mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject into new
This commit is contained in:
commit
f42ebd43d2
@ -29,7 +29,7 @@
|
||||
|
||||
### 云即资本
|
||||
|
||||
就像我们的 CEO Zac Smith 多次跟我说的:都是钱的问题。不仅要制造它,还要消费它!在云中,数十亿美元的投入才能让数据中心出现计算机,这样才能让开发者消费它。换句话说(根本没云,它只是别人的电脑而已):
|
||||
就像我们的 CEO Zac Smith 多次跟我说的:一切都是钱的事。不仅要制造它,还要消费它!在云中,数十亿美元的投入才能让数据中心出现计算机,这样才能让开发者消费它。换句话说(根本没云,它只是别人的电脑而已):
|
||||
|
||||
![][4]
|
||||
|
||||
@ -45,7 +45,7 @@
|
||||
|
||||
因为我们花费大量的时间去研究数据中心和连通性,需要注意的一件事情是,这一部分的变化非常快,尤其是在 5G 正式商用时,某些负载开始不再那么依赖中心化的基础设施了。
|
||||
|
||||
边缘接入即将到来!:-)
|
||||
边缘计算即将到来!:-)
|
||||
|
||||
![][6]
|
||||
|
||||
@ -53,7 +53,7 @@
|
||||
|
||||
居于“连通”和“动力”之上的这一层,我们爱称为“处理器层”。这是奇迹发生的地方 —— 我们将来自下层的创新和实物投资转变成一个 API 终端的某些东西。
|
||||
|
||||
由于这是纽约的一个大楼,我们让在这里的云供应商处于纽约的中心。这就是为什么你会看到([Digital Ocean][Digital Ocean] 系的)鲨鱼 Sammy 和在 Google 之上的 “meet me” 的房间中和我打招呼的原因了。
|
||||
由于这是纽约的一个大楼,我们让在这里的云供应商处于纽约的中心。这就是为什么你会看到([Digital Ocean][Digital Ocean] 系的)鲨鱼 Sammy 和对 “meet me” 房间里面的 Google 标志的致意的原因了。
|
||||
|
||||
正如你所见,这个场景是非常写实的。它是由多层机架堆叠起来的。尽管我们爱 EWR1 的设备经理(Michael Pedrazzini),我们努力去尽可能减少这种体力劳动。毕竟布线专业的博士学位是很难拿到的。
|
||||
|
||||
@ -61,7 +61,7 @@
|
||||
|
||||
### 供给
|
||||
|
||||
再上一层,在基础设施层之上是供给层。这是我们最喜欢的地方之一,它以前被我们称为<ruby>配置管理<rt>confing management</rt></ruby>。但是现在到处都是一开始就是<ruby>不可变基础设施<rt>immutable infrastructure</rt></ruby>和自动化:[Terraform][Terraform]、[Ansible][Ansible]、[Quay.io][Quay.io] 等等类似的东西。你可以看出软件是按它的方式来工作的,对吗?
|
||||
再上一层,在基础设施层之上是供给层。这是我们最喜欢的地方之一,它以前被我们称为<ruby>配置管理<rt>config management</rt></ruby>。但是现在到处都是一开始就是<ruby>不可变基础设施<rt>immutable infrastructure</rt></ruby>和自动化:[Terraform][Terraform]、[Ansible][Ansible]、[Quay.io][Quay.io] 等等类似的东西。你可以看出软件是按它的方式来工作的,对吗?
|
||||
|
||||
Kelsey Hightower 最近写道“呆在无聊的基础设施中是一个让人兴奋的时刻”,我不认为这说的是物理部分(虽然我们认为它非常让人兴奋),但是由于软件持续侵入到栈的所有层,那必将是一个疯狂的旅程。
|
||||
|
||||
@ -152,7 +152,7 @@ via: https://www.packet.net/blog/splicing-the-cloud-native-stack/
|
||||
作者:[Zoe Allen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)、[pityonline](https://github.com/pityonline)
|
||||
校对:[wxy](https://github.com/wxy), [pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,154 @@
|
||||
|
||||
如何确定你的Linux发行版中有没有某个软件包
|
||||
======
|
||||
|
||||

|
||||
|
||||
|
||||
有时,你可能会想知道如何在你的 Linux 发行版上寻找一个特定的软件包。或者,你仅仅只是想知道安装在你的 Linux 上的软件包有什么版本。如果这就是你想知道的信息,你今天走运了。我正好知道一个小工具能帮你抓到上述信息,下面隆重推荐—— Whohas:这是一个命令行工具,它能一次查询好几个软件包列表,以检查的你软件包是否存在。目前,whohas 支持 Arch、Debian、Fedora、Gentoo、Mandriva、openSUSE、Slackware、Source Mage、Ubuntu、FreeBSD、NetBSD、OpenBSD(LCTT 译注:*BSD 不是 Linux)、Fink、MacPorts 和 Cygwin。使用这个小工具,软件包的维护者能轻而易举从别的 Linux 发行版里找到 ebuilds、 pkgbuilds 等等类似的包定义文件。
|
||||
|
||||
Whohas 是用 Perl 语言开发的自由、开源的工具。
|
||||
|
||||
### 在你的 Linux 中寻找一个特定的包
|
||||
|
||||
#### 安装 Whohas
|
||||
|
||||
Whohas 在 Debian、Ubuntu、Linux Mint 的默认软件仓库里提供。如果你正在使用某种基于 DEB 的系统,你可以用如下命令安装:
|
||||
|
||||
```
|
||||
$ sudo apt-get install whohas
|
||||
```
|
||||
|
||||
对基于 Arch 的系统,[AUR][1] 里就有提供 whohas。你能使用任何的 AUR 助手程序来安装。
|
||||
|
||||
使用 [Packer][2]:
|
||||
|
||||
```
|
||||
$ packer -S whohas
|
||||
```
|
||||
|
||||
或使用[Trizen][3]:
|
||||
|
||||
```
|
||||
$ trizen -S whohas
|
||||
```
|
||||
|
||||
使用[Yay][4]:
|
||||
|
||||
```
|
||||
$ yay -S whohas
|
||||
```
|
||||
|
||||
使用 [Yaourt][5]:
|
||||
|
||||
```
|
||||
$ yaourt -S whohas
|
||||
```
|
||||
|
||||
在别的 Linux 发行版上,从[这里][6]下载源代码并手工编译安装。
|
||||
|
||||
#### 使用方法
|
||||
|
||||
Whohas 的主要目标是想让你知道:
|
||||
|
||||
* 哪个 Linux 发布版提供了用户依赖的包。
|
||||
* 对于各个 Linux 发行版,指定的软件包是什么版本,或者在这个 Linux 发行版的各个不同版本上,指定的软件包是什么版本。
|
||||
|
||||
让我们试试看上面的的功能,比如说,哪个 Linux 发行版里有 vim 这个软件?我们可以运行如下命令:
|
||||
|
||||
```
|
||||
$ whohas vim
|
||||
```
|
||||
|
||||
|
||||
这个命令将会显示所有包含可安装的 vim 的 Linux 发行版的信息,包括包的大小,仓库地址和下载URL。
|
||||
|
||||
![][8]
|
||||
|
||||
你甚至可以通过管道将输出的结果按照发行版的字母排序,只需加入 `sort` 命令即可。
|
||||
|
||||
```
|
||||
$ whohas vim | sort
|
||||
```
|
||||
|
||||
请注意上述命令将会显示所有以 vim 开头的软件包,包括 vim-spell、vimcommander、vimpager 等等。你可以继续使用 Linux 的 `grep` 命令在 “vim” 的前后加上空格来缩小你的搜索范围,直到满意为止。
|
||||
|
||||
```
|
||||
$ whohas vim | sort | grep " vim"
|
||||
$ whohas vim | sort | grep "vim "
|
||||
$ whohas vim | sort | grep " vim "
|
||||
```
|
||||
|
||||
所有将空格放在包名字前面的搜索将会显示以包名字结尾的包。所有将空格放在包名字后面的搜索将会显示以包名字开头的包。前后都有空格将会严格匹配。
|
||||
|
||||
又或者,你就使用 `--strict` 来严格限制结果。
|
||||
|
||||
```
|
||||
$ whohas --strict vim
|
||||
```
|
||||
|
||||
有时,你想知道一个包在不在一个特定的 Linux 发行版里。例如,你想知道 vim 是否在 Arch Linux 里,请运行:
|
||||
|
||||
```
|
||||
$ whohas vim | grep "^Arch"
|
||||
```
|
||||
|
||||
(LCTT译注:在结果里搜索以 Arch 开头的 Linux)
|
||||
|
||||
Linux 发行版的命名缩写为:'archlinux'、'cygwin'、'debian'、'fedora'、 'fink'、'freebsd'、'gentoo'、'mandriva'、'macports'、'netbsd'、'openbsd'、'opensuse'、'slackware'、'sourcemage' 和 'ubuntu'。
|
||||
|
||||
你也可以用 `-d` 选项来得到同样的结果。
|
||||
|
||||
```
|
||||
$ whohas -d archlinux vim
|
||||
```
|
||||
|
||||
这个命令将在仅仅 Arch Linux 发行版下搜索 vim 包。
|
||||
|
||||
如果要在多个 Linux 发行版下搜索,如 'archlinux'、'ubuntu',请使用如下命令。
|
||||
|
||||
```
|
||||
$ whohas -d archlinux,ubuntu vim
|
||||
```
|
||||
|
||||
|
||||
你甚至可以用 `whohas` 来查找哪个发行版有 whohas 包。
|
||||
|
||||
```
|
||||
$ whohas whohas
|
||||
```
|
||||
|
||||
更详细的信息,请参照手册。
|
||||
|
||||
```
|
||||
$ man whohas
|
||||
```
|
||||
|
||||
#### 最后的话
|
||||
|
||||
当然,任何一个 Linux 发行版的包管理器都能轻松的在对应的软件仓库里找到自己管理的包。不过,whohas 帮你整合并比较了在不同的 Linux 发行版下指定的软件包信息,这样你能轻易的跨平台之间进行比较。试一下 whohas,你一定不会失望的。
|
||||
|
||||
好了,今天就到这里吧,希望前面讲的对你有用,下次我还会带来更多好东西!!
|
||||
|
||||
欧耶!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/find-if-a-package-is-available-for-your-linux-distribution/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[DavidChenLiang](https://github.com/davidchenliang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://aur.archlinux.org/packages/whohas/
|
||||
[2]:https://www.ostechnix.com/install-packer-arch-linux-2/
|
||||
[3]:https://www.ostechnix.com/trizen-lightweight-aur-package-manager-arch-based-systems/
|
||||
[4]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[5]:https://www.ostechnix.com/install-yaourt-arch-linux/
|
||||
[6]:http://www.philippwesche.org/200811/whohas/intro.html
|
||||
[7]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/06/whohas-1.png
|
||||
@ -1,11 +1,11 @@
|
||||
逃离 Google,重获自由(与君共勉)
|
||||
======
|
||||
|
||||
原名:How I Fully Quit Google (And You Can, Too)
|
||||
|
||||
> 寻求挣脱科技巨头的一次开创性尝试
|
||||
|
||||
在过去的六个月里,难以想象我到底经历了些什么。艰难的、时间密集的、启发性的探索,为的只是完全摒弃一家公司 —— Google(谷歌)—— 的产品。本该是件简简单单的任务,但真要去做,花费在研究和测试上的又何止几个小时。但我成功了。现在,我已经不需要 Google 了,作为西方世界中极其少数的群体中的一份子,不再使用世界上最有价值的两家科技公司的产品(是的,我也不用 [Facebook(脸书)][6])。
|
||||

|
||||
|
||||
在过去的六个月里,难以想象我到底经历了些什么。艰难的、耗时的、开创性的探索,为的只是完全摒弃一家公司 —— Google(谷歌)—— 的产品。本该是件简简单单的任务,但真要去做,花费在研究和测试上的又何止几个小时。但我成功了。现在,我已经不需要 Google 了,作为西方世界中极其少数的群体中的一份子,不再使用世界上最有价值的两家科技公司的产品(是的,我也不用 [Facebook(脸书)][6])。
|
||||
|
||||
本篇指南将向你展示我逃离 Google 生态的始末。以及根据本人的研究和个人需求,选择的替代方案。我不是技术方面的专家,或者说程序员,但作为记者,我的工作要求我对安全和隐私的问题保持警惕。
|
||||
|
||||
@ -17,17 +17,17 @@
|
||||
|
||||
Google 很快就从仅提供检索服务转向提供其它服务,其中许多都是我欣然拥抱的服务。早在 2005 年,当时你们可能还只能[通过邀请][7]加入 Gmail 的时候,我就已经是早期使用者了。Gmail 采用了线程对话、归档、标签,毫无疑问是我使用过的最好的电子邮件服务。当 Google 在 2006 年推出其日历工具时,那种对操作的改进绝对是革命性的。针对不同日历使用不同的颜色进行编排、检索事件、以及发送可共享的邀请,操作极其简单。2007 年推出的 Google Docs 同样令人惊叹。在我的第一份全职工作期间,我还促成我们团队使用支持多人同时编辑的 Google 电子表格、文档和演示文稿来完成日常工作。
|
||||
|
||||
和许多人样,我也是 Google 开疆拓土过程中的受害者。从搜索(引擎)到电子邮件、文档、分析、再到照片,许多其它服务都建立在彼此之上,相互勾连。Google 从一家发布实用产品的公司转变成诱困用户公司,与此同时将整个互联网转变为牟利和数据采集的机器。Google 在我们的数字生活中几乎无处不在,这种程度的存在远非其他公司可以比拟。与之相比使用其他科技巨头的产品想要抽身就相对容易。对于 Apple(苹果),你要么身处 iWorld 之中,要么是局外人。亚马逊亦是如此,甚至连 Facebook 也不过是拥有少数的几个平台,不用(Facebook)更多的是[心理挑战][8],实际上并没有多么困难。
|
||||
和许多人一样,我也是 Google 开疆拓土过程中的受害者。从搜索(引擎)到电子邮件、文档、分析、再到照片,许多其它服务都建立在彼此之上,相互勾连。Google 从一家发布实用产品的公司转变成诱困用户的公司,与此同时将整个互联网转变为牟利和数据采集的机器。Google 在我们的数字生活中几乎无处不在,这种程度的存在远非其他公司可以比拟。与之相比使用其他科技巨头的产品想要抽身就相对容易。对于 Apple(苹果),你要么身处 iWorld 之中,要么是局外人。亚马逊亦是如此,甚至连 Facebook 也不过是拥有少数的几个平台,不用(Facebook)更多的是[心理挑战][8],实际上并没有多么困难。
|
||||
|
||||
然而,Google 无处不在。无论是笔记本电脑、智能手机或者平板电脑,我猜其中至少会有那么一个 Google 的应用程序。Google 就是搜索(引擎)、地图、电子邮件、浏览器和大多数智能手机操作系统的代名词。甚至还有些应用有赖于其提供的“[服务][9]”和分析,比方说 Uber 便需要采用 Google Maps 来运营其乘车服务。
|
||||
然而,Google 无处不在。无论是笔记本电脑、智能手机或者平板电脑,我猜其中至少会有那么一个 Google 的应用程序。Google 就是搜索(引擎)、地图、电子邮件、浏览器和大多数智能手机操作系统的代名词。甚至还有些应用有赖于其提供的“[服务][9]”和分析,比方说 Uber 便需要采用 Google 地图来运营其乘车服务。
|
||||
|
||||
Google 现在俨然已是许多语言中的单词,但彰显其超然全球统治地位的方面显然不止于此。可以说只要你不是极其注重个人隐私,那其庞大而成套的工具几乎没有多少众所周知或广泛使用的替代品。这恰好也是大家选择 Google 的原因,在很多方面能更好的替代现有的产品。但现在,使我们的难以割舍的主要原因其实是 Google 已经成为了默认选择,或者说由于其主导地位导致替代品无法对我们构成足够的吸引。
|
||||
|
||||
事实上,替代方案是存在的,这些年自 Edward Snowden(爱德华·斯诺登)披露 Google 涉事 [Prism(棱镜)][10]以来,又陆续涌现了许多替代品。我从去年年底开始着手这个项目。经过六个月的研究、测评以及大量的尝试和失败,我终于找到了所有我正在使用的 Google 产品对应的注重个人隐私的替代品。令我感到吃惊的是,其中的一些替代品比 Google 的做的还要好。
|
||||
事实上,替代方案是存在的,这些年自<ruby>爱德华·斯诺登<rt>Edward Snowden</rt></ruby>披露 Google 涉事 <ruby>[棱镜][10]<rt>Prism</rt></ruby>以来,又陆续涌现了许多替代品。我从去年年底开始着手这个项目。经过六个月的研究、测评以及大量的尝试和失败,我终于找到了所有我正在使用的 Google 产品对应的注重个人隐私的替代品。令我感到吃惊的是,其中的一些替代品比 Google 的做的还要好。
|
||||
|
||||
### 一些注意事项
|
||||
|
||||
过程中需要面临的几个挑战之一便是,大多数的替代方案,特别是那些注重隐私空间的开源替代方案,确实对用户不太友好。我不是技术人员,但是自己有一个网站,了解如何管理 Wordpress,可以排除一些基本的故障,但我用不来命令行,也做不来任何需要编码的事。
|
||||
这个过程中需要面临的几个挑战之一便是,大多数的替代方案,特别是那些注重隐私空间的开源替代方案,确实对用户不太友好。我不是技术人员,但是自己有一个网站,了解如何管理 Wordpress,可以排除一些基本的故障,但我用不来命令行,也做不来任何需要编码的事。
|
||||
|
||||
提供的这些替代方案中的大多数,即便不能完整替代 Google 产品的功能,但至少可以轻松上手。不过有些还是需要你有自己的 Web 主机或服务器的。
|
||||
|
||||
@ -39,7 +39,7 @@ Google 现在俨然已是许多语言中的单词,但彰显其超然全球统
|
||||
|
||||
[DuckDuckGo][12] 和 [startpage][13] 都是以保护个人隐私为中心的搜索引擎,不收集任何搜索数据。我用这两个搜索引擎来负责之前用 Google 搜索的所有需求。
|
||||
|
||||
其它的替代方案:实际上并不多,Google 坐拥全球 74% 的市场份额时,剩下的那些主要是因为中国的封锁。不过还有 Ask.com,以及 Bing……
|
||||
其它的替代方案:实际上并不多,Google 坐拥全球 74% 的市场份额时,剩下的那些主要是因为中国的原因。不过还有 Ask.com,以及 Bing……
|
||||
|
||||
#### Chrome
|
||||
|
||||
@ -129,11 +129,11 @@ Google 现在俨然已是许多语言中的单词,但彰显其超然全球统
|
||||
|
||||
有些确实更好!Jitsi Meet 运行更顺畅,需要的带宽更少,并且比 Hangouts 跨平台支持好。Firefox 比 Chrome 更稳定,占用的内存更少。Fastmail 的日历具有更好的时区集成。
|
||||
|
||||
还有些旗鼓相当。ProtonMail 具有 Gmail 的大部分功能,但缺少一些好用的集成,例如我之前使用的 Boomerang 邮件日程功能。还缺少联系人界面,但我正在使用 Nextcloud。说到 Nextcloud,它非常适合托管文件,联系人,还包含了一个漂亮的笔记工具(以及诸多其它插件)。但它没有 Google Docs 丰富的多人编辑功能。在我的预算中,还没有找到可行的替代方案。虽然还有 Collabora Office,但这需要升级我的服务器,这对我来说不能算切实可行。
|
||||
还有些旗鼓相当。ProtonMail 具有 Gmail 的大部分功能,但缺少一些好用的集成,例如我之前使用的 Boomerang 邮件日程功能。还缺少联系人界面,但我正在使用 Nextcloud。说到 Nextcloud,它非常适合托管文件、联系人,还包含了一个漂亮的笔记工具(以及诸多其它插件)。但它没有 Google Docs 丰富的多人编辑功能。在我的预算中,还没有找到可行的替代方案。虽然还有 Collabora Office,但这需要升级我的服务器,这对我来说不能算切实可行。
|
||||
|
||||
一些取决于位置。在一些国家(如印度尼西亚),MAPS.ME 实际上比 Google 地图更好用,而在另一些国家(包括美国)就差了许多。
|
||||
|
||||
还有些要求用户牺牲一些特性或功能。Piwic 是一个穷人的 Google Analytics,缺乏前者的许多详细报告和搜索功能。DuckDuckGo 适用于一般搜索,但是在特定的搜索方面还存在问题,当我搜索非英文内容时,它和 startpage 时常都会检索失败。
|
||||
还有些要求用户牺牲一些特性或功能。Piwic 是一个穷人版的 Google Analytics,缺乏前者的许多详细报告和搜索功能。DuckDuckGo 适用于一般搜索,但是在特定的搜索方面还存在问题,当我搜索非英文内容时,它和 startpage 时常都会检索失败。
|
||||
|
||||
### 最后,我不再心念 Google
|
||||
|
||||
@ -141,7 +141,7 @@ Google 现在俨然已是许多语言中的单词,但彰显其超然全球统
|
||||
|
||||
如果我们别无选择,只能使用 Google 的产品,那我们便失去了作为消费者的最后一丝力量。
|
||||
|
||||
我希望 Google,Facebook,Apple 和其他科技巨头在对待用户时不要这么理所当然,不要试图强迫我们进入其无所不包的生态系统。我也期待新选手能够出现并与之竞争,就像以前一样,Google 的新搜索工具可以与当时的行业巨头 Altavista 和 Yahoo 竞争,或者说 Facebook 的社交网络能够与 MySpace 和 Friendster 竞争。Google 给出了更好的搜索方案,使互联网变得更加美好。有选择是个好事,可移植也是。
|
||||
我希望 Google、Facebook、Apple 和其他科技巨头在对待用户时不要这么理所当然,不要试图强迫我们进入其无所不包的生态系统。我也期待新选手能够出现并与之竞争,就像以前一样,Google 的新搜索工具可以与当时的行业巨头 Altavista 和 Yahoo 竞争,或者说 Facebook 的社交网络能够与 MySpace 和 Friendster 竞争。Google 给出了更好的搜索方案,使互联网变得更加美好。有选择是个好事,可移植也是。
|
||||
|
||||
如今,我们很少有人哪怕只是尝试其它产品,因为我们已经习惯了 Google。我们不再更改邮箱地址,因为这太难了。我们甚至不尝试使用 Facebook 以外的替代品,因为我们所有的朋友都在 Facebook 上。这些我明白。
|
||||
|
||||
@ -1,19 +1,19 @@
|
||||
打包更多有用的 Unix 实用程序
|
||||
一套有用的 Unix 实用程序
|
||||
======
|
||||
|
||||

|
||||
|
||||
我们都了解 **<ruby>GNU 核心实用程序<rt>GNU Core Utilities</rt></ruby>**,所有类 Unix 操作系统都预装了它们。它们是 GNU 操作系统中与文件、Shell 和 文本处理相关的基础实用工具。GNU 核心实用程序包括很多日常操作命令,例如 `cat`,`ls`, `rm`,`mkdir`,`rmdir`,`touch`,`tail` 和 `wc` 等。除了这些实用程序,还有更多有用的实用程序没有预装在类 Unix 操作系统中,它们汇集起来构成了 `moreutilis` 这个日益增长的集合。`moreutils` 可以在 GNU/Linux 和包括 FreeBSD,openBSD 及 Mac OS 在内的多种 Unix 类型操作系统上安装。
|
||||
我们都了解 <ruby>GNU 核心实用程序<rt>GNU Core Utilities</rt></ruby>,所有类 Unix 操作系统都预装了它们。它们是 GNU 操作系统中与文件、Shell 和 文本处理相关的基础实用工具。GNU 核心实用程序包括很多日常操作命令,例如 `cat`、`ls`、`rm`、`mkdir`、`rmdir`、`touch`、`tail` 和 `wc` 等。除了这些实用程序,还有更多有用的实用程序没有预装在类 Unix 操作系统中,它们汇集起来构成了 `moreutilis` 这个日益增长的集合。`moreutils` 可以在 GNU/Linux 和包括 FreeBSD,openBSD 及 Mac OS 在内的多种 Unix 类型操作系统上安装。
|
||||
|
||||
截至到编写这份指南时, `moreutils` 提供如下实用程序:
|
||||
|
||||
* `chronic` – 运行程序并忽略正常运行的输出
|
||||
* `combine` – 使用布尔操作合并文件
|
||||
* `combine` – 使用布尔操作合并文件的行
|
||||
* `errno` – 查询 errno 名称及描述
|
||||
* `ifdata` – 获取网络接口信息,无需解析 `ifconfig` 的结果
|
||||
* `ifne` – 在标准输入非空的情况下运行程序
|
||||
* `isutf8` – 检查文件或标准输入是否采用 UTF-8 编码
|
||||
* `lckdo` – 运行程序时考虑文件锁
|
||||
* `lckdo` – 带锁运行程序
|
||||
* `mispipe` – 使用管道连接两个命令,返回第一个命令的退出状态
|
||||
* `parallel` – 同时运行多个任务
|
||||
* `pee` – 将标准输入传递给多个管道
|
||||
@ -56,7 +56,7 @@ $ sudo apt-get install moreutils
|
||||
|
||||
让我们看一下几个 `moreutils` 工具的用法细节。
|
||||
|
||||
##### combine 实用程序
|
||||
#### combine 实用程序
|
||||
|
||||
正如 `combine` 名称所示,moreutils 中的这个实用程序可以使用包括 `and`,`not`,`or` 和 `xor` 在内的布尔操作,合并两个文件中的行。
|
||||
|
||||
@ -102,7 +102,7 @@ where
|
||||
|
||||
从上面的输出中可以看出,`not` 操作输出 `file1` 包含但 `file2` 不包含的行。
|
||||
|
||||
##### ifdata 实用程序
|
||||
#### ifdata 实用程序
|
||||
|
||||
`ifdata` 实用程序可用于检查网络接口是否存在,也可用于获取网络接口的信息,例如 IP 地址等。与预装的 `ifconfig` 和 `ip` 命令不同,`ifdata` 的输出更容易解析,这种设计的初衷是便于在 Shell 脚本中使用。
|
||||
|
||||
@ -134,7 +134,7 @@ $ ifdata -pe wlp9s0
|
||||
yes
|
||||
```
|
||||
|
||||
##### pee 命令
|
||||
#### pee 命令
|
||||
|
||||
该命令某种程度上类似于 `tee` 命令。
|
||||
|
||||
@ -157,7 +157,7 @@ Welcome to OSTechNIx
|
||||
|
||||
从上面的命令输出中可以看出,有两个 `cat` 命令实例获取 `echo` 命令的输出并执行,因而终端中出现两个同样的输出。
|
||||
|
||||
##### sponge 实用程序
|
||||
#### sponge 实用程序
|
||||
|
||||
这是 `moreutils` 软件包中的另一个有用的实用程序。`sponge` 读取标准输入并写入到指定的文件中。与 Shell 中的重定向不同,`sponge` 接收到完整输入后再写入输出文件。
|
||||
|
||||
@ -197,7 +197,7 @@ You
|
||||
|
||||
看到了吧?并不需要创建新文件。在脚本编程中,这非常有用。另一个好消息是,如果待写入的文件已经存在,`sponge` 会保持其<ruby>权限信息<rt>permissions</rt></ruby>不变。
|
||||
|
||||
##### ts 实用程序
|
||||
#### ts 实用程序
|
||||
|
||||
正如名称所示,`ts` 命令在每一行输出的行首增加<ruby>时间戳<rt>timestamp</rt></ruby>。
|
||||
|
||||
@ -238,7 +238,7 @@ Aug 21 13:34:25 drwxr-xr-x 24 sk users 12288 Aug 21 13:06 Downloads
|
||||
[...]
