|
||||
|
||||
**样例输出:**
|
||||
|
||||
Startup: 1 at 03:52:16 PM 08/21/2015
|
||||
Uptime: 15 days, 9 hours, 22 minutes and 33 seconds
|
||||
|
||||
System startups: 1 since 03:52:16 PM 08/21/2015
|
||||
System shutdowns: 0 ok - 0 bad
|
||||
Average uptime: 15 days, 9 hours, 22 minutes and 33 seconds
|
||||
Average downtime: 0 seconds
|
||||
Current uptime: 15 days, 9 hours, 22 minutes and 33 seconds since 03:52:16 PM 08/21/2015
|
||||
Uptime rate: 100.0 %
|
||||
Downtime rate: 0.0 %
|
||||
System uptime: 15 days, 9 hours, 22 minutes and 33 seconds
|
||||
System downtime: 0 seconds
|
||||
System life: 15 days, 9 hours, 22 minutes and 33 seconds
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/hardware/howto-see-historical-statistical-uptime-on-linux-server/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.cyberciti.biz/hardware/howto-see-historical-statistical-uptime-on-linux-server/
|
||||
[2]:http://www.cyberciti.biz/faq/debian-ubunut-linux-download-a-git-repository/
|
||||
@ -0,0 +1,102 @@
|
||||
|
||||
在ubunt 14.04/15.04 上配置Node JS v4.0.0
|
||||
================================================================================
|
||||
大家好,Node.JS 4.0 发布了,主流的服务器端JS 平台已经将Node.js 和io.js 结合到一起。4.0 版就是两者结合的产物——共用一个代码库。这次最主要的变化是Node.js 封装了Google V8 4.5 JS 引擎,而这一版与当前的Chrome 一致。所以,紧跟V8 的版本号可以让Node.js 运行的更快、更安全,同时更好的利用ES6 的很多语言特性。
|
||||
|
||||

|
||||
|
||||
Node.js 4.0 的目标是为io.js 当前用户提供一个简单的升级途径,所以这次并没有太多重要的API 变更。剩下的内容会让我们看到如何轻松的在ubuntu server 上安装、配置Node.js。
|
||||
|
||||
### 基础系统安装 ###
|
||||
|
||||
Node 在Linux,Macintosh,Solaris 这几个系统上都可以完美的运行,同时linux 的发行版本当中Ubuntu 是最合适的。这也是我们为什么要尝试在ubuntu 15.04 上安装Node,当然了在14.04 上也可以使用相同的步骤安装。
|
||||
#### 1) 系统资源 ####
|
||||
|
||||
The basic system resources for Node depend upon the size of your infrastructure requirements. So, here in this tutorial we will setup Node with 1 GB RAM, 1 GHz Processor and 10 GB of available disk space with minimal installation packages installed on the server that is no web or database server packages are installed.
|
||||
|
||||
#### 2) 系统更新 ####
|
||||
|
||||
It always been recommended to keep your system upto date with latest patches and updates, so before we move to the installation on Node, let's login to your server with super user privileges and run update command.
|
||||
|
||||
# apt-get update
|
||||
|
||||
#### 3) 安装依赖 ####
|
||||
|
||||
Node JS only requires some basic system and software utilities to be present on your server, for its successful installation like 'make' 'gcc' and 'wget'. Let's run the below command to get them installed if they are not already present.
|
||||
|
||||
# apt-get install python gcc make g++ wget
|
||||
|
||||
### 下载最新版的Node JS v4.0.0 ###
|
||||
|
||||
使用链接 [Node JS Download Page][1] 下载源代码.
|
||||
|
||||

|
||||
|
||||
我们会复制最新源代码的链接,然后用`wget` 下载,命令如下:
|
||||
|
||||
# wget https://nodejs.org/download/rc/v4.0.0-rc.1/node-v4.0.0-rc.1.tar.gz
|
||||
|
||||
下载完成后使用命令`tar` 解压缩:
|
||||
|
||||
# tar -zxvf node-v4.0.0-rc.1.tar.gz
|
||||
|
||||

|
||||
|
||||
### 安装 Node JS v4.0.0 ###
|
||||
|
||||
现在可以开始使用下载好的源代码编译Nod JS。你需要在ubuntu serve 上开始编译前运行配置脚本来修改你要使用目录和配置参数。
|
||||
|
||||
root@ubuntu-15:~/node-v4.0.0-rc.1# ./configure
|
||||
|
||||

|
||||
|
||||
现在运行命令'make install' 编译安装Node JS:
|
||||
|
||||
root@ubuntu-15:~/node-v4.0.0-rc.1# make install
|
||||
|
||||
make 命令会花费几分钟完成编译,冷静的等待一会。
|
||||
|
||||
### 验证Node 安装 ###
|
||||
|
||||
一旦编译任务完成,我们就可以开始验证安装工作是否OK。我们运行下列命令来确认Node JS 的版本。
|
||||
|
||||
root@ubuntu-15:~# node -v
|
||||
v4.0.0-pre
|
||||
|
||||
在命令行下不带参数的运行`node` 就会进入REPL(Read-Eval-Print-Loop,读-执行-输出-循环)模式,它有一个简化版的emacs 行编辑器,通过它你可以交互式的运行JS和查看运行结果。
|
||||

|
||||
|
||||
### 写测试程序 ###
|
||||
|
||||
我们也可以写一个很简单的终端程序来测试安装是否成功,并且工作正常。要完成这一点,我们将会创建一个“tes.js” 文件,包含一下代码,操作如下:
|
||||
|
||||
root@ubuntu-15:~# vim test.js
|
||||
var util = require("util");
|
||||
console.log("Hello! This is a Node Test Program");
|
||||
:wq!
|
||||
|
||||
现在为了运行上面的程序,在命令行运行下面的命令。
|
||||
|
||||
root@ubuntu-15:~# node test.js
|
||||
|
||||

|
||||
|
||||
在一个成功安装了Node JS 的环境下运行上面的程序就会在屏幕上得到上图所示的输出,这个程序加载类 “util” 到变量“util” 中,接着用对象“util” 运行终端任务,console.log 这个命令作用类似C++ 里的cout
|
||||
|
||||
### 结论 ###
|
||||
|
||||
That’s it. Hope this gives you a good idea of Node.js going with Node.js on Ubuntu. If you are new to developing applications with Node.js. After all we can say that we can expect significant performance gains with Node JS Version 4.0.0.
|
||||
希望本文能够通过在ubuntu 上安装、运行Node.JS让你了解一下Node JS 的大概,如果你是刚刚开始使用Node.JS 开发应用程序。最后我们可以说我们能够通过Node JS v4.0.0 获取显著的性能。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/setup-node-js-4-0-ubuntu-14-04-15-04/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[译者ID](https://github.com/osk874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
[1]:https://nodejs.org/download/rc/v4.0.0-rc.1/
|
||||
@ -0,0 +1,70 @@
|
||||
Linux 问与答:如何在Linux 命令行下浏览天气预报
|
||||
================================================================================
|
||||
> **Q**: 我经常在Linux 桌面查看天气预报。然而,是否有一种在终端环境下,不通过桌面小插件或者网络查询天气预报的方法?
|
||||
|
||||
对于Linux 桌面用户来说,有很多办法获取天气预报,比如使用专门的天气应用,桌面小插件,或者面板小程序。但是如果你的工作环境实际与终端的,这里也有一些在命令行下获取天气的手段。
|
||||
|
||||
其中有一个就是 [wego][1],**一个终端下的小巧程序**。使用基于ncurses 的接口,这个命令行程序允许你查看当前的天气情况和之后的预报。它也会通过一个天气预报的API 收集接下来5 天的天气预报。
|
||||
|
||||
### 在Linux 下安装Wego ###
|
||||
安装wego 相当简单。wego 是用Go 编写的,引起第一个步骤就是安装[Go 语言][2]。然后再安装wego。
|
||||
|
||||
$ go get github.com/schachmat/wego
|
||||
|
||||
wego 会被安装到$GOPATH/bin,所以要将$GOPATH/bin 添加到$PATH 环境变量。
|
||||
|
||||
$ echo 'export PATH="$PATH:$GOPATH/bin"' >> ~/.bashrc
|
||||
$ source ~/.bashrc
|
||||
|
||||
现在就可与直接从命令行启动wego 了。
|
||||
|
||||
$ wego
|
||||
|
||||
第一次运行weg 会生成一个配置文件(~/.wegorc),你需要指定一个天气API key。
|
||||
你可以从[worldweatheronline.com][3] 获取一个免费的API key。免费注册和使用。你只需要提供一个有效的邮箱地址。
|
||||
|
||||

|
||||
|
||||
你的 .wegorc 配置文件看起来会这样:
|
||||
|
||||

|
||||
|
||||
除了API key,你还可以把你想要查询天气的地方、使用的城市/国家名称、语言配置在~/.wegorc 中。
|
||||
注意,这个天气API 的使用有限制:每秒最多5 次查询,每天最多250 次查询。
|
||||
当你重新执行wego 命令,你将会看到最新的天气预报(当然是你的指定地方),如下显示。
|
||||
|
||||

|
||||
|
||||
显示出来的天气信息包括:(1)温度,(2)风速和风向,(3)可视距离,(4)降水量和降水概率
|
||||
默认情况下会显示3 天的天气预报。如果要进行修改,可以通过参数改变天气范围(最多5天),比如要查看5 天的天气预报:
|
||||
|
||||
$ wego 5
|
||||
|
||||
如果你想检查另一个地方的天气,只需要提供城市名即可:
|
||||
|
||||
$ wego Seattle
|
||||
|
||||
### 问题解决 ###
|
||||
1. 可能会遇到下面的错误:
|
||||
|
||||
user: Current not implemented on linux/amd64
|
||||
|
||||
当你在一个不支持原生Go 编译器的环境下运行wego 时就会出现这个错误。在这种情况下你只需要使用gccgo ——一个Go 的编译器前端来编译程序即可。这一步可以通过下面的命令完成。
|
||||
|
||||
$ sudo yum install gcc-go
|
||||
$ go get -compiler=gccgo github.com/schachmat/wego
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/weather-forecasts-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:https://github.com/schachmat/wego
|
||||
[2]:http://ask.xmodulo.com/install-go-language-linux.html
|
||||
[3]:https://developer.worldweatheronline.com/auth/register
|
||||
@ -0,0 +1,48 @@
|
||||
开启Ubuntu系统自动升级
|
||||
================================================================================
|
||||
在学习如何开启Ubuntu系统自动升级之前,先解释下为什么需要自动升级。
|
||||
|
||||
默认情况下,ubuntu每天一次检查更新。但是一周只会弹出一次软件升级提醒,除非当有安全性升级时,才会立即弹出。所以,如果你已经使用Ubuntu一段时间,你肯定很熟悉这个画面:
|
||||
|
||||

|
||||
|
||||
但是做为一个正常桌面用户,根本不会去关心有什么更新细节。而且这个提醒完全就是浪费时间,你肯定信任Ubuntu提供的升级补丁,对不对?所以,大部分情况你肯定会选择“现在安装”,对不对?
|
||||
|
||||
所以,你需要做的就只是点一下升级按钮。现在,明白为什么需要自动系统升级了吧?开启自动系统升级意味着所有最新的更新都会自动下载并安装,并且没有请求确认。是不是很方便?
|
||||
|
||||
### 开启Ubuntu自动升级 ###
|
||||
|
||||
演示使用Ubuntu15.04,Ubuntu 14.04步骤类似。
|
||||
|
||||
打开Unity Dash ,找到软件&更新:
|
||||
|
||||

|
||||
|
||||
打开软件资源设置,切换到升级标签:
|
||||
|
||||

|
||||
|
||||
可以发现,默认设置就是每日检查并立即提醒安全升级。
|
||||
|
||||

|
||||
|
||||
改变 ‘当有安全升级’和‘当有其他升级’的选项为:下载并自动安装。
|
||||
|
||||

|
||||
|
||||
关闭对话框完成设定。这样每次Ubuntu检查更新后就会自动升级。事实上,这篇文章十分类似[改变Ubuntu升级提醒频率][1]。
|
||||
|
||||
你喜欢自动升级还是手动安装升级呢?欢迎评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/automatic-system-updates-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[Vic020/VicYu](http://vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/ubuntu-notify-updates-frequently/
|
||||
@ -0,0 +1,82 @@
|
||||
Linux 有问必答--如何找出哪个 CPU 内核正在运行进程
|
||||
================================================================================
|
||||
>问题:我有个 Linux 进程运行在多核处理器系统上。怎样才能找出哪个 CPU 内核正在运行该进程?
|
||||
|
||||
当你运行需要较高性能的 HPC 程序或非常消耗网络资源的程序在 [多核 NUMA 处理器上][1],CPU/memory 的亲和力是限度其发挥最大性能的重要因素之一。在同一 NUMA 节点上调整程序的亲和力可以减少远程内存访问。像英特尔 Sandy Bridge 处理器,该处理器有一个集成的 PCIe 控制器,要调整同一 NUMA 节点的网络 I/O 负载可以使用 网卡控制 PCI 和 CPU 亲和力。
|
||||
|
||||
由于性能优化和故障排除只是一部分,你可能想知道哪个 CPU 内核(或 NUMA 节点)被调度运行特定的进程。
|
||||
|
||||
这里有几种方法可以 **找出哪个 CPU 内核被调度来运行 给定的 Linux 进程或线程**。
|
||||
|
||||
### 方法一 ###
|
||||
|
||||
如果一个进程明确的被固定到 CPU 的特定内核,如使用 [taskset][2] 命令,你可以使用 taskset 命令找出被固定的 CPU 内核:
|
||||
|
||||
$ taskset -c -p <pid>
|
||||
|
||||
例如, 如果你对 PID 5357 这个进程有兴趣:
|
||||
|
||||
$ taskset -c -p 5357
|
||||
|
||||
----------
|
||||
|
||||
pid 5357's current affinity list: 5
|
||||
|
||||
输出显示这个过程被固定在 CPU 内核 5。
|
||||
|
||||
但是,如果你没有明确固定进程到任何 CPU 内核,你会得到类似下面的亲和力列表。
|
||||
|
||||
pid 5357's current affinity list: 0-11
|
||||
|
||||
输出表明,该进程可能会被安排在从0到11中的任何一个 CPU 内核。在这种情况下,taskset 不会识别该进程当前被分配给哪个 CPU 内核,你应该使用如下所述的方法。
|
||||
|
||||
### 方法二 ###
|
||||
|
||||
ps 命令可以告诉你每个进程/线程目前分配到的 (在“PSR”列)CPU ID。
|
||||
|
||||
|
||||
$ ps -o pid,psr,comm -p <pid>
|
||||
|
||||
----------
|
||||
|
||||
PID PSR COMMAND
|
||||
5357 10 prog
|
||||
|
||||
输出表示进程的 PID 为 5357(名为"prog")目前在CPU 内核 10 上运行着。如果该过程没有被固定,PSR 列可以保持随着时间变化,内核可能调度该进程到不同位置。
|
||||
|
||||
### 方法三 ###
|
||||
|
||||
top 命令也可以显示 CPU 被分配给哪个进程。首先,在top 命令中使用“P”选项。然后按“f”键,显示中会出现 "Last used CPU" 列。目前使用的 CPU 内核将出现在 “P”(或“PSR”)列下。
|
||||
|
||||
$ top -p 5357
|
||||
|
||||

