mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-18 02:00:18 +08:00
commit
f7438c6920
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11913-1.html)
|
||||
[#]: subject: (Zipping files on Linux: the many variations and how to use them)
|
||||
[#]: via: (https://www.networkworld.com/article/3333640/linux/zipping-files-on-linux-the-many-variations-and-how-to-use-them.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
@ -12,13 +12,13 @@
|
||||
|
||||
> 除了压缩和解压缩文件外,你还可以使用 zip 命令执行许多有趣的操作。这是一些其他的 zip 选项以及它们如何提供帮助。
|
||||
|
||||

|
||||

|
||||
|
||||
为了节省一些磁盘空间并将文件打包在一起进行归档,我们中的一些人已经在 Unix 和 Linux 系统上压缩文件数十年了。即使这样,并不是所有人都尝试过一些有趣的压缩工具的变体。因此,在本文中,我们将介绍标准的压缩和解压缩以及其他一些有趣的压缩选项。
|
||||
|
||||
### 基本的 zip 命令
|
||||
|
||||
首先,让我们看一下基本的 `zip` 命令。它使用了与 `gzip` 基本上相同的压缩算法,但是有一些重要的区别。一方面,`gzip` 命令仅用于压缩单个文件,而 `zip` 既可以压缩文件,也可以将多个文件结合在一起成为归档文件。另外,`gzip` 命令是“就地”压缩。换句话说,它会留下一个压缩文件,而不是原始文件。 这是工作中的 `gzip` 示例:
|
||||
首先,让我们看一下基本的 `zip` 命令。它使用了与 `gzip` 基本上相同的压缩算法,但是有一些重要的区别。一方面,`gzip` 命令仅用于压缩单个文件,而 `zip` 既可以压缩文件,也可以将多个文件结合在一起成为归档文件。另外,`gzip` 命令是“就地”压缩。换句话说,它会只留下一个压缩文件,而原始文件则没有了。 这是工作中的 `gzip` 示例:
|
||||
|
||||
```
|
||||
$ gzip onefile
|
||||
@ -26,7 +26,7 @@ $ ls -l
|
||||
-rw-rw-r-- 1 shs shs 10514 Jan 15 13:13 onefile.gz
|
||||
```
|
||||
|
||||
而这是 `zip`。请注意,此命令要求为压缩存档提供名称,其中 `gzip`(执行压缩操作后)仅使用原始文件名并添加 `.gz` 扩展名。
|
||||
而下面是 `zip`。请注意,此命令要求为压缩存档提供名称,其中 `gzip`(执行压缩操作后)仅使用原始文件名并添加 `.gz` 扩展名。
|
||||
|
||||
```
|
||||
$ zip twofiles.zip file*
|
||||
@ -61,7 +61,7 @@ $ zip mybin.zip ~/bin/*
|
||||
|
||||
### unzip 命令
|
||||
|
||||
`unzip` 命令将从一个 zip 文件中恢复内容,并且,如你所料,原来的 zip 文件还保留在那里,而类似的`gunzip` 命令将仅保留未压缩的文件。
|
||||
`unzip` 命令将从一个 zip 文件中恢复内容,并且,如你所料,原来的 zip 文件还保留在那里,而类似的 `gunzip` 命令将仅保留未压缩的文件。
|
||||
|
||||
```
|
||||
$ unzip twofiles.zip
|
||||
@ -272,13 +272,13 @@ $ zipnote twofiles.zip
|
||||
@ (zip file comment below this line)
|
||||
```
|
||||
|
||||
如果要添加注释,请先将 `zipnote` 命令的输出写入文件:
|
||||
如果要添加注释,请先将 `zipnote` 命令的输出写入到文件:
|
||||
|
||||
```
|
||||
$ zipnote twofiles.zip > comments
|
||||
```
|
||||
|
||||
接下来,编辑你刚刚创建的文件,将注释插入到 `(comment above this line)` 行上方。然后使用像这样的`zipnote` 命令添加注释:
|
||||
接下来,编辑你刚刚创建的文件,将注释插入到 `(comment above this line)` 行上方。然后使用像这样的 `zipnote` 命令添加注释:
|
||||
|
||||
```
|
||||
$ zipnote -w twofiles.zip < comments
|
||||
@ -286,7 +286,7 @@ $ zipnote -w twofiles.zip < comments
|
||||
|
||||
### zipsplit 命令
|
||||
|
||||
当归档文件太大时,可以使用 `zipsplit` 命令将一个 zip 归档文件分解为多个 zip 归档文件,这样你就可以将其中某一个文件放到小型 U 盘中。最简单的方法似乎是为每个部分的压缩文件指定最大大小,此大小必须足够大以容纳最大的包含文件。
|
||||
当归档文件太大时,可以使用 `zipsplit` 命令将一个 zip 归档文件分解为多个 zip 归档文件,这样你就可以将其中某一个文件放到小型 U 盘中。最简单的方法似乎是为每个部分的压缩文件指定最大大小,此大小必须足够大以容纳最大的所包含的文件。
|
||||
|
||||
```
|
||||
$ zipsplit -n 12000 twofiles.zip
|
||||
@ -312,7 +312,7 @@ via: https://www.networkworld.com/article/3333640/linux/zipping-files-on-linux-t
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,113 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (zhangxiangping)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11927-1.html)
|
||||
[#]: subject: (12 open source tools for natural language processing)
|
||||
[#]: via: (https://opensource.com/article/19/3/natural-language-processing-tools)
|
||||
[#]: author: (Dan Barker https://opensource.com/users/barkerd427)
|
||||
|
||||
12 种自然语言处理的开源工具
|
||||
======
|
||||
|
||||
> 让我们看看可以用在你自己的 NLP 应用中的十几个工具吧。
|
||||
|
||||

|
||||
|
||||
在过去的几年里,自然语言处理(NLP)推动了聊天机器人、语音助手、文本预测等这些渗透到我们的日常生活中的语音或文本应用程技术的发展。目前有着各种各样开源的 NLP 工具,所以我决定调查一下当前开源的 NLP 工具来帮助你制定开发下一个基于语音或文本的应用程序的计划。
|
||||
|
||||
尽管我并不熟悉所有工具,但我将从我所熟悉的编程语言出发来介绍这些工具(对于我不熟悉的语言,我无法找到大量的工具)。也就是说,出于各种原因,我排除了三种我熟悉的语言之外的工具。
|
||||
|
||||
R 语言可能是没有被包含在内的最重要的语言,因为我发现的大多数库都有一年多没有更新了。这并不一定意味着它们没有得到很好的维护,但我认为它们应该得到更多的更新,以便和同一领域的其他工具竞争。我还选择了最有可能用在生产场景中的语言和工具(而不是在学术界和研究中使用),而我主要是使用 R 作为研究和发现工具。
|
||||
|
||||
我也惊讶地发现 Scala 的很多库都没有更新了。我上次使用 Scala 已经过去了两年了,当时它非常流行。但是大多数库从那个时候就再没有更新过,或者只有少数一些有更新。
|
||||
|
||||
最后,我排除了 C++。 这主要是因为我上次使用 C++ 编写程序已经有很多年了,而我所工作的组织还没有将 C++ 用于 NLP 或任何数据科学方面的工作。
|
||||
|
||||
### Python 工具
|
||||
|
||||
#### 自然语言工具包(NLTK)
|
||||
|
||||
毋庸置疑,[自然语言工具包(NLTK)][2]是我调研过的所有工具中功能最完善的一个。它几乎实现了自然语言处理中多数功能组件,比如分类、令牌化、词干化、标注、分词和语义推理。每一个都有多种不同的实现方式,所以你可以选择具体的算法和方式。同时,它也支持不同的语言。然而,它以字符串的形式表示所有的数据,对于一些简单的数据结构来说可能很方便,但是如果要使用一些高级的功能来说就可能有点困难。它的使用文档有点复杂,但也有很多其他人编写的使用文档,比如[这本很棒的书][3]。和其他的工具比起来,这个工具库的运行速度有点慢。但总的来说,这个工具包非常不错,可以用于需要具体算法组合的实验、探索和实际应用当中。
|
||||
|
||||
#### SpaCy
|
||||
|
||||
[SpaCy][4] 可能是 NLTK 的主要竞争者。在大多数情况下都比 NLTK 的速度更快,但是 SpaCy 的每个自然语言处理的功能组件只有一个实现。SpaCy 把所有的东西都表示为一个对象而不是字符串,从而简化了应用构建接口。这也方便它与多种框架和数据科学工具的集成,使得你更容易理解你的文本数据。然而,SpaCy 不像 NLTK 那样支持多种语言。它确实接口简单,具有简化的选项集和完备的文档,以及用于语言处理和分析各种组件的多种神经网络模型。总的来说,对于需要在生产中表现出色且不需要特定算法的新应用程序,这是一个很不错的工具。
|
||||
|
||||
#### TextBlob
|
||||
|
||||
[TextBlob][5] 是 NLTK 的一个扩展库。你可以通过 TextBlob 用一种更简单的方式来使用 NLTK 的功能,TextBlob 也包括了 Pattern 库中的功能。如果你刚刚开始学习,这将会是一个不错的工具,可以用于对性能要求不太高的生产环境的应用。总体来说,TextBlob 适用于任何场景,但是对小型项目尤佳。
|
||||
|
||||
#### Textacy
|
||||
|
||||
这个工具是我用过的名字最好听的。先重读“ex”再带出“cy”,多读“[Textacy][6]”几次试试。它不仅仅是名字读起来好,同时它本身也是一个很不错的工具。它使用 SpaCy 作为它自然语言处理核心功能,但它在处理过程的前后做了很多工作。如果你想要使用 SpaCy,那么最好使用 Textacy,从而不用去编写额外的附加代码就可以处理不同种类的数据。
|
||||
|
||||
#### PyTorch-NLP
|
||||
|
||||
[PyTorch-NLP][7] 才出现短短的一年,但它已经有一个庞大的社区了。它适用于快速原型开发。当出现了最新的研究,或大公司或者研究人员推出了完成新奇的处理任务的其他工具时,比如图像转换,它就会被更新。总体来说,PyTorch 的目标用户是研究人员,但它也能用于原型开发,或使用最先进算法的初始生产载荷中。基于此基础上的创建的库也是值得研究的。
|
||||
|
||||
### Node.js 工具
|
||||
|
||||
#### Retext
|
||||
|
||||
[Retext][8] 是 [Unified 集合][9]的一部分。Unified 是一个接口,能够集成不同的工具和插件以便它们能够高效的工作。Retext 是 Unified 工具中使用的三种语法之一,另外的两个分别是用于 Markdown 的 Remark 和用于 HTML 的 Rehype。这是一个非常有趣的想法,我很高兴看到这个社区的发展。Retext 没有涉及很多的底层技术,更多的是使用插件去完成你在 NLP 任务中想要做的事情。拼写检查、字形修复、情绪检测和增强可读性都可以用简单的插件来完成。总体来说,如果你不想了解底层处理技术又想完成你的任务的话,这个工具和社区是一个不错的选择。
|
||||
|
||||
#### Compromise
|
||||
|
||||
[Compromise][10] 显然不是最复杂的工具,如果你正在找拥有最先进的算法和最完备的系统的话,它可能不适合你。然而,如果你想要一个性能好、功能广泛、还能在客户端运行的工具的话,Compromise 值得一试。总体来说,它的名字(“折中”)是准确的,因为作者更关注更具体功能的小软件包,而在功能性和准确性上有所折中,这些小软件包得益于用户对使用环境的理解。
|
||||
|
||||
#### Natural
|
||||
|
||||
[Natural][11] 包含了常规自然语言处理库所具有的大多数功能。它主要是处理英文文本,但也包括一些其它语言,它的社区也欢迎支持其它的语言。它能够进行令牌化、词干化、分类、语音处理、词频-逆文档频率计算(TF-IDF)、WordNet、字符相似度计算和一些变换。它和 NLTK 有的一比,因为它想要把所有东西都包含在一个包里头,但它更易于使用,而且不一定专注于研究。总的来说,这是一个非常完整的库,目前仍在活跃开发中,但可能需要对底层实现有更多的了解才能完全发挥效力。
|
||||
|
||||
#### Nlp.js
|
||||
|
||||
[Nlp.js][12] 建立在其他几个 NLP 库之上,包括 Franc 和 Brain.js。它为许多 NLP 组件提供了一个很好的接口,比如分类、情感分析、词干化、命名实体识别和自然语言生成。它也支持一些其它语言,在你处理英语之外的语言时能提供一些帮助。总之,它是一个不错的通用工具,并且提供了调用其他工具的简化接口。在你需要更强大或更灵活的工具之前,这个工具可能会在你的应用程序中用上很长一段时间。
|
||||
|
||||
### Java 工具
|
||||
|
||||
#### OpenNLP
|
||||
|
||||
[OpenNLP][13] 是由 Apache 基金会管理的,所以它可以很方便地集成到其他 Apache 项目中,比如 Apache Flink、Apache NiFi 和 Apache Spark。这是一个通用的 NLP 工具,包含了所有 NLP 组件中的通用功能,可以通过命令行或者以包的形式导入到应用中来使用它。它也支持很多种语言。OpenNLP 是一个很高效的工具,包含了很多特性,如果你用 Java 开发生产环境产品的话,它是个很好的选择。
|
||||
|
||||
#### Stanford CoreNLP
|
||||
|
||||
[Stanford CoreNLP][14] 是一个工具集,提供了统计 NLP、深度学习 NLP 和基于规则的 NLP 功能。这个工具也有许多其他编程语言的版本,所以可以脱离 Java 来使用。它是由高水平的研究机构创建的一个高效的工具,但在生产环境中可能不是最好的。此工具采用双许可证,具有可以用于商业目的的特定许可证。总之,在研究和实验中它是一个很棒的工具,但在生产系统中可能会带来一些额外的成本。比起 Java 版本来说,读者可能对它的 Python 版本更感兴趣。同样,在 Coursera 上最好的机器学习课程之一是斯坦福教授提供的,[点此][15]访问其他不错的资源。
|
||||
|
||||
#### CogCompNLP
|
||||
|
||||
[CogCompNLP][16] 由伊利诺斯大学开发的一个工具,它也有一个相似功能的 Python 版本。它可以用于处理文本,包括本地处理和远程处理,能够极大地缓解你本地设备的压力。它提供了很多处理功能,比如令牌化、词性标注、断句、命名实体标注、词型还原、依存分析和语义角色标注。它是一个很好的研究工具,你可以自己探索它的不同功能。我不确定它是否适合生产环境,但如果你使用 Java 的话,它值得一试。
|
||||
|
||||
* * *
|
||||
|
||||
你最喜欢的开源 NLP 工具和库是什么?请在评论区分享文中没有提到的工具。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/natural-language-processing-tools
|
||||
|
||||
作者:[Dan Barker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[zxp](https://github.com/zhangxiangping)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/barkerd427
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/talk_chat_communication_team.png?itok=CYfZ_gE7 (Chat bubbles)
|
||||
[2]: http://www.nltk.org/
|
||||
[3]: http://www.nltk.org/book_1ed/
|
||||
[4]: https://spacy.io/
|
||||
[5]: https://textblob.readthedocs.io/en/dev/
|
||||
[6]: https://readthedocs.org/projects/textacy/
|
||||
[7]: https://pytorchnlp.readthedocs.io/en/latest/
|
||||
[8]: https://www.npmjs.com/package/retext
|
||||
[9]: https://unified.js.org/
|
||||
[10]: https://www.npmjs.com/package/compromise
|
||||
[11]: https://www.npmjs.com/package/natural
|
||||
[12]: https://www.npmjs.com/package/node-nlp
|
||||
[13]: https://opennlp.apache.org/
|
||||
[14]: https://stanfordnlp.github.io/CoreNLP/
|
||||
[15]: https://opensource.com/article/19/2/learn-data-science-ai
|
||||
[16]: https://github.com/CogComp/cogcomp-nlp
|
||||
@ -1,22 +1,24 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (#:acid 'words: Handle Chromium & Firefox sessions with org-mode)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11926-1.html)
|
||||
[#]: subject: (Handle Chromium & Firefox sessions with org-mode)
|
||||
[#]: via: (https://acidwords.com/posts/2019-12-04-handle-chromium-and-firefox-sessions-with-org-mode.html)
|
||||
[#]: author: (Sanel Z https://acidwords.com/)
|
||||
|
||||
Handle Chromium & Firefox sessions with org-mode
|
||||
通过 Org 模式管理 Chromium 和 Firefox 会话
|
||||
======
|
||||
|
||||
I was big fan of [Session Manager][1], small addon for Chrome and Chromium that will save all open tabs, assign the name to session and, when is needed, restore it.
|
||||

|
||||
|
||||
Very useful, especially if you are like me, switching between multiple "mind sessions" during the day - research, development or maybe news reading. Or simply, you'd like to remember workflow (and tabs) you had few days ago.
|
||||
我是[会话管理器][1]的铁粉,它是 Chrome 和 Chromium 的小插件,可以保存所有打开的选项卡,为会话命名,并在需要时恢复会话。
|
||||
|
||||
After I decided to ditch all extensions from Chromium except [uBlock Origin][2], it was time to look for alternative. My main goal was it to be browser agnostic and session links had to be stored in text file, so I can enjoy all the goodies of plain text file. What would be better for that than good old [org-mode][3] ;)
|
||||
它非常有用,特别是如果你像我一样,白天的时候需要在多个“思维活动”之间切换——研究、开发或者阅读新闻。或者你只是单纯地希望记住几天前的工作流(和选项卡)。
|
||||
|
||||
Long time ago I found this trick: [Get the currently open tabs in Google Chrome via the command line][4] and with some elisp sugar and coffee, here is the code:
|
||||
在我决定放弃 chromium 上除了 [uBlock Origin][2] 之外的所有扩展后,就必须寻找一些替代品了。我的主要目标是使之与浏览器无关,同时会话链接必须保存在文本文件中,这样我就可以享受所有纯文本的好处了。还有什么比 [org 模式][3]更好呢 ;)
|
||||
|
||||
很久以前我就发现了这个小诀窍:[通过命令行获取当前在谷歌 Chrome 中打开的标签][4] 再加上些 elisp 代码:
|
||||
|
||||
```
|
||||
(require 'cl-lib)
|
||||
@ -57,9 +59,9 @@ Make sure to put cursor on date heading that contains list of urls."
|
||||
(forward-line 1)))))
|
||||
```
|
||||
|
||||
So, how does it work?
|
||||
那么,它的工作原理是什么呢?
|
||||
|
||||
Evaluate above code, open new org-mode file and call `M-x save-chromium-session`. It will create something like this:
|
||||
运行上述代码,打开一个新 org 模式文件并调用 `M-x save-chromium-session`。它会创建类似这样的东西:
|
||||
|
||||
```
|
||||
* [2019-12-04 12:14:02]
|
||||
@ -68,9 +70,9 @@ Evaluate above code, open new org-mode file and call `M-x save-chromium-session`
|
||||
- https://news.ycombinator.com
|
||||
```
|
||||
|
||||
or whatever urls are running in Chromium instance. To restore it back, put cursor on desired date and run `M-x restore-chromium-session`. All tabs should be back.
|
||||
也就是任何在 chromium 实例中运行着的 URL。要还原的话,则将光标置于所需日期上然后运行 `M-x restore-chromium-session`。所有标签都应该恢复了。
|
||||
|
||||
Here is how I use it, with randomly generated data for the purpose of this text:
|
||||
以下是我的使用案例,其中的数据是随机生成的:
|
||||
|
||||
```
|
||||
#+TITLE: Browser sessions
|
||||
@ -88,27 +90,27 @@ Here is how I use it, with randomly generated data for the purpose of this text:
|
||||
- https://news.ycombinator.com
|
||||
```
|
||||
|
||||
Note that hack for reading Chromium session isn't perfect: `strings` will read whatever looks like string and url from binary database and sometimes that will yield small artifacts in urls. But, you can easily edit those and keep session file lean and clean.
|
||||
请注意,用于读取 Chromium 会话的方法并不完美:`strings` 将从二进制数据库中读取任何类似 URL 字符串的内容,有时这将产生不完整的 URL。不过,你可以很方便地地编辑它们,从而保持会话文件简洁。
|
||||
|
||||
To actually open tabs, elisp code will use [browse-url][5] and it can be further customized to run Chromium, Firefox or any other browser with `browse-url-browser-function` variable. Make sure to read documentation for this variable.
|
||||
为了真正打开标签,elisp 代码中使用到了 [browse-url][5],它可以通过 `browse-url-browser-function` 变量进一步定制成运行 Chromium、Firefox 或任何其他浏览器。请务必阅读该变量的相关文档。
|
||||
|
||||
Don't forget to put session file in git, mercurial or svn and enjoy the fact that you will never loose your session history again :)
|
||||
别忘了把会话文件放在 git、mercurial 或 svn 中,这样你就再也不会丢失会话历史记录了 :)
|
||||
|
||||
### What about Firefox?
|
||||
### 那么 Firefox 呢?
|
||||
|
||||
If you are using Firefox (recent versions) and would like to pull session urls, here is how to do it.
|
||||
如果你正在使用 Firefox(最近的版本),并且想要获取会话 URL,下面是操作方法。
|
||||
|
||||
First, download and compile [lz4json][6], small tool that will decompress Mozilla lz4json format, where Firefox stores session data. Session data (at the time of writing this post) is stored in `$HOME/.mozilla/firefox/<unique-name>/sessionstore-backups/recovery.jsonlz4`.
|
||||
首先,下载并编译 [lz4json][6],这是一个可以解压缩 Mozilla lz4json 格式的小工具,Firefox 以这种格式来存储会话数据。会话数据(在撰写本文时)存储在 `$HOME/.mozilla/firefox/<unique-name>/sessionstore-backup /recovery.jsonlz4` 中。
|
||||
|
||||
If Firefox is not running, `recovery.jsonlz4` will not be present, but use `previous.jsonlz4` instead.
|
||||
如果 Firefox 没有运行,则没有 `recovery.jsonlz4`,这种情况下用 `previous.jsonlz4` 代替。
|
||||
|
||||
To extract urls, try this in terminal:
|
||||
要提取网址,尝试在终端运行:
|
||||
|
||||
```
|
||||
$ lz4jsoncat recovery.jsonlz4 | grep -oP '"(http.+?)"' | sed 's/"//g' | sort | uniq
|
||||
```
|
||||
|
||||
and update `save-chromium-session` with:
|
||||
然后更新 `save-chromium-session` 为:
|
||||
|
||||
```
|
||||
(defun save-chromium-session ()
|
||||
@ -122,7 +124,7 @@ and update `save-chromium-session` with:
|
||||
;; rest of the code is unchanged
|
||||
```
|
||||
|
||||
Updating documentation strings, function name and any further refactoring is left for exercise.
|
||||
更新本函数的文档字符串、函数名以及进一步的重构都留作练习。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -131,7 +133,7 @@ via: https://acidwords.com/posts/2019-12-04-handle-chromium-and-firefox-sessions
|
||||
作者:[Sanel Z][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,107 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11920-1.html)
|
||||
[#]: subject: (Screenshot your Linux system configuration with Bash tools)
|
||||
[#]: via: (https://opensource.com/article/20/1/screenfetch-neofetch)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||
|
||||
使用 Bash 工具截屏 Linux 系统配置
|
||||
======
|
||||
|
||||
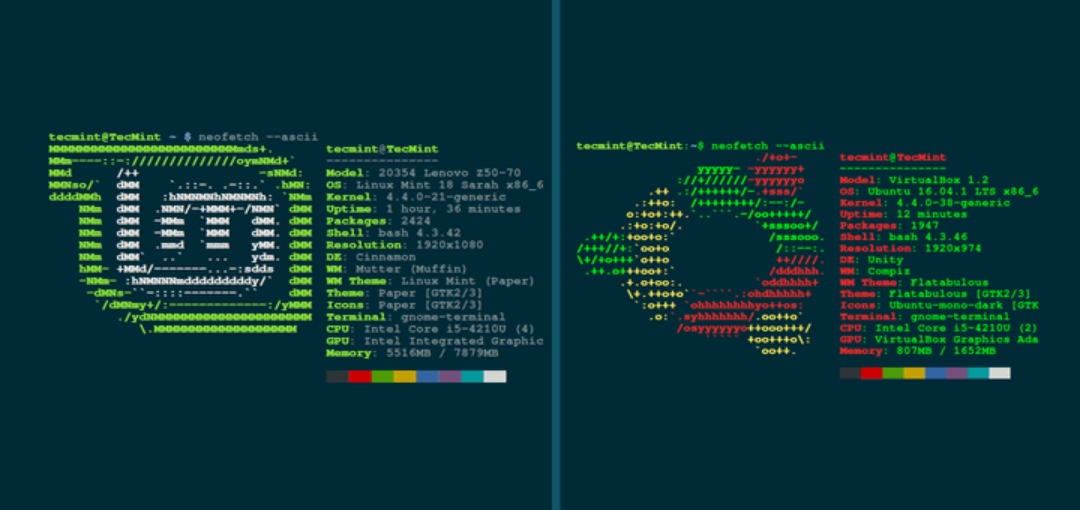
> 使用 ScreenFetch 和 Neofetch 与其他人轻松分享你的 Linux 环境。
|
||||
|
||||
|
||||
|
||||
你可能有很多原因想要与他人分享你的 Linux 配置。你可能正在寻求帮助来对系统上的问题进行故障排除,或者你对所创建的环境感到非常自豪,因此想向其他开源爱好者展示。
|
||||
|
||||
你可以在 Bash 提示符下使用 `cat /proc/cpuinfo` 或 `lscpu` 命令获取某些信息。但是,如果你想共享更多详细信息,例如你的操作系统、内核、运行时间、shell 环境,屏幕分辨率等,那么可以选择两个很棒的工具:screenFetch 和 Neofetch。
|
||||
|
||||
### screenFetch
|
||||
|
||||
[screenFetch][2] 是 Bash 命令行程序,它可以产生非常漂亮的系统配置和运行时间的截图。这是方便的与它人共享系统配置的方法。
|
||||
|
||||
在许多 Linux 发行版上安装 screenFetch 很简单。
|
||||
|
||||
在 Fedora 上,输入:
|
||||
|
||||
```
|
||||
$ sudo dnf install screenfetch
|
||||
```
|
||||
|
||||
在 Ubuntu 上,输入:
|
||||
|
||||
```
|
||||
$ sudo apt install screenfetch
|
||||
```
|
||||
|
||||
对于其他操作系统,包括 FreeBSD、MacOS 等,请查阅 screenFetch 的 wiki [安装页面][3]。安装 screenFetch 后,它可以生成详细而彩色的截图,如下所示:
|
||||
|
||||
![screenFetch][4]
|
||||
|
||||
ScreenFetch 还提供各种命令行选项来调整你的结果。例如,`screenfetch -v` 返回详细输出,逐行显示每个选项以及上面的显示。
|
||||
|
||||
`screenfetch -n` 在显示系统信息时消除了操作系统图标。
|
||||
|
||||
![screenfetch -n option][5]
|
||||
|
||||
其他选项包括 `screenfetch -N`,它去除所有输出的颜色。`screenfetch -t`,它根据终端的大小截断输出。`screenFetch -E`,它可抑制错误输出。
|
||||
|
||||
请检查手册页来了解其他选项。screenFetch 在 GPLv3 许可证下的开源,你可以在它的 [GitHub 仓库][6]中了解有关该项目的更多信息。
|
||||
|
||||
### Neofetch
|
||||
|
||||
[Neofetch][7] 是创建系统信息截图的另一个工具。它是用 Bash 3.2 编写的,在 [MIT 许可证][8]下开源。
|
||||
|
||||
根据项目网站所述,“Neofetch 支持近 150 种不同的操作系统。从 Linux 到 Windows,一直到 Minix、AIX 和 Haiku 等更晦涩的操作系统。”
|
||||
|
||||
![Neofetch][9]
|
||||
|
||||
该项目维护了一个 wiki,其中包含用于各种发行版和操作系统的出色的[安装文档][10]。
|
||||
|
||||
如果你使用的是 Fedora、RHEL 或 CentOS,那么可以在 Bash 提示符下使用以下命令安装 Neofetch:
|
||||
|
||||
```
|
||||
$ sudo dnf install neofetch
|
||||
```
|
||||
|
||||
在 Ubuntu 17.10 及更高版本上,你可以使用:
|
||||
|
||||
```
|
||||
$ sudo apt install neofetch
|
||||
```
|
||||
|
||||
首次运行时,Neofetch 将 `~/.config/neofetch/config.conf` 文件写入主目录(`.config/config.conf`),它让你可以[自定义和控制][11] Neofetch 输出的各个方面。例如,你可以配置 Neofetch 使用图像、ASCII 文件、你选择的壁纸,或者完全不使用。config.conf 文件还让与它人分享配置变得容易。
|
||||
|
||||
如果 Neofetch 不支持你的操作系统或不提供所需选项,请在项目的 [GitHub 仓库][12]中打开一个问题。
|
||||
|
||||
### 总结
|
||||
|
||||
无论为什么要共享系统配置,screenFetch 或 Neofetch 都应该能做到。你是否知道在 Linux 上提供此功能的另一个开源工具?请在评论中分享你的最爱。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/1/screenfetch-neofetch
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/metrics_data_dashboard_system_computer_analytics.png?itok=oxAeIEI- (metrics and data shown on a computer screen)
|
||||
[2]: https://github.com/KittyKatt/screenFetch
|
||||
[3]: https://github.com/KittyKatt/screenFetch/wiki/Installation
|
||||
[4]: https://opensource.com/sites/default/files/uploads/screenfetch.png (screenFetch)
|
||||
[5]: https://opensource.com/sites/default/files/uploads/screenfetch-n.png (screenfetch -n option)
|
||||
[6]: http://github.com/KittyKatt/screenFetch
|
||||
[7]: https://github.com/dylanaraps/neofetch
|
||||
[8]: https://github.com/dylanaraps/neofetch/blob/master/LICENSE.md
|
||||
[9]: https://opensource.com/sites/default/files/uploads/neofetch.png (Neofetch)
|
||||
[10]: https://github.com/dylanaraps/neofetch/wiki/Installation
|
||||
[11]: https://github.com/dylanaraps/neofetch/wiki/Customizing-Info
|
||||
[12]: https://github.com/dylanaraps/neofetch/issues
|
||||
@ -1,20 +1,22 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11899-1.html)
|
||||
[#]: subject: (How to stop typosquatting attacks)
|
||||
[#]: via: (https://opensource.com/article/20/1/stop-typosquatting-attacks)
|
||||
[#]: author: (Sam Bocetta https://opensource.com/users/sambocetta)
|
||||
|
||||
如何防范误植攻击
|
||||
======
|
||||
|
||||
> <ruby>误植<rt>Typosquatting</rt></ruby>是一种引诱用户将敏感数据泄露给不法分子的方式,针对这种攻击方式,我们很有必要了解如何保护我们的组织、我们的开源项目以及我们自己。
|
||||
|
||||
![Gears above purple clouds][1]
|
||||
|
||||
除了常规手段以外,不法分子还会利用社会工程的方式,试图让安全意识较弱的人泄露私人信息或是有价值的证书。很多[网络钓鱼骗局][2]的实质都是攻击者伪装成信誉良好的公司或组织,然后借此大规模分发病毒或恶意软件。
|
||||
除了常规手段以外,网络罪犯还会利用社会工程的方式,试图让安全意识较弱的人泄露私人信息或是有价值的证书。很多[网络钓鱼骗局][2]的实质都是攻击者伪装成信誉良好的公司或组织,然后借此大规模传播病毒或恶意软件。
|
||||
|
||||
[误植][3]就是其中一个常用的手法。它是一种社会工程学的攻击方式,通过使用一些合法网站的错误拼写 URL 以引诱用户访问恶意网站,这样的做法既使真正的原网站遭受声誉上的损害,又诱使用户向这些恶意网站提交个人敏感信息。因此,网站的管理人员和用户双方都应该意识到这个问题带来的风险,并采取措施加以保护。
|
||||
<ruby>[误植][3]<rt>Typosquatting</rt></ruby>就是其中一个常用的手法。它是一种社会工程学的攻击方式,通过使用一些合法网站的错误拼写的 URL 以引诱用户访问恶意网站,这样的做法既使真正的原网站遭受声誉上的损害,又诱使用户向这些恶意网站提交个人敏感信息。因此,网站的管理人员和用户双方都应该意识到这个问题带来的风险,并采取措施加以保护。
|
||||
|
||||
一些由广大开发者在公共代码库中维护的开源软件通常都被认为具有安全上的优势,但当面临社会工程学攻击或恶意软件植入时,开源软件也需要注意以免受到伤害。
|
||||
|
||||
@ -22,9 +24,9 @@
|
||||
|
||||
### 什么是误植?
|
||||
|
||||
误植是一种具体的网络犯罪手段,其背后通常是一个网络钓鱼骗局。不法分子首先会购买注册域名,而他们注册的域名通常是一个常用网站的错误拼写形式,例如在正确拼写的基础上添加一个额外的元音字母,又或者是将字母“i”替换成字母“l”。对于同一个正常域名,不法分子通常会注册数十个拼写错误的变体域名。
|
||||
误植是一种非常特殊的网络犯罪形式,其背后通常是一个更大的网络钓鱼骗局。不法分子首先会购买和注册域名,而他们注册的域名通常是一个常用网站的错误拼写形式,例如在正确拼写的基础上添加一个额外的元音字母,又或者是将字母“i”替换成字母“l”。对于同一个正常域名,不法分子通常会注册数十个拼写错误的变体域名。
|
||||
|
||||
用户一旦访问这样的域名,不法分子的目的就已经成功了一半。为此,他们会通过电子邮件的方式,诱导用户访问这样的伪造域名。伪造域名指向的页面中,通常都带有一个简单的登录界面,还会附上被模仿的网站的 logo,尽可能让用户认为自己访问的是正确的网站。
|
||||
用户一旦访问这样的域名,不法分子的目的就已经成功了一半。为此,他们会通过电子邮件的方式,诱导用户访问这样的伪造域名。伪造域名指向的页面中,通常都带有一个简单的登录界面,还会附上熟悉的被模仿网站的徽标,尽可能让用户认为自己访问的是真实的网站。
|
||||
|
||||
如果用户没有识破这一个骗局,在页面中提交了诸如银行卡号、用户名、密码等敏感信息,这些数据就会被不法分子所完全掌控。进一步来看,如果这个用户在其它网站也使用了相同的用户名和密码,那就有同样受到波及的风险。受害者最终可能会面临身份被盗、信用记录被破坏等危险。
|
||||
|
||||
@ -34,11 +36,11 @@
|
||||
|
||||
在几年之前就发生过[一起案件][4],很多健康保险客户收到了一封指向 we11point.com 的钓鱼电子邮件,其中 URL 里正确的字母“l”被换成了数字“1”,从而导致一批用户成为了这一次攻击的受害者。
|
||||
|
||||
最初,特定国家的顶级域名是不允许随意注册的。但后来国际域名规则中放开这一限制之后,又兴起了一波新的误植攻击。例如最常见的一种手法就是注册一个与 .com 域名类似的 .om 域名,一旦在输入 URL 时不慎遗漏了字母 c 就会给不法分子带来可乘之机。
|
||||
最初,与特定国家/地区相关的顶级域名是不允许随意注册的。但后来国际域名规则中放开这一限制之后,又兴起了一波新的误植攻击。例如最常见的一种手法就是注册一个与 .com 域名类似的 .om 域名,一旦在输入 URL 时不慎遗漏了字母 c 就会给不法分子带来可乘之机。
|
||||
|
||||
### 网站如何防范误植攻击
|
||||
|
||||
对于一个公司来说,最好的策略就是永远比误植攻击采取早一手的行动。
|
||||
对于一个公司来说,最好的策略就是永远比误植攻击采取早一步的行动。
|
||||
|
||||
也就是说,在注册域名的时候,不仅要注册自己商标名称的域名,最好还要同时注册可能由于拼写错误产生的其它域名。当然,没有太大必要把可能导致错误的所有顶级域名都注册掉,但至少要把可能导致错误的一些一级域名抢注下来。
|
||||
|
||||
@ -46,7 +48,7 @@
|
||||
|
||||
你可以使用类似 [DNS Twist][5] 的开源工具来扫描公司正在使用的域名,它可以确定是否有相似的域名已被注册,从而暴露潜在的误植攻击。DNS Twist 可以在 Linux 系统上通过一系列的 shell 命令来运行。
|
||||
|
||||
还有一些网络提供商会将防护误植攻击作为他们网络产品的一部分。这就相当于一层额外的保护,如果用户不慎输入了带有拼写错误的 URL,就会被提示该页面已经被阻止并重定向到正确的域名。
|
||||
还有一些网络提供商(ISP)会将防护误植攻击作为他们网络产品的一部分。这就相当于一层额外的保护,如果用户不慎输入了带有拼写错误的 URL,就会被提示该页面已经被阻止并重定向到正确的域名。
|
||||
|
||||
如果你是系统管理员,还可以考虑运行一个自建的 [DNS 服务器][6],以便通过黑名单的机制禁止对某些域名的访问。
|
||||
|
||||
@ -58,29 +60,27 @@
|
||||
|
||||
因为开源项目的源代码是公开的,所以其中大部分项目都会进行安全和渗透测试。但错误是不可能完全避免的,如果你参与了开源项目,还是有需要注意的地方。
|
||||
|
||||
当你收到一个不明来源的<ruby>合并请求<rt>Merge Request</rt></ruby>或补丁时,必须在合并之前仔细检查,尤其是相关代码涉及到网络层面的时候。一定要进行严格的检查和测试,以确保没有恶意代码混入正常的代码当中。
|
||||
当你收到一个不明来源的<ruby>合并请求<rt>Merge Request</rt></ruby>或补丁时,必须在合并之前仔细检查,尤其是相关代码涉及到网络层面的时候。不要屈服于只测试构建的诱惑; 一定要进行严格的检查和测试,以确保没有恶意代码混入正常的代码当中。
|
||||
|
||||
同时,还要严格按照正确的方法使用域名,避免不法分子创建仿冒的下载站点并提供带有恶意代码的软件。可以通过如下所示的方法使用数字签名来确保你的软件没有被篡改:
|
||||
|
||||
|
||||
```
|
||||
gpg --armor --detach-sig \
|
||||
\--output advent-gnome.sig \
|
||||
example-0.0.1.tar.xz
|
||||
--output advent-gnome.sig \
|
||||
example-0.0.1.tar.xz
|
||||
```
|
||||
|
||||
同时给出你提供的文件的校验和:
|
||||
|
||||
|
||||
```
|
||||
`sha256sum example-0.0.1.tar.xz > example-0.0.1.txt`
|
||||
sha256sum example-0.0.1.tar.xz > example-0.0.1.txt
|
||||
```
|
||||
|
||||
无论你的用户会不会去用上这些安全措施,你也应该提供这些必要的信息。因为只要有那么一个人留意到签名有异样,就能为你敲响警钟。
|
||||
|
||||
### 总结
|
||||
|
||||
人类犯错在所难免。世界上数百万人输入同一个,总会有人出现拼写的错误。不法分子也正是抓住了这个漏洞才得以实施误植攻击。
|
||||
人类犯错在所难免。世界上数百万人输入同一个网址时,总会有人出现拼写的错误。不法分子也正是抓住了这个漏洞才得以实施误植攻击。
|
||||
|
||||
用抢注域名的方式去完全根治误植攻击也是不太现实的,我们更应该关注这种攻击的传播方式以减轻它对我们的影响。最好的保护就是和用户之间建立信任,并积极检测误植攻击的潜在风险。作为开源社区,我们更应该团结起来一起应对误植攻击。
|
||||
|
||||
@ -91,7 +91,7 @@ via: https://opensource.com/article/20/1/stop-typosquatting-attacks
|
||||
作者:[Sam Bocetta][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,117 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11900-1.html)
|
||||
[#]: subject: (Use tmux to create the console of your dreams)
|
||||
[#]: via: (https://opensource.com/article/20/1/tmux-console)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
|
||||
|
||||
使用 tmux 创建你的梦想主控台
|
||||
======
|
||||
|
||||
> 使用 tmux 可以做很多事情,尤其是在将 tmuxinator 添加到其中时。在我们的二十篇系列文章的第十五期中查看它们,以在 2020 年实现开源生产力的提高。
|
||||
|
||||

|
||||
|
||||
去年,我在 19 天里给你介绍了 19 个新(对你而言)的生产力工具。今年,我换了一种方式:使用你在使用或者还没使用的工具,构建一个使你可以在新一年更加高效的环境。
|
||||
|
||||
### 使用 tmux 和 tmuxinator 全部放到主控台上
|
||||
|
||||
到目前为止,在本系列文章中,我已经撰写了有关单个应用程序和工具的文章。从今天开始,我将把它们放在一起进行全面设置以简化操作。让我们从命令行开始。为什么使用命令行?简而言之,在命令行上工作可以使我能够从运行 SSH 的任何位置访问许多这些工具和功能。我可以 SSH 进入我的一台个人计算机,并在工作计算机上运行与我的个人计算机上所使用的相同设置。我要使用的主要工具是 [tmux][2]。
|
||||
|
||||
大多数人都只使用了 tmux 非常基础的功能,比如说在远程服务器上打开 tmux,然后启动进程,也许还会打开第二个会话以查看日志文件或调试信息,然后断开连接并在稍后返回。但是其实你可以使用 tmux 做很多工作。
|
||||
|
||||
![tmux][3]
|
||||
|
||||
首先,如果你有一个已有的 tmux 配置文件,请对其进行备份。tmux 的配置文件是 `~/.tmux.conf`。将其移动到另一个目录,例如 `~/tmp`。现在,用 Git 克隆 [Oh My Tmux][4] 项目。从该克隆目录中将 `.tmux.conf` 符号链接到你的家目录,并复制该克隆目录中的 `.tmux.conf.local` 文件到家目录中以进行调整:
|
||||
|
||||
```
|
||||
cd ~
|
||||
mkdir ~/tmp
|
||||
mv ~/.tmux.conf ~/tmp/
|
||||
git clone https://github.com/gpakosz/.tmux.git
|
||||
ln -s ~/.tmux/.tmux.conf ./
|
||||
cp ~/.tmux/.tmux.conf.local ./
|
||||
```
|
||||
|
||||
`.tmux.conf.local` 文件包含了本地设置和覆盖的设置。例如,我稍微更改了默认颜色,然后启用了 [Powerline][5] 分隔线。下面的代码段仅显示了我更改过的内容:
|
||||
|
||||
```
|
||||
tmux_conf_theme_24b_colour=true
|
||||
tmux_conf_theme_focused_pane_bg='default'
|
||||
tmux_conf_theme_pane_border_style=fat
|
||||
tmux_conf_theme_left_separator_main='\uE0B0'
|
||||
tmux_conf_theme_left_separator_sub='\uE0B1'
|
||||
tmux_conf_theme_right_separator_main='\uE0B2'
|
||||
tmux_conf_theme_right_separator_sub='\uE0B3'
|
||||
#tmux_conf_battery_bar_symbol_full='◼'
|
||||
#tmux_conf_battery_bar_symbol_empty='◻'
|
||||
tmux_conf_battery_bar_symbol_full='♥'
|
||||
tmux_conf_battery_bar_symbol_empty='·'
|
||||
tmux_conf_copy_to_os_clipboard=true
|
||||
set -g mouse on
|
||||
```
|
||||
|
||||
请注意,你不需要安装 Powerline,你只需要支持 Powerline 符号的字体即可。我在与控制台相关的所有内容中几乎都使用 [Hack Nerd Font][6],因为它易于阅读并且具有许多有用的额外符号。你还会注意到,我打开了操作系统剪贴板支持和鼠标支持。
|
||||
|
||||
现在,当 tmux 启动时,底部的状态栏会以吸引人的颜色提供更多信息。`Ctrl` + `b` 仍然是输入命令的 “引导” 键,但其他一些进行了更改。现在水平拆分(顶部/底部)窗格为 `Ctrl` + `b` + `-`,垂直拆分为 `Ctrl` + `b` + `_`。启用鼠标模式后,你可以单击以在窗格之间切换,并拖动分隔线以调整其大小。打开新窗口仍然是 `Ctrl` + `b` + `n`,你现在可以单击底部栏上的窗口名称在它们之间进行切换。同样,`Ctrl` + `b` + `e` 将打开 `.tmux.conf.local` 文件以进行编辑。退出编辑器时,tmux 将重新加载配置,而不会重新加载其他任何内容。这很有用。
|
||||
|
||||
到目前为止,我仅对功能和视觉显示进行了一些简单的更改,并增加了鼠标支持。现在,我将它设置为以一种有意义的方式启动我想要的应用程序,而不必每次都重新定位和调整它们的大小。为此,我将使用 [tmuxinator][7]。tmuxinator 是 tmux 的启动器,它允许你指定和管理布局以及使用 YAML 文件自动启动应用程序。要使用它,请启动 tmux 并创建要在其中运行程序的窗格。然后,使用 `Ctrl` + `b` + `n` 打开一个新窗口,并执行 `tmux list-windows`。你将获得有关布局的详细信息。
|
||||
|
||||
![tmux layout information][8]
|
||||
|
||||
请注意上面代码中的第一行,我在其中设置了四个窗格,每个窗格中都有一个应用程序。保存运行时的输出以供以后使用。现在,运行 `tmuxinator new 20days` 以创建名为 “20days” 的布局。这将显示一个带有默认布局文件的文本编辑器。它包含很多有用的内容,我建议你阅读所有选项。首先输入上方的布局信息以及所需的应用程序:
|
||||
|
||||
```
|
||||
# /Users/ksonney/.config/tmuxinator/20days.yml
|
||||
name: 20days
|
||||
root: ~/
|
||||
windows:
|
||||
- mail:
|
||||
layout: d9da,208x60,0,0[208x26,0,0{104x26,0,0,0,103x26,105,0,5},208x33,0,27{104x33,0,27,1,103x33,105,27,4}]] @0
|
||||
panes:
|
||||
- alot
|
||||
- abook
|
||||
- ikhal
|
||||
- todo.sh ls +20days
|
||||
```
|
||||
|
||||
注意空格缩进!与 Python 代码一样,空格和缩进关系到文件的解释方式。保存该文件,然后运行 `tmuxinator 20days`。你应该会得到四个窗格,分别是 [alot][9] 邮件程序、[abook][10]、ikhal(交互式 [khal][11] 的快捷方式)以及 [todo.txt][12] 中带有 “+20days” 标签的任何内容。
|
||||
|
||||
![sample layout launched by tmuxinator][13]
|
||||
|
||||
你还会注意到,底部栏上的窗口标记为 “Mail”。你可以单击该名称(以及其他命名的窗口)以跳到该视图。漂亮吧?我在同一个文件中还设置了名为 “Social” 的第二个窗口,包括 [Tuir][14]、[Newsboat][15]、连接到 [BitlBee][16] 的 IRC 客户端和 [Rainbow Stream][17]。
|
||||
|
||||
tmux 是我跟踪所有事情的生产力动力之源,有了 tmuxinator,我不必在不断调整大小、放置和启动我的应用程序上费心。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/1/tmux-console
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/coffee_tea_laptop_computer_work_desk.png?itok=D5yMx_Dr (Person drinking a hat drink at the computer)
|
||||
[2]: https://github.com/tmux/tmux
|
||||
[3]: https://opensource.com/sites/default/files/uploads/productivity_15-1.png (tumux)
|
||||
[4]: https://github.com/gpakosz/.tmux
|
||||
[5]: https://github.com/powerline/powerline
|
||||
[6]: https://www.nerdfonts.com/
|
||||
[7]: https://github.com/tmuxinator/tmuxinator
|
||||
[8]: https://opensource.com/sites/default/files/uploads/productivity_15-2.png (tmux layout information)
|
||||
[9]: https://opensource.com/article/20/1/organize-email-notmuch
|
||||
[10]: https://opensource.com/article/20/1/sync-contacts-locally
|
||||
[11]: https://opensource.com/article/20/1/open-source-calendar
|
||||
[12]: https://opensource.com/article/20/1/open-source-to-do-list
|
||||
[13]: https://opensource.com/sites/default/files/uploads/productivity_15-3.png (sample layout launched by tmuxinator)
|
||||
[14]: https://opensource.com/article/20/1/open-source-reddit-client
|
||||
[15]: https://opensource.com/article/20/1/open-source-rss-feed-reader
|
||||
[16]: https://opensource.com/article/20/1/open-source-chat-tool
|
||||
[17]: https://opensource.com/article/20/1/tweet-terminal-rainbow-stream
|
||||
@ -0,0 +1,113 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11908-1.html)
|
||||
[#]: subject: (Use Vim to send email and check your calendar)
|
||||
[#]: via: (https://opensource.com/article/20/1/vim-email-calendar)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
|
||||
|
||||
使用 Vim 发送邮件和检查日历
|
||||
======
|
||||
|
||||
> 在 2020 年用开源实现更高生产力的二十种方式的第十六篇文章中,直接通过文本编辑器管理你的电子邮件和日历。
|
||||
|
||||

|
||||
|
||||
去年,我在 19 天里给你介绍了 19 个新(对你而言)的生产力工具。今年,我换了一种方式:使用你在使用或者还没使用的工具,构建一个使你可以在新一年更加高效的环境。
|
||||
|
||||
### 用 Vim 做(几乎)所有事情,第一部分
|
||||
|
||||
我经常使用两个文本编辑器 —— [Vim][2] 和 [Emacs][3]。为什么两者都用呢?它们有不同的使用场景,在本系列的后续几篇文章中,我将讨论其中的一些用例。
|
||||
|
||||
![][4]
|
||||
|
||||
好吧,为什么要在 Vim 中执行所有操作?因为如果有一个应用程序是我可以访问的每台计算机上都有的,那就是 Vim。如果你像我一样,可能已经在 Vim 中打发了很多时光。那么,为什么不将其用于**所有事情**呢?
|
||||
|
||||
但是,在此之前,你需要做一些事情。首先是确保你的 Vim 具有 Ruby 支持。你可以使用 `vim --version | grep ruby`。如果结果不是 `+ruby`,则需要解决这个问题。这可能有点麻烦,你应该查看发行版的文档以获取正确的软件包。在 MacOS 上,用的是官方的 MacVim(不是 Brew 发行的),在大多数 Linux 发行版中,用的是 vim-nox 或 vim-gtk,而不是 vim-gtk3。
|
||||
|
||||
我使用 [Pathogen][5] 自动加载插件和捆绑软件。如果你使用 [Vundle][6] 或其他 Vim 软件包管理器,则需要调整以下命令才能使用它。
|
||||
|
||||
#### 在 Vim 中管理你的邮件
|
||||
|
||||
使 Vim 在你的生产力计划中发挥更大作用的一个很好的起点是使用它通过 [Notmuch] [7] 发送和接收电子邮件,和使用 [abook] [8] 访问你的联系人列表。你需要为此安装一些东西。下面的所有示例代码都运行在 Ubuntu 上,因此如果你使用其他发行版,则需要对此进行调整。通过以下步骤进行设置:
|
||||
|
||||
```
|
||||
sudo apt install notmuch-vim ruby-mail
|
||||
curl -o ~/.vim/plugin/abook --create-dirs https://raw.githubusercontent.com/dcbaker/vim-abook/master/plugin/abook.vim
|
||||
```
|
||||
|
||||
到目前为止,一切都很顺利。现在启动 Vim 并执行 `:NotMuch`。由于是用较旧版本的邮件库 `notmuch-vim` 编写的,可能会出现一些警告,但总的来说,Vim 现在将成为功能齐全的 Notmuch 邮件客户端。
|
||||
|
||||
![Reading Mail in Vim][9]
|
||||
|
||||
如果要搜索特定标签,请输入 `\t`,输入标签名称,然后按回车。这将拉出一个带有该标签的所有消息的列表。`\s` 组合键会弹出 `Search:` 提示符,可以对 Notmuch 数据库进行全面搜索。使用箭头键浏览消息列表,按回车键显示所选项目,然后输入 `\q` 退出当前视图。
|
||||
|
||||
要撰写邮件,请使用 `\c` 按键。你将看到一条空白消息。这是 `abook.vim` 插件发挥作用的位置。按下 `Esc` 并输入 `:AbookQuery <SomeName>`,其中 `<SomeName>` 是你要查找的名称或电子邮件地址的一部分。你将在 abook 数据库中找到与你的搜索匹配的条目列表。通过键入你想要的地址的编号,将其添加到电子邮件的地址行中。完成电子邮件的键入和编辑,按 `Esc` 退出编辑模式,然后输入 `,s` 发送。
|
||||
|
||||
如果要在 `:NotMuch` 启动时更改默认文件夹视图,则可以将变量 `g:notmuch_folders` 添加到你的 `.vimrc` 文件中:
|
||||
|
||||
```
|
||||
let g:notmuch_folders = [
|
||||
\ [ 'new', 'tag:inbox and tag:unread' ],
|
||||
\ [ 'inbox', 'tag:inbox' ],
|
||||
\ [ 'unread', 'tag:unread' ],
|
||||
\ [ 'News', 'tag:@sanenews' ],
|
||||
\ [ 'Later', 'tag:@sanelater' ],
|
||||
\ [ 'Patreon', 'tag:@patreon' ],
|
||||
\ [ 'LivestockConservancy', 'tag:livestock-conservancy' ],
|
||||
\ ]
|
||||
```
|
||||
|
||||
Notmuch 插件的文档中涵盖了更多设置,包括设置标签键和使用其它的邮件程序。
|
||||
|
||||
#### 在 Vim 中查询日历
|
||||
|
||||
![][10]
|
||||
|
||||
遗憾的是,似乎没有使用 vCalendar 或 iCalendar 格式的 Vim 日历程序。有个 [Calendar.vim][11],做得很好。设置 Vim 通过以下方式访问你的日历:
|
||||
|
||||
```
|
||||
cd ~/.vim/bundle
|
||||
git clone git@github.com:itchyny/calendar.vim.git
|
||||
```
|
||||
|
||||
现在,你可以通过输入 `:Calendar` 在 Vim 中查看日历。你可以使用 `<` 和 `>` 键在年、月、周、日和时钟视图之间切换。如果要从一个特定的视图开始,请使用 `-view=` 标志告诉它你希望看到哪个视图。你也可以在任何视图中定位日期。例如,如果我想查看 2020 年 7 月 4 日这一周的情况,请输入 `:Calendar -view week 7 4 2020`。它的帮助信息非常好,可以使用 `?` 键参看。
|
||||
|
||||
![][13]
|
||||
|
||||
Calendar.vim 还支持 Google Calendar(我需要),但是在 2019 年 12 月,Google 禁用了它的访问权限。作者已在 [GitHub 上的这个提案][14]中发布了一种变通方法。
|
||||
|
||||
这样你就在 Vim 中有了这些:你的邮件、地址簿和日历。但是这些还没有完成; 下一篇你将在 Vim 上做更多的事情!
|
||||
|
||||
Vim 为作家提供了很多好处,无论他们是否具有技术意识。
|
||||
|
||||
需要保持时间表正确吗?了解如何使用这些免费的开源软件来做到这一点。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/1/vim-email-calendar
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/calendar.jpg?itok=jEKbhvDT (Calendar close up snapshot)
|
||||
[2]: https://www.vim.org/
|
||||
[3]: https://www.gnu.org/software/emacs/
|
||||
[4]: https://opensource.com/sites/default/files/uploads/day16-image1.png
|
||||
[5]: https://github.com/tpope/vim-pathogen
|
||||
[6]: https://github.com/VundleVim/Vundle.vim
|
||||
[7]: https://opensource.com/article/20/1/organize-email-notmuch
|
||||
[8]: https://opensource.com/article/20/1/sync-contacts-locally
|
||||
[9]: https://opensource.com/sites/default/files/uploads/productivity_16-2.png (Reading Mail in Vim)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/day16-image3.png
|
||||
[11]: https://github.com/itchyny/calendar.vim
|
||||
[12]: mailto:git@github.com
|
||||
[13]: https://opensource.com/sites/default/files/uploads/day16-image4.png
|
||||
[14]: https://github.com/itchyny/calendar.vim/issues/156
|
||||
@ -1,20 +1,22 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11912-1.html)
|
||||
[#]: subject: (Use Vim to manage your task list and access Reddit and Twitter)
|
||||
[#]: via: (https://opensource.com/article/20/1/vim-task-list-reddit-twitter)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
|
||||
|
||||
使用 Vim 管理任务列表和访问 Reddit 和 Twitter
|
||||
======
|
||||
在我们的 20 个使用开源提升生产力的系列的第十七篇文章中了解在编辑器中处理待办列表以及获取社交信息。
|
||||
![Chat via email][1]
|
||||
|
||||
> 在 2020 年用开源实现更高生产力的二十种方式的第十七篇文章中,了解在编辑器中处理待办列表以及获取社交信息。
|
||||
|
||||

|
||||
|
||||
去年,我在 19 天里给你介绍了 19 个新(对你而言)的生产力工具。今年,我换了一种方式:使用你在使用或者还没使用的工具,构建一个使你可以在新一年更加高效的环境。
|
||||
|
||||
### 使用 Vim 执行(几乎)所有操作,第 2 部分
|
||||
### 用 Vim 做(几乎)所有事情,第 2 部分
|
||||
|
||||
在[昨天的文章][2]中,你开始用 Vim 检查邮件和日历。今天,你可以做的更多。首先,你会在 Vim 编辑器中跟踪任务,然后获取社交信息。
|
||||
|
||||
@ -24,13 +26,12 @@
|
||||
|
||||
使用 Vim 编辑一个文本待办事件是一件自然的事,而 [todo.txt-vim][4] 包使其更加简单。首先安装 todo.txt-vim 包:
|
||||
|
||||
|
||||
```
|
||||
git clone <https://github.com/freitass/todo.txt-vim> ~/.vim/bundle/todo.txt-vim
|
||||
git clone https://github.com/freitass/todo.txt-vim ~/.vim/bundle/todo.txt-vim
|
||||
vim ~/path/to/your/todo.txt
|
||||
```
|
||||
|
||||
todo.txt-vim 自动识别以 todo.txt 和 done.txt 结尾的文件作为 [todo.txt][5] 文件。它添加特定于 todo.txt 格式的键绑定。你可以使用 **\x** 标记“已完成”的内容,使用 **\d** 将其设置为当前日期,然后使用 **\a**、**\b** 和 **\c** 更改优先级。你可以提升(**\k**)或降低(**\j**)优先级,并根据项目(**\s+**)、上下文(**\s@**)或日期(**\sd**)排序(**\s**)。完成后,你可以和平常一样关闭和保存文件。
|
||||
todo.txt-vim 自动识别以 `todo.txt` 和 `done.txt` 结尾的文件作为 [todo.txt][5] 文件。它添加特定于 todo.txt 格式的键绑定。你可以使用 `\x` 标记“已完成”的内容,使用 `\d` 将其设置为当前日期,然后使用 `\a`、`\b` 和 `\c` 更改优先级。你可以提升(`\k`)或降低(`\j`)优先级,并根据项目(`\s+`)、上下文(`\s@`)或日期(`\sd`)排序(`\s`)。完成后,你可以和平常一样关闭和保存文件。
|
||||
|
||||
todo.txt-vim 包是我几天前写的 [todo.sh 程序][6]的一个很好的补充,使用 [todo edit][7] 加载项,它可以增强的你待办事项列表跟踪。
|
||||
|
||||
@ -40,13 +41,12 @@ todo.txt-vim 包是我几天前写的 [todo.sh 程序][6]的一个很好的补
|
||||
|
||||
Vim 还有一个不错的用于 [Reddit][9] 的加载项,叫 [vim-reddit][10]。它不如 [Tuir][11] 好,但是用于快速查看最新的文章,它还是不错的。首先安装捆绑包:
|
||||
|
||||
|
||||
```
|
||||
git clone <https://github.com/DougBeney/vim-reddit.git> ~/.vim/bundle/vim-reddit
|
||||
git clone https://github.com/DougBeney/vim-reddit.git ~/.vim/bundle/vim-reddit
|
||||
vim
|
||||
```
|
||||
|
||||
现在输入 **:Reddit** 将加载 Reddit 首页。你可以使用 **:Reddit name** 加载特定子板。打开文章列表后,使用箭头键导航或使用鼠标滚动。按 **o** 将在 Vim 中打开文章(除非它多媒体文章,它会打开浏览器),然后按 **c** 打开评论。如果要直接转到页面,请按 **O** 而不是 **o**。只需按 **u** 就能返回。当你 Reddit 看完后,输入 **:bd** 就行。vim-reddit 唯一的缺点是无法登录或发布新文章和评论。话又说回来,有时这是一件好事。
|
||||
现在输入 `:Reddit` 将加载 Reddit 首页。你可以使用 `:Reddit name` 加载特定子板。打开文章列表后,使用箭头键导航或使用鼠标滚动。按 `o` 将在 Vim 中打开文章(除非它多媒体文章,它会打开浏览器),然后按 `c` 打开评论。如果要直接转到页面,请按 `O` 而不是 `o`。只需按 `u` 就能返回。当你 Reddit 看完后,输入 `:bd` 就行。vim-reddit 唯一的缺点是无法登录或发布新文章和评论。话又说回来,有时这是一件好事。
|
||||
|
||||
#### 使用 twitvim 在 Vim 中发推
|
||||
|
||||
@ -54,17 +54,15 @@ vim
|
||||
|
||||
最后,我们有 [twitvim][13],这是一个于阅读和发布 Twitter 的 Vim 软件包。它需要更多设置。首先从 GitHub 安装 twitvim:
|
||||
|
||||
|
||||
```
|
||||
`git clone https://github.com/twitvim/twitvim.git ~/.vim/bundle/twitvim`
|
||||
git clone https://github.com/twitvim/twitvim.git ~/.vim/bundle/twitvim
|
||||
```
|
||||
|
||||
现在你需要编辑 **.vimrc** 文件并设置一些选项。它帮助插件知道使用哪些库与 Twitter 交互。运行 **vim --version** 并查看哪些语言的前面有 **+** 就代表你的 Vim 支持它。
|
||||
现在你需要编辑 `.vimrc` 文件并设置一些选项。它帮助插件知道使用哪些库与 Twitter 交互。运行 `vim --version` 并查看哪些语言的前面有 `+` 就代表你的 Vim 支持它。
|
||||
|
||||
![Enabled and Disabled things in vim][14]
|
||||
|
||||
因为我的是 **+perl -python +python3**,所以我知道我可以启用 Perl 和 Python 3 但不是 Python 2 (python)。
|
||||
|
||||
因为我的是 `+perl -python +python3`,所以我知道我可以启用 Perl 和 Python 3 但不是 Python 2 (python)。
|
||||
|
||||
```
|
||||
" TwitVim Settings
|
||||
@ -73,9 +71,9 @@ let twitvim_enable_perl = 1
|
||||
let twitvim_enable_python3 = 1
|
||||
```
|
||||
|
||||
现在,你可以通过运行 **:SetLoginTwitter** 启动浏览器窗口,它会打开一个浏览器窗口要求你授权 VimTwit 访问你的帐户。在 Vim 中输入提供的 PIN 后就可以了。
|
||||
现在,你可以通过运行 `:SetLoginTwitter` 启动浏览器窗口,它会打开一个浏览器窗口要求你授权 VimTwit 访问你的帐户。在 Vim 中输入提供的 PIN 后就可以了。
|
||||
|
||||
Twitvim 的命令不像其他包中一样简单。要加载好友和关注者的时间线,请输入 **:FriendsTwitter**。要列出提及你的和回复,请使用 **:MentionsTwitter**。发布新推文是 **:PosttoTwitter <Your message>**。你可以滚动列表并输入 **\r** 回复特定推文,你可以用 **\d** 直接给某人发消息。
|
||||
Twitvim 的命令不像其他包中一样简单。要加载好友和关注者的时间线,请输入 `:FriendsTwitter`。要列出提及你的和回复,请使用 `:MentionsTwitter`。发布新推文是 `:PosttoTwitter <Your message>`。你可以滚动列表并输入 `\r` 回复特定推文,你可以用 `\d` 直接给某人发消息。
|
||||
|
||||
就是这些了。你现在可以在 Vim 中做(几乎)所有事了!
|
||||
|
||||
@ -86,14 +84,14 @@ via: https://opensource.com/article/20/1/vim-task-list-reddit-twitter
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/email_chat_communication_message.png?itok=LKjiLnQu (Chat via email)
|
||||
[2]: https://opensource.com/article/20/1/send-email-and-check-your-calendar-vim
|
||||
[2]: https://linux.cn/article-11908-1.html
|
||||
[3]: https://opensource.com/sites/default/files/uploads/productivity_17-1.png (to-dos and Twitter with Vim)
|
||||
[4]: https://github.com/freitass/todo.txt-vim
|
||||
[5]: http://todotxt.org
|
||||
@ -0,0 +1,146 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11932-1.html)
|
||||
[#]: subject: (Send email and check your calendar with Emacs)
|
||||
[#]: via: (https://opensource.com/article/20/1/emacs-mail-calendar)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
|
||||
|
||||
使用 Emacs 发送电子邮件和检查日历
|
||||
======
|
||||
|
||||
> 在 2020 年用开源实现更高生产力的二十种方式的第十八篇文章中,使用 Emacs 文本编辑器管理电子邮件和查看日程安排。
|
||||
|
||||

|
||||
|
||||
去年,我给你们带来了 2019 年的 19 天新生产力工具系列。今年,我将采取一种不同的方式:建立一个新的环境,让你使用已用或未用的工具来在新的一年里变得更有效率。
|
||||
|
||||
### 使用 Emacs 做(几乎)所有的事情,第 1 部分
|
||||
|
||||
两天前,我曾经说过我经常使用 [Vim][2] 和 [Emacs][3],在本系列的 [16][4] 和 [17][5] 天,我讲解了如何在 Vim 中做几乎所有的事情。现在,Emacs 的时间到了!
|
||||
|
||||
![Emacs 中的邮件和日历][6]
|
||||
|
||||
在深入之前,我需要说明两件事。首先,我这里使用默认的 Emacs 配置,而不是我之前[写过][8]的 [Spacemacs][7]。为什么呢?因为这样一来我使用的就是默认快捷键,从而使你可以参考文档,而不必将“原生的 Emacs” 转换为 Spacemacs。第二,在本系列文章中我没有对 Org 模式进行任何设置。Org 模式本身几乎可以自成一个完整的系列,它非常强大,但是设置可能非常复杂。
|
||||
|
||||
#### 配置 Emacs
|
||||
|
||||
配置 Emacs 比配置 Vim 稍微复杂一些,但以我之见,从长远来看,这样做是值得的。首先我们创建一个配置文件,并在 Emacs 中打开它:
|
||||
|
||||
```
|
||||
mkdir ~/.emacs.d
|
||||
emacs ~/.emacs.d/init.el
|
||||
```
|
||||
|
||||
接下来,向内置的包管理器添加一些额外的包源。在 `init.el` 中添加以下内容:
|
||||
|
||||
```
|
||||
(package-initialize)
|
||||
(add-to-list 'package-archives '("melpa" . "<http://melpa.org/packages/>"))
|
||||
(add-to-list 'package-archives '("org" . "<http://orgmode.org/elpa/>") t)
|
||||
(add-to-list 'package-archives '("gnu" . "<https://elpa.gnu.org/packages/>"))
|
||||
(package-refresh-contents)
|
||||
```
|
||||
|
||||
使用 `Ctrl+x Ctrl+s` 保存文件,然后按下 `Ctrl+x Ctrl+c` 退出,再重启 Emacs。Emacs 会在启动时下载所有的插件包列表,之后你就可以使用内置的包管理器安装插件了。输入 `Meta+x` 会弹出命令提示符(大多数键盘上 `Meta` 键就是的 `Alt` 键,而在 MacOS 上则是 `Option`)。在命令提示符下输入 `package-list-packages` 就会显示可以安装的包列表。遍历该列表并使用 `i` 键选择以下包:
|
||||
|
||||
```
|
||||
bbdb
|
||||
bbdb-vcard
|
||||
calfw
|
||||
calfw-ical
|
||||
notmuch
|
||||
```
|
||||
|
||||
选好软件包后按 `x` 安装它们。根据你的网络连接情况,这可能需要一段时间。你也许会看到一些编译错误,但是可以忽略它们。安装完成后,使用组合键 `Ctrl+x Ctrl+f` 打开 `~/.emacs.d/init.el`,并在 `(package-refresh-packages)` 之后、 `(custom-set-variables` 之前添加以下行到文件中。
|
||||
`(custom-set-variables` 行由 Emacs 内部维护,你永远不应该修改它之后的任何内容。以 `;;` 开头的行则是注释。
|
||||
|
||||
```
|
||||
;; Set up bbdb
|
||||
(require 'bbdb)
|
||||
(bbdb-initialize 'message)
|
||||
(bbdb-insinuate-message)
|
||||
(add-hook 'message-setup-hook 'bbdb-insinuate-mail)
|
||||
;; set up calendar
|
||||
(require 'calfw)
|
||||
(require 'calfw-ical)
|
||||
;; Set this to the URL of your calendar. Google users will use
|
||||
;; the Secret Address in iCalendar Format from the calendar settings
|
||||
(cfw:open-ical-calendar "<https://path/to/my/ics/file.ics>")
|
||||
;; Set up notmuch
|
||||
(require 'notmuch)
|
||||
;; set up mail sending using sendmail
|
||||
(setq send-mail-function (quote sendmail-send-it))
|
||||
(setq user-mail-address "[myemail@mydomain.com][9]"
|
||||
user-full-name "My Name")
|
||||
```
|
||||
|
||||
现在,你已经准备好使用自己的配置启动 Emacs 了!保存 `init.el` 文件(`Ctrl+x Ctrl+s`),退出 Emacs(`Ctrl+x Ctrl+c`),然后重启之。这次重启要多花些时间。
|
||||
|
||||
#### 使用 Notmuch 在 Emacs 中读写电子邮件
|
||||
|
||||
一旦你看到了 Emacs 启动屏幕,你就可以使用 [Notmuch][10] 来阅读电子邮件了。键入 `Meta+x notmuch`,你将看到 notmuch 的 Emacs 界面。
|
||||
|
||||
![使用 notmuch 阅读邮件][11]
|
||||
|
||||
所有加粗的项目都是指向电子邮件视图的链接。你可以通过点击鼠标或者使用 `tab` 键在它们之间跳转并按回车来访问它们。你可以使用搜索栏来搜索 Notmuch 的数据库,语法与 Notmuch 命令行上的[语法][12] 相同。如果你愿意,还可以使用 `[save]` 按钮保存搜索以便未来使用,这些搜索会被添加到屏幕顶部的列表中。如果你进入一个链接就会看到一个相关电子邮件的列表。你可以使用箭头键在列表中导航,并在要读取的消息上按回车。按 `r` 可以回复一条消息,`f` 转发该消息,`q` 退出当前屏幕。
|
||||
|
||||
你可以通过键入 `Meta+x compose-mail` 来编写新消息。撰写、回复和转发都将打开编写邮件的界面。写完邮件后,按 `Ctrl+c Ctrl+c` 发送。如果你决定不发送它,按 `Ctrl+c Ctrl+k` 关闭消息撰写缓冲区(窗口)。
|
||||
|
||||
#### 使用 BBDB 在 Emacs 中自动补完电子邮件地址
|
||||
|
||||
![在消息中使用 BBDB 地址][13]
|
||||
|
||||
那么通讯录怎么办?这就是 [BBDB][14] 发挥作用的地方。但首先我们需要从 [abook][15] 导入所有地址,方法是打开命令行并运行以下导出命令:
|
||||
|
||||
```
|
||||
abook --convert --outformat vcard --outfile ~/all-my-addresses.vcf --infile ~/.abook/addresses
|
||||
```
|
||||
|
||||
Emacs 启动后,运行 `Meta+x bbdb-vcard-import-file`。它将提示你输入要导入的文件名,即 `~/all-my-address.vcf`。导入完成后,在编写消息时,可以开始输入名称并使用 `Tab` 搜索和自动完成 “to” 字段的内容。BBDB 还会打开一个联系人缓冲区,以便你确保它是正确的。
|
||||
|
||||
既然在 [vdirsyncer][16] 中已经为每个地址都生成了对应的 .vcf 文件了,为什么我们还要这样做呢?如果你像我一样,有许多地址,一次处理一个地址是很麻烦的。这样做,你就可以把所有的东西都放在 abook 里,做成一个大文件。
|
||||
|
||||
#### 使用 calfw 在 Emacs 中浏览日历
|
||||
|
||||
![calfw 日历 ][17]
|
||||
|
||||
最后,你可以使用 Emacs 查看日历。在上面的配置中,你安装了 [calfw][18] 包,并添加了一些行来告诉它在哪里可以找到要加载的日历。Calfw 是 “<ruby>Emacs 日历框架<rt>Calendar Framework for Emacs</rt></ruby>”的简称,它支持多种日历格式。我使用的是谷歌日历,这也是我放在配置中的链接。日历将在启动时自动加载,你可以通过 `Ctrl+x+b` 命令切换到 cfw-calendar 缓冲区来查看日历。
|
||||
|
||||
Calfw 提供日、周、双周和月视图。你可以在日历顶部选择视图,并使用箭头键导航日历。不幸的是,calfw 只能查看日历,所以你仍然需要使用 [khal][19] 之类的工具或通过 web 界面来添加、删除和修改事件。
|
||||
|
||||
这就是 Emacs 中的邮件、日历和邮件地址。明天我会展示更多。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/1/emacs-mail-calendar
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/email_paper_envelope_document.png?itok=uPj_kouJ (Document sending)
|
||||
[2]: https://www.vim.org/
|
||||
[3]: https://www.gnu.org/software/emacs/
|
||||
[4]: https://linux.cn/article-11908-1.html
|
||||
[5]: https://linux.cn/article-11912-1.html
|
||||
[6]: https://opensource.com/sites/default/files/uploads/productivity_18-1.png (Mail and calendar in Emacs)
|
||||
[7]: https://www.spacemacs.org/
|
||||
[8]: https://opensource.com/article/19/12/spacemacs
|
||||
[9]: mailto:myemail@mydomain.com
|
||||
[10]: https://notmuchmail.org/
|
||||
[11]: https://opensource.com/sites/default/files/uploads/productivity_18-2.png (Reading mail with Notmuch)
|
||||
[12]: https://linux.cn/article-11807-1.html
|
||||
[13]: https://opensource.com/sites/default/files/uploads/productivity_18-3.png (Composing a message with BBDB addressing)
|
||||
[14]: https://www.jwz.org/bbdb/
|
||||
[15]: https://linux.cn/article-11834-1.html
|
||||
[16]: https://linux.cn/article-11812-1.html
|
||||
[17]: https://opensource.com/sites/default/files/uploads/productivity_18-4.png (calfw calendar)
|
||||
[18]: https://github.com/kiwanami/emacs-calfw
|
||||
[19]: https://khal.readthedocs.io/en/v0.9.2/index.html
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11896-1.html)
|
||||
[#]: subject: (Joplin: The True Open Source Evernote Alternative)
|
||||
[#]: via: (https://itsfoss.com/joplin/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
@ -10,53 +10,50 @@
|
||||
Joplin:真正的 Evernote 开源替代品
|
||||
======
|
||||
|
||||
_**简介:Joplin 是一个开源笔记记录和待办应用。你可以将笔记组织到笔记本中并标记它们。Joplin 还提供网络剪贴板来保存来自互联网的文章。**_
|
||||
|
||||
> Joplin 是一个开源笔记记录和待办应用。你可以将笔记组织到笔记本中并标记它们。Joplin 还提供网络剪贴板来保存来自互联网的文章。
|
||||
|
||||
### Joplin:开源笔记管理器
|
||||
|
||||
![][1]
|
||||
![][4]
|
||||
|
||||
如果你喜欢[Evernote][2],那么你不会不太适应开源软件 [Joplin][3]。
|
||||
如果你喜欢 [Evernote][2],那么你不会不太适应这个开源软件 [Joplin][3]。
|
||||
|
||||
Joplin 是一个优秀的开源笔记应用,拥有丰富的功能。你可以记笔记、写待办事项并且通过和 Dropbox 和 NextCloud 等云服务链接来跨设备同步笔记。同步通过端到端加密保护。
|
||||
Joplin 是一个优秀的开源笔记应用,拥有丰富的功能。你可以记笔记、记录待办事项并且通过和 Dropbox 和 NextCloud 等云服务链接来跨设备同步笔记。同步过程通过端到端加密保护。
|
||||
|
||||
Joplin 还有一个 Web 剪贴板,能让你将网页另存为笔记。网络剪贴板可用于 Firefox 和 Chrome/Chromium 浏览器。
|
||||
Joplin 还有一个 Web 剪贴板,能让你将网页另存为笔记。这个网络剪贴板可用于 Firefox 和 Chrome/Chromium 浏览器。
|
||||
|
||||
Joplin 可以导入 enex 格式的 Evernote 文件, 这让从 Evernote 切换变得容易。
|
||||
Joplin 可以导入 enex 格式的 Evernote 文件,这让从 Evernote 切换变得容易。
|
||||
|
||||
因为自己保存数据,你可以用 Joplin 格式或者原始格式导出所有文件。
|
||||
因为数据自行保存,所以你可以用 Joplin 格式或者原始格式导出所有文件。
|
||||
|
||||
### Joplin 的功能
|
||||
|
||||
![][4]
|
||||
![][1]
|
||||
|
||||
以下是 Joplin 的所有功能列表:
|
||||
|
||||
* 将笔记保存到笔记本和子笔记本中,以便更好地组织
|
||||
* 创建待办事项清单
|
||||
* 可以标记和搜索笔记
|
||||
* 离线优先,因此即使没有互联网连接,所有数据始终在设备上可用
|
||||
* Markdown 笔记支持图片、数学符号和复选框
|
||||
* 支持附件
|
||||
* 可在桌面、移动设备和终端(CLI)使用
|
||||
* 可在 Firefox 和 Chrome 使用[网页剪切板][5]
|
||||
* 端到端加密
|
||||
* 保留笔记历史
|
||||
* 根据名称、时间等对笔记进行排序
|
||||
* 可与 [Nextcloud][7]、Dropbox、WebDAV 和 OneDrive 等各种[云服务][6]同步
|
||||
* 从 Evernote 导入文件
|
||||
* 导出 JEX 文件(Joplin 导出格式)和原始文件
|
||||
* 支持笔记、待办事项、标签和笔记本
|
||||
* 任意跳转功能
|
||||
* 支持移动设备和桌面应用通知
|
||||
* 地理位置支持
|
||||
* 支持多种语言
|
||||
* 外部编辑器支持:在 Joplin 中一键用你最喜欢的编辑器打开笔记
|
||||
|
||||
* 将笔记保存到笔记本和子笔记本中,以便更好地组织
|
||||
* 创建待办事项清单
|
||||
* 笔记可以被标记和搜索
|
||||
* 离线优先,因此即使没有互联网连接,所有数据始终在设备上可用
|
||||
* Markdown 笔记支持图片、数学符号和复选框
|
||||
* 支持附件
|
||||
* 应用可在桌面、移动设备和终端(CLI)使用
|
||||
* 可在 Firefox 和 Chrome 使用[网页剪切板][5]
|
||||
* 端到端加密
|
||||
* 保留笔记历史
|
||||
* 根据名称,时间等对笔记进行排序
|
||||
* 与 [Nextcloud][7]、Dropbox、WebDAV 和 OneDrive 等各种[云服务][6]同步
|
||||
* 从 Evernote 导入文件
|
||||
* 导出 JEX 文件(Joplin 导出格式)和原始文件。
|
||||
* 支持笔记、待办事项、标签和笔记本。
|
||||
* 任意跳转功能。
|
||||
* 支持移动设备和桌面应用通知。
|
||||
* 地理位置支持。
|
||||
* 支持多种语言
|
||||
* 外部编辑器支持–在 Joplin 中一键用你最喜欢的编辑器打开笔记。
|
||||
|
||||
|
||||
### Installing Joplin on Linux and other platforms
|
||||
### 在 Linux 和其它平台上安装 Joplin
|
||||
|
||||
![][10]
|
||||
|
||||
@ -64,23 +61,23 @@ Joplin 可以导入 enex 格式的 Evernote 文件, 这让从 Evernote 切换
|
||||
|
||||
在 Linux 中,你可以获取 Joplin 的 [AppImage][14] 文件,并作为可执行文件运行。你需要为下载的文件授予执行权限。
|
||||
|
||||
[Download Joplin][15]
|
||||
- [下载 Joplin][15]
|
||||
|
||||
### 体验 Joplin
|
||||
|
||||
Joplin 中的笔记使用 markdown,但你不需要了解它。编辑器的顶部面板能让你以图形方式选择项目符号、标题、图像、链接等。
|
||||
Joplin 中的笔记使用 Markdown,但你不需要了解它。编辑器的顶部面板能让你以图形方式选择项目符号、标题、图像、链接等。
|
||||
|
||||
虽然 Joplin 提供了许多有趣的功能,但你需要自己去尝试。例如,默认情况下未启用 Web 剪切板,我需要发现如何打开它。
|
||||
|
||||
你需要从桌面应用启用剪切板。在顶部菜单中,进入 “Tools->Options”。你可以在此处找到 Web 剪切板选项:
|
||||
你需要从桌面应用启用剪切板。在顶部菜单中,进入 “Tools->Options”。你可以在此处找到 Web 剪切板选项:
|
||||
|
||||
![Enable Web Clipper from the desktop application first][16]
|
||||
|
||||
它的 Web 剪切板不如 Evernote 的 Web 剪切板聪明,后者可以以图形方式剪辑网页文章的一部分。但是,它也足够了。
|
||||
它的 Web 剪切板不如 Evernote 的 Web 剪切板聪明,后者可以以图形方式剪辑网页文章的一部分。但是,也足够了。
|
||||
|
||||
这是一个在积极开发中的开源软件,我希望它随着时间的推移得到更多的改进。
|
||||
这是一个在活跃开发中的开源软件,我希望它随着时间的推移得到更多的改进。
|
||||
|
||||
**总结**
|
||||
### 总结
|
||||
|
||||
如果你正在寻找一个不错的拥有 Web 剪切板的笔记应用,你可以试试 Joplin。如果你喜欢它,并将继续使用,尝试通过捐赠或改进代码和文档来帮助 Joplin 开发。我以 FOSS 的名义[捐赠][17]了 25 欧。
|
||||
|
||||
@ -93,7 +90,7 @@ via: https://itsfoss.com/joplin/
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,92 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11915-1.html)
|
||||
[#]: subject: (Meet FuryBSD: A New Desktop BSD Distribution)
|
||||
[#]: via: (https://itsfoss.com/furybsd/)
|
||||
[#]: author: (John Paul https://itsfoss.com/author/john/)
|
||||
|
||||
认识 FuryBSD:一个新的桌面 BSD 发行版
|
||||
======
|
||||
|
||||
在过去的几个月中,出现了一些新的桌面 BSD。之前有 [HyperbolaBSD,它之前是 Hyperbola GNU/Linux][1]。[BSD][2] 世界中的另一个新入者是 [FuryBSD][3]。
|
||||
|
||||
### FuryBSD:一个新的 BSD 发行版
|
||||
|
||||
![][4]
|
||||
|
||||
从本质上讲,FuryBSD 是一个非常简单的小东西。根据[它的网站][5]:“FuryBSD 一个是基于 FreeBSD 的轻量级桌面发行版。” 它基本上是预配置了桌面环境,并预安装了多个应用的 FreeBSD。目地是快速地在你的计算机上运行基于 FreeBSD 的系统。
|
||||
|
||||
你可能会认为这听起来很像其他几个已有的 BSD,例如 [NomadBSD][6] 和 [GhostBSD][7]。这些 BSD 与 FuryBSD 之间的主要区别在于 FuryBSD 与现有的 FreeBSD 更加接近。例如,FuryBSD 使用 FreeBSD 安装程序,而其他发行版则用了自己的安装程序和工具。
|
||||
|
||||
正如[它的网站][8]所说:“尽管 FuryBSD 可能类似于 PC-BSD 和 TrueOS 等图形化 BSD 项目,但 FuryBSD 是由不同的团队创建的,并且采用了不同与 FreeBSD 着重于紧密集成的方法。这样可以降低开销,并保持与上游的兼容性。”开发负责人还告诉我:“FuryBSD 的一个主要重点是使其成为一种小型现场版介质,并带有一些测试硬件驱动程序的辅助工具。”
|
||||
|
||||
当前,你可以进入 [FuryBSD 主页][3]并下载 XFCE 或 KDE 的 LiveCD。GNOME 版本正在开发中。
|
||||
|
||||
### FuryBSD 的背后是谁
|
||||
|
||||
FuryBSD 的主要开发者是 [Joe Maloney][9]。Joe 多年来一直是 FreeBSD 的用户。他为 PC-BSD 等其他 BSD 项目做过贡献。他还与 GhostBSD 的创建者 Eric Turgeon 一起重写了 GhostBSD LiveCD。在此过程中,他对 BSD 有了更好的了解,并开始形成自己如何做一个发行版的想法。
|
||||
|
||||
Joe 与其他参与 BSD 世界多年的开发者一起加入了开发,例如 Jaron Parsons、Josh Smith 和 Damian Szidiropulosz。
|
||||
|
||||
### FuryBSD 的未来
|
||||
|
||||
目前,FuryBSD 仅仅是预配置的 FreeBSD。但是,开发者有一份[要改进的清单][5]。包括:
|
||||
|
||||
* 可靠的加载框架、第三方专有图形驱动、无线网络
|
||||
* 进一步整理 LiveCD 体验,以使其更加友好
|
||||
* 开箱即用的打印支持
|
||||
* 包含更多默认应用,以提供完整的桌面体验
|
||||
* 集成的 [ZFS][10] 复制工具,用于备份和还原
|
||||
* Live 镜像持久化选项
|
||||
* 默认自定义 pkg 仓库
|
||||
* 用于应用更新的持续集成
|
||||
* 桌面 FreeBSD 的质量保证
|
||||
* 自定义、色彩方案和主题
|
||||
* 目录服务集成
|
||||
* 安全加固
|
||||
|
||||
开发者非常清楚地表明,他们所做的任何更改都需要大量的思考和研究。他们不会改进某个功能,只会在它破坏一些东西时删除或者修改它。
|
||||
|
||||
![FuryBSD desktop][11]
|
||||
|
||||
### 你可以如何帮助 FuryBSD?
|
||||
|
||||
目前,该项目还很年轻。由于所有项目都需要帮助才能生存,所以我问 Joe 他们正在寻求什么样的帮助。他说:“我们可以帮助[在论坛上回答问题][12]、回答 [GitHub][13] 上的问题,完善文档。”他还说如果人们想增加对其他桌面环境的支持,欢迎发起拉取请求。
|
||||
|
||||
### 最后的想法
|
||||
|
||||
尽管我还没有尝试过,但是我对 FuryBSD 感觉不错。听起来项目在掌握中。十多年来,Joe Maloney 一直在思考如何达到最佳的 BSD 桌面体验。与大多数 Linux 发行版基本上都是经过重新设计的 Ubuntu 不同,FuryBSD 背后的开发者知道他们在做什么,并且他们在更看重质量而不是花哨的功能。
|
||||
|
||||
你对这个在不断增长的桌面 BSD 市场的新入者怎么看?你尝试过 FuryBSD 或者会尝试一下吗?请在下面的评论中告诉我们。
|
||||
|
||||
如果你觉得这篇文章有趣,请在 Hacker News 或 [Reddit][14] 等社交媒体上分享它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/furybsd/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/hyperbola-linux-bsd/
|
||||
[2]: https://itsfoss.com/bsd/
|
||||
[3]: https://www.furybsd.org/
|
||||
[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/01/fury-bsd.jpg?ssl=1
|
||||
[5]: https://www.furybsd.org/manifesto/
|
||||
[6]: https://itsfoss.com/nomadbsd/
|
||||
[7]: https://ghostbsd.org/
|
||||
[8]: https://www.furybsd.org/furybsd-video-overview-at-knoxbug/
|
||||
[9]: https://github.com/pkgdemon
|
||||
[10]: https://itsfoss.com/what-is-zfs/
|
||||
[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/01/FuryBSDS-desktop.jpg?resize=800%2C450&ssl=1
|
||||
[12]: https://forums.furybsd.org/
|
||||
[13]: https://github.com/furybsd
|
||||
[14]: https://reddit.com/r/linuxusersgroup
|
||||
@ -0,0 +1,83 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qianmingtian)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11902-1.html)
|
||||
[#]: subject: (Give an old MacBook new life with Linux)
|
||||
[#]: via: (https://opensource.com/article/20/2/macbook-linux-elementary)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||
|
||||
用 Linux 让旧 MacBook 焕发新生
|
||||
======
|
||||
|
||||
> Elementary OS 的最新版本 Hera 是一个令人印象深刻的平台,它可以让过时的 MacBook 得以重生。
|
||||
|
||||
|
||||
|
||||
当我安装苹果的 [MacOS Mojave][2] 时,它使我以前可靠的 MacBook Air 慢得像爬一样。我的计算机发售于 2015 年,具有 4 GB 内存、i5 处理器和 Broadcom 4360 无线卡,但是对于我的日常使用来说,Mojava 有点过分了,它不能和 [GnuCash][3] 一起工作,这激起了我重返 Linux 的欲望。我很高兴能重返,但是我深感遗憾的是,我的这台出色的 MacBook 被闲置了。
|
||||
|
||||
我在 MacBook Air 上尝试了几种 Linux 发行版,但总会有缺陷。有时是无线网卡;还有一次,它缺少对触摸板的支持。看了一些不错的评论后,我决定尝试 [Elementary OS][4] 5.0(Juno)。我用 USB [制作了启动盘][5],并将其插入 MacBook Air 。我来到了一个<ruby>现场<rt>live</rt></ruby>桌面,并且操作系统识别出了我的 Broadcom 无线芯片组 —— 我认为这可能行得通!