|
||||
```
|
||||
|
||||
##### vidir 实用程序
|
||||
#### vidir 实用程序
|
||||
|
||||
`vidir` 实用程序可以让你使用 `vi` 编辑器(或其它 `$EDITOR` 环境变量指定的编辑器)编辑指定目录的内容。如果没有指定目录,`vidir` 会默认编辑你当前的目录。
|
||||
|
||||
@ -274,7 +274,7 @@ $ vidir *.png
|
||||
|
||||
这时命令只会编辑当前目录下以 `.PNG` 为后缀的文件。
|
||||
|
||||
##### vipe 实用程序
|
||||
#### vipe 实用程序
|
||||
|
||||
`vipe` 命令可以让你使用默认编辑器接收 Unix 管道输入,编辑之后使用管道输出供下一个程序使用。
|
||||
|
||||
@ -285,7 +285,7 @@ $ echo "Welcome to OSTechNIx" | vipe
|
||||
Hello World
|
||||
```
|
||||
|
||||
从上面的输出可以看出,我通过管道将“Welcome to OSTechNix”输入到 `vi` 编辑器中,将内容编辑为“Hello World”,最后显示该内容。
|
||||
从上面的输出可以看出,我通过管道将 “Welcome to OSTechNix” 输入到 `vi` 编辑器中,将内容编辑为 “Hello World”,最后显示该内容。
|
||||
|
||||
好了,就介绍这么多吧。我只介绍了一小部分实用程序,而 `moreutils` 包含更多有用的实用程序。我在文章开始的时候已经列出目前 `moreutils` 软件包内包含的实用程序,你可以通过 `man` 帮助页面获取更多相关命令的细节信息。举个例子,如果你想了解 `vidir` 命令,请运行:
|
||||
|
||||
@ -304,7 +304,7 @@ via: https://www.ostechnix.com/moreutils-collection-useful-unix-utilities/
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,104 @@
|
||||
15 command-line aliases to save you time
|
||||
======
|
||||
|
||||

|
||||
|
||||
Linux command-line aliases are great for helping you work more efficiently. Better still, some are included by default in your installed Linux distro.
|
||||
|
||||
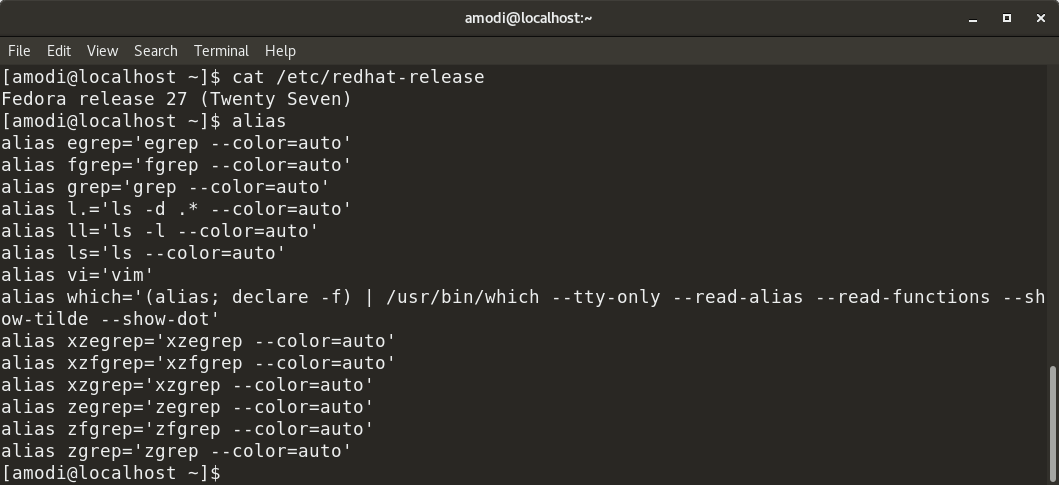
This is an example of a command-line alias in Fedora 27:
|
||||
|
||||
|
||||
|
||||
The command `alias` shows the list of existing aliases. Setting an alias is as simple as typing:
|
||||
|
||||
`alias new_name="command"`
|
||||
|
||||
Here are 15 command-line aliases that will save you time:
|
||||
|
||||
1. To install any utility/application:
|
||||
|
||||
`alias install="sudo yum install -y"`
|
||||
|
||||
Here, `sudo` and `-y` are optional as per user’s preferences:
|
||||
|
||||
|
||||
![install alias.png][2]
|
||||
|
||||
2. To update the system:
|
||||
|
||||
`alias update="sudo yum update -y"`
|
||||
|
||||
3. To upgrade the system:
|
||||
|
||||
`alias upgrade="sudo yum upgrade -y"`
|
||||
|
||||
4. To change to the root user:
|
||||
|
||||
`alias root="sudo su -"`
|
||||
|
||||
5. To change to "user," where "user" is set as your username:
|
||||
|
||||
`alias user="su user"`
|
||||
|
||||
6. To display the list of all available ports, their status, and IP:
|
||||
|
||||
`alias myip="ip -br -c a"`
|
||||
|
||||
7. To `ssh` to the server `myserver`:
|
||||
|
||||
`alias myserver="ssh user@my_server_ip”`
|
||||
|
||||
8. To list all processes in the system:
|
||||
|
||||
`alias process="ps -aux"`
|
||||
|
||||
9. To check the status of any system service:
|
||||
|
||||
`alias sstatus="sudo systemctl status"`
|
||||
|
||||
10. To restart any system service:
|
||||
|
||||
`alias srestart="sudo systemctl restart"`
|
||||
|
||||
11. To kill any process by its name:
|
||||
|
||||
`alias kill="sudo pkill"`
|
||||
|
||||
![kill process alias.png][4]
|
||||
|
||||
12. To display the total used and free memory of the system:
|
||||
|
||||
`alias mem="free -h"`
|
||||
|
||||
13. To display the CPU architecture, number of CPUs, threads, etc. of the system:
|
||||
|
||||
`alias cpu="lscpu"`
|
||||
|
||||
14. To display the total disk size of the system:
|
||||
|
||||
`alias disk="df -h"`
|
||||
|
||||
15. To display the current system Linux distro (for CentOS, Fedora, and Red Hat):
|
||||
|
||||
`alias os="cat /etc/redhat-release"`
|
||||
|
||||
![system_details alias.png][6]
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/time-saving-command-line-aliases
|
||||
|
||||
作者:[Aarchit Modi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/architmodi
|
||||
[2]:https://opensource.com/sites/default/files/uploads/install.png (install alias.png)
|
||||
[4]:https://opensource.com/sites/default/files/uploads/kill.png (kill process alias.png)
|
||||
[6]:https://opensource.com/sites/default/files/uploads/system_details.png (system_details alias.png)
|
||||
@ -1,316 +0,0 @@
|
||||
pinewall is translating
|
||||
|
||||
Anatomy of a Linux DNS Lookup – Part III
|
||||
============================================================
|
||||
|
||||
In [Anatomy of a Linux DNS Lookup – Part I][1] I covered:
|
||||
|
||||
* `nsswitch`
|
||||
|
||||
* `/etc/hosts`
|
||||
|
||||
* `/etc/resolv.conf`
|
||||
|
||||
* `ping` vs `host` style lookups
|
||||
|
||||
and in [Anatomy of a Linux DNS Lookup – Part II][2] I covered:
|
||||
|
||||
* `systemd` and its `networking` service
|
||||
|
||||
* `ifup` and `ifdown`
|
||||
|
||||
* `dhclient`
|
||||
|
||||
* `resolvconf`
|
||||
|
||||
and ended up here:
|
||||
|
||||
* * *
|
||||
|
||||

|
||||
|
||||
_A (roughly) accurate map of what’s going on_
|
||||
|
||||
Unfortunately, that’s not the end of the story. There’s still more things that can get involved. In Part III, I’m going to cover NetworkManager and dnsmasq and briefly show how they play a part.
|
||||
|
||||
* * *
|
||||
|
||||
# 1) NetworkManager
|
||||
|
||||
As mentioned in Part II, we are now well away from POSIX standards and into Linux distribution-specific areas of DNS resolution management.
|
||||
|
||||
In my preferred distribution (Ubuntu), there is a service that’s available and often installed for me as a dependency of some other package I install called [NetworkManager][3]. It’s actually a service developed by RedHat in 2004 to help manage network interfaces for you.
|
||||
|
||||
What does this have to do with DNS? Install it to find out:
|
||||
|
||||
```
|
||||
$ apt-get install -y network-manager
|
||||
```
|
||||
|
||||
In my distribution, I get a config file.
|
||||
|
||||
```
|
||||
$ cat /etc/NetworkManager/NetworkManager.conf
|
||||
[main]
|
||||
plugins=ifupdown,keyfile,ofono
|
||||
dns=dnsmasq
|
||||
|
||||
[ifupdown]
|
||||
managed=false
|
||||
```
|
||||
|
||||
See that `dns=dnsmasq` there? That means that NetworkManager will use `dnsmasq` to manage DNS on the host.
|
||||
|
||||
* * *
|
||||
|
||||
# 2) dnsmasq
|
||||
|
||||
The dnsmasq program is that now-familiar thing: yet another level of indirection for `/etc/resolv.conf`.
|
||||
|
||||
Technically, dnsmasq can do a few things, but is primarily it acts as a DNS server that can cache requests to other DNS servers. It runs on port 53 (the standard DNS port), on all local network interfaces.
|
||||
|
||||
So where is `dnsmasq` running? NetworkManager is running:
|
||||
|
||||
```
|
||||
$ ps -ef | grep NetworkManager
|
||||
root 15048 1 0 16:39 ? 00:00:00 /usr/sbin/NetworkManager --no-daemon
|
||||
```
|
||||
|
||||
But no `dnsmasq` process exists:
|
||||
|
||||
```
|
||||
$ ps -ef | grep dnsmasq
|
||||
$
|
||||
```
|
||||
|
||||
Although it’s configured to be used, confusingly it’s not actually installed! So you’re going to install it.
|
||||
|
||||
Before you install it though, let’s check the state of `/etc/resolv.conf`.
|
||||
|
||||
```
|
||||
$ cat /etc/resolv.conf
|
||||
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
|
||||
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
|
||||
nameserver 10.0.2.2
|
||||
search home
|
||||
```
|
||||
|
||||
It’s not been changed by NetworkManager.
|
||||
|
||||
If `dnsmasq` is installed:
|
||||
|
||||
```
|
||||
$ apt-get install -y dnsmasq
|
||||
```
|
||||
|
||||
Then `dnsmasq` is up and running:
|
||||
|
||||
```
|
||||
$ ps -ef | grep dnsmasq
|
||||
dnsmasq 15286 1 0 16:54 ? 00:00:00 /usr/sbin/dnsmasq -x /var/run/dnsmasq/dnsmasq.pid -u dnsmasq -r /var/run/dnsmasq/resolv.conf -7 /etc/dnsmasq.d,.dpkg-dist,.dpkg-old,.dpkg-new --local-service --trust-anchor=.,19036,8,2,49AAC11D7B6F6446702E54A1607371607A1A41855200FD2CE1CDDE32F24E8FB5
|
||||
```
|
||||
|
||||
And `/etc/resolv.conf` has changed again!
|
||||
|
||||
```
|
||||
root@linuxdns1:~# cat /etc/resolv.conf
|
||||
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
|
||||
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
|
||||
nameserver 127.0.0.1
|
||||
search home
|
||||
```
|
||||
|
||||
And `netstat` shows `dnsmasq` is serving on all interfaces at port 53:
|
||||
|
||||
```
|
||||
$ netstat -nlp4
|
||||
Active Internet connections (only servers)
|
||||
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
|
||||
tcp 0 0 127.0.0.1:53 0.0.0.0:* LISTEN 15286/dnsmasq
|
||||
tcp 0 0 10.0.2.15:53 0.0.0.0:* LISTEN 15286/dnsmasq
|
||||
tcp 0 0 172.28.128.11:53 0.0.0.0:* LISTEN 15286/dnsmasq
|
||||
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1237/sshd
|
||||
udp 0 0 127.0.0.1:53 0.0.0.0:* 15286/dnsmasq
|
||||
udp 0 0 10.0.2.15:53 0.0.0.0:* 15286/dnsmasq
|
||||
udp 0 0 172.28.128.11:53 0.0.0.0:* 15286/dnsmasq
|
||||
udp 0 0 0.0.0.0:68 0.0.0.0:* 10758/dhclient
|
||||
udp 0 0 0.0.0.0:68 0.0.0.0:* 10530/dhclient
|
||||
udp 0 0 0.0.0.0:68 0.0.0.0:* 10185/dhclient
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
# 3) Unpicking dnsmasq
|
||||
|
||||
Now we are in a situation where all DNS queries are going to `127.0.0.1:53` and from there what happens?
|
||||
|
||||
We can get a clue from looking again at the `/var/run` folder. The `resolv.conf` in `resolvconf` has been changed to point to where `dnsmasq` is being served:
|
||||
|
||||
```
|
||||
$ cat /var/run/resolvconf/resolv.conf
|
||||
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
|
||||
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
|
||||
nameserver 127.0.0.1
|
||||
search home
|
||||
```
|
||||
|
||||
while there’s a new `dnsmasq` folder with its own `resolv.conf`.
|
||||
|
||||
```
|
||||
$ cat /run/dnsmasq/resolv.conf
|
||||
nameserver 10.0.2.2
|
||||
```
|
||||
|
||||
which has the nameserver given to us by `DHCP`.
|
||||
|
||||
We can reason about this without looking too deeply, but what if we really want to know what’s going on?
|
||||
|
||||
* * *
|
||||
|
||||
# 4) Debugging Dnsmasq
|
||||
|
||||
Frequently I’ve found myself wondering what dnsmasq’s state is. Fortunately, you can get a good amount of information out of it if you set change this line in `/etc/dnsmasq.conf`:
|
||||
|
||||
```
|
||||
#log-queries
|
||||
```
|
||||
|
||||
to:
|
||||
|
||||
```
|
||||
log-queries
|
||||
```
|
||||
|
||||
and restart `dnsmasq`
|
||||
|
||||
Now, if you do a simple:
|
||||
|
||||
```
|
||||
$ ping -c1 bbc.co.uk
|
||||
```
|
||||
|
||||
you will see something like this in `/var/log/syslog` (the `[...]` indicates that the line’s start is the same as the previous one):
|
||||
|
||||
```
|
||||
Jul 3 19:56:07 ubuntu-xenial dnsmasq[15372]: query[A] bbc.co.uk from 127.0.0.1
|
||||
[...] forwarded bbc.co.uk to 10.0.2.2
|
||||
[...] reply bbc.co.uk is 151.101.192.81
|
||||
[...] reply bbc.co.uk is 151.101.0.81
|
||||
[...] reply bbc.co.uk is 151.101.64.81
|
||||
[...] reply bbc.co.uk is 151.101.128.81
|
||||
[...] query[PTR] 81.192.101.151.in-addr.arpa from 127.0.0.1
|
||||
[...] forwarded 81.192.101.151.in-addr.arpa to 10.0.2.2
|
||||
[...] reply 151.101.192.81 is NXDOMAIN
|
||||
```
|
||||
|
||||
which shows what `dnsmasq` received, where the query was forwarded to, and what reply was received.
|
||||
|
||||
If the query is returned from the cache (or, more exactly, the local ‘time-to-live’ for the query has not expired), then it looks like this in the logs:
|
||||
|
||||
```
|
||||
[...] query[A] bbc.co.uk from 127.0.0.1
|
||||
[...] cached bbc.co.uk is 151.101.64.81
|
||||
[...] cached bbc.co.uk is 151.101.128.81
|
||||
[...] cached bbc.co.uk is 151.101.192.81
|
||||
[...] cached bbc.co.uk is 151.101.0.81
|
||||
[...] query[PTR] 81.64.101.151.in-addr.arpa from 127.0.0.1
|
||||
```
|
||||
|
||||
and if you ever want to know what’s in your cache, you can provoke dnsmasq into sending it to the same log file by sending the `USR1` signal to the dnsmasq process id:
|
||||
|
||||
```
|
||||
$ kill -SIGUSR1 <(cat /run/dnsmasq/dnsmasq.pid)
|
||||
```
|
||||
|
||||
and the output of the dump looks like this:
|
||||
|
||||
```
|
||||
Jul 3 15:08:08 ubuntu-xenial dnsmasq[15697]: time 1530630488
|
||||
[...] cache size 150, 0/5 cache insertions re-used unexpired cache entries.
|
||||
[...] queries forwarded 2, queries answered locally 0
|
||||
[...] queries for authoritative zones 0
|
||||
[...] server 10.0.2.2#53: queries sent 2, retried or failed 0
|
||||
[...] Host Address Flags Expires
|
||||
[...] linuxdns1 172.28.128.8 4FRI H
|
||||
[...] ip6-localhost ::1 6FRI H
|
||||
[...] ip6-allhosts ff02::3 6FRI H
|
||||
[...] ip6-localnet fe00:: 6FRI H
|
||||
[...] ip6-mcastprefix ff00:: 6FRI H
|
||||
[...] ip6-loopback : 6F I H
|
||||
[...] ip6-allnodes ff02: 6FRI H
|
||||
[...] bbc.co.uk 151.101.64.81 4F Tue Jul 3 15:11:41 2018
|
||||
[...] bbc.co.uk 151.101.192.81 4F Tue Jul 3 15:11:41 2018
|
||||
[...] bbc.co.uk 151.101.0.81 4F Tue Jul 3 15:11:41 2018
|
||||
[...] bbc.co.uk 151.101.128.81 4F Tue Jul 3 15:11:41 2018
|
||||
[...] 151.101.64.81 4 R NX Tue Jul 3 15:34:17 2018
|
||||
[...] localhost 127.0.0.1 4FRI H
|
||||
[...] <Root> 19036 8 2 SF I
|
||||
[...] ip6-allrouters ff02::2 6FRI H
|
||||
```
|
||||
|
||||
In the above output, I believe (but don’t know, and ‘?’ indicates a relatively wild guess on my part) that:
|
||||
|
||||
* ‘4’ means IPv4
|
||||
|
||||
* ‘6’ means IPv6
|
||||
|
||||
* ‘H’ means address was read from an `/etc/hosts` file
|
||||
|
||||
* ‘I’ ? ‘Immortal’ DNS value? (ie no time-to-live value?)
|
||||
|
||||
* ‘F’ ?
|
||||
|
||||
* ‘R’ ?
|
||||
|
||||
* ‘S’?
|
||||
|
||||
* ‘N’?
|
||||
|
||||
* ‘X’
|
||||
|
||||
#### Alternatives to dnsmasq
|
||||
|
||||
`dnsmasq` is not the only option that can be passed to dns in NetworkManager. There’s `none` which does nothing to `/etc/resolv,conf`, `default`, which claims to ‘update `resolv.conf` to reflect currently active connections’, and `unbound`, which communicates with the `unbound` service and `dnssec-triggerd`, which is concerned with DNS security and is not covered here.
|
||||
|
||||
* * *
|
||||
|
||||
### End of Part III
|
||||
|
||||
That’s the end of Part III, where we covered the NetworkManager service, and its `dns=dnsmasq` setting.
|
||||
|
||||
Let’s briefly list some of the things we’ve come across so far:
|
||||
|
||||
* `nsswitch`
|
||||
|
||||
* `/etc/hosts`
|
||||
|
||||
* `/etc/resolv.conf`
|
||||
|
||||
* `/run/resolvconf/resolv.conf`
|
||||
|
||||
* `systemd` and its `networking` service
|
||||
|
||||
* `ifup` and `ifdown`
|
||||
|
||||
* `dhclient`
|
||||
|
||||
* `resolvconf`
|
||||
|
||||
* `NetworkManager`
|
||||
|
||||
* `dnsmasq`
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://zwischenzugs.com/2018/07/06/anatomy-of-a-linux-dns-lookup-part-iii/
|
||||
|
||||
作者:[ZWISCHENZUGS][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://zwischenzugs.com/
|
||||
[1]:https://zwischenzugs.com/2018/06/08/anatomy-of-a-linux-dns-lookup-part-i/
|
||||
[2]:https://zwischenzugs.com/2018/06/18/anatomy-of-a-linux-dns-lookup-part-ii/
|
||||
[3]:https://en.wikipedia.org/wiki/NetworkManager
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
An introduction to pipes and named pipes in Linux
|
||||
======
|
||||
|
||||
|
||||
59
sources/tech/20180827 A sysadmin-s guide to containers.md
Normal file
59
sources/tech/20180827 A sysadmin-s guide to containers.md
Normal file
@ -0,0 +1,59 @@
|
||||
A sysadmin's guide to containers
|
||||
======
|
||||
|
||||

|
||||
|
||||
The term "containers" is heavily overused. Also, depending on the context, it can mean different things to different people.
|
||||
|
||||
Traditional Linux containers are really just ordinary processes on a Linux system. These groups of processes are isolated from other groups of processes using resource constraints (control groups [cgroups]), Linux security constraints (Unix permissions, capabilities, SELinux, AppArmor, seccomp, etc.), and namespaces (PID, network, mount, etc.).
|
||||
|
||||
If you boot a modern Linux system and took a look at any process with `cat /proc/PID/cgroup`, you see that the process is in a cgroup. If you look at `/proc/PID/status`, you see capabilities. If you look at `/proc/self/attr/current`, you see SELinux labels. If you look at `/proc/PID/ns`, you see the list of namespaces the process is in. So, if you define a container as a process with resource constraints, Linux security constraints, and namespaces, by definition every process on a Linux system is in a container. This is why we often say [Linux is containers, containers are Linux][1]. **Container runtimes** are tools that modify these resource constraints, security, and namespaces and launch the container.
|
||||
|
||||
Docker introduced the concept of a **container image** , which is a standard TAR file that combines:
|
||||
|
||||
* **Rootfs (container root filesystem):** A directory on the system that looks like the standard root (`/`) of the operating system. For example, a directory with `/usr`, `/var`, `/home`, etc.
|
||||
* **JSON file (container configuration):** Specifies how to run the rootfs; for example, what **command** or **entrypoint** to run in the rootfs when the container starts; **environment variables** to set for the container; the container's **working directory** ; and a few other settings.
|
||||
|
||||
|
||||
|
||||
Docker "`tar`'s up" the rootfs and the JSON file to create the **base image**. This enables you to install additional content on the rootfs, create a new JSON file, and `tar` the difference between the original image and the new image with the updated JSON file. This creates a **layered image**.
|
||||
|
||||
The definition of a container image was eventually standardized by the [Open Container Initiative (OCI)][2] standards body as the [OCI Image Specification][3].
|
||||
|
||||
Tools used to create container images are called **container image builders**. Sometimes container engines perform this task, but several standalone tools are available that can build container images.
|
||||
|
||||
Docker took these container images ( **tarballs** ) and moved them to a web service from which they could be pulled, developed a protocol to pull them, and called the web service a **container registry**.
