diff --git a/published/20090203 How the Kernel Manages Your Memory.md b/published/20090203 How the Kernel Manages Your Memory.md
new file mode 100644
index 0000000000..2e72498165
--- /dev/null
+++ b/published/20090203 How the Kernel Manages Your Memory.md
@@ -0,0 +1,102 @@
+内核如何管理内存
+============================================================
+
+在学习了进程的 [虚拟地址布局][1] 之后,让我们回到内核,来学习它管理用户内存的机制。这里再次使用 Gonzo:
+
+
+
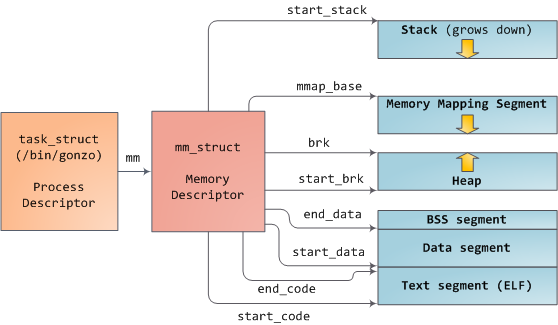
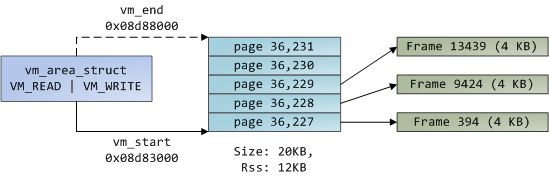
+Linux 进程在内核中是作为进程描述符 [task_struct][2] (LCTT 译注:它是在 Linux 中描述进程完整信息的一种数据结构)的实例来实现的。在 task_struct 中的 [mm][3] 域指向到**内存描述符**,[mm_struct][4] 是一个程序在内存中的执行摘要。如上图所示,它保存了起始和结束内存段,进程使用的物理内存页面的 [数量][5](RSS 常驻内存大小 )、虚拟地址空间使用的 [总数量][6]、以及其它片断。 在内存描述符中,我们可以获悉它有两种管理内存的方式:**虚拟内存区域**集和**页面表**。Gonzo 的内存区域如下所示:
+
+
+
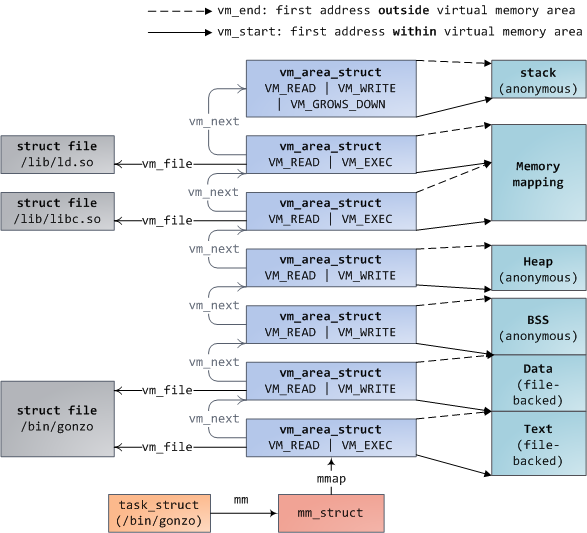
+每个虚拟内存区域(VMA)是一个连续的虚拟地址范围;这些区域绝对不会重叠。一个 [vm_area_struct][7] 的实例完整地描述了一个内存区域,包括它的起始和结束地址,[flags][8] 决定了访问权限和行为,并且 [vm_file][9] 域指定了映射到这个区域的文件(如果有的话)。(除了内存映射段的例外情况之外,)一个 VMA 是不能**匿名**映射文件的。上面的每个内存段(比如,堆、栈)都对应一个单个的 VMA。虽然它通常都使用在 x86 的机器上,但它并不是必需的。VMA 也不关心它们在哪个段中。
+
+一个程序的 VMA 在内存描述符中是作为 [mmap][10] 域的一个链接列表保存的,以起始虚拟地址为序进行排列,并且在 [mm_rb][12] 域中作为一个 [红黑树][11] 的根。红黑树允许内核通过给定的虚拟地址去快速搜索内存区域。在你读取文件 `/proc/pid_of_process/maps` 时,内核只是简单地读取每个进程的 VMA 的链接列表并[显示它们][13]。
+
+在 Windows 中,[EPROCESS][14] 块大致类似于一个 task_struct 和 mm_struct 的结合。在 Windows 中模拟一个 VMA 的是虚拟地址描述符,或称为 [VAD][15];它保存在一个 [AVL 树][16] 中。你知道关于 Windows 和 Linux 之间最有趣的事情是什么吗?其实它们只有一点小差别。
+
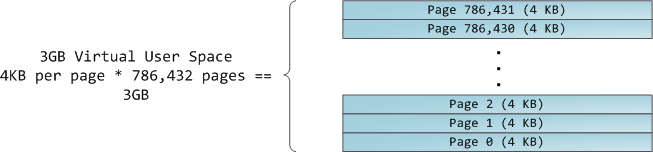
+4GB 虚拟地址空间被分配到**页面**中。在 32 位模式中的 x86 处理器中支持 4KB、2MB、以及 4MB 大小的页面。Linux 和 Windows 都使用大小为 4KB 的页面去映射用户的一部分虚拟地址空间。字节 0-4095 在页面 0 中,字节 4096-8191 在页面 1 中,依次类推。VMA 的大小 _必须是页面大小的倍数_ 。下图是使用 4KB 大小页面的总数量为 3GB 的用户空间:
+
+
+
+处理器通过查看**页面表**去转换一个虚拟内存地址到一个真实的物理内存地址。每个进程都有它自己的一组页面表;每当发生进程切换时,用户空间的页面表也同时切换。Linux 在内存描述符的 [pgd][17] 域中保存了一个指向进程的页面表的指针。对于每个虚拟页面,页面表中都有一个相应的**页面表条目**(PTE),在常规的 x86 页面表中,它是一个简单的如下所示的大小为 4 字节的记录:
+
+
+
+Linux 通过函数去 [读取][18] 和 [设置][19] PTE 条目中的每个标志位。标志位 P 告诉处理器这个虚拟页面是否**在**物理内存中。如果该位被清除(设置为 0),访问这个页面将触发一个页面故障。请记住,当这个标志位为 0 时,内核可以在剩余的域上**做任何想做的事**。R/W 标志位是读/写标志;如果被清除,这个页面将变成只读的。U/S 标志位表示用户/超级用户;如果被清除,这个页面将仅被内核访问。这些标志都是用于实现我们在前面看到的只读内存和内核空间保护。
+
+标志位 D 和 A 用于标识页面是否是“**脏的**”或者是已**被访问过**。一个脏页面表示已经被写入,而一个被访问过的页面则表示有一个写入或者读取发生过。这两个标志位都是粘滞位:处理器只能设置它们,而清除则是由内核来完成的。最终,PTE 保存了这个页面相应的起始物理地址,它们按 4KB 进行整齐排列。这个看起来不起眼的域是一些痛苦的根源,因为它限制了物理内存最大为 [4 GB][20]。其它的 PTE 域留到下次再讲,因为它是涉及了物理地址扩展的知识。
+
+由于在一个虚拟页面上的所有字节都共享一个 U/S 和 R/W 标志位,所以内存保护的最小单元是一个虚拟页面。但是,同一个物理内存可能被映射到不同的虚拟页面,这样就有可能会出现相同的物理内存出现不同的保护标志位的情况。请注意,在 PTE 中是看不到运行权限的。这就是为什么经典的 x86 页面上允许代码在栈上被执行的原因,这样会很容易导致挖掘出栈缓冲溢出漏洞(可能会通过使用 [return-to-libc][21] 和其它技术来找出非可执行栈)。由于 PTE 缺少禁止运行标志位说明了一个更广泛的事实:在 VMA 中的权限标志位有可能或可能不完全转换为硬件保护。内核只能做它能做到的,但是,最终的架构限制了它能做的事情。
+
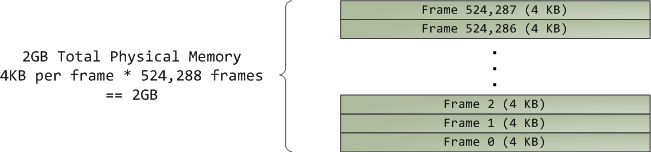
+虚拟内存不保存任何东西,它只是简单地 _映射_ 一个程序的地址空间到底层的物理内存上。物理内存被当作一个称之为**物理地址空间**的巨大块而由处理器访问。虽然内存的操作[涉及到某些][22]总线,我们在这里先忽略它,并假设物理地址范围从 0 到可用的最大值按字节递增。物理地址空间被内核进一步分解为**页面帧**。处理器并不会关心帧的具体情况,这一点对内核也是至关重要的,因为,**页面帧是物理内存管理的最小单元**。Linux 和 Windows 在 32 位模式下都使用 4KB 大小的页面帧;下图是一个有 2 GB 内存的机器的例子:
+
+
+
+在 Linux 上每个页面帧是被一个 [描述符][23] 和 [几个标志][24] 来跟踪的。通过这些描述符和标志,实现了对机器上整个物理内存的跟踪;每个页面帧的具体状态是公开的。物理内存是通过使用 [Buddy 内存分配][25] (LCTT 译注:一种内存分配算法)技术来管理的,因此,如果一个页面帧可以通过 Buddy 系统分配,那么它是**未分配的**(free)。一个被分配的页面帧可以是**匿名的**、持有程序数据的、或者它可能处于页面缓存中、持有数据保存在一个文件或者块设备中。还有其它的异形页面帧,但是这些异形页面帧现在已经不怎么使用了。Windows 有一个类似的页面帧号(Page Frame Number (PFN))数据库去跟踪物理内存。
+
+我们把虚拟内存区域(VMA)、页面表条目(PTE),以及页面帧放在一起来理解它们是如何工作的。下面是一个用户堆的示例:
+
+
+
+蓝色的矩形框表示在 VMA 范围内的页面,而箭头表示页面表条目映射页面到页面帧。一些缺少箭头的虚拟页面,表示它们对应的 PTE 的当前标志位被清除(置为 0)。这可能是因为这个页面从来没有被使用过,或者是它的内容已经被交换出去了。在这两种情况下,即便这些页面在 VMA 中,访问它们也将导致产生一个页面故障。对于这种 VMA 和页面表的不一致的情况,看上去似乎很奇怪,但是这种情况却经常发生。
+
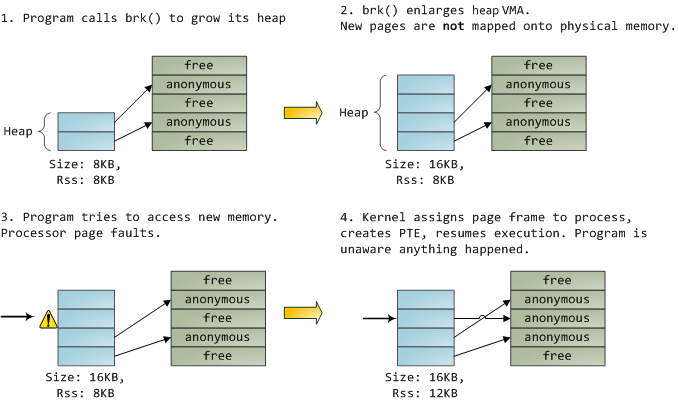
+一个 VMA 像一个在你的程序和内核之间的合约。你请求它做一些事情(分配内存、文件映射、等等),内核会回应“收到”,然后去创建或者更新相应的 VMA。 但是,它 _并不立刻_ 去“兑现”对你的承诺,而是它会等待到发生一个页面故障时才去 _真正_ 做这个工作。内核是个“懒惰的家伙”、“不诚实的人渣”;这就是虚拟内存的基本原理。它适用于大多数的情况,有一些类似情况和有一些意外的情况,但是,它是规则是,VMA 记录 _约定的_ 内容,而 PTE 才反映这个“懒惰的内核” _真正做了什么_。通过这两种数据结构共同来管理程序的内存;它们共同来完成解决页面故障、释放内存、从内存中交换出数据、等等。下图是内存分配的一个简单案例:
+
+
+
+当程序通过 [brk()][26] 系统调用来请求一些内存时,内核只是简单地 [更新][27] 堆的 VMA 并给程序回复“已搞定”。而在这个时候并没有真正地分配页面帧,并且新的页面也没有映射到物理内存上。一旦程序尝试去访问这个页面时,处理器将发生页面故障,然后调用 [do_page_fault()][28]。这个函数将使用 [find_vma()][30] 去 [搜索][29] 发生页面故障的 VMA。如果找到了,然后在 VMA 上进行权限检查以防范恶意访问(读取或者写入)。如果没有合适的 VMA,也没有所尝试访问的内存的“合约”,将会给进程返回段故障。
+
+当[找到][31]了一个合适的 VMA,内核必须通过查找 PTE 的内容和 VMA 的类型去[处理][32]故障。在我们的案例中,PTE 显示这个页面是 [不存在的][33]。事实上,我们的 PTE 是全部空白的(全部都是 0),在 Linux 中这表示虚拟内存还没有被映射。由于这是匿名 VMA,我们有一个完全的 RAM 事务,它必须被 [do_anonymous_page()][34] 来处理,它分配页面帧,并且用一个 PTE 去映射故障虚拟页面到一个新分配的帧。
+
+有时候,事情可能会有所不同。例如,对于被交换出内存的页面的 PTE,在当前(Present)标志位上是 0,但它并不是空白的。而是在交换位置仍有页面内容,它必须从磁盘上读取并且通过 [do_swap_page()][35] 来加载到一个被称为 [major fault][36] 的页面帧上。
+
+这是我们通过探查内核的用户内存管理得出的前半部分的结论。在下一篇文章中,我们通过将文件加载到内存中,来构建一个完整的内存框架图,以及对性能的影响。
+
+--------------------------------------------------------------------------------
+
+via: http://duartes.org/gustavo/blog/post/how-the-kernel-manages-your-memory/
+
+作者:[Gustavo Duarte][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://duartes.org/gustavo/blog/about/
+[1]:https://linux.cn/article-9255-1.html
+[2]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/sched.h#L1075
+[3]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/sched.h#L1129
+[4]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L173
+[5]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L197
+[6]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L206
+[7]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L99
+[8]:http://lxr.linux.no/linux+v2.6.28/include/linux/mm.h#L76
+[9]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L150
+[10]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L174
+[11]:http://en.wikipedia.org/wiki/Red_black_tree
+[12]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L175
+[13]:http://lxr.linux.no/linux+v2.6.28.1/fs/proc/task_mmu.c#L201
+[14]:http://www.nirsoft.net/kernel_struct/vista/EPROCESS.html
+[15]:http://www.nirsoft.net/kernel_struct/vista/MMVAD.html
+[16]:http://en.wikipedia.org/wiki/AVL_tree
+[17]:http://lxr.linux.no/linux+v2.6.28.1/include/linux/mm_types.h#L185
+[18]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/include/asm/pgtable.h#L173
+[19]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/include/asm/pgtable.h#L230
+[20]:http://www.google.com/search?hl=en&q=2^20+*+2^12+bytes+in+GB
+[21]:http://en.wikipedia.org/wiki/Return-to-libc_attack
+[22]:http://duartes.org/gustavo/blog/post/getting-physical-with-memory
+[23]:http://lxr.linux.no/linux+v2.6.28/include/linux/mm_types.h#L32
+[24]:http://lxr.linux.no/linux+v2.6.28/include/linux/page-flags.h#L14
+[25]:http://en.wikipedia.org/wiki/Buddy_memory_allocation
+[26]:http://www.kernel.org/doc/man-pages/online/pages/man2/brk.2.html
+[27]:http://lxr.linux.no/linux+v2.6.28.1/mm/mmap.c#L2050
+[28]:http://lxr.linux.no/linux+v2.6.28/arch/x86/mm/fault.c#L583
+[29]:http://lxr.linux.no/linux+v2.6.28/arch/x86/mm/fault.c#L692
+[30]:http://lxr.linux.no/linux+v2.6.28/mm/mmap.c#L1466
+[31]:http://lxr.linux.no/linux+v2.6.28/arch/x86/mm/fault.c#L711
+[32]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2653
+[33]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2674
+[34]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2681
+[35]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2280
+[36]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2316
diff --git a/published/20090518 How to use yum-cron to automatically update RHEL-CentOS Linux.md b/published/20090518 How to use yum-cron to automatically update RHEL-CentOS Linux.md
new file mode 100644
index 0000000000..e2d88ce4ec
--- /dev/null
+++ b/published/20090518 How to use yum-cron to automatically update RHEL-CentOS Linux.md
@@ -0,0 +1,146 @@
+如何使用 yum-cron 自动更新 RHEL/CentOS Linux
+======
+
+`yum` 命令是 RHEL / CentOS Linux 系统中用来安装和更新软件包的一个工具。我知道如何使用 [yum 命令行][1] 更新系统,但是我想用 cron 任务自动更新软件包。该如何配置才能使得 `yum` 使用 [cron 自动更新][2]系统补丁或更新呢?
+
+首先需要安装 yum-cron 软件包。该软件包提供以 cron 命令运行 `yum` 更新所需的文件。如果你想要每晚通过 cron 自动更新可以安装这个软件包。
+
+### CentOS/RHEL 6.x/7.x 上安装 yum cron
+
+输入以下 [yum 命令][3]:
+
+```
+$ sudo yum install yum-cron
+```
+
+
+
+使用 CentOS/RHEL 7.x 上的 `systemctl` 启动服务:
+
+```
+$ sudo systemctl enable yum-cron.service
+$ sudo systemctl start yum-cron.service
+$ sudo systemctl status yum-cron.service
+```
+
+在 CentOS/RHEL 6.x 系统中,运行:
+
+```
+$ sudo chkconfig yum-cron on
+$ sudo service yum-cron start
+```
+
+
+
+`yum-cron` 是 `yum` 的一个替代方式。使得 cron 调用 `yum` 变得非常方便。该软件提供了元数据更新、更新检查、下载和安装等功能。`yum-cron` 的各种功能可以使用配置文件配置,而不是输入一堆复杂的命令行参数。
+
+### 配置 yum-cron 自动更新 RHEL/CentOS Linux
+
+使用 vi 等编辑器编辑文件 `/etc/yum/yum-cron.conf` 和 `/etc/yum/yum-cron-hourly.conf`:
+
+```
+$ sudo vi /etc/yum/yum-cron.conf
+```
+
+确保更新可用时自动更新:
+
+```
+apply_updates = yes
+```
+
+可以设置通知 email 的发件地址。注意: localhost` 将会被 `system_name` 的值代替。
+
+```
+email_from = root@localhost
+```
+
+列出发送到的 email 地址。
+
+```
+email_to = your-it-support@some-domain-name
+```
+
+发送 email 信息的主机名。
+
+```
+email_host = localhost
+```
+
+[CentOS/RHEL 7.x][4] 上不想更新内核的话,添加以下内容:
+
+```
+exclude=kernel*
+```
+
+RHEL/CentOS 6.x 下[添加以下内容来禁用内核更新][5]:
+
+```
+YUM_PARAMETER=kernel*
+```
+
+[保存并关闭文件][6]。如果想每小时更新系统的话修改文件 `/etc/yum/yum-cron-hourly.conf`,否则文件 `/etc/yum/yum-cron.conf` 将使用以下命令每天运行一次(使用 [cat 命令][7] 查看):
+
+```
+$ cat /etc/cron.daily/0yum-daily.cron
+```
+
+示例输出:
+
+```
+#!/bin/bash
+
+# Only run if this flag is set. The flag is created by the yum-cron init
+# script when the service is started -- this allows one to use chkconfig and
+# the standard "service stop|start" commands to enable or disable yum-cron.
+if [[ ! -f /var/lock/subsys/yum-cron ]]; then
+ exit 0
+fi
+
+# Action!
+exec /usr/sbin/yum-cron /etc/yum/yum-cron-hourly.conf
+[root@centos7-box yum]# cat /etc/cron.daily/0yum-daily.cron
+#!/bin/bash
+
+# Only run if this flag is set. The flag is created by the yum-cron init
+# script when the service is started -- this allows one to use chkconfig and
+# the standard "service stop|start" commands to enable or disable yum-cron.
+if [[ ! -f /var/lock/subsys/yum-cron ]]; then
+ exit 0
+fi
+
+# Action!
+exec /usr/sbin/yum-cron
+```
+
+完成配置。现在你的系统将每天自动更新一次。更多细节请参照 yum-cron 的说明手册。
+
+```
+$ man yum-cron
+```
+
+### 关于作者
+
+作者是 nixCraft 的创始人,一个经验丰富的系统管理员和 Linux/Unix 脚本培训师。他曾与全球客户合作,领域涉及IT,教育,国防和空间研究以及非营利部门等多个行业。请在 [Twitter][9]、[Facebook][10]、[Google+][11] 上关注他。获取更多有关系统管理、Linux/Unix 和开源话题请关注[我的 RSS/XML 地址][12]。
+
+--------------------------------------------------------------------------------
+
+via: https://www.cyberciti.biz/faq/fedora-automatic-update-retrieval-installation-with-cron/
+
+作者:[Vivek Gite][a]
+译者:[shipsw](https://github.com/shipsw)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.cyberciti.biz/
+[1]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/
+[2]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses
+[3]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ [4]:https://www.cyberciti.biz/faq/yum-update-except-kernel-package-command/
+[5]:https://www.cyberciti.biz/faq/redhat-centos-linux-yum-update-exclude-packages/
+[6]:https://www.cyberciti.biz/faq/linux-unix-vim-save-and-quit-command/
+[7]:https://www.cyberciti.biz/faq/linux-unix-appleosx-bsd-cat-command-examples/
+[8]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses
+[9]:https://twitter.com/nixcraft
+[10]:https://facebook.com/nixcraft
+[11]:https://plus.google.com/+CybercitiBiz
+[12]:https://www.cyberciti.biz/atom/atom.xml
diff --git a/published/20091215 How To Create sar Graphs With kSar To Identifying Linux Bottlenecks.md b/published/20091215 How To Create sar Graphs With kSar To Identifying Linux Bottlenecks.md
new file mode 100644
index 0000000000..fe53159cec
--- /dev/null
+++ b/published/20091215 How To Create sar Graphs With kSar To Identifying Linux Bottlenecks.md
@@ -0,0 +1,435 @@
+使用 sar 和 kSar 来发现 Linux 性能瓶颈
+======
+
+`sar` 命令用用收集、报告、或者保存 UNIX / Linux 系统的活动信息。它保存选择的计数器到操作系统的 `/var/log/sa/sadd` 文件中。从收集的数据中,你可以得到许多关于你的服务器的信息:
+
+1. CPU 使用率
+2. 内存页面和使用率
+3. 网络 I/O 和传输统计
+4. 进程创建活动
+5. 所有的块设备活动
+6. 每秒中断数等等
+
+`sar` 命令的输出能够用于识别服务器瓶颈。但是,分析 `sar` 命令提供的信息可能比较困难,所以要使用 kSar 工具。kSar 工具可以将 `sar` 命令的输出绘制成基于时间周期的、易于理解的图表。
+
+### sysstat 包
+
+`sar`、`sa1`、和 `sa2` 命令都是 sysstat 包的一部分。它是 Linux 包含的性能监视工具集合。
+
+1. `sar`:显示数据
+2. `sa1` 和 `sa2`:收集和保存数据用于以后分析。`sa2` shell 脚本在 `/var/log/sa` 目录中每日写入一个报告。`sa1` shell 脚本将每日的系统活动信息以二进制数据的形式写入到文件中。
+3. sadc —— 系统活动数据收集器。你可以通过修改 `sa1` 和 `sa2` 脚本去配置各种选项。它们位于以下的目录:
+ * `/usr/lib64/sa/sa1` (64 位)或者 `/usr/lib/sa/sa1` (32 位) —— 它调用 `sadc` 去记录报告到 `/var/log/sa/sadX` 格式。
+ * `/usr/lib64/sa/sa2` (64 位)或者 `/usr/lib/sa/sa2` (32 位) —— 它调用 `sar` 去记录报告到 `/var/log/sa/sarX` 格式。
+
+#### 如何在我的系统上安装 sar?
+
+在一个基于 CentOS/RHEL 的系统上,输入如下的 [yum 命令][1] 去安装 sysstat:
+
+```
+# yum install sysstat
+```
+
+示例输出如下:
+
+```
+Loaded plugins: downloadonly, fastestmirror, priorities,
+ : protectbase, security
+Loading mirror speeds from cached hostfile
+ * addons: mirror.cs.vt.edu
+ * base: mirror.ash.fastserv.com
+ * epel: serverbeach1.fedoraproject.org
+ * extras: mirror.cogentco.com
+ * updates: centos.mirror.nac.net
+0 packages excluded due to repository protections
+Setting up Install Process
+Resolving Dependencies
+--> Running transaction check
+---> Package sysstat.x86_64 0:7.0.2-3.el5 set to be updated
+--> Finished Dependency Resolution
+
+Dependencies Resolved
+
+====================================================================
+ Package Arch Version Repository Size
+====================================================================
+Installing:
+ sysstat x86_64 7.0.2-3.el5 base 173 k
+
+Transaction Summary
+====================================================================
+Install 1 Package(s)
+Update 0 Package(s)
+Remove 0 Package(s)
+
+Total download size: 173 k
+Is this ok [y/N]: y
+Downloading Packages:
+sysstat-7.0.2-3.el5.x86_64.rpm | 173 kB 00:00
+Running rpm_check_debug
+Running Transaction Test
+Finished Transaction Test
+Transaction Test Succeeded
+Running Transaction
+ Installing : sysstat 1/1
+
+Installed:
+ sysstat.x86_64 0:7.0.2-3.el5
+
+Complete!
+```
+
+#### 为 sysstat 配置文件
+
+编辑 `/etc/sysconfig/sysstat` 文件去指定日志文件保存多少天(最长为一个月):
+
+```
+# vi /etc/sysconfig/sysstat
+```
+
+示例输出如下 :
+
+```
+# keep log for 28 days
+# the default is 7
+HISTORY=28
+```
+
+保存并关闭这个文件。
+
+### 找到 sar 默认的 cron 作业
+
+[默认的 cron 作业位于][2] `/etc/cron.d/sysstat`:
+
+```
+# cat /etc/cron.d/sysstat
+```
+
+示例输出如下:
+
+```
+# run system activity accounting tool every 10 minutes
+*/10 * * * * root /usr/lib64/sa/sa1 1 1
+# generate a daily summary of process accounting at 23:53
+53 23 * * * root /usr/lib64/sa/sa2 -A
+```
+
+#### 告诉 sadc 去报告磁盘的统计数据
+
+使用一个文本编辑器去编辑 `/etc/cron.d/sysstat` 文件,比如使用 `vim` 命令,输入如下:
+
+```
+# vi /etc/cron.d/sysstat
+```
+
+像下面的示例那样更新这个文件,以记录所有的硬盘统计数据(`-d` 选项强制记录每个块设备的统计数据,而 `-I` 选项强制记录所有系统中断的统计数据):
+
+```
+# run system activity accounting tool every 10 minutes
+*/10 * * * * root /usr/lib64/sa/sa1 -I -d 1 1
+# generate a daily summary of process accounting at 23:53
+53 23 * * * root /usr/lib64/sa/sa2 -A
+```
+
+在 CentOS/RHEL 7.x 系统上你需要传递 `-S DISK` 选项去收集块设备的数据。传递 `-S XALL` 选项去采集如下所列的数据:
+
+1. 磁盘
+2. 分区
+3. 系统中断
+4. SNMP
+5. IPv6
+
+```
+# Run system activity accounting tool every 10 minutes
+*/10 * * * * root /usr/lib64/sa/sa1 -S DISK 1 1
+# 0 * * * * root /usr/lib64/sa/sa1 600 6 &
+# Generate a daily summary of process accounting at 23:53
+53 23 * * * root /usr/lib64/sa/sa2 -A
+# Run system activity accounting tool every 10 minutes
+```
+
+保存并关闭这个文件。
+
+#### 打开 CentOS/RHEL 版本 5.x/6.x 的服务
+
+输入如下命令:
+
+```
+chkconfig sysstat on
+service sysstat start
+```
+
+示例输出如下:
+
+```
+Calling the system activity data collector (sadc):
+```
+
+对于 CentOS/RHEL 7.x,运行如下的命令:
+
+```
+# systemctl enable sysstat
+# systemctl start sysstat.service
+# systemctl status sysstat.service
+```
+
+示例输出:
+
+```
+● sysstat.service - Resets System Activity Logs
+ Loaded: loaded (/usr/lib/systemd/system/sysstat.service; enabled; vendor preset: enabled)
+ Active: active (exited) since Sat 2018-01-06 16:33:19 IST; 3s ago
+ Process: 28297 ExecStart=/usr/lib64/sa/sa1 --boot (code=exited, status=0/SUCCESS)
+ Main PID: 28297 (code=exited, status=0/SUCCESS)
+
+Jan 06 16:33:19 centos7-box systemd[1]: Starting Resets System Activity Logs...