|
||||
|
||||
我喜欢在 Elementary OS 中看到的内容。它的 [Pantheon][6] 桌面真的很棒,并且其外观和使用起来的感觉对 Apple 用户来说很熟悉 —— 它的显示屏底部有一个扩展坞,并带有一些指向常用应用程序的图标。我对我之前期待的预览感到满意,所以我决定安装它,然后我的无线设备消失了。真的很令人失望。我真的很喜欢 Elementary OS ,但是没有无线网络是不行的。
|
||||
|
||||
时间快进到 2019 年 12 月,当我在 [Linux4Everyone][7] 播客上听到有关 Elementary 最新版本 v.5.1(Hera) 使 MacBook 复活的评论时,我决定用 Hera 再试一次。我下载了 ISO ,创建了可启动驱动器,将其插入电脑,这次操作系统识别了我的无线网卡。我可以在上面工作了。
|
||||
|
||||
![运行 Hera 的 MacBook Air][8]
|
||||
|
||||
我非常高兴我轻巧又功能强大的 MacBook Air 通过 Linux 焕然一新。我一直在更详细地研究 Elementary OS,我可以告诉你我印象深刻的东西。
|
||||
|
||||
### Elementary OS 的功能
|
||||
|
||||
根据 [Elementary 的博客][9],“新设计的登录和锁定屏幕问候语看起来更清晰、效果更好,并且修复了以前问候语中报告的许多问题,包括输入焦点问题,HiDPI 问题和更好的本地化。Hera 的新设计是为了响应来自 Juno 的用户反馈,并启用了一些不错的新功能。”
|
||||
|
||||
“不错的新功能”是在轻描淡写 —— Elementary OS 拥有我见过的最佳设计的 Linux 用户界面之一。默认情况下,系统上的“系统设置”图标位于扩展坞上。更改设置很容易,很快我就按照自己的喜好配置了系统。我需要的文字大小比默认值大,辅助功能是易于使用的,允许我设置大文字和高对比度。我还可以使用较大的图标和其他选项来调整扩展坞。
|
||||
|
||||
![Elementary OS 的设置界面][10]
|
||||
|
||||
按下 Mac 的 Command 键将弹出一个键盘快捷键列表,这对新用户非常有帮助。
|
||||
|
||||
![Elementary OS 的键盘快捷键][11]
|
||||
|
||||
Elementary OS 附带的 [Epiphany][12] Web 浏览器,我发现它非常易于使用。它与 Chrome、Chromium 或 Firefox 略有不同,但它已经绰绰有余。
|
||||
|
||||
对于注重安全的用户(我们应该都是),Elementary OS 的安全和隐私设置提供了多个选项,包括防火墙、历史记录、锁定,临时和垃圾文件的自动删除以及用于位置服务开/关的开关。
|
||||
|
||||
![Elementary OS 的隐私与安全][13]
|
||||
|
||||
### 有关 Elementray OS 的更多信息
|
||||
|
||||
Elementary OS 最初于 2011 年发布,其最新版本 Hera 于 2019 年 12 月 3 日发布。 Elementary 的联合创始人兼 CXO 的 [Cassidy James Blaede][14] 是操作系统的 UX 架构师。 Cassidy 喜欢使用开放技术来设计和构建有用、可用和令人愉悦的数字产品。
|
||||
|
||||
Elementary OS 具有出色的用户[文档][15],其代码(在 GPL 3.0 下许可)可在 [GitHub][16] 上获得。Elementary OS 鼓励参与该项目,因此请务必伸出援手并[加入社区][17]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/macbook-linux-elementary
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qianmingtian][c]
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[b]: https://github.com/lujun9972
|
||||
[c]: https://github.com/qianmingtian
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/coffee_cafe_brew_laptop_desktop.jpg?itok=G-n1o1-o (Coffee and laptop)
|
||||
[2]: https://en.wikipedia.org/wiki/MacOS_Mojave
|
||||
[3]: https://www.gnucash.org/
|
||||
[4]: https://elementary.io/
|
||||
[5]: https://opensource.com/life/14/10/test-drive-linux-nothing-flash-drive
|
||||
[6]: https://opensource.com/article/19/12/pantheon-linux-desktop
|
||||
[7]: https://www.linux4everyone.com/20-macbook-pro-elementary-os
|
||||
[8]: https://opensource.com/sites/default/files/uploads/macbookair_hera.png (MacBook Air with Hera)
|
||||
[9]: https://blog.elementary.io/introducing-elementary-os-5-1-hera/
|
||||
[10]: https://opensource.com/sites/default/files/uploads/elementaryos_settings.png (Elementary OS's Settings screen)
|
||||
[11]: https://opensource.com/sites/default/files/uploads/elementaryos_keyboardshortcuts.png (Elementary OS's Keyboard shortcuts)
|
||||
[12]: https://en.wikipedia.org/wiki/GNOME_Web
|
||||
[13]: https://opensource.com/sites/default/files/uploads/elementaryos_privacy-security.png (Elementary OS's Privacy and Security screen)
|
||||
[14]: https://github.com/cassidyjames
|
||||
[15]: https://elementary.io/docs/learning-the-basics#learning-the-basics
|
||||
[16]: https://github.com/elementary
|
||||
[17]: https://elementary.io/get-involved
|
||||
@ -0,0 +1,158 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (guevaraya)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11930-1.html)
|
||||
[#]: subject: (Troubleshoot Kubernetes with the power of tmux and kubectl)
|
||||
[#]: via: (https://opensource.com/article/20/2/kubernetes-tmux-kubectl)
|
||||
[#]: author: (Abhishek Tamrakar https://opensource.com/users/tamrakar)
|
||||
|
||||
利用 Tmux 和 kubectl 解决 Kubernetes 故障
|
||||
======
|
||||
|
||||
> 一个使用 tmux 的 kubectl 插件可以使 Kubernetes 疑难问题变得更简单。
|
||||
|
||||

|
||||
|
||||
[Kubernetes][2] 是一个活跃的开源容器管理平台,它提供了可扩展性、高可用性、健壮性和富有弹性的应用程序管理。它的众多特性之一是支持通过其主要的二进制客户端 [kubectl][3] 运行定制脚本或可执行程序,kubectl 很强大的,允许用户在 Kubernetes 集群上用它直接做很多事情。
|
||||
|
||||
### 使用别名进行 Kubernetes 的故障排查
|
||||
|
||||
使用 Kubernetes 进行容器编排的人都知道由于设计上原因带来了其功能的复杂性。举例说,迫切需要以更快的速度并且几乎不需要手动干预的方式来简化 Kubernetes 中的故障排除(除过特殊情况)。
|
||||
|
||||
在故障排查功能方面,有很多场景需要考虑。在一种场景下,你知道你需要运行什么,但是这个命令的语法(即使作为一个单独的命令运行)过于复杂,或需要一、两次交互才能起作用。
|
||||
|
||||
例如,如果你需要经常进入一个系统命名空间中运行的容器,你可能发现自己在重复地键入:
|
||||
|
||||
```
|
||||
kubectl --namespace=kube-system exec -i -t <your-pod-name>
|
||||
```
|
||||
|
||||
为了简化故障排查,你可以用这些指令的命令行别名。比如,你可以增加下面命令到你的隐藏配置文件(`.bashrc` 或 `.zshrc`):
|
||||
|
||||
```
|
||||
alias ksysex='kubectl --namespace=kube-system exec -i -t'
|
||||
```
|
||||
|
||||
这是来自于 [Kubernetes 常见别名][4]存储库的一个例子,它展示了一种简化 `kubectl` 中的功能的方法。像这种场景下的简单情形,使用别名很有用。
|
||||
|
||||
### 切换到 kubectl 插件
|
||||
|
||||
更复杂的故障排查场景是需要一个一个的执行很多命令,调查环境,最后得出结论。仅仅用别名方法是不能解决这种情况的;你需要知道你所部署的 Kubernetes 之间逻辑和相关性,你真正需要的是自动化,以在更短的时间内输出你想要的。
|
||||
|
||||
考虑到你的集群有 10 ~ 20 或 50 ~ 100 个命名空间来提供不同的微服务。一般在进行故障排查时,什么对你有帮助?
|
||||
|
||||
* 你需要能够快速分辨出抛出错误的是哪个 命名空间的哪个 Pod 的东西。
|
||||
* 你需要一些可监视一个命名空间的所有 Pod 日志的东西。
|
||||
* 你可能也需要监视特定命名空间的出现错误的某个 Pod 的日志。
|
||||
|
||||
涵盖这些要点的解决方案对于定位生产环境的问题有很大的帮助,以及在开发和测试环节中也很有用。
|
||||
|
||||
你可以用 [kubectl 插件][5]创建比简单的别名更强大的功能。插件类似于其它用任何语言编写的独立脚本,但被设计为可以扩充 Kubernetes 管理员的主要命令。
|
||||
|
||||
创建一个插件,你必须用 `kubectl-<your-plugin-name>` 的正确的语法来拷贝这个脚本到 `$PATH` 中的导出目录之一,并需要为其赋予可执行权限(`chmod +x`)。
|
||||
|
||||
创建插件之后将其移动到路径中,你可以立即运行它。例如,我的路径下有一个 `kubectl-krawl` 和 `kubectl-kmux`:
|
||||
|
||||
```
|
||||
$ kubectl plugin list
|
||||
The following compatible plugins are available:
|
||||
|
||||
/usr/local/bin/kubectl-krawl
|
||||
/usr/local/bin/kubectl-kmux
|
||||
|
||||
$ kubectl kmux
|
||||
```
|
||||
|
||||
现在让我们见识下带有 tmux 的 Kubernetes 的有多强大。
|
||||
|
||||
### 驾驭强大的 tmux
|
||||
|
||||
[Tmux][6] 是一个非常强大的工具,许多管理员和运维团队都依赖它来解决与易操作性相关的问题:通过将窗口分成多个窗格以便在多台计算机上运行并行的调试来监视日志。它的主要的优点是可在命令行或自动化脚本中使用。
|
||||
|
||||
我创建[一个 kubectl 插件][7],使用 tmux 使故障排查更加简单。我将通过注释来解析插件背后的逻辑(插件的完整代码留待给你实现):
|
||||
|
||||
```
|
||||
# NAMESPACE 是要监控的名字空间
|
||||
# POD 是 Pod 名称
|
||||
# Containers 是容器名称
|
||||
|
||||
# 初始化一个计数器 n 以计算循环计数的数量,
|
||||
# 之后 tmux 使用它来拆分窗格。
|
||||
n=0;
|
||||
|
||||
# 在 Pod 和容器列表上开始循环
|
||||
while IFS=' ' read -r POD CONTAINERS
|
||||
do
|
||||
# tmux 为每个 Pod 创建一个新窗口
|
||||
tmux neww $COMMAND -n $POD 2>/dev/null
|
||||
# 对运行中的 Pod 中 的所有容器启动循环
|
||||
for CONTAINER in ${CONTAINERS//,/ }
|
||||
do
|
||||
if [ x$POD = x -o x$CONTAINER = x ]; then
|
||||
# 如果任何值为 null,则退出。
|
||||
warn "Looks like there is a problem getting pods data."
|
||||
break
|
||||
fi
|
||||
|
||||
# 设置要执行的命令
|
||||
COMMAND=”kubectl logs -f $POD -c $CONTAINER -n $NAMESPACE”
|
||||
# 检查 tmux 会话
|
||||
if tmux has-session -t <会话名> 2>/dev/null;
|
||||
then
|
||||
<设置会话退出>
|
||||
else
|
||||
<创建会话>
|
||||
fi
|
||||
# 在当前窗口为每个容器切分窗格
|
||||
tmux selectp -t $n \; \
|
||||
splitw $COMMAND \; \
|
||||
select-layout tiled \;
|
||||
# 终止容器循环
|
||||
done
|
||||
|
||||
# 用 Pod 名称重命名窗口以识别
|
||||
tmux renamew $POD 2>/dev/null
|
||||
|
||||
# 增加计数器
|
||||
((n+=1))
|
||||
|
||||
# 终止 Pod 循环
|
||||
done<<(<从 kubernetes 集群获取 Pod 和容器的列表>)
|
||||
|
||||
# 最后选择窗口并附加会话
|
||||
tmux selectw -t <会话名>:1 \; \
|
||||
attach-session -t <会话名>\;
|
||||
```
|
||||
|
||||
运行插件脚本后,将产生类似于下图的输出。每个 Pod 有一个自己的窗口,每个容器(如果有多个)被分割到其窗口中 Pod 窗格中,并在日志到达时输出。Tmux 之美如下可见;通过正确的配置,你甚至会看到哪个窗口正处于激活运行状态(可看到标签是白色的)。
|
||||
|
||||
![kmux 插件的输出][8]
|
||||
|
||||
### 总结
|
||||
|
||||
别名是在 Kubernetes 环境下常见的也有用的简易故障排查方法。当环境变得复杂,用高级脚本生成的kubectl 插件是一个更强大的方法。至于用哪个编程语言来编写 kubectl 插件是没有限制。唯一的要求是该名字在路径中是可执行的,并且不能与已知的 kubectl 命令重复。
|
||||
|
||||
要阅读完整的插件源码,或试试我创建的插件,请查看我的 [kube-plugins-github][7] 存储库。欢迎提交提案和补丁。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/kubernetes-tmux-kubectl
|
||||
|
||||
作者:[Abhishek Tamrakar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[guevaraya](https://github.com/guevaraya)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/tamrakar
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/OSDC_women_computing_4.png?itok=VGZO8CxT (一个坐在笔记本面前的妇女)
|
||||
[2]: https://opensource.com/resources/what-is-kubernetes
|
||||
[3]: https://kubernetes.io/docs/reference/kubectl/overview/
|
||||
[4]: https://github.com/ahmetb/kubectl-aliases/blob/master/.kubectl_aliases
|
||||
[5]: https://kubernetes.io/docs/tasks/extend-kubectl/kubectl-plugins/
|
||||
[6]: https://opensource.com/article/19/6/tmux-terminal-joy
|
||||
[7]: https://github.com/abhiTamrakar/kube-plugins
|
||||
[8]: https://raw.githubusercontent.com/abhiTamrakar/kube-plugins/master/kmux/kmux.png
|
||||
218
published/20200206 3 ways to use PostgreSQL commands.md
Normal file
218
published/20200206 3 ways to use PostgreSQL commands.md
Normal file
@ -0,0 +1,218 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Morisun029)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11904-1.html)
|
||||
[#]: subject: (3 ways to use PostgreSQL commands)
|
||||
[#]: via: (https://opensource.com/article/20/2/postgresql-commands)
|
||||
[#]: author: (Greg Pittman https://opensource.com/users/greg-p)
|
||||
|
||||
3 种使用 PostgreSQL 命令的方式
|
||||
======
|
||||
|
||||
> 无论你需要的东西简单(如一个购物清单)亦或复杂(如色卡生成器) ,PostgreSQL 命令都能使它变得容易起来。
|
||||
|
||||

|
||||
|
||||
在 [PostgreSQL 入门][2]一文中, 我解释了如何安装、设置和开始使用这个开源数据库软件。不过,使用 [PostgreSQL][3] 中的命令可以做更多事情。
|
||||
|
||||
例如,我使用 Postgres 来跟踪我的杂货店购物清单。我的大多数杂货店购物是在家里进行的,而且每周进行一次大批量的采购。我去几个不同的地方购买清单上的东西,因为每家商店都提供特定的选品或质量,亦或更好的价格。最初,我制作了一个 HTML 表单页面来管理我的购物清单,但这样无法保存我的输入内容。因此,在想到要购买的物品时我必须马上列出全部清单,然后到采购时我常常会忘记一些我需要或想要的东西。
|
||||
|
||||
相反,使用 PostgreSQL,当我想到需要的物品时,我可以随时输入,并在购物前打印出来。你也可以这样做。
|
||||
|
||||
### 创建一个简单的购物清单
|
||||
|
||||
首先,输入 `psql` 命令进入数据库,然后用下面的命令创建一个表:
|
||||
|
||||
```
|
||||
Create table groc (item varchar(20), comment varchar(10));
|
||||
```
|
||||
|
||||
输入如下命令在清单中加入商品:
|
||||
|
||||
```
|
||||
insert into groc values ('milk', 'K');
|
||||
insert into groc values ('bananas', 'KW');
|
||||
```
|
||||
|
||||
括号中有两个信息(逗号隔开):前面是你需要买的东西,后面字母代表你要购买的地点以及哪些东西是你每周通常都要买的(`W`)。
|
||||
|
||||
因为 `psql` 有历史记录,你可以按向上键在括号内编辑信息,而无需输入商品的整行信息。
|
||||
|
||||
在输入一小部分商品后,输入下面命令来检查前面的输入内容。
|
||||
|
||||
```
|
||||
Select * from groc order by comment;
|
||||
|
||||
item | comment
|
||||
----------------+---------
|
||||
ground coffee | H
|
||||
butter | K
|
||||
chips | K
|
||||
steak | K
|
||||
milk | K
|
||||
bananas | KW
|
||||
raisin bran | KW
|
||||
raclette | L
|
||||
goat cheese | L
|
||||
onion | P
|
||||
oranges | P
|
||||
potatoes | P
|
||||
spinach | PW
|
||||
broccoli | PW
|
||||
asparagus | PW
|
||||
cucumber | PW
|
||||
sugarsnap peas | PW
|
||||
salmon | S
|
||||
(18 rows)
|
||||
```
|
||||
|
||||
此命令按 `comment` 列对结果进行排序,以便按购买地点对商品进行分组,从而使你的购物更加方便。
|
||||
|
||||
使用 `W` 来指明你每周要买的东西,当你要清除表单为下周的列表做准备时,你可以将每周的商品保留在购物清单上。输入:
|
||||
|
||||
```
|
||||
delete from groc where comment not like '%W';
|
||||
```
|
||||
|
||||
注意,在 PostgreSQL 中 `%` 表示通配符(而非星号)。所以,要保存输入内容,需要输入:
|
||||
|
||||
```
|
||||
delete from groc where item like 'goat%';
|
||||
```
|
||||
|
||||
不能使用 `item = 'goat%'`,这样没用。
|
||||
|
||||
在购物时,用以下命令输出清单并打印或发送到你的手机:
|
||||
|
||||
```
|
||||
\o groclist.txt
|
||||
select * from groc order by comment;
|
||||
\o
|
||||
```
|
||||
|
||||
最后一个命令 `\o` 后面没有任何内容,将重置输出到命令行。否则,所有的输出会继续输出到你创建的杂货店购物文件 `groclist.txt` 中。
|
||||
|
||||
### 分析复杂的表
|
||||
|
||||
这个逐项列表对于数据量小的表来说没有问题,但是对于数据量大的表呢?几年前,我帮 [FreieFarbe.de][4] 的团队从 HLC 调色板中创建一个自由色的色样册。事实上,任何能想象到的打印色都可按色调、亮度、浓度(饱和度)来规定。最终结果是 [HLC Color Atlas][5],下面是我们如何实现的。
|
||||
|
||||
该团队向我发送了具有颜色规范的文件,因此我可以编写可与 Scribus 配合使用的 Python 脚本,以轻松生成色样册。一个例子像这样开始:
|
||||
|
||||
```
|
||||
HLC, C, M, Y, K
|
||||
H010_L15_C010, 0.5, 49.1, 0.1, 84.5
|
||||
H010_L15_C020, 0.0, 79.7, 15.1, 78.9
|
||||
H010_L25_C010, 6.1, 38.3, 0.0, 72.5
|
||||
H010_L25_C020, 0.0, 61.8, 10.6, 67.9
|
||||
H010_L25_C030, 0.0, 79.5, 18.5, 62.7
|
||||
H010_L25_C040, 0.4, 94.2, 17.3, 56.5
|
||||
H010_L25_C050, 0.0, 100.0, 15.1, 50.6
|
||||
H010_L35_C010, 6.1, 32.1, 0.0, 61.8
|
||||
H010_L35_C020, 0.0, 51.7, 8.4, 57.5
|
||||
H010_L35_C030, 0.0, 68.5, 17.1, 52.5
|
||||
H010_L35_C040, 0.0, 81.2, 22.0, 46.2
|
||||
H010_L35_C050, 0.0, 91.9, 20.4, 39.3
|
||||
H010_L35_C060, 0.1, 100.0, 17.3, 31.5
|
||||
H010_L45_C010, 4.3, 27.4, 0.1, 51.3
|
||||
```
|
||||
|
||||
这与原始数据相比,稍有修改,原始数据用制表符分隔。我将其转换成 CSV 格式(用逗号分割值),我更喜欢其与 Python 一起使用(CSV 文也很有用,因为它可轻松导入到电子表格程序中)。
|
||||
|
||||
在每一行中,第一项是颜色名称,其后是其 C、M、Y 和 K 颜色值。 该文件包含 1,793 种颜色,我想要一种分析信息的方法,以了解这些值的范围。这就是 PostgreSQL 发挥作用的地方。我不想手动输入所有数据 —— 我认为输入过程中我不可能不出错,而且令人头痛。幸运的是,PostgreSQL 为此提供了一个命令。
|
||||
|
||||
首先用以下命令创建数据库:
|
||||
|
||||
```
|
||||
Create table hlc_cmyk (color varchar(40), c decimal, m decimal, y decimal, k decimal);
|
||||
```
|
||||
|
||||
然后通过以下命令引入数据:
|
||||
|
||||
```
|
||||
\copy hlc_cmyk from '/home/gregp/HLC_Atlas_CMYK_SampleData.csv' with (header, format CSV);
|
||||
```
|
||||
|
||||
开头有反斜杠,是因为使用纯 `copy` 命令的权限仅限于 root 用户和 Postgres 的超级用户。在括号中,`header` 表示第一行包含标题,应忽略,`CSV` 表示文件格式为 CSV。请注意,在此方法中,颜色名称不需要用括号括起来。
|
||||
|
||||
如果操作成功,会看到 `COPY NNNN`,其中 N 表示插入到表中的行数。
|
||||
|
||||
最后,可以用下列命令查询:
|
||||
|
||||
```
|
||||
select * from hlc_cmyk;
|
||||
|
||||
color | c | m | y | k
|
||||
---------------+-------+-------+-------+------
|
||||
H010_L15_C010 | 0.5 | 49.1 | 0.1 | 84.5
|
||||
H010_L15_C020 | 0.0 | 79.7 | 15.1 | 78.9
|
||||
H010_L25_C010 | 6.1 | 38.3 | 0.0 | 72.5
|
||||
H010_L25_C020 | 0.0 | 61.8 | 10.6 | 67.9
|
||||
H010_L25_C030 | 0.0 | 79.5 | 18.5 | 62.7
|
||||
H010_L25_C040 | 0.4 | 94.2 | 17.3 | 56.5
|
||||
H010_L25_C050 | 0.0 | 100.0 | 15.1 | 50.6
|
||||
H010_L35_C010 | 6.1 | 32.1 | 0.0 | 61.8
|
||||
H010_L35_C020 | 0.0 | 51.7 | 8.4 | 57.5
|
||||
H010_L35_C030 | 0.0 | 68.5 | 17.1 | 52.5
|
||||
```
|
||||
|
||||
|
||||
所有的 1,793 行数据都是这样的。回想起来,我不能说此查询对于 HLC 和 Scribus 任务是绝对必要的,但是它减轻了我对该项目的一些担忧。
|
||||
|
||||
为了生成 HLC 色谱,我使用 Scribus 为色板页面中的 13,000 多种颜色自动创建了颜色图表。
|
||||
|
||||
我可以使用 `copy` 命令输出数据:
|
||||
|
||||
```
|
||||
\copy hlc_cmyk to '/home/gregp/hlc_cmyk_backup.csv' with (header, format CSV);
|
||||
```
|
||||
|
||||
我还可以使用 `where` 子句根据某些值来限制输出。
|
||||
|
||||
例如,以下命令将仅发送以 `H10` 开头的色调值。
|
||||
|
||||
```
|
||||
\copy hlc_cmyk to '/home/gregp/hlc_cmyk_backup.csv' with (header, format CSV) where color like 'H10%';
|
||||
```
|
||||
|
||||
### 备份或传输数据库或表
|
||||
|
||||
我在此要提到的最后一个命令是 `pg_dump`,它用于备份 PostgreSQL 数据库,并在 `psql` 控制台之外运行。 例如:
|
||||
|
||||
```
|
||||
pg_dump gregp -t hlc_cmyk > hlc.out
|
||||
pg_dump gregp > dball.out
|
||||
```
|
||||
|
||||
第一行是导出 `hlc_cmyk` 表及其结构。第二行将转储 `gregp` 数据库中的所有表。这对于备份或传输数据库或表非常有用。
|
||||
|
||||
要将数据库或表传输到另一台电脑(查看 [PostgreSQL 入门][2]那篇文章获取详细信息),首先在要转入的电脑上创建一个数据库,然后执行相反的操作。
|
||||
|
||||
```
|
||||
psql -d gregp -f dball.out
|
||||
```
|
||||
|
||||
一步创建所有表并输入数据。
|
||||
|
||||
### 总结
|
||||
|
||||
在本文中,我们了解了如何使用 `WHERE` 参数限制操作,以及如何使用 PostgreSQL 通配符 `%`。我们还了解了如何将大批量数据加载到表中,然后将部分或全部表数据输出到文件,甚至是将整个数据库及其所有单个表输出。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/postgresql-commands
|
||||
|
||||
作者:[Greg Pittman][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Morisun029](https://github.com/Morisun029)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/greg-p
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/todo_checklist_team_metrics_report.png?itok=oB5uQbzf (Team checklist and to dos)
|
||||
[2]: https://linux.cn/article-11593-1.html
|
||||
[3]: https://www.postgresql.org/
|
||||
[4]: http://freiefarbe.de
|
||||
[5]: https://www.freiefarbe.de/en/thema-farbe/hlc-colour-atlas/
|
||||
@ -0,0 +1,112 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (chai-yuan)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11897-1.html)
|
||||
[#]: subject: (Connect Fedora to your Android phone with GSConnect)
|
||||
[#]: via: (https://fedoramagazine.org/connect-fedora-to-your-android-phone-with-gsconnect/)
|
||||
[#]: author: (Lokesh Krishna https://fedoramagazine.org/author/lowkeyskywalker/)
|
||||
|
||||
使用 GSConnect 将 Android 手机连接到 Fedora 系统
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
苹果和微软公司都不同程度的提供了桌面产品与移动设备集成。Fedora 提供了类似甚至更高集成度的工具——GSConnect。它可以让你将安卓手机和你的 Fedora 桌面配对并使用。请继续阅读,以了解更多关于它的情况以及它是如何工作的信息。
|
||||
|
||||
### GSConnect 是什么?
|
||||
|
||||
GSConnect 是针对 GNOME 桌面定制的 KDE Connect 程序。KDE Connect 可以使你的设备能够互相通信。但是,在 Fedora 默认的 GNOME 桌面上安装它需要安装大量的 KDE 依赖。
|
||||
|
||||
GSConnect 是一个 KDE Connect 的完整实现,其以 GNOME shell 的拓展形式出现。安装后,GSConnect 允许你执行以下操作及更多:
|
||||
|
||||
* 在计算机上接收电话通知并回复信息
|
||||
* 用手机操纵你的桌面
|
||||
* 在不同设备之间分享文件与链接
|
||||
* 在计算机上查看手机电量
|
||||
* 让手机响铃以便你能找到它
|
||||
|
||||
### 设置 GSConnect 扩展
|
||||
|
||||
设置 GSConnect 需要安装两个组件:计算机上的 GSConnect 扩展和 Android 设备上的 KDE Connect 应用。
|
||||
|
||||
首先,从 GNOME Shell 扩展网站上安装 [GSConnect][2] 扩展。(Fedora Magazine 有一篇关于[如何安装 GNOME Shell 扩展][3]的文章,可以帮助你完成这一步。)
|
||||
|
||||
KDE Connect 应用程序可以在 Google 的 [Play 商店][4]上找到。它也可以在 FOSS Android 应用程序库 [F-Droid][5] 上找到。
|
||||
|
||||
一旦安装了这两个组件,就可以配对两个设备。安装扩展后它在你的系统菜单中显示为“<ruby>移动设备<rt>Mobile Devices</rt></ruby>”。单击它会出现一个下拉菜单,你可以从中访问“<ruby>移动设置<rt>Mobile Settings</rt></ruby>”。
|
||||
|
||||
![][6]
|
||||
|
||||
你可以在这里用 GSConnect 查看并管理已配对的设备。进入此界面后,需要在 Android 设备上启动应用程序。
|
||||
|
||||
你可以在任意一台设备上进行配对初始化,在这里我们从 Android 设备连接到计算机。点击应用程序上的“刷新”,只要两个设备都在同一个无线网络环境中,你的 Android 设备便可以搜索到你的计算机。现在可以向桌面发送配对请求,并在桌面上接受配对请求以完成配对。
|
||||
|
||||
![][7]
|
||||
|
||||
### 使用 GSConnect
|
||||
|
||||
配对后,你将需要在 Android 设备授予权限,才能使用 GSConnect 上提供的许多功能。单击设备列表中的已配对设备,便可以查看所有可用功能,并根据你的偏好和需要启用或禁用它们。
|
||||
|
||||
![][8]
|
||||
|
||||
请记住,你还需要在这个 Android 应用程序中授予相应的权限才能使用这些功能。启用权限后,你现在可以访问桌面上的移动联系人,获得消息通知并回复消息,甚至同步桌面和 Android 设备的剪贴板。
|
||||
|
||||
### 将你的浏览器与“文件”应用集成
|
||||
|
||||
GSConnect 允许你直接从计算机上的文件资源管理器的关联菜单向 Android 设备发送文件。
|
||||
|
||||
在 Fedora 的默认 GNOME 桌面上,你需要安装 `nautilus-python` 依赖包,以便在关联菜单中显示配对的设备。安装此命令非常简单,只需要在你的首选终端运行以下命令:
|
||||
|
||||
```
|
||||
$ sudo dnf install nautilus-python
|
||||
```
|
||||
|
||||
完成后,将在“<ruby>文件<rt>Files</rt></ruby>”应用的关联菜单中显示“<ruby>发送到移动设备<rt>Send to Mobile Device</rt></ruby>”选项。
|
||||
|
||||
![][9]
|
||||
|
||||
同样,为你的浏览器安装相应的 WebExtension,无论是 [Firefox][10] 还是 [Chrome][11] 浏览器,都可以将链接发送到你的 Android 设备。你可以选择直接发送链接以在浏览器中直接打开,或将其作为短信息发送。
|
||||
|
||||
### 运行命令
|
||||
|
||||
GSConnect 允许你定义命令,然后可以从远程设备在计算机上运行这些命令。这使得你可以远程截屏,或者从你的 Android 设备锁定和解锁你的桌面。
|
||||
|
||||
![][12]
|
||||
|
||||
要使用此功能,可以使用标准的 shell 命令和 GSConnect 提供的 CLI。该项目的 GitHub 存储库(CLI Scripting)中提供了有关此操作的文档。
|
||||
|
||||
[KDE UserBase Wiki][13] 有一个命令示例列表。这些例子包括控制桌面的亮度和音量、锁定鼠标和键盘,甚至更改桌面主题。其中一些命令是针对 KDE Plasma 设计的,需要进行修改才能在 GNOME 桌面上运行。
|
||||
|
||||
### 探索并享受乐趣
|
||||
|
||||
GSConnect 使我们能够享受到极大的便利和舒适。深入研究首选项,查看你可以做的所有事情,灵活的使用这些命令功能发挥创意,并在下面的评论中自由分享你解锁的新方式。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/connect-fedora-to-your-android-phone-with-gsconnect/
|
||||
|
||||
作者:[Lokesh Krishna][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[chai-yuan](https://github.com/chai-yuan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/lowkeyskywalker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/12/gsconnect-816x345.jpg
|
||||
[2]: https://extensions.gnome.org/extension/1319/gsconnect/
|
||||
[3]: https://fedoramagazine.org/install-gnome-shell-extension/
|
||||
[4]: https://play.google.com/store/apps/details?id=org.kde.kdeconnect_tp
|
||||
[5]: https://f-droid.org/en/packages/org.kde.kdeconnect_tp/
|
||||
[6]: https://fedoramagazine.org/wp-content/uploads/2020/01/within-the-menu-1024x576.png
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2020/01/pair-request-1024x576.png
|
||||
[8]: https://fedoramagazine.org/wp-content/uploads/2020/01/permissions-1024x576.png
|
||||
[9]: https://fedoramagazine.org/wp-content/uploads/2020/01/send-to-mobile-2-1024x576.png
|
||||
[10]: https://addons.mozilla.org/en-US/firefox/addon/gsconnect/
|
||||
[11]: https://chrome.google.com/webstore/detail/gsconnect/jfnifeihccihocjbfcfhicmmgpjicaec
|
||||
[12]: https://fedoramagazine.org/wp-content/uploads/2020/01/commands-1024x576.png
|
||||
[13]: https://userbase.kde.org/KDE_Connect/Tutorials/Useful_commands
|
||||
[14]: https://unsplash.com/@pathum_danthanarayana?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[15]: https://unsplash.com/s/photos/android?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -0,0 +1,118 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11905-1.html)
|
||||
[#]: subject: (Customize your internet with an open source search engine)
|
||||
[#]: via: (https://opensource.com/article/20/2/open-source-search-engine)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
用开源搜索引擎定制你的互联网
|
||||
======
|
||||
|
||||
> 上手开源的对等 Web 索引器 YaCy。
|
||||
|
||||

|
||||
|
||||
很久以前,互联网很小,小到几个人就可以索引它们,这些人收集了所有网站的名称和链接,并按主题将它们分别列在页面或印刷书籍中。随着万维网网络的发展,形成了“网站环”形式,具有类似的内容、主题或敏感性的站点捆绑在一起,形成了通往每个成员的循环路径。环中任何站点的访问者都可以单击按钮以转到环中的下一个或上一个站点,以发现与其兴趣相关的新站点。
|
||||
|
||||
又过了一段时间,互联网似乎变得臃肿不堪了。每个人都在网络上,有很多冗余信息和垃圾邮件,多到让你无法找到任何东西。Yahoo 和 AOL、CompuServe 以及类似的服务各自采用了不同的方法来解决这个问题,但是直到谷歌出现后,现代的搜索模型才得以普及。按谷歌的做法,互联网应该通过搜索引擎进行索引、排序和排名。
|
||||
|
||||
### 为什么选择开源替代品?
|
||||
|
||||
像谷歌和 DuckDuckGo 这样的搜索引擎显然是卓有成效的。你可能是通过搜索引擎访问的本站。尽管对于因主机没有选择遵循优化搜索引擎的最佳实践从而导致会内容陷入困境这件事仍存在争论,但用于管理丰富的文化、知识和轻率的信息(即互联网)的现代解决方案是冷冰冰的索引。
|
||||
|
||||
但是也许出于隐私方面的考虑,或者你希望为使互联网更加独立而做出贡献,你或许不愿意使用谷歌或 DuckDuckGo。如果你对此感兴趣,那么可以考虑参加 [YaCy][2],这是一个对等互联网索引器和搜索引擎。
|
||||
|
||||
### 安装 YaCy
|
||||
|
||||
要安装并尝试 YaCy,请首先确保已安装 Java。如果你使用的是 Linux,则可以按照我的《[如何在 Linux 上安装 Java][3]》中的说明进行操作。如果你使用 Windows 或 MacOS,请从 [AdoptOpenJDK.net][4] 获取安装程序。
|
||||
|
||||
安装 Java 后,请根据你的平台[下载安装程序][5]。
|
||||
|
||||
如果你使用的是 Linux,请解压缩 tarball 并将其移至 `/opt` 目录:
|
||||
|
||||
```
|
||||
$ sudo tar --extract --file yacy_*z --directory /opt
|
||||
```
|
||||
|
||||
根据下载的安装程序的说明启动 YaCy。
|
||||
|
||||
在 Linux 上,启动在后台运行的 YaCy:
|
||||
|
||||
```
|
||||
$ /opt/startYACY.sh &
|
||||
```
|
||||
|
||||
在 Web 浏览器中,导航到 `localhost:8090` 并进行搜索。
|
||||
|
||||
![YaCy start page][6]
|
||||
|
||||
### 将 YaCy 添加到你的地址栏
|
||||
|
||||
如果你使用的是 Firefox Web 浏览器,则只需单击几下,即可在 Awesome Bar(Mozilla 给 URL 栏起的名称)中将 YaCy 设置为默认搜索引擎。
|
||||
|
||||
首先,如果尚未显示,在 Firefox 工具栏中使专用搜索栏显示出来(你不必使搜索栏保持一直可见;只需要激活它足够长的时间即可添加自定义搜索引擎)。Firefox 右上角的“汉堡”菜单中的“自定义”菜单中提供了搜索栏。在 Firefox 工具栏上的搜索栏可见后,导航至 `localhost:8090`,然后单击刚添加的 Firefox 搜索栏中的放大镜图标。单击选项将 YaCy 添加到你的 Firefox 的搜索引擎中。
|
||||
|
||||
![Adding YaCy to Firefox][7]
|
||||
|
||||
完成此操作后,你可以在 Firefox 首选项中将其标记为默认值,或者仅在 Firefox 搜索栏中执行的搜索中选择性地使用它。如果将其设置为默认搜索引擎,则可能不需要专用搜索栏,因为 Awesome Bar 也使用默认引擎,因此可以将其从工具栏中删除。
|
||||
|
||||
### 对等搜索引擎如何工作
|
||||
|
||||
YaCy 是一个开源的分布式搜索引擎。它是用 [Java][8] 编写的,因此可以在任何平台上运行,并且可以执行 Web 爬网、索引和搜索。这是一个对等(P2P)网络,因此每个运行 YaCy 的用户都将努力地不断跟踪互联网的变化情况。当然,没有单个用户能拥有整个互联网的完整索引,因为这将需要一个数据中心来容纳,但是该索引分布在所有 YaCy 用户中且是冗余的。它与 BitTorrent 非常相似(因为它使用分布式哈希表 DHT 来引用索引条目),只不过你所共享的数据是单词和 URL 关联的矩阵。通过混合哈希表返回的结果,没人能说出谁搜索了哪些单词,因此所有搜索在功能上都是匿名的。这是用于无偏见、无广告、未跟踪和匿名搜索的有效系统,你只需要使用它就加入了它。
|
||||
|
||||
### 搜索引擎和算法
|
||||
|
||||
索引互联网的行为是指将网页分成单个单词,然后将页面的 URL 与每个单词相关联。在搜索引擎中搜索一个或多个单词将获取与该查询关联的所有 URL。YaCy 客户端在运行时也是如此。
|
||||
|
||||
客户端要做的另一件事是为你的浏览器提供搜索界面。你可以将 Web 浏览器指向 `localhost:8090` 来搜索 YaCy,而不是在要搜索时导航到谷歌。你甚至可以将其添加到浏览器的搜索栏中(取决于浏览器的可扩展性),因此可以从 URL 栏中进行搜索。
|
||||
|
||||
### YaCy 的防火墙设置
|
||||
|
||||
首次开始使用 YaCy 时,它可能运行在“初级”模式下。这意味着你的客户端爬网的站点仅对你可用,因为其他 YaCy 客户端无法访问你的索引条目。要加入对等环境,必须在路由器的防火墙(或者你正在运行的软件防火墙)中打开端口 8090,这称为“高级”模式。
|
||||
|
||||
如果你使用的是 Linux,则可以在《[使用防火墙让你的 Linux 更加强大][9]》中找到有关计算机防火墙的更多信息。在其他平台上,请参考操作系统的文档。
|
||||
|
||||
互联网服务提供商(ISP)提供的路由器上几乎总是启用了防火墙,并且有太多种类的防火墙无法准确说明。大多数路由器都提供了在防火墙上“打洞”的选项,因为许多流行的联网游戏都需要双向流量。
|
||||
|
||||
如果你知道如何登录路由器(通常为 192.168.0.1 或 10.1.0.1,但可能因制造商的设置而异),则登录并查找配置面板来控制“防火墙”或“端口转发”或“应用”。
|
||||
|
||||
找到路由器防火墙的首选项后,将端口 8090 添加到白名单。例如:
|
||||
|
||||
![Adding YaCy to an ISP router][10]
|
||||
|
||||
如果路由器正在进行端口转发,则必须使用相同的端口将传入的流量转发到计算机的 IP 地址。例如:
|
||||
|
||||
![Adding YaCy to an ISP router][11]
|
||||
|
||||
如果由于某种原因无法调整防火墙设置,那也没事。YaCy 将继续以初级模式运行并作为对等搜索网络的客户端运行。
|
||||
|
||||
### 你的互联网
|
||||
|
||||
使用 YaCy 搜索引擎可以做的不仅仅是被动搜索。你可以强制抓取不太显眼的网站,可以请求对网站进行网络抓取,可以选择使用 YaCy 进行本地搜索等等。你可以更好地控制*你的*互联网的所呈现的一切。高级用户越多,索引的网站就越多。索引的网站越多,所有用户的体验就越好。加入吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/open-source-search-engine
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/laptop_screen_desk_work_chat_text.png?itok=UXqIDRDD (Person using a laptop)
|
||||
[2]: https://yacy.net/
|
||||
[3]: https://linux.cn/article-11614-1.html
|
||||
[4]: https://adoptopenjdk.net/releases.html
|
||||
[5]: https://yacy.net/download_installation/
|
||||
[6]: https://opensource.com/sites/default/files/uploads/yacy-startpage.jpg (YaCy start page)
|
||||
[7]: https://opensource.com/sites/default/files/uploads/yacy-add-firefox.jpg (Adding YaCy to Firefox)
|
||||
[8]: https://opensource.com/resources/java
|
||||
[9]: https://opensource.com/article/19/7/make-linux-stronger-firewalls
|
||||
[10]: https://opensource.com/sites/default/files/uploads/router-add-app.jpg (Adding YaCy to an ISP router)
|
||||
[11]: https://opensource.com/sites/default/files/uploads/router-add-app1.jpg (Adding YaCy to an ISP router)
|
||||
@ -0,0 +1,98 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11916-1.html)
|
||||
[#]: subject: (What is WireGuard? Why Linux Users Going Crazy Over it?)
|
||||
[#]: via: (https://itsfoss.com/wireguard/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
什么是 WireGuard?为什么 Linux 用户为它疯狂?
|
||||
======
|
||||
|
||||
从普通的 Linux 用户到 Linux 创建者 [Linus Torvalds][1],每个人都对 WireGuard 很感兴趣。什么是 WireGuard,它为何如此特别?
|
||||
|
||||
### 什么是 WireGuard?
|
||||
|
||||
![][2]
|
||||
|
||||
[WireGuard][3] 是一个易于配置、快速且安全的开源 [VPN][4],它利用了最新的加密技术。目的是提供一种更快、更简单、更精简的通用 VPN,它可以轻松地在树莓派这类低端设备到高端服务器上部署。
|
||||
|
||||
[IPsec][5] 和 OpenVPN 等大多数其他解决方案是几十年前开发的。安全研究人员和内核开发人员 Jason Donenfeld 意识到它们速度慢且难以正确配置和管理。
|
||||
|
||||
这让他创建了一个新的开源 VPN 协议和解决方案,它更加快速、安全、易于部署和管理。
|
||||
|
||||
WireGuard 最初是为 Linux 开发的,但现在可用于 Windows、macOS、BSD、iOS 和 Android。它仍在活跃开发中。
|
||||
|
||||
### 为什么 WireGuard 如此受欢迎?
|
||||
|
||||
![][6]
|
||||
|
||||
除了可以跨平台之外,WireGuard 的最大优点之一就是易于部署。配置和部署 WireGuard 就像配置和使用 SSH 一样容易。
|
||||
|
||||
看看 [WireGuard 设置指南][7]。安装 WireGuard、生成公钥和私钥(像 SSH 一样),设置防火墙规则并启动服务。现在将它和 [OpenVPN 设置指南][8]进行比较——有太多要做的了。
|
||||
|
||||
WireGuard 的另一个好处是它有一个仅 4000 行代码的精简代码库。将它与 [OpenVPN][9](另一个流行的开源 VPN)的 100,000 行代码相比。显然,调试 WireGuard 更加容易。
|
||||
|
||||
不要因其简单而小看它。WireGuard 支持所有最新的加密技术,例如 [Noise 协议框架][10]、[Curve25519][11]、[ChaCha20][12]、[Poly1305][13]、[BLAKE2][14]、[SipHash24][15]、[HKDF][16] 和安全受信任结构。
|
||||
|
||||
由于 WireGuard 运行在[内核空间][17],因此可以高速提供安全的网络。
|
||||
|
||||
这些是 WireGuard 越来越受欢迎的一些原因。Linux 创造者 Linus Torvalds 非常喜欢 WireGuard,以至于将其合并到 [Linux Kernel 5.6][18] 中:
|
||||
|
||||
> 我能否再次声明对它的爱,并希望它能很快合并?也许代码不是完美的,但我不在乎,与 OpenVPN 和 IPSec 的恐怖相比,这是一件艺术品。
|
||||
>
|
||||
> Linus Torvalds
|
||||
|
||||
### 如果 WireGuard 已经可用,那么将其包含在 Linux 内核中有什么大惊小怪的?
|
||||
|
||||
这可能会让新的 Linux 用户感到困惑。你知道可以在 Linux 上安装和配置 WireGuard VPN 服务器,但同时也会看到 Linux Kernel 5.6 将包含 WireGuard 的消息。让我向您解释。
|
||||
|
||||
目前,你可以将 WireGuard 作为[内核模块][19]安装在 Linux 中。而诸如 VLC、GIMP 等常规应用安装在 Linux 内核之上(在 [用户空间][20]中),而不是内部。
|
||||
|
||||
当将 WireGuard 安装为内核模块时,基本上需要你自行修改 Linux 内核并向其添加代码。从 5.6 内核开始,你无需手动添加内核模块。默认情况下它将包含在内核中。
|
||||
|
||||
在 5.6 内核中包含 WireGuard 很有可能[扩展 WireGuard 的采用,从而改变当前的 VPN 场景][21]。
|
||||
|
||||
### 总结
|
||||
|
||||
WireGuard 之所以受欢迎是有充分理由的。诸如 [Mullvad VPN][23] 之类的一些流行的[关注隐私的 VPN][22] 已经在使用 WireGuard,并且在不久的将来,采用率可能还会增长。
|
||||
|
||||
希望你对 WireGuard 有所了解。与往常一样,欢迎提供反馈。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/wireguard/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/linus-torvalds-facts/
|
||||
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/02/wireguard.png?ssl=1
|
||||
[3]: https://www.wireguard.com/
|
||||
[4]: https://en.wikipedia.org/wiki/Virtual_private_network
|
||||
[5]: https://en.wikipedia.org/wiki/IPsec
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/02/wireguard-logo.png?ssl=1
|
||||
[7]: https://www.linode.com/docs/networking/vpn/set-up-wireguard-vpn-on-ubuntu/
|
||||
[8]: https://www.digitalocean.com/community/tutorials/how-to-set-up-an-openvpn-server-on-ubuntu-16-04
|
||||
[9]: https://openvpn.net/
|
||||
[10]: https://noiseprotocol.org/
|
||||
[11]: https://cr.yp.to/ecdh.html
|
||||
[12]: https://cr.yp.to/chacha.html
|
||||
[13]: https://cr.yp.to/mac.html
|
||||
[14]: https://blake2.net/
|
||||
[15]: https://131002.net/siphash/
|
||||
[16]: https://eprint.iacr.org/2010/264
|
||||
[17]: http://www.linfo.org/kernel_space.html
|
||||
[18]: https://itsfoss.com/linux-kernel-5-6/
|
||||
[19]: https://wiki.archlinux.org/index.php/Kernel_module
|
||||
[20]: http://www.linfo.org/user_space.html
|
||||
[21]: https://www.zdnet.com/article/vpns-will-change-forever-with-the-arrival-of-wireguard-into-linux/
|
||||
[22]: https://itsfoss.com/best-vpn-linux/
|
||||
[23]: https://mullvad.net/en/
|
||||
@ -1,18 +1,18 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11906-1.html)
|
||||
[#]: subject: (Install All Essential Media Codecs in Ubuntu With This Single Command [Beginner’s Tip])
|
||||
[#]: via: (https://itsfoss.com/install-media-codecs-ubuntu/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
使用此单条命令在 Ubuntu 中安装所有基本媒体编解码器(初学者技巧)
|
||||
一条命令在 Ubuntu 中安装所有基本的媒体编解码器
|
||||
======
|
||||
|
||||
如果你刚刚安装了 Ubuntu 或其他 [Ubuntu 特色版本][1] 如 Kubuntu、Lubuntu 等,你会注意到系统无法播放某些音频或视频文件。
|
||||
|
||||
对于视频文件,你可以[在 Ubuntu 上安装 VLC][2]。 [VLC][3] 是 [Linux 上的最佳视频播放器][4]之一,它几乎可以播放任何视频文件格式。但你仍然会遇到无法播放音频和 flash 的麻烦。
|
||||
对于视频文件,你可以[在 Ubuntu 上安装 VLC][2]。[VLC][3] 是 [Linux 上的最佳视频播放器][4]之一,它几乎可以播放任何视频文件格式。但你仍然会遇到无法播放音频和 flash 的麻烦。
|
||||
|
||||
好消息是 [Ubuntu][5] 提供了一个软件包来安装所有基本的媒体编解码器:ubuntu-restricted-extras。
|
||||
|
||||
@ -44,7 +44,7 @@ sudo add-apt-repository multiverse
|
||||
sudo apt install ubuntu-restricted-extras
|
||||
```
|
||||
|
||||
输入回车后,你会被要求输入密码,_**当你输入密码时,屏幕不会有显示**_。这是正常的。输入你的密码并回车。
|
||||
输入回车后,你会被要求输入密码,**当你输入密码时,屏幕不会有显示**。这是正常的。输入你的密码并回车。
|
||||
|
||||
它将显示大量要安装的包。按回车确认选择。
|
||||
|
||||
@ -60,7 +60,7 @@ sudo apt install ubuntu-restricted-extras
|
||||
|
||||
##### 在 Kubuntu、Lubuntu、Xubuntu 上安装受限制的额外软件包
|
||||
|
||||
请记住,Kubuntu、Lubuntu 和 Xubuntu 都有此软件包,并有各自的名称。它们本应使用相同的名字,但不幸的是并不是。
|
||||
请记住,Kubuntu、Lubuntu 和 Xubuntu 都有此软件包,并有各自不同的名称。它们本应使用相同的名字,但不幸的是并不是。
|
||||
|
||||
在 Kubuntu 上,使用以下命令:
|
||||
|
||||
@ -91,7 +91,7 @@ via: https://itsfoss.com/install-media-codecs-ubuntu/
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,118 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (chai-yuan)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11909-1.html)
|
||||
[#]: subject: (Playing Music on your Fedora Terminal with MPD and ncmpcpp)
|
||||
[#]: via: (https://fedoramagazine.org/playing-music-on-your-fedora-terminal-with-mpd-and-ncmpcpp/)
|
||||
[#]: author: (Carmine Zaccagnino https://fedoramagazine.org/author/carzacc/)
|
||||
|
||||
在你的 Fedora 终端上播放音乐
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
MPD(Music Playing Daemon),顾名思义,是一个音乐(Music)播放(Playing)守护进程(Daemon)。它可以播放音乐,并且作为一个守护进程,任何软件都可以与之交互并播放声音,包括一些 CLI 客户端。
|
||||
|
||||
其中一个被称为 `ncmpcpp`,它是对之前 `ncmpc` 工具的改进。名字的变化与编写它们的语言没有太大关系:都是 C++,而之所以被称为 `ncmpcpp`,因为它是 “NCurses Music Playing Client Plus Plus”。 缘故
|
||||
|
||||
### 安装 MPD 和 ncmpcpp
|
||||
|
||||
`ncmpmpcc` 的客户端可以从官方 Fedora 库中通过 `dnf` 命令直接安装。
|
||||
|
||||
```
|
||||
$ sudo dnf install ncmpcpp
|
||||
```
|
||||
|
||||
另一方面,MPD 必须从 RPMFusion free 库安装,你可以通过运行:
|
||||
|
||||
```
|
||||
$ sudo dnf install https://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-$(rpm -E %fedora).noarch.rpm
|
||||
```
|
||||
|
||||
然后你可以运行下面的命令安装它:
|
||||
|
||||
```
|
||||
$ sudo dnf install mpd
|
||||
```
|
||||
|
||||
### 配置并启用 MPD
|
||||
|
||||
设置 MPD 最简单的方法是以普通用户的身份运行它。默认情况是以专用 `mpd` 用户的身份运行它,但这会导致各种权限问题。
|
||||
|
||||
在运行它之前,我们需要创建一个本地配置文件,允许我们作为普通用户运行。
|
||||
|
||||
首先在 `~/.config` 里创建一个名叫 `mpd` 的目录:
|
||||
|
||||
```
|
||||
$ mkdir ~/.config/mpd
|
||||
```
|
||||
|
||||
将配置文件拷贝到此目录下:
|
||||
|
||||
```
|
||||
$ cp /etc/mpd.conf ~/.config/mpd
|
||||
```
|
||||
|
||||
然后用 `vim`、`nano` 或 `gedit` 之类的软件编辑它:
|
||||
|
||||
```
|
||||
$ nano ~/.config/mpd/mpd.conf
|
||||
```
|
||||
|
||||
我建议你通读所有内容,检查是否有任何需要做的事情,但对于大多数设置你都可以删除,只需保留以下内容:
|
||||
|
||||
```
|
||||
db_file "~/.config/mpd/mpd.db"
|
||||
log_file "syslog"
|
||||
```
|
||||
|
||||
现在你可以运行它了:
|
||||
|
||||
```
|
||||
$ mpd
|
||||
```
|
||||
|
||||
没有报错,这将在后台启动 MPD 守护进程。
|
||||
|
||||
### 使用 ncmpcpp
|
||||
|
||||
只需运行:
|
||||
|
||||
```
|
||||
$ ncmpcpp
|
||||
```
|
||||
|
||||
你将在终端中看到一个由 ncurses 所支持的图形用户界面。
|
||||
|
||||
按下 `4` 键,然后就可以看到本地的音乐目录,用方向键进行选择并按下回车进行播放。
|
||||
|
||||
多播放几个歌曲就会创建一个*播放列表*,让你可以使用 `>` 键(不是右箭头, 是右尖括号)移动到下一首,并使用 `<` 返回上一首。`+` 和 `–` 键可以调节音量。`Q` 键可以让你退出 `ncmpcpp` 但不停止播放音乐。你可以按下 `P` 来控制暂停和播放。
|
||||
|
||||
你可以按下 `1` 键来查看当前播放列表(这是默认的视图)。从这个视图中,你可以按 `i` 查看有关当前歌曲的信息(标签)。按 `6` 可更改当前歌曲的标签。
|
||||
|
||||
按 `\` 按钮将在视图顶部添加(或删除)信息面板。在左上角,你可以看到如下的内容:
|
||||
|
||||
```
|
||||
[------]
|
||||
```
|
||||
|
||||
按下 `r`、`z`、`y`、`R`、`x` 将会分别切换到 `repeat`、`random`、`single`、`consume` 和 `crossfade` 等播放模式,并将这个小指示器中的 `–` 字符替换为选定模式。
|
||||
|
||||
按下 `F1` 键将会显示一些帮助文档,包含一系列的键绑定列表,因此无需在此处列出完整列表。所以继续吧!做一个极客,在你的终端上播放音乐!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/playing-music-on-your-fedora-terminal-with-mpd-and-ncmpcpp/
|
||||
|
||||
作者:[Carmine Zaccagnino][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[chai-yuan](https://github.com/chai-yuan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/carzacc/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2020/02/play_music_mpd-816x346.png
|
||||
[2]: https://rpmfusion.org/Configuration
|
||||
@ -0,0 +1,101 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11919-1.html)
|
||||
[#]: subject: (Top hacks for the YaCy open source search engine)
|
||||
[#]: via: (https://opensource.com/article/20/2/yacy-search-engine-hacks)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
使用开源搜索引擎 YaCy 的技巧
|
||||
======
|
||||
|
||||
> 无需适应其他人的眼光,而是使用 YaCY 搜索引擎定义你想要的互联网。
|
||||
|
||||

|
||||
|
||||
在我以前介绍 [YaCy 入门][2]的文章中讲述过 [YaCy][3] 这个<ruby>对等<rt>peer-to-peer</rt></ruby>式的搜索引擎是如何安装和使用的。YaCy 最令人兴奋的一点就是它事实上是一个本地客户端,全球范围内的每一个 YaCy 用户都是构成整个这个分布式搜索引擎架构的一个节点,这意味着每个用户都可以掌控自己的互联网搜索体验。
|
||||
|
||||
Google 曾经提供过 google.com/linux 这样的主题简便方式以便快速筛选出和 Linux 相关的搜索内容,这个小功能受到了很多人的青睐,但 Google 最终还是在 2011 年的时候把它[下线][4]了。
|
||||
|
||||
而 YaCy 则让自定义搜索引擎变得可能。
|
||||
|
||||
### 自定义 YaCy
|
||||
|
||||
YaCy 安装好之后,只需要访问 `localhost:8090` 就可以使用了。要自定义搜索引擎,只需要点击右上角的“<ruby>管理<rt>Administration</rt></ruby>”按钮(它可能隐藏在小屏幕的菜单图标中)。
|
||||
|
||||
你可以在管理面板中配置 YaCy 对系统资源的使用策略,以及如何跟其它的 YaCy 客户端进行交互。
|
||||
|
||||
![YaCy profile selector][5]
|
||||
|
||||
例如,点击侧栏中的“<ruby>第一步<rt>First steps</rt></ruby>”按钮可以配置备用端口,以及设置 YaCy 对内存和硬盘的使用量;而“<ruby>监控<rt>Monitoring</rt></ruby>”面板则可以监控 YaCy 的运行状况。大多数功能都只需要在面板上点击几下就可以完成了,例如以下几个常用的功能。
|
||||
|
||||
### 内网搜索应用
|
||||
|
||||
目前市面上也有不少公司推出了[内网搜索应用][6],而 YaCy 可以免费为你提供一个。对于能够通过 HTTP、FTP、Samba 等协议访问的文件,YaCy 都可以进行索引,因此无论是作为私人的文件搜索还是企业内部的本地共享文件搜索,YaCy 都可以实现。它可以让内部网络中的用户使用你个人的 YaCy 实例来查找共享文件,于此同时保持对内部网络以外的用户不可见。
|
||||
|
||||
### 网络配置
|
||||
|
||||
YaCy 在默认情况下就支持隐私和隔离。点击“<ruby>用例与账号<rt>Use Case & Account</rt></ruby>”页面顶部的“<ruby>网络配置<rt>Network Configuration</rt></ruby>”链接,即可进入网络配置面板设置对等网络。
|
||||
|
||||
![YaCy network configuration][7]
|
||||
|
||||
### 爬取站点
|
||||
|
||||
YaCy 的分布式运作方式决定了它对页面的爬取是由用户驱动的。并没有一个大型公司对整个互联网上的所有可访问页面都进行搜索,对于 YaCy 来说也是这样,一个站点只有在被用户指定爬取的前提下,才会被 YaCy 爬取并进入索引。
|
||||
|
||||
YaCy 客户端提供了两种爬取页面的方式:你可以手动爬取,并让 YaCy 根据建议去爬取。
|
||||
|
||||
![YaCy advanced crawler][8]
|
||||
|
||||
#### 手动爬取
|
||||
|
||||
手动爬取是指由用户输入指定的网站 URL 并启动 YaCy 的爬虫任务。只需要点击“<ruby>高级爬虫<rt>Advanced Crawler</rt></ruby>”并输入计划爬取的若干 URL,然后选择页面底部的“<ruby>进行远程索引<rt>Do Remote indexing</rt></ruby>”选项,这个选项会让客户端向互联网广播它要索引的 URL,可选地接受这些请求的客户端可以帮助你爬取这些 URL。
|
||||
|
||||
点击页面底部的“<ruby>开始新爬虫任务<rt>Start New Crawl Job</rt></ruby>”按钮就可以开始进行爬取了,我就是这样对一些常用和有用站点进行爬取和索引的。
|
||||
|
||||
爬虫任务启动之后,YaCy 会将这些 URL 对应的页面在本地生成和存储索引。在高级模式下,也就是本地计算机允许 8090 端口流量进出时,全网的 YaCy 用户都可以使用到这一份索引。
|
||||
|
||||
#### 加入爬虫网络
|
||||
|
||||
尽管一些非常敬业的 YaCy 高级用户已经强迫症般地在互联网上爬取了很多页面,但对于全网浩如烟海的页面而言也只是沧海一粟。单个用户所拥有的资源远不及很多大公司的网络爬虫,但大量 YaCy 用户如果联合起来成为一个社区,能产生的力量就大得多了。只要开启了 YaCy 的爬虫请求广播功能,就可以让其它客户端参与进来爬取更多页面。
|
||||
|
||||
只需要在“<ruby>高级爬虫<rt>Advanced Crawler</rt></ruby>”面板中点击页面顶部的“<ruby>远程爬取<rt>Remote Crawling</rt></ruby>”,勾选“<ruby>加载<rt>Load</rt></ruby>”旁边的复选框,就可以让你的客户端接受其它人发来的爬虫任务请求了。
|
||||
|
||||
![YaCy remote crawling][9]
|
||||
|
||||
### YaCy 监控相关
|
||||
|
||||
YaCy 除了作为一个非常强大的搜索引擎,还提供了很丰富的主题和用户体验。你可以在“<ruby>监控<rt>Monitor</rt></ruby>”面板中监控 YaCy 客户端的网络运行状况,甚至还可以了解到有多少人从 YaCy 社区中获取到了自己所需要的东西。
|
||||
|
||||
![YaCy monitoring screen][10]
|
||||
|
||||
### 搜索引擎发挥了作用
|
||||
|
||||
你使用 YaCy 的时间越长,就越会思考搜索引擎如何改变自己的视野,因为你对互联网的体验很大一部分来自于你在搜索引擎中一次次简单查询的结果。实际上,当你和不同行业的人交流时,可能会注意到每个人对“互联网”的理解都有所不同。有些人会认为,互联网的搜索引擎中充斥着各种广告和推广,同时也仅仅能从搜索结果中获取到有限的信息。例如,假设有人不断搜索关于关键词 X 的内容,那么大部分商业搜索引擎都会在搜索结果中提高关键词 X 的权重,但与此同时,另一个关键词 Y 的权重则会相对降低,从而让关键词 Y 被淹没在搜索结果当中,即使这样对完成特定任务更好。
|
||||
|
||||
就像在现实生活中一样,走出虚拟的世界视野会让你看到一个更广阔的世界。尝试使用 YaCy,看看你发现了什么。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/yacy-search-engine-hacks
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/browser_desktop_website_checklist_metrics.png?itok=OKKbl1UR (Browser of things)
|
||||
[2]: https://linux.cn/article-11905-1.html
|
||||
[3]: https://yacy.net/
|
||||
[4]: https://www.linuxquestions.org/questions/linux-news-59/is-there-no-more-linux-google-884306/
|
||||
[5]: https://opensource.com/sites/default/files/uploads/yacy-profiles.jpg (YaCy profile selector)
|
||||
[6]: https://en.wikipedia.org/wiki/Vivisimo
|
||||
[7]: https://opensource.com/sites/default/files/uploads/yacy-network-config.jpg (YaCy network configuration)
|
||||
[8]: https://opensource.com/sites/default/files/uploads/yacy-advanced-crawler.jpg (YaCy advanced crawler)
|
||||
[9]: https://opensource.com/sites/default/files/uploads/yacy-remote-crawl-accept.jpg (YaCy remote crawling)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/yacy-monitor.jpg (YaCy monitoring screen)
|
||||
@ -0,0 +1,103 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11917-1.html)
|
||||
[#]: subject: (Dino is a Modern Looking Open Source XMPP Client)
|
||||
[#]: via: (https://itsfoss.com/dino-xmpp-client/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Dino:一个有着现代外观的开源 XMPP 客户端
|
||||
======
|
||||
|
||||
> Dino 是一个相对较新的开源 XMPP 客户端,它试图提供良好的用户体验,鼓励注重隐私的用户使用 XMPP 发送消息。
|
||||
|
||||
|
||||
|
||||
### Dino:一个开源 XMPP 客户端
|
||||
|
||||
![][1]
|
||||
|
||||
[XMPP][2](<ruby>可扩展通讯和表示协议<rt>eXtensible Messaging Presence Protocol</rt></ruby>) 是一个去中心化的网络模型,可促进即时消息传递和协作。去中心化意味着没有中央服务器可以访问你的数据。通信直接点对点。
|
||||
|
||||
我们中的一些人可能会称它为“老派”技术,可能是因为 XMPP 客户端通常用户体验非常糟糕,或者仅仅是因为它需要时间来适应(或设置它)。
|
||||
|
||||
这时候 [Dino][3] 作为现代 XMPP 客户端出现了,在不损害你的隐私的情况下提供干净清爽的用户体验。
|
||||
|
||||
### 用户体验
|
||||
|
||||
![][4]
|
||||
|
||||
Dino 试图改善 XMPP 客户端的用户体验,但值得注意的是,它的外观和感受将在一定程度上取决于你的 Linux 发行版。你的图标主题或 Gnome 主题会让你的个人体验更好或更糟。
|
||||
|
||||
从技术上讲,它的用户界面非常简单,易于使用。所以,我建议你看下 Ubuntu 中的[最佳图标主题][5]和 [GNOME 主题][6]来调整 Dino 的外观。
|
||||
|
||||
### Dino 的特性
|
||||
|
||||
![Dino Screenshot][7]
|
||||
|
||||
你可以将 Dino 用作 Slack、[Signal][8] 或 [Wire][9] 的替代产品,来用于你的业务或个人用途。
|
||||
|
||||
它提供了消息应用所需的所有基本特性,让我们看下你可以从中得到的:
|
||||
|
||||
* 去中心化通信
|
||||
* 如果无法设置自己的服务器,它支持公共 XMPP 的服务器
|
||||
* 和其他流行消息应用相似的 UI,因此易于使用
|
||||
* 图像和文件共享
|
||||
* 支持多个帐户
|
||||
* 高级消息搜索
|
||||
* 支持 [OpenPGP][10] 和 [OMEMO][11] 加密
|
||||
* 轻量级原生桌面应用
|
||||
|
||||
### 在 Linux 上安装 Dino
|
||||
|
||||
你可能会发现它列在你的软件中心中,也可能未找到。Dino 为基于 Debian(deb)和 Fedora(rpm)的发行版提供了可用的二进制文件。
|
||||
|
||||
Dino 在 Ubuntu 的 universe 仓库中,你可以使用以下命令安装它:
|
||||
|
||||
```
|
||||
sudo apt install dino-im
|
||||
```
|
||||
|
||||
类似地,你可以在 [GitHub 分发包页面][12]上找到其他 Linux 发行版的包。
|
||||
|
||||
如果你想要获取最新的,你可以在 [OpenSUSE 的软件页面][13]找到 Dino 的 **.deb** 和 .**rpm** (每日构建版)安装在 Linux 中。
|
||||
|
||||
在任何一种情况下,前往它的 [Github 页面][14]或点击下面的链接访问官方网站。
|
||||
|
||||
- [下载 Dino][3]
|
||||
|
||||
### 总结
|
||||
|
||||
在我编写这篇文章时快速测试过它,它工作良好,没有出过问题。我将尝试探索更多,并希望能涵盖更多有关 XMPP 的文章来鼓励用户使用 XMPP 的客户端和服务器用于通信。
|
||||
|
||||
你觉得 Dino 怎么样?你会推荐另一个可能好于 Dino 的开源 XMPP 客户端吗?在下面的评论中让我知道你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/dino-xmpp-client/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/02/dino-main.png?ssl=1
|
||||
[2]: https://xmpp.org/about/
|
||||
[3]: https://dino.im/
|
||||
[4]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/02/dino-xmpp-client.jpg?ssl=1
|
||||
[5]: https://itsfoss.com/best-icon-themes-ubuntu-16-04/
|
||||
[6]: https://itsfoss.com/best-gtk-themes/
|
||||
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/02/dino-screenshot.png?ssl=1
|
||||
[8]: https://itsfoss.com/signal-messaging-app/
|
||||
[9]: https://itsfoss.com/wire-messaging-linux/
|
||||
[10]: https://www.openpgp.org/
|
||||
[11]: https://en.wikipedia.org/wiki/OMEMO
|
||||
[12]: https://github.com/dino/dino/wiki/Distribution-Packages
|
||||
[13]: https://software.opensuse.org/download.html?project=network:messaging:xmpp:dino&package=dino
|
||||
[14]: https://github.com/dino/dino
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11903-1.html)
|
||||
[#]: subject: (How to Change the Default Terminal in Ubuntu)
|
||||
[#]: via: (https://itsfoss.com/change-default-terminal-ubuntu/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
@ -10,15 +10,13 @@
|
||||
如何在 Ubuntu 中更改默认终端
|
||||
======
|
||||
|
||||
终端是 Linux 系统的关键部分。它能让你通过 shell 访问 Linux 系统。Linux 上有多个终端应用(技术上称为终端仿真器)。
|
||||
<ruby>终端<rt>Terminal</rt></ruby>是 Linux 系统的关键部分。它能让你通过 shell 访问 Linux 系统。Linux 上有多个终端应用(技术上称为终端仿真器)。
|
||||
|
||||
大多数[桌面环境][1]都有自己的终端实现。它们的外观可能有所不同,并且可能有不同的快捷键。
|
||||
|
||||
例如,[Guake 终端][2]对高级用户非常有用,它提供了一些可能无法在发行版默认终端中使用的功能。
|
||||
大多数[桌面环境][1]都有自己的终端实现。它们的外观可能有所不同,并且可能有不同的快捷键。例如,[Guake 终端][2]对高级用户非常有用,它提供了一些可能无法在发行版默认终端中使用的功能。
|
||||
|
||||
你可以在系统上安装其他终端,并将其设为默认,并能通过[快捷键 Ctrl+Alt+T][3] 打开。
|
||||
|
||||
现在的问题来了,如何在 Ubuntu 中更改默认终端。它没有遵循[更改 Ubuntu 中的默认应用][4]的标准方式,要怎么做?
|
||||
现在问题来了,如何在 Ubuntu 中更改默认终端。它没有遵循[更改 Ubuntu 中的默认应用][4]的标准方式,要怎么做?
|
||||
|
||||
### 更改 Ubuntu 中的默认终端
|
||||
|
||||
@ -35,7 +33,7 @@ sudo update-alternatives --config x-terminal-emulator
|
||||
它将显示系统上存在的所有可作为默认值的终端仿真器。当前的默认终端标有星号。
|
||||
|
||||
```
|
||||
[email protected]:~$ sudo update-alternatives --config x-terminal-emulator
|
||||
abhishek@nuc:~$ sudo update-alternatives --config x-terminal-emulator
|
||||
There are 2 choices for the alternative x-terminal-emulator (providing /usr/bin/x-terminal-emulator).
|
||||
|
||||
Selection Path Priority Status
|
||||
@ -54,13 +52,13 @@ Press <enter> to keep the current choice[*], or type selection number: 1
|
||||
update-alternatives: using /usr/bin/gnome-terminal.wrapper to provide /usr/bin/x-terminal-emulator (x-terminal-emulator) in manual mode
|
||||
```
|
||||
|
||||
##### 自动模式 vs 手动模式
|
||||
|
||||
你可能已经在 update-alternatives 命令的输出中注意到了自动模式和手动模式。
|
||||
|
||||
如果选择自动模式,那么在安装或删除软件包时,系统可能会自动决定默认应用。该决定受优先级数字的影响(如上一节中的命令输出所示)。
|
||||
|
||||
假设你的系统上安装了 5 个终端仿真器,并删除了默认的仿真器。现在,你的系统将检查哪些仿真器处于自动模式。如果有多个,它将选择优先级最高的一个作为默认仿真器。
|
||||
> **自动模式 vs 手动模式**
|
||||
>
|
||||
> 你可能已经在 `update-alternatives` 命令的输出中注意到了自动模式和手动模式。
|
||||
>
|
||||
> 如果选择自动模式,那么在安装或删除软件包时,系统可能会自动决定默认应用。该决定受优先级数字的影响(如上一节中的命令输出所示)。
|
||||
>
|
||||
> 假设你的系统上安装了 5 个终端仿真器,并删除了默认的仿真器。现在,你的系统将检查哪些仿真器处于自动模式。如果有多个,它将选择优先级最高的一个作为默认仿真器。
|
||||
|
||||
我希望你觉得这个小技巧有用。随时欢迎提出问题和建议。
|
||||
|
||||
@ -71,7 +69,7 @@ via: https://itsfoss.com/change-default-terminal-ubuntu/
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
97
published/20200213 Why developers like to code at night.md
Normal file
97
published/20200213 Why developers like to code at night.md
Normal file
@ -0,0 +1,97 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Morisun029)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11924-1.html)
|
||||
[#]: subject: (Why developers like to code at night)
|
||||
[#]: via: (https://opensource.com/article/20/2/why-developers-code-night)
|
||||
[#]: author: (Matt Shealy https://opensource.com/users/mshealy)
|
||||
|
||||
程序员为什么喜欢在晚上编码
|
||||
======
|
||||
|
||||
> 对许多开源程序员来说,夜间的工作计划是创造力和生产力来源的关键。
|
||||
|
||||

|
||||
|
||||
如果你问大多数开发人员更喜欢在什么时候工作,大部人会说他们最高效的时间在晚上。这对于那些在工作之余为开源项目做贡献的人来说更是如此(尽管如此,希望在他们的健康范围内[避免透支][2])。
|
||||
|
||||
有些人喜欢从晚上开始,一直工作到凌晨,而另一些人则很早就起床(例如,凌晨 4 点),以便在开始日常工作之前完成大部分编程工作。
|
||||
|
||||
这种工作习惯可能会使许多开发人员看起来像个怪人,不合时宜。但是,为什么有这么多的程序员喜欢在非正常时间工作,原因有很多:
|
||||
|
||||
### 制造者日程
|
||||
|
||||
根据 <ruby>[保罗·格雷厄姆][3]<rt>Paul Graham</rt></ruby> 的观点,“生产东西”的人倾向于遵守 制造者日程 —— 他们更愿意以半天或更长时间为单位使用时间。事实上,大多数[开发人员也有相同的偏好][4]。(LCTT 译注:保罗·格雷厄姆有[一篇文章][8]述及制造者日程和管理者日程。)
|
||||
|
||||
一方面,开发人员从事大型抽象系统工作,需要思维空间来处理整个模型。将他们的日程分割成 15 分钟或 30 分钟的时间段来处理电子邮件、会议、电话以及来自同事的打断,工作效果只会适得其反。
|
||||
|
||||
另一方面,通常不可能以小时为单位进行有效编程。因为这么短的时间几乎不够让你把思绪放在手头的任务上并开始工作。
|
||||
|
||||
上下文切换也会对编程产生不利影响。在晚上工作,开发人员可以避免尽可能多的干扰。在没有不断的干扰的情况下,他们可以花几个小时专注于手头任务,并尽可能提高工作效率。
|
||||
|
||||
### 平和安静的环境
|
||||
|
||||
由于晚上或凌晨不太会有来自各种活动的噪音(例如,办公室闲谈、街道上的交通),这使许多程序员感到放松,促使他们更具创造力和生产力,特别是在处理诸如编码之类的精神刺激任务时。
|
||||
|
||||
独处与平静,加上他们知道自己将有几个小时不被中断的工作时间,通常会使他们摆脱白天工作计划相关的时间压力,从而产出高质量的工作。
|
||||
|
||||
更不用说了,当解决了一个棘手的问题后,没有什么比尽情享受自己最喜欢的午夜小吃更美好的事情了!
|
||||
|
||||
### 沟通
|
||||
|
||||
与在公司内工作的程序员相比,从事开源项目的开发人员可以拥有不同的沟通节奏。大多数开源项目的沟通都是通过邮件或 GitHub 上的评论等渠道异步完成的。很多时候,其他程序员在不同的国家和时区,因此实时交流通常需要开发人员变成一个夜猫子。
|
||||
|
||||
### 昏昏欲睡的大脑
|
||||
|
||||
这听起来可能违反直觉,但是随着时间的推移,大脑会变得非常疲倦,因此只能专注于一项任务。晚上工作从根本上消除了多任务处理,而这是保持专注和高效的主要障碍。当大脑处于昏昏欲睡的状态时,你是无法保持专注的!
