mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
commit
f674b9c60f
4
LCTT翻译规范.md
Normal file
4
LCTT翻译规范.md
Normal file
@ -0,0 +1,4 @@
|
||||
# Linux中国翻译规范
|
||||
1. 翻译中出现的专有名词,可参见Dict.md中的翻译。
|
||||
2. 英文人名,如无中文对应译名,一般不译。
|
||||
2. 缩写词,一般不须翻译,可考虑旁注中文全名。
|
||||
@ -0,0 +1,65 @@
|
||||
Debian 拋弃 Linux 标准规范(LSB)
|
||||
=======================
|
||||
|
||||
Linux 标准规范(LSB)是一个意图定义 Linux 发行版为第三方程序所提供的服务和应用层 ABI(Application Binary Interfaces,程序二进制界面) 的[规范][1]。但 Debian 项目内的某些人正在质疑是否值得维持兼容 LSB,他们认为,该项工作的工作量巨大,但好处有限。
|
||||
|
||||
LSB 于2001年首次公布,其模型建立在 [POSIX][2] 和[单一 UNIX 规范(Single UNIX Specification)][3]的基础之上。目前,LSB 由 Linux 基金会的一个[工作小组][4]维护。最新的版本是于2015年6月发布的 [LSB 5.0][5]。它定义了五个 LSB 模块(核芯(core)、桌面、语言、成像(imaging)和试用)。
|
||||
|
||||
每个模块都包含了一系列所需的库及其强制性版本,外加对每个库的公共函数和数据定义的描述。这些模块还包括命名和组织规范,如[文件系统层次标准(FHS,Filesystem Hierarchy Standard)][6]中的文件系统布局或象 Freedesktop 的[XDG 基础目录(XDG Base Directory)][7]规范这样的目录规范。
|
||||
|
||||
似乎只是一个巧合,就在 LSB 5.0 发布的同一周,Debian 项目内部针对其是否值得保持兼容 LSB 进行了一次讨论。在另一个贴子中,在提及兼容 LSB 后,Didier Raboud 顺势[提议][8]将 Debian 的兼容工作维持在最低水平。他说,目前的情况是,Debian 的“lsb-*” 元包( meta-packages)试图规定该标准中提及的库的正确版本,但事实上却没有人去检查所有的符号和数据定义是否满足要求。
|
||||
|
||||
另外,LSB 还不断在膨胀;他说, LSB 4.1 版(接近 Debian “jessie” 发布时的最新版本)包含“*1493个组件、1672个库、38491条命令、30176个类和716202个接口*”。似乎没有人有兴趣检查 Debian 包中的这些细节,他解释道,又补充说,“*去年在 DebConf 上我举行过一次 LSB BoF,后来又与很多人讨论过 src:lsb,我收回自己的‘几乎没有人在意’的说法*”。但,重要的是,Debian 似乎并不仅局限于兴趣的缺乏:
|
||||
|
||||
我认为,这个问题的关键在于是否值得去玩这整个游戏:我还没听说有哪个软件通过 LSB 包来发行。LSB 认证的应用清单上只有 6个公司的_8_个应用,其中仅有一个是针对不低于 LSB 4 的。
|
||||
|
||||
Raboud 提议 Debian 摈弃除了 [lsb-base][9] 包(目前包括一个用于启动系统所需的小的 shell 函数集合)和 [lsb-release][10] 包(提供一个简单工具,用户可用它查询发行版的身份以及该发行版宣称的与哪个 LSB 级别兼容)之外的所有内容。
|
||||
|
||||
[后来][11],他又称,将 LSB 基本上改变为“*Debian 和 FLOSS 世界中的所有的其它人所_实际_做的任何事*”可能会使得该标准(以及在 Debian 为支持它所做的工作)更有价值。但此时他再次质疑是否有人会对推动这个目标有兴趣。
|
||||
|
||||
如果说他最初称 LSB 中缺乏兴趣没有足够的证据,随后整整三个月之内没有任何人对维持 LSB 兼容的包提供支持,并进行了两次拋弃它们的投票。最后,9月17日,Raboud [宣布][12]他已经抽掉 `src:lsb` 包(如前所述,保留了`lsb-base` 和 `lsb-release`),将将其上载到 “unstable” 归档中。这个最小的工具集可以让感兴趣的用户在启动了下一个 Debian 版本后查询它是否兼容 LSB:结果将为“否”。
|
||||
|
||||
Raboud 补充说,即便摈弃了兼容 LSB,Debian 仍计划继续兼容 FHS:
|
||||
|
||||
但 Debian 并没有放弃所有的 LSB:我们仍将严格遵守 FHS(直到 Debian Policy 版本 2.3;虽然今年8月已经发布了3.0),而且我们的 SysV 启动脚本几乎全部遵循 VIII.22.{2-8}。但请不要误解,此次 src:lsb 上载明确说明我们将离开 LSB。
|
||||
|
||||
在该宣告之后,Nikolaus Rath [回应][13]称某些私有应用依赖`/lib`和`/lib64`中的符号链接`ld-lsb.so*`,而这些符号链接由`lsb-*`包提供。Raboud 则[建议][14]应改由`libc6`包提供;该包维护人员Aurelien Jarno [称][15],如果提供这样一个补丁,他将会接受它。
|
||||
|
||||
似乎唯一的遗留问题只是某些打印机驱动包会依赖 LSB 兼容。Raboud 称,在其首个贴子中已经说明,据他所知,实际发布的唯一一个依赖 LSB 兼容的包为 [OpenPrinting][16] 驱动程序。Michael Biebl [称][17],主归档中有这样一个驱动包;Raboud 则[回应][18]说,他认为这个有问题的包应该被移到非自由仓库,因其包括了一个二进制驱动。
|
||||
|
||||
于是,这个问题看上去已经尘埃落定,至于对于目前的 Debian 开发周期来说是如此的状况。很自然的是,未来让人更感觉兴趣的是,如果该决定存在一些影响的话,那么人们将会看到它对更广泛的 LSB 接受度有何影响。正如 Raboud 所说的那样,被认证为 LSB 兼容的发行版数量很[少][19]。人们很难不会注意到这些发行版很大程度上是“企业”的变种。
|
||||
|
||||
也许,对某些商业领域来说,LSB 仍很重要,但很难知道有多少那些企业发行版的客户真正关心 LSB 认证标签。然而,如果 Debian 的经验靠得住的话,对这种认证的一般兴趣可能会急剧下降。
|
||||
|
||||
----
|
||||
|
||||
via:https://lwn.net/Articles/658809/
|
||||
|
||||
作者:Nathan Willis
|
||||
译者:[Yuking](https://github.com/Yuking-net)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,
|
||||
[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[1]:http://refspecs.linuxfoundation.org/lsb.shtml
|
||||
[2]:https://en.wikipedia.org/wiki/POSIX
|
||||
[3]:https://en.wikipedia.org/wiki/Single_UNIX_Specification
|
||||
[4]:http://www.linuxfoundation.org/collaborate/workgroups/lsb
|
||||
[5]:http://www.linuxfoundation.org/collaborate/workgroups/lsb/lsb-50
|
||||
[6]:http://www.linuxfoundation.org/collaborate/workgroups/lsb/fhs
|
||||
[7]:http://standards.freedesktop.org/basedir-spec/basedir-spec-0.6.html
|
||||
[8]:https://lwn.net/Articles/658838/
|
||||
[9]:https://packages.debian.org/sid/lsb-base
|
||||
[10]:https://packages.debian.org/sid/lsb-release
|
||||
[11]:https://lwn.net/Articles/658842/
|
||||
[12]:https://lwn.net/Articles/658843/
|
||||
[13]:https://lwn.net/Articles/658846/
|
||||
[14]:https://lwn.net/Articles/658847/
|
||||
[15]:https://lwn.net/Articles/658848/
|
||||
[16]:http://www.linuxfoundation.org/collaborate/workgroups/openprinting/
|
||||
[17]:https://lwn.net/Articles/658844/
|
||||
[18]:https://lwn.net/Articles/658845/
|
||||
[19]:https://www.linuxbase.org/lsb-cert/productdir.php?by_lsb
|
||||
|
||||
@ -1,66 +0,0 @@
|
||||
Debian dropping the Linux Standard Base
|
||||
=======================================
|
||||
|
||||
The Linux Standard Base (LSB) is a [specification][1] that purports to define the services and application-level ABIs that a Linux distribution will provide for use by third-party programs. But some in the Debian project are questioning the value of maintaining LSB compliance—it has become, they say, a considerable amount of
|
||||
work for little measurable benefit.
|
||||
|
||||
The LSB was first released in 2001, and was modeled to a degree on the [POSIX][2] and [Single UNIX Specification][3] standards. Today, the LSB is maintained by a [working group][4] at the Linux Foundation. The most recent release was [LSB 5.0][5] in June 2015. It defines five LSB modules (Core, Desktop, Languages, Imaging, and Trial Use).
|
||||
|
||||
The bulk of each module consists of a list of required libraries and the mandatory version for each, plus a description of the public functions and data definitions for each library. Other contents of the modules include naming and organizational specifications, such as the filesystem layout in the [Filesystem Hierarchy Standard (FHS)][6] or directory specifications like the Freedesktop [XDG Base Directory][7] specification.
|
||||
|
||||
In what appears to be sheer coincidence, during the same week that LSB 5.0 was released, a discussion arose within the Debian project as to whether or not maintaining LSB compliance was a worthwhile pursuit for Debian. After LSB compliance was mentioned in passing in another thread, Didier Raboud took the opportunity to [propose][8] scaling back Debian's compliance efforts to the bare minimum. As it stands today, he said, Debian's `lsb-*` meta-packages attempt to require the correct versions of the libraries mentioned in the standard, but no one is actually checking that all of the symbols and data definitions are met as aresult.
|
||||
|
||||
Furthermore, the LSB continues to grow; the 4.1 release (the most recent when Debian "jessie" was released) consisted of "*1493 components, 1672 libs, 38491 commands, 30176 classes and 716202 interfaces*," he said. No one seems interested in checking those details in the Debian packages, he noted, adding that "*I've held an LSB BoF last year at DebConf, and discussed src:lsb with various people back then, and what I took back was 'roughly no one cares'.*" Just as importantly, though, the lack of interest does not seem to be limited to Debian:
|
||||
|
||||
The crux of the issue is, I think, whether this whole game is worth the work: I am yet to hear about software distribution happening through LSB packages. There are only _8_ applications by 6 companies on the LSB certified applications list, of which only one is against LSB >= 4.
|
||||
|
||||
Raboud proposed that Debian drop everything except for the [lsb-base][9] package (which currently includes a small set of shell functions for use by the init system) and the [lsb-release][10] package (which provides a simple tool that users can use to query the identity of the distribution and what level of LSB compliance it advertises).
|
||||
|
||||
In a follow-up [message][11],he noted that changing the LSB to be, essentially, "*whatever Debian as well as all other actors in the FLOSS world are _actually_ doing*" might make the standard—and the effort to support it in Debian—more valuable. But here again, he questioned whether anyone was interested in pursuing that objective.
|
||||
|
||||
If his initial comments about lack of interest in LSB were not evidence enough, a full three months then went by with no one offering any support for maintaining the LSB-compliance packages and two terse votes in favor of dropping them. Consequently, on September 17, Raboud [announced][12] that he had gutted the `src:lsb` package (leaving just `lsb-base` and `lsb-release` as described) and uploaded it to the "unstable" archive. That minimalist set of tools will allow an interested user to start up the next Debian release and query whether or not it is LSB-compliant—and the answer will be "no."
|
||||
|
||||
Raboud added that Debian does still plan to maintain FHS compliance, even though it is dropping LSB compliance:
|
||||
|
||||
But Debian's not throwing all of the LSB overboard: we're still firmly standing behind the FHS (version 2.3 through Debian Policy; although 3.0 was released in August this year) and our SysV init scripts mostly conform to LSB VIII.22.{2-8}. But don't get me wrong, this src:lsb upload is an explicit move away from the LSB.
|
||||
|
||||
After the announcement, Nikolaus Rath [replied][13] that some proprietary applications expect `ld-lsb.so*` symbolic links to be present in `/lib` and `/lib64`, and that those symbolic links had been provided by the `lsb-*` package set. Raboud [suggested][14] that the links should be provided by the `libc6` package instead; package maintainer Aurelien Jarno [said][15] he would accept such a patch if it was provided.
|
||||
|
||||
The only remaining wrinkle, it seems, is that there are some printer-driver packages that expect some measure of LSB compliance. Raboud had noted in his first message that [OpenPrinting][16] drivers were the only example of LSB-compliant packages he had seen actually distributed. Michael Biebl [noted][17] that there was one such driver package in the main archive; Raboud [replied][18] that he believed the package in question ought to be moved to the non-free repository anyway, since it contained a binary driver.
|
||||
|
||||
With that, the issue appears to be settled, at least for the current Debian development cycle. What will be more interesting, naturally, will be to see what effect, if any, the decision has on broader LSB acceptance. As Raboud alluded to, the number of distributions that are certified as LSB-compliant is [small][19]. It is hard not to notice that those distributions are largely of the "enterprise" variety.
|
||||
|
||||
Perhaps, then, LSB compliance is still important to some business sectors, but it is hard to know how many customers of those enterprise distributions genuinely care about the LSB certification stamp. If Debian's experience is anything to go by, however, general interest in such certification may be in steep decline.
|
||||
|
||||
---
|
||||
|
||||
via:https://lwn.net/Articles/658809/
|
||||
|
||||
作者:Nathan Willis
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,
|
||||
[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[1]:http://refspecs.linuxfoundation.org/lsb.shtml
|
||||
[2]:https://en.wikipedia.org/wiki/POSIX
|
||||
[3]:https://en.wikipedia.org/wiki/Single_UNIX_Specification
|
||||
[4]:http://www.linuxfoundation.org/collaborate/workgroups/lsb
|
||||
[5]:http://www.linuxfoundation.org/collaborate/workgroups/lsb/lsb-50
|
||||
[6]:http://www.linuxfoundation.org/collaborate/workgroups/lsb/fhs
|
||||
[7]:http://standards.freedesktop.org/basedir-spec/basedir-spec-0.6.html
|
||||
[8]:https://lwn.net/Articles/658838/
|
||||
[9]:https://packages.debian.org/sid/lsb-base
|
||||
[10]:https://packages.debian.org/sid/lsb-release
|
||||
[11]:https://lwn.net/Articles/658842/
|
||||
[12]:/Articles/658843/
|
||||
[13]:/Articles/658846/
|
||||
[14]:/Articles/658847/
|
||||
[15]:/Articles/658848/
|
||||
[16]:http://www.linuxfoundation.org/collaborate/workgroups/openprinting/
|
||||
[17]:/Articles/658844/
|
||||
[18]:/Articles/658845/
|
||||
|
||||
|
||||
@ -1,64 +0,0 @@
|
||||
alim0x translating
|
||||
|
||||
Open Source Media Player MPlayer 1.2 Released
|
||||
================================================================================
|
||||

