mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
commit
f51b24dae9
published
20170410 Writing a Time Series Database from Scratch.md20170414 5 projects for Raspberry Pi at home.md20180324 Memories of writing a parser for man pages.md20180416 How To Resize Active-Primary root Partition Using GParted Utility.md20180604 BootISO - A Simple Bash Script To Securely Create A Bootable USB Device From ISO File.md20180831 Get desktop notifications from Emacs shell commands .md20180914 A day in the life of a log message.md20190109 GoAccess - A Real-Time Web Server Log Analyzer And Interactive Viewer.md20190308 Blockchain 2.0 - Explaining Smart Contracts And Its Types -Part 5.md20190331 How to build a mobile particulate matter sensor with a Raspberry Pi.md20190404 Running LEDs in reverse could cool computers.md20190409 5 Linux rookie mistakes.md20190410 How we built a Linux desktop app with Electron.md20190423 Epic Games Store is Now Available on Linux Thanks to Lutris.md20190423 How to identify same-content files on Linux.md20190509 5 essential values for the DevOps mindset.md20190517 10 Places Where You Can Buy Linux Computers.md20190517 Using Testinfra with Ansible to verify server state.md20190520 Getting Started With Docker.md20190520 When IoT systems fail- The risk of having bad IoT data.md20190522 Securing telnet connections with stunnel.md20190525 4 Ways to Run Linux Commands in Windows.md20190527 5 GNOME keyboard shortcuts to be more productive.md20190527 A deeper dive into Linux permissions.md20190527 How To Check Available Security Updates On Red Hat (RHEL) And CentOS System.md20190527 How to write a good C main function.md20190529 NVMe on Linux.md20190531 Unity Editor is Now Officially Available for Linux.md20190531 Why translation platforms matter.md20190604 How To Verify NTP Setup (Sync) is Working or Not In Linux.md20190604 Two Methods To Check Or List Installed Security Updates on Redhat (RHEL) And CentOS System.md20190606 How Linux can help with your spelling.md20190607 5 reasons to use Kubernetes.md20190608 An open source bionic leg, Python data pipeline, data breach detection, and more news.md20190610 Expand And Unexpand Commands Tutorial With Examples.md20190610 Graviton- A Minimalist Open Source Code Editor.md20190610 Neofetch - Display Linux system Information In Terminal.md20190610 Screen Command Examples To Manage Multiple Terminal Sessions.md20190610 Search Linux Applications On AppImage, Flathub And Snapcraft Platforms.md20190610 Try a new game on Free RPG Day.md20190610 Welcoming Blockchain 3.0.md20190613 Ubuntu Kylin- The Official Chinese Version of Ubuntu.md
scripts/check
sources
news
20190606 Cisco to buy IoT security, management firm Sentryo.md20190606 Zorin OS Becomes Even More Awesome With Zorin 15 Release.md20190607 Free and Open Source Trello Alternative OpenProject 9 Released.md
talk
20170320 An Ubuntu User-s Review Of Dell XPS 13 Ubuntu Edition.md20171222 18 Cyber-Security Trends Organizations Need to Brace for in 2018.md20180209 A review of Virtual Labs virtualization solutions for MOOCs - WebLog Pro Olivier Berger.md20180705 New Training Options Address Demand for Blockchain Skills.md20180802 How blockchain will influence open source.md20180816 Debian Turns 25- Here are Some Interesting Facts About Debian Linux.md20181004 Interview With Peter Ganten, CEO of Univention GmbH.md20190228 Why CLAs aren-t good for open source.md20190311 Discuss everything Fedora.md20190322 How to save time with TiDB.md20190410 Google partners with Intel, HPE and Lenovo for hybrid cloud.md20190410 HPE and Nutanix partner for hyperconverged private cloud systems.md20190418 Cisco warns WLAN controller, 9000 series router and IOS-XE users to patch urgent security holes.md20190418 Fujitsu completes design of exascale supercomputer, promises to productize it.md20190419 Intel follows AMD-s lead (again) into single-socket Xeon servers.md20190424 IoT roundup- VMware, Nokia beef up their IoT.md20190425 Dell EMC and Cisco renew converged infrastructure alliance.md20190429 Venerable Cisco Catalyst 6000 switches ousted by new Catalyst 9600.md20190520 When IoT systems fail- The risk of having bad IoT data.md20190528 Managed WAN and the cloud-native SD-WAN.md20190528 Moving to the Cloud- SD-WAN Matters.md20190528 With Cray buy, HPE rules but does not own the supercomputing market.md20190529 Cisco security spotlights Microsoft Office 365 e-mail phishing increase.md20190529 Nvidia launches edge computing platform for AI processing.md20190529 Satellite-based internet possible by year-end, says SpaceX.md20190529 Survey finds SD-WANs are hot, but satisfaction with telcos is not.md20190601 HPE Synergy For Dummies.md20190601 True Hyperconvergence at Scale- HPE Simplivity With Composable Fabric.md20190602 IoT Roundup- New research on IoT security, Microsoft leans into IoT.md20190603 It-s time for the IoT to -optimize for trust.md20190604 5G will augment Wi-Fi, not replace it.md20190604 Data center workloads become more complex despite promises to the contrary.md20190604 Moving to the Cloud- SD-WAN Matters- Part 2.md20190605 Cisco will use AI-ML to boost intent-based networking.md20190606 Cloud adoption drives the evolution of application delivery controllers.md20190606 For enterprise storage, persistent memory is here to stay.md20190606 Juniper- Security could help drive interest in SDN.md20190606 Self-learning sensor chips won-t need networks.md20190606 What to do when yesterday-s technology won-t meet today-s support needs.md20190611 6 ways to make enterprise IoT cost effective.md20190611 Cisco launches a developer-community cert program.md20190611 The carbon footprints of IT shops that train AI models are huge.md20190612 Cisco offers cloud-based security for SD-WAN resources.md20190612 Dell and Cisco extend VxBlock integration with new features.md20190612 IoT security vs. privacy- Which is a bigger issue.md20190612 Software Defined Perimeter (SDP)- Creating a new network perimeter.md20190612 When to use 5G, when to use Wi-Fi 6.md20190613 Data centers should sell spare UPS capacity to the grid.md20190613 Oracle updates Exadata at long last with AI and machine learning abilities.md20190614 Report- Mirai tries to hook its tentacles into SD-WAN.md20190614 Western Digital launches open-source zettabyte storage initiative.md20190617 5 transferable higher-education skills.md20190617 Use ImageGlass to quickly view JPG images as a slideshow.md20190619 Cisco connects with IBM in to simplify hybrid cloud deployment.md
@ -0,0 +1,484 @@
|
||||
从零写一个时间序列数据库
|
||||
==================
|
||||
|
||||
编者按:Prometheus 是 CNCF 旗下的开源监控告警解决方案,它已经成为 Kubernetes 生态圈中的核心监控系统。本文作者 Fabian Reinartz 是 Prometheus 的核心开发者,这篇文章是其于 2017 年写的一篇关于 Prometheus 中的时间序列数据库的设计思考,虽然写作时间有点久了,但是其中的考虑和思路非常值得参考。长文预警,请坐下来慢慢品味。
|
||||
|
||||
---
|
||||
|
||||

|
||||
|
||||
我从事监控工作。特别是在 [Prometheus][2] 上,监控系统包含一个自定义的时间序列数据库,并且集成在 [Kubernetes][3] 上。
|
||||
|
||||
在许多方面上 Kubernetes 展现出了 Prometheus 所有的设计用途。它使得<ruby>持续部署<rt>continuous deployments</rt></ruby>,<ruby>弹性伸缩<rt>auto scaling</rt></ruby>和其他<ruby>高动态环境<rt>highly dynamic environments</rt></ruby>下的功能可以轻易地访问。查询语句和操作模型以及其它概念决策使得 Prometheus 特别适合这种环境。但是,如果监控的工作负载动态程度显著地增加,这就会给监控系统本身带来新的压力。考虑到这一点,我们就可以特别致力于在高动态或<ruby>瞬态服务<rt>transient services</rt></ruby>环境下提升它的表现,而不是回过头来解决 Prometheus 已经解决的很好的问题。
|
||||
|
||||
Prometheus 的存储层在历史以来都展现出卓越的性能,单一服务器就能够以每秒数百万个时间序列的速度摄入多达一百万个样本,同时只占用了很少的磁盘空间。尽管当前的存储做的很好,但我依旧提出一个新设计的存储子系统,它可以修正现存解决方案的缺点,并具备处理更大规模数据的能力。
|
||||
|
||||
> 备注:我没有数据库方面的背景。我说的东西可能是错的并让你误入歧途。你可以在 Freenode 的 #prometheus 频道上对我(fabxc)提出你的批评。
|
||||
|
||||
## 问题,难题,问题域
|
||||
|
||||
首先,快速地概览一下我们要完成的东西和它的关键难题。我们可以先看一下 Prometheus 当前的做法 ,它为什么做的这么好,以及我们打算用新设计解决哪些问题。
|
||||
|
||||
### 时间序列数据
|
||||
|
||||
我们有一个收集一段时间数据的系统。
|
||||
|
||||
```
|
||||
identifier -> (t0, v0), (t1, v1), (t2, v2), (t3, v3), ....
|
||||
```
|
||||
|
||||
每个数据点是一个时间戳和值的元组。在监控中,时间戳是一个整数,值可以是任意数字。64 位浮点数对于计数器和测量值来说是一个好的表示方法,因此我们将会使用它。一系列严格单调递增的时间戳数据点是一个序列,它由标识符所引用。我们的标识符是一个带有<ruby>标签维度<rt>label dimensions</rt></ruby>字典的度量名称。标签维度划分了单一指标的测量空间。每一个指标名称加上一个唯一标签集就成了它自己的时间序列,它有一个与之关联的<ruby>数据流<rt>value stream</rt></ruby>。
|
||||
|
||||
这是一个典型的<ruby>序列标识符<rt>series identifier</rt></ruby>集,它是统计请求指标的一部分:
|
||||
|
||||
```
|
||||
requests_total{path="/status", method="GET", instance=”10.0.0.1:80”}
|
||||
requests_total{path="/status", method="POST", instance=”10.0.0.3:80”}
|
||||
requests_total{path="/", method="GET", instance=”10.0.0.2:80”}
|
||||
```
|
||||
|
||||
让我们简化一下表示方法:度量名称可以当作另一个维度标签,在我们的例子中是 `__name__`。对于查询语句,可以对它进行特殊处理,但与我们存储的方式无关,我们后面也会见到。
|
||||
|
||||
```
|
||||
{__name__="requests_total", path="/status", method="GET", instance=”10.0.0.1:80”}
|
||||
{__name__="requests_total", path="/status", method="POST", instance=”10.0.0.3:80”}
|
||||
{__name__="requests_total", path="/", method="GET", instance=”10.0.0.2:80”}
|
||||
```
|
||||
|
||||
我们想通过标签来查询时间序列数据。在最简单的情况下,使用 `{__name__="requests_total"}` 选择所有属于 `requests_total` 指标的数据。对于所有选择的序列,我们在给定的时间窗口内获取数据点。
|
||||
|
||||
在更复杂的语句中,我们或许想一次性选择满足多个标签的序列,并且表示比相等条件更复杂的情况。例如,非语句(`method!="GET"`)或正则表达式匹配(`method=~"PUT|POST"`)。
|
||||
|
||||
这些在很大程度上定义了存储的数据和它的获取方式。
|
||||
|
||||
### 纵与横
|
||||
|
||||
在简化的视图中,所有的数据点可以分布在二维平面上。水平维度代表着时间,序列标识符域经纵轴展开。
|
||||
|
||||
```
|
||||
series
|
||||
^
|
||||
| . . . . . . . . . . . . . . . . . . . . . . {__name__="request_total", method="GET"}
|
||||
| . . . . . . . . . . . . . . . . . . . . . . {__name__="request_total", method="POST"}
|
||||
| . . . . . . .
|
||||
| . . . . . . . . . . . . . . . . . . . ...
|
||||
| . . . . . . . . . . . . . . . . . . . . .
|
||||
| . . . . . . . . . . . . . . . . . . . . . {__name__="errors_total", method="POST"}
|
||||
| . . . . . . . . . . . . . . . . . {__name__="errors_total", method="GET"}
|
||||
| . . . . . . . . . . . . . .
|
||||
| . . . . . . . . . . . . . . . . . . . ...
|
||||
| . . . . . . . . . . . . . . . . . . . .
|
||||
v
|
||||
<-------------------- time --------------------->
|
||||
```
|
||||
|
||||
Prometheus 通过定期地抓取一组时间序列的当前值来获取数据点。我们从中获取到的实体称为目标。因此,写入模式完全地垂直且高度并发,因为来自每个目标的样本是独立摄入的。
|
||||
|
||||
这里提供一些测量的规模:单一 Prometheus 实例从数万个目标中收集数据点,每个数据点都暴露在数百到数千个不同的时间序列中。
|
||||
|
||||
在每秒采集数百万数据点这种规模下,批量写入是一个不能妥协的性能要求。在磁盘上分散地写入单个数据点会相当地缓慢。因此,我们想要按顺序写入更大的数据块。
|
||||
|
||||
对于旋转式磁盘,它的磁头始终得在物理上向不同的扇区上移动,这是一个不足为奇的事实。而虽然我们都知道 SSD 具有快速随机写入的特点,但事实上它不能修改单个字节,只能写入一页或更多页的 4KiB 数据量。这就意味着写入 16 字节的样本相当于写入满满一个 4Kib 的页。这一行为就是所谓的[写入放大][4],这种特性会损耗你的 SSD。因此它不仅影响速度,而且还毫不夸张地在几天或几个周内破坏掉你的硬件。
|
||||
|
||||
关于此问题更深层次的资料,[“Coding for SSDs”系列][5]博客是极好的资源。让我们想想主要的用处:顺序写入和批量写入分别对于旋转式磁盘和 SSD 来说都是理想的写入模式。大道至简。
|
||||
|
||||
查询模式比起写入模式明显更不同。我们可以查询单一序列的一个数据点,也可以对 10000 个序列查询一个数据点,还可以查询一个序列几个周的数据点,甚至是 10000 个序列几个周的数据点。因此在我们的二维平面上,查询范围不是完全水平或垂直的,而是二者形成矩形似的组合。
|
||||
|
||||
[记录规则][6]可以减轻已知查询的问题,但对于<ruby>点对点<rt>ad-hoc</rt></ruby>查询来说并不是一个通用的解决方法。
|
||||
|
||||
我们知道我们想要批量地写入,但我们得到的仅仅是一系列垂直数据点的集合。当查询一段时间窗口内的数据点时,我们不仅很难弄清楚在哪才能找到这些单独的点,而且不得不从磁盘上大量随机的地方读取。也许一条查询语句会有数百万的样本,即使在最快的 SSD 上也会很慢。读入也会从磁盘上获取更多的数据而不仅仅是 16 字节的样本。SSD 会加载一整页,HDD 至少会读取整个扇区。不论哪一种,我们都在浪费宝贵的读取吞吐量。
|
||||
|
||||
因此在理想情况下,同一序列的样本将按顺序存储,这样我们就能通过尽可能少的读取来扫描它们。最重要的是,我们仅需要知道序列的起始位置就能访问所有的数据点。
|
||||
|
||||
显然,将收集到的数据写入磁盘的理想模式与能够显著提高查询效率的布局之间存在着明显的抵触。这是我们 TSDB 需要解决的一个基本问题。
|
||||
|
||||
#### 当前的解决方法
|
||||
|
||||
是时候看一下当前 Prometheus 是如何存储数据来解决这一问题的,让我们称它为“V2”。
|
||||
|
||||
我们创建一个时间序列的文件,它包含所有样本并按顺序存储。因为每几秒附加一个样本数据到所有文件中非常昂贵,我们在内存中打包 1Kib 样本序列的数据块,一旦打包完成就附加这些数据块到单独的文件中。这一方法解决了大部分问题。写入目前是批量的,样本也是按顺序存储的。基于给定的同一序列的样本相对之前的数据仅发生非常小的改变这一特性,它还支持非常高效的压缩格式。Facebook 在他们 Gorilla TSDB 上的论文中描述了一个相似的基于数据块的方法,并且[引入了一种压缩格式][7],它能够减少 16 字节的样本到平均 1.37 字节。V2 存储使用了包含 Gorilla 变体等在内的各种压缩格式。
|
||||
|
||||
```
|
||||
+----------+---------+---------+---------+---------+ series A
|
||||
+----------+---------+---------+---------+---------+
|
||||
+----------+---------+---------+---------+---------+ series B
|
||||
+----------+---------+---------+---------+---------+
|
||||
. . .
|
||||
+----------+---------+---------+---------+---------+---------+ series XYZ
|
||||
+----------+---------+---------+---------+---------+---------+
|
||||
chunk 1 chunk 2 chunk 3 ...
|
||||
```
|
||||
|
||||
尽管基于块存储的方法非常棒,但为每个序列保存一个独立的文件会给 V2 存储带来麻烦,因为:
|
||||
|
||||
* 实际上,我们需要的文件比当前收集数据的时间序列数量要多得多。多出的部分在<ruby>序列分流<rt>Series Churn</rt></ruby>上。有几百万个文件,迟早会使用光文件系统中的 [inode][1]。这种情况我们只能通过重新格式化来恢复磁盘,这种方式是最具有破坏性的。我们通常不想为了适应一个应用程序而格式化磁盘。
|
||||
* 即使是分块写入,每秒也会产生数千块的数据块并且准备持久化。这依然需要每秒数千次的磁盘写入。尽管通过为每个序列打包好多个块来缓解,但这反过来还是增加了等待持久化数据的总内存占用。
|
||||
* 要保持所有文件打开来进行读写是不可行的。特别是因为 99% 的数据在 24 小时之后不再会被查询到。如果查询它,我们就得打开数千个文件,找到并读取相关的数据点到内存中,然后再关掉。这样做就会引起很高的查询延迟,数据块缓存加剧会导致新的问题,这一点在“资源消耗”一节另作讲述。
|
||||
* 最终,旧的数据需要被删除,并且数据需要从数百万文件的头部删除。这就意味着删除实际上是写密集型操作。此外,循环遍历数百万文件并且进行分析通常会导致这一过程花费数小时。当它完成时,可能又得重新来过。喔天,继续删除旧文件又会进一步导致 SSD 产生写入放大。
|
||||
* 目前所积累的数据块仅维持在内存中。如果应用崩溃,数据就会丢失。为了避免这种情况,内存状态会定期的保存在磁盘上,这比我们能接受数据丢失窗口要长的多。恢复检查点也会花费数分钟,导致很长的重启周期。
|
||||
|
||||
我们能够从现有的设计中学到的关键部分是数据块的概念,我们当然希望保留这个概念。最新的数据块会保持在内存中一般也是好的主意。毕竟,最新的数据会大量的查询到。
|
||||
|
||||
一个时间序列对应一个文件,这个概念是我们想要替换掉的。
|
||||
|
||||
### 序列分流
|
||||
|
||||
在 Prometheus 的<ruby>上下文<rt>context</rt></ruby>中,我们使用术语<ruby>序列分流<rt>series churn</rt></ruby>来描述一个时间序列集合变得不活跃,即不再接收数据点,取而代之的是出现一组新的活跃序列。
|
||||
|
||||
例如,由给定微服务实例产生的所有序列都有一个相应的“instance”标签来标识其来源。如果我们为微服务执行了<ruby>滚动更新<rt>rolling update</rt></ruby>,并且为每个实例替换一个新的版本,序列分流便会发生。在更加动态的环境中,这些事情基本上每小时都会发生。像 Kubernetes 这样的<ruby>集群编排<rt>Cluster orchestration</rt></ruby>系统允许应用连续性的自动伸缩和频繁的滚动更新,这样也许会创建成千上万个新的应用程序实例,并且伴随着全新的时间序列集合,每天都是如此。
|
||||
|
||||
```
|
||||
series
|
||||
^
|
||||
| . . . . . .
|
||||
| . . . . . .
|
||||
| . . . . . .
|
||||
| . . . . . . .
|
||||
| . . . . . . .
|
||||
| . . . . . . .
|
||||
| . . . . . .
|
||||
| . . . . . .
|
||||
| . . . . .
|
||||
| . . . . .
|
||||
| . . . . .
|
||||
v
|
||||
<-------------------- time --------------------->
|
||||
```
|
||||
|
||||
所以即便整个基础设施的规模基本保持不变,过一段时间后数据库内的时间序列还是会成线性增长。尽管 Prometheus 很愿意采集 1000 万个时间序列数据,但要想在 10 亿个序列中找到数据,查询效果还是会受到严重的影响。
|
||||
|
||||
#### 当前解决方案
|
||||
|
||||
当前 Prometheus 的 V2 存储系统对所有当前保存的序列拥有基于 LevelDB 的索引。它允许查询语句含有给定的<ruby>标签对<rt>label pair</rt></ruby>,但是缺乏可伸缩的方法来从不同的标签选集中组合查询结果。
|
||||
|
||||
例如,从所有的序列中选择标签 `__name__="requests_total"` 非常高效,但是选择 `instance="A" AND __name__="requests_total"` 就有了可伸缩性的问题。我们稍后会重新考虑导致这一点的原因和能够提升查找延迟的调整方法。
|
||||
|
||||
事实上正是这个问题才催生出了对更好的存储系统的最初探索。Prometheus 需要为查找亿万个时间序列改进索引方法。
|
||||
|
||||
### 资源消耗
|
||||
|
||||
当试图扩展 Prometheus(或其他任何事情,真的)时,资源消耗是永恒不变的话题之一。但真正困扰用户的并不是对资源的绝对渴求。事实上,由于给定的需求,Prometheus 管理着令人难以置信的吞吐量。问题更在于面对变化时的相对未知性与不稳定性。通过其架构设计,V2 存储系统缓慢地构建了样本数据块,这一点导致内存占用随时间递增。当数据块完成之后,它们可以写到磁盘上并从内存中清除。最终,Prometheus 的内存使用到达稳定状态。直到监测环境发生了改变——每次我们扩展应用或者进行滚动更新,序列分流都会增加内存、CPU、磁盘 I/O 的使用。
|
||||
|
||||
如果变更正在进行,那么它最终还是会到达一个稳定的状态,但比起更加静态的环境,它的资源消耗会显著地提高。过渡时间通常为数个小时,而且难以确定最大资源使用量。
|
||||
|
||||
为每个时间序列保存一个文件这种方法也使得一个单个查询就很容易崩溃 Prometheus 进程。当查询的数据没有缓存在内存中,查询的序列文件就会被打开,然后将含有相关数据点的数据块读入内存。如果数据量超出内存可用量,Prometheus 就会因 OOM 被杀死而退出。
|
||||
|
||||
在查询语句完成之后,加载的数据便可以被再次释放掉,但通常会缓存更长的时间,以便更快地查询相同的数据。后者看起来是件不错的事情。
|
||||
|
||||
最后,我们看看之前提到的 SSD 的写入放大,以及 Prometheus 是如何通过批量写入来解决这个问题的。尽管如此,在许多地方还是存在因为批量太小以及数据未精确对齐页边界而导致的写入放大。对于更大规模的 Prometheus 服务器,现实当中会发现缩减硬件寿命的问题。这一点对于高写入吞吐量的数据库应用来说仍然相当普遍,但我们应该放眼看看是否可以解决它。
|
||||
|
||||
### 重新开始
|
||||
|
||||
到目前为止我们对于问题域、V2 存储系统是如何解决它的,以及设计上存在的问题有了一个清晰的认识。我们也看到了许多很棒的想法,这些或多或少都可以拿来直接使用。V2 存储系统相当数量的问题都可以通过改进和部分的重新设计来解决,但为了好玩(当然,在我仔细的验证想法之后),我决定试着写一个完整的时间序列数据库——从头开始,即向文件系统写入字节。
|
||||
|
||||
性能与资源使用这种最关键的部分直接影响了存储格式的选取。我们需要为数据找到正确的算法和磁盘布局来实现一个高性能的存储层。
|
||||
|
||||
这就是我解决问题的捷径——跳过令人头疼、失败的想法,数不尽的草图,泪水与绝望。
|
||||
|
||||
### V3—宏观设计
|
||||
|
||||
我们存储系统的宏观布局是什么?简而言之,是当我们在数据文件夹里运行 `tree` 命令时显示的一切。看看它能给我们带来怎样一副惊喜的画面。
|
||||
|
||||
```
|
||||
$ tree ./data
|
||||
./data
|
||||
+-- b-000001
|
||||
| +-- chunks
|
||||
| | +-- 000001
|
||||
| | +-- 000002
|
||||
| | +-- 000003
|
||||
| +-- index
|
||||
| +-- meta.json
|
||||
+-- b-000004
|
||||
| +-- chunks
|
||||
| | +-- 000001
|
||||
| +-- index
|
||||
| +-- meta.json
|
||||
+-- b-000005
|
||||
| +-- chunks
|
||||
| | +-- 000001
|
||||
| +-- index
|
||||
| +-- meta.json
|
||||
+-- b-000006
|
||||
+-- meta.json
|
||||
+-- wal
|
||||
+-- 000001
|
||||
+-- 000002
|
||||
+-- 000003
|
||||
```
|
||||
|
||||
在最顶层,我们有一系列以 `b-` 为前缀编号的<ruby>块<rt>block</rt></ruby>。每个块中显然保存了索引文件和含有更多编号文件的 `chunk` 文件夹。`chunks` 目录只包含不同序列<ruby>数据点的原始块<rt>raw chunks of data points</rt><ruby>。与 V2 存储系统一样,这使得通过时间窗口读取序列数据非常高效并且允许我们使用相同的有效压缩算法。这一点被证实行之有效,我们也打算沿用。显然,这里并不存在含有单个序列的文件,而是一堆保存着许多序列的数据块。
|
||||
|
||||
`index` 文件的存在应该不足为奇。让我们假设它拥有黑魔法,可以让我们找到标签、可能的值、整个时间序列和存放数据点的数据块。
|
||||
|
||||
但为什么这里有好几个文件夹都是索引和块文件的布局?并且为什么存在最后一个包含 `wal` 文件夹?理解这两个疑问便能解决九成的问题。
|
||||
|
||||
#### 许多小型数据库
|
||||
|
||||
我们分割横轴,即将时间域分割为不重叠的块。每一块扮演着完全独立的数据库,它包含该时间窗口所有的时间序列数据。因此,它拥有自己的索引和一系列块文件。
|
||||
|
||||
```
|
||||
|
||||
t0 t1 t2 t3 now
|
||||
+-----------+ +-----------+ +-----------+ +-----------+
|
||||
| | | | | | | | +------------+
|
||||
| | | | | | | mutable | <--- write ---- ┤ Prometheus |
|
||||
| | | | | | | | +------------+
|
||||
+-----------+ +-----------+ +-----------+ +-----------+ ^
|
||||
+--------------+-------+------+--------------+ |
|
||||
| query
|
||||
| |
|
||||
merge -------------------------------------------------+
|
||||
```
|
||||
|
||||
每一块的数据都是<ruby>不可变的<rt>immutable</rt></ruby>。当然,当我们采集新数据时,我们必须能向最近的块中添加新的序列和样本。对于该数据块,所有新的数据都将写入内存中的数据库中,它与我们的持久化的数据块一样提供了查找属性。内存中的数据结构可以高效地更新。为了防止数据丢失,所有传入的数据同样被写入临时的<ruby>预写日志<rt>write ahead log</rt></ruby>中,这就是 `wal` 文件夹中的一些列文件,我们可以在重新启动时通过它们重新填充内存数据库。
|
||||
|
||||
所有这些文件都带有序列化格式,有我们所期望的所有东西:许多标志、偏移量、变体和 CRC32 校验和。纸上得来终觉浅,绝知此事要躬行。
|
||||
|
||||
这种布局允许我们扩展查询范围到所有相关的块上。每个块上的部分结果最终合并成完整的结果。
|
||||
|
||||
这种横向分割增加了一些很棒的功能:
|
||||
|
||||
* 当查询一个时间范围,我们可以简单地忽略所有范围之外的数据块。通过减少需要检查的数据集,它可以初步解决序列分流的问题。
|
||||
* 当完成一个块,我们可以通过顺序的写入大文件从内存数据库中保存数据。这样可以避免任何的写入放大,并且 SSD 与 HDD 均适用。
|
||||
* 我们延续了 V2 存储系统的一个好的特性,最近使用而被多次查询的数据块,总是保留在内存中。
|
||||
* 很好,我们也不再受限于 1KiB 的数据块尺寸,以使数据在磁盘上更好地对齐。我们可以挑选对单个数据点和压缩格式最合理的尺寸。
|
||||
* 删除旧数据变得极为简单快捷。我们仅仅只需删除一个文件夹。记住,在旧的存储系统中我们不得不花数个小时分析并重写数亿个文件。
|
||||
|
||||
每个块还包含了 `meta.json` 文件。它简单地保存了关于块的存储状态和包含的数据,以便轻松了解存储状态及其包含的数据。
|
||||
|
||||
##### mmap
|
||||
|
||||
将数百万个小文件合并为少数几个大文件使得我们用很小的开销就能保持所有的文件都打开。这就解除了对 [mmap(2)][8] 的使用的阻碍,这是一个允许我们通过文件透明地回传虚拟内存的系统调用。简单起见,你可以将其视为<ruby>交换空间<rt>swap space</rt></ruby>,只是我们所有的数据已经保存在了磁盘上,并且当数据换出内存后不再会发生写入。
|
||||
|
||||
这意味着我们可以当作所有数据库的内容都视为在内存中却不占用任何物理内存。仅当我们访问数据库文件某些字节范围时,操作系统才会从磁盘上<ruby>惰性加载<rt>lazy load</rt></ruby>页数据。这使得我们将所有数据持久化相关的内存管理都交给了操作系统。通常,操作系统更有资格作出这样的决定,因为它可以全面了解整个机器和进程。查询的数据可以相当积极的缓存进内存,但内存压力会使得页被换出。如果机器拥有未使用的内存,Prometheus 目前将会高兴地缓存整个数据库,但是一旦其他进程需要,它就会立刻返回那些内存。
|
||||
|
||||
因此,查询不再轻易地使我们的进程 OOM,因为查询的是更多的持久化的数据而不是装入内存中的数据。内存缓存大小变得完全自适应,并且仅当查询真正需要时数据才会被加载。
|
||||
|
||||
就个人理解,这就是当今大多数数据库的工作方式,如果磁盘格式允许,这是一种理想的方式,——除非有人自信能在这个过程中超越操作系统。我们做了很少的工作但确实从外面获得了很多功能。
|
||||
|
||||
#### 压缩
|
||||
|
||||
存储系统需要定期“切”出新块并将之前完成的块写入到磁盘中。仅在块成功的持久化之后,才会被删除之前用来恢复内存块的日志文件(wal)。
|
||||
|
||||
我们希望将每个块的保存时间设置的相对短一些(通常配置为 2 小时),以避免内存中积累太多的数据。当查询多个块,我们必须将它们的结果合并为一个整体的结果。合并过程显然会消耗资源,一个星期的查询不应该由超过 80 个的部分结果所组成。
|
||||
|
||||
为了实现两者,我们引入<ruby>压缩<rt>compaction</rt></ruby>。压缩描述了一个过程:取一个或更多个数据块并将其写入一个可能更大的块中。它也可以在此过程中修改现有的数据。例如,清除已经删除的数据,或重建样本块以提升查询性能。
|
||||
|
||||
```
|
||||
|
||||
t0 t1 t2 t3 t4 now
|
||||
+------------+ +----------+ +-----------+ +-----------+ +-----------+
|
||||
| 1 | | 2 | | 3 | | 4 | | 5 mutable | before
|
||||
+------------+ +----------+ +-----------+ +-----------+ +-----------+
|
||||
+-----------------------------------------+ +-----------+ +-----------+
|
||||
| 1 compacted | | 4 | | 5 mutable | after (option A)
|
||||
+-----------------------------------------+ +-----------+ +-----------+
|
||||
+--------------------------+ +--------------------------+ +-----------+
|
||||
| 1 compacted | | 3 compacted | | 5 mutable | after (option B)
|
||||
+--------------------------+ +--------------------------+ +-----------+
|
||||
```
|
||||
|
||||
在这个例子中我们有顺序块 `[1,2,3,4]`。块 1、2、3 可以压缩在一起,新的布局将会是 `[1,4]`。或者,将它们成对压缩为 `[1,3]`。所有的时间序列数据仍然存在,但现在整体上保存在更少的块中。这极大程度地缩减了查询时间的消耗,因为需要合并的部分查询结果变得更少了。
|
||||
|
||||
#### 保留
|
||||
|
||||
我们看到了删除旧的数据在 V2 存储系统中是一个缓慢的过程,并且消耗 CPU、内存和磁盘。如何才能在我们基于块的设计上清除旧的数据?相当简单,只要删除我们配置的保留时间窗口里没有数据的块文件夹即可。在下面的例子中,块 1 可以被安全地删除,而块 2 则必须一直保留,直到它落在保留窗口边界之外。
|
||||
|
||||
```
|
||||
|
|
||||
+------------+ +----+-----+ +-----------+ +-----------+ +-----------+
|
||||
| 1 | | 2 | | | 3 | | 4 | | 5 | . . .
|
||||
+------------+ +----+-----+ +-----------+ +-----------+ +-----------+
|
||||
|
|
||||
|
|
||||
retention boundary
|
||||
```
|
||||
|
||||
随着我们不断压缩先前压缩的块,旧数据越大,块可能变得越大。因此必须为其设置一个上限,以防数据块扩展到整个数据库而损失我们设计的最初优势。
|
||||
|
||||
方便的是,这一点也限制了部分存在于保留窗口内部分存在于保留窗口外的块的磁盘消耗总量。例如上面例子中的块 2。当设置了最大块尺寸为总保留窗口的 10% 后,我们保留块 2 的总开销也有了 10% 的上限。
|
||||
|
||||
总结一下,保留与删除从非常昂贵到了几乎没有成本。
|
||||
|
||||
> 如果你读到这里并有一些数据库的背景知识,现在你也许会问:这些都是最新的技术吗?——并不是;而且可能还会做的更好。
|
||||
>
|
||||
> 在内存中批量处理数据,在预写日志中跟踪,并定期写入到磁盘的模式在现在相当普遍。
|
||||
>
|
||||
> 我们看到的好处无论在什么领域的数据里都是适用的。遵循这一方法最著名的开源案例是 LevelDB、Cassandra、InfluxDB 和 HBase。关键是避免重复发明劣质的轮子,采用经过验证的方法,并正确地运用它们。
|
||||
>
|
||||
> 脱离场景添加你自己的黑魔法是一种不太可能的情况。
|
||||
|
||||
### 索引
|
||||
|
||||
研究存储改进的最初想法是解决序列分流的问题。基于块的布局减少了查询所要考虑的序列总数。因此假设我们索引查找的复杂度是 `O(n^2)`,我们就要设法减少 n 个相当数量的复杂度,之后就相当于改进 `O(n^2)` 复杂度。——恩,等等……糟糕。
|
||||
|
||||
快速回顾一下“算法 101”课上提醒我们的,在理论上它并未带来任何好处。如果之前就很糟糕,那么现在也一样。理论是如此的残酷。
|
||||
|
||||
实际上,我们大多数的查询已经可以相当快响应。但是,跨越整个时间范围的查询仍然很慢,尽管只需要找到少部分数据。追溯到所有这些工作之前,最初我用来解决这个问题的想法是:我们需要一个更大容量的[倒排索引][9]。
|
||||
|
||||
倒排索引基于数据项内容的子集提供了一种快速的查找方式。简单地说,我可以通过标签 `app="nginx"` 查找所有的序列而无需遍历每个文件来看它是否包含该标签。
|
||||
|
||||
为此,每个序列被赋上一个唯一的 ID ,通过该 ID 可以恒定时间内检索它(`O(1)`)。在这个例子中 ID 就是我们的正向索引。
|
||||
|
||||
> 示例:如果 ID 为 10、29、9 的序列包含标签 `app="nginx"`,那么 “nginx”的倒排索引就是简单的列表 `[10, 29, 9]`,它就能用来快速地获取所有包含标签的序列。即使有 200 多亿个数据序列也不会影响查找速度。
|
||||
|
||||
简而言之,如果 `n` 是我们序列总数,`m` 是给定查询结果的大小,使用索引的查询复杂度现在就是 `O(m)`。查询语句依据它获取数据的数量 `m` 而不是被搜索的数据体 `n` 进行缩放是一个很好的特性,因为 `m` 一般相当小。
|
||||
|
||||
为了简单起见,我们假设可以在恒定时间内查找到倒排索引对应的列表。
|
||||
|
||||
实际上,这几乎就是 V2 存储系统具有的倒排索引,也是提供在数百万序列中查询性能的最低需求。敏锐的人会注意到,在最坏情况下,所有的序列都含有标签,因此 `m` 又成了 `O(n)`。这一点在预料之中,也相当合理。如果你查询所有的数据,它自然就会花费更多时间。一旦我们牵扯上了更复杂的查询语句就会有问题出现。
|
||||
|
||||
#### 标签组合
|
||||
|
||||
与数百万个序列相关的标签很常见。假设横向扩展着数百个实例的“foo”微服务,并且每个实例拥有数千个序列。每个序列都会带有标签 `app="foo"`。当然,用户通常不会查询所有的序列而是会通过进一步的标签来限制查询。例如,我想知道服务实例接收到了多少请求,那么查询语句便是 `__name__="requests_total" AND app="foo"`。
|
||||
|
||||
为了找到满足两个标签选择子的所有序列,我们得到每一个标签的倒排索引列表并取其交集。结果集通常会比任何一个输入列表小一个数量级。因为每个输入列表最坏情况下的大小为 `O(n)`,所以在嵌套地为每个列表进行<ruby>暴力求解<rt>brute force solution</rt><ruby>下,运行时间为 `O(n^2)`。相同的成本也适用于其他的集合操作,例如取并集(`app="foo" OR app="bar"`)。当在查询语句上添加更多标签选择子,耗费就会指数增长到 `O(n^3)`、`O(n^4)`、`O(n^5)`……`O(n^k)`。通过改变执行顺序,可以使用很多技巧以优化运行效率。越复杂,越是需要关于数据特征和标签之间相关性的知识。这引入了大量的复杂度,但是并没有减少算法的最坏运行时间。
|
||||
|
||||
这便是 V2 存储系统使用的基本方法,幸运的是,看似微小的改动就能获得显著的提升。如果我们假设倒排索引中的 ID 都是排序好的会怎么样?
|
||||
|
||||
假设这个例子的列表用于我们最初的查询:
|
||||
|
||||
```
|
||||
__name__="requests_total" -> [ 9999, 1000, 1001, 2000000, 2000001, 2000002, 2000003 ]
|
||||
app="foo" -> [ 1, 3, 10, 11, 12, 100, 311, 320, 1000, 1001, 10002 ]
|
||||
|
||||
intersection => [ 1000, 1001 ]
|
||||
```
|
||||
|
||||
它的交集相当小。我们可以为每个列表的起始位置设置游标,每次从最小的游标处移动来找到交集。当二者的数字相等,我们就添加它到结果中并移动二者的游标。总体上,我们以锯齿形扫描两个列表,因此总耗费是 `O(2n)=O(n)`,因为我们总是在一个列表上移动。
|
||||
|
||||
两个以上列表的不同集合操作也类似。因此 `k` 个集合操作仅仅改变了因子 `O(k*n)` 而不是最坏情况下查找运行时间的指数 `O(n^k)`。
|
||||
|
||||
我在这里所描述的是几乎所有[全文搜索引擎][10]使用的标准搜索索引的简化版本。每个序列描述符都视作一个简短的“文档”,每个标签(名称 + 固定值)作为其中的“单词”。我们可以忽略搜索引擎索引中通常遇到的很多附加数据,例如单词位置和和频率。
|
||||
|
||||
关于改进实际运行时间的方法似乎存在无穷无尽的研究,它们通常都是对输入数据做一些假设。不出意料的是,还有大量技术来压缩倒排索引,其中各有利弊。因为我们的“文档”比较小,而且“单词”在所有的序列里大量重复,压缩变得几乎无关紧要。例如,一个真实的数据集约有 440 万个序列与大约 12 个标签,每个标签拥有少于 5000 个单独的标签。对于最初的存储版本,我们坚持使用基本的方法而不压缩,仅做微小的调整来跳过大范围非交叉的 ID。
|
||||
|
||||
尽管维持排序好的 ID 听起来很简单,但实践过程中不是总能完成的。例如,V2 存储系统为新的序列赋上一个哈希值来当作 ID,我们就不能轻易地排序倒排索引。
|
||||
|
||||
另一个艰巨的任务是当磁盘上的数据被更新或删除掉后修改其索引。通常,最简单的方法是重新计算并写入,但是要保证数据库在此期间可查询且具有一致性。V3 存储系统通过每块上具有的独立不可变索引来解决这一问题,该索引仅通过压缩时的重写来进行修改。只有可变块上的索引需要被更新,它完全保存在内存中。
|
||||
|
||||
## 基准测试
|
||||
|
||||
我从存储的基准测试开始了初步的开发,它基于现实世界数据集中提取的大约 440 万个序列描述符,并生成合成数据点以输入到这些序列中。这个阶段的开发仅仅测试了单独的存储系统,对于快速找到性能瓶颈和高并发负载场景下的触发死锁至关重要。
|
||||
|
||||
在完成概念性的开发实施之后,该基准测试能够在我的 Macbook Pro 上维持每秒 2000 万的吞吐量 —— 并且这都是在打开着十几个 Chrome 的页面和 Slack 的时候。因此,尽管这听起来都很棒,它这也表明推动这项测试没有的进一步价值(或者是没有在高随机环境下运行)。毕竟,它是合成的数据,因此在除了良好的第一印象外没有多大价值。比起最初的设计目标高出 20 倍,是时候将它部署到真正的 Prometheus 服务器上了,为它添加更多现实环境中的开销和场景。
|
||||
|
||||
我们实际上没有可重现的 Prometheus 基准测试配置,特别是没有对于不同版本的 A/B 测试。亡羊补牢为时不晚,[不过现在就有一个了][11]!
|
||||
|
||||
我们的工具可以让我们声明性地定义基准测试场景,然后部署到 AWS 的 Kubernetes 集群上。尽管对于全面的基准测试来说不是最好环境,但它肯定比 64 核 128GB 内存的专用<ruby>裸机服务器<rt>bare metal servers</rt></ruby>更能反映出我们的用户群体。
|
||||
|
||||
我们部署了两个 Prometheus 1.5.2 服务器(V2 存储系统)和两个来自 2.0 开发分支的 Prometheus (V3 存储系统)。每个 Prometheus 运行在配备 SSD 的专用服务器上。我们将横向扩展的应用部署在了工作节点上,并且让其暴露典型的微服务度量。此外,Kubernetes 集群本身和节点也被监控着。整套系统由另一个 Meta-Prometheus 所监督,它监控每个 Prometheus 的健康状况和性能。
|
||||
|
||||
为了模拟序列分流,微服务定期的扩展和收缩来移除旧的 pod 并衍生新的 pod,生成新的序列。通过选择“典型”的查询来模拟查询负载,对每个 Prometheus 版本都执行一次。
|
||||
|
||||
总体上,伸缩与查询的负载以及采样频率极大的超出了 Prometheus 的生产部署。例如,我们每隔 15 分钟换出 60% 的微服务实例去产生序列分流。在现代的基础设施上,一天仅大约会发生 1-5 次。这就保证了我们的 V3 设计足以处理未来几年的工作负载。就结果而言,Prometheus 1.5.2 和 2.0 之间的性能差异在极端的环境下会变得更大。
|
||||
|
||||
总而言之,我们每秒从 850 个目标里收集大约 11 万份样本,每次暴露 50 万个序列。
|
||||
|
||||
在此系统运行一段时间之后,我们可以看一下数字。我们评估了两个版本在 12 个小时之后到达稳定时的几个指标。
|
||||
|
||||
> 请注意从 Prometheus 图形界面的截图中轻微截断的 Y 轴
|
||||
|
||||

|
||||
|
||||
*堆内存使用(GB)*
|
||||
|
||||
内存资源的使用对用户来说是最为困扰的问题,因为它相对的不可预测且可能导致进程崩溃。
|
||||
|
||||
显然,查询的服务器正在消耗内存,这很大程度上归咎于查询引擎的开销,这一点可以当作以后优化的主题。总的来说,Prometheus 2.0 的内存消耗减少了 3-4 倍。大约 6 小时之后,在 Prometheus 1.5 上有一个明显的峰值,与我们设置的 6 小时的保留边界相对应。因为删除操作成本非常高,所以资源消耗急剧提升。这一点在下面几张图中均有体现。
|
||||
|
||||

|
||||
|
||||
*CPU 使用(核心/秒)*
|
||||
|
||||
类似的模式也体现在 CPU 使用上,但是查询的服务器与非查询的服务器之间的差异尤为明显。每秒获取大约 11 万个数据需要 0.5 核心/秒的 CPU 资源,比起评估查询所花费的 CPU 时间,我们的新存储系统 CPU 消耗可忽略不计。总的来说,新存储需要的 CPU 资源减少了 3 到 10 倍。
|
||||
|
||||

|
||||
|
||||
*磁盘写入(MB/秒)*
|
||||
|
||||
迄今为止最引人注目和意想不到的改进表现在我们的磁盘写入利用率上。这就清楚的说明了为什么 Prometheus 1.5 很容易造成 SSD 损耗。我们看到最初的上升发生在第一个块被持久化到序列文件中的时期,然后一旦删除操作引发了重写就会带来第二个上升。令人惊讶的是,查询的服务器与非查询的服务器显示出了非常不同的利用率。
|
||||
|
||||
在另一方面,Prometheus 2.0 每秒仅向其预写日志写入大约一兆字节。当块被压缩到磁盘时,写入定期地出现峰值。这在总体上节省了:惊人的 97-99%。
|
||||
|
||||

|
||||
|
||||
*磁盘大小(GB)*
|
||||
|
||||
与磁盘写入密切相关的是总磁盘空间占用量。由于我们对样本(这是我们的大部分数据)几乎使用了相同的压缩算法,因此磁盘占用量应当相同。在更为稳定的系统中,这样做很大程度上是正确地,但是因为我们需要处理高的序列分流,所以还要考虑每个序列的开销。
|
||||
|
||||
如我们所见,Prometheus 1.5 在这两个版本达到稳定状态之前,使用的存储空间因其保留操作而急速上升。Prometheus 2.0 似乎在每个序列上的开销显著降低。我们可以清楚的看到预写日志线性地充满整个存储空间,然后当压缩完成后瞬间下降。事实上对于两个 Prometheus 2.0 服务器,它们的曲线并不是完全匹配的,这一点需要进一步的调查。
|
||||
|
||||
前景大好。剩下最重要的部分是查询延迟。新的索引应当优化了查找的复杂度。没有实质上发生改变的是处理数据的过程,例如 `rate()` 函数或聚合。这些就是查询引擎要做的东西了。
|
||||
|
||||

|
||||
|
||||
*第 99 个百分位查询延迟(秒)*
|
||||
|
||||
数据完全符合预期。在 Prometheus 1.5 上,查询延迟随着存储的序列而增加。只有在保留操作开始且旧的序列被删除后才会趋于稳定。作为对比,Prometheus 2.0 从一开始就保持在合适的位置。
|
||||
|
||||
我们需要花一些心思在数据是如何被采集上,对服务器发出的查询请求通过对以下方面的估计来选择:范围查询和即时查询的组合,进行更轻或更重的计算,访问更多或更少的文件。它并不需要代表真实世界里查询的分布。也不能代表冷数据的查询性能,我们可以假设所有的样本数据都是保存在内存中的热数据。
|
||||
|
||||
尽管如此,我们可以相当自信地说,整体查询效果对序列分流变得非常有弹性,并且在高压基准测试场景下提升了 4 倍的性能。在更为静态的环境下,我们可以假设查询时间大多数花费在了查询引擎上,改善程度明显较低。
|
||||
|
||||

|
||||
|
||||
*摄入的样本/秒*
|
||||
|
||||
最后,快速地看一下不同 Prometheus 服务器的摄入率。我们可以看到搭载 V3 存储系统的两个服务器具有相同的摄入速率。在几个小时之后变得不稳定,这是因为不同的基准测试集群节点由于高负载变得无响应,与 Prometheus 实例无关。(两个 2.0 的曲线完全匹配这一事实希望足够具有说服力)
|
||||
|
||||
尽管还有更多 CPU 和内存资源,两个 Prometheus 1.5.2 服务器的摄入率大大降低。序列分流的高压导致了无法采集更多的数据。
|
||||
|
||||
那么现在每秒可以摄入的<ruby>绝对最大<rt>absolute maximum</rt></ruby>样本数是多少?
|
||||
|
||||
但是现在你可以摄取的每秒绝对最大样本数是多少?
|
||||
|
||||
我不知道 —— 虽然这是一个相当容易的优化指标,但除了稳固的基线性能之外,它并不是特别有意义。
|
||||
|
||||
有很多因素都会影响 Prometheus 数据流量,而且没有一个单独的数字能够描述捕获质量。最大摄入率在历史上是一个导致基准出现偏差的度量,并且忽视了更多重要的层面,例如查询性能和对序列分流的弹性。关于资源使用线性增长的大致猜想通过一些基本的测试被证实。很容易推断出其中的原因。
|
||||
|
||||
我们的基准测试模拟了高动态环境下 Prometheus 的压力,它比起真实世界中的更大。结果表明,虽然运行在没有优化的云服务器上,但是已经超出了预期的效果。最终,成功将取决于用户反馈而不是基准数字。
|
||||
|
||||
> 注意:在撰写本文的同时,Prometheus 1.6 正在开发当中,它允许更可靠地配置最大内存使用量,并且可能会显著地减少整体的消耗,有利于稍微提高 CPU 使用率。我没有重复对此进行测试,因为整体结果变化不大,尤其是面对高序列分流的情况。
|
||||
|
||||
## 总结
|
||||
|
||||
Prometheus 开始应对高基数序列与单独样本的吞吐量。这仍然是一项富有挑战性的任务,但是新的存储系统似乎向我们展示了未来的一些好东西。
|
||||
|
||||
第一个配备 V3 存储系统的 [alpha 版本 Prometheus 2.0][12] 已经可以用来测试了。在早期阶段预计还会出现崩溃,死锁和其他 bug。
|
||||
|
||||
存储系统的代码可以在[这个单独的项目中找到][13]。Prometheus 对于寻找高效本地存储时间序列数据库的应用来说可能非常有用,这一点令人非常惊讶。
|
||||
|
||||
> 这里需要感谢很多人作出的贡献,以下排名不分先后:
|
||||
|
||||
> Bjoern Rabenstein 和 Julius Volz 在 V2 存储引擎上的打磨工作以及 V3 存储系统的反馈,这为新一代的设计奠定了基础。
|
||||
|
||||
> Wilhelm Bierbaum 对新设计不断的建议与见解作出了很大的贡献。Brian Brazil 不断的反馈确保了我们最终得到的是语义上合理的方法。与 Peter Bourgon 深刻的讨论验证了设计并形成了这篇文章。
|
||||
|
||||
> 别忘了我们整个 CoreOS 团队与公司对于这项工作的赞助与支持。感谢所有那些听我一遍遍唠叨 SSD、浮点数、序列化格式的同学。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fabxc.org/blog/2017-04-10-writing-a-tsdb/
|
||||
|
||||
作者:[Fabian Reinartz][a]
|
||||
译者:[LuuMing](https://github.com/LuuMing)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/fabxc
|
||||
[1]:https://en.wikipedia.org/wiki/Inode
|
||||
[2]:https://prometheus.io/
|
||||
[3]:https://kubernetes.io/
|
||||
[4]:https://en.wikipedia.org/wiki/Write_amplification
|
||||
[5]:http://codecapsule.com/2014/02/12/coding-for-ssds-part-1-introduction-and-table-of-contents/
|
||||
[6]:https://prometheus.io/docs/practices/rules/
|
||||
[7]:http://www.vldb.org/pvldb/vol8/p1816-teller.pdf
|
||||
[8]:https://en.wikipedia.org/wiki/Mmap
|
||||
[9]:https://en.wikipedia.org/wiki/Inverted_index
|
||||
[10]:https://en.wikipedia.org/wiki/Search_engine_indexing#Inverted_indices
|
||||
[11]:https://github.com/prometheus/prombench
|
||||
[12]:https://prometheus.io/blog/2017/04/10/promehteus-20-sneak-peak/
|
||||
[13]:https://github.com/prometheus/tsdb
|
||||
149
published/20170414 5 projects for Raspberry Pi at home.md
Normal file
149
published/20170414 5 projects for Raspberry Pi at home.md
Normal file
@ -0,0 +1,149 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (warmfrog)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10936-1.html)
|
||||
[#]: subject: (5 projects for Raspberry Pi at home)
|
||||
[#]: via: (https://opensource.com/article/17/4/5-projects-raspberry-pi-home)
|
||||
[#]: author: (Ben Nuttall https://opensource.com/users/bennuttall)
|
||||
|
||||
5 个可在家中使用的树莓派项目
|
||||
======================================
|
||||
|
||||
![5 projects for Raspberry Pi at home][1]
|
||||
|
||||
[树莓派][2] 电脑可被用来进行多种设置用于不同的目的。显然它在教育市场帮助学生在教室和创客空间中学习编程与创客技巧方面占有一席之地,它在工作场所和工厂中有大量行业应用。我打算介绍五个你可能想要在你的家中构建的项目。
|
||||
|
||||
### 媒体中心
|
||||
|
||||
在家中人们常用树莓派作为媒体中心来服务多媒体文件。它很容易搭建,树莓派提供了大量的 GPU(图形处理单元)运算能力来在大屏电视上渲染你的高清电视节目和电影。将 [Kodi][3](从前的 XBMC)运行在树莓派上是一个很棒的方式,它可以播放你的硬盘或网络存储上的任何媒体。你同样可以安装一个插件来播放 YouTube 视频。
|
||||
|
||||
还有几个略微不同的选择,最常见的是 [OSMC][4](开源媒体中心)和 [LibreELEC][5],都是基于 Kodi 的。它们在放映媒体内容方面表现的都非常好,但是 OSMC 有一个更酷炫的用户界面,而 LibreElec 更轻量级。你要做的只是选择一个发行版,下载镜像并安装到一个 SD 卡中(或者仅仅使用 [NOOBS][6]),启动,然后就准备好了。
|
||||
|
||||
![LibreElec ][7]
|
||||
|
||||
*LibreElec;树莓派基金会, CC BY-SA*
|
||||
|
||||
![OSMC][8]
|
||||
|
||||
*OSMC.tv, 版权所有, 授权使用*
|
||||
|
||||
在往下走之前,你需要决定[使用哪种树莓派][9]。这些发行版在任何树莓派(1、2、3 或 Zero)上都能运行,视频播放在这些树莓派中的任何一个上都能胜任。除了 Pi 3(和 Zero W)有内置 Wi-Fi,唯一可察觉的不同是用户界面的反应速度,在 Pi 3 上更快。Pi 2 也不会慢太多,所以如果你不需要 Wi-Fi 它也是可以的,但是当切换菜单时,你会注意到 Pi 3 比 Pi 1 和 Zero 表现的更好。
|
||||
|
||||
### SSH 网关
|
||||
|
||||
如果你想从外部网络访问你的家庭局域网的电脑和设备,你必须打开这些设备的端口来允许外部访问。在互联网中开放这些端口有安全风险,意味着你总是你总是处于被攻击、滥用或者其他各种未授权访问的风险中。然而,如果你在你的网络中安装一个树莓派,并且设置端口映射来仅允许通过 SSH 访问树莓派,你可以这么用来作为一个安全的网关来跳到网络中的其他树莓派和 PC。
|
||||
|
||||
大多数路由允许你配置端口映射规则。你需要给你的树莓派一个固定的内网 IP 地址来设置你的路由器端口 22 映射到你的树莓派端口 22。如果你的网络服务提供商给你提供了一个静态 IP 地址,你能够通过 SSH 和主机的 IP 地址访问(例如,`ssh pi@123.45.56.78`)。如果你有一个域名,你可以配置一个子域名指向这个 IP 地址,所以你没必要记住它(例如,`ssh pi@home.mydomain.com`)。
|
||||
|
||||
![][11]
|
||||
|
||||
然而,如果你不想将树莓派暴露在互联网上,你应该非常小心,不要让你的网络处于危险之中。如果你遵循一些简单的步骤来使它更安全:
|
||||
|
||||
1. 大多数人建议你更换你的登录密码(有道理,默认密码 “raspberry” 是众所周知的),但是这不能阻挡暴力攻击。你可以改变你的密码并添加一个双重验证(所以你需要你的密码*和*一个手机生成的与时间相关的密码),这么做更安全。但是,我相信最好的方法阻止入侵者访问你的树莓派是在你的 SSH 配置中[禁止密码认证][12],这样只能通过 SSH 密匙进入。这意味着任何试图猜测你的密码尝试登录的人都不会成功。只有你的私有密匙可以访问。简单来说,很多人建议将 SSH 端口从默认的 22 换成其他的,但是通过简单的 [Nmap][13] 扫描你的 IP 地址,你信任的 SSH 端口就会暴露。
|
||||
2. 最好,不要在这个树莓派上运行其他的软件,这样你不会意外暴露其他东西。如果你想要运行其他软件,你最好在网络中的其他树莓派上运行,它们没有暴露在互联网上。确保你经常升级来保证你的包是最新的,尤其是 `openssh-server` 包,这样你的安全缺陷就被打补丁了。
|
||||
3. 安装 [sshblack][14] 或 [fail2ban][15] 来将任何表露出恶意的用户加入黑名单,例如试图暴力破解你的 SSH 密码。
|
||||
|
||||
使树莓派安全后,让它在线,你将可以在世界的任何地方登录你的网络。一旦你登录到你的树莓派,你可以用 SSH 访问本地网络上的局域网地址(例如,192.168.1.31)访问其他设备。如果你在这些设备上有密码,用密码就好了。如果它们同样只允许 SSH 密匙,你需要确保你的密匙通过 SSH 转发,使用 `-A` 参数:`ssh -A pi@123.45.67.89`。
|
||||
|
||||
### CCTV / 宠物相机
|
||||
|
||||
另一个很棒的家庭项目是安装一个相机模块来拍照和录视频,录制并保存文件,在内网或者外网中进行流式传输。你想这么做有很多原因,但两个常见的情况是一个家庭安防相机或监控你的宠物。
|
||||
|
||||
[树莓派相机模块][16] 是一个优秀的配件。它提供全高清的相片和视频,包括很多高级配置,很[容易编程][17]。[红外线相机][18]用于这种目的是非常理想的,通过一个红外线 LED(树莓派可以控制的),你就能够在黑暗中看见东西。
|
||||
|
||||
如果你想通过一定频率拍摄静态图片来留意某件事,你可以仅仅写一个简短的 [Python][19] 脚本或者使用命令行工具 [raspistill][20], 在 [Cron][21] 中规划它多次运行。你可能想将它们保存到 [Dropbox][22] 或另一个网络服务,上传到一个网络服务器,你甚至可以创建一个[web 应用][23]来显示他们。
|
||||
|
||||
如果你想要在内网或外网中流式传输视频,那也相当简单。在 [picamera 文档][24]中(在 “web streaming” 章节)有一个简单的 MJPEG(Motion JPEG)例子。简单下载或者拷贝代码到文件中,运行并访问树莓派的 IP 地址的 8000 端口,你会看见你的相机的直播输出。
|
||||
|
||||
有一个更高级的流式传输项目 [pistreaming][25] 也可以,它通过在网络服务器中用 [JSMpeg][26] (一个 JavaScript 视频播放器)和一个用于相机流的单独运行的 websocket。这种方法性能更好,并且和之前的例子一样简单,但是如果要在互联网中流式传输,则需要包含更多代码,并且需要你开放两个端口。
|
||||
|
||||
一旦你的网络流建立起来,你可以将你的相机放在你想要的地方。我用一个来观察我的宠物龟:
|
||||
|
||||
![Tortoise ][27]
|
||||
|
||||
*Ben Nuttall, CC BY-SA*
|
||||
|
||||
如果你想控制相机位置,你可以用一个舵机。一个优雅的方案是用 Pimoroni 的 [Pan-Tilt HAT][28],它可以让你简单的在二维方向上移动相机。为了与 pistreaming 集成,可以看看该项目的 [pantilthat 分支][29].
|
||||
|
||||
![Pan-tilt][30]
|
||||
|
||||
*Pimoroni.com, Copyright, 授权使用*
|
||||
|
||||
如果你想将你的树莓派放到户外,你将需要一个防水的外围附件,并且需要一种给树莓派供电的方式。POE(通过以太网提供电力)电缆是一个不错的实现方式。
|
||||
|
||||
### 家庭自动化或物联网
|
||||
|
||||
现在是 2017 年(LCTT 译注:此文发表时间),到处都有很多物联网设备,尤其是家中。我们的电灯有 Wi-Fi,我们的面包烤箱比过去更智能,我们的茶壶处于俄国攻击的风险中,除非你确保你的设备安全,不然别将没有必要的设备连接到互联网,之后你可以在家中充分的利用物联网设备来完成自动化任务。
|
||||
|
||||
市场上有大量你可以购买或订阅的服务,像 Nest Thermostat 或 Philips Hue 电灯泡,允许你通过你的手机控制你的温度或者你的亮度,无论你是否在家。你可以用一个树莓派来催动这些设备的电源,通过一系列规则包括时间甚至是传感器来完成自动交互。用 Philips Hue,你做不到的当你进房间时打开灯光,但是有一个树莓派和一个运动传感器,你可以用 Python API 来打开灯光。类似地,当你在家的时候你可以通过配置你的 Nest 打开加热系统,但是如果你想在房间里至少有两个人时才打开呢?写一些 Python 代码来检查网络中有哪些手机,如果至少有两个,告诉 Nest 来打开加热器。
|
||||
|
||||
不用选择集成已存在的物联网设备,你可以用简单的组件来做的更多。一个自制的窃贼警报器,一个自动化的鸡笼门开关,一个夜灯,一个音乐盒,一个定时的加热灯,一个自动化的备份服务器,一个打印服务器,或者任何你能想到的。
|
||||
|
||||
### Tor 协议和屏蔽广告
|
||||
|
||||
Adafruit 的 [Onion Pi][31] 是一个 [Tor][32] 协议来使你的网络通讯匿名,允许你使用互联网而不用担心窥探者和各种形式的监视。跟随 Adafruit 的指南来设置 Onion Pi,你会找到一个舒服的匿名的浏览体验。
|
||||
|
||||
![Onion-Pi][33]
|
||||
|
||||
*Onion-pi from Adafruit, Copyright, 授权使用*
|
||||
|
||||
![Pi-hole][34]
|
||||
|
||||
可以在你的网络中安装一个树莓派来拦截所有的网络交通并过滤所有广告。简单下载 [Pi-hole][35] 软件到 Pi 中,你的网络中的所有设备都将没有广告(甚至屏蔽你的移动设备应用内的广告)。
|
||||
|
||||
树莓派在家中有很多用法。你在家里用树莓派来干什么?你想用它干什么?
|
||||
|
||||
在下方评论让我们知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/4/5-projects-raspberry-pi-home
|
||||
|
||||
作者:[Ben Nuttall][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[warmfrog](https://github.com/warmfrog)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bennuttall
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/raspberry_pi_home_automation.png?itok=2TnmJpD8 (5 projects for Raspberry Pi at home)
|
||||
[2]: https://www.raspberrypi.org/
|
||||
[3]: https://kodi.tv/
|
||||
[4]: https://osmc.tv/
|
||||
[5]: https://libreelec.tv/
|
||||
[6]: https://www.raspberrypi.org/downloads/noobs/
|
||||
[7]: https://opensource.com/sites/default/files/libreelec_0.png (LibreElec )
|
||||
[8]: https://opensource.com/sites/default/files/osmc.png (OSMC)
|
||||
[9]: https://opensource.com/life/16/10/which-raspberry-pi-should-you-choose-your-project
|
||||
[10]: mailto:pi@home.mydomain.com
|
||||
[11]: https://opensource.com/sites/default/files/resize/screenshot_from_2017-04-07_15-13-01-700x380.png
|
||||
[12]: http://stackoverflow.com/questions/20898384/ssh-disable-password-authentication
|
||||
[13]: https://nmap.org/
|
||||
[14]: http://www.pettingers.org/code/sshblack.html
|
||||
[15]: https://www.fail2ban.org/wiki/index.php/Main_Page
|
||||
[16]: https://www.raspberrypi.org/products/camera-module-v2/
|
||||
[17]: https://opensource.com/life/15/6/raspberry-pi-camera-projects
|
||||
[18]: https://www.raspberrypi.org/products/pi-noir-camera-v2/
|
||||
[19]: http://picamera.readthedocs.io/
|
||||
[20]: https://www.raspberrypi.org/documentation/usage/camera/raspicam/raspistill.md
|
||||
[21]: https://www.raspberrypi.org/documentation/linux/usage/cron.md
|
||||
[22]: https://github.com/RZRZR/plant-cam
|
||||
[23]: https://github.com/bennuttall/bett-bot
|
||||
[24]: http://picamera.readthedocs.io/en/release-1.13/recipes2.html#web-streaming
|
||||
[25]: https://github.com/waveform80/pistreaming
|
||||
[26]: http://jsmpeg.com/
|
||||
[27]: https://opensource.com/sites/default/files/tortoise.jpg (Tortoise)
|
||||
[28]: https://shop.pimoroni.com/products/pan-tilt-hat
|
||||
[29]: https://github.com/waveform80/pistreaming/tree/pantilthat
|
||||
[30]: https://opensource.com/sites/default/files/pan-tilt.gif (Pan-tilt)
|
||||
[31]: https://learn.adafruit.com/onion-pi/overview
|
||||
[32]: https://www.torproject.org/
|
||||
[33]: https://opensource.com/sites/default/files/onion-pi.jpg (Onion-Pi)
|
||||
[34]: https://opensource.com/sites/default/files/resize/pi-hole-250x250.png (Pi-hole)
|
||||
[35]: https://pi-hole.net/
|
||||
|
||||
|
||||
|
||||
103
published/20180324 Memories of writing a parser for man pages.md
Normal file
103
published/20180324 Memories of writing a parser for man pages.md
Normal file
@ -0,0 +1,103 @@
|
||||
为 man 手册页编写解析器的备忘录
|
||||
======
|
||||

|
||||
|
||||
我一般都很喜欢无所事事,但有时候太无聊了也不行 —— 2015 年的一个星期天下午就是这样,我决定开始写一个开源项目来让我不那么无聊。
|
||||
|
||||
在我寻求创意时,我偶然发现了一个请求,要求构建一个由 [Mathias Bynens][2] 提出的“[按 Web 标准构建的 Man 手册页查看器][1]”。没有考虑太多,我开始使用 JavaScript 编写一个手册页解析器,经过大量的反复思考,最终做出了一个 [Jroff][3]。
|
||||
|
||||
那时候,我非常熟悉手册页这个概念,而且使用过很多次,但我知道的仅止于此,我不知道它们是如何生成的,或者是否有一个标准。在经过两年后,我有了一些关于此事的想法。
|
||||
|
||||
### man 手册页是如何写的
|
||||
|
||||
当时令我感到惊讶的第一件事是,手册页的核心只是存储在系统某处的纯文本文件(你可以使用 `manpath` 命令检查这些目录)。
|
||||
|
||||
此文件中不仅包含文档,还包含使用了 20 世纪 70 年代名为 `troff` 的排版系统的格式化信息。
|
||||
|
||||
> troff 及其 GNU 实现 groff 是处理文档的文本描述以生成适合打印的排版版本的程序。**它更像是“你所描述的即你得到的”,而不是你所见即所得的。**
|
||||
>
|
||||
> - 摘自 [troff.org][4]
|
||||
|
||||
如果你对排版格式毫不熟悉,可以将它们视为 steroids 期刊用的 Markdown,但其灵活性带来的就是更复杂的语法:
|
||||
|
||||
![groff-compressor][5]
|
||||
|
||||
`groff` 文件可以手工编写,也可以使用许多不同的工具从其他格式生成,如 Markdown、Latex、HTML 等。
|
||||
|
||||
为什么 `groff` 和 man 手册页绑在一起是有历史原因的,其格式[随时间有变化][6],它的血统由一系列类似命名的程序组成:RUNOFF > roff > nroff > troff > groff。
|
||||
|
||||
但这并不一定意味着 `groff` 与手册页有多紧密的关系,它是一种通用格式,已被用于[书籍][7],甚至用于[照相排版][8]。
|
||||
|
||||
此外,值得注意的是 `groff` 也可以调用后处理器将其中间输出结果转换为最终格式,这对于终端显示来说不一定是 ascii !一些支持的格式是:TeX DVI、HTML、Canon、HP LaserJet4 兼容格式、PostScript、utf8 等等。
|
||||
|
||||
### 宏
|
||||
|
||||
该格式的其他很酷的功能是它的可扩展性,你可以编写宏来增强其基本功能。
|
||||
|
||||
鉴于 *nix 系统的悠久历史,有几个可以根据你想要生成的输出而将特定功能组合在一起的宏包,例如 `man`、`mdoc`、`mom`、`ms`、`mm` 等等。
|
||||
|
||||
手册页通常使用 `man` 和 `mdoc` 宏包编写。
|
||||
|
||||
区分原生的 `groff` 命令和宏的方式是通过标准 `groff` 包大写其宏名称。对于 `man` 宏包,每个宏的名称都是大写的,如 `.PP`、`.TH`、`.SH` 等。对于 `mdoc` 宏包,只有第一个字母是大写的: `.Pp`、`.Dt`、`.Sh`。
|
||||
|
||||
![groff-example][9]
|
||||
|
||||
### 挑战
|
||||
|
||||
无论你是考虑编写自己的 `groff` 解析器,还是只是好奇,这些都是我发现的一些更具挑战性的问题。
|
||||
|
||||
#### 上下文敏感的语法
|
||||
|
||||
表面上,`groff` 的语法是上下文无关的,遗憾的是,因为宏描述的是主体不透明的令牌,所以包中的宏集合本身可能不会实现上下文无关的语法。
|
||||
|
||||
这导致我在那时做不出来一个解析器生成器(不管好坏)。
|
||||
|
||||
#### 嵌套的宏
|
||||
|
||||
`mdoc` 宏包中的大多数宏都是可调用的,这差不多意味着宏可以用作其他宏的参数,例如,你看看这个:
|
||||
|
||||
* 宏 `Fl`(Flag)会在其参数中添加破折号,因此 `Fl s` 会生成 `-s`
|
||||
* 宏 `Ar`(Argument)提供了定义参数的工具
|
||||
* 宏 `Op`(Optional)会将其参数括在括号中,因为这是将某些东西定义为可选的标准习惯用法
|
||||
* 以下组合 `.Op Fl s Ar file ` 将生成 `[-s file]`,因为 `Op` 宏可以嵌套。
|
||||
|
||||
#### 缺乏适合初学者的资源
|
||||
|
||||
让我感到困惑的是缺乏一个规范的、定义明确的、清晰的来源,网上有很多信息,这些信息对读者来说很重要,需要时间来掌握。
|
||||
|
||||
### 有趣的宏
|
||||
|
||||
总结一下,我会向你提供一个非常简短的宏列表,我在开发 jroff 时发现它很有趣:
|
||||
|
||||
`man` 宏包:
|
||||
|
||||
* `.TH`:用 `man` 宏包编写手册页时,你的第一个不是注释的行必须是这个宏,它接受五个参数:`title`、`section`、`date`、`source`、`manual`。
|
||||
* `.BI`:粗体加斜体(特别适用于函数格式)
|
||||
* `.BR`:粗体加正体(特别适用于参考其他手册页)
|
||||
|
||||
`mdoc` 宏包:
|
||||
|
||||
* `.Dd`、`.Dt`、`.Os`:类似于 `man` 宏包需要 `.TH`,`mdoc` 宏也需要这三个宏,需要按特定顺序使用。它们的缩写分别代表:文档日期、文档标题和操作系统。
|
||||
* `.Bl`、`.It`、`.El`:这三个宏用于创建列表,它们的名称不言自明:开始列表、项目和结束列表。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://monades.roperzh.com/memories-writing-parser-man-pages/
|
||||
|
||||
作者:[Roberto Dip][a]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://monades.roperzh.com
|
||||
[1]:https://github.com/h5bp/lazyweb-requests/issues/114
|
||||
[2]:https://mathiasbynens.be/
|
||||
[3]:jroff
|
||||
[4]:https://www.troff.org/
|
||||
[5]:https://user-images.githubusercontent.com/4419992/37868021-2e74027c-2f7f-11e8-894b-80829ce39435.gif
|
||||
[6]:https://manpages.bsd.lv/history.html
|
||||
[7]:https://rkrishnan.org/posts/2016-03-07-how-is-gopl-typeset.html
|
||||
[8]:https://en.wikipedia.org/wiki/Phototypesetting
|
||||
[9]:https://user-images.githubusercontent.com/4419992/37866838-e602ad78-2f6e-11e8-97a9-2a4494c766ae.jpg
|
||||
@ -0,0 +1,191 @@
|
||||
如何使用 GParted 实用工具缩放根分区
|
||||
======
|
||||
|
||||
今天,我们将讨论磁盘分区。这是 Linux 中的一个好话题。这允许用户来重新调整在 Linux 中的活动 root 分区。
|
||||
|
||||
在这篇文章中,我们将教你如何使用 GParted 缩放在 Linux 上的活动根分区。
|
||||
|
||||
比如说,当我们安装 Ubuntu 操作系统时,并没有恰当地配置,我们的系统仅有 30 GB 磁盘。我们需要安装另一个操作系统,因此我们想在其中制作第二个分区。
|
||||
|
||||
虽然不建议重新调整活动分区。然而,我们要执行这个操作,因为没有其它方法来释放系统分区。
|
||||
|
||||
> 注意:在执行这个动作前,确保你备份了重要的数据,因为如果一些东西出错(例如,电源故障或你的系统重启),你可以得以保留你的数据。
|
||||
|
||||
### Gparted 是什么
|
||||
|
||||
[GParted][1] 是一个自由的分区管理器,它使你能够缩放、复制和移动分区,而不丢失数据。通过使用 GParted 的 Live 可启动镜像,我们可以使用 GParted 应用程序的所有功能。GParted Live 可以使你能够在 GNU/Linux 以及其它的操作系统上使用 GParted,例如,Windows 或 Mac OS X 。
|
||||
|
||||
#### 1) 使用 df 命令检查磁盘空间利用率
|
||||
|
||||
我只是想使用 `df` 命令向你显示我的分区。`df` 命令输出清楚地表明我仅有一个分区。
|
||||
|
||||
```
|
||||
$ df -h
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/sda1 30G 3.4G 26.2G 16% /
|
||||
none 4.0K 0 4.0K 0% /sys/fs/cgroup
|
||||
udev 487M 4.0K 487M 1% /dev
|
||||
tmpfs 100M 844K 99M 1% /run
|
||||
none 5.0M 0 5.0M 0% /run/lock
|
||||
none 498M 152K 497M 1% /run/shm
|
||||
none 100M 52K 100M 1% /run/user
|
||||
```
|
||||
|
||||
#### 2) 使用 fdisk 命令检查磁盘分区
|
||||
|
||||
我将使用 `fdisk` 命令验证这一点。
|
||||
|
||||
```
|
||||
$ sudo fdisk -l
|
||||
[sudo] password for daygeek:
|
||||
|
||||
Disk /dev/sda: 33.1 GB, 33129218048 bytes
|
||||
255 heads, 63 sectors/track, 4027 cylinders, total 64705504 sectors
|
||||
Units = sectors of 1 * 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disk identifier: 0x000473a3
|
||||
|
||||
Device Boot Start End Blocks Id System
|
||||
/dev/sda1 * 2048 62609407 31303680 83 Linux
|
||||
/dev/sda2 62611454 64704511 1046529 5 Extended
|
||||
/dev/sda5 62611456 64704511 1046528 82 Linux swap / Solaris
|
||||
```
|
||||
|
||||
#### 3) 下载 GParted live ISO 镜像
|
||||
|
||||
使用下面的命令来执行下载 GParted live ISO。
|
||||
|
||||
```
|
||||
$ wget https://downloads.sourceforge.net/gparted/gparted-live-0.31.0-1-amd64.iso
|
||||
```
|
||||
|
||||
#### 4) 使用 GParted Live 安装介质启动你的系统
|
||||
|
||||
使用 GParted Live 安装介质(如烧录的 CD/DVD 或 USB 或 ISO 镜像)启动你的系统。你将获得类似于下面屏幕的输出。在这里选择 “GParted Live (Default settings)” ,并敲击回车按键。
|
||||
|
||||
![][3]
|
||||
|
||||
#### 5) 键盘选择
|
||||
|
||||
默认情况下,它选择第二个选项,按下回车即可。
|
||||
|
||||
![][4]
|
||||
|
||||
#### 6) 语言选择
|
||||
|
||||
默认情况下,它选择 “33” 美国英语,按下回车即可。
|
||||
|
||||
![][5]
|
||||
|
||||
#### 7) 模式选择(图形用户界面或命令行)
|
||||
|
||||
默认情况下,它选择 “0” 图形用户界面模式,按下回车即可。
|
||||
|
||||
![][6]
|
||||
|
||||
#### 8) 加载 GParted Live 屏幕
|
||||
|
||||
现在,GParted Live 屏幕已经加载,它显示我以前创建的分区列表。
|
||||
|
||||
![][7]
|
||||
|
||||
#### 9) 如何重新调整根分区大小
|
||||
|
||||
选择你想重新调整大小的根分区,在这里仅有一个分区,所以我将编辑这个分区以便于安装另一个操作系统。
|
||||
|
||||
![][8]
|
||||
|
||||
为做到这一点,按下 “Resize/Move” 按钮来重新调整分区大小。
|
||||
|
||||
![][9]
|
||||
|
||||
现在,在第一个框中输入你想从这个分区中取出的大小。我将索要 “10GB”,所以,我添加 “10240MB”,并让该对话框的其余部分为默认值,然后点击 “Resize/Move” 按钮。
|
||||
|
||||
![][10]
|
||||
|
||||
它将再次要求你确认重新调整分区的大小,因为你正在编辑活动的系统分区,然后点击 “Ok”。
|
||||
|
||||
![][11]
|
||||
|
||||
分区从 30GB 缩小到 20GB 已经成功。也显示 10GB 未分配的磁盘空间。
|
||||
|
||||
![][12]
|
||||
|
||||
最后点击 “Apply” 按钮来执行下面剩余的操作。
|
||||
|
||||
![][13]
|
||||
|
||||
`e2fsck` 是一个文件系统检查实用程序,自动修复文件系统中与 HDD 相关的坏扇道、I/O 错误。
|
||||
|
||||
![][14]
|
||||
|
||||
`resize2fs` 程序将重新调整 ext2、ext3 或 ext4 文件系统的大小。它可以被用于扩大或缩小一个位于设备上的未挂载的文件系统。
|
||||
|
||||
![][15]
|
||||
|
||||
`e2image` 程序将保存位于设备上的关键的 ext2、ext3 或 ext4 文件系统的元数据到一个指定文件中。
|
||||
|
||||
![][16]
|
||||
|
||||
所有的操作完成,关闭对话框。
|
||||
|
||||
![][17]
|
||||
|
||||
现在,我们可以看到未分配的 “10GB” 磁盘分区。
|
||||
|
||||
![][18]
|
||||
|
||||
重启系统来检查这一结果。
|
||||
|
||||
![][19]
|
||||
|
||||
#### 10) 检查剩余空间
|
||||
|
||||
重新登录系统,并使用 `fdisk` 命令来查看在分区中可用的空间。是的,我可以看到这个分区上未分配的 “10GB” 磁盘空间。
|
||||
|
||||
```
|
||||
$ sudo parted /dev/sda print free
|
||||
[sudo] password for daygeek:
|
||||
Model: ATA VBOX HARDDISK (scsi)
|
||||
Disk /dev/sda: 32.2GB
|
||||
Sector size (logical/physical): 512B/512B
|
||||
Partition Table: msdos
|
||||
Disk Flags:
|
||||
|
||||
Number Start End Size Type File system Flags
|
||||
32.3kB 10.7GB 10.7GB Free Space
|
||||
1 10.7GB 32.2GB 21.5GB primary ext4 boot
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-resize-active-primary-root-partition-in-linux-using-gparted-utility/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/magesh/
|
||||
[1]:https://gparted.org/
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:https://www.2daygeek.com/wp-content/uploads/2014/08/how-to-resize-active-primary-root-partition-in-linux-using-gparted-utility-1.png
|
||||
[4]:https://www.2daygeek.com/wp-content/uploads/2014/08/how-to-resize-active-primary-root-partition-in-linux-using-gparted-utility-2.png
|
||||
[5]:https://www.2daygeek.com/wp-content/uploads/2014/08/how-to-resize-active-primary-root-partition-in-linux-using-gparted-utility-3.png
|
||||
[6]:https://www.2daygeek.com/wp-content/uploads/2014/08/how-to-resize-active-primary-root-partition-in-linux-using-gparted-utility-4.png
|
||||
[7]:https://www.2daygeek.com/wp-content/uploads/2014/08/how-to-resize-active-primary-root-partition-in-linux-using-gparted-utility-5.png
|
||||
[8]:https://www.2daygeek.com/wp-content/uploads/2014/08/how-to-resize-active-primary-root-partition-in-linux-using-gparted-utility-6.png
|
||||
[9]:https://www.2daygeek.com/wp-content/uploads/2014/08/how-to-resize-active-primary-root-partition-in-linux-using-gparted-utility-7.png
|
||||
[10]:https://www.2daygeek.com/wp-content/uploads/2014/08/how-to-resize-active-primary-root-partition-in-linux-using-gparted-utility-8.png
|
||||
[11]:https://www.2daygeek.com/wp-content/uploads/2014/08/how-to-resize-active-primary-root-partition-in-linux-using-gparted-utility-9.png
|
||||
[12]:https://www.2daygeek.com/wp-content/uploads/2014/08/how-to-resize-active-primary-root-partition-in-linux-using-gparted-utility-10.png
|
||||
[13]:https://www.2daygeek.com/wp-content/uploads/2014/08/how-to-resize-active-primary-root-partition-in-linux-using-gparted-utility-11.png
|
||||
[14]:https://www.2daygeek.com/wp-content/uploads/2014/08/how-to-resize-active-primary-root-partition-in-linux-using-gparted-utility-12.png
|
||||
[15]:https://www.2daygeek.com/wp-content/uploads/2014/08/how-to-resize-active-primary-root-partition-in-linux-using-gparted-utility-13.png
|
||||
[16]:https://www.2daygeek.com/wp-content/uploads/2014/08/how-to-resize-active-primary-root-partition-in-linux-using-gparted-utility-14.png
|
||||
[17]:https://www.2daygeek.com/wp-content/uploads/2014/08/how-to-resize-active-primary-root-partition-in-linux-using-gparted-utility-15.png
|
||||
[18]:https://www.2daygeek.com/wp-content/uploads/2014/08/how-to-resize-active-primary-root-partition-in-linux-using-gparted-utility-16.png
|
||||
[19]:https://www.2daygeek.com/wp-content/uploads/2014/08/how-to-resize-active-primary-root-partition-in-linux-using-gparted-utility-17.png
|
||||
@ -0,0 +1,172 @@
|
||||
BootISO:从 ISO 文件中创建一个可启动的 USB 设备
|
||||
======
|
||||
|
||||

|
||||
|
||||
为了安装操作系统,我们中的大多数人(包括我)经常从 ISO 文件中创建一个可启动的 USB 设备。为达到这个目的,在 Linux 中有很多自由可用的应用程序。甚至在过去我们写了几篇介绍这种实用程序的文章。
|
||||
|
||||
每个人使用不同的应用程序,每个应用程序有它们自己的特色和功能。在这些应用程序中,一些应用程序属于 CLI 程序,一些应用程序则是 GUI 的。
|
||||
|
||||
今天,我们将讨论名为 BootISO 的实用程序类似工具。它是一个简单的 bash 脚本,允许用户来从 ISO 文件中创建一个可启动的 USB 设备。
|
||||
|
||||
很多 Linux 管理员使用 `dd` 命令开创建可启动的 ISO ,它是一个著名的原生方法,但是与此同时,它也是一个非常危险的命令。因此,小心,当你用 `dd` 命令执行一些动作时。
|
||||
|
||||
建议阅读:
|
||||
|
||||
- [Etcher:从一个 ISO 镜像中创建一个可启动的 USB 驱动器 & SD 卡的简单方法][1]
|
||||
- [在 Linux 上使用 dd 命令来从一个 ISO 镜像中创建一个可启动的 USB 驱动器][2]
|
||||
|
||||
### BootISO 是什么
|
||||
|
||||
[BootISO][3] 是一个简单的 bash 脚本,允许用户来安全的从一个 ISO 文件中创建一个可启动的 USB 设备,它是用 bash 编写的。
|
||||
|
||||
它不提供任何图形用户界面而是提供了大量的选项,可以让初学者顺利地在 Linux 上来创建一个可启动的 USB 设备。因为它是一个智能工具,能自动地选择连接到系统上的 USB 设备。
|
||||
|
||||
当系统有多个 USB 设备连接,它将打印出列表。当你手动选择了另一个硬盘而不是 USB 时,在这种情况下,它将安全地退出,而不会在硬盘上写入任何东西。
|
||||
|
||||
这个脚本也将检查依赖关系,并提示用户安装,它可以与所有的软件包管理器一起工作,例如 apt-get、yum、dnf、pacman 和 zypper。
|
||||
|
||||
### BootISO 的功能
|
||||
|
||||
* 它检查选择的 ISO 是否是正确的 mime 类型。如果不是,那么退出。
|
||||
* 如果你选择除 USB 设备以外的任何其它的磁盘(本地硬盘),BootISO 将自动地退出。
|
||||
* 当你有多个驱动器时,BootISO 允许用户选择想要使用的 USB 驱动器。
|
||||
* 在擦除和分区 USB 设备前,BootISO 会提示用户确认。
|
||||
* BootISO 将正确地处理来自一个命令的任何错误,并退出。
|
||||
* BootISO 在遇到问题退出时将调用一个清理例行程序。
|
||||
|
||||
### 如何在 Linux 中安装 BootISO
|
||||
|
||||
在 Linux 中安装 BootISO 有几个可用的方法,但是,我建议用户使用下面的方法安装。
|
||||
|
||||
```
|
||||
$ curl -L https://git.io/bootiso -O
|
||||
$ chmod +x bootiso
|
||||
$ sudo mv bootiso /usr/local/bin/
|
||||
```
|
||||
|
||||
一旦 BootISO 已经安装,运行下面的命令来列出可用的 USB 设备。
|
||||
|
||||
```
|
||||
$ bootiso -l
|
||||
|
||||
Listing USB drives available in your system:
|
||||
NAME HOTPLUG SIZE STATE TYPE
|
||||
sdd 1 32G running disk
|
||||
```
|
||||
|
||||
如果你仅有一个 USB 设备,那么简单地运行下面的命令来从一个 ISO 文件中创建一个可启动的 USB 设备。
|
||||
|
||||
```
|
||||
$ bootiso /path/to/iso file
|
||||
```
|
||||
|
||||
```
|
||||
$ bootiso /opt/iso_images/archlinux-2018.05.01-x86_64.iso
|
||||
Granting root privileges for bootiso.
|
||||
Listing USB drives available in your system:
|
||||
NAME HOTPLUG SIZE STATE TYPE
|
||||
sdd 1 32G running disk
|
||||
Autoselecting `sdd' (only USB device candidate)
|
||||
The selected device `/dev/sdd' is connected through USB.
|
||||
Created ISO mount point at `/tmp/iso.vXo'
|
||||
`bootiso' is about to wipe out the content of device `/dev/sdd'.
|
||||
Are you sure you want to proceed? (y/n)>y
|
||||
Erasing contents of /dev/sdd...
|
||||
Creating FAT32 partition on `/dev/sdd1'...
|
||||
Created USB device mount point at `/tmp/usb.0j5'
|
||||
Copying files from ISO to USB device with `rsync'
|
||||
Synchronizing writes on device `/dev/sdd'
|
||||
`bootiso' took 250 seconds to write ISO to USB device with `rsync' method.
|
||||
ISO succesfully unmounted.
|
||||
USB device succesfully unmounted.
|
||||
USB device succesfully ejected.
|
||||
You can safely remove it !
|
||||
```
|
||||
|
||||
当你有多个 USB 设备时,可以使用 `--device` 选项指明你的设备名称。
|
||||
|
||||
```
|
||||
$ bootiso -d /dev/sde /opt/iso_images/archlinux-2018.05.01-x86_64.iso
|
||||
```
|
||||
|
||||
默认情况下,BootISO 使用 `rsync` 命令来执行所有的动作,如果你想使用 `dd` 命令代替它,使用下面的格式。
|
||||
|
||||
```
|
||||
$ bootiso --dd -d /dev/sde /opt/iso_images/archlinux-2018.05.01-x86_64.iso
|
||||
```
|
||||
|
||||
如果你想跳过 mime 类型检查,BootISO 实用程序带有下面的选项。
|
||||
|
||||
```
|
||||
$ bootiso --no-mime-check -d /dev/sde /opt/iso_images/archlinux-2018.05.01-x86_64.iso
|
||||
```
|
||||
|
||||
为 BootISO 添加下面的选项来跳过在擦除和分区 USB 设备前的用户确认。
|
||||
|
||||
```
|
||||
$ bootiso -y -d /dev/sde /opt/iso_images/archlinux-2018.05.01-x86_64.iso
|
||||
```
|
||||
|
||||
连同 `-y` 选项一起,启用自动选择 USB 设备。
|
||||
|
||||
```
|
||||
$ bootiso -y -a /opt/iso_images/archlinux-2018.05.01-x86_64.iso
|
||||
```
|
||||
|
||||
为知道更多的 BootISO 选项,运行下面的命令。
|
||||
|
||||
```
|
||||
$ bootiso -h
|
||||
Create a bootable USB from any ISO securely.
|
||||
Usage: bootiso [...]
|
||||
|
||||
Options
|
||||
|
||||
-h, --help, help Display this help message and exit.
|
||||
-v, --version Display version and exit.
|
||||
-d, --device Select block file as USB device.
|
||||
If is not connected through USB, `bootiso' will fail and exit.
|
||||
Device block files are usually situated in /dev/sXX or /dev/hXX.
|
||||
You will be prompted to select a device if you don't use this option.
|
||||
-b, --bootloader Install a bootloader with syslinux (safe mode) for non-hybrid ISOs. Does not work with `--dd' option.
|
||||
-y, --assume-yes `bootiso' won't prompt the user for confirmation before erasing and partitioning USB device.
|
||||
Use at your own risks.
|
||||
-a, --autoselect Enable autoselecting USB devices in conjunction with -y option.
|
||||
Autoselect will automatically select a USB drive device if there is exactly one connected to the system.
|
||||
Enabled by default when neither -d nor --no-usb-check options are given.
|
||||
-J, --no-eject Do not eject device after unmounting.
|
||||
-l, --list-usb-drives List available USB drives.
|
||||
-M, --no-mime-check `bootiso' won't assert that selected ISO file has the right mime-type.
|
||||
-s, --strict-mime-check Disallow loose application/octet-stream mime type in ISO file.
|
||||
-- POSIX end of options.
|
||||
--dd Use `dd' utility instead of mounting + `rsync'.
|
||||
Does not allow bootloader installation with syslinux.
|
||||
--no-usb-check `bootiso' won't assert that selected device is a USB (connected through USB bus).
|
||||
Use at your own risks.
|
||||
|
||||
Readme
|
||||
|
||||
Bootiso v2.5.2.
|
||||
Author: Jules Samuel Randolph
|
||||
Bugs and new features: https://github.com/jsamr/bootiso/issues
|
||||
If you like bootiso, please help the community by making it visible:
|
||||
* star the project at https://github.com/jsamr/bootiso
|
||||
* upvote those SE post: https://goo.gl/BNRmvm https://goo.gl/YDBvFe
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/bootiso-a-simple-bash-script-to-securely-create-a-bootable-usb-device-in-linux-from-iso-file/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/prakash/
|
||||
[1]:https://www.2daygeek.com/etcher-easy-way-to-create-a-bootable-usb-drive-sd-card-from-an-iso-image-on-linux/
|
||||
[2]:https://www.2daygeek.com/create-a-bootable-usb-drive-from-an-iso-image-using-dd-command-on-linux/
|
||||
[3]:https://github.com/jsamr/bootiso
|
||||
@ -1,21 +1,22 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10977-1.html)
|
||||
[#]: subject: (Get desktop notifications from Emacs shell commands ·)
|
||||
[#]: via: (https://blog.hoetzel.info/post/eshell-notifications/)
|
||||
[#]: author: (Jürgen Hötzel https://blog.hoetzel.info)
|
||||
|
||||
Get desktop notifications from Emacs shell commands ·
|
||||
让 Emacs shell 命令发送桌面通知
|
||||
======
|
||||
When interacting with the operating systems I always use [Eshell][1] because it integrates seamlessly with Emacs, supports (remote) [TRAMP][2] file names and also works nice on Windows.
|
||||
|
||||
After starting shell commands (like long running build jobs) I often lose track the task when switching buffers.
|
||||
我总是使用 [Eshell][1] 来与操作系统进行交互,因为它与 Emacs 无缝整合、支持处理 (远程) [TRAMP][2] 文件,而且在 Windows 上也能工作得很好。
|
||||
|
||||
Thanks to Emacs [hooks][3] mechanism you can customize Emacs to call a elisp function when an external command finishes.
|
||||
启动 shell 命令后 (比如耗时严重的构建任务) 我经常会由于切换缓冲区而忘了追踪任务的运行状态。
|
||||
|
||||
I use [John Wiegleys][4] excellent [alert][5] package to send desktop notifications:
|
||||
多亏了 Emacs 的 [钩子][3] 机制,你可以配置 Emacs 在某个外部命令完成后调用一个 elisp 函数。
|
||||
|
||||
我使用 [John Wiegleys][4] 所编写的超棒的 [alert][5] 包来发送桌面通知:
|
||||
|
||||
```
|
||||
(require 'alert)
|
||||
@ -32,7 +33,7 @@ I use [John Wiegleys][4] excellent [alert][5] package to send desktop notificati
|
||||
(add-hook 'eshell-kill-hook #'eshell-command-alert)
|
||||
```
|
||||
|
||||
[alert][5] rules can be setup programmatically. In my case I only want to get notified if the corresponding buffer is not visible:
|
||||
[alert][5] 的规则可以用程序来设置。就我这个情况来看,我只需要当对应的缓冲区不可见时得到通知:
|
||||
|
||||
```
|
||||
(alert-add-rule :status '(buried) ;only send alert when buffer not visible
|
||||
@ -40,7 +41,8 @@ I use [John Wiegleys][4] excellent [alert][5] package to send desktop notificati
|
||||
:style 'notifications)
|
||||
```
|
||||
|
||||
This even works on [TRAMP][2] buffers. Below is a screenshot showing a Gnome desktop notification of a failed `make` command.
|
||||
|
||||
这甚至对于 [TRAMP][2] 也一样生效。下面这个截屏展示了失败的 `make` 命令产生的 Gnome 桌面通知。
|
||||
|
||||
![../../img/eshell.png][6]
|
||||
|
||||
@ -51,7 +53,7 @@ via: https://blog.hoetzel.info/post/eshell-notifications/
|
||||
作者:[Jürgen Hötzel][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -62,4 +64,4 @@ via: https://blog.hoetzel.info/post/eshell-notifications/
|
||||
[3]: https://www.gnu.org/software/emacs/manual/html_node/emacs/Hooks.html (hooks)
|
||||
[4]: https://github.com/jwiegley (John Wiegleys)
|
||||
[5]: https://github.com/jwiegley/alert (alert)
|
||||
[6]: https://blog.hoetzel.info/img/eshell.png (../../img/eshell.png)
|
||||
[6]: https://blog.hoetzel.info/img/eshell.png
|
||||
56
published/20180914 A day in the life of a log message.md
Normal file
56
published/20180914 A day in the life of a log message.md
Normal file
@ -0,0 +1,56 @@
|
||||
一条日志消息的现代生活
|
||||
======
|
||||
|
||||
> 从一条日志消息的角度来巡览现代分布式系统。
|
||||
|
||||