|
||||
|
||||
相比于 ps 命令,使用 top 命令的好处是,你可以连续监视随着时间的改变, CPU 是如何分配的。
|
||||
|
||||
### 方法四 ###
|
||||
|
||||
另一种来检查一个进程/线程当前使用的是哪个 CPU 内核的方法是使用 [htop 命令][3]。
|
||||
|
||||
从命令行启动 htop。按 <F2> 键,进入"Columns",在"Available Columns"下会添加 PROCESSOR。
|
||||
|
||||
每个进程当前使用的 CPU ID 将出现在“CPU”列中。
|
||||
|
||||

|
||||
|
||||
请注意,所有以前使用的命令 taskset,ps 和 top 分配CPU 内核的 IDs 为 0,1,2,...,N-1。然而,htop 分配 CPU 内核 IDs 从 1开始(直到 N)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/cpu-core-process-is-running.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/identify-cpu-processor-architecture-linux.html
|
||||
[2]:http://xmodulo.com/run-program-process-specific-cpu-cores-linux.html
|
||||
[3]:http://ask.xmodulo.com/install-htop-centos-rhel.html
|
||||
@ -0,0 +1,60 @@
|
||||
在 Ubuntu 和 Linux Mint 上安装 Terminator 0.98
|
||||
================================================================================
|
||||
[Terminator][1],在一个窗口中有多个终端。该项目的目标之一是为管理终端提供一个有用的工具。它的灵感来自于类似 gnome-multi-term,quankonsole 等程序,这些程序关注于在窗格中管理终端。 Terminator 0.98 带来了更完美的标签功能,更好的布局保存/恢复,改进了偏好用户界面和多出 bug 修复。
|
||||
|
||||

|
||||
|
||||
###TERMINATOR 0.98 的更改和新特性
|
||||
- 添加了一个布局启动器,允许在不用布局之间简单切换(用 Alt + L 打开一个新的布局切换器);
|
||||
- 添加了一个新的手册(使用 F1 打开);
|
||||
- 保存的时候,布局现在会记住:
|
||||
- * 最大化和全屏状态
|
||||
- * 窗口标题
|
||||
- * 激活的标签
|
||||
- * 激活的终端
|
||||
- * 每个终端的工作目录
|
||||
- 添加选项用于启用/停用非同质标签和滚动箭头;
|
||||
- 添加快捷键用于按行/半页/一页向上/下滚动;
|
||||
- 添加使用 Ctrl+鼠标滚轮放大/缩小,Shift+鼠标滚轮向上/下滚动页面;
|
||||
- 为下一个/上一个 profile 添加快捷键
|
||||
- 改进自定义命令菜单的一致性
|
||||
- 新增快捷方式/代码来切换所有/标签分组;
|
||||
- 改进监视插件
|
||||
- 增加搜索栏切换;
|
||||
- 清理和重新组织窗口偏好,包括一个完整的全局便签更新
|
||||
- 添加选项用于设置 ActivityWatcher 插件静默时间
|
||||
- 其它一些改进和 bug 修复
|
||||
- [点击此处查看完整更新日志][2]
|
||||
|
||||
### 安装 Terminator 0.98:
|
||||
|
||||
Terminator 0.98 有可用的 PPA,首先我们需要在 Ubuntu/Linux Mint 上添加库。在终端里运行下面的命令来安装 Terminator 0.98。
|
||||
|
||||
$ sudo add-apt-repository ppa:gnome-terminator/nightly
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install terminator
|
||||
|
||||
如果你想要移除 Terminator,只需要在终端中运行下面的命令(可选)
|
||||
|
||||
$ sudo apt-get remove terminator
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ewikitech.com/articles/linux/terminator-install-ubuntu-linux-mint/
|
||||
|
||||
作者:[admin][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ewikitech.com/author/admin/
|
||||
[1]:https://launchpad.net/terminator
|
||||
[2]:http://bazaar.launchpad.net/~gnome-terminator/terminator/trunk/view/head:/ChangeLog
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,48 @@
|
||||
如何在Ubuntu中添加和删除书签[新手技巧]
|
||||
================================================================================
|
||||

|
||||
|
||||
这是一篇对完全是新手的一篇技巧,我将向你展示如何在Ubuntu文件管理器中添加书签。
|
||||
|
||||
现在如果你想知道为什么要这么做,答案很简单。它可以让你可以快速地在左边栏中访问。比如。我[在Ubuntu中安装了Copy][1]。现在它创建了/Home/Copy。先进入Home目录再进入Copy目录并不是一件大事,但是我想要更快地访问它。因此我添加了一个书签这样我就可以直接从侧边栏访问了。
|
||||
|
||||
### 在Ubuntu中添加书签 ###
|
||||
|
||||
打开Files。进入你想要保存快速访问的目录。你需要在标记书签的目录里面。
|
||||
|
||||
现在,你有两种方法。
|
||||
|
||||
#### 方法1: ####
|
||||
|
||||
当你在Files中时(Ubuntu中的文件管理器),查看顶部菜单。你会看到书签按钮。点击它你会看到将当前路径保存为书签的选项。
|
||||
|
||||

|
||||
|
||||
#### 方法 2: ####
|
||||
|
||||
你可以直接按下Ctrl+D就可以将当前位置保存位书签。
|
||||
|
||||
如你所见,这里左边栏就有一个新添加的Copy目录:
|
||||
|
||||

|
||||
|
||||
### 管理书签 ###
|
||||
|
||||
如果你不想要太多的书签或者你错误地添加了一个书签,你可以很简单地删除它。按下Ctrl+B查看所有的书签。现在选择想要删除的书签并点击删除。
|
||||
|
||||

|
||||
|
||||
这就是在Ubuntu中管理书签需要做的。我知道这对于大多数用户而言很贱,但是这也许多Ubuntu的新手而言或许还有用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/add-remove-bookmarks-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/install-copy-in-ubuntu-14-04/
|
||||
151
translated/tech/20150918 Install Justniffer In Ubuntu 15.04.md
Normal file
151
translated/tech/20150918 Install Justniffer In Ubuntu 15.04.md
Normal file
@ -0,0 +1,151 @@
|
||||
在 Ubuntu 15.04 上安装 Justniffer
|
||||
================================================================================
|
||||
### 简介 ###
|
||||
|
||||
[Justniffer][1] 是一个可用于替换 Snort 的网络协议分析器。它非常流行,可交互式地跟踪/探测一个网络连接。它能从实时环境中抓取流量,支持 “lipcap” 和 “tcpdump” 文件格式。它可以帮助用户分析一个用 wireshark 难以抓包的复杂网络。尤其是它可以有效的帮助分析应用层流量,能提取类似图像、脚本、HTML 等 http 内容。Justniffer 有助于理解不同组件之间是如何通信的。
|
||||
|
||||
### 功能 ###
|
||||
|
||||
Justniffer 收集一个复杂网络的所有流量而不影响系统性能,这是 Justniffer 的一个优势,它还可以保存日志用于之后的分析,Justniffer 其它一些重要功能包括:
|
||||
|
||||
#### 1. 可靠的 TCP 流重建 ####
|
||||
|
||||
它可以使用主机 Linux 内核的一部分用于记录并重现 TCP 片段和 IP 片段。
|
||||
|
||||
#### 2. 日志 ####
|
||||
|
||||
保存日志用于之后的分析,并能自定义保存内容和时间。
|
||||
|
||||
#### 3. 可扩展 ####
|
||||
|
||||
可以通过外部 python、 perl 和 bash 脚本扩展来从分析报告中获取一些额外的结果。
|
||||
|
||||
#### 4. 性能管理 ####
|
||||
|
||||
基于连接时间、关闭时间、响应时间或请求时间等提取信息。
|
||||
|
||||
### 安装 ###
|
||||
|
||||
Justniffer 可以通过 PPA 安装:
|
||||
|
||||
运行下面命令添加库:
|
||||
|
||||
$ sudo add-apt-repository ppa:oreste-notelli/ppa
|
||||
|
||||
更新系统:
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
安装 Justniffer 工具:
|
||||
|
||||
$ sudo apt-get install justniffer
|
||||
|
||||
make 的时候失败了,然后我运行下面的命令并尝试重新安装服务
|
||||
|
||||
$ sudo apt-get -f install
|
||||
|
||||
### 事例 ###
|
||||
|
||||
首先用 -v 选项验证安装的 Justniffer 版本,你需要用超级用户权限来使用这个工具。
|
||||
|
||||
$ sudo justniffer -V
|
||||
|
||||
事例输出:
|
||||
|
||||

|
||||
|
||||
**1. 为 eth1 接口导出 apache 中的流量到终端**
|
||||
|
||||
$ sudo justniffer -i eth1
|
||||
|
||||
事例输出:
|
||||
|
||||

|
||||
|
||||
**2. 可以永恒下面的选项跟踪正在运行的 tcp 流**
|
||||
|
||||
$ sudo justniffer -i eth1 -r
|
||||
|
||||
事例输出:
|
||||
|
||||

|
||||
|
||||
**3. 获取 web 服务器的响应时间**
|
||||
|
||||
$ sudo justniffer -i eth1 -a " %response.time"
|
||||
|
||||
事例输出:
|
||||
|
||||

|
||||
|
||||
**4. 使用 Justniffer 读取一个 tcpdump 抓取的文件**
|
||||
|
||||
首先,用 tcpdump 抓取流量。
|
||||
|
||||
$ sudo tcpdump -w /tmp/file.cap -s0 -i eth0
|
||||
|
||||
然后用 Justniffer 访问数据
|
||||
|
||||
$ justniffer -f file.cap
|
||||
|
||||
事例输出:
|
||||
|
||||

|
||||
|
||||
**5. 只抓取 http 数据**
|
||||
|
||||
$ sudo justniffer -i eth1 -r -p "port 80 or port 8080"
|
||||
|
||||
事例输出:
|
||||
|
||||

|
||||
|
||||
**6. 从一个指定主机获取 http 数据**
|
||||
|
||||
$ justniffer -i eth1 -r -p "host 192.168.1.250 and tcp port 80"
|
||||
|
||||
事例输出:
|
||||
|
||||

|
||||
|
||||
**7. 以更精确的格式抓取数据**
|
||||
|
||||
当你输入 **justniffer -h** 的时候你可以看到很多用于以更精确的方式获取数据的格式关键字
|
||||
|
||||
$ justniffer -h
|
||||
|
||||
事例输出:
|
||||
|
||||

|
||||
|
||||
让我们用 Justniffer 根据预先定义的参数提取数据
|
||||
|
||||
$ justniffer -i eth1 -l "%request.timestamp %request.header.host %request.url %response.time"
|
||||
|
||||
事例输出:
|
||||
|
||||

|
||||
|
||||
其中还有很多你可以探索的选项
|
||||
|
||||
### 总结 ###
|
||||
|
||||
Justniffer 是用于网络测试一个很好的工具。在我看来对于那些用 Snort 来进行网络探测的用户来说,Justniffer 是一个更简单的工具。它提供了很多 **格式关键字** 用于按照你的需要精确地提取数据。你可以用 .cap 文件格式记录网络信息,之后用于分析监视网络服务性能。
|
||||
|
||||
**参考资料:**
|
||||
|
||||
- [Justniffer 官网][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/install-justniffer-ubuntu-15-04/
|
||||
|
||||
作者:[Rajneesh Upadhyay][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/rajneesh/
|
||||
[1]:http://sourceforge.net/projects/justniffer/?source=directory
|
||||
[2]:http://justniffer.sourceforge.net/
|
||||
@ -0,0 +1,211 @@
|
||||
安装 Samba 并配置 Firewalld 和 SELinux 使得能在 Linux 和 Windows 之间共享文件 - 第六部分
|
||||
================================================================================
|
||||
由于计算机很少作为一个独立的系统工作,作为一个系统管理员或工程师,就应该知道如何在有多种类型的服务器之间搭设和维护网络。
|
||||
|
||||
在本篇以及该系列后面的文章中,我们会介绍用 Windows/Linux 配置 Samba 和 NFS 服务器以及 Linux 客户端。
|
||||
|
||||

|
||||
|
||||
RHCE 系列第六部分 - 设置 Samba 文件共享
|
||||
|
||||
如果有人叫你设置文件服务器用于协作或者配置很可能有多种不同类型操作系统和设备的企业环境,这篇文章就能派上用场。
|
||||
|
||||
由于你可以在网上找到很多关于 Samba 和 NFS 背景和技术方面的介绍,在这篇文章以及后续文章中我们就省略了这些部分直接进入到我们的主题。
|
||||
|
||||
### 步骤一: 安装 Samba 服务器 ###
|
||||
|
||||
我们当前的测试环境包括两台 RHEL 7 和一台 Windows 8:
|
||||
|
||||
1. Samba / NFS 服务器 [box1 (RHEL 7): 192.168.0.18],
|
||||
2. Samba 客户端 #1 [box2 (RHEL 7): 192.168.0.20]
|
||||
3. Samba 客户端 #2 [Windows 8 machine: 192.168.0.106]
|
||||
|
||||