|
||||
|
||||
Almost three years after [MPlaayer][1] 1.1, the new version of MPlayer has been released last week. MPlayer 1.2 brings up support for many new codecs in this release.
|
||||
|
||||
MPlayer is a cross-platform, open source media player. Its name is an abbreviation of “Movie Player”. MPlayer has been one of the oldest video players for Linux and during last 15 years, it has inspired a number of other media players. Some of the famous media players based on MPlayer are:
|
||||
|
||||
- [MPV][2]
|
||||
- SMPlayer
|
||||
- KPlayer
|
||||
- GNOME MPlayer
|
||||
- Deepin Player
|
||||
|
||||
#### What’s new in MPlayer 1.2? ####
|
||||
|
||||
- Compatibility with FFmpeg 2.8
|
||||
- VDPAU hardware acceleration for H.265/HEVC
|
||||
- A number of new codecs supported via FFmpeg
|
||||
- Improvements in TV and DVB support
|
||||
- GUI improvements
|
||||
- external dependency on libdvdcss/libdvdnav packages
|
||||
|
||||
#### Install MPlayer 1.2 in Linux ####
|
||||
|
||||
Most Linux distributions are still having MPlayer 1.1. If you want to use the new MPlayer 1.2, you’ll have to compile it from the source code which could be tricky at times for beginners.
|
||||
|
||||
I have used Ubuntu 15.04 for the installation of MPlayer 1.2. Installation instructions will remain the same for all Linux distributions except the part where you need to install yasm.
|
||||
|
||||
Open a terminal and use the following commands:
|
||||
|
||||
wget http://www.mplayerhq.hu/MPlayer/releases/MPlayer-1.2.tar.xz
|
||||
|
||||
tar xvf MPlayer-1.1.1.tar.xz
|
||||
|
||||
cd MPlayer-1.2
|
||||
|
||||
sudo apt-get install yasm
|
||||
|
||||
./configure
|
||||
|
||||
When you run make, it will throw a number of things on the terminal screen and takes some time to build it. Have patience.
|
||||
|
||||
make
|
||||
|
||||
sudo make install
|
||||
|
||||
If you feel uncomfortable using the source code, I advise you to either wait forMPlayer 1.2 to land in the repositories of your Linux distribution or use an alternate like MPV.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/mplayer-1-2-released/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:https://www.mplayerhq.hu/
|
||||
[2]:http://mpv.io/
|
||||
@ -0,0 +1,44 @@
|
||||
Curious about Linux? Try Linux Desktop on the Cloud
|
||||
================================================================================
|
||||
Linux maintains a very small market share as a desktop operating system. Current surveys estimate its share to be a mere 2%; contrast that with the various strains (no pun intended) of Windows which total nearly 90% of the desktop market. For Linux to challenge Microsoft's monopoly on the desktop, there needs to be a simple way of learning about this different operating system. And it would be naive to believe a typical Windows user is going to buy a second machine, tinker with partitioning a hard disk to set up a multi-boot system, or just jump ship to Linux without an easy way back.
|
||||
|
||||

|
||||
|
||||
We have examined a number of risk-free ways users can experiment with Linux without dabbling with partition management. Various options include Live CD/DVDs, USB keys and desktop virtualization software. For the latter, I can strongly recommend VMWare (VMWare Player) or Oracle VirtualBox, two relatively easy and free ways of installing and running multiple operating systems on a desktop or laptop computer. Each virtual machine has its own share of CPU, memory, network interfaces etc which is isolated from other virtual machines. But virtual machines still require some effort to get Linux up and running, and a reasonably powerful machine. Too much effort for a mere inquisitive mind.
|
||||
|
||||
It can be difficult to break down preconceptions. Many Windows users will have experimented with free software that is available on Linux. But there are many facets to learn on Linux. And it takes time to become accustomed to the way things work in Linux.
|
||||
|
||||
Surely there should be an effortless way for a beginner to experiment with Linux for the first time? Indeed there is; step forward the online cloud lab.
|
||||
|
||||
### LabxNow ###
|
||||
|
||||

|
||||
|
||||
LabxNow provides a free service for general users offering Linux remote desktop over the browser. The developers promote the service as having a personal remote lab (to play around, develop, whatever!) that will be accessible from anywhere, with the internet of course.
|
||||
|
||||
The service currently offers a free virtual private server with 2 cores, 4GB RAM and 10GB SSD space. The service runs on a 4 AMD 6272 CPU with 128GB RAM.
|
||||
|
||||
#### Features include: ####
|
||||
|
||||
- Machine images: Ubuntu 14.04 with Xfce 4.10, RHEL 6.5, CentOS with Gnome, and Oracle
|
||||
- Hardware: CPU - 1 or 2 cores; RAM: 512MB, 1GB, 2GB or 4GB
|
||||
- Fast network for data transfers
|
||||
- Works with all popular browsers
|
||||
- Install anything, run anything - an excellent way to experiment and learn all about Linux without any risk
|
||||
- Easily add, delete, manage and customize VMs
|
||||
- Share VMs, Remote desktop support
|
||||
|
||||
All you need is a reasonable Internet connected device. Forget about high cost VPS, domain space or hardware support. LabxNow offers a great way of experimenting with Ubuntu, RHEL and CentOS. It gives Windows users an excellent environment to dip their toes into the wonderful world of Linux. Further, it allows users to do (programming) work from anywhere in the word without having the stress of installing Linux on each machine. Point your web browser at [www.labxnow.org/labxweb/][1].
|
||||
|
||||
There are other services (mostly paid services) that allow users to experiment with Linux. These include Cloudsigma which offers a free 7 day trial, and Icebergs.io (full root access via HTML5). But for now, LabxNow gets my recommendation.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20151003095334682/LinuxCloud.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.labxnow.org/labxweb/
|
||||
61
sources/share/20151012 What is a good IDE for R on Linux.md
Normal file
61
sources/share/20151012 What is a good IDE for R on Linux.md
Normal file
@ -0,0 +1,61 @@
|
||||
What is a good IDE for R on Linux
|
||||
================================================================================
|
||||
Some time ago, I covered some of the [best IDEs for C/C++][1] on Linux. Obviously C and C++ are not the only programming languages out there, and it is time to turn to something a bit more specific.
|
||||
|
||||
If you have ever done some statistics, it is possible that you have encountered the [language R][2]. If you have not, I really recommend this open source programming language which is tailored for statistics and data mining. Coming from a coding background, you might be thrown off a bit by the syntax, but hopefully you will get seduced by the speed of its vector operations. In short, try it. And to do so, what better way to start with an IDE? R being a cross platform language, there are a bunch of good IDEs which make data analysis in R far more pleasurable. If you are very attached to a particular editor, there are also some very good plugins to turn that editor into a fully-fledged R IDE.
|
||||
|
||||
Here is a list of five good IDEs for R language in Linux environment.
|
||||
|
||||
### 1. RStudio ###
|
||||
|
||||
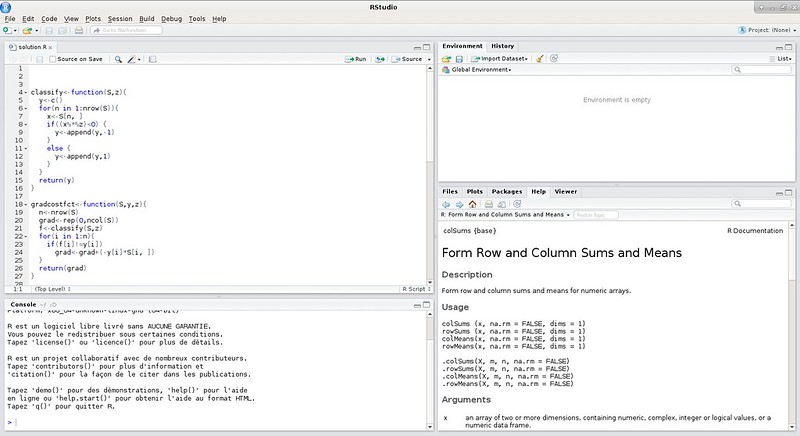
|
||||
|
||||
Let’s start hard with maybe one of the most popular R IDEs out there: [RStudio][3]. In addition to common IDE features like syntax highlighting and code completion, RStudio stands out for its integration of R documentation, its powerful debugger and its multiple views system. If you start with R, I can only recommend RStudio as the R console on the side is perfect for testing your code in real time, and the object explorer will help you understand what kind of data you are dealing with. Finally, what really conquered me was the integration of the plots visualiser, making it easy to export your graphs as images. On the downside, RStudio lacks the shortcuts and the advanced settings to make it a perfect IDE. Still, with a free version under AGPL license, Linux users have no excuses not to give this IDE a try.
|
||||
|
||||
### 2. Emacs with ESS ###
|
||||
|
||||
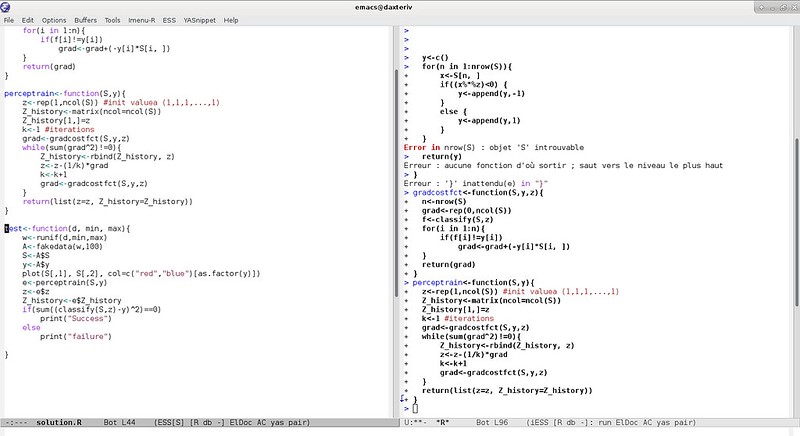
|
||||
|
||||
In my last post about IDEs, some people were disappointed by the absence of Emacs in my list. My main reason for that is that Emacs is kind of the wild card of IDE: you could place it on any list for any languages. But things are different for [R with the ESS plugin][4]. Emacs Speaks Statistics (ESS) is an amazing plugin which completely changes the way you use the Emacs editor and really fits the needs of R coders. A bit like RStudio which has multiple views, Emacs with ESS displays presents two panels: one with the code and one with an R console, making it easy to test your code in real time and explore the objects. But ESS's real strength is its seamless integration with other Emacs plugins you might have installed and its advanced configuration options. In short, if you like your Emacs shortcuts, you will like to be able to use them in an environment that makes sense for R development. For full disclosure, however, I have heard of and experienced some efficiency issues when dealing with a lot of data in ESS. Nothing too major to be a problem, but just enough have me prefer RStudio.
|
||||
|
||||
### 3. Vim with Vim-R-plugin ###
|
||||
|
||||
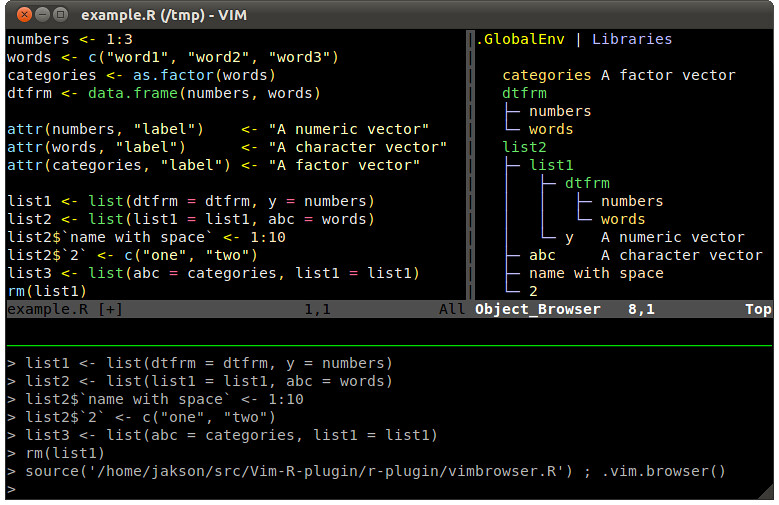
|
||||
|
||||
Because I do not want to discriminate after talking about Emacs, I also tried the equivalent for Vim: the [Vim-R-plugin][5]. Using the terminal tool called tmux, this plugin makes it possible to have an R console open and code at the same time. But most importantly, it brings syntax highlighting and omni-completion for R objects to Vim. You can also easily access R documentation and browse objects. But once again, the strength comes from its extensive customization capacities and the speed of Vim. If you are tempted by this option, I direct you to the extremely thorough [documentation][6] on installing and setting up your environment.
|
||||
|
||||
### 4. Gedit with RGedit ###
|
||||
|
||||
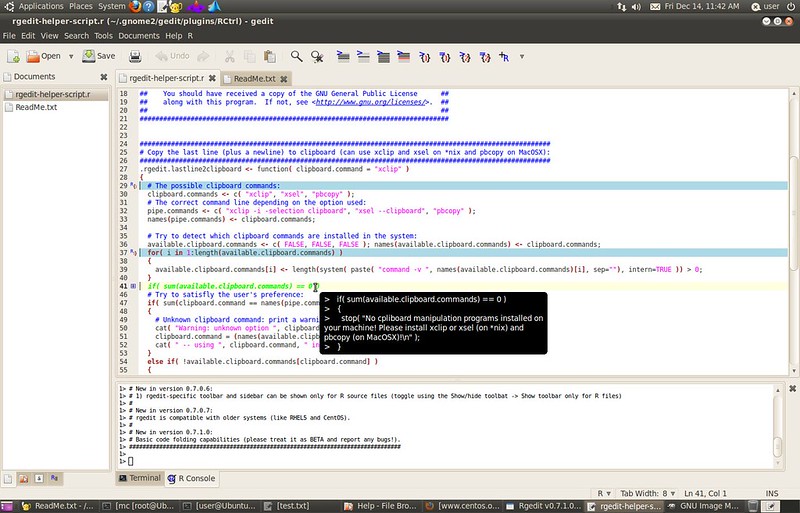
|
||||
|
||||
If neither Emacs or Vim is your cup of tea, and what you like is your default Gnome editor, then [RGedit][7] is made for you: a plugin to code in R from Gedit. Gedit is known to be more powerful than what it looks. With a very large library of plugins, it is possible to do a lot with it. And RGedit is precisely the plugin you need to code in R from Gedit. It comes with the classic syntax highlighting and integration of the R console at the bottom of the screen, but also a bunch of unique features like multiple profiles, code folding, file explorer, and even a GUI wizard to generate code from snippets. Despite my indifference towards Gedit, I have to admit that these features go beyond the basic plugin functionality and really make a difference when you spend a lot of time analyzing data. The only shadow is that the last update is from 2013. I really hope that this project can pick up again.
|
||||
|
||||
### 5. RKWard ###
|
||||
|
||||
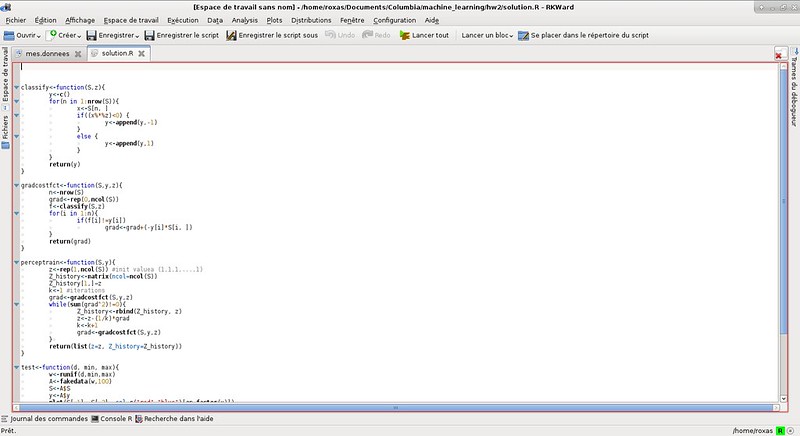
|
||||
|
||||
Finally, last but not least, [RKWard][8] is an R IDE made for KDE environments. What I love the most about it is its name. But honestly, its package management system and spreadsheet-like data editor come in close second. In addition to that, it includes an easy system for plotting and importing data, and can be extended by plugins. If you are not a fan of the KDE feel, you might be a bit uncomfortable, but if you are, I would really recommend checking it out.
|
||||
|
||||
To conclude, whether you are new to R or not, these IDEs might be useful to you. It does not matter if you prefer something that stands for itself, or a plugin for your favorite editor, I am sure that you will appreciate one of the features these software provide. I am also sure I missed a lot of good IDEs for R, which deserve to be on this list. So since you wrote a lot of very good comments for the post on the IDEs for C/C++, I invite you to do the same here and share your knowledge.
|
||||
|
||||
What do you feel is a good IDE for R on Linux? Please let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/good-ide-for-r-on-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://xmodulo.com/good-ide-for-c-cpp-linux.html
|
||||
[2]:https://www.r-project.org/
|
||||
[3]:https://www.rstudio.com/
|
||||
[4]:http://ess.r-project.org/
|
||||
[5]:http://www.vim.org/scripts/script.php?script_id=2628
|
||||
[6]:http://www.lepem.ufc.br/jaa/r-plugin.html
|
||||
[7]:http://rgedit.sourceforge.net/
|
||||
[8]:https://rkward.kde.org/
|
||||
@ -0,0 +1,101 @@
|
||||
The Brief History Of Aix, HP-UX, Solaris, BSD, And LINUX
|
||||
================================================================================
|
||||