|
||||
|
||||
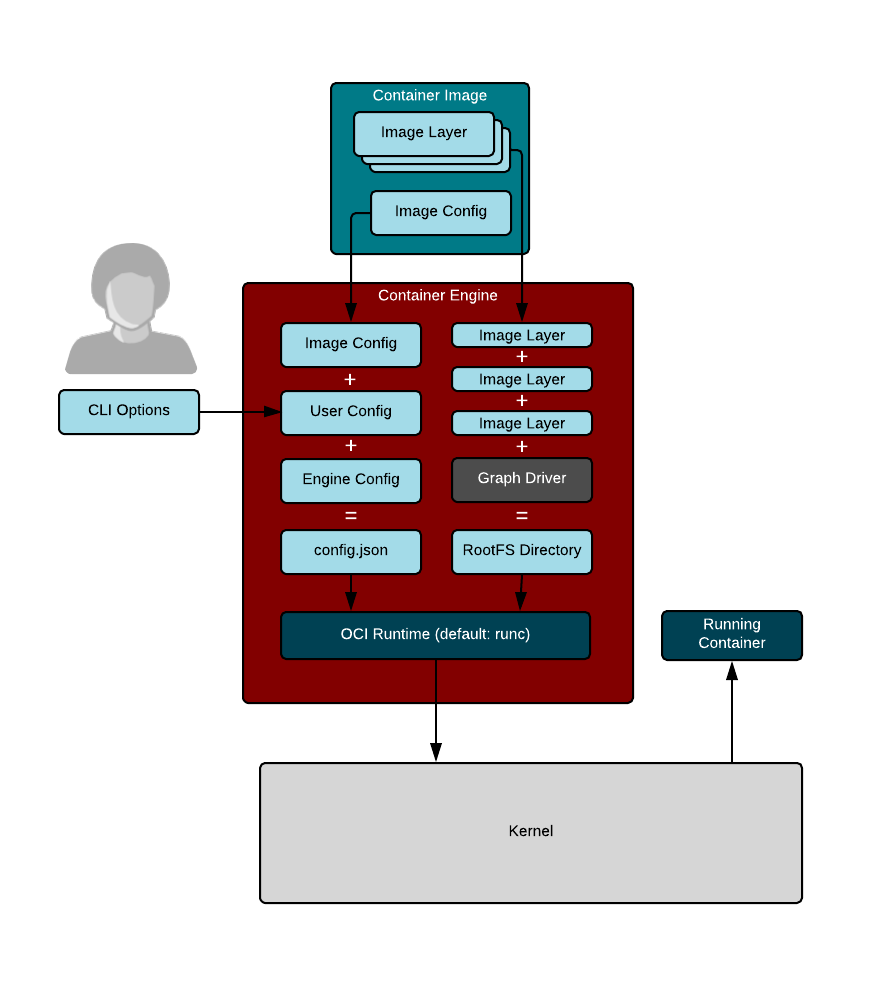
**Container engines** are programs that can pull container images from container registries and reassemble them onto **container storage**. Container engines also launch **container runtimes** (see below).
|
||||
|
||||
|
||||
|
||||
Container storage is usually a **copy-on-write** (COW) layered filesystem. When you pull down a container image from a container registry, you first need to untar the rootfs and place it on disk. If you have multiple layers that make up your image, each layer is downloaded and stored on a different layer on the COW filesystem. The COW filesystem allows each layer to be stored separately, which maximizes sharing for layered images. Container engines often support multiple types of container storage, including `overlay`, `devicemapper`, `btrfs`, `aufs`, and `zfs`.
|
||||
|
||||
|
||||
After the container engine downloads the container image to container storage, it needs to create aThe runtime configuration combines input from the caller/user along with the content of the container image specification. For example, the caller might want to specify modifications to a running container's security, add additional environment variables, or mount volumes to the container.
|
||||
|
||||
The layout of the container runtime configuration and the exploded rootfs have also been standardized by the OCI standards body as the [OCI Runtime Specification][4].
|
||||
|
||||
Finally, the container engine launches a **container runtime** that reads the container runtime specification; modifies the Linux cgroups, Linux security constraints, and namespaces; and launches the container command to create the container's **PID 1**. At this point, the container engine can relay `stdin`/`stdout` back to the caller and control the container (e.g., stop, start, attach).
|
||||
|
||||
Note that many new container runtimes are being introduced to use different parts of Linux to isolate containers. People can now run containers using KVM separation (think mini virtual machines) or they can use other hypervisor strategies (like intercepting all system calls from processes in containers). Since we have a standard runtime specification, these tools can all be launched by the same container engines. Even Windows can use the OCI Runtime Specification for launching Windows containers.
|
||||
|
||||
At a much higher level are **container orchestrators.** Container orchestrators are tools used to coordinate the execution of containers on multiple different nodes. Container orchestrators talk to container engines to manage containers. Orchestrators tell the container engines to start containers and wire their networks together. Orchestrators can monitor the containers and launch additional containers as the load increases.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/sysadmins-guide-containers
|
||||
|
||||
作者:[Daniel J Walsh][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rhatdan
|
||||
[1]:https://www.redhat.com/en/blog/containers-are-linux
|
||||
[2]:https://www.opencontainers.org/
|
||||
[3]:https://github.com/opencontainers/image-spec/blob/master/spec.md
|
||||
[4]:https://github.com/opencontainers/runtime-spec
|
||||
@ -0,0 +1,167 @@
|
||||
A Cat Clone With Syntax Highlighting And Git Integration
|
||||
======
|
||||
|
||||

|
||||
|
||||
In Unix-like systems, we use **‘cat’** command to print and concatenate files. Using cat command, we can print the contents of a file to the standard output, concatenate several files into the target file, and append several files into the target file. Today, I stumbled upon a similar utility named **“Bat”** , a clone to the cat command, with some additional cool features such as syntax highlighting, git integration and automatic paging etc. In this brief guide, we will how to install and use Bat command in Linux.
|
||||
|
||||
### Installation
|
||||
|
||||
Bat is available in the default repositories of Arch Linux. So, you can install it using pacman on any arch-based systems.
|
||||
```
|
||||
$ sudo pacman -S bat
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint systems, download the **.deb** file from the [**Releases page**][1] and install it as shown below.
|
||||
```
|
||||
$ sudo apt install gdebi
|
||||
|
||||
$ sudo gdebi bat_0.5.0_amd64.deb
|
||||
|
||||
```
|
||||
|
||||
For other systems, you may need to compile and install from source. Make sure you have installed Rust 1.26 or higher.
|
||||
|
||||
|
||||
|
||||
Then, run the following command to install Bat:
|
||||
```
|
||||
$ cargo install bat
|
||||
|
||||
```
|
||||
|
||||
Alternatively, you can install it using [**Linuxbrew**][2] package manager.
|
||||
```
|
||||
$ brew install bat
|
||||
|
||||
```
|
||||
|
||||
### Bat command Usage
|
||||
|
||||
The Bat command’s usage is very similar to cat command.
|
||||
|
||||
To create a new file using bat command, do:
|
||||
```
|
||||
$ bat > file.txt
|
||||
|
||||
```
|
||||
|
||||
To view the contents of a file using bat command, just do:
|
||||
```
|
||||
$ bat file.txt
|
||||
|
||||
```
|
||||
|
||||
You can also view multiple files at once:
|
||||
```
|
||||
$ bat file1.txt file2.txt
|
||||
|
||||
```
|
||||
|
||||
To append the contents of the multiple files in a single file:
|
||||
```
|
||||
$ bat file1.txt file2.txt file3.txt > document.txt
|
||||
|
||||
```
|
||||
|
||||
Like I already mentioned, apart from viewing and editing files, the Bat command has some additional cool features though.
|
||||
|
||||
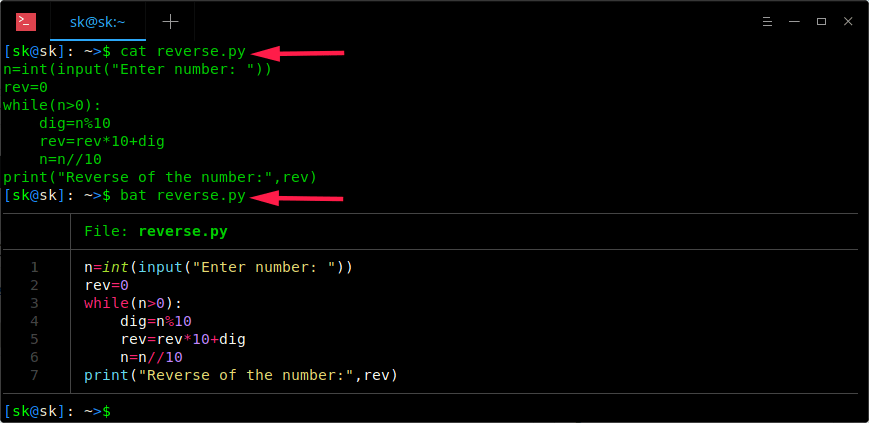
The bat command supports **syntax highlighting** for large number of programming and markup languages. For instance, look at the following example. I am going to display the contents of the **reverse.py** file using both cat and bat commands.
|
||||
|
||||
|
||||
|
||||
Did you notice the difference? Cat command shows the contents of the file in plain text format, whereas bat command shows output with syntax highlighting, order number in a neat tabular column format. Much better, isn’t it?
|
||||
|
||||
If you want to display only the line numbers (not the tabular column), use **-n** flag.
|
||||
```
|
||||
$ bat -n reverse.py
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||

|
||||
|
||||
Another notable feature of Bat command is it supports **automatic paging**. That means if output of a file is too large for one screen, the bat command automatically pipes its own output to **less** command, so you can view the output page by page.
|
||||
|
||||
Let me show you an example. When you view the contents of a file which spans multiple pages using cat command, the prompt quickly jumps to the last page of the file, and you do not see the content in the beginning or in the middle.
|
||||
|
||||
Have a look at the following output:
|
||||
|
||||

|
||||
|
||||
As you can see, the cat command displays last page of the file.
|
||||
|
||||
So, you may need to pipe the output of the cat command to **less** command to view it’s contents page by page from the beginning.
|
||||
```
|
||||
$ cat reverse.py | less
|
||||
|
||||
```
|
||||
|
||||
Now, you can view output page by page by hitting the ENTER key. However, it is not necessary if you use bat command. The bat command will automatically pipe the output of a file which spans multiple pages.
|
||||
```
|
||||
$ bat reverse.py
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
|
||||

|
||||
|
||||
Now hit the ENTER key to go to the next page.
|
||||
|
||||
The bat command also supports **GIT integration** , so you can view/edit the files in your Git repository without much hassle. It communicates with git to show modifications with respect to the index (see left side bar).
|
||||
|
||||

|
||||
|
||||
**Customizing Bat**
|
||||
|
||||
If you don’t like the default themes, you can change it too. Bat has option for that too.
|
||||
|
||||
To list the available themes, just run:
|
||||
```
|
||||
$ bat --list-themes
|
||||
1337
|
||||
DarkNeon
|
||||
Default
|
||||
GitHub
|
||||
Monokai Extended
|
||||
Monokai Extended Bright
|
||||
Monokai Extended Light
|
||||
Monokai Extended Origin
|
||||
TwoDark
|
||||
|
||||
```
|
||||
|
||||
To use a different theme, for example TwoDark, run:
|
||||
```
|
||||
$ bat --theme=TwoDark file.txt
|
||||
|
||||
```
|
||||
|
||||
If you want to make the theme permanent, use `export BAT_THEME="TwoDark"` in your shells startup file.
|
||||
|
||||
Bat also have the option to control the appearance of the output. To do so, use the `--style` option. To show only Git changes and line numbers but no grid and no file header, use `--style=numbers,changes`.
|
||||
|
||||
For more details, refer the Bat project GitHub Repository (Link at the end).
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/bat-a-cat-clone-with-syntax-highlighting-and-git-integration/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://github.com/sharkdp/bat/releases
|
||||
[2]:https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
|
||||
@ -0,0 +1,228 @@
|
||||
An Introduction to Quantum Computing with Open Source Cirq Framework
|
||||
======
|
||||
As the title suggests what we are about to begin discussing, this article is an effort to understand how far we have come in Quantum Computing and where we are headed in the field in order to accelerate scientific and technological research, through an Open Source perspective with Cirq.
|
||||
|
||||
First, we will introduce you to the world of Quantum Computing. We will try our best to explain the basic idea behind the same before we look into how Cirq would be playing a significant role in the future of Quantum Computing. Cirq, as you might have heard of recently, has been breaking news in the field and in this Open Science article, we will try to find out why.
|
||||
|
||||
<https://www.youtube.com/embed/WVv5OAR4Nik?enablejsapi=1&autoplay=0&cc_load_policy=0&iv_load_policy=1&loop=0&modestbranding=1&rel=0&showinfo=0&fs=1&playsinline=0&autohide=2&theme=dark&color=red&controls=2&>
|
||||
|
||||
Before we start with what Quantum Computing is, it is essential to get to know about the term Quantum, that is, a [subatomic particle][1] referring to the smallest known entity. The word [Quantum][2] is based on the Latin word Quantus, meaning, “how little”, as described in this short video:
|
||||
|
||||
<https://www.youtube.com/embed/-pUOxVsxu3o?enablejsapi=1&autoplay=0&cc_load_policy=0&iv_load_policy=1&loop=0&modestbranding=1&rel=0&showinfo=0&fs=1&playsinline=0&autohide=2&theme=dark&color=red&controls=2&>
|
||||
|
||||
It will be easier for us to understand Quantum Computing by comparing it first to Classical Computing. Classical Computing refers to how today’s conventional computers are designed to work. The device with which you are reading this article right now, can also be referred to as a Classical Computing Device.
|
||||
|
||||
### Classical Computing
|
||||
|
||||
Classical Computing is just another way to describe how a conventional computer works. They work via a binary system, i.e, information is stored using either 1 or 0. Our Classical computers cannot understand any other form.
|
||||
|
||||
In literal terms inside the computer, a transistor can be either on (1) or off (0). Whatever information we provide input to, is translated into 0s and 1s, so that the computer can understand and store that information. Everything is represented only with the help of a combination of 0s and 1s.
|
||||
|
||||
<https://www.youtube.com/embed/Xpk67YzOn5w?enablejsapi=1&autoplay=0&cc_load_policy=0&iv_load_policy=1&loop=0&modestbranding=1&rel=0&showinfo=0&fs=1&playsinline=0&autohide=2&theme=dark&color=red&controls=2&>
|
||||
|
||||
### Quantum Computing
|
||||
|
||||
Quantum Computing, on the other hand, does not follow an “on or off” model like Classical Computing. Instead, it can simultaneously handle multiple states of information with help of two phenomena called [superimposition and entanglement][3], thus accelerating computing at a much faster rate and also facilitating greater productivity in information storage.
|
||||
|
||||
Please note that superposition and entanglement are [not the same phenomena][4].
|
||||
|
||||
<https://www.youtube.com/embed/jiXuVIEg10Q?enablejsapi=1&autoplay=0&cc_load_policy=0&iv_load_policy=1&loop=0&modestbranding=1&rel=0&showinfo=0&fs=1&playsinline=0&autohide=2&theme=dark&color=red&controls=2&>
|
||||
|
||||
![][5]
|
||||
|
||||
So, if we have bits in Classical Computing, then in the case of Quantum Computing, we would have qubits (or Quantum bits) instead. To know more about the vast difference between the two, check this [page][6] from where the above pic was obtained for explanation.
|
||||
|
||||
Quantum Computers are not going to replace our Classical Computers. But, there are certain humongous tasks that our Classical Computers will never be able to accomplish and that is when Quantum Computers would prove extremely resourceful. The following video describes the same in detail while also describing how Quantum Computers work:
|
||||
|
||||
<https://www.youtube.com/embed/JhHMJCUmq28?enablejsapi=1&autoplay=0&cc_load_policy=0&iv_load_policy=1&loop=0&modestbranding=1&rel=0&showinfo=0&fs=1&playsinline=0&autohide=2&theme=dark&color=red&controls=2&>
|
||||
|
||||
A comprehensive video on the progress in Quantum Computing so far:
|
||||
|
||||
<https://www.youtube.com/embed/CeuIop_j2bI?enablejsapi=1&autoplay=0&cc_load_policy=0&iv_load_policy=1&loop=0&modestbranding=1&rel=0&showinfo=0&fs=1&playsinline=0&autohide=2&theme=dark&color=red&controls=2&>
|
||||
|
||||
### Noisy Intermediate Scale Quantum
|
||||
|
||||
According to the very recently updated research paper (31st July 2018), the term “Noisy” refers to inaccuracy because of producing an incorrect value caused by imperfect control over qubits. This inaccuracy is why there will be serious limitations on what Quantum devices can achieve in the near term.
|
||||
|
||||
“Intermediate Scale” refers to the size of Quantum Computers which will be available in the next few years, where the number of qubits can range from 50 to a few hundred. 50 qubits is a significant milestone because that’s beyond what can be simulated by [brute force][7] using the most powerful existing digital [supercomputers][8]. Read more in the paper [here][9].
|
||||
|
||||
With the advent of Cirq, a lot is about to change.
|
||||
|
||||
### What is Cirq?
|
||||
|
||||
Cirq is a python framework for creating, editing, and invoking Noisy Intermediate Scale Quantum (NISQ) circuits that we just talked about. In other words, Cirq can address challenges to improve accuracy and reduce noise in Quantum Computing.
|
||||
|
||||
Cirq does not necessarily require an actual Quantum Computer for execution. Cirq can also use a simulator-like interface to perform Quantum circuit simulations.
|
||||
|
||||
Cirq is gradually grabbing a lot of pace, with one of its first users being [Zapata][10], formed last year by a [group of scientists][11] from Harvard University focused on Quantum Computing.
|
||||
|
||||
### Getting started with Cirq on Linux
|
||||
|
||||
The developers of the Open Source [Cirq library][12] recommend the installation in a [virtual python environment][13] like [virtualenv][14]. The developers’ installation guide for Linux can be found [here][15].
|
||||
|
||||
However, we successfully installed and tested Cirq directly for Python3 on an Ubuntu 16.04 system via the following steps:
|
||||
|
||||
#### Installing Cirq on Ubuntu
|
||||
|
||||
![Cirq Framework for Quantum Computing in Linux][16]
|
||||
|
||||
First, we would require pip or pip3 to install Cirq. [Pip][17] is a tool recommended for installing and managing Python packages.
|
||||
|
||||
For Python 3.x versions, Pip can be installed with:
|
||||
```
|
||||
sudo apt-get install python3-pip
|
||||
|
||||
```
|
||||
|
||||
Python3 packages can be installed via:
|
||||
```
|
||||
pip3 install <package-name>
|
||||
|
||||
```
|
||||
|
||||
We went ahead and installed the Cirq library with Pip3 for Python3:
|
||||
```
|
||||
pip3 install cirq
|
||||
|
||||
```
|
||||
|
||||
#### Enabling Plot and PDF generation (optional)
|
||||
|
||||
Optional system dependencies not install-able with pip can be installed with:
|
||||
```
|
||||
sudo apt-get install python3-tk texlive-latex-base latexmk
|
||||
|
||||
```
|
||||
|
||||
* python3-tk is Python’s own graphic library which enables plotting functionality.
|
||||
* texlive-latex-base and latexmk enable PDF writing functionality.
|
||||
|
||||
|
||||
|
||||
Later, we successfully tested Cirq with the following command and code:
|
||||
```
|
||||
python3 -c 'import cirq; print(cirq.google.Foxtail)'
|
||||
|
||||
```
|
||||
|
||||
We got the resulting output as:
|
||||
|
||||
![][18]
|
||||
|
||||
#### Configuring Pycharm IDE for Cirq
|
||||
|
||||
We also configured a Python IDE [PyCharm on Ubuntu][19] to test the same results:
|
||||
|
||||
Since we installed Cirq for Python3 on our Linux system, we set the path to the project interpreter in the IDE settings to be:
|
||||
```
|
||||
/usr/bin/python3
|
||||
|
||||
```
|
||||
|
||||
![][20]
|
||||
|
||||
In the output above, you can note that the path to the project interpreter that we just set, is shown along with the path to the test program file (test.py). An exit code of 0 shows that the program has finished executing successfully without errors.
|
||||
|
||||
So, that’s a ready-to-use IDE environment where you can import the Cirq library to start programming with Python and simulate Quantum circuits.
|
||||
|
||||
#### Get started with Cirq
|
||||
|
||||
A good place to start are the [examples][21] that have been made available on Cirq’s Github page.
|
||||
|
||||
The developers have included this [tutorial][22] on GitHub to get started with learning Cirq. If you are serious about learning Quantum Computing, they recommend an excellent book called [“Quantum Computation and Quantum Information” by Nielsen and Chuang][23].
|
||||
|
||||
#### OpenFermion-Cirq
|
||||
|
||||
[OpenFermion][24] is an open source library for obtaining and manipulating representations of fermionic systems (including Quantum Chemistry) for simulation on Quantum Computers. Fermionic systems are related to the generation of [fermions][25], which according to [particle physics][26], follow [Fermi-Dirac statistics][27].
|
||||
|
||||
OpenFermion has been hailed as [a great practice tool][28] for chemists and researchers involved with [Quantum Chemistry][29]. The main focus of Quantum Chemistry is the application of [Quantum Mechanics][30] in physical models and experiments of chemical systems. Quantum Chemistry is also referred to as [Molecular Quantum Mechanics][31].
|
||||
|
||||
The advent of Cirq has now made it possible for OpenFermion to extend its functionality by providing routines and tools for using Cirq to compile and compose circuits for Quantum simulation algorithms.
|
||||
|
||||
#### Google Bristlecone
|
||||
|
||||
On March 5, 2018, Google presented [Bristlecone][32], their new Quantum processor, at the annual [American Physical Society meeting][33] in Los Angeles. The [gate-based superconducting system][34] provides a test platform for research into [system error rates][35] and [scalability][36] of Google’s [qubit technology][37], along-with applications in Quantum [simulation][38], [optimization][39], and [machine learning.][40]
|
||||
|
||||
In the near future, Google wants to make its 72 qubit Bristlecone Quantum processor [cloud accessible][41]. Bristlecone will gradually become quite capable to perform a task that a Classical Supercomputer would not be able to complete in a reasonable amount of time.
|
||||
|
||||
Cirq would make it easier for researchers to directly write programs for Bristlecone on the cloud, serving as a very convenient interface for real-time Quantum programming and testing.
|
||||
|
||||
Cirq will allow us to:
|
||||
|
||||
* Fine tune control over Quantum circuits,
|
||||
* Specify [gate][42] behavior using native gates,
|
||||
* Place gates appropriately on the device &
|
||||
* Schedule the timing of these gates.
|
||||
|
||||
|
||||
|
||||
### The Open Science Perspective on Cirq
|
||||
|
||||
As we all know Cirq is Open Source on GitHub, its addition to the Open Source Scientific Communities, especially those which are focused on Quantum Research, can now efficiently collaborate to solve the current challenges in Quantum Computing today by developing new ways to reduce error rates and improve accuracy in the existing Quantum models.
|
||||
|
||||
Had Cirq not followed an Open Source model, things would have definitely been a lot more challenging. A great initiative would have been missed out and we would not have been one step closer in the field of Quantum Computing.
|
||||
|
||||
### Summary
|
||||
|
||||
To summarize in the end, we first introduced you to the concept of Quantum Computing by comparing it to existing Classical Computing techniques followed by a very important video on recent developmental updates in Quantum Computing since last year. We then briefly discussed Noisy Intermediate Scale Quantum, which is what Cirq is specifically built for.
|
||||
|
||||
We saw how we can install and test Cirq on an Ubuntu system. We also tested the installation for usability on an IDE environment with some resources to get started to learn the concept.
|
||||
|
||||
Finally, we also saw two examples of how Cirq would be an essential advantage in the development of research in Quantum Computing, namely OpenFermion and Bristlecone. We concluded the discussion by highlighting some thoughts on Cirq with an Open Science Perspective.
|
||||
|
||||
We hope we were able to introduce you to Quantum Computing with Cirq in an easy to understand manner. If you have any feedback related to the same, please let us know in the comments section. Thank you for reading and we look forward to see you in our next Open Science article.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/qunatum-computing-cirq-framework/
|
||||
|
||||
作者:[Avimanyu Bandyopadhyay][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/avimanyu/
|
||||
[1]:https://en.wikipedia.org/wiki/Subatomic_particle
|
||||
[2]:https://en.wikipedia.org/wiki/Quantum
|
||||
[3]:https://www.clerro.com/guide/491/quantum-superposition-and-entanglement-explained
|
||||
[4]:https://physics.stackexchange.com/questions/148131/can-quantum-entanglement-and-quantum-superposition-be-considered-the-same-phenom
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/bit-vs-qubit.jpg
|
||||
[6]:http://www.rfwireless-world.com/Terminology/Difference-between-Bit-and-Qubit.html
|
||||
[7]:https://en.wikipedia.org/wiki/Proof_by_exhaustion
|
||||
[8]:https://www.explainthatstuff.com/how-supercomputers-work.html
|
||||
[9]:https://arxiv.org/abs/1801.00862
|
||||
[10]:https://www.xconomy.com/san-francisco/2018/07/19/google-partners-with-zapata-on-open-source-quantum-computing-effort/
|
||||
[11]:https://www.zapatacomputing.com/about/
|
||||
[12]:https://github.com/quantumlib/Cirq
|
||||
[13]:https://itsfoss.com/python-setup-linux/
|
||||
[14]:https://virtualenv.pypa.io
|
||||
[15]:https://cirq.readthedocs.io/en/latest/install.html#installing-on-linux
|
||||
[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/cirq-framework-linux.jpeg
|
||||
[17]:https://pypi.org/project/pip/
|
||||
[18]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/cirq-test-output.jpg
|
||||
[19]:https://itsfoss.com/install-pycharm-ubuntu/
|
||||
[20]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/cirq-tested-on-pycharm.jpg
|
||||
[21]:https://github.com/quantumlib/Cirq/tree/master/examples
|
||||
[22]:https://github.com/quantumlib/Cirq/blob/master/docs/tutorial.md
|
||||
[23]:http://mmrc.amss.cas.cn/tlb/201702/W020170224608149940643.pdf
|
||||
[24]:http://openfermion.org
|
||||
[25]:https://en.wikipedia.org/wiki/Fermion
|
||||
[26]:https://en.wikipedia.org/wiki/Particle_physics
|
||||
[27]:https://en.wikipedia.org/wiki/Fermi-Dirac_statistics
|
||||
[28]:https://phys.org/news/2018-03-openfermion-tool-quantum-coding.html
|
||||
[29]:https://en.wikipedia.org/wiki/Quantum_chemistry
|
||||
[30]:https://en.wikipedia.org/wiki/Quantum_mechanics
|
||||
[31]:https://ocw.mit.edu/courses/chemical-engineering/10-675j-computational-quantum-mechanics-of-molecular-and-extended-systems-fall-2004/lecture-notes/
|
||||
[32]:https://techcrunch.com/2018/03/05/googles-new-bristlecone-processor-brings-it-one-step-closer-to-quantum-supremacy/
|
||||
[33]:http://meetings.aps.org/Meeting/MAR18/Content/3475
|
||||
[34]:https://en.wikipedia.org/wiki/Superconducting_quantum_computing
|
||||
[35]:https://en.wikipedia.org/wiki/Quantum_error_correction
|
||||
[36]:https://en.wikipedia.org/wiki/Scalability
|
||||
[37]:https://research.googleblog.com/2015/03/a-step-closer-to-quantum-computation.html
|
||||
[38]:https://research.googleblog.com/2017/10/announcing-openfermion-open-source.html
|
||||
[39]:https://research.googleblog.com/2016/06/quantum-annealing-with-digital-twist.html
|
||||
[40]:https://arxiv.org/abs/1802.06002
|
||||
[41]:https://www.computerworld.com.au/article/644051/google-launches-quantum-framework-cirq-plans-bristlecone-cloud-move/
|
||||
[42]:https://en.wikipedia.org/wiki/Logic_gate
|
||||
@ -0,0 +1,91 @@
|
||||
How to Play Windows-only Games on Linux with Steam Play
|
||||
======
|
||||
The new experimental feature of Steam allows you to play Windows-only games on Linux. Here’s how to use this feature in Steam right now.
