mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-09 01:30:10 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
f9aba29bc4
@ -1,33 +1,35 @@
|
||||
怎样实现由专有环境向开源环境的职业转变
|
||||
======
|
||||
|
||||
> 学习一点转变到新的技术文化的小技巧。
|
||||
|
||||

|
||||
|
||||
作为一名软件工程师,我的职业生涯是从 Northern Telecom 开始的,在这里我开发出了电信级的通讯转换设备可以使用的专有软件等。 即使我已经在大学中学习了 Pascal 语言,公司还是给我进行了以 C 语言为基础是专有编程语言培养。在公司中我使用的也是专有操作系统和专有版本控制软件。
|
||||
作为一名软件工程师,我的职业生涯是从北电开始的,在这里我开发出了电信级的电话交换机所用的专有软件。 即使我已经在大学中学习了 Pascal 语言,公司还是给我进行了以 C 语言为基础是专有编程语言培养。在公司中我使用的也是专有操作系统和专有版本控制软件。
|
||||
|
||||
我很享受专有环境下的工作,并有幸接触了很多有趣的项目,这样过了很多年,直到一场招聘会,我遇到了事业转折点。那时我受邀在当地一所中学的 STEM 行业座谈会进行演讲,给学生们讲述了作为一名软件工程师的主要工作内容和责任,一名学生问我:“这些事是你一直梦想要做的吗?你热爱你现在的工作吗?”
|
||||
|
||||
每次领导问我这个问题时,保险起见,我都会回答他,“我当然热爱工作了!”但从来没有一名还在读六年级的单纯的 STEM 小爱好者问过我这个问题。我的回答还是一样,“我当然喜欢!”
|
||||
|
||||
我确实很热爱我当时的事业,但那名学生的话让我忍不住思考,我开始重新审视我的事业,重新审视专有环境。在我的领域里我如鱼得水,但这也有局限性:我只能用代码来定义我的领域。我忍不住反思,这些年我有没有试着去学一些其他可应用于专有环境的技术?在同行中我的技能组还算得上先进吗?我有没有混日子?我真的想继续为这项事业奋斗吗?
|
||||
我确实很热爱我当时的事业,但那名学生的话让我忍不住思考,我开始重新审视我的事业,重新审视专有环境。在我的领域里我如鱼得水,但这也有局限性:我只能用代码来定义我的领域。我忍不住反思,这些年我在专有环境中学到了不同的技术了吗?在同行中我的技能组还算得上先进吗?我有没有混日子?我真的想继续为这项事业奋斗吗?
|
||||
|
||||
我想了很多,忍不住问自己:当年的激情和创意还在吗?
|
||||
|
||||
时间不会停止,但我的生活发生了改变。我离开了 Nortel Networks ,打算休息一段时间来陪陪我的家人。
|
||||
时间不会停止,但我的生活发生了改变。我离开了北电 ,打算休息一段时间来陪陪我的家人。
|
||||
|
||||
在我准备返回工作岗位时,那个小朋友的话又在我的脑海中响起,这真的是我想要的工作吗?我投了很多份简历,有一个岗位是我最中意的,但那家公司的回复是,他们想要的是拥有五年及以上 Java and Python 工作经验的人。在过去十五年里我以之为生的知识和技术看起来已经过时了。
|
||||
在我准备返回工作岗位时,那个小朋友的话又在我的脑海中响起,这真的是我想要的工作吗?我投了很多份简历,有一个岗位是我最中意的,但那家公司的回复是,他们想要的是拥有五年及以上的 Java 和 Python 工作经验的人。在过去十五年里我以之为生的知识和技术看起来已经过时了。
|
||||
|
||||
### 机遇与挑战
|
||||
|
||||
我的第一项挑战是学会在新的环境下应用我先前在封闭环境学到的技能。IT 行业由专有环境转向开源后发生了天翻地覆的变化。我打算先自学眼下最需要的 Python 。接触 Python 后我意识到,我需要一个项目来证明自己的能力,让自己更具有竞争力。
|
||||
|
||||
我的第二个挑战是怎么获得 Python 相关的项目经验。我丈夫和之前的同事都向我推荐了开源软件,通过谷歌搜索我发现网上有许许多多的开源项目,它们分别来源于一个人的小团队,50 人左右的团队,还有跨国的百人大团队。
|
||||
我的第二个挑战是怎么获得 Python 相关的项目经验。我丈夫和之前的同事都向我推荐了开源软件,通过谷歌搜索我发现网上有许许多多的开源项目,它们分别来源于一个人的小团队、50 人左右的团队,还有跨国的百人大团队。
|
||||
|
||||
在 Github 上我用相关专业术语搜索出了许多适合我的项目。综合我的兴趣和网络相关的工作经验,我打算把第一个项目贡献给 OpenStack 。 我还注意到了 [Outreachy][1] 项目,它为不具备相关技术基础的人员提供三个月的实习期。
|
||||
在 Github 上我用相关专业术语搜索出了许多适合我的项目。综合我的兴趣和网络相关的工作经验,我打算把第一个项目贡献给 OpenStack。 我还注意到了 [Outreachy][1] 项目,它为不具备相关技术基础的人员提供三个月的实习期。
|
||||
|
||||
### 经验与教训
|
||||
|
||||
我学到的第一件事是我发现可以通过许多方式进行贡献。不论是文件编制、用户设计,还是测试用例,都是贡献的形式。我在探索中丰富了我的技能组,根本用不着5年的时间,只需要在开源平台上接受委托,之后做出成果。
|
||||
我学到的第一件事是我发现可以通过许多方式进行贡献。不论是文件编制、用户设计,还是测试用例,都是贡献的形式。我在探索中丰富了我的技能组,根本用不着 5 年的时间,只需要在开源平台上接受委托,之后做出成果。
|
||||
|
||||
在我为 OpenStack 做出的第一个贡献被合并、发表后,我正式成为了 Outreachy 项目的一员。 Outreachy 项目最好的一点是,项目分配给我的导师能够引领我在开源世界中找到方向。
|
||||
|
||||
@ -48,7 +50,7 @@ via: https://opensource.com/article/18/7/career-move
|
||||
作者:[Petra Sargent][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Valoniakim](https://github.com/Valoniakim)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
63
published/20180813 Convert file systems with Fstransform.md
Normal file
63
published/20180813 Convert file systems with Fstransform.md
Normal file
@ -0,0 +1,63 @@
|
||||
使用 Fstransform 转换文件系统
|
||||
======
|
||||
|
||||

|
||||
|
||||
很少有人知道他们可以将文件系统从一种类型转换为另一种类型而不会丢失数据(即非破坏性的)。这可能听起来像魔术,但 [Fstransform][1] 可以几乎以任意组合将 ext2、ext3、ext4、jfs、reiserfs 或 xfs 分区转换成另一类型。更重要的是,它可以直接执行,而无需格式化或复制数据。除此之外,还有一点好处:Fstransform 也可以处理 ntfs、btrfs、fat 和 exfat 分区。
|
||||
|
||||
### 在运行之前
|
||||
|
||||
Fstransform 存在一些警告和限制,因此强烈建议在尝试转换之前进行备份。此外,使用 Fstransform 时需要注意一些限制:
|
||||
|
||||
* 你的 Linux 内核必须支持源文件系统和目标文件系统。听起来很明显,如果你想使用 ext2、ext3、ext4、reiserfs、jfs 和 xfs 分区,这样不会出现风险。Fedora 支持所有分区,所以没问题。
|
||||
* 将 ext2 升级到 ext3 或 ext4 不需要 Fstransform。请使用 Tune2fs。
|
||||
* 源文件系统的设备必须至少有 5% 的可用空间。
|
||||
* 你需要在开始之前卸载源文件系统。
|
||||
* 源文件系统存储的数据越多,转换的时间就越长。实际速度取决于你的设备,但预计它大约为每分钟 1GB。大量的硬链接也会降低转换速度。
|
||||
* 虽然 Fstransform 被证明是稳定的,但请备份源文件系统上的数据。
|
||||
|
||||
### 安装说明
|
||||
|
||||
Fstransform 已经是 Fedora 的一部分。使用以下命令安装:
|
||||
|
||||
```
|
||||
sudo dnf install fstransform
|
||||
```
|
||||
|
||||
### 转换
|
||||
|
||||
![][2]
|
||||
|
||||
`fstransform` 命令的语法非常简单:`fstransform <源设备> <目标文件系统>`。请记住,它需要 root 权限才能运行,所以不要忘记在开头添加 `sudo`。这是一个例子:
|
||||
|
||||
```
|
||||
sudo fstransform /dev/sdb1 ext4
|
||||
```
|
||||
|
||||
请注意,无法转换根文件系统,这是一种安全措施。请改用测试分区或实验性 USB 盘。与此同时,Fstransform 会在控制台中有许多辅助输出。最有用的部分是预计完成时间,让你随时了解该过程需要多长时间。同样,在几乎空的驱动器上的几个小文件将使 Fstransform 在一分钟左右完成其工作,而更多真实世界的任务可能需要数小时的等待时间。
|
||||
|
||||
### 更多支持的文件系统
|
||||
|
||||
如上所述,可以尝试在 ntfs、btrfs、fat 和 exfat 分区使用 Fstransform。这些类型是早期实验性的,没有人能保证完美转换。尽管如此,还是有许多成功案例,你可以通过在测试分区上使用示例数据集测试 Fstransform 来添加自己的成功案例。可以使用 `--force-untested-file-systems` 参数启用这些额外的文件系统:
|
||||
|
||||
```
|
||||
sudo fstransform /dev/sdb1 ntfs --force-untested-file-systems
|
||||
```
|
||||
|
||||
有时,该过程可能会因错误而中断。请放心再次执行命令 —— 它可能最终会在两、三次尝试后完成转换。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/transform-file-systems-in-linux/
|
||||
|
||||
作者:[atolstoy][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/atolstoy/
|
||||
[1]:https://github.com/cosmos72/fstransform
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2018/08/Screenshot_20180805_230116.png
|
||||
@ -0,0 +1,71 @@
|
||||
Dropbox To End Sync Support For All Filesystems Except Ext4 on Linux
|
||||
======
|
||||
Dropbox is thinking of limiting the synchronization support to only a handful of file system types: NTFS for Windows, HFS+/APFS for macOS and Ext4 for Linux.