|
||||
|
||||
Always remember that when doors close on you, other doors open. [Ken Thompson][1] and [Dennis Richie][2] are a great example for such saying. They were two of the best information technology specialists in the **20th** century as they created the **UNIX** system which is considered one the most influential and inspirational software that ever written.
|
||||
|
||||
### The UNIX systems beginning at Bell Labs ###
|
||||
|
||||
**UNIX** which was originally called **UNICS** (**UN**iplexed **I**nformation and **C**omputing **S**ervice) has a great family and was never born by itself. The grandfather of UNIX was **CTSS** (**C**ompatible **T**ime **S**haring **S**ystem) and the father was the **Multics** (**MULT**iplexed **I**nformation and **C**omputing **S**ervice) project which supports interactive timesharing for mainframe computers by huge communities of users.
|
||||
|
||||
UNIX was born at **Bell Labs** in **1969** by **Ken Thompson** and later **Dennis Richie**. These two great researchers and scientists worked on a collaborative project with **General Electric** and the **Massachusetts Institute of Technology** to create an interactive timesharing system called the Multics.
|
||||
|
||||
Multics was created to combine timesharing with other technological advances, allowing the users to phone the computer from remote terminals, then edit documents, read e-mail, run calculations, and so on.
|
||||
|
||||
Over the next five years, AT&T corporate invested millions of dollars in the Multics project. They purchased mainframe computer called GE-645 and they dedicated to the effort of the top researchers at Bell Labs such as Ken Thompson, Stuart Feldman, Dennis Ritchie, M. Douglas McIlroy, Joseph F. Ossanna, and Robert Morris. The project was too ambitious, but it fell troublingly behind the schedule. And at the end, AT&T leaders decided to leave the project.
|
||||
|
||||
Bell Labs managers decided to stop any further work on operating systems which made many researchers frustrated and upset. But thanks to Thompson, Richie, and some researchers who ignored their bosses’ instructions and continued working with love on their labs, UNIX was created as one the greatest operating systems of all times.
|
||||
|
||||
UNIX started its life on a PDP-7 minicomputer which was a testing machine for Thompson’s ideas about the operating systems design and a platform for Thompsons and Richie’s game simulation that was called Space and Travel.
|
||||
|
||||
> “What we wanted to preserve was not just a good environment in which to do programming, but a system around which a fellowship could form. We knew from experience that the essence of communal computing, as supplied by remote-access, time-shared machines, is not just to type programs into a terminal instead of a keypunch, but to encourage close communication”. Dennis Richie Said.
|
||||
|
||||
UNIX was so close to be the first system under which the programmer could directly sit down at a machine and start composing programs on the fly, explore possibilities and also test while composing. All through UNIX lifetime, it has had a growing more capabilities pattern by attracting skilled volunteer effort from different programmers impatient with the other operating systems limitations.
|
||||
|
||||
UNIX has received its first funding for a PDP-11/20 in 1970, the UNIX operating system was then officially named and could run on the PDP-11/20. The first real job from UNIX was in 1971, it was to support word processing for the patent department at Bell Labs.
|
||||
|
||||
### The C revolution on UNIX systems ###
|
||||
|
||||
Dennis Richie invented a higher level programming language called “**C**” in **1972**, later he decided with Ken Thompson to rewrite the UNIX in “C” to give the system more portability options. They wrote and debugged almost 100,000 code lines that year. The migration to the “C” language resulted in highly portable software that require only a relatively small machine-dependent code to be then replaced when porting UNIX to another computing platform.
|
||||
|
||||
The UNIX was first formally presented to the outside world in 1973 on Operating Systems Principles, where Dennis Ritchie and Ken Thompson delivered a paper, then AT&T released Version 5 of the UNIX system and licensed it to the educational institutions, and then in 1975 they licensed Version 6 of UNIX to companies for the first time with a cost **$20.000**. The most widely used version of UNIX was Version 7 in 1980 where anybody could purchase a license but it was very restrictive terms in this license. The license included the source code, the machine dependents kernel which was written in PDP-11 assembly language. At all, versions of UNIX systems were determined by its user manuals editions.
|
||||
|
||||
### The AIX System ###
|
||||
|
||||
In **1983**, **Microsoft** had a plan to make a **Xenix** MS-DOS’s multiuser successor, and they created Xenix-based Altos 586 with **512 KB** RAM and **10 MB** hard drive by this year with cost $8,000. By 1984, 100,000 UNIX installations around the world for the System V Release 2. In 1986, 4.3BSD was released that included internet name server and the **AIX system** was announced by **IBM** with Installation base over 250,000. AIX is based on Unix System V, this system has BSD roots and is a hybrid of both.
|
||||
|
||||
AIX was the first operating system that introduced a **journaled file system (JFS)** and an integrated Logical Volume Manager (LVM). IBM ported AIX to its RS/6000 platform by 1989. The Version 5L was a breakthrough release that was introduced in 2001 to provide Linux affinity and logical partitioning with the Power4 servers.
|
||||
|
||||
AIX introduced virtualization by 2004 in AIX 5.3 with Advanced Power Virtualization (APV) which offered Symmetric multi-threading, micro-partitioning, and shared processor pools.
|
||||
|
||||
In 2007, IBM started to enhance its virtualization product, by coinciding with the AIX 6.1 release and the architecture of Power6. They also rebranded Advanced Power Virtualization to PowerVM.
|
||||
|
||||
The enhancements included form of workload partitioning that was called WPARs, that are similar to Solaris zones/Containers, but with much better functionality.
|
||||
|
||||
### The HP-UX System ###
|
||||
|
||||
The **Hewlett-Packard’s UNIX (HP-UX)** was based originally on System V release 3. The system initially ran exclusively on the PA-RISC HP 9000 platform. The Version 1 of HP-UX was released in 1984.
|
||||
|
||||
The Version 9, introduced SAM, its character-based graphical user interface (GUI), from which one can administrate the system. The Version 10, was introduced in 1995, and brought some changes in the layout of the system file and directory structure, which made it similar to AT&T SVR4.
|
||||
|
||||
The Version 11 was introduced in 1997. It was HP’s first release to support 64-bit addressing. But in 2000, this release was rebranded to 11i, as HP introduced operating environments and bundled groups of layered applications for specific Information Technology purposes.
|
||||
|
||||
In 2001, The Version 11.20 was introduced with support for Itanium systems. The HP-UX was the first UNIX that used ACLs (Access Control Lists) for file permissions and it was also one of the first that introduced built-in support for Logical Volume Manager.
|
||||
|
||||
Nowadays, HP-UX uses Veritas as primary file system due to partnership between Veritas and HP.
|
||||
|
||||
The HP-UX is up to release 11iv3, update 4.
|
||||
|
||||
### The Solaris System ###
|
||||
|
||||
The Sun’s UNIX version, **Solaris**, was the successor of **SunOS**, which was founded in 1992. SunOS was originally based on the BSD (Berkeley Software Distribution) flavor of UNIX but SunOS versions 5.0 and later were based on Unix System V Release 4 which was rebranded as Solaris.
|
||||
|
||||
SunOS version 1.0 was introduced with support for Sun-1 and Sun-2 systems in 1983. Version 2.0 was introduced later in 1985. In 1987, Sun and AT&T announced that they would collaborate on a project to merge System V and BSD into only one release, based on SVR4.
|
||||
|
||||
The Solaris 2.4 was first Sparc/x86 release by Sun. The last release of the SunOS was version 4.1.4 announced in November 1994. The Solaris 7 was the first 64-bit Ultra Sparc release and it added native support for file system metadata logging.
|
||||
|
||||
Solaris 9 was introduced in 2002, with support for Linux capabilities and Solaris Volume Manager. Then, Solaris 10 was introduced in 2005, and has number of innovations, such as support for its Solaris Containers, new ZFS file system, and Logical Domains.
|
||||
|
||||
The Solaris system is presently up to version 10 as the latest update was released in 2008.
|
||||
|
||||
### Linux ###
|
||||
|
||||
By 1991 there were growing requirements for a free commercial alternative. Therefore **Linus Torvalds** set out to create new free operating system kernel that eventually became **Linux**. Linux started with a small number of “C” files and under a license which prohibited commercial distribution. Linux is a UNIX-like system and is different than UNIX.
|
||||
|
||||
Version 3.18 was introduced in 2015 under a GNU Public License. IBM said that more than 18 million lines of code are Open Source and available to developers.
|
||||
|
||||
The GNU Public License becomes the most widely available free software license which you can find nowadays. In accordance with the Open Source principles, this license permits individuals and organizations the freedom to distribute, run, share by copying, study, and also modify the code of the software.
|
||||
|
||||
### UNIX vs. Linux: Technical Overview ###
|
||||
|
||||
- Linux can encourage more diversity, and Linux developers come from wider range of backgrounds with different experiences and opinions.
|
||||
- Linux can run on wider range of platforms and also types of architecture than UNIX.
|
||||
- Developers of UNIX commercial editions have a specific target platform and audience in mind for their operating system.
|
||||
- **Linux is more secure than UNIX** as it is less affected by virus threats or malware attacks. Linux has had about 60-100 viruses to date, but at the same time none of them are currently spreading. On the other hand, UNIX has had 85-120 viruses but some of them are still spreading.
|
||||
- With commands of UNIX, tools and elements are rarely changed, and even some interfaces and command lines arguments still remain in later versions of UNIX.
|
||||
- Some Linux development projects get funded on a voluntary basis such as Debian. The other projects maintain a community version of commercial Linux distributions such as SUSE with openSUSE and Red Hat with Fedora.
|
||||
- Traditional UNIX is about scale up, but on the other hand Linux is about scale out.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/brief-history-aix-hp-ux-solaris-bsd-linux/
|
||||
|
||||
作者:[M.el Khamlichi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/pirat9/
|
||||
[1]:http://www.unixmen.com/ken-thompson-unix-systems-father/
|
||||
[2]:http://www.unixmen.com/dennis-m-ritchie-father-c-programming-language/
|
||||
@ -1,96 +0,0 @@
|
||||
How to Run ISO Files Directly From the HDD with GRUB2
|
||||
================================================================================
|
||||

|
||||
|
||||
Most Linux distros offer a live environment, which you can boot up from a USB drive, for you to test the system without installing. You can either use it to evaluate the distro or as a disposable OS. While it is easy to copy these onto a USB disk, in certain cases one might want to run the same ISO image often or run different ones regularly. GRUB 2 can be configured so that you do not need to burn the ISOs to disk or use a USB drive, but need to run a live environment directly form the boot menu.
|
||||
|
||||
### Obtaining and checking bootable ISO images ###
|
||||
|
||||
To obtain an ISO image, you should usually visit the website of the desired distribution and download any image that is compatible with your setup. If the image can be started from a USB, it should be able to start from the GRUB menu as well.
|
||||
|
||||
Once the image has finished downloading, you should check its integrity by running a simple md5 check on it. This will output a long combination of numbers and alphanumeric characters
|
||||
|
||||

|
||||
|
||||
which you can compare against the MD5 checksum provided on the download page. The two should be identical.
|
||||
|
||||
### Setting up GRUB 2 ###
|
||||
|
||||
ISO images contain full systems. All you need to do is direct GRUB2 to the appropriate file, and tell it where it can find the kernel and the initramdisk or initram filesystem (depending on which one your distribution uses).
|
||||
|
||||
In this example, a Kubuntu 15.04 live environment will be set up to run on an Ubuntu 14.04 box as a Grub menu item. It should work for most newer Ubuntu-based systems and derivatives. If you have a different system or want to achieve something else, you can get some ideas on how to do this from one of [these files][1], although it will require a little experience with GRUB.
|
||||
|
||||
In this example the file `kubuntu-15.04-desktop-amd64.iso`
|
||||
|
||||
lives in `/home/maketecheasier/TempISOs/` on `/dev/sda1`.
|
||||
|
||||
To make GRUB2 look for it in the right place, you need to edit the
|
||||
|
||||
/etc/grub.d40-custom
|
||||
|
||||

|
||||
|
||||
To start Kubuntu from the above location, add the following code (after adjusting it to your needs) below the commented section, without modifying the original content.
|
||||
|
||||
menuentry "Kubuntu 15.04 ISO" {
|
||||
set isofile="/home/maketecheasier/TempISOs/kubuntu-15.04-desktop-amd64.iso"
|
||||
loopback loop (hd0,1)$isofile
|
||||
echo "Starting $isofile..."
|
||||
linux (loop)/casper/vmlinuz.efi boot=casper iso-scan/filename=${isofile} quiet splash
|
||||
initrd (loop)/casper/initrd.lz
|
||||
}
|
||||
|
||||

|
||||
|
||||
### Breaking down the above code ###
|
||||
|
||||
First set up a variable named `$menuentry`. This is where the ISO file is located. If you want to change to a different ISO, you need to change the bit where it says set `isofile="/path/to/file/name-of-iso-file-.iso"`.
|
||||
|
||||
The next line is where you specify the loopback device; you also need to give it the right partition number. This is the bit where it says
|
||||
|
||||
loopback loop (hd0,1)$isofile
|
||||
|
||||
Note the hd0,1 bit; it is important. This means first HDD, first partition (`/dev/sda1`).
|
||||
|
||||
GRUB’s naming here is slightly confusing. For HDDs, it starts counting from “0”, making the first HDD #0, the second one #1, the third one #2, etc. However, for partitions, it will start counting from 1. First partition is #1, second is #2, etc. There might be a good reason for this but not necessarily a sane one (UX-wise it is a disaster, to be sure)..
|
||||
|
||||
This makes fist disk, first partition, which in Linux would usually look something like `/dev/sda1` become `hd0,1` in GRUB2. The second disk, third partition would be `hd1,3`, and so on.
|
||||
|
||||
The next important line is
|
||||
|
||||
linux (loop)/casper/vmlinuz.efi boot=casper iso-scan/filename=${isofile} quiet splash
|
||||
|
||||
It will load the kernel image. On newer Ubuntu Live CDs, this would be in the `/casper` directory and called `vmlinuz.efi`. If you use a different system, your kernel might be missing the `.efi` extension or be located somewhere else entirely (You can easily check this by opening the ISO file with an archive manager and looking inside `/casper.`). The last options, `quiet splash`, would be your regular GRUB options, if you care to change them.
|
||||
|
||||
Finally
|
||||
|
||||
initrd (loop)/casper/initrd.lz
|
||||
|
||||
will load `initrd`, which is responsible to load a RAMDisk into memory for bootup.
|
||||
|
||||
### Booting into your live system ###
|
||||
|
||||
To make it all work, you will only need to update GRUB2
|
||||
|
||||
sudo update-grub
|
||||
|
||||

|
||||
|
||||
When you reboot your system, you should be presented with a new GRUB entry which will allow you to load into the ISO image you’ve just set up.
|
||||
|
||||

