mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-09 01:30:10 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject into translating
This commit is contained in:
commit
f86d6a6100
@ -1,8 +1,9 @@
|
||||
如何在 Linux 中为每个屏幕设置不同的壁纸
|
||||
======
|
||||
**简介:如果你想在 Ubuntu 18.04 或任何其他 Linux 发行版上使用 GNOME、MATE 或 Budgie 桌面环境在多个显示器上显示不同的壁纸,这个小工具将帮助你实现这一点。**
|
||||
|
||||
多显示器设置通常会在 Linux 上出现多个问题,但我不打算在本文中讨论这些问题。我有一篇关于 Linux 上多显示器支持的文章。
|
||||
> 如果你想在 Ubuntu 18.04 或任何其他 Linux 发行版上使用 GNOME、MATE 或 Budgie 桌面环境在多个显示器上显示不同的壁纸,这个小工具将帮助你实现这一点。
|
||||
|
||||
多显示器设置通常会在 Linux 上出现多个问题,但我不打算在本文中讨论这些问题。我有另外一篇关于 Linux 上多显示器支持的文章。
|
||||
|
||||
如果你使用多台显示器,也许你想为每台显示器设置不同的壁纸。我不确定其他 Linux 发行版和桌面环境,但是 [GNOME 桌面][1] 的 Ubuntu 本身并不提供此功能。
|
||||
|
||||
@ -18,11 +19,11 @@
|
||||
|
||||
#### 使用 FlatPak 在 Linux 上安装 HydraPaper
|
||||
|
||||
使用 [FlatPak][9] 可以轻松安装 HydraPaper。Ubuntu 18.04已 经提供对 FlatPaks 的支持,所以你需要做的就是下载应用文件并双击在 GNOME 软件中心中打开它。
|
||||
使用 [FlatPak][9] 可以轻松安装 HydraPaper。Ubuntu 18.04 已 经提供对 FlatPaks 的支持,所以你需要做的就是下载应用文件并双击在 GNOME 软件中心中打开它。
|
||||
|
||||
你可以参考这篇文章来了解如何在你的发行版[启用 FlatPak 支持][10]。启用 FlatPak 支持后,只需从 [FlatHub][11] 下载并安装即可。
|
||||
|
||||
[Download HydraPaper][12]
|
||||
- [下载 HydraPaper][12]
|
||||
|
||||
#### 使用 HydraPaper 在不同的显示器上设置不同的背景
|
||||
|
||||
@ -65,13 +66,13 @@ via: https://itsfoss.com/wallpaper-multi-monitor/
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://www.gnome.org/
|
||||
[2]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/05/multi-monitor-wallpaper-setup-800x450.jpeg
|
||||
[2]:https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/05/multi-monitor-wallpaper-setup.jpeg?w=800&ssl=1
|
||||
[3]:https://github.com/GabMus/HydraPaper
|
||||
[4]:https://www.gtk.org/
|
||||
[5]:https://itsfoss.com/gnome-tricks-ubuntu/
|
||||
@ -82,8 +83,8 @@ via: https://itsfoss.com/wallpaper-multi-monitor/
|
||||
[10]:https://flatpak.org/setup/
|
||||
[11]:https://flathub.org
|
||||
[12]:https://flathub.org/apps/details/org.gabmus.hydrapaper
|
||||
[13]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/05/different-wallpaper-each-monitor-hydrapaper-2-800x631.jpeg
|
||||
[14]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/05/different-wallpaper-each-monitor-hydrapaper-1.jpeg
|
||||
[15]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/05/different-wallpaper-each-monitor-hydrapaper-3.jpeg
|
||||
[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/05/hydra-paper-dual-monitor-800x450.jpeg
|
||||
[17]:https://www.reddit.com/r/LinuxUsersGroup/
|
||||
[13]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/05/different-wallpaper-each-monitor-hydrapaper-2.jpeg?w=800&ssl=1
|
||||
[14]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/05/different-wallpaper-each-monitor-hydrapaper-1.jpeg?w=799&ssl=1
|
||||
[15]:https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/05/different-wallpaper-each-monitor-hydrapaper-3.jpeg?w=799&ssl=1
|
||||
[16]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/05/hydra-paper-dual-monitor.jpeg?w=800&ssl=1
|
||||
[17]:https://www.reddit.com/r/LinuxUsersGroup/
|
||||
116
published/20181004 Archiving web sites.md
Normal file
116
published/20181004 Archiving web sites.md
Normal file
@ -0,0 +1,116 @@
|
||||
对网站进行归档
|
||||
======
|
||||
|
||||
我最近深入研究了网站归档,因为有些朋友担心遇到糟糕的系统管理或恶意删除时失去对放在网上的内容的控制权。这使得网站归档成为系统管理员工具箱中的重要工具。事实证明,有些网站比其他网站更难归档。本文介绍了对传统网站进行归档的过程,并阐述在面对最新流行单页面应用程序(SPA)的现代网站时,它有哪些不足。
|
||||
|
||||
### 转换为简单网站
|
||||
|
||||
手动编码 HTML 网站的日子早已不复存在。现在的网站是动态的,并使用最新的 JavaScript、PHP 或 Python 框架即时构建。结果,这些网站更加脆弱:数据库崩溃、升级出错或者未修复的漏洞都可能使数据丢失。在我以前是一名 Web 开发人员时,我不得不接受客户这样的想法:希望网站基本上可以永久工作。这种期望与 web 开发“快速行动和破除陈规”的理念不相符。在这方面,使用 [Drupal][2] 内容管理系统(CMS)尤其具有挑战性,因为重大更新会破坏与第三方模块的兼容性,这意味着客户很少承担的起高昂的升级成本。解决方案是将这些网站归档:以实时动态的网站为基础,将其转换为任何 web 服务器可以永久服务的纯 HTML 文件。此过程对你自己的动态网站非常有用,也适用于你想保护但无法控制的第三方网站。
|
||||
|
||||
对于简单的静态网站,古老的 [Wget][3] 程序就可以胜任。然而镜像保存一个完整网站的命令却是错综复杂的:
|
||||
|
||||
```
|
||||
$ nice wget --mirror --execute robots=off --no-verbose --convert-links \
|
||||
--backup-converted --page-requisites --adjust-extension \
|
||||
--base=./ --directory-prefix=./ --span-hosts \
|
||||
--domains=www.example.com,example.com http://www.example.com/
|
||||
```
|
||||
|
||||
以上命令下载了网页的内容,也抓取了指定域名中的所有内容。在对你喜欢的网站执行此操作之前,请考虑此类抓取可能对网站产生的影响。上面的命令故意忽略了 `robots.txt` 规则,就像现在[归档者的习惯做法][4],并以尽可能快的速度归档网站。大多数抓取工具都可以选择在两次抓取间暂停并限制带宽使用,以避免使网站瘫痪。
|
||||
|
||||
上面的命令还将获取 “页面所需(LCTT 译注:单页面所需的所有元素)”,如样式表(CSS)、图像和脚本等。下载的页面内容将会被修改,以便链接也指向本地副本。任何 web 服务器均可托管生成的文件集,从而生成原始网站的静态副本。
|
||||
|
||||
以上所述是事情一切顺利的时候。任何使用过计算机的人都知道事情的进展很少如计划那样;各种各样的事情可以使程序以有趣的方式脱离正轨。比如,在网站上有一段时间很流行日历块。内容管理系统会动态生成这些内容,这会使爬虫程序陷入死循环以尝试检索所有页面。灵巧的归档者可以使用正则表达式(例如 Wget 有一个 `--reject-regex` 选项)来忽略有问题的资源。如果可以访问网站的管理界面,另一个方法是禁用日历、登录表单、评论表单和其他动态区域。一旦网站变成静态的,(那些动态区域)也肯定会停止工作,因此从原始网站中移除这些杂乱的东西也不是全无意义。
|
||||
|
||||
### JavaScript 噩梦
|
||||
|
||||
很不幸,有些网站不仅仅是纯 HTML 文件构建的。比如,在单页面网站中,web 浏览器通过执行一个小的 JavaScript 程序来构建内容。像 Wget 这样的简单用户代理将难以重建这些网站的有意义的静态副本,因为它根本不支持 JavaScript。理论上,网站应该使用[渐进增强][5]技术,在不使用 JavaScript 的情况下提供内容和实现功能,但这些指引很少被人遵循 —— 使用过 [NoScript][6] 或 [uMatrix][7] 等插件的人都知道。
|
||||
|
||||
传统的归档方法有时会以最愚蠢的方式失败。在尝试为一个本地报纸网站([pamplemousse.ca][8])创建备份时,我发现 WordPress 在包含 的 JavaScript 末尾添加了查询字符串(例如:`?ver=1.12.4`)。这会使提供归档服务的 web 服务器不能正确进行内容类型检测,因为其靠文件扩展名来发送正确的 `Content-Type` 头部信息。在 web 浏览器加载此类归档时,这些脚本会加载失败,导致动态网站受损。
|
||||
|
||||
随着 web 向使用浏览器作为执行任意代码的虚拟机转化,依赖于纯 HTML 文件解析的归档方法也需要随之适应。这个问题的解决方案是在抓取时记录(以及重现)服务器提供的 HTTP 头部信息,实际上专业的归档者就使用这种方法。
|
||||
|
||||
### 创建和显示 WARC 文件
|
||||
|
||||
在 <ruby>[互联网档案馆][9]<rt>Internet Archive</rt></ruby> 网站,Brewster Kahle 和 Mike Burner 在 1996 年设计了 [ARC][10] (即 “ARChive”)文件格式,以提供一种聚合其归档工作所产生的百万个小文件的方法。该格式最终标准化为 WARC(“Web ARChive”)[规范][11],并在 2009 年作为 ISO 标准发布,2017 年修订。标准化工作由<ruby>[国际互联网保护联盟][12]<rt>International Internet Preservation Consortium</rt></ruby>(IIPC)领导,据维基百科称,这是一个“*为了协调为未来而保护互联网内容的努力而成立的国际图书馆组织和其他组织*”;它的成员包括<ruby>美国国会图书馆<rt>US Library of Congress</rt></ruby>和互联网档案馆等。后者在其基于 Java 的 [Heritrix crawler][13](LCTT 译注:一种爬虫程序)内部使用了 WARC 格式。
|
||||
|
||||
WARC 在单个压缩文件中聚合了多种资源,像 HTTP 头部信息、文件内容,以及其他元数据。方便的是,Wget 实际上提供了 `--warc` 参数来支持 WARC 格式。不幸的是,web 浏览器不能直接显示 WARC 文件,所以为了访问归档文件,一个查看器或某些格式转换是很有必要的。我所发现的最简单的查看器是 [pywb][14],它以 Python 包的形式运行一个简单的 web 服务器提供一个像“<ruby>时光倒流机网站<rt>Wayback Machine</rt></ruby>”的界面,来浏览 WARC 文件的内容。执行以下命令将会在 `http://localhost:8080/` 地址显示 WARC 文件的内容:
|
||||
|
||||
```
|
||||
$ pip install pywb
|
||||
$ wb-manager init example
|
||||
$ wb-manager add example crawl.warc.gz
|
||||
$ wayback
|
||||
```
|
||||
|
||||
顺便说一句,这个工具是由 [Webrecorder][15] 服务提供者建立的,Webrecoder 服务可以使用 web 浏览器保存动态页面的内容。
|
||||
|
||||
很不幸,pywb 无法加载 Wget 生成的 WARC 文件,因为它[遵循][16]的 [1.0 规范不一致][17],[1.1 规范修复了此问题][17]。就算 Wget 或 pywb 修复了这些问题,Wget 生成的 WARC 文件对我的使用来说不够可靠,所以我找了其他的替代品。引起我注意的爬虫程序简称 [crawl][19]。以下是它的调用方式:
|
||||
|
||||
```
|
||||
$ crawl https://example.com/
|
||||
```
|
||||
|
||||
(它的 README 文件说“非常简单”。)该程序支持一些命令行参数选项,但大多数默认值都是最佳的:它会从其他域获取页面所需(除非使用 `-exclude-related` 参数),但肯定不会递归出域。默认情况下,它会与远程站点建立十个并发连接,这个值可以使用 `-c` 参数更改。但是,最重要的是,生成的 WARC 文件可以使用 pywb 完美加载。
|
||||
|
||||
### 未来的工作和替代方案
|
||||
|
||||
这里还有更多有关使用 WARC 文件的[资源][20]。特别要提的是,这里有一个专门用来归档网站的 Wget 的直接替代品,叫做 [Wpull][21]。它实验性地支持了 [PhantomJS][22] 和 [youtube-dl][23] 的集成,即允许分别下载更复杂的 JavaScript 页面以及流媒体。该程序是一个叫做 [ArchiveBot][24] 的复杂归档工具的基础,ArchiveBot 被那些在 [ArchiveTeam][25] 的“*零散离群的归档者、程序员、作家以及演说家*”使用,他们致力于“*在历史永远丢失之前保存它们*”。集成 PhantomJS 好像并没有如团队期望的那样良好工作,所以 ArchiveTeam 也用其它零散的工具来镜像保存更复杂的网站。例如,[snscrape][26] 将抓取一个社交媒体配置文件以生成要发送到 ArchiveBot 的页面列表。该团队使用的另一个工具是 [crocoite][27],它使用无头模式的 Chrome 浏览器来归档 JavaScript 较多的网站。
|
||||
|
||||
如果没有提到称做“网站复制者”的 [HTTrack][28] 项目,那么这篇文章算不上完整。它工作方式和 Wget 相似,HTTrack 可以对远程站点创建一个本地的副本,但是不幸的是它不支持输出 WRAC 文件。对于不熟悉命令行的小白用户来说,它在人机交互方面显得更有价值。
|
||||
|
||||
同样,在我的研究中,我发现了叫做 [Wget2][29] 的 Wget 的完全重制版本,它支持多线程操作,这可能使它比前身更快。和 Wget 相比,它[舍弃了一些功能][30],但是最值得注意的是拒绝模式、WARC 输出以及 FTP 支持,并增加了 RSS、DNS 缓存以及改进的 TLS 支持。
|
||||
|
||||
最后,我个人对这些工具的愿景是将它们与我现有的书签系统集成起来。目前我在 [Wallabag][31] 中保留了一些有趣的链接,这是一种自托管式的“稍后阅读”服务,意在成为 [Pocket][32](现在由 Mozilla 拥有)的免费替代品。但是 Wallabag 在设计上只保留了文章的“可读”副本,而不是一个完整的拷贝。在某些情况下,“可读版本”实际上[不可读][33],并且 Wallabag 有时[无法解析文章][34]。恰恰相反,像 [bookmark-archiver][35] 或 [reminiscence][36] 这样其他的工具会保存页面的屏幕截图以及完整的 HTML 文件,但遗憾的是,它没有 WRAC 文件所以没有办法更可信的重现网页内容。
|
||||
|
||||
我所经历的有关镜像保存和归档的悲剧就是死数据。幸运的是,业余的归档者可以利用工具将有趣的内容保存到网上。对于那些不想麻烦的人来说,“互联网档案馆”看起来仍然在那里,并且 ArchiveTeam 显然[正在为互联网档案馆本身做备份][37]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://anarc.at/blog/2018-10-04-archiving-web-sites/
|
||||
|
||||
作者:[Anarcat][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[fuowang](https://github.com/fuowang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://anarc.at
|
||||
[1]: https://anarc.at/blog
|
||||
[2]: https://drupal.org
|
||||
[3]: https://www.gnu.org/software/wget/
|
||||
[4]: https://blog.archive.org/2017/04/17/robots-txt-meant-for-search-engines-dont-work-well-for-web-archives/
|
||||
[5]: https://en.wikipedia.org/wiki/Progressive_enhancement
|
||||
[6]: https://noscript.net/
|
||||
[7]: https://github.com/gorhill/uMatrix
|
||||
[8]: https://pamplemousse.ca/
|
||||
[9]: https://archive.org
|
||||
[10]: http://www.archive.org/web/researcher/ArcFileFormat.php
|
||||
[11]: https://iipc.github.io/warc-specifications/
|
||||
[12]: https://en.wikipedia.org/wiki/International_Internet_Preservation_Consortium
|
||||
[13]: https://github.com/internetarchive/heritrix3/wiki
|
||||
[14]: https://github.com/webrecorder/pywb
|
||||
[15]: https://webrecorder.io/
|
||||
[16]: https://github.com/webrecorder/pywb/issues/294
|
||||
[17]: https://github.com/iipc/warc-specifications/issues/23
|
||||
[18]: https://github.com/iipc/warc-specifications/pull/24
|
||||
[19]: https://git.autistici.org/ale/crawl/
|
||||
[20]: https://archiveteam.org/index.php?title=The_WARC_Ecosystem
|
||||
[21]: https://github.com/chfoo/wpull
|
||||
[22]: http://phantomjs.org/
|
||||
[23]: http://rg3.github.io/youtube-dl/
|
||||
[24]: https://www.archiveteam.org/index.php?title=ArchiveBot
|
||||
[25]: https://archiveteam.org/
|
||||
[26]: https://github.com/JustAnotherArchivist/snscrape
|
||||
[27]: https://github.com/PromyLOPh/crocoite
|
||||
[28]: http://www.httrack.com/
|
||||
[29]: https://gitlab.com/gnuwget/wget2
|
||||
[30]: https://gitlab.com/gnuwget/wget2/wikis/home
|
||||
[31]: https://wallabag.org/
|
||||
[32]: https://getpocket.com/
|
||||
[33]: https://github.com/wallabag/wallabag/issues/2825
|
||||
[34]: https://github.com/wallabag/wallabag/issues/2914
|
||||
[35]: https://pirate.github.io/bookmark-archiver/
|
||||
[36]: https://github.com/kanishka-linux/reminiscence
|
||||
[37]: http://iabak.archiveteam.org
|
||||
@ -1,89 +1,86 @@
|
||||
实验 3:用户环境
|
||||
Caffeinated 6.828:实验 3:用户环境
|
||||
======
|
||||
### 实验 3:用户环境
|
||||
|
||||
#### 简介
|
||||
### 简介
|
||||
|
||||
在本实验中,你将要实现一个基本的内核功能,要求它能够保护运行的用户模式环境(即:进程)。你将去增强这个 JOS 内核,去配置数据结构以便于保持对用户环境的跟踪、创建一个单一用户环境、将程序镜像加载到用户环境中、并将它启动运行。你也要写出一些 JOS 内核的函数,用来处理任何用户环境生成的系统调用,以及处理由用户环境引进的各种异常。
|
||||
|
||||
**注意:** 在本实验中,术语**_“环境”_** 和**_“进程”_** 是可互换的 —— 它们都表示同一个抽象概念,那就是允许你去运行的程序。我在介绍中使用术语**“环境”**而不是使用传统术语**“进程”**的目的是为了强调一点,那就是 JOS 的环境和 UNIX 的进程提供了不同的接口,并且它们的语义也不相同。
|
||||
**注意:** 在本实验中,术语**“环境”** 和**“进程”** 是可互换的 —— 它们都表示同一个抽象概念,那就是允许你去运行的程序。我在介绍中使用术语**“环境”**而不是使用传统术语**“进程”**的目的是为了强调一点,那就是 JOS 的环境和 UNIX 的进程提供了不同的接口,并且它们的语义也不相同。
|
||||
|
||||
##### 预备知识
|
||||
#### 预备知识
|
||||
|
||||
使用 Git 去提交你自实验 2 以后的更改(如果有的话),获取课程仓库的最新版本,以及创建一个命名为 `lab3` 的本地分支,指向到我们的 lab3 分支上 `origin/lab3` :
|
||||
|
||||
```
|
||||
athena% cd ~/6.828/lab
|
||||
athena% add git
|
||||
athena% git commit -am 'changes to lab2 after handin'
|
||||
Created commit 734fab7: changes to lab2 after handin
|
||||
4 files changed, 42 insertions(+), 9 deletions(-)
|
||||
athena% git pull
|
||||
Already up-to-date.
|
||||
athena% git checkout -b lab3 origin/lab3
|
||||
Branch lab3 set up to track remote branch refs/remotes/origin/lab3.
|
||||
Switched to a new branch "lab3"
|
||||
athena% git merge lab2
|
||||
Merge made by recursive.
|
||||
kern/pmap.c | 42 +++++++++++++++++++
|
||||
1 files changed, 42 insertions(+), 0 deletions(-)
|
||||
athena%
|
||||
athena% cd ~/6.828/lab
|
||||
athena% add git
|
||||
athena% git commit -am 'changes to lab2 after handin'
|
||||
Created commit 734fab7: changes to lab2 after handin
|
||||
4 files changed, 42 insertions(+), 9 deletions(-)
|
||||
athena% git pull
|
||||
Already up-to-date.
|
||||
athena% git checkout -b lab3 origin/lab3
|
||||
Branch lab3 set up to track remote branch refs/remotes/origin/lab3.
|
||||
Switched to a new branch "lab3"
|
||||
athena% git merge lab2
|
||||
Merge made by recursive.
|
||||
kern/pmap.c | 42 +++++++++++++++++++
|
||||
1 files changed, 42 insertions(+), 0 deletions(-)
|
||||
athena%
|
||||
```
|
||||
|
||||
实验 3 包含一些你将探索的新源文件:
|
||||
|
||||
```c
|
||||
inc/ env.h Public definitions for user-mode environments
|
||||
trap.h Public definitions for trap handling
|
||||
syscall.h Public definitions for system calls from user environments to the kernel
|
||||
lib.h Public definitions for the user-mode support library
|
||||
kern/ env.h Kernel-private definitions for user-mode environments
|
||||
env.c Kernel code implementing user-mode environments
|
||||
trap.h Kernel-private trap handling definitions
|
||||
trap.c Trap handling code
|
||||
trapentry.S Assembly-language trap handler entry-points
|
||||
syscall.h Kernel-private definitions for system call handling
|
||||
syscall.c System call implementation code
|
||||
lib/ Makefrag Makefile fragment to build user-mode library, obj/lib/libjos.a
|
||||
entry.S Assembly-language entry-point for user environments
|
||||
libmain.c User-mode library setup code called from entry.S
|
||||
syscall.c User-mode system call stub functions
|
||||
console.c User-mode implementations of putchar and getchar, providing console I/O
|
||||
exit.c User-mode implementation of exit
|
||||
panic.c User-mode implementation of panic
|
||||
user/ * Various test programs to check kernel lab 3 code
|
||||
inc/ env.h Public definitions for user-mode environments
|
||||
trap.h Public definitions for trap handling
|
||||
syscall.h Public definitions for system calls from user environments to the kernel
|
||||
lib.h Public definitions for the user-mode support library
|
||||
kern/ env.h Kernel-private definitions for user-mode environments
|
||||
env.c Kernel code implementing user-mode environments
|
||||
trap.h Kernel-private trap handling definitions
|
||||
trap.c Trap handling code
|
||||
trapentry.S Assembly-language trap handler entry-points
|
||||
syscall.h Kernel-private definitions for system call handling
|
||||
syscall.c System call implementation code
|
||||
lib/ Makefrag Makefile fragment to build user-mode library, obj/lib/libjos.a
|
||||
entry.S Assembly-language entry-point for user environments
|
||||
libmain.c User-mode library setup code called from entry.S
|
||||
syscall.c User-mode system call stub functions
|
||||
console.c User-mode implementations of putchar and getchar, providing console I/O
|
||||
exit.c User-mode implementation of exit
|
||||
panic.c User-mode implementation of panic
|
||||
user/ * Various test programs to check kernel lab 3 code
|
||||
```
|
||||
|
||||
另外,一些在实验 2 中的源文件在实验 3 中将被修改。如果想去查看有什么更改,可以运行:
|
||||
|
||||
```
|
||||
$ git diff lab2
|
||||
|
||||
$ git diff lab2
|
||||
```
|
||||
|
||||
你也可以另外去看一下 [实验工具指南][1],它包含了与本实验有关的调试用户代码方面的信息。
|
||||
|
||||
##### 实验要求
|
||||
#### 实验要求
|
||||
|
||||
本实验分为两部分:Part A 和 Part B。Part A 在本实验完成后一周内提交;你将要提交你的更改和完成的动手实验,在提交之前要确保你的代码通过了 Part A 的所有检查(如果你的代码未通过 Part B 的检查也可以提交)。只需要在第二周提交 Part B 的期限之前代码检查通过即可。
|
||||
|
||||
由于在实验 2 中,你需要做实验中描述的所有正则表达式练习,并且至少通过一个挑战(是指整个实验,不是每个部分)。写出详细的问题答案并张贴在实验中,以及一到两个段落的关于你如何解决你选择的挑战问题的详细描述,并将它放在一个名为 `answers-lab3.txt` 的文件中,并将这个文件放在你的 `lab` 目标的根目录下。(如果你做了多个问题挑战,你仅需要提交其中一个即可)不要忘记使用 `git add answers-lab3.txt` 提交这个文件。
|
||||
|
||||
##### 行内汇编语言
|
||||
#### 行内汇编语言
|
||||
|
||||
在本实验中你可能找到使用了 GCC 的行内汇编语言特性,虽然不使用它也可以完成实验。但至少你需要去理解这些行内汇编语言片段,这些汇编语言("`asm`" 语句)片段已经存在于提供给你的源代码中。你可以在课程 [参考资料][2] 的页面上找到 GCC 行内汇编语言有关的信息。
|
||||
在本实验中你可能发现使用了 GCC 的行内汇编语言特性,虽然不使用它也可以完成实验。但至少你需要去理解这些行内汇编语言片段,这些汇编语言(`asm` 语句)片段已经存在于提供给你的源代码中。你可以在课程 [参考资料][2] 的页面上找到 GCC 行内汇编语言有关的信息。
|
||||
|
||||
#### Part A:用户环境和异常处理
|
||||
### Part A:用户环境和异常处理
|
||||
|
||||
新文件 `inc/env.h` 中包含了在 JOS 中关于用户环境的基本定义。现在就去阅读它。内核使用数据结构 `Env` 去保持对每个用户环境的跟踪。在本实验的开始,你将只创建一个环境,但你需要去设计 JOS 内核支持多环境;实验 4 将带来这个高级特性,允许用户环境去 `fork` 其它环境。
|
||||
|
||||
正如你在 `kern/env.c` 中所看到的,内核维护了与环境相关的三个全局变量:
|
||||
|
||||
```
|
||||
struct Env *envs = NULL; // All environments
|
||||
struct Env *curenv = NULL; // The current env
|
||||
static struct Env *env_free_list; // Free environment list
|
||||
|
||||
struct Env *envs = NULL; // All environments
|
||||
struct Env *curenv = NULL; // The current env
|
||||
static struct Env *env_free_list; // Free environment list
|
||||
```
|
||||
|
||||
一旦 JOS 启动并运行,`envs` 指针指向到一个数组,即数据结构 `Env`,它保存了系统中全部的环境。在我们的设计中,JOS 内核将同时支持最大值为 `NENV` 个的活动的环境,虽然在一般情况下,任何给定时刻运行的环境很少。(`NENV` 是在 `inc/env.h` 中用 `#define` 定义的一个常量)一旦它被分配,对于每个 `NENV` 可能的环境,`envs` 数组将包含一个数据结构 `Env` 的单个实例。
|
||||
@ -92,38 +89,38 @@ JOS 内核在 `env_free_list` 上用数据结构 `Env` 保存了所有不活动
|
||||
|
||||
内核使用符号 `curenv` 来保持对任意给定时刻的 _当前正在运行的环境_ 进行跟踪。在系统引导期间,在第一个环境运行之前,`curenv` 被初始化为 `NULL`。
|
||||
|
||||
##### 环境状态
|
||||
#### 环境状态
|
||||
|
||||
数据结构 `Env` 被定义在文件 `inc/env.h` 中,内容如下:(在后面的实验中将添加更多的字段):
|
||||
|
||||
```c
|
||||
struct Env {
|
||||
struct Trapframe env_tf; // Saved registers
|
||||
struct Env *env_link; // Next free Env
|
||||
envid_t env_id; // Unique environment identifier
|
||||
envid_t env_parent_id; // env_id of this env's parent
|
||||
enum EnvType env_type; // Indicates special system environments
|
||||
unsigned env_status; // Status of the environment
|
||||
uint32_t env_runs; // Number of times environment has run
|
||||
struct Env {
|
||||
struct Trapframe env_tf; // Saved registers
|
||||
struct Env *env_link; // Next free Env
|
||||
envid_t env_id; // Unique environment identifier
|
||||
envid_t env_parent_id; // env_id of this env's parent
|
||||
enum EnvType env_type; // Indicates special system environments
|
||||
unsigned env_status; // Status of the environment
|
||||
uint32_t env_runs; // Number of times environment has run
|
||||
|
||||
// Address space
|
||||
pde_t *env_pgdir; // Kernel virtual address of page dir
|
||||
};
|
||||
// Address space
|
||||
pde_t *env_pgdir; // Kernel virtual address of page dir
|
||||
};
|
||||
```
|
||||
|
||||
以下是数据结构 `Env` 中的字段简介:
|
||||
|
||||
* **env_tf**:
|
||||
* `env_tf`:
|
||||
这个结构定义在 `inc/trap.h` 中,它用于在那个环境不运行时保持它保存在寄存器中的值,即:当内核或一个不同的环境在运行时。当从用户模式切换到内核模式时,内核将保存这些东西,以便于那个环境能够在稍后重新运行时回到中断运行的地方。
|
||||
* **env_link**:
|
||||
* `env_link`:
|
||||
这是一个链接,它链接到在 `env_free_list` 上的下一个 `Env` 上。`env_free_list` 指向到列表上第一个空闲的环境。
|
||||
* **env_id**:
|
||||
* `env_id`:
|
||||