|
||||
|
||||
![Dropbox ends support for various file system types][1]
|
||||
|
||||
[Dropbox][2] is one of the most popular [cloud services for Linux][3]. A lot of folks happen to utilize the Dropbox sync client for Linux. However, recently, some of the users received a warning on their Dropbox Linux desktop client that said:
|
||||
|
||||
> “Move Dropbox location
|
||||
> Dropbox will stop syncing in November“
|
||||
|
||||
### Dropbox will only support a handful of file systems
|
||||
|
||||
A [Reddit thread][4] highlighted the announcement where one of the users inquired about it on [Dropbox forums][5], which was addressed by a community moderator with an unexpected news. Here’s what the[reply][6] was:
|
||||
|
||||
> **“Hi everyone, on Nov. 7, 2018, we’re ending support for Dropbox syncing to drives with certain uncommon file systems. The supported file systems are NTFS for Windows, HFS+ or APFS for Mac, and Ext4 for Linux.**
|
||||
>
|
||||
> [Official Dropbox Forum][6]
|
||||
|
||||
![Dropbox official confirmation over limitation on supported file systems][7]
|
||||
Dropbox official confirmation over limitation on supported file systems
|
||||
|
||||
The move is intended to provide a stable and consistent experience. Dropbox has also updated its [desktop requirements.][8]
|
||||
|
||||
### So, what should you do?
|
||||
|
||||
If you are using Dropbox on an unsupported filesystem to sync with, you should consider changing the location.
|
||||
|
||||
Only Ext4 file system will be supported for Linux. And that’s not entirely a worrying news because chances are that you are already using Ext4 file system.
|
||||
|
||||
On Ubuntu or other Ubuntu based distributions, open the Disks application and see the file system for the partition where you have installed your Linux system.
|
||||
|
||||
![Check file system type on Ubuntu][9]
|
||||
Check file system type on Ubuntu
|
||||
|
||||
If you don’t have this Disk utility installed on your system, you can always [use the command line to find out file system type][10].
|
||||
|
||||
If you are using Ext4 file system and still getting the warning from Dropbox, check if you have an inactive computer/device linked for which you might be getting the notification. If yes, [unlink that system from your Dropbox account][11].
|
||||
|
||||
### Dropbox won’t support encrypted Ext4 as well?
|
||||
|
||||
Some users are also reporting that they received the warning while they have an encrypted Ext4 filesystem synced with. So, does this mean that the Dropbox client for Linux will only support unencrypted Ext4 filesystem? There is no official statement from Dropbox in this regard.
|
||||
|
||||
What filesystem are you using? Did you receive the warning as well? If you’re still not sure what to do after receiving the warning, you should head to the [official help center page][12] which mentions the solution.
|
||||
|
||||
Let us know your thoughts in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/dropbox-linux-ext4-only/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/dropbox-filesystem-support-featured.png
|
||||
[2]: https://www.dropbox.com/
|
||||
[3]: https://itsfoss.com/cloud-services-linux/
|
||||
[4]: https://www.reddit.com/r/linux/comments/966xt0/linux_dropbox_client_will_stop_syncing_on_any/
|
||||
[5]: https://www.dropboxforum.com/t5/Syncing-and-uploads/
|
||||
[6]: https://www.dropboxforum.com/t5/Syncing-and-uploads/Linux-Dropbox-client-warn-me-that-it-ll-stop-syncing-in-Nov-why/m-p/290065/highlight/true#M42255
|
||||
[7]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/dropbox-stopping-file-system-supports.jpeg
|
||||
[8]: https://www.dropbox.com/help/desktop-web/system-requirements#desktop
|
||||
[9]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/check-file-system-type-ubuntu.jpg
|
||||
[10]: https://www.thegeekstuff.com/2011/04/identify-file-system-type/
|
||||
[11]: https://www.dropbox.com/help/mobile/unlink-relink-computer-mobile
|
||||
[12]: https://www.dropbox.com/help/desktop-web/cant-establish-secure-connection#location
|
||||
@ -1,92 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
5 applications to manage your to-do list on Fedora
|
||||
======
|
||||
|
||||

|
||||
|
||||
Effective management of your to-do list can do wonders for your productivity. Some prefer just keeping a to-do list in a text file, or even just using a notepad and pen. For users that want more out of their to-do list, they often turn to an application. In this article we highlight 4 graphical applications and a terminal-based tool for managing your to-do list.
|
||||
|
||||
### GNOME To Do
|
||||
|
||||
[GNOME To Do][1] is a personal task manager designed specifically for the GNOME desktop (Fedora Workstation’s default desktop). When comparing GNOME To Do with some others in this list, it is has a range of neat features.
|
||||
|
||||
GNOME To Do provides organization of tasks by lists, and the ability to assign a colour to that list. Additionally, individual tasks can be assigned due dates & priorities, and notes for each task. Futhermore, GNOME To Do has extensions, allowing even more features, including support for [todo.txt][2] and syncing with online services such as [todoist][3].
|
||||
|
||||
![][4]
|
||||
|
||||
Install GNOME To Do either by using the Software application, or using the following command in the Terminal:
|
||||
```
|
||||
sudo dnf install gnome-todo
|
||||
|
||||
```
|
||||
|
||||
### Getting things GNOME!
|
||||
|
||||
Before GNOME To Do existed, the go-to application for tracking tasks on GNOME was [Getting things GNOME!][5] This older-style GNOME application has a multiple window layout, allowing you to show the details of multiple tasks at the same time. Rather than having lists of tasks, GTG has the ability to add sub-tasks to tasks and even to sub-tasks. GTG also has the ability to add due dates and start dates. Syncing to other apps and services is also possible in GTG via plugins.
|
||||
|
||||
![][6]
|
||||
|
||||
Install Getting Things GNOME either by using the Software application, or using the following command in the Terminal:
|
||||
```
|
||||
sudo dnf install gtg
|
||||
|
||||
```
|
||||
|
||||
### Go For It!
|
||||
|
||||
[Go For It!][7] is a super-simple task management application. It is used to simply create a list of tasks, and mark them as done when completed. It does not have the ability to group tasks, or create sub-tasks. By default, Go For It! stored tasks in the todo.txt format, allowing simpler syncing to online services and other applications. Additionally, Go For It! contains a simple timer to track how much time you have spent on the current task.
|
||||
|
||||
![][8]
|
||||
|
||||
Go For It is available to download from the Flathub application repository. To install, simply [enable Flathub as a software source][9], and then install via the Software application.
|
||||
|
||||
### Agenda
|
||||
|
||||
If you are looking for a no-fuss super simple to-do application, look no further than [Agenda][10]. Create tasks, mark them as complete, and then delete them from your list. Agenda shows all tasks (completed or open) until you remove them.
|
||||
|
||||
![][11]
|
||||
|
||||
Agenda is available to download from the Flathub application repository. To install, simply [enable Flathub as a software source][9], and then install via the Software application.
|
||||
|
||||
### Taskwarrior
|
||||
|
||||
[Taskwarrior][12] is a flexible command-line task management program. It is highly customizable, but can also be used “right out of the box.” Using simple commands, you can create tasks, mark them as complete, and list current open tasks. Additionally, tasks can be tagged, added to projects, searched and filtered. Furthermore, you can set up recurring tasks, and apply due dates to tasks.
|
||||
|
||||
[This previous article on the Fedora Magazine][13] provides a good overview of getting started with Taskwarrior.
|
||||
|
||||
![][14]
|
||||
|
||||
Install Taskwarrior with this command in the Terminal:
|
||||
```
|
||||
sudo dnf install task
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/5-tools-to-manage-your-to-do-list-on-fedora/
|
||||
|
||||
作者:[Ryan Lerch][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/introducing-flatpak/
|
||||
[1]:https://wiki.gnome.org/Apps/Todo/
|
||||
[2]:http://todotxt.org/
|
||||
[3]:https://en.todoist.com/
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/08/gnome-todo.png
|
||||
[5]:https://wiki.gnome.org/Apps/GTG
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/08/gtg.png
|
||||
[7]:http://manuel-kehl.de/projects/go-for-it/
|
||||
[8]:https://fedoramagazine.org/wp-content/uploads/2018/08/goforit.png
|
||||
[9]:https://fedoramagazine.org/install-flathub-apps-fedora/
|
||||
[10]:https://github.com/dahenson/agenda
|
||||
[11]:https://fedoramagazine.org/wp-content/uploads/2018/08/agenda.png
|
||||
[12]:https://taskwarrior.org/
|
||||
[13]:https://fedoramagazine.org/getting-started-taskwarrior/
|
||||
[14]:https://fedoramagazine.org/wp-content/uploads/2018/08/taskwarrior.png
|
||||
@ -0,0 +1,126 @@
|
||||
Orion Is A QML / C++ Twitch Desktop Client With VODs And Chat Support
|
||||
======
|
||||
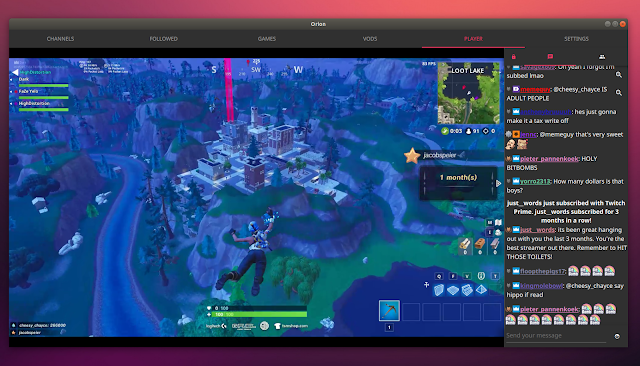
**[Orion][1] is a free and open source QML / C++ client for [Twitch.tv][2] which can use multiple player backends (including [mpv][3]). The application runs on Linux, Windows, macOS and Android.**
|
||||
|
||||
Using Orion you can watch live Twitch streams and past broadcasts, and browse or search games and channels using a nice material user interface. What's more, Orion lets you login to Twitch, so you can chat and follow channels (and receive notifications when a channel you follow goes online).