|
||||
|
||||
此外,许多开发人员在入睡时思考要解决的问题通常会取得重大进展。潜意识开始工作,答案通常在他们半睡半醒的凌晨时分就出现了。
|
||||
|
||||
这不足为奇,因为[睡眠可增强大脑功能][5],可帮助我们理解新信息并进行更有创造性的思考。当解决方案在凌晨出现时,这些开发人员便会起来开始工作,不错过任何机会。
|
||||
|
||||
### 灵活和创造性思考
|
||||
|
||||
许多程序员体会到晚上创造力会提升。前额叶皮层,即大脑中与集中能力有关的部分,在一天结束时会感到疲倦。这似乎为某些人提供了更灵活和更具创造性的思考。
|
||||
|
||||
匹兹堡大学医学院精神病学助理教授 [Brant Hasler][6] 表示:“由于自上而下的控制和‘认知抑制’的减少,大脑可能会解放出来进行更发散的思考,从而使人们更容易地将不同概念之间的联系建立起来。” 结合轻松环境所带来的积极情绪,开发人员可以更轻松地产生创新想法。
|
||||
|
||||
此外,在没有干扰的情况下集中精力几个小时,“沉浸在你做的事情中”。这可以帮助你更好地专注于项目并参与其中,而不必担心周围发生的事情。
|
||||
|
||||
### 明亮的电脑屏幕
|
||||
|
||||
因为整天看着明亮的屏幕, 许多程序员的睡眠周期被延迟。电脑屏幕发出的蓝光[扰乱我们的昼夜节律][7],延迟了释放诱发睡眠的褪黑激素和提高人的机敏性,并将人体生物钟重置到更晚的时间。从而导致,开发人员往往睡得越来越晚。
|
||||
|
||||
### 来自过去的影响
|
||||
|
||||
过去,大多数开发人员是出于必要在晚上工作,因为在白天当公司其他人都在使用服务器时,共享服务器的计算能力支撑不了编程工作,所以开发人员需要等到深夜才能执行白天无法进行的任务,例如测试项目、运行大量的“编码-编译-运行-调试”周期以及部署新代码。现在尽管服务器功能变强大了,大多数可以满足需求,但夜间工作的趋势仍是这种文化的一部分。
|
||||
|
||||
### 结语
|
||||
|
||||
尽管开发人员喜欢在晚上工作的原因很多,但请记住,做为夜猫子并不意味着你应该克扣睡眠时间。睡眠不足会导致压力和焦虑,并最终导致倦怠。
|
||||
|
||||
获得足够质量的睡眠是维持良好身体健康和大脑功能的关键。例如,它可以帮助你整合新信息、巩固记忆、创造性思考、清除身体积聚的毒素、调节食欲并防止过早衰老。
|
||||
|
||||
无论你是哪种日程,请确保让你的大脑得到充分的休息,这样你就可以在一整天及每天的工作中发挥最大的作用!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/why-developers-code-night
|
||||
|
||||
作者:[Matt Shealy][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Morisun029](https://github.com/Morisun029)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mshealy
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_code_programming_laptop.jpg?itok=ormv35tV (Person programming on a laptop on a building)
|
||||
[2]: https://opensource.com/article/19/11/burnout-open-source-communities
|
||||
[3]: http://www.paulgraham.com/makersschedule.html
|
||||
[4]: https://www.chamberofcommerce.com/business-advice/software-development-trends-overtaking-the-market
|
||||
[5]: https://amerisleep.com/blog/sleep-impacts-brain-health/
|
||||
[6]: https://www.vice.com/en_us/article/mb58a8/late-night-creativity-spike
|
||||
[7]: https://www.sleepfoundation.org/articles/how-blue-light-affects-kids-sleep
|
||||
[8]: http://www.paulgraham.com/makersschedule.html
|
||||
@ -0,0 +1,196 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11931-1.html)
|
||||
[#]: subject: (Digging up IP addresses with the Linux dig command)
|
||||
[#]: via: (https://www.networkworld.com/article/3527430/digging-up-ip-addresses-with-the-dig-command.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
使用 dig 命令挖掘域名解析信息
|
||||
======
|
||||
|
||||
> 命令行工具 `dig` 是用于解析域名和故障排查的一个利器。
|
||||
|
||||

|
||||
|
||||
从主要功能上来说,`dig` 和 `nslookup` 之间差异不大,但 `dig` 更像一个加强版的 `nslookup`,可以查询到一些由域名服务器管理的信息,这在排查某些问题的时候非常有用。总的来说,`dig` 是一个既简单易用又功能强大的命令行工具。(LCTT 译注:`dig` 和 `nslookup` 行为的主要区别来自于 `dig` 使用是是操作系统本身的解析库,而 `nslookup` 使用的是该程序自带的解析库,这有时候会带来一些行为差异。此外,从表现形式上看,`dig` 返回是结果是以 BIND 配置信息的格式返回的,也带有更多的技术细节。)
|
||||
|
||||
`dig` 最基本的功能就是查询域名信息,因此它的名称实际上是“<ruby>域名信息查询工具<rt>Domain Information Groper</rt></ruby>”的缩写。`dig` 向用户返回的内容可以非常详尽,也可以非常简洁,展现内容的多少完全由用户在查询时使用的选项来决定。
|
||||
|
||||
### 我只需要查询 IP 地址
|
||||
|
||||
如果只需要查询某个域名指向的 IP 地址,可以使用 `+short` 选项:
|
||||
|
||||
```
|
||||
$ dig facebook.com +short
|
||||
31.13.66.35
|
||||
```
|
||||
|
||||
在查询的时候发现有的域名会指向多个 IP 地址?这其实是网站提高其可用性的一种措施。
|
||||
|
||||
```
|
||||
$ dig networkworld.com +short
|
||||
151.101.2.165
|
||||
151.101.66.165
|
||||
151.101.130.165
|
||||
151.101.194.165
|
||||
```
|
||||
|
||||
也正是由于这些网站通过负载均衡实现高可用,在下一次查询的时候,或许会发现这几个 IP 地址的排序有所不同。(LCTT 译注:浏览器等应用默认会使用返回的第一个 IP 地址,因此这样实现了一种简单的负载均衡。)
|
||||
|
||||
```
|
||||
$ dig networkworld.com +short
|
||||
151.101.130.165
|
||||
151.101.194.165
|
||||
151.101.2.165
|
||||
151.101.66.165
|
||||
```
|
||||
|
||||
### 标准返回
|
||||
|
||||
`dig` 的标准返回内容则包括这个工具本身的一些信息,以及请求域名服务器时返回的响应内容:
|
||||
|
||||
```
|
||||
$ dig networkworld.com
|
||||
|
||||
; <<>> DiG 9.11.5-P4-5.1ubuntu2.1-Ubuntu <<>*gt; networkworld.com
|
||||
;; global options: +cmd
|
||||
;; Got answer:
|
||||
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 39932
|
||||
;; flags: qr rd ra; QUERY: 1, ANSWER: 4, AUTHORITY: 0, ADDITIONAL: 1
|
||||
|
||||
;; OPT PSEUDOSECTION:
|
||||
; EDNS: version: 0, flags:; udp: 65494
|
||||
;; QUESTION SECTION:
|
||||
;networkworld.com. IN A
|
||||
|
||||
;; ANSWER SECTION:
|
||||
networkworld.com. 300 IN A 151.101.194.165
|
||||
networkworld.com. 300 IN A 151.101.130.165
|
||||
networkworld.com. 300 IN A 151.101.66.165
|
||||
networkworld.com. 300 IN A 151.101.2.165
|
||||
|
||||
;; Query time: 108 msec
|
||||
;; SERVER: 127.0.0.53#53(127.0.0.53)
|
||||
;; WHEN: Thu Feb 13 13:49:53 EST 2020
|
||||
;; MSG SIZE rcvd: 109
|
||||
```
|
||||
|
||||
由于域名服务器有缓存机制,返回的内容可能是之前缓存好的信息。在这种情况下,`dig` 最后显示的<ruby>查询时间<rt>Query time</rt></ruby>会是 0 毫秒(0 msec):
|
||||
|
||||
```
|
||||
;; Query time: 0 msec <==
|
||||
;; SERVER: 127.0.0.53#53(127.0.0.53)
|
||||
;; WHEN: Thu Feb 13 15:30:09 EST 2020
|
||||
;; MSG SIZE rcvd: 109
|
||||
```
|
||||
|
||||
### 向谁查询?
|
||||
|
||||
在默认情况下,`dig` 会根据 `/etc/resolv.conf` 这个文件的内容决定向哪个域名服务器获取查询结果。你也可以使用 `@` 来指定 `dig` 请求的域名服务器。
|
||||
|
||||
在下面的例子中,就指定了 `dig` 向 Google 的域名服务器 8.8.8.8 查询域名信息。
|
||||
|
||||
```
|
||||
$ dig @8.8.8.8 networkworld.com
|
||||
|
||||
; <<>> DiG 9.11.5-P4-5.1ubuntu2.1-Ubuntu <<>> @8.8.8.8 networkworld.com
|
||||
; (1 server found)
|
||||
;; global options: +cmd
|
||||
;; Got answer:
|
||||
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 21163
|
||||
;; flags: qr rd ra; QUERY: 1, ANSWER: 4, AUTHORITY: 0, ADDITIONAL: 1
|
||||
|
||||
;; OPT PSEUDOSECTION:
|
||||
; EDNS: version: 0, flags:; udp: 512
|
||||
;; QUESTION SECTION:
|
||||
;networkworld.com. IN A
|
||||
|
||||
;; ANSWER SECTION:
|
||||
networkworld.com. 299 IN A 151.101.130.165
|
||||
networkworld.com. 299 IN A 151.101.66.165
|
||||
networkworld.com. 299 IN A 151.101.194.165
|
||||
networkworld.com. 299 IN A 151.101.2.165
|
||||
|
||||
;; Query time: 48 msec
|
||||
;; SERVER: 8.8.8.8#53(8.8.8.8)
|
||||
;; WHEN: Thu Feb 13 14:26:14 EST 2020
|
||||
;; MSG SIZE rcvd: 109
|
||||
```
|
||||
|
||||
想要知道正在使用的 `dig` 工具的版本,可以使用 `-v` 选项。你会看到类似这样:
|
||||
|
||||
```
|
||||
$ dig -v
|
||||
DiG 9.11.5-P4-5.1ubuntu2.1-Ubuntu
|
||||
```
|
||||
|
||||
或者这样的返回信息:
|
||||
|
||||
```
|
||||
$ dig -v
|
||||
DiG 9.11.4-P2-RedHat-9.11.4-22.P2.el8
|
||||
```
|
||||
|
||||
如果你觉得 `dig` 返回的内容过于详细,可以使用 `+noall`(不显示所有内容)和 `+answer`(仅显示域名服务器的响应内容)选项,域名服务器的详细信息就会被忽略,只保留域名解析结果。
|
||||
|
||||
```
|
||||
$ dig networkworld.com +noall +answer
|
||||
|
||||
; <<>> DiG 9.11.5-P4-5.1ubuntu2.1-Ubuntu <<>> networkworld.com +noall +answer
|
||||
;; global options: +cmd
|
||||
networkworld.com. 300 IN A 151.101.194.165
|
||||
networkworld.com. 300 IN A 151.101.130.165
|
||||
networkworld.com. 300 IN A 151.101.66.165
|
||||
networkworld.com. 300 IN A 151.101.2.165
|
||||
```
|
||||
|
||||
### 批量查询域名
|
||||
|
||||
如果你要查询多个域名,可以把这些域名写入到一个文件内(`domains`),然后使用下面的 `dig` 命令遍历整个文件并给出所有查询结果。
|
||||
|
||||
```
|
||||
$ dig +noall +answer -f domains
|
||||
networkworld.com. 300 IN A 151.101.66.165
|
||||
networkworld.com. 300 IN A 151.101.2.165
|
||||
networkworld.com. 300 IN A 151.101.130.165
|
||||
networkworld.com. 300 IN A 151.101.194.165
|
||||
world.std.com. 77972 IN A 192.74.137.5
|
||||
uushenandoah.org. 1982 IN A 162.241.24.209
|
||||
amazon.com. 18 IN A 176.32.103.205
|
||||
amazon.com. 18 IN A 176.32.98.166
|
||||
amazon.com. 18 IN A 205.251.242.103
|
||||
```
|
||||
|
||||
你也可以在上面的命令中使用 `+short` 选项,但如果其中有些域名指向多个 IP 地址,就无法看出哪些 IP 地址对应哪个域名了。在这种情况下,更好地做法应该是让 `awk` 对返回内容进行处理,只留下第一列和最后一列:
|
||||
|
||||
```
|
||||
$ dig +noall +answer -f domains | awk '{print $1,$NF}'
|
||||
networkworld.com. 151.101.66.165
|
||||
networkworld.com. 151.101.130.165
|
||||
networkworld.com. 151.101.194.165
|
||||
networkworld.com. 151.101.2.165
|
||||
world.std.com. 192.74.137.5
|
||||
amazon.com. 176.32.98.166
|
||||
amazon.com. 205.251.242.103
|
||||
amazon.com. 176.32.103.205
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3527430/digging-up-ip-addresses-with-the-dig-command.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/newsletters/signup.html
|
||||
[2]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE21620&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[3]: https://www.facebook.com/NetworkWorld/
|
||||
[4]: https://www.linkedin.com/company/network-world
|
||||
166
published/20200217 How to install Vim plugins.md
Normal file
166
published/20200217 How to install Vim plugins.md
Normal file
@ -0,0 +1,166 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qianmingtian)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11923-1.html)
|
||||
[#]: subject: (How to install Vim plugins)
|
||||
[#]: via: (https://opensource.com/article/20/2/how-install-vim-plugins)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
如何安装 Vim 插件
|
||||
======
|
||||
|
||||
> 无论你是手动安装还是通过包管理器安装,插件都可以帮助你在工作流中打造一个完美的 Vim 。
|
||||
|
||||

|
||||
|
||||
虽然 [Vim][2] 是快速且高效的,但在默认情况下,它仅仅只是一个文本编辑器。至少,这就是没有插件的情况 Vim 应当具备的样子,插件构建在 Vim 之上,并添加额外的功能,使 Vim 不仅仅是一个输入文本的窗口。有了合适的插件组合,你可以控制你的生活,形成你自己独特的 Vim 体验。你可以[自定义你的主题][3],你可以添加语法高亮,代码 linting,版本跟踪器等等。
|
||||
|
||||
### 怎么安装 Vim 插件
|
||||
|
||||
Vim 可以通过插件进行扩展,但很长一段时间以来,并没有官方的安装方式去安装这些插件。从 Vim 8 开始,有一个关于插件如何安装和加载的结构。你可能会在网上或项目自述文件中遇到旧的说明,但只要你运行 Vim 8 或更高版本,你应该根据 Vim 的[官方插件安装方法][4]安装或使用 Vim 包管理器。你可以使用包管理器,无论你运行的是什么版本(包括比 8.x 更老的版本),这使得安装过程比你自己维护更新更容易。
|
||||
|
||||
手动和自动安装方法都值得了解,所以请继续阅读以了解这两种方法。
|
||||
|
||||
### 手动安装插件(Vim 8 及以上版本)
|
||||
|
||||
所谓的 “Vim 包”是一个包含一个或多个插件的目录。默认情况下,你的 Vim 设置包含在 `~/.vim` 中,这是 Vim 在启动时寻找插件的地方。(下面的示例使用了通用名称 `vendor` 来表示插件是从其它地方获得的。)
|
||||
|
||||
当你启动 Vim 时,它首先处理你的 `.vimrc`文件,然后扫描 `~/.vim` 中的所有目录,查找包含在 `pack/*/start` 中的插件。
|
||||
|
||||
默认情况下,你的 `~/.vim` 目录(如果你有的话)中没有这样的文件结构,所以设置为:
|
||||
|
||||
```
|
||||
$ mkdir -p ~/.vim/pack/vendor/start
|
||||
```
|
||||
|
||||
现在,你可以将 Vim 插件放在 `~/.vim/pack/vendor/start` 中,它们会在你启动 Vim 时自动加载。
|
||||
|
||||
例如,尝试安装一下 [NERDTree][5],这是一个基于文本的 Vim 文件管理器。首先,使用 Git 克隆 NERDTree 存储库的快照:
|
||||
|
||||
```
|
||||
$ git clone --depth 1 \
|
||||
https://github.com/preservim/nerdtree.git \
|
||||
~/.vim/pack/vendor/start/nerdtree
|
||||
```
|
||||
|
||||
启动 Vim 或者 gvim,然后键入如下命令:
|
||||
|
||||
```
|
||||
:NERDTree
|
||||
```
|
||||
|
||||
Vim 窗口左侧将打开一个文件树。
|
||||
|
||||
![NERDTree plugin][6]
|
||||
|
||||
如果你不想让一个插件每次启动 Vim 时都自动加载,你可以在 `~/.vim/pack/vendor` 中创建 `opt` 文件夹:
|
||||
|
||||
```
|
||||
$ mkdir ~/.vim/pack/vendor/opt
|
||||
```
|
||||
|
||||
任何安装到 `opt` 的插件都可被 Vim 使用,但是只有当你使用 `packadd` 命令将它们添加到一个会话中时,它们才会被加载到内存中。例如,一个虚构的叫 foo 的插件:
|
||||
|
||||
```
|
||||
:packadd foo
|
||||
```
|
||||
|
||||
Vim 官方建议每个插件项目在 `~/.Vim/pack` 中创建自己的目录。例如,如果你要安装 NERDTree 插件和假想的 foo 插件,你需要创建这样的目录结构:
|
||||
|
||||
```
|
||||
$ mkdir -p ~/.vim/pack/NERDTree/start/
|
||||
$ git clone --depth 1 \
|
||||
https://github.com/preservim/nerdtree.git \
|
||||
~/.vim/pack/NERDTree/start/NERDTree
|
||||
$ mkdir -p ~/.vim/pack/foo/start/
|
||||
$ git clone --depth 1 \
|
||||
https://notabug.org/foo/foo.git \
|
||||
~/.vim/pack/foo/start/foo
|
||||
```
|
||||
|
||||
这样做是否方便取决于你。
|
||||
|
||||
### 使用 Vim 包管理器(任何 Vim 版本)
|
||||
|
||||
自从 Vim 8 以后,包管理器变得不那么有用了,但是一些用户仍然喜欢它们,因为它们能够自动更新一些插件。有几个包管理器可供选择,并且它们各不相同,但是 [vim-plug][7] 有一些很棒的特性和最好的文档,这使我们很容易开始并在以后深入研究。
|
||||
|
||||
#### 使用 vim-plug 安装插件
|
||||
|
||||
安装 vim-plug,以便它在启动时自动加载:
|
||||
|
||||
```
|
||||
$ curl -fLo ~/.vim/autoload/plug.vim --create-dirs \
|
||||
https://raw.githubusercontent.com/junegunn/vim-plug/master/plug.vim
|
||||
```
|
||||
|
||||
创建一个 `~/.vimrc` 文件(如果你还没有这个文件),然后输入以下文本:
|
||||
|
||||
```
|
||||
call plug#begin()
|
||||
Plug 'preservim/NERDTree'
|
||||
call plug#end()
|
||||
```
|
||||
|
||||
每次要安装插件时,都必须在 `plug#begin()` 和 `plug#end()` 之间输入插件的名称和位置(上面以 NERDTree 文件管理器为例)。如果你所需的插件未托管在 GitHub 上,你可以提供完整的 URL,而不仅仅是 GitHub 的用户名和项目 ID。你甚至可以在 `~/.vim` 目录之外“安装”本地插件。
|
||||
|
||||
最后,启动 Vim 并提示 vim-plug 安装 `~/.vimrc` 中列出的插件:
|
||||
|
||||
```
|
||||
:PlugInstall
|
||||
```
|
||||
|
||||
等待插件下载。
|
||||
|
||||
#### 通过 vim-plug 更新插件
|
||||
|
||||
与手动安装过程相比,编辑 `~/.vimrc` 并使用命令来进行安装可能看起来并没有多省事,但是 vim-plug 的真正优势在更新。更新所有安装的插件,使用这个 Vim 命令:
|
||||
|
||||
```
|
||||
:PlugUpdate
|
||||
```
|
||||
|
||||
如果你不想更新所有的插件,你可以通过添加插件的名字来更新任何插件:
|
||||
|
||||
```
|
||||
:PlugUpdate NERDTree
|
||||
```
|
||||
|
||||
#### 恢复插件
|
||||
|
||||
vim-plug 的另一个优点是它的导出和恢复功能。Vim 用户都知道,正是插件的缘故,通常每个用户使用 Vim 的工作方式都是独一无二的。一旦你安装和配置了正确的插件组合,你最不想要的局面就是再也找不到它们。
|
||||
|
||||
Vim-plug 有这个命令来生成一个脚本来恢复所有当前的插件:
|
||||
|
||||
```
|
||||
:PlugSnapshot ~/vim-plug.list
|
||||
```
|
||||
vim-plug 还有许多其他的功能,所以请参考它的[项目页面][7]以获得完整的文档。
|
||||
|
||||
### 打造一个完美的 Vim
|
||||
|
||||
当你整天都在做一个项目时,你希望每一个小细节都能为你提供最好的服务。了解 Vim 和它的许多插件,直到你为你所做的事情构建出一个完美的应用程序。
|
||||
|
||||
有喜欢的 Vim 插件吗?请在评论中告诉我们吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/how-install-vim-plugins
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qianmingtian][c]
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[c]: https://github.com/qianmingtian
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/todo_checklist_team_metrics_report.png?itok=oB5uQbzf (Team checklist and to dos)
|
||||
[2]: https://www.vim.org/
|
||||
[3]: https://opensource.com/article/19/12/colors-themes-vim
|
||||
[4]: https://github.com/vim/vim/blob/03c3bd9fd094c1aede2e8fe3ad8fd25b9f033053/runtime/doc/repeat.txt#L515
|
||||
[5]: https://github.com/preservim/nerdtree
|
||||
[6]: https://opensource.com/sites/default/files/uploads/vim-nerdtree.jpg (NERDTree plugin)
|
||||
[7]: https://github.com/junegunn/vim-plug
|
||||
104
published/20200219 Don-t like IDEs- Try grepgitvi.md
Normal file
104
published/20200219 Don-t like IDEs- Try grepgitvi.md
Normal file
@ -0,0 +1,104 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11934-1.html)
|
||||
[#]: subject: (Don't like IDEs? Try grepgitvi)
|
||||
[#]: via: (https://opensource.com/article/20/2/no-ide-script)
|
||||
[#]: author: (Yedidyah Bar David https://opensource.com/users/didib)
|
||||
|
||||
不喜欢 IDE?试试看 grepgitvi
|
||||
======
|
||||
|
||||
> 一个简单又原始的脚本来用 Vim 打开你选择的文件。
|
||||
|
||||

|
||||
|
||||
像大多数开发者一样,我整天都在搜索和阅读源码。就我个人而言,我从来没有习惯过集成开发环境 (IDE),多年来,我主要使用 `grep` (找到文件),并复制/粘贴文件名来打开 Vi(m)。
|
||||
|
||||
最终,我写了这个脚本,并根据需要缓慢地对其进行了完善。
|
||||
|
||||
它依赖 [Vim][2] 和 [rlwrap][3],并使用 Apache 2.0 许可证开源。要使用该脚本,请[将它放到 PATH 中][4],然后在文本目录下运行:
|
||||
|
||||
```
|
||||
grepgitvi <grep options> <grep/vim search pattern>
|
||||
```
|
||||
|
||||
它将返回搜索结果的编号列表,并提示你输入结果编号并打开 Vim。退出 Vim 后,它将再次显示列表,直到你输入除结果编号以外的任何内容。你也可以使用向上和向下箭头键选择一个文件。(这对我来说)更容易找到我已经看过的结果。
|
||||
|
||||
与现代 IDE 甚至与 Vim 的更复杂的用法相比,它简单而原始,但它对我有用。
|
||||
|
||||
### 脚本
|
||||
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
# grepgitvi - grep source files, interactively open vim on results
|
||||
# Doesn't really have to do much with git, other than ignoring .git
|
||||
#
|
||||
# Copyright Yedidyah Bar David 2019
|
||||
#
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Requires vim and rlwrap
|
||||
#
|
||||
# Usage: grepgitvi <grep options> <grep/vim pattern>
|
||||
#
|
||||
|
||||
TMPD=$(mktemp -d /tmp/grepgitvi.XXXXXX)
|
||||
UNCOLORED=${TMPD}/uncolored
|
||||
COLORED=${TMPD}/colored
|
||||
|
||||
RLHIST=${TMPD}/readline-history
|
||||
|
||||
[ -z "${DIRS}" ] && DIRS=.
|
||||
|
||||
cleanup() {
|
||||
rm -rf "${TMPD}"
|
||||
}
|
||||
|
||||
trap cleanup 0
|
||||
|
||||
find ${DIRS} -iname .git -prune -o \! -iname "*.min.css*" -type f -print0 > ${TMPD}/allfiles
|
||||
|
||||
cat ${TMPD}/allfiles | xargs -0 grep --color=always -n -H "$@" > $COLORED
|
||||
cat ${TMPD}/allfiles | xargs -0 grep -n -H "$@" > $UNCOLORED
|
||||
|
||||
max=`cat $UNCOLORED | wc -l`
|
||||
pat="${@: -1}"
|
||||
|
||||
inp=''
|
||||
while true; do
|
||||
echo "============================ grep results ==============================="
|
||||
cat $COLORED | nl
|
||||
echo "============================ grep results ==============================="
|
||||
prompt="Enter a number between 1 and $max or anything else to quit: "
|
||||
inp=$(rlwrap -H $RLHIST bash -c "read -p \"$prompt\" inp; echo \$inp")
|
||||
if ! echo "$inp" | grep -q '^[0-9][0-9]*$' || [ "$inp" -gt "$max" ]; then
|
||||
break
|
||||
fi
|
||||
|
||||
filename=$(cat $UNCOLORED | awk -F: "NR==$inp"' {print $1}')
|
||||
linenum=$(cat $UNCOLORED | awk -F: "NR==$inp"' {print $2-1}')
|
||||
vim +:"$linenum" +"norm zz" +/"${pat}" "$filename"
|
||||
done
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/no-ide-script
|
||||
|
||||
作者:[Yedidyah Bar David][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/didib
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/files_documents_paper_folder.png?itok=eIJWac15 (Files in a folder)
|
||||
[2]: https://www.vim.org/
|
||||
[3]: https://linux.die.net/man/1/rlwrap
|
||||
[4]: https://opensource.com/article/17/6/set-path-linux
|
||||
@ -0,0 +1,128 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11929-1.html)
|
||||
[#]: subject: (How to Install Latest Git Version on Ubuntu)
|
||||
[#]: via: (https://itsfoss.com/install-git-ubuntu/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
如何在 Ubuntu 上安装最新版本的 Git
|
||||
======
|
||||
|
||||
在 Ubuntu 上安装 Git 非常容易。它存在于 [Ubuntu 的主仓库][1]中,你可以像这样[使用 apt 命令][2]安装它:
|
||||
|
||||
```
|
||||
sudo apt install git
|
||||
```
|
||||
|
||||
很简单?是不是?
|
||||
|
||||
只有一点点小问题(这可能根本不是问题),就是它安装的 [Git][3] 版本。
|
||||
|
||||
在 LTS 系统上,软件稳定性至关重要,这就是为什么 Ubuntu 18.04 和其他发行版经常提供较旧但稳定的软件版本的原因,它们都经过发行版的良好测试。
|
||||
|
||||
这就是为什么当你检查 Git 版本时,会看到安装的版本会比 [Git 网站上当前最新 Git 版本][4]旧:
|
||||
|
||||
```
|
||||
$ git --version
|
||||
git version 2.17.1
|
||||
```
|
||||
|
||||
在编写本教程时,网站上提供的版本为 2.25。那么,如何在 Ubuntu 上安装最新的 Git?
|
||||
|
||||
### 在基于 Ubuntu 的 Linux 发行版上安装最新的 Git
|
||||
|
||||
![][5]
|
||||
|
||||
一种方法是[从源代码安装][6]。这种很酷又老派的方法不适合所有人。值得庆幸的是,Ubuntu Git 维护团队提供了 [PPA][7],莫可以使用它轻松地安装最新的稳定 Git 版本。
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:git-core/ppa
|
||||
sudo apt update
|
||||
sudo apt install git
|
||||
```
|
||||
|
||||
即使你以前使用 `apt` 安装了 Git,它也将更新为最新的稳定版本。
|
||||
|
||||
```
|
||||
$ git --version
|
||||
git version 2.25.0
|
||||
```
|
||||
|
||||
[使用PPA][8] 的好处在于,如果发布了新的 Git 稳定版本,那么就可以通过系统更新获得它。[仅更新 Ubuntu][9] 来获取最新的 Git 稳定版本。
|
||||
|
||||
### 配置 Git (推荐给开发者)
|
||||
|
||||
如果你出于开发目的安装了 Git,你会很快开始克隆仓库,进行更改并提交更改。
|
||||
|
||||
如果你尝试提交代码,那么你可能会看到 “Please tell me who you are” 这样的错误:
|
||||
|
||||
```
|
||||
$ git commit -m "update readme"
|
||||
|
||||
*** Please tell me who you are.
|
||||
|
||||
Run
|
||||
|
||||
git config --global user.email "you@example.com"
|
||||
git config --global user.name "Your Name"
|
||||
|
||||
to set your account's default identity.
|
||||
Omit --global to set the identity only in this repository.
|
||||
|
||||
fatal: unable to auto-detect email address (got 'abhishek@itsfoss.(none)')
|
||||
```
|
||||
|
||||
这是因为你还没配置必要的个人信息。
|
||||
|
||||
正如错误已经暗示的那样,你可以像这样设置全局 Git 配置:
|
||||
|
||||
```
|
||||
git config --global user.name "Your Name"
|
||||
git config --global user.email "you@example.com"
|
||||
```
|
||||
|
||||
你可以使用以下命令检查 Git 配置:
|
||||
|
||||
```
|
||||
git config --list
|
||||
```
|
||||
|
||||
它应该显示如下输出:
|
||||
|
||||
```
|
||||
user.email=you@example.com
|
||||
user.name=Your Name
|
||||
```
|
||||
|
||||
配置保存在 `~/.gitconfig` 中。你可以手动修改配置。
|
||||
|
||||
### 结尾
|
||||
|
||||
我希望这个小教程可以帮助你在 Ubuntu 上安装 Git。使用 PPA,你可以轻松获得最新的 Git 版本。
|
||||
|
||||
如果你有任何疑问或建议,请随时在评论部分提问。也欢迎直接写“谢谢” :)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-git-ubuntu/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/ubuntu-repositories/
|
||||
[2]: https://itsfoss.com/apt-command-guide/
|
||||
[3]: https://git-scm.com/
|
||||
[4]: https://git-scm.com/downloads
|
||||
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/02/install_git_ubuntu.png?ssl=1
|
||||
[6]: https://itsfoss.com/install-software-from-source-code/
|
||||
[7]: https://launchpad.net/~git-core/+archive/ubuntu/ppa
|
||||
[8]: https://itsfoss.com/ppa-guide/
|
||||
[9]: https://itsfoss.com/update-ubuntu/
|
||||
67
sources/talk/20200212 A SASE Crash Course.md
Normal file
67
sources/talk/20200212 A SASE Crash Course.md
Normal file
@ -0,0 +1,67 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (A SASE Crash Course)
|
||||
[#]: via: (https://www.networkworld.com/article/3526455/a-sase-crash-course.html)
|
||||
[#]: author: (Cato Networks https://www.networkworld.com/author/Matt-Conran/)
|
||||
|
||||
A SASE Crash Course
|
||||
======
|
||||
Get up to speed fast on the Secure Access Service Edge, an emerging converged networking and security category that Gartner has labelled transformational.
|
||||
peshkov
|
||||
|
||||
2020! What could better motivate you to push ahead with your resolutions and organization’s digital transformation than a new year AND a new decade. As you put together your digital strategy, check out a new transformation-empowering (and transformational) technology category Gartner coined the [Secure Access Service Edge][1] or SASE (pronounced “Sassy”). SASE converges wide area networking and identity-based security into a cloud service targeted directly to your branch offices, mobile users, cloud services, and even IoT devices, wherever they happen to be. The result: consistently high WAN performance, security, productivity, agility, and flexibility across the global, mobile, cloud-enabled enterprise.
|
||||
|
||||
To jumpstart your research into one of the few networking categories Gartner has labelled “transformational,” we’ve put together a very workable SASE crash course and reading list. Each lesson helps you dig a little deeper into SASE, so you can develop a good grasp of its components and transformational potential.
|
||||
|
||||
**Lesson 1: SASE as Defined by Gartner**
|
||||
|
||||
So, what is SASE exactly and why should you care? SASE was coined by [Gartner][2] analysts Neil McDonald and Joe Skorupa in a [July 29, 2019 Networking Hype Cycle][3] [Market Trends Report, How to Win as WAN Edge and Security Converge into the Secure Access Service Edge][4] and an August 30, 2019 [Gartner][2] report, The Future of Network Security is in the Cloud. If you don’t have access to these reports, Cato quotes the highlights of the former word for word in this short blog: [The Secure Access Service Edge (SASE), as Described in Gartner’s Hype Cycle for Enterprise Networking, 2019][5]. It’s a great place to get started on exactly what Gartner has to say about SASE and its drivers, likely development, and place in the digitally transforming enterprise. There are also some valuable links to more information on SASE and exactly how the Cato cloud fits into the SASE trend.
|
||||
|
||||
**Lesson 2: What SASE _Is_ and What It _Isn’t_**
|
||||
|
||||
After Gartner piques your interest, get some valuable insight from Cato in this blog: [The Secure Access Service Edge (SASE): Here’s Where Your Digital Business Network Starts][6]. Here you can learn why convergence of wide area networking and security is absolutely vital for the agile, digitally transforming enterprise and why legacy data center-centric solutions can’t deliver any more in a world of user mobility and the cloud. This blog breaks down the four essential attributes of SASE—identity driven, cloud native, support for all edges, and globally distributed—in detail. It also explains why SASE is _not_ anything like telco-managed services and summarizes how Cato delivers SASE effectively.
|
||||
|
||||
**Lesson 3: How Cato Delivers SASE**
|
||||
|
||||
Sometimes visual/audio-based learning can bring things into better focus than straight text, and few people are better at explaining WAN and security concepts than Yishay Yovel, Cato Network’s Chief Marketing Officer. In this short, 17-minute video presentation, [Intro to SASE by Yishay][7], Yishay digs into Gartner’s take on SASE, why WAN and security need to converge, and why SASE is one of only three (out of 29) Networking Hype Cycle categories that Gartner has labeled “transformational.” Yishay gets into a lot of nitty-gritty SASE details and offers valuable perspective on how Cato Networks delivers a complete cloud-native SASE software stack that supports all edges and is identity-driven, scalable, flexible, and easy to deploy and manage. Yishay also explains clearly why some of the other WAN and security solutions out there don’t fulfill some essential requirements of SASE, such as processing traffic close to the source. For visual learners, there are also some great architectural diagrams.
|
||||
|
||||
**Lesson 4: Gartner Webinar Breaks Down SASE and its Implications**
|
||||
|
||||
You’ve heard it from Yishay, now hear it from Gartner’s VP Distinguished Analyst Neil MacDonald _and_ Yishay in this 37-minute [Gartner Webinar: Is SASE the Future of SD-WAN and Network Security][8]? MacDonald explains SASE elements and drivers in depth, why SASE belongs in the cloud, how enterprises will adopt SASE, and how organizations should evaluate SASE offerings. There’s some good detail here on how SASE works in different contexts and scenarios, such as a mobile employee connecting to Salesforce securely from the airport, a contractor accessing a Web application from an unmanaged device, and even wind turbines collecting and aggregating data and sending it to the cloud for processing. Neil digs into core SASE requirements and recommends additional services and some other useful options. Yishay then takes over with why Cato is the world’s first true SASE platform.
|
||||
|
||||
**Lesson 5: The White Paper**
|
||||
|
||||
But wait, there’s more. Here’s a clear and concise white paper from Cato, [The Network for the Digital Business Starts with the Secure Access Service Edge][9]. This is a good piece to give out to the other digital transformation stakeholders in your business if you want them to get up to speed on SASE fast. It’s a quick read that explains why the digital, mobile, cloud-enabled business needs a new converged network/security model. It also covers the four elements of SASE, core SASE capabilities, SASE benefits, and clear examples of what SASE _isn’t_ and why. It describes the features that make Cato one of the most comprehensive SASE offerings on the market. It’s a clear, concise presentation broken into short paragraphs and bullet points to provide a fast introduction to SASE and the Cato Cloud.
|
||||
|
||||
**Lesson 6: Icing on the Cake: The Short and Sweet Video**
|
||||
|
||||
[SASE (Secure Access Service Edge)][10] is a short YouTube video to go along with the white paper, combining perspective and information from Gartner and Cato on why you need SASE simplicity for your digital transforming business.
|
||||
|
||||
We hope you have a happy, healthy, transforming New Year. To accelerate your organization’s digital transformation over the next decade, get up to speed on SASE with these useful blogs, videos, and white papers and find out how SASE can help you make that transformation happen quickly and more easily.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3526455/a-sase-crash-course.html
|
||||
|
||||
作者:[Cato Networks][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Matt-Conran/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://www.catonetworks.com/sase?utm_source=idg
|
||||
[2]: https://en.wikipedia.org/wiki/Gartner
|
||||
[3]: https://www.gartner.com/en/documents/3947237
|
||||
[4]: https://www.gartner.com/en/documents/3953690/market-trends-how-to-win-as-wan-edge-and-security-conver
|
||||
[5]: https://www.catonetworks.com/blog/the-secure-access-service-edge-sase-as-described-in-gartners-hype-cycle-for-enterprise-networking-2019/
|
||||
[6]: https://www.catonetworks.com/blog/the-secure-access-service-edge-sase?utm_source=idg
|
||||
[7]: https://catonetworks.wistia.com/medias/kn86smj7q4
|
||||
[8]: https://go.catonetworks.com/VOD-REG-Gartner-SASE?utm_source=idg
|
||||
[9]: https://go.catonetworks.com/The-Network-Starts-with-SASE?utm_source=idg
|
||||
[10]: https://www.youtube.com/watch?v=gLN4NUbjml8
|
||||
@ -0,0 +1,63 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Server sales projected to decline 10% due to coronavirus)
|
||||
[#]: via: (https://www.networkworld.com/article/3526605/server-sales-projected-to-decline-10-due-to-coronavirus.html)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Server sales projected to decline 10% due to coronavirus
|
||||
======
|
||||
Demand isn’t tapering off, but China is grinding to a halt under the strain of the pandemic.
|
||||
Writerfantast / Getty Images
|
||||
|
||||
Global server sales had been projected to grow by 1.2% compared to the most recent quarter, but the chaos wrought by the coronavirus in China will cause sales to decline 9.8% sequentially, according to DigiTimes Research.
|
||||
|
||||
DigiTimes is an IT publication based in Taiwan. Its proximity to Taiwanese and Chinese vendors gives it some good sources, but it can also be way off target. However, the signs are piling up that coronavirus is causing some real mayhem.
|
||||
|
||||
For example, DigiTimes also [reported][1] that less than 20% of Chinese factory employees would return to work after an extended Lunar New Year break due to the coronavirus outbreak, and that many components plants in China have decided not to restart production until February 25.
|
||||
|
||||
**[ Now read: [What is quantum computing (and why enterprises should care)][2] ]**
|
||||
|
||||
The Lunar New Year was January 25, so that means Chinese factories have been idle for a month. That’s a lot of supply not being answered, and DigiTimes notes that server demand from large data centers remained strong in the first quarter of 2020.
|
||||
|
||||
Facebook in particular is interested in buying high-density models from white box vendors like Wiwynn and Quanta Computer, but due to the outbreak, these orders, which were originally scheduled for shipment this quarter, have been postponed.
|
||||
|
||||
So it’s not like an economic crash is causing sales to go off a cliff like in 2008. Demand is there, but China can’t make the product right now. This year was expected to be a good year for the server vendors, with all of them projecting sales increases over last year. AMD is ramping up Epyc production, and Intel is expected to release its next-generation “Ice Lake” Xeon platform in the third or the fourth quarter of 2020.
|
||||
|
||||
The good news here is that Wuhan isn’t a major tech manufacturing hub. It does have five display fabs, both LCD and OLED, but so does Shanhai. However, Wuhan has the most advanced display fabs, producing flexible OLEDs, and has the largest capacity, according to David Hsieh, senior director, displays, at Omdia.
|
||||
|
||||
**[ [Get certified as an Apple Technical Coordinator with this seven-part online course from PluralSight.][3] ]**
|
||||
|
||||
Vladimir Galabov, principal analyst for data-center compute in Omdia’s cloud and data-center research practice, also expects to see server shipments impacted by the coronavirus driving a prolonged holiday period in China.
|
||||
|
||||
“I think the majority of the hit will be in the Chinese market,” he said. “This does impact server shipments globally as China represents about 30% of server shipments worldwide. So, I expect the quarterly decline to be more significant than the seasonal 10%. I expect that China will have a 5% additional downward impact on the growth.”
|
||||
|
||||
He added that Q4 of 2019 did significantly overachieve his expectations due to cloud service providers making massive purchases. Omdia expected servers shipped in 2019 to be flat compared to 2018 based on data from 1Q19-3Q19. Instead, it was up 2% to 3% for the year, thanks to the fourth-quarter spurt.
|
||||
|
||||
And servers aren’t the only products taking a hit. DigiTimes says that should the outbreak of the coronavirus last until June, sales of smartphones in the country would be slashed by about 30%, from a projected 400 million units to 280 million units in 2020.
|
||||
|
||||
Also, Mobile World Congress in Barcelona is cancelled due to concerns about the global coronavirus outbreak. The [official cancellation][4] came after a number of big-name companies, including Intel, Cisco, Amazon, Sony, NTT Docomo LG, ZTE, Nvidia, and Ericsson, bowed out of various events that were set for the show.
|
||||
|
||||
Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3526605/server-sales-projected-to-decline-10-due-to-coronavirus.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.digitimes.com/news/a20200210VL202.html
|
||||
[2]: https://www.networkworld.com/article/3275367/what-s-quantum-computing-and-why-enterprises-need-to-care.html
|
||||
[3]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fapple-certified-technical-trainer-10-11
|
||||
[4]: https://www.mwcbarcelona.com/attend/safety-security/gsma-statement-on-mwc-2020/
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,115 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (3 steps for product marketing your open source project)
|
||||
[#]: via: (https://opensource.com/article/20/2/product-marketing-open-source-project)
|
||||
[#]: author: (Kevin Xu https://opensource.com/users/kevin-xu)
|
||||
|
||||
3 steps for product marketing your open source project
|
||||
======
|
||||
Marketing an open source project is mainly about education, and
|
||||
traditional marketing techniques do not apply.
|
||||
![People meeting][1]
|
||||
|
||||
I frequently get questions from open source project creators or new founders of commercial open source software (COSS) companies about the best way to market their product. Implicit in that inquiry lies more foundational questions: "What the hell is product marketing? How much time should I spend on it?"
|
||||
|
||||
This article aims to share some knowledge and specific action items to help open source creators understand product marketing as a concept and how to bootstrap it on their own until a project reaches the next level of traction.
|
||||
|
||||
### What is product marketing?
|
||||
|
||||
Product marketing for COSS is materially different from product marketing for proprietary software and from general marketing practices like ads, lead generation, sponsorships, booths at conferences and trade shows, etc. Because the source code is open for all to see and the project's evolutionary history is completely transparent, you need to articulate—from a technical level to a technical audience—how and why your project works.
|
||||
|
||||
Using the word "marketing" in this context is, in fact, misleading. It's really about product _education_. Your role is more like a coach, mentor, or teaching assistant in a computer science class or a code bootcamp than a "marketing person."
|
||||
|
||||
Proprietary software products rarely need this level of technical education because no one can see the source code anyway. Therefore, these companies focus on educating their audience about the product's business value, not its technical advantages.
|
||||
|
||||
To build a successful open source project (and any commercial product that may be derived from it), you must educate your audience on _both_ its technical details and business value.
|
||||
|
||||
While this may sound like extra work, it's an advantage inherent to COSS because so much buying power for technology products is shifting to developers. They care deeply about technical details and want to see and understand the source code. Being able to learn, appreciate, and have confidence in a project's technical design, architecture, and future roadmap are key to its adoption.
|
||||
|
||||
Also, developers often treat open source technology as a way to scratch their technical itch and stay sharp in a fast-moving technology landscape. It's an audience that yearns for education, above all.
|
||||
|
||||
Being able to speak to an audience that has these goals and desires is what product marketing and education in the COSS context is all about.
|
||||
|
||||
### How to bootstrap product marketing
|
||||
|
||||
So you (or maybe one or two other engineers) are laboring away to create your open source project, likely in the evening after your day job or on the weekends. How do you bootstrap some effective product marketing on your own?
|
||||
|
||||
I recommend a three-step process to yield the best return for your time:
|
||||
|
||||
1. Peruse online forums
|
||||
2. Write content
|
||||
3. Do in-person meetups
|
||||
|
||||
|
||||
|
||||
#### Online forums
|
||||
|
||||
Rummaging through forums—from general ones like HackerNews and Reddit to ones like Discourse or Slack channels geared to projects that are closely related to what you are building—is a great way to figure out what questions developers have in your space. Starting with this step is less about inserting your project into the discussion and more about gathering ideas on what you should focus on when putting together educational materials about your project.
|
||||
|
||||
Effectively, what you are doing is akin to "listening to your customer."
|
||||
|
||||
Let's be honest; you already spend a lot of time on these forums anyway. The only change is one of mindset, not behavior: Have more focus, jot ideas down actively, practice absorbing critiques (you may see threads critical of your project), and develop some intuition about what developers are thinking about.
|
||||
|
||||
This step assumes you don't already have an active community where developers are asking questions directly. The long-term goal is to build your own community, and good product marketing directly helps with this.
|
||||
|
||||
#### Write
|
||||
|
||||
Now that you have gathered some ideas, it's time to produce some content. Compared to formats like videos and podcasts, _writing_ is the highest-leveraged medium. It has the best long-tail benefits, is most suited for ongoing reference material, and can be most easily repackaged into other mediums. Another factor: open source has a global audience, many of whom might speak English as a second (third, or fourth) language, and written content is easily consumable at a person's own pace.
|
||||
|
||||
Focus your writing on three categories that answer three fundamental questions:
|
||||
|
||||
* What problem does your project solve? In other words: _Why should it exist?_
|
||||
* How is the project architected, and why is it done that way? _Is this a technically well-designed solution that has potential, thus worth investing time in?_
|
||||
* How do I get a taste of it? _How quickly can I get some value out of it?_ This is crucial to reducing your time-to-value metric to the shortest amount possible. For more on this topic, please read my article [_A framework for building products from open source projects_][2].
|
||||
|
||||
|
||||
|
||||
A smart way to begin is by writing three blog posts, each addressing one of the three points. The posts should be canonical to your specific project so that repackaging them into different formats (e.g., slide decks, Quora answers, Twitter threads, podcast interviews, etc.) for different channels should be straightforward.
|
||||
|
||||
After you publish the posts, work the materials into your GitHub, GitLab, Bitbucket, or other repository along with the project's documentation. This is important because your public repo will likely be the face of your project for a long time, even if also you have a dedicated website. A repo with strong educational content will go a long way in building your social proof in the form of stars, forks, and downloads and may even yield some contributions.
|
||||
|
||||
One note on writing: Be patient! Your words likely won't go viral overnight (unless you are a celebrity developer). But if the material is educational, useful, and accessible (no need for fancy language), it will draw attention to your project in time. You do your part, and let Google's SEO algorithm do its part.
|
||||
|
||||
#### In-person meetups
|
||||
|
||||
With a few posts out in the wild, the next step is to find an in-person meetup where you can give a presentation about your project using your writing as foundational material to build a compelling talk.
|
||||
|
||||
You may wonder: "Why? Isn't doing something in-person the biggest time suck? I'd rather code!"
|
||||
|
||||
True. You are not wrong. I recommend this step _specifically_ at this moment, not earlier or later, because you'll get feedback on your output more quickly than what the internet can give. Comments and feedback on your posts will trickle in, but giving a talk at a meetup, taking questions, and chatting with attendees afterward over pizza is valuable and immediate.
|
||||
|
||||
The goal is not to shamelessly pitch your project (reminder: you are an educator, not a marketer), but to listen for the kinds of questions you get when you put your project (and yourself) out there. Another benefit is that it gives you practice delivering presentations, which will become important as your project grows, and you need to present in higher-stakes situations, including large conferences, demos with prospective users, etc.
|
||||
|
||||
I know this may not be practical if you don't live in a tech hub where meetups are aplenty. You may want to look for groups that are open to doing virtual meetups via video or work this into your existing travel plans. (But don't fly across the world to talk at one meetup.)
|
||||
|
||||
In-person meetups can feel scary. Public speaking is not for everyone, and it's a legitimate source of fear. My main tips: Just think of yourself as free entertainment, lower your expectations, don't overthink it, and offer yourself up to meetup organizers proactively because they will love you! Having been both a presenter and a meetup organizer, I know developer-focused meetups are very hungry for good technical education.
|
||||
|
||||
### Final words
|
||||
|
||||
There's a lot more nuance, strategy, and sheer work to effective product marketing, but I hope this post gives you enough guidance and specific action items to bootstrap it. Ultimately, you should still spend the bulk of your time building your technology. And if you have some revenue or funding, it's worth hiring someone who has deep expertise in product marketing, even as a part-time adviser.
|
||||
|
||||
Frankly, product marketing talent is hard to find. You need someone with both the technical chops and curiosity to learn about your project on a deep level and the communication skills to compellingly tell the world about it.
|
||||
|
||||
* * *
|
||||
|
||||
_This article originally appeared on [COSS Media][3] and is republished with permission._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/product-marketing-open-source-project
|
||||
|
||||
作者:[Kevin Xu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/kevin-xu
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/people_team_community_group.png?itok=Nc_lTsUK (People meeting)
|
||||
[2]: https://opensource.com/article/19/11/products-open-source-projects
|
||||
[3]: https://coss.media/open-source-creator-product-marketing/
|
||||
@ -0,0 +1,95 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Minicomputers and The Soul of a New Machine)
|
||||
[#]: via: (https://opensource.com/article/20/2/minicomputers-and-soul-new-machine)
|
||||
[#]: author: (Matthew Broberg https://opensource.com/users/mbbroberg)
|
||||
|
||||
Minicomputers and The Soul of a New Machine
|
||||
======
|
||||
The new season of Command Line Heroes begins with a story of increases
|
||||
in memory, company politics, and a forgotten technology at the heart of
|
||||
our computing history.
|
||||
![Command Line Heroes season 4 episode 1 covers the rise of minicomputers][1]
|
||||
|
||||
The [Command Line Heroes podcast][2] is back, and this season it covers the machines that run all the programming languages [I covered last season][3]. As the podcast staff puts it:
|
||||
|
||||
"This season, we'll look at what happens when idealistic teams come together to build visionary machines. Machines made with leaps of faith and a lot of hard, often unrecognized, work in basements and stifling cubicles. Machines that brought teams together and changed us as a society in ways we could only dream of."
|
||||
|
||||
This first episode looks at the non-fiction book (and engineering classic), [_The Soul of a New Machine_][4], to look at a critical moment in computing history. It covers the transition from large, hulking mainframes to the intermediate step of the minicomputer, which will eventually lead us to the PC revolution that we're still living in the wake of.
|
||||
|
||||
### The rise of minicomputers
|
||||
|
||||
One of the most important machines on the path to modern machines, most of us have since forgotten: the minicomputer.
|
||||
|
||||
It was a crucial link in the evolution from mainframe to PC (aka microcomputer). It was also extremely important in the development of software that would fuel the PC revolution, chiefly the operating system. The PDP-7 and PDP-11—on which [UNIX was developed][5]—were examples of minicomputers. So was the machine at the heart of _The Soul of the New Machine_.
|
||||
|
||||
This episode takes us back to this important time in computing and explores this forgotten machine—both in terms of its hardware and software.
|
||||
|
||||
From 1963 to 1977, minicomputers were 12 to 16-bit machines from computing giants DEC ([PDP][6]) and rival upstart [Data General][7] ([Nova][8], [Eclipse][9]). But in October 1977, DEC unveiled the VAX 11/780, a 32-bit CPU built from transistor-transistor logic with a five megahertz cycle-time and 2 megabytes of memory. The VAX launched DEC [into second place][10] in the largest computer company in the world.
|
||||
|
||||
The jump from a 12-bit to a 32-bit CPU is a jump from 4,096 bytes to 4,294,967,296 bytes of data. That increase massively increased the potential for software to do complex tasks while drastically shrinking the size of the computer. And with a 32-bit CPU, the VAX was nearly as powerful as an IBM/360 mainframe—but much smaller and much, much less expensive.
|
||||
|
||||
[The episode][11] goes into the drama that unfolds as teams within Data General race to have the most marketable minicomputer while working through company politics and strong personalities.
|
||||
|
||||
### Revisiting _The Soul of a New Machine_
|
||||
|
||||
_The Soul of a New Machine_ was written in 1981 by Tracy Kidder, and chronicles a small group of engineers at the now-former tech company, Data General, as they attempt to compete with a rival internal group and create a 32-bit minicomputer as a skunkworks project known as "Eagle." For those okay with spoilers, the computer would eventually be known as the [Eclipse MV/8000][12].
|
||||
|
||||
Earlier this year, [Jessie Frazelle][13], of Docker, Go, and Kubernetes fame, and [Bryan Cantrill][14], known for [DTrace][15], Joyent, and many other technologies, publicly wrote about reading the non-fiction classic. As it's written, Cantrill mentioned the book to Frazelle, who read it and then wrote an enthusiastic [blog post][16] about the book. As Frazelle put it:
|
||||
|
||||
"Personally, I look back on the golden age of computers as the time when people were building the first personal computers in their garage. There is a certain whimsy of that time fueled with a mix of hard work and passion for building something crazy with a very small team. In today's age, at large companies, most engineers take jobs where they work on one teeny aspect of a machine or website or app. Sometimes they are not even aware of the larger goal or vision but just their own little world.
|
||||
|
||||
In the book, a small team built an entire machine… The team wasn't driven by power or greed, but by accomplishment and self-fulfillment. They put a part of themselves in the machine, therefore, producing a machine with a soul…The team was made up of programmers with the utmost expertise and experience and also with new programmers."
|
||||
|
||||
Inspired by Frazelle's reaction, Cantrill re-read it and wrote [a blog article][17] about it and writes this beautiful note:
|
||||
|
||||
"…_The Soul of a New Machine_ serves to remind us that the soul of what we build is, above all, shared — that we do not endeavor alone but rather with a group of like-minded individuals."
|
||||
|
||||
Frazelle's and Cantrill's reading of the book and blog [sparked a wave of people][18] exploring and talking about this text. While it remains on my book list, this dialogue-by-book-review is at the heart of the CLH season 4 as it explores the entire machine.
|
||||
|
||||
### Why did the minicomputer go the way of the Neanderthal?
|
||||
|
||||
As we all know, minicomputers are not a popular purchase in today's technology market. Minicomputers ended up being great technology for timesharing. The irony is that they unwittingly sealed their own fate. The Internet, which started off as ARPANET, was basically a new kind of timesharing. They were so good at timesharing that at one point, the DEC PDP 11 accounted for over 30% of the nodes on ARPANET. Minicomputers were powering their own demise.*
|
||||
|
||||
Minicomputers paved the way for smaller computers and for more and more people to have access to these powerful, society-changing machines. But I'm getting ahead of myself. Keep listening to the [new season of Command Line Heroes][2] to continue the story of machines in computing history.
|
||||
|
||||
* * *
|
||||
|
||||
What's your minicomputer story? I'd love to read them in the comments.
|
||||
|
||||
(There were, of course, other factors leading to the end of this era. Minicomputers were fighting at the low end of the market with the rise of microcomputers, while Unix systems continued to push into the midrange market. The rise of the Internet was perhaps its final blow.)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/minicomputers-and-soul-new-machine
|
||||
|
||||
作者:[Matthew Broberg][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mbbroberg
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/command-line-heroes-minicomputers-s4-e1.png?itok=FRaff5i6 (Command Line Heroes season 4 episode 1 covers the rise of minicomputers)
|
||||
[2]: https://www.redhat.com/en/command-line-heroes
|
||||
[3]: https://opensource.com/article/19/6/command-line-heroes-python
|
||||
[4]: https://en.wikipedia.org/wiki/The_Soul_of_a_New_Machine
|
||||
[5]: https://opensource.com/19/9/command-line-heroes-bash
|
||||
[6]: https://en.wikipedia.org/wiki/PDP
|
||||
[7]: https://en.wikipedia.org/wiki/Data_General
|
||||
[8]: https://en.wikipedia.org/wiki/Data_General_Nova
|
||||
[9]: https://en.wikipedia.org/wiki/Data_General_Eclipse
|
||||
[10]: http://www.old-computers.com/history/detail.asp?n=20&t=3
|
||||
[11]: https://www.redhat.com/en/command-line-heroes/season-4/minicomputers
|
||||
[12]: https://en.wikipedia.org/wiki/Data_General_Eclipse_MV/8000
|
||||
[13]: https://twitter.com/jessfraz?lang=en
|
||||
[14]: https://en.wikipedia.org/wiki/Bryan_Cantrill
|
||||
[15]: https://en.wikipedia.org/wiki/DTrace
|
||||
[16]: https://blog.jessfraz.com/post/new-golden-age-of-building-with-soul/
|
||||
[17]: http://dtrace.org/blogs/bmc/2019/02/10/reflecting-on-the-soul-of-a-new-machine/
|
||||
[18]: https://twitter.com/search?q=jessfraz%20soul%20new%20machine&src=typed_query&f=live
|
||||
@ -0,0 +1,99 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Building a community of practice in 5 steps)
|
||||
[#]: via: (https://opensource.com/article/20/2/building-community-practice-5-steps)
|
||||
[#]: author: (Tracy Buckner https://opensource.com/users/tracyb)
|
||||
|
||||
Building a community of practice in 5 steps
|
||||
======
|
||||
A community of practice can kickstart innovation in your organization.
|
||||
Here's how to build one—and ensure it thrives.
|
||||
![Blocks for building][1]
|
||||
|
||||
In the [first part of this series][2], we defined community as a fundamental principle in open organizations, where people often define their roles, responsibilities, and affiliations through shared interests and passions, [not title, role, or position on an organizational chart][3]. Then, in the [second part of the series][4], we explored the many benefits communities of practice bring to open organizations—including fostering learning, encouraging collaboration, and offering an opportunity for creative problem-solving and innovation.
|
||||
|
||||
Now you know you'd like to _start_ a community of practice, but you may still be unsure _where_ to start. This article will help define your roadmap and build a plan for a successful community of practice—in five simple steps (summarized in Figure 1).
|
||||
|
||||
![][5]
|
||||
|
||||
### Step 1: Obtain executive sponsorship
|
||||
|
||||
While having a community manager focused on the day-to-day execution of community matters is important, an executive sponsor is also integral to the success of the community of practice. Typically, an executive sponsor will shoulder higher-level responsibilities, such as focusing on strategy and creating conditions for success (rather than implementation).
|
||||
|
||||
An executive sponsor can help ensure the community's goals are aligned with the overall strategy of the organization. This person can also communicate those goals and gather support for the community from other senior executives (potentially instrumental in securing financial support and resources for the community!).
|
||||
|
||||
Finding the right sponsor is important for the success of the program. An executive leader committed to fostering open culture, transparency, and collaboration will be very successful. Alternatively, you may wish to tap an executive focused on finding new ways to grow and reskill high-potential employees.
|
||||
|
||||
### Step 2: Determine mission and goals
|
||||
|
||||
Once you've established a vision for the community, you'll need to develop its mission statement. This is critical to your success because the mission begins explaining _how you'll achieve that vision_. Primarily, your community's mission should be to share knowledge, promote learning in a particular area, and align that work with organizational strategy. However, the mission statement may also include references to the audience that the community will serve.
|
||||
|
||||
Here's one example mission statement:
|
||||
|
||||
> _To identify and address needs within the cloud infrastructure space in support of the organization’s mission of defining the next generation of open hybrid cloud._
|
||||
|
||||
After articulating a mission like this, you'll need to set specific goals for achieving it. The goals can be long- or short-term, but in either case, you'll need to provide a clear roadmap explaining to community members what the community is trying to achieve.
|
||||
|
||||
### Step 3: Build a core team
|
||||
|
||||
Building a core team is essential to the success of a community. In a typical community of practice—or "CoP," for short—you'll notice four main roles:
|
||||
|
||||
* CoP program manager
|
||||
* CoP manager
|
||||
* Core team members
|
||||
* Members
|
||||
|
||||
|
||||
|
||||
The **CoP program manager** is the face of the community. This person is primarily responsible for supporting the managers and core teams by resolving questions, issues, and concerns. The program manager also guides new communities and evangelizes the communities of practice program inside the organization.
|
||||
|
||||
The **CoP manager** determines community strategy based on business and community needs. This person makes the latest news, content, and events available to community members and ensures that the CoP remains focused on its goals. This person also schedules regular meetings for members and shares other events that may be of interest to them.
|
||||
|
||||
The **CoP core team** is responsible for managing community collateral and best practices to meet the community's goals. The core team supports CoP manager(s) and assists with preparing and leading community meetings.
|
||||
|
||||
**Members** of a community attend meetings, share relevant content and best practices, and support the core team and manager(s) in reaching community goals.
|
||||
|
||||
### Step 4: Promote knowledge management
|
||||
|
||||
Communities of practice produce information—and members must be able to easily access and share that information. So it's important to develop a knowledge-management system for storing that information in a way that keeps it relevant and timely.
|
||||
|
||||
Communities of practice produce information—and members must be able to easily access and share that information. So it's important to develop a knowledge-management system for storing that information in a way that keeps it relevant and timely.
|
||||
|
||||
Over time, your community of practice will likely generate a lot of content. Some of that content may be duplicated, outdated or simply no longer relevant to the community. So it's important to periodically conduct a ROT Analysis of the content validating that the content is not **R**edundant, **O**utdated, or **T**rivial. Consider conducting a ROT analysis every six months or so, in order to keep the content fresh and relevant.
|
||||
|
||||
A number of different content management tools can assist with maintaining and displaying the content for community members. Some organizations use an intranet, while others prefer more robust content management such as [AO Docs][6] or [Drupal][7].
|
||||
|
||||
### Step 5: Engage in regular communication
|
||||
|
||||
The secret to success in maintaining a community of practice is regular communication and collaboration. Communities that speak with each other frequently and share knowledge, ideas, and best practices are most likely to remain intact. CoP managers should schedule regular meetings, meet-ups, and content creation sessions to ensure that members are engaged in the community. It is recommended to have at least a monthly meeting to maintain communication with the community members.
|
||||
|
||||
Chat/messaging apps are also a great tool for facilitating regular communication in communities of practice. These apps offer teams across the globe the ability to communicate in real-time, removing some collaboration boundaries. Members can pose questions and receive answers immediately, without the delay of sending and receiving emails. And should the questions arise again, most messaging apps also provide an easy search mechanism that can help members discover answers.
|
||||
|
||||
### Building your community
|
||||
|
||||
Remember: A community of practice is a cost-effective way to foster learning, encourage collaboration, and promote innovation in an organization. In [_The Open Organization_][8], Jim Whitehurst argues that "the beauty of an open organization is that it is not about pedaling harder, but about tapping into new sources of power both inside and outside to keep pace with all the fast-moving changes in your environment." Building communities of practice are the perfect way to do just that: stop pedaling harder and to tap into new sources of power within your organization.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/building-community-practice-5-steps
|
||||
|
||||
作者:[Tracy Buckner][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/tracyb
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/blocks_building.png?itok=eMOT-ire (Blocks for building)
|
||||
[2]: https://opensource.com/open-organization/19/11/what-is-community-practice
|
||||
[3]: https://opensource.com/open-organization/resources/open-org-definition
|
||||
[4]: https://opensource.com/open-organization/20/1/why-build-community-of-practice
|
||||
[5]: https://opensource.com/sites/default/files/resize/images/open-org/comm_practice_5_steps-700x440.png
|
||||
[6]: https://www.aodocs.com/
|
||||
[7]: https://www.drupal.org/
|
||||
[8]: https://opensource.com/open-organization/resources/what-open-organization
|
||||
@ -0,0 +1,62 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (A $399 device that translates brain signals into digital commands)
|
||||
[#]: via: (https://www.networkworld.com/article/3526446/nextmind-wearable-device-translates-brain-signals-into-digital-commands.html)
|
||||
[#]: author: (Patrick Nelson https://www.networkworld.com/author/Patrick-Nelson/)
|
||||
|
||||
A $399 device that translates brain signals into digital commands
|
||||
======
|
||||
Startup NextMind is readying a $399 development kit for its brain-computer interface technology that enables users to interact, hands-free, with computers and VR/AR headsets.
|
||||
MetamorWorks / Getty Images
|
||||
|
||||
Scientists have long envisioned brain-sensing technology that can translate thoughts into digital commands, eliminating the need for computer-input devices like a keyboard and mouse. One company is preparing to ship its latest contribution to the effort: a $399 development package for a noninvasive, AI-based, brain-computer interface.
|
||||
|
||||
The kit will let "users control anything in their digital world by using just their thoughts," [NextMind][1], a commercial spinoff of a cognitive neuroscience lab claims in a [press release][2].
|
||||
|
||||
[[Get regularly scheduled insights by signing up for Network World newsletters.]][3]
|
||||
|
||||
The company says that its puck-like device inserts into a cap or headband and rests on the back of the head. The dry electrode-based receiver then grabs data from the electrical signals generated through neuron activity. It uses machine learning algorithms to convert that signal output into computer controls. The interaction could be with a computer, artificial-reality or virtual-reality headset, or [IoT][4] module.
|
||||
|
||||
"Imagine taking your phone to send a text message without ever touching the screen, without using Siri, just by using the speed and power of your thoughts," said NextMind founder Sid Kouider in a [video presentation][5] at Helsinki startup conference Slush in late 2019.
|
||||
|
||||
Advances in neuroscience are enabling real-time consciousness-decoding, without surgery or a doctor visit, according to Kouider.
|
||||
|
||||
One obstacle that has thwarted previous efforts is the human skull, which can act as a barrier to sensors. It’s been difficult for scientists to differentiate indicators from noise, and some past efforts have only been able to discern basic things, such as whether or not a person is in a state of sleep or relaxation. New materials, better sensors, and more sophisticated algorithms and modeling have overcome some of those limitations. NextMind’s noninvasive technology "translates the data in real time," Kouider says.
|
||||
|
||||
Essentially, what happens is that a person’s eyes project an image of what they see onto the visual cortex in the back of the head, a bit like a projector. The NextMind device decodes the neural activity created as the object is viewed and sends that information, via an SDK, back as an input to a computer. So, by fixing one’s gaze on an object, one selects that object. For example, a user could select a screen icon by glancing at it.
|
||||
|
||||
[][6]
|
||||
|
||||
"The demos were by no means perfect, but there was no doubt in my mind that the technology worked," [wrote VentureBeat writer Emil Protalinski][7], who tested a pre-release device in January.
|
||||
|
||||
Kouider has stated it’s the "intent" aspect of the technology that’s most interesting; if a person focuses on one thing more than something else, the technology can decode the neural signals to capture that user’s intent.
|
||||
|
||||
"It really gives you a kind of sixth sense, where you can feel your brain in action, thanks to the feedback loop between your brain and a display," Kouider says in the Slush presentation.
|
||||
|
||||
Join the Network World communities on [Facebook][8] and [LinkedIn][9] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3526446/nextmind-wearable-device-translates-brain-signals-into-digital-commands.html
|
||||
|
||||
作者:[Patrick Nelson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Patrick-Nelson/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.next-mind.com/
|
||||
[2]: https://www.businesswire.com/news/home/20200105005107/en/CES-2020-It%E2%80%99s-Mind-Matter
|
||||
[3]: https://www.networkworld.com/newsletters/signup.html
|
||||
[4]: http://www.networkworld.com/cms/article/3207535
|
||||
[5]: https://youtu.be/RHuaNDSxH0o
|
||||
[6]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE21620&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[7]: https://venturebeat.com/2020/01/05/nextmind-is-building-a-real-time-brain-computer-interface-unveils-dev-kit-for-399/
|
||||
[8]: https://www.facebook.com/NetworkWorld/
|
||||
[9]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,54 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Fedora at the Czech National Library of Technology)
|
||||
[#]: via: (https://fedoramagazine.org/fedora-at-the-national-library-of-technology/)
|
||||
[#]: author: (Ben Cotton https://fedoramagazine.org/author/bcotton/)
|
||||
|
||||
Fedora at the Czech National Library of Technology
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Where do you turn when you have a fleet of public workstations to manage? If you’re the Czech [National Library of Technology][2] (NTK), you turn to Fedora. Located in Prague, the NTK is the Czech Republic’s largest science and technology library. As part of its public service mission, the NTK provides 150 workstations for public use.
|
||||
|
||||
In 2018, the NTK moved these workstations from Microsoft Windows to Fedora. In the [press release][3] announcing this change, Director Martin Svoboda said switching to Fedora will “reduce operating system support costs by about two-thirds.” The choice to use Fedora was easy, according to NTK Linux Engineer Miroslav Brabenec. “Our entire Linux infrastructure runs on RHEL or CentOS. So for desktop systems, Fedora was the obvious choice,” he told Fedora Magazine.
|
||||
|
||||
### User reception
|
||||
|
||||
Changing an operating system is always a little bit risky—it requires user training and outreach. Brabenec said that non-IT staff asked for training on the new system. Once they learned that the same (or compatible) software was available, they were fine.
|
||||
|
||||
The Library’s customers were on board right away. The Windows environment was based on thin client terminals, which were slow for intensive tasks like video playback and handling large office suite files. The only end-user education that the NTK needed to create was a [basic usage guide][4] and a desktop wallpaper that pointed to important UI elements.
|
||||
|
||||
![User guidance desktop wallpaper from the National Technology Library.][5]
|
||||
|
||||
Although Fedora provides development tools used by the Faculty of Information Technology at the Czech Technical University—and many of the NTK’s workstation users are CTU students—most of the application usage is what you might expect of a general-purpose workstation. Firefox dominates the application usage, followed by the Evince PDF viewer, and the LibreOffice suite.
|
||||
|
||||
### Updates
|
||||
|
||||
NTK first deployed the workstations with Fedora 28. They decided to skip Fedora 29 and upgraded to Fedora 30 in early June 2019. The process was simple, according to Brabenec. “We prepared configuration, put it into Ansible. Via AWX I restarted all systems to netboot, image with kickstart, after first boot called provisioning callback on AWX, everything automatically set up via Ansible.”
|
||||
|
||||
Initially, they had difficulties applying updates. Now they have a process for installing security updates daily. Each system is rebooted approximately every two weeks to make sure all of the updates get applied.
|
||||
|
||||
Although he isn’t aware of any concrete plans for the future, Brabenec expects the NTK to continue using Fedora for public workstations. “Everyone is happy with it and I think that no one has a good reason to change it.”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/fedora-at-the-national-library-of-technology/
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/bcotton/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2020/02/czech-techlib-816x345.png
|
||||
[2]: https://www.techlib.cz/en/
|
||||
[3]: https://www.techlib.cz/default/files/download/id/86431/tiskova-zprava-z-31-7-2018.pdf
|
||||
[4]: https://www.techlib.cz/en/82993-public-computers
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2020/02/ntk-wallpaper-1024x576.jpeg
|
||||
@ -0,0 +1,84 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Multicloud, security integration drive massive SD-WAN adoption)
|
||||
[#]: via: (https://www.networkworld.com/article/3527194/multicloud-security-integration-drive-massive-sd-wan-adoption.html)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
Multicloud, security integration drive massive SD-WAN adoption
|
||||
======
|
||||
40% year-over year SD-WAN growth through 2022 is being fueled by relationships built between vendors including Cisco, VMware, Juniper, and Arista and service provders AWS, Microsoft Azure, Google Anthos, and IBM RedHat.
|
||||
[Gratisography][1] [(CC0)][2]
|
||||
|
||||
Increasing cloud adoption as well as improved network security, visibility and manageability are driving enterprise software-defined WAN ([SD-WAN][3]) deployments at a breakneck pace.
|
||||
|
||||
According to research from IDC, software- and infrastructure-as-a-service (SaaS and IaaS) offerings in particular have been driving SD-WAN implementations in the past year, said Rohit Mehra, vice president, network infrastructure at IDC.
|
||||
|
||||
**Read about edge networking**
|
||||
|
||||
* [How edge networking and IoT will reshape data centers][4]
|
||||
* [Edge computing best practices][5]
|
||||
* [How edge computing can help secure the IoT][6]
|
||||
|
||||
|
||||
|
||||
For example, IDC says that its recent surveys of customers show that 95% will be using [SD-WAN][7] technology within two years, and that 42% have already deployed it. IDC also says the SD-WAN infrastructure market will hit $4.5 billion by 2022, growing at a more than 40% yearly clip between now and then.
|
||||
|
||||
“The growth of SD-WAN is a broad-based trend that is driven largely by the enterprise desire to optimize cloud connectivity for remote sites,” Mehra said.
|
||||
|
||||
Indeed the growth of multicloud networking is prompting many businesses to re-tool their networks in favor of SD-WAN technology, Cisco wrote recently. SD-WAN is critical for businesses adopting cloud services, acting as a connective tissue between the campus, branch, [IoT][8], [data center][9] and cloud. The company said surveys show Cisco customers have, on average, 30 paid SaaS applications each. And that they are actually using many more – over 100 in several cases, the company said.
|
||||
|
||||
Part of this trend is driven by the relationships that networking vendors such as Cisco, VMware, Juniper, Arista and others have been building with the likes of Amazon Web Services, Microsoft Azure, Google Anthos and IBM RedHat.
|
||||
|
||||
An indicator of the growing importance of the SD-WAN and multicloud relationship came last December when AWS announced key services for its cloud offering that included new integration technologies such as [AWS Transit Gateway][10], which lets customers connect their Amazon Virtual Private Clouds and their on-premises networks to a single gateway. Aruba, Aviatrix Cisco, Citrix Systems, Silver Peak and Versa already announced support for the technology which promises to simplify and enhance the performance of SD-WAN integration with AWS cloud resources.
|
||||
|
||||
[][11]
|
||||
|
||||
Going forward the addition of features such as cloud-based application insights and performance monitoring will be a key part of SD-WAN rollouts, Mehra said.
|
||||
|
||||
While the SD-WAN and cloud relationship is growing, so, too, is the need for integrated security features.
|
||||
|
||||
“The way SD-WAN offerings integrate security is so much better than traditional ways of securing WAN traffic which usually involved separate packages and services," Mehra said. "SD-WAN is a much more agile security environment.” Security, analytics and WAN optimization are viewed as top SD-WAN component, with integrated security being the top requirement for next-generation SD-WAN solutions, Mehra said.
|
||||
|
||||
Increasingly, enterprises will look less at point SD-WAN solutions and instead will favor platforms that solve a wider range of network management and security needs, Mehra said. They will look for SD-WAN platforms that integrate with other aspects of their IT infrastructure including corporate data-center networks, enterprise campus LANs, or [public-cloud][12] resources, he said. They will look for security services to be baked in, as well as support for a variety of additional functions such as visibility, analytics, and unified communications, he said.
|
||||
|
||||
“As customers continue to integrate their infrastructure components with software they can do things like implement consistent management and security policies based on user, device or application requirements across their LANs and WANs and ultimately achieve a better overall application experience,” Mehra said.
|
||||
|
||||
An emerging trend is the need for SD-WAN packages to support [SD-branch][13] technology. More than 70% of IDC's surveyed customers expect to use SD-Branch within next year, Mehra said. In recent weeks [Juniper][14] and [Aruba][15] have enhanced SD-Branch offerings, a trend that is expected to continue this year.
|
||||
|
||||
SD-Branch builds on the concepts and support of SD-WAN but is more specific to the networking and management needs of LANs in the branch. Going forward, how SD-Branch integrates other technologies such as analytics, voice, unified communications and video will be key drivers of that technology.
|
||||
|
||||
Join the Network World communities on [Facebook][16] and [LinkedIn][17] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3527194/multicloud-security-integration-drive-massive-sd-wan-adoption.html
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.pexels.com/photo/black-and-white-branches-tree-high-279/
|
||||
[2]: https://creativecommons.org/publicdomain/zero/1.0/
|
||||
[3]: https://www.networkworld.com/article/3031279/sd-wan-what-it-is-and-why-you-ll-use-it-one-day.html
|
||||
[4]: https://www.networkworld.com/article/3291790/data-center/how-edge-networking-and-iot-will-reshape-data-centers.html
|
||||
[5]: https://www.networkworld.com/article/3331978/lan-wan/edge-computing-best-practices.html
|
||||
[6]: https://www.networkworld.com/article/3331905/internet-of-things/how-edge-computing-can-help-secure-the-iot.html
|
||||
[7]: https://www.networkworld.com/article/3489938/what-s-hot-at-the-edge-for-2020-everything.html
|
||||
[8]: https://www.networkworld.com/article/3207535/what-is-iot-the-internet-of-things-explained.html
|
||||
[9]: https://www.networkworld.com/article/3223692/what-is-a-data-centerhow-its-changed-and-what-you-need-to-know.html
|
||||
[10]: https://aws.amazon.com/transit-gateway/
|
||||
[11]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE21620&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[12]: https://www.networkworld.com/article/2159885/cloud-computing-gartner-5-things-a-private-cloud-is-not.html
|
||||
[13]: https://www.networkworld.com/article/3250664/sd-branch-what-it-is-and-why-youll-need-it.html
|
||||
[14]: https://www.networkworld.com/article/3487801/juniper-broadens-sd-branch-management-switch-options.html
|
||||
[15]: https://www.networkworld.com/article/3513357/aruba-reinforces-sd-branch-with-security-management-upgrades.html
|
||||
[16]: https://www.facebook.com/NetworkWorld/
|
||||
[17]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,64 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Google Cloud moves to aid mainframe migration)
|
||||
[#]: via: (https://www.networkworld.com/article/3528451/google-cloud-moves-to-aid-mainframe-migration.html)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
Google Cloud moves to aid mainframe migration
|
||||
======
|
||||
Google bought Cornerstone Technology, whose technology facilitates moving mainframe applications to the cloud.
|
||||
Thinkstock
|
||||
|
||||
Google Cloud this week bought a mainframe cloud-migration service firm Cornerstone Technology with an eye toward helping Big Iron customers move workloads to the private and public cloud.
|
||||
|
||||
Google said the Cornerstone technology – found in its [G4 platform][1] – will shape the foundation of its future mainframe-to-Google Cloud offerings and help mainframe customers modernize applications and infrastructure.
|
||||
|
||||
[[Get regularly scheduled insights by signing up for Network World newsletters.]][2]
|
||||
|
||||
“Through the use of automated processes, Cornerstone’s tools can break down your Cobol, PL/1, or Assembler programs into services and then make them cloud native, such as within a managed, containerized environment” wrote Howard Weale, Google’s director, Transformation Practice, in a [blog][3] about the buy.
|
||||
|
||||
“As the industry increasingly builds applications as a set of services, many customers want to break their mainframe monolith programs into either Java monoliths or Java microservices,” Weale stated.
|
||||
|
||||
Google Cloud’s Cornerstone service will:
|
||||
|
||||
* Develop a migration roadmap where Google will assess a customer’s mainframe environment and create a roadmap to a modern services architecture.
|
||||
* Convert any language to any other language and any database to any other database to prepare applications for modern environments.
|
||||
* Automate the migration of workloads to the Google Cloud.
|
||||
|
||||
|
||||
|
||||
“Easy mainframe migration will go a long way as Google attracts large enterprises to its cloud,” said Matt Eastwood, senior vice president, Enterprise Infrastructure, Cloud, Developers and Alliances, IDC wrote in a statement.
|
||||
|
||||
The Cornerstone move is also part of Google’s effort stay competitive in the face of mainframe-migration offerings from [Amazon Web Services][4], [IBM/RedHat][5] and [Microsoft][6].
|
||||
|
||||
While the idea of moving legacy applications off the mainframe might indeed be beneficial to a business, Gartner last year warned that such decisions should be taken very deliberately.
|
||||
|
||||
“The value gained by moving applications from the traditional enterprise platform onto the next ‘bright, shiny thing’ rarely provides an improvement in the business process or the company’s bottom line. A great deal of analysis must be performed and each cost accounted for,” Gartner stated in a report entitled *[_Considering Leaving Legacy IBM Platforms? Beware, as Cost Savings May Disappoint, While Risking Quality_][7]. * “Legacy platforms may seem old, outdated and due for replacement. Yet IBM and other vendors are continually integrating open-source tools to appeal to more developers while updating the hardware. Application leaders should reassess the capabilities and quality of these platforms before leaving them.”
|
||||
|
||||
Join the Network World communities on [Facebook][8] and [LinkedIn][9] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3528451/google-cloud-moves-to-aid-mainframe-migration.html
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cornerstone.nl/solutions/modernization
|
||||
[2]: https://www.networkworld.com/newsletters/signup.html
|
||||
[3]: https://cloud.google.com/blog/topics/inside-google-cloud/helping-customers-migrate-their-mainframe-workloads-to-google-cloud
|
||||
[4]: https://aws.amazon.com/blogs/enterprise-strategy/yes-you-should-modernize-your-mainframe-with-the-cloud/
|
||||
[5]: https://www.networkworld.com/article/3438542/ibm-z15-mainframe-amps-up-cloud-security-features.html
|
||||
[6]: https://azure.microsoft.com/en-us/migration/mainframe/
|
||||
[7]: https://www.gartner.com/doc/reprints?id=1-6L80XQJ&ct=190429&st=sb
|
||||
[8]: https://www.facebook.com/NetworkWorld/
|
||||
[9]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,57 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Japanese firm announces potential 80TB hard drives)
|
||||
[#]: via: (https://www.networkworld.com/article/3528211/japanese-firm-announces-potential-80tb-hard-drives.html)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Japanese firm announces potential 80TB hard drives
|
||||
======
|
||||
Using some very fancy physics for stacking electrons, Showa Denko K.K. plans to quadruple the top end of proposed capacity.
|
||||
[geralt][1] [(CC0)][2]
|
||||
|
||||
Hard drive makers are staving off obsolescence to solid-state drives (SSDs) by offering capacities that are simply not feasible in an SSD. Seagate and Western Digital are both pushing to release 20TB hard disks in the next few years. A 20TB SSD might be doable but also cost more than a new car.
|
||||
|
||||
But Showa Denko K.K. of Japan has gone one further with the announcement of its next-generation of heat-assisted magnetic recording (HAMR) media for hard drives. The platters use all-new magnetic thin films to maximize their data density, with the goal of eventually enabling 70TB to 80TB hard drives in a 3.5-inch form factor.
|
||||
|
||||
[[Get regularly scheduled insights by signing up for Network World newsletters.]][3]
|
||||
|
||||
Showa Denko is the world’s largest independent maker of platters for hard drives, selling them to basically anyone left making hard drives not named Seagate and Western Digital. Those two make their own platters and are working on their own next-generation drives for release in the coming years.
|
||||
|
||||
While similar in concept, Seagate and Western Digital have chosen different solutions to the same problem. HAMR, championed by Seagate and Showa, works by temporarily heating the disk material during the write process so data can be written to a much smaller space, thus increasing capacity.
|
||||
|
||||
Western Digital supports a different technology called microwave-assisted magnetic recording (MAMR). It operates under a similar concept as HAMR but uses microwaves instead of heat to alter the drive platter. Seagate hopes to get to 48TB by 2023, while Western Digital is planning on releasing 18TB and 20TB drives this year.
|
||||
|
||||
Heat is never good for a piece of electrical equipment, and Showa Denko’s platters for HAMR HDDs are made of a special composite alloy to tolerate temperature and reduce wear, not to mention increase density. A standard hard disk has a density of about 1.1TB per square inch. Showa’s drive platters have a density of 5-6TB per square inch.
|
||||
|
||||
The question is when they will be for sale, and who will use them. Fellow Japanese electronics giant Toshiba is expected to ship drives with Showa platters later this year. Seagate will be the first American company to adopt HAMR, with 20TB drives scheduled to ship in late 2020.
|
||||
|
||||
[][4]
|
||||
|
||||
Know what’s scary? That still may not be enough. IDC predicts that our global datasphere – the total of all of the digital data we create, consume, or capture – will grow from a total of approximately 40 zettabytes of data in 2019 to 175 zettabytes total by 2025.
|
||||
|
||||
So even with the growth in hard-drive density, the growth in the global data pool – everything from Oracle databases to Instagram photos – may still mean deploying thousands upon thousands of hard drives across data centers.
|
||||
|
||||
Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3528211/japanese-firm-announces-potential-80tb-hard-drives.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://pixabay.com/en/data-data-loss-missing-data-process-2764823/
|
||||
[2]: https://creativecommons.org/publicdomain/zero/1.0/
|
||||
[3]: https://www.networkworld.com/newsletters/signup.html
|
||||
[4]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE21620&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,106 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Discussing Past, Present and Future of FreeBSD Project)
|
||||
[#]: via: (https://itsfoss.com/freebsd-interview-deb-goodkin/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
Discussing Past, Present and Future of FreeBSD Project
|
||||
======
|
||||
|
||||
[FreeBSD][1] is one of the most popular BSD distributions. It is used on desktop, servers and embedded devices for more than two decades.
|
||||
|
||||
We talked to Deb Goodkin, executive director, [FreeBSD Foundation][2] and discussed the past, present and future of FreeBSD project.
|
||||
|
||||
![][3]
|
||||
|
||||
**It’s FOSS: FreeBSD has been in the scene for more than 25 years. How do you see the journey of FreeBSD? **
|
||||
|
||||
Over the years, we’ve seen a lot of innovation happening on and with FreeBSD. When the Foundation came into play 20 years ago, we were able to step in and help accelerate changes in the operating system. Over the years, we’ve increased our marketing support, to provide more advocacy and educational material, and to increase the awareness and use of FreeBSD.
|
||||
|
||||
In addition, we’ve increased our staff of software developers to allow us to quickly step in to fix bugs, review patches, implement workarounds to hardware issues, and implement new features and functionality. We have also increased the number of development projects we are funding to improve various areas of FreeBSD.
|
||||
|
||||
The history of stability and reliability, along with all the improvements and growth with FreeBSD, is making it a compelling choice for companies, universities, and individuals.
|
||||
|
||||
**It’s FOSS: We know that Netflix uses FreeBSD extensively. What other companies or groups rely on FreeBSD? How do they contribute to BSD/FreeBSD (if they do at all)?**
|
||||
|
||||
Sony’s Playstation 4 uses a modified version of FreeBSD as their operating system, Apple with their MacOS and iOS, NetApp in their ONTAP product, Juniper Networks in [JunOS][4], Trivago in their backend infrastructure, University of Cambridge in security research including the Capability Hardware Enhanced RISC Instruction (CHERI) project, University of Notre Dame in their Engineering Department, Groupon in their datacenter, LA Times in their data center, as well as, other notable companies like Panasonic, and Nintendo.
|
||||
|
||||
I listed a variety of organizations to highlight the different FreeBSD use cases. Companies like [Netflix support FreeBSD][5] by supporting the Project financially, as well as, by upstreaming their code. Some of the companies, like Sony, take advantage of the BSD license and don’t give back at all.
|
||||
|
||||
![Deb Goodkin And Friend Promoting FreeBSD At Oscon][6]
|
||||
|
||||
**It’s FOSS: Linux is ruling the servers and cloud computing. It seems that BSD is lagging in that field?**
|
||||
|
||||
I wouldn’t characterize it as lagging, per se. Linux distributions do have a much higher market share than FreeBSD, but our strength falls in those two markets. FreeBSD does extremely well in these markets, because it provides a consistent and reliable foundation, and tends to just work. Known for having long term API stability, the user will integrate once and upgrade on their terms as both FreeBSD and their product evolves.
|
||||
|
||||
**It’s FOSS: Do you see the emergence of Linux as a threat to BSD? **
|
||||
|
||||
Sure, [there are so many Linux distributions][7] already, and most of them are supported by for profit companies. In fact, companies like Intel have many Linux developers on staff, so Linux is easily supported on their hardware.
|
||||
|
||||
However, thanks to the continuing education efforts and as our market share continues to grow, more developers will be available to support companies’ various FreeBSD use cases.