|
||||
|
||||
测试安装 Samba
|
||||
|
||||
在 box1 中安装以下软件包:
|
||||
|
||||
# yum update && yum install samba samba-client samba-common
|
||||
|
||||
在 box2:
|
||||
|
||||
# yum update && yum install samba samba-client samba-common cifs-utils
|
||||
|
||||
安装完成后,就可以配置我们的共享了。
|
||||
|
||||
### 步骤二: 设置通过 Samba 进行文件共享 ###
|
||||
|
||||
Samba 这么重要的原因之一是它为 SMB/CIFS 客户端(译者注:SMB 是微软和英特尔制定的一种通信协议,CIFS 是其中一个版本,更详细的介绍可以参考[Wiki][6])提供了文件和打印设备,这使得客户端看起来服务器就是一个 Windows 系统(我必须承认写这篇文章的时候我有一点激动,因为这是我多年前作为一个新手 Linux 系统管理员的第一次设置)。
|
||||
|
||||
**添加系统用户并设置权限和属性**
|
||||
|
||||
为了允许组协作,我们会在 box1 中用 [useradd 命令][1]创建一个有两个用户(user1 和 user2)的组 finance 和目录 /finance。
|
||||
|
||||
我们同时会把这个目录的组所有者更改为 finance 并把权限设置为 0777(所有者和组属主可读可写可执行):
|
||||
|
||||
# groupadd finance
|
||||
# useradd user1
|
||||
# useradd user2
|
||||
# usermod -a -G finance user1
|
||||
# usermod -a -G finance user2
|
||||
# mkdir /finance
|
||||
# chmod 0770 /finance
|
||||
# chgrp finance /finance
|
||||
|
||||
### 步骤三: 配置 SELinux 和 Firewalld ###
|
||||
|
||||
在配置 /finance 作为 Samba 共享目录之前,我们需要像下面那样停用 SELinux 或设置恰当的布尔值和安全选项(否则,SELinux 会阻止客户端访问共享目录):
|
||||
|
||||
# setsebool -P samba_export_all_ro=1 samba_export_all_rw=1
|
||||
# getsebool –a | grep samba_export
|
||||
# semanage fcontext –at samba_share_t "/finance(/.*)?"
|
||||
# restorecon /finance
|
||||
|
||||
另外我们必须确保 [firewalld][2] 允许 Samba 流量通过。
|
||||
|
||||
# firewall-cmd --permanent --add-service=samba
|
||||
# firewall-cmd --reload
|
||||
|
||||
### 步骤四: 配置 Samba 共享目录 ###
|
||||
|
||||
现在我们来看看配置文件 /etc/samba/smb.conf 并添加用于共享的章节(section):我们希望组 finance 的成员可以浏览 /finance 的内容,在里面保存/创建文件或者子目录(默认权限为 0777,组所有者为 finance):
|
||||
|
||||
**smb.conf**
|
||||
|
||||
----------
|
||||
|
||||
[finance]
|
||||
comment=Directory for collaboration of the company's finance team
|
||||
browsable=yes
|
||||
path=/finance
|
||||
public=no
|
||||
valid users=@finance
|
||||
write list=@finance
|
||||
writeable=yes
|
||||
create mask=0770
|
||||
Force create mode=0770
|
||||
force group=finance
|
||||
|
||||
保存文件然后用 testparm 工具进行测试。如果这里有任何错误,命令的输出或提示你需要如何修复。否则,会显示你 Samba 服务器配置的回顾:
|
||||
|
||||
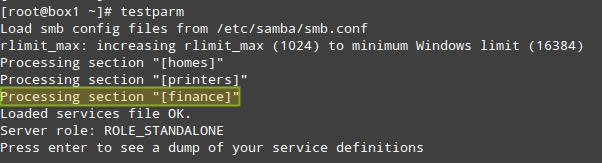
|
||||
|
||||
测试 Samba 配置
|
||||
|
||||
如果你要添加另一个公开的共享目录(意味着没有任何验证),在 /etc/samba/smb.conf 中创建另一章节,在共享目录名称下面复制上面的章节,只需要把 public=no 更改为 public=yes 并去掉有效用户和写列表命令。
|
||||
|
||||
### 步骤五: 添加 Samba 用户 ###
|
||||
|
||||
下一步,你需要添加 user1 和 user2 作为 Samba 的用户。要做到这点,你需要用 smbpasswd 命令,它会和 Samba 的数据库进行交互。会提示你输入一个命令用于你之后和共享目录连接:
|
||||
|
||||
# smbpasswd -a user1
|
||||
# smbpasswd -a user2
|
||||
|
||||
最后,重启 Samda,启用系统启动时自动启动服务,并确保共享目录对网络客户端可用:
|
||||
|
||||
# systemctl start smb
|
||||
# systemctl enable smb
|
||||
# smbclient -L localhost –U user1
|
||||
# smbclient -L localhost –U user2
|
||||
|
||||
|
||||

|
||||
|
||||
验证 Samba 共享
|
||||
|
||||
到这里,已经正确安装和配置了 Samba 文件服务器。现在让我们在 RHEL 7 和 Windows 8 客户端中测试该配置。
|
||||
|
||||
### 步骤六: 在 Linux 中挂载 Samba 共享 ###
|
||||
|
||||
首先,确保客户端可以访问 Samba 共享:
|
||||
|
||||
# smbclient –L 192.168.0.18 -U user2
|
||||
|
||||
|
||||

|
||||
|
||||
在 Linux 上挂载 Samba 共享
|
||||
|
||||
(为 user1 重复上面的命令)
|
||||
|
||||
正如任何其它存储介质,当你需要的时候你可以挂载(之后卸载)该网络共享:
|
||||
|
||||
# mount //192.168.0.18/finance /media/samba -o username=user1
|
||||
|
||||

|
||||
|
||||
挂载 Samba 网络共享
|
||||
|
||||
(其中 /media/samba 是一个已有的目录)
|
||||
|
||||
或者在 /etc/fstab 文件中添加下面的条目自动挂载:
|
||||
|
||||
**fstab**
|
||||
|
||||
----------
|
||||
|
||||
//192.168.0.18/finance /media/samba cifs credentials=/media/samba/.smbcredentials,defaults 0 0
|
||||
|
||||
其中隐藏文件 /media/samba/.smbcredentials(它的权限被设置为 600 和 root:root)有两行,指示允许使用共享的账户的用户名和密码:
|
||||
|
||||
**.smbcredentials**
|
||||
|
||||
----------
|
||||
|
||||
username=user1
|
||||
password=PasswordForUser1
|
||||
|
||||
最后,让我们在 /finance 中创建一个文件并检查权限和属性:
|
||||
|
||||
# touch /media/samba/FileCreatedInRHELClient.txt
|
||||
|
||||

|
||||
|
||||
在 Samba 共享中创建文件
|
||||
|
||||
正如你看到的,用权限 0770 和属主 user1:finance 创建了文件。
|
||||
|
||||
### 步骤七: 在 Windows 上挂载 Samba 共享 ###
|
||||
|
||||
要在 Windows 上挂载 Samba 共享,进入 ‘我的计算机’ 并选择 ‘计算机’,‘网络驱动映射’。下一步,为要映射的驱动分配一个字母并用不同的认证检查连接(下面的截图使用我的母语西班牙语):
|
||||
|
||||

|
||||
|
||||
在 Windows 中挂载 Samba 共享
|
||||
|
||||
最后,让我们新建一个文件并检查权限和属性:
|
||||
|
||||

|
||||
|
||||
在 Windows Samba 共享中新建文件
|
||||
|
||||
# ls -l /finance
|
||||
|
||||
这次文件属于 user2,因为这是我们用于从 Windows 客户端中连接的账户。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇文章中我们不仅介绍了如何使用不同操作系统设置 Samba 服务器和两个客户端,也介绍了[如何配置 Firewalld][3] 和 [服务器中的 SELinux][4] 以获取所需的组协作功能。
|
||||
|
||||
最后,同样重要的是,我推荐阅读网上的 [smb.conf man 手册][5] 查看其它可能针对你的情况比本文中介绍的场景更加合适的配置命令。
|
||||
|
||||
正如往常,欢迎在下面的评论框中留下你的评论或建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/setup-samba-file-sharing-for-linux-windows-clients/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/add-users-in-linux/
|
||||
[2]:http://www.tecmint.com/firewalld-vs-iptables-and-control-network-traffic-in-firewall/
|
||||
[3]:http://www.tecmint.com/configure-firewalld-in-centos-7/
|
||||
[4]:http://www.tecmint.com/selinux-essentials-and-control-filesystem-access/
|
||||
[5]:https://www.samba.org/samba/docs/man/manpages-3/smb.conf.5.html
|
||||
[6]:https://en.wikipedia.org/wiki/Server_Message_Block
|
||||
@ -0,0 +1,190 @@
|
||||
第七部分 - 在 Linux 客户端配置基于 Kerberos 身份验证的 NFS 服务器
|
||||
================================================================================
|
||||
在本系列的前一篇文章,我们回顾了[如何在可能包括多种类型操作系统的网络上配置 Samba 共享][1]。现在,如果你需要为一组类-Unix 客户端配置文件共享,很自然的你会想到网络文件系统,或简称 NFS。
|
||||
|
||||
|
||||

|
||||
|
||||
RHCE 系列:第七部分 - 设置使用 Kerberos 进行身份验证的 NFS 服务器
|
||||
|
||||
在这篇文章中我们会介绍配置基于 Kerberos 身份验证的 NFS 共享的整个流程。假设你已经配置好了一个 NFS 服务器和一个客户端。如果还没有,可以参考 [安装和配置 NFS 服务器][2] - 它列出了需要安装的依赖软件包并解释了在进行下一步之前如何在服务器上进行初始化配置。
|
||||
|
||||
另外,你可能还需要配置 [SELinux][3] 和 [firewalld][4] 以允许通过 NFS 进行文件共享。
|
||||
|
||||
下面的例子假设你的 NFS 共享目录在 box2 的 /nfs:
|
||||
|
||||
# semanage fcontext -a -t public_content_rw_t "/nfs(/.*)?"
|
||||
# restorecon -R /nfs
|
||||
# setsebool -P nfs_export_all_rw on
|
||||
# setsebool -P nfs_export_all_ro on
|
||||
|
||||
(其中 -P 标记指示重启持久有效)。
|
||||
|
||||
最后,别忘了:
|
||||
|
||||
#### 创建 NFS 组并配置 NFS 共享目录 ####
|
||||
|
||||
1. 新建一个名为 nfs 的组并给它添加用户 nfsnobody,然后更改 /nfs 目录的权限为 0770,组属主为 nfs。于是,nfsnobody(对应请求用户)在共享目录有写的权限,你就不需要在 /etc/exports 文件中使用 no_root_squash(译者注:设为 root_squash 意味着在访问 NFS 服务器上的文件时,客户机上的 root 用户不会被当作 root 用户来对待)。
|
||||
|
||||
# groupadd nfs
|
||||
# usermod -a -G nfs nfsnobody
|
||||
# chmod 0770 /nfs
|
||||
# chgrp nfs /nfs
|
||||
|
||||
2. 像下面那样更改 export 文件(/etc/exports)只允许从 box1 使用 Kerberos 安全验证的访问(sec=krb5)。
|
||||
|
||||
**注意**:anongid 的值设置为之前新建的组 nfs 的 GID:
|
||||
|
||||
**exports – 添加 NFS 共享**
|
||||
|
||||
----------
|
||||
|
||||
/nfs box1(rw,sec=krb5,anongid=1004)
|
||||
|
||||
3. 再次 exprot(-r)所有(-a)NFS 共享。为输出添加详情(-v)是个好主意,因为它提供了发生错误时解决问题的有用信息:
|
||||
|
||||
# exportfs -arv
|
||||
|
||||
4. 重启并启用 NFS 服务器以及相关服务。注意你不需要启动 nfs-lock 和 nfs-idmapd,因为系统启动时其它服务会自动启动它们:
|
||||
|
||||
# systemctl restart rpcbind nfs-server nfs-lock nfs-idmap
|
||||
# systemctl enable rpcbind nfs-server
|
||||
|
||||
#### 测试环境和其它前提要求 ####
|
||||
|
||||
在这篇指南中我们使用下面的测试环境:
|
||||
|
||||
- 客户端机器 [box1: 192.168.0.18]
|
||||
- NFS / Kerberos 服务器 [box2: 192.168.0.20] (也称为密钥分发中心,简称 KDC)。
|
||||
|
||||
**注意**:Kerberos 服务是至关重要的认证方案。
|
||||
|
||||
正如你看到的,为了简便,NFS 服务器和 KDC 在同一台机器上,当然如果你有更多可用机器你也可以把它们安装在不同的机器上。两台机器都在 `mydomain.com` 域。
|
||||
|
||||
最后同样重要的是,Kerberos 要求客户端和服务器中至少有一个域名解析的基本模式和[网络时间协议][5]服务,因为 Kerberos 身份验证的安全一部分基于时间戳。
|
||||
|
||||
为了配置域名解析,我们在客户端和服务器中编辑 /etc/hosts 文件:
|
||||
|
||||
**host 文件 – 为域添加 DNS**
|
||||
|
||||
----------
|
||||
|
||||
192.168.0.18 box1.mydomain.com box1
|
||||
192.168.0.20 box2.mydomain.com box2
|
||||
|
||||
在 RHEL 7 中,chrony 是用于 NTP 同步的默认软件:
|
||||
|
||||
# yum install chrony
|
||||
# systemctl start chronyd
|
||||
# systemctl enable chronyd
|
||||
|
||||
为了确保 chrony 确实在和时间服务器同步你系统的时间,你可能要输入下面的命令两到三次,确保时间偏差尽可能接近 0:
|
||||
|
||||
# chronyc tracking
|
||||
|
||||
|
||||

|
||||
|
||||
用 Chrony 同步服务器时间
|
||||
|
||||
### 安装和配置 Kerberos ###
|
||||
|
||||
要设置 KDC,首先在客户端和服务器安装下面的软件包(客户端不需要 server 软件包):
|
||||
|
||||
# yum update && yum install krb5-server krb5-workstation pam_krb5
|
||||
|
||||
安装完成后,编辑配置文件(/etc/krb5.conf 和 /var/kerberos/krb5kdc/kadm5.acl),像下面那样用 `mydomain.com` 替换所有 example.com。
|
||||
|
||||
下一步,确保 Kerberos 能功过防火墙并启动/启用相关服务。
|
||||
|
||||
**重要**:客户端也必须启动和启用 nfs-secure:
|
||||
|
||||
# firewall-cmd --permanent --add-service=kerberos
|
||||
# systemctl start krb5kdc kadmin nfs-secure
|
||||
# systemctl enable krb5kdc kadmin nfs-secure
|
||||
|
||||
现在创建 Kerberos 数据库(请注意这可能会需要一点时间,因为它会和你的系统进行多次交互)。为了加速这个过程,我打开了另一个终端并运行了 ping -f localhost 30 到 45 秒):
|
||||
|
||||
# kdb5_util create -s
|
||||
|
||||

|
||||
|
||||
创建 Kerberos 数据库
|
||||
|
||||
下一步,使用 kadmin.local 工具为 root 创建管理权限:
|
||||
|
||||
# kadmin.local
|
||||
# addprinc root/admin
|
||||
|
||||
添加 Kerberos 服务器到数据库:
|
||||
|
||||
# addprinc -randkey host/box2.mydomain.com
|
||||
|
||||
在客户端(box1)和服务器(box2)上对 NFS 服务同样操作。请注意下面的截图中在退出前我忘了在 box1 上进行操作:
|
||||
|
||||
# addprinc -randkey nfs/box2.mydomain.com
|
||||
# addprinc -randkey nfs/box1.mydomain.com
|
||||
|
||||
输入 quit 和回车键退出:
|
||||
|
||||

|
||||
|
||||
添加 Kerberos 到 NFS 服务器
|
||||
|
||||
为 root/admin 获取和缓存票据授权票据(ticket-granting ticket):
|
||||
|
||||
# kinit root/admin
|
||||
# klist
|
||||
|
||||
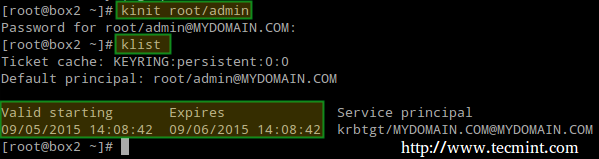
|
||||
|
||||
缓存 Kerberos
|
||||
|
||||
真正使用 Kerberos 之前的最后一步是保存被授权使用 Kerberos 身份验证的规则到一个密钥表文件(在服务器中):
|
||||
|
||||
# kdadmin.local
|
||||
# ktadd host/box2.mydomain.com
|
||||
# ktadd nfs/box2.mydomain.com
|
||||
# ktadd nfs/box1.mydomain.com
|
||||
|
||||
最后,挂载共享目录并进行一个写测试:
|
||||
|
||||
# mount -t nfs4 -o sec=krb5 box2:/nfs /mnt
|
||||
# echo "Hello from Tecmint.com" > /mnt/greeting.txt
|
||||
|
||||

|
||||
|
||||
挂载 NFS 共享
|
||||
|
||||
现在让我们卸载共享,在客户端中重命名密钥表文件(模拟它不存在)然后试着再次挂载共享目录:
|
||||
|
||||
# umount /mnt
|
||||
# mv /etc/krb5.keytab /etc/krb5.keytab.orig
|
||||
|
||||