|
||||
|
||||
The application allows customizing various aspects, like changing the stream quality, switching between light and dark user interface themes, and changing the chat position and font size.
|
||||
|
||||
|
||||
|
||||
**Main Orion Twitch client features:**
|
||||
|
||||
* **Play live Twitch streams or past VODs using one of 3 backends: mpv, QtAV or Qt5 Multimedia (mpv is default)**
|
||||
* **Browse and search Twitch games and channels**
|
||||
* **Login using your Twitch credentials**
|
||||
* **Desktop notifications when a followed channel comes online (including an option to show offline notifications)**
|
||||
* **Chat support**
|
||||
* **Light and Dark themes with configurable font**
|
||||
* **Change chat position (right, left or bottom)**
|
||||
* **Options to start minimized, close to tray and keep on top**
|
||||
|
||||
|
||||
|
||||
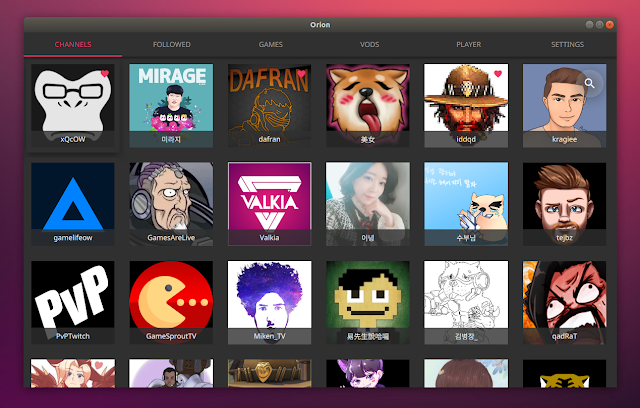
Here's how Orion works. When you go to the channels list, you'll notice that each channel uses its icon as a thumbnail, with the channel name in an overlay on top of the icon:
|
||||
|
||||
|
||||
|
||||
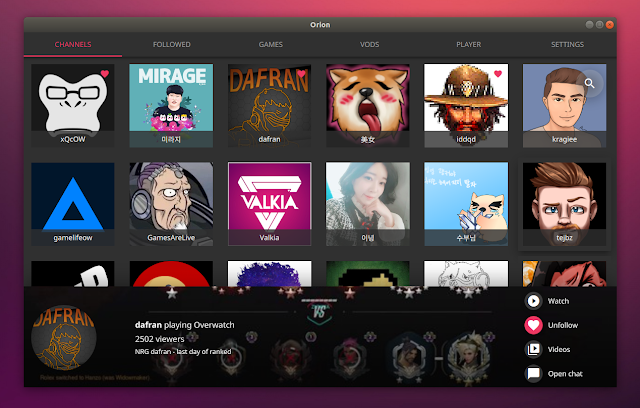
I would have liked to see the stream title, number of current viewers, and a preview in the channel list, or have an option for this. These are available, but not directly in the channel list. You can see a channel preview on mouse over, while the stream title and viewer count are available after you click on a channel:
|
||||
|
||||
|
||||
|
||||
From this bottom overlay (which is displayed after you click on a channel) you can start playing the stream, follow or unfollow the channel, open the chat without watching the stream, or access past videos. You can also right click a channel to access these options.
|
||||
|
||||
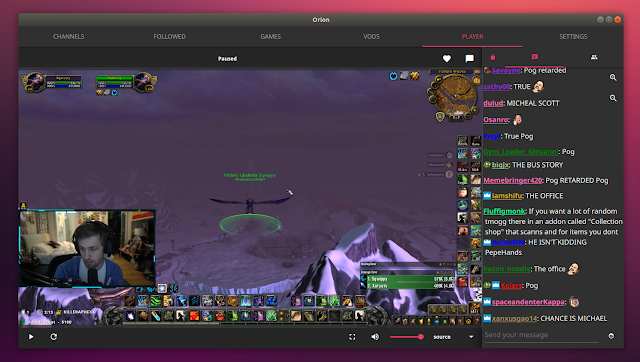
In the player view you'll find the regular video player controls, along with the quality selector (with source as the default quality) at the bottom, while the top overlay lets you follow / unfollow a channel or toggle the chat, which is displayed on the right-hand side of the screen by default:
|
||||
|
||||
|
||||
|
||||
The chat panel uses autohide by default, but you can force it to always be displayed by clicking the lock icon its upper left corner. When the chat is locked (set to always visible), the video is shifted to the left so the chat isn't displayed on top of the video, and the chat width is resizable.
|
||||
|
||||
### Download Orion
|
||||
|
||||
[Download Orion(binaries for Windows or macOS)][13]
|
||||
|
||||
The Orion GitHub project page doesn't offer any Linux binaries for download, but there are packages out there for multiple Linux distributions:
|
||||
|
||||
* **Arch Linux** AUR packages for the latest Orion [stable][4] or [Git][5].
|
||||
* **Ubuntu 18.04 / Linux Mint 19** : [here's][6] the latest Orion Twitch client as a DEB package (if you want to add the PPA you can find it [here][7]). There's [another][8] PPA which has the latest Orion for Ubuntu 18.04 and an older Orion version for Ubuntu 16.04 - I only tried the Ubuntu 18.04 package from this second PPA but the Orion window is very small upon launching the application, that's why I prefer the first package.
|
||||
* **Fedora 29, 28 and 27** have Orion in its [repositories][9].
|
||||
* **openSUSE Tumbleweed and Leap 15.0** have Orion in the official [repositories][10].
|
||||
|
||||
|
||||
|
||||
In case you're using a different Linux distribution, you'll need to search for Orion packages for yourself or build it from
|
||||
|
||||
**If you prefer to build Orion from source on Debian/Ubuntu-based Linux distributions** (with mpv as the backend), **here's how to compile it. Orion requires Qt 5.8 or newer!** That means you'll need Ubuntu 18.04 / Linux Mint 19 to build it, or if you want to compile it in an older Ubuntu version, you'll need to install a newer Qt version from a PPA, etc.
|
||||
|
||||
1\. Install the required dependencies on your Debian/Ubuntu-based Linux distribution:
|
||||
```
|
||||
sudo apt install qt5-default qtdeclarative5-dev qtquickcontrols2-5-dev libqt5svg5-dev libmpv-dev mesa-common-dev libgl1-mesa-dev libpulse-dev
|
||||
|
||||
```
|
||||
|
||||
2\. Download (using wget), build and install Orion:
|
||||
```
|
||||
cd && wget https://github.com/alamminsalo/orion/archive/1.6.5.tar.gz
|
||||
tar -xvf 1.6.5.tar.gz
|
||||
cd orion-1.6.5
|
||||
mkdir build && cd build
|
||||
qmake ../
|
||||
make && sudo make install
|
||||
|
||||
```
|
||||
|
||||
If you want to build a different Orion version, make sure you adjust the first 3 commands with the exact file/version name.
|
||||
|
||||
|
||||
### Fixing the default Orion theme when using QT_STYLE_OVERRIDE (not required in most cases)
|
||||
|
||||
I use `QT_STYLE_OVERRIDE` . Due to this, Orion does not use its default theme which causes some fonts to be invisible or hard to read.
|
||||
|
||||
This is how Orion looks when used with Kvantum set as the `QT_STYLE_OVERRIDE` :
|
||||
|
||||

|
||||
|
||||
If you're in the same situation, you can fix the Orion theme by launching the application like this:
|
||||
```
|
||||
QT_STYLE_OVERRIDE= orion
|
||||
|
||||
```
|
||||
|
||||
To change the Orion desktop file to include this so you can launch Orion from your menu and have it use the correct theme, copy the Orion desktop file from `/usr/share/applications/` to `~/.local/share/applications/` , edit it in this second location and change `Exec=orion` to `Exec=env QT_STYLE_OVERRIDE= orion`
|
||||
|
||||
You can do all of this from a terminal using these commands:
|
||||
```
|
||||
cp /usr/share/applications/Orion.desktop ~/.local/share/applications/
|
||||
|
||||
sed -i 's/Exec=orion/Exec=env QT_STYLE_OVERRIDE= orion/' ~/.local/share/applications/Orion.desktop
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/08/orion-is-qml-c-twitch-desktop-client.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://plus.google.com/118280394805678839070
|
||||
[1]: https://alamminsalo.github.io/orion/
|
||||
[2]: https://www.twitch.tv/
|
||||
[3]: https://mpv.io/
|
||||
[4]: https://aur.archlinux.org/packages/orion/
|
||||
[5]: https://aur.archlinux.org/packages/orion-git/
|
||||
[6]: http://ppa.launchpad.net/mortigar/orion/ubuntu/pool/main/o/orion/
|
||||
[7]: https://launchpad.net/~mortigar/+archive/ubuntu/orion
|
||||
[8]: https://launchpad.net/~rakslice/+archive/ubuntu/orion
|
||||
[9]: https://apps.fedoraproject.org/packages/orion
|
||||
[10]: https://software.opensuse.org/package/orion
|
||||
[11]: https://github.com/alamminsalo/orion#building-on-linux
|
||||
[12]: https://www.linuxuprising.com/2018/05/use-custom-themes-for-qt-applications.html
|
||||
[13]: https://github.com/alamminsalo/orion/releases
|
||||
143
sources/tech/20180829 4 open source monitoring tools.md
Normal file
143
sources/tech/20180829 4 open source monitoring tools.md
Normal file
@ -0,0 +1,143 @@
|
||||
4 open source monitoring tools
|
||||
======
|
||||
|
||||

|
||||
|
||||
Isn’t monitoring just monitoring? Doesn’t it include logging, visualization, and time-series data?