|
||||
|
||||
混沌系统往往是不可预测的。在构建像分布式系统这样复杂的东西时,这一点尤其明显。如果不加以控制,这种不可预测性会无止境的浪费时间。因此,分布式系统的每个组件,无论多小,都必须设计成以简化的方式组合在一起。
|
||||
|
||||
[Kubernetes][1] 为抽象计算资源提供了一个很有前景的模型 —— 但即使是它也必须与其他分布式平台(如 [Apache Kafka][2])协调一致,以确保可靠的数据传输。如果有人要整合这两个平台,它会如何运作?此外,如果你通过这样的系统跟踪像日志消息这么简单的东西,它会是什么样子?本文将重点介绍来自在 [OKD][3] 内运行的应用程序的日志消息如何通过 Kafka 进入数据仓库(OKD 是为 Red Hat OpenShift 提供支持的 Kubernetes 的原初社区发行版)。
|
||||
|
||||
### OKD 定义的环境
|
||||
|
||||
这样的旅程始于 OKD,因为该容器平台完全覆盖了它抽象的硬件。这意味着日志消息等待由驻留在容器中的应用程序写入 stdout 或 stderr 流。从那里,日志消息被容器引擎(例如 [CRI-O][4])重定向到节点的文件系统。
|
||||
|
||||
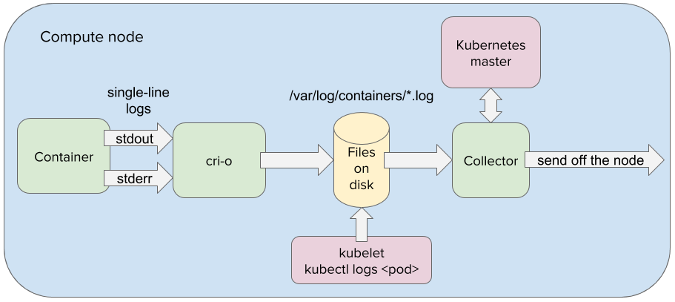
|
||||
|
||||
在 OpenShift 中,一个或多个容器封装在称为 pod(豆荚)的虚拟计算节点中。实际上,在 OKD 中运行的所有应用程序都被抽象为 pod。这允许应用程序以统一的方式操纵。这也大大简化了分布式组件之间的通信,因为 pod 可以通过 IP 地址和[负载均衡服务][5]进行系统寻址。因此,当日志消息由日志收集器应用程序从节点的文件系统获取时,它可以很容易地传递到在 OpenShift 中运行的另一个 pod 中。
|
||||
|
||||
### 在豆荚里的两个豌豆
|
||||
|
||||
为了确保可以在整个分布式系统中四处传播日志消息,日志收集器需要将日志消息传递到在 OpenShift 中运行的 Kafka 集群数据中心。通过 Kafka,日志消息可以以可靠且容错的方式低延迟传递给消费应用程序。但是,为了在 OKD 定义的环境中获得 Kafka 的好处,Kafka 需要完全集成到 OKD 中。
|
||||
|
||||
运行 [Strimzi 操作子][6]将所有 Kafka 组件实例化为 pod,并将它们集成在 OKD 环境中运行。 这包括用于排队日志消息的 Kafka 代理,用于从 Kafka 代理读取和写入的 Kafka 连接器,以及用于管理 Kafka 集群状态的 Zookeeper 节点。Strimzi 还可以将日志收集器实例化兼做 Kafka 连接器,允许日志收集器将日志消息直接提供给在 OKD 中运行的 Kafka 代理 pod。
|
||||
|
||||
### 在 OKD 内的 Kafka
|
||||
|
||||
当日志收集器 pod 将日志消息传递给 Kafka 代理时,收集器会写到单个代理分区,并将日志消息附加到该分区的末尾。使用 Kafka 的一个优点是它将日志收集器与日志的最终目标分离。由于解耦,日志收集器不关心日志最后是放在 [Elasticsearch][7]、Hadoop、Amazon S3 中的某个还是全都。Kafka 与所有基础设施连接良好,因此 Kafka 连接器可以在任何需要的地方获取日志消息。
|
||||
|
||||
一旦写入 Kafka 代理的分区,该日志消息就会在 Kafka 集群内的跨代理分区复制。这是它的一个非常强大的概念;结合平台的自愈功能,它创建了一个非常有弹性的分布式系统。例如,当节点变得不可用时,(故障)节点上运行的应用程序几乎立即在健康节点上生成。因此,即使带有 Kafka 代理的节点丢失或损坏,日志消息也能保证存活在尽可能多的节点上,并且新的 Kafka 代理将快速原位取代。
|
||||
|
||||
### 存储起来
|
||||
|
||||
在日志消息被提交到 Kafka 主题后,它将等待 Kafka 连接器使用它,该连接器将日志消息中继到分析引擎或日志记录仓库。在传递到其最终目的地时,可以分析日志消息以进行异常检测,也可以查询日志以立即进行根本原因分析,或用于其他目的。无论哪种方式,日志消息都由 Kafka 以安全可靠的方式传送到目的地。
|
||||
|
||||
OKD 和 Kafka 是正在迅速发展的功能强大的分布式平台。创建能够在不影响性能的情况下抽象出分布式计算的复杂特性的系统至关重要。毕竟,如果我们不能简化单一日志消息的旅程,我们怎么能夸耀全系统的效率呢?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/life-log-message
|
||||
|
||||
作者:[Josef Karásek][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jkarasek
|
||||
[1]: https://kubernetes.io/
|
||||
[2]: https://kafka.apache.org/
|
||||
[3]: https://www.okd.io/
|
||||
[4]: http://cri-o.io/
|
||||
[5]: https://kubernetes.io/docs/concepts/services-networking/service/
|
||||
[6]: http://strimzi.io/
|
||||
[7]: https://www.elastic.co/
|
||||
@ -0,0 +1,178 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10969-1.html)
|
||||
[#]: subject: (GoAccess – A Real-Time Web Server Log Analyzer And Interactive Viewer)
|
||||
[#]: via: (https://www.2daygeek.com/goaccess-a-real-time-web-server-log-analyzer-and-interactive-viewer/)
|
||||
[#]: author: (Vinoth Kumar https://www.2daygeek.com/author/vinoth/)
|
||||
|
||||
GoAccess:一个实时的 Web 日志分析器及交互式查看器
|
||||
======
|
||||
|
||||

|
||||
|
||||
分析日志文件对于 Linux 管理员来说是一件非常令人头疼的事情,因为它记录了很多东西。大多数新手和初级管理员都不知道如何分析。如果你在分析日志方面拥有很多知识,那么你就成了 *NIX 系统高手。
|
||||
|
||||
Linux 中有许多工具可以轻松分析日志。GoAccess 是允许用户轻松分析 Web 服务器日志的工具之一。我们将在本文中详细讨论 GoAccess 工具。
|
||||
|
||||
### GoAccess
|
||||
|
||||
GoAccess 是一个实时 Web 日志分析器和交互式查看器,可以在 *nix 系统中的终端运行或通过浏览器访问。
|
||||
|
||||
GoAccess 需要的依赖极少,它是用 C 语言编写的,只需要 ncurses。
|
||||
|
||||
它支持 Apache、Nginx 和 Lighttpd 日志。它为需要动态可视化服务器报告的系统管理员即时提供了快速且有价值的 HTTP 统计信息。
|
||||
|
||||
GoAccess 可以解析指定的 Web 日志文件并将数据输出到 X 终端和浏览器。
|
||||
|
||||
GoAccess 被设计成一个基于终端的快速日志分析器。其核心思想是实时快速分析和查看 Web 服务器统计信息,而无需使用浏览器。
|
||||
|
||||
默认输出是在终端输出,它也能够生成完整的、自包含的实时 HTML 报告,以及 JSON 和 CSV 报告。
|
||||
|
||||
GoAccess 支持任何自定义日志格式,并包含以下预定义日志格式选项:Apache/Nginx 中的组合日志格式 XLF/ELF,Apache 中的通用日志格式 CLF,但不限于此。
|
||||
|
||||
### GoAccess 功能
|
||||
|
||||
* 完全实时:所有指标在终端上每 200 毫秒更新一次,在 HTML 输出上每秒更新一次。
|
||||
* 跟踪应用程序响应时间:跟踪服务请求所需的时间。如果你想跟踪减慢了网站速度的网页,则非常有用。
|
||||
* 访问者:按小时或日期确定最慢运行的请求的点击量、访问者数、带宽数和指标。
|
||||
* 按虚拟主机的度量标准:如果有多个虚拟主机(`Server`),它提供了一个面板,可显示哪些虚拟主机正在消耗大部分 Web 服务器资源。
|
||||
|
||||
### 如何安装 GoAccess?
|
||||
|
||||
我建议用户在包管理器的帮助下从发行版官方的存储库安装 GoAccess。它在大多数发行版官方存储库中都可用。
|
||||
|
||||
我们知道,我们在标准发行方式的发行版中得到的是过时的软件包,而滚动发行方式的发行版总是包含最新的软件包。
|
||||
|
||||
如果你使用标准发行方式的发行版运行操作系统,我建议你检查替代选项,如 PPA 或 GoAccess 官方维护者存储库等,以获取最新的软件包。
|
||||
|
||||
对于 Debian / Ubuntu 系统,使用 [APT-GET 命令][1]或 [APT 命令][2]在你的系统上安装 GoAccess。
|
||||
|
||||
```
|
||||
# apt install goaccess
|
||||
```
|
||||
|
||||
要获取最新的 GoAccess 包,请使用以下 GoAccess 官方存储库。
|
||||
|
||||
```
|
||||
$ echo "deb https://deb.goaccess.io/ $(lsb_release -cs) main" | sudo tee -a /etc/apt/sources.list.d/goaccess.list
|
||||
$ wget -O - https://deb.goaccess.io/gnugpg.key | sudo apt-key add -
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install goaccess
|
||||
```
|
||||
|
||||
对于 RHEL / CentOS 系统,使用 [YUM 包管理器][3]在你的系统上安装 GoAccess。
|
||||
|
||||
```
|
||||
# yum install goaccess
|
||||
```
|
||||
|
||||
对于 Fedora 系统,使用 [DNF 包管理器][4]在你的系统上安装 GoAccess。
|
||||
|
||||
```
|
||||
# dnf install goaccess
|
||||
```
|
||||
|
||||
对于基于 ArchLinux / Manjaro 的系统,使用 [Pacman 包管理器][5]在你的系统上安装 GoAccess。
|
||||
|
||||
```
|
||||
# pacman -S goaccess
|
||||
```
|
||||
|
||||
对于 openSUSE Leap 系统,使用[Zypper 包管理器][6]在你的系统上安装 GoAccess。
|
||||
|
||||
```
|
||||
# zypper install goaccess
|
||||
# zypper ar -f obs://server:http
|
||||
# zypper ref && zypper in goaccess
|
||||
```
|
||||
|
||||
### 如何使用 GoAccess?
|
||||
|
||||
成功安装 GoAccess 后。只需输入 `goaccess` 命令,然后输入 Web 服务器日志位置即可查看。
|
||||
|
||||
```
|
||||
# goaccess [options] /path/to/Web Server/access.log
|
||||
# goaccess /var/log/apache/2daygeek_access.log
|
||||
```
|
||||
|
||||
执行上述命令时,它会要求您选择日志格式配置。
|
||||
|
||||
![][8]
|
||||
|
||||
我用 Apache 访问日志对此进行了测试。Apache 日志被分为十五个部分。详情如下。主要部分显示了这十五个部分的摘要。
|
||||
|
||||
以下屏幕截图包括四个部分,例如唯一身份访问者、请求的文件、静态请求、未找到的网址。
|
||||
|
||||
![][10]
|
||||
|
||||
以下屏幕截图包括四个部分,例如访客主机名和 IP、操作系统、浏览器、时间分布。
|
||||
|
||||
![][10]
|
||||
|
||||
以下屏幕截图包括四个部分,例如来源网址、来源网站,Google 的搜索引擎结果、HTTP状态代码。
|
||||
|
||||
![][11]
|
||||
|
||||
如果要生成 html 报告,请使用以下命令。最初我在尝试生成 html 报告时遇到错误。
|
||||
|
||||
```
|
||||
# goaccess 2daygeek_access.log -a > report.html
|
||||
|
||||
GoAccess - version 1.3 - Nov 23 2018 11:28:19
|
||||
Config file: No config file used
|
||||
|
||||
Fatal error has occurred
|
||||
Error occurred at: src/parser.c - parse_log - 2764
|
||||
No time format was found on your conf file.Parsing... [0] [0/s]
|
||||
```
|
||||
|
||||
它说“你的 conf 文件没有找到时间格式”。要解决此问题,请为其添加 “COMBINED” 日志格式选项。
|
||||
|
||||
```
|
||||
# goaccess -f 2daygeek_access.log --log-format=COMBINED -o 2daygeek.html
|
||||
Parsing...[0,165] [50,165/s]
|
||||
```
|
||||
|
||||
![][12]
|
||||
|
||||
GoAccess 也允许你访问和分析实时日志并进行过滤和解析。
|
||||
|
||||
```
|
||||
# tail -f /var/log/apache/2daygeek_access.log | goaccess -
|
||||
```
|
||||
|
||||
更多细节请参考其 man 手册页或帮助。
|
||||
|
||||
```
|
||||
# man goaccess
|
||||
或
|
||||
# goaccess --help
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/goaccess-a-real-time-web-server-log-analyzer-and-interactive-viewer/
|
||||
|
||||
作者:[Vinoth Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/vinoth/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[2]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[3]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[4]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[5]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[6]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
[7]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[8]: https://www.2daygeek.com/wp-content/uploads/2019/01/goaccess-a-real-time-web-server-log-analyzer-and-interactive-viewer-1.png
|
||||
[9]: https://www.2daygeek.com/wp-content/uploads/2019/01/goaccess-a-real-time-web-server-log-analyzer-and-interactive-viewer-2.png
|
||||
[10]: https://www.2daygeek.com/wp-content/uploads/2019/01/goaccess-a-real-time-web-server-log-analyzer-and-interactive-viewer-3.png
|
||||
[11]: https://www.2daygeek.com/wp-content/uploads/2019/01/goaccess-a-real-time-web-server-log-analyzer-and-interactive-viewer-4.png
|
||||
[12]: https://www.2daygeek.com/wp-content/uploads/2019/01/goaccess-a-real-time-web-server-log-analyzer-and-interactive-viewer-5.png
|
||||
@ -0,0 +1,163 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10956-1.html)
|
||||
[#]: subject: (Blockchain 2.0 – Explaining Smart Contracts And Its Types [Part 5])
|
||||
[#]: via: (https://www.ostechnix.com/blockchain-2-0-explaining-smart-contracts-and-its-types/)
|
||||
[#]: author: (editor https://www.ostechnix.com/author/editor/)
|
||||
|
||||
区块链 2.0:智能合约及其类型(五)
|
||||
======
|
||||
|
||||
![Explaining Smart Contracts And Its Types][1]
|
||||
|
||||
这是 区块链 2.0 系列的第 5 篇文章。本系列的前一篇文章探讨了我们如何[在房地产行业实现区块链][2]。本文简要探讨了区块链及相关技术领域内的<ruby>智能合约<rt>Smart Contract</rt></ruby>主题。智能合约是在区块链上验证和创建新“数据块”的基本协议,它被吹捧为该系统未来发展和应用的焦点。 然而,像所有“万灵药”一样,它不是一切的答案。我们将从基础知识中探索这个概念,以了解“智能合约”是什么以及它们不是什么。
|
||||
|
||||
### 不断发展的合同
|
||||
|
||||
这个世界建立在合同(合约)之上。在当前社会,没有合约的使用和再利用,地球上任何个人或公司都无法运作。订立、维护和执行合同的任务变得如此复杂,以至于整个司法和法律系统都必须以“合同法”的名义建立起来以支持它。事实上,大多数合同都是由一个“可信的”第三方监督,以确保最终的利益攸关者按照达成的条件得到妥善处理。有些合同甚至涉及到了第三方受益人。此类合同旨在对不是合同的活跃(或参与)方的第三方产生影响。解决和争论合同义务占据了民事诉讼所涉及的大部分法律纠纷。当然,更好的处理合同的方式来对于个人和企业来说都是天赐之物。更不用说它将以核查和证明的名义节省政府的巨大的[文书工作][7] [^1]。
|
||||
|
||||
本系列中的大多数文章都研究了如何利用现有的区块链技术。相比之下,这篇文章将更多地讲述对未来几年的预期。关于“智能合约”的讨论源于前一篇文章中提出的财产讨论。当前这篇文章旨在概述区块链自动执行“智能”可执行程序的能力。务实地处理这个问题意味着我们首先必须定义和探索这些“智能合约”是什么,以及它们如何适应现有的合同系统。我们将在下一篇题为“区块链 2.0:正在进行的项目”的文章中查看当前该领域正在进行的主要应用和项目。
|
||||
|
||||
### 定义智能合约
|
||||
|
||||
[本系列的第一篇文章][3]从基本的角度来看待区块链,将其看作由数据块组成的“分布式分类账本”,这些数据块是:
|
||||
|
||||
* 防篡改
|
||||
* 不可否认(意味着每个数据块都是由某人显式创建的,并且该人不能否认相同的责任)
|
||||
* 安全,且能抵御传统的网络攻击方法
|
||||
* 几乎是永久性的(当然这取决于区块链协议层)
|
||||
* 高度冗余,通过存在于多个网络节点或参与者系统上,其中一个节点的故障不会以任何方式影响系统的功能,并且,
|
||||
* 根据应用的不同可以提供更快的处理速度。
|
||||
|
||||
由于每个数据实例都是安全存储和通过适当的凭证访问的,因此区块链网络可以为精确验证事实和信息提供简便的基础,而无需第三方监督。区块链 2.0 开发也允许“分布式应用程序(DApp)”(我们将在接下来的文章中详细介绍这个术语)。这些分布式应用程序要求存在网络上并在其上运行。当用户需要它们时就会调用它们,并通过使用已经过审核并存储在区块链上的信息来执行它们。
|
||||
|
||||
上面的最后一段为智能合约的定义提供了基础。<ruby>数字商会<rt>The Chamber for Digital Commerce</rt></ruby>提供了一个许多专家都同意的智能合约定义。
|
||||
|
||||
> “(智能合约是一种)计算机代码,在发生指定条件时,能够根据预先指定的功能自动运行。该代码可以在分布式分类帐本上存储和处理,并将产生的任何更改写入分布式分类帐本” [^2]。
|
||||
|
||||
智能合约如上所述是一种简单的计算机程序,就像 “if-then” 或 “if-else if” 语句一样工作。关于其“智能”的方面来自这样一个事实,即该程序的预定义输入来自区块链分类账本,如上所述,它是一个记录信息的安全可靠的来源。如有必要,程序可以调用外部服务或来源以获取信息,以验证操作条款,并且仅在满足所有预定义条件后才执行。
|
||||
|
||||
必须记住,与其名称所暗示的不同,智能合约通常不是自治实体,严格来说,也不是合同。1996 年,Nick Szabo 很早就提到了智能合约,他将其与接受付款并交付用户选择的产品的自动售货机进行了比较。可以在[这里][4]查看全文。此外,人们正在制定允许智能合约进入主流合同使用的法律框架,因此目前该技术的使用仅限于法律监督不那么明确和严格的领域 [^4]。
|
||||
|
||||
### 智能合约的主要类型
|
||||
|
||||
假设读者对合同和计算机编程有基本的了解,并且基于我们对智能合约的定义,我们可以将智能合约和协议粗略地分类为以下主要类别。
|
||||
|
||||
#### 1、智能法律合约
|
||||
|
||||
这大概是最明显的一种。大多数(如果不是全部)合同都具有法律效力。在不涉及太多技术问题的情况下,智能法律合约是涉及到严格的法律追索权的合同,以防参与合同的当事人不履行其交易的目的。如前所述,不同国家和地区的现行法律框架对区块链上的智能和自动化合约缺乏足够的支持,其法律地位也不明确。但是,一旦制定了法律,就可以订立智能合约,以简化目前涉及严格监管的流程,如金融和房地产市场交易、政府补贴、国际贸易等。
|
||||
|
||||
#### 2、DAO
|
||||
|
||||
<ruby>去中心化自治组织<rt>Decentralized Autonomous Organization</rt></ruby>,即DAO,可以粗略地定义为区块链上存在的社区。该社区可以通过一组规则来定义,这些规则通过智能合约来体现并放入代码中。然后,每个参与者的每一个行动都将受到这些规则的约束,其任务是在程序中断的情况下执行并获得追索权。许多智能合约构成了这些规则,它们协同监管和监督参与者。
|
||||
|
||||
名为“创世纪 DAO” 的 DAO 是由以太坊参与者于 2016 年 5 月创建。该社区旨在成为众筹和风险投资平台。在极短的时间内,他们设法筹集了惊人的 1.5 亿美元。然而,由于黑客在系统中发现了漏洞,并设法从众筹投资者手中窃取价值约 5000 万美元的以太币。这次黑客破坏的后果导致以太坊区块链[分裂为两个][8],以太坊和以太坊经典。
|
||||
|
||||
#### 3、应用逻辑合约(ALC)
|
||||
|
||||
如果你已经听说过与区块链相结合的物联网,那么很可能它涉及到了<ruby>应用逻辑合约<rt>Application logic contract</rt></ruby>,即 ALC。此类智能合约包含特定于应用的代码,这些代码可以与区块链上的其他智能合约和程序一起工作。它们有助于与设备进行通信并验证设备之间的通信(在物联网领域)。ALC 是每个多功能智能合约的关键部分,并且大多数都是在一个管理程序下工作。在这里引用的大多数例子中,它们到处都能找到[应用][9] [^6]。
|
||||
|
||||
*由于该领域还在开发中,因此目前所说的任何定义或标准最多只能说是变化而模糊的。*
|
||||
|
||||
### 智能合约是如何工作的?
|
||||
|
||||
为简化起见,让我们用个例子来说明。
|
||||
|
||||
约翰和彼得是两个争论足球比赛得分的人。他们对比赛结果持有相互矛盾的看法,他们都支持不同的球队(这是背景情况)。由于他们两个都需要去其他地方并且无法看完比赛,所以约翰认为如果 A 队在比赛中击败 B 队,他就*支付*给彼得 100 美元。彼得*考虑*之后*接受*了该赌注,同时明确表示他们必须接受这些条款。但是,他们没有兑现该赌注的相互信任,也没有时间和钱来指定第三方监督赌注。
|
||||
|
||||
假设约翰和彼得都使用像 [Etherparty][5] 这样的智能合约平台,它可以在合约谈判时自动结算赌注,他们都会将基于区块链的身份链接到该合约,并设置条款,明确表示一旦比赛结束,该程序将找出获胜方是谁,并自动将该金额从输家中归入获胜者银行账户。一旦比赛结束并且媒体报道同样的结果,该程序将在互联网上搜索规定的来源,确定哪支球队获胜,将其与合约条款联系起来,在这种情况下,如果 A 队赢了彼得将从约翰哪里得到钱,也就是说将约翰的 100 美元转移到彼得的账户。执行完毕后,除非另有说明,否则智能合约将终止并在未来所有的时间内处于非活动状态。
|
||||
|
||||
抛开例子的简单不说,这种情况涉及到一个经典的合同,而参与者选择使用智能合约实现了相同目的。所有的智能合约基本上都遵循类似的原则,对程序进行编码,以便在预定义的参数上执行,并且只抛出预期的输出。智能合同咨询的外部来源可以是有时被称为 IT 世界中的<ruby>神谕<rt>Oracle</rt></ruby>。神谕是当今全球许多智能合约系统的常见部分。
|
||||
|
||||
在这种情况下使用智能合约使参与者可以获得以下好处:
|
||||
|
||||
* 它比在一起并手动结算更快。
|
||||
* 从其中删除了信任问题。
|
||||
* 消除了受信任的第三方代表有关各方处理和解的必要性。
|
||||
* 执行时无需任何费用。
|
||||
* 在如何处理参数和敏感数据方面是安全的。
|
||||
* 相关数据将永久保留在他们运行的区块链平台中,未来可以通过调用相同的函数并为其提供更多输入来设置投注。
|
||||
* 随着时间的推移,假设约翰和彼得变得赌博成瘾,该程序可以帮助他们开发可靠的统计数据来衡量他们的连胜纪录。
|
||||
|
||||
现在我们知道**什么是智能合约**和**它们如何工作**,我们还没有解决**为什么我们需要它们**。
|
||||
|
||||
### 智能合约的需要
|
||||
|
||||
正如之前的例子我们重点提到过的,出于各种原因,我们需要智能合约。
|
||||
|
||||
#### 透明度
|
||||
|
||||
交易对手非常清楚所涉及的条款和条件。此外,由于程序或智能合约的执行涉及某些明确的输入,因此用户可以非常直接地核实会影响他们和合约受益人的因素。
|
||||
|
||||
#### 时间效率
|
||||
|
||||
如上所述,智能合约一旦被控制变量或用户调用所触发,就立即开始工作。由于数据是通过区块链和网络中的其它来源即时提供给系统,因此执行不需要任何时间来验证和处理信息并解决交易。例如,转移土地所有权契约,这是一个涉及手工核实大量文书工作并且需要数周时间的过程,可以在几分钟甚至几秒钟内通过智能合约程序来处理文件和相关各方。
|
||||
|
||||
#### 精度
|
||||
|
||||
由于平台基本上只是计算机代码和预定义的内容,因此不存在主观错误,所有结果都是精确的,完全没有人为错误。
|
||||
|
||||
#### 安全
|
||||
|
||||
区块链的一个固有特征是每个数据块都是安全加密的。这意味着为了实现冗余,即使数据存储在网络上的多个节点上,**也只有数据所有者才能访问以查看和使用数据**。类似地,利用区块链在过程中存储重要变量和结果,所有过程都将是完全安全和防篡改的。同样也通过按时间顺序为审计人员提供原始的、未经更改的和不可否认的数据版本,简化了审计和法规事务。
|
||||
|
||||
#### 信任
|
||||
|
||||
这个文章系列开篇说到区块链为互联网及其上运行的服务增加了急需的信任层。智能合约在任何情况下都不会在执行协议时表现出偏见或主观性,这意味着所涉及的各方对结果完全有约束力,并且可以不附带任何条件地信任该系统。这也意味着,在具有重要价值的传统合同中所需的“可信第三方”,在此处不需要。当事人之间的犯规和监督将成为过去的问题。
|
||||
|
||||
#### 成本效益
|
||||
|
||||
如示例中所强调的,使用智能合约需要最低的成本。企业通常有专门从事使其交易合法并遵守法规的行政人员。如果交易涉及多方,则重复工作是不可避免的。智能合约基本上使前者无关紧要,并且消除了重复,因为双方可以同时完成尽职调查。
|
||||
|
||||
### 智能合约的应用
|
||||
|
||||
基本上,如果两个或多个参与方使用共同的区块链平台,并就一组原则或业务逻辑达成一致,他们可以一起在区块链上创建一个智能合约,并且在没有人为干预的情况下执行。没有人可以篡改所设置的条件,如果原始代码允许,任何更改都会加上时间戳并带有编辑者的指纹,从而增加了问责制。想象一下,在更大的企业级规模上出现类似的情况,你就会明白智能合约的能力是什么,实际上从 2016 年开始的 **Capgemini 研究** 发现智能合约实际上可能是**“未来几年的”** [^8] 商业主流。商业的应用涉及保险、金融市场、物联网、贷款、身份管理系统、托管账户、雇佣合同以及专利和版税合同等用途。像以太坊这样的区块链平台,是一个设计时就考虑了智能合约的系统,它允许个人私人用户免费使用智能合约。
|
||||
|
||||
通过对处理智能合约的公司的探讨,本系列的下一篇文章中将更全面地概述智能合约在当前技术问题上的应用。
|
||||
|
||||
### 那么,它有什么缺点呢?
|
||||
|
||||
这并不是说对智能合约的使用没有任何顾虑。这种担忧实际上也减缓了这方面的发展。所有区块链的防篡改性质实质上使得,如果所涉及的各方需要在没有重大改革或法律追索的情况下,几乎不可能修改或添加现有条款的新条款。
|
||||
|
||||
其次,即使公有链上的活动是开放的,所有人都可以看到和观察。交易中涉及的各方的个人身份并不总是已知的。这种匿名性造成在任何一方违约的情况下法律有罪不罚的问题,特别是因为现行法律和立法者并不完全适应现代技术。
|
||||
|
||||
第三,区块链和智能合约在很多方面仍然存在安全缺陷,因为对其所以涉及的技术仍处于发展的初期阶段。 对代码和平台的这种缺乏经验最终导致了 2016 年的 DAO 事件。
|
||||
|
||||
所有这些都可能导致企业或公司在需要调整区块链以供其使用时需要大量的初始投资。然而,这些是最初的一次性投资,并且随之而来的是潜在的节约,这才是人们感兴趣的。
|
||||
|
||||
### 结论
|
||||
|
||||
目前的法律框架并没有真正支持一个全面的智能合约的社会,并且由于显然的原因,在不久的将来也不会支持。一个解决方案是选择**“混合”合约**,它将传统的法律文本和文件与在为此目的设计的区块链上运行的智能合约代码相结合。然而,即使是混合合约仍然很大程度上尚未得到探索,因为需要创新的立法机构才能实现这些合约。这里简要提到的应用以及更多内容将在[本系列的下一篇文章][6]中详细探讨。
|
||||
|
||||
[^1]: S. C. A. Chamber of Digital Commerce, “Smart contracts – Is the law ready,” no. September, 2018.
|
||||
[^2]: S. C. A. Chamber of Digital Commerce, “Smart contracts – Is the law ready,” no. September, 2018.
|
||||
[^4]: Cardozo Blockchain Project, “‘Smart Contracts’ & Legal Enforceability,” vol. 2, p. 28, 2018.
|
||||
[^6]: F. Idelberger, G. Governatori, R. Riveret, and G. Sartor, “Evaluation of Logic-Based Smart Contracts for Blockchain Systems,” 2016, pp. 167–183.
|
||||
[^8]: B. Cant et al., “Smart Contracts in Financial Services : Getting from Hype to Reality,” Capgemini Consult., pp. 1–24, 2016.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/blockchain-2-0-explaining-smart-contracts-and-its-types/
|
||||
|
||||
作者:[ostechnix][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/03/smart-contracts-720x340.png
|
||||
[2]: https://linux.cn/article-10914-1.html
|
||||
[3]: https://linux.cn/article-10650-1.html
|
||||
[4]: http://www.fon.hum.uva.nl/rob/Courses/InformationInSpeech/CDROM/Literature/LOTwinterschool2006/szabo.best.vwh.net/smart_contracts_2.html
|
||||
[5]: https://etherparty.com/
|
||||
[6]: https://www.ostechnix.com/blockchain-2-0-ongoing-projects-the-state-of-smart-contracts-now/
|
||||
[7]: http://www.legal-glossary.org/
|
||||
[8]: https://futurism.com/the-dao-heist-undone-97-of-eth-holders-vote-for-the-hard-fork/
|
||||
[9]: https://www.everestgrp.com/2016-10-types-smart-contracts-based-applications-market-insights-36573.html/
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (tomjlw)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10939-1.html)
|
||||
[#]: subject: (How to build a mobile particulate matter sensor with a Raspberry Pi)
|
||||
[#]: via: (https://opensource.com/article/19/3/mobile-particulate-matter-sensor)
|
||||
[#]: author: (Stephan Tetzel https://opensource.com/users/stephan)
|
||||
@ -10,19 +10,19 @@
|
||||
如何用树莓派搭建一个颗粒物传感器
|
||||
======
|
||||
|
||||
用树莓派,一个廉价的传感器和一个便宜的屏幕监测空气质量
|
||||
> 用树莓派、一个廉价的传感器和一个便宜的屏幕监测空气质量。
|
||||
|
||||
![小组交流,讨论][1]
|
||||

|
||||
|
||||
大约一年前,我写了一篇关于如何使用树莓派和廉价传感器测量[空气质量][2]的文章。我们这几年已在学校里和私下使用了这个项目。然而它有一个缺点:由于它基于无线/有线网,因此它不是便携的。如果你的树莓派,你的智能手机和电脑不在同一个网络的话,你甚至都不能访问传感器测量的数据。
|
||||
大约一年前,我写了一篇关于如何使用树莓派和廉价传感器测量[空气质量][2]的文章。我们这几年已在学校里和私下使用了这个项目。然而它有一个缺点:由于它基于无线/有线网,因此它不是便携的。如果你的树莓派、你的智能手机和电脑不在同一个网络的话,你甚至都不能访问传感器测量的数据。
|
||||
|
||||
为了弥补这一缺陷,我们给树莓派添加了一块小屏幕,这样我们就可以直接从该设备上读取数据。以下是我们如何为我们的移动细颗粒物传感器搭建并配置好屏幕。
|
||||
|
||||
### 为树莓派搭建好屏幕
|
||||
|
||||
在[亚马逊][3],阿里巴巴以及其它来源有许多可以获取的树莓派屏幕,从 ePaper 屏幕到可触控 LCD。我们选择了一个便宜的带触控功能且分辨率为320*480像素的[3.5英寸 LCD][3],可以直接插进树莓派的 GPIO 引脚。一个3.5英寸屏幕和树莓派几乎一样大,这一点不错。
|
||||
在[亚马逊][3]、阿里巴巴以及其它来源有许多可以买到的树莓派屏幕,从 ePaper 屏幕到可触控 LCD。我们选择了一个便宜的带触控功能且分辨率为 320*480 像素的[3.5英寸 LCD][3],可以直接插进树莓派的 GPIO 引脚。3.5 英寸屏幕和树莓派几乎一样大,这一点不错。
|
||||
|
||||
当你第一次启动屏幕打开树莓派的时候,因为缺少驱动屏幕会保持白屏。你得首先为屏幕安装[合适的驱动][5]。通过 SSH 登入并执行以下命令:
|
||||
当你第一次启动屏幕打开树莓派的时候,会因为缺少驱动屏幕会保持白屏。你得首先为屏幕安装[合适的驱动][5]。通过 SSH 登入并执行以下命令:
|
||||
|
||||
```
|
||||
$ rm -rf LCD-show
|
||||
@ -55,22 +55,21 @@ $ sudo apt install raspberrypi-ui-mods
|
||||
$ sudo apt install chromium-browser
|
||||
```
|
||||
|
||||
需要自动登录以使测量数据在启动后直接显示;否则你将只会看到登录界面。然而自动登录并没有为树莓派用户默认设置好。你可以用 **raspi-config** 工具设置自动登录:
|
||||
需要自动登录以使测量数据在启动后直接显示;否则你将只会看到登录界面。然而树莓派用户并没有默认设置好自动登录。你可以用 `raspi-config` 工具设置自动登录:
|
||||
|
||||
```
|
||||
$ sudo raspi-config
|
||||
```
|
||||
|
||||
在菜单中,选择:**3 Boot Options → B1 Desktop / CLI → B4 Desktop Autologin**。
|
||||
在菜单中,选择:“3 Boot Options → B1 Desktop / CLI → B4 Desktop Autologin”。
|
||||
|
||||
在启动后用 Chromium 打开我们的网站这块少了一步。创建文件夹
|
||||
**/home/pi/.config/lxsession/LXDE-pi/**:
|
||||
在启动后用 Chromium 打开我们的网站这块少了一步。创建文件夹 `/home/pi/.config/lxsession/LXDE-pi/`:
|
||||
|
||||
```
|
||||
$ mkdir -p /home/pi/config/lxsession/LXDE-pi/
|
||||
```
|
||||
|
||||
然后在该文件夹里创建 **autostart** 文件:
|
||||
然后在该文件夹里创建 `autostart` 文件:
|
||||
|
||||
```
|
||||
$ nano /home/pi/.config/lxsession/LXDE-pi/autostart
|
||||
@ -88,7 +87,7 @@ $ nano /home/pi/.config/lxsession/LXDE-pi/autostart
|
||||
@chromium-browser --incognito --kiosk <http://localhost>
|
||||
```
|
||||
|
||||
如果你想要隐藏鼠标指针,你得安装 **unclutter** 包并移除 **autostart** 文件开头的注释。
|
||||
如果你想要隐藏鼠标指针,你得安装 `unclutter` 包并移除 `autostart` 文件开头的注释。
|
||||
|
||||
```
|
||||
$ sudo apt install unclutter
|
||||
@ -98,11 +97,11 @@ $ sudo apt install unclutter
|
||||
|
||||
我对去年的代码做了些小修改。因此如果你之前搭建过空气质量项目,确保用[原文章][2]中的指导为 AQI 网站重新下载脚本和文件。
|
||||
|
||||
通过添加触摸屏,你现在拥有了一个移动颗粒物传感器!我们在学校用它来检查教室里的空气质量或者进行比较测量。使用这种配置,你无需再依赖网络连接或 WLAN。你可以在任何地方使用小型测量站——你甚至可以使用移动电源以摆脱电网。
|
||||
通过添加触摸屏,你现在拥有了一个便携的颗粒物传感器!我们在学校用它来检查教室里的空气质量或者进行比较测量。使用这种配置,你无需再依赖网络连接或 WLAN。你可以在任何地方使用这个小型测量站——你甚至可以使用移动电源以摆脱电网。
|
||||
|
||||
* * *
|
||||
|
||||
_这篇文章原来在[开源学校解决方案(Open Scool Solutions)][8]上发表,获得许可重新发布。_
|
||||
这篇文章原来在<ruby>[开源学校解决方案][8]<rt>Open Scool Solutions</rt></ruby>上发表,获得许可重新发布。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -111,18 +110,18 @@ via: https://opensource.com/article/19/3/mobile-particulate-matter-sensor
|
||||
作者:[Stephan Tetzel][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/stephan
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/talk_chat_team_mobile_desktop.png?itok=d7sRtKfQ (Team communication, chat)
|
||||
[2]: https://opensource.com/article/18/3/how-measure-particulate-matter-raspberry-pi
|
||||
[2]: https://linux.cn/article-9620-1.html
|
||||
[3]: https://www.amazon.com/gp/search/ref=as_li_qf_sp_sr_tl?ie=UTF8&tag=openschoolsol-20&keywords=lcd%20raspberry&index=aps&camp=1789&creative=9325&linkCode=ur2&linkId=51d6d7676e10d6c7db203c4a8b3b529a
|
||||
[4]: https://amzn.to/2CcvgpC
|
||||
[5]: https://github.com/goodtft/LCD-show
|
||||
[6]: https://opensource.com/article/17/1/try-raspberry-pis-pixel-os-your-pc
|
||||
[6]: https://linux.cn/article-8459-1.html
|
||||
[7]: https://opensource.com/sites/default/files/uploads/mobile-aqi-sensor.jpg (Mobile particulate matter sensor)
|
||||
[8]: https://openschoolsolutions.org/mobile-particulate-matter-sensor/
|
||||
|
||||
@ -0,0 +1,64 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10984-1.html)
|
||||
[#]: subject: (Running LEDs in reverse could cool computers)
|
||||
[#]: via: (https://www.networkworld.com/article/3386876/running-leds-in-reverse-could-cool-computers.html#tk.rss_all)
|
||||
[#]: author: (Patrick Nelson https://www.networkworld.com/author/Patrick-Nelson/)
|
||||
|
||||
反向运行 LED 能够冷却计算机
|
||||
======
|
||||
|
||||
> 电子产品的小型化正在触及其极限,部分原因在于热量管理。许多人现在都在积极地尝试解决这个问题。其中一种正在探索的途径是反向运行的 LED。
|
||||
|
||||
![monsitj / Getty Images][1]
|
||||
|
||||
寻找更有效的冷却计算机的方法,几乎与渴望发现更好的电池化学成分一样,在科学家的研究日程中也处于重要位置。
|
||||
|
||||
更多的冷却手段对于降低成本至关重要。冷却技术也使得在较小的空间中可以进行更强大的处理,其有限的处理能力应该是进行计算而不是浪费热量。冷却技术可以阻止热量引起的故障,从而延长部件的使用寿命,并且可以促进环保的数据中心 —— 更少的热量意味着对环境的影响更小。
|
||||
|
||||
如何从微处理器中消除热量是科学家们一直在探索的一个方向,他们认为他们已经提出了一个简单而不寻常、且反直觉的解决方案。他们说可以运行一个发光二极管(LED)的变体,其电极反转可以迫使该元件表现得像处于异常低温下工作一样。如果将其置于较热的电子设备旁边,然后引入纳米级间隙,可以使 LED 吸收热量。
|
||||
|
||||
“一旦 LED 反向偏置,它就会像一个非常低温的物体一样,吸收光子,”密歇根大学机械工程教授埃德加·梅霍夫在宣布了这一突破的[新闻稿][4]中说。 “与此同时,该间隙可防止热量返回,从而产生冷却效果。”
|
||||
|
||||
研究人员表示,LED 和相邻的电子设备(在这种情况下是热量计,通常用于测量热能)必须非常接近。他们说他们已经能够证明达到了每平方米 6 瓦的冷却功率。他们解释说,这是差不多是地球表面所接受到的阳光的能量。
|
||||
|
||||
物联网(IoT)设备和智能手机可能是最终将受益于这种 LED 改造的电子产品。这两种设备都需要在更小的空间中容纳更多的计算功率。
|
||||
|
||||
“从微处理器中可以移除的热量开始限制在给定空间内容纳的功率,”密歇根大学的公告说。
|
||||
|
||||
### 材料科学和冷却计算机
|
||||
|
||||
[我之前写过关于新形式的计算机冷却的文章][5]。源自材料科学的外来材料是正在探索的想法之一。美国能源部劳伦斯伯克利国家实验室表示,钠铋(Na3Bi)可用于晶体管设计。这种新物质带电荷,重要的是具有可调节性;但是,它不需要像超导体那样进行冷却。
|
||||
|
||||
事实上,这是超导体的一个问题。不幸的是,它们比大多数电子设备需要更多的冷却 —— 通过极端冷却消除电阻。
|
||||
|
||||
另外,[康斯坦茨大学的德国研究人员][6]表示他们很快将拥有超导体驱动的计算机,没有废热。他们计划使用电子自旋 —— 一种新的电子物理维度,可以提高效率。该大学去年在一份新闻稿中表示,这种方法“显著降低了计算中心的能耗”。
|
||||
|
||||
另一种减少热量的方法可能是用嵌入在微处理器上的[螺旋和回路来取代传统的散热器][7]。宾汉姆顿大学的科学家们表示,印在芯片上的微小通道可以为冷却剂提供单独的通道。
|
||||
|
||||
康斯坦茨大学说:“半导体技术的小型化正在接近其物理极限。”热管理现在被科学家提上了议事日程。这是“小型化的一大挑战”。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3386876/running-leds-in-reverse-could-cool-computers.html#tk.rss_all
|
||||
|
||||
作者:[Patrick Nelson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Patrick-Nelson/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/02/big_data_center_server_racks_storage_binary_analytics_by_monsitj_gettyimages-944444446_3x2-100787357-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3242807/data-center/top-10-data-center-predictions-idc.html#nww-fsb
|
||||
[3]: https://www.networkworld.com/newsletters/signup.html#nww-fsb
|
||||
[4]: https://news.umich.edu/running-an-led-in-reverse-could-cool-future-computers/
|
||||
[5]: https://www.networkworld.com/article/3326831/computers-could-soon-run-cold-no-heat-generated.html
|
||||
[6]: https://www.uni-konstanz.de/en/university/news-and-media/current-announcements/news/news-in-detail/Supercomputer-ohne-Abwaerme/
|
||||
[7]: https://www.networkworld.com/article/3322956/chip-cooling-breakthrough-will-reduce-data-center-power-costs.html
|
||||
[8]: https://www.facebook.com/NetworkWorld/
|
||||
[9]: https://www.linkedin.com/company/network-world
|
||||
56
published/20190409 5 Linux rookie mistakes.md
Normal file
56
published/20190409 5 Linux rookie mistakes.md
Normal file
@ -0,0 +1,56 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10952-1.html)
|
||||
[#]: subject: (5 Linux rookie mistakes)
|
||||
[#]: via: (https://opensource.com/article/19/4/linux-rookie-mistakes)
|
||||
[#]: author: (Jen Wike Huger https://opensource.com/users/jen-wike/users/bcotton/users/petercheer/users/greg-p/users/greg-p)
|
||||
|
||||
5 个 Linux 新手会犯的失误
|
||||
======
|
||||
|
||||
> Linux 爱好者们分享了他们犯下的一些最大错误。
|
||||
|
||||

|
||||
|
||||
终身学习是明智的 —— 它可以让你的思维敏捷,让你在就业市场上更具竞争力。但是有些技能比其他技能更难学,尤其是那些小菜鸟错误,当你尝试修复它们时可能会花费你很多时间,给你带来很大困扰。
|
||||
|
||||
以学习 [Linux][2] 为例。如果你习惯于在 Windows 或 MacOS 图形界面中工作,那么转移到 Linux,要将不熟悉的命令输入到终端中,可能会有很大的学习曲线。但是,其回报是值得的,因为已经有数以百万计的人们已经证明了这一点。
|
||||
|
||||
也就是说,这趟学习之旅并不是一帆风顺的。我们让一些 Linux 爱好者回想了一下他们刚开始使用 Linux 的时候,并告诉我们他们犯下的最大错误。
|
||||
|
||||
“不要进入[任何类型的命令行界面(CLI)工作]时就期望命令会以合理或一致的方式工作,因为这可能会导致你感到挫折。这不是因为设计选择不当 —— 虽然当你在键盘上敲击时就像在敲在你的脑袋上一样 —— 而是反映了这些系统是历经了几代的软件和操作系统的发展而陆续添加完成的事实。顺其自然,写下或记住你需要的命令,并且(尽量不要)在[事情不是你所期望的][3]时感到沮丧。” —— [Gina Likins] [4]
|
||||
|
||||
“尽可能简单地复制和粘贴命令以使事情顺利进行,首先阅读命令,至少对将要执行的操作有一个大致的了解,特别是如果有管道命令时,如果有多个管道更要特别注意。有很多破坏性的命令看起来无害 —— 直到你意识到它们能做什么(例如 `rm`、`dd`),而你不会想要意外破坏什么东西(别问我怎么知道)。” —— [Katie McLaughlin] [5]
|
||||
|
||||
“在我的 Linux 之旅的早期,我并不知道我所处在文件系统中的位置的重要性。我正在删除一些我认为是我的主目录的文件,我输入了 `sudo rm -rf *`,然后就删除了我系统上的所有启动文件。现在,我经常使用 `pwd` 来确保我在发出这样的命令之前确认我在哪里。幸运的是,我能够使用 USB 驱动器启动被搞坏的笔记本电脑并恢复我的文件。” —— [Don Watkins] [6]
|
||||
|
||||
“不要因为你认为‘权限很难理解’而你希望应用程序可以访问某些内容时就将整个文件系统的权限重置为 [777][7]。”—— [Matthew Helmke] [8]
|
||||
|
||||
“我从我的系统中删除一个软件包,而我没有检查它依赖的其他软件包。我只是让它删除它想删除要的东西,最终导致我的一些重要程序崩溃并变得不可用。” —— [Kedar Vijay Kulkarni] [9]
|
||||
|
||||
你在学习使用 Linux 时犯过什么错误?请在评论中分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/linux-rookie-mistakes
|
||||
|
||||
作者:[Jen Wike Huger][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jen-wike/users/bcotton/users/petercheer/users/greg-p/users/greg-p
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/mistake_bug_fix_find_error.png?itok=PZaz3dga (magnifying glass on computer screen, finding a bug in the code)
|
||||
[2]: https://opensource.com/resources/linux
|
||||
[3]: https://lintqueen.com/2017/07/02/learning-while-frustrated/
|
||||
[4]: https://opensource.com/users/lintqueen
|
||||
[5]: https://opensource.com/users/glasnt
|
||||
[6]: https://opensource.com/users/don-watkins
|
||||
[7]: https://www.maketecheasier.com/file-permissions-what-does-chmod-777-means/
|
||||
[8]: https://twitter.com/matthewhelmke
|
||||
[9]: https://opensource.com/users/kkulkarn
|
||||
@ -0,0 +1,98 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10957-1.html)
|
||||
[#]: subject: (How we built a Linux desktop app with Electron)
|
||||
[#]: via: (https://opensource.com/article/19/4/linux-desktop-electron)
|
||||
[#]: author: (Nils Ganther https://opensource.com/users/nils-ganther)
|
||||
|
||||
我们是如何使用 Electron 构建 Linux 桌面应用程序的
|
||||
======
|
||||
|
||||
> 这是借助 Electron 框架,构建一个在 Linux 桌面上原生运行的开源电子邮件服务的故事。
|
||||
|
||||