内核在数据结构 `Env` 中保存了一个唯一标识当前环境的值(即:使用数组 `envs` 中的特定槽位)。在一个用户环境终止之后,内核可能给另外的环境重新分配相同的数据结构 `Env` —— 但是新的环境将有一个与已终止的旧的环境不同的 `env_id`,即便是新的环境在数组 `envs` 中复用了同一个槽位。
|
||||
* **env_parent_id**:
|
||||
* `env_parent_id`:
|
||||
内核使用它来保存创建这个环境的父级环境的 `env_id`。通过这种方式,环境就可以形成一个“家族树”,这对于做出“哪个环境可以对谁做什么”这样的安全决策非常有用。
|
||||
* **env_type**:
|
||||
* `env_type`:
|
||||
它用于去区分特定的环境。对于大多数环境,它将是 `ENV_TYPE_USER` 的。在稍后的实验中,针对特定的系统服务环境,我们将引入更多的几种类型。
|
||||
* **env_status**:
|
||||
* `env_status`:
|
||||
这个变量持有以下几个值之一:
|
||||
* `ENV_FREE`:
|
||||
表示那个 `Env` 结构是非活动的,并且因此它还在 `env_free_list` 上。
|
||||
@ -135,59 +132,64 @@ JOS 内核在 `env_free_list` 上用数据结构 `Env` 保存了所有不活动
|
||||
表示那个 `Env` 结构所代表的是一个当前活动的环境,但不是当前准备去运行的:例如,因为它正在因为一个来自其它环境的进程间通讯(IPC)而处于等待状态。
|
||||
* `ENV_DYING`:
|
||||
表示那个 `Env` 结构所表示的是一个僵尸环境。一个僵尸环境将在下一次被内核捕获后被释放。我们在实验 4 之前不会去使用这个标志。
|
||||
* **env_pgdir**:
|
||||
* `env_pgdir`:
|
||||
这个变量持有这个环境的内核虚拟地址的页目录。
|
||||
|
||||
|
||||
|
||||
就像一个 Unix 进程一样,一个 JOS 环境耦合了“线程”和“地址空间”的概念。线程主要由保存的寄存器来定义(`env_tf` 字段),而地址空间由页目录和 `env_pgdir` 所指向的页表所定义。为运行一个环境,内核必须使用保存的寄存器值和相关的地址空间去设置 CPU。
|
||||
|
||||
我们的 `struct Env` 与 xv6 中的 `struct proc` 类似。它们都在一个 `Trapframe` 结构中持有环境(即进程)的用户模式寄存器状态。在 JOS 中,单个的环境并不能像 xv6 中的进程那样拥有它们自己的内核栈。在这里,内核中任意时间只能有一个 JOS 环境处于活动中,因此,JOS 仅需要一个单个的内核栈。
|
||||
|
||||
##### 为环境分配数组
|
||||
#### 为环境分配数组
|
||||
|
||||
在实验 2 的 `mem_init()` 中,你为数组 `pages[]` 分配了内存,它是内核用于对页面分配与否的状态进行跟踪的一个表。你现在将需要去修改 `mem_init()`,以便于后面使用它分配一个与结构 `Env` 类似的数组,这个数组被称为 `envs`。
|
||||
|
||||
```markdown
|
||||
练习 1、修改在 `kern/pmap.c` 中的 `mem_init()`,以用于去分配和映射 `envs` 数组。这个数组完全由 `Env` 结构分配的实例 `NENV` 组成,就像你分配的 `pages` 数组一样。与 `pages` 数组一样,由内存支持的数组 `envs` 也将在 `UENVS`(它的定义在 `inc/memlayout.h` 文件中)中映射用户只读的内存,以便于用户进程能够从这个数组中读取。
|
||||
```
|
||||
> **练习 1**、修改在 `kern/pmap.c` 中的 `mem_init()`,以用于去分配和映射 `envs` 数组。这个数组完全由 `Env` 结构分配的实例 `NENV` 组成,就像你分配的 `pages` 数组一样。与 `pages` 数组一样,由内存支持的数组 `envs` 也将在 `UENVS`(它的定义在 `inc/memlayout.h` 文件中)中映射用户只读的内存,以便于用户进程能够从这个数组中读取。
|
||||
|
||||
你应该去运行你的代码,并确保 `check_kern_pgdir()` 是没有问题的。
|
||||
|
||||
##### 创建和运行环境
|
||||
#### 创建和运行环境
|
||||
|
||||
现在,你将在 `kern/env.c` 中写一些必需的代码去运行一个用户环境。因为我们并没有做一个文件系统,因此,我们将设置内核去加载一个嵌入到内核中的静态的二进制镜像。JOS 内核以一个 ELF 可运行镜像的方式将这个二进制镜像嵌入到内核中。
|
||||
现在,你将在 `kern/env.c` 中写一些必需的代码去运行一个用户环境。因为我们并没有做一个文件系统,因此,我们将设置内核去加载一个嵌入到内核中的静态的二进制镜像。JOS 内核以一个 ELF 可运行镜像的方式将这个二进制镜像嵌入到内核中。
|
||||
|
||||
在实验 3 中,`GNUmakefile` 将在 `obj/user/` 目录中生成一些二进制镜像。如果你看到 `kern/Makefrag`,你将注意到一些奇怪的的东西,它们“链接”这些二进制直接进入到内核中运行,就像 `.o` 文件一样。在链接器命令行上的 `-b binary` 选项,将因此把它们链接为“原生的”不解析的二进制文件,而不是由编译器产生的普通的 `.o` 文件。(就链接器而言,这些文件压根就不是 ELF 镜像文件 —— 它们可以是任何东西,比如,一个文本文件或图片!)如果你在内核构建之后查看 `obj/kern/kernel.sym` ,你将会注意到链接器很奇怪的生成了一些有趣的、命名很费解的符号,比如像 `_binary_obj_user_hello_start`、`_binary_obj_user_hello_end`、以及 `_binary_obj_user_hello_size`。链接器通过改编二进制文件的命令来生成这些符号;这种符号为普通内核代码使用一种引入嵌入式二进制文件的方法。
|
||||
|
||||
在 `kern/init.c` 的 `i386_init()` 中,你将写一些代码在环境中运行这些二进制镜像中的一种。但是,设置用户环境的关键函数还没有实现;将需要你去完成它们。
|
||||
|
||||
```markdown
|
||||
练习 2、在文件 `env.c` 中,写完以下函数的代码:
|
||||
> **练习 2**、在文件 `env.c` 中,写完以下函数的代码:
|
||||
|
||||
* `env_init()`
|
||||
初始化 `envs` 数组中所有的 `Env` 结构,然后把它们添加到 `env_free_list` 中。也称为 `env_init_percpu`,它通过配置硬件,在硬件上为 level 0(内核)权限和 level 3(用户)权限使用单独的段。
|
||||
* `env_setup_vm()`
|
||||
为一个新环境分配一个页目录,并初始化新环境的地址空间的内核部分。
|
||||
* `region_alloc()`
|
||||
为一个新环境分配和映射物理内存
|
||||
* `load_icode()`
|
||||
你将需要去解析一个 ELF 二进制镜像,就像引导加载器那样,然后加载它的内容到一个新环境的用户地址空间中。
|
||||
* `env_create()`
|
||||
使用 `env_alloc` 去分配一个环境,并调用 `load_icode` 去加载一个 ELF 二进制
|
||||
* `env_run()`
|
||||
在用户模式中开始运行一个给定的环境
|
||||
> * `env_init()`
|
||||
|
||||
> 初始化 `envs` 数组中所有的 `Env` 结构,然后把它们添加到 `env_free_list` 中。也称为 `env_init_percpu`,它通过配置硬件,在硬件上为 level 0(内核)权限和 level 3(用户)权限使用单独的段。
|
||||
|
||||
> * `env_setup_vm()`
|
||||
|
||||
在你写这些函数时,你可能会发现新的 cprintf 动词 `%e` 非常有用 -- 它可以输出一个错误代码的相关描述。比如:
|
||||
> 为一个新环境分配一个页目录,并初始化新环境的地址空间的内核部分。
|
||||
|
||||
r = -E_NO_MEM;
|
||||
panic("env_alloc: %e", r);
|
||||
> * `region_alloc()`
|
||||
|
||||
中 panic 将输出消息 "env_alloc: out of memory"。
|
||||
> 为一个新环境分配和映射物理内存
|
||||
|
||||
> * `load_icode()`
|
||||
|
||||
> 你将需要去解析一个 ELF 二进制镜像,就像引导加载器那样,然后加载它的内容到一个新环境的用户地址空间中。
|
||||
|
||||
> * `env_create()`
|
||||
|
||||
> 使用 `env_alloc` 去分配一个环境,并调用 `load_icode` 去加载一个 ELF 二进制
|
||||
|
||||
> * `env_run()`
|
||||
|
||||
> 在用户模式中开始运行一个给定的环境
|
||||
|
||||
> 在你写这些函数时,你可能会发现新的 cprintf 动词 `%e` 非常有用 -- 它可以输出一个错误代码的相关描述。比如:
|
||||
|
||||
> ```
|
||||
r = -E_NO_MEM;
|
||||
panic("env_alloc: %e", r);
|
||||
```
|
||||
|
||||
> 中 panic 将输出消息 "env_alloc: out of memory"。
|
||||
|
||||
下面是用户代码相关的调用图。确保你理解了每一步的用途。
|
||||
|
||||
* `start` (`kern/entry.S`)
|
||||
@ -200,107 +202,94 @@ JOS 内核在 `env_free_list` 上用数据结构 `Env` 保存了所有不活动
|
||||
* `env_run`
|
||||
* `env_pop_tf`
|
||||
|
||||
|
||||
|
||||
在完成以上函数后,你应该去编译内核并在 QEMU 下运行它。如果一切正常,你的系统将进入到用户空间并运行二进制的 `hello` ,直到使用 `int` 指令生成一个系统调用为止。在那个时刻将存在一个问题,因为 JOS 尚未设置硬件去允许从用户空间到内核空间的各种转换。当 CPU 发现没有系统调用中断的服务程序时,它将生成一个一般保护异常,找到那个异常并去处理它,还将生成一个双重故障异常,同样也找到它并处理它,并且最后会出现所谓的“三重故障异常”。通常情况下,你将随后看到 CPU 复位以及系统重引导。虽然对于传统的应用程序(在 [这篇博客文章][3] 中解释了原因)这是重大的问题,但是对于内核开发来说,这是一个痛苦的过程,因此,在打了 6.828 补丁的 QEMU 上,你将可以看到转储的寄存器内容和一个“三重故障”的信息。
|
||||
|
||||
我们马上就会去处理这些问题,但是现在,我们可以使用调试器去检查我们是否进入了用户模式。使用 `make qemu-gdb` 并在 `env_pop_tf` 处设置一个 GDB 断点,它是你进入用户模式之前到达的最后一个函数。使用 `si` 单步进入这个函数;处理器将在 `iret` 指令之后进入用户模式。然后你将会看到在用户环境运行的第一个指令,它将是在 `lib/entry.S` 中的标签 `start` 的第一个指令 `cmpl`。现在,在 `hello` 中的 `sys_cputs()` 的 `int $0x30` 处使用 `b *0x...`(关于用户空间的地址,请查看 `obj/user/hello.asm` )设置断点。这个指令 `int` 是系统调用去显示一个字符到控制台。如果到 `int` 还没有运行,那么可能在你的地址空间设置或程序加载代码时发生了错误;返回去找到问题并解决后重新运行。
|
||||
|
||||
##### 处理中断和异常
|
||||
#### 处理中断和异常
|
||||
|
||||
到目前为止,在用户空间中的第一个系统调用指令 `int $0x30` 已正式寿终正寝了:一旦处理器进入用户模式,将无法返回。因此,现在,你需要去实现基本的异常和系统调用服务程序,因为那样才有可能让内核从用户模式代码中恢复对处理器的控制。你所做的第一件事情就是彻底地掌握 x86 的中断和异常机制的使用。
|
||||
|
||||
```
|
||||
练习 3、如果你对中断和异常机制不熟悉的话,阅读 80386 程序员手册的第 9 章(或 IA-32 开发者手册的第 5 章)。
|
||||
```
|
||||
> **练习 3**、如果你对中断和异常机制不熟悉的话,阅读 80386 程序员手册的第 9 章(或 IA-32 开发者手册的第 5 章)。
|
||||
|
||||
在这个实验中,对于中断、异常、以其它类似的东西,我们将遵循 Intel 的术语习惯。由于如<ruby>异常<rt>exception</rt></ruby>、<ruby>陷阱<rt>trap</rt></ruby>、<ruby>中断<rt>interrupt</rt></ruby>、<ruby>故障<rt>fault</rt></ruby>和<ruby>中止<rt>abort</rt></ruby>这些术语在不同的架构和操作系统上并没有一个统一的标准,我们经常在特定的架构下(如 x86)并不去考虑它们之间的细微差别。当你在本实验以外的地方看到这些术语时,它们的含义可能有细微的差别。
|
||||
|
||||
##### 受保护的控制转移基础
|
||||
#### 受保护的控制转移基础
|
||||
|
||||
异常和中断都是“受保护的控制转移”,它将导致处理器从用户模式切换到内核模式(CPL=0)而不会让用户模式的代码干扰到内核的其它函数或其它的环境。在 Intel 的术语中,一个中断就是一个“受保护的控制转移”,它是由于处理器以外的外部异步事件所引发的,比如外部设备 I/O 活动通知。而异常正好与之相反,它是由当前正在运行的代码所引发的同步的、受保护的控制转移,比如由于发生了一个除零错误或对无效内存的访问。
|
||||
异常和中断都是“受保护的控制转移”,它将导致处理器从用户模式切换到内核模式(`CPL=0`)而不会让用户模式的代码干扰到内核的其它函数或其它的环境。在 Intel 的术语中,一个中断就是一个“受保护的控制转移”,它是由于处理器以外的外部异步事件所引发的,比如外部设备 I/O 活动通知。而异常正好与之相反,它是由当前正在运行的代码所引发的同步的、受保护的控制转移,比如由于发生了一个除零错误或对无效内存的访问。
|
||||
|
||||
为了确保这些受保护的控制转移是真正地受到保护,处理器的中断/异常机制设计是:当中断/异常发生时,当前运行的代码不能随意选择进入内核的位置和方式。而是,处理器在确保内核能够严格控制的条件下才能进入内核。在 x86 上,有两种机制协同来提供这种保护:
|
||||
|
||||
1. **中断描述符表** 处理器确保中断和异常仅能够导致内核进入几个特定的、由内核本身定义好的、明确的入口点,而不是去运行中断或异常发生时的代码。
|
||||
1. **中断描述符表** 处理器确保中断和异常仅能够导致内核进入几个特定的、由内核本身定义好的、明确的入口点,而不是去运行中断或异常发生时的代码。
|
||||
|
||||
x86 允许最多有 256 个不同的中断或异常入口点去进入内核,每个入口点都使用一个不同的中断向量。一个向量是一个介于 0 和 255 之间的数字。一个中断向量是由中断源确定的:不同的设备、错误条件、以及应用程序去请求内核使用不同的向量生成中断。CPU 使用向量作为进入处理器的中断描述符表(IDT)的索引,它是内核设置的内核私有内存,GDT 也是。从这个表中的适当的条目中,处理器将加载:
|
||||
x86 允许最多有 256 个不同的中断或异常入口点去进入内核,每个入口点都使用一个不同的中断向量。一个向量是一个介于 0 和 255 之间的数字。一个中断向量是由中断源确定的:不同的设备、错误条件、以及应用程序去请求内核使用不同的向量生成中断。CPU 使用向量作为进入处理器的中断描述符表(IDT)的索引,它是内核设置的内核私有内存,GDT 也是。从这个表中的适当的条目中,处理器将加载:
|
||||
|
||||
* 将值加载到指令指针寄存器(EIP),指向内核代码设计好的,用于处理这种异常的服务程序。
|
||||
* 将值加载到代码段寄存器(CS),它包含运行权限为 0—1 级别的、要运行的异常服务程序。(在 JOS 中,所有的异常处理程序都运行在内核模式中,运行级别为 level 0。)
|
||||
2. **任务状态描述符表** 处理器在中断或异常发生时,需要一个地方去保存旧的处理器状态,比如,处理器在调用异常服务程序之前的 `EIP` 和 `CS` 的原始值,这样那个异常服务程序就能够稍后通过还原旧的状态来回到中断发生时的代码位置。但是对于已保存的处理器的旧状态必须被保护起来,不能被无权限的用户模式代码访问;否则代码中的 bug 或恶意用户代码将危及内核。
|
||||
* 将值加载到代码段寄存器(CS),它包含运行权限为 0—1 级别的、要运行的异常服务程序。(在 JOS 中,所有的异常处理程序都运行在内核模式中,运行级别为 0。)
|
||||
|
||||
基于这个原因,当一个 x86 处理器产生一个中断或陷阱时,将导致权限级别的变更,从用户模式转换到内核模式,它也将导致在内核的内存中发生栈切换。有一个被称为 TSS 的任务状态描述符表规定段描述符和这个栈所处的地址。处理器在这个新栈上推送 `SS`、`ESP`、`EFLAGS`、`CS`、`EIP`、以及一个可选的错误代码。然后它从中断描述符上加载 `CS` 和 `EIP` 的值,然后设置 `ESP` 和 `SS` 去指向新的栈。
|
||||
2. **任务状态描述符表** 处理器在中断或异常发生时,需要一个地方去保存旧的处理器状态,比如,处理器在调用异常服务程序之前的 `EIP` 和 `CS` 的原始值,这样那个异常服务程序就能够稍后通过还原旧的状态来回到中断发生时的代码位置。但是对于已保存的处理器的旧状态必须被保护起来,不能被无权限的用户模式代码访问;否则代码中的 bug 或恶意用户代码将危及内核。
|
||||
|
||||
虽然 TSS 很大并且默默地为各种用途服务,但是 JOS 仅用它去定义当从用户模式到内核模式的转移发生时,处理器即将切换过去的内核栈。因为在 JOS 中的“内核模式”仅运行在 x86 的 level 0 权限上,当进入内核模式时,处理器使用 TSS 上的 `ESP0` 和 `SS0` 字段去定义内核栈。JOS 并不去使用 TSS 的任何其它字段。
|
||||
基于这个原因,当一个 x86 处理器产生一个中断或陷阱时,将导致权限级别的变更,从用户模式转换到内核模式,它也将导致在内核的内存中发生栈切换。有一个被称为 TSS 的任务状态描述符表规定段描述符和这个栈所处的地址。处理器在这个新栈上推送 `SS`、`ESP`、`EFLAGS`、`CS`、`EIP`、以及一个可选的错误代码。然后它从中断描述符上加载 `CS` 和 `EIP` 的值,然后设置 `ESP` 和 `SS` 去指向新的栈。
|
||||
|
||||
虽然 TSS 很大并且默默地为各种用途服务,但是 JOS 仅用它去定义当从用户模式到内核模式的转移发生时,处理器即将切换过去的内核栈。因为在 JOS 中的“内核模式”仅运行在 x86 的运行级别 0 权限上,当进入内核模式时,处理器使用 TSS 上的 `ESP0` 和 `SS0` 字段去定义内核栈。JOS 并不去使用 TSS 的任何其它字段。
|
||||
|
||||
|
||||
|
||||
##### 异常和中断的类型
|
||||
#### 异常和中断的类型
|
||||
|
||||
所有的 x86 处理器上的同步异常都能够产生一个内部使用的、介于 0 到 31 之间的中断向量,因此它映射到 IDT 就是条目 0-31。例如,一个页故障总是通过向量 14 引发一个异常。大于 31 的中断向量仅用于软件中断,它由 `int` 指令生成,或异步硬件中断,当需要时,它们由外部设备产生。
|
||||
|
||||
在这一节中,我们将扩展 JOS 去处理向量为 0-31 之间的、内部产生的 x86 异常。在下一节中,我们将完成 JOS 的 48(0x30)号软件中断向量,JOS 将(随意选择的)使用它作为系统调用中断向量。在实验 4 中,我们将扩展 JOS 去处理外部生成的硬件中断,比如时钟中断。
|
||||
|
||||
##### 一个示例
|
||||
#### 一个示例
|
||||
|
||||
我们把这些片断综合到一起,通过一个示例来巩固一下。我们假设处理器在用户环境下运行代码,遇到一个除零问题。
|
||||
|
||||
1. 处理器去切换到由 TSS 中的 `SS0` 和 `ESP0` 定义的栈,在 JOS 中,它们各自保存着值 `GD_KD` 和 `KSTACKTOP`。
|
||||
|
||||
2. 处理器在内核栈上推入异常参数,起始地址为 `KSTACKTOP`:
|
||||
1. 处理器去切换到由 TSS 中的 `SS0` 和 `ESP0` 定义的栈,在 JOS 中,它们各自保存着值 `GD_KD` 和 `KSTACKTOP`。
|
||||
2. 处理器在内核栈上推入异常参数,起始地址为 `KSTACKTOP`:
|
||||
|
||||
```
|
||||
+--------------------+ KSTACKTOP
|
||||
| 0x00000 | old SS | " - 4
|
||||
| old ESP | " - 8
|
||||
| old EFLAGS | " - 12
|
||||
| 0x00000 | old CS | " - 16
|
||||
| old EIP | " - 20 <---- ESP
|
||||
+--------------------+
|
||||
```
|
||||
+--------------------+ KSTACKTOP
|
||||
| 0x00000 | old SS | " - 4
|
||||
| old ESP | " - 8
|
||||
| old EFLAGS | " - 12
|
||||
| 0x00000 | old CS | " - 16
|
||||
| old EIP | " - 20 <---- ESP
|
||||
+--------------------+
|
||||
|
||||
```
|
||||
|
||||
3. 由于我们要处理一个除零错误,它将在 x86 上产生一个中断向量 0,处理器读取 IDT 的条目 0,然后设置 `CS:EIP` 去指向由条目描述的处理函数。
|
||||
|
||||
4. 处理服务程序函数将接管控制权并处理异常,例如中止用户环境。
|
||||
|
||||
|
||||
|
||||
3. 由于我们要处理一个除零错误,它将在 x86 上产生一个中断向量 0,处理器读取 IDT 的条目 0,然后设置 `CS:EIP` 去指向由条目描述的处理函数。
|
||||
4. 处理服务程序函数将接管控制权并处理异常,例如中止用户环境。
|
||||
|
||||
对于某些类型的 x86 异常,除了以上的五个“标准的”寄存器外,处理器还推入另一个包含错误代码的寄存器值到栈中。页故障异常,向量号为 14,就是一个重要的示例。查看 80386 手册去确定哪些异常推入一个错误代码,以及错误代码在那个案例中的意义。当处理器推入一个错误代码后,当从用户模式中进入内核模式,异常处理服务程序开始时的栈看起来应该如下所示:
|
||||
|
||||
```
|
||||
+--------------------+ KSTACKTOP
|
||||
| 0x00000 | old SS | " - 4
|
||||
| old ESP | " - 8
|
||||
| old EFLAGS | " - 12
|
||||
| 0x00000 | old CS | " - 16
|
||||
| old EIP | " - 20
|
||||
| error code | " - 24 <---- ESP
|
||||
+--------------------+
|
||||
+--------------------+ KSTACKTOP
|
||||
| 0x00000 | old SS | " - 4
|
||||
| old ESP | " - 8
|
||||
| old EFLAGS | " - 12
|
||||
| 0x00000 | old CS | " - 16
|
||||
| old EIP | " - 20
|
||||
| error code | " - 24 <---- ESP
|
||||
+--------------------+
|
||||
```
|
||||
|
||||
##### 嵌套的异常和中断
|
||||
#### 嵌套的异常和中断
|
||||
|
||||
处理器能够处理来自用户和内核模式中的异常和中断。当收到来自用户模式的异常和中断时才会进入内核模式中,而且,在推送它的旧寄存器状态到栈中和通过 IDT 调用相关的异常服务程序之前,x86 处理器会自动切换栈。如果当异常或中断发生时,处理器已经处于内核模式中(`CS` 寄存器低位两个比特为 0),那么 CPU 只是推入一些值到相同的内核栈中。在这种方式中,内核可以优雅地处理嵌套的异常,嵌套的异常一般由内核本身的代码所引发。在实现保护时,这种功能是非常重要的工具,我们将在稍后的系统调用中看到它。
|
||||
|
||||
如果处理器已经处于内核模式中,并且发生了一个嵌套的异常,由于它并不需要切换栈,它也就不需要去保存旧的 `SS` 或 `ESP` 寄存器。对于不推入错误代码的异常类型,在进入到异常服务程序时,它的内核栈看起来应该如下图:
|
||||
|
||||
```
|
||||
+--------------------+ <---- old ESP
|
||||
| old EFLAGS | " - 4
|
||||
| 0x00000 | old CS | " - 8
|
||||
| old EIP | " - 12
|
||||
+--------------------+
|
||||
+--------------------+ <---- old ESP
|
||||
| old EFLAGS | " - 4
|
||||
| 0x00000 | old CS | " - 8
|
||||
| old EIP | " - 12
|
||||
+--------------------+
|
||||
```
|
||||
|
||||
对于需要推入一个错误代码的异常类型,处理器将在旧的 `EIP` 之后,立即推入一个错误代码,就和前面一样。
|
||||
|
||||
关于处理器的异常嵌套的功能,这里有一个重要的警告。如果处理器正处于内核模式时发生了一个异常,并且不论是什么原因,比如栈空间泄漏,都不会去推送它的旧的状态,那么这时处理器将不能做任何的恢复,它只是简单地重置。毫无疑问,内核应该被设计为禁止发生这种情况。
|
||||
|
||||
##### 设置 IDT
|
||||
#### 设置 IDT
|
||||
|
||||
到目前为止,你应该有了在 JOS 中为了设置 IDT 和处理异常所需的基本信息。现在,我们去设置 IDT 以处理中断向量 0-31(处理器异常)。我们将在本实验的稍后部分处理系统调用,然后在后面的实验中增加中断 32-47(设备 IRQ)。
|
||||
|
||||
@ -311,102 +300,94 @@ x86 允许最多有 256 个不同的中断或异常入口点去进入内核,
|
||||
你将要实现的完整的控制流如下图所描述:
|
||||
|
||||
```c
|
||||
IDT trapentry.S trap.c
|
||||
IDT trapentry.S trap.c
|
||||
|
||||
+----------------+
|
||||
| &handler1 |---------> handler1: trap (struct Trapframe *tf)
|
||||
| | // do stuff {
|
||||
| | call trap // handle the exception/interrupt
|
||||
| | // ... }
|
||||
| &handler1 |----> handler1: trap (struct Trapframe *tf)
|
||||
| | // do stuff {
|
||||
| | call trap // handle the exception/interrupt
|
||||
| | // ... }
|
||||
+----------------+
|
||||
| &handler2 |--------> handler2:
|
||||
| | // do stuff
|
||||
| | call trap
|
||||
| | // ...
|
||||
| &handler2 |----> handler2:
|
||||
| | // do stuff
|
||||
| | call trap
|
||||
| | // ...
|
||||
+----------------+
|
||||
.
|
||||
.
|
||||
.
|
||||
+----------------+
|
||||
| &handlerX |--------> handlerX:
|
||||
| | // do stuff
|
||||
| | call trap
|
||||
| | // ...
|
||||
| &handlerX |----> handlerX:
|
||||
| | // do stuff
|
||||
| | call trap
|
||||
| | // ...
|
||||
+----------------+
|
||||
```
|
||||
|
||||
每个异常或中断都应该在 `trapentry.S` 中有它自己的处理程序,并且 `trap_init()` 应该使用这些处理程序的地址去初始化 IDT。每个处理程序都应该在栈上构建一个 `struct Trapframe`(查看 `inc/trap.h`),然后使用一个指针调用 `trap()`(在 `trap.c` 中)到 `Trapframe`。`trap()` 接着处理异常/中断或派发给一个特定的处理函数。
|
||||
|
||||
```markdown
|
||||
练习 4、编辑 `trapentry.S` 和 `trap.c`,然后实现上面所描述的功能。在 `trapentry.S` 中的宏 `TRAPHANDLER` 和 `TRAPHANDLER_NOEC` 将会帮你,还有在 `inc/trap.h` 中的 T_* defines。你需要在 `trapentry.S` 中为每个定义在 `inc/trap.h` 中的陷阱添加一个入口点(使用这些宏),并且你将有 t、o 提供的 `_alltraps`,这是由宏 `TRAPHANDLER`指向到它。你也需要去修改 `trap_init()` 来初始化 `idt`,以使它指向到每个在 `trapentry.S` 中定义的入口点;宏 `SETGATE` 将有助你实现它。
|
||||
> 练习 4、编辑 `trapentry.S` 和 `trap.c`,然后实现上面所描述的功能。在 `trapentry.S` 中的宏 `TRAPHANDLER` 和 `TRAPHANDLER_NOEC` 将会帮你,还有在 `inc/trap.h` 中的 T_* defines。你需要在 `trapentry.S` 中为每个定义在 `inc/trap.h` 中的陷阱添加一个入口点(使用这些宏),并且你将有 t、o 提供的 `_alltraps`,这是由宏 `TRAPHANDLER`指向到它。你也需要去修改 `trap_init()` 来初始化 `idt`,以使它指向到每个在 `trapentry.S` 中定义的入口点;宏 `SETGATE` 将有助你实现它。
|
||||
|
||||
你的 `_alltraps` 应该:
|
||||
> 你的 `_alltraps` 应该:
|
||||
|
||||
1. 推送值以使栈看上去像一个结构 Trapframe
|
||||
2. 加载 `GD_KD` 到 `%ds` 和 `%es`
|
||||
3. `pushl %esp` 去传递一个指针到 Trapframe 以作为一个 trap() 的参数
|
||||
4. `call trap` (`trap` 能够返回吗?)
|
||||
> 1. 推送值以使栈看上去像一个结构 Trapframe
|
||||
> 2. 加载 `GD_KD` 到 `%ds` 和 `%es`
|
||||
> 3. `pushl %esp` 去传递一个指针到 Trapframe 以作为一个 trap() 的参数
|
||||
> 4. `call trap` (`trap` 能够返回吗?)
|
||||
|
||||
> 考虑使用 `pushal` 指令;它非常适合 `struct Trapframe` 的布局。
|
||||
|
||||
> 使用一些在 `user` 目录中的测试程序来测试你的陷阱处理代码,这些测试程序在生成任何系统调用之前能引发异常,比如 `user/divzero`。在这时,你应该能够成功完成 `divzero`、`softint`、以有 `badsegment` 测试。
|
||||
|
||||
考虑使用 `pushal` 指令;它非常适合 `struct Trapframe` 的布局。
|
||||
.
|
||||
|
||||
使用一些在 `user` 目录中的测试程序来测试你的陷阱处理代码,这些测试程序在生成任何系统调用之前能引发异常,比如 `user/divzero`。在这时,你应该能够成功完成 `divzero`、`softint`、以有 `badsegment` 测试。
|
||||
> **小挑战!**目前,在 `trapentry.S` 中列出的 `TRAPHANDLER` 和他们安装在 `trap.c` 中可能有许多代码非常相似。清除它们。修改 `trapentry.S` 中的宏去自动为 `trap.c` 生成一个表。注意,你可以直接使用 `.text` 和 `.data` 在汇编器中切换放置其中的代码和数据。
|
||||
|
||||
.
|
||||
|
||||
> **问题**
|
||||
|
||||
> 在你的 `answers-lab3.txt` 中回答下列问题:
|
||||
|
||||
> 1. 为每个异常/中断设置一个独立的服务程序函数的目的是什么?(即:如果所有的异常/中断都传递给同一个服务程序,在我们的当前实现中能否提供这样的特性?)
|
||||
> 2. 你需要做什么事情才能让 `user/softint` 程序正常运行?评级脚本预计将会产生一个一般保护故障(trap 13),但是 `softint` 的代码显示为 `int $14`。为什么它产生的中断向量是 13?如果内核允许 `softint` 的 `int $14` 指令去调用内核页故障的服务程序(它的中断向量是 14)会发生什么事情?
|
||||
```
|
||||
|
||||
```markdown
|
||||
小挑战!目前,在 `trapentry.S` 中列出的 `TRAPHANDLER` 和他们安装在 `trap.c` 中可能有许多代码非常相似。清除它们。修改 `trapentry.S` 中的宏去自动为 `trap.c` 生成一个表。注意,你可以直接使用 `.text` 和 `.data` 在汇编器中切换放置其中的代码和数据。
|
||||
```
|
||||
|
||||
```markdown
|
||||
问题
|
||||
|
||||
在你的 `answers-lab3.txt` 中回答下列问题:
|
||||
|
||||
1. 为每个异常/中断设置一个独立的服务程序函数的目的是什么?(即:如果所有的异常/中断都传递给同一个服务程序,在我们的当前实现中能否提供这样的特性?)
|
||||
2. 你需要做什么事情才能让 `user/softint` 程序正常运行?评级脚本预计将会产生一个一般保护故障(trap 13),但是 `softint` 的代码显示为 `int $14`。为什么它产生的中断向量是 13?如果内核允许 `softint` 的 `int $14` 指令去调用内核页故障的服务程序(它的中断向量是 14)会发生什么事情?
|
||||
```
|
||||
|
||||
|
||||
本实验的 Part A 部分结束了。不要忘了去添加 `answers-lab3.txt` 文件,提交你的变更,然后在 Part A 作业的提交截止日期之前运行 `make handin`。
|
||||
|
||||
#### Part B:页故障、断点异常、和系统调用
|
||||
### Part B:页故障、断点异常、和系统调用
|
||||
|
||||
现在,你的内核已经有了最基本的异常处理能力,你将要去继续改进它,来提供依赖异常服务程序的操作系统原语。
|
||||
|
||||
##### 处理页故障
|
||||
#### 处理页故障
|
||||
|
||||
页故障异常,中断向量为 14(`T_PGFLT`),它是一个非常重要的东西,我们将通过本实验和接下来的实验来大量练习它。当处理器产生一个页故障时,处理器将在它的一个特定的控制寄存器(`CR2`)中保存导致这个故障的线性地址(即:虚拟地址)。在 `trap.c` 中我们提供了一个专门处理它的函数的一个雏形,它就是 `page_fault_handler()`,我们将用它来处理页故障异常。
|
||||
|
||||
```markdown
|
||||
练习 5、修改 `trap_dispatch()` 将页故障异常派发到 `page_fault_handler()` 上。你现在应该能够成功测试 `faultread`、`faultreadkernel`、`faultwrite`、和 `faultwritekernel` 了。如果它们中的任何一个不能正常工作,找出问题并修复它。记住,你可以使用 make run- _x_ 或 make run- _x_ -nox 去重引导 JOS 进入到一个特定的用户程序。比如,你可以运行 make run-hello-nox 去运行 the _hello_ user 程序。
|
||||
```
|
||||
> **练习 5**、修改 `trap_dispatch()` 将页故障异常派发到 `page_fault_handler()` 上。你现在应该能够成功测试 `faultread`、`faultreadkernel`、`faultwrite` 和 `faultwritekernel` 了。如果它们中的任何一个不能正常工作,找出问题并修复它。记住,你可以使用 `make run-x` 或 `make run-x-nox` 去重引导 JOS 进入到一个特定的用户程序。比如,你可以运行 `make run-hello-nox` 去运行 `hello` 用户程序。
|
||||
|
||||
下面,你将进一步细化内核的页故障服务程序,因为你要实现系统调用了。
|
||||
|
||||
##### 断点异常
|
||||
#### 断点异常
|
||||
|
||||
断点异常,中断向量为 3(`T_BRKPT`),它一般用在调试上,它在一个程序代码中插入断点,从而使用特定的 1 字节的 `int3` 软件中断指令来临时替换相应的程序指令。在 JOS 中,我们将稍微“滥用”一下这个异常,通过将它打造成一个伪系统调用原语,使得任何用户环境都可以用它来调用 JOS 内核监视器。如果我们将 JOS 内核监视认为是原始调试器,那么这种用法是合适的。例如,在 `lib/panic.c` 中实现的用户模式下的 `panic()` ,它在显示它的 `panic` 消息后运行一个 `int3` 中断。
|
||||
|
||||
```markdown
|
||||
练习 6、修改 `trap_dispatch()`,让它在调用内核监视器时产生一个断点异常。你现在应该可以在 `breakpoint` 上成功完成测试。
|
||||
```
|
||||
> **练习 6**、修改 `trap_dispatch()`,让它在调用内核监视器时产生一个断点异常。你现在应该可以在 `breakpoint` 上成功完成测试。
|
||||
|
||||
```markdown
|
||||
小挑战!修改 JOS 内核监视器,以便于你能够从当前位置(即:在 `int3` 之后,断点异常调用了内核监视器) '继续' 异常,并且因此你就可以一次运行一个单步指令。为了实现单步运行,你需要去理解 `EFLAGS` 寄存器中的某些比特的意义。
|
||||
.
|
||||
|
||||
可选:如果你富有冒险精神,找一些 x86 反汇编的代码 —— 即通过从 QEMU 中、或从 GNU 二进制工具中分离、或你自己编写 —— 然后扩展 JOS 内核监视器,以使它能够反汇编,显示你的每步的指令。结合实验 1 中的符号表,这将是你写的一个真正的内核调试器。
|
||||
```
|
||||
> **小挑战!**修改 JOS 内核监视器,以便于你能够从当前位置(即:在 `int3` 之后,断点异常调用了内核监视器) '继续' 异常,并且因此你就可以一次运行一个单步指令。为了实现单步运行,你需要去理解 `EFLAGS` 寄存器中的某些比特的意义。
|
||||
|
||||
```markdown
|
||||
问题
|
||||
> 可选:如果你富有冒险精神,找一些 x86 反汇编的代码 —— 即通过从 QEMU 中、或从 GNU 二进制工具中分离、或你自己编写 —— 然后扩展 JOS 内核监视器,以使它能够反汇编,显示你的每步的指令。结合实验 1 中的符号表,这将是你写的一个真正的内核调试器。
|
||||
|
||||
3. 在断点测试案例中,根据你在 IDT 中如何初始化断点条目的不同情况(即:你的从 `trap_init` 到 `SETGATE` 的调用),既有可能产生一个断点异常,也有可能产生一个一般保护故障。为什么?为了能够像上面的案例那样工作,你需要如何去设置它,什么样的不正确设置才会触发一个一般保护故障?