|
||||
|
||||
The terminology around monitoring has caused a lot of confusion over the years and has led to some poor tools that tout the ability to do everything in one format. Observability proponents recognize there are many levels for observing a system. Metrics aggregation is primarily time-series data, and that’s what we’ll discuss in this article.
|
||||
|
||||
### Features of time-series data
|
||||
|
||||
#### Counters
|
||||
|
||||
A counter is a metric that represents a numeric value that will only increase. (In other words, a counter should never decrease.) Counters accumulate values and present the current total when requested. These are commonly used for things like the total number of web requests, number of errors, number of visitors, etc. This is analogous to the person with a counter device standing at the entrance to an event counting all the people entering. There is generally no option to decrement the counter without resetting it.
|
||||
|
||||
#### Gauges
|
||||
|
||||
A gauge is similar to a counter in that it represents a single numeric value, but it can also decrease. It is essentially a representation of some value at a point in time. A thermometer is a good example of a gauge: It moves up and down with the temperature and offers a point-in-time reading. Other uses include CPU usage, memory usage, network usage, and number of threads.
|
||||
|
||||
#### Quantiles
|
||||
|
||||
Quantiles aren’t a type of metric, but they’re germane to the next two sections: histograms and summaries. Let’s clarify our understanding of quantiles with an example:
|
||||
|
||||
A percentile is a type of quantile. Percentiles are something we see regularly, and they should help us understand the general concept more easily. A percentile has 100 “buckets” of values. We often see them related to testing or performance and generally stated as someone scoring, for example, within the 85th percentile or some other value. This means the person scoring within that percentile had a real value that fell within the bucket between the 85th and 86th percentile. This person also scored in the top 15% of all students. We don’t know the scores in the bucket based off this metric, but that can be derived based on the sum of all scores in the bucket divided by the count of those scores.
|
||||
|
||||
Quantiles allow us to understand our data better than using a mean or some other statistical function that doesn’t take into account outliers and uneven distributions.
|
||||
|
||||
#### Histograms
|
||||
|
||||
A histogram is a little more complicated than a counter or a gauge. It is a sample of observations. It consists of a counter, which counts all the observations, and what is essentially a gauge that sums the values of the observations. It uses “buckets” or groupings to segment the values in order to bound the datasets in a productive way. This is commonly seen with quantiles related to request service-level agreements (SLAs). Let’s say we want to ensure that 95% of our requests are below 500ms. We could use a bucket with an upper bound of 0.5s to collect all values that fall under 500ms. We would then be able to determine how many of the total requests have fallen into that bucket. We can also determine how far we are from our SLA, but this can be difficult to do (as is explained more in the [Prometheus documentation][1]).
|
||||
|
||||
Histograms are aggregate metrics that are accumulated from multiple instances into a central server. This provides an opportunity to understand the system as a whole rather than on a node-by-node basis.
|
||||
|
||||
#### Summaries
|
||||
|
||||
Summaries are similar to histograms in that they are a sample of observations, but the aggregation occurs on the server side. Also, the estimate of the quantile is more accurate than in a histogram. A summary uses a sliding time window, so it serves a slightly different case than a histogram but is generally used for the same types of metrics. I normally use a histogram unless I need a very accurate measure of the quantile.
|
||||
|
||||
### Push/pull
|
||||
|
||||
No article can be written about metrics aggregation tools without addressing the push vs. pull debate.
|
||||
|
||||
The debate centers around whether it is better for your metrics aggregation system to have data pushed to it or to have your metrics aggregation system reach out and gather the data by scraping an endpoint. Multiple articles discuss this (like [this one][2] and [this one][3]). My perspective is that it mostly doesn’t matter. Additional research is left to the reader’s discretion.
|
||||
|
||||
### Tool options
|
||||
|
||||
There are many tools available, both open source and commercial. We will focus on open source tools, but some of these have an open core model with a paid component.
|
||||
|
||||
Some of these tools feature additional components of observability—principally alerting and visualizations. These will be covered in this section as additional features and won’t be covered in subsequent articles.
|
||||
|
||||
#### Prometheus
|
||||
|
||||
This is the most well-recognized time-series monitoring solution for cloud-native applications. It is hosted within the [Cloud Native Computing Foundation][4] (CNCF), but it was created by Matt Proud and Julius Volz and sponsored by [SoundCloud][5], with external contributors coming in early to help develop it. Brian Brazil of [Robust Perception][6] has built a business of helping companies adopt Prometheus. He also has an excellent [blog][7] on his website. The [Prometheus documentation][8] is extensive and provides a lot of detail for understanding and using the tool.
|
||||
|
||||
[Prometheus][9] is a pull-based system that uses local configuration to describe the endpoints to collect from and the interval desired for collection. Each endpoint has a client collecting the data and updating that representation upon each request (or however the client is configured). This data is collected and saved in a highly efficient storage engine on local disk. The storage system uses an append-only file per metric. This storage isn’t lossy, which means the fidelity of data from a year ago is as high as the data you are collecting today. However, you may not want to keep that much data locally. Fortunately, there is an option for remote storage for long-term retention and analysis.
|
||||
|
||||
Prometheus includes an advanced expression language for selecting and presenting data called [PromQL][10]. This data can be displayed graphically, tabularly, or used by external systems through a REST API. The expression language allows a user to create regressions, analyze real-time data, or trend historical data. Labels are also a great tool for filtering and querying data. Labels can be associated with each metric name.
|
||||
|
||||
Prometheus also offers a federation model, which encourages more localized control by allowing teams to have their own [Prometheis][11] while central teams can also have their own. The central systems could scrape the same endpoints as the local Prometheis, but they can also scrape the local Prometheis to get the aggregated data that the local instances are collecting. This reduces overhead on the endpoints. This federation model also allows local instances to collect data from each other.
|
||||
|
||||
Prometheus comes with [AlertManager][12] to handle alerts. This system allows for aggregation of alerts as well as more complex flows to limit when an alert is sent.
|
||||
|
||||
Let’s say 10 nodes suddenly go down at the same time a switch goes down. You probably don’t need to send an alert about the 10 nodes, as everyone who receives them will likely be unable to do anything until the switch is fixed. With the AlertManager, it’s possible to send an alert only to the networking team for the switch and include additional information about other systems that might be affected. It’s also possible to send an email (rather than a page) to the systems team so they know those nodes are down and they don’t need to respond unless the systems don’t come up after the switch is repaired. If that occurs, then AlertManager will reactivate those alerts that were suppressed by the switch alert.
|
||||
|
||||
#### Graphite
|
||||
|
||||
[Graphite][13] has been around for a long time, and James Turnbull's recent book [_The Art of Monitoring_][14] covers Graphite in detail. Graphite has become ubiquitous in the industry, with many large companies using it at scale.
|
||||
|
||||
Graphite is a push-based system that receives data from applications by having the application push the data into Graphite’s Carbon component. Carbon stores this data in the Whisper database, and that database and Carbon are read by the Graphite web component that allows a user to graph their data in a browser or pull it through an API. A really cool feature is the ability to export these graphs as images or data files to easily embed them in other applications.
|
||||
|
||||
Whisper is a fixed-size database that provides fast, reliable storage of numeric data over time. It is a lossy database, which means the resolution of your metrics will degrade over time. It will provide high-fidelity metrics for the most recent collections and gradually reduce that fidelity over time.
|
||||
|
||||
Graphite also uses dot-separated naming, which implies dimensionality. This dimensionality allows for some creative aggregation of metrics and relationships between metrics. This enables aggregation of services across different versions or data centers and (getting more specific) a single version running in one data center in a specific Kubernetes cluster. Granular-level comparisons can also be made to determine if a particular cluster is underperforming.
|
||||
|
||||
Another interesting feature of Graphite is the ability to store arbitrary events that should be related to time-series metrics. In particular, application or infrastructure deployments can be added and tracked within Graphite. This allows the operator or developer troubleshooting an issue to have more context about what has happened in the environment related to the anomalous behavior being investigated.
|
||||
|
||||
Graphite also has a substantial [list of functions][15] that can be applied to metrics series. However, it lacks a powerful query language, which some other tools include. It also lacks any alerting functionality or built-in alerting system.
|
||||
|
||||
#### InfluxDB
|
||||
|
||||
[InfluxDB][16] is a relatively new entrant, newer than Prometheus. It uses an open core model, which means scaling and clustering cost extra. InfluxDB is part of the larger [TICK stack][17] (of Telegraf, InfluxDB, Chronograf, and Kapacitor), so we will include all those components’ features in this analysis.
|
||||
|
||||
InfluxDB uses a key-value pair system called tags to add dimensionality to metrics, similar to Prometheus and Graphite. The results are similar to what we discussed previously for the other systems. The metric data can be of type **float64** , **int64** , **bool** , and **string** with nanosecond resolution. This is a broader range than most other tools in this space. In fact, the TICK stack is more of an event-aggregation platform than a native time-series metrics-aggregation system.
|
||||
|
||||
InfluxDB uses a system similar to a log-structured merge tree for storage. It is called a time-structured merge tree in this context. It uses a write-ahead log and a collection of read-only data files, which are similar to Sorted Strings Tables but have series data rather than pure log data. These files are sharded per block of time. To learn more, check out [this great resource][18] on the InfluxData website.
|
||||
|
||||
The architecture of the TICK stack is different depending on if it’s the open source or commercial version. The open source InfluxDB system is self-contained within a single host, while the commercial version is inherently distributed. This is true of the other central components as well. In the open source version, everything runs on a single host. No data or configuration is stored on external systems, so it is fairly easy to manage, but it isn’t as robust as the commercial version.
