mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-03 01:10:13 +08:00
commit
f614329d0c
@ -0,0 +1,97 @@
|
||||
谨慎使用 Linux find 命令
|
||||
======
|
||||
|
||||
> 当使用 Linux 下的 find 命令时,请使用 -ok 选项来避免文件被意外删除,这个选项会在移除任何文件之前都会请求你的许可。
|
||||
|
||||

|
||||
|
||||
最近有朋友提醒我有一个有用的选项来更加谨慎地运行 `find` 命令,它就是 `-ok`。除了一个重要的区别之外,它的工作方式与 `-exec` 相似,它使 `find` 命令在执行指定的操作之前请求权限。
|
||||
|
||||
这有一个例子。如果你使用 `find` 命令查找文件并删除它们,你可能使用的是下面的命令:
|
||||
|
||||
```
|
||||
$ find . -name runme -exec rm {} \;
|
||||
```
|
||||
|
||||
在当前目录及其子目录中中任何名为 “runme” 的文件都将被立即删除 —— 当然,你要有权限删除它们。改用 `-ok` 选项,你会看到类似这样的东西,但 `find` 命令将在删除文件之前会请求权限。回答 `y` 代表 “yes” 将允许 `find` 命令继续并逐个删除文件。
|
||||
|
||||
```
|
||||
$ find . -name runme -ok rm {} \;
|
||||
< rm ... ./bin/runme > ?
|
||||
```
|
||||
|
||||
### -execdir 命令也是一个选择
|
||||
|
||||
另一个可以用来修改 `find` 命令行为,并可能使其更可控的选项是 `-execdir` 。`-exec` 会运行指定的任何命令,而 `-execdir 则从文件所在的目录运行指定的命令,而不是在运行 `find` 命令的目录运行指定的命令。这是两个它的例子:
|
||||
|
||||
```
|
||||
$ pwd
|
||||
/home/shs
|
||||
$ find . -name runme -execdir pwd \;
|
||||
/home/shs/bin
|
||||
```
|
||||
|
||||
```
|
||||
$ find . -name runme -execdir ls \;
|
||||
ls rm runme
|
||||
```
|
||||
|
||||
到现在为止还挺好。但要记住的是,`-execdir` 也会在匹配文件的目录中执行该命令。如果运行下面的命令,并且目录包含一个名为 “ls” 的文件,那么即使该文件_没有_执行权限,它也将运行该文件。使用 `-exec` 或 `-execdir` 类似于通过 `source` 来运行命令。
|
||||
|
||||
```
|
||||
$ find . -name runme -execdir ls \;
|
||||
Running the /home/shs/bin/ls file
|
||||
```
|
||||
|
||||
```
|
||||
$ find . -name runme -execdir rm {} \;
|
||||
This is an imposter rm command
|
||||
```
|
||||
|
||||
```
|
||||
$ ls -l bin
|
||||
total 12
|
||||
-r-x------ 1 shs shs 25 Oct 13 18:12 ls
|
||||
-rwxr-x--- 1 shs shs 36 Oct 13 18:29 rm
|
||||
-rw-rw-r-- 1 shs shs 28 Oct 13 18:55 runme
|
||||
```
|
||||
|
||||
```
|
||||
$ cat bin/ls
|
||||
echo Running the $0 file
|
||||
$ cat bin/rm
|
||||
echo This is an imposter rm command
|
||||
```
|
||||
|
||||
### -okdir 选项也会请求权限
|
||||
|
||||
要更谨慎,可以使用 `-okdir` 选项。类似 `-ok`,该选项将请求权限来运行该命令。
|
||||
|
||||
```
|
||||
$ find . -name runme -okdir rm {} \;
|
||||
< rm ... ./bin/runme > ?
|
||||
```
|
||||
|
||||
你也可以小心地指定你想用的命令的完整路径,以避免像上面那样的冒牌命令出现的任何问题。
|
||||
|
||||
```
|
||||
$ find . -name runme -execdir /bin/rm {} \;
|
||||
```
|
||||
|
||||
`find` 命令除了默认打印之外还有很多选项,有些可以使你的文件搜索更精确,但谨慎一点总是好的。
|
||||
|
||||
在 [Facebook][1] 和 [LinkedIn][2] 上加入 Network World 社区来进行评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3233305/linux/using-the-linux-find-command-with-caution.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[Locez](https://github.com/locez)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://www.facebook.com/NetworkWorld/
|
||||
[2]:https://www.linkedin.com/company/network-world
|
||||
422
published/20171228 Dual Boot Ubuntu And Arch Linux.md
Normal file
422
published/20171228 Dual Boot Ubuntu And Arch Linux.md
Normal file
@ -0,0 +1,422 @@
|
||||
详解 Ubuntu 和 Arch Linux 双启动
|
||||
======
|
||||
|
||||

|
||||
|
||||
Ubuntu 和 Arch Linux 双启动不像听起来那么容易,然而,我将使这个过程尽可能地简单明了。首先,我们需要安装 Ubuntu,然后安装 Arch Linux,因为配置 Ubuntu grub 更容易实现 Ubuntu 和 Arch Linux 双启动。
|
||||
|
||||
### Ubuntu 和 Arch Linux 双启动
|
||||
|
||||
你需要准备好以下内容:
|
||||
|
||||
1、你需要准备你所选择的 Ubuntu 的特色版本,在这个例子中,我将使用 Ubuntu 17.10 ISO
|
||||
2、两个优盘
|
||||
3、Windows 或者 Linux 操作系统的 PC 机
|
||||
4、Arch Linux ISO
|
||||
5、基于 Windows 的 Rufus 或是基于 Linux 发行版的 etcher 的两款软件中的一种,要根据自己的系统类型来选择哦。
|
||||
|
||||
### 安装 Ubuntu
|
||||
|
||||
首先, 利用 Rufus 为 Ubuntu 和 Arch Linux [创建可启动的闪存驱动器][1]。另外,也可以使用 `etcher` 创建 Ubuntu 和 Arch Linux 的可启动闪存驱动器。
|
||||
|
||||
[][2]
|
||||
|
||||
为 Ubuntu 选择 ISO 映像文件,然后选择闪存驱动器,然后单击 `Flash!` 创建可引导的闪存驱动器。等到它完成,瞧!你的可启动闪存驱动器已经准备好使用了。
|
||||
|
||||
[][3]
|
||||
|
||||
打开你的机器并使用载有 Ubuntu 安装媒体的可启动闪存驱动器进行启动。确保引导到 UEFI 或 BIOS 兼容模式,这取决于您所使用的 PC 的类型。我更喜欢使用 UEFI 来构建新的 PC。
|
||||
|
||||
[][4]
|
||||
|
||||
在成功启动后,您将看到如上图显示,要求您尝试 Ubuntu 或安装 Ubuntu,选择安装 Ubuntu。
|
||||
|
||||
[][5]
|
||||
|
||||
然后检查安装第三方软件的图形和 WiFi 硬件、MP3 和其他媒体。如果你有一个互联网连接,你可以选择在安装 Ubuntu 的时候下载更新,因为它会节省安装时间,并且确保安装的是最新更新。
|
||||
|
||||
[][6]
|
||||
|
||||
然后选择点击“Something else”,这样我们就可以对硬盘进行分区,并预留出 Ubuntu 和 Archlinux 的分区以及它们的交换分区的空间。
|
||||
|
||||
[][7]
|
||||
|
||||
创建一个交换分区。最好是内存的一半大小。在我的例子中,我有 1 GB 的内存,因此创建一个 512 MB 的交换空间。
|
||||
|
||||
[][8]
|
||||
|
||||
然后创建挂载点为 `/` 的分区,并且点击“Install Now”按钮。
|
||||
|
||||
[][9]
|
||||
|
||||
接下来选择你的位置以选择语言和键盘设置。
|
||||
|
||||
[][10]
|
||||
|
||||
然后创建新用户的用户凭据。
|
||||
|
||||
[][11]
|
||||
|
||||
点击“Next”开始安装。
|
||||
|
||||
[][12]
|
||||
|
||||
当安装完成后点击“Restart Now”重启 PC。
|
||||
|
||||
[][13]
|
||||
|
||||
移除安装媒介,按下回车继续。
|
||||
|
||||
[][14]
|
||||
|
||||
在确认成功安装后,重新启动并利用 Arch Linux 安装媒介引导。
|
||||
|
||||
### 安装 Arch Linux
|
||||
|
||||
在引导到 Arch Linux 安装媒体时,您应该看到如下所示的初始屏幕。选择 “Boot Arch Linux(x86_64)”。注意 Arch Linux 更类似于一种 [DIY][15](自我定制)的操作系统。
|
||||
|
||||
[][16]
|
||||
|
||||
选择之后,它将打开一个`tty1`终端,您将使用它来安装操作系统。
|
||||
|
||||
[][17]
|
||||
|
||||
注意:为了成功安装 Arch Linux,您需要一个互联网连接来下载一些必须的系统安装包。所以我们需要检查一下互联网是否运行正常。输入以下命令到终端以检查网络连接。
|
||||
|
||||
```
|
||||
ping linuxandubuntu.com -c 4
|
||||
```
|
||||
|
||||
[][18]
|
||||
|
||||
如果互联网运行正常,你应该得到一个回显,显示发送和接收的数据包的数量。在这种情况下,我们发送了 4 个包,并得到了 4 个反馈,这意味着连接是正常的。
|
||||
|
||||
如果想在 Arch Linux 中设置 Wifi,请阅读[本文][19]以在 Arch Linux 中配置 Wifi。
|
||||
|
||||
接下来,我们需要选择之前在安装 Ubuntu 时预留出的空闲分区。
|
||||
|
||||
```
|
||||
fdisk -l
|
||||
```
|
||||
|
||||
上面的命令应该显示可用的磁盘分区在哪里。您应该能看到 Ubuntu 分区以及预留的空闲空间。我们将使用 `cfdisk`命令进行分区。
|
||||
|
||||
```
|
||||
cfdisk
|
||||
```
|
||||
|
||||
[][20]
|
||||
|
||||
执行命令后将看到分区情况。选择其它已分配分区下面的空闲空间。
|
||||
|
||||
您需要选择 “New”,然后输入分区大小。
|
||||
|
||||
[][21]
|
||||
|
||||
例如,9.3G - G 表示千兆字节。
|
||||
|
||||
[][22]
|
||||
|
||||
如下图所示,选择“primary”进行分区
|
||||
|
||||
[][23]
|
||||
|
||||
然后选择写分区条目。
|
||||
|
||||
[][24]
|
||||
|
||||
键入“yes”,以确认写入分区表。
|
||||
|
||||
[][25]
|
||||
|
||||
然后选择 “Quit”(退出)选项。
|
||||
|
||||
[][26] 然后键入:
|
||||
|
||||
```
|
||||
fdisk -l
|
||||
```
|
||||
|
||||
确认修改。
|
||||
|
||||
[][27]
|
||||
|
||||
然后使用磁盘分区命令:
|
||||
|
||||
```
|
||||
mkfs.ext4 /dev/sda3
|
||||
```
|
||||
|
||||
确保您选择的分区是我们创建的最后一个分区,这样我们就不会破坏 Ubuntu 分区。
|
||||
|
||||
[][28]
|
||||
|
||||
然后使用以下命令安装这个分区:
|
||||
|
||||
```
|
||||
mount /dev/sda3 /mnt
|
||||
```
|
||||
|
||||
[][29]
|
||||
|
||||
用下面命令创建“home”目录:
|
||||
|
||||
```
|
||||
mkdir .mnt/home
|
||||
```
|
||||
|
||||
[][30]
|
||||
|
||||
用以下命令安装“home”目录到这个分区上:
|
||||
|
||||
```
|
||||
mount /dev/sda3 /mnt/home
|
||||
```
|
||||
|
||||
[][31]
|
||||
|
||||
现在使用以下命令安装 Archlinux 的基本系统:
|
||||
|
||||
```
|
||||
pacstrap /mnt base
|
||||
```
|
||||
|
||||
请确保网络连接正常。
|
||||
|
||||
|
||||
接下来开始下载和配置安装所用时间取决于你的网速。
|
||||
|
||||
[][32]
|
||||
|
||||
这一步骤完成后,将完成 Archlinux 基本安装。
|
||||
|
||||
Arch Linux 基础系统安装完成后,使用以下命令创建一个 `fstab` 文件:
|
||||
|
||||
```
|
||||
genfstab -U /mnt >> /mnt/etc/fstab
|
||||
```
|
||||
|
||||
[][33]
|
||||
|
||||
在此之后,您需要验证`fstab`文件,使用下面命令:
|
||||
|
||||
```
|
||||
cat /mnt/etc/fstab
|
||||
```
|
||||
|
||||
[][34]
|
||||
|
||||
### 配置 Arch Linux 的基础配置
|
||||
|
||||
您将需要在安装时配置以下内容:
|
||||
|
||||
1. 系统语言和系统语言环境
|
||||
2. 系统时区
|
||||
3. Root 用户密码
|
||||
4. 设置主机名
|
||||
|
||||
首先,您需要使用以下命令将`root`切换为新安装的基础系统用户:
|
||||
|
||||
```
|
||||
arch-chroot /mnt
|
||||
```
|
||||
|
||||
#### 1. 系统语言和系统语言环境
|
||||
|
||||
然后必须配置系统语言。必须取消对 en_Utf-8 UTF-8的注释,并加载到文件 `/etc/local.gen` 中。
|
||||
|
||||
键入:
|
||||
|
||||
```
|
||||
nano /etc/local.gen
|
||||
```
|
||||
|
||||
然后将 en_UTF-8 UTF-8 取消注释。
|
||||
|
||||
键入命令:
|
||||
|
||||
```
|
||||
locale-gen
|
||||
```
|
||||
|
||||
生成本地化设置如下:
|
||||
|
||||
[][35]
|
||||
|
||||
相应的需要在 `locale.conf` 文件中配置 LANG 变量。例如:
|
||||
|
||||
```
|
||||
nano /etc/locale.conf
|
||||
```
|
||||
|
||||
修改为:
|
||||
|
||||
```
|
||||
LANG=en_US.UTF-8
|
||||
```
|
||||
|
||||
配置键盘布局,则在文件 `vconsole.conf` 中进行更改,如下操作:
|
||||
|
||||
```
|
||||
nano /etc/vconsole.conf
|
||||
```
|
||||
|
||||
修改为:
|
||||
|
||||
```
|
||||
KEYMAP=us-eng
|
||||
```
|
||||
|
||||
#### 2. 系统时区
|
||||
|
||||
配置时区需要利用以下命令实现:
|
||||
|
||||
```
|
||||
ln -sf /usr/share/zoneinfo/Region/City /etc/localtime
|
||||
```
|
||||
|
||||
要查看可用时区,可以在终端使用以下命令:
|
||||
|
||||
注意可选时区在屏幕截图中显示为蓝色:
|
||||
|
||||
```
|
||||
ls /usr/share/zoneinfo
|
||||
```
|
||||
|
||||
[][36]
|
||||
|
||||
[][37]
|
||||
|
||||
运行 `hwclock` 命令来生成 `/etc/adjtime`(假设硬件时钟被设置为 UTC):
|
||||
|
||||
```
|
||||
# hwclock --systohc
|
||||
```
|
||||
|
||||
#### 3. 配置 root 用户密码
|
||||
|
||||
要为 Arch Linux 系统用户 root 设置密码,请使用:
|
||||
|
||||
```
|
||||
passwd
|
||||
```
|
||||
|
||||
为 root 用户提供一个新的密码并确认密码使其生效。
|
||||
|
||||
[][38]
|
||||
|
||||
#### 4. 配置主机名和网络
|
||||
|
||||
需要创建主机名文件:
|
||||
|
||||
```
|
||||
nano /etc/hostname
|
||||
```
|
||||
|
||||
[][39]
|
||||
|
||||
将名字更改为您的用户名:
|
||||
|
||||
[][40]
|
||||
|
||||
然后向主机添加一个匹配的条目:
|
||||
|
||||
```
|
||||
nano /etc/hosts
|
||||
```
|
||||
|
||||
```
|
||||
127.0.0.1 localhost.localdomain localhost
|
||||
|
||||
::1 localhost.localdomain localhost
|
||||
|
||||
127.0.1.1 LinuxandUbuntu.localdomain LinuxandUbuntu
|
||||
```
|
||||
|
||||
您需要使网络保持连接,然后使用:
|
||||
|
||||
```
|
||||
systemctl enable dhcpd
|
||||
```
|
||||
|
||||
#### 配置 Grub
|
||||
|
||||
然后重启机器,进入 Ubuntu 配置 grub。
|
||||
|
||||
你可以键入:
|
||||
|
||||
```
|
||||
reboot
|
||||
```
|
||||
|
||||
[][41]
|
||||
|
||||
Arch Linux 仍然没有出现,因此我们需要在 Ubuntu 中使用 `update-grub` 来安装它。
|
||||
|
||||
[][42]
|
||||
|
||||
在Ubuntu中打开终端,输入:
|
||||
|
||||
```
|
||||
sudo update-grub
|
||||
```
|
||||
|
||||
这将更新 grub,添加 Arch Linux 记录。
|
||||
|
||||
### 小结
|
||||
|
||||
祝贺您成功地将 Ubuntu 和 Arch Linux 设置为双引导。Ubuntu 安装很简单,但是 Arch Linux 安装对新的 Linux 用户来说是一个挑战。我试着让这个教程变得简单。但是如果你对这篇文章有任何疑问,请在评论部分告诉我。还可以与您的朋友分享这篇文章,并帮助他们学习 Linux。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/dual-boot-ubuntu-and-arch-linux
|
||||
|
||||
作者:[LinuxAndUbuntu][a]
|
||||
译者:[stevenzdg988](https://github.com/stevenzdg988)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/home/etcher-burn-images-to-sd-card-make-bootable-usb
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/bootable-ubuntu-usb-etcher-image-writer_orig.jpg
|
||||
[3]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/make-ubuntu-usb-bootable-in-linux_orig.jpg
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/live-ubuntu-boot_orig.jpg
|
||||
[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/install-usb-from-live-usb_orig.jpg
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/custom-partition-hd-install-ubuntu_orig.jpg
|
||||
[7]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/create-swap-partition-ubuntu_orig.jpg
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/install-ubuntu-root-partition_orig.jpg
|
||||
[9]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/select-ubuntu-timezone_orig.jpg
|
||||
[10]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/install-ubuntu-select-location-keyboard-layout_orig.jpg
|
||||
[11]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/create-username-system-name-ubuntu-install_orig.jpg
|
||||
[12]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/ubuntu-installation-finishing_orig.jpg
|
||||
[13]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/ubuntu-installation-finished_orig.jpg
|
||||
[14]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/remove-installation-media-after-ubuntu_orig.jpg
|
||||
[15]:http://www.linuxandubuntu.com/home/arch-linux-take-your-linux-knowledge-to-next-level-review
|
||||
[16]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/arch-linux-installation-boot-menu_orig.jpg
|
||||
[17]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/arch-linux-tty1-linux_orig.png
|
||||
[18]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/arch-linux-ping-check-internet-connection_orig.png
|
||||
[19]:http://www.linuxandubuntu.com/home/how-to-setup-a-wifi-in-arch-linux-using-terminal
|
||||
[20]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/install-arch-partition-disk-with-cfdisk_orig.png
|
||||
[21]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/partition-free-space-swap-arch-linux_orig.png
|
||||
[22]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/install-arch-linux-partition_orig.png
|
||||
[23]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/make-arch-linux-root-as-primary-partition_orig.png
|
||||
[24]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/select-partition-to-install-arch_orig.png
|
||||
[25]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/install-arch-linux-confirm-create-partition_orig.png
|
||||
[26]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/quit-cfdisk-arch-linux_orig.png
|
||||
[27]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/confirm-partition-changes_orig.png
|
||||
[28]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/complete-arch-linux-installation-partition_orig.png
|
||||
[29]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/mount-base-partition-in-arch-linux.png
|
||||
[30]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/mount-home-partition-arch-linux.png
|
||||
[31]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/make-mount-home-directory.png
|
||||
[32]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/install-arch-linux-base.png
|
||||
[33]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/create-fstab-file-in-arch-linux.png
|
||||
[34]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/cat-fstab-file-data-terminal.png
|
||||
[35]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/generate-localization-arch-linux.png
|
||||
[36]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/setup-zonefile-in-arch-linux.png
|
||||
[37]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/setup-country-zonefile_orig.png
|
||||
[38]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/setup-arch-linux-root-password.png
|
||||
[39]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/set-arch-linux-hostname.png
|
||||
[40]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/set-arch-linux-username.png
|
||||
[41]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/reboot-system-after-arch-linux-installation.png
|
||||
[42]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/ubuntu-grub-menu.png
|
||||
197
published/20180118 Getting Started with ncurses.md
Normal file
197
published/20180118 Getting Started with ncurses.md
Normal file
@ -0,0 +1,197 @@
|
||||
ncurses 入门指南
|
||||
======
|
||||
|
||||
> 怎样使用curses来绘制终端屏幕?