|
||||
|
||||
挂载/卸载 Kerberos NFS 共享
|
||||
|
||||
现在你可以使用基于 Kerberos 身份验证的 NFS 共享了。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇文章中我们介绍了如何设置带 Kerberos 身份验证的 NFS。和我们在这篇指南中介绍的相比,该主题还有很多相关内容,可以在 [Kerberos 手册][6] 查看,另外至少可以说 Kerberos 有一点棘手,如果你在测试或实现中遇到了任何问题或需要帮助,别犹豫在下面的评论框中告诉我们吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/setting-up-nfs-server-with-kerberos-based-authentication/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/setup-samba-file-sharing-for-linux-windows-clients/
|
||||
[2]:http://www.tecmint.com/configure-nfs-server/
|
||||
[3]:http://www.tecmint.com/selinux-essentials-and-control-filesystem-access/
|
||||
[4]:http://www.tecmint.com/firewalld-rules-for-centos-7/
|
||||
[5]:http://www.tecmint.com/install-ntp-server-in-centos/
|
||||
[6]:http://web.mit.edu/kerberos/krb5-1.12/doc/admin/admin_commands/
|
||||
@ -0,0 +1,210 @@
|
||||
RHCE 系列: 使用网络安全服务(NSS)为 Apache 通过 TLS 实现 HTTPS
|
||||
================================================================================
|
||||
如果你是一个负责维护和确保 web 服务器安全的系统管理员,你不能不花费最大的精力确保服务器中处理和通过的数据任何时候都受到保护。
|
||||

|
||||
|
||||
RHCE 系列:第八部分 - 使用网络安全服务(NSS)为 Apache 通过 TLS 实现 HTTPS
|
||||
|
||||
为了在客户端和服务器之间提供更安全的连接,作为 HTTP 和 SSL(安全套接层)或者最近称为 TLS(传输层安全)的组合,产生了 HTTPS 协议。
|
||||
|
||||
由于一些严重的安全漏洞,SSL 已经被更健壮的 TLS 替代。由于这个原因,在这篇文章中我们会解析如何通过 TLS 实现你 web 服务器和客户端之间的安全连接。
|
||||
|
||||
这里假设你已经安装并配置好了 Apache web 服务器。如果还没有,在进入下一步之前请阅读下面站点中的文章。
|
||||
|
||||
- [在 RHEL/CentOS 7 上安装 LAMP(Linux,MySQL/MariaDB,Apache 和 PHP)][1]
|
||||
|
||||
### 安装 OpenSSL 和一些工具包 ###
|
||||
|
||||
首先,确保正在运行 Apache 并且允许 http 和 https 通过防火墙:
|
||||
|
||||
# systemctl start http
|
||||
# systemctl enable http
|
||||
# firewall-cmd --permanent –-add-service=http
|
||||
# firewall-cmd --permanent –-add-service=https
|
||||
|
||||
然后安装一些必须软件包:
|
||||
|
||||
# yum update && yum install openssl mod_nss crypto-utils
|
||||
|
||||
**重要**:请注意如果你想使用 OpenSSL 库而不是 NSS(网络安全服务)实现 TLS,你可以在上面的命令中用 mod\_ssl 替换 mod\_nss(使用哪一个取决于你,但在这篇文章中由于更加健壮我们会使用 NSS;例如,它支持最新的加密标准,比如 PKCS #11)。
|
||||
|
||||
如果你使用 mod\_nss,首先要卸载 mod\_ssl,反之如此。
|
||||
|
||||
# yum remove mod_ssl
|
||||
|
||||
### 配置 NSS(网络安全服务)###
|
||||
|
||||
安装完 mod\_nss 之后,会创建默认的配置文件 /etc/httpd/conf.d/nss.conf。你应该确保所有 Listen 和 VirualHost 指令都指向 443 号端口(HTTPS 默认端口):
|
||||
|
||||
nss.conf – 配置文件
|
||||
|
||||
----------
|
||||
|
||||
Listen 443
|
||||
VirtualHost _default_:443
|
||||
|
||||
然后重启 Apache 并检查是否加载了 mod\_nss 模块:
|
||||
|
||||
# apachectl restart
|
||||
# httpd -M | grep nss
|
||||
|
||||

|
||||
|
||||
检查 Apache 是否加载 mod\_nss 模块
|
||||
|
||||
下一步,在 `/etc/httpd/conf.d/nss.conf` 配置文件中做以下更改:
|
||||
|
||||
1. 指定 NSS 数据库目录。你可以使用默认的目录或者新建一个。本文中我们使用默认的:
|
||||
|
||||
NSSCertificateDatabase /etc/httpd/alias
|
||||
|
||||
2. 通过保存密码到数据库目录中的 /etc/httpd/nss-db-password.conf 文件避免每次系统启动时要手动输入密码:
|
||||
|
||||
NSSPassPhraseDialog file:/etc/httpd/nss-db-password.conf
|
||||
|
||||
其中 /etc/httpd/nss-db-password.conf 只包含以下一行,其中 mypassword 是后面你为 NSS 数据库设置的密码:
|
||||
|
||||
internal:mypassword
|
||||
|
||||
另外,要设置该文件的权限和属主为 0640 和 root:apache:
|
||||
|
||||
# chmod 640 /etc/httpd/nss-db-password.conf
|
||||
# chgrp apache /etc/httpd/nss-db-password.conf
|
||||
|
||||
3. 由于 POODLE SSLv3 漏洞,红帽建议停用 SSL 和 TLSv1.0 之前所有版本的 TLS(更多信息可以查看[这里][2])。
|
||||
|
||||
确保 NSSProtocol 指令的每个实例都类似下面一样(如果你没有托管其它虚拟主机,很可能只有一条):
|
||||
|
||||
NSSProtocol TLSv1.0,TLSv1.1
|
||||
|
||||
4. 由于这是一个自签名证书,Apache 会拒绝重启,并不会识别为有效发行人。由于这个原因,对于这种特殊情况我们还需要添加:
|
||||
|
||||
NSSEnforceValidCerts off
|
||||
|
||||
5. 虽然并不是严格要求,为 NSS 数据库设置一个密码同样很重要:
|
||||
|
||||
# certutil -W -d /etc/httpd/alias
|
||||
|
||||
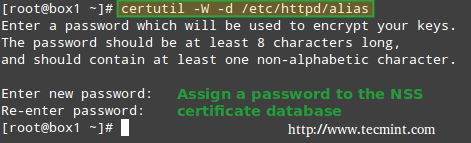
|
||||
|
||||
为 NSS 数据库设置密码
|
||||
|
||||
### 创建一个 Apache SSL 自签名证书 ###
|
||||
|
||||
下一步,我们会创建一个自签名证书为我们的客户机识别服务器(请注意这个方法对于生产环境并不是最好的选择;对于生产环境你应该考虑购买第三方可信证书机构验证的证书,例如 DigiCert)。
|
||||
|
||||
我们用 genkey 命令为 box1 创建有效期为 365 天的 NSS 兼容证书。完成这一步后:
|
||||
|
||||
# genkey --nss --days 365 box1
|
||||
|
||||
选择 Next:
|
||||
|
||||

|
||||
|
||||
创建 Apache SSL 密钥
|
||||
|
||||
你可以使用默认的密钥大小(2048),然后再次选择 Next:
|
||||
|
||||

|
||||
|
||||
选择 Apache SSL 密钥大小
|
||||
|
||||
等待系统生成随机比特:
|
||||
|
||||

|
||||
|
||||
生成随机密钥比特
|
||||
|
||||
为了加快速度,会提示你在控制台输入随机字符,正如下面的截图所示。请注意当没有从键盘接收到输入时进度条是如何停止的。然后,会让你选择:
|
||||
|
||||
1. 是否发送验证签名请求(CSR)到一个验证机构(CA):选择 No,因为这是一个自签名证书。
|
||||
|
||||
2. 为证书输入信息。
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" src="//www.youtube.com/embed/mgsfeNfuurA" allowfullscreen="allowfullscreen"></iframe>
|
||||
|
||||
最后,会提示你输入之前设置的密码到 NSS 证书:
|
||||
|
||||
# genkey --nss --days 365 box1
|
||||
|
||||

|
||||
|
||||
Apache NSS 证书密码
|
||||
|
||||
在任何时候你都可以用以下命令列出现有的证书:
|
||||
|
||||
# certutil –L –d /etc/httpd/alias
|
||||
|
||||

|
||||
|
||||
列出 Apache NSS 证书
|
||||
|
||||
然后通过名字删除(除非严格要求,用你自己的证书名称替换 box1):
|
||||
|
||||
# certutil -d /etc/httpd/alias -D -n "box1"
|
||||
|
||||
如果你需要继续的话:
|
||||
|
||||
### 测试 Apache SSL HTTPS 连接 ###
|
||||
|
||||
最后,是时候测试到我们服务器的安全连接了。当你用浏览器打开 https://<web 服务器 IP 或主机名\>,你会看到著名的信息 “This connection is untrusted”:
|
||||
|
||||

|
||||
|
||||
检查 Apache SSL 连接
|
||||
|
||||
在上面的情况中,你可以点击添加例外(Add Exception) 然后确认安全例外(Confirm Security Exception) - 但先不要这么做。让我们首先来看看证书看它的信息是否和我们之前输入的相符(如截图所示)。
|
||||
|
||||
要做到这点,点击上面的视图(View...)-> 详情(Details)选项卡,当你从列表中选择发行人你应该看到这个:
|
||||
|
||||

|
||||
|
||||
确认 Apache SSL 证书详情
|
||||
|
||||
现在你继续,确认例外(限于此次或永久),然后会通过 https 把你带到你 web 服务器的 DocumentRoot 目录,在这里你可以使用你浏览器自带的开发者工具检查连接详情:
|
||||
|
||||
在火狐浏览器中,你可以通过在屏幕中右击然后从上下文菜单中选择检查元素(Inspect Element)启动,尤其是通过网络选项卡:
|
||||
|
||||

|
||||
|
||||
检查 Apache HTTPS 连接
|
||||
|
||||
请注意这和之前显示的在验证过程中输入的信息一致。还有一种方式通过使用命令行工具测试连接:
|
||||
|
||||
左边(测试 SSLv3):
|
||||
|
||||
# openssl s_client -connect localhost:443 -ssl3
|
||||
|
||||
右边(测试 TLS):
|
||||
|
||||
# openssl s_client -connect localhost:443 -tls1
|
||||
|
||||

|
||||
|
||||
测试 Apache SSL 和 TLS 连接
|
||||
|
||||
参考上面的截图了解更相信信息。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
我确信你已经知道,使用 HTTPS 会增加会在你站点中输入个人信息的访客的信任(从用户名和密码到任何商业/银行账户信息)。
|
||||
|
||||
在那种情况下,你会希望获得由可信验证机构签名的证书,正如我们之前解释的(启用的步骤和发送 CSR 到 CA 然后获得签名证书的例子相同);另外的情况,就是像我们的例子中一样使用自签名证书。
|
||||
|
||||
要获取更多关于使用 NSS 的详情,可以参考关于 [mod-nss][3] 的在线帮助。如果你有任何疑问或评论,请告诉我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/create-apache-https-self-signed-certificate-using-nss/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[ictlyh](http://www.mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/install-lamp-in-centos-7/
|
||||
[1]:http://www.tecmint.com/author/gacanepa/
|
||||
[2]:https://access.redhat.com/articles/1232123
|
||||
[3]:https://git.fedorahosted.org/cgit/mod_nss.git/plain/docs/mod_nss.html
|
||||
@ -1,224 +0,0 @@
|
||||
RHCSA 系列: 如何管理RHEL7的用户和组 – Part 3
|
||||
================================================================================
|
||||
和管理其他Linux服务器一样,管理一个 RHEL 7 服务器 要求你能够添加,修改,暂停或删除用户帐户,并且授予他们文件,目录,其他系统资源所必要的权限。
|
||||

|
||||
|
||||
RHCSA: 用户和组管理 – Part 3
|
||||
|
||||
### 管理用户帐户##
|
||||
|
||||
如果想要给RHEL 7 服务器添加账户,你需要以root用户执行如下两条命令
|
||||
|
||||
# adduser [new_account]
|
||||
# useradd [new_account]
|
||||
|
||||
当添加新的用户帐户时,默认会执行下列操作。
|
||||
|
||||
- 他/她 的主目录就会被创建(一般是"/home/用户名",除非你特别设置)
|
||||
- 一些隐藏文件 如`.bash_logout`, `.bash_profile` 以及 `.bashrc` 会被复制到用户的主目录,并且会为用户的回话提供环境变量.你可以进一步查看他们的相关细节。
|
||||
- 会为您的账号添加一个邮件池目录
|
||||
- 会创建一个和用户名同样的组
|
||||
|
||||
用户帐户的全部信息被保存在`/etc/passwd `文件。这个文件以如下格式保存了每一个系统帐户的所有信息(以:分割)
|
||||
[username]:[x]:[UID]:[GID]:[Comment]:[Home directory]:[Default shell]
|
||||
|
||||
- `[username]` 和`[Comment]` 是用于自我解释的
|
||||
- ‘x’表示帐户的密码保护(详细在`/etc/shadow`文件),就是我们用于登录的`[username]`.
|
||||
- `[UID]` 和`[GID]`是用于显示`[username]` 的 用户认证和主用户组。
|
||||
|
||||
最后,
|
||||
|
||||
- `[Home directory]`显示`[username]`的主目录的绝对路径
|
||||
- `[Default shell]` 是当用户登录系统后使用的默认shell
|
||||
|
||||
另外一个你必须要熟悉的重要的文件是存储组信息的`/etc/group`.因为和`/etc/passwd`类似,所以也是由:分割
|
||||
[Group name]:[Group password]:[GID]:[Group members]
|
||||
|
||||
|
||||
|
||||
- `[Group name]` 是组名
|
||||
- 这个组是否使用了密码 (如果是"X"意味着没有).
|
||||
- `[GID]`: 和`/etc/passwd`中一样
|
||||
- `[Group members]`:用户列表,使用,隔开。里面包含组内的所有用户
|
||||
|
||||
添加过帐户后,任何时候你都可以通过 usermod 命令来修改用户战壕沟,基础的语法如下:
|
||||
# usermod [options] [username]
|
||||
|
||||
相关阅读
|
||||
|
||||
- [15 ‘useradd’ Command Examples][1]
|
||||
- [15 ‘usermod’ Command Examples][2]
|
||||
|
||||
#### 示例1 : 设置帐户的过期时间 ####
|
||||
|
||||
如果你的公司有一些短期使用的帐户或者你相应帐户在有限时间内使用,你可以使用 `--expiredate` 参数 ,后加YYYY-MM-DD格式的日期。为了查看是否生效,你可以使用如下命令查看
|
||||
# chage -l [username]
|
||||
|
||||
帐户更新前后的变动如下图所示
|
||||

|
||||
|
||||
修改用户信息
|
||||
|
||||
#### 示例 2: 向组内追加用户 ####
|
||||
|
||||
除了创建用户时的主用户组,一个用户还能被添加到别的组。你需要使用 -aG或 -append -group 选项,后跟逗号分隔的组名
|
||||
#### 示例 3: 修改用户主目录或默认Shell ####
|
||||
|
||||
如果因为一些原因,你需要修改默认的用户主目录(一般为 /home/用户名),你需要使用 -d 或 -home 参数,后跟绝对路径来修改主目录
|
||||
如果有用户想要使用其他的shell来取代bash(比如sh ),一般默认是bash .使用 usermod ,并使用 -shell 的参数,后加新的shell的路径
|
||||
#### 示例 4: 展示组内的用户 ####
|
||||
|
||||
当把用户添加到组中后,你可以使用如下命令验证属于哪一个组
|
||||
|
||||
# groups [username]
|
||||
# id [username]
|
||||
|
||||
下面图片的演示了示例2到示例四
|
||||
|
||||