|
||||
|
||||
InfluxDB includes a SQL-like language called InfluxQL for querying data from the databases. The primary means for querying data is the HTTP API. The query language doesn’t have as many built-in helper functions as Prometheus, but those familiar with SQL will likely feel more comfortable with the language.
|
||||
|
||||
The TICK stack also includes an alerting system. This system can do some mild aggregation but doesn’t have the full capabilities of Prometheus’ AlertManager. It does offer many integrations, though. Also, to reduce load on InfluxDB, continuous queries can be scheduled to store results of queries that Kapacitor will pick up for alerting.
|
||||
|
||||
#### OpenTSDB
|
||||
|
||||
[OpenTSDB][19] is an open source time-series database, as its name implies. It’s unique in this collection of tools in that it stores its metrics in Hadoop. This means it is inherently scalable. If you already have a Hadoop cluster, this might be a good option for metrics you want to store over the long term. If you don’t have a Hadoop cluster, the operational overhead might be too large of a burden for you to bear. However, OpenTSDB now supports Google’s [Bigtable][20] as a backend, which is a cloud service you don’t have to operate.
|
||||
|
||||
OpenTSDB shares a lot of features with the other systems. It uses a key-value pairing system it calls tags for identifying metrics and adding dimensionality. It has a query language, but it is more limited than Prometheus’ PromQL. It does, however, have several built-in functions that help with learning and usage. The API is the main entry point for querying, similar to InfluxDB. This system also stores all data forever, unless there’s a time-to-live set in HBase, so you don't have to worry about fidelity degradation.
|
||||
|
||||
OpenTSDB doesn’t offer an alerting capability, which will make it harder to integrate with your incident response process. This type of system might be great for long-term Prometheus data storage and for performing more historical analytics to reveal systemic issues, rather than as a tool to quickly identify and respond to acute concerns.
|
||||
|
||||
### OpenMetrics standard
|
||||
|
||||
[OpenMetrics][21] is a working group seeking to establish a standard exposition format for metrics data. It is influenced by Prometheus. If this initiative is successful, we’ll have an industry-wide abstraction that would allow us to switch between tools and providers with ease. Leading companies like [Datadog][22] have already started offering tools that can consume the Prometheus exposition format, which will be easy to convert to the OpenMetrics standard once it’s released.
|
||||
|
||||
It’s also important to note that the contributors to this project include Google and InfluxData (among others). This likely means InfluxDB will eventually adopt the OpenMetrics standard. This may also mean that one of the three largest cloud providers will adopt it if Google’s involvement is an indicator. Of course, the exposition format is already being used in the Google-created [Kubernetes][23] project. [SolarWinds][24], [Robust Perception][6], and [SpaceNet][25] are also involved.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/open-source-monitoring-tools
|
||||
|
||||
作者:[Dan barker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/barkerd427
|
||||
[1]: https://prometheus.io/docs/practices/histograms/
|
||||
[2]: https://thenewstack.io/exploring-prometheus-use-cases-brian-brazil/
|
||||
[3]: https://prometheus.io/blog/2016/07/23/pull-does-not-scale-or-does-it/
|
||||
[4]: https://www.cncf.io/
|
||||
[5]: https://soundcloud.com/
|
||||
[6]: https://www.robustperception.io/
|
||||
[7]: https://www.robustperception.io/blog/
|
||||
[8]: https://prometheus.io/docs/
|
||||
[9]: https://prometheus.io/
|
||||
[10]: https://prometheus.io/docs/prometheus/latest/querying/basics/
|
||||
[11]: https://prometheus.io/docs/introduction/faq/#what-is-the-plural-of-prometheus
|
||||
[12]: https://prometheus.io/docs/alerting/alertmanager/
|
||||
[13]: https://graphiteapp.org/
|
||||
[14]: https://www.artofmonitoring.com/
|
||||
[15]: http://graphite.readthedocs.io/en/latest/functions.html
|
||||
[16]: https://www.influxdata.com/
|
||||
[17]: https://www.thoughtworks.com/radar/platforms/tick-stack
|
||||
[18]: https://docs.influxdata.com/influxdb/v1.5/concepts/storage_engine/
|
||||
[19]: http://opentsdb.net/
|
||||
[20]: https://cloud.google.com/bigtable/
|
||||
[21]: https://github.com/RichiH/OpenMetrics
|
||||
[22]: https://www.datadoghq.com/blog/monitor-prometheus-metrics/
|
||||
[23]: https://opensource.com/resources/what-is-kubernetes
|
||||
[24]: https://www.solarwinds.com/
|
||||
[25]: https://spacenetchallenge.github.io/
|
||||
@ -0,0 +1,325 @@
|
||||
Add GUIs to your programs and scripts easily with PySimpleGUI
|
||||
======
|
||||
|
||||

|
||||
|
||||
Few people run Python programs by double-clicking the .py file as if it were a .exe file. When a typical user (non-programmer types) double-clicks an .exe file, they expect it to pop open with a window they can interact with. While GUIs, using tkinter, are possible using standard Python installations, it's unlikely many programs do this.
|
||||
|
||||
What if it were so easy to open a Python program into a GUI that complete beginners could do it? Would anyone care? Would anyone use it? It's difficult to answer because to date it's not been easy to build a custom GUI.
|
||||
|
||||
There seems to be a gap in the ability to add a GUI onto a Python program/script. Complete beginners are left using only the command line and many advanced programmers don't want to take the time required to code up a tkinter GUI.
|
||||
|
||||
### GUI frameworks
|
||||
|
||||
There is no shortage of GUI frameworks for Python. Tkinter, WxPython, Qt, and Kivy are a few of the major packages. In addition, there are a good number of dumbed-down GUI packages that "wrap" one of the major packages, including EasyGUI, PyGUI, and Pyforms.
|
||||
|
||||
The problem is that beginners (those with less than six weeks of experience) can't learn even the simplest of the major packages. That leaves the wrapper packages as a potential option, but it will still be difficult or impossible for most new users to build a custom GUI layout. Even if it's possible, the wrappers still require pages of code.
|
||||
|
||||
[PySimpleGUI][1] attempts to address these GUI challenges by providing a super-simple, easy-to-understand interface to GUIs that can be easily customized. Even many complex GUIs require less than 20 lines of code when PySimpleGUI is used.
|
||||
|
||||
### The secret
|
||||
|
||||
What makes PySimpleGUI superior for newcomers is that the package contains the majority of the code that the user is normally expected to write. Button callbacks are handled by PySimpleGUI, not the user's code. Beginners struggle to grasp the concept of a function, and expecting them to understand a call-back function in the first few weeks is a stretch.
|
||||
|
||||
With most GUIs, arranging GUI widgets often requires several lines of code… at least one or two lines per widget. PySimpleGUI uses an "auto-packer" that automatically creates the layout. No pack or grid system is needed to lay out a GUI window.
|
||||
|
||||
Finally, PySimpleGUI leverages the Python language constructs in clever ways that shorten the amount of code and return the GUI data in a straightforward manner. When a widget is created in a form layout, it is configured in place, not several lines of code away.
|
||||
|
||||
### What is a GUI?
|
||||
|
||||
Most GUIs do one thing: collect information from the user and return it. From a programmer's viewpoint, this could be summed up as a function call that looks like this:
|
||||
```
|
||||
button, values = GUI_Display(gui_layout)
|
||||
|
||||
```
|
||||
|
||||
What's expected from most GUIs is the button that was clicked (e.g., OK, cancel, save, yes, no, etc.) and the values input by the user. The essence of a GUI can be boiled down to a single line of code.
|
||||
|
||||
This is exactly how PySimpleGUI works (for simple GUIs). When the call is made to display the GUI, nothing executes until a button is clicked that closes the form.
|
||||
|
||||
There are more complex GUIs, such as those that don't close after a button is clicked. Examples include a remote control interface for a robot and a chat window. These complex forms can also be created with PySimpleGUI.
|
||||
|
||||
### Making a quick GUI
|
||||
|
||||
When is PySimpleGUI useful? Immediately, whenever you need a GUI. It takes less than five minutes to create and try a GUI. The quickest way to make a GUI is to copy one from the [PySimpleGUI Cookbook][2]. Follow these steps:
|
||||
|
||||
* Find a GUI that looks similar to what you want to create
|
||||
* Copy code from the Cookbook
|
||||
* Paste it into your IDE and run it
|
||||
|
||||
|
||||
|
||||
Let's look at the first recipe from the book.
|
||||
```
|
||||
import PySimpleGUI as sg
|
||||
|
||||
# Very basic form. Return values as a list
|
||||
form = sg.FlexForm('Simple data entry form') # begin with a blank form
|
||||
|
||||
layout = [
|
||||
[sg.Text('Please enter your Name, Address, Phone')],
|
||||
[sg.Text('Name', size=(15, 1)), sg.InputText('name')],
|
||||
[sg.Text('Address', size=(15, 1)), sg.InputText('address')],
|
||||
[sg.Text('Phone', size=(15, 1)), sg.InputText('phone')],
|
||||
[sg.Submit(), sg.Cancel()]
|
||||
]
|
||||
|
||||
button, values = form.LayoutAndRead(layout)
|
||||
|
||||
print(button, values[0], values[1], values[2])
|
||||
```
|
||||
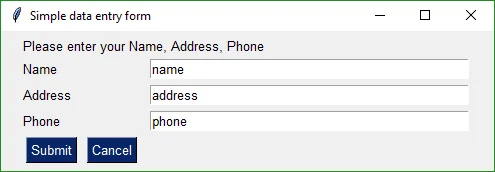
It's a reasonably sized form.
|
||||
|
||||
|
||||
|
||||
If you just need to collect a few values and they're all basically strings, you could copy this recipe and modify it to suit your needs.
|
||||
|
||||
You can even create a custom GUI layout in just five lines of code.