+Jan 06 16:33:19 centos7-box systemd[1]: Started Resets System Activity Logs.
+```
+
+### 如何使用 sar?如何查看统计数据?
+
+使用 `sar` 命令去显示操作系统中选定的累积活动计数器输出。在这个示例中,运行 `sar` 命令行,去实时获得 CPU 使用率的报告:
+
+```
+# sar -u 3 10
+```
+
+示例输出:
+
+```
+Linux 2.6.18-164.2.1.el5 (www-03.nixcraft.in) 12/14/2009
+
+09:49:47 PM CPU %user %nice %system %iowait %steal %idle
+09:49:50 PM all 5.66 0.00 1.22 0.04 0.00 93.08
+09:49:53 PM all 12.29 0.00 1.93 0.04 0.00 85.74
+09:49:56 PM all 9.30 0.00 1.61 0.00 0.00 89.10
+09:49:59 PM all 10.86 0.00 1.51 0.04 0.00 87.58
+09:50:02 PM all 14.21 0.00 3.27 0.04 0.00 82.47
+09:50:05 PM all 13.98 0.00 4.04 0.04 0.00 81.93
+09:50:08 PM all 6.60 6.89 1.26 0.00 0.00 85.25
+09:50:11 PM all 7.25 0.00 1.55 0.04 0.00 91.15
+09:50:14 PM all 6.61 0.00 1.09 0.00 0.00 92.31
+09:50:17 PM all 5.71 0.00 0.96 0.00 0.00 93.33
+Average: all 9.24 0.69 1.84 0.03 0.00 88.20
+```
+
+其中:
+
+ * 3 表示间隔时间
+ * 10 表示次数
+
+查看进程创建的统计数据,输入:
+
+```
+# sar -c 3 10
+```
+
+查看 I/O 和传输率统计数据,输入:
+
+```
+# sar -b 3 10
+```
+
+查看内存页面统计数据,输入:
+
+```
+# sar -B 3 10
+```
+
+查看块设备统计数据,输入:
+
+```
+# sar -d 3 10
+```
+
+查看所有中断的统计数据,输入:
+
+```
+# sar -I XALL 3 10
+```
+
+查看网络设备特定的统计数据,输入:
+
+```
+# sar -n DEV 3 10
+# sar -n EDEV 3 10
+```
+
+查看 CPU 特定的统计数据,输入:
+
+```
+# sar -P ALL
+# Only 1st CPU stats
+# sar -P 1 3 10
+```
+
+查看队列长度和平均负载的统计数据,输入:
+
+```
+# sar -q 3 10
+```
+
+查看内存和交换空间的使用统计数据,输入:
+
+```
+# sar -r 3 10
+# sar -R 3 10
+```
+
+查看 inode、文件、和其它内核表统计数据状态,输入:
+
+```
+# sar -v 3 10
+```
+
+查看系统切换活动统计数据,输入:
+
+```
+# sar -w 3 10
+```
+
+查看交换统计数据,输入:
+
+```
+# sar -W 3 10
+```
+
+查看一个 PID 为 3256 的 Apache 进程,输入:
+
+```
+# sar -x 3256 3 10
+```
+
+### kSar 介绍
+
+`sar` 和 `sadf` 提供了基于命令行界面的输出。这种输出可能会使新手用户/系统管理员感到无从下手。因此,你需要使用 kSar,它是一个图形化显示你的 `sar` 数据的 Java 应用程序。它也允许你以 PDF/JPG/PNG/CSV 格式导出数据。你可以用三种方式去加载数据:本地文件、运行本地命令、以及通过 SSH 远程运行的命令。kSar 可以处理下列操作系统的 `sar` 输出:
+
+1. Solaris 8, 9 和 10
+2. Mac OS/X 10.4+
+3. Linux (Systat Version >= 5.0.5)
+4. AIX (4.3 & 5.3)
+5. HPUX 11.00+
+
+#### 下载和安装 kSar
+
+访问 [官方][3] 网站去获得最新版本的源代码。使用 [wget][4] 去下载源代码,输入:
+
+```
+$ wget https://github.com/vlsi/ksar/releases/download/v5.2.4-snapshot-652bf16/ksar-5.2.4-SNAPSHOT-all.jar
+```
+
+#### 如何运行 kSar?
+
+首先要确保你的机器上 [JAVA jdk][5] 已安装并能够正常工作。输入下列命令去启动 kSar:
+
+```
+$ java -jar ksar-5.2.4-SNAPSHOT-all.jar
+```
+
+![Fig.01: kSar welcome screen][6]
+
+接下来你将看到 kSar 的主窗口,和有两个菜单的面板。
+
+![Fig.02: kSar - the main window][7]
+
+左侧有一个列表,是 kSar 根据数据已经解析出的可用图表的列表。右侧窗口将展示你选定的图表。
+
+#### 如何使用 kSar 去生成 sar 图表?
+
+首先,你需要从命名为 server1 的服务器上采集 `sar` 命令的统计数据。输入如下的命令:
+
+```
+[ server1 ]# LC_ALL=C sar -A > /tmp/sar.data.txt
+```
+
+接下来,使用 `scp` 命令从本地桌面拷贝到远程电脑上:
+
+```
+[ desktop ]$ scp user@server1.nixcraft.com:/tmp/sar.data.txt /tmp/
+```
+
+切换到 kSar 窗口,点击 “Data” > “Load data from text file” > 从 `/tmp/` 中选择 `sar.data.txt` > 点击 “Open” 按钮。
+
+现在,图表类型树已经出现在左侧面板中并选定了一个图形:
+
+![Fig.03: Processes for server1][8]
+
+![Fig.03: Disk stats (blok device) stats for server1][9]
+
+![Fig.05: Memory stats for server1][10]
+
+##### 放大和缩小
+
+通过移动你可以交互式缩放图像的一部分。在要缩放的图像的左上角点击并按下鼠标,移动到要缩放区域的右下角,可以选定要缩放的区域。返回到未缩放状态,点击并拖动鼠标到除了右下角外的任意位置,你也可以点击并选择 zoom 选项。
+
+##### 了解 kSar 图像和 sar 数据
+
+我强烈建议你去阅读 `sar` 和 `sadf` 命令的 man 页面:
+
+```
+$ man sar
+$ man sadf
+```
+
+### 案例学习:识别 Linux 服务器的 CPU 瓶颈
+
+使用 `sar` 命令和 kSar 工具,可以得到内存、CPU、以及其它子系统的详细快照。例如,如果 CPU 使用率在一个很长的时间内持续高于 80%,有可能就是出现了一个 CPU 瓶颈。使用 `sar -x ALL` 你可以找到大量消耗 CPU 的进程。
+
+[mpstat 命令][11] 的输出(sysstat 包的一部分)也会帮你去了解 CPU 的使用率。但你可以使用 kSar 很容易地去分析这些信息。
+
+#### 找出 CPU 瓶颈后 …
+
+对 CPU 执行如下的调整:
+
+1. 确保没有不需要的进程在后台运行。关闭 [Linux 上所有不需要的服务][12]。
+2. 使用 [cron][13] 在一个非高峰时刻运行任务(比如,备份)。
+3. 使用 [top 和 ps 命令][14] 去找出所有非关键的后台作业/服务。使用 [renice 命令][15] 去调整低优先级作业。
+4. 使用 [taskset 命令去设置进程使用的 CPU ][16] (卸载所使用的 CPU),即,绑定进程到不同的 CPU 上。例如,在 2# CPU 上运行 MySQL 数据库,而在 3# CPU 上运行 Apache。
+5. 确保你的系统使用了最新的驱动程序和固件。
+6. 如有可能在系统上增加额外的 CPU。
+7. 为单线程应用程序使用更快的 CPU(比如,Lighttpd web 服务器应用程序)。
+8. 为多线程应用程序使用多个 CPU(比如,MySQL 数据库服务器应用程序)。
+9. 为一个 web 应用程序使用多个计算节点并设置一个 [负载均衡器][17]。
+
+### isag —— 交互式系统活动记录器(替代工具)
+
+`isag` 命令图形化显示了以前运行 `sar` 命令时存储在二进制文件中的系统活动数据。`isag` 命令引用 `sar` 并提取出它的数据来绘制图形。与 kSar 相比,`isag` 的选项比较少。
+
+![Fig.06: isag CPU utilization graphs][18]
+
+### 关于作者
+
+本文作者是 nixCraft 的创始人和一位经验丰富的 Linux 操作系统/Unix shell 脚本培训师。他与包括 IT、教育、国防和空间研究、以及非营利组织等全球各行业客户一起合作。可以在 [Twitter][19]、[Facebook][20]、[Google+][21] 上关注他。
+
+--------------------------------------------------------------------------------
+
+via: https://www.cyberciti.biz/tips/identifying-linux-bottlenecks-sar-graphs-with-ksar.html
+
+作者:[Vivek Gite][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.cyberciti.biz
+[1]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ "See Linux/Unix yum command examples for more info"
+[2]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses/
+[3]:https://github.com/vlsi/ksar
+[4]:https://www.cyberciti.biz/tips/linux-wget-your-ultimate-command-line-downloader.html
+[5]:https://www.cyberciti.biz/faq/howto-ubuntu-linux-install-configure-jdk-jre/
+[6]:https://www.cyberciti.biz/media/new/tips/2009/12/sar-welcome.png "kSar welcome screen"
+[7]:https://www.cyberciti.biz/media/new/tips/2009/12/screenshot-kSar-a-sar-grapher-01.png "kSar - the main window"
+[8]:https://www.cyberciti.biz/media/new/tips/2009/12/cpu-ksar.png "Linux kSar Processes for server1 "
+[9]:https://www.cyberciti.biz/media/new/tips/2009/12/disk-stats-ksar.png "Linux Disk I/O Stats Using kSar"
+[10]:https://www.cyberciti.biz/media/new/tips/2009/12/memory-ksar.png "Linux Memory paging and its utilization stats"
+[11]:https://www.cyberciti.biz/tips/how-do-i-find-out-linux-cpu-utilization.html
+[12]:https://www.cyberciti.biz/faq/check-running-services-in-rhel-redhat-fedora-centoslinux/
+[13]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses/
+[14]:https://www.cyberciti.biz/faq/show-all-running-processes-in-linux/
+[15]:https://www.cyberciti.biz/faq/howto-change-unix-linux-process-priority/
+[16]:https://www.cyberciti.biz/faq/taskset-cpu-affinity-command/
+[17]:https://www.cyberciti.biz/tips/load-balancer-open-source-software.html
+[18]:https://www.cyberciti.biz/media/new/tips/2009/12/isag.cpu_.png "Fig.06: isag CPU utilization graphs"
+[19]:https://twitter.com/nixcraft
+[20]:https://facebook.com/nixcraft
+[21]:https://plus.google.com/+CybercitiBiz
diff --git a/published/20120424 How To Set Readonly File Permissions On Linux - Unix Web Server DocumentRoot.md b/published/20120424 How To Set Readonly File Permissions On Linux - Unix Web Server DocumentRoot.md
new file mode 100644
index 0000000000..2aad1679ba
--- /dev/null
+++ b/published/20120424 How To Set Readonly File Permissions On Linux - Unix Web Server DocumentRoot.md
@@ -0,0 +1,178 @@
+如何在 Web 服务器文档根目录上设置只读文件权限
+======
+
+**Q:如何对我存放在 `/var/www/html/` 目录中的所有文件设置只读权限?**
+
+你可以使用 `chmod` 命令对 Linux/Unix/macOS/OS X/*BSD 操作系统上的所有文件来设置只读权限。这篇文章介绍如何在 Linux/Unix 的 web 服务器(如 Nginx、 Lighttpd、 Apache 等)上来设置只读文件权限。
+
+[![Proper read-only permissions for Linux/Unix Nginx/Apache web server's directory][1]][1]
+
+### 如何设置文件为只读模式
+
+语法为:
+
+```
+### 仅针对文件 ###
+chmod 0444 /var/www/html/*
+chmod 0444 /var/www/html/*.php
+```
+
+### 如何设置目录为只读模式
+
+语法为:
+
+```
+### 仅针对目录 ###
+chmod 0444 /var/www/html/
+chmod 0444 /path/to/your/dir/
+# ***************************************************************************
+# 假如 web 服务器的用户/用户组是 www-data,文件拥有者是 ftp-data 用户/用户组
+# ***************************************************************************
+# 设置目录所有文件为只读
+chmod -R 0444 /var/www/html/
+# 设置文件/目录拥有者为 ftp-data
+chown -R ftp-data:ftp-data /var/www/html/
+# 所有目录和子目录的权限为 0445 (这样 web 服务器的用户或用户组就可以读取我们的文件)
+find /var/www/html/ -type d -print0 | xargs -0 -I {} chmod 0445 "{}"
+```
+
+找到所有 `/var/www/html` 下的所有文件(包括子目录),键入:
+
+```
+### 仅对文件有效 ###
+find /var/www/html -type f -iname "*" -print0 | xargs -I {} -0 chmod 0444 {}
+```
+
+然而,你需要在 `/var/www/html` 目录及其子目录上设置只读和执行权限,如此才能让 web 服务器能够访问根目录,键入:
+
+```
+### 仅对目录有效 ###
+find /var/www/html -type d -iname "*" -print0 | xargs -I {} -0 chmod 0544 {}
+```
+
+### 警惕写权限
+
+请注意在 `/var/www/html/` 目录上的写权限会允许任何人删除文件或添加新文件。也就是说,你可能需要设置一个只读权限给 `/var/www/html/` 目录本身。
+
+```
+### web根目录只读 ###
+chmod 0555 /var/www/html
+```
+
+在某些情况下,根据你的设置要求,你可以改变文件的属主和属组来设置严格的权限。
+
+```
+### 如果 /var/www/html 目录的拥有人是普通用户,你可以设置拥有人为:root:root 或 httpd:httpd (推荐) ###
+chown -R root:root /var/www/html/
+
+### 确保 apache 拥有 /var/www/html/ ###
+chown -R apache:apache /var/www/html/
+```
+
+### 关于 NFS 导出目录
+
+你可以在 `/etc/exports` 文件中指定哪个目录应该拥有[只读或者读写权限 ][2]。这个文件定义各种各样的共享在 NFS 服务器和他们的权限。如:
+
+
+```
+# 对任何人只读权限
+/var/www/html *(ro,sync)
+
+# 对192.168.1.10(upload.example.com)客户端读写权限访问
+/var/www/html 192.168.1.10(rw,sync)
+```
+
+### 关于用于 MS-Windows客户端的 Samba(CIFS)只读共享
+
+
+要以只读共享 `sales`,更新 `smb.conf`,如下:
+
+```
+[sales]
+comment = Sales Data
+path = /export/cifs/sales
+read only = Yes
+guest ok = Yes
+```
+
+### 关于文件系统表(fstab)
+
+你可以在 Unix/Linux 上的 `/etc/fstab` 文件中配置挂载某些文件为只读模式。
+
+你需要有专用分区,不要设置其他系统分区为只读模式。
+
+如下在 `/etc/fstab` 文件中设置 `/srv/html` 为只读模式。
+
+```
+/dev/sda6 /srv/html ext4 ro 1 1
+```
+
+你可以使用 `mount` 命令[重新挂载分区为只读模式][3](使用 root 用户)
+
+```
+# mount -o remount,ro /dev/sda6 /srv/html
+```
+
+或者
+
+```
+# mount -o remount,ro /srv/html
+```
+
+上面的命令会尝试重新挂载已挂载的文件系统到 `/srv/html`上。这是改变文件系统挂载标志的常用方法,特别是让只读文件改为可写的。这种方式不会改变设备或者挂载点。让文件变得再次可写,键入:
+
+```
+# mount -o remount,rw /dev/sda6 /srv/html
+```
+
+或
+
+```
+# mount -o remount,rw /srv/html
+```
+
+### Linux:chattr 命令
+
+
+你可以在 Linux 文件系统上使用 `chattr` 命令[改变文件属性为只读][4],如:
+
+```
+chattr +i /path/to/file.php
+chattr +i /var/www/html/
+
+# 查找任何在/var/www/html下的文件并设置为只读#
+find /var/www/html -iname "*" -print0 | xargs -I {} -0 chattr +i {}
+```
+
+通过提供 `-i` 选项可删除只读属性:
+
+```
+chattr -i /path/to/file.php
+```
+
+FreeBSD、Mac OS X 和其他 BSD Unix 用户可使用[`chflags`命令][5]:
+
+```
+### 设置只读 ##
+chflags schg /path/to/file.php
+
+### 删除只读 ##
+chflags noschg /path/to/file.php
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.cyberciti.biz/faq/howto-set-readonly-file-permission-in-linux-unix/
+
+作者:[Vivek Gite][a]
+译者:[yizhuoyan](https://github.com/yizhuoyan)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.cyberciti.biz
+[1]:https://www.cyberciti.biz/media/new/faq/2012/04/linux-unix-set-read-only-file-system-permission-for-apache-nginx.jpg
+[2]:https://www.cyberciti.biz//www.cyberciti.biz/faq/centos-fedora-rhel-nfs-v4-configuration/
+[3]:https://www.cyberciti.biz/faq/howto-freebsd-remount-partition/
+[4]:https://www.cyberciti.biz/tips/linux-password-trick.html
+[5]:https://www.cyberciti.biz/tips/howto-write-protect-file-with-immutable-bit.html
diff --git a/published/20140225 How To Safely Generate A Random Number - Quarrelsome.md b/published/20140225 How To Safely Generate A Random Number - Quarrelsome.md
new file mode 100644
index 0000000000..000b50f159
--- /dev/null
+++ b/published/20140225 How To Safely Generate A Random Number - Quarrelsome.md
@@ -0,0 +1,92 @@
+如何安全地生成随机数
+======
+
+### 使用 urandom
+
+使用 [urandom][1]!使用 [urandom][2]!使用 [urandom][3]!
+
+使用 [urandom][4]!使用 [urandom][5]!使用 [urandom][6]!
+
+### 但对于密码学密钥呢?
+
+仍然使用 [urandom][6]。
+
+### 为什么不是 SecureRandom、OpenSSL、havaged 或者 c 语言实现呢?
+
+这些是用户空间的 CSPRNG(伪随机数生成器)。你应该用内核的 CSPRNG,因为:
+
+* 内核可以访问原始设备熵。
+* 它可以确保不在应用程序之间共享相同的状态。
+* 一个好的内核 CSPRNG,像 FreeBSD 中的,也可以保证它播种之前不给你随机数据。
+
+研究过去十年中的随机失败案例,你会看到一连串的用户空间的随机失败案例。[Debian 的 OpenSSH 崩溃][7]?用户空间随机!安卓的比特币钱包[重复 ECDSA 随机 k 值][8]?用户空间随机!可预测洗牌的赌博网站?用户空间随机!
+
+用户空间的生成器几乎总是依赖于内核的生成器。即使它们不这样做,整个系统的安全性也会确保如此。**但用户空间的 CSPRNG 不会增加防御深度;相反,它会产生两个单点故障。**
+
+### 手册页不是说使用 /dev/random 嘛?
+
+这个稍后详述,保留你的意见。你应该忽略掉手册页。不要使用 `/dev/random`。`/dev/random` 和 `/dev/urandom` 之间的区别是 Unix 设计缺陷。手册页不想承认这一点,因此它产生了一个并不存在的安全顾虑。把 `random(4)` 中的密码学上的建议当作传说,继续你的生活吧。
+
+### 但是如果我需要的是真随机值,而非伪随机值呢?
+
+urandom 和 `/dev/random` 提供的是同一类型的随机。与流行的观念相反,`/dev/random` 不提供“真正的随机”。从密码学上来说,你通常不需要“真正的随机”。
+
+urandom 和 `/dev/random` 都基于一个简单的想法。它们的设计与流密码的设计密切相关:一个小秘密被延伸到不可预测值的不确定流中。 这里的秘密是“熵”,而流是“输出”。
+
+只在 Linux 上 `/dev/random` 和 urandom 仍然有意义上的不同。Linux 内核的 CSPRNG 定期进行密钥更新(通过收集更多的熵)。但是 `/dev/random` 也试图跟踪内核池中剩余的熵,并且如果它没有足够的剩余熵时,偶尔也会罢工。这种设计和我所说的一样蠢;这与基于“密钥流”中剩下多少“密钥”的 AES-CTR 设计类似。
+
+如果你使用 `/dev/random` 而非 urandom,那么当 Linux 对自己的 RNG(随机数生成器)如何工作感到困惑时,你的程序将不可预测地(或者如果你是攻击者,非常可预测地)挂起。使用 `/dev/random` 会使你的程序不太稳定,但这不会让你在密码学上更安全。
+
+### 这是个缺陷,对吗?
+
+不是,但存在一个你可能想要了解的 Linux 内核 bug,即使这并不能改变你应该使用哪一个 RNG。
+
+在 Linux 上,如果你的软件在引导时立即运行,或者这个操作系统你刚刚安装好,那么你的代码可能会与 RNG 发生竞争。这很糟糕,因为如果你赢了竞争,那么你可能会在一段时间内从 urandom 获得可预测的输出。这是 Linux 中的一个 bug,如果你正在为 Linux 嵌入式设备构建平台级代码,那你需要了解它。
+
+在 Linux 上,这确实是 urandom(而不是 `/dev/random`)的问题。这也是 [Linux 内核中的错误][9]。 但它也容易在用户空间中修复:在引导时,明确地为 urandom 提供种子。长期以来,大多数 Linux 发行版都是这么做的。但**不要**切换到不同的 CSPRNG。
+
+### 在其它操作系统上呢?
+
+FreeBSD 和 OS X 消除了 urandom 和 `/dev/random` 之间的区别;这两个设备的行为是相同的。不幸的是,手册页在解释为什么这样做上干的很糟糕,并延续了 Linux 上 urandom 可怕的神话。
+
+无论你使用 `/dev/random` 还是 urandom,FreeBSD 的内核加密 RNG 都不会停摆。 除非它没有被提供种子,在这种情况下,这两者都会停摆。与 Linux 不同,这种行为是有道理的。Linux 应该采用它。但是,如果你是一名应用程序开发人员,这对你几乎没有什么影响:Linux、FreeBSD、iOS,无论什么:使用 urandom 吧。
+
+### 太长了,懒得看
+
+直接使用 urandom 吧。
+
+### 结语
+
+[ruby-trunk Feature #9569][10]
+
+> 现在,在尝试检测 `/dev/urandom` 之前,SecureRandom.random_bytes 会尝试检测要使用的 OpenSSL。 我认为这应该反过来。在这两种情况下,你只需要将随机字节进行解压,所以 SecureRandom 可以跳过中间人(和第二个故障点),如果可用的话可以直接与 `/dev/urandom` 进行交互。
+
+总结:
+
+> `/dev/urandom` 不适合用来直接生成会话密钥和频繁生成其他应用程序级随机数据。
+>
+> GNU/Linux 上的 random(4) 手册所述......
+
+感谢 Matthew Green、 Nate Lawson、 Sean Devlin、 Coda Hale 和 Alex Balducci 阅读了本文草稿。公正警告:Matthew 只是大多同意我的观点。
+
+--------------------------------------------------------------------------------
+
+via: https://sockpuppet.org/blog/2014/02/25/safely-generate-random-numbers/
+
+作者:[Thomas & Erin Ptacek][a]
+译者:[kimii](https://github.com/kimii)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://sockpuppet.org/blog
+[1]:http://blog.cr.yp.to/20140205-entropy.html
+[2]:http://cr.yp.to/talks/2011.09.28/slides.pdf
+[3]:http://golang.org/src/pkg/crypto/rand/rand_unix.go
+[4]:http://security.stackexchange.com/questions/3936/is-a-rand-from-dev-urandom-secure-for-a-login-key
+[5]:http://stackoverflow.com/a/5639631
+[6]:https://twitter.com/bramcohen/status/206146075487240194
+[7]:http://research.swtch.com/openssl
+[8]:http://arstechnica.com/security/2013/08/google-confirms-critical-android-crypto-flaw-used-in-5700-bitcoin-heist/
+[9]:https://factorable.net/weakkeys12.extended.pdf
+[10]:https://bugs.ruby-lang.org/issues/9569
diff --git a/translated/tech/20150615 Let-s Build A Simple Interpreter. Part 1..md b/published/20150615 Let-s Build A Simple Interpreter. Part 1..md
similarity index 55%
rename from translated/tech/20150615 Let-s Build A Simple Interpreter. Part 1..md
rename to published/20150615 Let-s Build A Simple Interpreter. Part 1..md
index 3a62934f42..ed2e0f0a0e 100644
--- a/translated/tech/20150615 Let-s Build A Simple Interpreter. Part 1..md
+++ b/published/20150615 Let-s Build A Simple Interpreter. Part 1..md
@@ -1,26 +1,27 @@
-让我们做个简单的解释器(1)
+让我们做个简单的解释器(一)
======
+> “如果你不知道编译器是怎么工作的,那你就不知道电脑是怎么工作的。如果你不能百分百确定,那就是不知道它们是如何工作的。” --Steve Yegge
-> **" If you don't know how compilers work, then you don't know how computers work. If you're not 100% sure whether you know how compilers work, then you don't know how they work."** -- Steve Yegge
-> **“如果你不知道编译器是怎么工作的,那你就不知道电脑是怎么工作的。如果你不能百分百确定,那就是不知道他们是如何工作的。”** --Steve Yegge
+就是这样。想一想。你是萌新还是一个资深的软件开发者实际上都无关紧要:如果你不知道编译器和解释器是怎么工作的,那么你就不知道电脑是怎么工作的。就这么简单。
-就是这样。想一想。你是萌新还是一个资深的软件开发者实际上都无关紧要:如果你不知道编译器和解释器是怎么工作的,那么你就不知道电脑是怎么工作的。就这么简单。
+所以,你知道编译器和解释器是怎么工作的吗?我是说,你百分百确定自己知道他们怎么工作吗?如果不知道。
-所以,你知道编译器和解释器是怎么工作的吗?我是说,你百分百确定自己知道他们怎么工作吗?如果不知道。![][1]
+![][1]
-或者如果你不知道但你非常想要了解它。 ![][2]
+或者如果你不知道但你非常想要了解它。
-不用担心。如果你能坚持跟着这个系列做下去,和我一起构建一个解释器和编译器,最后你将会知道他们是怎么工作的。并且你会变成一个自信满满的快乐的人。至少我希望如此。![][3]。
+![][2]
+
+不用担心。如果你能坚持跟着这个系列做下去,和我一起构建一个解释器和编译器,最后你将会知道他们是怎么工作的。并且你会变成一个自信满满的快乐的人。至少我希望如此。
+
+![][3]
为什么要学习编译器和解释器?有三点理由。
- 1. 要写出一个解释器或编译器,你需要有很多的专业知识,并能融会贯通。写一个解释器或编译器能帮你加强这些能力,成为一个更厉害的软件开发者。而且,你要学的技能对写软件非常有用,而不是仅仅局限于解释器或编译器。
- 2. 你确实想要了解电脑是怎么工作的。一般解释器和编译器看上去很魔幻。你或许不习惯这种魔力。你会想去揭开构建解释器和编译器那层神秘的面纱,了解他们的原理,把事情做好。
- 3. 你想要创建自己的编程语言或者特定领域的语言。如果你创建了一个,你还要为它创建一个解释器或者编译器。最近,兴起了对新的编程语言的兴趣。你能看到几乎每天都有一门新的编程语言横空出世:Elixir,Go,Rust,还有很多。
-
-
-
+1. 要写出一个解释器或编译器,你需要有很多的专业知识,并能融会贯通。写一个解释器或编译器能帮你加强这些能力,成为一个更厉害的软件开发者。而且,你要学的技能对编写软件非常有用,而不是仅仅局限于解释器或编译器。
+2. 你确实想要了解电脑是怎么工作的。通常解释器和编译器看上去很魔幻。你或许不习惯这种魔力。你会想去揭开构建解释器和编译器那层神秘的面纱,了解它们的原理,把事情做好。
+3. 你想要创建自己的编程语言或者特定领域的语言。如果你创建了一个,你还要为它创建一个解释器或者编译器。最近,兴起了对新的编程语言的兴趣。你能看到几乎每天都有一门新的编程语言横空出世:Elixir,Go,Rust,还有很多。
好,但什么是解释器和编译器?