|
||||
|
||||
添加用户到额外的组
|
||||
|
||||
在上面的示例中:
|
||||
|
||||
# usermod --append --groups gacanepa,users --home /tmp --shell /bin/sh tecmint
|
||||
|
||||
如果想要从组内删除用户,省略 `--append` 切换,并且可以使用 `--groups` 来列举组内的用户
|
||||
|
||||
#### 示例 5: 通过锁定密码来停用帐户 ####
|
||||
|
||||
如果想要关闭帐户,你可以使用 -l(小写的L)或 -lock 选项来锁定用户的密码。这将会阻止用户登录。
|
||||
|
||||
#### 示例 6: 解锁密码 ####
|
||||
|
||||
当你想要重新启用帐户让他可以继续登录时,属于 -u 或 –unlock 选项来解锁用户的密码,就像示例5 介绍的那样
|
||||
|
||||
# usermod --unlock tecmint
|
||||
|
||||
下面的图片展示了示例5和示例6
|
||||
|
||||

|
||||
|
||||
锁定上锁用户
|
||||
|
||||
#### 示例 7:删除组和用户 ####
|
||||
|
||||
如果要删除一个组,你需要使用 groupdel ,如果需要删除用户 你需要使用 userdel (添加 -r 可以删除主目录和邮件池的内容)
|
||||
# groupdel [group_name] # 删除组
|
||||
# userdel -r [user_name] # 删除用户,并删除主目录和邮件池
|
||||
|
||||
如果一些文件属于组,他们将不会被删除。但是组拥有者将会被设置为删除掉的组的GID
|
||||
### 列举,设置,并且修改 ugo/rwx 权限 ###
|
||||
|
||||
著名的 [ls 命令][3] 是管理员最好的助手. 当我们使用 -l 参数, 这个工具允许您查看一个目录中的内容(或详细格式).
|
||||
|
||||
而且,该命令还可以应用于单个文件中。无论哪种方式,在“ls”输出中的前10个字符表示每个文件的属性。
|
||||
这10个字符序列的第一个字符用于表示文件类型:
|
||||
|
||||
- – (连字符): 一个标准文件
|
||||
- d: 一个目录
|
||||
- l: 一个符号链接
|
||||
- c: 字符设备(将数据作为字节流,即一个终端)
|
||||
- b: 块设备(处理数据块,即存储设备)
|
||||
|
||||
文件属性的下一个九个字符,分为三个组,被称为文件模式,并注明读(r),写(w),并执行(x)授予文件的所有者,文件的所有组,和其他的用户(通常被称为“世界”)。
|
||||
在文件的读取权限允许打开和读取相同的权限时,允许其内容被列出,如果还设置了执行权限,还允许它作为一个程序和运行。
|
||||
文件权限是通过chmod命令改变的,它的基本语法如下:
|
||||
|
||||
# chmod [new_mode] file
|
||||
|
||||
new_mode是一个八进制数或表达式,用于指定新的权限。适合每一个随意的案例。或者您已经有了一个更好的方式来设置文件的权限,所以你觉得可以自由地使用最适合你自己的方法。
|
||||
八进制数可以基于二进制等效计算,可以从所需的文件权限的文件的所有者,所有组,和世界。一定权限的存在等于2的幂(R = 22,W = 21,x = 20),没有时意为0。例如:
|
||||

|
||||
|
||||
文件权限
|
||||
|
||||
在八进制形式下设置文件的权限,如上图所示
|
||||
|
||||
# chmod 744 myfile
|
||||
|
||||
请用一分钟来对比一下我们以前的计算,在更改文件的权限后,我们的实际输出为:
|
||||
|
||||

|
||||
|
||||
长列表格式
|
||||
|
||||
#### 示例 8: 寻找777权限的文件 ####
|
||||
|
||||
出于安全考虑,你应该确保在正常情况下,尽可能避免777权限(读、写、执行的文件)。虽然我们会在以后的教程中教你如何更有效地找到所有的文件在您的系统的权限集的说明,你现在仍可以使用LS grep获取这种信息。
|
||||
在下面的例子,我们会寻找 /etc 目录下的777权限文件. 注意,我们要使用第二章讲到的管道的知识[第二章:文件和目录管理][4]:
|
||||
|
||||
# ls -l /etc | grep rwxrwxrwx
|
||||
|
||||

|
||||
|
||||
查找所有777权限的文件
|
||||
|
||||
#### 示例 9: 为所有用户指定特定权限 ####
|
||||
|
||||
shell脚本,以及一些二进制文件,所有用户都应该有权访问(不只是其相应的所有者和组),应该有相应的执行权限(我们会讨论特殊情况下的问题):
|
||||
# chmod a+x script.sh
|
||||
|
||||
**注意**: 我们可以设置文件模式使用表示用户权限的字母如“u”,组所有者权限的字母“g”,其余的为o 。所有权限为a.权限可以通过`+` 或 `-` 来管理。
|
||||
|
||||

|
||||
|
||||
为文件设置执行权限
|
||||
|
||||
长目录列表还显示了该文件的所有者和其在第一和第二列中的组主。此功能可作为系统中文件的第一级访问控制方法:
|
||||
|
||||

|
||||
|
||||
检查文件的属主和属组
|
||||
|
||||
改变文件的所有者,您将使用chown命令。请注意,您可以在同一时间或单独的更改文件的所有权:
|
||||
# chown user:group file
|
||||
|
||||
虽然可以在同一时间更改用户或组,或在同一时间的两个属性,但是不要忘记冒号区分,如果你想要更新其他属性,让另外的选项保持空白:
|
||||
# chown :group file # Change group ownership only
|
||||
# chown user: file # Change user ownership only
|
||||
|
||||
#### 示例 10:从一个文件复制权限到另一个文件####
|
||||
|
||||
If you would like to “clone” ownership from one file to another, you can do so using the –reference flag, as follows:
|
||||
如果你想“克隆”一个文件的所有权到另一个,你可以这样做,使用–reference参数,如下:
|
||||
# chown --reference=ref_file file
|
||||
|
||||
ref_file的所有信息会复制给 file
|
||||
|
||||

|
||||
|
||||
复制文件属主信息
|
||||
|
||||
### 设置 SETGID 协作目录 ###
|
||||
|
||||
你应该授予在一个特定的目录中拥有访问所有的文件的权限给一个特点的用户组,你将有可能使用目录设置setgid的方法。当setgid后设置,真实用户的有效GID成为团队的主人。
|
||||
因此,任何用户都可以访问该文件的组所有者授予的权限的文件。此外,当setgid设置在一个目录中,新创建的文件继承同一组目录,和新创建的子目录也将继承父目录的setgid。
|
||||
# chmod g+s [filename]
|
||||
|
||||
为了设置 setgid 在八进制形式,预先准备好数字2 来给基本的权限
|
||||
# chmod 2755 [directory]
|
||||
|
||||
### 总结 ###
|
||||
|
||||
扎实的用户和组管理知识,符合规则的,Linux权限管理,以及部分实践,可以帮你快速解决RHEL 7 服务器的文件权限。
|
||||
我向你保证,当你按照本文所概述的步骤和使用系统文档(和第一章解释的那样 [Part 1: Reviewing Essential Commands & System Documentation][5] of this series) 你将掌握基本的系统管理的能力。
|
||||
|
||||
请随时让我们知道你是否有任何问题或意见使用下面的表格。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-manage-users-and-groups/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[xiqingongzi](https://github.com/xiqingongzi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/add-users-in-linux/
|
||||
[2]:http://www.tecmint.com/usermod-command-examples/
|
||||
[3]:http://www.tecmint.com/ls-interview-questions/
|
||||
[4]:http://www.tecmint.com/file-and-directory-management-in-linux/
|
||||
[5]:http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
|
||||
@ -1,258 +0,0 @@
|
||||
RHCSA 系列:使用 Nano 和 Vim 编辑文本文件/使用 grep 和 regexps 分析文本 – Part 4
|
||||
================================================================================
|
||||
作为系统管理员的日常职责的一部分,每个系统管理员都必须处理文本文件,这包括编辑现存文件(大多可能是配置文件),或创建新的文件。有这样一个说法,假如你想在 Linux 世界中挑起一场圣战,你可以询问系统管理员们,什么是他们最喜爱的编辑器以及为什么。在这篇文章中,我们并不打算那样做,但我们将向你呈现一些技巧,这些技巧对使用两款在 RHEL 7 中最为常用的文本编辑器: nano(由于其简单和易用,特别是对于新手来说) 和 vi/m(由于其自身的几个特色使得它不仅仅是一个简单的编辑器)来说都大有裨益。我确信你可以找到更多的理由来使用其中的一个或另一个,或许其他的一些编辑器如 emacs 或 pico。这完全取决于你。
|
||||
|
||||

|
||||
|
||||
RHCSA: 使用 Nano 和 Vim 编辑文本文件 – Part 4
|
||||
|
||||
### 使用 Nano 编辑器来编辑文件 ###
|
||||
|
||||
要启动 nano,你可以在命令提示符下输入 `nano`,或选择性地跟上一个文件名(在这种情况下,若文件存在,它将在编辑模式中被打开)。若文件不存在,或我们省略了文件名, nano 也将在 编辑模式下开启,但将为我们开启一个空白屏以便开始输入:
|
||||
|
||||

|
||||
|
||||
Nano 编辑器
|
||||
|
||||
正如你在上一张图片中所见的那样, nano 在屏幕的底部呈现出一些功能,它们可以通过暗指的快捷键来触发(^,即插入记号,代指 Ctrl 键)。它们中的一些是:
|
||||
|
||||
- Ctrl + G: 触发一个帮助菜单,带有一个关于功能和相应的描述的完整列表;
|
||||
- Ctrl + X: 离开当前文件,假如更改没有被保存,则它们将被丢弃;
|
||||
- Ctrl + R: 通过指定一个完整的文件路径,让你选择一个文件来将该文件的内容插入到当前文件中;
|
||||
|
||||

|
||||
|
||||
Nano 编辑器帮助菜单
|
||||
|
||||
- Ctrl + O: 保存更改到一个文件。它将让你用一个与源文件相同或不同的名称来保存该文件,然后按 Enter 键来确认。
|
||||
|
||||

|
||||
|
||||
Nano 编辑器的保存更改模式
|
||||
|
||||
- Ctrl + X: 离开当前文件,假如更改没有被保存,则它们将被丢弃;
|
||||
- Ctrl + R: 通过指定一个完整的文件路径,让你选择一个文件来将该文件的内容插入到当前文件中;
|
||||
|
||||

|
||||
|
||||
Nano: 插入文件内容到主文件中
|
||||
|
||||
上图的操作将把 `/etc/passwd` 的内容插入到当前文件中。
|
||||
|
||||
- Ctrl + K: 剪切当前行;
|
||||
- Ctrl + U: 粘贴;
|
||||
- Ctrl + C: 取消当前的操作并返回先前的屏幕;
|
||||
|
||||
为了轻松地在打开的文件中浏览, nano 提供了下面的功能:
|
||||
|
||||
- Ctrl + F 和 Ctrl + B 分别先前或向后移动光标;而 Ctrl + P 和 Ctrl + N 则分别向上或向下移动一行,功能与箭头键相同;
|
||||
- Ctrl + space 和 Alt + space 分别向前或向后移动一个单词;
|
||||
|
||||
最后,
|
||||
|
||||
- 假如你想将光标移动到文档中的特定位置,使用 Ctrl + _ (下划线) 并接着输入 X,Y 将准确地带你到 第 X 行,第 Y 列。
|
||||
|
||||

|
||||
|
||||
在 nano 中定位到具体的行和列
|
||||
|
||||
上面的例子将带你到当前文档的第 15 行,第 14 列。
|
||||
|
||||
假如你可以回忆起你早期的 Linux 岁月,特别是当你刚从 Windows 迁移到 Linux 中,你就可能会同意:对于一个新手来说,使用 nano 来开始学习是最好的方式。
|
||||
|
||||
### 使用 Vim 编辑器来编辑文件 ###
|
||||
|
||||
|
||||
Vim 是 vi 的加强版本,它是 Linux 中一个著名的文本编辑器,可在所有兼容 POSIX 的 *nix 系统中获取到,例如在 RHEL 7 中。假如你有机会并可以安装 Vim,请继续;假如不能,这篇文章中的大多数(若不是全部)的提示也应该可以正常工作。
|
||||
|
||||
Vim 的一个出众的特点是可以在多个不同的模式中进行操作:
|
||||
|
||||
- 命令模式将允许你在文件中跳转和输入命令,这些命令是由一个或多个字母组成的简洁且对大小写敏感的组合。假如你想重复执行某个命令特定次,你可以在这个命令前加上需要重复的次数(这个规则只有极少数例外)。例如, yy(或 Y,yank 的缩写)可以复制整个当前行,而 4yy(或 4Y)则复制整个当前行到接着的 3 行(总共 4 行)。
|
||||
- 在 ex 模式中,你可以操作文件(包括保存当前文件和运行外部的程序或命令)。要进入 ex 模式,你必须在命令模式前(或其他词前,Esc + :)输入一个冒号(:),再直接跟上你想使用的 ex 模式命令的名称。
|
||||
- 对于插入模式,可以输入字母 i 进入,我们只需要输入文字即可。大多数的键击结果都将出现在屏幕中的文本中。
|
||||
- 我们总是可以通过敲击 Esc 键来进入命令模式(无论我们正工作在哪个模式下)。
|
||||
|
||||
现在,让我们看看如何在 vim 中执行在上一节列举的针对 nano 的相同的操作。不要忘记敲击 Enter 键来确认 vim 命令。
|
||||
|
||||
为了从命令行中获取 vim 的完整手册,在命令模式下键入 `:help` 并敲击 Enter 键:
|
||||
|
||||

|
||||
|
||||
vim 编辑器帮助菜单
|
||||
|
||||
上面的小节呈现出一个目录列表,而定义过的小节则主要关注 Vim 的特定话题。要浏览某一个小节,可以将光标放到它的上面,然后按 Ctrl + ] (闭方括号)。注意,底部的小节展示的是当前文件的内容。
|
||||
|
||||
1. 要保存更改到文件,在命令模式中运行下面命令中的任意一个,就可以达到这个目的:
|
||||
|
||||
```
|
||||
:wq!
|
||||
:x!
|
||||
ZZ (是的,两个 ZZ,前面无需添加冒号)
|
||||
```
|
||||
|
||||
2. 要离开并丢弃更改,使用 `:q!`。这个命令也将允许你离开上面描述过的帮助菜单,并返回到命令模式中的当前文件。
|
||||
|
||||
3. 剪切 N 行:在命令模式中键入 `Ndd`。
|
||||
|
||||
4. 复制 M 行:在命令模式中键入 `Myy`。
|
||||
|
||||
5. 粘贴先前剪贴或复制过的行:在命令模式中按 `P`键。
|
||||
|
||||
6. 要插入另一个文件的内容到当前文件:
|
||||
|
||||
:r filename
|
||||
|
||||
例如,插入 `/etc/fstab` 的内容,可以这样做:
|
||||
|
||||
[在 vi 编辑器中插入文件的内容](http://www.tecmint.com/wp-content/uploads/2015/03/Insert-Content-vi-Editor.png)
|
||||
|
||||
在 vi 编辑器中插入文件的内容
|
||||
|
||||
7. 插入一个命名的输出到当前文档:
|
||||
|
||||
:r! command
|
||||
|
||||
例如,要在光标所在的当前位置后面插入日期和时间:
|
||||
|
||||