|
||||
4. 你认为这些机制的意义是什么?尤其是要考虑 `user/softint` 测试程序的工作原理。
|
||||
```
|
||||
.
|
||||
|
||||
> **问题**
|
||||
|
||||
##### 系统调用
|
||||
> 3. 在断点测试案例中,根据你在 IDT 中如何初始化断点条目的不同情况(即:你的从 `trap_init` 到 `SETGATE` 的调用),既有可能产生一个断点异常,也有可能产生一个一般保护故障。为什么?为了能够像上面的案例那样工作,你需要如何去设置它,什么样的不正确设置才会触发一个一般保护故障?
|
||||
|
||||
> 4. 你认为这些机制的意义是什么?尤其是要考虑 `user/softint` 测试程序的工作原理。
|
||||
|
||||
#### 系统调用
|
||||
|
||||
用户进程请求内核为它做事情就是通过系统调用来实现的。当用户进程请求一个系统调用时,处理器首先进入内核模式,处理器和内核配合去保存用户进程的状态,内核为了完成系统调用会运行有关的代码,然后重新回到用户进程。用户进程如何获得内核的关注以及它如何指定它需要的系统调用的具体细节,这在不同的系统上是不同的。
|
||||
|
||||
@ -414,45 +395,43 @@ x86 允许最多有 256 个不同的中断或异常入口点去进入内核,
|
||||
|
||||
应用程序将在寄存器中传递系统调用号和系统调用参数。通过这种方式,内核就不需要去遍历用户环境的栈或指令流。系统调用号将放在 `%eax` 中,而参数(最多五个)将分别放在 `%edx`、`%ecx`、`%ebx`、`%edi`、和 `%esi` 中。内核将在 `%eax` 中传递返回值。在 `lib/syscall.c` 中的 `syscall()` 中已为你编写了使用一个系统调用的汇编代码。你可以通过阅读它来确保你已经理解了它们都做了什么。
|
||||
|
||||
```markdown
|
||||
练习 7、在内核中为中断向量 `T_SYSCALL` 添加一个服务程序。你将需要去编辑 `kern/trapentry.S` 和 `kern/trap.c` 的 `trap_init()`。还需要去修改 `trap_dispatch()`,以便于通过使用适当的参数来调用 `syscall()` (定义在 `kern/syscall.c`)以处理系统调用中断,然后将系统调用的返回值安排在 `%eax` 中传递给用户进程。最后,你需要去实现 `kern/syscall.c` 中的 `syscall()`。如果系统调用号是无效值,确保 `syscall()` 返回值一定是 `-E_INVAL`。为确保你理解了系统调用的接口,你应该去阅读和掌握 `lib/syscall.c` 文件(尤其是行内汇编的动作),对于在 `inc/syscall.h` 中列出的每个系统调用都需要通过调用相关的内核函数来处理A。
|
||||
> **练习 7**、在内核中为中断向量 `T_SYSCALL` 添加一个服务程序。你将需要去编辑 `kern/trapentry.S` 和 `kern/trap.c` 的 `trap_init()`。还需要去修改 `trap_dispatch()`,以便于通过使用适当的参数来调用 `syscall()` (定义在 `kern/syscall.c`)以处理系统调用中断,然后将系统调用的返回值安排在 `%eax` 中传递给用户进程。最后,你需要去实现 `kern/syscall.c` 中的 `syscall()`。如果系统调用号是无效值,确保 `syscall()` 返回值一定是 `-E_INVAL`。为确保你理解了系统调用的接口,你应该去阅读和掌握 `lib/syscall.c` 文件(尤其是行内汇编的动作),对于在 `inc/syscall.h` 中列出的每个系统调用都需要通过调用相关的内核函数来处理A。
|
||||
|
||||
在你的内核中运行 `user/hello` 程序(make run-hello)。它应该在控制台上输出 "`hello, world`",然后在用户模式中产生一个页故障。如果没有产生页故障,可能意味着你的系统调用服务程序不太正确。现在,你应该有能力成功通过 `testbss` 测试。
|
||||
> 在你的内核中运行 `user/hello` 程序(make run-hello)。它应该在控制台上输出 `hello, world`,然后在用户模式中产生一个页故障。如果没有产生页故障,可能意味着你的系统调用服务程序不太正确。现在,你应该有能力成功通过 `testbss` 测试。
|
||||
|
||||
.
|
||||
|
||||
> 小挑战!使用 `sysenter` 和 `sysexit` 指令而不是使用 `int 0x30` 和 `iret` 来实现系统调用。
|
||||
|
||||
> `sysenter/sysexit` 指令是由 Intel 设计的,它的运行速度要比 `int/iret` 指令快。它使用寄存器而不是栈来做到这一点,并且通过假定了分段寄存器是如何使用的。关于这些指令的详细内容可以在 Intel 参考手册 2B 卷中找到。
|
||||
|
||||
> 在 JOS 中添加对这些指令支持的最容易的方法是,在 `kern/trapentry.S` 中添加一个 `sysenter_handler`,在它里面保存足够多的关于用户环境返回、设置内核环境、推送参数到 `syscall()`、以及直接调用 `syscall()` 的信息。一旦 `syscall()` 返回,它将设置好运行 `sysexit` 指令所需的一切东西。你也将需要在 `kern/init.c` 中添加一些代码,以设置特殊模块寄存器(MSRs)。在 AMD 架构程序员手册第 2 卷的 6.1.2 节中和 Intel 参考手册的 2B 卷的 SYSENTER 上都有关于 MSRs 的很详细的描述。对于如何去写 MSRs,在[这里][4]你可以找到一个添加到 `inc/x86.h` 中的 `wrmsr` 的实现。
|
||||
|
||||
> 最后,`lib/syscall.c` 必须要修改,以便于支持用 `sysenter` 来生成一个系统调用。下面是 `sysenter` 指令的一种可能的寄存器布局:
|
||||
|
||||
> ```
|
||||
eax - syscall number
|
||||
edx, ecx, ebx, edi - arg1, arg2, arg3, arg4
|
||||
esi - return pc
|
||||
ebp - return esp
|
||||
esp - trashed by sysenter
|
||||
```
|
||||
|
||||
```markdown
|
||||
小挑战!使用 `sysenter` 和 `sysexit` 指令而不是使用 `int 0x30` 和 `iret` 来实现系统调用。
|
||||
> GCC 的内联汇编器将自动保存你告诉它的直接加载进寄存器的值。不要忘了同时去保存(`push`)和恢复(`pop`)你使用的其它寄存器,或告诉内联汇编器你正在使用它们。内联汇编器不支持保存 `%ebp`,因此你需要自己去增加一些代码来保存和恢复它们,返回地址可以使用一个像 `leal after_sysenter_label, %%esi` 的指令置入到 `%esi` 中。
|
||||
|
||||
`sysenter/sysexit` 指令是由 Intel 设计的,它的运行速度要比 `int/iret` 指令快。它使用寄存器而不是栈来做到这一点,并且通过假定了分段寄存器是如何使用的。关于这些指令的详细内容可以在 Intel 参考手册 2B 卷中找到。
|
||||
> 注意,它仅支持 4 个参数,因此你需要保留支持 5 个参数的系统调用的旧方法。而且,因为这个快速路径并不更新当前环境的 trap 帧,因此,在我们添加到后续实验中的一些系统调用上,它并不适合。
|
||||
|
||||
在 JOS 中添加对这些指令支持的最容易的方法是,在 `kern/trapentry.S` 中添加一个 `sysenter_handler`,在它里面保存足够多的关于用户环境返回、设置内核环境、推送参数到 `syscall()`、以及直接调用 `syscall()` 的信息。一旦 `syscall()` 返回,它将设置好运行 `sysexit` 指令所需的一切东西。你也将需要在 `kern/init.c` 中添加一些代码,以设置特殊模块寄存器(MSRs)。在 AMD 架构程序员手册第 2 卷的 6.1.2 节中和 Intel 参考手册的 2B 卷的 SYSENTER 上都有关于 MSRs 的很详细的描述。对于如何去写 MSRs,在[这里][4]你可以找到一个添加到 `inc/x86.h` 中的 `wrmsr` 的实现。
|
||||
> 在接下来的实验中我们启用了异步中断,你需要再次去评估一下你的代码。尤其是,当返回到用户进程时,你需要去启用中断,而 `sysexit` 指令并不会为你去做这一动作。
|
||||
|
||||
最后,`lib/syscall.c` 必须要修改,以便于支持用 `sysenter` 来生成一个系统调用。下面是 `sysenter` 指令的一种可能的寄存器布局:
|
||||
|
||||
eax - syscall number
|
||||
edx, ecx, ebx, edi - arg1, arg2, arg3, arg4
|
||||
esi - return pc
|
||||
ebp - return esp
|
||||
esp - trashed by sysenter
|
||||
|
||||
GCC 的内联汇编器将自动保存你告诉它的直接加载进寄存器的值。不要忘了同时去保存(push)和恢复(pop)你使用的其它寄存器,或告诉内联汇编器你正在使用它们。内联汇编器不支持保存 `%ebp`,因此你需要自己去增加一些代码来保存和恢复它们,返回地址可以使用一个像 `leal after_sysenter_label, %%esi` 的指令置入到 `%esi` 中。
|
||||
|
||||
注意,它仅支持 4 个参数,因此你需要保留支持 5 个参数的系统调用的旧方法。而且,因为这个快速路径并不更新当前环境的 trap 帧,因此,在我们添加到后续实验中的一些系统调用上,它并不适合。
|
||||
|
||||
在接下来的实验中我们启用了异步中断,你需要再次去评估一下你的代码。尤其是,当返回到用户进程时,你需要去启用中断,而 `sysexit` 指令并不会为你去做这一动作。
|
||||
```
|
||||
|
||||
##### 启动用户模式
|
||||
#### 启动用户模式
|
||||
|
||||
一个用户程序是从 `lib/entry.S` 的顶部开始运行的。在一些配置之后,代码调用 `lib/libmain.c` 中的 `libmain()`。你应该去修改 `libmain()` 以初始化全局指针 `thisenv`,使它指向到这个环境在数组 `envs[]` 中的 `struct Env`。(注意那个 `lib/entry.S` 中已经定义 `envs` 去指向到在 Part A 中映射的你的设置。)提示:查看 `inc/env.h` 和使用 `sys_getenvid`。
|
||||
|
||||
`libmain()` 接下来调用 `umain`,在 hello 程序的案例中,`umain` 是在 `user/hello.c` 中。注意,它在输出 "`hello, world`” 之后,它尝试去访问 `thisenv->env_id`。这就是为什么前面会发生故障的原因了。现在,你已经正确地初始化了 `thisenv`,它应该不会再发生故障了。如果仍然会发生故障,或许是因为你没有映射 `UENVS` 区域为用户可读取(回到前面 Part A 中 查看 `pmap.c`);这是我们第一次真实地使用 `UENVS` 区域)。
|
||||
|
||||
```markdown
|
||||
练习 8、添加要求的代码到用户库,然后引导你的内核。你应该能够看到 `user/hello` 程序会输出 "`hello, world`" 然后输出 "`i am environment 00001000`"。`user/hello` 接下来会通过调用 `sys_env_destroy()`(查看`lib/libmain.c` 和 `lib/exit.c`)尝试去"退出"。由于内核目前仅支持一个用户环境,它应该会报告它毁坏了唯一的环境,然后进入到内核监视器中。现在你应该能够成功通过 `hello` 的测试。
|
||||
```
|
||||
> **练习 8**、添加要求的代码到用户库,然后引导你的内核。你应该能够看到 `user/hello` 程序会输出 `hello, world` 然后输出 `i am environment 00001000`。`user/hello` 接下来会通过调用 `sys_env_destroy()`(查看`lib/libmain.c` 和 `lib/exit.c`)尝试去“退出”。由于内核目前仅支持一个用户环境,它应该会报告它毁坏了唯一的环境,然后进入到内核监视器中。现在你应该能够成功通过 `hello` 的测试。
|
||||
|
||||
##### 页故障和内存保护
|
||||
#### 页故障和内存保护
|
||||
|
||||
内存保护是一个操作系统中最重要的特性,通过它来保证一个程序中的 bug 不会破坏其它程序或操作系统本身。
|
||||
|
||||
@ -462,10 +441,8 @@ GCC 的内联汇编器将自动保存你告诉它的直接加载进寄存器的
|
||||
|
||||
对于内存保护,系统调用中有一个非常有趣的问题。许多系统调用接口让用户程序传递指针到内核中。这些指针指向用户要读取或写入的缓冲区。然后内核在执行系统调用时废弃这些指针。这样就有两个问题:
|
||||
|
||||
1. 内核中的页故障可能比用户程序中的页故障多的多。如果内核在维护它自己的数据结构时发生页故障,那就是一个内核 bug,而故障服务程序将使整个内核(和整个系统)崩溃。但是当内核废弃了由用户程序传递给它的指针后,它就需要一种方式去记住那些废弃指针所导致的页故障其实是代表用户程序的。
|
||||
2. 一般情况下内核拥有比用户程序更多的权限。用户程序可以传递一个指针到系统调用,而指针指向的区域有可能是内核可以读取或写入而用户程序不可访问的区域。内核必须要非常小心,不能被废弃的这种指针欺骗,因为这可能导致泄露私有信息或破坏内核的完整性。
|
||||
|
||||
|
||||
1. 内核中的页故障可能比用户程序中的页故障多的多。如果内核在维护它自己的数据结构时发生页故障,那就是一个内核 bug,而故障服务程序将使整个内核(和整个系统)崩溃。但是当内核废弃了由用户程序传递给它的指针后,它就需要一种方式去记住那些废弃指针所导致的页故障其实是代表用户程序的。
|
||||
2. 一般情况下内核拥有比用户程序更多的权限。用户程序可以传递一个指针到系统调用,而指针指向的区域有可能是内核可以读取或写入而用户程序不可访问的区域。内核必须要非常小心,不能被废弃的这种指针欺骗,因为这可能导致泄露私有信息或破坏内核的完整性。
|
||||
|
||||
由于以上的原因,内核在处理由用户程序提供的指针时必须格外小心。
|
||||
|
||||
@ -473,32 +450,33 @@ GCC 的内联汇编器将自动保存你告诉它的直接加载进寄存器的
|
||||
|
||||
这样,内核在废弃一个用户提供的指针时就绝不会发生页故障。如果内核出现这种页故障,它应该崩溃并终止。
|
||||
|
||||
```markdown
|
||||
练习 9、如果在内核模式中发生一个页故障,修改 `kern/trap.c` 去崩溃。
|
||||
> **练习 9**、如果在内核模式中发生一个页故障,修改 `kern/trap.c` 去崩溃。
|
||||
|
||||
提示:判断一个页故障是发生在用户模式还是内核模式,去检查 `tf_cs` 的低位比特即可。
|
||||
> 提示:判断一个页故障是发生在用户模式还是内核模式,去检查 `tf_cs` 的低位比特即可。
|
||||
|
||||
阅读 `kern/pmap.c` 中的 `user_mem_assert` 并在那个文件中实现 `user_mem_check`。
|
||||
> 阅读 `kern/pmap.c` 中的 `user_mem_assert` 并在那个文件中实现 `user_mem_check`。
|
||||
|
||||
修改 `kern/syscall.c` 去常态化检查传递给系统调用的参数。
|
||||
> 修改 `kern/syscall.c` 去常态化检查传递给系统调用的参数。
|
||||
|
||||
引导你的内核,运行 `user/buggyhello`。环境将被毁坏,而内核将不会崩溃。你将会看到:
|
||||
> 引导你的内核,运行 `user/buggyhello`。环境将被毁坏,而内核将不会崩溃。你将会看到:
|
||||
|
||||
[00001000] user_mem_check assertion failure for va 00000001
|
||||
[00001000] free env 00001000
|
||||
Destroyed the only environment - nothing more to do!
|
||||
最后,修改在 `kern/kdebug.c` 中的 `debuginfo_eip`,在 `usd`、`stabs`、和 `stabstr` 上调用 `user_mem_check`。如果你现在运行 `user/breakpoint`,你应该能够从内核监视器中运行回溯,然后在内核因页故障崩溃前看到回溯进入到 `lib/libmain.c`。是什么导致了这个页故障?你不需要去修复它,但是你应该明白它是如何发生的。
|
||||
> ```
|
||||
[00001000] user_mem_check assertion failure for va 00000001
|
||||
[00001000] free env 00001000
|
||||
Destroyed the only environment - nothing more to do!
|
||||
```
|
||||
|
||||
> 最后,修改在 `kern/kdebug.c` 中的 `debuginfo_eip`,在 `usd`、`stabs`、和 `stabstr` 上调用 `user_mem_check`。如果你现在运行 `user/breakpoint`,你应该能够从内核监视器中运行回溯,然后在内核因页故障崩溃前看到回溯进入到 `lib/libmain.c`。是什么导致了这个页故障?你不需要去修复它,但是你应该明白它是如何发生的。
|
||||
|
||||
注意,刚才实现的这些机制也同样适用于恶意用户程序(比如 `user/evilhello`)。
|
||||
|
||||
```
|
||||
练习 10、引导你的内核,运行 `user/evilhello`。环境应该被毁坏,并且内核不会崩溃。你应该能看到:
|
||||
> **练习 10**、引导你的内核,运行 `user/evilhello`。环境应该被毁坏,并且内核不会崩溃。你应该能看到:
|
||||
|
||||
[00000000] new env 00001000
|
||||
...
|
||||
[00001000] user_mem_check assertion failure for va f010000c
|
||||
[00001000] free env 00001000
|
||||
> ```
|
||||
[00000000] new env 00001000
|
||||
...
|
||||
[00001000] user_mem_check assertion failure for va f010000c
|
||||
[00001000] free env 00001000
|
||||
```
|
||||
|
||||
**本实验到此结束。**确保你通过了所有的等级测试,并且不要忘记去写下问题的答案,在 `answers-lab3.txt` 中详细描述你的挑战练习的解决方案。提交你的变更并在 `lab` 目录下输入 `make handin` 去提交你的工作。
|
||||
@ -512,13 +490,13 @@ via: https://pdos.csail.mit.edu/6.828/2018/labs/lab3/
|
||||
作者:[csail.mit][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://pdos.csail.mit.edu
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://pdos.csail.mit.edu/6.828/2018/labs/labguide.html
|
||||
[1]: https://linux.cn/article-10273-1.html
|
||||
[2]: https://pdos.csail.mit.edu/6.828/2018/labs/reference.html
|
||||
[3]: http://blogs.msdn.com/larryosterman/archive/2005/02/08/369243.aspx
|
||||
[4]: http://ftp.kh.edu.tw/Linux/SuSE/people/garloff/linux/k6mod.c
|
||||
@ -1,6 +1,8 @@
|
||||
提高 Linux 网络浏览器安全性的 5 个建议
|
||||
提高 Linux 的网络浏览器安全性的 5 个建议
|
||||
======
|
||||

|
||||
> 这些简单的步骤可以大大提高您的在线安全性。
|
||||
|
||||

|
||||
|
||||
如果你使用 Linux 桌面但从来不使用网络浏览器,那你算得上是百里挑一。网络浏览器是绝大多数人最常用的工具之一,无论是工作、娱乐、看新闻、社交、理财,对网络浏览器的依赖都比本地应用要多得多。因此,我们需要知道如何使用网络浏览器才是安全的。一直以来都有不法的犯罪分子以及他们建立的网页试图窃取私密的信息。正是由于我们需要通过网络浏览器收发大量的敏感信息,安全性就更是至关重要。
|
||||
|
||||
@ -8,17 +10,14 @@
|
||||
|
||||
### 正确选择浏览器
|
||||
|
||||
尽管我我提出的建议具有普适性,但是正确选择网络浏览器也是很必要的。网络浏览器的更新频率是它安全性的一个重要体现。网络浏览器会不断暴露出新的问题,因此版本越新的网络浏览器修复的问题就越多,也越安全。在主流的网络浏览器当中,2017 年版本更新的发布量排行榜如下:
|
||||
尽管我提出的建议具有普适性,但是正确选择网络浏览器也是很必要的。网络浏览器的更新频率是它安全性的一个重要体现。网络浏览器会不断暴露出新的问题,因此版本越新的网络浏览器修复的问题就越多,也越安全。在主流的网络浏览器当中,2017 年版本更新的发布量排行榜如下:
|
||||
|
||||
1. Chrome 发布了 8 个更新(Chromium 全年跟进发布了大量安全补丁)。
|
||||
2. Firefox 发布了 7 个更新。
|
||||
3. Edge 发布了 2 个更新。
|
||||
4. Safari 发布了 1 个更新(苹果也会每年发布 5 到 6 个安全补丁)。
|
||||
1. Chrome 发布了 8 个更新(Chromium 全年跟进发布了大量安全补丁)。
|
||||
2. Firefox 发布了 7 个更新。
|
||||
3. Edge 发布了 2 个更新。
|
||||
4. Safari 发布了 1 个更新(苹果也会每年发布 5 到 6 个安全补丁)。
|
||||
|
||||
|
||||
|
||||
|
||||
网络浏览器会经常发布更新,同时用户方面也要及时升级到最新的版本,否则毫无意义了。尽管大部分流行的 Linux 发行版都会自动更新网络浏览器到最新版本,但还是有一些 Linux 发行版不会自动进行更新,所以最好还是手动保持浏览器更新到最新版本。这就意味着你所使用的 Linux 发行版对应的标准软件库中存放的很可能就不是最新版本的网络浏览器,在这种情况下,你可以随时从网络浏览器开发者提供的最新版本下载页中进行下载安装。
|
||||
网络浏览器会经常发布更新,同时用户也要及时升级到最新的版本,否则毫无意义了。尽管大部分流行的 Linux 发行版都会自动更新网络浏览器到最新版本,但还是有一些 Linux 发行版不会自动进行更新,所以最好还是手动保持浏览器更新到最新版本。这就意味着你所使用的 Linux 发行版对应的标准软件库中存放的很可能就不是最新版本的网络浏览器,在这种情况下,你可以随时从网络浏览器开发者提供的最新版本下载页中进行下载安装。
|
||||
|
||||
如果你是一个勇于探索的人,你还可以尝试使用测试版或者<ruby>每日构建<rt>daily build</rt></ruby>版的网络浏览器,不过,这些版本将伴随着不能稳定运行的可能性。在基于 Ubuntu 的发行版中,你可以使用到每日构建版的 Firefox,只需要执行以下命令添加所需的存储库:
|
||||
|
||||
@ -43,60 +42,47 @@ sudo apt-get install firefox
|
||||
|
||||
### 保护好密码
|
||||
|
||||
有的人可能会认为,每次都需要重复输入密码,这样的操作太麻烦了。在 Firefox 中,如果你既想保护好自己的密码,又不想经常输入密码,就可以通过 Master Password 这一款内置的工具来实现你的需求。起用了这个工具之后,需要输入正确的主密码,才能后续使用保存在浏览器中的其它密码。你可以按照以下步骤进行操作:
|
||||
|
||||
1. 打开 Firefox。
|
||||
|
||||
2. 点击菜单按钮。
|
||||
|
||||
3. 点击“偏好设置”。
|
||||
|
||||
4. 在偏好设置页面,点击“隐私与安全”。
|
||||
|
||||
5. 在页面中勾选“使用主密码”选项(图 1)。
|
||||
|
||||
6. 确认以后,输入新的主密码(图 2)。
|
||||
|
||||
7. 重启 Firefox。
|
||||
|
||||
|
||||
有的人可能会认为,每次都需要重复输入密码,这样的操作太麻烦了。在 Firefox 中,如果你既想保护好自己的密码,又不想经常输入密码,就可以通过<ruby>主密码<rt>Master Password</rt></ruby>这一款内置的工具来实现你的需求。起用了这个工具之后,需要输入正确的主密码,才能后续使用保存在浏览器中的其它密码。你可以按照以下步骤进行操作:
|
||||
|
||||
1. 打开 Firefox。
|
||||
2. 点击菜单按钮。
|
||||
3. 点击“偏好设置”。
|
||||
4. 在偏好设置页面,点击“隐私与安全”。
|
||||
5. 在页面中勾选“使用主密码”选项(图 1)。
|
||||
6. 确认以后,输入新的主密码(图 2)。
|
||||
7. 重启 Firefox。
|
||||
|
||||
![Master Password][3]
|
||||
|
||||
图 1: Firefox 偏好设置页中的主密码设置。
|
||||
*图 1: Firefox 偏好设置页中的主密码设置。*
|
||||
|
||||
![Setting password][6]
|
||||
|
||||
图 2:在 Firefox 中设置主密码。
|
||||
*图 2:在 Firefox 中设置主密码。*
|
||||
|
||||
### 了解你使用的扩展和插件
|
||||
|
||||
大多数网络浏览器在保护隐私方面都有很多扩展,你可以根据自己的需求选择不同的扩展。而我自己则选择了一下这些扩展:
|
||||
|
||||
* [Firefox Multi-Account Containers][7] \- 允许将某些站点配置为在容器化选项卡中打开。
|
||||
* [Facebook Container][8] \- 始终在容器化选项卡中打开 Facebook(这个扩展需要 Firefox Multi-Account Containers)。
|
||||
* [Avast Online Security][9] \- 识别并拦截已知的钓鱼网站,并显示网站的安全评级(由超过 4 亿用户的 Avast 社区支持)。
|
||||
* [Mining Blocker][10] \- 拦截所有使用 CPU 的挖矿工具。
|
||||
* [PassFF][11] \- 通过集成 `pass` (一个 UNIX 密码管理器)以安全存储密码。
|
||||
* [Privacy Badger][12] \- 自动拦截网站跟踪。
|
||||
* [uBlock Origin][13] \- 拦截已知的网站跟踪。
|
||||
|
||||
* [Firefox Multi-Account Containers][7] —— 允许将某些站点配置为在容器化选项卡中打开。
|
||||
* [Facebook Container][8] —— 始终在容器化选项卡中打开 Facebook(这个扩展需要 Firefox Multi-Account Containers)。
|
||||
* [Avast Online Security][9] —— 识别并拦截已知的钓鱼网站,并显示网站的安全评级(由超过 4 亿用户的 Avast 社区支持)。
|
||||
* [Mining Blocker][10] —— 拦截所有使用 CPU 的挖矿工具。
|
||||
* [PassFF][11] —— 通过集成 `pass` (一个 UNIX 密码管理器)以安全存储密码。
|
||||
* [Privacy Badger][12] —— 自动拦截网站跟踪。
|
||||
* [uBlock Origin][13] —— 拦截已知的网站跟踪。
|
||||
|
||||
除此以外,以下这些浏览器还有很多安全方面的扩展:
|
||||
|
||||
+ [Firefox][2]
|
||||
|
||||
+ [Chrome、Chromium,、Vivaldi][5]
|
||||
|
||||
+ [Opera][14]
|
||||
|
||||
|
||||
但并非每一个网络浏览器都会向用户提供扩展或插件。例如 Midoria 就只有少量可以开启或关闭的内置插件(图 3),同时这些轻量级浏览器的第三方插件也相当缺乏。
|
||||
|
||||
![Midori Browser][15]
|
||||
|
||||
图 3:Midori 浏览器的插件窗口。
|
||||
*图 3:Midori 浏览器的插件窗口。*
|
||||
|
||||
### 虚拟化
|
||||
|
||||
@ -115,7 +101,7 @@ via: https://www.linux.com/learn/intro-to-linux/2018/11/5-easy-tips-linux-web-br
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
108
sources/talk/20181129 9 top tech-recruiting mistakes to avoid.md
Normal file
108
sources/talk/20181129 9 top tech-recruiting mistakes to avoid.md
Normal file
@ -0,0 +1,108 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (9 top tech-recruiting mistakes to avoid)
|
||||
[#]: via: (https://opensource.com/article/18/11/top-tech-recruiting-mistakes-avoid)
|
||||
[#]: author: (Rikki Endsley https://opensource.com/users/rikki-endsley)
|
||||
[#]: url: ( )
|
||||
|
||||
9 top tech-recruiting mistakes to avoid
|
||||
======
|
||||
We round up common mistakes tech recruiters make and a few best practices to adopt instead.
|
||||

|
||||
|
||||
Some of my best friends and colleagues are tech recruiters, and a bunch of my favorite humans are on the job hunt. With these fine folks in mind, I decided to help them connect by finding out what kinds of recruiting efforts stand out to potential hires. I reached out to my colleagues and contacts and asked them what they like (and hate) when it comes to recruiting, then I rounded up a list of top tech-recruiting mistakes to avoid and best practices to use instead.
|
||||
|
||||
### 9 common tech recruiting mistakes to avoid
|
||||
|
||||
Don’t even think about reaching out to a potential candidate without doing due diligence on their background, experience, and expertise. Not knowing what skills a recruit has and what kind of work they’ve done in the past instantly turns off job seekers. Recruiters who make it clear that they’ve done their homework signal that they aren’t planning to waste a candidate’s time and stand a better chance of piquing their interest from the beginning. Common recruiting mistakes also include:
|
||||
|
||||
**1\. Sending form letters — or even worse, broken form letters.**
|
||||
|
||||
Unless someone is job-seeking and not getting many offers, chances are your form letter won’t stand out or get much interest. And if your form letter is broken and has [NAME] where a candidate’s name should appear, forget about getting any qualified candidate responses.
|
||||
|
||||
**2\. Blowing the salutation.**
|
||||
|
||||
Be sure to spell the candidate’s name correctly, and typing “Mr.” or “Miss” in the greeting could be a big mistake. For example, I can’t tell you how many “Mr. Endsley” messages I get every month, and “Miss Endsley” won’t sit well with me, either.
|
||||
|
||||
**3\. Not understanding what the recruit does.**
|
||||
|
||||
Potential candidates can tell whether you’ve done your homework, dug through their LinkedIn profiles, and have a grasp of their backgrounds, experiences, and areas of interest. Reaching out to a UX designer about an engineering role won’t get you good results.
|
||||
|
||||
**4\. Sending unsolicited contact requests.**
|
||||
|
||||
Don’t send LinkedIn connection requests to people you don’t know. Just don’t do it.
|
||||
|
||||
**5\. Being too general about the job position.**
|
||||
|
||||
Kill the coy. Share as many details you can about the role, including any must-have and nice-to-have skills. Draw potential recruits a picture of what the work looks like to make qualified candidates take notice.
|
||||
|
||||
**6\. Being too vague or mysterious about the team and company.**
|
||||
|
||||
Tech professionals with in-demand skills and experience are being more selective about what kind of team dynamics they walk into and [organizational ethics][1]. Letting potential hires know right away what the team looks like (e.g., small vs. large, remote vs. on-site) and which company you represent can save everyone a lot of time.
|
||||
|
||||
**7\. Having unrealistic or overly specific requirements.**
|
||||
|
||||
Does the right candidate really need to be an expert in every technology and programming language and hold multiple degrees? Be clear about what skills a candidate needs vs. what skills might come in handy or can be acquired on the job.
|
||||
|
||||
**8\. Getting too cutesy or culture-y in a description.**
|
||||
|
||||
Not all of us consider office puppies, free booze, and ping pong to be job perks. If this is the messaging you lead with, you’re going to attract a pretty specific kind of applicant and quickly narrow down your list of potential candidates.
|
||||
|
||||
Also [avoid terms][2] like “guys,” “rock star,” and “recent graduate,” which can translate to “women, minorities, and anyone over 25 need not apply.” Ouch.
|
||||
|
||||
**9\. Asking for referrals to other potential candidates.**
|
||||
|
||||
This is a no-win for recruiters. For example, I’m happy to recommend job seekers in my network for roles, but lots of other folks working in tech see this as lazy recruiting. The safest approach might be to ask a candidate later in the process, after you’ve developed a friendly working relationship and you've both agreed that this role doesn’t quite fit their interests or expertise. Then they might have other contacts in mind for it.
|
||||
|
||||
### 6 best practices for tech recruiters
|
||||
|
||||
**1\. Provide a sincere and personalized greeting.**
|
||||
|
||||
A personalized greeting goes a long way. Let potential candidates know you understand their previous work experience, you’re familiar with what they do, and that you have an idea of what they want to be doing.
