mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-15 01:50:08 +08:00
Merge branch 'LCTT:master' into master
This commit is contained in:
commit
f4bbda6177
@ -0,0 +1,297 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Starryi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-14159-1.html)
|
||||
[#]: subject: (Create your own video streaming server with Linux)
|
||||
[#]: via: (https://opensource.com/article/19/1/basic-live-video-streaming-server)
|
||||
[#]: author: (Aaron J.Prisk https://opensource.com/users/ricepriskytreat)
|
||||
|
||||
使用 OBS 搭建视频流媒体服务器
|
||||
======
|
||||
|
||||
> 在 Linux 或 BSD 操作系统上设置基本的实时流媒体服务器。
|
||||
|
||||

|
||||
|
||||
实时视频流越来越流行。亚马逊的 Twitch 和谷歌的 YouTube 等平台拥有数百万用户,这些用户消磨了无数小时的来观看直播和录制视频。这些视频服务通常可以免费使用,但需要你拥有一个帐户,并且一般会将你的视频内容隐藏在广告中。有些人不希望他们的视频提供给大众观看,或者想更多地控制自己的视频内容。幸运的是,借助强大的开源软件,任何人都可以设置直播服务器。
|
||||
|
||||
### 入门
|
||||
|
||||
在本教程中,我将说明如何使用 Linux 或 BSD 操作系统设置基本的实时流媒体服务器。
|
||||
|
||||
搭建实时流媒体服务器不可避免地提到系统需求问题。这些需求多种多样,因为实时流媒体涉及许多因素,例如:
|
||||
|
||||
* **流媒体质量:** 你想以高清流媒体播放还是标清视频就可以满足你的需求?
|
||||
* **收视率:** 你的视频预计有多少观众?
|
||||
* **存储:** 你是否打算保留已保存的视频流副本?
|
||||
* **访问:** 你的视频流是私有的还是向全世界开放的?
|
||||
|
||||
在硬件要求方面没有固定规则,因此我建议你进行测试,以便找到最适合你需求的配置。本项目中,我将服务器安装在配有 4GB 内存、20GB 硬盘空间和单个 Intel i7 处理器内核的虚拟机上。
|
||||
|
||||
本项目使用<ruby>实时消息传递协议<rt>Real-Time Messaging Protocol</rt></ruby>(RTMP)来处理音频和视频流。当然还有其他协议可用,但我选择 RTMP 是因为它具有广泛的支持。鉴于像 WebRTC 这样的开放标准变得更加兼容,我比较推荐这条路线。
|
||||
|
||||
同样重要的是,要明白“实时”并不总是意味着即时。视频流必须经过编码、传输、缓冲和显示,这通常会增大延迟。延迟可以被缩短或延长,具体取决于你创建的流类型及其属性。
|
||||
|
||||
### 设置 Linux 服务器
|
||||
|
||||
你可以使用许多不同的 Linux 发行版,但我更喜欢 Ubuntu,因此我下载了 [Ubuntu 服务器版][1] 作为我的操作系统。如果你希望你的服务器具有图形用户界面(GUI),请随意使用 [Ubuntu 桌面版][2] 或其多种风味版本之一。然后,我在我的计算机或虚拟机上启动了 Ubuntu 安装程序,并选择了最适合我的环境的设置。以下是我采取的步骤。
|
||||
|
||||
注意:因为这是一个服务器,你可能需要设置静态网络。
|
||||
|
||||
|
||||
|
||||
安装程序完成并重新启动系统后,你会看到一个可爱的新 Ubuntu 系统。 与任何新安装的操作系统一样,安装任何可用的更新:
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
sudo apt upgrade
|
||||
```
|
||||
|
||||
这个流媒体服务器将使用非常强大通用的 Nginx 网络服务器,所以你需要安装它:
|
||||
|
||||
```
|
||||
sudo apt install nginx
|
||||
```
|
||||
|
||||
然后你需要获取 RTMP 模块,以便 Nginx 可以处理你的媒体流:
|
||||
|
||||
```
|
||||
sudo add-apt-repository universe
|
||||
sudo apt install libnginx-mod-rtmp
|
||||
```
|
||||
|
||||
修改你的网页服务器配置,使其能够接受和传送你的媒体流。
|
||||
|
||||
```
|
||||
sudo nano /etc/nginx/nginx.conf
|
||||
```
|
||||
|
||||
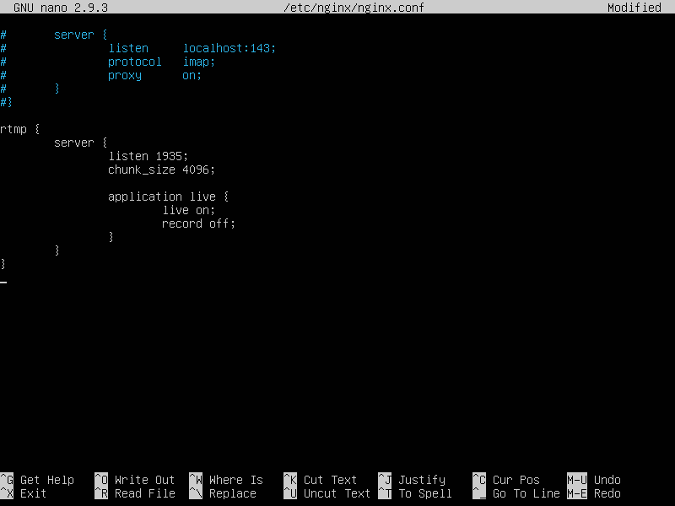
滚动到配置文件的底部并添加以下代码:
|
||||
|
||||
```
|
||||
rtmp {
|
||||
server {
|
||||
listen 1935;
|
||||
chunk_size 4096;
|
||||
|
||||
application live {
|
||||
live on;
|
||||
record off;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
保存配置。我是使用 [Nano][3] 来编辑配置文件的异端。在 Nano 中,你可以通过快捷键 `Ctrl+X`、`Y` 并按下回车来保存你的配置。
|
||||
|
||||
这么一个非常小的配置就可以创建一个可工作的流服务器。稍后你将添加更多内容到此配置中,但这是一个很好的起点。
|
||||
|
||||
在开始第一个流之前,你需要使用新配置重新启动 Nginx:
|
||||
|
||||
```
|
||||
sudo systemctl restart nginx
|
||||
```
|
||||
|
||||
### 设置 BSD 服务器
|
||||
|
||||
如果是“小恶魔”(LCTT 译者注:FreeBSD 的标志是一个拿着叉子的红色小恶魔)的信徒,那么建立并运行一个流媒体服务器也非常容易。
|
||||
|
||||
前往 [FreeBSD][4] 网站并下载最新版本。在你的计算机或虚拟机上启动 FreeBSD 安装程序,然后执行初始步骤并选择最适合你环境的设置。由于这是一个服务器,你可能需要设置静态网络。
|
||||
|
||||
在安装程序完成并重新启动系统后,你应该就拥有了一个闪亮的新 FreeBSD 系统。像任何其他新安装的系统一样,你可能希望更新所有内容(从这一步开始,请确保你以 root 身份登录):
|
||||
|
||||
```
|
||||
pkg update
|
||||
pkg upgrade
|
||||
```
|
||||
|
||||
安装 [Nano][3] 来编辑配置文件:
|
||||
|
||||
```
|
||||
pkg install nano
|
||||
```
|
||||
|
||||
这个流媒体服务器将使用非常强大通用的 Nginx 网络服务器。 你可以使用 FreeBSD 所拥有的优秀 ports 系统来构建 Nginx。
|
||||
|
||||
首先,更新你的 ports 树:
|
||||
|
||||
```
|
||||
portsnap fetch
|
||||
portsnap extract
|
||||
```
|
||||
|
||||
进入 Nginx ports 目录:
|
||||
|
||||
```
|
||||
cd /usr/ports/www/nginx
|
||||
```
|
||||
|
||||
运行如下命令开始构建 Nginx:
|
||||
|
||||
```
|
||||
make install
|
||||
```
|
||||
|
||||
你将看到一个屏幕,询问你的 Nginx 构建中要包含哪些模块。对于这个项目,你需要添加 RTMP 模块。向下滚动直到选中 RTMP 模块,并按下空格键。然后按回车键继续剩下的构建和安装。
|
||||
|
||||
Nginx 安装完成后,就该为它配置流式传输了。
|
||||
|
||||
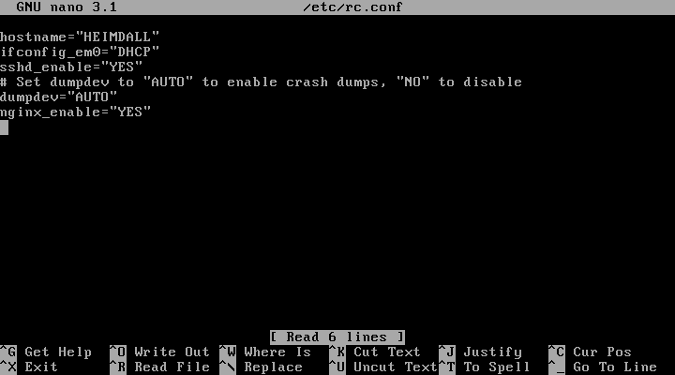
首先,在 `/etc/rc.conf` 中添加一个条目以确保 Nginx 服务器在系统启动时启动:
|
||||
|
||||
```
|
||||
nano /etc/rc.conf
|
||||
```
|
||||
|
||||
将此文本添加到文件中:
|
||||
|
||||
```
|
||||
nginx_enable="YES"
|
||||
```
|
||||
|
||||
|
||||
|
||||
接下来,创建一个网站根目录,Nginx 将从中提供其内容。我自己的目录叫 `stream`:
|
||||
|
||||
```
|
||||
cd /usr/local/www/
|
||||
mkdir stream
|
||||
chmod -R 755 stream/
|
||||
```
|
||||
|
||||
现在你已经创建了你的流目录,通过编辑配置文件来配置 Nginx:
|
||||
|
||||
```
|
||||
nano /usr/local/etc/nginx/nginx.conf
|
||||
```
|
||||
|
||||
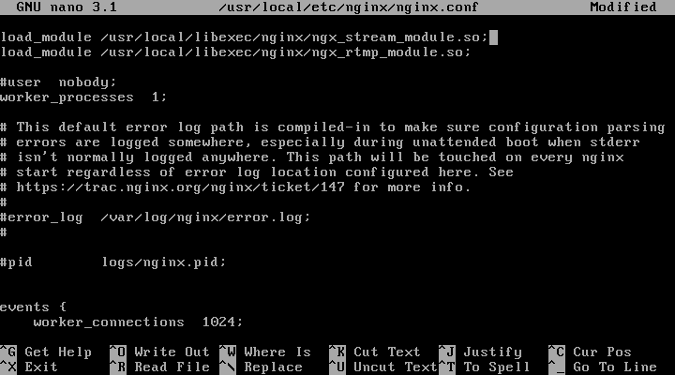
在文件顶部加载你的流媒体模块:
|
||||
|
||||
```
|
||||
load_module /usr/local/libexec/nginx/ngx_stream_module.so;
|
||||
load_module /usr/local/libexec/nginx/ngx_rtmp_module.so;
|
||||
```
|
||||
|
||||
|
||||
|
||||
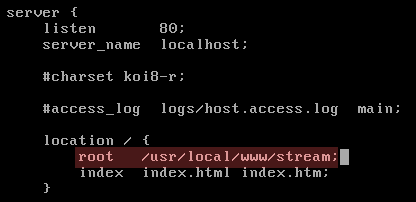
在 `Server` 部分下,更改 `root` 位置以匹配你之前创建的目录位置:
|
||||
|
||||
```nginx
|
||||
Location / {
|
||||
root /usr/local/www/stream
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
最后,添加你的 RTMP 设置,以便 Nginx 知道如何处理你的媒体流:
|
||||
|
||||
```
|
||||
rtmp {
|
||||
server {
|
||||
listen 1935;
|
||||
chunk_size 4096;
|
||||
|
||||
application live {
|
||||
live on;
|
||||
record off;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
保存配置。在 Nano 中,你可以通过快捷键 `Ctrl+X`、`Y`,然后按回车键来执行此操作。
|
||||
|
||||
如你所见,这么一个非常小的配置将创建一个工作的流服务器。稍后,你将添加更多内容到此配置中,但这将为你提供一个很好的起点。
|
||||
|
||||
但是,在开始第一个流之前,你需要使用新配置重新启动 Nginx:
|
||||
|
||||
```
|
||||
service nginx restart
|
||||
```
|
||||
|
||||
### 设置你的流媒体软件
|
||||
|
||||
#### 使用 OBS 进行广播
|
||||
|
||||
现在你的服务器已准备好接受你的视频流,是时候设置你的流媒体软件了。本教程使用功能强大的开源的 Open Broadcast Studio(OBS)。
|
||||
|
||||
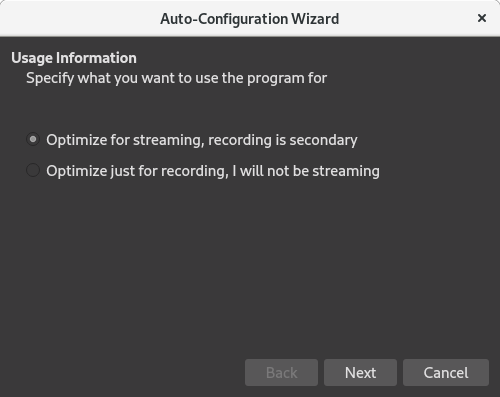
前往 [OBS 网站][5],找到适用于你的操作系统的版本并安装它。OBS 启动后,你应该会看到一个首次运行向导,该向导将帮助你使用最适合你的硬件的设置来配置 OBS。
|
||||
|
||||
|
||||
|
||||
OBS 没有捕获任何内容,因为你没有为其提供源。在本教程中,你只需为流捕获桌面。单击“<ruby>来源<rt>Source</rt></ruby>”下的 “+” 按钮,选择“<ruby>显示捕获<rt>Screen Capture</rt></ruby>”,然后选择要捕获的桌面。
|
||||
|
||||
单击“<ruby>确定<rt>OK</rt></ruby>”,你应该会看到 OBS 镜像了你的桌面。
|
||||
|
||||
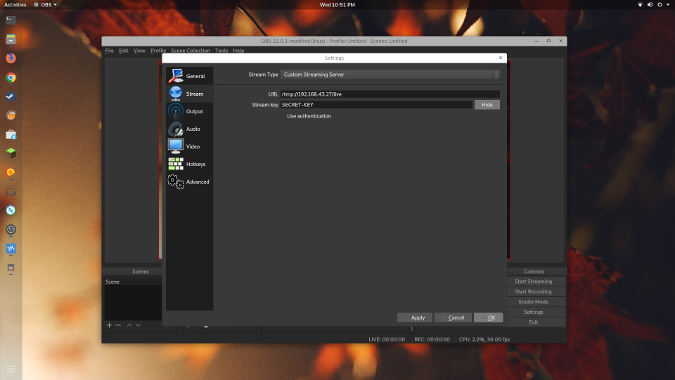
现在可以将你新配置的视频流发送到你的服务器了。在 OBS 中,单击“<ruby>文件 > 设置<rt>File > Settings</rt></ruby>”。 单击“<ruby>流<rt>Stream</rt></ruby>”部分,并将“<ruby>串流类型<rt>Stream Type</rt></ruby>” 设置为“<ruby>自定义流媒体服务器<rt>Custom Streaming Server</rt></ruby>”。
|
||||
|
||||
在 URL 框中,输入前缀 `rtmp://` 后跟流媒体服务器的 IP 地址,后跟 `/live`。例如,`rtmp://IP-ADDRESS/live`。
|
||||
|
||||
接下来,你可能需要输入“<ruby>串流密钥<rt>Stream key</rt></ruby>”,这是观看你的流所需的特殊标识符。 在“<ruby>串流密钥<rt>Stream key</rt></ruby>”框中输入你想要(并且可以记住)的任何关键词。
|
||||
|
||||
|
||||
|
||||