|
||||
|
||||
Selecting the new entry should boot you into the live environment, just like booting from a DVD or USB would.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/run-iso-files-hdd-grub2/
|
||||
|
||||
作者:[Attila Orosz][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/attilaorosz/
|
||||
[1]:http://git.marmotte.net/git/glim/tree/grub2
|
||||
@ -1,3 +1,5 @@
|
||||
alim0x translating
|
||||
|
||||
Display Awesome Linux Logo With Basic Hardware Info Using screenfetch and linux_logo Tools
|
||||
================================================================================
|
||||
Do you want to display a super cool logo of your Linux distribution along with basic hardware information? Look no further try awesome screenfetch and linux_logo utilities.
|
||||
@ -80,7 +82,7 @@ To take a screenshot and to save a file, enter:
|
||||
|
||||
You will see a screenshot file at ~/Desktop/screenFetch-*.jpg. To take a screenshot and upload to imgur directly, enter:
|
||||
|
||||
$ screenfetch -su imgur
|
||||
$ screenfetch -su imgur
|
||||
|
||||
**Sample outputs:**
|
||||
|
||||
@ -100,7 +102,7 @@ You will see a screenshot file at ~/Desktop/screenFetch-*.jpg. To take a screens
|
||||
`ossssssssssssssssssssss/ RAM: 6405MB / 8192MB
|
||||
:ooooooooooooooooooo+.
|
||||
`:+oo+/:-..-:/+o+/-
|
||||
|
||||
|
||||
Taking shot in 3.. 2.. 1.. 0.
|
||||
==> Uploading your screenshot now...your screenshot can be viewed at http://imgur.com/HKIUznn
|
||||
|
||||
@ -130,7 +132,7 @@ Simply type the following command as per your Linux distro.
|
||||
|
||||
Simply type the following command:
|
||||
|
||||
$ linux_logo
|
||||
$ linux_logo
|
||||
|
||||
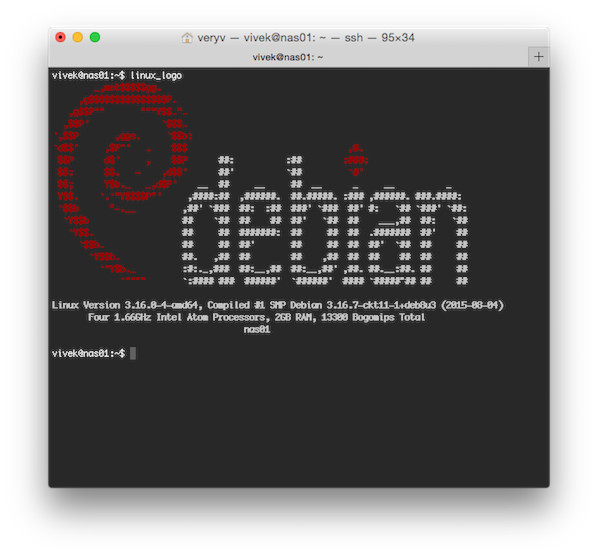
|
||||
|
||||
@ -176,7 +178,7 @@ You can see a list of compiled in logos using:
|
||||
28 Banner Yes sourcemage Source Mage GNU/Linux large
|
||||
29 Banner Yes suse SUSE Logo
|
||||
30 Banner Yes ubuntu Ubuntu Logo
|
||||
|
||||
|
||||
Do "linux_logo -L num" where num is from above to get the appropriate logo.
|
||||
Remember to also use -a to get ascii version.
|
||||
|
||||
@ -224,4 +226,4 @@ via: http://www.cyberciti.biz/hardware/howto-display-linux-logo-in-bash-terminal
|
||||
[2]:http://imgur.com/HKIUznn
|
||||
[3]:http://www.cyberciti.biz/faq/bash-for-loop/
|
||||
[4]:https://github.com/KittyKatt/screenFetch
|
||||
[5]:https://github.com/deater/linux_logo
|
||||
[5]:https://github.com/deater/linux_logo
|
||||
|
||||
@ -1,39 +0,0 @@
|
||||
Fix Shell Script Opens In Text Editor In Ubuntu
|
||||
================================================================================
|
||||

|
||||
|
||||
When you double click on a shell script (.sh file) what do you expect? The normal expectation would be that it is executed. But this might not be the case in Ubuntu, or I should better say in case of Files (Nautilus). You may go crazy yelling “Run, File, Run”, but the file won’t run and instead it gets opened in Gedit.
|
||||
|
||||
I know that you would say, does the file has execute permission? And I say, yes. The shell script has execute permission but still if I double click on it, it is opened in a text editor. I don’t want it and if you are facing the same issue, I assume that even you don’t want it.
|
||||
|
||||
I know that you would have been advised to run it in the terminal and I know that it would work but that’s not an excuse for the GUI way to not work. Is it?
|
||||
|
||||
In this quick tutorial, we shall see **how to make shell script run by double clicking on it**.
|
||||
|
||||
#### Fix Shell script opens in text editor in Ubuntu ####
|
||||
|
||||
The reason why shell scripts are opening in text editor is the default behavior set in Files (file manager in Ubuntu). In earlier versions, it would ask you if you want to run the file or open for editing. The default behavior has been changed in later versions.
|
||||
|
||||
To fix it, go in file manager and from the top menu and click on **Preference**:
|
||||
|
||||

|
||||
|
||||
Next in **Files preferences**, go to **Behavior** tab and you’ll see the option of “**Executables Text Files**“.
|
||||
|
||||
By default, it would have been set to “View executable text files when they are opened”. I would advise you to change it to “Ask each time” so that you’ll have the choice whether to execute it or edit but of course you can set it by default for execution. Your choice here really.
|
||||
|
||||

|
||||
|
||||
I hope this quick tip helped you to fix this little ‘issue’. Questions and suggestions are always welcomed.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/shell-script-opens-text-editor/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
@ -1,3 +1,4 @@
|
||||
ictlyh Translating
|
||||
How To Download Videos Using youtube-dl In Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
263
sources/tech/20151012 10 Useful Utilities For Linux Users.md
Normal file
263
sources/tech/20151012 10 Useful Utilities For Linux Users.md
Normal file
@ -0,0 +1,263 @@
|
||||
10 Useful Utilities For Linux Users
|
||||
================================================================================
|
||||

|
||||
|
||||
### Introduction ###
|
||||
|
||||
In this tutorial, I have collected 10 useful utility tools for Linux users which will include various network monitoring, system auditing or some another random commands which can help users to enhance their productivity. I hope you will enjoy them.
|
||||
|
||||
#### 1. w ####
|
||||
|
||||
Display who is logged into the system and what process executed by them.
|
||||
|
||||
$w
|
||||
|
||||

|
||||
|
||||
for help
|
||||
|
||||
$w -h
|
||||
|
||||
for current user
|
||||
|
||||
$w <username>
|
||||
|
||||

|
||||
|
||||
#### 2. nmon ####
|
||||
|
||||
Nmon or nigel’s monitor is a tool which displays performance information of the system.
|
||||
|
||||
$ sudo apt-get install nmon
|
||||
|
||||
----------
|
||||
|
||||
$ nmon
|
||||
|
||||

|
||||
|
||||
nmon can dump information related to netwrok, cpu, memory or disk uses.
|
||||
|
||||
**nmon cpu info (press c)**
|
||||
|
||||

|
||||
|
||||
**nmon network info (press n)**
|
||||
|
||||

|
||||
|
||||
**nman disk info (press d)**
|
||||
|
||||

|
||||
|
||||
#### 3. ncdu ####
|
||||
|
||||
A Command utility is a cursor based version of ‘du’, this command is used to analyze disk space occupied by various directories.
|
||||
|
||||
$apt-get install ncdu
|
||||
|
||||
----------
|
||||
|
||||
$ncdu /
|
||||
|
||||

|
||||
|
||||
Final output:
|
||||
|
||||

|
||||
|
||||
Press n to order by name or press s to order by file size(default).
|
||||
|
||||
#### 4. slurm ####
|
||||
|
||||
A command line utility used for command based network interface bandwidth monitoring, it will display ascii based graphic.
|
||||
|
||||
$ apt-get install slurm
|
||||
|
||||
Examples:
|
||||
|
||||
$ slurm -i <interface>
|
||||
|
||||
----------
|
||||
|
||||
$ slurm -i eth1
|
||||
|
||||

|
||||
|
||||
**options**
|
||||
|
||||
- Press **l** to display lx/tx led.
|
||||
- press **c** to switch to classic mode.
|
||||
- press **r** to refresh screen.
|
||||
- press **q** to quit.
|
||||
|
||||
#### 5.findmnt ####
|
||||
|
||||
Findmnt command is used to find mount file systems. It is used to list mount devices and can alos mount or unmount devices as and when required, it comes as a part of util-linux.
|
||||
|
||||
Examples:
|
||||
|
||||
$findmnt
|
||||
|
||||

|
||||
|
||||
To get output in list format.
|
||||
|
||||
$ findmnt -l
|
||||
|
||||

|
||||
|
||||
List file systems mounted in fstab.
|
||||
|
||||
$ findmnt -s
|
||||
|
||||

|
||||
|
||||
List mounted files systems by file type
|
||||
|
||||
$ findmnt -t ext4
|
||||
|
||||

|
||||
|
||||
#### 6. dstat ####
|
||||
|
||||
A combined and flexible tool which can be used to monitor memory, process, network or disk space performance, it is a good replacement of ifstat, iostat, dmstat etc.
|
||||
|
||||
$apt-get install dstat
|
||||
|
||||
Examples:
|
||||
|
||||
A detailed info about cpu, hard disk and network.
|
||||
|
||||
$ dstat
|
||||
|
||||

|
||||
|
||||
- **-c** cpu
|
||||
|
||||
$ dstat -c
|
||||
|
||||

|
||||
|
||||
Some more detailed information about cpu
|
||||
|
||||
$ dstat -cdl -D sda1
|
||||
|
||||

|
||||
|
||||
- **-d** disk
|
||||
|
||||
$ dstat -d
|
||||
|
||||

|
||||
|
||||
#### 7. saidar ####
|
||||
|
||||
Another cli based system statistics monitoring tool, provide information about disk uses, network, memory, swap etc.
|
||||
|
||||
$ sudo apt-get install saidar
|
||||
|
||||
Examples:
|
||||
|
||||
$ saidar
|
||||
|
||||

|
||||
|
||||
Enable colored output
|
||||
|
||||
$ saider -c
|
||||
|
||||

|
||||
|
||||
#### 8. ss ####
|
||||
|
||||
ss or socket statistics is a good alternative to netstat it directory gather information from kernel space nad play fast in comparision to the netstat utility.
|
||||
|
||||
Examples:
|
||||
|
||||
List all connections
|
||||
|
||||
$ ss |less
|
||||
|
||||

|
||||
|
||||
Greb only tcp traffic
|
||||
|
||||
$ ss -A tcp
|
||||
|
||||

|
||||
|
||||
Grab process name and pid
|
||||
|
||||
$ ss -ltp
|
||||
|
||||

|
||||
|
||||
#### 9. ccze ####
|
||||
|
||||
A tool that decorate your logs :).
|
||||
|
||||
$ apt-get install ccze
|
||||
|
||||
Examples:
|
||||
|
||||
$ tailf /var/log/syslog | ccze
|
||||
|
||||

|
||||
|
||||
List ccze modules:
|
||||
|
||||
$ ccze -l
|
||||
|
||||

|
||||
|
||||
Save log as html.
|
||||
|
||||
tailf /var/log/syslog | ccze -h > /home/tux/Desktop/rajneesh.html
|
||||
|
||||

|
||||
|
||||
#### 10. ranwhen.py ####
|
||||
|
||||
A python based terminal utility that can be used to display system activities graphically. Details are presented in a very colorful histogram.
|
||||
|
||||
Install python:
|
||||
|
||||
$ sudo apt-add-repository ppa:fkrull/deadsnakes
|
||||
|
||||
Update system:
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
Download python:
|
||||
|
||||
$ sudo apt-get install python3.2
|
||||
|
||||
- [Download ranwhen.py][1]
|
||||
|
||||
$ unzip ranwhen-master.zip && cd ranwhen-master
|
||||
|
||||
Run the tool.
|
||||
|
||||
$ python3.2 ranwhen.py
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
These are the less popular, yet important Linux administration tools. They can help user in their day to day activities. In our upcoming articles, we will try to bring some more Admin/user tools.
|
||||
|
||||
Have fun!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/10-useful-utilities-linux-users/
|
||||
|
||||
作者:[Rajneesh Upadhyay][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/rajneesh/
|
||||
[1]:https://github.com/p-e-w/ranwhen/archive/master.zip
|
||||
@ -0,0 +1,322 @@
|
||||
Getting Started to Calico Virtual Private Networking on Docker
|
||||
================================================================================
|
||||
Calico is a free and open source software for virtual networking in data centers. It is a pure Layer 3 approach to highly scalable datacenter for cloud virtual networking. It seamlessly integrates with cloud orchestration system such as openstack, docker clusters in order to enable secure IP communication between virtual machines and containers. It implements a highly productive vRouter in each node that takes advantage of the existing Linux kernel forwarding engine. Calico works in such an awesome technology that it has the ability to peer directly with the data center’s physical fabric whether L2 or L3, without the NAT, tunnels on/off ramps, or overlays. Calico makes full utilization of docker to run its containers in the nodes which makes it multi-platform and very easy to ship, pack and deploy. Calico has the following salient features out of the box.
|
||||
|
||||
- It can scale tens of thousands of servers and millions of workloads.
|
||||
- Calico is easy to deploy, operate and diagnose.
|
||||
- It is open source software licensed under Apache License version 2 and uses open standards.
|
||||
- It supports container, virtual machines and bare metal workloads.
|
||||
- It supports both IPv4 and IPv6 internet protocols.
|
||||
- It is designed internally to support rich, flexible and secure network policy.
|
||||
|
||||
In this tutorial, we'll perform a virtual private networking between two nodes running Calico in them with Docker Technology. Here are some easy steps on how we can do that.
|
||||
|
||||
### 1. Installing etcd ###
|
||||
|
||||
To get started with the calico virtual private networking, we'll need to have a linux machine running etcd. As CoreOS comes preinstalled and preconfigured with etcd, we can use CoreOS but if we want to configure Calico in other linux distributions, then we'll need to setup it in our machine. As we are running Ubuntu 14.04 LTS, we'll need to first install and configure etcd in our machine. To install etcd in our Ubuntu box, we'll need to add the official ppa repository of Calico by running the following command in the machine which we want to run etcd server. Here, we'll be installing etcd in our 1st node.
|
||||
|
||||
# apt-add-repository ppa:project-calico/icehouse
|
||||
|
||||
The primary source of Ubuntu packages for Project Calico based on OpenStack Icehouse, an open source solution for virtual networking in cloud data centers. Find out more at http://www.projectcalico.org/
|
||||
More info: https://launchpad.net/~project-calico/+archive/ubuntu/icehouse
|
||||
Press [ENTER] to continue or ctrl-c to cancel adding it
|
||||
gpg: keyring `/tmp/tmpi9zcmls1/secring.gpg' created
|
||||
gpg: keyring `/tmp/tmpi9zcmls1/pubring.gpg' created
|
||||
gpg: requesting key 3D40A6A7 from hkp server keyserver.ubuntu.com
|
||||
gpg: /tmp/tmpi9zcmls1/trustdb.gpg: trustdb created
|
||||
gpg: key 3D40A6A7: public key "Launchpad PPA for Project Calico" imported
|
||||
gpg: Total number processed: 1
|
||||
gpg: imported: 1 (RSA: 1)
|
||||
OK
|
||||
|
||||
Then, we'll need to edit /etc/apt/preferences and make changes to prefer Calico-provided packages for Nova and Neutron.
|
||||
|
||||
# nano /etc/apt/preferences
|
||||
|
||||
We'll need to add the following lines into it.
|
||||
|
||||
Package: *
|
||||
Pin: release o=LP-PPA-project-calico-*
|
||||
Pin-Priority: 100
|
||||
|
||||

|
||||
|
||||
Next, we'll also need to add the official BIRD PPA for Ubuntu 14.04 LTS so that bugs fixes are installed before its available on the Ubuntu repo.
|
||||
|
||||
# add-apt-repository ppa:cz.nic-labs/bird
|
||||
|
||||
The BIRD Internet Routing Daemon PPA (by upstream & .deb maintainer)
|
||||
More info: https://launchpad.net/~cz.nic-labs/+archive/ubuntu/bird
|
||||
Press [ENTER] to continue or ctrl-c to cancel adding it
|
||||
gpg: keyring `/tmp/tmphxqr5hjf/secring.gpg' created
|
||||
gpg: keyring `/tmp/tmphxqr5hjf/pubring.gpg' created
|
||||
gpg: requesting key F9C59A45 from hkp server keyserver.ubuntu.com
|
||||
apt-ggpg: /tmp/tmphxqr5hjf/trustdb.gpg: trustdb created
|
||||
gpg: key F9C59A45: public key "Launchpad Datov<6F> schr<68>nky" imported
|
||||
gpg: Total number processed: 1
|
||||
gpg: imported: 1 (RSA: 1)
|
||||
OK
|
||||
|
||||
Now, after the PPA jobs are done, we'll now gonna update the local repository index and then install etcd in our machine.
|
||||
|
||||
# apt-get update
|
||||
|
||||
To install etcd in our ubuntu machine, we'll gonna run the following apt command.
|
||||
|
||||
# apt-get install etcd python-etcd
|
||||
|
||||
### 2. Starting Etcd ###
|
||||
|
||||
After the installation is complete, we'll now configure the etcd configuration file. Here, we'll edit **/etc/init/etcd.conf** using a text editor and append the line exec **/usr/bin/etcd** and make it look like below configuration.
|
||||
|
||||
# nano /etc/init/etcd.conf
|
||||
exec /usr/bin/etcd --name="node1" \
|
||||
--advertise-client-urls="http://10.130.65.71:2379,http://10.130.65.71:4001" \
|
||||
--listen-client-urls="http://0.0.0.0:2379,http://0.0.0.0:4001" \
|
||||
--listen-peer-urls "http://0.0.0.0:2380" \
|
||||
--initial-advertise-peer-urls "http://10.130.65.71:2380" \
|
||||
--initial-cluster-token $(uuidgen) \
|
||||
--initial-cluster "node1=http://10.130.65.71:2380" \
|
||||
--initial-cluster-state "new"
|
||||
|
||||