|
||||
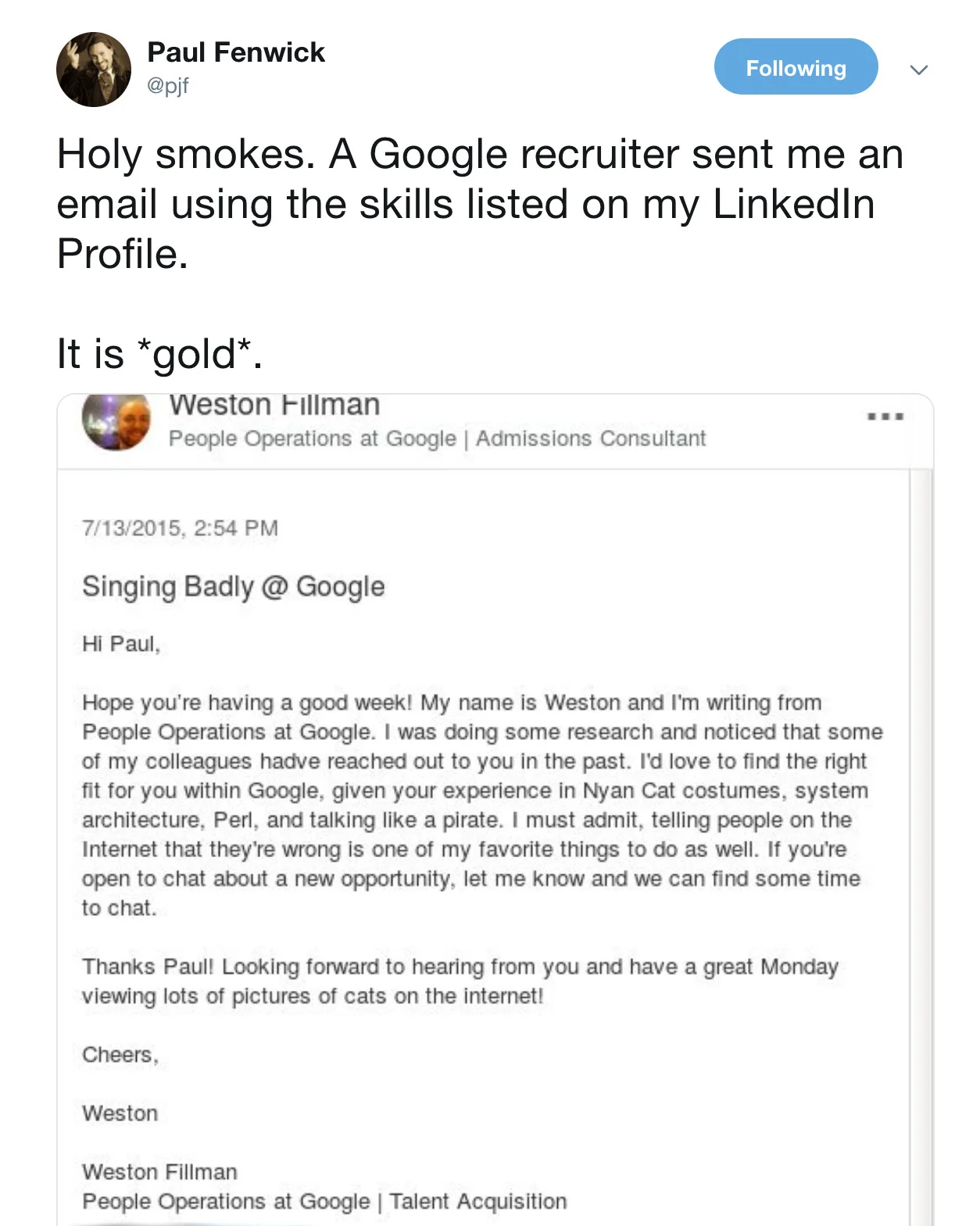
|
||||
|
||||
**2\. Offer a transparent description of the team and the role.**
|
||||
|
||||
Be as clear as you can when describing the team and the role. Using words like “rock star” or “fast-paced team” does nothing to help the potential candidate visualize what they’d be walking into. Is this a small team? Remote team?
|
||||
|
||||
Being mysterious about the role won’t build intrigue, so opt for transparency.
|
||||
|
||||
**3\. Give the company name.**
|
||||
|
||||
Telling job candidates that the organization is a startup or a Fortune 500 company also won’t work as well being transparent about the organization from the beginning. How can anyone know whether they’re interested in a role if they don’t know which organization they’d be joining?
|
||||
|
||||
**4\. Be persistent and specific.**
|
||||
|
||||
In addition to providing the job description and company name, specifying the salary range and why you think the potential candidate is a good fit for the role stands out. Also consider specifying the work authorization and whether the organization provides visa sponsorships, relocation, and additional benefits beyond an hourly or annual salary. If you have a good feeling about a candidate who might not be a 100% technical fit with the job posting, let them know and open those lines of communication.
|
||||
|
||||
**5\. Invite potential candidates to local recruiting events.**
|
||||
|
||||
The event should provide brief presentations about the company, refreshments, and a networking opportunity. Here’s your chance to show off the culture (i.e., people) part of your organization in person.
|
||||
|
||||
**6\. Maintain a relationship with potential recruits.**
|
||||
|
||||
If you talk to a candidate who isn’t the right fit for a role, but who would be a great addition to your organization, keep the lines of communication open. If candidates have a good experience with a recruiter, they’ll also be more inclined to join the organization later or send other job seekers their way in the future.
|
||||
|
||||
### Bonus advice for tech recruits
|
||||
|
||||
Keep in mind that recruiters, like you, are just trying to do their jobs. If you're tired of hearing from recruiters and annoyed when they contact you, step back and get a little perspective. Although you might be in the fortunate spot of being happily employed and in-demand, not everyone else is. Grumbling about recruiters on social media is a great way to humble brag, but not the best way to show empathy for the job-seekers or win any friends.
|
||||
|
||||
_Thank you to the many people who contributed to this article! What would you add to these lists? Let us know in the comments._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/top-tech-recruiting-mistakes-avoid
|
||||
|
||||
作者:[Rikki Endsley][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rikki-endsley
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://spectrum.ieee.org/view-from-the-valley/at-work/tech-careers/engineers-say-no-thanks-to-silicon-valley-recruiters-citing-ethical-concerns
|
||||
[2]: https://www.theladders.com/career-advice/job-descriptions-driving-away-women
|
||||
@ -0,0 +1,68 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (Why giving back is important to the DevOps culture)
|
||||
[#]: via: (https://opensource.com/article/18/11/why-sharing-important-devops-culture)
|
||||
[#]: author: (Matty Stratton https://opensource.com/users/mattstratton)
|
||||
[#]: url: ( )
|
||||
|
||||
Why giving back is important to the DevOps culture
|
||||
======
|
||||
Our habit of not sharing knowledge is doing us harm.
|
||||

|
||||
In the DevOps [CALMS][1] model (which stands for Culture, Automation, Lean, Measurement, and Sharing), Sharing is often overlooked or misunderstood. While each element of CALMS is just as important as the others, sharing knowledge is something that we often neglect.
|
||||
|
||||
### What happens if we don't share?
|
||||
|
||||
[Jeff Smith][2], director of production operations at [Centro][3], tells this story:
|
||||
|
||||
> A change to the level of granularity that gets stored in one of our reporting tables was made. The change increased the disk space usage on the database instance by 8x. Not only did this cause our existing database instance to rapidly fill up, but it also made operations question if the design pattern made sense. Because they weren't included in such an impactful change, all of the design decisions that went into the new process architecture were viewed as suspect and underwent a constant re-examination from ops. In a nutshell, a little bit of faith and trust was lost.
|
||||
|
||||
The damage caused by eroding faith can't be understated. Collaboration is based on trust. Every time this trust is chipped away, energy is spent on questioning the validity of decisions made by others.
|
||||
|
||||
### What are the benefits of sharing?
|
||||
|
||||
Today's systems are incredibly complex. The days when one person could hold an entire infrastructure and system interdependencies in their head are long gone. Communicating across boundaries of expertise makes our entire organization more robust and resilient.
|
||||
|
||||
Sharing isn't just about the technical data or access, though. "Inter-team communication should always start with the goal, not with one team's proposed solution to a problem," Jeff says. "When you start with a solution, the conversation veers in the wrong direction."
|
||||
|
||||
[Emily Freeman][4], CloudOps advocate at [Microsoft][5] says "Collaboration is impossible without sharing information." She points out that having a "mental map" of the skills and knowledge of other teams "enables people to ask questions more efficiently and reduces the fear they're asking too many questions or look stupid."
|
||||
|
||||
### How can we share better?
|
||||
|
||||
"Sharing doesn't have to be a drum circle every Tuesday at 10:30am," Emily says. "It's openness and authenticity. It's removing the shadows from your organization and ensuring everyone is honest and forthright and accountable."
|
||||
|
||||
At a minimum, there should be read-only access to logs, code, and after-incident reports for everyone. Before you cry "separation of concerns," please consider that the data that cannot be shared with everyone in the organization is a much smaller set than we usually think it is. It might require some additional effort to scrub and protect this small subset than to default to "nobody can see anything but their small part of it," but the benefits outweigh the effort.
|
||||
|
||||
"If anyone's excluded, they aren't part of your team, no matter what the org chart says," Emily reminds us.
|
||||
|
||||
It's more than the logs and the tooling, though. "The 'S' is often just seen as knowledge sharing, training, etc.," Jeff says. "But if it doesn't include the sharing of responsibility and ownership, it can be difficult to get your organization to that next level of productivity."
|
||||
|
||||
### Why don't we share?
|
||||
|
||||
There are many reasons that sharing information and knowledge isn't the default position for knowledge workers, but both Emily and Jeff agree it usually comes down to fear.
|
||||
|
||||
"Teams may feel that only their circle is capable of performing a particular task with the zeal and delicacy it deserves," Jeff says. "So information gets siloed, access gets restricted, and gates get constructed. But that diminishes our responsibility to build safe systems, instead leaning on 'operator expertise' as a crutch."
|
||||
|
||||
Emily agrees. "DevOps cultures never look to change the past," she says. "Instead, the companies that thrive at embracing the DevOps philosophy are realistic about where they are and work toward continuously improving their process so everyone on the team can thrive."
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/why-sharing-important-devops-culture
|
||||
|
||||
作者:[Matty Stratton][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mattstratton
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://whatis.techtarget.com/definition/CALMS
|
||||
[2]: https://twitter.com/DarkAndNerdy
|
||||
[3]: https://www.centro.net/
|
||||
[4]: https://twitter.com/editingemily
|
||||
[5]: http://dev.azure.com/
|
||||
@ -0,0 +1,93 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (3 emerging tipping points in open source)
|
||||
[#]: via: (https://opensource.com/article/18/11/3-new-tipping-points-open-source)
|
||||
[#]: author: (Bilgin lbryam https://opensource.com/users/bibryam)
|
||||
[#]: url: ( )
|
||||
|
||||
3 emerging tipping points in open source
|
||||
======
|
||||
Understand the factors advancing the open source model's evolution.
|
||||

|
||||
|
||||
Over the last two decades, open source has been expanding into all aspects of technology—from software to [hardware][1]; from small, disruptive startups to large, boring enterprises; from open standards to open [patents][2].
|
||||
|
||||
As movements evolve, they reach tipping points—stages that move the model in new directions. Following are three things that I believe are now reaching a tipping point in open source.
|
||||
|
||||
### Open for non-coders
|
||||
|
||||
As the name suggests, the open source model has mainly been focused on the source code. On the surface, that's probably because open source communities are usually made up of developers working on the source code, and the tools used in open source projects, such as source control systems, issue trackers, mailing list names, chat channel names, etc., all assume that developers are the center of the universe.
|
||||
|
||||
This has created big losses because it prevents creative people, designers, document writers, event organizers, community managers, lawyers, accountants, and many others from participating in open source communities. We need and want non-code contributors, but we don't have processes and tools to include them, means to measure their value, nor ways for their peers, the community, or their employers to reward their efforts. As a result, it has been a lose-lose for decades. We can see the implications in all the ugly websites, amateur logos, badly written and formatted documentation, disorganized events, etc., in open source projects.
|
||||
|
||||
The good news is that we are getting signals that change is on the way:
|
||||
|
||||
* [Linus Torvalds apologized][3] for his "bad behavior." While this wasn't specifically focused on non-coders, it symbolizes making open source a non-hostile place for less-technical contributors.
|
||||
* The Cloud Native Computing Foundation (CNCF) introduced the [Non-Code Contributor's Guide][4]. In addition to showing the many ways people can contribute to open source projects, it also set a baseline for non-code contributions that other open source projects and foundations will end up following.
|
||||
* The Apache Software Foundation (ASF) is working in the same direction. We've been holding long discussions, and we will have some concrete output very soon (note that is "ASF soon").
|
||||
|
||||
|
||||
|
||||
There is a little-known secret that is great news for non-coders and others new to open source: One of the easiest ways to be recognized as part of an established open source project is to do non-coding activities. Nowadays, with complex software stacks and tough competition, there is a pretty high bar for entering a project as a committer. Performing non-coding activities is less popular, and it opens a fast backdoor to open source communities.
|
||||
|
||||
|
||||
|
||||
### Macro acquisitions
|
||||
|
||||
Open source may have started in the hacker community as a way of scratching developers' personal itches, but today it is the place where innovation happens. Even the world's largest software companies are transitioning to the model to continue dominating their market.
|
||||
|
||||
Here are some good reasons enterprises have become so interested in contributing to open source:
|
||||
|
||||
* It multiplies the company's investments through contributions.
|
||||
* They can benefit from the most recent technology advances and avoid reinventing the wheel.
|
||||
* It helps spread knowledge of their software and its broader adoption.
|
||||
* It increases the developer base and hiring pool.
|
||||
* Internal developers' skills grow by learning from top coders in the field.
|
||||
* It builds a company's reputation—developers want to work for organizations they can boast about.
|
||||
* It aids recruitment and retention—developers want to work on exciting projects that affect large groups of people.
|
||||
* New companies and projects can start faster through the open source networking effect.
|
||||
|
||||
|
||||
|
||||
Many enterprises are trying to shortcut the process by acquiring open source companies—which leads to even more open source adoption. Building an open source company takes many years of effort done out in the open. Hiring good developers who are willing to work in the open, building a community around a project, and creating a successful business model require delicate effort. Companies that manage to do this are very attractive for investment and acquisition, as they serve as a catalyst to turn the acquirer into an open source company at scale. The number of [successful open source companies][5] that is acquired seems to get bigger every day, and this trend is only getting stronger.
|
||||
|
||||
### Micro-funding of open source software
|
||||
|
||||
In addition to macro investments through acquisitions of open source companies, there has also been an increase in decentralized [micro-funding of self-sustaining][6] open source projects.
|
||||
|
||||
On one end of the spectrum, there are open source projects that are maintained primarily by intrinsically motivated developers. On the other end, large companies are hiring developers to work on open source projects driven by company roadmaps and strategies. That leaves a large number of open source projects that are not exciting enough for accidental contributors nor on enterprise companies' radar.
|
||||
|
||||
In recent years, there has been an increase in [platforms for funding and sustaining][7] these open source projects through bug bounties, micro-payments, recurring donations, one-time contributions, subscriptions, etc. These open source funding platforms allow individuals to take responsibility for open source sustainability in their own hands by paying maintainers directly. This enables people to contribute to the open source model through value transfer rather than code contributions.
|
||||
|
||||
There are three basic channels for open source contributions:
|
||||
|
||||
* Hobbyists contribute to open source projects because of intrinsic motivations rather than monetary value.
|
||||
* Companies with open source business models (open core, SaaS, support, services, etc.) monetize open source projects directly with regular, planned, and centralized subsidization.
|
||||
* Independent open source users provide irregular, micro, decentralized subsidization through [OSS funding][7] platforms.
|
||||
|
||||
|
||||
|
||||
While hobbyists and hackers started the open source movement, it's turned into an enterprise monetization model. Having a model to sustain the remaining open source projects is welcome.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/3-new-tipping-points-open-source
|
||||
|
||||
作者:[Bilgin lbryam][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bibryam
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/resources/what-open-hardware
|
||||
[2]: https://www.redhat.com/en/blog/red-hat-welcomes-milestone-addition-open-invention-network-microsoft-joins-safeguard-linux-patent-attacks
|
||||
[3]: https://lkml.org/lkml/2018/9/16/167
|
||||
[4]: https://kubernetes.io/blog/2018/10/04/introducing-the-non-code-contributors-guide/
|
||||
[5]: http://oss.cash/
|
||||
[6]: https://opensource.com/article/18/8/open-source-tokenomics
|
||||
[7]: http://oss.fund/
|
||||
@ -1,180 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (Emacs #2: Introducing org-mode)
|
||||
[#]: via: (https://changelog.complete.org/archives/9865-emacs-2-introducing-org-mode)
|
||||
[#]: author: (John Goerzen http://changelog.complete.org/archives/author/jgoerzen)
|
||||
[#]: url: ( )
|
||||
|
||||
Emacs #2: Introducing org-mode
|
||||
======
|
||||
|
||||
In [my first post in my series on Emacs][1], I described returning to Emacs after over a decade of vim, and org-mode being the reason why.
|
||||
|
||||
I really am astounded at the usefulness, and simplicity, of org-mode. It is really a killer app.
|
||||
|
||||
**So what exactly is org-mode?**
|
||||
|
||||
I wrote yesterday:
|
||||
|
||||
> It’s an information organization platform. Its website says “Your life in plain text: Org mode is for keeping notes, maintaining TODO lists, planning projects, and authoring documents with a fast and effective plain-text system.”
|
||||
|
||||
That’s true, but doesn’t quite capture it. org-mode is a toolkit for you to organize things. It has reasonable out-of-the-box defaults, but it’s designed throughout for you to customize.
|
||||
|
||||
To highlight a few things:
|
||||
|
||||
* **Maintaining TODO lists** : items can be scattered across org-mode files, contain attachments, have tags, deadlines, schedules. There is a convenient “agenda” view to show you what needs to be done. Items can repeat.
|
||||
* **Authoring documents** : org-mode has special features for generating HTML, LaTeX, slides (with LaTeX beamer), and all sorts of other formats. It also supports direct evaluation of code in-buffer and literate programming in virtually any Emacs-supported language. If you want to bend your mind on this stuff, read [this article on literate devops][2]. The [entire Worg website][3]
|
||||
is made with org-mode.
|
||||
* **Keeping notes** : yep, it can do that too. With full-text search, cross-referencing by file (as a wiki), by UUID, and even into other systems (into mu4e by Message-ID, into ERC logs, etc, etc.)
|
||||
|
||||
|
||||
|
||||
**Getting started**
|
||||
|
||||
I highly recommend watching [Carsten Dominik’s excellent Google Talk on org-mode][4]. It is an excellent introduction.
|
||||
|
||||
org-mode is included with Emacs, but you’ll often want a more recent version. Debian users can `apt-get install org-mode`, or it comes with the Emacs packaging system; `M-x package-install RET org-mode RET` may do it for you.
|
||||
|
||||
Now, you’ll probably want to start with the org-mode compact guide’s [introduction section][5], noting in particular to set the keybindings mentioned in the [activation section][6].
|
||||
|
||||
**A good tutorial…**
|
||||
|
||||
I’ve linked to a number of excellent tutorials and introductory items; this post is not going to serve as a tutorial. There are two good videos linked at the end of this post, in particular.
|
||||
|
||||
**Some of my configuration**
|
||||
|
||||
I’ll document some of my configuration here, and go into a bit of what it does. This isn’t necessarily because you’ll want to copy all of this verbatim — but just to give you a bit of an idea of some of what can be configured, an idea of what to look up in the manual, and maybe a reference for “now how do I do that?”
|
||||
|
||||
First, I set up Emacs to work in UTF-8 by default.
|
||||
```
|
||||
(prefer-coding-system 'utf-8) (set-language-environment "UTF-8")
|
||||
```
|
||||
|
||||
org-mode can follow URLs. By default, it opens in Firefox, but I use Chromium.
|
||||
```
|
||||
(setq browse-url-browser-function 'browse-url-chromium)
|
||||
```
|
||||
|
||||
I set the basic key bindings as documented in the Guide, plus configure the M-RET behavior.
|
||||
|
||||
```
|
||||
(global-set-key "\C-cl" 'org-store-link)
|
||||
(global-set-key "\C-ca" 'org-agenda)
|
||||
(global-set-key "\C-cc" 'org-capture)
|
||||
(global-set-key "\C-cb" 'org-iswitchb)
|
||||
|
||||
(setq org-M-RET-may-split-line nil)
|
||||
```
|
||||
|
||||
|
||||
**Configuration: Capturing**
|
||||
|
||||
I can press `C-c c` from anywhere in Emacs. It will [capture something for me][7], and include a link back to whatever I was working on.
|
||||
|
||||
You can define [capture templates][8] to set how this will work. I am going to keep two journal files for general notes about meetings, phone calls, etc. One for personal, one for work items. If I press `C-c c j`, then it will capture a personal item. The %a in all of these includes the link to where I was (or a link I had stored with `C-c l`).
|
||||
|
||||
```
|
||||
(setq org-default-notes-file "~/org/tasks.org")
|
||||
(setq org-capture-templates
|
||||
'(
|
||||
("t" "Todo" entry (file+headline "inbox.org" "Tasks")
|
||||
"* TODO %?\n %i\n %u\n %a")
|
||||
("n" "Note/Data" entry (file+headline "inbox.org" "Notes/Data")
|
||||
"* %? \n %i\n %u\n %a")
|
||||
("j" "Journal" entry (file+datetree "~/org/journal.org")
|
||||
"* %?\nEntered on %U\n %i\n %a")
|
||||
("J" "Work-Journal" entry (file+datetree "~/org/wjournal.org")
|
||||
"* %?\nEntered on %U\n %i\n %a")
|
||||
))
|
||||
(setq org-irc-link-to-logs t)
|
||||
```
|
||||
|
||||
I like to link by UUIDs, which lets me move things between files without breaking locations. This helps generate UUIDs when I ask Org to store a link target for future insertion.
|
||||
|
||||
```
|
||||
(require 'org-id)
|
||||
(setq org-id-link-to-org-use-id 'create-if-interactive)
|
||||
```
|
||||
|
||||
**Configuration: agenda views**
|
||||
|
||||
I like my week to start on a Sunday, and for org to note the time when I mark something as done.
|
||||
|
||||
```
|
||||
(setq org-log-done 'time)
|
||||
(setq org-agenda-start-on-weekday 0)
|
||||
```
|
||||
|
||||
**Configuration: files and refiling**
|
||||
|
||||
Here I tell it what files to use in the agenda, and to add a few more to the plain text search. I like to keep a general inbox (from which I can move, or “refile”, content), and then separate tasks, journal, and knowledge base for personal and work items.
|
||||
|
||||
```
|
||||
(setq org-agenda-files (list "~/org/inbox.org"
|
||||
"~/org/email.org"
|
||||
"~/org/tasks.org"
|
||||
"~/org/wtasks.org"
|
||||
"~/org/journal.org"
|
||||
"~/org/wjournal.org"
|
||||
"~/org/kb.org"
|
||||
"~/org/wkb.org"
|
||||
))
|
||||
(setq org-agenda-text-search-extra-files
|
||||
(list "~/org/someday.org"
|
||||
"~/org/config.org"
|
||||
))
|
||||
|
||||
(setq org-refile-targets '((nil :maxlevel . 2)
|
||||
(org-agenda-files :maxlevel . 2)
|
||||
("~/org/someday.org" :maxlevel . 2)
|
||||
("~/org/templates.org" :maxlevel . 2)
|
||||
)
|
||||
)
|
||||
(setq org-outline-path-complete-in-steps nil) ; Refile in a single go
|
||||
(setq org-refile-use-outline-path 'file)
|
||||
```
|
||||
|
||||
**Configuration: Appearance**
|
||||
|
||||
I like a pretty screen. After you’ve gotten used to org a bit, you might try this.
|
||||
|
||||
```
|
||||
(require 'org-bullets)
|
||||
(add-hook 'org-mode-hook
|
||||
(lambda ()
|
||||
(org-bullets-mode t)))
|
||||
(setq org-ellipsis "⤵")
|
||||
```
|
||||
|
||||
**Coming up next…**
|
||||
|
||||
This hopefully showed a few things that org-mode can do. Coming up next, I’ll cover how to customize TODO keywords and tags, archiving old tasks, forwarding emails to org-mode, and using git to synchronize between machines.
|
||||
|
||||
You can also see a [list of all articles in this series][9].
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://changelog.complete.org/archives/9865-emacs-2-introducing-org-mode
|
||||
|
||||
作者:[John Goerzen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://changelog.complete.org/archives/author/jgoerzen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://changelog.complete.org/archives/9861-emacs-1-ditching-a-bunch-of-stuff-and-moving-to-emacs-and-org-mode
|
||||
[2]: http://www.howardism.org/Technical/Emacs/literate-devops.html
|
||||
[3]: https://orgmode.org/worg/
|
||||
[4]: https://www.youtube.com/watch?v=oJTwQvgfgMM
|
||||
[5]: https://orgmode.org/guide/Introduction.html#Introduction
|
||||
[6]: https://orgmode.org/guide/Activation.html#Activation
|
||||
[7]: https://orgmode.org/guide/Capture.html#Capture
|
||||
[8]: https://orgmode.org/guide/Capture-templates.html#Capture-templates
|
||||
[9]: https://changelog.complete.org/archives/tag/emacs2018
|
||||
@ -1,131 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (Emacs #3: More on org-mode)
|
||||
[#]: via: (https://changelog.complete.org/archives/9877-emacs-3-more-on-org-mode)
|
||||
[#]: author: (John Goerzen http://changelog.complete.org/archives/author/jgoerzen)
|
||||
[#]: url: ( )
|
||||
|
||||
Emacs #3: More on org-mode
|
||||
======
|
||||
|
||||
This is third in [a series on Emacs and org-mode][1].
|
||||
|
||||
**Todo tracking and keywords**
|
||||
|
||||
When using org-mode to [track your TODOs][2], it can have multiple states. You can press `C-c C-t` for a quick shift between states. I have set this:
|
||||
|
||||
```
|
||||
(setq org-todo-keywords '(
|
||||
(sequence "TODO(t!)" "NEXT(n!)" "STARTED(a!)" "WAIT(w@/!)" "OTHERS(o!)" "|" "DONE(d)" "CANCELLED(c)")
|
||||
))
|
||||
```
|
||||
|
||||
Here, I set up 5 states that are for a task that is not yet done: TODO, NEXT, STARTED, WAIT, and OTHERS. Each has a single-character shortcut (t, n, a, etc). The states after the pipe symbol are ones that are considered “done”. I have two: DONE (for things that I have done) and CANCELED (for things that I haven’t done, but for whatever reason, won’t).
|
||||
|
||||
The exclamation mark means to log the time when an item was changed to a state. I don’t add this to the done states because those are already logged anyhow. The @ sign means to prompt for a reason; so when switching to WAIT, org-mode will ask me why and add this to the note.
|
||||
|
||||
Here’s an example of an entry that has had some state changes:
|
||||
|
||||
```
|
||||
** DONE This is a test
|
||||
CLOSED: [2018-03-02 Fri 03:05]
|
||||
|
||||
- State "DONE" from "WAIT" [2018-03-02 Fri 03:05]
|
||||
- State "WAIT" from "TODO" [2018-03-02 Fri 03:05] \\
|
||||
waiting for pigs to fly
|
||||
- State "TODO" from "NEXT" [2018-03-02 Fri 03:05]
|
||||
- State "NEXT" from "TODO" [2018-03-02 Fri 03:05]
|
||||
```
|
||||
|
||||
Here, the most recent items are on top.
|
||||
|
||||
**Agenda mode, schedules, and deadlines**
|
||||
|
||||
When you’re in a todo item, C-c C-s or C-c C-d can set a schedule or a deadline for it, respectively. These show up in agenda mode. The difference is in intent and presentation. A schedule is something that you expect to work on at around a time, while a deadline is something that is due at a specific time. By default, the agenda view will start warning you about deadline items in advance.
|
||||
|
||||
And while we’re at it, the [agenda view][3] will show you the items that you have coming up, offers a nice way to search for items based on plain text or tags, and handles bulk manipulation of items even across multiple files. I covered setting the files for agenda mode in [part 2][4] of this series.
|
||||
|
||||
**Tags**
|
||||
|
||||
Of course org-mode has [tags][5]. You can quickly set them with C-c C-q.
|
||||
|
||||
You can set shortcuts for tags you might like to use often. Perhaps something like this:
|
||||
|
||||
```
|
||||
(setq org-tag-persistent-alist
|
||||
'(("@phone" . ?p)
|
||||
("@computer" . ?c)
|
||||
("@websurfing" . ?w)
|
||||
("@errands" . ?e)
|
||||
("@outdoors" . ?o)
|
||||
("MIT" . ?m)
|
||||
("BIGROCK" . ?b)
|
||||
("CONTACTS" . ?C)
|
||||
("INBOX" . ?i)
|
||||
))
|
||||
```
|
||||
|
||||
You can also add tags to this list on a per-file basis, and also set tags for something on a per-file basis. I use that for my inbox.org and email.org files to set an INBOX tag. I can then review all items tagged INBOX from the agenda view each day, and the simple act of refiling them into other files will cause them to lost the INBOX tag.
|
||||
|
||||
**Refiling**
|
||||
|
||||
“Refiling” is moving things around, either within a file or elsewhere. It has completion using your headlines. `C-c C-w` does this. I like these settings:
|
||||
|
||||
```
|
||||
(setq org-outline-path-complete-in-steps nil) ; Refile in a single go
|
||||
(setq org-refile-use-outline-path 'file)
|
||||
```
|
||||
|
||||
**Archiving**
|
||||
|
||||
After awhile, you’ll get your files all cluttered with things that are done. org-mode has an [archive][6] feature to move things out of your main .org files and into some other files for future reference. If you have your org files in git or something, you may wish to delete these other files since you’d have things in history anyhow, but I find them handy for grepping and searching.
|
||||
|
||||
I periodically want to go through and archive everything in my files. Based on a [stackoverflow discussion][7], I have this code:
|
||||
|
||||
```
|
||||
(defun org-archive-done-tasks ()
|
||||
(interactive)
|
||||
(org-map-entries
|
||||
(lambda ()
|
||||
(org-archive-subtree)
|
||||
(setq org-map-continue-from (outline-previous-heading)))
|
||||
"/DONE" 'file)
|
||||
(org-map-entries
|
||||
(lambda ()
|
||||
(org-archive-subtree)
|
||||
(setq org-map-continue-from (outline-previous-heading)))
|
||||
"/CANCELLED" 'file)
|
||||
)
|
||||
```
|
||||
|
||||
This is based on [a particular answer][8] — see the comments there for some additional hints. Now you can run `M-x org-archive-done-tasks` and everything in the current file marked DONE or CANCELED will be pulled out into a different file.
|
||||
|
||||
**Up next**
|
||||
|
||||
I’ll wrap up org-mode with a discussion of automatically receiving emails into org, and syncing org between machines.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://changelog.complete.org/archives/9877-emacs-3-more-on-org-mode
|
||||
|
||||
作者:[John Goerzen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://changelog.complete.org/archives/author/jgoerzen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://changelog.complete.org/archives/tag/emacs2018
|
||||
[2]: https://orgmode.org/guide/TODO-Items.html#TODO-Items
|
||||
[3]: https://orgmode.org/guide/Agenda-Views.html#Agenda-Views
|
||||
[4]: https://changelog.complete.org/archives/9865-emacs-2-introducing-org-mode
|
||||
[5]: https://orgmode.org/guide/Tags.html#Tags
|
||||
[6]: https://orgmode.org/guide/Archiving.html#Archiving
|
||||
[7]: https://stackoverflow.com/questions/6997387/how-to-archive-all-the-done-tasks-using-a-single-command
|
||||
[8]: https://stackoverflow.com/a/27043756
|
||||
@ -1,3 +1,4 @@
|
||||
robsean translating
|
||||
How To Remove Password From A PDF File in Linux
|
||||
======
|
||||
|
||||
|
||||
@ -1,313 +0,0 @@
|
||||
(translating by runningwater)
|
||||
Version Control Before Git with CVS
|
||||
======
|
||||
Github was launched in 2008. If your software engineering career, like mine, is no older than Github, then Git may be the only version control software you have ever used. While people sometimes grouse about its steep learning curve or unintuitive interface, Git has become everyone’s go-to for version control. In Stack Overflow’s 2015 developer survey, 69.3% of respondents used Git, almost twice as many as used the second-most-popular version control system, Subversion. After 2015, Stack Overflow stopped asking developers about the version control systems they use, perhaps because Git had become so popular that the question was uninteresting.
|
||||
|
||||
Git itself is not much older than Github. Linus Torvalds released the first version of Git in 2005. Though today younger developers might have a hard time conceiving of a world where the term “version control software” didn’t more or less just mean Git, such a world existed not so long ago. There were lots of alternatives to choose from. Open source developers preferred Subversion, enterprises and video game companies used Perforce (some still do), while the Linux kernel project famously relied on a version control system called BitKeeper.
|
||||
|
||||
Some of these systems, particularly BitKeeper, might feel familiar to a young Git user transported back in time. Most would not. BitKeeper aside, the version control systems that came before Git worked according to a fundamentally different paradigm. In a taxonomy offered by Eric Sink, author of Version Control by Example, Git is a third-generation version control system, while most of Git’s predecessors, the systems popular in the 1990s and early 2000s, are second-generation version control systems. Where third-generation version control systems are distributed, second-generation version control systems are centralized. You have almost certainly heard Git described as a “distributed” version control system before. I never quite understood the distributed/centralized distinction, at least not until I installed and experimented with a centralized second-generation version control system myself.
|
||||
|
||||
The system I installed was CVS. CVS, short for Concurrent Versions System, was the very first second-generation version control system. It was also the most popular version control system for about a decade until it was replaced in 2000 by Subversion. Even then, Subversion was supposed to be “CVS but better,” which only underscores how dominant CVS had become throughout the 1990s.
|
||||
|
||||
CVS was first developed in 1986 by a Dutch computer scientist named Dick Grune, who was looking for a way to collaborate with his students on a compiler project. CVS was initially little more than a collection of shell scripts wrapping RCS (Revision Control System), a first-generation version control system that Grune wanted to improve. RCS works according to a pessimistic locking model, meaning that no two programmers can work on a single file at once. In order to edit a file, you have to first ask RCS for an exclusive lock on the file, which you keep until you are finished editing. If someone else is already editing a file you need to edit, you have to wait. CVS improved on RCS and ushered in the second generation of version control systems by trading the pessimistic locking model for an optimistic one. Programmers could now edit the same file at the same time, merging their edits and resolving any conflicts later. (Brian Berliner, an engineer who later took over the CVS project, wrote a very readable [paper][1] about CVS’ innovations in 1990.)
|
||||
|
||||
In that sense, CVS wasn’t all that different from Git, which also works according to an optimistic model. But that’s where the similarities end. In fact, when Linus Torvalds was developing Git, one of his guiding principles was WWCVSND, or “What Would CVS Not Do.” Whenever he was in doubt about a decision, he strove to choose the option that had not been chosen in the design of CVS. So even though CVS predates Git by over a decade, it influenced Git as a kind of negative template.
|
||||
|
||||
I’ve really enjoyed playing around with CVS. I think there’s no better way to understand why Git’s distributed nature is such an improvement on what came before. So I invite you to come along with me on an exciting journey and spend the next ten minutes of your life learning about a piece of software nobody has used in the last decade. (See correction.)
