mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-03 23:40:14 +08:00
commit
f847583a75
59
published/20160812 What is copyleft.md
Executable file
59
published/20160812 What is copyleft.md
Executable file
@ -0,0 +1,59 @@
|
||||
什么是 Copyleft ?
|
||||
=============
|
||||
|
||||
如果你在开源项目中花费了很多时间的话,你可能会看到使用的术语 “copyleft”(GNU 官方网站上的释义:[中文][1],[英文][2])。虽然这个术语使用比较普遍,但是很多人却不理解它。软件许可是一个至少不亚于文件编辑器和打包格式的激烈辩论的主题。专家们对 copyleft 的理解可能会充斥在好多书中,但是这篇文章可以作为你理解 copyleft 启蒙之路的起点。
|
||||
|
||||
### 什么是 copyright?
|
||||
|
||||
在我们可以理解 copyleft 之前,我们必须先介绍一下 copyright 的概念。copyleft 并不是一个脱离于 copyright 的法律框架,copyleft 存在于 copyright 规则中。那么,什么是 copyright?
|
||||
|
||||
它的准确定义随着司法权的不同而不同,但是其本质就是:作品的作者对于作品的复制(copying)(因此这个术语称之为 “copyright”:copy right)、表现等有一定的垄断性。在美国,其宪法明确地阐述了美国国会的任务就是制定版权法律来“促进科学和实用艺术的进步”。
|
||||
|
||||
不同于以往,版权会立刻附加到作品上——而且不需要注册。默认情况下,所有的权力都是保留的。也就是说,没有经过作者的允许,没有人可以重新出版、表现或者修改作品。这种“允许”就是一种许可,可能还会附加有一定的条件。
|
||||
|
||||
如果希望得到对于 copyright 更彻底的介绍,Coursera 上的[教育工作者和图书管理员的著作权](https://www.coursera.org/learn/copyright-for-education)是一个非常优秀的课程。
|
||||
|
||||
### 什么是 copyleft?
|
||||
|
||||
先不要着急,在我们讨论 copyleft 是什么之前,还有一步。首先,让我们解释一下开源(open source)意味着什么。所有的开源许可协议,按照[开源倡议的定义(Open Source Inititative's definition)](https://opensource.org/osd)(规定),除其他形式外,必须以源码的形式发放。获得开源软件的任何人都有权利查看并修改源码。
|
||||
|
||||
copyleft 许可和所谓的 “自由(permissive)” 许可不同的地方在于,其衍生的作品中,也需要相同的 copyleft 许可。我倾向于通过这种方式来区分两者不同: 自由(permissive)许可向直接下游的开发者提供了最大的自由(包括能够在闭源项目中使用开源代码的权力),而 copyleft 许可则向最终用户提供最大的自由。
|
||||
|
||||
GNU 项目为 copyleft 提供了这个简单的定义([中文][3],[英文][4]):“规则就是当重新分发该程序时,你不可以添加限制来否认其他人对于[自由软件]的自由。(the rule that when redistributing the program, you cannot add restrictions to deny other people the central freedoms [of free software].)”这可以被认为权威的定义,因为 [GNU 通用许可证(GNU General Public License,GPL)](https://www.gnu.org/licenses/gpl.html)的各种版本的依然是最广泛使用的 copyleft 许可。
|
||||
|
||||
### 软件中的 copyleft
|
||||
|
||||
GPL 家族是最出名的 copyleft 许可,但是它们并不是唯一的。[Mozilla 公共许可协议(Mozilla Public License,MPL)](https://www.mozilla.org/en-US/MPL/)和[Eclipse 公共许可协议( Eclipse Public License,EPL)](https://www.eclipse.org/legal/epl-v10.html)也很出名。很多[其它的 copyleft 许可](https://tldrlegal.com/licenses/tags/Copyleft) 也有较少的采用。
|
||||
|
||||
就像之前章节介绍的那样,一个 copyleft 许可意味着下游的项目不可以在软件的使用上添加额外的限制。这最好用一个例子来说明。如果我写了一个名为 MyCoolProgram 的程序,并且使用 copyleft 许可来发布,你将有使用和修改它的自由。你可以发布你修改后的版本,但是你必须让你的用户拥有我给你的同样的自由。(但)如果我使用 “自由(permissive)” 许可,你将可以将它自由地合并到一个不提供源码的闭源软件中。
|
||||
|
||||
对于我的 MyCoolProgram 程序,和你必须能做什么同样重要的是你必须不能做什么。你不必用和我完全一样的许可协议,只要它们相互兼容就行(但一般的为了简单起见,下游的项目也使用相同的许可)。你不必向我贡献出你的修改,但是你这么做的话,通常被认为一个很好的形式,尤其是这些修改是 bug 修复的话。
|
||||
|
||||
### 非软件中的 copyleft
|
||||
|
||||
虽然,copyleft 的概念起始于软件世界,但是它也存在于之外的世界。“做你想做的,只要你保留其他人也有做同样的事的权力”的概念是应用于文字创作、视觉艺术等方面的知识共享署名许可([中文][5],[英文][6])的一个显著的特点(CC BY-SA 4.0 是贡献于 Opensource.com 默认的许可,也是很多开源网站,包括 [Linux.cn][7] 在内所采用的内容许可协议)。[GNU 自由文档许可证](https://www.gnu.org/licenses/fdl.html)是另一个非软件协议中 copyleft 的例子。在非软件中使用软件协议通常不被建议。
|
||||
|
||||
### 我是否需要选择一种 copyleft 许可?
|
||||
|
||||
关于项目应该使用哪一种许可,可以用(已经有了)成篇累牍的文章在阐述。我的建议是首先将许可列表缩小,以满足你的哲学信条和项目目标。GitHub 的 [choosealicense.com](http://choosealicense.com/) 是一种查找满足你的需求的许可协议的好方法。[tl;drLegal](https://tldrlegal.com/)使用平实的语言来解释了许多常见和不常见的软件许可。而且也要考虑你的项目所在的生态系统,围绕一种特定语言和技术的项目经常使用相同或者相似的许可。如果你希望你的项目可以运行的更出色,你可能需要确保你选择的许可是兼容的。
|
||||
|
||||
关于更多 copyleft 的信息,请查看 [copyleft 指南](https://copyleft.org/)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/resources/what-is-copyleft
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
译者:[yangmingming](https://github.com/yangmingming)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bcotton
|
||||
[1]: https://www.gnu.org/licenses/copyleft.zh-cn.html
|
||||
[2]: https://www.gnu.org/licenses/copyleft.en.html
|
||||
[3]: https://www.gnu.org/philosophy/free-sw.zh-cn.html
|
||||
[4]: https://www.gnu.org/philosophy/free-sw.en.html
|
||||
[5]: https://creativecommons.org/licenses/by-sa/4.0/deed.zh
|
||||
[6]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[7]: https://linux.cn/
|
||||
@ -0,0 +1,66 @@
|
||||
零配置部署 React
|
||||
========================
|
||||
|
||||
你想使用 [React][1] 来构建应用吗?“[入门][2]”是很容易的,可是接下来呢?
|
||||
|
||||
React 是一个构建用户界面的库,而它只是组成一个应用的一部分。应用还有其他的部分——风格、路由器、npm 模块、ES6 代码、捆绑和更多——这就是为什么使用它们的开发者不断流失的原因。这被称为 [JavaScript 疲劳][3]。尽管存在这种复杂性,但是使用 React 的用户依旧继续增长。
|
||||
|
||||
社区应对这一挑战的方法是共享[模版文件][4]。这些模版文件展示出开发者们架构选择的多样性。官方的“开始入门”似乎离一个实际可用的应用程序相去甚远。
|
||||
|
||||
### 新的,零配置体验
|
||||
|
||||
受开发者来自 [Ember.js][5] 和 [Elm][6] 的经验启发,Facebook 的人们想要提供一个简单、直接的方式。他们发明了一个[新的开发 React 应用的方法][10] :`create-react-app`。在初始的公开版发布的三个星期以来,它已经受到了极大的社区关注(超过 8000 个 GitHub 粉丝)和支持(许多的拉取请求)。
|
||||
|
||||
`create-react-app` 是不同于许多过去使用模板和开发启动工具包的尝试。它的目标是零配置的[惯例-优于-配置][7],使开发者关注于他们的应用的不同之处。
|
||||
|
||||
零配置一个强大的附带影响是这个工具可以在后台逐步成型。零配置奠定了工具生态系统的基础,创造的自动化和喜悦的开发远远超越 React 本身。
|
||||
|
||||
### 将零配置部署到 Heroku 上
|
||||
|
||||
多亏了 create-react-app 中打下的零配置基础,零配置的目标看起来快要达到了。因为这些新的应用都使用一个公共的、默认的架构,构建的过程可以被自动化,同时可以使用智能的默认项来配置。因此,[我们创造这个社区构建包来体验在 Heroku 零配置的过程][8]。
|
||||
|
||||
#### 在两分钟内创造和发布 React 应用
|
||||
|
||||
你可以免费在 Heroku 上开始构建 React 应用。
|
||||
```
|
||||
npm install -g create-react-app
|
||||
create-react-app my-app
|
||||
cd my-app
|
||||
git init
|
||||
heroku create -b https://github.com/mars/create-react-app-buildpack.git
|
||||
git add .
|
||||
git commit -m "react-create-app on Heroku"
|
||||
git push heroku master
|
||||
heroku open
|
||||
```
|
||||
[使用构建包文档][9]亲自试试吧。
|
||||
|
||||
### 从零配置出发
|
||||
|
||||
create-react-app 非常的新(目前版本是 0.2),同时因为它的目标是简洁的开发者体验,更多高级的使用情景并不支持(或者肯定不会支持)。例如,它不支持服务端渲染或者自定义捆绑。
|
||||
|
||||
为了支持更好的控制,create-react-app 包括了 npm run eject 命令。Eject 将所有的工具(配置文件和 package.json 依赖库)解压到应用所在的路径,因此你可以按照你心中的想法定做。一旦被弹出,你做的改变或许有必要选择一个特定的用 Node.js 或静态的构建包来布署。总是通过一个分支/拉取请求来使类似的工程改变生效,因此这些改变可以轻易撤销。Heroku 的预览应用对测试发布的改变是完美的。
|
||||
|
||||
我们将会追踪 create-react-app 的进度,当它们可用时,同时适配构建包来支持更多的高级使用情况。发布万岁!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.heroku.com/deploying-react-with-zero-configuration
|
||||
|
||||
作者:[Mars Hall][a]
|
||||
译者:[zky001](https://github.com/zky001)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://blog.heroku.com/deploying-react-with-zero-configuration
|
||||
[1]: https://facebook.github.io/react/
|
||||
[2]: https://facebook.github.io/react/docs/getting-started.html
|
||||
[3]: https://medium.com/@ericclemmons/javascript-fatigue-48d4011b6fc4
|
||||
[4]: https://github.com/search?q=react+boilerplate
|
||||
[5]: http://emberjs.com/
|
||||
[6]: http://elm-lang.org/
|
||||
[7]: http://rubyonrails.org/doctrine/#convention-over-configuration
|
||||
[8]: https://github.com/mars/create-react-app-buildpack
|
||||
[9]: https://github.com/mars/create-react-app-buildpack#usage
|
||||
[10]: https://github.com/facebookincubator/create-react-app
|
||||
@ -0,0 +1,59 @@
|
||||
Linux 发行版们应该禁用 IPv4 映射的 IPv6 地址吗?
|
||||
=============================================
|
||||
|
||||
从各方面来看,互联网向 IPv6 的过渡是件很缓慢的事情。不过在最近几年,可能是由于 IPv4 地址资源的枯竭,IPv6 的使用处于[上升态势][1]。相应的,开发者也有兴趣确保软件能在 IPv4 和 IPv6 下工作。但是,正如近期 OpenBSD 邮件列表的讨论所关注的,一个使得向 IPv6 转换更加轻松的机制设计同时也可能导致网络更不安全——并且 Linux 发行版们的默认配置可能并不安全。
|
||||
|
||||
### 地址映射
|
||||
|
||||
IPv6 在很多方面看起来可能很像 IPv4,但它是一个不同地址空间的不同的协议。服务器程序想要接受使用二者之中任意一个协议的连接,必须给两个不同的地址族分别打开一个套接字——IPv4 的 `AF_INET` 和 IPv6 的 `AF_INET6`。特别是一个程序希望在主机的使用两种地址协议的任意接口都接受连接的话,需要创建一个绑定到全零通配符地址(`0.0.0.0`)的 `AF_INET` 套接字和一个绑定到 IPv6 等效地址(写作 `::`)的 `AF_INET6` 套接字。它必须在两个套接字上都监听连接——或者有人会这么认为。
|
||||
|
||||
多年前,在 [RFC 3493][2],IETF 指定了一个机制,程序可以使用一个单独的 IPv6 套接字工作在两个协议之上。有了一个启用这个行为的套接字,程序只需要绑定到 `::` 来在所有接口上接受使用这两个协议连接。当创建了一个 IPv4 连接到该绑定端口,源地址会像 [RFC 2373][3] 中描述的那样映射到 IPv6。所以,举个例子,一个使用了这个模式的程序会将一个 `192.168.1.1` 的传入连接看作来自 `::ffff:192.168.1.1`(这个混合的写法就是这种地址通常的写法)。程序也能通过相同的映射方法打开一个到 IPv4 地址的连接。
|
||||
|
||||
RFC 要求这个行为要默认实现,所以大多数系统这么做了。不过也有些例外,OpenBSD 就是其中之一;在那里,希望在两种协议下工作的程序能做的只能是创建两个独立的套接字。但一个在 Linux 中打开两个套接字的程序会遇到麻烦:IPv4 和 IPv6 套接字都会尝试绑定到 IPv4 地址,所以不论是哪个后者都会失败。换句话说,一个绑定到 `::` 指定端口的套接字的程序会同时绑定到 IPv6 `::` 和 IPv4 `0.0.0.0` 地址的那个端口上。如果程序之后尝试绑定一个 IPv4 套接字到 `0.0.0.0` 的相同端口上时,这个操作会失败,因为这个端口已经被绑定了。
|
||||
|
||||
当然有个办法可以解决这个问题;程序可以调用 `setsockopt()` 来打开 `IPV6_V6ONLY` 选项。一个打开两个套接字并且设置了 `IPV6_V6ONLY` 的程序应该可以在所有的系统间移植。
|
||||
|
||||
读者们可能对不是每个程序都能正确处理这一问题没那么震惊。事实证明,这些程序的其中之一是网络时间协议(Network Time Protocol)的 [OpenNTPD][4] 实现。Brent Cook 最近给上游 OpenNTPD 源码[提交了一个小补丁][5],添加了必要的 `setsockopt()` 调用,它也被提交到了 OpenBSD 中了。不过那个补丁看起来不大可能被接受,最可能是因为 OpenBSD 式的理由(LCTT 译注:如前文提到的,OpenBSD 并不受这个问题的影响)。
|
||||
|
||||
### 安全担忧
|
||||
|
||||
正如上文所提到,OpenBSD 根本不支持 IPv4 映射的 IPv6 套接字。即使一个程序试着通过将 `IPV6_V6ONLY` 选项设置为 0 显式地启用地址映射,它的作者会感到沮丧,因为这个设置在 OpenBSD 系统中无效。这个决定背后的原因是这个映射带来了一些安全担忧。攻击打开的接口的攻击类型有很多种,但它们最后都会回到规定的两个途径到达相同的端口,每个端口都有它自己的控制规则。
|
||||
|
||||
任何给定的服务器系统可能都设置了防火墙规则,描述端口的允许访问权限。也许还会有适当的机制,比如 TCP wrappers 或一个基于 BPF 的过滤器,或一个网络上的路由器可以做连接状态协议过滤。结果可能是导致防火墙保护和潜在的所有类型的混乱连接之间的缺口导致同一 IPv4 地址可以通过两个不同的协议到达。如果地址映射是在网络边界完成的,情况甚至会变得更加复杂;参看[这个 2003 年的 RFC 草案][6],它描述了如果映射地址在主机之间传播,一些随之而来的其它攻击场景。
|
||||
|
||||
改变系统和软件正确地处理 IPv4 映射的 IPv6 地址当然可以实现。但那增加了系统的整体复杂度,并且可以确定这个改动没有实际地完整实现到它应该实现的范围内。如同 Theo de Raadt [说的][7]:
|
||||
|
||||
> **有时候人们将一个糟糕的想法放进了 RFC。之后他们发现这个想法是不可能的就将它丢回垃圾箱了。结果就是概念变得如此复杂,每个人都得在管理和编码方面是个全职专家。**
|
||||
|
||||
我们也根本不清楚这些全职专家有多少在实际配置使用 IPv4 映射的 IPv6 地址的系统和网络。
|
||||
|
||||
有人可能会说,尽管 IPv4 映射的 IPv6 地址造成了安全危险,更改一下程序让它在实现了地址映射的系统上关闭地址映射应该没什么危害。但 Theo [认为][8]不应该这么做,有两个理由。第一个是有许多破旧的程序,它们永远不会被修复。而实际的原因是给发行版们施加压力去默认关闭地址映射。正如他说的:“**最终有人会理解这个危害是系统性的,并更改系统默认行为使之‘secure by default’**。”
|
||||
|
||||
### Linux 上的地址映射
|
||||
|
||||
在 Linux 系统,地址映射由一个叫做 `net.ipv6.bindv6only` 的 sysctl 开关控制;它默认设置为 0(启用地址映射)。管理员(或发行版们)可以通过将它设置为 1 来关闭地址映射,但在部署这样一个系统到生产环境之前最好确认软件都能正常工作。一个快速调查显示没有哪个主要发行版改变这个默认值;Debian 在 2009 年的 “squeeze” 中[改变了这个默认值][9],但这个改动破坏了足够多的软件包(比如[任何包含 Java 的程序][10]),[在经过了几次的 Debian 式的讨论之后][11],它恢复到了原来的设置。看上去不少程序依赖于默认启用地址映射。
|
||||
|
||||
OpenBSD 有以“secure by default”的名义打破其核心系统之外的东西的传统;而 Linux 发行版们则更倾向于难以作出这样的改变。所以那些一般不愿意收到他们用户的不满的发行版们,不太可能很快对 bindv6only 的默认设置作出改变。好消息是这个功能作为默认已经很多年了,但很难找到被利用的例子。但是,正如我们都知道的,谁都无法保证这样的利用不可能发生。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://lwn.net/Articles/688462/
|
||||
|
||||
作者:[Jonathan Corbet][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://lwn.net/
|
||||
[1]: https://www.google.com/intl/en/ipv6/statistics.html
|
||||
[2]: https://tools.ietf.org/html/rfc3493#section-3.7
|
||||
[3]: https://tools.ietf.org/html/rfc2373#page-10
|
||||
[4]: https://github.com/openntpd-portable/
|
||||
[5]: https://lwn.net/Articles/688464/
|
||||
[6]: https://tools.ietf.org/html/draft-itojun-v6ops-v4mapped-harmful-02
|
||||
[7]: https://lwn.net/Articles/688465/
|
||||
[8]: https://lwn.net/Articles/688466/
|
||||
[9]: https://lists.debian.org/debian-devel/2009/10/msg00541.html
|
||||
[10]: https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=560056
|
||||
[11]: https://lists.debian.org/debian-devel/2010/04/msg00099.html
|
||||
@ -0,0 +1,76 @@
|
||||
Instagram 基于 Python 语言的 Web Service 效率提升之道
|
||||
===============================================
|
||||
|
||||
Instagram 目前部署了世界上最大规模的 Django Web 框架(该框架完全使用 Python 编写)。我们最初选用 Python 是因为它久负盛名的简洁性与实用性,这非常符合我们的哲学思想——“先做简单的事情”。但简洁性也会带来效率方面的折衷。Instagram 的规模在过去两年中已经翻番,并且最近已突破 5 亿用户,所以急需最大程度地提升 web 服务效率以便我们的平台能够继续顺利地扩大。在过去的一年,我们已经将效率计划(efficiency program)提上日程,并在过去的六个月,我们已经能够做到无需向我们的 Django 层(Django tiers)添加新的容量来维持我们的用户增长。我们将在本文分享一些由我们构建的工具以及如何使用它们来优化我们的日常部署流程。
|
||||
|
||||
### 为何需要提升效率?
|
||||
|
||||
Instagram,正如所有的软件,受限于像服务器和数据中心能源这样的物理限制。鉴于这些限制,在我们的效率计划中有两个我们希望实现的主要目标:
|
||||
|
||||
1. Instagram 应当能够利用持续代码发布正常地提供通信服务,防止因为自然灾害、区域性网络问题等造成某一个数据中心区丢失。
|
||||
2. Instagram 应当能够自由地滚动发布新产品和新功能,不必因容量而受阻。
|
||||
|
||||
想要实现这些目标,我们意识到我们需要持续不断地监控我们的系统并与回归(regressions)进行战斗。
|
||||
|
||||
### 定义效率
|
||||
|
||||
Web services 的瓶颈通常在于每台服务器上可用的 CPU 时间。在这种环境下,效率就意味着利用相同的 CPU 资源完成更多的任务,也就是说,每秒处理更多的用户请求(requests per second, RPS)。当我们寻找优化方法时,我们面临的第一个最大的挑战就是尝试量化我们当前的效率。到目前为止,我们一直在使用“每次请求的平均 CPU 时间”来评估效率,但使用这种指标也有其固有限制:
|
||||
|
||||
1. **设备多样性**。使用 CPU 时间来测量 CPU 资源并非理想方案,因为它同时受到 CPU 型号与 CPU 负载的影响。
|
||||
2. **请求影响数据**。测量每次请求的 CPU 资源并非理想方案,因为在使用每次请求测量(per-request measurement)方案时,添加或移除轻量级或重量级的请求也会影响到效率指标。
|
||||
|
||||
相对于 CPU 时间来说,CPU 指令是一种更好的指标,因为对于相同的请求,它会报告相同的数字,不管 CPU 型号和 CPU 负载情况如何。我们选择使用了一种叫做“每个活动用户(per active user)”的指标,而不是将我们所有的数据关联到每个用户请求上。我们最终采用“每个活动用户在高峰期间的 CPU 指令(CPU instruction per active user during peak minute)”来测量效率。我们建立好新的度量标准后,下一步就是通过对 Django 的分析来更多的了解一下我们的回归。
|
||||
|
||||
### Django web services 分析
|
||||
|
||||
通过分析我们的 Django web services,我们希望回答两个主要问题:
|
||||
|
||||
1. CPU 回归会发生吗?
|
||||
2. 是什么导致了 CPU 回归发生以及我们该怎样修复它?
|
||||
|
||||
想要回答第一个问题,我们需要追踪”每个活动用户的 CPU 指令(CPU-instruction-per-active-user)“指标。如果该指标增加,我们就知道已经发生了一次 CPU 回归。
|
||||
|
||||
我们为此构建的工具叫做 Dynostats。Dynostats 利用 Django 中间件以一定的速率采样用户请求,记录关键的效率以及性能指标,例如 CPU 总指令数、端到端请求时延、花费在访问内存缓存(memcache)和数据库服务的时间等。另一方面,每个请求都有很多可用于聚合的元数据(metadata),例如端点名称、HTTP 请求返回码、服务该请求的服务器名称以及请求中最新提交的哈希值(hash)。对于单个请求记录来说,有两个方面非常强大,因为我们可以在不同的维度上进行切割,那将帮助我们减少任何导致 CPU 回归的原因。例如,我们可以根据它们的端点名称聚合所有请求,正如下面的时间序列图所示,从图中可以清晰地看出在特定端点上是否发生了回归。
|
||||
|
||||