|
||||
|
||||
**Note**: In the above configuration, we'll need to replace 10.130.65.71 and node-1 with the private ip address and hostname of your etcd server box. After done with editing, we'll need to save and exit the file.
|
||||
|
||||
We can get the private ip address of our etcd server by running the following command.
|
||||
|
||||
# ifconfig
|
||||
|
||||

|
||||
|
||||
As our etcd configuration is done, we'll now gonna start our etcd service in our Ubuntu node. To start etcd daemon, we'll gonna run the following command.
|
||||
|
||||
# service etcd start
|
||||
|
||||
After done, we'll have a check if etcd is really running or not. To ensure that, we'll need to run the following command.
|
||||
|
||||
# service etcd status
|
||||
|
||||
### 3. Installing Docker ###
|
||||
|
||||
Next, we'll gonna install Docker in both of our nodes running Ubuntu. To install the latest release of docker, we'll simply need to run the following command.
|
||||
|
||||
# curl -sSL https://get.docker.com/ | sh
|
||||
|
||||

|
||||
|
||||
After the installation is completed, we'll gonna start the docker daemon in-order to make sure that its running before we move towards Calico.
|
||||
|
||||
# service docker restart
|
||||
|
||||
docker stop/waiting
|
||||
docker start/running, process 3056
|
||||
|
||||
### 3. Installing Calico ###
|
||||
|
||||
We'll now install calico in our linux machine in-order to run the calico containers. We'll need to install Calico in every node which we're wanting to connect into the Calico network. To install Calico, we'll need to run the following command under root or sudo permission.
|
||||
|
||||
#### On 1st Node ####
|
||||
|
||||
# wget https://github.com/projectcalico/calico-docker/releases/download/v0.6.0/calicoctl
|
||||
|
||||
--2015-09-28 12:08:59-- https://github.com/projectcalico/calico-docker/releases/download/v0.6.0/calicoctl
|
||||
Resolving github.com (github.com)... 192.30.252.129
|
||||
Connecting to github.com (github.com)|192.30.252.129|:443... connected.
|
||||
...
|
||||
Resolving github-cloud.s3.amazonaws.com (github-cloud.s3.amazonaws.com)... 54.231.9.9
|
||||
Connecting to github-cloud.s3.amazonaws.com (github-cloud.s3.amazonaws.com)|54.231.9.9|:443... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: 6166661 (5.9M) [application/octet-stream]
|
||||
Saving to: 'calicoctl'
|
||||
100%[=========================================>] 6,166,661 1.47MB/s in 6.7s
|
||||
2015-09-28 12:09:08 (898 KB/s) - 'calicoctl' saved [6166661/6166661]
|
||||
|
||||
# chmod +x calicoctl
|
||||
|
||||
After done with making it executable, we'll gonna make the binary calicoctl available as the command in any directory. To do so, we'll need to run the following command.
|
||||
|
||||
# mv calicoctl /usr/bin/
|
||||
|
||||
#### On 2nd Node ####
|
||||
|
||||
# wget https://github.com/projectcalico/calico-docker/releases/download/v0.6.0/calicoctl
|
||||
|
||||
--2015-09-28 12:09:03-- https://github.com/projectcalico/calico-docker/releases/download/v0.6.0/calicoctl
|
||||
Resolving github.com (github.com)... 192.30.252.131
|
||||
Connecting to github.com (github.com)|192.30.252.131|:443... connected.
|
||||
...
|
||||
Resolving github-cloud.s3.amazonaws.com (github-cloud.s3.amazonaws.com)... 54.231.8.113
|
||||
Connecting to github-cloud.s3.amazonaws.com (github-cloud.s3.amazonaws.com)|54.231.8.113|:443... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: 6166661 (5.9M) [application/octet-stream]
|
||||
Saving to: 'calicoctl'
|
||||
100%[=========================================>] 6,166,661 1.47MB/s in 5.9s
|
||||
2015-09-28 12:09:11 (1022 KB/s) - 'calicoctl' saved [6166661/6166661]
|
||||
|
||||
# chmod +x calicoctl
|
||||
|
||||
After done with making it executable, we'll gonna make the binary calicoctl available as the command in any directory. To do so, we'll need to run the following command.
|
||||
|
||||
# mv calicoctl /usr/bin/
|
||||
|
||||
Likewise, we'll need to execute the above commands to install in every other nodes.
|
||||
|
||||
### 4. Starting Calico services ###
|
||||
|
||||
After we have installed calico on each of our nodes, we'll gonna start our Calico services. To start the calico services, we'll need to run the following commands.
|
||||
|
||||
#### On 1st Node ####
|
||||
|
||||
# calicoctl node
|
||||
|
||||
WARNING: Unable to detect the xt_set module. Load with `modprobe xt_set`
|
||||
WARNING: Unable to detect the ipip module. Load with `modprobe ipip`
|
||||
No IP provided. Using detected IP: 10.130.61.244
|
||||
Pulling Docker image calico/node:v0.6.0
|
||||
Calico node is running with id: fa0ca1f26683563fa71d2ccc81d62706e02fac4bbb08f562d45009c720c24a43
|
||||
|
||||
#### On 2nd Node ####
|
||||
|
||||
Next, we'll gonna export a global variable in order to connect our calico nodes to the same etcd server which is hosted in node1 in our case. To do so, we'll need to run the following command in each of our nodes.
|
||||
|
||||
# export ETCD_AUTHORITY=10.130.61.244:2379
|
||||
|
||||
Then, we'll gonna run calicoctl container in our every our second node.
|
||||
|
||||
# calicoctl node
|
||||
|
||||
WARNING: Unable to detect the xt_set module. Load with `modprobe xt_set`
|
||||
WARNING: Unable to detect the ipip module. Load with `modprobe ipip`
|
||||
No IP provided. Using detected IP: 10.130.61.245
|
||||
Pulling Docker image calico/node:v0.6.0
|
||||
Calico node is running with id: 70f79c746b28491277e28a8d002db4ab49f76a3e7d42e0aca8287a7178668de4
|
||||
|
||||
This command should be executed in every nodes in which we want to start our Calico services. The above command start a container in the respective node. To check if the container is running or not, we'll gonna run the following docker command.
|
||||
|
||||
# docker ps
|
||||
|
||||

|
||||
|
||||
If we see the output something similar to the output shown below then we can confirm that Calico containers are up and running.
|
||||
|
||||
### 5. Starting Containers ###
|
||||
|
||||
Next, we'll need to start few containers in each of our nodes running Calico services. We'll assign a different name to each of the containers running ubuntu. Here, workload-A, workload-B, etc has been assigned as the unique name for each of the containers. To do so, we'll need to run the following command.
|
||||
|
||||
#### On 1st Node ####
|
||||
|
||||
# docker run --net=none --name workload-A -tid ubuntu
|
||||
|
||||
Unable to find image 'ubuntu:latest' locally
|
||||
latest: Pulling from library/ubuntu
|
||||
...
|
||||
91e54dfb1179: Already exists
|
||||
library/ubuntu:latest: The image you are pulling has been verified. Important: image verification is a tech preview feature and should not be relied on to provide security.
|
||||
Digest: sha256:73fbe2308f5f5cb6e343425831b8ab44f10bbd77070ecdfbe4081daa4dbe3ed1
|
||||
Status: Downloaded newer image for ubuntu:latest
|
||||
a1ba9105955e9f5b32cbdad531cf6ecd9cab0647d5d3d8b33eca0093605b7a18
|
||||
|
||||
# docker run --net=none --name workload-B -tid ubuntu
|
||||
|
||||
89dd3d00f72ac681bddee4b31835c395f14eeb1467300f2b1b9fd3e704c28b7d
|
||||
|
||||
#### On 2nd Node ####
|
||||
|
||||
# docker run --net=none --name workload-C -tid ubuntu
|
||||
|
||||
Unable to find image 'ubuntu:latest' locally
|
||||
latest: Pulling from library/ubuntu
|
||||
...
|
||||
91e54dfb1179: Already exists
|
||||
library/ubuntu:latest: The image you are pulling has been verified. Important: image verification is a tech preview feature and should not be relied on to provide security.
|
||||
Digest: sha256:73fbe2308f5f5cb6e343425831b8ab44f10bbd77070ecdfbe4081daa4dbe3ed1
|
||||
Status: Downloaded newer image for ubuntu:latest
|
||||
24e2d5d7d6f3990b534b5643c0e483da5b4620a1ac2a5b921b2ba08ebf754746
|
||||
|
||||
# docker run --net=none --name workload-D -tid ubuntu
|
||||
|
||||
c6f28d1ab8f7ac1d9ccc48e6e4234972ed790205c9ca4538b506bec4dc533555
|
||||
|
||||
Similarly, if we have more nodes, we can run ubuntu docker container into it by running the above command with assigning a different container name.
|
||||
|
||||
### 6. Assigning IP addresses ###
|
||||
|
||||
After we have got our docker containers running in each of our hosts, we'll go for adding a networking support to the containers. Now, we'll gonna assign a new ip address to each of the containers using calicoctl. This will add a new network interface to the containers with the assigned ip addresses. To do so, we'll need to run the following commands in the hosts running the containers.
|
||||
|
||||
#### On 1st Node ####
|
||||
|
||||
# calicoctl container add workload-A 192.168.0.1
|
||||
# calicoctl container add workload-B 192.168.0.2
|
||||
|
||||
#### On 2nd Node ####
|
||||
|
||||
# calicoctl container add workload-C 192.168.0.3
|
||||
# calicoctl container add workload-D 192.168.0.4
|
||||
|
||||
### 7. Adding Policy Profiles ###
|
||||
|
||||
After our containers have got networking interfaces and ip address assigned, we'll now need to add policy profiles to enable networking between the containers each other. After adding the profiles, the containers will be able to communicate to each other only if they have the common profiles assigned. That means, if they have different profiles assigned, they won't be able to communicate to eachother. So, before being able to assign. we'll need to first create some new profiles. That can be done in either of the hosts. Here, we'll run the following command in 1st Node.
|
||||
|
||||
# calicoctl profile add A_C
|
||||
|
||||
Created profile A_C
|
||||
|
||||
# calicoctl profile add B_D
|
||||
|
||||
Created profile B_D
|
||||
|
||||
After the profile has been created, we'll simply add our workload to the required profile. Here, in this tutorial, we'll place workload A and workload C in a common profile A_C and workload B and D in a common profile B_D. To do so, we'll run the following command in our hosts.
|
||||
|
||||
#### On 1st Node ####
|
||||
|
||||
# calicoctl container workload-A profile append A_C
|
||||
# calicoctl container workload-B profile append B_D
|
||||
|
||||
#### On 2nd Node ####
|
||||
|
||||
# calicoctl container workload-C profile append A_C
|
||||
# calicoctl container workload-D profile append B_D
|
||||
|
||||
### 8. Testing the Network ###
|
||||
|
||||
After we've added a policy profile to each of our containers using Calicoctl, we'll now test whether our networking is working as expected or not. We'll take a node and a workload and try to communicate with the other containers running in same or different nodes. And due to the profile, we should be able to communicate only with the containers having a common profile. So, in this case, workload A should be able to communicate with only C and vice versa whereas workload A shouldn't be able to communicate with B or D. To test the network, we'll gonna ping the containers having common profiles from the 1st host running workload A and B.
|
||||
|
||||
We'll first ping workload-C having ip 192.168.0.3 using workload-A as shown below.
|
||||
|
||||
# docker exec workload-A ping -c 4 192.168.0.3
|
||||
|
||||
Then, we'll ping workload-D having ip 192.168.0.4 using workload-B as shown below.
|
||||
|
||||
# docker exec workload-B ping -c 4 192.168.0.4
|
||||
|
||||

|
||||
|
||||
Now, we'll check if we're able to ping the containers having different profiles. We'll now ping workload-D having ip address 192.168.0.4 using workload-A.
|
||||
|
||||
# docker exec workload-A ping -c 4 192.168.0.4
|
||||
|
||||
After done, we'll try to ping workload-C having ip address 192.168.0.3 using workload-B.
|
||||
|
||||
# docker exec workload-B ping -c 4 192.168.0.3
|
||||
|
||||

|
||||
|
||||
Hence, the workloads having same profiles could ping each other whereas having different profiles couldn't ping to each other.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Calico is an awesome project providing an easy way to configure a virtual network using the latest docker technology. It is considered as a great open source solution for virtual networking in cloud data centers. Calico is being experimented by people in different cloud platforms like AWS, DigitalOcean, GCE and more these days. As Calico is currently under experiment, its stable version hasn't been released yet and is still in pre-release. The project consists a well documented documentations, tutorials and manuals in their [official documentation site][2].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/calico-virtual-private-networking-docker/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://docs.projectcalico.org/
|
||||
81
sources/tech/20151012 How To Use iPhone In Antergos Linux.md
Normal file
81
sources/tech/20151012 How To Use iPhone In Antergos Linux.md
Normal file
@ -0,0 +1,81 @@
|
||||
How To Use iPhone In Antergos Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
Troubles with iPhone and Arch Linux? iPhone and Linux never really go along very well. In this tutorial, I am going to show you how can you use iPhone in Antergos Linux. Since Antergos is based on Arch Linux, the same steps should be applicable to other Arch based Linux distros such as Manjaro Linux.
|
||||
|
||||
So, recently I bought me a brand new iPhone 6S and when I connected it to Antergos Linux to copy some pictures, it was not detected at all. I could see that iPhone was being charged and I had allowed iPhone to ‘trust the computer’ but there was nothing at all detected. I tried to run dmseg but there was no trace of iPhone or Apple there. What is funny that [libimobiledevice][1] was installed as well, which always fixes [iPhone mount issue in Ubuntu][2].
|
||||
|
||||
I am going to show you how I am using iPhone 6S, running on iOS 9 in Antergos. It goes more in command line way, but I presume since you are in Arch Linux zone, you are not scared of terminal (and you should not be as well).
|
||||
|
||||
### Mount iPhone in Arch Linux ###
|
||||
|
||||
**Step 1**: Unplug your iPhone, if it is already plugged in.
|
||||
|
||||
**Step 2**: Now, open a terminal and use the following command to install some necessary packages. Don’t worry if they are already installed.
|
||||
|
||||
sudo pacman -Sy ifuse usbmuxd libplist libimobiledevice
|
||||
|
||||
**Step 3**: Once these programs and libraries are installed, reboot your system.
|
||||
|
||||
sudo reboot
|
||||
|
||||
**Step 4**: Make a directory where you want the iPhone to be mounted. I would suggest making a directory named iPhone in your home directory.
|
||||
|
||||
mkdir ~/iPhone
|
||||
|
||||
**Step 5**: Unlock your phone and plug it in. If asked to trust the computer, allow it.
|
||||
|
||||

|
||||
|
||||
**Step 6**: Verify that iPhone is recognized by the system this time.
|
||||
|
||||
dmesg | grep -i iphone
|
||||
|
||||
This should show you some result with iPhone and Apple in it. Something like this:
|
||||
|
||||
[ 31.003392] ipheth 2-1:4.2: Apple iPhone USB Ethernet device attached
|
||||
[ 40.950883] ipheth 2-1:4.2: Apple iPhone USB Ethernet now disconnected
|
||||
[ 47.471897] ipheth 2-1:4.2: Apple iPhone USB Ethernet device attached
|
||||
[ 82.967116] ipheth 2-1:4.2: Apple iPhone USB Ethernet now disconnected
|
||||
[ 106.735932] ipheth 2-1:4.2: Apple iPhone USB Ethernet device attached
|
||||
|
||||
This means that iPhone has been successfully recognized by Antergos/Arch Linux.
|
||||
|
||||
**Step 7**: When everything is set, it’s time to mount the iPhone. Use the command below:
|
||||
|
||||
ifuse ~/iPhone
|
||||
|
||||
Since we created the mount directory in home, it won’t need root access and you should also be able to see it easily in your home directory. If the command is successful, you won’t see any output.
|
||||
|
||||
Go back to Files and see if the iPhone is recognized or not. For me, it looks like this in Antergos:
|
||||
|
||||

|
||||
|
||||
You can access the files in this directory. Copy files from it or to it.
|
||||
|
||||