|
||||
|
||||
You have heard the news. Game distribution platform [Steam is implementing a fork of WINE to allow you to play games that are available on Windows only][1]. This is definitely a great news for us Linux users for we have complained about the lack of the number of games for Linux.
|
||||
|
||||
This new feature is still in beta but you can try it out and play Windows-only games on Linux right now. Let’s see how to do that.
|
||||
|
||||
### Play Windows-only games in Linux with Steam Play
|
||||
|
||||
![Play Windows-only games on Linux][2]
|
||||
|
||||
You need to install Steam first. Steam is available for all major Linux distributions. I have written in detail about [installing Steam on Ubuntu][3] and you may refer to that article if you don’t have Steam installed yet.
|
||||
|
||||
Once you have Steam installed and you have logged into your Steam account, it’s time to see how to enable Windows games in Steam Linux client.
|
||||
|
||||
#### Step 1: Go to Account Settings
|
||||
|
||||
Run Steam client. On the top left, click on Steam and then on Settings.
|
||||
|
||||
![Enable steam play beta on Linux][4]
|
||||
|
||||
#### Step 2: Opt in to the beta program
|
||||
|
||||
In the Settings, select Account from left side pane and then click on the CHANGE button under Beta participation.
|
||||
|
||||
![Enable beta feature in Steam Linux][5]
|
||||
|
||||
You should select Steam Beta Update here.
|
||||
|
||||
![Enable beta feature in Steam Linux][6]
|
||||
|
||||
Once you save the settings here, Steam will restart and download the new beta updates.
|
||||
|
||||
#### Step 3: Enable Steam Play beta
|
||||
|
||||
Once Steam has downloaded the new beta updates, it will be restarted. Now you are almost set.
|
||||
|
||||
Go to Settings once again. You’ll see a new option Steam Play in the left side pane now. Click on it and check the boxes:
|
||||
|
||||
* Enable Steam Play for supported titles (You can play the whitelisted Windows-only games)
|
||||
* Enable Steam Play for all titles (You can try to play all Windows-only games)
|
||||
|
||||
|
||||
|
||||
![Play Windows games on Linux using Steam Play][7]
|
||||
|
||||
I don’t remember if Steam restarts at this point again or not but I guess that’s trivial. You should now see the option to install Windows-only games on Linux.
|
||||
|
||||
For example, I have Age of Empires in my Steam library which is not available on Linux normally. But after I enabled Steam Play beta for all Windows titles, it now gives me the option for installing Age of Empires on Linux.
|
||||
|
||||
![Install Windows-only games on Linux using Steam][8]
|
||||
Windows-only games can now be installed on Linux
|
||||
|
||||
### Things to know about Steam Play beta feature
|
||||
|
||||
There are a few things you should know and keep in mind about using Windows-only games on Linux with Steam Play beta.
|
||||
|
||||
* At present, [only 27 Windows-games are whitelisted][9] for Steam Play. These whitelisted games work seamlessly on Linux.
|
||||
* You can try any Windows game with Steam Play beta but it might not work all the time. Some games will crash sometimes while some game might not run at all.
|
||||
* While in beta, you won’t see the Windows-only games available for Linux in the Steam store. You’ll have to either try the game on your own or refer to [this community maintained list][10] to see the compatibility status of the said Windows game. You can also contribute to the list by filling [this form][11].
|
||||
* If you have games downloaded on Windows via Steam, you can save some download data by [sharing Steam game files between Linux and Windows][12].
|
||||
|
||||
|
||||
|
||||
I hope this tutorial helped you in running Windows-only games on Linux. Which game(s) are you looking forward to play on Linux?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/steam-play/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://itsfoss.com/steam-play-proton/
|
||||
[2]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/play-windows-games-on-linux-featured.jpeg
|
||||
[3]:https://itsfoss.com/install-steam-ubuntu-linux/
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta.jpeg
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta-2.jpeg
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta-3.jpeg
|
||||
[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta-4.jpeg
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/install-windows-games-linux.jpeg
|
||||
[9]:https://steamcommunity.com/games/221410
|
||||
[10]:https://docs.google.com/spreadsheets/d/1DcZZQ4HL_Ol969UbXJmFG8TzOHNnHoj8Q1f8DIFe8-8/htmlview?sle=true#
|
||||
[11]:https://docs.google.com/forms/d/e/1FAIpQLSeefaYQduMST_lg0IsYxZko8tHLKe2vtVZLFaPNycyhY4bidQ/viewform
|
||||
[12]:https://itsfoss.com/share-steam-files-linux-windows/
|
||||
@ -5,47 +5,47 @@
|
||||
|
||||
### 网络自动化
|
||||
|
||||
随着 IT 行业的技术变化,从服务器虚拟化到公有云和私有云,以及自服务能力、容器化应用、平台即服务(PaaS)交付,有一直以来落后的一个领域就是网络。
|
||||
随着 IT 行业的技术变化,从服务器虚拟化到公有云和私有云,以及自服务能力、容器化应用、平台即服务(PaaS)交付,而一直以来落后的一个领域就是网络。
|
||||
|
||||
在过去的五年多,网络行业似乎有很多新的趋势出现,它们中的很多被归入到软件定义网络(SDN)。
|
||||
在过去的五年多,网络行业似乎有很多新的趋势出现,它们中的很多被归入到<ruby>软件定义网络<rt>software-defined networking</rt></ruby>(SDN)。
|
||||
|
||||
>注意
|
||||
>注意:
|
||||
|
||||
> SDN 是新出现的一种构建、管理、操作和部署网络的方法。SDN 最初的定义是出于将控制层和数据层(包转发)物理分离的需要,并且,解耦合的控制层必须管理好各自的设备。
|
||||
|
||||
> 如今,在 SDN 旗下已经有许多技术,包括<ruby>基于控制器的网络<rt>controller-based networks</rt></ruby>、网络设备上的 API、网络自动化、白盒交换机、策略网络化、网络功能虚拟化(NFV)等等。
|
||||
> 如今,在 SDN 旗下已经有许多技术,包括<ruby>基于控制器的网络<rt>controller-based networks</rt></ruby>、网络设备 API、网络自动化、<ruby>白盒交换机<rt>whitebox switche</rt></ruby>、策略网络化、<ruby>网络功能虚拟化<rt>Network Functions Virtualization</rt></ruby>(NFV)等等。
|
||||
|
||||
> 由于这篇报告的目的,我们参考 SDN 的解决方案作为我们的解决方案,其中包括一个网络控制器作为解决方案的一部分,并且提升了该网络的可管理性,但并不需要从数据层解耦控制层。
|
||||
> 出于这篇报告的目的,我们参考 SDN 的解决方案作为我们的解决方案,其中包括一个网络控制器作为解决方案的一部分,并且提升了该网络的可管理性,但并不需要从数据层解耦控制层。
|
||||
|
||||
这些趋势的之一是,网络设备的 API 作为管理和操作这些设备的一种方法而出现,真正地提供了机器对机器的通讯。当需要自动化和构建网络应用时 API 简化了开发过程,在数据如何建模时提供了更多结构。例如,当启用 API 的设备以 JSON/XML 返回数据时,它是结构化的,并且比返回原生文本信息、需要手工去解析的仅支持命令行的设备更易于使用。
|
||||
这些趋势的之一是,网络设备的 API 作为管理和操作这些设备的一种方法而出现,真正地提供了机器对机器的通讯。当需要自动化和构建网络应用时 API 简化了开发过程,在数据如何建模时提供了更多结构。例如,当启用 API 的设备以 JSON/XML 返回数据时,它是结构化的,并且比返回原生文本信息 —— 需要手工去解析的仅支持命令行的设备更易于使用。
|
||||
|
||||
在 API 之前,用于配置和管理网络设备的两个主要机制是命令行接口(CLI)和简单网络管理协议(SNMP)。让我们来了解一下它们,CLI 是一个设备的人机界面,而 SNMP 并不是为设备提供的实时编程接口。
|
||||
|
||||
幸运的是,因为很多供应商争相为设备增加 API,有时候 _只是因为_ 它被放到需求建议书(RFP)中,这就带来了一个非常好的副作用 —— 支持网络自动化。当真正的 API 发布时,访问设备内数据的过程,以及管理配置,就会被极大简化,因此,我们将在本报告中对此进行评估。虽然使用许多传统方法也可以实现自动化,比如,CLI/SNMP。
|
||||
|
||||
> 注意
|
||||
> 注意:
|
||||
|
||||
> 随着未来几个月或几年的网络设备更新,供应商的 API 无疑应该被做为采购网络设备(虚拟和物理)的关键决策标准而测试和使用。如果供应商提供一些库或集成到自动化工具中,或者如果被用于一个开放的标准或协议,用户应该知道数据是如何通过设备建模的,API 使用的传输类型是什么。
|
||||
> 随着未来几个月或几年(LCTT 译注:本文发表于 2016 年)的网络设备更新,供应商的 API 无疑应该被做为采购网络设备(虚拟和物理)的关键决策标准而测试和使用。如果供应商提供一些库或集成到自动化工具中,或者如果被用于一个开放的标准或协议,用户应该知道数据是如何通过设备建模的,API 使用的传输类型是什么。
|
||||
|
||||
总而言之,网络自动化,像大多数类型的自动化一样,是为了更快地工作。工作的更快是好事,降低部署和配置改变的时间并不总是许多 IT 组织需要去解决的问题。
|
||||
总而言之,网络自动化,像大多数类型的自动化一样,是为了更快地工作。工作的更快是好事,减少部署和配置改变的时间并不总是许多 IT 组织需要去解决的问题。
|
||||
|
||||
包括速度在内,我们现在看看这些各种类型的 IT 组织逐渐采用网络自动化的几种原因。你应该注意到,同样的原则也适用于其它类型的自动化。
|
||||
|
||||
### 简化架构
|
||||
#### 简化架构
|
||||
|
||||
今天,每个网络都是一片独特的“雪花”,并且,网络工程师们为能够通过一次性的改变来解决传输和网络应用问题而感到自豪,而这最终导致网络不仅难以维护和管理,而且也很难去实现自动化。
|
||||
今天,每个网络都是一片独特的“雪花”,并且,网络工程师们为能够通过一次性的网络改变来解决传输和应用问题而感到自豪,而这最终导致网络不仅难以维护和管理,而且也很难去实现自动化。
|
||||
|
||||
网络自动化和管理需要从一开始就包含到新的架构和设计中去部署,而不是作为一个二级或三级项目。哪个特性可以跨不同的供应商工作?哪个扩展可以跨不同的平台工作?当使用特别的网络设备平台时,API 类型或者自动化工程是什么?当这些问题在设计过程之前得到答案,最终的架构将变成简单的、可重复的、并且易于维护 _和_ 自动化的,在整个网络中将很少启用供应商专用的扩展。
|
||||
网络自动化和管理需要从一开始就包含到新的架构和设计中去部署,而不是作为一个二级或三级项目。哪个特性可以跨不同的供应商工作?哪个扩展可以跨不同的平台工作?当使用具体的网络设备平台时,API 类型或者自动化工程是什么?当这些问题在设计过程之前得到答案,最终的架构将变成简单的、可重复的、并且易于维护 _和_ 自动化的,在整个网络中将很少启用供应商专用的扩展。
|
||||
|
||||
### 确定的结果
|
||||
#### 确定的结果
|
||||
|
||||
在一个企业组织中,<ruby>改变审查会议<rt>change review meeting</rt></ruby>会评估面临的网络变化、它们对外部系统的影响、以及回滚计划。在人们通过 CLI 来执行这些 _面临的变化_ 的世界上,输入错误的命令造成的影响是灾难性的。想像一下,一个有 3 位、4 位、5位,或者 50 位工程师的团队。每位工程师应对 _面临的变化_ 都有他们自己的独特的方法。并且,在管理这些变化的期间,一个人使用 CLI 或者 GUI 的能力并不会消除和减少出现错误的机率。
|
||||
|
||||
使用经过验证和测试过的网络自动化可以帮助实现更多的可预测行为,并且使执行团队更有可能实现确实性结果,在保证任务没有人为错误的情况下首次正确完成的道路上更进一步。
|
||||
使用经过验证的和测试过的网络自动化可以帮助实现更多的可预测行为,并且使执行团队更有可能实现确实性的结果,首次在保证任务没有人为错误的情况下正确完成的道路上更进一步。
|
||||
|
||||
### 业务灵活性
|
||||
#### 业务灵活性
|
||||
|
||||
不用说,网络自动化不仅为部署变化提供速度和灵活性,而且使得根据业务需要去从网络设备中检索数据的速度变得更快。自从服务器虚拟化到来以后,服务器和虚拟化使得管理员有能力在瞬间去部署一个新的应用程序。而且,随着应用程序可以更快地部署,随之浮现的问题是为什么还需要花费如此长的时间配置一个 VLAN(虚拟局域网)、路由器、FW ACL(防火墙的访问控制列表)或者负载均衡策略呢?
|
||||
不用说,网络自动化不仅为部署变化提供了速度和灵活性,而且使得根据业务需要去从网络设备中检索数据的速度变得更快。自从服务器虚拟化到来以后,服务器和虚拟化使得管理员有能力在瞬间去部署一个新的应用程序。而且,随着应用程序可以更快地部署,随之浮现的问题是为什么还需要花费如此长的时间配置一个 VLAN(虚拟局域网)、路由器、FW ACL(防火墙的访问控制列表)或者负载均衡策略呢?
|
||||
|
||||
通过了解在一个组织内最常见的工作流和 _为什么_ 真正需要改变网络,部署如 Ansible 这样的现代的自动化工具将使这些变得非常简单。
|
||||
|
||||
@ -61,9 +61,9 @@ _Ansible 是一个无需代理和可扩展的超级简单的自动化平台。_
|
||||
|
||||
让我们更深入地了解它的细节,并且看一看那些使 Ansible 在行业内获得广泛认可的属性。
|
||||
|
||||
### 简单
|
||||
#### 简单
|
||||
|
||||
Ansible 的其中一个吸引人的属性是,使用它你 _不_ 需要特定的编程技能。所有的指令,或者任务都是自动化的,以一个标准的、任何人都可以理解的人类可读的数据格式的文档化。在 30 分钟之内完成安装和自动化任务的情况并不罕见!
|
||||
Ansible 的其中一个吸引人的属性是,使用它你 **不** 需要特定的编程技能。所有的指令,或者说任务都是自动化的,以一个标准的、任何人都可以理解的人类可读的数据格式的文档化。在 30 分钟之内完成安装和自动化任务的情况并不罕见!
|
||||
|
||||
例如,下列来自一个 Ansible <ruby>剧本<rt>playbook</rt></ruby>的任务用于去确保在一个 VLAN 存在于一个 Cisco Nexus 交换机中:
|
||||
|
||||
@ -73,90 +73,83 @@ Ansible 的其中一个吸引人的属性是,使用它你 _不_ 需要特定
|
||||
|
||||
你无需熟悉或写任何代码就可以明确地看出它将要做什么!
|
||||
|
||||
> 注意
|
||||
> 注意:
|
||||
|
||||
> 这个报告的下半部分涉到 Ansible 术语(<ruby>剧本<rt>playbook</rt></ruby>、<ruby>行动<rt>play</rt></ruby>、<ruby>任务<rt>task</rt></ruby>、<ruby>模块<rt>module</rt></ruby>等等)的细节。在我们使用 Ansible 进行网络自动化时,提及这些关键概念时我们会有一些简短的示例。
|
||||
> 这个报告的下半部分涉到 Ansible 术语(<ruby>剧本<rt>playbook</rt></ruby>、<ruby>剧集<rt>play</rt></ruby>、<ruby>任务<rt>task</rt></ruby>、<ruby>模块<rt>module</rt></ruby>等等)的细节。在我们使用 Ansible 进行网络自动化时,提及这些关键概念时我们会有一些简短的示例。
|
||||
|
||||
### 无代理
|
||||
#### 无代理
|
||||
|
||||
如果你看到市面上的其它工具,比如 Puppet 和 Chef,你学习它们会发现,一般情况下,它们要求每个实现自动化的设备必须安装特定的软件。这种情况在 Ansible 上 _并不_需要,这就是为什么 Ansible 是实现网络自动化的最佳选择的主要原因。
|
||||
如果你看过市面上的其它工具,比如 Puppet 和 Chef,你会发现,一般情况下,它们要求每个实现自动化的设备必须安装特定的软件。这种情况在 Ansible 上 _并不_需要,这就是为什么 Ansible 是实现网络自动化的最佳选择的主要原因。
|
||||
|
||||
它很好理解,那些 IT 自动化工具,包括 Puppet、Chef、CFEngine、SaltStack、和 Ansible,它们最初构建是为管理和自动化配置 Linux 主机,以跟得上部署的应用程序增长的步伐。因为 Linux 系统是被配置成自动化的,要安装代理并不是一个技术难题。如果有的话,它会担误安装过程,因为,现在有 _N_ 多个(你希望去实现自动化的)主机需要在它们上面部署软件。
|
||||
这很好理解,那些 IT 自动化工具,包括 Puppet、Chef、CFEngine、SaltStack、和 Ansible,它们最初构建是为管理和自动化配置 Linux 主机,以跟得上部署的应用程序增长的步伐。因为 Linux 系统是被配置成自动化的,要安装代理并不是一个技术难题。如果有的话,它也只会延误安装过程,因为,现在有 _N_ 多个(你希望去实现自动化的)主机需要在它们上面部署软件。
|
||||
|
||||
再加上,当使用代理时,它们需要的 DNS 和 NTP 配置更加复杂。这些都是大多数环境中已经配置好的服务,但是,当你希望快速地获取一些东西或者只是简单地想去测试一下它能做什么的时候,它将极大地担误整个设置和安装的过程。
|
||||
再加上,当使用代理时,它们需要的 DNS 和 NTP 配置更加复杂。这些都是大多数环境中已经配置好的服务,但是,当你希望快速地获取一些东西或者只是简单地想去测试一下它能做什么的时候,它将极大地耽误整个设置和安装的过程。
|
||||
|
||||
由于本报告只是为介绍利用 Ansible 实现网络自动化,它最有价值的是,Ansible 作为一个无代理平台,对于系统管理员来说,它更具有吸引力,这是为什么呢?
|
||||
由于本报告只是为介绍利用 Ansible 实现网络自动化,我们希望指出,Ansible 作为一个无代理平台,对于网络管理员来说,其比对系统管理员更具有吸引力。这是为什么呢?
|
||||
|
||||
正如前面所说的那样,对网络管理员来说,它是非常有吸引力的,Linux 操作系统是开源的,并且,任何东西都可以安装在它上面。对于网络来说,虽然它正在逐渐改变,但事实并非如此。如果我们更广泛地部署网络操作系统,如 Cisco IOS,它就是这样的一个例子,并且问一个问题, _“第三方软件能否部署在基于 IOS (译者注:此处的 IOS,指的是思科的网络操作系统 IOS)的平台上吗?”_它并不会给你惊喜,它的回答是 _NO_。
|
||||
正如前面所说的那样,对网络管理员来说,它是非常有吸引力的,Linux 操作系统是开源的,并且,任何东西都可以安装在它上面。对于网络来说,却并非如此,虽然它正在逐渐改变。如果我们更广泛地部署网络操作系统,如 Cisco IOS,它就是这样的一个例子,并且问一个问题, _“第三方软件能否部署在基于 IOS (LCTT 译注:此处的 IOS,指的是思科的网络操作系统 IOS)的平台上吗?”_毫无疑问,它的回答是 _NO_。
|
||||
|
||||
在过去的二十多年里,几乎所有的网络操作系统都是闭源的,并且,垂直整合到底层的网络硬件中。在一个网络设备中(路由器、交换机、负载均衡、防火墙、等等),不需要供应商的支持,有一个像 Ansible 这样的自动化平台,从头开始去构建一个无代理、可扩展的自动化平台,就像是它专门为网络行业订制的一样。我们最终将开始减少并消除与网络的人工交互。
|
||||
在过去的二十多年里,几乎所有的网络操作系统都是闭源的,并且,垂直整合到底层的网络硬件中。没有供应商的支持,在一个网络设备中(路由器、交换机、负载均衡、防火墙、等等)载入一个代理并不那么轻松。有一个像 Ansible 这样的自动化平台,从头开始去构建一个无代理、可扩展的自动化平台,就像是它专门为网络行业订制的一样。我们最终将开始减少并消除与网络的人工交互。
|
||||
|
||||
### 可扩展
|
||||
#### 可扩展
|
||||
|
||||
Ansible 的可扩展性也非常的好。作为一个开源的,并且从代码开始将在网络行业中发挥重要的作用,有一个可扩展的平台是必需的。这意味着如果供应商或社区不提供一个特定的特性或功能,开源社区,终端用户,消费者,顾问者,或者,任何可能去 _扩展_ Ansible 的人,去启用一个给定的功能集。过去,网络供应商或者工具供应商通过一个 hook 去提供插件和集成。想像一下,使用一个像 Ansible 这样的自动化平台,并且,你选择的网络供应商发布了你 _真正_ 需要的自动化的一个新特性。从理论上说,网络供应商或者 Ansible 可以发行一个新的插件去实现自动化这个独特的特性,这是一件非常好的事情,从你的内部工程师到你的增值分销商(VARs)或者你的顾问中的任何人,都可以去提供这种集成。
|
||||
|
||||
正如前面所说的那样,Ansible 实际上是极具扩展性的,Ansible 最初就是为自动化应用程序和系统构建的。这是因为,Ansible 的可扩展性是被网络供应商编写集成的,包括但不限于 Cisco、Arista、Juniper、F5、HP、A10、Cumulus、和 Palo Alto Networks。
|
||||
Ansible 的可扩展性也非常的好。从开源、代码开始在网络行业中发挥重要的作用时起,有一个可扩展的平台是必需的。这意味着如果供应商或社区不提供一个特定的特性或功能,开源社区、终端用户、消费者、顾问,或者任何的人能够 _扩展_ Ansible 来启用一个给定的功能集。过去,网络供应商或者工具供应商通过一个 hook 去提供新的插件和集成。想像一下,使用一个像 Ansible 这样的自动化平台,并且,你选择的网络供应商发布了你 _真正_ 需要的一个自动化的新特性。从理论上说,网络供应商或者 Ansible 可以发行一个新的插件去实现自动化这个独特的特性,这是一件非常好的事情,从你的内部工程师到你的增值分销商(VAR)或者你的顾问中的任何一个人,都可以去提供这种集成。
|
||||
|
||||
正如前面所说的那样,Ansible 实际上是极具扩展性的,Ansible 最初就是为自动化应用程序和系统构建的。这是因为,Ansible 的可扩展性来自于其集成性是为网络供应商编写的,包括但不限于 Cisco、Arista、Juniper、F5、HP、A10、Cumulus 和 Palo Alto Networks。
|
||||
|
||||
### 对于网络自动化,为什么要使用 Ansible?
|
||||
|
||||
我们已经简单了解除了 Ansible 是什么,以及一些网络自动化的好处,但是,对于网络自动化,我们为什么要使用 Ansible?