|
||||
|
||||
**It’s FOSS: Let’s talk about desktop. Recently, the devs of Project Trident announced that they were moving away from FreeBSD as a base. They said that they made this decision because FreeBSD is slow to review updates and support for new hardware. For example, the most recent version of Telegram on FreeBSD is 9 releases behind the version available on Linux. How would you respond to their comments?**
|
||||
|
||||
There are quite a few FreeBSD distros for the desktop, with various focuses. The latest, is [FuryBSD][8], which coincidentally was started by iXsystems employees, but is independent of iXsystems, just like Project Trident is. In addition to FuryBSD, you may want to check out [NomadBSD][9] and [MidnightBSD][10].
|
||||
|
||||
Regarding supporting new hardware, we’ve stepped up our efforts to get FreeBSD working on more popular newer laptops. For example, the Foundation recently purchased a couple of the latest generation Lenovo X1 Carbon laptops and sponsored work to make sure that peripherals are supported out-of-the-box.
|
||||
|
||||
**It’s FOSS: Why should a desktop user consider choosing FreeBSD?**
|
||||
|
||||
There are many reasons people should consider using FreeBSD on their desktop! Just to highlight a few, it has rock solid stability; high performance; supports [ZFS][11] to protect your data; a community that is friendly, helpful, and approachable; excellent documentation to easily find answers; over 30,000 open source software packages that are easy to install, allowing you to easily set up your environment without a lot of extras, and that includes many choices of popular GUIs, and it follows the POLA philosophy ([Principle of Least Astonishment][12]) which means, don’t break things that work and upgrades are generally painless (even across major releases).
|
||||
|
||||
**It’s FOSS: Are there any plans to make it easier to install FreeBSD as a desktop system? The current focus seems to be on servers.**
|
||||
|
||||
The Foundation is supporting efforts to make sure FreeBSD works on the latest hardware and peripherals that appear in desktop systems, and will continue to support making FreeBSD easy to deploy, monitor, and configure to provide a great toolbox for building a desktop on top of it. That allows others to take as much or as little of FreeBSD to build a desktop version to produce a specific user experience they desire.
|
||||
|
||||
Like I mentioned above, there are other FreeBSD distributions that have taken these FreeBSD components and created their own desktop versions.
|
||||
|
||||
**It’s FOSS: What are your plans/roadmap for FreeBSD in the coming years?**
|
||||
|
||||
The FreeBSD Foundation’s purpose is to support the FreeBSD Project. While we’re an entirely separate entity, we work closely with the Core Team and the community to help move the Project forward. The Foundation identifies key areas we should support in the coming years, based on input from users and what we are seeing in the industry.
|
||||
|
||||
In 2019, we embarked on an even broader spectrum advocacy project to recruit new members throughout the world, while raising awareness about the benefits of learning FreeBSD. We are funding development projects including WiFi improvements, supporting OpenJDK, ZFS RAID-Z expansion, security, toolchain, performance improvements, and other features to keep FreeBSD innovative.
|
||||
|
||||
The FreeBSD Foundation will continue to host workshops and expand the amount of training opportunities and materials we provide. Finally, the [BSD Certification program][13] recently launched through Linux Professional Institute with greater availability.
|
||||
|
||||
**It’s FOSS: How can we bring more people to the BSD hold?**
|
||||
|
||||
We need more PR for FreeBSD and get more tech journalists like yourself to write about FreeBSD. We also need more trainings and classes that include FreeBSD in universities, trainings/workshops at technical conferences, more FreeBSD contributors giving talks at those conferences, more technical journalists, as well as, users writing about FreeBSD, and finally we need case studies from companies and organizations successfully using FreeBSD. It all takes having more resources! We’re working on all of the above.
|
||||
|
||||
**It’s FOSS: Any message you would like to convey to our readers?**
|
||||
|
||||
Readers should consider getting involved with the largest and oldest democratically run open source project!
|
||||
|
||||
Whether you want to learn systems programming or how an operating system works, the small size of the operating system makes it a great platform to learn from. The size of the Project makes it easier for anyone to make a notable contribution, and there is a strong mentorship culture to support new contributors.
|
||||
|
||||
Being a democratically run project, allows your voice to be heard and work in the areas you are interested in. I hope your readers will go to [freebsd.org][1] and try it out themselves.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/freebsd-interview-deb-goodkin/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.freebsd.org/
|
||||
[2]: https://www.freebsdfoundation.org/
|
||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/02/deb-goodkin-interview.png?ssl=1
|
||||
[4]: https://www.juniper.net/us/en/products-services/nos/junos/
|
||||
[5]: https://itsfoss.com/netflix-freebsd-cdn/
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/02/FreeBSDFoundation_Deb_Goodkin_and_friend_promoting_FreeBSD_at_OSCON.jpg?ssl=1
|
||||
[7]: https://itsfoss.com/best-linux-distributions/
|
||||
[8]: https://itsfoss.com/furybsd/
|
||||
[9]: https://itsfoss.com/nomadbsd/
|
||||
[10]: https://itsfoss.com/midnightbsd-1-0-release/
|
||||
[11]: https://itsfoss.com/what-is-zfs/
|
||||
[12]: https://en.wikipedia.org/wiki/Principle_of_least_astonishment
|
||||
[13]: https://www.lpi.org/our-certifications/bsd-overview
|
||||
@ -0,0 +1,74 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (7 tips for writing an effective technical resume)
|
||||
[#]: via: (https://opensource.com/article/20/2/technical-resume-writing)
|
||||
[#]: author: (Emily Brand https://opensource.com/users/emily-brand)
|
||||
|
||||
7 tips for writing an effective technical resume
|
||||
======
|
||||
Present yourself in the best light to potential employers by following
|
||||
these essentials.
|
||||
![Two hands holding a resume with computer, clock, and desk chair ][1]
|
||||
|
||||
If you're a software engineer or a manager in the technology sector, creating or updating your resume can be a daunting task. What is most important to consider? How should you handle the formatting, the content, and your objective or summary? What work experience is relevant? How can you make sure automated recruitment tools don't filter out your resume?
|
||||
|
||||
As a hiring manager over the last seven years, I have seen a wide range of resumes and CVs; while some have been impressive, many more have been terribly written.
|
||||
|
||||
When writing or updating your resume, here are seven easy rules to follow.
|
||||
|
||||
### 1\. Summary statement
|
||||
|
||||
The short paragraph at the top of your resume should be clean and concise, have a clear purpose, and avoid excessive use of adjectives and adverbs. Words such as "impressive," "extensive," and "excellent" do not improve your hiring chances; instead, they look and feel like overused filler words. An important question to ask yourself regarding your objective is: **Does it tell the hiring manager what kind of job I'm looking for and how I can provide value to them?** If not, either strengthen and streamline it to answer that question or leave it out altogether.
|
||||
|
||||
### 2\. Work experience
|
||||
|
||||
Numbers, numbers, numbers. Hard facts help you convey your point far more than general statements such as "Helped build, manage, deliver many projects that directly contributed to my customers' bottom line." Your wording should include statistics such as "Directly impacted five projects with top banks that accelerated their time to market by 40%," how many lines of code you committed, or how many teams you managed. Data is far more effective than frilly language to showcase your abilities and value.
|
||||
|
||||
If you are less-experienced and have fewer jobs to showcase, do not include irrelevant experience like part-time summer jobs. Instead, add detail about the specifics of your relevant experience and what you learned that would make you a better employee for the organization you are applying for.
|
||||
|
||||
### 3\. Search terms and jargon
|
||||
|
||||
With technology playing such a huge role in the hiring process, it is extremely important to make sure your resume gets flagged for the right positions—but do not oversell yourself on your resume. If you mention agile skills but do not know what kanban is, think twice. If you mention that you are skilled in Java but haven't used it in five years, beware. If there are languages and frameworks you are familiar with but not necessarily current in, create a different category or divide your experience into "proficient in" and "familiar with."
|
||||
|
||||
### 4\. Education
|
||||
|
||||
If you are not a recent college graduate, there is no need to include your GPA or the clubs or fraternities you participated in, unless you plan on using them as talking points to gain trust during an interview. Be sure that anything you have published or patented is included, even if it is not relevant to the job. If you do not have a college degree, add a certification section in place of education. If you were in the military, include your active duty and reserve time.
|
||||
|
||||
### 5\. Certifications
|
||||
|
||||
Do not include expired certifications unless you are trying to re-enter a field you have left, such as if you were a people manager and are now looking to get back into hands-on programming. If you have certifications that are no longer relevant to the field, do not include them since it can be distracting and unappealing. Leverage your LinkedIn profile to add more color to your resume, as most people will read your resume and your LinkedIn profile before they interview you.
|
||||
|
||||
### 6\. Spelling and grammar
|
||||
|
||||
Ask others to proofread your resume. So often, I have seen misspelled words in a resume or mistaken uses of words like their, they're, and there. These are avoidable and fixable errors that will create a negative impression. Ideally, your resume will be in active tense, but if that makes you uncomfortable, write it in past tense—the most important thing is to maintain a consistent tense throughout. Improper spelling and grammar will convey that you either do not really care about the job you are applying for or do not have the level of attention to detail necessary for the job.
|
||||
|
||||
### 7\. Formatting
|
||||
|
||||
Ensuring your resume looks up-to-date and appealing is an easy way to make a good first impression. Ensuring consistent formatting, e.g., similar margins, similar spacing, capitalization, and colors (but keep color palettes to a minimum) is the most mundane part of resume writing, but it's necessary to show that you take pride in your work and value yourself and your future employer. Use tables where appropriate to space information in a visually appealing way. If given the option, upload your resume in .pdf and .docx formats, and Google Docs exports to the .odt format, which can be opened easily in LibreOffice. Here is an easy Google Docs [resume template][2] that I recommend. You can also purchase templates from companies that do attractive designs for a small fee (under $10).
|
||||
|
||||
### Update regularly
|
||||
|
||||
Updating your resume regularly will minimize your stress if you're asked to (or want to) apply for a job, and it will help you create and maintain a more accurate version of yourself. When working on your resume, be forward-thinking and be sure to ask at least three other people to review it for content, spelling, and grammar. Even if you are recruited by or referred to a company, your interviewers may know you only by your resume, so ensure that it creates a positive first impression of you.
|
||||
|
||||
_Do you have additional tips to add?_
|
||||
|
||||
Emily Dunham shares her technique for leveraging open source contributions to stand out as a great...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/technical-resume-writing
|
||||
|
||||
作者:[Emily Brand][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/emily-brand
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/resume_career_document_general.png?itok=JEaFL2XI (Two hands holding a resume with computer, clock, and desk chair )
|
||||
[2]: https://docs.google.com/document/d/1ARVyybC5qQEiCzUOLElwAdPpKOK0Qf88srr682eHdCQ/edit
|
||||
@ -0,0 +1,86 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Spilling over: How working openly with anxiety affects my team)
|
||||
[#]: via: (https://opensource.com/open-organization/20/2/working-anxiety-team-performance)
|
||||
[#]: author: (Sam Knuth https://opensource.com/users/samfw)
|
||||
|
||||
Spilling over: How working openly with anxiety affects my team
|
||||
======
|
||||
The team might interpret my behavior as evidence of exacting standards
|
||||
or high expectations. But I know my anxiety does impact their
|
||||
performance.
|
||||
![Spider web on green background][1]
|
||||
|
||||
_Editor's note: This article is part of a series on working with mental health conditions. It details the author's personal experiences and is not meant to convey professional medical advice or guidance._
|
||||
|
||||
I was speaking with one of my direct reports recently about a discussion we'd had with the broader team earlier in the week. In that discussion I had expressed some frustration that we weren't as far along on a particular project as I thought we needed to be.
|
||||
|
||||
"I knew you were disappointed," my staff member said, recalling the meeting, "like you wanted us to be doing something that we weren't doing, or that what we were doing wasn't good enough."
|
||||
|
||||
They paused for a moment and then said, "Sam, I get this feeling from you all the time."
|
||||
|
||||
That comment struck me pretty profoundly. To my team member, perhaps the scenario above is a reflection of my exacting standards, my high expectations, or my desire to see continual improvement with the team. Those are all reasonable explanations for my behavior.
|
||||
|
||||
But there's another ingredient my team may not be aware of: my anxiety.
|
||||
|
||||
### It's not just personal
|
||||
|
||||
[Previously I discussed][2] how my anxiety, beginning with a worry that I'm not "doing enough," can fuel my proactive tendencies, leading to higher performance at work. What I hadn't considered is my team can interpret my _personal_ feeling of not doing enough as an indicator that _they_ are not doing enough.
|
||||
|
||||
Living with anxiety and other mental health conditions feels personal. It's not something I've talked about at work. It's not something I generally discuss, and it's something I've always felt I was coping with as a private part of my life.
|
||||
|
||||
Living with anxiety and other mental health conditions feels personal. It's not something I've talked about at work. It's not something I generally discuss, and it's something I've always felt I was coping with as a private part of my life.
|
||||
|
||||
But that discussion with my staff member made me realize that I can't contain my personality so neatly. In truth, my anxiety spills over to my team in ways I hadn't considered. I don't know if anxiety can "rub off" on someone, but when I try to think about it objectively, I imagine someone with anxiety would feel it heightened if they worked for me (perhaps my anxiety would feed theirs), and one without anxiety might feel I have unreasonable or unmeetable expectations.
|
||||
|
||||
As a leader—even in an open organization, where [hierarchy is not the most important factor][3] in determining influence—I'm aware that I am in a position of a certain amount of power. People observe my behavior more closely than I realize; how I treat people has a big impact on them, the broader organization, and ultimately the success of the team.
|
||||
|
||||
I try hard to treat people with respect, [to assume positive intent][4], to give people the room to do their work in the way they see fit. But, nonetheless, do my team members feel the kind of judgment from me that I continually impose on myself?
|
||||
|
||||
### Counting our achievements
|
||||
|
||||
What feels "good" to me (what calms my anxiety) is to focus _not_ on what we _have achieved_, but on what we _have yet to do_; not to _celebrate success_, but to _find areas for improvement_. So, when we hit a big milestone, my gut reaction is to say, "Great, now that we've come this far, what else can we do to have a bigger impact?" Stopping and celebrating the team's accomplishments before moving on to the next challenge feels foriegn to me. It also makes me anxious that we are pausing in our progress.
|
||||
|
||||
This is [what I've called an anxiety-driven performance loop][2]. The sense of accomplishment (and the external acknowledgement) after an achievement fuels a desire to immediately start looking for the next challenge. To some extent, this performance loop keeps me productive—even though it has other consequences, too.
|
||||
|
||||
What I want to _avoid_ is transferring my anxiety to my team members. I don't want them to feel that I am continually saying, "What have you done for me lately?" even though that is how I feel the world is looking at me. That's an aspect of what I've called [an anxiety inaction loop][5].
|
||||
|
||||
I try hard to treat people with respect, to assume positive intent, to give people the room to do their work in the way they see fit. But, nonetheless, do my team members feel the kind of judgment from me that I continually impose on myself?
|
||||
|
||||
At a fundamental level, I believe work is never done, that there is always another challenge to explore, other ways to have a larger impact. Leaders need to inspire and motivate us to embrace that reality as an exciting opportunity rather than an endless drudge or a source of continual worry.
|
||||
|
||||
As a leader who suffers from anxiety, this is more challenging to do in practice than it is to understand intellectually.
|
||||
|
||||
While this is an area of continual work for me, I've received some good advice on how to shield my colleagues from my own anxiety-driven loops, like:
|
||||
|
||||
* If celebrating success and acknowledging achievement doesn't come naturally for you, build it into the plan from the start. Ensure you have the celebration of accomplishment accounted for from the beginning of a project. This can help reduce the "what have you done for me lately?" impulse that comes from moving quickly to the next challenge without pausing to acknowledge achievements.
|
||||
* Work with another team member on acknowledgment and celebration efforts. Others might have different ideas on how to do this effectively, and may also enjoy the process. Giving this responsibility to someone else can help ensure it isn't lost.
|
||||
* Practice compassion, gratitude, and empathy. This may not come naturally and may take some effort. Putting yourself in someone else's shoes, thinking about their perspective, thanking people for what they have done, and understanding their challenges can go a long way in shifting your own perspective.
|
||||
* If you find yourself judging others, ask yourself, "Is this useful in terms of what I want or need from this situation?" That is, is carrying judgment going to help you accomplish your goal? Most likely, the answer is no. And, in fact, it may have the opposite effect!
|
||||
|
||||
|
||||
|
||||
The above tips have been helpful for me. But the goal of this series hasn't been to provide solutions but rather to share my experiences and to use writing to explore my own tendencies and the impact they have on myself and others. I believe that acknowledging and sharing our personal challenges can reduce the [stigma][6] associated with mental illness, create the space needed to start exploring solutions, and to create environments that are more positive and invigorating to work in.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/20/2/working-anxiety-team-performance
|
||||
|
||||
作者:[Sam Knuth][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/samfw
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/osdc-lead-web-internet.png?itok=UQ0zMNJ3 (Spider web on green background)
|
||||
[2]: https://opensource.com/open-organization/20/1/leading-openly-anxiety
|
||||
[3]: https://opensource.com/open-organization/resources/open-org-definition
|
||||
[4]: https://opensource.com/article/17/2/what-happens-when-we-just-assume-positive-intent
|
||||
[5]: https://opensource.com/open-organization/20/2/working-anxiety-inaction-loop
|
||||
[6]: https://www.bloomberg.com/news/articles/2019-11-13/mental-health-is-still-a-don-t-ask-don-t-tell-subject-at-work
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,110 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Screenshot your Linux system configuration with Bash tools)
|
||||
[#]: via: (https://opensource.com/article/20/1/screenfetch-neofetch)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||
|
||||
Screenshot your Linux system configuration with Bash tools
|
||||
======
|
||||
ScreenFetch and Neofetch make it easy to share your Linux environment
|
||||
with others.
|
||||
![metrics and data shown on a computer screen][1]
|
||||
|
||||
There are many reasons you might want to share your Linux configuration with other people. You might be looking for help troubleshooting a problem on your system, or maybe you're so proud of the environment you've created that you want to showcase it to fellow open source enthusiasts.
|
||||
|
||||
You could get some of that information with a **cat /proc/cpuinfo** or **lscpu** command at the Bash prompt. But if you want to share more details, such as your operating system, kernel, uptime, shell environment, screen resolution, etc., you have two great tools to choose: screenFetch and Neofetch.
|
||||
|
||||
### ScreenFetch
|
||||
|
||||
[ScreenFetch][2] is a Bash command-line utility that can produce a very nice screenshot of your system configuration and uptime. It is an easy way to share your system's configuration with others in a colorful way.
|
||||
|
||||
It's simple to install screenFetch for many Linux distributions.
|
||||
|
||||
On Fedora, enter:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo dnf install screenfetch`
|
||||
```
|
||||
|
||||
On Ubuntu, enter:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo apt install screenfetch`
|
||||
```
|
||||
|
||||
For other operating systems, including FreeBSD, MacOS, and more, consult the screenFetch wiki's [installation page][3]. Once screenFetch is installed, it can produce a detailed and colorful screenshot like this:
|
||||
|
||||
![screenFetch][4]
|
||||
|
||||
ScreenFetch also provides various command-line options to fine-tune your results. For example, **screenfetch -v** returns verbose output that presents each option line-by-line along with the display shown above.
|
||||
|
||||
And **screenfetch -n** eliminates the operating system icon when it displays your system information.
|
||||
|
||||
![screenfetch -n option][5]
|
||||
|
||||
Other options include **screenfetch -N**, which strips all color from the output; **screenfetch -t**, which truncates the output depending on the size of the terminal; and **screenFetch -E**, which suppresses errors.
|
||||
|
||||
Be sure to check the man page on your system for other options. ScreenFetch is open source under the GPLv3, and you can learn more about the project in its [GitHub repository][6].
|
||||
|
||||
### Neofetch
|
||||
|
||||
[Neofetch][7] is another tool to create a screenshot with your system information. It is written in Bash 3.2 and is open source under the [MIT License][8].
|
||||
|
||||
According to the project's website, "Neofetch supports almost 150 different operating systems. From Linux to Windows, all the way to more obscure operating systems like Minix, AIX, and Haiku."
|
||||
|
||||
![Neofetch][9]
|
||||
|
||||
The project maintains a wiki with excellent [installation documentation][10] for a variety of distributions and operating systems.
|
||||
|
||||
If you are on Fedora, RHEL, or CentOS, you can install Neofetch at the Bash prompt with:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo dnf install neofetch`
|
||||
```
|
||||
|
||||
On Ubuntu 17.10 and greater, you can use:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo apt install neofetch`
|
||||
```
|
||||
|
||||
On its first run, Neofetch writes a **~/.config/neofetch/config.conf** file to your home directory (**.config/config.conf**), which enables you to [customize and control][11] every aspect of Neofetch's output. For example, you can configure Neofetch to use the image, ASCII file, or wallpaper of your choice—or nothing at all. The config.conf file also makes it easy to share your customization with others.
|
||||
|
||||
If Neofetch doesn't support your operating system or provide all the options you are looking for, be sure to open up an issue in the project's [GitHub repo][12].
|
||||
|
||||
### Conclusion
|
||||
|
||||
No matter why you want to share your system configuration, screenFetch or Neofetch should enable you to do so. Do you know of another open source tool that provides this functionality on Linux? Please share your favorite in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/1/screenfetch-neofetch
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/metrics_data_dashboard_system_computer_analytics.png?itok=oxAeIEI- (metrics and data shown on a computer screen)
|
||||
[2]: https://github.com/KittyKatt/screenFetch
|
||||
[3]: https://github.com/KittyKatt/screenFetch/wiki/Installation
|
||||
[4]: https://opensource.com/sites/default/files/uploads/screenfetch.png (screenFetch)
|
||||
[5]: https://opensource.com/sites/default/files/uploads/screenfetch-n.png (screenfetch -n option)
|
||||
[6]: http://github.com/KittyKatt/screenFetch
|
||||
[7]: https://github.com/dylanaraps/neofetch
|
||||
[8]: https://github.com/dylanaraps/neofetch/blob/master/LICENSE.md
|
||||
[9]: https://opensource.com/sites/default/files/uploads/neofetch.png (Neofetch)
|
||||
[10]: https://github.com/dylanaraps/neofetch/wiki/Installation
|
||||
[11]: https://github.com/dylanaraps/neofetch/wiki/Customizing-Info
|
||||
[12]: https://github.com/dylanaraps/neofetch/issues
|
||||
@ -1,120 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Use tmux to create the console of your dreams)
|
||||
[#]: via: (https://opensource.com/article/20/1/tmux-console)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
|
||||
|
||||
Use tmux to create the console of your dreams
|
||||
======
|
||||
You can do a lot with tmux, especially when you add tmuxinator to the
|
||||
mix. Check them out in the fifteenth in our series on 20 ways to be more
|
||||
productive with open source in 2020.
|
||||
![Person drinking a hat drink at the computer][1]
|
||||
|
||||
Last year, I brought you 19 days of new (to you) productivity tools for 2019. This year, I'm taking a different approach: building an environment that will allow you to be more productive in the new year, using tools you may or may not already be using.
|
||||
|
||||
### Do it all on the console with tmux and tmuxinator
|
||||
|
||||
In this series so far, I've written about individual apps and tools. Starting today, I'll put them together into comprehensive setups to streamline things. Starting at the command line. Why the command line? Simply put, working at the command line allows me to access a lot of these tools and functions from anywhere I can run SSH. I can SSH into one of my personal machines and run the same setup on my work machine as I use on my personal one. And the primary tool I'm going to use for that is [tmux][2].
|
||||
|
||||
Most people use tmux for very basic functions, such as opening it on a remote server then starting a process, maybe opening a second session to watch log files or debug information, then disconnecting and coming back later. But you can do so much work with tmux.
|
||||
|
||||
![tmux][3]
|
||||
|
||||
First things first—if you have an existing tmux configuration file, back it up. The configuration file for tmux is **~/.tmux.conf**. Move it to another directory, like **~/tmp**. Now, clone the [Oh My Tmux][4] project with Git. Link to **.tmux.conf** from that and copy in the **.tmux.conf.local** file to make adjustments:
|
||||
|
||||
|
||||
```
|
||||
cd ~
|
||||
mkdir ~/tmp
|
||||
mv ~/.tmux.conf ~/tmp/
|
||||
git clone <https://github.com/gpakosz/.tmux.git>
|
||||
ln -s ~/.tmux/.tmux.conf ./
|
||||
cp ~/.tmux.conf.local ./
|
||||
```
|
||||
|
||||
The **.tmux.conf.local** file contains local settings and overrides. For example, I changed the default colors a bit and turned on the [Powerline][5] dividers. This snippet shows only the things I changed:
|
||||
|
||||
|
||||
```
|
||||
tmux_conf_theme_24b_colour=true
|
||||
tmux_conf_theme_focused_pane_bg='default'
|
||||
tmux_conf_theme_pane_border_style=fat
|
||||
tmux_conf_theme_left_separator_main='\uE0B0'
|
||||
tmux_conf_theme_left_separator_sub='\uE0B1'
|
||||
tmux_conf_theme_right_separator_main='\uE0B2'
|
||||
tmux_conf_theme_right_separator_sub='\uE0B3'
|
||||
#tmux_conf_battery_bar_symbol_full='◼'
|
||||
#tmux_conf_battery_bar_symbol_empty='◻'
|
||||
tmux_conf_battery_bar_symbol_full='♥'
|
||||
tmux_conf_battery_bar_symbol_empty='·'
|
||||
tmux_conf_copy_to_os_clipboard=true
|
||||
set -g mouse on
|
||||
```
|
||||
|
||||
Note that you do not need to have Powerline installed—you just need a font that supports the Powerline symbols. I use [Hack Nerd Font][6] for almost everything console-related since it is easy for me to read and has many, many useful extra symbols. You'll also note that I turn on operating system clipboard support and mouse support.
|
||||
|
||||
Now, when tmux starts up, the status bar at the bottom provides a bit more information—and in exciting colors. **Ctrl**+**b** is still the "leader" key for entering commands, but some others have changed. Splitting panes horizontally (top/bottom) is now **Ctrl**+**b**+**-** and vertically is now **Ctrl**+**b**+**_**. With mouse mode turned on, you can click to switch between the panes and drag the dividers to resize them. Opening a new window is still **Ctrl**+**b**+**n**, and you can now click on the window name on the bottom bar to switch between them. Also, **Ctrl**+**b**+**e** will open up the **.tmux.conf.local** file for editing. When you exit the editor, tmux will reload the configuration without reloading anything else. Very useful.
|
||||
|
||||
So far, I've only made some simple changes to functionality and visual display and added mouse support. Now I'll set it up to launch the apps I want in a way that makes sense and without having to reposition and resize them every time. For that, I'll use [tmuxinator][7]. Tmuxinator is a launcher for tmux that allows you to specify and manage layouts and autostart applications with a YAML file. To use it, start tmux and create panes with the things you want running in them. Then, open a new window with **Ctrl**+**b**+**n**, and execute **tmux list-windows**. You will get detailed information about the layout.
|
||||
|
||||
![tmux layout information][8]
|
||||
|
||||
Note the first line in the code above where I set up four panes with an application in each one.** **Save the output from when you run it for later. Now, run **tmuxinator new 20days** to create a layout named **20days**. This will bring up a text editor with the default layout file. It has a lot of useful stuff in it, and I encourage you to read up on all the options. Start by putting in the layout information above and what apps you want where:
|
||||
|
||||
|
||||
```
|
||||
# /Users/ksonney/.config/tmuxinator/20days.yml
|
||||
name: 20days
|
||||
root: ~/
|
||||
windows:
|
||||
- mail:
|
||||
layout: d9da,208x60,0,0[208x26,0,0{104x26,0,0,0,103x26,105,0,5},208x33,0,27{104x33,0,27,1,103x33,105,27,4}]] @0
|
||||
panes:
|
||||
- alot
|
||||
- abook
|
||||
- ikhal
|
||||
- todo.sh ls +20days
|
||||
```
|
||||
|
||||
Be careful with the spaces! Like Python code, the spaces and indentation matter to how the file is interpreted. Save the file and then run **tmuxinator 20days**. You should get four panes with the [alot][9] mail program, [abook][10], ikhal (a shortcut to [khal][11] interactive), and anything in [todo.txt][12] with the tag **+20days**.
|
||||
|
||||
![sample layout launched by tmuxinator][13]
|
||||
|
||||
You'll also notice that the window on the bottom bar is labeled Mail. You can click on the name (along with other named windows) to jump to that view. Nifty, right? I set up a second window named Social with [Tuir][14], [Newsboat][15], an IRC client connected to [BitlBee][16], and [Rainbow Stream][17] in the same file.
|
||||
|
||||
Tmux is my productivity powerhouse for keeping track of all the things, and with tmuxinator, I don't have to worry about constantly resizing, placing, and launching my applications.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/1/tmux-console
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/coffee_tea_laptop_computer_work_desk.png?itok=D5yMx_Dr (Person drinking a hat drink at the computer)
|
||||
[2]: https://github.com/tmux/tmux
|
||||
[3]: https://opensource.com/sites/default/files/uploads/productivity_15-1.png (tumux)
|
||||
[4]: https://github.com/gpakosz/.tmux
|
||||
[5]: https://github.com/powerline/powerline
|
||||
[6]: https://www.nerdfonts.com/
|
||||
[7]: https://github.com/tmuxinator/tmuxinator
|
||||
[8]: https://opensource.com/sites/default/files/uploads/productivity_15-2.png (tmux layout information)
|
||||
[9]: https://opensource.com/article/20/1/organize-email-notmuch
|
||||
[10]: https://opensource.com/article/20/1/sync-contacts-locally
|
||||
[11]: https://opensource.com/article/20/1/open-source-calendar
|
||||
[12]: https://opensource.com/article/20/1/open-source-to-do-list
|
||||
[13]: https://opensource.com/sites/default/files/uploads/productivity_15-3.png (sample layout launched by tmuxinator)
|
||||
[14]: https://opensource.com/article/20/1/open-source-reddit-client
|
||||
[15]: https://opensource.com/article/20/1/open-source-rss-feed-reader
|
||||
[16]: https://opensource.com/article/20/1/open-source-chat-tool
|
||||
[17]: https://opensource.com/article/20/1/tweet-terminal-rainbow-stream
|
||||
@ -1,117 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Use Vim to send email and check your calendar)
|
||||
[#]: via: (https://opensource.com/article/20/1/vim-email-calendar)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
|
||||
|
||||
Use Vim to send email and check your calendar
|
||||
======
|
||||
Manage your email and calendar right from your text editor in the
|
||||
sixteenth in our series on 20 ways to be more productive with open
|
||||
source in 2020.
|
||||
![Calendar close up snapshot][1]
|
||||
|
||||
Last year, I brought you 19 days of new (to you) productivity tools for 2019. This year, I'm taking a different approach: building an environment that will allow you to be more productive in the new year, using tools you may or may not already be using.
|
||||
|
||||
### Doing (almost) all the things with Vim, part 1
|
||||
|
||||
I use two text editors regularly—[Vim][2] and [Emacs][3]. Why both? They have different use cases, and I'll talk about some of them in the next few articles in this series.
|
||||
|
||||
![][4]
|
||||
|
||||
OK, so why do everything in Vim? Because if there is one application that is on every machine I have access to, it's Vim. And if you are like me, you probably already spend a lot of time in Vim. So why not use it for _all the things_?
|
||||
|
||||
Before that, though, you need to do some things. The first is to make sure you have Ruby support in Vim. You can check that with **vim --version | grep ruby**. If the result is not **+ruby**, that needs to be fixed. This can be tricky, and you should check your distribution's documentation for the right package to install. On MacOS, this is the official MacVim (not from Brew), and on most Linux distributions, this is either vim-nox or vim-gtk—NOT vim-gtk3.
|
||||
|
||||
I use [Pathogen][5] to autoload my plugins and bundles. If you use [Vundle][6] or another Vim package manager, you'll need to adjust the commands below to work with it.
|
||||
|
||||
#### Do your email in Vim
|
||||
|
||||
A good starting place for making Vim a bigger part of your productivity plan is using it to send and receive email with [Notmuch][7] using [abook][8] to access your contact list. You need to install some things for this. All the sample code below is on Ubuntu, so you'll need to adjust for that if you are using a different distribution. Do the setup with:
|
||||
|
||||
|
||||
```
|
||||
sudo apt install notmuch-vim ruby-mail
|
||||
curl -o ~/.vim/plugin/abook --create-dirs <https://raw.githubusercontent.com/dcbaker/vim-abook/master/plugin/abook.vim>
|
||||
```
|
||||
|
||||
So far, so good. Now start Vim and execute **:NotMuch**. There may be some warnings due to the older version of the mail library **notmuch-vim** was written for, but in general, Vim will now be a full-featured Notmuch mail client.
|
||||
|
||||
![Reading Mail in Vim][9]
|
||||
|
||||
If you want to perform a search for a specific tag, type **\t**, enter the name of the tag, and press Enter. This will pull up a list of all messages with that tag. The **\s** key combination brings up a **Search:** prompt that will do a full search of the Notmuch database. Navigate the message list with the arrow keys, press Enter to display the selected item, and enter **\q** to exit the current view.
|
||||
|
||||
To compose mail, use the **\c** keystroke. You will see a blank message. This is where the **abook.vim** plugin comes in. Hit **Esc** and enter **:AbookQuery <SomeName>**, where <SomeName> is a part of the name or email address you want to look for. You will get a list of entries in the abook database that match your search. Select the address you want by typing its number to add it to the email's address line. Finish typing and editing the email, press **Esc** to exit edit mode, and enter **,s** to send.
|
||||
|
||||
If you want to change the default folder view when **:NotMuch** starts up, you can add the variable **g:notmuch_folders** to your **.vimrc** file:
|
||||
|
||||
|
||||
```
|
||||
let g:notmuch_folders = [
|
||||
\ [ 'new', 'tag:inbox and tag:unread' ],
|
||||
\ [ 'inbox', 'tag:inbox' ],
|
||||
\ [ 'unread', 'tag:unread' ],
|
||||
\ [ 'News', 'tag:@sanenews' ],
|
||||
\ [ 'Later', 'tag:@sanelater' ],
|
||||
\ [ 'Patreon', 'tag:@patreon' ],
|
||||
\ [ 'LivestockConservancy', 'tag:livestock-conservancy' ],
|
||||
\ ]
|
||||
```
|
||||
|
||||
There are many more settings covered in the Notmuch plugin's documentation, including setting up keys for tags and using alternate mail programs.
|
||||
|
||||
#### Consult your calendar in Vim
|
||||
|
||||
![][10]
|
||||
|
||||
Sadly, there do not appear to be any calendar programs for Vim that use the vCalendar or iCalendar formats. There is [Calendar.vim][11], which is very well done. Set up Vim to access your calendar with:
|
||||
|
||||
|
||||
```
|
||||
cd ~/.vim/bundle
|
||||
git clone [git@github.com][12]:itchyny/calendar.vim.git
|
||||
```
|
||||
|
||||
Now, you can see your calendar in Vim by entering **:Calendar**. You can switch between year, month, week, day, and clock views with the **<** and **>** keys. If you want to start with a particular view, use the **-view=** flag to tell it which one you wish to see. You can also add a date to any of the views. For example, if I want to see what is going on the week of July 4, 2020, I would enter **:Calendar -view week 7 4 2020**. The help is pretty good and can be accessed with the **?** key.
|
||||
|
||||
![][13]
|
||||
|
||||
Calendar.vim also supports Google Calendar (which I need), but in December 2019 Google disabled the access for it. The author has posted a workaround in [the issue on
|
||||
GitHub][14].
|
||||
|
||||
So there you have it, your mail, addresses, and calendars in Vim. But you aren't done yet; you'll do even more with Vim tomorrow!
|
||||
|
||||
Vim offers great benefits to writers, regardless of whether they are technically minded or not.
|
||||
|
||||
Need to keep your schedule straight? Learn how to do it using open source with these free...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/1/vim-email-calendar
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/calendar.jpg?itok=jEKbhvDT (Calendar close up snapshot)
|
||||
[2]: https://www.vim.org/
|
||||
[3]: https://www.gnu.org/software/emacs/
|
||||
[4]: https://opensource.com/sites/default/files/uploads/day16-image1.png
|
||||
[5]: https://github.com/tpope/vim-pathogen
|
||||
[6]: https://github.com/VundleVim/Vundle.vim
|
||||
[7]: https://opensource.com/article/20/1/organize-email-notmuch
|
||||
[8]: https://opensource.com/article/20/1/sync-contacts-locally
|
||||
[9]: https://opensource.com/sites/default/files/uploads/productivity_16-2.png (Reading Mail in Vim)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/day16-image3.png
|
||||
[11]: https://github.com/itchyny/calendar.vim
|
||||
[12]: mailto:git@github.com
|
||||
[13]: https://opensource.com/sites/default/files/uploads/day16-image4.png
|
||||
[14]: https://github.com/itchyny/calendar.vim/issues/156
|
||||
@ -1,152 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Send email and check your calendar with Emacs)
|
||||
[#]: via: (https://opensource.com/article/20/1/emacs-mail-calendar)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
|
||||
|
||||
Send email and check your calendar with Emacs
|
||||
======
|
||||
Manage your email and view your schedule with the Emacs text editor in
|
||||
the eighteenth in our series on 20 ways to be more productive with open
|
||||
source in 2020.
|
||||
![Document sending][1]
|
||||
|
||||
Last year, I brought you 19 days of new (to you) productivity tools for 2019. This year, I'm taking a different approach: building an environment that will allow you to be more productive in the new year, using tools you may or may not already be using.
|
||||
|
||||
### Doing (almost) all the things with Emacs, part 1
|
||||
|
||||
Two days ago, I shared that I use both [Vim][2] and [Emacs][3] regularly, and on days [16][4] and [17][5] of this series, I explained how to do almost everything in Vim. Now, it's time for Emacs!
|
||||
|
||||
![Mail and calendar in Emacs][6]
|
||||
|
||||
Before I get too far, I should explain two things. First, I'm doing everything here using the default Emacs configuration, not [Spacemacs][7], which I have [written about][8]. Why? Because I will be using the default keyboard mappings so that you can refer back to the documentation and not have to translate things from "native Emacs" to Spacemacs. Second, I'm not setting up Org mode in this series. Org mode almost needs an entire series on its own, and, while it is very powerful, the setup can be quite complex.
|
||||
|
||||
#### Configure Emacs
|
||||
|
||||
Configuring Emacs is a little bit more complicated than configuring Vim, but in my opinion, it is worth it in the long run. Start by creating a configuration file and opening it in Emacs:
|
||||
|
||||
|
||||
```
|
||||
mkdir ~/.emacs.d
|
||||
emacs ~/.emacs.d/init.el
|
||||
```
|
||||
|
||||
Next, add some additional package sources to the built-in package manager. Add the following to **init.el**:
|
||||
|
||||
|
||||
```
|
||||
(package-initialize)
|
||||
(add-to-list 'package-archives '("melpa" . "<http://melpa.org/packages/>"))
|
||||
(add-to-list 'package-archives '("org" . "<http://orgmode.org/elpa/>") t)
|
||||
(add-to-list 'package-archives '("gnu" . "<https://elpa.gnu.org/packages/>"))
|
||||
(package-refresh-contents)
|
||||
```
|
||||
|
||||
Save the file with **Ctrl**+**x** **Ctrl**+**s**, exit with **Ctrl**+**x** **Ctrl**+**c**, and restart Emacs. It will download all the package lists at startup, and then you should be ready to install things with the built-in package manager. Start by typing **Meta**+**x** to bring up a command prompt (the **Meta** key is the **Alt** key on most keyboards or **Option** on MacOS). At the command prompt, type **package-list-packages** to bring up a list of packages you can install. Go through the list and select the following packages with the **i** key:
|
||||
|
||||
|
||||
```
|
||||
bbdb
|
||||
bbdb-vcard
|
||||
calfw
|
||||
calfw-ical
|
||||
notmuch
|
||||
```
|
||||
|
||||
Once the packages are selected, press **x** to install them. Depending on your internet connection, this could take a while. You may see some compile errors, but it's safe to ignore them. Once it completes, open **~/.emacs.d/init.el** with the key combination **Ctrl**+**x** **Ctrl**+**f**, and add the following lines to the file after **(package-refresh-packages)** and before **(custom-set-variables**. Emacs uses the **(custom-set-variables** line internally, and you should never, ever modify anything below it. Lines beginning with **;;** are comments.
|
||||
|
||||
|
||||
```
|
||||
;; Set up bbdb
|
||||
(require 'bbdb)
|
||||
(bbdb-initialize 'message)
|
||||
(bbdb-insinuate-message)
|
||||
(add-hook 'message-setup-hook 'bbdb-insinuate-mail)
|
||||
;; set up calendar
|
||||
(require 'calfw)
|
||||
(require 'calfw-ical)
|
||||
;; Set this to the URL of your calendar. Google users will use
|
||||
;; the Secret Address in iCalendar Format from the calendar settings
|
||||
(cfw:open-ical-calendar "<https://path/to/my/ics/file.ics>")
|
||||
;; Set up notmuch
|
||||
(require 'notmuch)
|
||||
;; set up mail sending using sendmail
|
||||
(setq send-mail-function (quote sendmail-send-it))
|
||||
(setq user-mail-address "[myemail@mydomain.com][9]"
|
||||
user-full-name "My Name")
|
||||
```
|
||||
|
||||
Now you are ready to start Emacs with your setup! Save the **init.el** file (**Ctrl**+**x** **Ctrl**+**s**), exit Emacs (**Ctrl**+**x** **Ctrl**+**c**), and then restart it. It will take a little longer to start this time.
|
||||
|
||||
#### Read and write email in Emacs with Notmuch
|
||||
|
||||
Once you are at the Emacs splash screen, you can start reading your email with [Notmuch][10]. Type **Meta**+**x notmuch**, and you'll get Notmuch's Emacs interface.
|
||||
|
||||
![Reading mail with Notmuch][11]
|
||||
|
||||
All the items in bold type are links to email views. You can access them with either a mouse click or by tabbing between them and pressing **Return** or **Enter**. You can use the search bar to
|
||||
|
||||
search Notmuch's database using the [same syntax][12] as you use on Notmuch's command line. If you want, you can save any searches for later use with the **[save]** button, and they will be added to the list at the top of the screen. If you follow one of the links, you will get a list of the relevant email messages. You can navigate the list with the **Arrow** keys, and press **Enter** on the message you want to read. Pressing **r** will reply to a message, **f** will forward the message, and **q** will exit the current screen.
|
||||
|
||||
You can write a new message by typing **Meta**+**x compose-mail**. Composing, replying, and forwarding all bring up the mail writing interface. When you are done writing your email, press **Ctrl**+**c Ctrl**+**c** to send it. If you decide you don't want to send it, press **Ctrl**+**c Ctrl**+**k** to kill the message compose buffer (window).
|
||||
|
||||
#### Autocomplete email addresses in Emacs with BBDB
|
||||
|
||||
![Composing a message with BBDB addressing][13]
|
||||
|
||||
But what about your address book? That's where [BBDB][14] comes in. But first, import all your addresses from [abook][15] by opening a command line and running the following export command:
|
||||
|
||||
|
||||
```
|
||||
`abook --convert --outformat vcard --outfile ~/all-my-addresses.vcf --infile ~/.abook/addresses`
|
||||
```
|
||||
|
||||
Once Emacs starts, run **Meta**+**x bbdb-vcard-import-file**. It will prompt you for the file name you want to import, which is **~/all-my-addresses.vcf**. After the import finishes, when you compose a message, you can start typing a name and use **Tab** to search and autocomplete the "To" field. BBDB will also open a buffer for the contact so you can make sure it's the correct one.
|
||||
|
||||
Why do it this way when you already have each address as a **vcf.** file from [vdirsyncer][16]? If you are like me, you have a LOT of addresses, and doing them one at a time is a lot of work. This way, you can take everything you have in abook and make one big file.
|
||||
|
||||
#### View your calendar in Emacs with calfw
|
||||
|
||||
![calfw calendar][17]
|
||||
|
||||
Finally, you can use Emacs to look at your calendar. In the configuration section above, you installed the [calfw][18] package and added lines to tell it where to find the calendars to load. Calfw is short for the Calendar Framework for Emacs, and it supports many calendar formats. Since I use Google calendar, that is the link I put into my config. Your calendar will auto-load at startup, and you can view it by switching the **cfw-calendar** buffer with the **Ctrl**+**x**+**b** command.
|
||||
|
||||
Calfw offers views by the day, week, two weeks, and month. You can select the view from the top of the calendar and navigate your calendar with the **Arrow** keys. Unfortunately, calfw can only view calendars, so you'll still need to use something like [khal][19] or a web interface to add, delete, and modify events.
|
||||
|
||||
So there you have it: mail, calendars, and addresses in Emacs. Tomorrow I'll do even more.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/1/emacs-mail-calendar
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/email_paper_envelope_document.png?itok=uPj_kouJ (Document sending)
|
||||
[2]: https://www.vim.org/
|
||||
[3]: https://www.gnu.org/software/emacs/
|
||||
[4]: https://opensource.com/article/20/1/vim-email-calendar
|
||||
[5]: https://opensource.com/article/20/1/vim-task-list-reddit-twitter
|
||||
[6]: https://opensource.com/sites/default/files/uploads/productivity_18-1.png (Mail and calendar in Emacs)
|
||||
[7]: https://www.spacemacs.org/
|
||||
[8]: https://opensource.com/article/19/12/spacemacs
|
||||
[9]: mailto:myemail@mydomain.com
|
||||
[10]: https://notmuchmail.org/
|
||||
[11]: https://opensource.com/sites/default/files/uploads/productivity_18-2.png (Reading mail with Notmuch)
|
||||
[12]: https://opensource.com/article/20/1/organize-email-notmuch
|
||||
[13]: https://opensource.com/sites/default/files/uploads/productivity_18-3.png (Composing a message with BBDB addressing)
|
||||
[14]: https://www.jwz.org/bbdb/
|
||||
[15]: https://opensource.com/article/20/1/sync-contacts-locally
|
||||
[16]: https://opensource.com/article/20/1/open-source-calendar
|
||||
[17]: https://opensource.com/sites/default/files/uploads/productivity_18-4.png (calfw calendar)
|
||||
[18]: https://github.com/kiwanami/emacs-calfw
|
||||
[19]: https://khal.readthedocs.io/en/v0.9.2/index.html
|
||||
@ -1,162 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Use Emacs to get social and track your todo list)
|
||||
[#]: via: (https://opensource.com/article/20/1/emacs-social-track-todo-list)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
|
||||
|
||||
Use Emacs to get social and track your todo list
|
||||
======
|
||||
Access Twitter, Reddit, chat, email, RSS, and your todo list in the
|
||||
nineteenth in our series on 20 ways to be more productive with open
|
||||
source in 2020.
|
||||
![Team communication, chat][1]
|
||||
|
||||
Last year, I brought you 19 days of new (to you) productivity tools for 2019. This year, I'm taking a different approach: building an environment that will allow you to be more productive in the new year, using tools you may or may not already be using.
|
||||
|
||||
### Doing (almost) all the things with Emacs, part 2
|
||||
|
||||
[Yesterday][2], I talked about how to read email, access your addresses, and show calendars in Emacs. Emacs has tons and tons of functionality, and you can also use it for Twitter, chatting, to-do lists, and more!
|
||||
|
||||
![All the things with Emacs][3]
|
||||
|
||||
To do all of this, you need to install some Emacs packages. As you did yesterday, open the Emacs package manager with **Meta**+**x package-manager** (Meta is **Alt** on most keyboards or **Option** on MacOS). Now select the following packages with **i**, then install them by typing **x**:
|
||||
|
||||
|
||||
```
|
||||
nnreddit
|
||||
todotxt
|
||||
twittering-mode
|
||||
```
|
||||
|
||||
Once they are installed, open **~/.emacs.d/init.el** with **Ctrl**+**x Ctrl**+**x**, and add the following before the **(custom-set-variables** line:
|
||||
|
||||
|
||||
```
|
||||
;; Todo.txt
|
||||
(require 'todotxt)
|
||||
(setq todotxt-file (expand-file-name "~/.todo/todo.txt"))
|
||||
|
||||
;; Twitter
|
||||
(require 'twittering-mode)
|
||||
(setq twittering-use-master-password t)
|
||||
(setq twittering-icon-mode t)
|
||||
|
||||
;; Python3 for nnreddit
|
||||
(setq elpy-rpc-python-command "python3")
|
||||
```
|
||||
|
||||
Save the file with **Ctrl**+**x Ctrl**+**a**, exit Emacs with **Ctrl**+**x Ctrl**+**c**, then restart Emacs.
|
||||
|
||||
#### Tweet from Emacs with twittering-mode
|
||||
|
||||
![Twitter in Emacs][4]
|
||||
|
||||
[Twittering-mode][5] is one of the best Emacs interfaces for Twitter. It supports almost all the features of Twitter and has some easy-to-use keyboard shortcuts.
|
||||
|
||||
To get started, type **Meta**+**x twit** to launch twittering-mode. It will give a URL to open—and prompt you to launch a browser with it if you want—so you can log in and get an authorization token. Copy and paste the token into Emacs, and your Twitter timeline should load. You can scroll with the **Arrow** keys, use **Tab** to move from item to item, and press **Enter** to view the URL the cursor is on. If the cursor is on a username, pressing **Enter** will open that timeline in a web browser. If you are on a tweet's text, pressing **Enter** will reply to that tweet. You can create a new tweet with **u**, retweet something with **Ctrl**+**c**+**Enter**, and send a direct message with **d**—the dialog it opens has instructions on how to send, cancel, and shorten URLs.
|
||||
|
||||
Pressing **V** will open a prompt to get to other timelines. To open your mentions, type **:mentions**. The home timeline is **:home**, and typing a username will take you to that user's timeline. Finally, pressing **q** will quit twittering-mode and close the window.
|
||||
|
||||
There is a lot more functionality available in twittering-mode, and I encourage you to read the [full list][6] on its GitHub page.
|
||||
|
||||
#### Track your to-do's in Emacs with Todotxt.el
|
||||
|
||||
![todo.txt in emacs][7]
|
||||
|
||||
[Todotxt.el][8] is a nice interface for the [todo.txt][9] to-do list manager. It has hotkeys for just about everything.
|
||||
|
||||
To start it up, type **Meta**+**x todotxt**, and it will load the todo.txt file you specified in the **todotxt-file** variable (which you set in the first part of this article). Inside the buffer (window) for todo.txt, you can press **a** to add a new task and **c** to mark it complete. You can set priorities with **r**, and add projects and context to an item with **t**. When you are ready to move everything to **done.txt**, just press **A**. And you can filter the list with **/** or refresh back to the full list with **l**. And again, you can press **q** to exit.
|
||||
|
||||
#### Chat in Emacs with ERC
|
||||
|
||||
![Chatting with erc][10]
|
||||
|
||||
One of Vim's shortcomings is that trying to use chat with it is difficult (at best). Emacs, on the other hand, has the [ERC][11] client built into the default distribution. Start ERC with **Meta**+**x erc**, and you will be prompted for a server name, username, and password. You can use the same information you used a few days ago when you set up [BitlBee][12]: server **localhost**, port **6667**, and the same username with no password. It should be the same as using almost any other IRC client. Each channel will be split into a new buffer (window), and you can switch between them with **Ctrl**+**x Ctrl**+**b**, which also switches between other buffers in Emacs. The **/quit** command will exit ERC.
|
||||
|
||||
#### Read email, Reddit, and RSS feeds with Gnus
|
||||
|
||||
![Mail, Reddit, and RSS feeds with Gnus][13]
|
||||
|
||||
I'm sure many long-time Emacs users were asking, "but what about [Gnus][14]?" yesterday when I was talking about reading mail in Emacs. And it's a valid question. Gnus is a mail and newsreader built into Emacs, although it doesn't support [Notmuch][15] as a mail reader, just as a search engine. However, if you are configuring it for Reddit and RSS feeds (as you'll do in a moment), it's smart to add in mail functionality as well.
|
||||
|
||||
Gnus was created for reading Usenet News and grew from there. So, a lot of its look and feel (and terminology) seem a lot like a Usenet newsreader.
|
||||
|
||||
Gnus has its own configuration file in **~/.gnus** (the configuration can also be included in the main **~/.emacs.d/init.el**). Open **~/.gnus** with **Ctrl**+**x Ctrl**+**f** and add the following:
|
||||
|
||||
|
||||
```
|
||||
;; Required packages
|
||||
(require 'nnir)
|
||||
(require 'nnrss)
|
||||
|
||||
;; Primary Mailbox
|
||||
(setq gnus-select-method
|
||||
'(nnmaildir "Local"
|
||||
(directory "~/Maildir")
|
||||
(nnir-search-engine notmuch)
|
||||
))
|
||||
(add-to-list 'gnus-secondary-select-methods
|
||||
'(nnreddit ""))
|
||||
```
|
||||
|
||||
Save the file with **Ctrl**+**x Ctrl**+**s**. This tells Gnus to read mail from the local mailbox in **~/Maildir** as the primary source (**gnus-select-method**) and add a second source (**gnus-secondary-select-methods**) using the [nnreddit][16] plugin. You can also define multiple secondary sources, including Usenet News (nntp), IMAP (nnimap), mbox (nnmbox), and virtual collections (nnvirtual). You can learn more about all the options in the [Gnus manual][17].
|
||||
|
||||
Once you save the file, start Gnus with **Meta**+**x gnus**. The first run will install [Reddit Terminal Viewer][18] in a Python virtual environment, which is how it gets Reddit articles. It will then launch your browser to log into Reddit. After that, it will scan and load your subscribed Reddit groups. You will see a list of email folders with new mail and the list of subreddits with new content. Pressing **Enter** on any of them will load the list of messages for the group. You can navigate with the **Arrow** keys and press **Enter** to load and read a message. Pressing **q** will go back to the prior view when viewing message lists, and pressing **q** from the main window will exit Gnus. When reading a Reddit group, **a** creates a new message; in a mail group, **m** creates a new email; and **r** replies to messages in either view.
|
||||
|
||||
You can also add RSS feeds to the Gnus interface and read them like mail and newsgroups. To add an RSS feed, type **G**+**R** and fill in the RSS feed's URL. You will be prompted for the title and description of the feed, which should be auto-filled from the feed. Now type **g** to check for new messages (this checks for new messages in all groups). Reading a feed is like reading Reddit groups and mail, so it uses the same keys.
|
||||
|
||||
There is a _lot_ of functionality in Gnus, and there are a whole lot more key combinations. The [Gnus Reference Card][19] lists all of them for each view (on five pages in very small type).
|
||||
|
||||
#### See your position with nyan-mode
|
||||
|
||||
As a final note, you might notice [Nyan cat][20] at the bottom of some of my screenshots. This is [nyan-mode][21], which indicates where you are in a buffer, so it gets longer as you get closer to the bottom of a document or buffer. You can install it with the package manager and set it up with the following code in **~/.emacs.d/init.el**:
|
||||
|
||||
|
||||
```
|
||||
;; Nyan Cat
|
||||
(setq nyan-wavy-trail t)
|
||||
(setq nyan-bar-length 20)
|
||||
(nyan-mode)
|
||||
```
|
||||
|
||||
### Scratching Emacs' surface
|
||||
|
||||
This is just scratching the surface of all the things you can do with Emacs. It is _very_ powerful, and it is one of my go-to tools for being productive whether I'm tracking to-dos, reading and responding to mail, editing text, or chatting with my friends and co-workers. It takes a bit of getting used to, but once you do, it can become one of the most useful tools on your desktop.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/1/emacs-social-track-todo-list
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/talk_chat_team_mobile_desktop.png?itok=d7sRtKfQ (Team communication, chat)
|
||||
[2]: https://opensource.com/article/20/1/emacs-mail-calendar
|
||||
[3]: https://opensource.com/sites/default/files/uploads/productivity_19-1.png (All the things with Emacs)
|
||||
[4]: https://opensource.com/sites/default/files/uploads/productivity_19-2.png (Twitter in Emacs)
|
||||
[5]: https://github.com/hayamiz/twittering-mode
|
||||
[6]: https://github.com/hayamiz/twittering-mode#features
|
||||
[7]: https://opensource.com/sites/default/files/uploads/productivity_19-3.png (todo.txt in emacs)
|
||||
[8]: https://github.com/rpdillon/todotxt.el
|
||||
[9]: http://todotxt.org/
|
||||
[10]: https://opensource.com/sites/default/files/uploads/productivity_19-4.png (Chatting with erc)
|
||||
[11]: https://www.gnu.org/software/emacs/manual/html_mono/erc.html
|
||||
[12]: https://opensource.com/article/20/1/open-source-chat-tool
|
||||
[13]: https://opensource.com/sites/default/files/uploads/productivity_19-5.png (Mail, Reddit, and RSS feeds with Gnus)
|
||||
[14]: https://www.gnus.org/
|
||||
[15]: https://opensource.com/article/20/1/organize-email-notmuch
|
||||
[16]: https://github.com/dickmao/nnreddit
|
||||
[17]: https://www.gnus.org/manual/gnus.html
|
||||
[18]: https://pypi.org/project/rtv/
|
||||
[19]: https://www.gnu.org/software/emacs/refcards/pdf/gnus-refcard.pdf
|
||||
[20]: http://www.nyan.cat/
|
||||
[21]: https://github.com/TeMPOraL/nyan-mode
|
||||
@ -1,94 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Meet FuryBSD: A New Desktop BSD Distribution)
|
||||
[#]: via: (https://itsfoss.com/furybsd/)
|
||||
[#]: author: (John Paul https://itsfoss.com/author/john/)
|
||||
|
||||
Meet FuryBSD: A New Desktop BSD Distribution
|
||||
======
|
||||
|
||||
In the last couple of months, a few new desktop BSD have been announced. There is [HyperbolaBSD which was Hyperbola GNU/Linux][1] previously. Another new entry in the [BSD][2] world is [FuryBSD][3].
|
||||
|
||||
### FuryBSD: A new BSD distribution
|
||||
|
||||
![][4]
|
||||
|
||||
At its heart, FuryBSD is a very simple beast. According to [the site][5], “FuryBSD is a back to basics lightweight desktop distribution based on stock FreeBSD.” It is basically FreeBSD with a desktop environment pre-configured and several apps preinstalled. The goal is to quickly get a FreeBSD-based system running on your computer.
|
||||
|
||||
You might be thinking that this sounds a lot like a couple of other BSDs that are available, such as [NomadBSD][6] and [GhostBSD][7]. The major difference between those BSDs and FuryBSD is that FuryBSD is much closer to stock FreeBSD. For example, FuryBSD uses the FreeBSD installer, while others have created their own installers and utilities.
|
||||
|
||||
As it states on the [site][8], “Although FuryBSD may resemble past graphical BSD projects like PC-BSD and TrueOS, FuryBSD is created by a different team and takes a different approach focusing on tight integration with FreeBSD. This keeps overhead low and maintains compatibility with upstream.” The lead dev also told me that “One key focus for FuryBSD is for it to be a small live media with a few assistive tools to test drivers for hardware.”
|
||||
|
||||
Currently, you can go to the [FuryBSD homepage][3] and download either an XFCE or KDE LiveCD. A GNOME version is in the works.
|
||||
|
||||
### Who’s is Behind FuryBSD?
|
||||
|
||||
The lead dev behind FuryBSD is [Joe Maloney][9]. Joe has been a FreeBSD user for many years. He contributed to other BSD projects, such as PC-BSD. He also worked with Eric Turgeon, the creator of GhostBSD, to rewrite the GhostBSD LiveCD. Along the way, he picked up a better understanding of BSD and started to form an idea of how he would make a distribution on his own.
|
||||
|
||||
Joe is joined by several other devs who have also spent many years in the BSD world, such as Jaron Parsons, Josh Smith, and Damian Szidiropulosz.
|
||||
|
||||
### The Future for FuryBSD
|
||||
|
||||
At the moment, FuryBSD is nothing more than a pre-configured FreeBSD setup. However, the devs have a [list of improvements][5] that they want to make going forward. These include:
|
||||
|
||||
* A sane framework for loading, 3rd party proprietary drivers graphics, wireless
|
||||
* Cleanup up the LiveCD experience a bit more to continue to make it more friendly
|
||||
* Printing support out of box
|
||||
* A few more default applications included to provide a complete desktop experience
|
||||
* Integrated [ZFS][10] replication tools for backup and restore
|
||||
* Live image persistence options
|
||||
* A custom pkg repo with sane defaults
|
||||
* Continuous integration for applications updates
|
||||
* Quality assurance for FreeBSD on the desktop
|
||||
* Tailored artwork, color scheming, and theming
|
||||
* Directory services integration
|
||||
* Security hardening
|
||||
|
||||
|
||||
|
||||
The devs make it quite clear that any changes they make will have a lot of thought and research behind them. They don’t want to compliment a feature, only to have to remove it or change it when it breaks something.
|
||||
|
||||
![FuryBSD desktop][11]
|
||||
|
||||
### How You Can Help FuryBSD?
|
||||
|
||||
At this moment the project is still very young. Since all projects need help to survive, I asked Joe what kind of help they were looking for. He said, “We could use help [answering questions on the forums][12], [GitHub][13] tickets, help with documentation are all needed.” He also said that if people wanted to add support for other desktop environments, pull requests are welcome.
|
||||
|
||||
### Final Thoughts
|
||||
|
||||
Although I have not tried it yet, I have a good feeling about FuryBSD. It sounds like the project is in capable hands. Joe Maloney has been thinking about how to make the best BSD desktop experience for over a decade. Unlike majority of Linux distros that are basically a rethemed Ubuntu, the devs behind FuryBSD know what they are doing and they are choosing quality over the fancy bells and whistles.
|
||||
|
||||
What are your thoughts on this new entry into the every growing desktop BSD market? Have you tried out FuryBSD or will you give it a try? Please let us know in the comments below.
|
||||
|
||||
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][14].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/furybsd/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/hyperbola-linux-bsd/
|
||||
[2]: https://itsfoss.com/bsd/
|
||||
[3]: https://www.furybsd.org/
|
||||
[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/01/fury-bsd.jpg?ssl=1
|
||||
[5]: https://www.furybsd.org/manifesto/
|
||||
[6]: https://itsfoss.com/nomadbsd/
|
||||
[7]: https://ghostbsd.org/
|
||||
[8]: https://www.furybsd.org/furybsd-video-overview-at-knoxbug/
|
||||
[9]: https://github.com/pkgdemon
|
||||
[10]: https://itsfoss.com/what-is-zfs/
|
||||
[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/01/FuryBSDS-desktop.jpg?resize=800%2C450&ssl=1
|
||||
[12]: https://forums.furybsd.org/
|
||||
[13]: https://github.com/furybsd
|
||||
[14]: https://reddit.com/r/linuxusersgroup
|
||||
@ -1,169 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( guevaraya)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Troubleshoot Kubernetes with the power of tmux and kubectl)
|
||||
[#]: via: (https://opensource.com/article/20/2/kubernetes-tmux-kubectl)
|
||||
[#]: author: (Abhishek Tamrakar https://opensource.com/users/tamrakar)
|
||||
|
||||
Troubleshoot Kubernetes with the power of tmux and kubectl
|
||||
======
|
||||
A kubectl plugin that uses tmux to make troubleshooting Kubernetes much
|
||||
simpler.
|
||||
![Woman sitting in front of her laptop][1]
|
||||
|
||||
[Kubernetes][2] is a thriving open source container orchestration platform that offers scalability, high availability, robustness, and resiliency for applications. One of its many features is support for running custom scripts or binaries through its primary client binary, [kubectl][3]. Kubectl is very powerful and allows users to do anything with it that they could do directly on a Kubernetes cluster.
|
||||
|
||||
### Troubleshooting Kubernetes with aliases
|
||||
|
||||
Anyone who uses Kubernetes for container orchestration is aware of its features—as well as the complexity it brings because of its design. For example, there is an urgent need to simplify troubleshooting in Kubernetes with something that is quicker and has little need for manual intervention (except in critical situations).
|
||||
|
||||
There are many scenarios to consider when it comes to troubleshooting functionality. In one scenario, you know what you need to run, but the command's syntax—even when it can run as a single command—is excessively complex, or it may need one or two inputs to work.
|
||||
|
||||
For example, if you frequently need to jump into a running container in the System namespace, you may find yourself repeatedly writing:
|
||||
|
||||
|
||||
```
|
||||
`kubectl --namespace=kube-system exec -i -t <your-pod-name>`
|
||||
```
|
||||
|
||||
To simplify troubleshooting, you could use command-line aliases of these commands. For example, you could add the following to your dotfiles (.bashrc or .zshrc):
|
||||
|
||||
|
||||
```
|
||||
`alias ksysex='kubectl --namespace=kube-system exec -i -t'`
|
||||
```
|
||||
|
||||
This is one of many examples from a [repository of common Kubernetes aliases][4] that shows one way to simplify functions in kubectl. For something simple like this scenario, an alias is sufficient.
|
||||
|
||||
### Switching to a kubectl plugin
|
||||
|
||||
A more complex troubleshooting scenario involves the need to run many commands, one after the other, to investigate an environment and come to a conclusion. Aliases alone are not sufficient for this use
|
||||
|
||||
case; you need repeatable logic and correlations between the many parts of your Kubernetes deployment. What you really need is automation to deliver the desired output in less time.
|
||||
|
||||
Consider 10 to 20—or even 50 to 100—namespaces holding different microservices on your cluster. What would be helpful for you to start troubleshooting this scenario?
|
||||
|
||||
* You would need something that can quickly tell which pod in which namespace is throwing errors.
|
||||
* You would need something that can watch logs of all the pods in a namespace.
|
||||
* You might also need to watch logs of certain pods in a specific namespace that have shown errors.
|
||||
|
||||
|
||||
|
||||
Any solution that covers these points would be very useful in investigating production issues as well as during development and testing cycles.
|
||||
|
||||
To create something more powerful than a simple alias, you can use [kubectl plugins][5]. Plugins are like standalone scripts written in any scripting language but are designed to extend the functionality of your main command when serving as a Kubernetes admin.
|
||||
|
||||
To create a plugin, you must use the proper syntax of **kubectl-<your-plugin-name>** to copy the script to one of the exported pathways in your **$PATH** and give it executable permissions (**chmod +x**).
|
||||
|
||||
After creating a plugin and moving it into your path, you can run it immediately. For example, I have kubectl-krawl and kubectl-kmux in my path:
|
||||
|
||||
|
||||
```
|
||||
$ kubectl plugin list
|
||||
The following compatible plugins are available:
|
||||
|
||||
/usr/local/bin/kubectl-krawl
|
||||
/usr/local/bin/kubectl-kmux
|
||||
|
||||
$ kubectl kmux
|
||||
```
|
||||
|
||||
Now let's explore what this looks like when you power Kubernetes with tmux.
|
||||
|
||||
### Harnessing the power of tmux
|
||||
|
||||
[Tmux][6] is a very powerful tool that many sysadmins and ops teams rely on to troubleshoot issues related to ease of operability—from splitting windows into panes for running parallel debugging on multiple machines to monitoring logs. One of its major advantages is that it can be used on the command line or in automation scripts.
|
||||
|
||||
I created [a kubectl plugin][7] that uses tmux to make troubleshooting much simpler. I will use annotations to walk through the logic behind the plugin (and leave it for you to go through the plugin's full code):
|
||||
|
||||
|
||||
```
|
||||
#NAMESPACE is namespace to monitor.
|
||||
#POD is pod name
|
||||
#Containers is container names
|
||||
|
||||
# initialize a counter n to count the number of loop counts, later be used by tmux to split panes.
|
||||
n=0;
|
||||
|
||||
# start a loop on a list of pod and containers
|
||||
while IFS=' ' read -r POD CONTAINERS
|
||||
do
|
||||
|
||||
# tmux create the new window for each pod
|
||||
tmux neww $COMMAND -n $POD 2>/dev/null
|
||||
|
||||
# start a loop for all containers inside a running pod
|
||||
for CONTAINER in ${CONTAINERS//,/ }
|
||||
do
|
||||
|
||||
if [ x$POD = x -o x$CONTAINER = x ]; then
|
||||
# if any of the values is null, exit.
|
||||
warn "Looks like there is a problem getting pods data."
|
||||
break
|
||||
fi
|
||||
|
||||
# set the command to execute
|
||||
COMMAND=”kubectl logs -f $POD -c $CONTAINER -n $NAMESPACE”
|
||||
# check tmux session
|
||||
if tmux has-session -t <session name> 2>/dev/null;
|
||||
then
|
||||
<set session exists>
|
||||
else
|
||||
<create session>
|
||||
fi
|
||||
|
||||
# split planes in the current window for each containers
|
||||
tmux selectp -t $n \; \
|
||||
splitw $COMMAND \; \
|
||||
select-layout tiled \;
|
||||
|
||||
# end loop for containers
|
||||
done
|
||||
|
||||
# rename the window to identify by pod name
|
||||
tmux renamew $POD 2>/dev/null
|
||||
|
||||
# increment the counter
|
||||
((n+=1))
|
||||
|
||||
# end loop for pods
|
||||
done< <(<fetch list of pod and containers from kubernetes cluster>)
|
||||
|
||||
# finally select the window and attach session
|
||||
tmux selectw -t <session name>:1 \; \
|
||||
attach-session -t <session name>\;
|
||||
```
|
||||
|
||||
After the plugin script runs, it will produce output similar to the image below. Each pod has its own window, and each container (if there is more than one) is split by the panes in its pod window, streaming logs as they arrive. The beauty of tmux can be seen below; with the proper configuration, you can even see which window has activity going on (see the white tabs).
|
||||
|
||||
![Output of kmux plugin][8]
|
||||
|
||||
### Conclusion
|
||||
|
||||
Aliases are always helpful for simple troubleshooting in Kubernetes environments. When the environment gets more complex, a kubectl plugin is a powerful option for using more advanced scripting. There are no limits on which programming language you can use to write kubectl plugins. The only requirements are that the naming convention in the path is executable, and it doesn't have the same name as an existing kubectl command.
|
||||
|
||||
To read the complete code or try the plugins I created, check my [kube-plugins-github][7] repository. Issues and pull requests are welcome.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/kubernetes-tmux-kubectl
|
||||
|
||||
作者:[Abhishek Tamrakar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/tamrakar
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/OSDC_women_computing_4.png?itok=VGZO8CxT (Woman sitting in front of her laptop)
|
||||
[2]: https://opensource.com/resources/what-is-kubernetes
|
||||
[3]: https://kubernetes.io/docs/reference/kubectl/overview/
|
||||
[4]: https://github.com/ahmetb/kubectl-aliases/blob/master/.kubectl_aliases
|
||||
[5]: https://kubernetes.io/docs/tasks/extend-kubectl/kubectl-plugins/
|
||||
[6]: https://opensource.com/article/19/6/tmux-terminal-joy
|
||||
[7]: https://github.com/abhiTamrakar/kube-plugins
|
||||
[8]: https://opensource.com/sites/default/files/uploads/kmux-output.png (Output of kmux plugin)
|
||||
@ -1,118 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Customize your internet with an open source search engine)
|
||||
[#]: via: (https://opensource.com/article/20/2/open-source-search-engine)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Customize your internet with an open source search engine
|
||||
======
|
||||
Get started with YaCy, an open source, P2P web indexer.
|
||||
![Person using a laptop][1]
|
||||
|
||||
A long time ago, the internet was small enough to be indexed by a few people who gathered the names and locations of all websites and listed them each by topic on a page or in a printed book. As the World Wide Web network grew, the "web rings" convention developed, in which sites with a similar theme or topic or sensibility banded together to form a circular path to each member. A visitor to any site in the ring could click a button to proceed to the next or previous site in the ring to discover new sites relevant to their interest.
|
||||
|
||||
Then for a while, it seemed the internet outgrew itself. Everyone was online, there was a lot of redundancy and spam, and there was no way to find anything. Yahoo and AOL and CompuServe and similar services had unique approaches, but it wasn't until Google came along that the modern model took hold. According to Google, the internet was meant to be indexed, sorted, and ranked through a search engine.
|
||||
|
||||
### Why choose an open source alternative?
|
||||
|
||||
Search engines like Google and DuckDuckGo are demonstrably effective. You may have reached this site through a search engine. While there's a debate to be had about content falling through the cracks because a host chooses not to follow best practices for search engine optimization, the modern solution for managing the wealth of culture and knowledge and frivolity that is the internet is relentless indexing.
|
||||
|
||||
But maybe you prefer not to use Google or DuckDuckGo because of privacy concerns or because you're looking to contribute to an effort to make the internet more independent. If that appeals to you, then consider participating in [YaCy][2], the peer-to-peer internet indexer and search engine.
|
||||
|
||||
### Install YaCy
|
||||
|
||||
To install and try YaCy, first ensure you have Java installed. If you're on Linux, you can follow the instructions in my [_How to install Java on Linux_][3] article. If you're on Windows or MacOS, obtain an installer from [AdoptOpenJDK.net][4].
|
||||
|
||||
Once you have Java installed, [download the installer][5] for your platform.
|
||||
|
||||
If you're on Linux, unarchive the tarball and move it to the **/opt** directory:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo tar --extract --file yacy_*z --directory /opt`
|
||||
```
|
||||
|
||||
Start YaCy according to instructions for the installer you downloaded.
|
||||
|
||||
On Linux, start YaCy running in the background:
|
||||
|
||||
|
||||
```
|
||||
`$ /opt/startYACY.sh &`
|
||||
```
|
||||
|
||||
In a web browser, navigate to **localhost:8090** and search.
|
||||
|
||||
![YaCy start page][6]
|
||||
|
||||
### Add YaCy to your URL bar
|
||||
|
||||
If you're using the Firefox web browser, you can make YaCy your default search engine in the Awesome Bar (that's Mozilla's name for the URL field) with just a few clicks.
|
||||
|
||||
First, make the dedicated search bar visible in the Firefox toolbar, if it's not already (you don't have to keep the search bar visible; you only need it active long enough to add a custom search engine). The search bar is available in the hamburger menu in the upper-right corner of Firefox in the **Customize** menu. Once the search bar is visible in your Firefox toolbar, navigate to **localhost:8090**, and click the magnifying glass icon in the Firefox search bar you just added. Click the option to add YaCy to your Firefox search engines.
|
||||
|
||||
![Adding YaCy to Firefox][7]
|
||||
|
||||
Once this is done, you can mark it as your default in Firefox preferences, or just use it selectively in searches performed in the Firefox search bar. If you set it as your default search engine, then you may have no need for the dedicated search bar because the default engine is also used by the Awesome Bar, so you can remove it from your toolbar.
|
||||
|
||||
### How to a P2P search engine works
|
||||
|
||||
YaCy is an open source and distributed search engine. It's written in [Java][8], so it runs on any platform, and it performs web crawls, indexing, and searching. It's a peer-to-peer (P2P) network, so every user running YaCy joins in the effort to track the internet as it changes from day to day. Of course, no single user possesses a full index of the entire internet because that would take a data center to house, but the index is distributed and redundant across all YaCy users. It's a lot like BitTorrent (as it uses distributed hash tables, or DHT, to reference index entries), except the data you're sharing is a matrix of words and URL associations. By mixing the results returned by the hash tables, no one can tell who has searched for what words, so all searches are functionally anonymous. It's an effective system for unbiased, ad-free, untracked, and anonymous searches, and you can join in just by using it.
|
||||
|
||||
### Search engines and algorithms
|
||||
|
||||
The act of indexing the internet refers to separating a web page into the singular words on it, then associating the page's URL with each word. Searching for one or more words in a search engine fetches all URLs associated with the query. That's one thing the YaCy client does while running.
|
||||
|
||||
The other thing the client does is provide a search interface for your browser. Instead of navigating to Google when you want to search, you can point your web browser to **localhost:8090** to search YaCy. You may even be able to add it to your browser's search bar (depending on your browser's extensibility), so you can search from the URL bar.
|
||||
|
||||
### Firewall settings for YaCy
|
||||
|
||||
When you first start using YaCy, it's probably running in "junior" mode. This means that the sites your client crawls are available only to you because no other YaCy client can reach your index entries. To join the P2P experience, you must open port 8090 in your router's firewall and possibly your software firewall if you're running one. This is called "senior" mode.
|
||||
|
||||
If you're on Linux, you can find out more about your computer's firewall in [_Make Linux stronger with firewalls_][9]. On other platforms, refer to your operating system's documentation.
|
||||
|
||||
A firewall is almost always active on the router provided by your internet service provider (ISP), and there are far too many varieties of them to document accurately here. Most routers provide the option to "poke a hole" in your firewall because many popular networked games require two-way traffic.
|
||||
|
||||
If you know how to log into your router (it's often either 192.168.0.1 or 10.1.0.1, but can vary depending on the manufacturer's settings), then log in and look for a configuration panel controlling the _firewall_ or _port forwarding_ or _applications_.
|
||||
|
||||
Once you find the preferences for your router's firewall, add port 8090 to the whitelist. For example:
|
||||
|
||||
![Adding YaCy to an ISP router][10]
|
||||
|
||||
If your router is doing port forwarding, then you must forward the incoming traffic to your computer's IP address, using the same port. For example:
|
||||
|
||||
![Adding YaCy to an ISP router][11]
|
||||
|
||||
If you can't adjust your firewall settings for any reason, that's OK. YaCy will continue to run and operate as a client of the P2P search network in junior mode.
|
||||
|
||||
### An internet of your own
|
||||
|
||||
There's much more you can do with the YaCy search engine than just search passively. You can force crawls of underrepresented websites, you can request the network crawl a site, you can choose to use YaCy for just on-premises searches, and much more. You have better control over what _your_ internet looks like. The more senior users there are, the more sites indexed. The more sites indexed, the better the experience for all users. Join in!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/open-source-search-engine
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/laptop_screen_desk_work_chat_text.png?itok=UXqIDRDD (Person using a laptop)
|
||||
[2]: https://yacy.net/
|
||||
[3]: https://opensource.com/article/19/11/install-java-linux
|
||||
[4]: https://adoptopenjdk.net/releases.html
|
||||
[5]: https://yacy.net/download_installation/
|
||||
[6]: https://opensource.com/sites/default/files/uploads/yacy-startpage.jpg (YaCy start page)
|
||||
[7]: https://opensource.com/sites/default/files/uploads/yacy-add-firefox.jpg (Adding YaCy to Firefox)
|
||||
[8]: https://opensource.com/resources/java
|
||||
[9]: https://opensource.com/article/19/7/make-linux-stronger-firewalls
|
||||
[10]: https://opensource.com/sites/default/files/uploads/router-add-app.jpg (Adding YaCy to an ISP router)
|
||||
[11]: https://opensource.com/sites/default/files/uploads/router-add-app1.jpg (Adding YaCy to an ISP router)
|
||||
@ -1,98 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What is WireGuard? Why Linux Users Going Crazy Over it?)
|
||||
[#]: via: (https://itsfoss.com/wireguard/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
What is WireGuard? Why Linux Users Going Crazy Over it?
|
||||
======
|
||||
|
||||
From normal Linux users to Linux creator [Linus Torvalds][1], everyone is in awe of WireGuard. What is WireGuard and what makes it so special?
|
||||
|
||||
### What is WireGuard?
|
||||
|
||||
![][2]
|
||||
|
||||
[WireGuard][3] is an easy to configure, fast, and secure open source [VPN][4] that utilizes state-of-the-art cryptography. It’s aim is to provide a faster, simpler and leaner general purpose VPN that can be easily deployed on low-end devices like Raspberry Pi to high-end servers.
|
||||
|
||||
Most of the other solutions like [IPsec][5] and OpenVPN were developed decades ago. Security researcher and kernel developer Jason Donenfeld realized that they were slow and difficult to configure and manage properly.
|
||||
|
||||
This made him create a new open source VPN protocol and solution which is faster, secure easier to deploy and manage.
|
||||
|
||||
WireGuard was originally developed for Linux but it is now available for Windows, macOS, BSD, iOS and Android. It is still under heavy development.
|
||||
|
||||
### Why is WireGuard so popular?
|
||||
|
||||
![][6]
|
||||
|
||||
Apart from being a cross-platform, one of the biggest plus point for WireGuard is the ease of deployment. Configuring and deploying WireGuard is as easy as configuring and using SSH.
|
||||
|
||||
Look at [WireGuard set up guide][7]. You install WireGuard, generate public and private keys (like SSH), set up firewall rules and start the service. Now compare it to the [OpenVPN set up guide][8]. There are way too many things to do here.
|
||||
|
||||
Another good thing about WireGuard is that it has a lean codebase with just 4000 lines of code. Compare it to 100,000 lines of code of [OpenVPN][9] (another popular open source VPN). It is clearly easier to debug WireGuard.
|
||||
|
||||
Don’t go by its simplicity. WireGuard supports all the state-of-the-art cryptography like like the [Noise protocol framework][10], [Curve25519][11], [ChaCha20][12], [Poly1305][13], [BLAKE2][14], [SipHash24][15], [HKDF][16], and secure trusted constructions.
|
||||
|
||||
Since WireGuard runs in the [kernel space][17], it provides secure networking at a high speed.
|
||||
|
||||
These are some of the reasons why WireGuard has become increasingly popular. Linux creator Linus Torvalds loves WireGuard so much that he is merging it in the [Linux Kernel 5.6][18]:
|
||||
|
||||
> Can I just once again state my love for it and hope it gets merged soon? Maybe the code isn’t perfect, but I’ve skimmed it, and compared to the horrors that are OpenVPN and IPSec, it’s a work of art.
|
||||
>
|
||||
> Linus Torvalds
|
||||
|
||||
### If WireGuard is already available, then what’s the fuss about including it in Linux kernel?
|
||||
|
||||
This could be confusing to new Linux users. You know that you can install and configure a WireGuard VPN server on Linux but then you also read the news that Linux Kernel 5.6 is going to include WireGuard. Let me explain it to you.
|
||||
|
||||
At present, you can install WireGuard on Linux as a [kernel module][19]. Regular applications like VLC, GIMP etc are installed on top of the Linux kernel (in [user space][20]), not inside it.
|
||||
|
||||
When you install WireGuard as a kernel module, you are basically modifying the Linux kernel on your own and add some code to it. Starting kernel 5.6, you won’t need manually add the kernel module. It will be included in the kernel by default.
|
||||
|
||||
The inclusion of WireGuard in Kernel 5.6 will most likely [extend the adoption of WireGuard and thus change the current VPN scene][21].
|
||||
|
||||
**Conclusion**
|
||||
|
||||
WireGuard is gaining popularity for the good reasons. Some of the popular [privacy focused VPNs][22] like [Mullvad VPN][23] are already using WireGuard and the adoption is likely to grow in the near future.
|
||||
|
||||
I hope you have a slightly better understanding of WireGuard. Your feedback is welcome, as always.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/wireguard/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/linus-torvalds-facts/
|
||||
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/02/wireguard.png?ssl=1
|
||||
[3]: https://www.wireguard.com/
|
||||
[4]: https://en.wikipedia.org/wiki/Virtual_private_network
|
||||
[5]: https://en.wikipedia.org/wiki/IPsec
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/02/wireguard-logo.png?ssl=1
|
||||
[7]: https://www.linode.com/docs/networking/vpn/set-up-wireguard-vpn-on-ubuntu/
|
||||
[8]: https://www.digitalocean.com/community/tutorials/how-to-set-up-an-openvpn-server-on-ubuntu-16-04
|
||||
[9]: https://openvpn.net/
|
||||
[10]: https://noiseprotocol.org/
|
||||
[11]: https://cr.yp.to/ecdh.html
|
||||
[12]: https://cr.yp.to/chacha.html
|
||||
[13]: https://cr.yp.to/mac.html
|
||||
[14]: https://blake2.net/
|
||||
[15]: https://131002.net/siphash/
|
||||
[16]: https://eprint.iacr.org/2010/264
|
||||
[17]: http://www.linfo.org/kernel_space.html
|
||||
[18]: https://itsfoss.com/linux-kernel-5-6/
|
||||
[19]: https://wiki.archlinux.org/index.php/Kernel_module
|
||||
[20]: http://www.linfo.org/user_space.html
|
||||
[21]: https://www.zdnet.com/article/vpns-will-change-forever-with-the-arrival-of-wireguard-into-linux/
|
||||
[22]: https://itsfoss.com/best-vpn-linux/
|
||||
[23]: https://mullvad.net/en/
|
||||
@ -1,118 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (chai-yuan)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Playing Music on your Fedora Terminal with MPD and ncmpcpp)
|
||||
[#]: via: (https://fedoramagazine.org/playing-music-on-your-fedora-terminal-with-mpd-and-ncmpcpp/)
|
||||
[#]: author: (Carmine Zaccagnino https://fedoramagazine.org/author/carzacc/)
|
||||
|
||||
Playing Music on your Fedora Terminal with MPD and ncmpcpp
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
MPD, as the name implies, is a Music Playing Daemon. It can play music but, being a daemon, any piece of software can interface with it and play sounds, including some CLI clients.
|
||||
|
||||
One of them is called _ncmpcpp_, which is an improvement over the pre-existing _ncmpc_ tool. The name change doesn’t have much to do with the language they’re written in: they’re both C++, but _ncmpcpp_ is called that because it’s the _NCurses Music Playing Client_ _Plus Plus_.