|
||||
|
||||
### Getting Started with CVS
|
||||
|
||||
Instructions for installing CVS can be found on the [project’s homepage][2]. On MacOS, you can install CVS using Homebrew.
|
||||
|
||||
Since CVS is centralized, it distinguishes between the client-side universe and the server-side universe in a way that something like Git does not. The distinction is not so pronounced that there are different executables. But in order to start using CVS, even on your own machine, you’ll have to set up the CVS backend.
|
||||
|
||||
The CVS backend, the central store for all your code, is called the repository. Whereas in Git you would typically have a repository for every project, in CVS the repository holds all of your projects. There is one central repository for everything, though there are ways to work with only a project at a time.
|
||||
|
||||
To create a local repository, you run the `init` command. You would do this somewhere global like your home directory.
|
||||
|
||||
```
|
||||
$ cvs -d ~/sandbox init
|
||||
```
|
||||
|
||||
CVS allows you to pass options to either the `cvs` command itself or to the `init` subcommand. Options that appear after the `cvs` command are global in nature, while options that appear after the subcommand are specific to the subcommand. In this case, the `-d` flag is global. Here it happens to tell CVS where we want to create our repository, but in general the `-d` flag points to the location of the repository we want to use for any given action. It can be tedious to supply the `-d` flag all the time, so the `CVSROOT` environment variable can be set instead.
|
||||
|
||||
Since we’re working locally, we’ve just passed a path for our `-d` argument, but we could also have included a hostname.
|
||||
|
||||
The command creates a directory called `sandbox` in your home directory. If you list the contents of `sandbox`, you’ll find that it contains another directory called `CVSROOT`. This directory, not to be confused with the environment variable, holds administrative files for the repository.
|
||||
|
||||
Congratulations! You’ve just created your first CVS repository.
|
||||
|
||||
### Checking In Code
|
||||
|
||||
Let’s say that you’ve decided to keep a list of your favorite colors. You are an artistically inclined but extremely forgetful person. You type up your list of colors and save it as a file called `favorites.txt`:
|
||||
|
||||
```
|
||||
blue
|
||||
orange
|
||||
green
|
||||
|
||||
definitely not yellow
|
||||
```
|
||||
|
||||
Let’s also assume that you’ve saved your file in a new directory called `colors`. Now you’d like to put your favorite color list under version control, because fifty years from now it will be interesting to look back and see how your tastes changed through time.
|
||||
|
||||
In order to do that, you will have to import your directory as a new CVS project. You can do that using the `import` command:
|
||||
|
||||
```
|
||||
$ cvs -d ~/sandbox import -m "" colors colors initial
|
||||
N colors/favorites.txt
|
||||
|
||||
No conflicts created by this import
|
||||
```
|
||||
|
||||
Here we are specifying the location of our repository with the `-d` flag again. The remaining arguments are passed to the `import` subcommand. We have to provide a message, but here we don’t really need one, so we’ve left it blank. The next argument, `colors`, specifies the name of our new directory in the repository; here we’ve just used the same name as the directory we are in. The last two arguments specify the vendor tag and the release tag respectively. We’ll talk more about tags in a minute.
|
||||
|
||||
You’ve just pulled your “colors” project into the CVS repository. There are a couple different ways to go about bringing code into CVS, but this is the method recommended by [Pragmatic Version Control Using CVS][3], the Pragmatic Programmer book about CVS. What makes this method a little awkward is that you then have to check out your work fresh, even though you’ve already got an existing `colors` directory. Instead of using that directory, you’re going to delete it and then check out the version that CVS already knows about:
|
||||
|
||||
```
|
||||
$ cvs -d ~/sandbox co colors
|
||||
cvs checkout: Updating colors
|
||||
U colors/favorites.txt
|
||||
```
|
||||
|
||||
This will create a new directory, also called `colors`. In this directory you will find your original `favorites.txt` file along with a directory called `CVS`. The `CVS` directory is basically CVS’ equivalent of the `.git` directory in every Git repository.
|
||||
|
||||
### Making Changes
|
||||
|
||||
Get ready for a trip.
|
||||
|
||||
Just like Git, CVS has a `status` subcommand:
|
||||
|
||||
```
|
||||
$ cvs status
|
||||
cvs status: Examining .
|
||||
===================================================================
|
||||
File: favorites.txt Status: Up-to-date
|
||||
|
||||
Working revision: 1.1.1.1 2018-07-06 19:27:54 -0400
|
||||
Repository revision: 1.1.1.1 /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
Commit Identifier: fD7GYxt035GNg8JA
|
||||
Sticky Tag: (none)
|
||||
Sticky Date: (none)
|
||||
Sticky Options: (none)
|
||||
```
|
||||
|
||||
This is where things start to look alien. CVS doesn’t have commit objects. In the above, there is something called a “Commit Identifier,” but this might be only a relatively recent edition—no mention of a “Commit Identifier” appears in Pragmatic Version Control Using CVS, which was published in 2003. (The last update to CVS was released in 2008.)
|
||||
|
||||
Whereas with Git you’d talk about the version of a file associated with commit `45de392`, in CVS files are versioned separately. The first version of your file is version 1.1, the next version is 1.2, and so on. When branches are involved, extra numbers are appended, so you might end up with something like the `1.1.1.1` above, which appears to be the default in our case even though we haven’t created any branches.
|
||||
|
||||
If you were to run `cvs log` (equivalent to `git log`) in a project with lots of files and commits, you’d see an individual history for each file. You might have a file at version 1.2 and a file at version 1.14 in the same project.
|
||||
|
||||
Let’s go ahead and make a change to version 1.1 of our `favorites.txt` file:
|
||||
|
||||
```
|
||||
blue
|
||||
orange
|
||||
green
|
||||
+cyan
|
||||
|
||||
definitely not yellow
|
||||
```
|
||||
|
||||
Once we’ve made the change, we can run `cvs diff` to see what CVS thinks we’ve done:
|
||||
|
||||
```
|
||||
$ cvs diff
|
||||
cvs diff: Diffing .
|
||||
Index: favorites.txt
|
||||
===================================================================
|
||||
RCS file: /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
retrieving revision 1.1.1.1
|
||||
diff -r1.1.1.1 favorites.txt
|
||||
3a4
|
||||
> cyan
|
||||
```
|
||||
|
||||
CVS recognizes that we added a new line containing the color “cyan” to the file. (Actually, it says we’ve made changes to the “RCS” file; you can see that CVS never fully escaped its original association with RCS.) The diff we are being shown is the diff between the copy of `favorites.txt` in our working directory and the 1.1.1.1 version stored in the repository.
|
||||
|
||||
In order to update the version stored in the repository, we have to commit the change. In Git, this would be a multi-step process. We’d have to stage the change so that it appears in our index. Then we’d commit the change. Finally, to make the change visible to anyone else, we’d have to push the commit up to the origin repository.
|
||||
|
||||
In CVS, all of these things happen when you run `cvs commit`. CVS just bundles up all the changes it can find and puts them in the repository:
|
||||
|
||||
```
|
||||
$ cvs commit -m "Add cyan to favorites."
|
||||
cvs commit: Examining .
|
||||
/Users/sinclairtarget/sandbox/colors/favorites.txt,v <-- favorites.txt
|
||||
new revision: 1.2; previous revision: 1.1
|
||||
```
|
||||
|
||||
I’m so used to Git that this strikes me as terrifying. Without an opportunity to stage changes, any old thing that you’ve touched in your working directory might end up as part of the public repository. Did you passive-aggressively rewrite a coworker’s poorly implemented function out of cathartic necessity, never intending for him to know? Too bad, he now thinks you’re a dick. You also can’t edit your commits before pushing them, since a commit is a push. Do you enjoy spending 40 minutes repeatedly running `git rebase -i` until your local commit history flows like the derivation of a mathematical proof? Sorry, you can’t do that here, and everyone is going to find out that you don’t actually write your tests first.
|
||||
|
||||
But I also now understand why so many people find Git needlessly complicated. If `cvs commit` is what you were used to, then I’m sure staging and pushing changes would strike you as a pointless chore.
|
||||
|
||||
When people talk about Git being a “distributed” system, this is primarily the difference they mean. In CVS, you can’t make commits locally. A commit is a submission of code to the central repository, so it’s not something you can do without a connection. All you’ve got locally is your working directory. In Git, you have a full-fledged local repository, so you can make commits all day long even while disconnected. And you can edit those commits, revert, branch, and cherry pick as much as you want, without anybody else having to know.
|
||||
|
||||
Since commits were a bigger deal, CVS users often made them infrequently. Commits would contain as many changes as today we might expect to see in a ten-commit pull request. This was especially true if commits triggered a CI build and an automated test suite.
|
||||
|
||||
If we now run `cvs status`, we can see that we have a new version of our file:
|
||||
|
||||
```
|
||||
$ cvs status
|
||||
cvs status: Examining .
|
||||
===================================================================
|
||||
File: favorites.txt Status: Up-to-date
|
||||
|
||||
Working revision: 1.2 2018-07-06 21:18:59 -0400
|
||||
Repository revision: 1.2 /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
Commit Identifier: pQx5ooyNk90wW8JA
|
||||
Sticky Tag: (none)
|
||||
Sticky Date: (none)
|
||||
Sticky Options: (none)
|
||||
```
|
||||
|
||||
### Merging
|
||||
|
||||
As mentioned above, in CVS you can edit a file that someone else is already editing. That was CVS’ big improvement on RCS. What happens when you need to bring your changes back together?
|
||||
|
||||
Let’s say that you have invited some friends to add their favorite colors to your list. While they are adding their colors, you decide that you no longer like the color green and remove it from the list.
|
||||
|
||||
When you go to commit your changes, you might discover that CVS notices a problem:
|
||||
|
||||
```
|
||||
$ cvs commit -m "Remove green"
|
||||
cvs commit: Examining .
|
||||
cvs commit: Up-to-date check failed for `favorites.txt'
|
||||
cvs [commit aborted]: correct above errors first!
|
||||
```
|
||||
|
||||
It looks like your friends committed their changes first. So your version of `favorites.txt` is not up-to-date with the version in the repository. If you run `cvs status`, you’ll see that your local copy of `favorites.txt` is version 1.2 with some local changes, but the repository version is 1.3:
|
||||
|
||||
```
|
||||
$ cvs status
|
||||
cvs status: Examining .
|
||||
===================================================================
|
||||
File: favorites.txt Status: Needs Merge
|
||||
|
||||
Working revision: 1.2 2018-07-07 10:42:43 -0400
|
||||
Repository revision: 1.3 /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
Commit Identifier: 2oZ6n0G13bDaldJA
|
||||
Sticky Tag: (none)
|
||||
Sticky Date: (none)
|
||||
Sticky Options: (none)
|
||||
```
|
||||
|
||||
You can run `cvs diff` to see exactly what the differences between 1.2 and 1.3 are:
|
||||
|
||||
```
|
||||
$ cvs diff -r HEAD favorites.txt
|
||||
Index: favorites.txt
|
||||
===================================================================
|
||||
RCS file: /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
retrieving revision 1.3
|
||||
diff -r1.3 favorites.txt
|
||||
3d2
|
||||
< green
|
||||
7,10d5
|
||||
<
|
||||
< pink
|
||||
< hot pink
|
||||
< bubblegum pink
|
||||
```
|
||||
|
||||
It seems that our friends really like pink. In any case, they’ve edited a different part of the file than we have, so the changes are easy to merge. CVS can do that for us when we run `cvs update`, which is similar to `git pull`:
|
||||
|
||||
```
|
||||
$ cvs update
|
||||
cvs update: Updating .
|
||||
RCS file: /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
retrieving revision 1.2
|
||||
retrieving revision 1.3
|
||||
Merging differences between 1.2 and 1.3 into favorites.txt
|
||||
M favorites.txt
|
||||
```
|
||||
|
||||
If you now take a look at `favorites.txt`, you’ll find that it has been modified to include the changes that your friends made to the file. Your changes are still there too. Now you are free to commit the file:
|
||||
|
||||
```
|
||||
$ cvs commit
|
||||
cvs commit: Examining .
|
||||
/Users/sinclairtarget/sandbox/colors/favorites.txt,v <-- favorites.txt
|
||||
new revision: 1.4; previous revision: 1.3
|
||||
```
|
||||
|
||||
The end result is what you’d get in Git by running `git pull --rebase`. Your changes have been added on top of your friends’ changes. There is no “merge commit.”
|
||||
|
||||
Sometimes, changes to the same file might be incompatible. If your friends had changed “green” to “olive,” for example, that would have conflicted with your change removing “green” altogether. In the early days of CVS, this was exactly the kind of case that caused people to worry that CVS wasn’t safe; RCS’ pessimistic locking ensured that such a case could never arise. But CVS guarantees safety by making sure that nobody’s changes get overwritten automatically. You have to tell CVS which change you want to keep going forward, so when you run `cvs update`, CVS marks up the file with both changes in the same way that Git does when Git detects a merge conflict. You then have to manually edit the file and pick the change you want to keep.
|
||||
|
||||
The interesting thing to note here is that merge conflicts have to be fixed before you can commit. This is another consequence of CVS’ centralized nature. In Git, you don’t have to worry about resolving merges until you push the commits you’ve got locally.
|
||||
|
||||
Since CVS doesn’t have easily addressable commit objects, the only way to group a collection of changes is to mark a particular working directory state with a tag.
|
||||
|
||||
Creating a tag is easy:
|
||||
|
||||
```
|
||||
$ cvs tag VERSION_1_0
|
||||
cvs tag: Tagging .
|
||||
T favorites.txt
|
||||
```
|
||||
|
||||
You’ll later be able to return files to this state by running `cvs update` and passing the tag to the `-r` flag:
|
||||
|
||||
```
|
||||
$ cvs update -r VERSION_1_0
|
||||
cvs update: Updating .
|
||||
U favorites.txt
|
||||
```
|
||||
|
||||
Because you need a tag to rewind to an earlier working directory state, CVS encourages a lot of preemptive tagging. Before major refactors, for example, you might create a `BEFORE_REFACTOR_01` tag that you could later use if the refactor went wrong. People also used tags if they wanted to generate project-wide diffs. Basically, all the things we routinely do today with commit hashes have to be anticipated and planned for with CVS, since you needed to have the tags available already.
|
||||
|
||||
Branches can be created in CVS, sort of. Branches are just a special kind of tag:
|
||||
|
||||
```
|
||||
$ cvs rtag -b TRY_EXPERIMENTAL_THING colors
|
||||
cvs rtag: Tagging colors
|
||||
```
|
||||
|
||||
That only creates the branch (in full view of everyone, by the way), so you still need to switch to it using `cvs update`:
|
||||
|
||||
```
|
||||
$ cvs update -r TRY_EXPERIMENTAL_THING
|
||||
```
|
||||
|
||||
The above commands switch onto the new branch in your current working directory, but Pragmatic Version Control Using CVS actually advises that you create a new directory to hold your new branch. Presumably its authors found switching directories easier than switching branches in CVS.
|
||||
|
||||
Pragmatic Version Control Using CVS also advises against creating branches off of an existing branch. They recommend only creating branches off of the mainline branch, which in Git is known as `master`. In general, branching was considered an “advanced” CVS skill. In Git, you might start a new branch for almost any trivial reason, but in CVS branching was typically used only when really necessary, such as for releases.
|
||||
|
||||
A branch could later be merged back into the mainline using `cvs update` and the `-j` flag:
|
||||
|
||||
```
|
||||
$ cvs update -j TRY_EXPERIMENTAL_THING
|
||||
```
|
||||
|
||||
### Thanks for the Commit Histories
|
||||
|
||||
In 2007, Linus Torvalds gave [a talk][4] about Git at Google. Git was very new then, so the talk was basically an attempt to persuade a roomful of skeptical programmers that they should use Git, even though Git was so different from anything then available. If you haven’t already seen the talk, I highly encourage you to watch it. Linus is an entertaining speaker, even if he never fails to be his brash self. He does an excellent job of explaining why the distributed model of version control is better than the centralized one. A lot of his criticism is reserved for CVS in particular.
|
||||
|
||||
Git is a [complex tool][5]. Learning it can be a frustrating experience. But I’m also continually amazed at the things that Git can do. In comparison, CVS is simple and straightforward, though often unable to do many of the operations we now take for granted. Going back and using CVS for a while is an excellent way to find yourself with a new appreciation for Git’s power and flexibility. It illustrates well why understanding the history of software development can be so beneficial—picking up and re-examining obsolete tools will teach you volumes about the why behind the tools we use today.
|
||||
|
||||
If you enjoyed this post, more like it come out every two weeks! Follow [@TwoBitHistory][6] on Twitter or subscribe to the [RSS feed][7] to make sure you know when a new post is out.
|
||||
|
||||
#### Correction
|
||||
|
||||
I’ve been told that there are many organizations, particularly risk-adverse organizations that do things like make medical device software, that still use CVS. Programmers in these organizations have developed little tricks for working around CVS’ limitations, such as making a new branch for almost every change to avoid committing directly to `HEAD`. (Thanks to Michael Kohne for pointing this out.)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://twobithistory.org/2018/07/07/cvs.html
|
||||
|
||||
作者:[Two-Bit History][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twobithistory.org
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://docs.freebsd.org/44doc/psd/28.cvs/paper.pdf
|
||||
[2]: https://www.nongnu.org/cvs/
|
||||
[3]: http://shop.oreilly.com/product/9780974514000.do
|
||||
[4]: https://www.youtube.com/watch?v=4XpnKHJAok8
|
||||
[5]: https://xkcd.com/1597/
|
||||
[6]: https://twitter.com/TwoBitHistory
|
||||
[7]: https://twobithistory.org/feed.xml
|
||||
@ -1,56 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
5 Firefox extensions to protect your privacy
|
||||
======
|
||||
|
||||

|
||||
|
||||
In the wake of the Cambridge Analytica story, I took a hard look at how far I had let Facebook penetrate my online presence. As I'm generally concerned about single points of failure (or compromise), I am not one to use social logins. I use a password manager and create unique logins for every site (and you should, too).
|
||||
|
||||
What I was most perturbed about was the pervasive intrusion Facebook was having on my digital life. I uninstalled the Facebook mobile app almost immediately after diving into the Cambridge Analytica story. I also [disconnected all apps, games, and websites][1] from Facebook. Yes, this will change your experience on Facebook, but it will also protect your privacy. As a veteran with friends spread out across the globe, maintaining the social connectivity of Facebook is important to me.
|
||||
|
||||
I went about the task of scrutinizing other services as well. I checked Google, Twitter, GitHub, and more for any unused connected applications. But I know that's not enough. I need my browser to be proactive in preventing behavior that violates my privacy. I began the task of figuring out how best to do that. Sure, I can lock down a browser, but I need to make the sites and tools I use work while trying to keep them from leaking data.
|
||||
|
||||
Following are five tools that will protect your privacy while using your browser. The first three extensions are available for Firefox and Chrome, while the latter two are only available for Firefox.
|
||||
|
||||
### Privacy Badger
|
||||
|
||||
[Privacy Badger][2] has been my go-to extension for quite some time. Do other content or ad blockers do a better job? Maybe. The problem with a lot of content blockers is that they are "pay for play." Meaning they have "partners" that get whitelisted for a fee. That is the antithesis of why content blockers exist. Privacy Badger is made by the Electronic Frontier Foundation (EFF), a nonprofit entity with a donation-based business model. Privacy Badger promises to learn from your browsing habits and requires minimal tuning. For example, I have only had to whitelist a handful of sites. Privacy Badger also allows granular controls of exactly which trackers are enabled on what sites. It's my #1, must-install extension, no matter the browser.
|
||||
|
||||
### DuckDuckGo Privacy Essentials
|
||||
|
||||
The search engine DuckDuckGo has typically been privacy-conscious. [DuckDuckGo Privacy Essentials][3] works across major mobile devices and browsers. It's unique in the sense that it grades sites based on the settings you give them. For example, Facebook gets a D, even with Privacy Protection enabled. Meanwhile, [chrisshort.net][4] gets a B with Privacy Protection enabled and a C with it disabled. If you're not keen on EFF or Privacy Badger for whatever reason, I would recommend DuckDuckGo Privacy Essentials (choose one, not both, as they essentially do the same thing).
|
||||
|
||||
### HTTPS Everywhere
|
||||
|
||||
[HTTPS Everywhere][5] is another extension from the EFF. According to HTTPS Everywhere, "Many sites on the web offer some limited support for encryption over HTTPS, but make it difficult to use. For instance, they may default to unencrypted HTTP or fill encrypted pages with links that go back to the unencrypted site. The HTTPS Everywhere extension fixes these problems by using clever technology to rewrite requests to these sites to HTTPS." While a lot of sites and browsers are getting better about implementing HTTPS, there are a lot of sites that still need help. HTTPS Everywhere will try its best to make sure your traffic is encrypted.
|
||||
|
||||
### NoScript Security Suite
|
||||
|
||||
[NoScript Security Suite][6] is not for the faint of heart. While the Firefox-only extension "allows JavaScript, Java, Flash, and other plugins to be executed only by trusted websites of your choice," it doesn't do a great job at figuring out what your choices are. But, make no mistake, a surefire way to prevent leaking data is not executing code that could leak it. NoScript enables that via its "whitelist-based preemptive script blocking." This means you will need to build the whitelist as you go for sites not already on it. Note that NoScript is only available for Firefox.
|
||||
|
||||
### Facebook Container
|
||||
|
||||
[Facebook Container][7] makes Firefox the only browser where I will use Facebook. "Facebook Container works by isolating your Facebook identity into a separate container that makes it harder for Facebook to track your visits to other websites with third-party cookies." This means Facebook cannot snoop on activity happening elsewhere in your browser. Suddenly those creepy ads will stop appearing so frequently (assuming you uninstalled the Facebook app from your mobile devices). Using Facebook in an isolated space will prevent any additional collection of data. Remember, you've given Facebook data already, and Facebook Container can't prevent that data from being shared.
|
||||
|
||||
These are my go-to extensions for browser privacy. What are yours? Please share them in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/firefox-extensions-protect-privacy
|
||||
|
||||
作者:[Chris Short][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/chrisshort
|
||||
[1]:https://www.facebook.com/help/211829542181913
|
||||
[2]:https://www.eff.org/privacybadger
|
||||
[3]:https://duckduckgo.com/app
|
||||
[4]:https://chrisshort.net
|
||||
[5]:https://www.eff.org/https-everywhere
|
||||
[6]:https://noscript.net/
|
||||
[7]:https://addons.mozilla.org/en-US/firefox/addon/facebook-container/
|
||||
163
sources/tech/20181105 5 Minimal Web Browsers for Linux.md
Normal file
163
sources/tech/20181105 5 Minimal Web Browsers for Linux.md
Normal file
@ -0,0 +1,163 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (5 Minimal Web Browsers for Linux)
|
||||
[#]: via: (https://www.linux.com/blog/intro-to-linux/2018/11/5-minimal-web-browsers-linux)
|
||||
[#]: author: (Jack Wallen https://www.linux.com/users/jlwallen)
|
||||
[#]: url: ( )
|
||||
|
||||
5 Minimal Web Browsers for Linux
|
||||
======
|
||||

|
||||
|
||||
There are so many reasons to enjoy the Linux desktop. One reason I often state up front is the almost unlimited number of choices to be found at almost every conceivable level. From how you interact with the operating system (via a desktop interface), to how daemons run, to what tools you use, you have a multitude of options.
|
||||
|
||||
The same thing goes for web browsers. You can use anything from open source favorites, such as [Firefox][1] and [Chromium][2], or closed sourced industry darlings like [Vivaldi][3] and [Chrome][4]. Those options are full-fledged browsers with every possible bell and whistle you’ll ever need. For some, these feature-rich browsers are perfect for everyday needs.
|
||||
|
||||
There are those, however, who prefer using a web browser without all the frills. In fact, there are many reasons why you might prefer a minimal browser over a standard browser. For some, it’s about browser security, while others look at a web browser as a single-function tool (as opposed to a one-stop shop application). Still others might be running low-powered machines that cannot handle the requirements of, say, Firefox or Chrome. Regardless of the reason, Linux has you covered.
|
||||
|
||||
Let’s take a look at five of the minimal browsers that can be installed on Linux. I’ll be demonstrating these browsers on the Elementary OS platform, but each of these browsers are available to nearly every distribution in the known Linuxverse. Let’s dive in.
|
||||
|
||||
### GNOME Web
|
||||
|
||||
GNOME Web (codename Epiphany, which means [“a usually sudden manifestation or perception of the essential nature or meaning of something”][5]) is the default web browser for Elementary OS, but it can be installed from the standard repositories. (Note, however, that the recommended installation of Epiphany is via Flatpak or Snap). If you choose to install via the standard package manager, issue a command such as sudo apt-get install epiphany-browser -y for successful installation.
|
||||
|
||||
Epiphany uses the WebKit rendering engine, which is the same engine used in Apple’s Safari browser. Couple that rendering engine with the fact that Epiphany has very little in terms of bloat to get in the way, you will enjoy very fast page-rendering speeds. Epiphany development follows strict adherence to the following guidelines:
|
||||
|
||||
* Simplicity - Feature bloat and user interface clutter are considered evil.
|
||||
|
||||
* Standards compliance - No non-standard features will ever be introduced to the codebase.
|
||||
|
||||
* Software freedom - Epiphany will always be released under a license that respects freedom.
|
||||
|
||||
* Human interface - Epiphany follows the [GNOME Human Interface Guidelines][6].
|
||||
|
||||
* Minimal preferences - Preferences are only added when they make sense and after careful consideration.
|
||||
|
||||
* Target audience - Non-technical users are the primary target audience (which helps to define the types of features that are included).
|
||||
|
||||
|
||||
|
||||
|
||||
GNOME Web is as clean and simple a web browser as you’ll find (Figure 1).
|
||||
|
||||
![GNOME Web][8]
|
||||
|
||||
Figure 1: The GNOME Web browser displaying a minimal amount of preferences for the user.
|
||||
|
||||
[Used with permission][9]
|
||||
|
||||
The GNOME Web manifesto reads:
|
||||
|
||||
A web browser is more than an application: it is a way of thinking, a way of seeing the world. Epiphany's principles are simplicity, standards compliance, and software freedom.
|
||||
|
||||
### Netsurf
|
||||
|
||||
The [Netsurf][10] minimal web browser opens almost faster than you can release the mouse button. Netsurf uses its own layout and rendering engine (designed completely from scratch), which is rather hit and miss in its rendering (Figure 2).
|
||||
|
||||

|
||||
|
||||
Although you might find Netsurf to suffer from rendering issues on certain sites, understand the Hubbub HTML parser is following the work-in-progress HTML5 specification, so there will be issues popup now and then. To ease those rendering headaches, Netsurf does include HTTPS support, web page thumbnailing, URL completion, scale view, bookmarks, full-screen mode, keyboard shorts, and no particular GUI toolkit requirements. That last bit is important, especially when you switch from one desktop to another.
|
||||
|
||||
For those curious as to the requirements for Netsurf, the browser can run on a machine as slow as a 30Mhz ARM 6 computer with 16MB of RAM. That’s impressive, by today’s standard.
|
||||
|
||||
### QupZilla
|
||||
|
||||
If you’re looking for a minimal browser that uses the Qt Framework and the QtWebKit rendering engine, [QupZilla][11] might be exactly what you’re looking for. QupZilla does include all the standard features and functions you’d expect from a web browser, such as bookmarks, history, sidebar, tabs, RSS feeds, ad blocking, flash blocking, and CA Certificates management. Even with those features, QupZilla still manages to remain a very fast lightweight web browser. Other features include: Fast startup, speed dial homepage, built-in screenshot tool, browser themes, and more.
|
||||
One feature that should appeal to average users is that QupZilla has a more standard preferences tools than found in many lightweight browsers (Figure 3). So, if going too far outside the lines isn’t your style, but you still want something lighter weight, QupZilla is the browser for you.
|
||||
|
||||
![QupZilla][13]
|
||||
|
||||
Figure 3: The QupZilla preferences tool.
|
||||
|
||||
[Used with permission][9]
|
||||
|
||||
### Otter Browser
|
||||
|
||||
Otter Browser is a free, open source attempt to recreate the closed-source offerings found in the Opera Browser. Otter Browser uses the WebKit rendering engine and has an interface that should be immediately familiar with any user. Although lightweight, Otter Browser does include full-blown features such as:
|
||||
|
||||
* Passwords manager
|
||||
|
||||
* Add-on manager
|
||||
|
||||
* Content blocking
|
||||
|
||||
* Spell checking
|
||||
|
||||
* Customizable GUI
|
||||
|
||||
* URL completion
|
||||
|
||||
* Speed dial (Figure 4)
|
||||
|
||||
* Bookmarks and various related features
|
||||
|
||||
* Mouse gestures
|
||||
|
||||
* User style sheets
|
||||
|
||||
* Built-in Note tool
|
||||
|
||||
|
||||
![Otter][15]
|
||||
|
||||
Figure 4: The Otter Browser Speed Dial tab.
|
||||
|
||||
[Used with permission][9]
|
||||
|
||||
Otter Browser can be run on nearly any Linux distribution from an [AppImage][16], so there’s no installation required. Just download the AppImage file, give the file executable permissions (with the command chmod u+x otter-browser-*.AppImage), and then launch the app with the command ./otter-browser*.AppImage.
|
||||
|
||||
Otter Browser does an outstanding job of rendering websites and could function as your go-to minimal browser with ease.
|
||||
|
||||
### Lynx
|
||||
|
||||
Let’s get really minimal. When I first started using Linux, back in ‘97, one of the web browsers I often turned to was a text-only take on the app called [Lynx][17]. It should come as no surprise that Lynx is still around and available for installation from the standard repositories. As you might expect, Lynx works from the terminal window and doesn’t display pretty pictures or render much in the way of advanced features (Figure 5). In fact, Lynx is as bare-bones a browser as you will find available. Because of how bare-bones this web browser is, it’s not recommended for everyone. But if you happen to have a gui-less web server and you have a need to be able to read the occasional website, Lynx can be a real lifesaver.
|
||||
|
||||
![Lynx][19]
|
||||
|
||||
Figure 5: The Lynx browser rendering the Linux.com page.
|
||||
|
||||
[Used with permission][9]
|
||||
|
||||
I have also found Lynx an invaluable tool when troubleshooting certain aspects of a website (or if some feature on a website is preventing me from viewing the content in a regular browser). Another good reason to use Lynx is when you only want to view the content (and not the extraneous elements).
|
||||
|
||||
### Plenty More Where This Came From
|
||||
|
||||
There are plenty more minimal browsers than this. But the list presented here should get you started down the path of minimalism. One (or more) of these browsers are sure to fill that need, whether you’re running it on a low-powered machine or not.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][20]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/intro-to-linux/2018/11/5-minimal-web-browsers-linux
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/jlwallen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.mozilla.org/en-US/firefox/new/
|
||||
[2]: https://www.chromium.org/
|
||||
[3]: https://vivaldi.com/
|
||||
[4]: https://www.google.com/chrome/
|
||||
[5]: https://www.merriam-webster.com/dictionary/epiphany
|
||||
[6]: https://developer.gnome.org/hig/stable/
|
||||
[7]: /files/images/minimalbrowsers1jpg
|
||||
[8]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/minimalbrowsers_1.jpg?itok=Q7wZLF8B (GNOME Web)
|
||||
[9]: /licenses/category/used-permission
|
||||
[10]: https://www.netsurf-browser.org/
|
||||
[11]: https://qupzilla.com/
|
||||
[12]: /files/images/minimalbrowsers3jpg
|
||||
[13]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/minimalbrowsers_3.jpg?itok=O8iMALWO (QupZilla)
|
||||
[14]: /files/images/minimalbrowsers4jpg
|
||||
[15]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/minimalbrowsers_4.jpg?itok=5bCa0z-e (Otter)
|
||||
[16]: https://sourceforge.net/projects/otter-browser/files/
|
||||
[17]: https://lynx.browser.org/
|
||||
[18]: /files/images/minimalbrowsers5jpg
|
||||
[19]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/minimalbrowsers_5.jpg?itok=p_Lmiuxh (Lynx)
|
||||
[20]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,79 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (Bio-Linux: A stable, portable scientific research Linux distribution)
|
||||
[#]: via: (https://opensource.com/article/18/11/bio-linux)
|
||||
[#]: author: (Matt Calverley https://opensource.com/users/mattcalverley)
|
||||
[#]: url: ( )
|
||||
|
||||
Bio-Linux: A stable, portable scientific research Linux distribution
|
||||
======
|
||||
Linux distro's integrated software approach offers powerful bioinformatic data analysis with a familiar look and feel.
|
||||
|
||||
|
||||
Bio-Linux was introduced and detailed in a [Nature Biotechnology paper in July 2006][1]. The distribution was a group effort by the Natural Environment Research Council in the UK. As the creators and authors point out, the analysis demands of high-throughput “-omic” (genomic, proteomic, metabolomic) science has necessitated the development of integrated computing solutions to analyze the resultant mountains of experimental data.
|
||||
|
||||
From this need, Bio-Linux was born. The distribution, [according to its creators][2], serves as a “free bioinformatics workstation platform that can be installed on anything from a laptop to a large server.” The current distro version, Bio-Linux 8, is built on an Ubuntu 14.04 LTS base. Thus, the general look and feel of Bio-Linux is similar to that of Ubuntu.
|
||||
|
||||
In my own work as a research immunologist, I can attest to both the need for and success of the integrated software approach in Bio-Linux's design and development. Bio-Linux functions as a true turnkey solution to data pipeline requirements of modern science. As the website mentions, Bio-Linux includes [more than 250 pre-installed software packages][3], many of which are specific to the requirements of bioinformatic data analysis.