|
||||
|
||||
CPU 指令对测量效率很重要——当然,它们也很难获得。Python 并没有支持直接访问 CPU 硬件计数器(CPU 硬件计数器是指可编程 CPU 寄存器,用于测量性能指标,例如 CPU 指令)的公共库。另一方面,Linux 内核提供了 `perf_event_open` 系统调用。通过 Python `ctypes` 桥接技术能够让我们调用标准 C 库的系统调用函数 `syscall`,它也为我们提供了兼容 C 的数据类型,从而可以编程硬件计数器并从它们读取数据。
|
||||
|
||||
使用 Dynostats,我们已经可以找出 CPU 回归,并探究 CPU 回归发生的原因,例如哪个端点受到的影响最多,谁提交了真正会导致 CPU 回归的变更等。然而,当开发者收到他们的变更已经导致一次 CPU 回归发生的通知时,他们通常难以找出问题所在。如果问题很明显,那么回归可能就不会一开始就被提交!
|
||||
|
||||
这就是为何我们需要一个 Python 分析器,(一旦 Dynostats 发现了它)从而使开发者能够使用它找出回归发生的根本原因。不同于白手起家,我们决定对一个现成的 Python 分析器 cProfile 做适当的修改。cProfile 模块通常会提供一个统计集合来描述程序不同的部分执行时间和执行频率。我们将 cProfile 的定时器(timer)替换成了一个从硬件计数器读取的 CPU 指令计数器,以此取代对时间的测量。我们在采样请求后产生数据并把数据发送到数据流水线。我们也会发送一些我们在 Dynostats 所拥有的类似元数据,例如服务器名称、集群、区域、端点名称等。
|
||||
|
||||
在数据流水线的另一边,我们创建了一个消费数据的尾随者(tailer)。尾随者的主要功能是解析 cProfile 的统计数据并创建能够表示 Python 函数级别的 CPU 指令的实体。如此,我们能够通过 Python 函数来聚合 CPU 指令,从而更加方便地找出是什么函数导致了 CPU 回归。
|
||||
|
||||
### 监控与警报机制
|
||||
|
||||
在 Instagram,我们[每天部署 30-50 次后端服务][1]。这些部署中的任何一个都能发生 CPU 回归的问题。因为每次发生通常都包含至少一个差异(diff),所以找出任何回归是很容易的。我们的效率监控机制包括在每次发布前后都会在 Dynostats 中扫描 CPU 指令,并且当变更超出某个阈值时发出警告。对于长期会发生 CPU 回归的情况,我们也有一个探测器为负载最繁重的端点提供日常和每周的变更扫描。
|
||||
|
||||
部署新的变更并非触发一次 CPU 回归的唯一情况。在许多情况下,新的功能和新的代码路径都由全局环境变量(global environment variables,GEV)控制。 在一个计划好的时间表上,给一部分用户发布新功能是很常见事情。我们在 Dynostats 和 cProfile 统计数据中为每个请求添加了这个信息作为额外的元数据字段。按这些字段将请求分组可以找出由全局环境变量(GEV)改变导致的可能的 CPU 回归问题。这让我们能够在它们对性能造成影响前就捕获到 CPU 回归。
|
||||
|
||||
### 接下来是什么?
|
||||
|
||||
Dynostats 和我们定制的 cProfile,以及我们建立的支持它们的监控和警报机制能够有效地找出大多数导致 CPU 回归的元凶。这些进展已经帮助我们恢复了超过 50% 的不必要的 CPU 回归,否则我们就根本不会知道。
|
||||
|
||||
我们仍然还有一些可以提升的方面,并很容易将它们地加入到 Instagram 的日常部署流程中:
|
||||
|
||||
1. CPU 指令指标应该要比其它指标如 CPU 时间更加稳定,但我们仍然观察了让我们头疼的差异。保持“信噪比(signal:noise ratio)”合理地低是非常重要的,这样开发者们就可以集中于真实的回归上。这可以通过引入置信区间(confidence intervals)的概念来提升,并在信噪比过高时发出警报。针对不同的端点,变化的阈值也可以设置为不同值。
|
||||
2. 通过更改 GEV 来探测 CPU 回归的一个限制就是我们要在 Dynostats 中手动启用这些比较的日志输出。当 GEV 的数量逐渐增加,开发了越来越多的功能,这就不便于扩展了。相反,我们能够利用一个自动化框架来调度这些比较的日志输出,并对所有的 GEV 进行遍历,然后当检查到回归时就发出警告。
|
||||
3. cProfile 需要一些增强以便更好地处理封装函数以及它们的子函数。
|
||||
|
||||
鉴于我们在为 Instagram 的 web service 构建效率框架中所投入的工作,所以我们对于将来使用 Python 继续扩展我们的服务很有信心。我们也开始向 Python 语言本身投入更多,并且开始探索从 Python 2 转移 Python 3 之道。我们将会继续探索并做更多的实验以继续提升基础设施与开发者效率,我们期待着很快能够分享更多的经验。
|
||||
|
||||
本文作者 Min Ni 是 Instagram 的软件工程师。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://engineering.instagram.com/web-service-efficiency-at-instagram-with-python-4976d078e366#.tiakuoi4p
|
||||
|
||||
作者:[Min Ni][a]
|
||||
译者:[ChrisLeeGit](https://github.com/chrisleegit)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://engineering.instagram.com/@InstagramEng?source=post_header_lockup
|
||||
[1]: https://engineering.instagram.com/continuous-deployment-at-instagram-1e18548f01d1#.p5adp7kcz
|
||||
@ -1,17 +1,17 @@
|
||||
科学音频处理(二):如何使用 Octave 对音频文件进行基本数学信号处理
|
||||
=========
|
||||
|
||||
# 科学音频处理,第二节 - 如何用 Ubuntu 上的 Octave 4.0 软件对音频文件进行基本数学信号处理
|
||||
在[前一篇的指导教程][1]中,我们看到了读、写以及重放音频文件的简单步骤,我们甚至看到如何从一个周期函数比如余弦函数合成一个音频文件。在这篇指导教程中,我们将会看到如何对信号进行叠加和倍乘(调整),并应用一些基本的数学函数看看它们对原始信号的影响。
|
||||
|
||||
在过去的指导教程中【previous tutorial】(https://www.howtoforge.com/tutorial/how-to-read-and-write-audio-files-with-octave-4-in-ubuntu/), 我们看到了读,写以及重放音频文件的简单步骤,我们甚至看到如何从一个周期函数比如余弦函数合成一个音频文件。在这个指导教程中【tutorial】,我们将会看到如何对信号进行相加和调整,并看一看基本数学函数它们对原始信号的影响。
|
||||
### 信号叠加
|
||||
|
||||
### 信号相加
|
||||
|
||||
两个信号 S1(t) 和 S2(t) 相加形成一个新的信号 R(t), 这个信号在任何瞬间的值等于构成它的两个信号在那个时刻的值之和。就像下面这样:
|
||||
两个信号 S1(t)和 S2(t)相加形成一个新的信号 R(t),这个信号在任何瞬间的值等于构成它的两个信号在那个时刻的值之和。就像下面这样:
|
||||
|
||||
```
|
||||
R(t) = S1(t) + S2(t)
|
||||
```
|
||||
|
||||
我们将用 Octave 重新产生两个信号的和并通过图表看达到的效果。首先,我们生成两个不同频率的信号,看一看它们的和信号是什么样的。
|
||||
我们将用 Octave 重新产生两个信号的和并通过图表看达到的效果。首先,我们生成两个不同频率的信号,看一看它们的叠加信号是什么样的。
|
||||
|
||||
#### 第一步:产生两个不同频率的信号(oog 文件)
|
||||
|
||||
@ -28,7 +28,7 @@ R(t) = S1(t) + S2(t)
|
||||
|
||||
然后我们绘制出两个信号的图像。
|
||||
|
||||
信号 1 的图像(440 赫兹)
|
||||
**信号 1 的图像(440 赫兹)**
|
||||
|
||||
```
|
||||
>> [y1, fs] = audioread(sig1);
|
||||
@ -37,7 +37,7 @@ R(t) = S1(t) + S2(t)
|
||||
|
||||
[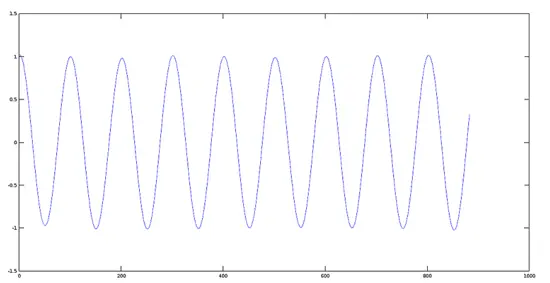](https://www.howtoforge.com/images/octave-audio-signal-processing-ubuntu/big/plotsignal1.png)
|
||||
|
||||
信号 2 的图像(880 赫兹)
|
||||
**信号 2 的图像(880 赫兹)**
|
||||
|
||||
```
|
||||
>> [y2, fs] = audioread(sig2);
|
||||
@ -46,7 +46,7 @@ R(t) = S1(t) + S2(t)
|
||||
|
||||
[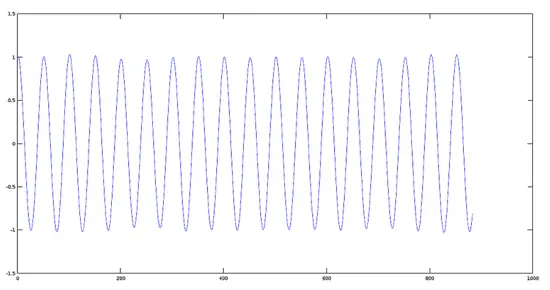](https://www.howtoforge.com/images/octave-audio-signal-processing-ubuntu/big/plotsignal2.png)
|
||||
|
||||
#### 第二部:把两个信号相加
|
||||
#### 第二步:把两个信号叠加
|
||||
|
||||
现在我们展示一下前面步骤中产生的两个信号的和。
|
||||
|
||||
@ -55,19 +55,19 @@ R(t) = S1(t) + S2(t)
|
||||
>> plot(sumres)
|
||||
```
|
||||
|
||||
和信号的图像
|
||||
叠加信号的图像
|
||||
|
||||
[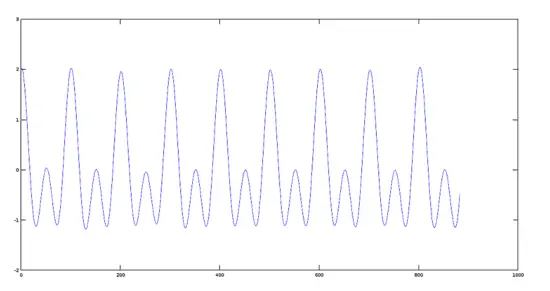](https://www.howtoforge.com/images/octave-audio-signal-processing-ubuntu/big/plotsum.png)
|
||||
|
||||
八度器(Octaver)的效果
|
||||
**Octaver 中的效果**
|
||||
|
||||
在八度器(Octaver)中,八度器的效果产生的声音是典型化的,因为它可以仿真音乐家弹奏的低八度或者高八度音符(取决于内部程序设计),仿真音符和原始音符成对,也就是两个音符发出相同的声音。
|
||||
在 Octaver 中,这个效果产生的声音是独特的,因为它可以仿真音乐家弹奏的低八度或者高八度音符(取决于内部程序设计),仿真音符和原始音符成对,也就是两个音符发出相同的声音。
|
||||
|
||||
#### 第三步:把两个真实的信号相加(比如两首音乐歌曲)
|
||||
|
||||
为了实现这个目的,我们使用格列高利圣咏(Gregorian Chants)中的两首歌曲(声音采样)。
|
||||
为了实现这个目的,我们使用格列高利圣咏(Gregorian Chants)中的两首歌曲(声音采样)。
|
||||
|
||||
圣母颂曲(Avemaria Track)
|
||||
**圣母颂曲(Avemaria Track)**
|
||||
|
||||
首先,我们看一下圣母颂曲并绘出它的图像:
|
||||
|
||||
@ -78,9 +78,9 @@ R(t) = S1(t) + S2(t)
|
||||
|
||||
[](https://www.howtoforge.com/images/octave-audio-signal-processing-ubuntu/big/avemaria.png)
|
||||
|
||||
赞美诗曲(Hymnus Track)
|
||||
**赞美诗曲(Hymnus Track)**
|
||||
|
||||
现在我们看一下赞美诗曲并绘出它的图像
|
||||
现在我们看一下赞美诗曲并绘出它的图像。
|
||||
|
||||
```
|
||||
>> [y2,fs]=audioread('hymnus.ogg');
|
||||
@ -89,7 +89,7 @@ R(t) = S1(t) + S2(t)
|
||||
|
||||
[](https://www.howtoforge.com/images/octave-audio-signal-processing-ubuntu/big/hymnus.png)
|
||||
|
||||
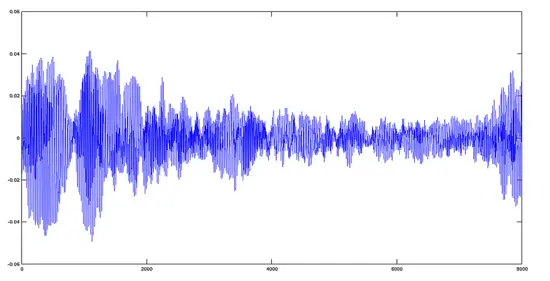
圣母颂曲 + 赞美诗曲
|
||||
**圣母颂曲 + 赞美诗曲**
|
||||
|
||||
```
|
||||
>> y='avehymnus.ogg';
|
||||
@ -98,11 +98,13 @@ R(t) = S1(t) + S2(t)
|
||||
>> plot(y)
|
||||
```
|
||||
|
||||
[](https://www.howtoforge.com/images/octave-audio-signal-processing-ubuntu/big/avehymnus.png)结果,从音频的角度来看,两个声音信号混合在了一起。
|
||||
[](https://www.howtoforge.com/images/octave-audio-signal-processing-ubuntu/big/avehymnus.png)
|
||||
|
||||
### 两个信号的乘
|
||||
结果,从音频的角度来看,两个声音信号混合在了一起。
|
||||
|
||||
对于求两个信号的乘,我们可以使用类似求它们和的方法。我们使用之前生成的相同文件。
|
||||
### 两个信号的乘积
|
||||
|
||||
对于求两个信号的乘积,我们可以使用类似求和的方法。我们使用之前生成的相同文件。
|
||||
|
||||
```
|
||||
R(t) = S1(t) * S2(t)
|
||||
@ -124,15 +126,15 @@ R(t) = S1(t) * S2(t)
|
||||
```
|
||||
|
||||
|
||||
注意:我们必须使用操作符 ‘.*’,因为在参数文件中,这个乘积是值与值相乘。更多信息,请参考【八度矩阵操作产品手册】。
|
||||
注意:我们必须使用操作符 ‘.*’,因为在参数文件中,这个乘积是值与值相乘。更多信息,请参考 Octave 矩阵操作产品手册。
|
||||
|
||||
#### 乘积生成信号的图像
|
||||
|
||||
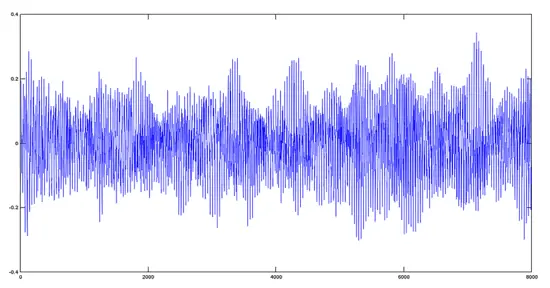
[](https://www.howtoforge.com/images/octave-audio-signal-processing-ubuntu/big/plotprod.png)
|
||||
|
||||
#### 两个基本频率相差很大的信号相乘后的图表效果(调制原理
|
||||
#### 两个基本频率相差很大的信号相乘后的图表效果(调制原理)
|
||||
|
||||
##### 第一步:
|
||||
**第一步:**
|
||||
|
||||
生成两个频率为 220 赫兹的声音信号。
|
||||
|
||||
@ -146,7 +148,7 @@ R(t) = S1(t) * S2(t)
|
||||
|
||||
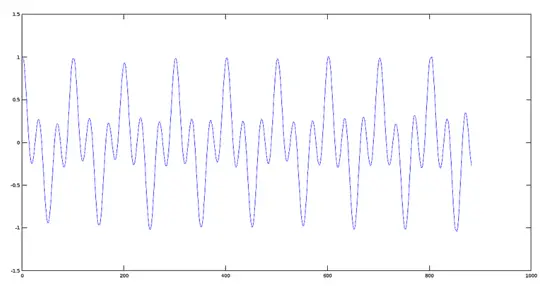
[](https://www.howtoforge.com/images/octave-audio-signal-processing-ubuntu/big/carrier.png)
|
||||
|
||||
##### 第二步:
|
||||
**第二步:**
|
||||
|
||||
生成一个 22000 赫兹的高频调制信号。
|
||||
|
||||
@ -157,7 +159,7 @@ R(t) = S1(t) * S2(t)
|
||||
|
||||
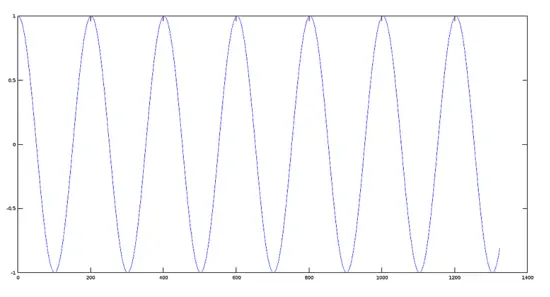
[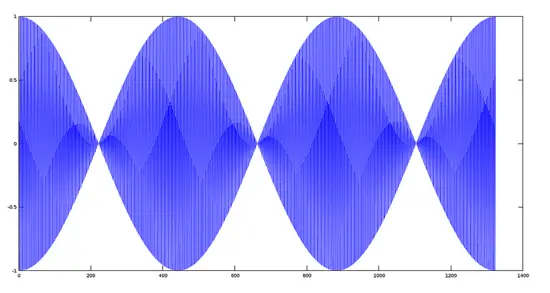](https://www.howtoforge.com/images/octave-audio-signal-processing-ubuntu/big/modulating.png)
|
||||
|
||||
##### 第三步:
|
||||
**第三步:**
|
||||
|
||||
把两个信号相乘并绘出图像。
|
||||
|
||||
@ -169,7 +171,7 @@ R(t) = S1(t) * S2(t)
|
||||
|
||||
### 一个信号和一个标量相乘
|
||||
|
||||
一个函数和一个标量相乘的效果等于更改它的值域,在某些情况下,更改的是相标志。给定一个标量 K ,一个函数 F(t) 和这个标量相乘定义为:
|
||||
一个函数和一个标量相乘的效果等于更改它的值域,在某些情况下,更改的是相标志。给定一个标量 K ,一个函数 F(t) 和这个标量相乘定义为:
|
||||
|
||||
```
|
||||
R(t) = K*F(t)
|
||||
@ -186,7 +188,7 @@ R(t) = K*F(t)
|
||||
>> audiowrite(res3, K3*y, fs);
|
||||
```
|
||||
|
||||
#### 原始信号的图像
|
||||
**原始信号的图像**
|
||||
|
||||
```
|
||||
>> plot(y)
|
||||
@ -194,7 +196,7 @@ R(t) = K*F(t)
|
||||
|
||||
[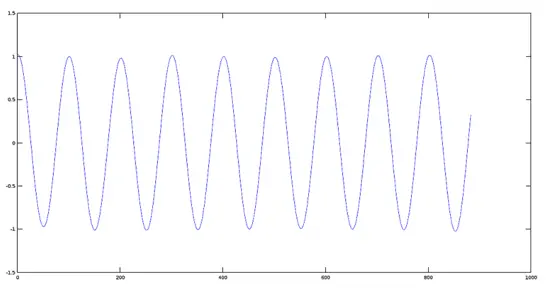](https://www.howtoforge.com/images/octave-audio-signal-processing-ubuntu/big/originalsignal.png)
|
||||
|
||||
信号振幅减为原始信号振幅的 0.2 倍后的图像
|
||||
**信号振幅减为原始信号振幅的 0.2 倍后的图像**
|
||||
|
||||
```
|
||||
>> plot(res1)
|
||||
@ -202,7 +204,7 @@ R(t) = K*F(t)
|
||||
|
||||
[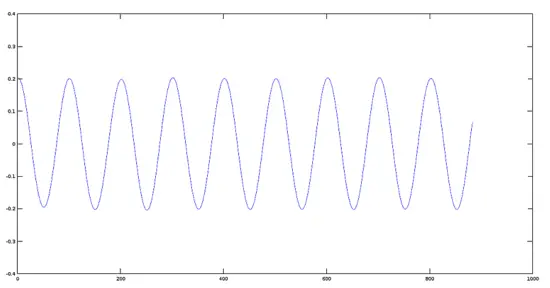](https://www.howtoforge.com/images/octave-audio-signal-processing-ubuntu/big/coslow.png)
|
||||
|
||||
信号振幅减为原始振幅的 0.5 倍后的图像
|
||||
**信号振幅减为原始振幅的 0.5 倍后的图像**
|
||||
|
||||
```
|
||||
>> plot(res2)
|
||||
@ -210,7 +212,7 @@ R(t) = K*F(t)
|
||||
|
||||
[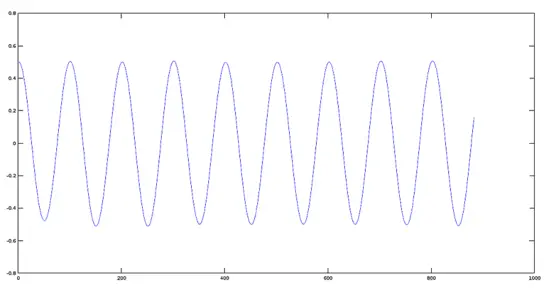](https://www.howtoforge.com/images/octave-audio-signal-processing-ubuntu/big/coshigh.png)
|
||||
|
||||
倒相后的信号图像
|
||||
**倒相后的信号图像**
|
||||
|
||||
```
|
||||
>> plot(res3)
|
||||
@ -228,8 +230,10 @@ via: https://www.howtoforge.com/tutorial/octave-audio-signal-processing-ubuntu/
|
||||
|
||||
作者:[David Duarte][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.howtoforge.com/tutorial/octave-audio-signal-processing-ubuntu/
|
||||
[1]: https://linux.cn/article-7755-1.html
|
||||
|
||||
80
published/201609/20160830 Spark comparison - AWS vs. GCP.md
Normal file
80
published/201609/20160830 Spark comparison - AWS vs. GCP.md
Normal file
@ -0,0 +1,80 @@
|
||||
AWS 和 GCP 的 Spark 技术哪家强?
|
||||
==============
|
||||
|
||||
> Tianhui Michael Li 和Ariel M’ndange-Pfupfu将在今年10月10、12和14号组织一个在线经验分享课程:[Spark 分布式计算入门][4]。该课程的内容包括创建端到端的运行应用程序和精通 Spark 关键工具。
|
||||
|
||||
毋庸置疑,云计算将会在未来数据科学领域扮演至关重要的角色。弹性,可扩展性和按需分配的计算能力作为云计算的重要资源,直接导致云服务提供商集体火拼。其中最大的两股势力正是[亚马逊网络服务(AWS)][1] 和[谷歌云平台(GCP)][2]。
|
||||
|
||||
本文依据构建时间和运营成本对 AWS 和 GCP 的 Spark 工作负载作一个简短比较。实验由我们的学生在数据孵化器(The Data Incubator)进行,[数据孵化器(The Data Incubator)][3]是一个大数据培训组织,专门为公司招聘顶尖数据科学家并为公司职员培训最新的大数据科学技能。尽管 Spark 效率惊人,分布式工作负载的时间和成本亦然可以大到不能忽略不计。因此我们一直努力寻求更高效的技术,以便我们的学生能够学习到最好和最快的工具。
|
||||
|
||||
### 提交 Spark 任务到云
|
||||
|
||||
[Spark][5] 是一个类 MapReduce 但是比 MapReduce 更灵活、更抽象的并行计算框架。Spark 提供 Python 和 Java 编程接口,但它更愿意用户使用原生的 Scala 语言进行应用程序开发。Scala 可以把应用程序和依赖文件打包在一个 JAR 文件从而使 Spark 任务提交变得简单。
|
||||
|
||||
通常情况下,Sprark 结合 HDFS 应用于分布式数据存储,而与 YARN 协同工作则应用于集群管理;这种堪称完美的配合使得 Spark 非常适用于 AWS 的弹性 MapReduce (EMR)集群和 GCP 的 Dataproc 集群。这两种集群都已有 HDFS 和 YARN 预配置,不需要额外进行配置。
|
||||
|
||||
### 配置云服务
|
||||
|
||||
通过命令行比通过网页界面管理数据、集群和任务具有更高的可扩展性。对 AWS 而言,这意味着客户需要安装 [CLI][6]。客户必须获得证书并为每个 EC2 实例创建[独立的密钥对][7]。除此之外,客户还需要为 EMR 用户和 EMR 本身创建角色(基本权限),主要是准入许可规则,从而使 EMR 用户获得足够多的权限(通常在 CLI 运行 `aws emr create-default-roles` 就可以)。
|
||||
|
||||
相比而言,GCP 的处理流程更加直接。如果客户选择安装 [Google Cloud SDK][8] 并且使用其 Google 账号登录,那么客户即刻可以使用 GCP 的几乎所有功能而无需其他任何配置。唯一需要提醒的是不要忘记通过 API 管理器启用计算引擎、Dataproc 和云存储 JSON 的 API。
|
||||
|
||||
当你安装你的喜好设置好之后,有趣的事情就发生了!比如可以通过`aws s3 cp`或者`gsutil cp`命令拷贝客户的数据到云端。再比如客户可以创建自己的输入、输出或者任何其他需要的 bucket,如此,运行一个应用就像创建一个集群或者提交 JAR 文件一样简单。请确定日志存放的地方,毕竟在云环境下跟踪问题或者调试 bug 有点诡异。
|
||||
|
||||
### 一分钱一分货
|
||||
|
||||
谈及成本,Google 的服务在以下几个方面更有优势。首先,购买计算能力的原始成本更低。4 个 vCPU 和 15G RAM 的 Google 计算引擎服务(GCE)每小时只需 0.20 美元,如果运行 Dataproc,每小时也只需区区 0.24 美元。相比之下,同等的云配置,AWS EMR 则需要每小时 0.336 美元。
|
||||
|
||||
其次,计费方式。AWS 按小时计费,即使客户只使用 15 分钟也要付足 1 小时的费用。GCP 按分钟计费,最低计费 10 分钟。在诸多用户案例中,资费方式的不同直接导致成本的巨大差异。
|
||||
|
||||
两种云服务都有其他多种定价机制。客户可以使用 AWS 的 Sport Instance 或 GCP 的 Preemptible Instance 来竞价它们的空闲云计算能力。这些服务比专有的、按需服务便宜,缺点是不能保证随时有可用的云资源提供服务。在 GCP 上,如果客户长时间(每月的 25% 至 100%)使用服务,可以获取更多折扣。在 AWS 上预付费或者一次购买大批量服务可以节省不少费用。底线是,如果你是一个超级用户,并且使用云计算已经成为一种常态,那么最好深入研究云计算,自己算计好成本。
|
||||
|
||||
最后,新手在 GCP 上体验云服务的费用较低。新手只需 300 美元信用担保,就可以免费试用 60 天 GCP 提供的全部云服务。AWS 只免费提供特定服务的特定试用层级,如果运行 Spark 任务,需要付费。这意味着初次体验 Spark,GCP 具有更多选择,也少了精打细算和讨价还价的烦恼。
|
||||
|
||||
### 性能比拼
|
||||
|
||||
我们通过实验检测一个典型 Spark 工作负载的性能与开销。实验分别选择 AWS 的 m3.xlarg 和 GCP 的 n1-standard-4,它们都是由一个 Master 和 5 个核心实例组成的集群。除了规格略有差别,虚拟核心和费用都相同。实际上它们在 Spark 任务的执行时间上也表现的惊人相似。
|
||||
|
||||
测试 Spark 任务包括对数据的解析、过滤、合并和聚合,这些数据来自公开的[堆栈交换数据转储(Stack Exchange Data Dump)][9]。通过运行相同的 JAR,我们首先对大约 50M 的数据子集进行[交叉验证][10],然后将验证扩大到大约 9.5G 的数据集。
|
||||
|
||||