|
||||
|
||||
虽然图形界面非常酷,但是不是所有的程序都需要点击式的界面。例如,令人尊敬的 Vi 编辑器在第一个 GUI 出现之前在纯文本终端运行了很久。
|
||||
|
||||
Vi 编辑器是一个在“文本”模式下绘制的<ruby>面向屏幕<rt>screen-oriented</rt></ruby>程序的例子。它使用了一个叫 curses 的库。这个库提供了一系列的编程接口来操纵终端屏幕。curses 库产生于 BSD UNIX,但是 Linux 系统通过 ncurses 库提供这个功能。
|
||||
|
||||
[要了解 ncurses “过去曾引起的风暴”,参见 [ncurses: Portable Screen-Handling for Linux][1], September 1, 1995, by Eric S. Raymond.]
|
||||
|
||||
使用 curses 创建程序实际上非常简单。在这个文章中,我展示了一个利用 curses 来在终端屏幕上绘图的示例程序。
|
||||
|
||||
### 谢尔宾斯基三角形
|
||||
|
||||
简单展示一些 curses 函数的一个方法是生成<ruby>谢尔宾斯基三角形<rt>Sierpinski's Triangle</rt></ruby>。如果你对生成谢尔宾斯基三角形的这种方法不熟悉的话,这里是一些产生谢尔宾斯基三角形的规则:
|
||||
|
||||
1. 设置定义三角形的三个点。
|
||||
2. 随机选择任意的一个点 `(x,y)`。
|
||||
|
||||
然后:
|
||||
|
||||
1. 在三角形的顶点中随机选择一个点。
|
||||
2. 将新的 `x,y` 设置为先前的 `x,y` 和三角顶点的中间点。
|
||||
3. 重复(上述步骤)。
|
||||
|
||||
所以我按照这些指令写了这个程序,程序使用 curses 函数来向终端屏幕绘制谢尔宾斯基三角形:
|
||||
|
||||
```
|
||||
/* triangle.c */
|
||||
|
||||
#include <curses.h>
|
||||
#include <stdlib.h>
|
||||
|
||||
#include "getrandom_int.h"
|
||||
|
||||
#define ITERMAX 10000
|
||||
|
||||
int main(void)
|
||||
{
|
||||
long iter;
|
||||
int yi, xi;
|
||||
int y[3], x[3];
|
||||
int index;
|
||||
int maxlines, maxcols;
|
||||
|
||||
/* initialize curses */
|
||||
|
||||
initscr();
|
||||
cbreak();
|
||||
noecho();
|
||||
|
||||
clear();
|
||||
|
||||
/* initialize triangle */
|
||||
|
||||
maxlines = LINES - 1;
|
||||
maxcols = COLS - 1;
|
||||
|
||||
y[0] = 0;
|
||||
x[0] = 0;
|
||||
|
||||
y[1] = maxlines;
|
||||
x[1] = maxcols / 2;
|
||||
|
||||
y[2] = 0;
|
||||
x[2] = maxcols;
|
||||
|
||||
mvaddch(y[0], x[0], '0');
|
||||
mvaddch(y[1], x[1], '1');
|
||||
mvaddch(y[2], x[2], '2');
|
||||
|
||||
/* initialize yi,xi with random values */
|
||||
|
||||
yi = getrandom_int() % maxlines;
|
||||
xi = getrandom_int() % maxcols;
|
||||
|
||||
mvaddch(yi, xi, '.');
|
||||
|
||||
/* iterate the triangle */
|
||||
|
||||
for (iter = 0; iter < ITERMAX; iter++) {
|
||||
index = getrandom_int() % 3;
|
||||
|
||||
yi = (yi + y[index]) / 2;
|
||||
xi = (xi + x[index]) / 2;
|
||||
|
||||
mvaddch(yi, xi, '*');
|
||||
refresh();
|
||||
}
|
||||
|
||||
/* done */
|
||||
|
||||
mvaddstr(maxlines, 0, "Press any key to quit");
|
||||
|
||||
refresh();
|
||||
|
||||
getch();
|
||||
endwin();
|
||||
|
||||
exit(0);
|
||||
}
|
||||
```
|
||||
|
||||
让我一边解释一边浏览这个程序。首先,`getrandom_int()` 函数是我对 Linux 系统调用 `getrandom()` 的包装器。它保证返回一个正整数(`int`)值。(LCTT 译注:`getrandom()` 系统调用按照字节返回随机值到一个变量中,值是随机的,不保证正负,使用 `stdlib.h` 的 `random()` 函数可以达到同样的效果)另外,按照上面的规则,你应该能够辨认出初始化和迭代谢尔宾斯基三角形的代码。除此之外,我们来看看我用来在终端上绘制三角形的 curses 函数。
|
||||
|
||||
大多数 curses 程序以这四条指令开头。 `initscr()` 函数获取包括大小和特征在内的终端类型,并设置终端支持的 curses 环境。`cbreak()` 函数禁用行缓冲并设置 curses 每次只接受一个字符。`noecho()` 函数告诉 curses 不要把输入回显到屏幕上。而 `clear()` 函数清空了屏幕:
|
||||
|
||||
```
|
||||
initscr();
|
||||
cbreak();
|
||||
noecho();
|
||||
|
||||
clear();
|
||||
```
|
||||
|
||||
之后程序设置了三个定义三角的顶点。注意这里使用的 `LINES` 和 `COLS`,它们是由 `initscr()` 来设置的。这些值告诉程序在终端的行数和列数。屏幕坐标从 `0` 开始,所以屏幕左上角是 `0` 行 `0` 列。屏幕右下角是 `LINES - 1` 行,`COLS - 1` 列。为了便于记忆,我的程序里把这些值分别设为了变量 `maxlines` 和 `maxcols`。
|
||||
|
||||
在屏幕上绘制文字的两个简单方法是 `addch()` 和 `addstr()` 函数。也可以使用相关的 `mvaddch()` 和 `mvaddstr()` 函数可以将字符放到一个特定的屏幕位置。我的程序在很多地方都用到了这些函数。首先程序绘制三个定义三角的点并标记为 `'0'`,`'1'` 和 `'2'`:
|
||||
|
||||
```
|
||||
mvaddch(y[0], x[0], '0');
|
||||
mvaddch(y[1], x[1], '1');
|
||||
mvaddch(y[2], x[2], '2');
|
||||
```
|
||||
|
||||
为了绘制任意的一个初始点,程序做了类似的一个调用:
|
||||
|
||||
```
|
||||
mvaddch(yi, xi, '.');
|
||||
```
|
||||
|
||||
还有为了在谢尔宾斯基三角形递归中绘制连续的点:
|
||||
|
||||
```
|
||||
mvaddch(yi, xi, '*');
|
||||
```
|
||||
|
||||
当程序完成之后,将会在屏幕左下角(在 `maxlines` 行,`0` 列)显示一个帮助信息:
|
||||
|
||||
```
|
||||
mvaddstr(maxlines, 0, "Press any key to quit");
|
||||
```
|
||||
|
||||
注意 curses 在内存中维护了一个版本的屏幕显示,并且只有在你要求的时候才会更新这个屏幕,这很重要。特别是当你想要向屏幕显示大量的文字的时候,这样程序会有更好的性能表现。这是因为 curses 只能更新在上次更新之后改变的这部分屏幕。想要让 curses 更新终端屏幕,请使用 `refresh()` 函数。
|
||||
|
||||
在我的示例程序中,我选择在“绘制”每个谢尔宾斯基三角形中的连续点时更新屏幕。通过这样做,用户可以观察三角形中的每次迭代。(LCTT 译注:由于 CPU 太快,迭代过程执行就太快了,所以其实很难直接看到迭代过程)
|
||||
|
||||
在退出之前,我使用 `getch()` 函数等待用户按下一个键。然后我调用 `endwin()` 函数退出 curses 环境并返回终端程序到一般控制。
|
||||
|
||||
```
|
||||
getch();
|
||||
endwin();
|
||||
```
|
||||
|
||||
### 编译和示例输出
|
||||
|
||||
现在你已经有了你的第一个 curses 示例程序,是时候编译运行它了。记住 Linux 操作系统通过 ncurses 库来实现 curses 功能,所以你需要在编译的时候通过 `-lncurses`来链接——例如:
|
||||
|
||||
```
|
||||
$ ls
|
||||
getrandom_int.c getrandom_int.h triangle.c
|
||||
|
||||
$ gcc -Wall -lncurses -o triangle triangle.c getrandom_int.c
|
||||
```
|
||||
|
||||
(LCTT 译注:此处命令行有问题,`-lncurses` 选项在我的 Ubuntu 16.04 系统 + gcc 4.9.3 环境下,必须放在命令行最后,否则找不到库文件,链接时会出现未定义的引用。)
|
||||
|
||||
在标准的 80x24 终端运行这个 `triangle` 程序并没什么意思。在那样的分辨率下你不能看见谢尔宾斯基三角形的很多细节。如果你运行终端窗口并设置非常小的字体大小,你可以更加容易地看到谢尔宾斯基三角形的不规则性质。在我的系统上,输出如图 1。
|
||||
|
||||

|
||||
|
||||
*图 1. triangle 程序的输出*
|
||||
|
||||
虽然迭代具有随机性,但是每次谢尔宾斯基三角形的运行看起来都会很一致。唯一的不同是最初绘制到屏幕的一些点的位置不同。在这个例子中,你可以看到三角形开始的一个小圆点,在点 1 附近。看起来程序接下来选择了点 2,然后你可以看到在圆点和“2”之间的星号。并且看起来程序随机选择了点 2 作为下一个随机数,因为你可以看到在第一个星号和“2”之间的星号。从这里开始,就不能继续分辨三角形是怎样被画出来的了,因为所有的连续点都属于三角形区域。
|
||||
|
||||
### 开始学习 ncurses
|
||||
|
||||
这个程序是一个怎样使用 curses 函数绘制字符到屏幕的简单例子。按照你的程序的需要,你可以通过 curses 做得更多。在下一篇文章中,我将会展示怎样使用 curses 让用户和屏幕交互。如果你对于学习 curses 有兴趣,我建议你去读位于 <ruby>[Linux 文档计划](http://www.tldp.org)<rt>Linux Documentation Project</rt></ruby>的 Pradeep Padala 写的 [NCURSES Programming HOWTO][2]。
|
||||
|
||||
### 关于作者
|
||||
|
||||
Jim Hall 是一个自由及开源软件的倡议者,他最有名的工作是 FreeDOS 计划,也同样致力于开源软件的可用性。Jim 是在明尼苏达州的拉姆齐县的首席信息官。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/getting-started-ncurses
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
译者:[leemeans](https://github.com/leemeans)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/users/jim-hall
|
||||
[1]:http://www.linuxjournal.com/article/1124
|
||||
[2]:http://tldp.org/HOWTO/NCURSES-Programming-HOWTO
|
||||
59
published/20180202 Which Linux Kernel Version Is Stable.md
Normal file
59
published/20180202 Which Linux Kernel Version Is Stable.md
Normal file
@ -0,0 +1,59 @@
|
||||
哪个 Linux 内核版本是 “稳定的”?
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
> Konstantin Ryabitsev 为你讲解哪个 Linux 内核版本可以被视作“稳定版”,以及你应该如何选择一个适用你的内核版本。
|
||||
|
||||
每次 Linus Torvalds 发布 [一个新 Linux 内核的主线版本][4],几乎都会引起这种困惑,那就是到底哪个内核版本才是最新的“稳定版”?是新的那个 X.Y,还是前面的那个 X.Y-1.Z ?最新的内核版本是不是太“新”了?你是不是应该坚持使用以前的版本?
|
||||
|
||||
[kernel.org][5] 网页上的信息并不会帮你解开这个困惑。目前,在该页面的最顶部,我们看到是最新稳定版内核是 4.15 — 但是在这个表格的下面,4.14.16 也被列为“<ruby>稳定版<rt>stable</rt></ruby>”,而 4.15 被列为“<ruby>主线版本<rt>mainline</rt></ruby>”,很困惑,是吧?