|
||||
|
||||
[Tutanota][2] 是一种安全的开源电子邮件服务,它可通过浏览器使用,也有 iOS 和 Android 应用。其客户端代码在 GPLv3 下发布,Android 应用程序可在 [F-Droid][3] 上找到,以便每个人都可以使用完全与 Google 无关的版本。
|
||||
|
||||
由于 Tutanota 关注开源和 Linux 客户端开发,因此我们希望为 Linux 和其他平台发布一个桌面应用程序。作为一个小团队,我们很快就排除了为 Linux、Windows 和 MacOS 构建原生应用程序的可能性,并决定使用 [Electron][4] 来构建我们的应用程序。
|
||||
|
||||
对于任何想要快速交付视觉一致的跨平台应用程序的人来说,Electron 是最适合的选择,尤其是如果你已经有一个 Web 应用程序,想要从浏览器 API 的束缚中摆脱出来时。Tutanota 就是这样一个案例。
|
||||
|
||||
Tutanota 基于 [SystemJS][5] 和 [Mithril][6],旨在为每个人提供简单、安全的电子邮件通信。 因此,它必须提供很多用户期望从电子邮件客户端获得的标准功能。
|
||||
|
||||
由于采用了现代 API 和标准,其中一些功能(如基本的推送通知、搜索文本和联系人以及支持双因素身份验证)很容易在浏览器中提供。其它功能(例如自动备份或无需我们的服务器中转的 IMAP 支持)需要对系统资源的限制性访问,而这正是 Electron 框架提供的功能。
|
||||
|
||||
虽然有人批评 Electron “只是一个基本的包装”,但它有明显的好处:
|
||||
|
||||
* Electron 可以使你能够快速地为 Linux、Windows 和 MacOS 桌面构造 Web 应用。事实上,大多数 Linux 桌面应用都是使用 Electron 构建的。
|
||||
* Electron 可以轻松地将桌面客户端与 Web 应用程序达到同样的功能水准。
|
||||
* 发布桌面应用程序后,你可以自由使用开发功能添加桌面端特定的功能,从而增强可用性和安全性。
|
||||
* 最后但同样重要的是,这是让应用程序具备原生的感觉、融入用户系统,而同时保持其识别度的好方法。
|
||||
|
||||
### 满足用户的需求
|
||||
|
||||
Tutanota 不依靠于大笔的投资资金,而是依靠社区驱动的项目。基于越来越多的用户升级到我们的免费服务的付费计划,我们有机地发展我们的团队。倾听用户的需求不仅对我们很重要,而且对我们的成功至关重要。
|
||||
|
||||
提供桌面客户端是 Tutanota 用户[最想要的功能][7],我们感到自豪的是,我们现在可以为所有用户提供免费的桌面客户端测试版。(我们还实现了另一个高度要求的功能 —— [搜索加密数据][8] —— 但这是另一个主题了。)
|
||||
|
||||
我们喜欢为用户提供签名版本的 Tutanota 并支持浏览器中无法实现的功能,例如通过后台进程推送通知。 现在,我们计划添加更多特定于桌面的功能,例如 IMAP 支持(而不依赖于我们的服务器充当代理),自动备份和离线可用性。
|
||||
|
||||
我们选择 Electron 是因为它的 Chromium 和 Node.js 的组合最适合我们的小型开发团队,因为它只需要对我们的 Web 应用程序进行最小的更改。在我们开始使用时,可以将浏览器 API 用于所有功能特别有用,随着我们的进展,慢慢地用更多原生版本替换这些组件。这种方法对附件下载和通知特别方便。
|
||||
|
||||
### 调整安全性
|
||||
|
||||
我们知道有些人关注 Electron 的安全问题,但我们发现 Electron 在 Web 应用程序中微调访问的选项非常令人满意。你可以使用 Electron 的[安全文档][9]和 Luca Carettoni 的[Electron 安全清单][10]等资源,来帮助防止 Web 应用程序中不受信任的内容发生灾难性事故。
|
||||
|
||||
### 实现特定功能
|
||||
|
||||
Tutanota Web 客户端从一开始就构建了一个用于进程间通信的可靠协议。我们利用 Web 线程在加密和请求数据时保持用户界面(UI)响应性。当我们开始实现我们的移动应用时,这就派上用场,这些应用程序使用相同的协议在原生部分和 Web 视图之间进行通信。
|
||||
|
||||
这就是为什么当我们开始构建桌面客户端时,很多用于本机推送通知、打开邮箱和使用文件系统的部分等已经存在,因此只需要实现原生端(Node.js)。
|
||||
|
||||
另一个便利是我们的构建过程使用 [Babel 转译器][11],它允许我们以现代 ES6 JavaScript 编写整个代码库,并在不同环境之间混合和匹配功能模块。这使我们能够快速调整基于 Electron 的桌面应用程序的代码。但是,我们也遇到了一些挑战。
|
||||
|
||||
### 克服挑战
|
||||
|
||||
虽然 Electron 允许我们很容易地与不同平台的桌面环境集成,但你不能低估投入的时间!最后,正是这些小事情占用了比我们预期更多的时间,但对完成桌面客户端项目也至关重要。
|
||||
|
||||
特定于平台的代码导致了大部分阻碍:
|
||||
|
||||
* 例如,窗口管理和托盘仍然在三个平台上以略有不同的方式处理。
|
||||
* 注册 Tutanota 作为默认邮件程序并设置自动启动需要深入 Windows 注册表,同时确保以 [UAC] [12] 兼容的方式提示用户进行管理员访问。
|
||||
* 我们需要使用 Electron 的 API 作为快捷方式和菜单,以提供复制、粘贴、撤消和重做等标准功能。
|
||||
|
||||
由于用户对不同平台上的应用程序的某些(有时不直接兼容)行为的期望,此过程有点复杂。使三个版本感觉像原生的需要一些迭代,甚至需要对 Web 应用程序进行一些适度的补充,以提供类似于浏览器中的文本搜索的功能。
|
||||
|
||||
### 总结
|
||||
|
||||
我们在 Electron 方面的经验基本上是积极的,我们在不到四个月的时间内完成了该项目。尽管有一些相当耗时的功能,但我们感到惊讶的是,我们可以轻松地为 Linux 提供一个测试版的 [Tutanota 桌面客户端][13]。如果你有兴趣,可以深入了解 [GitHub][14] 上的源代码。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/linux-desktop-electron
|
||||
|
||||
作者:[Nils Ganther][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/nils-ganther
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/email_paper_envelope_document.png?itok=uPj_kouJ (document sending)
|
||||
[2]: https://tutanota.com/
|
||||
[3]: https://f-droid.org/en/packages/de.tutao.tutanota/
|
||||
[4]: https://electronjs.org/
|
||||
[5]: https://github.com/systemjs/systemjs
|
||||
[6]: https://mithril.js.org/
|
||||
[7]: https://tutanota.uservoice.com/forums/237921-general/filters/top?status_id=1177482
|
||||
[8]: https://tutanota.com/blog/posts/first-search-encrypted-data/
|
||||
[9]: https://electronjs.org/docs/tutorial/security
|
||||
[10]: https://www.blackhat.com/docs/us-17/thursday/us-17-Carettoni-Electronegativity-A-Study-Of-Electron-Security-wp.pdf
|
||||
[11]: https://babeljs.io/
|
||||
[12]: https://en.wikipedia.org/wiki/User_Account_Control
|
||||
[13]: https://tutanota.com/blog/posts/desktop-clients/
|
||||
[14]: https://www.github.com/tutao/tutanota
|
||||
@ -0,0 +1,137 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Modrisco)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10968-1.html)
|
||||
[#]: subject: (Epic Games Store is Now Available on Linux Thanks to Lutris)
|
||||
[#]: via: (https://itsfoss.com/epic-games-lutris-linux/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
有了 Lutris,Linux 现在也可以启动 Epic 游戏商城
|
||||
======
|
||||
|
||||
> 开源游戏平台 Lutris 现在使你能够在 Linux 上使用 Epic 游戏商城。我们使用 Ubuntu 19.04 版本进行了测试,以下是我们的使用体验。
|
||||
|
||||
[在 Linux 上玩游戏][1] 正变得越来越容易。Steam [正在开发中的][3] 特性可以帮助你实现 [在 Linux 上玩 Windows 游戏][2]。
|
||||
|
||||
如果说 Steam 在 Linux 运行 Windows 游戏领域还是新玩家,而 Lutris 却已从事多年。
|
||||
|
||||
[Lutris][4] 是一款为 Linux 开发的开源游戏平台,提供诸如 Origin、Steam、战网等平台的游戏安装器。它使用 Wine 来运行 Linux 不能支持的程序。
|
||||
|
||||
Lutris 近期宣布你可以通过它来运行 Epic 游戏商店。
|
||||
|
||||
### Lutris 为 Linux 带来了 Epic 游戏
|
||||
|
||||
![Epic Games Store Lutris Linux][5]
|
||||
|
||||
[Epic 游戏商城][6] 是一个类似 Steam 的电子游戏分销平台。它目前只支持 Windows 和 macOS。
|
||||
|
||||
Lutris 团队付出了大量努力使 Linux 用户可以通过 Lutris 使用 Epic 游戏商城。虽然我不用 Epic 商城,但可以通过 Lutris 在 Linux 上运行 Epic 商城终归是个好消息。
|
||||
|
||||
> 好消息! 你现在可以通过 Lutris 安装获得 [@EpicGames][7] 商城在 Linux 下的全功能支持!没有发现任何问题。 <https://t.co/cYmd7PcYdG>[@TimSweeneyEpic][8] 可能会很喜欢 😊
|
||||
>
|
||||
> ![pic.twitter.com/7mt9fXt7TH][9]
|
||||
>
|
||||
> — Lutris Gaming (@LutrisGaming) [April 17, 2019][10]
|
||||
|
||||
作为一名狂热的游戏玩家和 Linux 用户,我立即得到了这个消息,并安装了 Lutris 来运行 Epic 游戏。
|
||||
|
||||
**备注:** 我使用 [Ubuntu 19.04][11] 来测试 Linux 环境下的游戏运行情况。
|
||||
|
||||
### 通过 Lutris 在 Linux 下使用 Epic 游戏商城
|
||||
|
||||
为了在你的 Linux 系统中安装 Epic 游戏商城,请确保你已经安装了 Wine 和 Python 3。接下来,[在 Ubuntu 中安装 Wine][12] ,或任何你正在使用的 Linux 发行版本也都可以。然后, [从官方网站下载 Lutris][13].
|
||||
|
||||
#### 安装 Epic 游戏商城
|
||||
|
||||
Lutris 安装成功后,直接启动它。
|
||||
|
||||
当我尝试时,我遇到了一个问题(当我用 GUI 启动时却没有遇到)。当我尝试在命令行输入 `lutris` 来启动时,我发现了下图所示的错误:
|
||||
|
||||
![][15]
|
||||
|
||||
感谢 Abhishek,我了解到了这是一个常见问题 (你可以在 [GitHub][16] 上查看这个问题)。
|
||||
|
||||
总之,为了解决这个问题,我需要在命令行中输入以下命令:
|
||||
|
||||
```
|
||||
export LC_ALL=C
|
||||
```
|
||||
|
||||
当你遇到同样的问题时,只要你输入这个命令,就能正常启动 Lutris 了。
|
||||
|
||||
**注意**:每次启动 Lutris 时都必须输入这个命令。因此,最好将其添加到 `.bashrc` 文件或环境变量列表中。
|
||||
|
||||
上述操作完成后,只要启动并搜索 “Epic Games Store” 会显示以下图片中的内容:
|
||||
|
||||
![Epic Games Store in Lutris][17]
|
||||
|
||||
在这里,我已经安装过了,所以你将会看到“安装”选项,它会自动询问你是否需要安装需要的包。只需要继续操作就可以成功安装。就是这样,不需要任何黑科技。
|
||||
|
||||
#### 玩一款 Epic 游戏商城中的游戏
|
||||
|
||||
![Epic Games Store][18]
|
||||
|
||||
现在我们已经通过 Lutris 在 Linux 上安装了 Epic 游戏商城,启动它并登录你的账号就可以开始了。
|
||||
|
||||
但这真会奏效吗?
|
||||
|
||||
*是的,Epic 游戏商城可以运行。* **但是所有游戏都不能玩。**(LCTT 译注:莫生气,请看文末的进一步解释!)
|
||||
|
||||
好吧,我并没有尝试过所有内容,但是我拿了一个免费的游戏(Transistor —— 一款回合制 ARPG 游戏)来检查它是否工作。
|
||||
|
||||
![Transistor – Epic Games Store][19]
|
||||
|
||||
很不幸,游戏没有启动。当我运行时界面显示了 “Running” 不过什么都没有发生。
|
||||
|
||||
到目前为止,我还不知道有什么解决方案 —— 所以如果我找到解决方案,我会尽力让你们知道最新情况。
|
||||
|
||||
### 总结
|
||||
|
||||
通过 Lutris 这样的工具使 Linux 的游戏场景得到了改善,这终归是个好消息 。不过,仍有许多工作要做。
|
||||
|
||||
对于在 Linux 上运行的游戏来说,无障碍运行仍然是一个挑战。其中可能就会有我遇到的这种问题,或者其它类似的。但它正朝着正确的方向发展 —— 即使还存在着一些问题。
|
||||
|
||||
你有什么看法吗?你是否也尝试用 Lutris 在 Linux 上启动 Epic 游戏商城?在下方评论让我们看看你的意见。
|
||||
|
||||
### 补充
|
||||
|
||||
Transistor 实际上有一个原生的 Linux 移植版。到目前为止,我从 Epic 获得的所有游戏都是如此。所以我会试着压下我的郁闷,而因为 Epic 只让你玩你通过他们的商店/启动器购买的游戏,所以在 Linux 机器上用 Lutris 玩这个原生的 Linux 游戏是不可能的。这简直愚蠢极了。Steam 有一个原生的 Linux 启动器,虽然不是很理想,但它可以工作。GOG 允许你从网站下载购买的内容,可以在你喜欢的任何平台上玩这些游戏。他们的启动器完全是可选的。
|
||||
|
||||
我对此非常恼火,因为我在我的 Epic 库中的游戏都是可以在我的笔记本电脑上运行得很好的游戏,当我坐在桌面前时,玩起来很有趣。但是因为那台桌面机是我唯一拥有的 Windows 机器……
|
||||
|
||||
我选择使用 Linux 时已经知道会存在兼容性问题,并且我有一个专门用于游戏的 Windows 机器,而我通过 Epic 获得的游戏都是免费的,所以我在这里只是表示一下不满。但是,他们两个作为最著名的竞争对手,Epic 应该有在我的 Linux 机器上玩原生 Linux 移植版的机制。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/epic-games-lutris-linux/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Modrisco](https://github.com/Modrisco)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-7316-1.html
|
||||
[2]: https://linux.cn/article-10061-1.html
|
||||
[3]: https://linux.cn/article-10054-1.html
|
||||
[4]: https://lutris.net/
|
||||
[5]: https://itsfoss.com/wp-content/uploads/2019/04/epic-games-store-lutris-linux-800x450.png
|
||||
[6]: https://www.epicgames.com/store/en-US/
|
||||
[7]: https://twitter.com/EpicGames?ref_src=twsrc%5Etfw
|
||||
[8]: https://twitter.com/TimSweeneyEpic?ref_src=twsrc%5Etfw
|
||||
[9]: https://pbs.twimg.com/media/D4XkXafX4AARDkW?format=jpg&name=medium
|
||||
[10]: https://twitter.com/LutrisGaming/status/1118552969816018948?ref_src=twsrc%5Etfw
|
||||
[11]: https://itsfoss.com/ubuntu-19-04-release-features/
|
||||
[12]: https://itsfoss.com/install-latest-wine/
|
||||
[13]: https://lutris.net/downloads/
|
||||
[14]: https://itsfoss.com/ubuntu-mate-entroware/
|
||||
[15]: https://itsfoss.com/wp-content/uploads/2019/04/lutris-error.jpg
|
||||
[16]: https://github.com/lutris/lutris/issues/660
|
||||
[17]: https://itsfoss.com/wp-content/uploads/2019/04/lutris-epic-games-store-800x520.jpg
|
||||
[18]: https://itsfoss.com/wp-content/uploads/2019/04/epic-games-store-800x450.jpg
|
||||
[19]: https://itsfoss.com/wp-content/uploads/2019/04/transistor-game-epic-games-store-800x410.jpg
|
||||
[20]: https://itsfoss.com/skpe-alpha-linux/
|
||||
@ -1,26 +1,25 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: translator: (tomjlw)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10955-1.html)
|
||||
[#]: subject: (How to identify same-content files on Linux)
|
||||
[#]: via: (https://www.networkworld.com/article/3390204/how-to-identify-same-content-files-on-linux.html#tk.rss_all)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
How to identify same-content files on Linux
|
||||
如何在 Linux 上识别同样内容的文件
|
||||
======
|
||||
Copies of files sometimes represent a big waste of disk space and can cause confusion if you want to make updates. Here are six commands to help you identify these files.
|
||||
> 有时文件副本相当于对硬盘空间的巨大浪费,并会在你想要更新文件时造成困扰。以下是用来识别这些文件的六个命令。
|
||||
|
||||
![Vinoth Chandar \(CC BY 2.0\)][1]
|
||||
|
||||
In a recent post, we looked at [how to identify and locate files that are hard links][2] (i.e., that point to the same disk content and share inodes). In this post, we'll check out commands for finding files that have the same _content_ , but are not otherwise connected.
|
||||
在最近的帖子中,我们看了[如何识别并定位硬链接的文件][2](即,指向同一硬盘内容并共享 inode)。在本文中,我们将查看能找到具有相同*内容*,却不相链接的文件的命令。
|
||||
|
||||
Hard links are helpful because they allow files to exist in multiple places in the file system while not taking up any additional disk space. Copies of files, on the other hand, sometimes represent a big waste of disk space and run some risk of causing some confusion if you want to make updates. In this post, we're going to look at multiple ways to identify these files.
|
||||
硬链接很有用是因为它们能够使文件存放在文件系统内的多个地方却不会占用额外的硬盘空间。另一方面,有时文件副本相当于对硬盘空间的巨大浪费,在你想要更新文件时也会有造成困扰之虞。在本文中,我们将看一下多种识别这些文件的方式。
|
||||
|
||||
**[ Two-Minute Linux Tips:[Learn how to master a host of Linux commands in these 2-minute video tutorials][3] ]**
|
||||
### 用 diff 命令比较文件
|
||||
|
||||
### Comparing files with the diff command
|
||||
|
||||
Probably the easiest way to compare two files is to use the **diff** command. The output will show you the differences between the two files. The < and > signs indicate whether the extra lines are in the first (<) or second (>) file provided as arguments. In this example, the extra lines are in backup.html.
|
||||
可能比较两个文件最简单的方法是使用 `diff` 命令。输出会显示你文件的不同之处。`<` 和 `>` 符号代表在当参数传过来的第一个(`<`)或第二个(`>`)文件中是否有额外的文字行。在这个例子中,在 `backup.html` 中有额外的文字行。
|
||||
|
||||
```
|
||||
$ diff index.html backup.html
|
||||
@ -30,18 +29,18 @@ $ diff index.html backup.html
|
||||
> </pre>
|
||||
```
|
||||
|
||||
If diff shows no output, that means the two files are the same.
|
||||
如果 `diff` 没有输出那代表两个文件相同。
|
||||
|
||||
```
|
||||
$ diff home.html index.html
|
||||
$
|
||||
```
|
||||
|
||||
The only drawbacks to diff are that it can only compare two files at a time, and you have to identify the files to compare. Some commands we will look at in this post can find the duplicate files for you.
|
||||
`diff` 的唯一缺点是它一次只能比较两个文件并且你必须指定用来比较的文件,这篇帖子中的一些命令可以为你找到多个重复文件。
|
||||
|
||||
### Using checksums
|
||||
### 使用校验和
|
||||
|
||||
The **cksum** (checksum) command computes checksums for files. Checksums are a mathematical reduction of the contents to a lengthy number (like 2819078353 228029). While not absolutely unique, the chance that files that are not identical in content would result in the same checksum is extremely small.
|
||||
`cksum`(checksum) 命令计算文件的校验和。校验和是一种将文字内容转化成一个长数字(例如2819078353 228029)的数学简化。虽然校验和并不是完全独有的,但是文件内容不同校验和却相同的概率微乎其微。
|
||||
|
||||
```
|
||||
$ cksum *.html
|
||||
@ -50,11 +49,11 @@ $ cksum *.html
|
||||
4073570409 227985 index.html
|
||||
```
|
||||
|
||||
In the example above, you can see how the second and third files yield the same checksum and can be assumed to be identical.
|
||||
在上述示例中,你可以看到产生同样校验和的第二个和第三个文件是如何可以被默认为相同的。
|
||||
|
||||
### Using the find command
|
||||
### 使用 find 命令
|
||||
|
||||
While the find command doesn't have an option for finding duplicate files, it can be used to search files by name or type and run the cksum command. For example:
|
||||
虽然 `find` 命令并没有寻找重复文件的选项,它依然可以被用来通过名字或类型寻找文件并运行 `cksum` 命令。例如:
|
||||
|
||||
```
|
||||
$ find . -name "*.html" -exec cksum {} \;
|
||||
@ -63,9 +62,9 @@ $ find . -name "*.html" -exec cksum {} \;
|
||||
4073570409 227985 ./index.html
|
||||
```
|
||||
|
||||
### Using the fslint command
|
||||
### 使用 fslint 命令
|
||||
|
||||
The **fslint** command can be used to specifically find duplicate files. Note that we give it a starting location. The command can take quite some time to complete if it needs to run through a large number of files. Here's output from a very modest search. Note how it lists the duplicate files and also looks for other issues, such as empty directories and bad IDs.
|
||||
`fslint` 命令可以被特地用来寻找重复文件。注意我们给了它一个起始位置。如果它需要遍历相当多的文件,这就需要花点时间来完成。注意它是如何列出重复文件并寻找其它问题的,比如空目录和坏 ID。
|
||||
|
||||
```
|
||||
$ fslint .
|
||||
@ -86,15 +85,15 @@ index.html
|
||||
-------------------------Non Stripped executables
|
||||
```
|
||||
|
||||
You may have to install **fslint** on your system. You will probably have to add it to your search path, as well:
|
||||
你可能需要在你的系统上安装 `fslint`。你可能也需要将它加入你的命令搜索路径:
|
||||
|
||||
```
|
||||
$ export PATH=$PATH:/usr/share/fslint/fslint
|
||||
```
|
||||
|
||||
### Using the rdfind command
|
||||
### 使用 rdfind 命令
|
||||
|
||||
The **rdfind** command will also look for duplicate (same content) files. The name stands for "redundant data find," and the command is able to determine, based on file dates, which files are the originals — which is helpful if you choose to delete the duplicates, as it will remove the newer files.
|
||||
`rdfind` 命令也会寻找重复(相同内容的)文件。它的名字意即“重复数据搜寻”,并且它能够基于文件日期判断哪个文件是原件——这在你选择删除副本时很有用因为它会移除较新的文件。
|
||||
|
||||
```
|
||||
$ rdfind ~
|
||||
@ -111,7 +110,7 @@ Totally, 223 KiB can be reduced.
|
||||
Now making results file results.txt
|
||||
```
|
||||
|
||||
You can also run this command in "dryrun" (i.e., only report the changes that might otherwise be made).
|
||||
你可以在 `dryrun` 模式中运行这个命令 (换句话说,仅仅汇报可能会另外被做出的改动)。
|
||||
|
||||
```
|
||||
$ rdfind -dryrun true ~
|
||||
@ -128,7 +127,7 @@ Removed 9 files due to unique sizes from list.2 files left.
|
||||
(DRYRUN MODE) Now making results file results.txt
|
||||
```
|
||||
|
||||
The rdfind command also provides options for things such as ignoring empty files (-ignoreempty) and following symbolic links (-followsymlinks). Check out the man page for explanations.
|
||||
`rdfind` 命令同样提供了类似忽略空文档(`-ignoreempty`)和跟踪符号链接(`-followsymlinks`)的功能。查看 man 页面获取解释。
|
||||
|
||||
```
|
||||
-ignoreempty ignore empty files
|
||||
@ -146,7 +145,7 @@ The rdfind command also provides options for things such as ignoring empty files
|
||||
-n, -dryrun display what would have been done, but don't do it
|
||||
```
|
||||
|
||||
Note that the rdfind command offers an option to delete duplicate files with the **-deleteduplicates true** setting. Hopefully the command's modest problem with grammar won't irritate you. ;-)
|
||||
注意 `rdfind` 命令提供了 `-deleteduplicates true` 的设置选项以删除副本。希望这个命令语法上的小问题不会惹恼你。;-)
|
||||
|
||||
```
|
||||
$ rdfind -deleteduplicates true .
|
||||
@ -154,11 +153,11 @@ $ rdfind -deleteduplicates true .
|
||||
Deleted 1 files. <==
|
||||
```
|
||||
|
||||
You will likely have to install the rdfind command on your system. It's probably a good idea to experiment with it to get comfortable with how it works.
|
||||
你将可能需要在你的系统上安装 `rdfind` 命令。试验它以熟悉如何使用它可能是一个好主意。
|
||||
|
||||
### Using the fdupes command
|
||||
### 使用 fdupes 命令
|
||||
|
||||
The **fdupes** command also makes it easy to identify duplicate files and provides a large number of useful options — like **-r** for recursion. In its simplest form, it groups duplicate files together like this:
|
||||
`fdupes` 命令同样使得识别重复文件变得简单。它同时提供了大量有用的选项——例如用来迭代的 `-r`。在这个例子中,它像这样将重复文件分组到一起:
|
||||
|
||||
```
|
||||
$ fdupes ~
|
||||
@ -173,7 +172,7 @@ $ fdupes ~
|
||||
/home/shs/hideme.png
|
||||
```
|
||||
|
||||
Here's an example using recursion. Note that many of the duplicate files are important (users' .bashrc and .profile files) and should clearly not be deleted.
|
||||
这是使用迭代的一个例子,注意许多重复文件是重要的(用户的 `.bashrc` 和 `.profile` 文件)并且不应被删除。
|
||||
|
||||
```
|
||||
# fdupes -r /home
|
||||
@ -204,7 +203,7 @@ Here's an example using recursion. Note that many of the duplicate files are imp
|
||||
/home/shs/PNGs/Sandra_rotated.png
|
||||
```
|
||||
|
||||
The fdupe command's many options are listed below. Use the **fdupes -h** command, or read the man page for more details.
|
||||
`fdupe` 命令的许多选项列如下。使用 `fdupes -h` 命令或者阅读 man 页面获取详情。
|
||||
|
||||
```
|
||||
-r --recurse recurse
|
||||
@ -229,15 +228,11 @@ The fdupe command's many options are listed below. Use the **fdupes -h** command
|
||||
-h --help displays help
|
||||
```
|
||||
|
||||
The fdupes command is another one that you're like to have to install and work with for a while to become familiar with its many options.
|
||||
`fdupes` 命令是另一个你可能需要安装并使用一段时间才能熟悉其众多选项的命令。
|
||||
|
||||
### Wrap-up
|
||||
### 总结
|
||||
|
||||
Linux systems provide a good selection of tools for locating and potentially removing duplicate files, along with options for where you want to run your search and what you want to do with duplicate files when you find them.
|
||||
|
||||
**[ Also see:[Invaluable tips and tricks for troubleshooting Linux][4] ]**
|
||||
|
||||
Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
|
||||
Linux 系统提供能够定位并(潜在地)能移除重复文件的一系列的好工具,以及能让你指定搜索区域及当对你所发现的重复文件时的处理方式的选项。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -245,8 +240,8 @@ via: https://www.networkworld.com/article/3390204/how-to-identify-same-content-f
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -258,3 +253,4 @@ via: https://www.networkworld.com/article/3390204/how-to-identify-same-content-f
|
||||
[4]: https://www.networkworld.com/article/3242170/linux/invaluable-tips-and-tricks-for-troubleshooting-linux.html
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
|
||||
@ -0,0 +1,83 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (arrowfeng)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10992-1.html)
|
||||
[#]: subject: (5 essential values for the DevOps mindset)
|
||||
[#]: via: (https://opensource.com/article/19/5/values-devops-mindset)
|
||||
[#]: author: (Brent Aaron Reed https://opensource.com/users/brentaaronreed/users/wpschaub/users/wpschaub/users/wpschaub/users/cobiacomm/users/marcobravo/users/brentaaronreed)
|
||||
|
||||
DevOps 思维模式的 5 个基本价值观
|
||||
======
|
||||
|
||||
> 人和流程比在解决的业务问题的任何技术“银弹”更重要,且需要花更多的时间。
|
||||
|
||||
![human head, brain outlined with computer hardware background][1]
|
||||
|
||||
今天的许多 IT 专业人士都在努力适应变化和扰动。这么说吧,你是否正在努力适应变化?你觉得不堪重负吗?这并不罕见。今天,IT 的现状还不够好,所以需要不断尝试重新自我演进。
|
||||
|
||||
凭借 30 多年的IT综合经验,我们见证了人员与关系对于 IT 企业提高效率和帮助企业蓬勃发展的重要性。但是,在大多数情况下,我们关于 IT 解决方案的对话始于技术,而不是从人员和流程开始。寻找“银弹”来解决业务和 IT 挑战的倾向过于普遍。但你不能想着可以买到创新、DevOps 或有效的团队和工作方式;他们需要得到培养,支持和引导。
|
||||
|
||||
由于扰动如此普遍,并且对变革速度存在如此迫切的需求,我们需要纪律和围栏。下面描述的 DevOps 思维模式的五个基本价值观将支持将我们的实践。这些价值观不是新观念;正如我们从经验中学到的那样,它们被重构了。一些价值观可以互换的,它们是灵活的,并且它们如支柱一样导向了支持这五个价值观的整体原则。
|
||||
|
||||
![5 essential values for the DevOps mindset][2]
|
||||
|
||||
### 1、利益相关方的反馈至关重要
|
||||
|
||||
我们如何知道我们是否为我们创造了比利益相关方更多的价值?我们需要持久的质量数据来分析、通知并推动更好的决策。来自可靠来源的相关信息对于任何业务的蓬勃发展至关重要。我们需要倾听并理解我们的利益相关方所说的,而不是说我们需要以一种方式实施变革,使我们能够调整我们的思维、流程和技术,并根据需要对其进行调整以使我们的利益相关者满意。由于信息(数据)不正确,我们常常看到的变化过少,或者由于错误的原因而发生了很多变化。因此,将变更与利益相关方的反馈结合起来是一项基本价值观,并有助我们专注于使公司成功最重要的事情。
|
||||
|
||||
> 关注我们的利益相关方及其反馈,而不仅仅是为了改变而改变。
|
||||
|
||||
### 2、超越当今流程的极限进行改进
|
||||
|
||||
我们希望我们的产品和服务能够不断让客户满意,他们是我们最重要的利益相关方。因此,我们需要不断改进。这不仅仅是关系到质量;它还可能意味着成本、可用性、相关性以及许多其他目标和因素。创建可重复的流程或使用通用框架是非常棒的,它们可以改善治理和许多其他问题。但是,这不应该是我们的最终目标。在寻找改进方法时,我们必须调整我们的流程,并辅以正确的技术和工具。可能有理由抛出一个“所谓的”框架,因为不这样做可能会增加浪费,更糟糕的是只是“货物结果”(做一些没有价值或目的的东西)。
|
||||
|
||||
> 力争始终创新并改进可重复的流程和框架。
|
||||
|
||||
### 3、不要用新的孤岛来打破旧的孤岛
|
||||
|
||||
孤岛和 DevOps 是不兼容的。我们经常能看到:IT 主管带来了所谓的“专家”来实施敏捷和 DevOps,他们做了什么?这些“专家”在现有问题的基础上创建了一个新问题,这是 IT 部门和业务中又增加了一个孤岛。创造“DevOps”职位违背了敏捷和 DevOps 基于打破孤岛的原则。在敏捷和 DevOps 中,团队合作是必不可少的,如果你不在自组织团队中工作,那么你就不会做任何事情。
|
||||
|
||||
> 相互激励和共享,而不是成为英雄或创建一个孤岛。
|
||||
|
||||
### 4、了解你的客户意味着跨组织协作
|
||||
|
||||
企业的任何一个部分都不是一个独立的实体,因为它们都有利益相关方,主要利益相关方始终是客户。“客户永远是对的”(或国王,我喜欢这样说)。关键是,没有客户就真的没有业务,而且为了保持业务,如今我们需要与竞争对手“区别对待”。我们还需要了解客户对我们的看法以及他们对我们的期望。了解客户的需求势在必行,需要及时反馈,以确保业务能够快速、负责地满足这些主要利益相关者的需求和关注。
|
||||
|
||||
![Minimize time spent with build-measure-learn process][3]
|
||||
|
||||
无论是想法、概念、假设还是直接利益相关方的反馈,我们都需要通过使用探索、构建、测试和交付生命周期来识别和衡量我们的产品提供的功能或服务。从根本上说,这意味着我们需要在整个组织中“插入”我们的组织。在持续创新、学习和 DevOps 方面没有任何边界。因此,当我们在整个企业中进行衡量时,我们可以理解整体并采取可行的、有意义的步骤来改进。
|
||||
|
||||
> 衡量整个组织的绩效,而不仅仅是在业务范围内。
|
||||
|
||||
### 5、通过热情鼓励采纳
|
||||
|
||||
不是每个人都要被驱使去学习、适应和改变;然而,就像微笑可能具有传染性一样,学习和意愿成为变革文化的一部分也是如此。在学习文化中适应和演化为一群人提供了学习和传递信息(即文化传播)的自然机制。学习风格、态度、方法和过程不断演化,因此我们可以改进它们。下一步是应用所学和改进的内容并与同事分享信息。学习不会自动发生;它需要努力、评估、纪律、意识,特别是沟通;遗憾的是,这些都是工具和自动化无法提供的。检查你的流程、自动化、工具策略和实施工作,使其透明化,并与你的同事协作重复使用和改进。
|
||||
|
||||
> 通过精益交付促进学习文化,而不仅仅是工具和自动化。
|
||||
|
||||
### 总结
|
||||
|
||||
![Continuous goals of DevOps mindset][4]
|
||||
|
||||
随着我们的公司采用 DevOps,我们继续在各种书籍、网站或自动化软件上倡导这五个价值观。采用这种思维方式需要时间,这与我们以前作为系统管理员所做的完全不同。这是一种全新的工作方式,需要很多年才能成熟。这些原则是否与你自己的原则一致?在评论或我们的网站 [Agents of chaos][5] 上分享。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/5/values-devops-mindset
|
||||
|
||||
作者:[Brent Aaron Reed][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[arrowfeng](https://github.com/arrowfeng)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/brentaaronreed/users/wpschaub/users/wpschaub/users/wpschaub/users/cobiacomm/users/marcobravo/users/brentaaronreed
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/brain_data.png?itok=RH6NA32X (human head, brain outlined with computer hardware background)
|
||||
[2]: https://opensource.com/sites/default/files/uploads/devops_mindset_values.png (5 essential values for the DevOps mindset)
|
||||
[3]: https://opensource.com/sites/default/files/uploads/devops_mindset_minimze-time.jpg (Minimize time spent with build-measure-learn process)
|
||||
[4]: https://opensource.com/sites/default/files/uploads/devops_mindset_continuous.png (Continuous goals of DevOps mindset)
|
||||
[5]: http://agents-of-chaos.org
|
||||
@ -0,0 +1,299 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (chen-ni)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10982-1.html)
|
||||
[#]: subject: (10 Places Where You Can Buy Linux Computers)
|
||||
[#]: via: (https://itsfoss.com/get-linux-laptops/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
可以买到 Linux 电脑的 10 个地方
|
||||
======
|
||||
|
||||
> 你在找 Linux 笔记本吗? 这里列出一些出售 Linux 电脑或者是专注于 Linux 系统的电商。
|
||||
|
||||
如今市面上几乎所有的电脑(苹果除外)都预装了 Windows 系统。Linux 使用者的惯常做法就是买一台这样的电脑,然后要么删除 Windows 系统并安装 Linux,要么[安装 Linux 和 Windows 的双系统][1]。
|
||||
|
||||
但 Windows 系统并非无法避免。你其实也可以买到 Linux 电脑。
|
||||
|
||||
不过,既然可以轻松地在任何一台电脑上安装 Linux,为什么还要买一台预装了 Linux 的电脑呢?下面列举几个原因:
|
||||
|
||||
* 预装 Windows 系统意味着你额外支付了 Windows 许可证的费用。你可以节省这笔开销。
|
||||
* 预装 Linux 的电脑都经过了硬件适配测试。你不需要担心系统无法正常运行 WiFi 或者蓝牙,也不再需要亲自去搞定这些事情了。
|
||||
* 购买 Linux 电脑相当于间接地支持了 Linux。更多的销售额可以反应出对 Linux 产品的需求,也就可能会有更多商家提供 Linux 作为一种可以选择的操作系统。
|
||||
|
||||
如果你正想买一台 Linux 的笔记本,不妨考虑一下我的建议。下面这些制造商或者商家都提供开箱即用的 Linux 系统。
|
||||
|
||||
![][2]
|
||||
|
||||
### 可以买到 Linux 笔记本或者台式机的 10 个地方
|
||||
|
||||
在揭晓这个提供预装 Linux 电脑的商家的清单之前,需要先声明一下。
|
||||
|
||||
请根据你的独立决策购买。我在这里只是简单地列出一些售卖 Linux 电脑的商家,并不保证他们的产品质量、售后服务等等这些事情。
|
||||
|
||||
这也并不是一个排行榜。清单并不是按照某个特定次序排列的,每一项前面的数字只是为了方便计数,而并不代表名次。
|
||||
|
||||
让我们看看你可以在哪儿买到预装 Linux 的台式机或者笔记本吧。
|
||||
|
||||
#### 1、戴尔
|
||||
|
||||
![戴尔 XPS Ubuntu | 图片所有权: Lifehacker][3]
|
||||
|
||||
戴尔提供 Ubuntu 笔记本已经有好几年了。他们的旗舰产品 XPS 系列的亮点之一就是预装了 Ubuntu 的开发者版本系列产品。
|
||||
|
||||
如果你读过我的 [戴尔 XPS Ubuntu 版本评测][4]就知道我是很喜欢这款笔记本的。两年多过去了,这个笔记本依然状况良好,没有性能恶化的迹象。
|
||||
|
||||
戴尔 XPS 是售价超过 1000 美元的昂贵设备。如果你的预算没有这么多,可以考虑戴尔更加亲民的 Inspiron 系列笔记本。
|
||||
|
||||
值得一提的是,戴尔并没有在它的官网上展示 Ubuntu 或者 Linux 笔记本产品。除非你知道戴尔提供 Linux 笔记本,你是不会找到它们的。
|
||||
|
||||
所以,去戴尔的官网上搜索关键字 “Ubuntu” 来获取预装 Ubuntu 的产品的信息吧。
|
||||
|
||||
**支持范围**:世界上大部分地区。
|
||||
|
||||
- [戴尔][5]
|
||||
|
||||
#### 2、System76
|
||||
|
||||
[System76][6] 是 Linux 计算机世界里的一个响亮的名字。这家总部设在美国的企业专注于运行 Linux 的高端技术设备。他们的目标用户群体是软件开发者。
|
||||
|
||||
最初,System76 在自己的机器上提供的是 Ubuntu 系统。2017 年,他们发布了属于自己的 Linux 发行版,基于 Ubuntu 的 [Pop!\_OS][7]。从此以后,Pop!\_OS 就是他们机器上的默认操作系统了,但是仍然保留了 Ubuntu 这个选择。
|
||||
|
||||
除了性能之外,System76 还格外重视设计。他们的 [Thelio 系列台式机][8] 采用纯手工木制设计。
|
||||
|
||||
![System76 Thelio 台式机][9]
|
||||
|
||||
你可以在 [这里][10] 查看他们提供的 Linux 笔记本。他们同时也提供 [基于 Linux 的迷你电脑][11] 和 [服务器][12]。
|
||||
|
||||
值得一提的是,System76 在美国制造他们的电脑,而没有使用中国大陆或者台湾这种常规的选择。也许是出于这个原因,他们产品的售价较为高昂。
|
||||
|
||||
**支持范围**:美国以及其它 60 个国家。在美国境外可能会有额外的关税。更多信息见[这里][13].
|
||||
|
||||
- [System76][6]
|
||||
|
||||
#### 3、Purism
|
||||
|
||||
Purism 是一个总部设在美国的企业,以提供确保数据安全和隐私的产品和服务为荣。这就是为什么 Purism 称自己为 “效力社会的公司”。
|
||||
|
||||
Purism 是从一个众筹项目开始的,该项目旨在创造一个几乎没有任何专有软件的高端开源笔记本。2015年,从这个 [成功的 25 万美元的众筹项目][15] 中诞生了 [Librem 15][16] 笔记本。
|
||||
|
||||
![Purism Librem 13][17]
|
||||
|
||||
后来 Purism 发布了一个 13 英寸的版本 [Librem 13][18]。Purism 还开发了一个自己的 Linux 发行版 [Pure OS][19],该发行版非常注重隐私和安全问题。
|
||||
|
||||
[Pure OS 在台式设备和移动设备上都可以运行][20],并且是 Librem 笔记本和[Librem 5 Linux 手机][21] 的默认操纵系统。
|
||||
|
||||
Purism 的零部件来自中国大陆、台湾、日本以及美国,并在美国完成组装。他们的所有设备都有可以直接关闭的硬件开关,用来关闭麦克风、摄像头、无线连接或者是蓝牙。
|
||||
|
||||
**支持范围**:全世界范围国际免邮。可能需要支付额外的关税。
|
||||
|
||||
- [Purism][22]
|
||||
|
||||
#### 4、Slimbook
|
||||
|
||||
Slimbook 是一个总部设在西班牙的 Linux 电脑销售商。Slimbook 在发行了 [第一款 KDE 品牌笔记本][23]之后成为了人们关注的焦点。
|
||||
|
||||
他们的产品不仅限于 KDE Neon。他们还提供 Ubuntu、Kubuntu、Ubuntu MATE、Linux Mint 以及包括 [Lliurex][24] 和 [Max][25] 这样的西班牙发行版。你也可以选择 Windows(需要额外付费)或者不预装任何操作系统。
|
||||
|
||||
Slimbook 有众多 Linux 笔记本、台式机和迷你电脑可供选择。他们另外一个非常不错的产品是一个类似于 iMac 的 24 英寸 [拥有内置 CPU 的曲面显示屏][26]。
|
||||
|
||||
![Slimbook Kymera Aqua 水冷 Linux 电脑][27]
|
||||
|
||||
想要一台水冷 Linux 电脑吗?Slimbook 的 [Kymera Aqua][28] 是合适之选。
|
||||
|
||||
**支持范围**:全世界范围,不过在邮费和关税上都可能产生额外费用。
|
||||
|
||||
- [Slimbook][29]
|
||||
|
||||
#### 5、TUXEDO
|
||||
|
||||
作为这个 Linux 电脑销售商清单里的另一个欧洲成员,[TUXEDO][30] 总部设在德国,主要服务德国用户,其次是欧洲用户。
|
||||
|
||||
TUXEDO 只使用 Linux 系统,产品都是“德国制造”,并且提供 5 年保修和终生售后支持。
|
||||
|
||||
TUXEDO 在 Linux 系统的硬件适配上下了很大功夫。并且如果你遇到了麻烦或者是想从头开始,可以通过系统恢复选项,自动恢复出厂设置。
|
||||
|
||||
![Tuxedo 电脑支持众多发行版][31]
|
||||
|
||||
TUXEDO 有许多 Linux 笔记本、台式机和迷你电脑产品可供选择。他们还同时支持 Intel 和 AMD 的处理器。除了电脑,TUXEDO 还提供一系列 Linux 支持的附件,比如扩展坞、DVD 和蓝光刻录机、移动电源以及其它外围设备。
|
||||
|
||||
**支持范围**:150 欧元以上的订单在德国和欧洲范围内免邮。欧洲外国家会有额外的运费和关税。更多信息见 [这里][32].
|
||||
|
||||
- [TUXEDO][33]
|
||||
|
||||
#### 6、Vikings
|
||||
|
||||
[Vikings][34] 的总部设在德国(而不是斯堪的纳维亚半岛,哈哈)。Vikings 拥有[自由软件基金会][35]的认证,专注于自由友好的硬件。
|
||||
|
||||
![Vikings 的产品经过了自由软件基金会认证][36]
|
||||
|
||||
Vikings 的 Linux 笔记本和台式机使用的是 [coreboot][37] 或者 [Libreboot][38],而不是像 BIOS 和 UEFI 这样的专有启动系统。你还可以购买不运行任何专有软件的 [硬件服务器][39]。
|
||||
|
||||
Vikings 还有包括路由器、扩展坞等在内的其它配件。他们的产品都是在德国组装完成的。
|
||||
|
||||
**支持范围**:全世界(除了朝鲜)。非欧洲国家可能会有额外关税费用。更多信息见[这里][40]。
|
||||
|
||||
- [Vikings][41]
|
||||
|
||||
#### 7、Ubuntushop.be
|
||||
|
||||
不不!尽管名字里有 Ubuntu,但这不是官方的 Ubuntu 商店。Ubuntushop 总部位于比利时,最初是销售安装了 Ubuntu 的电脑。
|
||||
|
||||
如今,你可以买到预装了包括 Mint、Manjaro、elementrayOS 在内的 Linux 发行版的笔记本电脑。你还可以要求所购买的设备上安装你所选择的发行版。
|
||||
|
||||
![][42]
|
||||
|
||||
Ubuntushop 的一个独特之处在于,它的所有电脑都带有默认的 Tails OS live 选项。即使你安装了某个其它的 Linux 发行版作为日常使用的系统,也随时可以选择启动到 Tails OS(不需要使用 live USB)。[Tails OS][43] 是一个基于 Debian 的发行版,它在用户注销后会删除所有使用痕迹,并且在默认情况下使用 Tor 网络。
|
||||
|
||||
和此列表中的许多其他重要玩家不同,我觉得 Ubuntushop 所提供的更像是一种“家庭工艺”。商家手动组装一个电脑,安装 Linux 然后卖给你。不过他们也在一些可选项上下了功夫,比如说轻松的重装系统,拥有自己的云服务器等等。
|
||||
|
||||
你可以找一台旧电脑快递给他们,就可以变成一台新安装 Linux 的电脑,他们就会在你的旧电脑上安装 [轻量级 Linux][45] 系统然后快递回来,这样你这台旧电脑就可以重新投入使用了。
|
||||
|
||||
**支持范围**:比利时以及欧洲的其它地区。
|
||||
|
||||
- [Ubuntushop.be][46]
|
||||
|
||||
#### 8、Minifree
|
||||
|
||||
[Minifree][47],是<ruby>自由部门<rt>Ministry of Freedom</rt></ruby>的缩写,他们是一家注册在英格兰的公司。
|
||||
|
||||
你可以猜到 Minifree 非常注重自由。他们提供安全以及注重隐私的电脑,预装 [Libreboot][38] 而不是 BIOS 或者 UEFI。
|
||||
|
||||
Minifree 的设备经过了 [自由软件基金会][48] 的认证,所以你可以放心买到的电脑都遵循了自由开源软件的指导规则。
|
||||
|
||||
![][49]
|
||||
|
||||
和这个清单中许多其它 Linux 笔记本销售商不同,Minifree 的电脑并不是特别贵。花 200 欧元就可以买到一台预装了 Libreboot 和 [Trisquel GNU/Linux][50] 的 Linux 电脑。
|
||||
|
||||
除了笔记本以外,Minifree 还有一系列的配件,比如 Libre 路由器、平板电脑、扩展坞、电池、键盘、鼠标等等。
|
||||
|
||||
如果你和 [Richard Stallman][51] 一样,希望只运行 100% 自由的软件的话,Minifree 就再适合不过了。
|
||||
|
||||
**支持范围**:全世界。运费信息见 [这里][52]。
|
||||
|
||||
- [Minifree][47]
|
||||
|
||||
#### 9、Entroware
|
||||
|
||||
[Entroware][53] 是另一个总部设在英国的销售商,专注基于 Linux 系统的笔记本、台式机和服务器。
|
||||
|
||||
和这个清单里的很多其它商家一样,Entroware 也选择 Ubuntu 作为 Linux 发行版。[Ubuntu MATE 也是 Entroware Linux 笔记本的一种可选系统][54].
|
||||
|
||||
![][55]
|
||||
|
||||
除了笔记本、台式机和服务器之外,Entroware 还拥有自己的 [迷你电脑 Aura][56],以及一个 iMac 风格的[内置 CPU 的显示器 Ares][57].
|
||||
|
||||
支持范围: 英国、爱尔兰、法国、德国、意大利、西班牙。
|
||||
|
||||
- [Entroware][58]
|
||||
|
||||
#### 10、Juno
|
||||
|
||||
这是我们清单上的一个新的 Linux 笔记本销售商。Juno 的总部同样设在英国,提供预装 Linux 的电脑。可选择的 Linux 发行版包括 elementary OS、Ubuntu 和 Solus OS。
|
||||
|
||||
Juno 提供一系列的笔记本,以及一款叫做 Olympia 迷你电脑。和列表里其它商家提供的大多数迷你电脑一样,Olympia 也基本上相当于一个 [Intel NUC][59]。
|
||||
|
||||
Juno 的主要特色是 Juve,一款售价 299 美元的 Chromebook 的低成本替代品。它运行一个双系统,包括 Solus 或者 elementray,以及一个基于安卓的电脑操作系统 [Prime OS][60]。
|
||||
|
||||
![Juve With Android-based Prime Os][61]
|
||||
|
||||
支持范围:英国、美国、加拿大、墨西哥、南美和欧洲的大部分地区、新西兰、亚洲和非洲的某些地区。更多信息见 [这里][62]。
|
||||
|
||||
- [Juno Computers][63]
|
||||
|
||||
#### 荣誉奖
|
||||
|
||||
我列举了 10 个可以买到 Linux 电脑的地方,但其实还有一些其它类似的商店。清单里放不下这么多,并且它们其中的几个似乎大多数商品都缺货。不过我还是要在这里稍微提一下它们,方便你自己查找相关信息:
|
||||
|
||||
* [ZaReason][64]
|
||||
* [Libiquity][65]
|
||||
* [StationX][66]
|
||||
* [Linux Certified][67]
|
||||
* [Think Penguin][68]
|
||||
|
||||
包括宏碁和联想在内的其它主流电脑生产商可能也有基于 Linux 系统的产品,所以你不妨也查看一下他们的产品目录吧。
|
||||
|
||||
你有没有买过 Linux 电脑?在哪儿买的?使用体验怎么样?Linux 笔记本值不值得买?分享一下你的想法吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/get-linux-laptops/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[chen-ni](https://github.com/chen-ni)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/guide-install-linux-mint-16-dual-boot-windows/
|
||||
[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/05/buy-linux-laptops.jpeg?resize=800%2C450&ssl=1
|
||||
[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/05/dell-xps-ubuntu.jpg?resize=800%2C450&ssl=1
|
||||
[4]: https://itsfoss.com/dell-xps-13-ubuntu-review/
|
||||
[5]: https://www.dell.com
|
||||
[6]: https://system76.com/
|
||||
[7]: https://itsfoss.com/pop-os-linux-review/
|
||||
[8]: https://system76.com/desktops
|
||||
[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/05/system76-thelio-desktop.jpg?ssl=1
|
||||
[10]: https://system76.com/laptops
|
||||
[11]: https://itsfoss.com/4-linux-based-mini-pc-buy-2015/
|
||||
[12]: https://system76.com/servers
|
||||
[13]: https://system76.com/shipping
|
||||
[14]: https://itsfoss.com/use-google-drive-linux/
|
||||
[15]: https://www.crowdsupply.com/purism/librem-15
|
||||
[16]: https://puri.sm/products/librem-15/
|
||||
[17]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/05/purism-librem-13.jpg?resize=800%2C471&ssl=1
|
||||
[18]: https://puri.sm/products/librem-13/
|
||||
[19]: https://www.pureos.net/
|
||||
[20]: https://itsfoss.com/pureos-convergence/
|
||||
[21]: https://itsfoss.com/librem-linux-phone/
|
||||
[22]: https://puri.sm/
|
||||
[23]: https://itsfoss.com/slimbook-kde/
|
||||
[24]: https://distrowatch.com/table.php?distribution=lliurex
|
||||
[25]: https://en.wikipedia.org/wiki/MAX_(operating_system)
|
||||
[26]: https://slimbook.es/en/aio-curve-all-in-one-for-gnu-linux
|
||||
[27]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/05/Slimbook-Kymera-Aqua-Liquid-Cool-Linux-Computer.jpg?ssl=1
|
||||
[28]: https://slimbook.es/en/kymera-aqua-the-gnu-linux-computer-with-custom-water-cooling
|
||||
[29]: https://slimbook.es/en/
|
||||
[30]: https://www.tuxedocomputers.com/
|
||||
[31]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/05/tuxedo-computers.jpeg?resize=800%2C400&ssl=1
|
||||
[32]: https://www.tuxedocomputers.com/en/Shipping-Returns.tuxedo
|
||||
[33]: https://www.tuxedocomputers.com/en#
|
||||
[34]: https://store.vikings.net/index.php?route=common/home
|
||||
[35]: https://www.fsf.org
|
||||
[36]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/05/vikings-computer.jpeg?resize=800%2C450&ssl=1
|
||||
[37]: https://www.coreboot.org/
|
||||
[38]: https://libreboot.org/
|
||||
[39]: https://store.vikings.net/libre-friendly-hardware/the-server-1u
|
||||
[40]: https://store.vikings.net/index.php?route=information/information&information_id=8
|
||||
[41]: https://store.vikings.net/libre-friendly-hardware
|
||||
[42]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/05/manjarobook-by-ubuntushop.jpeg?ssl=1
|
||||
[43]: https://tails.boum.org/
|
||||
[44]: https://itsfoss.com/things-to-do-after-installing-ubuntu-18-04/
|
||||
[45]: https://itsfoss.com/lightweight-linux-beginners/
|
||||
[46]: https://www.ubuntushop.be/index.php/en/
|
||||
[47]: https://minifree.org/
|
||||
[48]: https://www.fsf.org/
|
||||
[49]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/05/minifree.jpg?resize=800%2C550&ssl=1
|
||||
[50]: https://trisquel.info/
|
||||
[51]: https://en.wikipedia.org/wiki/Richard_Stallman
|
||||
[52]: https://minifree.org/shipping-costs/
|
||||
[53]: https://www.entroware.com/
|
||||
[54]: https://itsfoss.com/ubuntu-mate-entroware/
|
||||
[55]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/05/entroware.jpg?resize=800%2C450&ssl=1
|
||||
[56]: https://itsfoss.com/ubuntu-entroware-aura-mini-pc/
|
||||
[57]: https://www.entroware.com/store/ares
|
||||
[58]: https://www.entroware.com/store/index.php?route=common/home
|
||||
[59]: https://www.amazon.com/Intel-NUC-Mainstream-Kit-NUC8i3BEH/dp/B07GX4X4PW?psc=1&SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B07GX4X4PW (Intel NUC)
|
||||
[60]: https://primeos.in/
|
||||
[61]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/05/juve-with-prime-os.jpeg?ssl=1
|
||||
[62]: https://junocomputers.com/shipping
|
||||
[63]: https://junocomputers.com/
|
||||
[64]: https://zareason.com/
|
||||
[65]: https://libiquity.com/
|
||||
[66]: https://stationx.rocks/
|
||||
[67]: https://www.linuxcertified.com/linux_laptops.html
|
||||
[68]: https://www.thinkpenguin.com/
|
||||
@ -0,0 +1,154 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10943-1.html)
|
||||
[#]: subject: (Using Testinfra with Ansible to verify server state)
|
||||
[#]: via: (https://opensource.com/article/19/5/using-testinfra-ansible-verify-server-state)
|
||||
[#]: author: (Clement Verna https://opensource.com/users/cverna/users/paulbischoff/users/dcritch/users/cobiacomm/users/wgarry155/users/kadinroob/users/koreyhilpert)
|
||||
|
||||
使用 Testinfra 和 Ansible 验证服务器状态
|
||||
======
|
||||
|
||||
> Testinfra 是一个功能强大的库,可用于编写测试来验证基础设施的状态。另外它与 Ansible 和 Nagios 相结合,提供了一个用于架构即代码 (IaC) 的简单解决方案。
|
||||
|
||||
![Terminal command prompt on orange background][1]
|
||||
|
||||
根据设计,[Ansible][2] 传递机器的期望状态,以确保 Ansible 剧本或角色的内容部署到目标机器上。但是,如果你需要确保所有基础架构更改都在 Ansible 中,该怎么办?或者想随时验证服务器的状态?
|
||||
|
||||
[Testinfra][3] 是一个基础架构测试框架,它可以轻松编写单元测试来验证服务器的状态。它是一个 Python 库,使用强大的 [pytest][4] 测试引擎。
|
||||
|
||||
### 开始使用 Testinfra
|
||||
|
||||
可以使用 Python 包管理器(`pip`)和 Python 虚拟环境轻松安装 Testinfra。
|
||||
|
||||
```
|
||||
$ python3 -m venv venv
|
||||
$ source venv/bin/activate
|
||||
(venv) $ pip install testinfra
|
||||
```
|
||||
|
||||
Testinfra 也可以通过 Fedora 和 CentOS 的 EPEL 仓库中使用。例如,在 CentOS 7 上,你可以使用以下命令安装它:
|
||||
|
||||
```
|
||||
$ yum install -y epel-release
|
||||
$ yum install -y python-testinfra
|
||||
```
|
||||
|
||||
#### 一个简单的测试脚本
|
||||
|
||||
在 Testinfra 中编写测试很容易。使用你选择的代码编辑器,将以下内容添加到名为 `test_simple.py` 的文件中:
|
||||
|
||||
```
|
||||
import testinfra
|
||||
|
||||
def test_os_release(host):
|
||||
assert host.file("/etc/os-release").contains("Fedora")
|
||||
|
||||
def test_sshd_inactive(host):
|
||||
assert host.service("sshd").is_running is False
|
||||
```
|
||||
|
||||
默认情况下,Testinfra 为测试用例提供了一个 `host` 对象,该对象能访问不同的辅助模块。例如,第一个测试使用 `file` 模块来验证主机上文件的内容,第二个测试用例使用 `service` 模块来检查 systemd 服务的状态。
|
||||
|
||||
要在本机运行这些测试,请执行以下命令:
|
||||
|
||||
```
|
||||
(venv)$ pytest test_simple.py
|
||||
================================ test session starts ================================
|
||||
platform linux -- Python 3.7.3, pytest-4.4.1, py-1.8.0, pluggy-0.9.0
|
||||
rootdir: /home/cverna/Documents/Python/testinfra
|
||||
plugins: testinfra-3.0.0
|
||||
collected 2 items
|
||||
test_simple.py ..
|
||||
|
||||
================================ 2 passed in 0.05 seconds ================================
|
||||
```
|
||||
|
||||
有关 Testinfra API 的完整列表,你可以参考[文档][5]。
|
||||
|
||||
### Testinfra 和 Ansible
|
||||
|
||||
Testinfra 支持的后端之一是 Ansible,这意味着 Testinfra 可以直接使用 Ansible 的清单文件和清单中定义的一组机器来对它们进行测试。
|
||||
|
||||
我们使用以下清单文件作为示例:
|
||||
|
||||
```
|
||||
[web]
|
||||
app-frontend01
|
||||
app-frontend02
|
||||
|
||||
[database]
|
||||
db-backend01
|
||||
```
|
||||
|
||||
我们希望确保我们的 Apache Web 服务器在 `app-frontend01` 和 `app-frontend02` 上运行。让我们在名为 `test_web.py` 的文件中编写测试:
|
||||
|
||||
```
|
||||
def check_httpd_service(host):
|
||||
"""Check that the httpd service is running on the host"""
|
||||
assert host.service("httpd").is_running
|
||||
```
|
||||
|
||||
要使用 Testinfra 和 Ansible 运行此测试,请使用以下命令:
|
||||
|
||||
|
||||
```
|
||||
(venv) $ pip install ansible
|
||||
(venv) $ py.test --hosts=web --ansible-inventory=inventory --connection=ansible test_web.py
|
||||
```
|
||||
|
||||
在调用测试时,我们使用 Ansible 清单文件的 `[web]` 组作为目标计算机,并指定我们要使用 Ansible 作为连接后端。
|
||||
|
||||
#### 使用 Ansible 模块
|
||||
|
||||
Testinfra 还为 Ansible 提供了一个很好的可用于测试的 API。该 Ansible 模块能够在测试中运行 Ansible 动作,并且能够轻松检查动作的状态。
|
||||
|
||||
```
|
||||
def check_ansible_play(host):
|
||||
"""
|
||||
Verify that a package is installed using Ansible
|
||||
package module
|
||||
"""
|
||||
assert not host.ansible("package", "name=httpd state=present")["changed"]
|
||||
```
|
||||
|
||||
默认情况下,Ansible 的[检查模式][6]已启用,这意味着 Ansible 将报告在远程主机上执行动作时会发生的变化。
|
||||
|
||||
### Testinfra 和 Nagios
|
||||
|
||||
现在我们可以轻松地运行测试来验证机器的状态,我们可以使用这些测试来触发监控系统上的警报。这是捕获意外的更改的好方法。
|
||||
|
||||
Testinfra 提供了与 [Nagios][7] 的集成,它是一种流行的监控解决方案。默认情况下,Nagios 使用 [NRPE][8] 插件对远程主机进行检查,但使用 Testinfra 可以直接从 Nagios 主控节点上运行测试。
|
||||
|
||||
要使 Testinfra 输出与 Nagios 兼容,我们必须在触发测试时使用 `--nagios` 标志。我们还使用 `-qq` 这个 pytest 标志来启用 pytest 的静默模式,这样就不会显示所有测试细节。
|
||||
|
||||
```
|
||||
(venv) $ py.test --hosts=web --ansible-inventory=inventory --connection=ansible --nagios -qq line test.py
|
||||
TESTINFRA OK - 1 passed, 0 failed, 0 skipped in 2.55 seconds
|
||||
```
|
||||
|
||||
Testinfra 是一个功能强大的库,可用于编写测试以验证基础架构的状态。 另外与 Ansible 和 Nagios 相结合,提供了一个用于架构即代码 (IaC) 的简单解决方案。 它也是使用 [Molecule][9] 开发 Ansible 角色过程中添加测试的关键组件。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/5/using-testinfra-ansible-verify-server-state
|
||||
|
||||
作者:[Clement Verna][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/cverna/users/paulbischoff/users/dcritch/users/cobiacomm/users/wgarry155/users/kadinroob/users/koreyhilpert
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/terminal_command_linux_desktop_code.jpg?itok=p5sQ6ODE (Terminal command prompt on orange background)
|
||||
[2]: https://www.ansible.com/
|
||||
[3]: https://testinfra.readthedocs.io/en/latest/
|
||||
[4]: https://pytest.org/
|
||||
[5]: https://testinfra.readthedocs.io/en/latest/modules.html#modules
|
||||
[6]: https://docs.ansible.com/ansible/playbooks_checkmode.html
|
||||
[7]: https://www.nagios.org/
|
||||
[8]: https://en.wikipedia.org/wiki/Nagios#NRPE
|
||||
[9]: https://github.com/ansible/molecule
|
||||
@ -1,98 +1,98 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "zhang5788"
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
[#]: subject: "Getting Started With Docker"
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-10940-1.html"
|
||||
[#]: subject: "Getting Started With Docker"
|
||||
[#]: via: "https://www.ostechnix.com/getting-started-with-docker/"
|
||||
[#]: author: "sk https://www.ostechnix.com/author/sk/"
|
||||
[#]: author: "sk https://www.ostechnix.com/author/sk/"
|
||||
|
||||
Docker 入门指南
|
||||
======
|
||||
|
||||
![Getting Started With Docker][1]
|
||||
|
||||
在我们的上一个教程中,我们已经了解[**如何在ubuntu上安装Docker**][1],和如何在[**CentOS上安装Docker**][2]。今天,我们将会了解Docker的一些基础用法。该教程包含了如何创建一个新的docker容器,如何运行该容器,如何从现有的docker容器中创建自己的Docker镜像等Docker 的一些基础知识,操作。所有步骤均在Ubuntu 18.04 LTS server 版本下测试通过。
|
||||
在我们的上一个教程中,我们已经了解[如何在 Ubuntu 上安装 Docker][1],和如何在 [CentOS 上安装 Docker][2]。今天,我们将会了解 Docker 的一些基础用法。该教程包含了如何创建一个新的 Docker 容器,如何运行该容器,如何从现有的 Docker 容器中创建自己的 Docker 镜像等 Docker 的一些基础知识、操作。所有步骤均在 Ubuntu 18.04 LTS server 版本下测试通过。
|
||||
|
||||
### 入门指南
|
||||
|
||||
在开始指南之前,不要混淆Docker镜像和Docker容器这两个概念。在之前的教程中,我就解释过,Docker镜像是决定Docker容器行为的一个文件,Docker容器则是Docker镜像的运行态或停止态。(译者注:在`macOS`下使用docker终端时,不需要加`sudo`)
|
||||
在开始指南之前,不要混淆 Docker 镜像和 Docker 容器这两个概念。在之前的教程中,我就解释过,Docker 镜像是决定 Docker 容器行为的一个文件,Docker 容器则是 Docker 镜像的运行态或停止态。(LCTT 译注:在 macOS 下使用 Docker 终端时,不需要加 `sudo`)
|
||||
|
||||
##### 1. 搜索Docker镜像
|
||||
#### 1、搜索 Docker 镜像
|
||||
|
||||
我们可以从Docker的仓库中获取镜像,例如[**Docker hub**][3], 或者自己创建镜像。这里解释一下,`Docker hub`是一个云服务器,用来提供给Docker的用户们,创建,测试,和保存他们的镜像。
|
||||
我们可以从 Docker 仓库中获取镜像,例如 [Docker hub][3],或者自己创建镜像。这里解释一下,Docker hub 是一个云服务器,用来提供给 Docker 的用户们创建、测试,和保存他们的镜像。
|
||||
|
||||
`Docker hub`拥有成千上万个Docker 的镜像文件。你可以在这里搜索任何你想要的镜像,通过`docker search`命令。
|
||||
Docker hub 拥有成千上万个 Docker 镜像文件。你可以通过 `docker search`命令在这里搜索任何你想要的镜像。
|
||||
|
||||
例如,搜索一个基于ubuntu的镜像文件,只需要运行:
|
||||
例如,搜索一个基于 Ubuntu 的镜像文件,只需要运行:
|
||||
|
||||
```shell
|
||||
$ sudo docker search ubuntu
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
示例输出:
|
||||
|
||||
![][5]
|
||||
|
||||
搜索基于CentOS的镜像,运行:
|
||||
搜索基于 CentOS 的镜像,运行:
|
||||
|
||||
```shell
|
||||
$ sudo docker search ubuntu
|
||||
$ sudo docker search centos
|
||||
```
|
||||
|
||||
搜索AWS的镜像,运行:
|
||||
搜索 AWS 的镜像,运行:
|
||||
|
||||
```shell
|
||||
$ sudo docker search aws
|
||||
```
|
||||
|
||||
搜索`wordpress`的镜像:
|
||||
搜索 WordPress 的镜像:
|
||||
|
||||
```shell
|
||||
$ sudo docker search wordpress
|
||||
```
|
||||
|
||||
`Docker hub`拥有几乎所有种类的镜像,包含操作系统,程序和其他任意的类型,这些你都能在`docker hub`上找到已经构建完的镜像。如果你在搜索时,无法找到你想要的镜像文件,你也可以自己构建一个,将其发布出去,或者仅供你自己使用。
|
||||
Docker hub 拥有几乎所有种类的镜像,包含操作系统、程序和其他任意的类型,这些你都能在 Docker hub 上找到已经构建完的镜像。如果你在搜索时,无法找到你想要的镜像文件,你也可以自己构建一个,将其发布出去,或者仅供你自己使用。
|
||||
|
||||
##### 2. 下载Docker 镜像
|
||||
#### 2、下载 Docker 镜像
|
||||
|
||||
下载`ubuntu`的镜像,你需要在终端运行以下命令:
|
||||
下载 Ubuntu 的镜像,你需要在终端运行以下命令:
|
||||
|
||||
```shell
|
||||
$ sudo docker pull ubuntu
|
||||
```
|
||||
|
||||
这条命令将会从**Docker hub**下载最近一个版本的ubuntu镜像文件。
|
||||
这条命令将会从 Docker hub 下载最近一个版本的 Ubuntu 镜像文件。
|
||||
|
||||
**Sample output:**
|
||||
示例输出:
|
||||
|
||||
> ```shell
|
||||
> Using default tag: latest
|
||||
> latest: Pulling from library/ubuntu
|
||||
> 6abc03819f3e: Pull complete
|
||||
> 05731e63f211: Pull complete
|
||||
> 0bd67c50d6be: Pull complete
|
||||
> Digest: sha256:f08638ec7ddc90065187e7eabdfac3c96e5ff0f6b2f1762cf31a4f49b53000a5
|
||||
> Status: Downloaded newer image for ubuntu:latest
|
||||
> ```
|
||||
```
|
||||
Using default tag: latest
|
||||
latest: Pulling from library/ubuntu
|
||||
6abc03819f3e: Pull complete
|
||||
05731e63f211: Pull complete
|
||||
0bd67c50d6be: Pull complete
|
||||
Digest: sha256:f08638ec7ddc90065187e7eabdfac3c96e5ff0f6b2f1762cf31a4f49b53000a5
|
||||
Status: Downloaded newer image for ubuntu:latest
|
||||
```
|
||||
|
||||
![下载docker 镜像][6]
|
||||
![下载 Docker 镜像][6]
|
||||
|
||||
你也可以下载指定版本的ubuntu镜像。运行以下命令:
|
||||
你也可以下载指定版本的 Ubuntu 镜像。运行以下命令:
|
||||
|
||||
```shell
|
||||
$ docker pull ubuntu:18.04
|
||||
```
|
||||
|
||||
Dokcer允许在任意的宿主机操作系统下,下载任意的镜像文件,并运行。
|
||||
Docker 允许在任意的宿主机操作系统下,下载任意的镜像文件,并运行。
|
||||
|
||||
例如,下载CentOS镜像:
|
||||
例如,下载 CentOS 镜像:
|
||||
|
||||
```shell
|
||||
$ sudo docker pull centos
|
||||
```
|
||||
|
||||
所有下载的镜像文件,都被保存在`/var/lib/docker`文件夹下。(译者注:不同操作系统存放的文件夹并不是一致的,具体存放位置请在官方查询)
|
||||
所有下载的镜像文件,都被保存在 `/var/lib/docker` 文件夹下。(LCTT 译注:不同操作系统存放的文件夹并不是一致的,具体存放位置请在官方查询)
|
||||
|
||||
查看已经下载的镜像列表,可以使用以下命令:
|
||||
|
||||
@ -100,7 +100,7 @@ $ sudo docker pull centos
|
||||
$ sudo docker images
|
||||
```
|
||||
|
||||
**输出为:**
|
||||
示例输出:
|
||||
|
||||
```shell
|
||||
REPOSITORY TAG IMAGE ID CREATED SIZE
|
||||
@ -109,17 +109,17 @@ centos latest 9f38484d220f 2 months ago
|
||||
hello-world latest fce289e99eb9 4 months ago 1.84kB
|
||||
```
|
||||
|
||||
正如你看到的那样,我已经下载了三个镜像文件:**ubuntu**, **CentOS**和**Hello-world**.
|
||||
正如你看到的那样,我已经下载了三个镜像文件:`ubuntu`、`centos` 和 `hello-world`。
|
||||
|
||||
现在,让我们继续,来看一下如何运行我们刚刚下载的镜像。
|
||||
|
||||
##### 3. 运行Docker镜像
|
||||
#### 3、运行 Docker 镜像
|
||||
|
||||
运行一个容器有两种方法。我们可以使用`TAG`或者是`镜像ID`。`TAG`指的是特定的镜像快照。`镜像ID`是指镜像的唯一标识。
|
||||
运行一个容器有两种方法。我们可以使用标签或者是镜像 ID。标签指的是特定的镜像快照。镜像 ID 是指镜像的唯一标识。
|
||||
|
||||
正如上面结果中显示,`latest`是所有镜像的一个标签。**7698f282e524**是Ubuntu docker 镜像的`镜像ID`,**9f38484d220f**是CentOS镜像的`镜像ID`,**fce289e99eb9**是hello_world镜像的`镜像ID`。
|
||||
正如上面结果中显示,`latest` 是所有镜像的一个标签。`7698f282e524` 是 Ubuntu Docker 镜像的镜像 ID,`9f38484d220f`是 CentOS 镜像的镜像 ID,`fce289e99eb9` 是 hello_world 镜像的 镜像 ID。
|
||||
|
||||
下载完Docker镜像之后,你可以通过下面的命令来使用`TAG`的方式启动:
|
||||
下载完 Docker 镜像之后,你可以通过下面的命令来使用其标签来启动:
|
||||
|
||||
```shell
|
||||
$ sudo docker run -t -i ubuntu:latest /bin/bash
|
||||
@ -127,12 +127,12 @@ $ sudo docker run -t -i ubuntu:latest /bin/bash
|
||||
|
||||
在这条语句中:
|
||||
|
||||
* **-t**: 在该容器中启动一个新的终端
|
||||
* **-i**: 通过容器中的标准输入流建立交互式连接
|
||||
* **ubuntu:latest**:带有标签`latest`的ubuntu容器
|
||||
* **/bin/bash** : 在新的容器中启动`BASH Shell`
|
||||
* `-t`:在该容器中启动一个新的终端
|
||||
* `-i`:通过容器中的标准输入流建立交互式连接
|
||||
* `ubuntu:latest`:带有标签 `latest` 的 Ubuntu 容器
|
||||
* `/bin/bash`:在新的容器中启动 BASH Shell
|
||||
|
||||
或者,你可以通过`镜像ID`来启动新的容器:
|
||||
或者,你可以通过镜像 ID 来启动新的容器:
|
||||
|
||||
```shell
|
||||
$ sudo docker run -t -i 7698f282e524 /bin/bash
|
||||
@ -140,15 +140,15 @@ $ sudo docker run -t -i 7698f282e524 /bin/bash
|
||||
|
||||
在这条语句里:
|
||||
|
||||
* **7698f282e524** —`镜像ID`
|
||||
* `7698f282e524` — 镜像 ID
|
||||
|
||||
在启动容器之后,将会自动进入容器的`shell`中(注意看命令行的提示符)。
|
||||
在启动容器之后,将会自动进入容器的 shell 中(注意看命令行的提示符)。
|
||||
|
||||
![][7]
|
||||
|
||||
Docker 容器的`Shell`
|
||||
*Docker 容器的 Shell*
|
||||
|
||||
如果想要退回到宿主机的终端(在这个例子中,对我来说,就是退回到18.04 LTS),并且不中断该容器的执行,你可以按下`CTRL+P `,再按下`CTRL+Q`。现在,你就安全的返回到了你的宿主机系统中。需要注意的是,docker 容器仍然在后台运行,我们并没有中断它。
|
||||
如果想要退回到宿主机的终端(在这个例子中,对我来说,就是退回到 18.04 LTS),并且不中断该容器的执行,你可以按下 `CTRL+P`,再按下 `CTRL+Q`。现在,你就安全的返回到了你的宿主机系统中。需要注意的是,Docker 容器仍然在后台运行,我们并没有中断它。
|
||||
|
||||
可以通过下面的命令来查看正在运行的容器:
|
||||
|
||||
@ -156,7 +156,7 @@ Docker 容器的`Shell`
|
||||
$ sudo docker ps
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
示例输出:
|
||||
|
||||
```shell
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
@ -165,14 +165,14 @@ CONTAINER ID IMAGE COMMAND CREATED
|
||||
|
||||
![][8]
|
||||
|
||||
列出正在运行的容器
|
||||
*列出正在运行的容器*
|
||||
|
||||
可以看到:
|
||||
可以看到:
|
||||
|
||||
* **32fc32ad0d54** – `容器 ID`
|
||||
* **ubuntu:latest** – Docker 镜像
|
||||
* `32fc32ad0d54` – 容器 ID
|
||||
* `ubuntu:latest` – Docker 镜像
|
||||
|
||||
需要注意的是,**`容器ID`和Docker `镜像ID`是不同的**
|
||||
需要注意的是,容器 ID 和 Docker 的镜像 ID是不同的。
|
||||
|
||||
可以通过以下命令查看所有正在运行和停止运行的容器:
|
||||
|
||||
@ -192,13 +192,13 @@ $ sudo docker stop <container-id>
|
||||
$ sudo docker stop 32fc32ad0d54
|
||||
```
|
||||
|
||||
如果想要进入正在运行的容器中,你只需要运行
|
||||
如果想要进入正在运行的容器中,你只需要运行:
|
||||
|
||||
```shell
|
||||
$ sudo docker attach 32fc32ad0d54
|
||||
```
|
||||
|
||||
正如你看到的,**32fc32ad0d54**是一个容器的ID。当你在容器中想要退出时,只需要在容器内的终端中输入命令:
|
||||
正如你看到的,`32fc32ad0d54` 是一个容器的 ID。当你在容器中想要退出时,只需要在容器内的终端中输入命令:
|
||||
|
||||
```shell
|
||||
# exit
|
||||
@ -210,46 +210,44 @@ $ sudo docker attach 32fc32ad0d54
|
||||
$ sudo docker ps
|
||||
```
|
||||
|
||||
##### 4. 构建自己的Docker镜像
|
||||
#### 4、构建自己的 Docker 镜像
|
||||
|
||||
Docker不仅仅可以下载运行在线的容器,你也可以创建你的自己的容器。
|
||||
Docker 不仅仅可以下载运行在线的容器,你也可以创建你的自己的容器。
|
||||
|
||||
想要创建自己的Docker镜像,你需要先运行一个你已经下载完的容器:
|
||||
想要创建自己的 Docker 镜像,你需要先运行一个你已经下载完的容器:
|
||||
|
||||
```shell
|
||||
$ sudo docker run -t -i ubuntu:latest /bin/bash
|
||||
```
|
||||
|
||||
现在,你运行了一个容器,并且进入了该容器。
|
||||
现在,你运行了一个容器,并且进入了该容器。然后,在该容器安装任意一个软件或做任何你想做的事情。
|
||||
|
||||
然后,在该容器安装任意一个软件或做任何你想做的事情。
|
||||
例如,我们在容器中安装一个 Apache web 服务器。
|
||||
|
||||
例如,我们在容器中安装一个**Apache web 服务器**。
|
||||
|
||||
当你完成所有的操作,安装完所有的软件之后,你可以执行以下的命令来构建你自己的Docker镜像:
|
||||
当你完成所有的操作,安装完所有的软件之后,你可以执行以下的命令来构建你自己的 Docker 镜像:
|
||||
|
||||
```shell
|
||||
# apt update
|
||||
# apt install apache2
|
||||
```
|
||||
|
||||
同样的,安装和测试所有的你想要安装的软件在容器中。
|
||||
同样的,在容器中安装和测试你想要安装的所有软件。
|
||||
|
||||
当你安装完毕之后,返回的宿主机的终端。记住,不要关闭容器。想要返回到宿主机的host而不中断容器。请按下CTRL+P ,再按下CTRL+Q。
|
||||
当你安装完毕之后,返回的宿主机的终端。记住,不要关闭容器。想要返回到宿主机而不中断容器。请按下`CTRL+P`,再按下 `CTRL+Q`。
|
||||
|
||||
从你的宿主机的终端中,运行以下命令如寻找容器的ID:
|
||||
从你的宿主机的终端中,运行以下命令如寻找容器的 ID:
|
||||
|
||||
```shell
|
||||
$ sudo docker ps
|
||||
```
|
||||
|
||||
最后,从一个正在运行的容器中创建Docker镜像:
|
||||
最后,从一个正在运行的容器中创建 Docker 镜像:
|
||||
|
||||
```shell
|
||||
$ sudo docker commit 3d24b3de0bfc ostechnix/ubuntu_apache
|
||||
```
|
||||
|
||||
**输出为:**
|
||||
示例输出:
|
||||
|
||||
```shell
|
||||
sha256:ce5aa74a48f1e01ea312165887d30691a59caa0d99a2a4aa5116ae124f02f962
|
||||
@ -257,17 +255,17 @@ sha256:ce5aa74a48f1e01ea312165887d30691a59caa0d99a2a4aa5116ae124f02f962
|
||||
|
||||
在这里:
|
||||
|
||||
* **3d24b3de0bfc** — 指ubuntu容器的ID。
|
||||
* **ostechnix** — 我们创建的的名称
|
||||
* **ubuntu_apache** — 我们创建的镜像
|
||||
* `3d24b3de0bfc` — 指 Ubuntu 容器的 ID。
|
||||
* `ostechnix` — 我们创建的容器的用户名称
|
||||
* `ubuntu_apache` — 我们创建的镜像
|
||||
|
||||
让我们检查一下我们新创建的docker镜像
|
||||
让我们检查一下我们新创建的 Docker 镜像:
|
||||
|
||||
```shell
|
||||
$ sudo docker images
|
||||
```
|
||||
|
||||
**输出为:**
|
||||
示例输出:
|
||||
|
||||
```shell
|
||||
REPOSITORY TAG IMAGE ID CREATED SIZE
|
||||
@ -279,7 +277,7 @@ hello-world latest fce289e99eb9 4 months ago
|
||||
|
||||
![][9]
|
||||
|
||||
列出所有的docker镜像
|
||||
*列出所有的 Docker 镜像*
|
||||
|
||||
正如你看到的,这个新的镜像就是我们刚刚在本地系统上从运行的容器上创建的。
|
||||
|
||||
@ -289,9 +287,9 @@ hello-world latest fce289e99eb9 4 months ago
|
||||
$ sudo docker run -t -i ostechnix/ubuntu_apache /bin/bash
|
||||
```
|
||||
|
||||
##### 5. 移除容器
|
||||
#### 5、删除容器
|
||||
|
||||
如果你在docker上的工作已经全部完成,你就可以删除哪些你不需要的容器。
|
||||
如果你在 Docker 上的工作已经全部完成,你就可以删除那些你不需要的容器。
|
||||
|
||||
想要删除一个容器,首先,你需要停止该容器。
|
||||
|
||||
@ -301,14 +299,14 @@ $ sudo docker run -t -i ostechnix/ubuntu_apache /bin/bash
|
||||
$ sudo docker ps
|
||||
```
|
||||
|
||||
**输出为:**
|
||||
示例输出:
|
||||
|
||||
```shell
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
3d24b3de0bfc ubuntu:latest "/bin/bash" 28 minutes ago Up 28 minutes goofy_easley
|
||||
```
|
||||
|
||||
使用`容器ID`来停止该容器:
|
||||
使用容器 ID 来停止该容器:
|
||||
|
||||
```shell
|
||||
$ sudo docker stop 3d24b3de0bfc
|
||||
@ -328,7 +326,7 @@ $ sudo docker rm 3d24b3de0bfc
|
||||
$ sudo docker container prune
|
||||
```
|
||||
|
||||
按下"**Y**",来确认你的操作
|
||||
按下 `Y`,来确认你的操作:
|
||||
|
||||
```sehll
|
||||
WARNING! This will remove all stopped containers.
|
||||
@ -340,11 +338,11 @@ Deleted Containers:
|
||||
Total reclaimed space: 5B
|
||||
```
|
||||
|
||||
这个命令仅支持最新的docker。(译者注:仅支持1.25及以上版本的Docker)
|
||||
这个命令仅支持最新的 Docker。(LCTT 译注:仅支持 1.25 及以上版本的 Docker)
|
||||
|
||||
##### 6. 删除Docker镜像
|
||||
#### 6、删除 Docker 镜像
|
||||
|
||||
当你移除完不要的Docker容器后,你也可以删除你不需要的Docker镜像。
|
||||
当你删除了不要的 Docker 容器后,你也可以删除你不需要的 Docker 镜像。
|
||||
|
||||
列出已经下载的镜像:
|
||||
|
||||
@ -352,7 +350,7 @@ Total reclaimed space: 5B
|
||||
$ sudo docker images
|
||||
```
|
||||
|
||||
**输出为:**
|
||||
示例输出:
|
||||
|
||||
```shell
|
||||
REPOSITORY TAG IMAGE ID CREATED SIZE
|
||||
@ -364,13 +362,13 @@ hello-world latest fce289e99eb9 4 months ago
|
||||
|
||||
由上面的命令可以知道,在本地的系统中存在三个镜像。
|
||||
|
||||
使用`镜像ID`来删除镜像。
|
||||
使用镜像 ID 来删除镜像。
|
||||
|
||||
```shell
|
||||
$ sudo docekr rmi ce5aa74a48f1
|
||||
```
|
||||
|
||||
**输出为:**
|
||||
示例输出:
|
||||
|
||||
```shell
|
||||
Untagged: ostechnix/ubuntu_apache:latest
|
||||
@ -378,17 +376,17 @@ Deleted: sha256:ce5aa74a48f1e01ea312165887d30691a59caa0d99a2a4aa5116ae124f02f962
|
||||
Deleted: sha256:d21c926f11a64b811dc75391bbe0191b50b8fe142419f7616b3cee70229f14cd
|
||||
```
|
||||
|
||||
**解决问题**
|
||||
#### 解决问题
|
||||
|
||||
Docker禁止我们删除一个还在被容器使用的镜像。
|
||||
Docker 禁止我们删除一个还在被容器使用的镜像。
|
||||
|
||||
例如,当我试图删除Docker镜像**b72889fa879c**时,我只能获得一个错误提示:
|
||||
例如,当我试图删除 Docker 镜像 `b72889fa879c` 时,我只能获得一个错误提示:
|
||||
|
||||
```shell
|
||||
Error response from daemon: conflict: unable to delete b72889fa879c (must be forced) - image is being used by stopped container dde4dd285377
|
||||
```
|
||||
|
||||
这是因为这个Docker镜像正在被一个容器使用。
|
||||
这是因为这个 Docker 镜像正在被一个容器使用。
|
||||
|
||||
所以,我们来检查一个正在运行的容器:
|
||||
|
||||
@ -396,19 +394,19 @@ Error response from daemon: conflict: unable to delete b72889fa879c (must be for
|
||||
$ sudo docker ps
|
||||
```
|
||||
|
||||
**输出为:**
|
||||
示例输出:
|
||||
|
||||
![][10]
|
||||
|
||||
注意,现在并没有正在运行的容器!!!
|
||||
|
||||
查看一下所有的容器(包含所有的正在运行和已经停止的容器):
|
||||
查看一下所有的容器(包含所有的正在运行和已经停止的容器):
|
||||
|
||||
```shell
|
||||
$ sudo docker pa -a
|
||||
```
|
||||
|
||||
**输出为:**
|
||||
示例输出:
|
||||
|
||||
![][11]
|
||||
|
||||
@ -420,9 +418,9 @@ $ sudo docker pa -a
|
||||
$ sudo docker rm 12e892156219
|
||||
```
|
||||
|
||||
我们仍然使用容器ID来删除这些容器。
|
||||
我们仍然使用容器 ID 来删除这些容器。
|
||||
|
||||
当我们删除了所有使用该镜像的容器之后,我们就可以删除Docker的镜像了。
|
||||
当我们删除了所有使用该镜像的容器之后,我们就可以删除 Docker 的镜像了。
|
||||
|
||||
例如:
|
||||
|
||||
@ -438,19 +436,7 @@ $ sudo docker images
|
||||
|
||||
想要知道更多的细节,请参阅本指南末尾给出的官方资源的链接或者在评论区进行留言。
|
||||
|
||||
或者,下载以下的关于Docker的电子书来了解更多。
|
||||
|
||||
* **Download** – [**Free eBook: “Docker Containerization Cookbook”**][12]
|
||||
|
||||
* **Download** – [**Free Guide: “Understanding Docker”**][13]
|
||||
|
||||
* **Download** – [**Free Guide: “What is Docker and Why is it So Popular?”**][14]
|
||||
|
||||
* **Download** – [**Free Guide: “Introduction to Docker”**][15]
|
||||
|
||||
* **Download** – [**Free Guide: “Docker in Production”**][16]
|
||||
|
||||
这就是全部的教程了,希望你可以了解Docker的一些基础用法。
|
||||
这就是全部的教程了,希望你可以了解 Docker 的一些基础用法。
|
||||
|
||||
更多的教程马上就会到来,敬请关注。
|
||||
|
||||
@ -461,7 +447,7 @@ via: https://www.ostechnix.com/getting-started-with-docker/
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[zhang5788](https://github.com/zhang5788)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -482,4 +468,4 @@ via: https://www.ostechnix.com/getting-started-with-docker/
|
||||
[13]: https://ostechnix.tradepub.com/free/w_pacb32/prgm.cgi?a=1
|
||||
[14]: https://ostechnix.tradepub.com/free/w_pacb31/prgm.cgi?a=1
|
||||
[15]: https://ostechnix.tradepub.com/free/w_pacb29/prgm.cgi?a=1
|
||||
[16]: https://ostechnix.tradepub.com/free/w_pacb28/prgm.cgi?a=1
|
||||
[16]: https://ostechnix.tradepub.com/free/w_pacb28/prgm.cgi?a=1
|
||||
@ -0,0 +1,75 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (chen-ni)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10961-1.html)
|
||||
[#]: subject: (When IoT systems fail: The risk of having bad IoT data)
|
||||
[#]: via: (https://www.networkworld.com/article/3396230/when-iot-systems-fail-the-risk-of-having-bad-iot-data.html)
|
||||
[#]: author: (Fredric Paul https://www.networkworld.com/author/Fredric-Paul/)
|
||||
|
||||
当物联网系统出现故障:使用低质量物联网数据的风险
|
||||
======
|
||||
|
||||
> 伴随着物联网设备使用量的增长,这些设备产生的数据可以让消费者节约巨大的开支,也给商家带来新的机遇。但是当故障不可避免地出现的时候,会发生什么呢?
|
||||
|
||||
![Oonal / Getty Images][1]
|
||||
|
||||
不管你看的是什么统计数字,很明显物联网正在走进个人和私人生活的方方面面。这种增长虽然有不少好处,但是也带来了新的风险。一个很重要的问题是,出现问题的时候谁来负责呢?
|
||||
|
||||
也许最大的问题出在基于物联网数据进行的个性化营销以及定价策略上。[保险公司长期以来致力于寻找利用物联网数据的最佳方式][2],我去年写过家庭财产保险公司是如何开始利用物联网传感器减少水灾带来的损失的。一些公司正在研究保险公司竞购消费者的可能性:这种业务基于智能家居数据所揭示的风险的高低。
|
||||
|
||||
但是最大的进步出现在汽车保险领域。许多汽车保险公司已经可以让客户在车辆上安装追踪设备,如果数据证明他们的驾驶习惯良好就可以获取保险折扣。
|
||||
|
||||
- 延伸阅读:[保险公司终于有了一个利用智能家居物联网的好办法][3]
|
||||
|
||||
### UBI 车险的崛起
|
||||
|
||||
UBI(<ruby>基于使用的保险<rt>usage-based insurance</rt></ruby>)车险是一种“按需付费”的业务,可以通过追踪速度、位置,以及其他因素来评估风险并计算车险保费。到 2020 年,预计有 [5000 万美国司机][4]会加入到 UBI 车险的项目中。
|
||||
|
||||
不出所料,保险公司对 UBI 车险青睐有加,因为 UBI 车险可以帮助他们更加精确地计算风险。事实上,[AIG 爱尔兰已经在尝试让国家向 25 岁以下的司机强制推行 UBI 车险][5]。并且,被认定为驾驶习惯良好的司机自然也很乐意节省一笔费用。当然也有反对的声音了,大多数是来自于隐私权倡导者,以及会因此支付更多费用的群体。
|
||||
|
||||
### 出了故障会发生什么?
|
||||
|
||||
但是还有一个更加令人担忧的潜在问题:当物联网设备提供的数据有错误,或者在传输过程中出了问题会发生什么?因为尽管有自动化程序、错误检查等等,还是不可避免地会偶尔发生一些故障。
|
||||
|
||||
不幸的是,这并不是一个理论上某天会给细心的司机不小心多扣几块钱保费的问题。这已经是一个会带来严重后果的现实问题。就像[保险行业仍然没有想清楚谁应该“拥有”面向客户的物联网设备产生的数据][6]一样,我们也不清楚谁将对这些数据所带来的问题负责。
|
||||
|
||||
计算机“故障”据说曾导致赫兹的出租车辆被误报为被盗(虽然在这个例子中这并不是一个严格意义上的物联网问题),并且导致无辜的租车人被逮捕并扣留。结果呢?刑事指控,多年的诉讼官司,以及舆论的指责。非常强烈的舆论指责。
|
||||
|
||||
我们非常容易想象一些类似的情况,比如说一个物联网传感器出了故障,然后报告说某辆车超速了,然而事实上并没有超速。想想为这件事打官司的麻烦吧,或者想想和你的保险公司如何争执不下。
|
||||
|
||||
(当然,这个问题还有另外一面:消费者可能会想办法篡改他们的物联网设备上的数据,以获得更低的费率或者转移事故责任。我们同样也没有可行的办法来应对*这个问题*。)
|
||||
|
||||
### 政府监管是否有必要
|
||||
|
||||
考虑到这些问题的潜在影响,以及所涉及公司对处理这些问题的无动于衷,我们似乎有理由猜想政府干预的必要性。
|
||||
|
||||
这可能是美国众议员 Bob Latta(俄亥俄州,共和党)[重新引入 SMART IOT(物联网现代应用、研究及趋势的现状)法案][7]背后的一个动机。这项由 Latta 和美国众议员 Peter Welch(佛蒙特州,民主党)领导的两党合作物联网工作组提出的[法案][8],于去年秋天通过美国众议院,但被美国参议院驳回了。美国商务部需要研究物联网行业的状况,并在两年后向美国众议院能源与商业部和美国参议院商务委员会报告。
|
||||
|
||||
Latta 在一份声明中表示,“由于预计会有数万亿美元的经济影响,我们需要考虑物联网所带来的的政策,机遇和挑战。SMART IoT 法案会让人们更容易理解美国政府在物联网政策上的做法、可以改进的地方,以及美国联邦政策如何影响尖端技术的研究和发明。”
|
||||
|
||||
这项研究受到了欢迎,但该法案甚至可能不会被通过。即便通过了,物联网在两年的等待时间里也可能会翻天覆地,让美国政府还是无法跟上。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3396230/when-iot-systems-fail-the-risk-of-having-bad-iot-data.html
|
||||
|
||||
作者:[Fredric Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[chen-ni](https://github.com/chen-ni)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Fredric-Paul/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/08/cloud_connected_smart_cars_by_oonal_gettyimages-692819426_1200x800-100767788-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3264655/most-insurance-carriers-not-ready-to-use-iot-data.html
|
||||
[3]: https://www.networkworld.com/article/3296706/finally-a-smart-way-for-insurers-to-leverage-iot-in-smart-homes.html
|
||||
[4]: https://www.businessinsider.com/iot-is-changing-the-auto-insurance-industry-2015-8
|
||||
[5]: https://www.iotforall.com/iot-data-is-disrupting-the-insurance-industry/
|
||||
[6]: https://www.sas.com/en_us/insights/articles/big-data/5-challenges-for-iot-in-insurance-industry.html
|
||||
[7]: https://www.multichannel.com/news/latta-re-ups-smart-iot-act
|
||||
[8]: https://latta.house.gov/uploadedfiles/smart_iot_116th.pdf
|
||||
[9]: https://www.facebook.com/NetworkWorld/
|
||||
[10]: https://www.linkedin.com/company/network-world
|
||||
@ -1,44 +1,44 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10945-1.html)
|
||||
[#]: subject: (Securing telnet connections with stunnel)
|
||||
[#]: via: (https://fedoramagazine.org/securing-telnet-connections-with-stunnel/)
|
||||
[#]: author: (Curt Warfield https://fedoramagazine.org/author/rcurtiswarfield/)
|
||||
|
||||
Securing telnet connections with stunnel
|
||||
使用 stunnel 保护 telnet 连接
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Telnet is a client-server protocol that connects to a remote server through TCP over port 23. Telnet does not encrypt data and is considered insecure and passwords can be easily sniffed because data is sent in the clear. However there are still legacy systems that need to use it. This is where **stunnel** comes to the rescue.
|
||||
Telnet 是一种客户端-服务端协议,通过 TCP 的 23 端口连接到远程服务器。Telnet 并不加密数据,因此它被认为是不安全的,因为数据是以明文形式发送的,所以密码很容易被嗅探。但是,仍有老旧系统需要使用它。这就是用到 **stunnel** 的地方。
|
||||
|
||||
Stunnel is designed to add SSL encryption to programs that have insecure connection protocols. This article shows you how to use it, with telnet as an example.
|
||||
stunnel 旨在为使用不安全连接协议的程序增加 SSL 加密。本文将以 telnet 为例介绍如何使用它。
|
||||
|
||||
### Server Installation
|
||||
### 服务端安装
|
||||
|
||||
Install stunnel along with the telnet server and client [using sudo][2]:
|
||||
[使用 sudo][2] 安装 stunnel 以及 telnet 的服务端和客户端:
|
||||
|
||||
```
|
||||
sudo dnf -y install stunnel telnet-server telnet
|
||||
```
|
||||
|
||||
Add a firewall rule, entering your password when prompted:
|
||||
添加防火墙规则,在提示时输入你的密码:
|
||||
|
||||
```
|
||||
firewall-cmd --add-service=telnet --perm
|
||||
firewall-cmd --reload
|
||||
```
|
||||
|
||||
Next, generate an RSA private key and an SSL certificate:
|
||||
接下来,生成 RSA 私钥和 SSL 证书:
|
||||
|
||||
```
|
||||
openssl genrsa 2048 > stunnel.key
|
||||
openssl req -new -key stunnel.key -x509 -days 90 -out stunnel.crt
|
||||
```
|
||||
|
||||
You will be prompted for the following information one line at a time. When asked for _Common Name_ you must enter the correct host name or IP address, but everything else you can skip through by hitting the **Enter** key.
|
||||
系统将一次提示你输入以下信息。当询问 `Common Name` 时,你必须输入正确的主机名或 IP 地址,但是你可以按回车键跳过其他所有内容。
|
||||
|
||||
```
|
||||
You are about to be asked to enter information that will be
|
||||
@ -57,14 +57,14 @@ Common Name (eg, your name or your server's hostname) []:
|
||||
Email Address []
|
||||
```
|
||||
|
||||
Merge the RSA key and SSL certificate into a single _.pem_ file, and copy that to the SSL certificate directory:
|
||||
将 RSA 密钥和 SSL 证书合并到单个 `.pem` 文件中,并将其复制到 SSL 证书目录:
|
||||
|
||||
```
|
||||
cat stunnel.crt stunnel.key > stunnel.pem
|
||||
sudo cp stunnel.pem /etc/pki/tls/certs/
|
||||
```
|
||||
|
||||
Now it’s time to define the service and the ports to use for encrypting your connection. Choose a port that is not already in use. This example uses port 450 for tunneling telnet. Edit or create the _/etc/stunnel/telnet.conf_ file:
|
||||
现在可以定义服务和用于加密连接的端口了。选择尚未使用的端口。此例使用 450 端口进行隧道传输 telnet。编辑或创建 `/etc/stunnel/telnet.conf`:
|
||||
|
||||
```
|
||||
cert = /etc/pki/tls/certs/stunnel.pem
|
||||
@ -80,15 +80,15 @@ accept = 450
|
||||
connect = 23
|
||||
```
|
||||
|
||||
The **accept** option is the port the server will listen to for incoming telnet requests. The **connect** option is the internal port the telnet server listens to.
|
||||
`accept` 选项是服务器将监听传入 telnet 请求的接口。`connect` 选项是 telnet 服务器的内部监听接口。
|
||||
|
||||
Next, make a copy of the systemd unit file that allows you to override the packaged version:
|
||||
接下来,创建一个 systemd 单元文件的副本来覆盖原来的版本:
|
||||
|
||||
```
|
||||
sudo cp /usr/lib/systemd/system/stunnel.service /etc/systemd/system
|
||||
```
|
||||
|
||||
Edit the _/etc/systemd/system/stunnel.service_ file to add two lines. These lines create a chroot jail for the service when it starts.
|
||||
编辑 `/etc/systemd/system/stunnel.service` 来添加两行。这些行在启动时为服务创建 chroot 监狱。
|
||||
|
||||
```
|
||||
[Unit]
|
||||
@ -106,49 +106,49 @@ ExecStartPre=/usr/bin/chown -R nobody:nobody /var/run/stunnel
|
||||
WantedBy=multi-user.target
|
||||
```
|
||||
|
||||
Next, configure SELinux to listen to telnet on the new port you just specified:
|
||||
接下来,配置 SELinux 以在你刚刚指定的新端口上监听 telnet:
|
||||
|
||||
```
|
||||
sudo semanage port -a -t telnetd_port_t -p tcp 450
|
||||
```
|
||||
|
||||
Finally, add a new firewall rule:
|
||||
最后,添加新的防火墙规则:
|
||||
|
||||
```
|
||||
firewall-cmd --add-port=450/tcp --perm
|
||||
firewall-cmd --reload
|
||||
```
|
||||
|
||||
Now you can enable and start telnet and stunnel.
|
||||
现在你可以启用并启动 telnet 和 stunnel。
|
||||
|
||||
```
|
||||
systemctl enable telnet.socket stunnel@telnet.service --now
|
||||
```
|
||||
|
||||
A note on the _systemctl_ command is in order. Systemd and the stunnel package provide an additional [template unit file][3] by default. The template lets you drop multiple configuration files for stunnel into _/etc/stunnel_ , and use the filename to start the service. For instance, if you had a _foobar.conf_ file, you could start that instance of stunnel with _systemctl start[stunnel@foobar.service][4]_ , without having to write any unit files yourself.
|
||||
要注意 `systemctl` 命令是有顺序的。systemd 和 stunnel 包默认提供额外的[模板单元文件][3]。该模板允许你将 stunnel 的多个配置文件放到 `/etc/stunnel` 中,并使用文件名启动该服务。例如,如果你有一个 `foobar.conf` 文件,那么可以使用 `systemctl start stunnel@foobar.service` 启动该 stunnel 实例,而无需自己编写任何单元文件。
|
||||
|
||||
If you want, you can set this stunnel template service to start on boot:
|
||||
如果需要,可以将此 stunnel 模板服务设置为在启动时启动:
|
||||
|
||||
```
|
||||
systemctl enable stunnel@telnet.service
|
||||
```
|
||||
|
||||
### Client Installation
|
||||
### 客户端安装
|
||||
|
||||
This part of the article assumes you are logged in as a normal user ([with sudo privileges][2]) on the client system. Install stunnel and the telnet client:
|
||||
本文的这部分假设你在客户端系统上以普通用户([拥有 sudo 权限][2])身份登录。安装 stunnel 和 telnet 客户端:
|
||||
|
||||
```
|
||||
dnf -y install stunnel telnet
|
||||
```
|
||||
|
||||
Copy the _stunnel.pem_ file from the remote server to your client _/etc/pki/tls/certs_ directory. In this example, the IP address of the remote telnet server is 192.168.1.143.
|
||||
将 `stunnel.pem` 从远程服务器复制到客户端的 `/etc/pki/tls/certs` 目录。在此例中,远程 telnet 服务器的 IP 地址为 `192.168.1.143`。
|
||||
|
||||
```
|
||||
sudo scp myuser@192.168.1.143:/etc/pki/tls/certs/stunnel.pem
|
||||
/etc/pki/tls/certs/
|
||||
```
|
||||
|
||||
Create the _/etc/stunnel/telnet.conf_ file:
|
||||
创建 `/etc/stunnel/telnet.conf`:
|
||||
|
||||
```
|
||||
cert = /etc/pki/tls/certs/stunnel.pem
|
||||
@ -158,15 +158,15 @@ accept=450
|
||||
connect=192.168.1.143:450
|
||||
```
|
||||
|
||||
The **accept** option is the port that will be used for telnet sessions. The **connect** option is the IP address of your remote server and the port it’s listening on.
|
||||
`accept` 选项是用于 telnet 会话的端口。`connect` 选项是你远程服务器的 IP 地址以及监听的端口。
|
||||
|
||||
Next, enable and start stunnel:
|
||||
接下来,启用并启动 stunnel:
|
||||
|
||||
```
|
||||
systemctl enable stunnel@telnet.service --now
|
||||
```
|
||||
|
||||
Test your connection. Since you have a connection established, you will telnet to _localhost_ instead of the hostname or IP address of the remote telnet server:
|
||||
测试你的连接。由于有一条已建立的连接,你会 `telnet` 到 `localhost` 而不是远程 telnet 服务器的主机名或者 IP 地址。
|
||||
|
||||
```
|
||||
[user@client ~]$ telnet localhost 450
|
||||
@ -189,8 +189,8 @@ via: https://fedoramagazine.org/securing-telnet-connections-with-stunnel/
|
||||
|
||||
作者:[Curt Warfield][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -199,4 +199,3 @@ via: https://fedoramagazine.org/securing-telnet-connections-with-stunnel/
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/05/stunnel-816x345.jpg
|
||||
[2]: https://fedoramagazine.org/howto-use-sudo/
|
||||
[3]: https://fedoramagazine.org/systemd-template-unit-files/
|
||||
[4]: mailto:stunnel@foobar.service
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10935-1.html)
|
||||
[#]: subject: (4 Ways to Run Linux Commands in Windows)
|
||||
[#]: via: (https://itsfoss.com/run-linux-commands-in-windows/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
@ -10,13 +10,13 @@
|
||||
在 Windows 中运行 Linux 命令的 4 种方法
|
||||
======
|
||||
|
||||
_ **简介:想要使用 Linux 命令,但又不想离开 Windows ?以下是在 Windows 中运行 Linux bash 命令的几种方法。** _
|
||||
> 想要使用 Linux 命令,但又不想离开 Windows ?以下是在 Windows 中运行 Linux bash 命令的几种方法。
|
||||
|
||||
如果你在课程中正在学习 shell 脚本,那么需要使用 Linux 命令来练习命令和脚本。
|
||||
如果你正在课程中正在学习 shell 脚本,那么需要使用 Linux 命令来练习命令和脚本。
|
||||
|
||||
你的学校实验室可能安装了 Linux,但是你个人没有 [Linux 的笔记本][1],而是像其他人一样的 Windows 计算机。你的作业需要运行 Linux 命令,你也想想知道如何在 Windows 上运行 Bash 命令和脚本。
|
||||
你的学校实验室可能安装了 Linux,但是你自己没有安装了 [Linux 的笔记本电脑][1],而是像其他人一样的 Windows 计算机。你的作业需要运行 Linux 命令,你或许想知道如何在 Windows 上运行 Bash 命令和脚本。
|
||||
|
||||
你可以[在双启动模式下同时安装 Windows 和 Linux][2]。此方法能让你在启动计算机时选择 Linux 或 Windows。但是,为了运行 Linux 命令而单独使用分区的麻烦可能不适合所有人。
|
||||
你可以[在双启动模式下同时安装 Windows 和 Linux][2]。此方法能让你在启动计算机时选择 Linux 或 Windows。但是,为了运行 Linux 命令而使用单独分区的麻烦可能不适合所有人。
|
||||
|
||||
你也可以[使用在线 Linux 终端][3],但你的作业无法保存。
|
||||
|
||||
@ -24,32 +24,31 @@ _ **简介:想要使用 Linux 命令,但又不想离开 Windows ?以下是
|
||||
|
||||
### 在 Windows 中使用 Linux 命令
|
||||
|
||||
![][4]
|
||||

|
||||
|
||||
作为一个热心的 Linux 用户和推广者,我希望看到越来越多的人使用“真正的” Linux,但我知道有时候,这不是优先考虑的问题。如果你只是想练习 Linux 来通过考试,可以使用这些方法之一在 Windows 上运行 Bash 命令。
|
||||
|
||||
#### 1\. 在 Windows 10 上使用 Linux Bash Shell
|
||||
#### 1、在 Windows 10 上使用 Linux Bash Shell
|
||||
|
||||
你是否知道可以在 Windows 10 中运行 Linux 发行版? [Windows 的 Linux 子系统 (WSL)][5] 能让你在 Windows 中运行 Linux。即将推出的 WSL 版本将使用 Windows 内部的真正 Linux 内核。
|
||||
你是否知道可以在 Windows 10 中运行 Linux 发行版? [Windows 的 Linux 子系统 (WSL)][5] 能让你在 Windows 中运行 Linux。即将推出的 WSL 版本将在 Windows 内部使用真正 Linux 内核。
|
||||
|
||||
此 WSL 在 Windows 上也称为 Bash,它作为一个常规的 Windows 应用运行,并提供了一个命令行模式的 Linux 发行版。不要害怕命令行模式,因为你的目的是运行 Linux 命令。这就是你所需要的。
|
||||
此 WSL 也称为 Bash on Windows,它作为一个常规的 Windows 应用运行,并提供了一个命令行模式的 Linux 发行版。不要害怕命令行模式,因为你的目的是运行 Linux 命令。这就是你所需要的。
|
||||
|
||||
![Ubuntu Linux inside Windows][6]
|
||||
|
||||
你可以在 Windows 应用商店中找到一些流行的 Linux 发行版,如 Ubuntu、Kali Linux、openSUSE 等。你只需像任何其他 Windows 应用一样下载和安装它。安装后,你可以运行所需的所有 Linux 命令。
|
||||
|
||||
|
||||
![Linux distributions in Windows 10 Store][8]
|
||||
|
||||
请参考教程:[在 Windows 上安装 Linux bash shell][9]。
|
||||
|
||||
#### 2\. 使用 Git Bash 在 Windows 上运行 Bash 命令
|
||||
#### 2、使用 Git Bash 在 Windows 上运行 Bash 命令
|
||||
|
||||
、你可能知道 [Git][10] 是什么。它是由 [Linux 创建者 Linus Torvalds][11] 开发的版本控制系统。
|
||||
你可能知道 [Git][10] 是什么。它是由 [Linux 创建者 Linus Torvalds][11] 开发的版本控制系统。
|
||||
|
||||
[Git for Windows][12] 是一组工具,能让你在命令行和图形界面中使用 Git。Git for Windows 中包含的工具之一是 Git Bash。
|
||||
|
||||
Git Bash 为 Git 命令行提供了仿真层。除了 Git 命令,Git Bash 还支持许多 Bash 程序,如 ssh、scp、cat、find 等。
|
||||
Git Bash 为 Git 命令行提供了仿真层。除了 Git 命令,Git Bash 还支持许多 Bash 程序,如 `ssh`、`scp`、`cat`、`find` 等。
|
||||
|
||||
![Git Bash][13]
|
||||
|
||||
@ -57,21 +56,21 @@ Git Bash 为 Git 命令行提供了仿真层。除了 Git 命令,Git Bash 还
|
||||
|
||||
你可以从其网站免费下载和安装 Git for Windows 工具来在 Windows 中安装 Git Bash。
|
||||
|
||||
[下载 Git for Windows][12]
|
||||
- [下载 Git for Windows][12]
|
||||
|
||||
#### 3\. 使用 Cygwin 在 Windows 中使用 Linux 命令
|
||||
#### 3、使用 Cygwin 在 Windows 中使用 Linux 命令
|
||||
|
||||
如果要在 Windows 中运行 Linux 命令,那么 Cygwin 是一个推荐的工具。Cygwin 创建于 1995 年,旨在提供一个原生运行于 Windows 中的 POSIX 兼容环境。Cygwin 是由 Red Hat 员工和许多其他志愿者维护的免费开源软件。
|
||||
如果要在 Windows 中运行 Linux 命令,那么 Cygwin 是一个推荐的工具。Cygwin 创建于 1995 年,旨在提供一个原生运行于 Windows 中的 POSIX 兼容环境。Cygwin 是由 Red Hat 员工和许多其他志愿者维护的自由开源软件。
|
||||
|
||||
二十年来,Windows 用户使用 Cygwin 来运行和练习 Linux/Bash 命令。十多年前,我甚至用 Cygwin 来学习 Linux 命令。
|
||||
|
||||
![Cygwin | Image Credit][14]
|
||||
![Cygwin][14]
|
||||
|
||||
你可以从下面的官方网站下载 Cygwin。我还建议你参考这个 [Cygwin 备忘录][15]来开始使用。
|
||||
|
||||
[下载 Cygwin][16]
|
||||
- [下载 Cygwin][16]
|
||||
|
||||
#### 4\. 在虚拟机中使用 Linux
|
||||
#### 4、在虚拟机中使用 Linux
|
||||
|
||||
另一种方法是使用虚拟化软件并在其中安装 Linux。这样,你可以在 Windows 中安装 Linux 发行版(带有图形界面)并像常规 Windows 应用一样运行它。
|
||||
|
||||
@ -83,7 +82,7 @@ Git Bash 为 Git 命令行提供了仿真层。除了 Git 命令,Git Bash 还
|
||||
|
||||
你可以按照[本教程学习如何在 VirtualBox 中安装 Linux][20]。
|
||||
|
||||
**总结**
|
||||
### 总结
|
||||
|
||||
运行 Linux 命令的最佳方法是使用 Linux。当选择不安装 Linux 时,这些工具能让你在 Windows 上运行 Linux 命令。都试试看,看哪种适合你。
|
||||
|
||||
@ -94,7 +93,7 @@ via: https://itsfoss.com/run-linux-commands-in-windows/
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,82 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10997-1.html)
|
||||
[#]: subject: (5 GNOME keyboard shortcuts to be more productive)
|
||||
[#]: via: (https://fedoramagazine.org/5-gnome-keyboard-shortcuts-to-be-more-productive/)
|
||||
[#]: author: (Clément Verna https://fedoramagazine.org/author/cverna/)
|
||||
|
||||
5 个提高效率的 GNOME 快捷键
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
对于某些人来说,使用 GNOME Shell 作为传统的桌面管理器可能会感觉沮丧,因为它通常需要更多的鼠标操作。事实上,GNOME Shell 也是一个专为键盘操作而设计的[桌面管理器][2]。通过这五种使用键盘而不是鼠标的方法,了解如何使用 GNOME Shell 提高效率。
|
||||
|
||||
### GNOME 活动概述
|
||||
|
||||
可以使用键盘上的 `Super` 键轻松打开活动概述。(`Super` 键通常有一个标识——比如 Windows 徽标……)这在启动应用程序时非常有用。例如,使用以下键序列 `Super + f i r + Enter` 可以轻松启动 Firefox Web 浏览器
|
||||
|
||||
![][3]
|
||||
|
||||
### 消息托盘
|
||||
|
||||
在 GNOME 中,消息托盘中提供了通知。这也是日历和世界时钟出现的地方。要使用键盘打开信息托盘,请使用 `Super + m` 快捷键。要关闭消息托盘,只需再次使用相同的快捷方式。
|
||||
|
||||
![][4]
|
||||
|
||||
### 在 GNOME 中管理工作空间
|
||||
|
||||
GNOME Shell 使用动态工作空间,这意味着它可以根据需要创建更多工作空间。使用 GNOME 提高工作效率的一个好方法是为每个应用程序或每个专用活动使用一个工作区,然后使用键盘在这些工作区之间导航。
|
||||
|
||||
让我们看一个实际的例子。要在当前工作区中打开终端,请按以下键:`Super + t e r + Enter`。然后,要打开新工作区,请按 `Super + PgDn`。 打开 Firefox( `Super + f i r + Enter`)。 要返回终端(所在的工作空间),请使用 `Super + PgUp`。
|
||||
|
||||
![][5]
|
||||
|
||||
### 管理应用窗口
|
||||
|
||||
使用键盘也可以轻松管理应用程序窗口的大小。最小化、最大化和将应用程序移动到屏幕的左侧或右侧只需几个击键即可完成。使用 `Super + ↑` 最大化、`Super + ↓` 最小化、`Super + ←` 和 `Super + →` 左右移动窗口。
|
||||
|
||||
![][6]
|
||||
|
||||
### 同一个应用的多个窗口
|
||||
|
||||
使用活动概述启动应用程序非常有效。但是,尝试从已经运行的应用程序打开一个新窗口只能将焦点转移到已经打开的窗口。要创建一个新窗口,就不是简单地按 `Enter` 启动应用程序,请使用 `Ctrl + Enter`。
|
||||
|
||||
因此,例如,使用应用程序概述启动终端的第二个实例,`Super + t e r + (Ctrl + Enter)`。
|
||||
|
||||
![][7]
|
||||
|
||||
然后你可以使用 `Super` + ` 在同一个应用程序的窗口之间切换。
|
||||
|
||||
![][8]
|
||||
|
||||
如图所示,当用键盘控制时,GNOME Shell 是一个非常强大的桌面环境。学习使用这些快捷方式并训练你的肌肉记忆以不使用鼠标将为你提供更好的用户体验,并在使用 GNOME 时提高你的工作效率。有关其他有用的快捷方式,请查看 [GNOME wiki 上的此页面][9]。
|
||||
|
||||
*图片来自 [1AmFcS][10],[Unsplash][11]*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/5-gnome-keyboard-shortcuts-to-be-more-productive/
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/cverna/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/05/5-gnome-keycombos-816x345.jpg
|
||||
[2]: https://fedoramagazine.org/gnome-3-32-released-coming-to-fedora-30/
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2019/05/Peek-2019-05-23-10-50.gif
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2019/05/Peek-2019-05-23-11-01.gif
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2019/05/Peek-2019-05-23-12-57.gif
|
||||
[6]: https://fedoramagazine.org/wp-content/uploads/2019/05/Peek-2019-05-23-13-06.gif
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2019/05/Peek-2019-05-23-13-19.gif
|
||||
[8]: https://fedoramagazine.org/wp-content/uploads/2019/05/Peek-2019-05-23-13-22.gif
|
||||
[9]: https://wiki.gnome.org/Design/OS/KeyboardShortcuts
|
||||
[10]: https://unsplash.com/photos/MuTWth_RnEs?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[11]: https://unsplash.com/search/photos/keyboard?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
171
published/20190527 A deeper dive into Linux permissions.md
Normal file
171
published/20190527 A deeper dive into Linux permissions.md
Normal file
@ -0,0 +1,171 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10947-1.html)
|
||||
[#]: subject: (A deeper dive into Linux permissions)
|
||||
[#]: via: (https://www.networkworld.com/article/3397790/a-deeper-dive-into-linux-permissions.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
更深入地了解 Linux 权限
|
||||
======
|
||||
> 在 Linux 上查看文件权限时,有时你会看到的不仅仅是普通的 r、w、x 和 -。如何更清晰地了解这些字符试图告诉你什么以及这些权限如何工作?
|
||||
|
||||

|
||||
|
||||
在 Linux 上查看文件权限时,有时你会看到的不仅仅是普通的 `r`、`w`、`x` 和 `-`。除了在所有者、组和其他中看到 `rwx` 之外,你可能会看到 `s` 或者 `t`,如下例所示:
|
||||
|
||||
```
|
||||
drwxrwsrwt
|
||||
```
|
||||
|
||||
要进一步明确的方法之一是使用 `stat` 命令查看权限。`stat` 的第四行输出以八进制和字符串格式显示文件权限:
|
||||
|
||||
```
|
||||
$ stat /var/mail
|
||||
File: /var/mail
|
||||
Size: 4096 Blocks: 8 IO Block: 4096 directory
|
||||
Device: 801h/2049d Inode: 1048833 Links: 2
|
||||
Access: (3777/drwxrwsrwt) Uid: ( 0/ root) Gid: ( 8/ mail)
|
||||
Access: 2019-05-21 19:23:15.769746004 -0400
|
||||
Modify: 2019-05-21 19:03:48.226656344 -0400
|
||||
Change: 2019-05-21 19:03:48.226656344 -0400
|
||||
Birth: -
|
||||
```
|
||||
|
||||
这个输出提示我们,分配给文件权限的位数超过 9 位。事实上,有 12 位。这些额外的三位提供了一种分配超出通常的读、写和执行权限的方法 - 例如,`3777`(二进制 `011111111111`)表示使用了两个额外的设置。
|
||||
|
||||
该值的第一个 `1` (第二位)表示 SGID(设置 GID),为运行文件而赋予临时权限,或以该关联组的权限来使用目录。
|
||||
|
||||
```
|
||||
011111111111
|
||||
^
|
||||
```
|
||||
|
||||
SGID 将正在使用该文件的用户作为该组成员之一而分配临时权限。
|
||||
|
||||
第二个 `1`(第三位)是“粘连”位。它确保*只有*文件的所有者能够删除或重命名该文件或目录。
|
||||
|
||||
```
|
||||
011111111111
|
||||
^
|
||||
```
|
||||
|
||||
如果权限是 `7777` 而不是 `3777`,我们知道 SUID(设置 UID)字段也已设置。
|
||||
|
||||
```
|
||||
111111111111
|
||||
^
|
||||
```
|
||||
|
||||
SUID 将正在使用该文件的用户作为文件拥有者分配临时权限。
|
||||
|
||||
至于我们上面看到的 `/var/mail` 目录,所有用户都需要访问,因此需要一些特殊值来提供它。
|
||||
|
||||
但现在让我们更进一步。
|
||||
|
||||
特殊权限位的一个常见用法是使用 `passwd` 之类的命令。如果查看 `/usr/bin/passwd` 文件,你会注意到 SUID 位已设置,它允许你更改密码(以及 `/etc/shadow` 文件的内容),即使你是以普通(非特权)用户身份运行,并且对此文件没有读取或写入权限。当然,`passwd` 命令很聪明,不允许你更改其他人的密码,除非你是以 root 身份运行或使用 `sudo`。
|
||||
|
||||
```
|
||||
$ ls -l /usr/bin/passwd
|
||||
-rwsr-xr-x 1 root root 63736 Mar 22 14:32 /usr/bin/passwd
|
||||
$ ls -l /etc/shadow
|
||||
-rw-r----- 1 root shadow 2195 Apr 22 10:46 /etc/shadow
|
||||
```
|
||||
|
||||
现在,让我们看一下使用这些特殊权限可以做些什么。
|
||||
|
||||
### 如何分配特殊文件权限
|
||||
|
||||
与 Linux 命令行中的许多东西一样,你可以有不同的方法设置。 `chmod` 命令允许你以数字方式或使用字符表达式更改权限。
|
||||
|
||||
要以数字方式更改文件权限,你可以使用这样的命令来设置 SUID 和 SGID 位:
|
||||
|
||||
```
|
||||
$ chmod 6775 tryme
|
||||
```
|
||||
|
||||
或者你可以使用这样的命令:
|
||||
|
||||
```
|
||||
$ chmod ug+s tryme <== 用于 SUID 和 SGID 权限
|
||||
```
|
||||
|
||||
如果你要添加特殊权限的文件是脚本,你可能会对它不符合你的期望感到惊讶。这是一个非常简单的例子:
|
||||
|
||||
```
|
||||
$ cat tryme
|
||||
#!/bin/bash
|
||||
|
||||
echo I am $USER
|
||||
```
|
||||
|
||||
即使设置了 SUID 和 SGID 位,并且 root 是文件所有者,运行脚本也不会产生你可能期望的 “I am root”。为什么?因为 Linux 会忽略脚本的 SUID 和 SGID 位。
|
||||
|
||||
```
|
||||
$ ls -l tryme
|
||||
-rwsrwsrwt 1 root root 29 May 26 12:22 tryme
|
||||
$ ./tryme
|
||||
I am jdoe
|
||||
```
|
||||
|
||||
另一方面,如果你对一个编译的程序之类进行类似的尝试,就像下面这个简单的 C 程序一样,你会看到不同的效果。在此示例程序中,我们提示用户输入文件名并创建它,并给文件写入权限。
|
||||
|
||||
```
|
||||
#include <stdlib.h>
|
||||
|
||||
int main()
|
||||
{
|
||||
FILE *fp; /* file pointer*/
|
||||
char fName[20];
|
||||
|
||||
printf("Enter the name of file to be created: ");
|
||||
scanf("%s",fName);
|
||||
|
||||
/* create the file with write permission */
|
||||
fp=fopen(fName,"w");
|
||||
/* check if file was created */
|
||||
if(fp==NULL)
|
||||
{
|
||||
printf("File not created");
|
||||
exit(0);
|
||||
}
|
||||
|
||||
printf("File created successfully\n");
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
编译程序并运行该命令以使 root 用户成为所有者并设置所需权限后,你将看到它以预期的 root 权限运行 - 留下新创建的 root 为所有者的文件。当然,你必须具有 `sudo` 权限才能运行一些需要的命令。
|
||||
|
||||
```
|
||||
$ cc -o mkfile mkfile.c <== 编译程序
|
||||
$ sudo chown root:root mkfile <== 更改所有者和组为 “root”
|
||||
$ sudo chmod ug+s mkfile <== 添加 SUID and SGID 权限
|
||||
$ ./mkfile <== 运行程序
|
||||
Enter name of file to be create: empty
|
||||
File created successfully
|
||||
$ ls -l empty
|
||||
-rw-rw-r-- 1 root root 0 May 26 13:15 empty
|
||||
```
|
||||
|
||||
请注意,文件所有者是 root - 如果程序未以 root 权限运行,则不会发生这种情况。
|
||||
|
||||
权限字符串中不常见设置的位置(例如,rw**s**rw**s**rw**t**)可以帮助提醒我们每个位的含义。至少第一个 “s”(SUID) 位于所有者权限区域中,第二个 (SGID) 位于组权限区域中。为什么粘连位是 “t” 而不是 “s” 超出了我的理解。也许创造者想把它称为 “tacky bit”,但由于这个词的不太令人喜欢的第二个定义而改变了他们的想法。无论如何,额外的权限设置为 Linux 和其他 Unix 系统提供了许多额外的功能。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3397790/a-deeper-dive-into-linux-permissions.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/05/shs_rwsr-100797564-large.jpg
|
||||
[2]: https://www.facebook.com/NetworkWorld/
|
||||
[3]: https://www.linkedin.com/company/network-world
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( jdh8383 )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: translator: (jdh8383)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10938-1.html)
|
||||
[#]: subject: (How To Check Available Security Updates On Red Hat (RHEL) And CentOS System?)
|
||||
[#]: via: (https://www.2daygeek.com/check-list-view-find-available-security-updates-on-redhat-rhel-centos-system/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
@ -10,35 +10,29 @@
|
||||
如何在 CentOS 或 RHEL 系统上检查可用的安全更新?
|
||||
======
|
||||
|
||||
当你更新系统时,根据你所在公司的安全策略,有时候可能只需要打上与安全相关的补丁。
|
||||

|
||||
|
||||
大多数情况下,这应该是出于程序兼容性方面的考量。
|
||||
当你更新系统时,根据你所在公司的安全策略,有时候可能只需要打上与安全相关的补丁。大多数情况下,这应该是出于程序兼容性方面的考量。那该怎样实践呢?有没有办法让 `yum` 只安装安全补丁呢?
|
||||
|
||||
那该怎样实践呢?有没有办法让 yum 只安装安全补丁呢?
|
||||
答案是肯定的,可以用 `yum` 包管理器轻松实现。
|
||||
|
||||
答案是肯定的,可以用 yum 包管理器轻松实现。
|
||||
在这篇文章中,我们不但会提供所需的信息。而且,我们会介绍一些额外的命令,可以帮你获取指定安全更新的详实信息。
|
||||
|
||||
在这篇文章中,我们不但会提供所需的信息。
|
||||
希望这样可以启发你去了解并修复你列表上的那些漏洞。一旦有安全漏洞被公布,就必须更新受影响的软件,这样可以降低系统中的安全风险。
|
||||
|
||||
而且,我们会介绍一些额外的命令,可以帮你获取指定安全更新的详实信息。
|
||||
|
||||
希望这样可以启发你去了解并修复你列表上的那些漏洞。
|
||||
|
||||
一旦有安全漏洞被公布,就必须更新受影响的软件,这样可以降低系统中的安全风险。
|
||||
|
||||
对于 RHEL 或 CentOS 6 系统,运行下面的 **[Yum 命令][1]** 来安装 yum 安全插件。
|
||||
对于 RHEL 或 CentOS 6 系统,运行下面的 [Yum 命令][1] 来安装 yum 安全插件。
|
||||
|
||||
```
|
||||
# yum -y install yum-plugin-security
|
||||
```
|
||||
|
||||
在 RHEL 7&8 或是 CentOS 7&8 上面,这个插件已经是 yum 的一部分了,不用单独安装。
|
||||
在 RHEL 7&8 或是 CentOS 7&8 上面,这个插件已经是 `yum` 的一部分了,不用单独安装。
|
||||
|
||||
只列出全部可用的补丁(包括安全,Bug 修复以及产品改进),但不安装它们。
|
||||
要列出全部可用的补丁(包括安全、Bug 修复以及产品改进),但不安装它们:
|
||||
|
||||
```
|
||||
# yum updateinfo list available
|
||||
已加载插件: changelog, package_upload, product-id, search-disabled-repos,
|
||||
Loaded plugins: changelog, package_upload, product-id, search-disabled-repos,
|
||||
: subscription-manager, verify, versionlock
|
||||
RHSA-2014:1031 Important/Sec. 389-ds-base-1.3.1.6-26.el7_0.x86_64
|
||||
RHSA-2015:0416 Important/Sec. 389-ds-base-1.3.3.1-13.el7.x86_64
|
||||
@ -54,20 +48,18 @@ RHBA-2016:1048 bugfix 389-ds-base-1.3.4.0-30.el7_2.x86_64
|
||||
RHBA-2016:1298 bugfix 389-ds-base-1.3.4.0-32.el7_2.x86_64
|
||||
```
|
||||
|
||||
要统计补丁的大约数量,运行下面的命令。
|
||||
要统计补丁的大约数量,运行下面的命令:
|
||||
|
||||
```
|
||||
# yum updateinfo list available | wc -l
|
||||
11269
|
||||
```
|
||||
|
||||
想列出全部可用的安全补丁但不安装。
|
||||
|
||||
以下命令用来展示你系统里已安装和待安装的推荐补丁。
|
||||
想列出全部可用的安全补丁但不安装,以下命令用来展示你系统里已安装和待安装的推荐补丁:
|
||||
|
||||
```
|
||||
# yum updateinfo list security all
|
||||
已加载插件: changelog, package_upload, product-id, search-disabled-repos,
|
||||
Loaded plugins: changelog, package_upload, product-id, search-disabled-repos,
|
||||
: subscription-manager, verify, versionlock
|
||||
RHSA-2014:1031 Important/Sec. 389-ds-base-1.3.1.6-26.el7_0.x86_64
|
||||
RHSA-2015:0416 Important/Sec. 389-ds-base-1.3.3.1-13.el7.x86_64
|
||||
@ -81,13 +73,13 @@ RHBA-2016:1298 bugfix 389-ds-base-1.3.4.0-32.el7_2.x86_64
|
||||
RHSA-2018:1380 Important/Sec. 389-ds-base-1.3.7.5-21.el7_5.x86_64
|
||||
RHSA-2018:2757 Moderate/Sec. 389-ds-base-1.3.7.5-28.el7_5.x86_64
|
||||
RHSA-2018:3127 Moderate/Sec. 389-ds-base-1.3.8.4-15.el7.x86_64
|
||||
i RHSA-2014:1031 Important/Sec. 389-ds-base-libs-1.3.1.6-26.el7_0.x86_64
|
||||
RHSA-2014:1031 Important/Sec. 389-ds-base-libs-1.3.1.6-26.el7_0.x86_64
|
||||
```
|
||||
|
||||
要显示所有待安装的安全补丁。
|
||||
要显示所有待安装的安全补丁:
|
||||
|
||||
```
|
||||
# yum updateinfo list security all | egrep -v "^i"
|
||||
# yum updateinfo list security all | grep -v "i"
|
||||
|
||||
RHSA-2014:1031 Important/Sec. 389-ds-base-1.3.1.6-26.el7_0.x86_64
|
||||
RHSA-2015:0416 Important/Sec. 389-ds-base-1.3.3.1-13.el7.x86_64
|
||||
@ -102,14 +94,14 @@ RHBA-2016:1298 bugfix 389-ds-base-1.3.4.0-32.el7_2.x86_64
|
||||
RHSA-2018:2757 Moderate/Sec. 389-ds-base-1.3.7.5-28.el7_5.x86_64
|
||||
```
|
||||
|
||||
要统计全部安全补丁的大致数量,运行下面的命令。
|
||||
要统计全部安全补丁的大致数量,运行下面的命令:
|
||||
|
||||
```
|
||||
# yum updateinfo list security all | wc -l
|
||||
3522
|
||||
```
|
||||
|
||||
下面根据已装软件列出可更新的安全补丁。这包括 bugzillas(bug修复),CVEs(知名漏洞数据库),安全更新等。
|
||||
下面根据已装软件列出可更新的安全补丁。这包括 bugzilla(bug 修复)、CVE(知名漏洞数据库)、安全更新等:
|
||||
|
||||
```
|
||||
# yum updateinfo list security
|
||||
@ -118,7 +110,7 @@ RHBA-2016:1298 bugfix 389-ds-base-1.3.4.0-32.el7_2.x86_64
|
||||
|
||||
# yum updateinfo list sec
|
||||
|
||||
已加载插件: changelog, package_upload, product-id, search-disabled-repos,
|
||||
Loaded plugins: changelog, package_upload, product-id, search-disabled-repos,
|
||||
: subscription-manager, verify, versionlock
|
||||
|
||||
RHSA-2018:3665 Important/Sec. NetworkManager-1:1.12.0-8.el7_6.x86_64
|
||||
@ -134,11 +126,11 @@ RHSA-2018:3665 Important/Sec. NetworkManager-wifi-1:1.12.0-8.el7_6.x86_64
|
||||
RHSA-2018:3665 Important/Sec. NetworkManager-wwan-1:1.12.0-8.el7_6.x86_64
|
||||
```
|
||||
|
||||
显示所有与安全相关的更新,并且返回一个结果来告诉你是否有可用的补丁。
|
||||
显示所有与安全相关的更新,并且返回一个结果来告诉你是否有可用的补丁:
|
||||
|
||||
```
|
||||
# yum --security check-update
|
||||
已加载插件: changelog, package_upload, product-id, search-disabled-repos, subscription-manager, verify, versionlock
|
||||
Loaded plugins: changelog, package_upload, product-id, search-disabled-repos, subscription-manager, verify, versionlock
|
||||
rhel-7-server-rpms | 2.0 kB 00:00:00
|
||||
--> policycoreutils-devel-2.2.5-20.el7.x86_64 from rhel-7-server-rpms excluded (updateinfo)
|
||||
--> smc-raghumalayalam-fonts-6.0-7.el7.noarch from rhel-7-server-rpms excluded (updateinfo)
|
||||
@ -162,7 +154,7 @@ NetworkManager-libnm.x86_64 1:1.12.0-10.el7_6 rhel-7
|
||||
NetworkManager-ppp.x86_64 1:1.12.0-10.el7_6 rhel-7-server-rpms
|
||||
```
|
||||
|
||||
列出所有可用的安全补丁,并且显示其详细信息。
|
||||
列出所有可用的安全补丁,并且显示其详细信息:
|
||||
|
||||
```
|
||||
# yum info-sec
|
||||
@ -196,12 +188,12 @@ Description : The tzdata packages contain data files with rules for various
|
||||
Severity : None
|
||||
```
|
||||
|
||||
如果你想要知道某个更新的具体内容,可以运行下面这个命令。
|
||||
如果你想要知道某个更新的具体内容,可以运行下面这个命令:
|
||||
|
||||
```
|
||||
# yum updateinfo RHSA-2019:0163
|
||||
|
||||
已加载插件: changelog, package_upload, product-id, search-disabled-repos, subscription-manager, verify, versionlock
|
||||
Loaded plugins: changelog, package_upload, product-id, search-disabled-repos, subscription-manager, verify, versionlock
|
||||
rhel-7-server-rpms | 2.0 kB 00:00:00
|
||||
===============================================================================
|
||||
Important: kernel security, bug fix, and enhancement update
|
||||
@ -243,12 +235,12 @@ Description : The kernel packages contain the Linux kernel, the core of any
|
||||
updateinfo info done
|
||||
```
|
||||
|
||||
跟之前类似,你可以只查询那些通过 CVE 释出的系统漏洞。
|
||||
跟之前类似,你可以只查询那些通过 CVE 释出的系统漏洞:
|
||||
|
||||
```
|
||||
# yum updateinfo list cves
|
||||
|
||||
已加载插件: changelog, package_upload, product-id, search-disabled-repos,
|
||||
Loaded plugins: changelog, package_upload, product-id, search-disabled-repos,
|
||||
: subscription-manager, verify, versionlock
|
||||
CVE-2018-15688 Important/Sec. NetworkManager-1:1.12.0-8.el7_6.x86_64
|
||||
CVE-2018-15688 Important/Sec. NetworkManager-adsl-1:1.12.0-8.el7_6.x86_64
|
||||
@ -260,12 +252,12 @@ CVE-2018-15688 Important/Sec. NetworkManager-ppp-1:1.12.0-8.el7_6.x86_64
|
||||
CVE-2018-15688 Important/Sec. NetworkManager-team-1:1.12.0-8.el7_6.x86_64
|
||||
```
|
||||
|
||||
你也可以查看那些跟 bug 修复相关的更新,运行下面的命令。
|
||||
你也可以查看那些跟 bug 修复相关的更新,运行下面的命令:
|
||||
|
||||
```
|
||||
# yum updateinfo list bugfix | less
|
||||
|
||||
已加载插件: changelog, package_upload, product-id, search-disabled-repos,
|
||||
Loaded plugins: changelog, package_upload, product-id, search-disabled-repos,
|
||||
: subscription-manager, verify, versionlock
|
||||
RHBA-2018:3349 bugfix NetworkManager-1:1.12.0-7.el7_6.x86_64
|
||||
RHBA-2019:0519 bugfix NetworkManager-1:1.12.0-10.el7_6.x86_64
|
||||
@ -277,11 +269,11 @@ RHBA-2018:3349 bugfix NetworkManager-config-server-1:1.12.0-7.el7_6.noarch
|
||||
RHBA-2019:0519 bugfix NetworkManager-config-server-1:1.12.0-10.el7_6.noarch
|
||||
```
|
||||
|
||||
要想得到待安装更新的摘要信息,运行这个。
|
||||
要想得到待安装更新的摘要信息,运行这个:
|
||||
|
||||
```
|
||||
# yum updateinfo summary
|
||||
已加载插件: changelog, package_upload, product-id, search-disabled-repos, subscription-manager, verify, versionlock
|
||||
Loaded plugins: changelog, package_upload, product-id, search-disabled-repos, subscription-manager, verify, versionlock
|
||||
rhel-7-server-rpms | 2.0 kB 00:00:00
|
||||
Updates Information Summary: updates
|
||||
13 Security notice(s)
|
||||
@ -311,7 +303,7 @@ via: https://www.2daygeek.com/check-list-view-find-available-security-updates-on
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[jdh8383](https://github.com/jdh8383)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
474
published/20190527 How to write a good C main function.md
Normal file
474
published/20190527 How to write a good C main function.md
Normal file
@ -0,0 +1,474 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10949-1.html)
|
||||
[#]: subject: (How to write a good C main function)
|
||||
[#]: via: (https://opensource.com/article/19/5/how-write-good-c-main-function)
|
||||
[#]: author: (Erik O'Shaughnessy https://opensource.com/users/jnyjny)
|
||||
|
||||
如何写好 C main 函数
|
||||
======
|
||||
|
||||
> 学习如何构造一个 C 文件并编写一个 C main 函数来成功地处理命令行参数。
|
||||
|
||||

|
||||
|
||||
我知道,现在孩子们用 Python 和 JavaScript 编写他们的疯狂“应用程序”。但是不要这么快就否定 C 语言 —— 它能够提供很多东西,并且简洁。如果你需要速度,用 C 语言编写可能就是你的答案。如果你正在寻找稳定的职业或者想学习如何捕获[空指针解引用][2],C 语言也可能是你的答案!在本文中,我将解释如何构造一个 C 文件并编写一个 C main 函数来成功地处理命令行参数。
|
||||
|
||||
我:一个顽固的 Unix 系统程序员。
|
||||
|
||||
你:一个有编辑器、C 编译器,并有时间打发的人。
|
||||
|
||||
让我们开工吧。
|
||||
|
||||
### 一个无聊但正确的 C 程序
|
||||
|
||||
![Parody O'Reilly book cover, "Hating Other People's Code"][3]
|
||||
|
||||
C 程序以 `main()` 函数开头,通常保存在名为 `main.c` 的文件中。
|
||||
|
||||
```
|
||||
/* main.c */
|
||||
int main(int argc, char *argv[]) {
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
这个程序可以*编译*但不*干*任何事。
|
||||
|
||||
```
|
||||
$ gcc main.c
|
||||
$ ./a.out -o foo -vv
|
||||
$
|
||||
```
|
||||
|
||||
正确但无聊。
|
||||
|
||||
### main 函数是唯一的。
|
||||
|
||||
`main()` 函数是开始执行时所执行的程序的第一个函数,但不是第一个执行的函数。*第一个*函数是 `_start()`,它通常由 C 运行库提供,在编译程序时自动链入。此细节高度依赖于操作系统和编译器工具链,所以我假装没有提到它。
|
||||
|
||||
`main()` 函数有两个参数,通常称为 `argc` 和 `argv`,并返回一个有符号整数。大多数 Unix 环境都希望程序在成功时返回 `0`(零),失败时返回 `-1`(负一)。
|
||||
|
||||
参数 | 名称 | 描述
|
||||
---|---|---
|
||||
`argc` | 参数个数 | 参数向量的个数
|
||||
`argv` | 参数向量 | 字符指针数组
|
||||
|
||||
参数向量 `argv` 是调用你的程序的命令行的标记化表示形式。在上面的例子中,`argv` 将是以下字符串的列表:
|
||||
|
||||
```
|
||||
argv = [ "/path/to/a.out", "-o", "foo", "-vv" ];
|
||||
```
|
||||
|
||||
参数向量在其第一个索引 `argv[0]` 中确保至少会有一个字符串,这是执行程序的完整路径。
|
||||
|
||||
### main.c 文件的剖析
|
||||
|
||||
当我从头开始编写 `main.c` 时,它的结构通常如下:
|
||||
|
||||
```
|
||||
/* main.c */
|
||||
/* 0 版权/许可证 */
|
||||
/* 1 包含 */
|
||||
/* 2 定义 */
|
||||
/* 3 外部声明 */
|
||||
/* 4 类型定义 */
|
||||
/* 5 全局变量声明 */
|
||||
/* 6 函数原型 */
|
||||
|
||||
int main(int argc, char *argv[]) {
|
||||
/* 7 命令行解析 */
|
||||
}
|
||||
|
||||
/* 8 函数声明 */
|
||||
```
|
||||
|
||||
下面我将讨论这些编号的各个部分,除了编号为 0 的那部分。如果你必须把版权或许可文本放在源代码中,那就放在那里。
|
||||
|
||||
另一件我不想讨论的事情是注释。
|
||||
|
||||
```
|
||||
“评论谎言。”
|
||||
- 一个愤世嫉俗但聪明又好看的程序员。
|
||||
```
|
||||
|
||||
与其使用注释,不如使用有意义的函数名和变量名。
|
||||
|
||||
鉴于程序员固有的惰性,一旦添加了注释,维护负担就会增加一倍。如果更改或重构代码,则需要更新或扩充注释。随着时间的推移,代码会变得面目全非,与注释所描述的内容完全不同。
|
||||
|
||||
如果你必须写注释,不要写关于代码正在做*什么*,相反,写下代码*为什么*要这样写。写一些你将要在五年后读到的注释,那时你已经将这段代码忘得一干二净。世界的命运取决于你。*不要有压力。*
|
||||
|
||||
#### 1、包含
|
||||
|
||||
我添加到 `main.c` 文件的第一个东西是包含文件,它们为程序提供大量标准 C 标准库函数和变量。C 标准库做了很多事情。浏览 `/usr/include` 中的头文件,你可以了解到它们可以做些什么。
|
||||
|
||||
`#include` 字符串是 [C 预处理程序][4](cpp)指令,它会将引用的文件完整地包含在当前文件中。C 中的头文件通常以 `.h` 扩展名命名,且不应包含任何可执行代码。它只有宏、定义、类型定义、外部变量和函数原型。字符串 `<header.h>` 告诉 cpp 在系统定义的头文件路径中查找名为 `header.h` 的文件,它通常在 `/usr/include` 目录中。
|
||||
|
||||
```
|
||||
/* main.c */
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
#include <unistd.h>
|
||||
#include <libgen.h>
|
||||
#include <errno.h>
|
||||
#include <string.h>
|
||||
#include <getopt.h>
|
||||
#include <sys/types.h>
|
||||
```
|
||||
|
||||
这是我默认会全局包含的最小包含集合,它将引入:
|
||||
|
||||
\#include 文件 | 提供的东西
|
||||
---|---
|
||||
stdio | 提供 `FILE`、`stdin`、`stdout`、`stderr` 和 `fprint()` 函数系列
|
||||
stdlib | 提供 `malloc()`、`calloc()` 和 `realloc()`
|
||||
unistd | 提供 `EXIT_FAILURE`、`EXIT_SUCCESS`
|
||||
libgen | 提供 `basename()` 函数
|
||||
errno | 定义外部 `errno` 变量及其可以接受的所有值
|
||||
string | 提供 `memcpy()`、`memset()` 和 `strlen()` 函数系列
|
||||
getopt | 提供外部 `optarg`、`opterr`、`optind` 和 `getopt()` 函数
|
||||
sys/types | 类型定义快捷方式,如 `uint32_t` 和 `uint64_t`
|
||||
|
||||
#### 2、定义
|
||||
|
||||
```
|
||||
/* main.c */
|
||||
<...>
|
||||
|
||||
#define OPTSTR "vi:o:f:h"
|
||||
#define USAGE_FMT "%s [-v] [-f hexflag] [-i inputfile] [-o outputfile] [-h]"
|
||||
#define ERR_FOPEN_INPUT "fopen(input, r)"
|
||||
#define ERR_FOPEN_OUTPUT "fopen(output, w)"
|
||||
#define ERR_DO_THE_NEEDFUL "do_the_needful blew up"
|
||||
#define DEFAULT_PROGNAME "george"
|
||||
```
|
||||
|
||||
这在现在没有多大意义,但 `OPTSTR` 定义我这里会说明一下,它是程序推荐的命令行开关。参考 [getopt(3)][5] man 页面,了解 `OPTSTR` 将如何影响 `getopt()` 的行为。
|
||||
|
||||
`USAGE_FMT` 定义了一个 `printf()` 风格的格式字符串,它用在 `usage()` 函数中。
|
||||
|
||||
我还喜欢将字符串常量放在文件的 `#define` 这一部分。如果需要,把它们收集在一起可以更容易地修正拼写、重用消息和国际化消息。
|
||||
|
||||
最后,在命名 `#define` 时全部使用大写字母,以区别变量和函数名。如果需要,可以将单词放连在一起或使用下划线分隔,只要确保它们都是大写的就行。
|
||||
|
||||
#### 3、外部声明
|
||||
|
||||
```
|
||||
/* main.c */
|
||||
<...>
|
||||
|
||||
extern int errno;
|
||||
extern char *optarg;
|
||||
extern int opterr, optind;
|
||||
```
|
||||
|
||||
`extern` 声明将该名称带入当前编译单元的命名空间(即 “文件”),并允许程序访问该变量。这里我们引入了三个整数变量和一个字符指针的定义。`opt` 前缀的几个变量是由 `getopt()` 函数使用的,C 标准库使用 `errno` 作为带外通信通道来传达函数可能的失败原因。
|
||||
|
||||
#### 4、类型定义
|
||||
|
||||
```
|
||||
/* main.c */
|
||||
<...>
|
||||
|
||||
typedef struct {
|
||||
int verbose;
|
||||
uint32_t flags;
|
||||
FILE *input;
|
||||
FILE *output;
|
||||
} options_t;
|
||||
```
|
||||
|
||||
在外部声明之后,我喜欢为结构、联合和枚举声明 `typedef`。命名一个 `typedef` 是一种传统习惯。我非常喜欢使用 `_t` 后缀来表示该名称是一种类型。在这个例子中,我将 `options_t` 声明为一个包含 4 个成员的 `struct`。C 是一种空格无关的编程语言,因此我使用空格将字段名排列在同一列中。我只是喜欢它看起来的样子。对于指针声明,我在名称前面加上星号,以明确它是一个指针。
|
||||
|
||||
#### 5、全局变量声明
|
||||
|
||||
```
|
||||
/* main.c */
|
||||
<...>
|
||||
|
||||
int dumb_global_variable = -11;
|
||||
```
|
||||
|
||||
全局变量是一个坏主意,你永远不应该使用它们。但如果你必须使用全局变量,请在这里声明,并确保给它们一个默认值。说真的,*不要使用全局变量*。
|
||||
|
||||
#### 6、函数原型
|
||||
|
||||
```
|
||||
/* main.c */
|
||||
<...>
|
||||
|
||||
void usage(char *progname, int opt);
|
||||
int do_the_needful(options_t *options);
|
||||
```
|
||||
|
||||
在编写函数时,将它们添加到 `main()` 函数之后而不是之前,在这里放函数原型。早期的 C 编译器使用单遍策略,这意味着你在程序中使用的每个符号(变量或函数名称)必须在使用之前声明。现代编译器几乎都是多遍编译器,它们在生成代码之前构建一个完整的符号表,因此并不严格要求使用函数原型。但是,有时你无法选择代码要使用的编译器,所以请编写函数原型并继续这样做下去。
|
||||
|
||||
当然,我总是包含一个 `usage()` 函数,当 `main()` 函数不理解你从命令行传入的内容时,它会调用这个函数。
|
||||
|
||||
#### 7、命令行解析
|
||||
|
||||
```
|
||||
/* main.c */
|
||||
<...>
|
||||
|
||||
int main(int argc, char *argv[]) {
|
||||
int opt;
|
||||
options_t options = { 0, 0x0, stdin, stdout };
|
||||
|
||||
opterr = 0;
|
||||
|
||||
while ((opt = getopt(argc, argv, OPTSTR)) != EOF)
|
||||
switch(opt) {
|
||||
case 'i':
|
||||
if (!(options.input = fopen(optarg, "r")) ){
|
||||
perror(ERR_FOPEN_INPUT);
|
||||
exit(EXIT_FAILURE);
|
||||
/* NOTREACHED */
|
||||
}
|
||||
break;
|
||||
|
||||
case 'o':
|
||||
if (!(options.output = fopen(optarg, "w")) ){
|
||||
perror(ERR_FOPEN_OUTPUT);
|
||||
exit(EXIT_FAILURE);
|
||||
/* NOTREACHED */
|
||||
}
|
||||
break;
|
||||
|
||||
case 'f':
|
||||
options.flags = (uint32_t )strtoul(optarg, NULL, 16);
|
||||
break;
|
||||
|
||||
case 'v':
|
||||
options.verbose += 1;
|
||||
break;
|
||||
|
||||
case 'h':
|
||||
default:
|
||||
usage(basename(argv[0]), opt);
|
||||
/* NOTREACHED */
|
||||
break;
|
||||
}
|
||||
|
||||
if (do_the_needful(&options) != EXIT_SUCCESS) {
|
||||
perror(ERR_DO_THE_NEEDFUL);
|
||||
exit(EXIT_FAILURE);
|
||||
/* NOTREACHED */
|
||||
}
|
||||
|
||||
return EXIT_SUCCESS;
|
||||
}
|
||||
```
|
||||
|
||||
好吧,代码有点多。这个 `main()` 函数的目的是收集用户提供的参数,执行最基本的输入验证,然后将收集到的参数传递给使用它们的函数。这个示例声明一个使用默认值初始化的 `options` 变量,并解析命令行,根据需要更新 `options`。
|
||||
|
||||
`main()` 函数的核心是一个 `while` 循环,它使用 `getopt()` 来遍历 `argv`,寻找命令行选项及其参数(如果有的话)。文件前面定义的 `OPTSTR` 是驱动 `getopt()` 行为的模板。`opt` 变量接受 `getopt()` 找到的任何命令行选项的字符值,程序对检测命令行选项的响应发生在 `switch` 语句中。
|
||||
|
||||
如果你注意到了可能会问,为什么 `opt` 被声明为 32 位 `int`,但是预期是 8 位 `char`?事实上 `getopt()` 返回一个 `int`,当它到达 `argv` 末尾时取负值,我会使用 `EOF`(*文件末尾*标记)匹配。`char` 是有符号的,但我喜欢将变量匹配到它们的函数返回值。
|
||||
|
||||
当检测到一个已知的命令行选项时,会发生特定的行为。在 `OPTSTR` 中指定一个以冒号结尾的参数,这些选项可以有一个参数。当一个选项有一个参数时,`argv` 中的下一个字符串可以通过外部定义的变量 `optarg` 提供给程序。我使用 `optarg` 来打开文件进行读写,或者将命令行参数从字符串转换为整数值。
|
||||
|
||||
这里有几个关于代码风格的要点:
|
||||
|
||||
* 将 `opterr` 初始化为 `0`,禁止 `getopt` 触发 `?`。
|
||||
* 在 `main()` 的中间使用 `exit(EXIT_FAILURE);` 或 `exit(EXIT_SUCCESS);`。
|
||||
* `/* NOTREACHED */` 是我喜欢的一个 lint 指令。
|
||||
* 在返回 int 类型的函数末尾使用 `return EXIT_SUCCESS;`。
|
||||
* 显示强制转换隐式类型。
|
||||
|
||||
这个程序的命令行格式,经过编译如下所示:
|
||||
|
||||
```
|
||||
$ ./a.out -h
|
||||
a.out [-v] [-f hexflag] [-i inputfile] [-o outputfile] [-h]
|
||||
```
|
||||
|
||||
事实上,在编译后 `usage()` 就会向 `stderr` 发出这样的内容。
|
||||
|
||||
#### 8、函数声明
|
||||
|
||||
```
|
||||
/* main.c */
|
||||
<...>
|
||||
|
||||
void usage(char *progname, int opt) {
|
||||
fprintf(stderr, USAGE_FMT, progname?progname:DEFAULT_PROGNAME);
|
||||
exit(EXIT_FAILURE);
|
||||
/* NOTREACHED */
|
||||
}
|
||||
|
||||
int do_the_needful(options_t *options) {
|
||||
|
||||
if (!options) {
|
||||
errno = EINVAL;
|
||||
return EXIT_FAILURE;
|
||||
}
|
||||
|
||||
if (!options->input || !options->output) {
|
||||
errno = ENOENT;
|
||||
return EXIT_FAILURE;
|
||||
}
|
||||
|
||||
/* XXX do needful stuff */
|
||||
|
||||
return EXIT_SUCCESS;
|
||||
}
|
||||
```
|
||||
|
||||
我最后编写的函数不是个样板函数。在本例中,函数 `do_the_needful()` 接受一个指向 `options_t` 结构的指针。我验证 `options` 指针不为 `NULL`,然后继续验证 `input` 和 `output` 结构成员。如果其中一个测试失败,返回 `EXIT_FAILURE`,并且通过将外部全局变量 `errno` 设置为常规错误代码,我可以告知调用者常规的错误原因。调用者可以使用便捷函数 `perror()` 来根据 `errno` 的值发出便于阅读的错误消息。
|
||||
|
||||
函数几乎总是以某种方式验证它们的输入。如果完全验证代价很大,那么尝试执行一次并将验证后的数据视为不可变。`usage()` 函数使用 `fprintf()` 调用中的条件赋值验证 `progname` 参数。接下来 `usage()` 函数就退出了,所以我不会费心设置 `errno`,也不用操心是否使用正确的程序名。
|
||||
|
||||
在这里,我要避免的最大错误是解引用 `NULL` 指针。这将导致操作系统向我的进程发送一个名为 `SYSSEGV` 的特殊信号,导致不可避免的死亡。用户最不希望看到的是由 `SYSSEGV` 而导致的崩溃。最好是捕获 `NULL` 指针以发出更合适的错误消息并优雅地关闭程序。
|
||||
|
||||
有些人抱怨在函数体中有多个 `return` 语句,他们喋喋不休地说些“控制流的连续性”之类的东西。老实说,如果函数中间出现错误,那就应该返回这个错误条件。写一大堆嵌套的 `if` 语句只有一个 `return` 绝不是一个“好主意”™。
|
||||
|
||||
最后,如果你编写的函数接受四个以上的参数,请考虑将它们绑定到一个结构中,并传递一个指向该结构的指针。这使得函数签名更简单,更容易记住,并且在以后调用时不会出错。它还可以使调用函数速度稍微快一些,因为需要复制到函数堆栈中的东西更少。在实践中,只有在函数被调用数百万或数十亿次时,才会考虑这个问题。如果认为这没有意义,那也无所谓。
|
||||
|
||||
### 等等,你不是说没有注释吗!?!!
|
||||
|
||||
在 `do_the_needful()` 函数中,我写了一种特殊类型的注释,它被是作为占位符设计的,而不是为了说明代码:
|
||||
|
||||
```
|
||||
/* XXX do needful stuff */
|
||||
```
|
||||
|
||||
当你写到这里时,有时你不想停下来编写一些特别复杂的代码,你会之后再写,而不是现在。那就是我留给自己再次回来的地方。我插入一个带有 `XXX` 前缀的注释和一个描述需要做什么的简短注释。之后,当我有更多时间的时候,我会在源代码中寻找 `XXX`。使用什么前缀并不重要,只要确保它不太可能在另一个上下文环境(如函数名或变量)中出现在你代码库里。
|
||||
|
||||
### 把它们组合在一起
|
||||
|
||||
好吧,当你编译这个程序后,它*仍然*几乎没有任何作用。但是现在你有了一个坚实的骨架来构建你自己的命令行解析 C 程序。
|
||||
|
||||
```
|
||||
/* main.c - the complete listing */
|
||||
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
#include <unistd.h>
|
||||
#include <libgen.h>
|
||||
#include <errno.h>
|
||||
#include <string.h>
|
||||
#include <getopt.h>
|
||||
|
||||
#define OPTSTR "vi:o:f:h"
|
||||
#define USAGE_FMT "%s [-v] [-f hexflag] [-i inputfile] [-o outputfile] [-h]"
|
||||
#define ERR_FOPEN_INPUT "fopen(input, r)"
|
||||
#define ERR_FOPEN_OUTPUT "fopen(output, w)"
|
||||
#define ERR_DO_THE_NEEDFUL "do_the_needful blew up"
|
||||
#define DEFAULT_PROGNAME "george"
|
||||
|
||||
extern int errno;
|
||||
extern char *optarg;
|
||||
extern int opterr, optind;
|
||||
|
||||
typedef struct {
|
||||
int verbose;
|
||||
uint32_t flags;
|
||||
FILE *input;
|
||||
FILE *output;
|
||||
} options_t;
|
||||
|
||||
int dumb_global_variable = -11;
|
||||
|
||||
void usage(char *progname, int opt);
|
||||
int do_the_needful(options_t *options);
|
||||
|
||||
int main(int argc, char *argv[]) {
|
||||
int opt;
|
||||
options_t options = { 0, 0x0, stdin, stdout };
|
||||
|
||||
opterr = 0;
|
||||
|
||||
while ((opt = getopt(argc, argv, OPTSTR)) != EOF)
|
||||
switch(opt) {
|
||||
case 'i':
|
||||
if (!(options.input = fopen(optarg, "r")) ){
|
||||
perror(ERR_FOPEN_INPUT);
|
||||
exit(EXIT_FAILURE);
|
||||
/* NOTREACHED */
|
||||
}
|
||||
break;
|
||||
|
||||
case 'o':
|
||||
if (!(options.output = fopen(optarg, "w")) ){
|
||||
perror(ERR_FOPEN_OUTPUT);
|
||||
exit(EXIT_FAILURE);
|
||||
/* NOTREACHED */
|
||||
}
|
||||
break;
|
||||
|
||||
case 'f':
|
||||
options.flags = (uint32_t )strtoul(optarg, NULL, 16);
|
||||
break;
|
||||
|
||||
case 'v':
|
||||
options.verbose += 1;
|
||||
break;
|
||||
|
||||
case 'h':
|
||||
default:
|
||||
usage(basename(argv[0]), opt);
|
||||
/* NOTREACHED */
|
||||
break;
|
||||
}
|
||||
|
||||
if (do_the_needful(&options) != EXIT_SUCCESS) {
|
||||
perror(ERR_DO_THE_NEEDFUL);
|
||||
exit(EXIT_FAILURE);
|
||||
/* NOTREACHED */
|
||||
}
|
||||
|
||||
return EXIT_SUCCESS;
|
||||
}
|
||||
|
||||
void usage(char *progname, int opt) {
|
||||
fprintf(stderr, USAGE_FMT, progname?progname:DEFAULT_PROGNAME);
|
||||
exit(EXIT_FAILURE);
|
||||
/* NOTREACHED */
|
||||
}
|
||||
|
||||
int do_the_needful(options_t *options) {
|
||||
|
||||
if (!options) {
|
||||
errno = EINVAL;
|
||||
return EXIT_FAILURE;
|
||||
}
|
||||
|
||||
if (!options->input || !options->output) {
|
||||
errno = ENOENT;
|
||||
return EXIT_FAILURE;
|
||||
}
|
||||
|
||||
/* XXX do needful stuff */
|
||||
|
||||
return EXIT_SUCCESS;
|
||||
}
|
||||
```
|
||||
|
||||
现在,你已经准备好编写更易于维护的 C 语言。如果你有任何问题或反馈,请在评论中分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/5/how-write-good-c-main-function
|
||||
|
||||
作者:[Erik O'Shaughnessy][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jnyjny
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_hand_draw.png?itok=dpAf--Db (Hand drawing out the word "code")
|
||||
[2]: https://www.owasp.org/index.php/Null_Dereference
|
||||
[3]: https://opensource.com/sites/default/files/uploads/hatingotherpeoplescode-big.png (Parody O'Reilly book cover, "Hating Other People's Code")
|
||||
[4]: https://en.wikipedia.org/wiki/C_preprocessor
|
||||
[5]: https://linux.die.net/man/3/getopt
|
||||
[6]: http://www.opengroup.org/onlinepubs/009695399/functions/fopen.html
|
||||
[7]: http://www.opengroup.org/onlinepubs/009695399/functions/perror.html
|
||||
[8]: http://www.opengroup.org/onlinepubs/009695399/functions/exit.html
|
||||
[9]: http://www.opengroup.org/onlinepubs/009695399/functions/strtoul.html
|
||||
[10]: http://www.opengroup.org/onlinepubs/009695399/functions/fprintf.html
|
||||
68
published/20190529 NVMe on Linux.md
Normal file
68
published/20190529 NVMe on Linux.md
Normal file
@ -0,0 +1,68 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (warmfrog)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10946-1.html)
|
||||
[#]: subject: (NVMe on Linux)
|
||||
[#]: via: (https://www.networkworld.com/article/3397006/nvme-on-linux.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
Linux 上的 NVMe
|
||||
===============
|
||||
|
||||
> 如果你还没注意到,一些极速的固态磁盘技术已经可以用在 Linux 和其他操作系统上了。
|
||||
|
||||
![Sandra Henry-Stocker][1]
|
||||
|
||||
NVMe 意即<ruby>非易失性内存主机控制器接口规范<rt>non-volatile memory express</rt></ruby>,它是一个主机控制器接口和存储协议,用于加速企业和客户端系统以及固态驱动器(SSD)之间的数据传输。它通过电脑的高速 PCIe 总线工作。每当我看到这些名词时,我的感受是“羡慕”。而羡慕的原因很重要。
|
||||
|
||||
使用 NVMe,数据传输的速度比旋转磁盘快很多。事实上,NVMe 驱动能够比 SATA SSD 快 7 倍。这比我们今天很多人用的固态硬盘快了 7 倍多。这意味着,如果你用一个 NVMe 驱动盘作为启动盘,你的系统能够启动的非常快。事实上,如今任何人买一个新的系统可能都不会考虑那些没有自带 NVMe 的,不管是服务器或者个人电脑。
|
||||
|
||||
### NVMe 在 Linux 下能工作吗?
|
||||
|
||||
是的!NVMe 自 Linux 内核 3.3 版本就支持了。然而,要升级系统,通常同时需要一个 NVMe 控制器和一个 NVMe 磁盘。一些外置磁盘也行,但是要连接到系统上,需要的可不仅仅是通用的 USB 接口。
|
||||
|
||||
先使用下列命令检查内核版本:
|
||||
|
||||
```
|
||||
$ uname -r
|
||||
5.0.0-15-generic
|
||||
```
|
||||
|
||||
如果你的系统已经用了 NVMe,你将看到一个设备(例如,`/dev/nvme0`),但是只有在你安装了 NVMe 控制器的情况下才显示。如果你没有 NVMe 控制器,你可以用下列命令获取使用 NVMe 的相关信息。
|
||||
|
||||
```
|
||||
$ modinfo nvme | head -6
|
||||
filename: /lib/modules/5.0.0-15-generic/kernel/drivers/nvme/host/nvme.ko
|
||||
version: 1.0
|
||||
license: GPL
|
||||
author: Matthew Wilcox <willy@linux.intel.com>
|
||||
srcversion: AA383008D5D5895C2E60523
|
||||
alias: pci:v0000106Bd00002003sv*sd*bc*sc*i*
|
||||
```
|
||||
|
||||
### 了解更多
|
||||
|
||||
如果你想了解极速的 NVMe 存储的更多细节,可在 [PCWorld][3] 获取。
|
||||
|
||||
规范、白皮书和其他资源可在 [NVMexpress.org][4] 获取。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3397006/nvme-on-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[warmfrog](https://github.com/warmfrog)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/05/nvme-100797708-large.jpg
|
||||
[2]: https://www.networkworld.com/slideshow/153439/linux-best-desktop-distros-for-newbies.html#tk.nww-infsb
|
||||
[3]: https://www.pcworld.com/article/2899351/everything-you-need-to-know-about-nvme.html
|
||||
[4]: https://nvmexpress.org/
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,89 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10974-1.html)
|
||||
[#]: subject: (Unity Editor is Now Officially Available for Linux)
|
||||
[#]: via: (https://itsfoss.com/unity-editor-linux/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Unity 编辑器现已正式面向 Linux 推出
|
||||
======
|
||||
|
||||
如果你是设计师、开发者或艺术家,你可能一直在使用 Linux 上的实验性 [Unity 编辑器][1]。然而,不能一直用实验性版本 —— 开发者需要一个完整稳定的工作经验。
|
||||
|
||||
因此,他们最近宣布你可以在 Linux 上使用完整功能的 Unity 编辑器了。
|
||||
|
||||
虽然这是一个令人兴奋的消息,但它正式支持哪些 Linux 发行版?我们来谈谈更多细节……
|
||||
|
||||
> 非 FOSS 警告
|
||||
|
||||
> Linux (或任何其他平台)上的 Unity 编辑器不是开源软件。我们在这里介绍它是因为:
|
||||
|
||||
### 官方支持 Ubuntu 和 CentOS 7
|
||||
|
||||
![][2]
|
||||
|
||||
无论你拥有个人许可还是专业许可,如果你安装了 Unity 2019.1 或更高版本,都可以使用该编辑器。
|
||||
|
||||
此外,他们优先支持 Ubuntu 16.04、Ubuntu 18.04 和 CentOS 7。
|
||||
|
||||
在[公告][3]中,他们还提到了支持的配置:
|
||||
|
||||
* x86-64 架构
|
||||
* 运行在 X11 窗口系统之上的 Gnome 桌面环境
|
||||
* Nvidia 官方专有显卡驱动和 AMD Mesa 显卡驱动
|
||||
* 桌面计算机,在没有仿真或兼容层的设备/硬件上运行
|
||||
|
||||
你可以尝试其他的 —— 但最好坚持官方要求以获得最佳体验。
|
||||
|
||||
> 关于第三方工具的说明
|
||||
|
||||
> 如果你碰巧在某个项目中使用了任何第三方工具,那么必须单独检查它们是否支持。
|
||||
|
||||
### 如何在 Linux 上安装 Unity 编辑器
|
||||
|
||||
现在你已经了解了,那么该如何安装?
|
||||
|
||||
要安装 Unity,你需要下载并安装 [Unity Hub][4]。
|
||||
|
||||
![Unity Hub][5]
|
||||
|
||||
你需要完成以下步骤:
|
||||
|
||||
* 从[官方论坛页面][4]下载适用于 Linux 的 Unity Hub。
|
||||
* 它将下载一个 AppImage 文件。简单地说,让它可执行并运行它。如果你不了解,你应该查看关于[如何在 Linux 上使用 AppImage][6] 的指南。
|
||||
* 启动 Unity Hub 后,它会要求你使用 Unity ID 登录(或注册)以激活许可证。有关许可证生效的更多信息,请参阅他们的 [FAQ 页面][7]。
|
||||
* 使用 Unity ID 登录后,进入 “Installs” 选项(如上图所示)并添加所需的版本/组件。
|
||||
|
||||
就是这些了。这就是获取并快速安装的最佳方法。
|
||||
|
||||
### 总结
|
||||
|
||||
即使这是一个令人兴奋的消息,但官方配置支持似乎并不广泛。如果你在 Linux 上使用它,请在[他们的 Linux 论坛帖子][9]上分享你的反馈和意见。
|
||||
|
||||
你觉得怎么样?此外,你是使用 Unity Hub 安装它,还是有更好的方法来安装?
|
||||
|
||||
请在下面的评论中告诉我们你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/unity-editor-linux/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://unity3d.com/unity/editor
|
||||
[2]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/05/Unity-Editor-on-Linux.png?resize=800%2C450&ssl=1
|
||||
[3]: https://blogs.unity3d.com/2019/05/30/announcing-the-unity-editor-for-linux/
|
||||
[4]: https://forum.unity.com/threads/unity-hub-v-1-6-0-is-now-available.640792/
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/05/unity-hub.jpg?fit=800%2C532&ssl=1
|
||||
[6]: https://itsfoss.com/use-appimage-linux/
|
||||
[7]: https://support.unity3d.com/hc/en-us/categories/201268913-Licenses
|
||||
[9]: https://forum.unity.com/forums/linux-editor.93/
|
||||
87
published/20190531 Why translation platforms matter.md
Normal file
87
published/20190531 Why translation platforms matter.md
Normal file
@ -0,0 +1,87 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10953-1.html)
|
||||
[#]: subject: (Why translation platforms matter)
|
||||
[#]: via: (https://opensource.com/article/19/5/translation-platforms)
|
||||
[#]: author: (Jean-Baptiste Holcroft https://opensource.com/users/jibec/users/annegentle/users/bcotton)
|
||||
|
||||
什么是翻译平台最重要的地方?
|
||||
======
|
||||
|
||||
> 技术上的考虑并不是判断一个好的翻译平台的最佳方式。
|
||||
|
||||