|
||||
|
||||
**Step 8**: When you want to unmount it, you should use this command:
|
||||
|
||||
sudo umount ~/iPhone
|
||||
|
||||
### Worked for you? ###
|
||||
|
||||
I know that it is not very convenient and ideally, iPhone should be recognized as any other USB storage device but things don’t always behave as they are expected to. Good thing is that a little DIY hack can always fix the issue and it gives a sense of achievement (at least to me). That being said, I must say Antergos should work to fix this issue so that iPhone can be mounted by default.
|
||||
|
||||
Did this trick work for you? If you have questions or suggestions, feel free to drop a comment.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/iphone-antergos-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://www.libimobiledevice.org/
|
||||
[2]:http://itsfoss.com/mount-iphone-ipad-ios-7-ubuntu-13-10/
|
||||
@ -0,0 +1,90 @@
|
||||
How to Monitor Stock Prices from Ubuntu Command Line Using Mop
|
||||
================================================================================
|
||||
Having a side income is always good, especially when you can easily manage the work along with your full time job. If your regular work involves working on an Internet-connected computer, trading stocks is a popular option to earn a few extra bucks.
|
||||
|
||||
While there are quite a few stock-monitoring applications available for Linux, most of them are GUI-based. What if you’re a Linux professional who spends a lot (or all) of your time working on machines that do not have any GUI installed? Are you out of luck? Well, no, there are some command line stock-tracking tools, including Mop, which we’ll be discussing in this article.
|
||||
|
||||
### Mop ###
|
||||
|
||||
Mop, as already mentioned in the introduction above, is a command line tool that displays continuous and updated information about the US stock markets and individual stocks. Implemented in the GO programming language, the project is the brain child of Michael Dvorkin.
|
||||
|
||||
### Download and Install ###
|
||||
|
||||
Since the project is implemented in GO, before installing the tool, you’ll first have to make sure that the programming language is installed on your machine. Following are the steps required to install GO on a Debian-based system like Ubuntu:
|
||||
|
||||
sudo apt-get install golang
|
||||
mkdir ~/workspace
|
||||
echo 'export GOPATH="$HOME/workspace"' >> ~/.bashrc
|
||||
source ~/.bashrc
|
||||
|
||||
Once GO is installed, the next step is to install the Mop tool and set the environment, something which you can do by running the following commands:
|
||||
|
||||
sudo apt-get install git
|
||||
go get github.com/michaeldv/mop
|
||||
cd $GOPATH/src/github.com/michaeldv/mop
|
||||
make install
|
||||
export PATH="$PATH:$GOPATH/bin"
|
||||
|
||||
Once done, just run the following command to execute Mop:
|
||||
|
||||
cmd
|
||||
|
||||
### Features ###
|
||||
|
||||
When you run the Mop command for the first time, you’ll see an output similar to the following.
|
||||
|
||||

|
||||
|
||||
As you can see in the image above, the output – which auto-refreshes frequently – contains information related to various popular stock exchanges around the world as well as individual stocks.
|
||||
|
||||
### Add/remove stocks ###
|
||||
|
||||
Mop allows you to easily add/remove individual stocks to and from the output list. To add a stock, all you have to do is to press “+” and mention the stock listing name when prompted. For example, the following screenshot was taken while adding Facebook (FB) to the list.
|
||||
|
||||

|
||||
|
||||
As I pressed the “+” key, a row containing text “Add tickers:” appeared, prompting me to add the stock listing name – I added FB for Facebook and pressed Enter. The output refreshed, and the new stock was added to the list:
|
||||
|
||||

|
||||
|
||||
Similarly, you can delete a stock listing by pressing “-” and mentioning its name.
|
||||
|
||||
#### Group stocks based on value ####
|
||||
|
||||
There is a way to group stocks based on whether their value is going up or down – all you have to do is to press the “g” key. Following this, the stocks which are advancing will be grouped together and shown in green, while those whose value is going down will be represented in black.
|
||||
|
||||
Here is an example screenshot.
|
||||
|
||||

|
||||
|
||||
#### Column sort ####
|
||||
|
||||
Mop also allows you to change the sort order of individual columns. For this you first need to press “o” (this will select the first column by default), and then use the left and right arrow keys to select the column you want to sort. Once done, press enter to sort the column contents.
|
||||
|
||||
For example, the following screenshot shows the output after the contents of the first column were sorted in descending alphabetical order.
|
||||
|
||||

|
||||
|
||||
**Note**: to better understand, compare it with the previous screenshot.
|
||||
|
||||
#### Other options ####
|
||||
|
||||
Other available options include “p” for pausing market data and stock updates, “q” or “esc” for quitting the command line application, and “?” for displaying the help page.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Mop is a basic stock monitoring tool that doesn’t offer a plethora of features, but does what it promises. It’s quite obvious that the tool is not for stock trading professionals but is still a decent choice if all you want to do is some basic stock tracking on a command line-only machine.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/monitor-stock-prices-ubuntu-command-line/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/himanshu/
|
||||
@ -0,0 +1,111 @@
|
||||
How to Setup DockerUI - a Web Interface for Docker
|
||||
================================================================================
|
||||
Docker is getting more popularity day by day. The idea of running a complete Operating System inside a container rather than running inside a virtual machine is an awesome technology. Docker has made lives of millions of system administrators and developers pretty easy for getting their work done in no time. It is an open source technology that provides an open platform to pack, ship, share and run any application as a lightweight container without caring on which operating system we are running on the host. It has no boundaries of Language support, Frameworks or packaging system and can be run anywhere, anytime from a small home computers to high-end servers. Running docker containers and managing them may come a bit difficult and time consuming, so there is a web based application named DockerUI which is make managing and running container pretty simple. DockerUI is highly beneficial to people who are not much aware of linux command lines and want to run containerized applications. DockerUI is an open source web based application best known for its beautiful design and ease simple interface for running and managing docker containers.
|
||||
|
||||
Here are some easy steps on how we can setup Docker Engine with DockerUI in our linux machine.
|
||||
|
||||
### 1. Installing Docker Engine ###
|
||||
|
||||
First of all, we'll gonna install docker engine in our linux machine. Thanks to its developers, docker is very easy to install in any major linux distribution. To install docker engine, we'll need to run the following command with respect to which distribution we are running.
|
||||
|
||||
#### On Ubuntu/Fedora/CentOS/RHEL/Debian ####
|
||||
|
||||
Docker maintainers have written an awesome script that can be used to install docker engine in Ubuntu 15.04/14.10/14.04, CentOS 6.x/7, Fedora 22, RHEL 7 and Debian 8.x distributions of linux. This script recognizes the distribution of linux installed in our machine, then adds the required repository to the filesystem, updates the local repository index and finally installs docker engine and required dependencies from it. To install docker engine using that script, we'll need to run the following command under root or sudo mode.
|
||||
|
||||
# curl -sSL https://get.docker.com/ | sh
|
||||
|
||||
#### On OpenSuse/SUSE Linux Enterprise ####
|
||||
|
||||
To install docker engine in the machine running OpenSuse 13.1/13.2 or SUSE Linux Enterprise Server 12, we'll simply need to execute the zypper command. We'll gonna install docker using zypper command as the latest docker engine is available on the official repository. To do so, we'll run the following command under root/sudo mode.
|
||||
|
||||
# zypper in docker
|
||||
|
||||
#### On ArchLinux ####
|
||||
|
||||
Docker is available in the official repository of Archlinux as well as in the AUR packages maintained by the community. So, we have two options to install docker in archlinux. To install docker using the official arch repository, we'll need to run the following pacman command.
|
||||
|
||||
# pacman -S docker
|
||||
|
||||
But if we want to install docker from the Archlinux User Repository ie AUR, then we'll need to execute the following command.
|
||||
|
||||
# yaourt -S docker-git
|
||||
|
||||
### 2. Starting Docker Daemon ###
|
||||
|
||||
After docker is installed, we'll now gonna start our docker daemon so that we can run docker containers and manage them. We'll run the following command to make sure that docker daemon is installed and to start the docker daemon.
|
||||
|
||||
#### On SysVinit ####
|
||||
|
||||
# service docker start
|
||||
|
||||
#### On Systemd ####
|
||||
|
||||
# systemctl start docker
|
||||
|
||||
### 3. Installing DockerUI ###
|
||||
|
||||
Installing DockerUI is pretty easy than installing docker engine. We just need to pull the dockerui from the Docker Registry Hub and run it inside a container. To do so, we'll simply need to run the following command.
|
||||
|
||||
# docker run -d -p 9000:9000 --privileged -v /var/run/docker.sock:/var/run/docker.sock dockerui/dockerui
|
||||
|
||||

|
||||
|
||||
Here, in the above command, as the default port of the dockerui web application server 9000, we'll simply map the default port of it with -p flag. With -v flag, we specify the docker socket. The --privileged flag is required for hosts using SELinux.
|
||||
|
||||
After executing the above command, we'll now check if the dockerui container is running or not by running the following command.
|
||||
|
||||
# docker ps
|
||||
|
||||

|
||||
|
||||
### 4. Pulling an Image ###
|
||||
|
||||
Currently, we cannot pull an image directly from DockerUI so, we'll need to pull a docker image from the linux console/terminal. To do so, we'll need to run the following command.
|
||||
|
||||
# docker pull ubuntu
|
||||
|
||||

|
||||
|
||||
The above command will pull an image tagged as ubuntu from the official [Docker Hub][1]. Similarly, we can pull more images that we require and are available in the hub.
|
||||
|
||||
### 4. Managing with DockerUI ###
|
||||
|
||||
After we have started the dockerui container, we'll now have fun with it to start, pause, stop, remove and perform many possible activities featured by dockerui with docker containers and images. First of all, we'll need to open the web application using our web browser. To do so, we'll need to point our browser to http://ip-address:9000 or http://mydomain.com:9000 according to the configuration of our system. By default, there is no login authentication needed for the user access but we can configure our web server for adding authentication. To start a container, first we'll need to have images of the required application we want to run a container with.
|
||||
|
||||
#### Create a Container ####
|
||||
|
||||
To create a container, we'll need to go to the section named Images then, we'll need to click on the image id which we want to create a container of. After clicking on the required image id, we'll need to click on Create button then we'll be asked to enter the required properties for our container. And after everything is set and done. We'll need to click on Create button to finally create a container.
|
||||
|
||||

|
||||
|
||||
#### Stop a Container ####
|
||||
|
||||
To stop a container, we'll need to move towards the Containers page and then select the required container we want to stop. Now, we'll want to click on Stop option which we can see under Actions drop-down menu.
|
||||
|
||||

|
||||
|
||||
#### Pause and Resume ####
|
||||
|
||||
To pause a container, we simply select the required container we want to pause by keeping a check mark on the container and then click the Pause option under Actions . This is will pause the running container and then, we can simply resume the container by selecting Unpause option from the Actions drop down menu.
|
||||
|
||||
#### Kill and Remove ####
|
||||
|
||||
Like we had performed the above tasks, its pretty easy to kill and remove a container or an image. We just need to check/select the required container or image and then select the Kill or Remove button from the application according to our need.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
DockerUI is a beautiful utilization of Docker Remote API to develop an awesome web interface for managing docker containers. The developers have designed and developed this application in pure HTML and JS language. It is currently incomplete and is under heavy development so we don't recommend it for the use in production currently. It makes users pretty easy to manage their containers and images with simple clicks without needing to execute lines of commands to do small jobs. If we want to contribute DockerUI, we can simply visit its [Github Repository][2]. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you !
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/setup-dockerui-web-interface-docker/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://hub.docker.com/
|
||||
[2]:https://github.com/crosbymichael/dockerui/
|
||||
@ -0,0 +1,250 @@
|
||||
How to Setup Red Hat Ceph Storage on CentOS 7.0
|
||||
================================================================================
|
||||
Ceph is an open source software platform that stores data on a single distributed computer cluster. When you are planning to build a cloud, then on top of the requirements you have to decide on how to implement your storage. Open Source CEPH is one of RED HAT mature technology based on object-store system, called RADOS, with a set of gateway APIs that present the data in block, file, and object modes. As a result of its open source nature, this portable storage platform may be installed and used in public or private clouds. The topology of a Ceph cluster is designed around replication and information distribution, which are intrinsic and provide data integrity. It is designed to be fault-tolerant, and can run on commodity hardware, but can also be run on a number of more advanced systems with the right setup.
|
||||
|
||||
Ceph can be installed on any Linux distribution but it requires the recent kernel and other up-to-date libraries in order to be properly executed. But, here in this tutorial we will be using CentOS-7.0 with minimal installation packages on it.
|
||||
|
||||
### System Resources ###
|
||||
|
||||
**CEPH-STORAGE**
|
||||
OS: CentOS Linux 7 (Core)
|
||||
RAM:1 GB
|
||||
CPU:1 CPU
|
||||
DISK: 20
|
||||
Network: 45.79.136.163
|
||||
FQDN: ceph-storage.linoxide.com
|
||||
|
||||
**CEPH-NODE**
|
||||
OS: CentOS Linux 7 (Core)
|
||||
RAM:1 GB
|
||||
CPU:1 CPU
|
||||
DISK: 20
|
||||
Network: 45.79.171.138
|
||||
FQDN: ceph-node.linoxide.com
|
||||
|
||||
### Pre-Installation Setup ###
|
||||
|
||||
There are few steps that we need to perform on each of our node before the CEPH storage setup. So first thing is to make sure that each node is configured with its networking setup with FQDN that is reachable to other nodes.
|
||||
|
||||
**Configure Hosts**
|
||||
|
||||
To setup the hosts entry on each node let's open the default hosts configuration file as shown below.
|
||||
|
||||
# vi /etc/hosts
|
||||
|
||||
----------
|
||||
|
||||
45.79.136.163 ceph-storage ceph-storage.linoxide.com
|
||||
45.79.171.138 ceph-node ceph-node.linoxide.com
|
||||
|
||||
**Install VMware Tools**
|
||||
|
||||
While working on the VMware virtual environment, its recommended that you have installed its open VM tools. You can install using below command.
|
||||
|
||||
#yum install -y open-vm-tools
|
||||
|
||||
**Firewall Setup**
|
||||
|
||||
If you are working on a restrictive environment where your local firewall in enabled then make sure that the number of following ports are allowed from in your CEPH storge admin node and client nodes.
|
||||
|
||||
You must open ports 80, 2003, and 4505-4506 on your Admin Calamari node and port 80 to CEPH admin or Calamari node for inbound so that clients in your network can access the Calamari web user interface.
|
||||
|
||||
You can start and enable firewall in centos 7 with given below command.
|
||||
|
||||
#systemctl start firewalld
|
||||
#systemctl enable firewalld
|
||||
|
||||
To allow the mentioned ports in the Admin Calamari node run the following commands.
|
||||
|
||||
#firewall-cmd --zone=public --add-port=80/tcp --permanent
|
||||
#firewall-cmd --zone=public --add-port=2003/tcp --permanent
|
||||
#firewall-cmd --zone=public --add-port=4505-4506/tcp --permanent
|
||||
#firewall-cmd --reload
|
||||
|
||||
On the CEPH Monitor nodes you have to allow the following ports in the firewall.
|
||||
|
||||
#firewall-cmd --zone=public --add-port=6789/tcp --permanent
|
||||
|
||||
Then allow the following list of default ports for talking to clients and monitors and for sending data to other OSDs.
|
||||
|
||||
#firewall-cmd --zone=public --add-port=6800-7300/tcp --permanent
|
||||
|
||||
It quite fair that you should disable firewall and SELinux settings if you are working in a non-production environment , so we are going to disable the firewall and SELinux in our test environment.
|
||||
|
||||
#systemctl stop firewalld
|
||||
#systemctl disable firewalld
|
||||
|
||||
**System Update**
|
||||
|
||||
Now update your system and then give it a reboot to implement the required changes.
|
||||
|
||||
#yum update
|
||||
#shutdown -r 0
|
||||
|
||||
### Setup CEPH User ###
|
||||
|
||||
Now we will create a separate sudo user that will be used for installing the ceph-deploy utility on each node and allow that user to have password less access on each node because it needs to install software and configuration files without prompting for passwords on CEPH nodes.
|
||||
|
||||
To create new user with its separate home directory run the below command on the ceph-storage host.
|
||||
|
||||
[root@ceph-storage ~]# useradd -d /home/ceph -m ceph
|
||||
[root@ceph-storage ~]# passwd ceph
|
||||
|
||||
Each user created on the nodes must have sudo rights, you can assign the sudo rights to the user using running the following command as shown.
|
||||
|
||||
[root@ceph-storage ~]# echo "ceph ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/ceph
|
||||
ceph ALL = (root) NOPASSWD:ALL
|
||||
|
||||
[root@ceph-storage ~]# sudo chmod 0440 /etc/sudoers.d/ceph
|
||||
|
||||
### Setup SSH-Key ###
|
||||
|
||||
Now we will generate SSH keys on the admin ceph node and then copy that key to each Ceph cluster nodes.
|
||||
|
||||
Let's run the following command on the ceph-node to copy its ssh key on the ceph-storage.
|
||||
|
||||
[root@ceph-node ~]# ssh-keygen
|
||||
Generating public/private rsa key pair.
|
||||
Enter file in which to save the key (/root/.ssh/id_rsa):
|
||||
Created directory '/root/.ssh'.
|
||||
Enter passphrase (empty for no passphrase):
|
||||
Enter same passphrase again:
|
||||
Your identification has been saved in /root/.ssh/id_rsa.
|
||||
Your public key has been saved in /root/.ssh/id_rsa.pub.
|
||||
The key fingerprint is:
|
||||
5b:*:*:*:*:*:*:*:*:*:c9 root@ceph-node
|
||||
The key's randomart image is:
|
||||
+--[ RSA 2048]----+
|
||||
|
||||
----------
|
||||
|
||||
[root@ceph-node ~]# ssh-copy-id ceph@ceph-storage
|
||||
|
||||