|
||||
|
||||
不幸的是,这个问题并不好回答。我们在这里使用“稳定”这个词有两个不同的意思:一是,作为最初发布的 Git 树的名字,二是,表示这个内核可以被视作“稳定版”,用在“生产系统”。
|
||||
|
||||
由于 Git 的分布式特性,Linux 的开发工作在许多 [不同的分叉仓库中][6] 进行。所有的 bug 修复和新特性也是首先由各个子系统维护者收集和准备的,然后提交给 Linus Torvalds,由 Linus Torvalds 包含进 [他自己的 Linux 树][7] 中,他的 Git 树被认为是 Git 仓库的 “master”。我们称这个树为 “主线” Linux 树。
|
||||
|
||||
### 候选发布版(RC)
|
||||
|
||||
在每个新的内核版本发布之前,它都要经过几轮的“候选发布”,它由开发者进行测试并“打磨”所有的这些很酷的新特性。基于他们这几轮测试的反馈,Linus 决定最终版本是否已经准备就绪。通常有 7 个每周预发布版本,但是,这个数字经常走到 -rc8,并且有时候甚至达到 -rc9 及以上。当 Linus 确信那个新内核已经没有问题了,他就制作最终发行版,我们称这个版本为“稳定版”,表示它不再是一个“候选发布版”。
|
||||
|
||||
### Bug 修复
|
||||
|
||||
就像任何一个由不是十全十美的人所写的复杂软件一样,任何一个 Linux 内核的新版本都包含 bug,并且这些 bug 必须被修复。Linux 内核的 bug 修复规则非常简单:所有修复必须首先进入到 Linus 的树。一旦主线仓库中的 bug 被修复后,它接着会被应用到内核开发社区仍在维护的已发布内核中。在它们被考虑回迁到已发布的稳定版本之前,所有的 bug 修复必须满足 [一套重要的标准][8] — 标准的其中之一是,它们 “必须已经存在于 Linus 的树中”。这是一个 [独立的 Git 仓库][9],维护它的用途是回迁 bug 修复,而它也被称为“稳定”树 —— 因为它用于跟踪以前发布的稳定内核。这个树由 Greg Kroah-Hartman 策划和维护。
|
||||
|
||||
### 最新的稳定内核
|
||||
|
||||
因此,无论在什么时候,为了查看最新的稳定内核而访问 kernel.org 网站时,你应该去使用那个在大黄色按钮所说的“最新的稳定内核”。
|
||||
|
||||

|
||||
|
||||
但是,你可能会惊奇地发现 —— 4.15 和 4.14.16 都是稳定版本,那么到底哪一个更“稳定”呢?有些人不愿意使用 “.0” 的内核发行版,因为他们认为这个版本并不足够“稳定”,直到最新的是 ".1" 的为止。很难证明或者反驳这种观点的对与错,并且这两种观点都有赞成或者反对的理由,因此,具体选择哪一个取决于你的喜好。
|
||||
|
||||
一方面,任何一个进入到稳定树的发行版都必须首先被接受进入主线内核版本中,并且随后会被回迁到已发行版本中。这意味着内核的主线版本相比稳定树中的发行版本来说,总包含有最新的 bug 修复,因此,如果你想使用的发行版包含的“**已知 bug**”最少,那么使用 “.0” 的主线发行版是最佳选择。
|
||||
|
||||
另一方面,主线版本增加了所有很酷的新特性 —— 而新特性也给它们带来了**数量未知的“新 bug”**,而这些“新 bug”在老的稳定版中是**不会存在**的。而新的、未知的 bug 是否比旧的、已知的但尚未修复的 bug 更加令人担心呢? —— 这取决于你的选择。不过需要说明的一点是,许多 bug 修复只对内核的主线版本进行了彻底的测试。当补丁回迁到旧内核时,它们**可能**会工作的很好,但是它们**很少**做与旧内核的集成测试工作。通常都假定,“以前的稳定版本”足够接近当前的确信可用于生产系统的主线版本。而实际上也确实是这样的,当然,这也更加说明了为什么选择“哪个内核版本更稳定”是件**非常困难**的事情了。
|
||||
|
||||
因此,从根本上说,我们并没有定量的或者定性的手段去明确的告诉你哪个内核版本更加稳定 —— 4.15 还是 4.14.16?我们能够做到的只是告诉你,它们具有“**不同的**稳定性”,(这个答案可能没有帮到你,但是,至少你明白了这些版本的差别是什么?)。
|
||||
|
||||
_学习更多的 Linux 的知识,可以通过来自 Linux 基金会和 edX 的免费课程 ["认识 Linux" ][3]。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2018/2/which-linux-kernel-version-stable
|
||||
|
||||
作者:[KONSTANTIN RYABITSEV][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/apple1jpg
|
||||
[3]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[4]:https://linux.cn/article-9328-1.html
|
||||
[5]:https://www.kernel.org/
|
||||
[6]:https://git.kernel.org/pub/scm/linux/kernel/git/
|
||||
[7]:https://git.kernel.org/torvalds/c/v4.15
|
||||
[8]:https://www.kernel.org/doc/html/latest/process/stable-kernel-rules.html
|
||||
[9]:https://git.kernel.org/stable/linux-stable/c/v4.14.16
|
||||
@ -1,8 +1,9 @@
|
||||
TLP 帮助我们的 Linux 机器节能省电
|
||||
======
|
||||

|
||||
|
||||
我发现 Linux 下电池的寿命普遍要比 windows 下要短。尽管如此,这可是 [Linux][1],我们总会有有办法的。
|
||||

|
||||
|
||||
我发现 Linux 下电池的寿命普遍要比 Windows 下要短。尽管如此,这可是 Linux,我们总会有有办法的。
|
||||
|
||||
现在来讲一下这个名叫 TLP 的小工具,它能帮你的设备省点电。
|
||||
|
||||
@ -12,32 +13,27 @@ TLP 帮助我们的 Linux 机器节能省电
|
||||
sudo apt install tlp
|
||||
```
|
||||
|
||||
[][2]
|
||||
[][2]
|
||||
|
||||
对于其他的发行版,你可以阅读[官方网站 ][3] 上的指南。
|
||||
对于其他的发行版,你可以阅读其[官方网站][3]上的指南。
|
||||
|
||||
安装完成之后,你只有在第一次的时候需要运行下面命令来启动 tlp。TLP 会在下次启动系统时自动运行。
|
||||
|
||||
[][4]
|
||||
[][4]
|
||||
|
||||
现在 TLP 已经被启动起来了,而且已经设置好了节省电池所需要的默认配置。我们可以查看该配置文件。文件路径为 **/etc/default/tlp**。我们需要编辑该文件来修改各项配置。
|
||||
现在 TLP 已经被启动起来了,而且已经设置好了节省电池所需要的默认配置。我们可以查看该配置文件。文件路径为 `/etc/default/tlp`。我们需要编辑该文件来修改各项配置。
|
||||
|
||||
配置文件中有很多选项,要启用某个选项的话之胥敖删除行首的 **#** 就行了。每个选项能够赋予什么值都有说明。下面是你可能会用到的选项 -
|
||||
配置文件中有很多选项,要启用某个选项的话之胥敖删除行首的 `#` 就行了。每个选项能够赋予什么值都有说明。下面是你可能会用到的选项:
|
||||
|
||||
* 自动休眠 USB 设备
|
||||
|
||||
* 设定启动时启用/禁用无线设备
|
||||
|
||||
* 降低硬盘转速
|
||||
|
||||
* 关闭无线设备
|
||||
|
||||
* 设置 CPU 以性能优先还是节能优先
|
||||
|
||||
### 结论
|
||||
|
||||
TLP 是一个超棒的工具,可以延长 Linux 系统中电池的寿命。我个人的经验是使用 TLP 能延长至少 30-40% 的电池寿命。
|
||||
|
||||
TLP 是一个超棒的工具,可以延长 Linux 系统的电池使用寿命。我个人的经验是使用 TLP 能延长至少 30-40% 的电池使用寿命。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -45,7 +41,7 @@ via: http://www.linuxandubuntu.com/home/save-some-battery-on-our-linux-machines-
|
||||
|
||||
作者:[LinuxAndUbuntu][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,79 @@
|
||||
Can anonymity and accountability coexist?
|
||||
=========================================
|
||||
|
||||
Anonymity might be a boon to more open, meritocratic organizational cultures. But does it conflict with another important value: accountability?
|
||||
|
||||

|
||||
|
||||
Image by :opensource.com
|
||||
|
||||
### Get the newsletter
|
||||
|
||||
Join the 85,000 open source advocates who receive our giveaway alerts and article roundups.
|
||||
|
||||
Whistleblowing protections, crowdsourcing, anonymous voting processes, and even Glassdoor reviews—anonymous speech may take many forms in organizations.
|
||||
|
||||
As well-established and valued as these anonymous feedback mechanisms may be, anonymous speech becomes a paradoxical idea when one considers how to construct a more open organization. While an inability to discern speaker identity seems non-transparent, an opportunity for anonymity may actually help achieve a _more inclusive and meritocratic_ environment.
|
||||
|
||||
More about open organizations
|
||||
|
||||
* [Download free Open Org books](https://opensource.com/open-organization/resources/book-series?src=too_resource_menu1a)
|
||||
* [What is an Open Organization?](https://opensource.com/open-organization/resources/open-org-definition?src=too_resource_menu2a)
|
||||
* [How open is your organization?](https://opensource.com/open-organization/resources/open-org-maturity-model?src=too_resource_menu3a)
|
||||
* [What is an Open Decision?](https://opensource.com/open-organization/resources/open-decision-framework?src=too_resource_menu4a)
|
||||
* [The Open Org two years later](https://www.redhat.com/en/about/blog/open-organization-two-years-later-and-going-strong?src=too_resource_menu4b&intcmp=70160000000h1s6AAA)
|
||||
|
||||
But before allowing outlets for anonymous speech to propagate, however, leaders of an organization should carefully reflect on whether an organization's "closed" practices make anonymity the unavoidable alternative to free, non-anonymous expression. Though some assurance of anonymity is necessary in a few sensitive and exceptional scenarios, dependence on anonymous feedback channels within an organization may stunt the normalization of a culture that encourages diversity and community.
|
||||
|
||||
### The benefits of anonymity
|
||||
|
||||
In the case of [_Talley v. California (1960)_](https://supreme.justia.com/cases/federal/us/362/60/case.html), the Supreme Court voided a city ordinance prohibiting the anonymous distribution of handbills, asserting that "there can be no doubt that such an identification requirement would tend to restrict freedom to distribute information and thereby freedom of expression." Our judicial system has legitimized the notion that the protection of anonymity facilitates the expression of otherwise unspoken ideas. A quick scroll through any [subreddit](https://www.reddit.com/reddits/) exemplifies what the Court has codified: anonymity can foster [risk-taking creativity](https://www.reddit.com/r/sixwordstories/) and the [inclusion and support of marginalized voices](https://www.reddit.com/r/MyLittleSupportGroup/). Anonymity empowers individuals by granting them the safety to speak without [detriment to their reputations or, more importantly, their physical selves.](https://www.psychologytoday.com/blog/the-compassion-chronicles/201711/why-dont-victims-sexual-harassment-come-forward-sooner)
|
||||
|
||||
For example, an anonymous suggestion program to garner ideas from members or employees in an organization may strengthen inclusivity and enhance the diversity of suggestions the organization receives. It would also make for a more meritocratic decision-making process, as anonymity would ensure that the quality of the articulated idea, rather than the rank and reputation of the articulator, is what's under evaluation. Allowing members to anonymously vote for anonymously-submitted ideas would help curb the influence of office politics in decisions affecting the organization's growth.
|
||||
|
||||
### The harmful consequences of anonymity
|
||||
|
||||
Yet anonymity and the open value of _accountability_ may come into conflict with one another. For instance, when establishing anonymous programs to drive greater diversity and more meritocratic evaluation of ideas, organizations may need to sacrifice the ability to hold speakers accountable for the opinions they express.
|
||||
|
||||
Reliance on anonymous speech for serious organizational decision-making may also contribute to complacency in an organizational culture that falls short of openness. Outlets for anonymous speech may be as similar to open as crowdsourcing is—or rather, is not. [Like efforts to crowdsource creative ideas](https://opensource.com/business/10/4/why-open-source-way-trumps-crowdsourcing-way), anonymous suggestion programs may create an organizational environment in which diverse perspectives are only valued when an organization's leaders find it convenient to take advantage of members' ideas.
|
||||
|
||||
Anonymity and the open value of accountability may come into conflict with one another.
|
||||
|
||||
A similar concern holds for anonymous whistle-blowing or concern submission. Though anonymity is important for sexual harassment and assault reporting, regularly redirecting member concerns and frustrations to a "complaints box" makes it more difficult for members to hold their organization's leaders accountable for acting on concerns. It may also hinder intra-organizational support networks and advocacy groups from forming around shared concerns, as members would have difficulty identifying others with similar experiences. For example, many working mothers might anonymously submit requests for a lactation room in their workplace, then falsely attribute a lack of action from leaders to a lack of similar concerns from others.
|
||||
|
||||
### An anonymity checklist
|
||||
|
||||
Organizations in which anonymous speech is the primary mode of communication, like subreddits, have generated innovative works and thought-provoking discourse. These anonymous networks call attention to the potential for anonymity to help organizations pursue open values of diversity and meritocracy. Organizations in which anonymous speech is _not_ the main form of communication should acknowledge the strengths of anonymous speech, but carefully consider whether anonymity is the wisest means to the goal of sustainable openness.
|
||||
|
||||
Leaders may find reflecting on the following questions useful prior to establishing outlets for anonymous feedback within their organizations:
|
||||
|
||||
1\. _Availability of additional communication mechanisms_: Rather than investing time and resources into establishing a new, anonymous channel for communication, can the culture or structure of existing avenues of communication be reconfigured to achieve the same goal? This question echoes the open source affinity toward realigning, rather than reinventing, the wheel.
|
||||
|
||||
2\. _Failure of other communication avenues:_ How and why is the organization ill-equipped to handle the sensitive issue/situation at hand through conventional (i.e. non-anonymous) means of communication?
|
||||
|
||||
Careful deliberation on these questions may help prevent outlets for anonymous speech from leading to a dangerous sense of complacency.
|
||||
|
||||
3\. _Consequences of anonymity:_ If implemented, could the anonymous mechanism stifle the normalization of face-to-face discourse about issues important to the organization's growth? If so, how can leaders ensure that members consider the anonymous communication channel a "last resort," without undermining the legitimacy of the anonymous system?
|
||||
|
||||
4\. _Designing the anonymous communication channel:_ How can accountability be promoted in anonymous communication without the ability to determine the identity of speakers?
|
||||
|
||||
5\. _Long-term considerations_: Is the anonymous feedback mechanism sustainable, or a temporary solution to a larger organizational issue? If the latter, is [launching a campaign](https://opensource.com/open-organization/16/6/8-steps-more-open-communications) to address overarching problems with the organization's communication culture feasible?
|
||||
|
||||
These five points build off of one another to help leaders recognize the tradeoffs involved in legitimizing anonymity within their organization. Careful deliberation on these questions may help prevent outlets for anonymous speech from leading to a dangerous sense of complacency with a non-inclusive organizational structure.
|
||||
|
||||
About the author
|
||||
----------------
|
||||
|
||||
[](https://opensource.com/users/susiechoi)
|
||||
|
||||
Susie Choi - Susie is an undergraduate student studying computer science at Duke University. She is interested in the implications of technological innovation and open source principles for issues relating to education and socioeconomic inequality.
|
||||
|
||||
[More about me](https://opensource.com/users/susiechoi)
|
||||
|
||||
* * *
|
||||
|
||||
via: [https://opensource.com/open-organization/18/1/balancing-accountability-and-anonymity](https://opensource.com/open-organization/18/1/balancing-accountability-and-anonymity)
|
||||
|
||||
作者: [Susie Choi](https://opensource.com/users/susiechoi) 选题者: [@lujun9972](https://github.com/lujun9972) 译者: [译者ID](https://github.com/译者ID) 校对: [校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,259 @@
|
||||
translating by Auk7F7
|
||||
|
||||
How to Encrypt Files with Tomb on Ubuntu 16.04 LTS
|
||||
==================================================
|
||||
|
||||
Most people regard file encryption as a necessity nowadays, even on Linux systems. If, like me, you were originally attracted to Ubuntu because of the enhanced security of Linux systems, I’m afraid I’ve got bad news for you: Linux has become a victim of its own success. The vast increase in the number of users over recent years has led to attacks and theft on such systems growing exponentially.
|
||||
|
||||
There used to be a pretty easy solution to encrypting files on Linux systems like Ubuntu: it was called [Truecrypt](https://www.fossmint.com/secure-encrypt-files-folders-with-truecrypt-in-linux/). Up until 2015, it offered varying levels of military-grade encryption, and worked well with most Linux systems. Unfortunately, it has since been discontinued, and has therefore become pretty insecure.
|
||||
|
||||
### The Alternatives
|
||||
|
||||
Luckily, there are a few alternatives to Truecrypt. The direct successor of Truecrypt was [Veracrypt](https://www.fossmint.com/veracrypt-is-a-secure-alternative-encryption-tool-to-truecrypt-for-linux/), made by a group of developers who took the source code from Truecrypt and kept it updated.
|
||||
|
||||
The project has since grown into an impressive standalone system, but is now showing its age. Old systems, and especially those that deal with security, can only be updated so many times without introducing vulnerabilities.
|
||||
|
||||
For this reason, among many others, it’s worth looking a bit further afield for encryption software. My choice would be Tomb.
|
||||
|
||||
### Why Tomb?
|
||||
|
||||
In some ways, Tomb is pretty similar to other encryption software. It stores encrypted files in dedicated “Tomb Folders”, allowing you to quickly see which files you have encrypted.
|
||||
|
||||
It also uses a similar encryption standard to Veracrypt, [AES-256](https://www.dyne.org/software/tomb/). This standard is Applied by everyone from the NSA to Microsoft to Apple, and is regarded as one of the most secure encryption ciphers available. If you’re new to encryption, it’s worth reading a bit of [the background behind the technology](https://thebestvpn.com/advanced-encryption-standard-aes/), but if you just want fast, secure encryption, don’t worry: Tomb will deliver.
|
||||
|
||||
There are a couple of big differences with Tomb. The first is that it has been developed specifically for GNU/Linux systems, cutting out some of the compatibility issues of broader encryption software.
|
||||
|
||||
The second is that, although Tomb is open source, it makes use of statically linked libraries so that its source code is hard to audit. That means that it is not considered free by some OS distributors, but when it comes to security software this is actually a good thing: it means that Tomb is less likely to be hacked than completely “free” software.
|
||||
|
||||
Lastly, it has several advanced features like **steganography**, which allows you to hide your key files within another file. And though Tomb is primarily a command-line tool, it also comes with a GUI interface, gtomb, which allows beginners to use it graphically.
|
||||
|
||||
Sold? Well, before I take you through how to use Tomb, it’s worth noting that no encryption software can offer total protection. Tomb will not hide your online computing from your ISP, and nor does it protect files stored in the cloud. If you want to fully encrypt cloud storage, you’ll need to log into your preferred storage service using the Tor browser and a zero-logging VPN. There are plenty of options available here, but [Trust Zone](https://privacyaustralia.org/trust-zone-vpn-review/) is a good browser, and [Tinc](https://www.howtoforge.com/tutorial/how-to-properly-set-up-tinc-vpn-on-ubuntu-linux/) is a good VPN tool.
|
||||
|
||||
All that said, if you are looking for fast, easy, secure encryption for Ubuntu 16.04, Tomb is undoubtedly the way to go. Let’s get you started.
|
||||
|
||||
### Installing Tomb on Ubuntu 16.04
|
||||
|
||||
Because Tomb was made especially for Linux, install is super easy.
|
||||
|
||||
A couple of years back, the guys over at SparkyLinux (which is a pretty good Debian derivative in its own right) added Tomb to their official repositories. You can install it on your Ubuntu system by adding these repositories.
|
||||
|
||||
To do this, open a terminal and add a repository file:
|
||||
|
||||
`sudo vi /etc/apt/sources.list.d/sparky-repo.list`
|
||||
|
||||
And then add the following lines to the file:
|
||||
|
||||
```
|
||||
deb https://sparkylinux.org/repo stable main
|
||||
deb-src https://sparkylinux.org/repo stable main
|
||||
deb https://sparkylinux.org/repo testing main
|
||||
deb-src https://sparkylinux.org/repo testing main
|
||||
|
||||
```
|
||||
|
||||
Save and close that file.