|
||||
|
||||
The power of this approach becomes immediately evident when you try to duplicate the software installation process under another operating system. Integrating all software components and installing all required dependencies is immensely time-consuming, and in some instances is not even possible outside of the Linux operating system. The Bio-Linux distro provides a portable, stable, integrated environment with pre-installed software sufficient to begin a vast array of bioinformatic analysis tasks.
|
||||
|
||||
By now you’re probably saying, “I’m sold—how do I get this amazing distro?”
|
||||
|
||||
I’m glad you asked. I'll start by saying that there is excellent documentation on the Bio-Linux website. This [documentation][4] covers both installation instructions and a very thorough overview of using the distro.
|
||||
|
||||
The distro can be installed and run locally, run off a CD/DVD or USB, installed on a server, or run out of a virtual machine environment. To begin the installation process for local installation, [download the disk image or ISO][5] for the Bio-Linux distro. The disk image is a 3.3GB file, and depending on your internet download speed, this may be a good time to get a cup of coffee or take a nice nap.
|
||||
|
||||
Once the ISO has been downloaded, the Bio-Linux developers recommend using [UNetBootin][6], a freely available cross-platform software package used to make bootable USBs. There is a link provided for UNetBootin on the Bio-Linux website. I can attest to the effectiveness of UNetBootin in both Mac and Linux operating systems.
|
||||
|
||||
On Unix family operating systems (Mac OS and Linux), it is also possible to make a bootable USB from the command line using the `dd `command:
|
||||
|
||||
```
|
||||
sudo umount “USB location”
|
||||
|
||||
sudo dd bs=4M if=”ISO location” of =”USB location” conv=fdatasync
|
||||
```
|
||||
Regardless of the method you use, this might be another good time for a coffee break.
|
||||
|
||||
At this point in my installation, UNetBootin appeared to freeze at the `squashfs` file transfer during bootable USB creation. However, a quick check of the Ubuntu disks application confirmed that the file was still being written to the USB. In other words, be patient—it takes quite some time to make the bootable USB.
|
||||
|
||||
Once you’ve had your coffee and you have a finished USB in hand, you are ready to use Bio-Linux. As the Bio-Linux website points out, if you are trying to use a bootable USB with a Mac computer (particularly newer hardware versions), you may not be able to boot from the USB. There are workarounds, but they involve configuring the system for dual boot. Likewise, on Windows-based machines, it may be necessary to make changes to the boot order and possibly the secure boot settings for the machine from within BIOS.
|
||||
|
||||
From this point, how you use the distro is up to you. You can run the distro from the USB to test it. You can install the distro to your computer. You can even follow the instructions on the Bio-Linux website to make a VM instance of the distro or run it on a server. Regardless of how you use it, you have a high-powered bioinformatic data analysis workstation at your disposal.
|
||||
|
||||
Maybe you have a professional need for such a workstation, but even if you never use Bio-Linux as a professional researcher, it could provide a great resource for biology teaching professionals at all levels to introduce students to modern bioinformatics principles. For the price of a laptop and a USB, every school can have an in silico teaching resource to complement classroom lessons in the “-omics” age. Your only limitations are your creativity and the performance of your hardware.
|
||||
|
||||
### More on Linux
|
||||
|
||||
As an open source operating system with strong community support, the Linux kernel shares many of the strengths common to other successful open source software endeavors. Linux tends to be both stable and amenable to customization. It is also fairly hardware-agnostic, capable of running alongside other operating systems on a wide array of hardware configurations. In fact, installing Linux is a common method of regaining usability from dated hardware that is incapable of running other modern operating systems. Linux is also highly portable and can be run from any bootable external storage device, such as a USB drive, without the need to permanently install the operating system.
|
||||
|
||||
It is this combination of stability, customizability, and portability that initially drew me to Linux. Each Linux operating system variant is referred to as a distribution (or distro), and it seems as though there is a Linux distribution for every imaginable computing scenario or desire. The options can actually be rather intimidating, and I suspect they may often discourage people from trying Linux.
|
||||
|
||||
“How many different distributions can there possibly be?” you might wonder. If you have a few minutes, or even a few hours, have a look at [DistroWatch.com][7]. As its name implies, this site is devoted to the cataloging of all things Linux distribution-related. For visual learners, there is an amazing [Linux family tree][8] that really puts it into perspective.
|
||||
|
||||
While [entire books][9] are devoted to the topic of Linux distributions, the differences often depend on what software is included in the base installation, how the software is managed, and graphical differences affecting the “look and feel” of the distribution. Certainly, there are also subtleties of hardware compatibility, speed, and stability.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/bio-linux
|
||||
|
||||
作者:[Matt Calverley][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mattcalverley
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.nature.com/articles/nbt0706-801
|
||||
[2]: http://environmentalomics.org/bio-linux/
|
||||
[3]: http://environmentalomics.org/bio-linux-software-list/
|
||||
[4]: http://nebc.nerc.ac.uk/downloads/courses/Bio-Linux/bl8_latest.pdf
|
||||
[5]: http://environmentalomics.org/bio-linux-download/
|
||||
[6]: https://unetbootin.github.io/
|
||||
[7]: https://distrowatch.com/
|
||||
[8]: https://distrowatch.com/images/other/distro-family-tree.png
|
||||
[9]: https://www.amazon.com/Introducing-Linux-Distros-Dieguez-Castro/dp/1484213939
|
||||
@ -0,0 +1,127 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (Arch-Audit : A Tool To Check Vulnerable Packages In Arch Linux)
|
||||
[#]: via: (https://www.2daygeek.com/arch-audit-a-tool-to-check-vulnerable-packages-in-arch-linux/)
|
||||
[#]: author: (Prakash Subramanian https://www.2daygeek.com/author/prakash/)
|
||||
[#]: url: ( )
|
||||
|
||||
Arch-Audit : A Tool To Check Vulnerable Packages In Arch Linux
|
||||
======
|
||||
|
||||
We have to make the system up-to date to minimize the downtime and issues.
|
||||
|
||||
It’s one of the routine task for Linux administrator to patch the system once in a month or 60 days once or 90 days at maximum.
|
||||
|
||||
It would be sufficient schedule and we can’t do it this less than a month as it’s involve multiple activities and environments.
|
||||
|
||||
Basically infrastructure comes with Test, Development, QA a.k.a Staging & Prod environments.
|
||||
|
||||
Initially we will deploy the patches in the Test environment and corresponding team will be monitoring the system a week then they will give a status report like good or bad.
|
||||
|
||||
If it’s success then we will move forward to other environments. If everything is good then finally we will patch production servers.
|
||||
|
||||
Many of the organization has prepare to patch entire system. i mean full system update. It is a general patching schedule for a typical infrastructure.
|
||||
|
||||
In some of the infrastructure they may have only production environment so, we should not prepare for the full system update instead we can go with security patch to make the system more stable and secure.
|
||||
|
||||
Since Arch Linux and its derivatives distributions are fall under rolling release can be considered to be always up-to-date, as it uses the latest versions of software packages from the upstream.
|
||||
|
||||
In some cases if you want to update security patch alone then you have to use arch-audit tool to identify and fix the security patches.
|
||||
|
||||
### What is a Vulnerability?
|
||||
|
||||
A vulnerability is a security weakness in a software program or hardware components (firmware). It’s a flaw that can leave it open to attack.
|
||||
|
||||
To mitigate this we need to patch accordingly like for application/hardware it could be a code changes or config changes or parameter changes.
|
||||
|
||||
### What is Arch-Audit Tool?
|
||||
|
||||
[Arch-audit][1] is a tool like pkg-audit for Arch Linux system. It Uses data collected by the awesome Arch Security Team. It wont scan and find the vulnerable packages on your system like **yum –security check-update & yum updateinfo list available** and it will simply parse the <https://security.archlinux.org/> page and display the results in terminal. So, it would show the accurate data.
|
||||
|
||||
The Arch Security Team is a group of volunteers whose goal is to track security issues with Arch Linux packages. All issues are tracked on the Arch Linux security tracker.
|
||||
|
||||
The team was formerly known as the Arch CVE Monitoring Team. The mission of the Arch Security Team is to contribute to the improvement of the security of Arch Linux.
|
||||
|
||||
### How to Install arch-audit tool in Arch Linux
|
||||
|
||||
The arch-audit tool is available in community repository so you can use the Pacman Package Manager to install it.
|
||||
|
||||
```
|
||||
$ sudo pacman -S arch-audit
|
||||
```
|
||||
|
||||
Run the `arch-audit` tool to find the open vulnerable packages on Arch based distributions.
|
||||
|
||||
```
|
||||
$ arch-audit
|
||||
Package cairo is affected by CVE-2017-7475. Low risk!
|
||||
Package exiv2 is affected by CVE-2017-11592, CVE-2017-11591, CVE-2017-11553, CVE-2017-17725, CVE-2017-17724, CVE-2017-17723, CVE-2017-17722. Medium risk!
|
||||
Package libtiff is affected by CVE-2018-18661, CVE-2018-18557, CVE-2017-9935, CVE-2017-11613. High risk!. Update to 4.0.10-1!
|
||||
Package openssl is affected by CVE-2018-0735, CVE-2018-0734. Low risk!
|
||||
Package openssl-1.0 is affected by CVE-2018-5407, CVE-2018-0734. Low risk!
|
||||
Package patch is affected by CVE-2018-6952, CVE-2018-1000156. High risk!. Update to 2.7.6-7!
|
||||
Package pcre is affected by CVE-2017-11164. Low risk!
|
||||
Package systemd is affected by CVE-2018-6954, CVE-2018-15688, CVE-2018-15687, CVE-2018-15686. Critical risk!. Update to 239.300-1!
|
||||
Package unzip is affected by CVE-2018-1000035. Medium risk!
|
||||
Package webkit2gtk is affected by CVE-2018-4372. Critical risk!. Update to 2.22.4-1!
|
||||
```
|
||||
|
||||
The above result shows the vulnerability risk status as well such as Low, Medium and Critical.
|
||||
|
||||
To Show only vulnerable package names and their versions.
|
||||
|
||||
```
|
||||
$ arch-audit -q
|
||||
cairo
|
||||
exiv2
|
||||
libtiff>=4.0.10-1
|
||||
openssl
|
||||
openssl-1.0
|
||||
patch>=2.7.6-7
|
||||
pcre
|
||||
systemd>=239.300-1
|
||||
unzip
|
||||
webkit2gtk>=2.22.4-1
|
||||
```
|
||||
|
||||
To show only packages that have already been fixed.
|
||||
|
||||
```
|
||||
$ arch-audit --upgradable --quiet
|
||||
libtiff>=4.0.10-1
|
||||
patch>=2.7.6-7
|
||||
systemd>=239.300-1
|
||||
webkit2gtk>=2.22.4-1
|
||||
```
|
||||
|
||||
To cross check the above results, i’m going to test one of the package which is listed above in <https://www.archlinux.org/packages/> to confirm whether the vulnerability is still open or fixed it. Yes, it’s fixed and published the updated package in repository on yesterday.
|
||||
![][3]
|
||||
|
||||
To print only package names and associated CVEs alone.
|
||||
|
||||
```
|
||||
$ arch-audit -uf "%n|%c"
|
||||
libtiff|CVE-2018-18661,CVE-2018-18557,CVE-2017-9935,CVE-2017-11613
|
||||
patch|CVE-2018-6952,CVE-2018-1000156
|
||||
systemd|CVE-2018-6954,CVE-2018-15688,CVE-2018-15687,CVE-2018-15686
|
||||
webkit2gtk|CVE-2018-4372
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/arch-audit-a-tool-to-check-vulnerable-packages-in-arch-linux/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/ilpianista/arch-audit
|
||||
[2]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]: https://www.2daygeek.com/wp-content/uploads/2018/11/A-Tool-To-Check-Vulnerable-Packages-In-Arch-Linux.png
|
||||
93
sources/tech/20181129 4 open source Markdown editors.md
Normal file
93
sources/tech/20181129 4 open source Markdown editors.md
Normal file
@ -0,0 +1,93 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (4 open source Markdown editors)
|
||||
[#]: via: (https://opensource.com/article/18/11/markdown-editors)
|
||||
[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
|
||||
[#]: url: ( )
|
||||
|
||||
4 open source Markdown editors
|
||||
======
|
||||
If you're looking for an easy way to format Markdown text, these editors may fit your needs.
|
||||

|
||||
|
||||
I do most of my writing in a text editor and format it with [Markdown][1]—articles, essays, blog posts, and much more. I'm not the only one, either. Not only do countless people write with Markdown, but there are also more than a few publishing tools built around it.
|
||||
|
||||
Who'd have thought that a simple way to format web documents created by John Gruber and the late Aaron Schwartz would become so popular?
|
||||
|
||||
While most of my writing takes place in a text editor, I can understand the appeal of a dedicated Markdown editor. You get quick access to formatting, you can easily convert your documents to other formats, and you can get an instant preview.
|
||||
|
||||
If you're thinking about going Markdown and are looking for a dedicated editor, here are four open source options for your writing pleasure.
|
||||
|
||||
### Ghostwriter
|
||||
|
||||
[Ghostwriter][2] ranks in the top three of the dedicated Markdown editors I've used or tried. And I've used or tried a few!
|
||||
|
||||
|
||||
|
||||
As an editor, Ghostwriter is pretty much a blank canvas. Start typing and adding formatting by hand. If you don't want to do that, or are just learning Markdown and don't know what to add, you can select certain formatting from Ghostwriter's Format menu.
|
||||
|
||||
Admittedly, it's just basic formatting—lists, character formatting, and indenting. You'll have to add headings, code, and the like by hand. But the Task List option is interesting. I know a few people who create their to-do lists in Markdown, and this option makes creating and maintaining one much easier.
|
||||
|
||||
What sets Ghostwriter apart from other Markdown editors is its range of export options. You can choose the Markdown processor you want to use, including [Sundown][3], [Pandoc][4], or [Discount][5]. With a couple of clicks, you can convert what you're writing to HTML5, ODT, EPUB, LaTeX, PDF, or a Word document.
|
||||
|
||||
### Abricotine
|
||||
|
||||
If you like your Markdown editors simple, you'll like [Abricotine][6]. But don't let its simplicity fool you; Abricotine packs quite a punch.
|
||||
|
||||
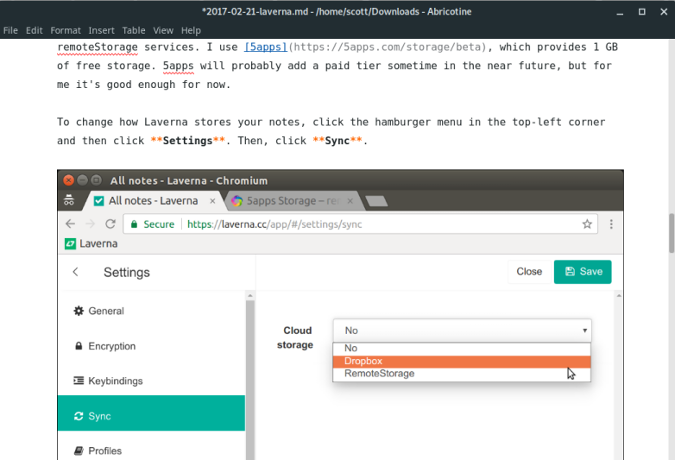
|
||||
|
||||
Like any other editor, you can enter formatting by hand or use the Format or Insert menus. Abricotine also has a menu for inserting a [GitHub Flavored Markdown][7] table. There are 16 pre-packaged table formats, and you can add rows or columns as you need them. If the tables are looking a bit messy, you can pretty them up by pressing Ctrl+Shift+B.
|
||||
|
||||
Abricotine can automatically display images, links, and math. You can turn all that off if you want to. The editor is, however, limited to exporting documents as HTML.
|
||||
|
||||
### Mark Text
|
||||
|
||||
Like Abricotine, [Mark Text][8] is a simple Markdown editor that might surprise you. It has a few features you might not expect and does quite a good job of handling documents formatted with Markdown.
|
||||
|
||||
|
||||
|
||||
Mark Text stays out of your way. There are no menus or toolbars. You get to the commands and functions by clicking the stacked menu in the top-left corner of the editor window. It's just you and your words.
|
||||
|
||||
The editor's default mode is a semi-WYSIWYG view, although you can change that to see the formatting code you've added to your writing. As for that formatting, Mark Text supports GitHub Flavored Markdown, so you can add tables and formatted blocks of code with syntax highlighting. In its default view, the editor displays any images in your document.
|
||||
|
||||
While Mark Text lacks Ghostwriter's range of export options, you can save your files as HTML or PDF. The output doesn't look too bad, either.
|
||||
|
||||
### Remarkable
|
||||
|
||||
[Remarkable][9] lies somewhere between Ghostwriter and Abricotine or Mark Text. It has that two-paned interface, but with a slightly more modern look. And it has a few useful features.
|
||||
|
||||
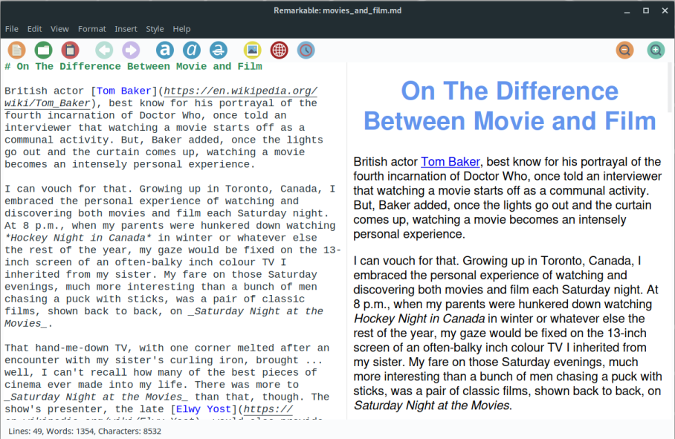
|
||||
|
||||
The first thing you notice about Remarkable is its [Material Design][10]-inspired look and feel. It's not for everyone, and I'll be honest: It took me a little while to get used to it. Once you do, it's easy to use.
|
||||
|
||||
You get quick access to formatting from the toolbar and the menus. You can also change the preview pane's style using one of 11 built-in Cascading Style Sheets or by creating one of your own.
|
||||
|
||||
Remarkable's export options are limited—you can export your work only as HTML or PDF files. You can, however, copy an entire document or a selected portion as HTML, which you can paste into another document or editor.
|
||||
|
||||
Do you have a favorite dedicated Markdown editor? Why not share it by leaving a comment?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/markdown-editors
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Markdown
|
||||
[2]: https://wereturtle.github.io/ghostwriter/
|
||||
[3]: https://github.com/vmg/sundown
|
||||
[4]: https://pandoc.org
|
||||
[5]: https://www.pell.portland.or.us/~orc/Code/discount/
|
||||
[6]: http://abricotine.brrd.fr/
|
||||
[7]: https://guides.github.com/features/mastering-markdown/
|
||||
[8]: https://marktext.github.io/website/
|
||||
[9]: https://remarkableapp.github.io/
|
||||
[10]: https://en.wikipedia.org/wiki/Material_Design
|
||||
@ -0,0 +1,344 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (Some Alternatives To ‘top’ Command line Utility You Might Want To Know)
|
||||
[#]: via: (https://www.ostechnix.com/some-alternatives-to-top-command-line-utility-you-might-want-to-know/)
|
||||
[#]: author: (SK https://www.ostechnix.com/author/sk/)
|
||||
[#]: url: ( )
|
||||
|
||||
Some Alternatives To ‘top’ Command line Utility You Might Want To Know
|
||||
======
|
||||
|
||||

|
||||
|
||||
Every now and then, I see a lot of open source programs, tools, and utilities are being added to GitHub and GitLab by developers across the world. Some of those programs are new and some of them are just alternative programs to the most popular and widely used existing Linux programs. In this tutorial, we are going to discuss about some good alternatives to [**‘top’**][1], the command line task manager program. Read on.
|
||||
|
||||
### Alternatives To ‘top’ Command line Utility
|
||||
|
||||
As of writing this guide, I am aware of the following 6 alternatives to Top program, namely:
|
||||
|
||||
1. Htop
|
||||
2. Vtop
|
||||
3. Gtop
|
||||
4. Gotop
|
||||
5. Ptop
|
||||
6. Hegemon
|
||||
|
||||
|
||||
|
||||
I will keep updating this list if I come across any similar utilities in the days to come. Bookmark this guide if you’re interested to know about such utilities.
|
||||
|
||||
#### 1\. Htop
|
||||
|
||||
The **htop** is a popular, open source and cross-platform interactive process manager. It is my favorite system activity monitor tool. htop is an enhanced version of the classic top program. It is originally developed for Linux, but the developer extended its support to other Unix-like operating systems such as FreeBSD and Mac OS X. htop is free open source, and ncurses-based utility released under GPLv2.
|
||||
|
||||
Compared to the classic top command, it has the following few advantages.
|
||||
|
||||
* htop starts faster than top program.
|
||||
* htop allows us to scroll horizontally and vertically to view all processes and full command lines.
|
||||
* There is no need to type the PID to kill a process in htop. But in top, you need to type the PID to kill the process.
|
||||
* There is no need to type PID to change the priority of a process, but in top command, you do.
|
||||
* We can kill multiple processes at once in htop.
|
||||
* In top program you are subject to a delay for each unassigned key you press. It is especially annoying when multi-key escape sequences are triggered by accident.
|
||||
|
||||
|
||||
|
||||
**Installing htop**
|
||||
|
||||
htop is available in the default repositories of most Linux distributions.
|
||||
|
||||
On Arch-based systems, run the following command to install htop.
|
||||
|
||||
```
|
||||
$ sudo pacman -S htop
|
||||
```
|
||||
|
||||
On Debian-based systems:
|
||||
|
||||
```
|
||||
$ sudo apt install htop
|
||||
```
|
||||
|
||||
On RPM-based systems:
|
||||
|
||||
```
|
||||
$ sudo dnf install htop
|
||||
```
|
||||
|
||||
Or,
|
||||
|
||||
```
|
||||
$ sudo yum install htop
|
||||
```
|
||||
|
||||
On openSUSE:
|
||||
|
||||
```
|
||||
$ sudo zypper in htop
|
||||
```
|
||||
|
||||
**Usage**
|
||||
|
||||
When you htop command without any arguments, you will see the following screen.
|
||||
|
||||
```
|
||||
$ htop
|
||||
```
|
||||

|
||||
|
||||
As you can see, htop task manager shows total memory and swap usage, total number of tasks, system average load and system uptime on the top. On the bottom side, just like top command, it displays the list of processes in multiple columns. Each column displays details such as pid, user, priority, nice value, virtual memory usage, cpu usage, memory usage by each process etc. You can read about these parameters in the top command tutorial linked in the first paragraph.
|
||||
|
||||
Unlike top command, htop allows you to perform each operation with a dedicated function key. Here is the list of shortcut keys to interact with htop.
|
||||
|
||||
* **F1, h, ?** – Open help section.
|
||||
* **F2, S(Shift+s)** – Go to the setup section, where you can configure the meters displayed at the top of the screen, set various display options, choose among color schemes, and select which columns are displayed, in which order etc.
|
||||
* **F3, /** – Search the command lines of all the displayed processes.
|
||||
* **F4, \** – Filter processes. Just type the part of the process name and you will see only the processes that matches the name. Press F4 again and hit ESC key to cancel filtering.
|
||||
* **F5, t** – Switch between tree view and default view. Press + to view the sub-tree.
|
||||
* **F6, <, >** – Sort the processes by PID, USER, PRIORITY, NICE value, CPU usage, MEMORY usage etc.
|
||||
* **F7, ]** – Increase the selected process’s priority.
|
||||
* **F8, [** – Decrease the selected process’s priority.
|
||||
* **F9, k** – Kill the processes. Use the UP/DOWN arrows to choose the process and press F9 or k to kill it.
|
||||
* **F10, q** – Exit htop.
|
||||
|
||||
|
||||
|
||||
All shortcuts keys are given at the bottom of the htop interface.
|
||||
|
||||
Please note that some of these function keys might be assigned to various Terminal operations. For example, when I hit the F2 key, it didn’t go to htop setup section. Instead it displayed the option to set the title to my Terminal window. In such cases, you might need to other keys given along with the function keys.
|
||||
|
||||
Apart from the above mentioned keys, there are few more keys available to perform different functions. For example,
|
||||
|
||||
* Press **‘u’** to show processes owned by a user.
|
||||
* **Shift+m** will sort the processes by memory usage.
|
||||
* **Shift+p** – Sort the processes by processor usage.
|
||||
* **Shit+t** – Sort the processes by time.
|
||||
* **CTRL+l** – Refresh screen.
|
||||
|
||||
|
||||
|
||||
htop can do everything using the shortcut keys without having to mention any options when launching it. However, you can use some flags when starting it.
|
||||
|
||||
For example, to start htop displaying only processes owned by given user, run:
|
||||
|
||||
```
|
||||
$ htop -u <username>
|
||||
```
|
||||
|
||||
Change the Output Refresh Interval:
|
||||
|
||||
```
|
||||
$ htop -d 10
|
||||
```
|
||||
|
||||
As you can see, htop usage is incredibly easier than the usage of top command.
|
||||
|
||||
Refer htop man pages to know more about the available options and functionalities.
|
||||
|
||||
```
|
||||
$ man htop
|
||||
```
|
||||
|
||||
Also, refer the project home page and HitHub repository.
|
||||
|
||||
+ [htop website](http://hisham.hm/htop/)
|
||||
+ [htop GitHub Repository](https://github.com/hishamhm/htop)
|
||||
|
||||
#### 2\. Vtop
|
||||
|
||||
**Vtop** is yet another alternative to good-old top utility. It is a free and open source, command-line system activity monitor written in **NodeJS** and released under MIT. It uses unicode braille characters to draw CPU and Memory charts, helping you to visualize spikes.
|
||||
|
||||
Make sure you have NodeJS installed on your system. If not installed yet, refer the following guide.
|
||||
|
||||
Once node installed, run the following command to install Vtop.
|
||||
|
||||
```
|
||||
$ npm install -g vtop
|
||||
```
|
||||
|
||||
After installing Vtop, simply run vtop to start monitoring.
|
||||
|
||||
```
|
||||
$ vtop
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
![][3]
|
||||
|
||||
As you can see, Vtop interface is little bit different than top and htop programs. It displays each details in a separate box layout. You will see all shortcuts keys to interact with Vtop at the bottom.
|
||||
|
||||
Here is the list of shortcuts:
|
||||
|
||||
* **dd** – Kill the processes.
|
||||
* **UP** arrow or **k** – Move up.
|
||||
* **DOWN** arrow or **j** – Move down.
|
||||
* **Left** arrow or or **h** to – Zoom the graphs in.
|
||||
* **Right** arrow or **l** – Zoom the graphs out.
|
||||
* **g** – Jump to top of the process list.
|
||||
* **SHIFT+g** – Jump to end of the process list.
|
||||
* **c** – Sort processes by CPU usage.
|
||||
* **m** – Sort processes by memory usage.
|
||||
|
||||
|
||||
|
||||
For more details, refer the following Vtop resources.
|
||||
|
||||
+ [Vtop website](http://parall.ax/vtop)
|
||||
+ [Vtop GitHub Repository](https://github.com/MrRio/vtop)
|
||||
|
||||
|
||||
#### 3\. Gtop
|
||||
|
||||
Gtop is same as Vtop system activity monitor. It is also written in NodeJS and released under MIT license.
|
||||
|
||||
To install it, run:
|
||||
|
||||
```
|
||||
$ npm install gtop -g
|
||||
```
|
||||
|
||||
Start gtop using command:
|
||||
|
||||
```
|
||||
$ gtop
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||

|
||||
|
||||
I noticed Gtop interface is very nice. It showed each elements with different set of colors which is eye-pleasing.
|
||||
|
||||
Keyboard shortcuts:
|
||||
|
||||
* **p** – Sort processes by process Id.
|
||||
* **c** – Sort processes by CPU usage.
|
||||
* **m** – Sort processes by Memory usage.
|
||||
* **q** or **ctrl+c** – Quit Gtop.
|
||||
|
||||
|
||||
|
||||
For more details, visit Gtop GitHub page.
|
||||
|
||||
+ [Gtop GitHub Repository](https://github.com/aksakalli/gtop)
|
||||
|
||||
|
||||
#### 4\. Gotop
|
||||
|
||||
As the name says, **Gotop** is a TUI graphical activity monitor, written in **Go** programming language. It is completely free, open source and inspired by **gtop** and **vtop** programs which we mentioned in the previous sections. We already have written about it a while ago. If you’re interested to learn about it, please visit the following link.
|
||||
|
||||
+ [Gotop – Yet Another TUI Graphical Activity Monitor, Written In Go
|
||||
](https://www.ostechnix.com/manage-python-packages-using-pip/)
|
||||
|
||||
#### 5\. Ptop
|
||||
|
||||
Some of you might not like programs written in NodeJS and Go. If you’re one of them, there is another process monitor program named **Ptop** , which is written in **Python** programming language. It is free, open source system activity monitor, released under MIT license.
|
||||
|
||||
Ptop is compatible with both Python2.x and Python3.x, so you can easily install it using **Pip** , a package manager to install programs developed in Python. If you haven’t installed Pip yet, refer the following link.
|
||||
|
||||
+ [How To Manage Python Packages Using Pip](https://www.ostechnix.com/manage-python-packages-using-pip/)
|
||||
|
||||
After installing Pip, run the following command to install ptop.
|
||||
|
||||
```
|
||||
$ pip install ptop
|
||||
```
|
||||
|
||||
Or, you can compile from source as shown below.
|
||||
|
||||
```
|
||||
$ git clone https://github.com/darxtrix/ptop
|
||||
$ cd ptop/
|
||||
$ pip install -r requirements.txt # install requirements
|
||||
$ sudo python setup.py install
|
||||
```
|
||||
|
||||
To update Ptop, run:
|
||||
|
||||
```
|
||||
$ pip install --upgrade ptop
|
||||
```
|
||||
|
||||
Even if you don’t update, Ptop will prompt you if you’d like to update to the latest version when launch it for the first time.
|
||||
|
||||
Now, let us run ptop and see what happens.
|
||||
|
||||
```
|
||||
$ ptop
|
||||
```
|
||||
|
||||
Here you go!
|
||||

|
||||
Here is the list of shortcuts keys to interact with ptop:
|
||||
|
||||
* **Ctrl+k** – Kill the process.
|
||||
* **Ctrl+n** – Sort processes by memory usage.
|
||||
* **Ctrl+t** – Sort processes by process lifetime.
|
||||
* **Ctrl+r** – Reset the stats.
|
||||
* **Ctrl+f** – Filter a specific process information. Just type process name and you will see its details only.
|
||||
* **Ctrl+l** – View the information of a selected process.
|
||||
* **g** – Go to the top of the process list.
|
||||
* **Ctrl+q** – Quit Ptop.
|
||||
|
||||
|
||||
|
||||
Ptop has a feature to change the theme. If you want a pretty output of Ptop, you could use any one of the available themes. Currently the following themes are supported:
|
||||
|
||||
* colorful
|
||||
* elegant
|
||||
* simple
|
||||
* dark
|
||||
* light
|
||||
|
||||
|
||||
|
||||
To set a theme, for example colorful, simply run:
|
||||
|
||||
```
|
||||
$ ptop -t colorful
|
||||
```
|
||||
|
||||
To view help section, use **-h** :
|
||||
|
||||
```
|
||||
$ ptop -h
|
||||
```
|
||||
|
||||
For more details, refer the project’s GitHub page.
|
||||
|
||||
+ [Ptop Github Repository](https://github.com/darxtrix/ptop)
|
||||
|
||||
#### 6\. Hegemon
|
||||
|
||||
**Hegemon** is another system activity monitor application written in **Rust** programming language. If you’re fan of programs written in Rust, hegemon might be a good choice. We have published a brief review about Hegemon a while ago. Please visit the following link to know more about this tool.
|
||||
|
||||
[Hegemon – A Modular System Monitor Application Written In Rust](https://www.ostechnix.com/hegemon-a-modular-system-monitor-application-written-in-rust/)
|
||||
|
||||
### Conclusion
|
||||
|
||||
You know now six alternatives to Top program. I won’t claim these programs are better than or best replacement for ‘top’ program. But it is always nice to know some alternatives. I use htop mostly to monitor the processes. Now is your turn. Have you used any tools listed here? Great! Which is your favorite tool and why? Please share your experience in the comment section below.
|
||||
|
||||
More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/some-alternatives-to-top-command-line-utility-you-might-want-to-know/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/the-top-command-tutorial-with-examples-for-beginners/
|
||||
[2]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]: http://www.ostechnix.com/wp-content/uploads/2018/11/vtop.png
|
||||
@ -0,0 +1,125 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (Boxing yourself in on the Linux command line)
|
||||
[#]: via: (https://opensource.com/article/18/12/linux-toy-boxes)
|
||||
[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
|
||||
[#]: url: ( )
|
||||
|
||||
Boxing yourself in on the Linux command line
|
||||
======
|
||||
Learn how to use the boxes utility to draw shapes with characters at the Linux terminal and make your words stand out.
|
||||

|
||||
|
||||
It's the holiday season, and every Linux terminal user deserves a little gift. It doesn't matter whether you celebrate Christmas, another holiday, or nothing at all. So I'm gathering together a collection of 24 Linux command-line toys over the next few weeks for you to enjoy and share with your friends. Let's have a little fun and add a little joy to a month that, at least here in the northern hemisphere, can be a little bit cold and dreary.
|
||||
|
||||
Chances are, there will be a few that you've heard of before. But, hopefully, we'll all have a chance to learn something new. (I know I did when doing some research to make sure I could make it to 24.)
|
||||
|
||||
The first of our 24 Linux terminal toys is a program called boxes. Why start with boxes? Because it's going to be hard to wrap up all of our other command-line presents to you without it!
|
||||
|
||||
On my Fedora machine, boxes wasn't installed by default, but it was in my normal repositories, so installing it was as simple as
|
||||
|
||||
```
|
||||
$ sudo dnf install boxes -y
|
||||
```
|
||||
|
||||
If you're on a different distribution, there's a good chance you'll find it in your default repositories as well.