|
||||
|
||||
### Installing MPD and ncmpcpp
|
||||
|
||||
The _ncmpmpcc_ client can be installed from the official Fedora repositories with DNF directly with
|
||||
|
||||
```
|
||||
$ sudo dnf install ncmpcpp
|
||||
```
|
||||
|
||||
On the other hand, MPD has to be installed from the RPMFusion _free_ repositories, which you can enable, [as per the official installation instructions][2], by running
|
||||
|
||||
```
|
||||
$ sudo dnf install https://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-$(rpm -E %fedora).noarch.rpm
|
||||
```
|
||||
|
||||
and then you can install MPD by running
|
||||
|
||||
```
|
||||
$ sudo dnf install mpd
|
||||
```
|
||||
|
||||
### Configuring and Starting MPD
|
||||
|
||||
The most painless way to set up MPD is to run it as a regular user. The default is to run it as the dedicated _mpd_ user, but that causes all sorts of issues with permissions.
|
||||
|
||||
Before we can run it, we need to create a local config file that will allow it to run as a regular user.
|
||||
|
||||
To do that, create a subdirectory called _mpd_ in _~/.config_:
|
||||
|
||||
```
|
||||
$ mkdir ~/.config/mpd
|
||||
```
|
||||
|
||||
copy the default config file into this directory:
|
||||
|
||||
```
|
||||
$ cp /etc/mpd.conf ~/.config/mpd
|
||||
```
|
||||
|
||||
and then edit it with a text editor like _vim_, _nano_ or _gedit_:
|
||||
|
||||
```
|
||||
$ nano ~/.config/mpd/mpd.conf
|
||||
```
|
||||
|
||||
I recommend you read through all of it to check if there’s anything you need to do, but for most setups you can delete everything and just leave the following:
|
||||
|
||||
```
|
||||
db_file "~/.config/mpd/mpd.db"
|
||||
log_file "syslog"
|
||||
```
|
||||
|
||||
At this point you should be able to just run
|
||||
|
||||
```
|
||||
$ mpd
|
||||
```
|
||||
|
||||
with no errors, which will start the MPD daemon in the background.
|
||||
|
||||
### Using ncmpcpp
|
||||
|
||||
Simply run
|
||||
|
||||
```
|
||||
$ ncmpcpp
|
||||
```
|
||||
|
||||
and you’ll see a ncurses-powered graphical user interface in your terminal.
|
||||
|
||||
Press _4_ and you should see your local music library, be able to change the selection using the arrow keys and press _Enter_ to play a song.
|
||||
|
||||
Doing this multiple times will create a _playlist_, which allows you to move to the next track using the _>_ button (not the right arrow, the _>_ closing angle bracket character) and go back to the previous track with _<_. The + and – buttons increase and decrease volume. The _Q_ button quits ncmpcpp but it doesn’t stop the music. You can play and pause with _P_.
|
||||
|
||||
You can see the current playlist by pressing the _1_ button (this is the default view). From this view you can press _i_ to look at the information (tags) about the current song. You can change the tags of the currently playing (or paused) song by pressing _6_.
|
||||
|
||||
Pressing the \ button will add (or remove) an informative panel at the top of the view. In the top left, you should see something that looks like this:
|
||||
|
||||
```
|
||||
[------]
|
||||
```
|
||||
|
||||
Pressing the _r_, _z_, _y_, _R_, _x_ buttons will respectively toggle the _repeat_, _random_, _single_, _consume_ and _crossfade_ playback modes and will replace one of the _–_ characters in that little indicator to the initial of the selected mode.
|
||||
|
||||
Pressing the _F1_ button will display some help text, which contains a list of keybindings, so there’s no need to write a complete list here. So now go on, be geeky, and play all your music from your terminal!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/playing-music-on-your-fedora-terminal-with-mpd-and-ncmpcpp/
|
||||
|
||||
作者:[Carmine Zaccagnino][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/carzacc/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2020/02/play_music_mpd-816x346.png
|
||||
[2]: https://rpmfusion.org/Configuration
|
||||
@ -1,104 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Dino is a Modern Looking Open Source XMPP Client)
|
||||
[#]: via: (https://itsfoss.com/dino-xmpp-client/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Dino is a Modern Looking Open Source XMPP Client
|
||||
======
|
||||
|
||||
_**Brief: Dino is a relatively new open-source XMPP client that tries to offer a good user experience while encouraging privacy-focused users to utilize XMPP for messaging.**_
|
||||
|
||||
### Dino: An Open Source XMPP Client
|
||||
|
||||
![][1]
|
||||
|
||||
[XMPP][2] (Extensible Messaging Presence Protocol) is a decentralized model of network to facilitate instant messaging and collaboration. Decentralize means there is no central server that has access to your data. The communication is directly between the end-points.
|
||||
|
||||
Some of us might call it an “old school” tech probably because the XMPP clients usually have a very bad user experience or simply just because it takes time to get used to (or set it up).
|
||||
|
||||
That’s when [Dino][3] comes to the rescue as a modern XMPP client to provide a clean and snappy user experience without compromising your privacy.
|
||||
|
||||
### The User Experience
|
||||
|
||||
![][4]
|
||||
|
||||
Dino does try to improve the user experience as an XMPP client but it is worth noting that the look and feel of it will depend on your Linux distribution to some extent. Your icon theme or the gnome theme might make it look better or worse for your personal experience.
|
||||
|
||||
Technically, the user interface is quite simple and easy to use. So, I suggest you take a look at some of the [best icon themes][5] and [GNOME themes][6] for Ubuntu to tweak the look of Dino.
|
||||
|
||||
### Features of Dino
|
||||
|
||||
![Dino Screenshot][7]
|
||||
|
||||
You can expect to use Dino as an alternative to Slack, [Signal][8] or [Wire][9] for your business or personal usage.
|
||||
|
||||
It offers all of the essential features you would need in a messaging application, let us take a look at a list of things that you can expect from it:
|
||||
|
||||
* Decentralized Communication
|
||||
* Public XMPP Servers supported if you cannot setup your own server
|
||||
* Similar to UI to other popular messengers – so it’s easy to use
|
||||
* Image & File sharing
|
||||
* Multiple accounts supported
|
||||
* Advanced message search
|
||||
* [OpenPGP][10] & [OMEMO][11] encryption supported
|
||||
* Lightweight native desktop application
|
||||
|
||||
|
||||
|
||||
### Installing Dino on Linux
|
||||
|
||||
You may or may not find it listed in your software center. Dino does provide ready to use binaries for Debian (deb) and Fedora (rpm) based distributions.
|
||||
|
||||
**For Ubuntu:**
|
||||
|
||||
Dino is available in the universe repository on Ubuntu and you can install it using this command:
|
||||
|
||||
```
|
||||
sudo apt install dino-im
|
||||
```
|
||||
|
||||
Similarly, you can find packages for other Linux distributions on their [GitHub distribution packages page][12].
|
||||
|
||||
If you want the latest and greatest, you can also find both **.deb** and .**rpm** files for Dino to install on your Linux distribution (nightly builds) from [OpenSUSE’s software webpage][13].
|
||||
|
||||
In either case, head to their [GitHub page][14] or click on the link below to visit the official site.
|
||||
|
||||
[Download Dino][3]
|
||||
|
||||
**Wrapping Up**
|
||||
|
||||
It works quite well without any issues (at the time of writing this and quick testing it). I’ll try exploring more about it and hopefully cover more XMPP-centric articles to encourage users to use XMPP clients and servers for communication.
|
||||
|
||||
What do you think about Dino? Would you recommend another open-source XMPP client that’s potentially better than Dino? Let me know your thoughts in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/dino-xmpp-client/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/02/dino-main.png?ssl=1
|
||||
[2]: https://xmpp.org/about/
|
||||
[3]: https://dino.im/
|
||||
[4]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/02/dino-xmpp-client.jpg?ssl=1
|
||||
[5]: https://itsfoss.com/best-icon-themes-ubuntu-16-04/
|
||||
[6]: https://itsfoss.com/best-gtk-themes/
|
||||
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/02/dino-screenshot.png?ssl=1
|
||||
[8]: https://itsfoss.com/signal-messaging-app/
|
||||
[9]: https://itsfoss.com/wire-messaging-linux/
|
||||
[10]: https://www.openpgp.org/
|
||||
[11]: https://en.wikipedia.org/wiki/OMEMO
|
||||
[12]: https://github.com/dino/dino/wiki/Distribution-Packages
|
||||
[13]: https://software.opensuse.org/download.html?project=network:messaging:xmpp:dino&package=dino
|
||||
[14]: https://github.com/dino/dino
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -0,0 +1,69 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Automating unit tests in test-driven development)
|
||||
[#]: via: (https://opensource.com/article/20/2/automate-unit-tests)
|
||||
[#]: author: (Alex Bunardzic https://opensource.com/users/alex-bunardzic)
|
||||
|
||||
Automating unit tests in test-driven development
|
||||
======
|
||||
What unit tests have in common with carpentry.
|
||||
![gears and lightbulb to represent innovation][1]
|
||||
|
||||
DevOps is a software engineering discipline focused on minimizing the lead time to achieve a desired business impact. While business stakeholders and sponsors have ideas on how to optimize business operations, those ideas need to be validated in the field. This means business automation (i.e., software products) must be placed in front of end users and paying customers. Only then will the business confirm whether the initial idea for improvement was fruitful or not.
|
||||
|
||||
Software engineering is a budding discipline, and it can get difficult to ship products that are defect-free. For that reason, DevOps resorts to maximizing automation. Any repeatable chore, such as testing implemented changes to the source code, should be automated by DevOps engineers.
|
||||
|
||||
This article looks at how to automate unit tests. These tests are focused on what I like to call "programming in the small." Much more important test automation (the so-called "programming in the large") must use a different discipline—integration testing. But that's a topic for another article.
|
||||
|
||||
### What is a unit?
|
||||
|
||||
When I'm teaching approaches to unit testing, often, my students cannot clearly determine what a testable unit is. Which is to say, the granularity of the processing is not always clear.
|
||||
|
||||
I like to point out that the easiest way to spot a valid unit is to think of it as a _unit of behavior_. For example (albeit a trivial one), when an authenticated customer begins online shopping, the unit of behavior is a cart that has zero items in it. Once we all agree that an empty shopping cart has zero items in it, we can focus on automating the unit test that will ensure that such a shopping cart always returns zero items.
|
||||
|
||||
### What is not a unit?
|
||||
|
||||
Any processing that involves more than a single behavior should not be viewed as a unit. For example, if shopping cart processing results in tallying up the number of items in the cart AND calculating the order total AND calculating sales tax AND calculating the suggested shipping method, that behavior is not a good candidate for unit testing. Such behavior is a good candidate for integration testing.
|
||||
|
||||
### When to write a unit test
|
||||
|
||||
There is a lot of debate about when to write a unit test. Received wisdom states that once the code has been written, it is a good idea to write automated scripts that will assert whether the implemented unit of behavior delivers functionality as expected. Not only does such a unit test (or a few unit tests) document the expected behavior, the collection of all unit tests ensures that future changes will not degrade quality. If a future change adversely affects the already implemented behavior, one or more unit tests will complain, which will alert developers that regression has occurred.
|
||||
|
||||
There is another way to look at software engineering. It is based on the traditional adage "measure twice, cut once." In that light, writing code before writing tests would be equivalent to cutting a part of some product (say, a chair leg) and measuring it only after it's cut. If the craftsperson doing the cutting is very skilled, that approach may work (kind of). But more likely than not, the chair legs cut this way would end up with unequal lengths. So, it is advisable to measure before cutting. What that means for the practice of software engineering is that the measurements are expressed in the unit tests. Once we measure the required values, we create a blueprint (a unit test). That blueprint is then used to guide the cutting of the code.
|
||||
|
||||
Common sense would suggest that it is more reasonable to measure first and, only then, do the cutting. According to that line of reasoning, writing unit tests before writing code is a recommended way to do proper software engineering. Technically speaking, this "measure twice, cut once" approach is called a "test-first" approach. The opposite approach, where we write the code first, is called "test-later." The test-first approach is the approach advocated by [test-driven development][2] (TDD) methodology. Writing tests later is called test-later development (TLD).
|
||||
|
||||
### Why is TLD harmful?
|
||||
|
||||
Cutting before measuring is not recommended. Even the most talented craftspeople will eventually make mistakes by cutting without doing so. A lack of measurement will eventually catch up with even the most experienced of us as we continue in our craft. So it's best to produce a blueprint (i.e., measurements) before cutting.
|
||||
|
||||
But that's not the only reason why the TLD approach is considered harmful. When we write code, we're simultaneously considering two separate concerns: the expected behavior of the code and the optimal structure of the code. These two concerns are very dissimilar. That fact makes it very challenging to do a proper job satisfying the expectations regarding both the desired behavior and the optimal (or at the very least, decent) code structure.
|
||||
|
||||
The TDD approach solves this conundrum by focusing undivided attention first on the expected desired behavior. We start by writing the unit test. In that test, we focus on _what_ we expect to happen. At this point, we don't care, in the least, _how_ the expected behavior is going to materialize.
|
||||
|
||||
Once we're done describing the _what_ (i.e., what manifest behavior are we expecting from the unit we are about to build?), we watch that expectation fail. It fails because the code that is concerned with _how_ the expected behavior is going to happen hasn't materialized yet. Now we are compelled to write the code that's going to take care of the _how_.
|
||||
|
||||
After we write the code responsible for how, we run the unit test(s) and see if the code we just wrote fulfills the expected behavior. If it does, we're done. Time to move on to fulfilling the next expectation. If it doesn't, we continue transforming the code until it succeeds in passing the test.
|
||||
|
||||
If we choose not to do TDD, but write code first and later write the unit test, we miss the opportunity to separate _what_ from _how_. In other words, we write the code while simultaneously taking care of what we expect the code to do _and_ how to structure the code to do it correctly.
|
||||
|
||||
As such, writing unit tests after we write code is considered harmful.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/automate-unit-tests
|
||||
|
||||
作者:[Alex Bunardzic][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/alex-bunardzic
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/innovation_lightbulb_gears_devops_ansible.png?itok=TSbmp3_M (gears and lightbulb to represent innovation)
|
||||
[2]: https://opensource.com/article/20/1/test-driven-development
|
||||
@ -0,0 +1,133 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Create web user interfaces with Qt WebAssembly instead of JavaScript)
|
||||
[#]: via: (https://opensource.com/article/20/2/wasm-python-webassembly)
|
||||
[#]: author: (Stephan Avenwedde https://opensource.com/users/hansic99)
|
||||
|
||||
Create web user interfaces with Qt WebAssembly instead of JavaScript
|
||||
======
|
||||
Get hands-on with Wasm, PyQt, and Qt WebAssembly.
|
||||
![Digital creative of a browser on the internet][1]
|
||||
|
||||
When I first heard about [WebAssembly][2] and the possibility of creating web user interfaces with Qt, just like I would in ordinary C++, I decided to take a deeper look at the technology.
|
||||
|
||||
My open source project [Pythonic][3] is completely Python-based (PyQt), and I use C++ at work; therefore, this minimal, straightforward WebAssembly tutorial uses Python on the backend and C++ Qt WebAssembly for the frontend. It is aimed at programmers who, like me, are not familiar with web development.
|
||||
|
||||
![Header Qt C++ frontend][4]
|
||||
|
||||
### TL;DR
|
||||
|
||||
|
||||
```
|
||||
git clone <https://github.com/hANSIc99/wasm\_qt\_example>
|
||||
|
||||
cd wasm_qt_example
|
||||
|
||||
python mysite.py
|
||||
```
|
||||
|
||||
Then visit <http://127.0.0.1:7000> with your favorite browser.
|
||||
|
||||
### What is WebAssembly?
|
||||
|
||||
WebAssembly (often shortened to Wasm) is designed primarily to execute portable binary code in web applications to achieve high-execution performance. It is intended to coexist with JavaScript, and both frameworks are executed in the same sandbox. [Recent performance benchmarks][5] showed that WebAssembly executes roughly 10–40% faster, depending on the browser, and given its novelty, we can still expect improvements. The downside of this great execution performance is its widespread adoption as the preferred malware language. Crypto miners especially benefit from its performance and harder detection of evidence due to its binary format.
|
||||
|
||||
### Toolchain
|
||||
|
||||
There is a [getting started guide][6] on the Qt wiki. I recommend sticking exactly to the steps and versions mentioned in this guide. You may need to select your Qt version carefully, as different versions have different features (such as multi-threading), with improvements happening with each release.
|
||||
|
||||
To get executable WebAssembly code, simply pass your Qt C++ application through [Emscripten][7]. Emscripten provides the complete toolchain, and the build script couldn't be simpler:
|
||||
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
source ~/emsdk/emsdk_env.sh
|
||||
~/Qt/5.13.1/wasm_32/bin/qmake
|
||||
make
|
||||
```
|
||||
|
||||
Building takes roughly 10 times longer than with a standard C++ compiler like Clang or g++. The build script will output the following files:
|
||||
|
||||
* WASM_Client.js
|
||||
* WASM_Client.wasm
|
||||
* qtlogo.svg
|
||||
* qtloader.js
|
||||
* WASM_Client.html
|
||||
* Makefile (intermediate)
|
||||
|
||||
|
||||
|
||||
The versions on my (Fedora 30) build system are:
|
||||
|
||||
* emsdk: 1.38.27
|
||||
* Qt: 5.13.1
|
||||
|
||||
|
||||
|
||||
### Frontend
|
||||
|
||||
The frontend provides some functionalities based on [WebSocket][8].
|
||||
|
||||
![Qt-made frontend in browser][9]
|
||||
|
||||
* **Send message to server:** Send a simple string message to the server with a WebSocket. You could have done this also with a simple HTTP POST request.
|
||||
* **Start/stop timer:** Create a WebSocket and start a timer on the server to send messages to the client at a regular interval.
|
||||
* **Upload file:** Upload a file to the server, where the file is saved to the home directory (**~/**) of the user who runs the server.
|
||||
|
||||
|
||||
|
||||
If you adapt the code and face a compiling error like this:
|
||||
|
||||
|
||||
```
|
||||
error: static_assert failed due to
|
||||
requirement ‘bool(-1 == 1)’ “Required feature http for file
|
||||
../../Qt/5.13.1/wasm_32/include/QtNetwork/qhttpmultipart.h not available.”
|
||||
QT_REQUIRE_CONFIG(http);
|
||||
```
|
||||
|
||||
it means that the requested feature is not available for Qt Wasm.
|
||||
|
||||
### Backend
|
||||
|
||||
The server work is done by [Eventlet][10]. I chose Eventlet because it is lightweight and easy to use. Eventlet provides WebSocket functionality and supports threading.
|
||||
|
||||
![Decorated functions for WebSocket handling][11]
|
||||
|
||||
Inside the repository under **mysite/template**, there is a symbolic link to **WASM_Client.html** in the root path. The static content under **mysite/static** is also linked to the root path of the repository. If you adapt the code and do a recompile, you just have to restart Eventlet to update the content to the client.
|
||||
|
||||
Eventlet uses the Web Server Gateway Interface for Python (WSGI). The functions that provide the specific functionality are extended with decorators.
|
||||
|
||||
Please note that this is an absolute minimum server implementation. It doesn't implement any multi-user capabilities — every client is able to start/stop the timer, even for other clients.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Take this example code as a starting point to get familiar with WebAssembly without wasting time on minor issues. I don't make any claims for completeness nor best-practice integration. I walked through a long learning curve until I got it running to my satisfaction, and I hope this gives you a brief look into this promising technology.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/wasm-python-webassembly
|
||||
|
||||
作者:[Stephan Avenwedde][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/hansic99
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/browser_web_internet_website.png?itok=g5B_Bw62 (Digital creative of a browser on the internet)
|
||||
[2]: https://webassembly.org/
|
||||
[3]: https://github.com/hANSIc99/Pythonic
|
||||
[4]: https://opensource.com/sites/default/files/uploads/cpp_qt.png (Header Qt C++ frontend)
|
||||
[5]: https://pspdfkit.com/blog/2018/a-real-world-webassembly-benchmark/
|
||||
[6]: https://wiki.qt.io/Qt_for_WebAssembly#Getting_Started
|
||||
[7]: https://emscripten.org/docs/introducing_emscripten/index.html
|
||||
[8]: https://en.wikipedia.org/wiki/WebSocket
|
||||
[9]: https://opensource.com/sites/default/files/uploads/wasm_frontend.png (Qt-made frontend in browser)
|
||||
[10]: https://eventlet.net/
|
||||
[11]: https://opensource.com/sites/default/files/uploads/python_backend.png (Decorated functions for WebSocket handling)
|
||||
@ -0,0 +1,69 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (10 Grafana features you need to know for effective monitoring)
|
||||
[#]: via: (https://opensource.com/article/20/2/grafana-features)
|
||||
[#]: author: (Daniel Lee https://opensource.com/users/daniellee)
|
||||
|
||||
10 Grafana features you need to know for effective monitoring
|
||||
======
|
||||
Learn how to make the most of this open source dashboard tool.
|
||||
![metrics and data shown on a computer screen][1]
|
||||
|
||||
The [Grafana][2] project [started in 2013][3] when [Torkel Ödegaard][4] decided to fork Kibana and turn it into a time-series and graph-focused dashboarding tool. His guiding vision: to make everything look more clean and elegant, with fewer things distracting you from the data.
|
||||
|
||||
More than 500,000 active installations later, Grafana dashboards are ubiquitous and instantly recognizable. (Even during a [SpaceX launch][5]!)
|
||||
|
||||
Whether you're a recent adopter or an experienced power user, you may not be familiar with all of the features that [Grafana Labs][6]—the company formed to accelerate the adoption of the Grafana project and to build a sustainable business around it—and the Grafana community at large have developed over the past 6+ years.
|
||||
|
||||
Here's a look at some of the most impactful:
|
||||
|
||||
1. **Dashboard templating**: One of the key features in Grafana, templating allows you to create dashboards that can be reused for lots of different use cases. Values aren't hard-coded with these templates, so for instance, if you have a production server and a test server, you can use the same dashboard for both. Templating allows you to drill down into your data, say, from all data to North America data, down to Texas data, and beyond. You can also share these dashboards across teams within your organization—or if you create a great dashboard template for a popular data source, you can contribute it to the whole community to customize and use.
|
||||
2. **Provisioning**: While it's easy to click, drag, and drop to create a single dashboard, power users in need of many dashboards will want to automate the setup with a script. You can script anything in Grafana. For example, if you're spinning up a new Kubernetes cluster, you can also spin up a Grafana automatically with a script that would have the right server, IP address, and data sources preset and locked. It's also a way of getting control over a lot of dashboards.
|
||||
3. **Annotations:** This feature, which shows up as a graph marker in Grafana, is useful for correlating data in case something goes wrong. You can create the annotations manually—just control-click on a graph and input some text—or you can fetch data from any data source. (Check out how Wikimedia uses annotations on its [public Grafana dashboard][7], and here is [another example][8] from the OpenHAB community.) A good example is if you automatically create annotations around releases, and a few hours after a new release, you start seeing a lot of errors, then you can go back to your annotation and correlate whether the errors started at the same time as the release. This automation can be achieved using the Grafana HTTP API (see examples [here][9] and [here][10]). Many of Grafana's largest customers use the HTTP API for a variety of tasks, particularly setting up databases and adding users. It's an alternative to provisioning for automation, and you can do more with it. For instance, the team at DigitalOcean used the API to integrate a [snapshot feature for reviewing dashboards][11].
|
||||
4. **Kiosk mode and playlists:** If you want to display your Grafana dashboards on a TV monitor, you can use the playlist feature to pick the dashboards that you or your team need to look at through the course of the day and have them cycle through on the screen. The [kiosk mode][12] hides all the user interface elements that you don't need in view-only mode. Helpful hint: The [Grafana Kiosk][13] utility handles logging in, switching to kiosk mode, and opening a playlist—eliminating the pain of logging in on a TV that has no keyboard.
|
||||
5. **Custom plugins:** Plugins allow you to extend Grafana with integrations with other tools, different visualizations, and more. Some of the most popular in the community are [Worldmap Panel][14] (for visualizing data on top of a map), [Zabbix][15] (an integration with Zabbix metrics), and [Influx Admin Panel][16] (which offers other functionality like creating databases or adding users). But they're only the tip of the iceberg. Just by writing a bit of code, you can get anything that produces a timestamp and a value visualized in Grafana. Plus, Grafana Enterprise customers have access to more plugins for integrations with Splunk, Datadog, New Relic, and others.
|
||||
6. **Alerting and alert hooks:** If you're using Grafana alerting, you can have alerts sent through a number of different notifiers, including PagerDuty, SMS, email, or Slack. Alert hooks allow you to create different notifiers with a bit of code if you prefer some other channels of communication.
|
||||
7. **Permissions and teams**: When organizations have one Grafana and multiple teams, they often want the ability to both keep things separate and share dashboards. Early on, the default in Grafana was that everybody could see everyone else's dashboards, and that was it. Later, Grafana introduced multi-tenant mode, in which you can switch organizations but can't share dashboards. Some people were using huge hacks to enable both, so Grafana decided to officially create an easier way to do this. Now you can create a team of users and then set permissions on folders, dashboards, and down to the data source level if you're using Grafana Enterprise.
|
||||
8. **SQL data sources:** Grafana's native support for SQL helps you turn anything—not just metrics—in an SQL database into metric data that you can graph. Power users are using SQL data sources to do a whole bunch of interesting things, like creating business dashboards that "make sense for your boss's boss," as the team at Percona put it. Check out their [presentation at GrafanaCon][17].
|
||||
9. **Monitoring your monitoring**: If you're serious about monitoring and you want to monitor your own monitoring, Grafana has its own Prometheus HTTP endpoint that Prometheus can scrape. It's quite simple to get dashboards and statics. There's also an enterprise version in development that will offer Google Analytics-style easy access to data, such as how much CPU your Grafana is using or how long alerting is taking.
|
||||
10. **Authentication**: Grafana supports different authentication styles, such as LDAP and OAuth, and allows you to map users to organizations. In Grafana Enterprise, you can also map users to teams: If your company has its own authentication system, Grafana allows you to map the teams in your internal systems to teams in Grafana. That way, you can automatically give people access to the dashboards designated for their teams.
|
||||
|
||||
|
||||
|
||||
Want to take a deeper dive? Join the [Grafana community][18], check out the [how-to section][19], and share what you think.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/grafana-features
|
||||
|
||||
作者:[Daniel Lee][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/daniellee
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/metrics_data_dashboard_system_computer_analytics.png?itok=oxAeIEI- (metrics and data shown on a computer screen)
|
||||
[2]: https://github.com/grafana/grafana
|
||||
[3]: https://grafana.com/blog/2019/09/03/the-mostly-complete-history-of-grafana-ux/
|
||||
[4]: https://grafana.com/author/torkel
|
||||
[5]: https://youtu.be/ANv5UfZsvZQ?t=29
|
||||
[6]: https://grafana.com/
|
||||
[7]: https://grafana.wikimedia.org/d/000000143/navigation-timing?orgId=1&refresh=5m
|
||||
[8]: https://community.openhab.org/t/howto-create-annotations-in-grafana-via-rules/48929
|
||||
[9]: https://docs.microsoft.com/en-us/azure/devops/service-hooks/services/grafana?view=azure-devops
|
||||
[10]: https://medium.com/contentsquare-engineering-blog/from-events-to-grafana-annotation-f35aafe8bd3d
|
||||
[11]: https://youtu.be/kV3Ua6guynI
|
||||
[12]: https://play.grafana.org/d/vmie2cmWz/bar-gauge?orgId=1&refresh=10s&kiosk
|
||||
[13]: https://github.com/grafana/grafana-kiosk
|
||||
[14]: https://grafana.com/grafana/plugins/grafana-worldmap-panel
|
||||
[15]: https://grafana.com/grafana/plugins/alexanderzobnin-zabbix-app
|
||||
[16]: https://grafana.com/grafana/plugins/natel-influx-admin-panel
|
||||
[17]: https://www.youtube.com/watch?v=-xlchgoqkqY
|
||||
[18]: https://community.grafana.com/
|
||||
[19]: https://community.grafana.com/c/howto/6
|
||||
124
sources/tech/20200218 Getting started with OpenTaxSolver.md
Normal file
124
sources/tech/20200218 Getting started with OpenTaxSolver.md
Normal file
@ -0,0 +1,124 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Getting started with OpenTaxSolver)
|
||||
[#]: via: (https://opensource.com/article/20/2/do-your-taxes-open-source-way)
|
||||
[#]: author: (Jessica Cherry https://opensource.com/users/jrepka)
|
||||
|
||||
Getting started with OpenTaxSolver
|
||||
======
|
||||
If you're a United States citizen, learn how to do your own state tax
|
||||
returns with OpenTaxSolver.
|
||||
![A document flying away][1]
|
||||
|
||||
OpenTaxSolver is an open source application for US taxpayers to calculate their state and federal income tax returns. Before I get into the software, I want to share some of the information I learned when researching this article. I spent about five hours a day for a week looking into open source options for doing your taxes, and I learned about a lot more than just tax software.
|
||||
|
||||
The Internal Revenue Service's (IRS's) [Use of federal tax information (FTI) in open source software][2] webpage offers a large amount of information, and it's especially relevant to anyone who may want to start their own open source tax software project. To hit the finer points:
|
||||
|
||||
* Federal tax information (FTI) can be used in any open source software
|
||||
* Software creators mush follow all security laws and compliance requirements
|
||||
* Any such software must be supported either by a vendor or a community
|
||||
* The software must be approved by the federal government
|
||||
|
||||
|
||||
|
||||
One other reason researching this topic was rather difficult (but ultimately rewarding) is that, by federal law, the major tax software companies are required to provide their services for free to any person earning under $69,000 per year. About 70% of Americans fit into this category, and if you are one of them, you can check the IRS's [Free File][3] webpage for links to free filing software from well-known companies. (The IRS reminds you that "you are responsible for determining your eligibility for one of the Free File Online offers.")
|
||||
|
||||
Please share this information broadly—knowledge is power, and not everyone can (or wants to) use open source software to do their taxes for reasons including:
|
||||
|
||||
* Lack of computer or software access
|
||||
* Low computer competence
|
||||
* Age or disability
|
||||
* Discomfort with doing taxes
|
||||
|
||||
|
||||
|
||||
If you don't fall into any of these categories and want to do your taxes the open source way, continue reading to learn about OpenTaxSolver.
|
||||
|
||||
### About OpenTaxSolver
|
||||
|
||||
[OpenTaxSolver][4] is meant to be used with the IRS's [tax booklet][5], which is published yearly. This booklet provides detailed information for doing your taxes, such as rules around tax credits and write-offs.
|
||||
|
||||
OpenTaxSolver cuts down on tax calculations when you fill out your tax forms and simplifies the hardest part of doing your taxes: the math. You still have to fill in your data and turn the paperwork in, but using the software means you can do it in about half of the time. Since OpenTaxSolver is running in beta, you have to double-check all of your number entries and information against the official IRS tax booklet after you use the software.
|
||||
|
||||
### Download and install OpenTaxSolver
|
||||
|
||||
First, [download the software][6]. There are versions for Linux, Windows, and macOS. If you're using one of the latter two, refer to the download page for installation instructions. I'm using my go-to operating system, Ubuntu Linux, which I installed by:
|
||||
|
||||
1. Downloading the TGZ file from the website
|
||||
2. Extracting it to my desktop (but you can choose any location on your computer)
|
||||
3. Clicking on **Run_taxsolve_GUI**
|
||||
|
||||
|
||||
|
||||
![OpenTaxSolver installation][7]
|
||||
|
||||
### Enter your tax data
|
||||
|
||||
I'll walk through this example using random numbers (for obvious reasons). This walkthrough will explain how do federal taxes with OpenTaxSolver, but if you have to pay state taxes, do that before you begin your federal return.
|
||||
|
||||
To do the common Federal 1040 tax return, select **US 1040**, click **Start New Return**, and start answering some basic questions about your tax situation. For this example, I selected the following itemized deductions: mortgage interest, donations, and some random itemizable write-offs. If you don't know what these are or what may apply to you, head over to the IRS website or google "itemizable write-offs."
|
||||
|
||||
Next, begin entering the data from your tax documents.
|
||||
|
||||
![OpenTaxSolver][8]
|
||||
|
||||
![OpenTaxSolver][9]
|
||||
|
||||
After you finish entering all your data and filling out the entire form, save it by clicking the **Save** button, and then click **Compute Tax** on the bottom of the screen.
|
||||
|
||||
![OpenTaxSolver][10]
|
||||
|
||||
### Check your return and file your taxes
|
||||
|
||||
If you made any mistakes (such as mistyping something or putting an incorrect value in any field), it will show an error on the bottom of the preview after the computation finishes.
|
||||
|
||||
![OpenTaxSolver preview][11]
|
||||
|
||||
The preview also reports your marginal tax rate and what percentage of your income you are paying in taxes.
|
||||
|
||||
![OpenTaxSolver preview][12]
|
||||
|
||||
After you review the information in the preview, make any corrections, and finish your return, click **Fill-out PDF Forms**, and it will provide printable tax forms with all of your information filled in.
|
||||
|
||||
![Tax return][13]
|
||||
|
||||
If you entered your name, address, and social security number when entering your data, all of that information will also appear in the right places on the form. Double-check everything, print it, and mail your tax return to the IRS.
|
||||
|
||||
### Final notes
|
||||
|
||||
OpenTaxSolver gives you the opportunity to file your own federal and state taxes. As always, with any federal related tax information (or federal anything, for that matter), always double-check and use due diligence. I found this software very useful for expanding my knowledge about my taxes.
|
||||
|
||||
The OpenTaxSolver website includes a request for contributors, so if you want to start contributing to an open source project that helps everyone, this is one I'd definitely suggest.
|
||||
|
||||
And if you're someone who likes to wait until the last minute to pay your taxes, this [clock][14] tells you how much time you have until your taxes are due.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/do-your-taxes-open-source-way
|
||||
|
||||
作者:[Jessica Cherry][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jrepka
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/osdc_odf_1109ay.png?itok=4CqrPAjt (A document flying away)
|
||||
[2]: https://www.irs.gov/privacy-disclosure/use-of-federal-tax-information-fti-in-open-source-software
|
||||
[3]: https://apps.irs.gov/app/freeFile/
|
||||
[4]: http://opentaxsolver.sourceforge.net/index.html
|
||||
[5]: https://www.irs.gov/pub/irs-pdf/i1040gi.pdf
|
||||
[6]: http://opentaxsolver.sourceforge.net/download2019.html?button=+Download+OTS+
|
||||
[7]: https://opensource.com/sites/default/files/uploads/tax2.png (OpenTaxSolver installation)
|
||||
[8]: https://opensource.com/sites/default/files/uploads/tax1.png (OpenTaxSolver)
|
||||
[9]: https://opensource.com/sites/default/files/uploads/tax7.png (OpenTaxSolver)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/tax6.png (OpenTaxSolver)
|
||||
[11]: https://opensource.com/sites/default/files/uploads/tax3.png (OpenTaxSolver preview)
|
||||
[12]: https://opensource.com/sites/default/files/uploads/tax4.png (OpenTaxSolver preview)
|
||||
[13]: https://opensource.com/sites/default/files/uploads/tax5.png (Tax return)
|
||||
[14]: https://countdown.onlineclock.net/countdowns/taxes/
|
||||
229
sources/tech/20200218 How to embed Twine stories in WordPress.md
Normal file
229
sources/tech/20200218 How to embed Twine stories in WordPress.md
Normal file
@ -0,0 +1,229 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to embed Twine stories in WordPress)
|
||||
[#]: via: (https://opensource.com/article/20/2/embed-twine-wordpress)
|
||||
[#]: author: (Roman Lukš https://opensource.com/users/romanluks)
|
||||
|
||||
How to embed Twine stories in WordPress
|
||||
======
|
||||
Share your Twine 2 interactive stories on your WordPress site with the
|
||||
Embed Twine plugin.
|
||||
![Person drinking a hat drink at the computer][1]
|
||||
|
||||
From the very beginning, I wanted the "About me" page on my WordPress website [romanluks.eu][2] to be interactive.
|
||||
|
||||
At first, I experimented with Dart, a programming language developed by Google that transcompiles into JavaScript. I killed the project when I realized I was making a game instead of an "About me" page.
|
||||
|
||||
A bit later, I discovered [Twine][3], an open source tool for creating interactive stories. It reminded me of the gamebooks I loved as a kid. It's so easy to create interconnected pieces of text in Twine, and it's ideal for the interview-like format I was aiming for. Because Twine publishes directly to HTML, you can do a lot of interesting things with it—including creating [interactive fiction][4] and [adventure games][5] or publishing stories on a blog or website.
|
||||
|
||||
### Early struggles
|
||||
|
||||
I created my "About me" page in Twine and tried to paste it into my WordPress page.
|
||||
|
||||
"No, can do," said WordPress and Twine.
|
||||
|
||||
You see, a Twine story exported from Twine is just a webpage (i.e., a file in HTML format). However, it not only includes HTML but JavaScript code, as well. And somehow it doesn't work when you simply try to copy-paste the contents. I tried copy-pasting just the body of the Twine story page without success.
|
||||
|
||||
I thought, "I guess I need to add that JavaScript code separately," and I tried custom fields.
|
||||
|
||||
Nope.
|
||||
|
||||
I took a break from my investigation. I just uploaded my "About me" Twine story via FTP and linked to it from my website's menu. People could visit it and interact with the story, however, there was no menu, and it didn't feel like a part of my website. I had made a trap for myself. It made me realize I really _really_ wanted my "About me" included directly on my website.
|
||||
|
||||
### DIY embed
|
||||
|
||||
I took a stab at the problem and came up with [this solution][6].
|
||||
|
||||
It worked. It wasn't perfect, but it worked.
|
||||
|
||||
But it wasn't _perfect_. Is there a better way? There is bound to be a better way…
|
||||
|
||||
It cost me a couple of pulled hairs, but I managed to get a [responsive iframe and autoscroll][7].
|
||||
|
||||
It was way better. I was proud of myself and shared it on [Reddit][8].
|
||||
|
||||
### The road to Embed Twine
|
||||
|
||||
Suddenly, an idea! What if, instead of following my tutorial, people could use a WordPress plugin?
|
||||
|
||||
They would only have to give the plugin a Twine story, and it would take care of the rest. Hassle-free. No need to copy-paste any JavaScript code.
|
||||
|
||||
Wouldn't that be glorious?!?
|
||||
|
||||
I had no idea how WordPress plugins work. I only knew they are written in PHP. A while back, I had part-time work as a PHP developer, and I remembered the basics.
|
||||
|
||||
### Containers and WordPress
|
||||
|
||||
I mentioned my idea to a friend, and he suggested I could use containers as my WordPress development environment.
|
||||
|
||||
In the past, I'd always used [XAMPP][9], but I wanted to try containers for a while.
|
||||
|
||||
No problem, I thought! I'll learn containers while I learn how to make a WordPress plugin and revive my PHP skills. That should be sufficiently stimulating.
|
||||
|
||||
And it was.
|
||||
|
||||
I can't recall how many times I stopped, removed, and rebuilt my containers. I had to use the command line. And the file permissions are painful.
|
||||
|
||||
Oh boy! It was like playing a game that you enjoy playing even though it makes you fairly angry. It was challenging but rewarding.
|
||||
|
||||
I found out that it's very easy to create a simple WordPress plugin:
|
||||
|
||||
* Write the source code
|
||||
* Save it in the WP plugin directory
|
||||
* Test it
|
||||
* Repeat
|
||||
|
||||
|
||||
|
||||
Containers make it easy to use a specific environment and are easy to clean up when you screw up and need to start over.
|
||||
|
||||
Using Git saved me from accidentally wiping out my entire codebase. I used [Sourcetree][10] as my Git user interface. Initially, I wrote my code in [Notepad++][11], but when I divided my code into multiple files, I switched to [Atom][12]. It's such a cool editor for geeks. Using it feels like the code writes itself.
|
||||
|
||||
### Intermission
|
||||
|
||||
So what do we know so far?
|
||||
|
||||
* I wanted an interactive "About me" page
|
||||
* I created an "About me" story in Twine
|
||||
* Twine exports webpages (as HTML files with JavaScript included)
|
||||
* WP plugins are easy to make
|
||||
* Containers are awesome
|
||||
|
||||
|
||||
|
||||
### Embed Twine is born
|
||||
|
||||
I wanted an easy way to embed Twine stories into WordPress. So, I used the power of software development, fooled around with containers, wrote a bit of PHP code, and published the result as a WordPress plugin called [Embed Twine][13].
|
||||
|
||||
### Install the plugin
|
||||
|
||||
1. Upload the plugin [files][14] to the **/wp-content/plugins/plugin-name** directory, or install the plugin through the WordPress Plugins screen.
|
||||
2. Activate the plugin through the Plugins screen in WordPress.
|
||||
|
||||
|
||||
|
||||
### Use the plugin
|
||||
|
||||
After you've installed the Embed Twine plugin and created a Twine 2 story, embed it in your WordPress site:
|
||||
|
||||
1. Export your Twine 2 story into an HTML file.
|
||||
2. Upload it via the plugin's interface.
|
||||
3. Insert the shortcode into the page or post.
|
||||
4. Enjoy your embedded story.
|
||||
|
||||
|
||||
|
||||
The plugin also provides autoscroll functionality to make it easy for users to navigate through your stories.
|
||||
|
||||
### Configure the plugin
|
||||
|
||||
The plugin is configurable via shortcode parameters. To use the shortcode, simply put **[embed_twine]** into your post.
|
||||
|
||||
You can use additional parameters in the format **[embed_twine story="Story" aheight=112 autoscroll=true ascroll=100]** as follows:
|
||||
|
||||
* **story:** Specify the story name (the filename without an extension).
|
||||
* If the story parameter is omitted, it defaults to "Story." This means there is no need to use this parameter if your Twine filename is Story.html.
|
||||
* If you upload a Twine story called MyFooBar.html, use the shortcode: **[embed_twine story="MyFooBar"]**.
|
||||
* **aheight:** Use this parameter to adjust the iframe's height. You might need to tweak **aheight** to get rid of an iframe scrollbar. The default value is 112; this value is added to the iframe height and used to set the iframe's **style.height**.
|
||||
* **autoscroll:** Autoscroll is enabled by default. You can turn it off with shortcode parameter **[embed_twine autoscroll=false]**.
|
||||
* **ascroll:** Use this to adjust the default position for autoscroll. The default value is 100; this value is subtracted from the iframe's top position and fed into JavaScript method **window.scrollTo()**.
|
||||
|
||||
|
||||
|
||||
### Known bugs
|
||||
|
||||
Currently, Twine passages that include images might report their height incorrectly, and the scrollbar might show up for these passages. Tweak the shortcode parameter **aheight** to get rid of them.
|
||||
|
||||
### The script
|
||||
|
||||
|
||||
```
|
||||
1 <?php
|
||||
2
|
||||
3 /**
|
||||
4 * Plugin Name: Embed Twine
|
||||
5 * Description: Insert Twine stories into WordPress
|
||||
6 * Version: 0.0.6
|
||||
7 * Author: Roman Luks
|
||||
8 * Author URI: <https://romanluks.eu/>
|
||||
9 * License: GPLv2 or later
|
||||
10 */
|
||||
11
|
||||
12 require_once('include/embed-twine-load-file.php');
|
||||
13 require_once('include/embed-twine-parent-page.php');
|
||||
14 require_once('include/embed-twine-process-story.php');
|
||||
15
|
||||
16 // Add plugin to WP menu
|
||||
17 function embed_twine_customplugin_menu() {
|
||||
18
|
||||
19 add_menu_page("Embed Twine", "Embed Twine","manage_options", __FILE__, "embed_twine_uploadfile");
|
||||
20 }
|
||||
21
|
||||
22 add_action("admin_menu", "embed_twine_customplugin_menu");
|
||||
23
|
||||
24 function embed_twine_uploadfile(){
|
||||
25 include "include/embed-twine-upload-file.php";
|
||||
26 }
|
||||
27
|
||||
28 // Add shortcode
|
||||
29 function embed_twine_shortcodes_init()
|
||||
30 {
|
||||
31 function embed_twine_shortcode($atts = [], $content = null)
|
||||
32 {
|
||||
33 // Attributes
|
||||
34 $atts = shortcode_atts(
|
||||
35 [array][15](
|
||||
36 'story' => 'Story',
|
||||
37 'aheight' => 112, //adjust for style.height (30) and margins of tw-story (2x41)
|
||||
38 'autoscroll' => true, //autoscroll enabled by default
|
||||
39 'ascroll' => 100, //adjust for autoscroll
|
||||
40 ),
|
||||
41 $atts,
|
||||
42 'embed_twine'
|
||||
43 );
|
||||
44
|
||||
45 $content = embed_twine_buildParentPage($atts['story'], $atts['aheight'], $atts['autoscroll'], $atts['ascroll']);
|
||||
46
|
||||
47 return $content;
|
||||
48 }
|
||||
49 add_shortcode('embed_twine', 'embed_twine_shortcode');
|
||||
50 }
|
||||
51 add_action('init', 'embed_twine_shortcodes_init');
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
_This article is adapted from [Roman Luks' blog][16] and [Embed Twine][13] page on WordPress plugins._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/embed-twine-wordpress
|
||||
|
||||
作者:[Roman Lukš][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/romanluks
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/coffee_tea_laptop_computer_work_desk.png?itok=D5yMx_Dr (Person drinking a hat drink at the computer)
|
||||
[2]: https://romanluks.eu/
|
||||
[3]: https://twinery.org/
|
||||
[4]: https://opensource.com/article/18/7/twine-vs-renpy-interactive-fiction
|
||||
[5]: https://opensource.com/article/18/2/twine-gaming
|
||||
[6]: https://romanluks.eu/blog/how-to-embed-twine-on-your-wordpress-website/
|
||||
[7]: https://romanluks.eu/blog/how-to-embed-twine-on-your-wordpress-website-with-responsive-iframe-and-autoscroll/
|
||||
[8]: https://www.reddit.com/r/twinegames/comments/dtln4z/how_to_embed_twine_on_your_wordpress_website_with/
|
||||
[9]: https://en.wikipedia.org/wiki/XAMPP
|
||||
[10]: https://www.sourcetreeapp.com/
|
||||
[11]: https://notepad-plus-plus.org/
|
||||
[12]: https://atom.io/
|
||||
[13]: https://wordpress.org/plugins/embed-twine/
|
||||
[14]: https://plugins.trac.wordpress.org/browser/embed-twine/
|
||||
[15]: http://www.php.net/array
|
||||
[16]: https://romanluks.eu/blog/embed-twine-wordpress-plugin/
|
||||
@ -0,0 +1,168 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Basic Vim Commands You Need to Know to Work in Vim Editor)
|
||||
[#]: via: (https://www.2daygeek.com/basic-vim-commands-cheat-sheet-quick-start-guide/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
Basic Vim Commands You Need to Know to Work in Vim Editor
|
||||
======
|
||||
|
||||
If you are a system administrator or developer, you may need to edit a file while working on the Linux terminal.
|
||||
|
||||
There are several file editors on Linux, and how to choose the right one for your needs.
|
||||
|
||||
I would like to recommend Vim editor.
|
||||
|
||||
### You may ask, why?
|
||||
|
||||
You may spend more time in the editor to modify an existing file than writing new text.
|
||||
|
||||
In this case, Vim Keyboard shortcuts allow you to efficiently meet your needs.
|
||||
|
||||
The following articles may help you learn about file and directory manipulation.
|
||||
|
||||
* [**L**][1]**[inux Basic – Linux and Unix Commands for File and Directory Manipulation][1]**
|
||||
* **[10 Methods to View Different File Formats in Linux][2]**
|
||||
|
||||
|
||||
|
||||
### What’s vim?
|
||||
|
||||
Vim is one of the most popular and powerful text editor that widely used by Linux administrators and developers.
|
||||
|
||||
It’s highly configurable text editor which enables efficient text editing. This is an updated version of the vi editor, which is already installed on most Unix systems.
|
||||
|
||||
Vim is often called a “programmer’s editor,” but it is not limited to it, and is suitable for all types of text editing.
|
||||
|
||||
It comes with many features like multi level undo, multi windows and buffers, syntax highlighting, command line editing, file name completion, visual selection.
|
||||
|
||||
You can easily obtain online help with the “:help” command.
|
||||
|
||||
### Understanding Vim Modes
|
||||
|
||||
Vim has two modes, the details are below:
|
||||
|
||||
**Command Mode:** When you launch Vim Editor, you will default to Command Mode. You can move around the file, and modify some parts of the text, cut, copy, and paste parts of the text and issue commands to do more (press ESC for Command Mode).
|
||||
|
||||
**Insert Mode:** The nsert mode is used to type text in a given given document (Press i for insert mode).
|
||||
|
||||
### How do I know which Vim mode I am on?
|
||||
|
||||
If you are in insert mode, you will see **“INSERT”** at the bottom of the editor. If nothing is shown, or if it shows the file name at the bottom of the editor, you are in “Command Mode”.
|
||||
|
||||
### Cursor Movement in Normal Mode
|
||||
|
||||
These Vim keyboard shortcuts allow you to move your cursor around a file in different ways.
|
||||
|
||||
* `G` – Go to the last line of the file
|
||||
* `gg` – Go to the first line of the file
|
||||
* `$` – Go to the end of line.
|
||||
* `0` (zero) – Go to the beginning of line.
|
||||
|
||||
|
||||
* `w` – Jump by start of words
|
||||
* `W` – Jump by words (spaces separate words)
|
||||
* `b` – Jump backward by words
|
||||
* `B` – Jump backward by words (spaces separate words)
|
||||
|
||||
|
||||
* `PgDn` Key – Move down page-wise
|
||||
* `PgUp` Key – Move up page-wise
|
||||
* `Ctrl+d` – Move half-page down
|
||||
* `Ctrl+u` – Move half-page up
|
||||
|
||||
|
||||
|
||||
### Insert mode – insert a text
|
||||
|
||||
These vim keyboard shortcuts allows you to insert a cursor in varies position based on your needs.
|
||||
|
||||
* `i` – Insert before the cursor
|
||||
* `a` – Insert after the cursor
|
||||
* `I` – Insert at the beginning of the line, this is useful when you are in the middle of the line.
|
||||
* `A` – Insert at the end of the line
|
||||
* `o` – Open a new line below the current line
|
||||
* `O` – Append a new line above the current line
|
||||
* `ea` – Insert at the end of the word
|
||||
|
||||
|
||||
|
||||
### Copy, Paste and Delete a Line
|
||||
|
||||
* `yy` – yank (copy) a line
|
||||
* `p/P` – Paste after cursor/ put before cursor
|
||||
* `dd` – delete a line
|
||||
* `dw` – delete the word
|
||||
|
||||
|
||||
|
||||
### Search and Replace Pattern in Vim
|
||||
|
||||
* `/pattern` – To search a given pattern
|
||||
* `?pattern` – To search backward a given pattern
|
||||
* `n` – To repeat search
|
||||
* `N` – To repeat backward search
|
||||
|
||||
|
||||
* `:%s/old-pattern/new-pattern/g` – Replace all old formats with the new format across the file.
|
||||
* `:s/old-pattern/new-pattern/g` – Replace all old formats with the new format in the current line.
|
||||
* `:%s/old-pattern/new-pattern/gc` – Replace all old formats with the new format across the file with confirmations.
|
||||
|
||||
|
||||
|
||||
### How do I go to a particular line in Vim Editor
|
||||
|
||||
You can do this in two ways, depending on your need. If you don’t know the line number I suggest you go with the first method.
|
||||
|
||||
Add line number by opening a file and running the command below.
|
||||
|
||||
```
|
||||
:set number
|
||||
```
|
||||
|
||||
Once you have set the line number, press **“: n”** to go to the corresponding line number. For example, if you want to go to **line 15**, enter.
|
||||
|
||||
```
|
||||
:15
|
||||
```
|
||||
|
||||
If you already know the line number, use the following method to go directly to the corresponding line. For example, if you want to move to line 20, enter the command below.
|
||||
|
||||
```
|
||||
$ vim +20 [File_Name]
|
||||
```
|
||||
|
||||
### Undo/Redo/Repeat Operation
|
||||
|
||||
* `u` – Undo the changes
|
||||
* `Ctrl+r` – Redo the changes
|
||||
* `.` – Repeat last command
|
||||
|
||||
|
||||
|
||||
### Saving and Exiting Vim
|
||||
|
||||
* `:w` – Save the changes but don’t exit
|
||||
* `:wq` – Write and quit
|
||||
* `:q!` – Force quit
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/basic-vim-commands-cheat-sheet-quick-start-guide/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/linux-basic-commands-file-directory-manipulation/
|
||||
[2]: https://www.2daygeek.com/unix-linux-command-to-view-file/
|
||||
@ -0,0 +1,182 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Here Are The Most Beautiful Linux Distributions in 2020)
|
||||
[#]: via: (https://itsfoss.com/beautiful-linux-distributions/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Here Are The Most Beautiful Linux Distributions in 2020
|
||||
======
|
||||
|
||||
It’s a no-brainer that there’s a Linux distribution for every user – no matter what they prefer or what they want to do.
|
||||
|
||||
Starting out with Linux? You can go with the [Linux distributions for beginners][1]. Switching from Windows? You have [Windows-like Linux distributions][2]. Have an old computer? You can [use lightweight Linux distros][3].
|
||||
|
||||
In this list, I’m going to focus only on the most beautiful Linux distros out there.
|
||||
|
||||
### Top 7 Most Beautiful Linux Distributions
|
||||
|
||||
![][4]
|
||||
|
||||
Wait! Is there a thing called a beautiful Linux distribution? Is it not redundant considering the fact that you can customize the looks of any distribution and make it look better with [themes][5] and [icons][6]?
|
||||
|
||||
You are right about that. But here, I am talking about the distributions that look great without any tweaks and customization effort from the user’s end. These distros provide a seamless, pleasant desktop experience right out of the box.
|
||||
|
||||
**Note:** _The list is in no particular order of ranking._
|
||||
|
||||
#### 1\. elementary OS
|
||||
|
||||
![][7]
|
||||
|
||||
elementary OS is one of the most beautiful Linux distros out there. It leans on a macOS-ish look while providing a great user experience for Linux users. If you’re already comfortable macOS – you will have no problem using the elementary OS.
|
||||
|
||||
Also, elementary OS is based on Ubuntu – so you can easily find plenty of applications to get things done.
|
||||
|
||||
Not just limited to the look and feel – but the elementary OS is always hard at work to introduce meaningful changes. So, you can expect the user experience to improve with every update you get.
|
||||
|
||||
[elementary OS][8]
|
||||
|
||||
#### 2\. Deepin
|
||||
|
||||
![][9]
|
||||
|
||||
Deepin is yet another beautiful Linux distro originally based on Debian’s stable branch. The animations (look and feel) could be too overwhelming for some – but it looks pretty.
|
||||
|
||||
It features its own Deepin Desktop Environment that involves a mix of essential features for the best user experience possible. It may not exactly resemble the UI of any other distribution but it’s quite easy to get used to.
|
||||
|
||||
My personal attention would go to the control center and the color scheme featured in Deepin OS. You can give it a try – it’s worth taking a look.
|
||||
|
||||
[Deepin][10]
|
||||
|
||||
#### 3\. Pop!_OS
|
||||
|
||||
![][11]
|
||||
|
||||
Pop!_OS manages to offer a great UI on top of Ubuntu while offering a pure [GNOME][12] experience.
|
||||
|
||||
It also happens to be my personal favorite which I utilize as my primary desktop OS. Pop!_OS isn’t flashy – nor involves any fancy animations. However, they’ve managed to get things right by having a perfect combo of icon/themes – while polishing the user experience from a technical point of view.
|
||||
|
||||
I don’t want to initiate a [Ubuntu vs Pop OS][13] debate but if you’re used to Ubuntu, Pop!_OS can be a great alternative for potentially better user experience.
|
||||
|
||||
[Pop!_OS][14]
|
||||
|
||||
#### 4\. Manjaro Linux
|
||||
|
||||
![][15]
|
||||
|
||||
Manjaro Linux is an [Arch][16]-based Linux distribution. While [installing Arch Linux][17] is a slightly complicated job, Manjaro provides an easier and smoother Arch experience.
|
||||
|
||||
It offers a variety of [desktop environment editions][18] to choose from while downloading. No matter what you choose, you still get enough options to customize the look and feel or the layout.
|
||||
|
||||
To me, it looks quite fantastic for an Arch-based distribution that works out of the box – you can give it a try!
|
||||
|
||||
[Manjaro Linux][19]
|
||||
|
||||
#### 5\. KDE Neon
|
||||
|
||||
![][20]
|
||||
|
||||
[KDE Neon][21] is for the users who want a simplified approach to the design language but still get a great user experience.
|
||||
|
||||
It is a lightweight Linux distro which is based on Ubuntu. As the name suggests, it features the KDE Plasma desktop and looks absolutely beautiful.
|
||||
|
||||
KDE Neon gives you the latest and greatest KDE Plasma desktop and KDE applications. Unlike [Kubuntu][22] or other KDE-based distributions, you don’t have to wait for months to get the new [KDE software][23].
|
||||
|
||||
You get a lot of customization options built-in with the KDE desktop – so feel free to try it out!
|
||||
|
||||
[KDE Neon][24]
|
||||
|
||||
#### 6\. Zorin OS
|
||||
|
||||
![][25]
|
||||
|
||||
Without a doubt, Zorin OS is an impressive Linux distro that manages to provide a good user experience – even with its lite edition.
|
||||
|
||||
You can try either the full version or the lite edition (with [Xfce desktop][26]). The UI is tailored for Windows and macOS users to get used to. While based on Ubuntu, it provides a great user experience with what it has to offer.
|
||||
|
||||
If you start like its user interface – you can also try [Zorin Grid][27] to manage multiple computers running Zorin OS at your workplace/home. With the ultimate edition, you can also control the layout of your desktop (as shown in the image above).
|
||||
|
||||
[Zorin OS][28]
|
||||
|
||||
#### 7\. Nitrux OS
|
||||
|
||||
![][29]
|
||||
|
||||
[Nitrux OS][30] is a unique take on a Linux distribution which is somewhat based on Ubuntu – but not completely.
|
||||
|
||||
It focuses on providing a good user experience to the users who are looking for a unique design language with a fresh take on a Linux distro. It uses Nomad desktop which is based on KDE.
|
||||
|
||||
Nitrux encourages to use of [AppImage][31] for applications. But you can also use Arch Linux’s pacman package manager in Nitrux which is based on Ubuntu. Awesome, isn’t it?
|
||||
|
||||
Even if it’s not the perfect OS to have installed (yet), it sure looks pretty and good enough for most of the basic tasks. You can also know more about it when you read our [interview with Nitrux’s founder][32].
|
||||
|
||||
Here’s a slightly old video of Nitrux but it still looks good:
|
||||
|
||||
[Nitrux OS][33]
|
||||
|
||||
#### Bonus: eXtern OS (in ‘stagnated’ development)
|
||||
|
||||
![][34]
|
||||
|
||||
If you want to try an experimental Linux distro, extern OS is going to be beautiful.
|
||||
|
||||
It isn’t actively maintained and should not be used for production systems. Yet, it provides unique user experience (thought not polished enough).
|
||||
|
||||
Just for the sake of trying a good-looking Linux distro, you can give it a try to experience it.
|
||||
|
||||
[eXtern OS][35]
|
||||
|
||||
**Wrapping Up**
|
||||
|
||||
Now, as the saying goes, beauty lies in the eyes of the beholder. So this list of beautiful Linux distributions is from my point of view. Feel free to disagree (politely of course) and mention your favorites.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/beautiful-linux-distributions/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/best-linux-beginners/
|
||||
[2]: https://itsfoss.com/windows-like-linux-distributions/
|
||||
[3]: https://itsfoss.com/lightweight-linux-beginners/
|
||||
[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/02/beautiful-linux-distros.png?ssl=1
|
||||
[5]: https://itsfoss.com/best-gtk-themes/
|
||||
[6]: https://itsfoss.com/best-icon-themes-ubuntu-16-04/
|
||||
[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/01/elementary-os-hera.png?ssl=1
|
||||
[8]: https://elementary.io/
|
||||
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/02/deepin-screenshot.jpg?ssl=1
|
||||
[10]: https://www.deepin.org/en/
|
||||
[11]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/02/pop-os-stock.jpg?ssl=1
|
||||
[12]: https://www.gnome.org/
|
||||
[13]: https://itsfoss.com/pop-os-vs-ubuntu/
|
||||
[14]: https://system76.com/pop
|
||||
[15]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/02/manjaro_kde.jpg?ssl=1
|
||||
[16]: https://en.wikipedia.org/wiki/Arch
|
||||
[17]: https://itsfoss.com/install-arch-linux/
|
||||
[18]: https://itsfoss.com/best-linux-desktop-environments/
|
||||
[19]: https://manjaro.org/download/
|
||||
[20]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/02/kde-neon-screenshot.jpg?ssl=1
|
||||
[21]: https://itsfoss.com/kde-neon-unveiled/
|
||||
[22]: https://kubuntu.org/
|
||||
[23]: https://kde.org/
|
||||
[24]: https://neon.kde.org/
|
||||
[25]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/11/zorin-lite-ultimate-appearance.jpg?ssl=1
|
||||
[26]: https://www.xfce.org/
|
||||
[27]: https://itsfoss.com/zorin-grid/
|
||||
[28]: https://zorinos.com/
|
||||
[29]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/02/nitrux-screenshot.jpg?ssl=1
|
||||
[30]: https://itsfoss.com/nitrux-linux-overview/
|
||||
[31]: https://itsfoss.com/use-appimage-linux/
|
||||
[32]: https://itsfoss.com/nitrux-linux/
|
||||
[33]: https://nxos.org/
|
||||
[34]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/02/extern-os.png?ssl=1
|
||||
[35]: https://externos.io/
|
||||
@ -0,0 +1,93 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to conveniently unsubscribe from a mailing list)
|
||||
[#]: via: (https://opensource.com/article/20/2/how-unsubscribe-mailing-list)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
How to conveniently unsubscribe from a mailing list
|
||||
======
|
||||
Cut down on your email clutter by removing yourself from email lists you
|
||||
no longer need.
|
||||
![Photo by Anthony Intraversato on Unsplash][1]
|
||||
|
||||
If you're on an email discussion group long enough, at some point, you'll see an email from a list member asking to be unsubscribed. Typically, at least 10 other people on the list will respond with instructions on how to unsubscribe, and those 10 responses will be answered by 10 more people confirming or commenting on the instructions. That's a _lot_ of traffic to a mailing list just so one person can unsubscribe.
|
||||
|
||||
But unsubscribing from a list can be confusing, especially if you've gotten on the list by accident. It's frustrating to discover that you've been added to a list, and it's annoying that you have to take time out of your day to extricate yourself. This article is here to help make unsubscribing fast, easy, and graceful.
|
||||
|
||||
Never send an unsubscribe email to the same email address you use to post messages
|
||||
|
||||
### Unsubscribe by email
|
||||
|
||||
Mailing lists are controlled by mailing list software (like [GNU Mailman][2]) on a server. You probably aren't aware of the software controlling a mailing list you're on, because they're usually designed to stay out of the way and just deliver mail. But as a member of a mailing list, you actually have some user control over the software.
|
||||
|
||||
Some mailing lists allow you to unsubscribe using an automated email address. It can be a little confusing because the email address you use to unsubscribe is NOT the email address you use to send messages to the list. Essentially, you're sending a special command to the email server, telling it to take you off the list. This is a convenient method of unsubscribing because it means you don't have to compose a message or wait for anyone to take action. You speak directly to the computer sending the email, and it does exactly as it's told.
|
||||
|
||||
To unsubscribe from a list, take the email address of the list, add **-leave** just before the **@** symbol, and send a message. You can email a blank message; the computer doesn't care. The fact that you're emailing the list with the **-leave** command in front of the **@** symbol is all it needs.
|
||||
|
||||
Here's an example.
|
||||
|
||||
Say you've joined the mailing list Funny Squirrels. You send a few messages to [funnysquirrels@example.com][3] but soon find that squirrels are not as amusing as you'd hoped. To unsubscribe, you can send an email to:
|
||||
|
||||
|
||||
```
|
||||
`funnysquirrels-leave@example.com`
|
||||
```
|
||||
|
||||
You may get a final confirmation email back, and then you'll hear from the mailing list no more.
|
||||
|
||||
#### Custom email commands
|
||||
|
||||
Sometimes the administrator of a mail server changes the command for unsubscribing. Ideally, they'll include the unsubscribe email address in the footer of emails sent to the mailing list, so check for that before sending your parting email.
|
||||
|
||||
The thing to keep in mind is that an unsubscribe email _never_ goes to the actual list, meaning you should never send an unsubscribe email to the same email address you use to post messages. There's a special, separate email address reserved for the unsubscribe command.
|
||||
|
||||
### Unsubscribing by webform
|
||||
|
||||
Some mailing lists have a webform for unsubscribing, and ideally, it can be found in the footer of each mailing list message. You can navigate to the webform and opt out of your subscription.
|
||||
|
||||
This method is common for commercial mailing lists, and it's sometimes a way for them to capture any feedback you have about the list, why you're leaving, and so on. Like the automated email method, the intent is for you to maintain full control of your own subscription. You never have to wait for a human to take you off of a list; instead, you can issue commands directly to a computer.
|
||||
|
||||
![Example unsubscribe web form][4]
|
||||
|
||||
A webform may send you a final confirmation email, and after that, you should hear nothing from that mailing list ever again.
|
||||
|
||||
### Unsubscribing like a pro
|
||||
|
||||
Leaving a mailing list is a guilt-free and nonaggressive act. When you want to leave a mailing list, you should be able to find an unsubscribe email address or webform to make it automated and final.
|
||||
|
||||
If, in spite of using the methods above, you can't leave a mailing list, don't email the list. Very few people on the mailing list have control over who is subscribed, and sometimes the people who have access to the list of subscribers are not monitoring the list—they're only maintaining the server. Instead, find out what server hosts the mailing list, and contact the hosting provider to alert them of the abuse.
|
||||
|
||||
You can find the host of a mailing list by searching for the server name (the part of the email address to the _right_ of the **@** symbol) on a **whois** service. If you're running Linux, you can do this from a terminal:
|
||||
|
||||
|
||||
```
|
||||
`$ whois <example.com>`
|
||||
```
|
||||
|
||||
Otherwise, use the [Whois.net][5] website.
|
||||
|
||||
Whois provides the internet hosting provider of any email server plus the abuse and support contact information.
|
||||
|
||||
Remember: you are always free to leave a mailing list for any reason, without getting permission from anyone else. And now that you know how, you'll be able to unsubscribe like a pro!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/how-unsubscribe-mailing-list
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/anthony-intraversato-pt_wqgzaiu8-unsplash.jpg?itok=5bbMlgt8 (Photo by Anthony Intraversato on Unsplash)
|
||||
[2]: https://www.list.org/
|
||||
[3]: mailto:funnysquirrels@example.com
|
||||
[4]: https://opensource.com/sites/default/files/uploads/mail-webform.jpg (Example unsubscribe web form)
|
||||
[5]: http://whois.net
|
||||
@ -0,0 +1,240 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (heguangzhi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to find what you’re looking for on Linux with find)
|
||||
[#]: via: (https://www.networkworld.com/article/3527420/how-to-find-what-you-re-looking-for-on-linux-with-find.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
How to find what you’re looking for on Linux with find
|
||||
======
|
||||
The find command has a huge array of options to help you locate exactly the files you're looking for on a Linux system. This post explores a series of extremely useful commands.
|
||||
CSA Images / Getty Images
|
||||
|
||||
There are a number of commands for finding files on Linux systems, but there are also a huge number of options that you can deploy when looking for them.
|
||||
|
||||
For example, you can find files not just by their names, but by their owners and/or groups, their age, their size, the assigned permissions, the last time they were accessed, the associated inodes and even whether the files belong to an account or group that no longer exists on the system and so on.
|
||||
|
||||
[[Get regularly scheduled insights by signing up for Network World newsletters.]][1]
|
||||
|
||||
You can also specify where a search should start, how deeply into the file system the search should reach and how much the search result will tell you about the files it finds.
|
||||
|
||||
And all these criteria can be handled by the **find** command.
|
||||
|
||||
Examples of finding files by these criteria are provided below. In some commands, errors (such as trying to list files that you don’t have read access to), error output will be sent to **/dev/null** so that we don’t have to look at it. In others, we’ll simply run as root to avoid this problem.
|
||||
|
||||
Keep in mind that additional options exist. This post covers a lot of ground, but not all of the ways that the **find** command can help locate files for you.
|
||||
|
||||
### Picking a starting point
|
||||
|
||||
With **find**, you can either select a point or start where you are. To select a starting spot, enter it following the word “find”. For example, “find /usr” or “find ./bin” would search starting the **/usr** directory or the **bin** directory in the current location while “find ~” would start in your home directory even if you’re currently located in some other location in the file system.
|
||||
|
||||
[][2]
|
||||
|
||||
### Picking what you want to see
|
||||
|
||||
One of the most commonly used search strategies is to search for files by name. This requires using the **-name** option.
|
||||
|
||||
By default, **find** will show you the full path to the files it finds. This is the same thing you would see if you add **-print** to your command. If you want to see the details associated with a file – its length, permissions, etc., you would need to add **-ls** to the end of your **find** command.
|
||||
|
||||
```
|
||||
$ find ~/bin -name tryme
|
||||
/home/shs/bin/tryme
|
||||
$ find ~/bin -name tryme -print
|
||||
/home/shs/bin/tryme
|
||||
$ find ~/bin -name tryme -ls
|
||||
917528 4 -rwx------ 1 shs shs 139 Apr 8 2019 /home/shs/bin/tryme
|
||||
```
|
||||
|
||||
You can also find files using substrings. For example, if you replace "tryme" in the example above with "try*", you'll find all the files with names that begin with "try".
|
||||
|
||||
Finding files by name is probably the most typical use of the **find** command, but there are so many other ways to look for files and good reasons to want to. The sections below show how to use many of the other criteria available.
|
||||
|
||||
In addition, when searching for files by size, group, inode etc., you probably will want some confirmation that the files found match what you were looking for. Using the **-ls** option to display the details is often very helpful.
|
||||
|
||||
### Finding files by size
|
||||
|
||||
Finding files by size requires use of the **-size** option and a little finesse with the specifications. If you specify **-size 189b**, for you example, you’re going to find files that are 189 blocks long, not 189 bytes. For bytes, you would need to use **-size 189c** (characters). And, if you specify **-size 200w**, you’re going to find files that are 200 words – words as in "two-byte increments", not words as in "those things we all say to each other". You can also look for file by providing sizes in kilobytes (k), megabytes (M) and gigabytes (G).
|
||||
|
||||
Most of the time, Linux users will be searching for files that are larger than some selected size. For example, to find files that are larger than a gigabyte, you might use a command like this where the +1G means "larger than a gigabyte":
|
||||
|
||||
```
|
||||
$ find -size +1G -ls 2>/dev/null
|
||||
787715 1053976 -rw-rw-r-- 1 shs shs 1079263432 Dec 21 2018 ./backup.zip
|
||||
801834 1052556 -rw-rw-r-- 1 shs shs 1077809525 Dec 21 2018 ./2019/hold.zip
|
||||
```
|
||||
|
||||
### Finding files by inode #
|
||||
|
||||
You can find files by the inode that is used to maintain the file’s metadata (i.e., everything but the file content and file name).
|
||||
|
||||
```
|
||||
$ find -inum 919674 -ls 2>/dev/null
|
||||
919674 4 -rw-rw-r-- 1 shs shs 512 Dec 27 15:25 ./bin/my.log
|
||||
```
|
||||
|
||||
### Finding files with a specific file owner or group
|
||||
|
||||
Finding files by owner or group is also very straightforward. Here we use sudo to overcome permission issues.
|
||||
|
||||
```
|
||||
$ sudo find /home -user nemo -name "*.png"-ls
|
||||
1705219 4 drwxr-xr-x 2 nemo nemo 4096 Jan 28 08:50 /home/nemo/Pictures/me.png
|
||||
```
|
||||
|
||||
In this command, we look for a file that is owned by a multi-user group called “admins”.
|
||||
|
||||
```
|
||||
# find /tmp -group admins -ls
|
||||
262199 4 -rwxr-x--- 1 dory admins 27 Feb 16 18:57 /tmp/testscript
|
||||
```
|
||||
|
||||
### Finding files with no owners or groups
|
||||
|
||||
You can look for files that don't belong to any users currently set up on the system by using the **-nouser** option as shown in the command below.
|
||||
|
||||
```
|
||||
# find /tmp -nouser -ls
|
||||
262204 4 -rwx------ 1 1016 1016 17 Feb 17 16:42 /tmp/hello
|
||||
```
|
||||
|
||||
Notice that the listing shows the old user's UID and GID – a clear indication that this user is not defined on the system. This kind of command will find files that were likely created in other-than-home directories by users whose accounts have since been removed from the system or in home directories that were not removed after the user account was removed. Similarly, the **-nogroup** option would find such files – especially when these users were the only members of the associated groups.
|
||||
|
||||
### Finding files by last update time
|
||||
|
||||
In this command, we look for files that have been updated in the last 24 hours in a particular user's home directory. The **sudo** is being used to allow searching another user’s home directory.
|
||||
|
||||
```
|
||||
$ sudo find /home/nemo -mtime -1
|
||||
/home/nemo
|
||||
/home/nemo/snap/cheat
|
||||
/home/nemo/tryme
|
||||
```
|
||||
|
||||
### Finding files by when permissions were last changed
|
||||
|
||||
The **-ctime** option can help you find files that have had their status (e.g., permissions) changed within some referenced time frame. Here’s an example of looking for files that had permission changes within the last day:
|
||||
|
||||
```
|
||||
$ find . -ctime -1 -ls
|
||||
787987 4 -rwxr-xr-x 1 shs shs 189 Feb 11 07:31 ./tryme
|
||||
```
|
||||
|
||||
Keep in mind that the date and time displayed reflect the last updates to the file contents. You will have to use a command like **stat** to see all three times associated with a file (file creation, modification and status changes) .
|
||||
|
||||
### Finding files based on last access times
|
||||
|
||||
In this command, we look for local pdf files that were accessed within the last two days using the **-atime** option.
|
||||
|
||||
```
|
||||
$ find -name "*.pdf" -atime -2
|
||||
./Wingding_Invites.pdf
|
||||
```
|
||||
|
||||
### Finding files based on their age relative to another file
|
||||
|
||||
You can use the -newer option to find files that are newer than some other file.
|
||||
|
||||
```
|
||||
$ find . -newer dig1 -ls
|
||||
786434 68 drwxr-xr-x 67 shs shs 69632 Feb 16 19:05 .
|
||||
1064442 4 drwxr-xr-x 5 shs shs 4096 Feb 16 11:06 ./snap/cheat
|
||||
791846 4 -rw-rw-r-- 1 shs shs 649 Feb 13 14:26 ./dig
|
||||
```
|
||||
|
||||
There is no corresponding **-older** option, but you can get a similar result with **! -newer** (i.e., not newer), which means almost the same thing.
|
||||
|
||||
### Finding files by type
|
||||
|
||||
Finding a file by file type, you get a lot of choices – regular files, directories, block and character files, etc. Here’s a list of the file type options:
|
||||
|
||||
```
|
||||
b block (buffered) special
|
||||
c character (unbuffered) special
|
||||
d directory
|
||||
p named pipe (FIFO)
|
||||
f regular file
|
||||
l symbolic link
|
||||
s socket
|
||||
```
|
||||
|
||||
Here’s an example looking for symbolic links:
|
||||
|
||||
```
|
||||
$ find . -type l -ls
|
||||
805717 0 lrwxrwxrwx 1 shs shs 11 Apr 10 2019 ./volcano -> volcano.pdf
|
||||
918552 0 lrwxrwxrwx 1 shs shs 1 Jun 16 2018 ./letter -> pers/letter2mom
|
||||
```
|
||||
|
||||
### Limiting how deeply find should look
|
||||
|
||||
The **-mindepth** and **-maxdepth** options control how deeply into the file system (from the current location or starting point) your searches will look.
|
||||
|
||||
```
|
||||
$ find -maxdepth 3 -name "*loop"
|
||||
./bin/save/oldloop
|
||||
./bin/long-loop
|
||||
./private/loop
|
||||
```
|
||||
|
||||
### Finding files only if empty
|
||||
|
||||
In this command, we look for empty files, but no further than directories and their subdirectories.
|
||||
|
||||
```
|
||||
$ find . -maxdepth 2 -empty -type f -ls
|
||||
917517 0 -rw-rw-r-- 1 shs shs 0 Sep 23 11:00 ./complaints/newfile
|
||||
792050 0 -rw-rw-r-- 1 shs shs 0 Oct 4 19:02 ./junk
|
||||
```
|
||||
|
||||
### Finding files by permissions
|
||||
|
||||
You can find files that have specific permissions set using the **-perm** option. In the example below, we are looking only for regular files (**-type f**) to avoid seeing symbolic links that are given these permissions by default even if the file they refer to is restricted.
|
||||
|
||||
```
|
||||
$ find -perm 777 -type f -ls
|
||||
find: ‘./.dbus’: Permission denied
|
||||
798748 4 -rwxrwxrwx 1 shs shs 15 Mar 28 2019 ./runme
|
||||
```
|
||||
|
||||
### Using find to help you get rid of files
|
||||
|
||||
You can use the find command to both locate and then remove files if you use a command like this one:
|
||||
|
||||
```
|
||||
$ find . -name runme -exec rm {} \;
|
||||
```
|
||||
|
||||
The {} represents the name of each of the files located by the search criteria.
|
||||
|
||||
One very useful option is to replace **-exec** with **-ok**. When you do this, **find** will ask for a confirmation before it removes any file.
|
||||
|
||||
```
|
||||
$ find . -name runme -ok rm -rf {} \;
|
||||
< rm ... ./bin/runme > ?
|
||||
```
|
||||
|
||||
Removing a file isn't the only thing that **-ok** and **-rm** can do for you. For example, you could copy, rename or move files.
|
||||
|
||||
There are really a lot of options for using the find command effectively and undoubtedly some that haven’t been covered in this post. I hope you’ve found some that are new and especially promising.
|
||||
|
||||
Join the Network World communities on [Facebook][3] and [LinkedIn][4] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3527420/how-to-find-what-you-re-looking-for-on-linux-with-find.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[heguangzhi](https://github.com/heguangzhi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/newsletters/signup.html
|
||||
[2]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE21620&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[3]: https://www.facebook.com/NetworkWorld/
|
||||
[4]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,335 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Try this Bash script for large filesystems)
|
||||
[#]: via: (https://opensource.com/article/20/2/script-large-files)
|
||||
[#]: author: (Nick Clifton https://opensource.com/users/nickclifton)
|
||||
|
||||
Try this Bash script for large filesystems
|
||||
======
|
||||
A simple script to list files, directories, executables, and links.
|
||||
![bash logo on green background][1]
|
||||
|
||||
Have you ever wanted to list all the files in a directory, but just the files, nothing else? How about just the directories? If you have, then the following script, which is open source under GPLv3, could be what you have been looking for.
|
||||
|
||||
Of course, you could use the **find** command:
|
||||
|
||||
|
||||
```
|
||||
`find . -maxdepth 1 -type f -print`
|
||||
```
|
||||
|
||||
But this is cumbersome to type, produces unfriendly output, and lacks some of the refinement of the **ls** command. You could also combine **ls** and **grep** to achieve the same result:
|
||||
|
||||
|
||||
```
|
||||
`ls -F . | grep -v /`
|
||||
```
|
||||
|
||||
But again, this is clunky. This script provides a simple alternative.
|
||||
|
||||
### Usage
|
||||
|
||||
The script provides four main functions, which depend upon which name you call: **lsf** lists files, **lsd** lists directories, **lsx** lists executables, and **lsl** lists links.
|
||||
|
||||
There is no need to install multiple copies of the script, as symbolic links work. This saves space and makes updating the script easier.
|
||||
|
||||
The script works by using the **find** command to do the searching, and then it runs **ls** on each item it finds. The nice thing about this is that any arguments given to the script are passed to the **ls** command. So, for example, this lists all files, even those that start with a dot:
|
||||
|
||||
|
||||
```
|
||||
`lsf -a`
|
||||
```
|
||||
|
||||
To list directories in long format, use the **lsd** command:
|
||||
|
||||
|
||||
```
|
||||
`lsd -l`
|
||||
```
|
||||
|
||||
You can provide multiple arguments, and also file and directory paths.
|
||||
|
||||
This provides a long classified listing of all of files in the current directory's parent directory, and in the **/usr/bin** directory:
|
||||
|
||||
|
||||
```
|
||||
`lsf -F -l .. /usr/bin`
|
||||
```
|
||||
|
||||
One thing that the script does not currently handle, however, is recursion. This command lists only the files in the current directory.
|
||||
|
||||
|
||||
```
|
||||
`lsf -R`
|
||||
```
|
||||
|
||||
The script does not descend into any subdirectories. This is something that may be fixed one day.
|
||||
|
||||
### Internals
|
||||
|
||||
The script is written in a top-down fashion with the initial functions at the start of the script and the body of the work performed near the end. There are only two functions that really matter in the script. The **parse_args()** function peruses the command line, separates options from pathnames, and scripts specific options from the **ls** command-line options.
|
||||
|
||||
The **list_things_in_dir()** function takes a directory name as an argument and runs the **find** command on it. Each item found is passed to the **ls** command for display.
|
||||
|
||||
### Conclusion
|
||||
|
||||
This is a simple script to accomplish a simple function. It is a time saver and can be surprisingly useful when working with large filesystems.