|
||||
```
|
||||
import PySimpleGUI as sg
|
||||
|
||||
form = sg.FlexForm('My first GUI')
|
||||
|
||||
layout = [ [sg.Text('Enter your name'), sg.InputText()],
|
||||
[sg.OK()] ]
|
||||
|
||||
button, (name,) = form.LayoutAndRead(layout)
|
||||
```
|
||||
|
||||
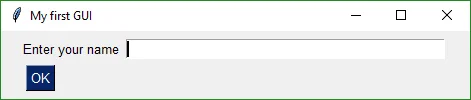
|
||||
|
||||
### Making a custom GUI in five minutes
|
||||
|
||||
If you have a straightforward layout, you should be able create a custom layout in PySimpleGUI in less than five minutes by modifying code from the Cookbook.
|
||||
|
||||
Widgets are called elements in PySimpleGUI. These elements are spelled exactly as you would type them into your Python code.
|
||||
|
||||
#### Core elements
|
||||
```
|
||||
Text
|
||||
InputText
|
||||
Multiline
|
||||
InputCombo
|
||||
Listbox
|
||||
Radio
|
||||
Checkbox
|
||||
Spin
|
||||
Output
|
||||
SimpleButton
|
||||
RealtimeButton
|
||||
ReadFormButton
|
||||
ProgressBar
|
||||
Image
|
||||
Slider
|
||||
Column
|
||||
```
|
||||
|
||||
#### Shortcut list
|
||||
|
||||
PySimpleGUI also has two types of element shortcuts. One type is simply other names for the exact same element (e.g., `T` instead of `Text`). The second type configures an element with a particular setting, sparing you from specifying all parameters (e.g., `Submit` is a button with the text "Submit" on it)
|
||||
```
|
||||
T = Text
|
||||
Txt = Text
|
||||
In = InputText
|
||||
Input = IntputText
|
||||
Combo = InputCombo
|
||||
DropDown = InputCombo
|
||||
Drop = InputCombo
|
||||
```
|
||||
|
||||
#### Button shortcuts
|
||||
|
||||
A number of common buttons have been implemented as shortcuts. These include:
|
||||
```
|
||||
FolderBrowse
|
||||
FileBrowse
|
||||
FileSaveAs
|
||||
Save
|
||||
Submit
|
||||
OK
|
||||
Ok
|
||||
Cancel
|
||||
Quit
|
||||
Exit
|
||||
Yes
|
||||
No
|
||||
```
|
||||
|
||||
There are also shortcuts for more generic button functions.
|
||||
```
|
||||
SimpleButton
|
||||
ReadFormButton
|
||||
RealtimeButton
|
||||
```
|
||||
|
||||
These are all the GUI widgets you can choose from in PySimpleGUI. If one isn't on these lists, it doesn't go in your form layout.
|
||||
|
||||
#### GUI design pattern
|
||||
|
||||
The stuff that tends not to change in GUIs are the calls that set up and show a window. The layout of the elements is what changes from one program to another.
|
||||
|
||||
Here is the code from the example above with the layout removed:
|
||||
```
|
||||
import PySimpleGUI as sg
|
||||
|
||||
form = sg.FlexForm('Simple data entry form')
|
||||
# Define your form here (it's a list of lists)
|
||||
button, values = form.LayoutAndRead(layout)
|
||||
```
|
||||
|
||||
The flow for most GUIs is:
|
||||
|
||||
* Create the form object
|
||||
* Define the GUI as a list of lists
|
||||
* Show the GUI and get results
|
||||
|
||||
|
||||
|
||||
These are line-for-line what you see in PySimpleGUI's design pattern.
|
||||
|
||||
#### GUI layout
|
||||
|
||||
To create your custom GUI, first break your form down into rows, because forms are defined one row at a time. Then place one element after another, working from left to right.
|
||||
|
||||
The result is a "list of lists" that looks something like this:
|
||||
```
|
||||
layout = [ [Text('Row 1')],
|
||||
[Text('Row 2'), Checkbox('Checkbox 1', OK()), Checkbox('Checkbox 2'), OK()] ]
|
||||
|
||||
```
|
||||
|
||||
This layout produces this window:
|
||||
|
||||
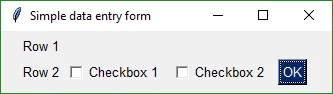
|
||||
|
||||
### Displaying the GUI
|
||||
|
||||
Once you have your layout complete and you've copied the lines of code that set up and show the form, it's time to display the form and get values from the user.
|
||||
|
||||
This is the line of code that displays the form and provides the results:
|
||||
```
|
||||
button, values = form.LayoutAndRead(layout)
|
||||
```
|
||||
|
||||
Forms return two values: the text of the button that is clicked and a list of values the user enters into the form.
|
||||
|
||||
If the example form is displayed and the user does nothing other than clicking the OK button, the results would be:
|
||||
```
|
||||
button == 'OK'
|
||||
values == [False, False]
|
||||
```
|
||||
|
||||
Checkbox elements return a value of True or False. Because the checkboxes defaulted to unchecked, both the values returned were False.
|
||||
|
||||
### Displaying results
|
||||
|
||||
Once you have the values from the GUI, it's nice to check what values are in the variables. Rather than printing them out using a `print` statement, let's stick with the GUI idea and output the data to a window.
|
||||
|
||||
PySimpleGUI has a number of message boxes to choose from. The data passed to the message box is displayed in a window. The function takes any number of arguments. You can simply indicate all the variables you want to see in the call.
|
||||
|
||||
The most commonly used message box in PySimpleGUI is MsgBox. To display the results from the previous example, write:
|
||||
```
|
||||
MsgBox('The GUI returned:', button, values)
|
||||
```
|
||||
|
||||
### Putting it all together
|
||||
|
||||
Now that you know the basics, let's put together a form that contains as many of PySimpleGUI's elements as possible. Also, to give it a nice appearance, we'll change the "look and feel" to a green and tan color scheme.
|
||||
```
|
||||
import PySimpleGUI as sg
|
||||
|
||||
sg.ChangeLookAndFeel('GreenTan')
|
||||
|
||||
form = sg.FlexForm('Everything bagel', default_element_size=(40, 1))
|
||||
|
||||
column1 = [[sg.Text('Column 1', background_color='#d3dfda', justification='center', size=(10,1))],
|
||||
[sg.Spin(values=('Spin Box 1', '2', '3'), initial_value='Spin Box 1')],
|
||||
[sg.Spin(values=('Spin Box 1', '2', '3'), initial_value='Spin Box 2')],
|
||||
[sg.Spin(values=('Spin Box 1', '2', '3'), initial_value='Spin Box 3')]]
|
||||
layout = [
|
||||
[sg.Text('All graphic widgets in one form!', size=(30, 1), font=("Helvetica", 25))],
|
||||
[sg.Text('Here is some text.... and a place to enter text')],
|
||||
[sg.InputText('This is my text')],
|
||||
[sg.Checkbox('My first checkbox!'), sg.Checkbox('My second checkbox!', default=True)],
|
||||
[sg.Radio('My first Radio! ', "RADIO1", default=True), sg.Radio('My second Radio!', "RADIO1")],
|
||||
[sg.Multiline(default_text='This is the default Text should you decide not to type anything', size=(35, 3)),
|
||||
sg.Multiline(default_text='A second multi-line', size=(35, 3))],
|
||||
[sg.InputCombo(('Combobox 1', 'Combobox 2'), size=(20, 3)),
|
||||
sg.Slider(range=(1, 100), orientation='h', size=(34, 20), default_value=85)],
|
||||
[sg.Listbox(values=('Listbox 1', 'Listbox 2', 'Listbox 3'), size=(30, 3)),
|
||||
sg.Slider(range=(1, 100), orientation='v', size=(5, 20), default_value=25),
|
||||
sg.Slider(range=(1, 100), orientation='v', size=(5, 20), default_value=75),
|
||||
sg.Slider(range=(1, 100), orientation='v', size=(5, 20), default_value=10),
|
||||
sg.Column(column1, background_color='#d3dfda')],
|
||||
[sg.Text('_' * 80)],
|
||||
[sg.Text('Choose A Folder', size=(35, 1))],
|
||||
[sg.Text('Your Folder', size=(15, 1), auto_size_text=False, justification='right'),
|
||||
sg.InputText('Default Folder'), sg.FolderBrowse()],
|
||||
[sg.Submit(), sg.Cancel()]
|
||||
]
|
||||
|
||||
button, values = form.LayoutAndRead(layout)
|
||||
sg.MsgBox(button, values)
|
||||
```
|
||||
|
||||
This may seem like a lot of code, but try coding this same GUI layout directly in tkinter and you'll quickly realize how tiny it is.
|
||||
|
||||
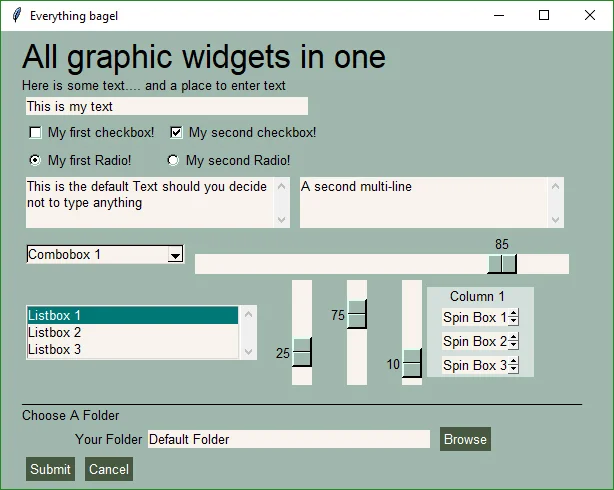
|
||||
|
||||
The last line of code opens a message box. This is how it looks:
|
||||
|
||||
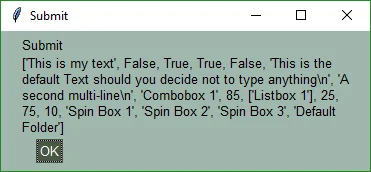
|
||||
|
||||
Each parameter to the message box call is displayed on a new line. There are two lines of text in the message box; the second line is very long and wrapped a number of times
|
||||
|
||||
Take a moment and pair up the results values with the GUI to get an understanding of how results are created and returned.