|
||||
|
||||
You now need to install the Sparky public key, using either:
|
||||
|
||||
```
|
||||
sudo apt-get install sparky-keyring
|
||||
|
||||
```
|
||||
|
||||
Or:
|
||||
|
||||
```
|
||||
wget -O - https://sparkylinux.org/repo/sparkylinux.gpg.key | sudo apt-key add -
|
||||
|
||||
```
|
||||
|
||||
You then need to update your repositories, using the standard command:
|
||||
|
||||
```
|
||||
sudo apt-get update
|
||||
|
||||
```
|
||||
|
||||
And then simply install Tomb using apt:
|
||||
|
||||
```
|
||||
sudo apt-get install tomb
|
||||
|
||||
```
|
||||
|
||||
If you want the GUI, install is just as easy. Just use apt to install gtomb:
|
||||
|
||||
```
|
||||
sudo apt-get install gtomb
|
||||
|
||||
```
|
||||
|
||||
And that’s it: you should now have a working version of Tomb installed. Let’s look at how to use it.
|
||||
|
||||
### Using Tomb
|
||||
|
||||
#### Using Tomb Through The Command Line
|
||||
|
||||
Tomb is primarily a command line tool, so I’ll cover this usage first. If you are not comfortable with using a terminal, you can skip this section and look below.
|
||||
|
||||
Actually, scratch that. If you’ve never used the command line before, Tomb is a great place to start, because it uses simple commands and there is little chance of you messing something up as long as you are careful.
|
||||
|
||||
Tomb actually uses a pretty amusing set of commands, all graveyard-themed. Each encrypted folder is referred to as a “tomb”, and (as I’ll come to shortly) they can be worked with using similarly Gothic commands.
|
||||
|
||||
First, let’s make a new tomb. You can specify the name and the size of your new tomb, so let’s use “Tomb1”, and make it 100mb.
|
||||
|
||||
You need root privileges, so open a terminal and type (or copy):
|
||||
|
||||
```
|
||||
sudo tomb dig -s 100 Tomb1.tomb
|
||||
|
||||
```
|
||||
|
||||
This should give you output similar to:
|
||||
|
||||
```
|
||||
tomb . Commanded to dig tomb Tomb1.tomb
|
||||
tomb (*) Creating a new tomb in Tomb1.tomb
|
||||
tomb . Generating Tomb1.tomb of 100MiB
|
||||
100 blocks (100Mb) written.
|
||||
100+0 records in
|
||||
100+0 records out
|
||||
-rw------- 1 Tomb1 Tomb1 100M Jul 4 18:53 Tomb1.tomb
|
||||
tomb (*) Done digging Tomb1
|
||||
tomb . Your tomb is not yet ready, you need to forge a key and lock it:
|
||||
tomb . tomb forge Tomb1.tomb.key
|
||||
tomb . tomb lock Tomb1.tomb -k Tomb1.tomb.key
|
||||
|
||||
```
|
||||
|
||||
As the output helpfully states, you now need to create a keyfile to lock your tomb:
|
||||
|
||||
```
|
||||
sudo tomb forge Tomb1.tomb.key
|
||||
|
||||
```
|
||||
|
||||
If, at this point, you get an error that mentions “an active swap partition”, you need to deactivate all of your active swap partititions:
|
||||
|
||||
```
|
||||
sudo swapoff -a
|
||||
|
||||
```
|
||||
|
||||
And then run the keyfile command above.
|
||||
|
||||
It might take a few minutes to generate a keyfile, depending on the speed of your system. After it is done, however, you’ll be asked to enter a new password to secure the key:
|
||||
|
||||
[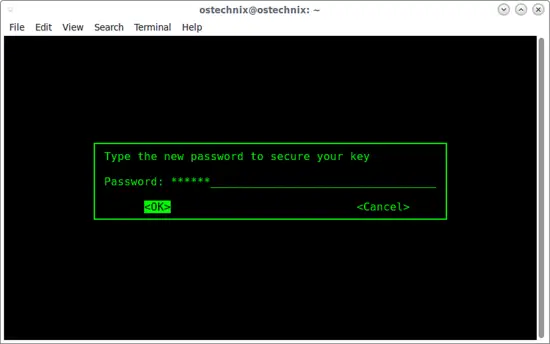](https://www.howtoforge.com/images/how_to_setup_and_install_tomb_on_ubuntu_1604/big/tomb1.png)
|
||||
|
||||
Enter it twice, and your new keyfile will be made.
|
||||
|
||||
You now need to lock your tomb using your new key. You can do this like this:
|
||||
|
||||
```
|
||||
sudo tomb lock Tomb1.tomb -k Tomb1.tomb.key
|
||||
|
||||
```
|
||||
|
||||
You will be asked to enter your password. Do this, and you should get something like the following output:
|
||||
|
||||
```
|
||||
tomb . Commanded to lock tomb Tomb1.tomb
|
||||
|
||||
[sudo] Enter password for user Tomb1 to gain superuser privileges
|
||||
|
||||
tomb . Checking if the tomb is empty (we never step on somebody else's bones).
|
||||
tomb . Fine, this tomb seems empty.
|
||||
tomb . Key is valid.
|
||||
tomb . Locking using cipher: aes-xts-plain64:sha256
|
||||
tomb . A password is required to use key Tomb1.tomb.key
|
||||
tomb . Password OK.
|
||||
tomb (*) Locking Tomb1.tomb with Tomb1.tomb.key
|
||||
tomb . Formatting Luks mapped device.
|
||||
tomb . Formatting your Tomb with Ext3/Ext4 filesystem.
|
||||
tomb . Done locking Tomb1 using Luks dm-crypt aes-xts-plain64:sha256
|
||||
tomb (*) Your tomb is ready in Tomb1.tomb and secured with key Tomb1.tomb.key
|
||||
|
||||
```
|
||||
|
||||
Now everything is set up, you can start using your new tomb.
|
||||
|
||||
A note here: because I’m just showing you what to do, I’ve stored my key and tomb in the same directory (in this case $HOME). You shouldn’t do this – store your key somewhere else, preferably where no-one but you is going to find it.
|
||||
|
||||
You’ll need to remember where you stored it, however, because you need it to unlock your tomb. To do this, enter:
|
||||
|
||||
```
|
||||
sudo tomb open Tomb1.tomb -k path/to/your/Tomb1.tomb.key
|
||||
|
||||
```
|
||||
|
||||
Enter your password, and you should be in. Tomb will generate something like:
|
||||
|
||||
```
|
||||
tomb (*) Success unlocking tomb Tomb1
|
||||
tomb . Checking filesystem via /dev/loop0
|
||||
fsck from util-linux 2.27.1
|
||||
Tomb1: clean, 11/25168 files, 8831/100352 blocks
|
||||
tomb (*) Success opening Tomb1.tomb on /media/Tomb1
|
||||
|
||||
```
|
||||
|
||||
And then you should see your new tomb, mounted in the finder window.
|
||||
|
||||
You can now save and open files from the tomb, but note that you will need root privileges in order to do so.
|
||||
|
||||
To unmount your tomb after you have finished using it, close it by using:
|
||||
|
||||
```
|
||||
sudo tomb close
|
||||
|
||||
```
|
||||
|
||||
Or, if you want to force close all open tombs, you can use:
|
||||
|
||||
```
|
||||
sudo tomb slam all
|
||||
|
||||
```
|
||||
|
||||
#### **Using Tomb Through The GUI**
|
||||
|
||||
If you are uncomfortable using the command line, or simply just want a graphical interface, you can use gtomb. Unlike a lot of GUI wrappers, gtomb is pretty straightforward to use.
|
||||
|
||||
Let’s look at how to set up a new tomb using gtomb. First, launch gtomb from the Menu. It will probably look like this:
|
||||
|
||||
[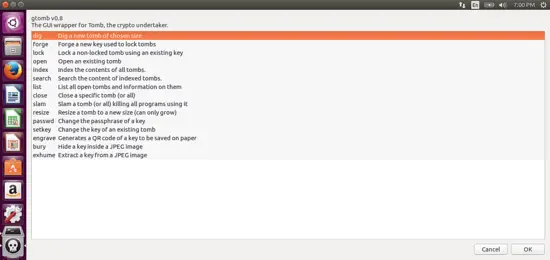](https://www.howtoforge.com/images/how_to_setup_and_install_tomb_on_ubuntu_1604/big/tomb2.png)
|
||||
|
||||
Everything is pretty self-explanatory, but for the sake of completeness I’ll run through how to set up your first tomb.
|
||||
|
||||
To start, click on the first option, “dig”. Click OK, and then choose a location.
|
||||
|
||||
Next, enter the size of your tomb:
|
||||
|
||||
[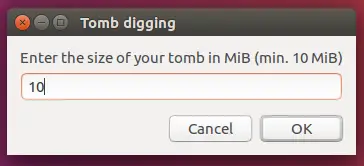](https://www.howtoforge.com/images/how_to_setup_and_install_tomb_on_ubuntu_1604/big/tomb3.png)
|
||||
|
||||
You’ve now got a new tomb, but you need to make a key before you can use it. To do this, click “forge” from the main menu:
|
||||
|
||||
[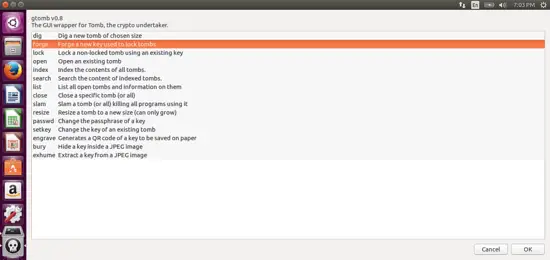](https://www.howtoforge.com/images/how_to_setup_and_install_tomb_on_ubuntu_1604/big/tomb4.png)
|
||||
|
||||
Tomb will ask you to enter a passcode twice, so do that.
|
||||
|
||||
Then lock your tomb using the key by clicking, you’ve guessed it, “lock”. To open it, click “open” and enter your passcode again.
|
||||
|
||||
As you can see from the screenshot above, usage of gtomb is really easy, and you shouldn’t encounter any problems. Most common tasks can be done with a few clicks, and for anything more complicated you can use the command line.
|
||||
|
||||
### Final Thoughts
|
||||
|
||||
That’s it! You should now have your first tomb set up and ready to go. Store anything you want to keep secret and secure in tombs, and this information will be much more secure.
|
||||
|
||||
You can use multiple tombs at the same time, and bind the files in them to your $HOME directory, so your programs don’t get confused.
|
||||
|
||||
I hope this guide has helped you get started. Using your tombs is just like using a standard folder, but for more complex commands you can always check the Tomb [Official Guide](https://www.dyne.org/software/tomb/).
|
||||
|
||||
* * *
|
||||
|
||||
via: [https://www.howtoforge.com/tutorial/how-to-install-and-use-tomb-file-encryption-on-ubuntu-1604/](https://www.howtoforge.com/tutorial/how-to-install-and-use-tomb-file-encryption-on-ubuntu-1604/)
|
||||
|
||||
作者: [Dan Fries](https://www.howtoforge.com/) 选题者: [@lujun9972](https://github.com/lujun9972) 译者: [译者ID](https://github.com/译者ID) 校对: [校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
Choosing a Linux Tracer (2015)
|
||||
======
|
||||
[![][1]][2]
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
Install a Centralized Log Server with Rsyslog in Debian 9
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
Torrents - Everything You Need to Know
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
Mail transfer agent (MTA) basics
|
||||
======
|
||||
|
||||
|
||||
@ -1,99 +0,0 @@
|
||||
What’s behind the Intel design flaw forcing numerous patches?
|
||||
============================================================
|
||||
|
||||
### There's obviously a big problem, but we don't know exactly what.
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
Both Windows and Linux are receiving significant security updates that can, in the worst case, cause performance to drop by half, to defend against a problem that as yet hasn't been fully disclosed.
|
||||
|
||||
Patches to the Linux kernel have been trickling in over the past few weeks. Microsoft has been [testing the Windows updates in the Insider program since November][3], and it is expected to put the alterations into mainstream Windows builds on Patch Tuesday next week. Microsoft's Azure has scheduled maintenance next week, and Amazon's AWS is scheduled for maintenance on Friday—presumably related.
|
||||
|
||||
Since the Linux patches [first came to light][4], a clearer picture of what seems to be wrong has emerged. While Linux and Windows differ in many regards, the basic elements of how these two operating systems—and indeed, every other x86 operating system such as FreeBSD and [macOS][5]—handle system memory is the same, because these parts of the operating system are so tightly coupled to the capabilities of the processor.
|
||||
|
||||
### Keeping track of addresses
|
||||
|
||||
Every byte of memory in a system is implicitly numbered, those numbers being each byte's address. The very earliest operating systems operated using physical memory addresses, but physical memory addresses are inconvenient for lots of reasons. For example, there are often gaps in the addresses, and (particularly on 32-bit systems), physical addresses can be awkward to manipulate, requiring 36-bit numbers, or even larger ones.
|
||||
|
||||
Accordingly, modern operating systems all depend on a broad concept called virtual memory. Virtual memory systems allow both programs and the kernels themselves to operate in a simple, clean, uniform environment. Instead of the physical addresses with their gaps and other oddities, every program, and the kernel itself, uses virtual addresses to access memory. These virtual addresses are contiguous—no need to worry about gaps—and sized conveniently to make them easy to manipulate. 32-bit programs see only 32-bit addresses, even if the physical address requires 36-bit or more numbering.
|
||||
|
||||
While this virtual addressing is transparent to almost every piece of software, the processor does ultimately need to know which physical memory a virtual address refers to. There's a mapping from virtual addresses to physical addresses, and that's stored in a large data structure called a page table. Operating systems build the page table, using a layout determined by the processor, and the processor and operating system in conjunction use the page table whenever they need to convert between virtual and physical addresses.
|
||||
|
||||
This whole mapping process is so important and fundamental to modern operating systems and processors that the processor has dedicated cache—the translation lookaside buffer, or TLB—that stores a certain number of virtual-to-physical mappings so that it can avoid using the full page table every time.
|
||||
|
||||
The use of virtual memory gives us a number of useful features beyond the simplicity of addressing. Chief among these is that each individual program is given its own set of virtual addresses, with its own set of virtual to physical mappings. This is the fundamental technique used to provide "protected memory;" one program cannot corrupt or tamper with the memory of another program, because the other program's memory simply isn't part of the first program's mapping.
|
||||
|
||||
But these uses of an individual mapping per process, and hence extra page tables, puts pressure on the TLB cache. The TLB isn't very big—typically a few hundred mappings in total—and the more page tables a system uses, the less likely it is that the TLB will include any particular virtual-to-physical translation.
|
||||
|
||||
### Half and half
|
||||
|
||||
To make the best use of the TLB, every mainstream operating system splits the range of virtual addresses into two. One half of the addresses is used for each program; the other half is used for the kernel. When switching between processes, only half the page table entries change—the ones belonging to the program. The kernel half is common to every program (because there's only one kernel), and so it can use the same page table mapping for every process. This helps the TLB enormously; while it still has to discard mappings belonging to the process' half of memory addresses, it can keep the mappings for the kernel's half.
|
||||
|
||||
This design isn't completely set in stone. Work was done on Linux to make it possible to give a 32-bit process the entire range of addresses, with no sharing between the kernel's page table and that of each program. While this gave the programs more address space, it carried a performance cost, because the TLB had to reload the kernel's page table entries every time kernel code needed to run. Accordingly, this approach was never widely used on x86 systems.
|
||||
|
||||
One downside of the decision to split the virtual address space between the kernel and each program is that the memory protection is weakened. If the kernel had its own set of page tables and virtual addresses, it would be afforded the same protection as different programs have from one another; the kernel's memory would be simply invisible. But with the split addressing, user programs and the kernel use the same address range, and, in principle, a user program would be able to read and write kernel memory.
|
||||
|
||||
To prevent this obviously undesirable situation, the processor and virtual addressing system have a concept of "rings" or "modes." x86 processors have lots of rings, but for this issue, only two are relevant: "user" (ring 3) and "supervisor" (ring 0). When running regular user programs, the processor is put into user mode, ring 3\. When running kernel code, the processor is in ring 0, supervisor mode, also known as kernel mode.
|
||||
|
||||
These rings are used to protect the kernel memory from user programs. The page tables aren't just mapping from virtual to physical addresses; they also contain metadata about those addresses, including information about which rings can access an address. The kernel's page table entries are all marked as only being accessible to ring 0; the program's entries are marked as being accessible from any ring. If an attempt is made to access ring 0 memory while in ring 3, the processor blocks the access and generates an exception. The result of this is that user programs, running in ring 3, should not be able to learn anything about the kernel and its ring 0 memory.
|
||||
|
||||
At least, that's the theory. The spate of patches and update show that somewhere this has broken down. This is where the big mystery lies.
|
||||
|
||||
### Moving between rings
|
||||
|
||||
Here's what we do know. Every modern processor performs a certain amount of speculative execution. For example, given some instructions that add two numbers and then store the result in memory, a processor might speculatively do the addition before ascertaining whether the destination in memory is actually accessible and writeable. In the common case, where the location _is_ writeable, the processor managed to save some time, as it did the arithmetic in parallel with figuring out what the destination in memory was. If it discovers that the location isn't accessible—for example, a program trying to write to an address that has no mapping and no physical location at all—then it will generate an exception and the speculative execution is wasted.
|
||||
|
||||
Intel processors, specifically—[though not AMD ones][6]—allow speculative execution of ring 3 code that writes to ring 0 memory. The processors _do_ properly block the write, but the speculative execution minutely disturbs the processor state, because certain data will be loaded into cache and the TLB in order to ascertain whether the write should be allowed. This in turn means that some operations will be a few cycles quicker, or a few cycles slower, depending on whether their data is still in cache or not. As well as this, Intel's processors have special features, such as the Software Guard Extensions (SGX) introduced with Skylake processors, that slightly change how attempts to access memory are handled. Again, the processor does still protect ring 0 memory from ring 3 programs, but again, its caches and other internal state are changed, creating measurable differences.