单击“<ruby>应用<rt>Apply</rt></ruby>”,然后单击“<ruby>确定<rt>OK</rt></ruby>”。
|
||||
|
||||
现在 OBS 已配置为将你的流发送到你的服务器,你可以开始你的第一个视频流。 单击“<ruby>开始推流<rt>Start Streaming</rt></ruby>”。
|
||||
|
||||
如果一切正常,你应该会看到按钮更改为“<ruby>停止推流<rt>Stop Streaming</rt></ruby>”,并且在 OBS 的底部将出现一些带宽指标。
|
||||
|
||||

|
||||
|
||||
如果你收到错误消息,请仔细检查 OBS 中的流设置是否有拼写错误。如果一切看起来都不错,则可能是另一个问题阻止了它的工作。
|
||||
|
||||
### 观看你的视频流
|
||||
|
||||
如果没有人观看,就说明直播视频不是很好,所以请成为你的第一个观众!
|
||||
|
||||
有许多支持 RTMP 的开源媒体播放器,但最著名的可能是 [VLC 媒体播放器][6]。
|
||||
|
||||
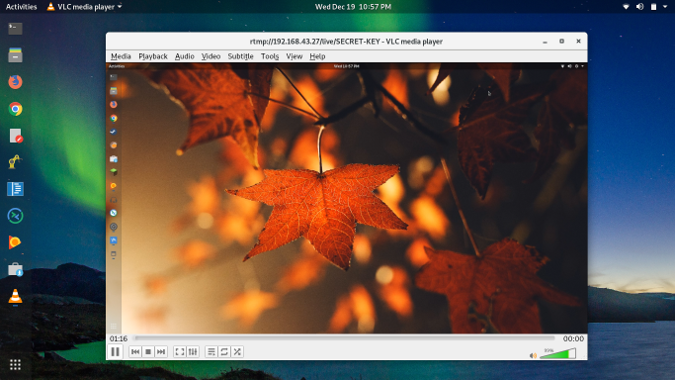
安装并启动 VLC 后,通过单击“<ruby>媒体 > 打开网络串流<rt>Media > Open Network Stream</rt></ruby>” 打开你的流。输入你的流的路径,添加你在 OBS 中设置的串流密钥,然后单击“<ruby>播放<rt>Play</rt></ruby>”。 例如,`rtmp://IP-ADDRESS/live/SECRET-KEY`。
|
||||
|
||||
你现在应该可以看到自己的实时视频流了!
|
||||
|
||||
|
||||
|
||||
### 接下来要做什么?
|
||||
|
||||
本项目是一个非常简单的设置,可以让你开始工作。 以下是你可能想要使用的另外两个功能。
|
||||
|
||||
* **限制访问:** 你可能想要做的下一件事情是限制对你服务器的访问,因为默认设置允许任何人与服务器之间进行流传输。有多种设置方法,例如操作系统防火墙、[.htaccess 文件][7],甚至使用 [STMP 模块中的内置访问控制][8]。
|
||||
* **录制流:** 这个简单的 Nginx 配置只会流传输而不会保存你的视频,但这很容易修改。在 Nginx 配置文件中的 RTMP 部分下,设置录制选项和要保存视频的位置。确保你设置的路径存在并且 Nginx 能够写入它。
|
||||
|
||||
```
|
||||
application live {
|
||||
live on;
|
||||
record all;
|
||||
record_path /var/www/html/recordings;
|
||||
record_unique on;
|
||||
}
|
||||
```
|
||||
|
||||
实时流媒体的世界在不断发展,如果你对更高级的用途感兴趣,可以在互联网上找到许多其他很棒的资源。祝你好运,直播快乐!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/basic-live-video-streaming-server
|
||||
|
||||
作者:[Aaron J.Prisk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Starryi](https://github.com/Starryi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ricepriskytreat
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ubuntu.com/download/server
|
||||
[2]: https://www.ubuntu.com/download/desktop
|
||||
[3]: https://www.nano-editor.org/
|
||||
[4]: https://www.freebsd.org/
|
||||
[5]: https://obsproject.com/
|
||||
[6]: https://www.videolan.org/vlc/index.html
|
||||
[7]: https://httpd.apache.org/docs/current/howto/htaccess.html
|
||||
[8]: https://github.com/arut/nginx-rtmp-module/wiki/Directives#access
|
||||
425
published/20210916 Crunch numbers in Python with NumPy.md
Normal file
425
published/20210916 Crunch numbers in Python with NumPy.md
Normal file
@ -0,0 +1,425 @@
|
||||
[#]: subject: "Crunch numbers in Python with NumPy"
|
||||
[#]: via: "https://opensource.com/article/21/9/python-numpy"
|
||||
[#]: author: "Ayush Sharma https://opensource.com/users/ayushsharma"
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "wxy"
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-14160-1.html"
|
||||
|
||||
用 NumPy 在 Python 中处理数字
|
||||
======
|
||||
|
||||
> 这篇文章讨论了安装 NumPy,然后创建、读取和排序 NumPy 数组。
|
||||
|
||||

|
||||
|
||||
NumPy(即 **Num**erical **Py**thon)是一个库,它使得在 Python 中对线性数列和矩阵进行统计和集合操作变得容易。[我在 Python 数据类型的笔记中介绍过][2],它比 Python 的列表快几个数量级。NumPy 在数据分析和科学计算中使用得相当频繁。
|
||||
|
||||
我将介绍安装 NumPy,然后创建、读取和排序 NumPy 数组。NumPy 数组也被称为 ndarray,即 N 维数组的缩写。
|
||||
|
||||
### 安装 NumPy
|
||||
|
||||
使用 `pip` 安装 NumPy 包非常简单,可以像安装其他软件包一样进行安装:
|
||||
|
||||
```
|
||||
pip install numpy
|
||||
```
|
||||
|
||||
安装了 NumPy 包后,只需将其导入你的 Python 文件中:
|
||||
|
||||
```
|
||||
import numpy as np
|
||||
```
|
||||
|
||||
将 `numpy` 以 `np` 之名导入是一个标准的惯例,但你可以不使用 `np`,而是使用你想要的任何其他别名。
|
||||
|
||||
### 为什么使用 NumPy? 因为它比 Python 列表要快好几个数量级
|
||||
|
||||
当涉及到处理大量的数值时,NumPy 比普通的 Python 列表快几个数量级。为了看看它到底有多快,我首先测量在普通 Python 列表上进行 `min()` 和 `max()` 操作的时间。
|
||||
|
||||
我将首先创建一个具有 999,999,999 项的 Python 列表:
|
||||
|
||||
```
|
||||
>>> my_list = range(1, 1000000000)
|
||||
>>> len(my_list)
|
||||
999999999
|
||||
```
|
||||
|
||||
现在我将测量在这个列表中找到最小值的时间:
|
||||
|
||||
```
|
||||
>>> start = time.time()
|
||||
>>> min(my_list)
|
||||
1
|
||||
>>> print('Time elapsed in milliseconds: ' + str((time.time() - start) * 1000))
|
||||
Time elapsed in milliseconds: 27007.00879096985
|
||||
```
|
||||
|
||||
这花了大约 27,007 毫秒,也就是大约 **27 秒**。这是个很长的时间。现在我试着找出寻找最大值的时间:
|
||||
|
||||
```
|
||||
>>> start = time.time()
|
||||
>>> max(my_list)
|
||||
999999999
|
||||
>>> print('Time elapsed in milliseconds: ' + str((time.time() - start) * 1000))
|
||||
Time elapsed in milliseconds: 28111.071348190308
|
||||
```
|
||||
|
||||
这花了大约 28,111 毫秒,也就是大约 **28 秒**。
|
||||
|
||||
现在我试试用 NumPy 找到最小值和最大值的时间:
|
||||
|
||||
```
|
||||
>>> my_list = np.arange(1, 1000000000)
|
||||
>>> len(my_list)
|
||||
999999999
|
||||
>>> start = time.time()
|
||||
>>> my_list.min()
|
||||
1
|
||||
>>> print('Time elapsed in milliseconds: ' + str((time.time() - start) * 1000))
|
||||
Time elapsed in milliseconds: 1151.1778831481934
|
||||
>>>
|
||||
>>> start = time.time()
|
||||
>>> my_list.max()
|
||||
999999999
|
||||
>>> print('Time elapsed in milliseconds: ' + str((time.time() - start) * 1000))
|
||||
Time elapsed in milliseconds: 1114.8970127105713
|
||||
```
|
||||
|
||||
找到最小值花了大约 1151 毫秒,找到最大值 1114 毫秒。这大约是 **1 秒**。
|
||||
|
||||
正如你所看到的,使用 NumPy 可以将寻找一个大约有 10 亿个值的列表的最小值和最大值的时间 **从大约 28 秒减少到 1 秒**。这就是 NumPy 的强大之处。
|
||||
|
||||
### 使用 Python 列表创建 ndarray
|
||||
|
||||
有几种方法可以在 NumPy 中创建 ndarray。
|
||||
|
||||
你可以通过使用元素列表来创建一个 ndarray:
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.array([1, 2, 3, 4, 5])
|
||||
>>> print(my_ndarray)
|
||||
[1 2 3 4 5]
|
||||
```
|
||||
|
||||
有了上面的 ndarray 定义,我将检查几件事。首先,上面定义的变量的类型是 `numpy.ndarray`。这是所有 NumPy ndarray 的类型:
|
||||
|
||||
```
|
||||
>>> type(my_ndarray)
|
||||
<class 'numpy.ndarray'>
|
||||
```
|
||||
|
||||
这里要注意的另一件事是 “<ruby>形状<rt>shape</rt></ruby>”。ndarray 的形状是 ndarray 的每个维度的长度。你可以看到,`my_ndarray` 的形状是 `(5,)`。这意味着 `my_ndarray` 包含一个有 5 个元素的维度(轴)。
|
||||
|
||||
```
|
||||
>>> np.shape(my_ndarray)
|
||||
(5,)
|
||||
```
|
||||
|
||||
数组中的维数被称为它的 “<ruby>秩<rt>rank</rt></ruby>”。所以上面的 ndarray 的秩是 1。
|
||||
|
||||
我将定义另一个 ndarray `my_ndarray2` 作为一个多维 ndarray。那么它的形状会是什么呢?请看下面:
|
||||
|
||||
```
|
||||
>>> my_ndarray2 = np.array([(1, 2, 3), (4, 5, 6)])
|
||||
>>> np.shape(my_ndarray2)
|
||||
(2, 3)
|
||||
```
|
||||
|
||||
这是一个秩为 2 的 ndarray。另一个要检查的属性是 `dtype`,也就是数据类型。检查我们的 ndarray 的 `dtype` 可以得到以下结果:
|
||||
|
||||
```
|
||||
>>> my_ndarray.dtype
|
||||
dtype('int64')
|
||||
```
|
||||
|
||||
`int64` 意味着我们的 ndarray 是由 64 位整数组成的。NumPy 不能创建混合类型的 ndarray,必须只包含一种类型的元素。如果你定义了一个包含混合元素类型的 ndarray,NumPy 会自动将所有的元素类型转换为可以包含所有元素的最高元素类型。
|
||||
|
||||
例如,创建一个 `int` 和 `float` 的混合序列将创建一个 `float64` 的 ndarray:
|
||||
|
||||
```
|
||||
>>> my_ndarray2 = np.array([1, 2.0, 3])
|
||||
>>> print(my_ndarray2)
|
||||
[1. 2. 3.]