|
||||
|
||||
### Configure PID Count ###
|
||||
|
||||
To configure the PID count value, we will make use of the following commands to check the default kernel value. By default its a small maximum number of threads that is '32768'.
|
||||
So will configure this value to a higher number of threads by editing the system conf file as shown in the image.
|
||||
|
||||

|
||||
|
||||
### Setup Your Administration Node Server ###
|
||||
|
||||
With all the networking setup and verified, now we will install ceph-deploy using the user ceph. So, check the hosts entry by opening its file.
|
||||
|
||||
#vim /etc/hosts
|
||||
ceph-storage 45.79.136.163
|
||||
ceph-node 45.79.171.138
|
||||
|
||||
Now to add its repository run the below command.
|
||||
|
||||
#rpm -Uhv http://ceph.com/rpm-giant/el7/noarch/ceph-release-1-0.el7.noarch.rpm
|
||||
|
||||

|
||||
|
||||
OR create a new file and update the CEPH repository parameters but do not forget to mention your current release and distribution.
|
||||
|
||||
[root@ceph-storage ~]# vi /etc/yum.repos.d/ceph.repo
|
||||
|
||||
----------
|
||||
|
||||
[ceph-noarch]
|
||||
name=Ceph noarch packages
|
||||
baseurl=http://ceph.com/rpm-{ceph-release}/{distro}/noarch
|
||||
enabled=1
|
||||
gpgcheck=1
|
||||
type=rpm-md
|
||||
gpgkey=https://ceph.com/git/?p=ceph.git;a=blob_plain;f=keys/release.asc
|
||||
|
||||
After this update your system and install the ceph deploy package.
|
||||
|
||||
### Installing CEPH-Deploy Package ###
|
||||
|
||||
To upate the system with latest ceph repository and other packages, we will run the following command along with ceph-deploy installation command.
|
||||
|
||||
#yum update -y && yum install ceph-deploy -y
|
||||
|
||||
Image-
|
||||
|
||||
### Setup the cluster ###
|
||||
|
||||
Create a new directory and move into it on the admin ceph-node to collect all output files and logs by using the following commands.
|
||||
|
||||
#mkdir ~/ceph-cluster
|
||||
#cd ~/ceph-cluster
|
||||
|
||||
----------
|
||||
|
||||
#ceph-deploy new storage
|
||||
|
||||

|
||||
|
||||
Upon successful execution of above command you can see it creating its configuration files.
|
||||
Now to configure the default configuration file of CEPH, open it using any editor and place the following two lines under its global parameters that reflects your public network.
|
||||
|
||||
#vim ceph.conf
|
||||
osd pool default size = 1
|
||||
public network = 45.79.0.0/16
|
||||
|
||||
### Installing CEPH ###
|
||||
|
||||
We are now going to install CEPH on each of the node associated with our CEPH cluster. To do so we make use of the following command to install CEPH on our both nodes that is ceph-storage and ceph-node as shown below.
|
||||
|
||||
#ceph-deploy install ceph-node ceph-storage
|
||||
|
||||

|
||||
|
||||
This will takes some time while processing all its required repositories and installing the required packages.
|
||||
|
||||
Once the ceph installation process is complete on both nodes we will proceed to create monitor and gather keys by running the following command on the same node.
|
||||
|
||||
#ceph-deploy mon create-initial
|
||||
|
||||

|
||||
|
||||
### Setup OSDs and OSD Daemons ###
|
||||
|
||||
Now we will setup disk storages, to do so first run the below command to List all of your usable disks by using the below command.
|
||||
|
||||
#ceph-deploy disk list ceph-storage
|
||||
|
||||
In results will get the list of your disks used on your storage nodes that you will use for creating the OSD. Let's run the following command that consists of your disks names as shown below.
|
||||
|
||||
#ceph-deploy disk zap storage:sda
|
||||
#ceph-deploy disk zap storage:sdb
|
||||
|
||||
Now to finalize the OSD setup let's run the below commands to setup the journaling disk along with data disk.
|
||||
|
||||
#ceph-deploy osd prepare storage:sdb:/dev/sda
|
||||
#ceph-deploy osd activate storage:/dev/sdb1:/dev/sda1
|
||||
|
||||
You will have to repeat the same command on all the nodes while it will clean everything present on the disk. Afterwards to have a functioning cluster, we need to copy the different keys and configuration files from the admin ceph-node to all the associated nodes by using the following command.
|
||||
|
||||
#ceph-deploy admin ceph-node ceph-storage
|
||||
|
||||
### Testing CEPH ###
|
||||
|
||||
We have almost completed the CEPH cluster setup, let's run the below command to check the status of the running ceph by using the below command on the admin ceph-node.
|
||||
|
||||
#ceph status
|
||||
#ceph health
|
||||
HEALTH_OK
|
||||
|
||||
So, if you did not get any error message at ceph status , that means you have successfully setup your ceph storage cluster on CentOS 7.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this detailed article we learned about the CEPH storage clustering setup using the two virtual Machines with CentOS 7 OS installed on them that can be used as a backup or as your local storage that can be used to precess other virtual machines by creating its pools. We hope you have got this article helpful. Do share your experiences when you try this at your end.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/storage/setup-red-hat-ceph-storage-centos-7-0/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
@ -0,0 +1,53 @@
|
||||
Linux FAQs with Answers--How to change USB device permission permanently on Linux
|
||||
================================================================================
|
||||
> **Question**: I am trying to run gpsd on my Linux with a USB GPS receiver. However, I am getting the following errors from gpsd.
|
||||
>
|
||||
> gpsd[377]: gpsd:ERROR: read-only device open failed: Permission denied
|
||||
> gpsd[377]: gpsd:ERROR: /dev/ttyUSB0: device activation failed.
|
||||
> gpsd[377]: gpsd:ERROR: device open failed: Permission denied - retrying read-only
|
||||
>
|
||||
> Looks like gpsd does not have permission to access the USB device (/dev/ttyUSB0). How can I change its default permission mode permanently on Linux?
|
||||
|
||||
When you run a process that wants to read or write to a USB device, the user/group of the process must have appropriate permission to do so. Of course you can change the permission of your USB device manually with chmod command, but such manual permission change will be temporary. The USB device will revert to its default permission mode when you reboot your Linux machine.
|
||||
|
||||

|
||||
|
||||
As a permanent solution, you can create a udev-based USB permission rule which assigns any custom permission mode of your choice. Here is how to do it.
|
||||
|
||||
First, you need to identify the vendorID and productID of your USB device. For that, use lsusb command.
|
||||
|
||||
$ lsusb -vvv
|
||||
|
||||
|
||||
|
||||
From the lsusb output, find your USB device's entry, and look for "idVendor" and "idProduct" fields. In this example, we have idVendor (0x067b) and idProduct (0x2303).
|
||||
|
||||
Next, create a new udev rule as follows.
|
||||
|
||||
$ sudo vi /etc/udev/rules.d/50-myusb.rules
|
||||
|
||||
----------
|
||||
|
||||
SUBSYSTEMS=="usb", ATTRS{idVendor}=="067b", ATTRS{idProduct}=="2303", GROUP="users", MODE="0666"
|
||||
|
||||
Replace "idVendor" and "idProduct" values with your own. **MODE="0666"** indicates the preferred permission of the USB device.
|
||||
|
||||
Now reboot your machine or reload udev rules:
|
||||
|
||||
$ sudo udevadm control --reload
|
||||
|
||||
Then verify the permission of the USB device.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/change-usb-device-permission-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
@ -0,0 +1,53 @@
|
||||
Linux FAQs with Answers--How to find information about built-in kernel modules on Linux
|
||||
================================================================================
|
||||
> **Question**: I would like to know what modules are built into the kernel of my Linux system, and what parameters are available in each module. Is there a way to get a list of all built-in kernel modules and device drivers, and find detailed information about them?
|
||||
|
||||
The modern Linux kernel has been growing significantly over the years to support a wide variety of hardware devices, file systems and networking functions. During this time, "loadable kernel modules (LKM)" came into being in order to keep the kernel from getting bloated, while flexibly extending its capabilities and hardware support under different environments, without having to rebuild it.
|
||||
|
||||
The Linux kernel shipped with the latest Linux distributions comes with relatively a small number of "built-in modules", while the rest of hardware-specific drivers or custom capabilities exist as "loadable modules" which you can selectively load or unload.
|
||||
|
||||
The built-in modules are statically compiled into the kernel. Unlike loadable kernel modules which can be dynamically loaded, unloaded, looked up or listed using commands like modprobe, insmod, rmmod, modinfo or lsmod, built-in kernel modules are always loaded in the kernel upon boot-up, and cannot be managed with these commands.
|
||||
|
||||
### Find a List of Built-in Kernel Modules ###
|
||||
|
||||
To get a list of all built-in modules, run the following command.
|
||||
|
||||
$ cat /lib/modules/$(uname -r)/modules.builtin
|
||||
|
||||
|
||||
|
||||
You can also get a hint on what modules are built-in by running:
|
||||
|
||||
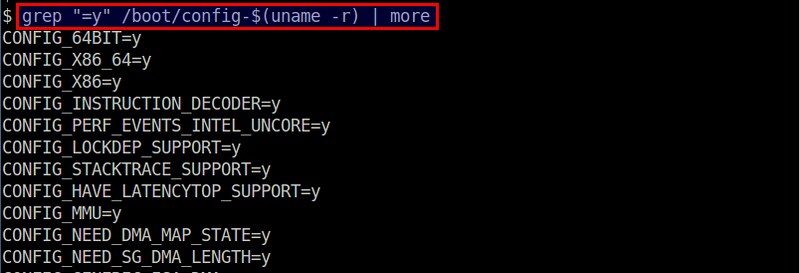
|
||||
|
||||
### Find Parameters of Built-in Kernel Modules ###
|
||||
|
||||
Each kernel module, whether it's built-in or loadable, comes with a set of parameters. For loadable kernel modules, the modinfo command will show parameter information about them. However, this command will not work with built-in modules. You will simply get the following error.
|
||||
|
||||
modinfo: ERROR: Module XXXXXX not found.
|
||||
|
||||
If you want to check what parameters are available in a given built-in module, and what their values are, you can instead examine the content in **/sys/module** directory.
|
||||
|
||||
Under /sys/module directory, you will find sub-directories named after existing kernel modules (both built-in and loadable). Then in each module directory, there is a directory named "parameters", which lists all available parameters for the module.
|
||||
|
||||
For example, let's say you want to find out parameters of a built-in module called tcp_cubic (the default TCP implementation of the kernel). Then you can do this:
|
||||
|
||||
$ ls /sys/module/tcp_cubic/parameters
|
||||
|
||||
And check the value of each parameter by reading a corresponding file.
|
||||
|
||||
$ cat /sys/module/tcp_cubic/parameters/tcp_friendliness
|
||||
|
||||
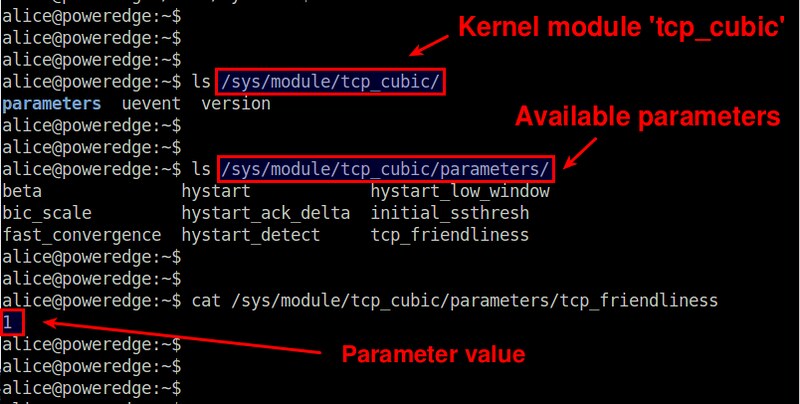
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/find-information-builtin-kernel-modules-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
@ -0,0 +1,54 @@
|
||||
Linux FAQs with Answers--How to force password change at the next login on Linux
|
||||
================================================================================
|
||||
> **Question**: I manage a Linux server for multiple users to share. I have just created a new user account with some default password, and I want the user to change the default password immediately after the first login. Is there a way to force a user to change his/her password at the next login?
|
||||
|
||||
In multi-user Linux environment, it's a standard practice to create user accounts with some random default password. Then after a successful login, a new user can change the default password to his or her own. For security reasons, it is often recommended to "force" users to change the default password after the first login to make sure that the initial one-time password is no longer used.
|
||||
|
||||
Here is **how to force a user to change his or her password on the next login**.
|
||||
|
||||
Every user account in Linux is associated with various password-related configurations and information. For example, it remembers the date of the last password change, the minimum/maximum number of days between password changes, and when to expire the current password, etc.
|
||||
|
||||
A command-line tool called chage can access and adjust password expiration related configurations. You can use this tool to force password change of any user at the next login.
|
||||
|
||||
To view password expiration information of a particular user (e.g., alice), run the following command. Note that you need root privilege only when you are checking password age information of any other user than yourself.
|
||||
|
||||
$ sudo chage -l alice
|
||||
|
||||
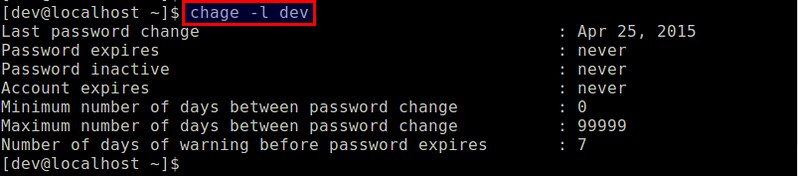
|
||||
|
||||
### Force Password Change for a User ###
|
||||
|
||||
If you want to force a user to change his or her password, use the following command.
|
||||
|
||||
$ sudo chage -d0 <user-name>
|
||||
|
||||
Originally the "-d <N>" option is supposed to set the "age" of a password (in terms of the number of days since January 1st, 1970 when the password was last changed). So "-d0" indicates that the password was changed on January 1st, 1970, which essentially expires the current password, and causes it to be changed on the next login.
|
||||
|
||||
Another way to expire the current password is via passwd command.
|
||||
|
||||
$ sudo passwd -e <user-name>
|
||||
|
||||
The above command has the same effect of "chage -d0", making the current password of the user expire immediately.
|
||||
|
||||
Now check the password information of the user again, and you will see:
|
||||
|
||||
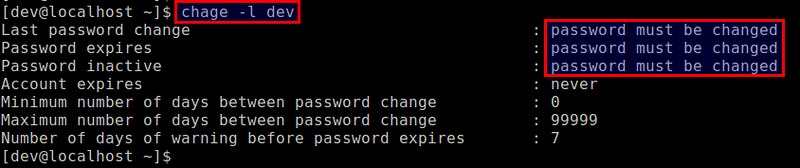
|
||||
|
||||
When you log in again, you will be asked to change the password. You will need to verify the current password one more time before the change.
|
||||
|
||||
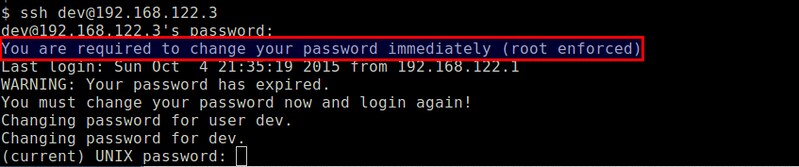
|
||||
|
||||
To set more comprehensive password policies (e.g., password complexity, reuse prevention), you can use PAM. See [the article][1] for more detail.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/force-password-change-next-login-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/set-password-policy-linux.html
|
||||
@ -0,0 +1,60 @@
|
||||
Remember sed and awk? All Linux admins should
|
||||
================================================================================
|
||||