|
||||
|
||||
### Adding a GUI to Your Program or Script
|
||||
|
||||
If you have a script that uses the command line, you don't have to abandon it in order to add a GUI. An easy solution is that if there are zero parameters given on the command line, then the GUI is run. Otherwise, execute the command line as you do today.
|
||||
|
||||
This kind of logic is all that's needed:
|
||||
```
|
||||
if len(sys.argv) == 1:
|
||||
# collect arguments from GUI
|
||||
else:
|
||||
# collect arguements from sys.argv
|
||||
```
|
||||
|
||||
The easiest way to get a GUI up and running quickly is to copy and modify one of the recipes from the [PySimpleGUI Cookbook][2].
|
||||
|
||||
Have some fun! Spice up the scripts you're tired of running by hand. Spend 5 or 10 minutes playing with the demo scripts. You may find one already exists that does exactly what you need. If not, you will find it's simple to create your own. If you really get lost, you've only invested 10 minutes.
|
||||
|
||||
### Resources
|
||||
|
||||
#### Installation
|
||||
|
||||
PySimpleGUI works on all systems that run tkinter, including Raspberry Pi, and it requires Python 3
|
||||
```
|
||||
pip install PySimpleGUI
|
||||
```
|
||||
|
||||
#### Documentation
|
||||
|
||||
+ [Manual][3]
|
||||
+ [Cookbook][4]
|
||||
+ [GitHub repository][5]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/pysimplegui
|
||||
|
||||
作者:[Mike Barnett][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/pysimplegui
|
||||
[1]: https://github.com/MikeTheWatchGuy/PySimpleGUI
|
||||
[2]: https://pysimplegui.readthedocs.io/en/latest/cookbook/
|
||||
[3]: https://pysimplegui.readthedocs.io/en/latest/cookbook/
|
||||
[4]: https://pysimplegui.readthedocs.io/en/latest/cookbook/
|
||||
[5]: https://github.com/MikeTheWatchGuy/PySimpleGUI
|
||||
174
sources/tech/20180829 Containers in Perl 6.md
Normal file
174
sources/tech/20180829 Containers in Perl 6.md
Normal file
@ -0,0 +1,174 @@
|
||||
Containers in Perl 6
|
||||
======
|
||||
|
||||

|
||||
|
||||
In the [first article][1] in this series comparing Perl 5 to Perl 6, we looked into some of the issues you might encounter when migrating code into Perl 6. In the [second article][2], we examined how garbage collection works in Perl 6. Here, in the third article, we'll focus on Perl 5's references and how they're handled in Perl 6, and introduce the concepts of binding and containers.
|
||||
|
||||
### References
|
||||
|
||||
There are no references in Perl 6, which is surprising to many people used to Perl 5's semantics. But worry not: because there are no references, you don't have to worry about whether something should be de-referenced or not.
|
||||
```
|
||||
# Perl 5
|
||||
my $foo = \@bar; # must add reference \ to make $foo a reference to @bar
|
||||
say @bar[1]; # no dereference needed
|
||||
say $foo->[1]; # must add dereference ->
|
||||
|
||||
# Perl 6
|
||||
my $foo = @bar; # $foo now contains @bar
|
||||
say @bar[1]; # no dereference needed, note: sigil does not change
|
||||
say $foo[1]; # no dereference needed either
|
||||
```
|
||||
|
||||
One could argue that everything in Perl 6 is a reference. Coming from Perl 5 (where an object is a blessed reference), this would be a logical conclusion about Perl 6 where everything is an object (or can be considered one). But that wouldn't do justice to the situation in Perl 6 and would hinder you in understanding how things work in Perl 6. Beware of [false friends][3]!
|
||||
|
||||
### Binding
|
||||
|
||||
Before we get to assignment, it is important to understand the concept of binding in Perl 6. You can bind something explicitly to something else using the `:=` operator. When you define a lexical variable, you can bind a value to it:
|
||||
```
|
||||
my $foo := 42; # note: := instead of =
|
||||
```
|
||||
|
||||
Simply put, this creates a key with the name "`$foo`" in the lexical pad (lexpad) (which you could consider a compile-time hash that contains information about things that are visible in that lexical scope) and makes `42` its literal value. Because this is a literal constant, you can't change it. Trying to do so will cause an exception. So don't do that!
|
||||
|
||||
This binding operation is used under the hood in many situations, for instance when iterating:
|
||||
```
|
||||
my @a = 0..9; # can also be written as ^10
|
||||
say @a; # [0 1 2 3 4 5 6 7 8 9]
|
||||
for @a { $_++ } # $_ is bound to each array element and incremented
|
||||
say @a; # [1 2 3 4 5 6 7 8 9 10]
|
||||
```
|
||||
|
||||
If you try to iterate over a constant list, then `$_` is bound to the literal values, which you can not increment:
|
||||
```
|
||||
for 0..9 { $_++ } # error: requires mutable arguments
|
||||
```
|
||||
|
||||
### Assignment
|
||||
|
||||
If you compare "create a lexical variable and assign to it" in Perl 5 and Perl 6, it looks the same on the outside:
|
||||
```
|
||||
my $bar = 56; # both Perl 5 and Perl 6
|
||||
```
|
||||
|
||||
In Perl 6, this also creates a key with the name "`$bar`" in the lexpad. But instead of directly binding the value to that lexpad entry, a container (a `Scalar` object) is created for you and that is bound to the lexpad entry of "`$bar`". Then, `56` is stored as the value in that container. In pseudo-code, you can think of this as:
|
||||
```
|
||||
my $bar := Scalar.new( value => 56 );
|
||||
```
|
||||
|
||||
Notice that the `Scalar` object is bound, not assigned. The closest thing to this in Perl 5 is a [tied scalar][4]. But of course "`= 56`" is much less to type!
|
||||
|
||||
Data structures such as `Array` and `Hash` also automatically put values in containers bound to the structure.
|
||||
```
|
||||
my @a; # empty Array
|
||||
@a[5] = 42; # bind a Scalar container to 6th element and put 42 in it
|
||||
```
|
||||
|
||||
### Containers
|
||||
|
||||
The `Scalar` container object is invisible for most operations in Perl 6, so most of the time you don't have to think about it. For instance, whenever you call a subroutine (or a method) with a variable as an argument, it will bind to the value in the container. And because you cannot assign to a value, you get:
|
||||
```
|
||||
sub frobnicate($this) {
|
||||
$this = 42;
|
||||
}
|
||||
my $foo = 666;
|
||||
frobnicate($foo); # Cannot assign to a readonly variable or a value
|
||||
```
|
||||
|
||||
If you want to allow assigning to the outer value, you can add the `is rw` trait to the variable in the signature. This will bind the variable in the signature to the container of the variable specified, thus allowing assignment:
|
||||
```
|
||||
sub oknicate($this is rw) {
|
||||
$this = 42;
|
||||
}
|
||||
my $foo = 666;
|
||||
oknicate($foo); # no problem
|
||||
say $foo; # 42
|
||||
```
|
||||
|
||||
### Proxy
|
||||
|
||||
Conceptually, the `Scalar` object in Perl 6 has a `FETCH` method (for producing the value in the object) and a `STORE` method (for changing the value in the object), just like a tied scalar in Perl 5.
|
||||
|
||||
Suppose you later assign the value `768` to the `$bar` variable:
|
||||
```
|
||||
$bar = 768;
|
||||
```
|
||||
|
||||
What happens is conceptually the equivalent of:
|
||||
```
|
||||
$bar.STORE(768);
|
||||
```
|
||||
|
||||
Suppose you want to add `20` to the value in `$bar`:
|
||||
```
|
||||
$bar = $bar + 20;
|
||||
```
|
||||
|
||||
What happens conceptually is:
|
||||
```
|
||||
$bar.STORE( $bar.FETCH + 20 );
|
||||
```
|
||||
|
||||
If you like to specify your own `FETCH` and `STORE` methods on a container, you can do that by binding to a [Proxy][5] object. For example, to create a variable that will always report twice the value that was assigned to it:
|
||||
```
|
||||
my $double := do { # $double now a Proxy, rather than a Scalar container
|
||||
my $value;
|
||||
Proxy.new(
|
||||
FETCH => method () { $value + $value },
|
||||
STORE => method ($new) { $value = $new }
|
||||
)
|
||||
}
|
||||
```
|
||||
|
||||
Note that you will need an extra variable to keep the value stored in such a container.
|
||||
|
||||
### Constraints and default
|
||||
|
||||
Apart from the value, a [Scalar][6] also contains extra information such as the type constraint and default value. Take this definition:
|
||||
```
|
||||
my Int $baz is default(42) = 666;
|
||||
```
|
||||
|
||||
It creates a Scalar bound with the name "`$baz`" to the lexpad, constrains the values in that container to types that successfully smartmatch with `Int`, sets the default value of the container to `42`, and puts the value `666` in the container.
|
||||
|
||||
Assigning a string to that variable will fail because of the type constraint:
|
||||
```
|
||||
$baz = "foo";
|
||||
# Type check failed in assignment to $baz; expected Int but got Str ("foo")
|
||||
```
|
||||
|
||||
If you do not give a type constraint when you define a variable, then the `Any` type will be assumed. If you do not specify a default value, then the type constraint will be assumed.