|
||||
|
||||
### The script
|
||||
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
# Script to list:
|
||||
# directories (if called "lsd")
|
||||
# files (if called "lsf")
|
||||
# links (if called "lsl")
|
||||
# or executables (if called "lsx")
|
||||
# but not any other type of filesystem object.
|
||||
# FIXME: add lsp (list pipes)
|
||||
#
|
||||
# Usage:
|
||||
# <command_name> [switches valid for ls command] [dirname...]
|
||||
#
|
||||
# Works with names that includes spaces and that start with a hyphen.
|
||||
#
|
||||
# Created by Nick Clifton.
|
||||
# Version 1.4
|
||||
# Copyright (c) 2006, 2007 Red Hat.
|
||||
#
|
||||
# This is free software; you can redistribute it and/or modify it
|
||||
# under the terms of the GNU General Public License as published
|
||||
# by the Free Software Foundation; either version 3, or (at your
|
||||
# option) any later version.
|
||||
|
||||
# It is distributed in the hope that it will be useful, but
|
||||
# WITHOUT ANY WARRANTY; without even the implied warranty of
|
||||
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
|
||||
# GNU General Public License for more details.
|
||||
|
||||
# ToDo:
|
||||
# Handle recursion, eg: lsl -R
|
||||
# Handle switches that take arguments, eg --block-size
|
||||
# Handle --almost-all, --ignore-backups, --format and --ignore
|
||||
|
||||
main ()
|
||||
{
|
||||
init
|
||||
|
||||
parse_args ${1+"$@"}
|
||||
|
||||
list_objects
|
||||
|
||||
exit 0
|
||||
}
|
||||
|
||||
report ()
|
||||
{
|
||||
echo $prog": " ${1+"$@"}
|
||||
}
|
||||
|
||||
fail ()
|
||||
{
|
||||
report " Internal error: " ${1+"$@"}
|
||||
exit 1
|
||||
}
|
||||
|
||||
# Initialise global variables.
|
||||
init ()
|
||||
{
|
||||
# Default to listing things in the current directory.
|
||||
dirs[0]=".";
|
||||
|
||||
# num_dirs is the number of directories to be listed minus one.
|
||||
# This is because we are indexing the dirs[] array from zero.
|
||||
num_dirs=0;
|
||||
|
||||
# Default to ignoring things that start with a period.
|
||||
no_dots=1
|
||||
|
||||
# Note - the global variables 'type' and 'opts' are initialised in
|
||||
# parse_args function.
|
||||
}
|
||||
|
||||
# Parse our command line
|
||||
parse_args ()
|
||||
{
|
||||
local no_more_args
|
||||
|
||||
no_more_args=0 ;
|
||||
|
||||
prog=`basename $0` ;
|
||||
|
||||
# Decide if we are listing files or directories.
|
||||
case $prog in
|
||||
lsf | lsf.sh)
|
||||
type=f
|
||||
opts="";
|
||||
;;
|
||||
lsd | lsd.sh)
|
||||
type=d
|
||||
# The -d switch to "ls" is presumed when listing directories.
|
||||
opts="-d";
|
||||
;;
|
||||
lsl | lsl.sh)
|
||||
type=l
|
||||
# Use -d to prevent the listed links from being followed.
|
||||
opts="-d";
|
||||
;;
|
||||
lsx | lsx.sh)
|
||||
type=f
|
||||
find_extras="-perm /111"
|
||||
;;
|
||||
*)
|
||||
fail "Unrecognised program name: '$prog', expected either 'lsd', 'lsf', 'lsl' or 'lsx'"
|
||||
;;
|
||||
esac
|
||||
|
||||
# Locate any additional command line switches for ls and accumulate them.
|
||||
# Likewise accumulate non-switches to the directories list.
|
||||
while [ $# -gt 0 ]
|
||||
do
|
||||
case "$1" in
|
||||
# FIXME: Handle switches that take arguments, eg --block-size
|
||||
# FIXME: Properly handle --almost-all, --ignore-backups, --format
|
||||
# FIXME: and --ignore
|
||||
# FIXME: Properly handle --recursive
|
||||
-a | -A | --all | --almost-all)
|
||||
no_dots=0;
|
||||
;;
|
||||
--version)
|
||||
report "version 1.2"
|
||||
exit 0
|
||||
;;
|
||||
--help)
|
||||
case $type in
|
||||
d) report "a version of 'ls' that lists only directories" ;;
|
||||
l) report "a version of 'ls' that lists only links" ;;
|
||||
f) if [ "x$find_extras" = "x" ] ; then
|
||||
report "a version of 'ls' that lists only files" ;
|
||||
else
|
||||
report "a version of 'ls' that lists only executables";
|
||||
fi ;;
|
||||
esac
|
||||
exit 0
|
||||
;;
|
||||
--)
|
||||
# A switch to say that all further items on the command line are
|
||||
# arguments and not switches.
|
||||
no_more_args=1 ;
|
||||
;;
|
||||
-*)
|
||||
if [ "x$no_more_args" = "x1" ] ;
|
||||
then
|
||||
dirs[$num_dirs]="$1";
|
||||
let "num_dirs++"
|
||||
else
|
||||
# Check for a switch that just uses a single dash, not a double
|
||||
# dash. This could actually be multiple switches combined into
|
||||
# one word, eg "lsd -alF". In this case, scan for the -a switch.
|
||||
# XXX: FIXME: The use of =~ requires bash v3.0+.
|
||||
if [[ "x${1:1:1}" != "x-" && "x$1" =~ "x-.*a.*" ]] ;
|
||||
then
|
||||
no_dots=0;
|
||||
fi
|
||||
opts="$opts $1";
|
||||
fi
|
||||
;;
|
||||
*)
|
||||
dirs[$num_dirs]="$1";
|
||||
let "num_dirs++"
|
||||
;;
|
||||
esac
|
||||
shift
|
||||
done
|
||||
|
||||
# Remember that we are counting from zero not one.
|
||||
if [ $num_dirs -gt 0 ] ;
|
||||
then
|
||||
let "num_dirs--"
|
||||
fi
|
||||
}
|
||||
|
||||
list_things_in_dir ()
|
||||
{
|
||||
local dir
|
||||
|
||||
# Paranoia checks - the user should never encounter these.
|
||||
if test "x$1" = "x" ;
|
||||
then
|
||||
fail "list_things_in_dir called without an argument"
|
||||
fi
|
||||
|
||||
if test "x$2" != "x" ;
|
||||
then
|
||||
fail "list_things_in_dir called with too many arguments"
|
||||
fi
|
||||
|
||||
# Use quotes when accessing $dir in order to preserve
|
||||
# any spaces that might be in the directory name.
|
||||
dir="${dirs[$1]}";
|
||||
|
||||
# Catch directory names that start with a dash - they
|
||||
# confuse pushd.
|
||||
if test "x${dir:0:1}" = "x-" ;
|
||||
then
|
||||
dir="./$dir"
|
||||
fi
|
||||
|
||||
if [ -d "$dir" ]
|
||||
then
|
||||
if [ $num_dirs -gt 0 ]
|
||||
then
|
||||
echo " $dir:"
|
||||
fi
|
||||
|
||||
# Use pushd rather passing the directory name to find so that the
|
||||
# names that find passes on to xargs do not have any paths prepended.
|
||||
pushd "$dir" > /dev/null
|
||||
if [ $no_dots -ne 0 ] ; then
|
||||
find . -maxdepth 1 -type $type $find_extras -not -name ".*" -printf "%f\000" \
|
||||
| xargs --null --no-run-if-empty ls $opts -- ;
|
||||
else
|
||||
find . -maxdepth 1 -type $type $find_extras -printf "%f\000" \
|
||||
| xargs --null --no-run-if-empty ls $opts -- ;
|
||||
fi
|
||||
popd > /dev/null
|
||||
else
|
||||
report "directory '$dir' could not be found"
|
||||
fi
|
||||
}
|
||||
|
||||
list_objects ()
|
||||
{
|
||||
local i
|
||||
|
||||
i=0;
|
||||
while [ $i -le $num_dirs ]
|
||||
do
|
||||
list_things_in_dir i
|
||||
let "i++"
|
||||
done
|
||||
}
|
||||
|
||||
# Invoke main
|
||||
main ${1+"$@"}
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/script-large-files
|
||||
|
||||
作者:[Nick Clifton][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/nickclifton
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/bash_command_line.png?itok=k4z94W2U (bash logo on green background)
|
||||
@ -0,0 +1,110 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Waterfox: Firefox Fork With Legacy Add-ons Options)
|
||||
[#]: via: (https://itsfoss.com/waterfox-browser/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Waterfox: Firefox Fork With Legacy Add-ons Options
|
||||
======
|
||||
|
||||
_**Brief: In this week’s open source software highlight, we take a look at a Firefox-based browser that supports legacy extensions that Firefox no longer supports while potentially providing fast user experience.**_
|
||||
|
||||
When it comes to web browsers, Google Chrome leads the market share. [Mozilla Firefox is there still providing hopes for a mainstream web browser that respects your privacy][1].
|
||||
|
||||
Firefox has improved a lot lately and one of the side-effects of the improvements is removal of add-ons. If your favorite add-on disappeared in last few months/years, you have a good new in the form of Witerfox.
|
||||
|
||||
Attention!
|
||||
|
||||
It’s been brought to our notice that Waterfox has been acquired by System1. This company also acquired privacy focused search engine Startpage.
|
||||
While System1 claims that they are providing privacy focused products because ‘there is a demand’, we cannot vouch for their claim.
|
||||
In other words, it’s up to you to trust System1 and Waterfox.
|
||||
|
||||
### Waterfox: A Firefox-based Browser
|
||||
|
||||
![Waterfox Classic][2]
|
||||
|
||||
[Waterfox][3] is a useful open-source browser built on top of Firefox that focuses on privacy and supports legacy extensions. It doesn’t pitch itself as a privacy-paranoid browser but it does respect the basics.
|
||||
|
||||
You get two separate Waterfox browser versions. The current edition aims to provide a modern experience and the classic version focuses to support [NPAPI plugins][4] and [bootstrap extensions][5].
|
||||
|
||||
![Waterfox Classic][6]
|
||||
|
||||
If you do not need to utilize bootstrap extensions but rely on [WebExtensions][7], Waterfox Current is the one you should go for.
|
||||
|
||||
And, if you need to set up a browser that needs NPAPI plugins or bootstrap extensions extensively, Waterfox Classic version will be suitable for you.
|
||||
|
||||
So, if you like Firefox, but want to try something different on the same line, this is a Firefox alternative for the job.
|
||||
|
||||
### Features of Waterfox
|
||||
|
||||
![Waterfox Current][8]
|
||||
|
||||
Of course, technically, you should be able to do a lot of things that Mozilla Firefox supports.
|
||||
|
||||
So, I’ll just highlight all the important features of Waterfox in a list here.
|
||||
|
||||
* Supports NPAPI Plugins
|
||||
* Supports Bootstrap Extensions
|
||||
* Offers separate editions for legacy extension support and modern WebExtension support.
|
||||
* Cross-platform support (Windows, Linux, and macOS)
|
||||
* Theme customization
|
||||
* Archived Add-ons supported
|
||||
|
||||
|
||||
|
||||
### Installing Waterfox on Ubuntu/Linux
|
||||
|
||||
Unlike other popular browsers, you don’t get a package to install. So, you will have to download the archived package from its [official download page][9].
|
||||
|
||||
![][10]
|
||||
|
||||
Depending on what edition (Current/Classic) you want – just download the file, which will be **.tar.bz2** extension file.
|
||||
|
||||
Once downloaded, simply extract the file.
|
||||
|
||||
Next, head on to the extracted folder and look for the “**Waterfox**” file. You can simply double-click on it to run start up the browser.
|
||||
|
||||
If that doesn’t work, you can utilize the terminal and navigate to the extracted **Waterfox** folder. Once there, you can simply run it with a single command. Here’s how it looks like:
|
||||
|
||||
```
|
||||
cd waterfox-classic
|
||||
./waterfox
|
||||
```
|
||||
|
||||
In either case, you can also head to its [GitHub page][11] and explore more options to get it installed on your system.
|
||||
|
||||
[Download Waterfox][3]
|
||||
|
||||
**Wrapping up**
|
||||
|
||||
I fired it up on my Pop!_OS 19.10 installation and it worked really well for me. Though I don’t think I could switch from Firefox to Waterfox because I am not using any legacy add-on. It could still be an impressive option for certain users.
|
||||
|
||||
You could give it a try and let me know your thoughts in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/waterfox-browser/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/why-firefox/
|
||||
[2]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/02/waterfox-classic.png?fit=800%2C423&ssl=1
|
||||
[3]: https://www.waterfox.net/
|
||||
[4]: https://en.wikipedia.org/wiki/NPAPI
|
||||
[5]: https://wiki.mozilla.org/Extension_Manager:Bootstrapped_Extensions
|
||||
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/02/waterfox-classic-screenshot.jpg?ssl=1
|
||||
[7]: https://wiki.mozilla.org/WebExtensions
|
||||
[8]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/02/waterfox-screenshot.jpg?ssl=1
|
||||
[9]: https://www.waterfox.net/download/
|
||||
[10]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/02/waterfox-download-page.jpg?ssl=1
|
||||
[11]: https://github.com/MrAlex94/Waterfox
|
||||
427
sources/tech/20200221 Don-t like loops- Try Java Streams.md
Normal file
427
sources/tech/20200221 Don-t like loops- Try Java Streams.md
Normal file
@ -0,0 +1,427 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Don't like loops? Try Java Streams)
|
||||
[#]: via: (https://opensource.com/article/20/2/java-streams)
|
||||
[#]: author: (Chris Hermansen https://opensource.com/users/clhermansen)
|
||||
|
||||
Don't like loops? Try Java Streams
|
||||
======
|
||||
It's 2020 and time to learn about Java Streams.
|
||||
![Person drinking a hat drink at the computer][1]
|
||||
|
||||
In this article, I will explain how to not write loops anymore.
|
||||
|
||||
What? Whaddaya mean, no more loops?
|
||||
|
||||
Yep, that's my 2020 resolution—no more loops in Java. Understand that it's not that loops have failed me, nor have they led me astray (well, at least, I can argue that point). Really, it is that I, a Java programmer of modest abilities since 1997 or so, must finally learn about all this new [Streams][2] stuff, saying "what" I want to do and not "how" I want to do it, maybe being able to parallelize some of my computations, and all that other good stuff.
|
||||
|
||||
I'm guessing that there are other Java programmers out there who also have been programming in Java for a decent amount of time and are in the same boat. Therefore, I'm offering my experiences as a guide to "how to not write loops in Java anymore."
|
||||
|
||||
### Find a problem worth solving
|
||||
|
||||
If you're like me, then the first show-stopper you run into is "right, cool stuff, but what am I solving for, and how do I apply this?" I realized that I can spot the perfect opportunity camouflaged as _Something I've Done Before_.
|
||||
|
||||
In my case, it's sampling land cover within a specific area and coming up with an estimate and a confidence interval around that estimate for the land cover across the whole area. The specific problem involves deciding whether an area is "forested" or not, given a specific legal definition: if at least 10% of the soil is covered over by tree crowns, then the area is considered to be forested; otherwise, it's something else.
|
||||
|
||||
![Image of land cover in an area][3]
|
||||
|
||||
It's a pretty esoteric example of a recurring problem; I'll grant you. But there it is. For the ecologists and foresters out there who are accustomed to cool temperate or tropical forests, 10% might sound kind of low, but in the case of dry areas with low-growing shrubs and trees, that's a reasonable number.
|
||||
|
||||
So the basic idea is: use images to stratify the area (i.e., areas completely devoid of trees, areas of predominantly small trees spaced quite far apart, areas of predominantly small trees spaced closer together, areas of somewhat larger trees), locate some samples in those strata, send the crew out to measure the samples, analyze the results, and calculate the proportion of soil covered by tree crowns across the area. Simple, right?
|
||||
|
||||
![Survey team assessing land cover][4]
|
||||
|
||||
### What the field data looks like
|
||||
|
||||
In the current project, the samples are rectangular areas 20 meters wide by 25 meters long, so 500 square meters each. On each patch, the field crew measured each tree: its species, its height, the maximum and minimum width of its crown, and the diameter of its trunk at trunk height (nominally 30cm above the ground). This information was collected, entered into a spreadsheet, and exported to a bar separated value (BSV) file for me to analyze. It looks like this:
|
||||
|
||||
Stratum# | Sample# | Tree# | Species | Trunk diameter (cm) | Crown diameter 1 (m) | Crown diameter 2 (m) | Height (m)
|
||||
---|---|---|---|---|---|---|---
|
||||
1 | 1 | 1 | Ac | 6 | 3.6 | 4.6 | 2.4
|
||||
1 | 1 | 2 | Ac | 6 | 2.2 | 2.3 | 2.5
|
||||
1 | 1 | 3 | Ac | 16 | 2.5 | 1.7 | 2.4
|
||||
1 | 1 | 4 | Ac | 6 | 1.5 | 2.1 | 1.8
|
||||
1 | 1 | 5 | Ac | 5 | 0.9 | 1.7 | 1.7
|
||||
1 | 1 | 6 | Ac | 6 | 1.7 | 1.3 | 1.6
|
||||
1 | 1 | 7 | Ac | 5 | 1.82 | 1.32 | 1.8
|
||||
1 | 1 | 1 | Ac | 1 | 0.3 | 0.25 | 0.9
|
||||
1 | 1 | 2 | Ac | 2 | 1.2 | 1.2 | 1.7
|
||||
|
||||
The first column is the stratum number (where 1 is "predominantly small trees spaced quite far apart," 2 is "predominantly small trees spaced closer together," and 3 is "somewhat larger trees"; we didn't sample the areas "completely devoid of trees"). The second column is the sample number (there are 73 samples altogether, located in the three strata in proportion to the area of each stratum). The third column is the tree number within the sample. The fourth is the two-letter species code, the fifth the trunk diameter (in this case, 10cm above ground or exposed roots), the sixth the smallest distance across the crown, the seventh the largest distance, and the eighth the height of the tree.
|
||||
|
||||
For the purposes of this exercise, I'm only concerned with the total amount of ground covered by the tree crowns—not the species, nor the height, nor the diameter of the trunk.
|
||||
|
||||
In addition to the measurement information above, I also have the areas of the three strata, also in a BSV:
|
||||
|
||||
stratum | hectares
|
||||
---|---
|
||||
1 | 114.89
|
||||
2 | 207.72
|
||||
3 | 29.77
|
||||
|
||||
### What I want to do (not how I want to do it)
|
||||
|
||||
In keeping with one of the main design goals of Java Streams, here is "what" I want to do:
|
||||
|
||||
1. Read the stratum area BSV and save the data as a lookup table.
|
||||
2. Read the measurements from the measurement BSV file.
|
||||
3. Accumulate each measurement (tree) to calculate the total area of the sample covered by tree crowns.
|
||||
4. Accumulate the sample tree crown area values and count the number of samples to estimate the mean tree crown area coverage and standard error of the mean for each stratum.
|
||||
5. Summarize the stratum figures.
|
||||
6. Weigh the stratum means and standard errors by the stratum areas (looked up from the table created in step 1) and accumulate them to estimate the mean tree crown area coverage and standard error of the mean for the total area.
|
||||
7. Summarize the weighted figures.
|
||||
|
||||
|
||||
|
||||
Generally speaking, the way to define "what" with Java Streams is by creating a stream processing pipeline of function calls that pass over the data. So, yes, there is actually a bit of "how" that ends up creeping in… in fact, quite a bit of "how." But, it needs a very different knowledge base than the good, old fashioned loop.
|
||||
|
||||
I'll go through each of these steps in detail.
|
||||
|
||||
#### Build the stratum area table
|
||||
|
||||
The first job is to convert the stratum areas BSV file to a lookup table:
|
||||
|
||||
|
||||
```
|
||||
[String][5] fileName = "stratum_areas.bsv";
|
||||
Stream<String> inputLineStream = Files.lines(Paths.get(fileName)); // (1)
|
||||
|
||||
final Map<[Integer][6],Double> stratumAreas = // (2)
|
||||
inputLineStream // (3)
|
||||
.skip(1) // (4)
|
||||
.map(l -> l.split("\\\|")) // (5)
|
||||
.collect( // (6)
|
||||
Collectors.toMap( // (7)
|
||||
a -> [Integer][6].parseInt(a[0]), // (8)
|
||||
a -> [Double][7].parseDouble(a[1]) // (9)
|
||||
)
|
||||
);
|
||||
inputLineStream.close(); // (10)
|
||||
|
||||
[System][8].out.println("stratumAreas = " + stratumAreas); // (11)
|
||||
```
|
||||
|
||||
I'll take this a line or two at a time, where the numbers in comments following the lines above—e.g., _// (3)_— correspond to the numbers below:
|
||||
|
||||
1. java.nio.Files.lines() gives a stream of strings corresponding to lines in the file.
|
||||
2. The goal is to create the lookup table, **stratumAreas**, which is a **Map<Integer,Double>**. Therefore, I can get the **double** value area for stratum 2 as **stratumAreas.get(2)**.
|
||||
3. This is the beginning of the stream "pipeline."
|
||||
4. Skip the first line in the pipeline since it's the header line containing the column names.
|
||||
5. Use **map()** to split the **String** input line into an array of **String** fields, with the first field being the stratum # and the second being the stratum area.
|
||||
6. Use **collect()** to [materialize the results][9].
|
||||
7. The materialized result will be produced as a sequence of **Map** entries.
|
||||
8. The key of each map entry is the first element of the array in the pipeline—the **int** stratum number. By the way, this is a _Java lambda_ expression—[an anonymous function][10] that takes an argument and returns that argument converted to an **int**.
|
||||
9. The value of each map entry is the second element of the array in the pipeline—the **double** stratum area.
|
||||
10. Don't forget to close the stream (file).
|
||||
11. Print out the result, which looks like: [code]`stratumAreas = {1=114.89, 2=207.72, 3=29.77}`
|
||||
```
|
||||
### Build the measurements table and accumulate the measurements into the sample totals
|
||||
|
||||
Now that I have the stratum areas, I can start processing the main body of data—the measurements. I combine the two tasks of building the measurements table and accumulating the measurements into the sample totals since I don't have any interest in the measurement data per se.
|
||||
```
|
||||
|
||||
|
||||
fileName = "sample_data_for_testing.bsv";
|
||||
inputLineStream = Files.lines(Paths.get(fileName));
|
||||
|
||||
final Map<[Integer][6],Map<[Integer][6],Double>> sampleValues =
|
||||
inputLineStream
|
||||
.skip(1)
|
||||
.map(l -> l.split("\\\|"))
|
||||
.collect( // (1)
|
||||
Collectors.groupingBy(a -> [Integer][6].parseInt(a[0]), // (2)
|
||||
Collectors.groupingBy(b -> [Integer][6].parseInt(b[1]), // (3)
|
||||
Collectors.summingDouble( // (4)
|
||||
c -> { // (5)
|
||||
double rm = ([Double][7].parseDouble(c[5]) +
|
||||
[Double][7].parseDouble(c[6]))/4d; // (6)
|
||||
return rm*rm * [Math][11].PI / 500d; // (7)
|
||||
})
|
||||
)
|
||||
)
|
||||
);
|
||||
inputLineStream.close();
|
||||
|
||||
[System][8].out.println("sampleValues = " + sampleValues); // (8)
|
||||
|
||||
```
|
||||
Again, a line or two or so at a time:
|
||||
|
||||
1. The first seven lines are the same in this task and the previous, except the name of this lookup table is **sampleValues**; and it is a **Map** of **Map**s.
|
||||
2. The measurement data is grouped into samples (by sample #), which are, in turn, grouped into strata (by stratum #), so I use **Collectors.groupingBy()** at the topmost level [to separate data][12] into strata, with **a[0]** here being the stratum number.
|
||||
3. I use **Collectors.groupingBy()** once more to separate data into samples, with **b[1]** here being the sample number.
|
||||
4. I use the handy **Collectors.summingDouble()** [to accumulate the data][13] for each measurement within the sample within the stratum.
|
||||
5. Again, a Java lambda or anonymous function whose argument **c** is the array of fields, where this lambda has several lines of code that are surrounded by **{** and **}** with a **return** statement just before the **}**.
|
||||
6. Calculate the mean crown radius of the measurement.
|
||||
7. Calculate the crown area of the measurement as a proportion of the total sample area and return that value as the result of the lambda.
|
||||
8. Again, similar to the previous task. The result looks like (with some numbers elided): [code]`sampleValues = {1={1=0.09083231861452731, 66=0.06088002082602869, ... 28=0.0837823490804228}, 2={65=0.14738326403381743, 2=0.16961183847374103, ... 63=0.25083064794883453}, 3={64=0.3306323635177101, 32=0.25911911184680053, ... 30=0.2642668470291564}}`
|
||||
```
|
||||
|
||||
|
||||
|
||||
This output shows the **Map** of **Map**s structure clearly—there are three entries in the top level corresponding to the strata 1, 2, and 3, and each stratum has subentries corresponding to the proportional area of the sample covered by tree crowns.
|
||||
|
||||
#### Accumulate the sample totals into the stratum means and standard errors
|
||||
|
||||
At this point, the task becomes more complex; I need to count the number of samples, sum up the sample values in preparation for calculating the sample mean, and sum up the squares of the sample values in preparation for calculating the standard error of the mean. I may as well incorporate the stratum area into this grouping of data as well, as I'll need it shortly to weigh the stratum results together.
|
||||
|
||||
So the first thing to do is create a class, **StratumAccumulator**, to handle the accumulation and provide the calculation of the interesting results. This class implements **java.util.function.DoubleConsumer**, which can be passed to **collect()** to handle accumulation:
|
||||
|
||||
|
||||
```
|
||||
class StratumAccumulator implements DoubleConsumer {
|
||||
private double ha;
|
||||
private int n;
|
||||
private double sum;
|
||||
private double ssq;
|
||||
public StratumAccumulator(double ha) { // (1)
|
||||
this.ha = ha;
|
||||
this.n = 0;
|
||||
this.sum = 0d;
|
||||
this.ssq = 0d;
|
||||
}
|
||||
public void accept(double d) { // (2)
|
||||
this.sum += d;
|
||||
this.ssq += d*d;
|
||||
this.n++;
|
||||
}
|
||||
public void combine(StratumAccumulator other) { // (3)
|
||||
this.sum += other.sum;
|
||||
this.ssq += other.ssq;
|
||||
this.n += other.n;
|
||||
}
|
||||
public double getHa() { // (4)
|
||||
return this.ha;
|
||||
}
|
||||
public int getN() { // (5)
|
||||
return this.n;
|
||||
}
|
||||
public double getMean() { // (6)
|
||||
return this.n > 0 ? this.sum / this.n : 0d;
|
||||
}
|
||||
public double getStandardError() { // (7)
|
||||
double mean = this.getMean();
|
||||
double variance = this.n > 1 ? (this.ssq - mean*mean*n)/(this.n - 1) : 0d;
|
||||
return this.n > 0 ? [Math][11].sqrt(variance/this.n) : 0d;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Line-by-line:
|
||||
|
||||
1. The constructor **StratumAccumulator(double ha)** takes an argument, the area of the stratum in hectares, which allows me to merge the stratum area lookup table into instances of this class.
|
||||
2. The **accept(double d)** method is used to accumulate the stream of double values, and I use it to:
|
||||
a. Count the number of values.
|
||||
b. Sum the values in preparation for computing the sample mean.
|
||||
c. Sum the squares of the values in preparation for computing the standard error of the mean.
|
||||
3. The **combine()** method is used to merge substreams of **StratumAccumulator**s (in case I want to process in parallel).
|
||||
4. The getter for the area of the stratum
|
||||
5. The getter for the number of samples in the stratum
|
||||
6. The getter for the mean sample value in the stratum
|
||||
7. The getter for the standard error of the mean in the stratum
|
||||
|
||||
|
||||
|
||||
Once I have this accumulator, I can use it to accumulate the sample values pertaining to each stratum:
|
||||
|
||||
|
||||
```
|
||||
final Map<[Integer][6],StratumAccumulator> stratumValues = // (1)
|
||||
sampleValues.entrySet().stream() // (2)
|
||||
.collect( // (3)
|
||||
Collectors.toMap( // (4)
|
||||
e -> e.getKey(), // (5)
|
||||
e -> e.getValue().entrySet().stream() // (6)
|
||||
.map([Map.Entry][14]::getValue) // (7)
|
||||
.collect( // (8)
|
||||
() -> new StratumAccumulator(stratumAreas.get(e.getKey())), // (9)
|
||||
StratumAccumulator::accept, // (10)
|
||||
StratumAccumulator::combine) // (11)
|
||||
)
|
||||
);
|
||||
```
|
||||
|
||||
Line-by-line:
|
||||
|
||||
1. This time, I'm using the pipeline to build **stratumValues**, which is a **Map<Integer,StratumAccumulator>**, so **stratumValues.get(3)** will return the **StratumAccumulator** instance for stratum 3.
|
||||
2. Here, I'm using the **entrySet().stream()** method provided by **Map** to get a stream of (key, value) pairs; recall these are **Map**s of sample values by stratum.
|
||||
3. Again, I'm using **collect()** to gather the pipeline results by stratum…
|
||||
4. using **Collectors.toMap()** to generate a stream of **Map** entries…
|
||||
5. whose keys are the key of the incoming stream (that is, the stratum #)…
|
||||
6. and whose values are the Map of sample values, and I again use **entrySet().stream()** to convert to a stream of Map entries, one for each sample.
|
||||
7. Using **map()** to get the value of the sample **Map** entry; I'm not interested in the key by this point.
|
||||
8. Yet again, using **collect()** to accumulate the sample results into the **StratumAccumulator** instances.
|
||||
9. Telling **collect()** how to create a new **StratumAccumulator**—I need to pass the stratum area into the constructor here, so I can't just use **StratumAccumulator::new**.
|
||||
10. Telling **collect()** to use the **accept()** method of **StratumAccumulator** to accumulate the stream of sample values.
|
||||
11. Telling **collect()** to use the **combine()** method of **StratumAccumulator** to merge **StratumAccumulator** instances.
|
||||
|
||||
|
||||
|
||||
#### Summarize the stratum figures
|
||||
|
||||
Whew! After all of that, printing out the stratum figures is pretty straightforward:
|
||||
|
||||
|
||||
```
|
||||
stratumValues.entrySet().stream()
|
||||
.forEach(e -> {
|
||||
StratumAccumulator sa = e.getValue();
|
||||
int n = sa.getN();
|
||||
double se66 = sa.getStandardError();
|
||||
double t = new TDistribution(n - 1).inverseCumulativeProbability(0.975d);
|
||||
[System][8].out.printf("stratum %d n %d mean %g se66 %g t %g se95 %g ha %g\n",
|
||||
e.getKey(), n, sa.getMean(), se66, t, se66 * t, sa.getHa());
|
||||
});
|
||||
```
|
||||
|
||||
In the above, once again, I use **entrySet().stream()** to transform the **stratumValues** Map to a stream, and then apply the **forEach()** method to the stream. **ForEach()** is pretty much what it sounds like—a loop! But the business of finding the head of the stream, finding the next element, and checking to see if hits the end is all handled by Java Streams. So, I just get to say what I want to do for each record, which is basically to print it out.
|
||||
|
||||
My code looks a bit more complicated because I declare some local variables to hold some intermediate results that I use more than once—**n**, the number of samples, and **se66**, the standard error of the mean. I also calculate the inverse T value to [convert my standard error of the mean to a 95% confidence interval][15].
|
||||
|
||||
The result looks like this:
|
||||
|
||||
|
||||
```
|
||||
stratum 1 n 24 mean 0.0903355 se66 0.0107786 t 2.06866 se95 0.0222973 ha 114.890
|
||||
stratum 2 n 38 mean 0.154612 se66 0.00880498 t 2.02619 se95 0.0178406 ha 207.720
|
||||
stratum 3 n 11 mean 0.223634 se66 0.0261662 t 2.22814 se95 0.0583020 ha 29.7700
|
||||
```
|
||||
|
||||
#### Accumulate the stratum means and standard errors into the total
|
||||
|
||||
Once again, the task becomes more complex, so I create a class, **TotalAccumulator**, to handle the accumulation and provide the calculation of the interesting results. This class implements **java.util.function.Consumer<T>**, which can be passed to **collect()** to handle accumulation:
|
||||
|
||||
|
||||
```
|
||||
class TotalAccumulator implements Consumer<StratumAccumulator> {
|
||||
private double ha;
|
||||
private int n;
|
||||
private double sumWtdMeans;
|
||||
private double ssqWtdStandardErrors;
|
||||
public TotalAccumulator() {
|
||||
this.ha = 0d;
|
||||
this.n = 0;
|
||||
this.sumWtdMeans = 0d;
|
||||
this.ssqWtdStandardErrors = 0d;
|
||||
}
|
||||
public void accept(StratumAccumulator sa) {
|
||||
double saha = sa.getHa();
|
||||
double sase = sa.getStandardError();
|
||||
this.ha += saha;
|
||||
this.n += sa.getN();
|
||||
this.sumWtdMeans += saha * sa.getMean();
|
||||
this.ssqWtdStandardErrors += saha * saha * sase * sase;
|
||||
}
|
||||
public void combine(TotalAccumulator other) {
|
||||
this.ha += other.ha;
|
||||
this.n += other.n;
|
||||
this.sumWtdMeans += other.sumWtdMeans;
|
||||
this.ssqWtdStandardErrors += other.ssqWtdStandardErrors;
|
||||
}
|
||||
public double getHa() {
|
||||
return this.ha;
|
||||
}
|
||||
public int getN() {
|
||||
return this.n;
|
||||
}
|
||||
public double getMean() {
|
||||
return this.ha > 0 ? this.sumWtdMeans / this.ha : 0d;
|
||||
}
|
||||
public double getStandardError() {
|
||||
return this.ha > 0 ? [Math][11].sqrt(this.ssqWtdStandardErrors) / this.ha : 0;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
I'm not going to go into much detail on this, since it's structurally pretty similar to **StratumAccumulator**. Of main interest:
|
||||
|
||||
1. The constructor takes no arguments, which simplifies its use.
|
||||
2. The **accept()** method accumulates instances of **StratumAccumulator**, not **double** values, hence the use of the **Consumer<T>** interface.
|
||||
3. As for the calculations, they are assembling a weighted average of the **StratumAccumulator** instances, so they make use of the stratum areas, and the formulas might look a bit strange to anyone who's not used to stratified sampling.
|
||||
|
||||
|
||||
|
||||
As for actually carrying out the work, it's easy-peasy:
|
||||
|
||||
|
||||
```
|
||||
final TotalAccumulator totalValues =
|
||||
stratumValues.entrySet().stream()
|
||||
.map([Map.Entry][14]::getValue)
|
||||
.collect(TotalAccumulator::new, TotalAccumulator::accept, TotalAccumulator::combine);
|
||||
```
|
||||
|
||||
Same old stuff as before:
|
||||
|
||||
1. Use **entrySet().stream()** to convert the **stratumValue Map** entries to a stream.
|
||||
2. Use **map()** to replace the **Map** entries with their values—the instances of **StratumAccumulator**.
|
||||
3. Use **collect()** to apply the **TotalAccumulator** to the instances of **StratumAccumulator**.
|
||||
|
||||
|
||||
|
||||
#### Summarize the total figures
|
||||
|
||||
Getting the interesting bits out of the **TotalAccumulator** instance is also pretty straightforward:
|
||||
|
||||
|
||||
```
|
||||
int nT = totalValues.getN();
|
||||
double se66T = totalValues.getStandardError();
|
||||
double tT = new TDistribution(nT - stratumValues.size()).inverseCumulativeProbability(0.975d);
|
||||
[System][8].out.printf("total n %d mean %g se66 %g t %g se95 %g ha %g\n",
|
||||
nT, totalValues.getMean(), se66T, tT, se66T * tT, totalValues.getHa());
|
||||
```
|
||||
|
||||
Similar to the **StratumAccumulator**, I just call the relevant getters to pick out the number of samples **nT** and the standard error **se66T**. I calculate the T value **tT** (using "n – 3" here since there are three strata), and then I print the result, which looks like this:
|
||||
|
||||
|
||||
```
|
||||
`total n 73 mean 0.139487 se66 0.00664653 t 1.99444 se95 0.0132561 ha 352.380`
|
||||
```
|
||||
|
||||
### In conclusion
|
||||
|
||||
Wow, that looks like a bit of a marathon. It feels like it, too. As is often the case, there is a great deal of information about how to use Java Streams, all illustrated with toy examples, which kind of help, but not really. I found that getting this to work with a real-world (albeit very simple) example was difficult.
|
||||
|
||||
Because I've been working in [Groovy][16] a lot lately, I kept finding myself wanting to accumulate into "maps of maps of maps" rather than creating accumulator classes, but I was never able to pull that off except in the case of totaling up the measurements in the sample. So, I worked with accumulator classes instead of maps of maps, and maps of accumulator classes instead of maps of maps of maps.
|
||||
|
||||
I don't feel like any kind of master of Java Streams at this point, but I do feel I have a pretty solid understanding of **collect()**, which is deeply important, along with various methods to reformat data structures into streams and to reformat stream elements themselves. So yeah, more to learn!
|
||||
|
||||
Speaking of collect(), in the examples I presented above, we can see moving from a very simple use of this fundamental method - using the Collectors.summingDouble() accumulation method - through defining an accumulator class that extends one of the pre-defined interfaces - in this case DoubleConsumer - to defining a full-blown accumulator of our own, used to accumulate the intermediate stratum class. I was tempted - sort of - to work backward and implement fully custom accumulators for the stratum and sample accumulators, but the point of this exercise was to learn more about Java Streams, not to become an expert in one single part of it all.
|
||||
|
||||
What's your experience with Java Streams? Done anything big and complicated yet? Please share it in the comments.
|
||||
|
||||
Optimizing your Java code requires an understanding of how the different elements in Java interact...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/java-streams
|
||||
|
||||
作者:[Chris Hermansen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/clhermansen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/coffee_tea_laptop_computer_work_desk.png?itok=D5yMx_Dr (Person drinking a hat drink at the computer)
|
||||
[2]: https://docs.oracle.com/javase/8/docs/api/java/util/stream/package-summary.html
|
||||
[3]: https://opensource.com/sites/default/files/uploads/landcover.png (Image of land cover in an area)
|
||||
[4]: https://opensource.com/sites/default/files/uploads/foresters.jpg (Survey team assessing land cover)
|
||||
[5]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+string
|
||||
[6]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+integer
|
||||
[7]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+double
|
||||
[8]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+system
|
||||
[9]: https://www.baeldung.com/java-8-collectors
|
||||
[10]: https://docs.oracle.com/javase/tutorial/java/javaOO/lambdaexpressions.html
|
||||
[11]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+math
|
||||
[12]: https://www.baeldung.com/java-groupingby-collector
|
||||
[13]: http://www.java2s.com/Tutorials/Java/java.util.stream/Collectors/Collectors.summingDouble_ToDoubleFunction_super_T_mapper_.htm
|
||||
[14]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+map.entry
|
||||
[15]: https://en.wikipedia.org/wiki/Standard_error
|
||||
[16]: http://groovy-lang.org/
|
||||
@ -0,0 +1,171 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Live video streaming with open source Video.js)
|
||||
[#]: via: (https://opensource.com/article/20/2/video-streaming-tools)
|
||||
[#]: author: (Aaron J. Prisk https://opensource.com/users/ricepriskytreat)
|
||||
|
||||
Live video streaming with open source Video.js
|
||||
======
|
||||
Video.js is a widely used protocol that will serve your live video
|
||||
stream to a wide range of devices.
|
||||
![video editing dashboard][1]
|
||||
|
||||
Last year, I wrote about [creating a video streaming server with Linux][2]. That project uses the Real-Time Messaging Protocol (RMTP), Nginx web server, Open Broadcast Studio (OBS), and VLC media player.
|
||||
|
||||
I used VLC to play our video stream, which may be fine for a small local deployment but isn't very practical on a large scale. First, your viewers have to use VLC, and RTMP streams can provide inconsistent playback. This is where [Video.js][3] comes into play! Video.js is an open source JavaScript framework for creating custom HTML5 video players. Video.js is incredibly powerful, and it's used by a host of very popular websites—largely due to its open nature and how easy it is to get up and running.
|
||||
|
||||
### Get started with Video.js
|
||||
|
||||
This project is based off of the video streaming project I wrote about last year. Since that project was set to serve RMTP streams, to use Video.js, you'll need to make some adjustments to that Nginx configuration. HTTP Live Streaming ([HLS][4]) is a widely used protocol developed by Apple that will serve your stream better to a multitude of devices. HLS will take your stream, break it into chunks, and serve it via a specialized playlist. This allows for a more fault-tolerant stream that can play on more devices.
|
||||
|
||||
First, create a directory that will house the HLS stream and give Nginx permission to write to it:
|
||||
|
||||
|
||||
```
|
||||
mkdir /mnt/hls
|
||||
chown www:www /mnt/hls
|
||||
```
|
||||
|
||||
Next, fire up your text editor, open the Nginx.conf file, and add the following under the **application live** section:
|
||||
|
||||
|
||||
```
|
||||
application live {
|
||||
live on;
|
||||
# Turn on HLS
|
||||
hls on;
|
||||
hls_path /mnt/hls/;
|
||||
hls_fragment 3;
|
||||
hls_playlist_length 60;
|
||||
# disable consuming the stream from nginx as rtmp
|
||||
deny play all;
|
||||
}
|
||||
```
|
||||
|
||||
Take note of the HLS fragment and playlist length settings. You may want to adjust them later, depending on your streaming needs, but this is a good baseline to start with. Next, we need to ensure that Nginx is able to listen for requests from our player and understand how to present it to the user. So, we'll want to add a new section at the bottom of our nginx.conf file.
|
||||
|
||||
|
||||
```
|
||||
server {
|
||||
listen 8080;
|
||||
|
||||
location / {
|
||||
# Disable cache
|
||||
add_header 'Cache-Control' 'no-cache';
|
||||
|
||||
# CORS setup
|
||||
add_header 'Access-Control-Allow-Origin' '*' always;
|
||||
add_header 'Access-Control-Expose-Headers' 'Content-Length';
|
||||
|
||||
# allow CORS preflight requests
|
||||
if ($request_method = 'OPTIONS') {
|
||||
add_header 'Access-Control-Allow-Origin' '*';
|
||||
add_header 'Access-Control-Max-Age' 1728000;
|
||||
add_header 'Content-Type' 'text/plain charset=UTF-8';
|
||||
add_header 'Content-Length' 0;
|
||||
return 204;
|
||||
}
|
||||
|
||||
types {
|
||||
application/dash+xml mpd;
|
||||
application/vnd.apple.mpegurl m3u8;
|
||||
video/mp2t ts;
|
||||
}
|
||||
|
||||
root /mnt/;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Visit Video.js's [Getting started][5] page to download the latest release and check out the release notes. Also on that page, Video.js has a great introductory template you can use to create a very basic web player. I'll break down the important bits of that template and insert the pieces you need to get your new HTML player to use your stream.
|
||||
|
||||
The **head** links in the Video.js library from a content-delivery network (CDN). You can also opt to download and store Video.js locally on your web server if you want.
|
||||
|
||||
|
||||
```
|
||||
<head>
|
||||
<link href="<https://vjs.zencdn.net/7.5.5/video-js.css>" rel="stylesheet" />
|
||||
|
||||
<!-- If you'd like to support IE8 (for Video.js versions prior to v7) -->
|
||||
<script src="[https://vjs.zencdn.net/ie8/1.1.2/videojs-ie8.min.js"\>\][6]</script>
|
||||
</head>
|
||||
```
|
||||
|
||||
Now to the real meat of the player. The **body** section sets the parameters of how the video player will be displayed. Within the **video** element, you need to define the properties of your player. How big do you want it to be? Do you want it to have a poster (i.e., a thumbnail)? Does it need any special player controls? This example defines a simple 600x600 pixel player with an appropriate (to me) thumbnail featuring Beastie (the BSD Demon) and Tux (the Linux penguin).
|
||||
|
||||
|
||||
```
|
||||
<body>
|
||||
<video
|
||||
id="my-video"
|
||||
class="video-js"
|
||||
controls
|
||||
preload="auto"
|
||||
width="600"
|
||||
height="600"
|
||||
poster="BEASTIE-TUX.jpg"
|
||||
data-setup="{}"
|
||||
>
|
||||
```
|
||||
|
||||
Now that you've set how you want your player to look, you need to tell it what to play. Video.js can handle a large number of different formats, including HLS streams.
|
||||
|
||||
|
||||
```
|
||||
<source src="<http://MY-WEB-SERVER:8080/hls/STREAM-KEY.m3u8>" type="application/x-mpegURL" />
|
||||
<p class="vjs-no-js">
|
||||
To view this video please enable JavaScript, and consider upgrading to a
|
||||
web browser that
|
||||
<a href="<https://videojs.com/html5-video-support/>" target="_blank"
|
||||
>supports HTML5 video</a
|
||||
>
|
||||
</p>
|
||||
</video>
|
||||
```
|
||||
|
||||
### Record your streams
|
||||
|
||||
Keeping a copy of your streams is super easy. Just add the following at the bottom of your **application live** section in the nginx.conf file:
|
||||
|
||||
|
||||
```
|
||||
# Enable stream recording
|
||||
record all;
|
||||
record_path /mnt/recordings/;
|
||||
record_unique on;
|
||||
```
|
||||
|
||||
Make sure that **record_path** exists and that Nginx has permissions to write to it:
|
||||
|
||||
|
||||
```
|
||||
`chown -R www:www /mnt/recordings`
|
||||
```
|
||||
|
||||
### Down the stream
|
||||
|
||||
That's it! You should now have a spiffy new HTML5-friendly live video player. There are lots of great resources out there on how to expand all your video-making adventures. If you have any questions or suggestions, feel free to reach out to me on [Twitter][7] or leave a comment below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/video-streaming-tools
|
||||
|
||||
作者:[Aaron J. Prisk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ricepriskytreat
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/video_editing_folder_music_wave_play.png?itok=-J9rs-My (video editing dashboard)
|
||||
[2]: https://opensource.com/article/19/1/basic-live-video-streaming-server
|
||||
[3]: https://videojs.com/
|
||||
[4]: https://en.wikipedia.org/wiki/HTTP_Live_Streaming
|
||||
[5]: https://videojs.com/getting-started
|
||||
[6]: https://vjs.zencdn.net/ie8/1.1.2/videojs-ie8.min.js"\>\
|
||||
[7]: https://twitter.com/AKernelPanic
|
||||
245
sources/tech/20200222 How to install TT-RSS on a Raspberry Pi.md
Normal file
245
sources/tech/20200222 How to install TT-RSS on a Raspberry Pi.md
Normal file
@ -0,0 +1,245 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to install TT-RSS on a Raspberry Pi)
|
||||
[#]: via: (https://opensource.com/article/20/2/ttrss-raspberry-pi)
|
||||
[#]: author: (Patrick H. Mullins https://opensource.com/users/pmullins)
|
||||
|
||||
How to install TT-RSS on a Raspberry Pi
|
||||
======
|
||||
Read your news feeds while keeping your privacy intact with Tiny Tiny
|
||||
RSS.
|
||||
![Raspberries with pi symbol overlay][1]
|
||||
|
||||
[Tiny Tiny RSS][2] (TT-RSS) is a free and open source web-based news feed (RSS/Atom) reader and aggregator. It's ideally suited to those who are privacy-focused and still rely on RSS for their daily news. Tiny Tiny RSS is self-hosted software, so you have 100% control of the server, your data, and your overall privacy. It also supports a wide range of plugins, add-ons, and themes, Want a dark mode interface? No problem. Want to filter your incoming news based on keywords? TT-RSS has you covered there, as well.
|
||||
|
||||
![Tiny Tiny RSS screenshot][3]
|
||||
|
||||
Now that you know what TT-RSS is and why you may want to use it, I'll explain everything you need to know about installing it on a Raspberry Pi or a Debian 10 server.
|
||||
|
||||
### Install and configure TT-RSS
|
||||
|
||||
To install TT-RSS on a Raspberry Pi, you must also install and configure the latest version of PHP (7.3 as of this writing), PostgreSQL for the database backend, the Nginx web server, Git, and finally, TT-RSS.
|
||||
|
||||
#### 1\. Install PHP 7
|
||||
|
||||
Installing PHP 7 is, by far, the most involved part of this process. Thankfully, it's not as difficult as it might appear. Start by installing the following support packages:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo apt install -y ca-certificates apt-transport-https`
|
||||
```
|
||||
|
||||
Now, add the repository PGP key:
|
||||
|
||||
|
||||
```
|
||||
`$ wget -q https://packages.sury.org/php/apt.gpg -O- | sudo apt-key add -`
|
||||
```
|
||||
|
||||
Next, add the PHP repository to your apt sources:
|
||||
|
||||
|
||||
```
|
||||
`$ echo "deb https://packages.sury.org/php/ buster main" | sudo tee /etc/apt/sources.list.d/php.list`
|
||||
```
|
||||
|
||||
Then update your repository index:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo apt update`
|
||||
```
|
||||
|
||||
Finally, install PHP 7.3 (or the latest version) and some common components:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo apt install -y php7.3 php7.3-cli php7.3-fpm php7.3-opcache php7.3-curl php7.3-mbstring php7.3-pgsql php7.3-zip php7.3-xml php7.3-gd php7.3-intl`
|
||||
```
|
||||
|
||||
The command above assumes you're using PostgreSQL as your database backend and installs **php7.3-pgsql**. If you'd rather use MySQL or MariaDB, you can easily change this to **php7.3-mysql**.
|
||||
|
||||
Next, verify that PHP is installed and running on your Raspberry Pi:
|
||||
|
||||
|
||||
```
|
||||
`$ php -v`
|
||||
```
|
||||
|
||||
Now it's time to install and configure the webserver.
|
||||
|
||||
#### 2\. Install Nginx
|
||||
|
||||
Nginx can be installed via apt with:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo apt install -y nginx`
|
||||
```
|
||||
|
||||
Modify the default Nginx virtual host configuration so that the webserver will recognize PHP files and know what to do with them:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo nano /etc/nginx/sites-available/default`
|
||||
```
|
||||
|
||||
You can safely delete everything in the original file and replace it with:
|
||||
|
||||
|
||||
```
|
||||
server {
|
||||
listen 80 default_server;
|
||||
listen [::]:80 default_server;
|
||||
|
||||
root /var/www/html;
|
||||
index index.html index.htm index.php;
|
||||
server_name _;
|
||||
|
||||
location / {
|
||||
try_files $uri $uri/ =404;
|
||||
}
|
||||
|
||||
location ~ \\.php$ {
|
||||
include snippets/fastcgi-php.conf;
|
||||
fastcgi_pass unix:/run/php/php7.3-fpm.sock;
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
Use **Ctrl+O** to save your new configuration file and then **Ctrl+X** to exit Nano. You can test your new configuration with:
|
||||
|
||||
|
||||
```
|
||||
`$ nginx -t`
|
||||
```
|
||||
|
||||
If there are no errors, restart the Nginx service:
|
||||
|
||||
|
||||
```
|
||||
`$ systemctl restart nginx`
|
||||
```
|
||||
|
||||
#### 3\. Install PostgreSQL
|
||||
|
||||
Next up is installing the database server. Installing PostgreSQL on the Raspberry Pi is super easy:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo apt install -y postgresql postgresql-client postgis`
|
||||
```
|
||||
|
||||
Check to see if the database server was successfully installed by entering:
|
||||
|
||||
|
||||
```
|
||||
`$ psql --version`
|
||||
```
|
||||
|
||||
#### 4\. Create the Tiny Tiny RSS database
|
||||
|
||||
Before you can do anything else, you need to create a database that the TT-RSS software will use to store data. First, log into the PostgreSQL server:
|
||||
|
||||
|
||||
```
|
||||
`sudo -u postgres psql`
|
||||
```
|
||||
|
||||
Next, create a new user and assign a password:
|
||||
|
||||
|
||||
```
|
||||
`CREATE USER username WITH PASSWORD 'your_password' VALID UNTIL 'infinity';`
|
||||
```
|
||||
|
||||
Then create the database that will be used by TT-RSS:
|
||||
|
||||
|
||||
```
|
||||
`CREATE DATABASE tinyrss;`
|
||||
```
|
||||
|
||||
Finally, grant full permissions to the new user:
|
||||
|
||||
|
||||
```
|
||||
`GRANT ALL PRIVILEGES ON DATABASE tinyrss to user_name;`
|
||||
```
|
||||
|
||||
That's it for the database. You can exit the **psql** app by typing **\q**.
|
||||
|
||||
#### 5\. Install Git
|
||||
|
||||
Installing TT-RSS requires Git, so install Git with:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo apt install git -y`
|
||||
```
|
||||
|
||||
Now, change directory to wherever Nginx serves web pages:
|
||||
|
||||
|
||||
```
|
||||
`$ cd /var/www/html`
|
||||
```
|
||||
|
||||
Then download the latest source for TT-RSS:
|
||||
|
||||
|
||||
```
|
||||
`$ git clone https://git.tt-rss.org/fox/tt-rss.git tt-rss`
|
||||
```
|
||||
|
||||
Note that this process creates a new **tt-rss** folder.
|
||||
|
||||
#### 6\. Install and configure Tiny Tiny RSS
|
||||
|
||||
It's finally time to install and configure your new TT-RSS server. First, verify that you can open **<http://your.site/tt-rss/install/index.php>** in a web browser. If you get a **403 Forbidden** error, your permissions are not set properly on the **/var/www/html** folder. The following will usually fix this issue:
|
||||
|
||||
|
||||
```
|
||||
`$ chmod 755 /var/www/html/ -v`
|
||||
```
|
||||
|
||||
If everything goes as planned, you'll see the TT-RSS Installer page, and it will ask you for some database information. Just tell it the database username and password that you created earlier; the database name; **localhost** for the hostname; and **5432** for the port.
|
||||
|
||||
Click **Test Configuration** to continue. If all went well, you should see a red button labeled **Initialize Database.** Click on it to begin the installation. Once finished, you'll have a configuration file that you can copy and save as **config.php** in the TT-RSS directory.
|
||||
|
||||
After finishing with the installer, open your TT-RSS installation at **<http://yoursite/tt-rss/>** and log in with the default credentials (username: **admin**, password: **password**). The system will recommend that you change the admin password as soon as you log in. I highly recommend that you follow that advice and change it as soon as possible.
|
||||
|
||||
### Set up TT-RSS
|
||||
|
||||
If all went well, you can start using TT-RSS right away. It's recommended that you create a new non-admin user, log in as the new user, and start importing your feeds, subscribing, and configuring it as you see fit.
|
||||
|
||||
Finally, and this is super important, don't forget to read the [Updating Feeds][4] section on TT-RSS's wiki. It describes how to create a simple systemd service that will update your feeds. If you skip this step, your RSS feeds will not update automatically.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Whew! That was a lot of work, but you did it! You now have your very own RSS aggregation server. Want to learn more about TT-RSS? I recommend checking out the official [FAQ][5], the [support][6] forum, and the detailed [installation][7] notes. Feel free to comment below if you have any questions or issues.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/ttrss-raspberry-pi
|
||||
|
||||
作者:[Patrick H. Mullins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/pmullins
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/life-raspberrypi_0.png?itok=Kczz87J2 (Raspberries with pi symbol overlay)
|
||||
[2]: https://tt-rss.org/
|
||||
[3]: https://opensource.com/sites/default/files/uploads/tt-rss.jpeg (Tiny Tiny RSS screenshot)
|
||||
[4]: https://tt-rss.org/wiki/UpdatingFeeds
|
||||
[5]: https://tt-rss.org/wiki/FAQ
|
||||
[6]: https://community.tt-rss.org/c/tiny-tiny-rss/support
|
||||
[7]: https://tt-rss.org/wiki/InstallationNotes
|
||||
@ -0,0 +1,272 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (17 Cool Arduino Project Ideas for DIY Enthusiasts)
|
||||
[#]: via: (https://itsfoss.com/cool-arduino-projects/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
17 Cool Arduino Project Ideas for DIY Enthusiasts
|
||||
======
|
||||
|
||||
[Arduino][1] is an open-source electronics platform that combines both open source software and hardware to let people make interactive projects with ease. You can get Arduino-compatible [single board computers][2] and use them to make something useful.
|
||||
|
||||
In addition to the hardware, you will also need to know the [Arduino language][3] to use the [Arduino IDE][4] to successfully create something.
|
||||
|
||||
You can code using the web editor or use the Arduino IDE offline. Nevertheless, you can always refer to the [official resources][5] available to learn about Arduino.
|
||||
|
||||
Considering that you know the essentials, I will be mentioning some of the best (or interesting) Arduino projects. You can try to make them for yourself or modify them to come up with something of your own.
|
||||
|
||||
### Interesting Arduino project ideas for beginners, experts, everyone
|
||||
|
||||
![][6]
|
||||
|
||||
The following projects need a variety of additional hardware – so make sure to check out the official link to the projects (_originally featured on the [official Arduino Project Hub][7]_) to learn more about them.
|
||||
|
||||
Also, it is worth noting that they aren’t particularly in any ranking order – so feel free to try what sounds best to you.
|
||||
|
||||
#### 1\. LED Controller
|
||||
|
||||
Looking for simple Arduino projects? Here’s one for you.
|
||||
|
||||
One of the easiest projects that let you control LED lights. Yes, you do not have to opt for expensive LED products just to decorate your room (or for any other use-case), you can simply make an LED controller and customize it to use it however you want.
|
||||
|
||||
It requires using the [Arduino UNO board][8] and a couple more things (which also includes an Android phone). You can learn more about it in the link to the project below.
|
||||
|
||||
[LED Controller][9]
|
||||
|
||||
#### 2\. Hot Glue LED Matrix Lamp
|
||||
|
||||
![][10]
|
||||
|
||||
Another Arduino LED project for you. Since we are talking about using LEDs to decorate, you can also make an LED lamp that looks beautiful.
|
||||
|
||||
For this, you might want to make sure that you have a 3D printer. Next, you need an LED strip and **Arduino Nano R3** as the primary materials.
|
||||
|
||||
Once you’ve printed the case and assembled the lamp section, all you need to do is to add the glue sticks and figure out the wiring. It does sound very simple to mention – you can learn more about it on the official Arduino project feature site.
|
||||
|
||||
[LED Matrix Lamp][11]
|
||||
|
||||
#### 3\. Arduino Mega Chess
|
||||
|
||||
![][12]
|
||||
|
||||
Want to have a personal digital chessboard? Why not?
|
||||
|
||||
You’ll need a TFT LCD touch screen display and an [Arduino Mega 2560][13] board as the primary materials. If you have a 3D printer, you can create a pretty case for it and make changes accordingly.
|
||||
|
||||
Take a look at the original project for inspiration.
|
||||
|
||||
[Arduino Mega Chess][14]
|
||||
|
||||
#### 4\. Enough Already: Mute My TV
|
||||
|
||||
A very interesting project. I wouldn’t argue the usefulness of it – but if you’re annoyed by certain celebrities (or personalities) on TV, you can simply mute their voice whenever they’re about to speak something on TV.
|
||||
|
||||
Technically, it was tested with the old tech back then (when you didn’t really stream anything). You can watch the video above to get an idea and try to recreate it or simply head to the link to read more about it.
|
||||
|
||||
[Mute My TV][15]
|
||||
|
||||
#### 5\. Robot Arm with Controller
|
||||
|
||||
![][16]
|
||||
|
||||
If you want to do something with the help of your robot and still have manual control over it, the robot arm with a controller is one of the most useful Arduino projects. It uses the [Arduino UNO board][8] if you’re wondering.
|
||||
|
||||
You will have a robot arm -for which you can make a case using the 3D printer to enhance its usage and you can use it for a variety of use-cases. For instance, to clean the carbage using the robot arm or anything similar where you don’t want to directly intervene.
|
||||
|
||||
[Robotic Arm With Controller][17]
|
||||
|
||||
#### 6\. Make Musical Instrument Using Arduino
|
||||
|
||||
I’ve seen a variety of musical instruments made using Arduino. You can explore the Internet if you want something different than this.
|
||||
|
||||
You would need a [Pi supply flick charge][18] and an **Arduino UNO** to make it happen. It is indeed a cool Arduino project where you get to simply tap and your hand waves will be converted to music. Also, it isn’t tough to make this – so you should have a lot of fun making this.
|
||||
|
||||
[Musical Instrument using Arduino][19]
|
||||
|
||||
#### 7\. Pet Trainer: The MuttMentor
|
||||
|
||||
An Arduino-based device that assists you to help train your pet – sounds exciting!
|
||||
|
||||
For this, they’re using the [Arduino Nano 33 BLE Sense][20] while utilizing TensorFlow to train a small neural network for all the common actions that your pet does. Accordingly, the buzzer will offer a reinforcing notification when your pet obeys your command.
|
||||
|
||||
This can have wide applications when tweaked as per your requirements. Check out the details below.
|
||||
|
||||
[The MuttMentor][21]
|
||||
|
||||
#### 8\. Basic Earthquake Detector
|
||||
|
||||
Normally, you depend on the government officials to announce/inform about the earthquake stats (or the warning for it).
|
||||
|
||||
But with Arduino boards, you can simply build a basic earthquake detector and have transparent results for yourself without depending on the authorities. Click on the button below to know about the relevant details to help make it.
|
||||
|
||||
[Basic Earthquake Detector][22]
|
||||
|
||||
#### 9\. Security Access Using RFID Reader
|
||||
|
||||
![][23]
|
||||
|
||||
As the project describes – “_RFID tagging is an ID system that uses small radio frequency identification_ “.
|
||||
|
||||
So, in this project, you will be making an RFID reader using Arduino while pairing it with an [Adafruit NFC card][24] for security access. Check out the full details using the button below and let me know how it works for you.
|
||||
|
||||
[Security Access using RFID reader][25]
|
||||
|
||||
#### 10\. Smoke Detection using MQ-2 Gas Sensor
|
||||
|
||||
![][26]
|
||||
|
||||
This could be potentially one of the best Arduino projects out there. You don’t need to spend a lot of money to equip smoke detectors for your home, you can manage with a DIY solution to some extent.
|
||||
|
||||
Of course, unless you want a complex failsafe set up along with your smoke detector, a basic inexpensive solution should do the trick. In either case, you can also find other applications for the smoke detector.
|
||||
|
||||
[Smoke Detector][27]
|
||||
|
||||
#### 11\. Arduino Based Amazon Echo using 1Sheeld
|
||||
|
||||
![][28]
|
||||
|
||||
In case you didn’t know [1Sheeld][29] basically replaces the need for an add-on Arduino board. You just need a smartphone and add Arduino shields to it so that you can do a lot of things with it.
|
||||
|
||||
Using 5 such shields, the original creator of this project made himself a DIY Amazon Echo. You can find all the relevant details, schematics, and code to make it happen.
|
||||
|
||||
[DIY Amazon Echo][30]
|
||||
|
||||
#### 12\. Audio Spectrum Visualizer
|
||||
|
||||
![][31]
|
||||
|
||||
Just want to make something cool? Well, here’s an idea for an audio spectrum visualizer.
|
||||
|
||||
For this, you will need an Arduino Nano R3 and an LED display as primary materials to get started with. You can tweak the display as required. You can connect it with your headphone output or simply a line-out amplifier.
|
||||
|
||||
Easily one of the cheapest Arduino projects that you can try for fun.
|
||||
|
||||
[Audio Spectrum Visualizer][32]
|
||||
|
||||
#### 13\. Motion Following Motorized Camera
|
||||
|
||||
![][33]
|
||||
|
||||
Up for a challenge? If you are – this will be one of the coolest Arduino Projects in our list.
|
||||
|
||||
Basically, this is meant to replace your home security camera which is limited to an angle of video recording. You can turn the same camera into a motorized camera that follows the motion.
|
||||
|
||||
So, whenever it detects a movement, it will change its angle to try to follow the object. You can read more about it to find out how to make it.
|
||||
|
||||
[Motion Following Motorized Camera][34]
|
||||
|
||||
#### 14\. Water Quality Monitoring System
|
||||
|
||||
![][35]
|
||||
|
||||
If you’re concerned about your health in connection to the water you drink, you can try making this.
|
||||
|
||||
It requires an Arduino UNO and the water quality sensors as the primary materials. To be honest, a useful Arduino project to go for. You can find everything you need to make this in the link below.
|
||||
|
||||
[Water Quality Monitoring System][36]
|
||||
|
||||
#### 15\. Punch Activated Arm Flamethrower
|
||||
|
||||
I would be very cautious about this – but seriously, one of the best (and coolest) Arduino projects I’ve ever come across.
|
||||
|
||||
Of course, this counts as a fun project to try out to see what bigger projects you can pull off using Arduino and here it is. In the project, he originally used the [SparkFun Arduino Pro Mini 328][37] along with an accelerometer as the primary materials.
|
||||
|
||||
[Punch Activated Flamethrower][38]
|
||||
|
||||
#### 16\. Polar Drawing Machine
|
||||
|
||||
![][39]
|
||||
|
||||
This isn’t any ordinary plotter machine that you might’ve seen people creating using Arduino boards.
|
||||
|
||||
With this, you can draw some cool vector graphics images or bitmap. It might sound like bit of overkill but then it could also be fun to do something like this.
|
||||
|
||||
This could be a tricky project, so you can refer to the details on the link to go through it thoroughly.
|
||||
|
||||
[Polar Drawing Machine][40]
|
||||
|
||||
#### 17\. Home Automation
|
||||
|
||||
Technically, this is just a broad project idea because you can utilize the Arduino board to automate almost anything you want at your home.
|
||||
|
||||
Just like I mentioned, you can go for a security access device, maybe create something that automatically waters the plants or simply make an alarm system.
|
||||
|
||||
Countless possibilities of what you can do to automate things at your home. For reference, I’ve linked to an interesting home automation project below.
|
||||
|
||||
[Home Automation][41]
|
||||
|
||||
#### Bonus: Robot Cat (OpenCat)
|
||||
|
||||
![][42]
|
||||
|
||||
A programmable robotic cat for AI-enhanced services and STEM education. In this project, both Arduino and Raspberry Pi boards have been utilized.
|
||||
|
||||
You can also look at the [Raspberry Pi alternatives][2] if you want. This project needs a lot of work, so you would want to invest a good amount of time to make it work.
|
||||
|
||||
[OpenCat][43]
|
||||
|
||||
**Wrapping Up**
|
||||
|
||||
With the help of Arduino boards (coupled with other sensors and materials), you can do a lot of projects with ease. Some of the projects that I’ve listed above are suitable for beginners and some are not. Feel free to take your time to analyze what you need and the cost of the project before proceeding.
|
||||
|
||||
Did I miss listing an interesting Arduino project that deserves the mention here? Let me know your thoughts in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/cool-arduino-projects/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.arduino.cc/
|
||||
[2]: https://itsfoss.com/raspberry-pi-alternatives/
|
||||
[3]: https://www.arduino.cc/reference/en/
|
||||
[4]: https://www.arduino.cc/en/main/software
|
||||
[5]: https://www.arduino.cc/en/Guide/HomePage
|
||||
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/02/arduino-project-ideas.jpg?ssl=1
|
||||
[7]: https://create.arduino.cc/projecthub
|
||||
[8]: https://store.arduino.cc/usa/arduino-uno-rev3
|
||||
[9]: https://create.arduino.cc/projecthub/mayooghgirish/arduino-bluetooth-basic-tutorial-d8b737?ref=platform&ref_id=424_trending___&offset=89
|
||||
[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/02/led-matrix-lamp.jpg?ssl=1
|
||||
[11]: https://create.arduino.cc/projecthub/john-bradnam/hot-glue-led-matrix-lamp-42322b?ref=platform&ref_id=424_trending___&offset=42
|
||||
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/02/arduino-chess-board.jpg?ssl=1
|
||||
[13]: https://store.arduino.cc/usa/mega-2560-r3
|
||||
[14]: https://create.arduino.cc/projecthub/Sergey_Urusov/arduino-mega-chess-d54383?ref=platform&ref_id=424_trending___&offset=95
|
||||
[15]: https://makezine.com/2011/08/16/enough-already-the-arduino-solution-to-overexposed-celebs/
|
||||
[16]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/02/robotic-arm-controller.jpg?ssl=1
|
||||
[17]: https://create.arduino.cc/projecthub/H0meMadeGarbage/robot-arm-with-controller-2038df?ref=platform&ref_id=424_trending___&offset=13
|
||||
[18]: https://uk.pi-supply.com/products/flick-hat-3d-tracking-gesture-hat-raspberry-pi
|
||||
[19]: https://create.arduino.cc/projecthub/lanmiLab/make-musical-instrument-using-arduino-and-flick-large-e2890b?ref=platform&ref_id=424_trending___&offset=24
|
||||
[20]: https://store.arduino.cc/usa/nano-33-ble-sense
|
||||
[21]: https://create.arduino.cc/projecthub/whatsupdog/the-muttmentor-9d9753?ref=platform&ref_id=424_trending___&offset=44
|
||||
[22]: https://www.instructables.com/id/Basic-Arduino-Earthquake-Detector/
|
||||
[23]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/02/security-access-arduino.jpg?ssl=1
|
||||
[24]: https://www.adafruit.com/product/359
|
||||
[25]: https://create.arduino.cc/projecthub/Aritro/security-access-using-rfid-reader-f7c746?ref=platform&ref_id=424_trending___&offset=85
|
||||
[26]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/02/smoke-detection-arduino.jpg?ssl=1
|
||||
[27]: https://create.arduino.cc/projecthub/Aritro/smoke-detection-using-mq-2-gas-sensor-79c54a?ref=platform&ref_id=424_trending___&offset=89
|
||||
[28]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/02/diy-amazon-echo.jpg?ssl=1
|
||||
[29]: https://1sheeld.com/
|
||||
[30]: https://create.arduino.cc/projecthub/ahmedismail3115/arduino-based-amazon-echo-using-1sheeld-84fa6f?ref=platform&ref_id=424_trending___&offset=91
|
||||
[31]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/02/audio-spectrum-visualizer.jpg?ssl=1
|
||||
[32]: https://create.arduino.cc/projecthub/Shajeeb/32-band-audio-spectrum-visualizer-analyzer-902f51?ref=platform&ref_id=424_trending___&offset=87
|
||||
[33]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/02/motion-following-camera.jpg?ssl=1
|
||||
[34]: https://create.arduino.cc/projecthub/lindsi8784/motion-following-motorized-camera-base-61afeb?ref=platform&ref_id=424_trending___&offset=86
|
||||
[35]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/02/water-quality-monitoring.jpg?ssl=1
|
||||
[36]: https://create.arduino.cc/projecthub/chanhj/water-quality-monitoring-system-ddcb43?ref=platform&ref_id=424_trending___&offset=93
|
||||
[37]: https://www.sparkfun.com/products/11113
|
||||
[38]: https://create.arduino.cc/projecthub/Advanced/punch-activated-arm-flamethrowers-real-firebending-95bb80
|
||||
[39]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/02/polar-drawing-machine.jpg?ssl=1
|
||||
[40]: https://create.arduino.cc/projecthub/ArduinoFT/polar-drawing-machine-f7a05c?ref=search&ref_id=drawing&offset=2
|
||||
[41]: https://create.arduino.cc/projecthub/ahmedel-hinidy2014/home-management-system-control-your-home-from-a-website-076846?ref=search&ref_id=home%20automation&offset=4
|
||||
[42]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/02/opencat.jpg?ssl=1
|
||||
[43]: https://create.arduino.cc/projecthub/petoi/opencat-845129?ref=platform&ref_id=424_popular___&offset=8
|
||||
@ -0,0 +1,237 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Make free encrypted backups to the cloud on Fedora)
|
||||
[#]: via: (https://fedoramagazine.org/make-free-encrypted-backups-to-the-cloud-on-fedora/)
|
||||
[#]: author: (Curt Warfield https://fedoramagazine.org/author/rcurtiswarfield/)
|
||||
|
||||
Make free encrypted backups to the cloud on Fedora
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Most free cloud storage is limited to 5GB or less. Even Google Drive is limited to 15GB. While not heavily advertised, IBM offers free accounts with a whopping **25GB** of cloud storage for free. This is not a limited time offer, and you don’t have to provide a credit card. It’s absolutely free! Better yet, since it’s S3 compatible, most of the S3 tools available for backups should work fine.
|
||||
|
||||
This article will show you how to use restic for encrypted backups onto this free storage. Please also refer to [this previous Magazine article about installing and configuring restic.][2] Let’s get started!
|
||||
|
||||
### Creating your free IBM account and storage
|
||||
|
||||
Head over to the IBM cloud services site and follow the steps to sign up for a free account here: <https://cloud.ibm.com/registration>. You’ll need to verify your account from the email confirmation that IBM sends to you.
|
||||
|
||||
Then log in to your account to bring up your dashboard, at <https://cloud.ibm.com/>.
|
||||
|
||||
Click on the **Create resource** button.
|
||||
|
||||
![][3]
|
||||
|
||||
Click on **Storage** and then **Object Storage**.
|
||||
|
||||
![][4]
|
||||
|
||||
Next click on the **Create Bucket** button.
|
||||
|
||||
![][5]
|
||||
|
||||
This brings up the **Configure your resource** section.
|
||||
|
||||
![][6]
|
||||
|
||||
Next, click on the ****Create** button to use the default settings.
|
||||
|
||||
![][7]
|
||||
|
||||
Under **Predefined buckets** click on the **Standard** box:
|
||||
|
||||
![][8]
|
||||
|
||||
A unique bucket name is automatically created, but it’s suggested that you change this.
|
||||
|
||||
![][9]
|
||||
|
||||
In this example, the bucket name is changed to __freecloudstorage_._**
|
||||
|
||||
Click on the **Next** button after choosing a bucket name:
|
||||
|
||||
![][10]
|
||||
|
||||
Continue to click on the **Next** button until you get the the **Summary** page:
|
||||
|
||||
![][11]
|
||||
|
||||
Scroll down to the **Endpoints** section.
|
||||
|
||||
![][12]
|
||||
|
||||
The information in the **Public** section is the location of your bucket. This is what you need to specify in restic when you create your backups. In this example, the location is **s3.us-south.cloud-object-storage.appdomain.cloud**.
|
||||
|
||||
### Making your credentials
|
||||
|
||||
The last thing that you need to do is create an access ID and secret key. To start, click on **Service credentials**.
|
||||
|
||||
![][13]
|
||||
|
||||
Click on the **New credential** button.
|
||||
|
||||
![][14]
|
||||
|
||||
Choose a name for your credential, make sure you check the **Include HMAC Credential** box and then click on the **Add** button. In this example I’m using the name **resticbackup**.
|
||||
|
||||
![][15]
|
||||
|
||||
Click on **View credentials**.
|
||||
|
||||
![][16]
|
||||
|
||||
The _access_key_id_ and _secret_access_key_ is what you are looking for. (For obvious reasons, the author’s details here are obscured.)
|
||||
|
||||
You will need to export these by calling them with the _export_ alias in the shell, or putting them into a backup script.
|
||||
|
||||
![][17]
|
||||
|
||||
### Preparing a new repository
|
||||
|
||||
Restic refers to your backup as a _repository_, and can make backups to any bucket on your IBM cloud account. First, setup the following environment variables using your _access_key_id_ and _secret_access_key_ that you retrieved from your IBM cloud bucket. These can also be set in any backup script you may create.
|
||||
|
||||
```
|
||||
$ export AWS_ACCESS_KEY_ID=<MY_ACCESS_KEY>
|
||||
$ export AWS_SECRET_ACCESS_KEY=<MY_SECRET_ACCESS_KEY>
|
||||
```
|
||||
|
||||
Even though you are using IBM Cloud and not AWS, as previously mentioned, IBM Cloud storage is S3 compatible, and restic uses its interal AWS commands for any S3 compatible storage. So these AWS keys really refer to the keys from your IBM bucket.
|
||||
|
||||
Create the repository by initializing it. A prompt appears for you to type a password for the repository. _**Do not lose this password because your data is irrecoverable without it!**_
|
||||
|
||||
```
|
||||
restic -r s3:http://PUBLIC_ENDPOINT_LOCATION/BUCKET init
|
||||
```
|
||||
|
||||
The _PUBLIC_ENDPOINT_LOCATION_ was specified in the Endpoint section of your Bucket summary.
|
||||
|
||||
![][18]
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
$ restic -r s3:http://s3.us-south.cloud-object-storage.appdomain.cloud/freecloudstorage init
|
||||
```
|
||||
|
||||
### Creating backups
|
||||
|
||||
Now it’s time to backup some data. Backups are called _snapshots_. Run the following command and enter the repository password when prompted.
|
||||
|
||||
```
|
||||
restic -r s3:http://PUBLIC_ENDPOINT_LOCATION/BUCKET backup files_to_backup
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
$ restic -r s3:http://s3.us-south.cloud-object-storage.appdomain.cloud/freecloudstorage backup Documents/
|
||||
Enter password for repository:
|
||||
repository 106a2eb4 opened successfully, password is correct
|
||||
Files: 51 new, 0 changed, 0 unmodified
|
||||
Dirs: 0 new, 0 changed, 0 unmodified
|
||||
Added to the repo: 11.451 MiB
|
||||
processed 51 files, 11.451 MiB in 0:06
|
||||
snapshot 611e9577 saved
|
||||
```
|
||||
|
||||
### Restoring from backups
|
||||
|
||||
Now that you’ve backed up some files, it’s time to make sure you know how to restore them. To get a list of all of your backup snapshots, use this command:
|
||||
|
||||
```
|
||||
restic -r s3:http://PUBLIC_ENDPOINT_LOCATION/BUCKET snapshots
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
$ restic -r s3:http://s3.us-south.cloud-object-storage.appdomain.cloud/freecloudstorage snapshots
|
||||
Enter password for repository:
|
||||
ID Date Host Tags Directory
|
||||
-------------------------------------------------------------------
|
||||
106a2eb4 2020-01-15 15:20:42 client /home/curt/Documents
|
||||
```
|
||||
|
||||
To restore an entire snapshot, run a command like this:
|
||||
|
||||
```
|
||||
restic -r s3:http://s3.us-south.cloud-object-storage.appdomain.cloud/freecloudstorage restore snapshotID --target restoreDirectory
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
$ restic -r s3:http://s3.us-south.cloud-object-storage.appdomain.cloud/freecloudstorage restore 106a2eb4 --target ~
|
||||
Enter password for repository:
|
||||
repository 106a2eb4 opened successfully, password is correct
|
||||
restoring <Snapshot 106a2eb4 of [/home/curt/Documents]
|
||||
```
|
||||
|
||||
If the directory still exists on your system, be sure to specify a different location for the *restoreDirectory. *For example:
|
||||
|
||||
```
|
||||
restic -r s3:http://s3.us-south.cloud-object-storage.appdomain.cloud/freecloudstorage restore 106a2eb4 --target /tmp
|
||||
```
|
||||
|
||||
To restore an individual file, run a command like this:
|
||||
|
||||
```
|
||||
restic -r s3:http://PUBLIC_ENDPOINT_LOCATION/BUCKET restore snapshotID --target restoreDirectory --include filename
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
$ restic -r s3:http://s3.us-south.cloud-object-storage.appdomain.cloud/freecloudstorage restore 106a2eb4 --target /tmp --include file1.txt
|
||||
Enter password for repository:
|
||||
restoring <Snapshot 106a2eb4 of [/home/curt/Documents] at 2020-01-16 15:20:42.833131988 -0400 EDT by curt@client> to /tmp
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
_Photo by [Alex Machado][19] on [Unsplash][20]._
|
||||
|
||||
[EDITORS NOTE: The Fedora Project is [sponsored][21] by [Red Hat][22], which is owned by [IBM][23].]
|
||||
|
||||
[EDITORS NOTE: Updated at 1647 UTC on 24 February 2020 to correct a broken link.]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/make-free-encrypted-backups-to-the-cloud-on-fedora/
|
||||
|
||||
作者:[Curt Warfield][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/rcurtiswarfield/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2020/01/encrypted-backups-ibm-cloud-816x345.jpg
|
||||
[2]: https://fedoramagazine.org/use-restic-encrypted-backups/
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2020/01/ibmclouddash-3-e1579713553261.png
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2020/01/ibmcloudresourcestorage-3.png
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2020/01/ibmcloudbucket-3.png
|
||||
[6]: https://fedoramagazine.org/wp-content/uploads/2020/01/ibmcloudbucket2.png
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2020/01/ibmcloudbucket3-e1579713758635.png
|
||||
[8]: https://fedoramagazine.org/wp-content/uploads/2020/01/ibmcloudbucket4.png
|
||||
[9]: https://fedoramagazine.org/wp-content/uploads/2020/01/createbucket1.png
|
||||
[10]: https://fedoramagazine.org/wp-content/uploads/2020/01/next.png
|
||||
[11]: https://fedoramagazine.org/wp-content/uploads/2020/01/bucketsummary-1024x368.png
|
||||
[12]: https://fedoramagazine.org/wp-content/uploads/2020/01/endpoints-1024x272.png
|
||||
[13]: https://fedoramagazine.org/wp-content/uploads/2020/01/servicecreds.png
|
||||
[14]: https://fedoramagazine.org/wp-content/uploads/2020/01/newcred.png
|
||||
[15]: https://fedoramagazine.org/wp-content/uploads/2020/01/addnewcred.png
|
||||
[16]: https://fedoramagazine.org/wp-content/uploads/2020/01/keys-1024x298.png
|
||||
[17]: https://fedoramagazine.org/wp-content/uploads/2020/01/keys2.png
|
||||
[18]: https://fedoramagazine.org/wp-content/uploads/2020/01/publicendpoint.png
|
||||
[19]: https://unsplash.com/@alexmachado?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[20]: https://unsplash.com/s/photos/backups-to-cloud?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[21]: https://getfedora.org/sponsors/
|
||||
[22]: https://redhat.com
|
||||
[23]: https://www.ibm.com/cloud/redhat
|
||||
@ -0,0 +1,130 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What developers need to know about domain-specific languages)
|
||||
[#]: via: (https://opensource.com/article/20/2/domain-specific-languages)
|
||||
[#]: author: (Girish Managoli https://opensource.com/users/gammay)
|
||||
|
||||
What developers need to know about domain-specific languages
|
||||
======
|
||||
DSLs are used for a specific context in a particular domain. Learn more
|
||||
about what they are and why you might want to use one.
|
||||
![Various programming languages in use][1]
|
||||
|
||||
A [domain-specific language][2] (DSL) is a language meant for use in the context of a particular domain. A domain could be a business context (e.g., banking, insurance, etc.) or an application context (e.g., a web application, database, etc.) In contrast, a general-purpose language (GPL) can be used for a wide range of business problems and applications.
|
||||
|
||||
A DSL does not attempt to please all. Instead, it is created for a limited sphere of applicability and use, but it's powerful enough to represent and address the problems and solutions in that sphere. A good example of a DSL is HTML. It is a language for the web application domain. It can't be used for, say, number crunching, but it is clear how widely used HTML is on the web.
|
||||
|
||||
A GPL creator does not know where the language might be used or the problems the user intends to solve with it. So, a GPL is created with generic constructs that potentially are usable for any problem, solution, business, or need. Java is a GPL, as it's used on desktops and mobile devices, embedded in the web across banking, finance, insurance, manufacturing, etc., and more.
|
||||
|
||||
### Classifying DSLs
|
||||
|
||||
In the DSL world, there are two types of languages:
|
||||
|
||||
* **Domain-specific language (DSL):** The language in which a DSL is written or presented
|
||||
* **Host language:** The language in which a DSL is executed or processed
|
||||
|
||||
|
||||
|
||||
A DSL written in a distinct language and processed by another host language is called an **external** DSL.
|
||||
|
||||
This is a DSL in SQL that can be processed in a host language:
|
||||
|
||||
|
||||
```
|
||||
SELECT account
|
||||
FROM accounts
|
||||
WHERE account = '123' AND branch = 'abc' AND amount >= 1000
|
||||
```
|
||||
|
||||
For that matter, a DSL could be written in English with a defined vocabulary and form that can be processed in another host language using a parser generator like ANTLR:
|
||||
|
||||
|
||||
```
|
||||
`if smokes then increase premium by 10%`
|
||||
```
|
||||
|
||||
If the DSL and host language are the same, then the DSL type is **internal**, where the DSL is written in the language's semantics and processed by it. These are also referred to as **embedded** DSLs. Here are two examples.
|
||||
|
||||
* A Bash DSL that can be executed in a Bash engine: [code]`if today_is_christmas; then apply_christmas_discount; fi` [/code] This is valid Bash that is written like English.
|
||||
* A DSL written in a GPL like Java: [code] orderValue = orderValue
|
||||
.applyFestivalDiscount()
|
||||
.applyCustomerLoyalityDiscount()
|
||||
.applyCustomerAgeDiscount(); [/code] This uses a fluent style and is readable like English.
|
||||
|
||||
|
||||
|
||||
Yes, the boundaries between DSL and GPL sometimes blur.
|
||||
|
||||
### DSL examples
|
||||
|
||||
Some languages used for DSLs include:
|
||||
|
||||
* Web: HTML
|
||||
* Shell: sh, Bash, CSH, and the likes for *nix; MS-DOS, Windows Terminal, PowerShell for Windows
|
||||
* Markup languages: XML
|
||||
* Modeling: UML
|
||||
* Data management: SQL and its variants
|
||||
* Business rules: Drools
|
||||
* Hardware: Verilog, VHD
|
||||
* Build tools: Maven, Gradle
|
||||
* Numerical computation and simulation: MATLAB (commercial), GNU Octave, Scilab
|
||||
* Various types of parsers and generators: Lex, YACC, GNU Bison, ANTLR
|
||||
|
||||
|
||||
|
||||
### Why DSL?
|
||||
|
||||
The purpose of a DSL is to capture or document the requirements and behavior of one domain. A DSL's usage might be even narrower for particular aspects within the domain (e.g., commodities trading in finance). DSLs bring business and technical teams together. This does not imply a DSL is for business use alone. For example, designers and developers can use a DSL to represent or design an application.
|
||||
|
||||
A DSL can also be used to generate source code for an addressed domain or problem. However, code generation from a DSL is not considered mandatory, as its primary purpose is domain knowledge. However, when it is used, code generation is a serious advantage in domain engineering.
|
||||
|
||||
### DSL pros and cons
|
||||
|
||||
On the plus side, DSLs are powerful for capturing a domain's attributes. Also, since DSLs are small, they are easy to learn and use. Finally, a DSL offers a language for domain experts and between domain experts and developers.
|
||||
|
||||
On the downside, a DSL is narrowly used within the intended domain and purpose. Also, a DSL has a learning curve, although it may not be very high. Additionally, although there may be advantages to using tools for DSL capture, they are not essential, and the development or configuration of such tools is an added effort. Finally, DSL creators need domain knowledge as well as language-development knowledge, and individuals rarely have both.
|
||||
|
||||
### DSL software options
|
||||
|
||||
Open source DSL software options include:
|
||||
|
||||
* **Xtext:** Xtext enables the development of DSLs and is integrated with Eclipse. It makes code generation possible and has been used by several open source and commercial products to provide specific functions. [MADS][3] (Multipurpose Agricultural Data System) is an interesting idea based on Xtext for "modeling and analysis of agricultural activities" (however, the project seems to be no longer active).
|
||||
* **JetBrains MPS:** JetBrains MPS is an integrated development environment (IDE) to create DSLs. It calls itself a projectional editor that stores a document as its underlying abstract tree structure. (This concept is also used by programs such as Microsoft Word.) JetBrains MPS also supports code generation to Java, C, JavaScript, or XML.
|
||||
|
||||
|
||||
|
||||
### DSL best practices
|
||||
|
||||
Want to use a DSL? Here are a few tips:
|
||||
|
||||
* DSLs are not GPLs. Try to address limited ranges of problems in the definitive domain.
|
||||
* You do not need to define your own DSL. That would be tedious. Look for an existing DSL that solves your need on sites like [DSLFIN][4], which lists DSLs for the finance domain. If you are unable to find a suitable DSL, you could define your own.
|
||||
* It is better to make DSLs "like English" rather than too technical.
|
||||
* Code generation from a DSL is not mandatory, but it offers significant and productive advantages when it is done.
|
||||
* DSLs are called languages but, unlike GPLs, they need not be executable. Being executable is not the intent of a DSL.