|
||||
>>> my_ndarray2.dtype
|
||||
dtype('float64')
|
||||
```
|
||||
|
||||
另外,将其中一个元素设置为 `string` 将创建 `dtype` 等于 `<U21` 的字符串 ndarray,意味着我们的 ndarray 包含 unicode 字符串:
|
||||
|
||||
```
|
||||
>>> my_ndarray2 = np.array([1, '2', 3])
|
||||
>>> print(my_ndarray2)
|
||||
['1' '2' '3']
|
||||
>>> my_ndarray2.dtype
|
||||
dtype('<U21')
|
||||
```
|
||||
|
||||
`size` 属性将显示我们的 ndarray 中存在的元素总数:
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.array([1, 2, 3, 4, 5])
|
||||
>>> my_ndarray.size
|
||||
5
|
||||
```
|
||||
|
||||
### 使用 NumPy 方法创建 ndarray
|
||||
|
||||
如果你不想直接使用列表来创建 ndarray,还有几种可以用来创建它的 NumPy 方法。
|
||||
|
||||
你可以使用 `np.zeros()` 来创建一个填满 0 的 ndarray。它需要一个“形状”作为参数,这是一个包含行数和列数的列表。它还可以接受一个可选的 `dtype` 参数,这是 ndarray 的数据类型:
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.zeros([2,3], dtype=int)
|
||||
>>> print(my_ndarray)
|
||||
[[0 0 0]
|
||||
[0 0 0]]
|
||||
```
|
||||
|
||||
你可以使用 `np. ones()` 来创建一个填满 `1` 的 ndarray:
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.ones([2,3], dtype=int)
|
||||
>>> print(my_ndarray)
|
||||
[[1 1 1]
|
||||
[1 1 1]]
|
||||
```
|
||||
|
||||
你可以使用 `np.full()` 来给 ndarray 填充一个特定的值:
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.full([2,3], 10, dtype=int)
|
||||
>>> print(my_ndarray)
|
||||
[[10 10 10]
|
||||
[10 10 10]]
|
||||
```
|
||||
|
||||
你可以使用 `np.eye()` 来创建一个单位矩阵 / ndarray,这是一个沿主对角线都是 `1` 的正方形矩阵。正方形矩阵是一个行数和列数相同的矩阵:
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.eye(3, dtype=int)
|
||||
>>> print(my_ndarray)
|
||||
[[1 0 0]
|
||||
[0 1 0]
|
||||
[0 0 1]]
|
||||
```
|
||||
|
||||
你可以使用 `np.diag()` 来创建一个沿对角线有指定数值的矩阵,而在矩阵的其他部分为 `0`:
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.diag([10, 20, 30, 40, 50])
|
||||
>>> print(my_ndarray)
|
||||
[[10 0 0 0 0]
|
||||
[ 0 20 0 0 0]
|
||||
[ 0 0 30 0 0]
|
||||
[ 0 0 0 40 0]
|
||||
[ 0 0 0 0 50]]
|
||||
```
|
||||
|
||||
你可以使用 `np.range()` 来创建一个具有特定数值范围的 ndarray。它是通过指定一个整数的开始和结束(不包括)范围以及一个步长来创建的:
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.arange(1, 20, 3)
|
||||
>>> print(my_ndarray)
|
||||
[ 1 4 7 10 13 16 19]
|
||||
```
|
||||
|
||||
### 读取 ndarray
|
||||
|
||||
ndarray 的值可以使用索引、分片或布尔索引来读取。
|
||||
|
||||
#### 使用索引读取 ndarray 的值
|
||||
|
||||
在索引中,你可以使用 ndarray 的元素的整数索引来读取数值,就像你读取 Python 列表一样。就像 Python 列表一样,索引从 `0` 开始。
|
||||
|
||||
例如,在定义如下的 ndarray 中:
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.arange(1, 20, 3)
|
||||
```
|
||||
|
||||
第四个值将是 `my_ndarray[3]`,即 `10`。最后一个值是 `my_ndarray[-1]`,即 `19`:
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.arange(1, 20, 3)
|
||||
>>> print(my_ndarray[0])
|
||||
1
|
||||
>>> print(my_ndarray[3])
|
||||
10
|
||||
>>> print(my_ndarray[-1])
|
||||
19
|
||||
>>> print(my_ndarray[5])
|
||||
16
|
||||
>>> print(my_ndarray[6])
|
||||
19
|
||||
```
|
||||
|
||||
#### 使用分片读取 ndarray
|
||||
|
||||
你也可以使用分片来读取 ndarray 的块。分片的工作方式是用冒号(`:`)操作符指定一个开始索引和一个结束索引。然后,Python 将获取该开始和结束索引之间的 ndarray 片断:
|
||||
|
||||
```
|
||||
>>> print(my_ndarray[:])
|
||||
[ 1 4 7 10 13 16 19]
|
||||
>>> print(my_ndarray[2:4])
|
||||
[ 7 10]
|
||||
>>> print(my_ndarray[5:6])
|
||||
[16]
|
||||
>>> print(my_ndarray[6:7])
|
||||
[19]
|
||||
>>> print(my_ndarray[:-1])
|
||||
[ 1 4 7 10 13 16]
|
||||
>>> print(my_ndarray[-1:])
|
||||
[19]
|
||||
```
|
||||
|
||||
分片创建了一个 ndarray 的引用(或视图)。这意味着,修改分片中的值也会改变原始 ndarray 的值。
|
||||
|
||||
比如说:
|
||||
|
||||
```
|
||||
>>> my_ndarray[-1:] = 100
|
||||
>>> print(my_ndarray)
|
||||
[ 1 4 7 10 13 16 100]
|
||||
```
|
||||
|
||||
对于秩超过 1 的 ndarray 的分片,可以使用 `[行开始索引:行结束索引, 列开始索引:列结束索引]` 语法:
|
||||
|
||||
```
|
||||
>>> my_ndarray2 = np.array([(1, 2, 3), (4, 5, 6)])
|
||||
>>> print(my_ndarray2)
|
||||
[[1 2 3]
|
||||
[4 5 6]]
|
||||
>>> print(my_ndarray2[0:2,1:3])
|
||||
[[2 3]
|
||||
[5 6]]
|
||||
```
|
||||
|
||||
#### 使用布尔索引读取 ndarray 的方法
|
||||
|
||||
读取 ndarray 的另一种方法是使用布尔索引。在这种方法中,你在方括号内指定一个过滤条件,然后返回符合该条件的 ndarray 的一个部分。
|
||||
|
||||
例如,为了获得一个 ndarray 中所有大于 5 的值,你可以指定布尔索引操作 `my_ndarray[my_ndarray > 5]`。这个操作将返回一个包含所有大于 5 的值的 ndarray:
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
|
||||
>>> my_ndarray2 = my_ndarray[my_ndarray > 5]
|
||||
>>> print(my_ndarray2)
|
||||
[ 6 7 8 9 10]
|
||||
```
|
||||
|
||||
例如,为了获得一个 ndarray 中的所有偶数值,你可以使用如下的布尔索引操作:
|
||||
|
||||
```
|
||||
>>> my_ndarray2 = my_ndarray[my_ndarray % 2 == 0]
|
||||
>>> print(my_ndarray2)
|
||||
[ 2 4 6 8 10]
|
||||
```
|
||||
|
||||
而要得到所有的奇数值,你可以用这个方法:
|
||||
|
||||
```
|
||||
>>> my_ndarray2 = my_ndarray[my_ndarray % 2 == 1]
|
||||
>>> print(my_ndarray2)
|
||||
[1 3 5 7 9]
|
||||
```
|
||||
|
||||
### ndarray 的矢量和标量算术
|
||||
|
||||
NumPy 的 ndarray 允许进行矢量和标量算术操作。在矢量算术中,在两个 ndarray 之间进行一个元素的算术操作。在标量算术中,算术运算是在一个 ndarray 和一个常数标量值之间进行的。
|
||||
|
||||
如下的两个 ndarray:
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.array([1, 2, 3, 4, 5])
|
||||
>>> my_ndarray2 = np.array([6, 7, 8, 9, 10])
|
||||
```
|
||||
|
||||
如果你将上述两个 ndarray 相加,就会产生一个两个 ndarray 的元素相加的新的 ndarray。例如,产生的 ndarray 的第一个元素将是原始 ndarray 的第一个元素相加的结果,以此类推:
|
||||
|
||||
```
|
||||
>>> print(my_ndarray2 + my_ndarray)
|
||||
[ 7 9 11 13 15]
|
||||
```
|
||||
|
||||
这里,`7` 是 `1` 和 `6` 的和,这是我相加的 ndarray 中的前两个元素。同样,`15` 是 `5` 和`10` 之和,是最后一个元素。
|
||||
|
||||
请看以下算术运算:
|
||||
|
||||
```
|
||||
>>> print(my_ndarray2 - my_ndarray)
|
||||
[5 5 5 5 5]
|
||||
>>>
|
||||
>>> print(my_ndarray2 * my_ndarray)
|
||||
[ 6 14 24 36 50]
|
||||
>>>
|
||||
>>> print(my_ndarray2 / my_ndarray)
|
||||
[6. 3.5 2.66666667 2.25 2. ]
|
||||
```
|
||||
|
||||
在 ndarray 中加一个标量值也有类似的效果,标量值被添加到 ndarray 的所有元素中。这被称为“<ruby>广播<rt>broadcasting</rt></ruby>”:
|
||||
|
||||
```
|
||||
>>> print(my_ndarray + 10)
|
||||
[11 12 13 14 15]
|
||||
>>>
|
||||
>>> print(my_ndarray - 10)
|
||||
[-9 -8 -7 -6 -5]
|
||||
>>>
|
||||
>>> print(my_ndarray * 10)
|
||||
[10 20 30 40 50]
|
||||
>>>
|
||||
>>> print(my_ndarray / 10)
|
||||
[0.1 0.2 0.3 0.4 0.5]
|
||||
```
|
||||
|
||||
### ndarray 的排序
|
||||
|
||||
有两种方法可以对 ndarray 进行原地或非原地排序。原地排序会对原始 ndarray 进行排序和修改,而非原地排序会返回排序后的 ndarray,但不会修改原始 ndarray。我将尝试这两个例子:
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.array([3, 1, 2, 5, 4])
|
||||
>>> my_ndarray.sort()
|
||||
>>> print(my_ndarray)
|
||||
[1 2 3 4 5]
|
||||
```
|
||||
|
||||
正如你所看到的,`sort()` 方法对 ndarray 进行原地排序,并修改了原数组。
|
||||
|
||||
还有一个方法叫 `np.sort()`,它对数组进行非原地排序:
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.array([3, 1, 2, 5, 4])
|
||||
>>> print(np.sort(my_ndarray))
|
||||
[1 2 3 4 5]
|
||||
>>> print(my_ndarray)
|
||||
[3 1 2 5 4]
|
||||
```
|
||||
|
||||
正如你所看到的,`np.sort()` 方法返回一个已排序的 ndarray,但没有修改它。
|
||||
|
||||
### 总结
|
||||
|
||||
我已经介绍了很多关于 NumPy 和 ndarray 的内容。我谈到了创建 ndarray,读取它们的不同方法,基本的向量和标量算术,以及排序。NumPy 还有很多东西可以探索,包括像 `union()` 和 `intersection()`这样的集合操作,像 `min()` 和 `max()` 这样的统计操作,等等。
|
||||
|
||||
我希望我上面演示的例子是有用的。祝你在探索 NumPy 时愉快。
|
||||
|
||||
本文最初发表于 [作者的个人博客][3],经授权后改编。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/9/python-numpy
|
||||
|
||||
作者:[Ayush Sharma][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ayushsharma
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/math_money_financial_calculator_colors.jpg?itok=_yEVTST1 (old school calculator)
|
||||
[2]: https://notes.ayushsharma.in/2018/09/data-types-in-python
|
||||
[3]: https://notes.ayushsharma.in/2018/10/working-with-numpy-in-python
|
||||
@ -1,460 +0,0 @@
|
||||
[#]: subject: "Crunch numbers in Python with NumPy"
|
||||
[#]: via: "https://opensource.com/article/21/9/python-numpy"
|
||||
[#]: author: "Ayush Sharma https://opensource.com/users/ayushsharma"
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: " "
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
|
||||
Crunch numbers in Python with NumPy
|
||||
======
|
||||