|
||||
>Figure 1. Credit: Michael Li and Ariel M'ndange-Pfupfu.
|
||||
|
||||

|
||||
>Figure 2. Credit: Michael Li and Ariel M'ndange-Pfupfu.
|
||||
|
||||
结果表明,短任务在 GCP 上具有明显的成本优势,这是因为 GCP 以分钟计费,并最终扣除了 10 分钟的费用,而 AWS 则收取了 1 小时的费用。但是即使长任务,因为计费方式占优,GPS 仍然具有相当优势。同样值得注意的是存储成本并不包括在此次比较当中。
|
||||
|
||||
###结论
|
||||
|
||||
AWS 是云计算的先驱,这甚至体现在 API 中。AWS 拥有巨大的生态系统,但其许可模型已略显陈旧,配置管理也有些晦涩难解。相比之下,Google 是云计算领域的新星并且将云计算服务打造得更加圆润自如。但是 GCP 缺少一些便捷的功能,比如通过简单方法自动结束集群和详细的任务计费信息分解。另外,其 Python 编程接口也不像 [AWS 的 Boto][11] 那么全面。
|
||||
|
||||
如果你初次使用云计算,GCP 因其简单易用,别具魅力。即使你已在使用 AWS,你也许会发现迁移到 GCP 可能更划算,尽管真正从 AWS 迁移到 GCP 的代价可能得不偿失。
|
||||
|
||||
当然,现在对两种云服务作一个全面的总结还非常困难,因为它们都不是单一的实体,而是由多个实体整合而成的完整生态系统,并且各有利弊。真正的赢家是用户。一个例证就是在数据孵化器(The Data Incubator),我们的博士数据科学研究员在学习分布式负载的过程中真正体会到成本的下降。虽然我们的[大数据企业培训客户][12]可能对价格不那么敏感,他们更在意能够更快速地处理企业数据,同时保持价格不增加。数据科学家现在可以享受大量的可选服务,这些都是从竞争激烈的云计算市场得到的实惠。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.oreilly.com/ideas/spark-comparison-aws-vs-gcp
|
||||
|
||||
作者:[Michael Li][a],[Ariel M'Ndange-Pfupfu][b]
|
||||
译者:[firstadream](https://github.com/firstadream)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.oreilly.com/people/76a5b-michael-li
|
||||
[b]: https://www.oreilly.com/people/Ariel-Mndange-Pfupfu
|
||||
[1]: https://aws.amazon.com/
|
||||
[2]: https://cloud.google.com/
|
||||
[3]: https://www.thedataincubator.com/training.html?utm_source=OReilly&utm_medium=blog&utm_campaign=AWSvsGCP
|
||||
[4]: http://www.oreilly.com/live-training/distributed-computing-with-spark.html?intcmp=il-data-olreg-lp-oltrain_20160828_new_site_spark_comparison_aws_gcp_post_top_note_training_link
|
||||
[5]: http://spark.apache.org/
|
||||
[6]: http://docs.aws.amazon.com/cli/latest/userguide/cli-chap-getting-set-up.html
|
||||
[7]: http://docs.aws.amazon.com/ElasticMapReduce/latest/DeveloperGuide/EMR_SetUp_KeyPair.html
|
||||
[8]: https://cloud.google.com/sdk/#Quick_Start
|
||||
[9]: https://archive.org/details/stackexchange
|
||||
[10]: http://stats.stackexchange.com/
|
||||
[11]: https://github.com/boto/boto3
|
||||
[12]: https://www.thedataincubator.com/training.html?utm_source=OReilly&utm_medium=blog&utm_campaign=AWSvsGCP
|
||||
@ -1,18 +1,17 @@
|
||||
Ubuntu 16.04上的服务器监控报警系统 Shinken
|
||||
在 Ubuntu 16.04 上安装和使用服务器监控报警系统 Shinken
|
||||
=====
|
||||
|
||||
Shinken 是一个用 Python 实现的开源的主机和网络监控框架,并与 Nagios like 兼容,它可以运行在所有支持 Python 程序的操作系统上,比如说 Linux、Unix 和 Windows,Shinken 是 Jean Gabes 为了验证一个新的 Nagios 架构思路而编写,但是这个想法被 Nagios 的作者拒绝后成为了一个独立的网络系统监视软件,并保持了与 Nagios 的兼容。
|
||||
|
||||
Shinken 是一个用 python 实现的,开源的主机和网络监视的,Nagios like 的框架,他可以运行在所有支持 python 程序的操作系统上,比如说 Linux,Unix 和Windows,Shinken 由 Jean Gabes 编写作为一个新的 Nagios 架构概念证明,但是这个想法被 Nagios 的作者拒绝而后成为了一个独立的类 Nagios 网络系统监视软件。
|
||||
在这篇教程中,我将会描述如何从源代码编译安装 Shinken 和向监视系统中添加一台 Linux 主机。我将会以 Ubuntu 16.04 Xenial Xerus 操作系统来作为 Shinken 服务器和所监控的主机。
|
||||
|
||||
在这篇教程中,我将会描述如何源代码编译安装 Shinken 和向监视系统中添加一台 Linux 主机。我将会以 Ubuntu 16.04 Xenial Xerus 操作系统来作为 Shinken 服务器和监控端。
|
||||
### 第一步 安装 Shinken 服务器
|
||||
|
||||
### 第一步-安装 Shinken 服务器
|
||||
|
||||
Shinken 是一个 python 框架,我们可以通过 pip 或者源码来安装他,在这一步中,我们将用源代码编译安装 Shinken。
|
||||
Shinken 是一个 Python 框架,我们可以通过 `pip` 安装或者从源码来安装它,在这一步中,我们将用源代码编译安装 Shinken。
|
||||
|
||||
在我们开始安装 Shinken 之前还需要完成几个步骤。
|
||||
|
||||
安装一些新的 python 软件包和创建 “shinken” 系统用户:
|
||||
安装一些新的 Python 软件包并创建一个名为 `shinken` 的系统用户:
|
||||
|
||||
```
|
||||
sudo apt-get install python-setuptools python-pip python-pycurl
|
||||
@ -33,22 +32,22 @@ git checkout 2.4.3
|
||||
python setup.py install
|
||||
```
|
||||
|
||||
然后,为了得到更好的效果,我们还需要在 Ubuntu 的软件库中安装 “python-cherrypy3“ 软件包:
|
||||
然后,为了得到更好的效果,我们还需要从 Ubuntu 软件库中安装 `python-cherrypy3` 软件包:
|
||||
|
||||
```
|
||||
sudo apt-get install python-cherrypy3
|
||||
```
|
||||
|
||||
到这里,Shinken 已经成功安装,接下来我们将 Shinken 添加到系统启动项并且启动他:
|
||||
到这里,Shinken 已经成功安装,接下来我们将 Shinken 添加到系统启动项并且启动它:
|
||||
|
||||
```
|
||||
update-rc.d shinken defaults
|
||||
systemctl start shinken
|
||||
```
|
||||
|
||||
### 第二部-安装 Shinken Webui2
|
||||
### 第二步 安装 Shinken Webui2
|
||||
|
||||
Webui2 是 Shinken 的 web 界面(在 shinken.io 可以找到)。最简单的安装 Sshinken webui2 的方法是使用shinken CLI 命令(必须作为 shinken 用户执行)。
|
||||
Webui2 是 Shinken 的 Web 界面(在 shinken.io 可以找到)。最简单的安装 Shinken webui2 的方法是使用shinken CLI 命令(必须作为 `shinken` 用户执行)。
|
||||
|
||||
切换到 shinken 用户:
|
||||
|
||||
@ -56,13 +55,13 @@ Webui2 是 Shinken 的 web 界面(在 shinken.io 可以找到)。最简单
|
||||
su - shinken
|
||||
```
|
||||
|
||||
初始化 shiken 配置文件-下面的命令将会创建一个新的配置文件 .shinken.ini:
|
||||
初始化 shiken 配置文件,下面的命令将会创建一个新的配置文件 `.shinken.ini` :
|
||||
|
||||
```
|
||||
shinken --init
|
||||
```
|
||||
|
||||
接下来用 shinken CLI 命令来安装 webui2:
|
||||
接下来用 shinken CLI 命令来安装 `webui2`:
|
||||
|
||||
```
|
||||
shinken install webui2
|
||||
@ -70,14 +69,14 @@ shinken install webui2
|
||||
|
||||
|
||||
|
||||
到现在 webui2 已经被安装,但是我们还需要用 pip 来安装安装 MongoDB 和另一个 python 软件包。在 root 下运行如下命令:
|
||||
至此 webui2 已经安装好,但是我们还需要安装 MongoDB 和用 `pip` 来安装另一个 Python 软件包。在 root 下运行如下命令:
|
||||
|
||||
```
|
||||
sudo apt-get install mongodb
|
||||
pip install pymongo>=3.0.3 requests arrow bottle==0.12.8
|
||||
```
|
||||
|
||||
接下来,切换到 shinken 目录下并且通过编辑 broker-master.cfg 文件来添加这个新的 webui2 模块:
|
||||
接下来,切换到 shinken 目录下并且通过编辑 `broker-master.cfg` 文件来添加这个新的 webui2 模块:
|
||||
|
||||
```
|
||||
cd /etc/shinken/brokers/
|
||||
@ -90,9 +89,9 @@ vim broker-master.cfg
|
||||
modules webui2
|
||||
```
|
||||
|
||||
保存文件并且退出编辑器
|
||||
保存文件并且退出编辑器。
|
||||
|
||||
现在进入 contacts 目录下编辑 admin.cfg 来进行管理配置。
|
||||
现在进入 `contacts` 目录下编辑 `admin.cfg` 来进行管理配置。
|
||||
|
||||
```
|
||||
cd /etc/shinken/contacts/
|
||||
@ -108,17 +107,17 @@ password yourpass # Pass 'mypass'
|
||||
|
||||
保存和退出。
|
||||
|
||||
### 第三步-安装 Nagios 插件和 Shinken 软件包
|
||||
### 第三步 安装 Nagios 插件和 Shinken 软件包
|
||||
|
||||
在这一步中,我们将安装 Nagios 插件和一些 perl 模块。然后从 shinken.io 安装其他的软件包来实现监视。
|
||||
在这一步中,我们将安装 Nagios 插件和一些 Perl 模块。然后从 shinken.io 安装其他的软件包来实现监视。
|
||||
|
||||
安装 Nagios 插件和安装 perl 模块所需要的 cpanminus:
|
||||
安装 Nagios 插件和安装 Perl 模块所需要的 `cpanminus`:
|
||||
|
||||
```
|
||||
sudo apt-get install nagios-plugins* cpanminus
|
||||
```
|
||||
|
||||
用 cpanm 命令来安装 perl 模块。
|
||||
用 `cpanm` 命令来安装 Perl 模块。
|
||||
|
||||
```
|
||||
cpanm Net::SNMP
|
||||
@ -126,7 +125,7 @@ cpanm Time::HiRes
|
||||
cpanm DBI
|
||||
```
|
||||
|
||||
现在我们创建了一个到 shinken 的目录的链接并且为日志文件创建了一个新的目录。
|
||||
现在我们创建一个 `utils.pm` 文件的链接到 shinken 的目录,并且为 `Log_File_Health` 创建了一个新的日志目录 。
|
||||
|
||||
```
|
||||
chmod u+s /usr/lib/nagios/plugins/check_icmp
|
||||
@ -135,7 +134,7 @@ mkdir -p /var/log/rhosts/
|
||||
touch /var/log/rhosts/remote-hosts.log
|
||||
```
|
||||
|
||||
然后,安装 shinken 软件包 ssh 和 linux-snmp 用来监视,从 shinken.io 来安装 SSH 和 SNMP :
|
||||
然后,从 shinken.io 安装 shinken 软件包 `ssh` 和 `linux-snmp` 来监视 SSH 和 SNMP :
|
||||
|
||||
```
|
||||
su - shinken
|
||||
@ -143,9 +142,10 @@ shinken install ssh
|
||||
shinken install linux-snmp
|
||||
```
|
||||
|
||||
### 第四步-添加一个 Linux 主机
|
||||
### 第四步 添加一个 Linux 主机 host-one
|
||||
|
||||
我们将添加一个新的将被监控的 Linux 主机,IP 地址为 192.168.1.121,主机名为 host-one 的 Ubuntu 16.04。
|
||||
|
||||
我们将添加一个新的 Linux 主机,它将被一台 IP 地址为 192.168.1.121,主机名为 host-one 的 Ubuntu 16.04 服务器监控。
|
||||
连接到 host-one 主机:
|
||||
|
||||
```
|
||||
@ -158,20 +158,20 @@ ssh host1@192.168.1.121
|
||||
sudo apt-get install snmp snmpd
|
||||
```
|
||||
|
||||
然后,用 vim 编辑 snmpd.conf 配置文件:
|
||||
然后,用 `vim` 编辑 `snmpd.conf` 配置文件:
|
||||
|
||||
```
|
||||
vim /etc/snmp/snmpd.conf
|
||||
```
|
||||
|
||||
注释掉第 15 行和取消注释第 17 行:
|
||||
注释掉第 15 行并取消注释第 17 行:
|
||||
|
||||
```
|
||||
#agentAddress udp:127.0.0.1:161
|
||||
agentAddress udp:161,udp6:[::1]:161
|
||||
```
|
||||
|
||||
注释掉第 51 和 53 行,然后添加如下配置:
|
||||
注释掉第 51 和 53 行,然后加一行新的配置,如下:
|
||||
|
||||
```
|
||||
#rocommunity mypass default -V systemonly
|
||||
@ -180,14 +180,15 @@ agentAddress udp:161,udp6:[::1]:161
|
||||
rocommunity mypass
|
||||
```
|
||||
|
||||
保存和退出。
|
||||
保存并退出。
|
||||
|
||||
现在用 `systemctl` 命令来启动 `snmpd` 服务:
|
||||
|
||||
现在启动用 systemctl 命令来启动 snmpd 服务:
|
||||
```
|
||||
systemctl start snmpd
|
||||
```
|
||||
|
||||
通过在 hosts 文件夹下创建新的文件来定义一个新的主机:
|
||||
在 shinken 服务器上通过在 `hosts` 文件夹下创建新的文件来定义一个新的主机:
|
||||
|
||||
```
|
||||
cd /etc/shinken/hosts/
|
||||
@ -206,7 +207,7 @@ define host{
|
||||
}
|
||||
```
|
||||
|
||||
保存和退出。
|
||||
保存并退出。
|
||||
|
||||
在 shinken 服务器上编辑 SNMP 配置文件。
|
||||
|
||||
@ -214,13 +215,13 @@ define host{
|
||||
vim /etc/shinken/resource.d/snmp.cfg
|
||||
```
|
||||
|
||||
将 public 改为 mypass -必须和你在客户端 snmpd 配置文件中使用的密码相同:
|
||||
将 `public` 改为 `mypass` -必须和你在客户端 `snmpd` 配置文件中使用的密码相同:
|
||||
|
||||
```
|
||||
$SNMPCOMMUNITYREAD$=mypass
|
||||
```
|
||||
|
||||
保存和退出。
|
||||
保存并退出。
|
||||
|
||||
现在将服务端和客户端都重启:
|
||||
|
||||
@ -230,37 +231,37 @@ reboot
|
||||
|
||||
现在 Linux 主机已经被成功地添加到 shinken 服务器中了。
|
||||
|
||||
### 第五步-访问 Shinken Webui2
|
||||
### 第五步 访问 Shinken Webui2
|
||||
|
||||
访问 Shinken webui2 在端口 7677(将 URL 中的 IP 替换成你自己的 IP 地址):
|
||||
在端口 7677 访问 Shinken webui2 (将 URL 中的 IP 替换成你自己的 IP 地址):
|
||||
|
||||
```
|
||||
http://192.168.1.120:7767
|
||||
```
|
||||
|
||||
用管理员用户和密码登陆(你在 admin.cfg 文件中设置的)
|
||||
用管理员用户和密码登录(你在 admin.cfg 文件中设置的)
|
||||
|
||||

|
||||
|
||||
Webui2 中的 Shinken 面板。
|
||||
Webui2 中的 Shinken 面板:
|
||||
|
||||
|
||||
|
||||
我们的两个服务器正在被 Shinken 监控。
|
||||
我们的两个服务器正在被 Shinken 监控:
|
||||
|
||||
|
||||
|
||||
列出所有被 linux-snmp 监控的服务。
|
||||
列出所有被 linux-snmp 监控的服务:
|
||||
|
||||
|
||||
|
||||
所有主机和服务的状态信息。
|
||||
|
||||
所有主机和服务的状态信息:
|
||||
|
||||
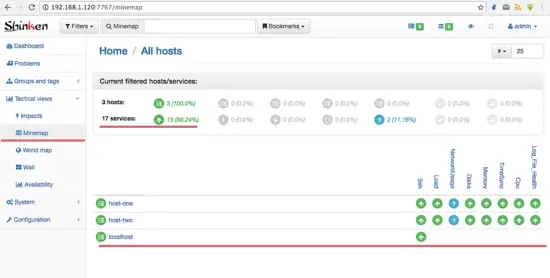
|
||||
|
||||
### 第6步- Shinken 常见的问题
|
||||
### 第6步 Shinken 的常见问题
|
||||
|
||||
- NTP 服务器相关的问题
|
||||
#### NTP 服务器相关的问题
|
||||
|
||||
当你得到如下的 NTP 错误提示
|
||||
|
||||
@ -269,7 +270,7 @@ TimeSync - CRITICAL ( NTP CRITICAL: No response from the NTP server)
|
||||
TimeSync - CRITICAL ( NTP CRITICAL: Offset unknown )
|
||||
```
|
||||
|
||||
为了解决这个问题,在所有 Linux 主机上安装 ntp
|
||||
为了解决这个问题,在所有 Linux 主机上安装 ntp。
|
||||
|
||||
```
|
||||
sudo apt-get install ntp ntpdate
|
||||
@ -304,7 +305,7 @@ restrict ::1
|
||||
NOTE: 192.168.1.120 is the Shinken server IP address.
|
||||
```
|
||||
|
||||
保存和退出。
|
||||
保存并退出。
|
||||
|
||||
启动 ntp 并且检查 Shinken 面板。
|
||||
|
||||
@ -312,7 +313,7 @@ NOTE: 192.168.1.120 is the Shinken server IP address.
|
||||
ntpd
|
||||
```
|
||||
|
||||
- check_netint.pl Not Found问题
|
||||
#### check_netint.pl Not Found 问题
|
||||
|
||||
从 github 仓库下载源代码到 shinken 的库目录下:
|
||||
|
||||
@ -323,7 +324,7 @@ chmod +x check_netint.pl
|
||||
chown shinken:shinken check_netint.pl
|
||||
```
|
||||
|
||||
- 网路占用率的问题
|
||||
#### 网络占用的问题
|
||||
|
||||
这是错误信息:
|
||||
|
||||
@ -331,11 +332,11 @@ chown shinken:shinken check_netint.pl
|
||||
ERROR : Unknown interface eth\d+
|
||||
```
|
||||
|
||||
检查你的网络接口并且编辑 linux-snmp模版。
|
||||
检查你的网络接口并且编辑 `linux-snmp` 模版。
|
||||
|
||||
在我的 Ununtu 服务器,网卡是 “enp0s8”,而不是 eth0,所以我遇到了这个错误。
|
||||
|
||||
vim 编辑 linux-snmp 模版:
|
||||
`vim` 编辑 `linux-snmp` 模版:
|
||||
|
||||
```
|
||||
vim /etc/shinken/packs/linux-snmp/templates.cfg
|
||||
@ -347,13 +348,15 @@ vim /etc/shinken/packs/linux-snmp/templates.cfg
|
||||
_NET_IFACES eth\d+|em\d+|enp0s8
|
||||
```
|
||||
|
||||
保存并退出。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/server-monitoring-with-shinken-on-ubuntu-16-04/
|
||||
|
||||
作者:[Muhammad Arul][a]
|
||||
译者:[LinuxBars](https://github.com/LinuxBars)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,140 @@
|
||||
15 个开源的顶级人工智能工具
|
||||
=========
|
||||
|
||||
人工智能(artificial intelligence, AI)是科技研究中最热门的方向之一。像 IBM、谷歌、微软、Facebook 和亚马逊等公司都在研发上投入大量的资金、或者收购那些在机器学习、神经网络、自然语言和图像处理等领域取得了进展的初创公司。考虑到人们对此感兴趣的程度,我们将不会惊讶于斯坦福的专家在[人工智能报告][1]中得出的结论:“越来越强大的人工智能应用,可能会对我们的社会和经济产生深远的积极影响,这将出现在从现在到 2030 年的时间段里。”
|
||||
|
||||
在最近的一篇[文章][2]中,我们概述了 45 个十分有趣或有前途的人工智能项目。在本文中,我们将聚焦于开源的人工智能工具,详细的了解下最著名的 15 个开源人工智能项目。
|
||||
|
||||

|
||||
|
||||
*开源人工智能*
|
||||
|
||||
以下这些开源人工智能应用都处于人工智能研究的最前沿。
|
||||
|
||||
### 1. Caffe
|
||||
|
||||

|
||||
|
||||
它是由[贾扬清][3]在加州大学伯克利分校的读博时创造的,[Caffe][4] 是一个基于表达体系结构和可扩展代码的深度学习框架。使它声名鹊起的是它的速度,这让它受到研究人员和企业用户的欢迎。根据其网站所言,它可以在一天之内只用一个 NVIDIA K40 GPU 处理 6000 万多个图像。它是由伯克利视野和学习中心(BVLC)管理的,并且由 NVIDIA 和亚马逊等公司资助来支持它的发展。
|
||||
|
||||
### 2. CNTK
|
||||
|
||||

|
||||
|
||||
它是计算网络工具包(Computational Network Toolkit)的缩写,[CNTK][5] 是一个微软的开源人工智能工具。不论是在单个 CPU、单个 GPU、多个 GPU 或是拥有多个 GPU 的多台机器上它都有优异的表现。微软主要用它做语音识别的研究,但是它在机器翻译、图像识别、图像字幕、文本处理、语言理解和语言建模方面都有着良好的应用。
|
||||
|
||||
### 3. Deeplearning4j
|
||||
|
||||

|
||||
|
||||
[Deeplearning4j][6] 是一个 java 虚拟机(JVM)的开源深度学习库。它运行在分布式环境并且集成在 Hadoop 和 Apache Spark 中。这使它可以配置深度神经网络,并且它与 Java、Scala 和 其他 JVM 语言兼容。
|
||||
|
||||
这个项目是由一个叫做 Skymind 的商业公司管理的,它为这个项目提供支持、培训和一个企业的发行版。
|
||||
|
||||
### 4. DMTK
|
||||
|
||||

|
||||
|
||||
[DMTK][7] 是分布式机器学习工具(Distributed Machine Learning Toolkit)的缩写,和 CNTK 一样,是微软的开源人工智能工具。作为设计用于大数据的应用程序,它的目标是更快的训练人工智能系统。它包括三个主要组件:DMTK 框架、LightLDA 主题模型算法和分布式(多义)字嵌入算法。为了证明它的速度,微软声称在一个八集群的机器上,它能够“用 100 万个主题和 1000 万个单词的词汇表(总共 10 万亿参数)训练一个主题模型,在一个文档中收集 1000 亿个符号,”。这一成绩是别的工具无法比拟的。
|
||||
|
||||
### 5. H20
|
||||
|
||||

|
||||
|
||||
相比起科研,[H2O][8] 更注重将 AI 服务于企业用户,因此 H2O 有着大量的公司客户,比如第一资本金融公司、思科、Nielsen Catalina、PayPal 和泛美都是它的用户。它声称任何人都可以利用机器学习和预测分析的力量来解决业务难题。它可以用于预测建模、风险和欺诈分析、保险分析、广告技术、医疗保健和客户情报。
|
||||
|
||||
它有两种开源版本:标准版 H2O 和 Sparking Water 版,它被集成在 Apache Spark 中。也有付费的企业用户支持。
|
||||
|
||||
### 6. Mahout
|
||||
|
||||

|
||||
|
||||
它是 Apache 基金会项目,[Mahout][9] 是一个开源机器学习框架。根据它的网站所言,它有着三个主要的特性:一个构建可扩展算法的编程环境、像 Spark 和 H2O 一样的预制算法工具和一个叫 Samsara 的矢量数学实验环境。使用 Mahout 的公司有 Adobe、埃森哲咨询公司、Foursquare、英特尔、领英、Twitter、雅虎和其他许多公司。其网站列了出第三方的专业支持。
|
||||
|
||||
### 7. MLlib
|
||||
|
||||

|
||||
|
||||
由于其速度,Apache Spark 成为一个最流行的大数据处理工具。[MLlib][10] 是 Spark 的可扩展机器学习库。它集成了 Hadoop 并可以与 NumPy 和 R 进行交互操作。它包括了许多机器学习算法如分类、回归、决策树、推荐、集群、主题建模、功能转换、模型评价、ML 管道架构、ML 持久、生存分析、频繁项集和序列模式挖掘、分布式线性代数和统计。
|
||||
|
||||
### 8. NuPIC
|
||||
|
||||

|
||||
|
||||
由 [Numenta][11] 公司管理的 [NuPIC][12] 是一个基于分层暂时记忆(Hierarchical Temporal Memory, HTM)理论的开源人工智能项目。从本质上讲,HTM 试图创建一个计算机系统来模仿人类大脑皮层。他们的目标是创造一个 “在许多认知任务上接近或者超越人类认知能力” 的机器。
|
||||
|
||||
除了开源许可,Numenta 还提供 NuPic 的商业许可协议,并且它还提供技术专利的许可证。
|
||||
|
||||
### 9. OpenNN
|
||||
|
||||