|
||||
|
||||
在一个完全透明的环境下,已经说的很多的理由是 Ansible 可以做什么,比如,作为一个很大的自动化应用程序部署平台,但是,我们现在要深入一些,更多地关注于网络,并且继续总结一些更需要注意的其它关键点。
|
||||
大家很清楚,使得 Ansible 成为如此伟大的一个自动化应用部署平台的许多原因已经被大家所提及了。但是,我们现在要深入一些,更多地关注于网络,并且继续总结一些更需要注意的其它关键点。
|
||||
|
||||
#### 无代理
|
||||
|
||||
### 无代理
|
||||
在实现网络自动化的时候,无代理架构的重要性并不是重点强调的,特别是当它适用于现有的自动化设备时。如果,我们看一下当前网络中已经安装的各种设备时,从 DMZ 和园区,到分支机构和数据中心,最大份额的设备 _并不_ 具有最新 API 的设备。从自动化的角度来看,API 可以使做一些事情变得很简单,像 Ansible 这样的无代理平台有可能去自动化和管理那些 _老旧(传统)_ 的设备。例如,_基于 CLI 的设备_,它的工具可以被用于任何网络环境中。
|
||||
|
||||
> 注意:
|
||||
|
||||
在实现网络自动化的时候,无代理架构的重要性并不是重点强调的,特别是当它适用于现有的自动化设备时。如果,我们看一下当前网络中已经安装的各种设备时,从 DMZ 和园区,到分支和数据中心,最大份额的设备 _并不_ 具有最新 API 的设备。从自动化的角度来看,API 可以使做一些事情变得很简单,像 Ansible 这样的无代理平台有可能去自动化和管理那些 _传统_ 的设备。例如,_基于CLI 的设备_,它的工具可以被用于任何网络环境中。
|
||||
> 如果仅支持 CLI 的设备已经集成进 Ansible,它的机制就像是,怎么在设备上通过协议如 telnet、SSH 和 SNMP 去进行只读访问和读写操作。
|
||||
|
||||
###### 注意
|
||||
作为一个独立的网络设备,像路由器、交换机、和防火墙正在持续去增加 API 的支持,SDN 解决方案也正在出现。SDN 解决方案的其中一个常见主题是,它们都提供一个单点集成和策略管理,通常是以一个 SDN 控制器的形式出现。这对于 Cisco ACI、VMware NSX、Big Switch Big Cloud Fabric 和 Juniper Contrail,以及其它的 SDN 提供者,比如 Nuage、Plexxi、Plumgrid、Midokura 和 Viptela,是一个真实的解决方案。这甚至包含开源的控制器,比如 OpenDaylight。
|
||||
|
||||
如果仅 CLI 的设备已经集成进 Ansible,它的机制就像是,怎么在设备上通过协议如 telnet、SSH、和 SNMP,去进行只读访问和读写操作。
|
||||
所有的这些解决方案都简化了网络管理,就像它们可以让一个管理员开始从“box-by-box”管理(LCTT 译者注:指的是单个设备挨个去操作的意思)迁移到网络范围的管理。这是在正确方向上迈出的很大的一步,这些解决方案并不能消除在变更期间中人类犯错的机率。例如,比起配置 _N_ 个交换机,你可能需要去配置一个单个的 GUI,它需要很长的时间才能实现所需要的配置改变 —— 它甚至可能更复杂,毕竟,相对于一个 CLI,他们更喜欢 GUI!另外,你可能有不同类型的 SDN 解决方案部署在每个应用程序、网络、区域或者数据中心。
|
||||
|
||||
作为一个独立的网络设备,像路由器、交换机、和防火墙持续去增加 APIs 的支持,SDN 解决方案也正在出现。SDN 解决方案的其中一个主题是,它们都提供一个单点集成和策略管理,通常是以一个 SDN 控制器的形式出现。这是真实的解决方案,比如,Cisco ACI、VMware NSX、Big Switch Big Cloud Fabric、和 Juniper Contrail,同时,其它的 SDN 提供者,比如 Nuage、Plexxi、Plumgrid、Midokura、和 Viptela。甚至包含开源的控制器,比如 OpenDaylight。
|
||||
在需要自动化的网络中,对于配置管理、监视和数据收集,当行业开始向基于控制器的网络架构中迁移时,这些需求并不会消失。
|
||||
|
||||
所有的这些解决方案都简化了网络管理,就像他们允许一个管理员去开始从“box-by-box”管理(译者注:指的是单个设备挨个去操作的意思)迁移到网络范围的管理。这是在正确方向上迈出的很大的一步,这些解决方案并不能消除在改变窗口中人类犯错的机率。例如,比起配置 _N_ 个交换机,你可能需要去配置一个单个的 GUI,它需要很长的时间才能实现所需要的配置改变 — 它甚至可能更复杂,毕竟,相对于一个 CLI,他们更喜欢 GUI!另外,你可能有不同类型的 SDN 解决方案部署在每个应用程序、网络、区域、或者数据中心。
|
||||
大量的软件定义网络中都部署有控制器,几乎所有的控制器都<ruby>提供<rt>expose</rt></ruby>一个最新的 REST API。并且,因为 Ansible 是一个无代理架构,它实现自动化是非常简单的,而不仅仅是对那些没有 API 的传统设备,但也有通过 REST API 的软件定义网络解决方案,在所有的终端上不需要有额外的软件(LCTT 译注:指的是代理)。最终的结果是,使用 Ansible,无论有或没有 API,可以使任何类型的设备都能够自动化。
|
||||
|
||||
在需要自动化的网络中,对于配置管理、监视、和数据收集,当行业开始向基于控制器的网络架构中迁移时,这些需求并不会消失。
|
||||
#### 自由开源软件(FOSS)
|
||||
|
||||
大量的软件定义网络中都部署有控制器,所有最新的控制器都提供(expose)一个最新的 REST API。并且,因为 Ansible 是一个无代理架构,它实现自动化是非常简单的,而不仅仅是没有 API 的传统设备,但也有通过 REST APIs 的软件定义网络解决方案,在所有的终端上不需要有额外的软件(译者注:指的是代理)。最终的结果是,使用 Ansible,无论有或没有 API,可以使任何类型的设备都能够自动化。
|
||||
Ansible 是一个开源软件,它的全部代码在 GitHub 上都是公开可访问的,使用 Ansible 是完全免费的。它可以在几分钟内完成安装并为网络工程师提供有用的价值。Ansible 这个开源项目,或者 Ansible 公司,在它们交付软件之前,你不会遇到任何一个销售代表。那是显而易见的事实,因为它是一个真正的开源项目,但是,作为开源的、社区驱动的软件项目在网络行业中的使用是非常少的,但是,也在逐渐增加,我们想明确指出这一点。
|
||||
|
||||
同样需要指出的一点是,Ansible, Inc. 也是一个公司,它也需要去赚钱,对吗?虽然 Ansible 是开源的,它也有一个叫 Ansible Tower 的企业产品,它增加了一些特性,比如,基于规则的访问控制(RBAC)、报告、 web UI、REST API、多租户等等,(相比 Ansible)它更适合于企业去部署。并且,更重要的是,Ansible Tower 甚至可以最多在 10 台设备上 _免费_ 使用,至少,你可以去体验一下,它是否会为你的组织带来好处,而无需花费一分钱,并且,也不需要与无数的销售代表去打交道。
|
||||
|
||||
### 免费和开源软件(FOSS)
|
||||
#### 可扩展性
|
||||
|
||||
Ansible 是一个开源软件,它的全部代码在 GitHub 上都是公开的、可访问的,使用 Ansible 是完全免费的。它可以在几分钟内完成安装并为网络工程师提供有用的价值。Ansible,这个开源项目,或者 Ansible 公司,在它们交付软件之前,你不会遇到任何一个销售代表。那是显而易见的事实,因为它是一个真正的开源项目,但是,开源项目的使用,在网络行业中社区驱动的软件是非常少的,但是,也在逐渐增加,我们想明确指出这一点。
|
||||
我们在前面说过,Ansible 主要是为部署 Linux 应用程序而构建的自动化平台,虽然从早期开始已经扩展到 Windows。需要指出的是,Ansible 开源项目并没有“自动化网络基础设施”的目标。事实上是,Ansible 社区更明白如何在底层的 Ansible 架构上更具灵活性和可扩展性,对于他们的自动化需要(包括网络)更容易成为一个 _扩展_ 的 Ansible。在过去的两年中,部署有许多的 Ansible 集成,许多是有行业独立人士进行的,比如,Matt Oswalt、Jason Edelman、Kirk Byers、Elisa Jasinska、David Barroso、Michael Ben-Ami、Patrick Ogenstad 和 Gabriele Gerbino,也有网络系统供应商的领导者,比如,Arista、Juniper、Cumulus、Cisco、F5、和 Palo Alto Networks。
|
||||
|
||||
同样需要指出的一点是,Ansible, Inc. 也是一个公司,它也需要去赚钱,对吗?虽然 Ansible 是开源的,它也有一个叫 Ansible Tower 的企业产品,它增加了一些特性,比如,基于规则的访问控制(RBAC)、报告、 web UI、REST APIs、多租户、等等,(相比 Ansible)它更适合于企业去部署。并且,更重要的是,Ansible Tower 甚至可以最多在 10 台设备上 _免费_ 使用,至少,你可以去体验一下,它是否会为你的组织带来好处,而无需花费一分钱,并且,也不需要与无数的销售代表去打交道。
|
||||
#### 集成到已存在的 DevOps 工作流中
|
||||
|
||||
Ansible 在 IT 组织中被用于应用程序部署。它被用于需要管理部署、监视和管理各种类型的应用程序的运维团队中。通过将 Ansible 集成到网络基础设施中,当新应用程序到来或迁移后,它扩展了可能的范围。而不是去等待一个新的顶架交换机(LCTT 译注:TOR,一种数据中心设备接入的方式)的到来、去添加一个 VLAN、或者去检查接口的速度/双工,所有的这些以网络为中心的任务都可以被自动化,并且可以集成到 IT 组织内已经存在的工作流中。
|
||||
|
||||
### 可扩展性
|
||||
#### 幂等性
|
||||
|
||||
我们在前面说过,Ansible 主要是为部署 Linux 应用程序而构建的自动化平台,虽然从早期开始已经扩展到 Windows。需要指出的是,Ansible 开源项目并没有自动化网络基础设施的目标。事实上是,Ansible 社区更多地理解了在底层的 Ansible 架构上怎么更具灵活性和可扩展性,对于他们的自动化需要,它变成了 _扩展_ 的 Ansible,它包含了网络。在过去的两年中,部署有许多的 Ansible 集成,许多行业独立人士(industry independents),比如,Matt Oswalt、Jason Edelman、Kirk Byers、Elisa Jasinska、David Barroso、Michael Ben-Ami、Patrick Ogenstad、和 Gabriele Gerbino,以及网络系统供应商的领导者,比如,Arista、Juniper、Cumulus、Cisco、F5、和 Palo Alto Networks。
|
||||
术语<ruby>幂等性<rt>idempotency</rt></ruby> (读作 item-potency)经常用于软件开发的领域中,尤其是当使用 REST API 工作的时候,以及在 _DevOps_ 自动化和配置管理框架的领域中,包括 Ansible。Ansible 的其中一个信念是,所有的 Ansible 模块(集成的)应该是幂等的。那么,对于一个模块来说,幂等是什么意思呢?毕竟,对大多数网络工程师来说,这是一个新的术语。
|
||||
|
||||
答案很简单。幂等性的本质是允许定义的任务,运行一次或者上千次都不会在目标系统上产生不利影响,仅仅是一种一次性的改变。换句话说,如果有一个要做的改变去使系统进入到它期望的状态,这种改变完成之后,并且,如果这个设备已经达到这种状态,就不会再发生改变。这不像大多数传统的定制脚本和拷贝、黏贴到那些终端窗口中的 CLI 命令。当相同的命令或者脚本在同一个系统上重复运行,(有时候)会出现错误。即使是粘贴一组命令到一个路由器中,也可能会遇到一些使你的其余的配置失效的错误。好玩吧?
|
||||
|
||||
### 集成到已存在的 DevOps 工作流中
|
||||
另外的例子是,如果你有一个配置 10 个 VLAN 的文件文件或者脚本,那么 _每次_ 运行这个脚本,相同的命令命令会被输入 10 次。如果使用一个幂等的 Ansible 模块,首先会从网络设备中采集已存在的配置,并且,每个新的 VLAN 被配置后会再次检查当前配置。仅仅当这个新的 VLAN 需要被添加(或者,比如说改变 VLAN 名字)是一个变更,命令才会真实地推送到设备。
|
||||
|
||||
Ansible 在 IT 组织中被用于应用程序部署。它被用于需要管理部署、监视、和管理各种类型的应用程序的操作团队中。通过将 Ansible 集成到网络基础设施中,当新应用程序到来或迁移后,它扩展了可能的范围。而不是去等待一个新的顶架交换机(TOR,译者注:一种数据中心设备接入的方式)的到来、去添加一个 VLAN、或者去检查接口的速度/双工,所有的这些以网络为中心的任务都可以被自动化,并且可以集成到 IT 组织内已经存在的工作流中。
|
||||
当一个技术越来越复杂,幂等性的价值就越高,在你修改的时候,你并不能注意到 _已存在_ 的网络设备的状态,而仅仅是从一个网络配置和策略角度去尝试达到 _期望的_ 状态。
|
||||
|
||||
#### 网络范围的和临时(Ad Hoc)的改变
|
||||
|
||||
### 幂等性
|
||||
用配置管理工具解决的其中一个问题是,配置“飘移”(当设备的期望配置逐渐漂移,或者改变,随着时间的推移,手动改变和/或在一个环境中使用了多个不同的工具),事实上,这也是像 Puppet 和 Chef 所使用的地方。代理商<ruby>电联<rt>phone home</rt></ruby>到前端服务器,验证它的配置,并且,如果需要变更,则改变它。这个方法是非常简单的。如果有故障了,需要去排除怎么办?你通常需要跳过管理系统,直接连到设备,找到并修复它,然后,马上离开,对不对?果然,在下次当代理电连回来,这个修复问题的改变被覆盖了(基于主/前端服务器是怎么配置的)。在高度自动化的环境中,一次性的改变应该被限制,但是,仍然允许使用它们(LCTT 译注:指的是一次性改变)的工具是非常有价值的。正如你想到的,其中一个这样的工具是 Ansible。
|
||||
|
||||
术语 _幂等性_ (明显能提升项目的效能) 经常用于软件开发的领域中,尤其是当使用 REST APIs工作的时候,以及在 _DevOps_ 自动化和配置管理框架的领域中,包括 Ansible。Ansible 的其中一个信念是,所有的 Ansible 模块(集成的)应该是幂等的。那么,对于一个模块来说,幂等是什么意思呢?毕竟,对大多数网络工程师来说,这是一个新的术语。
|
||||
因为 Ansible 是无代理的,这里并没有一个默认的推送或者拉取去防止配置漂移。自动化任务被定义在 Ansible <ruby剧本<rt>playbook</rt></ruby>中,当使用 Ansible 时,它让用户去运行剧本。如果剧本在一个给定的时间间隔内运行,并且你没有用 Ansible Tower,你肯定知道任务的执行频率;如果你只是在终端提示符下使用一个原生的 Ansible 命令行,那么该剧本就运行一次,并且仅运行一次。
|
||||
|
||||
答案很简单。幂等性的本质是允许定义的任务,运行一次或者上千次都不会在目标系统上产生不利影响,仅仅是一种一次性的改变。换句话说,如果一个请求的改变去使系统进入到它期望的状态,这种改变完成之后,并且,如果这个设备已经达到这种状态,它不会再发生改变。这不像大多数传统的定制脚本,和拷贝(copy),以及过去的那些终端窗口中的 CLI 命令。当相同的命令或者脚本在同一个系统上重复运行,会出现错误(有时候)。以前,粘贴一组命令到一个路由器中,然后得到一些使你的其余的配置失效的错误类型?好玩吧?
|
||||
|
||||
另外的例子是,如果你有一个配置 10 个 VLANs 的文件文件或者脚本,那么 _每次_ 运行这个脚本,相同的命令命令会被输入 10 次。如果使用一个幂等的 Ansible 模块,首先会从网络设备中采集已存在的配置,并且,每个新的 VLAN 被配置后会再次检查当前配置。仅仅是这个新的 VLAN 需要去被添加(或者,改变 VLAN 名字,作为一个示例)是一个改变,或者命令真实地推送到设备。
|
||||
|
||||
当一个技术越来越复杂,幂等性的价值就越高,在你修改的时候,你并不能注意到 _已存在_ 的网络设备的状态,仅仅是从一个网络配置和策略角度去尝试达到 _期望的_ 状态。
|
||||
|
||||
|
||||
### 网络范围的和临时(Ad Hoc)的改变
|
||||
|
||||
用配置管理工具解决的其中一个问题是,配置“飘移”(当设备的期望配置逐渐漂移,或者改变,随着时间的推移手动改变和/或在一个环境中使用了多个不同的工具),事实上,这也是像 Puppet 和 Chef 得到使用的地方。代理商 _phone home_ 到前端服务器,验证它的配置,并且,如果需要一个改变,则改变它。这个方法是非常简单的。如果有故障了,需要去排除怎么办?你通常需要通过管理系统,直接连到设备,找到并修复它,然后,马上离开,对不对?果然,在下次当代理的电话打到家里,修复问题的改变被覆盖了(基于主/前端服务器是怎么配置的)。在高度自动化的环境中,一次性的改变应该被限制,但是,仍然允许它们(译者注:指的是一次性改变)使用的工具是非常有价值的。正如你想到的,其中一个这样的工具是 Ansible。
|
||||
|
||||
因为 Ansible 是无代理的,这里并没有一个默认的推送或者拉取去防止配置漂移。自动化任务被定义在 Ansible playbook 中,当使用 Ansible 时,它推送到用户去运行 playbook。如果 playbook 在一个给定的时间间隔内运行,并且你没有用 Ansible Tower,你肯定知道任务的执行频率;如果你正好在终端提示符下使用一个原生的 Ansible 命令行,playbook 运行一次,并且仅运行一次。
|
||||
|
||||
缺省运行的 playbook 对网络工程师是很具有吸引力的,让人欣慰的是,在设备上手动进行的改变不会自动被覆盖。另外,当需要的时候,一个 playbook 运行的设备范围很容易被改变,即使是对一个单个设备进行自动化的单次改变,Ansible 仍然可以用,设备的 _范围_ 由一个被称为 Ansible 清单(inventory)的文件决定;这个清单可以是一台设备或者是一千台设备。
|
||||
缺省运行一次的剧本对网络工程师是很具有吸引力的,让人欣慰的是,在设备上手动进行的改变不会自动被覆盖。另外,当需要的时候,一个剧本所运行的设备范围很容易被改变,即使是对一个单个设备进行自动化的单次变更,Ansible 仍然可以用,设备的 _范围_ 由一个被称为 Ansible <ruby>清单<rt>inventory</rt></ruby>的文件决定;这个清单可以是一台设备或者是一千台设备。
|
||||
|
||||
下面展示的一个清单文件示例,它定义了两组共六台设备:
|
||||
|
||||
@ -172,13 +165,13 @@ leaf3
|
||||
leaf4
|
||||
```
|
||||
|
||||
为了自动化所有的主机,你的 play 定义的 playbook 的一个片段看起来应该是这样的:
|
||||
为了自动化所有的主机,你的剧本中的<ruby>剧集<rt>play</rt></ruby>定义的一个片段看起来应该是这样的:
|
||||
|
||||
```
|
||||
hosts: all
|
||||
```
|
||||
|
||||
并且,一个自动化的叶子节点交换机,它看起来应该像这样:
|
||||
并且,要只自动化一个叶子节点交换机,它看起来应该像这样:
|
||||
|
||||
```
|
||||
hosts: leaf1
|
||||
@ -190,27 +183,27 @@ hosts: leaf1
|
||||
hosts: core-switches
|
||||
```
|
||||
|
||||
###### 注意
|
||||
> 注意
|
||||
|
||||
正如前面所说的那样,这个报告的后面部分将详细介绍 playbooks、plays、和清单(inventories)。
|
||||
> 正如前面所说的那样,这个报告的后面部分将详细介绍剧本、剧集、和清单。
|
||||
|
||||
因为能够很容易地对一台设备或者 _N_ 台设备进行自动化,所以在需要对这些设备进行一次性改变时,Ansible 成为了最佳的选择。在网络范围内的改变它也做的很好:可以是关闭给定类型的所有接口、配置接口描述、或者是在一个跨企业园区布线的网络中添加 VLANs。
|
||||
因为能够很容易地对一台设备或者 _N_ 台设备进行自动化,所以在需要对这些设备进行一次性变更时,Ansible 成为了最佳的选择。在网络范围内的变更它也做的很好:可以是关闭给定类型的所有接口、配置接口描述、或者是在一个跨企业园区布线的网络中添加 VLAN。
|
||||
|
||||
### 使用 Ansible 实现网络任务自动化
|
||||
|
||||
这个报告从两个方面逐渐深入地讲解一些技术。第一个方面是围绕 Ansible 架构和它的细节,第二个方面是,从一个网络的角度,讲解使用 Ansible 可以完成什么类型的自动化。在这一章中我们将带你去详细了解第二方面的内容。
|
||||
|
||||
自动化一般被认为是速度快,但是,考虑到一些任务并不要求速度,这就是为什么一些 IT 团队没有认识到自动化的价值所在。VLAN 配置是一个非常好的例子,因为,你可能会想,“创建一个 VLAN 到底有多快?一般情况下每天添加多少个 VLANs?我真的需要自动化吗?”
|
||||
自动化一般被认为是速度快,但是,考虑到一些任务并不要求速度,这就是为什么一些 IT 团队没有认识到自动化的价值所在。VLAN 配置是一个非常好的例子,因为,你可能会想,“创建一个 VLAN 到底有多快?一般情况下每天添加多少个 VLAN?我真的需要自动化吗?”
|
||||
|
||||
在这一节中,我们专注于另外几种有意义的自动化任务,比如,设备准备、数据收集、报告、和遵从情况。但是,需要注意的是,正如我们前面所说的,自动化为你、你的团队、以及你的精确的更可预测的结果和更多的确定性,提供了更快的速度和敏捷性。
|
||||
在这一节中,我们专注于另外几种有意义的自动化任务,比如,设备准备、数据收集、报告和遵从情况。但是,需要注意的是,正如我们前面所说的,自动化为你、你的团队、以及你的精确的更可预测的结果和更多的确定性,提供了更快的速度和敏捷性。
|
||||
|
||||
### 设备准备
|
||||
#### 设备准备
|
||||
|
||||
为网络自动化开始使用 Ansible 的最容易也是最快的方法是,为设备最初投入使用创建设备配置文件,并且将配置文件推送到网络设备中。
|
||||
为网络自动化开始使用 Ansible 的最容易也是最快的方法是,为设备的最初投入使用创建设备配置文件,并且将配置文件推送到网络设备中。
|
||||
|
||||
如果我们去完成这个过程,它将分解为两步,第一步是创建一个配置文件,第二步是推送这个配置到设备中。
|
||||
|
||||
首先,我们需要去从供应商配置文件的底层专用语法(CLI)中解耦 _输入_。这意味着我们需要对配置参数中分离出文件和值,比如,VLANs、域信息、接口、路由、和其它的内容、等等,然后,当然是一个配置的模块文件。在这个示例中,这里有一个标准模板,它可以用于所有设备的初始部署。Ansible 将帮助提供配置模板中需要的输入和值之间的部分。几秒钟之内,Ansible 可以生成数百个可靠的和可预测的配置文件。
|
||||
首先,我们需要去从供应商配置文件的底层专用语法(CLI)中解耦 _输入_。这意味着我们需要对配置参数中分离出文件和值,比如,VLAN、域信息、接口、路由、和其它的内容等等,然后,当然是一个配置的模块文件。在这个示例中,这里有一个标准模板,它可以用于所有设备的初始部署。Ansible 将帮助提供配置模板中需要的输入和值之间的部分。几秒钟之内,Ansible 可以生成数百个可靠的和可预测的配置文件。
|
||||
|
||||
让我们快速的看一个示例,它使用当前的配置,并且分解它到一个模板和单独的一个(作为一个输入源的)变量文件中。
|
||||
|
||||
@ -238,13 +231,13 @@ vlan 50
|
||||
|
||||
如果我们提取输入值,这个文件将被转换成一个模板。
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
Ansible 使用基于 Python 的 Jinja2 模板化语言,因此,这个被命名为 _leaf.j2_ 的文件是一个 Jinja2 模板。
|
||||
> Ansible 使用基于 Python 的 Jinja2 模板化语言,因此,这个被命名为 _leaf.j2_ 的文件是一个 Jinja2 模板。
|
||||
|
||||
注意,下列的示例中,_双大括号({{)_ 代表一个变量。
|
||||
注意,下列的示例中,_双大括号(`{{}}`)_ 代表一个变量。
|
||||
|
||||
模板看起来像这些,并且给它命名为 _leaf.j2_:
|
||||
模板看起来像这些,并且给它命名为 `leaf.j2`:
|
||||
|
||||
```
|
||||
!
|
||||
@ -273,17 +266,17 @@ vlans:
|
||||
- { id: 50, name: misc }
|
||||
```
|
||||
|
||||
这意味着,如果管理 VLANs 的团队希望在网络设备中添加一个 VLAN,很简单,他们只需要在变量文件中改变它,然后,使用 Ansible 中一个叫 `template` 的模块,去重新生成一个新的配置文件。这整个过程也是幂等的;仅仅是在模板或者值发生改变时,它才会去生成一个新的配置文件。
|
||||
这意味着,如果管理 VLAN 的团队希望在网络设备中添加一个 VLAN,很简单,他们只需要在变量文件中改变它,然后,使用 Ansible 中一个叫 `template` 的模块,去重新生成一个新的配置文件。这整个过程也是幂等的;仅仅是在模板或者值发生改变时,它才会去生成一个新的配置文件。
|
||||
|
||||
一旦配置文件生成,它需要去 _推送_ 到网络设备。推送配置文件到网络设备使用一个叫做 `napalm_install_config`的开源的 Ansible 模块。
|
||||
|
||||
接下来的示例是一个简单的 playbook 去 _构建并推送_ 一个配置文件到网络设备。同样地,playbook 使用一个名叫 `template` 的模块去构建配置文件,然后使用一个名叫 `napalm_install_config` 的模块去推送它们,并且激活它作为设备上运行的新的配置文件。
|
||||
接下来的示例是一个 _构建并推送_ 一个配置文件到网络设备的简单剧本。同样地,该剧本使用一个名叫 `template` 的模块去构建配置文件,然后使用一个名叫 `napalm_install_config` 的模块去推送它们,并且激活它作为设备上运行的新的配置文件。
|
||||
|
||||
虽然没有详细解释示例中的每一行,但是,你仍然可以看明白它们实际上做了什么。
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
下面的 playbook 介绍了新的概念,比如,内置变量 `inventory_hostname`。这些概念包含在 [Ansible 术语和入门][1] 中。
|
||||
> 下面的剧本介绍了新的概念,比如,内置变量 `inventory_hostname`。这些概念包含在 [Ansible 术语和入门][1] 中。
|
||||
|
||||
```
|
||||
---
|
||||
@ -310,17 +303,17 @@ vlans:
|
||||
replace_config=0
|
||||
```
|
||||
|
||||
这个两步的过程是一个使用 Ansible 进行网络自动化入门的简单方法。通过模板简化了你的配置,构建配置文件,然后,推送它们到网络设备 — 因此,被称为 _BUILD 和 PUSH_ 方法。
|
||||
这个两步的过程是一个使用 Ansible 进行网络自动化入门的简单方法。通过模板简化了你的配置,构建配置文件,然后,推送它们到网络设备 — 因此,被称为 `BUILD` 和 `PUSH` 方法。
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
像这样的更详细的例子,请查看 [Ansible 网络集成][2]。
|
||||
> 像这样的更详细的例子,请查看 [Ansible 网络集成][2]。
|
||||
|
||||
### 数据收集和监视
|
||||
#### 数据收集和监视
|
||||
|
||||
监视工具一般使用 SNMP — 这些工具拉某些管理信息库(MIBs),然后给监视工具返回数据。基于返回的数据,它可能多于也可能少于你真正所需要的数据。如果接口基于返回的数据统计你正在拉的内容,你可能会返回在 _show interface_ 命令中显示的计数器。如果你仅需要 _interface resets_ 并且,希望去看到与重置相关的邻接 CDP/LLDP 的接口,那该怎么做呢?当然,这也可以使用当前的技术;可以运行多个显示命令去手动解析输出信息,或者,使用基于 SNMP 的工具,在 GUI 中切换不同的选项卡(Tab)找到真正你所需要的数据。Ansible 怎么能帮助我们去完成这些工作呢?