|
||||
|
||||
What we don't know, yet, is just how much kernel memory information can be leaked to user programs or how easily that leaking can occur. And which Intel processors are affected? Again it's not entirely clear, but indications are that every Intel chip with speculative execution (which is all the mainstream processors introduced since the Pentium Pro, from 1995) can leak information this way.
|
||||
|
||||
The first wind of this problem came from researchers from [Graz Technical University in Austria][7]. The information leakage they discovered was enough to undermine kernel mode Address Space Layout Randomization (kernel ASLR, or KASLR). ASLR is something of a last-ditch effort to prevent the exploitation of [buffer overflows][8]. With ASLR, programs and their data are placed at random memory addresses, which makes it a little harder for attackers to exploit security flaws. KASLR applies that same randomization to the kernel so that the kernel's data (including page tables) and code are randomly located.
|
||||
|
||||
The Graz researchers developed [KAISER][9], a set of Linux kernel patches to defend against the problem.
|
||||
|
||||
If the problem were just that it enabled the derandomization of ASLR, this probably wouldn't be a huge disaster. ASLR is a nice protection, but it's known to be imperfect. It's meant to be a hurdle for attackers, not an impenetrable barrier. The industry reaction—a fairly major change to both Windows and Linux, developed with some secrecy—suggests that it's not just ASLR that's defeated and that a more general ability to leak information from the kernel has been developed. Indeed, researchers have [started to tweet][10] that they're able to leak and read arbitrary kernel data. Another possibility is that the flaw can be used to escape out of a virtual machine and compromise a hypervisor.
|
||||
|
||||
The solution that both the Windows and Linux developers have picked is substantially the same, and derived from that KAISER work: the kernel page table entries are no longer shared with each process. In Linux, this is called Kernel Page Table Isolation (KPTI).
|
||||
|
||||
With the patches, the memory address is still split in two; it's just the kernel half is almost empty. It's not quite empty, because a few kernel pieces need to be mapped permanently, whether the processor is running in ring 3 _or_ ring 0, but it's close to empty. This means that even if a malicious user program tries to probe kernel memory and leak information, it will fail—there's simply nothing to leak. The real kernel page tables are only used when the kernel itself is running.
|
||||
|
||||
This undermines the very reason for the split address space in the first place. The TLB now needs to clear out any entries related to the real kernel page tables every time it switches to a user program, putting an end to the performance saving that splitting enabled.
|
||||
|
||||
The impact of this will vary depending on the workload. Every time a program makes a call into the kernel—to read from disk, to send data to the network, to open a file, and so on—that call will be a little more expensive, since it will force the TLB to be flushed and the real kernel page table to be loaded. Programs that don't use the kernel much might see a hit of perhaps 2-3 percent—there's still some overhead because the kernel always has to run occasionally, to handle things like multitasking.
|
||||
|
||||
But workloads that call into the kernel a ton will see much greater performance drop off. In a benchmark, a program that does virtually nothing _other_ than call into the kernel saw [its performance drop by about 50 percent][11]; in other words, each call into the kernel took twice as long with the patch than it did without. Benchmarks that use Linux's loopback networking also see a big hit, such as [17 percent][12] in this Postgres benchmark. Real database workloads using real networking should see lower impact, because with real networks, the overhead of calling into the kernel tends to be dominated by the overhead of using the actual network.
|
||||
|
||||
While Intel systems are the ones known to have the defect, they may not be the only ones affected. Some platforms, such as SPARC and IBM's S390, are immune to the problem, as their processor memory management doesn't need the split address space and shared kernel page tables; operating systems on those platforms have always isolated their kernel page tables from user mode ones. But others, such as ARM, may not be so lucky; [comparable patches for ARM Linux][13] are under development.
|
||||
|
||||
<aside class="ad_native" id="ad_xrail_native" style="box-sizing: inherit;"></aside>
|
||||
|
||||
[][15][PETER BRIGHT][14]Peter is Technology Editor at Ars. He covers Microsoft, programming and software development, Web technology and browsers, and security. He is based in Brooklyn, NY.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://arstechnica.com/gadgets/2018/01/whats-behind-the-intel-design-flaw-forcing-numerous-patches/
|
||||
|
||||
作者:[ PETER BRIGHT ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://arstechnica.com/author/peter-bright/
|
||||
[1]:https://arstechnica.com/author/peter-bright/
|
||||
[2]:https://arstechnica.com/gadgets/2018/01/whats-behind-the-intel-design-flaw-forcing-numerous-patches/?comments=1
|
||||
[3]:https://twitter.com/aionescu/status/930412525111296000
|
||||
[4]:https://lwn.net/SubscriberLink/741878/eb6c9d3913d7cb2b/
|
||||
[5]:https://twitter.com/aionescu/status/948609809540046849
|
||||
[6]:https://lkml.org/lkml/2017/12/27/2
|
||||
[7]:https://gruss.cc/files/kaiser.pdf
|
||||
[8]:https://arstechnica.com/information-technology/2015/08/how-security-flaws-work-the-buffer-overflow/
|
||||
[9]:https://github.com/IAIK/KAISER
|
||||
[10]:https://twitter.com/brainsmoke/status/948561799875502080
|
||||
[11]:https://twitter.com/grsecurity/status/947257569906757638
|
||||
[12]:https://www.postgresql.org/message-id/20180102222354.qikjmf7dvnjgbkxe@alap3.anarazel.de
|
||||
[13]:https://lwn.net/Articles/740393/
|
||||
[14]:https://arstechnica.com/author/peter-bright
|
||||
[15]:https://arstechnica.com/author/peter-bright
|
||||
@ -1,155 +0,0 @@
|
||||
How to install/update Intel microcode firmware on Linux
|
||||
======
|
||||
|
||||
|
||||
I am a new Linux sysadmin. How do I install or update microcode firmware for Intel/AMD CPUs on Linux using the command line option?
|
||||
|
||||
|
||||
A microcode is nothing but CPU firmware provided by Intel or AMD. The Linux kernel can update the CPU's firmware without the BIOS update at boot time. Processor microcode is stored in RAM and kernel update the microcode during every boot. These microcode updates from Intel/AMD needed to fix bugs or apply errata to avoid CPU bugs. This page shows how to install AMD or Intel microcode update using package manager or processor microcode updates supplied by Intel on Linux.
|
||||
|
||||
## How to find out current status of microcode
|
||||
|
||||
|
||||
Run the following command as root user:
|
||||
`# dmesg | grep microcode`
|
||||
Sample outputs:
|
||||
|
||||
[![Verify microcode update on a CentOS RHEL Fedora Ubuntu Debian Linux][1]][1]
|
||||
|
||||
Please note that it is entirely possible that there is no microcode update available for your CPU. In that case it will look as follows:
|
||||
```
|
||||
[ 0.952699] microcode: sig=0x306a9, pf=0x10, revision=0x1c
|
||||
[ 0.952773] microcode: Microcode Update Driver: v2.2.
|
||||
|
||||
```
|
||||
|
||||
## How to install Intel microcode firmware on Linux using a package manager
|
||||
|
||||
Tool to transform and deploy CPU microcode update for x86/amd64 comes with Linux. The procedure to install AMD or Intel microcode firmware on Linux is as follows:
|
||||
|
||||
1. Open the terminal app
|
||||
2. Debian/Ubuntu Linux user type: **sudo apt install intel-microcode**
|
||||
3. CentOS/RHEL Linux user type: **sudo yum install microcode_ctl**
|
||||
|
||||
|
||||
|
||||
The package names are as follows for popular Linux distros:
|
||||
|
||||
* microcode_ctl and linux-firmware - CentOS/RHEL microcode update package
|
||||
* intel-microcode - Debian/Ubuntu and clones microcode update package for Intel CPUS
|
||||
* amd64-microcode - Debian/Ubuntu and clones microcode firmware for AMD CPUs
|
||||
* linux-firmware - Arch Linux microcode firmware for AMD CPUs (installed by default and no action is needed on your part)
|
||||
* intel-ucode - Arch Linux microcode firmware for Intel CPUs
|
||||
* microcode_ctl and ucode-intel - Suse/OpenSUSE Linux microcode update package
|
||||
|
||||
|
||||
|
||||
**Warning** : In some cases, microcode update may cause boot issues such as server getting hang or resets automatically at the time of boot. The procedure worked for me, and I am an experienced sysadmin. I do not take responsibility for any hardware failures. Do it at your own risk.
|
||||
|
||||
### Examples
|
||||
|
||||
Type the following [apt command][2]/[apt-get command][3] on a Debian/Ubuntu Linux for Intel CPU:
|
||||
|
||||
`$ sudo apt-get install intel-microcode`
|
||||
|
||||
Sample outputs:
|
||||
|
||||
[![How to install Intel microcode firmware Linux][4]][4]
|
||||
|
||||
You [must reboot the box to activate micocode][5] update:
|
||||
|
||||
`$ sudo reboot`
|
||||
|
||||
Verify it after reboot:
|
||||
|
||||
`# dmesg | grep 'microcode'`
|
||||
|
||||
Sample outputs:
|
||||
|
||||
```
|
||||
[ 0.000000] microcode: microcode updated early to revision 0x1c, date = 2015-02-26
|
||||
[ 1.604672] microcode: sig=0x306a9, pf=0x10, revision=0x1c
|
||||
[ 1.604976] microcode: Microcode Update Driver: v2.01 <tigran@aivazian.fsnet.co.uk>, Peter Oruba
|
||||
|
||||
```
|
||||
|
||||
If you are using RHEL/CentOS try installing or updating the following two packages using [yum command][6]:
|
||||
|
||||
```
|
||||
$ sudo yum install linux-firmware microcode_ctl
|
||||
$ sudo reboot
|
||||
$ sudo dmesg | grep 'microcode'
|
||||
```
|
||||
|
||||
## How to update/install microcode downloaded from Intel site
|
||||
|
||||
Only use the following method when recommended by your vendor otherwise stick to Linux packages as described above. Most Linux distro maintainer update microcode via the package manager. Package manager method is safe as tested by many users.
|
||||
|
||||
### How to install Intel processor microcode blob for Linux (20180108 release)
|
||||
|
||||
Ok, first visit AMD or [Intel site][7] to grab the latest microcode firmware. In this example, I have a file named ~/Downloads/microcode-20180108.tgz (don't forget to check for checksum) that suppose to help with meltdown/Spectre. First extract it using the tar command:
|
||||
```
|
||||
$ mkdir firmware
|
||||
$ cd firmware
|
||||
$ tar xvf ~/Downloads/microcode-20180108.tgz
|
||||
$ ls -l
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
|
||||
```
|
||||
drwxr-xr-x 2 vivek vivek 4096 Jan 8 12:41 intel-ucode
|
||||
-rw-r--r-- 1 vivek vivek 4847056 Jan 8 12:39 microcode.dat
|
||||
-rw-r--r-- 1 vivek vivek 1907 Jan 9 07:03 releasenote
|
||||
|
||||
```
|
||||
|
||||
Make sure /sys/devices/system/cpu/microcode/reload exits:
|
||||
|
||||
`$ ls -l /sys/devices/system/cpu/microcode/reload`
|
||||
|
||||
You must copy all files from intel-ucode to /lib/firmware/intel-ucode/ using the [cp command][8]:
|
||||
|
||||
`$ sudo cp -v intel-ucode/* /lib/firmware/intel-ucode/`
|
||||
|
||||
You just copied intel-ucode directory to /lib/firmware/. Write the reload interface to 1 to reload the microcode files:
|
||||
|
||||
`# echo 1 > /sys/devices/system/cpu/microcode/reload`
|
||||
|
||||
Update an existing initramfs so that next time it get loaded via kernel:
|
||||
|
||||
```
|
||||
$ sudo update-initramfs -u
|
||||
$ sudo reboot
|
||||
```
|
||||
Verifying that microcode got updated on boot or reloaded by echo command:
|
||||
`# dmesg | grep microcode`
|
||||
|
||||
That is all. You have just updated firmware for your Intel CPU.
|
||||
|
||||
## about the author
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][9], [Facebook][10], [Google+][11].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/install-update-intel-microcode-firmware-linux/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/faq/2018/01/Verify-microcode-update-on-a-CentOS-RHEL-Fedora-Ubuntu-Debian-Linux.jpg
|
||||
[2]:https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ (See Linux/Unix apt command examples for more info)
|
||||
[3]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html (See Linux/Unix apt-get command examples for more info)
|
||||
[4]:https://www.cyberciti.biz/media/new/faq/2018/01/How-to-install-Intel-microcode-firmware-Linux.jpg
|
||||
[5]:https://www.cyberciti.biz/faq/howto-reboot-linux/
|
||||
[6]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ (See Linux/Unix yum command examples for more info)
|
||||
[7]:https://downloadcenter.intel.com/download/27431/Linux-Processor-Microcode-Data-File
|
||||
[8]:https://www.cyberciti.biz/faq/cp-copy-command-in-unix-examples/ (See Linux/Unix cp command examples for more info)
|
||||
[9]:https://twitter.com/nixcraft
|
||||
[10]:https://facebook.com/nixcraft
|
||||
[11]:https://plus.google.com/+CybercitiBiz
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
Building a Linux-based HPC system on the Raspberry Pi with Ansible
|
||||
============================================================
|
||||
|
||||
@ -150,4 +151,4 @@ via: https://opensource.com/article/18/1/how-build-hpc-system-raspberry-pi-and-o
|
||||
[28]:https://opensource.com/tags/raspberry-pi
|
||||
[29]:https://opensource.com/tags/programming
|
||||
[30]:https://opensource.com/tags/linux
|
||||
[31]:https://opensource.com/tags/ansible
|
||||
[31]:https://opensource.com/tags/ansible
|
||||
|
||||
@ -1,93 +0,0 @@
|
||||
谨慎使用 Linux find 命令
|
||||
======
|
||||

|
||||
最近有朋友提醒我可以添加一个有用的选项来更加谨慎地运行 find 命令,它是 -ok。除了一个重要的区别之外,它的工作方式与 -exec 相似,它使 find 命令在执行指定的操作之前请求权限。
|
||||
|
||||
这有一个例子。如果你使用 find 命令查找文件并删除它们,则可以运行下面的命令:
|
||||
```
|
||||
$ find . -name runme -exec rm {} \;
|
||||
|
||||
```
|
||||
|
||||
在当前目录及其子目录中中任何名为 “runme” 的文件都将被立即删除 - 当然,你要有权删除它们。改用 -ok 选项,你会看到类似这样的东西,find 命令将在删除文件之前会请求权限。回答 **y** 代表 “yes” 将允许 find 命令继续并逐个删除文件。
|
||||
```
|
||||
$ find . -name runme -ok rm {} \;
|
||||
< rm ... ./bin/runme > ?
|
||||
|
||||
```
|
||||
|
||||
### -exedir 命令也是一个选项
|
||||
|
||||
另一个可以用来修改 find 命令行为并可能使其更可控的选项是 -execdir 。其中 -exec 运行指定的任何命令,-execdir 从文件所在的目录运行指定的命令,而不是在运行 find 命令的目录运行。这是一个它的例子:
|
||||
```
|
||||
$ pwd
|
||||
/home/shs
|
||||
$ find . -name runme -execdir pwd \;
|
||||
/home/shs/bin
|
||||
|
||||
```
|
||||
```
|
||||
$ find . -name runme -execdir ls \;
|
||||
ls rm runme
|
||||
|
||||
```
|
||||
|
||||
到现在为止还挺好。但要记住的是,-execdir 也会在匹配文件的目录中执行命令。如果运行下面的命令,并且目录包含一个名为 “ls” 的文件,那么即使该文件没有_执行权限,它也将运行该文件。使用 **-exec** 或 **-execdir** 类似于通过 source 来运行命令。
|
||||
```
|
||||
$ find . -name runme -execdir ls \;
|
||||
Running the /home/shs/bin/ls file
|
||||
|
||||
```
|
||||
```
|
||||
$ find . -name runme -execdir rm {} \;
|
||||
This is an imposter rm command
|
||||
|
||||
```
|
||||
```
|
||||
$ ls -l bin
|
||||
total 12
|
||||
-r-x------ 1 shs shs 25 Oct 13 18:12 ls
|
||||
-rwxr-x--- 1 shs shs 36 Oct 13 18:29 rm
|
||||
-rw-rw-r-- 1 shs shs 28 Oct 13 18:55 runme
|
||||
|
||||
```
|
||||
```
|
||||
$ cat bin/ls
|
||||
echo Running the $0 file
|
||||
$ cat bin/rm
|
||||
echo This is an imposter rm command
|
||||
|
||||
```
|
||||
|
||||
### -okdir 选项也会请求权限
|
||||
|
||||
要更谨慎,可以使用 **-okdir** 选项。类似 **-ok**,该选项将请求权限来运行该命令。
|
||||
```
|
||||
$ find . -name runme -okdir rm {} \;
|
||||
< rm ... ./bin/runme > ?