This article discusses installing NumPy, and then creating, reading, and
|
||||
sorting NumPy arrays.
|
||||
![old school calculator][1]
|
||||
|
||||
NumPy, or **Num**erical **Py**thon, is a library that makes it easy to do statistical and set operations on linear series and matrices in Python. It is orders of magnitude faster than Python lists, [which I covered in my notes on Python Data Types][2]. NumPy is used quite frequently in data analysis and scientific calculations.
|
||||
|
||||
I'm going to go over installing NumPy, and then creating, reading, and sorting NumPy arrays. NumPy arrays are also called _ndarrays_, short for **n-dimensional arrays**.
|
||||
|
||||
### Installing NumPy
|
||||
|
||||
Installing the NumPy package is really simple using `pip`, and it can be installed just like you would install any other package.
|
||||
|
||||
|
||||
```
|
||||
pip install numpy
|
||||
```
|
||||
|
||||
With the NumPy package installed, just import it into your Python file.
|
||||
|
||||
|
||||
```
|
||||
import numpy as np
|
||||
```
|
||||
|
||||
Importing `numpy` as `np` is a standard convention, but instead of using `np` you can use any other alias that you want.
|
||||
|
||||
### Why use NumPy? Because it is orders of magnitude faster than Python lists.
|
||||
|
||||
NumPy is orders of magnitude faster than normal Python lists when it comes to handling a large number of values. To see exactly how fast it is, I'm going to first measure the time it takes for `min()` and `max()` operations on a normal Python list.
|
||||
|
||||
I will first create a Python list with 999,999,999 items.
|
||||
|
||||
|
||||
```
|
||||
>>> my_list = range(1, 1000000000)
|
||||
>>> len(my_list)
|
||||
999999999
|
||||
```
|
||||
|
||||
Now I'll measure the time for finding the minimum value in this list.
|
||||
|
||||
|
||||
```
|
||||
>>> start = time.time()
|
||||
>>> min(my_list)
|
||||
1
|
||||
>>> print('Time elapsed in milliseconds: ' + str((time.time() - start) * 1000))
|
||||
Time elapsed in milliseconds: 27007.00879096985
|
||||
```
|
||||
|
||||
That took about 27,007 milliseconds or about **27 seconds**. That’s a long time. Now I'll try to find the time for finding the maximum value.
|
||||
|
||||
|
||||
```
|
||||
>>> start = time.time()
|
||||
>>> max(my_list)
|
||||
999999999
|
||||
>>> print('Time elapsed in milliseconds: ' + str((time.time() - start) * 1000))
|
||||
Time elapsed in milliseconds: 28111.071348190308
|
||||
```
|
||||
|
||||
That took about 28,111 milliseconds, which is about **28 seconds**.
|
||||
|
||||
Now I'll try to find the time to find the minimum and maximum value using NumPy.
|
||||
|
||||
|
||||
```
|
||||
>>> my_list = np.arange(1, 1000000000)
|
||||
>>> len(my_list)
|
||||
999999999
|
||||
>>> start = time.time()
|
||||
>>> my_list.min()
|
||||
1
|
||||
>>> print('Time elapsed in milliseconds: ' + str((time.time() - start) * 1000))
|
||||
Time elapsed in milliseconds: 1151.1778831481934
|
||||
>>>
|
||||
>>> start = time.time()
|
||||
>>> my_list.max()
|
||||
999999999
|
||||
>>> print('Time elapsed in milliseconds: ' + str((time.time() - start) * 1000))
|
||||
Time elapsed in milliseconds: 1114.8970127105713
|
||||
```
|
||||
|
||||
That took about 1151 milliseconds for finding the minimum value, and 1114 milliseconds for finding the maximum value. These are around **1 second**.
|
||||
|
||||
As you can see, using NumPy reduces the time to find the minimum and maximum of a list of around a billion values **from around 28 seconds to 1 second**. This is the power of NumPy.
|
||||
|
||||
### Creating ndarrays using Python lists
|
||||
|
||||
There are several ways to create an ndarray in NumPy.
|
||||
|
||||
You can create an ndarray by using a list of elements.
|
||||
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.array([1, 2, 3, 4, 5])
|
||||
>>> print(my_ndarray)
|
||||
[1 2 3 4 5]
|
||||
```
|
||||
|
||||
With the above ndarray defined, I'll check out a few things. First, the type of the variable defined above is `numpy.ndarray`. This is the type of all NumPy ndarrays.
|
||||
|
||||
|
||||
```
|
||||
>>> type(my_ndarray)
|
||||
<class 'numpy.ndarray'>
|
||||
```
|
||||
|
||||
Another thing to note here would be _shape_. The shape of an ndarray is the length of each dimension of the ndarray. As you can see, the shape of `my_ndarray` is `(5,)`. This means that `my_ndarray` contains one dimension with 5 elements.
|
||||
|
||||
|
||||
```
|
||||
>>> np.shape(my_ndarray)
|
||||
(5,)
|
||||
```
|
||||
|
||||
The number of dimensions in the array is called its _rank_. So the above ndarray has a rank of 1.
|
||||
|
||||
I'll define another ndarray `my_ndarray2` as a multi-dimensional ndarray. What will its shape be then? See below.
|
||||
|
||||
|
||||
```
|
||||
>>> my_ndarray2 = np.array([(1, 2, 3), (4, 5, 6)])
|
||||
>>> np.shape(my_ndarray2)
|
||||
(2, 3)
|
||||
```
|
||||
|
||||
This is a rank 2 ndarray. Another attribute to check is the `dtype`, which is the data type. Checking the `dtype` for our ndarray gives us the following:
|
||||
|
||||
|
||||
```
|
||||
>>> my_ndarray.dtype
|
||||
dtype('int64')
|
||||
```
|
||||
|
||||
The `int64` means that our ndarray is made up of 64-bit integers. NumPy cannot create an ndarray of mixed types, and must contain only one type of element. If you define an ndarray containing a mix of element types, NumPy will automatically typecast all the elements to the highest element type available that can contain all the elements.
|
||||
|
||||
For example, creating a mix of `int`s and `float`s will create a `float64` ndarray.
|
||||
|
||||
|
||||
```
|
||||
>>> my_ndarray2 = np.array([1, 2.0, 3])
|
||||
>>> print(my_ndarray2)
|
||||
[1. 2. 3.]
|
||||
>>> my_ndarray2.dtype
|
||||
dtype('float64')
|
||||
```
|
||||
|
||||
Also, setting one of the elements as `string` will create string ndarray of `dtype` equal to `<U21`, meaning our ndarray contains unicode strings.
|
||||
|
||||
|
||||
```
|
||||
>>> my_ndarray2 = np.array([1, '2', 3])
|
||||
>>> print(my_ndarray2)
|
||||
['1' '2' '3']
|
||||
>>> my_ndarray2.dtype
|
||||
dtype('<U21')
|
||||
```
|
||||
|
||||
The `size` attribute will show the total number of elements that are present in our ndarray.
|
||||
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.array([1, 2, 3, 4, 5])
|
||||
>>> my_ndarray.size
|
||||
5
|
||||
```
|
||||
|
||||
### Creating ndarrays using NumPy methods
|
||||
|
||||
There are several NumPy methods available for creating ndarrays in case you don’t want to create them directly using a list.
|
||||
|
||||
You can use `np.zeros()` to create an ndarray full of zeroes. It takes a shape as a parameter, which is a list containing the number of rows and columns. It can also take an optional `dtype` parameter which is the data type of the ndarray.
|
||||
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.zeros([2,3], dtype=int)
|
||||
>>> print(my_ndarray)
|
||||
[[0 0 0]
|
||||
[0 0 0]]
|
||||
```
|
||||
|
||||
You can use `np.ones()` to create an ndarray full of ones.
|
||||
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.ones([2,3], dtype=int)
|
||||
>>> print(my_ndarray)
|
||||
[[1 1 1]
|
||||
[1 1 1]]
|
||||
```
|
||||
|
||||
You can use `np.full()` to fill an ndarray with a specific value.
|
||||
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.full([2,3], 10, dtype=int)
|
||||
>>> print(my_ndarray)
|
||||
[[10 10 10]
|
||||
[10 10 10]]
|
||||
```
|
||||
|
||||
You can use `np.eye()` to create an identity matrix/ndarray, which is a square matrix with ones all along the main diagonal. A square matrix is a matrix with the same number of rows and columns.