|
||||
|
||||
Assigning `Nil` (the Perl 6 equivalent of Perl 5's `undef`) to that variable will reset it to the default value:
|
||||
```
|
||||
say $baz; # 666
|
||||
$baz = Nil;
|
||||
say $baz; # 42
|
||||
```
|
||||
|
||||
### Summary
|
||||
|
||||
|
||||
Perl 5 has values and references to values. Perl 6 has no references, but it has values and containers. There are two types of containers in Perl 6: [Proxy][5] (which is much like a tied scalar in Perl 5) and [Scalar][6] . Simply stated, a variable, as well as an element of a [List][7] [Array][8] , or [Hash][9] , is either a value (if it is bound), or a container (if it is assigned). Whenever a subroutine (or method) is called, the given arguments are de-containerized and bound to the parameters of the subroutine (unless told to do otherwise). A container also keeps information such as type constraints and a default value. Assigningto a variable will return it to its default value, which isif you do not specify a type constraint.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/containers-perl-6
|
||||
|
||||
作者:[Elizabeth Mattijsen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/lizmat
|
||||
[1]: https://opensource.com/article/18/7/migrating-perl-5-perl-6
|
||||
[2]: https://opensource.com/article/18/7/garbage-collection-perl-6
|
||||
[3]: https://en.wikipedia.org/wiki/False_friend
|
||||
[4]: https://metacpan.org/pod/distribution/perl/pod/perltie.pod#Tying-Scalars
|
||||
[5]: https://docs.perl6.org/type/Proxy
|
||||
[6]: https://docs.perl6.org/type/Scalar
|
||||
[7]: https://docs.perl6.org/type/List
|
||||
[8]: https://docs.perl6.org/type/Array
|
||||
[9]: https://docs.perl6.org/type/Hash
|
||||
@ -0,0 +1,91 @@
|
||||
5 个在 Fedora 上管理待办事项的程序
|
||||
======
|
||||
|
||||

|
||||
|
||||
有效管理待办事项可以为你的工作效率创造奇迹。有些人更喜欢在文本中保存待办事项,甚至只使用记事本和笔。对于需要更多待办事项功能的用户,他们通常会使用应用程序。在本文中,我们将重点介绍 4 个图形程序和一个基于终端的工具来管理待办事项。
|
||||
|
||||
### GNOME To Do
|
||||
|
||||
GNOME To Do][1] 是专为 GNOME 桌面(Fedora Workstation 的默认桌面)设计的个人任务管理器。将 GNOME To Do 与其他程序进行比较时,它有一系列简洁的功能。
|
||||
|
||||
GNOME To Do 提供列表形式的任务组织,并能为该列表指定颜色。此外,可以为各个任务分配截止日期和优先级,以及每项任务的注释。此外,GNOME To Do 还支持扩展,能添加更多功能,包括支持 [todo.txt][2] 以及与 [todoist][3] 等在线服务同步。
|
||||
|
||||
![][4]
|
||||
|
||||
使用软件中心或者在终端中使用下面的命令安装 GNOME To Do:
|
||||
```
|
||||
sudo dnf install gnome-todo
|
||||
|
||||
```
|
||||
|
||||
### Getting things GNOME!
|
||||
|
||||
、在 GNOME To Do 存在之前,在 GNOME 上追踪任务的首选程序是 [Getting things GNOME!][5] 这个稍来的 GNOME 程序有多个窗口层,能然你同时显示多个任务的细节。GTG 没有任务列表,它能在任务中添加子任务,甚至在子任务中添加子任务。GTG 同样能添加截止日期和开始日期。通过插件同步其他程序和服务也是可能的。
|
||||
|
||||
![][6]
|
||||
|
||||
在软件中心或者在终端中使用下面的命令安装 Getting Things GNOME:
|
||||
```
|
||||
sudo dnf install gtg
|
||||
|
||||
```
|
||||
|
||||
### Go For It!
|
||||
|
||||
[Go For It!][7] 是一个超级简单的任务管理程序。它能简单地创建一个任务列表,并在完成后标记它们。它没有组任务,也不能创建子任务。默认 Go For It! 将任务存储在 todo.txt 中,这能更方便地同步到在线服务或者其他程序中。额外地,Go For It! 包含了一个简单定时器来追踪你在当前任务花费了多少时间。
|
||||
|
||||
![][8]
|
||||
|
||||
Go For It 能在 Flathub 应用仓库中找到。要安装它,只需[启用 Flathub 作为软件源][9],接着在软件中心中安装。
|
||||
|
||||
|
||||
### Agenda
|
||||
|
||||
如果你在寻找一款非常简单的待办应用,[Agenda][10] 非常合适。创建任务,标记完成,接着从列表中删除它们。Agenda 会在你删除它们之前显示所有任务(完成或者进行中)。
|
||||
|
||||
![][11]
|
||||
|
||||
Agenda 能从 Flathub 应用仓库下载。要安装它,只需[启用 Flathub 作为软件源][9],接着在软件中心中安装。
|
||||
|
||||
### Taskwarrior
|
||||
|
||||
[Taskwarrior][12] 是一个灵活的命令行任务管理程序。它高度可定制化,但同样“开箱即用”。使用简单的命令,你可以创建任务,标记完成,并列出当前进行中的任务。另外,任务可以被标记、添加到项目、搜索和过滤。此外,你可以设置循环任务,并设置任务截止日期。
|
||||
|
||||
[之前在 Fedora Magazine 上的文章][13] 对 Taskwarrior 的入门做了很好的概述。
|
||||
|
||||
![][14]
|
||||
|
||||
在终端中使用这个命令安装 Taskwarrior:
|
||||
```
|
||||
sudo dnf install task
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/5-tools-to-manage-your-to-do-list-on-fedora/
|
||||
|
||||
作者:[Ryan Lerch][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/introducing-flatpak/
|
||||
[1]:https://wiki.gnome.org/Apps/Todo/
|
||||
[2]:http://todotxt.org/
|
||||
[3]:https://en.todoist.com/
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/08/gnome-todo.png
|
||||
[5]:https://wiki.gnome.org/Apps/GTG
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/08/gtg.png
|
||||
[7]:http://manuel-kehl.de/projects/go-for-it/
|
||||
[8]:https://fedoramagazine.org/wp-content/uploads/2018/08/goforit.png
|
||||
[9]:https://fedoramagazine.org/install-flathub-apps-fedora/
|
||||
[10]:https://github.com/dahenson/agenda
|
||||
[11]:https://fedoramagazine.org/wp-content/uploads/2018/08/agenda.png
|
||||
[12]:https://taskwarrior.org/
|
||||
[13]:https://fedoramagazine.org/getting-started-taskwarrior/
|
||||
[14]:https://fedoramagazine.org/wp-content/uploads/2018/08/taskwarrior.png
|
||||
@ -1,65 +0,0 @@
|
||||
使用 Fstransform 转换文件系统
|
||||
======
|
||||
|
||||

|
||||
|
||||
很少有人知道他们可以将文件系统从一种类型转换为另一种类型而不会丢失数据,即非破坏性的。这可能听起来像魔术,但 [Fstransform][1] 可以几乎以任意组合将 ext2、ext3、ext4、jfs、reiserfs 或 xfs 分区转换成另一类型。更重要的是,它可以直接执行,而无需格式化或复制数据。除此之外,还有一点好处:Fstransform 也可以处理 ntfs、btrfs、fat 和 exfat 分区。
|
||||
|
||||
### 在运行之前
|
||||
|
||||
Fstransform 中存在一些警告和限制,因此强烈建议在尝试转换之前进行备份。此外,使用 Fstransform 时需要注意一些限制:
|
||||
|
||||
* Linux 内核必须支持源文件系统和目标文件系统。听起来很明显,如果你想使用 ext2、ext3、ext4、reiserfs、jfs 和 xfs 分区,这样不会出现风险。Fedora 支持所有分区,所以没问题。
|
||||
* 将 ext2 升级到 ext3 或 ext4 不需要 Fstransform。请使用 Tune2fs。
|
||||
* 源文件系统的设备必须至少有 5% 的可用空间。
|
||||
* 你需要在开始之前卸载源文件系统。
|
||||
* 源文件系统存储的数据越多,转换的时间就越长。实际速度取决于你的设备,但预计它大约为每分钟 1GB。大量的硬链接也会降低转换速度。
|
||||
* 虽然 Fstransform 被证明是稳定的,但请备份源文件系统上的数据。
|
||||
|
||||
|
||||
|
||||
### 安装说明
|
||||
|
||||
Fstransform 已经是 Fedora 的一部分。使用以下命令安装:
|
||||
```
|
||||
sudo dnf install fstransform
|
||||
|
||||
```
|
||||
|
||||
### 转换时间
|
||||
|
||||
![][2]
|
||||
|
||||
fstransform 命令的语法非常简单:fstransform <源设备> <目标文件系统>。请记住,它需要 root 权限才能运行,所以不要忘记在开头添加 sudo。这是一个例子:
|
||||
```
|
||||
sudo fstransform /dev/sdb1 ext4
|
||||
|
||||
```
|
||||
|
||||
请注意,无法转换根文件系统,这是一种安全措施。请改用测试分区或实验性 USB。与此同时,Fstransform 会在控制台中有许多辅助输出。最有用的部分是预计完成时间,让你随时了解该过程需要多长时间。同样,几乎空的驱动器上的几个小文件将使 Fstransform 在一分钟左右完成其工作,而更多真实世界的任务可能需要数小时的等待时间。
|
||||
|
||||
### 更多支持的文件系统
|
||||
|
||||
如上所述,可以尝试在 ntfs、btrfs、fat 和 exfat 分区使用 Fstransform。这些类型是非常实验性的,没有人能保证完美转换。尽管如此,还是有许多成功案例,你可以通过在测试分区上使用示例数据集测试 Fstransform 来添加自己的成功案例。可以使用 -force-untested-file-systems 参数启用这些额外的文件系统:
|
||||
```
|
||||
sudo fstransform /dev/sdb1 ntfs --force-untested-file-systems
|
||||
|
||||
```
|
||||
|
||||
有时,该过程可能会因错误而中断。请放心再次执行命令 - 它可能最终会在 2,3 次尝试后完成转换。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/transform-file-systems-in-linux/
|
||||
|
||||
作者:[atolstoy][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/atolstoy/
|
||||
[1]:https://github.com/cosmos72/fstransform
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2018/08/Screenshot_20180805_230116.png
|
||||
Loading…
Reference in New Issue
Block a user