|
||||
|
||||
```
|
||||
|
||||
你也可以小心地指定你想用的命令的完整路径,以避免像上面那样的冒牌命令出现的任何问题。
|
||||
```
|
||||
$ find . -name runme -execdir /bin/rm {} \;
|
||||
|
||||
```
|
||||
|
||||
find 命令除了默认打印之外还有很多选项,有些可以使你的文件搜索更精确,但谨慎一点总是好的。
|
||||
|
||||
在 [Facebook][1] 和 [LinkedIn][2] 上加入网络世界社区来进行评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3233305/linux/using-the-linux-find-command-with-caution.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[Locez](https://github.com/locez)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://www.facebook.com/NetworkWorld/
|
||||
[2]:https://www.linkedin.com/company/network-world
|
||||
@ -1,299 +0,0 @@
|
||||
Ubuntu 和 Arch Linux 双启动
|
||||
======
|
||||

|
||||
|
||||
**Ubuntu And Arch Linux 双启动** 不像听起来那么容易, 然而,我将使这个过程尽可能地简单明了。首先,我们需要安装 Ubuntu,然后安装 Arch Linux,因为配置 Ubuntu grub更容易实现**Ubuntu 和 Arch Linux 双启动**
|
||||
### Ubuntu And Arch Linux 双启动
|
||||
|
||||
你需要准备好以下内容:
|
||||
|
||||
1、你需要准备你所选择的 Ubuntu 的特色版本,在这个例子中,我将使用 Ubuntu 17.10 ISO
|
||||
|
||||
2、两个优盘
|
||||
|
||||
3、Windows 或者 Linux 操作系统的 PC 机
|
||||
|
||||
4、Arch Linux ISO
|
||||
|
||||
5、基于 Windows 的 Rufus 或是基于 Linux 发行版的 etcher 的两款软件中的一种,要根据自己的系统类型来选择哦。
|
||||
### 安装 Ubuntu
|
||||
|
||||
首先, 利用 `Rufus` 为 Ubuntu 和 Arch Linux[创建可引导的闪存驱动器][1]。另外,也可以使用 `etcher` 创建 Ubuntu 和 Arch Linux 的可引导闪存驱动器。
|
||||
|
||||
[][2]
|
||||
|
||||
为 Ubuntu 选择 ISO 映像文件,然后选择闪存驱动器,然后单击 `Flash` 创建可引导的闪存驱动器。等到它完成,瞧!你的启动闪存已经准备好使用了。
|
||||
[][3]
|
||||
|
||||
|
||||
打开你的机器并使用载有 Ubuntu 安装媒体的启动闪存驱动器进行启动。确保引导到 UEFI 或 BIOS 兼容模式,这取决于您所使用的 PC 的类型。我更喜欢使用 UEFI 来构建新的 PC 。
|
||||
[][4]
|
||||
|
||||
在成功启动后,您将看到如上图显示,要求您尝试 Ubuntu 或安装 Ubuntu,选择安装 Ubuntu。
|
||||
[][5]
|
||||
|
||||
然后检查安装第三方软件的图形和 Wifi 硬件,MP3 和其他媒体。如果你有一个互联网连接,你可以选择在安装 Ubuntu 的时候下载更新,因为它会节省安装时间,并且确保安装的是最新更新。
|
||||
[][6]
|
||||
|
||||
然后选择点击`Something else`,这样我们就可以对硬盘进行分区,并预留出 Ubuntu 和 Archlinux 的分区以及他们的交换分区的空间。
|
||||
[][7]
|
||||
|
||||
创建一个交换分区。最好是内存的一半大小。在我的例子中,我有 1 GB 的内存,因此创建一个 512 MB 的交换空间。
|
||||
[][8]
|
||||
|
||||
然后创建一个带有挂载点`/`的根分区并且点击`Install Now`按钮。
|
||||
[][9]
|
||||
|
||||
接下来选择语言和键盘设置。
|
||||
[][10]
|
||||
|
||||
然后创建新用户的用户凭据。
|
||||
[][11]
|
||||
|
||||
点击`Next`开始安装。
|
||||
[][12]
|
||||
|
||||
当安装完成后点击`Restart Now`重启 PC。
|
||||
[][13]
|
||||
|
||||
移除安装媒介,按下回车继续。
|
||||
[][14]
|
||||
|
||||
在确认成功安装后,重新启动并利用 Arch Linux 安装媒介引导。
|
||||
### 安装 Arch Linux
|
||||
|
||||
在引导到 **Arch Linux 安装媒体**时,您应该看到如下所示的初始屏幕。选择 `Boot Arch Linux(x86_64)`。注意 Arch Linux 更多情况下类似于 [DYF][15] (自我定制)的一种操作系统。
|
||||
[][16]
|
||||
|
||||
选择之后,它将打开一个`tty1`终端,您将使用它来安装操作系统。
|
||||
[][17] 注意:为了成功安装 Arch Linux,您需要一个互联网连接来下载一些必须的系统安装包。所以我们需要检查一下互联网是否运行正常。输入以下命令到终端以检查网络连接。
|
||||
```ping linuxandubuntu.com -c 4```
|
||||
|
||||
[][18]
|
||||
|
||||
如果因特网运行正常,你应该得到一个回显,显示发送和接收的数据包的数量。在这种情况下,我们发送了4个回波,并得到了4个反馈,这意味着连接是正常的。
|
||||
|
||||
如果想在 Arch Linux 中设置 Wifi,请阅读[本文][19],在 Arch Linux 中配置 Wifi。
|
||||
接下来,我们需要选择之前在安装 Ubuntu 时预留出的空闲分区。
|
||||
```fdisk -l``
|
||||
|
||||
上面的命令应该显示可用的磁盘分区在哪里。您应该能看到 Ubuntu 分区以及预留的空闲空间。我们将使用`cfdisk`命令进行分区。
|
||||
```cfdisk```
|
||||
|
||||
[][20]
|
||||
|
||||
执行命令后将看到分区情况。选择其他已分配分区下面的空闲空间。
|
||||
您需要选择 `New`,然后输入分区大小。
|
||||
[][21] 例如,9.3G - G 表示千兆字节。[][22]
|
||||
|
||||
如下图所示,选择`primary`进行分区
|
||||
[][23] 然后选择写分区条目。 [][24]
|
||||
|
||||
键入`yes`,以确认写入分区表。
|
||||
[][25]
|
||||
|
||||
然后选择 `Quit`(退出)选项。
|
||||
[][26] 然后键入:
|
||||
|
||||
```fdisk -l```
|
||||
|
||||
确认修改
|
||||
[][27]
|
||||
|
||||
然后使用磁盘分区命令:
|
||||
```mkfs.ext4 /dev/sda3```
|
||||
|
||||
确保您选择的分区是我们创建的最后一个分区,这样我们就不会破坏 Ubuntu 分区。
|
||||
[][28]
|
||||
|
||||
然后使用以下命令安装这个分区 -
|
||||
```mount /dev/sda3 /mnt```
|
||||
|
||||
[][29]
|
||||
|
||||
用下面命令创建`home`目录
|
||||
```mkdir .mnt/home```
|
||||
|
||||
[][30]
|
||||
|
||||
用一下命令安装`home`目录到这个分区上
|
||||
mount /dev/sda3 /mnt/home
|
||||
|
||||
[][31]
|
||||
|
||||
现在使用以下命令安装 Archlinux 的基本系统:
|
||||
```pacstrap /mnt base```
|
||||
|
||||
请确保网络连接正常。
|
||||
|
||||
|
||||
接下来开始下载和配置安装所用时间取决于你的网速。
|
||||
[][32]
|
||||
|
||||
这一步骤完成后,将完成 Archlinux 基本安装。
|
||||
Arch Linux 基础系统安装完成后,使用以下命令创建一个`fstab`文件:
|
||||
genfstab -U /mnt >> /mnt/etc/fstab
|
||||
|
||||
[][33]
|
||||
|
||||
在此之后,您需要验证`fstab`文件,使用下面命令:
|
||||
```cat /mnt/etc/fstab```
|
||||
|
||||
[][34]
|
||||
|
||||
### Configuring Arch Linux: the basic configuration配置 Arch Linux:基础配置
|
||||
|
||||
您将需要在安装时配置以下内容:
|
||||
1. 系统语言和系统语言环境
|
||||
|
||||
2. 系统时区
|
||||
|
||||
3. Root用户密码
|
||||
|
||||
4. 设置主机名
|
||||
|
||||
Firstly, you will need to switch to the newly installed base by changing root into the system using the command:
|
||||
首先,您需要使用以下命令将`root`切换为新安装的基础系统用户:
|
||||
```arch-chroot /mnt```
|
||||
|
||||
#### 系统语言和系统语言环境
|
||||
|
||||
然后必须配置系统语言。必须取消对 en_Utf-8 UTF-8的注释,并加载到文件`/etc/local.gen`中
|
||||
键入:
|
||||
|
||||
```nano /etc/local.gen```
|
||||
|
||||
然后将 en_UTF-8 UTF-8 取消注释
|
||||
键入命令:
|
||||
|
||||
```locale-gen```
|
||||
|
||||
生成本地化设置如下:
|
||||
[][35] 相应的需要在`locale.conf`文件中配置 LANG 变量。例如:
|
||||
|
||||
```nano /etc/locale.conf```
|
||||
|
||||
修改为:
|
||||
```LANG=en_US.UTF-8```
|
||||
|
||||
配置键盘布局,则在文件`vconsole.conf`中进行更改,如下操作:
|
||||
```nano /etc/vconsole.conf```
|
||||
|
||||
修改为:
|
||||
```KEYMAP=us-eng```
|
||||
|
||||
#### 2\. 系统时区
|
||||
|
||||
配置时区需要利用一下命令实现
|
||||
```ln -sf /usr/share/zoneinfo/Region/City /etc/localtime```
|
||||
|
||||
要查看可用时区,可以在终端使用以下命令:
|
||||
|
||||
注意可选时区在屏幕截图中显示为蓝色:
|
||||
```ls /usr/share/zoneinfo```
|
||||
|
||||
[][36] [][37] 运行`hwclock`命令来生成``/etc/adjtime``(假设硬件时钟被设置为UTC):
|
||||
|
||||
```# hwclock --systohc```
|
||||
|
||||
#### 3\. 配置 Root 用户密码
|
||||
|
||||
要为 Arch Linux 系统用户`root`设置密码,请使用:
|
||||
```Passwd```
|
||||
|
||||
为`root`用户提供一个新的密码并确认密码使其生效。
|
||||
[][38]
|
||||
|
||||
#### 4\. 配置主机名和网络
|
||||
|
||||
需要创建主机名文件:
|
||||
```nano /etc/hostname```
|
||||
|
||||
[][39]
|
||||
|
||||
将名字更改为您的用户名:
|
||||
[][40] 然后向主机添加一个匹配的条目:
|
||||
|
||||
```nano /etc/hosts
|
||||
|
||||
127.0.0.1 localhost.localdomain localhost
|
||||
|
||||
::1 localhost.localdomain localhost
|
||||
|
||||
127.0.1.1 LinuxandUbuntu.localdomain LinuxandUbuntu```
|
||||
|
||||
|
||||
|
||||
您需要使网络保持连接,然后使用:
|
||||
```systemctl enable dhcpd```
|
||||
|
||||
#### 配置 Grub
|
||||
|
||||
然后重启机器,进入 Ubuntu 配置 grub。
|
||||
你可以键入:
|
||||
```reboot```
|
||||
|
||||
[][41]
|
||||
|
||||
Arch Linux 安装仍然没有出现,因此我们需要在 Ubuntu 中使用 `update-grub`来安装它。
|
||||
[][42] 在Ubuntu中打开终端,输入:
|
||||
|
||||
```sudo update-grub```
|
||||
|
||||
它应该更新grub,添加 Arch Linux 记录。
|
||||
### 小结
|
||||
|
||||
祝贺您成功地将Ubuntu和Arch Linux设置为双引导。Ubuntu安装很简单,但是Arch Linux安装对新的Linux用户来说是一个挑战。我试着让这个教程变得简单。但是如果你对这篇文章有任何疑问,请在评论部分告诉我。还可以与您的朋友分享这篇文章,并帮助他们学习Linux。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/dual-boot-ubuntu-and-arch-linux
|
||||
|
||||
作者:[LinuxAndUbuntu][a]
|
||||
译者:[stevenzdg988](https://github.com/stevenzdg988)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/home/etcher-burn-images-to-sd-card-make-bootable-usb
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/bootable-ubuntu-usb-etcher-image-writer_orig.jpg
|
||||
[3]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/make-ubuntu-usb-bootable-in-linux_orig.jpg
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/live-ubuntu-boot_orig.jpg
|
||||
[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/install-usb-from-live-usb_orig.jpg
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/custom-partition-hd-install-ubuntu_orig.jpg
|
||||
[7]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/create-swap-partition-ubuntu_orig.jpg
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/install-ubuntu-root-partition_orig.jpg
|
||||
[9]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/select-ubuntu-timezone_orig.jpg
|
||||
[10]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/install-ubuntu-select-location-keyboard-layout_orig.jpg
|
||||
[11]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/create-username-system-name-ubuntu-install_orig.jpg
|
||||
[12]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/ubuntu-installation-finishing_orig.jpg
|
||||
[13]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/ubuntu-installation-finished_orig.jpg
|
||||
[14]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/remove-installation-media-after-ubuntu_orig.jpg
|
||||
[15]:http://www.linuxandubuntu.com/home/arch-linux-take-your-linux-knowledge-to-next-level-review
|
||||
[16]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/arch-linux-installation-boot-menu_orig.jpg
|
||||
[17]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/arch-linux-tty1-linux_orig.png
|
||||
[18]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/arch-linux-ping-check-internet-connection_orig.png
|
||||
[19]:http://www.linuxandubuntu.com/home/how-to-setup-a-wifi-in-arch-linux-using-terminal
|
||||
[20]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/install-arch-partition-disk-with-cfdisk_orig.png
|
||||
[21]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/partition-free-space-swap-arch-linux_orig.png
|
||||
[22]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/install-arch-linux-partition_orig.png
|
||||
[23]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/make-arch-linux-root-as-primary-partition_orig.png
|
||||
[24]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/select-partition-to-install-arch_orig.png
|
||||
[25]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/install-arch-linux-confirm-create-partition_orig.png
|
||||
[26]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/quit-cfdisk-arch-linux_orig.png
|
||||
[27]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/confirm-partition-changes_orig.png
|
||||
[28]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/complete-arch-linux-installation-partition_orig.png
|
||||
[29]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/mount-base-partition-in-arch-linux.png
|
||||
[30]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/mount-home-partition-arch-linux.png
|
||||
[31]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/make-mount-home-directory.png
|
||||
[32]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/install-arch-linux-base.png
|
||||
[33]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/create-fstab-file-in-arch-linux.png
|
||||
[34]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/cat-fstab-file-data-terminal.png
|
||||
[35]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/generate-localization-arch-linux.png
|
||||
[36]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/setup-zonefile-in-arch-linux.png
|
||||
[37]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/setup-country-zonefile_orig.png
|
||||
[38]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/setup-arch-linux-root-password.png
|
||||
[39]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/set-arch-linux-hostname.png
|
||||
[40]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/set-arch-linux-username.png
|
||||
[41]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/reboot-system-after-arch-linux-installation.png
|
||||
[42]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/edited/ubuntu-grub-menu.png
|
||||
@ -0,0 +1,99 @@
|
||||
Intel 设计缺陷背后的原因是什么?