|
||||
|
||||
语言翻译可以使开源软件能够被世界各地的人们使用,这是非开发人员参与他们喜欢的(开源)项目的好方法。有许多[翻译工具][2],你可以根据他们处理翻译中涉及的主要功能区域的能力来评估:技术交互能力、团队支持能力和翻译支持能力。
|
||||
|
||||
技术交互方面包括:
|
||||
|
||||
* 支持的文件格式
|
||||
* 与开源存储库的同步
|
||||
* 自动化支持工具
|
||||
* 接口可能性
|
||||
|
||||
对团队合作(也可称为“社区活力”)的支持包括该平台如何:
|
||||
|
||||
* 监控变更(按译者、项目等)
|
||||
* 跟进由项目推动的更新
|
||||
* 显示进度状态
|
||||
* 是否启用审核和验证步骤
|
||||
* 协助(来自同一团队和跨语言的)翻译人员和项目维护人员之间的讨论
|
||||
* 平台支持的全球通讯(新闻等)
|
||||
|
||||
翻译协助包括:
|
||||
|
||||
* 清晰、符合人体工程学的界面
|
||||
* 简单几步就可以找到项目并开始工作
|
||||
* 可以简单地了解到翻译和分发之间流程
|
||||
* 可以使用翻译记忆机
|
||||
* 词汇表丰富
|
||||
|
||||
前两个功能区域与源代码管理平台的差别不大,只有一些小的差别。我觉得最后一个区域也主要与源代码有关。但是,它们处理的数据非常不同,翻译平台的用户通常也不如开发人员了解技术,而数量也更多。
|
||||
|
||||
### 我的推荐
|
||||
|
||||
在我看来,GNOME 平台提供了最好的翻译平台,原因如下:
|
||||
|
||||
* 其网站包含了团队组织和翻译平台。很容易看出谁在负责以及他们在团队中的角色。一切都集中在几个屏幕之内。
|
||||
* 很容易找到要处理的内容,并且你会很快意识到你必须将文件下载到本地计算机并在修改后将其发回。这个流程不是很先进,但逻辑很容易理解。
|
||||
* 一旦你发回文件,平台就可以向邮件列表发送通告,以便团队知道后续步骤,并且可以全局轻松讨论翻译(而不是评论特定句子)。
|
||||
* 它支持多达 297 种语言。
|
||||
* 它显示了基本句子、高级菜单和文档的明确的进度百分比。
|
||||
|
||||
再加上可预测的 GNOME 发布计划,社区可以使用一切可以促进社区工作的工具。
|
||||
|
||||
如果我们看看 Debian 翻译团队,他们多年来一直在为 Debian (LCTT 译注:此处原文是“Fedora”,疑为笔误)翻译了难以想象的大量内容(尤其是新闻),我们看到他们有一个高度以来于规则的翻译流程,完全基于电子邮件,手动推送到存储库。该团队还将所有内容都放在流程中,而不是工具中,尽管这似乎需要相当大的技术能力,但它已成为领先的语言群体之一,已经运作多年。
|
||||
|
||||
我认为,成功的翻译平台的主要问题不是基于单一的(技术、翻译)工作的能力,而是基于如何构建和支持翻译团队的流程。这就是可持续性的原因。
|
||||
|
||||
生产过程是构建团队最重要的方式;通过正确地将它们组合在一起,新手很容易理解该过程是如何工作的,采用它们,并将它们解释给下一组新人。
|
||||
|
||||
要建立一个可持续发展的社区,首先要考虑的是支持协同工作的工具,然后是可用性。
|
||||
|
||||
这解释了我为什么对 [Zanata][3] 工具沮丧,从技术和界面的角度来看,这是有效的,但在帮助构建社区方面却很差。我认为翻译是一个社区驱动的过程(可能是开源软件开发中最受社区驱动的过程之一),这对我来说是一个关键问题。
|
||||
|
||||
* * *
|
||||
|
||||
本文改编自“[什么是一个好的翻译平台?][4]”,最初发表在 Jibec 期刊上,并经许可重复使用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/5/translation-platforms
|
||||
|
||||
作者:[Jean-Baptiste Holcroft][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jibec/users/annegentle/users/bcotton
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/people_remote_teams_world.png?itok=_9DCHEel
|
||||
[2]: https://opensource.com/article/17/6/open-source-localization-tools
|
||||
[3]: http://zanata.org/
|
||||
[4]: https://jibecfed.fedorapeople.org/blog-hugo/en/2016/09/whats-a-good-translation-platform/
|
||||
@ -0,0 +1,145 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10951-1.html)
|
||||
[#]: subject: (How To Verify NTP Setup (Sync) is Working or Not In Linux?)
|
||||
[#]: via: (https://www.2daygeek.com/check-verify-ntp-sync-is-working-or-not-in-linux-using-ntpq-ntpstat-timedatectl/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
如何在 Linux 下确认 NTP 是否同步?
|
||||
======
|
||||
|
||||

|
||||
|
||||
NTP 意即<ruby>网络时间协议<rt>Network Time Protocol</rt></ruby>,它通过网络同步计算机系统之间的时钟。NTP 服务器可以使组织中的所有服务器保持同步,以准确时间执行基于时间的作业。NTP 客户端会将其时钟与 NTP 服务器同步。
|
||||
|
||||
我们已经写了一篇关于 NTP 服务器和客户端安装和配置的文章。如果你想查看这些文章,请导航至以下链接。
|
||||
|
||||
* [如何在 Linux 上安装、配置 NTP 服务器和客户端?][1]
|
||||
* [如何安装和配置 Chrony 作为 NTP 客户端?][2]
|
||||
|
||||
我假设我你经使用上述链接设置了 NTP 服务器和 NTP 客户端。现在,如何验证 NTP 设置是否正常工作?
|
||||
|
||||
Linux 中有三个命令可用于验证 NTP 同步情况。详情如下。在本文中,我们将告诉您如何使用所有这些命令验证 NTP 同步。
|
||||
|
||||
* `ntpq`:ntpq 是一个标准的 NTP 查询程序。
|
||||
* `ntpstat`:显示网络世界同步状态。
|
||||
* `timedatectl`:它控制 systemd 系统中的系统时间和日期。
|
||||
|
||||
### 方法 1:如何使用 ntpq 命令检查 NTP 状态?
|
||||
|
||||
`ntpq` 实用程序用于监视 NTP 守护程序 `ntpd` 的操作并确定性能。
|
||||
|
||||
该程序可以以交互模式运行,也可以使用命令行参数进行控制。它通过向服务器发送多个查询来打印出连接的对等项列表。如果 NTP 正常工作,你将获得类似于下面的输出。
|
||||
|
||||
```
|
||||
# ntpq -p
|
||||
|
||||
remote refid st t when poll reach delay offset jitter
|
||||
==============================================================================
|
||||
*CentOS7.2daygee 133.243.238.163 2 u 14 64 37 0.686 0.151 16.432
|
||||
```
|
||||
|
||||
细节:
|
||||
|
||||
* `-p`:打印服务器已知的对等项列表以及其状态摘要。
|
||||
|
||||
### 方法 2:如何使用 ntpstat 命令检查 NTP 状态?
|
||||
|
||||
`ntpstat` 将报告在本地计算机上运行的 NTP 守护程序(`ntpd`)的同步状态。如果发现本地系统与参考时间源保持同步,则 `ntpstat` 将报告大致的时间精度。
|
||||
|
||||
`ntpstat` 命令根据 NTP 同步状态返回三种状态码。详情如下。
|
||||
|
||||
* `0`:如果时钟同步则返回 0。
|
||||
* `1`:如果时钟不同步则返回 1。
|
||||
* `2`:如果时钟状态不确定,则返回 2,例如 ntpd 不可联系时。
|
||||
|
||||
```
|
||||
# ntpstat
|
||||
|
||||
synchronised to NTP server (192.168.1.8) at stratum 3
|
||||
time correct to within 508 ms
|
||||
polling server every 64 s
|
||||
```
|
||||
|
||||
### 方法 3:如何使用 timedatectl 命令检查 NTP 状态?
|
||||
|
||||
[timedatectl 命令][3]用于查询和更改系统时钟及其在 systmed 系统中的设置。
|
||||
|
||||
```
|
||||
# timedatectl
|
||||
或
|
||||
# timedatectl status
|
||||
|
||||
Local time: Thu 2019-05-30 05:01:05 CDT
|
||||
Universal time: Thu 2019-05-30 10:01:05 UTC
|
||||
RTC time: Thu 2019-05-30 10:01:05
|
||||
Time zone: America/Chicago (CDT, -0500)
|
||||
NTP enabled: yes
|
||||
NTP synchronized: yes
|
||||
RTC in local TZ: no
|
||||
DST active: yes
|
||||
Last DST change: DST began at
|
||||
Sun 2019-03-10 01:59:59 CST
|
||||
Sun 2019-03-10 03:00:00 CDT
|
||||
Next DST change: DST ends (the clock jumps one hour backwards) at
|
||||
Sun 2019-11-03 01:59:59 CDT
|
||||
Sun 2019-11-03 01:00:00 CST
|
||||
```
|
||||
|
||||
### 更多技巧
|
||||
|
||||
Chrony 是一个 NTP 客户端的替代品。它可以更快地同步系统时钟,时间精度更高,对于一直不在线的系统尤其有用。
|
||||
|
||||
chronyd 较小,它使用较少的内存,只在必要时才唤醒 CPU,这样可以更好地节省电能。即使网络拥塞较长时间,它也能很好地运行。
|
||||
|
||||
你可以使用以下任何命令来检查 Chrony 状态。
|
||||
|
||||
检查 Chrony 跟踪状态。
|
||||
|
||||
```
|
||||
# chronyc tracking
|
||||
|
||||
Reference ID : C0A80105 (CentOS7.2daygeek.com)
|
||||
Stratum : 3
|
||||
Ref time (UTC) : Thu Mar 28 05:57:27 2019
|
||||
System time : 0.000002545 seconds slow of NTP time
|
||||
Last offset : +0.001194361 seconds
|
||||
RMS offset : 0.001194361 seconds
|
||||
Frequency : 1.650 ppm fast
|
||||
Residual freq : +184.101 ppm
|
||||
Skew : 2.962 ppm
|
||||
Root delay : 0.107966967 seconds
|
||||
Root dispersion : 1.060455322 seconds
|
||||
Update interval : 2.0 seconds
|
||||
Leap status : Normal
|
||||
```
|
||||
|
||||
运行 `sources` 命令以显示有关当前时间源的信息。
|
||||
|
||||
```
|
||||
# chronyc sources
|
||||
|
||||
210 Number of sources = 1
|
||||
MS Name/IP address Stratum Poll Reach LastRx Last sample
|
||||
===============================================================================
|
||||
^* CentOS7.2daygeek.com 2 6 17 62 +36us[+1230us] +/- 1111ms
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/check-verify-ntp-sync-is-working-or-not-in-linux-using-ntpq-ntpstat-timedatectl/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-10811-1.html
|
||||
[2]: https://linux.cn/article-10820-1.html
|
||||
[3]: https://www.2daygeek.com/change-set-time-date-and-timezone-on-linux/
|
||||
@ -0,0 +1,164 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10960-1.html)
|
||||
[#]: subject: (Two Methods To Check Or List Installed Security Updates on Redhat (RHEL) And CentOS System)
|
||||
[#]: via: (https://www.2daygeek.com/check-installed-security-updates-on-redhat-rhel-and-centos-system/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
在 RHEL 和 CentOS 上检查或列出已安装的安全更新的两种方法
|
||||
======
|
||||
|
||||

|
||||
|
||||
我们过去曾写过两篇关于这个主题的文章,每篇文章都是根据不同的要求发表的。如果你想在开始之前浏览这些文章。请通过以下链接:
|
||||
|
||||
* [如何检查 RHEL 和 CentOS 上的可用安全更新?][1]
|
||||
* [在 RHEL 和 CentOS 上安装安全更新的四种方法?][2]
|
||||
|
||||
这些文章与其他文章相互关联,因此,在深入研究之前,最好先阅读这些文章。
|
||||
|
||||
在本文中,我们将向你展示如何检查已安装的安全更新。我会介绍两种方法,你可以选择最适合你的。
|
||||
|
||||
此外,我还添加了一个小的 shell 脚本,它为你提供已安装的安全包计数。
|
||||
|
||||
运行以下命令获取系统上已安装的安全更新的列表。
|
||||
|
||||
```
|
||||
# yum updateinfo list security installed
|
||||
|
||||
Loaded plugins: changelog, package_upload, product-id, search-disabled-repos,
|
||||
: subscription-manager, verify, versionlock
|
||||
RHSA-2015:2315 Moderate/Sec. ModemManager-glib-1.1.0-8.git20130913.el7.x86_64
|
||||
RHSA-2015:2315 Moderate/Sec. NetworkManager-1:1.0.6-27.el7.x86_64
|
||||
RHSA-2016:2581 Low/Sec. NetworkManager-1:1.4.0-12.el7.x86_64
|
||||
RHSA-2017:2299 Moderate/Sec. NetworkManager-1:1.8.0-9.el7.x86_64
|
||||
RHSA-2015:2315 Moderate/Sec. NetworkManager-adsl-1:1.0.6-27.el7.x86_64
|
||||
RHSA-2016:2581 Low/Sec. NetworkManager-adsl-1:1.4.0-12.el7.x86_64
|
||||
RHSA-2017:2299 Moderate/Sec. NetworkManager-adsl-1:1.8.0-9.el7.x86_64
|
||||
RHSA-2015:2315 Moderate/Sec. NetworkManager-bluetooth-1:1.0.6-27.el7.x86_64
|
||||
```
|
||||
|
||||
要计算已安装的安全包的数量,请运行以下命令:
|
||||
|
||||
```
|
||||
# yum updateinfo list security installed | wc -l
|
||||
1046
|
||||
```
|
||||
|
||||
仅打印安装包列表:
|
||||
|
||||
```
|
||||
# yum updateinfo list security all | grep -w "i"
|
||||
|
||||
i RHSA-2015:2315 Moderate/Sec. ModemManager-glib-1.1.0-8.git20130913.el7.x86_64
|
||||
i RHSA-2015:2315 Moderate/Sec. NetworkManager-1:1.0.6-27.el7.x86_64
|
||||
i RHSA-2016:2581 Low/Sec. NetworkManager-1:1.4.0-12.el7.x86_64
|
||||
i RHSA-2017:2299 Moderate/Sec. NetworkManager-1:1.8.0-9.el7.x86_64
|
||||
i RHSA-2015:2315 Moderate/Sec. NetworkManager-adsl-1:1.0.6-27.el7.x86_64
|
||||
i RHSA-2016:2581 Low/Sec. NetworkManager-adsl-1:1.4.0-12.el7.x86_64
|
||||
i RHSA-2017:2299 Moderate/Sec. NetworkManager-adsl-1:1.8.0-9.el7.x86_64
|
||||
i RHSA-2015:2315 Moderate/Sec. NetworkManager-bluetooth-1:1.0.6-27.el7.x86_64
|
||||
i RHSA-2016:2581 Low/Sec. NetworkManager-bluetooth-1:1.4.0-12.el7.x86_64
|
||||
i RHSA-2017:2299 Moderate/Sec. NetworkManager-bluetooth-1:1.8.0-9.el7.x86_64
|
||||
i RHSA-2015:2315 Moderate/Sec. NetworkManager-config-server-1:1.0.6-27.el7.x86_64
|
||||
i RHSA-2016:2581 Low/Sec. NetworkManager-config-server-1:1.4.0-12.el7.x86_64
|
||||
i RHSA-2017:2299 Moderate/Sec. NetworkManager-config-server-1:1.8.0-9.el7.noarch
|
||||
```
|
||||
|
||||
要计算已安装的安全包的数量,请运行以下命令:
|
||||
|
||||
```
|
||||
# yum updateinfo list security all | grep -w "i" | wc -l
|
||||
1043
|
||||
```
|
||||
|
||||
或者,你可以检查指定包修复的漏洞列表。
|
||||
|
||||
在此例中,我们将检查 “openssh” 包中已修复的漏洞列表:
|
||||
|
||||
```
|
||||
# rpm -q --changelog openssh | grep -i CVE
|
||||
|
||||
- Fix for CVE-2017-15906 (#1517226)
|
||||
- CVE-2015-8325: privilege escalation via user's PAM environment and UseLogin=yes (#1329191)
|
||||
- CVE-2016-1908: possible fallback from untrusted to trusted X11 forwarding (#1298741)
|
||||
- CVE-2016-3115: missing sanitisation of input for X11 forwarding (#1317819)
|
||||
- prevents CVE-2016-0777 and CVE-2016-0778
|
||||
- Security fixes released with openssh-6.9 (CVE-2015-5352) (#1247864)
|
||||
- only query each keyboard-interactive device once (CVE-2015-5600) (#1245971)
|
||||
- add new option GSSAPIEnablek5users and disable using ~/.k5users by default CVE-2014-9278
|
||||
- prevent a server from skipping SSHFP lookup - CVE-2014-2653 (#1081338)
|
||||
- change default value of MaxStartups - CVE-2010-5107 (#908707)
|
||||
- CVE-2010-4755
|
||||
- merged cve-2007_3102 to audit patch
|
||||
- fixed audit log injection problem (CVE-2007-3102)
|
||||
- CVE-2006-5794 - properly detect failed key verify in monitor (#214641)
|
||||
- CVE-2006-4924 - prevent DoS on deattack detector (#207957)
|
||||
- CVE-2006-5051 - don't call cleanups from signal handler (#208459)
|
||||
- use fork+exec instead of system in scp - CVE-2006-0225 (#168167)
|
||||
```
|
||||
|
||||
同样,你可以通过运行以下命令来检查相应的包中是否修复了指定的漏洞:
|
||||
|
||||
```
|
||||
# rpm -q --changelog openssh | grep -i CVE-2016-3115
|
||||
|
||||
- CVE-2016-3115: missing sanitisation of input for X11 forwarding (#1317819)
|
||||
```
|
||||
|
||||
### 如何使用 Shell 脚本计算安装的安全包?
|
||||
|
||||
我添加了一个小的 shell 脚本,它可以帮助你计算已安装的安全包列表。
|
||||
|
||||
```
|
||||
# vi /opt/scripts/security-check.sh
|
||||
|
||||
#!/bin/bash
|
||||
echo "+-------------------------+"
|
||||
echo "|Security Advisories Count|"
|
||||
echo "+-------------------------+"
|
||||
for i in Important Moderate Low
|
||||
do
|
||||
sec=$(yum updateinfo list security installed | grep $i | wc -l)
|
||||
echo "$i: $sec"
|
||||
done | column -t
|
||||
echo "+-------------------------+"
|
||||
```
|
||||
|
||||
给 `security-check.sh` 文件执行权限。
|
||||
|
||||
```
|
||||
$ chmod +x security-check.sh
|
||||
```
|
||||
|
||||
最后执行脚本统计。
|
||||
|
||||
```
|
||||
# sh /opt/scripts/security-check.sh
|
||||
|
||||
+-------------------------+
|
||||
|Security Advisories Count|
|
||||
+-------------------------+
|
||||
Important: 480
|
||||
Moderate: 410
|
||||
Low: 111
|
||||
+-------------------------+
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/check-installed-security-updates-on-redhat-rhel-and-centos-system/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-10938-1.html
|
||||
[2]: https://www.2daygeek.com/install-security-updates-on-redhat-rhel-centos-system/
|
||||
262
published/20190606 How Linux can help with your spelling.md
Normal file
262
published/20190606 How Linux can help with your spelling.md
Normal file
@ -0,0 +1,262 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Modrisco)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10986-1.html)
|
||||
[#]: subject: (How Linux can help with your spelling)
|
||||
[#]: via: (https://www.networkworld.com/article/3400942/how-linux-can-help-with-your-spelling.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
如何用 Linux 帮助你拼写
|
||||
======
|
||||
|
||||
> 无论你是纠结一个难以理解的单词,还是在将报告发给老板之前再检查一遍,Linux 都可以帮助你解决拼写问题。
|
||||
|
||||

|
||||
|
||||
Linux 为数据分析和自动化提供了各种工具,它也帮助我们解决了一个一直都在纠结的问题 —— 拼写!无论在写每周报告时努力拼出一个单词,还是在提交商业计划书之前想要借助计算机的“眼睛”来找出你的拼写错误。现在我们来看一下它是如何帮助你的。
|
||||
|
||||
### look
|
||||
|
||||
`look` 是其中一款工具。如果你知道一个单词的开头,你就可以用这个命令来获取以这些字母开头的单词列表。除非提供了替代词源,否则 `look` 将使用 `/usr/share/dict/words` 中的内容来为你标识单词。这个文件有数十万个单词,可以满足我们日常使用的大多数英语单词的需要,但是它可能不包含我们计算机领域中的一些人倾向于使用的更加生僻的单词,如 zettabyte。
|
||||
|
||||
`look` 命令的语法非常简单。输入 `look word` ,它将遍历单词文件中的所有单词并找到匹配项。
|
||||
|
||||
```
|
||||
$ look amelio
|
||||
ameliorable
|
||||
ameliorableness
|
||||
ameliorant
|
||||
ameliorate
|
||||
ameliorated
|
||||
ameliorates
|
||||
ameliorating
|
||||
amelioration
|
||||
ameliorations
|
||||
ameliorativ
|
||||
ameliorative
|
||||
amelioratively
|
||||
ameliorator
|
||||
amelioratory
|
||||
```
|
||||
|
||||
如果你遇到系统中单词列表中未包含的单词,将无法获得任何输出。
|
||||
|
||||
```
|
||||
$ look zetta
|
||||
$
|
||||
```
|
||||
|
||||
如果你没有看到你所希望出现的单词,也不要绝望。你可以在你的单词文件中添加单词,甚至引用一个完全不同的单词列表,在网上找一个或者干脆自己创建一个。你甚至不必将添加的单词放在按字母顺序排列的正确位置;只需将其添加到文件的末尾即可。但是,你必须以 root 用户身份执行此操作。例如(要注意 `>>`!):
|
||||
|
||||
```
|
||||
# echo “zettabyte” >> /usr/share/dict/words
|
||||
```
|
||||
|
||||
当使用不同的单词列表时,例如这个例子中的 “jargon” ,你只需要添加文件的名称。如果不采用默认文件时,请使用完整路径。
|
||||
|
||||
```
|
||||
$ look nybble /usr/share/dict/jargon
|
||||
nybble
|
||||
nybbles
|
||||
```
|
||||
|
||||
`look` 命令大小写不敏感,因此你不必关心要查找的单词是否应该大写。
|
||||
|
||||
```
|
||||
$ look zet
|
||||
ZETA
|
||||
Zeta
|
||||
zeta
|
||||
zetacism
|
||||
Zetana
|
||||
zetas
|
||||
Zetes
|
||||
zetetic
|
||||
Zethar
|
||||
Zethus
|
||||
Zetland
|
||||
Zetta
|
||||
```
|
||||
|
||||
当然,不是所有的单词列表都是一样的。一些 Linux 发行版在单词文件中提供了*多得多*的内容。你的文件中可能有十万或者更多倍的单词。
|
||||
|
||||
在我的一个 Linux 系统中:
|
||||
|
||||
```
|
||||
$ wc -l /usr/share/dict/words
|
||||
102402 /usr/share/dict/words
|
||||
```
|
||||
|
||||
在另一个系统中:
|
||||
|
||||
```
|
||||
$ wc -l /usr/share/dict/words
|
||||
479828 /usr/share/dict/words
|
||||
```
|
||||
|
||||
请记住,`look` 命令只适用于通过单词开头查找,但如果你不想从单词的开头查找,还可以使用其他选项。
|
||||
|
||||
### grep
|
||||
|
||||
我们深爱的 `grep` 命令像其他工具一样可以从一个单词文件中选出单词。如果你正在找以某些字母开头或结尾的单词,使用 `grep` 命令是自然而然的事情。它可以通过单词的开头、结尾或中间部分来匹配单词。系统中的单词文件可以像使用 `look` 命令时在 `grep` 命令中轻松使用。不过唯一的缺点是你需要指定文件,这一点与 `look` 不尽相同。
|
||||
|
||||
在单词的开头前加上 `^`:
|
||||
|
||||
```
|
||||
$ grep ^terra /usr/share/dict/words
|
||||
terrace
|
||||
terrace's
|
||||
terraced
|
||||
terraces
|
||||
terracing
|
||||
terrain
|
||||
terrain's
|
||||
terrains
|
||||
terrapin
|
||||
terrapin's
|
||||
terrapins
|
||||
terraria
|
||||
terrarium
|
||||
terrarium's
|
||||
terrariums
|
||||
```
|
||||
|
||||
在单词的结尾后加上 `$`:
|
||||
|
||||
```
|
||||
$ grep bytes$ /usr/share/dict/words
|
||||
bytes
|
||||
gigabytes
|
||||
kilobytes
|
||||
megabytes
|
||||
terabytes
|
||||
```
|
||||
|
||||
使用 `grep` 时,你需要考虑大小写,不过 `grep` 命令也提供了一些选项。
|
||||
|
||||
```
|
||||
$ grep ^[Zz]et /usr/share/dict/words
|
||||
Zeta
|
||||
zeta
|
||||
zetacism
|
||||
Zetana
|
||||
zetas
|
||||
Zetes
|
||||
zetetic
|
||||
Zethar
|
||||
Zethus
|
||||
Zetland
|
||||
Zetta
|
||||
zettabyte
|
||||
```
|
||||
|
||||
为单词文件添加软连接能使这种搜索方式更加便捷:
|
||||
|
||||
```
|
||||
$ ln -s /usr/share/dict/words words
|
||||
$ grep ^[Zz]et words
|
||||
Zeta
|
||||
zeta
|
||||
zetacism
|
||||
Zetana
|
||||
zetas
|
||||
Zetes
|
||||
zetetic
|
||||
Zethar
|
||||
Zethus
|
||||
Zetland
|
||||
Zetta
|
||||
zettabytye
|
||||
```
|
||||
|
||||
### aspell
|
||||
|
||||
`aspell` 命令提供了一种不同的方式。它提供了一种方法来检查你提供给它的任何文件或文本的拼写。你可以通过管道将文本传递给它,然后它会告诉你哪些单词看起来有拼写错误。如果所有单词都拼写正确,则不会有任何输出。
|
||||
|
||||
```
|
||||
$ echo Did I mispell that? | aspell list
|
||||
mispell
|
||||
$ echo I can hardly wait to try out aspell | aspell list
|
||||
aspell
|
||||
$ echo Did I misspell anything? | aspell list
|
||||
$
|
||||
```
|
||||
|
||||
`list` 参数告诉 `aspell` 为标准输入单词提供拼写错误的单词列表。
|
||||
|
||||
你还可以使用 `aspell` 来定位和更正文本文件中的单词。如果它发现一个拼写错误的单词,它将为你提供一个相似(但拼写正确的)单词列表来替换这个单词,你也可以将该单词加入个人词库(`~/.aspell.en.pws`)并忽略拼写错误,或者完全中止进程(使文件保持处理前的状态)。
|
||||
|
||||
```
|
||||
$ aspell -c mytext
|
||||
```
|
||||
|
||||
一旦 `aspell` 发现一个单词出现了拼写错误,它将会为不正确的 “mispell” 提供一个选项列表:
|
||||
|
||||
```
|
||||
1) mi spell 6) misplay
|
||||
2) mi-spell 7) spell
|
||||
3) misspell 8) misapply
|
||||
4) Ispell 9) Aspell
|
||||
5) misspells 0) dispel
|
||||
i) Ignore I) Ignore all
|
||||
r) Replace R) Replace all
|
||||
a) Add l) Add Lower
|
||||
b) Abort x) Exit
|
||||
```
|
||||
|
||||
请注意,备选单词和拼写是数字编号的,而其他选项是由字母选项表示的。你可以选择备选拼写中的一项或者自己输入替换项。“Abort” 选项将使文件保持不变,即使你已经为某些单词选择了替换。你选择添加的单词将被插入到本地单词文件中(例如 `~/.aspell.en.pws`)。
|
||||
|
||||
#### 其他单词列表
|
||||
|
||||
厌倦了英语? `aspell` 命令可以在其他语言中使用,只要你添加了相关语言的单词列表。例如,在 Debian 系统中添加法语的词库,你可以这样做:
|
||||
|
||||
```
|
||||
$ sudo apt install aspell-fr
|
||||
```
|
||||
|
||||
这个新的词库文件会被安装为 `/usr/share/dict/French`。为了使用它,你只需要简单地告诉 `aspell` 你想要使用替换的单词列表:
|
||||
|
||||
```
|
||||
$ aspell --lang=fr -c mytext
|
||||
```
|
||||
|
||||
这种情况下,当 `aspell` 读到单词 “one” 时,你可能会看到下面的情况:
|
||||
|
||||
```
|
||||
1) once 6) orné
|
||||
2) onde 7) ne
|
||||
3) ondé 8) né
|
||||
4) onze 9) on
|
||||
5) orne 0) cône
|
||||
i) Ignore I) Ignore all
|
||||
r) Replace R) Replace all
|
||||
a) Add l) Add Lower
|
||||
b) Abort x) Exit
|
||||
```
|
||||
|
||||
你也可以从 [GNU 官网][3]获取其他语言的词库。
|
||||
|
||||
### 总结
|
||||
|
||||
即使你是全国拼字比赛的冠军,你可能偶尔也会需要一点拼写方面的帮助,哪怕只是为了找出你手滑打错的单词。`aspell` 工具,加上 `look` 和 `grep` 命令已经准备来助你一臂之力了。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3400942/how-linux-can-help-with-your-spelling.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Modrisco](https://github.com/Modrisco)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/06/linux-spelling-100798596-large.jpg
|
||||
[2]: https://www.youtube.com/playlist?list=PL7D2RMSmRO9J8OTpjFECi8DJiTQdd4hua
|
||||
[3]: ftp://ftp.gnu.org/gnu/aspell/dict/0index.html
|
||||
[4]: https://www.facebook.com/NetworkWorld/
|
||||
[5]: https://www.linkedin.com/company/network-world
|
||||
68
published/20190607 5 reasons to use Kubernetes.md
Normal file
68
published/20190607 5 reasons to use Kubernetes.md
Normal file
@ -0,0 +1,68 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10973-1.html)
|
||||
[#]: subject: (5 reasons to use Kubernetes)
|
||||
[#]: via: (https://opensource.com/article/19/6/reasons-kubernetes)
|
||||
[#]: author: (Daniel Oh https://opensource.com/users/daniel-oh)
|
||||
|
||||
使用 Kubernetes 的 5 个理由
|
||||
======
|
||||
|
||||
> Kubernetes 解决了一些开发和运维团队每天关注的的常见问题。
|
||||
|
||||