@@ -32,11 +33,12 @@
我希望你现在确信你很想学习构建一个编译器和解释器。你期望在这个教程里学习解释器的哪些知识呢?
-你看这样如何。你和我一起做一个简单的解释器当作 [Pascal][5] 语言的子集。在这个系列结束的时候你能做出一个可以运行的 Pascal 解释器和一个像 Python 的 [pdb][6] 那样的源代码级别的调试器。
+你看这样如何。你和我一起为 [Pascal][5] 语言的一个大子集做一个简单的解释器。在这个系列结束的时候你能做出一个可以运行的 Pascal 解释器和一个像 Python 的 [pdb][6] 那样的源代码级别的调试器。
-你或许会问,为什么是 Pascal?有一点,它不是我为了这个系列而提出的一个虚构的语言:它是真实存在的一门编程语言,有很多重要的语言结构。有些陈旧但有用的计算机书籍使用 Pascal 编程语言作为示例(我知道对于选择一门语言来构建解释器,这个理由并不令人信服,但我认为学一门非主流的语言也不错:)。
+你或许会问,为什么是 Pascal?一方面,它不是我为了这个系列而提出的一个虚构的语言:它是真实存在的一门编程语言,有很多重要的语言结构。有些陈旧但有用的计算机书籍使用 Pascal 编程语言作为示例(我知道对于选择一门语言来构建解释器,这个理由并不令人信服,但我认为学一门非主流的语言也不错 :))。
+
+这有个 Pascal 中的阶乘函数示例,你将能用自己的解释器解释代码,还能够用可交互的源码级调试器进行调试,你可以这样创造:
-这有个 Pascal 中的阶乘函数示例,你能用自己的解释器解释代码,还能够用可交互的源码级调试器进行调试,你可以这样创造:
```
program factorial;
@@ -57,15 +59,14 @@ begin
end.
```
-这个 Pascal 解释器的实现语言会用 Python,但你也可以用其他任何语言,因为这里展示的思想不依赖任何特殊的实现语言。好,让我们开始干活。准备好了,出发!
-
-你会从编写一个简单的算术表达式解析器,也就是常说的计算器,开始学习解释器和编译器。今天的目标非常简单:让你的计算器能处理两个个位数相加,比如 **3+5**。这是你的计算器的源代码,不好意思,是解释器:
+这个 Pascal 解释器的实现语言会使用 Python,但你也可以用其他任何语言,因为这里展示的思想不依赖任何特殊的实现语言。好,让我们开始干活。准备好了,出发!
+你会从编写一个简单的算术表达式解析器,也就是常说的计算器,开始学习解释器和编译器。今天的目标非常简单:让你的计算器能处理两个个位数相加,比如 `3+5`。下面是你的计算器的源代码——不好意思,是解释器:
```
# 标记类型
#
-# EOF (end-of-file 文件末尾) 标记是用来表示所有输入都解析完成
+# EOF (end-of-file 文件末尾)标记是用来表示所有输入都解析完成
INTEGER, PLUS, EOF = 'INTEGER', 'PLUS', 'EOF'
@@ -73,7 +74,7 @@ class Token(object):
def __init__(self, type, value):
# token 类型: INTEGER, PLUS, MINUS, or EOF
self.type = type
- # token 值: 0, 1, 2. 3, 4, 5, 6, 7, 8, 9, '+', 或 None
+ # token 值: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, '+', 或 None
self.value = value
def __str__(self):
@@ -187,7 +188,8 @@ if __name__ == '__main__':
```
-把上面的代码保存到 calc1.py 文件,或者直接从 [GitHub][7] 上下载。在你深入研究代码前,在命令行里面运行它看看效果。试一试!这是我笔记本上的示例会话(如果你想在 Python3 下运行,你要把 raw_input 换成 input):
+把上面的代码保存到 `calc1.py` 文件,或者直接从 [GitHub][7] 上下载。在你深入研究代码前,在命令行里面运行它看看效果。试一试!这是我笔记本上的示例会话(如果你想在 Python3 下运行,你要把 `raw_input` 换成 `input`):
+
```
$ python calc1.py
calc> 3+4
@@ -205,31 +207,32 @@ calc>
* 此时支持的唯一一个运算符是加法
* 输入中不允许有任何的空格符号
-
-
要让计算器变得简单,这些限制非常必要。不用担心,你很快就会让它变得很复杂。
好,现在让我们深入它,看看解释器是怎么工作,它是怎么评估出算术表达式的。
-当你在命令行中输入一个表达式 3+5,解释器就获得了字符串 “3+5”。为了让解释器能够真正理解要用这个字符串做什么,它首先要把输入 “3+5” 分到叫做 **token(标记)** 的容器里。**标记** 是一个拥有类型和值的对象。比如说,对字符 “3” 而言,标记的类型是 INTEGER 整数,对应的值是 3。
+当你在命令行中输入一个表达式 `3+5`,解释器就获得了字符串 “3+5”。为了让解释器能够真正理解要用这个字符串做什么,它首先要把输入 “3+5” 分到叫做 `token`(标记)的容器里。标记 是一个拥有类型和值的对象。比如说,对字符 “3” 而言,标记的类型是 INTEGER 整数,对应的值是 3。
-把输入字符串分成标记的过程叫 **词法分析**。因此解释器的需要做的第一步是读取输入字符,并将其转换成标记流。解释器中的这一部分叫做 **词法分析器**,或者简短点叫 **lexer**。你也可以给它起别的名字,诸如 **扫描器** 或者 **标记器**。他们指的都是同一个东西:解释器或编译器中将输入字符转换成标记流的那部分。
+把输入字符串分成标记的过程叫词法分析。因此解释器的需要做的第一步是读取输入字符,并将其转换成标记流。解释器中的这一部分叫做词法分析器,或者简短点叫 **lexer**。你也可以给它起别的名字,诸如扫描器或者标记器。它们指的都是同一个东西:解释器或编译器中将输入字符转换成标记流的那部分。
-Interpreter 类中的 get_next_token 方法就是词法分析器。每次调用它的时候,你都能从传入解释器的输入字符中获得创建的下一个标记。仔细看看这个方法,看看它是如何完成把字符转换成标记的任务的。输入被存在可变文本中,它保存了输入的字符串和关于该字符串的索引(把字符串想象成字符数组)。pos 开始时设为 0,指向 ‘3’.这个方法一开始检查字符是不是数字,如果是,就将 pos 加 1,并返回一个 INTEGER 类型的标记实例,并把字符 ‘3’ 的值设为整数,也就是整数 3:
+`Interpreter` 类中的 `get_next_token` 方法就是词法分析器。每次调用它的时候,你都能从传入解释器的输入字符中获得创建的下一个标记。仔细看看这个方法,看看它是如何完成把字符转换成标记的任务的。输入被存在可变文本中,它保存了输入的字符串和关于该字符串的索引(把字符串想象成字符数组)。`pos` 开始时设为 0,指向字符 ‘3’。这个方法一开始检查字符是不是数字,如果是,就将 `pos` 加 1,并返回一个 INTEGER 类型的标记实例,并把字符 ‘3’ 的值设为整数,也就是整数 3:
![][8]
-现在 pos 指向文本中的 ‘+’ 号。下次调用这个方法的时候,它会测试 pos 位置的字符是不是个数字,然后检测下一个字符是不是个加号,就是这样。结果这个方法把 pos 加一,返回一个新创建的标记,类型是 PLUS,值为 ‘+’。
+现在 `pos` 指向文本中的 ‘+’ 号。下次调用这个方法的时候,它会测试 `pos` 位置的字符是不是个数字,然后检测下一个字符是不是个加号,就是这样。结果这个方法把 `pos` 加 1,返回一个新创建的标记,类型是 PLUS,值为 ‘+’。
![][9]
-pos 现在指向字符 ‘5’。当你再调用 get_next_token 方法时,该方法会检查这是不是个数字,就是这样,然后它把 pos 加一,返回一个新的 INTEGER 标记,该标记的值被设为 5:
+`pos` 现在指向字符 ‘5’。当你再调用 `get_next_token` 方法时,该方法会检查这是不是个数字,就是这样,然后它把 `pos` 加 1,返回一个新的 INTEGER 标记,该标记的值被设为整数 5:
+
![][10]
-因为 pos 索引现在到了字符串 “3+5” 的末尾,你每次调用 get_next_token 方法时,它将会返回 EOF 标记:
+因为 `pos` 索引现在到了字符串 “3+5” 的末尾,你每次调用 `get_next_token` 方法时,它将会返回 EOF 标记:
+
![][11]
自己试一试,看看计算器里的词法分析器的运行:
+
```
>>> from calc1 import Interpreter
>>>
@@ -248,17 +251,16 @@ Token(EOF, None)
>>>
```
-既然你的解释器能够从输入字符中获取标记流,解释器需要做点什么:它需要在词法分析器 get_next_token 中获取的标记流中找出相应的结构。你的解释器应该能够找到流中的结构:INTEGER -> PLUS -> INTEGER。就是这样,它尝试找出标记的序列:整数后面要跟着加号,加号后面要跟着整数。
+既然你的解释器能够从输入字符中获取标记流,解释器需要对它做点什么:它需要在词法分析器 `get_next_token` 中获取的标记流中找出相应的结构。你的解释器应该能够找到流中的结构:INTEGER -> PLUS -> INTEGER。就是这样,它尝试找出标记的序列:整数后面要跟着加号,加号后面要跟着整数。
-负责找出并解释结构的方法就是 expr。该方法检验标记序列确实与期望的标记序列是对应的,比如 INTEGER -> PLUS -> INTEGER。成功确认了这个结构后,就会生成加号左右两边的标记的值相加的结果,这样就成功解释你输入到解释器中的算术表达式了。
+负责找出并解释结构的方法就是 `expr`。该方法检验标记序列确实与期望的标记序列是对应的,比如 INTEGER -> PLUS -> INTEGER。成功确认了这个结构后,就会生成加号左右两边的标记的值相加的结果,这样就成功解释你输入到解释器中的算术表达式了。
-expr 方法用了一个助手方法 eat 来检验传入的标记类型是否与当前的标记类型相匹配。在匹配到传入的标记类型后,eat 方法获取下一个标记,并将其赋给 current_token 变量,然后高效地 “吃掉” 当前匹配的标记,并将标记流的虚拟指针向后移动。如果标记流的结构与期望的 INTEGER PLUS INTEGER 标记序列不对应,eat 方法就抛出一个异常。
+`expr` 方法用了一个助手方法 `eat` 来检验传入的标记类型是否与当前的标记类型相匹配。在匹配到传入的标记类型后,`eat` 方法会获取下一个标记,并将其赋给 `current_token` 变量,然后高效地 “吃掉” 当前匹配的标记,并将标记流的虚拟指针向后移动。如果标记流的结构与期望的 INTEGER -> PLUS -> INTEGER 标记序列不对应,`eat` 方法就抛出一个异常。
让我们回顾下解释器做了什么来对算术表达式进行评估的:
- * 解释器接受输入字符串,就把它当作 “3+5”
- * 解释器调用 expr 方法,在词法分析器 get_next_token 返回的标记流中找出结构。这个结构就是 INTEGER PLUS INTEGER 这样的格式。在确认了格式后,它就通过把两个整型标记相加解释输入,因为此时对于解释器来说很清楚,他要做的就是把两个整数 3 和 5 进行相加。
-
+* 解释器接受输入字符串,比如说 “3+5”
+* 解释器调用 `expr` 方法,在词法分析器 `get_next_token` 返回的标记流中找出结构。这个结构就是 INTEGER -> PLUS -> INTEGER 这样的格式。在确认了格式后,它就通过把两个整型标记相加来解释输入,因为此时对于解释器来说很清楚,它要做的就是把两个整数 3 和 5 进行相加。
恭喜。你刚刚学习了怎么构建自己的第一个解释器!
@@ -268,42 +270,38 @@ expr 方法用了一个助手方法 eat 来检验传入的标记类型是否与
看了这篇文章,你肯定觉得不够,是吗?好,准备好做这些练习:
- 1. 修改代码,允许输入多位数,比如 “12+3”
- 2. 添加一个方法忽略空格符,让你的计算器能够处理带有空白的输入,比如“12 + 3”
- 3. 修改代码,用 ‘-’ 号而非 ‘+’ 号去执行减法比如 “7-5”
-
+1. 修改代码,允许输入多位数,比如 “12+3”
+2. 添加一个方法忽略空格符,让你的计算器能够处理带有空白的输入,比如 “12 + 3”
+3. 修改代码,用 ‘-’ 号而非 ‘+’ 号去执行减法比如 “7-5”
**检验你的理解**
- 1. 什么是解释器?
- 2. 什么是编译器
- 3. 解释器和编译器有什么差别?
- 4. 什么是标记?
- 5. 将输入分隔成若干个标记的过程叫什么?
- 6. 解释器中进行词法分析的部分叫什么?
- 7. 解释器或编译器中进行词法分析的部分有哪些其他的常见名字?
-
-
+1. 什么是解释器?
+2. 什么是编译器
+3. 解释器和编译器有什么差别?
+4. 什么是标记?
+5. 将输入分隔成若干个标记的过程叫什么?
+6. 解释器中进行词法分析的部分叫什么?
+7. 解释器或编译器中进行词法分析的部分有哪些其他的常见名字?
在结束本文前,我衷心希望你能留下学习解释器和编译器的承诺。并且现在就开始做。不要把它留到以后。不要拖延。如果你已经看完了本文,就开始吧。如果已经仔细看完了但是还没做什么练习 —— 现在就开始做吧。如果已经开始做练习了,那就把剩下的做完。你懂得。而且你知道吗?签下承诺书,今天就开始学习解释器和编译器!
+> 本人, ______,身体健全,思想正常,在此承诺从今天开始学习解释器和编译器,直到我百分百了解它们是怎么工作的!
-_本人, ______,身体健全,思想正常,在此承诺从今天开始学习解释器和编译器,直到我百分百了解它们是怎么工作的!_
+>
-签字人:
+> 签字人:
-日期:
+> 日期:
![][13]
签字,写上日期,把它放在你每天都能看到的地方,确保你能坚守承诺。谨记你的承诺:
-> "Commitment is doing the thing you said you were going to do long after the mood you said it in has left you." -- Darren Hardy
> “承诺就是,你说自己会去做的事,在你说完就一直陪着你的东西。” —— Darren Hardy
好,今天的就结束了。这个系列的下一篇文章里,你将会扩展自己的计算器,让它能够处理更复杂的算术表达式。敬请期待。
-
--------------------------------------------------------------------------------
via: https://ruslanspivak.com/lsbasi-part1/
@@ -311,7 +309,7 @@ via: https://ruslanspivak.com/lsbasi-part1/
作者:[Ruslan Spivak][a]
译者:[BriFuture](https://github.com/BriFuture)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20150708 Choosing a Linux Tracer (2015).md b/published/20150708 Choosing a Linux Tracer (2015).md
new file mode 100644
index 0000000000..2d04d8594f
--- /dev/null
+++ b/published/20150708 Choosing a Linux Tracer (2015).md
@@ -0,0 +1,189 @@
+Linux 跟踪器之选
+======
+
+[![][1]][2]
+
+> Linux 跟踪很神奇!
+
+跟踪器是一个高级的性能分析和调试工具,如果你使用过 `strace(1)` 或者 `tcpdump(8)`,你不应该被它吓到 ... 你使用的就是跟踪器。系统跟踪器能让你看到很多的东西,而不仅是系统调用或者数据包,因为常见的跟踪器都可以跟踪内核或者应用程序的任何东西。
+
+有大量的 Linux 跟踪器可供你选择。由于它们中的每个都有一个官方的(或者非官方的)的吉祥物,我们有足够多的选择给孩子们展示。
+
+你喜欢使用哪一个呢?
+
+我从两类读者的角度来回答这个问题:大多数人和性能/内核工程师。当然,随着时间的推移,这也可能会发生变化,因此,我需要及时去更新本文内容,或许是每年一次,或者更频繁。(LCTT 译注:本文最后更新于 2015 年)
+
+### 对于大多数人
+
+大多数人(开发者、系统管理员、运维人员、网络可靠性工程师(SRE)…)是不需要去学习系统跟踪器的底层细节的。以下是你需要去了解和做的事情:
+
+#### 1. 使用 perf_events 进行 CPU 剖析
+
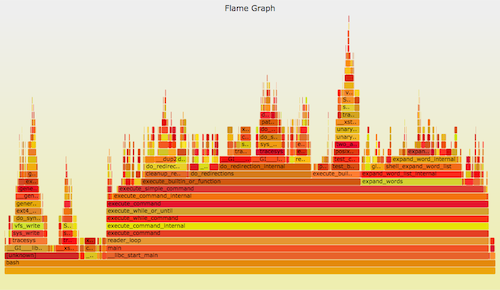
+可以使用 perf_events 进行 CPU 剖析。它可以用一个 [火焰图][3] 来形象地表示。比如:
+
+```
+git clone --depth 1 https://github.com/brendangregg/FlameGraph
+perf record -F 99 -a -g -- sleep 30
+perf script | ./FlameGraph/stackcollapse-perf.pl | ./FlameGraph/flamegraph.pl > perf.svg
+```
+
+
+
+Linux 的 perf_events(即 `perf`,后者是它的命令)是官方为 Linux 用户准备的跟踪器/分析器。它位于内核源码中,并且维护的非常好(而且现在它的功能还在快速变强)。它一般是通过 linux-tools-common 这个包来添加的。
+
+`perf` 可以做的事情很多,但是,如果我只能建议你学习其中的一个功能的话,那就是 CPU 剖析。虽然从技术角度来说,这并不是事件“跟踪”,而是采样。最难的部分是获得完整的栈和符号,这部分在我的 [Linux Profiling at Netflix][4] 中针对 Java 和 Node.js 讨论过。
+
+#### 2. 知道它能干什么
+
+正如一位朋友所说的:“你不需要知道 X 光机是如何工作的,但你需要明白的是,如果你吞下了一个硬币,X 光机是你的一个选择!”你需要知道使用跟踪器能够做什么,因此,如果你在业务上确实需要它,你可以以后再去学习它,或者请会使用它的人来做。
+
+简单地说:几乎任何事情都可以通过跟踪来了解它。内部文件系统、TCP/IP 处理过程、设备驱动、应用程序内部情况。阅读我在 lwn.net 上的 [ftrace][5] 的文章,也可以去浏览 [perf_events 页面][6],那里有一些跟踪(和剖析)能力的示例。
+
+#### 3. 需要一个前端工具
+
+如果你要购买一个性能分析工具(有许多公司销售这类产品),并要求支持 Linux 跟踪。想要一个直观的“点击”界面去探查内核的内部,以及包含一个在不同堆栈位置的延迟热力图。就像我在 [Monitorama 演讲][7] 中描述的那样。
+
+我创建并开源了我自己的一些前端工具,虽然它是基于 CLI 的(不是图形界面的)。这样可以使其它人使用跟踪器更快更容易。比如,我的 [perf-tools][8],跟踪新进程是这样的:
+
+```
+# ./execsnoop
+Tracing exec()s. Ctrl-C to end.
+ PID PPID ARGS
+ 22898 22004 man ls
+ 22905 22898 preconv -e UTF-8
+ 22908 22898 pager -s
+ 22907 22898 nroff -mandoc -rLL=164n -rLT=164n -Tutf8
+[...]
+```
+
+在 Netflix 公司,我正在开发 [Vector][9],它是一个实例分析工具,实际上它也是一个 Linux 跟踪器的前端。
+
+### 对于性能或者内核工程师
+
+一般来说,我们的工作都非常难,因为大多数人或许要求我们去搞清楚如何去跟踪某个事件,以及因此需要选择使用哪个跟踪器。为完全理解一个跟踪器,你通常需要花至少一百多个小时去使用它。理解所有的 Linux 跟踪器并能在它们之间做出正确的选择是件很难的事情。(我或许是唯一接近完成这件事的人)
+
+在这里我建议选择如下,要么:
+
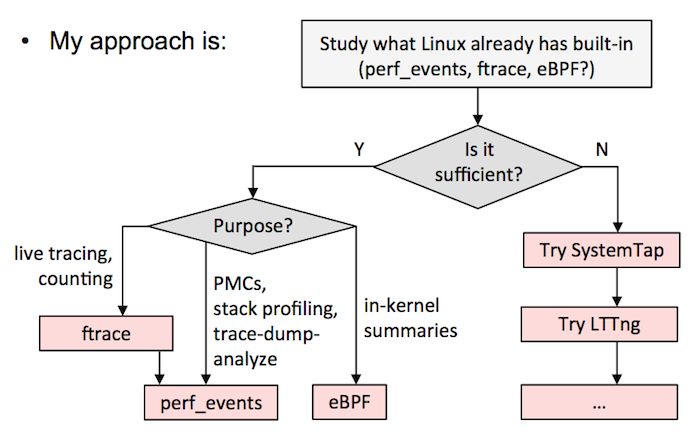
+A)选择一个全能的跟踪器,并以它为标准。这需要在一个测试环境中花大量的时间来搞清楚它的细微差别和安全性。我现在的建议是 SystemTap 的最新版本(例如,从 [源代码][10] 构建)。我知道有的公司选择的是 LTTng ,尽管它并不是很强大(但是它很安全),但他们也用的很好。如果在 `sysdig` 中添加了跟踪点或者是 kprobes,它也是另外的一个候选者。
+
+B)按我的 [Velocity 教程中][11] 的流程图。这意味着尽可能使用 ftrace 或者 perf_events,eBPF 已经集成到内核中了,然后用其它的跟踪器,如 SystemTap/LTTng 作为对 eBPF 的补充。我目前在 Netflix 的工作中就是这么做的。
+
+
+
+以下是我对各个跟踪器的评价:
+
+#### 1. ftrace
+
+我爱 [ftrace][12],它是内核黑客最好的朋友。它被构建进内核中,它能够利用跟踪点、kprobes、以及 uprobes,以提供一些功能:使用可选的过滤器和参数进行事件跟踪;事件计数和计时,内核概览;函数流步进。关于它的示例可以查看内核源代码树中的 [ftrace.txt][13]。它通过 `/sys` 来管理,是面向单一的 root 用户的(虽然你可以使用缓冲实例以让其支持多用户),它的界面有时很繁琐,但是它比较容易调校,并且有个前端:ftrace 的主要创建者 Steven Rostedt 设计了一个 trace-cmd,而且我也创建了 perf-tools 集合。我最诟病的就是它不是可编程的,因此,举个例子说,你不能保存和获取时间戳、计算延迟,以及将其保存为直方图。你需要转储事件到用户级以便于进行后期处理,这需要花费一些成本。它也许可以通过 eBPF 实现可编程。
+
+#### 2. perf_events
+
+[perf_events][14] 是 Linux 用户的主要跟踪工具,它的源代码位于 Linux 内核中,一般是通过 linux-tools-common 包来添加的。它又称为 `perf`,后者指的是它的前端,它相当高效(动态缓存),一般用于跟踪并转储到一个文件中(perf.data),然后可以在之后进行后期处理。它可以做大部分 ftrace 能做的事情。它不能进行函数流步进,并且不太容易调校(而它的安全/错误检查做的更好一些)。但它可以做剖析(采样)、CPU 性能计数、用户级的栈转换、以及使用本地变量利用调试信息进行行级跟踪。它也支持多个并发用户。与 ftrace 一样,它也不是内核可编程的,除非 eBPF 支持(补丁已经在计划中)。如果只学习一个跟踪器,我建议大家去学习 perf,它可以解决大量的问题,并且它也相当安全。
+
+#### 3. eBPF
+
+扩展的伯克利包过滤器(eBPF)是一个内核内的虚拟机,可以在事件上运行程序,它非常高效(JIT)。它可能最终为 ftrace 和 perf_events 提供内核内编程,并可以去增强其它跟踪器。它现在是由 Alexei Starovoitov 开发的,还没有实现完全的整合,但是对于一些令人印象深刻的工具,有些内核版本(比如,4.1)已经支持了:比如,块设备 I/O 的延迟热力图。更多参考资料,请查阅 Alexei 的 [BPF 演示][15],和它的 [eBPF 示例][16]。
+
+#### 4. SystemTap
+
+[SystemTap][17] 是一个非常强大的跟踪器。它可以做任何事情:剖析、跟踪点、kprobes、uprobes(它就来自 SystemTap)、USDT、内核内编程等等。它将程序编译成内核模块并加载它们 —— 这是一种很难保证安全的方法。它开发是在内核代码树之外进行的,并且在过去出现过很多问题(内核崩溃或冻结)。许多并不是 SystemTap 的过错 —— 它通常是首次对内核使用某些跟踪功能,并率先遇到 bug。最新版本的 SystemTap 是非常好的(你需要从它的源代码编译),但是,许多人仍然没有从早期版本的问题阴影中走出来。如果你想去使用它,花一些时间去测试环境,然后,在 irc.freenode.net 的 #systemtap 频道与开发者进行讨论。(Netflix 有一个容错架构,我们使用了 SystemTap,但是我们或许比起你来说,更少担心它的安全性)我最诟病的事情是,它似乎假设你有办法得到内核调试信息,而我并没有这些信息。没有它我实际上可以做很多事情,但是缺少相关的文档和示例(我现在自己开始帮着做这些了)。
+
+#### 5. LTTng
+
+[LTTng][18] 对事件收集进行了优化,性能要好于其它的跟踪器,也支持许多的事件类型,包括 USDT。它的开发是在内核代码树之外进行的。它的核心部分非常简单:通过一个很小的固定指令集写入事件到跟踪缓冲区。这样让它既安全又快速。缺点是做内核内编程不太容易。我觉得那不是个大问题,由于它优化的很好,可以充分的扩展,尽管需要后期处理。它也探索了一种不同的分析技术。很多的“黑匣子”记录了所有感兴趣的事件,以便可以在 GUI 中以后分析它。我担心该记录会错失之前没有预料的事件,我真的需要花一些时间去看看它在实践中是如何工作的。这个跟踪器上我花的时间最少(没有特别的原因)。
+
+#### 6. ktap
+
+[ktap][19] 是一个很有前途的跟踪器,它在内核中使用了一个 lua 虚拟机,不需要调试信息和在嵌入时设备上可以工作的很好。这使得它进入了人们的视野,在某个时候似乎要成为 Linux 上最好的跟踪器。然而,由于 eBPF 开始集成到了内核,而 ktap 的集成工作被推迟了,直到它能够使用 eBPF 而不是它自己的虚拟机。由于 eBPF 在几个月过去之后仍然在集成过程中,ktap 的开发者已经等待了很长的时间。我希望在今年的晚些时间它能够重启开发。
+
+#### 7. dtrace4linux
+
+[dtrace4linux][20] 主要由一个人(Paul Fox)利用业务时间将 Sun DTrace 移植到 Linux 中的。它令人印象深刻,一些供应器可以工作,还不是很完美,它最多应该算是实验性的工具(不安全)。我认为对于许可证的担心,使人们对它保持谨慎:它可能永远也进入不了 Linux 内核,因为 Sun 是基于 CDDL 许可证发布的 DTrace;Paul 的方法是将它作为一个插件。我非常希望看到 Linux 上的 DTrace,并且希望这个项目能够完成,我想我加入 Netflix 时将花一些时间来帮它完成。但是,我一直在使用内置的跟踪器 ftrace 和 perf_events。
+
+#### 8. OL DTrace
+
+[Oracle Linux DTrace][21] 是将 DTrace 移植到 Linux (尤其是 Oracle Linux)的重大努力。过去这些年的许多发布版本都一直稳定的进步,开发者甚至谈到了改善 DTrace 测试套件,这显示出这个项目很有前途。许多有用的功能已经完成:系统调用、剖析、sdt、proc、sched、以及 USDT。我一直在等待着 fbt(函数边界跟踪,对内核的动态跟踪),它将成为 Linux 内核上非常强大的功能。它最终能否成功取决于能否吸引足够多的人去使用 Oracle Linux(并为支持付费)。另一个羁绊是它并非完全开源的:内核组件是开源的,但用户级代码我没有看到。
+
+#### 9. sysdig
+
+[sysdig][22] 是一个很新的跟踪器,它可以使用类似 `tcpdump` 的语法来处理系统调用事件,并用 lua 做后期处理。它也是令人印象深刻的,并且很高兴能看到在系统跟踪领域的创新。它的局限性是,它的系统调用只能是在当时,并且,它转储所有事件到用户级进行后期处理。你可以使用系统调用来做许多事情,虽然我希望能看到它去支持跟踪点、kprobes、以及 uprobes。我也希望看到它支持 eBPF 以查看内核内概览。sysdig 的开发者现在正在增加对容器的支持。可以关注它的进一步发展。
+
+### 深入阅读
+
+我自己的工作中使用到的跟踪器包括:
+
+- **ftrace** : 我的 [perf-tools][8] 集合(查看示例目录);我的 lwn.net 的 [ftrace 跟踪器的文章][5]; 一个 [LISA14][8] 演讲;以及帖子: [函数计数][23]、 [iosnoop][24]、 [opensnoop][25]、 [execsnoop][26]、 [TCP retransmits][27]、 [uprobes][28] 和 [USDT][29]。
+- **perf_events** : 我的 [perf_events 示例][6] 页面;在 SCALE 的一个 [Linux Profiling at Netflix][4] 演讲;和帖子:[CPU 采样][30]、[静态跟踪点][31]、[热力图][32]、[计数][33]、[内核行级跟踪][34]、[off-CPU 时间火焰图][35]。
+- **eBPF** : 帖子 [eBPF:一个小的进步][36],和一些 [BPF-tools][37] (我需要发布更多)。
+- **SystemTap** : 很久以前,我写了一篇 [使用 SystemTap][38] 的文章,它有点过时了。最近我发布了一些 [systemtap-lwtools][39],展示了在没有内核调试信息的情况下,SystemTap 是如何使用的。
+- **LTTng** : 我使用它的时间很短,不足以发布什么文章。
+- **ktap** : 我的 [ktap 示例][40] 页面包括一行程序和脚本,虽然它是早期的版本。
+- **dtrace4linux** : 在我的 [系统性能][41] 书中包含了一些示例,并且在过去我为了某些事情开发了一些小的修补,比如, [timestamps][42]。
+- **OL DTrace** : 因为它是对 DTrace 的直接移植,我早期 DTrace 的工作大多与之相关(链接太多了,可以去 [我的主页][43] 上搜索)。一旦它更加完美,我可以开发很多专用工具。
+- **sysdig** : 我贡献了 [fileslower][44] 和 [subsecond offset spectrogram][45] 的 chisel。
+- **其它** : 关于 [strace][46],我写了一些告诫文章。
+
+不好意思,没有更多的跟踪器了! … 如果你想知道为什么 Linux 中的跟踪器不止一个,或者关于 DTrace 的内容,在我的 [从 DTrace 到 Linux][47] 的演讲中有答案,从 [第 28 张幻灯片][48] 开始。
+
+感谢 [Deirdre Straughan][49] 的编辑,以及跟踪小马的创建(General Zoi 是小马的创建者)。
+
+--------------------------------------------------------------------------------
+
+via: http://www.brendangregg.com/blog/2015-07-08/choosing-a-linux-tracer.html
+
+作者:[Brendan Gregg][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.brendangregg.com
+[1]:http://www.brendangregg.com/blog/images/2015/tracing_ponies.png
+[2]:http://www.slideshare.net/brendangregg/velocity-2015-linux-perf-tools/105
+[3]:http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html
+[4]:http://www.brendangregg.com/blog/2015-02-27/linux-profiling-at-netflix.html
+[5]:http://lwn.net/Articles/608497/
+[6]:http://www.brendangregg.com/perf.html
+[7]:http://www.brendangregg.com/blog/2015-06-23/netflix-instance-analysis-requirements.html
+[8]:http://www.brendangregg.com/blog/2015-03-17/linux-performance-analysis-perf-tools.html
+[9]:http://techblog.netflix.com/2015/04/introducing-vector-netflixs-on-host.html
+[10]:https://sourceware.org/git/?p=systemtap.git;a=blob_plain;f=README;hb=HEAD
+[11]:http://www.slideshare.net/brendangregg/velocity-2015-linux-perf-tools
+[12]:http://lwn.net/Articles/370423/
+[13]:https://www.kernel.org/doc/Documentation/trace/ftrace.txt
+[14]:https://perf.wiki.kernel.org/index.php/Main_Page
+[15]:http://www.phoronix.com/scan.php?page=news_item&px=BPF-Understanding-Kernel-VM
+[16]:https://github.com/torvalds/linux/tree/master/samples/bpf
+[17]:https://sourceware.org/systemtap/wiki
+[18]:http://lttng.org/
+[19]:http://ktap.org/
+[20]:https://github.com/dtrace4linux/linux
+[21]:http://docs.oracle.com/cd/E37670_01/E38608/html/index.html
+[22]:http://www.sysdig.org/
+[23]:http://www.brendangregg.com/blog/2014-07-13/linux-ftrace-function-counting.html
+[24]:http://www.brendangregg.com/blog/2014-07-16/iosnoop-for-linux.html
+[25]:http://www.brendangregg.com/blog/2014-07-25/opensnoop-for-linux.html
+[26]:http://www.brendangregg.com/blog/2014-07-28/execsnoop-for-linux.html
+[27]:http://www.brendangregg.com/blog/2014-09-06/linux-ftrace-tcp-retransmit-tracing.html
+[28]:http://www.brendangregg.com/blog/2015-06-28/linux-ftrace-uprobe.html
+[29]:http://www.brendangregg.com/blog/2015-07-03/hacking-linux-usdt-ftrace.html
+[30]:http://www.brendangregg.com/blog/2014-06-22/perf-cpu-sample.html
+[31]:http://www.brendangregg.com/blog/2014-06-29/perf-static-tracepoints.html
+[32]:http://www.brendangregg.com/blog/2014-07-01/perf-heat-maps.html
+[33]:http://www.brendangregg.com/blog/2014-07-03/perf-counting.html
+[34]:http://www.brendangregg.com/blog/2014-09-11/perf-kernel-line-tracing.html
+[35]:http://www.brendangregg.com/blog/2015-02-26/linux-perf-off-cpu-flame-graph.html
+[36]:http://www.brendangregg.com/blog/2015-05-15/ebpf-one-small-step.html
+[37]:https://github.com/brendangregg/BPF-tools
+[38]:http://dtrace.org/blogs/brendan/2011/10/15/using-systemtap/
+[39]:https://github.com/brendangregg/systemtap-lwtools
+[40]:http://www.brendangregg.com/ktap.html
+[41]:http://www.brendangregg.com/sysperfbook.html
+[42]:https://github.com/dtrace4linux/linux/issues/55
+[43]:http://www.brendangregg.com
+[44]:https://github.com/brendangregg/sysdig/commit/d0eeac1a32d6749dab24d1dc3fffb2ef0f9d7151
+[45]:https://github.com/brendangregg/sysdig/commit/2f21604dce0b561407accb9dba869aa19c365952
+[46]:http://www.brendangregg.com/blog/2014-05-11/strace-wow-much-syscall.html
+[47]:http://www.brendangregg.com/blog/2015-02-28/from-dtrace-to-linux.html
+[48]:http://www.slideshare.net/brendangregg/from-dtrace-to-linux/28
+[49]:http://www.beginningwithi.com/
diff --git a/published/20160810 How does gdb work.md b/published/20160810 How does gdb work.md
new file mode 100644
index 0000000000..58fb60873e
--- /dev/null
+++ b/published/20160810 How does gdb work.md
@@ -0,0 +1,208 @@
+gdb 如何工作?