|
||||
|
||||
Credit: Shutterstock
|
||||
|
||||
**We aren’t doing the next generation of Linux and Unix admins any favors by forgetting init scripts and fundamental tools**
|
||||
|
||||
I happened across a post on Reddit by chance, [asking about textfile manipulation][1]. It was a fairly simple request, similar to those that folks in Unix see nearly every day. In this case, it was how to remove all duplicate lines in a file, keeping one instance of each. This sounds relatively easy, but can get a bit complicated if the source file is sufficiently large and random.
|
||||
|
||||
There are countless answers to this problem. You could write a script in nearly any language to do this, with varying levels of complexity and time investment, which I suspect is what most would do. It might take 20 or 60 minutes depending on skill level, but armed with Perl, Python, or Ruby, you could make quick work of it.
|
||||
|
||||
Or you could use the answer stated in that thread, which warmed my heart: Just use awk.
|
||||
|
||||
That answer is the most concise and simplest solution to the problem by far. It’s one line:
|
||||
|
||||
awk '!seen[$0]++' <filename>.
|
||||
|
||||
Let’s take a look at this.
|
||||
|
||||
In this command, there’s a lot of hidden code. Awk is a text processing language, and as such it makes a lot of assumptions. For starters, what you see here is actually the meat of a for loop. Awk assumes you want to loop through every line of the input file, so you don’t need to explicitly state it. Awk also assumes you want to print the postprocessed output, so you don’t need to state that either. Finally, Awk then assumes the loop ends when the last statement finishes, so no need to state it.
|
||||
|
||||
The string seen in this example is the name given to an associative array. $0 is a variable that represents the entirety of the current line of the file. Thus, this command translates to “Evaluate every line in this file, and if you haven’t seen this line before, print it.” Awk does this by adding $0 to the seen array if it doesn’t already exist and incrementing the value so that it will not match the pattern the next time around and, thus, not print.
|
||||
|
||||
Some will see this as elegant, while others may see this as obfuscation. Anyone who uses awk on a daily basis will be in the first group. Awk is designed to do this. You can write multiline programs in awk. You can even write [disturbingly complex functions in awk][2]. But at the end of the day, awk is designed to do text processing, generally within a pipe. Eliminating the extraneous cruft of loop definition is simply a shortcut for a very common use case. If you like, you could write the same thing as the following:
|
||||
|
||||
awk '{ if (!seen[$0]) print $0; seen[$0]++ }’
|
||||
|
||||
It would lead to the same result.
|
||||
|
||||
Awk is the perfect tool for this job. Nevertheless, I believe many admins -- especially newer admins -- would jump into [Bash][3] or Python to try to accomplish this task, because knowledge of awk and what it can do seems to be fading as time goes on. I think it may be an indicator of things to come, where problems that have been solved for decades suddenly emerge again, based on lack of exposure to the previous solutions.
|
||||
|
||||
The shell, grep, sed, and awk are fundaments of Unix computing. If you’re not completely comfortable with their use, you’re artificially hamstrung because they form the basis of interaction with Unix systems via the CLI and shell scripting. One of the best ways to learn how these tools work is by observing and working with live examples, which every Unix flavor has in spades with their init systems -- or had, in the case of Linux distros that have adopted [systemd][4].
|
||||
|
||||
Millions of Unix admins learned how shell scripting and Unix tools worked by reading, writing, modifying, and working with init scripts. Init scripts differ greatly from OS to OS, even from distribution to distribution in the case of Linux, but they are all rooted in sh, and they all use core CLI tools like sed, awk, and grep.
|
||||
|
||||
I’ve heard many complaints that init scripts are “ancient” and “difficult,” but in fact, init scripts use the same tools that Unix admins work with every day, and thus provide an excellent way to become more familiar and comfortable with those tools. Saying that init scripts are hard to read or difficult to work with is to admit that you lack fundamental familiarity with the Unix toolset.
|
||||
|
||||
Speaking of things found on Reddit, I also came across this question from a budding Linux sys admin, [asking whether he should bother to learn sysvinit][5]. Most of the answers in the thread are good -- yes, definitely learn sysvinit and systemd. One commenter even notes that init scripts are a great way to learn Bash, and another states that the Fortune 50 company he works for has no plans to move to a systemd-based release.
|
||||
|
||||
But it concerns me that this is a question at all. If we continue down the path of eliminating scripts and roping off core system elements within our operating systems, we will inadvertently make it harder for new admins to learn the fundamental Unix toolset due to the lack of exposure.
|
||||
|
||||
I’m not sure why some want to cover up Unix internals with abstraction after abstraction, but such a path may reduce a generation of Unix admins to hapless button pushers dependent on support contracts. I’m pretty sure that would not be a good development.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2985804/linux/remember-sed-awk-linux-admins-should.html
|
||||
|
||||
作者:[Paul Venezia][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Paul-Venezia/
|
||||
[1]:https://www.reddit.com/r/linuxadmin/comments/3lwyko/how_do_i_remove_every_occurence_of_duplicate_line/
|
||||
[2]:http://intro-to-awk.blogspot.com/2008/08/awk-more-complex-examples.html
|
||||
[3]:http://www.infoworld.com/article/2613338/linux/linux-how-to-script-a-bash-crash-course.html
|
||||
[4]:http://www.infoworld.com/article/2608798/data-center/systemd--harbinger-of-the-linux-apocalypse.html
|
||||
[5]:https://www.reddit.com/r/linuxadmin/comments/3ltq2y/when_i_start_learning_about_linux_administration/
|
||||
@ -0,0 +1,62 @@
|
||||
开源媒体播放器 MPlayer 1.2 发布
|
||||
================================================================================
|
||||

|
||||
|
||||
在 [MPlayer][1] 1.1 发布将近3年后,新版 MPlayer 终于在上周发布了。在新版本 MPlayer 1.2 中带来了对许多新编码的解码支持。
|
||||
|
||||
MPlayer 是一款跨平台的开源媒体播放器。它的名字是“Movie Player”的缩写。MPlayer 已经成为 Linux 上最老牌的媒体播放器之一,在过去的15年里,它还启发了许多其他媒体播放器。著名的基于 MPlayer 的媒体播放器有:
|
||||
|
||||
- [MPV][2]
|
||||
- SMPlayer
|
||||
- KPlayer
|
||||
- GNOME MPlayer
|
||||
- Deepin Player(深度影音)
|
||||
|
||||
#### MPlayer 1.2 更新了些什么? ####
|
||||
|
||||
- 兼容 FFmpeg 2.8
|
||||
- 对 H.265/HEVC 的 VDPAU 硬件加速
|
||||
- 通过 FFmpeg 支持一些新的编码解码
|
||||
- 改善电视与数字视频广播支持
|
||||
- 界面优化
|
||||
- libdvdcss/libdvdnav 包外部依赖
|
||||
|
||||
#### 在 Linux 安装 MPlayer 1.2 ####
|
||||
|
||||
大多数 Linux 发行版仓库中还是 MPlayer 1.1 版本。如果你想使用新的 MPlayer 1.2 版本,你需要从源码手动编译,这对新手来说可能有点棘手。
|
||||
|
||||
我是在 Ubuntu 15.04 上安装的 MPlayer 1.2。除了需要安装 yasm 的地方以外,对所有 Linux 发行版来说安装说明都是一样的。
|
||||
|
||||
打开一个终端,运行下列命令:
|
||||
|
||||
wget http://www.mplayerhq.hu/MPlayer/releases/MPlayer-1.2.tar.xz
|
||||
|
||||
tar xvf MPlayer-1.1.1.tar.xz
|
||||
|
||||
cd MPlayer-1.2
|
||||
|
||||
sudo apt-get install yasm
|
||||
|
||||
./configure
|
||||
|
||||
在你运行 make 的时候,在你的终端屏幕上会显示一些东西,并且你需要一些时间来编译它。保持耐心。
|
||||
|
||||
make
|
||||
|
||||
sudo make install
|
||||
|
||||
如果你觉得从源码编译不大习惯的话,我建议你等待 MPlayer 1.2 提交到你的 Linux 发行版仓库中,或者用其它的播放器替代,比如 MPV。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/mplayer-1-2-released/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:https://www.mplayerhq.hu/
|
||||
[2]:http://mpv.io/
|
||||
@ -0,0 +1,91 @@
|
||||
如何使用 GRUB 2 直接从硬盘运行 ISO 文件
|
||||
================================================================================
|
||||

|
||||
大多数 Linux 发行版都会提供一个可以从 USB 启动的 live 环境,以便用户无需安装即可测试系统。我们可以用它来评测这个发行版或仅仅是当成一个一次性系统,并且很容易将这些文件复制到一个 U 盘上,在某些情况下,我们可能需要经常运行同一个或不同的 ISO 镜像。GRUB 2 可以配置成直接从启动菜单运行一个 live 环境,而不需要烧录这些 ISO 到硬盘或 USB 设备。
|
||||
|
||||
### 获取和检查可启动的 ISO 镜像 ###
|
||||
为了获取 ISO 镜像,我们通常应该访问所需要的发行版的网站下载与我们架构兼容的镜像文件。如果这个镜像可以从 U 盘启动,那它也应该可以从 GRUB 菜单启动。
|
||||
|
||||
当镜像下载完后,我们应该通过 MD5 校验检查它的完整性。这会输出一大串数字与字母合成的序列。
|
||||
|
||||

|
||||
|
||||
将这个序列与下载页提供的 MD5 校验码进行比较,两者应该完全相同。
|
||||
|
||||
### 配置 GRUB 2 ###
|
||||
ISO 镜像文件包含了整个系统。我们要做的仅仅是告诉 GRUB 2 哪里可以找到 kernel 和 initramdisk 或 initram 文件系统(这取决于我们所使用的发行版)。
|
||||
|
||||
在下面的例子中,一个 Kubuntu 15.04 live 环境将被配置到 Ubuntu 14.04 盒子的 Grub 启动菜单项。这应该能在大多数新的以 Ubuntu 为基础的系统上运行。如果你是其他系统并且想实现一些其它的东西,你可以从[这些文件][1]获取灵感,但这会要求你拥有一点 GRUB 使用经验。
|
||||
|
||||
这个例子的文件 `kubuntu-15.04-desktop-amd64.iso`
|
||||
|
||||
放在位于 `/dev/sda1` 的 `/home/maketecheasier/TempISOs/` 上.
|
||||
|
||||
为了使 GRUB 2 能正确找到它,我们应该编辑
|
||||
|
||||
/etc/grub.d40-custom
|
||||
|
||||

|
||||
|
||||
menuentry "Kubuntu 15.04 ISO" {
|
||||
set isofile="/home/maketecheasier/TempISOs/kubuntu-15.04-desktop-amd64.iso"
|
||||
loopback loop (hd0,1)$isofile
|
||||
echo "Starting $isofile..."
|
||||
linux (loop)/casper/vmlinuz.efi boot=casper iso-scan/filename=${isofile} quiet splash
|
||||
initrd (loop)/casper/initrd.lz
|
||||
}
|
||||
|
||||

|
||||
|
||||
### 分析上述代码 ###
|
||||
|
||||
首先设置了一个变量名 `$menuentry` ,这是 ISO 文件的所在位置 。如果你想改变一个 ISO ,你应该修改 `isofile="/path/to/file/name-of-iso-file-.iso"`.
|
||||
|
||||
下一行是指定回环设备,且必须给出正确的分区号码。
|
||||
|
||||
loopback loop (hd0,1)$isofile
|
||||
|
||||
注意 hd0,1 这里非常重要,它的意思是第一硬盘,第一分区 (`/dev/sda1`)。
|
||||
|
||||
GRUB 的命名在这里稍微有点困惑,对于硬盘来说,它从 “0” 开始计数,第一块硬盘为 #0 ,第二块为 #1 ,第三块为 #2 ,依此类推。但是对于分区来说,它从 “1” 开始计数,第一个分区为 #1 ,第二个分区为 #2 ,依此类推。也许这里有一个很好的原因,但肯定不是明智的(明显用户体验很糟糕)..
|
||||
|
||||
在 Linux 中第一块硬盘,第一个分区是 `/dev/sda1` ,但在 GRUB2 中则是 `hd0,1` 。第二块硬盘,第三个分区则是 `hd1,3`, 依此类推.
|
||||
|
||||
下一个重要的行是
|
||||
|
||||
linux (loop)/casper/vmlinuz.efi boot=casper iso-scan/filename=${isofile} quiet splash
|
||||
|
||||
这会载入内核镜像,在新的 Ubuntu Live CD 中,内核被存放在 `/casper` 目录,并且命名为 `vmlinuz.efi` 。如果你使用的是其它系统,可能会没有 `.efi` 扩展名或内核被存放在其它地方 (可以使用归档管理器打开 ISO 文件在 `/casper` 中查找确认)。最后一个选项, `quiet splash`, 是一个常规的 GRUB 选项无论你是否在意改动它们。
|
||||
|
||||
最后
|
||||
|
||||
initrd (loop)/casper/initrd.lz
|
||||
|
||||
这会载入 `initrd` ,它负责载入 RAMDisk 到内存用于启动。
|
||||
|
||||
### 启动 live 系统 ###
|
||||
|
||||
做完上面所有的步骤后,需要更新 GRUB2
|
||||
|
||||
sudo update-grub
|
||||
|
||||

|
||||
|
||||
当重启系统后,应该可以看见一个新的,并且允许我们启动刚刚配置的 ISO 镜像的 GRUB 条目
|
||||
|
||||

|
||||
|
||||
选择这个新条目就允许我们像从 DVD 或 U 盘中启动一个 live 环境一样。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/run-iso-files-hdd-grub2/
|
||||
|
||||
作者:[Attila Orosz][a]
|
||||
译者:[Locez](https://github.com/locez)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/attilaorosz/
|
||||
[1]:http://git.marmotte.net/git/glim/tree/grub2
|
||||
@ -0,0 +1,39 @@
|
||||
修复Sheell脚本在Ubuntu中用文本编辑器打开的方式
|
||||
================================================================================
|
||||

|
||||
|
||||
当你双击一个脚本(.sh文件)的时候,你想要做的是什么?通常的想法是执行它。但是在Ubuntu下面却不是这样,或者我应该更确切地说是在Files(Nautilus)中。你可能会疯狂地大叫“运行文件,运行文件”,但是文件没有运行而是用Gedit打开了。
|
||||
|
||||
我知道你也许会说文件有可执行权限么?我会说是的。脚本有可执行权限但是当我双击它的时候,它还是用文本编辑器打开了。我不希望这样如果你遇到了同样的问题,我想你也许也不需要这样。
|
||||
|
||||
我知道你或许已经被建议在终端下面运行,我知道这个可行但是这不是一个在GUI下不能运行的借口是么?
|
||||
|
||||
这篇教程中,我们会看到**如何在双击后运行shell脚本。**
|
||||
|
||||
#### 修复在Ubuntu中shell脚本用文本编辑器打开的方式 ####
|
||||
|
||||
shell脚本用文件编辑器打开的原因是Files(Ubuntu中的文件管理器)中的默认行为设置。在更早的版本中,它或许会询问你是否运行文件或者用编辑器打开。默认的行位在新的版本中被修改了。
|
||||
|
||||
要修复这个,进入文件管理器,并在菜单中点击**选项**:
|
||||
|
||||

|
||||
|
||||
接下来在**文件选项**中进入**行为**标签中,你会看到**文本文件执行**选项。
|
||||
|
||||
默认情况下,它被设置成“在打开是显示文本文件”。我建议你把它改成“每次询问”,这样你可以选择是执行还是编辑了,当然了你也可以选择默认执行。你可以自行选择。
|
||||
|
||||

|
||||
|
||||
我希望这个贴士可以帮你修复这个小“问题”。欢迎提出问题和建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/shell-script-opens-text-editor/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
Loading…
Reference in New Issue
Block a user