|
||||
|
||||
[Kubernetes][2](K8S)是面向企业的开源容器编排工具的事实标准。它提供了应用部署、扩展、容器管理和其他功能,使企业能够通过容错能力快速优化硬件资源利用率并延长生产环境运行时间。该项目最初由谷歌开发,并将该项目捐赠给[云原生计算基金会][3](CNCF)。2018 年,它成为第一个从 CNCF [毕业][4]的项目。
|
||||
|
||||
这一切都很好,但它并不能解释为什么开发者和运维人员应该在 Kubernetes 上投入宝贵的时间和精力。Kubernetes 之所以如此有用,是因为它有助于开发者和运维人员迅速解决他们每天都在努力解决的问题。
|
||||
|
||||
以下是 Kubernetes 帮助开发者和运维人员解决他们最常见问题的五种能力。
|
||||
|
||||
### 1、厂商无关
|
||||
|
||||
许多公有云提供商不仅提供托管 Kubernetes 服务,还提供许多基于这些服务构建的云产品,来用于本地应用容器编排。由于与供应商无关,使运营商能够轻松、安全地设计、构建和管理多云和混合云平台,而不会有供应商锁定的风险。Kubernetes 还消除了运维团队对复杂的多云/混合云战略的担忧。
|
||||
|
||||
### 2、服务发现
|
||||
|
||||
为了开发微服务应用,Java 开发人员必须控制服务可用性(就应用是否可以提供服务而言),并确保服务持续存在,以响应客户端的请求,而没有任何例外。Kubernetes 的[服务发现功能][5]意味着开发人员不再需要自己管理这些东西。
|
||||
|
||||
### 3、触发
|
||||
|
||||
你的 DevOps 会如何在上千台虚拟机上部署多语言、云原生应用?理想情况下,开发和运维会在 bug 修复、功能增强、新功能、安全更新时触发部署。Kubernetes 的[部署功能][6]会自动化这个日常工作。更重要的时,它支持高级部署策略,例如[蓝绿部署和金丝雀部署][7]。
|
||||
|
||||
### 4、可伸缩性
|
||||
|
||||
自动扩展是处理云环境中大量工作负载所需的关键功能。通过构建容器平台,你可以为终端用户提高系统可靠性。[Kubernetes Horizontal Pod Autoscaler][8](HPA)允许一个集群增加或减少应用程序(或 Pod)的数量,以应对峰值流量或性能峰值,从而减少对意外系统中断的担忧。
|
||||
|
||||
### 5、容错性
|
||||
|
||||
在现代应用体系结构中,应考虑故障处理代码来控制意外错误并快速从中恢复。但是开发人员需要花费大量的时间和精力来模拟偶然的错误。Kubernetes 的 [ReplicaSet][9] 通过确保指定数量的 Pod 持续保持活动来帮助开发人员解决此问题。
|
||||
|
||||
### 结论
|
||||
|
||||
Kubernetes 使企业能够轻松、快速、安全地解决常见的开发和运维问题。它还提供其他好处,例如构建无缝的多云/混合云战略,节省基础架构成本以及加快产品上市时间。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/6/reasons-kubernetes
|
||||
|
||||
作者:[Daniel Oh][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/daniel-oh
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/ship_wheel_gear_devops_kubernetes.png?itok=xm4a74Kv
|
||||
[2]: https://opensource.com/resources/what-is-kubernetes
|
||||
[3]: https://www.cncf.io/projects/
|
||||
[4]: https://www.cncf.io/blog/2018/03/06/kubernetes-first-cncf-project-graduate/
|
||||
[5]: https://kubernetes.io/docs/concepts/services-networking/service/
|
||||
[6]: https://kubernetes.io/docs/concepts/workloads/controllers/deployment/
|
||||
[7]: https://opensource.com/article/17/5/colorful-deployments
|
||||
[8]: https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
|
||||
[9]: https://kubernetes.io/docs/concepts/workloads/controllers/replicaset/
|
||||
@ -0,0 +1,82 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10965-1.html)
|
||||
[#]: subject: (An open source bionic leg, Python data pipeline, data breach detection, and more news)
|
||||
[#]: via: (https://opensource.com/article/19/6/news-june-8)
|
||||
[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
|
||||
|
||||
开源新闻:开源仿生腿、Python 数据管道、数据泄露检测
|
||||
======
|
||||
|
||||
> 了解过去两周来最大的开源头条新闻。
|
||||
|
||||
![][1]
|
||||
|
||||
在本期开源新闻综述中,我们将介绍一个开源仿生腿、一个新的开源医学影像组织,麦肯锡发布的首个开源软件,以及更多!
|
||||
|
||||
### 使用开源推进仿生学
|
||||
|
||||
我们这一代人从电视剧《六百万美元人》和《仿生女人》中学到了仿生学一词。让科幻小说(尽管基于事实)正在成为现实的,要归功于[由密歇根大学和 Shirley Ryan AbilityLab 设计][2]的假肢。
|
||||
|
||||
该腿采用简单、低成本的模块化设计,“旨在通过为仿生学领域的零碎研究工作提供统一的平台,提高患者的生活质量并加速科学进步”。根据首席设计师 Elliot Rouse 的说法,它将“使研究人员能够有效地解决与一系列的实验室和社区活动中控制仿生腿相关的挑战。”
|
||||
|
||||
你可以从[开源腿][3]网站了解有该腿的更多信息并下载该设计。
|
||||
|
||||
### 麦肯锡发布了一个用于构建产品级数据管道的 Python 库
|
||||
|
||||
咨询巨头麦肯锡公司最近发布了其[第一个开源工具][4],名为 Kedro,它是一个用于创建机器学习和数据管道的 Python 库。
|
||||
|
||||
Kedro 使得“管理大型工作流程更加容易,并确保整个项目的代码质量始终如一”,产品经理 Yetunde Dada 说。虽然它最初是作为一种专有的工具,但麦肯锡开源了 Kedro,因此“客户可以在我们离开项目后使用它 —— 这是我们回馈的方式,”工程师 Nikolaos Tsaousis 说。
|
||||
|
||||
如果你有兴趣了解一下,可以从 GitHub 上获取 [Kedro 的源代码][5]。
|
||||
|
||||
### 新联盟推进开源医学成像
|
||||
|
||||
一组专家和患者倡导者聚集在一起组成了[开源成像联盟][6]。该联盟旨在“通过数字成像和机器学习帮助推进特发性肺纤维化和其他间质性肺病的诊断。”
|
||||
|
||||
根据联盟执行董事 Elizabeth Estes 的说法,该项目旨在“协作加速诊断,帮助预后处置,最终让医生更有效地治疗患者”。为此,他们正在组织和分享“来自患者的 15,000 个匿名图像扫描和临床数据,这将作为机器学习程序的输入数据来开发算法。”
|
||||
|
||||
### Mozilla 发布了一种简单易用的方法,以确定你是否遭受过数据泄露
|
||||
|
||||
向不那么精通软件的人解释安全性始终是一项挑战,无论你的技能水平如何,都很难监控你的风险。Mozilla 发布了 [Firefox Monitor][7],其数据由 [Have I Been Pwned][8] 提供,它是一种查看你的任何电子邮件是否出现在重大数据泄露事件中的简单方式。你可以输入电子邮件逐个搜索,或注册他们的服务以便将来通知你。
|
||||
|
||||
该网站还提供了大量有用的教程,用于了解黑客如何做的,数据泄露后如何处理以及如何创建强密码。请务必将网站加入书签,以防家人要求你在假日期间提供建议。
|
||||
|
||||
### 其它新闻
|
||||
|
||||
* [想要一款去谷歌化的 Android?把你的手机发送给这个人][9]
|
||||
* [CockroachDB 发行版使用了非 OSI 批准的许可证,但仍然保持开源][10]
|
||||
* [基础设施自动化公司 Chef 承诺开源][11]
|
||||
* [俄罗斯的 Windows 替代品将获得安全升级][12]
|
||||
* [使用此代码在几分钟内从 Medium 切换到你自己的博客][13]
|
||||
* [开源推进联盟宣布与台湾自由软件协会建立新合作伙伴关系][14]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/6/news-june-8
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/weekly_news_roundup_tv.png?itok=B6PM4S1i
|
||||
[2]: https://news.umich.edu/open-source-bionic-leg-first-of-its-kind-platform-aims-to-rapidly-advance-prosthetics/
|
||||
[3]: https://opensourceleg.com/
|
||||
[4]: https://www.information-age.com/kedro-mckinseys-open-source-software-tool-123482991/
|
||||
[5]: https://github.com/quantumblacklabs/kedro
|
||||
[6]: https://pulmonaryfibrosisnews.com/2019/05/31/international-open-source-imaging-consortium-osic-launched-to-advance-ipf-diagnosis/
|
||||
[7]: https://monitor.firefox.com/
|
||||
[8]: https://haveibeenpwned.com/
|
||||
[9]: https://fossbytes.com/want-a-google-free-android-send-your-phone-to-this-guy/
|
||||
[10]: https://www.cockroachlabs.com/blog/oss-relicensing-cockroachdb/
|
||||
[11]: https://www.infoq.com/news/2019/05/chef-open-source/
|
||||
[12]: https://www.nextgov.com/cybersecurity/2019/05/russias-would-be-windows-replacement-gets-security-upgrade/157330/
|
||||
[13]: https://github.com/mathieudutour/medium-to-own-blog
|
||||
[14]: https://opensource.org/node/994
|
||||
@ -0,0 +1,146 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10983-1.html)
|
||||
[#]: subject: (Expand And Unexpand Commands Tutorial With Examples)
|
||||
[#]: via: (https://www.ostechnix.com/expand-and-unexpand-commands-tutorial-with-examples/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
expand 与 unexpand 命令实例教程
|
||||
======
|
||||
|
||||
![Expand And Unexpand Commands Explained][1]
|
||||
|
||||
本指南通过实际的例子解释两个 Linux 命令,即 `expand` 和 `unexpand`。对于好奇的人,`expand` 和 `unexpand` 命令用于将文件中的 `TAB` 字符替换为空格,反之亦然。在 MS-DOS 中也有一个名为 `expand` 的命令,它用于解压压缩文件。但 Linux 的 `expand` 命令只是将 `TAB` 转换为空格。这两个命令是 GNU coreutils 包的一部分,由 David MacKenzie 编写。
|
||||
|
||||
为了演示,我将在本文使用名为 `ostechnix.txt` 的文本文件。下面给出的所有命令都在 Arch Linux 中进行测试。
|
||||
|
||||
### expand 命令示例
|
||||
|
||||
与我之前提到的一样,`expand` 命令使用空格替换文件中的 `TAB` 字符。
|
||||
|
||||
现在,让我们将 `ostechnix.txt` 中的 `TAB` 转换为空格,并将结果写入标准输出:
|
||||
|
||||
```
|
||||
$ expand ostechnix.txt
|
||||
```
|
||||
|
||||
如果你不想在标准输出中显示结果,只需将其写入另一个文件,如下所示。
|
||||
|
||||
```
|
||||
$ expand ostechnix.txt>output.txt
|
||||
```
|
||||
|
||||
我们还可以将标准输入中的 `TAB` 转换为空格。为此,只需运行 `expand` 命令而不带文件名:
|
||||
|
||||
```
|
||||
$ expand
|
||||
```
|
||||
|
||||
只需输入文本并按回车键就能将 `TAB` 转换为空格。按 `CTRL+C` 退出。
|
||||
|
||||
如果你不想转换非空白字符后的 `TAB`,请使用 `-i` 标记,如下所示。
|
||||
|
||||
```
|
||||
$ expand -i ostechnix.txt
|
||||
```
|
||||
|
||||
我们还可以设置每个 `TAB` 为指定数字的宽度,而不是 `8`(默认值)。
|
||||
|
||||
```
|
||||
$ expand -t=5 ostechnix.txt
|
||||
```
|
||||
|
||||
我们甚至可以使用逗号分隔指定多个 `TAB` 位置,如下所示。
|
||||
|
||||
```
|
||||
$ expand -t 5,10,15 ostechnix.txt
|
||||
```
|
||||
|
||||
或者,
|
||||
|
||||
```
|
||||
$ expand -t "5 10 15" ostechnix.txt
|
||||
```
|
||||
|
||||
有关更多详细信息,请参阅手册页。
|
||||
|
||||
```
|
||||
$ man expand
|
||||
```
|
||||
|
||||
### unexpand 命令示例
|
||||
|
||||
正如你可能已经猜到的那样,`unexpand` 命令将执行与 `expand` 命令相反的操作。即它会将空格转换为 `TAB`。让我向你展示一些例子,以了解如何使用 `unexpand` 命令。
|
||||
|
||||
要将文件中的空白(当然是空格)转换为 `TAB` 并将输出写入标准输出,请执行以下操作:
|
||||
|
||||
```
|
||||
$ unexpand ostechnix.txt
|
||||
```
|
||||
|
||||
如果要将输出写入文件而不是仅将其显示到标准输出,请使用以下命令:
|
||||
|
||||
```
|
||||
$ unexpand ostechnix.txt>output.txt
|
||||
```
|
||||
|
||||
从标准输出读取内容,将空格转换为制表符:
|
||||
|
||||
```
|
||||
$ unexpand
|
||||
```
|
||||
|
||||
默认情况下,`unexpand` 命令仅转换初始的空格。如果你想转换所有空格而不是只是一行开头的空格,请使用 `-a` 标志:
|
||||
|
||||
```
|
||||
$ unexpand -a ostechnix.txt
|
||||
```
|
||||
|
||||
仅转换一行开头的空格(请注意它会覆盖 `-a`):
|
||||
|
||||
```
|
||||
$ unexpand --first-only ostechnix.txt
|
||||
```
|
||||
|
||||
使多少个空格替换成一个 `TAB`,而不是 `8`(会启用 `-a`):
|
||||
|
||||
```
|
||||
$ unexpand -t 5 ostechnix.txt
|
||||
```
|
||||
|
||||
相似地,我们可以使用逗号分隔指定多个 `TAB` 的位置。
|
||||
|
||||
```
|
||||
$ unexpand -t 5,10,15 ostechnix.txt
|
||||
```
|
||||
|
||||
或者,
|
||||
|
||||
```
|
||||
$ unexpand -t "5 10 15" ostechnix.txt
|
||||
```
|
||||
|
||||
有关更多详细信息,请参阅手册页。
|
||||
|
||||
```
|
||||
$ man unexpand
|
||||
```
|
||||
|
||||
在处理大量文件时,`expand` 和 `unexpand` 命令对于用空格替换不需要的 `TAB` 时非常有用,反之亦然。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/expand-and-unexpand-commands-tutorial-with-examples/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/05/Expand-And-Unexpand-Commands-720x340.png
|
||||
@ -0,0 +1,85 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10988-1.html)
|
||||
[#]: subject: (Graviton: A Minimalist Open Source Code Editor)
|
||||
[#]: via: (https://itsfoss.com/graviton-code-editor/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
Graviton:极简的开源代码编辑器
|
||||
======
|
||||
|
||||
[Graviton][1]是一款开发中的自由开源的跨平台代码编辑器。他的开发者 16 岁的 Marc Espin 强调说,它是一个“极简”的代码编辑器。我不确定这点,但它确实有一个清爽的用户界面,就像其他的[现代代码编辑器,如 Atom][2]。
|
||||
|
||||
![Graviton Code Editor Interface][3]
|
||||
|
||||
开发者还将其称为轻量级代码编辑器,尽管 Graviton 基于 [Electron][4]。
|
||||
|
||||
Graviton 拥有你在任何标准代码编辑器中所期望的功能,如语法高亮、自动补全等。由于 Graviton 仍处于测试阶段,因此未来版本中将添加更多功能。
|
||||
|
||||
![Graviton Code Editor with Syntax Highlighting][5]
|
||||
|
||||
### Graviton 代码编辑器的特性
|
||||
|
||||
Graviton 一些值得一说的特性有:
|
||||
|
||||
* 使用 [CodeMirrorJS][6] 为多种编程语言提供语法高亮
|
||||
* 自动补全
|
||||
* 支持插件和主题。
|
||||
* 提供英语、西班牙语和一些其他欧洲语言。
|
||||
* 适用于 Linux、Windows 和 macOS。
|
||||
|
||||
我快速看来一下 Graviton,它可能不像 [VS Code][7] 或 [Brackets][8] 那样功能丰富,但对于一些简单的代码编辑来说,它还算不错的工具。
|
||||
|
||||
### 下载并安装 Graviton
|
||||
|
||||
![Graviton Code Editor][9]
|
||||
|
||||
如上所述,Graviton 是一个可用于 Linux、Windows 和 macOS 的跨平台代码编辑器。它仍处于测试阶段,这意味着将来会添加更多功能,并且你可能会遇到一些 bug。
|
||||
|
||||
你可以在其发布页面上找到最新版本的 Graviton。Debian 和 [Ubuntu 用户可以使用 .deb 安装][10]。它已提供 [AppImage][11],以便可以在其他发行版中使用它。DMG 和 EXE 文件也分别可用于 macOS 和 Windows。
|
||||
|
||||
- [下载 Graviton][12]
|
||||
|
||||
如果你有兴趣,你可以在 GitHub 仓库中找到 Graviton 的源代码:
|
||||
|
||||
- [GitHub 中 Graviton 的源码][13]
|
||||
|
||||
如果你决定使用 Graviton 并发现了一些问题,请在[此处][14]写一份错误报告。如果你使用 GitHub,你可能想为 Graviton 项目加星。这可以提高开发者的士气,因为他知道有更多的用户欣赏他的努力。
|
||||
|
||||
如果你看到现在,我相信你了解[如何从源码安装软件][16]
|
||||
|
||||
### 写在最后
|
||||
|
||||
有时,简单本身就成了一个特性,而 Graviton 专注于极简可以帮助它在已经拥挤的代码编辑器世界中获取一席之地。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/graviton-code-editor/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://graviton.ml/
|
||||
[2]: https://itsfoss.com/best-modern-open-source-code-editors-for-linux/
|
||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/06/graviton-code-editor-interface.jpg?resize=800%2C571&ssl=1
|
||||
[4]: https://electronjs.org/
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/06/graviton-code-editor-interface-2.jpg?resize=800%2C522&ssl=1
|
||||
[6]: https://codemirror.net/
|
||||
[7]: https://itsfoss.com/install-visual-studio-code-ubuntu/
|
||||
[8]: https://itsfoss.com/install-brackets-ubuntu/
|
||||
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/06/graviton-code-editor-800x473.jpg?resize=800%2C473&ssl=1
|
||||
[10]: https://itsfoss.com/install-deb-files-ubuntu/
|
||||
[11]: https://itsfoss.com/use-appimage-linux/
|
||||
[12]: https://github.com/Graviton-Code-Editor/Graviton-App/releases
|
||||
[13]: https://github.com/Graviton-Code-Editor/Graviton-App
|
||||
[14]: https://github.com/Graviton-Code-Editor/Graviton-App/issues
|
||||
[16]: https://itsfoss.com/install-software-from-source-code/
|
||||
[17]: https://itsfoss.com/contact-us/
|
||||
@ -0,0 +1,216 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10991-1.html)
|
||||
[#]: subject: (Neofetch – Display Linux system Information In Terminal)
|
||||
[#]: via: (https://www.ostechnix.com/neofetch-display-linux-systems-information/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
Neofetch:在终端中显示 Linux 系统信息
|
||||
======
|
||||
|
||||
![Display Linux system information using Neofetch][1]
|
||||
|
||||
Neofetch 是一个简单但有用的命令行系统信息工具,它用 Bash 编写。它会收集有关系统软硬件的信息,并在终端中显示结果。默认情况下,系统信息将与操作系统的 logo 一起显示。但是,你可以进一步地自定义使用 ascii 图像或其他任何图片。你还可以配置 Neofetch 显示的信息、信息的显示位置和时间。Neofetch 主要用于系统信息的截图。它支持 Linux、BSD、Mac OS X、iOS 和 Windows 操作系统。在这个简短的教程中,让我们看看如何使用 Neofetch 显示 Linux 系统信息。
|
||||
|
||||
### 安装 Neofetch
|
||||
|
||||
Neofetch 可在大多数 Linux 发行版的默认仓库中找到。
|
||||
|
||||
在 Arch Linux 及其衍生版上,使用这个命令安装它:
|
||||
|
||||
```
|
||||
$ sudo pacman -S netofetch
|
||||
```
|
||||
|
||||
在 Debian(Stretch / Sid)上:
|
||||
|
||||
```
|
||||
$ sudo apt-get install neofetch
|
||||
```
|
||||
|
||||
在 Fedora 27 上:
|
||||
|
||||
```
|
||||
$ sudo dnf install neofetch
|
||||
```
|
||||
|
||||
在 RHEL、CentOS 上:
|
||||
|
||||
启用 EPEL 仓库:
|
||||
|
||||
```
|
||||
# yum install epel-relase
|
||||
```
|
||||
|
||||
获取 neofetch 仓库:
|
||||
|
||||
```
|
||||
# curl -o /etc/yum.repos.d/konimex-neofetch-epel-7.repo
|
||||
https://copr.fedorainfracloud.org/coprs/konimex/neofetch/repo/epel-7/konimex-neofetch-epel-7.repo
|
||||
```
|
||||
|
||||
然后,安装 Neofetch:
|
||||
|
||||
```
|
||||
# yum install neofetch
|
||||
```
|
||||
|
||||
在 Ubuntu 17.10 和更新版本上:
|
||||
|
||||
```
|
||||
$ sudo apt-get install neofetch
|
||||
```
|
||||
|
||||
在 Ubuntu 16.10 和更低版本上:
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:dawidd0811/neofetch
|
||||
|
||||
$ sudo apt update
|
||||
|
||||
$ sudo apt install neofetch
|
||||
```
|
||||
|
||||
在 NixOS 上:
|
||||
|
||||
```
|
||||
$ nix-env -i neofetch
|
||||
```
|
||||
|
||||
### 使用 Neofetch 显示 Linux 系统信息
|
||||
|
||||
Neofetch 非常简单直接。让我们看一些例子。
|
||||
|
||||
打开终端,然后运行以下命令:
|
||||
|
||||
```
|
||||
$ neofetch
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![][2]
|
||||
|
||||
*使用 Neofetch 显示 Linux 系统信息*
|
||||
|
||||
正如你在上面的输出中所看到的,Neofetch 显示了我的 Arch Linux 系统的以下详细信息:
|
||||
|
||||
* 已安装操作系统的名称,
|
||||
* 笔记本型号,
|
||||
* 内核详细信息,
|
||||
* 系统运行时间,
|
||||
* 默认和其他软件包管理器安装的软件数量
|
||||
* 默认 shell,
|
||||
* 屏幕分辨率,
|
||||
* 桌面环境,
|
||||
* 窗口管理器,
|
||||
* 窗口管理器的主题,
|
||||
* 系统主题,
|
||||
* 系统图标,
|
||||
* 默认终端,
|
||||
* CPU 类型,
|
||||
* GPU 类型,
|
||||
* 已安装的内存。
|
||||
|
||||
Neofetch 还有很多其他选项。我们会看到其中一些。
|
||||
|
||||
### 如何在 Neofetch 输出中使用自定义图像?
|
||||
|
||||
默认情况下,Neofetch 将显示你的操作系统 logo 以及系统信息。当然,你可以根据需要更改图像。
|
||||
|
||||
要显示图像,Linux 系统应该安装以下依赖项:
|
||||
|
||||
1. w3m-img(用于显示图像。w3m-img 有时与 w3m 包捆绑在一起),
|
||||
2. Imagemagick(用于创建缩略图),
|
||||
3. 支持 `\033[14t` 或者 xdotool 或者 xwininfo + xprop 或者 xwininfo + xdpyinfo 的终端。
|
||||
|
||||
大多数 Linux 发行版的默认仓库中都提供了 W3m-img 和 ImageMagick 包。因此,你可以使用你的发行版的默认包管理器来安装它们。
|
||||
|
||||
例如,运行以下命令在 Debian、Ubuntu、Linux Mint 上安装 w3m-img 和 ImageMagick:
|
||||
|
||||
```
|
||||
$ sudo apt install w3m-img imagemagick
|
||||
```
|
||||
|
||||
以下是带 w3m-img 支持的终端列表:
|
||||
|
||||
1. Gnome-terminal,
|
||||
2. Konsole,
|
||||
3. st,
|
||||
4. Terminator,
|
||||
5. Termite,
|
||||
6. URxvt,
|
||||
7. Xfce4-Terminal,
|
||||
8. Xterm
|
||||
|
||||
如果你的系统上已经有了 kitty、Terminology 和 iTerm,那么就无需安装 w3m-img。
|
||||
|
||||
现在,运行以下命令以使用自定义图像显示系统信息:
|
||||
|
||||
```
|
||||
$ neofetch --w3m /home/sk/Pictures/image.png
|
||||
```
|
||||
|
||||
或者,
|
||||
|
||||
```
|
||||
$ neofetch --w3m --source /home/sk/Pictures/image.png
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![][3]
|
||||
|
||||
*使用自定义 logo 的 Neofetch 输出*
|
||||
|
||||
使用你自己的图片替换上面图片的路径。
|
||||
|
||||
或者,你可以指向包含以下图像的目录。
|
||||
|
||||
```
|
||||
$ neofetch --w3m <path-to-directory>
|
||||
```
|
||||
|
||||
### 配置 Neofetch
|
||||
|
||||
当我们第一次运行 Neofetch 时,它默认会为每个用户在 `$HOME/.config/neofetch/config.conf` 中创建一个配置文件。它还会在 `$HOME/.config/neofetch/config` 中创建一个全局的 neofetch 配置文件。你可以调整此文件来告诉 neofetch 该显示、删除和/或修改哪些详细信息。
|
||||
|
||||
还可以在不同版本中保留此配置文件。这意味着你只需根据自己的喜好自定义一次,并在升级到更新版本后使用相同的设置。你甚至可以将此文件共享给你的朋友和同事,使他拥有与你相同的设置。
|
||||
|
||||
要查看 Neofetch 帮助部分,请运行:
|
||||
|
||||
```
|
||||
$ neofetch --help
|
||||
```
|
||||
|
||||
就我测试的 Neofetch 而言,它在我的 Arch Linux 系统中完美地工作。它是一个非常方便的工具,可以在终端中轻松快速地打印系统的详细信息。
|
||||
|
||||
相关阅读:
|
||||
|
||||
* [如何使用 inxi 查看 Linux 系统详细信息][4]
|
||||
|
||||
资源:
|
||||
|
||||
* [Neofetch 的 GitHub 页面][5]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/neofetch-display-linux-systems-information/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2016/06/neofetch-1-720x340.png
|
||||
[2]: http://www.ostechnix.com/wp-content/uploads/2016/06/Neofetch-1.png
|
||||
[3]: http://www.ostechnix.com/wp-content/uploads/2016/06/Neofetch-with-custom-logo.png
|
||||
[4]: https://www.ostechnix.com/how-to-find-your-system-details-using-inxi/
|
||||
[5]: https://github.com/dylanaraps/neofetch
|
||||
@ -0,0 +1,282 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10962-1.html)
|
||||
[#]: subject: (Screen Command Examples To Manage Multiple Terminal Sessions)
|
||||
[#]: via: (https://www.ostechnix.com/screen-command-examples-to-manage-multiple-terminal-sessions/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
screen 命令示例:管理多个终端会话
|
||||
======
|
||||
|
||||

|
||||
|
||||
GNU Screen 是一个终端多路复用器(窗口管理器)。顾名思义,Screen 可以在多个交互式 shell 之间复用物理终端,因此我们可以在每个终端会话中执行不同的任务。所有的 Screen 会话都完全独立地运行程序。因此,即使会话意外关闭或断开连接,在 Screen 会话内运行的程序或进程也将继续运行。例如,当通过 SSH [升级 Ubuntu][2] 服务器时,`screen` 命令将继续运行升级过程,以防万一 SSH 会话因任何原因而终止。
|
||||
|
||||
GNU Screen 允许我们轻松创建多个 Screen 会话,在不同会话之间切换,在会话之间复制文本,随时连上或脱离会话等等。它是每个 Linux 管理员应该在必要时学习和使用的重要命令行工具之一。在本简要指南中,我们将看到 `screen` 命令的基本用法以及在 Linux 中的示例。
|
||||
|
||||
### 安装 GNU Screen
|
||||
|
||||
GNU Screen 在大多数 Linux 操作系统的默认存储库中都可用。
|
||||
|
||||
要在 Arch Linux 上安装 GNU Screen,请运行:
|
||||
|
||||
```
|
||||
$ sudo pacman -S screen
|
||||
```
|
||||
|
||||
在 Debian、Ubuntu、Linux Mint 上:
|
||||
|
||||
```
|
||||
$ sudo apt-get install screen
|
||||
```
|
||||
|
||||
在 Fedora 上:
|
||||
|
||||
```
|
||||
$ sudo dnf install screen
|
||||
```
|
||||
|
||||
在 RHEL、CentOS 上:
|
||||
|
||||
```
|
||||
$ sudo yum install screen
|
||||
```
|
||||
|
||||
在 SUSE/openSUSE 上:
|
||||
|
||||
```
|
||||
$ sudo zypper install screen
|
||||
```
|
||||
|
||||
让我们继续看一些 `screen` 命令示例。
|
||||
|
||||
### 管理多个终端会话的 Screen 命令示例
|
||||
|
||||
在 Screen 中所有命令的默认前缀快捷方式是 `Ctrl + a`。使用 Screen 时,你需要经常使用此快捷方式。所以,要记住这个键盘快捷键。
|
||||
|
||||
#### 创建新的 Screen 会话
|
||||
|
||||
让我们创建一个新的 Screen 会话并连上它。为此,请在终端中键入以下命令:
|
||||
|
||||
```
|
||||
screen
|
||||
```
|
||||
|
||||
现在,在此会话中运行任何程序或进程,即使你与此会话断开连接,正在运行的进程或程序也将继续运行。
|
||||
|
||||
#### 从 Screen 会话脱离
|
||||
|
||||
要从屏幕会话中脱离,请按 `Ctrl + a` 和 `d`。你无需同时按下两个组合键。首先按 `Ctrl + a` 然后按 `d`。从会话中脱离后,你将看到类似下面的输出。
|
||||
|
||||
```
|
||||
[detached from 29149.pts-0.sk]
|
||||
```
|
||||
|
||||
这里,`29149` 是 Screen ID,`pts-0.sk` 是屏幕会话的名称。你可以使用 Screen ID 或相应的会话名称来连上、脱离和终止屏幕会话。
|
||||
|
||||
#### 创建命名会话
|
||||
|
||||
你还可以用你选择的任何自定义名称创建一个 Screen 会话,而不是默认用户名,如下所示。
|
||||
|
||||
```
|
||||
screen -S ostechnix
|
||||
```
|
||||
|
||||
上面的命令将创建一个名为 `xxxxx.ostechnix` 的新 Screen 会话,并立即连上它。要从当前会话中脱离,请按 `Ctrl + a`,然后按 `d`。
|
||||
|
||||
当你想要查找哪些进程在哪些会话上运行时,命名会话会很有用。例如,当在会话中设置 LAMP 系统时,你可以简单地将其命名为如下所示。
|
||||
|
||||
```
|
||||
screen -S lampstack
|
||||
```
|
||||
|
||||
#### 创建脱离的会话
|
||||
|
||||
有时,你可能想要创建一个会话,但不希望自动连上该会话。在这种情况下,运行以下命令来创建名为`senthil` 的已脱离会话:
|
||||
|
||||
```
|
||||
screen -S senthil -d -m
|
||||
```
|
||||
|
||||
也可以缩短为:
|
||||
|
||||
```
|
||||
screen -dmS senthil
|
||||
```
|
||||
|
||||
上面的命令将创建一个名为 `senthil` 的会话,但不会连上它。
|
||||
|
||||
#### 列出屏幕会话
|
||||
|
||||
要列出所有正在运行的会话(连上的或脱离的),请运行:
|
||||
|
||||
```
|
||||
screen -ls
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
There are screens on:
|
||||
29700.senthil (Detached)
|
||||
29415.ostechnix (Detached)
|
||||
29149.pts-0.sk (Detached)
|
||||
3 Sockets in /run/screens/S-sk.
|
||||
```
|
||||
|
||||
如你所见,我有三个正在运行的会话,并且所有会话都已脱离。
|
||||
|
||||
#### 连上 Screen 会话
|
||||
|
||||
如果你想连上会话,例如 `29415.ostechnix`,只需运行:
|
||||
|
||||
```
|
||||
screen -r 29415.ostechnix
|
||||
```
|
||||
|
||||
或:
|
||||
|
||||
```
|
||||
screen -r ostechnix
|
||||
```
|
||||
|
||||
或使用 Screen ID:
|
||||
|
||||
```
|
||||
screen -r 29415
|
||||
```
|
||||
|
||||
要验证我们是否连上到上述会话,只需列出打开的会话并检查。
|
||||
|
||||
```
|
||||
screen -ls
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
There are screens on:
|
||||
29700.senthil (Detached)
|
||||
29415.ostechnix (Attached)
|
||||
29149.pts-0.sk (Detached)
|
||||
3 Sockets in /run/screens/S-sk.
|
||||
```
|
||||
|
||||
如你所见,在上面的输出中,我们目前已连上到 `29415.ostechnix` 会话。要退出当前会话,请按 `ctrl + a d`。
|
||||
|
||||
#### 创建嵌套会话
|
||||
|
||||
当我们运行 `screen` 命令时,它将为我们创建一个会话。但是,我们可以创建嵌套会话(会话内的会话)。
|
||||
|
||||
首先,创建一个新会话或连上已打开的会话。然后我将创建一个名为 `nested` 的新会话。
|
||||
|
||||
```
|
||||
screen -S nested
|
||||
```
|
||||
|
||||
现在,在会话中按 `Ctrl + a` 和 `c` 创建另一个会话。只需重复此操作即可创建任意数量的嵌套 Screen 会话。每个会话都将分配一个号码。号码将从 `0` 开始。
|
||||
|
||||
你可以按 `Ctrl + n` 移动到下一个会话,然后按 `Ctrl + p` 移动到上一个会话。
|
||||
|
||||
以下是管理嵌套会话的重要键盘快捷键列表。
|
||||
|
||||
* `Ctrl + a "` - 列出所有会话
|
||||
* `Ctrl + a 0` - 切换到会话号 0
|
||||
* `Ctrl + a n` - 切换到下一个会话
|
||||
* `Ctrl + a p` - 切换到上一个会话
|
||||
* `Ctrl + a S` - 将当前区域水平分割为两个区域
|
||||
* `Ctrl + a l` - 将当前区域垂直分割为两个区域
|
||||
* `Ctrl + a Q` - 关闭除当前会话之外的所有会话
|
||||
* `Ctrl + a X` - 关闭当前会话
|
||||
* `Ctrl + a \` - 终止所有会话并终止 Screen
|
||||
* `Ctrl + a ?` - 显示键绑定。要退出,请按回车
|
||||
|
||||
#### 锁定会话
|
||||
|
||||
Screen 有一个锁定会话的选项。为此,请按 `Ctrl + a` 和 `x`。 输入你的 Linux 密码以锁定。
|
||||
|
||||
```
|
||||
Screen used by sk <sk> on ubuntuserver.
|
||||
Password:
|
||||
```
|
||||
|
||||
#### 记录会话
|
||||
|
||||
你可能希望记录 Screen 会话中的所有内容。为此,只需按 `Ctrl + a` 和 `H` 即可。
|
||||
|
||||
或者,你也可以使用 `-L` 参数启动新会话来启用日志记录。
|
||||
|
||||
```
|
||||
screen -L
|
||||
```
|
||||
|
||||
从现在开始,你在会话中做的所有活动都将记录并存储在 `$HOME` 目录中名为 `screenlog.x` 的文件中。这里,`x` 是一个数字。
|
||||
|
||||
你可以使用 `cat` 命令或任何文本查看器查看日志文件的内容。
|
||||
|
||||
![][3]
|
||||
|
||||
*记录 Screen 会话*
|
||||
|
||||
#### 终止 Screen 会话
|
||||
|
||||
如果不再需要会话,只需杀死它。要杀死名为 `senthil` 的脱离会话:
|
||||
|
||||
```
|
||||
screen -r senthil -X quit
|
||||
```
|
||||
|
||||
或:
|
||||
|
||||
```
|
||||
screen -X -S senthil quit
|
||||
```
|
||||
|
||||
或:
|
||||
|
||||
```
|
||||
screen -X -S 29415 quit
|
||||
```
|
||||
|
||||
如果没有打开的会话,你将看到以下输出:
|
||||
|
||||
```
|
||||
$ screen -ls
|
||||
No Sockets found in /run/screens/S-sk.
|
||||
```
|
||||
|
||||
更多细节请参照 man 手册页:
|
||||
|
||||
```
|
||||
$ man screen
|
||||
```
|
||||
|
||||
还有一个名为 Tmux 的类似的命令行实用程序,它与 GNU Screen 执行相同的工作。要了解更多信息,请参阅以下指南。
|
||||
|
||||
* [Tmux 命令示例:管理多个终端会话][5]
|
||||
|
||||
### 资源
|
||||
|
||||
* [GNU Screen 主页][6]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/screen-command-examples-to-manage-multiple-terminal-sessions/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/06/Screen-Command-Examples-720x340.jpg
|
||||
[2]: https://www.ostechnix.com/how-to-upgrade-to-ubuntu-18-04-lts-desktop-and-server/
|
||||
[3]: https://www.ostechnix.com/wp-content/uploads/2019/06/Log-screen-sessions.png
|
||||
[4]: https://www.ostechnix.com/record-everything-terminal/
|
||||
[5]: https://www.ostechnix.com/tmux-command-examples-to-manage-multiple-terminal-sessions/
|
||||
[6]: https://www.gnu.org/software/screen/
|
||||
@ -0,0 +1,90 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10994-1.html)
|
||||
[#]: subject: (Search Linux Applications On AppImage, Flathub And Snapcraft Platforms)
|
||||
[#]: via: (https://www.ostechnix.com/search-linux-applications-on-appimage-flathub-and-snapcraft-platforms/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
在 AppImage、Flathub 和 Snapcraft 平台上搜索 Linux 应用
|
||||
======
|
||||
|
||||
![Search Linux Applications On AppImage, Flathub And Snapcraft][1]
|
||||
|
||||
Linux 一直在发展。过去,开发人员必须分别为不同的 Linux 发行版构建应用。由于存在多种 Linux 变体,因此为所有发行版构建应用变得很繁琐,而且非常耗时。后来一些开发人员发明了包转换器和构建器,如 [Checkinstall][2]、[Debtap][3] 和 [Fpm][4]。但他们也没有完全解决问题。所有这些工具都只是将一种包格式转换为另一种包格式。我们仍然需要找到应用并安装运行所需的依赖项。
|
||||
|
||||
好吧,时代已经变了。我们现在有了通用的 Linux 应用。这意味着我们可以在大多数 Linux 发行版上安装这些应用。无论是 Arch Linux、Debian、CentOS、Redhat、Ubuntu 还是任何流行的 Linux 发行版,通用应用都可以正常使用。这些应用与所有必需的库和依赖项打包在一个包中。我们所要做的就是在我们使用的任何 Linux 发行版上下载并运行它们。流行的通用应用格式有 AppImage、[Flatpak][5] 和 [Snap][6]。
|
||||
|
||||
AppImage 由 Simon peter 创建和维护。许多流行的应用,如 Gimp、Firefox、Krita 等等,都有这些格式,并可直接在下载页面下载。只需下载它们,使其可执行并立即运行它。你甚至无需 root 权限来运行 AppImage。
|
||||
|
||||
Flatpak 的开发人员是 Alexander Larsson(RedHat 员工)。Flatpak 应用托管在名为 “Flathub” 的中央仓库(商店)中。如果你是开发人员,建议你使用 Flatpak 格式构建应用,并通过 Flathub 将其分发给用户。
|
||||
|
||||
Snap 由 Canonical 而建,主要用于 Ubuntu。但是,其他 Linux 发行版的开发人员开始为 Snap 打包格式做出贡献。因此,Snap 也开始适用于其他 Linux 发行版。Snap 可以直接从应用的下载页面下载,也可以从 Snapcraft 商店下载。
|
||||
|
||||
许多受欢迎的公司和开发人员已经发布了 AppImage、Flatpak 和 Snap 格式的应用。如果你在寻找一款应用,只需进入相应的商店并获取你选择的应用并运行它,而不用管你使用何种 Linux 发行版。
|
||||
|
||||
还有一个名为 “Chob” 的命令行通用应用搜索工具可在 AppImage、Flathub 和 Snapcraft 平台上轻松搜索 Linux 应用。此工具仅搜索给定的应用并在默认浏览器中显示官方链接。它不会安装它们。本指南将解释如何安装 Chob 并使用它来搜索 Linux 上的 AppImage、Flatpak 和 Snap。
|
||||
|
||||
### 使用 Chob 在 AppImage、Flathub 和 Snapcraft 平台上搜索 Linux 应用
|
||||
|
||||
从[发布页面][7]下载最新的 Chob 二进制文件。在编写本指南时,最新版本为 0.3.5。
|
||||
|
||||
```
|
||||
$ wget https://github.com/MuhammedKpln/chob/releases/download/0.3.5/chob-linux
|
||||
```
|
||||
|
||||
使其可执行:
|
||||
|
||||
```
|
||||
$ chmod +x chob-linux
|
||||
```
|
||||
|
||||
最后,搜索你想要的应用。例如,我将搜索与 Vim 相关的应用。
|
||||
|
||||
```
|
||||
$ ./chob-linux vim
|
||||
```
|
||||
|
||||
Chob 将在 AppImage、Flathub 和 Snapcraft 平台上搜索给定的应用(和相关应用)并显示结果。
|
||||
|
||||
![][8]
|
||||
|
||||
*使用 Chob 搜索 Linux 应用*
|
||||
|
||||
只需要输入你想要应用前面的数字就可在默认浏览器中打开它的官方链接,并可在其中阅读应用的详细信息。
|
||||
|
||||
![][9]
|
||||
|
||||
在浏览器中查看 Linux 应用的详细信息
|
||||
|
||||
有关更多详细信息,请查看下面的 Chob 官方 GitHub 页面。
|
||||
|
||||
资源:
|
||||
|
||||
* [Chob 的 GitHub 仓库][10]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/search-linux-applications-on-appimage-flathub-and-snapcraft-platforms/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/05/chob-720x340.png
|
||||
[2]: https://www.ostechnix.com/build-packages-source-using-checkinstall/
|
||||
[3]: https://www.ostechnix.com/convert-deb-packages-arch-linux-packages/
|
||||
[4]: https://www.ostechnix.com/build-linux-packages-multiple-platforms-easily/
|
||||
[5]: https://www.ostechnix.com/flatpak-new-framework-desktop-applications-linux/
|
||||
[6]: https://www.ostechnix.com/introduction-ubuntus-snap-packages/
|
||||
[7]: https://github.com/MuhammedKpln/chob/releases
|
||||
[8]: http://www.ostechnix.com/wp-content/uploads/2019/05/Search-Linux-applications-Using-Chob.png
|
||||
[9]: http://www.ostechnix.com/wp-content/uploads/2019/05/View-Linux-applications-Details.png
|
||||
[10]: https://github.com/MuhammedKpln/chob
|
||||
84
published/20190610 Try a new game on Free RPG Day.md
Normal file
84
published/20190610 Try a new game on Free RPG Day.md
Normal file
@ -0,0 +1,84 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10976-1.html)
|
||||
[#]: subject: (Try a new game on Free RPG Day)
|
||||
[#]: via: (https://opensource.com/article/19/5/free-rpg-day)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth/users/erez/users/seth)
|
||||
|
||||
在免费 RPG 日试玩一下新游戏
|
||||
======
|
||||
|
||||
> 6 月 15 日,你可以在当地的游戏商家庆祝桌面角色扮演游戏并获得免费的 RPG 资料。
|
||||
|
||||

|
||||
|
||||
(LCTT 译注:“<ruby>免费 RPG 日<rt>Free RPG Day</rt></ruby>”是受“<ruby>免费漫画书日<rt>Free Comic Book Day</rt></ruby>”启发而发起的庆祝活动,从 2007 年开始已经举办多次。这里的 RPG 游戏并非我们通常所指的电脑 RPG 游戏,而是指使用纸和笔的桌面游戏,是一种西方传统游戏形式。)
|
||||
|
||||
你有没有想过尝试一下《<ruby>龙与地下城<rt>Dungeons & Dragons</rt></ruby>》,但不知道如何开始?你是否在年轻时玩过《<ruby>开拓者<rt>Pathfinder</rt></ruby>》并一直在考虑重返快乐时光?你是否对角色扮演游戏(RPG)感到好奇,但不确定你是否想玩一个?你是否对桌面游戏的概念完全陌生,直到现在才听说过这种 RPG 游戏?无论是哪一个并不重要,因为[免费 RPG 日] [2]适合所有人!
|
||||
|
||||
第一个免费 RPG 日活动发生在 2007 年,是由世界各地的桌面游戏商家举办的。这个想法是以 0 美元的价格为新手和有经验的游戏玩家带来新的、独家的 RPG 快速入门规则和冒险体验。在这样的一天里,你可以走进当地的桌面游戏商家,得到一本小册子,其中包含桌面 RPG 的简单的初学者规则,你可以在商家里与那里的人或者回家与朋友一起玩。这本小册子是给你的,应该一直留着的。
|
||||
|
||||
这一活动如此的受欢迎,此后该传统一直延续至今。今年,免费 RPG 日定于 6 月 15 日星期六举行。
|
||||
|
||||
### 有什么收获?
|
||||
|
||||
显然,免费 RPG 日背后的想法是让你沉迷于桌面 RPG 游戏。但在你本能的犬儒主义开始之前,考虑到它会慢慢上瘾,爱上一个鼓励你阅读规则和知识的游戏并不太糟,这样你和你的家人、朋友就有了共度时光的借口了。桌面 RPG 是一个功能强大、富有想象力和有趣的媒介,而免费 RPG 日则是对这种游戏很好的介绍。
|
||||
|
||||
![FreeRPG Day logo][3]
|
||||
|
||||
### 开源游戏
|
||||
|
||||
像许多其他行业一样,开源现象影响了桌面游戏。回到世纪之交,《Magic:The Gathering and Dungeons&Dragons》 的提供者<ruby>[威世智公司][4]<rt>Wizards of the Coast</rt></ruby>决定通过开发<ruby>[开源游戏许可证][5]<rt>Open Game License</rt></ruby>(OGL)来采用开源方法。他们将此许可证用于世界上第一个 RPG(《<ruby>龙与地下城<rt>Dungeons & Dragons</rt></ruby>》,D&D)的版本 3 和 3.5。几年后,当他们在第四版上(对开源)产生了动摇时,《<ruby>龙<rt>Dragon</rt></ruby>》杂志的出版商复刻了 D&D 3.5 的“代码”,将其混制版本发布为《<ruby>开拓者<rt>Pathfinder</rt></ruby>》 RPG,从而保持了创新和整个第三方游戏开发者产业的健康发展。最近,威世智公司在 D&D 5e 版本中才又重回了 OGL。
|
||||
|
||||
OGL 允许开发人员至少可以在他们自己产品中使用该游戏的机制。不管你可以不可以使用自定义怪物、武器、王国或流行角色的名称,但你可以随时使用 OGL 游戏的规则和数学计算。事实上,OGL 游戏的规则通常作为[系统参考文档][6](SRD)免费发布的,因此,无论你是否购买了规则书的副本,你都可以了解游戏的玩法。
|
||||
|
||||
如果你之前从未玩过桌面 RPG,那么使用笔和纸玩的游戏也可以拥有游戏引擎似乎很奇怪,但计算就是计算,不管是数字的还是模拟的。作为一个简单的例子:假设游戏引擎规定玩家角色有一个代表其力量的数字。当那个玩家角色与一个有其两倍力量的巨人战斗时,在玩家掷骰子以增加她的角色的力量攻击时,真的会感到紧张。如果没有掷出一个很好的点数的话,她的力量将无法与巨人相匹敌。知道了这一点,第三方或独立开发者就可以为这个游戏引擎设计一个怪物,同时了解骰子滚动可能对玩家的能力得分产生的影响。这意味着他们可以根据游戏引擎的优先级进行数学计算。他们可以设计一系列用来杀死的怪物,在游戏引擎的环境中它们具有有意义的能力和技能,并且他们可以宣称与该引擎的兼容性。
|
||||
|
||||
此外,OGL 允许出版商为其材料定义产品标识。产品标识可以是出版物的商业外观(图形元素和布局)、徽标、术语、传说、专有名称等。未经出版商同意,任何定义为产品标识的内容都可能**无法**重复使用。例如,假设一个出版商发行了一本武器手册,其中包括一个名为 Sigint 的魔法砍刀,它对所有针对僵尸的攻击都给予 +2 魔法附加攻击值。这个特性来自一个故事,该砍刀是一个具有潜伏的僵尸基因的科学家锻造的。但是,该出版物在 OGL 第 1e 节中列出的所有武器的正确名称都被保留为产品标识。这意味着你可以在自己的出版物中使用该数字(武器的持久性、它所造成的伤害,+2 魔法奖励等等)以及与该武器相关的传说(它由一个潜伏的僵尸锻造),但是你不能使用该武器的名称(Sigint)。
|
||||
|
||||
OGL 是一个非常灵活的许可证,因此开发人员必须仔细阅读其第 1e 节。 一些出版商只保留出版物本身的布局,而其他出版商保留除数字和最通用术语之外的所有内容。
|
||||
|
||||
当卓越的 RPG 特许经营权拥抱开源时,至今仍能感受到的它给整个行业掀起的波澜。第三方开发人员可以为 5e 和《开拓者》系统创建内容。由威世智公司创建的整个 [DungeonMastersGuild.com][7] 网站为 D&D 5e 制作了独立内容,旨在促进独立出版。[Starfinder][8]、[OpenD6][9]、[战士,盗贼和法师][10]、[剑与巫师][11] 等及很多其它游戏都采用了 OGL。其他系统,如 Brent Newhall 的 《[Dungeon Delvers][12]》、《[Fate][13]》、《[Dungeon World][14]》 等等,都是根据[知识共享许可][15]授权的的。
|
||||
|
||||
### 获取你的 RPG
|
||||
|
||||
在免费 RPG 日,你可以前往当地游戏商铺,玩 RPG 以及获取与朋友将来一起玩的 RPG 游戏材料。就像<ruby>[Linux 安装节][16]<rt>Linux installfest</rt></ruby> 或 <ruby>[软件自由日][17]<rt>Software Freedom Day</rt></ruby>一样,该活动的定义很松散。每个商家举办的自由 RPG 日都有所不同,每个商家都可以玩他们选择的任何游戏。但是,游戏发行商捐赠的免费内容每年都是相同的。显然,免费的东西视情况而定,但是当你参加免费 RPG 日活动时,请注意有多少游戏采用了开源许可证(如果是 OGL 游戏,OGL 会打印在书背面)。《开拓者》、《Starfinder》 和 D&D 的任何内容肯定都会带有 OGL 的一些优势。许多其他系统的内容使用知识共享许可。有些则像 90 年代复活的 [Dead Earth][18] RPG 一样,使用 [GNU 自由文档许可证] [19]。
|
||||
|
||||
有大量的游戏资源是通过开源许可证开发的。你可能需要也可能不需要关心游戏的许可证;毕竟,许可证与你是否可以与朋友一起玩无关。但是如果你喜欢支持[自由文化][20]而不仅仅是你运行的软件,那么试试一些 OGL 或知识共享游戏吧。如果你不熟悉游戏,请在免费 RPG 日在当地游戏商家试玩桌面 RPG 游戏!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/5/free-rpg-day
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth/users/erez/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/team-game-play-inclusive-diversity-collaboration.png?itok=8sUXV7W1 (plastic game pieces on a board)
|
||||
[2]: https://www.freerpgday.com/
|
||||
[3]: https://opensource.com/sites/default/files/uploads/freerpgday-logoblank.jpg (FreeRPG Day logo)
|
||||
[4]: https://company.wizards.com/
|
||||
[5]: http://www.opengamingfoundation.org/licenses.html
|
||||
[6]: https://www.d20pfsrd.com/
|
||||
[7]: https://www.dmsguild.com/
|
||||
[8]: https://paizo.com/starfinder
|
||||
[9]: https://ogc.rpglibrary.org/index.php?title=OpenD6
|
||||
[10]: http://www.stargazergames.eu/games/warrior-rogue-mage/
|
||||
[11]: https://froggodgames.com/frogs/product/swords-wizardry-complete-rulebook/
|
||||
[12]: http://brentnewhall.com/games/doku.php?id=games:dungeon_delvers
|
||||
[13]: http://www.faterpg.com/licensing/licensing-fate-cc-by/
|
||||
[14]: http://dungeon-world.com/
|
||||
[15]: https://creativecommons.org/
|
||||
[16]: https://www.tldp.org/HOWTO/Installfest-HOWTO/introduction.html
|
||||
[17]: https://www.softwarefreedomday.org/
|
||||
[18]: https://mixedsignals.ml/games/blog/blog_dead-earth
|
||||
[19]: https://www.gnu.org/licenses/fdl-1.3.en.html
|
||||
[20]: https://opensource.com/article/18/1/creative-commons-real-world
|
||||
105
published/20190610 Welcoming Blockchain 3.0.md
Normal file
105
published/20190610 Welcoming Blockchain 3.0.md
Normal file
@ -0,0 +1,105 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (murphyzhao)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10987-1.html)
|
||||
[#]: subject: (Welcoming Blockchain 3.0)
|
||||
[#]: via: (https://www.ostechnix.com/welcoming-blockchain-3-0/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
迎接区块链 3.0
|
||||
======
|
||||
|
||||
![欢迎区块链 3.0][1]
|
||||
|
||||
“[区块链 2.0][2]” 系列文章讨论了自 2008 年比特币等加密货币问世以来区块链技术的发展。本文将探讨区块链的未来发展。**区块链 3.0** 这一新的 DLT(<ruby>分布式分类帐本技术<rt>Distributed Ledger Technology</rt></ruby>)演进浪潮将回答当前区块链所面临的问题(每一个问题都会在这里总结)。下一版本的技术标准也将带来全新的应用和使用案例。在本文的最后,我们也会看一些当前使用这些原则的案例。
|
||||
|
||||
以下是现有区块链平台的几个缺点,并针对这些缺点给出了建议的解决方案。
|
||||
|
||||
### 问题 1:可扩展性
|
||||
|
||||
这个问题 [^1]被视为普遍采用该技术的第一个主要障碍。正如之前所讨论的,很多因素限制了区块链同时处理大量交易的能力。诸如 [以太坊][3] 之类的现有网络每秒能够进行 10-15 次交易(TPS),而像 Visa 所使用的主流网络每秒能够进行超过 2000 次交易。**可扩展性**是困扰所有现代数据库系统的问题。正如我们在这里看到的那样,改进的共识算法和更好的区块链架构设计正在改进它。
|
||||
|
||||
#### 解决可扩展性
|
||||
|
||||
已经提出了更精简、更有效的一致性算法来解决可扩展性问题,并且不会影响区块链的主要结构。虽然大多数加密货币和区块链平台使用资源密集型的 PoW 算法(例如,比特币和以太坊)来生成区块,但是存在更新的 DPoS 和 PoET 算法来解决这个问题。DPoS 和 PoET 算法(还有一些正在开发中)需要更少的资源来维持区块链,并且已显示具有高达 1000 TPS 的吞吐量,可与流行的非区块链系统相媲美。
|
||||
|
||||
可扩展性问题的第二个解决方案是完全改变区块链结构和功能。我们不会详细介绍这一点,但已经提出了诸如<ruby>有向无环图<rt>Directed Acyclic Graph</rt></ruby>(DAG)之类的替代架构来处理这个问题。从本质上讲,这项工作假设并非所有网络节点都需要整个区块链的副本才能使区块链正常工作,或者并非所有的参与者需要从 DLT 系统获得好处。系统不要求所有参与者验证交易,只需要交易发生在共同的参考框架中并相互链接。
|
||||
|
||||
在比特币系统中使用<ruby>[闪电网络][11]<rt>Lightning network</rt></ruby>来实现 DAG,而以太坊使用他们的<ruby>[切片][12]<rt>Sharding</rt></ruby> 协议来实现 DAG。本质上,从技术上来看 DAG 实现并不是区块链。它更像是一个错综复杂的迷宫,只是仍然保留了区块链的点对点和分布式数据库属性。稍后我们将在另一篇文章中探讨 DAG 和 Tangle 网络。
|
||||
|
||||
### 问题 2:互通性
|
||||
|
||||
**互通性**[^4] [^5] 被称为跨链访问,基本上就是指不同区块链之间彼此相互通信以交换指标和信息。由于目前有数不清的众多平台,不同公司为各种应用提供了各种专有系统,平台之间的互操作性就至关重要。例如,目前在一个平台上拥有数字身份的人无法利用其他平台提供的功能,因为各个区块链彼此之间互不了解、不能沟通。这是由于缺乏可靠的验证、令牌交换等有关的问题仍然存在。如果平台之间不能够相互通信,面向全球推出[智能合约][4]也是不可行的。
|
||||
|
||||
#### 解决互通性
|
||||
|
||||
有一些协议和平台专为实现互操作性而设计。这些平台实现了原子交换协议,并向不同的区块链系统提供开放场景,以便在它们之间进行通信和交换信息。**“0x (ZRX)”** 就是其中的一个例子,稍后将对进行描述。
|
||||
|
||||
### 问题 3:治理
|
||||
|
||||
公有链中的治理 [^6] 本身不是限制,而是需要像社区道德指南针一样,在区块链的运作中考虑每个人的意见。结合起来并规模性地看,能预见这样一个问题,即要么协议更改太频繁,要么协议被拥有最多令牌的“中央”权威一时冲动下修改。不过这不是大多数公共区块链目前正在努力避免的问题,因为其运营规模和运营性质不需要更严格的监管。
|
||||
|
||||
#### 解决治理问题
|
||||
|
||||
上面提到的复杂的框架或 DAG 几乎可以消除对全球(平台范围)治理法规的需要和使用。相反,程序可以自动监督事务和用户类型,并决定需要执行的法律。
|
||||
|
||||
### 问题 4:可持续性
|
||||
|
||||
可持续性再次建立在可扩展性问题的基础上。当前的区块链和加密货币因不可长期持续而倍遭批评,这是由于仍然需要大量的监督,并且需要大量资源保持系统运行。如果你读过最近“挖掘加密货币”已经没有这么大利润的相关报道,你就知道“挖矿”图利就是它的本来面目。保持现有平台运行所需的资源量在全球范围和主流使用方面根本不实用。
|
||||
|
||||
#### 解决不可持续性问题
|
||||
|
||||
从资源或经济角度来看,可持续性的答案与可扩展性的答案类似。但是,要在全球范围内实施这一制度,法律和法规必须予以认可。然而,这取决于世界各国政府。来自美国和欧洲政府的有利举措重新燃起了对这方面的希望。
|
||||
|
||||
### 问题 5:用户采用
|
||||
|
||||
目前,阻止消费者广泛采用 [^7] 基于区块链的应用程序的一个障碍是消费者对平台及其底层的技术不熟悉。事实上,大多数应用程序都需要某种技术和计算背景来弄清楚它们是如何工作的,这在这方面也没有帮助。区块链开发的第三次浪潮旨在缩小消费者知识与平台可用性之间的差距。
|
||||
|
||||
#### 解决用户采用问题
|
||||
|
||||
互联网花了很长的时间才发展成现在的样子。多年来,人们在开发标准化互联网技术栈方面做了大量的工作,使 Web 能够像现在这样运作。开发人员正在开发面向用户的前端分布式应用程序,这些应用程序应作为现有 Web 3.0 技术之上的一层,同时由下面的区块链和开放协议的支持。这样的[分布式应用][5]将使用户更熟悉底层技术,从而增加主流采用。
|
||||
|
||||
### 在当前场景中的应用
|
||||
|
||||
我们已经从理论上讨论了上述问题的解决方法,现在我们将继续展示这些方法在当前场景中的应用。
|
||||
|
||||
- [0x][6] – 是一种去中心化的令牌交换,不同平台的用户可以在不需要中央权威机构审查的情况下交换令牌。他们的突破在于,他们如何设计系统使得仅在交易结算后才记录和审查数据块,而不是通常的在交易之间进行(为了验证上下文,通常也会验证交易之前的数据块)。这使在线数字资产交换更快速。
|
||||
- [Cardano][7] – 由以太坊的联合创始人之一创建,Cardano 自诩为一个真正“科学”的平台,和采用了严格的协议,对开发的代码和算法进行了多次审查。Cardano 的所有内容都在数学上尽可能的进行了优化。他们的共识算法叫做 **Ouroboros**,是一种改进的<ruby>权益证明<rt>Proof of Stake</rt></ruby>(PoS)算法。Cardano 是用 [**haskell**][8] 开发的,智能合约引擎使用 haskell 的衍生工具 **plutus** 进行操作。这两者都是函数式编程语言,可以保证安全交易而不会影响效率。
|
||||
- EOS – 我们已经在 [这篇文章][9] 中描述了 EOS。
|
||||
- [COTI][10] – 一个鲜为人知的架构,COTI 不需要挖矿,而且在运行过程中趋近于零功耗。它还将资产存储在本地用户设备上的离线钱包中,而不是存储在纯粹的对等网络上。它们也遵循基于 DAG 的架构,并声称处理吞吐量高达 10000 TPS。他们的平台允许企业在不利用区块链的情况下建立自己的加密货币和数字化货币钱包。
|
||||
|
||||
[^1]: A. P. Paper, K. Croman, C. Decker, I. Eyal, A. E. Gencer, and A. Juels, “On Scaling Decentralized Blockchains | SpringerLink,” 2018.
|
||||
[^4]: [Why is blockchain interoperability important][13]
|
||||
[^5]: [The Importance of Blockchain Interoperability][14]
|
||||
[^6]: R. Beck, C. Müller-Bloch, and J. L. King, “Governance in the Blockchain Economy: A Framework and Research Agenda,” J. Assoc. Inf. Syst., pp. 1020–1034, 2018.
|
||||
[^7]: J. M. Woodside, F. K. A. Jr, W. Giberson, F. K. J. Augustine, and W. Giberson, “Blockchain Technology Adoption Status and Strategies,” J. Int. Technol. Inf. Manag., vol. 26, no. 2, pp. 65–93, 2017.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/welcoming-blockchain-3-0/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[murphyzhao](https://github.com/murphyzhao)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/06/blockchain-720x340.jpg
|
||||
[2]: https://linux.cn/article-10650-1.html
|
||||
[3]: https://www.ostechnix.com/blockchain-2-0-what-is-ethereum/
|
||||
[4]: https://www.ostechnix.com/blockchain-2-0-explaining-smart-contracts-and-its-types/
|
||||
[5]: https://www.ostechnix.com/blockchain-2-0-explaining-distributed-computing-and-distributed-applications/
|
||||
[6]: https://0x.org/
|
||||
[7]: https://www.cardano.org/en/home/
|
||||
[8]: https://www.ostechnix.com/getting-started-haskell-programming-language/
|
||||
[9]: https://www.ostechnix.com/blockchain-2-0-eos-io-is-building-infrastructure-for-developing-dapps/
|
||||
[10]: https://coti.io/
|
||||
[11]: https://cryptoslate.com/beyond-blockchain-directed-acylic-graphs-dag/
|
||||
[12]: https://github.com/ethereum/wiki/wiki/Sharding-FAQ#introduction
|
||||
[13]: https://www.capgemini.com/2019/02/can-the-interoperability-of-blockchains-change-the-world/
|
||||
[14]: https://medium.com/wanchain-foundation/the-importance-of-blockchain-interoperability-b6a0bbd06d11
|
||||
@ -0,0 +1,119 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (robsean)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10995-1.html)
|
||||
[#]: subject: (Ubuntu Kylin: The Official Chinese Version of Ubuntu)
|
||||
[#]: via: (https://itsfoss.com/ubuntu-kylin/)
|
||||
[#]: author: (Avimanyu Bandyopadhyay https://itsfoss.com/author/avimanyu/)
|
||||
|
||||
优麒麟:Ubuntu 的官方中文版本
|
||||
======
|
||||
|
||||
> 让我们来看看国外是如何看优麒麟的。
|
||||
|
||||
[Ubuntu 有几个官方特色版本][1],优麒麟(Ubuntu Kylin)是它们中的一个。在这篇文章中,你将了解到优麒麟,它是什么,它为什么被创建,它的特色是什么。
|
||||
|
||||
麒麟操作系统最初由中华人民共和国的[国防科技大学][2]的院士在 2001 年开发。名字来源于[麒麟][3],这是一种来自中国神话的神兽。
|
||||
|
||||
麒麟操作系统的第一个版本基于 [FreeBSD][4],计划用于中国军方和其它政府组织。麒麟 3.0 完全基于 Linux 内核,并且在 2010 年 12 月发布一个称为 [NeoKylin][5] 的版本。
|
||||
|
||||
在 2013 年,[Canonical][6] (Ubuntu 的母公司) 与中华人民共和国的[工业和信息化部][7] 达成共识,共同创建和发布一个针对中国市场特色的基于 Ubuntu 的操作系统。
|
||||
|
||||
![Ubuntu Kylin][8]
|
||||
|
||||
### 优麒麟是什么?
|
||||
|
||||
根据上述 2013 年的共识,优麒麟现在是 Ubuntu 的官方中国版本。它不仅仅是语言本地化。事实上,它决心服务中国市场,就像 Ubuntu 服务全球市场一样。
|
||||
|
||||
[优麒麟][9]的第一个版本与 Ubuntu 13.04 一起到来。像 Ubuntu 一样,优麒麟也有 LTS (长期支持)和非 LTS 版本。
|
||||
|
||||
当前,优麒麟 19.04 LTS 采用了 [UKUI][10] 桌面环境,修改了启动动画、登录/锁屏程序和操作系统主题。为给用户提供更友好的体验,它修复了一些错误,带有文件预览、定时注销等功能,最新的 [WPS 办公组件][11]和 [搜狗][12] 输入法集成于其中。
|
||||
|
||||
- [https://youtu.be/kZPtFMWsyv4](https://youtu.be/kZPtFMWsyv4)
|
||||
|
||||
银河麒麟 4.0.2 是一个基于优麒麟 16.04 LTS 的社区版本。它包含一些带有长期稳定支持的第三方应用程序。它非常适合服务器和日常桌面办公使用,欢迎开发者[下载][13]。麒麟论坛积极地获取来自提供的反馈以及解决问题来找到解决方案。
|
||||
|
||||
#### UKUI:优麒麟的桌面环境
|
||||
|
||||
![Ubuntu Kylin 19.04 with UKUI Desktop][15]
|
||||
|
||||
[UKUI][16] 由优麒麟开发小组设计和开发,有一些非常好的特色和预装软件:
|
||||
|
||||
* 类似 Windows 的交互功能,带来更友好的用户体验。安装导向易于使用,用户可以快速使用优麒麟。
|
||||
* 控制中心对主题和窗口采用了新的设置。如开始菜单、任务栏、文件管理器、窗口管理器和其它的组件进行了更新。
|
||||
* 在 Ubuntu 和 Debian 存储库上都可用,为 Debian/Ubuntu 发行版和其全球衍生版的的用户提供一个新单独桌面环境。
|
||||
* 新的登录和锁定程序,它更稳定和具有很多功能。
|
||||
* 包括一个反馈问题的实用的反馈程序。
|
||||
|
||||
#### 麒麟软件中心
|
||||
|
||||
![Kylin Software Center][17]
|
||||
|
||||
麒麟有一个软件中心,类似于 Ubuntu 软件中心,并被称为优麒麟软件中心。它是优麒麟软件商店的一部分,该商店也包含优麒麟开发者平台和优麒麟存储库,具有一个简单的用户界面,并功能强大。它同时支持 Ubuntu 和优麒麟存储库,并特别适用于由优麒麟小组开发的中文特有的软件的快速安装!
|
||||
|
||||
#### 优客:一系列的工具
|
||||
|
||||
优麒麟也有一系列被命名为优客的工具。在麒麟开始菜单中输入 “Youker” 将带来麒麟助手。如果你在键盘上按 “Windows” 按键,像你在 Windows 上一样,它将打开麒麟开始菜单。
|
||||
|
||||
![Kylin Assistant][18]
|
||||
|
||||
其它麒麟品牌的应用程序包括麒麟影音(播放器)、麒麟刻录,优客天气、优客 Fcitx 输入法,它们更好地支持办公工作和个人娱乐。
|
||||
|
||||
![Kylin Video][19]
|
||||
|
||||
#### 特别专注于中文
|
||||
|
||||
通过与金山软件合作,优麒麟开发者也致力于 Linux 版本的搜狗拼音输入法、快盘和优麒麟版本的金山 WPS,并解决了智能拼音、云存储和办公应用程序方面的问题。[拼音][20] 是中文字符的拉丁化系统。使用这个系统,用户用英文键盘输入,但在屏幕上将显示中文字符。
|
||||
|
||||
#### 有趣的事实:优麒麟运行在中国超级计算机上
|
||||
|
||||
![Tianhe-2 Supercomputer. Photo by O01326 – Own work, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=45399546][22]
|
||||
|
||||
众所周知[世界上最快的超级计算机 500 强都在运行 Linux][23]。中国超级计算机[天河-1][24]和[天河-2][25]都使用优麒麟的 64 位版本,致力于高性能的[并行计算][26]优化、电源管理和高性能的[虚拟化计算][27]。
|
||||
|
||||
### 总结
|
||||
|
||||
我希望你喜欢这篇优麒麟世界的介绍。你可以从它的[官方网站][28]获得优麒麟 19.04 或基于 Ubuntu 16.04 的社区版本(银河麒麟)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/ubuntu-kylin/
|
||||
|
||||
作者:[Avimanyu Bandyopadhyay][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/avimanyu/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/which-ubuntu-install/
|
||||
[2]: https://english.nudt.edu.cn
|
||||
[3]: https://www.thoughtco.com/what-is-a-qilin-195005
|
||||
[4]: https://itsfoss.com/freebsd-12-release/
|
||||
[5]: https://thehackernews.com/2015/09/neokylin-china-linux-os.html
|
||||
[6]: https://www.canonical.com/
|
||||
[7]: http://english.gov.cn/state_council/2014/08/23/content_281474983035940.htm
|
||||
[8]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/06/Ubuntu-Kylin.jpeg?resize=800%2C450&ssl=1
|
||||
[9]: http://www.ubuntukylin.com/
|
||||
[10]: http://ukui.org
|
||||
[11]: https://www.wps.com/
|
||||
[12]: https://en.wikipedia.org/wiki/Sogou_Pinyin
|
||||
[13]: http://www.ubuntukylin.com/downloads/show.php?lang=en&id=122
|
||||
[14]: https://itsfoss.com/solve-ubuntu-error-failed-to-download-repository-information-check-your-internet-connection/
|
||||
[15]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/06/ubuntu-Kylin-19-04-desktop.jpg?resize=800%2C450&ssl=1
|
||||
[16]: http://www.ukui.org/
|
||||
[17]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/06/kylin-software-center.jpg?resize=800%2C496&ssl=1
|
||||
[18]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/06/kylin-assistant.jpg?resize=800%2C535&ssl=1
|
||||
[19]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/06/kylin-video.jpg?resize=800%2C533&ssl=1
|
||||
[20]: https://en.wikipedia.org/wiki/Pinyin
|
||||
[21]: https://itsfoss.com/remove-old-kernels-ubuntu/
|
||||
[22]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/06/tianhe-2.jpg?resize=800%2C600&ssl=1
|
||||
[23]: https://itsfoss.com/linux-runs-top-supercomputers/
|
||||
[24]: https://en.wikipedia.org/wiki/Tianhe-1
|
||||
[25]: https://en.wikipedia.org/wiki/Tianhe-2
|
||||
[26]: https://en.wikipedia.org/wiki/Parallel_computing
|
||||
[27]: https://computer.howstuffworks.com/how-virtual-computing-works.htm
|
||||
[28]: http://www.ubuntukylin.com
|
||||
@ -10,7 +10,7 @@ export TSL_DIR='translated' # 已翻译
|
||||
export PUB_DIR='published' # 已发布
|
||||
|
||||
# 定义匹配规则
|
||||
export CATE_PATTERN='(talk|tech)' # 类别
|
||||
export CATE_PATTERN='(talk|tech|news)' # 类别
|
||||
export FILE_PATTERN='[0-9]{8} [a-zA-Z0-9_.,() -]*\.md' # 文件名
|
||||
|
||||
# 获取用于匹配操作的正则表达式
|
||||
|
||||
@ -0,0 +1,106 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (hopefully2333)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Cisco to buy IoT security, management firm Sentryo)
|
||||
[#]: via: (https://www.networkworld.com/article/3400847/cisco-to-buy-iot-security-management-firm-sentryo.html)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
Cisco to buy IoT security, management firm Sentryo
|
||||
======
|
||||
Buying Sentryo will give Cisco support for anomaly and real-time threat detection for the industrial internet of things.
|
||||
![IDG Worldwide][1]
|
||||
|
||||
Looking to expand its IoT security and management offerings Cisco plans to acquire [Sentryo][2], a company based in France that offers anomaly detection and real-time threat detection for Industrial Internet of Things ([IIoT][3]) networks.
|
||||
|
||||
Founded in 2014 Sentryo products include ICS CyberVision – an asset inventory, network monitoring and threat intelligence platform – and CyberVision network edge sensors, which analyze network flows.
|
||||
|
||||
**More on IoT:**
|
||||
|
||||
* [What is the IoT? How the internet of things works][4]
|
||||
* [What is edge computing and how it’s changing the network][5]
|
||||
* [Most powerful Internet of Things companies][6]
|
||||
* [10 Hot IoT startups to watch][7]
|
||||
* [The 6 ways to make money in IoT][8]
|
||||
* [What is digital twin technology? [and why it matters]][9]
|
||||
* [Blockchain, service-centric networking key to IoT success][10]
|
||||
* [Getting grounded in IoT networking and security][11]
|
||||
* [Building IoT-ready networks must become a priority][12]
|
||||
* [What is the Industrial IoT? [And why the stakes are so high]][13]
|
||||
|
||||
|
||||
|
||||
“We have incorporated Sentryo’s edge sensor and our industrial networking hardware with Cisco’s IOx application framework,” wrote Rob Salvagno, Cisco vice president of Corporate Development and Cisco Investments in a [blog][14] about the proposed buy.
|
||||
|
||||
“We believe that connectivity is foundational to IoT projects and by unleashing the power of the network we can dramatically improve operational efficiencies and uncover new business opportunities. With the addition of Sentryo, Cisco can offer control systems engineers deeper visibility into assets to optimize, detect anomalies and secure their networks.”
|
||||
|
||||
Gartner [wrote][15] of Sentryo’s system: “ICS CyberVision product provides visibility into its customers'' OT networks in way all OT users will understand, not just technical IT staff. With the increased focus of both hackers and regulators on industrial control systems, it is vital to have the right visibility of an organization’s OT. Many OT networks not only are geographically dispersed, but also are complex and consist of hundreds of thousands of components.”
|
||||
|
||||
Sentryo's ICS CyberVision lets enterprises ensure continuity, resilience and safety of their industrial operations while preventing possible cyberattacks, said [Nandini Natarajan][16] , industry analyst at Frost & Sullivan. "It automatically profiles assets and communication flows using a unique 'universal OT language' in the form of tags, which describe in plain text what each asset is doing. ICS CyberVision gives anyone immediate insights into an asset's role and behaviors; it offers many different analytic views leveraging artificial intelligence algorithms to let users deep-dive into the vast amount of data a typical industrial control system can generate. Sentryo makes it easy to see important or relevant information."
|
||||
|
||||
In addition, Sentryo's platform uses deep packet inspection (DPI) to extract information from communications among industrial assets, Natarajan said. This DPI engine is deployed through an edge-computing architecture that can run either on Sentryo sensor appliances or on network equipment that is already installed. Thus, Sentryo can embed visibility and cybersecurity features in the industrial network rather than deploying an out-of-band monitoring network, Natarajan said.
|
||||
|
||||
**[[Prepare to become a Certified Information Security Systems Professional with this comprehensive online course from PluralSight. Now offering a 10-day free trial!][17] ]**
|
||||
|
||||
Sentryo’s technology will broaden [Cisco’s][18] overarching IoT plan. In January it [launched][19] a family of switches, software, developer tools and blueprints to meld IoT and industrial networking with [intent-based networking][20] (IBN) and classic IT security, monitoring and application-development support.
|
||||
|
||||
The new platforms can be managed by Cisco’s DNA Center, and Cisco IoT Field Network Director, letting customers fuse their IoT and industrial-network control with their business IT world.
|
||||
|
||||
DNA Center is Cisco’s central management tool for enterprise networks, featuring automation capabilities, assurance setting, fabric provisioning and policy-based segmentation. It is also at the center of the company’s IBN initiative offering customers the ability to automatically implement network and policy changes on the fly and ensure data delivery. The IoT Field Network Director is software that manages multiservice networks of Cisco industrial, connected grid routers and endpoints.
|
||||
|
||||
Liz Centoni, senior vice president and general manager of Cisco's IoT business group said the company expects the [Sentryo technology to help][21] IoT customers in a number of ways:
|
||||
|
||||
Network-enabled, passive DPI capabilities to discover IoT and OT assets, and establish communication patterns between devices and systems. Sentryo’s sensor is natively deployable on Cisco’s IOx framework and can be built into the industrial network these devices run on instead of adding additional hardware.
|
||||
|
||||
As device identification and communication patterns are created, Cisco will integrate this with DNA Center and Identity Services Engine(ISE) to allow customers to easily define segmentation policy. This integration will allow OT teams to leverage IT security teams’ expertise to secure their environments without risk to the operational processes.
|
||||
|
||||
With these IoT devices lacking modern embedded software and security capabilities, segmentation will be the key technology to allow communication from operational assets to the rightful systems, and reduce risk of cyber security incidents like we saw with [WannaCry][22] and [Norsk Hydro][23].
|
||||
|
||||
According to [Crunchbase][24], Sentryo has $3.5M in estimated revenue annually and it competes most closely with Cymmetria, Team8, and Indegy. The acquisition is expected to close before the end of Cisco’s Q1 Fiscal Year 2020 -- October 26, 2019. Financial details of the acquisition were not detailed.
|
||||
|
||||
Sentryo is Cisco’s second acquisition this year. It bought Singularity for its network analytics technology in January. In 2018 Cisco bought six companies including Duo security software.
|
||||
|
||||
** **
|
||||
|
||||
Join the Network World communities on [Facebook][25] and [LinkedIn][26] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3400847/cisco-to-buy-iot-security-management-firm-sentryo.html
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/09/nwan_019_iiot-100771131-large.jpg
|
||||
[2]: https://www.sentryo.net/
|
||||
[3]: https://www.networkworld.com/article/3243928/what-is-the-industrial-iot-and-why-the-stakes-are-so-high.html
|
||||
[4]: https://www.networkworld.com/article/3207535/internet-of-things/what-is-the-iot-how-the-internet-of-things-works.html
|
||||
[5]: https://www.networkworld.com/article/3224893/internet-of-things/what-is-edge-computing-and-how-it-s-changing-the-network.html
|
||||
[6]: https://www.networkworld.com/article/2287045/internet-of-things/wireless-153629-10-most-powerful-internet-of-things-companies.html
|
||||
[7]: https://www.networkworld.com/article/3270961/internet-of-things/10-hot-iot-startups-to-watch.html
|
||||
[8]: https://www.networkworld.com/article/3279346/internet-of-things/the-6-ways-to-make-money-in-iot.html
|
||||
[9]: https://www.networkworld.com/article/3280225/internet-of-things/what-is-digital-twin-technology-and-why-it-matters.html
|
||||
[10]: https://www.networkworld.com/article/3276313/internet-of-things/blockchain-service-centric-networking-key-to-iot-success.html
|
||||
[11]: https://www.networkworld.com/article/3269736/internet-of-things/getting-grounded-in-iot-networking-and-security.html
|
||||
[12]: https://www.networkworld.com/article/3276304/internet-of-things/building-iot-ready-networks-must-become-a-priority.html
|
||||
[13]: https://www.networkworld.com/article/3243928/internet-of-things/what-is-the-industrial-iot-and-why-the-stakes-are-so-high.html
|
||||
[14]: https://blogs.cisco.com/news/cisco-industrial-iot-news
|
||||
[15]: https://www.globenewswire.com/news-release/2018/06/28/1531119/0/en/Sentryo-Named-a-Cool-Vendor-by-Gartner.html
|
||||
[16]: https://www.linkedin.com/pulse/industrial-internet-things-iiot-decoded-nandini-natarajan/
|
||||
[17]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
|
||||
[18]: https://www.cisco.com/c/dam/en_us/solutions/iot/ihs-report.pdf
|
||||
[19]: https://www.networkworld.com/article/3336454/cisco-goes-after-industrial-iot.html
|
||||
[20]: https://www.networkworld.com/article/3202699/what-is-intent-based-networking.html
|
||||
[21]: https://blogs.cisco.com/news/securing-the-internet-of-things-cisco-announces-intent-to-acquire-sentryo
|
||||
[22]: https://blogs.cisco.com/security/talos/wannacry
|
||||
[23]: https://www.securityweek.com/norsk-hydro-may-have-lost-40m-first-week-after-cyberattack
|
||||
[24]: https://www.crunchbase.com/organization/sentryo#section-web-traffic-by-similarweb
|
||||
[25]: https://www.facebook.com/NetworkWorld/
|
||||
[26]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,116 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Zorin OS Becomes Even More Awesome With Zorin 15 Release)
|
||||
[#]: via: (https://itsfoss.com/zorin-os-15-release/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Zorin OS Becomes Even More Awesome With Zorin 15 Release
|
||||
======
|
||||
|
||||
Zorin OS has always been known as one of the [beginner-focused Linux distros][1] out there. Yes, it may not be the most popular – but it sure is a good distribution specially for Windows migrants.
|
||||
|
||||
A few years back, I remember, a friend of mine always insisted me to install [Zorin OS][2]. Personally, I didn’t like the UI back then. But, now that Zorin OS 15 is here – I have more reasons to get it installed as my primary OS.
|
||||
|
||||
Fret not, in this article, we’ll talk about everything that you need to know.
|
||||
|
||||
### New Features in Zorin 15
|
||||
|
||||
Let’s see the major changes in the latest release of Zorin. Zorin 15 is based on Ubuntu 18.04.2 and thus it brings the performance improvement under the hood. Other than that, there are several UI (User Interface) improvements.
|
||||
|
||||
#### Zorin Connect
|
||||
|
||||
![Zorin Connect][3]
|
||||
|
||||
Zorin OS 15’s main highlight is – Zorin Connect. If you have an Android device, you are in for a treat. Similar to [PushBullet][4], [Zorin Connect][5] integrates your phone with the desktop experience.
|
||||
|
||||
You get to sync your smartphone’s notifications on your desktop while also being able to reply to it. Heck, you can also reply to the SMS messages and view those conversations.
|
||||
|
||||
In addition to these, you get the following abilities:
|
||||
|
||||
* Share files and web links between devices
|
||||
* Use your phone as a remote control for your computer
|
||||
* Control media playback on your computer from your phone, and pause playback automatically when a phone call arrives
|
||||
|
||||
|
||||
|
||||
As mentioned in their [official announcement post][6], the data transmission will be on your local network and no data will be transmitted to the cloud. To access Zorin Connect, navigate your way through – Zorin menu > System Tools > Zorin Connect.
|
||||
|
||||
[Get ZORIN CONNECT ON PLAY STORE][5]
|
||||
|
||||
#### New Desktop Theme (with dark mode!)
|
||||
|
||||
![Zorin Dark Mode][7]
|
||||
|
||||
I’m all in when someone mentions “Dark Mode” or “Dark Theme”. For me, this is the best thing that comes baked in with Zorin OS 15.
|
||||
|
||||
[][8]
|
||||
|
||||
Suggested read Necuno is a New Open Source Smartphone Running KDE
|
||||
|
||||
It’s so pleasing to my eyes when I enable the dark mode on anything, you with me?
|
||||
|
||||
Not just a dark theme, the UI is a lot cleaner and intuitive with subtle new animations. You can find all the settings from the Zorin Appearance app built-in.
|
||||
|
||||
#### Adaptive Background & Night Light
|
||||
|
||||
You get an option to let the background adapt according to the brightness of the environment every hour of the day. Also, you can find the night mode if you don’t want the blue light to stress your eyes.
|
||||
|
||||
#### To do app
|
||||
|
||||
![Todo][9]
|
||||
|
||||
I always wanted this to happen so that I don’t have to use a separate service that offers a Linux client to add my tasks. It’s good to see a built-in app with integration support for Google Tasks and Todoist.
|
||||
|
||||
#### There’s More?
|
||||
|
||||
Yes! Other major changes include the support for Flatpak, a touch layout for convertible laptops, a DND mode, and some redesigned apps (Settings, Libre Office) to give you better user experience.
|
||||
|
||||
If you want the detailed list of changes along with the minor improvements, you can follow the [announcement post][6]. If you are already a Zorin user, you would notice that they have refreshed their website with a new look as well.
|
||||
|
||||
### Download Zorin OS 15
|
||||
|
||||
**Note** : _Direct upgrades from Zorin OS 12 to 15 – without needing to re-install the operating system – will be available later this year._
|
||||
|
||||
In case you didn’t know, there are three versions of Zorin OS – Ultimate, Core, and the Lite version.
|
||||
|
||||
If you want to support the devs and the project while unlocking the full potential of Zorin OS, you should get the ultimate edition for $39.
|
||||
|
||||
If you just want the essentials, the core edition will do just fine (which you can download for free). In either case, if you have an old computer, the lite version is the one to go with.
|
||||
|
||||
[DOWNLOAD ZORIN OS 15][10]
|
||||
|
||||
**What do you think of Zorin 15?**
|
||||
|
||||
[][11]
|
||||
|
||||
Suggested read Ubuntu 14.04 Codenamed Trusty Tahr
|
||||
|
||||
I’m definitely going to give it a try as my primary OS – fingers crossed. What about you? What do you think about the latest release? Feel free to let us know in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/zorin-os-15-release/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/best-linux-beginners/
|
||||
[2]: https://zorinos.com/
|
||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/06/zorin-connect.jpg?fit=800%2C473&ssl=1
|
||||
[4]: https://www.pushbullet.com/
|
||||
[5]: https://play.google.com/store/apps/details?id=com.zorinos.zorin_connect&hl=en_IN
|
||||
[6]: https://zoringroup.com/blog/2019/06/05/zorin-os-15-is-here-faster-easier-more-connected/
|
||||
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/06/zorin-dark-mode.jpg?fit=722%2C800&ssl=1
|
||||
[8]: https://itsfoss.com/necunos-linux-smartphone/
|
||||
[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/06/Todo.jpg?fit=800%2C652&ssl=1
|
||||
[10]: https://zorinos.com/download/
|
||||
[11]: https://itsfoss.com/ubuntu-1404-codenamed-trusty-tahr/
|
||||
@ -0,0 +1,85 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Free and Open Source Trello Alternative OpenProject 9 Released)
|
||||
[#]: via: (https://itsfoss.com/openproject-9-release/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Free and Open Source Trello Alternative OpenProject 9 Released
|
||||
======
|
||||
|
||||
[OpenProject][1] is a collaborative open source project management software. It’s an alternative to proprietary solutions like [Trello][2] and [Jira][3].
|
||||
|
||||
You can use it for free if it’s for personal use and you set it up (and host it) on your own server. This way, you control your data.
|
||||
|
||||
Of course, you get access to premium features and priority help if you are a [Cloud or Enterprise edition user][4].
|
||||
|
||||
The OpenProject 9 release emphasizes on new board views, package list view, and work templates.
|
||||
|
||||
If you didn’t know about this, you can give it a try. But, if you are an existing user – you should know what’s new before migrating to OpenProject 9.
|
||||
|
||||
### What’s New in OpenProject 9?
|
||||
|
||||
Here are some of the major changes in the latest release of OpenProject.
|
||||
|
||||
#### Scrum & Agile Boards
|
||||
|
||||
![][5]
|
||||
|
||||
For Cloud and Enterprise editions, there’s a new [scrum][6] and [agile][7] board view. You also get to showcase your work in a [kanban-style][8] fashion, making it easier to support your agile and scrum teams.
|
||||
|
||||
The new board view makes it easy to know who’s assigned for the task and update the status in a jiffy. You also get different board view options like basic board, status board, and version boards.
|
||||
|
||||
#### Work Package templates
|
||||
|
||||
![Work Package Template][9]
|
||||
|
||||
You don’t have to create everything from scratch for every unique work package. So, instead, you just keep a template – so that you can use it whenever you need to create a new work package. It will save a lot of time.
|
||||
|
||||
#### New Work Package list view
|
||||
|
||||
![Work Package View][10]
|
||||
|
||||
In the work package list, there’s a subtle new addition that lets you view the avatars of the assigned people for a specific work.
|
||||
|
||||
#### Customizable work package view for my page
|
||||
|
||||
Your own page to display what you are working on (and the progress) shouldn’t be always boring. So, now you get the ability to customize it and even add a Gantt chart to visualize your work.
|
||||
|
||||
[][11]
|
||||
|
||||
Suggested read Ubuntu 12.04 Has Reached End of Life
|
||||
|
||||
**Wrapping Up**
|
||||
|
||||
For detailed instructions on migrating and installation, you should follow the [official announcement post][12] covering all the essential details for the users.
|
||||
|
||||
Also, we would love to know about your experience with OpenProject 9, let us know about it in the comments section below! If you use some other project management software, feel free to suggest it to us and rest of your fellow It’s FOSS readers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/openproject-9-release/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.openproject.org/
|
||||
[2]: https://trello.com/
|
||||
[3]: https://www.atlassian.com/software/jira
|
||||
[4]: https://www.openproject.org/pricing/
|
||||
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/06/open-project-9-scrum-agile.jpeg?fit=800%2C517&ssl=1
|
||||
[6]: https://en.wikipedia.org/wiki/Scrum_(software_development)
|
||||
[7]: https://en.wikipedia.org/wiki/Agile_software_development
|
||||
[8]: https://en.wikipedia.org/wiki/Kanban
|
||||
[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/06/work-package-template.jpg?ssl=1
|
||||
[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/06/work-package-view.jpg?fit=800%2C454&ssl=1
|
||||
[11]: https://itsfoss.com/ubuntu-12-04-end-of-life/
|
||||
[12]: https://www.openproject.org/openproject-9-new-scrum-agile-board-view/
|
||||
@ -0,0 +1,199 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (An Ubuntu User’s Review Of Dell XPS 13 Ubuntu Edition)
|
||||
[#]: via: (https://itsfoss.com/dell-xps-13-ubuntu-review)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
An Ubuntu User’s Review Of Dell XPS 13 Ubuntu Edition
|
||||
======
|
||||
|
||||
_**Brief: Sharing my feel and experience about Dell XPS 13 Kaby Lake Ubuntu edition after using it for over three months.**_
|
||||
|
||||
During Black Friday sale last year, I took the bullet and ordered myself a [Dell XPS 13][1] with the new [Intel Kaby Lake processor][2]. It got delivered in the second week of December and if you [follow It’s FOSS on Facebook][3], you might have seen the [live unboxing][4].
|
||||
|
||||
Though I was tempted to do the review of Dell XPS 13 Ubuntu edition almost at the same time, I knew it won’t be fair. A brand new system will, of course, feel good and work smooth.
|
||||
|
||||
But that’s not the real experience. The real experience of any system comes after weeks, if not months, of use. That’s the reason I hold myself back and waited three months to review Dell XPS Kobylake Ubuntu edition.
|
||||
|
||||
### Dell XPS 13 Ubuntu Edition Review
|
||||
|
||||
Before we saw what’s hot and what’s not in the latest version of Dell XPS 13, I should tell you that I was using an Acer R13 ultrabook book before this. So I may compare the new Dell system with the older Acer one.
|
||||
|
||||
![Dell XPS 13 Ubuntu Edition System Settings][5]![Dell XPS 13 Ubuntu Edition System Settings][5]
|
||||
|
||||
Dell XPS 13 has several versions based on processor. The one I am reviewing is Dell XPS13 MLK (9360). It has i5-7200U 7th generation processor. Since I hardly used the touch screen in Acer Aspire R13, I chose to go with the non-touch version of XPS. This decision also saved me a couple of hundreds of Euro.
|
||||
|
||||
It has 8 GB of LPDDR3 1866MHz RAM and 256 GB SSD PCIe. Graphics is Intel HD. On connectivity side, it’s got Killer 1535 Wi-Fi 802.11ac 2×2 and Bluetooth 4.1. Screen is InfinityEdge Full HD (1 920 x 1080).
|
||||
|
||||
Now, you know what kind of hardware we’ve got here, let’s see what works and what sucks.
|
||||
|
||||
#### Look and feel
|
||||
|
||||
![Dell XPS 13 Kaby Lake Ubuntu Edition][6]![Dell XPS 13 Kaby Lake Ubuntu Edition][6]
|
||||
|
||||
At 13.3″, Dell XPS 13 looks even smaller than a regular 13.3″ laptop, thanks to its non-existent bezel which is the specialty of the infinite display. It is light as a feather with weight just under 1.23 Kg.
|
||||
|
||||
The outer surface is metallic, not very shiny but a decent aluminum look. On the interior, the palm rest is made of carbon fiber which is very comfortable at the rest. Unlike the MacBook Air that uses metallic palm rests, the carbon fiber ones are more friendly, especially in winters.
|
||||
|
||||
It is almost centimeter and a half high at it’s thickest part (around hinges). This also adds a plus point to the elegance of XPS 13.
|
||||
|
||||
Overall, Dell XPS 13 has a compact body and an elegant body.
|
||||
|
||||
#### Keyboard and touchpad
|
||||
|
||||
The keyboard and touchpad mix well with the carbon fiber interiors. The keys are smooth with springs in the back (perhaps) and give a rich feel while typing. All of the important keys are present and are not tiny in size, something you might be worried of, considering the overall tiny size of XPS13.
|
||||
|
||||
Oh! the keyboards have backlit support. Which adds to the rich feel of this expensive laptop.
|
||||
|
||||
While the keyboard is a great experience, the same cannot be said about the touchpad. In fact, the touchpad is the weakest part which mars the overall good experience of XPS 13.
|
||||
|
||||
The touchpad has a cheap feeling because it makes an irritating sound while tapping on the right side as if it’s hollow underneath. This is [something that has been noticed in the earlier versions of XPS 13][7] but hasn’t been given enough consideration to fix it. This is something you do not expect from a product at such a price.
|
||||
|
||||
Also, the touchpad scroll on websites is hideous. It is also not suitable for pixel works because of difficulty in moving little adjustments.
|
||||
|
||||
#### Ports
|
||||
|
||||
Dell XPS 13 has two USB 3.0 ports, one of them with PowerShare. If you did not know, [USB 3.0 PowerShare][8] ports allow you to charge external devices even when your system is turned off.
|
||||
|
||||
![Dell XPS 13 Kaby Lake Ubuntu edition ports][9]![Dell XPS 13 Kaby Lake Ubuntu edition ports][9]
|
||||
|
||||
It also has a [Thunderbolt][10] (doubles up as [USB Type-C port][11]). It doesn’t have HDMI port, Ethernet port or VGA port. However, all of these three can be used via the Thunderbolt port and external adapters (sold separately).
|
||||
|
||||
![Dell XPS 13 Kaby Lake Ubuntu edition ports][12]![Dell XPS 13 Kaby Lake Ubuntu edition ports][12]
|
||||
|
||||
It also has an SD card reader and a headphone jack. In addition to all these, there is an [anti-theft slot][13] (a common security practice in enterprises).
|
||||
|
||||
#### Display
|
||||
|
||||
The model I have packs 1920x1080px. It’s full HD and display quality is at par. It perfectly displays the high definition pictures and 1080p video files.
|
||||
|
||||
I cannot compare it with the [qHD model][14] as I never used it. But considering that there are not enough 4K contents for now, full HD display should be sufficient for next few years.
|
||||
|
||||
#### Sound
|
||||
|
||||
Compared to Acer R13, XPS 13 has better audio quality. Even the max volume is louder than that of Acer R13. The dual speakers give a nice stereo effect.
|
||||
|
||||
#### Webcam
|
||||
|
||||
The weirdest part of Dell XPS 13 review comes now. We all have been accustomed of seeing the webcam at the top-middle position on any laptop. But this is not the case here.
|
||||
|
||||
XPS 13 puts the webcam on the bottom left corner of the laptop. This is done to keep the bezel as thin as possible. But this creates a problem.
|
||||
|
||||
![Image captured with laptop screen at 90 degree][15]
|
||||
|
||||
When you video chat with someone, it is natural to look straight up. With the top-middle webcam, your face is in direct line with the camera. But with the bottom left position of web cam, it looks like those weird accidental selfies you take with the front camera of your smartphone. Heck, people on the other side might see inside of your nostrils.
|
||||
|
||||
#### Battery
|
||||
|
||||
Battery life is the strongest point of Dell XPS 13. While Dell claims an astounding 21-hour battery life, but in my experience, it smoothly gives a battery life of 8-10 hours. This is when I watch movies, browse the internet and other regular stuff.
|
||||
|
||||
There is one strange thing that I noticed, though. It charges pretty quick until 90% but the charging slows down afterward. And it almost never goes beyond 98%.
|
||||
|
||||
The battery indicator turns red when the battery status falls below 30% and it starts displaying notifications if the battery goes below 10%. There is small light indicator under the touchpad that turns yellow when the battery is low and it turns white when the charger is plugged in.
|
||||
|
||||
#### Overheating
|
||||
|
||||
I have previously written about ways to [reduce laptop overheating in Linux][16]. Thankfully, so far, I didn’t need to employ those tricks.
|
||||
|
||||
Dell XPS 13 remains surprisingly cool when you are using it on battery, even in long runs. The bottom does get heated a little when you use it while charging.
|
||||
|
||||
Overall, XPS 13 manages overheating very well.
|
||||
|
||||
#### The Ubuntu experience with Dell XPS 13
|
||||
|
||||
So far we have seen pretty generic things about the Dell XPS 13. Let’s talk about how good a Linux laptop it is.
|
||||
|
||||
Until now, I used to manually [install Linux on Windows laptop][17]. This is the first Linux laptop I ever bought. I would also like to mention the awesome first boot animation of Dell’s Ubuntu laptop. Here’s a YouTube video of the same:
|
||||
|
||||
One thing I would like to mention here is that Dell never displays Ubuntu laptops on its website. You’ll have to search the website with Ubuntu then you’ll see the Ubuntu editions. Also, Ubuntu edition is cheaper just by 50 Euro in comparison to its Windows counterpart whereas I was expecting it to be at least 100 Euro less than that of Windows.
|
||||
|
||||
Despite being an Ubuntu preloaded laptop, the super key still comes with Windows logo on it. It’s trivial but I would have loved to see the Ubuntu logo on it.
|
||||
|
||||
Now talking about Ubuntu experience, the first thing I noticed was that there was no hardware issue. Even the function and media keys work perfectly in Ubuntu, which is a pleasant surprise.
|
||||
|
||||
Dell has also added its own repository in the software sources to provide for some Dell specific tools. You can see the footprints of Dell in the entire system.
|
||||
|
||||
You might be interested to see how Dell partitioned the 256Gb of disk space. Let me show that to you.
|
||||
|
||||
![Default disk partition by Dell][18]
|
||||
|
||||
As you can see, there is 524MB reserved for [EFI][19]. Then there is 3.2 GB of factory restore image perhaps.
|
||||
|
||||
Dell is using 17Gb of Swap partition, which is more than double of the RAM size. It seems Dell didn’t put enough thought here because this is simply waste of disk space, in my opinion. I would have used not [more than 11 GB of Swap partition][20] here.
|
||||
|
||||
As I mentioned before, Dell adds a “restore to factory settings” option in the Grub menu. This is a nice little feature to have.
|
||||
|
||||
One thing which I don’t like in the XPS 13 Ubuntu edition is the long boot time. It takes entire 23 seconds to reach the login screen after pressing the power button. I would expect it to be faster considering that it uses SSD PCIe.
|
||||
|
||||
If it interests you, the XPS 13 had Chromium and Google Chrome browsers installed by default instead of Firefox.
|
||||
|
||||
As far my experience goes, I am fairly impressed with Dell XPS 13 Ubuntu edition. It gives a smooth Ubuntu experience. The laptop seems to be a part of Ubuntu. Though it is an expensive laptop, I would say it is definitely worth the money.
|
||||
|
||||
To summarize, let’s see the good, the bad and the ugly of Dell XPS 13 Ubuntu edition.
|
||||
|
||||
#### The Good
|
||||
|
||||
* Ultralight weight
|
||||
* Compact
|
||||
* Keyboard
|
||||
* Carbon fiber palm rest
|
||||
* Full hardware support for Ubuntu
|
||||
* Factory restore option for Ubuntu
|
||||
* Nice display and sound quality
|
||||
* Good battery life
|
||||
|
||||
|
||||
|
||||
#### The bad
|
||||
|
||||
* Poor touchpad
|
||||
* A little pricey
|
||||
* Long boot time for SSD powered laptop
|
||||
* Windows key still present :P
|
||||
|
||||
|
||||
|
||||
#### The ugly
|
||||
|
||||
* Weird webcam placement
|
||||
|
||||
|
||||
|
||||
How did you like the **Dell XPS 13 Ubuntu edition review** from an Ubuntu user’s point of view? Do you find it good enough to spend over a thousand bucks? Do share your views in the comment below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/dell-xps-13-ubuntu-review
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://amzn.to/2ImVkCV
|
||||
[2]: http://www.techradar.com/news/computing-components/processors/kaby-lake-intel-core-processor-7th-gen-cpu-news-rumors-and-release-date-1325782
|
||||
[3]: https://www.facebook.com/itsfoss/
|
||||
[4]: https://www.facebook.com/itsfoss/videos/810293905778045/
|
||||
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2017/02/Dell-XPS-13-Ubuntu-Edition-spec.jpg?resize=540%2C337&ssl=1
|
||||
[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2017/03/Dell-XPS-13-Ubuntu-review.jpeg?resize=800%2C600&ssl=1
|
||||
[7]: https://www.youtube.com/watch?v=Yt5SkI0c3lM
|
||||
[8]: http://www.dell.com/support/article/fr/fr/frbsdt1/SLN155147/usb-powershare-feature?lang=EN
|
||||
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2017/03/Dell-Ubuntu-XPS-13-Kaby-Lake-ports-1.jpg?resize=800%2C435&ssl=1
|
||||
[10]: https://en.wikipedia.org/wiki/Thunderbolt_(interface)
|
||||
[11]: https://en.wikipedia.org/wiki/USB-C
|
||||
[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2017/03/Dell-Ubuntu-XPS-13-Kaby-Lake-ports-2.jpg?resize=800%2C325&ssl=1
|
||||
[13]: http://accessories.euro.dell.com/sna/productdetail.aspx?c=ie&l=en&s=dhs&cs=iedhs1&sku=461-10169
|
||||
[14]: https://recombu.com/mobile/article/quad-hd-vs-qhd-vs-4k-ultra-hd-what-does-it-all-mean_M20472.html
|
||||
[15]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2017/03/Dell-XPS-13-webcam-issue.jpg?resize=800%2C450&ssl=1
|
||||
[16]: https://itsfoss.com/reduce-overheating-laptops-linux/
|
||||
[17]: https://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/
|
||||
[18]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2017/03/Dell-XPS-13-Ubuntu-Edition-disk-partition.jpeg?resize=800%2C448&ssl=1
|
||||
[19]: https://en.wikipedia.org/wiki/EFI_system_partition
|
||||
[20]: https://itsfoss.com/swap-size/
|
||||
@ -1,116 +0,0 @@
|
||||
18 Cyber-Security Trends Organizations Need to Brace for in 2018
|
||||
======
|
||||
|
||||
### 18 Cyber-Security Trends Organizations Need to Brace for in 2018
|
||||
|
||||
Enterprises, end users and governments faced no shortage of security challenges in 2017. Some of those same challenges will continue into 2018, and there will be new problems to solve as well. Ransomware has been a concern for several years and will likely continue to be a big issue in 2018. The new year is also going to bring the formal introduction of the European Union's General Data Protection Regulation (GDPR), which will impact how organizations manage private information. A key trend that emerged in 2017 was an increasing use of artificial intelligence (AI) to help solve cyber-security challenges, and that's a trend that will continue to accelerate in 2018. What else will the new year bring? In this slide show, eWEEK presents 18 security predictions for the year ahead from 18 security experts.
|
||||
|
||||
|
||||
### Africa Emerges as New Area for Threat Actors and Targets
|
||||
|
||||
"In 2018, Africa will emerge as a new focus area for cyber-threats--both targeting organizations based there and attacks originating from the continent. With its growth in technology adoption and operations and rising economy, and its increasing number of local resident threat actors, Africa has the largest potential for net-new impactful cyber events." -Steve Stone, IBM X-Force IRIS
|
||||
|
||||
|
||||
### AI vs. AI
|
||||
|
||||
"2018 will see a rise in AI-based attacks as cyber-criminals begin using machine learning to spoof human behaviors. The cyber-security industry will need to tune their own AI tools to better combat the new threats. The cat and mouse game of cybercrime and security innovation will rapidly escalate to include AI-enabled tools on both sides." --Caleb Barlow, vice president of Threat Intelligence, IBM Security
|
||||
|
||||
|
||||
### Cyber-Security as a Growth Driver
|
||||
|
||||
"CEOs view cyber-security as one of their top risks, but many also see it as an opportunity to innovate and find new ways to generate revenue. In 2018 and beyond, effective cyber-security measures will support companies that are transforming their security, privacy and continuity controls in an effort to grow their businesses." -Greg Bell, KMPG's Global Cyber Security Practice co-leader
|
||||
|
||||
|
||||
### GDPR Means Good Enough Isn't Good Enough
|
||||
|
||||
"Too many professionals share a 'good enough' philosophy that they've adopted from their consumer mindset that they can simply upgrade and patch to comply with the latest security and compliance best practices or regulations. In 2018, with the upcoming enforcement of the EU GDPR 'respond fast' rules, organizations will quickly come to terms, and face fines, with why 'good enough' is not 'good' anymore." -Kris Lovejoy, CEO of BluVector
|
||||
|
||||
|
||||
### Consumerization of Cyber-Security
|
||||
|
||||
"2018 will mark the debut of the 'consumerization of cyber-security.' This means consumers will be offered a unified, comprehensive suite of security offerings, including, in addition to antivirus and spyware protection, credit and identify abuse monitoring and identity restoration. This is a big step forward compared to what is available in one package today. McAfee Total Protection, which safeguards consumer identities in addition to providing virus and malware protection, is an early, simplified example of this. Consumers want to feel more secure." -Don Dixon, co-founder and managing director, Trident Capital Cybersecurity
|
||||
|
||||
|
||||
### Ransomware Will Continue
|
||||
|
||||
"Ransomware will continue to plague organizations with 'old' attacks 'refreshed' and reused. The threat of ransomware will continue into 2018. This year we've seen ransomware wreak havoc across the globe with both WannaCry and NotPetya hitting the headlines. Threats of this type and on this scale will be a common feature of the next 12 months." -Andrew Avanessian, chief operating officer at Avecto
|
||||
|
||||
|
||||
### More Encryption Will Be Needed
|
||||
|
||||
"It will become increasingly clear in the industry that HTTPS does not offer the robust security and end-to-end encryption as is commonly believed, and there will be a push to encrypt data before it is sent over HTTPS." -Darren Guccione, CEO and co-founder, Keeper Security
|
||||
|
||||
|
||||
### Denial of Service Will Become Financially Lucrative
|
||||
|
||||
"Denial of service will become as financially lucrative as identity theft. Using stolen identities for new account fraud has been the major revenue driver behind breaches. However, in recent years ransomware attacks have caused as much if not more damage, as increased reliance on distributed applications and cloud services results in massive business damage when information, applications or systems are held hostage by attackers." -John Pescatore. SANS' director of emerging security trends
|
||||
|
||||
|
||||
### Goodbye Social Security Number
|
||||
|
||||
"2018 is the turning point for the retirement of the Social Security number. At this point, the vast majority of SSNs are compromised, and we can no longer rely on them--nor should we have previously." -Michael Sutton, CISO, Zscaler
|
||||
|
||||
|
||||
### Post-Quantum Cyber-Security Discussion Warms Up the Boardroom
|
||||
|
||||
"The uncertainty of cyber-security in a post-quantum world is percolating some circles, but 2018 is the year the discussions gain momentum in the top levels of business. As security experts grapple with preparing for a post-quantum world, top executives will begin to ask what can be done to ensure all of our connected 'things' remain secure." -Malte Pollmann, CEO of Utimaco
|
||||
|
||||
|
||||
### Market Consolidation Is Coming
|
||||
|
||||
"There will be accelerated consolidation of cyber niche markets flooded with too many 'me-too' companies offering extremely similar products and services. As an example, authentication, end-point security and threat intelligence now boast a total of more than 25 competitors. Ultimately, only three to six companies in each niche can survive." -Mike Janke, co-founder of DataTribe
|
||||
|
||||
|
||||
### Health Care Will Be a Lucrative Target
|
||||
|
||||
"Health records are highly valued on the black market because they are saturated with Personally Identifiable Information (PII). Health care institutions will continue to be a target as they have tighter allocations for security in their IT budgets. Also, medical devices are hard to update and often run on older operating system versions." -Larry Cashdollar, senior engineer, Security Intelligence Response Team, Akamai
|
||||
|
||||
|
||||
### 2018: The Year of Simple Multifactor Authentication for SMBs
|
||||
|
||||
"Unfortunately, effective multifactor authentication (MFA) solutions have remained largely out of reach for the average small- and medium-sized business. Though enterprise multifactor technology is quite mature, it often required complex on-premises solutions and expensive hardware tokens that most small businesses couldn't afford or manage. However, the growth of SaaS and smartphones has introduced new multifactor solutions that are inexpensive and easy for small businesses to use. Next year, many SMBs will adopt these new MFA solutions to secure their more privileged accounts and users. 2018 will be the year of MFA for SMBs." -Corey Nachreiner, CTO at WatchGuard Technologies
|
||||
|
||||
|
||||
### Automation Will Improve the IT Skills Gap
|
||||
|
||||
"The security skills gap is widening every year, with no signs of slowing down. To combat the skills gap and assist in the growing adoption of advanced analytics, automation will become an even higher priority for CISOs." -Haiyan Song, senior vice president of Security Markets at Splunk
|
||||
|
||||
|
||||
### Industrial Security Gets Overdue Attention
|
||||
|
||||
"The high-profile attacks of 2017 acted as a wake-up call, and many plant managers now worry that they could be next. Plant manufacturers themselves will offer enhanced security. Third-party companies going on their own will stay in a niche market. The industrial security manufacturers themselves will drive a cooperation with the security industry to provide security themselves. This is because there is an awareness thing going on and impending government scrutiny. This is different from what happened in the rest of IT/IoT where security vendors just go to market by themselves as a layer on top of IT (i.e.: an antivirus on top of Windows)." -Renaud Deraison, co-founder and CTO, Tenable
|
||||
|
||||
|
||||
### Cryptocurrencies Become the New Playground for Identity Thieves
|
||||
|
||||
"The rising value of cryptocurrencies will lead to greater attention from hackers and bad actors. Next year we'll see more fraud, hacks and money laundering take place across the top cryptocurrency marketplaces. This will lead to a greater focus on identity verification and, ultimately, will result in legislation focused on trader identity." -Stephen Maloney, executive vice president of Business Development & Strategy, Acuant
|
||||
|
||||
|
||||
### GDPR Compliance Will Be a Challenge
|
||||
|
||||
"In 2018, three quarters of companies or apps will be ruled out of compliance with GDPR and at least one major corporation will be fined to the highest extent in 2018 to set an example for others. Most companies are preparing internally by performing more security assessments and recruiting a mix of security professionals with privacy expertise and lawyers, but with the deadline quickly approaching, it's clear the bulk of businesses are woefully behind and may not be able to avoid these consequences." -Sanjay Beri, founder and CEO, Netskope
|
||||
|
||||
|
||||
### Data Security Solidifies Its Spot in the IT Security Stack
|
||||
|
||||
"Many businesses are stuck in the mindset that security of networks, servers and applications is sufficient to protect their data. However, the barrage of breaches in 2017 highlights a clear disconnect between what organizations think is working and what actually works. In 2018, we expect more businesses to implement data security solutions that complement their existing network security deployments." -Jim Varner, CEO of SecurityFirst
|
||||
|
||||
|
||||
### [Eight Cyber-Security Vendors Raise New Funding in November 2017][1]
|
||||
|
||||
Though the pace of funding slowed in November, multiple firms raised new venture capital to develop and improve their cyber-security products.
|
||||
|
||||
Though the pace of funding slowed in November, multiple firms raised new venture capital to develop and improve their cyber-security products.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://voip.eweek.com/security/18-cyber-security-trends-organizations-need-to-brace-for-in-2018
|
||||
|
||||
作者:[Sean Michael Kerner][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://voip.eweek.com/Authors/sean-michael-kerner
|
||||
[1]:http://voip.eweek.com/security/eight-cyber-security-vendors-raise-new-funding-in-november-2017
|
||||
@ -1,255 +0,0 @@
|
||||
A review of Virtual Labs virtualization solutions for MOOCs – WebLog Pro Olivier Berger
|
||||
======
|
||||
### 1 Introduction
|
||||
|
||||
This is a memo that tries to capture some of the experience gained in the [FLIRT project][3] on the topic of Virtual Labs for MOOCs (Massive Open Online Courses).
|
||||
|
||||
In this memo, we try to draw an overview of some benefits and concerns with existing approaches at using virtualization techniques for running Virtual Labs, as distributions of tools made available for distant learners.
|
||||
|
||||
We describe 3 main technical architectures: (1) running Virtual Machine images locally on a virtual machine manager, or (2) displaying the remote execution of similar virtual machines on a IaaS cloud, and (3) the potential of connecting to the remote execution of minimized containers on a remote PaaS cloud.
|
||||
|
||||
We then elaborate on some perspectives for locally running ports of applications to the WebAssembly virtual machine of the modern Web browsers.
|
||||
|
||||
Disclaimer: This memo doesn’t intend to point to extensive literature on the subject, so part of our analysis may be biased by our particular context.
|
||||
|
||||
### 2 Context : MOOCs
|
||||
|
||||
Many MOOCs (Massive Open Online Courses) include a kind of “virtual laboratory” for learners to experiment with tools, as a way to apply the knowledge, practice, and be more active in the learning process. In quite a few (technical) disciplines, this can consist in using a set of standard applications in a professional domain, which represent typical tools that would be used in real life scenarii.
|
||||
|
||||
Our main perspective will be that of a MOOC editor and of MOOC production teams which want to make “virtual labs” available for MOOC participants.
|
||||
|
||||
Such a “virtual lab” would typically contain installations of existing applications, pre-installed and configured, and loaded with scenario data in order to perform a lab.
|
||||
|
||||
The main constraint here is that such labs would typically be fabricated with limited software development expertise and funds[1][4]. Thus we consider here only the assembly of existing “normal” applications and discard the option of developping novel “serious games” and simulator applications for such MOOCs.
|
||||
|
||||
#### 2.1 The FLIRT project
|
||||
|
||||
The [FLIRT project][5] groups a consortium of 19 partners in Industry, SMEs and Academia to work on a collection of MOOCs and SPOCs for professional development in Networks and Telecommunications. Lead by Institut Mines Telecom, it benefits from the funding support of the French “Investissements d’avenir” programme.
|
||||
|
||||
As part of the FLIRT roadmap, we’re leading an “innovation task” focused on Virtual Labs in the context of the Cloud. This memo was produced as part of this task.
|
||||
|
||||
#### 2.2 Some challenges in virtual labs design for distant learning
|
||||
|
||||
Virtual Labs used in distance learning contexts require the use of software applications in autonomy, either running on a personal, or professional computer. In general, the technical skills of participants may be diverse. So much for the quality (bandwith, QoS, filtering, limitations: firewaling) of the hardware and networks they use at home or at work. It’s thus very optimistic to seek for one solution fits all strategy.
|
||||
|
||||
Most of the time there’s a learning curve on getting familiar with the tools which students will have to use, which constitutes as many challenges to overcome for beginners. These tools may not be suited for beginners, but they will still be selected by the trainers as they’re representative of the professional context being taught.
|
||||
|
||||
In theory, this usability challenge should be addressed by devising an adapted pedagogical approach, especially in a context of distance learning, so that learners can practice the labs on their own, without the presence of a tutor or professor. Or some particular prerequisite skills could be required (“please follow System Administration 101 before applying to this course”).
|
||||
|
||||
Unfortunately there are many cases where instructors basically just translate to a distant learning scenario, previous lab resources that had previously been devised for in presence learning. This lets learner faced with many challenges to overcome. The only support resource is often a regular forum on the MOOC’s LMS (Learning Management System).
|
||||
|
||||
My intuition[2][6] is that developing ad-hoc simulators for distant education would probably be more efficient and easy to use for learners. But that would require a too high investment for the designers of the courses.
|
||||
|
||||
In the context of MOOCs which are mainly free to participate to, not much investment is possible in devising ad-hoc lab applications, and instructors have to rely on existing applications, tools and scenarii to deliver a cheap enough environment. Furthermore, technical or licensing constraints[3][7] may lead to selecting lab tools which may not be easy to learn, but have the great advantage or being freely redistributable[4][8].
|
||||
|
||||
### 3 Virtual Machines for Virtual Labs
|
||||
|
||||
The learners who will try unattended learning in such typical virtual labs will face difficulties in making specialized applications run. They must overcome the technical details of downloading, installing and configuring programs, before even trying to perform a particular pedagogical scenario linked to the matter studied.
|
||||
|
||||
To diminish these difficulties, one traditional approach for implementing labs in MOOCs has been to assemble in advance a Virtual Machine image. This already made image can then be downloaded and run with a virtual machine simulator (like [VirtualBox][9][5][10]).
|
||||
|
||||
The pre-loaded VM will already have everything ready for use, so that the learners don’t have to install anything on their machines.
|
||||
|
||||
An alternative is to let learners download and install the needed software tools themselves, but this leads to so many compatibility issues or technical skill prerequisites, that this is often not advised, and mentioned only as a fallback option.
|
||||
|
||||
#### 3.1 Downloading and installation issues
|
||||
|
||||
Experience shows[2][11] that such virtual machines also bring some issues. Even if installation of every piece of software is no longer required, learners still need to be able to run the VM simulator on a wide range of diverse hardware, OSes and configurations. Even managing to download the VMs, still causes many issues (lack admin privileges, weight vs download speed, memory or CPU load, disk space, screen configurations, firewall filtering, keayboard layout, etc.).
|
||||
|
||||
These problems aren’t generally faced by the majority of learners, but the impacted minority is not marginal either, and they generally will produce a lot of support requests for the MOOC team (usually in the forums), which needs to be anticipated by the community managers.
|
||||
|
||||
The use of VMs is no show stopper for most, but can be a serious problem for a minority of learners, and is then no silver bullet.
|
||||
|
||||
Some general usability issues may also emerge if users aren’t used to the look and feel of the enclosed desktop. For instance, the VM may consist of a GNU/Linux desktop, whereas users would use a Windows or Mac OS system.
|
||||
|
||||
#### 3.2 Fabrication issues for the VM images
|
||||
|
||||
On the MOOC team’s side, the fabrication of a lightweight, fast, tested, license-free and easy to use VM image isn’t necessarily easy.
|
||||
|
||||
Software configurations tend to rot as time passes, and maintenance may not be easy when the later MOOC editions evolutions lead to the need to maintain the virtual lab scenarii years later.
|
||||
|
||||
Ideally, this would require adopting an “industrial” process in building (and testing) the lab VMs, but this requires quite an expertise (system administration, packaging, etc.) that may or not have been anticipated at the time of building the MOOC (unlike video editing competence, for instance).
|
||||
|
||||
Our experiment with the [Vagrant][12] technology [[0][13]] and Debian packaging was interesting in this respect, as it allowed us to use a well managed “script” to precisely control the build of a minimal VM image.
|
||||
|
||||
### 4 Virtual Labs as a Service
|
||||
|
||||
To overcome the difficulties in downloading and running Virtual Machines on one’s local computer, we have started exploring the possibility to run these applications in a kind of Software as a Service (SaaS) context, “on the cloud”.
|
||||
|
||||
But not all applications typically used in MOOC labs are already available for remote execution on the cloud (unless the course deals precisely with managing email in GMail).
|
||||
|
||||
We have then studied the option to use such an approach not for a single application, but for a whole virtual “desktop” which would be available on the cloud.
|
||||
|
||||
#### 4.1 IaaS deployments
|
||||
|
||||
A way to achieve this goal is to deploy Virtual Machine images quite similar to the ones described above, on the cloud, in an Infrastructure as a Service (IaaS) context[6][14], to offer access to remote desktops for every learners.
|
||||
|
||||
There are different technical options to achieve this goal, but a simplified description of the architecture can be seen as just running Virtual Machines on a single IaaS platform instead of on each learner’s computer. Access to the desktop and application interfaces is made possible with the use of Web pages (or other dedicated lightweight clients) which will display a “full screen” display of the remote desktop running for the user on the cloud VM. Under the hood, the remote display of a Linux desktop session is made with technologies like [VNC][15] and [RDP][16] connecting to a [Guacamole][17] server on the remote VM.
|
||||
|
||||
In the context of the FLIRT project, we have made early experiments with such an architecture. We used the CloVER solution by our partner [ProCAN][18] which provides a virtual desktops broker between [OpenEdX][19] and an [OpenStack][20] IaaS public platform.
|
||||
|
||||
The expected benefit is that users don’t have to install anything locally, as the only tool needed locally is a Web browser (displaying a full-screen [HTML5 canvas][21] displaying the remote desktop run by the Guacamole server running on the cloud VM.
|
||||
|
||||
But there are still some issues with such an approach. First, the cost of operating such an infrastructure : Virtual Machines need to be hosted on a IaaS platform, and that cost of operation isn’t null[7][22] for the MOOC editor, compared to the cost of VirtualBox and a VM running on the learner’s side (basically zero for the MOOC editor).
|
||||
|
||||
Another issue, which could be more problematic lies in the need for a reliable connection to the Internet during the whole sequences of lab execution by the learners[8][23]. Even if Guacamole is quite efficient at compressing rendering traffic, some basic connectivity is needed during the whole Lab work sessions, preventing some mobile uses for instance.
|
||||
|
||||
One other potential annoyance is the potential delays for making a VM available to a learner (provisioning a VM), when huge VMs images need to be copied inside the IaaS platform when a learner connects to the Virtual Lab activity for the first time (several minutes delays). This may be worse if the VM image is too big (hence the need for optimization of the content[9][24]).
|
||||
|
||||
However, the fact that all VMs are running on a platform under the control of the MOOC editor allows new kind of features for the MOOC. For instance, learners can submit results of their labs directly to the LMS without the need to upload or copy-paste results manually. This can help monitor progress or perform evaluation or grading.
|
||||
|
||||
The fact that their VMs run on the same platform also allows new kinds of pedagogical scenarii, as VMs of multiple learners can be interconnected, allowing cooperative activities between learners. The VM images may then need to be instrumented and deployed in particular configurations, which may require the use of a dedicated broker like CloVER to manage such scenarii.
|
||||
|
||||
For the records, we have yet to perform a rigorous benchmarking of such a solution in order to evaluate its benefits, or constraints given particular contexts. In FLIRT, our main focus will be in the context of SPOCs for professional training (a bit different a context than public MOOCs).
|
||||
|
||||
Still this approach doesn’t solve the VMs fabrication issues for the MOOC staff. Installing software inside a VM, be it local inside a VirtualBox simulator of over the cloud through a remote desktop display, makes not much difference. This relies mainly on manual operations and may not be well managed in terms of quality of the process (reproducibility, optimization).
|
||||
|
||||
#### 4.2 PaaS deployments using containers
|
||||
|
||||
Some key issues in the IaaS context described above, are the cost of operation of running full VMs, and long provisioning delays.
|
||||
|
||||
We’re experimenting with new options to address these issues, through the use of [Linux containers][25] running on a PaaS (Platform as a Service) platform, instead of full-fleshed Virtual Machines[10][26].
|
||||
|
||||
The main difference, with containers instead of Virtual Machines, lies in the reduced size of images, and much lower CPU load requirements, as the container remove the need for one layer of virtualization. Also, the deduplication techniques at the heart of some virtual file-systems used by container platforms lead to really fast provisioning, avoiding the need to wait for the labs to start.
|
||||
|
||||
The traditional making of VMs, done by installing packages and taking a snapshot, was affordable for the regular teacher, but involved manual operations. In this respect, one other major benefit of containers is the potential for better industrialization of the virtual lab fabrication, as they are generally not assembled manually. Instead, one uses a “scripting” approach in describing which applications and their dependencies need to be put inside a container image. But this requires new competence from the Lab creators, like learning the [Docker][27] technology (and the [OpenShift][28] PaaS, for instance), which may be quite specialized. Whereas Docker containers tend to become quite popular in Software Development faculty (through the “[devops][29]” hype), they may be a bit new to other field instructors.
|
||||
|
||||
The learning curve to mastering the automation of the whole container-based labs installation needs to be evaluated. There’s a trade-off to consider in adopting technology like Vagrant or Docker: acquiring container/PaaS expertise vs quality of industrialization and optimization. The production of a MOOC should then require careful planning if one has to hire or contract with a PaaS expert for setting up the Virtual Labs.
|
||||
|
||||
We may also expect interesting pedagogical benefits. As containers are lightweight, and platforms allow to “easily” deploy multiple interlinked containers (over dedicated virtual networks), this enables the setup of more realistic scenarii, where each learner may be provided with multiple “nodes” over virtual networks (all running their individual containers). This would be particularly interesting for Computer Networks or Security teaching for instance, where each learner may have access both to client and server nodes, to study client-server protocols, for instance. This is particularly interesting for us in the context of our FLIRT project, where we produce a collection of Computer Networks courses.
|
||||
|
||||
Still, this mode of operation relies on a good connectivity of the learners to the Cloud. In contexts of distance learning in poorly connected contexts, the PaaS architecture doesn’t solve that particular issue compared to the previous IaaS architecture.
|
||||
|
||||
### 5 Future server-less Virtual Labs with WebAssembly
|
||||
|
||||
As we have seen, the IaaS or PaaS based Virtual Labs running on the Cloud offer alternatives to installing local virtual machines on the learner’s computer. But they both require to be connected for the whole duration of the Lab, as the applications would be executed on the remote servers, on the Cloud (either inside VMs or containers).
|
||||
|
||||
We have been thinking of another alternative which could allow the deployment of some Virtual Labs on the local computers of the learners without the hassles of downloading and installing a Virtual Machine manager and VM image. We envision the possibility to use the infrastructure provided by modern Web browsers to allow running the lab’s applications.
|
||||
|
||||
At the time of writing, this architecture is still highly experimental. The main idea is to rebuild the applications needed for the Lab so that they can be run in the “generic” virtual machine present in the modern browsers, the [WebAssembly][30] and Javascript execution engine.
|
||||
|
||||
WebAssembly is a modern language which seeks for maximum portability, and as its name hints, is a kind of assembly language for the Web platform. What is of interest for us is that WebAssembly is portable on most modern Web browsers, making it a very interesting platform for portability.
|
||||
|
||||
Emerging toolchains allow recompiling applications written in languages like C or C++ so that they can be run on the WebAssembly virtual machine in the browser. This is interesting as it doesn’t require modifying the source code of these programs. Of course, there are limitations, in the kind of underlying APIs and libraries compatible with that platform, and on the sandboxing of the WebAssembly execution engine enforced by the Web browser.
|
||||
|
||||
Historically, WebAssembly has been developped so as to allow running games written in C++ for a framework like Unity, in the Web browser.
|
||||
|
||||
In some contexts, for instance for tools with an interactive GUI, and processing data retrieved from files, and which don’t need very specific interaction with the underlying operating system, it seems possible to port these programs to WebAssembly for running them inside the Web browser.
|
||||
|
||||
We have to experiment deeper with this technology to validate its potential for running Virtual Labs in the context of a Web browser.
|
||||
|
||||
We used a similar approach in the past in porting a Relational Database course lab to the Web browser, for standalone execution. A real database would run in the minimal SQLite RDBMS, recompiled to JavaScript[11][31]. Instead of having to download, install and run a VM with a RDBMS, the students would only connect to a Web page, which would load the DBMS in memory, and allow performing the lab SQL queries locally, disconnected from any third party server.
|
||||
|
||||
In a similar manner, we can think for instance, of a Lab scenario where the Internet packet inspector features of the Wireshark tool would run inside the WebAssembly virtual machine, to allow dissecting provided capture files, without having to install Wireshard, directly into the Web browser.
|
||||
|
||||
We expect to publish a report on that last experiment in the future with more details and results.
|
||||
|
||||
### 6 Conclusion
|
||||
|
||||
The most promising architecture for Virtual Lab deployments seems to be the use of containers on a PaaS platform for deploying virtual desktops or virtual application GUIs available in the Web browser.
|
||||
|
||||
This would allow the controlled fabrication of Virtual Labs containing the exact bits needed for learners to practice while minimizing the delays.
|
||||
|
||||
Still the need for always-on connectivity can be a problem.
|
||||
|
||||
Also, the potential for inter-networked containers allowing the kind of multiple nodes and collaborative scenarii we described, would require a lot of expertise to develop, and management platforms for the MOOC operators, which aren’t yet mature.
|
||||
|
||||
We hope to be able to report on our progress in the coming months and years on those aspects.
|
||||
|
||||
### 7 References
|
||||
|
||||
|
||||
|
||||
[0]
|
||||
Olivier Berger, J Paul Gibson, Claire Lecocq and Christian Bac “Designing a virtual laboratory for a relational database MOOC”. International Conference on Computer Supported Education, SCITEPRESS, 23-25 may 2015, Lisbonne, Portugal, 2015, vol. 7, pp. 260-268, ISBN 978-989-758-107-6 – [DOI: 10.5220/0005439702600268][1] ([preprint (HTML)][2])
|
||||
|
||||
### 8 Copyright
|
||||
|
||||
[][45]
|
||||
|
||||
This work is licensed under a [Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License][46]
|
||||
|
||||
.
|
||||
|
||||
### Footnotes:
|
||||
|
||||
[1][32] – The FLIRT project also works on business model aspects of MOOC or SPOC production in the context of professional development, but the present memo starts from a minimalitic hypothesis where funding for course production is quite limited.
|
||||
|
||||
[2][33] – research-based evidence needed
|
||||
|
||||
[3][34] – In typical MOOCs which are free to participate, the VM should include only gratis tools, which typically means a GNU/Linux distribution loaded with applications available under free and open source licenses.
|
||||
|
||||
[4][35] – Typically, Free and Open Source software, aka Libre Software
|
||||
|
||||
[5][36] – VirtualBox is portable on many operating systems, making it a very popular solution for such a need
|
||||
|
||||
[6][37] – the IaaS platform could typically be an open cloud for MOOCs or a private cloud for SPOCs (for closer monitoring of student activity or security control reasons).
|
||||
|
||||
[7][38] – Depending of the expected use of the lab by learners, this cost may vary a lot. The size and configuration required for the included software may have an impact (hence the need to minimize the footprint of the VM images). With diminishing costs in general this may not be a show stopper. Refer to marketing figures of commercial IaaS offerings for accurate figures. Attention to additional licensing costs if the OS of the VM isn’t free software, or if other licenses must be provided for every learners.
|
||||
|
||||
[8][39] – The needs for always-on connectivity may not be a problem for professional development SPOCs where learners connect from enterprise networks for instance. It may be detrimental when MOOCs are very popular in southern countries where high bandwidth is both unreliable and expensive.
|
||||
|
||||
[9][40] – In this respect, providing a full Linux desktop inside the VM doesn’t necessarily make sense. Instead, running applications full-screen may be better, avoiding installation of whole desktop environments like Gnome or XFCE… but which has usability consequences. Careful tuning and testing is needed in any case.
|
||||
|
||||
[10][41] – The availability of container based architectures is quite popular in the industry, but has not yet been deployed to a large scale in the context of large public MOOC hosting platforms, to our knowledge, at the time of writing. There are interesting technical challenges which the FLIRT project tries to tackle together with its partner ProCAN.
|
||||
|
||||
[11][42] – See the corresponding paragraph [http://www-inf.it-sudparis.eu/PROSE/csedu2015/#standalone-sql-env][43] in [0][44]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www-public.tem-tsp.eu/~berger_o/weblog/a-review-of-virtual-labs-virtualization-solutions-for-moocs/
|
||||
|
||||
作者:[Author;Olivier Berger;Télécom Sudparis][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www-public.tem-tsp.eu
|
||||
[1]:http://dx.doi.org/10.5220/0005439702600268
|
||||
[2]:http://www-inf.it-sudparis.eu/PROSE/csedu2015/
|
||||
[3]:https://www-public.tem-tsp.eu/~berger_o/weblog/a-review-of-virtual-labs-virtualization-solutions-for-moocs/#org50fdc1a
|
||||
[4]:https://www-public.tem-tsp.eu/~berger_o/weblog/a-review-of-virtual-labs-virtualization-solutions-for-moocs/#fn.1
|
||||
[5]:http://flirtmooc.wixsite.com/flirt-mooc-telecom
|
||||
[6]:https://www-public.tem-tsp.eu/~berger_o/weblog/a-review-of-virtual-labs-virtualization-solutions-for-moocs/#fn.2
|
||||
[7]:https://www-public.tem-tsp.eu/~berger_o/weblog/a-review-of-virtual-labs-virtualization-solutions-for-moocs/#fn.3
|
||||
[8]:https://www-public.tem-tsp.eu/~berger_o/weblog/a-review-of-virtual-labs-virtualization-solutions-for-moocs/#fn.4
|
||||
[9]:http://virtualbox.org
|
||||
[10]:https://www-public.tem-tsp.eu/~berger_o/weblog/a-review-of-virtual-labs-virtualization-solutions-for-moocs/#fn.5
|
||||
[11]:https://www-public.tem-tsp.eu/~berger_o/weblog/a-review-of-virtual-labs-virtualization-solutions-for-moocs/#fn.2
|
||||
[12]:https://www.vagrantup.com/
|
||||
[13]:https://www-public.tem-tsp.eu/~berger_o/weblog/a-review-of-virtual-labs-virtualization-solutions-for-moocs/#orgde5af50
|
||||
[14]:https://www-public.tem-tsp.eu/~berger_o/weblog/a-review-of-virtual-labs-virtualization-solutions-for-moocs/#fn.6
|
||||
[15]:https://en.wikipedia.org/wiki/Virtual_Network_Computing
|
||||
[16]:https://en.wikipedia.org/wiki/Remote_Desktop_Protocol
|
||||
[17]:http://guacamole.apache.org/
|
||||
[18]:https://www.procan-group.com/
|
||||
[19]:https://open.edx.org/
|
||||
[20]:http://openstack.org/
|
||||
[21]:https://en.wikipedia.org/wiki/Canvas_element
|
||||
[22]:https://www-public.tem-tsp.eu/~berger_o/weblog/a-review-of-virtual-labs-virtualization-solutions-for-moocs/#fn.7
|
||||
[23]:https://www-public.tem-tsp.eu/~berger_o/weblog/a-review-of-virtual-labs-virtualization-solutions-for-moocs/#fn.8
|
||||
[24]:https://www-public.tem-tsp.eu/~berger_o/weblog/a-review-of-virtual-labs-virtualization-solutions-for-moocs/#fn.9
|
||||
[25]:https://www.redhat.com/en/topics/containers
|
||||
[26]:https://www-public.tem-tsp.eu/~berger_o/weblog/a-review-of-virtual-labs-virtualization-solutions-for-moocs/#fn.10
|
||||
[27]:https://en.wikipedia.org/wiki/Docker_(software)
|
||||
[28]:https://www.openshift.com/
|
||||
[29]:https://en.wikipedia.org/wiki/DevOps
|
||||
[30]:http://webassembly.org/
|
||||
[31]:https://www-public.tem-tsp.eu/~berger_o/weblog/a-review-of-virtual-labs-virtualization-solutions-for-moocs/#fn.11
|
||||
[32]:https://www-public.tem-tsp.eu/~berger_o/weblog/a-review-of-virtual-labs-virtualization-solutions-for-moocs/#fnr.1
|
||||
[33]:https://www-public.tem-tsp.eu/~berger_o/weblog/a-review-of-virtual-labs-virtualization-solutions-for-moocs/#fnr.2
|
||||
[34]:https://www-public.tem-tsp.eu/~berger_o/weblog/a-review-of-virtual-labs-virtualization-solutions-for-moocs/#fnr.3
|
||||
[35]:https://www-public.tem-tsp.eu/~berger_o/weblog/a-review-of-virtual-labs-virtualization-solutions-for-moocs/#fnr.4
|
||||
[36]:https://www-public.tem-tsp.eu/~berger_o/weblog/a-review-of-virtual-labs-virtualization-solutions-for-moocs/#fnr.5
|
||||
[37]:https://www-public.tem-tsp.eu/~berger_o/weblog/a-review-of-virtual-labs-virtualization-solutions-for-moocs/#fnr.6
|
||||
[38]:https://www-public.tem-tsp.eu/~berger_o/weblog/a-review-of-virtual-labs-virtualization-solutions-for-moocs/#fnr.7
|
||||
[39]:https://www-public.tem-tsp.eu/~berger_o/weblog/a-review-of-virtual-labs-virtualization-solutions-for-moocs/#fnr.8
|
||||
[40]:https://www-public.tem-tsp.eu/~berger_o/weblog/a-review-of-virtual-labs-virtualization-solutions-for-moocs/#fnr.9
|
||||
[41]:https://www-public.tem-tsp.eu/~berger_o/weblog/a-review-of-virtual-labs-virtualization-solutions-for-moocs/#fnr.10
|
||||
[42]:https://www-public.tem-tsp.eu/~berger_o/weblog/a-review-of-virtual-labs-virtualization-solutions-for-moocs/#fnr.11
|
||||
[43]:http://www-inf.it-sudparis.eu/PROSE/csedu2015/#standalone-sql-env
|
||||
[44]:https://www-public.tem-tsp.eu/~berger_o/weblog/a-review-of-virtual-labs-virtualization-solutions-for-moocs/#orgde5af50
|
||||
[45]:http://creativecommons.org/licenses/by-nc-sa/4.0/
|
||||
[46]:http://creativecommons.org/licenses/by-nc-sa/4.0/
|
||||
@ -1,45 +0,0 @@
|
||||
New Training Options Address Demand for Blockchain Skills
|
||||
======
|
||||
|
||||

|
||||
|
||||
Blockchain technology is transforming industries and bringing new levels of trust to contracts, payment processing, asset protection, and supply chain management. Blockchain-related jobs are the second-fastest growing in today’s labor market, [according to TechCrunch][1]. But, as in the rapidly expanding field of artificial intelligence, there is a pronounced blockchain skills gap and a need for expert training resources.
|
||||
|
||||
### Blockchain for Business
|
||||
|
||||
A new training option was recently announced from The Linux Foundation. Enrollment is now open for a free training course called[Blockchain: Understanding Its Uses and Implications][2], as well as a [Blockchain for Business][2] professional certificate program. Delivered through the edX training platform, the new course and program provide a way to learn about the impact of blockchain technologies and a means to demonstrate that knowledge. Certification, in particular, can make a difference for anyone looking to work in the blockchain arena.
|
||||
|
||||
“In the span of only a year or two, blockchain has gone from something seen only as related to cryptocurrencies to a necessity for businesses across a wide variety of industries,” [said][3] Linux Foundation General Manager, Training & Certification Clyde Seepersad. “Providing a free introductory course designed not only for technical staff but business professionals will help improve understanding of this important technology, while offering a certificate program through edX will enable professionals from all over the world to clearly demonstrate their expertise.”
|
||||
|
||||