+============================================================
+
+大家好!今天,我开始进行我的 [ruby 堆栈跟踪项目][1],我发觉我现在了解了一些关于 `gdb` 内部如何工作的内容。
+
+最近,我使用 `gdb` 来查看我的 Ruby 程序,所以,我们将对一个 Ruby 程序运行 `gdb` 。它实际上就是一个 Ruby 解释器。首先,我们需要打印出一个全局变量的地址:`ruby_current_thread`。
+
+### 获取全局变量
+
+下面展示了如何获取全局变量 `ruby_current_thread` 的地址:
+
+```
+$ sudo gdb -p 2983
+(gdb) p & ruby_current_thread
+$2 = (rb_thread_t **) 0x5598a9a8f7f0
+```
+
+变量能够位于的地方有堆、栈或者程序的文本段。全局变量是程序的一部分。某种程度上,你可以把它们想象成是在编译的时候分配的。因此,我们可以很容易的找出全局变量的地址。让我们来看看,`gdb` 是如何找出 `0x5598a9a87f0` 这个地址的。
+
+我们可以通过查看位于 `/proc` 目录下一个叫做 `/proc/$pid/maps` 的文件,来找到这个变量所位于的大致区域。
+
+
+```
+$ sudo cat /proc/2983/maps | grep bin/ruby
+5598a9605000-5598a9886000 r-xp 00000000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
+5598a9a86000-5598a9a8b000 r--p 00281000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
+5598a9a8b000-5598a9a8d000 rw-p 00286000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
+
+```
+
+所以,我们看到,起始地址 `5598a9605000` 和 `0x5598a9a8f7f0` 很像,但并不一样。哪里不一样呢,我们把两个数相减,看看结果是多少:
+
+```
+(gdb) p/x 0x5598a9a8f7f0 - 0x5598a9605000
+$4 = 0x48a7f0
+
+```
+
+你可能会问,这个数是什么?让我们使用 `nm` 来查看一下程序的符号表。
+
+```
+sudo nm /proc/2983/exe | grep ruby_current_thread
+000000000048a7f0 b ruby_current_thread
+```
+
+我们看到了什么?能够看到 `0x48a7f0` 吗?是的,没错。所以,如果我们想找到程序中一个全局变量的地址,那么只需在符号表中查找变量的名字,然后再加上在 `/proc/whatever/maps` 中的起始地址,就得到了。
+
+所以现在,我们知道 `gdb` 做了什么。但是,`gdb` 实际做的事情更多,让我们跳过直接转到…
+
+### 解引用指针
+
+```
+(gdb) p ruby_current_thread
+$1 = (rb_thread_t *) 0x5598ab3235b0
+```
+
+我们要做的下一件事就是解引用 `ruby_current_thread` 这一指针。我们想看一下它所指向的地址。为了完成这件事,`gdb` 会运行大量系统调用比如:
+
+```
+ptrace(PTRACE_PEEKTEXT, 2983, 0x5598a9a8f7f0, [0x5598ab3235b0]) = 0
+
+```
+
+你是否还记得 `0x5598a9a8f7f0` 这个地址?`gdb` 会问:“嘿,在这个地址中的实际内容是什么?”。`2983` 是我们运行 gdb 这个进程的 ID。gdb 使用 `ptrace` 这一系统调用来完成这一件事。
+
+好极了!因此,我们可以解引用内存并找出内存地址中存储的内容。有一些有用的 `gdb` 命令,比如 `x/40w 变量` 和 `x/40b 变量` 分别会显示给定地址的 40 个字/字节。
+
+### 描述结构
+
+一个内存地址中的内容可能看起来像下面这样。可以看到很多字节!
+
+```
+(gdb) x/40b ruby_current_thread
+0x5598ab3235b0: 16 -90 55 -85 -104 85 0 0
+0x5598ab3235b8: 32 47 50 -85 -104 85 0 0
+0x5598ab3235c0: 16 -64 -55 115 -97 127 0 0
+0x5598ab3235c8: 0 0 2 0 0 0 0 0
+0x5598ab3235d0: -96 -83 -39 115 -97 127 0 0
+```
+
+这很有用,但也不是非常有用!如果你是一个像我一样的人类并且想知道它代表什么,那么你需要更多内容,比如像这样:
+
+```
+(gdb) p *(ruby_current_thread)
+$8 = {self = 94114195940880, vm = 0x5598ab322f20, stack = 0x7f9f73c9c010,
+ stack_size = 131072, cfp = 0x7f9f73d9ada0, safe_level = 0, raised_flag = 0,
+ last_status = 8, state = 0, waiting_fd = -1, passed_block = 0x0,
+ passed_bmethod_me = 0x0, passed_ci = 0x0, top_self = 94114195612680,
+ top_wrapper = 0, base_block = 0x0, root_lep = 0x0, root_svar = 8, thread_id =
+ 140322820187904,
+```
+
+太好了。现在就更加有用了。`gdb` 是如何知道这些所有域的,比如 `stack_size` ?是从 `DWARF` 得知的。`DWARF` 是存储额外程序调试数据的一种方式,从而像 `gdb` 这样的调试器能够工作的更好。它通常存储为二进制的一部分。如果我对我的 Ruby 二进制文件运行 `dwarfdump` 命令,那么我将会得到下面的输出:
+
+(我已经重新编排使得它更容易理解)
+
+```
+DW_AT_name "rb_thread_struct"
+DW_AT_byte_size 0x000003e8
+DW_TAG_member
+ DW_AT_name "self"
+ DW_AT_type <0x00000579>
+ DW_AT_data_member_location DW_OP_plus_uconst 0
+DW_TAG_member
+ DW_AT_name "vm"
+ DW_AT_type <0x0000270c>
+ DW_AT_data_member_location DW_OP_plus_uconst 8
+DW_TAG_member
+ DW_AT_name "stack"
+ DW_AT_type <0x000006b3>
+ DW_AT_data_member_location DW_OP_plus_uconst 16
+DW_TAG_member
+ DW_AT_name "stack_size"
+ DW_AT_type <0x00000031>
+ DW_AT_data_member_location DW_OP_plus_uconst 24
+DW_TAG_member
+ DW_AT_name "cfp"
+ DW_AT_type <0x00002712>
+ DW_AT_data_member_location DW_OP_plus_uconst 32
+DW_TAG_member
+ DW_AT_name "safe_level"
+ DW_AT_type <0x00000066>
+
+```
+
+所以,`ruby_current_thread` 的类型名为 `rb_thread_struct`,它的大小为 `0x3e8` (即 1000 字节),它有许多成员项,`stack_size` 是其中之一,在偏移为 `24` 的地方,它有类型 `31` 。`31` 是什么?不用担心,我们也可以在 DWARF 信息中查看。
+
+```
+< 1><0x00000031> DW_TAG_typedef
+ DW_AT_name "size_t"
+ DW_AT_type <0x0000003c>
+< 1><0x0000003c> DW_TAG_base_type
+ DW_AT_byte_size 0x00000008
+ DW_AT_encoding DW_ATE_unsigned
+ DW_AT_name "long unsigned int"
+
+```
+
+所以,`stack_size` 具有类型 `size_t`,即 `long unsigned int`,它是 8 字节的。这意味着我们可以查看该栈的大小。
+
+如果我们有了 DWARF 调试数据,该如何分解:
+
+1. 查看 `ruby_current_thread` 所指向的内存区域
+2. 加上 `24` 字节来得到 `stack_size`
+3. 读 8 字节(以小端的格式,因为是在 x86 上)
+4. 得到答案!
+
+在上面这个例子中是 `131072`(即 128 kb)。
+
+对我来说,这使得调试信息的用途更加明显。如果我们不知道这些所有变量所表示的额外的元数据,那么我们无法知道存储在 `0x5598ab325b0` 这一地址的字节是什么。
+
+这就是为什么你可以为你的程序单独安装程序的调试信息,因为 `gdb` 并不关心从何处获取这些额外的调试信息。
+
+### DWARF 令人迷惑
+
+我最近阅读了大量的 DWARF 知识。现在,我使用 libdwarf,使用体验不是很好,这个 API 令人迷惑,你将以一种奇怪的方式初始化所有东西,它真的很慢(需要花费 0.3 秒的时间来读取我的 Ruby 程序的所有调试信息,这真是可笑)。有人告诉我,来自 elfutils 的 libdw 要好一些。
+
+同样,再提及一点,你可以查看 `DW_AT_data_member_location` 来查看结构成员的偏移。我在 Stack Overflow 上查找如何完成这件事,并且得到[这个答案][2]。基本上,以下面这样一个检查开始:
+
+```
+dwarf_whatform(attrs[i], &form, &error);
+ if (form == DW_FORM_data1 || form == DW_FORM_data2
+ form == DW_FORM_data2 || form == DW_FORM_data4
+ form == DW_FORM_data8 || form == DW_FORM_udata) {
+```
+
+继续往前。为什么会有 800 万种不同的 `DW_FORM_data` 需要检查?发生了什么?我没有头绪。
+
+不管怎么说,我的印象是,DWARF 是一个庞大而复杂的标准(可能是人们用来生成 DWARF 的库稍微不兼容),但是我们有的就是这些,所以我们只能用它来工作。
+
+我能够编写代码并查看 DWARF ,这就很酷了,并且我的代码实际上大多数能够工作。除了程序崩溃的时候。我就是这样工作的。
+
+### 展开栈路径
+
+在这篇文章的早期版本中,我说过,`gdb` 使用 libunwind 来展开栈路径,这样说并不总是对的。
+
+有一位对 `gdb` 有深入研究的人发了大量邮件告诉我,为了能够做得比 libunwind 更好,他们花费了大量时间来尝试如何展开栈路径。这意味着,如果你在程序的一个奇怪的中间位置停下来了,你所能够获取的调试信息又很少,那么你可以对栈做一些奇怪的事情,`gdb` 会尝试找出你位于何处。
+
+### gdb 能做的其他事
+
+我在这儿所描述的一些事请(查看内存,理解 DWARF 所展示的结构)并不是 `gdb` 能够做的全部事情。阅读 Brendan Gregg 的[昔日 gdb 例子][3],我们可以知道,`gdb` 也能够完成下面这些事情:
+
+* 反汇编
+* 查看寄存器内容
+
+在操作程序方面,它可以:
+
+* 设置断点,单步运行程序
+* 修改内存(这是一个危险行为)
+
+了解 `gdb` 如何工作使得当我使用它的时候更加自信。我过去经常感到迷惑,因为 `gdb` 有点像 C,当你输入 `ruby_current_thread->cfp->iseq`,就好像是在写 C 代码。但是你并不是在写 C 代码。我很容易遇到 `gdb` 的限制,不知道为什么。
+
+知道使用 DWARF 来找出结构内容给了我一个更好的心智模型和更加正确的期望!这真是极好的!
+
+--------------------------------------------------------------------------------
+
+via: https://jvns.ca/blog/2016/08/10/how-does-gdb-work/
+
+作者:[Julia Evans][a]
+译者:[ucasFL](https://github.com/ucasFL)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://jvns.ca/
+[1]:http://jvns.ca/blog/2016/06/12/a-weird-system-call-process-vm-readv/
+[2]:https://stackoverflow.com/questions/25047329/how-to-get-struct-member-offset-from-dwarf-info
+[3]:http://www.brendangregg.com/blog/2016-08-09/gdb-example-ncurses.html
diff --git a/published/20170310 9 Lightweight Linux Applications to Speed Up Your System.md b/published/20170310 9 Lightweight Linux Applications to Speed Up Your System.md
new file mode 100644
index 0000000000..bf2e2d972a
--- /dev/null
+++ b/published/20170310 9 Lightweight Linux Applications to Speed Up Your System.md
@@ -0,0 +1,210 @@
+9 个提高系统运行速度的轻量级 Linux 应用
+======
+
+**简介:** [加速 Ubuntu 系统][1]有很多方法,办法之一是使用轻量级应用来替代一些常用应用程序。我们之前之前发布过一篇 [Linux 必备的应用程序][2],如今将分享这些应用程序在 Ubuntu 或其他 Linux 发行版的轻量级替代方案。
+
+![在 ubunt 使用轻量级应用程序替代方案][4]
+
+### 9 个常用 Linux 应用程序的轻量级替代方案
+
+你的 Linux 系统很慢吗?应用程序是不是很久才能打开?你最好的选择是使用[轻量级的 Linux 系统][5]。但是重装系统并非总是可行,不是吗?
+
+所以如果你想坚持使用你现在用的 Linux 发行版,但是想要提高性能,你应该使用更轻量级应用来替代你一些常用的应用。这篇文章会列出各种 Linux 应用程序的轻量级替代方案。
+
+由于我使用的是 Ubuntu,因此我只提供了基于 Ubuntu 的 Linux 发行版的安装说明。但是这些应用程序可以用于几乎所有其他 Linux 发行版。你只需去找这些轻量级应用在你的 Linux 发行版中的安装方法就可以了。
+
+### 1. Midori: Web 浏览器
+
+[Midori][8] 是与现代互联网环境具有良好兼容性的最轻量级网页浏览器之一。它是开源的,使用与 Google Chrome 最初所基于的相同的渲染引擎 —— WebKit。并且超快速,最小化但高度可定制。
+
+![Midori Browser][6]
+
+Midori 浏览器有很多可以定制的扩展和选项。如果你有最高权限,使用这个浏览器也是一个不错的选择。如果在浏览网页的时候遇到了某些问题,请查看其网站上[常见问题][7]部分 -- 这包含了你可能遇到的常见问题及其解决方案。
+
+
+#### 在基于 Ubuntu 的发行版上安装 Midori
+
+在 Ubuntu 上,可通过官方源找到 Midori 。运行以下指令即可安装它:
+
+```
+sudo apt install midori
+```
+
+### 2. Trojita:电子邮件客户端
+
+[Trojita][11] 是一款开源强大的 IMAP 电子邮件客户端。它速度快,资源利用率高。我可以肯定地称它是 [Linux 最好的电子邮件客户端之一][9]。如果你只需电子邮件客户端提供 IMAP 支持,那么也许你不用再进一步考虑了。
+
+![Trojitá][10]
+
+Trojita 使用各种技术 —— 按需电子邮件加载、离线缓存、带宽节省模式等 —— 以实现其令人印象深刻的性能。
+
+#### 在基于 Ubuntu 的发行版上安装 Trojita
+
+Trojita 目前没有针对 Ubuntu 的官方 PPA 。但这应该不成问题。您可以使用以下命令轻松安装它:
+
+```
+sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/jkt-gentoo:/trojita/xUbuntu_16.04/ /' > /etc/apt/sources.list.d/trojita.list"
+wget http://download.opensuse.org/repositories/home:jkt-gentoo:trojita/xUbuntu_16.04/Release.key
+sudo apt-key add - < Release.key
+sudo apt update
+sudo apt install trojita
+```
+
+### 3. GDebi:包安装程序
+
+有时您需要快速安装 DEB 软件包。Ubuntu 软件中心是一个消耗资源严重的应用程序,仅用于安装 .deb 文件并不明智。
+
+Gdebi 无疑是一款可以完成同样目的的漂亮工具,而它只有个极简的图形界面。
+
+![GDebi][12]
+
+GDebi 是完全轻量级的,完美无缺地完成了它的工作。你甚至应该[让 Gdebi 成为 DEB 文件的默认安装程序][13]。
+
+#### 在基于 Ubuntu 的发行版上安装 GDebi
+
+只需一行指令,你便可以在 Ubuntu 上安装 GDebi:
+
+```
+sudo apt install gdebi
+```
+
+### 4. App Grid:软件中心
+
+如果您经常在 Ubuntu 上使用软件中心搜索、安装和管理应用程序,则 [App Grid][15] 是必备的应用程序。它是默认的 Ubuntu 软件中心最具视觉吸引力且速度最快的替代方案。
+
+![App Grid][14]
+
+App Grid 支持应用程序的评分、评论和屏幕截图。
+
+#### 在基于 Ubuntu 的发行版上安装 App Grid
+
+App Grid 拥有 Ubuntu 的官方 PPA。使用以下指令安装 App Grid:
+
+```
+sudo add-apt-repository ppa:appgrid/stable
+sudo apt update
+sudo apt install appgrid
+```
+
+### 5. Yarock:音乐播放器
+
+[Yarock][17] 是一个优雅的音乐播放器,拥有现代而最轻量级的用户界面。尽管在设计上是轻量级的,但 Yarock 有一个全面的高级功能列表。
+
+![Yarock][16]
+
+Yarock 的主要功能包括多种音乐收藏、评级、智能播放列表、多种后端选项、桌面通知、音乐剪辑、上下文获取等。
+
+### 在基于 Ubuntu 的发行版上安装 Yarock
+
+您得通过 PPA 使用以下指令在 Ubuntu 上安装 Yarock:
+
+```
+sudo add-apt-repository ppa:nilarimogard/webupd8
+sudo apt update
+sudo apt install yarock
+```
+
+### 6. VLC:视频播放器
+
+谁不需要视频播放器?谁还从未听说过 [VLC][19]?我想并不需要对它做任何介绍。
+
+![VLC][18]
+
+VLC 能满足你在 Ubuntu 上播放各种媒体文件的全部需求,而且它非常轻便。它甚至可以在非常旧的 PC 上完美运行。
+
+#### 在基于 Ubuntu 的发行版上安装 VLC
+
+VLC 为 Ubuntu 提供官方 PPA。可以输入以下命令来安装它:
+
+```
+sudo apt install vlc
+```
+
+### 7. PCManFM:文件管理器
+
+PCManFM 是 LXDE 的标准文件管理器。与 LXDE 的其他应用程序一样,它也是轻量级的。如果您正在为文件管理器寻找更轻量级的替代品,可以尝试使用这个应用。
+
+![PCManFM][20]
+
+尽管来自 LXDE,PCManFM 也同样适用于其他桌面环境。
+
+#### 在基于 Ubuntu 的发行版上安装 PCManFM
+
+在 Ubuntu 上安装 PCManFM 只需要一条简单的指令:
+
+```
+sudo apt install pcmanfm
+```
+
+### 8. Mousepad:文本编辑器
+
+在轻量级方面,没有什么可以击败像 nano、vim 等命令行文本编辑器。但是,如果你想要一个图形界面,你可以尝试一下 Mousepad -- 一个最轻量级的文本编辑器。它非常轻巧,速度非常快。带有简单的可定制的用户界面和多个主题。
+
+![Mousepad][21]
+
+Mousepad 支持语法高亮显示。所以,你也可以使用它作为基础的代码编辑器。
+
+#### 在基于 Ubuntu 的发行版上安装 Mousepad
+
+想要安装 Mousepad ,可以使用以下指令:
+
+```
+sudo apt install mousepad
+```
+
+### 9. GNOME Office:办公软件
+
+许多人需要经常使用办公应用程序。通常,大多数办公应用程序体积庞大且很耗资源。Gnome Office 在这方面非常轻便。Gnome Office 在技术上不是一个完整的办公套件。它由不同的独立应用程序组成,在这之中 AbiWord&Gnumeric 脱颖而出。
+
+**AbiWord** 是文字处理器。它比其他替代品轻巧并且快得多。但是这样做是有代价的 —— 你可能会失去宏、语法检查等一些功能。AdiWord 并不完美,但它可以满足你基本的需求。
+
+![AbiWord][22]
+
+**Gnumeric** 是电子表格编辑器。就像 AbiWord 一样,Gnumeric 也非常快速,提供了精确的计算功能。如果你正在寻找一个简单轻便的电子表格编辑器,Gnumeric 已经能满足你的需求了。
+
+![Gnumeric][23]
+
+在 [Gnome Office][24] 下面还有一些其它应用程序。你可以在官方页面找到它们。
+
+#### 在基于 Ubuntu 的发行版上安装 AbiWord&Gnumeric
+
+要安装 AbiWord&Gnumeric,只需在终端中输入以下指令:
+
+```
+sudo apt install abiword gnumeric
+```
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/lightweight-alternative-applications-ubuntu/
+
+作者:[Munif Tanjim][a]
+译者:[imquanquan](https://github.com/imquanquan)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://itsfoss.com/author/munif/
+[1]:https://itsfoss.com/speed-up-ubuntu-1310/
+[2]:https://itsfoss.com/essential-linux-applications/
+[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Lightweight-alternative-applications-for-Linux-800x450.jpg
+[5]:https://itsfoss.com/lightweight-linux-beginners/
+[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Midori-800x497.png
+[7]:http://midori-browser.org/faqs/
+[8]:http://midori-browser.org/
+[9]:https://itsfoss.com/best-email-clients-linux/
+[10]:http://trojita.flaska.net/img/2016-03-22-trojita-home.png
+[11]:http://trojita.flaska.net/
+[12]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/GDebi.png
+[13]:https://itsfoss.com/gdebi-default-ubuntu-software-center/
+[14]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/AppGrid-800x553.png
+[15]:http://www.appgrid.org/
+[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Yarock-800x529.png
+[17]:https://seb-apps.github.io/yarock/
+[18]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/VLC-800x526.png
+[19]:http://www.videolan.org/index.html
+[20]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/PCManFM.png
+[21]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Mousepad.png
+[22]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/AbiWord-800x626.png
+[23]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Gnumeric-800x470.png
+[24]:https://gnome.org/gnome-office/
diff --git a/translated/tech/20170921 How to answer questions in a helpful way.md b/published/20170921 How to answer questions in a helpful way.md
similarity index 57%
rename from translated/tech/20170921 How to answer questions in a helpful way.md
rename to published/20170921 How to answer questions in a helpful way.md
index acc67fd10c..41436b0a90 100644
--- a/translated/tech/20170921 How to answer questions in a helpful way.md
+++ b/published/20170921 How to answer questions in a helpful way.md
@@ -1,28 +1,21 @@
-
如何提供有帮助的回答
=============================
-如果你的同事问你一个不太清晰的问题,你会怎么回答?我认为提问题是一种技巧(可以看 [如何提出有意义的问题][1]) 同时,合理地回答问题也是一种技巧。他们都是非常实用的。
+如果你的同事问你一个不太清晰的问题,你会怎么回答?我认为提问题是一种技巧(可以看 [如何提出有意义的问题][1]) 同时,合理地回答问题也是一种技巧,它们都是非常实用的。
-一开始 - 有时向你提问的人不尊重你的时间,这很糟糕。
-
-理想情况下,我们假设问你问题的人是一个理性的人并且正在尽力解决问题而你想帮助他们。和我一起工作的人是这样,我所生活的世界也是这样。当然,现实生活并不是这样。
+一开始 —— 有时向你提问的人不尊重你的时间,这很糟糕。理想情况下,我们假设问你问题的人是一个理性的人并且正在尽力解决问题,而你想帮助他们。和我一起工作的人是这样,我所生活的世界也是这样。当然,现实生活并不是这样。
下面是有助于回答问题的一些方法!