|
||||
|
||||
作为一个为开发者和科研人员设计的具有高级理解力的人工智能,[OpenNN][13] 是一个实现神经网络算法的 c++ 编程库。它的关键特性包括深度的架构和快速的性能。其网站上可以查到丰富的文档,包括一个解释了神经网络的基本知识的入门教程。OpenNN 的付费支持由一家从事预测分析的西班牙公司 [Artelnics][14] 提供。
|
||||
|
||||
### 10. OpenCyc
|
||||
|
||||

|
||||
|
||||
由 Cycorp 公司开发的 [OpenCyc][15] 提供了对 Cyc 知识库的访问和常识推理引擎。它拥有超过 239,000 个条目,大约 2,093,000 个三元组和大约 69,000 owl:这是一种类似于链接到外部语义库的命名空间。它在富领域模型、语义数据集成、文本理解、特殊领域的专家系统和游戏 AI 中有着良好的应用。该公司还提供另外两个版本的 Cyc:一个免费的用于科研但是不开源,和一个提供给企业的但是需要付费。
|
||||
|
||||
### 11. Oryx 2
|
||||
|
||||

|
||||
|
||||
构建在 Apache Spark 和 Kafka 之上的 [Oryx 2][16] 是一个专门针对大规模机器学习的应用程序开发框架。它采用一个独特的三层 λ 架构。开发者可以使用 Orys 2 创建新的应用程序,另外它还拥有一些预先构建的应用程序可以用于常见的大数据任务比如协同过滤、分类、回归和聚类。大数据工具供应商 Cloudera 创造了最初的 Oryx 1 项目并且一直积极参与持续发展。
|
||||
|
||||
### 12. PredictionIO
|
||||
|
||||

|
||||
|
||||
今年的二月,Salesforce 收购了 [PredictionIO][17],接着在七月,它将该平台和商标贡献给 Apache 基金会,Apache 基金会将其列为孵育计划。所以当 Salesforce 利用 PredictionIO 技术来提升它的机器学习能力时,成效将会同步出现在开源版本中。它可以帮助用户创建带有机器学习功能的预测引擎,这可用于部署能够实时动态查询的 Web 服务。
|
||||
|
||||
### 13. SystemML
|
||||
|
||||

|
||||
|
||||
最初由 IBM 开发, [SystemML][18] 现在是一个 Apache 大数据项目。它提供了一个高度可伸缩的平台,可以实现高等数学运算,并且它的算法用 R 或一种类似 python 的语法写成。企业已经在使用它来跟踪汽车维修客户服务、规划机场交通和连接社会媒体数据与银行客户。它可以在 Spark 或 Hadoop 上运行。
|
||||
|
||||
### 14. TensorFlow
|
||||
|
||||

|
||||
|
||||
[TensorFlow][19] 是一个谷歌的开源人工智能工具。它提供了一个使用数据流图进行数值计算的库。它可以运行在多种不同的有着单或多 CPU 和 GPU 的系统,甚至可以在移动设备上运行。它拥有深厚的灵活性、真正的可移植性、自动微分功能,并且支持 Python 和 c++。它的网站拥有十分详细的教程列表来帮助开发者和研究人员沉浸于使用或扩展他的功能。
|
||||
|
||||
### 15. Torch
|
||||
|
||||

|
||||
|
||||
[Torch][20] 将自己描述为:“一个优先使用 GPU 的拥有机器学习算法广泛支持的科学计算框架”,它的特点是灵活性和速度。此外,它可以很容易的通过软件包用于机器学习、计算机视觉、信号处理、并行处理、图像、视频、音频和网络等方面。它依赖一个叫做 LuaJIT 的脚本语言,而 LuaJIT 是基于 Lua 的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/slideshows/15-top-open-source-artificial-intelligence-tools.html
|
||||
|
||||
作者:[Cynthia Harvey][a]
|
||||
译者:[Chao-zhi](https://github.com/Chao-zhi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.datamation.com/author/Cynthia-Harvey-6460.html
|
||||
[1]: https://ai100.stanford.edu/sites/default/files/ai_100_report_0906fnlc_single.pdf
|
||||
[2]: http://www.datamation.com/applications/artificial-intelligence-software-45-ai-projects-to-watch-1.html
|
||||
[3]: http://daggerfs.com/
|
||||
[4]: http://caffe.berkeleyvision.org/
|
||||
[5]: https://www.cntk.ai/
|
||||
[6]: http://deeplearning4j.org/
|
||||
[7]: http://www.dmtk.io/
|
||||
[8]: http://www.h2o.ai/
|
||||
[9]: http://mahout.apache.org/
|
||||
[10]: https://spark.apache.org/mllib/
|
||||
[11]: http://numenta.com/
|
||||
[12]: http://numenta.org/
|
||||
[13]: http://www.opennn.net/
|
||||
[14]: https://www.artelnics.com/
|
||||
[15]: http://www.cyc.com/platform/opencyc/
|
||||
[16]: http://oryx.io/
|
||||
[17]: https://prediction.io/
|
||||
[18]: http://systemml.apache.org/
|
||||
[19]: https://www.tensorflow.org/
|
||||
[20]: http://torch.ch/
|
||||
@ -1,17 +1,19 @@
|
||||
如何使用 Awk 语言写脚本 - Part 13
|
||||
awk 系列:如何使用 awk 语言编写脚本
|
||||
====
|
||||
|
||||
从 Awk 系列开始直到第 12 部分,我们都是在命令行或者脚本文件写一些简短的 Awk 命令和程序。
|
||||

|
||||
|
||||
然而 Awk 和 Shell 一样也是一个解释语言。通过从开始到现在的一系列的学习,你现在能写可以执行的 Awk 脚本了。
|
||||
从 awk 系列开始直到[第 12 部分][1],我们都是在命令行或者脚本文件里写一些简短的 awk 命令和程序。
|
||||
|
||||
和写 shell 脚本差不多,Awk 脚本以下面这一行开头:
|
||||
然而 awk 和 shell 一样也是一个解释型语言。通过从开始到现在的一系列的学习,你现在能写可以执行的 awk 脚本了。
|
||||
|
||||
和写 shell 脚本差不多,awk 脚本以下面这一行开头:
|
||||
|
||||
```
|
||||
#! /path/to/awk/utility -f
|
||||
```
|
||||
|
||||
例如在我的系统上,Awk 工具安装在 /user/bin/awk 目录,所以我的 Awk 脚本以如下内容作为开头:
|
||||
例如在我的系统上,awk 工具安装在 /user/bin/awk 目录,所以我的 awk 脚本以如下内容作为开头:
|
||||
|
||||
```
|
||||
#! /usr/bin/awk -f
|
||||
@ -19,13 +21,11 @@
|
||||
|
||||
上面一行的解释如下:
|
||||
|
||||
```
|
||||
#! – 称为 Shebang,指明使用那个解释器来执行脚本中的命令
|
||||
/usr/bin/awk –解释器
|
||||
-f – 解释器选项,用来指定读取的程序文件
|
||||
```
|
||||
- `#!` ,称为[释伴(Shebang)][2],指明使用那个解释器来执行脚本中的命令
|
||||
- `/usr/bin/awk` ,即解释器
|
||||
- `-f` ,解释器选项,用来指定读取的程序文件
|
||||
|
||||
说是这么说,现在从下面的简单例子开始,让我们深入研究一些可执行的 Awk 脚本。使用你最喜欢的编辑器创建一个新文件,像下面这样:
|
||||
说是这么说,现在从下面的简单例子开始,让我们深入研究一些可执行的 awk 脚本。使用你最喜欢的编辑器创建一个新文件,像下面这样:
|
||||
|
||||
```
|
||||
$ vi script.awk
|
||||
@ -35,7 +35,7 @@ $ vi script.awk
|
||||
|
||||
```
|
||||
#!/usr/bin/awk -f
|
||||
BEGIN { printf "%s\n","Writing my first Awk executable script!" }
|
||||
BEGIN { printf "%s\n","Writing my first awk executable script!" }
|
||||
```
|
||||
|
||||
保存文件后退出,然后执行下面命令,使得脚本可执行:
|
||||
@ -53,10 +53,10 @@ $ ./script.awk
|
||||
输出样例:
|
||||
|
||||
```
|
||||
Writing my first Awk executable script!
|
||||
Writing my first awk executable script!
|
||||
```
|
||||
|
||||
一个严格的程序员一定会问:“注释呢?”。是的,你可以在 Awk 脚本中包含注释。在代码中写注释是一种良好的编程习惯。
|
||||
一个严格的程序员一定会问:“注释呢?”。是的,你可以在 awk 脚本中包含注释。在代码中写注释是一种良好的编程习惯。
|
||||
|
||||
它有利于其它程序员阅读你的代码,理解程序文件或者脚本中每一部分的功能。
|
||||
|
||||
@ -64,20 +64,20 @@ Writing my first Awk executable script!
|
||||
|
||||
```
|
||||
#!/usr/bin/awk -f
|
||||
#This is how to write a comment in Awk
|
||||
#using the BEGIN special pattern to print a sentence
|
||||
BEGIN { printf "%s\n","Writing my first Awk executable script!" }
|
||||
# 这是如何在 awk 中写注释的示例
|
||||
# 使用特殊模式 BEGIN 来输出一句话
|
||||
BEGIN { printf "%s\n","Writing my first awk executable script!" }
|
||||
```
|
||||
|
||||
接下来我们看一个读文件的例子。我们想从帐号文件 /etc/passwd 中查找一个叫 aaronkilik 的用户,然后像下面这样打印用户名,用户的 ID,用户的 GID (译者注:组 ID):
|
||||
接下来我们看一个读文件的例子。我们想从帐号文件 /etc/passwd 中查找一个叫 aaronkilik 的用户,然后像下面这样打印用户名、用户的 ID、用户的 GID (LCTT译注:组 ID):
|
||||
|
||||
下面是我们脚本文件的内容,文件名为 second.awk。
|
||||
|
||||
```
|
||||
#! /usr/bin/awk -f
|
||||
#use BEGIN sepecial character to set FS built-in variable
|
||||
# 使用 BEGIN 指定字符来设定 FS 内置变量
|
||||
BEGIN { FS=":" }
|
||||
#search for username: aaronkilik and print account details
|
||||
# 搜索用户名 aaronkilik 并输出账号细节
|
||||
/aaronkilik/ { print "Username :",$1,"User ID :",$3,"User GID :",$4 }
|
||||
```
|
||||
|
||||
@ -88,13 +88,13 @@ $ chmod +x second.awk
|
||||
$ ./second.awk /etc/passwd
|
||||
```
|
||||
|
||||
输出样例
|
||||
输出样例:
|
||||
|
||||
```
|
||||
Username : aaronkilik User ID : 1000 User GID : 1000
|
||||
```
|
||||
|
||||
在下面最后一个例子中,我们将使用 do while 语句来打印数字 0-10:
|
||||
在下面最后一个例子中,我们将使用 `do while` 语句来打印数字 0-10:
|
||||
|
||||
下面是我们脚本文件的内容,文件名为 do.awk。
|
||||
|
||||
@ -138,22 +138,24 @@ $ ./do.awk
|
||||
|
||||
### 总结
|
||||
|
||||
我们已经到达这个精彩的 Awk 系列的最后,我希望你从整个 13 部分中学到了很多知识,把这些当作你 Awk 编程语言的入门指导。
|
||||
我们已经到达这个精彩的 awk 系列的最后,我希望你从整个 13 个章节中学到了很多知识,把这些当作你 awk 编程语言的入门指导。
|
||||
|
||||
我一开始就提到过,Awk 是一个完整的文本处理语言,所以你可以学习很多 Awk 编程语言的其它方面,例如环境变量,数组,函数(内置的或者用户自定义的),等等。
|
||||
我一开始就提到过,awk 是一个完整的文本处理语言,所以你可以学习很多 awk 编程语言的其它方面,例如环境变量、数组、函数(内置的或者用户自定义的),等等。
|
||||
|
||||
Awk 编程还有其它内容需要学习和掌握,所以在文末我提供了一些重要的在线资源的链接,你可以利用他们拓展你的 Awk 编程技能。但这不是必须的,你也可以阅读一些关于 Awk 的书籍。
|
||||
awk 编程还有其它内容需要学习和掌握,所以在文末我提供了一些重要的在线资源的链接,你可以利用他们拓展你的 awk 编程技能。但这不是必须的,你也可以阅读一些关于 awk 的书籍。
|
||||
|
||||
如果你任何想要分享的想法或者问题,在下面留言。记得保持关注 Tecmint,会有更多的精彩内容。
|
||||
如果你任何想要分享的想法或者问题,在下面留言。记得保持关注我们,会有更多的精彩内容。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/write-shell-scripts-in-awk-programming/
|
||||
|
||||
作者:[Aaron Kili |][a]
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[chunyang-wen](https://github.com/chunyang-wen)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
[1]: https://linux.cn/article-7723-1.html
|
||||
[2]: https://linux.cn/article-3664-1.html
|
||||
@ -1,7 +1,7 @@
|
||||
如何使用 Awk 中的流控制语句 - part12
|
||||
awk 系列:如何在 awk 中使用流控制语句
|
||||
====
|
||||
|
||||
回顾从 Awk 系列最开始到现在我们所讲的所有关于 Awk 的例子,你会发现不同例子中的所有命令都是顺序执行的,也就是一个接一个的执行。但是在某些场景下,我们可能希望根据一些条件来执行一些文本过滤,这个时候流控制语句就派上用场了。
|
||||
回顾从 Awk 系列,从最开始到现在我们所讲的所有关于 Awk 的例子,你会发现不同例子中的所有命令都是顺序执行的,也就是一个接一个的执行。但是在某些场景下,我们可能希望根据一些条件来执行一些[文本过滤操作][1],这个时候流控制语句就派上用场了。
|
||||
|
||||

|
||||
|
||||
@ -17,7 +17,7 @@ Awk 包含很多的流控制语句,包括:
|
||||
- nextfile 语句
|
||||
- exit 语句
|
||||
|
||||
但是在这个系列中,我们将详细解释:if-else,for,while,do-while 语句。关于如何使用 next 语句,如果你们记得的话,我们已经在 Awk 系列的第6部分介绍过了。
|
||||
但是在这个系列中,我们将详细解释:`if-else`,`for`,`while`,`do-while` 语句。关于如何使用 `next` 语句,如果你们记得的话,我们已经在 [Awk 系列的第6部分][2]介绍过了。
|
||||
|
||||
### 1. if-else 语句
|
||||
|
||||
@ -36,7 +36,7 @@ actions2
|
||||
|
||||
当 condition1 满足时,意味着它的值是 true,此时会执行 actions1,if 语句退出,否则(译注:condition1 为 false)执行 actions2。
|
||||
|
||||
if 语句可以扩展成如下的 if-else_if-else:
|
||||
if 语句可以扩展成如下的 `if-else_if-else`:
|
||||
|
||||
```
|
||||
if (condition1){
|
||||
@ -52,7 +52,7 @@ actions3
|
||||
|
||||
上面例子中,如果 condition1 为 true,执行 actions1,if 语句退出;否则对 condition2 求值,如果值为 true,那么执行 actions2,if 语句退出。然而如果 condition2 是 false,那么会执行 actions3 退出 if语句。
|
||||
|
||||
下面是一个使用 if 语句的例子,我们有一个存储用户和他们年龄列表的文件,users.txt。
|
||||
下面是一个使用 if 语句的例子,我们有一个存储用户和他们年龄列表的文件 users.txt。
|
||||
|
||||
我们想要打印用户的名字以及他们的年龄是大于 25 还是小于 25。
|
||||
|
||||
@ -85,7 +85,7 @@ $ chmod +x test.sh
|
||||
$ ./test.sh
|
||||
```
|
||||
|
||||
输出样例
|
||||
输出样例:
|
||||
|
||||
```
|
||||
User Sarah L is more than 25 years old
|
||||
@ -96,7 +96,7 @@ User Kili Seth is more than 25 years old
|
||||
|
||||
### 2. for 语句
|
||||
|
||||
如果你想循环执行一些 Awk 命令,那么 for 语句十分合适,它的语法如下:
|
||||
如果你想循环执行一些 Awk 命令,那么 `for` 语句十分合适,它的语法如下:
|
||||
|
||||
这里只是简单的定义一个计数器来控制循环的执行。首先你要初始化那个计数器 (counter),然后根据某个条件判断是否执行,如果该条件为 true 则执行,最后增加计数器。当计数器不满足条件时则终止循环。
|
||||
|
||||
@ -106,7 +106,7 @@ actions
|
||||
}
|
||||
```
|
||||
|
||||
下面的 Awk 命令利用打印数字 0-10 来说明 for 语句是怎么工作的。
|
||||
下面的 Awk 命令利用打印数字 0-10 来说明 `for` 语句是怎么工作的。
|
||||
|
||||
```
|
||||
$ awk 'BEGIN{ for(counter=0;counter<=10;counter++){ print counter} }'
|
||||
@ -130,7 +130,7 @@ $ awk 'BEGIN{ for(counter=0;counter<=10;counter++){ print counter} }'
|
||||
|
||||
### 3. while 语句
|
||||
|
||||
传统的 while 语句语法如下:
|
||||
传统的 `while` 语句语法如下:
|
||||
|
||||
```
|
||||
while ( condition ) {
|
||||
@ -138,7 +138,7 @@ actions
|
||||
}
|
||||
```
|
||||
|
||||
上面的 condition 是 Awk 表达式,actions 是当 condition 为 true 时执行的 Awk命令。
|
||||
上面的 condition 是 Awk 表达式,actions 是当 condition 为 true 时执行的 Awk 命令。
|
||||
|
||||
下面是仍然用打印数字 0-10 来解释 while 语句的用法:
|
||||
|
||||
@ -159,8 +159,7 @@ $ chmod +x test.sh
|
||||
$ ./test.sh
|
||||
```
|
||||
|
||||
输出样例
|
||||
Sample Output
|
||||
输出样例:
|
||||
|
||||
```
|
||||
0
|
||||
@ -178,7 +177,7 @@ Sample Output
|
||||
|
||||
### 4. do-while 语句
|
||||
|
||||
这个是上面的 while 语句语法的一个变化,其语法如下:
|
||||
这个是上面的 `while` 语句语法的一个变化,其语法如下:
|
||||
|
||||
```
|
||||
do {
|
||||
@ -187,7 +186,7 @@ actions
|
||||
while (condition)
|
||||
```
|
||||
|
||||
二者的区别是,在 do-while 中,Awk 的命令在条件求值前先执行。我们使用 while 语句中同样的例子来解释 do-while 的使用,将 test.sh 脚本中的 Awk 命令做如下更改:
|
||||
二者的区别是,在 `do-while` 中,Awk 的命令在条件求值前先执行。我们使用 `while` 语句中同样的例子来解释 `do-while` 的使用,将 test.sh 脚本中的 Awk 命令做如下更改:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
@ -238,10 +237,11 @@ via: http://www.tecmint.com/use-flow-control-statements-with-awk-command/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[chunyang-wen](https://github.com/chunyang-wen)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]: http://www.tecmint.com/use-linux-awk-command-to-filter-text-string-in-files/
|
||||
[2]: http://www.tecmint.com/use-next-command-with-awk-in-linux/
|
||||
|
||||
@ -1,3 +1,10 @@
|
||||
Translating by WangYueScream
|
||||
============================================================================
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Should Smartphones Do Away with the Headphone Jack? Here Are Our Thoughts
|
||||
====
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
willcoderwang 正在翻译
|
||||
|
||||
What the rise of permissive open source licenses means
|
||||
====
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating by theArcticOcean.
|
||||
|
||||
Part III - How to apply Advanced Mathematical Processing Effects on Audio files with Octave 4.0 on Ubuntu
|
||||
=====
|
||||
|
||||
|
||||
@ -1,437 +0,0 @@
|
||||
translating by ucasFL
|
||||
HOSTING .NET CORE ON LINUX WITH DOCKER - A NOOB'S GUIDE
|
||||
=====
|
||||
|
||||
This post builds on my previous [introduction to .NET Core][1]. First I upgrade that RESTful API from .NET Core RC1 to .NET Core 1.0, then I add support for Docker and describe how to host it on Linux in a production environment.
|
||||
|
||||
|
||||