|
||||
|
||||
在 vi 编辑器中插入时间和日期
|
||||
|
||||
在另一篇我写的文章中,([LFCS 系列的 Part 2][1]),我更加详细地解释了在 vim 中可用的键盘快捷键和功能。或许你可以参考那个教程来查看如何使用这个强大的文本编辑器的更深入的例子。
|
||||
|
||||
### 使用 Grep 和正则表达式来分析文本 ###
|
||||
|
||||
到现在为止,你已经学习了如何使用 nano 或 vim 创建和编辑文件。打个比方说,假如你成为了一个文本编辑器忍者 – 那又怎样呢? 在其他事情上,你也需要知道如何在文本中搜索正则表达式。
|
||||
|
||||
正则表达式(也称为 "regex" 或 "regexp") 是一种识别一个特定文本字符串或模式的方式,使得一个程序可以将这个模式和任意的文本字符串相比较。尽管利用 grep 来使用正则表达式值得用一整篇文章来描述,这里就让我们复习一些基本的知识:
|
||||
|
||||
**1. 最简单的正则表达式是一个由数字和字母构成的字符串(即,单词 "svm") 或两个(在使用两个字符串时,你可以使用 `|`(或) 操作符):**
|
||||
|
||||
# grep -Ei 'svm|vmx' /proc/cpuinfo
|
||||
|
||||
上面命令的输出结果中若有这两个字符串之一的出现,则标志着你的处理器支持虚拟化:
|
||||
|
||||

|
||||
|
||||
正则表达式示例
|
||||
|
||||
**2. 第二种正则表达式是一个范围列表,由方括号包裹。**
|
||||
|
||||
例如, `c[aeiou]t` 匹配字符串 cat,cet,cit,cot 和 cut,而 `[a-z]` 和 `[0-9]` 则相应地匹配小写字母或十进制数字。假如你想重复正则表达式 X 次,在正则表达式的后面立即输入 `{X}`即可。
|
||||
|
||||
例如,让我们从 `/etc/fstab` 中析出存储设备的 UUID:
|
||||
|
||||
# grep -Ei '[0-9a-f]{8}-([0-9a-f]{4}-){3}[0-9a-f]{12}' -o /etc/fstab
|
||||
|
||||

|
||||
|
||||
从一个文件中析出字符串
|
||||
|
||||
方括号中的第一个表达式 `[0-9a-f]` 被用来表示小写的十六进制字符,`{8}`是一个量词,暗示前面匹配的字符串应该重复的次数(在一个 UUID 中的开头序列是一个 8 个字符长的十六进制字符串)。
|
||||
|
||||
在圆括号中,量词 `{4}`和连字符暗示下一个序列是一个 4 个字符长的十六进制字符串,接着的量词 `({3})`表示前面的表达式要重复 3 次。
|
||||
|
||||
最后,在 UUID 中的最后一个 12 个字符长的十六进制字符串可以由 `[0-9a-f]{12}` 取得, `-o` 选项表示只打印出在 `/etc/fstab`中匹配行中的匹配的(非空)部分。
|
||||
|
||||
**3. POSIX 字符类 **
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="201"></colgroup>
|
||||
<colgroup width="440"></colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="center" height="25" bgcolor="#999999" style="border: 1px solid #000000;"><b>字符类</b></td>
|
||||
<td align="center" bgcolor="#999999" style="border: 1px solid #000000;"><b>匹配 …</b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:alnum:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> 任意字母或数字 [a-zA-Z0-9] </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:alpha:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> 任意字母 [a-zA-Z] </td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:blank:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> 空格或制表符</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:cntrl:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> 任意控制字符 (ASCII 码的 0 至 32)</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:digit:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> 任意数字 [0-9]</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:graph:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> 任意可见字符</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:lower:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> 任意小写字母 [a-z] </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:print:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> 任意非控制字符 <td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:space:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> 任意空格</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:punct:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> 任意标点字符</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:upper:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> 任意大写字母 [A-Z] </td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [[:xdigit:]]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> 任意十六进制数字 [0-9a-fA-F]</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> [:word:]</td>
|
||||
<td align="left" bgcolor="#FFFFFF" style="border: 1px solid #000000;"> 任意字母,数字和下划线 [a-zA-Z0-9_]</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
例如,我们可能会对查找已添加到我们系统中给真实用户的 UID 和 GID(参考这个系列的 [Part 2][2]来回忆起这些知识)感兴趣。那么,我们将在 `/etc/passwd` 文件中查找 4 个字符长的序列:
|
||||
|
||||
# grep -Ei [[:digit:]]{4} /etc/passwd
|
||||
|
||||

|
||||
|
||||
在文件中查找一个字符串
|
||||
|
||||
上面的示例可能不是真实世界中使用正则表达式的最好案例,但它清晰地启发了我们如何使用 POSIX 字符类来使用 grep 分析文本。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
|
||||
在这篇文章中,我们已经提供了一些技巧来最大地利用针对命令行用户的两个文本编辑器 nano 和 vim,这两个工具都有相关的扩展文档可供阅读,你可以分别查询它们的官方网站(链接在下面给出)以及使用这个系列中的 [Part 1][3] 给出的建议。
|
||||
|
||||
#### 参考文件链接 ####
|
||||
|
||||
- [http://www.nano-editor.org/][4]
|
||||
- [http://www.vim.org/][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-how-to-use-nano-vi-editors/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/vi-editor-usage/
|
||||
[2]:http://www.tecmint.com/file-and-directory-management-in-linux/
|
||||
[3]:http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
|
||||
[4]:http://www.nano-editor.org/
|
||||
[5]:http://www.vim.org/
|
||||
@ -1,214 +0,0 @@
|
||||
RHECSA 系列:RHEL7 中的进程管理:开机,关机,以及两者之间的所有其他事项 – Part 5
|
||||
================================================================================
|
||||
我们将概括和简要地复习从你按开机按钮来打开你的 RHEL 7 服务器到呈现出命令行界面的登录屏幕之间所发生的所有事情,以此来作为这篇文章的开始。
|
||||
|
||||

|
||||
|
||||
Linux 开机过程
|
||||
|
||||
**请注意:**
|
||||
|
||||
1. 相同的基本原则也可以应用到其他的 Linux 发行版本中,但可能需要较小的更改,并且
|
||||
2. 下面的描述并不是旨在给出开机过程的一个详尽的解释,而只是介绍一些基础的东西
|
||||
|
||||
### Linux 开机过程 ###
|
||||
|
||||
1.初始化 POST(加电自检)并执行硬件检查;
|
||||
|
||||
2.当 POST 完成后,系统的控制权将移交给启动管理器的第一阶段,它存储在一个硬盘的引导扇区(对于使用 BIOS 和 MBR 的旧式的系统)或存储在一个专门的 (U)EFI 分区上。
|
||||
|
||||
3.启动管理器的第一阶段完成后,接着进入启动管理器的第二阶段,通常大多数使用的是 GRUB(GRand Unified Boot Loader 的简称),它驻留在 `/boot` 中,反过来加载内核和驻留在 RAM 中的初始化文件系统(被称为 initramfs,它包含执行必要操作所需要的程序和二进制文件,以此来最终挂载真实的根文件系统)。
|
||||
|
||||
4.接着经历了闪屏过后,呈现在我们眼前的是类似下图的画面,它允许我们选择一个操作系统和内核来启动:
|
||||
|
||||

|
||||
|
||||
启动菜单屏幕
|
||||
|
||||
5.然后内核对挂载到系统的硬件进行设置,一旦根文件系统被挂载,接着便启动 PID 为 1 的进程,反过来这个进程将初始化其他的进程并最终呈现给我们一个登录提示符界面。
|
||||
|
||||
注意:假如我们想在后面这样做(注:这句话我总感觉不通顺,不明白它的意思,希望改一下),我们可以使用 [dmesg 命令][1](注:这篇文章已经翻译并发表了,链接是 https://linux.cn/article-3587-1.html )并使用这个系列里的上一篇文章中解释过的工具(注:即 grep)来过滤它的输出。
|
||||
|
||||

|
||||
|
||||
登录屏幕和进程的 PID
|
||||
|
||||
在上面的例子中,我们使用了众所周知的 `ps` 命令来显示在系统启动过程中的一系列当前进程的信息,它们的父进程(或者换句话说,就是那个开启这些进程的进程) 为 systemd(大多数现代的 Linux 发行版本已经切换到的系统和服务管理器):
|
||||
|
||||
# ps -o ppid,pid,uname,comm --ppid=1
|
||||
|
||||
记住 `-o`(为 -format 的简写)选项允许你以一个自定义的格式来显示 ps 的输出,以此来满足你的需求;这个自定义格式使用 man ps 里 STANDARD FORMAT SPECIFIERS 一节中的特定关键词。
|
||||
|
||||
另一个你想自定义 ps 的输出而不是使用其默认输出的情形是:当你需要找到引起 CPU 或内存消耗过多的那些进程,并按照下列方式来对它们进行排序时:
|
||||
|
||||
# ps aux --sort=+pcpu # 以 %CPU 来排序(增序)
|
||||
# ps aux --sort=-pcpu # 以 %CPU 来排序(降序)
|
||||
# ps aux --sort=+pmem # 以 %MEM 来排序(增序)
|
||||
# ps aux --sort=-pmem # 以 %MEM 来排序(降序)
|
||||
# ps aux --sort=+pcpu,-pmem # 结合 %CPU (增序) 和 %MEM (降序)来排列
|
||||
|
||||

|
||||
|
||||
自定义 ps 命令的输出
|
||||
|
||||
### systemd 的一个介绍 ###
|
||||
|
||||
在 Linux 世界中,很少有决定能够比在主流的 Linux 发行版本中采用 systemd 引起更多的争论。systemd 的倡导者根据以下事实命名其主要的优势:
|
||||
|
||||
另外请阅读: ['init' 和 'systemd' 背后的故事][2]
|
||||
|
||||
1. 在系统启动期间,systemd 允许并发地启动更多的进程(相比于先前的 SysVinit,SysVinit 似乎总是表现得更慢,因为它一个接一个地启动进程,检查一个进程是否依赖于另一个进程,然后等待守护进程去开启可以开始的更多的服务),并且
|
||||
2. 在一个运行着的系统中,它作为一个动态的资源管理器来工作。这样在开机期间,当一个服务被需要时,才启动它(以此来避免消耗系统资源)而不是在没有一个合理的原因的情况下启动额外的服务。
|
||||
3. 向后兼容 sysvinit 的脚本。
|
||||
|
||||
systemd 由 systemctl 工具控制,假如你带有 SysVinit 背景,你将会对以下的内容感到熟悉:
|
||||
|
||||
- service 工具, 在旧一点的系统中,它被用来管理 SysVinit 脚本,以及
|
||||
- chkconfig 工具, 为系统服务升级和查询运行级别信息
|
||||
- shutdown, 你一定使用过几次来重启或关闭一个运行的系统。
|
||||
|
||||
下面的表格展示了使用传统的工具和 systemctl 之间的相似之处:
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="237"></colgroup>
|
||||
<colgroup width="256"></colgroup>
|
||||
<colgroup width="1945"></colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="left" height="25" bgcolor="#B7B7B7" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial; font-size: small;">Legacy tool</span></b></td>
|
||||
<td align="left" bgcolor="#B7B7B7" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial; font-size: small;">Systemctl equivalent</span></b></td>
|
||||
<td align="left" bgcolor="#B7B7B7" style="border: 1px solid #000000;"><b><span style="color: black; font-family: Arial; font-size: small;">Description</span></b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name start</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl start name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Start name (where name is a service)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name stop</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl stop name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Stop name</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name condrestart</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl try-restart name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Restarts name (if it’s already running)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name restart</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl restart name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Restarts name</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name reload</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl reload name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Reloads the configuration for name</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service name status</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl status name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Displays the current status of name</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">service –status-all</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Displays the status of all current services</span></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig name on</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl enable name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Enable name to run on startup as specified in the unit file (the file to which the symlink points). The process of enabling or disabling a service to start automatically on boot consists in adding or removing symbolic links inside the /etc/systemd/system directory.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig name off</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl disable name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Disables name to run on startup as specified in the unit file (the file to which the symlink points)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="21" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig –list name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl is-enabled name</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;">Verify whether name (a specific service) is currently enabled</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">chkconfig –list</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl –type=service</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Displays all services and tells whether they are enabled or disabled</span></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">shutdown -h now</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl poweroff</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Power-off the machine (halt)</span></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td align="left" height="23" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">shutdown -r now</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Courier New;">systemctl reboot</span></td>
|
||||
<td align="left" style="border: 1px solid #000000;"><span style="color: black; font-family: Arial;">Reboot the system</span></td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
systemd 也引进了单元(它可能是一个服务,一个挂载点,一个设备或者一个网络套接字)和目标(它们定义了 systemd 如何去管理和同时开启几个相关的进程,并可认为它们与在基于 SysVinit 的系统中的运行级别等价,尽管事实上它们并不等价)。
|
||||
|
||||
### 总结归纳 ###
|
||||
|
||||
其他与进程管理相关,但并不仅限于下面所列的功能的任务有:
|
||||
|
||||
**1. 在考虑到系统资源的使用上,调整一个进程的执行优先级:**
|
||||
|
||||
这是通过 `renice` 工具来完成的,它可以改变一个或多个正在运行着的进程的调度优先级。简单来说,调度优先级是一个允许内核(当前只支持 >= 2.6 的版本)根据某个给定进程被分配的执行优先级(即优先级,从 -20 到 19)来为其分配系统资源的功能。
|
||||
|
||||
`renice` 的基本语法如下:
|
||||
|
||||
# renice [-n] priority [-gpu] identifier
|
||||
|
||||
在上面的通用命令中,第一个参数是将要使用的优先级数值,而另一个参数可以解释为进程 ID(这是默认的设定),进程组 ID,用户 ID 或者用户名。一个常规的用户(即除 root 以外的用户)只可以更改他或她所拥有的进程的调度优先级,并且只能增加优先级的层次(这意味着占用更少的系统资源)。
|
||||
|
||||

|
||||
|
||||
进程调度优先级
|
||||
|
||||
**2. 按照需要杀死一个进程(或终止其正常执行):**
|
||||
|
||||
更精确地说,杀死一个进程指的是通过 [kill 或 pkill][3]命令给该进程发送一个信号,让它优雅地(SIGTERM=15)或立即(SIGKILL=9)结束它的执行。
|
||||
|
||||
这两个工具的不同之处在于前一个被用来终止一个特定的进程或一个进程组,而后一个则允许你在进程的名称和其他属性的基础上,执行相同的动作。
|
||||
|
||||
另外, pkill 与 pgrep 相捆绑,pgrep 提供将受影响的进程的 PID 给 pkill 来使用。例如,在运行下面的命令之前:
|
||||
|
||||
# pkill -u gacanepa
|
||||
|
||||
查看一眼由 gacanepa 所拥有的 PID 或许会带来点帮助:
|
||||
|
||||
# pgrep -l -u gacanepa
|
||||
|
||||