-
-### 如果他们提问不清楚,帮他们澄清
+### 如果他们的提问不清楚,帮他们澄清
通常初学者不会提出很清晰的问题,或者问一些对回答问题没有必要信息的问题。你可以尝试以下方法 澄清问题:
-* ** 重述为一个更明确的问题 ** 来回复他们(”你是想问 X 吗?“)
-
-* ** 向他们了解更具体的他们并没有提供的信息 ** (”你使用 IPv6 ?”)
-
-* ** 问是什么导致了他们的问题 ** 例如,有时有些人会进入我的团队频道,询问我们的服务发现(service discovery )如何工作的。这通常是因为他们试图设置/重新配置服务。在这种情况下,如果问“你正在使用哪种服务?可以给我看看你正在处理的 pull requests 吗?”是有帮助的。
-
-这些方法很多来自 [如何提出有意义的问题][2]中的要点。(尽管我永远不会对某人说“噢,你得先看完 “如何提出有意义的问题”这篇文章后再来像我提问)
+* **重述为一个更明确的问题**来回复他们(“你是想问 X 吗?”)
+* **向他们了解更具体的他们并没有提供的信息** (“你使用 IPv6 ?”)
+* **问是什么导致了他们的问题**。例如,有时有些人会进入我的团队频道,询问我们的服务发现如何工作的。这通常是因为他们试图设置/重新配置服务。在这种情况下,如果问“你正在使用哪种服务?可以给我看看你正在处理的‘拉取请求’吗?”是有帮助的。
+这些方法很多来自[如何提出有意义的问题][2]中的要点。(尽管我永远不会对某人说“噢,你得先看完《如何提出有意义的问题》这篇文章后再来向我提问)
### 弄清楚他们已经知道了什么
@@ -30,66 +23,54 @@
Harold Treen 给了我一个很好的例子:
-> 前几天,有人请我解释“ Redux-Sagas ”。与其深入解释不如说“ 他们就像 worker threads 监听行为(actions),让你更新 Redux store 。
+> 前几天,有人请我解释 “Redux-Sagas”。与其深入解释,不如说 “它们就像监听 action 的工人线程,并可以让你更新 Redux store。
-> 我开始搞清楚他们对 Redux 、行为(actions)、store 以及其他基本概念了解多少。将这些概念都联系在一起再来解释会容易得多。
+> 我开始搞清楚他们对 Redux、action、store 以及其他基本概念了解多少。将这些概念都联系在一起再来解释会容易得多。
-弄清楚问你问题的人已经知道什么是非常重要的。因为有时他们可能会对基础概念感到疑惑(“ Redux 是什么?“),或者他们可能是专家但是恰巧遇到了微妙的极端情况(corner case)。如果答案建立在他们不知道的概念上会令他们困惑,但如果重述他们已经知道的的又会是乏味的。
+弄清楚问你问题的人已经知道什么是非常重要的。因为有时他们可能会对基础概念感到疑惑(“Redux 是什么?”),或者他们可能是专家,但是恰巧遇到了微妙的极端情况。如果答案建立在他们不知道的概念上会令他们困惑,但如果重述他们已经知道的的又会是乏味的。
这里有一个很实用的技巧来了解他们已经知道什么 - 比如可以尝试用“你对 X 了解多少?”而不是问“你知道 X 吗?”。
-
### 给他们一个文档
-“RTFM” (“去读那些他妈的手册”(Read The Fucking Manual))是一个典型的无用的回答,但事实上如果向他们指明一个特定的文档会是非常有用的!当我提问题的时候,我当然很乐意翻看那些能实际解决我的问题的文档,因为它也可能解决其他我想问的问题。
+“RTFM” (“去读那些他妈的手册”)是一个典型的无用的回答,但事实上如果向他们指明一个特定的文档会是非常有用的!当我提问题的时候,我当然很乐意翻看那些能实际解决我的问题的文档,因为它也可能解决其他我想问的问题。
我认为明确你所给的文档的确能够解决问题是非常重要的,或者至少经过查阅后确认它对解决问题有帮助。否则,你可能将以下面这种情形结束对话(非常常见):
* Ali:我应该如何处理 X ?
+* Jada:\<文档链接>
+* Ali: 这个没有实际解释如何处理 X ,它仅仅解释了如何处理 Y !
-* Jada:<文档链接>
-
-* Ali: 这个并有实际解释如何处理 X ,它仅仅解释了如何处理 Y !
-
-如果我所给的文档特别长,我会指明文档中那个我将会谈及的特定部分。[bash 手册][3] 有44000个字(真的!),所以如果只说“它在 bash 手册中有说明”是没有帮助的:)
-
+如果我所给的文档特别长,我会指明文档中那个我将会谈及的特定部分。[bash 手册][3] 有 44000 个字(真的!),所以如果只说“它在 bash 手册中有说明”是没有帮助的 :)
### 告诉他们一个有用的搜索
-在工作中,我经常发现我可以利用我所知道的关键字进行搜索找到能够解决我的问题的答案。对于初学者来说,这些关键字往往不是那么明显。所以说“这是我用来寻找这个答案的搜索”可能有用些。再次说明,回答时请经检查后以确保搜索能够得到他们所需要的答案:)
-
+在工作中,我经常发现我可以利用我所知道的关键字进行搜索来找到能够解决我的问题的答案。对于初学者来说,这些关键字往往不是那么明显。所以说“这是我用来寻找这个答案的搜索”可能有用些。再次说明,回答时请经检查后以确保搜索能够得到他们所需要的答案 :)
### 写新文档
-人们经常一次又一次地问我的团队同样的问题。很显然这并不是他们的错(他们怎么能够知道在他们之前已经有10个人问了这个问题,且知道答案是什么呢?)因此,我们会尝试写新文档,而不是直接回答回答问题。
+人们经常一次又一次地问我的团队同样的问题。很显然这并不是他们的错(他们怎么能够知道在他们之前已经有 10 个人问了这个问题,且知道答案是什么呢?)因此,我们会尝试写新文档,而不是直接回答回答问题。
1. 马上写新文档
-
2. 给他们我们刚刚写好的新文档
-
3. 公示
写文档有时往往比回答问题需要花很多时间,但这是值得的。写文档尤其重要,如果:
a. 这个问题被问了一遍又一遍
-
b. 随着时间的推移,这个答案不会变化太大(如果这个答案每一个星期或者一个月就会变化,文档就会过时并且令人受挫)
-
### 解释你做了什么
对于一个话题,作为初学者来说,这样的交流会真让人沮丧:
* 新人:“嗨!你如何处理 X ?”
-
* 有经验的人:“我已经处理过了,而且它已经完美解决了”
-
* 新人:”...... 但是你做了什么?!“
如果问你问题的人想知道事情是如何进行的,这样是有帮助的:
* 让他们去完成任务而不是自己做
-
* 告诉他们你是如何得到你给他们的答案的。
这可能比你自己做的时间还要长,但对于被问的人来说这是一个学习机会,因为那样做使得他们将来能够更好地解决问题。
@@ -97,88 +78,74 @@ b. 随着时间的推移,这个答案不会变化太大(如果这个答案
这样,你可以进行更好的交流,像这:
* 新人:“这个网站出现了错误,发生了什么?”
-
-* 有经验的人:(2分钟后)”oh 这是因为发生了数据库故障转移“
-
-* 新人: ”你是怎么知道的??!?!?“
-
-* 有经验的人:“以下是我所做的!“:
-
+* 有经验的人:(2分钟后)“oh 这是因为发生了数据库故障转移”
+* 新人: “你是怎么知道的??!?!?”
+* 有经验的人:“以下是我所做的!”:
1. 通常这些错误是因为服务器 Y 被关闭了。我查看了一下 `$PLACE` 但它表明服务器 Y 开着。所以,并不是这个原因导致的。
-
2. 然后我查看 X 的仪表盘 ,仪表盘的这个部分显示这里发生了数据库故障转移。
-
3. 然后我在日志中找到了相应服务器,并且它显示连接数据库错误,看起来错误就是这里。
如果你正在解释你是如何调试一个问题,解释你是如何发现问题,以及如何找出问题的。尽管看起来你好像已经得到正确答案,但感觉更好的是能够帮助他们提高学习和诊断能力,并了解可用的资源。
-
### 解决根本问题
-这一点有点棘手。有时候人们认为他们依旧找到了解决问题的正确途径,且他们只再多一点信息就可以解决问题。但他们可能并不是走在正确的道路上!比如:
+这一点有点棘手。有时候人们认为他们依旧找到了解决问题的正确途径,且他们只要再多一点信息就可以解决问题。但他们可能并不是走在正确的道路上!比如:
-* George:”我在处理 X 的时候遇到了错误,我该如何修复它?“
-
-* Jasminda:”你是正在尝试解决 Y 吗?如果是这样,你不应该处理 X ,反而你应该处理 Z 。“
-
-* George:“噢,你是对的!!!谢谢你!我回反过来处理 Z 的。“
+* George:“我在处理 X 的时候遇到了错误,我该如何修复它?”
+* Jasminda:“你是正在尝试解决 Y 吗?如果是这样,你不应该处理 X ,反而你应该处理 Z 。”
+* George:“噢,你是对的!!!谢谢你!我回反过来处理 Z 的。”
Jasminda 一点都没有回答 George 的问题!反而,她猜测 George 并不想处理 X ,并且她是猜对了。这是非常有用的!
如果你这样做可能会产生高高在上的感觉:
-* George:”我在处理 X 的时候遇到了错误,我该如何修复它?“
+* George:“我在处理 X 的时候遇到了错误,我该如何修复它?”
+* Jasminda:“不要这样做,如果你想处理 Y ,你应该反过来完成 Z 。”
+* George:“好吧,我并不是想处理 Y 。实际上我想处理 X 因为某些原因(REASONS)。所以我该如何处理 X 。”
-* Jasminda:不要这样做,如果你想处理 Y ,你应该反过来完成 Z 。
-
-* George:“好吧,我并不是想处理 Y 。实际上我想处理 X 因为某些原因(REASONS)。所以我该如何处理 X 。
-
-所以不要高高在上,且要记住有时有些提问者可能已经偏离根本问题很远了。同时回答提问者提出的问题以及他们本该提出的问题都是合理的:“嗯,如果你想处理 X ,那么你可能需要这么做,但如果你想用这个解决 Y 问题,可能通过处理其他事情你可以更好地解决这个问题,这就是为什么可以做得更好的原因。
+所以不要高高在上,且要记住有时有些提问者可能已经偏离根本问题很远了。同时回答提问者提出的问题以及他们本该提出的问题都是合理的:“嗯,如果你想处理 X ,那么你可能需要这么做,但如果你想用这个解决 Y 问题,可能通过处理其他事情你可以更好地解决这个问题,这就是为什么可以做得更好的原因。”
-### 询问”那个回答可以解决您的问题吗?”
+### 询问“那个回答可以解决您的问题吗?”
-我总是喜欢在我回答了问题之后核实是否真的已经解决了问题:”这个回答解决了您的问题吗?您还有其他问题吗?“在问完这个之后最好等待一会,因为人们通常需要一两分钟来知道他们是否已经找到了答案。
+我总是喜欢在我回答了问题之后核实是否真的已经解决了问题:“这个回答解决了您的问题吗?您还有其他问题吗?”在问完这个之后最好等待一会,因为人们通常需要一两分钟来知道他们是否已经找到了答案。
我发现尤其是问“这个回答解决了您的问题吗”这个额外的步骤在写完文档后是非常有用的。通常,在写关于我熟悉的东西的文档时,我会忽略掉重要的东西而不会意识到它。
-
### 结对编程和面对面交谈
我是远程工作的,所以我的很多对话都是基于文本的。我认为这是沟通的默认方式。
今天,我们生活在一个方便进行小视频会议和屏幕共享的世界!在工作时候,在任何时间我都可以点击一个按钮并快速加入与他人的视频对话或者屏幕共享的对话中!
-例如,最近有人问如何自动调节他们的服务容量规划。我告诉他们我们有几样东西需要清理,但我还不太确定他们要清理的是什么。然后我们进行了一个简短的视屏会话并在5分钟后,我们解决了他们问题。
+例如,最近有人问如何自动调节他们的服务容量规划。我告诉他们我们有几样东西需要清理,但我还不太确定他们要清理的是什么。然后我们进行了一个简短的视频会话并在 5 分钟后,我们解决了他们问题。
我认为,特别是如果有人真的被困在该如何开始一项任务时,开启视频进行结对编程几分钟真的比电子邮件或者一些即时通信更有效。
-
### 不要表现得过于惊讶
这是源自 Recurse Center 的一则法则:[不要故作惊讶][4]。这里有一个常见的情景:
-* 某人1:“什么是 Linux 内核”
+* 某甲:“什么是 Linux 内核”
+* 某乙:“你竟然不知道什么是 Linux 内核?!!!!?!!!????”
-* 某人2:“你竟然不知道什么是 Linux 内核(LINUX KERNEL)?!!!!?!!!????”
+某乙的表现(无论他们是否真的如此惊讶)是没有帮助的。这大部分只会让某甲不好受,因为他们确实不知道什么是 Linux 内核。
-某人2表现(无论他们是否真的如此惊讶)是没有帮助的。这大部分只会让某人1不好受,因为他们确实不知道什么是 Linux 内核。
+我一直在假装不惊讶,即使我事实上确实有点惊讶那个人不知道这种东西。
-我一直在假装不惊讶即使我事实上确实有点惊讶那个人不知道这种东西但它是令人敬畏的。
-
-### 回答问题是令人敬畏的
+### 回答问题真的很棒
显然并不是所有方法都是合适的,但希望你能够发现这里有些是有帮助的!我发现花时间去回答问题并教导人们是其实是很有收获的。
-特别感谢 Josh Triplett 的一些建议并做了很多有益的补充,以及感谢 Harold Treen、Vaibhav Sagar、Peter Bhat Hatkins、Wesley Aptekar Cassels 和 Paul Gowder的阅读或评论。
+特别感谢 Josh Triplett 的一些建议并做了很多有益的补充,以及感谢 Harold Treen、Vaibhav Sagar、Peter Bhat Hatkins、Wesley Aptekar Cassels 和 Paul Gowder 的阅读或评论。
--------------------------------------------------------------------------------
via: https://jvns.ca/blog/answer-questions-well/
-作者:[ Julia Evans][a]
+作者:[Julia Evans][a]
译者:[HardworkFish](https://github.com/HardworkFish)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20171002 Bash Bypass Alias Linux-Unix Command.md b/published/20171002 Bash Bypass Alias Linux-Unix Command.md
similarity index 59%
rename from translated/tech/20171002 Bash Bypass Alias Linux-Unix Command.md
rename to published/20171002 Bash Bypass Alias Linux-Unix Command.md
index e4dec43782..e055c1f519 100644
--- a/translated/tech/20171002 Bash Bypass Alias Linux-Unix Command.md
+++ b/published/20171002 Bash Bypass Alias Linux-Unix Command.md
@@ -1,23 +1,34 @@
-绕过 Linux/Unix 命令别名
+4 种绕过 Linux/Unix 命令别名的方法
======
+
我在我的 Linux 系统上定义了如下 mount 别名:
+
```
alias mount='mount | column -t'
```
-但是我需要在挂载文件系统和其他用途时绕过 bash 别名。我如何在 Linux、\*BSD、macOS 或者类 Unix 系统上临时禁用或者绕过 bash shell 呢?
+但是我需要在挂载文件系统和其他用途时绕过这个 bash 别名。我如何在 Linux、*BSD、macOS 或者类 Unix 系统上临时禁用或者绕过 bash shell 呢?
+
+你可以使用 `alias` 命令定义或显示 bash shell 别名。一旦创建了 bash shell 别名,它们将优先于外部或内部命令。本文将展示如何暂时绕过 bash 别名,以便你可以运行实际的内部或外部命令。
-你可以使用 alias 命令定义或显示 bash shell 别名。一旦创建了 bash shell 别名,它们将优先于外部或内部命令。本文将展示如何暂时绕过 bash 别名,以便你可以运行实际的内部或外部命令。
[![Bash Bypass Alias Linux BSD macOS Unix Command][1]][1]
-## 4 种绕过 bash 别名的方法
-
+### 4 种绕过 bash 别名的方法
尝试以下任意一种方法来运行被 bash shell 别名绕过的命令。让我们[如下定义一个别名][2]:
-`alias mount='mount | column -t'`
+
+```
+alias mount='mount | column -t'
+```
+
运行如下:
-`mount `
+
+```
+mount
+```
+
示例输出:
+
```
sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime)
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
@@ -30,45 +41,83 @@ binfmt_misc on /proc/sys/fs/binfmt_misc type binfmt_m
lxcfs on /var/lib/lxcfs type fuse.lxcfs (rw,nosuid,nodev,relatime,user_id=0,group_id=0,allow_other)
```
-### 方法1 - 使用 \command
+#### 方法 1 - 使用 `\command`
-输入以下命令暂时绕过名为 mount 的 bash 别名:
-`\mount`
+输入以下命令暂时绕过名为 `mount` 的 bash 别名:
-### 方法2 - 使用 "command" 或 'command'
+```
+\mount
+```
+
+#### 方法 2 - 使用 `"command"` 或 `'command'`
+
+如下引用 `mount` 命令调用实际的 `/bin/mount`:
+
+```
+"mount"
+```
-如下引用 mount 命令调用实际的 /bin/mount:
-`"mount"`
或者
-`'mount'`
-### Method 3 - Use full command path
+```
+'mount'
+```
-Use full binary path such as /bin/mount:
-`/bin/mount
-/bin/mount /dev/sda1 /mnt/sda`
+#### 方法 3 - 使用命令的完全路径
-### 方法3 - 使用完整的命令路径
+使用完整的二进制路径,如 `/bin/mount`:
+
+```
+/bin/mount
+/bin/mount /dev/sda1 /mnt/sda
+```
+
+#### 方法 4 - 使用内部命令 `command`
语法是:
-`command cmd
-command cmd arg1 arg2`
-要覆盖 .bash_aliases 中设置的别名,例如 mount:
-`command mount
-command mount /dev/sdc /mnt/pendrive/`
-[”command“ 运行命令或显示][3]关于命令的信息。它带参数运行命令会抑制 shell 函数查询或者别名,或者显示有关给定命令的信息。
-## 关于 unalias 命令的说明
+```
+command cmd
+command cmd arg1 arg2
+```
+
+要覆盖 `.bash_aliases` 中设置的别名,例如 `mount`:
+
+```
+command mount
+command mount /dev/sdc /mnt/pendrive/
+```
+
+[“command” 直接运行命令或显示][3]关于命令的信息。它带参数运行命令会抑制 shell 函数查询或者别名,或者显示有关给定命令的信息。
+
+### 关于 unalias 命令的说明
+
+要从当前会话的已定义别名列表中移除别名,请使用 `unalias` 命令:
+
+```
+unalias mount
+```
-要从当前会话的已定义别名列表中移除别名,请使用 unalias 命令:
-`unalias mount`
要从当前 bash 会话中删除所有别名定义:
-`unalias -a`
-确保你更新你的 ~/.bashrc 或 $HOME/.bash_aliases。如果要永久删除定义的别名,则必须删除定义的别名:
-`vi ~/.bashrc`
+
+```
+unalias -a
+```
+
+确保你更新你的 `~/.bashrc` 或 `$HOME/.bash_aliases`。如果要永久删除定义的别名,则必须删除定义的别名:
+
+```
+vi ~/.bashrc
+```
+
或者
-`joe $HOME/.bash_aliases`
+
+```
+joe $HOME/.bash_aliases
+```
+
想了解更多信息,参考[这里][4]的在线手册,或者输入下面的命令查看:
+
```
man bash
help command
@@ -76,14 +125,13 @@ help unalias
help alias
```
-
--------------------------------------------------------------------------------
via: https://www.cyberciti.biz/faq/bash-bypass-alias-command-on-linux-macos-unix/
作者:[Vivek Gite][a]
译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20171002 Reset Linux Desktop To Default Settings With A Single Command.md b/published/20171002 Reset Linux Desktop To Default Settings With A Single Command.md
similarity index 51%
rename from translated/tech/20171002 Reset Linux Desktop To Default Settings With A Single Command.md
rename to published/20171002 Reset Linux Desktop To Default Settings With A Single Command.md
index d486a777de..cfeade8a8b 100644
--- a/translated/tech/20171002 Reset Linux Desktop To Default Settings With A Single Command.md
+++ b/published/20171002 Reset Linux Desktop To Default Settings With A Single Command.md
@@ -1,18 +1,20 @@
-使用一个命令重置 Linux 桌面到默认设置
+使用一个命令重置 Linux 桌面为默认设置
======
+

-前段时间,我们分享了一篇关于 [**Resetter**][1] 的文章 - 这是一个有用的软件,可以在几分钟内将 Ubuntu 重置为出厂默认设置。使用 Resetter,任何人都可以轻松地将 Ubuntu 重置为第一次安装时的状态。今天,我偶然发现了一个类似的东西。不,它不是一个应用程序,而是一个单行的命令来重置你的 Linux 桌面设置、调整和定制到默认状态。
+前段时间,我们分享了一篇关于 [Resetter][1] 的文章 - 这是一个有用的软件,可以在几分钟内将 Ubuntu 重置为出厂默认设置。使用 Resetter,任何人都可以轻松地将 Ubuntu 重置为第一次安装时的状态。今天,我偶然发现了一个类似的东西。不,它不是一个应用程序,而是一个单行的命令来重置你的 Linux 桌面设置、调整和定制到默认状态。
### 将 Linux 桌面重置为默认设置
-这个命令会将 Ubuntu Unity、Gnome 和 MATE 桌面重置为默认状态。我在我的 **Arch Linux MATE** 和 **Ubuntu 16.04 Unity** 上测试了这个命令。它可以在两个系统上工作。我希望它也能在其他桌面上运行。在写这篇文章的时候,我还没有安装 GNOME 的 Linux 桌面,因此我无法确认。但是,我相信它也可以在 Gnome 桌面环境中使用。
+这个命令会将 Ubuntu Unity、Gnome 和 MATE 桌面重置为默认状态。我在我的 Arch Linux MATE 和 Ubuntu 16.04 Unity 上测试了这个命令。它可以在两个系统上工作。我希望它也能在其他桌面上运行。在写这篇文章的时候,我还没有安装 GNOME 的 Linux 桌面,因此我无法确认。但是,我相信它也可以在 Gnome 桌面环境中使用。
-**一句忠告:**请注意,此命令将重置你在系统中所做的所有定制和调整,包括 Unity 启动器或 Dock 中的固定应用程序、桌面小程序、桌面指示器、系统字体、GTK主题、图标主题、显示器分辨率、键盘快捷键、窗口按钮位置、菜单和启动器行为等。
+**一句忠告:**请注意,此命令将重置你在系统中所做的所有定制和调整,包括 Unity 启动器或 Dock 中固定的应用程序、桌面小程序、桌面指示器、系统字体、GTK主题、图标主题、显示器分辨率、键盘快捷键、窗口按钮位置、菜单和启动器行为等。
-好的是它只会重置桌面设置。它不会影响其他不使用 dconf 的程序。此外,它不会删除你的个人资料。
+好的是它只会重置桌面设置。它不会影响其他不使用 `dconf` 的程序。此外,它不会删除你的个人资料。
现在,让我们开始。要将 Ubuntu Unity 或其他带有 GNOME/MATE 环境的 Linux 桌面重置,运行下面的命令:
+
```
dconf reset -f /
```
@@ -29,12 +31,13 @@ dconf reset -f /
看见了么?现在,我的 Ubuntu 桌面已经回到了出厂设置。
-有关 “dconf” 命令的更多详细信息,请参阅手册页。
+有关 `dconf` 命令的更多详细信息,请参阅手册页。
+
```
man dconf
```
-在重置桌面上我个人更喜欢 “Resetter” 而不是 “dconf” 命令。因为,Resetter 给用户提供了更多的选择。用户可以决定删除哪些应用程序、保留哪些应用程序、是保留现有用户帐户还是创建新用户等等。如果你懒得安装 Resetter,你可以使用这个 “dconf” 命令在几分钟内将你的 Linux 系统重置为默认设置。
+在重置桌面上我个人更喜欢 “Resetter” 而不是 `dconf` 命令。因为,Resetter 给用户提供了更多的选择。用户可以决定删除哪些应用程序、保留哪些应用程序、是保留现有用户帐户还是创建新用户等等。如果你懒得安装 Resetter,你可以使用这个 `dconf` 命令在几分钟内将你的 Linux 系统重置为默认设置。
就是这样了。希望这个有帮助。我将很快发布另一篇有用的指导。敬请关注!
@@ -48,12 +51,12 @@ via: https://www.ostechnix.com/reset-linux-desktop-default-settings-single-comma
作者:[Edwin Arteaga][a]
译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
[a]:https://www.ostechnix.com
-[1]:https://www.ostechnix.com/reset-ubuntu-factory-defaults/
+[1]:https://linux.cn/article-9217-1.html
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
-[3]:http://www.ostechnix.com/wp-content/uploads/2017/10/Before-resetting-Ubuntu-to-default-1.png ()
-[4]:http://www.ostechnix.com/wp-content/uploads/2017/10/After-resetting-Ubuntu-to-default-1.png ()
+[3]:http://www.ostechnix.com/wp-content/uploads/2017/10/Before-resetting-Ubuntu-to-default-1.png
+[4]:http://www.ostechnix.com/wp-content/uploads/2017/10/After-resetting-Ubuntu-to-default-1.png
diff --git a/published/20171007 How to use GNU Stow to manage programs installed from source and dotfiles.md b/published/20171007 How to use GNU Stow to manage programs installed from source and dotfiles.md
new file mode 100644
index 0000000000..306684f885
--- /dev/null
+++ b/published/20171007 How to use GNU Stow to manage programs installed from source and dotfiles.md
@@ -0,0 +1,137 @@
+如何使用 GNU Stow 来管理从源代码安装的程序和点文件
+=====
+
+### 目的
+
+使用 GNU Stow 轻松管理从源代码安装的程序和点文件(LCTT 译注:点文件,即以 `.` 开头的文件,在 *nix 下默认为隐藏文件,常用于存储程序的配置信息。)
+
+### 要求
+
+* root 权限
+
+### 难度
+
+简单
+
+### 约定
+
+* `#` - 给定的命令要求直接以 root 用户身份或使用 `sudo` 命令以 root 权限执行
+* `$` - 给定的命令将作为普通的非特权用户来执行
+
+### 介绍
+
+有时候我们必须从源代码安装程序,因为它们也许不能通过标准渠道获得,或者我们可能需要特定版本的软件。 GNU Stow 是一个非常不错的符号链接工厂程序,它可以帮助我们保持文件的整洁,易于维护。
+
+### 获得 stow
+
+你的 Linux 发行版本很可能包含 `stow`,例如在 Fedora,你安装它只需要:
+
+```
+# dnf install stow
+```
+
+在 Ubuntu/Debian 中,安装 `stow` 需要执行:
+
+```
+# apt install stow
+```
+
+在某些 Linux 发行版中,`stow` 在标准库中是不可用的,但是可以通过一些额外的软件源(例如 RHEL 和 CentOS7 中的EPEL )轻松获得,或者,作为最后的手段,你可以从源代码编译它。只需要很少的依赖关系。
+
+### 从源代码编译
+
+最新的可用 stow 版本是 `2.2.2`。源码包可以在这里下载:`https://ftp.gnu.org/gnu/stow/`。
+
+一旦你下载了源码包,你就必须解压它。切换到你下载软件包的目录,然后运行:
+
+```
+$ tar -xvpzf stow-2.2.2.tar.gz
+```
+
+解压源文件后,切换到 `stow-2.2.2` 目录中,然后编译该程序,只需运行:
+
+```
+$ ./configure
+$ make
+```
+
+最后,安装软件包:
+
+```
+# make install
+```
+
+默认情况下,软件包将安装在 `/usr/local/` 目录中,但是我们可以改变它,通过配置脚本的 `--prefix` 选项指定目录,或者在运行 `make install` 时添加 `prefix="/your/dir"`。
+
+此时,如果所有工作都按预期工作,我们应该已经在系统上安装了 `stow`。
+
+### stow 是如何工作的?