|
||||
|
||||
I’m completely new to Docker and I’m far from a Linux expert, so these are very much the thoughts of a noob.
|
||||
|
||||
### INSTALLATION
|
||||
|
||||
Follow the instructions on https://www.microsoft.com/net/core to install .NET Core on your development machine. This will include the dotnet command line tool and the latest Visual Studio tooling for Windows.
|
||||
|
||||
### SOURCE CODE
|
||||
|
||||
You can jump straight to the finished source code on GitHub.
|
||||
|
||||
### CONVERTING TO .NET CORE 1.0
|
||||
|
||||
Naturally, my first port of call when thinking about how to upgrade the API from RC1 to 1.0 was to Google it with Bing. There are two pretty comprehensive guides that I followed:
|
||||
|
||||
- [Migrating from DNX to .NET Core CLI][2]
|
||||
- [Migrating from ASP.NET 5 RC1 to ASP.NET Core 1.0][3]
|
||||
|
||||
I advise reading through both of these very carefully when migrating your code because I tried to skim read the second one without reading the first one and got very confused and frustrated!
|
||||
|
||||
I won’t describe the changes in detail because you can look at the commit on GitHub. Here is a summary of what I changed:
|
||||
|
||||
- Updated version numbers on global.json and project.json
|
||||
- Removed obsolete sections from project.json
|
||||
- Using the more lightweight ControllerBase rather than Controller because I don’t need methods related to MVC views (this was an optional change)
|
||||
- Removed the Http prefix from helper methods e.g. HttpNotFound -> NotFound
|
||||
- LogVerbose -> LogTrace
|
||||
- Namespace changes: Microsoft.AspNetCore.*
|
||||
- Using SetBasePath in Startup (appsettings.json won’t be found without this)
|
||||
- Running via WebHostBuilder rather than WebApplication.Run
|
||||
- Removed Serilog (at the time of writing it does not support .NET Core 1.0)
|
||||
|
||||
The only real headache here is the need to remove Serilog. I could have implemented my own file logger, but I just deleted file logging because I didn’t want to focus on it for this exercise.
|
||||
|
||||
Unfortunately, there will be plenty of third party developers that will be playing catch up with support for .NET Core 1.0 but I have sympathy for them because they are often working in their spare time without anything close to the resources available to Microsoft. I recommend reading Travis Illig’s [.NET Core 1.0 is Released, but Where is Autofac][4]? for a third party developer’s point of view on this!
|
||||
|
||||
Having made these changes I was able to dotnet restore, dotnet build and dotnet run from the project.json directory and see the API working as before.
|
||||
|
||||
### RUNNING WITH DOCKER
|
||||
|
||||
At the time of writing, Docker only really works on Linux. There is beta support for Docker on Windows and OS X but they both rely on virtualisation so I’ve chosen to run Ubuntu 14.04 as a VirtualBox. Follow these instructions if you haven’t already got Docker installed.
|
||||
|
||||
I’ve been doing a bit of reading about Docker recently but I’ve never tried to actually do anything with it until now. I’ll assume the reader has no Docker knowledge so I’ll explain all parts of the commands that I’m using.
|
||||
|
||||
#### HELLO DOCKER
|
||||
|
||||
Having installed Docker on my Ubuntu machine, my next move was to follow the instructions at https://www.microsoft.com/net/core#docker to see how to get started with .NET Core and Docker.
|
||||
|
||||
First start a container with .NET Core installed:
|
||||
|
||||
```
|
||||
docker run -it microsoft/dotnet:latest
|
||||
```
|
||||
|
||||
The -it option means interactive so having executed this command you will be inside the container and free to run any bash commands you like.
|
||||
|
||||
Then we can run five commands to get Microsoft’s Hello World .NET Core console application running inside Docker!
|
||||
|
||||
1. mkdir hwapp
|
||||
2. cd hwapp
|
||||
3. dotnet new
|
||||
4. dotnet restore
|
||||
5. dotnet run
|
||||
|
||||
You can exit to leave the container, then docker ps -a to show that you have created a container which has exited. You should really now tidy up that container using docker rm <container_name>.
|
||||
|
||||
#### MOUNTING THE SOURCE
|
||||
|
||||
My next move was to use the same microsoft/dotnet image as above but to mount the source for my application as a data volume.
|
||||
|
||||
First check out the repository at the relevant commit:
|
||||
|
||||
1. git clone https://github.com/niksoper/aspnet5-books.git
|
||||
2. cd aspnet5-books/src/MvcLibrary
|
||||
3. git checkout dotnet-core-1.0
|
||||
|
||||
Now start a container running .NET Core 1.0 with the source located at /books. Note that you’ll need to change the /path/to/repo part to match your machine:
|
||||
|
||||
```
|
||||
docker run -it \
|
||||
-v /path/to/repo/aspnet5-books/src/MvcLibrary:/books \
|
||||
microsoft/dotnet:latest
|
||||
```
|
||||
|
||||
Now you can run the application inside the container!
|
||||
|
||||
```
|
||||
cd /books
|
||||
dotnet restore
|
||||
dotnet run
|
||||
```
|
||||
|
||||
That’s great as a proof of concept but we don’t really want to have to worry about mounting the source code into a container like this whenever we want to start the application.
|
||||
|
||||
#### ADDING A DOCKERFILE
|
||||
|
||||
The next step I took was to introduce a Dockerfile, which will allow the application to be started easily inside its own container.
|
||||
|
||||
My Dockerfile lives in the src/MvcLibrary directory alongside project.json and looks like this:
|
||||
|
||||
```
|
||||
FROM microsoft/dotnet:latest
|
||||
|
||||
# Create directory for the app source code
|
||||
RUN mkdir -p /usr/src/books
|
||||
WORKDIR /usr/src/books
|
||||
|
||||
# Copy the source and restore dependencies
|
||||
COPY . /usr/src/books
|
||||
RUN dotnet restore
|
||||
|
||||
# Expose the port and start the app
|
||||
EXPOSE 5000
|
||||
CMD [ "dotnet", "run" ]
|
||||
```
|
||||
|
||||
Strictly, the `RUN mkdir -p /usr/src/books` command is not needed because COPY will create any missing directories automatically.
|
||||
|
||||
Docker images are built in layers. We start from the image containing .NET Core and add another layer which builds the application from source then runs the application.
|
||||
|
||||
Having added the Dockerfile, I then ran the following commands to build the image and start a container using that image (make sure you are in the same directory as the Dockerfile and you should really use your own username):
|
||||
|
||||
1. docker build -t niksoper/netcore-books .
|
||||
2. docker run -it niksoper/netcore-books
|
||||
|
||||
You should see that the application started listening just as before, except this time we don’t need to bother mounting the source code because it’s already contained in the docker image.
|
||||
|
||||
#### EXPOSING AND PUBLISHING A PORT
|
||||
|
||||
This API isn’t going to be very useful unless we can communicate with it from outside the container. Docker has the concept of exposing and publishing ports, which are two very different things.
|
||||
|
||||
From the official Docker documentation:
|
||||
|
||||
>The EXPOSE instruction informs Docker that the container listens on the specified network ports at runtime. EXPOSE does not make the ports of the container accessible to the host. To do that, you must use either the -p flag to publish a range of ports or the -P flag to publish all of the exposed ports.
|
||||
|
||||
EXPOSE only adds metadata to the image so you can think of it as documentation for the consumers of the image. Technically, I could have left out the EXPOSE 5000 line completely because I know the port that the API is listening on but leaving it in is helpful and certainly recommended.
|
||||
|
||||
At this stage I want to access the API directly from the host so I need to use -p to publish the port - this allows a request to port 5000 on the host be forwarded to port 5000 in the container regardless of whether the port has previously been exposed via the Dockerfile:
|
||||
|
||||
```
|
||||
docker run -d -p 5000:5000 niksoper/netcore-books
|
||||
```
|
||||
|
||||
Using -d tells docker to run the container in detached mode so we won’t see its output but it will still be running and listening on port 5000 - prove this to yourself with docker ps.
|
||||
|
||||
So then I prepared to celebrate by making a request from the host to the container:
|
||||
|
||||
```
|
||||
curl http://localhost:5000/api/books
|
||||
```
|
||||
|
||||
It didn’t work.
|
||||
|
||||
Making the same curl request repeatedly, I see one of two errors - either curl: (56) Recv failure: Connection reset by peer or curl: (52) Empty reply from server.
|
||||
|
||||
I went back to the docker run documentation and double checked I was using the -p option correctly as well as EXPOSE in the Dockerfile. I couldn’t see the problem and became a bit sad…
|
||||
|
||||
After pulling myself together, I decided to consult one of my local DevOps heroes - Dave Wybourn (also mentioned in this post on Docker Swarm). His team had run into this exact problem and the issue was the way that I had (not) configured Kestrel - the new lightweight, cross platform web server used for .NET Core.
|
||||
|
||||
By default, Kestrel will listen on http://localhost:5000. The problem here is that localhost is a loopback interface.
|
||||
|
||||
From Wikipedia:
|
||||
|
||||
>In computer networking, localhost is a hostname that means this computer. It is used to access the network services that are running on the host via its loopback network interface. Using the loopback interface bypasses any local network interface hardware.
|
||||
|
||||
This is a problem when running inside a container because localhost can only be reached from within that container. The solution was to update the Main method in Startup.cs to configure the URLs that Kestrel will listen on:
|
||||
|
||||
```
|
||||
public static void Main(string[] args)
|
||||
{
|
||||
var host = new WebHostBuilder()
|
||||
.UseKestrel()
|
||||
.UseContentRoot(Directory.GetCurrentDirectory())
|
||||
.UseUrls("http://*:5000") // listen on port 5000 on all network interfaces
|
||||
.UseIISIntegration()
|
||||
.UseStartup<Startup>()
|
||||
.Build();
|
||||
|
||||
host.Run();
|
||||
}
|
||||
```
|
||||
|
||||
With this extra configuration in place, I could then rebuild image and run the application in a container which will accept requests from the host:
|
||||
|
||||
1. docker build -t niksoper/netcore-books .
|
||||
2. docker run -d -p 5000:5000 niksoper/netcore-books
|
||||
3. curl -i http://localhost:5000/api/books
|
||||
|
||||
I now get the following response:
|
||||
|
||||
```
|
||||
HTTP/1.1 200 OK
|
||||
Date: Tue, 30 Aug 2016 15:25:43 GMT
|
||||
Transfer-Encoding: chunked
|
||||
Content-Type: application/json; charset=utf-8
|
||||
Server: Kestrel
|
||||
|
||||
[{"id":"1","title":"RESTful API with ASP.NET Core MVC 1.0","author":"Nick Soper"}]
|
||||
```
|
||||
|
||||
### KESTREL IN PRODUCTION
|
||||
|
||||
Microsoft’s words:
|
||||
|
||||
>Kestrel is great for serving dynamic content from ASP.NET, however the web serving parts aren’t as feature rich as full-featured servers like IIS, Apache or Nginx. A reverse proxy-server can allow you to offload work like serving static content, caching requests, compressing requests, and SSL termination from the HTTP server.
|
||||
|
||||
So I need to set up Nginx on my Linux machine to act as my reverse proxy. Microsoft spell out how to do this in Publish to a Linux Production Environment. I’ll summarise the instructions here:
|
||||
|
||||
1. Use dotnet publish to produce a self contained package for the application
|
||||
2. Copy the published application to the server
|
||||
3. Install and configure Nginx (as a reverse proxy server)
|
||||
4. Install and configure supervisor (for keeping the Kestrel server running)
|
||||
5. Enable and configure AppArmor (for limiting the resources available to an application)
|
||||
6. Configure the server firewall
|
||||
7. Secure Nginx (involves building from source and configuring SSL)
|
||||
|
||||
It’s beyond the scope of this post to cover all of that, so I’m only going to concentrate on configuring Nginx as a reverse proxy - and naturally, I’m going to use Docker to do it.
|
||||
|
||||
### RUN NGINX IN ANOTHER CONTAINER
|
||||
|
||||
My aim is to run Nginx in a second Docker container and configure it as a reverse proxy to my application container.
|
||||
|
||||
I’ve used the official Nginx image from Docker Hub. First I tried it out like this:
|
||||
|
||||
```
|
||||
docker run -d -p 8080:80 --name web nginx
|
||||
```
|
||||
|
||||
This starts a container running Nginx and maps port 8080 on the host to port 80 in the container. Hitting http://localhost:8080 in the browser now shows the default Nginx landing page.
|
||||
|
||||
Now we’ve proved how easy it is to get Nginx running, we can kill the container.
|
||||
|
||||
```
|
||||
docker rm -f web
|
||||
```
|
||||
|
||||
### CONFIGURING NGINX AS A REVERSE PROXY
|
||||
|
||||
Nginx can be configured as a reverse proxy by editing the config file at /etc/nginx/conf.d/default.conf like this:
|
||||
|
||||
```
|
||||
server {
|
||||
listen 80;
|
||||
|
||||
location / {
|
||||
proxy_pass http://localhost:6666;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
The config above will cause Nginx to proxy all requests from the root to http://localhost:6666. Remember localhost here refers to the container running Nginx. We can use our own config file inside the Nginx container using a volume:
|
||||
|
||||
```
|
||||
docker run -d -p 8080:80 \
|
||||
-v /path/to/my.conf:/etc/nginx/conf.d/default.conf \
|
||||
nginx
|
||||
```
|
||||
|
||||
Note: this maps a single file from the host to the container, rather than an entire directory.
|
||||
|
||||
### COMMUNICATING BETWEEN CONTAINERS
|
||||
|
||||
Docker allows inter-container communication using shared virtual networks. By default, all containers started by the Docker daemon will have access to a virtual network called bridge. This allows containers to be referenced from other containers on the same network via IP address and port.
|
||||
|
||||
You can discover the IP address of a running container by inspecting it. I’ll start a container from the niksoper/netcore-books image that I created earlier, and inspect it:
|
||||
|
||||
1. docker run -d -p 5000:5000 --name books niksoper/netcore-books
|
||||
2. docker inspect books
|
||||
|
||||
|
||||
|
||||
We can see this container has "IPAddress": "172.17.0.3".
|
||||
|
||||
So now if I create the following Nginx config file, then start an Nginx container using that file, then it will proxy requests to my API:
|
||||
|
||||
```
|
||||
server {
|
||||
listen 80;
|
||||
|
||||
location / {
|
||||
proxy_pass http://172.17.0.3:5000;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Now I can start an Nginx container using that config (note I’m mapping port 8080 on the host to port 80 on the Nginx container):
|
||||
|
||||
```
|
||||
docker run -d -p 8080:80 \
|
||||
-v ~/dev/nginx/my.nginx.conf:/etc/nginx/conf.d/default.conf \
|
||||
nginx
|
||||
```
|
||||
|
||||
A request to http://localhost:8080 will now be proxied to my application. Note the Server header in the following curl response:
|
||||
|
||||
|
||||
|
||||
### DOCKER COMPOSE
|
||||
|
||||
At this point I was fairly pleased with my progress but I thought there must be a better way of configuring Nginx without needing to know the exact IP address of the application container. Another of the local Scott Logic DevOps heroes - Jason Ebbin - stepped up at this point and suggested Docker Compose.
|
||||
|
||||
As a high level description - Docker Compose makes it very easy to start up a collection of interconnected containers using a declarative syntax. I won’t go into the details of how Docker Compose works because you can read about it in this previous post.
|
||||
|
||||
I’ll start with the docker-compose.yml file that I’m using:
|
||||
|
||||
```
|
||||
version: '2'
|
||||
services:
|
||||
books-service:
|
||||
container_name: books-api
|
||||
build: .
|
||||
|
||||
reverse-proxy:
|
||||
container_name: reverse-proxy
|
||||
image: nginx
|
||||
ports:
|
||||
- "9090:8080"
|
||||
volumes:
|
||||
- ./proxy.conf:/etc/nginx/conf.d/default.conf
|
||||
```
|
||||
|
||||
This is version 2 syntax, so you’ll need to have at least version 1.6 of Docker Compose in order for this to work.
|
||||
|
||||
This file tells Docker to create two services - one for the application and another for the Nginx reverse proxy.
|
||||
|
||||
### BOOKS-SERVICE
|
||||
|
||||
This builds a container called books-api from the Dockerfile in the same directory as this docker-compose.yml. Note that this container does not need to publish any ports because it only needs to be accessed from the reverse-proxy container rather than the host operating system.
|
||||
|
||||
### REVERSE-PROXY
|
||||
|
||||
This starts a container called reverse-proxy based on the nginx image with a proxy.conf file mounted as the config from the current directory. It maps port 9090 on the host to port 8080 in the container which allows us to access the container from the host at http://localhost:9090.
|
||||
|
||||
The proxy.conf file looks like this:
|
||||
|
||||
```
|
||||
server {
|
||||
listen 8080;
|
||||
|
||||
location / {
|
||||
proxy_pass http://books-service:5000;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
The key point here is that we can now refer to books-service by name so we don’t need to know the IP address of the books-api container!
|
||||
|
||||
Now we can start the two containers with a working reverse proxy (-d means detached so we don’t see the output from the containers):
|
||||
|
||||
```
|
||||
docker compose up -d
|
||||
```
|
||||
|
||||
Prove the containers were created:
|
||||
|
||||
```
|
||||
docker ps
|
||||
```
|
||||
|
||||
And finally confirm that we can hit the API via the reverse proxy:
|
||||
|
||||
```
|
||||
curl -i http://localhost:9090/api/books
|
||||
```
|
||||
|
||||
### WHAT’S GOING ON?
|
||||
|
||||
Docker Compose makes this happen by creating a new virtual network called mvclibrary_default which is used by both books-api and reverse-proxy containers (the name is based on the parent directory of the docker-compose.yml file).
|
||||
|
||||
Prove the network exists with docker network ls:
|
||||
|
||||

|
||||
|
||||
You can see the details of the new network using docker network inspect mvclibrary_default:
|
||||
|
||||
|
||||
|
||||
Note that Docker has assigned "Subnet": "172.18.0.0/16" to the network. The /16 part is CIDR notation and a full explanation is way beyond the scope of this post but CIDR just refers to a range of IP addresses. Running docker network inspect bridge shows "Subnet": "172.17.0.0/16" so the two networks do not overlap.
|
||||
|
||||
Now docker inspect books-api to confirm the application container is using this network:
|
||||
|
||||
|
||||
|
||||
Notice the two "Aliases" for the container are the container identifier (3c42db680459) and the service name given in docker-compose.yml (books-service). We’re using the books-service alias to reference the application container in the custom Nginx configuration file. This could have been done manually with docker network create but I like Docker Compose because it wraps up container creation and interdependencies cleanly and succinctly.
|
||||
|
||||
### CONCLUSION
|
||||
|
||||
So now I can get the application running on Linux with Nginx in a few easy steps, without making any lasting changes to the host operating system:
|
||||
|
||||
```
|
||||
git clone https://github.com/niksoper/aspnet5-books.git
|
||||
cd aspnet5-books/src/MvcLibrary
|
||||
git checkout blog-docker
|
||||
docker-compose up -d
|
||||
curl -i http://localhost:9090/api/books
|
||||
```
|
||||
|
||||
I know what I have described in this post is not a truly production ready setup because I’ve not spoken about any of the following, but most of these topics could take an entire post on their own:
|
||||
|
||||
- Security concerns like firewalls or SSL configuration
|
||||
- How to ensure the application keeps running
|
||||
- How to be selective about what to include in a Docker image (I dumped everything in via the Dockerfile)
|
||||
- Databases - how to manage them in containers
|
||||
|
||||
This has been a very interesting learning experience for me because for a while now I have been curious to explore the new cross platform support that comes with ASP.NET Core, and the opportunity to explore a little bit of the DevOps world using Docker Compose for a “Configuration as Code” approach has been both enjoyable and educational.
|
||||
|
||||
If you’re at all curious about Docker then I encourage you to get stuck in by trying it out - especially if this puts you out of your comfort zone. Who knows, you might enjoy it?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://blog.scottlogic.com/2016/09/05/hosting-netcore-on-linux-with-docker.html?utm_source=webopsweekly&utm_medium=email
|
||||
|
||||
作者:[Nick Soper][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://blog.scottlogic.com/nsoper
|
||||
[1]: http://blog.scottlogic.com/2016/01/20/restful-api-with-aspnet50.html
|
||||
[2]: https://docs.microsoft.com/en-us/dotnet/articles/core/migrating-from-dnx
|
||||
[3]: https://docs.asp.net/en/latest/migration/rc1-to-rtm.html
|
||||
[4]: http://www.paraesthesia.com/archive/2016/06/29/netcore-rtm-where-is-autofac/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
wcnnbdk1 Translating
|
||||
Content Security Policy, Your Future Best Friend
|
||||
=====
|
||||
|
||||
|
||||
@ -1,207 +0,0 @@
|
||||
Monitoring Docker Containers with Elasticsearch and cAdvisor
|
||||
=======
|
||||
|
||||
If you’re running a Swarm Mode cluster or even a single Docker engine, you’ll end up asking this question:
|
||||
|
||||
>How do I keep track of all that’s happening?
|
||||
|
||||
The answer is “not easily.”
|
||||
|
||||
You need a few things to have a complete overview of stuff like:
|
||||
|
||||
|
||||
1. Number and status of containers
|
||||
2. If, where, and when a container has been moved to another node
|
||||
3. Number of containers on a given node
|
||||
4. Traffic peaks at a given time
|
||||
5. Orphan volumes and networks
|
||||
6. Free disk space, free inodes
|
||||
7. Number of containers against number of veths attached to the docker0 and docker_gwbridge bridges
|
||||
8. Up and down Swarm nodes
|
||||
9. Centralize logs
|
||||
|
||||
The goal of this post is to demonstrate the use of [Elasticsearch][1] + [Kibana][2] + [cAdvisor][3] as tools to analyze and gather metrics and visualize dashboards for Docker containers.
|
||||
|
||||
Later on in this post, you can find a dashboard trying to address a few points from the previous list. There are also points that can’t be addressed by simply using cAdvisor, like the status of Swarm Mode nodes.
|
||||
|
||||
Also, if you have specific needs that aren’t covered by cAdvisor or another tool, I encourage you to write your own data collector and data shipper (e.g., [Beats][4]). Note that I won’t be showing you how to centralize Docker containers log on Elasticsearch.
|
||||
|
||||
>[“How do you keep track of all that’s happening in a Swarm Mode cluster? Not easily.” via @fntlnz][5]
|
||||
|
||||
### Why Do We Need to Monitor Containers?
|
||||
|
||||
Imagine yourself in the classic situation of managing a virtual machine, either just one or several. You are a tmux hero, so you have your sessions preconfigured to do basically everything, monitoring included. There’s a problem in production? You just do a top, htop, iotop, jnettop, whatevertop on all your machines, and you’re ready for troubleshooting!
|
||||
|
||||
Now imagine that you have the same three nodes but split into 50 containers. You need some history displayed nicely in a single place where you can perform queries to know what happened instead of just risking your life in front of those ncurses tools.
|
||||
|
||||
### What Is the Elastic Stack?
|
||||
|
||||
The Elastic Stack is a set of tools composed of:
|
||||
|
||||
- Elasticsearch
|
||||
- Kibana
|
||||
- Logstash
|
||||
- Beats
|
||||
|
||||
We’re going to use a few open-source tools from the Elastic Stack, such as Elasticsearch for the JSON-based analytics engine and Kibana to visualize data and create dashboards.
|
||||
|
||||
Another important piece of the Elastic Stack is Beats, but in this post, we’re focused on containers. There’s no official Beat for Docker, so we’ll just use cAdvisor that can natively talk with Elasticsearch.
|
||||
|
||||
cAdvisor is a tool that collects, aggregates, and exports metrics about running containers. In our case, those metrics are being exported to an Elasticsearch storage.
|
||||
|
||||
Two cool facts about cAdvisor are:
|
||||
|
||||
- It’s not limited to Docker containers.
|
||||
- It has its own webserver with a simple dashboard to visualize gathered metrics for the current node.
|
||||
|
||||
### Set Up a Test Cluster or BYOI
|
||||
|
||||
As I did in my previous posts, my habit is to provide a small script to allow the reader to set up a test environment on which to try out my project’s steps in no time. So you can use the following not-for-production-use script to set up a little Swarm Mode cluster with Elasticsearch running as a container.
|
||||
|
||||
>If you have enough time/experience, you can BYOI (Bring Your Own Infrastructure).
|
||||
|
||||
|
||||
To follow this post, you’ll just need:
|
||||
|
||||
- One or more nodes running the Docker daemon >= 1.12
|
||||
- At least a stand-alone Elasticsearch node 2.4.X
|
||||
|
||||
Again, note that this post is not about setting up a production-ready Elasticsearch cluster. A single node cluster is not recommended for production. So if you’re planning a production installation, please refer to [Elastic guidelines][6].
|
||||
|
||||
### A friendly note for early adopters
|
||||
|
||||
I’m usually an early adopter (and I’m already using the latest alpha version in production, of course). But for this post, I chose not to use the latest Elasticsearch 5.0.0 alpha. Their roadmap is not perfectly clear to me, and I don’t want be the root cause of your problems!
|
||||
|
||||
So the Elasticsearch reference version for this post is the latest stable version, 2.4.0 at the moment of writing.
|
||||
|
||||
### Test cluster setup script
|
||||
|
||||
As said, I wanted to provide this script for everyone who would like to follow the blog without having to figure out how to create a Swarm cluster and install an Elasticsearch. Of course, you can skip this if you choose to use your own Swarm Mode engines and your own Elasticsearch nodes.
|
||||
|
||||
To execute the setup script, you’ll need:
|
||||
|
||||
- [Docker Machine][7] – latest version: to provision Docker engines on DigitalOcean
|
||||
- [DigitalOcean API Token][8]: to allow docker-machine to start nodes on your behalf
|
||||
|
||||

|
||||
|
||||
### Create Cluster Script
|
||||
|
||||
Now that you have everything we need, you can copy the following script in a file named create-cluster.sh:
|
||||
|
||||
```
|
||||
#!/usr/bin/env bash
|
||||
#
|
||||
# Create a Swarm Mode cluster with a single master and a configurable number of workers
|
||||
|
||||
workers=${WORKERS:-"worker1 worker2"}
|
||||
|
||||
#######################################
|
||||
# Creates a machine on Digital Ocean
|
||||
# Globals:
|
||||
# DO_ACCESS_TOKEN The token needed to access DigitalOcean's API
|
||||
# Arguments:
|
||||
# $1 the actual name to give to the machine
|
||||
#######################################
|
||||
create_machine() {
|
||||
docker-machine create \
|
||||
-d digitalocean \
|
||||
--digitalocean-access-token=$DO_ACCESS_TOKEN \
|
||||
--digitalocean-size 2gb \
|
||||
$1
|
||||
}
|
||||
|
||||
#######################################
|
||||
# Executes a command on the specified machine
|
||||
# Arguments:
|
||||
# $1 The machine on which to run the command
|
||||
# $2..$n The command to execute on that machine
|
||||
#######################################
|
||||
machine_do() {
|
||||
docker-machine ssh $@
|
||||
}
|
||||
|
||||
main() {
|
||||
|
||||
if [ -z "$DO_ACCESS_TOKEN" ]; then
|
||||
echo "Please export a DigitalOcean Access token: https://cloud.digitalocean.com/settings/api/tokens/new"
|
||||
echo "export DO_ACCESS_TOKEN=<yourtokenhere>"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [ -z "$WORKERS" ]; then
|
||||
echo "You haven't provided your workers by setting the \$WORKERS environment variable, using the default ones: $workers"
|
||||
fi
|
||||
|
||||
# Create the first and only master
|
||||
echo "Creating the master"
|
||||
|
||||
create_machine master1
|
||||
|
||||
master_ip=$(docker-machine ip master1)
|
||||
|
||||
# Initialize the swarm mode on it
|
||||
echo "Initializing the swarm mode"
|
||||
machine_do master1 docker swarm init --advertise-addr $master_ip
|
||||
|
||||
# Obtain the token to allow workers to join
|
||||
worker_tkn=$(machine_do master1 docker swarm join-token -q worker)
|
||||
echo "Worker token: ${worker_tkn}"