|
||||
|
||||
找到用户拥有的 PID
|
||||
|
||||
默认情况下,kill 和 pkiill 都发送 SIGTERM 信号给进程,如我们上面提到的那样,这个信号可以被忽略(即该进程可能会终止其自身的执行或者不终止),所以当你因一个合理的理由要真正地停止一个运行着的进程,则你将需要在命令行中带上特定的 SIGKILL 信号:
|
||||
|
||||
# kill -9 identifier # 杀死一个进程或一个进程组
|
||||
# kill -s SIGNAL identifier # 同上
|
||||
# pkill -s SIGNAL identifier # 通过名称或其他属性来杀死一个进程
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们解释了在 RHEL 7 系统中,有关开机启动过程的基本知识,并分析了一些可用的工具来帮助你通过使用一般的程序和 systemd 特有的命令来管理进程。
|
||||
|
||||
请注意,这个列表并不旨在涵盖有关这个话题的所有花哨的工具,请随意使用下面的评论栏来添加你自已钟爱的工具和命令。同时欢迎你的提问和其他的评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-boot-process-and-process-management/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/dmesg-commands/
|
||||
[2]:http://www.tecmint.com/systemd-replaces-init-in-linux/
|
||||
[3]:http://www.tecmint.com/how-to-kill-a-process-in-linux/
|
||||
@ -0,0 +1,195 @@
|
||||
[xiqingongzi translating]
|
||||
RHCSA Series: Yum 包管理, 自动任务计划和系统监控日志 – Part 10
|
||||
================================================================================
|
||||
在这篇文章中,我们将回顾如何在REHL7中安装,更新和删除软件包。我们还将介绍如何使用cron任务的自动化,并完成如何查找和监控系统日志文件以及为什么这些技能是系统管理员必备技能
|
||||
|
||||

|
||||
|
||||
RHCSA: Yum包管理, 任务计划和系统监控 – 第十章
|
||||
|
||||
### 使用yum 管理包 ###
|
||||
|
||||
要安装一个包以及所有尚未安装的依赖包,您可以使用:
|
||||
|
||||
# yum -y install package_name(s)
|
||||
|
||||
package_name(s) 需要是一个存在的包名
|
||||
|
||||
例如,安装httpd和mlocate(按顺序),类型。
|
||||
|
||||
# yum -y install httpd mlocate
|
||||
|
||||
**注意**: 字符y表示绕过执行下载和安装前的确认提示,如果需要,你可以删除它
|
||||
|
||||
默认情况下,yum将安装与操作系统体系结构相匹配的包,除非通过在包名加入架构名
|
||||
|
||||
例如,在64位系统上,使用yum安装包将安装包的x86_64版本,而package.x86 yum安装(如果有的话)将安装32位。
|
||||
|
||||
有时,你想安装一个包,但不知道它的确切名称。搜索可以在当前启用的存储库中去搜索包名称或在它的描述中搜索,并分别进行。
|
||||
|
||||
比如,
|
||||
|
||||
# yum search log
|
||||
|
||||
将搜索安装的软件包中名字与该词类似的软件,而
|
||||
|
||||
# yum search all log
|
||||
|
||||
也将在包描述和网址中寻找寻找相同的关键字
|
||||
|
||||
一旦搜索返回包列表,您可能希望在安装前显示一些信息。这时info选项派上用场:
|
||||
|
||||
# yum info logwatch
|
||||
|
||||

|
||||
|
||||
搜索包信息
|
||||
|
||||
您可以定期用以下命令检查更新:
|
||||
|
||||
# yum check-update
|
||||
|
||||
上述命令将返回可以更新的所有安装包。在下图所示的例子中,只有rhel-7-server-rpms有可用更新:
|
||||
|
||||

|
||||
检查包更新
|
||||
|
||||
然后,您可以更新该包,
|
||||
|
||||
# yum update rhel-7-server-rpms
|
||||
|
||||
如果有几个包,可以一同更新,yum update 将一次性更新所有的包
|
||||
|
||||
现在,当你知道一个可执行文件的名称,如ps2pdf,但不知道那个包提供了它?你可以通过 `yum whatprovides “*/[executable]”`找到:
|
||||
|
||||
# yum whatprovides “*/ps2pdf”
|
||||
|
||||

|
||||
|
||||
查找文件属于哪个包
|
||||
|
||||
现在,当删除包时,你可以使用 yum remove Package ,很简单吧?Yum 是一个完整的强大的包管理器。
|
||||
|
||||
# yum remove httpd
|
||||
|
||||
Read Also: [20 Yum Commands to Manage RHEL 7 Package Management][1]
|
||||
|
||||
### 文本式RPM工具 ###
|
||||
|
||||
RPM(又名RPM包管理器,或原本RedHat软件包管理器)也可用于安装或更新软件包来当他们在独立`rpm`包装形式。
|
||||
|
||||
往往使用`-Uvh` 表面这个包应该被安装而不是已存在或尝试更新。安装是`-U` ,显示详细输出用`-v`,显示进度条用`-h` 例如
|
||||
# rpm -Uvh package.rpm
|
||||
|
||||
另一个典型的使用rpm 是产生一个列表,目前安装的软件包的code > rpm -qa(缩写查询所有)
|
||||
|
||||
# rpm -qa
|
||||
|
||||

|
||||
|
||||
查询所有包
|
||||
|
||||
Read Also: [20 RPM Commands to Install Packages in RHEL 7][2]
|
||||
|
||||
### Cron任务计划 ###
|
||||
|
||||
Linux和UNIX类操作系统包括其他的工具称为Cron允许你安排任务(即命令或shell脚本)运行在周期性的基础上。每分钟定时检查/var/spool/cron目录中有在/etc/passwd帐户文件中指定名称的文件。
|
||||
|
||||
执行命令时,输出是发送到crontab的所有者(或者在/etc/crontab,在MailTO环境变量中指定的用户,如果它存在的话)。
|
||||
|
||||
crontab文件(这是通过键入crontab e和按Enter键创建)的格式如下:
|
||||
|
||||

|
||||
|
||||
crontab条目
|
||||
|
||||
因此,如果我们想更新本地文件数据库(这是用于定位文件或图案)每个初二日上午2:15,我们需要添加以下crontab条目:
|
||||
|
||||
15 02 2 * * /bin/updatedb
|
||||
|
||||
以上的条目写着:”每年每月第二天的凌晨2:15运行 /bin/updatedb“ 无论是周几”,我想你也猜到了。星号作为通配符
|
||||
|
||||
添加一个cron作业后,你可以看到一个文件名为root被添加在/var/spool/cron,正如我们前面所提到的。该文件列出了所有的crond守护进程运行的任务:
|
||||
|
||||
# ls -l /var/spool/cron
|
||||
|
||||

|
||||
|
||||
检查所有cron工作
|
||||
|
||||
在上图中,显示当前用户的crontab可以使用 cat /var/spool/cron 或
|
||||
|
||||
# crontab -l
|
||||
|
||||
如果你需要在一个更精细的时间上运行的任务(例如,一天两次或每月三次),cron也可以帮助你。
|
||||
|
||||
例如,每个月1号和15号运行 /my/script 并将输出导出到 /dev/null,您可以添加如下两个crontab条目:
|
||||
|
||||
01 00 1 * * /myscript > /dev/null 2>&1
|
||||
01 00 15 * * /my/script > /dev/null 2>&1
|
||||
|
||||
不过为了简单,你可以将他们合并
|
||||
|
||||
01 00 1,15 * * /my/script > /dev/null 2>&1
|
||||
在前面的例子中,我们可以在每三个月的第一天的凌晨1:30运行 /my/other/script .
|
||||
|
||||
30 01 1 1,4,7,10 * /my/other/script > /dev/null 2>&1
|
||||
|
||||
但是当你必须每一个“十”分钟,数小时,数天或数月的重复某个任务时,你可以通过所需的频率来划分正确的时间。以下为前一个crontab条目具有相同的意义:
|
||||
|
||||
30 01 1 */3 * /my/other/script > /dev/null 2>&1
|
||||
|
||||
或者也许你需要在一个固定的时间段或系统启动后运行某个固定的工作,例如。你可以使用下列五个字符串中的一个字符串来指示你想让你的任务计划工作的确切时间:
|
||||
|
||||
@reboot 仅系统启动时运行.
|
||||
@yearly 一年一次, 类似与 00 00 1 1 *.
|
||||
@monthly 一月一次, 类似与 00 00 1 * *.
|
||||
@weekly 一周一次, 类似与 00 00 * * 0.
|
||||
@daily 一天一次, 类似与 00 00 * * *.
|
||||
@hourly 一小时一次, 类似与 00 * * * *.
|
||||
|
||||
Read Also: [11 Commands to Schedule Cron Jobs in RHEL 7][3]
|
||||
|
||||
### 定位和查看日志###
|
||||
|
||||
系统日志存放在 /var/log 目录.根据Linux的文件系统层次标准,这个目录包括各种日志文件,并包含一些必要的子目录(如 audit, httpd, 或 samba ,如下图),并由相应的系统守护进程操作
|
||||
|
||||
# ls /var/log
|
||||
|
||||

|
||||
|
||||
Linux 日志定位
|
||||
|
||||
其他有趣的日志比如 [dmesg][4](包括了所有内核缓冲区的信息),安全(用户认证尝试链接),信息(系统信息),和wtmp(记录了所有用户的登录登出)
|
||||
|
||||
日志是非常重要的,他们让你可以看到是任何时刻发生在你的系统的事情,甚至是已经过去的事情。他们是无价的工具,解决和监测一个Linux服务器,并因此经常使用的 “tail -f command ”来实时显示正在发生并实时写入的事件。
|
||||
|
||||
举个例子,如果你想看你的内核的日志,你需要输入如下命令
|
||||
|
||||
# tail -f /var/log/dmesg
|
||||
|
||||
同样的,如果你想查看你的网络服务器日志,你需要输入如下命令
|
||||
|
||||
# tail -f /var/log/httpd/access.log
|
||||
|
||||
### 总结 ###
|
||||
|
||||
如果你知道如何有效的管理包,安排任务,以及知道在哪寻找系统当前和过去操作的信息,你可以放心你将不会总是有太多的惊喜。我希望这篇文章能够帮你学习或回顾这些基础知识。
|
||||
|
||||
如果你有任何问题或意见,请使用下面的表格反馈给我们。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/yum-package-management-cron-job-scheduling-monitoring-linux-logs/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[xiqingongzi](https://github.com/xiqingongzi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[2]:http://www.tecmint.com/20-practical-examples-of-rpm-commands-in-linux/
|
||||
[3]:http://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
|
||||
[4]:http://www.tecmint.com/dmesg-commands/
|
||||
|
||||
@ -0,0 +1,142 @@
|
||||
RHCSA 系列: 使用 ‘Kickstart’完成 RHEL 7 的自动化安装 – Part 12
|
||||
================================================================================
|
||||
无论是在数据中心还是实验室环境,Linux 服务器很少是独立的机子,很可能有时你不得不安装多个以某种方式相互联系的机子。假如你将在单个服务器上手动安装 RHEL 7 所花的时间乘以你需要配置的机子个数,则这将导致你必须做出一场相当长的努力,而通过使用被称为 kicksta 的无人值守安装工具则可以避免这样的麻烦。
|
||||
|
||||
在这篇文章中,我们将向你展示使用 kickstart 工具时所需的一切,以便在安装过程中,不用你时不时地照看“处在襁褓中”的服务器。
|
||||
|
||||

|
||||
|
||||
RHCSA: RHEL 7 的自动化 Kickstart 安装
|
||||
|
||||
#### Kickstart 和自动化安装简介 ####
|
||||
|
||||
Kickstart 是一种被用来执行无人值守操作系统安装和配置的自动化安装方法,主要被 RHEL(和其他 Fedora 的副产品,如 CentOS,Oracle Linux 等)所使用。因此,kickstart 安装方法可使得系统管理员只需考虑需要安装的软件包组和系统的配置,便可以得到相同的系统,从而省去必须手动安装这些软件包的麻烦。
|
||||
|
||||
### 准备一次 Kickstart 安装 ###
|
||||
|
||||
要执行一次 kickstart 安装,我们需要遵循下面的这些步骤:
|
||||
|
||||
1. 创建一个 Kickstart 文件,它是一个带有多个预定义配置选项的纯文本文件。
|
||||
|
||||
2. 使得 Kickstart 文件在可移动介质上可得,如一个硬盘或一个网络位置。客户端将使用 `rhel-server-7.0-x86_64-boot.iso` 镜像文件,而你还需要使得完全的 ISO 镜像(`rhel-server-7.0-x86_64-dvd.iso`)可从一个网络资源上获取得到,例如通过一个 FTP 服务器的 HTTP(在我们当前的例子中,我们将使用另一个 IP 地址为 192.168.0.18 的 RHEL 7 机子)。
|
||||
|
||||
3. 开始 Kickstart 安装。
|
||||
|
||||
为创建一个 kickstart 文件,请登陆你的红帽客户门户网站帐户,并使用 [Kickstart 配置工具][1] 来选择所需的安装选项。在向下滑动之前请仔细阅读每个选项,然后选择最适合你需求的选项:
|
||||
|
||||

|
||||
|
||||
Kickstart 配置工具
|
||||
|
||||
假如你指定安装将通过 HTTP,FTP,NFS 来执行,请确保服务器上的防火墙允许这些服务通过。
|
||||
|
||||
尽管你可以使用红帽的在线工具来创建一个 kickstart 文件,但你还可以使用下面的代码来作为参考手动地创建它。例如,你可以注意到,下面的代码指定了安装过程将使用英语环境,使用拉丁美洲键盘布局,并设定时区为 America/Argentina/San_Luis 时区:
|
||||
|
||||
lang en_US
|
||||
keyboard la-latin1
|
||||
timezone America/Argentina/San_Luis --isUtc
|
||||
rootpw $1$5sOtDvRo$In4KTmX7OmcOW9HUvWtfn0 --iscrypted
|
||||
#platform x86, AMD64, or Intel EM64T
|
||||
text
|
||||
url --url=http://192.168.0.18//kickstart/media
|
||||
bootloader --location=mbr --append="rhgb quiet crashkernel=auto"
|
||||
zerombr
|
||||
clearpart --all --initlabel
|
||||
autopart
|
||||
auth --passalgo=sha512 --useshadow
|
||||
selinux --enforcing
|
||||
firewall --enabled
|
||||
firstboot --disable
|
||||
%packages
|
||||
@base
|
||||
@backup-server
|
||||
@print-server
|
||||
%end
|
||||
|
||||
在上面的在线配置工具中,在选择以 HTTP 来作为安装源后,设置好在安装过程中使用 192.168.0.18 来作为 HTTP 服务器的地址,`/kickstart/tecmint.bin` 作为 HTTP 目录。
|
||||
|
||||
在上面的 kickstart 示例文件中,你需要特别注意
|
||||
|
||||
url --url=http://192.168.0.18//kickstart/media
|
||||
|
||||
这个目录是你解压 DVD 或 ISO 安装介质的地方。在执行解压之前,我们将把 ISO 安装文件作为一个回环设备挂载到 /media/rhel 目录下:
|
||||
|
||||
# mount -o loop /var/www/html/kickstart/rhel-server-7.0-x86_64-dvd.iso /media/rhel
|
||||
|
||||