|
||||
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.eye(3, dtype=int)
|
||||
>>> print(my_ndarray)
|
||||
[[1 0 0]
|
||||
[0 1 0]
|
||||
[0 0 1]]
|
||||
```
|
||||
|
||||
You can use `np.diag()` to create a matrix with the specified values along the diagonal, and zeroes in the rest of the matrix.
|
||||
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.diag([10, 20, 30, 40, 50])
|
||||
>>> print(my_ndarray)
|
||||
[[10 0 0 0 0]
|
||||
[ 0 20 0 0 0]
|
||||
[ 0 0 30 0 0]
|
||||
[ 0 0 0 40 0]
|
||||
[ 0 0 0 0 50]]
|
||||
```
|
||||
|
||||
You can use `np.arange()` to create an ndarray with a specific range of values. It is used by specifying a start and end (exclusive) range of integers and a step size.
|
||||
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.arange(1, 20, 3)
|
||||
>>> print(my_ndarray)
|
||||
[ 1 4 7 10 13 16 19]
|
||||
```
|
||||
|
||||
### Reading ndarrays
|
||||
|
||||
The values of an ndarray can be read using indexing, slicing, or boolean indexing.
|
||||
|
||||
#### Reading ndarrays using indexing
|
||||
|
||||
In indexing, you can read the values using the integer indices of the elements of the ndarray, much like you would read a Python list. Just like Python lists, the indices start from zero.
|
||||
|
||||
For example, in the ndarray defined as below:
|
||||
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.arange(1, 20, 3)
|
||||
```
|
||||
|
||||
The fourth value will be `my_ndarray[3]`, or `10`. The last value will be `my_ndarray[-1]`, or `19`.
|
||||
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.arange(1, 20, 3)
|
||||
>>> print(my_ndarray[0])
|
||||
1
|
||||
>>> print(my_ndarray[3])
|
||||
10
|
||||
>>> print(my_ndarray[-1])
|
||||
19
|
||||
>>> print(my_ndarray[5])
|
||||
16
|
||||
>>> print(my_ndarray[6])
|
||||
19
|
||||
```
|
||||
|
||||
#### Reading ndarrays using slicing
|
||||
|
||||
You can also use slicing to read chunks of the ndarray. Slicing works by specifying a start index and an end index using a colon (`:`) operator. Python will then fetch the slice of the ndarray between that start and end index.
|
||||
|
||||
|
||||
```
|
||||
>>> print(my_ndarray[:])
|
||||
[ 1 4 7 10 13 16 19]
|
||||
>>> print(my_ndarray[2:4])
|
||||
[ 7 10]
|
||||
>>> print(my_ndarray[5:6])
|
||||
[16]
|
||||
>>> print(my_ndarray[6:7])
|
||||
[19]
|
||||
>>> print(my_ndarray[:-1])
|
||||
[ 1 4 7 10 13 16]
|
||||
>>> print(my_ndarray[-1:])
|
||||
[19]
|
||||
```
|
||||
|
||||
Slicing creates a reference, or view, of an ndarray. This means that modifying the values in a slice will also change the values of the original ndarray.
|
||||
|
||||
For example:
|
||||
|
||||
|
||||
```
|
||||
>>> my_ndarray[-1:] = 100
|
||||
>>> print(my_ndarray)
|
||||
[ 1 4 7 10 13 16 100]
|
||||
```
|
||||
|
||||
For slicing ndarrays with rank more than 1, the `[row-start-index:row-end-index, column-start-index:column-end-index]` syntax can be used.
|
||||
|
||||
|
||||
```
|
||||
>>> my_ndarray2 = np.array([(1, 2, 3), (4, 5, 6)])
|
||||
>>> print(my_ndarray2)
|
||||
[[1 2 3]
|
||||
[4 5 6]]
|
||||
>>> print(my_ndarray2[0:2,1:3])
|
||||
[[2 3]
|
||||
[5 6]]
|
||||
```
|
||||
|
||||
#### Reading ndarrays using boolean indexing
|
||||
|
||||
Another way to read ndarrays is using boolean indexing. In this method, you specify a filtering condition within square brackets and a section of the ndarray that matches that criteria is returned.
|
||||
|
||||
For example, to get all the values in an ndarray greater than 5, you might specify a boolean indexing operation as `my_ndarray[my_ndarray > 5]`. This operation will return an ndarray that contains all values greater than 5.
|
||||
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
|
||||
>>> my_ndarray2 = my_ndarray[my_ndarray > 5]
|
||||
>>> print(my_ndarray2)
|
||||
[ 6 7 8 9 10]
|
||||
```
|
||||
|
||||
For example, to get all the even values in an ndarray, you might use a boolean indexing operation as follows:
|
||||
|
||||
|
||||
```
|
||||
>>> my_ndarray2 = my_ndarray[my_ndarray % 2 == 0]
|
||||
>>> print(my_ndarray2)
|
||||
[ 2 4 6 8 10]
|
||||
```
|
||||
|
||||
And to get all the odd values, you might use this:
|
||||
|
||||
|
||||
```
|
||||
>>> my_ndarray2 = my_ndarray[my_ndarray % 2 == 1]
|
||||
>>> print(my_ndarray2)
|
||||
[1 3 5 7 9]
|
||||
```
|
||||
|
||||
### Vector and scalar arithmetic with ndarrays
|
||||
|
||||
NumPy ndarrays allow vector and scalar arithmetic operations. In vector arithmetic, an element-wise arithmetic operation is performed between two ndarrays. In scalar arithmetic, an arithmetic operation is performed between an ndarray and a constant scalar value.
|
||||
|
||||
Consider the two ndarrays below.
|
||||
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.array([1, 2, 3, 4, 5])
|
||||
>>> my_ndarray2 = np.array([6, 7, 8, 9, 10])
|
||||
```
|
||||
|
||||
If you add the above two ndarrays, it would produce a new ndarray where each element of the two ndarrays would be added. For example, the first element of the resultant ndarray would be the result of adding the first elements of the original ndarrays, and so on.
|
||||
|
||||
|
||||
```
|
||||
>>> print(my_ndarray2 + my_ndarray)
|
||||
[ 7 9 11 13 15]
|
||||
```
|
||||
|
||||
Here, `7` is the sum of `1` and `6`, which are the first two elements of the ndarrays I've added together. Similarly, `15` is the sum of `5` and `10`, which are the last elements.
|
||||
|
||||
Consider the following arithmetic operations:
|
||||
|
||||
|
||||
```
|
||||
>>> print(my_ndarray2 - my_ndarray)
|
||||
[5 5 5 5 5]
|
||||
>>>
|
||||
>>> print(my_ndarray2 * my_ndarray)
|
||||
[ 6 14 24 36 50]
|
||||
>>>
|
||||
>>> print(my_ndarray2 / my_ndarray)
|
||||
[6. 3.5 2.66666667 2.25 2. ]
|
||||
```
|
||||
|
||||
Adding a scalar value to an ndarray has a similar effect—the scalar value is added to all the elements of the ndarray. This is called _broadcasting_.
|
||||
|
||||
|
||||
```
|
||||
>>> print(my_ndarray + 10)
|
||||
[11 12 13 14 15]
|
||||
>>>
|
||||
>>> print(my_ndarray - 10)
|
||||
[-9 -8 -7 -6 -5]
|
||||
>>>
|
||||
>>> print(my_ndarray * 10)
|
||||
[10 20 30 40 50]
|
||||
>>>
|
||||
>>> print(my_ndarray / 10)
|
||||
[0.1 0.2 0.3 0.4 0.5]
|
||||
```
|
||||
|
||||
### Sorting ndarrays
|
||||
|
||||
There are two ways available to sort ndarrays—in-place or out-of-place. In-place sorting sorts and modifies the original ndarray, and out-of-place sorting will return the sorted ndarray but not modify the original one. I'll try out both examples.
|
||||
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.array([3, 1, 2, 5, 4])
|
||||
>>> my_ndarray.sort()
|
||||
>>> print(my_ndarray)
|
||||
[1 2 3 4 5]
|
||||
```
|
||||
|
||||
As you can see, the `sort()` method sorts the ndarray in-place and modifies the original array.
|
||||
|
||||
There is another method called `np.sort()` which sorts the array out of place.
|
||||
|
||||
|
||||
```
|
||||
>>> my_ndarray = np.array([3, 1, 2, 5, 4])
|
||||
>>> print(np.sort(my_ndarray))
|
||||
[1 2 3 4 5]
|
||||
>>> print(my_ndarray)
|
||||
[3 1 2 5 4]
|
||||
```
|
||||
|
||||
As you can see, the `np.sort()` method returns a sorted ndarray but does not modify it.
|
||||
|
||||
### Conclusion
|
||||
|
||||
I've covered quite a bit about NumPy and ndarrays. I talked about creating ndarrays, the different ways of reading them, basic vector and scalar arithmetic, and sorting. There is a lot more to explore with NumPy, including set operations like `union()` and `intersection()`, statistical operations like `min()` and `max()`, etc.
|
||||
|
||||
I hope the examples I demonstrated above were useful. Have fun exploring NumPy.
|
||||
|
||||
* * *
|
||||
|
||||
_This article was originally published on the [author's personal blog][3] and has been adapted with permission._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/9/python-numpy
|
||||
|
||||
作者:[Ayush Sharma][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ayushsharma
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/math_money_financial_calculator_colors.jpg?itok=_yEVTST1 (old school calculator)
|
||||
[2]: https://notes.ayushsharma.in/2018/09/data-types-in-python
|
||||
[3]: https://notes.ayushsharma.in/2018/10/working-with-numpy-in-python
|
||||
@ -0,0 +1,172 @@
|
||||
[#]: subject: "Lock your camera to a specific USB port in OBS"
|
||||
[#]: via: "https://opensource.com/article/22/1/cameras-usb-ports-obs"
|
||||
[#]: author: "Seth Kenlon https://opensource.com/users/seth"
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: " "
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
|
||||
Lock your camera to a specific USB port in OBS
|
||||
======
|
||||
To standardize a complex camera setup, you can impose some special rules
|
||||
on how cameras get assigned to locations in the Linux filesystem.
|
||||
![Person using a laptop][1]
|
||||
|
||||
If you [stream with OBS][2] with multiple cameras on Linux, you might notice that cameras are loaded as they are detected during boot. You probably don't give it much thought, normally, but if you have a permanent streaming setup with complex OBS templates, you need to know which camera in the physical world is going to show up in which screen in the virtual one. In other words, you don't want to assign one device as Camera A today only to have it end up as Camera B tomorrow.
|
||||
|
||||
To standardize a complex camera setup, you can impose some special rules on how cameras get assigned to locations in the Linux filesystem.
|
||||
|
||||
### The udev subsystem
|
||||
|
||||
The system dealing with hardware peripherals on Linux is called udev. It detects and manages all devices you plug into your computer. You're probably not aware of it because it doesn't draw too much attention to itself, although you've certainly interacted with it when you plug in a USB thumb drive to open on your desktop or attached a printer.
|
||||
|
||||
### Hardware detection
|
||||
|
||||
Assume you have two USB cameras: One on the left of your computer and one on the right. The left camera is shooting a close-up, the right camera is shooting a long shot, and you switch between the two during your stream. In OBS, you add each camera to your **Sources** panel and, intuitively, call one **camLEFT** and the other **camRIGHT**.
|
||||
|
||||
Assuming the worst-case scenario, say you have two of the _same_ cameras: They're the same brand and the same model number. This is the worst-case scenario because when two pieces of hardware are identical, there's little chance each one has any kind of unique ID for your computer to differentiate them from one another.
|
||||
|
||||
There's a solution to this puzzle, though, and it just requires a little investigation using some simple terminal commands.