|
||||
监视工具一般使用 SNMP —— 这些工具拉取某些管理信息库(MIB),然后给监视工具返回数据。基于返回的数据,它可能多于也可能少于你真正所需要的数据。如果接口基于返回的数据统计你正在拉取的内容,你可能会返回在 `show interface` 命令中显示的计数器。如果你仅需要 `interface resets` 并且,希望去看到与重置相关的邻接 CDP/LLDP 的接口,那该怎么做呢?当然,这也可以使用当前的技术;可以运行多个显示命令去手动解析输出信息,或者,使用基于 SNMP 的工具,在 GUI 中切换不同的选项卡(Tab)找到真正你所需要的数据。Ansible 怎么能帮助我们去完成这些工作呢?
|
||||
|
||||
由于 Ansible 是完全开放并且是可扩展的,它可以精确地去收集和监视所需要的计数器或者值。这可能需要一些预先的定制工作,但是,最终这些工作是非常有价值的。因为采集的数据是你所需要的,而不是供应商提供给你的。Ansible 也提供直观的方法去执行某些条件任务,这意味着基于正在返回的数据,你可以执行子任务,它可以收集更多的数据或者产生一个配置改变。
|
||||
由于 Ansible 是完全开源并且是可扩展的,它可以精确地去收集和监视所需要的计数器或者值。这可能需要一些预先的定制工作,但是,最终这些工作是非常有价值的。因为采集的数据是你所需要的,而不是供应商提供给你的。Ansible 也提供了执行某些条件任务的直观方法,这意味着基于正在返回的数据,你可以执行子任务,它可以收集更多的数据或者产生一个配置改变。
|
||||
|
||||
网络设备有 _许多_ 统计和隐藏在里面的临时数据,而 Ansible 可以帮你提取它们。
|
||||
|
||||
@ -342,26 +335,23 @@ vlans:
|
||||
|
||||
你现在可以决定某些事情,而不需要事先知道是什么类型的设备。你所需要知道的仅仅是设备的只读通讯字符串。
|
||||
|
||||
#### 迁移
|
||||
|
||||
### 迁移
|
||||
从一个平台迁移到另外一个平台,可能是从同一个供应商或者是从不同的供应商,迁移从来都不是件容易的事。供应商可能提供一个脚本或者一个工具去帮助你迁移。Ansible 可以被用于去为所有类型的网络设备构建配置模板,然后,操作系统用这个方法去为所有的供应商生成一个配置文件,然后作为一个(通用数据模型的)输入设置。当然,如果有供应商专用的扩展,它也是会被用到的。这种灵活性不仅对迁移有帮助,而且也可以用于<ruby>灾难恢复<rt>disaster recovery</rt></ruby>(DR),它在生产系统中不同的交换机型号之间和灾备数据中心中是经常使用的,即使是在不同的供应商的设备上。
|
||||
|
||||
从一个平台迁移到另外一个平台,可能是从同一个供应商或者是从不同的供应商,迁移从来都不是件容易的事。供应商可能提供一个脚本或者一个工具去帮助你迁移。Ansible 可以被用于去为所有类型的网络设备构建配置模板,然后,操作系统用这个方法去为所有的供应商生成一个配置文件,然后作为一个(通用数据模型的)输入设置。当然,如果有供应商专用的扩展,它也是会被用到的。这种灵活性不仅对迁移有帮助,而且也可以用于灾难恢复(DR),它在生产系统中不同的交换机型号之间和灾备数据中心中是经常使用的,即使是在不同的供应商的设备上。
|
||||
#### 配置管理
|
||||
|
||||
正如前面所说的,配置管理是最常用的自动化类型。Ansible 可以很容易地做到创建<ruby>角色<rt>role</rt></ruby>去简化基于任务的自动化。从更高的层面来看,角色是指针对一个特定设备组的可重用的自动化任务的逻辑分组。关于角色的另一种说法是,认为角色就是相关的<ruby>工作流<rt>workflow</rt></ruby>。首先,在开始自动化添加值之前,需要理解工作流和过程。不论是开始一个小的自动化任务还是扩展它,理解工作流和过程都是非常重要的。
|
||||
|
||||
### 配置管理
|
||||
|
||||
正如前面所说的,配置管理是最常用的自动化类型。Ansible 可以很容易地做到创建 _角色(roles)_ 去简化基于任务的自动化。从更高的层面来看,角色是指针对一个特定设备组的可重用的自动化任务的逻辑分组。关于角色的另一种说法是,认为角色就是相关的工作流(workflows)。首先,在开始自动化添加值之前,需要理解工作流和过程。不论是开始一个小的自动化任务还是扩展它,理解工作流和过程都是非常重要的。
|
||||
|
||||
例如,一组自动化配置路由器和交换机的任务是非常常见的,并且它们也是一个很好的起点。但是,配置在哪台网络设备上?配置的 IP 地址是什么?或许需要一个 IP 地址管理方案?一旦用一个给定的功能分配了 IP 地址并且已经部署,DNS 也更新了吗?DHCP 的范围需要创建吗?
|
||||
例如,一组自动化地配置路由器和交换机的任务是非常常见的,并且它们也是一个很好的起点。但是,配置在哪台网络设备上?配置的 IP 地址是什么?或许需要一个 IP 地址管理方案?一旦用一个给定的功能分配了 IP 地址并且已经部署,DNS 也更新了吗?DHCP 的范围需要创建吗?
|
||||
|
||||
你可以看到工作流是怎么从一个小的任务开始,然后逐渐扩展到跨不同的 IT 系统?因为工作流持续扩展,所以,角色也一样(持续扩展)。
|
||||
|
||||
#### 遵从性
|
||||
|
||||
### 遵从性
|
||||
和其它形式的自动化工具一样,用任何形式的自动化工具产生配置改变都被视为风险。手工去产生改变可能看上去风险更大,正如你看到的和亲身经历过的那样,Ansible 有能力去做自动数据收集、监视、和配置构建,这些都是“只读的”和“低风险”的动作。其中一个 _低风险_ 使用案例是,使用收集的数据进行配置遵从性检查和配置验证。部署的配置是否满足安全要求?是否配置了所需的网络?协议 XYZ 禁用了吗?因为每个模块、或者用 Ansible 返回数据的整合,它只是非常简单地 _声明_ 那些事是 _TRUE_ 还是 _FALSE_。然后接着基于 _它_ 是 _TRUE_ 或者是 _FALSE_, 接着由你决定应该发生什么 —— 或许它只是被记录下来,或者,也可能执行一个复杂操作。
|
||||
|
||||
和其它形式的自动化工具一样,用任何形式的自动化工具产生配置改变都视为风险。手工去产生改变可能看上去风险更大,正如你看到的和亲身经历过的那样,Ansible 有能力去做自动数据收集、监视、和配置构建,这些都是“只读的”和“低风险”的动作。其中一个 _低风险_ 使用案例是,使用收集的数据进行配置遵从性检查和配置验证。部署的配置是否满足安全要求?是否配置了所需的网络?协议 XYZ 禁用了吗?因为每个模块、或者用 Ansible 返回数据的整合,它只是非常简单地 _声明_ 那些事是 _TRUE_ 还是 _FALSE_。然后接着基于 _它_ 是 _TRUE_ 或者是 _FALSE_, 接着由你决定应该发生什么 —— 或许它只是被记录下来,或者,也可能执行一个复杂操作。
|
||||
|
||||
### 报告
|
||||
#### 报告
|
||||
|
||||
我们现在知道,Ansible 也可以用于去收集数据和执行遵从性检查。Ansible 可以根据你想要做的事情去从设备中返回和收集数据。或许返回的数据成为其它的任务的输入,或者你想去用它创建一个报告。从模板中生成报告,并将真实的数据插入到模板中,创建和使用报告模板的过程与创建配置模板的过程是相同的。
|
||||
|
||||
@ -369,22 +359,21 @@ vlans:
|
||||
|
||||
创建报告的用处很多,不仅是为行政管理,也为了运营工程师,因为它们通常有双方都需要的不同指标。
|
||||
|
||||
|
||||
### Ansible 怎么工作
|
||||
|
||||
从一个网络自动化的角度理解了 Ansible 能做什么之后,我们现在看一下 Ansible 是怎么工作的。你将学习到从一个 Ansible 管理主机到一个被自动化的节点的全部通讯流。首先,我们回顾一下,Ansible 是怎么 _开箱即用的(out of the box)_,然后,我们看一下 Ansible 怎么去做到的,具体说就是,当网络设备自动化时,Ansible _模块_是怎么去工作的。
|
||||
从一个网络自动化的角度理解了 Ansible 能做什么之后,我们现在看一下 Ansible 是怎么工作的。你将学习到从一个 Ansible 管理主机到一个被自动化的节点的全部通讯流。首先,我们回顾一下,Ansible 是怎么<ruby>开箱即用<rt>out of the box</rt></ruby>的,然后,我们看一下 Ansible 怎么去做到的,具体说就是,当网络设备自动化时,Ansible _模块_是怎么去工作的。
|
||||
|
||||
### 开箱即用
|
||||
#### 开箱即用
|
||||
|
||||
到目前为止,你已经明白了,Ansible 是一个自动化平台。实际上,它是一个安装在一台单个服务器上或者企业中任何一位管理员的笔记本中的轻量级的自动化平台。当然,(安装在哪里?)这是由你来决定的。在基于 Linux 的机器上,使用一些实用程序(比如 pip、apt、和 yum)安装 Ansible 是非常容易的。
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
在本报告的其余部分,安装 Ansible 的机器被称为 _控制主机_。
|
||||
> 在本报告的其余部分,安装 Ansible 的机器被称为<ruby>控制主机<rt>control host</rt></ruby>。
|
||||
|
||||
控制主机将执行在 Ansible 的 playbook (不用担心,稍后我们将讲到 playbook 和其它的 Ansible 术语)中定义的所有自动化任务。现在,我们只需要知道,一个 playbook 是简单的一组自动化任务和在给定数量的主机上执行的指令。
|
||||
控制主机将执行定义在 Ansible 的<ruby>剧本<rt>playbook</rt></ruby> (不用担心,稍后我们将讲到剧本和其它的 Ansible 术语)中的所有自动化任务。现在,我们只需要知道,一个剧本是简单的一组自动化任务和在给定数量的主机上执行的指令。
|
||||
|
||||
当一个 playbook 创建之后,你还需要去定义它要自动化的主机。映射一个 playbook 和要自动化运行的主机,是通过一个被称为 Ansible 清单的文件。这是一个前面展示的示例,但是,这里是同一个清单文件的另外两个组:`cisco` 和 `arista`:
|
||||
当一个剧本创建之后,你还需要去定义它要自动化的主机。映射一个剧本和要自动化运行的主机,是通过一个被称为 Ansible <ruby>清单<rt>inventory</rt></ruby>的文件。这是一个前面展示的示例,但是,这里是同一个清单文件的另外两个组:`cisco` 和 `arista`:
|
||||
|
||||
```
|
||||
[cisco]
|
||||
@ -396,13 +385,13 @@ sfo1.acme.com
|
||||
sfo2.acme.com
|
||||
```
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
你也可以在清单文件中使用 IP 地址,而不是主机名。对于这样的示例,主机名将是通过 DNS 可解析的。
|
||||
> 你也可以在清单文件中使用 IP 地址,而不是主机名。对于这样的示例,主机名将是通过 DNS 可解析的。
|
||||
|
||||
正如你所看到的,Ansible 清单文件是一个文本文件,它列出了主机和主机组。然后,你可以在 playbook 中引用一个具体的主机或者组,以此去决定对给定的 play 和 playbook 在哪台主机上进行自动化。下面展示了两个示例。
|
||||
正如你所看到的,Ansible 清单文件是一个文本文件,它列出了主机和主机组。然后,你可以在剧本中引用一个具体的主机或者组,以此去决定对给定的<ruby>剧集<rt>play</rt></ruby>和剧本在哪台主机上进行自动化。下面展示了两个示例。
|
||||
|
||||
展示的第一个示例它看上去像是,你想去自动化 `cisco` 组中所有的主机,而展示的第二个示例只对 _nyc1.acme.com_ 主机进行自动化:
|
||||
展示的第一个示例它看上去像是,你想去自动化 `cisco` 组中所有的主机,而展示的第二个示例只对 `nyc1.acme.com` 主机进行自动化:
|
||||
|
||||
```
|
||||
---
|
||||
@ -424,7 +413,7 @@ sfo2.acme.com
|
||||
- TASKS YOU WANT TO AUTOMATE
|
||||
```
|
||||
|
||||
现在,我们已经理解了基本的清单文件,我们可以看一下(在控制主机上的)Ansible 是怎么与 _开箱即用_ 的设备通讯的,和在 Linux 终端上自动化的任务。这里需要明白一个重要的观点就是,需要去自动化的网络设备通常是不一样的。(译者注:指的是设备的类型、品牌、型号等等)
|
||||
现在,我们已经理解了基本的清单文件,我们可以看一下(在控制主机上的)Ansible 是怎么与 _开箱即用_ 的设备通讯的,和在 Linux 终端上自动化的任务。这里需要明白一个重要的观点就是,需要去自动化的网络设备通常是不一样的。(LCTT 译注:指的是设备的类型、品牌、型号等等)
|
||||
|
||||
Ansible 对基于 Linux 的系统去开箱即用自动化工作有两个要求。它们是 SSH 和 Python。
|
||||
|
||||
@ -434,31 +423,26 @@ Ansible 对基于 Linux 的系统去开箱即用自动化工作有两个要求
|
||||
|
||||
如果我们详细解释这个开箱即用工作流,它将分解成如下的步骤:
|
||||
|
||||
1. 当一个 Ansible play 被执行,控制主机使用 SSH 连接到基于 Linux 的目标节点。
|
||||
|
||||
2. 对于每个任务,也就是说,Ansible 模块将在这个 play 中被执行,通过 SSH 发送 Python 代码并直接在远程系统中执行。
|
||||
|
||||
1. 当执行一个 Ansible 剧集时,控制主机使用 SSH 连接到基于 Linux 的目标节点。
|
||||
2. 对于每个任务,也就是说,Ansible 模块将在这个剧集中被执行,通过 SSH 发送 Python 代码并直接在远程系统中执行。
|
||||
3. 在远程系统上运行的每个 Ansible 模块将返回 JSON 数据到控制主机。这些数据包含有信息,比如,配置改变、任务成功/失败、以及其它模块特定的数据。
|
||||
|
||||
4. JSON 数据返回给 Ansible,然后被用于去生成报告,或者被用作接下来模块的输入。
|
||||
5. 在剧集中为每个任务重复第 3 步。
|
||||
6. 在剧本中为每个剧集重复第 1 步。
|
||||
|
||||
5. 在 play 中为每个任务重复第 3 步。
|
||||
|
||||
6. 在 playbook 中为每个 play 重复第 1 步。
|
||||
|
||||
是不是意味着每个网络设备都可以被 Ansible 开箱即用?因为它们也都支持 SSH,确实,网络设备都支持 SSH,但是,它是第一个和第二要求的组合限制了网络设备可能的功能。
|
||||
是不是意味着每个网络设备都可以被 Ansible 开箱即用?因为它们也都支持 SSH,确实,网络设备都支持 SSH,但是,第一个和第二要求的组合限制了网络设备可能的功能。
|
||||
|
||||
刚开始时,大多数网络设备并不支持 Python,因此,使用默认的 Ansible 连接机制是无法进行的。换句话说,在过去的几年里,供应商在几个不同的设备平台上增加了 Python 支持。但是,这些平台中的大多数仍然缺乏必要的集成,以允许 Ansible 去直接通过 SSH 访问一个 Linux shell,并以适当的权限去拷贝所需的代码、创建临时目录和文件、以及在设备中执行代码。尽管 Ansible 中所有的这些部分都可以在基于 Linux 的网络设备上使用 SSH/Python 在本地运行,它仍然需要网络设备供应商去更进一步开放他们的系统。
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
值的注意的是,Arista 确实也提供了原生的集成,因为它可以放弃 SSH 用户,直接进入到一个 Linux shell 中访问 Python 引擎,它可以允许 Ansible 去使用默认连接机制。因为我们调用了 Arista,我们也需要着重强调与 Ansible 默认连接机制一起工作的 Cumulus。这是因为 Cumulus Linux 是原生 Linux,并且它并不需要为 Cumulus Linux 操作系统使用供应商 API。
|
||||
> 值的注意的是,Arista 确实也提供了原生的集成,因为它可以无需 SSH 用户,直接进入到一个 Linux shell 中访问 Python 引擎,它可以允许 Ansible 去使用其默认连接机制。因为我们调用了 Arista,我们也需要着重强调与 Ansible 默认连接机制一起工作的 Cumulus。这是因为 Cumulus Linux 是原生 Linux,并且它并不需要为 Cumulus Linux 操作系统使用供应商 API。
|
||||
|
||||
### Ansible 网络集成
|
||||
#### Ansible 网络集成
|
||||
|
||||
前面的节讲到过 Ansible 默认的工作方式。我们看一下,在开始一个 _play_ 之后,Ansible 是怎么去设置一个到设备的连接、通过执行拷贝 Python 代码到设备去运行任务、运行代码、和返回结果给 Ansible 控制主机。
|
||||
前面的节讲到过 Ansible 默认的工作方式。我们看一下,在开始一个 _剧集_ 之后,Ansible 是怎么去设置一个到设备的连接、通过拷贝 Python 代码到设备、运行代码、和返回结果给 Ansible 控制主机来执行任务。
|
||||
|
||||
在这一节中,我们将看一看,当使用 Ansible 进行自动化网络设备时都做了什么。正如前面讲过的,Ansible 是一个可拔插的连接架构。对于 _大多数_ 的网络集成, `connection` 参数设置为 `local`。在 playbook 中大多数的连接类型都设置为 `local`,如下面的示例所展示的:
|
||||
在这一节中,我们将看一看,当使用 Ansible 进行自动化网络设备时都做了什么。正如前面讲过的,Ansible 是一个可拔插的连接架构。对于 _大多数_ 的网络集成, `connection` 参数设置为 `local`。在剧本中大多数的连接类型都设置为 `local`,如下面的示例所展示的:
|
||||
|
||||
```
|
||||
---
|
||||
@ -471,15 +455,15 @@ Ansible 对基于 Linux 的系统去开箱即用自动化工作有两个要求
|
||||
- TASKS YOU WANT TO AUTOMATE
|
||||
```
|
||||
|
||||
注意在 play 中是怎么定义的,这个示例增加 `connection` 参数去和前面节中的示例进行比较。
|
||||
注意在剧集中是怎么定义的,这个示例增加 `connection` 参数去和前面节中的示例进行比较。
|
||||
|
||||
这告诉 Ansible 不要通过 SSH 去连接到目标设备,而是连接到本地机器运行这个 playbook。基本上,这是把连接职责委托给 playbook 中 _任务_ 节中使用的真实的 Ansible 模块。每个模块类型的委托权利允许这个模块在必要时以各种形式去连接到设备。这可能是 Juniper 和 HP Comware7 的 NETCONF、Arista 的 eAPI、Cisco Nexus 的 NX-API、或者甚至是基于传统系统的 SNMP,它们没有可编程的 API。
|
||||
这告诉 Ansible 不要通过 SSH 去连接到目标设备,而是连接到本地机器运行这个剧本。基本上,这是把连接职责委托给剧本中<ruby>任务<rt>task</rt></ruby> 节中使用的真实的 Ansible 模块。每个模块类型的委托权利允许这个模块在必要时以各种形式去连接到设备。这可能是 Juniper 和 HP Comware7 的 NETCONF、Arista 的 eAPI、Cisco Nexus 的 NX-API、或者甚至是基于传统系统的 SNMP,它们没有可编程的 API。
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
网络集成在 Ansible 中是以 Ansible 模块的形式带来的。尽管我们持续使用术语来吊你的胃口,比如,playbooks、plays、任务、和讲到的关键概念 `模块`,这些术语中的每一个都会在 [Ansible 术语和入门][3] 和 [动手实践使用 Ansible 去进行网络自动化][4] 中详细解释。
|
||||
> 网络集成在 Ansible 中是以 Ansible 模块的形式带来的。尽管我们持续使用术语来吊你的胃口,比如,剧本、剧集、任务、和讲到的关键概念模块,这些术语中的每一个都会在 [Ansible 术语和入门][3] 和 [动手实践使用 Ansible 去进行网络自动化][4] 中详细解释。
|
||||
|
||||
让我们看一看另外一个 playbook 的示例:
|
||||
让我们看一看另外一个剧本的示例:
|
||||
|
||||
```
|
||||
---
|
||||
@ -492,22 +476,21 @@ Ansible 对基于 Linux 的系统去开箱即用自动化工作有两个要求
|
||||
- nxos_vlan: vlan_id=10 name=WEB_VLAN
|
||||
```
|
||||
|
||||
你注意到了吗,这个 playbook 现在包含一个任务,并且这个任务使用了 `nxos_vlan` 模块。`nxos_vlan` 模块是一个 Python 文件,并且,在这个文件中它是使用 NX-API 连接到 Cisco 的 NX-OS 设备。可是,这个连接可能是使用其它设备 API 设置的,这就是为什么供应商和用户像我们这样能够去建立自己的集成的原因。集成(模块)通常是以每特性(per-feature)为基础完成的,虽然,你已经看到了像 `napalm_install_config` 这样的模块,它们也可以被用来 _推送_ 一个完整的配置文件。
|
||||
你注意到了吗,这个剧本现在包含一个任务,并且这个任务使用了 `nxos_vlan` 模块。`nxos_vlan` 模块是一个 Python 文件,并且,在这个文件中它是使用 NX-API 连接到 Cisco 的 NX-OS 设备。可是,这个连接可能是使用其它设备 API 设置的,这就是为什么供应商和用户像我们这样能够去建立自己的集成的原因。集成(模块)通常是以<ruby>每特性<rt>per-feature</rt></ruby>为基础完成的,虽然,你已经看到了像 `napalm_install_config` 这样的模块,它们也可以被用来 _推送_ 一个完整的配置文件。
|
||||
|
||||
主要区别之一是使用的默认连接机制,Ansible 启动一个持久的 SSH 连接到设备,并且这个连接为一个给定的 play 持续。当在一个模块中发生连接设置和拆除时,与许多使用 `connection=local` 的网络模块一样,对发生在 play 级别上的 _每个_ 任务,Ansible 将登入/登出设备。
|
||||
主要区别之一是使用的默认连接机制,Ansible 启动一个持久的 SSH 连接到设备,并且对于一个给定的剧集而已该连接将持续存在。当在一个模块中发生连接设置和拆除时,与许多使用 `connection=local` 的网络模块一样,对发生在剧集级别上的 _每个_ 任务,Ansible 将登入/登出设备。
|
||||
|
||||
而在传统的 Ansible 形式下,每个网络模块返回 JSON 数据。仅有的区别是相对于目标节点,数据的推取发生在本地的 Ansible 控制主机上。相对于每供应商(per vendor)和模块类型,数据返回到 playbook,但是作为一个示例,许多的 Cisco NX-OS 模块返回已存在的状态、建议状态、和最终状态,以及发送到设备的命令(如果有的话)。
|
||||
而在传统的 Ansible 形式下,每个网络模块返回 JSON 数据。仅有的区别是相对于目标节点,数据的推取发生在本地的 Ansible 控制主机上。相对于<ruby>每供应商<rt>per vendor</rt></ruby>和模块类型,数据返回到剧本,但是作为一个示例,许多的 Cisco NX-OS 模块返回已存在的状态、建议状态、和最终状态,以及发送到设备的命令(如果有的话)。
|
||||
|
||||
作为使用 Ansible 进行网络自动化的开始,最重要的是,为 Ansible 的连接设备/拆除过程,记着去设置连接参数为 `local`,并且将它留在模块中。这就是为什么模块支持不同类型的供应商平台,它将与设备使用不同的方式进行通讯。
|
||||
|
||||
|
||||
### Ansible 术语和入门
|
||||
|
||||
这一章我们将介绍许多 Ansible 的术语和报告中前面部分出现过的关键概念。比如, _清单文件_、_playbook_、_play_、_任务_、和 _模块_。我们也会去回顾一些其它的概念,这些术语和概念对我们学习使用 Ansible 去进行网络自动化非常有帮助。
|
||||
这一章我们将介绍许多 Ansible 的术语和报告中前面部分出现过的关键概念。比如, <ruby>清单文件<rt>inventory file</rt></ruby>、<ruby>剧本<rt>playbook</rt></ruby>、<ruby>剧集<rt>play</rt></ruby>、<ruby>任务<rt>task</rt></ruby>和<ruby>模块<rt>module</rt></ruby>。我们也会去回顾一些其它的概念,这些术语和概念对我们学习使用 Ansible 去进行网络自动化非常有帮助。
|
||||
|
||||
在这一节中,我们将引用如下的一个简单的清单文件和 playbook 的示例,它们将在后面的章节中持续出现。
|
||||
在这一节中,我们将引用如下的一个简单的清单文件和剧本的示例,它们将在后面的章节中持续出现。
|
||||
|
||||
_清单示例_:
|
||||
_清单示例_ :
|
||||
|
||||
```
|
||||
# sample inventory file
|
||||
@ -528,7 +511,7 @@ core1
|
||||
core2
|
||||
```
|
||||
|
||||
_playbook 示例_:
|
||||
_剧本示例_ :
|
||||
|
||||
```
|
||||
---
|
||||
@ -577,54 +560,50 @@ _playbook 示例_:
|
||||
- 50
|
||||
```
|
||||
|
||||
### 清单文件
|
||||
#### 清单文件
|
||||
|
||||
使用一个清单文件,比如前面提到的那个,允许我们去为自动化任务指定主机、和使用每个 play 顶部节中(如果存在)的参数 `hosts` 所引用的主机/组指定的主机组。
|
||||
使用一个清单文件,比如前面提到的那个,允许我们去为自动化任务指定主机、和使用每个剧集顶部节中(如果存在)的参数 `hosts` 所引用的主机/组指定的主机组。
|
||||
|
||||
它也可能在一个清单文件中存储变量。如这个示例中展示的那样。如果变量在同一行视为一台主机,它是一个具体主机变量。如果变量定义在方括号中(“[ ]”),比如,`[all:vars]`,它的意思是指变量在组中的范围 `all`,它是一个默认组,包含了清单文件中的 _所有_ 主机。
|
||||
它也可能在一个清单文件中存储变量。如这个示例中展示的那样。如果变量在同一行视为一台主机,它是一个具体主机变量。如果变量定义在方括号中(`[ ]`),比如,`[all:vars]`,它的意思是指变量在组中的范围 `all`,它是一个默认组,包含了清单文件中的 _所有_ 主机。
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
清单文件是使用 Ansible 开始自动化的快速方法,但是,你应该已经有一个真实的网络设备源,比如一个网络管理工具或者 CMDB,它可以去创建和使用一个动态的清单脚本,而不是一个静态的清单文件。
|
||||
> 清单文件是使用 Ansible 开始自动化的快速方法,但是,你应该已经有一个真实的网络设备源,比如一个网络管理工具或者 CMDB,它可以去创建和使用一个动态的清单脚本,而不是一个静态的清单文件。
|
||||
|
||||
### Playbook
|
||||
#### 剧本
|
||||
|
||||
playbook 是去运行自动化网络设备的顶级对象。在我们的示例中,它是一个 _site.yml_ 文件,如前面的示例所展示的。一个 playbook 使用 YAML 去定义一组自动化任务,并且,每个 playbook 由一个或多个 plays 组成。这类似于一个橄榄球的剧本。就像在橄榄球赛中,团队有剧集组成的剧本,Ansible 的 playbooks 也是由 play 组成的。
|
||||
剧本是去运行自动化网络设备的顶级对象。在我们的示例中,它是 `site.yml` 文件,如前面的示例所展示的。一个剧本使用 YAML 去定义一组自动化任务,并且,每个剧本由一个或多个剧集组成。这类似于一个橄榄球的剧本。就像在橄榄球赛中,团队有剧集组成的剧本,Ansible 的剧本也是由剧集组成的。