|
||||
============================================================
|
||||
|
||||
### 我们知道有问题,但是并不知道问题的详细情况。
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
最近 Windows 和 Linux 都发送了重大安全更新,为防范这个尚未完全公开的问题,在最坏的情况下,它可能会导致性能下降多达一半。
|
||||
|
||||
在过去的几周,Linux 内核陆续打了几个补丁。Microsoft [自 11 月份开始也内部测试了 Windows 更新][3],并且它预计在下周二的例行补丁中将这个改进推送到主流 Windows 构建版中。Microsoft 的 Azure 也在下周的维护窗口中做好了安排,而 Amazon 的 AWS 也安排在周五对相关的设施进行维护。
|
||||
|
||||
自从 Linux 第一个补丁 [KPTI:内核页表隔离的当前的发展][4] ,明确描绘了出现的错误以后。虽然 Linux 和 Windows 基于不同的考虑,对此持有不同的看法,但是这两个操作系统 — 当然还有其它的 x86 操作系统,比如 FreeBSD 和 [macOS][5] — 对系统内存的处理采用了相同的方式,因为对于操作系统在这一部分特性是与底层的处理器高度耦合的。
|
||||
|
||||
### 保持地址跟踪
|
||||
|
||||
在一个系统中的每个内存字节都是隐性编码的,这些数字是每个字节的地址。早期的操作系统使用物理内存地址,但是,物理内存地址由于各种原因,它并不很合适。例如,在地址中经常会有空隙,并且(尤其是 32 位的系统上)物理地址很难操作,需要 36 位的数字,甚至更多。
|
||||
|
||||
因此,现在操作系统完全依赖一个叫虚拟内存的概念。虚拟内存系统允许程序和内核一起在一个简单、清晰、统一的环境中各自去操作。而不是使用空隙和其它奇怪的东西的物理内存,每个程序和内核自身都使用虚拟地址去访问内存。这些虚拟地址是连续的 — 不用担心有空隙 — 并且合适的大小也更便于操作。32 位的程序仅可以看到 32 位的地址,而不用管物理地址是 36 位还是更多位。
|
||||
|
||||
虽然虚拟地址对每个软件几乎是透明的,但是,处理器最终还是需要知道虚拟地址引用的物理地址是哪个。因此,有一个虚拟地址到物理地址的映射,它保存在一个被称为页面表的数据结构中。操作系统构建页面表,使用一个由处理器决定的布局,并且处理器和操作系统在虚拟地址和物理地址之间进行转换时就需要用到页面表。
|
||||
|
||||
这个映射过程是非常重要的,它也是现代操作系统和处理器的重要基础,处理器有专用的缓存 — translation lookaside buffer(简称 TLB)— 它保存了一定数量的虚拟地址到物理地址的映射,这样就不需要每次都使用全部页面。
|
||||
|
||||
虚拟内存的使用为我们提供了很多除了简单寻址之外的有用的特性。其中最主要的是,每个程序都有了自己独立的一组虚拟地址,有了它自己的一组虚拟地址到物理地址的映射。这就是用于提供“内存保护”的关键技术,一个程序不能破坏或者篡改其它程序使用的内存,因为其它程序的内存并不在它的地址映射范围之内。
|
||||
|
||||
由于每个进程使用一个单独的映射,因此每个程序也就有了一个额外的页面表,这就使得 TLB 缓存很拥挤。TLB 并不大 — 一般情况下总共可以容纳几百个映射 — 而系统使用的页面表越多,TLB 能够包含的任何特定的虚拟地址到物理地址的映射就越少。
|
||||
|
||||
### 一半一半
|
||||
|
||||
为了更好地使用 TLB,每个主流的操作系统都将虚拟地址范围一分为二。一半用于程序;另一半用于内核。当进程切换时,仅有一半的页面表条目发生变化 — 仅属于程序的那一半。内核的那一半是每个程序公用的(因为只有一个内核)并且因此它可以为每个进程使用相同的页面表映射。这对 TLB 的帮助非常大;虽然它仍然会丢弃属于进程的那一半内存地址映射;但是它还保持着另一半属于内核的映射。
|
||||
|
||||
这种设计并不是一成不变的。在 Linux 上做了一项工作,使它可以为一个 32 位的进程提供整个地址范围,而不用在内核页面表和每个进程之间共享。虽然这样为程序提供了更多的地址空间,但这是以牺牲性能为代价的,因为每次内核代码需要运行时,TLB 重新加载内核的页面表条目。因此,这种方法并没有广泛应用到 x86 的系统上。
|
||||
|
||||
在内核和每个程序之间分割虚拟地址的这种做法的一个负面影响是,内存保护被削弱了。如果内核有它自己的一组页面表和虚拟地址,它将在不同的程序之间提供相同的保护;内核内存将是简单的不可见。但是使用地址分割之后,用户程序和内核使用了相同的地址范围,并且从原理上来说,一个用户程序有可能去读写内核内存。
|
||||
|
||||
为避免这种明显不好的情况,处理器和虚拟地址系统有一个 “Ring" 或者 ”模式“的概念。x86 处理器有许多 rings,但是对于这个问题,仅有两个是相关的:"user" (ring 3)和 "supervisor"(ring 0)。当运行普通的用户程序时,处理器将置为用户模式 (ring 3)。当运行内核代码时,处理器将处于 ring 0 —— supervisor 模式,也称为内核模式。
|
||||
|
||||
这些 rings 也用于从用户程序中保护内核内存。页面表并不仅仅有虚拟地址到物理地址的映射;它也包含关于这些地址的元数据,包含哪个 rings 可能访问哪个地址的信息。内核页面表条目被标记为仅 ring 0 可以访问;程序的条目被标记为任何 ring 都可以访问。如果一个处于 ring 3 中的进程去尝试访问标记为 ring 0 的内存,处理器将阻止这个访问并生成一个意外错误信息。运行在 ring 3 中的用户程序不能得到内核以及运行在 ring 0 内存中的任何东西。
|
||||
|
||||
至少理论上是这样的。大量的补丁和更新表明,这个地方已经被突破了。这就是最大的谜团所在。
|
||||
|
||||
### Ring 间迁移
|
||||
|
||||
这就是我们所知道的。每个现代处理器都执行一定数量的推测运行。例如,给一些指令,让两个数加起来,然后将结果保存在内存中,在查明内存中的目标是否可访问和可写入之前,一个处理器可能已经推测性地做了加法。在一些常见案例中,在位置是可写入的地方,处理器节省了一些时间,因为它以并行方式计算出内存中的目标是什么。如果它发现目标位置不可写入 — 例如,一个程序尝试去写入到一个没有映射的地址以及压根就不存在的物理位置— 然后它将产生一个意外错误,而推测运行就白做了。
|
||||
|
||||
Intel 处理器,尤其是 — [虽然不是 AMD 的][6] — 但允许对 ring 3 代码进行推测运行并写入到 ring 0 内存中的处理器上。处理器并不完全阻止这种写入,但是推测运行轻微扰乱了处理器状态,因为,为了查明目标位置是否可写入,某些数据已经被加载到缓存和 TLB 中。这又意味着一些操作可能快几个周期,或者慢几个周期,这取决于它们所需要的数据是否仍然在缓存中。除此之外,Intel 的处理器还有一些特殊的功能,比如,在 Skylake 处理器上引入的软件保护扩展(SGX)指令,它改变了一点点访问内存的方式。同样的,处理器仍然是保护 ring 0 的内存不被来自 ring 3 的程序所访问,但是同样的,它的缓存和其它内部状态已经发生了变化,产生了可测量的差异。
|
||||
|
||||
我们至今仍然并不知道具体的情况,到底有多少内核的内存信息泄露给了用户程序,或者信息泄露的情况有多容易发生。以及有哪些 Intel 处理器会受到影响?也或者并不完全清楚,但是,有迹象表明每个 Intel 芯片都使用了推测运行(是自 1995 年 Pentium Pro 以来的,所有主流处理器吗?),它们都可能会因此而泄露信息。
|
||||
|
||||
这个问题第一次被披露是由来自 [奥地利的 Graz Technical University][7] 的研究者。他们披露的信息表明这个问题已经足够破坏内核模式地址空间布局随机化(内核 ASLR,或称 KASLR)。ASLR 是防范 [缓冲区溢出][8] 漏洞利用的最后一道防线。启用 ASLR 之后,程序和它们的数据被置于随机的内存地址中,它将使一些安全漏洞利用更加困难。KASLR 将这种随机化应用到内核中,这样就使内核的数据(包括页面表)和代码也随机化分布。
|
||||
|
||||
Graz 的研究者开发了 [KAISER][9],一组防范这个问题的 Linux 内核补丁。
|
||||
|
||||
如果这个问题正好使 ASLR 的随机化被破坏了,这或许将成为一个巨大的灾难。ASLR 是一个非常强大的保护措施,但是它并不是完美的,这意味着对于黑客来说将是一个很大的障碍,一个无法逾越的障碍。整个行业对此的反应是 — Windows 和 Linux 都有一个非常重要的变化,秘密开发 — 这表明不仅是 ASLR 被破坏了,而且从内核泄露出信息的更普遍的技术被开发出来了。确实是这样的,研究者已经 [在 tweet 上发布信息][10],他们已经可以随意泄露和读取内核数据了。另一种可能是,漏洞可能被用于从虚拟机中”越狱“,并可能会危及 hypervisor。
|
||||
|
||||
Windows 和 Linux 选择的解决方案是非常相似的,将 KAISER 分为两个区域:内核页面表的条目不再是由每个进程共享。在 Linux 中,这被称为内核页面表隔离(KPTI)。
|
||||
|
||||
应用补丁后,内存地址仍然被一分为二:这样使内核的那一半几乎是空的。当然它并不是非常的空,因为一些内核片断需要永久映射,不论进程是运行在 ring 3 还是 ring 0 中,它都几乎是空的。这意味着如果恶意用户程序尝试去探测内核内存以及泄露信息,它将会失败 — 因为那里几乎没有信息。而真正的内核页面中只有当内核自身运行的时刻它才能被用到。
|
||||
|
||||
这样做就破坏了最初将地址空间分割的理由。现在,每次切换到用户程序时,TLB 需要实时去清除与内核页面表相关的所有条目,这样就失去了启用分割带来的性能提升。
|
||||
|
||||
影响的具体大小取决于工作负载。每当一个程序被调入到内核 — 从磁盘读入、发送数据到网络、打开一个文件等等 — 这种调用的成本可能会增加一点点,因为它强制 TLB 清除了缓存并实时加载内核页面表。不使用内核的程序可能会观测到 2 - 3 个百分点的性能影响 — 这里仍然有一些开销,因为内核仍然是偶尔会运行去处理一些事情,比如多任务等等。
|
||||
|
||||
但是大量调用进入到内核的工作负载将观测到很大的性能损失。在一个基准测试中,一个除了调入到内核之外什么都不做的程序,观察到 [它的性能下降大约为 50%][11];换句话说就是,打补丁后每次对内核的调用的时间要比不打补丁调用内核的时间增加一倍。基准测试使用的 Linux 的网络回环(loopback)也观测到一个很大的影响,比如,在 Postgres 的基准测试中大约是 [17%][12]。真实的数据库负载使用了实时网络可能观测到的影响要低一些,因为使用实时网络时,内核调用的开销基本是使用真实网络的开销。
|
||||
|
||||
虽然对 Intel 系统的影响是众所周知的,但是它们可能并不是唯一受影响的。其它的一些平台,比如 SPARC 和 IBM 的 S390,是不受这个问题影响的,因为它们的处理器的内存管理并不需要分割地址空间和共享内核页面表;在这些平台上的操作系统一直就是将它们的内核页面表从用户模式中隔离出来的。但是其它的,比如 ARM,可能就没有这么幸运了;[适用于 ARM Linux 的类似补丁][13] 正在开发中。
|
||||
|
||||
<aside class="ad_native" id="ad_xrail_native" style="box-sizing: inherit;"></aside>
|
||||
|
||||
[][15][PETER BRIGHT][14] 是 Ars 的一位技术编辑。他涉及微软、编程及软件开发、Web 技术和浏览器、以及安全方面。它居住在纽约的布鲁克林。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://arstechnica.com/gadgets/2018/01/whats-behind-the-intel-design-flaw-forcing-numerous-patches/
|
||||
|
||||
作者:[ PETER BRIGHT ][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://arstechnica.com/author/peter-bright/
|
||||
[1]:https://arstechnica.com/author/peter-bright/
|
||||
[2]:https://arstechnica.com/gadgets/2018/01/whats-behind-the-intel-design-flaw-forcing-numerous-patches/?comments=1
|
||||
[3]:https://twitter.com/aionescu/status/930412525111296000
|
||||
[4]:https://linux.cn/article-9201-1.html
|
||||
[5]:https://twitter.com/aionescu/status/948609809540046849
|
||||
[6]:https://lkml.org/lkml/2017/12/27/2
|
||||
[7]:https://gruss.cc/files/kaiser.pdf
|
||||
[8]:https://arstechnica.com/information-technology/2015/08/how-security-flaws-work-the-buffer-overflow/
|
||||
[9]:https://github.com/IAIK/KAISER
|
||||
[10]:https://twitter.com/brainsmoke/status/948561799875502080
|
||||
[11]:https://twitter.com/grsecurity/status/947257569906757638
|
||||
[12]:https://www.postgresql.org/message-id/20180102222354.qikjmf7dvnjgbkxe@alap3.anarazel.de
|
||||
[13]:https://lwn.net/Articles/740393/
|
||||
[14]:https://arstechnica.com/author/peter-bright
|
||||
[15]:https://arstechnica.com/author/peter-bright
|
||||
@ -0,0 +1,155 @@
|
||||
如何在 Linux 上安装/更新 Intel 微码固件
|
||||
======
|
||||
|
||||
|
||||
如果你是一个 Linux 系统管理方面的新手,如何在 Linux 上使用命令行选项去安装或者更新 Intel/AMD CPU 的微码固件?
|
||||
|
||||
|
||||
微码只是由 Intel/AMD 提供的 CPU 固件而已。Linux 的内核可以在系统引导时不需要升级 BIOS 的情况下更新 CPU 的固件。处理器微码保存在内存中,在每次启动系统时,内核可以更新这个微码。这些来自 Intel/AMD 的升级微码可以去修复 bug 或者使用补丁来防范 bugs。这篇文章演示了如何使用包管理器去安装 AMD 或者 Intel 微码更新,或者由 lntel 提供的 Linux 上的处理器微码更新。
|
||||
|
||||
## 如何查看当前的微码状态
|
||||
|
||||
|
||||
以 root 用户运行下列命令:
|
||||
`# dmesg | grep microcode`
|
||||
输出如下:
|
||||
|
||||
[![Verify microcode update on a CentOS RHEL Fedora Ubuntu Debian Linux][1]][1]
|
||||
|
||||
请注意,你的 CPU 在这里完全有可能出现没有可用的微码更新的情况。如果是这种情况,它的输出可能是如下图这样的:
|
||||
```
|
||||
[ 0.952699] microcode: sig=0x306a9, pf=0x10, revision=0x1c
|
||||
[ 0.952773] microcode: Microcode Update Driver: v2.2.
|
||||
|
||||
```
|
||||
|
||||
## 如何在 Linux 上使用包管理器去安装微码固件更新
|
||||
|
||||
对于运行在 Linux 系统的 x86/amd64 架构的 CPU 上,Linux 自带了工具去更改或者部署微码固件。在 Linux 上安装 AMD 或者 Intel 的微码固件的过程如下:
|
||||
|
||||
1. 打开终端应用程序
|
||||
2. Debian/Ubuntu Linux 用户推输入:**sudo apt install intel-microcode**
|
||||
3. CentOS/RHEL Linux 用户输入:**sudo yum install microcode_ctl**
|
||||
|
||||
|
||||
|
||||
对于流行的 Linux 发行版,这个包的名字一般如下 :
|
||||
|
||||
* microcode_ctl 和 linux-firmware —— CentOS/RHEL 微码更新包
|
||||
* intel-microcode —— Debian/Ubuntu 和 clones 发行版适用于 Intel CPU 的微码更新包
|
||||
* amd64-microcode —— Debian/Ubuntu 和 clones 发行版适用于 AMD CPU 的微码固件
|
||||
* linux-firmware —— 适用于 AMD CPU 的 Arch Linux 发行版微码固件(你不用做任何操作,它是默认安装的)
|
||||
* intel-ucode —— 适用于 Intel CPU 的 Arch Linux 发行版微码固件
|
||||
* microcode_ctl 和 ucode-intel —— Suse/OpenSUSE Linux 微码更新包
|
||||
|
||||
|
||||
|
||||
**警告 :在某些情况下,更新微码可能会导致引导问题,比如,服务器在引导时被挂起或者自动重置。以下的步骤是在我的机器上运行过的,并且我是一个经验丰富的系统管理员。对于由此引发的任何硬件故障,我不承担任何责任。在做固件更新之前,请充分评估操作风险!**
|
||||
|
||||
### 示例
|
||||
|
||||
在使用 Intel CPU 的 Debian/Ubuntu Linux 系统上,输入如下的 [apt 命令][2]/[apt-get 命令][3]:
|
||||
|
||||
`$ sudo apt-get install intel-microcode`
|
||||
|
||||
示例输出如下:
|
||||
|
||||
[![How to install Intel microcode firmware Linux][4]][4]
|
||||
|
||||
你 [必须重启服务器以激活微码][5] 更新:
|
||||
|
||||
`$ sudo reboot`
|
||||
|
||||
重启后检查微码状态:
|
||||
|
||||
`# dmesg | grep 'microcode'`
|
||||
|
||||
示例输出如下:
|
||||
|
||||
```
|
||||
[ 0.000000] microcode: microcode updated early to revision 0x1c, date = 2015-02-26
|
||||
[ 1.604672] microcode: sig=0x306a9, pf=0x10, revision=0x1c
|
||||
[ 1.604976] microcode: Microcode Update Driver: v2.01 <tigran@aivazian.fsnet.co.uk>, Peter Oruba
|
||||
|
||||
```
|
||||
|
||||
如果你使用的是 RHEL/CentOS 系统,使用 [yum 命令][6] 尝试去安装或者更新以下两个包:
|
||||
|
||||
```
|
||||
$ sudo yum install linux-firmware microcode_ctl
|
||||
$ sudo reboot
|
||||
$ sudo dmesg | grep 'microcode'
|
||||
```
|
||||
|
||||
## 如何去更新/安装从 Intel 网站上下载的微码
|
||||
|
||||
仅当你的 CPU 制造商建议这么做的时候,才可以使用下列的方法去更新/安装微码,除此之外,都应该使用上面的方法去更新。大多数 Linux 发行版都可以通过包管理器来维护更新微码。使用包管理器的方法是经过测试的,对大多数用户来说是最安全的方式。
|
||||
|
||||
### 如何为 Linux 安装 Intel 处理器微码块(20180108 发布)
|
||||
|
||||
首先通过 AMD 或 [Intel 网站][7] 去获取最新的微码固件。在本示例中,我有一个名称为 ~/Downloads/microcode-20180108.tgz(不要忘了去验证它的检验和),它的用途是去防范 meltdown/Spectre bugs。先使用 tar 命令去提取它:
|
||||
```
|
||||
$ mkdir firmware
|
||||
$ cd firmware
|
||||
$ tar xvf ~/Downloads/microcode-20180108.tgz
|
||||
$ ls -l
|
||||
```
|
||||
|
||||
示例输出如下:
|
||||
|
||||
```
|
||||
drwxr-xr-x 2 vivek vivek 4096 Jan 8 12:41 intel-ucode
|
||||
-rw-r--r-- 1 vivek vivek 4847056 Jan 8 12:39 microcode.dat
|
||||
-rw-r--r-- 1 vivek vivek 1907 Jan 9 07:03 releasenote
|
||||
|
||||
```
|
||||
|
||||
检查一下,确保存在 /sys/devices/system/cpu/microcode/reload 目录:
|
||||
|
||||
`$ ls -l /sys/devices/system/cpu/microcode/reload`
|
||||
|
||||
你必须使用 [cp 命令][8] 拷贝 intel-ucode 目录下的所有文件到 /lib/firmware/intel-ucode/ 下面:
|
||||
|
||||
`$ sudo cp -v intel-ucode/* /lib/firmware/intel-ucode/`
|
||||
|
||||
你只需要将 intel-ucode 这个目录整个拷贝到 /lib/firmware/ 目录下即可。然后在重新加载接口中写入 1 去重新加载微码文件:
|
||||
|
||||
`# echo 1 > /sys/devices/system/cpu/microcode/reload`
|
||||
|
||||
更新现有的 initramfs,以便于下次启动时通过内核来加载:
|
||||
|
||||
```
|
||||
$ sudo update-initramfs -u
|
||||
$ sudo reboot
|
||||
```
|
||||
重启后通过以下的命令验证微码是否已经更新:
|
||||
`# dmesg | grep microcode`
|
||||
|
||||
到此为止,就是更新处理器微码的全部步骤。如果一切顺利的话,你的 Intel CPU 的固件将已经是最新的版本了。
|
||||
|
||||
## 关于作者
|
||||
|
||||
作者是 nixCraft 的创始人、一位经验丰富的系统管理员、Linux/Unix 操作系统 shell 脚本培训师。他与全球的包括 IT、教育、国防和空间研究、以及非盈利组织等各行业的客户一起工作。可以在 [Twitter][9]、[Facebook][10]、[Google+][11] 上关注他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/install-update-intel-microcode-firmware-linux/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/faq/2018/01/Verify-microcode-update-on-a-CentOS-RHEL-Fedora-Ubuntu-Debian-Linux.jpg
|
||||
[2]:https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ "See Linux/Unix apt command examples for more info"
|
||||
[3]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html "See Linux/Unix apt-get command examples for more info"
|
||||
[4]:https://www.cyberciti.biz/media/new/faq/2018/01/How-to-install-Intel-microcode-firmware-Linux.jpg
|
||||
[5]:https://www.cyberciti.biz/faq/howto-reboot-linux/
|
||||
[6]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ "See Linux/Unix yum command examples for more info"
|
||||
[7]:https://downloadcenter.intel.com/download/27431/Linux-Processor-Microcode-Data-File
|
||||
[8]:https://www.cyberciti.biz/faq/cp-copy-command-in-unix-examples/ "See Linux/Unix cp command examples for more info"
|
||||
[9]:https://twitter.com/nixcraft
|
||||
[10]:https://facebook.com/nixcraft
|
||||
[11]:https://plus.google.com/+CybercitiBiz
|
||||
@ -1,214 +0,0 @@
|
||||
ncurses入门指南
|
||||
======
|
||||
怎样使用curses来绘制终端屏幕。
|
||||
|
||||
虽然图形界面非常酷,但是不是所有的程序都需要点击式的界面。例如,令人尊敬的vi编辑器在第一个GUI(出现)之前在纯文本终端运行了很久。
|
||||
|
||||
vi编辑器是一个在"文本"模式下绘制的面向屏幕程序的例子。它使用了一个叫curses的库。这个库提供了一系列的编程接口来操纵终端屏幕。curses库产生于BSD UNIX,但是Linux系统通过ncurses库提供这个功能。
|
||||
|
||||
[了解ncurses"过去曾引起的风暴",参见 ["ncurses: Portable Screen-Handling for Linux"][1], September 1, 1995, by Eric S. Raymond.]