|
||||
|
||||
# Create and join the workers
|
||||
for worker in $workers; do
|
||||
echo "Creating worker ${worker}"
|
||||
create_machine $worker
|
||||
machine_do $worker docker swarm join --token $worker_tkn $master_ip:2377
|
||||
done
|
||||
}
|
||||
|
||||
main $@
|
||||
```
|
||||
|
||||
And make it executable:
|
||||
|
||||
```
|
||||
chmod +x create-cluster.sh
|
||||
```
|
||||
|
||||
### Create the cluster
|
||||
|
||||
As the name suggests, we’ll use the script to create the cluster. By default, the script will create a cluster with a single master and two workers. If you want to configure the number of workers, you can do that by setting the WORKERS environment variable.
|
||||
|
||||
Now, let’s create that cluster!
|
||||
|
||||
```
|
||||
./create-cluster.sh
|
||||
```
|
||||
|
||||
Ok, now you can go out for a coffee. This will take a while.
|
||||
|
||||
Finally the cluster is ready!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.codeship.com/monitoring-docker-containers-with-elasticsearch-and-cadvisor/
|
||||
|
||||
作者:[Lorenzo Fontana][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://blog.codeship.com/author/lorenzofontana/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
[1]: https://github.com/elastic/elasticsearch
|
||||
[2]: https://github.com/elastic/kibana
|
||||
[3]: https://github.com/google/cadvisor
|
||||
[4]: https://github.com/elastic/beats
|
||||
[5]: https://twitter.com/share?text=%22How+do+you+keep+track+of+all+that%27s+happening+in+a+Swarm+Mode+cluster%3F+Not+easily.%22+via+%40fntlnz&url=https://blog.codeship.com/monitoring-docker-containers-with-elasticsearch-and-cadvisor/
|
||||
[6]: https://www.elastic.co/guide/en/elasticsearch/guide/2.x/deploy.html
|
||||
[7]: https://docs.docker.com/machine/install-machine/
|
||||
[8]: https://cloud.digitalocean.com/settings/api/tokens/new
|
||||
@ -1,60 +0,0 @@
|
||||
发行版分发者应该禁用 IPv4 映射的 IPv6 地址吗
|
||||
=============================================
|
||||
|
||||
大家都说,互联网向 IPv6 的过渡是件很缓慢的事情。不过在最近几年,可能是由于 IPv4 地址资源的枯竭,IPv6 的使用处于[上升态势][1]。相应的,开发者也有兴趣确保软件能在 IPv4 和 IPv6 下工作。但是,正如近期 OpenBSD 邮件列表的讨论所关注的,一个使得向 IPv6 转换更加轻松的机制设计同时也可能导致网络更不安全——并且 Linux 发行版们的默认配置可能并不安全。
|
||||
|
||||
### 地址映射
|
||||
|
||||
IPv6 在很多方面看起来可能很像 IPv4,但它是带有不同地址空间的不同的协议。服务器程序想要接受使用二者之中任意一个协议的连接,必须给两个不同的地址族分别打开一个套接字——IPv4 的 AF_INET 和 IPv6 的 AF_INET6。特别是一个程序希望接受使用任意协议到任意主机接口的连接的话,需要创建一个绑定到全零通配符地址(0.0.0.0)的 AF_INET 套接字和一个绑定到 IPv6 等效地址(写作“::”)的 AF_INET6 套接字。它必须在两个套接字上都监听连接——或者有人会这么认为。
|
||||
|
||||
多年前,在 [RFC 3493][2],IETF 指定了一个机制,程序可以使用一个单独的 IPv6 套接字工作在两个协议之上。有了一个启用这个行为的套接字,程序只需要绑定到 :: 来接受使用这两个协议到达所有接口的连接。当创建了一个 IPv4 连接到绑定端口,源地址会像 [RFC 2373][3] 中描述的那样映射到 IPv6。所以,举个例子,一个使用了这个模式的程序会将一个 192.168.1.1 的传入连接看作来自 ::ffff:192.168.1.1(这个混合的写法就是这种地址通常的写法)。程序也能通过相同的映射方法打开一个到 IPv4 地址的连接。
|
||||
|
||||
RFC 要求这个行为要默认实现,所以大多数系统这么做了。不过也有些例外,OpenBSD 就是其中之一;在那里,希望在两种协议下工作的程序能做的只能是创建两个独立的套接字。但一个在 Linux 中打开两个套接字的程序会遇到麻烦:IPv4 和 IPv6 套接字都会尝试绑定到 IPv4 地址,所以不论是哪个后者都会失败。换句话说,一个绑定到 :: 指定端口的套接字的程序会同时绑定到 IPv6 :: 和 IPv4 0.0.0.0 地址的那个端口上。如果程序之后尝试绑定一个 IPv4 套接字到 0.0.0.0 的相同端口上时,这个操作会失败,因为这个端口已经被绑定了。
|
||||
|
||||
当然有个办法可以解决这个问题;程序可以调用 setsockopt() 来打开 IPV6_V6ONLY 选项。一个打开两个套接字并且设置了 IPV6_V6ONLY 的程序应该可以在所有的系统间移植。
|
||||
|
||||
读者们可能对不是每个程序都能正确处理这一问题没那么震惊。事实证明,这些程序的其中之一是网络时间协议(Network Time Protocol)的 [OpenNTPD][4] 实现。Brent Cook 最近给上游 OpenNTPD 源码[提交了一个小补丁][5],添加了必要的 setsockopt() 调用,它也被提交到了 OpenBSD 中了。尽管那个补丁看起来不大可能被接受,最可能是因为 OpenBSD 式的理由(LCTT 译注:如前文提到的,OpenBSD 并不受这个问题的影响)。
|
||||
|
||||
### 安全担忧
|
||||
|
||||
正如上文所提到,OpenBSD 根本不支持 IPv4 映射的 IPv6 套接字。即使一个程序试着通过将 IPV6_V6ONLY 选项设置为 0 显式地启用地址映射,它的作者会感到沮丧,因为这个设置在 OpenBSD 系统中无效。这个决定背后的原因是这个映射带来了一些安全担忧。攻击打开接口的攻击类型有很多种,但它们最后都会回到规定的两个途径到达相同的端口,每个端口都有它自己的控制规则。
|
||||
|
||||
任何给定的服务器系统可能都设置了防火墙规则,描述端口的允许访问权限。也许还会有适当的机制,比如 TCP wrappers 或一个基于 BPF 的过滤器,或一个网络上的路由可以做连接状态协议过滤。结果可能是导致防火墙保护和潜在的所有类型的混乱连接之间的缺口导致同一 IPv4 地址可以通过两个不同的协议到达。如果地址映射是在网络边界完成的,情况甚至会变得更加复杂;参看[这个 2003 年的 RFC 草案][6],它描述了如果映射地址在主机之间传送,一些随之而来的其它攻击场景。
|
||||
|
||||
改变系统和软件合适地处理 IPv4 映射的 IPv6 地址当然可以实现。但那增加了系统的整体复杂度,并且可以确定这个改动没有实际完整实现到它应该实现的范围内。如同 Theo de Raadt [说的][7]:
|
||||
|
||||
**有时候人们将一个坏主意放进了 RFC。之后他们发现不可能将这个主意扔回垃圾箱了。结果就是概念变得如此复杂,每个人都得在管理和编码方面是个全职专家。**
|
||||
|
||||
我们也根本不清楚这些全职专家有多少在实际配置使用 IPv4 映射的 IPv6 地址的系统和网络。
|
||||
|
||||
有人可能会说,尽管 IPv4 映射的 IPv6 地址造成了安全危险,更改一下程序让它关闭部署实现它的系统上的地址映射应该没什么危害。但 Theo 认为不应该这么做,有两个理由。第一个是有许多破损的程序,它们永远不会被修复。但实际的原因是给发行版分发者压力去默认关闭地址映射。正如他说的:“**最终有人会理解这个危害是系统性的,并更改系统默认行为使之‘secure by default’**。”
|
||||
|
||||
### Linux 上的地址映射
|
||||
|
||||
在 Linux 系统,地址映射由一个叫做 net.ipv6.bindv6only 的 sysctl 开关控制;它默认设置为 0(启用地址映射)。管理员(或发行版分发者)可以通过将它设置为 1 关闭地址映射,但在部署这样一个系统到生产环境之前最好确认软件都能正常工作。一个快速调查显示没有哪个主要发行版分发者改变这个默认值;Debian 在 2009 年的 “squeeze” 中[改变了这个默认值][9],但这个改动破坏了足够多的软件包(比如[任何包含 Java 的][10]),[在经过了一定数量的 Debian 式讨论之后][11],它恢复到了原来的设置。看上去不少程序依赖于默认启用地址映射。
|
||||
|
||||
OpenBSD 有自由以“secure by default”的名义打破其核心系统之外的东西;Linux 发行版分发者倾向于更难以作出这样的改变。所以那些一般不愿意收到他们用户的不满的发行版分发者,不太可能很快对 bindv6only 的默认设置作出改变。好消息是这个功能作为默认已经很多年了,但很难找到利用的例子。但是,正如我们都知道的,谁都无法保证这样的利用不可能发生。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://lwn.net/Articles/688462/
|
||||
|
||||
作者:[Jonathan Corbet][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://lwn.net/
|
||||
[1]: https://www.google.com/intl/en/ipv6/statistics.html
|
||||
[2]: https://tools.ietf.org/html/rfc3493#section-3.7
|
||||
[3]: https://tools.ietf.org/html/rfc2373#page-10
|
||||
[4]: https://github.com/openntpd-portable/
|
||||
[5]: https://lwn.net/Articles/688464/
|
||||
[6]: https://tools.ietf.org/html/draft-itojun-v6ops-v4mapped-harmful-02
|
||||
[7]: https://lwn.net/Articles/688465/
|
||||
[8]: https://lwn.net/Articles/688466/
|
||||
[9]: https://lists.debian.org/debian-devel/2009/10/msg00541.html
|
||||
[10]: https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=560056
|
||||
[11]: https://lists.debian.org/debian-devel/2010/04/msg00099.html
|
||||
@ -1,78 +0,0 @@
|
||||
Instagram Web 服务效率与 Python
|
||||
===============================================
|
||||
|
||||
Instagram 目前是世界上最大规模部署 Django web 框架(该框架完全使用 Python 编写)的主角。我们最初选用 Python 是因为它久负盛名的简洁性与实用性,这非常符合我们的哲学思想——“先做简单的事情”。但简洁性也会带来效率方面的折衷。Instagram 的规模在过去两年中已经翻番,并且最近已突破 5 亿用户,所以急需最大程度地提升 web 服务效率以便我们的平台能够继续顺利地扩大。在过去的一年,我们已经将效率计划(efficiency program)提上日程,并在过去的六个月,我们已经能够做到无需向我们的 Django 层(Django tiers)添加新的容量来维护我们的用户增长。我们将在本文分享一些由我们构建的工具以及如何使用它们来优化我们的日常部署流程。
|
||||
|
||||
### 为何需要提升效率?
|
||||
|
||||
Instagram,正如所有的软件,受限于像服务器和数据中心能源这样的样物理限制。鉴于这些限制,在我们的效率计划中有两个我们希望实现的主要目标:
|
||||
|
||||
1. Instagram 应当能够利用持续代码发布提供正常地通信服务,防止因为自然灾害、区域性网络问题等造成某一个数据中心区丢失。
|
||||
2. Instagram 应当能够自由地滚动发布新产品和新功能,不必因容量而受阻。
|
||||
|
||||
想要实现这些目标,我们意识到我们需要持续不断地监控我们的系统并在战斗中回归(battle regression)。
|
||||
|
||||
|
||||
### 定义效率
|
||||
|
||||
Web 服务器的瓶颈通常在于每台服务器上可用的 CPU 时间。在这种环境下,效率就意味着利用相同的 CPU 资源完成更多的任务,也就是说,每秒处理更多的用户请求(requests per second, RPS)。当我们寻找优化方法时,我们面临的第一个最大的挑战就是尝试量化我们当前的效率。到目前为止,我们一直在使用“每次请求的平均 CPU 时间”来评估效率,但使用这种指标也有其固有限制:
|
||||
|
||||
1. 设备多样性。使用 CPU 时间来测量 CPU 资源并非理想方案,因为它同时受到 CPU 模型与 CPU 负载影响。
|
||||
1. 请求影响数据。测量每次请求的 CPU 资源并非理想方案,因为在使用每次请求测量(per-request measurement)方案时,添加或移除轻量级或重量级的请求也会影响到效率指标。
|
||||
|
||||
相对于 CPU 时间来说,CPU 指令是一种更好的指标,因为对于相同的请求,它会报告相同的数字,不管 CPU 模型和 CPU 负载情况如何。我们选择使用了一种叫做”每个活动用户(per active user)“的指标,而不是将我们所有的数据链接到每个用户请求上。我们最终采用”每个活动用户在高峰期间的 CPU 指令(CPU instruction per active user during peak minute)“来测量效率。我们建立好新的度量标准后,下一步就是通过对 Django 的分析来学习更多关于我们的回归(our regressions)。
|
||||
|
||||
### Django 服务分析
|
||||
|
||||
通过分析我们的 Django web 服务,我们希望回答两个主要问题:
|
||||
|
||||
1. 一次 CPU 回归会发生吗?
|
||||
2. 是什么导致了 CPU 回归问题发生以及我们该怎样修复它?
|
||||
|
||||
想要回答第一个问题,我们需要追踪”每个活动用户的 CPU 指令(CPU-instruction-per-active-user)“指标。如果该指标增加,我们就知道一次 CPU 回归已经发生了。
|
||||
|
||||
我们为此构建的工具叫做 Dynostats。Dynostats 利用 Django 中间件以一定的速率采样用户请求,记录键效率以及性能指标,例如 CPU 总指令数、端到端请求时延、花费在访问内存缓存(memcache)和数据库服务的时间等。另一方面,每个请求都有很多可用于聚合的元数据(metadata),例如端点名称、HTTP 请求返回码、服务该请求的服务器名称以及请求中最新提交的哈希值(hash)。对于单个请求记录来说,有两个方面非常强大,因为我们可以在不同的维度上进行切割,那将帮助我们减少任何导致 CPU 回归的原因。例如,我们可以根据他们的端点名称聚合所有请求,正如下面的时间序列图所示,从图中可以清晰地看出在特定端点上是否发生了回归。
|
||||
|
||||

|
||||
|
||||
CPU 指令对测量效率很重要——当然,它们也很难获得。Python 并没有支持直接访问 CPU 硬件计数器(CPU 硬件计数器是指可编程 CPU 寄存器,用于测量性能指标,例如 CPU 指令)的公共库。另一方面,Linux 内核提供了 `perf_event_open` 系统调用。通过 Python ctypes 桥接技术能够让我们调用标准 C 库编写的系统调用函数,它也为我们提供了兼容 C 的数据类型,从而可以编程硬件计数器并从它们读取数据。
|
||||
|
||||
使用 Dynostats,我们已经可以找出 CPU 回归,并探究 CPU 回归发生的原因,例如哪个端点受到的影响最多,谁提交了真正会导致 CPU 回归的变更等。然而,当开发者收到他们的变更已经导致一次 CPU 回归发生的通知时,他们通常难以找出问题所在。如果问题很明显,那么回归可能就不会一开始就被提交!
|
||||
|
||||
这就是为何我们需要一个 Python 分析器,从而使开发者能够使用它找出回归(一旦 Dynostats 发现了它)发生的根本原因。不同于白手起家,我们决定对一个现成的 Python 分析器 cProfile 做适当的修改。cProfile 模块通常会提供一个统计集合来描述程序不同的部分执行时间和执行频率。我们将 cProfile 的定时器(timer)替换成了一个从硬件计数器读取的 CPU 指令计数器,以此取代对时间的测量。我们在采样请求后产生数据并把数据发送到数据流水线。我们也会发送一些我们在 Dynostats 所拥有的类似元数据,例如服务器名称、集群、区域、端点名称等。
|
||||
在数据流水线的另一边,我们创建了一个消费数据的尾随者(tailer)。尾随者的主要功能是解析 cProfile 的统计数据并创建能够表示 Python 函数级别的 CPU 指令的实体。如此,我们能够通过 Python 函数来聚集 CPU 指令,从而更加方便地找出是什么函数导致了 CPU 回归。
|
||||
|
||||
### 监控与警报机制
|
||||
|
||||
在 Instagram,我们 [每天部署 30-50 次后端服务][1]。这些部署中的任何一个都能发生 CPU 回归的问题。因为每次发生通常都包含至少一个区别(diff),所以找出任何回归是很容易的。我们的效率监控机制包含在每次发布前后都会在 Dynostats 中哦了过扫描 CPU 指令,并且当变更超出某个阈值时发出警告。对于长期会发生 CPU 回归的情况,我们也有一个探测器为负载最繁重的端点提供日常和每周的变更扫描。
|
||||
|
||||
部署新的变更并非触发一次 CPU 回归的唯一情况。在许多情况下,新的功能和新的代码路径都由全局环境变量(global environment variables, GEV)控制。 在一个计划好的时间表上,给一个用户子集发布新功能有一些非常一般的实践。我们在 Dynostats 和 cProfile 统计数据中为每个请求添加了这个信息作为额外的元数据字段。来自这些字段的组请求通过转变全局环境变量(GEV),从而暴露出可能的 CPU 回归问题。这让我们能够在它们对性能造成影响前就捕获到 CPU 回归。
|
||||
|
||||
|
||||
### 接下来是什么?
|
||||
|
||||
Dynostats 和我们定制的 cProfile,以及我们建立去支持它们的监控和警报机制能够有效地找出大多数导致 CPU 回归的元凶。这些进展已经帮助我们恢复了超过 50% 的不必要的 CPU 回归,否则我们就根本不会知道。
|
||||
|
||||
我们仍然还有一些可以提升的方面并可以更加便捷将它们地加入到 Instagram 的日常部署流程中:
|
||||
|
||||
1. CPU 指令指标应该要比其它指标如 CPU 时间更加稳定,但我们仍然观察了让我们头疼的差异。保持信号“信噪比(noise ratio)”合理地低是非常重要的,这样开发者们就可以集中于真实的回归上。这可以通过引入置信区间(confidence intervals)的概念来提升,并在信噪比过高时发出警报。针对不同的端点,变化的阈值也可以设置为不同值。
|
||||
2. 通过更改 GEV 来探测 CPU 回归的一个限制就是我们要在 Dynostats 中手动启用这些比较的日志输出。当 GEV 逐渐增加,越来越多的功能被开发出来,这就不便于扩展了。
|
||||
作为替代,我们能够利用一个自动化框架来调度这些比较的日志输出,并对所有的 GEV 进行遍历,然后当检查到回归时就发出警告。
|
||||
3. cProfile 需要一些增强以便更好地处理装饰器函数以及它们的子函数。
|
||||
|
||||
鉴于我们在为 Instagram 的 web 服务构建效率框架中所投入的工作,所以我们对于将来使用 Python 继续扩展我们的服务很有信心。
|
||||
我们也开始向 Python 语言自身投入更多,并且开始探索从 Python 2 转移 Python 3 之道。我们将会继续探索并做更多的实验以继续提升基础设施与开发者效率,我们期待着很快能够分享更多的经验。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://engineering.instagram.com/web-service-efficiency-at-instagram-with-python-4976d078e366#.tiakuoi4p
|
||||
|
||||
作者:[Min Ni][a]
|
||||
译者:[ChrisLeeGit](https://github.com/chrisleegit)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://engineering.instagram.com/@InstagramEng?source=post_header_lockup
|
||||
[1]: https://engineering.instagram.com/continuous-deployment-at-instagram-1e18548f01d1#.p5adp7kcz
|
||||
@ -1,54 +0,0 @@
|
||||
copyleft 是什么?
|
||||
=============
|
||||
|
||||
如果你在开源项目中花费很多时间的话,你可能会看到使用的术语 “copyleft”。虽然这个术语使用比较普遍,但是很多人却不理解它。软件许可是一个至少不亚于文件编辑器和打包格式的激烈辩论的学科。专家的理解可能会充斥在好多书中,但是这篇文章可以作为你理解 copyleft 道路的起点。
|
||||
|
||||
|
||||
## 什么是 copyright?
|
||||
|
||||
在我们可以理解 copyleft 之前,我们必须先介绍一下 copyright 的概念。copyleft 并不是一个脱离于 copyright 的独立的法律框架,copyleft 存在于 copyright 规则中。那么,什么是 copyright?
|
||||
|
||||
准确的定义随着地域的不同而不同,但是其本质就是:作品的作者对于作品的仿制【注:英文为 copying】(因此成为 “copyright”)、性能等有有限的垄断权。在美国,宪法明确地阐述了美国国会的任务就是制定版权法律来“促进科学和实用艺术的进步”。
|
||||
|
||||
不同于以往,版权会立马附加到作品上——而且不需要注册。默认的,所有的权力都是保留的。也就是说,没有经过作者的允许,没有人可以出版、执行或者修改作品。这种允许就是一种许可,可能还会附加一定的条件。
|
||||
|
||||
如果希望得到对于 copyright 更彻底的介绍,Coursera 上的[教育工作者和图书管理员的著作权](https://www.coursera.org/learn/copyright-for-education)是一个非常优秀的课程。
|
||||
|
||||
## 什么是 copyleft?
|
||||
|
||||
先不要着急,在我们讨论 copyleft 是什么之前,还有一步。首先,让我们解释一下开源意味着什么。所有的开源许可协议,通过[开源 Inititative ](https://opensource.org/osd)定义,除其他形式外,必须以源码的形式发放。获得源码的任何人都有权利查看并修改源码。
|
||||
|
||||
copyleft 许可和所谓的 “permissive” 许可不同的地方在于,其衍生的作品中,也需要相同的 copyleft 许可。我倾向于通过这种方式来讨论两者不同: permissive 许可向直接下游的开发者提供了最大的自由(包括闭源项目中使用开源代码的权力),而 copyleft 许可则向最终用户提供最大的自由。
|
||||
|
||||
GNU 项目为 copyleft 提供了这个[简单的定义](https://www.gnu.org/philosophy/free-sw.en.html):规则就是当重新编辑程序时,你不可以添加限制来拒绝其他人对于[免费软件]的自由。这可以被认为典型的定义,自从不同版本的 GNU 通用许可证(GPL)依然是最广泛使用的 copyleft 许可。
|
||||
|
||||
## 软件中的 Copyleft
|
||||
|
||||
GPL 家族是最出名的 copyleft 许可,但是它们并不是唯一的。[Mozilla 公共许可协议]和[Eclipse 公共许可协议]也很出名。很多[其他的 copyleft 许可](https://tldrlegal.com/licenses/tags/Copyleft) 则存在于很小的脚注那儿。
|
||||
|
||||
就像之前章节介绍的那样,一个 copyleft 许可意味着下游的项目不可以在软件的使用上添加额外的限制。这最好用一个例子来说明。如果我写了一个很酷的程序,并且使用 copyleft 许可来发布,你将有使用和修改它的自由。你可以发布你修改后的版本,但是你必须让你的用户有我给你同样的自由。如果我使用 “permissive” 许可,你将可以自由的合并到一个不提供源码的软件中。
|
||||
|
||||
对于我的很酷的程序,和你必须要做什么同样重要的是你必须不能做什么。你不必用和我完全一样的许可协议,只要它们相互兼容就行(一般的为了简单起见,下游的项目使用相同的许可)。你不必向我共享出你的修改,但是你这么做的话,通常被认为一个很好的形式,尤其是一些修改是为了bug的修复。
|
||||
|
||||
## 非软件中的 Copyleft
|
||||
|
||||
虽然,copyleft 起始于软件世界,但是它也存在之外的世界。“做你想做的,只要你保留其他人也有做同样的事的权力”的概念是应用于文字创作、视觉艺术等的知识共享署名许可的一个显著的特点(CC BY-SA 4.0 是贡献于 Opensource.com 默认的许可)。[GNU 自由文档许可证](https://www.gnu.org/licenses/fdl.html)是另一个非软件协议中 copyleft 的例子。在非软件中使用软件协议通常不被建议。
|
||||
|
||||
|
||||
## 我是否需要选择一种 copyleft 许可?
|
||||
|
||||
文章可以(并且已经!)写一个项目应该使用哪一种许可。我的建议是首先缩小满足你项目的哲学和目标的许可列表。GitHub 的[choosealicense.com](http://choosealicense.com/) 是一种查找满足你的需求的许可协议的好方法。[tldrLegal](https://tldrlegal.com/)使用纯语言说明许多相同和不同的软件许可。而且研究了你的项目所在的生态系统。围绕一种特定语言和技术的项目经常使用相同或者相似的许可。如果你希望你的项目可以运行的更出色,你可能需要确保你选择的许可是兼容的。
|
||||
|
||||
关于更多 copyleft 的信息,请查看 [copyleft 指南](https://copyleft.org/)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/firewall/pfsense-setup-basic-configuration/
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bcotton
|
||||
@ -1,74 +0,0 @@
|
||||
使用Zero配置开发React
|
||||
========================
|
||||
|
||||
你想使用[React][1]来构建应用吗?"[入门][2]"是很容易的,可是接下来呢?
|
||||
|
||||
React是一个构建用户界面的库,用户界面是组成一个应用的一部分。取决于所有其他的部分-风格,路由器,npm模块,ES6代码,捆绑和更多-然后指出如何使用它们对开发者来说是很浪费的。
|
||||
|
||||
这被称为[JavaScript疲劳][3]。尽管存在这种复杂性,但是使用React的用户依旧继续增长。
|
||||
|
||||
社区应对这一挑战的方法是共享样板文件。这些[样板文件][4]展示出架构师必须在缤纷的选项中做出选择。
|
||||
官方的“开始入门”似乎是离现实的一个可操作的应用程序如此远。
|
||||
|
||||
|
||||
### 新的,Zero-configuration体验
|
||||
|
||||
由[Ember.js][5]和[Elm][6]有凝聚力的开发经验的启发,Facebook的人们想要提供一个简单,直接的方式。他们发明了一个新的开发React应用的方法,`create-react-app`。在初始的公开版发布的三个星期以来,它已经收到了极大的社区关注(超过8,000个GitHub梦想家)和支持(许多的拉请求)。
|
||||
|
||||
`create-react-app`是不同意许多过去使用模板和开发启动工具包的尝试。它的目标是零配置[[惯例-优于-配置]][7],使开发者关注于他们的应用的不同之处。
|
||||
|
||||
zero configuration一个强大的附带影响是这个工具可以在后台逐步成型。零配置奠定了工具生态系统的基础,创造的自动化和喜悦的开发远远超越React本身。
|
||||
|
||||
### 将Zero-configuration部署到Heroku上
|
||||
|
||||
多亏了create-react-app的zero-config功能,zero-config的点子看起来才快要达到了。因为这些新的应用都使用一个公共的,默认的架构,构建的过程可以被自动化同时可以使用智能的默认项来配置。因此,[我们创造这个社区构建包来体验在Heroku零配置的过程][8]。
|
||||
|
||||
|
||||
#### 在两分钟内创造和发布React应用
|
||||
|
||||
你可以在Heroku上免费开始构建React应用。
|
||||
```
|
||||
npm install -g create-react-app
|
||||
create-react-app my-app
|
||||
cd my-app
|
||||
git init
|
||||
heroku create -b https://github.com/mars/create-react-app-buildpack.git
|
||||
git add .
|
||||
git commit -m "react-create-app on Heroku"
|
||||
git push heroku master
|
||||
heroku open
|
||||
```
|
||||
[使用构建包文档][9]亲自试试吧。
|
||||
|
||||
### 从零配置出发
|
||||
|
||||
|
||||
create-react-app是非常的新(目前版本是0.2)同时因为它的目标是简洁的开发者体验,更多高级的使用情景并不支持(或者许多从来不被支持)。例如,它不支持服务端渲染或者自定义捆绑。
|
||||
|
||||
为了支持更好的控制,create-react-app包括了npm run eject命令。Eject将所有的工具(配置文件和package.json依赖库)解压到应用所在的路径,因此你可以按照你心中的想法定做。一旦被弹出,你做的改变或许有必要选择一个特定的用Node.js和/或静态的构建包来布署。总通过一个分支/拉请求来使类似的工程改变生效,因此这些改变可以轻易撤销。Heroku的预览应用对测试发布的改变是完美的。
|
||||
|
||||
我们将会追踪create-react-app的进度同时适配构建包来支持更多的高级使用情况当这些是可得到之时。发布万岁!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.heroku.com/deploying-react-with-zero-configuration?c=7013A000000NnBFQA0&utm_campaign=Display%20-%20Endemic%20-Cooper%20-Node%20-%20Blog%20-%20Zero-Configuration&utm_medium=display&utm_source=cooperpress&utm_content=blog&utm_term=node
|
||||
|
||||
作者:[Mars Hall][a]
|
||||
译者:[译者ID](https://github.com/zky001)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://blog.heroku.com/deploying-react-with-zero-configuration?c=7013A000000NnBFQA0&utm_campaign=Display%20-%20Endemic%20-Cooper%20-Node%20-%20Blog%20-%20Zero-Configuration&utm_medium=display&utm_source=cooperpress&utm_content=blog&utm_term=node
|
||||
[1]: https://facebook.github.io/react/
|
||||
[2]: https://facebook.github.io/react/docs/getting-started.html
|
||||
[3]: https://medium.com/@ericclemmons/javascript-fatigue-48d4011b6fc4
|
||||
[4]: https://github.com/search?q=react+boilerplate
|
||||
[5]: http://emberjs.com/
|
||||
[6]: http://elm-lang.org/
|
||||
[7]: http://rubyonrails.org/doctrine/#convention-over-configuration
|
||||
[8]: https://github.com/mars/create-react-app-buildpack
|
||||
[9]: https://github.com/mars/create-react-app-buildpack#usage
|
||||
|
||||
@ -1,80 +0,0 @@
|
||||
|
||||
AWS和GCP Spark技术哪家强?
|
||||
===========
|
||||
|
||||
|
||||
>Tianhui Michael Li 和Ariel M’ndange-Pfupfu将在今年10月10、12和14号组织一个在线经验分享课程:Spark分布式计算入门。该课程的内容包括创建端到端的运行应用程序和精通Spark关键工具。
|
||||
|
||||
毋庸置疑,云计算将会在未来数据科学领域扮演至关重要的角色。弹性,可扩展性和按需分配的计算能力作为云计算的重要资源,直接导致云服务提供商集体火拼。其中最大的两股势力正是亚马逊网络服务(AWS)【1】和谷歌云平台(GCP)【2】。
|
||||
|
||||
本文依据构建时间和运营成本对AWS和GCP的Spark工作负载作一个简短比较。实验由我们的学生在数据孵化器进行,数据孵化器【3】是一个大数据培训组织,专门为公司招聘顶尖数据科学家并为公司职员培训最新的大数据科学技能。尽管内置的Spark效率惊人,分布式工作负载的时间和成本亦然可以大到不能忽略不计。因此我们一直努力寻求更高效的技术,我们的学生也因此能够学习到最好和最快的工具。
|
||||
|
||||
###提交Spark任务到云
|
||||
|
||||
Spark是一个类MapReduce但是比MapReduce更灵活、更抽象的并行计算框架。Spark提供Python和Java 编程接口,但它更愿意用户使用原生的Scala语言进行应用程序开发。Scala可以把应用程序和依赖文件打包在一个JAR文件从而使Spark任务提交变得简单。
|
||||
|
||||
通常情况下,Sprark结合HDFS应用于分布式数据存储,而与YARN协同工作则应用于集群管理;这种堪称完美的配合使得Spark非常适用于AWS的弹性MapReduce(EMR)集群和GCP的Dataproc集群。这两种集群都已有HDFS和YARN预配置,不需要额外进行配置。
|
||||
|
||||
通过命令行比通过网页接口管理数据、集群和任务具有更高的可扩展性。对AWS而言,这意味着客户需要安装CLI。客户必须获得证书并为每个EC2实例创建独立的密钥对。除此之外,客户还需要为EMR用户和EMR本身创建规则,主要是准入许可规则,从而使EMR用户获得足够多的权限。
|
||||
|
||||
相比而言,GCP的处理流程更加直接。如果客户选择安装Google Cloud SDK并且使用其Google账号登录,那么客户即刻可以使用GCP的几乎所有功能而无需其他任何配置。唯一需要提醒的是不要忘记通过API管理器使能计算引擎、Dataproc和云存储JSON的API。
|
||||
|
||||
AWS就是这样,实现自己喜欢的应用,一旦火力全开,根本停不下来!比如可以通过“aws s3 cp”或者“gsutil cp”命令拷贝客户的数据到云端。再比如客户可以创建自己的输入、输出或者任何其他需要的bucket,如此,运行一个应用就像创建一个集群或者提交JAR文件一样简单。请确定日志存放的地方,毕竟在云环境下跟踪问题或者调试bug有点诡异。
|
||||
|
||||
###一分钱一分货
|
||||
|
||||
谈及成本,Google的服务在以下几个方面更有优势。首先,购买计算能力的原始成本更低。4个vCPU和15G RAM的Google计算引擎服务每小时只需0.20美元,如果运行Dataproc,每小时也只需区区0.24美元。相比之下,同等的云配置,AWS EMR则需要每小时0.336美元。
|
||||
|
||||
其次,计费方式。AWS按小时计费,即使客户只使用15分钟也要付足1小时的费用。GCP按分钟计费,最低计费10分钟。在诸多用户案例中,资费方式的不同直接导致成本的巨大差异。
|
||||
|
||||
两种云服务都有其他多种定价机制。客户可以使用Sport Instance或Preemptible Instance竞价AWS或GCP的空闲云计算能力。这些服务比专有的、按需服务便宜,缺点是不能保证随时有可用的云资源提供服务。在GCP上,如果客户长时间(每月的25%至100%)使用服务,可以获取更多折扣。在AWS上预付费或者一次购买大批量服务可以节省不少费用。底线是,如果你是一个超级用户,并且使用云计算已经成为一种常态,那么最好深入研究云计算,自建云计算服务。
|
||||
|
||||
最后,新手在GCP上体验云服务的费用较低。新手只需300美元信用担保,就可以免费试用60天GCP提供的全部云服务。AWS只免费提供特定服务的特定试用层级,如果运行Spark任务,需要付费。这意味着初次体验Spark,GCP具有更多选择,也少了精打细算和讨价还价的烦恼。
|
||||
|
||||
###性能比拼
|
||||
|
||||
我们通过实验检测一个典型Spark工作负载的性能与开销。实验分别选择AWS的m3.xlarg和GCP的n1-standard-4,它们都是由一个Master和5个核心实例组成的集群。除了规格略有差别,虚拟核心和费用都相同。实际上它们在Spark任务的执行时间上也表现的惊人相似。
|
||||
|
||||
测试Spark任务包括对数据的解析、过滤、合并和聚合,这些数据来自堆栈交换数据转储。通过运行相同的JAR,我们首先对大约50M的数据子集进行交叉验证,然后将验证扩大到大约9.5G的数据集。
|
||||
|
||||

|
||||
>Figure 1. Credit: Michael Li and Ariel M'ndange-Pfupfu.
|
||||
|
||||

|
||||
>Figure 2. Credit: Michael Li and Ariel M'ndange-Pfupfu.
|
||||
|
||||
结果表明,短任务在GCP 上具有明显的成本优势,这是因为GCP以分钟计费,并最终扣除了10分钟的费用,而AWS则收取了1小时的费用。但是即使长任务,因为计费方式占优,GPS仍然具有相当优势。同样值得注意的是存储成本并不包括在此次比较当中。
|
||||
|
||||
###结论
|
||||
|
||||
AWS是云计算的先驱,这甚至体现在API中。AWS拥有巨大的生态系统,但其准入模型已略显陈旧,配置管理也有些晦涩难解。相比之下,Google是云计算领域的新星并且抛光了云计算中一些粗糙的边缘问题。但是GCP缺少一些便捷的功能,比如通过简单方法自动结束集群和详细的任务计费信息分解。另外,其Python编程接口也不像AWS的Boto那么全面。
|
||||
|
||||
如果你初次使用云计算,GCP因简单易用,别具魅力。即使你已在使用AWS,你也许会发现迁移到GCP可能更划算,尽管真正从AWS迁移到GCP的代价可能得不偿失。
|
||||
|
||||
当然,现在对两种云服务作一个全面的总结还非常困难,因为它们都不是单一的实体,而是由多个实体整合而成的完整生态系统,并且各有利弊。真正的赢家是用户。一个例证就是在数据孵化器,我们的博士数据科学研究员在学习过程中真正体会到成本的下降。虽然我们的大数据企业培训客户可能对价格不那么敏感,他们很欣慰能够更快速地处理企业数据,同时保持价格不增加。数据科学家现在可以享受大量的可选服务,这些都是从竞争激烈的云计算市场得到的实惠。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.oreilly.com/ideas/spark-comparison-aws-vs-gcp?utm_source=dbweekly&utm_medium=email
|
||||
|
||||
作者:[Michael Li][a] [Ariel M'Ndange-Pfupfu][b]
|
||||
译者:[firstadream](https://github.com/firstadream)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.oreilly.com/people/76a5b-michael-li
|
||||
[b]: https://www.oreilly.com/people/Ariel-Mndange-Pfupfu
|
||||
[1]: https://aws.amazon.com/
|
||||
[2]: https://cloud.google.com/
|
||||
[3]: https://www.thedataincubator.com/training.html?utm_source=OReilly&utm_medium=blog&utm_campaign=AWSvsGCP
|
||||
@ -0,0 +1,446 @@
|
||||
|
||||
新手指南 - 通过 DOCKER 在 Linux 上托管 .NET 核心
|
||||
=====
|
||||
|
||||
这篇文章基于我之前的文章【.NET 核心入门】【1】。首先,我把应用程序界面【API】从 .NET Core RC1 升级到了 .NET Core 1.0,然后,我增加了对 Docker 的支持并描述了如何在 Linux 生产环境里托管它。
|
||||
|
||||

|
||||
|
||||
我是首次接触 Docker 并且距离成为一名 Linux 高手还有很远的一段路程。因此,这里的很多想法是来自一个新手。
|
||||
|
||||
### 安装
|
||||
|
||||
按照 https://www.microsoft.com/net/core 上的介绍在你的电脑上安装 .NET 核心。这将会同时在 Windows 上安装 dotnet 命令行工具以及最新的 Visual Studio 工具。
|
||||
|
||||
### 源代码
|
||||
|
||||
你可以直接到 GitHub 上找最到最新完整的源代码。
|
||||
|
||||
### 转换到 .NET CORE 1.0
|
||||
|
||||
|
||||
自然地,当我考虑如何把应用程序界面【API】 .NET Core RC1 升级到 .NET Core 1.0 时想到的第一个求助的地方就是谷歌搜索。我是按照下面这两条非常全面的指导来进行升级的:
|
||||
|
||||
- [Migrating from DNX to .NET Core CLI][2]
|
||||
- [Migrating from ASP.NET 5 RC1 to ASP.NET Core 1.0][3]
|
||||
|
||||
当你迁移代码的时候,我建议仔细阅读这两条指导,因为我在没有阅读第一篇指导的情况下又尝试浏览第二篇,结果感到非常迷惑和沮丧。
|
||||
|
||||
我不想描述细节上的改变因为你可以看 GitHub 上的提交。这儿是我所作改变的摘要:
|
||||
|
||||
- 更新 global.json and project.json 上的版本数
|
||||
- 删除 project.json 上的废弃章节
|
||||
- 使用轻型 ControllerBase 而不是 Controller, 因为我不需要与 MVC 视图相关的方法(这是一个可选的改变)。
|
||||
- 从辅助方法中去掉前缀,比如:HttpNotFound -> NotFound
|
||||
- LogVerbose -> LogTrace
|
||||
- 名字空间改变: Microsoft.AspNetCore.*
|
||||
- 使用 SetBasePath 启动(没有它 appsettings.json 将不会被发现)
|
||||
- 通过 WebHostBuilder 来运行而不是通过 WebApplication.Run 来运行
|
||||
- 删除 Serilog(在写文章的时候,它不支持 .NET Core 1.0)
|
||||
|
||||
唯一令我真正头疼的事是需要移动 Serilog。我本能够执行自己的文件记录器,但是我删除了文件记录因为我不想为了这次操作集中精力在这件事情上。
|
||||
|
||||
不幸的是,将有大量的第三方开发者扮演追赶 .NET Core 1.0 的角色,我非常同情他们,因为他们通常在休息时间还坚持工作但却依旧根本无法接近微软的可用资源。我建议阅读 Travis Illig 的文章【.NET Core 1.0 发布了,但 Autofac 在哪儿】【4】?这是一篇关于第三方开发者观点的文章。
|
||||
|
||||
做了这些改变以后,我可以从 project.json 目录恢复、构建并运行 dotnet,可以看到应用程序界面【API】又像以前一样工作了。
|
||||
|
||||
### 通过 DOCKER 运行
|
||||
|
||||
在我写这篇文章的时候, Docker 只能够在 Linux 系统上工作。在 Windows 系统和 OS X 上有 beta 支持 Docker,但是它们都必须依赖于虚拟化技术,因此,我选择把 Ubuntu 14.04 当作虚拟机来运行。如果你还没有安装过 Docker,请按照指导来安装。
|
||||
|
||||
我最近阅读了一些关于 Docker 的东西,但我直到现在还没有真正用它来干任何事。我假设读者还没有关于 Docker 的知识,因此我会解释我所使用的所有命令。
|
||||
|
||||
#### HELLO DOCKER
|
||||
|
||||
在 Ubuntu 上安装好 Docker 之后,我所进行的下一步就是按照 https://www.microsoft.com/net/core#docke 上的介绍来开始运行 .NET 核心和 Docker.
|
||||
|
||||
首先启动一个已安装有 .NET Core 的 container。
|
||||
|
||||
|
||||
```
|
||||
docker run -it microsoft/dotnet:latest
|
||||
```
|
||||
|
||||
-it 选项意味着你可以在 container 内交互执行这条命令并按照你所希望的那样自由执行任何 bash 命令。
|
||||
|
||||
然后我们可以运行下面这五条命令个来获得在 Docker 内部运行的 Microsoft’s Hello World .NET 核心控制台运用程序。
|
||||
|
||||
1. mkdir hwapp
|
||||
2. cd hwapp
|
||||
3. dotnet new
|
||||
4. dotnet restore
|
||||
5. dotnet run
|
||||
|
||||
|
||||
你可以通过退出来离开 container,然后在 Docker 内运行 ps -a 命令,这会显示你已经创建了一个已退出的 container。你可以通过在 Docker 上运行命令 rm <container_name>. 来整理一下 Container。
|
||||
|
||||
|
||||
#### 安装源代码
|
||||
|
||||
我的下一步骤是使用和上面相同的 microsoft/dotnet 图像,但是将我的应用程序的源代码作为数据卷
|
||||
|
||||
首先检查有相关提交的仓库:
|
||||
|
||||
1. git clone https://github.com/niksoper/aspnet5-books.git
|
||||
2. cd aspnet5-books/src/MvcLibrary
|
||||
3. git checkout dotnet-core-1.0
|
||||
|
||||
现在启动一个 container 来运行位于 /book 目录下伴有源程序的 .NET Core 1.0。 注意更改 /path/to/repo 这部分文件来匹配你的电脑:
|
||||
|
||||
```
|
||||
docker run -it \
|
||||
-v /path/to/repo/aspnet5-books/src/MvcLibrary:/books \
|
||||
microsoft/dotnet:latest
|
||||
```
|
||||
|
||||
现在你可以运行 container 中的应用程序了!
|
||||
|
||||
```
|
||||
cd /books
|
||||
dotnet restore
|
||||
dotnet run
|
||||
```
|
||||
|
||||
作为一个概念的证明,这的确很棒,但是我们不想无论何时打算运行一个程序都要考虑如何把源代码安装到 container 里。
|
||||
|
||||
|
||||
#### 增加一个 DOCKERFILE
|
||||
|
||||
我的下一步骤是引入一个 Docker 文件,这将允许应用程序很容易在自己的 container 内启动。
|
||||
|
||||
我的 Docker 文件和 project.json 一样位于 src/MvcLibrary 目录下,看起来像下面这样:
|
||||
|
||||
|
||||
```
|
||||
FROM microsoft/dotnet:latest
|
||||
|
||||
# 为应用程序源代码创建目录
|
||||
RUN mkdir -p /usr/src/books
|
||||
WORKDIR /usr/src/books
|
||||
|
||||
# 复制源代码并恢复依赖关系
|
||||
|
||||
COPY . /usr/src/books
|
||||
RUN dotnet restore
|
||||
|
||||
# 暴露端口并运行应用程序
|
||||
EXPOSE 5000
|
||||
CMD [ "dotnet", "run" ]
|
||||
```
|
||||
|
||||
严格来说,‘RUN mkdir -p /usr/src/books’ 命令是不需要的,因为 COPY 会自动为丢失的目录创建副本。
|
||||
|
||||
|
||||
Docker 图像是建立在图层里面的,我们从包含 .NET Core 的图像开始,添加另一个从源生成应用程序的层,然后运行这个运用程序。
|
||||
|
||||
添加了 Docker 文件以后,我通过运行下面的命令来生成一个图像并使用生成的图像打开一个 container(确保在和 Docker 文件相同的目录下进行操作并且你应该使用自己的用户名)。
|
||||
|
||||
1. docker build -t niksoper/netcore-books .
|
||||
2. docker run -it niksoper/netcore-books
|
||||
|
||||
你应该看到程序能够和之前一样的运行,不过这一次我们不需要像之前那样安装源代码,因为源代码已经包含在 docker 图像里面了。
|
||||
|
||||
|
||||
#### 暴露并发布端口
|
||||
|
||||
应用程序界面【API】用处不大,除非我们可以从 container 外面和它进行通信。 Docker 已经有了暴露和发布端口的概念,但这是两件完全不同的事。
|
||||
|
||||
|
||||
通过 Docker 官方文件:
|
||||
|
||||
> EXPOSE 指令通知 Docker 上的 container 监听正在运行的特殊网络端口。EXPOSE 指令不能够让 container 访问主机。要使 container 能够访问主机,你必须通过 -p 标志来发布一系列端口或者使用 -P 标志来发布所有暴露的端口
|
||||
|
||||
EXPOSE 指令只会将元数据添加到图像上,所以你可以认为它是图像消费者的文件。从技术上讲,我本应该忽略 5000 行 EXPOSE 指令因为我知道应用程序界面【API】正在监听的端口,但把它们留下很有用并且是值得推荐的。
|
||||
|
||||
在这个阶段,我想直接从主机访问应用程序界面【API】,因此我需要通过 -p 指令来发布端口,这将允许请求从主机上的端口 5000 转发到 container 上的端口 5000,无论这个端口是不是之前通过 Docker 文件暴露的。
|
||||
|
||||
```
|
||||
docker run -d -p 5000:5000 niksoper/netcore-books
|
||||
```
|
||||
|
||||
通过 -d 指令告诉 docker 在分离模式下运行 container,因此我们不能看到它的输出,但是它依旧会运行和监听端口 5000。你可以通过 docker ps 来证实这件事。
|
||||
|
||||
|
||||
因此,接下来我准备庆祝成功把一个请求从主机转发到了 container 里:
|
||||
|
||||
```
|
||||
curl http://localhost:5000/api/books
|
||||
```
|
||||
|
||||
它不能够工作。
|
||||
|
||||
重复进行相同请求,我看到了一两个错误:(56)接收失败:连接相同等或卷曲复位:(52)来自服务器的空回复。
|
||||
|
||||
我返回 docker运行文件,然后双重检查我所使用的 -p 选项以及 Docker 文件中的 EXPOSE 指令是否正确。我没有发现任何问题,这让我开始有些沮丧。
|
||||
|
||||
重新站起来以后,我决定去咨询当地的一个大师 - Dave Wybourn(他也在文章里提到 Docker Swarm),他的团队也曾遇到这个实际问题。但问题是,我没有配置过 Kestral - 一个全新的轻量级跨平台 web 服务器,用于 .NET 核心。
|
||||
|
||||
默认情况下, Kestrel 会监听 http://localhost:5000。但问题是,这儿的本地主机是一个回路接口。
|
||||
|
||||
通过维基百科:
|
||||
|
||||
> 在计算机网络中,本地主机是一个象征着这台电脑的主机名。本地主机可以通过网络回路接口访问在主机上运行的网络服务。通过使用回路接口可以绕过任何硬件网络接口。
|
||||
|
||||
在 container 内运行应用是一个新的问题,因为本地主机只能够通过 container 到达。解决方法是更新 Startup.cs 里的主要方法来配置被 Kestral 监听的 URLs:
|
||||
|
||||
```
|
||||
public static void Main(string[] args)
|
||||
{
|
||||
var host = new WebHostBuilder()
|
||||
.UseKestrel()
|
||||
.UseContentRoot(Directory.GetCurrentDirectory())
|
||||
.UseUrls("http://*:5000") // listen on port 5000 on all network interfaces
|
||||
.UseIISIntegration()
|
||||
.UseStartup<Startup>()
|
||||
.Build();
|
||||
|
||||
host.Run();
|
||||
}
|
||||
```
|
||||
|
||||
通过这些额外的配置,我可以重建图像,并在 container 中运行应用程序,它将能够接收来自主机的请求:
|
||||
|
||||
|
||||
1. docker build -t niksoper/netcore-books .
|
||||
2. docker run -d -p 5000:5000 niksoper/netcore-books
|
||||
3. curl -i http://localhost:5000/api/books
|
||||
|
||||
我现在得到下面这些回应:
|
||||
|
||||
```
|
||||
HTTP/1.1 200 OK
|
||||
日期:Tue, 30 Aug 2016 15:25:43 GMT
|
||||
编码传输: chunked
|
||||
内容类型: application/json; charset=utf-8
|
||||
服务器: Kestrel
|
||||
|
||||
[{"id":"1","title":"RESTful API with ASP.NET Core MVC 1.0","author":"Nick Soper"}]
|
||||
```
|
||||
|
||||
### 创建 KESTREL
|
||||
|
||||
微软的介绍:
|
||||
|
||||
>Kestrel 可以很好的处理来自 ASP.NET 的动态内容,然而,网络服务部分的特性没有达到 IIS,Apache 或者 Niginx 那样的全特性服务器好。反向代理服务器可以让你不用去做像处理静态内容,缓存请求,压缩请求,来自 HTTP 服务器的 SSL 终止这样的工作。
|
||||
|
||||
因此我需要在 Linux 上把 Nginx 设置成一个反向代理服务器。微软发布了如何在 Linux 生产环境下进行设置的指导教程。我把说明总结在这儿:
|
||||
|
||||
1. 通过 dotnet 发布来给应用程序产生一个自包含包。
|
||||
2. 把已发布的应用程序复制到服务器上
|
||||
3. 安装并配置 Nginx(如同配置一个反向代理服务器一样)
|
||||
4.安装并配置管理员(确保 Nginx 服务器处于运行状态中)
|
||||
5.安装并配置 AppArmor(限制应用的可用资源)
|
||||
6.配置服务器防火墙
|
||||
7.保护好 Nginx(涉及从源代码构建和配置 SSL)
|
||||
|
||||
这些内容已经超出了本文的范围,因此我将侧重于如何把 Nginx 配置成一个反向代理服务器。自然地,我通过 Docker 来完成这件事。
|
||||
|
||||
### 在另一个 CONTAIER 中运行 NGINX
|
||||
|
||||
我的目标是在一个二级 Docker container 中运行 Nginx 并把它配置成应用程序 container 的反向代理服务器。
|
||||
|
||||
我使用的是来自 Docker Hub 的官方 Nginx 图像。首先我尝试这样做:
|
||||
|
||||
```
|
||||
docker run -d -p 8080:80 --name web nginx
|
||||
```
|
||||
|
||||
这启动了一个运行 Nginx 的 container 并把主机上的 8080 端口映射到了 container 的 80 端口上。现在在浏览器中打开网址 http://localhost:8080 会显示出 Nginx 的默认登录页面。
|
||||
|
||||
现在我们证实了运行 Nginx 是多么的简单,我们可以关闭 container.
|
||||
|
||||
```
|
||||
docker rm -f web
|
||||
```
|
||||
|
||||
### 把 NGINX配置成一个反向代理服务器
|
||||
|
||||
可以通过像下面这样编辑位于目录 /etc/nginx/conf.d/default.conf 下的配置文件把 Nginx 配置成一个反向代理服务器:
|
||||
|
||||
```
|
||||
server {
|
||||
listen 80;
|
||||
|
||||
location / {
|
||||
proxy_pass http://localhost:6666;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
通过上面的配置可以让 Nginx 代理从 root 到 http://localhost:6666 的所有请求。记住这里的本地主机指的是运行 Nginx 的 container. 我们可以利用卷来使用在 Nginx container 内部的配置文件:
|
||||
|
||||
```
|
||||
docker run -d -p 8080:80 \
|
||||
-v /path/to/my.conf:/etc/nginx/conf.d/default.conf \
|
||||
nginx
|
||||
```
|
||||
|
||||
注意:这把一个单一文件从主机映射到 container 中,而不是一个完整目录。
|
||||
|
||||
### 在 CONTAINER 间进行通信
|
||||
|
||||
Docer 允许内部 container 通过共享虚拟网络进行通信。默认情况下,所有
|
||||
通过 Dcocker 后台程序启动的 container 都可以访问一种叫做桥的虚拟网络。这使得一个 container 可以被另一个 container 在相同的网络上通过 IP 地址和端口来引用。
|
||||
你可以通过监测 container 来找到它的 IP 地址。我将从之前创建的 niksoper/netcore-books 图像中启动一个 container 并监测它:
|
||||
|
||||
1. docker run -d -p 5000:5000 --name books niksoper/netcore-books
|
||||
2. docker inspect books
|
||||
|
||||