TechCrunch [also reports][4] that venture capital is rapidly flowing toward blockchain-focused startups. And, this new program is designed for business professionals who need to understand the potential – or threat – of blockchain to their company and industry.
|
||||
|
||||
“Professional Certificate programs on edX deliver career-relevant education in a flexible, affordable way, by focusing on the critical skills industry leaders and successful professionals are seeking today,” said Anant Agarwal, edX CEO and MIT Professor.
|
||||
|
||||
### Hyperledger Fabric
|
||||
|
||||
The Linux Foundation is steward to many valuable blockchain resources and includes some notable community members. In fact, a recent New York Times article — “[The People Leading the Blockchain Revolution][5]” — named Brian Behlendorf, Executive Director of The Linux Foundation’s [Hyperledger Project][6], one of the [top influential voices][7] in the blockchain world.
|
||||
|
||||
Hyperledger offers proven paths for gaining credibility and skills in the blockchain space. For example, the project offers a free course titled Introduction to Hyperledger Fabric for Developers. Fabric has emerged as a key open source toolset in the blockchain world. Through the Hyperledger project, you can also take the B9-lab Certified Hyperledger Fabric Developer course. More information on both courses is available [here][8].
|
||||
|
||||
“As you can imagine, someone needs to do the actual coding when companies move to experiment and replace their legacy systems with blockchain implementations,” states the Hyperledger website. “With training, you could gain serious first-mover advantage.”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/7/new-training-options-address-demand-blockchain-skills
|
||||
|
||||
作者:[SAM DEAN][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://techcrunch.com/2018/02/14/blockchain-engineers-are-in-demand/
|
||||
[2]:https://www.edx.org/course/understanding-blockchain-and-its-implications
|
||||
[3]:https://www.linuxfoundation.org/press-release/as-demand-skyrockets-for-blockchain-expertise-the-linux-foundation-and-edx-offer-new-introductory-blockchain-course-and-blockchain-for-business-professional-certificate-program/
|
||||
[4]:https://techcrunch.com/2018/05/20/with-at-least-1-3-billion-invested-globally-in-2018-vc-funding-for-blockchain-blows-past-2017-totals/
|
||||
[5]:https://www.nytimes.com/2018/06/27/business/dealbook/blockchain-stars.html
|
||||
[6]:https://www.hyperledger.org/
|
||||
[7]:https://www.linuxfoundation.org/blog/hyperledgers-brian-behlendorf-named-as-top-blockchain-influencer-by-new-york-times/
|
||||
[8]:https://www.hyperledger.org/resources/training
|
||||
@ -1,185 +0,0 @@
|
||||
How blockchain will influence open source
|
||||
======
|
||||
|
||||

|
||||
|
||||
What [Satoshi Nakamoto][1] started as Bitcoin a decade ago has found a lot of followers and turned into a movement for decentralization. For some, blockchain technology is a religion that will have the same impact on humanity as the Internet has had. For others, it is hype and technology suitable only for Ponzi schemes. While blockchain is still evolving and trying to find its place, one thing is for sure: It is a disruptive technology that will fundamentally transform certain industries. And I'm betting open source will be one of them.
|
||||
|
||||
### The open source model
|
||||
|
||||
Open source is a collaborative software development and distribution model that allows people with common interests to gather and produce something that no individual can create on their own. It allows the creation of value that is bigger than the sum of its parts. Open source is enabled by distributed collaboration tools (IRC, email, git, wiki, issue trackers, etc.), distributed and protected by an open source licensing model and often governed by software foundations such as the [Apache Software Foundation][2] (ASF), [Cloud Native Computing Foundation][3] (CNCF), etc.
|
||||
|
||||
One interesting aspect of the open source model is the lack of financial incentives in its core. Some people believe open source work should remain detached from money and remain a free and voluntary activity driven only by intrinsic motivators (such as "common purpose" and "for the greater good”). Others believe open source work should be rewarded directly or indirectly through extrinsic motivators (such as financial incentive). While the idea of open source projects prospering only through voluntary contributions is romantic, in reality, the majority of open source contributions are done through paid development. Yes, we have a lot of voluntary contributions, but these are on a temporary basis from contributors who come and go, or for exceptionally popular projects while they are at their peak. Creating and sustaining open source projects that are useful for enterprises requires developing, documenting, testing, and bug-fixing for prolonged periods, even when the software is no longer shiny and exciting. It is a boring activity that is best motivated through financial incentives.
|
||||
|
||||
### Commercial open source
|
||||
|
||||
Software foundations such as ASF survive on donations and other income streams such as sponsorships, conference fees, etc. But those funds are primarily used to run the foundations, to provide legal protection for the projects, and to ensure there are enough servers to run builds, issue trackers, mailing lists, etc.
|
||||
|
||||
Similarly, CNCF has member fees and other income streams, which are used to run the foundation and provide resources for the projects. These days, most software is not built on laptops; it is run and tested on hundreds of machines on the cloud, and that requires money. Creating marketing campaigns, brand designs, distributing stickers, etc. takes money, and some foundations can assist with that as well. At its core, foundations implement the right processes to interact with users, developers, and control mechanisms and ensure distribution of available financial resources to open source projects for the common good.
|
||||
|
||||
If users of open source projects can donate money and the foundations can distribute it in a fair way, what is missing?
|
||||
|
||||
What is missing is a direct, transparent, trusted, decentralized, automated bidirectional link for transfer of value between the open source producers and the open source consumer. Currently, the link is either unidirectional or indirect:
|
||||
|
||||
* **Unidirectional** : A developer (think of a "developer" as any role that is involved in the production, maintenance, and distribution of software) can use their brain juice and devote time to do a contribution and share that value with all open source users. But there is no reverse link.
|
||||
|
||||
* **Indirect** : If there is a bug that affects a specific user/company, the options are:
|
||||
|
||||
* To have in-house developers to fix the bug and do a pull request. That is ideal, but it not always possible to hire in-house developers who are knowledgeable about hundreds of open source projects used daily.
|
||||
|
||||
* To hire a freelancer specializing in that specific open source project and pay for the services. Ideally, the freelancer is also a committer for the open source project and can directly change the project code quickly. Otherwise, the fix might not ever make it to the project.
|
||||
|
||||
* To approach a company providing services around the open source project. Such companies typically employ open source committers to influence and gain credibility in the community and offer products, expertise, and professional services.
|
||||
|
||||
|
||||
|
||||
|
||||
The third option has been a successful [model][4] for sustaining many open source projects. Whether they provide services (training, consulting, workshops), support, packaging, open core, or SaaS, there are companies that employ hundreds of staff members who work on open source full time. There is a long [list of companies][5] that have managed to build a successful open source business model over the years, and that list is growing steadily.
|
||||
|
||||
The companies that back open source projects play an important role in the ecosystem: They are the catalyst between the open source projects and the users. The ones that add real value do more than just package software nicely; they can identify user needs and technology trends, and they create a full stack and even an ecosystem of open source projects to address these needs. They can take a boring project and support it for years. If there is a missing piece in the stack, they can start an open source project from scratch and build a community around it. They can acquire a closed source software company and open source the projects (here I got a little carried away, but yes, I'm talking about my employer, [Red Hat][6]).
|
||||
|
||||
To summarize, with the commercial open source model, projects are officially or unofficially managed and controlled by a very few individuals or companies that monetize them and give back to the ecosystem by ensuring the project is successful. It is a win-win-win for open source developers, managing companies, and end users. The alternative is inactive projects and expensive closed source software.
|
||||
|
||||
### Self-sustaining, decentralized open source
|
||||
|
||||
For a project to become part of a reputable foundation, it must conform to certain criteria. For example, ASF and CNCF require incubation and graduation processes, respectively, where apart from all the technical and formal requirements, a project must have a healthy number of active committer and users. And that is the essence of forming a sustainable open source project. Having source code on GitHub is not the same thing as having an active open source project. The latter requires committers who write the code and users who use the code, with both groups enforcing each other continuously by exchanging value and forming an ecosystem where everybody benefits. Some project ecosystems might be tiny and short-lived, and some may consist of multiple projects and competing service providers, with very complex interactions lasting for many years. But as long as there is an exchange of value and everybody benefits from it, the project is developed, maintained, and sustained.
|
||||
|
||||
If you look at ASF [Attic][7], you will find projects that have reached their end of life. When a project is no longer technologically fit for its purpose, it is usually its natural end. Similarly, in the ASF [Incubator][8], you will find tons of projects that never graduated but were instead retired. Typically, these projects were not able to build a large enough community because they are too specialized or there are better alternatives available.
|
||||
|
||||
But there are also cases where projects with high potential and superior technology cannot sustain themselves because they cannot form or maintain a functioning ecosystem for the exchange of value. The open source model and the foundations do not provide a framework and mechanisms for developers to get paid for their work or for users to get their requests heard. There isn’t a common value commitment framework for either party. As a result, some projects can sustain themselves only in the context of commercial open source, where a company acts as an intermediary and value adder between developers and users. That adds another constraint and requires a service provider company to sustain some open source projects. Ideally, users should be able to express their interest in a project and developers should be able to show their commitment to the project in a transparent and measurable way, which forms a community with common interest and intent for the exchange of value.
|
||||
|
||||
Imagine there is a model with mechanisms and tools that enable direct interaction between open source users and developers. This includes not only code contributions through pull requests, questions over the mailing lists, GitHub stars, and stickers on laptops, but also other ways that allow users to influence projects' destinies in a richer, more self-controlled and transparent manner.
|
||||
|
||||
This model could include incentives for actions such as:
|
||||
|
||||
* Funding open source projects directly rather than through software foundations
|
||||
|
||||
* Influencing the direction of projects through voting (by token holders)
|
||||
|
||||
* Feature requests driven by user needs
|
||||
|
||||
* On-time pull request merges
|
||||
|
||||
* Bounties for bug hunts
|
||||
|
||||
* Better test coverage incentives
|
||||
|
||||
* Up-to-date documentation rewards
|
||||
|
||||
* Long-term support guarantees
|
||||
|
||||
* Timely security fixes
|
||||
|
||||
* Expert assistance, support, and services
|
||||
|
||||
* Budget for evangelism and promotion of the projects
|
||||
|
||||
* Budget for regular boring activities
|
||||
|
||||
* Fast email and chat assistance
|
||||
|
||||
* Full visibility of the overall project findings, etc.
|
||||
|
||||
|
||||
|
||||
|
||||
If you haven't guessed, I'm talking about using blockchain and [smart contracts][9] to allow such interactions between users and developers—smart contracts that will give power to the hand of token holders to influence projects.
|
||||
|
||||
![blockchain_in_open_source_ecosystem.png][11]
|
||||
|
||||
The usage of blockchain in the open source ecosystem
|
||||
|
||||
Existing channels in the open source ecosystem provide ways for users to influence projects through financial commitments to service providers or other limited means through the foundations. But the addition of blockchain-based technology to the open source ecosystem could open new channels for interaction between users and developers. I'm not saying this will replace the commercial open source model; most companies working with open source do many things that cannot be replaced by smart contracts. But smart contracts can spark a new way of bootstrapping new open source projects, giving a second life to commodity projects that are a burden to maintain. They can motivate developers to apply boring pull requests, write documentation, get tests to pass, etc., providing a direct value exchange channel between users and open source developers. Blockchain can add new channels to help open source projects grow and become self-sustaining in the long term, even when company backing is not feasible. It can create a new complementary model for self-sustaining open source projects—a win-win.
|
||||
|
||||
### Tokenizing open source
|
||||
|
||||
There are already a number of initiatives aiming to tokenize open source. Some focus only on an open source model, and some are more generic but apply to open source development as well:
|
||||
|
||||
* [Gitcoin][12] \- grow open source, one of the most promising ones in this area.
|
||||
|
||||
* [Oscoin][13] \- cryptocurrency for open source
|
||||
|
||||
* [Open collective][14] \- a platform for supporting open source projects.
|
||||
|
||||
* [FundYourselfNow][15] \- Kickstarter and ICOs for projects.
|
||||
|
||||
* [Kauri][16] \- support for open source project documentation.
|
||||
|
||||
* [Liberapay][17] \- a recurrent donations platform.
|
||||
|
||||
* [FundRequest][18] \- a decentralized marketplace for open source collaboration.
|
||||
|
||||
* [CanYa][19] \- recently acquired [Bountysource][20], now the world’s largest open source P2P bounty platform.
|
||||
|
||||
* [OpenGift][21] \- a new model for open source monetization.
|
||||
|
||||
* [Hacken][22] \- a white hat token for hackers.
|
||||
|
||||
* [Coinlancer][23] \- a decentralized job market.
|
||||
|
||||
* [CodeFund][24] \- an open source ad platform.
|
||||
|
||||
* [IssueHunt][25] \- a funding platform for open source maintainers and contributors.
|
||||
|
||||
* [District0x 1Hive][26] \- a crowdfunding and curation platform.
|
||||
|
||||
* [District0x Fixit][27] \- github bug bounties.
|
||||
|
||||
|
||||
|
||||
|
||||
This list is varied and growing rapidly. Some of these projects will disappear, others will pivot, but a few will emerge as the [SourceForge][28], the ASF, the GitHub of the future. That doesn't necessarily mean they'll replace these platforms, but they'll complement them with token models and create a richer open source ecosystem. Every project can pick its distribution model (license), governing model (foundation), and incentive model (token). In all cases, this will pump fresh blood to the open source world.
|
||||
|
||||
### The future is open and decentralized
|
||||
|
||||
* Software is eating the world.
|
||||
|
||||
* Every company is a software company.
|
||||
|
||||
* Open source is where innovation happens.
|
||||
|
||||
|
||||
|
||||
|
||||
Given that, it is clear that open source is too big to fail and too important to be controlled by a few or left to its own destiny. Open source is a shared-resource system that has value to all, and more importantly, it must be managed as such. It is only a matter of time until every company on earth will want to have a stake and a say in the open source world. Unfortunately, we don't have the tools and the habits to do it yet. Such tools would allow anybody to show their appreciation or ignorance of software projects. It would create a direct and faster feedback loop between producers and consumers, between developers and users. It will foster innovation—innovation driven by user needs and expressed through token metrics.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/open-source-tokenomics
|
||||
|
||||
作者:[Bilgin lbryam][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bibryam
|
||||
[1]:https://en.wikipedia.org/wiki/Satoshi_Nakamoto
|
||||
[2]:https://www.apache.org/
|
||||
[3]:https://www.cncf.io/
|
||||
[4]:https://medium.com/open-consensus/3-oss-business-model-progressions-dafd5837f2d
|
||||
[5]:https://docs.google.com/spreadsheets/d/17nKMpi_Dh5slCqzLSFBoWMxNvWiwt2R-t4e_l7LPLhU/edit#gid=0
|
||||
[6]:http://jobs.redhat.com/
|
||||
[7]:https://attic.apache.org/
|
||||
[8]:http://incubator.apache.org/
|
||||
[9]:https://en.wikipedia.org/wiki/Smart_contract
|
||||
[10]:/file/404421
|
||||
[11]:https://opensource.com/sites/default/files/uploads/blockchain_in_open_source_ecosystem.png (blockchain_in_open_source_ecosystem.png)
|
||||
[12]:https://gitcoin.co/
|
||||
[13]:http://oscoin.io/
|
||||
[14]:https://opencollective.com/opensource
|
||||
[15]:https://www.fundyourselfnow.com/page/about
|
||||
[16]:https://kauri.io/
|
||||
[17]:https://liberapay.com/
|
||||
[18]:https://fundrequest.io/
|
||||
[19]:https://canya.io/
|
||||
[20]:https://www.bountysource.com/
|
||||
[21]:https://opengift.io/pub/
|
||||
[22]:https://hacken.io/
|
||||
[23]:https://www.coinlancer.com/home
|
||||
[24]:https://codefund.io/
|
||||
[25]:https://issuehunt.io/
|
||||
[26]:https://blog.district0x.io/district-proposal-spotlight-1hive-283957f57967
|
||||
[27]:https://github.com/district0x/district-proposals/issues/177
|
||||
[28]:https://sourceforge.net/
|
||||
@ -1,116 +0,0 @@
|
||||
Debian Turns 25! Here are Some Interesting Facts About Debian Linux
|
||||
======
|
||||
One of the oldest Linux distribution still in development, Debian has just turned 25. Let’s have a look at some interesting facts about this awesome FOSS project.
|
||||
|
||||
### 10 Interesting facts about Debian Linux
|
||||
|
||||
![Interesting facts about Debian Linux][1]
|
||||
|
||||
The facts presented here have been collected from various sources available from the internet. They are true to my knowledge, but in case of any error, please remind me to update the article.
|
||||
|
||||
#### 1\. One of the oldest Linux distributions still under active development
|
||||
|
||||
[Debian project][2] was announced on 16th August 1993 by Ian Murdock, Debian Founder. Like Linux creator [Linus Torvalds][3], Ian was a college student when he announced Debian project.
|
||||
|
||||

|
||||
|
||||
#### 2\. Some people get tattoo while some name their project after their girlfriend’s name
|
||||
|
||||
The project was named by combining the name of Ian and his then-girlfriend Debra Lynn. Ian and Debra got married and had three children. Debra and Ian got divorced in 2008.
|
||||
|
||||
#### 3\. Ian Murdock: The Maverick behind the creation of Debian project
|
||||
|
||||
![Debian Founder Ian Murdock][4]
|
||||
Ian Murdock
|
||||
|
||||
[Ian Murdock][5] led the Debian project from August 1993 until March 1996. He shaped Debian into a community project based on the principals of Free Software. The [Debian Manifesto][6] and the [Debian Social Contract][7] are still governing the project.
|
||||
|
||||
He founded a commercial Linux company called [Progeny Linux Systems][8] and worked for a number of Linux related companies such as Sun Microsystems, Linux Foundation and Docker.
|
||||
|
||||
Sadly, [Ian committed suicide in December 2015][9]. His contribution to Debian is certainly invaluable.
|
||||
|
||||
#### 4\. Debian is a community project in the true sense
|
||||
|
||||
Debian is a community based project in true sense. No one ‘owns’ Debian. Debian is being developed by volunteers from all over the world. It is not a commercial project, backed by corporates like many other Linux distributions.
|
||||
|
||||
Debian Linux distribution is composed of Free Software only. It’s one of the few Linux distributions that is true to the spirit of [Free Software][10] and takes proud in being called a GNU/Linux distribution.
|
||||
|
||||
Debian has its non-profit organization called [Software in Public Interest][11] (SPI). Along with Debian, SPI supports many other open source projects financially.
|
||||
|
||||
#### 5\. Debian and its 3 branches
|
||||
|
||||
Debian has three branches or versions: Debian Stable, Debian Unstable (Sid) and Debian Testing.
|
||||
|
||||
Debian Stable, as the name suggests, is the stable branch that has all the software and packages well tested to give you a rock solid stable system. Since it takes time before a well-tested software lands in the stable branch, Debian Stable often contains older versions of programs and hence people joke that Debian Stable means stale.
|
||||
|
||||
[Debian Unstable][12] codenamed Sid is the version where all the development of Debian takes place. This is where the new packages first land or developed. After that, these changes are propagated to the testing version.
|
||||
|
||||
[Debian Testing][13] is the next release after the current stable release. If the current stable release is N, Debian testing would be the N+1 release. The packages from Debian Unstable are tested in this version. After all the new changes are well tested, Debian Testing is then ‘promoted’ as the new Stable version.
|
||||
|
||||
There is no strict release schedule for Debian.
|
||||
|
||||
#### 7\. There was no Debian 1.0 release
|
||||
|
||||
Debian 1.0 was never released. The CD vendor, InfoMagic, accidentally shipped a development release of Debian and entitled it 1.0 in 1996. To prevent confusion between the CD version and the actual Debian release, the Debian Project renamed its next release to “Debian 1.1”.
|
||||
|
||||
#### 8\. Debian releases are codenamed after Toy Story characters
|
||||
|
||||
![Toy Story Characters][14]
|
||||
|
||||
Debian releases are codenamed after the characters from Pixar’s hit animation movie series [Toy Story][15].
|
||||
|
||||
Debian 1.1 was the first release with a codename. It was named Buzz after the Toy Story character Buzz Lightyear.
|
||||
|
||||
It was in 1996 and [Bruce Perens][16] had taken over leadership of the Project from Ian Murdock. Bruce was working at Pixar at the time.
|
||||
|
||||
This trend continued and all the subsequent releases had codenamed after Toy Story characters. For example, the current stable release is Stretch while the upcoming release has been codenamed Buster.
|
||||
|
||||
The unstable Debian version is codenamed Sid. This character in Toy Story is a kid with emotional problems and he enjoys breaking toys. This is symbolic in the sense that Debian Unstable might break your system with untested packages.
|
||||
|
||||
#### 9\. Debian also has a BSD ditribution
|
||||
|
||||
Debian is not limited to Linux. Debian also has a distribution based on FreeBSD kernel. It is called [Debian GNU/kFreeBSD][17].
|
||||
|
||||
#### 10\. Google uses Debian
|
||||
|
||||
[Google uses Debian][18] as its in-house development platform. Earlier, Google used a customized version of Ubuntu as its development platform. Recently they opted for Debian based gLinux.
|
||||
|
||||
#### Happy 25th birthday Debian
|
||||
|
||||
![Happy 25th birthday Debian][19]
|
||||
|
||||
I hope you liked these little facts about Debian. Stuff like these are reasons why people love Debian.
|
||||
|
||||
I wish a very happy 25th birthday to Debian. Please continue to be awesome. Cheers :)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/debian-facts/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/Interesting-facts-about-debian.jpeg
|
||||
[2]:https://www.debian.org
|
||||
[3]:https://itsfoss.com/linus-torvalds-facts/
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/ian-murdock.jpg
|
||||
[5]:https://en.wikipedia.org/wiki/Ian_Murdock
|
||||
[6]:https://www.debian.org/doc/manuals/project-history/ap-manifesto.en.html
|
||||
[7]:https://www.debian.org/social_contract
|
||||
[8]:https://en.wikipedia.org/wiki/Progeny_Linux_Systems
|
||||
[9]:https://itsfoss.com/ian-murdock-dies-mysteriously/
|
||||
[10]:https://www.fsf.org/
|
||||
[11]:https://www.spi-inc.org/
|
||||
[12]:https://www.debian.org/releases/sid/
|
||||
[13]:https://www.debian.org/releases/testing/
|
||||
[14]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/toy-story-characters.jpeg
|
||||
[15]:https://en.wikipedia.org/wiki/Toy_Story_(franchise)
|
||||
[16]:https://perens.com/about-bruce-perens/
|
||||
[17]:https://wiki.debian.org/Debian_GNU/kFreeBSD
|
||||
[18]:https://itsfoss.com/goobuntu-glinux-google/
|
||||
[19]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/happy-25th-birthday-Debian.jpeg
|
||||
@ -1,97 +0,0 @@
|
||||
Interview With Peter Ganten, CEO of Univention GmbH
|
||||
======
|
||||
I have been asking the Univention team to share the behind-the-scenes story of [**Univention**][1] for a couple of months. Finally, today we got the interview of **Mr. Peter H. Ganten** , CEO of Univention GmbH. Despite his busy schedule, in this interview, he shares what he thinks of the Univention project and its impact on open source ecosystem, what open source developers and companies will need to do to keep thriving and what are the biggest challenges for open source projects.
|
||||
|
||||
**OSTechNix: What’s your background and why have you founded Univention?**
|
||||
|
||||
**Peter Ganten:** I studied physics and psychology. In psychology I was a research assistant and coded evaluation software. I realized how important it is that results have to be disclosed in order to verify or falsify them. The same goes for the code that leads to the results. This brought me into contact with Open Source Software (OSS) and Linux.
|
||||
|
||||

|
||||
|
||||
I was a kind of technical lab manager and I had the opportunity to try out a lot, which led to my book about Debian. That was still in the New Economy era where the first business models emerged on how to make money with Open Source. When the bubble burst, I had the plan to make OSS a solid business model without venture capital but with Hanseatic business style – seriously, steadily, no bling bling.
|
||||
|
||||
**What were the biggest challenges at the beginning?**
|
||||
|
||||
When I came from the university, the biggest challenge clearly was to gain entrepreneurial and business management knowledge. I quickly learned that it’s not about Open Source software as an end to itself but always about customer value, and the benefits OSS offers its customers. We all had to learn a lot.
|
||||
|
||||
In the beginning, we expected that Linux on the desktop would become established in a similar way as Linux on the server. However, this has not yet been proven true. The replacement has happened with Android and the iPhone. Our conclusion then was to change our offerings towards ID management and enterprise servers.
|
||||
|
||||
**Why does UCS matter? And for whom makes it sense to use it?**
|
||||
|
||||
There is cool OSS in all areas, but many organizations are not capable to combine it all together and make it manageable. For the basic infrastructure (Windows desktops, users, user rights, roles, ID management, apps) we need a central instance to which groupware, CRM etc. is connected. Without Univention this would have to be laboriously assembled and maintained manually. This is possible for very large companies, but far too complex for many other organizations.
|
||||
|
||||
[**UCS**][2] can be used out of the box and is scalable. That’s why it’s becoming more and more popular – more than 10,000 organizations are using UCS already today.
|
||||
|
||||
**Who are your users and most important clients? What do they love most about UCS?**
|
||||
|
||||
The Core Edition is free of charge and used by organizations from all sectors and industries such as associations, micro-enterprises, universities or large organizations with thousands of users. In the enterprise environment, where Long Term Servicing (LTS) and professional support are particularly important, we have organizations ranging in size from 30-50 users to several thousand users. One of the target groups is the education system in Germany. In many large cities and within their school administrations UCS is used, for example, in Cologne, Hannover, Bremen, Kassel and in several federal states. They are looking for manageable IT and apps for schools. That’s what we offer, because we can guarantee these authorities full control over their users’ identities.
|
||||
|
||||
Also, more and more cloud service providers and MSPs want to take UCS to deliver a selection of cloud-based app solutions.
|
||||
|
||||
**Is UCS 100% Open Source? If so, how can you run a profitable business selling it?**
|
||||
|
||||
Yes, UCS is 100% Open Source, every line, the whole code is OSS. You can download and use UCS Core Edition for **FREE!**
|
||||
|
||||
We know that in large, complex organizations, vendor support and liability is needed for LTS, SLAs, and we offer that with our Enterprise subscriptions and consulting services. We don’t offer these in the Core Edition.
|
||||
|
||||
**And what are you giving back to the OS community?**
|
||||
|
||||
A lot. We are involved in the Debian team and co-finance the LTS maintenance for Debian. For important OS components in UCS like [**OpenLDAP**][3], Samba or KVM we co-finance the development or have co-developed them ourselves. We make it all freely available.
|
||||
|
||||
We are also involved on the political level in ensuring that OSS is used. We are engaged, for example, in the [**Free Software Foundation Europe (FSFE)**][4] and the [**German Open Source Business Alliance**][5], of which I am the chairman. We are working hard to make OSS more successful.
|
||||
|
||||
**How can I get started with UCS?**
|
||||
|
||||
It’s easy to get started with the Core Edition, which, like the Enterprise Edition, has an App Center and can be easily installed on your own hardware or as an appliance in a virtual machine. Just [**download Univention ISO**][6] and install it as described in the below link.
|
||||
|
||||
Alternatively, you can try the [**UCS Online Demo**][7] to get a first impression of Univention Corporate Server without actually installing it on your system.
|
||||
|
||||
**What do you think are the biggest challenges for Open Source?**
|
||||
|
||||
There is a certain attitude you can see over and over again even in bigger projects: OSS alone is viewed as an almost mandatory prerequisite for a good, sustainable, secure and trustworthy IT solution – but just having decided to use OSS is no guarantee for success. You have to carry out projects professionally and cooperate with the manufacturers. A danger is that in complex projects people think: “Oh, OSS is free, I just put it all together by myself”. But normally you do not have the know-how to successfully implement complex software solutions. You would never proceed like this with Closed Source. There people think: “Oh, the software costs 3 $ millions, so it’s okay if I have to spend another 300,000 Dollars on consultants.”
|
||||
|
||||
At OSS this is different. If such projects fail and leave burnt ground behind, we have to explain again and again that the failure of such projects is not due to the nature of OSS but to its poor implementation and organization in a specific project: You have to conclude reasonable contracts and involve partners as in the proprietary world, but you’ll gain a better solution.
|
||||
|
||||
Another challenge: We must stay innovative, move forward, attract new people who are enthusiastic about working on projects. That’s sometimes a challenge. For example, there are a number of proprietary cloud services that are good but lead to extremely high dependency. There are approaches to alternatives in OSS, but no suitable business models yet. So it’s hard to find and fund developers. For example, I can think of Evernote and OneNote for which there is no reasonable OSS alternative.
|
||||
|
||||
**And what will the future bring for Univention?**
|
||||
|
||||
I don’t have a crystal ball, but we are extremely optimistic. We see a very high growth potential in the education market. More OSS is being made in the public sector, because we have repeatedly experienced the dead ends that can be reached if we solely rely on Closed Source.
|
||||
|
||||
Overall, we will continue our organic growth at double-digit rates year after year.
|
||||
|
||||
UCS and its core functionalities of identity management, infrastructure management and app center will increasingly be offered and used from the cloud as a managed service. We will support our technology in this direction, e.g., through containers, so that a hypervisor or bare metal is not always necessary for operation.
|
||||
|
||||
**You have been the CEO of Univention for a long time. What keeps you motivated?**
|
||||
|
||||
I have been the CEO of Univention for more than 16 years now. My biggest motivation is to realize that something is moving. That we offer the better way for IT. That the people who go this way with us are excited to work with us. I go home satisfied in the evening (of course not every evening). It’s totally cool to work with the team I have. It motivates and pushes you every time I need it myself.
|
||||
|
||||
I’m a techie and nerd at heart, I enjoy dealing with technology. So I’m totally happy at this place and I’m grateful to the world that I can do whatever I want every day. Not everyone can say that.
|
||||
|
||||
**Who gives you inspiration?**
|
||||
|
||||
My employees, the customers and the Open Source projects. The exchange with other people.
|
||||
|
||||
The motivation behind everything is that we want to make sure that mankind will be able to influence and change the IT that surrounds us today and in the future just the way we want it and we thinks it’s good. We want to make a contribution to this. That is why Univention is there. That is important to us every day.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/interview-with-peter-ganten-ceo-of-univention-gmbh/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.ostechnix.com/introduction-univention-corporate-server/
|
||||
[2]: https://www.univention.com/products/ucs/
|
||||
[3]: https://www.ostechnix.com/redhat-and-suse-announced-to-withdraw-support-for-openldap/
|
||||
[4]: https://fsfe.org/
|
||||
[5]: https://osb-alliance.de/
|
||||
[6]: https://www.univention.com/downloads/download-ucs/
|
||||
[7]: https://www.univention.com/downloads/ucs-online-demo/
|
||||
@ -1,76 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Why CLAs aren't good for open source)
|
||||
[#]: via: (https://opensource.com/article/19/2/cla-problems)
|
||||
[#]: author: (Richard Fontana https://opensource.com/users/fontana)
|
||||
|
||||
Why CLAs aren't good for open source
|
||||
======
|
||||
Few legal topics in open source are as controversial as contributor license agreements.
|
||||

|
||||
|
||||
Few legal topics in open source are as controversial as [contributor license agreements][1] (CLAs). Unless you count the special historical case of the [Fedora Project Contributor Agreement][2] (which I've always seen as an un-CLA), or, like [Karl Fogel][3], you classify the [DCO][4] as a [type of CLA][5], today Red Hat makes no use of CLAs for the projects it maintains.
|
||||
|
||||
It wasn't always so. Red Hat's earliest projects followed the traditional practice I've called "inbound=outbound," in which contributions to a project are simply provided under the project's open source license with no execution of an external, non-FOSS contract required. But in the early 2000s, Red Hat began experimenting with the use of contributor agreements. Fedora started requiring contributors to sign a CLA based on the widely adapted [Apache ICLA][6], while a Free Software Foundation-derived copyright assignment agreement and a pair of bespoke CLAs were inherited from the Cygnus and JBoss acquisitions, respectively. We even took [a few steps][7] towards adopting an Apache-style CLA across the rapidly growing set of Red Hat-led projects.
|
||||
|
||||
This came to an end, in large part because those of us on the Red Hat legal team heard and understood the concerns and objections raised by Red Hat engineers and the wider technical community. We went on to become de facto leaders of what some have called the anti-CLA movement, marked notably by our [opposition to Project Harmony][8] and our [efforts][9] to get OpenStack to replace its CLA with the DCO. (We [reluctantly][10] sign tolerable upstream project CLAs out of practical necessity.)
|
||||
|
||||
### Why CLAs are problematic
|
||||
|
||||
Our choice not to use CLAs is a reflection of our values as an authentic open source company with deep roots in the free software movement. Over the years, many in the open source community have explained why CLAs, and the very similar mechanism of copyright assignment, are a bad policy for open source.
|
||||
|
||||
One reason is the red tape problem. Normally, open source development is characterized by frictionless contribution, which is enabled by inbound=outbound without imposition of further legal ceremony or process. This makes it relatively easy for new contributors to get involved in a project, allowing more effective growth of contributor communities and driving technical innovation upstream. Frictionless contribution is a key part of the advantage open source development holds over proprietary alternatives. But frictionless contribution is negated by CLAs. Having to sign an unusual legal agreement before a contribution can be accepted creates a bureaucratic hurdle that slows down development and discourages participation. This cost persists despite the growing use of automation by CLA-using projects.
|
||||
|
||||
CLAs also give rise to an asymmetry of legal power among a project's participants, which also discourages the growth of strong contributor and user communities around a project. With Apache-style CLAs, the company or organization leading the project gets special rights that other contributors do not receive, while those other contributors must shoulder certain legal obligations (in addition to the red tape burden) from which the project leader is exempt. The problem of asymmetry is most severe in copyleft projects, but it is present even when the outbound license is permissive.
|
||||
|
||||
When assessing the arguments for and against CLAs, bear in mind that today, as in the past, the vast majority of the open source code in any product originates in projects that follow the inbound=outbound practice. The use of CLAs by a relatively small number of projects causes collateral harm to all the others by signaling that, for some reason, open source licensing is insufficient to handle contributions flowing into a project.
|
||||
|
||||
### The case for CLAs
|
||||
|
||||
Since CLAs continue to be a minority practice and originate from outside open source community culture, I believe that CLA proponents should bear the burden of explaining why they are necessary or beneficial relative to their costs. I suspect that most companies using CLAs are merely emulating peer company behavior without critical examination. CLAs have an understandable, if superficial, appeal to risk-averse lawyers who are predisposed to favor greater formality, paper, and process regardless of the business costs. Still, some arguments in favor of CLAs are often advanced and deserve consideration.
|
||||
|
||||
**Easy relicensing:** If administered appropriately, Apache-style CLAs give the project steward effectively unlimited power to sublicense contributions under terms of the steward's choice. This is sometimes seen as desirable because of the potential need to relicense a project under some other open source license. But the value of easy relicensing has been greatly exaggerated by pointing to a few historical cases involving major relicensing campaigns undertaken by projects with an unusually large number of past contributors (all of which were successful without the use of a CLA). There are benefits in relicensing being hard because it results in stable legal expectations around a project and encourages projects to consult their contributor communities before undertaking significant legal policy changes. In any case, most inbound=outbound open source projects never attempt to relicense during their lifetime, and for the small number that do, relicensing will be relatively painless because typically the number of past contributors to contact will not be large.
|
||||
|
||||
**Provenance tracking:** It is sometimes claimed that CLAs enable a project to rigorously track the provenance of contributions, which purportedly has some legal benefit. It is unclear what is achieved by the use of CLAs in this regard that is not better handled through such non-CLA means as preserving Git commit history. And the DCO would seem to be much better suited to tracking contributions, given that it is normally used on a per-commit basis, while CLAs are signed once per contributor and are administratively separate from code contributions. Moreover, provenance tracking is often described as though it were a benefit for the public, yet I know of no case where a project provides transparent, ready public access to CLA acceptance records.
|
||||
|
||||
**License revocation:** Some CLA advocates warn of the prospect that a contributor may someday attempt to revoke a past license grant. To the extent that the concern is about largely judgment-proof individual contributors with no corporate affiliation, it is not clear why an Apache-style CLA provides more meaningful protection against this outcome compared to the use of an open source license. And, as with so many of the legal risks raised in discussions of open source legal policy, this appears to be a phantom risk. I have heard of only a few purported attempts at license revocation over the years, all of which were resolved quickly when the contributor backed down in the face of community pressure.
|
||||
|
||||
**Unauthorized employee contribution:** This is a special case of the license revocation issue and has recently become a point commonly raised by CLA advocates. When an employee contributes to an upstream project, normally the employer owns the copyrights and patents for which the project needs licenses, and only certain executives are authorized to grant such licenses. Suppose an employee contributed proprietary code to a project without approval from the employer, and the employer later discovers this and demands removal of the contribution or sues the project's users. This risk of unauthorized contributions is thought to be minimized by use of something like the [Apache CCLA][11] with its representations and signature requirement, coupled with some adequate review process to ascertain that the CCLA signer likely was authorized to sign (a step which I suspect is not meaningfully undertaken by most CLA-using companies).
|
||||
|
||||
Based on common sense and common experience, I contend that in nearly all cases today, employee contributions are done with the actual or constructive knowledge and consent of the employer. If there were an atmosphere of high litigation risk surrounding open source software, perhaps this risk should be taken more seriously, but litigation arising out of open source projects remains remarkably uncommon.
|
||||
|
||||
More to the point, I know of no case where an allegation of copyright or patent infringement against an inbound=outbound project, not stemming from an alleged open source license violation, would have been prevented by use of a CLA. Patent risk, in particular, is often cited by CLA proponents when pointing to the risk of unauthorized contributions, but the patent license grants in Apache-style CLAs are, by design, quite narrow in scope. Moreover, corporate contributions to an open source project will typically be few in number, small in size (and thus easily replaceable), and likely to be discarded as time goes on.
|
||||
|
||||
### Alternatives
|
||||
|
||||
If your company does not buy into the anti-CLA case and cannot get comfortable with the simple use of inbound=outbound, there are alternatives to resorting to an asymmetric and administratively burdensome Apache-style CLA requirement. The use of the DCO as a complement to inbound=outbound addresses at least some of the concerns of risk-averse CLA advocates. If you must use a true CLA, there is no need to use the Apache model (let alone a [monstrous derivative][10] of it). Consider the non-specification core of the [Eclipse Contributor Agreement][12]—essentially the DCO wrapped inside a CLA—or the Software Freedom Conservancy's [Selenium CLA][13], which merely ceremonializes an inbound=outbound contribution policy.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/2/cla-problems
|
||||
|
||||
作者:[Richard Fontana][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/fontana
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/18/3/cla-vs-dco-whats-difference
|
||||
[2]: https://opensource.com/law/10/6/new-contributor-agreement-fedora
|
||||
[3]: https://www.red-bean.com/kfogel/
|
||||
[4]: https://developercertificate.org
|
||||
[5]: https://producingoss.com/en/contributor-agreements.html#developer-certificate-of-origin
|
||||
[6]: https://www.apache.org/licenses/icla.pdf
|
||||
[7]: https://www.freeipa.org/page/Why_CLA%3F
|
||||
[8]: https://opensource.com/law/11/7/trouble-harmony-part-1
|
||||
[9]: https://wiki.openstack.org/wiki/OpenStackAndItsCLA
|
||||
[10]: https://opensource.com/article/19/1/cla-proliferation
|
||||
[11]: https://www.apache.org/licenses/cla-corporate.txt
|
||||
[12]: https://www.eclipse.org/legal/ECA.php
|
||||
[13]: https://docs.google.com/forms/d/e/1FAIpQLSd2FsN12NzjCs450ZmJzkJNulmRC8r8l8NYwVW5KWNX7XDiUw/viewform?hl=en_US&formkey=dFFjXzBzM1VwekFlOWFWMjFFRjJMRFE6MQ#gid=0
|
||||
@ -1,45 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Discuss everything Fedora)
|
||||
[#]: via: (https://fedoramagazine.org/discuss-everything-fedora/)
|
||||
[#]: author: (Ryan Lerch https://fedoramagazine.org/introducing-flatpak/)
|
||||
|
||||
Discuss everything Fedora
|
||||
======
|
||||

|
||||
|
||||
Are you interested in how Fedora is being developed? Do you want to get involved, or see what goes into making a release? You want to check out [Fedora Discussion][1]. It is a relatively new place where members of the Fedora Community meet to discuss, ask questions, and interact. Keep reading for more information.
|
||||
|
||||
Note that the Fedora Discussion system is mainly aimed at contributors. If you have questions on using Fedora, check out [Ask Fedora][2] (which is being migrated in the future).
|
||||
|
||||
![][3]
|
||||
|
||||
Fedora Discussion is a forum and discussion site that uses the [Discourse open source discussion platform][4].
|
||||
|
||||
There are already several categories useful for Fedora users, including [Desktop][5] (covering Fedora Workstation, Fedora Silverblue, KDE, XFCE, and more) and the [Server, Cloud, and IoT][6] category . Additionally, some of the [Fedora Special Interest Groups (SIGs) have discussions as well][7]. Finally, the [Fedora Friends][8] category helps you connect with other Fedora users and Community members by providing discussions about upcoming meetups and hackfests.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/discuss-everything-fedora/
|
||||
|
||||
作者:[Ryan Lerch][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/introducing-flatpak/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://discussion.fedoraproject.org/
|
||||
[2]: https://ask.fedoraproject.org
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2019/03/discussion-screenshot-1024x663.png
|
||||
[4]: https://www.discourse.org/about
|
||||
[5]: https://discussion.fedoraproject.org/c/desktop
|
||||
[6]: https://discussion.fedoraproject.org/c/server
|
||||
[7]: https://discussion.fedoraproject.org/c/sigs
|
||||
[8]: https://discussion.fedoraproject.org/c/friends
|
||||
@ -1,143 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to save time with TiDB)
|
||||
[#]: via: (https://opensource.com/article/19/3/how-save-time-tidb)
|
||||
[#]: author: (Morgan Tocker https://opensource.com/users/morgo)
|
||||
|
||||
How to save time with TiDB
|
||||
======
|
||||
|
||||
TiDB, an open source-compatible, cloud-based database engine, simplifies many of MySQL database administrators' common tasks.
|
||||
|
||||
![Team checklist][1]
|
||||
|
||||
Last November, I wrote about key [differences between MySQL and TiDB][2], an open source-compatible, cloud-based database engine, from the perspective of scaling both solutions in the cloud. In this follow-up article, I'll dive deeper into the ways [TiDB][3] streamlines and simplifies administration.
|
||||
|
||||
If you come from a MySQL background, you may be used to doing a lot of manual tasks that are either not required or much simpler with TiDB.
|
||||
|
||||
The inspiration for TiDB came from the founders managing sharded MySQL at scale at some of China's largest internet companies. Since requirements for operating a large system at scale are a key concern, I'll look at some typical MySQL database administrator (DBA) tasks and how they translate to TiDB.
|
||||
|
||||
[![TiDB architecture][4]][5]
|
||||
|
||||
In [TiDB's architecture][5]:
|
||||
|
||||
* SQL processing is separated from data storage. The SQL processing (TiDB) and storage (TiKV) components independently scale horizontally.
|
||||
* PD (Placement Driver) acts as the cluster manager and stores metadata.
|
||||
* All components natively provide high availability, with PD and TiKV using the [Raft consensus algorithm][6].
|
||||
* You can access your data via either MySQL (TiDB) or Spark (TiSpark) protocols.
|
||||
|
||||
|
||||
|
||||
### Adding/fixing replication slaves
|
||||
|
||||
**tl;dr:** It doesn't happen in the same way as in MySQL.
|
||||
|
||||
Replication and redundancy of data are automatically managed by TiKV. You also don't need to worry about creating initial backups to seed replicas, as _both_ the provisioning and replication are handled for you.
|
||||
|
||||
Replication is also quorum-based using the Raft consensus algorithm, so you don't have to worry about the inconsistency problems surrounding failures that you do with asynchronous replication (the default in MySQL and what many users are using).
|
||||
|
||||
TiDB does support its own binary log, so it can be used for asynchronous replication between clusters.
|
||||
|
||||
### Optimizing slow queries
|
||||
|
||||
**tl;dr:** Still happens in TiDB
|
||||
|
||||
There is no real way out of optimizing slow queries that have been introduced by development teams.
|
||||
|
||||
As a mitigating factor though, if you need to add breathing room to your database's capacity while you work on optimization, the TiDB's architecture allows you to horizontally scale.
|
||||
|
||||
### Upgrades and maintenance
|
||||
|
||||
**tl;dr:** Still required, but generally easier
|
||||
|
||||
Because the TiDB server is stateless, you can roll through an upgrade and deploy new TiDB servers. Then you can remove the older TiDB servers from the load balancer pool, shutting down them once connections have drained.
|
||||
|
||||
Upgrading PD is also quite straightforward since only the PD leader actively answers requests at a time. You can perform a rolling upgrade and upgrade PD's non-leader peers one at a time, and then change the leader before upgrading the final PD server.
|
||||
|
||||
For TiKV, the upgrade is marginally more complex. If you want to remove a node, I recommend first setting it to be a follower on each of the regions where it is currently a leader. After that, you can bring down the node without impacting your application. If the downtime is brief, TiKV will recover with its regional peers from the Raft log. In a longer downtime, it will need to re-copy data. This can all be managed for you, though, if you choose to deploy using Ansible or Kubernetes.
|
||||
|
||||
### Manual sharding
|
||||
|
||||
**tl;dr:** Not required
|
||||
|
||||
Manual sharding is mainly a pain on the part of the application developers, but as a DBA, you might have to get involved if the sharding is naive or has problems such as hotspots (many workloads do) that require re-balancing.
|
||||
|
||||
In TiDB, re-sharding or re-balancing happens automatically in the background. The PD server observes when data regions (TiKV's term for chunks of data in key-value form) get too small, too big, or too frequently accessed.
|
||||
|
||||
You can also explicitly configure PD to store regions on certain TiKV servers. This works really well when combined with MySQL partitioning.
|
||||
|
||||
### Capacity planning
|
||||
|
||||
**tl;dr:** Much easier
|
||||
|
||||
Capacity planning on a MySQL database can be a little bit hard because you need to plan your physical infrastructure requirements two to three years from now. As data grows (and the working set changes), this can be a difficult task. I wouldn't say it completely goes away in the cloud either, since changing a master server's hardware is always hard.
|
||||
|
||||
TiDB splits data into approximately 100MiB chunks that it distributes among TiKV servers. Because this increment is much smaller than a full server, it's much easier to move around and redistribute data. It's also possible to add new servers in smaller increments, which is easier on planning.
|
||||
|
||||
### Scaling
|
||||
|
||||
**tl;dr:** Much easier
|
||||
|
||||
This is related to capacity planning and sharding. When we talk about scaling, many people think about very large _systems,_ but that is not exclusively how I think of the problem:
|
||||
|
||||
* Scaling is being able to start with something very small, without having to make huge investments upfront on the chance it could become very large.
|
||||
* Scaling is also a people problem. If a system requires too much internal knowledge to operate, it can become hard to grow as an engineering organization. The barrier to entry for new hires can become very high.
|
||||
|
||||
|
||||
|
||||
Thus, by providing automatic sharding, TiDB can scale much easier.
|
||||
|
||||
### Schema changes (DDL)
|
||||
|
||||
**tl;dr:** Mostly better
|
||||
|
||||
The data definition language (DDL) supported in TiDB is all online, which means it doesn't block other reads or writes to the system. It also doesn't block the replication stream.
|
||||
|
||||
That's the good news, but there are a couple of limitations to be aware of:
|
||||
|
||||
* TiDB does not currently support all DDL operations, such as changing the primary key or some "change data type" operations.
|
||||
* TiDB does not currently allow you to chain multiple DDL changes in the same command, e.g., _ALTER TABLE t1 ADD INDEX (x), ADD INDEX (y)_. You will need to break these queries up into individual DDL queries.
|
||||
|
||||
|
||||
|
||||
This is an area that we're looking to improve in [TiDB 3.0][7].
|
||||
|
||||
### Creating one-off data dumps for the reporting team
|
||||
|
||||
**tl;dr:** May not be required
|
||||
|
||||
DBAs loathe manual tasks that create one-off exports of data to be consumed by another team, perhaps in an analytics tool or data warehouse.
|
||||
|
||||
This is often required when the types of queries that are be executed on the dataset are analytical. TiDB has hybrid transactional/analytical processing (HTAP) capabilities, so in many cases, these queries should work fine. If your analytics team is using Spark, you can also use the [TiSpark][8] connector to allow them to connect directly to TiKV.
|
||||
|
||||
This is another area we are improving with [TiFlash][7], a column store accelerator. We are also working on a plugin system to support external authentication. This will make it easier to manage access by the reporting team.
|
||||
|
||||
### Conclusion
|
||||
|
||||
In this post, I looked at some common MySQL DBA tasks and how they translate to TiDB. If you would like to learn more, check out our [TiDB Academy course][9] designed for MySQL DBAs (it's free!).
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/how-save-time-tidb
|
||||
|
||||
作者:[Morgan Tocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/morgo
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/checklist_todo_clock_time_team.png?itok=1z528Q0y (Team checklist)
|
||||
[2]: https://opensource.com/article/18/11/key-differences-between-mysql-and-tidb
|
||||
[3]: https://github.com/pingcap/tidb
|
||||
[4]: https://opensource.com/sites/default/files/uploads/tidb_architecture.png (TiDB architecture)
|
||||
[5]: https://pingcap.com/docs/architecture/
|
||||
[6]: https://raft.github.io/
|
||||
[7]: https://pingcap.com/blog/tidb-3.0-beta-stability-at-scale/
|
||||
[8]: https://github.com/pingcap/tispark
|
||||
[9]: https://pingcap.com/tidb-academy/
|
||||
@ -1,60 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Google partners with Intel, HPE and Lenovo for hybrid cloud)
|
||||
[#]: via: (https://www.networkworld.com/article/3388062/google-partners-with-intel-hpe-and-lenovo-for-hybrid-cloud.html#tk.rss_all)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Google partners with Intel, HPE and Lenovo for hybrid cloud
|
||||
======
|
||||
Google boosted its on-premises and cloud connections with Kubernetes and serverless computing.
|
||||
![Ilze Lucero \(CC0\)][1]
|
||||
|
||||
Still struggling to get its Google Cloud business out of single-digit marketshare, Google this week introduced new partnerships with Lenovo and Intel to help bolster its hybrid cloud offerings, both built on Google’s Kubernetes container technology.
|
||||
|
||||
At Google’s Next ’19 show this week, Intel and Google said they will collaborate on Google's Anthos, a new reference design based on the second-Generation Xeon Scalable processor introduced last week and an optimized Kubernetes software stack designed to deliver increased workload portability between public and private cloud environments.
|
||||
|
||||
**[ Read also:[What hybrid cloud means in practice][2] | Get regularly scheduled insights: [Sign up for Network World newsletters][3] ]**
|
||||
|
||||
As part the Anthos announcement, Hewlett Packard Enterprise (HPE) said it has validated Anthos on its ProLiant servers, while Lenovo has done the same for its ThinkAgile platform. This solution will enable customers to get a consistent Kubernetes experience between Google Cloud and their on-premises HPE or Lenovo servers. No official word from Dell yet, but they can’t be far behind.
|
||||
|
||||
Users will be able to manage their Kubernetes clusters and enforce policy consistently across environments – either in the public cloud or on-premises. In addition, Anthos delivers a fully integrated stack of hardened components, including OS and container runtimes that are tested and validated by Google, so customers can upgrade their clusters with confidence and minimize downtime.
|
||||
|
||||
### What is Google Anthos?
|
||||
|
||||
Google formally introduced [Anthos][4] at this year’s show. Anthos, formerly Cloud Services Platform, is meant to allow users to run their containerized applications without spending time on building, managing, and operating Kubernetes clusters. It runs both on Google Cloud Platform (GCP) with Google Kubernetes Engine (GKE) and in your data center with GKE On-Prem. Anthos will also let you manage workloads running on third-party clouds such as Amazon Web Services (AWS) and Microsoft Azure.
|
||||
|
||||
Google also announced the beta release of Anthos Migrate, which auto-migrates virtual machines (VM) from on-premises or other clouds directly into containers in GKE with minimal effort. This allows enterprises to migrate their infrastructure in one streamlined motion, without upfront modifications to the original VMs or applications.
|
||||
|
||||
Intel said it will publish the production design as an Intel Select Solution, as well as a developer platform, making it available to anyone who wants it.
|
||||
|
||||
### Serverless environments
|
||||
|
||||
Google isn’t stopping with Kubernetes containers, it’s also pushing ahead with serverless environments. [Cloud Run][5] is Google’s implementation of serverless computing, which is something of a misnomer. You still run your apps on servers; you just aren’t using a dedicated physical server. It is stateless, so resources are not allocated until you actually run or use the application.
|
||||
|
||||
Cloud Run is a fully serverless offering that takes care of all infrastructure management, including the provisioning, configuring, scaling, and managing of servers. It automatically scales up or down within seconds, even down to zero depending on traffic, ensuring you pay only for the resources you actually use. Cloud Run can be used on GKE, offering the option to run side by side with other workloads deployed in the same cluster.
|
||||
|
||||
Join the Network World communities on [Facebook][6] and [LinkedIn][7] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3388062/google-partners-with-intel-hpe-and-lenovo-for-hybrid-cloud.html#tk.rss_all
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/03/cubes_blocks_squares_containers_ilze_lucero_cc0_via_unsplash_1200x800-100752172-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3249495/what-hybrid-cloud-mean-practice
|
||||
[3]: https://www.networkworld.com/newsletters/signup.html
|
||||
[4]: https://cloud.google.com/blog/topics/hybrid-cloud/new-platform-for-managing-applications-in-todays-multi-cloud-world
|
||||
[5]: https://cloud.google.com/blog/products/serverless/announcing-cloud-run-the-newest-member-of-our-serverless-compute-stack
|
||||
[6]: https://www.facebook.com/NetworkWorld/
|
||||
[7]: https://www.linkedin.com/company/network-world
|
||||
@ -1,60 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (HPE and Nutanix partner for hyperconverged private cloud systems)
|
||||
[#]: via: (https://www.networkworld.com/article/3388297/hpe-and-nutanix-partner-for-hyperconverged-private-cloud-systems.html#tk.rss_all)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
HPE and Nutanix partner for hyperconverged private cloud systems
|
||||
======
|
||||
Both companies will sell HP ProLiant appliances with Nutanix software but to different markets.
|
||||
![Hewlett Packard Enterprise][1]
|
||||
|
||||
Hewlett Packard Enterprise (HPE) has partnered with Nutanix to offer Nutanix’s hyperconverged infrastructure (HCI) software available as a managed private cloud service and on HPE-branded appliances.
|
||||
|
||||
As part of the deal, the two companies will be competing against each other in hardware sales, sort of. If you want the consumption model you get through HPE’s GreenLake, where your usage is metered and you pay for only the time you use it (similar to the cloud), then you would get the ProLiant hardware from HPE.
|
||||
|
||||
If you want an appliance model where you buy the hardware outright, like in the traditional sense of server sales, you would get the same ProLiant through Nutanix.
|
||||
|
||||
**[ Read also:[What is hybrid cloud computing?][2] and [Multicloud mania: what to know][3] ]**
|
||||
|
||||
As it is, HPE GreenLake offers multiple cloud offerings to customers, including virtualization courtesy of VMware and Microsoft. With the Nutanix partnership, HPE is adding Nutanix’s free Acropolis hypervisor to its offerings.
|
||||
|
||||
“Customers get to choose an alternative to VMware with this,” said Pradeep Kumar, senior vice president and general manager of HPE’s Pointnext consultancy. “They like the Acropolis license model, since it’s license-free. Then they have choice points so pricing is competitive. Some like VMware, and I think it’s our job to offer them both and they can pick and choose.”
|
||||
|
||||
Kumar added that the whole Nutanix stack is 15 to 18% less with Acropolis than a VMware-powered system, since they save on the hypervisor.
|
||||
|
||||
The HPE-Nutanix partnership offers a fully managed hybrid cloud infrastructure delivered as a service and deployed in customers’ data centers or co-location facility. The managed private cloud service gives enterprises a hyperconverged environment in-house without having to manage the infrastructure themselves and, more importantly, without the burden of ownership. GreenLake operates more like a lease than ownership.
|
||||
|
||||
### HPE GreenLake's private cloud services promise to significantly reduce costs
|
||||
|
||||
HPE is pushing hard on GreenLake, which basically mimics cloud platform pricing models of paying for what you use rather than outright ownership. Kumar said HPE projects the consumption model will account for 30% of HPE’s business in the next few years.
|
||||
|
||||
GreenLake makes some hefty promises. According to Nutanix-commissioned IDC research, customers will achieve a 60% reduction in the five-year cost of operations, while a HPE-commissioned Forrester report found customers benefit from a 30% Capex savings due to eliminated need for overprovisioning and a 90% reduction in support and professional services costs.
|
||||
|
||||
By shifting to an IT as a Service model, HPE claims to provide a 40% increase in productivity by reducing the support load on IT operations staff and to shorten the time to deploy IT projects by 65%.
|
||||
|
||||
The two new offerings from the partnership – HPE GreenLake’s private cloud service running Nutanix software and the HPE-branded appliances integrated with Nutanix software – are expected to be available during the 2019 third quarter, the companies said.
|
||||
|
||||
Join the Network World communities on [Facebook][4] and [LinkedIn][5] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3388297/hpe-and-nutanix-partner-for-hyperconverged-private-cloud-systems.html#tk.rss_all
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.techhive.com/images/article/2015/11/hpe_building-100625424-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3233132/cloud-computing/what-is-hybrid-cloud-computing.html
|
||||
[3]: https://www.networkworld.com/article/3252775/hybrid-cloud/multicloud-mania-what-to-know.html
|
||||
[4]: https://www.facebook.com/NetworkWorld/
|
||||
[5]: https://www.linkedin.com/company/network-world
|
||||
@ -1,76 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Cisco warns WLAN controller, 9000 series router and IOS/XE users to patch urgent security holes)
|
||||
[#]: via: (https://www.networkworld.com/article/3390159/cisco-warns-wlan-controller-9000-series-router-and-iosxe-users-to-patch-urgent-security-holes.html#tk.rss_all)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
Cisco warns WLAN controller, 9000 series router and IOS/XE users to patch urgent security holes
|
||||
======
|
||||
Cisco says unpatched vulnerabilities could lead to DoS attacks, arbitrary code execution, take-over of devices.
|
||||
![Woolzian / Getty Images][1]
|
||||
|
||||
Cisco this week issued 31 security advisories but directed customer attention to “critical” patches for its IOS and IOS XE Software Cluster Management and IOS software for Cisco ASR 9000 Series routers. A number of other vulnerabilities also need attention if customers are running Cisco Wireless LAN Controllers.
|
||||
|
||||
The [first critical patch][2] has to do with a vulnerability in the Cisco Cluster Management Protocol (CMP) processing code in Cisco IOS and Cisco IOS XE Software that could allow an unauthenticated, remote attacker to send malformed CMP-specific Telnet options while establishing a Telnet session with an affected Cisco device configured to accept Telnet connections. An exploit could allow an attacker to execute arbitrary code and obtain full control of the device or cause a reload of the affected device, Cisco said.
|
||||
|
||||
**[ Also see[What to consider when deploying a next generation firewall][3]. | Get regularly scheduled insights by [signing up for Network World newsletters][4]. ]**
|
||||
|
||||
The problem has a Common Vulnerability Scoring System number of 9.8 out of 10.
|
||||
|
||||
According to Cisco, the Cluster Management Protocol utilizes Telnet internally as a signaling and command protocol between cluster members. The vulnerability is due to the combination of two factors:
|
||||
|
||||
* The failure to restrict the use of CMP-specific Telnet options only to internal, local communications between cluster members and instead accept and process such options over any Telnet connection to an affected device
|
||||
* The incorrect processing of malformed CMP-specific Telnet options.
|
||||
|
||||
|
||||
|
||||
Cisco says the vulnerability can be exploited during Telnet session negotiation over either IPv4 or IPv6. This vulnerability can only be exploited through a Telnet session established _to_ the device; sending the malformed options on Telnet sessions _through_ the device will not trigger the vulnerability.
|
||||
|
||||
The company says there are no workarounds for this problem, but disabling Telnet as an allowed protocol for incoming connections would eliminate the exploit vector. Cisco recommends disabling Telnet and using SSH instead. Information on how to do both can be found on the [Cisco Guide to Harden Cisco IOS Devices][5]. For patch information [go here][6].
|
||||
|
||||
The second critical patch involves a vulnerability in the sysadmin virtual machine (VM) on Cisco’s ASR 9000 carrier class routers running Cisco IOS XR 64-bit Software could let an unauthenticated, remote attacker access internal applications running on the sysadmin VM, Cisco said in the [advisory][7]. This CVSS also has a 9.8 rating.
|
||||
|
||||
**[[Prepare to become a Certified Information Security Systems Professional with this comprehensive online course from PluralSight. Now offering a 10-day free trial!][8] ]**
|
||||
|
||||
Cisco said the vulnerability is due to incorrect isolation of the secondary management interface from internal sysadmin applications. An attacker could exploit this vulnerability by connecting to one of the listening internal applications. A successful exploit could result in unstable conditions, including both denial of service (DoS) and remote unauthenticated access to the device, Cisco stated.
|
||||
|
||||
Cisco has released [free software updates][6] that address the vulnerability described in this advisory.
|
||||
|
||||
Lastly, Cisco wrote that [multiple vulnerabilities][9] in the administrative GUI configuration feature of Cisco Wireless LAN Controller (WLC) Software could let an authenticated, remote attacker cause the device to reload unexpectedly during device configuration when the administrator is using this GUI, causing a DoS condition on an affected device. The attacker would need to have valid administrator credentials on the device for this exploit to work, Cisco stated.
|
||||
|
||||
“These vulnerabilities are due to incomplete input validation for unexpected configuration options that the attacker could submit while accessing the GUI configuration menus. An attacker could exploit these vulnerabilities by authenticating to the device and submitting crafted user input when using the administrative GUI configuration feature,” Cisco stated.
|
||||
|
||||
“These vulnerabilities have a Security Impact Rating (SIR) of High because they could be exploited when the software fix for the Cisco Wireless LAN Controller Cross-Site Request Forgery Vulnerability is not in place,” Cisco stated. “In that case, an unauthenticated attacker who first exploits the cross-site request forgery vulnerability could perform arbitrary commands with the privileges of the administrator user by exploiting the vulnerabilities described in this advisory.”
|
||||
|
||||
Cisco has released [software updates][10] that address these vulnerabilities and said that there are no workarounds.
|
||||
|
||||
Join the Network World communities on [Facebook][11] and [LinkedIn][12] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3390159/cisco-warns-wlan-controller-9000-series-router-and-iosxe-users-to-patch-urgent-security-holes.html#tk.rss_all
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/02/compromised_data_security_breach_vulnerability_by_woolzian_gettyimages-475563052_2400x1600-100788413-large.jpg
|
||||
[2]: https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20170317-cmp
|
||||
[3]: https://www.networkworld.com/article/3236448/lan-wan/what-to-consider-when-deploying-a-next-generation-firewall.html
|
||||
[4]: https://www.networkworld.com/newsletters/signup.html
|
||||
[5]: http://www.cisco.com/c/en/us/support/docs/ip/access-lists/13608-21.html
|
||||
[6]: https://www.cisco.com/c/en/us/about/legal/cloud-and-software/end_user_license_agreement.html
|
||||
[7]: https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190417-asr9k-exr
|
||||
[8]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
|
||||
[9]: https://tools.cisco.com/security/center/content/CiscoSecurityAdvisory/cisco-sa-20190417-wlc-iapp
|
||||
[10]: https://www.cisco.com/c/en/us/support/web/tsd-cisco-worldwide-contacts.html
|
||||
[11]: https://www.facebook.com/NetworkWorld/
|
||||
[12]: https://www.linkedin.com/company/network-world
|
||||
@ -1,58 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Fujitsu completes design of exascale supercomputer, promises to productize it)
|
||||
[#]: via: (https://www.networkworld.com/article/3389748/fujitsu-completes-design-of-exascale-supercomputer-promises-to-productize-it.html#tk.rss_all)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Fujitsu completes design of exascale supercomputer, promises to productize it
|
||||
======
|
||||
Fujitsu hopes to be the first to offer exascale supercomputing using Arm processors.
|
||||
![Riken Advanced Institute for Computational Science][1]
|
||||
|
||||
Fujitsu and Japanese research institute Riken announced the design for the post-K supercomputer, to be launched in 2021, is complete and that they will productize the design for sale later this year.
|
||||
|
||||
The K supercomputer was a massive system, built by Fujitsu and housed at the Riken Advanced Institute for Computational Science campus in Kobe, Japan, with more than 80,000 nodes and using Sparc64 VIIIfx processors, a derivative of the Sun Microsystems Sparc processor developed under a license agreement that pre-dated Oracle buying out Sun in 2010.
|
||||
|
||||
**[ Also read:[10 of the world's fastest supercomputers][2] ]**
|
||||
|
||||
It was ranked as the top supercomputer when it was launched in June 2011 with a computation speed of over 8 petaflops. And in November 2011, K became the first computer to top 10 petaflops. It was eventually surpassed as the world's fastest supercomputer by the IBM’s Sequoia, but even now, eight years later, it’s still in the top 20 of supercomputers in the world.
|
||||
|
||||
### What's in the Post-K supercomputer?
|
||||
|
||||
The new system, dubbed “Post-K,” will feature an Arm-based processor called A64FX, a high-performance CPU developed by Fujitsu, designed for exascale systems. The chip is based off the Arm8 design, which is popular in smartphones, with 48 cores plus four “assistant” cores and the ability to access up to 32GB of memory per chip.
|
||||
|
||||
A64FX is the first CPU to adopt the Scalable Vector Extension (SVE), an instruction set specifically designed for Arm-based supercomputers. Fujitsu claims A64FX will offer a peak double precision (64-bit) floating point operations performance of over 2.7 teraflops per chip. The system will have one CPU per node and 384 nodes per rack. That comes out to one petaflop per rack.
|
||||
|
||||
Contrast that with Summit, the top supercomputer in the world built by IBM for the Oak Ridge National Laboratory using IBM Power9 processors and Nvidia GPUs. A Summit rack has a peak computer of 864 teraflops.
|
||||
|
||||
Let me put it another way: IBM’s Power processor and Nvidia’s Tesla are about to get pwned by a derivative chip to the one in your iPhone.
|
||||
|
||||
**[[Get certified as an Apple Technical Coordinator with this seven-part online course from PluralSight.][3] ]**
|
||||
|
||||
Fujitsu will productize the Post-K design and sell it as the successor to the Fujitsu Supercomputer PrimeHPC FX100. The company said it is also considering measures such as developing an entry-level model that will be easy to deploy, or supplying these technologies to other vendors.
|
||||
|
||||
Post-K will be installed in the Riken Center for Computational Science (R-CCS), where the K computer is currently located. The system will be one of the first exascale supercomputers in the world, although the U.S. and China are certainly gunning to be first if only for bragging rights.
|
||||
|
||||
Join the Network World communities on [Facebook][4] and [LinkedIn][5] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3389748/fujitsu-completes-design-of-exascale-supercomputer-promises-to-productize-it.html#tk.rss_all
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/06/riken_advanced_institute_for_computational_science_k-computer_supercomputer_1200x800-100762135-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3236875/embargo-10-of-the-worlds-fastest-supercomputers.html
|
||||
[3]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fapple-certified-technical-trainer-10-11
|
||||
[4]: https://www.facebook.com/NetworkWorld/
|
||||
[5]: https://www.linkedin.com/company/network-world
|
||||
@ -1,61 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Intel follows AMD’s lead (again) into single-socket Xeon servers)
|
||||
[#]: via: (https://www.networkworld.com/article/3390201/intel-follows-amds-lead-again-into-single-socket-xeon-servers.html#tk.rss_all)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Intel follows AMD’s lead (again) into single-socket Xeon servers
|
||||
======
|
||||
Intel's new U series of processors are aimed at the low-end market where one processor is good enough.
|
||||
![Intel][1]
|
||||
|
||||
I’m really starting to wonder who the leader in x86 really is these days because it seems Intel is borrowing another page out of AMD’s playbook.
|
||||
|
||||
Intel launched a whole lot of new Xeon Scalable processors earlier this month, but they neglected to mention a unique line: the U series of single-socket processors. The folks over at Serve The Home sniffed it out first, and Intel has confirmed the existence of the line, just that they “didn’t broadly promote them.”
|
||||
|
||||
**[ Read also:[Intel makes a play for high-speed fiber networking for data centers][2] ]**
|
||||
|
||||
To backtrack a bit, AMD made a major push for [single-socket servers][3] when it launched the Epyc line of server chips. Epyc comes with up to 32 cores and multithreading, and Intel (and Dell) argued that one 32-core/64-thread processor was enough to handle many loads and a lot cheaper than a two-socket system.
|
||||
|
||||
The new U series isn’t available in the regular Intel [ARK database][4] listing of Xeon Scalable processors, but they do show up if you search. Intel says they are looking into that .There are two processors for now, one with 24 cores and two with 20 cores.
|
||||
|
||||
The 24-core Intel [Xeon Gold 6212U][5] will be a counterpart to the Intel Xeon Platinum 8260, with a 2.4GHz base clock speed and a 3.9GHz turbo clock and the ability to access up to 1TB of memory. The Xeon Gold 6212U will have the same 165W TDP as the 8260 line, but with a single socket that’s 165 fewer watts of power.
|
||||
|
||||
Also, Intel is suggesting a price of about $2,000 for the Intel Xeon Gold 6212U, a big discount over the Xeon Platinum 8260’s $4,702 list price. So, that will translate into much cheaper servers.
|
||||
|
||||
The [Intel Xeon Gold 6210U][6] with 20 cores carries a suggested price of $1,500, has a base clock rate of 2.50GHz with turbo boost to 3.9GHz and a 150 watt TDP. Finally, there is the 20-core Intel [Xeon Gold 6209U][7] with a price of around $1,000 that is identical to the 6210 except its base clock speed is 2.1GHz with a turbo boost of 3.9GHz and a TDP of 125 watts due to its lower clock speed.
|
||||
|
||||
**[[Get certified as an Apple Technical Coordinator with this seven-part online course from PluralSight.][8] ]**
|
||||
|
||||
All of the processors support up to 1TB of DDR4-2933 memory and Intel’s Optane persistent memory.
|
||||
|
||||
In terms of speeds and feeds, AMD has a slight advantage over Intel in the single-socket race, and Epyc 2 is rumored to be approaching completion, which will only further advance AMD’s lead.
|
||||
|
||||
Join the Network World communities on [Facebook][9] and [LinkedIn][10] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3390201/intel-follows-amds-lead-again-into-single-socket-xeon-servers.html#tk.rss_all
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/06/intel_generic_cpu_background-100760187-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3307852/intel-makes-a-play-for-high-speed-fiber-networking-for-data-centers.html
|
||||
[3]: https://www.networkworld.com/article/3253626/amd-lands-dell-as-its-latest-epyc-server-processor-customer.html
|
||||
[4]: https://ark.intel.com/content/www/us/en/ark/products/series/192283/2nd-generation-intel-xeon-scalable-processors.html
|
||||
[5]: https://ark.intel.com/content/www/us/en/ark/products/192453/intel-xeon-gold-6212u-processor-35-75m-cache-2-40-ghz.html
|
||||
[6]: https://ark.intel.com/content/www/us/en/ark/products/192452/intel-xeon-gold-6210u-processor-27-5m-cache-2-50-ghz.html
|
||||
[7]: https://ark.intel.com/content/www/us/en/ark/products/193971/intel-xeon-gold-6209u-processor-27-5m-cache-2-10-ghz.html
|
||||
[8]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fapple-certified-technical-trainer-10-11
|
||||
[9]: https://www.facebook.com/NetworkWorld/
|
||||
[10]: https://www.linkedin.com/company/network-world
|
||||
@ -1,69 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (IoT roundup: VMware, Nokia beef up their IoT)
|
||||
[#]: via: (https://www.networkworld.com/article/3390682/iot-roundup-vmware-nokia-beef-up-their-iot.html#tk.rss_all)
|
||||
[#]: author: (Jon Gold https://www.networkworld.com/author/Jon-Gold/)
|
||||
|
||||
IoT roundup: VMware, Nokia beef up their IoT
|
||||
======
|
||||
Everyone wants in on the ground floor of the internet of things, and companies including Nokia, VMware and Silicon Labs are sharpening their offerings in anticipation of further growth.
|
||||
![Getty Images][1]
|
||||
|
||||
When attempting to understand the world of IoT, it’s easy to get sidetracked by all the fascinating use cases: Automated oil and gas platforms! Connected pet feeders! Internet-enabled toilets! (Is “the Internet of Toilets” a thing yet?) But the most important IoT trend to follow may be the way that major tech vendors are vying to make large portions of the market their own.
|
||||
|
||||
VMware’s play for a significant chunk of the IoT market is called Pulse IoT Center, and the company released version 2.0 of it this week. It follows the pattern set by other big companies getting into IoT: Leveraging their existing technological strengths and applying them to the messier, more heterodox networking environment that IoT represents.
|
||||
|
||||
Unsurprisingly, given that it’s VMware we’re talking about, there’s now a SaaS option, and the company was also eager to talk up that Pulse IoT Center 2.0 has simplified device-onboarding and centralized management features.
|
||||
|
||||
**More about edge networking**
|
||||
|
||||
* [How edge networking and IoT will reshape data centers][2]
|
||||
* [Edge computing best practices][3]
|
||||
* [How edge computing can help secure the IoT][4]
|
||||
|
||||
|
||||
|
||||
That might sound familiar, and for good reason – companies with any kind of a background in network management, from HPE/Aruba to Amazon, have been pushing to promote their system as the best framework for managing a complicated and often decentralized web of IoT devices from a single platform. By rolling features like software updates, onboarding and security into a single-pane-of-glass management console, those companies are hoping to be the organizational base for customers trying to implement IoT.
|
||||
|
||||
Whether they’re successful or not remains to be seen. While major IT companies have been trying to capture market share by competing across multiple verticals, the operational orientation of the IoT also means that non-traditional tech vendors with expertise in particular fields (particularly industrial and automotive) are suddenly major competitors.
|
||||
|
||||
**Nokia spreads the IoT network wide**
|
||||
|
||||
As a giant carrier-equipment vendor, Nokia is an important company in the overall IoT landscape. While some types of enterprise-focused IoT are heavily localized, like connected factory floors or centrally managed office buildings, others are so geographically disparate that carrier networks are the only connectivity medium that makes sense.
|
||||
|
||||
The Finnish company earlier this month broadened its footprint in the IoT space, announcing that it had partnered with Nordic Telecom to create a wide-area network focused on enabling IoT and emergency services. The network, which Nokia is billing as the first mission-critical communications network, operates using LTE technology in the 410-430MHz band – a relatively low frequency, which allows for better propagation and a wide effective range.
|
||||
|
||||
The idea is to provide a high-throughput, low-latency network option to any user on the network, whether it’s an emergency services provider needing high-speed video communication or an energy or industrial company with a low-delay-tolerance application.
|
||||
|
||||
**Silicon Labs packs more onto IoT chips**
|
||||
|
||||
The heart of any IoT implementation remains the SoCs that make devices intelligent in the first place, and Silicon Labs announced that it's building more muscle into its IoT-focused product lineup.
|
||||
|
||||
The Austin-based chipmaker said that version 2 of its Wireless Gecko platform will pack more than double the wireless connectivity range of previous entries, which could seriously ease design requirements for companies planning out IoT deployments. The chipsets support Zigbee, Thread and Bluetooth mesh networking, and are designed for line-powered IoT devices, using Arm Cortex-M33 processors for relatively strong computing capacity and high energy efficiency.
|
||||
|
||||
Chipset advances aren’t the type of thing that will pay off immediately in terms of making IoT devices more capable, but improvements like these make designing IoT endpoints for particular uses that much easier, and new SoCs will begin to filter into line-of-business equipment over time.
|
||||
|
||||
Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3390682/iot-roundup-vmware-nokia-beef-up-their-iot.html#tk.rss_all
|
||||
|
||||
作者:[Jon Gold][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Jon-Gold/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/08/nw_iot-news_internet-of-things_smart-city_smart-home5-100768494-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3291790/data-center/how-edge-networking-and-iot-will-reshape-data-centers.html
|
||||
[3]: https://www.networkworld.com/article/3331978/lan-wan/edge-computing-best-practices.html
|
||||
[4]: https://www.networkworld.com/article/3331905/internet-of-things/how-edge-computing-can-help-secure-the-iot.html
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
@ -1,52 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Dell EMC and Cisco renew converged infrastructure alliance)
|
||||
[#]: via: (https://www.networkworld.com/article/3391071/dell-emc-and-cisco-renew-converged-infrastructure-alliance.html#tk.rss_all)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Dell EMC and Cisco renew converged infrastructure alliance
|
||||
======
|
||||
Dell EMC and Cisco renewed their agreement to collaborate on converged infrastructure (CI) products for a few more years even though the momentum is elsewhere.
|
||||
![Dell EMC][1]
|
||||
|
||||
Dell EMC and Cisco have renewed a collaboration on converged infrastructure (CI) products that has run for more than a decade, even as the momentum shifts elsewhere. The news was announced via a [blog post][2] by Pete Manca, senior vice president for solutions engineering at Dell EMC.
|
||||
|
||||
The deal is centered around Dell EMC’s VxBlock product line, which originally started out in 2009 as a joint venture between EMC and Cisco called VCE (Virtual Computing Environment). EMC bought out Cisco’s stake in the venture before Dell bought EMC.
|
||||
|
||||
The devices offered UCS servers and networking from Cisco, EMC storage, and VMware virtualization software in pre-configured, integrated bundles. VCE was retired in favor of new brands, VxBlock, VxRail, and VxRack. The lineup has been pared down to one device, the VxBlock 1000.
|
||||
|
||||
**[ Read also:[How to plan a software-defined data-center network][3] ]**
|
||||
|
||||
“The newly inked agreement entails continued company alignment across multiple organizations: executive, product development, marketing, and sales,” Manca wrote in the blog post. “This means we’ll continue to share product roadmaps and collaborate on strategic development activities, with Cisco investing in a range of Dell EMC sales, marketing and training initiatives to support VxBlock 1000.”
|
||||
|
||||
Dell EMC cites IDC research that it holds a 48% market share in converged systems, nearly 1.5 times that of any other vendor. But IDC's April edition of the Converged Systems Tracker said the CI category is on the downswing. CI sales fell 6.4% year over year, while the market for hyperconverged infrastructure (HCI) grew 57.2% year over year.
|
||||
|
||||
For the unfamiliar, the primary difference between converged and hyperconverged infrastructure is that CI relies on hardware building blocks, while HCI is software-defined and considered more flexible and scalable than CI and operates more like a cloud system with resources spun up and down as needed.
|
||||
|
||||
Despite this, Dell is committed to CI systems. Just last month it announced an update and expansion of the VxBlock 1000, including higher scalability, a broader choice of components, and the option to add new technologies. It featured updated VMware vRealize and vSphere support, the option to consolidate high-value, mission-critical workloads with new storage and data protection options and support for Cisco UCS fabric and servers.
|
||||
|
||||
For customers who prefer to build their own infrastructure solutions, Dell EMC introduced Ready Stack, a portfolio of validated designs with sizing, design, and deployment resources that offer VMware-based IaaS, vSphere on Dell EMC PowerEdge servers and Dell EMC Unity storage, and Microsoft Hyper-V on Dell EMC PowerEdge servers and Dell EMC Unity storage.
|
||||
|
||||
Join the Network World communities on [Facebook][4] and [LinkedIn][5] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3391071/dell-emc-and-cisco-renew-converged-infrastructure-alliance.html#tk.rss_all
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/04/dell-emc-vxblock-1000-100794721-large.jpg
|
||||
[2]: https://blog.dellemc.com/en-us/dell-technologies-cisco-reaffirm-joint-commitment-converged-infrastructure/
|
||||
[3]: https://www.networkworld.com/article/3284352/data-center/how-to-plan-a-software-defined-data-center-network.html
|
||||
[4]: https://www.facebook.com/NetworkWorld/
|
||||
[5]: https://www.linkedin.com/company/network-world
|
||||
@ -1,86 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Venerable Cisco Catalyst 6000 switches ousted by new Catalyst 9600)
|
||||
[#]: via: (https://www.networkworld.com/article/3391580/venerable-cisco-catalyst-6000-switches-ousted-by-new-catalyst-9600.html#tk.rss_all)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
Venerable Cisco Catalyst 6000 switches ousted by new Catalyst 9600
|
||||
======
|
||||
Cisco introduced Catalyst 9600 switches, that let customers automate, set policy, provide security and gain assurance across wired and wireless networks.
|
||||
![Martyn Williams][1]
|
||||
|
||||
Few events in the tech industry are truly transformative, but Cisco’s replacement of its core Catalyst 6000 family could be one of those actions for customers and the company.
|
||||
|
||||
Introduced in 1999, [iterations of the Catalyst 6000][2] have nestled into the core of scores of enterprise networks, with the model 6500 becoming the company’s largest selling box ever.
|
||||
|
||||
**Learn about edge networking**
|
||||
|
||||
* [How edge networking and IoT will reshape data centers][3]
|
||||
* [Edge computing best practices][4]
|
||||
* [How edge computing can help secure the IoT][5]
|
||||
|
||||
|
||||
|
||||
It goes without question that migrating these customers alone to the new switch – the Catalyst 9600 which the company introduced today – will be of monumental importance to Cisco as it looks to revamp and continue to dominate large campus-core deployments. The first [Catalyst 9000][6], introduced in June 2017, is already the fastest ramping product line in Cisco’s history.
|
||||
|
||||
“There are at least tens of thousands of Cat 6000s running in campus cores all over the world,” said [Sachin Gupta][7], senior vice president for product management at Cisco. ”It is the Swiss Army knife of switches in term of features, and we have taken great care and over two years developing feature parity and an easy migration path for those users to the Cat 9000.”
|
||||
|
||||
Indeed the 9600 brings with it for Cat 6000 features such as support for MPLS, virtual switching and IPv6, while adding or bolstering support for newer items such as Intent-based networking (IBN), wireless networks and security segmentation. Strategically the 9600 helps fill out the company’s revamped lineup which includes the 9200 family of access switches, the [9500][8] aggregation switch and [9800 wireless controller.][9]
|
||||
|
||||
Some of the nitty-gritty details about the 9600:
|
||||
|
||||
* It is a purpose-built 40 Gigabit and 100 Gigabit Ethernet line of modular switches targeted for the enterprise campus with a wired switching capacity of up to 25.6 Tbps, with up to 6.4 Tbps of bandwidth per slot.
|
||||
* The switch supports granular port densities that fit diverse campus needs, including nonblocking 40 Gigabit and 100 Gigabit Ethernet Quad Small Form-Factor Pluggable (QSFP+, QSFP28) and 1, 10, and 25 GE Small Form-Factor Pluggable Plus (SFP, SFP+, SFP28).
|
||||
* It can be configured to support up to 48 nonblocking 100 Gigabit Ethernet QSPF28 ports with the Cisco Catalyst 9600 Series Supervisor Engine 1; Up to 96 nonblocking 40 Gigabit Ethernet QSFP+ ports with the Cisco Catalyst 9600 Series Supervisor Engine 1 and Up to 192 nonblocking 25 Gigabit/10 Gigabit Ethernet SFP28/SFP+ ports with the Cisco Catalyst 9600 Series Supervisor Engine 1.
|
||||
* It supports advanced routing and infrastructure services (MPLS, Layer 2 and Layer 3 VPNs, Multicast VPN, and Network Address Translation.
|
||||
* Cisco Software-Defined Access capabilities (such as a host-tracking database, cross-domain connectivity, and VPN Routing and Forwarding [VRF]-aware Locator/ID Separation Protocol; and network system virtualization with Cisco StackWise virtual technology.
|
||||
|
||||
|
||||
|
||||
The 9600 series runs Cisco’s IOS XE software which now runs across all Catalyst 9000 family members. The software brings with it support for other key products such as Cisco’s [DNA Center][10] which controls automation capabilities, assurance setting, fabric provisioning and policy-based segmentation for enterprise networks. What that means is that with one user interface, DNA Center, customers can automate, set policy, provide security and gain assurance across the entire wired and wireless network fabric, Gupta said.
|
||||
|
||||
“The 9600 is a big deal for Cisco and customers as it brings together the campus core and lets users establish standards access and usage policies across their wired and wireless environments,” said Brandon Butler, a senior research analyst with IDC. “It was important that Cisco add a powerful switch to handle the increasing amounts of traffic wireless and cloud applications are bringing to the network.”
|
||||
|
||||
IOS XE brings with it automated device provisioning and a wide variety of automation features including support for the network configuration protocol NETCONF and RESTCONF using YANG data models. The software offers near-real-time monitoring of the network, leading to quick detection and rectification of failures, Cisco says.
|
||||
|
||||
The software also supports hot patching which provides fixes for critical bugs and security vulnerabilities between regular maintenance releases. This support lets customers add patches without having to wait for the next maintenance release, Cisco says.
|
||||
|
||||
As with the rest of the Catalyst family, the 9600 is available via subscription-based licensing. Cisco says the [base licensing package][11] includes Network Advantage licensing options that are tied to the hardware. The base licensing packages cover switching fundamentals, management automation, troubleshooting, and advanced switching features. These base licenses are perpetual.
|
||||
|
||||
An add-on licensing package includes the Cisco DNA Premier and Cisco DNA Advantage options. The Cisco DNA add-on licenses are available as a subscription.
|
||||
|
||||
IDC’S Butler noted that there are competitors such as Ruckus, Aruba and Extreme that offer switches capable of melding wired and wireless environments.
|
||||
|
||||
The new switch is built for the next two decades of networking, Gupta said. “If any of our competitors though they could just go in and replace the Cat 6k they were misguided.”
|
||||
|
||||
Join the Network World communities on [Facebook][12] and [LinkedIn][13] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3391580/venerable-cisco-catalyst-6000-switches-ousted-by-new-catalyst-9600.html#tk.rss_all
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.techhive.com/images/article/2017/02/170227-mwc-02759-100710709-large.jpg
|
||||
[2]: https://www.networkworld.com/article/2289826/133715-The-illustrious-history-of-Cisco-s-Catalyst-LAN-switches.html
|
||||
[3]: https://www.networkworld.com/article/3291790/data-center/how-edge-networking-and-iot-will-reshape-data-centers.html
|
||||
[4]: https://www.networkworld.com/article/3331978/lan-wan/edge-computing-best-practices.html
|
||||
[5]: https://www.networkworld.com/article/3331905/internet-of-things/how-edge-computing-can-help-secure-the-iot.html
|
||||
[6]: https://www.networkworld.com/article/3256264/cisco-ceo-we-are-still-only-on-the-front-end-of-a-new-version-of-the-network.html
|
||||
[7]: https://blogs.cisco.com/enterprise/looking-forward-catalyst-9600-switch-and-9100-access-point-meraki
|
||||
[8]: https://www.networkworld.com/article/3202105/cisco-brings-intent-based-networking-to-the-end-to-end-network.html
|
||||
[9]: https://www.networkworld.com/article/3321000/cisco-links-wireless-wired-worlds-with-new-catalyst-9000-switches.html
|
||||
[10]: https://www.networkworld.com/article/3280988/cisco/cisco-opens-dna-center-network-control-and-management-software-to-the-devops-masses.html
|
||||
[11]: https://www.cisco.com/c/en/us/td/docs/switches/lan/catalyst9600/software/release/16-11/release_notes/ol-16-11-9600.html#id_67835
|
||||
[12]: https://www.facebook.com/NetworkWorld/
|
||||
[13]: https://www.linkedin.com/company/network-world
|
||||
@ -1,75 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (When IoT systems fail: The risk of having bad IoT data)
|
||||
[#]: via: (https://www.networkworld.com/article/3396230/when-iot-systems-fail-the-risk-of-having-bad-iot-data.html)
|
||||
[#]: author: (Fredric Paul https://www.networkworld.com/author/Fredric-Paul/)
|
||||
|
||||
When IoT systems fail: The risk of having bad IoT data
|
||||
======
|
||||
As the use of internet of things (IoT) devices grows, the data they generate can lead to significant savings for consumers and new opportunities for businesses. But what happens when errors inevitably crop up?
|
||||
![Oonal / Getty Images][1]
|
||||
|
||||
No matter what numbers you look at, it’s clear that the internet of things (IoT) continues to worm its way into more and more areas of personal and private life. That growth brings many benefits, but it also poses new risks. A big question is who takes responsibility when things go wrong.
|
||||
|
||||
Perhaps the biggest issue surrounds the use of IoT-generated data to personalize the offering and pricing of various products and services. [Insurance companies have long struggled with how best to use IoT data][2], but last year I wrote about how IoT sensors are beginning to be used to help home insurers reduce water damage losses. And some companies are looking into the potential for insurers to bid for consumers: business based on the risks (or lack thereof) revealed by their smart-home data.
|
||||
|
||||
But some of the biggest progress has come in the area of automobile insurance, where many automobile insurers already let customers install tracking devices in their cars in exchange for discounts for demonstrating safe-driving habits.
|
||||
|
||||
**[ Also read:[Finally, a smart way for insurers to leverage IoT in smart homes][3] ]**
|
||||
|
||||
### **The rise of usage-based insurance**
|
||||
|
||||
Called usage-based insurance (UBI), this “pay-as-you-drive” approach tracks speed, location, and other factors to assess risk and calculate auto insurance premiums. An estimated [50 million U.S. drivers][4] will have enrolled in UBI programs by 2020.
|
||||
|
||||
Not surprisingly, insurers love UBI because it helps them calculate their risks more precisely. In fact, [AIG Ireland is trying to get the country to require UBI for drivers under 25][5]. And demonstrably safe drivers are also often happy save some money. There has been pushback, of course, mostly from privacy advocates and groups who might have to pay more under this model.
|
||||
|
||||
### **What happens when something goes wrong?**
|
||||
|
||||
But there’s another, more worrisome, potential issue: What happens when the data provided by the IoT device is wrong or gets garbled somewhere along the way? Because despite all the automation, error-checking, and so on, occasional errors inevitably slip through the cracks.
|
||||
|
||||
Unfortunately, this isn’t just an academic concern that might someday accidentally cost some careful drivers a few extra bucks on their insurance. It’s already a real-world problem with serious consequences. And just like [the insurance industry still hasn’t figured out who should “own” data generated by customer-facing IoT devices][6], it’s not clear who would take responsibility for dealing with problems with that data.
|
||||
|
||||
Though not strictly an IoT issue, computer “glitches” allegedly led to Hertz rental cars erroneously being reported stolen and innocent renters being arrested and detained. The result? Criminal charges, years of litigation, and finger pointing. Lots and lots of finger pointing.
|
||||
|
||||
With that in mind, it’s easy to imagine, for example, an IoT sensor getting confused and indicating that a car was speeding even while safely under the speed limit. Think of the hassles of trying to fight _that_ in court, or arguing with your insurance company over it.
|
||||
|
||||
(Of course, there’s also the flip side of this problem: Consumers may find ways to hack the data shared by their IoT devices to fraudulently qualify for lower rates or deflect blame for an incident. There’s no real plan in place to deal with _that_ , either.)
|
||||
|
||||
### **Studying the need for government regulation**
|
||||
|
||||
Given the potential impacts of these issues, and the apparent lack of interest in dealing with them from the many companies involved, it seems legitimate to wonder if government intervention is warranted.
|
||||
|
||||
That could be one motivation behind the [reintroduction of the SMART (State of Modern Application, Research, and Trends of) IoT Act][7] by Rep. Bob Latta (R-Ohio). [The bill][8], stemming from a bipartisan IoT working group helmed by Latta and Rep. Peter Welch (D-Vt.), passed the House last fall but failed in the Senate. It would require the Commerce Department to study the state of the IoT industry and report back to the House Energy & Commerce and Senate Commerce Committee in two years.
|
||||
|
||||
In a statement, Latta said, “With a projected economic impact in the trillions of dollars, we need to look at the policies, opportunities, and challenges that IoT presents. The SMART IoT Act will make it easier to understand what the government is doing on IoT policy, what it can do better, and how federal policies can impact the research and discovery of cutting-edge technologies.”
|
||||
|
||||
The research is welcome, but the bill may not even pass. Even it does, with its two-year wait time, the IoT will likely evolve too fast for the government to keep up.
|
||||
|
||||
Join the Network World communities on [Facebook][9] and [LinkedIn][10] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3396230/when-iot-systems-fail-the-risk-of-having-bad-iot-data.html
|
||||
|
||||
作者:[Fredric Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Fredric-Paul/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/08/cloud_connected_smart_cars_by_oonal_gettyimages-692819426_1200x800-100767788-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3264655/most-insurance-carriers-not-ready-to-use-iot-data.html
|
||||
[3]: https://www.networkworld.com/article/3296706/finally-a-smart-way-for-insurers-to-leverage-iot-in-smart-homes.html
|
||||
[4]: https://www.businessinsider.com/iot-is-changing-the-auto-insurance-industry-2015-8
|
||||
[5]: https://www.iotforall.com/iot-data-is-disrupting-the-insurance-industry/
|
||||
[6]: https://www.sas.com/en_us/insights/articles/big-data/5-challenges-for-iot-in-insurance-industry.html
|
||||
[7]: https://www.multichannel.com/news/latta-re-ups-smart-iot-act
|
||||
[8]: https://latta.house.gov/uploadedfiles/smart_iot_116th.pdf
|
||||
[9]: https://www.facebook.com/NetworkWorld/
|
||||
[10]: https://www.linkedin.com/company/network-world
|
||||
121
sources/talk/20190528 Managed WAN and the cloud-native SD-WAN.md
Normal file
121
sources/talk/20190528 Managed WAN and the cloud-native SD-WAN.md
Normal file
@ -0,0 +1,121 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Managed WAN and the cloud-native SD-WAN)
|
||||
[#]: via: (https://www.networkworld.com/article/3398476/managed-wan-and-the-cloud-native-sd-wan.html)
|
||||
[#]: author: (Matt Conran https://www.networkworld.com/author/Matt-Conran/)
|
||||
|
||||
Managed WAN and the cloud-native SD-WAN
|
||||
======
|
||||
The motivation for WAN transformation is clear, today organizations require: improved internet access and last mile connectivity, additional bandwidth and a reduction in the WAN costs.
|
||||
![Gerd Altmann \(CC0\)][1]
|
||||
|
||||
In recent years, a significant number of organizations have transformed their wide area network (WAN). Many of these organizations have some kind of cloud-presence across on-premise data centers and remote site locations.
|
||||
|
||||
The vast majority of organizations that I have consulted with have over 10 locations. And it is common to have headquarters in both the US and Europe, along with remote site locations spanning North America, Europe, and Asia.
|
||||
|
||||
A WAN transformation project requires this diversity to be taken into consideration when choosing the best SD-WAN vendor to satisfy both; networking and security requirements. Fundamentally, SD-WAN is not just about physical connectivity, there are many more related aspects.
|
||||
|
||||
**[ Related:[MPLS explained – What you need to know about multi-protocol label switching][2]**
|
||||
|
||||
### Motivations for transforming the WAN
|
||||
|
||||
The motivation for WAN transformation is clear: Today organizations prefer improved internet access and last mile connectivity, additional bandwidth along with a reduction in the WAN costs. Replacing Multiprotocol Label Switching (MPLS) with SD-WAN has of course been the main driver for the SD-WAN evolution, but it is only a single piece of the jigsaw puzzle.
|
||||
|
||||
Many SD-WAN vendors are quickly brought to their knees when they try to address security and gain direct internet access from remote site locations. The problem is how to ensure optimized cloud access that is secure, has improved visibility and predictable performance without the high costs associated with MPLS? SD-WAN is not just about connecting locations. Primarily, it needs to combine many other important network and security elements into one seamless worldwide experience.
|
||||
|
||||
According to a recent report from [Cato Networks][3] into enterprise IT managers, a staggering 85% will confront use cases in 2019 that are poorly addressed or outright ignored by SD-WAN. Examples includes providing secure, Internet access from any location (50%) and improving visibility into and control over mobile access to cloud applications, such as Office 365 (46%).
|
||||
|
||||
### Issues with traditional SD-WAN vendors
|
||||
|
||||
First and foremost, SD-WAN unable to address the security challenges that arise during the WAN transformation. Such security challenges include protection against malware, ransomware and implementing the necessary security policies. Besides, there is a lack of visibility that is required to police the mobile users and remote site locations accessing resources in the public cloud.
|
||||
|
||||
To combat this, organizations have to purchase additional equipment. There has always been and will always be a high cost associated with buying such security appliances. Furthermore, the additional tools that are needed to protect the remote site locations increase the network complexity and reduce visibility. Let’s us not forget that the variety of physical appliances require talented engineers for design, deployment and maintenance.
|
||||
|
||||
There will often be a single network-cowboy. This means the network and security configuration along with the design essentials are stored in the mind of the engineer, not in a central database from where the knowledge can be accessed if the engineer leaves his or her employment.
|
||||
|
||||
The physical appliance approach to SD-WAN makes it hard, if not impossible, to accommodate for the future. If the current SD-WAN vendors continue to focus just on connecting the devices with the physical appliances, they will have limited ability to accommodate for example, with the future of network IoT devices. With these factors in mind what are the available options to overcome the SD-WAN shortcomings?
|
||||
|
||||
One can opt for a do it yourself (DIY) solution, or a managed service, which can fall into the category of telcos, with the improvements of either co-managed or self-managed service categories.
|
||||
|
||||
### Option 1: The DIY solution
|
||||
|
||||
Firstly DIY, from the experience of trying to stitch together a global network, this is not only costly but also complex and is a very constrained approach to the network transformation. We started with physical appliances decades ago and it was sufficient to an extent. The reason it worked was that it suited the requirements of the time, but our environment has changed since then. Hence, we need to accommodate these changes with the current requirements.
|
||||
|
||||
Even back in those days, we always had a breachable perimeter. The perimeter-approach to networking and security never really worked and it was just a matter of time before the bad actor would penetrate the guarded walls.
|
||||
|
||||
Securing a global network involves more than just firewalling the devices. A solid security perimeter requires URL filtering, anti-malware and IPS to secure the internet traffic. If you try to deploy all these functions in a single device, such as, unified threat management (UTM), you will hit scaling problems. As a result, you will be left with appliance sprawl.
|
||||
|
||||
Back in my early days as an engineer, I recall stitching together a global network with a mixture of security and network appliances from a variety of vendors. It was me and just two others who used to get the job done on time and for a production network, our uptime levels were superior to most.
|
||||
|
||||
However, it involved too many late nights, daily flights to our PoPs and of course the major changes required a forklift. A lot of work had to be done at that time, which made me want to push some or most of the work to a 3rd party.
|
||||
|
||||
### Option 2: The managed service solution
|
||||
|
||||
Today, there is a growing need for the managed service approach to SD-WAN. Notably, it simplifies the network design, deployment and maintenance activities while offloading the complexity, in line with what most CIOs are talking about today.
|
||||
|
||||
Managed service provides a number of benefits, such as the elimination of backhauling to centralized cloud connectors or VPN concentrators. Evidently, backhauling is never favored for a network architect. More than often it will result in increased latency, congested links, internet chokepoints, and last-mile outages.
|
||||
|
||||
Managed service can also authenticate mobile users at the local communication hub and not at a centralized point which would increase the latency. So what options are available when considering a managed service?
|
||||
|
||||
### Telcos: An average service level
|
||||
|
||||
Let’s be honest, telcos have a mixed track record and enterprises rely on them with caution. Essentially, you are building a network with 3rd party appliances and services that put the technical expertise outside of the organization.
|
||||
|
||||
Secondly, the telco must orchestrate, monitor and manage numerous technical domains which are likely to introduce further complexity. As a result, troubleshooting requires close coordination with the suppliers which will have an impact on the customer experience.
|
||||
|
||||
### Time equals money
|
||||
|
||||
To resolve a query could easily take two or three attempts. It’s rare that you will get to the right person straight away. This eventually increases the time to resolve problems. Even for a minor feature change, you have to open tickets. Hence, with telcos, it increases the time required to solve a problem.
|
||||
|
||||
In addition, it takes time to make major network changes such as opening new locations, which could take up to 45 days. In the same report mentioned above, 71% of the respondents are frustrated with the telco customer-service-time to resolve the problems, 73% indicated that deploying new locations requires at least 15 days and 47% claimed that “high bandwidth costs” is the biggest frustration while working with telcos.
|
||||
|
||||