+
+`stow` 背后主要的概念在程序手册中有很好的解释:
+
+> Stow 使用的方法是将每个软件包安装到自己的目录树中,然后使用符号链接使它看起来像文件一样安装在公共的目录树中
+
+为了更好地理解这个软件的运作,我们来分析一下它的关键概念:
+
+#### stow 文件目录
+
+stow 目录是包含所有 stow 软件包的根目录,每个包都有自己的子目录。典型的 stow 目录是 `/usr/local/stow`:在其中,每个子目录代表一个软件包。
+
+#### stow 软件包
+
+如上所述,stow 目录包含多个“软件包”,每个软件包都位于自己单独的子目录中,通常以程序本身命名。包就是与特定软件相关的文件和目录列表,作为一个实体进行管理。
+
+#### stow 目标目录
+
+stow 目标目录解释起来是一个非常简单的概念。它是包文件应该安装到的目录。默认情况下,stow 目标目录被视作是调用 stow 的目录。这种行为可以通过使用 `-t` 选项( `--target` 的简写)轻松改变,这使我们可以指定一个替代目录。
+
+### 一个实际的例子
+
+我相信一个好的例子胜过 1000 句话,所以让我来展示 `stow` 如何工作。假设我们想编译并安装 `libx264`,首先我们克隆包含其源代码的仓库:
+
+```
+$ git clone git://git.videolan.org/x264.git
+```
+
+运行该命令几秒钟后,将创建 `x264` 目录,它将包含准备编译的源代码。我们切换到 `x264` 目录中并运行 `configure` 脚本,将 `--prefix` 指定为 `/usr/local/stow/libx264` 目录。
+
+```
+$ cd x264 && ./configure --prefix=/usr/local/stow/libx264
+```
+
+然后我们构建该程序并安装它:
+
+```
+$ make
+# make install
+```
+
+`x264` 目录应该创建在 `stow` 目录内:它包含了所有通常直接安装在系统中的东西。 现在,我们所要做的就是调用 `stow`。 我们必须从 `stow` 目录内运行这个命令,通过使用 `-d` 选项来手动指定 `stow` 目录的路径(默认为当前目录),或者通过如前所述用 `-t` 指定目标。我们还应该提供要作为参数存储的软件包的名称。 在这里,我们从 `stow` 目录运行程序,所以我们需要输入的内容是:
+
+```
+# stow libx264
+```
+
+libx264 软件包中包含的所有文件和目录现在已经在调用 stow 的父目录 (/usr/local) 中进行了符号链接,因此,例如在 `/usr/local/ stow/x264/bin` 中包含的 libx264 二进制文件现在符号链接在 `/usr/local/bin` 之中,`/usr/local/stow/x264/etc` 中的文件现在符号链接在 `/usr/local/etc` 之中等等。通过这种方式,系统将显示文件已正常安装,并且我们可以容易地跟踪我们编译和安装的每个程序。要反转该操作,我们只需使用 `-D` 选项:
+
+```
+# stow -d libx264
+```
+
+完成了!符号链接不再存在:我们只是“卸载”了一个 stow 包,使我们的系统保持在一个干净且一致的状态。 在这一点上,我们应该清楚为什么 stow 还可以用于管理点文件。 通常的做法是在 git 仓库中包含用户特定的所有配置文件,以便轻松管理它们并使它们在任何地方都可用,然后使用 stow 将它们放在适当位置,如放在用户主目录中。
+
+stow 还会阻止你错误地覆盖文件:如果目标文件已经存在,并且没有指向 stow 目录中的包时,它将拒绝创建符号链接。 这种情况在 stow 术语中称为冲突。
+
+就是这样!有关选项的完整列表,请参阅 stow 帮助页,并且不要忘记在评论中告诉我们你对此的看法。
+
+--------------------------------------------------------------------------------
+
+via: https://linuxconfig.org/how-to-use-gnu-stow-to-manage-programs-installed-from-source-and-dotfiles
+
+作者:[Egidio Docile][a]
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://linuxconfig.org
diff --git a/published/20171009 10 layers of Linux container security - Opensource.com.md b/published/20171009 10 layers of Linux container security - Opensource.com.md
new file mode 100644
index 0000000000..26188dd1ec
--- /dev/null
+++ b/published/20171009 10 layers of Linux container security - Opensource.com.md
@@ -0,0 +1,129 @@
+Linux 容器安全的 10 个层面
+======
+
+> 应用这些策略来保护容器解决方案的各个层面和容器生命周期的各个阶段的安全。
+
+
+
+容器提供了打包应用程序的一种简单方法,它实现了从开发到测试到投入生产系统的无缝传递。它也有助于确保跨不同环境的连贯性,包括物理服务器、虚拟机、以及公有云或私有云。这些好处使得一些组织为了更方便地部署和管理为他们提升业务价值的应用程序,而快速地采用了容器技术。
+
+
+
+企业需要高度安全,在容器中运行核心服务的任何人都会问,“容器安全吗?”以及“我们能信任运行在容器中的应用程序吗?”
+
+对容器进行安全保护就像是对运行中的进程进行安全保护一样。在你部署和运行你的容器之前,你需要去考虑整个解决方案各个层面的安全。你也需要去考虑贯穿了应用程序和容器整个生命周期的安全。
+
+请尝试从这十个关键的因素去确保容器解决方案栈不同层面、以及容器生命周期的不同阶段的安全。
+
+### 1. 容器宿主机操作系统和多租户环境
+
+由于容器将应用程序和它的依赖作为一个单元来处理,使得开发者构建和升级应用程序变得更加容易,并且,容器可以启用多租户技术将许多应用程序和服务部署到一台共享主机上。在一台单独的主机上以容器方式部署多个应用程序、按需启动和关闭单个容器都是很容易的。为完全实现这种打包和部署技术的优势,运营团队需要运行容器的合适环境。运营者需要一个安全的操作系统,它能够在边界上保护容器安全、从容器中保护主机内核,以及保护容器彼此之间的安全。
+
+容器是隔离而资源受限的 Linux 进程,允许你在一个共享的宿主机内核上运行沙盒化的应用程序。保护容器的方法与保护你的 Linux 中运行的任何进程的方法是一样的。降低权限是非常重要的,也是保护容器安全的最佳实践。最好使用尽可能小的权限去创建容器。容器应该以一个普通用户的权限来运行,而不是 root 权限的用户。在 Linux 中可以使用多个层面的安全加固手段,Linux 命名空间、安全强化 Linux([SELinux][1])、[cgroups][2] 、capabilities(LCTT 译注:Linux 内核的一个安全特性,它打破了传统的普通用户与 root 用户的概念,在进程级提供更好的安全控制)、以及安全计算模式( [seccomp][3] ),这五种 Linux 的安全特性可以用于保护容器的安全。
+
+### 2. 容器内容(使用可信来源)
+
+在谈到安全时,首先要考虑你的容器里面有什么?例如 ,有些时候,应用程序和基础设施是由很多可用组件所构成的。它们中的一些是开源的软件包,比如,Linux 操作系统、Apache Web 服务器、Red Hat JBoss 企业应用平台、PostgreSQL,以及 Node.js。这些软件包的容器化版本已经可以使用了,因此,你没有必要自己去构建它们。但是,对于你从一些外部来源下载的任何代码,你需要知道这些软件包的原始来源,是谁构建的它,以及这些包里面是否包含恶意代码。
+
+### 3. 容器注册(安全访问容器镜像)
+
+你的团队的容器构建于下载的公共容器镜像,因此,访问和升级这些下载的容器镜像以及内部构建镜像,与管理和下载其它类型的二进制文件的方式是相同的,这一点至关重要。许多私有的注册库支持容器镜像的存储。选择一个私有的注册库,可以帮你将存储在它的注册中的容器镜像实现策略自动化。
+
+### 4. 安全性与构建过程
+
+在一个容器化环境中,软件构建过程是软件生命周期的一个阶段,它将所需的运行时库和应用程序代码集成到一起。管理这个构建过程对于保护软件栈安全来说是很关键的。遵守“一次构建,到处部署”的原则,可以确保构建过程的结果正是生产系统中需要的。保持容器的恒定不变也很重要 — 换句话说就是,不要对正在运行的容器打补丁,而是,重新构建和部署它们。
+
+不论是因为你处于一个高强度监管的行业中,还是只希望简单地优化你的团队的成果,设计你的容器镜像管理以及构建过程,可以使用容器层的优势来实现控制分离,因此,你应该去这么做:
+
+ * 运营团队管理基础镜像
+ * 架构师管理中间件、运行时、数据库,以及其它解决方案
+ * 开发者专注于应用程序层面,并且只写代码
+
+
+
+最后,标记好你的定制构建容器,这样可以确保在构建和部署时不会搞混乱。
+
+### 5. 控制好在同一个集群内部署应用
+
+如果是在构建过程中出现的任何问题,或者在镜像被部署之后发现的任何漏洞,那么,请在基于策略的、自动化工具上添加另外的安全层。
+
+我们来看一下,一个应用程序的构建使用了三个容器镜像层:内核、中间件,以及应用程序。如果在内核镜像中发现了问题,那么只能重新构建镜像。一旦构建完成,镜像就会被发布到容器平台注册库中。这个平台可以自动检测到发生变化的镜像。对于基于这个镜像的其它构建将被触发一个预定义的动作,平台将自己重新构建应用镜像,合并该修复的库。
+
+一旦构建完成,镜像将被发布到容器平台的内部注册库中。在它的内部注册库中,会立即检测到镜像发生变化,应用程序在这里将会被触发一个预定义的动作,自动部署更新镜像,确保运行在生产系统中的代码总是使用更新后的最新的镜像。所有的这些功能协同工作,将安全功能集成到你的持续集成和持续部署(CI/CD)过程和管道中。
+
+### 6. 容器编配:保护容器平台安全
+
+当然了,应用程序很少会以单一容器分发。甚至,简单的应用程序一般情况下都会有一个前端、一个后端、以及一个数据库。而在容器中以微服务模式部署的应用程序,意味着应用程序将部署在多个容器中,有时它们在同一台宿主机上,有时它们是分布在多个宿主机或者节点上,如下面的图所示:
+
+
+
+在大规模的容器部署时,你应该考虑:
+
+ * 哪个容器应该被部署在哪个宿主机上?
+ * 那个宿主机应该有什么样的性能?
+ * 哪个容器需要访问其它容器?它们之间如何发现彼此?
+ * 你如何控制和管理对共享资源的访问,像网络和存储?
+ * 如何监视容器健康状况?
+ * 如何去自动扩展性能以满足应用程序的需要?
+ * 如何在满足安全需求的同时启用开发者的自助服务?
+
+考虑到开发者和运营者的能力,提供基于角色的访问控制是容器平台的关键要素。例如,编配管理服务器是中心访问点,应该接受最高级别的安全检查。API 是规模化的自动容器平台管理的关键,可以用于为 pod、服务,以及复制控制器验证和配置数据;在入站请求上执行项目验证;以及调用其它主要系统组件上的触发器。
+
+### 7. 网络隔离
+
+在容器中部署现代微服务应用,经常意味着跨多个节点在多个容器上部署。考虑到网络防御,你需要一种在一个集群中的应用之间的相互隔离的方法。一个典型的公有云容器服务,像 Google 容器引擎(GKE)、Azure 容器服务,或者 Amazon Web 服务(AWS)容器服务,是单租户服务。他们让你在你初始化建立的虚拟机集群上运行你的容器。对于多租户容器的安全,你需要容器平台为你启用一个单一集群,并且分割流量以隔离不同的用户、团队、应用、以及在这个集群中的环境。
+
+使用网络命名空间,容器内的每个集合(即大家熟知的 “pod”)都会得到它自己的 IP 和绑定的端口范围,以此来从一个节点上隔离每个 pod 网络。除使用下面所述的方式之外,默认情况下,来自不同命名空间(项目)的 pod 并不能发送或者接收其它 pod 上的包和不同项目的服务。你可以使用这些特性在同一个集群内隔离开发者环境、测试环境,以及生产环境。但是,这样会导致 IP 地址和端口数量的激增,使得网络管理更加复杂。另外,容器是被设计为反复使用的,你应该在处理这种复杂性的工具上进行投入。在容器平台上比较受欢迎的工具是使用 [软件定义网络][4] (SDN) 提供一个定义的网络集群,它允许跨不同集群的容器进行通讯。
+
+### 8. 存储
+
+容器即可被用于无状态应用,也可被用于有状态应用。保护外加的存储是保护有状态服务的一个关键要素。容器平台对多种受欢迎的存储提供了插件,包括网络文件系统(NFS)、AWS 弹性块存储(EBS)、GCE 持久磁盘、GlusterFS、iSCSI、 RADOS(Ceph)、Cinder 等等。
+
+一个持久卷(PV)可以通过资源提供者支持的任何方式装载到一个主机上。提供者有不同的性能,而每个 PV 的访问模式被设置为特定的卷支持的特定模式。例如,NFS 能够支持多路客户端同时读/写,但是,一个特定的 NFS 的 PV 可以在服务器上被发布为只读模式。每个 PV 有它自己的一组反应特定 PV 性能的访问模式的描述,比如,ReadWriteOnce、ReadOnlyMany、以及 ReadWriteMany。
+
+### 9. API 管理、终端安全、以及单点登录(SSO)
+
+保护你的应用安全,包括管理应用、以及 API 的认证和授权。
+
+Web SSO 能力是现代应用程序的一个关键部分。在构建它们的应用时,容器平台带来了开发者可以使用的多种容器化服务。
+
+API 是微服务构成的应用程序的关键所在。这些应用程序有多个独立的 API 服务,这导致了终端服务数量的激增,它就需要额外的管理工具。推荐使用 API 管理工具。所有的 API 平台应该提供多种 API 认证和安全所需要的标准选项,这些选项既可以单独使用,也可以组合使用,以用于发布证书或者控制访问。
+
+这些选项包括标准的 API key、应用 ID 和密钥对,以及 OAuth 2.0。
+
+### 10. 在一个联合集群中的角色和访问管理
+
+在 2016 年 7 月份,Kubernetes 1.3 引入了 [Kubernetes 联合集群][5]。这是一个令人兴奋的新特性之一,它是在 Kubernetes 上游、当前的 Kubernetes 1.6 beta 中引用的。联合是用于部署和访问跨多集群运行在公有云或企业数据中心的应用程序服务的。多个集群能够用于去实现应用程序的高可用性,应用程序可以跨多个可用区域,或者去启用部署公共管理,或者跨不同的供应商进行迁移,比如,AWS、Google Cloud、以及 Azure。
+
+当管理联合集群时,你必须确保你的编配工具能够提供你所需要的跨不同部署平台的实例的安全性。一般来说,认证和授权是很关键的 —— 不论你的应用程序运行在什么地方,将数据安全可靠地传递给它们,以及管理跨集群的多租户应用程序。Kubernetes 扩展了联合集群,包括对联合的秘密数据、联合的命名空间、以及 Ingress objects 的支持。
+
+### 选择一个容器平台
+
+当然,它并不仅关乎安全。你需要提供一个你的开发者团队和运营团队有相关经验的容器平台。他们需要一个安全的、企业级的基于容器的应用平台,它能够同时满足开发者和运营者的需要,而且还能够提高操作效率和基础设施利用率。
+
+想从 Daniel 在 [欧盟开源峰会][7] 上的 [容器安全的十个层面][6] 的演讲中学习更多知识吗?这个峰会已于 10 月 23 - 26 日在 Prague 举行。
+
+### 关于作者
+
+Daniel Oh;Microservives;Agile;Devops;Java Ee;Container;Openshift;Jboss;Evangelism
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/17/10/10-layers-container-security
+
+作者:[Daniel Oh][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/daniel-oh
+[1]:https://en.wikipedia.org/wiki/Security-Enhanced_Linux
+[2]:https://en.wikipedia.org/wiki/Cgroups
+[3]:https://en.wikipedia.org/wiki/Seccomp
+[4]:https://en.wikipedia.org/wiki/Software-defined_networking
+[5]:https://kubernetes.io/docs/concepts/cluster-administration/federation/
+[6]:https://osseu17.sched.com/mobile/#session:f2deeabfc1640d002c1d55101ce81223
+[7]:http://events.linuxfoundation.org/events/open-source-summit-europe
diff --git a/published/20171016 Make -rm- Command To Move The Files To -Trash Can- Instead Of Removing Them Completely.md b/published/20171016 Make -rm- Command To Move The Files To -Trash Can- Instead Of Removing Them Completely.md
new file mode 100644
index 0000000000..3d4478ece2
--- /dev/null
+++ b/published/20171016 Make -rm- Command To Move The Files To -Trash Can- Instead Of Removing Them Completely.md
@@ -0,0 +1,91 @@
+给 “rm” 命令添加个“垃圾桶”
+============
+
+人类犯错误是因为我们不是一个可编程设备,所以,在使用 `rm` 命令时要额外注意,不要在任何时候使用 `rm -rf *`。当你使用 `rm` 命令时,它会永久删除文件,不会像文件管理器那样将这些文件移动到 “垃圾箱”。
+
+有时我们会将不应该删除的文件删除掉,所以当错误地删除了文件时该怎么办? 你必须看看恢复工具(Linux 中有很多数据恢复工具),但我们不知道是否能将它百分之百恢复,所以要如何解决这个问题?
+
+我们最近发表了一篇关于 [Trash-Cli][1] 的文章,在评论部分,我们从用户 Eemil Lgz 那里获得了一个关于 [saferm.sh][2] 脚本的更新,它可以帮助我们将文件移动到“垃圾箱”而不是永久删除它们。
+
+将文件移动到“垃圾桶”是一个好主意,当你无意中运行 `rm` 命令时,可以拯救你;但是很少有人会说这是一个坏习惯,如果你不注意“垃圾桶”,它可能会在一定的时间内被文件和文件夹堆积起来。在这种情况下,我建议你按照你的意愿去做一个定时任务。
+
+这适用于服务器和桌面两种环境。 如果脚本检测到 GNOME 、KDE、Unity 或 LXDE 桌面环境(DE),则它将文件或文件夹安全地移动到默认垃圾箱 `$HOME/.local/share/Trash/files`,否则会在您的主目录中创建垃圾箱文件夹 `$HOME/Trash`。
+
+`saferm.sh` 脚本托管在 Github 中,可以从仓库中克隆,也可以创建一个名为 `saferm.sh` 的文件并复制其上的代码。
+
+```
+$ git clone https://github.com/lagerspetz/linux-stuff
+$ sudo mv linux-stuff/scripts/saferm.sh /bin
+$ rm -Rf linux-stuff
+```
+
+在 `.bashrc` 文件中设置别名,
+
+```
+alias rm=saferm.sh
+```
+
+执行下面的命令使其生效,
+
+```
+$ source ~/.bashrc
+```
+
+一切就绪,现在你可以执行 `rm` 命令,自动将文件移动到”垃圾桶”,而不是永久删除它们。
+
+测试一下,我们将删除一个名为 `magi.txt` 的文件,命令行明确的提醒了 `Moving magi.txt to $HOME/.local/share/Trash/file`。
+
+
+```
+$ rm -rf magi.txt
+Moving magi.txt to /home/magi/.local/share/Trash/files
+```
+
+也可以通过 `ls` 命令或 `trash-cli` 进行验证。
+
+```
+$ ls -lh /home/magi/.local/share/Trash/files
+Permissions Size User Date Modified Name
+.rw-r--r-- 32 magi 11 Oct 16:24 magi.txt
+```
+
+或者我们可以通过文件管理器界面中查看相同的内容。
+
+![![][3]][4]
+
+(LCTT 译注:原文此处混淆了部分 trash-cli 的内容,考虑到文章衔接和逻辑,此处略。)
+
+要了解 `saferm.sh` 的其他选项,请查看帮助。
+
+```
+$ saferm.sh -h
+This is saferm.sh 1.16. LXDE and Gnome3 detection.
+Will ask to unsafe-delete instead of cross-fs move. Allows unsafe (regular rm) delete (ignores trashinfo).
+Creates trash and trashinfo directories if they do not exist. Handles symbolic link deletion.
+Does not complain about different user any more.
+
+Usage: /path/to/saferm.sh [OPTIONS] [--] files and dirs to safely remove
+OPTIONS:
+-r allows recursively removing directories.
+-f Allow deleting special files (devices, ...).
+-u Unsafe mode, bypass trash and delete files permanently.
+-v Verbose, prints more messages. Default in this version.
+-q Quiet mode. Opposite of verbose.
+
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/rm-command-to-move-files-to-trash-can-rm-alias/
+
+作者:[2DAYGEEK][a]
+译者:[amwps290](https://github.com/amwps290)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.2daygeek.com/author/2daygeek/
+[1]:https://www.2daygeek.com/trash-cli-command-line-trashcan-linux-system/
+[2]:https://github.com/lagerspetz/linux-stuff/blob/master/scripts/saferm.sh
+[3]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[4]:https://www.2daygeek.com/wp-content/uploads/2017/10/rm-command-to-move-files-to-trash-can-rm-alias-1.png
diff --git a/published/20171017 What Are the Hidden Files in my Linux Home Directory For.md b/published/20171017 What Are the Hidden Files in my Linux Home Directory For.md
new file mode 100644
index 0000000000..c221094e63
--- /dev/null
+++ b/published/20171017 What Are the Hidden Files in my Linux Home Directory For.md
@@ -0,0 +1,59 @@
+我的 Linux 主目录中的隐藏文件是干什么用的?
+======
+
+
+
+在 Linux 系统中,你可能会在主目录中存储了大量文件和文件夹。但在这些文件之外,你知道你的主目录还附带了很多隐藏的文件和文件夹吗?如果你在主目录中运行 `ls -a`,你会发现一堆带有点前缀的隐藏文件和目录。这些隐藏的文件到底做了什么?
+
+### 在主目录中隐藏的文件是干什么用的?
+
+![hidden-files-liunux-2][1]
+
+通常,主目录中的隐藏文件和目录包含该用户程序访问的设置或数据。它们不打算让用户编辑,只需要应用程序进行编辑。这就是为什么它们被隐藏在用户的正常视图之外。
+
+通常,删除和修改自己主目录中的文件不会损坏操作系统。然而,依赖这些隐藏文件的应用程序可能不那么灵活。从主目录中删除隐藏文件时,通常会丢失与其关联的应用程序的设置。
+
+依赖该隐藏文件的程序通常会重新创建它。 但是,你将从“开箱即用”设置开始,如全新用户一般。如果你在使用应用程序时遇到问题,那实际上可能是一个巨大的帮助。它可以让你删除可能造成麻烦的自定义设置。但如果你不这样做,这意味着你需要把所有的东西都设置成原来的样子。
+
+### 主目录中某些隐藏文件的特定用途是什么?
+
+![hidden-files-linux-3][2]
+
+每个人在他们的主目录中都会有不同的隐藏文件。每个人都有一些。但是,无论应用程序如何,这些文件都有类似的用途。
+
+#### 系统设置
+
+系统设置包括桌面环境和 shell 的配置。
+
+* shell 和命令行程序的**配置文件**:根据你使用的特定 shell 和类似命令的应用程序,特定的文件名称会变化。你会看到 `.bashrc`、`.vimrc` 和 `.zshrc`。这些文件包含你已经更改的有关 shell 的操作环境的任何设置,或者对 `vim` 等命令行实用工具的设置进行的调整。删除这些文件将使关联的应用程序返回到其默认状态。考虑到许多 Linux 用户多年来建立了一系列微妙的调整和设置,删除这个文件可能是一个非常头疼的问题。
+* **用户配置文件**:像上面的配置文件一样,这些文件(通常是 `.profile` 或 `.bash_profile`)保存 shell 的用户设置。该文件通常包含你的 `PATH` 环境变量。它还包含你设置的[别名][3]。用户也可以在 `.bashrc` 或其他位置放置别名。`PATH` 环境变量控制着 shell 寻找可执行命令的位置。通过添加或修改 `PATH`,可以更改 shell 的命令查找位置。别名更改了原有命令的名称。例如:一个别名可能将 `ls -l` 设置为 `ll`。这为经常使用的命令提供基于文本的快捷方式。如果删除 `.profile` 文件,通常可以在 `/etc/skel` 目录中找到默认版本。
+* **桌面环境设置**:这里保存你的桌面环境的任何定制。其中包括桌面背景、屏幕保护程序、快捷键、菜单栏和任务栏图标以及用户针对其桌面环境设置的其他任何内容。当你删除这个文件时,用户的环境会在下一次登录时恢复到新的用户环境。
+
+#### 应用配置文件
+
+你会在 Ubuntu 的 `.config` 文件夹中找到它们。 这些是针对特定应用程序的设置。 它们将包含喜好列表和设置等内容。
+
+* **应用程序的配置文件**:这包括应用程序首选项菜单中的设置、工作区配置等。 你在这里找到的具体取决于应用程序。
+* **Web 浏览器数据**:这可能包括书签和浏览历史记录等内容。这些文件大部分是缓存。这是 Web 浏览器临时存储下载文件(如图片)的地方。删除这些内容可能会降低你首次访问某些媒体网站的速度。
+* **缓存**:如果用户应用程序缓存仅与该用户相关的数据(如 [Spotify 应用程序存储播放列表的缓存][4]),则主目录是存储该目录的默认地点。 这些缓存可能包含大量数据或仅包含几行代码:这取决于应用程序需要什么。 如果你删除这些文件,则应用程序会根据需要重新创建它们。
+* **日志**:一些用户应用程序也可能在这里存储日志。根据开发人员设置应用程序的方式,你可能会发现存储在你的主目录中的日志文件。然而,这不是一个常见的选择。
+
+### 结论
+
+在大多数情况下,你的 Linux 主目录中的隐藏文件用于存储用户设置。 这包括命令行程序以及基于 GUI 的应用程序的设置。删除它们将删除用户设置。 通常情况下,它不会导致程序被破坏。
+
+--------------------------------------------------------------------------------
+
+via: https://www.maketecheasier.com/hidden-files-linux-home-directory/
+
+作者:[Alexander Fox][a]
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.maketecheasier.com/author/alexfox/
+[1]:https://www.maketecheasier.com/assets/uploads/2017/06/hidden-files-liunux-2.png (hidden-files-liunux-2)
+[2]:https://www.maketecheasier.com/assets/uploads/2017/06/hidden-files-linux-3.png (hidden-files-linux-3)
+[3]:https://www.maketecheasier.com/making-the-linux-command-line-a-little-friendlier/#aliases
+[4]:https://www.maketecheasier.com/clear-spotify-cache/
diff --git a/published/20171102 What is huge pages in Linux.md b/published/20171102 What is huge pages in Linux.md
new file mode 100644
index 0000000000..1f1d0b50a0
--- /dev/null
+++ b/published/20171102 What is huge pages in Linux.md
@@ -0,0 +1,140 @@
+Linux 中的“大内存页”(hugepage)是个什么?