|
||||
* DSLs can be written with word processors. However, using a DSL editor makes syntax and semantics checks easier.
|
||||
|
||||
|
||||
|
||||
If you are using DSL now or plan to do so in the future, please share your experience in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/domain-specific-languages
|
||||
|
||||
作者:[Girish Managoli][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/gammay
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/programming_language_c.png?itok=mPwqDAD9 (Various programming languages in use)
|
||||
[2]: https://en.wikipedia.org/wiki/Domain-specific_language
|
||||
[3]: http://mads.sourceforge.net/
|
||||
[4]: http://www.dslfin.org/resources.html
|
||||
118
sources/tech/20200225 3 eBook readers for the Linux desktop.md
Normal file
118
sources/tech/20200225 3 eBook readers for the Linux desktop.md
Normal file
@ -0,0 +1,118 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (3 eBook readers for the Linux desktop)
|
||||
[#]: via: (https://opensource.com/article/20/2/linux-ebook-readers)
|
||||
[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
|
||||
|
||||
3 eBook readers for the Linux desktop
|
||||
======
|
||||
Any of these open source eBook applications will make it easy to read
|
||||
your books on a larger screen.
|
||||
![Computer browser with books on the screen][1]
|
||||
|
||||
I usually read eBooks on my phone or with my Kobo eReader. I've never been comfortable reading books on larger screens. However, many people regularly read books on their laptops or desktops. If you are one of them (or think you might be), I'd like to introduce you to three eBook readers for the Linux desktop.
|
||||
|
||||
### Bookworm
|
||||
|
||||
[Bookworm][2] is billed as a "simple, focused eBook reader." And it is. Bookworm has a basic set of features, which some people will complain about being _too basic_ or lacking _functionality_ (whatever that word means). Bookworm does one thing and does it well without unnecessary frills.
|
||||
|
||||
The application's interface is very clean and uncluttered.
|
||||
|
||||
![Bookworm e-book application][3]
|
||||
|
||||
You navigate through a book by pressing:
|
||||
|
||||
* The space bar to move down a page
|
||||
* The Down and Up arrow keys to move down and up a single line
|
||||
* The Right and Left arrow keys to jump to the next or previous chapter
|
||||
|
||||
|
||||
|
||||
You can also annotate portions of a book and insert bookmarks to jump back to a page.
|
||||
|
||||
![Annotations in Bookworm][4]
|
||||
|
||||
Bookworm doesn't have many configuration options. You can change the size and spacing of a book's font, enable a two-page reading view or dark mode, and add folders that Bookworm will scan to find new eBooks.
|
||||
|
||||
![Bookworm preferences][5]
|
||||
|
||||
Bookworm supports the most widely used eBook formats: EPUB, PDF, MOBI, and [FB2][6]. You can also use Bookworm to read popular digital comic book formats [CBR][7] and CBZ. I've tested Bookworm with only the first three formats. PDF files are readable, but they load slowly and the formatting can be rather ugly.
|
||||
|
||||
### Foliate
|
||||
|
||||
As far as features go, [Foliate][8] is a step or two above Bookworm. Not only does it have several more features, but it also has more configuration options. You get all of that in a zippy, clean, and uncluttered package.
|
||||
|
||||
![Foliate e-book application][9]
|
||||
|
||||
You can navigate through an eBook in Foliate using the space bar, arrow keys, or PgUp and PgDn keys. There's nothing unique there.
|
||||
|
||||
You can also annotate text, look up and translate words and phrases, and look up the meanings of words. If you have a text-to-speech application installed on your computer, Foliate can use it to read books aloud.
|
||||
|
||||
![Annotating a book in Foliate][10]
|
||||
|
||||
Foliate has a few more customization options than Bookworm. You can change a book's font and its size, the spacing of lines, and the size of a book's margins. You can also increase or decrease the brightness and select one of four built-in themes.
|
||||
|
||||
![Foliate settings][11]
|
||||
|
||||
You can read books in the EPUB, MOBI, AZW, and AZW3 formats using Foliate. In case you're wondering, the latter three are closed formats used with books published for Amazon's Kindle eReader
|
||||
|
||||
### Calibre's eBook viewer
|
||||
|
||||
[eBook viewer][12] is a component of the [Calibre][13] eBook management tool. Like its parent, the eBook viewer feature isn't the prettiest piece of software out there.
|
||||
|
||||
![E-book Viewer application][14]
|
||||
|
||||
Don't let that put you off, though. It's a solid desktop eBook reader.
|
||||
|
||||
You navigate through an eBook in Calibre's e-book viewer using the arrow and PgUp/PgDn keys or by pressing the space bar. You can also look up words in an online dictionary and add bookmarks throughout a book. E-book viewer lacks an annotation function, but its built-in search engine is solid, and you can save books as PDFs (though I'm not sure why you'd want to).
|
||||
|
||||
Configuration options are an area where this eBook viewer shines. It has far more of them than both Bookworm and Foliate combined. You can change everything from fonts to the layout of text to how text is broken up into pages. On top of that, you can customize the keyboard shortcuts for using the application and add your favorite dictionary website or sites to help you look up words in a book you're reading.
|
||||
|
||||
![E-book Viewer preferences][15]
|
||||
|
||||
One useful feature of Calibre's eBook viewer is the ability to apply your own CSS file to your e-books. CSS, in case you're wondering, is a way to format web pages (which is what many e-books are made of). If you're a master with CSS, you can copy and paste your CSS file into the **User stylesheet** tab in eBook viewer's Preferences window. That's the ultimate in customization.
|
||||
|
||||
eBook viewer, according to its developer, "can display all the major e-book formats." If you're wondering what those formats are, [here's a list][16]. I've tested it with just a few of those formats and have had no problems with them.
|
||||
|
||||
### Final thought
|
||||
|
||||
Whether you're looking for a simple eBook reader or one with bells and whistles and whatever else, the three applications in this article are good choices. Any of them can make reading an eBook on a larger screen easier.
|
||||
|
||||
* * *
|
||||
|
||||
_This article is based on an article published on [Open Source Musings][17] and appears here via a [CC BY-SA 4.0][18] license._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/linux-ebook-readers
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_browser_program_books_read.jpg?itok=iNMWe8Bu (Computer browser with books on the screen)
|
||||
[2]: https://babluboy.github.io/bookworm/
|
||||
[3]: https://opensource.com/sites/default/files/uploads/bookworm-reading.png (Bookworm e-book application)
|
||||
[4]: https://opensource.com/sites/default/files/uploads/bookworm-annotations.png (Annotations in Bookworm)
|
||||
[5]: https://opensource.com/sites/default/files/uploads/bookworm-preferences.png (Bookworm preferences)
|
||||
[6]: https://en.wikipedia.org/wiki/FictionBook
|
||||
[7]: https://en.wikipedia.org/wiki/Comic_book_archive
|
||||
[8]: https://johnfactotum.github.io/foliate/
|
||||
[9]: https://opensource.com/sites/default/files/uploads/foliate-reading.png (Foliate e-book application)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/foliate-annotation_0.png
|
||||
[11]: https://opensource.com/sites/default/files/uploads/foliate-settings.png (Foliate settings)
|
||||
[12]: https://calibre-ebook.com/about
|
||||
[13]: https://opensourcemusings.com/managing-your-ebooks-with-calibre
|
||||
[14]: https://opensource.com/sites/default/files/uploads/e-book_viewer-reading.png (E-book Viewer application)
|
||||
[15]: https://opensource.com/sites/default/files/uploads/ebook-viewer-preferences.png (E-book Viewer preferences)
|
||||
[16]: https://manual.calibre-ebook.com/faq.html#what-formats-does-calibre-support-conversion-to-from
|
||||
[17]: https://opensourcemusings.com/three-ebook-readers-for-the-linux-desktop
|
||||
[18]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
243
translated/tech/20170918 Fun and Games in Emacs.md
Normal file
243
translated/tech/20170918 Fun and Games in Emacs.md
Normal file
@ -0,0 +1,243 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Fun and Games in Emacs)
|
||||
[#]: via: (https://www.masteringemacs.org/article/fun-games-in-emacs)
|
||||
[#]: author: (Mickey Petersen https://www.masteringemacs.org/about)
|
||||
|
||||
Emacs 中的游戏与乐趣
|
||||
======
|
||||
|
||||
又是周一,你正在为你的老板 Lumbergh 努力倒腾那些 [无聊之极的文档 ][1]。为什么不玩玩 Emacs 中类似 zork 的文本冒险游戏来让你的大脑从单调的工作中解脱出来呢?
|
||||
|
||||
但说真的,Emacs 中既有游戏,也有古怪的玩物。有些你可能有所耳闻。这些玩意唯一的共同点就是,它们大多是很久以前就添加到 Emacs 中的:有些东西真的是相当古怪(如您将在下面看到的),而另一些则显然是由无聊的员工或毕业生编写的。
|
||||
它们中都带着一种奇思妙想和随意性,这在今天的 Emacs 中很少见。
|
||||
Emacs 现在变得十分严肃,在某种程度上,它已经与 20 世纪 80 年代那些玩意被编写出来的时候大不一样。
|
||||
|
||||
|
||||
### 汉诺塔
|
||||
|
||||
[汉诺塔 ][2] 是一款古老的数学解密游戏,有些人可能对它很熟悉,因为它的递归和迭代解决方案经常被用与计算机科学教学辅助。
|
||||
|
||||
|
||||
|
||||
|
||||
Emacs 中有三个命令可以运行汉诺塔:`M-x hanoi` 默认为 3 个碟子; `M-x hanoi-unix` 和 `M-x hanoi-unix-64` 使用 unix 时间戳的位数 (32bit 或 64bit) 作为默认盘子的个数,并且每秒钟自动移动一次,两者不同之处在于后者假装使用 64 位时钟(因此有 64 个碟子)。
|
||||
|
||||
Emacs 中汉诺塔的实现可以追溯到 20 世纪 80 年代中期——确实是久得可怕。它有一些自定义选项 (`M-x customize-group RET hanoi RET`),如启用彩色光盘等。
|
||||
当你离开汉诺塔缓冲区或输入一个字符,你会收到一个讽刺的告别信息(见上文)。
|
||||
|
||||
### 5x5
|
||||
|
||||
|
||||
|
||||
|
||||
5x5 的游戏是一个逻辑解密游戏:你有一个 5x5 的网格,中间的十字被填满;你的目标是通过按正确的顺序切换它们的空满状态来填充所有的单元格,从而获得胜利。这并不像听起来那么容易!
|
||||
|
||||
输入 `M-x 5x5` 就可以开始玩了,使用可选的数字参数可以改变网格的大小。
|
||||
这款游戏的有趣之处在于它能向你建议下一步行动并尝试解决该游戏网格。它用到了了 Emacs 自己的一款非常酷的符号 RPN 计算器 `M-x calc` (在 [Fun with Emacs Calc][3] 这篇文章中,我使用它来解决了一个简单的问题。)
|
||||
|
||||
所以我喜欢这个游戏的原因是它提供了一个非常复杂的解决器——真的,你应该通过 `M-x find-library RET 5x5` 来阅读其源代码——和一个试图通过强力破解游戏的“破解器”。
|
||||
|
||||
创建一个更大的游戏网格,例如输入 `M-10 M-x 5x5`,然后运行下面某个 `crack` 命令。破坏者将尝试通过迭代获得最佳解决方案。它会实时运行该游戏,观看起来非常有趣:
|
||||
|
||||
- `M-x 5x5-crack-mutating-best`: 试图通过修改最佳解决方案来破解 5x5。
|
||||
|
||||
- `M-x 5x5-crack-mutating-current`: 试图通过修改当前解决方案来破解 5x5。
|
||||
|
||||
- `M-x 5x5-crack-random`: 尝试使用随机方案解破解 5x5。
|
||||
|
||||
- `M-x 5x5-crack-xor-mutate`: 尝试通过将当前方案和最佳方案进行异或运算来破解 5x5。
|
||||
|
||||
### 文本动画
|
||||
|
||||
您可以通过运行 `M-x animation-birthday-present` 并给出名字来显示一个奇特的生日礼物动画。它看起来很酷!
|
||||
|
||||

|
||||
|
||||
`M-x butterfly` 命令中也使用了 `animate` 包,butterfly 命令被添加到 Emacs 中,以向上面的 [XKCD][4] 漫画致敬。当然,漫画中的 Emacs 命令在技术上是无效的,但它的幽默足以弥补这一点。
|
||||
|
||||
### 黑箱
|
||||
|
||||
我将逐字引用这款游戏的目标:
|
||||
|
||||
> 游戏的目标是通过向黑盒子发射光线来找到四个隐藏的球。有四种可能:
|
||||
> 1) 射线将通过盒子不受干扰,
|
||||
> 2) 它将击中一个球并被吸收,
|
||||
> 3) 它将偏转并退出盒子,或
|
||||
> 4) 立即偏转,甚至不被允许进入盒子。
|
||||
|
||||
所以,这有点像我们小时候玩的 [Battleship][5],但是……是专为物理专业高学历的人准备的?
|
||||
|
||||
这是另一款添加于 20 世纪 80 年代的游戏。我建议你输入 `C-h f blackbox` 来阅读玩法说明(文档巨大)。
|
||||
|
||||
|
||||
### 泡泡
|
||||
|
||||
|
||||
|
||||
|
||||
`M-x bubble` 游戏相当简单:你必须用尽可能少移动清除尽可能多的“泡泡”。当你移除气泡时,其他气泡会掉落并粘在一起。
|
||||
这是一款有趣的游戏,此外如果你使用 Emacs 的图形用户界面,它还支持图像现实。而且它还支持鼠标。
|
||||
|
||||
您可以通过调用 `M-x bubbles-set-game-< 难度>` 来设置难度,其中嗯 `<难度>` 可以是其中之一:`easy`,`medium=,=difficult`,`hard`,或 `userdefined`。
|
||||
此外,您可以使用:`M-x custom-group bubbles` 来更改图形、网格大小和颜色。
|
||||
|
||||
由于它即简单又有趣,这是 Emacs 中我最喜欢的游戏之一。
|
||||
|
||||
### 幸运饼干
|
||||
|
||||
我喜欢 `fortune` 命令。每当我启动一个新 shell 时,就会有刻薄、无益、常常带有讽刺意味的“建议(以及文学摘要,谜语)”就会点亮我的一天。
|
||||
|
||||
令人困惑的是,Emacs 中有两个包做了类似的事情:`fortune` 和 `cookie`。前者主要用于在电子邮件签名中添加幸运饼干消息,而后者只是一个简单的 fortune 格式阅读器。
|
||||
|
||||
不管怎样,使用 Emacs 的 `cookie` 包前,你首先需要通过 `customize-option RET cookie RET` 来自定义变量 `cookie-file` 告诉它从哪找到 fortune 文件。
|
||||
|
||||
如果你的操作系统是 Ubuntu,那么你先安装 `fortune` 软件包,然后就能在 `/usr/share/games/fortune/` 目录中找到这些文件了。
|
||||
|
||||
之后你就可以调用 `M-x cookie` 随机显示 fortune 内容,或者,如果你想的话,也可以调用 `M-x cookie-apropos` 查找所有匹配的 cookie。
|
||||
|
||||
### Decipher
|
||||
|
||||
这个包完美地抓住了 Emacs 的实用本质:这个包为你破解简单的替换密码(如密码谜题)提供了一个很有用的界面。
|
||||
你知道,二十多年前,某人确实迫切需要破解很多基础密码。正是像这个模块这样的小玩意让我非常高兴地用起 Emacs 来:这个模块只对少数人有用,但是,如果你突然需要它了,那么它就在那里等着你。
|
||||
|
||||
那么如何使用它呢?让我们假设使用 “rot13” 密码:在 26 个字符的字母表中,将字符旋转 13 个位置。
|
||||
通过 `M-x ielm` (Emacs 用于 [运行 Elisp][6] 的 REPL 环境)可以很容易在 Emacs 中进行尝试:
|
||||
|
||||
|
||||
```
|
||||
*** Welcome to IELM *** Type (describe-mode) for help.
|
||||
ELISP> (rot13 "Hello, World")
|
||||
"Uryyb, Jbeyq"
|
||||
ELISP> (rot13 "Uryyb, Jbeyq")
|
||||
"Hello, World"
|
||||
ELISP>
|
||||
```
|
||||
|
||||
那么,decipher 模块又是如何帮助我们的呢?让我们创建一个新的缓冲区 `test-cipher` 并输入您的密码文本(在我的例子中是 `Uryyb,Jbeyq`)
|
||||
|
||||

|
||||
|
||||
您现在面对的是一个相当复杂的接口。现在把光标放在紫行秘文中的任意字符上,猜猜这个字符可能是什么:Emacs 将根据你的选择更新其他明文的猜测结果,并告诉你字母表中的字符是如何分配的。
|
||||
|
||||
您现在可以下面各种 helper 命令来帮助推断密码字符可能对应的明文字符:
|
||||
|
||||
- **`D`:** 显示数字符号(密码中两个字符组合)及其频率的列表
|
||||
|
||||
- **`F`:** 表示每个密文字母的频率
|
||||
|
||||
- **`N`:** 显示字符的邻接信息。我不确定这是干啥的。
|
||||
|
||||
- **`M` 和 `R`:** 保存和恢复一个检查点,允许你对工作进行分支以探索破解密码的不同方法。
|
||||
|
||||
总而言之,对于这样一个深奥的任务,这个包是相当令人印象深刻的!如果你经常破解密码,也许这个程序包能帮上忙?
|
||||
|
||||
### 医生
|
||||
|
||||
|
||||
|
||||
啊,Emacs 医生。其基于最初的 [ELIZA][7],“ 医生”试图对你说的话进行心理分析,并试图把问题复述给你。体验它的那几分钟相当有趣,它也是 Emacs 中最著名的古怪玩意之一。你可以使用 `M-x doctor` 来运行它。
|
||||
|
||||
### Dunnet
|
||||
|
||||
Emacs 自己特有的类 Zork 文本冒险游戏。输入 `M-x dunnet` 就能玩了。
|
||||
这是一款相当不错的游戏,虽然时间不长,但非常著名,很少有人真正玩到最后。
|
||||
|
||||
如果你发现自己能在无聊的文档工作之间空出时间来,那么这是一个超级棒的游戏,内置“老板屏幕”,因为它是纯文本的。
|
||||
|
||||
哦,还有,不要吃掉那块 CPU 卡 :)
|
||||
|
||||
### 五子棋
|
||||
|
||||
|
||||
|
||||
另一款写于 20 世纪 80 年代的游戏。你必须连接 5 个方块,井字游戏风格。你可以运行 `M-x gomoku` 来与 Emacs 对抗。游戏还支持鼠标,非常方便。您也可以自定义 `gomoku` 组来调整网格的大小。
|
||||
|
||||
### 生命游戏
|
||||
|
||||
[Conway 的生命游戏 ][8] 是细胞自动机的一个著名例子。Emacs 版本提供了一些启动模式,你可以(通过 elisp 编程)通过调整 `life-patterns` 变量来更改这些模式。
|
||||
|
||||
你可以用 `M-x life` 触发生命游戏。事实上,所有的东西,包括代码,注释和所有的东西,总共不到 300 行,这也让人印象深刻。
|
||||
|
||||
### 乒乓,贪吃蛇和俄罗斯方块
|
||||
|
||||
|
||||
|
||||
这些经典游戏都是使用 Emacs 包 `gamegrid` 实现的,这是一个用于构建网格游戏(如俄罗斯方块和贪吃蛇)的通用框架。gamegrid 包的伟大之处在于它同时兼容图形化和终端 Emacs: 如果你在 GUI 中运行 Emacs,你会得到精美的图形;如果你没有,你得到简单的 ASCII 艺术。
|
||||
|
||||
你可以通过输入 `M-x pong`,`M-x snake`,`M-x tetris` 来运行这些游戏。
|
||||
|
||||
特别是俄罗斯方块游戏实现的非常到位,会逐渐增加速度并且能够滑块。而且既然你已经有了源代码,你完全可以移除那个讨厌的 Z 形块,没人喜欢它!
|
||||
|
||||
### Solitaire
|
||||
|
||||
|
||||
|
||||
可惜,这不是纸牌游戏,而是一个基于 peg 的游戏,你可以选择一块石头 (`o`) 并“跳过”相邻的石头进入洞中(`。`),并在这个过程中去掉你跳过的那些石头,最终只能在棋盘上留下一块石头,
|
||||
重复该过程直到板子被请空(只保留一个石头)。
|
||||
|
||||
如果你卡住了,有一个内置的解题器名为 `M-x solitire-solve`。
|
||||
|
||||
### Zone
|
||||
|
||||
我的另一个最爱。这是一个屏幕保护程序——或者更确切地说,是一系列的屏幕保护程序。
|
||||
|
||||
输入 `M-x zone`,然后看看屏幕上发生了什么!
|
||||
|
||||
您可以通过运行 `M-x zone-when-idle` (或从 elisp 调用它)来配置屏幕保护程序的空闲时间,时间以秒为单位。
|
||||
您也可以通过 `M-x zone-leave-me-alone` 来关闭它。
|
||||
|
||||
如果它在你的同事看着的时候被启动,你的同事肯定会抓狂的。
|
||||
|
||||
### 乘法解谜
|
||||
|
||||
|
||||
|
||||
这是另一个脑筋急转弯的益智游戏。当您运行 `M-x mpuz` 时,将看到一个乘法解谜题,你必须将字母替换为对应的数字,并确保数字相加(相乘?)符合结果
|
||||
|
||||
如果遇到难题,可以运行 `M-x mpuz-show-solution` 来解决。
|
||||
|
||||
### 杂项
|
||||
|
||||
还有更多好玩的东西,但它们就不如刚才那些那么好玩好用了:
|
||||
|
||||
- 你可以通过 `M-x morse-region` 和 `M-x unmorse-region` 将一个区域翻译成莫尔斯电码。
|
||||
- Dissociated Press 是一个非常简单的命令,它将类似随机游动 markov 链生成器应用到 buffer 中的文本中,并以此生成无意义的文本。试一下 `M-x dissociated-press`。
|
||||
- Gamegrid 包是构建网格游戏的通用框架。到目前为止,只有俄罗斯方块,乒乓和贪吃蛇使用了它。其名为 `gamegrid`。
|
||||
- `gametree` 软件包是一个通过电子邮件记录和跟踪国际象棋游戏的复杂方法。
|
||||
- `M-x spook` 命令插入随机单词(通常是在电子邮件中),目的是混淆/超载 “NSA trukn trawler”—— 记住,这个模块可以追溯到 20 世纪 80 年代和 90 年代——那时应该有间谍们在监听各种单词。当然,即使是在十年前,这样做也会显得非常偏执和古怪,不过现在看来已经不那么奇怪了……
|
||||
|
||||
|
||||
### 结论
|
||||
|
||||
我喜欢 Emacs 附带的游戏和玩具。它们大多来自于,嗯,我们姑且称之为一个不同的时代:一个允许或甚至鼓励奇思妙想的时代。
|
||||
有些玩意非常经典(如俄罗斯方块和汉诺塔),有些对经典游戏进行了有趣的变种(如黑盒)——但我很高兴这么多年后他们依然在 Emacs 中。
|
||||
我想知道时至今日,这些玩意是否还会纳入 Emacs 的代码库中;嗯,它们很可能不会——它们将被归入包管理仓库中,而在这个干净而贫瘠的世界中,它们无疑属于包管理仓库。
|
||||
|
||||
Emacs 要求将对 Emacs 体验不重要的内容转移到包管理仓库 ELPA 中。我的意思是,作为一个开发者,这是有道理的,但是……对于每一个被移出并流放到 ELPA 的包,我们都在蚕食 Emacs 的精髓。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: https://www.masteringemacs.org/article/fun-games-in-emacs
|
||||
|
||||
作者:[Mickey Petersen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.masteringemacs.org/about
|
||||
[b]:https://github.com/lujun9972
|
||||
[1]:https://en.wikipedia.org/wiki/Office_Space
|
||||
[2]:https://en.wikipedia.org/wiki/Tower_of_Hanoi
|
||||
[3]:https://www.masteringemacs.org/article/fun-emacs-calc
|
||||
[4]:http://www.xkcd.com
|
||||
[5]:https://en.wikipedia.org/wiki/Battleship_(game)
|
||||
[6]:https://www.masteringemacs.org/article/evaluating-elisp-emacs
|
||||
[7]:https://en.wikipedia.org/wiki/ELIZA
|
||||
[8]:https://en.wikipedia.org/wiki/Conway's_Game_of_Life
|
||||
@ -0,0 +1,161 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Some Advice for How to Make Emacs Tetris Harder)
|
||||
[#]: via: (https://nickdrozd.github.io/2019/01/14/tetris.html)
|
||||
[#]: author: (nickdrozd https://nickdrozd.github.io)
|
||||
|
||||
让 Emacs 俄罗斯方块变得更难的一些建议 (Advice)
|
||||
======
|
||||
|
||||
你知道吗,**Emacs** 与 **俄罗斯方块** 的实现捆绑在一起了?只需要输入 `M-x tetris` 就行了。
|
||||
|
||||
|
||||
|
||||
在文本编辑器讨论中,Emacs 倡导者经常提到这一点。“没错,但是那个编辑器能运行俄罗斯方块吗?”
|
||||
我很好奇,这会让大家相信 Emacs 更优秀吗?比如,为什么有人会关心他们是否可以在文本编辑器中玩游戏呢?“是的,但是那台吸尘器能播放 mp3 吗?”
|
||||
|
||||
有人说,俄罗斯方块总是很有趣的。像 Emacs 中的所有东西一样,它的源代码是开放的,易于检查和修改,因此 **我们可以使它变得更加有趣**。所谓更多的乐趣,我意思是更难。
|
||||
|
||||
让游戏变得更困难的一个最简单的方法就是“不要下一个块预览”。你无法再在知道下一个块会填满空间的情况下有意地将 S/Z 块放在一个危险的位置——你必须碰碰运气,希望出现最好的情况。
|
||||
下面是没有预览的情况(如你所见,没有预览,我做出的某些选择带来了“可怕的后果”):
|
||||
|
||||
|
||||
|
||||
预览框由一个名为 `tetris-draw-next-shape` 的函数设置:
|
||||
|
||||
```
|
||||
(defun tetris-draw-next-shape ()
|
||||
(dotimes (x 4)
|
||||
(dotimes (y 4)
|
||||
(gamegrid-set-cell (+ tetris-next-x x)
|
||||
(+ tetris-next-y y)
|
||||
tetris-blank)))
|
||||
(dotimes (i 4)
|
||||
(let ((tetris-shape tetris-next-shape)
|
||||
(tetris-rot 0))
|
||||
(gamegrid-set-cell (+ tetris-next-x
|
||||
(aref (tetris-get-shape-cell i) 0))
|
||||
(+ tetris-next-y
|
||||
(aref (tetris-get-shape-cell i) 1))
|
||||
tetris-shape))))
|
||||
```
|
||||
|
||||
首先,我们引入一个标志,决定是否允许显示下一个预览块:
|
||||
|
||||
```
|
||||
(defvar tetris-preview-next-shape nil
|
||||
"When non-nil, show the next block the preview box.")
|
||||
```
|
||||
|
||||
现在的问题是,我们如何才能让 `tetris-draw-next-shape` 遵从这个标志?最明显的方法是重新定义它:
|
||||
|
||||
```
|
||||
(defun tetris-draw-next-shape ()
|
||||
(when tetris-preview-next-shape
|
||||
;; existing tetris-draw-next-shape logic
|
||||
))
|
||||
```
|
||||
|
||||
但这不是理想的解决方案。同一个函数有两个定义,这很容易引起混淆,如果上游版本发生变化,我们必须维护修改后的定义。
|
||||
|
||||
一个更好的方法是使用 **advice**。Emacs 的 advice 类似于 **Python 装饰器**,但是更加灵活,因为 advice 可以从任何地方添加到函数中。这意味着我们可以修改函数而不影响原始的源文件。
|
||||
|
||||
有很多不同的方法使用 Emacs advice([ 查看手册 ][4]),但是这里我们只使用 `advice-add` 函数和 `:around` 标志。advise 函数将原始函数作为参数,原始函数可能执行也可能不执行。我们这里,我们让原始函数只有在预览标志是非空的情况下才能执行:
|
||||
|
||||
```
|
||||
(defun tetris-maybe-draw-next-shape (tetris-draw-next-shape)
|
||||
(when tetris-preview-next-shape
|
||||
(funcall tetris-draw-next-shape)))
|
||||
|
||||
(advice-add 'tetris-draw-next-shape :around #'tetris-maybe-draw-next-shape)
|
||||
```
|
||||
|
||||
这段代码将修改 `tetris-draw-next-shape` 的行为,而且它可以存储在配置文件中,与实际的俄罗斯方块代码分离。
|
||||
|
||||
去掉预览框是一个简单的改变。一个更激烈的变化是,**让块随机停止在空中**:
|
||||
|
||||
|
||||
|
||||
本图中,红色的 I 和绿色的 T 部分没有掉下来,它们被固定下来了。这会让游戏变得 **及其难玩**,但却很容易实现。
|
||||
|
||||
和前面一样,我们首先定义一个标志:
|
||||
|
||||
```
|
||||
(defvar tetris-stop-midair t
|
||||
"If non-nil, pieces will sometimes stop in the air.")
|
||||
```
|
||||
|
||||
目前,**Emacs 俄罗斯方块的工作方式** 类似这样子:活动部件有 x 和 y 坐标。在每个时钟滴答声中,y 坐标递增(块向下移动一行),然后检查是否有与现存的块重叠。
|
||||
如果检测到重叠,则将该块回退(其 y 坐标递减)并设置该活动块到位。为了让一个块在半空中停下来,我们所要做的就是破解检测函数 `tetris-test-shape`。
|
||||
|
||||
**这个函数内部做什么并不重要** —— 重要的是它是一个返回布尔值的无参数函数。我们需要它在正常情况下返回布尔值 true( 否则我们将出现奇怪的重叠情况),但在其他时候也需要它返回 true。我相信有很多方法可以做到这一点,以下是我的方法的:
|
||||
|
||||
```
|
||||
(defun tetris-test-shape-random (tetris-test-shape)
|
||||
(or (and
|
||||
tetris-stop-midair
|
||||
;; Don't stop on the first shape.
|
||||
(< 1 tetris-n-shapes )
|
||||
;; Stop every INTERVAL pieces.
|
||||
(let ((interval 7))
|
||||
(zerop (mod tetris-n-shapes interval)))
|
||||
;; Don't stop too early (it makes the game unplayable).
|
||||
(let ((upper-limit 8))
|
||||
(< upper-limit tetris-pos-y))
|
||||
;; Don't stop at the same place every time.
|
||||
(zerop (mod (random 7) 10)))
|
||||
(funcall tetris-test-shape)))
|
||||
|
||||
(advice-add 'tetris-test-shape :around #'tetris-test-shape-random)
|
||||
```
|
||||
|
||||
这里的硬编码参数使游戏变得更困难,但仍然可玩。当时我在飞机上喝醉了,所以它们可能需要进一步调整。
|
||||
|
||||
顺便说一下,根据我的 `tetris-scores` 文件,我的 **最高分** 是
|
||||
|
||||
```
|
||||
01389 Wed Dec 5 15:32:19 2018
|
||||
```
|
||||
|
||||
该文件中列出的分数默认最多为五位数,因此这个分数看起来不是很好。
|
||||
|
||||
**给读者的练习**
|
||||
|
||||
1。使用 advice 修改 Emacs 俄罗斯方块,使得每当方块下移动时就闪烁显示讯息 “OH SHIT”。消息的大小与块堆的高度成比例(当没有块时,消息应该很小的或不存在的,当最高块接近天花板时,消息应该很大)。
|
||||
|
||||
2。在这里给出的 `tetris-test-shape-random` 版本中,每隔七格就有一个半空中停止。一个玩家有可能能计算出时间间隔,并利用它来获得优势。修改它,使间隔随机在一些合理的范围内(例如,每 5 到 10 格)。
|
||||
|
||||
3。另一个对使用 Tetris 使用 advise 的场景,你可以试试 [`autotetris-mode`][1]。
|
||||
|
||||
4。想出一个有趣的方法来打乱块的旋转机制,然后使用 advice 来实现它。
|
||||
|
||||
|
||||
附注
|
||||
============================================================
|
||||
|
||||
[1][5] Emacs 只有一个巨大的全局命名空间,因此函数和变量名一般以包名做前缀以避免冲突。
|
||||
|
||||
[2][6] 很多人会说你不应该使用已有的命名空间前缀而且应该将自己定义的所有东西都放在一个预留的命名空间中,比如像这样 `my/tetris-preview-next-shape`,然而这样很难看而且没什么意义,因此我不会这么干。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://nickdrozd.github.io/2019/01/14/tetris.html
|
||||
|
||||
作者:[nickdrozd][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://nickdrozd.github.io
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://nullprogram.com/blog/2014/10/19/
|
||||
[2]: https://nickdrozd.github.io/2019/01/14/tetris.html#fn.1
|
||||
[3]: https://nickdrozd.github.io/2019/01/14/tetris.html#fn.2
|
||||
[4]: https://www.gnu.org/software/emacs/manual/html_node/elisp/Advising-Functions.html
|
||||
[5]: https://nickdrozd.github.io/2019/01/14/tetris.html#fnr.1
|
||||
[6]: https://nickdrozd.github.io/2019/01/14/tetris.html#fnr.2
|
||||
@ -1,111 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (zhangxiangping)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (12 open source tools for natural language processing)
|
||||
[#]: via: (https://opensource.com/article/19/3/natural-language-processing-tools)
|
||||
[#]: author: (Dan Barker https://opensource.com/users/barkerd427)
|
||||
|
||||
12种自然语言处理的开源工具
|
||||
======
|
||||
|
||||
看看可以用在你自己NLP应用中的十几个工具吧。
|
||||
|
||||
![Chat bubbles][1]
|
||||
|
||||
在过去的几年里,自然语言处理(NLP)推动了聊天机器人、语音助手、文本预测,这些在我们的日常生活中常用的语音或文本应用程技术的发展。目前有着各种各样开源的NLP工具,所以我决定调查一下当前开源的NLP工具来帮助您制定您开发下一个基于语音或文本的应用程序的计划。
|
||||
|
||||
我将从我所熟悉的编程语言出发来介绍这些工具,尽管我对这些工具不是很熟悉(我没有在我不熟悉的语言中找工具)。也就是说,出于各种原因,我排除了三种我熟悉的语言中的工具。
|
||||
|
||||
R语言是没有被包含在内的,因为我发现的大多数库都有一年多没有更新了。这并不总是意味着他们没有得到很好的维护,但我认为他们应该得到更多的更新,以便和同一领域的其他工具竞争。我还选择了最有可能在生产场景中使用的语言和工具(而不是在学术界和研究中使用),虽然我主要是使用R作为研究和发现工具。
|
||||
|
||||
我发现Scala的很多库都没有更新了。我上次使用Scala已经有好几年了,当时它非常流行。但是大多数库从那个时候就再没有更新过,或者只有少数一些有更新。
|
||||
|
||||
最后,我排除了C++。这主要是因为我在的公司很久没有使用C++来进行NLP或者任何数据科学的工作。
|
||||
|
||||
### Python工具
|
||||
#### Natural Language Toolkit (NLTK)
|
||||
|
||||
[Natural Language Toolkit (NLTK)][2]是我调研的所有工具中功能最完善的一个。它完美地实现了自然语言处理中多数功能组件,比如分类,令牌化,词干化,标注,分词和语义推理。每一种方法都有多种不同的实现方式,所以你可以选择具体的算法和方式去使用它。同时,它也支持不同语言。然而,它将所有的数据都表示为字符串的形式,对于一些简单的数据结构来说可能很方便,但是如果要使用一些高级的功能来说就可能有点困难。它的使用文档有点复杂,但也有很多其他人编写的使用文档,比如[a great book][3]。和其他的工具比起来,这个工具库的运行速度有点慢。但总的来说,这个工具包非常不错,可以用于需要具体算法组合的实验,探索和实际应用当中。
|
||||
|
||||
#### SpaCy
|
||||
|
||||
[SpaCy][4]是NLTK的主要竞争者。在大多数情况下都比NLTK的速度更快,但是SpaCy对自然语言处理的功能组件只有单一实现。SpaCy把所有的东西都表示为一个对象而不是字符串,这样就能够为构建应用简化接口。这也方便它能够集成多种框架和数据科学的工具,使得你更容易理解你的文本数据。然而,SpaCy不像NLTK那样支持多种语言。它对每个接口都有一些简单的选项和文档,包括用于语言处理和分析各种组件的多种神经网络模型。总的来说,如果创造一个新的应用的生产过程中不需要使用特定的算法的话,这是一个很不错的工具。
|
||||
|
||||
#### TextBlob
|
||||
|
||||
[TextBlob][5]是NLTK的一个扩展库。你可以通过TextBlob用一种更简单的方式来使用NLTK的功能,TextBlob也包括了Pattern库中的功能。如果你刚刚开始学习,这将会是一个不错的工具可以用于生产对性能要求不太高的应用。TextBlob适用于任何场景,但是对小型项目会更加合适。
|
||||
|
||||
#### Textacy
|
||||
|
||||
这个工具是我用过的名字最好听的。读"[Textacy][6]" 时先发出"ex"再发出"cy"。它不仅仅是名字好,同时它本身也是一个很不错的工具。它使用SpaCy作为它自然语言处理核心功能,但它在处理过程的前后做了很多工作。如果你想要使用SpaCy,你可以先使用Textacy,从而不用去多写额外的附加代码你就可以处理不同种类的数据。
|
||||
|
||||
#### PyTorch-NLP
|
||||
|
||||
[PyTorch-NLP][7]才出现短短的一年,但它已经有一个庞大的社区了。它适用于快速原型开发。当公司或者研究人员推出很多其他工具去完成新奇的处理任务,比如图像转换,它就会被更新。PyTorch的目标用户是研究人员,但它也能用于原型开发,或在最开始的生产任务中使用最好的算法。基于此基础上的创建的库也是值得研究的。
|
||||
|
||||
### 节点工具
|
||||
|
||||
#### Retext
|
||||
|
||||
[Retext][8]是[unified collective][9]的一部分。Unified是一个接口,能够集成不同的工具和插件以便他们能够高效的工作。Retext是unified工具集三个中的一个,另外的两个分别是用于markdown编辑的Remark和用于HTML处理的Rehype。这是一个非常有趣的想法,我很高兴看到这个社区的发展。Retext没有暴露过多的底层技术,更多的是使用插件去完成你在NLP任务中想要做的事情。拼写检查,固定排版,情绪检测和可读性分析都可以用简单的插件来完成。如果你不想了解底层处理技术又想完成你的任务的话,这个工具和社区是一个不错的选择。
|
||||
|
||||
#### Compromise
|
||||
|
||||
如果你在找拥有最高级的功能和最复杂的系统的工具的话,[Compromise][10]不是你的选择。 然而,如果你想要一个性能好,应用广泛,还能在客户端运行的工具的话,Compromise值得一试。实际上,它的名字是准确的,因为作者更关注更具体功能的小软件包,而在功能性和准确性上做出了牺牲,这些功能得益于用户对使用环境的理解。
|
||||
|
||||
#### Natural
|
||||
|
||||
[Natural][11]包含了一般自然语言处理库所具有的大多数功能。它主要是处理英文文本,但也包括一些其他语言,它的社区也支持额外的语言。它能够进行令牌化,词干化,分类,语音处理,词频-逆文档频率计算(TF-IDF),WordNet,字符相似度计算和一些变换。它和NLTK有的一比,因为它想要把所有东西都包含在一个包里头,使用方便但是可能不太适合专注的研究。总的来说,这是一个不错的功能齐全的库,目前仍在开发但可能需要对底层实现有更多的了解才能完更有效。
|
||||
|
||||
#### Nlp.js
|
||||
|
||||
[Nlp.js][12]是在其他几个NLP库上开发的,包括Franc和Brain.js。它提供了一个能很好支持NLP组件的接口,比如分类,情感分析,词干化,命名实体识别和自然语言生成。它也支持一些其他语言,在你处理除了英语之外的语言时也能提供一些帮助。总之,它是一个不错的通用工具,能够提供简单的接口去调用其他工具。在你需要更强大或更灵活的工具之前,这个工具可能会在你的应用程序中用上很长一段时间。
|
||||
|
||||
### Java工具
|
||||
#### OpenNLP
|
||||
|
||||
[OpenNLP][13]是由Apache基金会维护的,所以它可以很方便地集成到其他Apache项目中,比如Apache Flink,Apache NiFi和Apache Spark。这是一个通用的NLP工具,包含了所有NLP组件中的通用功能,可以通过命令行或者以包的形式导入到应用中来使用它。它也支持很多种语言。OpenNLP是一个很高效的工具,包含了很多特性,如果你用Java开发生产的话,它是个很好的选择。
|
||||
|
||||
#### StanfordNLP
|
||||
|
||||
[Stanford CoreNLP][14]是一个工具集,提供了基于统计的,基于深度学习和基于规则的NLP功能。这个工具也有许多其他编程语言的版本,所以可以脱离Java来使用。它是由高水平的研究机构创建的一个高效的工具,但在生产环境中可能不是最好的。此工具具有双重许可,并具有可以用于商业目的的特殊许可。总之,在研究和实验中它是一个很棒的工具,但在生产系统中可能会带来一些额外的开销。比起Java版本来说,读者可能对它的Python版本更感兴趣。斯坦福教授在Coursera上教的最好的机器学习课程之一,[点此][15]访问其他不错的资源。
|
||||
|
||||
#### CogCompNLP
|
||||
|
||||
[CogCompNLP][16]由伊利诺斯大学开发的一个工具,它也有一个相似功能的Python版本事项。它可以用于处理文本,包括本地处理和远程处理,能够极大地缓解你本地设备的压力。它提供了很多处理函数,比如令牌化,词性分析,标注,断句,命名实体标注,词型还原,依存分析和语义角色标注。它是一个很好的研究工具,你可以自己探索它的不同功能。我不确定它是否适合生产环境,但如果你使用Java的话,它值得一试。
|
||||
|
||||
* * *
|
||||
|
||||
你最喜欢的开源的NLP工具和库是什么?请在评论区分享文中没有提到的工具。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/natural-language-processing-tools
|
||||
|
||||
作者:[Dan Barker (Community Moderator)][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[zxp](https://github.com/zhangxiangping)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/barkerd427
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/talk_chat_communication_team.png?itok=CYfZ_gE7 (Chat bubbles)
|
||||
[2]: http://www.nltk.org/
|
||||
[3]: http://www.nltk.org/book_1ed/
|
||||
[4]: https://spacy.io/
|
||||
[5]: https://textblob.readthedocs.io/en/dev/
|
||||
[6]: https://readthedocs.org/projects/textacy/
|
||||
[7]: https://pytorchnlp.readthedocs.io/en/latest/
|
||||
[8]: https://www.npmjs.com/package/retext
|
||||
[9]: https://unified.js.org/
|
||||
[10]: https://www.npmjs.com/package/compromise
|
||||
[11]: https://www.npmjs.com/package/natural
|
||||
[12]: https://www.npmjs.com/package/node-nlp
|
||||
[13]: https://opennlp.apache.org/
|
||||
[14]: https://stanfordnlp.github.io/CoreNLP/
|
||||
[15]: https://opensource.com/article/19/2/learn-data-science-ai
|
||||
[16]: https://github.com/CogComp/cogcomp-nlp
|
||||
@ -0,0 +1,165 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Use Emacs to get social and track your todo list)
|
||||
[#]: via: (https://opensource.com/article/20/1/emacs-social-track-todo-list)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
|
||||
|
||||
使用 Emacs 进行社交并跟踪你的待办事项列表
|
||||
======
|
||||
访问 Twitter、Reddit、 交谈、电子邮件 、RSS 和你的待办事项列表,这是我们关于 2020 年使用开源提高效率的 20 个方法系列的第 19 个。
|
||||
![团队沟通、交谈 ][1]
|
||||
|
||||
去年,我给你们带来了 2019 年的 19 天新生产力工具。今年,我将采取一种不同的方法:建立一个新的环境,让你使用已用或未用的工具在新的一年里更有效率,。
|
||||
|
||||
### 使用 Emacs 做(几乎)所有的事情,第 2 部分
|
||||
|
||||
[昨天 ][2],我谈到了如何在 Emacs 中读取电子邮件、访问电子邮件地址和显示日历。Emacs 功能繁多,你还可以将它用于 Twitter、 交谈、待办事项列表等等!
|
||||
|
||||
[在 Emacs 中处理所有事情 ][3]
|
||||
|
||||
要完成所有这些,您需要安装一些 Emacs 包。和昨天一样,用 `Meta+x package-manager` 打开 Emacs 包管理器 (Meta 在大多数键盘上是 **Alt**,在 MacOS 上是 **Option**)。然后通过 **i** 选择以下带有的软件包,然后输入 **x** 进行安装:
|
||||
|
||||
|
||||
```
|
||||
nnreddit
|
||||
todotxt
|
||||
twittering-mode
|
||||
```
|
||||
|
||||
安装之后,按下 `Ctrl+x ctrl+f` 打开 `~/.emacs.d/init.el`,并在 `(custom-set-variables` 行前加上:
|
||||
|
||||
|
||||
```
|
||||
;; Todo.txt
|
||||
(require 'todotxt)
|
||||
(setq todotxt-file (expand-file-name "~/.todo/todo.txt"))
|
||||
|
||||
;; Twitter
|
||||
(require 'twittering-mode)
|
||||
(setq twittering-use-master-password t)
|
||||
(setq twittering-icon-mode t)
|
||||
|
||||
;; Python3 for nnreddit
|
||||
(setq elpy-rpc-python-command "python3")
|
||||
```
|
||||
|
||||
按下 `Ctrl+x Ctrl+s` 保存文件,使用 `Ctrl+x Ctrl+c` 退出 Emacs,然后重启 Emacs。
|
||||
|
||||
#### 使用 twittering-mode 在 Emacs 中发推
|
||||
|
||||
![Emacs 中的 Twitter][4]
|
||||
|
||||
[Twittering-mode][5] 是 Twitter 最好的 Emacs 接口之一。它几乎支持 Twitter 的所有功能,并且键盘快捷键也易于使用。
|
||||
|
||||
首先,输入 `Meta+x twit` 来启动 twitter-mode。它会提供一个 URL 并提示你启动浏览器来访问它,你登录该 URL 后就能获得授权令牌。将令牌复制并粘贴到 Emacs 中,您的 Twitter 时间线就会加载了。您可以使用**箭头**键滚动,使用 **Tab** 从一个项目移动到另一个项目,并按 **Enter** 访问光标所在的 URL。如果光标在用户名上,按 **Enter** 将在 web 浏览器中打开时间轴。如果你在一条 tweet 的文本上,按 **Enter** 将回复该 tweet。你可以用 **u** 创建一个新的 tweet,用 `Ctrl+c+Enter` 转发一些内容,然后用 **d** 发送一条直接消息——它打开的对话框中有关于如何发送、取消和缩短 url 的说明。
|
||||
|
||||
按 **V** 会打开一个提示让你跳转到其他时间线。输入 **:mentions** 打开你的提及。输入 **:home** 打开你的主时间线,输入用户名将进入该用户的时间线。最后,按 **q** 会退出 twittering-mode 并关闭窗口。
|
||||
|
||||
twitter-mode 还有更多功能,我鼓励你阅读它 GitHub 页面上的[完整功能列表 ][6]。
|
||||
|
||||
#### 在 Emacs 上使用 Todotxt.el 追踪你的待办事项
|
||||
|
||||
![Emacs 中的 todo.txt][7]
|
||||
|
||||
[Todotxt.el][8] 是一个很棒的 [todo.txt][9] 待办列表管理器接口。它的快捷键几乎无所不包。
|
||||
|
||||
输入 `Meta+x todotxt` 启动它将加载 **todotxt-file** 变量中指定的 todo.txt 文件(本文的第一部分中设置了该文件)。
|
||||
在 todo.txt 的缓冲区(窗口*,您可以按 **a** 添加新任务并和按 **c** 标记它已被完成。你还可以使用 **r** 设置优先级,并使用 **t** 添加项目和上下文。
|
||||
完成事项后只需要按下 **A** 即可将任务移如 **done.txt**。你可以使用**/**过滤列表,也可以使用 **l** 刷新完整列表。同样,您可以按 **q** 退出。
|
||||
|
||||
#### 在 Emacs 中使用 ERC 进行交谈
|
||||
|
||||
![使用 ERC 与人交谈 ][10]
|
||||
|
||||
Vim 的缺点之一是很难用它与人交谈。另一方面,Emacs 则将 [ERC][11] 客户端内置到默认发行版中。使用 `Meta+x ERC` 启动 ERC,系统将提示您输入服务器、用户名和密码。你可以使用几天前介绍设置 [BitlBee][12] 时使用的相同信息:服务器为 **localhost**,端口为 **6667**,相同用户名,无需密码。
|
||||
ERC 使用起来与其他 IRC 客户端一样。每个频道单独一个缓冲区(窗口),您可以使用 `Ctrl+x ctrl+b` 进行频道间切换,这也可以在 Emacs 中的其他缓冲区之间进行切换。`/quit` 命令将退出 ERC。
|
||||
|
||||
#### 使用 Gnus 阅读电子邮件,Reddit 和 RSS
|
||||
|
||||
![Mail,Reddit,and RSS feeds with Gnus][13]
|
||||
|
||||
我相信昨天在我提及在 Emacs 中阅读邮件时,许多 Emacs 的老用户会问,“怎么没有 [Gnus][14] 呢?”
|
||||
这个疑问很合理。Gnus 是一个内置在 Emacs 中的邮件和新闻阅读器,尽管它这个邮件阅读器不支持以 [Notmuch][15] 作为搜索引擎。但是,如果你将其配置来阅读 Reddit 和 RSS feed( 稍后您将这样做),那么同时使用它来阅读邮件是个聪明的选择。
|
||||
|
||||
Gnus 是为阅读 Usenet 新闻而创建的,并从此发展而来。因此,它的很多外观和感觉(以及术语)看起来很像 Usenet 的新闻阅读器。
|
||||
|
||||
Gnus 以 `~/.gnus` 作为自己的配置文件。(该配置也可以包含在 `~/.emacs.d/init.el` 中)。使用 `Ctrl+x Ctrl+f` 打开 `~/.gnus`,并添加以下内容:
|
||||
|
||||
|
||||
```
|
||||
;; Required packages
|
||||
(require 'nnir)
|
||||
(require 'nnrss)
|
||||
|
||||
;; Primary Mailbox
|
||||
(setq gnus-select-method
|
||||
'(nnmaildir "Local"
|
||||
(directory "~/Maildir")
|
||||
(nnir-search-engine notmuch)
|
||||
))
|
||||
(add-to-list 'gnus-secondary-select-methods
|
||||
'(nnreddit ""))
|
||||
```
|
||||
|
||||
用 `Ctrl+x Ctrl+s` 保存文件。这分配置告诉 Gnus 从 `~/Maildir` 这个本地邮箱中读取邮件作为主源(参见 **gnus-select-method** 变量),并使用 [nnreddit][16] 插件添加辅源 (**gnus-secondary-select-methods** 变量)。你还可以定义多个辅助源,包括 Usenet 新闻 (nntp)、IMAP (nnimap)、mbox (nnmbox) 和虚拟集合 (nnvirtual)。您可以在 [Gnus 手册 ][17] 中了解更多有关所有选项的信息。
|
||||
|
||||
保存文件后,使用 `Meta+x Gnus` 启动 Gnus。第一次运行将在 Python 虚拟环境中安装 [Reddit 终端查看器 ][18],Gnus 通过它获取 Reddit 上的文章。然后它会启动浏览器来登录 Reddit。之后,它会扫描并加载你订阅的 Reddit 群组。你会看到一个有新邮件的邮件夹列表和一个有新内容的看板列表。在任一列表上按 **Enter** 将加载该组中的消息列表。您可以使用**箭头**键导航并按 **Enter** 加载和读取消息。在查看消息列表时,按 **q** 将返回到前一个视图,从主窗口按 **q** 将退出 Gnus。在阅读 Reddit 群组时,**a** 会创建一条新消息;在邮件组中,**m** 创建一个新的电子邮件;并且在任何一个视图中按 **r** 回复邮件。
|
||||
|
||||
您还可以向 Gnus 接口中添加 RSS feed,并像阅读邮件和新闻组一样阅读它们。要添加 RSS feed,输入 `G+R` 并填写 RSS feed 的 URL。会有提示让你输入 feed 的标题和描述,这些信息可以从 feed 中提取出来并填充进去。现在输入 **g** 来检查新消息(这将检查所有组中的新消息)。阅读 feed 就像阅读 Reddit 群组和邮件一样,它们使用相同的快捷键。
|
||||
|
||||
Gnus 中有_很多_功能,还有大量的键组合。[Gnus 参考卡 ][19] 为每个视图列出了所有这些键组合(以非常小的字体显示在 5 页纸上)。
|
||||
|
||||
#### 使用 nyan-mode 查看位置
|
||||
|
||||
As a final note,you might notice [Nyan cat][20] at the bottom of some of my screenshots。This is [nyan-mode][21],which indicates where you are in a buffer,so it gets longer as you get closer to the bottom of a document or buffer。You can install it with the package manager and set it up with the following code in **~/.emacs.d/init.el**:
|
||||
最后,你可能会一些截屏底部注意到 [Nyan cat][20]。这是 [nyan-mode][21],它指示了你在缓冲区中的位置,因此当您接近文档或缓冲区的底部时,它会变长。您可以使用包管理器安装它,并在 `~/.emacs.d/init.el` 中使用以下代码进行设置:
|
||||
|
||||
|
||||
```
|
||||
;; Nyan Cat
|
||||
(setq nyan-wavy-trail t)
|
||||
(setq nyan-bar-length 20)
|
||||
(nyan-mode)
|
||||
```
|
||||
|
||||
### Emacs 的皮毛
|
||||
|
||||
这只是 Emacs 所有功能的皮毛。Emacs_ 非常_强大,是我用来提高工作效率的必要工具之一,无论我是在追踪待办事项、阅读和回复邮件、编辑文本,还是与朋友和同事交流我都用它。这需要一点时间来适应,但是一旦你习惯了,它就会成为你桌面上最有用的工具之一。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/1/emacs-social-track-todo-list
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/talk_chat_team_mobile_desktop.png?itok=d7sRtKfQ (Team communication, chat)
|
||||
[2]: https://opensource.com/article/20/1/emacs-mail-calendar
|
||||
[3]: https://opensource.com/sites/default/files/uploads/productivity_19-1.png (All the things with Emacs)
|
||||
[4]: https://opensource.com/sites/default/files/uploads/productivity_19-2.png (Twitter in Emacs)
|
||||
[5]: https://github.com/hayamiz/twittering-mode
|
||||
[6]: https://github.com/hayamiz/twittering-mode#features
|
||||
[7]: https://opensource.com/sites/default/files/uploads/productivity_19-3.png (todo.txt in emacs)
|
||||
[8]: https://github.com/rpdillon/todotxt.el
|
||||
[9]: http://todotxt.org/
|
||||
[10]: https://opensource.com/sites/default/files/uploads/productivity_19-4.png (Chatting with erc)
|
||||
[11]: https://www.gnu.org/software/emacs/manual/html_mono/erc.html
|
||||
[12]: https://opensource.com/article/20/1/open-source-chat-tool
|
||||
[13]: https://opensource.com/sites/default/files/uploads/productivity_19-5.png (Mail, Reddit, and RSS feeds with Gnus)
|
||||
[14]: https://www.gnus.org/
|
||||
[15]: https://opensource.com/article/20/1/organize-email-notmuch
|
||||
[16]: https://github.com/dickmao/nnreddit
|
||||
[17]: https://www.gnus.org/manual/gnus.html
|
||||
[18]: https://pypi.org/project/rtv/
|
||||
[19]: https://www.gnu.org/software/emacs/refcards/pdf/gnus-refcard.pdf
|
||||
[20]: http://www.nyan.cat/
|
||||
[21]: https://github.com/TeMPOraL/nyan-mode
|
||||
@ -1,83 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qianmingtian)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Give an old MacBook new life with Linux)
|
||||
[#]: via: (https://opensource.com/article/20/2/macbook-linux-elementary)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||
|
||||
用 Linux 给旧 MacBook 以新生
|
||||
======
|
||||
|
||||
Elementary OS 的最新版本 Hera 是一个令人印象深刻的平台,它让过时的 MacBook 得以重生。
|
||||
|
||||
![Coffee and laptop][1]
|
||||
|
||||
当我安装苹果的 [MacOS Mojave][2] 时,它使我以前可靠的 MacBook Air 运行变慢了。我的计算机于 2015 年发布,具有 4 GB 内存, i5 处理器和 Broadcom 4360 无线卡,但是 Mojava 提供的日常驱动程序使 [GnuCash][3] 不可用,这激起了我重返 Linux 的欲望。我很高兴能做到这一点,但是我感到非常遗憾的是,我的这台 MacBook 被闲置了。
|
||||
|
||||
我在 MacBook Air 上尝试了几种 Linux 发行版,但总是会有陷阱。有时是无线网卡;还有一次,它缺少对触摸板的支持。看了一些不错的评论后,我决定尝试 [Elementary OS][4] 5.0(Juno)。我用 USB [制作了启动盘][5],并将其插入 MacBook Air 。我来到了一个实时桌面,并且操作系统识别了我的 Broadcom 无线芯片组-我认为这可能已经正常工作了!
|
||||
|
||||
我喜欢在 Elementary OS 中看到的内容。它的 [Pantheon][6] 桌面真的很棒,并且其外观和使用起来的感觉对 Apple 用户来说很熟悉-它的显示屏底部有一个底座,并带有可引导常用应用程序的图标。我喜欢我之前期待的预览,所以我决定安装它,然后我的无线设备消失了。真的很令人失望。我真的很喜欢 Elementary OS ,但是没有无线是不行的。
|
||||
|
||||
时间快进到 2019 年 12 月,当我在 [Linux4Everyone][7] 播客上听到有关 Elementary 最新版本 v.5.1(Hera) 使MacBook复活的评论时,我决定用 Hera 再试一次。我下载了 ISO ,创建了可启动驱动器,将其插入电脑,这次操作系统识别了我的无线网卡。我可以在上面工作了。
|
||||
|
||||
![MacBook Air with Hera][8]
|
||||
|
||||
我非常高兴我轻巧又功能强大的 MacBook Air 通过 Linux 焕然一新。我一直在更详细地研究 Elementary OS ,我可以告诉你我印象深刻的东西。
|
||||
|
||||
### Elementary OS 的功能
|
||||
|
||||
根据 [Elementary 的博客][9],“新设计的登录和锁定屏幕问候语看起来更清晰,效果更好,并且修复了以前问候语中报告的许多问题,包括焦点问题, HiDPI 问题和更好的本地化。 Hera 的新设计是为了响应来自 Juno 的用户反馈,并启用了一些不错的新功能。”
|
||||
|
||||
轻描淡写的“不错的新功能” — Elementary OS 拥有我见过的最佳设计的 Linux 用户界面之一。默认情况下,系统上的“系统设置”图标位于扩展坞上。更改设置很容易,很快我就按照自己的喜好配置了系统。我需要的文字大小比默认值大,辅助功能要易于使用并且允许我设置大文字和高对比度。我还可以使用较大的图标和其他选项来调整底座。
|
||||
|
||||
![Elementary OS 的设置界面][10]
|
||||
|
||||
按下 Mac 的 Command 键将弹出一个键盘快捷键列表,这对新用户非常有帮助。
|
||||
|
||||
![Elementary OS' 的键盘快捷键][11]
|
||||
|
||||
Elementary OS 附带的 [Epiphany][12] Web 浏览器,我发现它非常易于使用。 它与 Chrome , Chromium 或 Firefox 略有不同,但它已经绰绰有余。
|
||||
|
||||
对于注重安全的用户(我们应该都是), Elementary OS 的安全和隐私设置提供了多个选项,包括防火墙,历史记录,锁定,临时和垃圾文件的自动删除以及用于位置服务开/关的开关。
|
||||
|
||||
![Elementary OS 的隐私与安全][13]
|
||||
|
||||
### 有关 Elementray OS 的更多信息
|
||||
|
||||
Elementary OS 最初于 2011 年发布,其最新版本 Hera 于 2019 年 12 月 3 日发布。 Elementary 的联合创始人兼 CXO 的 [Cassidy James Blaede][14] 是操作系统的 UX 架构师。 Cassidy 喜欢使用开放技术来设计和构建有用,可用和令人愉悦的数字产品。
|
||||
|
||||
Elementary OS 具有出色的用户[文档][15],其代码(在 GPL 3.0 下许可)可在 [GitHub][16] 上获得。 Elementary OS 鼓励参与该项目,因此请务必伸出援手并[加入社区][17]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/macbook-linux-elementary
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qianmingtian][c]
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[b]: https://github.com/lujun9972
|
||||
[c]: https://github.com/qianmingtian
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/coffee_cafe_brew_laptop_desktop.jpg?itok=G-n1o1-o (Coffee and laptop)
|
||||
[2]: https://en.wikipedia.org/wiki/MacOS_Mojave
|
||||
[3]: https://www.gnucash.org/
|
||||
[4]: https://elementary.io/
|
||||
[5]: https://opensource.com/life/14/10/test-drive-linux-nothing-flash-drive
|
||||
[6]: https://opensource.com/article/19/12/pantheon-linux-desktop
|
||||
[7]: https://www.linux4everyone.com/20-macbook-pro-elementary-os
|
||||
[8]: https://opensource.com/sites/default/files/uploads/macbookair_hera.png (MacBook Air with Hera)
|
||||
[9]: https://blog.elementary.io/introducing-elementary-os-5-1-hera/
|
||||
[10]: https://opensource.com/sites/default/files/uploads/elementaryos_settings.png (Elementary OS's Settings screen)
|
||||
[11]: https://opensource.com/sites/default/files/uploads/elementaryos_keyboardshortcuts.png (Elementary OS's Keyboard shortcuts)
|
||||
[12]: https://en.wikipedia.org/wiki/GNOME_Web
|
||||
[13]: https://opensource.com/sites/default/files/uploads/elementaryos_privacy-security.png (Elementary OS's Privacy and Security screen)
|
||||
[14]: https://github.com/cassidyjames
|
||||
[15]: https://elementary.io/docs/learning-the-basics#learning-the-basics
|
||||
[16]: https://github.com/elementary
|
||||
[17]: https://elementary.io/get-involved
|
||||
@ -1,228 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Morisun029)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (3 ways to use PostgreSQL commands)
|
||||
[#]: via: (https://opensource.com/article/20/2/postgresql-commands)
|
||||
[#]: author: (Greg Pittman https://opensource.com/users/greg-p)
|
||||
|
||||
3种使用 PostgreSQL 命令的方式
|
||||
======
|
||||
无论你需要的东西简单(如一个购物清单)亦或复杂(如色卡生成器)
|
||||
PostgreSQL 命令都能使它变得容易起来。
|
||||
|
||||
![Team checklist and to dos][1]
|
||||
|
||||
在 _[PostgreSQL 入门][2]_ 一文中, 我解释了如何安装,设置和开始使用开源数据库软件。然而,使用 [PostgreSQL][3] 中的命令可以做更多事情。
|
||||
|
||||
例如,我使用 Postgres 来跟踪我杂货店的购物清单。我杂货店里的大多数购物是在家里进行的,其中每周进行一次大批量的采购。我去几个不同的地方购买清单上的东西,因为每家商店都提供特定的选择或质量,亦或更好的价格。最初,我制作了一个HTML表单页面来管理我的购物清单,但这样无法保存我的输入内容。因此,在想到要购买的物品时我必须要马上列出清单,因为到采购时我常常会忘记一些我需要或想要的东西。
|
||||
|
||||
相反,使用 PostgreSQL,当我想到需要的物品时,我可以随时输入,并在购物前打印出来。你也可以这样做。
|
||||
|
||||
|
||||
### 创建一个简单的购物清单
|
||||
|
||||
|
||||
首先,数据库中输入**psql ** 命令,然后用下面的命令创建一个表:
|
||||
```
|
||||
`Create table groc (item varchar(20), comment varchar(10));`
|
||||
```
|
||||
|
||||
输入如下命令在清单中加入商品:
|
||||
|
||||
```
|
||||
insert into groc values ('milk', 'K');
|
||||
insert into groc values ('bananas', 'KW');
|
||||
```
|
||||
|
||||
括号中有两个信息(逗号隔开):前面是你需要买的东西,后面字母代表你要购买的地点以及哪些东西是你每周通常都要买的(W)。
|
||||
|
||||
因为 **psql** 有历史记录,你可以按向上键在括号内编辑信息,而无需输入商品的整行信息。
|
||||
|
||||
在输入一小部分商品后,输入下面命令来检查前面的输入内容。
|
||||
|
||||
```
|
||||
Select * from groc order by comment;
|
||||
|
||||
item | comment
|
||||
\----------------+---------
|
||||
ground coffee | H
|
||||
butter | K
|
||||
chips | K
|
||||
steak | K
|
||||
milk | K
|
||||
bananas | KW
|
||||
raisin bran | KW
|
||||
raclette | L
|
||||
goat cheese | L
|
||||
onion | P
|
||||
oranges | P
|
||||
potatoes | P
|
||||
spinach | PW
|
||||
broccoli | PW
|
||||
asparagus | PW
|
||||
cucumber | PW
|
||||
sugarsnap peas | PW
|
||||
salmon | S
|
||||
(18 rows)
|
||||
```
|
||||
|
||||
此命令按_comment_ 列对结果进行排序,以便按购买地点对商品进行分组,从而是你的购物更加方便。
|
||||
|
||||
使用W来指明你每周要买的东西,当你要清除表单为下周的列表做准备时,你可以将每周的商品保留在购物清单上。输入:
|
||||
|
||||
```
|
||||
`delete from groc where comment not like '%W';`
|
||||
```
|
||||
|
||||
注意,在 PostgreSQL 中 **%** 表示通配符(而非星号)。所以,要保存输入内容,需要输入:
|
||||
|
||||
```
|
||||
`delete from groc where item like 'goat%';`
|
||||
```
|
||||
|
||||
不能使用**item = 'goat%'**,这样没用。
|
||||
|
||||
|
||||
在购物时,用以下命令输出清单并打印出来发送到你的手机:
|
||||
|
||||
```
|
||||
\o groclist.txt
|
||||
select * from groc order by comment;
|
||||
\o
|
||||
```
|
||||
|
||||
最后一个命令**\o*,重置输出到命令行。否则,所有的输出会继续输出到你创建的杂货店购物文件中。
|
||||
|
||||
### 分析复杂的表
|
||||
|
||||
This item-by-item entry may be okay for short tables, but what about really big ones? A couple of years ago, I was helping the team at [FreieFarbe.de][4] to create a swatchbook of the free colors (freieFarbe means "free colors" in German) from its HLC color palette, where virtually any imaginable print color can be specified by its hue, luminosity (brightness), and chroma (saturation). The result was the [HLC Color Atlas][5], and here's how we did it.
|
||||
|
||||
逐个输入对于数据量小的表来说没有问题,但是对于数据量大的表呢?几年前,我帮团队从 HLC 调色板中创建一个自由色的色样册。事实上,任何能想象到的打印色都可按色调、亮度、浓度(饱和度)来规定。最终结果是[HLC Color Atlas][5],下面是我们如何实现的。
|
||||
|
||||
该团队向我发送了具有颜色规范的文件,因此我可以编写可与 Scribus 配合使用的 Python 脚本,以轻松生成色样册。一个例子像这样开始:
|
||||
|
||||
|
||||
```
|
||||
HLC, C, M, Y, K
|
||||
H010_L15_C010, 0.5, 49.1, 0.1, 84.5
|
||||
H010_L15_C020, 0.0, 79.7, 15.1, 78.9
|
||||
H010_L25_C010, 6.1, 38.3, 0.0, 72.5
|
||||
H010_L25_C020, 0.0, 61.8, 10.6, 67.9
|
||||
H010_L25_C030, 0.0, 79.5, 18.5, 62.7
|
||||
H010_L25_C040, 0.4, 94.2, 17.3, 56.5
|
||||
H010_L25_C050, 0.0, 100.0, 15.1, 50.6
|
||||
H010_L35_C010, 6.1, 32.1, 0.0, 61.8
|
||||
H010_L35_C020, 0.0, 51.7, 8.4, 57.5
|
||||
H010_L35_C030, 0.0, 68.5, 17.1, 52.5
|
||||
H010_L35_C040, 0.0, 81.2, 22.0, 46.2
|
||||
H010_L35_C050, 0.0, 91.9, 20.4, 39.3
|
||||
H010_L35_C060, 0.1, 100.0, 17.3, 31.5
|
||||
H010_L45_C010, 4.3, 27.4, 0.1, 51.3
|
||||
```
|
||||
|
||||
这与原文件相比,稍有修改,将数据用制表符分隔。我将其转换成 CSV 格式(逗号分割值),我更喜欢其与 Python 一起使用(CSV 文也很有用因为它可轻松导入到电子表格程序中)。
|
||||
|
||||
在每一行中,第一项是颜色名称,其后是其 C,M,Y 和 K 颜色值。 该文件包含1,793种颜色,我想要一种分析信息的方法,以了解这些值的范围。 这就是 PostgreSQL 发挥作用的地方。 我不想手动输入所有数据-我认为输入过程中我不可能不出错。 幸运的是,PostgreSQL 为此提供了一个命令。
|
||||
|
||||
首先用以下命令创建数据库:
|
||||
|
||||
```
|
||||
`Create table hlc_cmyk (color varchar(40), c decimal, m decimal, y decimal, k decimal);`
|
||||
```
|
||||
|
||||
然后通过以下命令引入数据:
|
||||
|
||||
|
||||
```
|
||||
`\copy hlc_cmyk from '/home/gregp/HLC_Atlas_CMYK_SampleData.csv' with (header, format CSV);`
|
||||
```
|
||||
|
||||
|
||||
开头有反斜杠,是因为使用纯**copy** 命令仅限于 root 用户和 Postgres 的超级用户。 在括号中,**header** 表示第一行包含标题,应忽略,**CSV** 表示文件格式为 CSV。 请注意,在此方法中,颜色名称周围不需要括号。
|
||||
|
||||
如果操作成功,会看到 **COPY NNNN**,其中 N 表示插入到表中的行号。
|
||||
|
||||
最后,可以用下列命令查询:
|
||||
|
||||
```
|
||||
select * from hlc_cmyk;
|
||||
|
||||
color | c | m | y | k
|
||||
\---------------+-------+-------+-------+------
|
||||
H010_L15_C010 | 0.5 | 49.1 | 0.1 | 84.5
|
||||
H010_L15_C020 | 0.0 | 79.7 | 15.1 | 78.9
|
||||
H010_L25_C010 | 6.1 | 38.3 | 0.0 | 72.5
|
||||
H010_L25_C020 | 0.0 | 61.8 | 10.6 | 67.9
|
||||
H010_L25_C030 | 0.0 | 79.5 | 18.5 | 62.7
|
||||
H010_L25_C040 | 0.4 | 94.2 | 17.3 | 56.5
|
||||
H010_L25_C050 | 0.0 | 100.0 | 15.1 | 50.6
|
||||
H010_L35_C010 | 6.1 | 32.1 | 0.0 | 61.8
|
||||
H010_L35_C020 | 0.0 | 51.7 | 8.4 | 57.5
|
||||
H010_L35_C030 | 0.0 | 68.5 | 17.1 | 52.5
|
||||
```
|
||||
|
||||
|
||||
所有1,793行数据都是这样的。 回想起来,我不能说此查询对于HLC和Scribus任务是绝对必要的,但是它减轻了我对该项目的一些担忧。
|
||||
|
||||
为了生成 HLC 色谱,我使用 Scribus 为色板页面中的13,000多种颜色自动创建了颜色图表。
|
||||
|
||||
我可以使用 **copy** 命令输出数据:
|
||||
|
||||
```
|
||||
`\copy hlc_cmyk to '/home/gregp/hlc_cmyk_backup.csv' with (header, format CSV);`
|
||||
```
|
||||
|
||||
|
||||
我还可以使用 ** where ** 子句根据某些值来限制输出。
|
||||
|
||||
例如,以下命令将仅发送以 H10 开头的色调值。
|
||||
|
||||
|
||||
```
|
||||
`\copy hlc_cmyk to '/home/gregp/hlc_cmyk_backup.csv' with (header, format CSV) where color like 'H10%';`
|
||||
```
|
||||
|
||||
### 备份或传输数据库或表
|
||||
|
||||
我在此要提到的最后一个命令是**pg_dump**,它用于备份 PostgreSQL 数据库,并在 **psql** 控制台之外运行。 例如:
|
||||
|
||||
```
|
||||
pg_dump gregp -t hlc_cmyk > hlc.out
|
||||
pg_dump gregp > dball.out
|
||||
```
|
||||
|
||||
第一行是导出 **hlc_cmyk** 表及其结构。第二行将转储 **gregp** 数据库中的所有表。 这对于备份或传输数据库或表非常有用。
|
||||
|
||||
|
||||
要将数据库或表转到另一台电脑( 查看"[ PostgreSQL 入门][2]" 那篇文章获取详细信息),首先在要转入的电脑上创建一个数据库,然后执行相反的操作。
|
||||
|
||||
```
|
||||
`psql -d gregp -f dball.out`
|
||||
```
|
||||
|
||||
一步创建所有表并输入数据。
|
||||
|
||||
### 总结
|
||||
|
||||
在本文中,我们了解了如何使用 **WHERE** 参数限制操作,以及如何使用 PostgreSQL 通配符 **%**。 我们还了解了如何将大批量数据加载到表中,然后将部分或全部表数据输出到文件,甚至是将整个数据库及其所有单个表输出。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/postgresql-commands
|
||||
|
||||
作者:[Greg Pittman][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Morisun029](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/greg-p
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/todo_checklist_team_metrics_report.png?itok=oB5uQbzf (Team checklist and to dos)
|
||||
[2]: https://opensource.com/article/19/11/getting-started-postgresql
|
||||
[3]: https://www.postgresql.org/
|
||||
[4]: http://freiefarbe.de
|
||||
[5]: https://www.freiefarbe.de/en/thema-farbe/hlc-colour-atlas/
|
||||
@ -1,118 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (chai-yuan)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Connect Fedora to your Android phone with GSConnect)
|
||||
[#]: via: (https://fedoramagazine.org/connect-fedora-to-your-android-phone-with-gsconnect/)
|
||||
[#]: author: (Lokesh Krishna https://fedoramagazine.org/author/lowkeyskywalker/)
|
||||
|
||||
使用GSConnect将Android手机连接到Fedora系统
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
苹果和微软公司都提供了集成好的与移动设备交互的应用。Fedora提供了类似的工具——**GSConnect**。它可以让你将你的安卓手机和你的Fedora桌面配对并使用。读下去,来了解更多关于它是什么以及它是如何工作的信息。
|
||||
|
||||
### GSConnect是什么?
|
||||
|
||||
GSConnect是基于KDE Connect项目而为GNOME桌面定制的程序。KDE Connect使你的设备相互之间能够进行通信。但是,在Fedora的默认GNOME桌面上安装它需要安装大量的KDE依赖。
|
||||
|
||||
GSConnect基于KDE Connect实现,作为GNOME shell的拓展应用。一旦安装,GSConnect允许您执行以下操作:
|
||||
|
||||
* 在电脑上接收电话通知并回复信息
|
||||
* 用手机操纵你的桌面
|
||||
* 在不同设备之间分享文件与链接
|
||||
* 在电脑上查看手机电量
|
||||
* 让手机响铃以便你能找到它
|
||||
|
||||
|
||||
|
||||
### 设置GSConnect扩展
|
||||
|
||||
设置GSConnect需要安装两款软件:电脑上的GSConnect扩展和Android设备上的KDE Connect应用。
|
||||
|
||||
首先,从GNOME Shell扩展网站[GSConnect][2]安装GSConnect扩展。(Fedora Magazine有一篇关于[如何安装GNOMEShell扩展名][3]的文章,可以帮助你完成这一步。)
|
||||
|
||||
KDE Connect应用程序可以在Google的[Play Store][4]上找到。它也可以在FOSS Android应用程序库[F-Droid][5]上找到。
|
||||
|
||||
一旦安装了这两个组件,就可以配对两个设备。安装扩展后再系统菜单中显示“移动设备(Mobile Devices)”。单击它会出现一个下拉菜单,你可以从中访问“移动设置(Mobile Settings)”。
|
||||
|
||||
![][6]
|
||||
|
||||
在这里,你可以用GSConnect查看并管理配对的设备。进入此界面后,需要在Android设备上启动应用程序。
|
||||
|
||||
配对的初始化可以再任意一台设备上进行,在这里我们从Android设备连接到电脑。点击应用程序上的刷新(refresh),只要两个设备都在同一个无线网络环境中,你的Android设备便可以搜索到你的电脑。现在可以向桌面发送配对请求,并在桌面上接受配对请求以完成配对。
|
||||
|
||||
![][7]
|
||||
|
||||
### 使用 GSConnect
|
||||
|
||||
配对后,你将需要授予对Android设备的权限,才能使用GSConnect上提供的许多功能。单击设备列表中的配对设备,便可以查看所有可用功能,并根据你的偏好和需要启用或禁用它们。
|
||||
|
||||
![][8]
|
||||
|
||||
请记住,你还需要在Android应用程序中授予相应的权限才能使用这些功能。启用权限后,你现在可以访问桌面上的移动联系人,获得消息通知并回复消息,甚至同步桌面和Android设备剪贴板。
|
||||
|
||||
### 集成在文件系统与浏览器上
|
||||
|
||||
GSConnect允许你直接从桌面文件资源管理器向Android设备发送文件。
|
||||
|
||||
在Fedora的默认GNOME桌面上,你需要安装_nautilus-python_依赖包,以便在菜单中显示配对的设备。安装它只需要再终端中输入:
|
||||
|
||||
```
|
||||
$ sudo dnf install nautilus-python
|
||||
```
|
||||
|
||||
完成后,将在“文件(Files)”的菜单中显示“发送到移动设备(Send to Mobile Device)”选项。
|
||||
|
||||
![][9]
|
||||
|
||||
同样,为你的浏览器安装相应的WebExtension,无论是[Firefox][10]还是[Chrome][11]浏览器,都可以将链接发送到你的Android设备。你可以选择直接在浏览器中发送要启动的链接,或将其作为短信息发送。
|
||||
|
||||
### 运行命令
|
||||
|
||||
GSConnect允许你定义命令,然后可以从远程设备在电脑上运行这些命令。这使得你可以远程截屏,或者从你的Android设备锁定和解锁你的桌面。
|
||||
|
||||
![][12]
|
||||
|
||||
要使用此功能,可以使用标准shell命令和GSConnect公开的CLI。项目的GitHub存储库中提供了有关此操作的文档: _CLI Scripting_。
|
||||
|
||||
[KDE UserBase Wiki][13]有一个命令示例列表。这些例子包括控制桌面的亮度和音量,锁定鼠标和键盘,甚至更改桌面主题。其中一些命令是针对KDE Plasma设计的,需要进行修改才能在GNOME桌面上运行。
|
||||
|
||||
### 探索并享受乐趣
|
||||
|
||||
GSConnect使我们能够享受到极大的便利和舒适。深入研究首选项,查看你可以做的所有事情,灵活的使用这些命令功能。并在下面的评论中自由分享你解锁的新方式。
|
||||
|
||||
* * *
|
||||
|
||||
_Photo by [Pathum Danthanarayana][14] on [Unsplash][15]._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/connect-fedora-to-your-android-phone-with-gsconnect/
|
||||
|
||||
作者:[Lokesh Krishna][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[chai-yuan](https://github.com/chai-yuan)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/lowkeyskywalker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/12/gsconnect-816x345.jpg
|
||||
[2]: https://extensions.gnome.org/extension/1319/gsconnect/
|
||||
[3]: https://fedoramagazine.org/install-gnome-shell-extension/
|
||||
[4]: https://play.google.com/store/apps/details?id=org.kde.kdeconnect_tp
|
||||
[5]: https://f-droid.org/en/packages/org.kde.kdeconnect_tp/
|
||||
[6]: https://fedoramagazine.org/wp-content/uploads/2020/01/within-the-menu-1024x576.png
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2020/01/pair-request-1024x576.png
|
||||
[8]: https://fedoramagazine.org/wp-content/uploads/2020/01/permissions-1024x576.png
|
||||
[9]: https://fedoramagazine.org/wp-content/uploads/2020/01/send-to-mobile-2-1024x576.png
|
||||
[10]: https://addons.mozilla.org/en-US/firefox/addon/gsconnect/
|
||||
[11]: https://chrome.google.com/webstore/detail/gsconnect/jfnifeihccihocjbfcfhicmmgpjicaec
|
||||
[12]: https://fedoramagazine.org/wp-content/uploads/2020/01/commands-1024x576.png
|
||||
[13]: https://userbase.kde.org/KDE_Connect/Tutorials/Useful_commands
|
||||
[14]: https://unsplash.com/@pathum_danthanarayana?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[15]: https://unsplash.com/s/photos/android?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
@ -7,23 +7,23 @@
|
||||
[#]: via: (https://opensource.com/article/20/2/kubernetes-scanner)
|
||||
[#]: author: (Abhishek Tamrakar https://opensource.com/users/tamrakar)
|
||||
|
||||
Scan Kubernetes for errors with KRAWL
|
||||
使用 KRAWL 扫描 Kubernetes 错误
|
||||
======
|
||||
The KRAWL script identifies errors in Kubernetes pods and containers.
|
||||
用 KRAWL 脚本来标识 Kubernetes pod 和容器中的错误。
|
||||
![Ship captain sailing the Kubernetes seas][1]
|
||||
|
||||
When you're running containers with Kubernetes, you often find that they pile up. This is by design. It's one of the advantages of containers: they're cheap to start whenever a new one is needed. You can use a front-end like OpenShift or OKD to manage pods and containers. Those make it easy to visualize what you have set up, and have a rich set of commands for quick interactions.
|
||||
当你使用 Kubernetes 运行容器时,你通常会发现它们堆积。这是设计使然。它是容器的优点之一:每当需要新的容器时,它们启动成本都很低。你可以使用前端(如 OpenShift 或 OKD)来管理 pod 和容器。这些工具使可视化设置变得容易,并且它具有一组丰富的用于快速交互的命令。
|
||||
|
||||
If a platform to manage containers doesn't fit your requirements, though, you can also get that information using only a Kubernetes toolchain, but there are a lot of commands you need for a full overview of a complex environment. For that reason, I wrote [KRAWL][2], a simple script that scans pods and containers under the namespaces on Kubernetes clusters and displays the output of events, if any are found. It can also be used as Kubernetes plugin for the same purpose. It's a quick and easy way to get a lot of useful information.
|
||||
如果管理容器的平台不符合你的要求,你也可以仅使用 Kubernetes 工具链获取这些信息,但这需要大量命令才能全面了解复杂环境。出于这个原因,我编写了 [KRAWL][2],这是一个简单的脚本,可用于扫描 Kubernetes 集群命名空间下的 pod 和容器,并在发现任何事件时,显示事件的输出。它也可用作为 Kubernetes 插件使用。这是获取大量有用信息的快速简便方法。
|
||||
|
||||
### Prerequisites
|
||||
### 预先条件
|
||||
|
||||
* You must have kubectl installed.
|
||||
* Your cluster's kubeconfig must be either in its default location ($HOME/.kube/config) or exported (KUBECONFIG=/path/to/kubeconfig).