|
||||
|
||||
使用curses创建程序实际上非常简单。在这个文章中,我展示了一个利用curses来在终端屏幕上绘图的示例程序。
|
||||
|
||||
### 谢尔宾斯基三角形
|
||||
|
||||
简单展示一些curses函数的一个方法是生成谢尔宾斯基三角形。如果你对生成谢尔宾斯基三角形的这种方法不熟悉的话,这里是一些(产生谢尔宾斯基三角形的)规则:
|
||||
|
||||
1. 设置定义三角形的三个点。
|
||||
|
||||
2. 随机选择任意的一个点(x,y)。
|
||||
|
||||
然后:
|
||||
|
||||
1. 在三角形的顶点中随机选择一个点
|
||||
|
||||
2. 将新的x,y设置为先前的x,y和三角顶点的中间点。
|
||||
|
||||
3. 重复(上述步骤)。
|
||||
|
||||
所以我按照这些指令写了这个程序,程序使用curses函数来向终端屏幕绘制谢尔宾斯基三角形:
|
||||
|
||||
```
|
||||
|
||||
1 /* triangle.c */
|
||||
2
|
||||
3 #include <curses.h>
|
||||
4 #include <stdlib.h>
|
||||
5
|
||||
6 #include "getrandom_int.h"
|
||||
7
|
||||
8 #define ITERMAX 10000
|
||||
9
|
||||
10 int main(void)
|
||||
11 {
|
||||
12 long iter;
|
||||
13 int yi, xi;
|
||||
14 int y[3], x[3];
|
||||
15 int index;
|
||||
16 int maxlines, maxcols;
|
||||
17
|
||||
18 /* 初始化 curses */
|
||||
19
|
||||
20 initscr();
|
||||
21 cbreak();
|
||||
22 noecho();
|
||||
23
|
||||
24 clear();
|
||||
25
|
||||
26 /* 初始化三角形 */
|
||||
27
|
||||
28 maxlines = LINES - 1;
|
||||
29 maxcols = COLS - 1;
|
||||
30
|
||||
31 y[0] = 0;
|
||||
32 x[0] = 0;
|
||||
33
|
||||
34 y[1] = maxlines;
|
||||
35 x[1] = maxcols / 2;
|
||||
36
|
||||
37 y[2] = 0;
|
||||
38 x[2] = maxcols;
|
||||
39
|
||||
40 mvaddch(y[0], x[0], '0');
|
||||
41 mvaddch(y[1], x[1], '1');
|
||||
42 mvaddch(y[2], x[2], '2');
|
||||
43
|
||||
44 /* 将 yi,xi 初始化为随机值 */
|
||||
45
|
||||
46 yi = getrandom_int() % maxlines;
|
||||
47 xi = getrandom_int() % maxcols;
|
||||
48
|
||||
49 mvaddch(yi, xi, '.');
|
||||
50
|
||||
51 /* 迭代(形成)三角形 */
|
||||
52
|
||||
53 for (iter = 0; iter < ITERMAX; iter++) {
|
||||
54 index = getrandom_int() % 3;
|
||||
55
|
||||
56 yi = (yi + y[index]) / 2;
|
||||
57 xi = (xi + x[index]) / 2;
|
||||
58
|
||||
59 mvaddch(yi, xi, '*');
|
||||
60 refresh();
|
||||
61 }
|
||||
62
|
||||
63 /* 完成 */
|
||||
64
|
||||
65 mvaddstr(maxlines, 0, "Press any key to quit");
|
||||
66
|
||||
67 refresh();
|
||||
68
|
||||
69 getch();
|
||||
70 endwin();
|
||||
71
|
||||
72 exit(0);
|
||||
73 }
|
||||
|
||||
```
|
||||
|
||||
让我一边解释一边浏览这个程序。首先,getrandom_int()函数是我对Linux系统调用getrandom()的包装器。它保证返回一个正整数(int)值。(译者注:getrandom()系统按照字节返回随机值到一个变量中,值是随机的,不保证正负,使用stdlib.h的random()函数可以达到同样的效果) 另外,按照上面的规则,你应该能够辨认出初始化和迭代谢尔宾斯基三角形的代码。除此之外,我们来看看我用来在终端上绘制三角形的curses函数。
|
||||
|
||||
大多数curses程序以这四条指令开头。1)initscr()函数获取包括大小和特征在内的终端类型,并设置终端支持的curses环境。cbreak()函数禁用行缓冲并设置curses每次只接受一个字符。noecho()函数告诉curses不要把输入回显到屏幕上。而clear()函数清空了屏幕():
|
||||
|
||||
```
|
||||
|
||||
20 initscr();
|
||||
21 cbreak();
|
||||
22 noecho();
|
||||
23
|
||||
24 clear();
|
||||
|
||||
```
|
||||
|
||||
之后程序设置了三个定义三角的顶点。注意这里使用的LINES和COLS,它们是由initscr()来设置的。这些值告诉程序在终端的行数和列数。屏幕坐标从0开始,所以屏幕左上角是0行0列。屏幕右下角是LINES - 1行,COLS - 1列。为了便于记忆,我的程序里把这些值分别设为了变量maxlines和maxcols。
|
||||
|
||||
在屏幕上绘制文字的两个简单方法是addch()和addstr()函数。也可以使用相关的mvaddch()和mvaddstr()函数可以将字符放到一个特定的屏幕位置。我的程序在很多地方都用到了这些函数。首先程序绘制三个定义三角的点并标记为"0","1"和"2":
|
||||
|
||||
```
|
||||
|
||||
40 mvaddch(y[0], x[0], '0');
|
||||
41 mvaddch(y[1], x[1], '1');
|
||||
42 mvaddch(y[2], x[2], '2');
|
||||
|
||||
```
|
||||
|
||||
为了绘制任意的一个初始点,程序做了类似的一个调用:
|
||||
|
||||
```
|
||||
|
||||
49 mvaddch(yi, xi, '.');
|
||||
|
||||
```
|
||||
|
||||
还有为了在谢尔宾斯基三角形递归中绘制连续的点:
|
||||
|
||||
```
|
||||
|
||||
59 mvaddch(yi, xi, '*');
|
||||
|
||||
```
|
||||
|
||||
当程序完成之后,将会在屏幕左下角(在maxlines行,0列)显示一个帮助信息:
|
||||
|
||||
```
|
||||
|
||||
65 mvaddstr(maxlines, 0, "Press any key to quit");
|
||||
|
||||
```
|
||||
|
||||
注意curses在内存中维护了一个版本的屏幕并且只有在你要求的时候才会更新这个屏幕,这很重要。特别是当你想要向屏幕显示大量的文字的时候,这样(程序会有)更好的表现。这是因为curses只能更新在上次更新之后可以被改变的这部分屏幕。想要引得curses更新终端屏幕,请使用refresh()函数。
|
||||
|
||||
在我的示例程序中,我选择在"绘制"每个谢尔宾斯基三角形中的连续点时更新屏幕。通过这样做,用户可以观察三角形中的每次迭代。(译者注:迭代过程执行太快了,所以其实很难直接看到迭代过程)
|
||||
|
||||
在退出之前,我使用getch()函数等待用户按下一个键。然后我调用endwin()函数退出curses环境并返回终端程序到一般控制。
|
||||
|
||||
```
|
||||
|
||||
69 getch();
|
||||
70 endwin();
|
||||
|
||||
```
|
||||
|
||||
### 编译和示例输出
|
||||
|
||||
现在你已经有了你的第一个curses示例程序,是时候编译运行它了。记住Linux操作系统通过ncurses库来实现curses功能,所以你需要在编译的时候通过-lncurses来链接--例如:
|
||||
|
||||
```
|
||||
|
||||
$ ls
|
||||
getrandom_int.c getrandom_int.h triangle.c
|
||||
|
||||
$ gcc -Wall -lncurses -o triangle triangle.c getrandom_int.c
|
||||
|
||||
```
|
||||
|
||||
译注:此处命令行有问题,`-lncurses`选项在我的Ubuntu16.04系统+gcc 4.9.3 环境下,必须放在命令行最后,否则找不到库文件,链接时会出现未定义的引用。
|
||||
|
||||
在标准的80x24终端运行这个triangle程序并没什么意思。在那样的分辨率下你不能看见谢尔宾斯基三角形的很多细节。如果你运行终端窗口并设置非常小的字体大小,你可以更加容易地看到谢尔宾斯基三角形的不规则性质。在我的系统上,输出如图1。
|
||||
|
||||

|
||||
|
||||
图 1. triangle程序的输出
|
||||
|
||||
虽然迭代具有随机性,但是每次谢尔宾斯基三角形的运行看起来都会很一致。唯一的不同是最初绘制到屏幕的一些点。在这个例子中,你可以看到开创三角形的一个小圆点,在点1附近。看起来程序接下来选择了点2,然后你可以看到在圆点和"2"之间的星号。并且看起来程序随机选择了点2作为下一个随机数,因为你可以看到在第一个星号和"2"之间的星号。从这里开始,就不能继续分辨三角形是怎样被画出来的了,因为所有的连续点都属于三角形区域。
|
||||
|
||||
### 开始学习ncurses
|
||||
|
||||
这个程序是一个怎样使用curses函数绘制字符到屏幕的简单例子。按照你的程序的需要,你可以通过curses做得更多。在下一篇文章中,我将会展示怎样使用curses让用户和屏幕交互。如果你对于在curses有一个良好开端有兴趣,我支持你去读位于Linux文档中Pradeep Padala的 ["NCURSES Programming HOWTO"][2]
|
||||
|
||||
### 关于作者
|
||||
|
||||
Jim Hall是一个免费和开源软件的倡议者,他最有名的工作是FreeDOS计划,也同样致力于开源软件的可用性。Jim是在明尼苏达州的拉姆齐县的首席资讯长。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/getting-started-ncurses
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
译者:[leemeans](https://github.com/leemeans)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/users/jim-hall
|
||||
[1]:http://www.linuxjournal.com/article/1124
|
||||
[2]:http://tldp.org/HOWTO/NCURSES-Programming-HOWTO
|
||||
@ -1,59 +0,0 @@
|
||||
哪个 Linux 内核版本是 “稳定的”?
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
Konstantin Ryabitsev 为你讲解哪个 Linux 内核版本将被考虑作为“稳定版”,以及你如何选择一个适用你的内核版本。[Creative Commons Zero][1]
|
||||
|
||||
每次 Linus Torvalds 发布 [一个新 Linux 内核的主线版本][4],几乎都会引起这种困惑,那就是到底哪个内核版本才是最新的“稳定版”?是新的那个 X.Y,还是前面的那个 X.Y-1.Z ?最新的内核版本是不是太“新”了?你是不是应该坚持使用以前的版本?
|
||||
|
||||
[kernel.org][5] 网页上的信息并不会帮你解开这个困惑。目前,在页面的最顶部,我们看到是最新稳定版内核是 4.15 — 但是在这个表格的下面,4.14.16 也被列为“稳定版”,而 4.15 被列为“主线版本”,很困惑,是吧?
|
||||
|
||||
不幸的是,这个问题并不好回答。我们在这里使用“稳定”这个词有两个不同的意思:一是,作为最初发布的 Git 树的名字,二是,表示这个内核已经被考虑为“稳定版”,可以作为“生产系统”使用了。
|
||||
|
||||
由于 Git 的分布式特性,Linux 的开发工作在许多 [不同的 fork 仓库中][6] 进行。所有的 bug 修复和新特性也是由子系统维护者首次收集和准备的,然后提交给 Linus Torvalds,由 Linus Torvalds 包含进 [他的 Linux 树][7] 中,它的 Git 树被认为是 Git 仓库的 “master”。我们称这个树为 ”主线" Linux 树。
|
||||
|
||||
### 候选发布版
|
||||
|
||||
在每个新的内核版本发布之前,它都要经过几轮的“候选发布”,它由开发者进行测试并“打磨”所有的这些很酷的新特性。基于他们这几轮测试的反馈,Linus 决定最终版本是否准备就绪。通常每周发布一个候选版本,但是,这个数字经常走到 -rc8,并且有时候甚至达到 -rc9 及以上。当 Linus 确信那个新内核已经没有问题了,他就制作最终发行版,我们称这个版本为“稳定版”,表示它不再是一个“候选发布版”。
|
||||
|
||||
### Bug 修复
|
||||
|
||||
就像任何一个由不是十全十美的人所写的复杂软件一样,任何一个 Linux 内核的新版本都包含 bug,并且这些 bug 必须被修复。Linux 内核的 bug 修复规则是非常简单的:所有修复必须首先进入到 Linus 的树。一旦在主线仓库中 bug 被修复后,它接着会被应用到由内核开发社区仍然在维护的已发布的内核中。在它们被考虑回迁到已发布的稳定版本之前,所有的 bug 修复必须满足 [一套重要的标准][8] — 标准的其中之一是,它们 “必须已经存在于 Linus 的树中”。这是一个 [独立的 Git 仓库][9],维护它的用途是回迁 bug 修复,而它也被称为“稳定”树 — 因为它用于跟踪以前发布的稳定内核。这个树由 Greg Kroah-Hartman 策划和维护。
|
||||
|
||||
### 最新的稳定内核
|
||||
|
||||
因此,无论在什么时候,为了查看最新的稳定内核而访问 kernel.org 网站时,你应该去使用那个在大黄色按钮所说的“最新的稳定内核”。
|
||||
|
||||

|
||||
|
||||
但是,你可能会惊奇地发现 -- 4.15 和 4.14.16 都是稳定版本,那么到底哪一个更“稳定”呢?有些人不愿意使用 ".0" 的内核发行版,因为他们认为这个版本并不足够“稳定”,直到最新的是 ".1" 的为止。很难证明或者反驳这种观点的对与错,并且这两种观点都有赞成或者反对的理由,因此,具体选择哪一个取决于你的喜好。
|
||||
|
||||
一方面,任何一个进入到稳定树的发行版都必须首先被接受进入主线内核版本中,并且随后会被回迁到已发行版本中。这意味着内核的主线版本相比稳定树中的发行版本来说,总包含有最新的 bug 修复,因此,如果你想使用的发行版包含的“**已知 bug**”最少,那么使用 “.0” 的主线发行版是最佳选择。
|
||||
|
||||
另一方面,主线版本增加了所有很酷的新特性 — 而新特性也给它们带来了**数量未知的“新 bug”**,而这些“新 bug”在老的稳定版中是**不会存在**的。而新的、未知的 bug 是否比旧的、已知的但尚未修复的 bug 更加令人担心呢? -- 这取决于你的选择。不过需要说明的一点是,许多 bug 修复仅对内核的主线版本进行了彻底的测试。当补丁回迁到旧内核时,它们**可能**会工作的很好,但是它们**很少**做与旧内核的集成测试工作。通常都假定,“以前的稳定版本”足够接近当前的确信可用于生产系统的主线版本。而实际上也确实是这样做的,当然,这也更加说明了为什么选择”哪个内核版本更稳定“是件**非常困难**的事情了。
|
||||
|
||||
因此,从根本上说,我们并没有定量的或者定性的手段去明确的告诉你哪个内核版本更加稳定 -- 4.15 还是 4.14.16?我们能够做到的只是告诉你,它们具有”**不同的**稳定性“,(这个答案可能没有帮到你,但是,至少你明白了这些版本的差别是什么?)。
|
||||
|
||||
_学习更多的 Linux 的知识,可以通过来自 Linux 基金会和 edX 的免费课程 ["认识 Linux" ][3]。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2018/2/which-linux-kernel-version-stable
|
||||
|
||||
作者:[KONSTANTIN RYABITSEV ][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/apple1jpg
|
||||
[3]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[4]:https://www.linux.com/blog/intro-to-linux/2018/1/linux-kernel-415-unusual-release-cycle
|
||||
[5]:https://www.kernel.org/
|
||||
[6]:https://git.kernel.org/pub/scm/linux/kernel/git/
|
||||
[7]:https://git.kernel.org/torvalds/c/v4.15
|
||||
[8]:https://www.kernel.org/doc/html/latest/process/stable-kernel-rules.html
|
||||
[9]:https://git.kernel.org/stable/linux-stable/c/v4.14.16
|
||||
Loading…
Reference in New Issue
Block a user