+======
+
+> 学习 Linux 中的大内存页。理解什么是“大内存页”,如何进行配置,如何查看当前状态以及如何禁用它。
+
+![Huge Pages in Linux][1]
+
+本文中我们会详细介绍大内存页,让你能够回答:Linux 中的“大内存页”是什么?在 RHEL6、RHEL7、Ubuntu 等 Linux 中,如何启用/禁用“大内存页”?如何查看“大内存页”的当前值?
+
+首先让我们从“大内存页”的基础知识开始讲起。
+
+### Linux 中的“大内存页”是个什么玩意?
+
+“大内存页”有助于 Linux 系统进行虚拟内存管理。顾名思义,除了标准的 4KB 大小的页面外,它们还能帮助管理内存中的巨大的页面。使用“大内存页”,你最大可以定义 1GB 的页面大小。
+
+在系统启动期间,你能用“大内存页”为应用程序预留一部分内存。这部分内存,即被“大内存页”占用的这些存储器永远不会被交换出内存。它会一直保留其中,除非你修改了配置。这会极大地提高像 Oracle 数据库这样的需要海量内存的应用程序的性能。
+
+### 为什么使用“大内存页”?
+
+在虚拟内存管理中,内核维护一个将虚拟内存地址映射到物理地址的表,对于每个页面操作,内核都需要加载相关的映射。如果你的内存页很小,那么你需要加载的页就会很多,导致内核会加载更多的映射表。而这会降低性能。
+
+使用“大内存页”,意味着所需要的页变少了。从而大大减少由内核加载的映射表的数量。这提高了内核级别的性能最终有利于应用程序的性能。
+
+简而言之,通过启用“大内存页”,系统具只需要处理较少的页面映射表,从而减少访问/维护它们的开销!
+
+### 如何配置“大内存页”?
+
+运行下面命令来查看当前“大内存页”的详细内容。
+
+```
+root@kerneltalks # grep Huge /proc/meminfo
+AnonHugePages: 0 kB
+HugePages_Total: 0
+HugePages_Free: 0
+HugePages_Rsvd: 0
+HugePages_Surp: 0
+Hugepagesize: 2048 kB
+```
+
+从上面输出可以看到,每个页的大小为 2MB(`Hugepagesize`),并且系统中目前有 `0` 个“大内存页”(`HugePages_Total`)。这里“大内存页”的大小可以从 `2MB` 增加到 `1GB`。
+
+运行下面的脚本可以知道系统当前需要多少个巨大页。该脚本取之于 Oracle。
+
+```
+#!/bin/bash
+#
+# hugepages_settings.sh
+#
+# Linux bash script to compute values for the
+# recommended HugePages/HugeTLB configuration
+#
+# Note: This script does calculation for all shared memory
+# segments available when the script is run, no matter it
+# is an Oracle RDBMS shared memory segment or not.
+# Check for the kernel version
+KERN=`uname -r | awk -F. '{ printf("%d.%d\n",$1,$2); }'`
+# Find out the HugePage size
+HPG_SZ=`grep Hugepagesize /proc/meminfo | awk {'print $2'}`
+# Start from 1 pages to be on the safe side and guarantee 1 free HugePage
+NUM_PG=1
+# Cumulative number of pages required to handle the running shared memory segments
+for SEG_BYTES in `ipcs -m | awk {'print $5'} | grep "[0-9][0-9]*"`
+do
+ MIN_PG=`echo "$SEG_BYTES/($HPG_SZ*1024)" | bc -q`
+ if [ $MIN_PG -gt 0 ]; then
+ NUM_PG=`echo "$NUM_PG+$MIN_PG+1" | bc -q`
+ fi
+done
+# Finish with results
+case $KERN in
+ '2.4') HUGETLB_POOL=`echo "$NUM_PG*$HPG_SZ/1024" | bc -q`;
+ echo "Recommended setting: vm.hugetlb_pool = $HUGETLB_POOL" ;;
+ '2.6' | '3.8' | '3.10' | '4.1' ) echo "Recommended setting: vm.nr_hugepages = $NUM_PG" ;;
+ *) echo "Unrecognized kernel version $KERN. Exiting." ;;
+esac
+# End
+```
+
+将它以 `hugepages_settings.sh` 为名保存到 `/tmp` 中,然后运行之:
+
+```
+root@kerneltalks # sh /tmp/hugepages_settings.sh
+Recommended setting: vm.nr_hugepages = 124
+```
+
+你的输出类似如上结果,只是数字会有一些出入。
+
+这意味着,你系统需要 124 个每个 2MB 的“大内存页”!若你设置页面大小为 4MB,则结果就变成了 62。你明白了吧?
+
+### 配置内核中的“大内存页”
+
+本文最后一部分内容是配置上面提到的 [内核参数 ][2] ,然后重新加载。将下面内容添加到 `/etc/sysctl.conf` 中,然后输入 `sysctl -p` 命令重新加载配置。
+
+```
+vm.nr_hugepages=126
+```
+
+注意我们这里多加了两个额外的页,因为我们希望在实际需要的页面数量之外多一些额外的空闲页。
+
+现在,内核已经配置好了,但是要让应用能够使用这些“大内存页”还需要提高内存的使用阀值。新的内存阀值应该为 126 个页 x 每个页 2 MB = 252 MB,也就是 258048 KB。
+
+你需要编辑 `/etc/security/limits.conf` 中的如下配置:
+
+```
+soft memlock 258048
+hard memlock 258048
+```
+
+某些情况下,这些设置是在指定应用的文件中配置的,比如 Oracle DB 就是在 `/etc/security/limits.d/99-grid-oracle-limits.conf` 中配置的。
+
+这就完成了!你可能还需要重启应用来让应用来使用这些新的巨大页。
+
+### 如何禁用“大内存页”?
+
+“大内存页”默认是开启的。使用下面命令来查看“大内存页”的当前状态。
+
+```
+root@kerneltalks# cat /sys/kernel/mm/transparent_hugepage/enabled
+[always] madvise never
+```
+
+输出中的 `[always]` 标志说明系统启用了“大内存页”。
+
+若使用的是基于 RedHat 的系统,则应该要查看的文件路径为 `/sys/kernel/mm/redhat_transparent_hugepage/enabled`。
+
+若想禁用“大内存页”,则在 `/etc/grub.conf` 中的 `kernel` 行后面加上 `transparent_hugepage=never`,然后重启系统。
+
+--------------------------------------------------------------------------------
+
+via: https://kerneltalks.com/services/what-is-huge-pages-in-linux/
+
+作者:[Shrikant Lavhate][a]
+译者:[lujun9972](https://github.com/lujun9972)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://kerneltalks.com
+[1]:https://a1.kerneltalks.com/wp-content/uploads/2017/11/hugepages-in-linux.png
+[2]:https://kerneltalks.com/linux/how-to-tune-kernel-parameters-in-linux/
diff --git a/published/20171108 How to Use GNOME Shell Extensions [Complete Guide].md b/published/20171108 How to Use GNOME Shell Extensions [Complete Guide].md
new file mode 100644
index 0000000000..47cb18df76
--- /dev/null
+++ b/published/20171108 How to Use GNOME Shell Extensions [Complete Guide].md
@@ -0,0 +1,210 @@
+如何使用 GNOME Shell 扩展
+=====
+
+> 简介:这是一份详细指南,我将会向你展示如何手动或通过浏览器轻松安装 GNOME Shell 扩展。
+
+在讨论 [如何在 Ubuntu 17.10 上安装主题][1] 一文时,我简要地提到了 GNOME Shell 扩展,它用来安装用户主题。今天,我们将详细介绍 Ubuntu 17.10 中的 GNOME Shell 扩展。
+
+我可能会使用术语 GNOME 扩展而不是 GNOME Shell 扩展,但是这两者在这里具有相同的含义。
+
+什么是 GNOME Shell 扩展?如何安装 GNOME Shell 扩展,以及如何管理和删除 GNOME Shell 扩展?我会一一解释所有的问题。
+
+在此之前,如果你喜欢视频,我已经在 [FOSS 的 YouTube 频道][2] 上展示了所有的这些操作。我强烈建议你订阅它来获得更多有关 Linux 的视频。
+
+### 什么是 GNOME Shell 扩展?
+
+[GNOME Shell 扩展][3] 根本上来说是增强 GNOME 桌面功能的一小段代码。
+
+把它看作是你的浏览器的一个附加组件。例如,你可以在浏览器中安装附加组件来禁用广告。这个附加组件是由第三方开发者开发的。虽然你的 Web 浏览器默认不提供此项功能,但安装此附加组件可增强你 Web 浏览器的功能。
+
+同样, GNOME Shell 扩展就像那些可以安装在 GNOME 之上的第三方附加组件和插件。这些扩展程序是为执行特定任务而创建的,例如显示天气状况、网速等。大多数情况下,你可以在顶部面板中访问它们。
+
+![GNOME Shell 扩展显示天气信息][5]
+
+也有一些 GNOME 扩展在顶部面板上不可见,但它们仍然可以调整 GNOME 的行为。例如,有一个这样的扩展可以让鼠标中键来关闭应用程序。
+
+### 安装 GNOME Shell 扩展
+
+现在你知道了什么是 GNOME Shell 扩展,那么让我们来看看如何安装它吧。有三种方式可以使用 GNOME 扩展:
+
+* 使用来自 Ubuntu (或你的 Linux 发行版)的最小扩展集
+* 在 Web 浏览器中查找并安装扩展程序
+* 下载并手动安装扩展
+
+在你学习如何使用 GNOME Shell 扩展之前,你应该安装 GNOME Tweak Tool。你可以在软件中心找到它,或者你可以使用以下命令:
+
+```
+sudo apt install gnome-tweak-tool
+```
+
+有时候,你需要知道你正在使用的 GNOME Shell 的版本,这有助于你确定扩展是否与系统兼容。你可以使用下面的命令来找到它:
+
+```
+gnome-shell --version
+```
+
+#### 1. 使用 gnome-shell-extensions 包 [最简单最安全的方式]
+
+Ubuntu(以及其他几个 Linux 发行版,如 Fedora )提供了一个包,这个包有最小集合的 GNOME 扩展。由于 Linux 发行版经过测试,所以你不必担心兼容性问题。
+
+如果你不想费神,你只需获得这个包,你就可以安装 8-10 个 GNOME 扩展。
+
+```
+sudo apt install gnome-shell-extensions
+```
+
+你将需要重新启动系统(或者重新启动 GNOME Shell,我具体忘了是哪个)。之后,启动 GNOME Tweaks,你会发现一些扩展自动安装了,你只需切换按钮即可开始使用已安装的扩展程序。
+
+![Change GNOME Shell theme in Ubuntu 17.1][6]
+
+#### 2. 从 Web 浏览器安装 GNOME Shell 扩展
+
+GNOME 项目有一个专门用于扩展的网站,不干别的,你可以在这里找到并安装扩展,并管理它们,甚至不需要 GNOME Tweaks Tool。
+
+- [GNOME Shell Extensions Website][3]
+
+但是为了安装 Web 浏览器扩展,你需要两件东西:浏览器附加组件和本地主机连接器。
+
+**步骤 1: 安装 浏览器附加组件**
+
+当你访问 GNOME Shell 扩展网站时,你会看到如下消息:
+
+> “要使用此站点控制 GNOME Shell 扩展,你必须安装由两部分组成的 GNOME Shell 集成:浏览器扩展和本地主机消息应用。”
+
+![Installing GNOME Shell Extensions][7]
+
+你只需在你的 Web 浏览器上点击建议的附加组件链接即可。你也可以从下面的链接安装它们:
+
+- 对于 Google Chrome、Chromium 和 Vivaldi: [Chrome Web 商店][21]
+- 对于 Firefox: [Mozilla Addons][22]
+- 对于 Opera: [Opera Addons][23]
+
+**步骤 2: 安装本地连接器**
+
+仅仅安装浏览器附加组件并没有帮助。你仍然会看到如下错误:
+
+> “尽管 GNOME Shell 集成扩展正在运行,但未检测到本地主机连接器。请参阅文档以获取有关安装连接器的信息。”
+
+![How to install GNOME Shell Extensions][8]
+
+这是因为你尚未安装主机连接器。要做到这一点,请使用以下命令:
+
+```
+sudo apt install chrome-gnome-shell
+```
+
+不要担心包名中的 “chrome” 前缀,它与 Chrome 无关,你无需再次安装 Firefox 或 Opera 的单独软件包。
+
+**步骤 3: 在 Web 浏览器中安装 GNOME Shell 扩展**
+
+一旦你完成了这两个要求,你就可以开始了。现在,你将看不到任何错误消息。
+
+![GNOME Shell Extension][9]
+
+一件好的做法是按照 GNOME Shell 版本对扩展进行排序,但这不是强制性的。这是因为开发人员是为其当前的 GNOME 版本创建的扩展。而在一年之内,会发布两个或更多 GNOME 发行版本,但开发人员没有时间(在新的 GNOME 版本上)测试或更新他/她的扩展。
+
+因此,你不知道该扩展是否与你的系统兼容。尽管扩展已经存在很长一段时间了,但是有可能在最新的 GNOME Shell 版本中,它也能正常工作。同样它也有可能不工作。
+
+你也可以去搜索扩展程序。假设你想要安装有关天气的扩展,只要搜索它并选择一个搜索结果即可。
+
+当你访问扩展页面时,你会看到一个切换按钮。
+
+![Installing GNOME Shell Extension ][10]
+
+点击它,你会被提示是否要安装这个扩展:
+
+![Install GNOME Shell Extensions via web browser][11]
+
+显然,直接安装就好。安装完成后,你会看到切换按钮已打开,旁边有一个设置选项。你也可以使用设置选项配置扩展,也可以禁用扩展。
+
+![Configuring installed GNOME Shell Extensions][12]
+
+你也可以在 GNOME Tweaks Tool 中配置通过 Web 浏览器安装的扩展:
+
+![GNOME Tweaks to handle GNOME Shell Extensions][13]
+
+你可以在 GNOME 网站中 [已安装的扩展部分][14] 下查看所有已安装的扩展。
+
+![Manage your installed GNOME Shell Extensions][15]
+
+使用 GNOME 扩展网站的一个主要优点是你可以查看扩展是否有可用的更新,你不会在 GNOME Tweaks 或系统更新中得到更新(和提示)。
+
+#### 3. 手动安装 GNOME Shell 扩展
+
+你不需要始终在线才能安装 GNOME Shell 扩展,你可以下载文件并稍后安装,这样就不必使用互联网了。
+
+去 GNOME 扩展网站下载最新版本的扩展。
+
+![Download GNOME Shell Extension][16]
+
+解压下载的文件,将该文件夹复制到 `~/.local/share/gnome-shell/extensions` 目录。到主目录下并按 `Ctrl+H` 显示隐藏的文件夹,在这里找到 `.local` 文件夹,你可以找到你的路径,直至 `extensions` 目录。
+
+一旦你将文件复制到正确的目录后,进入它并打开 `metadata.json` 文件,寻找 `uuid` 的值。
+
+确保该扩展的文件夹名称与 `metadata.json` 中的 `uuid` 值相同。如果不相同,请将目录重命名为 `uuid` 的值。
+
+![Manually install GNOME Shell extension][17]
+
+差不多了!现在重新启动 GNOME Shell。 按 `Alt+F2` 并输入 `r` 重新启动 GNOME Shell。
+
+![Restart GNOME Shell][18]
+
+同样重新启动 GNOME Tweaks Tool。你现在应该可以在 Tweaks Tool 中看到手动安装的 GNOME 扩展,你可以在此处配置或启用新安装的扩展。
+
+这就是安装 GNOME Shell 扩展你需要知道的所有内容。
+
+### 移除 GNOME Shell 扩展
+
+你可能想要删除一个已安装的 GNOME Shell 扩展,这是完全可以理解的。
+
+如果你是通过 Web 浏览器安装的,你可以到 [GNOME 网站的以安装的扩展部分][14] 那移除它(如前面的图片所示)。
+
+如果你是手动安装的,可以从 `~/.local/share/gnome-shell/extensions` 目录中删除扩展文件来删除它。
+
+### 特别提示:获得 GNOME Shell 扩展更新的通知
+
+到目前为止,你已经意识到除了访问 GNOME 扩展网站之外,无法知道更新是否可用于 GNOME Shell 扩展。
+
+幸运的是,有一个 GNOME Shell 扩展可以通知你是否有可用于已安装扩展的更新。你可以从下面的链接中获得它:
+
+- [Extension Update Notifier][19]
+
+### 你如何管理 GNOME Shell 扩展?
+
+我觉得很奇怪不能通过系统更新来更新扩展,就好像 GNOME Shell 扩展不是系统的一部分。
+
+如果你正在寻找一些建议,请阅读这篇文章: [关于最佳 GNOME 扩展][20]。同时,你可以分享有关 GNOME Shell 扩展的经验。你经常使用它们吗?如果是,哪些是你最喜欢的?
+
+--------------------------------------------------------------------------------
+
+via: [https://itsfoss.com/gnome-shell-extensions/](https://itsfoss.com/gnome-shell-extensions/)
+
+作者:[Abhishek Prakash][a]
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://itsfoss.com/author/abhishek/
+[1]:https://itsfoss.com/install-themes-ubuntu/
+[2]:https://www.youtube.com/c/itsfoss?sub_confirmation=1
+[3]:https://extensions.gnome.org/
+[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-weather.jpeg
+[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/enableuser-themes-extension-gnome.jpeg
+[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-1.jpeg
+[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-2.jpeg
+[9]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-3.jpeg
+[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-4.jpeg
+[11]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-5.jpeg
+[12]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-6.jpeg
+[13]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-7-800x572.jpeg
+[14]:https://extensions.gnome.org/local/
+[15]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-8.jpeg
+[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-9-800x456.jpeg
+[17]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-10-800x450.jpg
+[18]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/restart-gnome-shell-800x299.jpeg
+[19]:https://extensions.gnome.org/extension/1166/extension-update-notifier/
+[20]:https://itsfoss.com/best-gnome-extensions/
+[21]:https://chrome.google.com/webstore/detail/gnome-shell-integration/gphhapmejobijbbhgpjhcjognlahblep
+[22]:https://addons.mozilla.org/en/firefox/addon/gnome-shell-integration/
+[23]:https://addons.opera.com/en/extensions/details/gnome-shell-integration/
\ No newline at end of file
diff --git a/translated/tech/20171109 Concurrent Servers- Part 4 - libuv.md b/published/20171109 Concurrent Servers- Part 4 - libuv.md
similarity index 64%
rename from translated/tech/20171109 Concurrent Servers- Part 4 - libuv.md
rename to published/20171109 Concurrent Servers- Part 4 - libuv.md
index e819027b7d..2e714c630f 100644
--- a/translated/tech/20171109 Concurrent Servers- Part 4 - libuv.md
+++ b/published/20171109 Concurrent Servers- Part 4 - libuv.md
@@ -12,17 +12,17 @@
### 使用 libuv 抽象出事件驱动循环
-在 [第三节][11] 中,我们看到了基于 `select` 和 `epoll` 的服务器的相似之处,并且,我说过,在它们之间抽象出细微的差别是件很有吸引力的事。许多库已经做到了这些,所以在这一部分中我将去选一个并使用它。我选的这个库是 [libuv][12],它最初设计用于 Node.js 底层的可移植平台层,并且,后来发现在其它的项目中已有使用。libuv 是用 C 写的,因此,它具有很高的可移植性,非常适用嵌入到像 JavaScript 和 Python 这样的高级语言中。
+在 [第三节][11] 中,我们看到了基于 `select` 和 `epoll` 的服务器的相似之处,并且,我说过,在它们之间抽象出细微的差别是件很有吸引力的事。许多库已经做到了这些,所以在这一部分中我将去选一个并使用它。我选的这个库是 [libuv][12],它最初设计用于 Node.js 底层的可移植平台层,并且,后来发现在其它的项目中也有使用。libuv 是用 C 写的,因此,它具有很高的可移植性,非常适用嵌入到像 JavaScript 和 Python 这样的高级语言中。
-虽然 libuv 为抽象出底层平台细节已经变成了一个相当大的框架,但它仍然是以 _事件循环_ 思想为中心的。在我们第三部分的事件驱动服务器中,事件循环在 `main` 函数中是很明确的;当使用 libuv 时,该循环通常隐藏在库自身中,而用户代码仅需要注册事件句柄(作为一个回调函数)和运行这个循环。此外,libuv 会在给定的平台上使用更快的事件循环实现,对于 Linux 它是 epoll,等等。
+虽然 libuv 为了抽象出底层平台细节已经变成了一个相当大的框架,但它仍然是以 _事件循环_ 思想为中心的。在我们第三部分的事件驱动服务器中,事件循环是显式定义在 `main` 函数中的;当使用 libuv 时,该循环通常隐藏在库自身中,而用户代码仅需要注册事件句柄(作为一个回调函数)和运行这个循环。此外,libuv 会在给定的平台上使用更快的事件循环实现,对于 Linux 它是 `epoll`,等等。

-libuv 支持多路事件循环,并且,因此事件循环在库中是非常重要的;它有一个句柄 —— `uv_loop_t`,和创建/杀死/启动/停止循环的函数。也就是说,在这篇文章中,我将仅需要使用 “默认的” 循环,libuv 可通过 `uv_default_loop()` 提供它;多路循环大多用于多线程事件驱动的服务器,这是一个更高级别的话题,我将留在这一系列文章的以后部分。
+libuv 支持多路事件循环,因此事件循环在库中是非常重要的;它有一个句柄 —— `uv_loop_t`,以及创建/杀死/启动/停止循环的函数。也就是说,在这篇文章中,我将仅需要使用 “默认的” 循环,libuv 可通过 `uv_default_loop()` 提供它;多路循环大多用于多线程事件驱动的服务器,这是一个更高级别的话题,我将留在这一系列文章的以后部分。
### 使用 libuv 的并发服务器
-为了对 libuv 有一个更深的印象,让我们跳转到我们的可靠协议的服务器,它通过我们的这个系列已经有了一个强大的重新实现。这个服务器的结构与第三部分中的基于 select 和 epoll 的服务器有一些相似之处,因为,它也依赖回调。完整的 [示例代码在这里][13];我们开始设置这个服务器的套接字绑定到一个本地端口:
+为了对 libuv 有一个更深的印象,让我们跳转到我们的可靠协议的服务器,它通过我们的这个系列已经有了一个强大的重新实现。这个服务器的结构与第三部分中的基于 `select` 和 `epoll` 的服务器有一些相似之处,因为,它也依赖回调。完整的 [示例代码在这里][13];我们开始设置这个服务器的套接字绑定到一个本地端口:
```
int portnum = 9090;
@@ -47,9 +47,9 @@ if ((rc = uv_tcp_bind(&server_stream, (const struct sockaddr*)&server_address, 0
}
```
-除了它被封装进 libuv API 中之外,你看到的是一个相当标准的套接字。在它的返回中,我们取得一个可工作于任何 libuv 支持的平台上的可移植接口。
+除了它被封装进 libuv API 中之外,你看到的是一个相当标准的套接字。在它的返回中,我们取得了一个可工作于任何 libuv 支持的平台上的可移植接口。
-这些代码也展示了很认真负责的错误处理;多数的 libuv 函数返回一个整数状态,返回一个负数意味着出现了一个错误。在我们的服务器中,我们把这些错误看做致命问题进行处理,但也可以设想为一个更优雅的错误恢复。
+这些代码也展示了很认真负责的错误处理;多数的 libuv 函数返回一个整数状态,返回一个负数意味着出现了一个错误。在我们的服务器中,我们把这些错误看做致命问题进行处理,但也可以设想一个更优雅的错误恢复。
现在,那个套接字已经绑定,是时候去监听它了。这里我们运行首个回调注册:
@@ -73,7 +73,7 @@ uv_run(uv_default_loop(), UV_RUN_DEFAULT);
return uv_loop_close(uv_default_loop());
```
-注意,在运行事件循环之前,只有一个回调是通过 main 注册的;我们稍后将看到怎么去添加更多的回调。在事件循环的整个运行过程中,添加和删除回调并不是一个问题 —— 事实上,大多数服务器就是这么写的。
+注意,在运行事件循环之前,只有一个回调是通过 `main` 注册的;我们稍后将看到怎么去添加更多的回调。在事件循环的整个运行过程中,添加和删除回调并不是一个问题 —— 事实上,大多数服务器就是这么写的。
这是一个 `on_peer_connected`,它处理到服务器的新的客户端连接:
@@ -132,8 +132,8 @@ void on_peer_connected(uv_stream_t* server_stream, int status) {
这些代码都有很好的注释,但是,这里有一些重要的 libuv 语法我想去强调一下:
-* 传入自定义数据到回调中:因为 C 还没有闭包,这可能是个挑战,libuv 在它的所有的处理类型中有一个 `void* data` 字段;这些字段可以被用于传递用户数据。例如,注意 `client->data` 是如何指向到一个 `peer_state_t` 结构上,以便于 `uv_write` 和 `uv_read_start` 注册的回调可以知道它们正在处理的是哪个客户端的数据。
-* 内存管理:在带有垃圾回收的语言中进行事件驱动编程是非常容易的,因为,回调通常运行在一个它们注册的完全不同的栈帧中,使得基于栈的内存管理很困难。它总是需要传递堆分配的数据到 libuv 回调中(当所有回调运行时,除了 main,其它的都运行在栈上),并且,为了避免泄漏,许多情况下都要求这些数据去安全释放。这些都是些需要实践的内容 [[1]][6]。
+* 传入自定义数据到回调中:因为 C 语言还没有闭包,这可能是个挑战,libuv 在它的所有的处理类型中有一个 `void* data` 字段;这些字段可以被用于传递用户数据。例如,注意 `client->data` 是如何指向到一个 `peer_state_t` 结构上,以便于 `uv_write` 和 `uv_read_start` 注册的回调可以知道它们正在处理的是哪个客户端的数据。
+* 内存管理:在带有垃圾回收的语言中进行事件驱动编程是非常容易的,因为,回调通常运行在一个与它们注册的地方完全不同的栈帧中,使得基于栈的内存管理很困难。它总是需要传递堆分配的数据到 libuv 回调中(当所有回调运行时,除了 `main`,其它的都运行在栈上),并且,为了避免泄漏,许多情况下都要求这些数据去安全释放(`free()`)。这些都是些需要实践的内容 ^注1 。
这个服务器上对端的状态如下:
@@ -146,7 +146,7 @@ typedef struct {
} peer_state_t;
```
-它与第三部分中的状态非常类似;我们不再需要 sendptr,因为,在调用 "done writing" 回调之前,`uv_write` 将确保去发送它提供的整个缓冲。我们也为其它的回调使用保持了一个到客户端的指针。这里是 `on_wrote_init_ack`:
+它与第三部分中的状态非常类似;我们不再需要 `sendptr`,因为,在调用 “done writing” 回调之前,`uv_write` 将确保发送它提供的整个缓冲。我们也为其它的回调使用保持了一个到客户端的指针。这里是 `on_wrote_init_ack`:
```
void on_wrote_init_ack(uv_write_t* req, int status) {
@@ -171,7 +171,7 @@ void on_wrote_init_ack(uv_write_t* req, int status) {
}
```
-然后,我们确信知道了这个初始的 '*' 已经被发送到对端,我们通过调用 `uv_read_start` 去监听从这个对端来的入站数据,它注册一个回调(`on_peer_read`)去被调用,不论什么时候,事件循环都在套接字上接收来自客户端的调用:
+然后,我们确信知道了这个初始的 `'*'` 已经被发送到对端,我们通过调用 `uv_read_start` 去监听从这个对端来的入站数据,它注册一个将被事件循环调用的回调(`on_peer_read`),不论什么时候,事件循环都在套接字上接收来自客户端的调用:
```
void on_peer_read(uv_stream_t* client, ssize_t nread, const uv_buf_t* buf) {
@@ -236,11 +236,11 @@ void on_peer_read(uv_stream_t* client, ssize_t nread, const uv_buf_t* buf) {
}
```
-这个服务器的运行时行为非常类似于第三部分的事件驱动服务器:所有的客户端都在一个单个的线程中并发处理。并且一些行为被维护在服务器代码中:服务器的逻辑实现为一个集成的回调,并且长周期运行是禁止的,因为它会阻塞事件循环。这一点也很类似。让我们进一步探索这个问题。
+这个服务器的运行时行为非常类似于第三部分的事件驱动服务器:所有的客户端都在一个单个的线程中并发处理。并且类似的,一些特定的行为必须在服务器代码中维护:服务器的逻辑实现为一个集成的回调,并且长周期运行是禁止的,因为它会阻塞事件循环。这一点也很类似。让我们进一步探索这个问题。
### 在事件驱动循环中的长周期运行的操作
-单线程的事件驱动代码使它先天地对一些常见问题非常敏感:整个循环中的长周期运行的代码块。参见如下的程序:
+单线程的事件驱动代码使它先天就容易受到一些常见问题的影响:长周期运行的代码会阻塞整个循环。参见如下的程序:
```
void on_timer(uv_timer_t* timer) {
@@ -280,23 +280,21 @@ on_timer [18850 ms]
...