|
||||
|
||||
#### 1\. Get the vendor and product IDs
|
||||
|
||||
First, plugin just one camera into the USB port you want it assigned to. Then issue this command:
|
||||
|
||||
|
||||
```
|
||||
|
||||
|
||||
$ lsusb
|
||||
Bus 006 Device 002: ID 0951:1666 Kingston Technology DataTraveler G4
|
||||
Bus 005 Device 003: ID 03f0:3817 Hewlett-Packard LaserJet P2015 series
|
||||
Bus 003 Device 006: ID 045e:0779 Microsoft Corp. LifeCam HD-3000
|
||||
Bus 003 Device 002: ID 8087:0025 Intel Corp.
|
||||
Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub
|
||||
Bus 001 Device 003: ID 046d:c216 Logitech, Inc. Dual Action Gamepad
|
||||
Bus 001 Device 002: ID 048d:5702 Integrated Technology Express, Inc.
|
||||
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
|
||||
[...]
|
||||
|
||||
```
|
||||
|
||||
You can usually search specifically for the string "cam" to narrow down the results because most (but not all) cameras report as a camera.
|
||||
|
||||
|
||||
```
|
||||
|
||||
|
||||
$ lsusb | grep -i cam
|
||||
Bus 003 Device 006: ID 045e:0779 Microsoft Corp. LifeCam HD-3000
|
||||
|
||||
```
|
||||
|
||||
There's a lot of information here. The ID is listed as `045e:0779`. The first number is the vendor ID, and the second is the product ID. Write those down because you'll need them later.
|
||||
|
||||
#### 2\. Get the USB identifier
|
||||
|
||||
You've also obtained the device path to the camera: bus 3, device 6. There's a saying in Linux that "everything is a file," and indeed USB devices are described to udev as a file path starting with `/dev/bus/usb/` and ending with the bus (003 in this case) and the device (006 in this case). Look at the bus and device numbers in the `lsusb` output. They tell you that this camera is located on `/dev/bus/usb/003/006`.
|
||||
|
||||
You can use the `udevadm` command to obtain the kernel's designator for this USB device:
|
||||
|
||||
|
||||
```
|
||||
|
||||
|
||||
$ sudo udevadm info \
|
||||
\--attribute-walk \
|
||||
/dev/bus/usb/003/006 | grep "KERNEL="
|
||||
|
||||
KERNEL=="3-6.2.1"
|
||||
|
||||
```
|
||||
|
||||
The kernel USB identifier in this example is `3-6.2.1`. Write down the identifier for your system because you'll also need it later.
|
||||
|
||||
#### 3\. Repeat for each camera
|
||||
|
||||
Attach the other camera (or cameras, if you have more than two) to the USB port you want it assigned to. This is _different_ than the USB port you used for the other camera!
|
||||
|
||||
Repeat the process, obtaining the vendor and product ID (if the cameras are the same make and model, these should be the same as the first one) and the kernel USB identifier.
|
||||
|
||||
|
||||
```
|
||||
|
||||
|
||||
$ lsusb | grep -i cam
|
||||
Bus 001 Device 004: ID 045e:0779 Microsoft Corp. LifeCam HD-3000
|
||||
$ sudo udevadm info \
|
||||
\--attribute-walk \
|
||||
/dev/bus/usb/001/004 | grep "KERNEL="
|
||||
|
||||
KERNEL=="1-6"
|
||||
|
||||
```
|
||||
|
||||
In this example, I've determined that I have my cameras attached to 1-6 and 3-6.2.1 (the first one is a USB port on my machine, the other one is a hub plugged into the monitor plugged into my machine, which is why one is more complex than the other.)
|
||||
|
||||
### Write a udev rule
|
||||
|
||||
You have everything you need, so now you can write a rule to tell udev to give each camera a consistent identifier when one is found at a specific USB port.
|
||||
|
||||
Create and open a file called `/etc/udev/rules.d/50-camera.conf`, and enter these two rules, using the vendor and product IDs and kernel identifiers appropriate for your own system:
|
||||
|
||||
|
||||
```
|
||||
|
||||
|
||||
SUBSYSTEM=="usb", KERNEL=="1-6", ATTR{idVendor}=="045e", ATTR{idProduct}=="0779", SYMLINK+="video100"
|
||||
|
||||
SUBSYSTEM=="usb", KERNEL=="3-6.2.1", ATTR{idVendor}=="045e", ATTR{idProduct}=="0779", SYMLINK+="video101"
|
||||
|
||||
```
|
||||
|
||||
These rules tell udev that when it finds a device matching a specific vendor and product ID at those specific USB locations, to create a symlink (sometimes also called an "alias") named `video100` and `video101`. The symlinks are mostly arbitrary. I give them high numbers, so they're easy to spot and because the number must not clash with existing devices. If you actually do have more than 101 cameras attached to your computer, use `video200` and `video201` just to be safe (and get in contact! I'd love to learn more about _that_ project).
|
||||
|
||||
### Reboot
|
||||
|
||||
Reboot your computer. You can leave the cameras attached for now, but it doesn't actually matter. Once udev has a rule loaded, it follows those rules whether a device was attached during boot or is plugged in later.
|
||||
|
||||
Many people say that Linux never needs to reboot, but udev loads its rules during boot, and besides, you want to prove that your udev rules are working across reboots.
|
||||
|
||||
Once your computer is back up and running, take a look in `/dev/video`, where cameras are registered:
|
||||
|
||||
|
||||
```
|
||||
|
||||
|
||||
$ ls -1 /dev/video*
|
||||
/dev/video0
|
||||
/dev/video1
|
||||
/dev/video100
|
||||
/dev/video101
|
||||
/dev/video2
|
||||
/dev/video3
|
||||
|
||||
```
|
||||
|
||||
As you can see, there are entries at `video100` and `video101`. Today, these are symlinks to `/dev/video2` and `/dev/video3`, but tomorrow they may be symlinks to `/dev/video1` and `/dev/video2`, or any other combination based on when Linux detected and assigned them a file.
|
||||
|
||||
![Two camera angles][3]
|
||||
|
||||
(Photo by [Jeff Siepman][4])
|
||||
|
||||
You can use the symlinks in OBS, though, so that camLEFT is always camLEFT, and camRIGHT is always camRIGHT.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/22/1/cameras-usb-ports-obs
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/laptop_screen_desk_work_chat_text.png?itok=UXqIDRDD (Person using a laptop)
|
||||
[2]: https://opensource.com/life/15/12/real-time-linux-video-editing-with-obs-studio
|
||||
[3]: https://opensource.com/sites/default/files/uploads/obs-udev.jpg (Two camera angles)
|
||||
[4]: https://unsplash.com/@jeffsiepman?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
91
sources/tech/20220107 Try FreeDOS in 2022.md
Normal file
91
sources/tech/20220107 Try FreeDOS in 2022.md
Normal file
@ -0,0 +1,91 @@
|
||||
[#]: subject: "Try FreeDOS in 2022"
|
||||
[#]: via: "https://opensource.com/article/22/1/try-freedos"
|
||||
[#]: author: "Jim Hall https://opensource.com/users/jim-hall"
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: " "
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
|
||||
Try FreeDOS in 2022
|
||||
======
|
||||
15 resources for new users and longtime fans of this free operating
|
||||
system.
|
||||
![Puzzle pieces coming together to form a computer screen][1]
|
||||
|
||||
Throughout the 1980s and into the 1990s, DOS was king of the desktop. Not satisfied with a proprietary version of DOS, programmers worldwide worked together to create an open source version of DOS called FreeDOS, which first became available in 1994. [The FreeDOS Project][2] continues to grow in 2021 and beyond.
|
||||
|
||||
We've run several articles about FreeDOS on Opensource.com to help new users get started with FreeDOS and learn new programs. Here are a few of our most popular FreeDOS articles from the last year:
|
||||
|
||||
### New to FreeDOS
|
||||
|
||||
Are you new to FreeDOS? If you'd like to learn the basics of how to boot and run FreeDOS, check out these articles:
|
||||
|
||||
* [Get started with FreeDOS][3]: It looks like retro computing, but FreeDOS is a modern OS you can use to get things done.
|
||||
* [How FreeDOS boots][4]: Learn how your computer boots up and starts FreeDOS, from power on to the command-line prompt.
|
||||
* [Configure FreeDOS in plain text][5]: Learn how to configure FreeDOS with the `fdconfig.sys` file.
|
||||
* [How to navigate FreeDOS with CD and DIR][6]: Armed with just two commands, `DIR` and `CD`, you can navigate your FreeDOS system from the command line.
|
||||
* [Set and use environment variables in FreeDOS][7]: Environment variables are helpful in almost every command-line environment, including FreeDOS.
|
||||
|
||||
|
||||
|
||||
### FreeDOS for Linux users
|
||||
|
||||
If you're already familiar with the Linux command line, you might like to try these commands and programs that create a similar environment on FreeDOS:
|
||||
|
||||
* [FreeDOS commands for Linux fans][8]: If you're already familiar with the Linux command line, try these commands to help ease into FreeDOS.
|
||||
* [Edit text like Emacs in FreeDOS][9]: If you're already familiar with GNU Emacs, you should feel right at home in Freemacs.
|
||||
* [Copy files between Linux and FreeDOS][10]: Learn how to transfer files between a FreeDOS virtual machine and a Linux desktop system.
|
||||
* [How to archive files on FreeDOS][11]: There's a version of ****`tar` on FreeDOS, but the standard way to archive on DOS is Zip and Unzip.
|
||||
* [Use this nostalgic text editor on FreeDOS][12]: Reminiscent of Linux ed(1), Edlin is a joy to use when you want to edit text the old-school way.
|
||||
|
||||
|
||||
|
||||
### Using FreeDOS
|
||||
|
||||
Once you've booted into FreeDOS, you can use these great tools and apps to get work done or to install other software:
|
||||
|
||||
* [How to use the FreeDOS text editor][13]: FreeDOS provides a user-friendly text editor called FreeDOS Edit.
|
||||
* [Listen to music on FreeDOS][14]: Mplayer is an open source media player usually found on Linux, Windows, Mac, and DOS.
|
||||
* [Install and remove software packages on FreeDOS][15]: Learn how to use FDIMPLES, the FreeDOS package manager, to install and remove packages on your FreeDOS system.
|
||||
* [Why I love programming on FreeDOS with GW-BASIC][16]: BASIC was my entry into computer programming. I haven't written BASIC code in years, but I'll always have a fondness for BASIC and GW-BASIC.
|
||||
* [Program on FreeDOS with Bywater BASIC][17]: Install Bywater BASIC on your FreeDOS system and start experimenting with BASIC programming.
|
||||
|
||||
|
||||
|
||||
Throughout its nearly 30-year journey, FreeDOS has tried to be a modern DOS. If you'd like to learn more, you can read about the origins and development of FreeDOS in [A brief history of FreeDOS][18]. Also, check out Don Watkins' interview about FreeDOS in [How a college student founded a free and open source operating system][19].
|
||||
|
||||
If you'd like to try FreeDOS, download FreeDOS 1.3 RC5, released in December 2021. This version has a ton of new changes and improvements, including an updated kernel and command shell, new programs and games, better international support, and network support. Download FreeDOS 1.3 RC5 from the [FreeDOS website][2].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/22/1/try-freedos
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jim-hall
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/puzzle_computer_solve_fix_tool.png?itok=U0pH1uwj (Puzzle pieces coming together to form a computer screen)
|
||||
[2]: https://www.freedos.org/
|
||||
[3]: https://opensource.com/article/21/6/get-started-freedos
|
||||
[4]: https://opensource.com/article/21/6/freedos-boots
|
||||
[5]: https://opensource.com/article/21/6/freedos-fdconfigsys
|
||||
[6]: https://opensource.com/article/21/6/navigate-freedos-cd-dir
|
||||
[7]: https://opensource.com/article/21/6/freedos-environment-variables
|
||||
[8]: https://opensource.com/article/21/6/freedos-linux-users
|
||||
[9]: https://opensource.com/article/21/6/freemacs
|
||||
[10]: https://opensource.com/article/21/6/copy-files-linux-freedos
|
||||
[11]: https://opensource.com/article/21/6/archive-files-freedos
|
||||
[12]: https://opensource.com/article/21/6/edlin-freedos
|
||||
[13]: https://opensource.com/article/21/6/freedos-text-editor
|
||||
[14]: https://opensource.com/article/21/6/listen-music-freedos
|
||||
[15]: https://opensource.com/article/21/6/freedos-package-manager
|
||||
[16]: https://opensource.com/article/21/6/freedos-gw-basic
|
||||
[17]: https://opensource.com/article/21/6/freedos-bywater-basic
|
||||
[18]: https://opensource.com/article/21/6/history-freedos
|
||||
[19]: https://opensource.com/article/21/6/freedos-founder
|
||||
@ -0,0 +1,175 @@
|
||||
[#]: subject: "Brave vs. Google Chrome: Which is the better browser for you?"