|
||||
|
||||
我们可以看到这个 container 的 IP 地址是 "IPAddress": "172.17.0.3".
|
||||
|
||||
所以现在如果我创建下面的 Nginx 配置文件,并使用这个文件启动一个 Nginx container, 它将代理请求到我的应用程序界面【API】:
|
||||
|
||||
```
|
||||
server {
|
||||
listen 80;
|
||||
|
||||
location / {
|
||||
proxy_pass http://172.17.0.3:5000;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
现在我可以使用这个配置文件启动一个 Nginx container(注意我把主机上的 8080 端口映射到了 Nginx container 上的 80 端口):
|
||||
|
||||
```
|
||||
docker run -d -p 8080:80 \
|
||||
-v ~/dev/nginx/my.nginx.conf:/etc/nginx/conf.d/default.conf \
|
||||
nginx
|
||||
```
|
||||
|
||||
一个到 http://localhost:8080 的请求代理到应用上。注意下面卷反应的服务器标题:
|
||||
|
||||

|
||||
|
||||
### DOCKER Compose
|
||||
|
||||
在这个地方,我为自己的进步而感到高兴,但我认为一定还有更好的方法来配置 Nginx,可以不需要知道应用程序 container 的确切 IP 地址。另一个当地的大师 Jason Ebbin - Scott Logic DevOps 在这个地方进行了改进,并建议使用 Docker Compose。
|
||||
|
||||
作为一个高层次的描述 - Docker Compose 使得一组互相连接的 container 很容易通过声明式语法来启动。我不想再细说 Docker Compose 是如何工作的因为你可以在之前的文章中找到。
|
||||
|
||||
我将通过一个我所使用的 docker-compose.yml 文件来启动:
|
||||
|
||||
```
|
||||
version: '2'
|
||||
services:
|
||||
books-service:
|
||||
container_name: books-api
|
||||
build: .
|
||||
|
||||
reverse-proxy:
|
||||
container_name: reverse-proxy
|
||||
image: nginx
|
||||
ports:
|
||||
- "9090:8080"
|
||||
volumes:
|
||||
- ./proxy.conf:/etc/nginx/conf.d/default.conf
|
||||
```
|
||||
|
||||
这是版本 2 的语法,所以为了能够正常工作,你至少需要 1.6 版本的 Docker Compose.
|
||||
|
||||
这个文件告诉 Docker 创建两条服务 - 一条是给应用的,另一条是给 Nginx 反向代理服务器的。
|
||||
|
||||
### 服务列表
|
||||
|
||||
这将从相同目录下的 Docker 文件创建一个叫做 books-api 的 conainer 作为 docker-compose.yml。注意这个 container 不需要发布任何端口,因为只要能够从反向代理服务器访问它就可以,而不需要从主机操作系统访问它。
|
||||
|
||||
### 反向代理
|
||||
|
||||
这将启动一个基于 nginx 图像叫做 反向代理(reverse-proxy)的container,并把位于当前目录下的 proxy.conf 文件安装成为配置。它把主机上的 9090 端口映射到 container 中的 8080 端口,这将允许我们在 http://localhost:9090. 上通过主机访问 container.
|
||||
|
||||
proxy.conf 文件看起来像下面这样:
|
||||
|
||||
```
|
||||
server {
|
||||
listen 8080;
|
||||
|
||||
location / {
|
||||
proxy_pass http://books-service:5000;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
这儿的关键点是我们现在可以通过名字引用 【服务列表】,因此我们不需要知道 books-api 这个 container 的 IP 地址!
|
||||
|
||||
现在我们可以通过一个运行着的反向代理启动两个 container(-d 意味着这是独立的,因此我们不能看到来自 container 的输出):
|
||||
|
||||
```
|
||||
docker compose up -d
|
||||
```
|
||||
|
||||
证实我们所创建的 container:
|
||||
|
||||
```
|
||||
docker ps
|
||||
```
|
||||
|
||||
最后来证实我们可以通过反向代理来控制应用程序界面【API】:
|
||||
|
||||
```
|
||||
curl -i http://localhost:9090/api/books
|
||||
```
|
||||
|
||||
### 发生了什么?
|
||||
|
||||
Docker Compose 通过创建一个新的叫做 mvclibrary_default 的虚拟网络来实现这件事,这个虚拟网络同时用于 books-api 和反向代理的 container(名字是基于 docker-compose.yml 文件的父目录)。
|
||||
|
||||