|
||||
* 必须安装 kubectl。
|
||||
* 集群的 kubeconfig 配置必须在它的默认位置 ($HOME/.kube/config) 或已被导出。
|
||||
|
||||
|
||||
|
||||
### Usage
|
||||
### 使用
|
||||
|
||||
|
||||
```
|
||||
@ -32,7 +32,7 @@ If a platform to manage containers doesn't fit your requirements, though, you ca
|
||||
|
||||
![KRAWL script][3]
|
||||
|
||||
### The script
|
||||
### 脚本
|
||||
|
||||
|
||||
```
|
||||
@ -201,7 +201,7 @@ get_pod_events
|
||||
|
||||
* * *
|
||||
|
||||
_This was originally published as the README in [KRAWL's GitHub repository][2] and is reused with permission._
|
||||
_此文最初发布在 [KRAWL 的 GitHub 仓库][2]下的 README 中,并被或许重用。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -209,7 +209,7 @@ via: https://opensource.com/article/20/2/kubernetes-scanner
|
||||
|
||||
作者:[Abhishek Tamrakar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,99 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Top hacks for the YaCy open source search engine)
|
||||
[#]: via: (https://opensource.com/article/20/2/yacy-search-engine-hacks)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
使用开源搜索引擎 YaCy 的技巧
|
||||
======
|
||||
> 不想再受制于各种版本的搜索引擎?使用 YaCy 自定义一款吧。
|
||||
![Browser of things][1]
|
||||
|
||||
在我以前介绍 [YaCy 入门][2]的文章中讲述过 [YaCy][3] 这个<ruby>点对点<rt>peer-to-peer</rt></ruby>式的搜索引擎是如何安装和使用的。YaCy 最大的一个特点就是可以在本地部署,全球范围内的每一个 YaCy 用户都是构成整个分布式搜索引擎架构的其中一个节点,因此每个用户都可以掌控自己的互联网搜索体验。
|
||||
|
||||
Google 曾经提供过 `google.com/linux` 这样的简便方式以便快速筛选出和 Linux 相关的搜索内容,这个功能受到了很多人的青睐,但 Google 最终还是在 2011 年的时候把它[下线][4]了。
|
||||
|
||||
而 YaCy 则让自定义搜索引擎变得可能。
|
||||
|
||||
### 自定义 YaCy
|
||||
|
||||
YaCy 安装好之后,只需要访问 `localhost:8090` 就可以使用了。要开始自定义搜索引擎,只需要点击右上角的“<ruby>管理<rt>Administration</rt></ruby>”按钮,如果没有找到,需要点击菜单图标打开菜单。
|
||||
|
||||
你可以在管理面板中配置 YaCy 对系统资源的使用策略,以及如何跟其它的 YaCy 客户端进行交互。
|
||||
|
||||
![YaCy profile selector][5]
|
||||
|
||||
例如,点击侧栏中的“<ruby>初步<rt>First steps</rt></ruby>”按钮可以配置备用端口,以及设置 YaCy 对内存和硬盘的使用量;而“<ruby>监控<rt>Monitoring</rt></ruby>”面板则可以监控 YaCy 的运行状况。大多数功能都只需要在面板上点击几下就可以完成了,例如以下几个常用的功能。
|
||||
|
||||
### 搜索应用
|
||||
|
||||
目前市面上也有不少公司推出了[内网搜索应用][6],而 YaCy 的优势是免费使用。对于能够通过 HTTP、FTP、Samba 等协议访问的文件,YaCy 都可以进行索引,因此无论是作为私人的文件搜索还是企业内部的本地共享文件搜索,YaCy 都可以实现。它可以让内部网络中的用户使用自定义配置的 YaCy 查找共享文件,于此同时保持对内部网络以外的用户不可见。
|
||||
|
||||
### 网络配置
|
||||
|
||||
YaCy 在默认情况下就对隐私隔离有比较好的支持。点击“<ruby>用例与账号<rt>Use Case & Account</rt></ruby>”页面顶部的“<ruby>网络配置<rt>Network Configuration</rt></ruby>”链接,即可进入网络配置面板设置点对点网络。
|
||||
|
||||
![YaCy network configuration][7]
|
||||
|
||||
### 爬取站点
|
||||
|
||||
YaCy 点对点的分布式运作方式决定了它对页面的爬取是由用户驱动的。任何一个公司的爬虫都不可能完全访问到整个互联网上的所有页面,对于 YaCy 来说也是这样,一个站点只有在被用户指定爬取的前提下,才会被 YaCy 爬取并进入索引。
|
||||
|
||||
YaCy 客户端提供了两种爬取页面的方式:一是自定义爬虫,二是使用 YaCy 推荐的爬虫。
|
||||
|
||||
![YaCy advanced crawler][8]
|
||||
|
||||
#### 自定义爬虫任务
|
||||
|
||||
自定义爬虫是指由用户输入指定的网站 URL 并启动 YaCy 的爬虫任务。只需要点击“<ruby>高级爬虫<rt>Advanced Crawler</rt></ruby>”并输入计划爬取的 URL,然后选择页面底部的“<ruby>进行远程索引<rt>Do Remote indexing</rt></ruby>”选项,这个选项会让客户端将上面输入的 URL 向互联网广播,接收到广播的其它远程客户端就会开始爬取这些 URL 所指向的页面。
|
||||
|
||||
点击页面底部的“<ruby>开始新爬虫任务<rt>Start New Crawl Job</rt></ruby>”按钮就可以开始进行爬取了,我就是这样对一些常用和有用站点进行爬取和索引的。
|
||||
|
||||
爬虫任务启动之后,YaCy 会将这些 URL 对应的页面在本地生成和存储索引。在高级模式下,也就是本地计算机允许 8090 端口流量进出时,全网的 YaCy 用户都可以使用到这一份索引。
|
||||
|
||||
#### 加入爬虫任务
|
||||
|
||||
尽管 YaCy 用户已经在互联网上爬取了很多页面,但对于全网浩如烟海的页面而言也只是沧海一粟。单个用户所拥有的资源远不及很多大公司的网络爬虫,但大量 YaCy 用户如果联合起来成为一个社区,能产生的力量就大得多了。只要开启了 YaCy 的爬虫请求广播功能,就可以让其它客户端参与进来爬取更多页面。
|
||||
|
||||
只需要在“<ruby>高级爬虫<rt>Advanced Crawler</rt></ruby>”面板中点击页面顶部的“<ruby>远程爬取<rt>Remote Crawling</rt></ruby>”,勾选“<ruby>加载<rt>Load</rt></ruby>”复选框,就可以让你的客户端接受其它人发来的爬虫任务请求了。
|
||||
|
||||
![YaCy remote crawling][9]
|
||||
|
||||
### YaCy 监控相关
|
||||
|
||||
YaCy 除了作为一个非常强大的搜索引擎,还提供了很丰富的用户体验。你可以在“<ruby>监控<rt>Monitor</rt></ruby>”面板中监控 YaCy 客户端的网络运行状况,甚至还可以了解到有多少人从 YaCy 社区中获取到了自己所需要的东西。
|
||||
|
||||
![YaCy monitoring screen][10]
|
||||
|
||||
### 搜索引擎发挥了作用
|
||||
|
||||
你使用 YaCy 的时间越长,就越会思考搜索引擎如何改变自己的视野,因为你对互联网的体验很大一部分来自于你在搜索引擎中一次次简单查询的结果。实际上,当你和不同行业的人交流时,可能会注意到每个人对“互联网”的理解都有所不同。有些人会认为,互联网的搜索引擎中充斥着各种广告和推广,同时也仅仅能从搜索结果中获取到有限的信息。例如,假设有人不断搜索关于关键词 X 的内容,那么大部分商业搜索引擎都会在搜索结果中提高关键词 X 的权重,但与此同时,另一个关键词 Y 的权重则会相对降低,从而让关键词 Y 被淹没在搜索结果当中。
|
||||
|
||||
就像在现实生活中一样,走出舒适圈会让你看到一个更广阔的世界。尝试使用 YaCy,看看你会不会有所收获。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/yacy-search-engine-hacks
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/browser_desktop_website_checklist_metrics.png?itok=OKKbl1UR (Browser of things)
|
||||
[2]: https://opensource.com/article/20/2/open-source-search-engine
|
||||
[3]: https://yacy.net/
|
||||
[4]: https://www.linuxquestions.org/questions/linux-news-59/is-there-no-more-linux-google-884306/
|
||||
[5]: https://opensource.com/sites/default/files/uploads/yacy-profiles.jpg (YaCy profile selector)
|
||||
[6]: https://en.wikipedia.org/wiki/Vivisimo
|
||||
[7]: https://opensource.com/sites/default/files/uploads/yacy-network-config.jpg (YaCy network configuration)
|
||||
[8]: https://opensource.com/sites/default/files/uploads/yacy-advanced-crawler.jpg (YaCy advanced crawler)
|
||||
[9]: https://opensource.com/sites/default/files/uploads/yacy-remote-crawl-accept.jpg (YaCy remote crawling)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/yacy-monitor.jpg (YaCy monitoring screen)
|
||||
@ -1,101 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Morisun029)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Why developers like to code at night)
|
||||
[#]: via: (https://opensource.com/article/20/2/why-developers-code-night)
|
||||
[#]: author: (Matt Shealy https://opensource.com/users/mshealy)
|
||||
|
||||
开发人员为什么喜欢在晚上编码
|
||||
======
|
||||
对许多开源程序员来说,夜间工作计划是创造力和生产力来源的关键。
|
||||
![Person programming on a laptop on a building][1]
|
||||
|
||||
|
||||
如果你问大多数开发人员更喜欢在什么时候工作,大部人会说他们最高效的时间在晚上。这对于那些在工作之余为开源项目做贡献的人来说更是如此(尽管如此,希望在他们的健康范围内[避免透支][2])。
|
||||
|
||||
有些人喜欢从晚上开始,一直工作到凌晨,而另一些人则很早就起床(例如,凌晨4点),以便在开始日常工作之前完成大部分编程工作。
|
||||
|
||||
这种工作习惯可能会使许多开发人员看起来像个怪胎和不称职。 但是,为什么有这么多的程序员喜欢在非正常时间工作,这其中有很多原因:
|
||||
|
||||
### maker 日程
|
||||
|
||||
根据[Paul Graham][3]的观点, "生产东西" 的人倾向于遵守 maker's schedule—他们更愿意以半天或更长时间为单位使用时间。事实上,大多数 [开发人员也有相同的偏好][4].
|
||||
|
||||
一方面,开发人员从事大型抽象系统工作,需要思维空间来处理整个模型。 将他们的日程分割成15分钟或30分钟的时间段来处理电子邮件,会议,电话以及来自同事的打断,工作效果只会适得其反。
|
||||
|
||||
另一方面,通常不可能以一个小时为单位进行有效编程。 因为这么短的时间几乎不够来处理当前的任务并开始工作。
|
||||
|
||||
上下文切换也会对编程产生不利影响。 在晚上工作,开发人员可以避免尽可能多的干扰。 在没有持续中断的情况下,他们可以花几个小时专注于手头任务,并尽可能提高工作效率。
|
||||
|
||||
### 平和安静的环境
|
||||
|
||||
由于晚上或凌晨不太会有来自各种活动的噪音(例如,办公室闲谈,街道上的交通),这使许多程序员感到放松,促使他们更具创造力和生产力,特别是在处理诸如编码之类的精神刺激任务时。
|
||||
|
||||
独处与平和,加上知道自己将有几个小时不被中断的工作时间,通常会使他们摆脱白天工作计划相关的时间压力,从而产出高质量的工作。
|
||||
|
||||
更不用说了,当解决了一个棘手的问题后,没有什么比尽情享受自己最喜欢的午夜小吃更美好的事情了!
|
||||
|
||||
|
||||
### 沟通
|
||||
|
||||
与在公司内里工作的程序员相比,从事开源项目的开发人员可以拥有不同的沟通节奏。 大多数开源项目的沟通都是通过邮件或 GitHub 上的评论等渠道异步完成。 很多时候,其他程序员在不同的国家和时区,因此实时交流通常需要开发人员变成一个夜猫子。
|
||||
|
||||
### 昏昏欲睡的大脑
|
||||
|
||||
|
||||
这听起来可能违反直觉,但是随着时间的推移,大脑会变得非常疲倦,因此只能专注于一项任务。 晚上工作从根本上消除了多任务处理,多任务处理是保持专注和高效的主要障碍。 当大脑处于昏昏欲睡的状态时,你是无法保持专注的!
|
||||
|
||||
许多开发人员在入睡时思考要解决的问题通常会取得重大进展。 潜意识开始工作,答案通常在他们半睡半醒的早些时候就出现了。
|
||||
|
||||
这不足为奇,因为[睡眠可增强大脑功能][5],可帮助我们理解新信息并进行更有创造性的思考。当解决方案在凌晨出现时,这些开发人员便会起来并开始工作,不错过任何机会。
|
||||
|
||||
|
||||
|
||||
### 灵活和创造性思考
|
||||
|
||||
许多程序员体会到晚上创造力会提升。 前额叶皮层,即与集中能力有关的大脑部分,在一天结束时会感到疲倦。 这似乎为某些人提供了更灵活和更具创造性的思考。
|
||||
|
||||
匹兹堡大学医学院精神病学助理教授[Brant Hasler][6] 表示:“由于自上而下的控制和'认知抑制'功能较少,大脑可能会解放出来进行更多样化的思考,从而使人们更容易地将不同概念之间的联系建立起来。” 结合轻松环境所带来的积极情绪,开发人员可以更轻松地产生创新想法。
|
||||
|
||||
此外,在没有干扰的情况下集中精力几个小时,“沉浸在你做的事情中”。 这可以帮助你更好地专注于项目并参与其中,而不必担心周围发生的事情。
|
||||
|
||||
### 明亮的电脑屏幕
|
||||
|
||||
|
||||
因为整天看着明亮的屏幕, 许多程序员的睡眠周期被延迟。电脑屏幕发出的蓝光[扰乱我们的昼夜节律][7]通过延迟释放诱发睡眠的褪黑激素和提高人的机敏性将人体生物钟重置到更晚的时间。从而导致,开发人员往往睡得越来越晚。
|
||||
|
||||
### 过去的影响
|
||||
|
||||
过去,大多数开发人员是出于必要在晚上工作,因为在白天当公司其他人都在使用服务器时,共享服务器的计算能力支撑不了编程工作,所以开发人员需要等到深夜才能执行白天无法进行的任务,例如测试项目,运行大量的代码编译运行调试周期以及部署新代码。现在尽管服务器功能变强大了,大多数可以满足需求,但夜间工作的趋势仍是这种文化的一部分。
|
||||
|
||||
### 结语
|
||||
|
||||
尽管开发人员喜欢在晚上工作出于多种原因,但请记住,成为夜猫子并不意味着你应该克扣睡眠时间。 睡眠不足会导致压力和焦虑,并最终导致倦怠。
|
||||
|
||||
获得足够质量的睡眠是维持良好身体健康和大脑功能的关键。 例如,它可以帮助你整合新信息,巩固记忆,创造性思考,清除身体积聚的毒素,调节食欲并防止过早衰老。
|
||||
|
||||
无论你是哪种日程,请确保让你的大脑得到充分的休息,这样你就可以在一整天及每天的工作中发挥最大的作用!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/why-developers-code-night
|
||||
|
||||
作者:[Matt Shealy][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Morisun029](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mshealy
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_code_programming_laptop.jpg?itok=ormv35tV (Person programming on a laptop on a building)
|
||||
[2]: https://opensource.com/article/19/11/burnout-open-source-communities
|
||||
[3]: http://www.paulgraham.com/makersschedule.html
|
||||
[4]: https://www.chamberofcommerce.com/business-advice/software-development-trends-overtaking-the-market
|
||||
[5]: https://amerisleep.com/blog/sleep-impacts-brain-health/
|
||||
[6]: https://www.vice.com/en_us/article/mb58a8/late-night-creativity-spike
|
||||
[7]: https://www.sleepfoundation.org/articles/how-blue-light-affects-kids-sleep
|
||||
132
translated/tech/20200217 How to get MongoDB Server on Fedora.md
Normal file
132
translated/tech/20200217 How to get MongoDB Server on Fedora.md
Normal file
@ -0,0 +1,132 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to get MongoDB Server on Fedora)
|
||||
[#]: via: (https://fedoramagazine.org/how-to-get-mongodb-server-on-fedora/)
|
||||
[#]: author: (Honza Horak https://fedoramagazine.org/author/hhorak/)
|
||||
|
||||
如何在 Fedora 上获取 MongoDB 服务器
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Mongo(来自 “humongous”)是一个高性能,开源,无模式的面向文档的数据库,它是最受欢迎的 [NoSQL][2] 数据库之一。它使用 JSON 作为文档格式,并且可以在多个服务器节点之间进行扩展和复制。
|
||||
|
||||
### 有关许可证更改的故事
|
||||
|
||||
上游 MongoD 决定更改服务器代码的许可证已经一年多了。先前的许可证是 GNU Affero General Public License v3(AGPLv3)。但是,上游写了一个新许可证,为了使运行 MongoDB 即服务的公司回馈社区。新许可证称为 Server Side Public License(SSPLv1),关于这个及其原理的更多说明,请参见[MongoDB SSPL FAQ][3]。
|
||||
|
||||
Fedora 一直只包含自由软件。当 SSPL 发布后,Fedora [确定][4]它并不是自由软件许可。许可证更改日期(2018 年 10 月)之前发布的所有 MongoDB 版本都可保留在 Fedora 中,但之后再也不更新软件包会带来安全问题。因此,从 Fedora 30 开始,Fedora 社区决定完全[移除 MongoDB 服务器][5]。
|
||||
|
||||
### 开发人员还有哪些选择?
|
||||
|
||||
是的,还有替代方案,例如 PostgreSQL 在最新版本中也支持 JSON,它可以在无法再使用 MongoDB 的情况下使用它。使用 JSONB 类型,索引在 PostgreSQL 中可以很好地工作,其性能可与 MongoDB 媲美,甚至不会受到 ACID 的影响。
|
||||
|
||||
开发人员可能选择 MongoDB 的技术原因并未随许可证而改变,因此许多人仍想使用它。重要的是要意识到,SSPL 许可证仅更改仅针对 MongoDB 服务器。MongoDB 上游还开发了其他项目,例如 MongoDB 工具,C 和 C++ 客户端库以及用于各种动态语言的连接器,这些项目在客户端(要通过网络与服务器通信的应用中)使用。由于这些包的许可证是自由的(主要是 Apache 许可证),因此它们保留在 Fedora 仓库中,因此用户可以将其用于应用开发。
|
||||
|
||||
唯一的变化实际是服务器包本身,它已从 Fedora 仓库中完全删除。让我们看看 Fedora 用户可以如何获取非自由的包。
|
||||
|
||||
### 如何从上游安装 MongoDB 服务器
|
||||
|
||||
当 Fedora 用户想要安装 MongoDB 服务器时,他们需要直接向上游获取 MongoDB。但是,上游不为 Fedora 提供 RPM 包。相反,MongoDB 服务器可以获取源码 tarball,用户需要自己进行编译(这需要一些开发知识),或者 Fedora 用户可以使用一些兼容的包。在兼容的选项中,最好的选择是 RHEL-8 RPM。以下步骤描述了如何安装它们以及如何启动守护进程。
|
||||
|
||||
#### 1\. 使用上游 RPM 创建仓库(RHEL-8 构建)
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
$ sudo cat > /etc/yum.repos.d/mongodb.repo &lt;&lt;EOF
|
||||
[mongodb-upstream]
|
||||
name=MongoDB Upstream Repository
|
||||
baseurl=<https://repo.mongodb.org/yum/redhat/8Server/mongodb-org/4.2/x86\_64/>
|
||||
gpgcheck=1
|
||||
enabled=1
|
||||
gpgkey=<https://www.mongodb.org/static/pgp/server-4.2.asc>
|
||||
EOF
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
#### 2\. 安装元软件包,来拉取服务器和工具包
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
$ sudo dnf install mongodb-org
|
||||
&lt;snipped>
|
||||
Installed:
|
||||
mongodb-org-4.2.3-1.el8.x86_64 mongodb-org-mongos-4.2.3-1.el8.x86_64
|
||||
mongodb-org-server-4.2.3-1.el8.x86_64 mongodb-org-shell-4.2.3-1.el8.x86_64
|
||||
mongodb-org-tools-4.2.3-1.el8.x86_64
|
||||
|
||||
Complete!
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
#### 3\. 启动 MongoDB 守护进程
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
$ sudo systemctl status mongod
|
||||
● mongod.service - MongoDB Database Server
|
||||
Loaded: loaded (/usr/lib/systemd/system/mongod.service; enabled; vendor preset: disabled)
|
||||
Active: active (running) since Sat 2020-02-08 12:33:45 EST; 2s ago
|
||||
Docs: <https://docs.mongodb.org/manual>
|
||||
Process: 15768 ExecStartPre=/usr/bin/mkdir -p /var/run/mongodb (code=exited, status=0/SUCCESS)
|
||||
Process: 15769 ExecStartPre=/usr/bin/chown mongod:mongod /var/run/mongodb (code=exited, status=0/SUCCESS)
|
||||
Process: 15770 ExecStartPre=/usr/bin/chmod 0755 /var/run/mongodb (code=exited, status=0/SUCCESS)
|
||||
Process: 15771 ExecStart=/usr/bin/mongod $OPTIONS (code=exited, status=0/SUCCESS)
|
||||
Main PID: 15773 (mongod)
|
||||
Memory: 70.4M
|
||||
CPU: 611ms
|
||||
CGroup: /system.slice/mongod.service
|
||||
└─15773 /usr/bin/mongod -f /etc/mongod.conf
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
#### 4\. 通过 mongo shell 连接服务器来验证是否运行
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
$ mongo
|
||||
MongoDB shell version v4.2.3
|
||||
connecting to: mongodb://127.0.0.1:27017/?compressors=disabled&amp;gssapiServiceName=mongodb
|
||||
Implicit session: session { "id" : UUID("20b6e61f-c7cc-4e9b-a25e-5e306d60482f") }
|
||||
MongoDB server version: 4.2.3
|
||||
Welcome to the MongoDB shell.
|
||||
For interactive help, type "help".
|
||||
For more comprehensive documentation, see
|
||||
<http://docs.mongodb.org/>
|
||||
\---
|
||||
|
||||
> _
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
就是这样了。如你所见,RHEL-8 包完美兼容,只要 Fedora 包还与 RHEL-8 兼容,它就应该会一直兼容。 请注意,在使用时必须遵守 SSPLv1 许可证。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/how-to-get-mongodb-server-on-fedora/
|
||||
|
||||
作者:[Honza Horak][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/hhorak/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2020/02/mongodb-816x348.png
|
||||
[2]: https://en.wikipedia.org/wiki/NoSQL
|
||||
[3]: https://www.mongodb.com/licensing/server-side-public-license/faq
|
||||
[4]: https://lists.fedoraproject.org/archives/list/legal@lists.fedoraproject.org/thread/IQIOBOGWJ247JGKX2WD6N27TZNZZNM6C/
|
||||
[5]: https://fedoraproject.org/wiki/Changes/MongoDB_Removal
|
||||
@ -0,0 +1,50 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (heguangzhi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How Kubernetes Became the Standard for Compute Resources)
|
||||
[#]: via: (https://www.linux.com/articles/how-kubernetes-became-the-standard-for-compute-resources/)
|
||||
[#]: author: (Swapnil Bhartiya https://www.linux.com/author/swapnil/)
|
||||
|
||||
Kubernetes 如何成为计算资源的标准
|
||||
======
|
||||
|
||||
|
||||
<https://www.linux.com/wp-content/uploads/2019/08/elevator-1598431_1920.jpg>
|
||||
|
||||
对于原生云生态系统来说,2019年是改变游戏规则的一年。有大的[并购][1),如 Red Hat Docker 和 Pivotal,并出现其他的玩家 如Rancher Labs 和 Mirantis 。
|
||||
|
||||
“所有这些并购",Rancher Labs (一家为采用容器的团队提供完整软件栈的公司) 的联合创始人兼首席执行官盛亮表示:“这一领域的成功表明市场成熟的速度很快。”。
|
||||
|
||||
传统上,像 Kubernetes 和 Docker 这样的新兴技术吸引着开发者和像脸书和谷歌这样的超级用户。这群人之外没什么其他的兴趣。然而,这两种技术都在企业层面得到了广泛采用。突然间,有了一个巨大的市场,有了巨大的机会。几乎每个人都跳了进去。有人带来了创新的解决方案,也有人试图赶上其他人。它很快变得非常拥挤和热闹起来。
|
||||
|
||||
它也改变了创新的方式。[早期采用者通常是精通技术的公司。][2]现在,几乎每个人都在使用它,即使是在不被认为是 Kubernetes 地盘的地方。它改变了市场动态,像 Rancher Labs 这样的公司见证了独特的用例。
|
||||
|
||||
梁补充道,“我从来没有经历过像 Kubernete 这样快速、动态的市场或这样的技术进化。当我们五年前开始的时候,这是一个非常拥挤的空间。随着时间的推移,我们大多数的同龄人因为这样或那样的原因消失了。他们要么无法适应变化,要么选择不适应某些变化。”
|
||||
|
||||
在 Kubernetes 的早期,最明显的机会是建立 Kubernetes 发行版本和 Kubernetes 业务。这是新技术。众所周知,它的安装、升级和操作相当的复杂。
|
||||
|
||||
当谷歌、AWS 和微软进入市场时,一切都变了。当时,有一群供应商蜂拥而至,为平台提供解决方案。梁表示:“一旦像谷歌这样的云提供商决定将Kubernetes 作为一项服务,并亏本出售的商品免费提供,以推动基础设施消费;我们就知道,运营和支持 Kubernetes 业务的优势将非常有限了。”。
|
||||
|
||||
对非谷歌玩家来说,并非一切都不好。由于云供应商通过将它作为服务来提供,消除了 Kubernetes 带来的所有复杂性,这意味着更广泛地采用该技术,即使是那些由于运营成本而不愿使用该技术的人也是如此。这意味着 Kubernetes 将变得无处不在,并将成为一个行业标准。
|
||||
|
||||
“Rancher Labs 是极少数将此视为机遇并比其他公司看得更远的公司之一。我们意识到 Kubernetes 将成为新的计算标准,就像TCP/IP成为网络标准一样,”梁说。
|
||||
|
||||
CNCF围绕 Kubernetes 构建一个充满活力的生态系统方面发挥着至关重要的作用,创建了一个庞大的社区来构建、培育和商业化原生云开源技术。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/articles/how-kubernetes-became-the-standard-for-compute-resources/
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[heguangzhi](https://github.com/heguangzhi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/author/swapnil/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cloudfoundry.org/blog/2019-is-the-year-of-consolidation-why-ibms-deal-with-red-hat-is-a-harbinger-of-things-to-come/
|
||||
[2]: https://www.packet.com/blog/open-source-season-on-the-kubernetes-highway/
|
||||
104
translated/tech/20200220 Tools for SSH key management.md
Normal file
104
translated/tech/20200220 Tools for SSH key management.md
Normal file
@ -0,0 +1,104 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Tools for SSH key management)
|
||||
[#]: via: (https://opensource.com/article/20/2/ssh-tools)
|
||||
[#]: author: (Ben Nuttall https://opensource.com/users/bennuttall)
|
||||
|
||||
SSH 密钥管理工具
|
||||
======
|
||||
|
||||
> 常用开源工具的省时快捷方式。
|
||||
|
||||
![collection of hardware on blue backround][1]
|
||||
|
||||
我经常使用 SSH。我发现自己每天都要登录多个服务器和树莓派(与我位于同一房间,并接入互联网)。我有许多设备需要访问,并且获得访问权限的要求也不同,因此,除了使用各种 `ssh` / `scp` 命令选项之外,我还必须维护一个包含所有连接详细信息的配置文件。
|
||||
|
||||
随着时间的推移,我发现了一些省时的技巧和工具,你可能也会发现它们有用。
|
||||
|
||||
### SSH 密钥
|
||||
|
||||
SSH 密钥是一种在不使用密码的情况下认证 SSH 连接的方法,可以用来加快访问速度或作为一种安全措施(如果你关闭了密码访问权限并确保仅允许授权的密钥)。要创建 SSH 密钥,请运行以下命令:
|
||||
|
||||
```
|
||||
$ ssh-keygen
|
||||
```
|
||||
|
||||
这将在 `~/.ssh/` 中创建一个密钥对(公钥和私钥)。将私钥(`id_rsa`)保留在 PC 上,切勿共享。你可以与其他人共享公钥(`id_rsa.pub`)或将其放置在其他服务器上。
|
||||
|
||||
### ssh-copy-id
|
||||
|
||||
如果我在家中或公司工作时使用树莓派,则倾向于将 SSH 设置保留为默认设置,因为我不担心内部信任网络上的安全性,并且通常将 SSH 密钥(公钥)复制到树莓派上,以避免每次都使用密码进行身份验证。为此,我使用 `ssh-copy-id` 命令将其复制到树莓派。这会自动将你的密钥(公钥)添加到树莓派:
|
||||
|
||||
```
|
||||
$ ssh-copy-id pi@192.168.1.20
|
||||
```
|
||||
|
||||
在生产服务器上,我倾向于关闭密码身份验证,仅允许授权的 SSH 密钥登录。
|
||||
|
||||
### ssh-import-id
|
||||
|
||||
另一个类似的工具是 `ssh-import-id`。你可以使用此方法通过从 GitHub 导入密钥来授予你自己(或其他人)对计算机或服务器的访问权限。例如,我已经在我的 GitHub 帐户中注册了各个 SSH 密钥,因此无需密码即可推送到 GitHub。这些公钥是有效的,因此 `ssh-import-id` 可以使用它们在我的任何计算机上授权我:
|
||||
|
||||
```
|
||||
$ ssh-import-id gh:bennuttall
|
||||
```
|
||||
|
||||
我还可以使用它来授予其他人访问服务器的权限,而无需询问他们的密钥:
|
||||
|
||||
```
|
||||
$ ssh-import-id gh:waveform80
|
||||
```
|
||||
|
||||
### storm
|
||||
|
||||
我还使用了名为 Storm 的工具,该工具可帮助你将 SSH 连接添加到 SSH 配置中,因此你不必记住这些连接细节信息。你可以使用 `pip` 安装它:
|
||||
|
||||
```
|
||||
$ sudo pip3 install stormssh
|
||||
```
|
||||
|
||||
然后,你可以使用以下命令将 SSH 连接添加到配置中:
|
||||
|
||||
```
|
||||
$ storm add pi3 pi@192.168.1.20
|
||||
```
|
||||
|
||||
然后,你可以只使用 `ssh pi3` 来获得访问权限。类似的还有 `scp file.txt pi3:` 或 `sshfs pi pi3:`。
|
||||
|
||||
你还可以使用更多的 SSH 选项,例如端口号:
|
||||
|
||||
```
|
||||
$ storm add pi3 pi@192.168.1.20:2000
|
||||
```
|
||||
|
||||
你可以参考 Storm 的[文档][2]轻松列出、搜索和编辑已保存的连接。Storm 实际所做的只是管理 SSH 配置文件 `~/.ssh/config` 中的项目。一旦了解了它们是如何存储的,你就可以选择手动编辑它们。配置中的示例连接如下所示:
|
||||
|
||||
```
|
||||
Host pi3
|
||||
user pi
|
||||
hostname 192.168.1.20
|
||||
port 22
|
||||
```
|
||||
|
||||
### 结论
|
||||
|
||||
从树莓派到大型的云基础设施,SSH 是系统管理的重要工具。熟悉密钥管理会很方便。你还有其他 SSH 技巧要添加吗?我希望你在评论中分享他们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/ssh-tools
|
||||
|
||||
作者:[Ben Nuttall][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bennuttall
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/osdc_BUS_Apple_520.png?itok=ZJu-hBV1 (collection of hardware on blue backround)
|
||||
[2]: https://stormssh.readthedocs.io/en/stable/usage.html
|
||||
@ -0,0 +1,689 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (heguangzhi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Using Python and GNU Octave to plot data)
|
||||
[#]: via: (https://opensource.com/article/20/2/python-gnu-octave-data-science)
|
||||
[#]: author: (Cristiano L. Fontana https://opensource.com/users/cristianofontana)
|
||||
|
||||
使用 Python 和 GNU Octave 绘制数据
|
||||
======
|
||||
|
||||
了解如何使用 Python 和 GNU Octave 完成一项常见的数据科学任务。
|
||||
![分析:图表和图形][1]
|
||||
|
||||
数据科学是跨越编程语言的知识领域。有些人以解决这一领域的问题而闻名,而另一些人则鲜为人知。这篇文章将帮助你熟悉用一些流行语言做数据科学。
|
||||
|
||||
### 为数据科学选择 Python 和 GNU Octave
|
||||
|
||||
我经常尝试学习一种新的编程语言。为什么?这主要是对旧方式的厌倦和对新方式的好奇的结合。当我开始编程时,我唯一知道的语言是 C 语言。那些年的编程生涯既艰难又危险,因为我不得不手动分配内存,管理指针,并记得释放内存。
|
||||
|
||||
然后一个朋友建议我试试 Python,现在编程生活变得简单多了。虽然程序运行变得慢多了,但我不必通过编写分析软件来受苦了。然而,我很快就意识到每种语言都有比其他语言更适合自己应用场景。后来我学习了其他一些语言,每种语言都给我带来了一些新的启发。发现新的编程风格让我可以将一些解决方案移植到其他语言中,这样一切都变得有趣多了。
|
||||
|
||||
为了对一种新的编程语言(及其文档)有所了解,我总是从编写一些执行我熟悉的任务的示例程序开始。为此,我将解释如何用 Python 和 GNU Octave 编写一个程序来完成一个你可以归类为数据科学的特殊任务。如果你已经熟悉其中一种语言,从中开始,浏览其他语言,寻找相似之处和不同之处。这并不是对编程语言的详尽比较,只是一个小小的展示。
|
||||
|
||||
所有的程序都应该在[命令行][2]上运行,而不是用[图形用户界面][3](GUI)。完整的例子可以在[多语种知识库][4]中找到。
|
||||
|
||||
### 编程任务
|
||||
|
||||
你将在本系列中编写的程序:
|
||||
|
||||
* 从[CSV文件][5]中读取数据
|
||||
* 用直线插入数据(例如 _f(x)=m ⋅ x + q_)
|
||||
* 将结果生成图像文件
|
||||
|
||||
这是许多数据科学家遇到的常见情况。示例数据是第一组[Anscombe's quartet][6],如下表所示。这是一组人工构建的数据,当用直线拟合时会给出相同的结果,但是它们的曲线非常不同。数据文件是一个文本文件,以制表符作为列分隔,以几行作为标题。此任务将仅使用第一组(例如:前两列)。
|
||||
|
||||
I
|
||||
|
||||
II
|
||||
|
||||
III
|
||||
|
||||
IV
|
||||
|
||||
x
|
||||
|
||||
y
|
||||
|
||||
x
|
||||
|
||||
y
|
||||
|
||||
x
|
||||
|
||||
y
|
||||
|
||||
x
|
||||
|
||||
y
|
||||
|
||||
10.0
|
||||
|
||||
8.04
|
||||
|
||||
10.0
|
||||
|
||||
9.14
|
||||
|
||||
10.0
|
||||
|
||||
7.46
|
||||
|
||||
8.0
|
||||
|
||||
6.58
|
||||
|
||||
8.0
|
||||
|
||||
6.95
|
||||
|
||||
8.0
|
||||
|
||||
8.14
|
||||
|
||||
8.0
|
||||
|
||||
6.77
|
||||
|
||||
8.0
|
||||
|
||||
5.76
|
||||
|
||||
13.0
|
||||
|
||||
7.58
|
||||
|
||||
13.0
|
||||
|
||||
8.74
|
||||
|
||||
13.0
|
||||
|
||||
12.74
|
||||
|
||||
8.0
|
||||
|
||||
7.71
|
||||
|
||||
9.0
|
||||
|
||||
8.81
|
||||
|
||||
9.0
|
||||
|
||||
8.77
|
||||
|
||||
9.0
|
||||
|
||||
7.11
|
||||
|
||||
8.0
|
||||
|
||||
8.84
|
||||
|
||||
11.0
|
||||
|
||||
8.33
|
||||
|
||||
11.0
|
||||
|
||||
9.26
|
||||
|
||||
11.0
|
||||
|
||||
7.81
|
||||
|
||||
8.0
|
||||
|
||||
8.47
|
||||
|
||||
14.0
|
||||
|
||||
9.96
|
||||
|
||||
14.0
|
||||
|
||||
8.10
|
||||
|
||||
14.0
|
||||
|
||||
8.84
|
||||
|
||||
8.0
|
||||
|
||||
7.04
|
||||
|
||||
6.0
|
||||
|
||||
7.24
|
||||
|
||||
6.0
|
||||
|
||||
6.13
|
||||
|
||||
6.0
|
||||
|
||||
6.08
|
||||
|
||||
8.0
|
||||
|
||||
5.25
|
||||
|
||||
4.0
|
||||
|
||||
4.26
|
||||
|
||||
4.0
|
||||
|
||||
3.10
|
||||
|
||||
4.0
|
||||
|
||||
5.39
|
||||
|
||||
19.0
|
||||
|
||||
12.50
|
||||
|
||||
12.0
|
||||
|
||||
10.84
|
||||
|
||||
12.0
|
||||
|
||||
9.13
|
||||
|
||||
12.0
|
||||
|
||||
8.15
|
||||
|
||||
8.0
|
||||
|
||||
5.56
|
||||
|
||||
7.0
|
||||
|
||||
4.82
|
||||
|
||||
7.0
|
||||
|
||||
7.26
|
||||
|
||||
7.0
|
||||
|
||||
6.42
|
||||
|
||||
8.0
|
||||
|
||||
7.91
|
||||
|
||||
5.0
|
||||
|
||||
5.68
|
||||
|
||||
5.0
|
||||
|
||||
4.74
|
||||
|
||||
5.0
|
||||
|
||||
5.73
|
||||
|
||||
8.0
|
||||
|
||||
6.89
|
||||
|
||||
### Python 方式
|
||||
|
||||
|
||||
[Python][7]是一种通用编程语言,是当今最流行的语言之一(从[TIOBE index][8]、[RedMonk编程语言排名][9]、[编程语言流行指数][10]、[State of the Octoverse of GitHub][11]和其他来源的调查结果可以看出)。这是一种[解释的语言][12];因此,源代码由执行指令的程序读取和评估。它有一个全面的[标准库][13]并且总体上非常好用(我没有参考这最后一句话;这只是我的拙见)。
|
||||
|
||||
#### 安装
|
||||
|
||||
要使用 Python 开发,你需要解释器和一些库。最低要求是:
|
||||
|
||||
* [NumPy][14]用于合适的数组和矩阵操作
|
||||
* [SciPy][15]进行数据科学
|
||||
* [Matplotlib][16]绘图
|
||||
|
||||
在 [Fedora][17] 安装它们是很容易的:
|
||||
|
||||
|
||||
```
|
||||
`sudo dnf install python3 python3-numpy python3-scipy python3-matplotlib`
|
||||
```
|
||||
|
||||
#### 注释代码
|
||||
|
||||
|
||||
在 Python中,[注释][18]是通过在行首添加一个 **#** 来实现的,该行的其余部分将被解释器丢弃:
|
||||
|
||||
```
|
||||
`# This is a comment ignored by the interpreter.`
|
||||
```
|
||||
|
||||
[fitting_python.py][19]示例使用注释在源代码中插入许可信息,第一行是[特殊注释][20],它允许在命令行上执行脚本:
|
||||
|
||||
```
|
||||
`#! /usr/bin/env python3`
|
||||
```
|
||||
这一行通知命令行解释器,脚本需要由程序**python3**执行。
|
||||
|
||||
#### Required libraries
|
||||
|
||||
在 Python 中,库和模块可以作为一个对象导入(如示例中的第一行),其中包含库的所有函数和成员。通过使用 **as** 规范可以用于定义标签并重命名它们:
|
||||
|
||||
```
|
||||
import numpy as np
|
||||
from scipy import stats
|
||||
import matplotlib.pyplot as plt
|
||||
```
|
||||
|
||||
你也可以决定只导入一个子模块(如第二行和第三行)。语法有两个(或多或少)等效选项: **import module.submodule** 和 **from module import submodule**。
|
||||
|
||||
#### 定义变量
|
||||
|
||||
Python 的变量是在第一次赋值时被声明的:
|
||||
|
||||
```
|
||||
input_file_name = "anscombe.csv"
|
||||
delimiter = "\t"
|
||||
skip_header = 3
|
||||
column_x = 0
|
||||
column_y = 1
|
||||
```
|
||||
|
||||
变量类型由分配给变量的值推断。没有常量值的变量,除非它们在模块中声明并且只能被读取。习惯上,不被修改的变量应该用大写字母命名。
|
||||
|
||||
#### 打印输出
|
||||
|
||||
通过命令行运行程序意味着输出只能打印在终端上。Python 有[**print()**][21]函数,默认情况下,该函数打印其参数,并在输出的末尾添加一个换行符:
|
||||
|
||||
```
|
||||
`print("#### Anscombe's first set with Python ####")`
|
||||
```
|
||||
|
||||
在 Python 中,可以将**print()**函数与[字符串类][23]的[格式化能力][22]相结合。字符串具有**format**方法,可用于向字符串本身添加一些格式化文本。例如,可以添加格式化的浮点数,例如:
|
||||
|
||||
|
||||
```
|
||||
`print("Slope: {:f}".format(slope))`
|
||||
```
|
||||
|
||||
#### 读取数据
|
||||
|
||||
使用 NumPy 和 函数[**genfromtxt()**][24]读取CSV文件非常容易,该函数生成[NumPy数组][25]:
|
||||
|
||||
|
||||
```
|
||||
`data = np.genfromtxt(input_file_name, delimiter = delimiter, skip_header = skip_header)`
|
||||
```
|
||||
|
||||
在 Python中,一个函数可以有可变数量的参数,您可以通过指定所需的参数来让它传递一个子集。数组是非常强大的矩阵状对象,可以很容易地分割成更小的数组:
|
||||
|
||||
```
|
||||
x = data[:, column_x]
|
||||
y = data[:, column_y]
|
||||
```
|
||||
|
||||
冒号选择整个范围,也可以用来选择子范围。例如,要选择数组的前两行,可以使用:
|
||||
|
||||
```
|
||||
`first_two_rows = data[0:1, :]`
|
||||
```
|
||||
|
||||
#### 拟合数据
|
||||
|
||||
SciPy提供了方便的数据拟合功能,例如[**linregress()**][26]功能。该函数提供了一些与拟合相关的重要值,如斜率、截距和两个数据集的相关系数:
|
||||
|
||||
```
|
||||
slope, intercept, r_value, p_value, std_err = stats.linregress(x, y)
|
||||
|
||||
print("Slope: {:f}".format(slope))
|
||||
print("Intercept: {:f}".format(intercept))
|
||||
print("Correlation coefficient: {:f}".format(r_value))
|
||||
```
|
||||
|
||||
因为**linregress()**提供了几条信息,所以结果可以同时保存到几个变量中。
|
||||
|
||||
#### 绘图
|
||||
|
||||
Matplotlib 库仅仅绘制数据点,因此,你应该定义要绘制的点的坐标。已经定义了**x** 和 **y** 数组,所以你可以直接绘制它们,但是你还需要代表直线的数据点。
|
||||
|
||||
```
|
||||
`fit_x = np.linspace(x.min() - 1, x.max() + 1, 100)`
|
||||
```
|
||||
|
||||
[**linspace()**][27]函数可以方便地在两个值之间生成一组等距值。利用强大的 NumPy 数组可以轻松计算纵坐标,该数组可以像普通数值变量一样在公式中使用:
|
||||
|
||||
```
|
||||
`fit_y = slope * fit_x + intercept`
|
||||
```
|
||||
|
||||
公式在数组中逐元素应用;因此,结果在初始数组中具有相同数量的条目。
|
||||
|
||||
要绘图,首先,定义一个包含所有图形的[图形对象][28]:
|
||||
|
||||
```
|
||||
fig_width = 7 #inch
|
||||
fig_height = fig_width / 16 * 9 #inch
|
||||
fig_dpi = 100
|
||||
|
||||
fig = plt.figure(figsize = (fig_width, fig_height), dpi = fig_dpi)
|
||||
```
|
||||
|
||||
一个图形可以画几个图;在 Matplotlib 中,这些图块被称为[轴][29]。本示例定义一个单轴对象来绘制数据点:
|
||||
|
||||
```
|
||||
ax = fig.add_subplot(111)
|
||||
|
||||
ax.plot(fit_x, fit_y, label = "Fit", linestyle = '-')
|
||||
ax.plot(x, y, label = "Data", marker = '.', linestyle = '')
|
||||
|
||||
ax.legend()
|
||||
ax.set_xlim(min(x) - 1, max(x) + 1)
|
||||
ax.set_ylim(min(y) - 1, max(y) + 1)
|
||||
ax.set_xlabel('x')
|
||||
ax.set_ylabel('y')
|
||||
```
|
||||
|
||||
将该图保存到[PNG image file][30]中,有:
|
||||
|
||||
```
|
||||
`fig.savefig('fit_python.png')`
|
||||
```
|
||||
|
||||
如果要显示(而不是保存)绘图,请调用:
|
||||
|
||||
|
||||
```
|
||||
`plt.show()`
|
||||
```
|
||||
|
||||
此示例引用了绘图部分中使用的所有对象:它定义了对象 **fig** 和对象 **ax**。这种技术细节是不必要的,因为 **plt** 对象可以直接用于绘制数据集。《[Matplotlib 教程][31]展示了这样一个界面:
|
||||
|
||||
```
|
||||
`plt.plot(fit_x, fit_y)`
|
||||
```
|
||||
|
||||
坦率地说,我不喜欢这种方法,因为它隐藏了各种对象之间发生的重要的的交互。不幸的是,有时[官方的例子][32]有点令人困惑,因为他们倾向于使用不同的方法。在这个简单的例子中,引用图形对象是不必要的,但是在更复杂的例子中(例如在图形用户界面中嵌入图形时),引用图形对象就变得很重要了。
|
||||
|
||||
#### 结果
|
||||
|
||||
命令行输入:
|
||||
|
||||
```
|
||||
#### Anscombe's first set with Python ####
|
||||
Slope: 0.500091
|
||||
Intercept: 3.000091
|
||||
Correlation coefficient: 0.816421
|
||||
```
|
||||
|
||||
这是 Matplotlib 产生的图像:
|
||||
|
||||
![Plot and fit of the dataset obtained with Python][33]
|
||||
|
||||
### GNU Octave 方式
|
||||
|
||||
[GNU Octave][34]语言主要用于数值计算。它提供了一个简单的操作向量和矩阵的语法,并且有一些强大的绘图工具。这是一种像 Python 一样的解释语言。由于 Octave的语法是[最兼容][35] [MATLAB][36],它经常被描述为一个免费的替代 MATLAB 的方案。Octave 没有被列为最流行的编程语言,但是 MATLAB 是,所以 Octave 在某种意义上是相当流行的。MATLAB 早于 NumPy,我觉得它是受到了前者的启发。当你看这个例子时,你会看到相似之处。
|
||||
|
||||
#### 安装
|
||||
|
||||
[fitting_octave.m][37]的例子只需要基本的 Octave 包,在 Fedora 中安装相当简单:
|
||||
|
||||
```
|
||||
`sudo dnf install octave`
|
||||
```
|
||||
|
||||
#### 注释代码
|
||||
|
||||
在Octave中,你可以用百分比符号(**%**)为代码添加注释,如果不需要与 MATLAB 兼容,你也可以使用 **#**。使用 **#** 的选项允许你从 Python 示例中编写相同的特殊注释行,以便直接在命令行上执行脚本。
|
||||
|
||||
#### 必要的库
|
||||
|
||||
本例中使用的所有内容都包含在基本包中,因此你不需要加载任何新的库。如果你需要一个库,[语法][38]是 **pkg load module**。该命令将模块的功能添加到可用功能列表中。在这方面,Python 具有更大的灵活性。
|
||||
|
||||
#### 定义变量
|
||||
|
||||
变量的定义与 Python 的语法基本相同:
|
||||
|
||||
```
|
||||
input_file_name = "anscombe.csv";
|
||||
delimiter = "\t";
|
||||
skip_header = 3;
|
||||
column_x = 1;
|
||||
column_y = 2;
|
||||
```
|
||||
|
||||
请注意,行尾有一个分号;这不是必需的,但是它会抑制行结果的输出。如果没有分号,解释器将打印表达式的结果:
|
||||
|
||||
```
|
||||
octave:1> input_file_name = "anscombe.csv"
|
||||
input_file_name = anscombe.csv
|
||||
octave:2> sqrt(2)
|
||||
ans = 1.4142
|
||||
```
|
||||
|
||||
#### 打印输出结果
|
||||
|
||||
强大的功能[**printf()**][39]是用来在终端上打印的。与 Python 不同,**printf()** 函数不会自动在打印字符串的末尾添加换行,因此你必须添加它。第一个参数是一个字符串,可以包含要传递给函数的其他参数的格式信息,例如:
|
||||
|
||||
```
|
||||
`printf("Slope: %f\n", slope);`
|
||||
```
|
||||
|
||||
在 Python 中,格式是内置在字符串本身中的,但是在 Octave 中,它是特定于 **printf()** 函数。
|
||||
|
||||
#### 读取数据
|
||||
|
||||
[**dlmread()**][40]函数可以读取类似CSV文件的文本内容:
|
||||
|
||||
```
|
||||
`data = dlmread(input_file_name, delimiter, skip_header, 0);`
|
||||
```
|
||||
|
||||
结果是一个[矩阵][41]对象,这是 Octave 中的基本数据类型之一。矩阵可以用类似于 Python 的语法进行切片:
|
||||
|
||||
```
|
||||
x = data(:, column_x);
|
||||
y = data(:, column_y);
|
||||
```
|
||||
|
||||
根本的区别是索引从1开始,而不是从0开始。因此,在该示例中,__x__列是第一列。
|
||||
|
||||
#### 拟合数据
|
||||
|
||||
要用直线拟合数据,可以使用[**polyfit()**][42]函数。它用一个多项式拟合输入数据,所以你只需要使用一阶多项式:
|
||||
|
||||
|
||||
```
|
||||
p = polyfit(x, y, 1);
|
||||
|
||||
slope = p(1);
|
||||
intercept = p(2);
|
||||
```
|
||||
|
||||
结果是具有多项式系数的矩阵;因此,它选择前两个索引。要确定相关系数,请使用[**corr()**][43]函数:
|
||||
|
||||
|
||||
```
|
||||
`r_value = corr(x, y);`
|
||||
```
|
||||
|
||||
最后,使用 **printf()** 函数打印结果:
|
||||
|
||||
```
|
||||
printf("Slope: %f\n", slope);
|
||||
printf("Intercept: %f\n", intercept);
|
||||
printf("Correlation coefficient: %f\n", r_value);
|
||||
```
|
||||
|
||||
#### 绘图
|
||||
|
||||
与 Matplotlib 示例一样,首先需要创建一个表示拟合直线的数据集:
|
||||
|
||||
```
|
||||
fit_x = linspace(min(x) - 1, max(x) + 1, 100);
|
||||
fit_y = slope * fit_x + intercept;
|
||||
```
|
||||
|
||||
与 NumPy 的相似性也很明显,因为它使用了[**linspace()**][44]函数,其行为就像 Python 的等效版本一样。
|
||||
|
||||
同样,与 Matplotlib 一样,首先创建一个[图][45]对象,然后创建一个[轴][46]对象来保存这些图:
|
||||
|
||||
```
|
||||
fig_width = 7; %inch
|
||||
fig_height = fig_width / 16 * 9; %inch
|
||||
fig_dpi = 100;
|
||||
|
||||
fig = figure("units", "inches",
|
||||
"position", [1, 1, fig_width, fig_height]);
|
||||
|
||||
ax = axes("parent", fig);
|
||||
|
||||
set(ax, "fontsize", 14);
|
||||
set(ax, "linewidth", 2);
|
||||
```
|
||||
|
||||
|
||||
要设置轴对象的属性,请使用[**set()**][47]函数。然而,该接口相当混乱,因为该函数需要一个逗号分隔的属性和值对列表。这些对只是代表属性名的一个字符串和代表该属性值的第二个对象的连续。还有其他设置各种属性的功能:
|
||||
|
||||
```
|
||||
xlim(ax, [min(x) - 1, max(x) + 1]);
|
||||
ylim(ax, [min(y) - 1, max(y) + 1]);
|
||||
xlabel(ax, 'x');
|
||||
ylabel(ax, 'y');
|
||||
```
|
||||
|
||||
标图是用[**plot()**][48]功能实现的。默认行为是每次调用都会重置坐标轴,因此需要使用函数[**hold()**][49]。
|
||||
|
||||
|
||||
```
|
||||
hold(ax, "on");
|
||||
|
||||
plot(ax, fit_x, fit_y,
|
||||
"marker", "none",
|
||||
"linestyle", "-",
|
||||
"linewidth", 2);
|
||||
plot(ax, x, y,
|
||||
"marker", ".",
|
||||
"markersize", 20,
|
||||
"linestyle", "none");
|
||||
|
||||
hold(ax, "off");
|
||||
```
|
||||
|
||||
此外,还可以在 **plot()** 函数中添加属性和值对。[legend][50]必须单独创建,标签应手动声明:
|
||||
|
||||
```
|
||||
lg = legend(ax, "Fit", "Data");
|
||||
set(lg, "location", "northwest");
|
||||
```
|
||||
|
||||
最后,将输出保存到PNG图像:
|
||||
|
||||
```
|
||||
image_size = sprintf("-S%f,%f", fig_width * fig_dpi, fig_height * fig_dpi);
|
||||
image_resolution = sprintf("-r%f,%f", fig_dpi);
|
||||
|
||||
print(fig, 'fit_octave.png',
|
||||
'-dpng',
|
||||
image_size,
|
||||
image_resolution);
|
||||
```
|
||||
|
||||
令人困惑的是,在这种情况下,选项被作为一个字符串传递,带有属性名和值。因为在 Octave 字符串中没有 Python 的格式化工具,所以必须使用[**sprintf()**][51]函数。它的行为就像**printf()**函数,但是它的结果不是打印出来的,而是作为字符串返回的。
|
||||
|
||||
在这个例子中,就像在 Python 中一样,图形对象很明显被引用以保持它们之间的交互。如果说 Python 在这方面的文档有点混乱,那么[Octave 的文档][52]就更糟糕了。我发现的大多数例子都不关心引用对象;相反,它们依赖于绘图命令作用于当前活动图形。全局[根图形对象][53]跟踪现有的图形和轴。
|
||||
|
||||
#### 结果
|
||||
|
||||
命令行上的结果输出是:
|
||||
|
||||
```
|
||||
#### Anscombe's first set with Octave ####
|
||||
Slope: 0.500091
|
||||
Intercept: 3.000091
|
||||
Correlation coefficient: 0.816421
|
||||
```
|
||||
|
||||
它显示了用 Octave 生成的结果图像。
|
||||
|
||||
![Plot and fit of the dataset obtained with Octave][54]
|
||||
|
||||
### 下一个
|
||||
|
||||
Python 和 GNU Octave 都可以绘制出相同的信息,尽管它们的实现方式不同。如果你想探索其他语言来完成类似的任务,我强烈建议你看看[Rosetta 代码][55]。这是一个了不起的资源,可以看到如何用多种语言解决同样的问题。
|
||||
|
||||
你喜欢用什么语言绘制数据?在评论中分享你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/python-gnu-octave-data-science
|
||||
|
||||
作者:[Cristiano L. Fontana][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[heguangzhi](https://github.com/heguangzhi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/cristianofontana
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/analytics-graphs-charts.png?itok=sersoqbV (Analytics: Charts and Graphs)
|
||||
[2]: https://en.wikipedia.org/wiki/Command-line_interface
|
||||
[3]: https://en.wikipedia.org/wiki/Graphical_user_interface
|
||||
[4]: https://gitlab.com/cristiano.fontana/polyglot_fit
|
||||
[5]: https://en.wikipedia.org/wiki/Comma-separated_values
|
||||
[6]: https://en.wikipedia.org/wiki/Anscombe%27s_quartet
|
||||
[7]: https://www.python.org/
|
||||
[8]: https://www.tiobe.com/tiobe-index/
|
||||
[9]: https://redmonk.com/sogrady/2019/07/18/language-rankings-6-19/
|
||||
[10]: http://pypl.github.io/PYPL.html
|
||||
[11]: https://octoverse.github.com/
|
||||
[12]: https://en.wikipedia.org/wiki/Interpreted_language
|
||||
[13]: https://docs.python.org/3/library/
|
||||
[14]: https://numpy.org/
|
||||
[15]: https://www.scipy.org/
|
||||
[16]: https://matplotlib.org/
|
||||
[17]: https://getfedora.org/
|
||||
[18]: https://en.wikipedia.org/wiki/Comment_(computer_programming)
|
||||
[19]: https://gitlab.com/cristiano.fontana/polyglot_fit/-/blob/master/fitting_python.py
|
||||
[20]: https://en.wikipedia.org/wiki/Shebang_(Unix)
|
||||
[21]: https://docs.python.org/3/library/functions.html#print
|
||||
[22]: https://docs.python.org/3/library/string.html#string-formatting
|
||||
[23]: https://docs.python.org/3/library/string.html
|
||||
[24]: https://docs.scipy.org/doc/numpy/reference/generated/numpy.genfromtxt.html
|
||||
[25]: https://docs.scipy.org/doc/numpy/reference/generated/numpy.array.html
|
||||
[26]: https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.linregress.html
|
||||
[27]: https://docs.scipy.org/doc/numpy/reference/generated/numpy.linspace.html
|
||||
[28]: https://matplotlib.org/api/_as_gen/matplotlib.figure.Figure.html#matplotlib.figure.Figure
|
||||
[29]: https://matplotlib.org/api/axes_api.html#matplotlib.axes.Axes
|
||||
[30]: https://en.wikipedia.org/wiki/Portable_Network_Graphics
|
||||
[31]: https://matplotlib.org/tutorials/introductory/pyplot.html#sphx-glr-tutorials-introductory-pyplot-py
|
||||
[32]: https://matplotlib.org/gallery/index.html
|
||||
[33]: https://opensource.com/sites/default/files/uploads/fit_python.png (Plot and fit of the dataset obtained with Python)
|
||||
[34]: https://www.gnu.org/software/octave/
|
||||
[35]: https://wiki.octave.org/FAQ#Differences_between_Octave_and_Matlab
|
||||
[36]: https://en.wikipedia.org/wiki/MATLAB
|
||||
[37]: https://gitlab.com/cristiano.fontana/polyglot_fit/-/blob/master/fitting_octave.m
|
||||
[38]: https://octave.org/doc/v5.1.0/Using-Packages.html#Using-Packages
|
||||
[39]: https://octave.org/doc/v5.1.0/Formatted-Output.html#XREFprintf
|
||||
[40]: https://octave.org/doc/v5.1.0/Simple-File-I_002fO.html#XREFdlmread
|
||||
[41]: https://octave.org/doc/v5.1.0/Matrices.html
|
||||
[42]: https://octave.org/doc/v5.1.0/Polynomial-Interpolation.html
|
||||
[43]: https://octave.org/doc/v5.1.0/Correlation-and-Regression-Analysis.html#XREFcorr
|
||||
[44]: https://octave.sourceforge.io/octave/function/linspace.html
|
||||
[45]: https://octave.org/doc/v5.1.0/Multiple-Plot-Windows.html
|
||||
[46]: https://octave.org/doc/v5.1.0/Graphics-Objects.html#XREFaxes
|
||||
[47]: https://octave.org/doc/v5.1.0/Graphics-Objects.html#XREFset
|
||||
[48]: https://octave.org/doc/v5.1.0/Two_002dDimensional-Plots.html#XREFplot
|
||||
[49]: https://octave.org/doc/v5.1.0/Manipulation-of-Plot-Windows.html#XREFhold
|
||||
[50]: https://octave.org/doc/v5.1.0/Plot-Annotations.html#XREFlegend
|
||||
[51]: https://octave.org/doc/v5.1.0/Formatted-Output.html#XREFsprintf
|
||||
[52]: https://octave.org/doc/v5.1.0/Two_002dDimensional-Plots.html#Two_002dDimensional-Plots
|
||||
[53]: https://octave.org/doc/v5.1.0/Graphics-Objects.html#XREFgroot
|
||||
[54]: https://opensource.com/sites/default/files/uploads/fit_octave.png (Plot and fit of the dataset obtained with Octave)
|
||||
[55]: http://www.rosettacode.org/
|
||||
516
translated/tech/20200224 Using C and C-- for data science.md
Normal file
516
translated/tech/20200224 Using C and C-- for data science.md
Normal file
@ -0,0 +1,516 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Using C and C++ for data science)
|
||||
[#]: via: (https://opensource.com/article/20/2/c-data-science)
|
||||
[#]: author: (Cristiano L. Fontana https://opensource.com/users/cristianofontana)
|
||||
|
||||
在数据科学中使用 C 和 C++
|
||||
======
|
||||
|
||||
> 让我们使用 C99 和 C++ 11 完成常见的数据科学任务。
|
||||
|
||||
![metrics and data shown on a computer screen][1]
|
||||
|
||||
虽然 [Python][2] 和 [R][3] 之类的语言在数据科学中越来越受欢迎,但是 C 和 C++ 对于高效的数据科学来说是一个不错的选择。在本文中,我们将使用 [C99][4] 和 [C++11][5] 编写一个程序,该程序使用 [Anscombe 的四重奏][6]数据集,下面将对其进行解释。
|
||||
|
||||
我在一篇涉及 [Python 和 GNU Octave][7] 的文章中写了我不断学习语言的动机,值得大家回顾。所有程序都应在[命令行][8]上运行,而不是在[图形用户界面(GUI)][9]上运行。完整的示例可在 [polyglot_fit 存储库][10]中找到。
|
||||
|
||||
### 编程任务
|
||||
|
||||
你将在本系列中编写的程序:
|
||||
|
||||
* 从 [CSV 文件] [11]中读取数据
|
||||
* 用直线插值数据(即 `f(x)=m ⋅ x + q`)
|
||||
* 将结果绘制到图像文件
|
||||
|
||||
这是许多数据科学家遇到的普遍情况。示例数据是 [Anscombe 的四重奏] [6]的第一组,如下表所示。这是一组人工构建的数据,当拟合直线时可以提供相同的结果,但是它们的曲线非常不同。数据文件是一个文本文件,其中的制表符用作列分隔符,几行作为标题。该任务将仅使用第一组(即前两列)。
|
||||
|
||||
[Anscombe 的四重奏][6]
|
||||
|
||||
|
||||
### C 语言的方式
|
||||
|
||||
[C][12] 语言是通用编程语言,是当今使用最广泛的语言之一(依据 [TIOBE 榜单][13]、[RedMonk 编程语言排名][14]、[编程语言流行度榜单][15]和 [GitHub Octoverse 状态][16])。这是一种相当古老的语言(大约诞生在 1973 年),并且用它编写了许多成功的程序(例如 Linux 内核和 Git 仅是其中两个例子)。它也是最接近计算机内部运行的语言之一,因为它直接用于操作内存。它是一种[编译语言] [17];因此,源代码必须由[编译器][18]转换为[机器代码][19]。它的[标准库][20]很小,功能也不多,因此开发了其他库来提供缺少的功能。
|
||||
|
||||
我最常在[数字运算][21]中使用该语言,主要是因为其性能。我觉得使用起来很繁琐,因为它需要很多[样板代码][22],但是它在各种环境中都得到了很好的支持。C99 标准是最新版本,增加了一些漂亮的功能,并且得到了编译器的良好支持。
|
||||
|
||||
我将一路介绍 C 和 C++ 编程的必要背景,以便初学者和高级用户都可以继续学习。
|
||||
|
||||
#### 安装
|
||||
|
||||
要使用 C99 进行开发,你需要一个编译器。我通常使用 [Clang][23],不过 [GCC][24] 是另一个有效的开源编译器。对于线性拟合,我选择使用 [GNU 科学库] [25]。对于绘图,我找不到任何明智的库,因此该程序依赖于外部程序:[Gnuplot] [26]。该示例还使用动态数据结构来存储数据,该结构在[伯克利软件分发版(BSD)][27]中定义。
|
||||
|
||||
在 [Fedora][28] 中安装很容易:
|
||||
|
||||
```
|
||||
sudo dnf install clang gnuplot gsl gsl-devel
|
||||
```
|
||||
|
||||
#### 注释代码
|
||||
|
||||
在 C99 中,[注释][29]的格式是在行的开头放置 `//`,行的其它部分将被解释器丢弃。另外,`/*` 和 `*/` 之间的任何内容也将被丢弃。
|
||||
|
||||
```
|
||||
// 这是一个注释,会被解释器忽略
|
||||
/* 这也被忽略 */
|
||||
```
|
||||
|
||||
#### 必要的库
|
||||
|
||||
库由两部分组成:
|
||||
|
||||
* [头文件][30],其中包含函数说明
|
||||
* 包含函数定义的源文件
|
||||
|
||||
头文件包含在源文件中,而库文件的源文件则与可执行文件[链接][31]。因此,此示例所需的头文件是:
|
||||
|
||||
```
|
||||
// 输入/输出功能
|
||||
#include <stdio.h>
|
||||
// 标准库
|
||||
#include <stdlib.h>
|
||||
// 字符串操作功能
|
||||
#include <string.h>
|
||||
// BSD 队列
|
||||
#include <sys/queue.h>
|
||||
// GSL 科学功能
|
||||
#include <gsl/gsl_fit.h>
|
||||
#include <gsl/gsl_statistics_double.h>
|
||||
```
|
||||
|
||||
#### 主函数
|
||||
|
||||
在 C 语言中,程序必须位于称为主函数 [main()][32]:的特殊函数内:
|
||||
|
||||
```
|
||||
int main(void) {
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
这与上一教程中介绍的 Python 不同,后者将运行在源文件中找到的所有代码。
|
||||
|
||||
#### 定义变量
|
||||
|
||||
在 C 语言中,变量必须在使用前声明,并且必须与类型关联。每当你要使用变量时,都必须决定要在其中存储哪种数据。你也可以指定是否打算将变量用作常量值,这不是必需的,但是编译器可以从此信息中受益。 来自存储库中的 [fitting_C99.c 程序] [33]:
|
||||
|
||||
```
|
||||
const char *input_file_name = "anscombe.csv";
|
||||
const char *delimiter = "\t";
|
||||
const unsigned int skip_header = 3;
|
||||
const unsigned int column_x = 0;
|
||||
const unsigned int column_y = 1;
|
||||
const char *output_file_name = "fit_C99.csv";
|
||||
const unsigned int N = 100;
|
||||
```
|
||||
|
||||
C 语言中的数组不是动态的,从某种意义上说,数组的长度必须事先确定(即,在编译之前):
|
||||
|
||||
```
|
||||
int data_array[1024];
|
||||
```
|
||||
|
||||
由于你通常不知道文件中有多少个数据点,因此请使用[单链接列表][34]。这是一个动态数据结构,可以无限增长。幸运的是,BSD [提供了链表][35]。这是一个示例定义:
|
||||
|
||||
```
|
||||
struct data_point {
|
||||
double x;
|
||||
double y;
|
||||
|
||||
SLIST_ENTRY(data_point) entries;
|
||||
};
|
||||
|
||||
SLIST_HEAD(data_list, data_point) head = SLIST_HEAD_INITIALIZER(head);
|
||||
SLIST_INIT(&head);
|
||||
```
|
||||
|
||||
该示例定义了一个由结构化值组成的 `data_point` 列表,该结构化值同时包含 `x` 值和 `y` 值。语法相当复杂,但是很直观,详细描述它就会太冗长了。
|
||||
|
||||
#### 打印输出
|
||||
|
||||
要在终端上打印,可以使用 [printf()][36] 函数,其功能类似于 Octave 的 `printf()` 函数(在第一篇文章中介绍):
|
||||
|
||||
```
|
||||
printf("#### Anscombe's first set with C99 ####\n");
|
||||
```
|
||||
|
||||
`printf()` 函数不会在打印字符串的末尾自动添加换行符,因此你必须添加换行符。第一个参数是一个字符串,可以包含传递给函数的其他参数的格式信息,例如:
|
||||
|
||||
```
|
||||
printf("Slope: %f\n", slope);
|
||||
```
|
||||
|
||||
#### 读取数据
|
||||
|
||||
现在来到了困难的部分……有一些用 C 语言解析 CSV 文件的库,但是似乎没有一个库足够稳定或流行到可以放入到 Fedora 软件包存储库中。我没有为本教程添加依赖项,而是决定自己编写此部分。同样,讨论这些细节太啰嗦了,所以我只会解释大致的思路。为了简洁起见,将忽略源代码中的某些行,但是你可以在存储库中找到完整的示例。
|
||||
|
||||
首先,打开输入文件:
|
||||
|
||||
```
|
||||
FILE* input_file = fopen(input_file_name, "r");
|
||||
```
|
||||
|
||||
然后逐行读取文件,直到出现错误或文件结束:
|
||||
|
||||
```
|
||||
while (!ferror(input_file) && !feof(input_file)) {
|
||||
size_t buffer_size = 0;
|
||||
char *buffer = NULL;
|
||||
|
||||
getline(&buffer, &buffer_size, input_file);
|
||||
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
[getline()][39] 函数是 [POSIX.1-2008 标准][40]新增的一个不错的函数。它可以读取文件中的整行,并负责分配必要的内存。然后使用 [strtok()][42] 函数将每一行分成<ruby>[字元][41]<rt>token</rt></ruby>。遍历字元,选择所需的列:
|
||||
|
||||
```
|
||||
char *token = strtok(buffer, delimiter);
|
||||
|
||||
while (token != NULL)
|
||||
{
|
||||
double value;
|
||||
sscanf(token, "%lf", &value);
|
||||
|
||||
if (column == column_x) {
|
||||
x = value;
|
||||
} else if (column == column_y) {
|
||||
y = value;
|
||||
}
|
||||
|
||||
column += 1;
|
||||
token = strtok(NULL, delimiter);
|
||||
}
|
||||
```
|
||||
|
||||
最后,当选择了 `x` 和 `y` 值时,将新数据点插入链表中:
|
||||
|
||||
```
|
||||
struct data_point *datum = malloc(sizeof(struct data_point));
|
||||
datum->x = x;
|
||||
datum->y = y;
|
||||
|
||||
SLIST_INSERT_HEAD(&head, datum, entries);
|
||||
```
|
||||
|
||||
[malloc()][46] 函数为新数据点动态分配(保留)一些持久性内存。
|
||||
|
||||
#### 拟合数据
|
||||
|
||||
GSL 线性拟合函数 [gsl_fit_linear()][47] 期望其输入为简单数组。因此,由于你将不知道要创建的数组的大小,因此必须手动分配它们的内存:
|
||||
|
||||
```
|
||||
const size_t entries_number = row - skip_header - 1;
|
||||
|
||||
double *x = malloc(sizeof(double) * entries_number);
|
||||
double *y = malloc(sizeof(double) * entries_number);
|
||||
```
|
||||
|
||||
然后,遍历链接列表以将相关数据保存到数组:
|
||||
|
||||
```
|
||||
SLIST_FOREACH(datum, &head, entries) {
|
||||
const double current_x = datum->x;
|
||||
const double current_y = datum->y;
|
||||
|
||||
x[i] = current_x;
|
||||
y[i] = current_y;
|
||||
|
||||
i += 1;
|
||||
}
|
||||
```
|
||||
|
||||
现在你已经完成了链接列表,请清理它。要**总是**释放已手动分配的内存,以防止[内存泄漏][48]。内存泄漏是糟糕的、糟糕的、糟糕的(重要的话说三遍)。每次内存没有释放时,花园侏儒都会找不到自己的头:
|
||||
|
||||
```
|
||||
while (!SLIST_EMPTY(&head)) {
|
||||
struct data_point *datum = SLIST_FIRST(&head);
|
||||
|
||||
SLIST_REMOVE_HEAD(&head, entries);
|
||||
|
||||
free(datum);
|
||||
}
|
||||
```
|
||||
|
||||
终于,终于!你可以拟合你的数据了:
|
||||
|
||||
```
|
||||
gsl_fit_linear(x, 1, y, 1, entries_number,
|
||||
&intercept, &slope,
|
||||
&cov00, &cov01, &cov11, &chi_squared);
|
||||
const double r_value = gsl_stats_correlation(x, 1, y, 1, entries_number);
|
||||
|
||||
printf("Slope: %f\n", slope);
|
||||
printf("Intercept: %f\n", intercept);
|
||||
printf("Correlation coefficient: %f\n", r_value);
|
||||
```
|
||||
|
||||
#### 绘图
|
||||
|
||||
你必须使用外部程序进行绘图。因此,将拟合数据保存到外部文件:
|
||||
|
||||
```
|
||||
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
|
||||
|
||||
for (unsigned int i = 0; i < N; i += 1) {
|
||||
const double current_x = (min_x - 1) + step_x * i;
|
||||
const double current_y = intercept + slope * current_x;
|
||||
|
||||
fprintf(output_file, "%f\t%f\n", current_x, current_y);
|
||||
}
|
||||
```
|
||||
|
||||
用于绘制两个文件的 Gnuplot 命令是:
|
||||
|
||||
```
|
||||
plot 'fit_C99.csv' using 1:2 with lines title 'Fit', 'anscombe.csv' using 1:2 with points pointtype 7 title 'Data'
|
||||
```
|
||||
|
||||
#### 结果
|
||||
|
||||
在运行程序之前,你必须编译它:
|
||||
|
||||
```
|
||||
clang -std=c99 -I/usr/include/ fitting_C99.c -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_C99
|
||||
```
|
||||
|
||||
这个命令告诉编译器使用 C99 标准,读取 `fitting_C99.c` 文件,加载 `gsl` 和 `gslcblas` 库,并将结果保存到 `fitting_C99`。命令行上的结果输出为:
|
||||
|
||||
```
|
||||
#### Anscombe's first set with C99 ####
|
||||
Slope: 0.500091
|
||||
Intercept: 3.000091
|
||||
Correlation coefficient: 0.816421
|
||||
```
|
||||
|
||||
这是用 Gnuplot 生成的结果图像。
|
||||
|
||||
![Plot and fit of the dataset obtained with C99][52]
|
||||
|
||||
### C++11 方式
|
||||
|
||||
[C++][53] 语言是一种通用编程语言,也是当今使用的最受欢迎的语言之一。它是作为 [C 的继承人][54]创建的(诞生于 1983 年),重点是[面向对象程序设计(OOP)][55]。C++ 通常被视为 C 的超集,因此 C 程序应该能够使用 C++ 编译器进行编译。这并非完全正确,因为在某些极端情况下它们的行为有所不同。 根据我的经验,C++ 比 C 需要更少的样板代码,但是如果要进行对象开发,语法会更困难。C++11 标准是最新版本,增加了一些漂亮的功能,并且或多或少得到了编译器的支持。
|
||||
|
||||
由于 C++ 在很大程度上与 C 兼容,因此我将仅强调两者之间的区别。我在本部分中没有涵盖的任何部分,则意味着它与 C 中的相同。
|
||||
|
||||
#### 安装
|
||||
|
||||
这个 C++ 示例的依赖项与 C 示例相同。 在 Fedora 上,运行:
|
||||
|
||||
```
|
||||
sudo dnf install clang gnuplot gsl gsl-devel
|
||||
```
|
||||
|
||||
#### 必要的库
|
||||
|
||||
库的工作方式与 C 语言相同,但是 `include` 指令略有不同:
|
||||
|
||||
|
||||
```
|
||||
#include <cstdlib>
|
||||
#include <cstring>
|
||||
#include <iostream>
|
||||
#include <fstream>
|
||||
#include <string>
|
||||
#include <vector>
|
||||
#include <algorithm>
|
||||
|
||||
extern "C" {
|
||||
#include <gsl/gsl_fit.h>
|
||||
#include <gsl/gsl_statistics_double.h>
|
||||
}
|
||||
```
|
||||
|
||||
由于 GSL 库是用 C 编写的,因此你必须将这种特殊性告知编译器。
|
||||
|
||||
#### 定义变量
|
||||
|
||||
与 C 语言相比,C++ 支持更多的数据类型(类),例如,与其 C 语言版本相比,`string` 类型具有更多的功能。相应地更新变量的定义:
|
||||
|
||||
```
|
||||
const std::string input_file_name("anscombe.csv");
|
||||
```
|
||||
|
||||
对于字符串之类的结构化对象,你可以定义变量而无需使用 `=` 符号。
|
||||
|
||||
#### 打印输出
|
||||
|
||||
你可以使用 `printf()` 函数,但是 `cout` 对象更惯用。使用运算符 `<<` 来指示要使用 `cout` 打印的字符串(或对象):
|
||||
|
||||
```
|
||||
std::cout << "#### Anscombe's first set with C++11 ####" << std::endl;
|
||||
|
||||
...
|
||||
|
||||
std::cout << "Slope: " << slope << std::endl;
|
||||
std::cout << "Intercept: " << intercept << std::endl;
|
||||
std::cout << "Correlation coefficient: " << r_value << std::endl;
|
||||
```
|
||||
|
||||
#### 读取数据
|
||||
|
||||
该方案与以前相同。将打开文件并逐行读取文件,但语法不同:
|
||||
|
||||
```
|
||||
std::ifstream input_file(input_file_name);
|
||||
|
||||
while (input_file.good()) {
|
||||
std::string line;
|
||||
|
||||
getline(input_file, line);
|
||||
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
使用与 C99 示例相同的功能提取行字元。代替使用标准的 C 数组,而是使用两个[向量][56]。向量是 [C++ 标准库][57]中对 C 数组的扩展,它允许动态管理内存而无需显式调用 `malloc()`:
|
||||
|
||||
```
|
||||
std::vector<double> x;
|
||||
std::vector<double> y;
|
||||
|
||||
// Adding an element to x and y:
|
||||
x.emplace_back(value);
|
||||
y.emplace_back(value);
|
||||
```
|
||||
|
||||
#### 拟合数据
|
||||
|
||||
要在 C++ 中拟合,你不必遍历列表,因为向量可以保证具有连续的内存。你可以将向量缓冲区的指针直接传递给拟合函数:
|
||||
|
||||
```
|
||||
gsl_fit_linear(x.data(), 1, y.data(), 1, entries_number,
|
||||
&intercept, &slope,
|
||||
&cov00, &cov01, &cov11, &chi_squared);
|
||||
const double r_value = gsl_stats_correlation(x.data(), 1, y.data(), 1, entries_number);
|
||||
|
||||
std::cout << "Slope: " << slope << std::endl;
|
||||
std::cout << "Intercept: " << intercept << std::endl;
|
||||
std::cout << "Correlation coefficient: " << r_value << std::endl;
|
||||
```
|
||||
|
||||
#### 绘图
|
||||
|
||||
使用与以前相同的方法进行绘图。 写入文件:
|
||||
|
||||
```
|
||||
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
|
||||
|
||||
for (unsigned int i = 0; i < N; i += 1) {
|
||||
const double current_x = (min_x - 1) + step_x * i;
|
||||
const double current_y = intercept + slope * current_x;
|
||||
|
||||
output_file << current_x << "\t" << current_y << std::endl;
|
||||
}
|
||||
|
||||
output_file.close();
|
||||
```
|
||||
|
||||
然后使用 Gnuplot 进行绘图。
|
||||
|
||||
#### 结果
|
||||
|
||||
在运行程序之前,必须使用类似的命令对其进行编译:
|
||||
|
||||
```
|
||||
clang++ -std=c++11 -I/usr/include/ fitting_Cpp11.cpp -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_Cpp11
|
||||
```
|
||||
|
||||
命令行上的结果输出为:
|
||||
|
||||
```
|
||||
#### Anscombe's first set with C++11 ####
|
||||
Slope: 0.500091
|
||||
Intercept: 3.00009
|
||||
Correlation coefficient: 0.816421
|
||||
```
|
||||
|
||||
这就是用 Gnuplot 生成的结果图像。
|
||||
|
||||
![Plot and fit of the dataset obtained with C++11][58]
|
||||
|
||||
### 结论
|
||||
|
||||
本文提供了用 C99 和 C++11 编写的数据拟合和绘图任务的示例。由于 C++ 在很大程度上与 C 兼容,因此本文利用了它们的相似性来编写了第二个示例。在某些方面,C++ 更易于使用,因为它部分减轻了显式管理内存的负担。但是其语法更加复杂,因为它引入了为 OOP 编写类的可能性。但是,仍然可以用 C 使用 OOP 方法编写软件。由于 OOP 是一种编程风格,因此可以以任何语言使用。在 C 中有一些很好的 OOP 示例,例如 [GObject][59] 和 [Jansson][60]库。
|
||||
|
||||
对于数字运算,我更喜欢在 C99 中进行,因为它的语法更简单并且得到了广泛的支持。直到最近,C++11 还没有得到广泛的支持,我倾向于避免使用先前版本中的粗糙不足之处。对于更复杂的软件,C++ 可能是一个不错的选择。
|
||||
|
||||
你是否也将 C 或 C++ 用于数据科学? 在评论中分享你的经验。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/c-data-science
|
||||
|
||||
作者:[Cristiano L. Fontana][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/cristianofontana
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/metrics_data_dashboard_system_computer_analytics.png?itok=oxAeIEI- (metrics and data shown on a computer screen)
|
||||
[2]: https://opensource.com/article/18/9/top-3-python-libraries-data-science
|
||||
[3]: https://opensource.com/article/19/5/learn-python-r-data-science
|
||||
[4]: https://en.wikipedia.org/wiki/C99
|
||||
[5]: https://en.wikipedia.org/wiki/C%2B%2B11
|
||||
[6]: https://en.wikipedia.org/wiki/Anscombe%27s_quartet
|
||||
[7]: https://opensource.com/article/20/2/python-gnu-octave-data-science
|
||||
[8]: https://en.wikipedia.org/wiki/Command-line_interface
|
||||
[9]: https://en.wikipedia.org/wiki/Graphical_user_interface
|
||||
[10]: https://gitlab.com/cristiano.fontana/polyglot_fit
|
||||
[11]: https://en.wikipedia.org/wiki/Comma-separated_values
|
||||
[12]: https://en.wikipedia.org/wiki/C_%28programming_language%29
|
||||
[13]: https://www.tiobe.com/tiobe-index/
|
||||
[14]: https://redmonk.com/sogrady/2019/07/18/language-rankings-6-19/
|
||||
[15]: http://pypl.github.io/PYPL.html
|
||||
[16]: https://octoverse.github.com/
|
||||
[17]: https://en.wikipedia.org/wiki/Compiled_language
|
||||
[18]: https://en.wikipedia.org/wiki/Compiler
|
||||
[19]: https://en.wikipedia.org/wiki/Machine_code
|
||||
[20]: https://en.wikipedia.org/wiki/C_standard_library
|
||||
[21]: https://en.wiktionary.org/wiki/number-crunching
|
||||
[22]: https://en.wikipedia.org/wiki/Boilerplate_code
|
||||
[23]: https://clang.llvm.org/
|
||||
[24]: https://gcc.gnu.org/
|
||||
[25]: https://www.gnu.org/software/gsl/
|
||||
[26]: http://www.gnuplot.info/
|
||||
[27]: https://en.wikipedia.org/wiki/Berkeley_Software_Distribution
|
||||
[28]: https://getfedora.org/
|
||||
[29]: https://en.wikipedia.org/wiki/Comment_(computer_programming)
|
||||
[30]: https://en.wikipedia.org/wiki/Include_directive
|
||||
[31]: https://en.wikipedia.org/wiki/Linker_%28computing%29
|
||||
[32]: https://en.wikipedia.org/wiki/Entry_point#C_and_C++
|
||||
[33]: https://gitlab.com/cristiano.fontana/polyglot_fit/-/blob/master/fitting_C99.c
|
||||
[34]: https://en.wikipedia.org/wiki/Linked_list#Singly_linked_list
|
||||
[35]: http://man7.org/linux/man-pages/man3/queue.3.html
|
||||
[36]: https://en.wikipedia.org/wiki/Printf_format_string
|
||||
[37]: http://www.opengroup.org/onlinepubs/009695399/functions/ferror.html
|
||||
[38]: http://www.opengroup.org/onlinepubs/009695399/functions/feof.html
|
||||
[39]: http://man7.org/linux/man-pages/man3/getline.3.html
|
||||
[40]: https://en.wikipedia.org/wiki/POSIX
|
||||
[41]: https://en.wikipedia.org/wiki/Lexical_analysis#Token
|
||||
[42]: http://man7.org/linux/man-pages/man3/strtok.3.html
|
||||
[43]: http://www.opengroup.org/onlinepubs/009695399/functions/strtok.html
|
||||
[44]: http://www.opengroup.org/onlinepubs/009695399/functions/sscanf.html
|
||||
[45]: http://www.opengroup.org/onlinepubs/009695399/functions/malloc.html
|
||||
[46]: http://man7.org/linux/man-pages/man3/malloc.3.html
|
||||
[47]: https://www.gnu.org/software/gsl/doc/html/lls.html
|
||||
[48]: https://en.wikipedia.org/wiki/Memory_leak
|
||||
[49]: http://www.opengroup.org/onlinepubs/009695399/functions/free.html
|
||||
[50]: http://www.opengroup.org/onlinepubs/009695399/functions/printf.html
|
||||
[51]: http://www.opengroup.org/onlinepubs/009695399/functions/fprintf.html
|
||||
[52]: https://opensource.com/sites/default/files/uploads/fit_c99.png (Plot and fit of the dataset obtained with C99)
|
||||
[53]: https://en.wikipedia.org/wiki/C%2B%2B
|
||||
[54]: http://www.cplusplus.com/info/history/
|
||||
[55]: https://en.wikipedia.org/wiki/Object-oriented_programming
|
||||
[56]: https://en.wikipedia.org/wiki/Sequence_container_%28C%2B%2B%29#Vector
|
||||
[57]: https://en.wikipedia.org/wiki/C%2B%2B_Standard_Library
|
||||
[58]: https://opensource.com/sites/default/files/uploads/fit_cpp11.png (Plot and fit of the dataset obtained with C++11)
|
||||
[59]: https://en.wikipedia.org/wiki/GObject
|
||||
[60]: http://www.digip.org/jansson/
|
||||
Loading…
Reference in New Issue
Block a user