|
||||
[#]: via: "https://itsfoss.com/brave-vs-chrome/"
|
||||
[#]: author: "Ankush Das https://itsfoss.com/author/ankush/"
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: " "
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
|
||||
Brave vs. Google Chrome: Which is the better browser for you?
|
||||
======
|
||||
|
||||
Google Chrome is undoubtedly one of the [best web browsers available for Linux][1]. It offers a good blend of user experience and feature set for many, regardless of what platform you use it on.
|
||||
|
||||
On the other hand, Brave is popular as a privacy-focused open-source option available cross-platform.
|
||||
|
||||
So, what should you pick as your primary web browser? Is Chrome for you? Who should use Brave?
|
||||
|
||||
Here, we compare all the important aspects (including benchmarks) on both browsers to help you decide.
|
||||
|
||||
### User Interface
|
||||
|
||||
![][2]
|
||||
|
||||
[Google Chrome][3] provides a clean user interface without unnecessary distractions out of the box.
|
||||
|
||||
By default, it blends in with the system theme on Linux (GTK), as per my experience. So, it might look a bit different as per your customizations.
|
||||
|
||||
![][4]
|
||||
|
||||
If you are not using it on Linux, everything else should look similar except the color scheme.
|
||||
|
||||
When it comes to [Brave][5], it does not adapt to your system color scheme out of the box. But, you can head to the Appearance settings and enable the GTK theme if you prefer.
|
||||
|
||||
Brave gets close to the Chrome user interface, with some unique tweaks/options to access.
|
||||
|
||||
![][6]
|
||||
|
||||
You can’t go wrong with either, considering the user interface. They’re both easy to navigate.
|
||||
|
||||
However, Brave provides a few extra options to customize the appearance, like removing the tab search button (left to the minimize button), showing the full URL, etc.
|
||||
|
||||
![][7]
|
||||
|
||||
If you find this helpful, Brave is your friend. With Google Chrome, you do not get a lot of control in terms of UI customization.
|
||||
|
||||
### Open Source vs. Proprietary
|
||||
|
||||
![][8]
|
||||
|
||||
Brave is an open-source web browser based on Chromium. We also have a list of [open-source browsers not based on Chromium][9], if you are curious.
|
||||
|
||||
Google Chrome is also based on Chromium, but it adds several proprietary elements, making it a closed source offering.
|
||||
|
||||
While you can expect the benefits of open-source software and transparency with Brave, Google can be quite fast when patching issues considering they have a dedicated security team.
|
||||
|
||||
None of these should be noticeable for an average user. But, if you prefer open-source and software that believes in transparency, Brave should be the pick. In either case, if you have no issues with proprietary code and trust Google with their products, Google Chrome can be a choice.
|
||||
|
||||
If you want an open-source browser with a similar UI to Chrome, you may want to check our comparison between [Chrome vs Chromium][10] to pick one.
|
||||
|
||||
### Feature Differences
|
||||
|
||||
You should find all the essential functionalities on both the browsers, with similar behavior.
|
||||
|
||||
However, there are some notable differences between the two.
|
||||
|
||||
As mentioned above, you will notice differences in the ability to customize the look and feel.
|
||||
|
||||
There is also a big difference in the ability to sync browser data between multiple devices.
|
||||
|
||||
![][11]
|
||||
|
||||
With Google Chrome, you can quickly sign in to your Google account and sync everything to your phone and other devices.
|
||||
|
||||
Brave also lets you sync, but it could be inconvenient for some. You will need access to one of your devices, where you use Brave to sync successfully.
|
||||
|
||||
Your sync data is not stored in the cloud. So, you will have to authorize using a QR code or a secret phrase to transfer/sync browsing data to another device.
|
||||
|
||||
![][12]
|
||||
|
||||
Hence, you must export the bookmarks and other associated data for external backup.
|
||||
|
||||
Thankfully, there’s an alternative if you want the convenience of sync and an open-source browser. Head to our [Firefox vs Brave comparison][13] article to know why that can be a good pick for you.
|
||||
|
||||
In addition to these differences, Brave offers support [IPFS protocol][14], which is a peer-to-peer secure protocol aimed to fight against censorship.
|
||||
|
||||
Not to forget, Brave comes with [Brave Search][15] as its search engine by default. So, if you prefer it over Google as a [private search engine][16], that’s a good thing as well.
|
||||
|
||||
Brave Rewards is also an interesting addition, where you earn rewards for enabling Brave’s privacy-friendly ads and can contribute them back to websites you frequently visit.
|
||||
|
||||
You can share resources using it directly to the recipient if cloud storage services or any online platform normally blocks it.
|
||||
|
||||
Overall, Brave offers numerous interesting things. But, Google Chrome is a simpler alternative that can be a convenient option for many.
|
||||
|
||||
### The Privacy Angle
|
||||
|
||||
The presence of tracking protection on Brave should be good for privacy enthusiasts. You can block ads and trackers using the Shield feature. In addition to that, you also get several filters available to toggle if you want aggressive blocking (which might result in broken websites).
|
||||
|
||||
Google Chrome does not offer this feature. But, you can always use some privacy-focused chrome extensions, and Google’s Safe Browsing feature should keep you safe from malicious websites.
|
||||
|
||||
Generally speaking, if you do not visit shady websites, you should be OK with Google Chrome. And, if you are a privacy enthusiast, Brave can be a better choice.
|
||||
|
||||
### Performance
|
||||
|
||||
While Brave is usually considered the fastest, it didn’t seem to be the case in my benchmark tests. That’s a surprise!
|
||||
|
||||
However, the real-world difference should not be noticeable for most.
|
||||
|
||||
![][17]
|
||||
|
||||
I used the popular benchmark tests: [JetStream 2][18], [Speedometer 2.0][19], and [Basemark Web 3.0][20].
|
||||
|
||||
Note that the Linux distribution used is **Pop!_OS 21.10**, and the browser versions tested were **Chrome 97.0.4692.71** and **Brave 97.0.4692.71**.
|
||||
|
||||
To give you an idea, I had nothing running in the background, except the browser on my PC powered by **Intel i5-11600k @4.7 GHz, 32 GB 3200 MHz RAM, and 1050ti Nvidia Graphics**.
|
||||
|
||||
### Installation
|
||||
|
||||
![][21]
|
||||
|
||||
Google Chrome provides DEB/RPM packages to download and install on Ubuntu, Debian, Fedora, or openSUSE.
|
||||
|
||||
Brave also supports the same Linux distributions, but you will have to use the terminal and follow the commands mentioned in their download page to get it installed.
|
||||
|
||||
![][22]
|
||||
|
||||
You can follow our installation guide to [install Brave in Fedora][23].
|
||||
|
||||
None of them are available in the software center. Also, you do not get any [Flatpak package][24] or snaps.
|
||||
|
||||
If you want something directly from the software center, a flatpak package, or a snap, Firefox is your friend.
|
||||
|
||||
### What Should You Pick?
|
||||
|
||||
If you want more customizations and advanced features, Brave should be an impressive choice. But, if you do not have a problem using a proprietary browser on your Linux distro and want slightly better performance, Google Chrome is a viable choice.
|
||||
|
||||
For privacy-focused users, the answer is obvious. But, you do have to think about the convenience of sync. So, if you are confused about your priorities, I encourage you to evaluate your requirements and decide what you want.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/brave-vs-chrome/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/best-browsers-ubuntu-linux/
|
||||
[2]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2022/01/chrome-brave-ui.png?resize=800%2C435&ssl=1
|
||||
[3]: https://www.google.com/chrome/index.html
|
||||
[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2022/01/google-chrome-ui.png?resize=800%2C479&ssl=1
|
||||
[5]: https://brave.com
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2022/01/brave-browser-ui.png?resize=800%2C479&ssl=1
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2022/01/brave-appearance-options.png?resize=800%2C563&ssl=1
|
||||
[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/11/open-source-proprietary.png?resize=800%2C450&ssl=1
|
||||
[9]: https://itsfoss.com/open-source-browsers-linux/
|
||||
[10]: https://itsfoss.com/chrome-vs-chromium/
|
||||
[11]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2022/01/google-chrome-sync.png?resize=800%2C555&ssl=1
|
||||
[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/07/brave-sync.png?resize=800%2C383&ssl=1
|
||||
[13]: https://itsfoss.com/brave-vs-firefox/
|
||||
[14]: https://ipfs.io
|
||||
[15]: https://itsfoss.com/brave-search-features/
|
||||
[16]: https://itsfoss.com/privacy-search-engines/
|
||||
[17]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2022/01/chrome-brave-benchmarks.png?resize=800%2C450&ssl=1
|
||||
[18]: https://webkit.org/blog/8685/introducing-the-jetstream-2-benchmark-suite/
|
||||
[19]: https://webkit.org/blog/8063/speedometer-2-0-a-benchmark-for-modern-web-app-responsiveness/
|
||||
[20]: https://web.basemark.com
|
||||
[21]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2022/01/google-chrome-package.png?resize=800%2C561&ssl=1
|
||||
[22]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2022/01/brave-install-linux.png?resize=800%2C325&ssl=1
|
||||
[23]: https://itsfoss.com/install-brave-browser-fedora/
|
||||
[24]: https://itsfoss.com/what-is-flatpak/
|
||||
@ -1,301 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Starryi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Create your own video streaming server with Linux)
|
||||
[#]: via: (https://opensource.com/article/19/1/basic-live-video-streaming-server)
|
||||
[#]: author: (Aaron J.Prisk https://opensource.com/users/ricepriskytreat)
|
||||
|
||||
使用 Linux 创建你自己的视频流服务器
|
||||
======
|
||||
在 Linux 或 BSD 操作系统上设置基本的实时流媒体服务器。
|
||||

|
||||
|
||||
实时视频流越来越流行。亚马逊的 Twitch 和谷歌的 YouTube 等平台拥有数百万用户,这些用户观看和消费无数小时的直播和录制视频。这些视频服务通常可以被免费使用,但需要你拥有一个帐户,并且一般会将你的视频内容隐藏在广告中。 有些人不希望他们的视频可供大众观看,或者只是想更多地控制自己的视频内容。 幸运的是,借助强大的开源软件,任何人都可以设置直播服务器。
|
||||
|
||||
### 入门
|
||||
|
||||
在本教程中,我将说明如何使用 Linux 或 BSD 操作系统设置基本的实时流媒体服务器。
|
||||
|
||||
搭建实时流媒体服务器不可避免地存在系统需求问题。 这些需求多种多样,因为实时流媒体涉及许多变量,例如:
|
||||
|
||||
* **流媒体质量:**你想以高清流媒体播放还是标清视频就可以满足你的需求?
|
||||
* **收视率:**你的视频预计有多少观众?
|
||||
* **存储:**你是否打算保留已保存的视频流副本?
|
||||
* **访问:**你的视频流是私有的还是向全世界开放的?