When it comes to lead times for projects, an engineer does not care. Does a project manager care if you have an optimum network design? No, many don’t, most just care about the timeframes. During my career, now spanning 18 years, I have never seen comments from any of my contacts saying “you must adhere to your project manager’s timelines”.
|
||||
|
||||
However, out of the experience, the project managers have their ways and lead times do become a big part of your daily job. So as an engineer, 45-day lead time will certainly hit your brand hard, especially if you are an external consultant.
|
||||
|
||||
There is also a problem with bandwidth costs. Telcos need to charge due to their complexity. There is always going to be a series of problems when working with them. Let’s face it, they offer an average service level.
|
||||
|
||||
### Co-management and self-service management
|
||||
|
||||
What is needed is a service that equips with the visibility and control of DIY to managed services. This, ultimately, opens the door to co-management and self-service management.
|
||||
|
||||
Co-management allows both the telco and enterprise to make changes to the WAN. Then we have the self-service management of WAN that allows the enterprises to have sole access over the aspect of their network.
|
||||
|
||||
However, these are just sticking plasters covering up the flaws. We need a managed service that not only connects locations but also synthesizes the site connectivity, along with security, mobile access, and cloud access.
|
||||
|
||||
### Introducing the cloud-native approach to SD-WAN
|
||||
|
||||
There should be a new style of managed services that combines the best of both worlds. It should offer the uptime, predictability and reach of the best telcos along with the cost structure and versatility of cloud providers. All such requirements can be met by what is known as the cloud-native carrier.
|
||||
|
||||
Therefore, we should be looking for a platform that can connect and secure all the users and resources at scale, no matter where they are positioned. Eventually, such a platform will limit the costs and increase the velocity and agility.
|
||||
|
||||
This is what a cloud-native carrier can offer you. You could say it’s a new kind of managed service, which is what enterprises are now looking for. A cloud-native carrier service brings the best of cloud services to the world of networking. This new style of managed service brings to SD-WAN the global reach, self-service, and agility of the cloud with the ability to easily migrate from MPLS.
|
||||
|
||||
In summary, a cloud-native carrier service will improve global connectivity to on-premises and cloud applications, enable secure branch to internet access, and both securely and optimally integrate cloud datacenters.
|
||||
|
||||
**This article is published as part of the IDG Contributor Network.[Want to Join?][4]**
|
||||
|
||||
Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3398476/managed-wan-and-the-cloud-native-sd-wan.html
|
||||
|
||||
作者:[Matt Conran][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Matt-Conran/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.techhive.com/images/article/2017/03/network-wan-100713693-large.jpg
|
||||
[2]: https://www.networkworld.com/article/2297171/sd-wan/network-security-mpls-explained.html
|
||||
[3]: https://www.catonetworks.com/news/digital-transformation-survey
|
||||
[4]: /contributor-network/signup.html
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
69
sources/talk/20190528 Moving to the Cloud- SD-WAN Matters.md
Normal file
69
sources/talk/20190528 Moving to the Cloud- SD-WAN Matters.md
Normal file
@ -0,0 +1,69 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Moving to the Cloud? SD-WAN Matters!)
|
||||
[#]: via: (https://www.networkworld.com/article/3397921/moving-to-the-cloud-sd-wan-matters.html)
|
||||
[#]: author: (Rami Rammaha https://www.networkworld.com/author/Rami-Rammaha/)
|
||||
|
||||
Moving to the Cloud? SD-WAN Matters!
|
||||
======
|
||||
|
||||
![istock][1]
|
||||
|
||||
This is the first in a two-part blog series that will explore how enterprises can realize the full transformation promise of the cloud by shifting to a business first networking model powered by a business-driven [SD-WAN][2]. The focus for this installment will be on automating secure IPsec connectivity and intelligently steering traffic to cloud providers.
|
||||
|
||||
Over the past several years we’ve seen a major shift in data center strategies where enterprise IT organizations are shifting applications and workloads to cloud, whether private or public. More and more, enterprises are leveraging software as-a-service (SaaS) applications and infrastructure as-a-service (IaaS) cloud services from leading providers like [Amazon AWS][3], [Google Cloud][4], [Microsoft Azure][5] and [Oracle Cloud Infrastructure][6]. This represents a dramatic shift in enterprise data traffic patterns as fewer and fewer applications are hosted within the walls of the traditional corporate data center.
|
||||
|
||||
There are several drivers for the shift to IaaS cloud services and SaaS apps, but business agility tops the list for most enterprises. The traditional IT model for provisioning and deprovisioning applications is rigid and inflexible and is no longer able to keep pace with changing business needs.
|
||||
|
||||
According to [LogicMonitor’s Cloud Vision 2020][7] study, more than 80 percent of enterprise workloads will run in the cloud by 2020 with more than 40 percent running on public cloud platforms. This major shift in the application consumption model is having a huge [impact on organizations and infrastructure][8]. A recent article entitled “[How Amazon Web Services is luring banks to the cloud][9],” published by CNBC, reported that some companies already have completely migrated all of their applications and IT workloads to public cloud infrastructures. An interesting fact is that while many enterprises must comply with stringent regulatory compliance mandates such as PCI-DSS or HIPAA, they still have made the move to the cloud. This tells us two things – the maturity of using public cloud services and the trust these organizations have in using them is at an all-time high. Again, it is all about speed and agility – without compromising performance, security and reliability.
|
||||
|
||||
### **Is there a direct correlation between moving to the cloud and adopting SD-WAN?**
|
||||
|
||||
As the cloud enables businesses to move faster, an SD-WAN architecture where top-down business intent is the driver is critical to ensuring success, especially when branch offices are geographically distributed across the globe. Traditional router-centric WAN architectures were never designed to support today’s cloud consumption model for applications in the most efficient way. With a conventional router-centric WAN approach, access to applications residing in the cloud means traversing unnecessary hops, resulting in wasted bandwidth, additional cost, added latency and potentially higher packet loss. In addition, under the existing, traditional WAN model where management tends to be rigid, complex network changes can be lengthy, whether setting up new branches or troubleshooting performance issues. This leads to inefficiencies and a costly operational model. Therefore, enterprises greatly benefit from taking a business-first WAN approach toward achieving greater agility in addition to realizing substantial CAPEX and OPEX savings.
|
||||
|
||||
A business-driven SD-WAN platform is purpose-built to tackle the challenges inherent to the traditional router-centric model and more aptly support today’s cloud consumption model. This means application policies are defined based on business intent, connecting users securely and directly to applications where ever they reside without unnecessary extra hops or security compromises. For example, if the application is hosted in the cloud and is trusted, a business-driven SD-WAN can automatically connect users to it without backhauling traffic to a POP or HQ data center. Now, in general this traffic is usually going across an internet link which, on its own, may not be secure. However, the right SD-WAN platform will have a unified stateful firewall built-in for local internet breakout allowing only branch-initiated sessions to enter the branch and providing the ability to service chain traffic to a cloud-based security service if necessary, before forwarding it to its final destination. If the application is moved and becomes hosted by another provider or perhaps back to a company’s own data center, traffic must be intelligently redirected, wherever the application is being hosted. Without automation and embedded machine learning, dynamic and intelligent traffic steering is impossible.
|
||||
|
||||
### **A closer look at how the Silver Peak EdgeConnect™ SD-WAN edge platform addresses these challenges: **
|
||||
|
||||
**Automate traffic steering and connectivity to cloud providers**
|
||||
|
||||
An [EdgeConnect][10] virtual instance is easily spun up in any of the [leading cloud providers][11] through their respective marketplaces. For an SD-WAN to intelligently steer traffic to its destination, it requires insights into both HTTP and HTTPS traffic; it must be able to identify apps on the first packet received in order to steer traffic to the right destination in accordance with business intent. This is critical capability because once a TCP connection is NAT’d with a public IP address, it cannot be switched thus it can’t be re-routed once a connection is established. So, the ability of EdgeConnect to identify, classify and automatically steer traffic based on the first packet – and not the second or tenth packet – to the correct destination will assure application SLAs, minimize wasting expensive bandwidth and deliver the highest quality of experience.
|
||||
|
||||
Another critical capability is automatic performance optimization. Irrespective of which link the traffic ends up traversing based on business intent and the unique requirements of the application, EdgeConnect automatically optimizes application performance without human intervention by correcting for out of order packets using Packet Order Correction (POC) or even under high latency conditions that can be related to distance or other issues. This is done using adaptive Forward Error Correction (FEC) and tunnel bonding where a virtual tunnel is created, resulting in a single logical overlay that traffic can be dynamically moved between the different paths as conditions change with each underlay WAN service. In this [lightboard video][12], Dinesh Fernando, a technical marketing engineer at Silver Peak, explains how EdgeConnect automates tunnel creation between sites and cloud providers, how it simplifies data transfers between multi-clouds, and how it improves application performance.
|
||||
|
||||
If your business is global and increasingly dependent on the cloud, the business-driven EdgeConnect SD-WAN edge platform enables seamless multi-cloud connectivity, turning the network into a business accelerant. EdgeConnect delivers:
|
||||
|
||||
1. A consistent deployment from the branch to the cloud, extending the reach of the SD-WAN into virtual private cloud environments
|
||||
2. Multi-cloud flexibility, making it easier to initiate and distribute resources across multiple cloud providers
|
||||
3. Investment protection by confidently migrating on premise IT resources to any combination of the leading public cloud platforms, knowing their cloud-hosted instances will be fully supported by EdgeConnect
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3397921/moving-to-the-cloud-sd-wan-matters.html
|
||||
|
||||
作者:[Rami Rammaha][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Rami-Rammaha/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/05/istock-899678028-100797709-large.jpg
|
||||
[2]: https://www.silver-peak.com/sd-wan/sd-wan-explained
|
||||
[3]: https://www.silver-peak.com/company/tech-partners/cloud/aws
|
||||
[4]: https://www.silver-peak.com/company/tech-partners/cloud/google-cloud
|
||||
[5]: https://www.silver-peak.com/company/tech-partners/cloud/microsoft-azure
|
||||
[6]: https://www.silver-peak.com/company/tech-partners/cloud/oracle-cloud
|
||||
[7]: https://www.logicmonitor.com/resource/the-future-of-the-cloud-a-cloud-influencers-survey/?utm_medium=pr&utm_source=businesswire&utm_campaign=cloudsurvey
|
||||
[8]: http://www.networkworld.com/article/3152024/lan-wan/in-the-age-of-digital-transformation-why-sd-wan-plays-a-key-role-in-the-transition.html
|
||||
[9]: http://www.cnbc.com/2016/11/30/how-amazon-web-services-is-luring-banks-to-the-cloud.html?__source=yahoo%257cfinance%257cheadline%257cheadline%257cstory&par=yahoo&doc=104135637
|
||||
[10]: https://www.silver-peak.com/products/unity-edge-connect
|
||||
[11]: https://www.silver-peak.com/company/tech-partners?strategic_partner_type=69
|
||||
[12]: https://www.silver-peak.com/resource-center/automate-connectivity-to-cloud-networking-with-sd-wan
|
||||
@ -0,0 +1,59 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (With Cray buy, HPE rules but does not own the supercomputing market)
|
||||
[#]: via: (https://www.networkworld.com/article/3397087/with-cray-buy-hpe-rules-but-does-not-own-the-supercomputing-market.html)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
With Cray buy, HPE rules but does not own the supercomputing market
|
||||
======
|
||||
In buying supercomputer vendor Cray, HPE has strengthened its high-performance-computing technology, but serious competitors remain.
|
||||
![Cray Inc.][1]
|
||||
|
||||
Hewlett Packard Enterprise was already the leader in the high-performance computing (HPC) sector before its announced acquisition of supercomputer maker Cray earlier this month. Now it has a commanding lead, but there are still competitors to the giant.
|
||||
|
||||
The news that HPE would shell out $1.3 billion to buy the company came just as Cray had announced plans to build three of the biggest systems yet — all exascale, and all with the same deployment time of 2021.
|
||||
|
||||
Sales had been slowing for HPC systems, but our government, with its endless supply of money, came to the rescue, throwing hundreds of millions at Cray for systems to be built at Lawrence Berkeley National Laboratory, Argonne National Laboratory and Oak Ridge National Laboratory.
|
||||
|
||||
**[ Read also:[How to plan a software-defined data-center network][2] ]**
|
||||
|
||||
And HPE sees a big revenue opportunity in HPC, a market that was $2 billion in 1990 and now nearly $30 billion, according to Steve Conway, senior vice president with Hyperion Research, which follows the HPC market. HPE thinks the HPC market will grow to $35 billion by 2021, and it hopes to earn a big chunk of that pie.
|
||||
|
||||
“They were solidly in the lead without Cray. They were already in a significant lead over the No. 2 company, Dell. This adds to their lead and gives them access to very high end of market, especially government supercomputers that sell for $300 million to $600 million each,” said Conway.
|
||||
|
||||
He’s not exaggerating. Earlier this month the U.S. Department of Energy announced a contract with Cray to build Frontier, an exascale supercomputer at Oak Ridge National Laboratory, sometime in 2021, with a $600 million price tag. Frontier will be powered by AMD Epyc processors and Radeon GPUs, which must have them doing backflips at AMD.
|
||||
|
||||
With Cray, HPE is sitting on a lot of technology for the supercomputing and even the high-end, non-HPC market. It had the ProLiant business, the bulk of server sales (and proof the Compaq acquisition wasn’t such a bad idea), Integrity NonStop mission-critical servers, the SGI business it acquired in in 2016, plus a variety running everything from Arm to Xeon Scalable processors.
|
||||
|
||||
Conway thinks all of those technologies fit in different spaces, so he doubts HPE will try to consolidate any of it. All HPE has said so far is it will keep the supercomputer products it has now under the Cray business unit.
|
||||
|
||||
But the company is still getting something it didn’t have. “It takes a certain kind of technical experience [to do HPC right] and only a few companies able to play at that level. Before this deal, HPE was not one of them,” said Conway.
|
||||
|
||||
And in the process, HPE takes Cray away from its many competitors: IBM, Lenovo, Dell/EMC, Huawei (well, not so much now), Super Micro, NEC, Hitachi, Fujitsu, and Atos.
|
||||
|
||||
“[The acquisition] doesn’t fundamentally change things because there’s still enough competitors that buyers can have competitive bids. But it’s gotten to be a much bigger market,” said Conway.
|
||||
|
||||
Cray sells a lot to government, but Conway thinks there is a new opportunity in the ever-expanding AI race. “Because HPC is indispensable at the forefront of AI, there is a new area for expanding the market,” he said.
|
||||
|
||||
Join the Network World communities on [Facebook][3] and [LinkedIn][4] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3397087/with-cray-buy-hpe-rules-but-does-not-own-the-supercomputing-market.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/06/the_cray_xc30_piz_daint_system_at_the_swiss_national_supercomputing_centre_via_cray_inc_3x2_978x652-100762113-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3284352/data-center/how-to-plan-a-software-defined-data-center-network.html
|
||||
[3]: https://www.facebook.com/NetworkWorld/
|
||||
[4]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,92 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Cisco security spotlights Microsoft Office 365 e-mail phishing increase)
|
||||
[#]: via: (https://www.networkworld.com/article/3398925/cisco-security-spotlights-microsoft-office-365-e-mail-phishing-increase.html)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
Cisco security spotlights Microsoft Office 365 e-mail phishing increase
|
||||
======
|
||||
Cisco blog follows DHS Cybersecurity and Infrastructure Security Agency (CISA) report detailing risks around Office 365 and other cloud services
|
||||
![weerapatkiatdumrong / Getty Images][1]
|
||||
|
||||
It’s no secret that if you have a cloud-based e-mail service, fighting off the barrage of security issues has become a maddening daily routine.
|
||||
|
||||
The leading e-mail service – in [Microsoft’s Office 365][2] package – seems to be getting the most attention from those attackers hellbent on stealing enterprise data or your private information via phishing attacks. Amazon and Google see their share of phishing attempts in their cloud-based services as well.
|
||||
|
||||
**[ Also see[What to consider when deploying a next generation firewall][3]. | Get regularly scheduled insights by [signing up for Network World newsletters][4]. ]**
|
||||
|
||||
But attackers are crafting and launching phishing campaigns targeting Office 365 users, [wrote][5] Ben Nahorney, a Threat Intelligence Analyst focused on covering the threat landscape for Cisco Security in a blog focusing on the Office 365 phishing issue.
|
||||
|
||||
Nahorney wrote of research from security vendor [Agari Data][6], that found over the last few quarters, there has been a steady increase in the number of phishing emails impersonating Microsoft. While Microsoft has long been the most commonly impersonated brand, it now accounts for more than half of all brand impersonations seen in the last quarter.
|
||||
|
||||
Recently cloud security firm Avanan wrote in its [annual phishing report][7], one in every 99 emails is a phishing attack, using malicious links and attachments as the main vector. “Of the phishing attacks we analyzed, 25 percent bypassed Office 365 security, a number that is likely to increase as attackers design new obfuscation methods that take advantage of zero-day vulnerabilities on the platform,” Avanan wrote.
|
||||
|
||||
The attackers attempt to steal a user’s login credentials with the goal of taking over accounts. If successful, attackers can often log into the compromised accounts, and perform a wide variety of malicious activity: Spread malware, spam and phishing emails from within the internal network; carry out tailored attacks such as spear phishing and [business email compromise][8] [a long-standing business scam that uses spear-phishing, social engineering, identity theft, e-mail spoofing], and target partners and customers, Nahorney wrote.
|
||||
|
||||
Nahorney wrote that at first glance, this may not seem very different than external email-based attacks. However, there is one critical distinction: The malicious emails sent are now coming from legitimate accounts.
|
||||
|
||||
**[[Prepare to become a Certified Information Security Systems Professional with this comprehensive online course from PluralSight. Now offering a 10-day free trial!][9] ]**
|
||||
|
||||
“For the recipient, it’s often even someone that they know, eliciting trust in a way that would not necessarily be afforded to an unknown source. To make things more complicated, attackers often leverage ‘conversation hijacking,’ where they deliver their payload by replying to an email that’s already located in the compromised inbox,” Nahorney stated.
|
||||
|
||||
The methods used by attackers to gain access to an Office 365 account are fairly straightforward, Nahorney wrote.
|
||||
|
||||
“The phishing campaigns usually take the form of an email from Microsoft. The email contains a request to log in, claiming the user needs to reset their password, hasn’t logged in recently or that there’s a problem with the account that needs their attention. A URL is included, enticing the reader to click to remedy the issue,” Nahorney wrote.
|
||||
|
||||
Once logged in, nefarious activities can go on unnoticed as the attacker has what look like authorized credentials.
|
||||
|
||||
“This gives the attacker time for reconnaissance: a chance to observe and plan additional attacks. Nor will this type of attack set off a security alert in the same way something like a brute-force attack against a webmail client will, where the attacker guesses password after password until they get in or are detected,” Nahorney stated.
|
||||
|
||||
Nahorney suggested the following steps customers can take to protect email:
|
||||
|
||||
* Use multi-factor authentication. If a login attempt requires a secondary authorization before someone is allowed access to an inbox, this will stop many attackers, even with phished credentials.
|
||||
* Deploy advanced anti-phishing technologies. Some machine-learning technologies can use local identity and relationship modeling alongside behavioral analytics to spot deception-based threats.
|
||||
* Run regular phishing exercises. Regular, mandated phishing exercises across the entire organization will help to train employees to recognize phishing emails, so that they don’t click on malicious URLs, or enter their credentials into malicious website.
|
||||
|
||||
|
||||
|
||||
### Homeland Security flags Office 365, other cloud email services
|
||||
|
||||
The U.S. government, too, has been warning customers of Office 365 and other cloud-based email services that they should be on alert for security risks. The US Department of Homeland Security's Cybersecurity and Infrastructure Security Agency (CISA) this month [issued a report targeting][10] Office 365 and other cloud services saying:
|
||||
|
||||
“Organizations that used a third party have had a mix of configurations that lowered their overall security posture (e.g., mailbox auditing disabled, unified audit log disabled, multi-factor authentication disabled on admin accounts). In addition, the majority of these organizations did not have a dedicated IT security team to focus on their security in the cloud. These security oversights have led to user and mailbox compromises and vulnerabilities.”
|
||||
|
||||
The agency also posted remediation suggestions including:
|
||||
|
||||
* Enable unified audit logging in the Security and Compliance Center.
|
||||
* Enable mailbox auditing for each user.
|
||||
* Ensure Azure AD password sync is planned for and configured correctly, prior to migrating users.
|
||||
* Disable legacy email protocols, if not required, or limit their use to specific users.
|
||||
|
||||
|
||||
|
||||
Join the Network World communities on [Facebook][11] and [LinkedIn][12] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3398925/cisco-security-spotlights-microsoft-office-365-e-mail-phishing-increase.html
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/05/cso_phishing_social_engineering_security_threat_by_weerapatkiatdumrong_gettyimages-489433130_3x2_2400x1600-100796450-large.jpg
|
||||
[2]: https://docs.microsoft.com/en-us/office365/securitycompliance/security-roadmap
|
||||
[3]: https://www.networkworld.com/article/3236448/lan-wan/what-to-consider-when-deploying-a-next-generation-firewall.html
|
||||
[4]: https://www.networkworld.com/newsletters/signup.html
|
||||
[5]: https://blogs.cisco.com/security/office-365-phishing-threat-of-the-month
|
||||
[6]: https://www.agari.com/
|
||||
[7]: https://www.avanan.com/hubfs/2019-Global-Phish-Report.pdf
|
||||
[8]: https://www.networkworld.com/article/3195072/fbi-ic3-vile-5b-business-e-mail-scam-continues-to-breed.html
|
||||
[9]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
|
||||
[10]: https://www.us-cert.gov/ncas/analysis-reports/AR19-133A
|
||||
[11]: https://www.facebook.com/NetworkWorld/
|
||||
[12]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,53 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Nvidia launches edge computing platform for AI processing)
|
||||
[#]: via: (https://www.networkworld.com/article/3397841/nvidia-launches-edge-computing-platform-for-ai-processing.html)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Nvidia launches edge computing platform for AI processing
|
||||
======
|
||||
EGX platform goes to the edge to do as much processing there as possible before sending data upstream to major data centers.
|
||||
![Leo Wolfert / Getty Images][1]
|
||||
|
||||
Nvidia is launching a new platform called EGX Platform designed to bring real-time artificial intelligence (AI) to edge networks. The idea is to put AI computing closer to where sensors collect data before it is sent to larger data centers.
|
||||
|
||||
The edge serves as a buffer to data sent to data centers. It whittles down the data collected and only sends what is relevant up to major data centers for processing. This can mean discarding more than 90% of data collected, but the trick is knowing which data to keep and which to discard.
|
||||
|
||||
“AI is required in this data-driven world,” said Justin Boitano, senior director for enterprise and edge computing at Nvidia, on a press call last Friday. “We analyze data near the source, capture anomalies and report anomalies back to the mothership for analysis.”
|
||||
|
||||
**[ Now read[20 hot jobs ambitious IT pros should shoot for][2]. ]**
|
||||
|
||||
Boitano said we are hitting crossover where there is more compute at edge than cloud because more work needs to be done there.
|
||||
|
||||
EGX comes from 14 server vendors in a range of form factors, combining AI with network, security and storage from Mellanox. Boitano said that the racks will fit in any industry-standard rack, so they will fit into edge containers from the likes of Vapor IO and Schneider Electric.
|
||||
|
||||
EGX uses Nvidia’s low-power Jetson Nano processor, but also all the way up to Nvidia T4 processors that can deliver more than 10,000 trillion operations per second (TOPS) for real-time speech recognition and other real-time AI tasks.
|
||||
|
||||
Nvdia is working on software stack called Nvidia Edge Stack that can be updated constantly, and the software runs in containers, so no reboots are required, just a restart of the container. EGX runs enterprise-grade Kubernetes container platforms like Red Hat Openshift.
|
||||
|
||||
Edge Stack is optimized software that includes Nvidia drivers, a CUDA Kubernetes plugin, a CUDA container runtime, CUDA-X libraries and containerized AI frameworks and applications, including TensorRT, TensorRT Inference Server and DeepStream.
|
||||
|
||||
The company is boasting more than 40 early adopters, including BMW Group Logistics, which uses EGX and its own Isaac robotic platforms to handle increasingly complex logistics with real-time efficiency.
|
||||
|
||||
Join the Network World communities on [Facebook][3] and [LinkedIn][4] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3397841/nvidia-launches-edge-computing-platform-for-ai-processing.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/02/industry_4-0_industrial_iot_smart_factory_by_leowolfert_gettyimages-689799380_2400x1600-100788464-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3276025/careers/20-hot-jobs-ambitious-it-pros-should-shoot-for.html
|
||||
[3]: https://www.facebook.com/NetworkWorld/
|
||||
[4]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,63 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Satellite-based internet possible by year-end, says SpaceX)
|
||||
[#]: via: (https://www.networkworld.com/article/3398940/space-internet-maybe-end-of-year-says-spacex.html)
|
||||
[#]: author: (Patrick Nelson https://www.networkworld.com/author/Patrick-Nelson/)
|
||||
|
||||
Satellite-based internet possible by year-end, says SpaceX
|
||||
======
|
||||
Amazon, Tesla-associated SpaceX and OneWeb are emerging as just some of the potential suppliers of a new kind of data-friendly satellite internet service that could bring broadband IoT connectivity to most places on Earth.
|
||||
![Getty Images][1]
|
||||
|
||||
With SpaceX’s successful launch of an initial array of broadband-internet-carrying satellites last week, and Amazon’s surprising posting of numerous satellite engineering-related job openings on its [job board][2] this month, one might well be asking if the next-generation internet space race is finally getting going. (I first wrote about [OneWeb’s satellite internet plans][3] it was concocting with Airbus four years ago.)
|
||||
|
||||
This new batch of satellite-driven internet systems, if they work and are eventually switched on, could provide broadband to most places, including previously internet-barren locations, such as rural areas. That would be good for high-bandwidth, low-latency remote-internet of things (IoT) and increasingly important edge-server connections for verticals like oil and gas and maritime. [Data could even end up getting stored in compliance-friendly outer space, too][4]. Leaky ground-based connections, also, perhaps a thing of the past.
|
||||
|
||||
Of the principal new internet suppliers, SpaceX has gotten farthest along. That’s in part because it has commercial impetus. It needed to create payload for its numerous rocket projects. The Tesla electric-car-associated company (the two firms share materials science) has not only launched its first tranche of 60 satellites for its own internet constellation, called Starlink, but also successfully launched numerous batches (making up the full constellation of 75 satellites) for Iridium’s replacement, an upgraded constellation called Iridium NEXT.
|
||||
|
||||
[The time of 5G is almost here][5]
|
||||
|
||||
Potential competitor OneWeb launched its first six Airbus-built satellites in February. [It has plans for 900 more][6]. SpaceX has been approved for 4,365 more by the FCC, and Project Kuiper, as Amazon’s space internet project is known, wants to place 3,236 satellites in orbit, according to International Telecommunication Union filings [discovered by _GeekWire_][7] earlier this year. [Startup LeoSat, which I wrote about last year, aims to build an internet backbone constellation][8]. Facebook, too, is exploring [space-delivered internet][9].
|
||||
|
||||
### Why the move to space?
|
||||
|
||||
Laser technical progress, where data is sent in open, free space, rather than via a restrictive, land-based cable or via traditional radio paths, is partly behind this space-internet rush. “Bits travel faster in free space than in glass-fiber cable,” LeoSat explained last year. Additionally, improving microprocessor tech is also part of the mix.
|
||||
|
||||
One important difference from existing older-generation satellite constellations is that this new generation of internet satellites will be located in low Earth orbit (LEO). Initial Starlink satellites will be placed at about 350 miles above Earth, with later launches deployed at 710 miles.
|
||||
|
||||
There’s an advantage to that. Traditional satellites in geostationary orbit, or GSO, have been deployed about 22,000 miles up. That extra distance versus LEO introduces latency and is one reason earlier generations of Internet satellites are plagued by slow round-trip times. Latency didn’t matter when GSO was introduced in 1964, and commercial satellites, traditionally, have been pitched as one-way video links, such as are used by sporting events for broadcast, and not for data.
|
||||
|
||||
And when will we get to experience these new ISPs? “Starlink is targeted to offer service in the Northern U.S. and Canadian latitudes after six launches,” [SpaceX says on its website][10]. Each launch would deliver about 60 satellites. “SpaceX is targeting two to six launches by the end of this year.”
|
||||
|
||||
Global penetration of the “populated world” could be obtained after 24 launches, it thinks.
|
||||
|
||||
Join the Network World communities on [Facebook][11] and [LinkedIn][12] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3398940/space-internet-maybe-end-of-year-says-spacex.html
|
||||
|
||||
作者:[Patrick Nelson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Patrick-Nelson/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/10/network_iot_world-map_us_globe_nodes_global-100777483-large.jpg
|
||||
[2]: https://www.amazon.jobs/en/teams/projectkuiper
|
||||
[3]: https://www.itworld.com/article/2938652/space-based-internet-starts-to-get-serious.html
|
||||
[4]: https://www.networkworld.com/article/3200242/data-should-be-stored-data-in-space-firm-says.html
|
||||
[5]: https://www.networkworld.com/article/3354477/mobile-world-congress-the-time-of-5g-is-almost-here.html
|
||||
[6]: https://www.airbus.com/space/telecommunications-satellites/oneweb-satellites-connection-for-people-all-over-the-globe.html
|
||||
[7]: https://www.geekwire.com/2019/amazon-lists-scores-jobs-bellevue-project-kuiper-broadband-satellite-operation/
|
||||
[8]: https://www.networkworld.com/article/3328645/space-data-backbone-gets-us-approval.html
|
||||
[9]: https://www.networkworld.com/article/3338081/light-based-computers-to-be-5000-times-faster.html
|
||||
[10]: https://www.starlink.com/
|
||||
[11]: https://www.facebook.com/NetworkWorld/
|
||||
[12]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,69 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Survey finds SD-WANs are hot, but satisfaction with telcos is not)
|
||||
[#]: via: (https://www.networkworld.com/article/3398478/survey-finds-sd-wans-are-hot-but-satisfaction-with-telcos-is-not.html)
|
||||
[#]: author: (Zeus Kerravala https://www.networkworld.com/author/Zeus-Kerravala/)
|
||||
|
||||
Survey finds SD-WANs are hot, but satisfaction with telcos is not
|
||||
======
|
||||
A recent survey of over 400 IT executives by Cato Networks found that legacy telcos might be on the outside looking in for SD-WANs.
|
||||
![istock][1]
|
||||
|
||||
This week SD-WAN vendor Cato Networks announced the results of its [Telcos and the Future of the WAN in 2019 survey][2]. The study was a mix of companies of all sizes, with 42% being enterprise-class (over 2,500 employees). More than 70% had a network with more than 10 locations, and almost a quarter (24%) had over 100 sites. All of the respondents have a cloud presence, and almost 80% have at least two data centers. The survey had good geographic diversity, with 57% of respondents coming from the U.S. and 24% from Europe.
|
||||
|
||||
Highlights of the survey include the following key findings:
|
||||
|
||||
## **SD-WANs are hot but not a panacea to all networking challenges**
|
||||
|
||||
The survey found that 44% of respondents have already deployed or will deploy an SD-WAN within the next 12 months. This number is up sharply from 25% when Cato ran the survey a year ago. Another 33% are considering SD-WAN but have no immediate plans to deploy. The primary drivers for the evolution of the WAN are improved internet access (46%), increased bandwidth (39%), improved last-mile availability (38%) and reduced WAN costs (37%). It’s good to see cost savings drop to fourth in motivation, since there is so much more to SD-WAN.
|
||||
|
||||
[The time of 5G is almost here][3]
|
||||
|
||||
It’s interesting that the majority of respondents believe SD-WAN alone can’t address all challenges facing the WAN. A whopping 85% stated they would be confronting issues not addressed by SD-WAN alone. This includes secure, local internet breakout, improved visibility, and control over mobile access to cloud apps. This indicates that customers are looking for SD-WAN to be the foundation of the WAN but understand that other technologies need to be deployed as well.
|
||||
|
||||
## **Telco dissatisfaction is high**
|
||||
|
||||
The traditional telco has been a point of frustration for network professionals for years, and the survey spelled that out loud and clear. Prior to being an analyst, I held a number of corporate IT positions and found telcos to be the single most frustrating group of companies to deal with. The problem was, there was no choice. If you need MPLS services, you need a telco. The same can’t be said for SD-WANs, though; businesses have more choices.
|
||||
|
||||
Respondents to the survey ranked telco service as “average.” It’s been well documented that we are now in the customer-experience era and “good enough” service is no longer good enough. Regarding pricing, 54% gave telcos a failing grade. Although price isn’t everything, this will certainly open the door to competitive SD-WAN vendors. Respondents gave the highest marks for overall experience to SaaS providers, followed by cloud computing suppliers. Global telcos scored the lowest of all vendor types.
|
||||
|
||||
A look deeper explains the frustration level. The network is now mission-critical for companies, but 48% stated they are able to reach the support personnel with the right expertise to solve a problem only on a second attempt. No retailer, airline, hotel or other type of company could survive this, but telco customers had no other options for years.
|
||||
|
||||
**[[Prepare to become a Certified Information Security Systems Professional with this comprehensive online course from PluralSight. Now offering a 10-day free trial!][4] ]**
|
||||
|
||||
Another interesting set of data points is the speed at which telcos address customer needs. Digital businesses compete on speed, but telco process is the antithesis of fast. Moves, adds and changes take at least one business day for half of the respondents. Also, 70% indicated that opening a new location takes 15 days, and 38% stated it requires 45 days or more.
|
||||
|
||||
## **Security is now part of SD-WAN**
|
||||
|
||||
The use of broadband, cloud access and other trends raise the bar on security for SD-WAN, and the survey confirmed that respondents are skeptical that SD-WANs could address these issues. Seventy percent believe SD-WANs can’t address malware/ransomware, and 49% don’t think SD-WAN helps with enforcing company policies on mobile users. Because of this, network professionals are forced to buy additional security tools from other vendors, but that can drive up complexity. SD-WAN vendors that have intrinsic security capabilities can use that as a point of differentiation.
|
||||
|
||||
## **Managed services are critical to the growth of SD-WANs**
|
||||
|
||||
The survey found that 75% of respondents are using some kind of managed service provider, versus only 25% using an appliance vendor. This latter number was 32% last year. I’m not surprised by this shift and expect it to continue. Legacy WANs were inefficient but straightforward to deploy. D-WANs are highly agile and more cost-effective, but complexity has gone through the roof. Network engineers need to factor in cloud connectivity, distributed security, application performance, broadband connectivity and other issues. Managed services can help businesses enjoy the benefits of SD-WAN while masking the complexity.
|
||||
|
||||
Despite the desire to use an MSP, respondents don’t want to give up total control. Eighty percent stated they preferred self-service or co-managed models. This further explains the shift away from telcos, since they typically work with fully managed models.
|
||||
|
||||
Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3398478/survey-finds-sd-wans-are-hot-but-satisfaction-with-telcos-is-not.html
|
||||
|
||||
作者:[Zeus Kerravala][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Zeus-Kerravala/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/02/istock-465661573-100750447-large.jpg
|
||||
[2]: https://www.catonetworks.com/news/digital-transformation-survey/
|
||||
[3]: https://www.networkworld.com/article/3354477/mobile-world-congress-the-time-of-5g-is-almost-here.html
|
||||
[4]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
77
sources/talk/20190601 HPE Synergy For Dummies.md
Normal file
77
sources/talk/20190601 HPE Synergy For Dummies.md
Normal file
@ -0,0 +1,77 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (HPE Synergy For Dummies)
|
||||
[#]: via: (https://www.networkworld.com/article/3399618/hpe-synergy-for-dummies.html)
|
||||
[#]: author: (HPE https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
HPE Synergy For Dummies
|
||||
======
|
||||
|
||||
![istock/venimo][1]
|
||||
|
||||
Business must move fast today to keep up with competitive forces. That means IT must provide an agile — anytime, anywhere, any workload — infrastructure that ensures growth, boosts productivity, enhances innovation, improves the customer experience, and reduces risk.
|
||||
|
||||
A composable infrastructure helps organizations achieve these important objectives that are difficult — if not impossible — to achieve via traditional means, such as the ability to do the following:
|
||||
|
||||
* Deploy quickly with simple flexing, scaling, and updating
|
||||
* Run workloads anywhere — on physical servers, on virtual servers, or in containers
|
||||
* Operate any workload upon which the business depends, without worrying about infrastructure resources or compatibility
|
||||
* Ensure the infrastructure is able to provide the right service levels so the business can stay in business
|
||||
|
||||
|
||||
|
||||
In other words, IT must inherently become part of the fabric of products and services that are rapidly innovated at every company, with an anytime, anywhere, any workload infrastructure.
|
||||
|
||||
**The anytime paradigm**
|
||||
|
||||
For organizations that seek to embrace DevOps, collaboration is the cultural norm. Development and operations staff work side‐by‐side to support software across its entire life cycle, from initial idea to production support.
|
||||
|
||||
To provide DevOps groups — as well as other stakeholders — the IT infrastructure required at the rate at which it is demanded, enterprise IT must increase its speed, agility, and flexibility to enable people anytime composition and re‐composition of resources. Composable infrastructure enables this anytime paradigm.
|
||||
|
||||
**The anywhere ability**
|
||||
|
||||
Bare metal and virtualized workloads are just two application foundations that need to be supported in the modern data center. Today, containers are emerging as a compelling construct, providing significant benefits for certain kinds of workloads. Unfortunately, with traditional infrastructure approaches, IT needs to build out custom, unique infrastructure to support them, at least until an infrastructure is deployed that can seamlessly handle physical, virtual, and container‐based workloads.
|
||||
|
||||
Each environment would need its own hardware and software and might even need its own staff members supporting it.
|
||||
|
||||
Composable infrastructure provides an environment that supports the ability to run physical, virtual, or containerized workloads.
|
||||
|
||||
**Support any workload**
|
||||
|
||||
Do you have a legacy on‐premises application that you have to keep running? Do you have enterprise resource planning (ERP) software that currently powers your business but that will take ten years to phase out? At the same time, do you have an emerging DevOps philosophy under which you’d like to empower developers to dynamically create computing environments as a part of their development efforts?
|
||||
|
||||
All these things can be accomplished simultaneously on the right kind of infrastructure. Composable infrastructure enables any workload to operate as a part of the architecture.
|
||||
|
||||
**HPE Synergy**
|
||||
|
||||
HPE Synergy brings to life the architectural principles of composable infrastructure. It is a single, purpose-built platform that reduces operational complexity for workloads and increases operational velocity for applications and services.
|
||||
|
||||
Download a copy of the [HPE Synergy for Dummies eBook][2] to learn how to:
|
||||
|
||||
* Infuse the IT architecture with the ability to enable agility, flexibility, and speed
|
||||
* Apply composable infrastructure concepts to support both traditional and cloud-native applications
|
||||
* Deploy HPE Synergy infrastructure to revolutionize workload support in the data center
|
||||
|
||||
|
||||
|
||||
Also, you will find more information about HPE Synergy [here][3].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3399618/hpe-synergy-for-dummies.html
|
||||
|
||||
作者:[HPE][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/06/istock-1026657600-100798064-large.jpg
|
||||
[2]: https://www.hpe.com/us/en/resources/integrated-systems/synergy-for-dummies.html
|
||||
[3]: http://hpe.com/synergy
|
||||
@ -0,0 +1,28 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (True Hyperconvergence at Scale: HPE Simplivity With Composable Fabric)
|
||||
[#]: via: (https://www.networkworld.com/article/3399619/true-hyperconvergence-at-scale-hpe-simplivity-with-composable-fabric.html)
|
||||
[#]: author: (HPE https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
True Hyperconvergence at Scale: HPE Simplivity With Composable Fabric
|
||||
======
|
||||
|
||||
Many hyperconverged solutions only focus on software-defined storage. However, many networking functions and technologies can be consolidated for simplicity and scale in the data center. This video describes how HPE SimpliVity with Composable Fabric gives organizations the power to run any virtual machine anywhere, anytime. Read more about HPE SimpliVity [here][1].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3399619/true-hyperconvergence-at-scale-hpe-simplivity-with-composable-fabric.html
|
||||
|
||||
作者:[HPE][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://hpe.com/info/simplivity
|
||||
@ -0,0 +1,71 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (IoT Roundup: New research on IoT security, Microsoft leans into IoT)
|
||||
[#]: via: (https://www.networkworld.com/article/3398607/iot-roundup-new-research-on-iot-security-microsoft-leans-into-iot.html)
|
||||
[#]: author: (Jon Gold https://www.networkworld.com/author/Jon-Gold/)
|
||||
|
||||
IoT Roundup: New research on IoT security, Microsoft leans into IoT
|
||||
======
|
||||
Verizon sets up widely available narrow-band IoT service, while most Americans think IoT manufacturers should ensure their products protect personal information.
|
||||
As with any technology whose use is expanding at such speed, it can be tough to track exactly what’s going on in the [IoT][1] world – everything from basic usage numbers to customer attitudes to more in-depth slices of the market is constantly changing. Fortunately, the month of May brought several new pieces of research to light, which should help provide at least a partial outline of what’s really happening in IoT.
|
||||
|
||||
### Internet of things polls
|
||||
|
||||
Not all of the news is good. An IPSOS Mori poll performed on behalf of the Internet Society and Consumers International (respectively, an umbrella organization for open development and Internet use and a broad-based consumer advocacy group) found that, despite the skyrocketing numbers of smart devices in circulation around the world, more than half of users in large parts of the western world don’t trust those devices to safeguard their privacy.
|
||||
|
||||
**More on IoT:**
|
||||
|
||||
* [What is the IoT? How the internet of things works][2]
|
||||
* [What is edge computing and how it’s changing the network][3]
|
||||
* [Most powerful Internet of Things companies][4]
|
||||
* [10 Hot IoT startups to watch][5]
|
||||
* [The 6 ways to make money in IoT][6]
|
||||
* [What is digital twin technology? [and why it matters]][7]
|
||||
* [Blockchain, service-centric networking key to IoT success][8]
|
||||
* [Getting grounded in IoT networking and security][9]
|
||||
* [Building IoT-ready networks must become a priority][10]
|
||||
* [What is the Industrial IoT? [And why the stakes are so high]][11]
|
||||
|
||||
|
||||
|
||||
While almost 70 percent of respondents owned connected devices, 55 percent said they didn’t feel their personal information was adequately protected by manufacturers. A further 28 percent said they had avoided using connected devices – smart home, fitness tracking and similar consumer gadgetry – primarily because they were concerned over privacy issues, and a whopping 85 percent of Americans agreed with the argument that manufacturers had a responsibility to produce devices that protected personal information.
|
||||
|
||||
Those concerns are understandable, according to data from the Ponemon Institute, a tech-research organization. Its survey of corporate risk and security personnel, released in early May, found that there have been few concerted efforts to limit exposure to IoT-based security threats, and that those threats are sharply on the rise when compared to past years, with the percentage of organizations that had experienced a data breach related to unsecured IoT devices rising from 15 percent in fiscal 2017 to 26 percent in fiscal 2019.
|
||||
|
||||
Beyond a lack of organizational wherewithal to address those threats, part of the problem in some verticals is technical. Security vendor Forescout said earlier this month that its research showed 40 percent of all healthcare IT environments had more than 20 different operating systems, and more than 30 percent had more than 100 – hardly an ideal situation for smooth patching and updating.
|
||||
|
||||
To continue reading this article register now
|
||||
|
||||
[Get Free Access][12]
|
||||
|
||||
[Learn More][13] Existing Users [Sign In][12]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3398607/iot-roundup-new-research-on-iot-security-microsoft-leans-into-iot.html
|
||||
|
||||
作者:[Jon Gold][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Jon-Gold/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3207535/what-is-iot-how-the-internet-of-things-works.html
|
||||
[2]: https://www.networkworld.com/article/3207535/internet-of-things/what-is-the-iot-how-the-internet-of-things-works.html
|
||||
[3]: https://www.networkworld.com/article/3224893/internet-of-things/what-is-edge-computing-and-how-it-s-changing-the-network.html
|
||||
[4]: https://www.networkworld.com/article/2287045/internet-of-things/wireless-153629-10-most-powerful-internet-of-things-companies.html
|
||||
[5]: https://www.networkworld.com/article/3270961/internet-of-things/10-hot-iot-startups-to-watch.html
|
||||
[6]: https://www.networkworld.com/article/3279346/internet-of-things/the-6-ways-to-make-money-in-iot.html
|
||||
[7]: https://www.networkworld.com/article/3280225/internet-of-things/what-is-digital-twin-technology-and-why-it-matters.html
|
||||
[8]: https://www.networkworld.com/article/3276313/internet-of-things/blockchain-service-centric-networking-key-to-iot-success.html
|
||||
[9]: https://www.networkworld.com/article/3269736/internet-of-things/getting-grounded-in-iot-networking-and-security.html
|
||||
[10]: https://www.networkworld.com/article/3276304/internet-of-things/building-iot-ready-networks-must-become-a-priority.html
|
||||
[11]: https://www.networkworld.com/article/3243928/internet-of-things/what-is-the-industrial-iot-and-why-the-stakes-are-so-high.html
|
||||
[12]: javascript://
|
||||
[13]: /learn-about-insider/
|
||||
@ -0,0 +1,102 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (It’s time for the IoT to 'optimize for trust')
|
||||
[#]: via: (https://www.networkworld.com/article/3399817/its-time-for-the-iot-to-optimize-for-trust.html)
|
||||
[#]: author: (Fredric Paul https://www.networkworld.com/author/Fredric-Paul/)
|
||||
|
||||
It’s time for the IoT to 'optimize for trust'
|
||||
======
|
||||
If we can't trust the internet of things (IoT) to gather accurate data and use it appropriately, IoT adoption and innovation are likely to suffer.
|
||||
![Bose][1]
|
||||
|
||||
One of the strengths of internet of things (IoT) technology is that it can do so many things well. From smart toothbrushes to predictive maintenance on jetliners, the IoT has more use cases than you can count. The result is that various IoT uses cases require optimization for particular characteristics, from cost to speed to long life, as well as myriad others.
|
||||
|
||||
But in a recent post, "[How the internet of things will change advertising][2]" (which you should definitely read), the always-insightful Stacy Higginbotham tossed in a line that I can’t stop thinking about: “It's crucial that the IoT optimizes for trust."
|
||||
|
||||
**[ Read also: Network World's[corporate guide to addressing IoT security][3] ]**
|
||||
|
||||
### Trust is the IoT's most important attribute
|
||||
|
||||
Higginbotham was talking about optimizing for trust as opposed to clicks, but really, trust is more important than just about any other value in the IoT. It’s more important than bandwidth usage, more important than power usage, more important than cost, more important than reliability, and even more important than security and privacy (though they are obviously related). In fact, trust is the critical factor in almost every aspect of the IoT.
|
||||
|
||||
Don’t believe me? Let’s take a quick look at some recent developments in the field:
|
||||
|
||||
For one thing, IoT devices often don’t take good care of the data they collect from you. Over 90% of data transactions on IoT devices are not fully encrypted, according to a new [study from security company Zscaler][4]. The [problem][5], apparently, is that many companies have large numbers of consumer-grade IoT devices on their networks. In addition, many IoT devices are attached to the companies’ general networks, and if that network is breached, the IoT devices and data may also be compromised.
|
||||
|
||||
In some cases, ownership of IoT data can raise surprisingly serious trust concerns. According to [Kaiser Health News][6], smartphone sleep apps, as well as smart beds and smart mattress pads, gather amazingly personal information: “It knows when you go to sleep. It knows when you toss and turn. It may even be able to tell when you’re having sex.” And while companies such as Sleep Number say they don’t share the data they gather, their written privacy policies clearly state that they _can_.
|
||||
|
||||
### **Lack of trust may lead to new laws**
|
||||
|
||||
In California, meanwhile, "lawmakers are pushing for new privacy rules affecting smart speakers” such as the Amazon Echo. According to the _[LA Times][7]_ , the idea is “to ensure that the devices don’t record private conversations without permission,” requiring a specific opt-in process. Why is this an issue? Because consumers—and their elected representatives—don’t trust that Amazon, or any IoT vendor, will do the right thing with the data it collects from the IoT devices it sells—perhaps because it turns out that thousands of [Amazon employees have been listening in on what Alexa users are][8] saying to their Echo devices.
|
||||
|
||||
The trust issues get even trickier when you consider that Amazon reportedly considered letting Alexa listen to users even without a wake word like “Alexa” or “computer,” and is reportedly working on [wearable devices designed to read human emotions][9] from listening to your voice.
|
||||
|
||||
“The trust has been breached,” said California Assemblyman Jordan Cunningham (R-Templeton) to the _LA Times_.
|
||||
|
||||
As critics of the bill ([AB 1395][10]) point out, the restrictions matter because voice assistants require this data to improve their ability to correctly understand and respond to requests.
|
||||
|
||||
### **Some first steps toward increasing trust**
|
||||
|
||||
Perhaps recognizing that the IoT needs to be optimized for trust so that we are comfortable letting it do its job, Amazon recently introduced a new Alexa voice command: “[Delete what I said today][11].”
|
||||
|
||||
Moves like that, while welcome, will likely not be enough.
|
||||
|
||||
For example, a [new United Nations report][12] suggests that “voice assistants reinforce harmful gender stereotypes” when using female-sounding voices and names like Alexa and Siri. Put simply, “Siri’s ‘female’ obsequiousness—and the servility expressed by so many other digital assistants projected as young women—provides a powerful illustration of gender biases coded into technology products, pervasive in the technology sector and apparent in digital skills education.” I'm not sure IoT vendors are eager—or equipped—to tackle issues like that.
|
||||
|
||||
**More on IoT:**
|
||||
|
||||
* [What is the IoT? How the internet of things works][13]
|
||||
* [What is edge computing and how it’s changing the network][14]
|
||||
* [Most powerful Internet of Things companies][15]
|
||||
* [10 Hot IoT startups to watch][16]
|
||||
* [The 6 ways to make money in IoT][17]
|
||||
* [What is digital twin technology? [and why it matters]][18]
|
||||
* [Blockchain, service-centric networking key to IoT success][19]
|
||||
* [Getting grounded in IoT networking and security][20]
|
||||
* [Building IoT-ready networks must become a priority][21]
|
||||
* [What is the Industrial IoT? [And why the stakes are so high]][22]
|
||||
|
||||
|
||||
|
||||
Join the Network World communities on [Facebook][23] and [LinkedIn][24] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3399817/its-time-for-the-iot-to-optimize-for-trust.html
|
||||
|
||||
作者:[Fredric Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Fredric-Paul/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/09/bose-sleepbuds-2-100771579-large.jpg
|
||||
[2]: https://mailchi.mp/iotpodcast/stacey-on-iot-how-iot-changes-advertising?e=6bf9beb394
|
||||
[3]: https://www.networkworld.com/article/3269165/internet-of-things/a-corporate-guide-to-addressing-iot-security-concerns.html
|
||||
[4]: https://www.zscaler.com/blogs/research/iot-traffic-enterprise-rising-so-are-threats
|
||||
[5]: https://www.csoonline.com/article/3397044/over-90-of-data-transactions-on-iot-devices-are-unencrypted.html
|
||||
[6]: https://khn.org/news/a-wake-up-call-on-data-collecting-smart-beds-and-sleep-apps/
|
||||
[7]: https://www.latimes.com/politics/la-pol-ca-alexa-google-home-privacy-rules-california-20190528-story.html
|
||||
[8]: https://www.usatoday.com/story/tech/2019/04/11/amazon-employees-listening-alexa-customers/3434732002/
|
||||
[9]: https://www.bloomberg.com/news/articles/2019-05-23/amazon-is-working-on-a-wearable-device-that-reads-human-emotions
|
||||
[10]: https://leginfo.legislature.ca.gov/faces/billTextClient.xhtml?bill_id=201920200AB1395
|
||||
[11]: https://venturebeat.com/2019/05/29/amazon-launches-alexa-delete-what-i-said-today-voice-command/
|
||||
[12]: https://unesdoc.unesco.org/ark:/48223/pf0000367416.page=1
|
||||
[13]: https://www.networkworld.com/article/3207535/internet-of-things/what-is-the-iot-how-the-internet-of-things-works.html
|
||||
[14]: https://www.networkworld.com/article/3224893/internet-of-things/what-is-edge-computing-and-how-it-s-changing-the-network.html
|
||||
[15]: https://www.networkworld.com/article/2287045/internet-of-things/wireless-153629-10-most-powerful-internet-of-things-companies.html
|
||||
[16]: https://www.networkworld.com/article/3270961/internet-of-things/10-hot-iot-startups-to-watch.html
|
||||
[17]: https://www.networkworld.com/article/3279346/internet-of-things/the-6-ways-to-make-money-in-iot.html
|
||||
[18]: https://www.networkworld.com/article/3280225/internet-of-things/what-is-digital-twin-technology-and-why-it-matters.html
|
||||
[19]: https://www.networkworld.com/article/3276313/internet-of-things/blockchain-service-centric-networking-key-to-iot-success.html
|
||||
[20]: https://www.networkworld.com/article/3269736/internet-of-things/getting-grounded-in-iot-networking-and-security.html
|
||||
[21]: https://www.networkworld.com/article/3276304/internet-of-things/building-iot-ready-networks-must-become-a-priority.html
|
||||
[22]: https://www.networkworld.com/article/3243928/internet-of-things/what-is-the-industrial-iot-and-why-the-stakes-are-so-high.html
|
||||
[23]: https://www.facebook.com/NetworkWorld/
|
||||
[24]: https://www.linkedin.com/company/network-world
|
||||
102
sources/talk/20190604 5G will augment Wi-Fi, not replace it.md
Normal file
102
sources/talk/20190604 5G will augment Wi-Fi, not replace it.md
Normal file
@ -0,0 +1,102 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (GraveAccent)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5G will augment Wi-Fi, not replace it)
|
||||
[#]: via: (https://www.networkworld.com/article/3399978/5g-will-augment-wi-fi-not-replace-it.html)
|
||||
[#]: author: (Zeus Kerravala https://www.networkworld.com/author/Zeus-Kerravala/)
|
||||
|
||||
5G will augment Wi-Fi, not replace it
|
||||
======
|
||||
Jeff Lipton, vice president of strategy and corporate development at Aruba, adds a dose of reality to the 5G hype, discussing how it and Wi-Fi will work together and how to maximize the value of both.
|
||||
![Thinkstock][1]
|
||||
|
||||
There’s arguably no technology topic that’s currently hotter than [5G][2]. It was a major theme of the most recent [Mobile World Congress][3] show and has reared its head in other events such as Enterprise Connect and almost every vendor event I attend.
|
||||
|
||||
Some vendors have positioned 5G as a panacea to all network problems and predict it will eradicate all other forms of networking. Views like that are obviously extreme, but I do believe that 5G will have an impact on the networking industry and is something that network engineers should be aware of.
|
||||
|
||||
To help bring some realism to the 5G hype, I recently interviewed Jeff Lipton, vice president of strategy and corporate development at Aruba, a Hewlett Packard company, as I know HPE has been deeply involved in the evolution of both 5G and Wi-Fi.
|
||||
|
||||
**[ Also read:[The time of 5G is almost here][3] ]**
|
||||
|
||||
### Zeus Kerravala: 5G is being touted as the "next big thing." Do you see it that way?
|
||||
|
||||
**Jeff Lipton:** The next big thing is connecting "things" and generating actionable insights and context from those things. 5G is one of the technologies that serve this trend. Wi-Fi 6 is another — so are edge compute, Bluetooth Low Energy (BLE), artificial intelligence (AI) and machine learning (ML). These all are important, and they each have a place.
|
||||
|
||||
### Do you see 5G eclipsing Wi-Fi in the enterprise?
|
||||
|
||||
![Jeff Lipton, VP of strategy and corporate development, Aruba][4]
|
||||
|
||||
**Lipton:** No. 5G, like all cellular access, is appropriate if you need macro area coverage and high-speed handoffs. But it’s not ideal for most enterprise applications, where you generally don’t need these capabilities. From a performance standpoint, [Wi-Fi 6][5] and 5G are roughly equal on most metrics, including throughput, latency, reliability, and connection density. Where they aren’t close is economics, where Wi-Fi is far better. I don’t think many customers would be willing to trade Wi-Fi for 5G unless they need macro coverage or high-speed handoffs.
|
||||
|
||||
### Can Wi-Fi and 5G coexist? How would an enterprise use 5G and Wi-Fi together?
|
||||
|
||||
**Lipton:** Wi-Fi and 5G can and should be complementary. The 5G architecture decouples the cellular core and Radio Access Network (RAN). Consequently, Wi-Fi can be the enterprise radio front end and connect tightly with a 5G core. Since the economics of Wi-Fi — especially Wi-Fi 6 — are favorable and performance is extremely good, we envision many service providers using Wi-Fi as the radio front end for their 5G systems where it makes sense, as an alternative to Distributed Antenna (DAS) and small-cell systems.
|
||||
|
||||
Wi-Fi and 5G can and should be complementary." — Jeff Lipton
|
||||
|
||||
### If a business were considering moving to 5G only, how would this be done and how practical is it?
|
||||
|
||||
**Lipton:** To use 5G for primary in-building access, a customer would need to upgrade their network and virtually all of their devices. 5G provides good coverage outdoors, but cellular signals can’t reliably penetrate buildings. And this problem will become worse with 5G, which partially relies on higher frequency radios. So service providers will need a way to provide indoor coverage. To provide this coverage, they propose deploying DAS or small-cell systems — paid for by the end customer. The customers would then connect their devices directly to these cellular systems and pay a service component for each device.
|
||||
|
||||
**[[Take this mobile device management course from PluralSight and learn how to secure devices in your company without degrading the user experience.][6] ]**
|
||||
|
||||
There are several problems with this approach. First, DAS and small-cell systems are significantly more expensive than Wi-Fi networks. And the cost doesn’t stop with the network. Every device would need to have a 5G cellular modem, which costs tens of dollars wholesale and usually over a hundred dollars to an end user. Since few, if any MacBooks, PCs, printers or AppleTVs today have 5G modems, these devices would need to be upgraded. I don’t believe many enterprises would be willing to pay this additional cost and upgrade most of their equipment for an unclear benefit.
|
||||
|
||||
### Are economics a factor in the 5G versus Wi-Fi debate?
|
||||
|
||||
**Lipton:** Economics is always a factor. Let’s focus the conversation on in-building enterprise applications, since this is the use case some carriers intend to target with 5G. We’ve already mentioned that upgrading to 5G would require enterprises to deploy expensive DAS or small-cell systems for in-building coverage, upgrade virtually all of their equipment to contain 5G modems, and pay service contracts for each of these devices. It’s also important to understand 5G cellular networks and DAS systems operate over licensed spectrum, which is analogous to a private highway. Service providers paid billions of dollars for this spectrum, and this expense needs to be monetized and embedded in service costs. So, from both deployment and lifecycle perspectives, Wi-Fi economics are favorable to 5G.
|
||||
|
||||
### Are there any security implications of 5G versus Wi-Fi?
|
||||
|
||||
**Lipton:** Cellular technologies are perceived by some to be more secure than Wi-Fi, but that’s not true. LTE is relatively secure, but it also has weak points. For example, LTE is vulnerable to a range of attacks, including data interception and device tracking, according to researchers at Purdue and the University of Iowa. 5G improves upon LTE security with multiple authentication methods and better key management.
|
||||
|
||||
Wi-Fi security isn’t standing still either and continues to advance. Of course, Wi-Fi implementations that do not follow best practices, such as those without even basic password protection, are not optimal. But those configured with proper access controls and passwords are highly secure. With new standards — specifically, WPA3 and Enhanced Open — Wi-Fi network security has improved even further.
|
||||
|
||||
It’s also important to keep in mind that enterprises have made enormous investments in security and compliance solutions tailored to their specific needs. With cellular networks, including 5G, enterprises lose the ability to deploy their chosen security and compliance solutions, as well as most visibility into traffic flows. While future versions of 5G will offer high-levels of customization with a feature called network slicing, enterprises would still lose the level of security and compliance customization they currently need and have.
|
||||
|
||||
### Any parting thoughts to add to the discussion around 5G versus Wi-Fi?
|
||||
|
||||
**Lipton:** The debate around Wi-Fi versus 5G misses the point. They each have their place, and they are in many ways complementary. The Wi-Fi and 5G markets both will grow, driven by the need to connect and analyze a growing number of things. If a customer needs macro coverage or high-speed handoffs and can pay the additional cost for these capabilities, 5G makes sense.
|
||||
|
||||
5G also could be a fit for certain industrial use cases where customers require physical network segmentation. But for the vast majority of enterprise customers, Wi-Fi will continue to prove its value as a reliable, secure, and cost-effective wireless access technology, as it does today.
|
||||
|
||||
**More about 802.11ax (Wi-Fi 6):**
|
||||
|
||||
* [Why 802.11ax is the next big thing in wireless][7]
|
||||
* [FAQ: 802.11ax Wi-Fi][8]
|
||||
* [Wi-Fi 6 (802.11ax) is coming to a router near you][9]
|
||||
* [Wi-Fi 6 with OFDMA opens a world of new wireless possibilities][10]
|
||||
* [802.11ax preview: Access points and routers that support Wi-Fi 6 are on tap][11]
|
||||
|
||||
|
||||
|
||||
Join the Network World communities on [Facebook][12] and [LinkedIn][13] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3399978/5g-will-augment-wi-fi-not-replace-it.html
|
||||
|
||||
作者:[Zeus Kerravala][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Zeus-Kerravala/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/05/wireless_connection_speed_connectivity_bars_cell_tower_5g_by_thinkstock-100796921-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3203489/what-is-5g-how-is-it-better-than-4g.html
|
||||
[3]: https://www.networkworld.com/article/3354477/mobile-world-congress-the-time-of-5g-is-almost-here.html
|
||||
[4]: https://images.idgesg.net/images/article/2019/06/headshot_jlipton_aruba-100798360-small.jpg
|
||||
[5]: https://www.networkworld.com/article/3215907/why-80211ax-is-the-next-big-thing-in-wi-fi.html
|
||||
[6]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fmobile-device-management-big-picture
|
||||
[7]: https://www.networkworld.com/article/3215907/mobile-wireless/why-80211ax-is-the-next-big-thing-in-wi-fi.html
|
||||
[8]: https://%20https//www.networkworld.com/article/3048196/mobile-wireless/faq-802-11ax-wi-fi.html
|
||||
[9]: https://www.networkworld.com/article/3311921/mobile-wireless/wi-fi-6-is-coming-to-a-router-near-you.html
|
||||
[10]: https://www.networkworld.com/article/3332018/wi-fi/wi-fi-6-with-ofdma-opens-a-world-of-new-wireless-possibilities.html
|
||||
[11]: https://www.networkworld.com/article/3309439/mobile-wireless/80211ax-preview-access-points-and-routers-that-support-the-wi-fi-6-protocol-on-tap.html
|
||||
[12]: https://www.facebook.com/NetworkWorld/
|
||||
[13]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,64 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Data center workloads become more complex despite promises to the contrary)
|
||||
[#]: via: (https://www.networkworld.com/article/3400086/data-center-workloads-become-more-complex-despite-promises-to-the-contrary.html)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Data center workloads become more complex despite promises to the contrary
|
||||
======
|
||||
The data center is shouldering a greater burden than ever, despite promises of ease and the cloud.
|
||||
![gorodenkoff / Getty Images][1]
|
||||
|
||||
Data centers are becoming more complex and still run the majority of workloads despite the promises of simplicity of deployment through automation and hyperconverged infrastructure (HCI), not to mention how the cloud was supposed to take over workloads.
|
||||
|
||||
That’s the finding of the Uptime Institute's latest [annual global data center survey][2] (registration required). The majority of IT loads still run on enterprise data centers even in the face of cloud adoption, putting pressure on administrators to have to manage workloads across the hybrid infrastructure.
|
||||
|
||||
**[ Learn[how server disaggregation can boost data center efficiency][3] | Get regularly scheduled insights: [Sign up for Network World newsletters][4] ]**
|
||||
|
||||
With workloads like artificial intelligence (AI) and machine language coming to the forefront, that means facilities face greater power and cooling challenges, since AI is extremely processor-intensive. That puts strain on data center administrators and power and cooling vendors alike to keep up with the growth in demand.
|
||||
|
||||
On top of it all, everyone is struggling to get enough staff with the right skills.
|
||||
|
||||
### Outages, staffing problems, lack of public cloud visibility among top concerns
|
||||
|
||||
Among the key findings of Uptime's report:
|
||||
|
||||
* The large, privately owned enterprise data center facility still forms the bedrock of corporate IT and is expected to be running half of all workloads in 2021.
|
||||
* The staffing problem affecting most of the data center sector has only worsened. Sixty-one percent of respondents said they had difficulty retaining or recruiting staff, up from 55% a year earlier.
|
||||
* Outages continue to cause significant problems for operators. Just over a third (34%) of all respondents had an outage or severe IT service degradation in the past year, while half (50%) had an outage or severe IT service degradation in the past three years.
|
||||
* Ten percent of all respondents said their most recent significant outage cost more than $1 million.
|
||||
* A lack of visibility, transparency, and accountability of public cloud services is a major concern for enterprises that have mission-critical applications. A fifth of operators surveyed said they would be more likely to put workloads in a public cloud if there were more visibility. Half of those using public cloud for mission-critical applications also said they do not have adequate visibility.
|
||||
* Improvements in data center facility energy efficiency have flattened out and even deteriorated slightly in the past two years. The average PUE for 2019 is 1.67.
|
||||
* Rack power density is rising after a long period of flat or minor increases, causing many to rethink cooling strategies.
|
||||
* Power loss was the single biggest cause of outages, accounting for one-third of outages. Sixty percent of respondents said their data center’s outage could have been prevented with better management/processes or configuration.
|
||||
|
||||
|
||||
|
||||
Traditionally data centers are improving their reliability through "rigorous attention to power, infrastructure, connectivity and on-site IT replication," the Uptime report says. The solution, though, is pricy. Data center operators are getting distributed resiliency through active-active data centers where at least two active data centers replicate data to each other. Uptime found up to 40% of those surveyed were using this method.
|
||||
|
||||
The Uptime survey was conducted in March and April of this year, surveying 1,100 end users in more than 50 countries and dividing them into two groups: the IT managers, owners, and operators of data centers and the suppliers, designers, and consultants that service the industry.
|
||||
|
||||
Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3400086/data-center-workloads-become-more-complex-despite-promises-to-the-contrary.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/05/cso_cloud_computing_backups_it_engineer_data_center_server_racks_connections_by_gorodenkoff_gettyimages-943065400_3x2_2400x1600-100796535-large.jpg
|
||||
[2]: https://uptimeinstitute.com/2019-data-center-industry-survey-results
|
||||
[3]: https://www.networkworld.com/article/3266624/how-server-disaggregation-could-make-cloud-datacenters-more-efficient.html
|
||||
[4]: https://www.networkworld.com/newsletters/signup.html
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,66 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Moving to the Cloud? SD-WAN Matters! Part 2)
|
||||
[#]: via: (https://www.networkworld.com/article/3398488/moving-to-the-cloud-sd-wan-matters-part-2.html)
|
||||
[#]: author: (Rami Rammaha https://www.networkworld.com/author/Rami-Rammaha/)
|
||||
|
||||
Moving to the Cloud? SD-WAN Matters! Part 2
|
||||
======
|
||||
|
||||
![istock][1]
|
||||
|
||||
This is the second installment of the blog series exploring how enterprises can realize the full transformation promise of the cloud by shifting to a business first networking model powered by a business-driven [SD-WAN][2]. The first installment explored automating secure IPsec connectivity and intelligently steering traffic to cloud providers. We also framed the direct correlation between moving to the cloud and adopting an SD-WAN. In this blog, we will expand upon several additional challenges that can be addressed with a business-driven SD-WAN when embracing the cloud:
|
||||
|
||||
### Simplifying and automating security zone-based segmentation
|
||||
|
||||
Securing cloud-first branches requires a robust multi-level approach that addresses following considerations:
|
||||
|
||||
* Restricting outside traffic coming into the branch to sessions exclusively initiated by internal users with a built-in stateful firewall, avoiding appliance sprawl and lowering operational costs; this is referred to as the app whitelist model
|
||||
* Encrypting communications between end points within the SD-WAN fabric and between branch locations and public cloud instances
|
||||
* Service chaining traffic to a cloud-hosted security service like [Zscaler][3] for Layer 7 inspection and analytics for internet-bound traffic
|
||||
* Segmenting traffic spanning the branch, WAN and data center/cloud
|
||||
* Centralizing policy orchestration and automation of zone-based firewall, VLAN and WAN overlays
|
||||
|
||||
|
||||
|
||||
A traditional device-centric WAN approach for security segmentation requires the time-consuming manual configuration of routers and/or firewalls on a device-by-device and site-by-site basis. This is not only complex and cumbersome, but it simply can’t scale to 100s or 1000s of sites. Anusha Vaidyanathan, director of product management at Silver Peak, explains how to automate end-to-end zone-based segmentation, emphasizing the advantages of a business-driven approach in this [lightboard video][4].
|
||||
|
||||
### Delivering the Highest Quality of Experience to IT teams
|
||||
|
||||
The goal for enterprise IT is enabling business agility and increasing operational efficiency. The traditional router-centric WAN approach doesn’t provide the best quality of experience for IT as management and on-going network operations are manual and time consuming, device-centric, cumbersome, error-prone and inefficient.
|
||||
|
||||
A business-driven SD-WAN such as the Silver Peak [Unity EdgeConnect™][5] unified SD-WAN edge platform centralizes the orchestration of business-driven policies. EdgeConnect automation, machine learning and open APIs easily integrate with third-party management tools and real-time visibility tools to deliver the highest quality of experience for IT, enabling them to reclaim nights and weekends. Manav Mishra, vice president of product management at Silver Peak, explains the latest Silver Peak innovations in this [lightboard video][6].
|
||||
|
||||
As enterprises become increasingly dependent on the cloud and embrace a multi-cloud strategy, they must address a number of new challenges:
|
||||
|
||||
* A centralized approach to securely embracing the cloud and the internet
|
||||
* How to extend the on-premise data center to a public cloud and migrating workloads between private and public cloud, taking application portability into account
|
||||
* Deliver consistent high application performance and availability to hosted applications whether they reside in the data center, private or public clouds or are delivered as SaaS services
|
||||
* A proactive way to quickly resolve complex issues that span the data center and cloud as well as multiple WAN transport services by harnessing the power of advanced visibility and analytics tools
|
||||
|
||||
|
||||
|
||||
The business-driven EdgeConnect SD-WAN edge platform enables enterprise IT organizations to easily and consistently embrace the public cloud. Unified security and performance capabilities with automation deliver the highest quality of experience for both users and IT while lowering overall WAN expenditures.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3398488/moving-to-the-cloud-sd-wan-matters-part-2.html
|
||||
|
||||
作者:[Rami Rammaha][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Rami-Rammaha/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/05/istock-909772962-100797711-large.jpg
|
||||
[2]: https://www.silver-peak.com/sd-wan/sd-wan-explained
|
||||
[3]: https://www.silver-peak.com/company/tech-partners/zscaler
|
||||
[4]: https://www.silver-peak.com/resource-center/how-to-create-sd-wan-security-zones-in-edgeconnect
|
||||
[5]: https://www.silver-peak.com/products/unity-edge-connect
|
||||
[6]: https://www.silver-peak.com/resource-center/how-to-optimize-quality-of-experience-for-it-using-sd-wan
|
||||
@ -0,0 +1,87 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Cisco will use AI/ML to boost intent-based networking)
|
||||
[#]: via: (https://www.networkworld.com/article/3400382/cisco-will-use-aiml-to-boost-intent-based-networking.html)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
Cisco will use AI/ML to boost intent-based networking
|
||||
======
|
||||
Cisco explains how artificial intelligence and machine learning fit into a feedback loop that implements and maintain desired network conditions to optimize network performance for workloads using real-time data.
|
||||
![xijian / Getty Images][1]
|
||||
|
||||
Artificial Intelligence and machine learning are expected to be some of the big topics at next week’s Cisco Live event and the company is already talking about how those technologies will help drive the next generation of [Intent-Based Networking][2].
|
||||
|
||||
“Artificial intelligence will change how we manage networks, and it’s a change we need,” wrote John Apostolopoulos Cisco CTO and vice president of Enterprise Networking in a [blog][3] about how Cisco says these technologies impact the network.
|
||||
|
||||
**[ Now see[7 free network tools you must have][4]. ]**
|
||||
|
||||
AI is the next major step for networking capabilities, and while researchers have talked in the past about how great AI would be, now the compute power and algorithms exist to make it possible, Apostolopoulos told Network World.
|
||||
|
||||
To understand how AI and ML can boost IBN, Cisco says it's necessary to understand four key factors an IBN environment needs: infrastructure, translation, activation and assurance.
|
||||
|
||||
Infrastructure can be virtual or physical and include wireless access points, switches, routers, compute and storage. “To make the infrastructure do what we want, we use the translation function to convert the intent, or what we are trying to make the network accomplish, from a person or computer into the correct network and security policies. These policies then must be activated on the network,” Apostolopoulos said.
|
||||
|
||||
The activation step takes the network and security polices and couples them with a deep understanding of the network infrastructure that includes both real-time and historic data about its behavior. It then activates or automates the policies across all of the network infrastructure elements, ideally optimizing for performance, reliability and security, Apostolopoulos wrote.
|
||||
|
||||
Finally assurance maintains a continuous validation-and-verification loop. IBN improves on translation and assurance to form a valuable feedback loop about what’s going on in the network that wasn’t available before. ** **
|
||||
|
||||
Apostolopoulos used the example of an international company that wanted to set up a world-wide video all-hands meeting. Everyone on the call had to have high-quality, low-latency video, and also needed the capability to send high-quality video into the call when it was time for Q&A.
|
||||
|
||||
“By applying machine learning and related machine reasoning, assurance can also sift through the massive amount of data related to such a global event to correctly identify if there are any problems arising. We can then get solutions to these issues – and even automatically apply solutions – more quickly and more reliably than before,” Apostolopoulos said.
|
||||
|
||||
In this case, assurance could identify that the use of WAN bandwidth to certain sites is increasing at a rate that will saturate the network paths and could proactively reroute some of the WAN flows through alternative paths to prevent congestion from occurring, Apostolopoulos wrote.
|
||||
|
||||
“In prior systems, this problem would typically only be recognized after the bandwidth bottleneck occurred and users experienced a drop in call quality or even lost their connection to the meeting. It would be challenging or impossible to identify the issue in real time, much less to fix it before it distracted from the experience of the meeting. Accurate and fast identification through ML and MR coupled with intelligent automation through the feedback loop is key to successful outcome.”
|
||||
|
||||
Apostolopoulos said AI can accelerate the path from intent into translation and activation and then examine network and behavior data in the assurance step to make sure everything is working correctly. Activation uses the insights to drive more intelligent actions for improved performance, reliability and security, creating a cycle of network optimization.
|
||||
|
||||
So what might an implementation of this look like? Applications that run on Cisco’s DNA Center may be the central component in an IBN environment. Introduced on 2017 as the heart of its IBN initiative, [Cisco DNA Center][5] features automation capabilities, assurance setting, fabric provisioning and policy-based segmentation for enterprise networks.
|
||||
|
||||
“DNA Center can bring together AI and ML in a unified manner,” Apostolopoulos said. “It can store data from across the network and then customers can do AI and ML on that data.”
|
||||
|
||||
Central to Cisco's push is being able to gather metadata about traffic as it passes without slowing the traffic, which is accomplished through the use of ASICs in its campus and data-center switches.
|
||||
|
||||
“We have designed our networking gear from the ASIC, OS and software levels to gather key data via our IBN architecture, which provides unified data collection and performs algorithmic analysis across the entire network (wired, wireless, LAN, WAN, datacenter), Apostolopoulos said. “We have a massive collection of network data, including a database of problems and associated root causes, from being the world’s top enterprise network vendor over the past 20-plus years. And we have been investing for many years to create innovative network-data analysis and ML, MR, and other AI techniques to identify and solve key problems.”
|
||||
|
||||
Machine learning and AI can then be applied to all that data to help network operators handle everything from policy setting and network control to security.
|
||||
|
||||
“I also want to stress that the feedback the IT user gets from the IBN system with AI is not overwhelming telemetry data,” Apostolopoulos said. Instead it is valuable and actionable insights at scale, derived from immense data and behavioral analytics using AI.
|
||||
|
||||
Managing and developing new AI/ML-based applications from enormous data sets beyond what Cisco already has is a key driver behind it’s the company’s Unified Compute System (UCS) server that wasa rolled out last September. While the new server, the UCS C480 ML, is powerful – it includes eight Nvidia Tesla V100-32G GPUs with 128GB of DDR4 RAM, 24 SATA hard drives and more – it is the ecosystem of vendors – Cloudera, HortonWorks and others that will end up being more important.
|
||||
|
||||
[Earlier this year Cisco forecast][6] that [AI and ML][7] will significantly boost network management this year.
|
||||
|
||||
“In 2019, companies will start to adopt Artificial Intelligence, in particular Machine Learning, to analyze the telemetry coming off networks to see these patterns, in an attempt to get ahead of issues from performance optimization, to financial efficiency, to security,” said [Anand Oswal][8], senior vice president of engineering in Cisco’s Enterprise Networking Business. The pattern-matching capabilities of ML will be used to spot anomalies in network behavior that might otherwise be missed, while also de-prioritizing alerts that otherwise nag network operators but that aren’t critical, Oswal said.
|
||||
|
||||
“We will also start to use these tools to categorize and cluster device and user types, which can help us create profiles for use cases as well as spot outlier activities that could indicate security incursions,” he said.
|
||||
|
||||
The first application of AI in network management will be smarter alerts that simply report on activities that break normal patterns, but as the technology advances it will react to more situations autonomously. The idea is to give customers more information so they and the systems can make better network decisions. Workable tools should appear later in 2019, Oswal said.
|
||||
|
||||
Join the Network World communities on [Facebook][9] and [LinkedIn][10] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3400382/cisco-will-use-aiml-to-boost-intent-based-networking.html
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/05/ai-vendor-relationship-management_bar-code_purple_artificial-intelligence_hand-on-virtual-screen-100795252-large.jpg
|
||||
[2]: http://www.networkworld.com/cms/article/3202699
|
||||
[3]: https://blogs.cisco.com/enterprise/improving-networks-with-ai
|
||||
[4]: https://www.networkworld.com/article/2825879/7-free-open-source-network-monitoring-tools.html
|
||||
[5]: https://www.networkworld.com/article/3280988/cisco-opens-dna-center-network-control-and-management-software-to-the-devops-masses.html
|
||||
[6]: https://www.networkworld.com/article/3332027/cisco-touts-5-technologies-that-will-change-networking-in-2019.html
|
||||
[7]: https://www.networkworld.com/article/3320978/data-center/network-operations-a-new-role-for-ai-and-ml.html
|
||||
[8]: https://blogs.cisco.com/author/anandoswal
|
||||
[9]: https://www.facebook.com/NetworkWorld/
|
||||
[10]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,67 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Cloud adoption drives the evolution of application delivery controllers)
|
||||
[#]: via: (https://www.networkworld.com/article/3400897/cloud-adoption-drives-the-evolution-of-application-delivery-controllers.html)
|
||||
[#]: author: (Zeus Kerravala https://www.networkworld.com/author/Zeus-Kerravala/)
|
||||
|
||||
Cloud adoption drives the evolution of application delivery controllers
|
||||
======
|
||||
Application delivery controllers (ADCs) are on the precipice of shifting from traditional hardware appliances to software form factors.
|
||||
![Aramyan / Getty Images / Microsoft][1]
|
||||
|
||||
Migrating to a cloud computing model will obviously have an impact on the infrastructure that’s deployed. This shift has already been seen in the areas of servers, storage, and networking, as those technologies have evolved to a “software-defined” model. And it appears that application delivery controllers (ADCs) are on the precipice of a similar shift.
|
||||
|
||||
In fact, a new ZK Research [study about cloud computing adoption and the impact on ADCs][2] found that, when looking at the deployment model, hardware appliances are the most widely deployed — with 55% having fully deployed or are currently testing and only 15% currently researching hardware. (Note: I am an employee of ZK Research.)
|
||||
|
||||
Juxtapose this with containerized ADCs where only 34% have deployed or are testing but 24% are currently researching and it shows that software in containers will outpace hardware for growth. Not surprisingly, software on bare metal and in virtual machines showed similar although lower, “researching” numbers that support the thesis that the market is undergoing a shift from hardware to software.
|
||||
|
||||
**[ Read also:[How to make hybrid cloud work][3] ]**
|
||||
|
||||
The study, conducted in collaboration with Kemp Technologies, surveyed 203 respondents from the U.K. and U.S. The demographic split was done to understand regional differences. An equal number of mid and large size enterprises were looked at, with 44% being from over 5,000 employees and the other 56% from companies that have 300 to 5,000 people.
|
||||
|
||||
### Incumbency helps but isn’t a fait accompli for future ADC purchases
|
||||
|
||||
The primary tenet of my research has always been that incumbents are threatened when markets transition, and this is something I wanted to investigate in the study. The survey asked whether buyers would consider an alternative as they evolve their applications from legacy (mode 1) to cloud-native (mode 2). The results offer a bit of good news and bad news for the incumbent providers. Only 8% said they would definitely select a new vendor, but 35% said they would not change. That means the other 57% will look at alternatives. This is sensible, as the requirements for cloud ADCs are different than ones that support traditional applications.
|
||||
|
||||
### IT pros want better automation capabilities
|
||||
|
||||
This begs the question as to what features ADC buyers want for a cloud environment versus traditional ones. The survey asked specifically what features would be most appealing in future purchases, and the top response was automation, followed by central management, application analytics, on-demand scaling (which is a form of automation), and visibility.
|
||||
|
||||
The desire to automate was a positive sign for the evolution of buyer mindset. Just a few years ago, the mere mention of automation would have sent IT pros into a panic. The reality is that IT can’t operate effectively without automation, and technology professionals are starting to understand that.
|
||||
|
||||
The reason automation is needed is that manual changes are holding businesses back. The survey asked how the speed of ADC changes impacts the speed at which applications are rolled out, and a whopping 60% said it creates significant or minor delays. In an era of DevOps and continuous innovation, multiple minor delays create a drag on the business and can cause it to fall behind is more agile competitors.
|
||||
|
||||
![][4]
|
||||
|
||||
### ADC upgrades and service provisioning benefit most from automation
|
||||
|
||||
The survey also drilled down on specific ADC tasks to see where automation would have the most impact. Respondents were asked how long certain tasks took, answering in minutes, days, weeks, or months. Shockingly, there wasn’t a single task where the majority said it could be done in minutes. The closest was adding DNS entries for new virtual IP addresses (VIPs) where 46% said they could do that in minutes.
|
||||
|
||||
Upgrading, provisioning new load balancers, and provisioning new VIPs took the longest. Looking ahead, this foreshadows big problems. As the data center gets more disaggregated and distributed, IT will deploy more software-based ADCs in more places. Taking days or weeks or month to perform these functions will cause the organization to fall behind.
|
||||
|
||||
The study clearly shows changes are in the air for the ADC market. For IT pros, I strongly recommend that as the environment shifts to the cloud, it’s prudent to evaluate new vendors. By all means, see what your incumbent vendor has, but look at least at two others that offer software-based solutions. Also, there should be a focus on automating as much as possible, so the primary evaluation criteria for ADCs should be how easy it is to implement automation.
|
||||
|
||||
Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3400897/cloud-adoption-drives-the-evolution-of-application-delivery-controllers.html
|
||||
|
||||
作者:[Zeus Kerravala][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Zeus-Kerravala/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/05/cw_microsoft_sharepoint_vs_onedrive_clouds_and_hands_by_aramyan_gettyimages-909772962_2400x1600-100796932-large.jpg
|
||||
[2]: https://kemptechnologies.com/research-papers/adc-market-research-study-zeus-kerravala/?utm_source=zkresearch&utm_medium=referral&utm_campaign=zkresearch&utm_term=zkresearch&utm_content=zkresearch
|
||||
[3]: https://www.networkworld.com/article/3119362/hybrid-cloud/how-to-make-hybrid-cloud-work.html#tk.nww-fsb
|
||||
[4]: https://images.idgesg.net/images/article/2019/06/adc-survey-zk-research-100798593-large.jpg
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,118 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (For enterprise storage, persistent memory is here to stay)
|
||||
[#]: via: (https://www.networkworld.com/article/3398988/for-enterprise-storage-persistent-memory-is-here-to-stay.html)
|
||||
[#]: author: (John Edwards )
|
||||
|
||||
For enterprise storage, persistent memory is here to stay
|
||||
======
|
||||
Persistent memory – also known as storage class memory – has tantalized data center operators for many years. A new technology promises the key to success.
|
||||
![Thinkstock][1]
|
||||
|
||||
It's hard to remember a time when semiconductor vendors haven't promised a fast, cost-effective and reliable persistent memory technology to anxious [data center][2] operators. Now, after many years of waiting and disappointment, technology may have finally caught up with the hype to make persistent memory a practical proposition.
|
||||
|
||||
High-capacity persistent memory, also known as storage class memory ([SCM][3]), is fast and directly addressable like dynamic random-access memory (DRAM), yet is able to retain stored data even after its power has been switched off—intentionally or unintentionally. The technology can be used in data centers to replace cheaper, yet far slower traditional persistent storage components, such as [hard disk drives][4] (HDD) and [solid-state drives][5] (SSD).
|
||||
|
||||
**Learn more about enterprise storage**
|
||||
|
||||
* [Why NVMe over Fabric matters][6]
|
||||
* [What is hyperconvergence?][7]
|
||||
* [How NVMe is changing enterprise storage][8]
|
||||
* [Making the right hyperconvergence choice: HCI hardware or software?][9]
|
||||
|
||||
|
||||
|
||||
Persistent memory can also be used to replace DRAM itself in some situations without imposing a significant speed penalty. In this role, persistent memory can deliver crucial operational benefits, such as lightning-fast database-server restarts during maintenance, power emergencies and other expected and unanticipated reboot situations.
|
||||
|
||||
Many different types of strategic operational applications and databases, particularly those that require low-latency, high durability and strong data consistency, can benefit from persistent memory. The technology also has the potential to accelerate virtual machine (VM) storage and deliver higher performance to multi-node, distributed-cloud applications.
|
||||
|
||||
In a sense, persistent memory marks a rebirth of core memory. "Computers in the ‘50s to ‘70s used magnetic core memory, which was direct access, non-volatile memory," says Doug Wong, a senior member of [Toshiba Memory America's][10] technical staff. "Magnetic core memory was displaced by SRAM and DRAM, which are both volatile semiconductor memories."
|
||||
|
||||
One of the first persistent memory devices to come to market is [Intel’s Optane DC][11]. Other vendors that have released persistent memory products or are planning to do so include [Samsung][12], Toshiba America Memory and [SK Hynix][13].
|
||||
|
||||
### Persistent memory: performance + reliability
|
||||
|
||||
With persistent memory, data centers have a unique opportunity to gain faster performance and lower latency without enduring massive technology disruption. "It's faster than regular solid-state NAND flash-type storage, but you're also getting the benefit that it’s persistent," says Greg Schulz, a senior advisory analyst at vendor-independent storage advisory firm [StorageIO.][14] "It's the best of both worlds."
|
||||
|
||||
Yet persistent memory offers adopters much more than speedy, reliable storage. In an ideal IT world, all of the data associated with an application would reside within DRAM to achieve maximum performance. "This is currently not practical due to limited DRAM and the fact that DRAM is volatile—data is lost when power fails," observes Scott Nelson, senior vice president and general manager of Toshiba Memory America's memory business unit.
|
||||
|
||||
Persistent memory transports compatible applications to an "always on" status, providing continuous access to large datasets through increased system memory capacity, says Kristie Mann, [Intel's][15] director of marketing for data center memory and storage. She notes that Optane DC can supply data centers with up to three-times more system memory capacity (as much as 36TBs), system restarts in seconds versus minutes, 36% more virtual machines per node, and up to 8-times better performance on [Apache Spark][16], a widely used open-source distributed general-purpose cluster-computing framework.
|
||||
|
||||
System memory currently represents 60% of total platform costs, Mann says. She observes that Optane DC persistent memory provides significant customer value by delivering 1.2x performance/dollar on key customer workloads. "This value will dramatically change memory/storage economics and accelerate the data-centric era," she predicts.
|
||||
|
||||
### Where will persistent memory infiltrate enterprise storage?
|
||||
|
||||
Persistent memory is likely to first enter the IT mainstream with minimal fanfare, serving as a high-performance caching layer for high performance SSDs. "This could be adopted relatively-quickly," Nelson observes. Yet this intermediary role promises to be merely a stepping-stone to increasingly crucial applications.
|
||||
|
||||
Over the next few years, persistent technology will impact data centers serving enterprises across an array of sectors. "Anywhere time is money," Schulz says. "It could be financial services, but it could also be consumer-facing or sales-facing operations."
|
||||
|
||||
Persistent memory supercharges anything data-related that requires extreme speed at extreme scale, observes Andrew Gooding, vice president of engineering at [Aerospike][17], which delivered the first commercially available open database optimized for use with Intel Optane DC.
|
||||
|
||||
Machine learning is just one of many applications that stand to benefit from persistent memory. Gooding notes that ad tech firms, which rely on machine learning to understand consumers' reactions to online advertising campaigns, should find their work made much easier and more effective by persistent memory. "They’re collecting information as users within an ad campaign browse the web," he says. "If they can read and write all that data quickly, they can then apply machine-learning algorithms and tailor specific ads for users in real time."
|
||||
|
||||
Meanwhile, as automakers become increasingly reliant on data insights, persistent memory promises to help them crunch numbers and refine sophisticated new technologies at breakneck speeds. "In the auto industry, manufacturers face massive data challenges in autonomous vehicles, where 20 exabytes of data needs to be processed in real time, and they're using self-training machine-learning algorithms to help with that," Gooding explains. "There are so many fields where huge amounts of data need to be processed quickly with machine-learning techniques—fraud detection, astronomy... the list goes on."
|
||||
|
||||
Intel, like other persistent memory vendors, expects cloud service providers to be eager adopters, targeting various types of in-memory database services. Google, for example, is applying persistent memory to big data workloads on non-relational databases from vendors such as Aerospike and [Redis Labs][18], Mann says.
|
||||
|
||||
High-performance computing (HPC) is yet another area where persistent memory promises to make a tremendous impact. [CERN][19], the European Organization for Nuclear Research, is using Intel's Optane DC to significantly reduce wait times for scientific computing. "The efficiency of their algorithms depends on ... persistent memory, and CERN considers it a major breakthrough that is necessary to the work they are doing," Mann observes.
|
||||
|
||||
### How to prepare storage infrastructure for persistent memory
|
||||
|
||||
Before jumping onto the persistent memory bandwagon, organizations need to carefully scrutinize their IT infrastructure to determine the precise locations of any existing data bottlenecks. This task will be primary application-dependent, Wong notes. "If there is significant performance degradation due to delays associated with access to data stored in non-volatile storage—SSD or HDD—then an SCM tier will improve performance," he explains. Yet some applications will probably not benefit from persistent memory, such as compute-bound applications where CPU performance is the bottleneck.
|
||||
|
||||
Developers may need to reevaluate fundamental parts of their storage and application architectures, Gooding says. "They will need to know how to program with persistent memory," he notes. "How, for example, to make sure writes are flushed to the actual persistent memory device when necessary, as opposed to just sitting in the CPU cache."
|
||||
|
||||
To leverage all of persistent memory's potential benefits, significant changes may also be required in how code is designed. When moving applications from DRAM and flash to persistent memory, developers will need to consider, for instance, what happens when a program crashes and restarts. "Right now, if they write code that leaks memory, that leaked memory is recovered on restart," Gooding explains. With persistent memory, that isn't necessarily the case. "Developers need to make sure the code is designed to reconstruct a consistent state when a program restarts," he notes. "You may not realize how much your designs rely on the traditional combination of fast volatile DRAM and block storage, so it can be tricky to change your code designs for something completely new like persistent memory."
|
||||
|
||||
Older versions of operating systems may also need to be updated to accommodate the new technology, although newer OSes are gradually becoming persistent memory aware, Schulz says. "In other words, if they detect that persistent memory is available, then they know how to utilize that either as a cache, or some other memory."
|
||||
|
||||
Hypervisors, such as [Hyper-V][20] and [VMware][21], now know how to leverage persistent memory to support productivity, performance and rapid restarts. By utilizing persistent memory along with the latest versions of VMware, a whole system can see an uplift in speed and also maximize the number of VMs to fit on a single host, says Ian McClarty, CEO and president of data center operator [PhoenixNAP Global IT Services][22]. "This is a great use case for companies who want to own less hardware or service providers who want to maximize hardware to virtual machine deployments."
|
||||
|
||||
Many key enterprise applications, particularly databases, are also becoming persistent memory aware. SQL Server and [SAP’s][23] flagship [HANA][24] database management platform have both embraced persistent memory. "The SAP HANA platform is commonly used across multiple industries to process data and transactions, and then run advanced analytics ... to deliver real-time insights," Mann observes.
|
||||
|
||||
In terms of timing, enterprises and IT organizations should begin persistent memory planning immediately, Schulz recommends. "You should be talking with your vendors and understanding their roadmap, their plans, for not only supporting this technology, but also in what mode: as storage, as memory."
|
||||
|
||||
Join the Network World communities on [Facebook][25] and [LinkedIn][26] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3398988/for-enterprise-storage-persistent-memory-is-here-to-stay.html
|
||||
|
||||
作者:[John Edwards][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2017/08/file_folder_storage_sharing_thinkstock_477492571_3x2-100732889-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3353637/the-data-center-is-being-reimagined-not-disappearing.html
|
||||
[3]: https://www.networkworld.com/article/3026720/the-next-generation-of-storage-disruption-storage-class-memory.html
|
||||
[4]: https://www.networkworld.com/article/2159948/hard-disk-drives-vs--solid-state-drives--are-ssds-finally-worth-the-money-.html
|
||||
[5]: https://www.networkworld.com/article/3326058/what-is-an-ssd.html
|
||||
[6]: https://www.networkworld.com/article/3273583/why-nvme-over-fabric-matters.html
|
||||
[7]: https://www.networkworld.com/article/3207567/what-is-hyperconvergence
|
||||
[8]: https://www.networkworld.com/article/3280991/what-is-nvme-and-how-is-it-changing-enterprise-storage.html
|
||||
[9]: https://www.networkworld.com/article/3318683/making-the-right-hyperconvergence-choice-hci-hardware-or-software
|
||||
[10]: https://business.toshiba-memory.com/en-us/top.html
|
||||
[11]: https://www.intel.com/content/www/us/en/architecture-and-technology/optane-dc-persistent-memory.html
|
||||
[12]: https://www.samsung.com/semiconductor/
|
||||
[13]: https://www.skhynix.com/eng/index.jsp
|
||||
[14]: https://storageio.com/
|
||||
[15]: https://www.intel.com/content/www/us/en/homepage.html
|
||||
[16]: https://spark.apache.org/
|
||||
[17]: https://www.aerospike.com/
|
||||
[18]: https://redislabs.com/
|
||||
[19]: https://home.cern/
|
||||
[20]: https://docs.microsoft.com/en-us/virtualization/hyper-v-on-windows/about/
|
||||
[21]: https://www.vmware.com/
|
||||
[22]: https://phoenixnap.com/
|
||||
[23]: https://www.sap.com/index.html
|
||||
[24]: https://www.sap.com/products/hana.html
|
||||
[25]: https://www.facebook.com/NetworkWorld/
|
||||
[26]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,89 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Juniper: Security could help drive interest in SDN)
|
||||
[#]: via: (https://www.networkworld.com/article/3400739/juniper-sdn-snapshot-finds-security-legacy-network-tech-impacts-core-network-changes.html)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
Juniper: Security could help drive interest in SDN
|
||||
======
|
||||
Juniper finds that enterprise interest in software-defined networking (SDN) is influenced by other factors, including artificial intelligence (AI) and machine learning (ML).
|
||||
![monsitj / Getty Images][1]
|
||||
|
||||
Security challenges and developing artificial intelligence/maching learning (AI/ML) technologies are among the key issues driving [software-defined networking][2] (SDN) implementations, according to a new Juniper survey of 500 IT decision makers.
|
||||
|
||||
And SDN interest abounds – 98% of the 500 said they were already using or considering an SDN implementation. Juniper said it had [Wakefield Research][3] poll IT decision makers of companies with 500 or more employees about their SDN strategies between May 7 and May 14, 2019.
|
||||
|
||||
**More about SD-WAN**
|
||||
|
||||
* [How to buy SD-WAN technology: Key questions to consider when selecting a supplier][4]
|
||||
* [How to pick an off-site data-backup method][5]
|
||||
* [SD-Branch: What it is and why you’ll need it][6]
|
||||
* [What are the options for security SD-WAN?][7]
|
||||
|
||||
|
||||
|
||||
SDN includes technologies that separate the network control plane from the forwarding plane to enable more automated provisioning and policy-based management of network resources.
|
||||
|
||||
IDC estimates that the worldwide data-center SDN market will be worth more than $12 billion in 2022, recording a CAGR of 18.5% during the 2017-2022 period. The market-generated revenue of nearly $5.15 billion in 2017 was up more than 32.2% from 2016.
|
||||
|
||||
There are many ideas driving the development of SDN. For example, it promises to reduce the complexity of statically defined networks; make automating network functions much easier; and allow for simpler provisioning and management of networked resources from the data center to the campus or wide area network.
|
||||
|
||||
While the evolution of SDN is ongoing, Juniper’s study pointed out an issue that was perhaps not unexpected – many users are still managing operations via the command line interface (CLI). CLI is the primary text-based user interface used for configuring, monitoring and maintaining most networked devices.
|
||||
|
||||
“If SDN is as attractive as it is then why manage the network with the same legacy technology of the past?” said Michael Bushong, vice president of enterprise and cloud marketing at Juniper Networks. “If you deploy SDN and don’t adjust the operational model then it is difficult to reap all the benefits SDN can bring. It’s the difference between managing devices individually which you may have done in the past to managing fleets of devices via SDN – it simplifies and reduces operational expenses.”
|
||||
|
||||
Juniper pointed to a [Gartner prediction][8] that stated “by 2020, only 30% of network operations teams will use the command line interface (CLI) as their primary interface, down from 85% at years end 2016.” Garter stated that poll results from a recent Gartner conference found some 71% still using CLI as the primary way to make network changes.
|
||||
|
||||
Gartner [wrote][9] in the past that CLI has remained the primary operational tool for mainstream network operations teams for easily the past 15-20 years but that “moving away from the CLI is a good thing for the networking industry, and while it won’t disappear completely (advanced/nuanced troubleshooting for example), it will be supplanted as the main interface into networking infrastructure.”
|
||||
|
||||
Juniper’s study found that 87% of businesses are still doing most or some of their network management at the device level.
|
||||
|
||||
What all of this shows is that customers are obviously interested in SDN but are still grappling with the best ways to get there, Bushong said.
|
||||
|
||||
The Juniper study also found users interested in SDN because of the potential for a security boost.
|
||||
|
||||
SDN can empowers a variety of security benefits. A customer can split up a network connection between an end user and the data center and have different security settings for the various types of network traffic. A network could have one public-facing, low-security network that does not touch any sensitive information. Another segment could have much more fine-grained remote-access control with software-based [firewall][10] and encryption policies on it, which allow sensitive data to traverse over it. SDN users can roll out security policies across the network from the data center to the edge much more rapidly than traditional network environments.