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
YAML 是一种被所有编程语言支持的数据格式。YAML 本身就是 JSON 的超集,并且,YAML 文件非常易于识别,因为它总是三个破折号(连字符)开始,比如,`---`。
|
||||
> YAML 是一种被所有编程语言支持的数据格式。YAML 本身就是 JSON 的超集,并且,YAML 文件非常易于识别,因为它总是三个破折号(连字符)开始,比如,`---`。
|
||||
|
||||
|
||||
### Play
|
||||
#### 剧集
|
||||
|
||||
一个 Ansible playbook 可以存在一个或多个 plays。在前面的示例中,它在 playbook 中有两个 plays。每个 play 开始的地方都有一个 _header_ 节,它定义了具体的参数。
|
||||
一个 Ansible 剧本可以存在一个或多个剧集。在前面的示例中,它在剧本中有两个剧集。每个剧集开始的地方都有一个 _头部_,它定义了具体的参数。
|
||||
|
||||
示例中两个 plays 都定义了下面的参数:
|
||||
示例中两个剧集都定义了下面的参数:
|
||||
|
||||
`name`
|
||||
|
||||
文件 `PLAY 1 - Top of Rack (TOR) Switches` 是任意内容的,它在 playbook 运行的时候,去改善 playbook 运行和报告期间的可读性。这是一个可选参数。
|
||||
文件 `PLAY 1 - Top of Rack (TOR) Switches` 是任意内容的,它在剧本运行的时候,去改善剧本运行和报告期间的可读性。这是一个可选参数。
|
||||
|
||||
`hosts`
|
||||
|
||||
正如前面讲过的,这是在特定的 play 中要去进行自动化的主机或主机组。这是一个必需参数。
|
||||
正如前面讲过的,这是在特定的剧集中要去进行自动化的主机或主机组。这是一个必需参数。
|
||||
|
||||
`connection`
|
||||
|
||||
正如前面讲过的,这是 play 连接机制的类型。这是个可选参数,但是,对于网络自动化 plays,一般设置为 `local`。
|
||||
正如前面讲过的,这是剧集连接机制的类型。这是个可选参数,但是,对于网络自动化剧集,一般设置为 `local`。
|
||||
|
||||
每个剧集都是由一个或多个任务组成。
|
||||
|
||||
|
||||
每个 play 都是由一个或多个任务组成。
|
||||
|
||||
|
||||
|
||||
### 任务
|
||||
#### 任务
|
||||
|
||||
任务是以声明的方式去表示自动化的内容,而不用担心底层的语法或者操作是怎么执行的。
|
||||
|
||||
在我们的示例中,第一个 play 有两个任务。每个任务确保存在 10 个 VLAN。第一个任务是为 Cisco Nexus 设备的,而第二个任务是为 Arista 设备的:
|
||||
在我们的示例中,第一个剧集有两个任务。每个任务确保存在 10 个 VLAN。第一个任务是为 Cisco Nexus 设备的,而第二个任务是为 Arista 设备的:
|
||||
|
||||
```
|
||||
tasks:
|
||||
@ -638,19 +617,17 @@ tasks:
|
||||
when: vendor == "nxos"
|
||||
```
|
||||
|
||||
任务也可以使用 `name` 参数,就像 plays 一样。和 plays 一样,文本内容是任意的,并且当 playbook 运行时显示,去改善 playbook 运行和报告期间的可读性。它对每个任务都是可选参数。
|
||||
任务也可以使用 `name` 参数,就像剧集一样。和剧集一样,文本内容是任意的,并且当剧本运行时显示,去改善剧本运行和报告期间的可读性。它对每个任务都是可选参数。
|
||||
|
||||
示例任务中的下一行是以 `nxos_vlan` 开始的。它告诉我们这个任务将运行一个叫 `nxos_vlan` 的 Ansible 模块。
|
||||
|
||||
现在,我们将进入到模块中。
|
||||
|
||||
#### 模块
|
||||
|
||||
在 Ansible 中理解模块的概念是至关重要的。虽然任何编辑语言都可以用来写 Ansible 模块,只要它们能够返回 JSON 键/值对即可,但是,几乎所有的模块都是用 Python 写的。在我们示例中,我们看到有两个模块被运行: `nxos_vlan` 和 `eos_vlan`。这两个模块都是 Python 文件;而事实上,在你不能看到剧本的时候,真实的文件名分别是 `eos_vlan.py` 和 `nxos_vlan.py`。
|
||||
|
||||
### 模块
|
||||
|
||||
在 Ansible 中理解模块的概念是至关重要的。虽然任何编辑语言都可以用来写 Ansible 模块,只要它们能够返回 JSON 键 — 值对即可,但是,几乎所有的模块都是用 Python 写的。在我们示例中,我们看到有两个模块被运行: `nxos_vlan` 和 `eos_vlan`。这两个模块都是 Python 文件;而事实上,在你不能看到 playbook 的时候,真实的文件名分别是 _eos_vlan.py_ 和 _nxos_vlan.py_。
|
||||
|
||||
让我们看一下前面的示例中第一个 play 中的第一个 任务:
|
||||
让我们看一下前面的示例中第一个剧集中的第一个任务:
|
||||
|
||||
```
|
||||
- name: ENSURE VLAN 10 EXISTS ON CISCO TOR SWITCHES
|
||||
@ -678,48 +655,39 @@ tasks:
|
||||
|
||||
用于登入到交换机的密码。
|
||||
|
||||
示例中最后的片断部分使用了一个 `when` 语句。这是在一个剧集中使用的 Ansible 的执行条件任务。正如我们所了解的,在这个剧集的 `tor` 组中有多个设备和设备类型。使用 `when` 基于任意标准去提供更多的选择。这里我们仅自动化 Cisco 设备,因为,我们在这个任务中使用了 `nxos_vlan` 模块,在下一个任务中,我们仅自动化 Arista 设备,因为,我们使用了 `eos_vlan` 模块。
|
||||
|
||||
示例中最后的片断部分使用了一个 `when` 语句。这是在一个 play 中使用的 Ansible 的执行条件任务。正如我们所了解的,在这个 play 的 `tor` 组中有多个设备和设备类型。使用 `when` 基于任意标准去提供更多的选择。这里我们仅自动化 Cisco 设备,因为,我们在这个任务中使用了 `nxos_vlan` 模块,在下一个任务中,我们仅自动化 Arista 设备,因为,我们使用了 `eos_vlan` 模块。
|
||||
> 注意:
|
||||
|
||||
###### 注意
|
||||
|
||||
这并不是区分设备的唯一方法。这里仅是演示如何使用 `when`,并且可以在清单文件中定义变量。
|
||||
> 这并不是区分设备的唯一方法。这里仅是演示如何使用 `when`,并且可以在清单文件中定义变量。
|
||||
|
||||
在清单文件中定义变量是一个很好的开端,但是,如果你继续使用 Ansible,你将会为了扩展性、版本控制、对给定文件的改变最小化而去使用基于 YAML 的变量。这也将简化和改善清单文件和每个使用的变量的可读性。在设备准备的构建/推送方法中讲过一个变量文件的示例。
|
||||
|
||||
在最后的示例中,关于任务有几点需要去搞清楚:
|
||||
|
||||
* Play 1 任务 1 展示了硬编码了 `username` 和 `password` 作为参数进入到具体的模块中(`nxos_vlan`)。
|
||||
|
||||
* Play 1 任务 1 和 play 2 在模块中使用了变量,而不是硬编码它们。这掩饰了 `username` 和 `password` 参数,但是,需要值得注意的是,(在这个示例中)这些变量是从清单文件中提取出现的。
|
||||
|
||||
* Play 1 中为进入到模块中的参数使用了一个 _水平的(horizontal)_ 的 key=value 语法,虽然 play 2 使用了垂直的(vertical) key=value 语法。它们都工作的非常好。你也可以使用垂直的 YAML “key: value” 语法。
|
||||
|
||||
* 最后的任务也介绍了在 Ansible 中怎么去使用一个 _loop_ 循环。它通过使用 `with_items` 来完成,并且它类似于一个 for 循环。那个特定的任务是循环进入五个 VLANs 中去确保在交换机中它们都存在。注意:它也可能被保存在一个外部的 YAML 变量文件中。还需要注意的一点是,不使用 `with_items` 的替代方案是,每个 VLAN 都有一个任务 —— 如果这样做,它就失去了弹性!
|
||||
|
||||
* 剧集 1 任务 1 展示了硬编码了 `username` 和 `password` 作为参数进入到具体的模块中(`nxos_vlan`)。
|
||||
* 剧集 1 任务 1 和 剧集 2 在模块中使用了变量,而不是硬编码它们。这掩饰了 `username` 和 `password` 参数,但是,需要值得注意的是,(在这个示例中)这些变量是从清单文件中提取出现的。
|
||||
* 剧集 1 中为进入到模块中的参数使用了一个 _水平的_ 的 key=value 语法,虽然剧集 2 使用了垂直的 key=value 语法。它们都工作的非常好。你也可以使用垂直的 YAML “key: value” 语法。
|
||||
* 最后的任务也介绍了在 Ansible 中怎么去使用一个循环。它通过使用 `with_items` 来完成,并且它类似于一个 for 循环。那个特定的任务是循环进入五个 VLAN 中去确保在交换机中它们都存在。注意:它也可能被保存在一个外部的 YAML 变量文件中。还需要注意的一点是,不使用 `with_items` 的替代方案是,每个 VLAN 都有一个任务 —— 如果这样做,它就失去了弹性!
|
||||
|
||||
### 动手实践使用 Ansible 去进行网络自动化
|
||||
|
||||
在前面的章节中,提供了 Ansible 术语的一个概述。它已经覆盖了大多数具体的 Ansible 术语,比如 playbooks、plays、任务、模块、和清单文件。这一节将继续提供示例去讲解使用 Ansible 实现网络自动化,而且将提供在不同类型的设备中自动化工作的模块的更多细节。示例中的将要进行自动化设备由多个供应商提供,包括 Cisco、Arista、Cumulus、和 Juniper。
|
||||
在前面的章节中,提供了 Ansible 术语的一个概述。它已经覆盖了大多数具体的 Ansible 术语,比如剧本、剧集、任务、模块和清单文件。这一节将继续提供示例去讲解使用 Ansible 实现网络自动化,而且将提供在不同类型的设备中自动化工作的模块的更多细节。示例中的将要进行自动化设备由多个供应商提供,包括 Cisco、Arista、Cumulus、和 Juniper。
|
||||
|
||||
在本节中的示例,假设的前提条件如下:
|
||||
|
||||
* Ansible 已经安装。
|
||||
|
||||
* 在设备中(NX-API、eAPI、NETCONF)适合的 APIs 已经启用。
|
||||
|
||||
* 用户在系统上有通过 API 去产生改变的适当权限。
|
||||
|
||||
* 所有的 Ansible 模块已经在系统中存在,并且也在库的路径变量中。
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
可以在 _ansible.cfg_ 文件中设置模块和库路径。在你运行一个 playbook 时,你也可以使用 `-M` 标志从命令行中去改变它。
|
||||
> 可以在 `ansible.cfg` 文件中设置模块和库路径。在你运行一个剧本时,你也可以使用 `-M` 标志从命令行中去改变它。
|
||||
|
||||
在本节中示例使用的清单如下。(删除了密码,IP 地址也发生了变化)。在这个示例中,(和前面的示例一样)某些主机名并不是完全合格域名(FQDNs)。
|
||||
在本节中示例使用的清单如下。(删除了密码,IP 地址也发生了变化)。在这个示例中,(和前面的示例一样)某些主机名并不是完全合格域名(FQDN)。
|
||||
|
||||
|
||||
### 清单文件
|
||||
#### 清单文件
|
||||
|
||||
```
|
||||
[cumulus]
|
||||
@ -735,19 +703,19 @@ nx1 hostip=5.6.7.8 un=USERNAME pwd=PASSWORD
|
||||
vsrx hostip=9.10.11.12 un=USERNAME pwd=PASSWORD
|
||||
```
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
正如你所知道的,Ansible 支持将密码存储在一个加密文件中的功能。如果你想学习关于这个特性的更多内容,请查看在 Ansible 网站上的文档中的 [Ansible Vault][5] 部分。
|
||||
> 正如你所知道的,Ansible 支持将密码存储在一个加密文件中的功能。如果你想学习关于这个特性的更多内容,请查看在 Ansible 网站上的文档中的 [Ansible Vault][5] 部分。
|
||||
|
||||
这个清单文件有四个组,每个组定义了一台单个的主机。让我们详细回顾一下每一节:
|
||||
|
||||
Cumulus
|
||||
**Cumulus**
|
||||
|
||||
主机 `cvx` 是一个 Cumulus Linux (CL) 交换机,并且它是 `cumulus` 组中的唯一设备。记住,CL 是原生 Linux,因此,这意味着它是使用默认连接机制(SSH)连到到需要自动化的 CL 交换机。因为 `cvx` 在 DNS 或者 _/etc/hosts_ 文件中没有定义,我们将让 Ansible 知道不要在清单文件中定义主机名,而是在 `ansible_ssh_host` 中定义的名字/IP。登陆到 CL 交换机的用户名被定义在 playbook 中,但是,你可以看到密码使用变量 `ansible_ssh_pass` 定义在清单文件中。
|
||||
主机 `cvx` 是一个 Cumulus Linux (CL) 交换机,并且它是 `cumulus` 组中的唯一设备。记住,CL 是原生 Linux,因此,这意味着它是使用默认连接机制(SSH)连到到需要自动化的 CL 交换机。因为 `cvx` 在 DNS 或者 `/etc/hosts` 文件中没有定义,我们将让 Ansible 知道不要在清单文件中定义主机名,而是在 `ansible_ssh_host` 中定义的名字/IP。登陆到 CL 交换机的用户名被定义在 playbook 中,但是,你可以看到密码使用变量 `ansible_ssh_pass` 定义在清单文件中。
|
||||
|
||||
Arista
|
||||
**Arista**
|
||||
|
||||
被称为 `veos1` 的是一台运行 EOS 的 Arista 交换机。它是在 `arista` 组中唯一的主机。正如你在 Arista 中看到的,在清单文件中并没有其它的参数存在。这是因为 Arista 为它们的设备使用了一个特定的配置文件。在我们的示例中它的名字为 _.eapi.conf_,它存在在 home 目录中。下面是正确使用配置文件的这个功能的示例:
|
||||
被称为 `veos1` 的是一台运行 EOS 的 Arista 交换机。它是在 `arista` 组中唯一的主机。正如你在 Arista 中看到的,在清单文件中并没有其它的参数存在。这是因为 Arista 为它们的设备使用了一个特定的配置文件。在我们的示例中它的名字为 `.eapi.conf`,它存在在 home 目录中。下面是正确使用配置文件的这个功能的示例:
|
||||
|
||||
```
|
||||
[connection:veos1]
|
||||
@ -756,27 +724,26 @@ username: unadmin
|
||||
password: pwadmin
|
||||
```
|
||||
|
||||
这个文件包含了定义在配置文件中的 Ansible 连接到设备(和 Arista 的被称为 _pyeapi_ 的 Python 库)所需要的全部信息。
|
||||
这个文件包含了定义在配置文件中的 Ansible 连接到设备(和 Arista 的被称为 `pyeapi` 的 Python 库)所需要的全部信息。
|
||||
|
||||
Cisco
|
||||
**Cisco**
|
||||
|
||||
和 Cumulus 和 Arista 一样,这里仅有一台主机(`nx1`)存在于 `cisco` 组中。这是一台 NX-OS-based Cisco Nexus 交换机。注意在这里为 `nx1` 定义了三个变量。它们包括 `un` 和 `pwd`,这是为了在 playbook 中访问和为了进入到 Cisco 模块去连接到设备。另外,这里有一个称为 `hostip` 的参数,它是必需的,因为,`nx1` 没有在 DNS 中或者是 _/etc/hosts_ 配置文件中定义。
|
||||
和 Cumulus 和 Arista 一样,这里仅有一台主机(`nx1`)存在于 `cisco` 组中。这是一台 NX-OS-based Cisco Nexus 交换机。注意在这里为 `nx1` 定义了三个变量。它们包括 `un` 和 `pwd`,这是为了在 playbook 中访问和为了进入到 Cisco 模块去连接到设备。另外,这里有一个称为 `hostip` 的参数,它是必需的,因为,`nx1` 没有在 DNS 中或者是 `/etc/hosts` 配置文件中定义。
|
||||
|
||||
> 注意:
|
||||
|
||||
###### 注意
|
||||
> 如果自动化一个原生的 Linux 设备,我们可以将这个参数命名为任何东西。`ansible_ssh_host` 被用于到如我们看到的那个 Cumulus 示例(如果在清单文件中的定义不能被解析)。在这个示例中,我们将一直使用 `ansible_ssh_host`,但是,它并不是必需的,因为我们将这个变量作为一个参数进入到 Cisco 模块,而 `ansible_ssh_host` 是在使用默认的 SSH 连接机制时自动检查的。
|
||||
|
||||
如果自动化一个原生的 Linux 设备,我们可以将这个参数命名为任何东西。`ansible_ssh_host` 被用于到如我们看到的那个 Cumulus 示例(如果在清单文件中的定义不能被解析)。在这个示例中,我们将一直使用 `ansible_ssh_host`,但是,它并不是必需的,因为我们将这个变量作为一个参数进入到 Cisco 模块,而 `ansible_ssh_host` 是在使用默认的 SSH 连接机制时自动检查的。
|
||||
|
||||
Juniper
|
||||
**Juniper**
|
||||
|
||||
和前面的三个组和主机一样,在 `juniper` 组中有一个单个的主机 `vsrx`。它在清单文件中的设置与 Cisco 相同,因为两者在 playbook 中使用了相同的方式。
|
||||
|
||||
|
||||
### Playbook
|
||||
### 剧本
|
||||
|
||||
接下来的 playbook 有四个不同的 plays。每个 play 是基于特定的供应商类型的设备组的自动化构建的。注意,那是在一个单个的 playbook 中执行这些任务的唯一的方法。这里还有其它的方法,它可以使用条件(`when` 语句)或者创建 Ansible 角色(它在这个报告中没有介绍)。
|
||||
接下来的剧本有四个不同的剧集。每个剧集是基于特定的供应商类型的设备组的自动化构建的。注意,那是在一个单个的剧本中执行这些任务的唯一的方法。这里还有其它的方法,它可以使用条件(`when` 语句)或者创建 Ansible 角色(它在这个报告中没有介绍)。
|
||||
|
||||
这里有一个 playbook 的示例:
|
||||
这里有一个剧本的示例:
|
||||
|
||||
```
|
||||
---
|
||||
@ -833,29 +800,29 @@ Juniper
|
||||
diffs_file=junpr.diff
|
||||
```
|
||||
|
||||
你将注意到,前面的两个 plays 是非常类似的,我们已经在最初的 Cisco 和 Arista 示例中讲过了。唯一的区别是每个要自动化的组(`cisco` and `arista`) 定义了它们自己的 play,我们在前面介绍使用 `when` 条件时比较过。
|
||||
你将注意到,前面的两个剧集是非常类似的,我们已经在最初的 Cisco 和 Arista 示例中讲过了。唯一的区别是每个要自动化的组(`cisco` and `arista`) 定义了它们自己的剧集,我们在前面介绍使用 `when` 条件时比较过。
|
||||
|
||||
这里有一个不正确的或者是错误的方式去做这些。这取决于你预先知道的信息是什么和适合你的环境和使用的最佳案例是什么,但我们的目的是为了展示做同一件事的几种不同的方法。
|
||||
|
||||
第三个 play 是在 Cumulus Linux 交换机的 `swp1` 接口上进行自动化配置。在这个 play 中的第一个任务是去确认 `swp1` 是一个三层接口,并且它配置的 IP 地址是 100.10.10.1。因为 Cumulus Linux 是原生的 Linux,网络服务在改变后需要重启才能生效。这也可以使用 Ansible 的操作来达到这个目的(这已经超出了本报告讨论的范围),这里有一个被称为 `service` 的 Ansible 核心模块来做这些,但它会中断交换机上的网络;使用 `ifreload` 重新启动则不会中断。
|
||||
第三个剧集是在 Cumulus Linux 交换机的 `swp1` 接口上进行自动化配置。在这个剧集中的第一个任务是去确认 `swp1` 是一个三层接口,并且它配置的 IP 地址是 100.10.10.1。因为 Cumulus Linux 是原生的 Linux,网络服务在改变后需要重启才能生效。这也可以使用 Ansible 的操作来达到这个目的(这已经超出了本报告讨论的范围),这里有一个被称为 `service` 的 Ansible 核心模块来做这些,但它会中断交换机上的网络;使用 `ifreload` 重新启动则不会中断。
|
||||
|
||||
本节到现在为止,我们已经讲解了专注于特定任务的 Ansible 模块,比如,配置接口和 VLANs。第四个 play 使用了另外的选项。我们将看到一个 _pushes_ 模块,它是一个完整的配置文件并且立即激活它作为正在运行的新的配置。这里将使用 `napalm_install_config`来展示前面的示例,但是,这个示例使用了一个 Juniper 专用的模块。
|
||||
本节到现在为止,我们已经讲解了专注于特定任务的 Ansible 模块,比如,配置接口和 VLAN。第四个剧集使用了另外的选项。我们将看到一个 `pushes` 模块,它是一个完整的配置文件并且立即激活它作为正在运行的新的配置。这里将使用 `napalm_install_config` 来展示前面的示例,但是,这个示例使用了一个 Juniper 专用的模块。
|
||||
|
||||
`junos_install_config` 模块接受几个参数,如下面的示例中所展示的。到现在为止,你应该理解了什么是 `user`、`passwd`、和 `host`。其它的参数定义如下:
|
||||
|
||||
`file`
|
||||
`file`:
|
||||
|
||||
这是一个从 Ansible 控制主机拷贝到 Juniper 设备的配置文件。
|
||||
|
||||
`logfile`
|
||||
`logfile`:
|
||||
|
||||
这是可选的,但是,如果你指定它,它会被用于存储运行这个模块时生成的信息。
|
||||
|
||||
`overwrite`
|
||||
`overwrite`:
|
||||
|
||||
当你设置为 yes/true 时,完整的配置将被发送的配置覆盖。(默认是 false)
|
||||
|
||||
`diffs_file`
|
||||
`diffs_file`:
|
||||
|
||||
这是可选的,但是,如果你指定它,当应用配置时,它将存储生成的差异。当应用配置时将存储一个生成的差异。当正好更改了主机名,但是,仍然发送了一个完整的配置文件时会生成一个差异,如下的示例:
|
||||
|
||||
@ -867,11 +834,11 @@ Juniper
|
||||
```
|
||||
|
||||
|
||||
上面已经介绍了 playbook 概述的细节。现在,让我们看看当 playbook 运行时发生了什么:
|
||||
上面已经介绍了剧本概述的细节。现在,让我们看看当剧本运行时发生了什么:
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
注意:`-i` 标志是用于指定使用的清单文件。也可以设置环境变量 `ANSIBLE_HOSTS`,而不用每次运行 playbook 时都去使用一个 `-i` 标志。
|
||||
注意:`-i` 标志是用于指定使用的清单文件。也可以设置环境变量 `ANSIBLE_HOSTS`,而不用每次运行剧本时都去使用一个 `-i` 标志。
|
||||
|
||||
```
|
||||
ntc@ntc:~/ansible/multivendor$ ansible-playbook -i inventory demo.yml
|
||||
@ -949,12 +916,11 @@ veos1 : ok=1 changed=0 unreachable=0 failed=0
|
||||
vsrx : ok=1 changed=0 unreachable=0 failed=0
|
||||
```
|
||||
|
||||
注意:这里有 0 个改变,但是,每次运行任务,正如期望的那样,它们都返回 “ok”。说明在这个 playbook 中的每个模块都是幂等的。
|
||||
|
||||
注意:这里有 0 个改变,但是,每次运行任务,正如期望的那样,它们都返回 “ok”。说明在这个剧本中的每个模块都是幂等的。
|
||||
|
||||
### 总结
|
||||
|
||||
Ansible 是一个超级简单的、无代理和可扩展的自动化平台。网络社区持续不断地围绕 Ansible 去重整它作为一个能够执行一些自动化网络任务的平台,比如,做配置管理、数据收集和报告,等等。你可以使用 Ansible 去推送完整的配置文件,配置具体的使用幂等模块的网络资源,比如,接口、VLANs,或者,简单地自动收集信息,比如,领居、序列号、启动时间、和接口状态,以及按你的需要定制一个报告。
|
||||
Ansible 是一个超级简单的、无代理和可扩展的自动化平台。网络社区持续不断地围绕 Ansible 去重整它作为一个能够执行一些自动化网络任务的平台,比如,做配置管理、数据收集和报告,等等。你可以使用 Ansible 去推送完整的配置文件,配置具体的使用幂等模块的网络资源,比如,接口、VLAN,或者,简单地自动收集信息,比如,领居、序列号、启动时间、和接口状态,以及按你的需要定制一个报告。
|
||||
|
||||
因为它的架构,Ansible 被证明是一个在这里可用的、非常好的工具,它可以帮助你实现从传统的基于 _CLI/SNMP_ 的网络设备到基于 _API 驱动_ 的现代化网络设备的自动化。
|
||||
|
||||
@ -976,7 +942,7 @@ via: https://www.oreilly.com/learning/network-automation-with-ansible
|
||||
|
||||
作者:[Jason Edelman][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -1,195 +0,0 @@
|
||||
|
||||
如何确定你的Linux发行版中有没有某个软件包
|
||||
======
|
||||
|
||||

|
||||
|
||||
|
||||
有时,你可能会想知道如何在你的Linux发行版上寻找一个特定的软件包。或者,你仅仅只是想知道安装在你的Linux上的软件包有什么版本。如果这就是你想知道的信息,你今天走运了。我正好知道一个小工具能帮你抓到上述信息,下面隆重推荐--'Whohas':这是一个命令行工具,它能一次查询好几个软件包列表,以检查的你软件包是否存在。目前,whohas支持Arch, Debian, Fedora, Gentoo, Mandriva, openSUSE, Slackware, Source Mage, Ubuntu, FreeBSD, NetBSD, OpenBSD(LCTT译注:*BSD不是Linux), Fink, MacPorts 和Cygwin. 使用这个小工具,软件包的维护者能轻而易举从别的Linux发行版里找到ebuilds, pkgbuilds 等等类似的包定义文件。
|
||||
'Whohas'是用Perl语言开发的免费,开源的工具。
|
||||
|
||||
###在你的Linux中寻找一个特定的包
|