|
||||
|
||||
|
||||
|
||||
在硬件要求方面没有固定规则,因此我建议你进行测试,以便找到最适合你需求的配置。 本项目中,我将服务器安装在具有 4GB 内存、20GB 硬盘空间和单个 Intel i7 处理器内核的虚拟机上。
|
||||
|
||||
本项目使用实时消息传递协议 (RTMP) 来处理音频和视频流。 当然还有其他协议可用,但我选择 RTMP 是因为它有广泛的支持。 鉴于像 WebRTC 这样的开放标准变得更加兼容,我比较推荐这条路线。
|
||||
|
||||
同样重要的是,要明白“实时”并不总是意味着即时。 视频流必须经过编码、传输、缓冲和显示,这通常会增大延迟。 延迟可以被缩短或延长,具体取决于你创建的流类型及其属性。
|
||||
|
||||
### 设置 Linux 服务器
|
||||
|
||||
你可以使用许多不同的 Linux 发行版,但我更喜欢 Ubuntu,因此我下载了 [Ubuntu Server][1] 作为我的操作系统。 如果你希望你的服务器具有图形用户界面 (GUI),请随意使用 [Ubuntu 桌面][2] 或其多种风味版本之一。 然后,我在我的计算机或虚拟机上启动了 Ubuntu 安装程序,并选择了最适合我的环境的设置。 以下是我采取的步骤。
|
||||
|
||||
注意:因为这是一个服务器,你可能需要设置静态网络。
|
||||
|
||||

|
||||
|
||||
安装程序完成并重新启动系统后,你会看到一个可爱的新 Ubuntu 系统。 与任何新安装的操作系统一样,安装任何可用的更新:
|
||||
|
||||
```bash
|
||||
sudo apt update
|
||||
sudo apt upgrade
|
||||
```
|
||||
|
||||
这个流媒体服务器将使用非常强大通用的 Nginx 网络服务器,所以你需要安装它:
|
||||
|
||||
```bash
|
||||
sudo apt install nginx
|
||||
```
|
||||
|
||||
然后你需要获取 RTMP 模块,以便 Nginx 可以处理你的媒体流:
|
||||
|
||||
```bash
|
||||
sudo add-apt-repository universe
|
||||
sudo apt install libnginx-mod-rtmp
|
||||
```
|
||||
|
||||
修改你的网络服务器配置,使其能够接受和传送你的媒体流。
|
||||
|
||||
```bash
|
||||
sudo nano /etc/nginx/nginx.conf
|
||||
```
|
||||
|
||||
滚动到配置文件的底部并添加以下代码:
|
||||
|
||||
```nginx
|
||||
rtmp {
|
||||
server {
|
||||
listen 1935;
|
||||
chunk_size 4096;
|
||||
|
||||
application live {
|
||||
live on;
|
||||
record off;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
保存配置。 我是使用 [Nano][3] 来编辑配置文件的异端。 在 Nano 中,你可以通过快捷键 **Ctrl+X** 、 **Y** 或 **Enter.** 来保存你的配置。
|
||||
|
||||
这么一个非常小的配置会创建一个工作的流服务器。 稍后你将添加更多内容到此配置中,但这是一个很好的起点。
|
||||
|
||||
在开始第一个流之前,你需要使用新配置重新启动 Nginx:
|
||||
|
||||
```bash
|
||||
sudo systemctl restart nginx
|
||||
```
|
||||
|
||||
### 设置 BSD 服务器
|
||||
|
||||
如果你相信“小恶魔”(LCTT 译者注:FreeBSD 的标志是一个拿着叉子的红色小恶魔)的说辞,那么启动并运行流媒体服务器也非常容易。
|
||||
|
||||
前往 [FreeBSD][4] 网站并下载最新版本。 在你的计算机或虚拟机上启动 FreeBSD 安装程序,然后执行初始步骤并选择最适合你环境的设置。 由于这是一个服务器,你可能需要设置静态网络。
|
||||
|
||||
安装程序完成并重新启动系统后,你应该拥有一个闪亮的新 FreeBSD 系统。 像任何其他新安装的系统一样,你可能希望更新所有内容(从这一步开始,请确保你以 root 身份登录):
|
||||
|
||||
```bash
|
||||
pkg update
|
||||
pkg upgrade
|
||||
```
|
||||
|
||||
安装 [Nano][3] 来编辑配置文件:
|
||||
|
||||
```bash
|
||||
pkg install nano
|
||||
```
|
||||
|
||||
这个流媒体服务器将使用非常强大通用的 Nginx 网络服务器。 你可以使用 FreeBSD 所拥有的优秀 ports 系统来构建 Nginx。
|
||||
|
||||
首先,更新你的 ports 树:
|
||||
|
||||
```bash
|
||||
portsnap fetch
|
||||
portsnap extract
|
||||
```
|
||||
|
||||
进入 Nginx ports 目录:
|
||||
|
||||
```bash
|
||||
cd /usr/ports/www/nginx
|
||||
```
|
||||
|
||||
运行如下命令开始构建 Nginx:
|
||||
|
||||
```bash
|
||||
make install
|
||||
```
|
||||
|
||||
你将看到一个屏幕,询问你的 Nginx 构建中要包含哪些模块。 对于这个项目,你需要添加 RTMP 模块。 向下滚动直到选中 RTMP 模块,然后按 **Space**。 然后按 **Enter** 继续剩下的构建和安装。
|
||||
|
||||
Nginx 安装完成后,就该为它配置流式传输了。
|
||||
|
||||
首先,在 **/etc/rc.conf** 中添加一个条目以确保 Nginx 服务器在系统启动时启动:
|
||||
|
||||
```bash
|
||||
nano /etc/rc.conf
|
||||
```
|
||||
|
||||
将此文本添加到文件中:
|
||||
|
||||
```conf
|
||||
nginx_enable="YES"
|
||||
```
|
||||
|
||||

|
||||
|
||||
接下来,创建一个 webroot 目录,Nginx 将从中提供其内容。 我自己的目录叫 **stream** :
|
||||
|
||||
```bash
|
||||
cd /usr/local/www/
|
||||
mkdir stream
|
||||
chmod -R 755 stream/
|
||||
```
|
||||
|
||||
现在你已经创建了你的流目录,通过编辑配置文件来配置 Nginx:
|
||||
|
||||
```bash
|
||||
nano /usr/local/etc/nginx/nginx.conf
|
||||
```
|
||||
|
||||
在文件顶部加载你的流媒体模块:
|
||||
|
||||
```nginx
|
||||
load_module /usr/local/libexec/nginx/ngx_stream_module.so;
|
||||
load_module /usr/local/libexec/nginx/ngx_rtmp_module.so;
|
||||
```
|
||||
|
||||

|
||||
|
||||
在 **Server** 部分下,更改 webroot 位置以匹配你之前创建的目录位置:
|
||||
|
||||
```nginx
|
||||
Location / {
|
||||
root /usr/local/www/stream
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
|
||||
最后,添加你的 RTMP 设置,以便 Nginx 知道如何处理你的媒体流:
|
||||
|
||||
```nginx
|
||||
rtmp {
|
||||
server {
|
||||
listen 1935;
|
||||
chunk_size 4096;
|
||||
|
||||
application live {
|
||||
live on;
|
||||
record off;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
保存配置。 在 Nano 中,你可以通过快捷键 **Ctrl+X** 、 **Y** 或 **Enter.** 来执行此操作。
|
||||
|
||||
如你所见,这么一个非常小的配置将创建一个工作的流服务器。 稍后,你将添加更多内容到此配置中,但这将为你提供一个很好的起点。
|
||||
|
||||
但是,在开始第一个流之前,你需要使用新配置重新启动 Nginx:
|
||||
|
||||
```bash
|
||||
service nginx restart
|
||||
```
|
||||
|
||||
### 设置你的流媒体软件
|
||||
|
||||
#### 使用 OBS 进行广播
|
||||
|
||||
现在你的服务器已准备好接受你的视频流,是时候设置你的流媒体软件了。 本教程使用功能强大的开源 Open Broadcast Studio (OBS)。
|
||||
|
||||
前往 [OBS 网站][5],找到适用于你的操作系统的版本并安装它。 OBS 启动后,你应该会看到一个首次运行向导,该向导将帮助你使用最适合你的硬件的设置来配置 OBS。
|
||||
|
||||

|
||||
|
||||
OBS 没有捕获任何内容,因为你没有为其提供源。 在本教程中,你只需为流捕获桌面。 单击**来源**下的 **+** 按钮,选择**显示捕获**,然后选择要捕获的桌面。
|
||||
|
||||
单击“确定”,你应该会看到 OBS 镜像你的桌面。
|
||||
|
||||
现在是时候将你新配置的视频流发送到你的服务器了。 在 OBS 中,单击**文件** > **设置**。 单击**流**部分,并将**串流类型** 设置为**自定义流媒体服务器**。
|
||||
|
||||
在 URL 框中,输入前缀 **rtmp://** 后跟流媒体服务器的 IP 地址,后跟 **/live**。 例如,**rtmp://IP-ADDRESS/live**。
|
||||
|
||||
接下来,你可能需要输入流密钥——观看你的流所需的特殊标识符。 在**串流密钥**框中输入你想要(并且可以记住)的任何关键词。
|
||||
|
||||

|
||||
|
||||
单击**应用**,然后单击**确定**。
|
||||
|
||||
现在 OBS 已配置为将你的流发送到你的服务器,你可以开始你的第一个视频流。 单击**开始推流**。
|
||||
|
||||
如果一切正常,你应该会看到按钮更改为**停止推流**,并且一些带宽指标将出现在 OBS 的底部。
|
||||
|
||||

|
||||
|
||||
如果你收到错误消息,请仔细检查 OBS 中的流设置是否有拼写错误。 如果一切看起来都不错,则可能是另一个问题阻止了它的工作。
|
||||
|
||||
### 观看你的视频流
|
||||
|
||||
如果没有人观看,直播视频就不是很好,所以请成为你的第一个观众!
|
||||
|
||||
有许多支持 RTMP 的开源媒体播放器,但最著名的可能是 [VLC 媒体播放器][6]。
|
||||
|
||||
安装并启动 VLC 后,通过单击**媒体** > **打开网络串流** 打开你的流。 输入你的流的路径,添加你在 OBS 中设置的流密钥,然后单击**播放**。 例如,**rtmp://IP-ADDRESS/live/SECRET-KEY**。
|
||||
|
||||
你现在应该可以看到自己的实时视频流了!
|
||||
|
||||

|
||||
|
||||
### 接下来要做什么?
|
||||
|
||||
本项目是一个非常简单的设置,可以让你开始工作。 以下是你可能想要使用的另外两个功能。
|
||||
|
||||
* **限制访问:** 你可能想要做的下一件事情是限制对你服务器的访问,因为默认设置允许任何人与服务器之间进行流传输。 有多种设置方法,例如操作系统防火墙、[.htaccess 文件][7],甚至使用 [STMP 模块中的内置访问控制][8]。
|
||||
|
||||
* **录制流:** 这个简单的 Nginx 配置只会流传输而不会保存你的视频,但这很容易修改。 在 Nginx 配置文件中的 RTMP 部分下,设置录制选项和要保存视频的位置。 确保你设置的路径存在并且 Nginx 能够写入它。
|
||||
|
||||
|
||||
|
||||
|
||||
```nginx
|
||||
application live {
|
||||
live on;
|
||||
record all;
|
||||
record_path /var/www/html/recordings;
|
||||
record_unique on;
|
||||
}
|
||||
```
|
||||
|
||||
实时流媒体的世界在不断发展,如果你对更高级的用途感兴趣,可以在互联网上找到许多其他很棒的资源。 祝你好运,直播快乐!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/basic-live-video-streaming-server
|
||||
|
||||
作者:[Aaron J.Prisk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Starryi](https://github.com/Starryi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ricepriskytreat
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ubuntu.com/download/server
|
||||
[2]: https://www.ubuntu.com/download/desktop
|
||||
[3]: https://www.nano-editor.org/
|
||||
[4]: https://www.freebsd.org/
|
||||
[5]: https://obsproject.com/
|
||||
[6]: https://www.videolan.org/vlc/index.html
|
||||
[7]: https://httpd.apache.org/docs/current/howto/htaccess.html
|
||||
[8]: https://github.com/arut/nginx-rtmp-module/wiki/Directives#access
|
||||
Loading…
Reference in New Issue
Block a user