|
||||
|
||||
“Many enterprises see security—not speed—as the biggest consequence of not making this transition in the next five years, with nearly 40 percent identifying the inability to quickly address new threats as one of their main concerns,” wrote Manoj Leelanivas, chief product officer at Juniper Networks, in a blog about the survey.
|
||||
|
||||
“SDN is not often associated with greater security but this makes sense when we remember this is an operational transformation. In security, the challenge lies not in identifying threats or creating solutions, but in applying these solutions to a fragmented network. Streamlining complex security operations, touching many different departments and managing multiple security solutions, is where a software-defined approach can provide the answer,” Leelanivas stated.
|
||||
|
||||
Some of the other key findings from Juniper included:
|
||||
|
||||
* **The future of AI** : The deployment of artificial intelligence is about changing the operational model, Bushong said. “The ability to more easily manage workflows over groups of devices and derive usable insights to help customers be more proactive rather than reactive is the direction we are moving. Everything will ultimately be AI-driven, he said.
|
||||
* **Automation** : While automation is often considered a threat, Juniper said its respondents see it positively within the context of SDN, with 38% reporting it will improve security and 25% that it will enhance their jobs by streamlining manual operations.
|
||||
* **Flexibility** : Agility is the #1 benefit respondents considering SDN want to gain (48%), followed by improved reliability (43%) and greater simplicity (38%).
|
||||
* **SD-WAN** : The majority, 54%, have rolled out or are in the process of rolling out SD-WAN, while an additional 34% have it under current consideration.
|
||||
|
||||
|
||||
|
||||
Join the Network World communities on [Facebook][11] and [LinkedIn][12] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3400739/juniper-sdn-snapshot-finds-security-legacy-network-tech-impacts-core-network-changes.html
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/03/sdn_software-defined-network_architecture-100791938-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3209131/what-sdn-is-and-where-its-going.html
|
||||
[3]: https://www.wakefieldresearch.com/
|
||||
[4]: https://www.networkworld.com/article/3323407/sd-wan/how-to-buy-sd-wan-technology-key-questions-to-consider-when-selecting-a-supplier.html
|
||||
[5]: https://www.networkworld.com/article/3328488/backup-systems-and-services/how-to-pick-an-off-site-data-backup-method.html
|
||||
[6]: https://www.networkworld.com/article/3250664/lan-wan/sd-branch-what-it-is-and-why-youll-need-it.html
|
||||
[7]: https://www.networkworld.com/article/3285728/sd-wan/what-are-the-options-for-securing-sd-wan.html?nsdr=true
|
||||
[8]: https://blogs.gartner.com/andrew-lerner/2018/01/04/checking-in-on-the-death-of-the-cli/
|
||||
[9]: https://blogs.gartner.com/andrew-lerner/2016/11/22/predicting-the-death-of-the-cli/
|
||||
[10]: https://www.networkworld.com/article/3230457/what-is-a-firewall-perimeter-stateful-inspection-next-generation.html
|
||||
[11]: https://www.facebook.com/NetworkWorld/
|
||||
[12]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,82 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Self-learning sensor chips won’t need networks)
|
||||
[#]: via: (https://www.networkworld.com/article/3400659/self-learning-sensor-chips-wont-need-networks.html)
|
||||
[#]: author: (Patrick Nelson https://www.networkworld.com/author/Patrick-Nelson/)
|
||||
|
||||
Self-learning sensor chips won’t need networks
|
||||
======
|
||||
Scientists working on new, machine-learning networks aim to embed everything needed for artificial intelligence (AI) onto a processor, eliminating the need to transfer data to the cloud or computers.
|
||||
![Jiraroj Praditcharoenkul / Getty Images][1]
|
||||
|
||||
Tiny, intelligent microelectronics should be used to perform as much sensor processing as possible on-chip rather than wasting resources by sending often un-needed, duplicated raw data to the cloud or computers. So say scientists behind new, machine-learning networks that aim to embed everything needed for artificial intelligence (AI) onto a processor.
|
||||
|
||||
“This opens the door for many new applications, starting from real-time evaluation of sensor data,” says [Fraunhofer Institute for Microelectronic Circuits and Systems][2] on its website. No delays sending unnecessary data onwards, along with speedy processing, means theoretically there is zero latency.
|
||||
|
||||
Plus, on-microprocessor, self-learning means the embedded, or sensor, devices can self-calibrate. They can even be “completely reconfigured to perform a totally different task afterwards,” the institute says. “An embedded system with different tasks is possible.”
|
||||
|
||||
**[ Also read:[What is edge computing?][3] and [How edge networking and IoT will reshape data centers][4] ]**
|
||||
|
||||
Much internet of things (IoT) data sent through networks is redundant and wastes resources: a temperature reading taken every 10 minutes, say, when the ambient temperature hasn’t changed, is one example. In fact, one only needs to know when the temperature has changed, and maybe then only when thresholds have been met.
|
||||
|
||||
### Neural network-on-sensor chip
|
||||
|
||||
The commercial German research organization says it’s developing a specific RISC-V microprocessor with a special hardware accelerator designed for a [brain-copying, artificial neural network (ANN) it has developed][5]. The architecture could ultimately be suitable for the condition-monitoring or predictive sensors of the kind we will likely see more of in the industrial internet of things (IIoT).
|
||||
|
||||
Key to Fraunhofer IMS’s [Artificial Intelligence for Embedded Systems (AIfES)][6] is that the self-learning takes place at chip level rather than in the cloud or on a computer, and that it is independent of “connectivity towards a cloud or a powerful and resource-hungry processing entity.” But it still offers a “full AI mechanism, like independent learning,”
|
||||
|
||||
It’s “decentralized AI,” says Fraunhofer IMS. "It’s not focused towards big-data processing.”
|
||||
|
||||
Indeed, with these kinds of systems, no connection is actually required for the raw data, just for the post-analytical results, if indeed needed. Swarming can even replace that. Swarming lets sensors talk to one another, sharing relevant information without even getting a host network involved.
|
||||
|
||||
“It is possible to build a network from small and adaptive systems that share tasks among themselves,” Fraunhofer IMS says.
|
||||
|
||||
Other benefits in decentralized neural networks include that they can be more secure than the cloud. Because all processing takes place on the microprocessor, “no sensitive data needs to be transferred,” Fraunhofer IMS explains.
|
||||
|
||||
### Other edge computing research
|
||||
|
||||
The Fraunhofer researchers aren’t the only academics who believe entire networks become redundant with neuristor, brain-like AI chips. Binghamton University and Georgia Tech are working together on similar edge-oriented tech.
|
||||
|
||||
“The idea is we want to have these chips that can do all the functioning in the chip, rather than messages back and forth with some sort of large server,” Binghamton said on its website when [I wrote about the university's work last year][7].
|
||||
|
||||
One of the advantages of no major communications linking: Not only don't you have to worry about internet resilience, but also that energy is saved creating the link. Energy efficiency is an ambition in the sensor world — replacing batteries is time consuming, expensive, and sometimes, in the case of remote locations, extremely difficult.
|
||||
|
||||
Memory or storage for swaths of raw data awaiting transfer to be processed at a data center, or similar, doesn’t have to be provided either — it’s been processed at the source, so it can be discarded.
|
||||
|
||||
**More about edge networking:**
|
||||
|
||||
* [How edge networking and IoT will reshape data centers][4]
|
||||
* [Edge computing best practices][8]
|
||||
* [How edge computing can help secure the IoT][9]
|
||||
|
||||
|
||||
|
||||
Join the Network World communities on [Facebook][10] and [LinkedIn][11] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3400659/self-learning-sensor-chips-wont-need-networks.html
|
||||
|
||||
作者:[Patrick Nelson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Patrick-Nelson/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/02/industry_4-0_industrial_iot_smart_factory_automation_by_jiraroj_praditcharoenkul_gettyimages-902668940_2400x1600-100788458-large.jpg
|
||||
[2]: https://www.ims.fraunhofer.de/en.html
|
||||
[3]: https://www.networkworld.com/article/3224893/internet-of-things/what-is-edge-computing-and-how-it-s-changing-the-network.html
|
||||
[4]: https://www.networkworld.com/article/3291790/data-center/how-edge-networking-and-iot-will-reshape-data-centers.html
|
||||
[5]: https://www.ims.fraunhofer.de/en/Business_Units_and_Core_Competencies/Electronic_Assistance_Systems/News/AIfES-Artificial_Intelligence_for_Embedded_Systems.html
|
||||
[6]: https://www.ims.fraunhofer.de/en/Business_Units_and_Core_Competencies/Electronic_Assistance_Systems/technologies/Artificial-Intelligence-for-Embedded-Systems-AIfES.html
|
||||
[7]: https://www.networkworld.com/article/3326557/edge-chips-could-render-some-networks-useless.html
|
||||
[8]: https://www.networkworld.com/article/3331978/lan-wan/edge-computing-best-practices.html
|
||||
[9]: https://www.networkworld.com/article/3331905/internet-of-things/how-edge-computing-can-help-secure-the-iot.html
|
||||
[10]: https://www.facebook.com/NetworkWorld/
|
||||
[11]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,53 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What to do when yesterday’s technology won’t meet today’s support needs)
|
||||
[#]: via: (https://www.networkworld.com/article/3399875/what-to-do-when-yesterday-s-technology-won-t-meet-today-s-support-needs.html)
|
||||
[#]: author: (Anand Rajaram )
|
||||
|
||||
What to do when yesterday’s technology won’t meet today’s support needs
|
||||
======
|
||||
|
||||
![iStock][1]
|
||||
|
||||
You probably already know that end user technology is exploding and are feeling the effects of it in your support organization every day. Remember when IT sanctioned and standardized every hardware and software instance in the workplace? Those days are long gone. Today, it’s the driving force of productivity that dictates what will or won’t be used – and that can be hard on a support organization.
|
||||
|
||||
Whatever users need to do their jobs better, faster, more efficiently is what you are seeing come into the workplace. So naturally, that’s what comes into your service desk too. Support organizations see all kinds of [devices, applications, systems, and equipment][2], and it’s adding a great deal of complexity and demand to keep up with. In fact, four of the top five factors causing support ticket volumes to rise are attributed to new and current technology.
|
||||
|
||||
To keep up with the steady [rise of tickets][3] and stay out in front of this surge, support organizations need to take a good, hard look at the processes and technologies they use. Yesterday’s methods won’t cut it. The landscape is simply changing too fast. Supporting today’s users and getting them back to work fast requires an expanding set of skills and tools.
|
||||
|
||||
So where do you start with a new technology project? Just because a technology is new or hyped doesn’t mean it’s right for your organization. It’s important to understand your project goals and the experience you really want to create and match your technology choices to those goals. But don’t go it alone. Talk to your teams. Get intimately familiar with how your support organization works today. Understand your customers’ needs at a deep level. And bring the right people to the table to cover:
|
||||
|
||||
* Business problem analysis: What existing business issue are stakeholders unhappy with?
|
||||
* The impact of that problem: How does that issue justify making a change?
|
||||
* Process automation analysis: What area(s) can technology help automate?
|
||||
* Other solutions: Have you considered any other options besides technology?
|
||||
|
||||
|
||||
|
||||
With these questions answered, you’re ready to entertain your technology options. Put together your “must-haves” in a requirements document and reach out to potential suppliers. During the initial information-gathering stage, assess if the supplier understands your goals and how their technology helps you meet them. To narrow the field, compare solutions side by side against your goals. Select the top two or three for more in-depth product demos before moving into product evaluations. By the time you’re ready for implementation, you have empirical, practical knowledge of how the solution will perform against your business goals.
|
||||
|
||||
The key takeaway is this: Technology for technology’s sake is just technology. But technology that drives business value is a solution. If you want a solution that drives results for your organization and your customers, it’s worth following a strategic selection process to match your goals with the best technology for the job.
|
||||
|
||||
For more insight, check out the [LogMeIn Rescue][4] and HDI webinar “[Technology and the Service Desk: Expanding Mission, Expanding Skills”][5].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3399875/what-to-do-when-yesterday-s-technology-won-t-meet-today-s-support-needs.html
|
||||
|
||||
作者:[Anand Rajaram][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/06/istock-1019006240-100798168-large.jpg
|
||||
[2]: https://www.logmeinrescue.com/resources/datasheets/infographic-mobile-support-are-your-employees-getting-what-they-need?utm_source=idg%20media&utm_medium=display&utm_campaign=native&sfdc=
|
||||
[3]: https://www.logmeinrescue.com/resources/analyst-reports/the-importance-of-remote-support-in-a-shift-left-world?utm_source=idg%20media&utm_medium=display&utm_campaign=native&sfdc=
|
||||
[4]: https://www.logmeinrescue.com/?utm_source=idg%20media&utm_medium=display&utm_campaign=native&sfdc=
|
||||
[5]: https://www.brighttalk.com/webcast/8855/312289?utm_source=LogMeIn7&utm_medium=brighttalk&utm_campaign=312289
|
||||
@ -0,0 +1,89 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (6 ways to make enterprise IoT cost effective)
|
||||
[#]: via: (https://www.networkworld.com/article/3401082/6-ways-to-make-enterprise-iot-cost-effective.html)
|
||||
[#]: author: (Fredric Paul https://www.networkworld.com/author/Fredric-Paul/)
|
||||
|
||||
6 ways to make enterprise IoT cost effective
|
||||
======
|
||||
Rob Mesirow, a principal at PwC’s Connected Solutions unit, offers tips for successfully implementing internet of things (IoT) projects without breaking the bank.
|
||||
![DavidLeshem / Getty][1]
|
||||
|
||||
There’s little question that the internet of things (IoT) holds enormous potential for the enterprise, in everything from asset tracking to compliance.
|
||||
|
||||
But enterprise uses of IoT technology are still evolving, and it’s not yet entirely clear which use cases and practices currently make economic and business sense. So, I was thrilled to trade emails recently with [Rob Mesirow][2], a principal at [PwC’s Connected Solutions][3] unit, about how to make enterprise IoT implementations as cost effective as possible.
|
||||
|
||||
“The IoT isn’t just about technology (hardware, sensors, software, networks, communications, the cloud, analytics, APIs),” Mesirow said, “though tech is obviously essential. It also includes ensuring cybersecurity, managing data governance, upskilling the workforce and creating a receptive workplace culture, building trust in the IoT, developing interoperability, and creating business partnerships and ecosystems—all part of a foundation that’s vital to a successful IoT implementation.”
|
||||
|
||||
**[ Also read:[Enterprise IoT: Companies want solutions in these 4 areas][4] ]**
|
||||
|
||||
Yes, that sounds complicated—and a lot of work for a still-hard-to-quantify return. Fortunately, though, Mesirow offered up some tips on how companies can make their IoT implementations as cost effective as possible.
|
||||
|
||||
### 1\. Don’t wait for better technology
|
||||
|
||||
Mesirow advised against waiting to implement IoT projects until you can deploy emerging technology such as [5G networks][5]. That makes sense, as long as your implementation doesn’t specifically require capabilities available only in the new technology.
|
||||
|
||||
### 2\. Start with the basics, and scale up as needed
|
||||
|
||||
“Companies need to start with the basics—building one app/task at a time—instead of jumping ahead with enterprise-wide implementations and ecosystems,” Mesirow said.
|
||||
|
||||
“There’s no need to start an IoT initiative by tackling a huge, expensive ecosystem. Instead, begin with one manageable use case, and build up and out from there. The IoT can inexpensively automate many everyday tasks to increase effectiveness, employee productivity, and revenue.”
|
||||
|
||||
After you pick the low-hanging fruit, it’s time to become more ambitious.
|
||||
|
||||
“After getting a few successful pilots established, businesses can then scale up as needed, building on the established foundation of business processes, people experience, and technology," Mesirow said,
|
||||
|
||||
### 3\. Make dumb things smart
|
||||
|
||||
Of course, identifying the ripest low-hanging fruit isn’t always easy.
|
||||
|
||||
“Companies need to focus on making dumb things smart, deploying infrastructure that’s not going to break the bank, and providing enterprise customers the opportunity to experience what data intelligence can do for their business,” Mesirow said. “Once they do that, things will take off.”
|
||||
|
||||
### 4\. Leverage lower-cost networks
|
||||
|
||||
“One key to building an IoT inexpensively is to use low-power, low-cost networks (Low-Power Wide-Area Networks (LPWAN)) to provide IoT services, which reduces costs significantly,” Mesirow said.
|
||||
|
||||
Naturally, he mentioned that PwC has three separate platforms with some 80 products that hang off those platforms, which he said cost “a fraction of traditional IoT offerings, with security and privacy built in.”
|
||||
|
||||
Despite the product pitch, though, Mesirow is right to call out the efficiencies involved in using low-cost, low-power networks instead of more expensive existing cellular.
|
||||
|
||||
### 5\. Balance security vs. cost
|
||||
|
||||
Companies need to plan their IoT network with costs vs. security in mind, Mesirow said. “Open-source networks will be less expensive, but there may be security concerns,” he said.
|
||||
|
||||
That’s true, of course, but there may be security concerns in _any_ network, not just open-source solutions. Still, Mesirow’s overall point remains valid: Enterprises need to carefully consider all the trade-offs they’re making in their IoT efforts.
|
||||
|
||||
### 6\. Account for _all_ the value IoT provides
|
||||
|
||||
Finally, Mesirow pointed out that “much of the cost-effectiveness comes from the _value_ the IoT provides,” and its important to consider the return, not just the investment.
|
||||
|
||||
“For example,” Mesirow said, the IoT “increases productivity by enabling the remote monitoring and control of business operations. It saves on energy costs by automatically turning off lights and HVAC when spaces are vacant, and predictive maintenance alerts lead to fewer machine repairs. And geolocation can lead to personalized marketing to customer smartphones, which can increase sales to nearby stores.”
|
||||
|
||||
**[ Now read this:[5 reasons the IoT needs its own networks][6] ]**
|
||||
|
||||
Join the Network World communities on [Facebook][7] and [LinkedIn][8] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3401082/6-ways-to-make-enterprise-iot-cost-effective.html
|
||||
|
||||
作者:[Fredric Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Fredric-Paul/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/02/money_financial_salary_growth_currency_by-davidleshem-100787975-large.jpg
|
||||
[2]: https://twitter.com/robmesirow
|
||||
[3]: https://digital.pwc.com/content/pwc-digital/en/products/connected-solutions.html
|
||||
[4]: https://www.networkworld.com/article/3396128/the-state-of-enterprise-iot-companies-want-solutions-for-these-4-areas.html
|
||||
[5]: https://www.networkworld.com/article/3203489/what-is-5g-how-is-it-better-than-4g.html
|
||||
[6]: https://www.networkworld.com/article/3284506/5-reasons-the-iot-needs-its-own-networks.html
|
||||
[7]: https://www.facebook.com/NetworkWorld/
|
||||
[8]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,66 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Cisco launches a developer-community cert program)
|
||||
[#]: via: (https://www.networkworld.com/article/3401524/cisco-launches-a-developer-community-cert-program.html)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
Cisco launches a developer-community cert program
|
||||
======
|
||||
Cisco has revamped some of its most critical certification and career-development programs in an effort to address the emerging software-oriented-network environment.
|
||||
![Getty Images][1]
|
||||
|
||||
SAN DIEGO – Cisco revamped some of its most critical certification and career-development tools in an effort to address the emerging software-oriented network environment.
|
||||
|
||||
Perhaps one of the biggest additions – rolled out here at the company’s Cisco Live customer event – is the new set of professional certifications for developers utilizing Cisco’s growing DevNet developer community.
|
||||
|
||||
**[ Also see[4 job skills that can boost networking salaries][2] and [20 hot jobs ambitious IT pros should shoot for][3].]**
|
||||
|
||||
The Cisco Certified DevNet Associate, Specialist and Professional certifications will cover software development for applications, automation, DevOps, cloud and IoT. They will also target software developers and network engineers who develop software proficiency to develop applications and automated workflows for operational networks and infrastructure.
|
||||
|
||||
“This certification evolution is the next step to reflect the critical skills network engineers must have to be at the leading edge of networked-enabled business disruption and delivering customer excellence,” said Mike Adams, vice president and general manager of Learning@Cisco. “To perform effectively in this new world, every IT professional needs skills that are broader, deeper and more agile than ever before. And they have to be comfortable working as a multidisciplinary team including infrastructure network engineers, DevOps and automation specialists, and software professionals.”
|
||||
|
||||
Other Cisco Certifications changes include:
|
||||
|
||||
* Streamlined certifications to validate engineering professionals with Cisco Certified Network Associate (CCNA) and Cisco Specialist certifications as well as Cisco Certified Network Professional (CCNP) and Cisco Certified Internetwork Expert (CCIE) certifications in enterprise, data center, service provider, security and collaboration.
|
||||
* For more senior professionals, the CCNP will give learners a choice of five tracks, covering enterprise technologies including infrastructure and wireless, service provider, data center, security and collaboration. Candidates will be able to further specialize in a particular focus area within those technologies.
|
||||
* Cisco says it will eliminate pre-requisites for certifications, meaning engineers can change career options without having to take a defined path.
|
||||
* Expansion of Cisco Networking Academy offerings to train entry level network professionals and software developers. Courses prepare students to earn CCNA and Certified DevNet Associate certifications, equipping them for high-demand jobs in IT.
|
||||
|
||||
|
||||
|
||||
New network technologies such as intent-based networking, multi-domain networking, and programmability fundamentally change the capabilities of the network, giving network engineers the opportunity to architect solutions that utilize the programmable network in new and exciting ways, wrote Susie Wee senior vice president and chief technology officer of DevNet.
|
||||
|
||||
“DevOps practices can be applied to the network, making the network more agile and enabling automation at scale. The new network provides more than just connectivity, it can now use policy and intent to securely connect applications, users, devices and data across multiple environments – from the data center and cloud, to the campus and branch, to the edge, and to the device,” Wee wrote.
|
||||
|
||||
**[[Looking to upgrade your career in tech? This comprehensive online course teaches you how.][4] ]**
|
||||
|
||||
She also announced the DevNet Automation Exchange, a community that will offer shared code, best practices and technology tools for users, developers or channel partners interested in developing automation apps.
|
||||
|
||||
Wee said Cisco seeded the Automation Exchange with over 50 shared code repositories.
|
||||
|
||||
“It is becoming increasingly clear that network ops can be handled much more efficiently with automation, and offering the tools to develop better applications is crucial going forward,” said Zeus Kerravala, founder and principal analyst with ZK Research.
|
||||
|
||||
Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3401524/cisco-launches-a-developer-community-cert-program.html
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/01/run_digital-vanguard_business-executive-with-briefcase_career-growth-100786736-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3227832/lan-wan/4-job-skills-that-can-boost-networking-salaries.html
|
||||
[3]: https://www.networkworld.com/article/3276025/careers/20-hot-jobs-ambitious-it-pros-should-shoot-for.html
|
||||
[4]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fupgrading-your-technology-career
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,68 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (The carbon footprints of IT shops that train AI models are huge)
|
||||
[#]: via: (https://www.networkworld.com/article/3401919/the-carbon-footprints-of-it-shops-that-train-ai-models-are-huge.html)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
The carbon footprints of IT shops that train AI models are huge
|
||||
======
|
||||
Artificial intelligence (AI) model training can generate five times more carbon dioxide than a car does in a lifetime, researchers at the University of Massachusetts, Amherst find.
|
||||
![ipopba / Getty Images][1]
|
||||
|
||||
A new research paper from the University of Massachusetts, Amherst looked at the carbon dioxide (CO2) generated over the course of training several common large artificial intelligence (AI) models and found that the process can generate nearly five times the amount as an average American car over its lifetime plus the process of making the car itself.
|
||||
|
||||
The [paper][2] specifically examined the model training process for natural-language processing (NLP), which is how AI handles natural language interactions. The study found that during the training process, more than 626,000 pounds of carbon dioxide is generated.
|
||||
|
||||
This is significant, since AI training is one IT process that has remained firmly on-premises and not moved to the cloud. Very expensive equipment is needed, as is large volumes of data, so the cloud isn’t right work for most AI training, and the report notes this. Plus, IT shops want to keep that kind of IP in house. So, if you are experimenting with AI, that power bill is going to go up.
|
||||
|
||||
**[ Read also:[How to plan a software-defined data-center network][3] ]**
|
||||
|
||||
While the report used carbon dioxide as a measure, that’s still the product of electricity generation. Training involves the use of the most powerful processors, typically Nvidia GPUs, and they are not known for being low-power draws. And as the paper notes, “model training also incurs a substantial cost to the environment due to the energy required to power this hardware for weeks or months at a time.”
|
||||
|
||||
Training is the most processor-intensive portion of AI. It can take days, weeks, or even months to “learn” what the model needs to know. That means power-hungry Nvidia GPUs running at full utilization for the entire time. In this case, how to handle and process natural language questions rather than broken sentences of keywords like your typical Google search.
|
||||
|
||||
The report said training one model with a neural architecture generated 626,155 pounds of CO2. By contrast, one passenger flying round trip between New York and San Francisco would generate 1,984 pounds of CO2, an average American would generate 11,023 pounds in one year, and a car would generate 126,000 pounds over the course of its lifetime.
|
||||
|
||||
### How the researchers calculated the CO2 amounts
|
||||
|
||||
The researchers used four models in the NLP field that have been responsible for the biggest leaps in performance. They are Transformer, ELMo, BERT, and GPT-2. They trained all of the models on a single Nvidia Titan X GPU, with the exception of ELMo which was trained on three Nvidia GTX 1080 Ti GPUs. Each model was trained for a maximum of one day.
|
||||
|
||||
**[[Learn Java from beginning concepts to advanced design patterns in this comprehensive 12-part course!][4] ]**
|
||||
|
||||
They then used the number of training hours listed in the model’s original papers to calculate the total energy consumed over the complete training process. That number was converted into pounds of carbon dioxide equivalent based on the average energy mix in the U.S.
|
||||
|
||||
The big takeaway is that computational costs start out relatively inexpensive, but they mushroom when additional tuning steps were used to increase the model’s final accuracy. A tuning process known as neural architecture search ([NAS][5]) is the worst offender because it does so much processing. NAS is an algorithm that searches for the best neural network architecture. It is seriously advanced AI and requires the most processing time and power.
|
||||
|
||||
The researchers suggest it would be beneficial to directly compare different models to perform a cost-benefit (accuracy) analysis.
|
||||
|
||||
“To address this, when proposing a model that is meant to be re-trained for downstream use, such as re-training on a new domain or fine-tuning on a new task, authors should report training time and computational resources required, as well as model sensitivity to hyperparameters. This will enable direct comparison across models, allowing subsequent consumers of these models to accurately assess whether the required computational resources,” the authors wrote.
|
||||
|
||||
They also say researchers who are cost-constrained should pool resources and avoid the cloud, as cloud compute time is more expensive. In an example, it said a GPU server with eight Nvidia 1080 Ti GPUs and supporting hardware is available for approximately $20,000. To develop the sample models used in their study, that hardware would cost $145,000, plus electricity to run the models, about half the estimated cost to use on-demand cloud GPUs.
|
||||
|
||||
“Unlike money spent on cloud compute, however, that invested in centralized resources would continue to pay off as resources are shared across many projects. A government-funded academic compute cloud would provide equitable access to all researchers,” they wrote.
|
||||
|
||||
Join the Network World communities on [Facebook][6] and [LinkedIn][7] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3401919/the-carbon-footprints-of-it-shops-that-train-ai-models-are-huge.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/05/ai-vendor-relationship-management_artificial-intelligence_hand-on-virtual-screen-100795246-large.jpg
|
||||
[2]: https://arxiv.org/abs/1906.02243
|
||||
[3]: https://www.networkworld.com/article/3284352/data-center/how-to-plan-a-software-defined-data-center-network.html
|
||||
[4]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fjava
|
||||
[5]: https://www.oreilly.com/ideas/what-is-neural-architecture-search
|
||||
[6]: https://www.facebook.com/NetworkWorld/
|
||||
[7]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,95 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Cisco offers cloud-based security for SD-WAN resources)
|
||||
[#]: via: (https://www.networkworld.com/article/3402079/cisco-offers-cloud-based-security-for-sd-wan-resources.html)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
Cisco offers cloud-based security for SD-WAN resources
|
||||
======
|
||||
Cisco adds support for its cloud-based security gateway Umbrella to SD-WAN software
|
||||
![Thinkstock][1]
|
||||
|
||||
SAN DIEGO— As many companies look to [SD-WAN][2] technology to reduce costs, improve connectivity and streamline branch office access, one of the key requirements will be solid security technologies to protect corporate resources.
|
||||
|
||||
At its Cisco Live customer event here this week, the company took aim at that need by telling customers it added support for the its cloud-based security gateway – known as Umbrella – to its SD-WAN software offerings.
|
||||
|
||||
**More about SD-WAN**
|
||||
|
||||
* [How to buy SD-WAN technology: Key questions to consider when selecting a supplier][3]
|
||||
* [How to pick an off-site data-backup method][4]
|
||||
* [SD-Branch: What it is and why you’ll need it][5]
|
||||
* [What are the options for security SD-WAN?][6]
|
||||
|
||||
|
||||
|
||||
At its most basic, SD-WAN lets companies aggregate a variety of network connections – including MPLS, 4G LTE and DSL – into a branch or network-edge location and provides a management software that can turn up new sites, prioritize traffic and set security policies. SD-WAN's driving principle is to simplify the way big companies turn up new links to branch offices, better manage the way those links are utilized – for data, voice or video – and potentially save money in the process.
|
||||
|
||||
According to Cisco, Umbrella can provide the first line of defense against threats on the internet. By analyzing and learning from internet activity patterns, Umbrella automatically uncovers attacker infrastructure and proactively blocks requests to malicious destinations before a connection is even established — without adding latency for users. With Umbrella, customers can stop phishing and malware infections earlier, identify already infected devices faster and prevent data exfiltration, Cisco says.
|
||||
|
||||
Branch offices and roaming users are more vulnerable to attacks, and attackers are looking to exploit them, said Gee Rittenhouse, senior vice president and general manager of Cisco's Security Business Group. He pointed to Enterprise Strategy Group research that says 68 percent of branch offices and roaming users were the source of compromise in recent attacks. And as organizations move to more direct internet access, this becomes an even greater risk, Rittenhouse said.
|
||||
|
||||
“Scaling security at every location often means more appliances to ship and manage, more policies to separately maintain, which translates into more money and resources needed – but Umbrella offers an alternative to all that," he said. "Umbrella provides simple deployment and management, and in a single cloud platform, it unifies multiple layers of security, ncluding DNS, secure web gateway, firewall and cloud-access security,” Rittenhouse said.
|
||||
|
||||
“It also acts as your secure onramp to the internet by offering secure internet access and controlled SaaS usage across all locations and roaming users.”
|
||||
|
||||
Basically users can set up Umbrella support via the SD-WAN dashboard vManage, and the system automatically creates a secure tunnel to the cloud.** ** Once the SD-WAN traffic is pointed at the cloud, firewall and other security policies can be set. Customers can then see traffic and collect information about patterns or set policies and respond to anomalies, Rittenhouse said.
|
||||
|
||||
Analysts said the Umbrella offering is another important security option offered by Cisco for SD-WAN customers.
|
||||
|
||||
“Since it is cloud-based, using Umbrella is a great option for customers with lots of branch or SD-WAN locations who don’t want or need to have a security gateway on premises,” said Rohit Mehra, vice president of Network Infrastructure at IDC. “One of the largest requirements for large customers going forward will be the need for all manner of security technologies for the SD-WAN environment, and Cisco has a big menu of offerings that can address those requirements.”
|
||||
|
||||
IDC says the SD-WAN infrastructure market will hit $4.5 billion by 2022, growing at a more than 40 percent yearly clip between now and then.
|
||||
|
||||
The Umbrella announcement is on top of other recent SD-WAN security enhancements the company has made. In May [Cisco added support for Advanced Malware Protection (AMP) to its million-plus ISR/ASR edge routers][7] in an effort to reinforce branch- and core-network malware protection across the SD-WAN.
|
||||
|
||||
“Together with Cisco Talos [Cisco’s security-intelligence arm], AMP imbues your SD-WAN branch, core and campuses locations with threat intelligence from millions of worldwide users, honeypots, sandboxes and extensive industry partnerships,” Cisco said.
|
||||
|
||||
In total, AMP identifies more than 1.1 million unique malware samples a day and when AMP in Cisco SD-WAN platform spots malicious behavior it automatically blocks it, Cisco said.
|
||||
|
||||
Last year Cisco added its [Viptela SD-WAN technology to the IOS XE][8] version 16.9.1 software that runs its core ISR/ASR routers such as the ISR models 1000, 4000 and ASR 1000, in use by organizations worldwide. Cisco bought Viptela in 2017.
|
||||
|
||||
The release of Cisco IOS XE offered an instant upgrade path for creating cloud-controlled SD-WAN fabrics to connect distributed offices, people, devices and applications operating on the installed base, Cisco said. At the time Cisco said that Cisco SD-WAN on edge routers builds a secure virtual IP fabric by combining routing, segmentation, security, policy and orchestration.
|
||||
|
||||
With the recent release of IOS-XE SD-WAN 16.11, Cisco has brought AMP and other enhancements to its SD-WAN.
|
||||
|
||||
AMP support is added to a menu of security features already included in Cisco's SD-WAN software including support for URL filtering, Snort Intrusion Prevention, the ability to segment users across the WAN and embedded platform security, including the Cisco Trust Anchor module.
|
||||
|
||||
The software also supports SD-WAN Cloud onRamp for CoLocation, which lets customers tie distributed multicloud applications back to a local branch office or local private data center. That way a cloud-to-branch link would be shorter, faster and possibly more secure that tying cloud-based applications directly to the data center.
|
||||
|
||||
Also in May [Cisco and Teridion][9] said they would team to deliver faster enterprise software-defined WAN services. The integration links Cisco Meraki MX Security/SD-WAN appliances and its Auto VPN technology which lets users quickly bring up and configure secure sessions between branches and data centers with Teridion’s cloud-based WAN service. Teridion’s service promises customers better performance and control over traffic running from remote offices over the public internet to the data center.
|
||||
|
||||
Teridion said the Meraki integration creates an IPSec connection from the Cisco Meraki MX to the Teridion edge. Customers create locations in the Teridion portal and apply the preconfigured Meraki template to them, or just upload a csv file if they have a lot of locations. Then, from each Meraki MX, they can create a third-party IPSec tunnel to the Teridion edge IP addresses that are generated as part of the Teridion configuration, the company stated.
|
||||
|
||||
The combined Cisco Meraki and Teridion offering brings SD-WAN and security capabilities at the WAN edge that are tightly integrated with a WAN service delivered over cost-effective broadband or dedicated Internet access. Meraki’s MX family supports everything from SD-WAN and [Wi-Fi][10] features to next-generation [firewall][11] and intrusion prevention in a single package.
|
||||
|
||||
Join the Network World communities on [Facebook][12] and [LinkedIn][13] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3402079/cisco-offers-cloud-based-security-for-sd-wan-resources.html
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.techhive.com/images/article/2015/10/cloud-security-ts-100622309-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3209131/what-sdn-is-and-where-its-going.html
|
||||
[3]: https://www.networkworld.com/article/3323407/sd-wan/how-to-buy-sd-wan-technology-key-questions-to-consider-when-selecting-a-supplier.html
|
||||
[4]: https://www.networkworld.com/article/3328488/backup-systems-and-services/how-to-pick-an-off-site-data-backup-method.html
|
||||
[5]: https://www.networkworld.com/article/3250664/lan-wan/sd-branch-what-it-is-and-why-youll-need-it.html
|
||||
[6]: https://www.networkworld.com/article/3285728/sd-wan/what-are-the-options-for-securing-sd-wan.html?nsdr=true
|
||||
[7]: https://www.networkworld.com/article/3394597/cisco-adds-amp-to-sd-wan-for-israsr-routers.html
|
||||
[8]: https://www.networkworld.com/article/3296007/cisco-upgrade-enables-sd-wan-in-1m-israsr-routers.html
|
||||
[9]: https://www.networkworld.com/article/3396628/cisco-ties-its-securitysd-wan-gear-with-teridions-cloud-wan-service.html
|
||||
[10]: https://www.networkworld.com/article/3318119/what-to-expect-from-wi-fi-6-in-2019.html
|
||||
[11]: https://www.networkworld.com/article/3230457/what-is-a-firewall-perimeter-stateful-inspection-next-generation.html
|
||||
[12]: https://www.facebook.com/NetworkWorld/
|
||||
[13]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,72 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Dell and Cisco extend VxBlock integration with new features)
|
||||
[#]: via: (https://www.networkworld.com/article/3402036/dell-and-cisco-extend-vxblock-integration-with-new-features.html)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Dell and Cisco extend VxBlock integration with new features
|
||||
======
|
||||
Dell EMC and Cisco took another step in their alliance, announcing plans to expand VxBlock 1000 integration across servers, networking, storage, and data protection.
|
||||
![Dell EMC][1]
|
||||
|
||||
Just two months ago [Dell EMC and Cisco renewed their converged infrastructure][2] vows, and now the two have taken another step in the alliance. At this year’s at [Cisco Live][3] event taking place in San Diego, the two announced plans to expand VxBlock 1000 integration across servers, networking, storage, and data protection.
|
||||
|
||||
This is done through support of NVMe over Fabrics (NVMe-oF), which allows enterprise SSDs to talk to each other directly through a high-speed fabric. NVMe is an important advance because SATA and PCI Express SSDs could never talk directly to other drives before until NVMe came along.
|
||||
|
||||
To leverage NVMe-oF to its fullest extent, Dell EMC has unveiled a new integrated Cisco compute (UCS) and storage (MDS) 32G options, extending PowerMax capabilities to deliver NVMe performance across the VxBlock stack.
|
||||
|
||||
**More news from Cisco Live 2019:**
|
||||
|
||||
* [Cisco offers cloud-based security for SD-WAN resources][4]
|
||||
* [Cisco software to make networks smarter, safer, more manageable][5]
|
||||
* [Cisco launches a developer-community cert program][6]
|
||||
|
||||
|
||||
|
||||
Dell EMC said this will enhance the architecture, high-performance consistency, availability, and scalability of VxBlock and provide its customers with high-performance, end-to-end mission-critical workloads that can deliver microsecond responses.
|
||||
|
||||
These new compute and storage options will be available to order sometime later this month.
|
||||
|
||||
### Other VxBlock news from Dell EMC
|
||||
|
||||
Dell EMC also announced it is extending its factory-integrated on-premise integrated protection solutions for VxBlock to hybrid and multi-cloud environments, such as Amazon Web Services (AWS). This update will offer to help protect VMware workloads and data via the company’s Data Domain Virtual Edition and Cloud Disaster Recovery software options. This will be available in July.
|
||||
|
||||
The company also plans to release VxBlock Central 2.0 software next month. VxBlock Central is designed to help customers simplify CI administration through converged awareness, automation, and analytics.
|
||||
|
||||
New to version 2.0 is modular licensing that matches workflow automation, advanced analytics, and life-cycle management/upgrade options to your needs.
|
||||
|
||||
VxBlock Central 2.0 has a variety of license features, including the following:
|
||||
|
||||
**Base** – Free with purchase of a VxBlock, the base license allows you to manage your system and improve compliance with inventory reporting and alerting. **Workflow Automation** – Provision infrastructure on-demand using engineered workflows through vRealize Orchestrator. New workflows available with this package include Cisco UCS server expansion with Unity and XtremIO storage arrays. **Advanced Analytics** – View capacity and KPIs to discover deeper actionable insights through vRealize Operations. **Lifecycle Management** (new, available later in 2019) – Apply “guided path” software upgrades to optimize system performance.
|
||||
|
||||
* Lifecycle Management includes a new multi-tenant, cloud-based database based on Cloud IQ that will collect and store the CI component inventory structured by the customer, extending the value and ease of use of the cloud-based analytics monitoring.
|
||||
* This feature extends the value and ease of use of the cloud-based analytics monitoring Cloud IQ already provides for individual Dell EMC storage arrays.
|
||||
|
||||
|
||||
|
||||
Join the Network World communities on [Facebook][7] and [LinkedIn][8] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3402036/dell-and-cisco-extend-vxblock-integration-with-new-features.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/04/dell-emc-vxblock-1000-100794721-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3391071/dell-emc-and-cisco-renew-converged-infrastructure-alliance.html
|
||||
[3]: https://www.ciscolive.com/global/
|
||||
[4]: https://www.networkworld.com/article/3402079/cisco-offers-cloud-based-security-for-sd-wan-resources.html
|
||||
[5]: https://www.networkworld.com/article/3401523/cisco-software-to-make-networks-smarter-safer-more-manageable.html
|
||||
[6]: https://www.networkworld.com/article/3401524/cisco-launches-a-developer-community-cert-program.html
|
||||
[7]: https://www.facebook.com/NetworkWorld/
|
||||
[8]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,95 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (IoT security vs. privacy: Which is a bigger issue?)
|
||||
[#]: via: (https://www.networkworld.com/article/3401522/iot-security-vs-privacy-which-is-a-bigger-issue.html)
|
||||
[#]: author: (Fredric Paul https://www.networkworld.com/author/Fredric-Paul/)
|
||||
|
||||
IoT security vs. privacy: Which is a bigger issue?
|
||||
======
|
||||
When it comes to the internet of things (IoT), security has long been a key concern. But privacy issues could be an even bigger threat.
|
||||
![Ring][1]
|
||||
|
||||
If you follow the news surrounding the internet of things (IoT), you know that security issues have long been a key concern for IoT consumers, enterprises, and vendors. Those issues are very real, but I’m becoming increasingly convinced that related but fundamentally different _privacy_ vulnerabilities may well be an even bigger threat to the success of the IoT.
|
||||
|
||||
In June alone, we’ve seen a flood of IoT privacy issues inundate the news cycle, and observers are increasingly sounding the alarm that IoT users should be paying attention to what happens to the data collected by IoT devices.
|
||||
|
||||
**[ Also read:[It’s time for the IoT to 'optimize for trust'][2] and [A corporate guide to addressing IoT security][2] ]**
|
||||
|
||||
Predictably, most of the teeth-gnashing has come on the consumer side, but that doesn’t mean enterprises users are immune to the issue. One the one hand, just like consumers, companies are vulnerable to their proprietary information being improperly shared and misused. More immediately, companies may face backlash from their own customers if they are seen as not properly guarding the data they collect via the IoT. Too often, in fact, enterprises shoot themselves in the foot on privacy issues, with practices that range from tone-deaf to exploitative to downright illegal—leading almost [two-thirds (63%) of consumers to describe IoT data collection as “creepy,”][3] while more than half (53%) “distrust connected devices to protect their privacy and handle information in a responsible manner.”
|
||||
|
||||
### Ring becoming the poster child for IoT privacy issues
|
||||
|
||||
As a case in point, let’s look at the case of [Ring, the IoT doorbell company now owned by Amazon][4]. Ring is [reportedly working with police departments to build a video surveillance network in residential neighborhoods][5]. Police in more than 50 cities and towns across the country are apparently offering free or discounted Ring doorbells, and sometimes requiring the recipients to share footage for use in investigations. (While [Ring touts the security benefits][6] of working with law enforcement, it has asked police departments to end the practice of _requiring_ users to hand over footage, as it appears to violate the devices’ terms of service.)
|
||||
|
||||
Many privacy advocates are troubled by this degree of cooperation between police and Ring, but that’s only part of the problem. Last year, for example, [Ring workers in Ukraine reportedly watched customer feeds][7]. Amazingly, though, even that only scratches the surface of the privacy flaps surrounding Ring.
|
||||
|
||||
### Guilty by video?
|
||||
|
||||
According to [Motherboard][8], “Ring is using video captured by its doorbell cameras in Facebook advertisements that ask users to identify and call the cops on a woman whom local police say is a suspected thief.” While the police are apparently appreciative of the “additional eyes that may see this woman and recognize her,” the ad calls the woman a thief even though she has not been charged with a crime, much less convicted!
|
||||
|
||||
Ring may be today’s poster child for IoT privacy issues, but IoT privacy complaints are widespread. In many cases, it comes down to what IoT users—or others nearby—are getting in return for giving up their privacy. According to the [Guardian][9], for example, Google’s Sidewalk Labs smart city project is little more than “surveillance capitalism.” And while car owners may get a discount on auto insurance in return for sharing their driving data, that relationship is hardly set in stone. It may not be long before drivers have to give up their data just to get insurance at all.
|
||||
|
||||
**[[Prepare to become a Certified Information Security Systems Professional with this comprehensive online course from PluralSight. Now offering a 10-day free trial!][10] ]**
|
||||
|
||||
And as the recent [data breach at the U.S. Customs and Border Protection][11] once again demonstrates, private data is “[a genie without a bottle][12].” No matter what legal or technical protections are put in place, the data may always be revealed or used in unforeseen ways. Heck, when you put it all together, it’s enough to make you wonder [whether doorbells really need to be smart][13] at all?
|
||||
|
||||
**Read more about IoT:**
|
||||
|
||||
* [Google’s biggest, craziest ‘moonshot’ yet][14]
|
||||
* [What is the IoT? How the internet of things works][15]
|
||||
* [What is edge computing and how it’s changing the network][16]
|
||||
* [Most powerful internet of things companies][17]
|
||||
* [10 Hot IoT startups to watch][18]
|
||||
* [The 6 ways to make money in IoT][19]
|
||||
* [What is digital twin technology? [and why it matters]][20]
|
||||
* [Blockchain, service-centric networking key to IoT success][21]
|
||||
* [Getting grounded in IoT networking and security][22]
|
||||
* [Building IoT-ready networks must become a priority][23]
|
||||
* [What is the Industrial IoT? [And why the stakes are so high]][24]
|
||||
|
||||
|
||||
|
||||
Join the Network World communities on [Facebook][25] and [LinkedIn][26] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3401522/iot-security-vs-privacy-which-is-a-bigger-issue.html
|
||||
|
||||
作者:[Fredric Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Fredric-Paul/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/04/ringvideodoorbellpro-100794084-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3269165/internet-of-things/a-corporate-guide-to-addressing-iot-security-concerns.html
|
||||
[3]: https://www.cpomagazine.com/data-privacy/consumers-still-concerned-about-iot-security-and-privacy-issues/
|
||||
[4]: https://www.cnbc.com/2018/02/27/amazon-buys-ring-a-former-shark-tank-reject.html
|
||||
[5]: https://www.cnet.com/features/amazons-helping-police-build-a-surveillance-network-with-ring-doorbells/
|
||||
[6]: https://blog.ring.com/2019/02/14/how-rings-neighbors-creates-safer-more-connected-communities/
|
||||
[7]: https://www.theinformation.com/go/b7668a689a
|
||||
[8]: https://www.vice.com/en_us/article/pajm5z/amazon-home-surveillance-company-ring-law-enforcement-advertisements
|
||||
[9]: https://www.theguardian.com/cities/2019/jun/06/toronto-smart-city-google-project-privacy-concerns
|
||||
[10]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
|
||||
[11]: https://www.washingtonpost.com/technology/2019/06/10/us-customs-border-protection-says-photos-travelers-into-out-country-were-recently-taken-data-breach/?utm_term=.0f3a38aa40ca
|
||||
[12]: https://smartbear.com/blog/test-and-monitor/data-scientists-are-sexy-and-7-more-surprises-from/
|
||||
[13]: https://slate.com/tag/should-this-thing-be-smart
|
||||
[14]: https://www.networkworld.com/article/3058036/google-s-biggest-craziest-moonshot-yet.html
|
||||
[15]: https://www.networkworld.com/article/3207535/internet-of-things/what-is-the-iot-how-the-internet-of-things-works.html
|
||||
[16]: https://www.networkworld.com/article/3224893/internet-of-things/what-is-edge-computing-and-how-it-s-changing-the-network.html
|
||||
[17]: https://www.networkworld.com/article/2287045/internet-of-things/wireless-153629-10-most-powerful-internet-of-things-companies.html
|
||||
[18]: https://www.networkworld.com/article/3270961/internet-of-things/10-hot-iot-startups-to-watch.html
|
||||
[19]: https://www.networkworld.com/article/3279346/internet-of-things/the-6-ways-to-make-money-in-iot.html
|
||||
[20]: https://www.networkworld.com/article/3280225/internet-of-things/what-is-digital-twin-technology-and-why-it-matters.html
|
||||
[21]: https://www.networkworld.com/article/3276313/internet-of-things/blockchain-service-centric-networking-key-to-iot-success.html
|
||||
[22]: https://www.networkworld.com/article/3269736/internet-of-things/getting-grounded-in-iot-networking-and-security.html
|
||||
[23]: https://www.networkworld.com/article/3276304/internet-of-things/building-iot-ready-networks-must-become-a-priority.html
|
||||
[24]: https://www.networkworld.com/article/3243928/internet-of-things/what-is-the-industrial-iot-and-why-the-stakes-are-so-high.html
|
||||
[25]: https://www.facebook.com/NetworkWorld/
|
||||
[26]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,121 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Software Defined Perimeter (SDP): Creating a new network perimeter)
|
||||
[#]: via: (https://www.networkworld.com/article/3402258/software-defined-perimeter-sdp-creating-a-new-network-perimeter.html)
|
||||
[#]: author: (Matt Conran https://www.networkworld.com/author/Matt-Conran/)
|
||||
|
||||
Software Defined Perimeter (SDP): Creating a new network perimeter
|
||||
======
|
||||
Considering the way networks work today and the change in traffic patterns; both internal and to the cloud, this limits the effect of the fixed perimeter.
|
||||
![monsitj / Getty Images][1]
|
||||
|
||||
Networks were initially designed to create internal segments that were separated from the external world by using a fixed perimeter. The internal network was deemed trustworthy, whereas the external was considered hostile. However, this is still the foundation for most networking professionals even though a lot has changed since the inception of the design.
|
||||
|
||||
More often than not the fixed perimeter consists of a number of network and security appliances, thereby creating a service chained stack, resulting in appliance sprawl. Typically, the appliances that a user may need to pass to get to the internal LAN may vary. But generally, the stack would consist of global load balancers, external firewall, DDoS appliance, VPN concentrator, internal firewall and eventually LAN segments.
|
||||
|
||||
The perimeter approach based its design on visibility and accessibility. If an entity external to the network can’t see an internal resource, then access cannot be gained. As a result, external entities were blocked from coming in, yet internal entities were permitted to passage out. However, it worked only to a certain degree. Realistically, the fixed network perimeter will always be breachable; it's just a matter of time. Someone with enough skill will eventually get through.
|
||||
|
||||
**[ Related:[MPLS explained – What you need to know about multi-protocol label switching][2]**
|
||||
|
||||
### Environmental changes – the cloud and mobile workforce
|
||||
|
||||
Considering the way networks work today and the change in traffic patterns; both internal and to the cloud, this limits the effect of the fixed perimeter. Nowadays, we have a very fluid network perimeter with many points of entry.
|
||||
|
||||
Imagine a castle with a portcullis that was used to gain access. To gain entry into the portcullis was easy as we just needed to pass one guard. There was only one way in and one way out. But today, in this digital world, we have so many small doors and ways to enter, all of which need to be individually protected.
|
||||
|
||||
This boils down to the introduction of cloud-based application services and changing the location of the perimeter. Therefore, the existing networking equipment used for the perimeter is topologically ill-located. Nowadays, everything that is important is outside the perimeter, such as, remote access workers, SaaS, IaaS and PaaS-based applications.
|
||||
|
||||
Users require access to the resources in various cloud services regardless of where the resources are located, resulting in complex-to-control multi-cloud environments. Objectively, the users do not and should not care where the applications are located. They just require access to the application. Also, the increased use of mobile workforce that demands anytime and anywhere access from a variety of devices has challenged the enterprises to support this dynamic workforce.
|
||||
|
||||
There is also an increasing number of devices, such as, BYOD, on-site contractors, and partners that will continue to grow internal to the network. This ultimately leads to a world of over-connected networks.
|
||||
|
||||
### Over-connected networks
|
||||
|
||||
Over-connected networks result in complex configurations of network appliances. This results in large and complex policies without any context.
|
||||
|
||||
They provide a level of coarse-grained access to a variety of services where the IP address does not correspond to the actual user. Traditional appliances that use static configurations to limit the incoming and outgoing traffic are commonly based on information in the IP packet and the port number.
|
||||
|
||||
Essentially, there is no notion of policy and explanation of why a given source IP address is on the list. This approach fails to take into consideration any notion of trust and dynamically adjust access in relation to the device, users and application request events.
|
||||
|
||||
### Problems with IP addresses
|
||||
|
||||
Back in the early 1990s, RFC 1597 declared three IP ranges reserved for private use: 10.0.0.0/8, 172.16.0.0/12 and 192.168.0.0/16. If an end host was configured with one of these addresses, it was considered more secure. However, this assumption of trust was shattered with the passage of time and it still haunts us today.
|
||||
|
||||
Network Address Translation (NAT) also changed things to a great extent. NAT allowed internal trusted hosts to communicate directly with the external untrusted hosts. However, since Transmission Control Protocol (TCP) is bidirectional, it allows the data to be injected by the external hosts while connecting back to the internal hosts.
|
||||
|
||||
Also, there is no contextual information regarding the IP addresses as the sole purpose revolved around connectivity. If you have the IP address of someone, you can connect to them. The authentication was handled higher up in the stack.
|
||||
|
||||
Not only do user’s IP addresses change regularly, but there’s also not a one-to-one correspondence between the users and IP addresses. Anyone can communicate from any IP address they please and also insert themselves between you and the trusted resource.
|
||||
|
||||
Have you ever heard of the 20-year old computer that responds to an internet control message protocol (ICMP) request, yet no one knows where it is? But this would not exist on a zero trust network as the network is dark until the administrator turns the lights on with a whitelist policy rule set. This is contrary to the legacy black policy rule set. You can find more information on zero trust in my course: [Zero Trust Networking: The Big Picture][3].
|
||||
|
||||
Therefore, we can’t just rely on the IP addresses and expect them to do much more other than connect. As a result, we have to move away from the IP addresses and network location as the proxy for access trust. The network location can longer be the driver of network access levels. It is not fully equipped to decide the trust of a device, user or application.
|
||||
|
||||
### Visibility – a major gap
|
||||
|
||||
When we analyze networking and its flaws, visibility is a major gap in today’s hybrid environments. By and large, enterprise networks are complex beasts. More than often networking pros do not have accurate data or insights into who or what is accessing the network resource.
|
||||
|
||||
I.T does not have the visibility in place to detect, for example, insecure devices, unauthorized users and potentially harmful connections that could propagate malware or perform data exfiltration.
|
||||
|
||||
Also, once you know how network elements connect, how do you ensure that they don’t reconnect through a broader definition of connectivity? For this, you need contextual visibility. You need full visibility into the network to see who, what, when, and how they are connecting with the device.
|
||||
|
||||
### What’s the workaround?
|
||||
|
||||
A new approach is needed that enables the application owners to protect the infrastructure located in a public or private cloud and on-premise data center. This new network architecture is known as [software-defined perimeter][4] (SDP). Back in 2013, Cloud Security Alliance (CSA) launched the SDP initiative, a project designed to develop the architecture for creating more robust networks.
|
||||
|
||||
The principles behind SDPs are not entirely new. Organizations within the DoD and Intelligence Communities (IC) have implemented a similar network architecture that is based on authentication and authorization prior to network access.
|
||||
|
||||
Typically, every internal resource is hidden behind an appliance. And a user must authenticate before visibility of the authorized services is made available and access is granted.
|
||||
|
||||
### Applying the zero trust framework
|
||||
|
||||
SDP is an extension to [zero trust][5] which removes the implicit trust from the network. The concept of SDP started with Google’s BeyondCorp, which is the general direction that the industry is heading to right now.
|
||||
|
||||
Google’s BeyondCorp puts forward the idea that the corporate network does not have any meaning. The trust regarding accessing an application is set by a static network perimeter containing a central appliance. This appliance permits the inbound and outbound access based on a very coarse policy.
|
||||
|
||||
However, access to the application should be based on other parameters such as who the user is, the judgment of the security stance of the device, followed by some continuous assessment of the session. Rationally, only then should access be permitted.
|
||||
|
||||
Let’s face it, the assumption that internal traffic can be trusted is flawed and zero trust assumes that all hosts internal to the network are internet facing, thereby hostile.
|
||||
|
||||
### What is software-defined perimeter (SDP)?
|
||||
|
||||
The SDP aims to deploy perimeter functionality for dynamically provisioned perimeters meant for clouds, hybrid environments, and on-premise data center infrastructures. There is often a dynamic tunnel that automatically gets created during the session. That is a one-to-one mapping between the requesting entity and the trusted resource. The important point to note here is that perimeters are formed not solely to obey a fixed location already design by the network team.
|
||||
|
||||
SDP relies on two major pillars and these are the authentication and authorization stages. SDPs require endpoints to authenticate and be authorized first before obtaining network access to the protected entities. Then, encrypted connections are created in real-time between the requesting systems and application infrastructure.
|
||||
|
||||
Authenticating and authorizing the users and their devices before even allowing a single packet to reach the target service, enforces what's known as least privilege at the network layer. Essentially, the concept of least privilege is for an entity to be granted only the minimum privileges that it needs to get its work done. Within a zero trust network, privilege is more dynamic than it would be in traditional networks since it uses many different attributes of activity to determine the trust score.
|
||||
|
||||
### The dark network
|
||||
|
||||
Connectivity is based on a need-to-know model. Under this model, no DNS information, internal IP addresses or visible ports of internal network infrastructure are transmitted. This is the reason why SDP assets are considered as “dark”. As a result, SDP isolates any concerns about the network and application. The applications and users are considered abstract, be it on-premise or in the cloud, which becomes irrelevant to the assigned policy.
|
||||
|
||||
Access is granted directly between the users and their devices to the application and resource, regardless of the underlying network infrastructure. There simply is no concept of inside and outside of the network. This ultimately removes the network location point as a position of advantage and also eliminates the excessive implicit trust that IP addresses offer.
|
||||
|
||||
**This article is published as part of the IDG Contributor Network.[Want to Join?][6]**
|
||||
|
||||
Join the Network World communities on [Facebook][7] and [LinkedIn][8] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3402258/software-defined-perimeter-sdp-creating-a-new-network-perimeter.html
|
||||
|
||||
作者:[Matt Conran][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Matt-Conran/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/03/sdn_software-defined-network_architecture-100791938-large.jpg
|
||||
[2]: https://www.networkworld.com/article/2297171/sd-wan/network-security-mpls-explained.html
|
||||
[3]: http://pluralsight.com/courses/zero-trust-networking-big-picture
|
||||
[4]: https://network-insight.net/2018/09/software-defined-perimeter-zero-trust/
|
||||
[5]: https://network-insight.net/2018/10/zero-trust-networking-ztn-want-ghosted/
|
||||
[6]: /contributor-network/signup.html
|
||||
[7]: https://www.facebook.com/NetworkWorld/
|
||||
[8]: https://www.linkedin.com/company/network-world
|
||||
83
sources/talk/20190612 When to use 5G, when to use Wi-Fi 6.md
Normal file
83
sources/talk/20190612 When to use 5G, when to use Wi-Fi 6.md
Normal file
@ -0,0 +1,83 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (When to use 5G, when to use Wi-Fi 6)
|
||||
[#]: via: (https://www.networkworld.com/article/3402316/when-to-use-5g-when-to-use-wi-fi-6.html)
|
||||
[#]: author: (Lee Doyle )
|
||||
|
||||
When to use 5G, when to use Wi-Fi 6
|
||||
======
|
||||
5G is a cellular service, and Wi-Fi 6 is a short-range wireless access technology, and each has attributes that make them useful in specific enterprise roles.
|
||||
![Thinkstock][1]
|
||||
|
||||
We have seen hype about whether [5G][2] cellular or [Wi-Fi 6][3] will win in the enterprise, but the reality is that the two are largely complementary with an overlap for some use cases, which will make for an interesting competitive environment through the early 2020s.
|
||||
|
||||
### The potential for 5G in enterprises
|
||||
|
||||
The promise of 5G for enterprise users is higher speed connectivity with lower latency. Cellular technology uses licensed spectrum which largely eliminates potential interference that may occur with unlicensed Wi-Fi spectrum. Like current 4G LTE technologies, 5G can be supplied by cellular wireless carriers or built as a private network .
|
||||
|
||||
The architecture for 5G requires many more radio access points and can suffer from poor or no connectivity indoors. So, the typical organization needs to assess its [current 4G and potential 5G service][4] for its PCs, routers and other devices. Deploying indoor microcells, repeaters and distributed antennas can help solve indoor 5G service issues. As with 4G, the best enterprise 5G use case is for truly mobile connectivity such as public safety vehicles and in non-carpeted environments like mining, oil and gas extraction, transportation, farming and some manufacturing.
|
||||
|
||||
In addition to broad mobility, 5G offers advantages in terms of authentication while roaming and speed of deployment as might be needed to provide WAN connectivity to a pop-up office or retail site. 5G will have the capacity to offload traffic in cases of data congestion such as live video. As 5G standards mature, the technology will improve its options for low-power IoT connectivity.
|
||||
|
||||
5G will gradually roll out over the next four to five years starting in large cities and specific geographies; 4G technology will remain prevalent for a number of years. Enterprise users will need new devices, dongles and routers to connect to 5G services. For example, Apple iPhones are not expected to support 5G until 2020, and IoT devices will need specific cellular compatibility to connect to 5G.
|
||||
|
||||
Doyle Research expects the 1Gbps and higher bandwidth promised by 5G will have a significant impact on the SD-WAN market. 4G LTE already enables cellular services to become a primary WAN link. 5G is likely to be cost competitive or cheaper than many wired WAN options such as MPLS or the internet. 5G gives enterprise WAN managers more options to provide increased bandwidth to their branch sites and remote users – potentially displacing MPLS over time.
|
||||
|
||||
### The potential for Wi-Fi 6 in enterprises
|
||||
|
||||
Wi-Fi is nearly ubiquitous for connecting mobile laptops, tablets and other devices to enterprise networks. Wi-Fi 6 (802.11ax) is the latest version of Wi-Fi and brings the promise of increased speed, low latency, improved aggregate bandwidth and advanced traffic management. While it has some similarities with 5G (both are based on orthogonal frequency division multiple access), Wi-Fi 6 is less prone to interference, requires less power (which prolongs device battery life) and has improved spectral efficiency.
|
||||
|
||||
**[[Take this mobile device management course from PluralSight and learn how to secure devices in your company without degrading the user experience.][5] ]**
|
||||
|
||||
As is typical for Wi-Fi, early [vendor-specific versions of Wi-Fi 6][6] are currently available from many manufacturers. The Wi-Fi alliance plans for certification of Wi-Fi 6-standard gear in 2020. Most enterprises will upgrade to Wi-Fi 6 along standard access-point life cycles of three years or so unless they have specific performance/latency requirements that prompt an upgrade sooner.
|
||||
|
||||
Wi-Fi access points continue to be subject to interference, and it can be challenging to design and site APs to provide appropriate coverage. Enterprise LAN managers will continue to need vendor-supplied tools and partners to configure optimal Wi-Fi coverage for their organizations. Wi-Fi 6 solutions must be integrated with wired campus infrastructure. Wi-Fi suppliers need to do a better job at providing unified network management across wireless and wired solutions in the enterprise.
|
||||
|
||||
### Need for wired backhaul
|
||||
|
||||
For both technologies, wireless is combined with wired-network infrastructure to deliver high-speed communications end-to-end. In the enterprise, Wi-Fi is typically paired with wired Ethernet switches for campus and larger branches. Some devices are connected via cable to the switch, others via Wi-Fi – and laptops may use both methods. Wi-Fi access points are connected via Ethernet inside the enterprise and to the WAN or internet by fiber connections.
|
||||
|
||||
The architecture for 5G makes extensive use of fiber optics to connect the distributed radio access network back to the core of the 5G network. Fiber is typically required to provide the high bandwidth needed to connect 5G endpoints to SaaS-based applications, and to provide live video and high-speed internet access. Private 5G networks will also have to meet high-speed wired-connectivity requirements.
|
||||
|
||||
### Handoff issues
|
||||
|
||||
Enterprise IT managers need to be concerned with handoff challenges as phones switch between 5G and Wi-Fi 6. These issues can affect performance and user satisfaction. Several groups are working towards standards to promote better interoperability between Wi-Fi 6 and 5G. As the architectures of Wi-Fi 6 align with 5G, the experience of moving between cellular and Wi-Fi networks should become more seamless.
|
||||
|
||||
### 5G vs Wi-Fi 6 depends on locations, applications and devices
|
||||
|
||||
Wi-Fi 6 and 5G are competitive with each other for specific situations in the enterprise environment that depend on location, application and device type. IT managers should carefully evaluate their current and emerging connectivity requirements. Wi-Fi will continue to dominate indoor environments and cellular wins for broad outdoor coverage.
|
||||
|
||||
Some of the overlap cases occur in stadiums, hospitality and other large event spaces with many users competing for bandwidth. Government applications, including aspect of smart cities, can be applicable to both Wi-Fi and cellular. Health care facilities have many distributed medical devices and users that need connectivity. Large distributed manufacturing environments share similar characteristics. The emerging IoT deployments are perhaps the most interesting “competitive” environment with many overlapping use cases.
|
||||
|
||||
### Recommendations for IT Leaders
|
||||
|
||||
While the wireless technologies enabling them are converging, Wi-Fi 6 and 5G are fundamentally distinct networks – both of which have their role in enterprise connectivity. Enterprise IT leaders should focus on how Wi-Fi and cellular can complement each other, with Wi-Fi continuing as the in-building technology to connect PCs and laptops, offload phone and tablet data, and for some IoT connectivity.
|
||||
|
||||
4G LTE moving to 5G will remain the truly mobile technology for phone and tablet connectivity, an option (via dongle) for PC connections, and increasingly popular for connecting some IoT devices. 5G WAN links will increasingly become standard as a backup for improved SD-WAN reliability and as primary links for remote offices.
|
||||
|
||||
Join the Network World communities on [Facebook][7] and [LinkedIn][8] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3402316/when-to-use-5g-when-to-use-wi-fi-6.html
|
||||
|
||||
作者:[Lee Doyle][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2017/07/wi-fi_wireless_communication_network_abstract_thinkstock_610127984_1200x800-100730107-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3203489/what-is-5g-how-is-it-better-than-4g.html
|
||||
[3]: https://www.networkworld.com/article/3215907/why-80211ax-is-the-next-big-thing-in-wi-fi.html
|
||||
[4]: https://www.networkworld.com/article/3330603/5g-versus-4g-how-speed-latency-and-application-support-differ.html
|
||||
[5]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fmobile-device-management-big-picture
|
||||
[6]: https://www.networkworld.com/article/3309439/80211ax-preview-access-points-and-routers-that-support-the-wi-fi-6-protocol-on-tap.html
|
||||
[7]: https://www.facebook.com/NetworkWorld/
|
||||
[8]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,59 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Data centers should sell spare UPS capacity to the grid)
|
||||
[#]: via: (https://www.networkworld.com/article/3402039/data-centers-should-sell-spare-ups-capacity-to-the-grid.html)
|
||||
[#]: author: (Patrick Nelson https://www.networkworld.com/author/Patrick-Nelson/)
|
||||
|
||||
Data centers should sell spare UPS capacity to the grid
|
||||
======
|
||||
Distributed Energy is gaining traction, providing an opportunity for data centers to sell excess power in data center UPS batteries to the grid.
|
||||
![Getty Images][1]
|
||||
|
||||
The energy storage capacity in uninterruptable power supply (UPS) batteries, languishing often dormant in data centers, could provide new revenue streams for those data centers, says Eaton, a major electrical power management company.
|
||||
|
||||
Excess, grid-generated power, created during times of low demand, should be stored on the now-proliferating lithium-backup power systems strewn worldwide in data centers, Eaton says. Then, using an algorithm tied to grid-demand, electricity should be withdrawn as necessary for grid use. It would then be slid back onto the backup batteries when not needed.
|
||||
|
||||
**[ Read also:[How server disaggregation can boost data center efficiency][2] | Get regularly scheduled insights: [Sign up for Network World newsletters][3] ]**
|
||||
|
||||
The concept is called Distributed Energy and has been gaining traction in part because electrical generation is changing—emerging green power, such as wind and solar, being used now at the grid-level have considerations that differ from the now-retiring, fossil-fuel power generation. You can generate solar only in daylight, yet much demand takes place on dark evenings, for example.
|
||||
|
||||
Coal, gas, and oil deliveries have always been, to a great extent, pre-planned, just-in-time, and used for electrical generation in real time. Nowadays, though, fluctuations between supply, storage, and demand are kicking in. Electricity storage on the grid is required.
|
||||
|
||||
Eaton says that by piggy-backing on existing power banks, electricity distribution could be evened out better. The utilities would deliver power more efficiently, despite the peaks and troughs in demand—with the data center UPS, in effect, acting like a quasi-grid-power storage battery bank, or virtual power plant.
|
||||
|
||||
The objective of this UPS use case, called EnergyAware, is to regulate frequency in the grid. That’s related to the tolerances needed to make the grid work—the cycles per second, or hertz, inherent in electrical current can’t deviate too much. Abnormalities happen if there’s a suddent spike in demand but no power on hand to supply the surge.
|
||||
|
||||
### How the Distributed Energy concept works
|
||||
|
||||
The distributed energy resource (DER), which can be added to any existing lithium-ion battery bank, in any building, allows for the consumption of energy, or the distribution of it, based on a Frequency Regulation grid-demand algorithm. It charges or discharges the backup battery, connected to the grid, thus balancing the grid frequency.
|
||||
|
||||
Often, not much power will need to be removed, just “micro-bursts of energy,” explains Sean James, director of Energy Research at Microsoft, in an Eaton-published promotional video. Microsoft Innovation Center in Virginia has been working with Eaton on the project. Those bursts are enough to get the frequency tolerances back on track, but the UPS still functions as designed.
|
||||
|
||||
Eaton says data centers should start participating in energy markets. That could mean bidding, as a producer of power, to those who need to buy it—the electricity market, also known as the grid. Data centers could conceivably even switch on generators to operate the data halls if the price for its battery-stored power was particularly lucrative at certain times.
|
||||
|
||||
“A data center in the future wouldn’t just be a huge load on the grid,” James says. “In the future, you don’t have a data center or a power plant. It’s something in the middle. A data plant,” he says on the Eaton [website][4].
|
||||
|
||||
Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3402039/data-centers-should-sell-spare-ups-capacity-to-the-grid.html
|
||||
|
||||
作者:[Patrick Nelson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Patrick-Nelson/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/10/business_continuity_server-100777720-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3266624/how-server-disaggregation-could-make-cloud-datacenters-more-efficient.html
|
||||
[3]: https://www.networkworld.com/newsletters/signup.html
|
||||
[4]: https://www.eaton.com/us/en-us/products/backup-power-ups-surge-it-power-distribution/backup-power-ups/dual-purpose-ups-technology.html
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,68 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Oracle updates Exadata at long last with AI and machine learning abilities)
|
||||
[#]: via: (https://www.networkworld.com/article/3402559/oracle-updates-exadata-at-long-last-with-ai-and-machine-learning-abilities.html)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Oracle updates Exadata at long last with AI and machine learning abilities
|
||||
======
|
||||
Oracle to update the Oracle Exadata Database Machine X8 server line to include artificial intelligence (AI) and machine learning capabilities, plus support for hybrid cloud.
|
||||
![Magdalena Petrova][1]
|
||||
|
||||
After a rather [long period of silence][2], Oracle announced an update to its server line, the Oracle Exadata Database Machine X8, which features hardware and software enhancements that include artificial intelligence (AI) and machine learning capabilities, as well as support for hybrid cloud.
|
||||
|
||||
Oracle acquired a hardware business nine years ago with the purchase of Sun Microsystems. It steadily whittled down the offerings, getting out of the commodity hardware business in favor of high-end mission-critical hardware. Whereas the Exalogic line is more of a general-purpose appliance running Oracle’s own version of Linux, Exadata is a purpose-built database server, and they really made some upgrades.
|
||||
|
||||
The Exadata X8 comes with the latest Intel Xeon Scalable processors and PCIe NVME flash technology to drive performance improvements, which Oracle promises a 60% increase in I/O throughput for all-Flash storage and a 25% increase in IOPS per storage server compared to Exadata X7. The X8 offers a 60% performance improvement over the previous generation for analytics with up to 560GB per second throughput. It can scan a 1TB table in under two seconds.
|
||||
|
||||
**[ Also read:[What is quantum computing (and why enterprises should care)][3] ]**
|
||||
|
||||
The company also enhanced the storage server to offload Oracle Database processing, and the X8 features 60% more cores and 40% higher capacity disk drives over the X7.
|
||||
|
||||
But the real enhancements come on the software side. With Exadata X8, Oracle introduces new machine-learning capabilities, such as Automatic Indexing, which continuously learns and tunes the database as usage patterns change. The Indexing technology originated with the Oracle Autonomous Database, the cloud-based software designed to automate management of Oracle databases.
|
||||
|
||||
And no, MySQL is not included in the stack. This is for Oracle databases only.
|
||||
|
||||
“We’re taking code from Autonomous Database and making it available on prem for our customers,” said Steve Zivanic, vice president for converged infrastructure at Oracle’s Cloud Business Group. “That enables companies rather than doing manual indexing for various Oracle databases to automate it with machine learning.”
|
||||
|
||||
In one test, it took a 15-year-old Netsuite database with over 9,000 indexes built up over the lifespan of the database, and in 24 hours, its AI indexer rebuilt the indexes with just 6,000, reducing storage space and greatly increasing performance of the database, since the number of indexes to search were smaller.
|
||||
|
||||
### Performance improvements with Exadata
|
||||
|
||||
Zivanic cited several examples of server consolidation done with Exadata but would not identify companies by name. He told of a large healthcare company that achieved a 10-fold performance improvement over IBM Power servers and consolidated 600 Power servers with 50 Exadata systems.
|
||||
|
||||
A financial services company replaced 4,000 Dell servers running Red Hat Linux and VMware with 100 Exadata systems running 6,000 production Oracle databases. Not only did it reduce its power footprint, but patching was down 99%. An unnamed retailer with 28 racks of hardware from five vendors went from installing 1,400 patches per year to 16 patches on four Exadata racks.
|
||||
|
||||
Because Oracle owns the entire stack, from hardware to OS to middleware and database, Exadata can roll all of its patch components – 640 in all – into a single bundle.
|
||||
|
||||
“The trend we’ve noticed is you see these [IT hardware] companies who try to maintain an erector set mentality,” said Zivanic. “And you have people saying why are we trying to build pods? Why don’t we buy finished goods and focus on our core competency rather than build erector sets?”
|
||||
|
||||
### Oracle Zero Data Loss Recovery Appliance X8 now available
|
||||
|
||||
Oracle also announced the availability of the Oracle Zero Data Loss Recovery Appliance X8, its database backup appliance, which offers up to 10 times faster data recovery of an Oracle Database than conventional data deduplication appliances while providing sub-second recoverability of all transactions.
|
||||
|
||||
The new Oracle Recovery Appliance X8 now features 30% larger capacity, nearly a petabyte in a single rack, for the same price, Oracle says.
|
||||
|
||||
Join the Network World communities on [Facebook][4] and [LinkedIn][5] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3402559/oracle-updates-exadata-at-long-last-with-ai-and-machine-learning-abilities.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.techhive.com/images/article/2017/03/vid-still-79-of-82-100714308-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3317564/is-oracles-silence-on-its-on-premises-servers-cause-for-concern.html
|
||||
[3]: https://www.networkworld.com/article/3275367/what-s-quantum-computing-and-why-enterprises-need-to-care.html
|
||||
[4]: https://www.facebook.com/NetworkWorld/
|
||||
[5]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,71 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Report: Mirai tries to hook its tentacles into SD-WAN)
|
||||
[#]: via: (https://www.networkworld.com/article/3403016/report-mirai-tries-to-hook-its-tentacles-into-sd-wan.html)
|
||||
[#]: author: (Jon Gold https://www.networkworld.com/author/Jon-Gold/)
|
||||
|
||||
Report: Mirai tries to hook its tentacles into SD-WAN
|
||||
======
|
||||
|
||||
Mirai – the software that has hijacked hundreds of thousands of internet-connected devices to launch massive DDoS attacks – now goes beyond recruiting just IoT products; it also includes code that seeks to exploit a vulnerability in corporate SD-WAN gear.
|
||||
|
||||
That specific equipment – VMware’s SDX line of SD-WAN appliances – now has an updated software version that fixes the vulnerability, but by targeting it Mirai’s authors show that they now look beyond enlisting security cameras and set-top boxes and seek out any vulnerable connected devices, including enterprise networking gear.
|
||||
|
||||
**More about SD-WAN**
|
||||
|
||||
* [How to buy SD-WAN technology: Key questions to consider when selecting a supplier][1]
|
||||
* [How to pick an off-site data-backup method][2]
|
||||
* [SD-Branch: What it is and why you’ll need it][3]
|
||||
* [What are the options for security SD-WAN?][4]
|
||||
|
||||
|
||||
|
||||
“I assume we’re going to see Mirai just collecting as many devices as it can,” said Jen Miller-Osborn, deputy director of threat research at Palo Alto Networks’ Unit 42, which recently issued [a report][5] about Mirai.
|
||||
|
||||
### Exploiting SD-WAN gear is new
|
||||
|
||||
While the exploit against the SD-WAN appliances was a departure for Mirai, it doesn’t represent a sea-change in the way its authors are approaching their work, according Miller-Osborn.
|
||||
|
||||
The idea, she said, is simply to add any devices to the botnet, regardless of what they are. The fact that SD-WAN devices were targeted is more about those particular devices having a vulnerability than anything to do with their SD-WAN capabilities.
|
||||
|
||||
### Responsible disclosure headed off execution of exploits
|
||||
|
||||
[The vulnerability][6] itself was discovered last year by independent researchers who responsibly disclosed it to VMware, which then fixed it in a later software version. But the means to exploit the weakness nevertheless is included in a recently discovered new variant of Mirai, according to the Unit 42 report.
|
||||
|
||||
The authors behind Mirai periodically update the software to add new targets to the list, according to Unit 42, and the botherders’ original tactic of simply targeting devices running default credentials has given way to a strategy that also exploits vulnerabilities in a wide range of different devices. The updated variant of the malicious software includes a total of eight new-to-Mirai exploits.
|
||||
|
||||
**[[Prepare to become a Certified Information Security Systems Professional with this comprehensive online course from PluralSight. Now offering a 10-day free trial!][7] ]**
|
||||
|
||||
The remediated version of the VMware SD-WAN is SD-WAN Edge 3.1.2. The vulnerability still affects SD-WAN Edge 3.1.1 and earlier, [according to a VMware security advisory][8]. After the Unit 42 report came out VMware posted [a blog][9] that says it is conducting its own investigation into the matter.
|
||||
|
||||
Detecting whether a given SD-WAN implementation has been compromised depends heavily on the degree of monitoring in place on the network. Any products that give IT staff the ability to notice unusual traffic to or from an affected appliance could flag that activity. Otherwise, it could be difficult to tell if anything’s wrong, Miller-Osborne said. “You honestly might not notice it unless you start seeing a hit in performance or an outside actor notifies you about it.”
|
||||
|
||||
Join the Network World communities on [Facebook][10] and [LinkedIn][11] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3403016/report-mirai-tries-to-hook-its-tentacles-into-sd-wan.html
|
||||
|
||||
作者:[Jon Gold][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Jon-Gold/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3323407/sd-wan/how-to-buy-sd-wan-technology-key-questions-to-consider-when-selecting-a-supplier.html
|
||||
[2]: https://www.networkworld.com/article/3328488/backup-systems-and-services/how-to-pick-an-off-site-data-backup-method.html
|
||||
[3]: https://www.networkworld.com/article/3250664/lan-wan/sd-branch-what-it-is-and-why-youll-need-it.html
|
||||
[4]: https://www.networkworld.com/article/3285728/sd-wan/what-are-the-options-for-securing-sd-wan.html?nsdr=true
|
||||
[5]: https://unit42.paloaltonetworks.com/new-mirai-variant-adds-8-new-exploits-targets-additional-iot-devices/
|
||||
[6]: https://www.exploit-db.com/exploits/44959
|
||||
[7]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
|
||||
[8]: https://www.vmware.com/security/advisories/VMSA-2018-0011.html
|
||||
[9]: https://blogs.vmware.com/security/2019/06/vmsa-2018-0011-revisited.html
|
||||
[10]: https://www.facebook.com/NetworkWorld/
|
||||
[11]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,60 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Western Digital launches open-source zettabyte storage initiative)
|
||||
[#]: via: (https://www.networkworld.com/article/3402318/western-digital-launches-open-source-zettabyte-storage-initiative.html)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Western Digital launches open-source zettabyte storage initiative
|
||||
======
|
||||
Western Digital's Zoned Storage initiative leverages new technology to create more efficient zettabyte-scale data storage for data centers by improving how data is organized when it is stored.
|
||||
![monsitj / Getty Images][1]
|
||||
|
||||
Western Digital has announced a project called the Zoned Storage initiative that leverages new technology to create more efficient zettabyte-scale data storage for data centers by improving how data is organized when it is stored.
|
||||
|
||||
As part of this, the company also launched a [developer site][2] that will host open-source, standards-based tools and other resources.
|
||||
|
||||
The Zoned Storage architecture is designed for Western Digital hardware and its shingled magnetic recording (SMR) HDDs, which hold up to 15TB of data, as well as the emerging zoned namespaces (ZNS) standard for NVMe SSDs, designed to deliver better endurance and predictability.
|
||||
|
||||
**[ Now read:[What is quantum computing (and why enterprises should care)][3] ]**
|
||||
|
||||
This initiative is not being retrofitted for non-SMR drives or non-NVMe SSDs. Western Digital estimates that by 2023, half of all its HDD shipments are expected to be SMR. And that will be needed because IDC predicts data will be generated at a rate of 103 zettabytes a year by 2023.
|
||||
|
||||
With this project Western Digital is targeting cloud and hyperscale providers and anyone building a large data center who has to manage a large amount of data, according to Eddie Ramirez, senior director of product marketing for Western Digital.
|
||||
|
||||
Western Digital is changing how data is written and stored from the traditional random 4K block writes to large blocks of sequential data, like Big Data workloads and video streams, which are rapidly growing in size and use in the digital age.
|
||||
|
||||
“We are now looking at a one-size-fits-all architecture that leaves a lot of TCO [total cost of ownership] benefits on the table if you design for a single architecture,” Ramirez said. “We are looking at workloads that don’t rely on small block randomization of data but large block sequential write in nature.”
|
||||
|
||||
Because drives use 4k write blocks, that leads to overprovisioning of storage, especially around SSDs. This is true of consumer and enterprise SSDs alike. My 1TB SSD drive has only 930GB available. And that loss scales. An 8TB SSD has only 6.4TB available, according to Ramirez. SSDs also have to be built with DRAM for caching of small block random writes. You need about 1GB of DRAM per 1TB of NAND to act as a buffer, according to Ramirez.
|
||||
|
||||
### The benefits of Zoned Storage
|
||||
|
||||
Zoned Storage allows for 15-20% more storage on a HDD the than traditional storage mechanism. It eliminates the overprovisioning of SSDs, so you get all the NAND flash the drive has and you need far fewer DRAM chips on an SSD. Additionally, Western Digital promises you will need up to one-eighth as much DRAM to act as a cache in future SSD drives, lowering the cost.
|
||||
|
||||
Ramirez also said quality of service will improve, not necessarily that peak performance is better, but it will manage latency from outliers better.
|
||||
|
||||
Western Digital has not disclosed what if any pricing is associated with the project. It plans to work with the open-source community, customers, and industry players to help accelerate application development around Zoned Storage through its website.
|
||||
|
||||
Join the Network World communities on [Facebook][4] and [LinkedIn][5] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3402318/western-digital-launches-open-source-zettabyte-storage-initiative.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/02/big_data_center_server_racks_storage_binary_analytics_by_monsitj_gettyimages-951389152_3x2-100787358-large.jpg
|
||||
[2]: http://ZonedStorage.io
|
||||
[3]: https://www.networkworld.com/article/3275367/what-s-quantum-computing-and-why-enterprises-need-to-care.html
|
||||
[4]: https://www.facebook.com/NetworkWorld/
|
||||
[5]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,64 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5 transferable higher-education skills)
|
||||
[#]: via: (https://opensource.com/article/19/6/5-transferable-higher-education-skills)
|
||||
[#]: author: (Stephon Brown https://opensource.com/users/stephb)
|
||||
|
||||
5 transferable higher-education skills
|
||||
======
|
||||
If you're moving from the Ivory Tower to the Matrix, you already have
|
||||
the foundation for success in the developer role.
|
||||
![Two hands holding a resume with computer, clock, and desk chair ][1]
|
||||
|
||||
My transition from a higher-education professional into the tech realm was comparable to moving from a pond into an ocean. There was so much to learn, and after learning, there was still so much more to learn!
|
||||
|
||||
Rather than going down the rabbit hole and being overwhelmed by what I did not know, in the last two to three months, I have been able to take comfort in the realization that I was not entirely out of my element as a developer. The skills I acquired during my six years as a university professional gave me the foundation to be successful in the developer role.
|
||||
|
||||
These skills are transferable in any direction you plan to go within or outside tech, and it's valuable to reflect on how they apply to your new position.
|
||||
|
||||
### 1\. Composition and documentation
|
||||
|
||||
Higher education is replete with opportunities to develop skills related to composition and communication. In most cases, clear writing and communication are mandatory requirements for university administrative and teaching positions. Although you may not yet be well-versed in deep technical concepts, learning documentation and writing your progress may be two of the strongest skills you bring as a former higher education administrator. All of those "In response to…" emails will finally come in handy when describing the inner workings of a class or leaving succinct comments for other developers to follow what you have implemented.
|
||||
|
||||
### 2\. Problem-solving and critical thinking
|
||||
|
||||
Whether you've been an adviser who sits with students and painstakingly develops class schedules for graduation or a finance buff who balances government funds, you will not leave critical thinking behind as you transition into a developer role. Although your critical thinking may have seemed specialized for your work, the skill of turning problems into opportunities is not lost when contributing to code. The experience gained while spending long days and nights revising recruitment strategies will be necessary when composing algorithms and creative ways of delivering data. Continue to foster a passion for solving problems, and you will not have any trouble becoming an efficient and skillful developer.
|
||||
|
||||
### 3\. Communication
|
||||
|
||||
Though it may seem to overlap with writing (above), communication spans verbal and written disciplines. When you're interacting with clients and leadership, you may have a leg up over your peers because of your higher-education experience. Being approachable and understanding how to manage interactions are skills that some software practitioners may not have fostered to an impactful level. Although you will experience days of staring at a screen and banging your head against the keyboard, you can rest well in knowing you can describe technical concepts and interact with a wide range of audiences, from clients to peers.
|
||||
|
||||
### 4\. Leadership
|
||||
|
||||
Sitting on that panel; planning that event; leading that workshop. All of those experiences provide you with the grounding to plan and lead smaller projects as a new developer. Leadership is not limited to heading up large and small teams; its essence lies in taking initiative. This can be volunteering to do research on a new feature or do more extensive unit tests for your code. However you use it, your foundation as an educator will allow you to go further in technology development and maintenance.
|
||||
|
||||
### 5\. Research
|
||||
|
||||
You can Google with the best of them. Being able to clearly truncate your query into the idea you are searching for is characteristic of a higher-education professional. Most administrator or educator jobs focus on solving problems in a defined process for qualitative, quantitative, or mixed results; therefore, cultivating your scientific mind is valuable when providing software solutions. Your research skills also open opportunities for branching into data science and machine learning.
|
||||
|
||||
### Bonus: Collaboration
|
||||
|
||||
Being able to reach across various offices and fields for event planning and program implementation fit well within team collaboration—both within your new team and across development teams. This may leak into the project management realm, but being able to plan and divide work between teams and establish accountability will allow you as a new developer to understand the software development lifecycle process a little more intimately because of your past related experience.
|
||||
|
||||
### Summary
|
||||
|
||||
As a developer jumping head-first into technology after years of walking students through the process of navigating higher education, [imposter syndrome][2] has been a constant fear since moving into technology. However, I have been able to take heart in knowing my experience as an educator and an administrator has not gone in vain. If you are like me, be encouraged in knowing that these transferable skills, some of which fall into the soft-skills and other categories, will continue to benefit you as a developer and a professional.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/6/5-transferable-higher-education-skills
|
||||
|
||||
作者:[Stephon Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/stephb
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/resume_career_document_general.png?itok=JEaFL2XI (Two hands holding a resume with computer, clock, and desk chair )
|
||||
[2]: https://en.wikipedia.org/wiki/Impostor_syndrome
|
||||
@ -0,0 +1,53 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Use ImageGlass to quickly view JPG images as a slideshow)
|
||||
[#]: via: (https://opensource.com/article/19/6/use-imageglass-view-jpg-images-slideshow-windows-10)
|
||||
[#]: author: (Jeff Macharyas https://opensource.com/users/jeffmacharyas)
|
||||
|
||||
Use ImageGlass to quickly view JPG images as a slideshow
|
||||
======
|
||||
Want to view images from a folder one-by-one in a slideshow on Windows
|
||||
10? Open source to the rescue.
|
||||
![Looking back with binoculars][1]
|
||||
|
||||
Welcome to today’s episode of "How Can I Make This Work?" In my case, I was trying to view a folder of JPG images as a slideshow on Windows 10. As often happens, I turned to open source to solve the issue.
|
||||
|
||||
On a Mac, viewing a folder of JPG images as a slideshow is a simple matter of selecting all the images in a folder ( **Command-A** ), and then pressing **Option-Command-Y**. From there, you can advance the images with the arrow key. Of course, you can do a similar thing on Windows by selecting the first image, then clicking on the window frame's yellow **Manage** bar, then selecting **Slide Show**. There, you can control the speed, but only to a point: slow, medium, and fast.
|
||||
|
||||
I wanted to advance the images in Windows the same way I do it on a Mac. Naturally, I fired up the Googler and searched for a solution. There, I found the [ImageGlass][2] open source app, [licensed GPL 3.0][3], and it did the trick perfectly. Here's what it looks like:
|
||||
|
||||
![Viewing an image in ImageGlass.][4]
|
||||
|
||||
### About ImageGlass
|
||||
|
||||
ImageGlass was developed by Dương Diệu Pháp, a Vietnamese developer who works on the front end for Chainstack, according to his website. He collaborates with US-based [Kevin Routley][5], who "develops new features for ImageGlass." The source code is available on [GitHub][6].
|
||||
|
||||
ImageGlass supports most common image formats, including JPG, GIF, PNG, WEBP, SVG, and RAW. Users can customize this extension list easily.
|
||||
|
||||
My specific problem was needing to find an image for a catalog cover. Unfortunately, it was in a folder containing dozens of photos. Navigating through the slideshow in ImageGlass, stopping on the image I wanted, and downloading it into my project folder turned out to be easy. Open source to the rescue yet again, and the app took only seconds to download and use.
|
||||
|
||||
ImageGlass was featured as a Picasa alternative in Jason Baker’s article [9 open source alternatives to][7] [Picasa][7] from March 10, 2016. There are some other interesting image-related open source tools in there as well if you are in need.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/6/use-imageglass-view-jpg-images-slideshow-windows-10
|
||||
|
||||
作者:[Jeff Macharyas][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jeffmacharyas
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/look-binoculars-sight-see-review.png?itok=NOw2cm39 (Looking back with binoculars)
|
||||
[2]: https://imageglass.org/
|
||||
[3]: https://github.com/d2phap/ImageGlass/blob/master/LICENSE
|
||||
[4]: https://opensource.com/sites/default/files/uploads/imageglass-screenshot.png (Viewing an image in ImageGlass.)
|
||||
[5]: https://github.com/fire-eggs
|
||||
[6]: https://github.com/d2phap/ImageGlass
|
||||
[7]: https://opensource.com/alternatives/picasa
|
||||
@ -0,0 +1,85 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Cisco connects with IBM in to simplify hybrid cloud deployment)
|
||||
[#]: via: (https://www.networkworld.com/article/3403363/cisco-connects-with-ibm-in-to-simplify-hybrid-cloud-deployment.html)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
Cisco connects with IBM in to simplify hybrid cloud deployment
|
||||
======
|
||||
Cisco and IBM are working todevelop a hybrid-cloud architecture that meld Cisco’s data-center, networking and analytics platforms with IBM’s cloud offerings.
|
||||
![Ilze Lucero \(CC0\)][1]
|
||||
|
||||
Cisco and IBM said the companies would meld their [data-center][2] and cloud technologies to help customers more easily and securely build and support on-premises and [hybrid-cloud][3] applications.
|
||||
|
||||
Cisco, IBM Cloud and IBM Global Technology Services (the professional services business of IBM) said they will work to develop a hybrid-cloud architecture that melds Cisco’s data-center, networking and analytics platforms with IBM’s cloud offerings. IBM's contribution includea a heavy emphasis on Kubernetes-based offerings such as Cloud Foundry and Cloud Private as well as a catalog of [IBM enterprise software][4] such as Websphere and open source software such as Open Whisk, KNative, Istio and Prometheus.
|
||||
|
||||
**[ Read also:[How to plan a software-defined data-center network][5] ]**
|
||||
|
||||
Cisco said customers deploying its Virtual Application Centric Infrastructure (ACI) technologies can now extend that network fabric from on-premises to the IBM Cloud. ACI is Cisco’s [software-defined networking (SDN)][6] data-center package, but it also delivers the company’s Intent-Based Networking technology, which brings customers the ability to automatically implement network and policy changes on the fly and ensure data delivery.
|
||||
|
||||
[IBM said Cisco ACI Virtual Pod][7] (vPOD) software can now run on IBM Cloud bare-metal servers. “vPOD consists of virtual spines and leafs and supports up to eight instances of ACI Virtual Edge. These elements are often deployed on VMware services on the IBM Cloud to support hybrid deployments from on-premises environments to the IBM Cloud," the company stated.
|
||||
|
||||
“Through a new relationship with IBM’s Global Technology Services team, customers can implement Virtual ACI on their IBM Cloud,” Cisco’s Kaustubh Das, vice president of strategy and product development wrote in a [blog][8] about the agreement. “Virtual ACI is a software-only solution that you can deploy wherever you have at least two servers on which you can run the VMware ESXi hypervisor. In the future, the ability to deploy IBM Cloud Pak for Applications in a Cisco ACI environment will also be supported,” he stated.
|
||||
|
||||
IBM’s prepackaged Cloud Paks include a secured Kubernetes container and containerized IBM middleware designed to let customers quickly spin-up enterprise-ready containers, Big Blue said.
|
||||
|
||||
Additionally IBM said it would add support for its IBM Cloud Private, which manages Kubernetes and other containers, on Cisco HyperFlex and HyperFlex Edge hyperconverged infrastructure (HCI) systems. HyperFlex is Cisco's HCI that offers computing, networking and storage resources in a single system. The package can be managed via Cisco’s Intersight software-as-a-service cloud management platform that offers a central dashboard of HyperFlex operations.
|
||||
|
||||
IBM said it was adding Hyperflex support to its IBM Cloud Pak for Applications as well.
|
||||
|
||||
The paks include IBM Multicloud Manager which is a Kubernetes-based platform that runs on the company’s [IBM Cloud Private][9] platform and lets customers manage and integrate workloads on clouds from other providers such as Amazon, Red Hat and Microsoft.
|
||||
|
||||
At the heart of the Multi-cloud Manager is a dashboard interface for managing thousands of Kubernetes applications and huge volumes of data regardless of where in the organization they are located.
|
||||
|
||||
The idea is that Multi-cloud Manager lets operations and development teams get visibility of Kubernetes applications and components across the different clouds and clusters via a single control pane.
|
||||
|
||||
“With IBM Multicloud Manager, enterprises can have a single place to manage multiple clusters running across multiple on-premises, public and private cloud environments, providing consistent visibility, governance and automation from on-premises to the edge, wrote IBM’s Evaristus Mainsah, general manager of IBM Cloud Private Ecosystem in a [blog][7] about the relationship.
|
||||
|
||||
Distributed workloads can be pushed out and managed directly at the device at a much larger scale across multiple public clouds and on-premises locations. Visibility, compliance and governance are provided with extended MCM capabilities that will be available at the lightweight device layer, with a connection back to the central server/gateway, Mainsah stated.
|
||||
|
||||
In addition, Cisco’s AppDynamics\can be tied in to monitor infrastructure and business performance, Cisco stated. Cisco recently added [AppDynamics for Kubernetes][10], which Cisco said will reduce the time it takes to identify and troubleshoot performance issues across Kubernetes clusters.
|
||||
|
||||
The companies said the hybrid-cloud architecture they envision will help reduce the complexity of setting up and managing hybrid-cloud environments.
|
||||
|
||||
Cisco and IBM are both aggressively pursuing cloud customers. Cisco[ ramped up][11] its own cloud presence in 2018 with all manner of support stemming from an [agreement with Amazon Web Services][12] (AWS) that will offer enterprise customers an integrated platform to help them more simply build, secure and connect [Kubernetes][13] clusters across private [data centers][14] and the AWS cloud.
|
||||
|
||||
Cisco and Google in [April expanded their joint cloud-development][15] activities to help customers more easily build secure multicloud and hybrid applications everywhere from on-premises data centers to public clouds.
|
||||
|
||||
IBM is waiting to close [its $34 billion Red Hat deal][16] that it expects will give it a huge presence in the hotly contested hybrid-cloud arena and increase its inroads to competitors – Google, Amazon and Microsoft among others. Gartner says that market will be worth $240 billion by next year.
|
||||
|
||||
Join the Network World communities on [Facebook][17] and [LinkedIn][18] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3403363/cisco-connects-with-ibm-in-to-simplify-hybrid-cloud-deployment.html
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/03/cubes_blocks_squares_containers_ilze_lucero_cc0_via_unsplash_1200x800-100752172-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3223692/what-is-a-data-centerhow-its-changed-and-what-you-need-to-know.html
|
||||
[3]: https://www.networkworld.com/article/3233132/what-is-hybrid-cloud-computing.html
|
||||
[4]: https://www.networkworld.com/article/3340043/ibm-marries-on-premises-private-and-public-cloud-data.html
|
||||
[5]: https://www.networkworld.com/article/3284352/data-center/how-to-plan-a-software-defined-data-center-network.html
|
||||
[6]: https://www.networkworld.com/article/3209131/what-sdn-is-and-where-its-going.html
|
||||
[7]: https://www.ibm.com/blogs/cloud-computing/2019/06/18/ibm-cisco-collaborating-hybrid-cloud-modern-enterprise/
|
||||
[8]: https://blogs.cisco.com/datacenter/cisco-and-ibm-cloud-announce-hybrid-cloud-partnership
|
||||
[9]: https://www.ibm.com/cloud/private
|
||||
[10]: https://blog.appdynamics.com/product/kubernetes-monitoring-with-appdynamics/
|
||||
[11]: https://www.networkworld.com/article/3322937/lan-wan/what-will-be-hot-for-cisco-in-2019.html?nsdr=true
|
||||
[12]: https://www.networkworld.com/article/3319782/cloud-computing/cisco-aws-marriage-simplifies-hybrid-cloud-app-development.html?nsdr=true
|
||||
[13]: https://www.networkworld.com/article/3269848/cloud-computing/cisco-embraces-kubernetes-pushing-container-software-into-mainstream.html
|
||||
[14]: https://www.networkworld.com/article/3223692/data-center/what-is-a-data-centerhow-its-changed-and-what-you-need-to-know.html
|
||||
[15]: https://www.networkworld.com/article/3388218/cisco-google-reenergize-multicloudhybrid-cloud-joint-development.html
|
||||
[16]: https://www.networkworld.com/article/3316960/ibm-says-buying-red-hat-makes-it-the-biggest-in-hybrid-cloud.html
|
||||
[17]: https://www.facebook.com/NetworkWorld/
|
||||
[18]: https://www.linkedin.com/company/network-world
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user