|
||||
|
||||
你可以看到新的网络通过 docker 网络来监测 mvclibrary_default 的所有细节:
|
||||
|
||||

|
||||
|
||||
注意 Docker 已经分配了子网:“172.18.0.0/16”。/16 部分是无类域内路由选择【CIDR】,一个完整的解释已经超出了本文的范围,但无类域内路由选择【CIDR】仅表示一个 IP 地址范围。运行 docker 网络来监测桥,显示子网:“172.17.0.0/16”,因此这两个网络是不重叠的。
|
||||
|
||||
现在用 docker 来监测 books-api 从而证实应用程序的 container 是使用该网络:
|
||||
|
||||

|
||||
|
||||
注意 container 的两个别名是 container 标识符(3c42db680459)和由 docker-compose.yml (服务列表)给出的服务名。我们通过服务列表别名来引用在自定义 Nginx 配置文件中的应用程序的 container。这本可以通过 docker 网络手动创建,但是我喜欢用 Docker Compose,因为它可以干净简洁的收捲已创建和相互依存的 container。
|
||||
|
||||
### 结论
|
||||
|
||||
所以现在我可以通过几个简单的步骤在 Linux 系统上用 Nginx 运行应用程序,不需要对主机操作系统做任何长期的改变:
|
||||
|
||||
```
|
||||
git clone https://github.com/niksoper/aspnet5-books.git
|
||||
cd aspnet5-books/src/MvcLibrary
|
||||
git checkout blog-docker
|
||||
docker-compose up -d
|
||||
curl -i http://localhost:9090/api/books
|
||||
```
|
||||
|
||||
我知道我在这篇文章中所写的内容不是一个真正的生产准备设置,因为我没有写任何有关下面这些的内容,但是绝大多数下面的这些主题都需要用单独一篇完整的文章来叙述。
|
||||
|
||||
- 安全考虑比如防火墙和 SSL 配置
|
||||
- 如何确保应用程序保持运行状态
|
||||
- 如何选择需要包含的 Docker 图像(我把所有的都放入了 Dockerfile 中)
|
||||
- 数据库 - 如何在 container 中管理应用
|
||||
|
||||
对我来说这是一个非常有趣的学习经历,因为有一段时间我对探索伴有 ASP.NET 核心的跨平台支持非常好奇,使用针对 “Configuratin as Code” 的 Docker Compose 方法来探索一下 DevOps 的世界也是非常愉快并且很有教育意义的。
|
||||
|
||||
如果你对 Docker 很好奇,那么我鼓励你来尝试学习它 - 特别地,这是否会让你感到痛苦,谁知道呢,有可能你会喜欢它?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://blog.scottlogic.com/2016/09/05/hosting-netcore-on-linux-with-docker.html?utm_source=webopsweekly&utm_medium=email
|
||||
|
||||
作者:[Nick Soper][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://blog.scottlogic.com/nsoper
|
||||
[1]: http://blog.scottlogic.com/2016/01/20/restful-api-with-aspnet50.html
|
||||
[2]: https://docs.microsoft.com/en-us/dotnet/articles/core/migrating-from-dnx
|
||||
[3]: https://docs.asp.net/en/latest/migration/rc1-to-rtm.html
|
||||
[4]: http://www.paraesthesia.com/archive/2016/06/29/netcore-rtm-where-is-autofac/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,126 +0,0 @@
|
||||
|
||||
排名前 15 的开源人工智能工具
|
||||
====
|
||||
|
||||
人工智能(artificial intelligence, AI)是科技研究中最热门的方向之一。像 IBM、谷歌、微软、Facebook 和 亚马逊等公司都在研发上投入大量的资金、或者收购那些在机器学习、神经网络、自然语言和图像处理等领域取得了进展的初创公司。考虑到人们对此感兴趣的程度,我们将不会惊讶于斯坦福的专家在[人工智能报告][1]中得出的结论:“越来越强大的人工智能应用,可能会对我们的社会和经济产生深远的积极影响,这将出现在从现在到2030年的时间段里。”
|
||||
|
||||
在最近的一篇[文章][2]中,我们概述了45个十分有趣或有前途的人工智能项目。在本文中,我们将聚焦于开源的人工智能工具,详细的了解下最著名的15个开源人工智能项目。
|
||||
|
||||

|
||||
|
||||
开源人工智能
|
||||
|
||||
以下这些开源人工智能应用都处于人工智能研究的最前沿。
|
||||
|
||||

|
||||
|
||||
### 1. Caffe
|
||||
|
||||
它是由[贾扬清][3]在加州大学伯克利分校的读博时创造的,Caffe 是一个基于表达体系结构和可扩展代码的深度学习框架。使它声名鹊起的是它的速度,这让它受到研究人员和企业用户的欢迎。根据其网站所言,它可以在一天之内处理 6000 万多个图像而只用一个 NVIDIA K40 GPU。它是由伯克利视野和学习中心(BVLC)管理的,并且由 NVIDIA 和亚马逊等公司资助来支持它的发展。
|
||||
|
||||

|
||||
|
||||
### 2. CNTK
|
||||
|
||||
计算网络工具包(Computational Network Toolkit)的缩写,CNIK 是一个微软的开源人工智能工具。不论是在单个 CPU、单个 GPU、多个 GPU 或是拥有多个 GPUs 的多台机器上它都有优异的表现。微软主要用它做语音识别的研究,但是它在机器翻译、图像识别、图像字幕、文本处理、语言理解和语言建模方面都有着良好的应用。
|
||||
|
||||

|
||||
|
||||
### 3. Deeplearning4j
|
||||
|
||||
Deeplearning4j 是一个 java 虚拟机(JVM)的开源深度学习库。它运行在分布式环境并且集成在 Hadoop 和 Apache Spark 中。这使它可以配置深度神经网络,并且它与 Java、Scala 和 其他 JVM 语言兼容。
|
||||
|
||||
这个项目是由一个叫做 Skymind 的商业公司管理的,它为这个项目提供支持、培训和一个企业的发行版。
|
||||
|
||||

|
||||
|
||||
### 4. Distributed Machine Learning Toolkit(分布式机器学习工具)
|
||||
|
||||
和 CNTK 一样,分布式机器学习工具(Distributed Machine Learning Toolkit, DMTK)是微软的开源人工智能工具。作为设计用于大数据的应用程序,它的目标是更快的训练人工智能系统。它包括三个主要组件:DMTK 框架、LightLDA 主题模型算法和分布式(多义)字嵌入算法。为了证明它的速度,微软声称在一个 8 集群的机器上,他能够 “用 100 万个主题和 1000 万个单词的词汇表(总共 10 万亿参数)训练一个主题模型,在一个文档中收集 1000 亿个符号,”。这一成绩是别的工具无法比拟的。
|
||||
|
||||

|
||||
|
||||
### 5. H20
|
||||
|
||||
相比起科研,H2O 更注重将 AI 服务于企业用户,因此 H2O 有着大量的公司客户,比如第一资本金融公司、思科、Nielsen Catalina、PayPal 和泛美都是他的用户。它声称任何人都可以利用机器学习和预测分析的力量来解决业务难题。它可以用于预测建模、风险和欺诈分析、保险分析、广告技术、医疗保健和客户情报。
|
||||
|
||||
它有两种开源版本:标准版 H2O 和 Sparking Water 版,他被集成在 Apache Spark 中。也有付费的企业用户支持。
|
||||
|
||||

|
||||
|
||||
### 6. Mahout
|
||||
|
||||
它是 Apache 基金项目,是一个开源机器学习框架。根据它的网站所言,它有着三个主要的特性:一个构建可扩展算法的编程环境、像 Spark 和 H2O 一样的预制算法工具和一个叫 Samsara 的矢量数学实验环境。使用 Mahout 的公司有 Adobe、埃森哲咨询公司、Foursquare、英特尔、领英、Twitter、雅虎和其他许多公司。其网站列了出第三方的专业支持。
|
||||
|
||||

|
||||
|
||||
### 7. MLlib
|
||||
|
||||
由于其速度,Apache Spark 成为一个最流行的大数据处理工具。MLlib 是 Spark 的可扩展机器学习库。它集成了 Hadoop 并可以与 NumPy 和 R 进行交互操作。它包括了许多机器学习算法如分类、回归、决策树、推荐、集群、主题建模、功能转换、模型评价、ML管道架构、ML持续、生存分析、频繁项集和序列模式挖掘、分布式线性代数和统计。
|
||||
|
||||

|
||||
|
||||
### 8. NuPIC
|
||||
|
||||
由 Numenta 公司管理的 NuPIC 是一个基于分层暂时记忆(Hierarchical Temporal Memory, HTM)理论的开源人工智能项目。从本质上讲,HTM 试图创建一个计算机系统来模仿人类大脑皮层。他们的目标是创造一个 “在许多认知任务上接近或者超越人类认知能力” 的机器。
|
||||
|
||||
除了开源许可,Numenta 还提供 NuPic 的商业许可协议,并且它还提供技术专利的许可证。
|
||||
|
||||

|
||||
|
||||
### 9. OpenNN
|
||||
|
||||
作为一个为开发者和科研人员设计的具有高级理解力的人工智能,OpenNN 是一个实现神经网络算法的 c++ 编程库。它的关键特性包括深度的架构和快速的性能。其网站上可以查到丰富的文档,包括一个解释了神经网络的基本知识的入门教程。OpenNN 的付费支持由一家从事预测分析的西班牙公司 Artelnics 提供。
|
||||
|
||||

|
||||
|
||||
### 10. OpenCyc
|
||||
|
||||
由 Cycorp 公司开发的 OpenCyc 提供了对 Cyc 知识库的访问和常识推理引擎。它拥有超过 239,000 个条目,大约 2,093,000 个三元组和大约 69,000 owl:一种类似于链接到外部语义库的命名空间。它在富领域模型、语义数据集成、文本理解、特殊领域的专家系统和游戏 AI 中有着良好的应用。该公司还提供另外两个版本的 Cyc:一个免费的用于科研但是不开源和一个提供给企业的但是需要付费。
|
||||
|
||||

|
||||
|
||||
### 11. Oryx 2
|
||||
|
||||
构建在 Apache Spark 和 Kafka 之上的 Oryx 2 是一个专门针对大规模机器学习的应用程序开发框架。它采用一个独特的三层 λ 架构。开发者可以使用 Orys 2 创建新的应用程序,另外它还拥有一些预先构建的应用程序可以用于常见的大数据任务比如协同过滤、分类、回归和聚类。大数据工具供应商 Cloudera 创造了最初的 Oryx 1 项目并且一直积极参与持续发展。
|
||||
|
||||

|
||||
|
||||
### 12. PredictionIO
|
||||
|
||||
今年的二月, Salesforce 买下 PredictionIO,接着在七月,他将该平台和商标贡献给 Apache 基金会,Apache 基金会将其列为孵育计划。所以当 Salesforce 利用 PredictionIO 技术来发展他的机器学习性能,工作将会同步出现在开源版本中。它可以帮助用户创建有机器学习功能的预测引擎,这可用于部署能够实时动态查询的Web服务。
|
||||
|
||||

|
||||
|
||||
### 13. SystemML
|
||||
|
||||
首先由 IBM 开发 SystemML 现在是一个 Apache 大数据项目。它提供了一个高度可伸缩的平台,可以实现高等数学运算,并且他的算法用 R 或类似 python 的语法写成。企业已经在使用它来跟踪汽车维修客户服务、规划机场交通和连接社会媒体数据与银行客户。他可以在 Spark 或 Hadoop 上运行。
|
||||
|
||||

|
||||
|
||||
### 14. TensorFlow
|
||||
|
||||
TensorFlow 是一个谷歌的开源人工智能工具。它提供了一个使用数据流图进行数值计算的库。它可以运行在多种不同的有着单或多 CPUs 和 GPUs 的系统,甚至可以在移动设备上运行。它拥有深厚的灵活性、真正的可移植性、自动微分功能并且支持 Python 和 c++。它的网站拥有十分详细的教程列表来帮助开发者和研究人员沉浸于使用或扩展他的功能。
|
||||
|
||||

|
||||
|
||||
### 15. Torch
|
||||
|
||||
Torch 将自己描述为:“一个优先使用 GPUs 的拥有机器学习算法广泛支持的科学计算框架”,他的特点是灵活性和速度。此外,它可以很容易的运用机器学习、计算机视觉、信号处理、并行处理、图像、视频、音频和网络的包。他依赖一个叫做 LuaJIT 的脚本语言,而 LuaJIT 是基于 Lua 的。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/slideshows/15-top-open-source-artificial-intelligence-tools.html
|
||||
|
||||
作者:[Cynthia Harvey][a]
|
||||
译者:[Chao-zhi](https://github.com/Chao-zhi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.datamation.com/author/Cynthia-Harvey-6460.html
|
||||
[1]: https://ai100.stanford.edu/sites/default/files/ai_100_report_0906fnlc_single.pdf
|
||||
[2]: http://www.datamation.com/applications/artificial-intelligence-software-45-ai-projects-to-watch-1.html
|
||||
[3]: http://daggerfs.com/
|
||||
@ -0,0 +1,206 @@
|
||||
使用 Elasticsearch 和 cAdvisor 监控 Docker 容器
|
||||
=======
|
||||
|
||||
如果你正在运行 Swarm 模式的集群,或者只运行单台 Docker,你都会有下面的疑问:
|
||||
|
||||
>我如何才能监控到它们都在干些什么?
|
||||
|
||||
这个问题的答案是“很不容易”。
|
||||
|
||||
你需要监控下面的参数:
|
||||
|
||||
1. 容器的数量和状态。
|
||||
2. 一台容器是否已经移到另一个结点了,如果是,那是在什么时候,移动到哪个节点?
|
||||
3. 一个结点上运行着的容器数量。
|
||||
4. 一段时间内的通信峰值。
|
||||
5. 孤儿卷和网络(LCTT 译注:孤儿卷就是当你删除容器时忘记删除它的卷,这个卷就不会再被使用,但会一直占用资源)。
|
||||
6. 回收磁盘空间,回收结点。
|
||||
7. 容器数量与连接在 docker0 和 docker_gwbridge 上的虚拟网卡数量不一致(LCTT 译注:当docker启动时,它会在宿主机器上创建一个名为docker0的虚拟网络接口)。
|
||||
8. 开启和关闭 Swarm 节点。
|
||||
9. 收集并集中处理日志。
|
||||
|
||||
本文的目标是介绍 [Elasticsearch][1] + [Kibana][2] + [cAdvisor][3] 的用法,使用它们来收集 Docker 容器的参数,分析数据并产生可视化报表。
|
||||
|
||||
阅读本文后你会发现有一个报表会显示上述9个参数的部分内容,如果简单使用 cAdvisor,有些参数就无法显示出来,比如 Swarm 模式的节点。
|
||||
|
||||
如果你的一些 cAdvisor 或其他工具无法提供的特殊需求,我建议你开发自己的数据收集器和数据处理器(比如 [Beats][4]),请注意我不会演示如何使用 Elasticsearch 来收集 Docker 容器的日志。
|
||||
|
||||
>[“你要如何才能监控到 Swarm 模式集群里面发生了什么事情?要做到这点很不容易。” 作者 @fntlnz][5]
|
||||
|
||||
### 我们为什么要监控容器?
|
||||
|
||||
想象一下这个经典场景:你在管理一台或多台虚拟机,你把 tmux 工具用得很溜,用各种 session 事先设定好了所有基础的东西,包括监控。然后生产环境出问题了,你使用 top htop iotop jnettop 各种 top 来排查,然后你准备好修复故障。
|
||||
|
||||
现在重新想象一下你有3个节点,包含50台容器,你需要在一个地方查看整洁的历史数据知道问题出在哪个地方,而不是把你的生命浪费在那些字符界面来赌你可以找到问题点。
|
||||
|
||||
### 什么是 Elastic Stack ?
|
||||
|
||||
Elastic Stack 就一个工具集,包括以下工具:
|
||||
|
||||
- Elasticsearch
|
||||
- Kibana
|
||||
- Logstash
|
||||
- Beats
|
||||
|
||||
我们会使用其中一部分工具,比如使用 Elasticsearch 来分析基于 JSON 格式的文本,以及使用 Kibana 来可视化数据并产生报表。
|
||||
|
||||
另一个重要的工具是 Beats,但在本文中我们还是把精力放在容器上,官方的 Beats 工具不支持 Docker,所以我们选择原生兼容 Elasticsearch 的 cAdvisor。
|
||||
|
||||
cAdvisor 工具负责收集、整合容器数据,并导出报表。在本文中,这些报表被到入到 Elasticsearch 中。
|
||||
|
||||
cAdvisor 有两个比较酷的特性:
|
||||
|
||||
- 它不只局限于 Docker 容器。
|
||||
- 它有自己的 web 服务器,可以简单地显示当前节点的可视化报表。
|
||||
|
||||
### 设置测试集群,或搭建自己的基础架构
|
||||
|
||||
和我以前的文章一样,我习惯提供一个简单的脚本,让读者不用花很多时间就能部署好和我一样的测试环境。你可以使用以下(非生产环境使用的)脚本来搭建一个 Swarm 模式的集群,其中一个容器运行着 Elasticsearch。
|
||||
|
||||
> 如果你有充足的时间和经验,你可以搭建自己的基础架构。
|
||||
|
||||
|
||||
如果要继续阅读本文,你需要:
|
||||
|
||||
- 一个或多个节点,运行 Docker 进程(docker 版本号大于等于 1.12)。
|
||||
- 至少有一个独立运行的 Elasticsearch 节点(版本号 2.4.X)。
|
||||
|
||||
重申一下,此 Elasticsearch 集群环境不能放在生产环境中使用。生产环境也不推荐使用单节点集群,所以如果你计划安装一个生产环境,请参考 [Elastic guidelines][6]。
|
||||
|
||||
### 对喜欢尝鲜的用户的友情提示
|
||||
|
||||
我就是一个喜欢尝鲜的人(当然我也已经在生产环境中使用了 alpha 版本),但是在本文中,我不会使用最新的 Elasticsearch 5.0.0 alpha 版本,我还不是很清楚这个版本的功能,所以我不想成为那个引导你们出错的关键。
|
||||
|
||||
所以本文中涉及的 Elasticsearch 版本为最新稳定版 2.4.0。
|
||||
|
||||
### 测试集群部署脚本
|
||||
|
||||
前面已经说过,我提供这个脚本给你们,让你们不必费神去部署 Swarm 集群和 Elasticsearch,当然你也可以跳过这一步,用你自己的 Swarm 模式引擎和你自己的 Elasticserch 节点。
|
||||
|
||||
执行这段脚本之前,你需要:
|
||||
|
||||
- [Docker Machine][7] – 最终版:在 DigitalOcean 中提供 Docker 引擎。
|
||||
- [DigitalOcean API Token][8]: 让 docker 机器按照你的意思来启动节点。
|
||||
|
||||

|
||||
|
||||
### 创建集群的脚本
|
||||
|
||||
现在万事俱备,你可以把下面的代码拷到 create-cluster.sh 文件中:
|
||||
|
||||
```
|
||||
#!/usr/bin/env bash
|
||||
#
|
||||
# Create a Swarm Mode cluster with a single master and a configurable number of workers
|
||||
|
||||
workers=${WORKERS:-"worker1 worker2"}
|
||||
|
||||
#######################################
|
||||
# Creates a machine on Digital Ocean
|
||||
# Globals:
|
||||
# DO_ACCESS_TOKEN The token needed to access DigitalOcean's API
|
||||
# Arguments:
|
||||
# $1 the actual name to give to the machine
|
||||
#######################################
|
||||
create_machine() {
|
||||
docker-machine create \
|
||||
-d digitalocean \
|
||||
--digitalocean-access-token=$DO_ACCESS_TOKEN \
|
||||
--digitalocean-size 2gb \
|
||||
$1
|
||||
}
|
||||
|
||||
#######################################
|
||||
# Executes a command on the specified machine
|
||||
# Arguments:
|
||||
# $1 The machine on which to run the command
|
||||
# $2..$n The command to execute on that machine
|
||||
#######################################
|
||||
machine_do() {
|
||||
docker-machine ssh $@
|
||||
}
|
||||
|
||||
main() {
|
||||
|
||||
if [ -z "$DO_ACCESS_TOKEN" ]; then
|
||||
echo "Please export a DigitalOcean Access token: https://cloud.digitalocean.com/settings/api/tokens/new"
|
||||
echo "export DO_ACCESS_TOKEN=<yourtokenhere>"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [ -z "$WORKERS" ]; then
|
||||
echo "You haven't provided your workers by setting the \$WORKERS environment variable, using the default ones: $workers"
|
||||
fi
|
||||
|
||||
# Create the first and only master
|
||||
echo "Creating the master"
|
||||
|
||||
create_machine master1
|
||||
|
||||
master_ip=$(docker-machine ip master1)
|
||||
|
||||
# Initialize the swarm mode on it
|
||||
echo "Initializing the swarm mode"
|
||||
machine_do master1 docker swarm init --advertise-addr $master_ip
|
||||
|
||||
# Obtain the token to allow workers to join
|
||||
worker_tkn=$(machine_do master1 docker swarm join-token -q worker)
|
||||
echo "Worker token: ${worker_tkn}"
|
||||
|
||||
# Create and join the workers
|
||||
for worker in $workers; do
|
||||
echo "Creating worker ${worker}"
|
||||
create_machine $worker
|
||||
machine_do $worker docker swarm join --token $worker_tkn $master_ip:2377
|
||||
done
|
||||
}
|
||||
|
||||
main $@
|
||||
```
|
||||
|
||||
赋予它可执行权限:
|
||||
|
||||
```
|
||||
chmod +x create-cluster.sh
|
||||
```
|
||||
|
||||
### 创建集群
|
||||
|
||||
如文件名所示,我们可以用它来创建集群。默认情况下这个脚本会创建一个 master 和两个 worker,如果你想修改 worker 个数,可以设置环境变量 WORKERS。
|
||||
|
||||
现在就来创建集群吧。
|
||||
|
||||
```
|
||||
./create-cluster.sh
|
||||
```
|
||||
|
||||
你可以出去喝杯咖啡,因为这需要花点时间。
|
||||
|
||||
最后集群部署好了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.codeship.com/monitoring-docker-containers-with-elasticsearch-and-cadvisor/
|
||||
|
||||
作者:[Lorenzo Fontana][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://blog.codeship.com/author/lorenzofontana/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
[1]: https://github.com/elastic/elasticsearch
|
||||
[2]: https://github.com/elastic/kibana
|
||||
[3]: https://github.com/google/cadvisor
|
||||
[4]: https://github.com/elastic/beats
|
||||
[5]: https://twitter.com/share?text=%22How+do+you+keep+track+of+all+that%27s+happening+in+a+Swarm+Mode+cluster%3F+Not+easily.%22+via+%40fntlnz&url=https://blog.codeship.com/monitoring-docker-containers-with-elasticsearch-and-cadvisor/
|
||||
[6]: https://www.elastic.co/guide/en/elasticsearch/guide/2.x/deploy.html
|
||||
[7]: https://docs.docker.com/machine/install-machine/
|
||||
[8]: https://cloud.digitalocean.com/settings/api/tokens/new
|
||||
Loading…
Reference in New Issue
Block a user