|
||||
|
||||
挂载 RHEL ISO 镜像
|
||||
|
||||
接下来,复制 /media/rhel 中的全部文件到 /var/www/html/kickstart/media 目录:
|
||||
|
||||
# cp -R /media/rhel /var/www/html/kickstart/media
|
||||
|
||||
这一步做完后,/var/www/html/kickstart/media 目录中的文件列表和磁盘使用情况将如下所示:
|
||||
|
||||

|
||||
|
||||
Kickstart 媒体文件
|
||||
|
||||
现在,我们已经准备好开始 kickstart 安装了。
|
||||
|
||||
不管你如何选择创建 kickstart 文件的方式,在执行安装之前检查这个文件的语法总是一个不错的主意。为此,我们需要安装 pykickstart 软件包。
|
||||
|
||||
# yum update && yum install pykickstart
|
||||
|
||||
然后使用 ksvalidator 工具来检查这个文件:
|
||||
|
||||
# ksvalidator /var/www/html/kickstart/tecmint.bin
|
||||
|
||||
假如文件中的语法正确,你将不会得到任何输出,反之,假如文件中存在错误,你得到警告,向你提示在某一行中语法不正确或出错原因未知。
|
||||
|
||||
### 执行一次 Kickstart 安装 ###
|
||||
|
||||
首先,使用 rhel-server-7.0-x86_64-boot.iso 来启动你的客户端。当初始屏幕出现时,选择安装 RHEL 7.0 ,然后按 Tab 键来追加下面这一句,接着按 Enter 键:
|
||||
|
||||
# inst.ks=http://192.168.0.18/kickstart/tecmint.bin
|
||||
|
||||

|
||||
|
||||
RHEL Kickstart 安装
|
||||
|
||||
其中 tecmint.bin 是先前创建的 kickstart 文件。
|
||||
|
||||
当你按了 Enter 键后,自动安装就开始了,且你将看到一个列有正在被安装的软件的列表(软件包的数目和名称根据你所选择的程序和软件包组而有所不同):
|
||||
|
||||

|
||||
|
||||
RHEL 7 的自动化 Kickstart 安装
|
||||
|
||||
当自动化过程结束后,将提示你移除安装介质,接着你就可以启动到你新安装的系统中了:
|
||||
|
||||

|
||||
|
||||
RHEL 7 启动屏幕
|
||||
|
||||
尽管你可以像我们前面提到的那样,手动地创建你的 kickstart 文件,但你应该尽可能地考虑使用受推荐的方式:你可以使用在线配置工具,或者使用在安装过程中创建的位于 root 家目录下的 anaconda-ks.cfg 文件。
|
||||
|
||||
这个文件实际上就是一个 kickstart 文件,所以你或许想在选择好所有所需的选项(可能需要更改逻辑卷布局或机子上所用的文件系统)后手动地安装第一个机子,接着使用产生的 anaconda-ks.cfg 文件来自动完成其余机子的安装过程。
|
||||
|
||||
另外,使用在线配置工具或 anaconda-ks.cfg 文件来引导将来的安装将允许你使用一个加密的 root 密码来执行系统的安装。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
既然你知道了如何创建 kickstart 文件并如何使用它们来自动完成 RHEL 7 服务器的安装,你就可以忘记时时照看安装进度的过程了。这将给你时间来做其他的事情,或者若你足够幸运,你还可以用来休闲一番。
|
||||
|
||||
无论以何种方式,请使用下面的评论栏来让我们知晓你对这篇文章的看法。提问也同样欢迎!
|
||||
|
||||
另外,请阅读:[使用 PXE 和 kickstart 来自动化安装多个 RHEL/CentOS 7 发行版本][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/automatic-rhel-installations-using-kickstart/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:https://access.redhat.com/labs/kickstartconfig/
|
||||
[2]:http://www.tecmint.com/multiple-centos-installations-using-kickstart/
|
||||
@ -0,0 +1,177 @@
|
||||
RHCSA 系列: 在 RHEL 7 中使用 SELinux 进行强制访问控制 – Part 13
|
||||
================================================================================
|
||||
在本系列的前面几篇文章中,我们已经详细地探索了至少两种访问控制方法:标准的 ugo/rwx 权限([管理用户和组 – Part 3][1]) 和访问控制列表([在文件系统中配置 ACL – Part 7][2])。
|
||||
|
||||

|
||||
|
||||
RHCSA 认证:SELinux 精要和控制文件系统的访问
|
||||
|
||||
尽管作为第一级别的权限和访问控制机制是必要的,但它们同样有一些局限,而这些局限则可以由安全增强 Linux(Security Enhanced Linux,简称为 SELinux) 来处理。
|
||||
|
||||
这些局限的一种情形是:某个用户可能通过一个未加详细阐述的 chmod 命令将一个文件或目录暴露在安全漏洞面前(注:这句我的翻译有点问题),从而引起访问权限的意外传播。结果,由该用户开启的任意进程可以对属于该用户的文件进行任意的操作,最终一个恶意的或受损的软件对整个系统可能会实现 root 级别的访问权限。
|
||||
|
||||
考虑到这些局限性,美国国家安全局(NSA) 率先设计出了 SELinux,一种强制的访问控制方法,它根据最小权限模型去限制进程在系统对象(如文件,目录,网络接口等)上的访问或执行其他的操作的能力,而这些限制可以在后面根据需要进行修改。简单来说,系统的每一个元素只给某个功能所需要的那些权限。
|
||||
|
||||
在 RHEL 7 中,SELinux 被并入了内核中,且默认情况下以强制模式开启。在这篇文章中,我们将简要地介绍有关 SELinux 及其相关操作的基本概念。
|
||||
|
||||
### SELinux 的模式 ###
|
||||
|
||||
SELinux 可以以三种不同的模式运行:
|
||||
|
||||
- 强制模式:SELinux 根据 SELinux 策略规则拒绝访问,这些规则是用以控制安全引擎的一系列准则;
|
||||
- 宽容模式:SELinux 不拒绝访问,但对于那些运行在强制模式下会被拒绝访问的行为,它会进行记录;
|
||||
- 关闭 (不言自明,即 SELinux 没有实际运行).
|
||||
|
||||
使用 `getenforce` 命令可以展示 SELinux 当前所处的模式,而 `setenforce` 命令(后面跟上一个 1 或 0) 则被用来将当前模式切换到强制模式或宽容模式,但只对当前的会话有效。
|
||||
|
||||
为了使得在登出和重启后上面的设置还能保持作用,你需要编辑 `/etc/selinux/config` 文件并将 SELINUX 变量的值设为 enforcing,permissive,disabled 中之一:
|
||||
|
||||
# getenforce
|
||||
# setenforce 0
|
||||
# getenforce
|
||||
# setenforce 1
|
||||
# getenforce
|
||||
# cat /etc/selinux/config
|
||||
|
||||

|
||||
|
||||
设置 SELinux 模式
|
||||
|
||||
通常情况下,你将使用 `setenforce` 来在 SELinux 模式间进行切换(从强制模式到宽容模式,或反之),以此来作为你排错的第一步。假如 SELinux 当前被设置为强制模式,而你遇到了某些问题,但当你把 SELinux 切换为宽容模式后问题不再出现了,则你可以确信你遇到了一个 SELinux 权限方面的问题。
|
||||
|
||||
### SELinux 上下文 ###
|
||||
|
||||
一个 SELinux 上下文由一个权限控制环境所组成,在这个环境中,决定的做出将基于 SELinux 的用户,角色和类型(和可选的级别):
|
||||
|
||||
- 一个 SELinux 用户是通过将一个常规的 Linux 用户账户映射到一个 SELinux 用户账户来实现的,反过来,在一个会话中,这个 SELinux 用户账户在 SELinux 上下文中被进程所使用,为的是能够显示地定义它们所允许的角色和级别。
|
||||
- 角色的概念是作为域和处于该域中的 SELinux 用户之间的媒介,它定义了 SELinux 可以访问到哪个进程域和哪些文件类型。这将保护您的系统免受提权漏洞的攻击。
|
||||
- 类型则定义了一个 SELinux 文件类型或一个 SELinux 进程域。在正常情况下,进程将会被禁止访问其他进程正使用的文件,并禁止对其他进程进行访问。这样只有当一个特定的 SELinux 策略规则允许它访问时,才能够进行访问。
|
||||
|
||||
下面就让我们看看这些概念是如何在下面的例子中起作用的。
|
||||
|
||||
**例 1:改变 sshd 守护进程的默认端口**
|
||||
|
||||
在[加固 SSH – Part 8][3] 中,我们解释了更改 sshd 所监听的默认端口是加固你的服务器免收外部攻击的首个安全措施。下面,就让我们编辑 `/etc/ssh/sshd_config` 文件并将端口设置为 9999:
|
||||
|
||||
Port 9999
|
||||
|
||||
保存更改并重启 sshd:
|
||||
|
||||
# systemctl restart sshd
|
||||
# systemctl status sshd
|
||||
|
||||

|
||||
|
||||
重启 SSH 服务
|
||||
|
||||
正如你看到的那样, sshd 启动失败,但为什么会这样呢?
|
||||
|
||||
快速检查 `/var/log/audit/audit.log` 文件会发现 sshd 已经被拒绝在端口 9999 上开启(SELinux 日志信息包含单词 "AVC",所以这类信息可以被轻易地与其他信息相区分),因为这个端口是 JBoss 管理服务的保留端口:
|
||||
|
||||
# cat /var/log/audit/audit.log | grep AVC | tail -1
|
||||
|
||||

|
||||
|
||||
查看 SSH 日志
|
||||
|
||||
在这种情况下,你可以像先前解释的那样禁用 SELinux(但请不要这样做!),并尝试重启 sshd,且这种方法能够起效。但是, `semanage` 应用可以告诉我们在哪些端口上可以开启 sshd 而不会出现任何问题。
|
||||
|
||||
运行:
|
||||
|
||||
# semanage port -l | grep ssh
|
||||
|
||||
便可以得到一个 SELinux 允许 sshd 在哪些端口上监听的列表:
|
||||
|
||||

|
||||
|
||||
Semanage 工具
|
||||
|
||||
所以让我们在 `/etc/ssh/sshd_config` 中将端口更改为 9998 端口,增加这个端口到 ssh_port_t 的上下文,然后重启 sshd 服务:
|
||||
|
||||
# semanage port -a -t ssh_port_t -p tcp 9998
|
||||
# systemctl restart sshd
|
||||
# systemctl is-active sshd
|
||||
|
||||

|
||||
|
||||
Semanage 添加端口
|
||||
|
||||
如你所见,这次 sshd 服务被成功地开启了。这个例子告诉我们这个事实:SELinux 控制 TCP 端口数为它自己端口类型中间定义。
|
||||
|
||||
**例 2:允许 httpd 访问 sendmail**
|
||||
|
||||
这是一个 SELinux 管理一个进程来访问另一个进程的例子。假如在你的 RHEL 7 服务器上,你要实现 Apache 的 mod_security 和 mod_evasive(注:这里少添加了一个链接,链接的地址是 http://www.tecmint.com/protect-apache-using-mod_security-and-mod_evasive-on-rhel-centos-fedora/),你需要允许 httpd 访问 sendmail,以便在遭受到 (D)DoS 攻击时能够用邮件来提醒你。在下面的命令中,如果你不想使得更改在重启后任然生效,请去掉 `-P` 选项。
|
||||
|
||||
# semanage boolean -1 | grep httpd_can_sendmail
|
||||
# setsebool -P httpd_can_sendmail 1
|
||||
# semanage boolean -1 | grep httpd_can_sendmail
|
||||
|
||||

|
||||
|
||||
允许 Apache 发送邮件
|
||||
|
||||
从上面的例子中,你可以知道 SELinux 布尔设定(或者只是布尔值)分别对应于 true 或 false,被嵌入到了 SELinux 策略中。你可以使用 `semanage boolean -l` 来列出所有的布尔值,也可以管道至 grep 命令以便筛选输出的结果。
|
||||
|
||||
**例 3:在一个特定目录而非默认目录下服务一个静态站点**
|
||||
|
||||
假设你正使用一个不同于默认目录(`/var/www/html`)的目录来服务一个静态站点,例如 `/websites` 目录(这种情形会出现在当你把你的网络文件存储在一个共享网络设备上,并需要将它挂载在 /websites 目录时)。
|
||||
|
||||
a). 在 /websites 下创建一个 index.html 文件并包含如下的内容:
|
||||
|
||||
<html>
|
||||
<h2>SELinux test</h2>
|
||||
</html>
|
||||
|
||||
假如你执行
|
||||
|
||||
# ls -lZ /websites/index.html
|
||||
|
||||
你将会看到这个 index.html 已经被标记上了 default_t SELinux 类型,而 Apache 不能访问这类文件:
|
||||
|
||||

|
||||
|
||||
检查 SELinux 文件的权限
|
||||
|
||||
b). 将 `/etc/httpd/conf/httpd.conf` 中的 DocumentRoot 改为 /websites,并不要忘了
|
||||
更新相应的 Directory 代码块。然后重启 Apache。
|
||||
|
||||
c). 浏览到 `http://<web server IP address>`,则你应该会得到一个 503 Forbidden 的 HTTP 响应。
|
||||
|
||||
d). 接下来,递归地改变 /websites 的标志,将它的标志变为 httpd_sys_content_t 类型,以便赋予 Apache 对这些目录和其内容的只读访问权限:
|
||||
|
||||
# semanage fcontext -a -t httpd_sys_content_t "/websites(/.*)?"
|
||||
|
||||
e). 最后,应用在 d) 中创建的 SELinux 策略:
|
||||
|
||||
# restorecon -R -v /websites
|
||||
|
||||
现在重启 Apache 并再次浏览到 `http://<web server IP address>`,则你可以看到被正确展现出来的 html 文件:
|
||||
|
||||

|
||||
|
||||
确认 Apache 页面
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在本文中,我们详细地介绍了 SELinux 的基础知识。请注意,由于这个主题的广泛性,在单篇文章中做出一个完全详尽的解释是不可能的,但我们相信,在这个指南中列出的基本原则将会对你进一步了解更高级的话题有所帮助,假如你想了解的话。
|
||||
|
||||
假如可以,请让我推荐两个必要的资源来入门 SELinux:[NSA SELinux 页面][4] 和 [针对用户和系统管理员的 RHEL 7 SELinux 指南][5]。
|
||||
|
||||
假如你有任何的问题或评论,请不要犹豫,让我们知晓吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/selinux-essentials-and-control-filesystem-access/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/rhcsa-exam-manage-users-and-groups
|
||||
[2]:http://www.tecmint.com/rhcsa-exam-configure-acls-and-mount-nfs-samba-shares/
|
||||
[3]:http://www.tecmint.com/rhcsa-series-secure-ssh-set-hostname-enable-network-services-in-rhel-7/
|
||||
[4]:https://www.nsa.gov/research/selinux/index.shtml
|
||||
[5]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/SELinux_Users_and_Administrators_Guide/part_I-SELinux.html
|
||||
Loading…
Reference in New Issue
Block a user