|
||||
|
||||
Boxes a utility I really wish I had in my high school and college computer science courses, where well-intentioned teachers insisted I provide very specific looking comment at the beginning of every source file, function, code block, etc.
|
||||
|
||||
```
|
||||
/***************/
|
||||
/* Hello World */
|
||||
/***************/
|
||||
```
|
||||
|
||||
It turns out, once you add a few lines of text inside, formatting them can get, well, tedious. Enter boxes. Boxes is a simple utility for surrounding a block of text with an ASCII art-style box. It comes with defaults for source code commenting, as well as other options.
|
||||
|
||||
It's really easy to use. Using pipes, I can push a short greeting into a box.
|
||||
|
||||
```
|
||||
$ cat greeting.txt | boxes -d diamonds -a c
|
||||
```
|
||||
|
||||
Which will give us the output as follows:
|
||||
|
||||
```
|
||||
/\ /\ /\
|
||||
/\//\\/\ /\//\\/\ /\//\\/\
|
||||
/\//\\\///\\/\//\\\///\\/\//\\\///\\/\
|
||||
//\\\//\/\\///\\\//\/\\///\\\//\/\\///\\
|
||||
\\//\/ \/\\//
|
||||
\/ \/
|
||||
/\ I'm wishing you all a /\
|
||||
//\\ joyous holiday season //\\
|
||||
\\// and a Happy Gnu Year! \\//
|
||||
\/ \/
|
||||
/\ /\
|
||||
//\\/\ /\//\\
|
||||
\\///\\/\//\\\///\\/\//\\\///\\/\//\\\//
|
||||
\/\\///\\\//\/\\///\\\//\/\\///\\\//\/
|
||||
\/\\//\/ \/\\//\/ \/\\//\/
|
||||
\/ \/ \/
|
||||
```
|
||||
|
||||
Or perhaps something more fun, like:
|
||||
|
||||
```
|
||||
echo "I am a dog" | boxes -d dog -a c
|
||||
```
|
||||
|
||||
Which will, unsurprisingly, give you the following:
|
||||
|
||||
```
|
||||
__ _,--="=--,_ __
|
||||
/ \." .-. "./ \
|
||||
/ ,/ _ : : _ \/` \
|
||||
\ `| /o\ :_: /o\ |\__/
|
||||
`-'| :="~` _ `~"=: |
|
||||
\` (_) `/
|
||||
.-"-. \ | / .-"-.
|
||||
.---{ }--| /,.-'-.,\ |--{ }---.
|
||||
) (_)_)_) \_/`~-===-~`\_/ (_(_(_) (
|
||||
( I am a dog )
|
||||
) (
|
||||
'---------------------------------------'
|
||||
```
|
||||
|
||||
Boxes comes with [lots of options][1] for padding, position, and even processing regular expressions. You can learn more about boxes on the [project's homepage][2], or head over to [GitHub][3] to download the source code or contribute your own box. In fact, if you're looking for an idea to submit, I've got an idea for you: why not a holiday present?
|
||||
|
||||
```
|
||||
_ _
|
||||
/_\/_\
|
||||
_______\_\/_/_______
|
||||
| ///\\\ |
|
||||
| /// \\\ |
|
||||
| |
|
||||
| "Happy pull |
|
||||
| request!" |
|
||||
|____________________|
|
||||
```
|
||||
|
||||
Boxes is open source under a GPLv2 license.
|
||||
|
||||
Do you have a favorite command-line toy that you think I ought to profile? The calendar for this series is mostly filled out but I've got a few spots left. Let me know in the comments below, and I'll check it out. If there's space, I'll try to include it. If not, but I get some good submissions, I'll do a round-up of honorable mentions at the end.
|
||||
|
||||
Or check out tomorrow's command-line toy, [Drive a locomotive through your Linux terminal][4].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/linux-toy-boxes
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-baker
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://boxes.thomasjensen.com/examples.html
|
||||
[2]: https://boxes.thomasjensen.com/
|
||||
[3]: https://github.com/ascii-boxes/boxes
|
||||
[4]: https://opensource.com/article/18/12/linux-toy-sl
|
||||
@ -0,0 +1,71 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (Drive a locomotive through your Linux terminal)
|
||||
[#]: via: (https://opensource.com/article/18/12/linux-toy-sl)
|
||||
[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
|
||||
[#]: url: ( )
|
||||
|
||||
Drive a locomotive through your Linux terminal
|
||||
======
|
||||
Using the sl command, you can train yourself to get on track with a fun command-line experience.
|
||||
|
||||
|
||||
It's December, and every Linux terminal user deserves a reward just for making through the year. So we're bringing you a sort of advent calendar of Linux command-line toys. What's a command-line toy? It might be a game, a pointless little time waster, or just something to bring you joy at the terminal.
|
||||
|
||||
**sl** , which is short for steam locomotive.
|
||||
|
||||
Today's Linux command-line toy is a suggestion from Opensource.com community moderator [Ben Cotton][1] . Ben suggested, which is short for steam locomotive.
|
||||
|
||||
It's also, conveniently and not coincidentally, a common typo for the Linux **ls** command. Want to stop mistyping ls? Try installing **sl**. It's probably packaged for your default repos. For me, in Fedora, that means it was as simple to install as:
|
||||
|
||||
```
|
||||
$ sudo dnf install sl -y
|
||||
```
|
||||
|
||||
Now, just type **sl** to try it out.
|
||||
|
||||

|
||||
|
||||
You may notice, as I did, that **Ctrl+C** doesn't derail your train, so you have to wait for the entire train to pass. That'll teach you to mistype **ls**!
|
||||
|
||||
Want to check out the source to **sl**? It's over [on GitHub][2].
|
||||
|
||||
**sl** is also a great opportunity to share a personal PSA about open source licensing. While its [license][3] was "open source enough" to be packaged for my distribution, it's not technically an [OSI-approved][4] license. After the copyright line, the license reads simply:
|
||||
|
||||
```
|
||||
Everyone is permitted to do anything on this program including copying,
|
||||
modifying, and improving, unless you try to pretend that you wrote it.
|
||||
i.e., the above copyright notice has to appear in all copies.
|
||||
THE AUTHOR DISCLAIMS ANY RESPONSIBILITY WITH REGARD TO THIS SOFTWARE.
|
||||
```
|
||||
|
||||
Unfortunately, when you chose a license that's not OSI-approved, you may accidentally be creating extra work for your users, as they must figure out whether your license will work for their situation. Do their corporate policies allow them to contribute? Can they even legally use the program? Does the license mesh with the license of another program they wish to integrate with it?
|
||||
|
||||
Unless you're a lawyer (and perhaps, even if you are), navigating the space of non-standard licenses can be tricky. So if you're still looking for a New Year's Resolution, why not resolve to choose only OSI-approved licenses for any new projects you start in 2019.
|
||||
|
||||
No disrespect to the creator, though. **sl** is still a great little command-line toy.
|
||||
|
||||
Do you have a favorite command-line toy that you think I ought to profile? The calendar for this series is mostly filled out but I've got a few spots left. Let me know in the comments below, and I'll check it out. If there's space, I'll try to include it. If not, but I get some good submissions, I'll do a round-up of honorable mentions at the end.
|
||||
|
||||
Check out yesterday's toy, [Box yourself in on the Linux command line][5], and check back tomorrow for another!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/linux-toy-sl
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-baker
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/users/bcotton
|
||||
[2]: https://github.com/mtoyoda/sl
|
||||
[3]: https://github.com/mtoyoda/sl/blob/master/LICENSE
|
||||
[4]: https://opensource.org/licenses
|
||||
[5]: https://opensource.com/article/18/12/linux-toy-boxes
|
||||
177
translated/tech/20180228 Emacs -2- Introducing org-mode.md
Normal file
177
translated/tech/20180228 Emacs -2- Introducing org-mode.md
Normal file
@ -0,0 +1,177 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (oneforalone)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (Emacs #2: Introducing org-mode)
|
||||
[#]: via: (https://changelog.complete.org/archives/9865-emacs-2-introducing-org-mode)
|
||||
[#]: author: (John Goerzen http://changelog.complete.org/archives/author/jgoerzen)
|
||||
[#]: url: ( )
|
||||
|
||||
Emacs 系列(二):`Org` 模式介绍
|
||||
======
|
||||
|
||||
在我 Emacs 系列中的[第一片文章][1]里,我介绍了我在用了几十年的 vim 后转向了 Emacs,`Org` 模式就是我为什么这样做的原因。
|
||||
|
||||
`Org` 模式的精简和高效真的震惊了我,它真的是个“杀手”应用。
|
||||
|
||||
**所以,`Org`模式到底是什么呢?**
|
||||
|
||||
这是我昨天写的:
|
||||
|
||||
> 它是一个组织信息的平台,它的主页上这样写着:“一切都是纯文本:`Org` 模式用于记笔记、维护待办事项列表、计划项目和使用快速有效的纯文本系统编写文档。”
|
||||
|
||||
这是事实,但并不是很准确。`Org` 模式是一个你用来组织事务的小工具。它有一些非常合理的默认设置,但也允许你自己定制。
|
||||
|
||||
主要突出在这几件事上:
|
||||
|
||||
* **维护待办事项列表** : 项目可以分散在 `Org` 文件中,包含附件,有标签,截止日期,时间表。有一个方便的“日程”视图,显示需要做什么。项目也可以重复。
|
||||
* **编写文档** : `Org` 模式有个特殊的功能来生成 HTML、LaTeX、 幻灯片(用 LaTeX beamer)和其他所有的格式。它也支持直接在缓冲区中运行和编写几乎任何一种 Emacs 所支持的的语言。如果你想要深入了解这项功能的话,参阅[开发者文档][2]。官网给出的[文档][3]完全不对。
|
||||
* **记笔记** : 对,它也能做笔记。通过全文所搜,文件的交叉引用(类似 wiki),UUID,甚至可以与其他的系统进行交互(通过信息 ID 与 mu4e 交互, 通过 ERC 的日志等等……)
|
||||
|
||||
**开始**
|
||||
|
||||
我强烈建议去阅读 [Carsten Dominik 写的一篇很棒的关于 `Org` 模式的 Google 讲话][4]。那篇文章真的很赞。
|
||||
|
||||
Emacs 中自带了 `Org` 模式,但如果你想要个比较新的版本的话,Debian 用户可以使用命令 `apt-get install org-mode` 来更新,或者使用 Emacs 的包管理系统命令 `M-x package-install RET org-mode RET`。
|
||||
|
||||
现在,你可能需要阅读一下 `Org` 模式的精简版教程中的[导读部分][5],特别注意,你要设置下[启动部分][6]中提到的那些键的绑定。
|
||||
|
||||
**一份好的教程**
|
||||
|
||||
我会给出一些好的教程和介绍的链接,但这篇文章不会是一篇教程。特别是在本文末尾,有两个很不错的视频链接。
|
||||
|
||||
**我的一些配置**
|
||||
|
||||
我将在这里记录下一些我的配置并介绍它的作用。你没有必要每行每句将它拷贝到你的配置中——这只是一个参考,告诉你哪些可以配置,要怎么在手册中查找,或许只是一个“我现在该怎么做”的参考。
|
||||
|
||||
首先,我将 Emacs 的编码默认设置为 UTF-8。
|
||||
```
|
||||
(prefer-coding-system 'utf-8) (set-language-environment "UTF-8")
|
||||
```
|
||||
|
||||
`Org` 模式中可以打开 URL。默认的,它会在 Firefox 中打开,但我喜欢用 Chromium。
|
||||
```
|
||||
(setq browse-url-browser-function 'browse-url-chromium)
|
||||
```
|
||||
|
||||
我把基本的键的绑定和设为教程里的一样,再加上 `M-RET` 的操作的配置。
|
||||
|
||||
```
|
||||
(global-set-key "\C-cl" 'org-store-link)
|
||||
(global-set-key "\C-ca" 'org-agenda)
|
||||
(global-set-key "\C-cc" 'org-capture)
|
||||
(global-set-key "\C-cb" 'org-iswitchb)
|
||||
|
||||
(setq org-M-RET-may-split-line nil)
|
||||
```
|
||||
|
||||
|
||||
**捕获配置**
|
||||
|
||||
我可以在 Emacs 的任何模式中按 `C-c c`,按下后它就会[帮我捕获某些事][7],其中包括一个指向我正在处理事务的链接。
|
||||
|
||||
你可以通过定义[捕获模板][8]来配置它。我将保存两个日志文件,作为会议、电话等的通用记录。一个是私人用的,一个是办公用的。如果我按下 `C-c c j`,它就会帮我捕获为私人项. 下面包含 `%a` 的配置是表示我当前的位置(或是我使用 `C-c l` 保存的链接)的链接。
|
||||
|
||||
```
|
||||
(setq org-default-notes-file "~/org/tasks.org")
|
||||
(setq org-capture-templates
|
||||
'(
|
||||
("t" "Todo" entry (file+headline "inbox.org" "Tasks")
|
||||
"* TODO %?\n %i\n %u\n %a")
|
||||
("n" "Note/Data" entry (file+headline "inbox.org" "Notes/Data")
|
||||
"* %? \n %i\n %u\n %a")
|
||||
("j" "Journal" entry (file+datetree "~/org/journal.org")
|
||||
"* %?\nEntered on %U\n %i\n %a")
|
||||
("J" "Work-Journal" entry (file+datetree "~/org/wjournal.org")
|
||||
"* %?\nEntered on %U\n %i\n %a")
|
||||
))
|
||||
(setq org-irc-link-to-logs t)
|
||||
```
|
||||
|
||||
我喜欢通过 UUID 来建立链接,这让我在文件之间移动而不会破坏位置。当我要 `Org` 存储一个链接目标以便将来插入时,以下配置有助于生成 UUID。
|
||||
|
||||
```
|
||||
(require 'org-id)
|
||||
(setq org-id-link-to-org-use-id 'create-if-interactive)
|
||||
```
|
||||
|
||||
**议程配置**
|
||||
|
||||
我喜欢将星期天作为一周的开始,当我将某件事标记为完成时,我也喜欢记下时间。
|
||||
|
||||
```
|
||||
(setq org-log-done 'time)
|
||||
(setq org-agenda-start-on-weekday 0)
|
||||
```
|
||||
|
||||
**文件归档配置**
|
||||
|
||||
在这我将配置它, 让它知道在议程中该使用哪些文件,而且在纯文本的搜索中添加一点点小功能。我喜欢保留一个通用的文件夹(我可以从其中移动或“重新归档”内容),然后将个人和工作项的任务、日志和知识库分开。
|
||||
|
||||
```
|
||||
(setq org-agenda-files (list "~/org/inbox.org"
|
||||
"~/org/email.org"
|
||||
"~/org/tasks.org"
|
||||
"~/org/wtasks.org"
|
||||
"~/org/journal.org"
|
||||
"~/org/wjournal.org"
|
||||
"~/org/kb.org"
|
||||
"~/org/wkb.org"
|
||||
))
|
||||
(setq org-agenda-text-search-extra-files
|
||||
(list "~/org/someday.org"
|
||||
"~/org/config.org"
|
||||
))
|
||||
|
||||
(setq org-refile-targets '((nil :maxlevel . 2)
|
||||
(org-agenda-files :maxlevel . 2)
|
||||
("~/org/someday.org" :maxlevel . 2)
|
||||
("~/org/templates.org" :maxlevel . 2)
|
||||
)
|
||||
)
|
||||
(setq org-outline-path-complete-in-steps nil) ; Refile in a single go
|
||||
(setq org-refile-use-outline-path 'file)
|
||||
```
|
||||
|
||||
**外观配置**
|
||||
|
||||
我喜欢一个较漂亮的的屏幕。在你开始习惯 `Org` 之后,你可以试试这个。
|
||||
|
||||
```
|
||||
(require 'org-bullets)
|
||||
(add-hook 'org-mode-hook
|
||||
(lambda ()
|
||||
(org-bullets-mode t)))
|
||||
(setq org-ellipsis "⤵")
|
||||
```
|
||||
|
||||
**下一篇**
|
||||
|
||||
希望这篇文章展示了 `Org` 模式的一些功能。接下来,我将介绍如何定制 `TODO` 关键字和标记、归档旧任务、将电子邮件转发到 `Org` 模式,以及如何使用 `git` 在不同电脑之间进行同步。
|
||||
|
||||
你也可以查看[本系列的所有文章列表][9]。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://changelog.complete.org/archives/9865-emacs-2-introducing-org-mode
|
||||
|
||||
作者:[John Goerzen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[oneforalone](https://github.com/oneforalone)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://changelog.complete.org/archives/author/jgoerzen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://changelog.complete.org/archives/9861-emacs-1-ditching-a-bunch-of-stuff-and-moving-to-emacs-and-org-mode
|
||||
[2]: http://www.howardism.org/Technical/Emacs/literate-devops.html
|
||||
[3]: https://orgmode.org/worg/
|
||||
[4]: https://www.youtube.com/watch?v=oJTwQvgfgMM
|
||||
[5]: https://orgmode.org/guide/Introduction.html#Introduction
|
||||
[6]: https://orgmode.org/guide/Activation.html#Activation
|
||||
[7]: https://orgmode.org/guide/Capture.html#Capture
|
||||
[8]: https://orgmode.org/guide/Capture-templates.html#Capture-templates
|
||||
[9]: https://changelog.complete.org/archives/tag/emacs2018
|
||||
131
translated/tech/20180302 Emacs -3- More on org-mode.md
Normal file
131
translated/tech/20180302 Emacs -3- More on org-mode.md
Normal file
@ -0,0 +1,131 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (oneforalone)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (Emacs #3: More on org-mode)
|
||||
[#]: via: (https://changelog.complete.org/archives/9877-emacs-3-more-on-org-mode)
|
||||
[#]: author: (John Goerzen http://changelog.complete.org/archives/author/jgoerzen)
|
||||
[#]: url: ( )
|
||||
|
||||
Emacs 系列(三): `Org` 模式的补充
|
||||
======
|
||||
|
||||
这是 [Emacs 和 `Org` 模式系列][1]的第三篇。
|
||||
|
||||
**Todo 的跟进及关键字**
|
||||
|
||||
当你使用 `Org` 模式来跟进的的 TODO 时,它有多种状态。你可以用 `C-c C-t` 来快速切换状态。我将它设为这样:
|
||||
|
||||
```
|
||||
(setq org-todo-keywords '(
|
||||
(sequence "TODO(t!)" "NEXT(n!)" "STARTED(a!)" "WAIT(w@/!)" "OTHERS(o!)" "|" "DONE(d)" "CANCELLED(c)")
|
||||
))
|
||||
```
|
||||
|
||||
在这里,我设置了一个任务未完成的五种状态:`TODO`、`NEXT`、`STARTED`、`WAIT` 及 `OTHERS`。每一个状态都单个字的快捷键(t,n,a 等)。这些符号之后的状态被认为是“完成”的状态。我有两个“完成”状态:`DONE`(已经完成)及 `CANCELLED`(还没完成,但由于其它的原因无法完成)。
|
||||
|
||||
`!` 的含义是记录某项更改为状态的时间。我不把这个添加到完成的状态,是因为它们已经被记录了。`@` 符号表示带理由的提示,所以当切换到 `WAIT` 时,`Org` 会问我为什么,并将这个添加到笔记中。
|
||||
|
||||
以下是项目状态发生变化的例子:
|
||||
|
||||
```
|
||||
** DONE This is a test
|
||||
CLOSED: [2018-03-02 Fri 03:05]
|
||||
|
||||
- State "DONE" from "WAIT" [2018-03-02 Fri 03:05]
|
||||
- State "WAIT" from "TODO" [2018-03-02 Fri 03:05] \\
|
||||
waiting for pigs to fly
|
||||
- State "TODO" from "NEXT" [2018-03-02 Fri 03:05]
|
||||
- State "NEXT" from "TODO" [2018-03-02 Fri 03:05]
|
||||
```
|
||||
|
||||
在这里,最新的项目在最上面。
|
||||
|
||||
**议程模式,日程及期限**
|
||||
|
||||
当你处在一个待办项时,`C-c C-s` 或 `C-c C-d` 可以为其设置相应的日程或期限。这些都是在议程模式中的功能。区别在于意图和表现。日程是你希望在某个时候完成的事情,而期限是在某个特定的时间应该完成的事情。默认情况下,议程视图将在项目的截止日期前提醒你。
|
||||
|
||||
在此过程中,[议程视图][3]将显示即将出现的项目,提供了一种基于纯文本或标记搜索项目的方法,甚至可以进行跨多个文件处理项目的批量操作。我在本系列的[第 2 部分][4]中介绍了为议程模式配置。
|
||||
|
||||
**标签**
|
||||
|
||||
`Org` 模式当然也支持标签了。你可以通过 `C-c C-q` 快速的建立标签。
|
||||
|
||||
你可能会想为一些常用的标签设置快捷键。就像这样:
|
||||
|
||||
```
|
||||
(setq org-tag-persistent-alist
|
||||
'(("@phone" . ?p)
|
||||
("@computer" . ?c)
|
||||
("@websurfing" . ?w)
|
||||
("@errands" . ?e)
|
||||
("@outdoors" . ?o)
|
||||
("MIT" . ?m)
|
||||
("BIGROCK" . ?b)
|
||||
("CONTACTS" . ?C)
|
||||
("INBOX" . ?i)
|
||||
))
|
||||
```
|
||||
|
||||
你还可以根据每个文件向该列表添加标记,也可以根据每个文件为某些内容设置标记。我就在我的 `inbox.org` 和 `email.org` 文件中设置了一个 `INBOX` 的标签。然后我可以每天从日程视图中查看所有标记为 `INBOX` 的项目,像将它们重新归档到其他文件中的简单操作将让它们去掉 `INBOX` 标记。
|
||||
|
||||
**重新归档**
|
||||
|
||||
“重新归档”就是在文件中或其他地方移动。它是使用标来题完成。`C-c C-w` 就是做这个的。我设置成这样:
|
||||
|
||||
```
|
||||
(setq org-outline-path-complete-in-steps nil) ; Refile in a single go
|
||||
(setq org-refile-use-outline-path 'file)
|
||||
```
|
||||
|
||||
**归档分类**
|
||||
|
||||
一段时间后,你的文件就会被已经完成的事情弄得乱七八糟。`Org` 模式有一个[归档][6]特性,可以将主 `.org` 文件移到其他文件中,以备将来参考。如果你在 `git` 或其他软件中 有 `Org` 文件,你可能希望删除这些其他文件,因为无论如何都会在历史中拥有这些文件,但是我发现它们对于 `grepping` 和搜索非常方便。
|
||||
|
||||
我会定期检查并归档文件中的所有内容。基于 [stackoverflow 的讨论][7],我有以下代码:
|
||||
|
||||
```
|
||||
(defun org-archive-done-tasks ()
|
||||
(interactive)
|
||||
(org-map-entries
|
||||
(lambda ()
|
||||
(org-archive-subtree)
|
||||
(setq org-map-continue-from (outline-previous-heading)))
|
||||
"/DONE" 'file)
|
||||
(org-map-entries
|
||||
(lambda ()
|
||||
(org-archive-subtree)
|
||||
(setq org-map-continue-from (outline-previous-heading)))
|
||||
"/CANCELLED" 'file)
|
||||
)
|
||||
```
|
||||
|
||||
这基于[一个特定的答案][8]——你可以从评论那获得一些额外的提示。现在你可以运行 `M-x org-archive-done-tasks`,当前文件中所有标记为 `DONE` 或 `CANCELED` 的内容都将放到另一个文件中。
|
||||
|
||||
**下一篇**
|
||||
|
||||
我将通过讨论在 `Org` 模式中自动接受邮件以及在不同的机子上同步来对 `Org` 模式进行总结。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://changelog.complete.org/archives/9877-emacs-3-more-on-org-mode
|
||||
|
||||
作者:[John Goerzen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[oneforalone](https://github.com/oneforalone)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://changelog.complete.org/archives/author/jgoerzen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://changelog.complete.org/archives/tag/emacs2018
|
||||
[2]: https://orgmode.org/guide/TODO-Items.html#TODO-Items
|
||||
[3]: https://orgmode.org/guide/Agenda-Views.html#Agenda-Views
|
||||
[4]: https://changelog.complete.org/archives/9865-emacs-2-introducing-org-mode
|
||||
[5]: https://orgmode.org/guide/Tags.html#Tags
|
||||
[6]: https://orgmode.org/guide/Archiving.html#Archiving
|
||||
[7]: https://stackoverflow.com/questions/6997387/how-to-archive-all-the-done-tasks-using-a-single-command
|
||||
[8]: https://stackoverflow.com/a/27043756
|
||||
316
translated/tech/20180707 Version Control Before Git with CVS.md
Normal file
316
translated/tech/20180707 Version Control Before Git with CVS.md
Normal file
@ -0,0 +1,316 @@
|
||||
Git 之前使用 CVS 进行版本控制
|
||||
======
|
||||
Github 网站于 2008 年发布。如果你的软件工程师职业生涯跟我一样,也是晚于此时间的话,Git 可能是你用过的唯一版本控制软件。虽然其陡峭的学习曲线和不直观地用户界面时常会遭人抱怨,但不可否认的是, Git 已经成为人们学习版本控制的最佳选择。 2015 年,Stack Overflow 进行的开发者调查显示,69.3% 的被调查者在使用 Git,几乎是排名第二的 Subversion 版本控制系统使用者数量的两倍。2015 年之后,也许是因为 Git 太受欢迎了,大家对此话题不再感兴趣,所以 Stack Overflow 停止了关于开发人员使用版本控制系统软件的问卷调查。
|
||||
|
||||
Github 的发布时间距离 Git 自身发布时间很近。2005 年, Linus Torvalds 发布了 Git 的首个版本。现在的年经一代开发者可能很难想象“版本控制软件”生命周期所代表的世界并不仅仅只有 Git,虽然这样的世界诞生的时间并不长。除了 Git 外,还有很多可供选择。开源开发者较喜欢 Subversion,企业和视频游戏公司使用 Perforce (到如今有些仍在用),而 Linux 内核项目依赖于名为 BitKeeper 的版本控制系统。
|
||||
|
||||
其中一些系统,特别是 BitKeeper,会让年经一代的 Git 用户感觉很熟悉,上手也很快,但大多数相差很大。除了 BitKeeper,Git 之前的版本控制系统都是以不同的架构模型为基础运行的。作者 Eric Sink 在他的 [Version Control By Example][8] 一书中对版本控制进行了分类,按其说法,Git 属于第三代版本控制系统,而大多数 Git 的前身,即流行于二十世纪九零年代和二十一世纪早期的系统,都属于第二代版本控制系统。第三代版本控制系统是分布式的,第二代是集中式。你们以前大概都听过 Git 被描述为一款“分布式”版本控制系统。我一直都不明白分布式/集中式之间的区别,随后自己亲自安装了一款第二代的集中式版本控件系统,并做了相关实验,至少明白了一些。
|
||||
|
||||
我安装的版本系统是 CVS。CVS,即 `Concurrent Versions System` 的缩写,是最初的第二代版本控制系统。大约十年,它是最为流行的版本控制系统,直到 2000 年被 Subversion 所取代。即便如此,Subversion 被认为是 “CVS 但做的更好”,这更进一步突出了 CVS 在二十世纪九零年代的主导地位。
|
||||
|
||||
CVS 最早是由一位名叫 Dick Grune 的荷兰科学家在 1986 年间开发的,当时有一个编译器项目,他正在寻找一种能与其学生合作的方法。CVS 最初仅仅只是一个包装了 RCS(修订控制系统) 的 Shell 脚本集合,Grune 想改进这个第一代的版本控制系统。 RCS 是按悲观锁模式工作的,这意味着两个程序员不可以同时处理同一个文件。需要编辑一个文件话,首先得向 RCS 系统请求一个排它锁,锁定此文件直到完成编辑,如果你想编辑的文件有人正在编辑,你就必须等待。CVS 在 RCS 基础上改进,并把悲观锁模型替换成乐观锁模型,迎来了第二代版本控制系统的时代。现在,程序员可以同时编辑同一个文件、合并编辑部分,随后解决合并冲突问题。(后来接管 CVS 项目的工程师布莱恩·柏林(Brian Berliner)于 1990 年撰写了一篇关于 CVS 创新的非常易读的 [论文][1]。)
|
||||
|
||||
从这个意义上来讲,CVS 与 Git 并无差异,因为 Git 也是运行于乐观锁模式的,但也仅仅只有此点相似。实际上,Linus Torvalds 开发 Git 时,他的一个指导原则是 WWCVSND,即 “What Would CVS
|
||||
Not Do (CVS 不能做的).” 每当他做决策时,他都会力争选择那些在 CVS 设计里没有使用的功能选项。所以即使 CVS 要早于 Git 十多年,但它对 Git 的影响是为负数的。
|
||||
|
||||
我非常喜欢折腾 CVS。我认为要弄明白为什么 Git 的分布式特性是对以前的版本控制系统的较大改善的话,除了折腾 CVS 外,没有更好的办法。因此,我邀请您跟我一起来一段激动人心的旅程,并在接下来的十分钟内了解下这个近十年来无人使用的软件。(可以看看修正部分)
|
||||
|
||||
### CVS 入门
|
||||
|
||||
CVS 的安装教程可以在其 [项目主页][2] 上找到。MacOS 系统的话,可以使用 Homebrew 安装。
|
||||
|
||||
由于 CVS 是集中式的,所以它有客户端和服务端之区分,这种模式 Git 是没有的。两端分别有不同的可执行文件,其区别不太明显。但要开始使用 CVS 的话,即使只在您的本地机器上使用,也必须设置 CVS 的服务后端。
|
||||
|
||||
CVS 的后端,即所有代码的中央存储区,被叫做存储库 (repository)。在 Git 中每一个项目都有一个存储库,而 CVS 中一个存储库就包含所有的项目。尽管有办法保证一次只能访问一个项目,但一个中央存储库包含所有东西是改变不了的。
|
||||
|
||||
要在本地创建存储库的话,请运行 `init` 命令。您可以像如下所示在家(home)目录创建,也可以在您本地的任何地方创建。
|
||||
|
||||
```
|
||||
$ cvs -d ~/sandbox init
|
||||
```
|
||||
|
||||
CVS 允许您将选项传递给 `cvs` 命令本身或 `init` 子命令。出现在 `cvs` 命令之后的选项默认是全局的,而出现在子命令之后的是子命令特有选项。上面所示例子中,`-d` 标志是全局选项。在这儿是告诉 CVS 我们想要创建存储库路径在哪里,但通用的 `-d` 标志指的是我们想要使用的且已经存在的存储库位置。一直使用 `-d` 标志很单调乏味,所以可以设置 `CVSROOT` 环境变量来代替。
|
||||
|
||||
因为我们只是在本地操作,所以仅仅使用 `-d` 参考来传送路径就可以,但也可以包含个主机名。
|
||||
|
||||
此命令在您的家目录创建了一个名叫 `sandbox` 的目录。 如果您列出 `sandbox` 内容,会发现下面包含有 `CVSROOT` 的目录。请不要把此目录与我们的环境变量混淆,它保存存储库的管理文件。
|
||||
|
||||
恭喜! 您刚刚创建了第一个 CVS 存储库。
|
||||
|
||||
### 检入代码
|
||||
|
||||
假设你决定留存下自己喜欢的颜色清单。因为您是一个有艺术倾向但很健忘的人,所以你键入颜色列表清单,并保存到一个叫 `favorites.txt` 的文件中:
|
||||
|
||||
```
|
||||
blue
|
||||
orange
|
||||
green
|
||||
|
||||
definitely not yellow
|
||||
```
|
||||
|
||||
我们也假设您把文件保存到一个叫 `colors` 的目录中。现在你想要把喜欢的颜色列表清单置于版本控制之下,因为从现在起的五十年间会回顾下,随着时间的推移自己的品味怎么变化,这件事很有意思。
|
||||
|
||||
为此,您必须将您的目录导入为新的 CVS 项目。可以使用 `import` 命令:
|
||||
|
||||
```
|
||||
$ cvs -d ~/sandbox import -m "" colors colors initial
|
||||
N colors/favorites.txt
|
||||
|
||||
No conflicts created by this import
|
||||
```
|
||||
|
||||
这里我们再次使用 `-d` 标志来指定存储库的位置,其余的参数是传输给 `import ` 子命令的。必须要提供一条消息,但这儿没必要,所以留空。下一个参数 `colors`,指定了存储库中新目录的名字,这儿给的名字跟检入的目录名称一致。最后的两个参数分别指定了 vendor 标签和 release 标签。我们稍后就会谈论标签。
|
||||
|
||||
我们刚将 `colors` 项目拉入 CVS 存储库。将代引入 CVS 有很多种不同的方法,但这是 [Pragmatic Version Control Using CVS][3] 一书所推荐方法,这是一本关于 CVS 的程序员实用指导书籍。使用这种方法有点尴尬的就是你得重新检出 (check out) 工作项目,即使已经存在有 `colors` 此项目了。不要使用该目录,首先删除它,然后从 CVS 中检出刚才的版本,如下示:
|
||||
|
||||
```
|
||||
$ cvs -d ~/sandbox co colors
|
||||
cvs checkout: Updating colors
|
||||
U colors/favorites.txt
|
||||
```
|
||||
|
||||
这个过程会创建一个新的目录,也叫做 `colors`。此目录里会发现您的源文件 `favorites.txt`,还有一个叫 `CVS` 的目录。这个 `CVS` 目录基本上与 Git 存储库的 `.git` 目录等同。
|
||||
|
||||
### 做出改动
|
||||
|
||||
准备旅行。
|
||||
|
||||
和 Git 一样,CVS 也有 `status` 命令:
|
||||
|
||||
```
|
||||
$ cvs status
|
||||
cvs status: Examining .