```
-`on_timer` 忠实地每秒执行一次,直到随机出现的睡眠为止。在那个时间点,`on_timer` 不再被调用,直到睡眠时间结束;事实上,_没有其它的回调_ 在这个时间帧中被调用。这个睡眠调用阻塞当前线程,它正是被调用的线程,并且也是事件循环使用的线程。当这个线程被阻塞后,事件循环也被阻塞。
+`on_timer` 忠实地每秒执行一次,直到随机出现的睡眠为止。在那个时间点,`on_timer` 不再被调用,直到睡眠时间结束;事实上,_没有其它的回调_ 会在这个时间帧中被调用。这个睡眠调用阻塞了当前线程,它正是被调用的线程,并且也是事件循环使用的线程。当这个线程被阻塞后,事件循环也被阻塞。
这个示例演示了在事件驱动的调用中为什么回调不能被阻塞是多少的重要。并且,同样适用于 Node.js 服务器、客户端侧的 Javascript、大多数的 GUI 编程框架、以及许多其它的异步编程模型。
-但是,有时候运行耗时的任务是不可避免的。并不是所有任务都有一个异步 APIs;例如,我们可能使用一些仅有同步 API 的库去处理,或者,正在执行一个可能的长周期计算。我们如何用事件驱动编程去结合这些代码?线程可以帮到你!
+但是,有时候运行耗时的任务是不可避免的。并不是所有任务都有一个异步 API;例如,我们可能使用一些仅有同步 API 的库去处理,或者,正在执行一个可能的长周期计算。我们如何用事件驱动编程去结合这些代码?线程可以帮到你!
-### “转换” 阻塞调用到异步调用的线程
+### “转换” 阻塞调用为异步调用的线程
-一个线程池可以被用于去转换阻塞调用到异步调用,通过与事件循环并行运行,并且当任务完成时去由它去公布事件。一个给定的阻塞函数 `do_work()`,这里介绍了它是怎么运行的:
+一个线程池可以用于转换阻塞调用为异步调用,通过与事件循环并行运行,并且当任务完成时去由它去公布事件。以阻塞函数 `do_work()` 为例,这里介绍了它是怎么运行的:
-1. 在一个回调中,用 `do_work()` 代表直接调用,我们将它打包进一个 “任务”,并且请求线程池去运行这个任务。当任务完成时,我们也为循环去调用它注册一个回调;我们称它为 `on_work_done()`。
+1. 不在一个回调中直接调用 `do_work()` ,而是将它打包进一个 “任务”,让线程池去运行这个任务。当任务完成时,我们也为循环去调用它注册一个回调;我们称它为 `on_work_done()`。
+2. 在这个时间点,我们的回调就可以返回了,而事件循环保持运行;在同一时间点,线程池中的有一个线程运行这个任务。
+3. 一旦任务运行完成,通知主线程(指正在运行事件循环的线程),并且事件循环调用 `on_work_done()`。
-2. 在这个时间点,我们的回调可以返回并且事件循环保持运行;在同一时间点,线程池中的一个线程运行这个任务。
-
-3. 一旦任务运行完成,通知主线程(指正在运行事件循环的线程),并且,通过事件循环调用 `on_work_done()`。
-
-让我们看一下,使用 libuv 的工作调度 API,是怎么去解决我们前面的 timer/sleep 示例中展示的问题的:
+让我们看一下,使用 libuv 的工作调度 API,是怎么去解决我们前面的计时器/睡眠示例中展示的问题的:
```
void on_after_work(uv_work_t* req, int status) {
@@ -327,7 +325,7 @@ int main(int argc, const char** argv) {
}
```
-通过一个 work_req [[2]][14] 类型的句柄,我们进入一个任务队列,代替在 `on_timer` 上直接调用 sleep,这个函数在任务中(`on_work`)运行,并且,一旦任务完成(`on_after_work`),这个函数被调用一次。`on_work` 在这里是指发生的 “work”(阻塞中的/耗时的操作)。在这两个回调传递到 `uv_queue_work` 时,注意一个关键的区别:`on_work` 运行在线程池中,而 `on_after_work` 运行在事件循环中的主线程上 - 就好像是其它的回调一样。
+通过一个 `work_req` ^注2 类型的句柄,我们进入一个任务队列,代替在 `on_timer` 上直接调用 sleep,这个函数在任务中(`on_work`)运行,并且,一旦任务完成(`on_after_work`),这个函数被调用一次。`on_work` 是指 “work”(阻塞中的/耗时的操作)进行的地方。注意在这两个回调传递到 `uv_queue_work` 时的一个关键区别:`on_work` 运行在线程池中,而 `on_after_work` 运行在事件循环中的主线程上 —— 就好像是其它的回调一样。
让我们看一下这种方式的运行:
@@ -347,25 +345,25 @@ on_timer [97578 ms]
...
```
-即便在 sleep 函数被调用时,定时器也每秒钟滴答一下,睡眠(sleeping)现在运行在一个单独的线程中,并且不会阻塞事件循环。
+即便在 sleep 函数被调用时,定时器也每秒钟滴答一下,睡眠现在运行在一个单独的线程中,并且不会阻塞事件循环。
### 一个用于练习的素数测试服务器
-因为通过睡眼去模拟工作并不是件让人兴奋的事,我有一个事先准备好的更综合的一个示例 - 一个基于套接字接受来自客户端的数字的服务器,检查这个数字是否是素数,然后去返回一个 “prime" 或者 “composite”。完整的 [服务器代码在这里][15] - 我不在这里粘贴了,因为它太长了,更希望读者在一些自己的练习中去体会它。
+因为通过睡眠去模拟工作并不是件让人兴奋的事,我有一个事先准备好的更综合的一个示例 —— 一个基于套接字接受来自客户端的数字的服务器,检查这个数字是否是素数,然后去返回一个 “prime" 或者 “composite”。完整的 [服务器代码在这里][15] —— 我不在这里粘贴了,因为它太长了,更希望读者在一些自己的练习中去体会它。
这个服务器使用了一个原生的素数测试算法,因此,对于大的素数可能花很长时间才返回一个回答。在我的机器中,对于 2305843009213693951,它花了 ~5 秒钟去计算,但是,你的方法可能不同。
-练习 1:服务器有一个设置(通过一个名为 MODE 的环境变量)要么去在套接字回调(意味着在主线程上)中运行素数测试,要么在 libuv 工作队列中。当多个客户端同时连接时,使用这个设置来观察服务器的行为。当它计算一个大的任务时,在阻塞模式中,服务器将不回复其它客户端,而在非阻塞模式中,它会回复。
+练习 1:服务器有一个设置(通过一个名为 `MODE` 的环境变量)要么在套接字回调(意味着在主线程上)中运行素数测试,要么在 libuv 工作队列中。当多个客户端同时连接时,使用这个设置来观察服务器的行为。当它计算一个大的任务时,在阻塞模式中,服务器将不回复其它客户端,而在非阻塞模式中,它会回复。
-练习 2;libuv 有一个缺省大小的线程池,并且线程池的大小可以通过环境变量配置。你可以通过使用多个客户端去实验找出它的缺省值是多少?找到线程池缺省值后,使用不同的设置去看一下,在重负载下怎么去影响服务器的响应能力。
+练习 2:libuv 有一个缺省大小的线程池,并且线程池的大小可以通过环境变量配置。你可以通过使用多个客户端去实验找出它的缺省值是多少?找到线程池缺省值后,使用不同的设置去看一下,在重负载下怎么去影响服务器的响应能力。
### 在非阻塞文件系统中使用工作队列
-对于仅傻傻的演示和 CPU 密集型的计算来说,将可能的阻塞操作委托给一个线程池并不是明智的;libuv 在它的文件系统 APIs 中本身就大量使用了这种性能。通过这种方式,libuv 使用一个异步 API,在一个轻便的方式中,显示出它强大的文件系统的处理能力。
+对于只是呆板的演示和 CPU 密集型的计算来说,将可能的阻塞操作委托给一个线程池并不是明智的;libuv 在它的文件系统 API 中本身就大量使用了这种能力。通过这种方式,libuv 使用一个异步 API,以一个轻便的方式显示出它强大的文件系统的处理能力。
-让我们使用 `uv_fs_read()`,例如,这个函数从一个文件中(以一个 `uv_fs_t` 句柄为代表)读取一个文件到一个缓冲中 [[3]][16],并且当读取完成后调用一个回调。换句话说,`uv_fs_read()` 总是立即返回,甚至如果文件在一个类似 NFS 的系统上,并且,数据到达缓冲区可能需要一些时间。换句话说,这个 API 与这种方式中其它的 libuv APIs 是异步的。这是怎么工作的呢?
+让我们使用 `uv_fs_read()`,例如,这个函数从一个文件中(表示为一个 `uv_fs_t` 句柄)读取一个文件到一个缓冲中 ^注3,并且当读取完成后调用一个回调。换句话说,`uv_fs_read()` 总是立即返回,即使是文件在一个类似 NFS 的系统上,而数据到达缓冲区可能需要一些时间。换句话说,这个 API 与这种方式中其它的 libuv API 是异步的。这是怎么工作的呢?
-在这一点上,我们看一下 libuv 的底层;内部实际上非常简单,并且它是一个很好的练习。作为一个便携的库,libuv 对于 Windows 和 Unix 系统在它的许多函数上有不同的实现。我们去看一下在 libuv 源树中的 src/unix/fs.c。
+在这一点上,我们看一下 libuv 的底层;内部实际上非常简单,并且它是一个很好的练习。作为一个可移植的库,libuv 对于 Windows 和 Unix 系统在它的许多函数上有不同的实现。我们去看一下在 libuv 源树中的 `src/unix/fs.c`。
这是 `uv_fs_read` 的代码:
@@ -400,9 +398,9 @@ int uv_fs_read(uv_loop_t* loop, uv_fs_t* req,
}
```
-第一次看可能觉得很困难,因为它延缓真实的工作到 INIT 和 POST 宏中,在 POST 中与一些本地变量一起设置。这样做可以避免了文件中的许多重复代码。
+第一次看可能觉得很困难,因为它延缓真实的工作到 `INIT` 和 `POST` 宏中,以及为 `POST` 设置了一些本地变量。这样做可以避免了文件中的许多重复代码。
-这是 INIT 宏:
+这是 `INIT` 宏:
```
#define INIT(subtype) \
@@ -421,9 +419,9 @@ int uv_fs_read(uv_loop_t* loop, uv_fs_t* req,
while (0)
```
-它设置了请求,并且更重要的是,设置 `req->fs_type` 域为真实的 FS 请求类型。因为 `uv_fs_read` 调用 invokes INIT(READ),它意味着 `req->fs_type` 被分配一个常数 `UV_FS_READ`。
+它设置了请求,并且更重要的是,设置 `req->fs_type` 域为真实的 FS 请求类型。因为 `uv_fs_read` 调用 `INIT(READ)`,它意味着 `req->fs_type` 被分配一个常数 `UV_FS_READ`。
-这是 POST 宏:
+这是 `POST` 宏:
```
#define POST \
@@ -440,31 +438,25 @@ int uv_fs_read(uv_loop_t* loop, uv_fs_t* req,
while (0)
```
-它做什么取决于回调是否为 NULL。在 libuv 文件系统 APIs 中,一个 NULL 回调意味着我们真实地希望去执行一个 _同步_ 操作。在这种情况下,POST 直接调用 `uv__fs_work`(我们需要了解一下这个函数的功能),而对于一个 non-NULL 回调,它提交 `uv__fs_work` 作为一个工作事项到工作队列(指的是线程池),然后,注册 `uv__fs_done` 作为回调;该函数执行一些登记并调用用户提供的回调。
+它做什么取决于回调是否为 `NULL`。在 libuv 文件系统 API 中,一个 `NULL` 回调意味着我们真实地希望去执行一个 _同步_ 操作。在这种情况下,`POST` 直接调用 `uv__fs_work`(我们需要了解一下这个函数的功能),而对于一个非 `NULL` 回调,它把 `uv__fs_work` 作为一个工作项提交到工作队列(指的是线程池),然后,注册 `uv__fs_done` 作为回调;该函数执行一些登记并调用用户提供的回调。
-如果我们去看 `uv__fs_work` 的代码,我们将看到它使用很多宏去按需路由工作到真实的文件系统调用。在我们的案例中,对于 `UV_FS_READ` 这个调用将被 `uv__fs_read` 生成,它(最终)使用普通的 POSIX APIs 去读取。这个函数可以在一个 _阻塞_ 方式中很安全地实现。因为,它通过异步 API 调用时被置于一个线程池中。
+如果我们去看 `uv__fs_work` 的代码,我们将看到它使用很多宏按照需求将工作分发到实际的文件系统调用。在我们的案例中,对于 `UV_FS_READ` 这个调用将被 `uv__fs_read` 生成,它(最终)使用普通的 POSIX API 去读取。这个函数可以在一个 _阻塞_ 方式中很安全地实现。因为,它通过异步 API 调用时被置于一个线程池中。
-在 Node.js 中,fs.readFile 函数是映射到 `uv_fs_read` 上。因此,可以在一个非阻塞模式中读取文件,甚至是当底层文件系统 API 是阻塞方式时。
+在 Node.js 中,`fs.readFile` 函数是映射到 `uv_fs_read` 上。因此,可以在一个非阻塞模式中读取文件,甚至是当底层文件系统 API 是阻塞方式时。
* * *
-
-[[1]][1] 为确保服务器不泄露内存,我在一个启用泄露检查的 Valgrind 中运行它。因为服务器经常是被设计为永久运行,这是一个挑战;为克服这个问题,我在服务器上添加了一个 “kill 开关” - 一个从客户端接收的特定序列,以使它可以停止事件循环并退出。这个代码在 `theon_wrote_buf` 句柄中。
-
-
-[[2]][2] 在这里我们不过多地使用 `work_req`;讨论的素数测试服务器接下来将展示怎么被用于去传递上下文信息到回调中。
-
-
-[[3]][3] `uv_fs_read()` 提供了一个类似于 preadv Linux 系统调用的通用 API:它使用多缓冲区用于排序,并且支持一个到文件中的偏移。基于我们讨论的目的可以忽略这些特性。
-
+- 注1: 为确保服务器不泄露内存,我在一个启用泄露检查的 Valgrind 中运行它。因为服务器经常是被设计为永久运行,这是一个挑战;为克服这个问题,我在服务器上添加了一个 “kill 开关” —— 一个从客户端接收的特定序列,以使它可以停止事件循环并退出。这个代码在 `theon_wrote_buf` 句柄中。
+- 注2: 在这里我们不过多地使用 `work_req`;讨论的素数测试服务器接下来将展示怎么被用于去传递上下文信息到回调中。
+- 注3: `uv_fs_read()` 提供了一个类似于 `preadv` Linux 系统调用的通用 API:它使用多缓冲区用于排序,并且支持一个到文件中的偏移。基于我们讨论的目的可以忽略这些特性。
--------------------------------------------------------------------------------
via: https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/
-作者:[Eli Bendersky ][a]
+作者:[Eli Bendersky][a]
译者:[qhwdw](https://github.com/qhwdw)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20171110 How to configure login banners in Linux (RedHat, Ubuntu, CentOS, Fedora).md b/published/20171110 How to configure login banners in Linux (RedHat, Ubuntu, CentOS, Fedora).md
new file mode 100644
index 0000000000..bd0959ea64
--- /dev/null
+++ b/published/20171110 How to configure login banners in Linux (RedHat, Ubuntu, CentOS, Fedora).md
@@ -0,0 +1,94 @@
+如何在 Linux 中配置 ssh 登录导语
+======
+
+> 了解如何在 Linux 中创建登录导语,来向要登录或登录后的用户显示不同的警告或消息。
+
+![Login banners in Linux][1]
+
+无论何时登录公司的某些生产系统,你都会看到一些登录消息、警告或关于你将登录或已登录的服务器的信息,如下所示。这些是登录导语。
+
+![Login welcome messages in Linux][2]
+
+在本文中,我们将引导你配置它们。
+
+你可以配置两种类型的导语。
+
+1. 用户登录前显示的导语信息(在你选择的文件中配置,例如 `/etc/login.warn`)
+2. 用户成功登录后显示的导语信息(在 `/etc/motd` 中配置)
+
+### 如何在用户登录前连接系统时显示消息
+
+当用户连接到服务器并且在登录之前,这个消息将被显示给他。意味着当他输入用户名时,该消息将在密码提示之前显示。
+
+你可以使用任何文件名并在其中输入信息。在这里我们使用 `/etc/login.warn` 并且把我们的消息放在里面。
+
+```
+# cat /etc/login.warn
+ !!!! Welcome to KernelTalks test server !!!!
+This server is meant for testing Linux commands and tools. If you are
+not associated with kerneltalks.com and not authorized please dis-connect
+immediately.
+```
+
+现在,需要将此文件和路径告诉 `sshd` 守护进程,以便它可以为每个用户登录请求获取此标语。对于此,打开 `/etc/sshd/sshd_config` 文件并搜索 `#Banner none`。
+
+这里你需要编辑该配置文件,并写下你的文件名并删除注释标记(`#`)。它应该看起来像:`Banner /etc/login.warn`。
+
+保存文件并重启 `sshd` 守护进程。为避免断开现有的连接用户,请使用 HUP 信号重启 sshd。
+
+```
+root@kerneltalks # ps -ef | grep -i sshd
+root 14255 1 0 18:42 ? 00:00:00 /usr/sbin/sshd -D
+root 19074 14255 0 18:46 ? 00:00:00 sshd: ec2-user [priv]
+root 19177 19127 0 18:54 pts/0 00:00:00 grep -i sshd
+
+root@kerneltalks # kill -HUP 14255
+```
+
+就是这样了!打开新的会话并尝试登录。你将看待你在上述步骤中配置的消息。
+
+![Login banner in Linux][3]
+
+你可以在用户输入密码登录系统之前看到此消息。
+
+### 如何在用户登录后显示消息
+
+消息用户在成功登录系统后看到的当天消息(MOTD)由 `/etc/motd` 控制。编辑这个文件并输入当成功登录后欢迎用户的消息。
+
+```
+root@kerneltalks # cat /etc/motd
+ W E L C O M E
+Welcome to the testing environment of kerneltalks.
+Feel free to use this system for testing your Linux
+skills. In case of any issues reach out to admin at
+info@kerneltalks.com. Thank you.
+
+```
+
+你不需要重启 `sshd` 守护进程来使更改生效。只要保存该文件,`sshd` 守护进程就会下一次登录请求时读取和显示。
+
+![motd in linux][4]
+
+你可以在上面的截图中看到:黄色框是由 `/etc/motd` 控制的 MOTD,绿色框就是我们之前看到的登录导语。
+
+你可以使用 [cowsay][5]、[banner][6]、[figlet][7]、[lolcat][8] 等工具创建出色的引人注目的登录消息。此方法适用于几乎所有 Linux 发行版,如 RedHat、CentOs、Ubuntu、Fedora 等。
+
+--------------------------------------------------------------------------------
+
+via: https://kerneltalks.com/tips-tricks/how-to-configure-login-banners-in-linux/
+
+作者:[kerneltalks][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://kerneltalks.com
+[1]:https://a3.kerneltalks.com/wp-content/uploads/2017/11/login-banner-message-in-linux.png
+[2]:https://a3.kerneltalks.com/wp-content/uploads/2017/11/Login-message-in-linux.png
+[3]:https://a1.kerneltalks.com/wp-content/uploads/2017/11/login-banner.png
+[4]:https://a3.kerneltalks.com/wp-content/uploads/2017/11/motd-message-in-linux.png
+[5]:https://kerneltalks.com/tips-tricks/cowsay-fun-in-linux-terminal/
+[6]:https://kerneltalks.com/howto/create-nice-text-banner-hpux/
+[7]:https://kerneltalks.com/tips-tricks/create-beautiful-ascii-text-banners-linux/
+[8]:https://kerneltalks.com/linux/lolcat-tool-to-rainbow-color-linux-terminal/
diff --git a/published/20171115 How to create better documentation with a kanban board.md b/published/20171115 How to create better documentation with a kanban board.md
new file mode 100644
index 0000000000..fa92553ea2
--- /dev/null
+++ b/published/20171115 How to create better documentation with a kanban board.md
@@ -0,0 +1,46 @@
+如何使用看板(kanban)创建更好的文档
+======
+> 通过卡片分类和看板来给用户提供他们想要的信息。
+
+
+
+如果你正在处理文档、网站或其他面向用户的内容,那么了解用户希望找到的内容(包括他们想要的信息以及信息的组织和结构)很有帮助。毕竟,如果人们无法找到他们想要的东西,那么再出色的内容也没有用。
+
+卡片分类是一种简单而有效的方式,可以从用户那里收集有关菜单界面和页面的内容。最简单的实现方式是在计划在网站或文档中的部分分类标注一些索引卡,并要求用户按照查找信息的方式对卡片进行分类。一个变体是让人们编写自己的菜单标题或内容元素。
+
+我们的目标是了解用户的期望以及他们希望在哪里找到它,而不是自己弄清楚菜单和布局。当与用户处于相同的物理位置时,这是相对简单的,但当尝试从多个位置的人员获得反馈时,这会更具挑战性。
+
+我发现[看板][1]对于这些情况是一个很好的工具。它允许人们轻松拖动虚拟卡片进行分类和排名,而且与专门卡片分类软件不同,它们是多用途的。
+
+我经常使用 Trello 进行卡片分类,但有几种你可能想尝试的[开源替代品][2]。
+
+### 怎么运行的
+
+我最成功的看板体验是在写 [Gluster][3] 文档的时候 —— 这是一个自由开源的可扩展的网络存储文件系统。我需要携带大量随着时间而增长的文档,并将其分成若干类别以创建导航系统。由于我没有必要的技术知识来分类,我向 Gluster 团队和开发人员社区寻求指导。
+
+首先,我创建了一个共享看板。我列出了一些通用名称,这些名称可以为我计划在文档中涵盖的所有主题排序和创建卡片。我标记了一些不同颜色的卡片,以表明某个主题缺失并需要创建,或者它存在并需要删除。然后,我把所有卡片放入“未排序”一列,并要求人们将它们拖到他们认为这些卡片应该组织到的地方,然后给我一个他们认为是理想状态的截图。
+
+处理所有截图是最棘手的部分。我希望有一个合并或共识功能可以帮助我汇总每个人的数据,而不必检查一堆截图。幸运的是,在第一个人对卡片进行分类之后,人们或多或少地对该结构达成一致,而只做了很小的修改。当对某个主题的位置有不同意见时,我发起一个快速会议,让人们可以解释他们的想法,并且可以排除分歧。
+
+### 使用数据
+
+在这里,很容易将捕捉到的信息转换为菜单并对其进行优化。如果用户认为项目应该成为子菜单,他们通常会在评论中或在电话聊天时告诉我。对菜单组织的看法因人们的工作任务而异,所以从来没有完全达成一致意见,但用户进行测试意味着你不会对人们使用什么以及在哪里查找有很多盲点。
+
+将卡片分类与分析功能配对,可以让你更深入地了解人们在寻找什么。有一次,当我对一些我正在写的培训文档进行分析时,我惊讶地发现搜索量最大的页面是关于资本的。所以我在顶层菜单层面上显示了该页面,即使我的“逻辑”设置将它放在了子菜单中。
+
+我发现看板卡片分类是一种很好的方式,可以帮助我创建用户想要查看的内容,并将其放在希望被找到的位置。你是否发现了另一种对用户友好的组织内容的方法?或者看板的另一种有趣用途是什么?如果有的话,请在评论中分享你的想法。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/17/11/kanban-boards-card-sorting
+
+作者:[Heidi Waterhouse][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/hwaterhouse
+[1]:https://en.wikipedia.org/wiki/Kanban
+[2]:https://opensource.com/alternatives/trello
+[3]:https://www.gluster.org/
diff --git a/published/20171116 Record and Share Terminal Session with Showterm.md b/published/20171116 Record and Share Terminal Session with Showterm.md
new file mode 100644
index 0000000000..a82efb3744
--- /dev/null
+++ b/published/20171116 Record and Share Terminal Session with Showterm.md
@@ -0,0 +1,78 @@
+使用 Showterm 录制和分享终端会话
+======
+
+
+
+你可以使用几乎所有的屏幕录制程序轻松录制终端会话。但是,你很可能会得到超大的视频文件。Linux 中有几种终端录制程序,每种录制程序都有自己的优点和缺点。Showterm 是一个可以非常容易地记录终端会话、上传、分享,并将它们嵌入到任何网页中的工具。一个优点是,你不会有巨大的文件来处理。
+
+Showterm 是开源的,该项目可以在这个 [GitHub 页面][1]上找到。
+
+**相关**:[2 个简单的将你的终端会话录制为视频的 Linux 程序][2]
+
+### 在 Linux 中安装 Showterm
+
+Showterm 要求你在计算机上安装了 Ruby。以下是如何安装该程序。
+
+```
+gem install showterm
+```
+
+如果你没有在 Linux 上安装 Ruby,可以这样:
+
+```
+sudo curl showterm.io/showterm > ~/bin/showterm
+sudo chmod +x ~/bin/showterm
+```
+
+如果你只是想运行程序而不是安装:
+
+```
+bash <(curl record.showterm.io)
+```
+
+你可以在终端输入 `showterm --help` 得到帮助页面。如果没有出现帮助页面,那么可能是未安装 `showterm`。现在你已安装了 Showterm(或正在运行独立版本),让我们开始使用该工具进行录制。
+
+**相关**:[如何在 Ubuntu 中录制终端会话][3]
+
+### 录制终端会话
+
+![showterm terminal][4]
+
+录制终端会话非常简单。从命令行运行 `showterm`。这会在后台启动终端录制。所有从命令行输入的命令都由 Showterm 记录。完成录制后,请按 `Ctrl + D` 或在命令行中输入`exit` 停止录制。
+
+Showterm 会上传你的视频并输出一个看起来像 `http://showterm.io/<一长串字符>` 的链接的视频。不幸的是,终端会话会立即上传,而没有任何提示。请不要惊慌!你可以通过输入 `showterm --delete ` 删除任何已上传的视频。在上传视频之前,你可以通过在 `showterm` 命令中添加 `-e` 选项来改变计时。如果视频无法上传,你可以使用 `showterm --retry
+
+
+```
+
+
+我也喜欢 Vue 提供的简短绑定语法,`:` 用于在模板中绑定数据变量,`@` 用于绑定事件。这是一个细节,但写起来很爽而且能够让你的组件代码简洁。
+
+### 2、 单文件组件
+
+大多数人使用 Vue,都使用“单文件组件”。本质上就是一个 .vue 文件对应一个组件,其中包含三部分(CSS、HTML和JavaScript)。
+
+这种技术结合是对的。它让人很容易在一个单独的地方了解每个组件,同时也非常好的鼓励了大家保持每个组件代码的简短。如果你的组件中 JavaScript、CSS 和 HTML 代码占了很多行,那么就到了进一步模块化的时刻了。
+
+在使用 Vue 组件中的 `
-```
-
-
-I also like the short-bindings provided by Vue, ‘:’ for binding data variables into your template and ‘@’ for binding to events. It’s a small thing, but it feels nice to type and keeps your components succinct.
-
-2\. Single File Components
-
-When most people write Vue, they do so using ‘single file components’. Essentially it is a file with the suffix .vue containing up to 3 parts (the css, html and javascript) for each component.
-
-This coupling of technologies feels right. It makes it easy to understand each component in a single place. It also has the nice side effect of encouraging you to keep your code short for each component. If the JavaScript, CSS and HTML for your component is taking up too many lines then it might be time to modularise further.
-
-When it comes to the