||||
|
||||
**安装 Whohas**
|
||||
|
||||
|
||||
Whohas 在Debian, Ubuntu, Linux Mint的默认软件仓库里提供。如果你正在使用某种基于DEB的系统, 你可以用如下命令安装:
|
||||
|
||||
```
|
||||
$ sudo apt-get install whohas
|
||||
|
||||
```
|
||||
|
||||
对基于Arch的系统,[**AUR**][1]里就有提供whohas。你能使用任何的ARU助手程序来安装。
|
||||
|
||||
|
||||
使用 [**Packer**][2]:
|
||||
|
||||
```
|
||||
$ packer -S whohas
|
||||
|
||||
```
|
||||
|
||||
或使用[**Trizen**][3]:
|
||||
|
||||
|
||||
```
|
||||
$ trizen -S whohas
|
||||
|
||||
```
|
||||
|
||||
使用[**Yay**][4]:
|
||||
|
||||
```
|
||||
$ yay -S whohas
|
||||
|
||||
```
|
||||
|
||||
使用[**Yaourt**][5]:
|
||||
|
||||
```
|
||||
$ yaourt -S whohas
|
||||
|
||||
```
|
||||
|
||||
|
||||
在别的Linux发行版上,从[**here**][6]下载源代码并手工编译安装。
|
||||
|
||||
**使用方法**
|
||||
|
||||
|
||||
|
||||
Whohas的主要目标是想让你知道:
|
||||
|
||||
|
||||
* 哪个Linux发布版提供了用户依赖的包。
|
||||
* 对于各个Linux发行版,指定的软件包是什么版本,或者在这个Linux发行版的各个不同版本上,指定的软件包是什么版本。
|
||||
|
||||
|
||||
|
||||
让我们试试看上面的的功能,比如说,哪个Linux发行版里有**vim**这个软件?我们可以运行如下命令:
|
||||
|
||||
```
|
||||
$ whohas vim
|
||||
|
||||
```
|
||||
|
||||
|
||||
这个命令将会显示所有包含可安装的vim的Linux发行版的信息,包括包的大小,仓库地址和下载URL。
|
||||
|
||||
![][8]
|
||||
|
||||
|
||||
你甚至可以通过管道将输出的结果按照发行版的字母排序,只需加入‘sort’ 命令即可。
|
||||
|
||||
```
|
||||
$ whohas vim | sort
|
||||
|
||||
```
|
||||
|
||||
|
||||
请注意上述命令将会显示所有以**vim**开头的软件包,包括vim-spell,vimcommander, vimpager等等。你可以继续使用Linux的grep命令在vim的前后加上空格来缩小你的搜索范围,直到满意为止。
|
||||
|
||||
```
|
||||
$ whohas vim | sort | grep " vim"
|
||||
|
||||
$ whohas vim | sort | grep "vim "
|
||||
|
||||
$ whohas vim | sort | grep " vim "
|
||||
|
||||
```
|
||||
|
||||
|
||||
所有将空格放在包名字前面的搜索将会显示以包名字结尾的包。所有将空格放在包名字后面的搜索将会显示以包名字开头的包。前后都有空格将会严格匹配。
|
||||
|
||||
|
||||
又或者,你就使用‘--strict’来严格限制结果。
|
||||
|
||||
```
|
||||
$ whohas --strict vim
|
||||
|
||||
```
|
||||
|
||||
|
||||
有时,你想知道一个包在不在一个特定的Linux发行版里。例如,你想知道vim是否在Arch Linux里,请运行:
|
||||
|
||||
|
||||
```
|
||||
$ whohas vim | grep "^Arch"
|
||||
|
||||
```
|
||||
|
||||
(LCTT译注:在结果里搜索以Arch开头的Linux)
|
||||
|
||||
|
||||
Linux发行版的命名缩写为:'archlinux', 'cygwin', 'debian', 'fedora', 'fink', 'freebsd', 'gentoo', 'mandriva', 'macports', 'netbsd', 'openbsd', 'opensuse', 'slackware', 'sourcemage'和‘ubuntu’。
|
||||
|
||||
|
||||
你也可以用**-d**选项来得到同样的结果。
|
||||
|
||||
|
||||
```
|
||||
$ whohas -d archlinux vim
|
||||
|
||||
```
|
||||
|
||||
|
||||
这个命令将在仅仅Arch Linux发行版下搜索vim包。
|
||||
|
||||
|
||||
如果要在多个Linux发行版下搜索,如’arch linux‘,'ubuntu',请使用如下命令。
|
||||
|
||||
|
||||
```
|
||||
$ whohas -d archlinux,ubuntu vim
|
||||
|
||||
```
|
||||
|
||||
|
||||
你甚至可以用‘whohas’来查找哪个发行版有'whohas'包。
|
||||
|
||||
```
|
||||
$ whohas whohas
|
||||
|
||||
```
|
||||
|
||||
更详细的信息,请参照手册。
|
||||
|
||||
```
|
||||
$ man whohas
|
||||
|
||||
```
|
||||
|
||||
**最后的话**
|
||||
|
||||
|
||||
当然,任何一个Linux发行版的包管理器都能轻松的在对应的软件仓库里找到自己管理的包。不过, whohas帮你整合并比较了在不同的Linux发行版下指定的软件包信息,这样你能轻易的跨平台之间进行比较。试一下whohas,你一定不会失望的。
|
||||
|
||||
|
||||
好了,今天就到这里吧,希望前面讲的对你有用,下次我还会带来更多好东西!!
|
||||
|
||||
|
||||
欧耶!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/find-if-a-package-is-available-for-your-linux-distribution/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[DavidChenLiang](https://github.com/davidchenliang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://aur.archlinux.org/packages/whohas/
|
||||
[2]:https://www.ostechnix.com/install-packer-arch-linux-2/
|
||||
[3]:https://www.ostechnix.com/trizen-lightweight-aur-package-manager-arch-based-systems/
|
||||
[4]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[5]:https://www.ostechnix.com/install-yaourt-arch-linux/
|
||||
[6]:http://www.philippwesche.org/200811/whohas/intro.html
|
||||
[7]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/06/whohas-1.png
|
||||
@ -0,0 +1,300 @@
|
||||
Linux DNS 查询剖析(第三部分)
|
||||
============================================================
|
||||
|
||||
在 [Linux DNS 查询剖析(第一部分)][1]中,我们介绍了:
|
||||
|
||||
* `nsswitch`
|
||||
* `/etc/hosts`
|
||||
* `/etc/resolv.conf`
|
||||
* `ping` 与 `host` 查询方式的对比
|
||||
|
||||
and in [Linux DNS 查询剖析(第二部分)][2],我们介绍了:
|
||||
|
||||
* `systemd` 和对应的 `networking` 服务
|
||||
* `ifup` 和 `ifdown`
|
||||
* `dhclient`
|
||||
* `resolvconf`
|
||||
|
||||
剖析进展如下:
|
||||
|
||||
* * *
|
||||
|
||||
![linux-dns-2 (2)][4]
|
||||
|
||||
_(大致)准确的关系图_
|
||||
|
||||
很可惜,故事还没有结束,还有不少东西也会影响 DNS 查询。在第三部分中,我将介绍 `NetworkManager` 和 `dnsmasq`,简要说明它们如何影响 DNS 查询。
|
||||
|
||||
* * *
|
||||
|
||||
### 1) NetworkManager
|
||||
|
||||
在第二部分已经提到,我们现在介绍的内容已经偏离 POSIX 标准,涉及的 DNS 解析管理部分在各个发行版上形式并不统一。
|
||||
|
||||
在我使用的发行版 (Ubuntu)中,有一个名为 [NetworkManager][3] 的服务,它通常作为一些其它软件包的依赖被安装而且处于<ruby>激活<rt>available</rt></ruby>状态。它实际上是 RedHat 在 2004 年开发的一个服务,用于帮助你管理网络接口。
|
||||
|
||||
它与 DNS 查询有什么关系呢?让我们安装这个服务并找出答案:
|
||||
|
||||
```
|
||||
$ apt-get install -y network-manager
|
||||
```
|
||||
|
||||
对于 Ubuntu,在软件包安装后,你可以发现一个新的配置文件:
|
||||
|
||||
```
|
||||
$ cat /etc/NetworkManager/NetworkManager.conf
|
||||
[main]
|
||||
plugins=ifupdown,keyfile,ofono
|
||||
dns=dnsmasq
|
||||
|
||||
[ifupdown]
|
||||
managed=false
|
||||
```
|
||||
|
||||
看到 `dns=dnsmasq` 了吧?这意味着 `NetworkManager` 将使用 `dnsmasq` 管理主机上的 DNS。
|
||||
|
||||
* * *
|
||||
|
||||
### 2) dnsmasq
|
||||
|
||||
`dnsmasq` 程序是我们很熟悉的程序:只是 `/etc/resolv.conf` 之上的又一个间接层。
|
||||
|
||||
理论上,`dnsmasq` 有多种用途,但主要被用作 DNS 缓存服务器,缓存到其它 DNS 服务器的请求。`dnsmasq` 在本地所有网络接口上监听 53 端口(标准的 DNS 端口)。
|
||||
|
||||
那么 `dnsmasq` 运行在哪里呢?`NetworkManager` 的运行情况如下:
|
||||
|
||||
```
|
||||
$ ps -ef | grep NetworkManager
|
||||
root 15048 1 0 16:39 ? 00:00:00 /usr/sbin/NetworkManager --no-daemon
|
||||
```
|
||||
|
||||
但并没有找到 `dnsmasq` 相关的进程:
|
||||
|
||||
```
|
||||
$ ps -ef | grep dnsmasq
|
||||
$
|
||||
```
|
||||
|
||||
令人迷惑的是,虽然 `dnsmasq` 被配置用于管理 DNS,但其实并没有安装在系统上!因而,你需要自己安装它。
|
||||
|
||||
安装之前,让我们查看一下 `/etc/resolv.conf` 文件的内容:
|
||||
|
||||
```
|
||||
$ cat /etc/resolv.conf
|
||||
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
|
||||
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
|
||||
nameserver 10.0.2.2
|
||||
search home
|
||||
```
|
||||
|
||||
可见,并没有被 `NetworkManager` 修改。
|
||||
|
||||
如果安装 `dnsmasq`:
|
||||
|
||||
```
|
||||
$ apt-get install -y dnsmasq
|
||||
```
|
||||
|
||||
这时,`dnsmasq` 已经启动运行:
|
||||
|
||||
```
|
||||
$ ps -ef | grep dnsmasq
|
||||
dnsmasq 15286 1 0 16:54 ? 00:00:00 /usr/sbin/dnsmasq -x /var/run/dnsmasq/dnsmasq.pid -u dnsmasq -r /var/run/dnsmasq/resolv.conf -7 /etc/dnsmasq.d,.dpkg-dist,.dpkg-old,.dpkg-new --local-service --trust-anchor=.,19036,8,2,49AAC11D7B6F6446702E54A1607371607A1A41855200FD2CE1CDDE32F24E8FB5
|
||||
```
|
||||
|
||||
然后,`/etc/resolv.conf` 文件内容又改变了!
|
||||
|
||||
```
|
||||
root@linuxdns1:~# cat /etc/resolv.conf
|
||||
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
|
||||
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
|
||||
nameserver 127.0.0.1
|
||||
search home
|
||||
```
|
||||
|
||||
运行 `netstat` 命令,可以看出 `dnsmasq` 在所有网络接口上监听 53 端口:
|
||||
|
||||
```
|
||||
$ netstat -nlp4
|
||||
Active Internet connections (only servers)
|
||||
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
|
||||
tcp 0 0 127.0.0.1:53 0.0.0.0:* LISTEN 15286/dnsmasq
|
||||
tcp 0 0 10.0.2.15:53 0.0.0.0:* LISTEN 15286/dnsmasq
|
||||
tcp 0 0 172.28.128.11:53 0.0.0.0:* LISTEN 15286/dnsmasq
|
||||
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1237/sshd
|
||||
udp 0 0 127.0.0.1:53 0.0.0.0:* 15286/dnsmasq
|
||||
udp 0 0 10.0.2.15:53 0.0.0.0:* 15286/dnsmasq
|
||||
udp 0 0 172.28.128.11:53 0.0.0.0:* 15286/dnsmasq
|
||||
udp 0 0 0.0.0.0:68 0.0.0.0:* 10758/dhclient
|
||||
udp 0 0 0.0.0.0:68 0.0.0.0:* 10530/dhclient
|
||||
udp 0 0 0.0.0.0:68 0.0.0.0:* 10185/dhclient
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
### 3) 分析 dnsmasq
|
||||
|
||||
在目前的情况下,所有的 DNS 查询都会使用 `127.0.0.1:53` 这个 DNS 服务器,下一步会发生什么呢?
|
||||
|
||||
我再次查看 `/var/run` 目录,可以发现一个线索:
|
||||
`resolvconf` 目录下 `resolv.conf` 文件中的配置也相应变更,变更为 `dnsmasq` 对应的 DNS 服务器:
|
||||
|
||||
```
|
||||
$ cat /var/run/resolvconf/resolv.conf
|
||||
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
|
||||
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
|
||||
nameserver 127.0.0.1
|
||||
search home
|
||||
```
|
||||
|
||||
同时,出现了一个新的 `dnsmasq` 目录,也包含一个 `resolv.conf` 文件:
|
||||
|
||||
```
|
||||
$ cat /run/dnsmasq/resolv.conf
|
||||
nameserver 10.0.2.2
|
||||
```
|
||||
|
||||
(LCTT 译注:这里依次提到了 `/var/run` 和 `/run`,使用 Ubuntu 16.04 LTS 验证发现,`/var/run` 其实是指向 `/run/` 的软链接)
|
||||
|
||||
该文件包含我们从 `DHCP` 获取的 `nameserver`。
|
||||
|
||||
虽然可以推导出这个结论,但如何查看具体的调用逻辑呢?
|
||||
|
||||
* * *
|
||||
|
||||
### 4) 调试 dnsmasq
|
||||
|
||||
我经常思考 `dnsmasq` (在整个过程中)的功能定位。幸运的是,如果你将 `/etc/dnsmasq.conf` 中的一行做如下调整,你可以获取大量 `dnsmasq` 状态的信息:
|
||||
|
||||
```
|
||||
#log-queries
|
||||
```
|
||||
|
||||
修改为:
|
||||
|
||||
```
|
||||
log-queries
|
||||
```
|
||||
|
||||
然后重启 `dnsmasq`。
|
||||
|
||||
接下来,只要运行一个简单的命令:
|
||||
|
||||
```
|
||||
$ ping -c1 bbc.co.uk
|
||||
```
|
||||
|
||||
你就可以在 `/var/log/syslog` 中找到类似的内容(其中 `[...]` 表示行首内容与上一行相同):
|
||||
|
||||
```
|
||||
Jul 3 19:56:07 ubuntu-xenial dnsmasq[15372]: query[A] bbc.co.uk from 127.0.0.1
|
||||
[...] forwarded bbc.co.uk to 10.0.2.2
|
||||
[...] reply bbc.co.uk is 151.101.192.81
|
||||
[...] reply bbc.co.uk is 151.101.0.81
|
||||
[...] reply bbc.co.uk is 151.101.64.81
|
||||
[...] reply bbc.co.uk is 151.101.128.81
|
||||
[...] query[PTR] 81.192.101.151.in-addr.arpa from 127.0.0.1
|
||||
[...] forwarded 81.192.101.151.in-addr.arpa to 10.0.2.2
|
||||
[...] reply 151.101.192.81 is NXDOMAIN
|
||||
```
|
||||
|
||||
可以清晰看出 `dnsmasq` 收到的查询、查询被转发到了哪里以及收到的回复。
|
||||
|
||||
如果查询被缓存命中(或者说,本地的查询结果还在<ruby>存活时间<rt>time-to-live</rt></ruby>内,并未过期),日志显示如下:
|
||||
|
||||
```
|
||||
[...] query[A] bbc.co.uk from 127.0.0.1
|
||||
[...] cached bbc.co.uk is 151.101.64.81
|
||||
[...] cached bbc.co.uk is 151.101.128.81
|
||||
[...] cached bbc.co.uk is 151.101.192.81
|
||||
[...] cached bbc.co.uk is 151.101.0.81
|
||||
[...] query[PTR] 81.64.101.151.in-addr.arpa from 127.0.0.1
|
||||
```
|
||||
|
||||
如果你想了解缓存中有哪些记录,可以向 `dnsmasq` 进程 id 发送 `USR1` 信号,这样 `dnsmasq` 会将缓存记录导出并写入到相同的日志文件中:
|
||||
|
||||
```
|
||||
$ kill -SIGUSR1 $(cat /run/dnsmasq/dnsmasq.pid)
|
||||
```
|
||||
|
||||
(LCTT 译注:原文中命令执行报错,已变更成最接近且符合作者意图的命令)
|
||||
|
||||
导记录对应如下输出:
|
||||
|
||||
```
|
||||
Jul 3 15:08:08 ubuntu-xenial dnsmasq[15697]: time 1530630488
|
||||
[...] cache size 150, 0/5 cache insertions re-used unexpired cache entries.
|
||||
[...] queries forwarded 2, queries answered locally 0
|
||||
[...] queries for authoritative zones 0
|
||||
[...] server 10.0.2.2#53: queries sent 2, retried or failed 0
|
||||
[...] Host Address Flags Expires
|
||||
[...] linuxdns1 172.28.128.8 4FRI H
|
||||
[...] ip6-localhost ::1 6FRI H
|
||||
[...] ip6-allhosts ff02::3 6FRI H
|
||||
[...] ip6-localnet fe00:: 6FRI H
|
||||
[...] ip6-mcastprefix ff00:: 6FRI H
|
||||
[...] ip6-loopback : 6F I H
|
||||
[...] ip6-allnodes ff02: 6FRI H
|
||||
[...] bbc.co.uk 151.101.64.81 4F Tue Jul 3 15:11:41 2018
|
||||
[...] bbc.co.uk 151.101.192.81 4F Tue Jul 3 15:11:41 2018
|
||||
[...] bbc.co.uk 151.101.0.81 4F Tue Jul 3 15:11:41 2018
|
||||
[...] bbc.co.uk 151.101.128.81 4F Tue Jul 3 15:11:41 2018
|
||||
[...] 151.101.64.81 4 R NX Tue Jul 3 15:34:17 2018
|
||||
[...] localhost 127.0.0.1 4FRI H
|
||||
[...] <Root> 19036 8 2 SF I
|
||||
[...] ip6-allrouters ff02::2 6FRI H
|
||||
```
|
||||
|
||||
在上面的输出中,我猜测(并不确认,`?` 代表我比较疯狂的猜测)如下:
|
||||
|
||||
* `4` 代表 IPv4
|
||||
* `6` 代表 IPv6
|
||||
* `H` 代表从 `/etc/hosts` 中读取 IP 地址
|
||||
* `I` ? “永生”的 DNS 记录 ? (例如,没有设置存活时间数值 ?)
|
||||
* `F` ?
|
||||
* `R` ?
|
||||
* `S` ?
|
||||
* `N` ?
|
||||
* `X`
|
||||
|
||||
(LCTT 译注:查看 `dnsmasq` 的源代码 [`cache.c`][5] 可知,`4` 代表 `IPV4`,`6` 代表 `IPV6`,`C` 代表 `CNAME`,`S` 代表 `DNSSEC`,`F` 代表 `FORWARD`,`R` 代表 `REVERSE`,`I` 代表 `IMMORTAL`,`N` 代表 `NEG`,`X` 代表 `NXDOMAIN`,`H` 代表 `HOSTS`。更具体的含义需要查看代码或相关文档)
|
||||
|
||||
#### dnsmasq 的替代品
|
||||
|
||||
`NetworkManager` 配置中的 `dns` 字段并不是只能使用 `dnsmasq`,可选项包括 `none`,`default`,`unbound` 和 `dnssec-triggered` 等。使用 `none` 时,`NetworkManager` 不会改动 `/etc/resolv.conf`;使用 `default` 时,`NetworkManager` 会根据当前的<ruby>活跃连接<rt>active connections</rt></ruby>更新 `resolv.conf`;使用 `unbound` 时,`NetworkManager` 会与 `unbound` 服务通信;`dnssec-triggered` 与 DNS 安全相关,不在本文讨论范围。
|
||||
|
||||
* * *
|
||||
|
||||
### 第三部分总结
|
||||
|
||||
第三部分到此结束,其中我们介绍了 `NetworkManager` 服务及其 `dns=dnsmasq` 的配置。
|
||||
|
||||
下面简要罗列一下我们已经介绍过的全部内容:
|
||||
|
||||
* `nsswitch`
|
||||
* `/etc/hosts`
|
||||
* `/etc/resolv.conf`
|
||||
* `/run/resolvconf/resolv.conf`
|
||||
* `systemd` 及对应的 `networking` 服务
|
||||
* `ifup` 和 `ifdown`
|
||||
* `dhclient`
|
||||
* `resolvconf`
|
||||
* `NetworkManager`
|
||||
* `dnsmasq`
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://zwischenzugs.com/2018/07/06/anatomy-of-a-linux-dns-lookup-part-iii/
|
||||
|
||||
作者:[ZWISCHENZUGS][a]
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://zwischenzugs.com/
|
||||
[1]:https://linux.cn/article-9943-1.html
|
||||
[2]:https://linux.cn/article-9949-1.html
|
||||
[3]:https://en.wikipedia.org/wiki/NetworkManager
|
||||
[4]:https://zwischenzugs.files.wordpress.com/2018/06/linux-dns-2-2.png?w=525
|
||||
[5]:https://github.com/imp/dnsmasq/blob/master/src/cache.c
|
||||
Loading…
Reference in New Issue
Block a user