|
||||
===================================================================
|
||||
File: favorites.txt Status: Up-to-date
|
||||
|
||||
Working revision: 1.1.1.1 2018-07-06 19:27:54 -0400
|
||||
Repository revision: 1.1.1.1 /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
Commit Identifier: fD7GYxt035GNg8JA
|
||||
Sticky Tag: (none)
|
||||
Sticky Date: (none)
|
||||
Sticky Options: (none)
|
||||
```
|
||||
|
||||
到这儿事情开始陌生起来了。CVS 没有提交对象这一概念。如上示,有一个叫 “提交标识符 Commit Identifier ” 的东西,但这可能是一个较新版本的标识,在 2003 年出版的《Pragmatic Version Control Using CVS》一书中并没有提到 “提交标识符” 这个概念。 (CVS 的最新版本于 2008 年发布的。)
|
||||
|
||||
在 Git 中,我们所谈论某文件版本其实是在谈论如 `commit 45de392` 相关的东西,而 CVS 中文件是独立版本化的。文件的第一个版本为 1.1 版本,下一个是 1.2 版本,依此类推。涉及分支时,会在后面添加扩展数字。因此您会看到如上所示的 `1.1.1.1` 的内容,这就是示例的版本号,即使我们没有创建分支,似乎默认的会给加上。
|
||||
|
||||
一个项目中会有很多的文件和很多次的提交,如果您运行 `cvs log` 命令(等同于 `git log`),会看到每个文件提交历史信息。同一个项目中,有可能一个文件处于 1.2 版本,一个文件处于 1.14 版本。
|
||||
|
||||
继续,我们对 1.1 版本的 `favorites.txt` 文件做些修改:
|
||||
|
||||
```
|
||||
blue
|
||||
orange
|
||||
green
|
||||
+cyan
|
||||
|
||||
definitely not yellow
|
||||
```
|
||||
|
||||
修改完成,就可以运行 `cvs diff` 来看看 CVS 发生了什么:
|
||||
|
||||
```
|
||||
$ cvs diff
|
||||
cvs diff: Diffing .
|
||||
Index: favorites.txt
|
||||
===================================================================
|
||||
RCS file: /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
retrieving revision 1.1.1.1
|
||||
diff -r1.1.1.1 favorites.txt
|
||||
3a4
|
||||
> cyan
|
||||
```
|
||||
|
||||
CVS 识别出我们我在文件中添加了一个包含颜色 "cyan" 的新行。(实际上,它说我们已经对 “RCS” 文件进行了更改;你可以看到,CVS 底层使用的还是 RCS。) 此差异指的是当前工作目录中的 `favorites.txt` 副本与存储库中 1.1.1.1 版本的文件之间的差异。
|
||||
|
||||
为了更新存储库中的版本,我们必须提交更改。Git 中,这个操作要好几个步骤。首先,暂存此修改,使其在索引中出现,然后提交此修改,最后,为了使此修改让其他人可见,我们必须把此提交推送到源存储库中。
|
||||
|
||||
而 CVS 中,只需要运行 `cvs commit` 命令就搞定一切。CVS 会查找所有修改的东西,进行捆绑,然后把它们放到存储库中。
|
||||
|
||||
```
|
||||
$ cvs commit -m "Add cyan to favorites."
|
||||
cvs commit: Examining .
|
||||
/Users/sinclairtarget/sandbox/colors/favorites.txt,v <-- favorites.txt
|
||||
new revision: 1.2; previous revision: 1.1
|
||||
```
|
||||
|
||||
我已经习惯了 Git, 所以这种操作会让我感到十分恐惧。因为没有变更暂存区的机制,工作目录下修改的一些老旧的东西都会一股脑给提交到公共存储库中。您有过因为不爽,私下里重写了某个同事不佳的功能实现,但仅仅只是自我宣泄一下并不想让他知道的时候吗?如果不小心提交上去了,就太糟糕了,他会认为你是个混蛋。在推送之前,你也不能修改提交过的东西了,因为提交就是推送。还是您愿意花费 40 分钟的时间来反复运行 `git rebase -i` 命令,以使得本地提交历史记录跟数学证明一样清晰严谨?很遗憾,CVS 里不支持,结果就是,大家都会看到您没有先写测试用例。
|
||||
|
||||
不过,到现在我终于理解了为什么那么多人都觉得 Git 没必要搞那么复杂。对那些早已经习惯直接 `cvs commit` 的人来说,进行暂存变更和推送变更操作确实是毫无意义的差事。
|
||||
|
||||
人们常谈论 Git 是一个 “分布式” 系统,其意思中分布式与非分布式的主要区别为:在 CVS 中,无法进行本地提交。一次提交操作就是向中央存储库提交代码,所以没有网络连接,刚无法执行此操作,获取到本地的只是您的工作目录;在 Git 中,会有一个完完全全的本地存储库,所以即使断网了也可以无间断执行提交操作。您还可以进行编辑提交内容、回退、分支和随心所欲的操作,且无人知晓。
|
||||
|
||||
虽然提交是个很大的话题,但 CVS 用户很少会关注。提交会包含很多的内容修改及今天我们盼望看到的十多次提交请求。还有很特别的,提交触发 CI 构建和触发自动测试程序等。
|
||||
|
||||
现在我们运行 `cvs status`,会看到产生了文件的新版本:
|
||||
|
||||
```
|
||||
$ cvs status
|
||||
cvs status: Examining .
|
||||
===================================================================
|
||||
File: favorites.txt Status: Up-to-date
|
||||
|
||||
Working revision: 1.2 2018-07-06 21:18:59 -0400
|
||||
Repository revision: 1.2 /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
Commit Identifier: pQx5ooyNk90wW8JA
|
||||
Sticky Tag: (none)
|
||||
Sticky Date: (none)
|
||||
Sticky Options: (none)
|
||||
```
|
||||
|
||||
### 合并
|
||||
|
||||
如上所述,在 CVS 中,你可以同时编辑其他人正在编辑的文件。这是 CVS 对 RCS 的重大改进。当需要将更改的部分重新组合在一起时会发生什么?
|
||||
|
||||
假设您邀请了一些来将他们喜欢的颜色添加到您的列表中。在他们添加的时候,您确定了不再喜欢绿色,然后把它从列表中删除。
|
||||
|
||||
当你提交更新的时候,会发现 CVS 报出了个问题:
|
||||
|
||||
```
|
||||
$ cvs commit -m "Remove green"
|
||||
cvs commit: Examining .
|
||||
cvs commit: Up-to-date check failed for `favorites.txt'
|
||||
cvs [commit aborted]: correct above errors first!
|
||||
```
|
||||
|
||||
好像是朋友们首先提交了更新。所以您的 `favorites.txt` 文件版本没有更新到存储库中的最新版本。此时运行 `cvs status` 就可以看到,本地的 `favorites.txt` 文件副本有一些变更且是 1.2 版本的而存储库上的版本号是 1.3,如下示:
|
||||
|
||||
```
|
||||
$ cvs status
|
||||
cvs status: Examining .
|
||||
===================================================================
|
||||
File: favorites.txt Status: Needs Merge
|
||||
|
||||
Working revision: 1.2 2018-07-07 10:42:43 -0400
|
||||
Repository revision: 1.3 /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
Commit Identifier: 2oZ6n0G13bDaldJA
|
||||
Sticky Tag: (none)
|
||||
Sticky Date: (none)
|
||||
Sticky Options: (none)
|
||||
```
|
||||
|
||||
你可以运行 `cvs diff` 来了解 1.2 版本与 1.3 版本的确切差异:
|
||||
|
||||
```
|
||||
$ cvs diff -r HEAD favorites.txt
|
||||
Index: favorites.txt
|
||||
===================================================================
|
||||
RCS file: /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
retrieving revision 1.3
|
||||
diff -r1.3 favorites.txt
|
||||
3d2
|
||||
< green
|
||||
7,10d5
|
||||
<
|
||||
< pink
|
||||
< hot pink
|
||||
< bubblegum pink
|
||||
```
|
||||
|
||||
看来我们的朋友是真的喜欢粉红色,但好在他们编辑的是此文件的不同部分,所以很容易地合并此修改。跟 `git pull` 类似,只要运行 `cvs update` 命令,CVS 就可以为我们做合并操作,如下示:
|
||||
|
||||
```
|
||||
$ cvs update
|
||||
cvs update: Updating .
|
||||
RCS file: /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
retrieving revision 1.2
|
||||
retrieving revision 1.3
|
||||
Merging differences between 1.2 and 1.3 into favorites.txt
|
||||
M favorites.txt
|
||||
```
|
||||
|
||||
此时查看 `favorites.txt` 文件内容的话,你会发现你的朋友对文件所做的更改已经包含进去了,你的修改也在里面。现在你可以自由的提交文件了,如下示:
|
||||
|
||||
```
|
||||
$ cvs commit
|
||||
cvs commit: Examining .
|
||||
/Users/sinclairtarget/sandbox/colors/favorites.txt,v <-- favorites.txt
|
||||
new revision: 1.4; previous revision: 1.3
|
||||
```
|
||||
|
||||
最终的结果就跟在 Git 中运行 `git pull --rebase` 一样。你的修改是添加在你朋友的修改之后的,所以没有 “合并提交” 这操作。
|
||||
|
||||
某些时候,对同一文件的修改可能导致冲突。例如,如果你的朋友把 “green” 修改成 “olive”,同时你完全删除 “green”,就会出现冲突。早期的时候,正是这种情况导致人们担心 CVS 不安全,而 RCS 的悲观锁机制可以确保此情况永不会发生。但 CVS 提供了一个安全保障机制,可以确保不会自动的覆盖任何人的修改。因此,当运行 `cvs update` 的时候,你必须告诉 CVS 想要做哪些修改才能继续下一步操作。CVS 会标记文件的所有变更,这跟 Git 检测到合并冲突时所做的方式一样,然后,你必须手工编辑文件,选择需要保留的变更进行合并。
|
||||
|
||||
这儿需要注意的有趣事情就是在进行提交之前必须修复并合并冲突。这是 CVS 集中式特性的另一个结果。而在 Git 里,在推送本地的提交内容之前,您都不用担心合并冲突问题。
|
||||
|
||||
由于 CVS 没有易于记录的提交对象,因此对变更集合进行分组的唯一方法就是对于特定的工作目录状态打个标记。
|
||||
|
||||
创建一个标记是很容易的:
|
||||
|
||||
```
|
||||
$ cvs tag VERSION_1_0
|
||||
cvs tag: Tagging .
|
||||
T favorites.txt
|
||||
```
|
||||
|
||||
稍后,运行 `cvs update` 命令并把标签传输给 `-r` 标志就可以把文件恢复到此状态,如下示:
|
||||
|
||||
```
|
||||
$ cvs update -r VERSION_1_0
|
||||
cvs update: Updating .
|
||||
U favorites.txt
|
||||
```
|
||||
|
||||
因为你需要一个标记来回退到早期的工作目录状态,所以 CVS 鼓励创建大量的抢占标记。例如,在重大的重构之前,你可以创建一个 `BEFORE_REFACTOR_01` 标记,如果重构出错,就可以使用此标记回退。你果想在项目范围上生成有差异的版本的话,也可以使用标记。基本上,我们使用 CVS 来管理的, 对于今天日常所做的所有事情都是预测性和计划性的,所以需要打上标记,以备回退修改。
|
||||
|
||||
可以在 CVS 中创建分支。分支只是一种特殊的标记,如下示:
|
||||
|
||||
```
|
||||
$ cvs rtag -b TRY_EXPERIMENTAL_THING colors
|
||||
cvs rtag: Tagging colors
|
||||
```
|
||||
|
||||
(顺便提醒一下读者)这命令仅仅只是创建了分支,所以还需要使用 `cvs update` 命令来切换分支,如下示:
|
||||
|
||||
```
|
||||
$ cvs update -r TRY_EXPERIMENTAL_THING
|
||||
```
|
||||
|
||||
上面的命令就会把您的当前工作目录切换到新的分支,但《Pragmatic Version Control Using CVS》一书实际上是建议创建一个新的目录来间接替代新分支。估计,其作者发现在 CVS 里切换目录要比切换分支来得更简单吧。
|
||||
|
||||
此书也建议不要从现有分支创建分支,而只在主线分支,Git 中被叫做 `master`,上创建分支。一般来说,分支在 CVS 中主认为是 “高级” 技能。而在 Git 中,您几乎可以无理由的就创建新分支,但 CVS 中要在真正需要的时候才能创建,比如发布项目。
|
||||
|
||||
稍后可以使用 `cvs update` 和 `-j` 标志将分支合并回主线:
|
||||
|
||||
```
|
||||
$ cvs update -j TRY_EXPERIMENTAL_THING
|
||||
```
|
||||
|
||||
### 感谢历史上的贡献者
|
||||
|
||||
2007 年,Linus Torvalds 在 Google 进行了一场关于 Git 的 [演讲][4](译者注:需要梯子,国内用户可以访问 [腾讯视频][9])。当时 Git 是很新的东西,整场演讲基本上都是在说服满屋子都持有怀疑态度的程序员们,尽管 Git 是如此的与众不同,也应该使用 Git。如果没有看过这个视频的话,我强烈建议你去看看。Linus 是个有趣的演讲者,即使他有些傲慢。他非常出色地解释了为什么分布式的版本控制系统要比集中式的优秀。他的很多评论是直接针对 CVS 的。
|
||||
|
||||
Git 是一个 [相当复杂的工具][5]。学习起来是一个令人沮丧的经历,但也不断的给我惊喜,Git 还能做这样的事情。相比之下,CVS 简单明了,但是,许多我们认为理所当然的操作都做不了。想要对 Git 的强大功能和灵活性有全新的认识的话,就回过头来用用 CVS 吧,这是种很好的学习方式。这很好的诠释了为什么理解软件的开发历史可以让人受益匪浅。重拾过期淘汰的工具可以让我们理解今天所使用的工具后面所隐藏的哲理。
|
||||
|
||||
如果您喜欢此博文的话,每两周会有一次更新!请在 Twitter 上关注 [@TwoBitHistory][6] 或都通过 [RSS feed][7] 订阅,新博文出来会有通知。
|
||||
|
||||
#### 修正
|
||||
|
||||
有人告诉我,有很多组织企业,特别是像做医疗设备软件等这种规避风险类的企业,仍在使用 CVS。这些企业中的程序员通过使用一些小技巧来解决 CVS 的限制,例如为几乎每个更改创建一个新分支以避免直接提交给 `HEAD`。 (感谢 Michael Kohne 指出这一点。)
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://twobithistory.org/2018/07/07/cvs.html
|
||||
|
||||
作者:[Two-Bit History][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twobithistory.org
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://docs.freebsd.org/44doc/psd/28.cvs/paper.pdf
|
||||
[2]: https://www.nongnu.org/cvs/
|
||||
[3]: http://shop.oreilly.com/product/9780974514000.do
|
||||
[4]: https://www.youtube.com/watch?v=4XpnKHJAok8
|
||||
[5]: https://xkcd.com/1597/
|
||||
[6]: https://twitter.com/TwoBitHistory
|
||||
[7]: https://twobithistory.org/feed.xml
|
||||
[8]: https://ericsink.com/vcbe/index.html
|
||||
[9]: https://v.qq.com/x/page/o0772kqh5iv.html
|
||||
@ -0,0 +1,63 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (5 Firefox extensions to protect your privacy)
|
||||
[#]: via: (https://opensource.com/article/18/7/firefox-extensions-protect-privacy)
|
||||
[#]: author: ([Chris Short](https://opensource.com/users/chrisshort)
|
||||
[#]: url: ( )
|
||||
|
||||
5 个保护你隐私的 Firefox 扩展
|
||||
======
|
||||
|
||||

|
||||
|
||||
在剑桥分析公司这件事后,我仔细研究了我让 Facebook 渗透到我的网络生活的程度。由于我一般担心单点故障,我不是一个使用社交登录的人。我使用密码管理器为每个站点创建唯一的登录(你也应该这样做)。
|
||||
|
||||
我最担心的 Facebook 对我的数字生活的普遍侵扰。在深入了解剑桥分析公司这件事后,我几乎立即卸载了 Facebook 的移动程序。我还从 Facebook [取消连接了所有应用、游戏和网站][1]。是的,这将改变你在 Facebook 上的体验,但它也将保护您的隐私。作为一名有遍布全球朋友的人,保持 Facebook 的社交连接对我来说非常重要。
|
||||
|
||||
我还仔细审查了其他服务。我检查了 Google、Twitter、GitHub 以及任何未使用的连接应用。但我知道这还不够。我需要我的浏览器主动防止侵犯我隐私的行为。我开始研究如何做到最好。当然,我可以锁定浏览器,但是我需要使我用的网站和工具正常使用,同时试图防止它们泄露数据。
|
||||
|
||||
以下是五种可在使用浏览器时保护你隐私的工具。前三个扩展可用于 Firefox 和 Chrome,而后两个仅适用于 Firefox。
|
||||
|
||||
### Privacy Badger
|
||||
|
||||
我已经使用 [Privacy Badger][2] 有一段时间了。其他内容或广告拦截器做得更好吗?也许。很多内容拦截器的问题在于它们“付费显示”。这意味着他们有收费的“合作伙伴”白名单。这就站在了为什么存在内容拦截器的对立面。Privacy Badger 是由电子前沿基金会 (EFF) 制作的,这是一家以捐赠为基础的商业模式的非营利实体。Privacy Badger 承诺从你的浏览习惯中学习,并且很少需要调整。例如,我只需将一些网站列入白名单。Privacy Badger 允许精确控制在哪些站点上启用哪些跟踪器。这是我的第一个无论在哪个浏览器必须安装的扩展。
|
||||
|
||||
### DuckDuckGo Privacy Essentials
|
||||
|
||||
搜索引擎 DuckDuckGo 通常有隐私意识。[DuckDuckGo Privacy Essentials][3] 适用于主流的移动设备和浏览器。它的独特之处在于它根据你提供的设置对网站进行评分。例如,即使启用了隐私保护,Facebook 也会获得 D。同时,[chrisshort.net][4] 在启用隐私保护时获得 B 和禁用时获得 C。如果你因任何原因不喜欢于 EFF 或 Privacy Badger,我会推荐 DuckDuckGo Privacy Essentials(选择一个,而不是两个,因为它们基本上做同样的事情)。
|
||||
|
||||
### HTTPS Everywhere
|
||||
|
||||
[HTTPS Everywhere][5] 是 EFF 的另一个扩展。根据 HTTPS Everywhere 的说法,“网络上的许多网站都通过 HTTPS 提供一些有限的加密支持,但使它难以使用。例如,它们可能默认为未加密的 HTTP 或在加密的页面里面使用返回到未加密站点的链接。HTTPS Everywhere 扩展通过使用聪明的技术将对这些站点的请求重写为 HTTPS 来解决这些问题。“虽然许多网站和浏览器在实施 HTTPS 方面越来越好,但仍有很多网站仍需要帮助。HTTPS Everywhere 将尽力确保你的流量已加密。
|
||||
|
||||
### NoScript Security Suite
|
||||
|
||||
[NoScript Security Suite][6] 不适合胆小的人。虽然这个 Firefox 独有扩展“允许 JavaScript、Java、Flash 和其他插件只能由你选择的受信任网站执行”,但它并不能很好地确定你的选择。但是,毫无疑问,防止泄漏数据的可靠方法是不执行可能会泄露数据的代码。NoScript 通过其“基于白名单的抢占式脚本阻止”实现了这一点。这意味着你需要为尚未加入白名单的网站构建白名单。请注意,NoScript 仅适用于 Firefox。
|
||||
|
||||
### Facebook Container
|
||||
|
||||
Facebook Container][7] 使 Firefox 成为我在使用 Facebook 时的唯一浏览器。 “Facebook Container 的工作原理是将你的 Facebook 身份隔离到一个单独的容器中,这使得 Facebook 更难以使用第三方 Cookie 跟踪你访问其他网站。” 这意味着 Facebook 无法窥探浏览器中其他地方发生的活动。 突然间,这些令人毛骨悚然的广告将停止频繁出现(假设你在移动设备上卸载了 Facebook 应用)。 在隔离的空间中使用 Facebook 将阻止任何额外的数据收集。 请记住,你已经提供了 Facebook 数据,而 Facebook Container 无法阻止这些数据被共享。
|
||||
|
||||
这些是我浏览器隐私的首选扩展。 你的是什么? 请在评论中分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/firefox-extensions-protect-privacy
|
||||
|
||||
作者:[Chris Short][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/chrisshort
|
||||
[1]:https://www.facebook.com/help/211829542181913
|
||||
[2]:https://www.eff.org/privacybadger
|
||||
[3]:https://duckduckgo.com/app
|
||||
[4]:https://chrisshort.net
|
||||
[5]:https://www.eff.org/https-everywhere
|
||||
[6]:https://noscript.net/
|
||||
[7]:https://addons.mozilla.org/en-US/firefox/addon/facebook-container/
|
||||
@ -1,119 +0,0 @@
|
||||
存档网站
|
||||
======
|
||||
|
||||
我最近深入研究了网站存档,因为有些朋友担心遇到糟糕的系统管理或恶意入侵时失去对在线托管的工作的控制。这使得网站存档成为任意系统管理员工具箱中的重要工具。事实证明,有些网站比其他网站更难存档。本文介绍了对传统网站进行存档的过程,并阐述在面对最新流行的单页面应用程序的现代网站时,它有哪些不足。
|
||||
|
||||
### 转换为简单网站
|
||||
|
||||
手动开发 HTML 网站的日子早已不复存在。现在的网站是动态的,并使用最新的 JavaScript,PHP 或 Python 框架即时构建。结果,这些网站更加脆弱:数据库崩溃,升级出错或者未修复的漏洞都可能使数据丢失。在我以前是一名 Web 开发人员时,我不得不接受客户希望网站基本上可以永久工作的想法。这种期望与 web 开发“快速行动和破除陈规”的理念不相符。在这方面,使用 [Drupal][2] 内容管理系统(CMS)尤其具有挑战性,因为重大更新会破坏与第三方模块的兼容性,这意味着客户很少承担的起高昂的升级成本。解决方案是将这些网站存档:以实时动态的网站为基础,将其转换为任何 web 服务器可以永久服务的纯 HTML 文件。此过程对你自己的动态网站非常有用,也适用于你想保护但无法控制的第三方网站。
|
||||
|
||||
对于简单的静态网站,古老的 [Wget][3] 程序就可以胜任。然而,镜像保存一个完整页面的方法,虽然复杂但很固定:
|
||||
|
||||
```
|
||||
$ nice wget --mirror --execute robots=off --no-verbose --convert-links \
|
||||
--backup-converted --page-requisites --adjust-extension \
|
||||
--base=./ --directory-prefix=./ --span-hosts \
|
||||
--domains=www.example.com,example.com http://www.example.com/
|
||||
|
||||
```
|
||||
|
||||
以上命令下载了网页的内容,但也抓取了指定域名中的所有内容。在对你喜欢的网站执行此操作之前,请考虑此类抓取可能对网站产生的影响。上面的命令故意忽略了 `robots.txt` 规则,就像现在[档案管理者的习惯做法][4],并尽可能快的存档网站。大多数抓取工具都可以选择点击暂停并限制带宽使用,以避免使网站瘫痪。
|
||||
|
||||
上面的命令还将获取 “page requisites(译者注:单页面所需的所有元素)”,像样式表(CSS),图像和脚本等。下载的页面内容将会被修改,以便链接也指向本地副本。任意 web 服务器均可托管生成的文件集,从而生成原始网站的静态副本。
|
||||
|
||||
以上所述是事情一切顺利的时候。任意使用过计算机的人都知道事情的进展很少如计划那样;各种各样的事情可以使程序以有趣的方式脱离正规。比如,在网站上有一个日历块很流行。内容管理系统会动态生成这些内容,这会使爬虫程序陷入死循环以尝试检索所有页面。灵巧的存档者可以使用正则表达式(例如 Wget 有一个 `--reject-regex` 选项)来忽略有问题的资源。如果可以访问网站的管理界面,另一个方法是禁用日历、登录表单、评论表单和其他动态区域。一旦网站变成静态的,(那些动态区域)也肯定会停止工作,因此从原始网站中移除这些杂乱的东西也不是全无意义。
|
||||
|
||||
### JavaScript 的厄运
|
||||
|
||||
很不幸,有些网站不仅仅是纯 HTML 文件构建的。比如,在单页面网站中,web 浏览器通过执行一个小的 JavaScript 程序来构建内容。像 Wget 这样的简单用户代理将难以重建这些网站的有意义的静态副本,因为它根本不支持 JavaScript。理论上,网站应该使用[渐进增强][5]技术,在不使用 JavaScript 的情况下提供内容和实现功能,但这些指示很少被遵循,因为使用 [NoScript][6] 或 [uMatrix][7] 等插件的人都很确定。
|
||||
|
||||
传统的存档方法有时是最愚蠢的方式,会导致失败。在尝试为一个本地报纸网站([pamplemousse.ca][8])创建备份时,我发现 WordPress 在末尾包含 JavaScript,且添加了查询字符串(例如:`?ver=1.12.4`)。这会使提供存档服务的 web 服务器不能正确进行内容类型检测,因为其靠文件扩展名来发送正确的 `Content-Type` 头部信息。在 web 浏览器加载此类存档时,这些脚本将无法加载,导致动态网站受损。
|
||||
|
||||
随着 web 向使用浏览器作为虚拟机执行任意代码转化,依赖于纯 HTML 文件解析的存档方法也需要随之适应。这个问题的解决方案是在抓取时记录(以及重现)服务器提供的 HTTP 头部信息,实际上专业的档案管理者就使用这种方法。
|
||||
|
||||
### 创建和显示 WARC 文件Creating and displaying WARC files
|
||||
|
||||
在 [Internet Archive][9] 网站,Brewster Kahle 和 Mike Burner 在 1996 年设计了 [ARC][10] (用于 "ARChive")文件格式,以提供一种聚合档案工作产生的百万个小文件的方法。该格式最终标准化为 WARC(“Web ARChive”)[规范][11],并在 2009 年作为 ISO 标准发布,2017 年修订。标准化工作由[国际互联网保护联盟][12](IIPC)领导,据维基百科称,这是一个“为共同保护未来互联网内容而建立的图书馆和国际组织”;它有美国国会图书馆和互联网档案馆等成员。后者内部在其基于 Java 的 [Heritrix crawler][13](译者注:一种爬虫程序)上使用 WARC 格式。
|
||||
|
||||
WARC 在单个压缩文件中聚合了多种资源,像 HTTP 头部信息,文件内容,以及其他元数据。方便的是实际上 Wget 提供了 `--warc` 参数来支持 WARC 格式。不幸的是 web 浏览器不能直接显示 WARC 文件,所以为了访问存档文件,一个查看器或某些格式转换是很有必要的。我所发现的最简单的查看器是 [pywb][14],它以 Python 包的形式运行一个简单的 web 服务器提供一个像网站时光倒流机网站的界面,来浏览 WARC 文件的内容。执行以下命令将会在 `http://localhost:8080/` 地址显示 WARC 文件的内容:
|
||||
|
||||
```
|
||||
$ pip install pywb
|
||||
$ wb-manager init example
|
||||
$ wb-manager add example crawl.warc.gz
|
||||
$ wayback
|
||||
|
||||
```
|
||||
|
||||
顺便说一句,这个工具是由 [Webrecorder][15] 服务提供者建立的,Webrecoder 服务可以使用 web 浏览器保存动态页面的内容。
|
||||
|
||||
很不幸,pywb 无法加载 Wget 生成的 WARC 文件,因为它[遵循][16][不一致的 1.0 规范][17],[1.1 规范修复了此问题][17]。就算 Wget 或 pywb 修复了这些问题,Wget 生成的 WARC 文件对我的使用来说不够可靠,所以我找了其他的替代品。引起我注意的爬虫程序简称 [crawl][19]。以下是它的调用方式:
|
||||
|
||||
```
|
||||
$ crawl https://example.com/
|
||||
|
||||
```
|
||||
|
||||
(它的 README 文件说“非常简单”。)该程序确实支持一些命令行参数选项,但大多数默认值都是最佳的:它会从其他域获取页面需求(除非使用 `-exclude-related` 参数),但肯定不会递归出域。默认情况下,它会与远程站点建立十个并发连接,这个值可以使用 `-c` 参数更改。但是,最重要的是,生成的 WARC 文件可以使用 pywb 完美加载。
|
||||
|
||||
### 未来的工作和替代方案
|
||||
|
||||
这里还有更多有关使用 WARC 文件的[资源][20]。特别要提的是,这里有一个专门用来存档网站的 Wget 的直接替代品,叫做 [Wpull][21]。它实验性地支持了 [PhantomJS][22] 和 [youtube-dl][23] 的集成,即允许分别下载更复杂的 JavaScript 页面以及流媒体。该程序是一个叫做 [ArchiveBot][24] 的复杂档案工具的基础,ArchiveBot 被那些在 [ArchiveTeam][25] 的“零散离群的档案管理者、程序员、作家以及演说家”使用,他们致力于“在历史永远丢失之前保存他们”。集成 PhantomJS 好像并没有如团队期望的那样良好工作,所以 ArchiveTeam 也用其他的低等工具来镜像保存更复杂的网站。例如,[snscrape][26] 将抓取社交媒体配置文件以生成要发送到 ArchiveBot 的页面列表。团队使用的另一个工具是 [crocoite][27],它在 Chrome 浏览器下以无头文件信息的模式来存档 JavaScript 较多的网站。
|
||||
|
||||
如果没有提到称做“网站复制者”的 [HTTrack][28] 项目,那么这篇文章算不上完整。工作方式和 Wget 相似,HTTrack 可以对远程站点创建一个本地的副本,但是不幸的是它不支持输出 WRAC 文件。对于不熟悉命令行的小白用户来说,它在人机交互方面显得更有价值。
|
||||
|
||||
同样,在我的研究中,我发现了叫做 [Wget2][29] 的 Wget 的完全重制版本,它支持多线程操作,这可能使它比前身更快。和 Wget 相比,它[舍弃了一些功能][30],但是最值得注意的是拒绝模式、WARC 输出以及 FTP 支持,并增加了 RSS、DNS 缓存以及改进的 TLS 支持。
|
||||
|
||||
最后,我个人对这些工具的愿景是将他们与现有的书签系统集成起来。目前我在 [Wallabag][31] 中保留了一些有趣的链接,这是一种自托管式的“稍后阅读”服务,意在成为 [Pocket][32](现在由 Mozilla 拥有)的免费替代品。但是 Wallabag 在设计上只保留了文章的“可读”副本,而不是一个完整的拷贝。在某些情况下,“可读版本”实际上[不可读][33],并且 Wallabag 有时[无法解析文章][34]。恰恰相反,像 [bookmark-archiver][35] 或 [reminiscence][36] 这样其他的工具会保存页面的屏幕截图以及完整的 HTML 文件,但遗憾的是,它没有 WRAC 文件所以没有办法更可信的重现网页内容。
|
||||
|
||||
我所经历的有关镜像保存和存档的悲剧就是死数据。幸运的是,业余档案管理者可以利用工具将有趣的内容保存到网上。对于那些不想麻烦的人来说,互联网档案馆依然要留在这里,并且存档团队显然[正在为互联网档案馆本身做备份][37]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://anarc.at/blog/2018-10-04-archiving-web-sites/
|
||||
|
||||
作者:[Anarcat][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[fuowang](https://github.com/fuowang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://anarc.at
|
||||
[1]: https://anarc.at/blog
|
||||
[2]: https://drupal.org
|
||||
[3]: https://www.gnu.org/software/wget/
|
||||
[4]: https://blog.archive.org/2017/04/17/robots-txt-meant-for-search-engines-dont-work-well-for-web-archives/
|
||||
[5]: https://en.wikipedia.org/wiki/Progressive_enhancement
|
||||
[6]: https://noscript.net/
|
||||
[7]: https://github.com/gorhill/uMatrix
|
||||
[8]: https://pamplemousse.ca/
|
||||
[9]: https://archive.org
|
||||
[10]: http://www.archive.org/web/researcher/ArcFileFormat.php
|
||||
[11]: https://iipc.github.io/warc-specifications/
|
||||
[12]: https://en.wikipedia.org/wiki/International_Internet_Preservation_Consortium
|
||||
[13]: https://github.com/internetarchive/heritrix3/wiki
|
||||
[14]: https://github.com/webrecorder/pywb
|
||||
[15]: https://webrecorder.io/
|
||||
[16]: https://github.com/webrecorder/pywb/issues/294
|
||||
[17]: https://github.com/iipc/warc-specifications/issues/23
|
||||
[18]: https://github.com/iipc/warc-specifications/pull/24
|
||||
[19]: https://git.autistici.org/ale/crawl/
|
||||
[20]: https://archiveteam.org/index.php?title=The_WARC_Ecosystem
|
||||
[21]: https://github.com/chfoo/wpull
|
||||
[22]: http://phantomjs.org/
|
||||
[23]: http://rg3.github.io/youtube-dl/
|
||||
[24]: https://www.archiveteam.org/index.php?title=ArchiveBot
|
||||
[25]: https://archiveteam.org/
|
||||
[26]: https://github.com/JustAnotherArchivist/snscrape
|
||||
[27]: https://github.com/PromyLOPh/crocoite
|
||||
[28]: http://www.httrack.com/
|
||||
[29]: https://gitlab.com/gnuwget/wget2
|
||||
[30]: https://gitlab.com/gnuwget/wget2/wikis/home
|
||||
[31]: https://wallabag.org/
|
||||
[32]: https://getpocket.com/
|
||||
[33]: https://github.com/wallabag/wallabag/issues/2825
|
||||
[34]: https://github.com/wallabag/wallabag/issues/2914
|
||||
[35]: https://pirate.github.io/bookmark-archiver/
|
||||
[36]: https://github.com/kanishka-linux/reminiscence
|
||||
[37]: http://iabak.archiveteam.org
|
||||
Loading…
Reference in New Issue
Block a user